alumnos semana 4
DESCRIPTION
estadistica industrial unmsmTRANSCRIPT

Distribución F
Esta distribución probabilística se utiliza como estadístico de prueba en varias situaciones. Sirve para demostrar si dos varianzas muestrales provienen de la misma población o de poblaciones iguales, y también se aplica cuando se desean comparar simultáneamente tres o más medias poblacionales. Esta comparación simultánea de varias medias poblacionales se denomina Análisis de varianza (de análisis of variance). En estos dos casos, las poblaciones deben ser normales y los datos deben estar al menos medidos en escala de intervalo.

Características de la distribución F
1. Existe una “familia” de distribuciones F. Un elemento específico de la familia está determinado por dos parámetros: los grados de libertad en el numerador y los grados de libertad en el denominador.
2. El valor de F no puede ser negativo. 3. La distribución F es una distribución continua. 4. La curva que representa una distribución F tiene un sesgo positivo. 5. Sus valores varían de 0 a . A medida que aumenta el valor de F, la curva se
aproxima al eje X, pero nunca lo toca.

Comparación de dos varianzas poblacionales
La distribución F se utiliza para demostrar la hipótesis de que la varianza de una población normal es igual a la varianza de otra poblacional normal. Así, la prueba es útil para determinar si una población normal tiene o no más variación que otra. En los siguientes ejemplo se muestra el uso de esta prueba:
•Dos cizallas se ajustan para producir elementos de acero de la misma longitud. Por tanto, los elementos tener la misma longitud. Se desea estar seguro que además de tener la misma longitud, tengan una variación similar.
•La tasa media de rendimiento a la inversión de dos tipos de acciones puede ser la mismo, pero hay más variación en el rendimiento de una que de otra. Una muestra de 10 acciones de industria aeroespacial y 10 acciones de servicios podrían mostrar la misma tasa media de rendimiento, pero es probable que haya más variación en el rendimiento de las acciones aeroespaciales.

Consideraciones de validación
Al comparar las varianzas de dos poblaciones usaremos datos reunidos de dos muestras aleatorias independientes, una de la población 1 y la otra de la población 2. Las dos varianzas de las muestras, 2
1s y 22s serán la base para hacer inferencias acerca de las
dos varianzas poblacionales 21 y 2
2 . Siempre que las dos varianzas poblacionales sean iguales ( 2
1 = 22 ), la distribución de la relación de
las dos varianzas de las muestras 21s / 2
2s es la siguiente:

Distribución muestral de 21s / 2
2s cuando 21 = 2
2 Siempre que se seleccionan muestras aleatorias simples de tamaño n1 y n2 a partir de poblaciones normales con varianzas iguales, la distribución de las muestras
22
21
s
s (9)
tiene distribución F con n1 – 1 grados de libertad para el numerador y n2 – 1 grados de libertad para el denominador;
21s es la varianza de la muestra de los n1 artículos
procedentes de la población 1 y 22s es la de los n2 artículos
procedentes de la población 2.

EJEMPLO
La Escuela bancaria va a renovar su contrato de servicio de autobús escolar para el año próximo, y debe seleccionar entre las empresas Transportes rápidos, S.A. y Transportes eficaces, S.A.. Usaremos la varianza de los tiempos de recepciones que se tarda en recoger y entregar alumnos como medida principal de la calidad del servicio. Los valores bajos de varianza indican que el servicio es más consistente y de mayor calidad. Si las varianzas de los tiempos de llegada asociadas con los dos servicios son iguales, los administradores de la Escuela bancaria seleccionarán la empresa que ofrezca mejores condiciones financieras. Sin embargo, si los datos de las muestras de tiempos de llegada para las dos empresas indican que hay una gran diferencia entre las varianzas, los administradores tendrán muy en cuenta a la que tenga menor varianza del servicio

Las hipótesis de prueba son las siguientes: 22
211
22
210
:
:
H
H
Si se puede rechazar 0H , es adecuada la conclusión de distinta calidad en los servicios. En tal caso, se preferirá a la empresa con menor varianza de la muestra.

