universidad salesiana -...
TRANSCRIPT

UNIVERSIDAD SALESIANADE BOLIVIA
INGENIERIA DE SISTEMAS
DOSSIERMATERIA: PROYECTO DE SOFTWARE
PARALELO: ”A1”
DOCENTES: Lic. ADRIAN QUISBERT VILELA

INDICE
INDICE..................................................................................................................................2PRESENTACIÓN..................................................................................................................3
UNIDAD I INTRODUCCIÓN AL DESARROLLO DE PROYECTOS DE SOFTWARE …9
UNIDAD II FUNDAMENTOS DE PROGRMACION JAVA ……………………………… 25
UNIDAD III PROGRAMACIÓN EN JAVA …………………………………………………… 55
UNIDAD IV ACCESOS A BASES DE DATOS MEDIANTE JDBC-ODBC ……………… 88
UNIDAD V JAVA EN EL LADO CLIENTE ………………………………………………… 113
UNIDAD VI ARQUITRECTURA CLIENTE / SERVIDOR ……………………………….. 126
BIBLIOGRAFIA ………………………………………………………………………………..176
GLOSARIO…………………………………………………………………………………….176
LECTURAS COMPLEMENTARIAS.................................................................................179

PRESENTACIÓNEl presente documento es un esfuerzo de los docentes de la materia de Proyecto de Software que se plasma en un texto cuyo fin es el de poner al alcance de los estudiantes, un instrumento complementario a los conceptos y saberes impartidos en aula.Su objetivo es el de proporcionar a los estudiantes y comunidad salesiana en general, una herramienta complementaria y de apoyo a los conocimientos impartidos en aula y laboratorio de la materia Proyecto de Software.
El contenido está estructurado de manera secuencial y en función a los planes de trabajo establecidos, de tal forma que el contenido de este material pueda ser también aprovechado y explotado por los estudiantes.
Este documento tiene gran importancia, ya que es un elemento muy importante en el ámbito de la planificación de la materia durante esta gestión, también en la coordinación de avance de materia entre los diferentes paralelos y por ultimo permite transparentar la gestión de aula, cátedra y aprendizaje universitario en la Universidad Salesiana.
Los docentes

OBJETIVOS DE LA MATERIA
GENERAL
Desarrollar proyectos de software utilizando tecnologías y herramientas nuevas de tal forma que el estudiante pueda desarrollare software de calidad. Desarrollar las destrezas necesarias para programar aplicaciones orientadas a objetos utilizando lenguajes de programación tal como es el Java así también el acceso a bases de datos mediante JDBC-ODBC en lado cliente y lado servidor demostrando al mismo tiempo la arquitectura cliente / servidor.
ESPECÍFICOS- Dar a conocer los conceptos fundamentales sobre análisis diseño y
programación orientada a objetos para el desarrollo de software.
- Introducir al alumno en los conceptos sobre el lenguaje de programación JAVA.
- Dar a conocer toda la teoría de desarrollo de proyecto de software para sus desarrollo, utilizando la norma IEE 830.
- Dar a conocer los conceptos de la arquitectura cliente / servidor para el desarrollo de software.
COMPETENCIAS
Asimila los fundamentos necesarios(métodos, técnicas procedimientos y
herramientas) sobre programación en java, conocimiento que lo aplica en la
optimización de soluciones de problemas de la vida real.
Establece con mayor detalle los métodos de resolución general de problemas aplicando métodos y normas de desarrollo de proyectos software
Construir Algoritmos que permitan resolver problemas reales.
Desarrolla proyectos software con arquitectura cliente / servidor


COMPETENCIAS POR UNIDADES DIDACTICAS
Contenido COMPETENCIAS ESPECIFICASINTRODUCCIÓN Asimila y aplica los conceptos de
desarrollo de software .
Comprende la importancia de aplicar las normas de desarrollo de software
JAVA DEVELOPMENT KIT (JDK Conceptualiza e instala los programas java para su aplicación y desarrollo de aplicaciones en JAVA
CONCEPTOS DE PROGRAMACIÓN ORIENTADA A OBJETOS
Aplica los conceptos fundamentales de programación orientada a objetos
Comprende la importancia de una buena programación
Evalúa los fundamentos de programación en java
Conoce el uso de reglas en programación que aplica en desarrollo de software.
TECNOLOGIA DE OBJETOS Comceptualiza y aplica las terorias de programación orientada a objetos en la resolución de problemas.
SINTAXIS DEL JAVA VARIABLES Y TIPOS DE DATOS
Conoce la sintaxis del leguaje java y desarrolla diferentes aplicación con estructuras de datosDesarrolla programas con interfaces graficasAplica todo el conocimiento de programación grafica.
INTRODUCCIÓN A LOS APPLETS Comprende la programación en el lado cliente
Mejora la presentaciones de las paginas web con los applets
LAS EXCEPCIONES Conceptualiza y maneja las excepciones para el control de errores en tiempo de ejecución.
Aplica las diferentes excepciones en las aplicaciones.
ACCESO A BASE DE DATOS MEDIANTE JDBC-ODBC
Aplica conceptos de bases de datosRealiza conexiones de bases de datos

mediante ODBCAplica consultas SQL.
SERVLETS Aplica la arquitectura cliente servidor en
programación via web, utilizando los
servlets.


UNIDAD I
DESARROLLO DE PROYECTOS DE SOFTWARE
1. INTRODUCCIÓN AL DESARROLLO DE UN SOFTWARE
El proceso de desarrollo de software puede definirse como un conjunto de herramientas, métodos y prácticas que se emplean para producir software. Como cualquier otra organización, las dedicadas al desarrollo de software mantienen entre sus principales fines, la producción de software de acuerdo con la planificación inicial realizada, además de una constante mejora con el fin de lograr los tres objetivos últimos de cualquier proceso de producción: alta calidad y bajo coste, en el mínimo tiempo. La gestión de un PDS engloba, por tanto, todas las funciones que mantengan a un proyecto dentro de unos objetivos de coste, calidad y duración previamente estimados. La mayoría de estas funciones y técnicas de gestión y control empleadas, se han importado de otras industrias de producción que desarrollaron estos métodos a principios de siglo.
Sin embargo, los problemas de gestión que surgen en las organizaciones de desarrollo provienen principalmente de la gestión estratégica, como puede ser el entorno socio/político de la organización, su nivel de madurez y los factores humanos o del personal técnico. De hecho, la incapacidad de las técnicas de gestión actuales para tratar el complicado factor humano ha sido reconocida como uno de los principales problemas.Para definir lo que es un proyecto de software partiremos de la definición misma de software y continuaremos con la definición de lo que es un proyecto.
1.1 ¿Qué es el software?
(1) Instrucciones de ordenador que cuando se ejecutan proporcionan la función y el comportamiento deseado.(2) Estructuras de datos que facilitan a los programas manipular adecuadamente la información.(3) Documentos que describen la operación y el uso de los programas.
1.2 Características del software
• El software se desarrolla, no se fabrica en sentido estricto.• El software no se estropea se deteriora.• La mayoría del software se construye a medida.
1.3 ¿Qué es un proyecto?

Un proyecto es esencialmente un conjunto de actividades interrelacionadas, con un inicio y una finalización definida, que utiliza recursos limitados para lograr un objetivo deseado.
Los dos elementos básicos que incluye esta definición son: las actividades y los recursos.
1.3.1 Las ActividadesSon las tareas que deben ejecutarse para llegar en conjunto a un fin preestablecido (objetivo deseado); por ejemplo: recopilar información; realizar diagnósticos; confeccionar un diseño global de un procedimiento, programar, escribir manuales de procedimiento, etc. (Ver Metodología para el desarrollo de sistemas)
Un aspecto fundamental en todo proyecto es el orden en el cual se realizan las actividades. Y para determinar la secuencia lógica de las actividades se debe establecer el método, el tiempo y el costo de cada operación.
1.3.2 Los Recursos Son los elementos utilizados para poder realizar la ejecución de cada una de las tareas; como por ejemplo: hardware, programas de base (sistemas operativos), programas de aplicación, discos de almacenamiento, energía, servicios, inversiones de capital, personal, información, dinero y tiempo (Ver Consideraciones en un plan estratégico informático).
Entonces: El fin primario de desarrollar un proyecto debe ser producir un programa calendario en el cual los recursos, siempre limitados, se asignen a cada una de las actividades en forma económicamente óptima.
Estas limitaciones en cuyo contexto se resuelve planear un proyecto pueden ser internas, por ejemplo: computadoras disponibles, capacidad del personal, disposiciones presupuestarias, o bien externas, como ser: fechas de entrega de cualquier tipo de recursos, factores climáticos, aprobaciones de organismos oficiales. En ambos casos las limitaciones deben tenerse particularmente en cuenta al estimar los tiempos de cada actividad.
En cuanto al objetivo del proyecto, este puede ser sencillo y no demandar ni muchas tareas ni demasiados recursos; o por el contrario, puede ser complejo y exigir múltiples actividades y una gran cantidad de recursos para poder alcanzarlo.
Pero independientemente de su complejidad, característicamente todo proyecto reúne la mayoría de los siguientes criterios:
Tener un principio y un fin Tener un calendario definido de ejecución

Plantearse de una sola vez Constar de una sucesión de actividades o de fases Agrupar personas en función de las necesidades específicas de cada actividad Contar con los recursos necesarios para desenvolver las actividades
Ahora piense por un instante en cada uno de los proyectos que se desarrollan en las organizaciones, y verá que todos ellos tienen cometidos que deben cumplirse en un cierto plazo de tiempo y que además requieren de la concurrencia de otras personas.
Y es aquí donde empieza a tener relevancia la figura del administrador, en los proyectos a realizarse en las organizaciones; incluidos los proyectos informáticos.
Los administradores eficaces de proyectos, son los que logran que el trabajo se ejecute a tiempo, dentro del presupuesto, y conforme a las normas de calidad especificadas.
2. PLANIFICACIÓN DE LA REALIZACIÓN DE UN SOFTWARE
2.1 ¿Qué es un proyecto de software?
De la definición de proyectos, vista en el punto anterior, podemos aplicarla a los proyectos de software; y decir que:
Es un sistema de cursos de acción simultáneos y/o secuenciales que incluye personas, equipamientos de hardware, software y comunicaciones, enfocados en obtener uno o más resultados deseables sobre un sistema de información.
Es el Proceso de gestión para la creación de un Sistema o software, la cual encierra un conjunto de actividades, una de las cuales es la estimación, estimar es echar un vistazo al futuro y aceptamos resignados cierto grado de incertidumbre. Aunque la estimación, es mas un arte que una Ciencia, es una actividad importante que no debe llevarse a cabo de forma descuidada. Existen técnicas útiles para la estimación de costes de tiempo. Y dado que la estimación es la base de todas las demás actividades de planificación del proyecto y sirve como guía para una buena Ingeniería Sistemas y Software.
Al estimar tomamos en cuenta no solo del procedimiento técnico a utilizar en el proyecto, sino que se toma en cuenta los recursos, costos y planificación. El Tamaño del proyecto es otro factor importante que puede afectar la precisión de las estimaciones. A medida que el tamaño aumenta, crece rápidamente la interdependencia entre varios elementos del Software.
La disponibilidad de información Histórica es otro elemento que determina el riesgo de la estimación.

2.2 Objetivos de la Planificación del ProyectoEl objetivo de la Planificación del proyecto de Software es proporcionar un marco de trabajo que permita al gestor hacer estimaciones razonables de recursos costos y planificación temporal. Estas estimaciones se hacen dentro de un marco de tiempo limitado al comienzo de un proyecto de software, y deberían actualizarse regularmente medida que progresa el proyecto. Además las estimaciones deberían definir los escenarios del mejor caso, y peor caso, de modo que los resultados del proyecto pueden limitarse.
El Objetivo de la planificación se logra mediante un proceso de descubrimiento de la información que lleve a estimaciones razonables.
El inicio de un proyecto de software generalmente está dado en la solicitud de requerimientos de los usuarios, y siendo que los diferentes Sistemas de Información abordan los diferentes tipos de problemas organizacionales; podemos clasificar a los Sistemas de Información según sean las aplicaciones que necesite cada usuario en: Sistemas de Transacciones, Sistemas de Soporte para la toma de decisiones, y Sistemas Expertos.Los recursos mas frecuentemente utilizados que caracterizan a un sistema de información, son los componentes de la Tecnología de la Información ( TI ) como ser el uso de Hardware, Software y Comunicaciones.
En cuanto a estos elementos de la Tecnología de la Información, podemos considerar que ya han llegado a un desarrollo más que suficiente para la aplicación en una operación informática. Lo que nos lleva a que la gestión de un hecho informático como un proyecto integral, tanto sea en su entorno de diseño, como en su planificación y control, definen una nueva etapa; una mayoría de edad en el tratamiento informático.
Es así que hoy dada la evolución en la Tecnología de la Información, los proyectos de aplicación típicamente administrativos, desarrollados principalmente en pequeñas y medianas empresas, y que desarrollan su planeamiento informático basado en el uso de las microcomputadoras; puedan ser administrados por un único profesional
Es por todo esto que, los conceptos de Proyecto y de Metodología de diseño que, hasta hace poco tiempo, eran solamente aplicados a grandes emprendimientos; hoy también deben ser aplicados a medianos y pequeños emprendimientos.
Considerando entonces, la importancia que la informática tiene en los planes estratégicos de cualquier empresa moderna; no solamente se debe tener en cuenta la evolución de los recursos de la tecnología de la información, sino también las distintas metodologías para el desarrollo de los sistemas de información.

Así es que, el solo hecho de considerar a un asunto informático como un proyecto al que se asocian técnicas y procedimientos de diseño, supone un paso importante.
3. ETAPAS DE LA REALIZACIÓN DE UN SOFTWARE
3.1 Inicio de un proyecto informático
Ya vimos una clasificación, que nos permite clarificar el origen de un proyecto informático, pero ¿cómo podremos determinar la magnitud de un Proyecto informático?.
En un entorno informático estable, la decisión de iniciar un proyecto viene dada por las necesidades de: mantenimiento, modificación, mejoramiento, reemplazo o capacidad; encuadrándose así, el proyecto informático, dentro de una categoría de complejidad mostrada en la figura 3.1.
Figura 3.1 Categorías de los sistemas de información
3.2 El mantenimiento del programaEs una consecuencia de una omisión realizada en la etapa del diseño del sistema (Ver Metodología para el desarrollo de sistemas) e involucra solucionar fallas menores del sistema, que obligará a la realización de cambios en el programa; como por ejemplo el descuido de no considerar que puedan ocurrir en el sistema, ciertas condiciones extraordinarias; como sería el caso de un aumento no previsto del 60 %, en la emisión de órdenes de compra. Las fallas también pueden provenir de otros factores, como ser en el caso de que existan cambios en las expectativas de los usuarios.
3.3 La modificación del programaInvolucra algo más que un simple cambio en el programa; involucra un cambio estructural de una entidad Por ejemplo, un cambio en el número de dígitos del código postal, o en el código de zona telefónica. La diferencia con el Mantenimiento es el grado de importancia.
3.4 El mejoramiento del sistema

Es el agregado de capacidades que no formaron parte del sistema de información original; por ejemplo cuando en una división se implementó un sistema de inventarios, este sistema no incluía un modulo para calcular la futura demanda de bienes y partes. La inclusión de este sofisticado módulo de cálculo es considerado un mejoramiento del sistema.
3.5 El reemplazo del sistemaOcurre cuando los sistemas de información se tornan físicamente, tecnológicamente o competitivamente obsoletos. Como es el caso de la utilización del láser, en el reconocimiento óptico de caracteres para la lectura del código de barras, remplazando a la entrada por teclado.
3.6 La nueva capacidad del sistemaSon sistemas de información para los cuales no es necesario el uso de la automatización. Están dados por la capacidad de poder modelizar la aplicabilidad de nuevos sistemas. Un ejemplo de ello, es la aplicación de los sistemas expertos.
4. ANÁLISIS Y DISEÑO ORIENTADO A OBJETOSPara el desarrollo de software orientado a objetos no basta usar un lenguaje orientado a objetos. También se necesitará realizar un análisis y diseño orientado a objetos.
El modelamiento visual es la clave para realizar el análisis OO. Desde los inicios del desarrollo de software OO han existido diferentes metodologías para hacer esto del modelamiento, pero sin lugar a duda, el Lenguaje de Modelamiento Unificado (UML) puso fin a la guerra de metodologías.
Según los mismos diseñadores del lenguaje UML, éste tiene como fin modelar cualquier tipo de sistemas (no solamente de software) usando los conceptos de la orientación a objetos. Y además, este lenguaje debe ser entendible para los humanos y máquinas.
Actualmente en la industria del desarrollo de software tenemos al UML como un estándar para el modelamiento de sistemas OO. Fue la empresa Racional que creó estas definiciones y especificaciones del estándar UML, y lo abrió al mercado. La misma empresa creó uno de los programas más conocidos hoy en día para este fin; el Racional Rose, pero también existen otros programas como el Poseidon que trae licencias del tipo community edition que permiten su uso libremente.
El UML consta de todos los elementos y diagramas que permiten modelar los sistemas en base al paradigma orientado a objetos. Los modelos orientados a objetos cuando se construyen en forma correcta, son fáciles de comunicar,

cambiar, expandir, validar y verificar. Este modelamiento en UML es flexible al cambio y permite crear componentes plenamente reutilizables.
5. CONCEPTOS FUNDAMENTALES SOBRE LA PROGRAMACIÓN ORIENTADA A OBJETOS
La tecnología de objetos es una colección de análisis, diseño y metodologíasde programación. Para que un lenguaje de programación sea considerado "Orientado a Objetos" debe soportar como mínimo cuatro características importantes.
EncapsulaciónPolimorfismoHerenciaEnlace Dinámico
¿QUÉ SON LOS OBJETOS?Los objetos son modelos de programación, con los cuales se pueden crear botones, listas, menús, etc., en las aplicaciones de software. En la programación e implementación de un objeto los estados se guardan como variables, las cuales son privadas para los objetos, a menos que en la creación se especifiquen como publicas, las variables son inaccesibles desde fuera de los objetos.
Las conductas de los objetos están definidos en los métodos. Los métodos se encargan de modificar las variables para cambiar los estados o crear nuevos objetos.
¿CÓMO CREAR OBJETOS?En Java, se puede crear un objeto al crear una instancia de una clase. Cuando una clase es llamada para crear un objeto, se dice entonces que el objeto es unainstancia de la clase. Por ejemplo:
new Rectangle(x,y,width,height);new Rectangle(0,0,60,100);
Aquí Rentangle(0,0,60,100), es una llamada al constructor para la clase Rectangle.
Los constructores son métodos especiales provistos en cada clase Java que permiten a los programadores crear e inicializar objetos de este tipo. En este caso (new) muestra como inicializar el nuevo objeto Rectangle para ser localizado en el origen (0,0), con un ancho de 60 y un alto de 100.
Un Constructor es un método invocado automáticamente, cuando la instancia de una clase es creada los constructores utilizan los mismos nombres que las clases y son usados para inicializar las variables de los objetos recientemente creados.

Como ya mencionamos los constructores tienen el mismo nombre que la clase, y una clase puede tener cualquier numero de constructores con el mismo nombre, estos se diferencian por el número y tipo de argumentos.
Por ejemplo la clase: Java.awt.Rectangle tiene los siguientes constructores, los cuales se diferencian por los argumentos:
Rectangle()Rectangle(int x,int y,int width,int height)Rectangle(int width,int height)Rectangle(Point p,Dimension d)Rectangle(Point p)Rectangle(Dimension d)
Más adelante trataremos acerca de la clase Rectangle.
¿CÓMO USAR LOS OBJETOS?Una vez creado el objeto, por ejemplo el Rectángulo, necesitamos moverlo por la pantalla de la computadora es decir imaginemos 2 variables x,y que definen la posición del objeto, las cuales van cambiando esto originará el movimiento de nuestro rectángulo.
Si recordamos un poco, la clase Rectangle, tiene 2 variables x,y que definen la posición del objeto Rectangle y además tiene un método, llamado move(), el cual permite mover el rectángulo: move(int x,int y).
REFERENCIA A VARIABLES DE LOS OBJETOS
Se puede hacer referencia a las variables de los objetos de la siguiente manera:
Referencia_del_objeto.variable
Esto permite ver o modificar las variables de los objetos, por ejemplo en el caso de la clase Rectangle, si cuadro es la referencia al objeto y (x,y) las variables entonces con:
cuadro.xcuadro.y
pueden ser usadas para hacer referencia a las variables del objeto, en la sentencias y expresiones en Java.
Para cambiar los valores de x,y podemos usar lo siguiente:
cuadro.x = 10; /// x ahora tiene el valor 10cuadro.y = 20; /// y ahora tiene el valor 20

No olvidemos que la clase Rectangle, tiene otras 2 variables (Width,Height)
cuadro.widthcuadro.Height
Entonces si se nos pide calcular el área del rectángulo, tendríamos:
área = cuadro.Width * cuadro.Height;
LLAMADA A LOS MÉTODOS DE LOS OBJETOSPara hacer referencia a los métodos de un objeto se coloca la referencia del objeto separada por un punto con el método y los argumentos necesarios encerrados entre paréntesis si no hubiese argumentos los paréntesis deberán ir vacíos:
Referencia_al_objeto.nombre_del_método(argumentos);
o
Referencia_al_objeto.nombre_del_método();
Por ejemplo, para mover el rectángulo, necesitamos hacer uso del método move(), que ya menciónamos unas líneas atrás. Lo hacemos de la siguiente manera:
cuadro.move(10,20);
Esta instrucción llama al método move, con 2 valores enteros 10 y 20 pasados como parámetros, para que el objeto referenciado como cuadro, se mueva según las coordenadas x,y. Las llamadas a los métodos son también conocidas como Mensajes.
RECOLECTOR DE BASURAOtros lenguajes de programación orientada a objetos, requieren que se guarde la pista de los objetos que se han venido creando para más adelante si no se usan sean destruidos, esto trae como consecuencia realizar un trabajo tedioso y con posibilidad de cometer muchos errores.
En Java, no es necesario preocuparse de los objetos que se van creando ya que si existe un objeto en tiempo de ejecución que ya ha dejado de usarse Java lo elimina. Este proceso es conocido como el Recolector de Basura. El Recolector de Basura se ejecuta en prioridad baja, dependiendo de la situación y del sistema en el que se este ejecutando Java, puede correr sincronizada o desincronizadamente.
Se ejecuta sincronizadamente cuando el sistema corre fuera de memoria o en respuesta a un requerimiento de un programa Java. Se ejecuta desincronizadamente cuando el sistema está ocioso, es decir tiene ratos libres entre tárea y tárea, como (Windows 95).

¿QUÉ SON LOS MÉTODOS?En conclusión los métodos son usados en la programación orientada a objetos para referirse a un procedimiento o una función.
¿QUÉ SON LAS CLASES?Las clases representan el modelo clásico de la programación orientada a objetos. Ellas soportan abstracción de datos y la implementación dada a los datos. En Java, cada nueva clase crea un nuevo tipo.
En conclusión una clase es una colección de datos y métodos. Los datos y los métodos juntos usualmente sirven para definir el contenido y las capacidades de algunos tipos de objetos.
Ejemplo de la estructura de una clase:
class Nombre_de_clase {. . .Declaración de variables. . .Declaración de métodos. . .}
Ejemplo de la creacion de una clase
public class Circulo{public double x, y; // las coordenadas del centropublic double r; // el radio// métodos que retornan la circunferencia y el área de circulo.public double area() {return 3.14159 * r * r;}}
Más adelante se explicara acerca del ámbito de las clases y los tipos de datos por ahora este ejemplo tiene la intención de mostrarle como esta organizada una clase.
LOS OBJETOS SON INSTANCIAS DE LAS CLASESAhora que hemos definido parcialmente la clase Circulo, haremos algunas cosas con esta. Nosotros no podemos hacer nada con la propia clase Circulo, necesitamos una instancia de la clase, un simple objeto de tipo Circulo. Al definir la clase Circulo en Java nosotros hemos creado un nuevo tipo de dato y por lo tanto podemos declarar variables de ese tipo por ejemplo:
Circulo c;
Pero esta variable c es simplemente un nombre que se refiere a un objetoCirculo, esta (la variable) todavía no es un objeto. En Java todos los objetos deben

ser creados dinámicamente.
Esto es casi siempre hecho con la palabra new :
Circulo c;c = new Circulo();
Ahora hemos creado una instancia de nuestra clase Circulo (un objeto circulo) y tenemos asignado este a la variable c, la cual es de tipo Circulo.
MANEJANDO DATOS DE OBJETOSAhora que hemos creado un objeto podemos usar sus campos de datos. La siguiente sintaxis le debe ser familiar a los programadores de C:
Circulo c = new Circulo();// inicializamos nuestro circulo para tener centro (2,2) y radio 1.0.c.x = 2.0;c.y = 2.0;c.r = 1.0;
USANDO LOS MÉTODOS DEL OBJETOAquí comienzan a tornarse interesantes las cosas. Para acceder al método de un objeto usamos la misma sintaxis que si accedieramos a los datos de un objeto:
Circulo c = new Circulo();double a;c.r = 2.5;a = c.area();
Chequea la ultima línea, nosotros no decimos a = area(c); sino a = c.area(); Esta es la razón por la que se llama programación orientada al objeto, es decir el objeto es el foco aquí y no la llamada a la función. Este es probablemente el mecanismo simple más importante de el paradigma orientado a objetos.
SUBCLASES, SUPERCLASES Y HERENCIAPara crear una nueva clase, el programador debe basar esta en una clase existente. La nueva clase es derivada de la clase existente. La clase derivada es también llamada una subclase de la otra, la cual es conocida como la superclase. La derivación de clases es transitiva: si B es una subclase de A, y C es una subclase de B, entonces C es una subclase de A.
Para declarar que una clase es subclase de otra, se deberá indicar lo siguiente:
class MouseEvent extends Event {. . .}

Para crear una subclase se debe incluir la clausula (extends) en la declaración de la clase. Esta declaración, por ejemplo, indica que la clase mouseEvent es una subclase de la clase Event.
Una subclase hereda variables y métodos de la superclase, la herencia es uno de los paradigmas mas potentes de la programación orientada a objetos.
SOBREESCRIBIENDO MÉTODOSCuando una clase define un método usando el mismo nombre, retorna tipos y argumentos como un método en la superclase, el método en la clase sobreescribe el método en la superclase. Cuando el método es invocado en la clase la nueva definición del método es llamada, no la antigua definición que está en la superclase.
La técnica de sobreescribir métodos es importante en la programación orientada al objeto. Supongamos que definimos una subclase Elipse de nuestra clase Circle y definimos nuestras propias versiones de las funciones área y circunferencia para Elipse puesto que las que heredamos de la clase Circle no se aplican para elipses. Cabe resaltar que esto no debe confundirse con la sobrecarga de métodos que significa tener varios métodos con el mismo nombre dentro de una clase, pero diferenciados por los argumentos de cada uno.
OCULTAMIENTO Y ENCAPSULACIÓN DE DATOSAnteriormente describimos una clase como “una colección de datos y métodos”. Una de las mas importantes técnicas que no hemos tocado hasta este momento es el ocultamiento de datos dentro de una clase, y hacer que estén disponibles (los datos ocultados) solamente a través de los métodos. Esta técnica es usualmente conocida a menudo como ENCAPSULACIÓN por que este cierra herméticamente los datos de la clase dentro de la cápsula de seguridad, los cuales solo pueden ser accedidos por usuarios que tengan derechos -de acceso- para los métodos de la clase.Aquí algunas de las razones para ocultar datos:
Una clase contiene un número de variables que son interdependientes y Deben tener un estado consistente.
Si permites a un programador (que puedes ser tu mismo) manipular esas variables directamente la clase puede entrar en un estado inconsistente y funcionar inapropiadamente.
Cuando todas las variables de la clase están ocultas y los métodos son la única posibilidad para cambiar los valores de las variables ocultas en objetos de la clase, todo funciona bien. Por que si mediante un método tratamos de cambiar un valor para una variable y el valor no es correcto el método tiene la facultad para rechazarlo.

Si nosotros permitimos que las variables sean directamente manipuladas, sin intervención de los métodos de la clase, el numero de posibilidades que tienes que comprobar se vuelve inmanejable.
Si una variable es visible en tu clase, entonces debes documentar esta. Una manera de ahorrar tiempo en la documentación es ocultar esta al usuario de la clase.
CONTROL DE ACCESO A LOS MÉTODOSCuando se declara un método, dentro de una clase Java, usted puede permitir o bloquear que otras clases y objetos puedan llamar a los métodos para esto tendrá que hacer uso de los especificadores de acceso. Java soporta 5 diferentes niveles de acceso para los métodos los cuales son:
privateprivate protectedprotectedpublic, y ademas "friendly"
Veamos la siguiente tabla:
La X de la primera columna indica que la clase misma puede llamar al método definido con el especificador private.
La X de la segunda columna indica que la subclase de la clase puede llamar al método especificado como private protected.
La tercera columna indica que la clase como las clases del mismo paquete pueden llamar al método. Y la cuarta columna indica que cualquier clase puede llamar al método.
Private:
En este nivel de acceso, sólo la clase que contiene al método puede llamarlo para declarar un método privado utilizamos la palabra reservada private ejemplo:
class prueba {

private void texto1() {System.out.println("como se ve..");}}
Los objetos de tipo prueba, pueden llamar al método texto1, pero los objetos de otro tipo no pueden hacerlo.
Private Protected:Este nivel de acceso incluye el acceso private, además permite que cualquier subclase de la clase pueda llamar al método. La siguiente clase esta definida como private protected:
class prueba2 {private protected void texto2() {System.out.println("y ahora como se ve..");}}
Los objetos del tipo prueba2, pueden llamar al método texto2(), ademas las subclases de prueba2, también tienen acceso a texto2(). Por instancia, la subclase de prueba2, subprueba puede llamar al método texto2() de un objeto prueba2.
class subprueba extends prueba2 {void maspruebas(prueba2 a) {a.texto2();}}
Protected:Este nivel permite que la clase, las subclases y todas las clases en el mismo paquete puedan llamar al método.
Veamos un ejemplo:
package curso;class lección3 {protected void contenido() {System.out.println("Imprimiendo..baaa");}}
Ahora supongamos que otra clase, llamada lección4, será declarada miembro del paquete curso la clase lección4, puede llamar al método contenido() declarado dentro de la clase lección3, porque está dentro del mismo paquete.

package curso;class lección4 {void Métododeacceso() {lección3 a = new lección3();a.contenido();}}
Public:Cuando los métodos son públicos todas las clases tienen acceso a ellos.
package curso;class lección3 {public void contenidopub() {System.out.println("todos pueden ver loscontenidos");}}package html;class lección4 {void métododeacceso() {lección3 a = new lección3();a.contenidopub();}}
Como se ve podemos llamar al método contenidopub() en la clase lección3.
Friendly:
Veamos un ejemplo:
package curso;class A {void invitado() {System.out.println("Como estan amigos");}}
La clase A, puede llamar al método invitado(), pero además todas las clases declaradas dentro del mismo paquete curso, pueden llamar al método invitado().
EL MÉTODO main()Escriba este código en cualquier editor de textos, guárdelo como fecha.Java.
import Java.util.Date;class fecha {

public static void main(String args[]) {Date hoy = new Date();System.out.println(hoy);}}
Explicando:
public static void main(String args[])
Como se podrá ver el método main() contiene tres modificadores:
public:Indica que el método main(), puede ser llamado por cualquier objeto, ya lo explicamos arriba.
static:Indica que el método main() es una clase método.
void:Indica que el método main(), no retorna valores. En Java cuando se ejecuta una aplicación el interprete de Java (Java.exe) inicia con el método main(), el método main(), llama entonces todos los otros métodos requeridos por la aplicación.
Utilice el compilador Javac, con su archivo fecha.Java, luego si todo está correcto, con el interprete de Java escriba: Java classname (sin extensión) para visualizar el resultado.
Argumentos del método main()
public static void main(String args[])
Este arreglo de cadenas es el mecanismo mediante el cual el sistema, en tiempo de ejecución pasa información a la aplicación cada cadena en el arreglo es llamada como un comando de línea. Más adelante se explicara acerca de las cadenas y arreglos.

