series parte 1
TRANSCRIPT

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Objetivos del módulo: Identificar los factores componentes que influyen en una serie de tiempo. Explicar qué causa la tendencia en una serie de tiempo y desarrollar una ecuación para modelarla. Calcular la componente cíclica en una serie de tiempo e identificar lo que causa la variación. Identificar la variación estacional en una serie de tiempo y calcular los índices estacionales para describirlas. Eliminar la estacionalidad en los datos. Desarrollar la descomposición de series para modelos de pronósticos a corto y largo plazo. Medir los errores generados por un procedimiento de pronósticos. Usar técnicas intuitivas de promedios móviles y suavizamiento exponencial para crear un pronóstico. Calcular un coeficiente de autocorrelación. Construir un correlograma. Identificar si los datos son aleatorios, no estacionarios o estacionales. Detectar una correlación serial en una serie de tiempo. Utilizar modelos autorregresivos y de regresión para pronósticos.
1

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Introducción
La mayoría de los procedimientos estadísticos está diseñado para ser aplicados a datos que se originan en una serie de experimentos aleatorios independientes. Los datos resultantes son representativos de una cierta población y el análisis estadístico realiza inferencias sobre ciertos aspectos de la población a partir de la muestra . Con este tipo de datos el orden en que aparecen los datos es irrelevante. Sin embargo en muchos casos necesitamos de los pronósticos o predicciones como herramienta esencial en cualquier proceso de toma de decisiones. Pronosticar supone proyectar la experiencia pasada hacia el futuro, desde la suposición que las condiciones que generaron los datos históricos no serán diferentes de las condiciones futuras. Se debe tener presente que, la calidad de las predicciones que podemos efectuar está estrechamente relacionada con la información que se puede extraer y utilizar de los datos que se tengan.
nx,.......,x1
nx,.......,x1
El análisis de series temporales es un método cuantitativo ampliamente usado como ayuda a tener una visión con incertidumbre acerca del futuro.
Una serie de tiempo o serie cronológica es una sucesión de observaciones (t= 1, 2,...,T) realizadas secuencialmente en el tiempo, por ejemplo cada mes.
En este caso el orden en que aparecen los datos es de suma importancia y los procedimientos clásicos no son directamente aplicables. Las series de tiempo son comunes en muchos campos. Algunos ejemplos son:
ty
Economía : Desempleo, precios, ventas, demanda, etc. Meteorología : Precipitaciones, velocidad del viento, etc. Medicina : Electrocardiogramas, electroencefalogramas, etc. Física : Sismología, oceanografía, etc. Química : Temperatura, viscosidad, concentración, rendimiento, etc.
Algunas series pueden ser observadas continuamente en el tiempo (por ejemplo, temperatura, electrocardiogramas). Se les denomina series de tiempo continuas. En la mayoría de las series, sin embargo, las observaciones se realizan equiespaciadamente en el tiempo. Ellas se denominan series de tiempo discretas y son las únicas que consideraremos en este módulo. 1) DESCOMPOSICIÓN DE UNA SERIE DE TIEMPO 1.1 Descomposición:
En la introducción de este módulo se definió una serie de tiempo como los valores de datos que se recogen, registran u observan en incrementos sucesivos de tiempo. Cuando se registra y observa una serie de tiempo variable, muchas veces es difícil o imposible visualizar sus diferentes componentes. El propósito de descomponer una serie de tiempo es observar cada uno de sus elementos aislados. Al hacerlo, se puede tener una mejor idea de las causas de la variabilidad de la serie. Una segunda razón importante para aislar las
2

