web viewla función de azar y la función de supervivencia están relacionadas...
TRANSCRIPT

19
Los Modelos de Regresión de CoxCon frecuencia en el campo de la medicina, la biología o de la ingeniería se requiere determinar cuándo si o cuando no ciertas variables continúas están correlacionadas con el tiempo de falla o de supervivencia.
Para establecer esta correlación se usa un modelo de regresión para el riesgo o la supervivencia, en función de las variables explicativas, un modelo que permita estimar el riesgo, o la supervivencia, tomando en cuenta el efecto de otras variables.
Con estos modelos se puede obtener información sobre las variables que tienen relevancia como factores del pronóstico, se pueden clasificar a los pacientes de acuerdo un buen o mal pronóstico y hacer el pronóstico más probable para un paciente con unas características concretas.
En un caso clínico, por ejemplo, la supervivencia a dos tratamientos alternativos puede depender no sólo del tratamiento, sino también de otras variables como la edad, el sexo, o la gravedad de la afección de cada paciente.
Los modelos de regresión lineal clásica son las técnicas comúnmente usadas para determinar cómo ciertas variables continuas están correlacionadas con el tiempo de supervivencia, sin embargo existen dos razones fundamentales por las cuales las técnicas clásicas de regresión lineal no pueden ser usadas para establecer la correlación que existe entre el tiempo de vida y las otras variables consideradas:
1. La variable tiempo de supervivencia o de falla no está normalmente distribuida, esta variable sigue generalmente una distribución exponencial o una distribución de Weibull.
2. Algunas observaciones son registradas en forma incompleta y se presentan algunas observaciones censuradas
Por esta razones se han desarrollado modelos especiales de regresión, que considerando las dos circunstancias que se presentan en estos casos, pueda determinar la correlación entre los tiempos de fallas y algunas variables independientes.
La Función de azar. La función de azar es la tasa instantánea de muerte, es la probabilidad de morir en el instante siguiente al tiempo t, dado que se ha vivido al menos hasta el tiempo t., una función de azar constante significa que el riesgo de muerte no varía a lo largo del tiempo y una función decreciente muestra una disminución del riesgo de muerte.
La función de azar y la función de supervivencia están relacionadas matemáticamente, al conocer una de esas funciones se puede deducir matemáticamente la otra.

20
Las funciones de azar se utilizan para modelar los tiempos de supervivencia, y para construir pruebas paramétricas en los estudios de los tiempos de supervivencia.
Los métodos utilizados habitualmente en el estudio de datos de supervivencia son métodos no paramétricos.
Los Modelos de RegresiónSe han desarrollado cuatro modelos especiales de regresión para estudiar la correlación entre el tiempo de falla y las variables independientes continuas con datos censurados:
1. Modelo de Regresión Riesgo Proporcional de Cox2. Modelo de Regresión Exponencial3. Modelo de Regresión Normal4. Modelo de Regresión Log-Normal
El Modelo de RiesgoProporcional de Cox
Entre los modelos que se usan para establecer una relaciónentre el tiempo de falla y las variables independientes continuas con datos censurados, el más aplicado es el modelo de riesgos proporcionales, también conocido como modelo de Cox, y del que podemos encontrar gran número de estudios, sobre todo en áreas relativas a enfermedades crónicas con los conocidos modelos de Framingham, y el modelo Score, en los trasplantes, en oncología, en epidemiologia y otras.
El modelo de riesgos proporcionales fue desarrollado por Cox (1972) con el fin de tratar los datos continuos de tiempo de supervivencia, con este modelo se puede derivar información sobre las variables que tienen relevancia como factores del pronóstico, se pueden clasificar a los pacientes de acuerdo un buen o mal pronóstico y se pueden hacer pronósticos más probables para cada paciente con unas características concretas.
El modelo del riesgo proporcional de Cox no requiere suponer la naturaleza o forma de la distribución de los tiempos de supervivencia, la distribución de los tiempos de supervivencia puede ser exponencial, weibull, log normal, logística u otra
El modelo asume que la razón de riesgo es una función de las variables independientes y no hace ningún supuesto sobre la naturaleza y forma de la distribución de la función de riesgo por lo que la regresión de Cox se considere como un método no paramétrico.
El modelo Proporcional de Riesgo de Cox puede ser expresado como:
h{(t),(x1, x3 ,..,x m)} = h0 (t) exp(b1 x1 +...+bm xm )

21
donde h{(t),(x1,x2 ,..,xm)}es el riesgo, dado el valor de los m covariantes para los respectivos casos (x1, x2, ..., xm) y el respectivo tiempo de supervivencia (t).
El termino h0(t) se llama el riesgo básico y es el riesgo para un valor de cero de las variables independientes.
Se puede linializar el modelo dividiendo ambos términos entre h0(t) y luego tomar el logaritmo de ambos lados.
ln[h{(t),(x...)}/h0 (t)] = b1x1 +...+bmxm
Un modelo lineal simple que puede ser fácilmente estimado como un modelo regresión lineal simple.
Selección de las variablesPara identificar el subconjunto de variables independientes que forman parte del modelo final. de riesgos proporcionales de Cox se puede utilizar un procedimiento clásico de selección de las variables para modelos de regresión de tres tipos de selecciones:
1. Selección hacia adelante: El proceso de selección se inicia mediante la adición de la variable con la mayor contribución al modelo, si una segunda variable es tal que su probabilidad de entrada es mayor que el valor umbral de entrada, entonces se añade al modelo. Este proceso se repite hasta que ninguna variable se puede introducir en el modelo
2. Selección hacia atrás: Este método es similar al anterior pero comienza a partir de un modelo completo.
3. Stepwise (paso a paso), es una modificación de la selección hacia adelante de modo que cada vez que se añade una variable se verifica si alguna de las variables introducidas es no significativa y si esto es así dicha variable se elimina del modelo y con ello se consigue un modelo final en el que intervienen únicamente las variables significativas.
Si no hay censura de la variable dependiente, la relación entre la variable dependiente y las variables independientes se determina con la regresión lineal.
Los estimadores son de máxima verosimilitud y el contraste de hipótesis sobre cada coeficiente se hace usando la prueba de Wald y el contraste de hipótesis sobre el modelo completo o sobre un conjunto de coeficientes se hace con el logaritmo del cociente de verosimilitudes
En la regresión de Cox los estimadores de la asociación no son los coeficientes i sino los riesgos relativos, por lo tanto los intervalos de confianza que interesan calcular son los de los riesgos relativos, un intervalo de confianza de (1- )% para el coeficiente i es: i ±
Z )