UNIDAD II
FUNDAMENTOS DE PROGRMACION JAVA
1. ORIGENES DEL LENGUAJE JAVA
1.1 INTRODUCCIÓN
Internet, la red de redes mas grande del planeta ha venido evolucionando a ritmos muy acelerados, en sus inicios el correo electrónico fue la sensación. En la actualidad sigue siendo una herramienta fundamental en las comunicaciones, pero se han venido desarrollando otras herramientas y tecnologías como el hipertexto, los cuales vienen a ser objetos de información los cuales pueden contener textos, gráficos, audio, vídeo además de vínculos a otros hipertextos. La World Wide Web se encarga de la transferencia de los hipertextos utilizando el protocolo HTTP, hasta aquí Internet había crecido y madurado un poco, cada vez eran mas los sites donde se podían encontrar paginas web mostrando información de todo tipo, pero había un detalle: las paginas eran estáticas, y de pronto Sun Microsystems anuncia un nuevo producto asegurando que JAVA, así se llamaba, iba revolucionar Internet, las paginas Web se convertirían en dinámicas e interactivas.
El avance de la tecnología informática y de las telecomunicaciones ha hecho posible que estemos viviendo tiempos en donde la globalización de la información, nos permita alcanzar uno de los grandes sueños de la humanidad: “Tener igualdad de condiciones para acceder al conocimiento”, y esto se ha venido logrando gracias a Internet.
1.2 ¿QUÉ ES JAVA?Java es un nuevo lenguaje de programación orientado a objetos desarrollado por Sun Microsystems. Sun describe al lenguaje Java de la siguiente manera: Simple, orientado a objetos, distribuido, interpretado, robusto, seguro, de arquitectura neutral, portable, de alto rendimiento, multitarea y dinámico. Sun admite totalmente que lo dicho anteriormente es una cadena de halagos por parte suya, pero el hecho es que todo ello describe al lenguaje Java. Java permite hacer cosas excitantes con las paginas Web que antes no eran posibles. De manera que en este momento la gran interactividad que proporciona Java marca la diferencia en las paginas Web. Imagina un Web donde puedes jugar a un juego, como el fútbol, tú y otras personas que están en lugares remotos forman parte de un equipo y otras mas del contrario, verías a los jugadores animados en la pantalla obedeciendo las instrucciones de las personas que están jugando al juego desde sitios remotos.
Además las puntuaciones quedarían registradas. O un Web con una aplicación en donde el usuario pueda hacer transacciones y estas se actualicen en tiempo real. O un sitio que ofrezca pequeñas aplicaciones como hojas de calculo o

calculadoras para uso de los visitantes. O uno que muestre figuras 3D, tales como moléculas o dinosaurios que pueden ser rotados con un click del ratón.
Java también aumenta el contenido multimedia de un sitio, ofreciendo animaciones fluidas, gráficos mejorados, sonido y vídeo, fuera de lo necesario para enganchar aplicaciones de ayuda dentro de sus navegadores Web.
Y no solamente lo que se ha mencionado sino también que lenguaje java es un lenguaje muy robusto que no permite desarrollar cualquier tipo de proyecto ya sea en una base de dato, o aplicaciones por puertos entre ellos.
1.3 BREVE HISTORIA DE JAVAA finales de la década de los 80 Sun Microsystems inicia un proyecto de investigación encabezado por James Gosling con el propósito de desarrollar un lenguaje de programación para dispositivos electrónicos como tostadoras, hornos microondas y asistentes digitales personales. Gosling y su equipo de investigación llegaron a la conclusión de que el software para dispositivos de consumo tiene algunos requerimientos de diseño únicos. Por ejemplo, el software necesita ser capaz de trabajar en nuevos chips de computadora. Cuando los chips son introducidos, los fabricantes más de una vez los cambian por otros por ser más baratos o introducir nuevos mecanismos. El software también necesita ser extremadamente inteligente, porque cuando un producto del consumidor falla, el fabricante usualmente tiene que reemplazar todo el dispositivo y no el componente que originó el fallo. Gosling y su equipo también descubrieron que existían lenguajes de programación como C y C++ con los cuales no se podía realizar la tarea de hacer un software que fuera independiente de la arquitectura en donde se este ejecutando. Un programa escrito en C o C++ debe ser compilado para un chip de computadora particular. Cuando se cambia de chip el programa debe ser recompilado. La complejidad de C y C++ también hace extremadamente dificultoso escribir software fiable.
Como resultado de lo dicho anteriormente, en 1990 Gosling comenzó a diseñar un nuevo lenguaje de programación que fuera mas apropiado para dispositivos que utilizan software electrónico. Este lenguaje fue conocido originalmente como Oak. Fue pequeño, de fiar e independiente de la arquitectura. En 1993 cuando el equipo de Java continuaba trabajando en el diseño del nuevo lenguaje, la Word Wide Web apareció y tomó a todos por sorpresa. El equipo de Java pensó que un lenguaje de arquitectura neutral sería ideal para programar en la Internet, porque un programa correría en todos los diferentes tipos de computadoras conectadas a Internet. Y fue un hecho; todas las metas alcanzadas con las investigaciones anteriores coincidentemente sirvieron idealmente para la programación en Internet.
En ese momento el desarrollo de Java se tornó en un asunto de mayor importancia para Sun. El equipo escribió un navegador Web llamado HotJava, que fue el primero en soportar applets de Java. Un applet es un pequeño programa

que puede ser incrustado en una página Web. Puedes incluir un applet en un documento HTML para proporcionar interactividad y dar vida a una página Web. HotJava demostró el poder del lenguaje Java y lo puso de moda entre los programadores y el resto de la gente. Y lo demás es historia.
Los programadores comenzaron con la versión Alpha de Java que Sun puso a disposición de toda la gente, creando las clasificaciones de applets más maravillosas. La experiencia de Sun y la retroalimentación por parte de los usuarios ayudaron a refinar el lenguaje y la interfaz de programación de aplicaciones (API). Al mismo tiempo que Sun sacó la versión Beta de el lenguaje, Netscape anunció que la version 2.0 del Web browser, Netscape Navigator soportaría applets de Java. Esto sirvió para incrementar el fuerte interés en la tecnología Java, en el mundo de la computación y en Internet.
Con compañías como IBM, SGI y Oracle licenciando la tecnología Java de Sun se puede estar seguro de que más productos de software y hardware incorporarán la tecnología Java.
2. CARACTERÍSTICAS DEL LENGUAJE JAVA
Las características principales que nos ofrece Java respecto a cualquier otro lenguaje de programación, son: 2.1 SimpleJava ofrece toda la funcionalidad de un lenguaje potente, pero sin las características menos usadas y más confusas de éstos. C++ es un lenguaje que adolece de falta de seguridad, pero C y C++ son lenguajes más difundidos, por ello Java se diseñó para ser parecido a C++ y así facilitar un rápido y fácil aprendizaje.
Java elimina muchas de las características de otros lenguajes como C++, para mantener reducidas las especificaciones del lenguaje y añadir características muy útiles como el garbage collector (reciclador de memoria dinámica). No es necesario preocuparse de liberar memoria, el reciclador se encarga de ello y como es un thread de baja prioridad, cuando entra en acción, permite liberar bloques de memoria muy grandes, lo que reduce la fragmentación de la memoria. Java reduce en un 50% los errores más comunes de programación con lenguajes como C y C++ al eliminar muchas de las características de éstos, entre las que destacan:
Aritmética de punteros No existen referencias Registros (struct) Definición de tipos (typedef) Macros (#define) Necesidad de liberar memoria (free)

Aunque, en realidad, lo que hace es eliminar las palabras reservadas (struct, typedef), ya que las clases son algo parecido. Además, el intérprete completo de Java que hay en este momento es muy pequeño, solamente ocupa 215 Kb de RAM. 2.2 Orientado a objetosJava implementa la tecnología básica de C++ con algunas mejoras y elimina algunas cosas para mantener el objetivo de la simplicidad del lenguaje. Java trabaja con sus datos como objetos y con interfaces a esos objetos. Soporta las tres características propias del paradigma de la orientación a objetos: encapsulación, herencia y polimorfismo. Las plantillas de objetos son llamadas, como en C++, clases y sus copias, instancias. Estas instancias, como en C++, necesitan ser construidas y destruidas en espacios de memoria. Java incorpora funcionalidades inexistentes en C++ como por ejemplo, la resolución dinámica de métodos. Esta característica deriva del lenguaje Objective C, propietario del sistema operativo Next. En C++ se suele trabajar con librerías dinámicas (DLLs) que obligan a recompilar la aplicación cuando se retocan las funciones que se encuentran en su interior. Este inconveniente es resuelto por Java mediante una interfaz específica llamada RTTI (RunTime Type Identification) que define la interacción entre objetos excluyendo variables de instancias o implementación de métodos. Las clases en Java tienen una representación en el runtime que permite a los programadores interrogar por el tipo de clase y enlazar dinámicamente la clase con el resultado de la búsqueda. 2.3 DistribuidoJava se ha construido con extensas capacidades de interconexión TCP/IP. Existen librerías de rutinas para acceder e interactuar con protocolos como http y ftp. Esto permite a los programadores acceder a la información a través de la red con tanta facilidad como a los ficheros locales. La verdad es que Java en sí no es distribuido, sino que proporciona las librerías y herramientas para que los programas puedan ser distribuidos, es decir, que se corran en varias máquinas, interactuando. 2.4 RobustoJava realiza verificaciones en busca de problemas tanto en tiempo de compilación como en tiempo de ejecución. La comprobación de tipos en Java ayuda a detectar errores, lo antes posible, en el ciclo de desarrollo. Java obliga a la declaración explícita de métodos, reduciendo así las posibilidades de error. Maneja la memoria para eliminar las preocupaciones por parte del programador de la liberación o corrupción de memoria. También implementa los arrays auténticos, en vez de listas enlazadas de punteros, con comprobación de límites, para evitar la posibilidad de sobreescribir o

corromper memoria resultado de punteros que señalan a zonas equivocadas. Estas características reducen drásticamente el tiempo de desarrollo de aplicaciones en Java. Además, para asegurar el funcionamiento de la aplicación, realiza una verificación de los byte-codes, que son el resultado de la compilación de un programa Java. Es un código de máquina virtual que es interpretado por el intérprete Java. No es el código máquina directamente entendible por el hardware, pero ya ha pasado todas las fases del compilador: análisis de instrucciones, orden de operadores, etc., y ya tiene generada la pila de ejecución de órdenes. Java proporciona, pues:
Comprobación de punteros Comprobación de límites de arrays Excepciones Verificación de byte-codes
2.5 Arquitectura neutralPara establecer Java como parte integral de la red, el compilador Java compila su código a un fichero objeto de formato independiente de la arquitectura de la máquina en que se ejecutará. Cualquier máquina que tenga el sistema de ejecución (run-time) puede ejecutar ese código objeto, sin importar en modo alguno la máquina en que ha sido generado. Actualmente existen sistemas run-time para Solaris 2.x, SunOs 4.1.x, Windows 95, Windows NT, Linux, Irix, Aix, Mac, Apple y probablemente haya grupos de desarrollo trabajando en el porting a otras plataformas.

El código fuente Java se "compila" a un código de bytes de alto nivel independiente de la máquina. Este código (byte-codes) está diseñado para ejecutarse en una máquina hipotética que es implementada por un sistema run-time, que sí es dependiente de la máquina.
En una representación en que tuviésemos que indicar todos los elementos que forman parte de la arquitectura de Java sobre una plataforma genérica, obtendríamos una figura como la siguiente:

En ella podemos ver que lo verdaderamente dependiente del sistema es la Máquina Virtual Java (JVM) y las librerías fundamentales, que también nos permitirían acceder directamente al hardware de la máquina. Además, habrá APIs de Java que también entren en contacto directo con el hardware y serán dependientes de la máquina, como ejemplo de este tipo de APIs podemos citar: Java 2D: gráficos 2D y manipulación de imágenes Java Media Framework : Elementos críticos en el tiempo: audio, video... Java Animation: Animación de objetos en 2D Java Telephony: Integración con telefonía Java Share: Interacción entre aplicaciones multiusuario Java 3D: Gráficos 3D y su manipulación 2.6 SeguroLa seguridad en Java tiene dos facetas. En el lenguaje, características como los punteros o el casting implícito que hacen los compiladores de C y C++ se eliminan para prevenir el acceso ilegal a la memoria. Cuando se usa Java para crear un navegador, se combinan las características del lenguaje con protecciones de sentido común aplicadas al propio navegador. El lenguaje C, por ejemplo, tiene lagunas de seguridad importantes, como son los errores de alineación. Los programadores de C utilizan punteros en conjunción con operaciones aritméticas. Esto le permite al programador que un puntero referencie a un lugar conocido de la memoria y pueda sumar (o restar) algún valor, para referirse a otro lugar de la memoria. Si otros programadores conocen nuestras estructuras de datos pueden extraer información confidencial de nuestro

sistema. Con un lenguaje como C, se pueden tomar números enteros aleatorios y convertirlos en punteros para luego acceder a la memoria: printf( "Escribe un valor entero: " );scanf( "%u",&puntero );printf( "Cadena de memoria: %s\n",puntero ); Otra laguna de seguridad u otro tipo de ataque, es el Caballo de Troya. Se presenta un programa como una utilidad, resultando tener una funcionalidad destructiva. Por ejemplo, en UNIX se visualiza el contenido de un directorio con el comando ls. Si un programador deja un comando destructivo bajo esta referencia, se puede correr el riesgo de ejecutar código malicioso, aunque el comando siga haciendo la funcionalidad que se le supone, después de lanzar su carga destructiva.Por ejemplo, después de que el caballo de Troya haya enviado por correo el /etc/shadow a su creador, ejecuta la funcionalidad de ls persentando el contenido del directorio. Se notará un retardo, pero nada inusual. El código Java pasa muchos tests antes de ejecutarse en una máquina. El código se pasa a través de un verificador de byte-codes que comprueba el formato de los fragmentos de código y aplica un probador de teoremas para detectar fragmentos de código ilegal -código que falsea punteros, viola derechos de acceso sobre objetos o intenta cambiar el tipo o clase de un objeto-. Si los byte-codes pasan la verificación sin generar ningún mensaje de error, entonces sabemos que:
El código no produce desbordamiento de operandos en la pila El tipo de los parámetros de todos los códigos de operación son conocidos
y correctos. No ha ocurrido ninguna conversión ilegal de datos, tal como convertir
enteros en punteros. El acceso a los campos de un objeto se sabe que es legal: public, private,
protected. No hay ningún intento de violar las reglas de acceso y seguridad
establecidas El Cargador de Clases también ayuda a Java a mantener su seguridad, separando el espacio de nombres del sistema de ficheros local, del de los recursos procedentes de la red. Esto limita cualquier aplicación del tipo Caballo de Troya, ya que las clases se buscan primero entre las locales y luego entre las procedentes del exterior. Las clases importadas de la red se almacenan en un espacio de nombres privado, asociado con el origen. Cuando una clase del espacio de nombres privado accede a otra clase, primero se busca en las clases predefinidas (del sistema local) y

luego en el espacio de nombres de la clase que hace la referencia. Esto imposibilita que una clase suplante a una predefinida.
En resumen, las aplicaciones de Java resultan extremadamente seguras, ya que no acceden a zonas delicadas de memoria o de sistema, con lo cual evitan la interacción de ciertos virus. Java no posee una semántica específica para modificar la pila de programa, la memoria libre o utilizar objetos y métodos de un programa sin los privilegios del kernel del sistema operativo. Además, para evitar modificaciones por parte de los crackers de la red, implementa un método ultraseguro de autentificación por clave pública. El Cargador de Clases puede verificar una firma digital antes de realizar una instancia de un objeto. Por tanto, ningún objeto se crea y almacena en memoria, sin que se validen los privilegios de acceso. Es decir, la seguridad se integra en el momento de compilación, con el nivel de detalle y de privilegio que sea necesario. Dada, pues la concepción del lenguaje y si todos los elementos se mantienen dentro del estándar marcado por Sun, no hay peligro. Java imposibilita, también, abrir ningún fichero de la máquina local (siempre que se realizan operaciones con archivos, éstas trabajan sobre el disco duro de la máquina de donde partió el applet), no permite ejecutar ninguna aplicación nativa de una plataforma e impide que se utilicen otros ordenadores como puente, es decir, nadie puede utilizar nuestra máquina para hacer peticiones o realizar operaciones con otra. Además, los intérpretes que incorporan los navegadores de la Web son aún más restrictivos. Bajo estas condiciones (y dentro de la filosofía de que el único ordenador seguro es el que está apagado, desenchufado, dentro de una cámara acorazada en un bunker y rodeado por mil soldados de los cuerpos especiales del ejército), se puede considerar que Java es un lenguaje seguro y que los applets están libres de virus. Respecto a la seguridad del código fuente, no ya del lenguaje, JDK proporciona un desemsamblador de byte-code, que permite que cualquier programa pueda ser convertido a código fuente, lo que para el programador significa una vulnerabilidad total a su código. Utilizando javap no se obtiene el código fuente original, pero sí desmonta el programa mostrando el algoritmo que se utiliza, que es lo realmente interesante. La protección de los programadores ante esto es utilizar llamadas a programas nativos, externos (incluso en C o C++) de forma que no sea descompilable todo el código; aunque así se pierda portabilidad. Esta es otra de las cuestiones que Java tiene pendientes. 2.7 PortableMás allá de la portabilidad básica por ser de arquitectura independiente, Java implementa otros estándares de portabilidad para facilitar el desarrollo. Los enteros son siempre enteros y además, enteros de 32 bits en complemento a 2. Además, Java construye sus interfaces de usuario a través de un sistema abstracto de ventanas de forma que las ventanas puedan ser implantadas en entornos Unix, Pc o Mac.

2.8 InterpretadoEl intérprete Java (sistema run-time) puede ejecutar directamente el código objeto. Enlazar (linkar) un programa, normalmente, consume menos recursos que compilarlo, por lo que los desarrolladores con Java pasarán más tiempo desarrollando y menos esperando por el ordenador. No obstante, el compilador actual del JDK es bastante lento. Por ahora, que todavía no hay compiladores específicos de Java para las diversas plataformas, Java es más lento que otros lenguajes de programación, como C++, ya que debe ser interpretado y no ejecutado como sucede en cualquier programa tradicional. Se dice que Java es de 10 a 30 veces más lento que C, y que tampoco existen en Java proyectos de gran envergadura como en otros lenguajes. La verdad es que ya hay comparaciones ventajosas entre Java y el resto de los lenguajes de programación, y una ingente cantidad de folletos electrónicos que supuran fanatismo en favor y en contra de los distintos lenguajes contendientes con Java. Lo que se suele dejar de lado en todo esto, es que primero habría que decidir hasta que punto Java, un lenguaje en pleno desarrollo y todavía sin definición definitiva, está maduro como lenguaje de programación para ser comparado con otros; como por ejemplo con Smalltalk, que lleva más de 20 años en cancha. La verdad es que Java para conseguir ser un lenguaje independiente del sistema operativo y del procesador que incorpore la máquina utilizada, es tanto interpretado como compilado. Y esto no es ningún contrasentido, me explico, el código fuente escrito con cualquier editor se compila generando el byte-code. Este código intermedio es de muy bajo nivel, pero sin alcanzar las instrucciones máquina propias de cada plataforma y no tiene nada que ver con el p-code de Visual Basic. El byte-code corresponde al 80% de las instrucciones de la aplicación. Ese mismo código es el que se puede ejecutar sobre cualquier plataforma. Para ello hace falta el run-time, que sí es completamente dependiente de la máquina y del sistema operativo, que interpreta dinámicamente el byte-code y añade el 20% de instrucciones que faltaban para su ejecución. Con este sistema es fácil crear aplicaciones multiplataforma, pero para ejecutarlas es necesario que exista el run-time correspondiente al sistema operativo utilizado. 2.9 MultithreadedAl ser multithreaded (multihilvanado, en mala traducción), Java permite muchas actividades simultáneas en un programa. Los threads (a veces llamados, procesos ligeros), son básicamente pequeños procesos o piezas independientes de un gran proceso. Al estar los threads contruidos en el lenguaje, son más fáciles de usar y más robustos que sus homólogos en C o C++. El beneficio de ser miltithreaded consiste en un mejor rendimiento interactivo y mejor comportamiento en tiempo real. Aunque el comportamiento en tiempo real está limitado a las capacidades del sistema operativo subyacente (Unix, Windows, etc.), aún supera a los entornos de flujo único de programa (single-threaded) tanto en facilidad de desarrollo como en rendimiento.

Cualquiera que haya utilizado la tecnología de navegación concurrente, sabe lo frustrante que puede ser esperar por una gran imagen que se está trayendo. En Java, las imágenes se pueden ir trayendo en un thread independiente, permitiendo que el usuario pueda acceder a la información en la página sin tener que esperar por el navegador. 2.10 DinámicoJava se beneficia todo lo posible de la tecnología orientada a objetos. Java no intenta conectar todos los módulos que comprenden una aplicación hasta el tiempo de ejecución. Las librería nuevas o actualizadas no paralizarán las aplicaciones actuales (siempre que mantengan el API anterior).
Java también simplifica el uso de protocolos nuevos o actualizados. Si su sistema ejecuta una aplicación Java sobre la red y encuentra una pieza de la aplicación que no sabe manejar, tal como se ha explicado en párrafos anteriores, Java es capaz de traer automáticamente cualquiera de esas piezas que el sistema necesita para funcionar.
Java, para evitar que los módulos de byte-codes o los objetos o nuevas clases, haya que estar trayéndolos de la red cada vez que se necesiten, implementa las opciones de persistencia, para que no se eliminen cuando de limpie la caché de la máquina.
3. JAVA VS. OTROS LENGUAJES DE PROGRAMACIÓN ORIENTADAS A OBJETOS
A. IntroducciónLa sintaxis de Java resulta muy familiar a los programadores de C++, debido mayoritariamente a que Java proviene de C++. Sin embargo Java pretende mejorar a C++ en muchos aspectos (sobre todo en los aspectos orientados a objeto del lenguaje), aunque prohíbe muchas de las tareas por las que C++ fue tan extendido.

Se observa que las diferencias han sido diseñadas como mejoras del lenguaje, ya que uno de los aspectos más criticado (y defendido) de C++ es su capacidad para hacer cosas "no orientadas a objetos", así como acceder a los recursos de las máquinas (lo que le permitía atacar sistemas, siendo uno de los lenguajes más difundidos entre los programadores de virus).
En este apéndice pretendemos mostrar aquellas diferencias significativas, para que los programadores familiarizados con C++ puedan programar en Java, conociendo sus posibilidades y limitaciones.
B. Diferencias sintáticas
a) Elementos similaresUso de bibliotecas (paquetes): Como no existen macros como #include, se utiliza import.
Operador de herencia: La herencia en Java se especifica con la palabra clave extends, en lugar del operador :: de C++.
Constantes: En lugar de const de C++ las variables constantes se declaran como static final.
b) Elementos equivalentes
Miembros estáticos: No es necesaria declaración previa (fuera de las clases) de los miembros estáticos (static).
Métodos inline: En Java no existen (hay que incluir el cuerpo de los métodos junto a su definición), aunque los compiladores Java suelen intentar expandir en línea (a modo de los métodos inline) los métodos declarados como final.
Métodos virtuales: Todos los métodos no estáticos (static) se consideran virtual en Java.
Forward: No existe en Java. Simplemente se llama el método, y el compilador se encarga de buscarlo.
Clases anidadas: Aunque Java no permite anidar clases, sí que se puede modelizar este concepto mediante los paquetes Java y la composición.
No existen "amigos" (friend): Es su lugar se considera amigas a todas las clases y elementos que componen un paquete.
c) Elementos añadidosComentarios: Java soporta los dos tipos de comentarios de C++, e incorpora un tercero, con la sintaxis /** comentario */, para la documentación automática.

Operador >>> : Java añade este operador para desplazamientos a la derecha sin signo.Iniciación: Todos las variables de tipo simple y las referencias a objeto se inician a un valor 0 (o equivalente), y null para las referencias a objeto.
Referencia super: En Java super hace referencia a la superclase (clase padre) de la clase actual. Dicha clase sólo puede ser una, porque Java solo soporta herencia simple.d.) Elementos suprimidosgoto: No existe en Java, aunque con break y continue, combinados con etiquetas de bloque, se puede suplir.Condiciones: Deben utilizarse expresiones booleanas y nunca números.Argumentos por defecto: Java no los soporta.
C. Diferencias de diseño
a) Tipos de datos
Tipos simples: Soporta los mismos que C++, añadiendo boolean (true/false), y ampliando el tipo char, para soportar caracteres Unicode de 16 bits.
Punteros: En Java no hay punteros, permitiendo así programación segura. En su lugar se crean las referencias a objeto, que pueden ser reasignadas (como si fueran un puntero a objeto de C++).
Vectores: Son objetos de sólo lectura, con un método length() para averiguar su longitud, y que lanzan una excepción si se intenta acceder a un elemento fuera del vector.
Clases: Todo debe de estar incluído en clases; no existen enumeraciones (enum) ni registros (struct).
Elementos globales: No existen variables o funciones globales, aunque se puede utilizar static para simularlas.
b) Diseño de las clases
Cuerpo de los métodos: Todos los cuerpos de las clases han de estar codificados en las definiciones de las clases. No se pueden separa como se hace en C++ mediante ficheros de cabecera (".h").
Constructores: Aunque existen constructores, como en C++, no existen constructores copia, puesto que los argumentos son pasados por referencia.
Destructores: No existen destructores en Java, ya que tiene recolección automática de basura, aunque en su lugar se pueden escribir métodos finalize(), que serán ejecutados cuando el recolector de basura de Java destruya el objeto.

Árbol de herencia: En Java todas las clases se relacionan en un único árbol de herencia, en cuya cúspide se encuentra la clase Object, con lo que todas las clases heredan de ella. En C++ sin embargo se pueden declarar clases que no tengan padre.
Herencia no restrictiva: Al heredar, no se puede reducir las ocultaciones del padre: En C++ sí se podría ampliar la visibilidad de uno de los elementos heredados. En todo caso sí se puede restringir.
Herencia simple de clases: No existe la herencia múltiple de clases. Aún así se puede implementar una herencia múltiple utilizando interfaces, dado que ellas sí la soportan.
Sobrecarga de métodos: Es exactamente igual que la de C++.
Sobrecarga de operadores: No existe. En los objetos String el operador + y += se permiten para la comparación de cadenas.
c) Nuevos diseños
Plantillas (templates): En Java no se soportan plantillas p clases genéricas de C++, aunque existen una serie de clases en la API de Java que tratan objetos genéricos (clase Object) como Vector o Stack.
Interfaces (interface): Que son unas especies de clases abstractas con métodos abstractos, y que permiten herencia múltiple, utilizando la palabra reservada implements.
Diferente gestión de excepciones: Todas las excepciones de Java heredan de la clase Throwable, que las dota de una interfaz común.
D. Diferencias de ejecucióna) Aspectos modificados:
Cadenas: Las cadenas entrecomilladas se convierten en objetos String, no en vectores estáticos de caracteres.
Instanciación: Los objetos se crean en el montículo (new) y nunca en la pila (malloc), y los tipos simples no permiten new (excepto los vectores de tipos simples, iguales que los de C++).
Intérprete: Los intérpretes Java son unas 20 veces más lentos que los de C, aunque esta diferencia se está reduciendo con lo compiladores JIT(Just In Time) para Java que están apareciendo en el mercado.

Bibliotecas estándar: En C++ existía casi una biblioteca por plataforma (si existía) para hacer cosas como: Trabajo en red, conexión a bases de datos, uso de múltiples hilos de control, uso de objetos distribuídos o compresión. Java incorpora bibliotecas estándar multiplataforma para todas estas tareas en su API.
Excepciones por fallos de descriptores: Java lanza excepciones cuando hay errores en el acceso a un descriptor, permitiendo al programador gestionar dichos fallos, y recuperar al programa de ellos.Gestión de errores al compilar: Además comprobar el lanzamiento de excepciones en tiempo de compilación, comprueba el cumplimiento del lanzamiento de excepciones por los métodos sobreescritos.
b) Aspectos eliminados:
Preprocesador: Java no tiene preprocesador, por lo que las macros (#include, #define,...) no existen.
Acceso directo al hardware: En Java está restringido, aunque para eso permite la utilización de métodos nativos, escritos para la plataforma (normalmente C/C++). En cualquier caso las applets no pueden utilizar estos métodos nativos, sólo las aplicaciones Java pueden hacerlo.
c) Aspectos introducidos
Multiples hilos de control (multithreating): Java permite la utilización de múltiples hilos de control y la ejecución en paralelo (y sincronizada) de múltiples tareas, mediante la clase Thread.
Applets Java: Este tipo de aplicaciones son seguras, distribuíbles por Internet y ejecutables por los navegadores, aunque tienen restricciones (como la escritura en disco).
Extracción automática de documentación: Un nuevo tipo de comentario (/**com_doc*/) permite a los programadores extraer de manera automática comentarios de sus fuentes, generando automáticamente documentación estandarizada.
JavaBeans: Mediante esta biblioteca se permite crear elementos visuales multiplataforma, algo impensable en C++.
E. Comparativa sobre características de la POO
a) IntroducciónEn este apartado se va a comparar Java con los lenguajes C++ y Smalltalk (primer lenguaje que presentaba un modelo de objeto).

Característica Java Smalltalk C++
Sencillez Sí Sí No
Robustez Sí Sí No
Seguridad Sí Algo No
Interpretado Sí Sí No
Dinamicidad Sí Sí No
Portabilidad Sí Algo No
Neutralidad Sí Algo No
Threads Sí No No
Garbage Colection Sí Sí No
Excepciones Sí Sí Algunas
Representación Alta Media Alta
Tabla 1: Comparación entre Java, SmallTalk y C++
4. Los primeros pasos en Java. Tipos de aplicaciones en Java y ejemplos
Como cualquier otro lenguaje, Java se usa para crear aplicaciones. Pero, además Java tiene la particularidad especial de poder crear aplicaciones muy especiales, son los applets, que es una mini (let) aplicación (app) diseñada para ejecutarse en un navegador. A continuación se verá en detalle lo mínimo que se puede hacer en ambos casos, lo que permitirá presentar la secuencia de edición, compilación, ejecución en Java, que será imprescindible a la hora de estudiar detalles más concretos de Java, porque los ejemplos que se muestren serán mejor comprendidos.
Una mini aplicación en JavaLa aplicación más pequeña posible es la que simplemente imprime un mensaje en la pantalla. Tradicionalmente, el mensaje suele ser "Hola Mundo!". Esto es justamente lo que hace el siguiente fragmento de código: // Aplicación HolaMundo de ejemplo // class HolaMundoApp { public static void main( String args[] ) { System.out.println( "Hola Mundo!" );

} }
HolaMundo!
Hay que ver en detalle la aplicación anterior, línea a línea. Esas líneas de código contienen los componentes mínimos para imprimir Hola Mundo! en la pantalla. Es un ejemplo muy simple, que no instancia objetos de ninguna otra clase; sin embargo, accede a otra clase incluida en el JDK.
// Aplicación HolaMundo de ejemplo //
Estas dos primeras líneas son comentarios. Hay tres tipos de comentarios en Java, // es un comentario orientado a línea. class HolaMundoApp {
Esta línea declara la clase HolaMundoApp. El nombre de la clase especificado en el fichero fuente se utiliza para crear un fichero nombredeclase.class en el directorio en el que se compila la aplicación. En este caso, el compilador creará un fichero llamado HolaMundoApp.class.
public static void main( String args[] ) {
Esta línea especifica un método que el intérprete Java busca para ejecutar en primer lugar. Igual que en otros lenguajes, Java utiliza una palabra clave main para especificar la primera función a ejecutar. En este ejemplo tan simple no se pasan argumentos.
public significa que el método main() puede ser llamado por cualquiera, incluyendo el intérprete Java.
static es una palabra clave que le dice al compilador que main se refiere a la propia clase HolaMundoApp y no a ninguna instancia de la clase. De esta forma, si alguien intenta hacer otra instancia de la clase, el método main() no se instanciaría.
void indica que main() no devuelve nada. Esto es importante ya que Java realiza una estricta comprobación de tipos, incluyendo los tipos que se ha declarado que devuelven los métodos.
args[] es la declaración de un array de Strings. Estos son los argumentos escritos tras el nombre de la clase en la línea de comandos: %java HolaMundoApp arg1 arg2 ...
System.out.println( "Hola Mundo!" );

Esta es la funcionalidad de la aplicación. Esta línea muestra el uso de un nombre de clase y método. Se usa el método println() de la clase out que está en el paquete System.
A una variable de tipo class se puede acceder sin necesidad de instanciar ningún objeto de esa clase. Por ello ha de ser un tipo básico o primitivo, o bien puede ser una referencia que apunta a otro objeto. En este caso, la variable out es una referencia que apunta a un objeto de otro tipo, aquí una instancia de la clase PrintStream (un objeto PrintStream), que es automáticamente instanciado cuando la clase System es cargada en la aplicación. Esto es algo semejante al hecho de que los objetos stream de entrada/salida, cin y cout son automáticamente instanciados y enlazados a los dispositivos estándar de entrada y salida cuando un programa C++ comienza su ejecución.
El método println() toma una cadena como argumento y la escribe en el stream de salida estándar; en este caso, la ventana donde se lanza la aplicación. La clase PrintStream tiene un método instanciable llamado println(), que lo hace e presentar en la salida estándar del Sistema el argumento que se le pase. En este caso, se utiliza la variable o instancia de out para acceder al método. } }Finalmente, se cierran las llaves que limitan el método main() y la clase HolaMundoApp. En C++, la función main() en un programa puede tener cualquiera de los siguientes prototipos:
tipo_retorno main() tipo_retorno main( int argc,char argv[] )
El tipo_retorno puede ser cualquier tipo válido, o void, para indicar que la función no tiene que devolver valor alguno. La lista de argumentos puede estar vacía, o contener los argumentos de soporte para pasar parámetros en la línea de comandos. Esta forma de implementación la función difiere de la que acaba de presentar para Java, que siempre habrá de ser la misma, independientemente de los valores de retorno o la lista de parámetros que se pasen en la lista de argumentos a la aplicación.
Compilación y Ejecución de HolaMundoA continuación se puede ver el resultado de esta primera y sencilla aplicación Java en pantalla. Se genera un fichero con el código fuente de la aplicación, se compilará y se utilizará el intérprete Java para ejecutarlo.
Ficheros Fuente JavaLos ficheros fuente en Java terminan con la extensión ".java". Crear un fichero utilizando cualquier editor de texto ascii que tenga como contenido el código de las ocho líneas de nuestra mínima aplicación, y salvarlo en un fichero con el nombre de HolaMundoApp.java. Para crear los ficheros con código fuente Java no es necesario un procesador de textos, aunque puede utilizarse siempre que tenga

salida a fichero de texto plano o ascii, sino que es suficiente con cualquier otro editor.
CompilaciónEl compilador javac se encuentra en el directorio bin por debajo del directorio java, donde se haya instalado el JDK. Este directorio bin, si se han seguido las instrucciones de instalación, debería formar parte de la variable de entorno PATH del sistema. Si no es así, tendría que revisar la Instalación del JDK. El compilador de Java traslada el código fuente Java a byte-codes, que son los componentes que entiende la Máquina Virtual Java que está incluida en los navegadores con soporte Java y en appletviewer.
Una vez creado el fichero fuente HolaMundoApp.java, se puede compilar con la línea siguiente:
%javac HolaMundoApp.java
Si no se han cometido errores al teclear ni se han tenido problemas con el path al fichero fuente ni al compilador, no debería aparecer mensaje alguno en la pantalla, y cuando vuelva a aparecer el prompt del sistema, se debería ver un fichero HolaMundoApp.class nuevo en el directorio donde se encuentra el fichero fuente.Si ha habido algún problema, en Problemas de compilación al final de esta sección, hemos intentado reproducir los que más frecuentemente se suelen dar, se pueden consultar por si pueden aportar un poco de luz al error que haya aparecido.
Ejecución
Para ejecutar la aplicación HolaMundoApp, hemos de recurrir al intérprete java, que también se encuentra en el directorio bin, bajo el directorio en donde se haya instalado el JDK. Se ejecutará la aplicación con la línea:
%java HolaMundoApp
y debería aparecer en pantalla la respuesta de Java:
%Hola Mundo!
El símbolo % representa al prompt del sistema, y se utilizará aquí para presentar las respuestas que devuelva el sistema como resultado de la ejecución de los comandos que se introduzcan por teclado o para indicar las líneas de comandos a introducir.
Cuando se ejecuta una aplicación Java, el intérprete Java busca e invoca al método main() de la clase cuyo nombre coincida con el nombre del fichero .class que se indique en la línea de comandos. En el ejemplo, se indica al Sistema Operativo que arranque el intérprete Java y luego se indica al intérprete Java que

busque y ejecute el método main() de la aplicación Java almacenada en el fichero HolaMundoApp.class.
Problemas de compilaciónA continuación se encuentra una lista de los errores más frecuentes que se presentan a la hora de compilar un fichero con código fuente Java, tomando como base los errores provocados sobre la mínima aplicación Java que se está utilizando como ejemplo, pero también podría generalizarse sin demasiados problemas.
%javac: Command not found
No se ha establecido correctamente la variable PATH del sistema para el compilador javac. El compilador javac se encuentra en el directorio bin, que cuelga del directorio donde se haya instalado el JDK (Java Development Kit).
%HolaMundoApp.java:3: Method printl(java.lang.String) not found in classjava.io.PrintStream.
System.out.printl( "HolaMundo! ); ^Error tipográfico, el método es println no printl.%In class HolaMundoApp: main must be public and static
Error de ejecución, se olvidó colocar la palabra static en la declaración del método main de la aplicación.
%Can´t find class HolaMundoApp
Este es un error muy sutil. Generalmente significa que el nombre de la clase es distinto al del fichero que contiene el código fuente, con lo cual el fichero nombre_fichero.class que se genera es diferente del que cabría esperar. Por ejemplo, si en el fichero de código fuente de la aplicación HolaMundoApp.java se coloca en vez de la declaración actual de la clase HolaMundoApp, la línea:
class HolaMundoapp {
se creará un fichero HolaMundoapp.class, que es diferente del HolaMundoApp.class, que es el nombre esperado de la clase; la diferencia se encuentra en la a minúscula y mayúscula.
%Note: prueba.java uses a deprecated API. Recompile with "-deprecation" for details. 1 Warning
Esto es originado por otra de las cosas que ha introducido el JDK 1.1 como son los elementos obsoletos (deprecated), es decir, aquellas clases o métodos que no se recomienda utilizar, aunque sigan siendo válidos, porque están destinados a

desaparecer de la faz de la Tierra a partir de alguna de las versiones posteriores del JDK. Si se compila un programa que hace uso de uno de estas clases, o bien utiliza o sobrecarga un método obsoleto, el compilador mostrará un mensaje de este tipo.Solamente se genera un aviso por módulo, independientemente del número de métodos obsoletos que se estén utilizando, por eso hay que seguir la recomendación del aviso si se quieren saber los detalles completos de todas las clases y métodos obsoletos que se están utilizando.
No obstante, en este caso y a pesar de estos avisos, el compilador genera código perfectamente ejecutable.
5. EL KIT DE DESARROLLO DE JDK (JAVA DEVELOPERS KIT)
5.1 ¿CÓMO Y DÓNDE OBTENER EL JDK?
El primer paso será descargar(download) el JDK (Java Developers Kit), el cual esta disponible para las siguientes plataformas:
SPARC Solaris (2.3 o superior)Intel x86 SolarisWindows NT/95 (Intel x86)Macintosh 7.5
En la siguiente URL: http://Java.sun.com/devcorner.html Si su plataforma de desarrollo es Windows 95, pueden bajarse el JDK desde:
ftp://ftp.rcp.net.pe/pub/networks/win95/webedit
Ahora si tienen alguna plataforma como AIX, OS2, Windows 3.x, pueden revisar la documentación de la URL:
http://ncc.hursley.ibm.com/Javainfo
en donde encontraran mayor información sobre compiladores (Just in Time -JIT).
5.2 EL ENTORNO DE DESARROLLO DE JAVA
Existen distintos programas comerciales que permiten desarrollar código Java. La compañía Sun, creadora de Java, distribuye gratuitamente el Java(tm) Development Kit (JDK). Se trata de un conjunto de programas y librerías que permiten desarrollar, compilar y ejecutar programas en Java.
Incorpora además la posibilidad de ejecutar parcialmente el programa, deteniendo la ejecución en el punto deseado y estudiando en cada momento el valor de cada