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
componentes de una serie de tiempo es facilitar el proceso para determinar los pronósticos. Si se entiende el movimiento de los elementos de una serie, el pronóstico resulta más sencillo.
Para entender los elementos de una serie de tiempo, deben considerarse las relaciones matemáticas entre las componentes. Existen tres modelos de descomposición de una serie, que suelen usarse alternativamente en las aplicaciones, según se comporte la serie analizada. Estos tres modelos son el aditivo,
Yt = Tt + Ct + Et + It (1) el multiplicativo Yt = Tt x Ct x E tx It (2) y el mixto, que puede tomar, por ejemplo, la forma siguiente: Yt = Tt(1+Ct)(1+Et)+It (3) Donde en cada caso: Yt es el valor observado de la variable de interés Tt es la componente llamada tendencia Ct es un término llamado componente cíclica Et es la llamada componente estacional It es la llamada componente irregular . El modelo que más se usa para la descomposición de las series de tiempo es el modelo multiplicativo, en el que Yt es el producto de cuatro elementos que actúan en combinación para producir la serie. A fin de ilustrar la descomposición de una serie, consideremos el siguiente ejemplo: Ejemplo 1.1.1: Los datos que se muestran a continuación corresponden al número de nuevas unidades habitacionales comenzadas en el país desde el tercer trimestre de 1984 al segundo trimestre de 1992.
Año I II III IV1984 398 3521985 283 454 392 3451986 274 392 290 2101987 218 382 382 3401988 298 452 423 3721989 336 468 387 3091990 264 399 408 3961991 389 604 579 5131992 510 661
Representar gráficamente la serie ¿qué puede comentar?
3
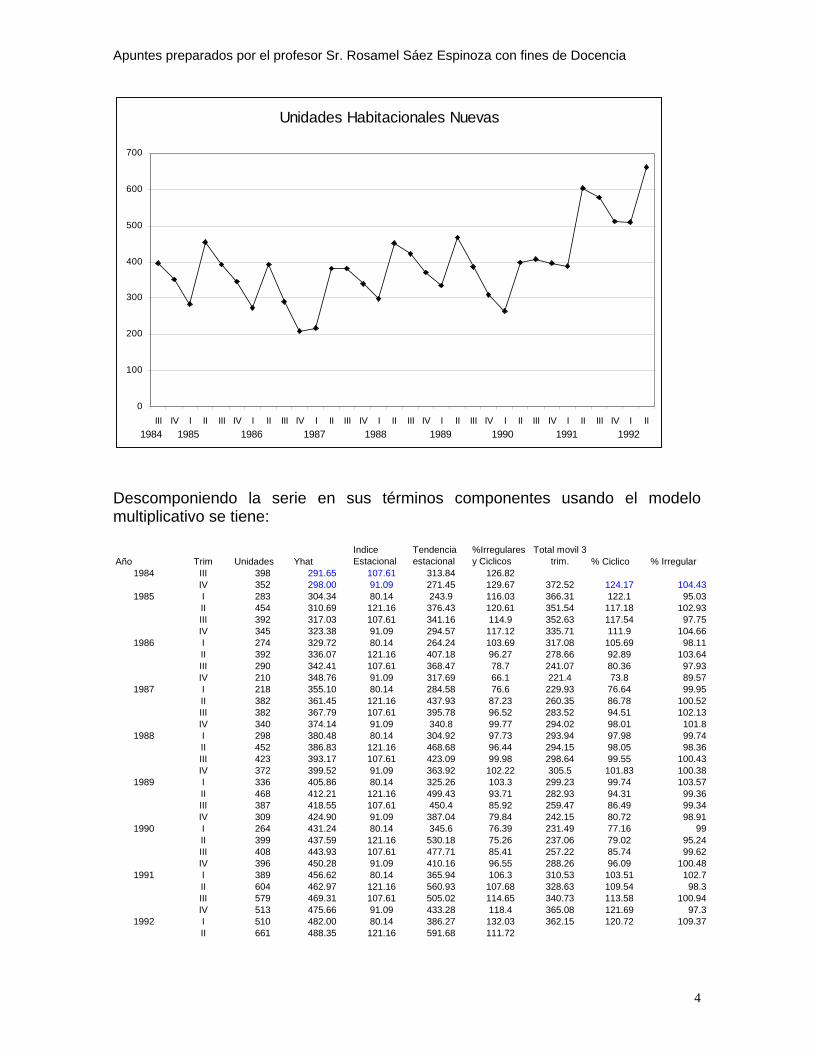
Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Unidades Habitacionales Nuevas
0
100
200
300
400
500
600
700
III IV I II III IV I II III IV I II III IV I II III IV I II III IV I II III IV I II III IV I II1985 1986 1987 19891988 1990 1991 19921984
Descomponiendo la serie en sus términos componentes usando el modelo multiplicativo se tiene: Año Trim Unidades Yhat
Indice Estacional
Tendencia estacional
%Irregulares y Ciclicos
Total movil 3 trim. % Ciclico % Irregular
1984 III 398 291.65 107.61 313.84 126.82IV 352 298.00 91.09 271.45 129.67 372.52 124.17 104.43
1985 I 283 304.34 80.14 243.9 116.03 366.31 122.1 95.03II 454 310.69 121.16 376.43 120.61 351.54 117.18 102.93III 392 317.03 107.61 341.16 114.9 352.63 117.54 97.75IV 345 323.38 91.09 294.57 117.12 335.71 111.9 104.66
1986 I 274 329.72 80.14 264.24 103.69 317.08 105.69 98.11II 392 336.07 121.16 407.18 96.27 278.66 92.89 103.64III 290 342.41 107.61 368.47 78.7 241.07 80.36 97.93IV 210 348.76 91.09 317.69 66.1 221.4 73.8 89.57
1987 I 218 355.10 80.14 284.58 76.6 229.93 76.64 99.95II 382 361.45 121.16 437.93 87.23 260.35 86.78 100.52III 382 367.79 107.61 395.78 96.52 283.52 94.51 102.13IV 340 374.14 91.09 340.8 99.77 294.02 98.01 101.8
1988 I 298 380.48 80.14 304.92 97.73 293.94 97.98 99.74II 452 386.83 121.16 468.68 96.44 294.15 98.05 98.36III 423 393.17 107.61 423.09 99.98 298.64 99.55 100.43IV 372 399.52 91.09 363.92 102.22 305.5 101.83 100.38
1989 I 336 405.86 80.14 325.26 103.3 299.23 99.74 103.57II 468 412.21 121.16 499.43 93.71 282.93 94.31 99.36III 387 418.55 107.61 450.4 85.92 259.47 86.49 99.34IV 309 424.90 91.09 387.04 79.84 242.15 80.72 98.91
1990 I 264 431.24 80.14 345.6 76.39 231.49 77.16 99II 399 437.59 121.16 530.18 75.26 237.06 79.02 95.24III 408 443.93 107.61 477.71 85.41 257.22 85.74 99.62IV 396 450.28 91.09 410.16 96.55 288.26 96.09 100.48
1991 I 389 456.62 80.14 365.94 106.3 310.53 103.51 102.7II 604 462.97 121.16 560.93 107.68 328.63 109.54 98.3III 579 469.31 107.61 505.02 114.65 340.73 113.58 100.94IV 513 475.66 91.09 433.28 118.4 365.08 121.69 97.3
1992 I 510 482.00 80.14 386.27 132.03 362.15 120.72 109.37II 661 488.35 121.16 591.68 111.72
4