22
Interpretación de unmodelo regresión de Cox Se examinan los coeficientes de cada variable explicativa, un coeficiente de regresión positivo para una variable explicativa significa que el riesgo para el paciente que tiene un valor positivo alto que el variable en particular es alta y por el contrario, un coeficiente de regresión negativa implica un mejor pronóstico para los pacientes con valores más altos de esa variable.
El método de Cox no asume ninguna distribución en particular para los tiempos de supervivencia y supone que los efectos de las distintas variables en la supervivencia son constantes en el tiempo
La función de riesgo es la probabilidad de que un individuo experimentará un evento (por ejemplo, la muerte) dentro de un intervalo de tiempo, dado que el individuo ha sobrevivido hasta el comienzo del intervalo, el riesgo se puede interpretar como el riesgo de muerte en el tiempo t, en este modelo el logaritmo del riesgo relativo es una función lineal de las variables independientes.
El riesgo relativo, a diferencia del riesgo propiamente dicho, no depende del tiempo, es constante a lo largo del tiempo y de ahí el nombre de modelo de riesgo proporcional.
El valor i es el logaritmo del riesgo relativo cuando Xi aumenta una unidad, manteniéndose constantes las demás variables y exp(i) es el riesgo relativo cuando Xi aumenta una unidad, manteniéndose constantes las demás variables.
Contrastes de hipótesisde los coeficientes
Para contrastar la hipótesis de que los coeficientes de la regresión no son nulos están disponibles varias pruebas como la prueba de razón de verosimilitud (-2 Log (Verosimilitud) y la prueba de Wald, los estadísticos de estas dos pruebas siguen una distribución Chi2
Prueba de WaldHipótesisHo: i = 0Ha: i ≠ 0
Estadístico de PruebaSe determina el valor del Estadístico de Prueba W = i – b ) /VARi),
donde b es la constante de la ecuación de regresión.
Wse distribuye como una Chi-cuadrado con 1 grado de libertad, y por lo tanto la regla de decisión será:

23
Regla de Decisión
Si W >21Se acepta Ho
Si W <2 Se rechaza Ho
Análisis de los residuosen la regresión Cox
En el análisis de supervivencia la mayor parte de los procedimientos de verificación del modelo se basan en los errores o residuos, un error o residual es la diferencia entre el valor observado y el valor estimado por la ecuación de regresión, es decir a lo que la ecuación de regresión deja sin explicar para cada individuo
Los procedimientos de visualización para determinar si el modelo está bien construido se basan en representar gráficamente estos errores y determinar si ellos presentan patrones anómalos respecto a la forma simétrica que teóricamente deberían presentar.
El residuo se calcula para cada individuo y proporciona información en cuanto a la diferencia entre el valor de supervivencia observado para ese individuo y el valor estimado por la ecuación de regresión, cuanto mayor es esa diferencia mayor será el valor del residuo, con su signo correspondiente.
Los residuos definidos y usados para validar una regresión de Cox son: la desviación, el residuo martingala, el residuo Schoenfeld y los residuos de Cox-Snell.
Los residuos de Cox-SnellEl residual Cox–Snell correspondiente al tiempo t i, esta dado por − ln [ S (t i ) ]donde S (t i) es el valor de la función de survivor estimado en tiempo t i
Si el modelo es correcto, entonces los residuos deben tener una distribución exponencial con media 1.
Los residuos martingala.La martingala residual Mi mide la diferencia en (0, t] entre el numero de eventos de interés que experimenta el individuo i-ésimo y el número esperado de eventos basado en el modelo.Mi = di - ri
di = 1 si ocurre el suceso (muerto)
di = 0 si la observación es censurada o incompleta
Donde ri es el error Cox-Snell y son iguales al negativo del logaritmo natural de la probabilidad de supervivencia para cada observación: ri¿−ln [ S (t i) ], por definición el residuo

24
martingala para un individuo incompleto (censurado) será negativo.
La martingala residual para el individuo i-ésimo es:
El valor máximo de la martingala residual es uno y el mínimo valor posible es infinito negativo, el residuo es muy sesgado por la izquierda. Una martingala residual negativa y grande indica un individuo de alto riesgo que todavía tenía un largo tiempo de supervivencia.
Los residuos de martingala tienen dos usos principales: pueden utilizarse para encontrar valores atípicos de individuos que son mal ajustadas por el modelo y pueden utilizarse para determinar la forma funcional de cada una de las variables en el modelo.
La suma de estos residuos es cero y no están correlacionados, su valor esperado es cero y aun cuando el modelo sea adecuado no se distribuyen de forma simétrica en torno a cero, lo cual dificulta la interpretación de los gráficos,
Los residuos de desviaciónLa desviación de un modelo de regresión es el estadístico que se utiliza para cuantificar hasta qué punto el modelo estimado se aleja de un modelo teórico que se ajustaria perfectamente a nuestros datos(denominado modelo completo o modelo saturado).
Los residuos de desviación D son una transformación de los residuos martingala y se determina a partir de la siguiente expresión:
D= -2 (ln LA - ln LS)donde LA corresponde a las funciones de verosimilitud para el modelo real y LS para el modelo ajustado La suma de los cuadrados de los residuos de desviación corresponde al valor de la desviación del modelo, los residuos de desviación se construyen transformando los residuos martingala de tal manera que produzcan valores simétricos en torno de 0.Un residuo con un valor negativo grande corresponderá a individuos que tienen un tiempo de supervivencia grande.
Un residuo de desviación con un valor negativo alto corresponde a individuos con un tiempo de supervivencia pequeño, contrariamente a lo que nos sugiere el modelo.
Análisis Grafico