una de las variables (es el denominado Debugger). Cualquier programador con un mínimo de experiencia sabe que una parte muy importante (muchas veces la mayor parte) del tiempo destinado a la elaboración de un programa se destina a la detección y corrección de errores. Existe también una versión reducida del JDK, denominada JRE (Java Runtime Environment) destinada únicamente a ejecutar código Java (no permite compilar). Los IDEs (Integrated Developmen Environment), tal y como su nombre indica, son entornos de desarrollo integrados.
En un mismo programa es posible escribir el código Java, compilarlo y ejecutarlo sin tener que cambiar de aplicación. Algunos incluyen una herramienta para realizar Debug gráficamente, frente a la versión que incorpora el JDK basada en la utilización de una consola (denominada habitualmente ventana de comandos de MS-DOS, en Windows NT/95/98) bastante difícil y pesada de utilizar. Estos entornos integrados permiten desarrollar las aplicaciones de forma mucho más rápida, incorporando en muchos casos librerías con componentes ya desarrollados, los cuales se incorporan al proyecto o programa. Como inconvenientes se pueden señalar algunos fallos de compatibilidad entre plataformas y ficheros resultantes de mayor tamaño que los basados en clases estándar.
¿QUÉ ES EL JDK?El JDK, es un conjunto de herramientas de desarrollo el cual consta de:
El compilador de JavaSe trata de una de las herramientas de desarrollo incluidas en el JDK. Realiza un análisis de sintaxis del código escrito en los ficheros fuente de Java (con extensión *.java). Si no encuentra errores en el código genera los ficheros compilados (con extensión *.class). En otro caso muestra la línea o líneas erróneas. En el JDK de Sun dicho compilador se llama javac.exe. Tiene numerosas opciones, algunas de las cuales varían de una versión a otra. Se aconseja consultar la documentación de la versión del JDK utilizada para obtener una información detallada de las distintas posibilidades.
La Java Virtual MachinaTal y como se ha comentado al comienzo, la existencia de distintos tipos de procesadores y ordenadores llevó a los ingenieros de Sun a la conclusión de que era muy importante conseguir un software que no dependiera del tipo de procesador utilizado. Se plantea la necesidad de conseguir un código capaz de ejecutarse en cualquier tipo de máquina. Una vez compilado no debería ser necesaria ninguna modificación por el hecho de cambiar de procesador o de ejecutarlo en otra máquina. La clave consistió en desarrollar un código “neutro” el cual estuviera preparado para ser ejecutado sobre una “máquina hipotética o virtual”, denominada Java Virtual Machine (JVM). Es esta JVM quien interpreta este código neutro convirtiéndolo a código particular de la CPU o chip utilizada. Se evita tener que realizar un programa diferente para cada CPU o plataforma. La JVM es el intérprete de Java. Ejecuta los “bytecodes” (ficheros compilados con extensión *.class) creados por el compilador de Java (javac.exe). Tiene

numerosas opciones entre las que destaca la posibilidad de utilizar el denominado JIT (Just-In-Time Compiler), que puede mejorar entre 10 y 20 veces la velocidad de ejecución de un programa.
Las variables PATH y CLASSPATHEl desarrollo y ejecución de aplicaciones en Java exige que las herramientas para compilar (javac.exe) y ejecutar (java.exe) se encuentren accesibles. El ordenador, desde una ventana de comandos de MS-DOS, sólo es capaz de ejecutar los programas que se encuentran en los directorios indicados en la variable PATH del ordenador. Si se desea compilar o ejecutar código en Java en estos casos el directorio donde se encuentran estos programas (java.exe y javac.exe) deberán encontrarse en el PATH. Tecleando set PATH en una ventana de comandos de MS-DOS se muestran los nombres de directorios incluidos en dicha variable de entorno. Java utiliza además una nueva variable de entorno denominada CLASSPATH, la cual determina dónde buscar tanto las clases o librerías de Java (el API de Java) como otras clases de usuario. A partir de la versión 1.1.4 del JDK no es necesario indicar esta variable, salvo que se desee añadir conjuntos de clases de usuario que no vengan con dicho JDK.La variable CLASSPATH puede incluir la ruta de directorios o ficheros *.zip o *.jar en los que se encuentren los ficheros *.class. En el caso de los ficheros *.zip hay que indicar que los ficheros en él incluidos no deben estar comprimidos. En el caso de archivos *.jar existe una herramienta (jar.exe), incorporada en el JDK, que permite generar estos ficheros a partir de los archivos compilados *.class. Los ficheros *.jar son archivos comprimidos y por lo tanto ocupan menos espacio que los archivos *.class por separado o que el fichero *.zip equivalente. Una forma general de indicar estas dos variables es crear un fichero batch de MS-DOS (*.bat) donde se indiquen los valores de dichas variables.
Cada vez que se abra una ventana de MS-DOS será necesario ejecutar este fichero *.bat para asignar adecuadamente estos valores. Un posible fichero llamado jdk117.bat, podría ser como sigue:
set JAVAPATH=C:\jdk1.3set PATH=.;%JAVAPATH%\bin;%PATH%set CLASSPATH=.\;%JAVAPATH%\lib\classes.zip;%CLASSPATH%
lo cual sería válido en el caso de que el JDK estuviera situado en el directorio C:\jdk1.3.
Si no se desea tener que ejecutar este fichero cada vez que se abre una consola de MS-DOS es necesario indicar estos cambios de forma “permanente”. La forma de hacerlo difiere entre Windows 95/98 y Windows NT. En Windows 95/98 es necesario modificar el fichero Autoexec.bat situado en C:\, añadiendo las líneas antes mencionadas. Una vez rearrancado el ordenador estarán presentes en cualquier consola de MS-DOS que se cree. La modificación al fichero Autoexec.bat en Windows 95/98 será la siguiente:

set JAVAPATH=C:\jdk1.3set PATH=.;%JAVAPATH%\bin;%PATH%set CLASSPATH=
En el caso de utilizar Windows NT se añadirá la variable PATH en el cuadro de diálogo que se abre con Start -> Settings -> Control Panel -> System -> Environment -> User Variables for NombreUsuario: También es posible utilizar la opción –classpath en el momento de llamar al compilador javac.exe o al intérprete java.exe. Los ficheros *.jar deben ponerse con el nombre completo en el CLASSPATH: no basta poner el PATH o directorio en el que se encuentra. Por ejemplo, si se desea compilar y ejecutar el fichero ContieneMain.java, y éste necesitara la librería de clases G:\MyProject\OtherClasses.jar, además de las incluidas en el CLASSPATH, la forma de compilar y ejecutar sería:
javac -classpath .\;G:\MyProject\OtherClasses.jar ContieneMain.javajava -classpath .\;G:\MyProject\OtherClasses.jar ContieneMain
Se aconseja consultar la ayuda correspondiente a la versión que se esté utilizando, debido a que existen pequeñas variaciones entre las distintas versiones del JDK. Cuando un fichero filename.java se compila y en ese directorio existe ya un fichero filename.class, se comparan las fechas de los dos ficheros. Si el fichero filename.java es más antiguo que el filename.class no se produce un nuevo fichero filename.class. Esto sólo es válido para ficheros *.class que se corresponden con una clase public.
En resumen se puede decir que tiene las siguientes herramientas.
appletviewer.exe
Descripción: Es el visor de applets de Java. El appletviewer descarga uno o mas documentos HTML especificados por la URL en la línea de comando. Descarga todos los applets referenciados en cada documento y muestra estos. Cada uno en su propia ventana. Si ninguno de los documentos mostrados tiene una marca <APPLET>, appletviewer no hace nada.
Opciónes:-debug Inicia el Java debugger jdb, permitiéndote depurar el applet en el documento.
Java.exe
Descripción: Es el intérprete de Java ejecuta byte-codes creados por Javac, el compilador de Java. El argumento nombre_de_clase es el nombre de la clase a ser ejecutada y argumentos son los parámeros pasados a la clase.
Sintaxis:Java [opciónes] nombre_de_clase <argumentos>

Java_g [opciónes] nombre_de_clase <argumentos>
Opciónes:-debug Permite que el jdb (Java debugger) se conecte a si mismo a la sesión de Java. Cuando
-debug es especificado en la línea de comandos, Java muestra una contraseña, la cual debe ser usada cuando comienza la sesión de depuración.
-cs, Compara la fecha de modificación del archivo de la clase.
-checksource Con la del archivo fuente. Cuando la clase es cargada, si el archivo fuente tiene una fecha mas reciente que la del archivo de la clase entonces el archivo fuente es recompilado y los byte-codes resultantes vueltos a cargar.
-classpath Especifica el camino que Java usa para buscar las clases.
-path Sobreescribe el establecido por defecto o la variable de entorno CLASSPATH si esta ha sido establecida anteriormente.
Los Directorios en la variable CLASSPATH son separados con punto y coma (;).
Hasta aquí el formato general para el path es: .;<tu_camino>
Por ejemplo:
C:\users\avh\classes\;C:\jdk\classes
-mx x Establece el tamaño máximo de la memoria del colector de basura para x. El valor por defecto es 16 megabytes de memoria. x debe ser mayor que 1000 bytes.
Por defecto, x es menciónado en bytes, pero se puede especificar en kilobytes o megabytes poniendo después de x la letra k para kilobytes y m para megabytes.
-ms x Establece el tamaño de inicio de la memoria del colector de basura para x. El valor por defecto es 1 megabyte de memoria. x debe ser mayor que 1000 bytes. Por defecto, x es menciónado en bytes, pero se puede especificar en kilobytes o megabytes poniendo después de x la letra k para kilobytes y m para megabytes.
-noasyncgc Apaga el colector asíncrono de basura. Cuando el colector está activado no actúa a menos que este sea explícitamente llamado o el programa corra fuera de memoria. Normalmente el colector de basura se ejecuta como una tárea síncrona en paralelo con otras táreas.
-ss x Cada tárea en Java tiene dos pilas: una para el código de Java y otra para el código de C.

-ss establece el tamaño máximo de la pila mediante el valor x que puede ser usada por el código de C en una tárea. Todas las táreas que resultan de la ejecución del programa pasado a Java tienen a x como tamaño de pila para C. La unida por defecto para x son bytes. x debe ser mayor que 1000 bytes. Puedes modificar el significado de x adiciónando la letra k para kilobytes o la letra m para megabytes. El tamaño por defecto de la pila es 128 kilobytes (-ss 128k).
-oss x Cada tárea en Java tiene dos pilas: una para el código de Java y otra para el código de C.
-oss establece el tamaño máximo de la pila mediante el valor x que puede ser usada por el código de Java en una tárea. Todas las táreas que resultan de la ejecución del programa pasado a Java tienen a x como tamaño de pila para Java. La unidad por defecto para x son bytes. x debe ser mayor que 1000 bytes.
Puedes modificar el significado de x adiciónando la letra k para kilobytes o la letra m para megabytes. El tamaño por defecto de la pila es 400 kilobytes (-oss 400k).
-t Imprime el rastro de las instrucciónes ejecutadas (sólo Java_g)
-v, -verbose Hace que Java imprima un mensaje en la salida estándar cada vez que un archivo de clase es cargado.
-verify Ejecuta el verificador de todo el código.
-verify Ejecuta el verificador de todo el código que es cargado en remote el sistema via un classloader. verifyremote es el valor por defecto para el interprete.
-verbosegc Hace que el colector de basura imprima mensajes cada que este libera memoria.
-Dproperty Redefine el valor de una propiedad. propertyName es el Name(nombre) de la propiedad cuyo valor se quiere cambiar y newValue es valor a ser asignado. Por ejemplo, este comando de línea:Java - awt.button.color=green
establece el valor de la propiedad awt.button.color a green(verde). Java acepta cualquier numero de opciónes -D en la línea de comandos.
Entorno:CLASSPATH Esta variable de entorno es usada para indicar al sistema la ruta de las clases definidas por el usuario.
Por ejemplo:
C:\users\avh\classes;C:\jdk\classes

Javac.exe
Descripción: Javac, es el compilador del lenguaje Java, es decir compila los archivos (*.Java) en byte-codes Java archivos (*.class), el compilador Javac ha sido escrito en el mismo Java. Por defecto Javac, genera los archivos (*.class), en el mismo directorio del archivo fuente (*.Java)
Cuando un archivo fuente de Java hace referencia a una clase que no esta definida en alguno de los archivos fuente del comando de línea, entonces Javac hace uso del Classpath, por defecto el Classpath, solo contiene las clases del sistema.
Sintaxis:Javac [opciónes] archivos
Opciónes:
-classpath ruta Aquí ruta, le dice a classpath a donde tiene que ir a buscar las clases especificadas en el código fuente. Esta opción elimina el path por defecto y cualquier otra ruta especificada en classpath la ruta especificada puede ser una lista de directorios separados por (;) para sistemas Windows y (.) para sistemas Unís -d directorio Directorio, especifica el lugar donde usted desea se guarden sus clases, por defecto las clases se guardan en el mismo directorio que las fuentes (*.Java)
Javac -d [ruta de clases] [ruta de fuentes]Ejemplo:
Javac -d c:\Java\clases c:\Java\fuentes\work1.Java
-g Esta opción permite al Javac adiciónar numero de línea y la información de variables locales a los archivos de clases, esto sólo podrá ser visualizado cuando use el Jdb (Java debuggers)
-nowarn Permite que el Javac no muestre los mensajes de erroren la compilación.
-verbose permite al compilador mostrar los mensajes
Javadoc.exeDescripción: Javadoc genera documentación API en formato HTML para el paquete especificado o para los archivos fuentes individuales en Java en la líneade comandos.
Sintaxis:Javadoc [opciónes] nombre_de_paqueteJavadoc [opciónes] nombre_de_archivo

Opciónes:-classpath path El path que Javap usa para encontrar las clases nombradas en la línea de comandos.
-d directory Especifica un directorio en donde Javadoc almacena los archivos HTML que genera. Por defecto es el directorio actual.-verbose Hace que Javadoc imprima mensajes acerca de lo que esta haciendo.
Javah.exeDescripción: Javah genera archivos fuentes y de cabecera en C (archivos .h y .c) que describen las clases especificadas. Estos archivos de C proveen la información necesaria para implementar métodos nativos para las clases especificadas en C.
Sintaxis:Javah [opciónes] nombre_de_clase
Opciónes:-classpath path El path que Javah usa para encontrar las clases nombradas en la línea decomandos.
-d directory Especifica un directorio en donde Javah almacena los archivos que genera. Por defecto los almacena en el directorio actual.
-o outputfile Combina todos los archivos .h o .c en un simple archivo, outputfile.
-stubs Genera archivos .c stub para la clase o clases, y no genera archivos de cabecera .h.
-td directory El directorio donde Javah almacena los archivos temporales. Por defecto es /tmp.
-v Hace que Javah imprima mensajes acerca del trabajo que está realizando.
Javap.exeDescripción: Javah desensambla el archivo de clases especificado por los nombres de clases en la línea de comandos e imprime una versión humanamente comprensible de esas clases.
Sintaxis:Javap [opciónes] nombre de_clase
Opciónes:

-c Imprime las instrucciónes de la maquína virtual de Java para cada uno de los métodos en cada una de las clases especificadas. Esta opción desensambla todos los métodos incluyendo los privados y protegidos.
-classpath path El path que Javap usa para encontrar las clasesnombradas en la línea de comandos.
-l Imprime números de línea y tablas de variables locales además de los campos públicos de las clases. Note que los números de línea y la información de variables es incluida para usar con debuggers. La información de variables locales esta disponible sólo si una clase fue compilada con la opción
-g de Javac, la información de números de línea esta disponible sólo si una clase fue compilada con la opción -O.
-p Imprime métodos privados y protegidos y variables de la clase especificada además de las publicas.
jdb.exeDescripción: jdb es un depurador para clases de Java. Este esta basado en una línea de comandos de texto y tiene una sintaxis de comandos como la del dbx en UNIX o depuradores gdb.
Sintaxis:jdb [opciónes de Java] classjdb [-host hostname] -password password
Opciónes:-host hostname-password password
Comandos:
catch [clase de excepción]classesclear [class:line]contdown [n]dump id(s)exit (o quit)gchelp o ?ignore clase de excepciónlist [numero de línea]load classnamelocals

memorymethods classprint id(s)resume [thread(s)]run [class] [args]stepstop [at class:line]stop [in class.method]suspend [threads(s)]thread threadthreadgroup namethreadgroupsthreads [threadgroups]up [n]use [ruta_archivo_fuente]where [thread] [all]

UNIDAD III
PROGRAMACIÓN EN JAVA
1. SINTAXIS DEL LENGUAJE JAVA VARIABLES Y TIPOS DE DATOS
1.1 Introducción
Java es un lenguaje orientado a objetos, que se deriva en alto grado de C++, de tal forma que puede ser considerado como un C++ nuevo y modernizado o bien como un C++ al que se le han amputado elementos heredados del lenguaje estructurado C.
1.2 Tokens
Un token es el elemento más pequeño de un programa que es significativo para el compilador. Estos tokens definen la estructura de Java.
Cuando se compila un programa Java, el compilador analiza el texto, reconoce y elimina los espacios en blanco y comentarios y extrae tokens individuales. Los tokens resultantes se compilan, traduciéndolos a código de byte Java, que es independiente del sistema e interpretable dentro de un entorno Java.
Los códigos de byte se ajustan al sistema de máquina virtual Java, que abstrae las diferencias entre procesadores a un procesador virtual único.
Los tokens Java pueden subdividirse en cinco categorías: Identificadores, palabras clave, constantes, operadores y separadores.
a) Identificadores
Los identificadores son tokens que representan nombres asignables a variables, métodos y clases para identificarlos de forma única ante el compilador y darles nombres con sentido para el programador.
Todos los identificadores de Java diferencian entre mayúsculas y minúsculas (Java es Case Sensitive o Sensible a mayúsculas) y deben comenzar con una letra, un subrayado(_) o símbolo de dólar($). Los caracteres posteriores del identificador pueden incluir las cifras del 0 al 9. Como nombres de identificadores no se pueden usar palabras claves de Java.
En la siguiente línea de código se puede apreciar la declaración de una variable entera (int) con su correspondiente identificador:

int alturaMedia;
b) Palabras clave
Las palabras claves son aquellos identificadores reservados por Java para un objetivo determinado y se usan sólo de la forma limitada y específica. Java tiene un conjunto de palabras clave más rico que C o que C++.
Las siguientes palabras son palabras reservadas de Java:
Abstact boolean break byte byvalue
Case cast catch char class
const continue default do double
else extends false final finally
float for future generic goto
if implements import inner instanceof
int interface long native new
null operator outer package private
protected public rest return short
static super switch syncroniced this
throw throws transient true try
var void volatile while
Tabla 2: Palabras reservadas Java

c) Literales y constantes
Los literales son sintaxis para asignar valores a las variables. Cada variable es de un tipo de datos concreto, y dichos tipos de datos tienen sus propios literales.
Mediante determinados modificadores (static y final) podremos crear variables constantes, que no modifican su valor durante la ejecución de un programa. Las constantes pueden ser numéricas, booleanas, caracteres (Unicode) o cadenas (String).
Las cadenas, que contienen múltiples caracteres, aún se consideran constantes, aunque están implementadas en Java como objetos.
Veamos un ejemplo de constante declarada por el usuario:
final static int ALTURA_MAXIMA = 200;
d) Operadores
Indican una evaluación o computación para ser realizada en objetos o datos, y en definitiva sobre identificadores o constantes. Los operadores admitidos por Java son:
+ ^ <= ++ %=
>>>= - ~ >= -
&= . * && <<
== <<= [ / ||
>> += ^= ] %
! >>> = != (

& < *= ) |
> ?!! /= >>
Tabla 3: Operadores Java
Por ejemplo el siguiente fragmento de código incrementa el valor de la variable miNumero en dos unidades, mediante la utilización del operador aritmético + que se utiliza para la suma:
int miNumero=0;
miNumero = miNumero + 2;
e) Separadores
Se usan para informar al compilador de Java de cómo están agrupadas las cosas en el código.
Los separadores admitidos por Java son: { } , : ;
f) Comentarios y espacios en blanco
El compilador de Java reconoce y elimina los espacios en blanco, tabuladores, retornos
de carro y comentarios durante el análisis del código fuente.
Los comentarios se pueden presentar en tres formatos distintos:
Formato Uso
/*comentario*/ Se ignoran todos los caracteres entre /* */. Proviene del C
//comentario Se ignoran todos los caracteres detrás de // hasta el fin de

línea. Proviene del C++
/**comentario*/ Lo mismo que /* */ pero se podrán utilizar para documentación automática.
Tabla 4: Formatos de comentarios Java
Por ejemplo la siguiente línea de código presenta un comentario:
int alturaMinima = 150; // No menos de 150 centímetros
1.3 Expresiones
Los operadores, variables y las llamadas a métodos pueden ser combinadas en secuencias conocidas como expresiones. El comportamiento real de un programa Java se logra a través de expresiones, que se agrupan para crear sentencias.
Una expresión es una serie de variables, operadores y llamadas a métodos (construida conforme a la sintaxis del lenguaje) que se evalúa a un único valor.
Entre otras cosas, las expresiones son utilizadas para realizar cálculos, para asignar valores a variables, y para ayudar a controlar la ejecución del flujo del programa. La tarea de una expresión se compone de dos partes: realiza el cálculo indicado por los elementos de la expresión y devuelve el valor obtenido como resultado del cálculo.
Por ejemplo, las siguientes sentencias son una expresión:
int contador=1;
contador++;
Una expresión de llamada a un método se evalúa al valor de retorno del método; así el tipo de dato de la expresión de llamada a un método es el mismo que el tipo de dato del valor de retorno de ese método.
Otra sentencia interesante sería:

in.read( ) != -1 // in es un flujo de entrada
Esta sentencia se compone de dos expresiones:
1. La primera expresión es una llamada al método in.read(). El método in.read() ha sido declarado para devolver un entero, por lo que la expresión in.read() se evalúa a un entero. 2. La segunda expresión contenida en la sentencia utiliza el operador !=, que comprueba si dos operandos son distintos. En la sentencia en cuestión, los operandos son in.read() y -1. El operando in.read() es válido para el operador != porque in.read() es una expresión que se evalúa a un entero, así que la expresión in.read()!=-1 compara dos enteros. El valor devuelto por esta expresión será verdadero o falso dependiendo del resultado de la lectura del fichero in.
Como se puede observar, Java permite construir sentencias (expresiones compuestas) a partir de varias expresiones más pequeñas con tal que los tipos de datos requeridos por una parte de la expresión concuerden con los tipos de datos de la otra.
1.4 Bloques y ámbito
En Java el código fuente está dividido en partes separadas por llaves, denominas bloques. Cada bloque existe independiente de lo que está fuera de él, agrupando en su interior sentencias (expresiones) relacionadas.
Desde un bloque externo parece que todo lo que está dentro de llaves se ejecuta como una sentencia. Pero, ¿qué es un bloque externo?. Esto tiene explicación si entendemos que existe una jerarquía de bloques, y que un bloque puede contener uno o más subbloques anidados.
El concepto de ámbito está estrechamente relacionado con el concepto de bloque y es muy importante cuando se trabaja con variables en Java. El ámbito se refiere a cómo las secciones de un programa (bloques) afectan el tiempo de vida de las variables.
Toda variable tiene un ámbito, en el que es usada, que viene determinado por los bloques. Una variable definida en un bloque interno no es visible por el bloque externo.
Las llaves de separación son importantes no sólo en un sentido lógico, ya que son la forma de que el compilador diferencie dónde acaba una sección de código y

dónde comienza otra, sino que tienen una connotación estética que facilita la lectura de los programas al ser humano.
Así mismo, para identificar los diferentes bloques se utilizan sangrías. Las sangrías se utilizan para el programador, no para el compilador.
{
// Bloque externo
int x = 1;
{
// Bloque interno invisible al exterior
int y = 2;
}
x = y; // Da error: Y fuera de ámbito
}
2. TIPOS DE DATOS
2.1 Tipos de datos simples
Es uno de los conceptos fundamentales de cualquier lenguaje de programación. Estos definen los métodos de almacenamiento disponibles para representar información, junto con la manera en que dicha información ha de ser interpretada.
Para crear una variable (de un tipo simple) en memoria debe declararse indicando su tipo de variable y su identificador que la identificará de forma única. La sintaxis de declaración de variables es la siguiente:
TipoSimple Identificador1, Identificador2;
Esta sentencia indica al compilador que reserve memoria para dos variables del tipo simple TipoSimple con nombres Identificador1 e Identificador2.
Los tipos de datos en Java pueden dividirse en dos categorías: simples y compuestos. Los simples son tipos nucleares que no se derivan de otros tipos, como los enteros, de coma flotante, booleanos y de carácter. Los tipos compuestos se basan en los tipos simples, e incluyen las cadenas, las matrices y tanto las clases como las interfaces, en general.

Cada tipo de datos simple soporta un conjunto de literales que le pueden ser asignados, para darles valor. En este apartado se explican los tipos de datos simples (o primitivos) que presenta Java, así como los literales que soporta (sintaxis de los valores que se les puede asignar).
a) Tipos de datos enteros
Se usan para representar números enteros con signo. Hay cuatro tipos: byte, short, int y long.
Tipo Tamaño
byte 1Byte (8 bits)
short 2 Bytes (16 bits)
int 4 Bytes (32 bits)
long 8 Bytes (64 bits)
Tabla 5: Tipos de datos enteros
Literales enteros
Son básicos en la programación en Java y presentan tres formatos:
Decimal: Los literales decimales aparecen como números ordinarios sin ninguna notación especial.
Hexadecimal: Los hexadecimales (base 16) aparecen con un 0x ó 0X inicial, notación similar a la utilizada en C y C++.
Octal: Los octales aparecen con un 0 inicial delante de los dígitos.
Por ejemplo, un literal entero para el número decimal 12 se representa en Java como 12 en decimal, como 0xC en hexadecimal, y como 014 en octal.
Los literales enteros se almacenan por defecto en el tipo int, (4 bytes con signo), o si se trabaja con números muy grandes, con el tipo long, (8 bytes con signo), añadiendo una L ó l al final del número.
La declaración de variables enteras es muy sencilla. Un ejemplo de ello sería:
long numeroLargo = 0xC; // Por defecto vale 12
b) Tipos de datos en coma flotante

Se usan para representar números con partes fraccionarias. Hay dos tipos de coma flotante: float y double. El primero reserva almacenamiento para un número de precisión simple de 4 bytes y el segundo lo hace para un numero de precisión doble de 8 bytes.
Tipo Tamaño
float 4 Byte (32 bits)
double 8 Bytes (64 bits)
Tabla 6: Tipos de datos numéricos en coma flotante
Literales en coma flotante
Representan números decimales con partes fraccionarias. Pueden representarse con notación estándar (563,84) o científica (5.6384e2).
De forma predeterminada son del tipo double (8 bytes). Existe la opción de usar un tipo más corto (el tipo float de 4 bytes), especificándolo con una F ó f al final del número.
La declaración de variables de coma flotante es muy similar a la de las variables enteras. Por ejemplo:
double miPi = 314.16e-2 ; // Aproximadamente
float temperatura = (float)36.6; // Paciente sin fiebre
Se realiza un moldeado a temperatura, porque todos los literales con decimales por defecto se consideran double.
c) Tipo de datos boolean
Se usa para almacenar variables que presenten dos estados, que serán representados por los valores true y false. Representan valores bi-estado, provenientes del denominado álgebra de Boole.
Literales Booleanos
Java utiliza dos palabras clave para los estados: true (para verdadero) y false (para falso). Este tipo de literales es nuevo respecto a C/C++, lenguajes en los que

el valor de falso se representaba por un 0 numérico, y verdadero cualquier número que no fuese el 0.
Para declarar un dato del tipo booleano se utiliza la palabra reservada boolean:
boolean reciboPagado = false; // ¡¿Aun no nos han pagado?!
d) Tipo de datos carácter
Se usa para almacenar caracteres Unicode simples. Debido a que el conjunto de caracteres Unicode se compone de valores de 16 bits, el tipo de datos char se almacena en un entero sin signo de 16 bits.
Java a diferencia de C/C++ distingue entre matrices de caracteres y cadenas.
Literales carácter
Representan un único carácter (de la tabla de caracteres Unicode 1.1) y aparecen dentro de un par de comillas simples. De forma similar que en C/C++. Los caracteres especiales (de control y no imprimibles) se representan con una barra invertida ('\') seguida del código carácter.
Descripción Representación Valor Unicode
Caracter Unicode \udddd
Numero octal \ddd
Barra invertida \\ \u005C
Continuación \ \
Retroceso \b \u0008
Retorno de carro \r \u000D
Alimentación de formularios
\f \u000C
Tabulación horizontal \t \u0009
Línea nueva \n \u000A
Comillas simples \’ \u0027

Comillas dobles \" \u0022
Números arábigos ASCII 0-9 \u0030 a \u0039
Alfabeto ASCII en mayúsculas
A.-Z \u0041 a \u005A
Alfabeto ASCII en minúsculas
a.-z \u0061 a \u007A
Tabla 7: Caracteres especiales Java
Las variables de tipo char se declaran de la siguiente forma:
char letraMayuscula = 'A'; // Observe la necesidad de las ' '
char letraV = '\u0056'; // Letra 'V'
e) Conversión de tipos de datos
En Java es posible transformar el tipo de una variable u objeto en otro diferente al original con el que fue declarado. Este proceso se denomina "conversión", "moldeado" o "tipado". La conversión se lleva a cabo colocando el tipo destino entre paréntesis, a la izquierda del valor que queremos convertir de la forma siguiente:
char c = (char)System.in.read();
La función read devuelve un valor int, que se convierte en un char debido a la conversión (char), y el valor resultante se almacena en la variable de tipo carácter c.
El tamaño de los tipos que queremos convertir es muy importante. No todos los tipos se convertirán de forma segura. Por ejemplo, al convertir un long en un int, el compilador corta los 32 bits superiores del long (de 64 bits), de forma que encajen en los 32 bits del int, con lo que si contienen información útil, esta se perderá.
Por ello se establece la norma de que "en las conversiones el tipo destino siempre debe ser igual o mayor que el tipo fuente":
Tipo Origen Tipo Destino
byte double, float, long, int, char, short

short double, float, long, int
char double, float, long, int
int double, float, long
long double, float
float double
Tabla 8: Conversiones sin pérdidas de información
2. Vectores y Matrices
Una matriz es una construcción que proporciona almacenaje a una lista de elementos del mismo tipo, ya sea simple o compuesto. Si la matriz tiene solo una dimensión, se la denomina vector.
En Java los vectores se declaran utilizando corchetes ( [ y ] ), tras la declaración del tipo de datos que contendrá el vector. Por ejemplo, esta sería la declaración de un vector de números enteros (int):
int vectorNumeros[ ]; // Vector de números
Se observa la ausencia de un número que indique cuántos elementos componen el vector, debido a que Java no deja indicar el tamaño de un vector vacío cuando le declara. La asignación de memoria al vector se realiza de forma explícita en algún momento del programa.
Para ello o se utiliza el operador new:
int vectorNumeros = new int[ 5 ]; // Vector de 5 números
O se asigna una lista de elementos al vector:
int vectorIni = { 2, 5, 8}; // == int vectorIni[3]=new int[3];
Se puede observar que los corchetes son opcionales en este tipo de declaración de vector, tanto después del tipo de variable como después del identificador.
Si se utiliza la forma de new se establecerá el valor 0 a cada uno de los elementos del vector.
3. Cadenas

En Java se tratan como una clase especial llamada String. Las cadenas se gestionan internamente por medio de una instancia de la clase String. Una instancia de la clase String es un objeto que ha sido creado siguiendo la descripción de la clase.
Cadenas constantes
Representan múltiples caracteres y aparecen dentro de un par de comillas dobles. Se implementan en Java con la clase String. Esta representación es muy diferente de la de C/C++ de cadenas como una matriz de caracteres.
Cuando Java encuentra una constante de cadena, crea un caso de la clase String y define su estado, con los caracteres que aparecen dentro de las comillas dobles.
Vemos un ejemplo de cadena declarada con la clase String de Java:
String capitalUSA = "Washington D.C.";
String nombreBonito = "Amelia";
3. OPERADORES
3.1 Introducción
Los operadores son un tipo de tokens que indican una evaluación o computación para ser realizada en objetos o datos, y en definitiva sobre identificadores o constantes.
Además de realizar la operación, un operador devuelve un valor, ya que son parte fundamental de las expresiones.
El valor y tipo que devuelve depende del operador y del tipo de sus operandos. Por ejemplo, los operadores aritméticos devuelven un número como resultado de su operación.
Los operadores realizan alguna función sobre uno, dos o tres operandos.
Los operadores que requieren un operando son llamados operadores unarios. Por ejemplo, el operador "++" es un operador unario que incrementa el valor de su operando en una unidad.
Los operadores unarios en Java pueden utilizar tanto la notación prefija como la postfija.

La notación prefija indica que el operador aparece antes que su operando.
++contador // Notación prefija, se evalúa a: contador+1
La notación postfija indica que el operador aparece después de su operando:
contador++ // Notación postfija, se evalúa a: contador
Los operadores que requieren dos operandos se llaman operadores binarios. Por ejemplo el operador "=" es un operador binario que asigna el valor del operando del lado derecho al operando del lado izquierdo.
Todas los operadores binarios en Java utilizan notación infija, lo cual indica que el operador aparece entre sus operandos.
operando1 operador operando2
Por último, los operadores ternarios son aquellos que requieren tres operandos. El lenguaje Java tiene el operador ternario, "?":, que es una sentencia similar a la if-else.
Este operador ternario usa notación infija; y cada parte del operador aparece entre operandos:
expresión ? operación1 : operación2
Los operadores de Java se pueden dividir en las siguientes cuatro categorías:
Aritméticos. De comparación y condicionales. A nivel de bits y lógicos. De asignación.
3.2 Operadores aritméticos
El lenguaje Java soporta varios operadores aritméticos para los números enteros y en coma flotante. Se incluye + (suma), - (resta), * (multiplicación), / (división), y % (módulo, es decir, resto de una división entera). Por ejemplo:
sumaEste + aEste; //Suma los dos enteros
divideEste % entreEste; //Calcula el resto de dividir 2 enteros
Operador Uso Descripción

+ op1 + op2 Suma op1 y op2- op1 - op2 Resta op2 de op1* op1 * op2 Multiplica op1 por op2/ op1 / op2 Divide op1 por op2
% op1 % op2 Calcula el resto de dividir op1 entre op2
Tabla 9: Operadores aritméticos binarios de Java
El tipo de los datos devueltos por una operación aritmética depende del tipo de sus operandos; si se suman dos enteros, se obtiene un entero como tipo devuelto con el valor de la suma de los dos enteros.
Estos operadores se deben utilizar con operandos del mismo tipo, o si no realizar una conversión de tipos de uno de los dos operandos al tipo del otro.
El lenguaje Java sobrecarga la definición del operador + para incluir la concatenación de cadenas. El siguiente ejemplo utiliza + para concatenar la cadena "Contados ", con el valor de la variable contador y la cadena " caracteres.":
System.out.print("Contados" + contador + "caracteres.");
Esta operación automáticamente convierte el valor de contador a una cadena de caracteres.
Los operadores + y - tienen versiones unarias que realizan las siguientes operaciones:
Operador Uso Descripción
+ +op Convierte op a entero si es un byte, short o char
- -op Niega aritméticamente op
Tabla 10: Versiones unarias de los operadores "+" y "-"
El operador - realiza una negación del número en complemento A2, es decir, cambiando de valor todos sus bits y sumando 1 al resultado final:
42 -> 00101010
-42 -> 11010110

Existen dos operadores aritméticos que funcionan como atajo de la combinación de otros: ++ que incrementa su operando en 1, y -- que decrementa su operando en 1.
Ambos operadores tienen una versión prefija, y otra posfija. La utilización la correcta es crítica en situaciones donde el valor de la sentencia es utilizado en mitad de un cálculo más complejo, por ejemplo para control de flujos:
Operador Uso Descripción++ op++ Incrementa op en 1; se evalúa al valor anterior al incremento
++ ++op Incrementa op en 1; se evalúa al valor posterior al incremento
-- op-- Decrementa op en 1; se evalúa al valor anterior al incremento
-- --op Decrementa op en 1; se evalúa al valor posterior al incremento
Tabla 11: Operaciones con "++" y "--"
3.3 Operadores de comparación y condicionales
Un operador de comparación compara dos valores y determina la relación existente entre ambos. Por ejemplo, el operador != devuelve verdadero (true) si los dos operandos son distintos. La siguiente tabla resume los operadores de comparación de Java:
Operador Uso Devuelve verdadero si> op1 > op2 op1 es mayor que op2>= op1 >= op2 op1 es mayor o igual que op2< op1 < op2 op1 es menor que op2<= op1 <= op2 op1 es menor o igual que op2== op1 == op2 op1 y op2 son iguales!= op1 != op2 op1 y op2 son distintos
Tabla 12: Operadores de comparación
Los operadores de comparación suelen ser usados con los operadores condicionales para construir expresiones complejas que sirvan para la toma de

decisiones. Un operador de este tipo es &&, el cual realiza la operación booleana and. Por ejemplo, se pueden utilizar dos operaciones diferentes de comparación con && para determinar si ambas relaciones son ciertas. La siguiente línea de código utiliza esta técnica para determinar si la variable index de una matriz se encuentra entre dos límites (mayor que cero y menor que la constante NUMERO_ENTRADAS):
( 0 < index ) && ( index < NUMERO_ENTRADAS )
Se debe tener en cuenta que en algunos casos, el segundo operando de un operador condicional puede no ser evaluado. En caso de que el primer operando del operador && valga falso, Java no evaluará el operando de la derecha:
(contador < NUMERO_ENTRADAS) && ( in.read() != -1 )
Si contador es menor que NUMERO_ENTRADAS, el valor de retorno de && puede ser determinado sin evaluar el operando de la parte derecha. En este caso in.read no será llamado y un carácter de la entrada estándar no será leído.
Si el programador quiere que se evalúe la parte derecha, deberá utilizar el operador & en lugar de &&.
De la misma manera se relacionan los operadores || y | para la exclusión lógica (OR).
Java soporta cinco operadores condicionales, mostrados en la siguiente tabla:
Operador Uso Devuelve verdadero si...
&& op1 && op2 op1 y op2 son ambos verdaderos, condicionalmente evalúa op2
& op1 & op2 op1 y op2 son ambos verdaderos, siempre evalúa op1 y op2
|| op1 || op2 op1 o op2 son verdaderos, condicionalmente evalúa op2
| op1 | op2 op1 o op2 son verdaderos, siempre evalúa op1 y op2! ! op op es falso
Tabla 13: Operadores condicionales
Además Java soporta un operador ternario, el ?:, que se comporta como una versión reducida de la sentencia if-else:

expresion ? operacion1 : operacion2
El operador ?: evalúa la expresion y devuelve operación1 si es cierta, o devuelve operación2 si expresion es falsa.
3.4 Operadores de bit
Un operador de bit permite realizar operaciones de bit sobre los datos. Existen dos tipos: los que desplazan (mueven) bits, y operadores lógicos de bit.
a) Operadores de desplazamiento de bits
Operador Uso Operación>> op1 >> op2 Desplaza los bits de op1 a la derecha op2 veces<< op1 << op2 Desplaza los bits de op1 a la izquierda op2 veces
>>> op1 >>> op2 Desplaza los bits de op1 a la derecha op2 veces (sin signo)
Tabla 14: Operadores de desplazamiento de bits
Los tres operadores de desplazamiento simplemente desplazan los bits del operando de la parte izquierda el número de veces indicado por el operando de la parte derecha. El desplazamiento ocurre en la dirección indicada por el operador. Por ejemplo, la siguiente sentencia, desplaza los bits del entero 13 a la derecha una posición:
13 >> 1;
La representación en binario del número 13 es 1101. El resultado de la operación de desplazamiento es 1101 desplazado una posición a la derecha, 110 o 6 en decimal. Se debe tener en cuenta que el bit más a la derecha se pierde en este caso.
Un desplazamiento a la derecha una posición es equivalente a dividir el operando del lado izquierdo por 2, mientras que un desplazamiento a la izquierda de una posición equivale a multiplicar por 2, pero un desplazamiento es más eficiente, computacionalmente hablando, que una división o multiplicación.
El desplazamiento sin signo >>> funciona de la siguiente manera:
Si se desplaza con signo el número -1 (1111), seguirá valiendo -1, dado que la extensión de signo sigue introduciendo unos en los bits más significativos.
Con el desplazamiento sin signo se consigue introducir ceros por la izquierda, obteniendo el número 7 (0111).