Suponga que se hará la prueba de hipótesis con = 0.10 y que se obtienen muestras de tiempos de llegada con escuelas que actualmente usan los servicios de los dos transportistas. Se obtiene una muestra de 25 tiempos para los rápidos (población 1) y una de 16 para los eficaces (población 2). La figura 3 es la gráfica de la distribución F con n1 – 1 = 24 grados de libertad en el numerador y n2 – 1 = 15 grados de libertad en el denominador.
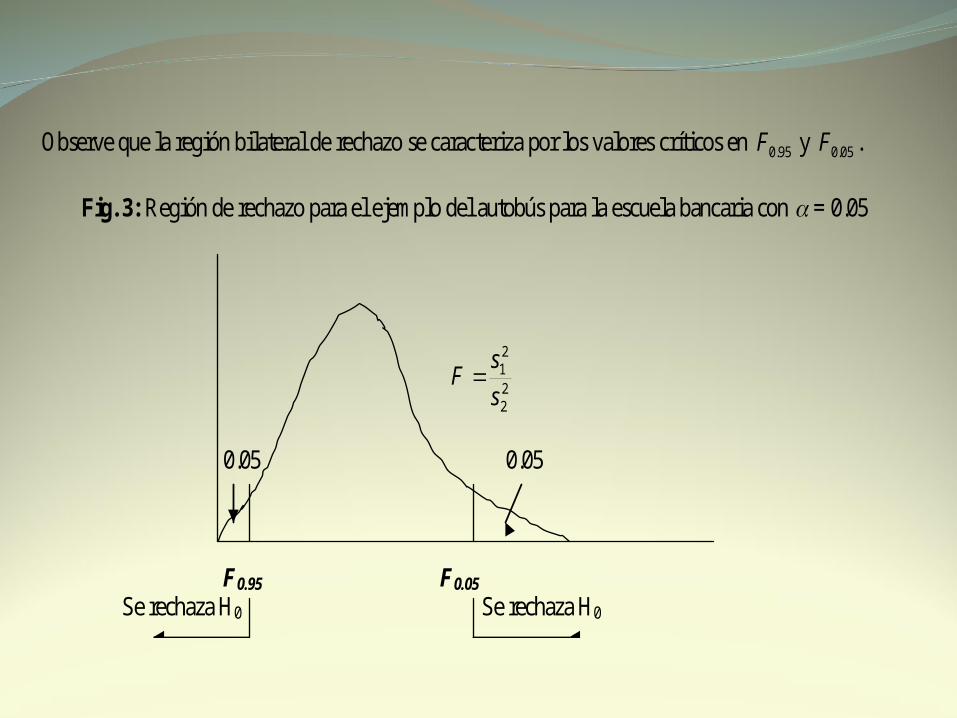
Observe que la región bilateral de rechazo se caracteriza por los valores críticos en 95.0F y 05.0F .
Fig. 3: Región de rechazo para el ejemplo del autobús para la escuela bancaria con = 0.05
22
21
s
sF
0.05 0.05 F0.95 F0.05 Se rechaza H0 Se rechaza H0

Suponga que las dos muestras de tiempos de llegada del autobús produjeron las varianzas 2
1s = 48 para los rápidos y 2
2s = 20 para los eficaces. ¿Qué conclusión es la adecuada? Se supone que las dos poblaciones de tiempos de llegada tienen distribuciones normales de probabilidad, y que 0H es verdadera si 2
1 = 22 . Se puede aplicar la
distribución F para llegar a una conclusión. Específicamente, se calcula 2
221 / ssF y se emplea la
región de rechazo que vemos en la figura 3.

De este modo, llegamos a:
40.220
4822
21 s
sF
Consultando la tabla, vemos que el valor crítico unilateral superior (de la cola superior) con 24 grados de libertad en el numerador y 15 en el denominador es 29.205.0 F . Aunque la tabla no indica valores 95.0F observamos que no es necesaria la determinación de este valor crítico unilateral inferior. Se puede observar que F = 2.40 es mayor que 29.205.0 F . Entonces, con un nivel de significancia de 0.10 se rechaza H0.

Este resultado conduce a la conclusión de que los dos servicios de autobús son distintos en lo concerniente a varianzas de tiempos de recepción y de llegada. Nuestra recomendación es que los administradores de la Escuela bancaria den consideración especial al mejor servicio, con menor varianza, que ofrecen los Transportes eficaces, S.A. También se puede usar el criterio del valor p para una prueba de hipótesis acerca de dos varianzas poblacionales. Se aplica la regla de rechazo común: rechazar H0 si el valor p < . Sin embargo, al igual que con la distribución ji cuadrada, es difícil determinar el valor p directamente de las tablas de la distribución F.

Prueba bilateral de la varianza de dos poblaciones
22
211
22
210
:
:
H
H
Se denota la población que tiene la mayor varianza de la muestra como población 1. Estadístico de prueba
22
21
s
sF
Regla de rechazo Con el estadístico de prueba: Rechazar 0H si
2/FF Con el valor p : Rechazar 0H si el valor p< Donde el valor 2/F se basa en una distribución F con n1 –1 grados de libertad en el numerador y n2
–1 grados de libertad en el denominador.