25
Los procedimientos de visualización para determinar si el modelo está bien construido se basan en hacer representaciones gráficas de los residuos y determinar si ellos presentan patrones anómalos respecto a la forma simétrica que teóricamente deberían presentar. Para verificar el supuesto de adecuación de la forma funcional de cada covariable continua que interviene en el modelo, se utiliza el gráfico de los residuos de martingala versus el valor correspondiente a cada una de las covariables, acompañada de la curva de ajuste suavizadaLas graficas de residuos de Schoenfeld versus el tiempo son útiles para evaluar si se cumple la asunción de riesgos proporcionales, si la línea de mínimos cuadrados es horizontal, el supuesto de riesgo proporcional es razonable y para determinar valores atípicos de las covariables.
Para facilitar la interpretación de estas gráficas se suele superponer una curva de ajuste.
La verificación del supuesto de que no existen valores influyentes sobre la estimación del modelo se hace graficando los residuos de desviación versuslos individuos.
Modelo de Regresión Exponencial En este modelo se asume que la distribución de los tiempos de supervivencia es una distribución exponencial.
La rata de fallas expresada con la distribución exponencial se expresa como:
S(x) = exp(a+b1 x1 +...+bmxm )
S(x) es el tiempo de supervivencia, a es una constante y los bi los parámetros de la regresión.
Una regresión exponencial es equivalente a una regresión lineal, pues al tomar logaritmos a ambos lados de la ecuación de regresión S(x) =a*exp(b*X) se obtiene: ln(S(x)) = ln(a)+b*Xy si se hace: Z = ln(S(x))y U = ln(a),finalmente se tiene:
Z = U + b*X, que es el modelo lineal.
Si una de las variables independientes cambia con el tiempo, se puede utilizar el procedimiento de Cox con covariables dependientes del tiempo.
Básicamente, este modelo supone que la distribución del tiempo de supervivencia es exponencial, y depende de los valores de un conjunto de variables independientes (Xi ).
El parámetro tipo de la distribución exponencial entonces se puede expresar como:

26
S (x) = exp ( + 1 * x1 + 2 * x2 + ... + m* xm)
S (x) denota los tiempos de supervivencia, alfa es una constante, y los i son los parámetros de regresión.
La bondad de ajuste El valor Chi-cuadrado de bondad de ajuste se calcula en función del logaritmo de la verosimilitud para el modelo con todas las estimaciones de los parámetros, y el logaritmo de la verosimilitud del modelo en el que todas las covariables se hacen igual a 0.
Si el valor Chi-cuadrado es significativo, se rechaza la hipótesis nula y se supone que las variables independientes están significativamente relacionadas con los tiempos de supervivencia.
Estadística de orden exponencial. Una forma de comprobar la hipótesis de que un modelo es exponencial es graficar los tiempos de supervivencia residuales contra la norma estadística exponencial theta, si el supuesto de que es exponencial se cumplen, entonces todos los puntos en esta grafica se dispondrán aproximadamente en una línea recta.Básicamente, este modelo supone que la distribución del tiempo de supervivencia es exponencial, y depende de los valores de un conjunto de variables independientes (Xi ). El parámetro tipo de la distribución exponencial entonces se puede expresar como: S (x) = exp ( + 1 * x1 + 2 * x 2 + ... + m* x m )
S (x) denota los tiempos de supervivencia, alfa es una constante, y los i son los parámetros de regresión.
La bondad de ajuste El valor Chi-cuadrado de bondad de ajuste se calcula en función del logaritmo de la verosimilitud para el modelo con todas las estimaciones de los parámetros, y el logaritmo de la verosimilitud del modelo en el que todas las covariables se hacen igual a 0.
Si el valor Chi-cuadrado es significativo, se rechaza la hipótesis nula y se supone que las variables independientes están significativamente relacionadas con los tiempos de supervivencia.sicamente, este modelo supone que la distribución del tiempo de supervivencia es exponencial, y depende de los valores de un conjunto de variables independientes (Xi ).

27
El parámetro tipo de la distribución exponencial entonces se puede expresar como:
S (x) = exp ( + 1 * x1 + 2 * x 2 + ... + m* x m )
S (x) denota los tiempos de supervivencia, alfa es una constante, y los i son los parámetros de regresión.
La bondad de ajuste El valor Chi-cuadrado de bondad de ajuste se calcula en función del logaritmo de la verosimilitud para el modelo con todas las estimaciones de los parámetros, y el logaritmo de la verosimilitud del modelo en el que todas las covariables se ven obligados a ser 0.
Si el valor Chi-cuadrado es significativo, se rechaza la hipótesis nula y se supone que las variables independientes están significativamente relacionadas con los tiempos de supervivencia.
Estadística de orden exponencial.
Una forma de comprobar la hipótesis de que un modelo es exponencial es graficar los tiempos de supervivencia residuales contra la norma estadística exponencial theta, si el supuesto de que es exponencial se cumplen, entonces todos los puntos en esta grafica se dispondrán aproximadamente en una línea recta.
La regresión normal y log-normal
En este modelo, se asume que los tiempos de supervivencia (o tiempos de registro de la supervivencia) provienen una distribución normal, el modelo resultante es básicamente idéntico al del modelo de regresión múltiple ordinaria, y puede formularse así:
T = ( + 1 * x1 + 2 * x 2 + ... + m* x m )
donde Tdenota el tiempo de supervivencia.
Para la regresión log-normal, t se sustituye por su logaritmo natural, el modelo de regresión normal es particularmente útil porque muchosconjuntos de datos se pueden transformar para dar aproximaciones de la distribución normal.
Este modelo es completamente paramétrico, a diferencia de modelo de riesgo proporcional de Cox, que no es paramétrico.
Las estimaciones del modelo de regresión log-normal se pueden obtener para una variedad de diferentes distribuciones de supervivencia subyacentes.
La bondad de ajuste. El valor de Chi-cuadrado se calcula en función del logaritmo de la verosimilitud para el modelo con todas las variables independientes y el logaritmo de la verosimilitud del modelo en el que todas las variables independientes se ven obligadas a ser 0.