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
En el ejemplo 1.1.1 observamos que si en el IV trimestre de 1984, multiplicamos el valor 298 de la columna Yhat por el valor 91.09/100 de la columna Indice estacional, resultado que multiplicamos por 124.17/100 de la columna % cíclico y por último multiplicamos por 104.43/100 de la columna % Irregular observamos que el valor resultante es 352, que corresponde al valor observado de la serie para este periodo. Esto mismo lo puede repetir para las líneas siguientes.
En este ejemplo se muestra claramente como la serie se descompone en sus cuatro términos componentes. Se debe tener presente que una serie de tiempo debe tener al menos una de las cuatro componentes.
Con el fin de describir cada una de las componentes de una serie, consideremos el siguiente ejemplo: Ejemplo 1.1.2: Los datos que se muestran a continuación corresponden al registro
anual de automóviles nuevos (en millones de unidades) en los Estados Unidos entre 1960 y 1991.
Año Autos Año Autos Año Autos Año Autos1960 6.577 1970 8.388 1980 8.761 1990 9.1031961 5.855 1971 9.831 1981 8.444 1991 8.2341962 6.939 1972 10.409 1982 7.7541963 7.557 1973 11.351 1983 8.9241964 8.065 1974 8.701 1984 10.1181965 9.314 1975 8.168 1985 10.8891966 9.009 1976 9.752 1986 11.141967 8.357 1977 10.826 1987 10.1831968 9.404 1978 10.946 1988 10.3981969 9.447 1979 10.357 1989 9.853
Gráficamente
5
6
7
8
9
10
11
12
1960
1962
1964
1966
1968
1970
1972
1974
1976
1978
1980
1982
1984
1986
1988
1990
Figura 1.1.1: Registro anual de automóviles nuevos entre 1960 y 1961
5

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Observe el gráfico ¿qué puede comentar? TENDENCIA La tendencia de una serie de tiempo, también llamada tendencia secular, es la componente que hace que el valor de la variable tienda a aumentar o disminuir en un periodo muy largo. En la figura 1.1.1, se observa una tendencia creciente.
Las fuerzas básicas responsables de la tendencia de una serie son población, crecimiento, inflación de precios, cambios tecnológicos e incrementos de la productividad.
COMPONENTE CÍCLICA
La componente cíclica es una fluctuación con apariencia de ondas alrededor de la tendencia. Cualquier patrón no necesariamente regular de observaciones arriba o abajo de la recta de la tendencia es atribuible a la componente cíclica de la serie de tiempo. La figura 1.1.1 ilustra un patrón típico de fluctuación cíclica por encima y por debajo de la línea de tendencia. Note que los movimientos cíclicos no siguen ningún patrón regular, sino que se mueven de una forma un tanto impredecible. Casi siempre, las fluctuaciones cíclicas están influidas por las condiciones económicas. LA COMPONENTE ESTACIONAL
La componente estacional también llamada variación temporal, se refiere al patrón de cambio que se repite de un año a otro. Para una serie mensual, la componente estacional mide la variabilidad de las series cada enero, cada febrero, etcétera. Para una serie trimestral, existen cuatro medidas estacionales, una para cada trimestre. La variación estacional puede reflejar las condiciones del clima, los días festivos o las longitudes variables de los meses del calendario. COMPONENTE IRREGULAR La componente irregular es una medida de la variabilidad restante de la serie de tiempo después de eliminar las otras componentes. Es la que describe la variabilidad aleatoria en una serie de tiempo causada por factores no previsibles y no recurrentes. La mayor parte de la componente irregular está formada por la variabilidad aleatoria. Sin embargo, algunos eventos no previstos como huelgas, cambios de clima (sequías, inundaciones o sismos), resultados de una elección, conflictos armados o nuevas legislaciones causan irregularidades en una variable.
6