Prueba unilateral sobre las varianzas de dos poblaciones
22
211
22
210
:
:
H
H
Se denota la población que tiene la mayor varianza de la muestra como población 1. Estadístico de prueba
22
21
s
sF
Regla de rechazo Con el estadístico de prueba: Rechazar 0H si FF Con el valor p : Rechazar 0H si el valor p< Donde el valor F se basa en una distribución F con n1 –1 grados de libertad en el numerador y n2 –1 grados de libertad en el denominador.

AnovaNoción general
El segundo uso de la distribución F comprende la técnica del análisis de varianza, que se simboliza por ANOVA. Básicamente, en ese análisis se emplea información muestral para determinar si tres o más tratamientos producen o no resultados diferentes. El uso de la palabra tratamiento tiene su origen en la investigación agrícola. Se trataron campos con distintos fertilizantes o fumigantes, para determinar si había o no una diferencia global en la productividad. Se probará si cinco aditivos para la gasolina (los tratamientos) dan o no como resultado una diferencia en el rendimiento en millas por galón. Además se explotará la siguiente pregunta: ¿Los cuatros métodos de entrenamiento (los tratamientos) son igualmente efectivos?

Tratamiento: Causa o fuente específica de variación en un conjunto de datos.

Consideraciones en que se basa la prueba ANOVA
Antes de realizar una prueba utilizando la técnica ANOVA se examinarán las consideraciones en que se basa la prueba. Si no pueden cumplirse las consideraciones siguientes, es posible aplicar otra técnica de análisis de varianza (que desarrollaron Kruskal y Wallis).
1.Las tres o más poblaciones de interés están distribuidas normalmente.2.Tales poblaciones tienen desviaciones estándar iguales.3.Las muestras que se seleccionan de cada una de las poblaciones son aleatorias e independientes, es decir, no están relacionadas entre sí.

Ejemplo
Suponga que renunció el gerente de la sucursal de Los Olivos de la cadena de tiendas comerciales “Metro”, y se considera que tres vendedores pueden ocupar este puesto. Los tres tienen la misma antigüedad, educación, etc. Para tomar una decisión, el gerente de personal, sugirió examinar los registros de ventas mensuales de cada uno.

En la siguiente tabla se muestran los resultados maestrales de las ventas por mes: Ventas mensuales ($ 000) Sr. Quiroz Sr. Huarote Sr. Martínez 15 15 19 10 10 12 9 12 16 5 11 16 16 12 17 Media muestral: 11 12 16 En este problema los vendedores son los “tratamientos”.

3210 : H La hipótesis nula expresa que no hay diferencia significativa entre las ventas medias de los tres vendedores.
:1H Plantea que al menos una media es diferente. Se seleccionó un nivel de significancia = 0.05. El estadístico de prueba adecuado es la distribución F. Este procedimiento se basa en varias consideraciones: 1) Los datos deben estar al menos en nivel de intervalo; 2) La selección real de las ventas debe hacerse utilizando un procedimiento de tipo probabilístico; 3) La distribución de las venta mensuales para cada una de las poblaciones es normal y 4) Las varianzas de las tres poblaciones son iguales, es decir,
23
22
21 .

F es la razón de dos varianzas:
muestraslaseniaciónlasegúnestimadalpoblacionaVarianza
muestralesmediasentreiaciónsegúnestimadalpoblacionaVarianzaF
var
var
La terminología común para el numerador es “varianza entre muestras”. Para el denominador es “varianza en las muestras”. El numerador tiene 1k grados de libertad. El denominador tiene
kN grados de libertad; donde k es el número de tratamientos y N es el número de observaciones.

Para este problema relativo a un nuevo gerente de almacén, hay tres tratamientos (vendedores), por lo que se tiene k – 1 = 3 – 1 = 2 g.l. en el numerado. Hay 15 observaciones (tres muestras de cinco cada una), por tanto, hay N – k = 15 – 3 = 12 g.l. en el denominador.
El valor crítico, esto es, el punto divisorio entre la región de aceptación y la de rechazo, se obtiene consultando la tabla correspondiente. Ese número es 3.89, y es el valor crítico de F para el nivel 0.05.