28
Los análisis estratificadosEl propósito de un análisis estratificado es poner a prueba la hipótesis de si los modelos de regresión son apropiados para los diferentes grupos, es decir, si las relaciones entre las variables independientes y la supervivencia son idénticas en los diferentes grupos. Para llevar a cabo un análisis estratificado, primero hay que ajustar el modelo de regresión respectiva separado dentro de cada grupo. La suma de los log verosimilitudes de estos análisis representa el logaritmo de la verosimilitud del modelo con diferentes coeficientes de regresión en los diferentes grupos.El siguiente paso es ajustar el modelo de regresión a todos los datos solicitados en la forma habitual, haciendo caso omiso de la pertenencia al grupo, y calcular el logaritmo de la verosimilitud para el ajuste global. La diferencia entre las probabilidades de registro puede hacerse la prueba de significación estadística (a través del Chi-cuadrado estadístico).El valor de Chi-cuadrado se calcula en función del logaritmo de la verosimilitud para el modelo con todas las variables independientes y el logaritmo de la verosimilitud del modelo donde todas las variables independientes se han obligado a ser igual a cero. Los análisis estratificados de regresión de CoxEl propósito de un análisis estratificado de regresión es poner a prueba la hipótesis de si los mismos modelos de regresión son apropiados para aplicarse a grupos diferentes.Se trata de averiguar, si las relaciones entre las variables independientes y la supervivencia se mantienen idénticas en los diferentes grupos. Se ajusta el modelo de regresión dentro de cada grupo por separado y se calcula la suma de los log verosimilitudes para cada grupo Se ajusta el modelo de regresión para todos los datos, haciendo caso omiso de la pertenencia al grupo, y se calcula el logaritmo de la verosimilitud para el ajuste global. Si los mismos modelos de regresión son apropiados para aplicarse a grupos diferentes, la diferencia entre el log verosimilitud para el ajuste global y la suma de los log verosimilitudes para cada grupo debería ser igual a cero.Aplicación de la Regresión de CoxEjemplo 1NefrectomíaLa tabla contiene datos de un estudio de n = 36 pacientes con tumores malignos en el riñón, divulgado por Collett (1994). El tiempo de supervivencia es en meses, Se clasifican los pacientes en tres grupos de edades. La edad se cifra como 1 para los pacientes con menos de 60 años, 2 para los pacientes entre 60 y 70, y 3 para los pacientes con más de 70 años.
Algunos pacientes en cada grupo habían experimentado una nefrectomía (retiro quirúrgico del riñón), mientras que otros no. La nefrectomía se cifra como 1 para esos pacientes que riñones fueron quitados y 0 para las que no tenían la cirugía.
Tiempo 9 6 21 15 8 17 12104 9 56 35 52 68 77 84 8 38 72
Censura 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0

29
Edad 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
Nefrectomía 1 1 1 2 2 2 3 1 1 1 1 1 1 1 1 1 1 1
Tiempo 36 48 26108 5
108 26 14
115 52 5 18 36 9 10 9 18 6
Censura 0 0 26 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0
Edad 1 1 26 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Nefrectomía 1 1 26 1 1 2 2 2 2 2 2 2 2 2 3 3 3 3
Se usara el modelo proporcional de los riesgos de Cox para determinar el efecto que produce la variable predictora sobre la función de riesgo.
El riesgo puede expresarse como el producto de un termino que incluye la variable predictora x y una función del riesgo básico h(t|0).
h{(t),(x1 , x2 ,..,x m)} = h0 (t) exp(1 x1 +...+m xm )
SoluciónModelo 1Variable dependiente: Tiempo de SupervivenciaCensura: CensuraFactores: Nefrectomía Edad
Número de valores no censurados: 32Número de valores censurados por derecha: 4
Modelo de Regresión EstimadoError LC Inferior 95,0% LC Superior 95,0%
Parámetro Estimado Estándar Límite de Conf. Límite de Conf.Nefrectomía -1,39666 0,374018 -2,12972 -0,663594Edad 0,461279 0,206183 0,0571666 0,865391Log verosimilitud = -83,9336
Pruebas de Razón de VerosimilitudFactor Chi-Cuadrada Gl Valor-PNefrectomía 6,5546 1 0,0105Edad 2,37943 1 0,1229
La salida muestra los resultados de ajustar un modelo de regresión Cox para describir la relación entre Tiempo de Supervivencia y 2 variables independientes.
La función de riesgo en una combinación seleccionada de factores de entrada por la función de riesgo basal h(t|0), como se muestra abajo:
h(t|x)=h(t|0)*exp(-1,39666*Nefrectomía + 0,461279*Edad)