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
1.2) ANÁLISIS DE TENDENCIA Las tendencias se manifiestan en muchas series mediante un crecimiento regular a largo plazo. Otras muestran un decrecimiento, en tanto que algunas parecen constantes o estacionarias, y otras presentan ondas u oscilaciones de periodo muy elevado. Las tendencias suelen representarse mediante funciones del tiempo continuas y diferenciables. Los modelos de regresión más utilizados son: i) Lineal. ii) Polinómico. iii) Exponencial iv) Modelo autorregresivo v) Curva de Gompertz. Disponiendo de observaciones muestrales, el procedimiento consiste en “ajustar” la función más adecuada a los datos aplicando el análisis de regresión. Hay dos tipos de problemas relacionados con el análisis de tendencias: la predicción a largo plazo y la eliminación de tendencias. ¿Porqué estudiar la tendencia? Existen tres razones por la cual resulta útil estudiar la tendencia:
i) El estudio de la tendencia nos permite describir un patrón histórico. ii) El estudio de la tendencia nos permite proyectar patrones pasados, o
tendencias, hacia el futuro. iii) En muchas situaciones, el estudio de la tendencia de una serie de tiempo
nos permite eliminar la componente de tendencia de la serie. Esto facilita el estudio de las otras tres componentes.
1.2.1 Ajuste de tendencia lineal Si la gráfica de la serie sugiere una tendencia lineal, se plantea el ajuste de la función tt tY εββ ++= 10 ; t= 1, 2, ...,T (1.2.1) donde los tε son variables aleatorias que satisfacen los supuestos dados en el modelo de regresión simple. Observe que si retardamos t en un periodo en (1.2.1) y restamos de la ezpresión original se tiene: ttt uYY +=− − 11 β (1.2.2) con 1−−= tttu εε . La expresión (1.2.2) muestra que en el modelo de tendencia lineal la variable crece, aproximadamente, según una progresión aritmética de razón 1β .
7

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Observe además que la serie Zt = Yt – Yt-1 dada por (1.2.2) carece de tendencia, por lo que este procedimiento de generar la serie Zt es un procedimiento habitual para eliminar la tendencia. El procedimiento que se usa para encontrar la recta que mejor se ajusta a los datos observados de la serie de tiempo es el de mínimos cuadrados, el cual corresponde al mismo procedimiento usado para minimizar SCE en el análisis de regresión.
El periodo puede venir expresado en días, semanas, meses, trimestres o años por lo que, lo más practico para trabajar con el periodo en los modelos es codificarlo de manera correlativa desde 1 a T. Para el ejemplo 1.1.2, al año 1960 le corresponde el valor 1, a 1961 el valor 2 y así sucesivamente. Luego, para este ejemplo, ajustando un modelo lineal simple usando excel se tiene: Resumen
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.52237069Coeficiente de determinación R^2 0.27287113R^2 ajustado 0.2486335Error típico 1.18495869Observaciones 32
ANÁLISIS DE VARIANZA
Grados de libertad
Suma de cuadrados
Promedio de los
cuadrados FValor crítico
de FRegresión 1 15.8078891 15.8078891 11.2581612 0.00216301Residuos 30 42.1238127 1.40412709Total 31 57.9317019
Coeficientes Error típico Estadístico t Probabilidad Inferior 95%Superior
95%Intercepción 7.90191129 0.42896223 18.4209957 6.6452E-18 7.02585446 8.77796813Periodo 0.0761228 0.02268721 3.35531835 0.00216301 0.02978939 0.12245621 Observe que el coeficiente de determinación es sólo de un 27,3%, es decir, sólo el 27.3% de la variabilidad de la variable registros de automóviles nuevos es explicada por la variable tiempo.
De los datos observamos que el modelo ajustado para la tendencia es: XY 076123.0901911.7ˆ += Del modelo, se espera que el registro anual de automóviles nuevos se incremente cada año en promedio 0.076123 millones de unidades o 76,123 automóviles nuevos. Veamos ahora cuál sería nuestra estimación de registro de automóviles nuevos para 1992 (tiempo=33) haciendo uso sólo de la tendencia. )33(076123.0901911.7ˆ +=Y
8