Al utilizar el nivel predeterminado de 0.05, la regla de decisión es aceptar la hipótesis nula si el valor calculado de F es menor que o igual a 3.89; se rechaza la hipótesis nula y se acepta la alternativa, si el valor calculado de F es mayor que 3.89.
Para calcular F y tomar una decisión, el primer paso es organizar una tabla ANOVA. Esta es sólo una forma conveniente de registrar la suma de cuadrados y otros cálculos. El formato general para un problema de análisis de varianza en un sentido se muestra en la siguiente tabla:

Fuente de Suma de Grados
de Cuadrados variación cuadrados libertad medios
Entre tratamientos SST k - 1
SST/k-1= MSTR
Error (en los tratamientos) SSE N - k
SSE/N-k = MSE
Total Total SS
MSE
MSTR
kN
SSEk
SST
F
1
en donde: MSTR: cuadrado medio entre tratamientos. MSE : cuadrado medio debido al error. También se denomina cuadrado medio dentro de tratamiento. SST : suma de cuadrados de tratamiento.

Se obtiene mediante la siguiente fórmula:
N
X
n
TSST
c
c
22 )(
en donde:
2cT : indica elevar al cuadrado el total de cada columna
(el subíndice c se refiere a la columna) cn : es el número de observaciones para cada
tratamiento respectivo (columna). Hay cinco cifras de ventas para el Sr. Quiroz, cinco para el Sr. Huarote y cinco para el Sr. Martínez. X : es la suma de todas las observaciones (ventas). Es $ 195. k : es el número de tratamientos (vendedores). Hay tres. N : es el número total de observaciones. Hay 15.

Sr. Quiroz Sr. Huarote Sr. Martínez
1X 21X 2X 2
2X 3X 23X
15 225 15 225 19 361 10 100 10 100 12 144 9 81 12 144 16 256 5 25 11 121 16 256 16 256 12 144 17 289 Total Totales de columna: 55 60 80 195 Tamaño de muestra 5 5 5 15 Suma de cuadrados 687 734 1306 2727
Cálculo de SST
70535,2605,215
)195(
5
)80(
5
)60(
5
)55()( 22222
N
X
n
TSST
c
c
Cálculo de SSE
122605,2727,22
2
c
c
n
TXSSE
La variación total (Total SS) es la suma de la variación entre columnas y entre renglones; es decir, Total SS = SST + SSE = 70 + 122 = 192.

Verificación
192535,2727,215
)195(727,2
)( 222
N
XXSSTotal
Las tres sumas de cuadrados y los cálculos necesarios para determinar F, se presentan en el siguiente cuadro:
Fuente de Suma de Grados de Cuadrados variación cuadrados libertad medios
Entre tratamientos SST= 70 k – 1=3-1=2 70/2=35 = MSTR Error (en los tratamientos) SSE=122 N – k=15-3=12 122/12 =10.17= MSE Total SS Total SS=192
Cálculo de F
44.317.10
351
MSE
MSTR
kN
SSEk
SST
F

La regla de decisión indica que si el valor calculado de F es menor que o igual al valor crítico de 3.89, la hipótesis nula se acepta. Si el valor de F es mayor que 3.89, la hipótesis nula se rechaza y la hipótesis alternativa se acepta. Puesto que 3.44 < 3.89, la hipótesis nula se acepta al nivel 0.05. En otras palabras, las diferencias en las ventas medias mensuales ($11,000, $12,000 y $16,000) se atribuyen al azar (muestreo). Desde el punto de vista práctico, los niveles de ventas de los tres vendedores que se consideran para el puesto de gerente de almacén son iguales. No puede tomarse una decisión respecto al puesto, con base en las ventas mensuales