30
Para determinar si el modelo puede ser simplificado, se nota que el P-valor más alto para las pruebas de verosimilitud es 0,1229, que pertenece a Edad. Como el P-valor es mayor o igual que 0,05, ese término no es estadísticamente significativo al nivel de confianza del 95,0%. Por lo que se debe eliminar Edad del modelo.
Modelo 2Variable dependiente: Tiempo de SupervivenciaCensura: CensuraFactores: NefrectomíaNúmero de valores no censurados: 32Número de valores censurados por derecha: 4
Modelo de Regresión EstimadoError LC Inferior 95,0% LC Superior 95,0%
Parámetro Estimado Estándar Límite de Conf. Límite de Conf.
Nefrectomía -1,47939 0,354789 -2,17476 -0,784013
Log verosimilitud = -85,1233
Pruebas de Razón de VerosimilitudFactor Chi-Cuadrada Gl Valor-PNefrectomía 7,41988 1 0,0064
La salida muestra los resultados de ajustar el modelo de regresión Cox para describir la relación entre Tiempo de Supervivencia y 1 variable independiente La función de riesgo es:
h(t|x)=h(t|0)*exp(-1,47939*Nefrectomía)
Para determinar si el modelo puede ser simplificado, se nota que el valor-P más alto para las pruebas de verosimilitud es 0,0064, que pertenece a Nefrectomía. Como el valor-P es menor que 0,05, ese término es estadísticamente significativo al nivel de confianza del 95,0%. Consecuentemente, no se debe eliminar ninguna variable del modelo. y la expresión final para el riesgo será:
h(t|x)=h(t|0)*exp(-1,47939*Nefrectomía)
Tablas y GraficasEsta tabla muestra la función de riesgo estimada, la función de supervivencia y la función de riesgo acumulada cuando las variables independientes se han establecido en:

31
Nefrectomía = 0,5 Edad = 2Función de Función de Riesgo
Tiempo de Supervivencia
Riesgo Supervivencia Acumulado
0.0- 0.0 1.0 0.05,0- 0,0385844 0,961566 0,03919186,0- 0,077914 0,887242 0,1196378,0- 0,0846968 0,812746 0,2073369,0- 0,180824 0,668554 0,40263810,0- 0,0567573 0,630828 0,460722
GraficasSe presentan las graficas del riesgo estimado y de riesgo acumulado para los valores de Edad = 2
TIEMPO DE SUPERVIVENCIA
Ries
go p
or u
nida
d de
tie
mpo
CIRUGIANOSI
0 20 40 60 80 100 120
Función de Riesgo EstimadaEDAD = 2
0
0,03
0,06
0,09
0,12
0,15
EDAD = 2
TIEMPO DE SUPERVIVENCIA
Rie
sgo
Acu
mul
ado
0 20 40 60 80 100 120
Función Estimada de Riesgo Acumulado
0
1
2
3
4
5 CIRUGIANOSI
ResiduosEsta tabla despliega varios tipos de residuos. Los residuos Cox-Snell deberían comportarse como una muestra Proveniente de una distribución exponencial con media igual a 1

32
Residuo Residuo Residuo Residuo
Fila SUPER TIEMPO Cox-Snell C.S. Modificado Martingala de Desviación
1 9,0 0,510345 0,510345 0,489655 0,605001
2 6,0 0,151641 0,151641 0,848359 1,44075
3 21,0 1,44709 1,44709 -0,447094 -0,393793
4 15,0 1,37497 1,37497 -0,374974 -0,336271
5 8,0 0,416827 0,416827 0,583173 0,764082
Los residuos Cox-Snell deberían comportarse como una muestra proveniente de una distribución exponencial con media igual a 1. Los residuos Martingala y de Desviación deberían dispersarse aleatoriamente alrededor de 0.
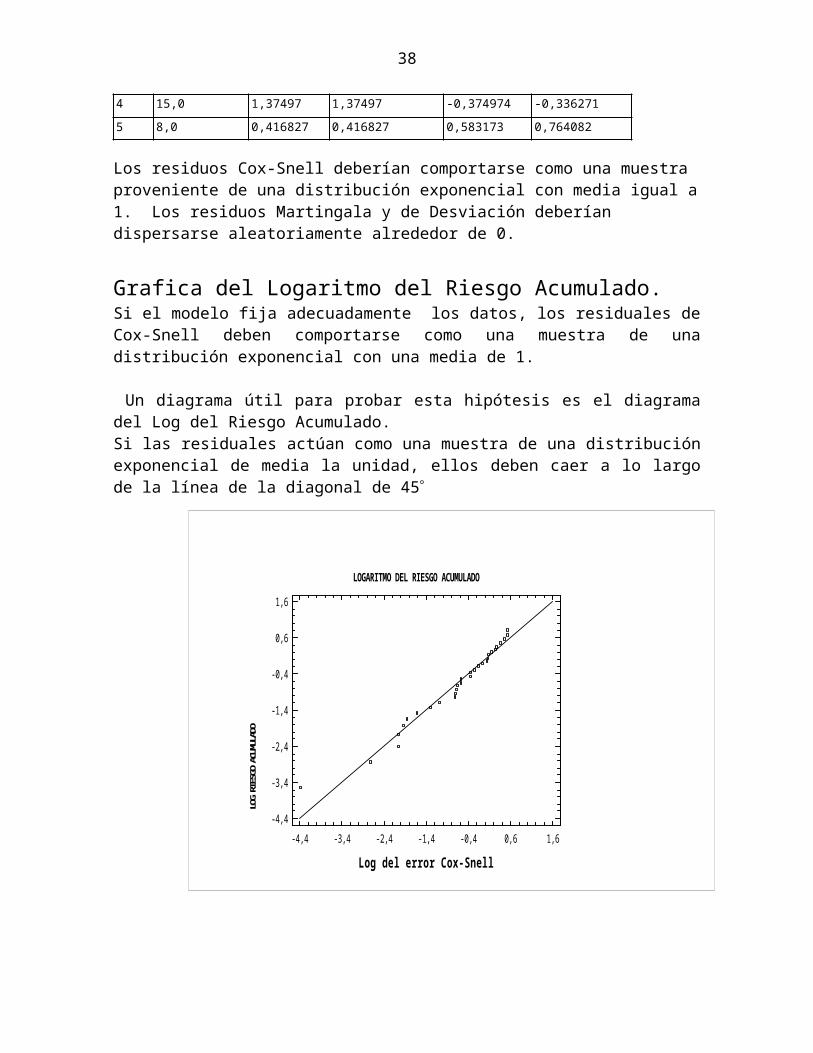
Grafica del Logaritmo del Riesgo Acumulado.Si el modelo fija adecuadamente los datos, los residuales de Cox-Snell deben comportarse como una muestra de una distribución exponencial con una media de 1.
Un diagrama útil para probar esta hipótesis es el diagrama del Log del Riesgo Acumulado.Si las residuales actúan como una muestra de una distribución exponencial de media la unidad, ellos deben caer a lo largo de la línea de la diagonal de 45
Log del error Cox-Snell
LOGARITMO DEL RIESGO ACUMULADO
LOG R
IESG
O A
CUMULA
DO
-4,4 -3,4 -2,4 -1,4 -0,4 0,6 1,6-4,4
-3,4
-2,4
-1,4
-0,4
0,6
1,6