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
millones de autos 4139.10= Así, para el año 1992 se esperan 10,413,900 automóviles nuevos en los Estados Unidos. 1.2.2 Ajuste de tendencia polinómica La función polinomial de grado p, (1.2.3) p
pttttf ββββ ++++= ...)( 2210
posee la atractiva propiedad de aproximar a cualquier función no lineal continua , de derivadas también continuas, con cualquier grado de exactitud dentro de un intervalo dado, para lo cual hay que tomar p lo suficientemente grande. De hecho, tomando p=T-1, es posible determinar exactamente pβββ ,...,, 10 de manera que el polinomio reproduzca los T valores observados de Yt. Si bien el polinomio así obtenido describiría exactamente el pasado de la serie temporal Yt, como instrumento predictivo sería poco confiable, pues nada garantiza que la ecuación haya recogido las pautas de comportamientos regulares de la serie. Si se toma p<T-1, los coeficientes del polinomio dejan de estar determinados, y su elección es ya un problema estadístico, que puede resolverse por el método de los mínimos cuadrados. Si lo que pretende es utilizar el polinomio estimado para predecir, hay que tener en cuenta que las predicciones vendrán fuertemente influidas por los términos en los que t figura elevado a la mayor potencia. Ajustemos una tendencia cuadrática al ejemplo 1.1.2. De excel tenemos que:
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.70035924Coeficiente de determinación R^2 0.49050307R^2 ajustado 0.45536535Error típico 1.00885774Observaciones 32
ANÁLISIS DE VARIANZA
Grados de libertad
Suma de cuadrados
Promedio de los
cuadrados FValor crítico
de FRegresión 2 28.4156776 14.2078388 13.9594453 5.6696E-05Residuos 29 29.5160243 1.01779394Total 31 57.9317019
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior 95%Intercepción 6.36026613 0.57030046 11.1524828 5.2542E-12 5.19387008 7.52666218t 0.34817783 0.07967461 4.36999704 0.00014534 0.18522486 0.5111308t2 -0.00824409 0.00234236 -3.51956935 0.00144796 -0.01303475 -0.00345343
9

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
El modelo de tendencia cuadrática es Yt = 6,3603 + 0,3482t – 0,00824t2 con un R2 ajust= 0,455 1.2.2.1 Eliminación de tendencias polinómicas. De la expresión (1.2.2) vimos que si a una serie de tiempo con tendencia lineal se le aplica la primera diferencia, desaparece la tendencia. Siguiendo este procedimiento con una serie de tiempo que presente tendencia polinómica de segundo grado, para eliminar la tendencia hay que realizar dos operaciones consecutivas de obtención de diferencias. Sea , entonces, tt ttY εβββ +++= 2
210
12211 2 −− −++−=−= ttttt tYYZ εεβββ la cual es una expresión lineal en t. Obteniendo las segundas diferencias se tiene que, 2121 22 −−− +−+=− ttttt ZZ εεεβ expresión que ya no tiene tendencia. En general, para eliminar la tendencia polinómica de grado p, se toman diferencias sucesivas de la serie hasta p veces. 1.2.3 Estimación de tendencia exponencial. Suponiendo que la tendencia de la serie de tiempo es dada por la expresión
t=1, 2,...,T (1.2.4) teaeY rtt
ε=el problema estadístico consiste en estimar a y r, a partir del conjunto de observaciones Yt, t=1, 2, ...,T
r<0
r>0
Si tomamos logaritmo natural en la expresión (1.2.4) se tiene, lnYt= lna + rt + tε (1.2.5)
10

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
expresión lineal por lo que, para estimar r se puede usar el método de mínimos cuadrados, suponiendo para tε que satisface los supuestos del modelo de regresión. Para eliminar tendencias exponenciales basta con tomar diferencias usando la expresión (1.2.5). Así lnYt – lnYt-1 = r + utDonde 1−−= tttu εε 1.2.4 Modelo Autorregresivo En algunas ocasiones se usa la relación ttt YY εγγ ++= −110 , 1γ >0 (1.2.6) denominado modelo autorregresivo y sirve para representar tendencias. Una aplicación directa de este modelo es para representar tendencias que presentan dos componentes aditivas, una lineal y otra exponencial.
511 ,=γ
11 =γ
601 ,=γ
Ejemplo 1.2.4.1: Los índices de consumo de energía eléctrica, registrados en una determinada área geográfica en expansión fueron los siguientes : Año 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 Yt 100 195 295 386 537 660 827 973 1318 1425 Graficando la serie, tenemos
11