Este tipo de desplazamientos es especialmente útil en la utilización de máscaras gráficas.
b) Operadores de lógica de bits
La lógica de bits (lógica de Bool) se utiliza para modelizar condiciones biestado y trabajar con ellas (cierto/falso, true/false, 1/0).
En Java hay cuatro operadores de lógica de bits:
Operador Uso Operación& op1 & op2 AND| op1 | op2 OR^ op1 ^ op2 OR Exclusivo~ ~op2 Complemento
Tabla 15: Operadores de lógica de bits
El operador & realiza la operación AND de bit. Aplica la función AND sobre cada par de bits de igual peso de cada operando. La función AND es evaluada a cierto si ambos operandos son ciertos.
Por ejemplo vamos a aplicar la operación AND a los valores 12 y 13:
12 & 13
El resultado de esta operación es 12. ¿Por qué?. La representación en binario de 12 es 1100, y de 13 es 1101. La función AND pone el bit de resultado a uno si los dos bits de los operandos son 1, sino, el bit de resultado es 0:
1101
& 1100
------
1100
El operador | realiza la operación OR de bit. Aplica la función OR sobre cada par de bits de igual peso de cada operando. La función OR es evaluada a cierto si alguno de los operandos es cierto.

El operador ^ realiza la operación OR exclusivo de bit (XOR). Aplica la función XOR sobre cada par de bits de igual peso de cada operando. La función XOR es evaluada a cierto si los operandos tienen el mismo valor.
Para finalizar, el operador de complemento invierte el valor de cada bit del operando. Convierte el falso en cierto, y el cierto en falso:
Entre otras cosas, la manipulación bit es útil para gestionar indicadores booleanos (banderas). Supongamos, por ejemplo, que se tiene varios indicadores booleanos en nuestro programa, los cuales muestran el estado de varios componentes del programa: esVisible, esArrastrable, etc... En lugar de definir una variable booleana para cada indicador, se puede definir una única variable para todos ellos. Cada bit de dicha variable representará el estado vigente de uno de los indicadores. Se deberán utilizar entonces manipulaciones de bit para establecer y leer cada indicador.
Primero, se deben preparar las constantes de cada indicador. Esos indicadores deben ser diferentes unos de otros (en sus bits) para asegurar que el bit de activación no se solape con otro indicador. Después se debe definir la variable de banderas, cuyos bits deben de poder ser configurados según el estado vigente en cada indicador.
El siguiente ejemplo inicia la variable de banderas flags a 0, lo que significa que todos los indicadores están desactivados (ninguno de los bits es 1):
final int VISIBLE = 1;
final int ARRASTRABLE = 2;
final int SELECCIONABLE = 4;
final int MODIFICABLE = 8;
int flags = 0;
Para activar el indicador VISIBLE, se deberá usar la sentencia:
flags = flags | VISIBLE;
Para comprobar la visibilidad se deberá usar la sentencia:
if ( (flags & VISIBLE) == 1 )
//Lo que haya que hacer

3.5 Operadores de asignación
El operador de asignación básico es el =, que se utiliza para asignar un valor a otro. Por ejemplo:
int contador = 0;
Inicia la variable contador con un valor 0.
Java además proporciona varios operadores de asignación que permiten realizar un atajo en la escritura de código. Permiten realizar operaciones aritméticas, lógicas, de bit y de asignación con un único operador.
Supongamos que necesitamos sumar un número a una variable y almacenar el resultado en la misma variable, como a continuación:
i = i + 2;
Se puede abreviar esta sentencia con el operador de atajo +=, de la siguiente manera:
i += 2;
La siguiente tabla muestra los operadores de atajo de asignación y sus equivalentes largos:
Operador Uso Equivalente a += op1 += op2 op1 = op1 + op2-= op1 -= op2 op1 = op1 - op2*= op1 *= op2 op1 = op1 * op2/= op1 /= op2 op1 = op1 / op2%= op1 %= op2 op1 = op1 % op2&= op1 &= op2 op1 = op1 & op2
Tabla 16: Operadores de atajo de asignación
3.6 Precedencia de operadores
Cuando en una sentencia aparecen varios operadores el compilador deberá de elegir en qué orden aplica los operadores. A esto se le llama precedencia.

Los operadores con mayor precedencia son evaluados antes que los operadores con una precedencia relativa menor.
Cuando en una sentencia aparecen operadores con la misma precedencia:
Los operadores de asignación son evaluados de derecha a izquierda. Los operadores binarios, (menos los de asignación) son evaluados de
izquierda a derecha.
Se puede indicar explícitamente al compilador de Java cómo se desea que se evalúe la expresión con paréntesis balanceados ( ). Para hacer que el código sea más fácil de leer y mantener, es preferible ser explícito e indicar con paréntesis que operadores deben ser evaluados primero.
La siguiente tabla muestra la precedencia asignada a los operadores de Java. Los operadores de la tabla están listados en orden de precedencia: cuanto más arriba aparezca un operador, mayor es su precedencia. Los operadores en la misma línea tienen la misma precedencia:
Tipo de operadores Operadores de este tipoOperadores posfijos [ ] . (parametros) expr++ expr--Operadores unarios ++expr --expr +expr -expr ~ !Creación o conversión new (tipo) exprMultiplicación * / %Suma + -Desplazamiento <<Comparación < <= = instanceofIgualdad == !=AND a nivel de bit &OR a nivel de bit ^XOR a nivel de bit |AND lógico &&OR lógico ||Condicional ? :Asignación = += -= *= /= %= &= ^= |= <<= = =
Tabla 17: Precedencia de operadores

Por ejemplo, la siguiente expresión produce un resultado diferente dependiendo de si se realiza la suma o división en primer lugar:
x + y / 100
Si no se indica explícitamente al compilador el orden en que se quiere que se realicen las operaciones, entonces el compilador decide basándose en la precedencia asignada a los operadores. Como el operador de división tiene mayor precedencia que el operador de suma el compilador evaluará y/100 primero.
Así:
x + y / 100
Es equivalente a:
x + (y / 100)
ARRAYSMucho de lo que se ha aprendido en lo que se refiere a tipos de datos y objetos es aplicable a los arreglos en Java.
Los arrays son manipulados por referencia. Son creados con new. Son enviados automaticamente al colector de basura cuando dejan de ser
usados.
Creando y destruyendo Arrays:Hay dos maneras de crear arrays en Java. La primera usa new, y especifica el tamaño del array:
byte buffer_octetos[] = new byte[1024];Button botones[] = new Buttons[10];
Cuando se crea un aray de esta forma no se crean los objetos que son almacenados en el array, no hay un constructor para llamar, y la lista de argumentos es omitida con la palabra new. Los elementos de un array creados de esta manera con el valor por defecto del tipo. Los elementos de un array de int son inicializados a 0, por ejemplo, y los de un array de objetos a null (no apuntan a nada). La otra manera de crear un array es mediante un inicializador estatico que tiene la misma apariencia que en C:
int tabla[] = {1,2,4,8,16,32,64,128};
Esta sintaxis crea un array dinámicamente e inicializa sus elementos a los valores especificados. Los elementos especificados en la inicialización de un array deben

ser expresiones arbitrarias. Esto es diferente que en C, donde deben ser expresiones constantes.
Accediendo a elementos de un Array:El acceso a elementos de un array en Java es similar a C, se accede a un elemento del array poniendo una expresión de valor entero entre corchetes (nombre_array[valor_entero]) despues del nombre del array:
int a[] = new int[100];a[0] = 0;for (int i = 1; i < a.length; i++)a[i] = i + a[i - 1];
En todas las referencias a los elementos del array el índice es chequeado constantemente. Este no debe ser menor que cero ni mayor que el numero de elementos del array menos 1.
En el ejemplo anterior los elementos de a estarian en el rango (0..99). Si el índice especificado no esta en el rango se genera un error de excepción (ArrayIndexOfBoundsException) pero no interrumpe la ejecución del programa sino que ejecuta una sección de código previamente escrita para tratar este error y luego continua con la ejecución. Esta es una de las maneras en que Java trabaja para prevenir bugs (errores) y problemas de seguridad.
Arrays multidimensionales:Java también soporta arrays multidimensionales. Estos son implementados como arrays de arrays, similar a C. Se especifica una variable como un tipo de array multidimensional simplemente agregando un segundo par de corchetes al final del par anterior. La dimensión de los arrays se especifica entre los corchetes con un valor para cada dimensión.
Ejemplo:
byte ArrayDosDim[][] = new byte[256][16];
Cuando creas un array multidimensional es opcional especificar el numero de elementos contenidos en cada dimensión, por ejemplo :
int ArrayTresDim = new int[10][][];
Este array contiene 10 elementos, cada uno de tipo int[][]. Esto quiere decir que es un array de una sola dimensión, cuando los elementos del array sean inicializados pasará a ser multidimensional. La regla para este tipo de arrays es que las primeras n dimensiones (donde n es al menos una) debe tener el numero de elementos especificado, y esas dimensiones deben ser seguidas por m dimensiones adiciónales que no tengan un tamaño de dimensión especificado.

La siguiente Declaración se considera legal :
String conjunto_strings[][][][] = new String[5][3][][];
Esta Declaración no se considera legal:
double temperature_data[][][] = new double[100][][10];
Ejemplo de creación e inicialización de un array multidimensional:
short triangle[][] = new short[10][];for (int i = 0; i < triangle.length; i++) {triangle[i] = new short[i+ 1];for (int j = 0; j < i + 1; j++)triangle[i][j] = i + j;}
Asi mismo se pueden declarar y inicializar arrays de esta manera :
static int[][] DosDim = {{1,2},{3,4,5},{5,6,7,8}}
¿Son los Arrays objetos?La evidencia sugiere que los arrays son, en realidad objetos. Java define bastante sintaxis especial para arrays, no obstante, para referenciar arrays y objetos se utilizan maneras distintas.
STRINGSLos strings en Java no son arrays de caracteres terminados en null como en C. En vez de ello son instancias de la clase Java.lang.String. Un string es creado cuando el compilador de Java encuentra una cadena entre comillas(“”). Toda la teoria especificada para la creación de tipos de objetos dicha anteriormente es aplicada aquí mismo.
EJEMPLOS DE ARRAYS Y CLASESEl siguiente ejemplo muestra una aplicación de l manejo de clases y metodos.
Resuelve el sistema de ecuaciones lineales de la forma AX = B// programa que utiliza estructura de control basico// que utiliza un constructorclass Ecuacion{static int n;float pivote;float [] B;float [] [] A;// constructor

Ecuacion (){System.out.println ("programa que reseulve un sistema de ecuaciones");System.out.println ("introdusca el numero de ecuanciones");n = Leer.datoShort ();llenaMatriz (n);mostrarMatriz (n);resuelve (n);}// metodo para mostrar la matrizpublic void mostrarMatriz (int n){int i, j;for (i = 0 ; i < n ; i++){for (j = 0 ; j < n ; j++){System.out.print (" " + A [i] [j] + "X" + i + " ");}System.out.println (" = " + B [i]);}System.out.println ("");}// programa que llena dos matricespublic void llenaMatriz (int n){int i, j;float nn;A = new float [n] [n];B = new float [n];for (i = 0 ; i < n ; i++){for (j = 0 ; j < n ; j++){System.out.print ("A[" + i + "," + j + "]=");nn = Leer.datoFloat ();A [i] [j] = nn;}System.out.print ("B[" + i + "]=");nn = Leer.datoFloat ();B [i] = nn;}}// resuelve el sistema de ecuaciones de Ax = Bpublic void resuelve (int n){int i, j, k;

for (i = 0 ; i < n ; i++){if (A [i] [i] != 1){pivote = A [i] [i];for (j = i ; j < n ; j++){A [i] [j] = A [i] [j] / pivote;}B [i] = B [i] / pivote;mostrarMatriz (n);}for (j = i + 1 ; j < n ; j++){pivote = A [j] [i] * (- 1);for (k = i ; k < n ; k++){A [j] [k] = (A [i] [k] * pivote) + A [j] [k];}B [j] = (B [i] * pivote) + B [j];}mostrarMatriz (n);}for (i = n - 1 ; i > 0 ; i--){for (j = i - 1 ; j >= 0 ; j--){pivote = A [j] [i] * (- 1);A [j] [i] = (A [i] [i] * pivote) + A [j] [i];B [j] = (B [i] * pivote) + B [j];}mostrarMatriz (n);}for (i = 0 ; i < n ; i++){System.out.println ("X" + i + "=" + B [i]);}}// programa principalpublic static void main (String arg []){Ecuacion m = new Ecuacion ();}}
MAS SOBRE IMPORT

Para utilizar los objetos contenidos en un paquete, bien sea creado por ustedes o incluido con el entorno de programación de Java, es necesario importar dichos paquetes.Por ejemplo para importar un objeto similar a “Applet” del paquete de clases “Java.applet” se deberá utilizar la siguiente instrucción:
import Java.applet.Applet;
Y para importar todos los objetos del paquete entonces se escribe:
import Java.applet.*;
Al importar todos los objetos o solamente uno del paquete de clases, estamos creando la definición e implementación disponible para el paquete actual, supongamos:
class NuestroApplet extends Applet {. . .}
Ahora si ustedes intentan compilar este applet sin importar la clase:
Java.applet.Applet
Entonces, el compilador se “molestara” y enviara un mensaje de error con algo similar a:
"Super class Applet of class NuestroApplet not found"
INSTRUCCIONES DE BLOQUEUn bloque es un conjunto de sentencias encerradas por ({}) por ejemplo:void bloque() {int a = 20;{ // Aquí empieza el bloque, Ah esto es un comentario.int b = 30;System.out.println(“Aquí estamos dentro del bloque:”);System.out.println(“a:” + a);System.out.println(“b:” + b);} // Fin del bloque.}
CONDICIONALES: IFLa sentencia condicional (if) permite ejecutar código Java de manera muysimilar a la sentencia (if) en el lenguaje C, (if) es la palabra reservada de estacondicional seguido por una expresión_booleana y una sentencia o bloque desentencias, las cuales serán ejecutadas si la expresión_booleana es verdadera.

if (edad < 18)System.out.println("No se admiten menores de edad.");
Además existe la palabra reservada else, que permite ejecutar una sentencia o unbloque de sentencias si la expresión_booleana es falsa.
if (edad < 18)System.out.println("No se admiten menores de edad.");else System.out.println("Bienvenido, pase adelante.");
OPERADOR CONDICIONALOtro modo de utilizar la condiciónal (if)..(else) es usar el operador conciónal (?) el cual tiene la siguiente sintaxis:
Expresión_booleana ? Valor_True : Valor_False
En una sentencia de este tipo el operador condicional sólo permite retornar un valor si al evaluar la expresión_booleana es verdadera, entonces el operador condicional retorna el Valor_true, de lo contrario retorna Valor_False. Este operador es usado para condicionales pequeñas.
Ejemplo, el mayor de 2 numeros a y b:int mayor = a > b ? a : b;
CONDICIONALES SWITCHPara evitar el uso repetido de la sentencia (if), al evaluar el valor de algunas variables por ejemplo:
if (evento == MouseClick)Sentencia o bloque;else if (evento == Drop)Sentencias o bloque;else if (evento == Fail)Sentencias o bloque;else if (evento == Complete)Sentencias o bloque;
Este tipo de sentencias (if), es conocida como los (if) anidados. En Java existe un forma mas abreviada de de manejar los (if) anidados, usando la sentencia (switch), cuya sintaxis es:
switch (Evaluar) {case valor1:Sentencia o bloque;break;case valor2:Sentencia o bloque;

break;case valor3:Sentencia o bloque;break;...default: Sentencia o bloque por defecto;}
En la sentencia (switch), el testeo es comparado con cada uno de los valores (case) si se encuentra una coincidencia la sentencia o sentencias después del case es ejecutada.Si no se encuentran coincidencias, la sentencia (default) es ejecutada. La sentencia (default) es opcional.
Como varia el ejemplo del (if) anidado con la sentencia (switch):
switch (evento) {case MouseClick:Sentencia o bloque;break;case Drop:Sentencia o bloque;break;case Fail:Sentencia o bloque;break;case Complete:Sentencia o bloque;break;default: Sentencia o bloque por defecto;}
Por ejemplo en el siguiente ejemplo:(Num, es un numero par) sera impreso si Num, tiene como valor: 2,4,6 o 8 cualquier otro valor de Num, imprimira (Num, es un numero impar)
switch (Num) {case 2:case 4:case 6:case 8:System.out.println("Num, es un numero par");break;default: System.out.println("Num, es un numero impar");}
BUCLES FOR

El bucle (for) en Java, funciona de manera similar que en C, repite una sentencia o bloque de sentencias un numero de veces hasta que alguna condición se cumpla.
for (Valor_de_inicio; Expresion_booleana; Incremento) {sentencias o bloque;}Explicando las secciónes:
Valor_de_inicio:Aquí deberá indicar cual es el valor con el que comenzara el bucle por ejemplo:
int cont = 0
Las variables que se declaren en esta sección del bucle seran locales para el bucle estas dejan de existir cuando el bucle a terminado.
Expresion_booleana:Aquí se chequea la expresión_booleana después de cada paso por el bucle por ejemplo: cont < 50 ,si el resultado es verdadero entonces se ejcuta el bucle. si es falso para la ejecución.
Incremento:El incremento permite cambiar el valor del índice del bucle.Revise, ¿qué es lo que hace este código e intente explicarlo?
String strArray[] = new String[15];int Num; // Índice del buclefor (Num = 0; Num < strArray.length; Num++)strArray[Num] = "";
BUCLE DO WHILE:do {cuerpo} while (condición)
El bucle do {cuerpo} while (condición) es similar a un bucle while (condición) {cuerpo} puesto que ejecutan una sentencia o bloque de sentencias (cuerpo) hasta que la condición sea falsa. La principal diferencia es que while (condición) {cuerpo} testea la condición antes de ejecutar el bloque sentencias (cuerpo), mientras que do {cuerpo} while (condición) lo hace al final del bloque de sentencias. De esta manera siempre se ejecutaran al menos una vez las sentencias en un bucle do {cuerpo} while (condición) aunque la condición sea falsa; puesto que primero se ejecuta el bloque de sentencias y luego se evalua la condición.
Ejemplo:
int a = 1;

do {System.out.println("Iteración: " + a);a++;} while (a <= 10);
Este código de programa se ejecuta en los siguientes pasos:
1. Primero se crea e inicializa la variable a con el valor 1.2. Se ejecuta la instrucción System.out.println("Iteración : " + a); que hace que se imprima en la salida estándar (pantalla por defecto) Iteración: (Valor de a).3. Se incrementa la variable a en 1.4. Se evalúa la condición (a <= 10) que produce un valor verdadero o falso.
Si esta condición es verdadera se ejecuta nuevamente el paso 2; de lo contrario continua con la siguiente instrucción debajo del do..while.
La salida que produciría seria:
Iteración: 1Iteración: 2Iteración: 3Iteración: 4Iteración: 5Iteración: 6Iteración: 7Iteración: 8Iteración: 9Iteración: 10
Breaking Out of Loops (Ruptura del bucle)En todos los bucles (for, while y do), el bucle finaliza cuando la condición no se cumple. Algunas veces puede ocurrir que se quiera salir del bucle antes de evaluarse la condición, es decir romper el bucle. Para esto se usan las sentencias break y continue.
Si se esta usando break como parte de una sentencia switch; este para la ejecución del switch y el programa continua. Cuando se usa la sentencia break en un loop, para la ejecución del loop actual y ejecuta la siguiente sentencia luego del loop.
Cuando se usa en bucles anidados el programa salta a la siguiente instrucción al final del bucle y ejecuta las instrucciones del bucle anterior.
Por ejemplo :
int contador = 0;while (contador < array1.length) {

if (array1[contador] == 0) {break;}array2[contador] = (float) array1[contador++];}
En este ejemplo se copian elementos del array1 (array de enteros) al array2 (array de floats) hasta que todos los elementos del array1 sean copiados o que el valor al que se hace referencia para copiar del array1 sea 0.
El primer valor del array1 que coincida con 0 no es copiado al array2 y la sentencia break hace que la ejecución del programa se traslade a la siguiente instrucción luego del bucle.Continue es similar a break excepto que en vez de romper la ejecución del bucle hace que la ejecución del programa se traslade a la evaluación de la condición del bucle y comience una nueva iteración, dejando sin efecto la ejecución de las instrucciones que están debajo de la instrucción continue.
Ejemplo:
int contador1 = 0;int contador2 = 0;while (countador1 < array1.length) {if (array1[contador1] == 0) {contador1++;continue;}array2[contador2++] = (float)array1[contador1++];}
En este ejemplo se copian solo los elementos del array1 (array de enteros) que no sean 0 al array2, la sentencia continue en este caso nos sirve para que la ejecución del programa se traslade nuevamente a la evaluación de la condición y el elemento del array1 no se copie al array2
Labeled Loops (Bucles etiquetados)Break y Continue pueden opcionalmente contener etiquetas, estas le dicen a Java donde debe saltar la ejecución del programa.
Para usar un bucle etiquetado, adicionar la etiqueta seguida de dos puntos (:) antes del comienzo del bucle. Luego cuando uses break o continue con el nombre de esta etiqueta, la ejecución se trasladara a la instrucción que esta luego de la etiqueta.
Por ejemplo:

fuera:For (int i = 0; i < 10; i++) {While (x < 50) {if (i * x == 400)break fuera;...}...}
Cuando este fragmento de código se ejecute y se cumpla que la multiplicación de i * x sea igual a 400 la ejecución del programa se trasladará a la instrucción que le sigua a la etiqueta fuera que viene a ser el bucle for.
Aquí otro ejemplo:
for (int i = 1; i <= 5; i++)for (int j = 1; j <= 3; j++) {System.out.println("i es " + i + ", j es " + j);if ((i + j) > 4)break fuera;}System.out.println("Final de bucles");
Aquí la salida que produciría el programa:
i es 1, j es 1i es 1, j es 2i es 1, j es 3i es 2, j es 1i es 2, j es 2i es 2, j es 3
Final de bucles.

UNIDAD IVACCESO A BASE DE DATOS MEDIANTE JDBC-ODBC
1. QUE ES UN JDBC – ODBC?
JDBC es la API estándar de acceso a Bases de Datos con Java, y se incluye con el Kit de Desarrollo de Java (JDK) a partir de la versión 1.1. Sun optó por crear una nueva API, en lugar de utilizar APIs ya existentes, como ODBC, con la intención de obviar los problemas que presenta el uso desde Java de estas APIs, que suelen ser de muy bajo nivel y utilizar características no soportadas directamente por Java, como punteros, etc.
Aunque el nivel de abstracción al que trabaja JDBC es alto en comparación, por ejemplo, con ODBC, la intención de Sun es que sea la base de partida para crear librerías de más alto nivel, en las que incluso el hecho de que se use SQL para acceder a la información sea invisible.
Para trabajar con JDBC es necesario tener controladores (drivers) que permitan acceder a las distintas Bases de Datos: cada vez hay más controladores nativos JDBC. Sin embargo, ODBC es hoy en día la API más popular para acceso a Bases de Datos: Sun admite este hecho, por lo que, en colaboración con Intersolv (uno de principales proveedores de drivers ODBC) ha diseñado un puente que permite utilizar la API de JDBC en combinación con controladores ODBC.
Algunos fabricantes, como Microsoft, ofrecen sus propias APIs, en lugar de JDBC, como RDO, etc. Aunque estas APIs pueden ser muy eficientes, y perfectamente utilizables con Java, su uso requiere tener muy claras las consecuencias, sobre todo la pérdida de portabilidad, factor decisivo en la mayor parte de los casos para escoger Java en lugar de otro lenguaje.
JDBC es un API de Java que permite que programas en Java ejecuten comandos SQL, permitiendo esto que los programas puedan usar bases de datos en ese esquema. Dado que casi todos los sistemas de administración de bases de datos relacionales (DBMS) soportan SQL(Structured Query Language), y que Java corre en la mayoría de las plataformas, JDBC hace posible escribir una sóla aplicación de base de datos que pueda correr en diferentes plataformas e interactuar con distintos DBMS.
La conectividad de la base de datos de Java (JDBC) es un marco de rogramación para los desarrolladores de Java que escriben los programas que tienen acceso a la informAción guardada en bases de datos, hojas de calculo, y archivos "planos". JDBC se utiliza comúnmente para conectar un programa del usuario con una base de datos por “detrás de la escena”, sin importar qué software de administración o manejo de base de datos se utilice para controlarlo. De esta manera, JDBC es una

plataforma-cruzada. El acceso a la base de datos de los programas de Java utilizan las clases JDBC API, que está disponible para la transferencia directa libre del sitio de Sun.
Los puentes de JDBC-ODBC se han creado para permitir que los programas de Java conecten con el software compatible ODBC de la base de datos.
JDBC no sólo provee un interfaz para acceso a motores de bases de datos, sino que también define una arquitectura estándar, para que los fabricantes puedan crear los drivers que permitan a las aplicaciones java el acceso a los datos.
Sun define JDBC como: “The JDBC API is the industry standard for database-independent connectivity between the Java programming language and a wide range of databases.”
Filosofía y Objetivos de JDBCAlgunas características son:
API A NIVEL SQL. JDBC es un API de bajo nivel, es decir, que está orientado a permitir ejecutar comandos SQL directamente, y procesar los resultados obtenidos. Esto supone que será tarea del programador crear APIs de más alto nivel apoyándose directamente sobre JDBC.
COMPATIBLE CON SQL. Cada motor de Base de Datos implementa una amplia variedad de comandos SQL, y muchos de ellos no tienen porque ser compatibles con el resto de motores de Base de Datos. JDBC, para solventar este problema de incompatibilidad, ha tomado la siguiente posición:
JDBC permite que cualquier comando SQL pueda ser pasado al driver directamente, con lo que una aplicación Java puede hacer uso de toda la funcionalidad que provea el motor de Base de Datos, con el riesgo de que esto pueda producir errores o no en función del motor de Base de Datos.
Con el objetivo de conseguir que un driver sea compatible con SQL (SQL compliant), se obliga a que al menos, el driver cumpla el Estándar ANSI SQL 92.
JDBC debe ser utilizable sobre cualquier otro API de acceso a Bases de Datos, o más en particular ODBC (Open Database Connectivity)
JDBC debe proveer un interfaz homogéneo al resto de APIs de Java. JDBC debe ser un API simple, y desde ahí, ir creciendo. JDBC debe ser fuertemente tipado, y siempre que sea posible de
manera estática, es decir, en tiempo de compilación, para evitar errores en tiempo de ejecución.
JDBC debe mantener los casos comunes de acceso a Base de Datos lo más sencillo posible:
Mantener la sencillez en los casos más comunes (SELECT, INSERT, DELETE y UPDATE)

Hacer realizables los casos menos comunes: Invocación de procedimientos almacenados...
Crear múltiples métodos para múltiple funcionalidad. JDBC ha preferido incluir gran cantidad de métodos, en lugar de hacer métodos complejos con gran cantidad de parámetros.
2. CONTROLADORES JDBC Los controladores (conectores o drivers) JDBC proveen clases que implementan la interfaz JDBC. JDBC define cuatro tipos de controladores, y cada una tiene una mezcla variada de ejecutables sistema operativo dependientes y código de Java como se indica a continuación:
Tipo 1. JDBC-ODBC bridge más driver ODBC: “BRIDGE”Permite el acceso a Base de Datos JDBC mediante un driver ODBC. Cada máquina cliente que use el puente, debe tener librerías clientes de ODBC(dll propias del S.O).
Ventajas : Buena forma de aprender JDBC. También puede ser buena idea usarlo, en sistemas donde cada máquina cliente tenga ya instalado los drivers ODBC. También es posible que sea la única forma de acceder a ciertos motores de Bases de Datos.
Inconvenientes : No es buena idea usar esta solución para aplicaciones que exijan un gran rendimiento, ya que la transformación JDBC-ODBC es costosa. Tampoco es buena solución para aplicaciones con alto nivel de escalabilidad.
Tipo 2. Driver Java parciales: “NATIVE”Traducen las llamadas al API de JDBC Java en llamadas propias del motor de Base de Datos (Oracle, Informix...). Al igual que el tipo anterior, exige en las máquinas clientes código binario propio del cliente de la Base de datos específica y del sistema operativo.
Ventajas: Mejor rendimiento que el anterior. Quizá puede ser buena solución para entornos controlados como intranets. Ejemplo OCI oracle.
Inconvenientes: Principalmente la escalabilidad, ya que estos drivers exigen que en la máquina cliente librerías del cliente de la Base de Datos.
Tipo 3. Driver JDBC a través de Middleware: “NETWORK”Traduce las llamadas al API JDBC en llamadas propias del protocolo específico del broker. Éste se encargará de traducirlas de nuevo en sentencias propias del motor de Base de Datos de cada caso.
Ventajas : Buena solución cuando necesitamos acceder a Bases de Datos distintas y se quiere usar un único driver JDBC para acceder a las mismas.

Al residir la traducción en el servidor del middleware, los clientes no necesitan librerías específicas, tan solo el driver.
Inconvenientes : La desventaja principal reside en la configuración del servidor donde se encuentra el middleware. Necesitará librerías específicas para cada motor de base de datos distinto, etc.
Tipo 4: Driver java puro (acceso directo a Base de Datos): “THIN”.Convierte o traduce las llamadas al API JDBC en llamadas al protocolo de red usado por el motor de bases de datos, lo que en realidad es una invocación directa al motor de bases de datos.
Ventajas : 100 % portable. Buen rendimiento. El cliente sólo necesita el driver.
Inconvenientes : Al ser independiente de la plataforma, no aprovecha las características específicas del S.O
2.1 Instalación de JDBCEl proceso de instalación de JDBC se podría dividir en tres partes distintas:
Descargar el API de JDBCJDBC viene incluido en el corazón de la plataforma Java, tanto en la J2SE como en la J2EE.http://java.sun.com/products/jdbc/download.html
Instalar el driver en la máquina cliente (máquina que crea las conexiones)La instalación del driver dependerá en gran medida del tipo de driver que hayamos seleccionado.
Para los tipo 1 y 2, además de las librerías del driver, necesitaremos ciertas librerías propias del cliente del motor de base de datos que estemos usando y quizá ficheros de configuración.
Para el tipo 3, en la máquina cliente tan solo necesitaremos el driver. En el servidor donde resida el middleware, necesitaremos drivers específicos de cada motor de base de datos y en su caso, librerías propias del cliente del motor de base de datos.
Para el tipo 4, tan solo necesitaremos el driver.
Instalar el controlador o motor de base de datos.Evidentemente, necesitaremos tener instalado un motor de base de datos. Esta instalación será distinta en función de la Base de Datos y del S.O donde vaya a correr.
2.2 Arquitecturas JDBC

La arquitectura básica de JDBC es simple. Una clase llamada DriverManager provee un mecanismo para controlar un conjunto de drivers JDBC. Esta clase intenta cargar los drivers especificados en la propiedad del sistema jdbc.drivers.
También podemos cargar un driver explicitamente usando Class.forName(). Durante la carga, el driver intentará registrarse a si mismo usando el método clase DriverManager.registerDriver(). Cuando se invoque al método driverManager.getConnection(), ésta buscará el primer driver de los registrados que pueda manejar una conexión como la descrita en la URL y retornará un objeto que implemente el interfaz java.sql.Connection.
Sin embargo, en función de la localización de la base de datos, el driver, la aplicación y el protocolo de comunicación usado, nos podemos encontrar distintos escenarios que accedan a Base de Datos a través de JDBC:
1. Aplicaciones standalone2. Applets comunicando con un servidor Web3. Aplicaciones y applets comunicando con una base de datos a través de un
puente JDBC/ODBC.4. Aplicaciones accediendo a recursos remotos usando mecanismos como
Java RMI
Todos ellos se pueden agrupar en dos tipos distintos de arquitecturas:
2.2.1 Arquitecturas JDBC en dos capasLa aplicación que accede a la base de datos reside en el mismo lugar que el driver de la base de datos. El driver accederá al servidor donde corra el motor de base de datos.
En este caso, será el driver el encargado de manejar la comunicación a través de la red. En el ejemplo, una aplicación java corriendo en una máquina cliente que usa el driver también local. Toda la comunicación a través de la red con la base de datos será manejada por el driver de forma transparente a la aplicación Java.
2.2.2 Arquitecturas JDBC en tres capas.Una aplicación o applet corriendo en una máquina y accediendo a un driver de base de datos situado en otra máquina. Ejemplos de esta situación:
1. Un applet accediendo al driver a través de un Web Server2. Una aplicación accediendo a un servidor remoto que comunica localmente
con el driver3. Una aplicación comunicando con un servidor de aplicaciones que accede a
la base de datos por nosotros.