33
Aplicación de la Regresión de CoxEjemplo 2
El tiempo de supervivencia de un paciente a un enfermedad puede depender no sólo del tratamiento, sino también de otras variables como la edad, el tiempo desde el diagnostico de la enfermedad o el estado de gravedad de la afección del paciente.
Para ilustrar la aplicación de la regresión de Cox se tratara de estudiar la relación entre el tiempo de supervivencia de un paciente y de cuatro covariables: la edad, el sexo, el status (estado de la enfermedad), los meses de diagnostico y la terapia.Se hará un estudio del tiempo de supervivencia de los pacientes usando una data hipotética para las siguientes variables:
TIEMPO DE VIDA Días de supervivencia.CENSURA Indicador de Censura.STATUS Estado de avance de la enfermedad.MESES Meses del diagnostico.EDAD Edad en años.TERAPIA Indicador de Terapia: 0 No, 10 Si.
Riesgos Proporcionales de Cox – Caso TerapiaDATA
T TVIDA CENSURA STATUS MESES EDAD TERAPIA
72 1 60 7 69 0
411 1 70 5 64 10
228 1 60 3 38 0
126 1 60 9 63 10
118 1 70 11 65 10
10 1 20 5 49 0
82 1 40 10 69 10
110 1 80 29 68 0
314 1 50 18 43 0
100 0 70 6 70 0
42 1 60 4 81 0
8 1 40 58 63 10
144 1 30 4 63 0
25 0 80 9 52 10
SoluciónSe aplicara el método forward (hacia atrás) para la selección de las variables salientes del modelo y se usara un p-valor de 0.05 para eliminar una variable del modelo. 1. Modelo con 4 variables

34
Variable dependiente: TVIDACensura: CENSURAFactores: STATUS MESES EDAD TERAPIANúmero de valores no censurados: 2Número de valores censurados por derecha: 12Modelo de Regresión Estimado
Error LC Inferior 95,0% LC Superior 95,0%Parámetro Estimado Estándar Límite de Conf. Límite de Conf.STATUS 5,81784 0,0183044 5,78196 5,85372MESES -3,77485 0,0227314 -3,8194 -3,7303EDAD -0,625714 0,0281058 -0,6808 -0,570628TERAPIA -3,26251 0,0662176 -3,39229 -3,13272Log verosimilitud = -2,45564E-11
Pruebas de Razón de VerosimilitudFactor Chi-Cuadrada Gl Valor-PSTATUS 8,76554 1 0,0031MESES 5,97339 1 0,0145EDAD -4,91127E-11 1 1,0000TERAPIA 0,00000691799 1 0,9979
La salida muestra los resultados de ajustar un modelo de regresión de Cox para describir la relación entre TVIDA y 4 variables independientes.
La función de riesgo en una combinación seleccionada de factores de entrada x es un múltiplo de la función de riesgo basal h(t|0), como se muestra abajo:
h(t|x)=h(t|0)*exp(5,81784*STATUS - 3,77485*MESES - 0,625714*EDAD - 3,26251*TERAPIA)
Para determinar si el modelo puede ser simplificado, se observa que el valor-P más alto para las pruebas de verosimilitud es 1,0000, que pertenece a la variable EDAD.
Como el valor-P para la variable EDAD es mayor o igual que 0,05, ese término no es estadísticamente significativo al nivel de confianza del 95,0% o mayor, razón por la cual se debería eliminar variable EDAD del modelo.
Modelo sin la variable EDADModelo con 3 variablesVariable dependiente: T TVIDACensura: CENSURAFactores: MESES STATUS TERAPIA