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
0
200
400
600
800
1000
1200
1400
1600
1800
2000
1978 1980 1982 1984 1986 1988 1990 Del gráfico vemos que existe la posibilidad de ajustar un modelo autorregresivo. Si ajustamos una tendencia lineal, R2= 0,969. Ahora si ajustamos una tendencia exponencial, R2 = 0,956, en cambio un ajuste de un modelo autorregresivo entrega la siguiente salida excel.
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.98671069Coeficiente de determinación R^2 0.97359799R^2 ajustado 0.96982627Error típico 76.0379182Observaciones 9
ANÁLISIS DE VARIANZA
Grados de libertad
Suma de cuadrados
Promedio de los
cuadrados FValor crítico
de FRegresión 1 1492454.53 1492454.53 258.131303 8.7937E-07Residuos 7 40472.355 5781.765Total 8 1532926.89
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior 95%Intercepción 96.6226997 47.1351354 2.04990818 0.07954117 -14.8341047 208.079504Variable Yt-1 1.08606987 0.06759856 16.0664652 8.7937E-07 0.9262248 1.24591495 De la salida, el modelo autorregresivo es , Yt= 96,623 + 1,086Yt-1 con un R2= 0,974 el cual es mas satisfactorio como modelo para predecir la tendencia.
12

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
1.2.5. Curva de Gompertz. Tendencia Para describir fenómenos de crecimiento con un punto de inflexión se puede utilizar la curva Gompertz, que responde a la ecuación:
T(t) = T* (1.2.7) rteb
−
en donde r, b y T* son parámetros positivos. La representación gráfica de esta curva es:
T*
F
La ordenada del punto de inflexión, F, es TF = e-1T* La máxima tasa de crecimiento tiene lugar en el punto de inflexión. 1.3) Estudio de la Componente Cíclica
El procedimiento utilizado para identificar la componente cíclica es el método de los residuos. Cuando observamos una serie temporal consistente en datos anuales, solamente se toman en cuenta las componentes de tendencia secular, cíclica e irregular. La componente cíclica se definió como la fluctuación con forma de onda alrededor de la tendencia. En la figura 1.1.1, las cumbres y valles arriba y debajo de la recta de tendencia representan fluctuaciones cíclicas en el número de registros anuales de automóviles nuevos. Estas fluctuaciones pueden estar influidas por las condiciones cambiantes de la economía como: tasa de interés demanda de los consumidores, niveles de inventarios, condiciones del mercado, etc. Para determinar la componente cíclica cuando la serie temporal está compuesta por datos anuales, empleamos la ecuación conocida como método de los residuos:
)100(YYC = (7)
13