EjemploUn profesor pidió a los estudiantes de un grupo grande del curso de estadística que evaluara su desempeño en el curso como 1 (excelente), 2 (bueno), 3 (aceptable) o 4 (deficiente). Un ayudante del profesor recolectó las evaluaciones y aseguró a los estudiantes que el profesor no las recibiría hasta después que las calificaciones del curso se hubieran ingresado en la Dirección Académica. La evaluación (el tratamiento) que un estudiante asignó al profesor se comparó con su calificación final del curso. Lógicamente, se esperaría que en general, el grupo de estudiantes que pensó que el profesor era excelente tuvieran una calificación promedio final del curso significativamente más alta que los alumnos que lo evaluaron como bueno, aceptable o regular, o deficiente. También se esperaría que los alumnos que lo evaluaron como deficiente tuvieran las calificaciones promedio más bajas.
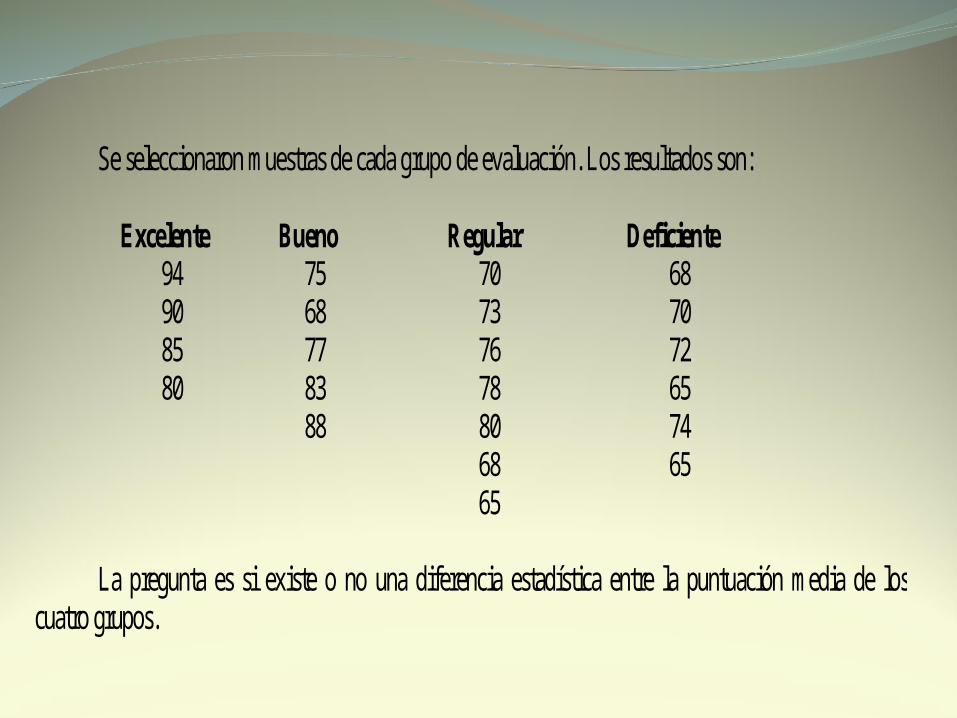
Se seleccionaron muestras de cada grupo de evaluación. Los resultados son:
Excelente Bueno Regular Deficiente 94 75 70 68 90 68 73 70 85 77 76 72 80 83 78 65 88 80 74 68 65 65 La pregunta es si existe o no una diferencia estadística entre la puntuación media de los cuatro grupos.

Se seleccionó el nivel de significación 0.01.
La regla de decisión es que la hipótesis nula, que plantea que no hay diferencia entre las medias, no se rechazará si el valor calculado de F es menor que el valor crítico. De otra manera, la hipótesis nula se rechazará y se aceptará la hipótesis alternativa.

Recuérdese que los grados de libertad en el numerador de la razón F se obtienen por k – 1, donde k es el número de tratamientos (grupos de evaluación del profesor). Hay cuatro tratamientos, de manera que 4 – 1 = 3 g.l. Los grados de libertad en el denominador son en total 18, que se obtienen mediante N – k, en donde N es el número total de estudiantes en la muestra. Hay 22 estudiantes, por lo que 22 – 4 = 18 g.l.
Obsérvese que el valor crítico de F es 5.09, de acuerdo al valor indicado en la tabla correspondiente. La regla de decisión será: acepte la hipótesis nula al nivel 0.01 si el valor calculado de F es menor que o igual a 5.09, y rechace la hipótesis nula si el valor calculado es mayor que 5.09.

Los cálculos necesarios para determinar la razón F se muestran en la siguiente tabla:
Excelente Bueno Aceptable Deficiente
1X 21X 2X 2
2X 3X 23X
4X 24X
94 8836 75 5625 70 4900 68 4624 90 8100 68 4624 73 5329 70 4900 85 7225 77 5929 76 5776 72 5184 80 6400 83 6889 78 6084 65 4225 88 7744 80 6400 74 5476 68 4624 65 4225 65 4225
cT 349 391 510 414
cn 4 5 7 6
2X 30561 30811 37338 28634
Nótese que la suma de los totales por columna )( ix es 1 664; el total de los tamaños de
muestras (N) es 22; y la suma de los cuadrados 127344. Calculando SST, SSE y total SS, se obtiene:
68.89022
)1664(
6
)414(
7
)510(
5
)391(
4
)349()( 2222222
N
X
n
TSST
c
c
41.59459.1267491273442
2
c
c
n
TXSSE
Total SS = SST + SSE = 890.68 + 594.41 = 1485.09 Como verificación:
09.14859.12585812734422
)1664(127344
)( 222
N
XXSSTotal