35
Número de valores no censurados: 2Número de valores censurados por derecha: 12
Modelo de Regresión EstimadoError LC Inferior 95,0% LC Superior 95,0%
Parámetro Estimado Estándar Límite de Conf. Límite de Conf.
MESES -10,2777 0,0219045 -10,3206 -10,2347
STATUS 10,2859 0,0173659 10,2519 10,3199
TERAPIA -4,08772 0,0637157 -4,2126 -3,96284
La salida muestra los resultados de ajustar un modelo de regresión Cox para describir la relación entre TVIDA y 3 variables independientes. La función de riesgo en una combinación seleccionada de factores de entrada x es un múltiplo de la función de riesgo basal h(t|0), como se muestra abajo:h(t|x)=h(t|0)*exp(-10,2777*MESES + 10,2859*STATUS - 4,08772*TERAPIA)
Para determinar si el modelo puede ser simplificado, se observa que el valor-P más alto para las pruebas de verosimilitud es 0,1563 y que pertenece a la variable TERAPIA.
Como el valor-P es mayor o igual que 0,05, ese término no es estadísticamente significativo al nivel de confianza del 95,0%.o mas, por lo que se debería eliminar la variable TERAPIA del modelo. Modelo sin la variables TERAPIA y EDADModelo con 2 variables
Variable dependiente: T TVIDACensura: CENSURAFactores: STATUS MESESNúmero de valores no censurados: 2Número de valores censurados por derecha: 12Modelo de Regresión Estimado
Error LC Inferior 95,0% LC Superior 95,0%
Parámetro Estimado Estándar Límite de Conf. Límite de Conf.
STATUS 0,64584 0,0162675 0,613956 0,677724
MESES -0,416125 0,0201204 -0,45556 -0,376689
Log verosimilitud = -1,00465
Pruebas de Razón de Verosimilitud

36
Factor Chi-Cuadrada Gl Valor-P
STATUS 6,83712 1 0,0089
MESES 4,24891 1 0,0393
La salida muestra los resultados de ajustar un modelo de regresión falla-tiempo para describir la relación entre T TVIDA y 2 variable(s) independiente(s). La función de riesgo en una combinación seleccionada de factores de entrada x es un múltiplo de la función de riesgo basal h(t|0), como se muestra abajo:
h(t|x)=h(t|0)*exp(0,64584*STATUS - 0,416125*MESES)
Para determinar si el modelo puede ser simplificado, se observa que el valor-P más alto para las pruebas de verosimilitud es 0,0393 y que pertenece a la variable MESES
Como el valor-P es menor que 0,05, ese término es estadísticamente significativo al nivel de confianza del 95,0%. O más, por lo que no se debería eliminar la variable MESES del modelo
MODELO FINALDe los resultados obtenidos para ajustar un modelo de regresión de Cox para describir la relación entre TVIDA y 4 variables independientes indican que no existe relación entre la variable TERAPIA y la variable EDAD con el tiempo de Supervivencia, mientras que sí indican una asociación significativa entre el tiempo de supervivencia y las otras dos variables: MESES desde el Diagnostico y el STATUS de la enfermedad. ConclusiónEl modelo exponencial de riesgo proporcional de Cox es un modelo adecuado para ajustar el tiempo de supervivencia de los pacientes del ejemplo hipotético, con un modelo de regresión exponencial: h(t|x)=h(t|0)*exp(0,64584*STATUS - 0,416125*

37
0,000
1,250
2,500
3,750
5,000
0,0 125,0 250,0 375,0 500,0
SUPER ACUMULADA
MESES
SUPE
R A
CU
MU
LAD
ATERAPIA
010
MESES)Graficas de la regresión de Cox para TerapiaGRAFICAS DE SUPERVIVENCIA
Y SU
0,000
0,250
0,500
0,750
1,000
0,0 125,0 250,0 375,0 500,0
SUPERVIVENCIA
MESES
PRO
B SU
PER
VIVE
NC
IA
TERAPIA010
PERVIVENCIA ACUMULADA
Aplicación de la Regresión de CoxEjemplo 3: Antigüedad
38
Se usara la Regresión de Cox para determinar la relación que pueda existir entre la antigüedad de los trabajadores activos e inactivos de una empresa con cinco covariables: la edad del trabajador, el departamento al cual pertenece, el tiempo de educación, el sexo y el salario mensualANTIGUEDAD Meses de antigüedad en la empresa.CENSURA Indicador de Censura (Activos = 1, Inactivos = 0)SEXO Sexo del TrabajadorDEPARTAMENTO Departamento donde labora el Trabajador.SALARIO Salario Mensual del Trabajador. Miles de BolivaresEDAD Edad del Trabajador en años.EDUCACION Grado de Educación del Trabajador.DATACENSURA
SEXO
DPTO
SALAR
ANTIG
EDUC
EDAD
CENSURA
SEXO
DPTO
SALAR
ANTIG
EDUC
EDAD
1 1 1 1000 92 2 24 1 2 2 900 208 3 42
1 2 1 1200 195 2 40 0 2 2 1200 88 2 30
1 1 1 1400 234 2 55 1 2 2 1300 98 4 29
0 1 1 900 75 3 25 1 1 2 1500 233 4 41
1 1 1 1400 232 4 51 1 1 3 1900 254 4 50
1 2 1 900 295 5 50 0 1 3 1000 307 5 47
1 1 1 1000 65 2 27 1 2 3 980 75 2 28
0 2 1 900 98 2 26 1 1 3 1800 122 1 28
0 1 1 1800 243 3 48 1 1 3 1300 226 3 43
1 1 2 1100 178 1 28 1 2 3 1100 99 3 29
1 2 2 1600 250 4 46 1 2 3 1100 210 4 39
1 1 2 1150 124 3 33 1 1 4 1300 186 3 32
1 2 2 900 208 3 42 0 1 4 1400 130 4 35
Se usara el Método de Regresión de Cox con data censurada para tratar de determinar la existencia de una relación entre la antigüedad de los trabajadores de la empresa con algunas de las covariables y para ello se presentara:
1. Un reporte tabular de la R de Cox (Coeficientes, Modelo y Residual).2. Un reporte grafico de la regresión de Cox.3. Las conclusiones sobre el resultado de la regresión.
VARIABLE: ANTIGUEDADCENSURA: CENSURA
COVARIABLES:SEXO DEPARTAMENTO SALARIO