3. PASOS PARA EL ACCESO DE BASE DE DATOS CON JDBCLo primero que tenemos que hacer es asegurarnos de que disponemos de la configuración apropiada. Esto incluye los siguientes pasos.
1. Instalar Java y el JDBC en nuestra máquina. Para instalar tanto la plataforma JAVA como el API JDBC, simplemente tenemos que seguir las instrucciones de descarga de la última versión del JDK (Java Development Kit). Junto con el JDK también viene el JDBC.. El código de ejemplo de desmostración del API del JDBC 1.0 fue escrito para el JDK 1.1 y se ejecutará en cualquier versión de la plataforma Java compatible con el JDK 1.1, incluyendo el JDK1.2. Teniendo en cuenta que los ejemplos del API del JDBC 2.0 requieren el JDK 1.2 y no se podrán ejecutar sobe el JDK 1.1.
2. Instalar un driver en nuestra máquina. Nuestro Driver debe incluir instrucciones para su instalación. Para los drivers JDBC escritos para controladores de bases de datos específicos la instalación consiste sólo en copiar el driver en nuesta máquina; no se necesita ninguna configuración especial.
El driver "puente JDBC-ODBC" no es tan sencillo de configurar. Si descargamos las versiones Solaris o Windows de JDK 1.1, automáticamente obtendremos una versión del driver Bridge JDBC-ODBC, que tampoco requiere una configuración especial. Si embargo, ODBC, si lo necesita. Si no tenemos ODBC en nuestra máquina, necesitaremos preguntarle al vendedor del driver ODBC sobre su instalación y configuración.
3. Instalar nuestro Controlador de Base de Datos si es necesario. Si no tenemos instalado un controlador de base de datos, necesitaremos seguir las instrucciones de instalación del vendedor. La mayoría de los usuarios tienen un controlador de base de datos instalado y trabajarán con un base de datos establecida.
3.1 Procedemiento de conexión y acceso a datos con jdbc
3.1.2 Consideraciones previasEl proceso de acceso a una Base de Datos a través de JDBC, exige dar una serie de pasos previos antes de crear la conexión al motor de Base de Datos. El primer paso es determinar el entorno en el que el proyecto va a ser instalado, y más en concreto, que parámetros del entorno afectan directamente a JDBC:

¿ Qué motor de Base de Datos vamos a usar ?Debemos considerar las características específicas de una base de datos, como por ejemplo, como mapear los tipos de datos SQL a Java.
¿ Qué driver vamos a usar ?Es probable encontrarnos varios drivers distintos para la misma fuente de datos. Debemos saber detectar cual es el driver más adecuado para nuestra aplicación, por ejemplo, si elegimos un driver ODBC/JDBC, tendremos más flexibilidad para elegir distintas fuentes de datos, pero si por ejemplo trabajamos con una Base de Datos Oracle, un driver JDBC diseñado específicamente para esta base de datos será mucho más eficiente.
¿ Donde estará localizado el driver ?En función de donde se encuentre el driver físicamente, debemos considerar aspectos de rendimiento y seguridad. Por ejemplo, si cargamos el driver desde un servidor remoto tendremos que considerar aspectos sobre seguridad de Java.
3.1.3 Procedimiento de conexión.El procedimiento de conexión con el controlador de la base de datos, independientemente de la arquitectura es siempre muy similar.
1. Cargar el driver. Cualquier driver JDBC, independientemente del tipo debe implementar el interfaz java.sql.Driver. La carga del driver se puede realizar de dos maneras distintas:
Definiendo los drivers en la variable sql.driver (variable que mantiene todos las clases de los drivers separados por comas) Cuando la clase DriverManager se inicializa, busca esta propiedad en el sistema.
El programador puede forzar la carga de un driver específico, usando el método Class.forName(driver).
2. Registro del driver. Independientemente de la forma de carga del driver que llevemos a cabo, será responsabilidad de cada driver registrarse a sí mismo, usando el método DriverManager.registerDriver. Esto permite a la clase DriverManager, usar cada driver para crear conexiones con el controlador de Base de Datos. Por motivos de seguridad, la capa que gestiona JDBC, controlará en todo momento que driver es el que se está usando, y cuando se realicen conexiones, sólo se podrán usar drivers que estén en el sistema local de ficheros o que usen el mismo ClassLoader que el código que está intentando crear la conexión.

En el primero de los casos (a través de la propiedad sql.driver), JDBC usará el primer driver que permita conectarse correctamente a la Base de Datos.Crear una conexión. El objetivo es conseguir un objeto del tipo java.sql.Connection a través del método driverManager.getConnection(String url). La capa de gestión, cuando este método es invocado, tratará de encontrar un driver adecuado para conectar a la base de datos especificada en la URL, intentándolo por el orden especificado en la variable sql.driver. Cada driver debería examinar si ellos proveen el “subprotocolo” que especifica la URL.JDBC provee un mecanismo para permitir nombrar las bases de datos, para que los programadores puedan especificar a que base de datos desean conectarse.
Este sistema debe tener las siguientes características:
Drivers de diferentes tipos pueden tener diferentes formas de nombrar las bases de datos.
Este sistema de nombrado debe ser capaz de acoger diversos parámetros de configuración de la red.
Debería ser capaz de acoger cierto nivel de indirección, para que los nombres pudiesen ser resueltos de alguna manera (DNS...)
URL. Estas características están ya estandarizadas en el concepto de URL. JDBC recomienda la siguiente estructura de nombrado de bases de datos: jdbc:<subprotocol>:<subname>
jdbc: parte fija subprotocol: mecanismo particular se acceso a base de datos subname: dependerá del subprotocolo. JDBC recomienda seguir
también la convención de nombrado URL: //hostname:port/subsubname
El subprotocolo odbc: Este subprotocolo ha sido reservado para aquellos que quieran seguir la convención ODBC para nombrado de bases de datos:jdbc:odbc:<data-source-name>[;<attribute-name>=<attribute-value>]
El API JDBC, también provee la posibilidad de pasar una lista de propiedades para crear la conexión: DriverManager.getConnection(String URL, Properties props); Dos propiedades definidas por convención son
user password
4. LA API DE JDBC Pasamos en este punto a dar una breve descripción de cada una de las interfaces y clases que componen el paquete java.sql.
4.1 InterfacesDriver

Es la interfaz que deben implementar todos los controladores JDBC en alguna de sus clases. Cuando se cargue una clase Driver, ésta creará una instancia de sí misma que se registrará posteriormente mediante el administrador de controladores.Connection Representa una sesión de trabajo con una base de datos. Sus métodos, aparte de permitir modificarla y consultar sus tablas, también permiten obtener información sobre su estructura.
Statement Mediante esta interfaz, se envían las órdenes SQL individuales a la base de datos a través del controlador JDBC y se recogen los resultados de las mismas.
ResultSet Mediante esta interfaz, se organizan en tablas los resultados de las órdenes SQL. Las filas deben leerse una detrás de otra, pero las columnas pueden leerse en cualquier orden.
ResultSetMetaData Contiene información sobre las columnas de los objetos ResultSet.
PreparedStatement Los objetos PreparedStatement contienen órdenes SQL precompiladas que pueden por tanto ejecutarse muchas veces.
CallableStatement Los objetos CallableStatement se emplean para ejecutar procedimientos almacenados.
DatabaseMetaData Contiene diversa, y abundantísima, información sobre la base de datos. Algunos de sus métodos devuelven los resultados como tablas ResultSet, y pueden tratarse como éstos.
4.2 Clases DriverManager Contiene métodos para trabajar con un conjunto de controladores JDBC.
Types Define una serie de constantes usadas para identificar los tipos de datos SQL.
Time Esta clase añade a la clase Date del paquete java.util los métodos y características para trabajar con cláusulas de escape JDBC identificándolo como un tipo TIME de SQL.
Date

Esta clase añade a la clase Date del paquete java.util los métodos y características para trabajar con cláusulas de escape JDBC como un tipo DATE de SQL.
Timestamp Esta clase añade a la clase Date del paquete java.util los métodos y características para trabajar con cláusulas de escape JDBC identificándolo como un tipo TIMESTAMP de SQL.
DriverPropertyInfo Contiene métodos para averiguar y trabajar con las propiedades de los controladores JDBC.
SQLException Proporciona diversa inmformación acerca de los errores producidos durante el acceso a una base de datos.
SQLWarning Contiene información sobre los avisos que se producen durante el trabajo con una base de datos. Los avisos se encadenan al objeto que los provocó.
5. INSTRUCCIONES SQL ESTATICAS Y DINAMICAS
En JDBC existen dos formas principales de ejecutar y crear sentencias SQL, la primera es usando un Statement, y la segunda es creando un PreparedStatement.
5.1. Statement
Fue la primera manera de enviar sentencias SQL usando java, este método está cada vez más en desuso, ya que no protege ante la inyección de código SQL.
La forma de usarlo seria la siguiente:
Statement stmt = con.createStatement(); Stringcondicion="nombre='"+nombreDeLaWeb+"' AND pass='"+passDeLaWeb+"'";//Creamos la sentencia SQL String sqlSelect = "SELECT * FROM tabla WHERE "+condicion; //Ejecutamos la sentencia SQL stmt.executeQuery(sqlSelect);
Nota:Observeseque sipassDeLaWebes = “' OR '1'='1 ”tendríamos una un fallo en la seguridadde la aplicación ya que tendría acceso sin saber la contraseña.
5.2 PreparedStatement

Es otra forma de crear sentencias SQL, esta forma evita la inyección y si la sentencia es más larga se entiende mejor.
La forma de usarlo es la siguiente:
//Creamos la sentencia SQL String sqlSelect = "SELECT * FROM tabla WHERE nombre=? AND pass=?";//Ejecutamos la sentencia SQL PreparedStatement ps = con.createPreparedStatement(sqlSelect); ps.setString(1,nombreDeLaWeb);ps.setString(2,passDeLaWeb); ps.executeQuery();
Obtener los resultadosCada vez que ejecutamos una sentencia SELECT tanto el Statement como el PreparedStatement al hacer el executeQuery() nos devuelve un objeto de tipo ResultSet, este objeto como se puede adivinar por el nombre es un Set, por lo tanto es iterable.Para obtener los resultados de la base de datos usando esta clase resulta muy facil, solo hay que usar getes, es decir si en la base de datos tenemos almacenado un entero haríamos getInt(“nombreCol”); si es una cadena getString(“nombreCol”); ... veamos un trozo de código:
String sqlSelect = "SELECT * FROM tabla"; ResultSetrs = con.createStatement().executeQuery(sqlSelect);while(rs.next()){ System.out.println(rs.getString("nombre")); System.out.println(rs.getString("pass")); }
6. ACCESO A UNA BASE DE DATOS CON ODBC
El puente JDBC-ODBC (Ejemplo de Conexión entre Java y Access)
6.1 El puente jdbc-odbcEn este punto se explica la manera de implementar el puente JDBC-ODBC para que una aplicación escrita en Java pueda acceder una base de datos en MS Access.
El puente JDBC-ODBC también puede implementarse para conectar a Java con bases de datos como FoxPro. Se mostrará también la manera de crear y configurar un origen de datos con nombre DSN.

6.2 Introducción a el Puente JDBC-ODBCExistiendo ODBC drivers, estos pueden utilizarse para aplicaciones Java por medio de el puente JDBC-ODBC proporcionado por Sun. Usar el puente JDBC-ODBC no es una solución ideal dado que requiere de la instalación de drivers ODBC y entradas de registro. Los drivers ODBC a su vez son implementados nativamente lo que compromete el soporte multiplataforma y la seguridad de applets.
El puente es por si mismo un driver basado en tecnología JDBC que está definida en la clase sun.jdbc.odbc.JdbcOdbcDriver.
El puente JDBC-ODBC debe ser considerado como una solución transitoria. Sun Microsystems y las tecnologías DataDirect estan trabajando para hacerlo más confiable y robusto, pero ellos no lo consideran un producto recomendado. Con el desarrollo de drivers puros en Java, el puente se volverá innecesario.
Lo ideal es “Java Puro”: no código nativo, no características de plataforma dependiente. Sin embargo puede utilizarse si se requiere desarrollar inmediatamente sin poder esperar a que el fabricante de la base de datos utilizada proporcione el driver JDBC. Los drivers parcialmente nativos, como el puente JDBC-ODBC, le permiten crear programas que pueden fácilmente ser adaptados a drivers puros en Java tan pronto como estén disponibles.
Hasta aquí con la pequeña introducción acerca del puente JDBC-ODBC. La última parte de esta introducción nos habla de adaptar nuestras aplicaciones basadas en puentes JDBC-ODBC a drivers puros JDBC. Esto es verdadero, sin casi nada de cambio en el código. Personalmente he creado proyectos que trabajan inicialmente con Access y el puente JDBC-ODBC, posteriormente he migrado estas aplicaciones a servidores como MySQL y SQLServer, para los cuales solo debe implementarse el driver JDBC correspondiente.
6.3 Conectando una aplicación Java con Access mediante puente JDBC-ODBCSupongamos ahora que necesita conectar una aplicación en Java con Access, sea porque es su primer pinino o porque realmente los requerimientos de su sistema se adaptan a esta base de datos. Para este ejemplo, supongamos que la base de datos de Access se crea en el siguiente directorio:
C:\proyecto\bd1.mdb
Antes de mostrar el código en java para conectar la aplicación a esta base de datos, se mostrará la forma de crear el driver u origen de datos (DSN) de la base de datos, para ello se procede de la siguiente manera (Windows 2000, XP)
4. Hacer click en el botón inicio. 5. Seleccionar Panel de Control. 6. Hacer doble click en el icono de Herramientas administrativas.

7. Hacer doble click en orígenes de datos (ODBC). Aparecerá la pantalla Administrador de orígenes de datos ODBC.
8. De la pantalla anterior elija la pestaña DSN de usuario y posteriormente oprima el botón Agregar.
9. Elija de la lista de drivers desplegada, el driver “Microsoft Access Driver (*.mdb)” y enseguida oprima el botón finalizar.
10.Aparecerá la pantalla de Configuración de ODBC Microsoft Access, llene los campos de esta pantalla como se muestra a continuación. En esta misma pantalla, en el apartado Base de datos oprima el botón Seleccionar y seleccione el directorio de la base de datos (C:\proyecto\bd1.mdb). Oprima enseguida el botón Avanzadas.
11.En la pantalla de opciones avanzadas debe crear un Nombre de inicio de sesión y Contraseña . En nuestro caso el inicio de sesión será cvazquez y la contraseña vazquez. En el apartado Opciones, seleccione el campo Driver y establezca el Valor de Driver como PDRV o como lo haya llamado.
Oprima el botón Aceptar. Oprima a su vez los botones aceptar de las pantallas subsecuentes. Con esto el driver ya ha sido creado y puede ser accedido desde nuestra aplicación.
El resultado de la creación del driver de la base de datos que se usa en este proyecto de ejemplo es el siguiente:
Nombre de driver: PDRVNombre de inicio de sesión: cvazquezContraseña: vazquez
Estos campos serán utilizados desde la aplicación en Java para conectarse a la base de datos.
La siguiente clase en Java, contiene los métodos necesarios para conectar nuestra aplicación con la base de datos Access.
import java.sql.*;public class cConnection {/*Atributos*/private String url = "jdbc:odbc:";private String driver = "PDRV";private String usr = "cvazquez";private String pswd = "vazquez";private Connection con;/*Constructor, carga puente JDBC-ODBC*/public cConnection() {loadDriver();}/*** Carga el driver de la conexión a la base de datos

*/private void loadDriver(){try{//Instancía de una nueva clase para el puente//sun.jdbc.odbc.JdbcOdbcDriver//El puente sirve entre la aplicación y el driver.Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );}catch(ClassNotFoundException e){System.out.println("Error al crear el puente JDBC-ODBC"); }}/*** Obtiene una conexión con el nombre del driver especificado* @param driverName Nombre del driver de la base de datos* @return*/public Connection mkConection(){url = url + driver;System.out.println("Estableciendo conexión con " + url);try{//Obtiene la conexióncon = DriverManager.getConnection( url,usr,pswd);}catch(SQLException sqle){System.out.println("No se pudo establecer la conexión");return null;}System.out.println("Conexión establecida con:\t " + url);//Regresa la conexiónreturn con;}/* Cerrar la conexión.*/public boolean closeConecction(){try{con.close();}catch(SQLException sqle)

{System.out.println("No se cerro la conexión");return false;}System.out.println("Conexión cerrada con éxito ");return true;}}El siguiente fragmento de código muestra la manera de establecer la conexión con la base de datos.…//Crear un objeto de la clase de conexióncConnection conect = new cConnection(); //Obtener la conexiónConnection con = conect.mkConection();if(con == null){//Error al establecer la conexión}Si la conexión fue realizada con éxito, podemos ejecutar sentencias SQL. El siguiente fragmento de código muestra la ejecución de la sentencia SQL select (suponiendo que tablas de la base de datos fueron creadas con anterioridad).…ResultSet rs = null;Statement stm = con.createStatement();String strSQL = "SELECT * FROM mitabla";//Ejecuta la consulta SQLrs = stm.executeQuery(strSQL); //Trabajar con el result set… //Cerrar todors.close();stm.close();boolean isClosed = conect.closeConecction()if(!isClosed){//Error al cerrar la conexión}
7. EJEMPLO DE APLICACIÓN
7.1 Preparación del entorno de desarrolloAntes de comenzar a estudiar las distintas clases proporcionadas por JDBC, vamos a abordar la creación de una fuente de datos ODBC, a través de la cuál accederemos a una Base de Datos Interbase. Hemos escogido este modo de

acceso en lugar de utilizar un driver JDBC nativo para Interbase porque ello nos permitirá mostrar el uso de drivers ODBC: de este modo, aquél que no disponga de Interbase, podrá crear una Base de Datos Access, BTrieve o de cualquier otro tipo para el que sí tenga un driver ODBC instalado en su sistema, y utilizar el código fuente incluido con el diskette que acompaña a la revista.
El Listado A muestra el SQL utilizado para crear nuestra pequeña Base de Datos de ejemplo, incluida en el diskette. Nótese que el campo ID de la tabla CONTACTOS es del tipo contador o autoincremento, y requiere de la definición de un trigger y un contador en Interbase: otros sistemas de Base de Datos pueden tener soporte directo para este tipo de campo, lo que hará innecesario parte del código SQL del Listado A.
/* No se hace commit automatico de sentencias de definicion de datos, DDL */SET AUTODDL OFF;
/********** Creacion de la base de datos **********//* Necesario USER y PASSWORD si no se ha hecho login previo */CONNECT "h:\work\artículos\jdbc\1\fuente\agenda.gdb" USER "SYSDBA" PASSWORD "masterkey";
/* Eliminación de la Base de datos */DROP DATABASE;CREATE DATABASE "h:\work\artículos\jdbc\1\fuente\agenda.gdb" USER "SYSDBA" PASSWORD "masterkey";
CONNECT "h:\work\artículos\jdbc\1\fuente\agenda.gdb" USER "SYSDBA" PASSWORD "masterkey";
/***** Creación de la tabla de Contactos *****/CREATE TABLE CONTACTOS ( ID INTEGER NOT NULL, NOMBRE CHAR(30) NOT NULL, EMPRESA CHAR(30), CARGO CHAR(20), DIRECCION CHAR(40), NOTAS VARCHAR(150), PRIMARY KEY( ID ));
CREATE INDEX I_NOMBRE ON CONTACTOS( NOMBRE );
/* Creamos un contador para CONTACTOS.ID */CREATE GENERATOR CONTACTOS_ID_Gen;

SET GENERATOR CONTACTOS_ID_Gen TO 0;
/* Creamos trigger para insertar código del contador en CONTACTOS */SET TERM !! ;CREATE TRIGGER Set_CONTACTOS_ID FOR CONTACTOSBEFORE INSERT ASBEGIN New.ID = GEN_ID( CONTACTOS_ID_Gen, 1);END !!SET TERM ; !!
/**** Creación de la tabla de teléfonos de contactos ****/CREATE TABLE TELEFONOS ( CONTACTO INTEGER NOT NULL, TELEFONO CHAR(14) NOT NULL, NOTAS VARCHAR(50), PRIMARY KEY( CONTACTO, TELEFONO ));
/* Se hace COMMIT */EXIT;
Listado A: SQL utilizado para crear la Base de Datos de ejemplo, AGENDA.GDB, con Interbase.
El primer paso, evidentemente, será crear la Base de Datos, que en nuestro caso se llama AGENDA.GDB. Una vez hecho esto, debemos crear una fuente de datos ODBC: para ello, se debe escoger en el Panel de Control el icono "32bit ODBC", correspondiente al gestor de fuentes de datos ODBC, y hacer click sobre el botón "Add..." de la página "User DSN", con lo que aparecerá la ventana de la Figura A.
Figura A: Ventana del gestor de fuentes de datos ODBC utilizada para añadir nuevas fuentes de datos.
Hecho esto, queda configurar la fuente de datos, indicando el nombre que le vamos a dar (que utilizaremos a la hora de conectarnos a la Base de Datos), así como otros datos. La Figura B muestra la ventana de configuración de una fuente de datos Interbase, utilizando un driver de Visigenic.
Data Source Name es el nombre que utilizaremos para identificar la fuente de datos, y en nuestro caso será JDBC_AGENDA. Description es un texto explicativo optativo, y Database especifica cómo se llama y dónde se encuentra la Base de Datos que vamos a acceder a través de esta fuente de datos. Para poder utilizar los programas de ejemplo, deberemos introducir aquí el directorio donde copiemos los ejemplos, seguido del nombre de la Base de Datos, AGENDA.GDB. En mi caso, Database es h:\work\artículos\jdbc\1\fuente\AGENDA.GDB.

El hecho de que para acceder una Base de Datos mediante ODBC se utilice el nombre de la fuente de datos, en lugar del nombre de la Base de Datos, nos permite cambiar la ubicación e incluso el nombre de la misma sin tener que modificar el código fuente de nuestros programas, ya que estos utilizarán el nombre de la fuente de datos para identificarla.
En cuanto a los demás parámetros de la fuente de datos, se debe escoger como Network Protocol la opción <local>. El nombre de usuario (User name) y la contraseña (Password), se indicarán manualmente desde dentro de nuestro programa: no suele ser aconsejable especificarlo en la misma fuente de datos, dado que esto daría acceso a la Base de Datos a cualquier programa que acceda a la misma a través de la misma.
Figura B: Ventana de configuración de una fuente de datos ODBC.
Como último paso, no debemos olvidar arrancar el servidor de Base de Datos, si utilizamos un gestor que incluye uno, como sucede con Interbase.
7.2 El primer programa con JDBCComo es lógico, la API JDBC incluye varias clases que se deben utilizar para conseguir acceso a una Base de Datos. La Tabla A muestra la lista de clases e interfaces más importantes que JDBC ofrece, junto con una breve descripción. Estas clases se encuentran en el paquete java.sql.
Clase/Interface
Descripción
Driver Permite conectarse a una Base de Datos: cada gestor de Base de Datos requiere un Driver distinto.
DriverManager
Permite gestionar todos los Drivers instalados en el sistema.
DriverPropertyInfo
Proporciona diversa información acerca de un Driver.
Connection Representa una conexión con una Base de Datos. Una aplicación puede tener más de una conexión a más de una Base de Datos.
DatabaseMetadata
Proporciona información acerca de una Base de Datos, como las tablas que contiene, etc.
Statement Permite ejecutar sentencias SQL sin parámetros.PreparedStatement
Permite ejecutar sentencias SQL con parámetros de entrada.
CallableStatement
Permite ejecutar sentencias SQL con parámetros de entrada y salida, típicamente procedimientos almacenados.

ResultSet Contiene las filas o registros obtenidos al ejecutar un SELECT.
ResultSetMetadata
Permite obtener información sobre un ResultSet, como el número de columnas, sus nombres, etc.
Tabla A: Clases e interfaces definidos por JDBC.
El mejor modo de comenzar a estudiar la API de JDBC es empezar con un pequeño programa. El Listado B corresponde a un programa que carga el driver utilizado para conectarnos a bases de datos utilizando controladores ODBC.
// Importamos el paquete que da soporte a JDBC, java.sqlimport java.sql.*;import java.io.*;
class jdbc1 { public static void main( String[] args ) { try { // Accederemos a la fuente de datos // ODBC llamada JDBC_AGENDA String urlBD = "jdbc:odbc:JDBC_AGENDA"; String usuarioBD = "SYSDBA"; String passwordBD = "masterkey";
// Cargamos la clase que implementa // el puente JDBC=>ODBC Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );
// Establecemos una conexion con la Base de Datos System.out.println( "Estableciendo conexión con " + urlBD + "..." ); Connection conexion = DriverManager.getConnection( urlBD, usuarioBD, passwordBD ); System.out.println( "Conexión establecida." ); conexion.close(); System.out.println("Conexión a " + urlBD " cerrada."); } catch( Exception ex ) { System.out.println( "Se produjo un error." ); } }}
Listado B: Código básico para llevar a cabo la conexión con una Base de Datos a través de ODBC.

Establecer una conexión con una Base de Datos mediante JDBC es sencillo: en primer lugar, registramos el Driver a utilizar (que en nuestro caso es el puente JDBC/ODBC), mediante el código:
Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );
Si no se registra este driver, se producirá un error intentar la conexión. A continuación, se lleva a cabo la conexión a la Base de Datos mediante el código:Connection conexion = DriverManager.getConnection( urlBD, usuarioBD, passwordBD );
La clase DriverManager gestiona los Drivers registrados en el sistema: al llamar a getConnection, recorre la lista de Drivers cargados hasta encontrar uno que sea capaz de gestionar la petición especificada por urlBD, que en nuestro ejemplo es "jdbc:odbc:JDBC_AGENDA". Los parámetros usuarioBD y passwordBD corresponden al nombre del usuario y su contraseña, necesarios la mayor parte de las veces para acceder a cualquier Base de Datos.
Cómo se especifica la Base de Datos a utilizar depende del Driver utilizado: en nuestro caso, en que utilizamos el puente ODBC/JDBC, todas las peticiones serán de la forma "jdbc:odbc:NOMBRE_FUENTE_DATOS".
La cadena utilizada para indicar la Base de Datos siempre tiene tres partes, separadas por el carácter ":". La primera parte es siempre "jdbc". La segunda parte indica el subprotocolo, y depende del Sistema de Gestión de Base de Datos utilizado: en nuestro caso, es "odbc", pero para SQLAnyware, por ejemplo, es "dbaw". La tercera parte identifica la Base de Datos concreta a la que nos deseamos conectar, en nuestro caso la especificada por la fuente de datos ODBC llamada "JDBC_AGENDA". Aquí también se pueden incluir diversos parámetros necesarios para establecer la conexión, o cualquier otra información que el fabricante del SGBD indique.
Siguiendo con el Listado B, a continuación se establece una conexión con la Base de Datos, mediante el código:
Connection conexion = controlador.connect( urlBD, usuarioBD, passwordBD );
Acto seguido cerramos la conexión, con:
conexión.close();
Es conveniente cerrar las conexiones a Bases de Datos tan pronto como dejen de utilizarse, para liberar recursos rápidamente. Sin embargo, ha de tenerse en cuenta que establecer una conexión es una operación lenta, por lo que tampoco se debe estar abriendo y cerrando conexiones con frecuencia.

7.3 Consultas en JDBCUn programa que realice una consulta y quiera mostrar el resultado de la misma requerirá del uso de varias clases: la priemra es DriverManager, que permitirá llevar a cabo una conexión con una Base de Datos, conexión que se representa mediante un objeto que soporta el interface Connection. También será necesario además ejecutar una sentencia SELECT para llevar a cabo la consulta, que se representará por un objeto que soporte el interface Statement (o PreparedStatement, o CallableStatement, que estudiaremos más adelante). Una sentencia SELECT puede devolver diversos registros o filas: esta información es accesible mediante un objeto que soporte el interface ResultSet.
El Listado C muestra el código fuente correspondiente a un pequeño programa que muestra los nombres de todos los contactos que hemos almacenado en la Base de Datos AGENDA.GDB, y que utiliza las clases anteriormente mencionadas.
import java.sql.*;import java.io.*;
class jdbc2 { public static void main( String[] args ) { try { // Accederemos al alias ODBC llamado JDBC_DEMO String urlBD = "jdbc:odbc:JDBC_AGENDA"; String usuarioBD = "SYSDBA"; String passwordBD = "masterkey";
// Cargamos el puente JDBC=>ODBC Class.forName ("sun.jdbc.odbc.JdbcOdbcDriver");
// Intentamos conectarnos a la base de datos JDBC_DEMO Connection conexion = DriverManager.getConnection ( urlBD, usuarioBD, passwordBD );
// Creamos una sentencia SQL Statement select = conexion.createStatement();
// Ejecutamos una sentencia SELECT ResultSet resultadoSelect = select.executeQuery( "SELECT * FROM CONTACTOS ORDER BY NOMBRE" );
// Imprimimos el nombre de cada contacto encontrado // por el SELECT System.out.println( "NOMBRE" ); System.out.println( "------" );

int col = resultadoSelect.findColumn( "NOMBRE" ); boolean seguir = resultadoSelect.next(); // Mientras queden registros... while( seguir ) { System.out.println( resultadoSelect.getString( col ) ); seguir = resultadoSelect.next(); };
// Liberamos recursos rápidamente resultadoSelect.close(); select.close(); conexion.close(); } catch( SQLException ex ) { // Mostramos toda la informaci¢n sobre // el error disponible System.out.println( "Error: SQLException" ); while (ex != null) { System.out.println ("SQLState: " + ex.getSQLState ()); System.out.println ("Mensaje: " + ex.getMessage ()); System.out.println ("Vendedor: " + ex.getErrorCode ()); ex = ex.getNextException(); System.out.println (""); } } catch( Exception ex ) { System.out.println( "Se produjo un error inesperado" ); } }}
Listado C: Ejecución de una sentencia SELECT e impresión de los resultados con java.
Echemos un vistazo al código en el Listado C. El código para registrar el controlador (Driver) a utilizar es el mismo del Listado B. A continuación se crea una sentencia SQL (Statement), y se ejecuta, obteniendo seguidamente el resultado de la misma (ResultSet), para lo que se utiliza el siguiente código:
// Creamos una sentencia SQL Statement select = conexion.createStatement(); // Ejecutamos una sentencia SELECT ResultSet resultadoSelect = select.executeQuery(

"SELECT * FROM CONTACTOS ORDER BY NOMBRE" );
Además del método executeQuery, utilizado para ejecutar sentencias SELECT, Statement también proporciona otros métodos: executeUpdate ejecuta una sentencia UPDATE, DELETE, INSERT o cualquier otra sentencia SQL que no devuelva un conjunto de registros, y retorna el número de registros afectados por la sentencia (o -1 si no los hubo). El método getResultSet devuelve el ResultSet de la sentencia, si lo tiene, mientras que getUpdateCount devuelve el mismo valor que executeUpdate.
Es posible limitar el número máximo de registros devuelto al hacer un executeQuery mediante setMaxRows, y averiguar dicho número mediante getMaxRows. Es posible también obtener el último aviso generado al ejecutar una sentencia, mediante getWarning, así como limitar el tiempo en segundos que el controlador esperará hasta que el SGBD devuelva un resultado, mediante setQueryTimeout. Por último, el método close libera los recursos asociados a la sentencia.
El interface ResultSet es el que encapsula el resultado de una sentencia SELECT. Para recuperar la información es necesario acceder a las distintas columnas (o campos), y recuperarla mediante una serie de métodos getString, getFloat, getInt, etc. Al utilizar estos métodos debe indicarse el número correspondiente a la columna que estamos accediendo: si lo desconocemos, podemos averiguar el número correspondiente a una columna, dado el nombre, mediante findColumn. Por último, dado que un ResultSet puede contener más de un registro, para ir avanzando por la lista de registros que contiene deberemos utilizar el método next, que devuelve un valor booleano indicando si existe otro registro delante del actual. El uso de los métodos anteriores se ilustra en el Listado C, que recorre la lista de contactos en la Base de Datos, obteniendo el valor del campo (o columna) "NOMBRE", e imprimiéndolo, mediante un bucle en el que se llama repetidamente al método next y a getString.
Además de estos métodos, ResultSet también cuenta con getWarnings, que devuelve el primer aviso obtenido al manipular los registros, así como wasNull, que indica si el contenido de la última columna accedida es un NULL SQL. Por último, el método close libera los recursos asociados al ResultSet.
Excepción DescripciónSQLException
Error SQL.
SQLWarning
Advertencia SQL.
DataTruncation
Producida cuando se truncan datos inesperadamente, por ejemplo al intentar almacenar un texto demasiado largo en un campo.
Tabla B: Excepciones que puede generar la API de JDBC

Al utilizar la API JDBC es posible obtener diversos errores debido a que se ha escrito incorrectamente una sentencia SQL, a que no se puede establecer una conexión con la Base de Datos por cualquier problema, etc.
El paquete java.sql proporciona tres nuevas excepciones, listadas en la Tabla A. En el Listado C se muestra un ejemplo de uso de las excepciones del tipo SQLException: es posible que se encadenen varias excepciones de este tipo, motivo por el que esta clase proporciona el método getNextException.
La excepción SQLWarning es silenciosa, no se suele elevar: para averiguar si la Base de Datos emitió un aviso se debe utilizar el método getWarnings de Statement y otras clases, que devuelve excepciones de esta clase. Dado que es posible que se obtengan varios avisos encadenados, esta clase proporciona el método getNextWarning, que devuelve el siguiente aviso, si lo hay.
Por último, las excepciones del tipo DataTruncation se producen cuando se trunca información inesperadamente, ya sea al leerla o al escribirla.

UNIDAD VJAVA EN EL LADO CLIENTE
1. INTRODUCCIÓN A LOS APPLETS
Los applets de Java son miniprogramas que pueden ejecutarse desde un navegador World Wide Web usando marcas especiales, cuando el browser carga una página que contiene un applet, el browser descarga el applet desde el servidor Web y lo ejecuta en el sistema local.
El mensaje que aparece en la parte inferior del browser cuando carga una página que contiene un Applet, es similar al siguiente: "initializing... starting...", esto indica que el applet, se esta cargando. Entonces, ¿qué está pasando?
Una instancia de la clase applet es creada. El applet se inicializa a si mismo. El applet empieza a ejecutarse.
Cuando el usuario se encuentra en una página web, que contiene un applet y salta a otra página entonces el applet se detiene (stopping) a si mismo, y si el usuario retorna a la pagina el applet, vuelve a ejecutarse (start) nuevamente. Cuando el usuario sale del browser el applet, tiene un tiempo para detenerse y hacer una limpieza final antes de salir del browser.
Estructura de un Applet.public class Miapplet extends Applet {................public void init() {.......}public void start() {.......}public void stop() {.......}public void destroy() {.......}.........}init() permite inicializar el applet cada vez que este es cargado o recargado.start() inicia la ejecución del applet una vez cargado o cuando el usuario regresa a la pagina.stop() detiene la ejecución del applet como cuando se sale del browser.destroy() antes de salir del browser hace la limpieza final.
Veamos algunos ejemplos:
class Applet1 extends Applet {

............public void paint(Graphics g) {........}...........}El método paint() es el método básico para imprimir información, y el método update() puede ser usado con paint() para un mejor rendimiento en el pintado.
Aquí el famoso programa HelloWorld, escrito como un applet de Java.
import Java.awt.Graphics;import Java.applet.Applet;public class HelloWorld extends Applet{public void paint(Graphics g){g.drawString("Helloworld",50,25);}}
Explicando:
En primer lugar recuerde que debe guardar el programa como:
HelloWorld.Java, luego utilizar el compilador (Javac) para compilar HelloWorld.Java.
Si todo es correcto le devolverá HelloWorld.class
drawString es un método de la clase Graphics del paquete Java.awt
drawString(String str, int x, int y) permite dibujar una cadena de caracteres usando los siguientes parametros:
str La cadena a ser dibujadax La coordenada xy La coordenada y
2. COMO INCLUIR UN APPLET EN UNA PAGINA HTML<APPLET>
Usamos este tag especial el cual es una extensión HTML, de la siguiente forma:
<HTML><HEAD><TITLE>A ver como nos va..</TITLE></HEAD><BODY><BR>

<APPLET CODE="HelloWorld.class" WIDTH=200HEIGHT=50></APPLET></BODY></HTML>
Explicando:
CODEEl atributo code indica el nombre de la clase, es decir el archivo que contiene el applet, incluyendo la extensión (class) en este caso el archivo class debe estar en el mismo directorio que el archivo HTML.
Si desea almacenar sus clases en un directorio diferente al directorio donde se almacenan sus archivos HTML, entonces deberá usar CODEBASE, CODE contiene solamente el nombre de la clase (applet) mientras que CODEBASE contiene la ruta donde se encuentran sus clases.WIDTH y HEIGHT establecen el tamaño para el applet. Un segundo ejemplo:
import Java.awt.Graphics;import Java.applet.Applet;public class Applet2 extends Applet{String texto;public void init(){texto=getParameter(“text”);}public void paint(Graphics g){g.drawString(texto,50,25);}}Como es de esperar este archivo deberá guardarse como Applet2.Java luego de ser compilado les devolverá el applet, Applet2.class
Explicando:
getParameter es un método de la clase Applet del paquete Java.applet la sintaxis:
getParameter(String str)
retorna el valor del parametro str en el tag HTML,
por ejemplo:
<applet code=”Constru.class” width=50 height=50><param name=speed value=5></applet>

Al llamar a getParameter(“speed”) retorna el valor 5
Código HTML:<HTML><HEAD><TITLE>A ver como nos va..</TITLE></HEAD><BODY><BR><HTML><HEAD><TITLE>y Ahora que sigue...</TITLE></HEAD><BODY><BR><applet code=Applet2.class WIDTH=100 Height=40><PARAM NAME=”text” VALUE=”Estan viendo mi 2do. Applet!!”></applet></BODY></HTML>
3. PRIORIDAD EN LA EJECUCIÓN DE TAREASAnteriormente se dijo que los procesos se ejecutan concurrentemente.Conceptualmente esto es verdadero, pero en la práctica no ocurre así. Muchas computadoras tienen un simple CPU (nos estamos refiriendo específicamente al microprocesador) por lo tanto este solo puede ejecutar una instrucción a la vez y esta instrucción a su vez corresponde a un programa cargado en la memoria.
Pueden haber muchos programas cargados en la memoria. Quien decide que programa debe ejecutarse es el planificador de procesos que asigna un tiempo de CPU a cada una de los procesos en espera de acuerdo a su una prioridad.
Cuando se vence el tiempo de ejecución de un proceso y esta no se ha completado se guarda la posición en donde se quedo la ejecución de programa para ser usada luego cuando se tenga que retomar la ejecución de este proceso.
Seguidamente la CPU ejecuta el siguiente proceso en espera. Todo este esquemade ejecución le da la ilusión al usuario de la computadora que esta está ejecutando varios procesos concurrentemente.
El ejecutor de programas de Java soporta este modelo de manera muy simple, con un planificador determinístico. Que utiliza un algoritmo conocido como planificador de prioridad fija. Este algoritmo planificador de procesos se basa en laprioridad del proceso pero tomando en cuenta también los otros procesos de tipo Runnable.