Estos valores se colocan en la tabla ANOVA:
Fuente de Suma de Grados de Cuadrados variación cuadrados libertad medios
Tratamiento (entre columnas) SST= 890.68 k – 1=4-1=3 890.68/3=296.89 MSTR Error (entre renglones) SSE=594.41 N – k=22-4=18 594.41/18 =33.02= MSE Total SS Total SS=1485.09
Introduciendo los cuadrados medios en la fórmula de F, se obtiene:
99.802.33
89.296
MSE
MSTRF

La decisión: como el valor calculado de F de 8.99 es mayor que el valor crítico de 5.09, la hipótesis nula de que no existe diferencia entre las medias se rechaza al nivel 0.01. Básicamente esto indica que es muy probable que las diferencias observadas entre las medias no se deban al azar. Desde el punto de vista práctica, se sugiere que las calificaciones que obtuvieron los estudiantes en un curso están relacionadas con las opiniones que tienen de la capacidad general y la forma como se conduce en clase el profesor.

Inferencias acerca de las medias de tratamiento
Supóngase que al aplicar el procedimiento ANOVA, se decide rechazar la hipótesis nula. Esto permite concluir que todas las medias de tratamiento no son iguales. Algunas veces esta conclusión puede considerarse satisfactoria, pero en otros casos se desea saber cuáles medias de tratamiento son diferentes.
En este ejemplo, la hipótesis nula se rechazó y la alternativa se aceptó. Si las opiniones de los estudiantes son en realidad diferentes, la pregunta es: ¿Entre qué grupos difieren las medias de tratamiento?
Existen varios procedimientos para responder esta pregunta. Tal vez el más sencillo es mediante el uso de niveles de confianza.

La distribución t se utiliza como base para esta prueba. Recuérdese que una suposición básica de ANOVA es que las varianzas poblacionales son iguales para todos los tratamientos. Como se observó, este valor poblacional común se denomina error cuadrado medio (MSE) que se obtiene mediante SSE/(N-k).

Un intervalo de confianza para la diferencia entre dos medias poblacionales se logra mediante:
2121
11)(
nnMSEtxx
1x : es la media del primer tratamiento.
2x : es la media del segundo tratamiento t : se obtiene a partir del la tabla t. Los grados de libertad son N – k. MSE : es el error cuadrado medio que se obtiene a partir de la tabla ANOVA.
1n : es el número de observaciones en el primer tratamiento.
2n : es el número de observaciones en el segundo tratamiento.

Si el intervalo de confianza incluye al 0, se concluye que no hay diferencia en el par de medias de tratamiento. Sin embargo, si ambos extremos del intervalo de confianza tienen el mismo signo, esto indica que las medias de tratamiento son diferentes.
Utilizando el ejemplo anterior acerca de las opiniones de estudiantes y el nivel de confianza de 0.95, los extremos del intervalo de confianza son 10.46 y 26.04, que se obtienen por:

04.2646.10
79.725.18
6
1
4
10.33101.2)00.6925.87(
11)(
2121
y
nnMSEtxx
Se conoce que el intervalo de confianza de 95% varía de 10.46 hasta 26.04. Ambos extremos son positivos; en consecuencia, podemos concluir que estas medias de tratamiento difieren significativamente. Es decir, los estudiantes que evaluaron al profesor como excelente tienen calificaciones más altas que los que lo evaluaron como malo.

Precaución
La investigación de diferencias de medias de tratamiento es un proceso secuencial. El paso inicial es realizar la prueba ANOVA. Sólo si se rechaza, la hipótesis nula de que la medias de tratamiento son iguales, debe intentarse llevar a cabo cualquier análisis de las medias de tratamiento