39
EDUCACION EDAD
Modelo CompletoCOVARIABLES: SEXO DEPARTAMENTO SALARIO EDUCACION EDAD
Valor del ParámetroError Estándar
LimiteInferior 95,0%
LimiteSuperior 95,0%
Parámetro Estimación Conf. Limite Conf. LimiteEDAD -0,255778 0,00750135 -0,27048 -0,241075EDUCACION -0,560848 0,0592712 -0,677017 -0,444678SALARIO -0,0000759182 0,000213171 -0,000493727 0,000341891SEXO 0,701814 0,107707 0,490712 0,912915DEPARTAMENTO -0,059534 0,0567489 -0,17076 0,0516919Log Verosimilitud = -28,4015
Tests de VerosimilitudFactor Chi-Squared Df P-ValueEDAD 15,3129 1 0,0001EDUCACION 2,02038 1 0,1552SALARIO 0,00505854 1 0,9433SEXO 1,35681 1 0,2441DEPARTAMENTO 0,027065 1 0,8693
La salida muestra el resultado de aplicar la regresión de Cox para describir la relación entre la ANTIGUEDAD y 5 variables independientes
La función de riesgo para una selección de las covariables es:
h(t|x)=h(t|0)*exp(-0,255*EDAD - 0,560*EDUCACION - 0,000075*SALARIO + 0,7018*SEXO - 0,059*DEPARTAMENTO)
La variable SALARIO presenta el mayor valor del P-value( 0,9433) por lo que para mejorar el modelo, se remueve la variable SALARIO.
Modelo 2COVARIABLES:SEXO DEPARTAMENTO EDUCACION EDAD
Standard Lower 95,0% Upper 95,0%Parámetro Estimado Error Conf. Limite Conf. LimiteEDAD -0,257515 0,00635992 -0,26998 -0,24505EDUCACION -0,549998 0,055709 -0,659186 -0,440811SEXO 0,708095 0,100362 0,511389 0,9048DEPARTAMENTO -0,0693051 0,0519317 -0,17109 0,0324792Log Verosimilitud = -28,404
40
Tests de VerosimilitudFactor Chi-
SquaredDf P-Valué
EDAD 17,0795 1 0,0000EDUCACION 2,28627 1 0,1305SEXO 1,42601 1 0,2324DEPARTAMENTO 0,043343 1 0,8351
La salida muestra el resultado de aplicar la regresión de Cox para describir la relación entre la ANTIGUEDAD y 5 variables independientes
La función de riesgo para una selección de las covariables es:
h(t|x)=h(t|0)*exp(-0,25*EDAD - 0,5499*EDUCACION + 0,708*SEXO - 0,0693*DEPARTAMENTO)
La variable DEPARTAMENTO presenta el mayor valor del P-value (0,8351) por lo que para mejorar el modelo, se remueve la variable DEPARTAMENTO.
Modelo 3COVARIABLES: SEXO EDUCACION EDAD
Standard Lower 95,0% Upper 95,0%Parámetro Estimado Error Conf. Limite Conf. LimiteEDAD -0,254369 0,00630838 -0,266734 -0,242005EDUCACION -0,578756 0,0545075 -0,685589 -0,471923SEXO 0,756307 0,102243 0,555915 0,9567Log Verosimilitud = -28,4257
Test de VerosimilitudFactor Chi-
SquaredDf P-Valué
EDAD 19,8473 1 0,0000EDUCACION 2,97488 1 0,0846SEXO 1,86952 1 0,1715
La salida muestra el resultado de aplicar la regresión de Cox para describir la relación entre la ANTIGUEDAD y 3 variables independientes La función de riesgo para una selección de las covariables es:
h(t|x)=h(t|0)*exp(-0,254369*EDAD - 0,578756*EDUCACION + 0,756307*SEXO)

41
La variable SEXO presenta el mayor valor del P-value ( 0,1715) por lo que para mejorar el modelo, se remueve la variable SEXO
Modelo 4COVARIABLES:1
EDUCACION EDADStandard Lower 95,0% Upper 95,0%
Parámetro Estimado Error Conf. Limite Conf. LimiteEDAD -0,244969 0,00610982 -0,256944 -0,232994EDUCACION -0,466294 0,0529003 -0,569977 -0,362611Log Verosimilitud = -29,3605
Test de VerosimilitudFactor Chi-Squared Df P-ValuéEDAD 20,0266 1 0,0000EDUCACION 2,1893 1 0,1390
La salida muestra el resultado de aplicar la regresión de Cox para describir la relación entre la ANTIGUEDAD y 2 variables independientes
La función de riesgo para una selección de las covariables es:h(t|x)=h(t|0)*exp(-0,244969*EDAD - 0,466294*EDUCACION)
La variable EDUCACION presenta el mayor valor del P-valor (0,1390) por lo que para mejorar el modelo, se remueve la variable EDUCACION.
Modelo FinalCOVARIABLES: EDAD
Standard Lower 95,0% Upper 95,0%
Parámetro Estimado Error Conf. Limite Conf. Limite
EDAD -0,275709 0,00501396 -0,285536 -0,265882
Log Verosimilitud = -30,4551Test de Verosimilitud
1

42
FUNCION DE RIESGO
ANTIGUEDAD
RIES
GO
POR
UNID
AD D
E TI
EMPO
0 100 200 300 400
EDAD_1=39,5,SALAR_1=1400,0,DPTO_1=2,5,SEXO_1=1,5
0
0,02
0,04
0,06
0,08
0,1 EDUC_11,05,0
Factor Chi-Quered Df P-Valué
EDAD 28,12 1 0,0000
La salida muestra el resultado de aplicar la regresión de Cox para describir la relación entre la ANTIGUEDAD y 1 variable independiente.
La función de riesgo para el modelo final es:h(t|x)=h(t|0)*exp(-0,275709*edad)log[h{(t),(x..)}/h0 (t)] = 0,275709*edad
Antiguedad Observada vs. Prediccion
ANTIG. PREDICCION
ANTI
GU
EDAD
40
80
120
160
200
240
280
320
360
40 100 160 220 280 340