Cuando un proceso en Java es creado, esta hereda la prioridad del proceso que lo creo (hereda la prioridad de su padre). Se puede modificar la prioridad de los procesos en cualquier momento luego de su creación usando el método setpriority().
La prioridad del proceso se expresa en números que están en van desde MIN_PRIORITY hasta MAX_PRIORITY (constantes definidas en la clase Thread). El proceso que tiene el número mas alto es la que se ejecuta primero.
Cuando varios procesos están listos para se ejecutadas el planificador de Java elige aquella que es del tipo Runnable.
Este código fuente de Java implementa un applet que anima una carrera entre dos procesos runner con diferentes prioridades. Cuando se clickea el Mouse sobre el applet comienza la carrera. El primer proceso tiene una prioridad de 2 y el segundo proceso 3.
Este es el método run() para ambos runners:
public int tick = 1;public void run() {while (tick < 400000) {tick++;}}
Este metodo run() simplemente cuenta desde 1 a 400,000. La variable de instancia tick es publica porque el applet usa este valor para determinar que tanto ha progresado el runner. Adicionalmente a los dos procesos runner este applet tiene un tercer proceso que se encarga de dibujar. El metodo run() del proceso que dibuja contiene un loop infinito; durante cada interacción del loop, este dibuja una línea por cada runner. La tarea que dibuja tiene una prioridad de 4.
Ejemplo de un applets.
/* button actions */import java.awt.*;public class ButtonActionsTest extends java.applet.Applet {public void init() {setBackground(Color.white);add(new Button("Red"));add(new Button("Blue"));add(new Button("Green"));add(new Button("White"));add(new Button("Black"));}

public boolean action(Event evt, Object arg) {if (evt.target instanceof Button)changeColor((String)arg);return true;}void changeColor(String bname) {if (bname.equals("Red")) setBackground(Color.red);else if (bname.equals("Blue")) setBackground(Color.blue);else if (bname.equals("Green")) setBackground(Color.green);else if (bname.equals("White")) setBackground(Color.white);else setBackground(Color.black);}}
4. LAS EXCEPCIONES4.1 ¿QUé es una excepción?El termino excepción es conocido de manera corta como un “evento excepcional” y puede ser definido de la siguiente manera: Una excepción es un evento que ocurre durante la ejecución de un programa que desbarata o desorganiza el normal funcionamiento del flujo de las instrucciones de un programa. Visto desde el lenguaje Java una excepción es cualquier objeto que es una instancia de la clase Throwable (o cualquiera de sus subclases).
Las excepciones causan muchos tipos de errores, desde problemas serios de hardware, como caídas de disco duro a simples errores de programa, tales como acceso a elementos de un array que no han sido declarados lo que produce una invasión de memoria que puede estar ocupada por otros programas. Cuando tales errores ocurren el método crea un objeto de tipo excepción y este actúa como una mano milagrosa que salva al programa de la caída, luego de tratarse el error la ejecución del programa continúa desde la siguiente línea de código que produjo el error.
4.2 El bloque TRY:El primer paso en la construcción de un manejador de excepción es encerrar las declaraciones que tengan la posibilidad de generar un error de excepción durante la ejecución del programa. En general un bloque try es de la siguiente manera:
try {// Declaraciones Java}
El segmento de código llamado ‘Declaraciones Java’ esta compuesto de una o mas declaraciones legales que podrían generar una excepción.
El siguiente programa usa una declaración try para el método entero por que elcódigo es fácil de leer.

PrintStream pstr;try {int i;
System.out.println("Entrando a la declaracion try");pStr = new PrintStream(new BufferedOutputStream(new FileOutputStream("ArchivoSalida.txt")));for (i = 0; i < size; i++)pStr.println("Valor en : " + i + " = " +victor.elementAt(i));}
La declaración try gobierna las sentencias encerradas con este y define el campo de acción de esta. Una declaración try debe ser acompañada por al menos un bloque catch o un bloque finally.
El bloque CATCH:Como se explicó anteriormente, la sentencia try define el alcance del manejador de excepción. Se asocia el manejador con una declaración try poniendo uno o mas bloques catch directamente después que el bloque try :
try {. . .} catch ( . . . ) {. . .} catch ( . . . ) {. . .} . . .
Cabe resaltar que no puede haber código entre el final de la declaración try y el comienzo de la declaración catch. La forma general de la declaración catch de Java es:
catch (AlgunObjectoThrow Nombrevariable) {// Declaraciones Java}
Como se puede observar la declaración catch requiere un argumento simple. El argumento para la declaración catch es un argumento como si lo fuera para la declaración de un método. El tipo de argumento AlgunObjetoThrow declara el tipo de excepción que el manejador puede manejar y debe ser el mismo de la clase que hereda de la clase definida en el paquete java.lang; NombreVariable es el nombre por el cual el manejador puede referirse a la excepción que esta comprometida por el manejador.

El bloque catch contiene una serie de declaraciones Java. Esas declaraciones son ejecutadas cuando el manejador de excepción es invocado.
Aqui un ejemplo:
El método writeList() de la clase ListOfNumbers usa dos manejadores de excepción para la declaración try, con un manejador para cada tipo de excepción que están en el ámbito del try.
try {int a[10];int c;c = a[11];} catch (ArrayIndexOutOfBoundsException e) {System.err.println("Tratamiento deArrayIndexOutOfBoundsException: " + e.getMessage());} catch (IOException e) {System.err.println("Tratamiento de IOException: " +e.getMessage());}
El bloque FINALLY:El paso final en el establecimiento de un manejador de excepción es proveer un mecanismo para borrar el estado del método después (posiblemente) permitiendo que el control sea pasado a una parte diferente del programa. Hacemos esto encerrando el código a limpiar con un bloque finally.
try {. . . .} finally {if (pStr != null) {System.out.println("Cerrando PrintStream");pStr.close();} else {System.out.println("PrintStream no abierto");}}
Aquí algunos ejemplos:
SomeFileClass f = new SomeFileClass();if (f.open("/a/file/name/path")) {try {someReallyExceptionalMethod();} finally {f.close();}

}
El uso del finally en el código anterior se comporta como el siguiente:
SomeFileClass f = new SomeFileClass();if (f.open("/a/file/name/path")) {try {someReallyExceptionalMethod();} catch (Throwable t) {f.close();throw t;}}
Aqui una compleja demostracion con finally :
public class MiClaseExcepcional extends ClaseContexto {public static void main(String argv[]) {int EstadoMisterioso = getContext();while (true) {System.out.print("Quien ");try {System.out.print("es ");if (EstadoMisterioso == 1)return;System.out.print("ese ");if (EstadoMisterioso == 2)break;System.out.print("extrano ");if (EstadoMisterioso == 3)continue;System.out.print("pero amable ");if (EstadoMisterioso == 4)throw new UncaughtException();System.out.print("en absoluto ");} finally {
System.out.print("y divertido?\n");}System.out.print("Yo quiero reunirme con ese sujeto");}System.out.print("Por favor llamame!\n");}}

5. CONTROL DE EVENTOSSe llaman eventos a aquellas acciones que realizan los usuarios cuando presionan una tecla, arrastran el ratón o presionan el botón izquierdo del ratón, etc.
Los eventos en Java se encuentran especificados en el paquete AWT (Abstract Windowing Toolkit),
5.1 Los Objetos EventosSon el resultado de un evento, estos incluyen la siguiente información:
El tipo de evento Por ejemplo, keypress, mouse click, etc. El objeto que ha generado el evento El Momento en el que ocurrió el evento. La coordenada (x,y) donde ocurrió el evento La tecla que se ha presionado (para eventos keypress) Un argumento, asociado con el evento El estado del modificador de tecla Shift y Control cuando el evento ocurre.
5.2 Implementar un manejador de eventosLa clase Component, define muchos manejadores cada método manejador de eventos puede ser usado solo para un tipo particular de evento excepto handleEvent().
La clase Component define los siguientes métodos para manejar eventos:
action() (Event.ACTION_EVENT)mouseEnter() (Event.MOUSE_ENTER)mouseExit() (Event.MOUSE_EXIT)mouseMove() (Event.MOUSE_MOVE)mouseDown() (Event.MOUSE_DOWN)mouseDrag() (Event.MOUSE_DRAG)mouseUp() (Event.MOUSE_UP)keyDown() (Event.KEY_PRESS o Event.KEY_ACTION)keyUp() (Event.KEY_RELEASE oEvent.KEY_ACTION_RELEASE)gotFocus() (Event.GOT_FOCUS)lostFocus() (Event.LOST_FOCUS)handleEvent() (todos los tipos de eventos)
Cuando un evento ocurre, el método manejador de evento que coincida con el evento que ha ocurrido es llamado, siendo un poco mas explícito, cuando ocurre un evento el evento pasa primero al método handleEvent(), el cual se encarga de llamar al método apropiado para el tipo de evento.
El método action() tiene una importancia especial ya que controla componentes básicos como Pushbutton, Checkboxes, Lists, MenuItem y objetos de entrada de

texto TextField, todos ellos producen el evento action, todos los metodos manejadores de eventos tienen al menos un argumento (Event) y retornan un valor booleano, al retornar un valor FALSE, el manejador del evento indica que el evento debe continuar hasta alcanzar una jerarquía mas alta.
Un valor TRUE indica que el evento no debe ser enviado mas alla. El método handleEvent() casi siempre retorna el método super.handleEvent(), para asegurarse que todos los eventos son enviados al método manejador de eventos apropiado.
5.3 Eventos Mouse-clickEsto ocurre cuando el usuario hace click, con en el ratón en el cuerpo de un applet usted puede interceptar los eventos click, por ejemplo para pasar de una URL a otra, para cambiar el estado de un archivo de audio de on a off, etc. 5.4 MouseDown y mouseUpCuando usted hace un click con el ratón una sola vez, el AWT genera 2 eventos uno es el evento mouseDown que ocurre cuando el botón izquierdo del ratón es presionado y el otro mouseUp que ocurre cuando el botón es liberado.
Usted ya habrá notado la importancia de manejar 2 eventos UP y DOWN, con el ratón, un ejemplo claro es al seleccionar una opción de un menú.
Ejemplo de uso del evento mouseDown
public boolean mouseDown(Event evt, int x, int y) {...}El metodo mouseDown() y el metodo mouseUp() toman 3 parametros:
El evento mismo Las coordenadas x,y donde el evento ocurrio
El argumento “event” es una instancia de la clase “Event” el cual contiene información acerca de cuando el evento se generó y el tipo de evento.
Los argumentos x,y le indican dónde ocurrió el click del mouse, veamos por ejemplo este método que imprime la coordenada x,y.
public boolean mouseDown(Event evt, int x, int y) {System.out.println("Mouse down aqui fue.. " + x + "," + y);return true;}
La otra parte del evento mouse es el método mouseUp() el cual es llamado cuando el botón del ratón es liberado veamos la sintaxis del evento mouseUp.

public boolean mouseUp(Event evt, int x, int y) {....}
Veamos un ejemplo usando los eventos del mouse
---Guardar este archivo como Textmove.java---
import java.awt.Graphics;import java.applet.Applet;import java.awt.Event;public class Textmove extends Applet implements Runnable{String text_in;int xpos=0;Thread killme=null;boolean suspended = false;public void init(){text_in=getParameter("text");}public void paint(Graphics g){g.drawString(text_in,xpos,100);}public void start(){if(killme==null){killme=new Thread(this);killme.start();}}public void set_x(){xpos =xpos-5;if(xpos<-120){xpos=size().width;}}public void run(){while(killme != null){try {Thread.sleep(100);}catch(InterruptedException e){}set_x();repaint();}}public boolean handleEvent(Event evt) {if (evt.id == Event.MOUSE_DOWN) {if (suspended) {killme.resume();} else {killme.suspend();

}suspended = !suspended;}return true;}public void stop(){if(killme != null)killme.stop();killme=null;}}
---Compilar usando el javac del JDK---
Agregar el siguiente código para su documento HTML:
<HTML><TITLE> Eventos del Mouse </TITLE><BODY><H1> Abajo el Applet</H1><HR><APPLET CODE="Textmove.class" WIDTH=150 HEIGHT=100></APPLET></BODY></HTML>
De preferencia todos los archivos en la misma carpeta.

UNIDAD VI
APLICACIONES CLIENTE – SERVIDOR
1. COMPUTACIÓN BASADA EN INTERNET
"Java es una piedra angular fundamental de la Computación Basada en Internet, por la cual la compañía cree que es el gran cambio en arquitectura de computadoras que favorece el concepto de servidor centralizado de SCO", dijo Scott McGregor, vicepresidente senior de Productos de SCO. "La promesa de escribir una vez, y correr en cualquier lugar es intrigante para los desarrolladores y gerentes de sistemas en todos los segmentos de negocios".
Esto es parte de todo lo que sucede en la industria, que está llevando a Java a ser la plataforma de desarrollo e implementación preferida para la computación basada en Internet.
La independencia de plataforma de Java significa que cualquier desarrollador de software puede crear una versión de una aplicación e implementarla en una gran cantidad de sistemas, ahorrando tiempo, dinero, y otros recursos. Para soportar aún más la computación basada en Internet, SCO esta formando un equipo de proveedores de Internet para producir herramientas de desarrollo que soporten los sistemas SCO, incluyendo el VirtuFlex Internet Application Engine.
2. HTML BÁSICO
El HTML (Hyper Text Markup Language) es un sistema para estructurar documentos. Estos documentos pueden ser mostrados por los visores de páginas Web en Internet, como Netscape, Mosaic o Microsoft Explorer. Por el momento no existe un estándar de HTML, aunque existen diferentes revisiones o niveles de estandarización, el 1.0, el 2.0 , el 3.0, el 3.2 y el 4.0, lo que produce que algunos visores no "comprendan" en su totalidad el contenido de un documento. En este manual se ha utilizado la revisión 3.2 de HTML. Esto quiere decir que algunas de las órdenes de HTML que aquí se indican puede que no sean reconocidas por algunos visores de páginas Web. Netscape 2.x y Microsoft Explorer 3.x reconocen prácticamente todas las órdenes HTML vistas en este manual. (Para los estilos, tendrá que ser Netscape 4.x).
Básicamente, el HTML consta de texto plano (ASCII) y una serie de órdenes a través de marcas o etiquetas (tags), que indican al visor que estemos utilizando, la forma de representar los elementos (texto, gráficos, etc...) que contenga el documento. En este manual nos referiremos a estas órdenes con la palabra

"directiva". Un documento HTML se puede crear usando cualquier editor o procesador de textos que permita trabajar con texto ASCII.
Una directiva será un texto incluido entre los símbolos menor que < y mayor que >. Este texto será una orden que explique la utilidad de la etiqueta, y es indistinto que se escriba en mayúsculas o minúsculas. Las directivas de HTML pueden ser de dos tipos, cerradas o abiertas. Las directivas cerradas son aquellas que tienen una etiqueta que indica el principio de la directiva y otra que indica el final. La del final contendrá el mismo texto, añadiéndole al principio el carácter /. El efecto que define la directiva se aplicará sobre todo lo que esté incluido entre estas dos etiquetas. Entre ambas etiquetas se pueden encontrar otras directivas. Las directivas abiertas constan de una sola etiqueta.
Las directivas pueden contener modificadores que llamaremos "parámetros" o "atributos". En el caso de las directivas cerradas, se escriben sólo en la etiqueta de inicio y consisten, normalmente, en el nombre del parámetro y un valor, unidos por el carácter =. Si se incluyen varios, se separan por espacios y su orden es indistinto. Si el valor que toma el parámetro es más de una palabra, deberá escribirse entre comillas.
Ejemplos:
Directiva cerrada <CENTER> Mi página Web </CENTER>
Directiva abierta <HR>
Directiva con parámetros <BODY bgcolor="#FFFFFF"> </BODY>
Los ficheros que contienen documentos HTML suelen tener la extensión .html o .htm. En este manual se han fijado los siguientes criterios a la hora de escribir la sintaxis de las directivas de HTML:
1º) Las directivas se indican en letra mayúscula y en negrilla.2º) Los parámetros de las directivas se indican en letra minúscula y negrilla. 3º) El resto de elementos se indican en letra normal.4º) Las palabras a resaltar en el texto se indican en cursiva y negrilla.
2.1 Estructura básica de un documento HTML
Un documento escrito en HTML contendría básicamente las siguientes directivas:
<HTML> <HEAD> <TITLE> </TITLE>
Indica el inicio del documento. Inicio de la cabecera. Inicio del título del documento. Final del título del documento.

</HEAD> <BODY> </BODY></HTML>
Final de la cabecera del documento. Inicio del cuerpo del documento. Final del cuerpo del documento. Final del documento.
El documento se hallará situado en algún ordenador al que se pueda acceder a través de Internet. Para indicar la situación del documento en Internet se utiliza la URL (Uniform Resource Locator). La URL es el camino que ha de seguir nuestro visor a través de Internet para acceder a un determinado recurso, bien sea una página Web, un fichero, un grupo de noticias, etc. Es decir, lo que el visor de páginas Web hace es acceder a un fichero situado en un ordenador que está conectado a la red Internet. La estructura de una URL para una página Web suele ser del tipo http://dominio/directorio/fichero. El dominio indica el nombre del ordenador al que accedemos, el directorio es el nombre del directorio de ese ordenador y fichero el nombre del fichero que contiene la página Web escrita en HTML. Por ejemplo:
http://ares.six.udc.es/cine/corunha2.html
Donde ....
http://ares.six.udc.es/cine/corunha2.html
es el indicador de pagina Webes el Dominio (nombre) del ordenadores el Directorio dentro del ordenadores el Fichero que contiene la página Web
2.2 Cabecera del documento
La directiva <HEAD></HEAD> delimita la cabecera del documento. Dentro de la cabecera es importante definir el título de la página por medio de la directiva <TITLE></TITLE>. Este título será el que aparezca en la barra de nuestro visor de páginas Web.
Ejemplo:
<TITLE>La página Web de Juan</TITLE>
Dentro de la cabecera de nuestro documento podemos incluir otras directivas adicionales. La directiva <META> indica al visor de Internet las palabras clave y contenido de nuestra página Web. Muchos de los buscadores de páginas Web de Internet (Google, Yahoo, Lycos, etc...) utilizan el contenido de esta directiva para incluir la página en sus bases de datos. La directiva <META> lleva generalmente dos parámetros, name y content.
Ejemplos:

<META name = "Descripción" content = "Mi página personal, Música y Películas">
Indica al visor la descripción de la página y sus contenidos principales. <META name = "keywords" content = "música, películas, links">
Indica al visor las palabras clave para los buscadores de Internet. <meta name="title" content="AgregaWeb">
Indica el título de la Página
Hay páginas para registrar automáticamente, por ejemplo: Agregaweb, Recursos gratis,...
Otro uso de la directiva <META> es la de indicar documentos con "refresco automático". Si se indica una URL se sustituirá el documento por el indicado una vez transcurridos el número de segundos especificados. Si no se incluye ninguna URL se volverá a cargar en el visor el documento en uso transcurridos los segundos indicados. Esto es útil para páginas que cambian de contenido con mucha frecuencia o para redireccionar a la persona que visita nuestra página Web a una nueva dirección donde se encuentra una versión actualizada de nuestra página Web.
Ejemplo :
<META http-equiv= "refresh" content = "15;url=http://www.pangea.org"> Transcurridos 15 segundos se accederá a la pagina Web de Pangea.
La directiva <BASE> indica la localización de los ficheros, gráficos, sonidos, etc... a los que se hace referencia en nuestra página Web. Si no se incluye esta directiva el visor entiende que dichos elementos se encuentran en el mismo lugar donde se encuentra nuestra página Web.
Ejemplo:
<BASE href = "http://www.jet.es/jose/">
2.3 Cuerpo del documento
La directiva <BODY></BODY> indica el inicio y final de nuestra pagina Web. Será entre el inicio y el final de esta directiva donde pongamos los contenidos de nuestra página, textos, gráficos, enlaces, etc.... Esta directiva tiene una serie de parámetros opcionales que nos permiten indicar la "apariencia" global del documento:
background= "nombre de fichero gráfico" Indica el nombre de un fichero gráfico que servirá como "fondo" de nuestra página. Si la imagen no ocupa todo el fondo del documento, esta será reproducida tantas veces como sea necesario.

bgcolor = "código de color" Indica un color para el fondo de nuestro documento. Se ignora si se ha usado el parámetro background. Aun así es bueno indicarlo ya que en el caso de que el visor que utilicemos tenga desactivado los gráficos sí se verá.
text = "código de color" Indica un color para el texto que incluyamos en nuestro documento. Por defecto es negro.
link = "código de color" Indica el color de los textos que dan acceso a un Hyperenlace. Por defecto es azul.
vlink = "código de color" Indica el color de los textos que dan acceso a un Hyperenlace que ya hemos visitado con nuestro visor. Por defecto es azul oscuro.
El código de color es un número compuesto por tres pares de cifras hexadecimales que indican la proporción de los colores "primarios", rojo, verde y azul. El código de color se antecede del símbolo #.
El primer par de cifras indican la proporción de color Rojo, el segundo par de cifras la proporción de color Verde y, las dos últimas, la proporción de color Azul. Estos números están en numeración hexadecimal. Esta numeración se caracteriza por tener 16 dígitos (en lugar de los 10 habituales). Estos dígitos son:
0 1 2 3 4 5 6 7 8 9 A B C D E F
Es decir, que en nuestro caso, el número menor es el 00 y el mayor el FF. Combinando las proporciones de cada color primario obtendremos diferentes colores.
Ejemplos:
#000000#FF0000#00FF00#0000FF#FFFFFF
Color NegroColor RojoColor VerdeColor AzulColor Blanco
Cuando la gente no usa color verdadero, sino 256 colores hay que tener en cuenta que los navegadores sólo permiten ver con exactitud 216. Estos se conseguirán con ternas de parejas expresadas como: 00, 33, 66, 99, CC y FF. Cualquier otra combinación se visualizará como el color más parecido.
La paleta de colores de 216 que asegura una visión real de los colores en la web será:
FFFFFF FFFFC FFFF99 FFFF66 FFFF33 FFFF00 CCFFFF CCFFC

C C
CCFF99 CCFF66 CCFF33 CCFF00 99FFFF 99FFCC 99FF99 66FFFF
99FF66 99FF33 66FFCC FFCCFF 99FF00 33FFFF FFCCCC 33FFCC
00FFFF 66FF99 FFCC99 66FF66 66FF33 00FFCC 66FF00 33FF99
FFCC66 FFCC33 CCCCFF 33FF66 33FF33 00FF99 FFCC00 33FF00
00FF66 00FF33 00FF00 CCCCCC
CCCC99 99CCFF CCCC6
6CCCC0
0
CCCC33
99CCCC FF99FF 99CC99 66CCFF FF99CC 99CC66 66CCC
C
99CC33 00CCFF 33CCFF 99CC00 FF9999 66CC99 FF9966 66CC66
33CCCC CC99FF 00CCC
C FF9933 FF9900 66CC33 66CC00 33CC99
00CC99 CC99CC 33CC66 00CC66 CC9999 FF66FF 33CC33 33CC00
CC9966 00CC33 9999FF 00CC00 CC9933 CC9900 FF66CC 9999CC
FF6699 999999 6699FF FF6666 CC66FF 999966 6699CC 999933
FF6633 FF6600 FF33FF 3399FF 999900 669999 CC66CC 0099FF
FF33CC 3399CC CC6699 669966 FF00FF 339999 669933 669900
FF3399 0099CC 9966FF CC6666 009999 CC6633 CC6600 339966
FF00CC FF3366 009966 CC33FF FF3333 339933 009933 9966CC
FF3300 FF0099 339900 009900 6666FF CC33CC FF0066 996699
FF0033 FF0000 CC00FF CC3399 996666 6666CC 996633 996600
3366FF CC3366 CC00CC 9933FF 0066FF 666699 CC3333 CC3300
3366CC CC0099 9933CC 666666 666633 0066CC 9900FF 666600
CC0066 336699 993399 CC0033 6633FF 336666 006699 CC0000
993366 9900CC 336633 006666 336600 6633CC 3333FF 006633
993333 993300 6600FF 990099 006600 0033FF 663399 990066
3333CC 663366 6600CC 990033 0033CC 990000 3300FF 663333
663300# 660099 0000FF 333399 3300CC 003399 333300 660066

333333 003366 0000CC 660033 333300 660000 330099 003333
003300 000099 330066 330033 000066 330000 000033 000000
De cualquier forma la mayoría de los editores de HTML nos permiten obtener el código de color correspondiente escogiendo directamente el color de una paleta. Así mismo la mayor parte de los navegadores actuales tienen algunos colores predefinidos por lo que pueden ser referenciados por su nombre. La paleta de colores que se pueden poner con nombre es más limitada, sólo 140:
White Snow Seashell FloralWhite OldLaceLinen GhostWhite WhiteSmoke Gainsboro LightGreySilver DarkGray LightCyan Azure AliceBlue
Lavender LavenderBlush MistyRose MintCream HoneydewBeige Cornsilk AntiqueWhite PapayaWhip Ivory
LightYellow LightGoldenrodYellow LemonChiffon PaleGoldenrod KhakiBlanchedAlmond Bisque Moccasin Wheat NavajoWhite
PeachPuff LightSteelBlue LightBlue SkyBlue LightSkyBlueDeepSkyBlue DodgerBlue CornflowerBlue SteelBlue RoyalBlue
Blue MediumBlue DarkBlue MediumSlateBlue SlateBlueDarkSlateBlue Indigo Navy MidnightBlue MediumPurple
BlueViolet DarkViolet DarkOrchid DarkMagenta PurpleThistle Plum Magenta Violet Orchid
MediumOrchid Pink LightPink HotPink DeepPinkPaleVioletRed MediumVioletRed Burlywood LightSalmon DarkSalmon
RosyBrown Salmon LightCoral Coral TomatoOrangeRed Red IndianRed Crimson Firebrick
Brown Sienna SaddleBrown DarkRed MaroonTan SandyBrown Orange DarkOrange ChocolatePeru DarkSeaGreen DarkKhaki Yellow Gold
Goldenrod DarkGoldenrod OliveDrab ForestGreen GreenOlive DarkOliveGreen DarkGreen SeaGreen MediumSeaGreen
LimeGreen YellowGreen Chartreuse GreenYellow LawnGreenLime MediumSpringGreen SpringGreen LightGreen PaleGreenCyan PaleTurquoise PowderBlue Turquoise MediumTurquoise
DarkTurquoise Aquamarine MediumAquamarine LightSeaGreen CadetBlueDarkCyan Teal LightSlateGray SlateGray Gray

DimGray DarkSlateGray Black
2.4 Juego de caracteres del Documento
Todos los visores de páginas Web actuales soportan todos los caracteres gráficos de la especificación ISO 8859-1, que permite escribir textos en la mayoría de los países occidentales.
De cualquier forma y como muchos sistemas tienen distintos juegos de caracteres ASCII, se han definido dos formas de representar caracteres especiales usando solamente el código ASCII de 7 bits. Para hacer referencia a estos caracteres se les asigna un código numérico o un nombre de "entidad". Asimismo hay caracteres que se utilizan para las directivas de HTML, por ejemplo < y >. Estos caracteres pueden ser representados por un código numérico o una entidad cuando deseemos que aparezcan en el documento "tal cual". Las entidades comienzan por el símbolo & (ampersand) y terminan con el símbolo ; (punto y coma).
A continuación veamos una tabla con las principales entidades:
Carácter Código Entidad Carácter Código Entidad! ! -- " " --
# # -- $ $ --
% % -- & & --
' ' -- ( ( --
) ) -- * * --
+ + -- , , --
- - -- . . --
/ / -- : : --
; ; -- < < --
= = -- > > --
? ? -- @ @ --
[ [ -- \ \ --
] ] -- ^ ^ --
_ _ -- ` ` --
{ { -- | | --
} } -- ~ ~ --
  nbsp ¡ ¡ iexcl

¢ ¢ cent £ £ pound
¤ ¤ curren ¥ ¥ yen
¦ ¦ brvbar § § sect
¨ ¨ uml © © copy
ª ª ordf « « laquo
¬ ¬ not ­ shy
® ® reg ¯ ¯ macr
° ° deg ± ± plusmn
² ² sup2 ³ ³ sup3
´ ´ acute µ µ micro
¶ ¶ para · · middot
¸ ¸ cedil ¹ ¹ sup1
º º ordm » » raquo
¼ ¼ frac14 ½ ½ frac12
¾ ¾ frac34 ¿ ¿ iquest
À À Agrave Á Á Aacute
  Acirc à à Atilde
Ä Ä Auml Å Å Aring
Æ Æ AElig Ç Ç Ccedil
È È Egrave É É Eacute
Ê Ê Ecirc Ë Ë Euml
Ì Ì Igrave Í Í Iacute
Î Î Icirc Ï Ï Iuml
Ð Ð ETH Ñ Ñ Ntilde
Ò Ò Ograve Ó Ó Oacute
Ô Ô Ocirc Õ Õ Otilde
Ö Ö Ouml × × times
Ø Ø Oslash Ù Ù Ugrave
Ú Ú Uacute Û Û Ucirc
Ü Ü Uuml Ý Ý Yacute
Þ Þ THORN ß ß szlig
à à agrave á á aacute

â â acirc ã ã atilde
ä ä auml å å aring
æ æ aelig ç ç ccedil
è è egrave é é eacute
ê ê ecirc ë ë euml
ì ì igrave í í iacute
î î icirc ï ï iuml
ð ð eth ñ ñ ntilde
ò ò ograve ó ó oacute
ô ô ocirc õ õ otilde
ö ö ouml ÷ ÷ divide
ø ø oslash ù ù ugrave
ú ú uacute û û ucirc
ü ü uuml ý ý yacute
þ þ thorn ÿ ÿ yuml
Por lo tanto, la palabra página la podríamos escribir como:
página página página
Si deseamos que cualquier visor de páginas Web pueda visualizar las letras acentuadas de nuestro documento debemos utilizar sus correspondientes entidades o códigos para representarlas.
2.5 Espaciados y saltos de línea
En HTML sólo se reconoce un espacio entre palabra y palabra, el resto de los espacios serán ignorados por el visor.
Ejemplo Se verá como
Esto es una frase Esto es una frase
Asimismo tampoco se respetan las tabulaciones, retornos de carro etc... Para ello existen una serie de directivas que indican estos códigos. La directiva

<PRE></PRE> obliga al visor a visualizar el texto tal y como ha sido escrito, respetando tabulaciones, espacios, retornos de carro, etc.. pero se verá con una fuente tipo máquina (courier).
Ejemplo Se verá como
<PRE> Este texto ha sido
preformateado .
</PRE>
Este texto ha sido
preformateado .
Para indicar un salto de línea se utiliza la directiva <BR> y para un cambio de párrafo (deja una línea en blanco en medio) se utiliza la directiva <P>.
Ejemplo Se verá como
Este texto tiene<BR>saltos de línea y <P> de párrafo. Este texto tienesaltos de línea y de párrafo.
La directiva <P> tiene el parámetro opcional:
align = posición Alinea el párrafo a la izquierda (left), a la derecha (right), lo centra (center) o lo justifica (justify). Este último parámetro sólo funciona en navegadores versiones 4 o superiores.
La directiva <HR> muestra una línea horizontal de tamaño determinable. Tiene los siguientes parámetros opcionales:
align = posición Alinea la línea a la izquierda (left), a la derecha (right) o la centra (center).
noshade No muestra sombra, evitando el efecto en tres dimensiones.
size = número Indica el grosor de la línea en pixels.
width = % ó número Indica el ancho de la línea en tanto por ciento en función del ancho de la ventana del visor, o en pixels si indicamos un número sin porcentaje.
Ejemplo:

<HR align= center size= 20 width= 50%>
La directiva <HR> sin ningún parámetro mostrará una línea horizontal que ocupará todo el ancho de la página. Estas líneas sencillas son las que ves en este manual para separar las diferentes secciones.
2.6 Cabeceras
En un documento de HTML se pueden indicar seis tipos de cabeceras (tamaños de letra) por medio de las directivas <H1><H2><H3><H4><H5> y <H6>. El texto que escribamos entre el inicio y el fin de la directiva será el afectado por las cabeceras. La cabecera <H1> será la que muestre el texto en mayor tamaño.
Ejemplo Se vería como
<H1>Texto de Prueba</H1>
Texto de prueba<H2>Texto de Prueba</H2>
Texto de Prueba
<H3>Texto de Prueba</H3> Texto de Prueba
<H4>Texto de Prueba</H4> Texto de Prueba
<H5>Texto de Prueba</H5> Texto de Prueba
<H6>Texto de Prueba</H6> Texto de Prueba
Los textos marcados como "cabeceras" provocan automáticamente un retorno de carro sin necesidad de incluir la directiva <BR>. Por ejemplo:
Ejemplo Se vería como
<H3>Página de José</H3>Esta es mi página personal. Página de JoséEsta es mi página personal
2. 7 Atributos del Texto

Para indicar atributos de texto (negrilla, subrayado, etc...) tenemos varias directivas. Algunas de ellas no son reconocidas por determinados visores de Internet, es por ello que según el visor que estés utilizando, verás el resultado correctamente o no.
Atributo Directiva Ejemplo Resultado
Negrita <B></B> <B>Texto de prueba</B> Texto de prueba
Cursiva <I></I> <I>Texto de prueba</I> Texto de prueba
Teletype <TT></TT> <TT>Texto de prueba</TT> Texto de prueba
Subrayado <U></U> <U>Texto de prueba</U> Texto de prueba
Tachado <S></S> <S>Texto de prueba</S> Texto de prueba
Parpadeo <BLINK></BLINK> <BLINK>Texto de prueba</BLINK>
Texto de prueba
Superíndice <SUP></SUP> <SUP>Texto de prueba</SUP>
Texto de prueba
Subíndice <SUB></SUB> <SUB>Texto de prueba</SUB> Texto de prueba
Centrado <CENTER></CENTER> <CENTER>Texto de prueba</CENTER>
Texto de prueba
Por otro lado, la directiva <FONT></FONT> nos permite variar el aspecto del texto, con los siguientes parámetros:
size = valor Da al texto un tamaño en puntos determinado.
size = +/- valor Da al texto un tamaño tantas veces superior (+) o inferior (-) como indique el valor.
color = "código de color" Escribe el texto en el color cuyo código se especifica.
face = "fuente_de_letra" Permite cambiar la fuente de la letra, por ejemplo: Arial. Se pueden poner varias separadas por comas. De esa manera si el navegador no tiene la primara, probará con la segunda, etc. Por ejemplo: Helvetica, Arial, Sans Serif.
Ejemplo Se vería como
<FONT size = +2 color = "#FF0000"> Texto de prueba Texto de

</FONT> prueba
El tamaño por defecto de la letra es 3. Pero la directiva <BASEFONT>, con el parámetro size permite cambiarlo.
Existen otras directivas que realizan las mismas operaciones que las antes vistas en los atributos del texto.
Directiva Hace lo mismo que
<STRONG></STRONG> <B></B>
<CITE></CITE> <I></I>
<STRIKE></STRIKE> <S></S>
Para sangrar el texto se puede utilizar la directiva <BLOCKQUOTE></BLOCKQUOTE>
Para incluir comentarios en la página Web que no sean mostrados en la página, se utiliza la directiva <!-- -->.
Ejemplo:
<!-- Esto es un comentario sobre mi página Web -->
2.8 Listas de elementos
Existen tres tipos de listas: numeradas, sin numerar y de definición. Las listas numeradas representarán los elementos de la lista numerando cada uno de ellos según el lugar que ocupan en la lista. Para este tipo de lista se utiliza la directiva <OL></OL>. Cada uno de los elementos de la lista irá precedido de la directiva <LI>. La directiva <OL> puede llevar los siguientes parámetros:
start = num Indica que número será el primero de la lista. Si no se indica se entiende que empezará por el número 1. Se indica numéricamente, independientemente del tipo que se elija.
type = tipo

Indica el tipo de numeración utilizada. Si no se indica se entiende que será una lista ordenada numéricamente.
Los tipos posibles son:
1 = Numéricamente. (1, 2, 3, 4, ... etc.)a = Letras minúsculas. (a, b, c, d, ... etc.)A = Letras mayúsculas. (A, B, C, D, ... etc.)i = Números romanos en minúsculas. (i, ii, iii, iv, v, ... etc.)I = Números romanos en mayúsculas. (I, II, III, IV, V, ... etc.)
Ejemplo Resultado<OL><LI>España<LI>Francia<LI>Italia<LI>Portugal</OL>
1. España 2. Francia 3. Italia
4. Portugal
<OL type = A ><LI>España<LI>Francia<LI>Italia<LI>Portugal</OL>
A. España B. Francia C. Italia
D. Portugal
Las listas sin numerar representan los elementos de la lista con un "topo" o marca que antecede a cada uno de ellos. Se utiliza la directiva <UL></UL> para delimitar la lista, y <LI> para indicar cada uno de los elementos. La directiva <UL> puede contener el parámetro type que indica la forma del "topo" o marca que antecede a cada elemento de la lista. Los valores de type pueden ser disc, circle o square, con lo que el topo o marca puede ser un disco, un circulo o un cuadrado.
Ejemplo Resultado<UL type = disc ><LI>España<LI>Francia<LI>Italia<LI>Portugal</UL>
España Francia Italia
Portugal
<UL type = square><LI>España<LI>Francia<LI>Italia
España Francia Italia