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
la cual es una medida de la variación cíclica como un porcentaje de la tendencia, donde;
C : componente cíclica Y : Valor real de la variable de interés. Y : Pronóstico del valor de Y para el periodo seleccionado. Otra medida de la variación cíclica es el residuo cíclico relativo, cuya expresión
de cálculo está dada por
100)Y
YY(Crel−
= (8)
Aplicando este método a nuestros datos de registros de automóviles nuevos en
los Estados Unidos, obtenemos los siguientes resultados:.
Año Registro Tiempo Pronóstico Indice Residuo Y X Y Cíclico Cíclico Relativo 1960 6,577 1 7,978 82,439 -17,561 1961 5,855 2 8,054 72,697 -27,303 1962 6,939 3 8,130 85,351 -14,649 1963 7,557 4 8,206 92,091 -7,909 1964 8,065 5 8,283 97,368 -2,632 1965 9,314 6 8,359 111,425 11,425 1966 9,009 7 8,435 106,805 6,805 1967 8,357 8 8,511 98,191 -1,809 1968 9,404 9 8,587 109,514 9,514 1969 9,447 10 8,663 109,050 9,050 1970 8,388 11 8,739 95,984 -4,016 1971 9,831 12 8,815 111,526 11,526 1972 10,409 13 8,892 117,060 17,060 1973 11,351 14 8,968 126,572 26,572 1974 8,701 15 9,044 96,207 -3,793 1975 8,168 16 9,120 89,561 -10,439 1976 9,752 17 9,196 106,046 6,046 1977 10,826 18 9,272 116,760 16,760 1978 10,946 19 9,348 117,095 17,095 1979 10,357 20 9,424 109,900 9,900 1980 8,761 21 9,500 92,221 -7,779 1981 8,444 22 9,577 88,170 -11,830 1982 7,754 23 9,653 80,327 -19,673 1983 8,924 24 9,729 91,726 -8,274 1984 10,118 25 9,805 103,192 3,192 1985 10,889 26 9,881 110,201 10,201 1986 11,140 27 9,957 111,881 11,881 1987 10,183 28 10,033 101,495 1,495 1988 10,398 29 10,109 102,859 2,859 1989 9,853 30 10,186 96,731 -3,269 1990 9,103 31 10,262 88,706 -11,294 1991 8,234 32 10,338 79,648 -20,352
14
Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
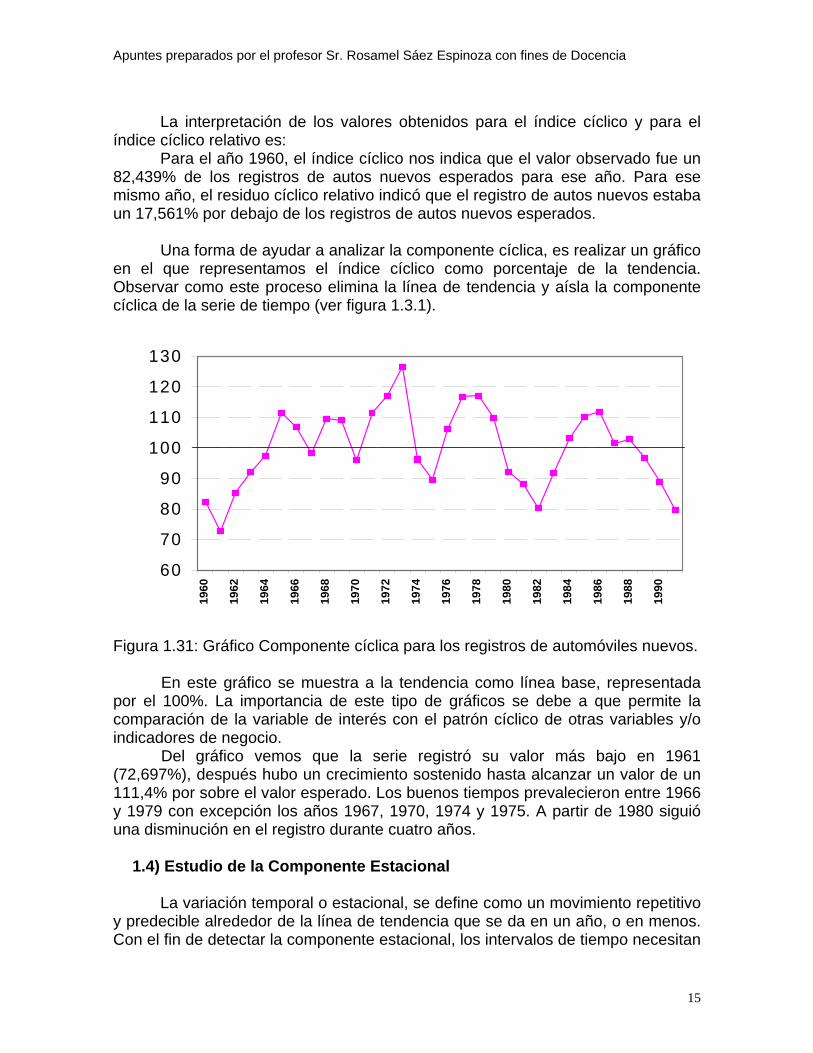
La interpretación de los valores obtenidos para el índice cíclico y para el índice cíclico relativo es: Para el año 1960, el índice cíclico nos indica que el valor observado fue un 82,439% de los registros de autos nuevos esperados para ese año. Para ese mismo año, el residuo cíclico relativo indicó que el registro de autos nuevos estaba un 17,561% por debajo de los registros de autos nuevos esperados.
Una forma de ayudar a analizar la componente cíclica, es realizar un gráfico en el que representamos el índice cíclico como porcentaje de la tendencia. Observar como este proceso elimina la línea de tendencia y aísla la componente cíclica de la serie de tiempo (ver figura 1.3.1).
60
70
80
90
100
110
120
130
1960
1962
1964
1966
1968
1970
1972
1974
1976
1978
1980
1982
1984
1986
1988
1990
Figura 1.31: Gráfico Componente cíclica para los registros de automóviles nuevos.
En este gráfico se muestra a la tendencia como línea base, representada por el 100%. La importancia de este tipo de gráficos se debe a que permite la comparación de la variable de interés con el patrón cíclico de otras variables y/o indicadores de negocio.
Del gráfico vemos que la serie registró su valor más bajo en 1961 (72,697%), después hubo un crecimiento sostenido hasta alcanzar un valor de un 111,4% por sobre el valor esperado. Los buenos tiempos prevalecieron entre 1966 y 1979 con excepción los años 1967, 1970, 1974 y 1975. A partir de 1980 siguió una disminución en el registro durante cuatro años.
1.4) Estudio de la Componente Estacional
La variación temporal o estacional, se define como un movimiento repetitivo y predecible alrededor de la línea de tendencia que se da en un año, o en menos. Con el fin de detectar la componente estacional, los intervalos de tiempo necesitan
15