ANOVA en dos sentidos
Una compañía de autobuses, está ampliando el servicio desde el centro de Lima al Aeropuerto por cuatro rutas diferentes. La Empresa realizó recorridos de prueba para determinar si hay diferencia significativa en los tiempos medios del trayecto en las cuatro rutas. Los tiempos del trayecto en minutos en cada una de las cuatro rutas se muestran a continuación:
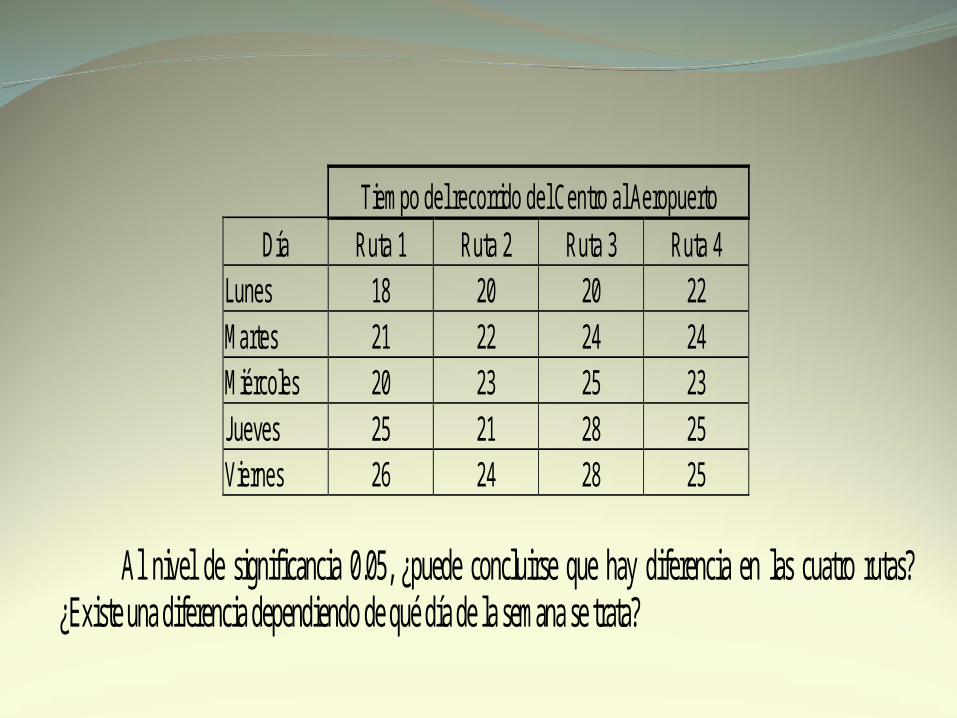
Tiempo del recorrido del Centro al Aeropuerto
Día Ruta 1 Ruta 2 Ruta 3 Ruta 4 Lunes 18 20 20 22 Martes 21 22 24 24 Miércoles 20 23 25 23 Jueves 25 21 28 25 Viernes 26 24 28 25
Al nivel de significancia 0.05, ¿puede concluirse que hay diferencia en las cuatro rutas? ¿Existe una diferencia dependiendo de qué día de la semana se trata?

En este caso, el día de la semana se denomina variable de bloque. En consecuencia, se tiene variación debida al tratamiento y debida a los bloques. La suma de cuadrados debida a los bloques (SSB) se calcula como sigue:
N
x
k
BSSB r
22 )(
en donde Br se refiere al total del bloque, es decir, al total de cada renglón, y k es el número de elementos en cada bloque. El mismo formato que sirve para el caso de ANOVA en un sentido se utiliza para la tabla ANOVA en dos sentidos. Los totales de SST y SS se calculan igual que antes. SSE se obtiene por sustracción (SSE = Total SS – SST – SSB). En la siguiente tabla se muestran los cálculos necesarios:
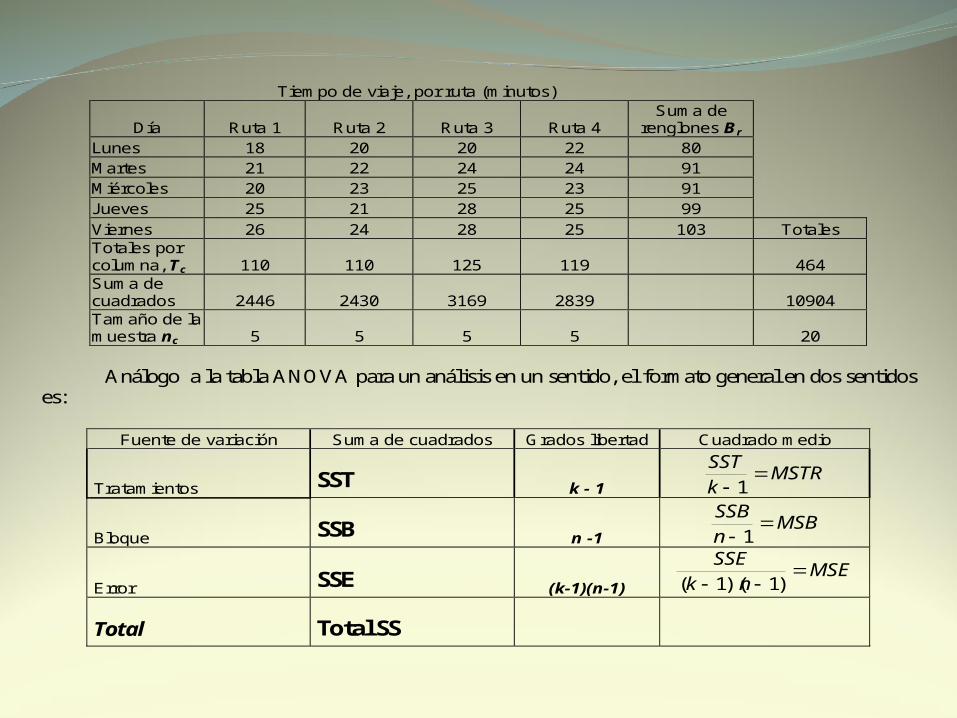
Tiempo de viaje, por ruta (minutos)
Día Ruta 1 Ruta 2 Ruta 3 Ruta 4 Suma de
renglones Br Lunes 18 20 20 22 80 Martes 21 22 24 24 91 Miércoles 20 23 25 23 91 Jueves 25 21 28 25 99
Viernes 26 24 28 25 103 Totales Totales por columna, Tc 110 110 125 119 464 Suma de cuadrados 2446 2430 3169 2839 10904 Tamaño de la muestra nc 5 5 5 5 20
Análogo a la tabla ANOVA para un análisis en un sentido, el formato general en dos sentidos es:
Fuente de variación Suma de cuadrados Grados libertad Cuadrado medio
Tratamientos SST k - 1 MSTR
k
SST
1
Bloque SSB n -1 MSB
n
SSB
1
Error SSE (k-1)(n-1) MSE
nk
SSE
)1)(1(
Total Total SS