<LI>Portugal</UL> Portugal
Las listas de definición muestran los elementos tipo Diccionario, o sea, término y definición. Se utiliza para ellas la directiva <DL></DL>. El elemento marcado como término se antecede de la directiva <DT>, el marcado como definición se antecede de la directiva <DD>.
Ejemplo Resultado<DL><DT>WWW<DD>Abreviatura de World Wide Web<DT>FTP<DD>Abreviatura de File Transfer Protocol<DT>IRC<DD>Abreviatura de Internet Relay Chat</DL>
WWW Abreviatura de World Wide Web
FTP Abreviatura de File Transfer Protocol
IRC Abreviatura de Internet Relay Chat
Existen otros dos tipos de listas menos comunes. Las listas de Menú o Directorio se comportan igual que las listas sin numerar. La lista de Menú utiliza la directiva <MENU></MENU> y los elementos se anteceden de <LI> El resultado es una lista sin numerar más "compacta" es decir, con menos espacio interlineal entre los elementos. La lista de Directorio utiliza la directiva <DIR></DIR> y los elementos se anteceden de <LI>. Los elementos tienen un limite de 20 caracteres.
Todas las listas se pueden "anidar", es decir incluir una lista dentro de otra, con lo que se consigue una estructura tipo "índice de materias".
Ejemplo Resultado<UL type= disc>
<LI>Buscadores <UL> <LI>Google <LI>Yahoo <LI>Ole <LI>El índice </UL> <LI>Links <UL> <LI>Pangea <LI>PIE
Buscadores Google Yahoo Ole El índice
Links Pangea
PIE

</UL> </UL>
2.9 Imágenes
Hasta el momento hemos visto como se puede escribir texto en una página Web, así como sus posibles formatos. Para incluir una imagen en nuestra página Web utilizaremos la directiva <IMG>. Hay dos formatos de imágenes que todos los navegadores modernos reconocen. Son las imágenes GIF y JPG. Cualquier otro tipo de fichero gráfico o de imagen (BMP, PCX, CDR, etc...) no será mostrado por el visor, a no ser que disponga de un programa externo que permita su visualización.
La directiva <IMG> tiene varios parámetros:
src = "imagen" Indica el nombre del fichero gráfico a mostrar.
alt = "Texto" Mostrará el texto indicado en el caso de que el navegador utilizado para ver la página no sea capaz de visualizar la imagen.
align = TOP / MIDDLE / BOTTOM Las imágenes, por defecto, se comportan como si fueran un carácter, alineándose en la misma línea que el texto que las precede o que las sigue. Éste parámetro indica como se alineará el texto que siga a la imagen con respecto a ésta. TOP alinea el texto con la parte superior de la imagen, MIDDLE con la parte central, y BOTTOM con la parte inferior. Otras opciones más avanzadas serían: TEXTTOP se alinea justo al comienzo del texto más alto de la línea, ABSMIDDLE, se alinea en el centro real de la imagen y ABSBOTTOM, coloca el texto justo al final de la imagen. Estos tres parámetros son más precisos, pero no todos los navegadores los aceptan.
align = LEFT / RIGHT Si en el parámetro align tiene los valores left o right, la imagen dejará de comportarse como un carácter colocándose a la izquierda o a la dercha y permitiendo escribir texto a su otro lado (si no, sólo se podrá escribir una línea).
border = tamaño Indica el tamaño del "borde" de la imagen. A toda imagen se le asigna un borde que será visible cuando la imagen forme parte de un Hyperenlace.
height = tamaño Indica el alto de la imagen en puntos o en porcentaje. Se puede usar para variar el tamaño de la imagen original, aunque es mejor redimensionarla en un programa de retoque fotográfico ya que será de mejor calidad y el archivo tendrá el tamaño apropiado.

width = tamaño Indica el ancho de la imagen en puntos o en porcentaje. Se puede usar para variar el tamaño de la imagen original, aunque es mejor redimensionarla en un programa de retoque fotográfico ya que será de mejor calidad y el archivo tendrá el tamaño apropiado.
hspace = margen Indica el número de espacios horizontales, en puntos, que separarán la imagen del texto que la siga y la anteceda.
vspace = margen Indica el número de puntos verticales que separaran la imagen del texto que le siga y la anteceda.
Ejemplo Se vería como
<IMG src="caution.gif" alt= "Obras !!" >
Si el visor no pudiese visualizar el gráfico..... Obras!!
La imagen a mostrar puede encontrarse en el mismo lugar (URL) que la página Web. Si este no fuera el caso, el nombre de la imagen ha de contener la URL o la trayectoria de donde se encuentre la imagen.
Ejemplo:
<IMG src= "http://www.microsoft.com/iexplorer.gif">
<IMG src= "/imagenes/iexplorer.gif"> (imágenes sería un subdirectorio de aquel donde se encuentra la página HTML que estamos usando)
Veamos varios ejemplos "jugando" con los tamaños de la imagen, así como comprobando la alineación de los textos. (Recuerda que en función del visor que utilices pueden verse o no los efectos de cada parámetro).
Ejemplo Se vería como
<IMG src="caution.gif"width=100 >
<IMG src="caution.gif"height=20 >

<IMG src="caution.gif"align=TOP>Atención !!! Atención !!!
<IMG src="caution.gif" align=MIDDLE>Atención !!! Atención !!!
<IMG src="caution.gif"align=BOTTOM>Atención !!! Atención !!!
Tenga en cuenta<IMG src="caution.gif"hspace=20>esta indicación. Tenga en cuenta esta indicación
Tenga en cuenta<IMG src="caution.gif"vspace=40>esta indicación. Tenga en cuenta esta indicación.
Siempre es bueno especificar el tamaño de la imagen, incluso aunque no se quiera redimensionar y se use el suyo propio, ya que esto acelerará la velocidad de visualización de la página.
2.10 HyperEnlaces
La característica principal de una página Web es que podemos incluir Hyperenlaces. Un Hyperenlace es un elemento de la página que hace que el navegador acceda a otro recurso, otra página Web, un archivo, etc...
Para incluir un Hyperenlace se utiliza la directiva <A></A>. El texto o imagen que se encuentre dentro de los límites de esta directiva será sensible, esto quiere decir que si situamos el ratón sobre él aparecerá una mano con el dedo apuntando y si pulsamos se realzará la función de hyperenlace indicada por la directiva <A></A>. Si el Hyperenlace está indicado por un texto, este aparecerá subrayado y en distinto color, si se trata de una imagen, esta aparecerá con un borde rodeándola. Esta directiva tiene el parámetro href que indica el lugar a donde nos llevará el Hyperenlace si lo pulsamos.
Ejemplo Se vería como<A href = "http://www.pangea.org/"> Pulse para ir a la página de Pangea</A>
Pulse para ir a la página de Pangea

Si situamos el ratón encima de la frase y pulsamos, el navegador accederá a la página Web indicada por el parámetro href, es decir, accederá a la página situada en http://www.pangea.org
Lo mismo podríamos hacer con un gráfico.
Ejemplo Se vería comoPara buscar en Internet : <A href = "http://www.yahoo.com/" ><IMG src = "yahoo.gif"></A>
Para buscar en Internet :
Pulsando sobre la imagen se accedería a la página situada en http://www.yahoo.com/.
Cuando queremos ir a una página fuera de nuestro sitio web, siempre hay que usar una referencia absoluta, es decir, hay que poner la url completa, incluido el protocolo, etc. Por ejemplo: http://www.pangea.org/pacoc/manuales.
Cuando queremos ir a una página de nuestro sitio web se debe poner siempre una referencia relativa, es decir, sólo el nombre de la página ala que queremos ir si está en la misma carpeta, o el camino para ir desde donde estamos a donde queremos ir. Por ejemplo, para ir a la página "principal.htm" que estuviera en la subcarpeta "paginas" de la que estamos, habría que poner: <A HREF="paginas/principal.htm>.
Un Hyperenlace también puede llevarnos a una zona de nuestra página. Para ello debemos marcar en nuestra página las diferentes secciones en las que se divide. Lo haremos con el parámetro name.
Ejemplo:<A name = "seccion1"></A>
Esta instrucción marca el inicio de una sección dentro de nuestra página. La sección se llamará seccion1. Para hacer un enlace a esta sección dentro de nuestra página lo haríamos de la siguiente forma:
<A href = "#seccion1">Primera Parte</A>O también :
<A href = "http://www.jet.es/mipagina.htm#seccion1">Primera Parte</A>

Un Hyperenlace puede hacerse a cualquier tipo de fichero. Con las directivas anteriores hemos visto como hacer enlaces a páginas Web o secciones dentro de una página web, pero podríamos hacer un Hyperenlace a un grupo de noticias, o a otro servicio de Internet.
Ejemplo:<A href = "news://news.actualidad.es/">Noticias de actualidad</A>
Asimismo podemos hacer que el Hyperenlace de como resultado el envío de un correo electrónico a una dirección de correo determinada.
Ejemplo:<A href = "mailto: [email protected]">Envíame tus sugerencias</A>
También podemos realizar un Hyperenlace a un fichero cualquiera. En este caso el navegador intentará "ejecutar" el fichero, y si no puede hacerlo nos preguntará si deseamos grabarlo en nuestro ordenador. Esta es una forma sencilla de permitir a los visitantes de nuestra página copiar ficheros a su ordenador.
Ejemplo:<A href = "manual.zip">Pulsa aquí para llevarte una copia del manual.</A>
2.11 Tablas
Las tablas nos permiten representar cualquier elemento de nuestra página (texto, listas, imágenes, etc...) en diferentes filas y columnas separadas entre sí. Es una herramienta muy útil para "ordenar" contenidos de distintas partes de nuestra página. La tabla se define mediante la directiva <TABLE></TABLE>. Los parámetros opcionales de esta directiva son:
border = num Indica el ancho del borde de la tabla en puntos.
cellspacing = num Indica el espacio en puntos que separa las celdas que están dentro de la tabla. Por defecto 2.
cellpadding = num Indica el espacio en puntos que separa el borde de cada celda y el contenido de esta. Por defecto 1.
width = num ó % Indica la anchura de la tabla en puntos o en porcentaje en función del ancho de la ventana del visor. Si no se indica este parámetro, el ancho se adecuará al tamaño de los contenidos de las celdas.
height = num ó %

Indica la altura de la tabla en puntos o en porcentaje en función del alto de la ventana del visor. Si no se indica este parámetro, la altura se adecuará a la altura de los contenidos de las celdas.
bgcolor = "código de color" Indica el color del fondo de la tabla.
background = "código de color" Indica una imagen de fondo para la tabla.
Para definir las celdas que componen la tabla se utilizan las directivas <TD> y <TH>. <TD> indica una celda normal, y <TH> indica una celda de "cabecera", es decir, el contenido será resaltado en negrita y en un tamaño ligeramente superior al normal. Los parámetros opcionales de ambas directivas son:
align = LEFT / CENTER / RIGHT / JUSTIFY Indica como se debe alinear el contenido de la celda, a la izquierda (LEFT), a la derecha (RIGHT), centrado (CENTER) o justificado (JUSTIFY).
valign = TOP / MIDDLE / BOTTOM Indica la alineación vertical del contenido de la celda, en la parte superior (TOP), en la inferior (BOTTOM), o en el centro (MIDDLE).
rowspan = num Indica el número de filas que ocupará la celda. Por defecto ocupa una sola fila.
colspan = num Indica el número de columnas que ocupará la celda. Por defecto ocupa una sola columna.
bgcolor = "código de color" Indica el color del fondo de la celda.
background = "código de color" Indica una imagen de fondo para la celda.
Para indicar que acaba una fila de celdas se utiliza la directiva <TR>. A continuación mostraremos un ejemplo de una tabla que contiene sólo texto. Como se indicó anteriormente el contenido de las celdas puede ser cualquier elemento de HTML, un texto, una imagen, un Hyperenlace, una Lista, etc...
Ejemplo<TABLE border = 4 cellspacing = 4 cellpadding = 4 width =80%>
<TH align = center>Buscadores <TH align = center colspan = 2>Otros Links <TR> <TD align = LEFT>Yahoo <TD align = LEFT>El índice <TD align = LEFT>Pangea <TR> <TD align = LEFT>APC <TD align = LEFT>Web verde

<TD align = LEFT>Agenda alternativa </TABLE>
Se vería como
Buscadores Otros LinksYahoo El índice Pangea
APC Web verde Agenda alternativa
Las directivas <TD> y <TH> son cerradas según el estándar de HTML, es decir, que un elemento de tabla <TD> debería cerrarse con un </TD>, sin embargo los visores asumen que un elemento de la tabla, queda automáticamente "cerrado" cuando se "abre" el siguiente.
La directiva CAPTION se utiliza para poner una cabecera o un pie a la tabla, según se indique en el parámetro align que puede tener los valores top y bottom.
Por ejemplo, <CAPTION ALIGN="BOTTOM">Titulo tabla</CAPTION>.
2.12 Mapas
Un Mapa es una imagen que permite realizar diferentes Hyperenlaces en función de la "zona" de la imagen que se pulse. Para crear un mapa debemos tener un fichero con la imagen y un conjunto de órdenes donde indicaremos las coordenadas de la imagen que nos enlazarán con cada Hyperenlace. Actualmente hay dos maneras de hacer los mapas: a través de un programa externo (CGI) que pueda "procesar" el fichero .map en el que habremos metidos las órdenes, o a través de la directiva que soportan los Navegadores a partir de su versión 2 y 3 de Netscape y Explorer, respectivamente. En el primer caso el mapa se dice que corre en el servidor, ya que tiene que hacer llamadas a el y a su CGI para que funcione, en el segundo, corre en el cliente. Para el segundo caso, se utilizan las directivas <MAP></MAP> y <AREA>.
La directiva <MAP> identifica al mapa y tiene el parámetro name para indicar el nombre del mapa.
La directiva <AREA> define las áreas sensibles de la imagen y tiene los siguientes parámetros obligatorios:
shape = "tipo" Indica el tipo de área a definir.
coords = "coordenadas" Indica las coordenadas de la figura indicada con shape.

href = "URL" Indica la dirección a la que se accede si se pulsa en la zona delimitada por el área indicada.
Los tipos de área pueden ser los siguientes:
rect Área rectangular. Se deben especificar las coordenadas de la esquina superior izquierda y las de la esquina inferior derecha.
poly Polígono. Se deben especificar las coordenadas de todos los vértices del polígono. El visor se encarga de "cerrar" la figura.
circle Círculo. Se debe especificar en primer lugar las coordenadas del centro del círculo y a continuación el valor del radio (en puntos).
Si dos áreas se superponen, se ejecutará la que se encuentre en primer lugar en la definición del mapa. Es importante definir una última área que abarque la totalidad del gráfico para direccionar a una URL "por defecto", con el objeto de contemplar el caso de que no se pulse sobre un área definida.
Veamos un ejemplo completo.
<MAP name = "casa"><AREA shape = "poly" coords = "2,62,57,62,28,1" href= "tejado.htm"><AREA shape = "rect" coords = "21,101,35,138" href= "puerta.htm"><AREA shape = "rect" coords = "2,64,57,138" href= "casa.htm"><AREA shape = "circle" coords = "80,76,21" href= "arbol.htm"><AREA shape = "rect" coords = "78,98,85,138" href= "tronco.htm"><AREA shape = "rect" coords = "0,0,96,138" href= "dibujo.htm"></MAP>
Para activar el mapa debemos indicar la imagen a mostrar, indicando que dicha imagen es tratada por un mapa. Para ello escribiríamos la siguiente directiva:
<IMG src = "grafico.gif" usemap = "#casa">
Si tu visor tiene la capacidad de gestionar este tipo de mapas (Netscape 2.x o Ms-Explorer 2.x), prueba a pulsar sobre alguna parte del mapa que hemos definido y que te aparecerá a continuación:

2.13 Extensiones del HTML
Netscape y Microsoft han añadido al estándar de HTML diversas directivas para hacer más atractiva la visualización de las páginas Web. Veremos aquí las más interesantes y la forma de usarlas.
Estas directivas pueden no funcionar en algún visor de HTML, pero el uso de ellas por parte de los dos "grandes" del software para Internet hace prever que serán inmediatamente incluidas en las nuevas versiones del resto de los visores.
2.14 Marquee
La directiva <MARQUEE></MARQUEE> crea una marquesina con un texto en su interior que se desplaza. Funciona únicamente con Ms-Explorer. Sus parámetros son los siguientes:
align = top / middle / bottom Indica si el texto del interior de la marquesina se alinea en la zona alta (top), en la baja (bottom) o en el centro (middle) de la misma.
bgcolor = "código de color" Indica el color del fondo de la marquesina.
direction = left / right Indica hacia que lugar se desplaza el texto, hacia la izquierda (left) o hacia la derecha (right)
height = num o % Indica la altura de la marquesina en puntos o porcentaje en función de la ventana del visor.
width = num o % Indica la anchura de la marquesina en puntos o porcentaje en función de la ventana del visor.
loop = num / infinite Indica el número de veces que se desplazará el texto por la marquesina. Si se indica infinite, se desplazará indefinidamente.
scrolldelay = num.

Indica el número de milisegundos que tarda en reescribirse el texto por la marquesina, a mayor número más lentamente se desplazará el texto.
Veamos un ejemplo de esta directiva:
<MARQUEE bgcolor = "#FFFFFF" width = 50% scrolldelay = 0 > Bienvenido a mi página personal en Internet.</MARQUEE>
Si estás utilizando Ms-Explorer verás el efecto producido a continuación:
2.14 Sonido de fondo
Nuestra página Web puede tener un sonido que se active al entrar en la página. Esta característica de Ms Explorer utiliza la directiva <BGSOUND> y tiene los siguientes parámetros:
src = "fichero" Indica el nombre del fichero que contiene el sonido (.wav, .mid).
loop = num / infinite Indica el número de veces que se reproducirá el sonido. Si se indica infinite, el sonido se reproducirá de forma continua hasta que abandonemos la página.
Un ejemplo de esta directiva sería:
<BGSOUND src= "yesterday.mid" loop= infinite>
2.15 Embed y sonido de fondo en netscape
Para lograr el sonido de fondo en Netscape se puede utilizar la directiva <EMBED>, que también nos permitirá incorporar cualquier tipo de archivo en cualquier posición. Para que pueda mostrarse el archivo se deberá tener el plug-in adecuado. Es una directiva cerrada y tiene los siguientes parámetros:
src = "fichero" Indica el nombre del fichero (sonido .wav o .mid, o cualquier otro).
loop = num / infinite Indica el número de veces que se reproducirá el sonido. Si se indica infinite, el sonido se reproducirá de forma continua hasta que abandonemos la página.
width = "número"

Ancho del objeto insertado. Si se quiere que no se vea se puede poner en 0 o utilizar el parámetro <HIDDEN>
height = "número" Altura del objeto insertado. Si se quiere que no se vea se puede poner en 0 o utilizar el parámetro <HIDDEN>
HIDDEN = true Ocultar el gestor de sonidos.
AUTOSTART = true Se activará el sonido al cargarse la página.
Estos dos últimos parámetros los utilizaremos cuando queramos poner sonidos de fondo para Netscape. Habrá que utilizar tanto esta directiva como la <BGSOUND>. De esta manera el sonido de fondo funcionará tanto en Netscape como en Explorer.
2.16 Frames (marcos)
Los marcos son una técnica para dividir la ventana del visor en diferentes zonas. Cada una de estos marcos se podrá manipular por separado, permitiéndonos mostrar en cada una de ellos una página Web diferente. Esto es muy útil para, por ejemplo, mostrar permanentemente en un marco los diferentes contenidos de nuestra página, y en otro mostrar el contenido seleccionado.
Para definir los diferentes marcos o frames se utilizan las directivas <FRAMESET> </FRAMESET> y <FRAME>. La directiva <FRAMESET> indica como se va a dividir la ventana principal. Pueden incluirse varias directivas <FRAMESET> anidadas con el objeto de subdividir una división. Los parámetros de <FRAMESET> son rows y cols en función de si la división de la pantalla se realiza por filas (rows) o columnas (cols). Los parámetros rows y cols se acompañan de un grupo de números que indican en puntos o en porcentaje el tamaño de cada uno de los marcos. En caso de utilizar rows los tamaños de los marcos se entienden indicados de arriba a abajo, es decir, el primer valor será el asignado al marco superior, el segundo al marco inmediatamente inferior, etc... En el caso de cols los tamaños se aplican de izquierda a derecha.
Ejemplos Resultado
<FRAMESET rows = "25%,50%,25%">Crea tres marcos horizontales, la primera ocupará un 20% de la ventana principal, la segunda un 50% y la tercera un 25%.
<FRAMESET cols = "120,*,100"> Crea tres marcos verticales, la primera y la tercera tendrán un "ancho" fijo de 120 y 100 puntos respectivamente. La segunda ocupará el resto de la ventana

principal (*).
<FRAMESET cols = "15%,*"> <FRAMESET rows = 20%,*">
En este caso "anidamos" dos directivas. La primera divide la ventana principal en dos marcos verticales, la primera ocupa un 15% de la ventana principal y la segunda el resto. La segunda directiva vuelve a subdividir el primer marco creado anteriormente, pero esta vez en dos marcos horizontales, el superior ocupará un 20% de la ventana, y el inferior el resto.
La directiva <FRAMESET> tiene los siguientes parámetros:
border = "número" Permite cambiar o quitar (0) el borde entre los marcos. Por defecto, aparece. Para que también funcione en Explorer habrá que usar frameborder = 0
framespacing = "número" Permite cambiar el espacio entre el borde del marco y la página.
La directiva <FRAME> indica las propiedades de cada marco. Es necesario indicar una directiva <FRAME> para cada marco creado. Los parámetros de <FRAME> son:
name = "nombre" Indica el nombre por el que nos referiremos a ese marco.
src = "URL" El marco mostrará en principio el contenido del documento HTML que se indique.
marginwidth = num. Indica, en puntos, el margen izquierdo y derecho del marco.
marginheight = num Indica, en puntos, el margen superior e inferior del marco.
scrolling = "yes / no / auto" Indica si se aplica una barra de desplazamiento al marco en el caso de que la página que se cargue en ella no quepa en los límites del marco. El valor "yes" muestra siempre la barra de desplazamiento, "no" no la muestra nunca (la zona de la página que no quepa en el marco no la veremos), y "auto" la muestra sólo en caso de que sea necesario para poder ver la página.
noresize

Si se indica este parámetro, el usuario no podrá "redimensionar" los marcos con el visor. Un usuario que esté viendo una página con marcos puede redimensionarlos seleccionando un borde del marco con el ratón y desplazándolo.
Los visores que no soportan la característica de marcos, no mostrarán nada de lo indicado con estas directivas. Es por ello que existe una directiva llamada <NOFRAMES> </NOFRAMES>. Todo lo indicado entre esta directiva será lo que muestren los visores sin capacidad para visualizar marcos. Los visores que soporten marcos obviarán las directivas incluidas entre <NOFRAMES> </NOFRAMES>.
3. DEFINICIÓN DE LA ARQUITECTURA CLIENTE-SERVIDOR
En vista del aprendizaje que tenemos diariamente en el aula de clases, nos vemos desafiados por un mundo lleno de conocimientos que invoca a la investigación.
Este trabajo fue realizado precisamente para llenar las expectativas y ansias de intelectualidad que nos brinda la carrera, desde bases de datos, vemos la importancia de la arquitectura cliente servidor.
Es exactamente lo que se plasmara en el siguiente trabajo, la forma de
Conocer una arquitectura que en este momento es una de las más importantes y utilizadas en el ámbito de enviar y recibir información, también es una herramienta potente para guardar los datos en una base de datos como servidor.
Con respecto a la definición de arquitectura cliente/servidor se encuentran las siguientes definiciones:
Cualquier combinación de sistemas que pueden colaborar entre si para dar a los usuarios toda la información que ellos necesiten sin que tengan que saber donde esta ubicada.
Es una arquitectura de procesamientos cooperativo donde uno de los componentes pide servicios a otro.
Es un procesamiento de datos de índole colaborativo entre dos o más computadoras conectadas a una red.
El término cliente/servidor es originalmente aplicado a la arquitectura de software que describe el procesamiento entre dos o más programas: una aplicación y un servicio soportante.
IBM define al modelo Cliente/Servidor. "Es la tecnología que proporciona al usuario final el acceso transparente a las aplicaciones, datos, servicios de cómputo o cualquier otro recurso del grupo de trabajo y/o, a través de la organización, en múltiples plataformas. El modelo soporta un medio

ambiente distribuido en el cual los requerimientos de servicio hechos por estaciones de trabajo inteligentes o "clientes'', resultan en un trabajo realizado por otros computadores llamados servidores".
"Es un modelo para construir sistemas de información, que se sustenta en la idea de repartir el tratamiento de la información y los datos por todo el sistema informático, permitiendo mejorar el rendimiento del sistema global de información"
Elementos principales
"Los elementos principales de la arquitectura cliente servidor son justamente el elemento llamado cliente y el otro elemento llamado servidor". Por ejemplo dentro de un ambiente multimedia, el elemento cliente seria el dispositivo que puede observar el vídeo, cuadros y texto, o reproduce el audio distribuido por el elemento servidor.
Por otro lado el cliente también puede ser una computadora personal o una televisión inteligente que posea la capacidad de entender datos digitales. Dentro de este caso el elemento servidor es el depositario del vídeo digital, audio, fotografías digitales y texto y los distribuye bajo demanda de ser una maquina que cuenta con la capacidad de almacenar los datos y ejecutar todo el software que brinda éstos al cliente.
En Resumen
C/S es una relación entre procesos corriendo en máquinas separadas
El servidor (S) es un proveedor de servicios.
El cliente (C) es un consumidor de servicios.
C y S Interactúan por un mecanismo de pasaje de mensajes:
Pedido de servicio.
Respuesta
ALGUNOS ANTECEDENTES, ¿PORQUE FUE CREADO?
Existen diversos puntos de vista sobre la manera en que debería efectuarse el procesamiento de datos, aunque la mayoría que opina, coincide en que nos encontramos en medio de un proceso de evolución que se prolongará todavía por algunos años y que cambiará la forma en que obtenemos y utilizamos la información almacenada electrónicamente.
El principal motivo detrás de esta evolución es la necesidad que tienen las organizaciones (empresas o instituciones públicas o privadas), de realizar sus

operaciones más ágil y eficientemente, debido a la creciente presión competitiva a la que están sometidas, lo cual se traduce en la necesidad de que su personal sea mas productivo, que se reduzcan los costos y gastos de operación, al mismo tiempo que se generan productos y servicios más rápidamente y con mejor calidad.
En este contexto, es necesario establecer una infraestructura de procesamiento de información, que cuente con los elementos requeridos para proveer información adecuada, exacta y oportuna en la toma de decisiones y para proporcionar un mejor servicio a los clientes.
El modelo Cliente/Servidor reúne las características necesarias para proveer esta infraestructura, independientemente del tamaño y complejidad de las operaciones de las organizaciones públicas o privadas y, consecuentemente desempeña un papel importante en este proceso de evolución.
Evolución de la arquitectura cliente servidor
La era de la computadora central
"Desde sus inicios el modelo de administración de datos a través de computadoras se basaba en el uso de terminales remotas, que se conectaban de manera directa a una computadora central". Dicha computadora central se encargaba de prestar servicios caracterizados por que cada servicio se prestaba solo a un grupo exclusivo de usuarios.
La era de las computadoras dedicadas
Esta es la era en la que cada servicio empleaba su propia computadora que permitía que los usuarios de ese servicio se conectaran directamente. Esto es consecuencia de la aparición de computadoras pequeñas, de fácil uso, más baratas y más poderosas de las convencionales.
La era de la conexión libre
Hace mas de 10 años que la computadoras escritorio aparecieron de manera masiva. Esto permitió que parte apreciable de la carga de trabajo de cómputo tanto en el ámbito de cálculo como en el ámbito de la presentación se lleven a cabo desde el escritorio del usuario. En muchos de los casos el usuario obtiene la información que necesita de alguna computadora de servicio. Estas computadoras de escritorio se conectan a las computadoras de servicio empleando software que permite la emulación de algún tipo de terminal. En otros de los casos se les transfiere la información haciendo uso de recursos magnéticos o por trascripción.
La era del cómputo a través de redes

Esta es la era que esta basada en el concepto de redes de computadoras, en la que la información reside en una o varias computadoras, los usuarios de esta información hacen uso de computadoras para laborar y todas ellas se encuentran conectadas entre si. Esto brinda la posibilidad de que todos los usuarios puedan acceder a la información de todas las computadoras y a la vez que los diversos sistemas intercambien información.
La era de la arquitectura cliente servidor
"En esta arquitectura la computadora de cada uno de los usuarios, llamada cliente, produce una demanda de información a cualquiera de las computadoras que proporcionan información, conocidas como servidores"estos últimos responden a la demanda del cliente que la produjo.
Los clientes y los servidores pueden estar conectados a una red local o una red amplia, como la que se puede implementar en una empresa o a una red mundial como lo es la Internet.
Bajo este modelo cada usuario tiene la libertad de obtener la información que requiera en un momento dado proveniente de una o varias fuentes locales o distantes y de procesarla como según le convenga. Los distintos servidores también pueden intercambiar información dentro de esta arquitectura.
QUE ES UNA ARQUITECTURA
Una arquitectura es un entramado de componentes funcionales que aprovechando diferentes estándares, convenciones, reglas y procesos, permite integrar una amplia gama de productos y servicios informáticos, de manera que pueden ser utilizados eficazmente dentro de la organización.
Debemos señalar que para seleccionar el modelo de una arquitectura, hay que partir del contexto tecnológico y organizativo del momento y, que la arquitectura Cliente/Servidor requiere una determinada especialización de cada uno de los diferentes componentes que la integran.
QUE ES UN CLIENTE
Es el que inicia un requerimiento de servicio. El requerimiento inicial puede convertirse en múltiples requerimientos de trabajo a través de redes LAN o WAN. La ubicación de los datos o de las aplicaciones es totalmente transparente para el cliente.
QUE ES UN SERVIDOR
Es cualquier recurso de cómputo dedicado a responder a los requerimientos del cliente. Los servidores pueden estar conectados a los clientes a través de redes

LANs o WANs, para proveer de múltiples servicios a los clientes y ciudadanos tales como impresión, acceso a bases de datos, fax, procesamiento de imágenes, etc.
Para ver el gráfico seleccione la opción ¨Descargar trabajo¨ del menú superior
Este es el ejemplo gráfico de la arquitectura cliente servidor.
ELEMENTOS DE LA ARQUITECTURA CLIENTE/SERVIDOR
En esta aproximación, y con el objetivo de definir y delimitar el modelo de referencia de una arquitectura Cliente/Servidor, debemos identificar los componentes que permitan articular dicha arquitectura, considerando que toda aplicación de un sistema de información está caracterizada por tres componentes básicos:
Presentación/Captación de Información Procesos Almacenamiento de la Información
Los cuales se suelen distribuir tal como se presenta en la figura:
Aplicaciones Cliente/Servidor Para ver el gráfico seleccione la opción ¨Descargar trabajo¨ del menú superior
Y se integran en una arquitectura Cliente/Servidor en base a los elementos que caracterizan dicha arquitectura, es decir:
Puestos de Trabajo Comunicaciones Servidores
De estos elementos debemos destacar:
El Puesto de Trabajo o Cliente
Una Estación de trabajo o microcomputador (PC: Computador Personal) conectado a una red, que le permite acceder y gestionar una serie de recursos» el cual se perfila como un puesto de trabajo universal. Nos referimos a un microcomputador conectado al sistema de información y en el que se realiza una parte mayoritaria de los procesos.
Se trata de un fenómeno en el sector informático. Aquellos responsables informáticos que se oponen a la utilización de los terminales no programables, acaban siendo marginados por la presión de los usuarios.

Debemos destacar que el puesto de trabajo basado en un microcomputador conectado a una red, favorece la flexibilidad y el dinamismo en las organizaciones. Entre otras razones, porque permite modificar la ubicación de los puestos de trabajo, dadas las ventajas de la red.
Los Servidores o Back-end
Una máquina que suministra una serie de servicios como Bases de Datos, Archivos, Comunicaciones,...).Los Servidores, según la especialización y los requerimientos de los servicios que debe suministrar pueden ser:
Mainframes Miniordenadores Especializados (Dispositivos de Red, Imagen, etc.)
Una característica a considerar es que los diferentes servicios, según el caso, pueden ser suministrados por un único Servidor o por varios Servidores especializados.
Las Comunicaciones
En sus dos vertientes:
Infraestructura de redes Infraestructura de comunicaciones
Infraestructura de redes
Componentes Hardware y Software que garantizan la conexión física y la transferencia de datos entre los distintos equipos de la red.
Infraestructura de comunicaciones
Componentes Hardware y Software que permiten la comunicación y su gestión, entre los clientes y los servidores.La arquitectura Cliente/Servidor es el resultado de la integración de dos culturas. Por un lado, la del Mainframe que aporta capacidad de almacenamiento, integridad y acceso a la información y, por el otro, la del computador que aporta facilidad de uso (cultura de PC), bajo costo, presentación atractiva (aspecto lúdico) y una amplia oferta en productos y aplicaciones.
CARACTERISTICAS DEL MODELO CLIENTE/SERVIDOR
En el modelo CLIENTE/SERVIDOR podemos encontrar las siguientes características:

1. El Cliente y el Servidor pueden actuar como una sola entidad y también pueden actuar como entidades separadas, realizando actividades o tareas independientes.
2. Las funciones de Cliente y Servidor pueden estar en plataformas separadas, o en la misma plataforma.
Para ver el gráfico seleccione la opción ¨Descargar trabajo¨ del menú superior
3. Un servidor da servicio a múltiples clientes en forma concurrente.
4. Cada plataforma puede ser escalable independientemente. Los cambios realizados en las plataformas de los Clientes o de los Servidores, ya sean por actualización o por reemplazo tecnológico, se realizan de una manera transparente para el usuario final.
5. La interrelación entre el hardware y el software están basados en una infraestructura poderosa, de tal forma que el acceso a los recursos de la red no muestra la complejidad de los diferentes tipos de formatos de datos y de los protocolos.
6. Un sistema de servidores realiza múltiples funciones al mismo tiempo que presenta una imagen de un solo sistema a las estaciones Clientes. Esto se logra combinando los recursos de cómputo que se encuentran físicamente separados en un solo sistema lógico, proporcionando de esta manera el servicio más efectivo para el usuario final.
También es importante hacer notar que las funciones Cliente/Servidor pueden ser dinámicas. Ejemplo, un servidor puede convertirse en cliente cuando realiza la solicitud de servicios a otras plataformas dentro de la red.
Su capacidad para permitir integrar los equipos ya existentes en una organización, dentro de una arquitectura informática descentralizada y heterogénea.
7. Además se constituye como el nexo de unión mas adecuado para reconciliar los sistemas de información basados en mainframes o minicomputadores, con aquellos otros sustentados en entornos informáticos pequeños y estaciones de trabajo.
8. Designa un modelo de construcción de sistemas informáticos de carácter distribuido.
1. Su representación típica es un centro de trabajo (PC), en donde el usuario dispone de sus propias aplicaciones de oficina y sus propias bases de datos, sin dependencia directa del sistema central de información de la organización, al tiempo que puede acceder a los

2. recursos de este host central y otros sistemas de la organización ponen a su servicio.
En conclusión, Cliente/Servidor puede incluir múltiples plataformas, bases de datos, redes y sistemas operativos. Estos pueden ser de distintos proveedores, en arquitecturas propietarias y no propietarias y funcionando todos al mismo tiempo. Por lo tanto, su implantación involucra diferentes tipos de estándares: APPC, TCP/IP, OSI, NFS, DRDA corriendo sobre DOS, OS/2, Windows o PC UNIX, en TokenRing, Ethernet, FDDI o medio coaxial, sólo por mencionar algunas de las posibilidades.
TIPOS DE CLIENTES
1. "cliente flaco":
o Servidor rápidamente saturado. o Gran circulación de datos de interfase en la red.
1. "cliente gordo":
o Casi todo el trabajo en el cliente. o No hay centralización de la gestión de la BD. o Gran circulación de datos inútiles en la red.
TIPOS DE SERVIDOR
Servidores de archivos
Servidor donde se almacena archivos y aplicaciones de productividad como por ejemplo procesadores de texto, hojas de cálculo, etc.
Servidores de bases de datos

Servidor donde se almacenan las bases de datos, tablas, índices. Es uno de los servidores que más carga tiene.
Servidores de transacciones
Servidor que cumple o procesa todas las transacciones. Valida primero y recién genera un pedido al servidor de bases de datos.
Servidores de Groupware
Servidor utilizado para el seguimiento de operaciones dentro de la red.Servidores de objetos
Contienen objetos que deben estar fuera del servidor de base de datos. Estos objetos pueden ser videos, imágenes, objetos multimedia en general.Servidores Web
Se usan como una forma inteligente para comunicación entre empresas a través de Internet.
Este servidor permite transacciones con el acondicionamiento de un browser específico.
Estilos del modelo cliente servidor
PRESENTACIÓN DISTRIBUIDA
1. Se distribuye la interfaz entre el cliente y la plataforma servidora. 2. La aplicación y los datos están ambos en el servidor. 3. Similar a la arquitectura tradicional de un Host y Terminales. 4. El PC se aprovecha solo para mejorar la interfaz gráfica del usuario.
Ventajas
Revitaliza los sistemas antiguos. Bajo costo de desarrollo. No hay cambios en los sistemas existentes.
Desventajas
El sistema sigue en el Host. No se aprovecha la GUI y/o LAN. La interfaz del usuario se mantiene en muchas plataformas.
PRESENTACIÓN REMOTA

1. La interfaz para el usuario esta completamente en el cliente. 2. La aplicación y los datos están en el servidor.
Ventajas
La interfaz del usuario aprovecha bien la GUI y la LAN. La aplicación aprovecha el Host. Adecuado para algunos tipos de aplicaciones de apoyo a la toma de
decisiones.
Desventajas
Las aplicaciones pueden ser complejas de desarrollar. Los programas de la aplicación siguen en el Host. El alto volumen de tráfico en la red puede hacer difícil la operación de
aplicaciones muy pesadas.
LÓGICA DISTRIBUIDA
1. La interfaz esta en el cliente. 2. La base de datos esta en el servidor. 3. La lógica de la aplicación esta distribuida entre el cliente y el servidor.
Ventajas
Arquitectura mas corriente que puede manejar todo tipo de aplicaciones. Los programas del sistema pueden distribuirse al nodo mas apropiado. Pueden utilizarse con sistemas existentes.
Desventajas
Es difícil de diseñar. Difícil prueba y mantenimiento si los programas del cliente y el servidor están
hechos en distintos lenguajes de programación. No son manejados por la GUI 4GL.
ADMINISTRACIÓN DE DATOS REMOTA
1. En el cliente residen tanto la interfaz como los procesos de la aplicación. 2. Las bases de datos están en el servidor. 3. Es lo que comúnmente imaginamos como aplicación cliente servidor
Ventajas
Configuración típica de la herramienta GUI 4GL.

Muy adecuada para las aplicaciones de apoyo a las decisiones del usuario final.
Fácil de desarrollar ya que los programas de aplicación no están distribuidos. Se descargan los programas del Host.
Desventajas
No maneja aplicaciones pesadas eficientemente. La totalidad de los datos viaja por la red, ya que no hay procesamiento que
realice el Host.
BASE DE DATOS DISTRIBUIDA
1. La interfaz, los procesos de la aplicación, y , parte de los datos de la base de datos están en cliente.
2. El resto de los datos están en el servidor.
Ventajas
Configuración soportada por herramientas GUI 4GL. Adecuada para las aplicaciones de apoyo al usuario final. Apoya acceso a datos almacenados en ambientes heterogéneos. Ubicación de los datos es transparente para la aplicación.
Desventajas
No maneja aplicaciones grandes eficientemente. El acceso a la base de datos distribuida es dependiente del proveedor del
software administrador de bases de datos.
Definición de middleware
"Es un termino que abarca a todo el software distribuido necesario para el soporte de interacciones entre Clientes y Servidores".
Es el enlace que permite que un cliente obtenga un servicio de un servidor.
Este se inicia en el modulo de API de la parte del cliente que se emplea para invocar un servicio real; esto pertenece a los dominios del servidor. Tampoco a la interfaz del usuario ni la a la lógica de la aplicación en los dominios del cliente.Tipos de Middleware
Existen dos tipos de middleware:
1. Middleware general

Este tipo permite la impresión de documentos remotos, manejos de transacciones, autenticación de usuarios, etc.
2. Middleware de servicios específicos
Generalmente trabajan orientados a mensajes. Trabaja uno sola transacción a la vez.
Funciones de un programa servidor
1. Espera las solicitudes de los clientes. 2. Ejecuta muchas solicitudes al mismo tiempo. 3. Atiende primero a los clientes VIP. 4. Emprende y opera actividades de tareas en segundo plano. 5. Se mantiene activa en forma permanente.
4. MANEJO DE SOCKETS
Número de identificación compuesto por dos números: la dirección IP y el número de puerto TCP. En la misma red, el número IP es el mismo, mientras que el número de puerto es el que cambia. En máquinas de distintas redes, pueden tener el mismo número de puerto sin llevar a confusión, pues el número IP las distingue.
El protocolo TCP/IP gestiona el envío y la recepción de la información los denominados paquetes, que resultan de su división en trozos más pequeños. La biblioteca que controla el envío/ercepción de estos paquetes se denomina socket.
4.1 ¿Qué es un socket?
Un descriptor de fichero no es más que un entero asociado a un archivo abierto. Pero (y aquí está el quid de la cuestión) ese fichero puede ser una conexión de red, una cola FIFO, un tubo [pipe], un terminal, un fichero real de disco, o cualquier otra cosa. ¡Todo en Unix es un fichero! Por eso, si quieres comunicarte con otro programa a través de Internet vas a tener que hacerlo con un descriptor de fichero, es mejor que lo creas.
"¿De dónde saco yo este descriptor de fichero para comunicar a través de la red, señor sabelotodo?" Esta es probablemente la última pregunta en la que piensas ahora, pero voy a contestarla de todas maneras: usas la llamada al sistema socket(). Te devuelve un descriptor de fichero y tú te comunicas con él usando las llamadas al sistema especializadas send() y recv() ( man send , man recv ).
"¡Pero, oye!" puede que exclames ahora. "Si es un descriptor de fichero, por qué, en el nombre de Neptuno, no puedo usar las llamadas normales read() y write()

para comunicarme a través de un socket ." La respuesta corta es, "¡Sí que puedes!" La respuesta larga es, "Puedes usarlas, pero send() y recv() te ofrecen mucho más control sobre la transmisión de datos."
¿Y ahora qué? Qué tal esto: hay muchos tipos de sockets. Existen las direcciones de Internet DARPA (sockets de internet), rutas sobre nodos locales (sockets de Unix), direcciones X.25 del CCITT ( sockets éstos de X.25 que puedes ignorar perfectamente) y probablemente muchos más en función de la modalidad de Unix que estés ejecutando. Este documento se ocupa únicamente de los primeros: los sockets de Internet.
4.2 Dos tipos de sockets de internet
¿Qué es esto? ¿Hay dos tipos de sockets de internet? Sí. Bueno no, estoy mintiendo. En realidad hay más pero no quería asustarte. Aquí sólo voy a hablar de dos tipos. A excepción de esta frase, en la que voy a mencionar que los sockets puros [Raw Sockets] son también muy potentes y quizás quieras buscarlos más adelante.
Muy bien. ¿Cuáles son estos dos tipos? El primer tipo de sockets lo definen los sockets de flujo [Stream sockets]; El otro, los sockets de datagramas [Datagram sockets], a los que en adelante me referiré, respectivamente como "SOCK_STREAM" y "SOCK_DGRAM ". En ocasiones, a los sockets de datagramas se les llama también "sockets sin conexión". (Aunque se puede usar connect() con ellos, si se quiere. Consulta connect() , más abajo.)
Los sockets de flujo definen flujos de comunicación en dos direcciones, fiables y con conexión. Si envías dos ítems a través del socket en el orden "1, 2" llegarán al otro extremo en el orden "1, 2", y llegarán sin errores. Cualquier error que encuentres es producto de tu extraviada mente, y no lo vamos a discutir aquí.
¿Qué aplicación tienen los sockets de flujo? Bueno, quizás has oído hablar del programa telnet. ¿Sí? telnet usa sockets de flujo. Todos los carácteres que tecleas tienen que llegar en el mismo orden en que tú los tecleas, ¿no? También los navegadores, que usan el protocolo HTTP , usan sockets de flujo para obtener las páginas. De hecho, si haces telnet a un sitio de la web sobre el puerto 80, y escribes " GET / ", recibirás como respuesta el código HTML.
¿Cómo consiguen los sockets de flujo este alto nivel de calidad en la transmisión de datos? Usan un protocolo llamado "Protocolo de Control de Transmisión", más conocido como "TCP" (consulta el RFC-793 para información extremadamente detallada acerca de TCP). TCP asegura que tu información llega secuencialmente y sin errores. Puede que hayas oído antes "TCP" como parte del acrónimo " TCP/IP ", donde "IP" significa "Protocolo de Internet" (consulta el RFC-791 .) IP se encarga básicamente del encaminamiento a través de Internet y en general no es responsable de la integridad de los datos.

Estupendo. ¿Qué hay de los sockets de datagramas? ¿Por qué se les llama sockets sin conexión? ¿De qué va esto, en definitiva, y por qué no son fiables? Bueno, estos son los hechos: si envías un datagrama, puede que llegue. Puede que llegue fuera de secuencia. Si llega, los datos que contiene el paquete no tendrán errores.
Los sockets de datagramas también usan IP para el encaminamiento, pero no usan TCP; usan el "Protocolo de Datagramas de Usuario" o "UDP" (consulta el RFC-768 .)
¿Por qué son sin conexión? Bueno, básicamente porque no tienes que mantener una conexión abierta como harías con los sockets de flujo. Simplemente montas un paquete, le metes una cabecera IP con la información de destino y lo envías. No se necesita conexión. Generalmente se usan para transferencias de información por paquetes. Aplicaciones que usan este tipo de sockets son, por ejemplo, tftp y bootp.
"¡Basta!" puede que grites. "¿Cómo pueden siquiera funcionar estos programas si los datagramas podrían llegar a perderse?". Bien, mi amigo humano, cada uno tiene su propio protocolo encima de UDP. Por ejemplo, el protocolo tftp establece que, para cada paquete enviado, el receptor tiene que devolver un paquete que diga, "¡Lo tengo!" (un paquete "ACK"). Si el emisor del paquete original no obtiene ninguna respuesta en, vamos a decir, cinco segundos, retransmitirá el paquete hasta que finalmente reciba un ACK . Este procedimiento de confirmaciones es muy importante si se implementan aplicaciones basadas en SOCK_DGRAM.
4.3 Tonterías de bajo nivel y teoría de redes
Puesto que acabo de mencionar la disposición en capas de los protocolos, es el momento de hablar acerca de como funcionan las redes realmente, y de mostrar algunos ejemplos de como se construyen los paquetes SOCK_DGRAM . Probablemente, en la práctica puedes saltarte esta sección. Sin embargo no está mal como culturilla.
Figura 1. Encapsulación de datos.
¡Eh tíos, es hora de aprender algo sobre Encapsulación de datos ! Esto es muy, muy importante. Tan importante que podrías aprenderlo si te matricularas en el curso de redes aquí, en el estado de Chico ;-). Básicamente consiste en esto: un paquete de datos nace, el paquete se envuelve (se "encapsula") con una cabecera (y raramente con un pie) por el primer protocolo (por ejemplo el protocolo TFTP), entonces todo ello (cabecera de TFTP incluida) se encapsula otra vez por el

siguiente protocolo (por ejemplo UDP), y otra vez por el siguiente (IP) y otra vez por el protocolo final o nivel (físico) del hardware (por ejemplo, Ethernet)
Cuando otro ordenador recibe el paquete, el hardware retira la cabecera Ethernet, el núcleo [kernel] retira las cabeceras IP y UDP, el programa TFTP retira la cabecera TFTP , y finalmente obtiene los datos.
Ahora puedo finalmente hablar del conocido Modelo de redes en niveles [Layered Network Model]. Este modelo de red describe un sistema de funcionalidades de red que tiene muchas ventajas sobre otros modelos. Por ejemplo, puedes escribir programas de sockets sin preocuparte de cómo los datos se transmiten físicamente (serie, thin ethernet, AUI, lo que sea) porque los programas en los niveles más bajos se ocupan de eso por ti. El hardware y la topología real de la red son transparentes para el programador de sockets.
Sin más preámbulos, te presento los niveles del modelo completo. Recuerda esto para tus exámenes de redes:
Aplicación Presentación
Sesión
Transporte
Red
Enlace de datos
Físico
El nivel físico es el hardware (serie, Ethernet, etc.) El nivel de aplicación está tan lejos del nivel físico como puedas imaginar--es el lugar donde los usarios interactúan con la red.
Sin embargo, este modelo es tan general que si quisieras podrías usarlo como una guía para reparar coches. Un modelo de niveles más consistente con Unix podría ser:
Nivel de aplicación (telnet, ftp, etc.) Nivel de transporte entre Hosts (TCP, UDP)
Nivel de Internet (IP y encaminamiento)
Nivel de acceso a la red (Ethernet, ATM, o lo que sea)

En este momento, probablemente puedes ver como esos niveles se corresponden con la encapsulación de los datos originales.
¿Ves cuánto trabajo se necesita para construir un solo paquete? ¡Dios! ¡Y tienes que teclear la cabecera de los paquetes tú mismo, usando "cat"! Sólo bromeaba. Todo lo que tienes que hacer con los sockets de flujo es usar send() para enviar tus datos. Para los sockets de datagramas tienes que encapsular el paquete según el método de tu elección y enviarlo usando sendto(). El núcleo implementa los niveles de Internet y de Transporte por ti, y el hardware el nivel de acceso a la red. Ah, tecnología moderna.
Así finaliza nuestra breve incursión en la teoría de redes. Ah, olvidaba contarte todo lo que quería decir acerca del encaminamiento: ¡nada! Exacto, no voy a hablar de él en absoluto. el encaminador retira la información de la cabecera IP, consulta su tabla de encaminamiento, bla, bla, bla. Consulta el RFC sobre IP si de verdad te importa. Si nunca aprendes nada de eso probablemente sobrevivirás.
5. DEFINICIÓN DE SERVLETS
5.1 Introducción
Los Servlets son módulos que extienden los servidores orientados a petición-respuesta, como los servidores web compatibles con Java. Por ejemplo, un servlet podría ser responsable de tomar los datos de un formulario de entrada de pedidos en HTML y aplicarle la lógica de negocios utilizada para actualizar la base de datos de pedidos de la compañia.
Los Servlets son para los servidores lo que los applets son para los navegadores. Sin embargo, al contrario que los applets, los servlets no tienen interface gráfico de usuario.
Los servelts pueden ser incluidos en muchos servidores diferentes porque el API Servlet, el que se utiliza para escribir Servlets, no asume nada sobre el entorno o protocolo del servidor. Los servlets se están utilizando ampliamente dentro de servidores HTTP; muchos servidores Web soportan el API Servlet.

5.2 Utilizar Servlets en lugar de Scripts CGI!
Los Servlets son un reemplazo efectivo para los scripts CGI. Proporcionan una forma de generar documentos dinámicos que son fáciles de escribir y rápidos en ejecutarse. Los Servlets también solucionan el problema de hacer la programación del lado del servidor con APIs específicos de la plataforma: están desarrollados con el API Java Servlet, una extensión estándard de Java.
Por eso se utilizan los servlets para manejar peticiones de cliente HTTP. Por ejemplo, tener un servlet procesando datos POSTeados sobre HTTP utilizando un formulario HTML, incluyendo datos del pedido o de la tarjeta de crédito. Un servlet como este podría ser parte de un sistema de procesamiento de pedidos, trabajando con bases de datos de productos e inventarios, y quizas un sistema de pago on-line.
5. 3 Otros usos de los Servlets
Permitir la colaboración entre la gente. Un servlet puede manejar múltiples peticiones concurrentes, y puede sincronizarlas. Esto permite a los servlets soportar sistemas como conferencias on-line.
Reenviar peticiones. Los Servlets pueden reenviar peticiones a otros servidores y servlets. Con esto los servlets pueden ser utilizados para cargar balances desde varios servidores que reflejan el mismo contenido, y para particionar un único servicio lógico en varios servidores, de acuerdo con los tipos de tareas o la organización compartida.
5.4 Arquitectura del Paquete Servlet
El paquete javax.servlet proporciona clases e interfaces para escribir servlets. La arquitectura de este paquete se describe a continuación.
5.4.1 El Interface Servlet
La abstración central en el API Servlet es el interface Servlet. Todos los servlets implementan este interface, bien directamente o, más comunmente, extendiendo una clase que lo implemente como HttpServlet

El interface Servlet declara, pero no implementa, métodos que manejan el Servlet y su comunicación con los clientes. Los escritores de Servlets proporcionan algunos de esos métodos cuando desarrollan un servlet.
5.4.2 Interación con el Cliente
Cuando un servlet acepta una llamada de un cliente, recibe dos objetos.
Un ServletRequest, que encapsula la comunicación desde el cliente al servidor.
Un ServletResponse, que encapsula la comunicación de vuelta desde el servlet hacia el cliente.
ServletRequest y ServletResponse son interfaces definidos en el paquete javax.servlet.
5.4.3 El Interface ServletRequest
El Interface ServletRequest permite al servlet aceder a :
Información como los nombres de los parámetros pasados por el cliente, el protocolo (esquema) que está siendo utilizado por el cliente, y los nombres del host remote que ha realizado la petición y la del server que la ha recibido.
El stream de entrada, ServletInputStream. Los Servlets utilizan este stream para obtener los datos desde los clientes que utilizan protocolos como los métodos POST y PUT del HTTP.
Los interfaces que extienden el interface ServletRequest permiten al servlet recibir más datos específicos del protocolo. Por ejemplo, el interface HttpServletRequest contiene métodos para acceder a información de cabecera específica HTTP.

5.4.4 El Interface ServletResponse
El Interface ServletResponse le da al servlet los métodos para responder al cliente.
Permite al servlet seleccionar la longitud del contenido y el tipo MIME de la respuesta.
Proporciona un stream de salida, ServletOutputStream, y un Writer a través del cual el servlet puede responder datos.
Los interfaces que extienden el interface ServletResponse le dan a los servlets más capacidades específicas del protocolo. Por ejemplo, el interface HttpServletResponse contiene métodos que permiten al servlet manipular información de cabecera específica HTTP.
5.4.5 Capacidades Adicionales de los Servlets HTTP
Las clases e interfaces descritos anteriormente construyen un servlet básico. Los servlets HTTP tienen algunos objetos adicionales que proporcionan capacidades de seguimiento de sesión. El escritor se servlets pueden utilizar esos APIs para mantener el estado entre el servlet y el cliente persiste a través de múltiples conexiones durante un periodo de tiempo. Los servlets HTTP también tienen objetos que proporcionan cookies. El API cookie se utiliza para guardar datos dentro del cliente y recuperar esos datos.
5.5 Un Servlet Sencillo
La siguiente clase define completamente un servlet.
public class SimpleServlet extends HttpServlet { /** * Maneja el método GET de HTPP para construir una sencilla página Web. */ public void doGet (HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
PrintWriter out; String title = "Simple Servlet Output";
// primero selecciona el tipo de contenidos y otros campos de cabecera de la respuesta response.setContentType("text/html");

// Luego escribe los datos de la respuesta out = response.getWriter();
out.println("<HTML><HEAD><TITLE>"); out.println(title); out.println("</TITLE></HEAD><BODY>"); out.println("<H1>" + title + "</H1>"); out.println("<P>This is output from SimpleServlet."); out.println("</BODY></HTML>"); out.close();
} }
6. INSTALACIÓN DE APACHE - TOMCAT
En este apartado se explica como realizar la instalación de un servidor Apache con soporte para jsp y servlets mediante el uso de Tomcat.
Tomcat
El primer paso es la instalación de Java Development Kit, a partir de la versión 1.1. Podemos obtener el archivo jdk-1_2_2_007-linux.i386.tar desde el ftp situado en ftp.renr.es, dentro del directorio /pub/linux/java. Nos situamos en /usr/local/ y descomprimimos mediante tar -xvf jdk-1_2_2_007_linux.i386.tar. Con esto se creará el directorio jdk1.2.2. Tan solo nos quedará darle valor a ciertas variables de entorno. Para ello, editamos .bash_profile del usuario correspondiente, y añadimos las siguientes variables:
JAVA_HOME=/usr/local/jdk1.2.2
CLASS_PATH=$JAVA_HOME/jre/lib/ext
Añadimos a la variable PATH lo siguiente: $JAVA_HOME/bin
Dentro de este fichero también añadimos a EXPORT las variables recién creadas.
Descargamos el API Java para el procesamiento de XML desde http://java.sun.com/xml (el primero de los productos listados). Lo descomprimimos usando unzip jaxp-1_1.zip, y tan solo deberemos copiar todos los archivos con extensión .jar a /usr/local/jdk1.2.2/jre/lib/ext/ .
Descargamos el Java Secure Sockets Extensions (JSSE) desde http://java.sun.com/products/jsse (la versión 1.0.2, es decir, la no integrada en J2SDK). Concretamente, la versión global (y no la de Estados Unidos y Canadá). Descomprimimos el archivo descargado de forma habitual en
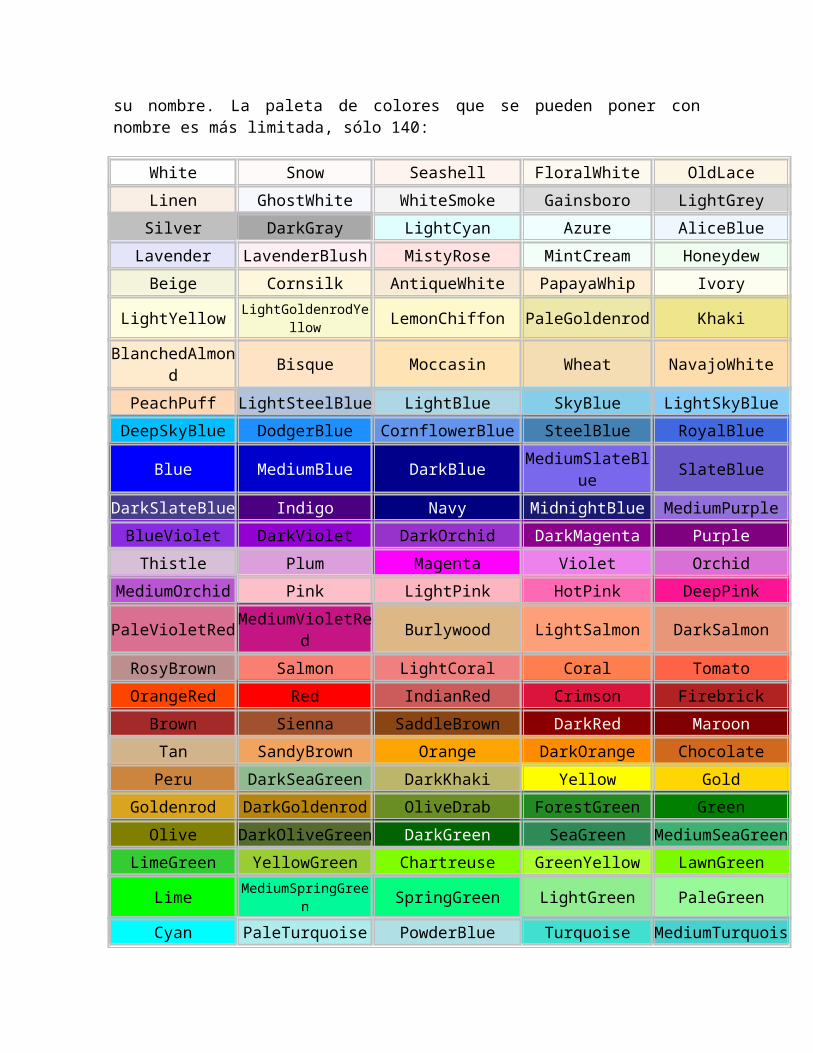
un .zip : unzip jsse-1_0_2-gl.zip. Como en el caso anterior, copiamos todos los archivos .jar (que en este caso se encontrarán dentro del directorio lib) en /usr/local/jdk1.2.2/jre/lib/ext/.
Deberemos descargar la distribución 'jakarta-ant'. Un buen lugar desde el que hacerlo es este. Deberemos crear el directorio /usr/local/jakarta, y añadir la variable JAKARTA_HOME=/usr/local/jakarta al .bash_profile correspondiente. Tras descomprimir el fichero descargado mediante tar -xvzf jakarta-ant-src.tar.gz deberemos copiarlo todo en /usr/local/jakarta/jakarta-ant, y teclear lo siguiente:
./bootstrap.sh
El resultado será un fichero denominado ant.jar dentro del directorio /lib, que será utilizado durante la compilación de Tomcat.
Descargamos desde el ftp de ftp.renr.es el archivo jakarta-servletapi-3.2-src.tar.gz desde el directorio /pub/linux/tomcat, y descomprimos el contenido en un directorio denominado /usr/local/jakarta/jakarta-servletapi. Tras hacer esto, tecleamos lo siguiente:
./build.sh dist
Esto tendrá como resultado el archivo servlet.jar en el subdirectorio lib/, que será necesario para la compilación de WatchDog.
Desde el mismo directorio dentro del ftp descargamos el archivo jakarta-tomcat-3.2.1-src.tar.gz, y lo descomprimimos en /usr/local/jakarta/jakarta-tomcat. Dentro de dicho directorio tecleamos:
./build.sh dist
Con esto habremos terminado de instalar Tomcat. Podemos probar su funcionamiento ejecutando /usr/local/jakarta/dist/tomcat/bin/startup.sh, lo cual arrancará un pequeño servidor web, y usando el navegador para acceder a http://localhost:8080. Para detenerlo ejecutamos /usr/local/jakarta/dist/tomcat/bin/shutdown.sh.
Sin embargo, como vamos a utilizar Apache como servidor Web, tendremos que deshabilitar esta última característica de Tomcat. Para ello, editamos el archivo /usr/local/jakarta/dist/tomcat/conf/server.xml y comentamos, mediante comentarios de HTML (<!-- -->) las líneas siguientes:
<!-- Normal HTTP --> <Connector ClassName="org.apache.tomcat.service.PoolTcpConnector"> <Parameter name="handler" value="org.apache.tomcat.service.http.HttpConnectionHandler" />

<Parameter name="port" value ="8080" /> </Connector>
Apache
Podemos instalar Apache a partir de las fuentes que podemos descargar desde la web de Apache . Tras descomprimir el archivo descargado en cualquier directorio que usemos para compilar (por ejemplo, /var/instalacion/), mediante tar -xvzf apache_1.3.20.tar.gz, modificamos el archivo /var/instalacion/apache_1.3.20/src/ Configuration.tmpl , descomentando la línea AddModule modules/standard/mod_so.o . Tras hacer esto nos situamos en la raiz del directorio de fuentes de Apache, y ejecutamos:
./configure --prefix=/usr/local/apache make make install
Para probar que el servidor está correctamente instalado tan solo deberemos ejecutar /usr/local/apache/bin/apachectl start y entrar mediante el navegador en la dirección http://localhost.
Integración Apache-Tomcat
Para que haya comunicación entre ambos, deberemos compilar un módulo de Tomcat, situado en /usr/local/jakarta/jakarta-tomcat/src/native/apache1.3 . Tras situarnos en ese directorio, editamos Makefile.linux, y en la linea donde se le de valor a la variable APXS, ponemos como valor el directorio /usr/local/apache/bin. Tras esto compilamos con Makefile -f Makefile.linux. El fichero resultante, mod_jk.so, debe ser copiado en /usr/local/apache/libexec/. Por último, dentro de /usr/local/apache/conf/httpd.conf añadimos al final la siguiente línea:
include /usr/local/jakarta/dist/tomcat/conf/mod_jk.conf-auto
Hay que tener en cuenta que todos lo incluido dentro del directorio /usr/local/jakarta/dist/tomcat/webapps será servido por el servidor, aunque dicho directorio no haya sido incluido en los archivos de configuración. Es por ello que deberemos borrar este directorio si no deseamos que esto sea así.
7. APLICACIONES: ACCESO A BASE DE DATOS CON SERVLETS
Con los Servlets se puede implementar por ejemplo:

Típicos sistemas middleware que hasta ahora únicamente se implementaban con CGI's. Para consultar las bases de batos, los Servlets pueden utilizar JDBC (Java Data Base Connection), lo que les permite extraer información de cualquier sistema de Base de Datos.
Automatización de un sistema de recepción y publicación de información. Por ejemplo podríamos montarnos una simple estación meteorológica que permitiese acceso a su información mediante una página WEB. Por un lado tendríamos un servlet que recolectaría la información de los diversos tipos de sensores y la almacenaría en bases de datos, y por otro lado, un servlet que se encargaría de presentar esta información en función de las peticiones del cliente basándose en estas mismas bases de datos.
Control de la recepción de correo electrónico, y de sistemas de news, chats, etc. Conviene recordar que Java está especialmente indicado para la programación utilizando los protocolos TCP/IP.
Dado que pueden manejar múltiples peticiones en forma concurrente, es posible implementar aplicaciones de colaboración, como por ejemplo una aplicación de videoconferencia.
BIBLIOGRAFIA
“Como programar en Java”, Deitel & Deitel, Pearson Education – primera edición
“Aprendiendo Java en 21 dias”, Lemay – Perkins, Sams.net Publishing – primera
edición
“Aprendiendo Java como si estuviera en primero”, J. Garcia , J. Rodríguez –
Universidad de Navarra
“Java” , Abraham Otero – tutorial de Javahispano.org
GLOSARIOabstract: Abstracto.Aplicable a clases o métodos.
array: Variable que posee varias posiciones para almacenar un valor en cada posición. Las posiciones son accedidas mediante un índice numérico.

break: Palabra clave que finaliza la ejecución de un bucle o de una instrucción switch.
bucles: Tipo de estructura iterativa, que permite repetir un conjunto de instrucciones un número variable de veces.
clase: Estructura que define como son los objetos, indicando sus atributos y sus acciones.
clase base: Clase de la cuál se hereda para construir otra clase, denominada derivada.
CLASSPATH: Variable de entorno que permite a la máquina virtual java saber donde localizar sus clases.
constructor: Función especial empleada para inicializar a los objetos, cada clase posee sus propios constructores.
derivada: Clase que hereda de una clase base.
Excepcion: Objeto empleado para representar una situación de excepción (error) dentro de una aplicación java.
herencia: Característica que permite que una clase posea las características de otra, sin tener que reescribir el código.
herencia sencilla y múltiple: Dos tipos de herencia, con una sóla clase base, o con varias.
instancia: Un objeto creado a partir de una clase.
instanciación: Proceso de creación de un objeto a partir de una clase.
interfaz: Define un tipo de datos, pero sólo indica el prototipo de sus métodos, nunca la implementación.
JDK: Java Development Kit, es el conjunto de herramientas proporcionadas por sun, que permite compilar y ejecutar código java.
jerarquía de herencia: Árbol construido mediante las relaciones de herencia en las clases java.
máquina virtual: Es la encargada de ejecutar el código java.
multiplataforma: Posibilidad de existir en varias plataformas (sistemas operativos)

package: Paquete. Carpeta creada para contener clases java, y así poder organizarlas.
PATH: Variable de entorno, empleada por los sistemas operativos para saber donde localizar sus programas ejecutables.
Sobrescritura: Poseer el mismo método, pero con código distinto, en una clase base y en una clase que deriva de ella.
transformación de datos: Cómo cambiar el tipo de una información, por ejemplo cambiar el literal "23" al valor numérico 23.
try/catch/finally: Instrucciones empleadas para gestionar los posibles errores que se puedan provocar en un programa java.

LECTURAS COMPLEMENTARIAS
Leer los Conceptos de Progrmamcion orientada a objetos
Leer y averiguar la historia del lenguaje JAVA
Leer y averiguar Las instrucciones TRY y CATCH
Leer los Conceptos de FINALLY Y STATIC
Averiguar los conceptos 20 instrucciones del paquete AWT
Averiguar los conceptos de SWING

Averiguar otras formas de conectar BASES de DATOS
Leer y averiguar sobre la arquitectura cliente servidor
Averiguar los conceptos de programación en hillos
Leer y averiguar sobre los SOCKETS
Leer y averiguar Las instrucciones DO POST y DO GET
Tutorial de Java para Principiantes basado en el JDK de Sun.www.itapizaco.edu.mx/paginas/JavaTut/froufe/introduccion/indice.html Tutorial de Java - Home Page Tutorial de Java. JavaSoft Headquarters. Esta versión está en Desarrollo, consulta la Tabla de Contenido para ver qué temas están ya publicados. ...www.itapizaco.edu.mx/paginas/JavaTut/froufe/ Tutorial de Java - Home Page Tutorial de Java, en español. El Tutorial se ve mejor con Netscape 3.0 · Microsoft Internet Explorer. AVISOS. EL TUTORIAL YA ESTA TERMINADO. ...www.ulpgc.es/otros/tutoriales/java/
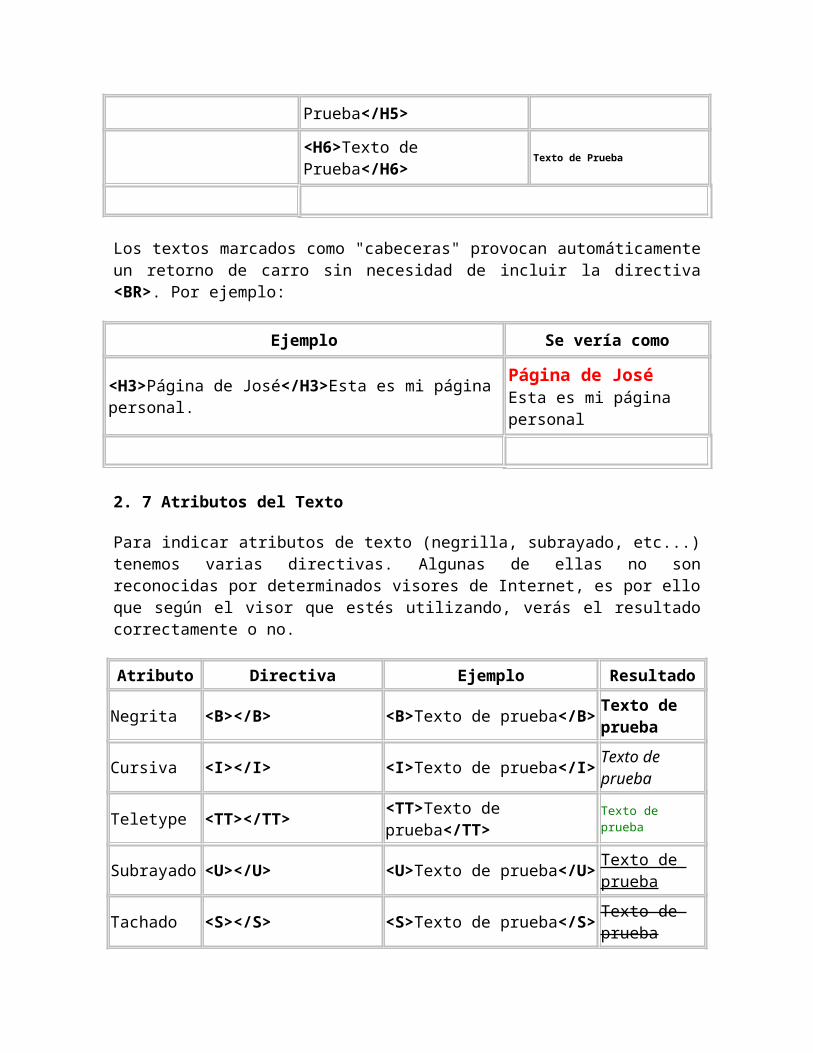
Tutorial de Java - Tabla de Contenido Dentro de nuestras posibilidades, veríamos la forma de incluir más capítulos en este Tutorial. linea2. menu. Tutorial de Java ...www.cica.es/formacion/JavaTut/Intro/tabla.html Aprenda JavaFormato de archivo: PDF/Adobe AcrobatSan Sebastián, Enero 2000. Aprenda Java. como si estuviera en primero. Javier García de Jalón • José Ignacio Rodríguez • Iñigo Mingo • Aitor Imaz www.tecnun.es/asignaturas/Informat1/ayudainf/aprendainf/Java/Java2.pdf Tutorial de Java - Wikilearning Tutorial de Java. Amplio tutorial de Java para empezar a trabajar y ampliar conocimientos de este lenguaje.www.wikilearning.com/tutorial_de_java-wkc-3938.htm Java en castellano java jspArtículos, tutoriales descargables y noticias. Lista de correo para discusión y ayuda.www.programacion.com/java/tutoriales/ Java en castellano. TutorJava Nivel Básico java jspEnvio (26/09/2007). Por Me pueden enviar el tutorial de Java a mi correo [email protected]. Tutorial muy oportuno (22/09/2007) ...www.programacion.com/java/tutorial/java_basico/