Como antes, para calcular SST:
4.3220
)464(
5
)119(
5
)125(
5
)110(
5
)110()( 2222222
N
X
n
TSST
c
c
SSB se obtiene mediante:
2.7820
)464(
4
)103(
4
)99(
4
)91(
4
)91(
4
)80()( 22222222
N
x
k
BSSB r
Los demás términos de suma de cuadrados son:
2.13920
)464(10904
)( 222
N
XXSSTotal
SSE = Total SS – SST – SSB=139.2 – 32.4 – 78.2 = 28.6

Los valores para los diferentes componentes de la tabla ANOVA se calculan de la siguiente manera:
Fuente de variación Suma de cuadrados Grados libertad Cuadrado medio
Tratamientos 32.4 3 8.10
3
4.32
Bloque 78.2 4 55.19
4
2.78
Error 28.6 12 38.2
12
6.28
Total 139.0

1.- 43210 : H . Las medias de tratamiento son iguales. :1H Las medias de tratamiento no son iguales.
2.- 543210 : H . Las medias de bloques son iguales.
1H : Las medias de bloques no son iguales.

Primero se demostrará la hipótesis sobre las medias de tratamiento. Hay k – 1 = 4 – 1 = 3 grados de libertad en el numerador y (k – 1) (n – 1) = (4 – 1) (5 – 1) = 12 grados de libertad en el denominador. Al nivel de significancia 0.05, el valor crítico de F es 3.49. La hipótesis nula de que los tiempos medios para las cuatro rutas son iguales se rechaza si la razón F es mayor que 3.49.
54.438.2
8.10
MSE
MSTRF
La hipótesis nula se rechaza y se acepta la hipótesis alternativa. Se concluye que el tiempo promedio de trayecto no es igual para todas las rutas. La empresa desea efectuar algunas pruebas para determinar qué medias de tratamiento difieren.

A continuación, se hace una prueba para determinar si el tiempo del trayecto es igual para diferentes días de la semana. Los grados de libertad en el numerador para bloques es n – 1 = 5 – 1 = 4. Los grados de libertad en el denominador son igual que antes, es decir, 12. La hipótesis nula de que las medias de bloques son iguales se rechaza si la razón F es mayor que 3.26.
21.838.2
55.19
MSE
MSBF
La hipótesis nula se rechaza, y la hipótesis alternativa se acepta. El tiempo promedio del trayecto no es igual para los diferentes días de la semana.

En MINITAB los resultados son los siguientes: Two-way Analysis of Variance Analysis of Variance for Tiempos Source DF SS MS F P rutas 3 32.40 10.80 4.53 0.024 dias 4 78.20 19.55 8.20 0.002 Error 12 28.60 2.38 Total 19 139.20 Individual 95% CI rutas Mean ----+---------+---------+---------+------- 1 22.00 (---------*---------) 2 22.00 (---------*---------) 3 25.00 (---------*---------) 4 23.80 (---------*---------) ----+---------+---------+---------+------- 21.00 22.50 24.00 25.50

Individual 95% CI dias Mean -------+---------+---------+---------+---- 1 20.00 (------*------) 2 22.75 (------*------) 3 22.75 (------*------) 4 24.75 (------*------) 5 25.75 (------*------) -------+---------+---------+---------+---- 20.00 22.50 25.00 27.50 “Estadística para Administración y Economía”, Mason y Lind