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
ser medidos en unidades más pequeñas, como días, semanas, meses o trimestres. La descomposición de una serie de tiempo mensual o trimestral puede revelar las componentes estacional e irregular, además de las componentes de tendencia y cíclica. Al examinar cada una de estas cuatro componentes por separado se puede descubrir información interesante y útil que permita al analista combinar estos elementos para producir un buen pronóstico. Los pronósticos que usan series de tiempo mensuales o trimestrales se hacen por lo general para 1 a 12 meses, o para 1 a 4 trimestres futuros. El analista debe tener de 4 a 7 años de datos mensuales o trimestrales para realizar cálculos necesarios para un análisis estacional.
La primera componente que debe aislarse en una serie de tiempo mensual o trimestral es la componente estacional. Se requiere un índice para cada 12 meses o cada 4 trimestres del año; los programas de computación de la serie de tiempo se usan para calcular estos índices. A continuación se da una descripción del procedimiento que usan tales programas para datos mensuales.
La idea básica al calcular un índice estacional mensual es comparar los valores reales de la variable (Y) con un promedio de 12 meses para esa variable. De esta manera se puede determinar si el valor de Y es mayor o menor que el promedio anual y por cuánto. Si se analizan datos trimestrales, se calcula el promedio de cuatro trimestres para la comparación.
Al calcular el promedio anual para la comparación mensual, se debe usar un promedio centrado en el mes que se está examinando. Desafortunadamente, cuando se promedian 12 meses, el centro del promedio no está en el centro del mes sino en el punto en el que termina un mes y comienza otro. Ésta es la razón por la que se usan los siguientes pasos para centrar un promedio de 12 meses para Y en el mes que se examina. (Estos cuatro pasos suponen que los datos comienzan en enero.)
Paso 1 Se calcula el total móvil de 12 meses, de enero a diciembre para los datos del primer año y se coloca opuesto a julio. Se calcula el siguiente total de 12 meses quitando enero del primer año y agregando enero del segundo año. Éste es el total móvil de 12 meses de febrero del primer año a enero del segundo año; se coloca opuesto a agosto.
Paso 2 Se calcula un total móvil de dos años sumando los totales móviles opuestos a julio y a agosto. Los totales de dos años incluyen datos de 24 meses (enero del primer año una vez, de febrero a diciembre dos veces y enero del segundo año una vez). Este total se centra en julio.
Paso 3 Se divide el total móvil de dos años entre 24 para obtener el promedio de 12 meses centrado corregido en julio.
Paso 4 Se calcula el índice estacional para cada mes con la división del valor real de cada mes entre el promedio centrado corregido de 12 meses y se multiplica por 1 00 para convertir la razón en un número índice. A continuación se indica cómo se realiza este cálculo:
16

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Índice estacional
E = )(100TCI
TECI (9)
donde E = índice estacional
TECI = valor real de Y TCI = promedio centrado de 12 meses
Ejemplo 1.4.1La tabla que se muestra a continuación contiene los datos
mensuales de 1985 a 1986 para los registros nuevos de automóviles, y los resultados de los cálculos de los índices estacionales mensuales ilustrado anteriormente.
Tabla 4.1: Procedimiento para el cálculo del índice estacional mensual
Periodo
Registro
Total Móvil 12 meses
Total Móvil De 2 años
Promedio Móvil
Centrado de 12 meses
Índice Estacional
1985 Enero 781 Febrero 790 Marzo 927 Abril 936 Mayo 912 Junio 923 10899 Julio 949 (2) 21930 (3) 913.75 103.86 (4) (1) 11031 Agosto 926 22094 920.58 100.59 11063 Septiembre 1105 22047 918.63 120.29 10984 Octubre 973 21938 914.08 106.45 10954 Noviembre 828 21914 913.08 90.68 10960 Diciembre 849 22009 917.04 92.58 11049 1986 22083 920.13 99.23 Enero 913 11034 Febrero 822 22036 918.17 89.53 11002
17

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Marzo 848 22048 918.67 92.31 11046 Abril 906 22067 919.46 98.54 11021 Mayo 918 21933 913.88 100.45 10912 Junio 1012 21877 911.54 111.02 10965 Julio 934 Agosto 894 Septiembre 1149 Octubre 948 Noviembre 719 Diciembre 902 El paso siguiente es determinar un índice estacional para cada mes. Como este ejemplo contenía pocos datos no determinaremos el índice estacional. Para lograr una mayor comprensión de este método, veamos el siguiente ejemplo. Ejemplo 1.4.2:Los datos que se muestran a continuación, representan el número
de huésped registrados en cada trimestre durante los últimos cinco años:
TRIMESTRE Año I II III IV 1988 1.861 2.203 2.415 1.9081989 1.921 2.343 2.514 1.986 1990 1.834 2.154 2.098 1.799 1991 1.837 2.025 2.304 1.965 1992 2.073 2.414 2.339 1.967 En la tabla que a continuación se anexa, se muestra el desarrollo que conduce
a la obtención del índice estacional para cada trimestre. Tabla 1.4.2.1: Procedimiento para el cálculo del índice estacional por trimestre
Número Total Móvil Total Móvil Promedio Índice Año Trimestre Huésped 4 trimestres de 2 años Móvil
centrado 4 trimestres
Estacional
1988 I 1.861 II 2.203 8.387 III 2.415 16.834 2.104,250 114,8 8.447 IV 1.908 17.034 2.129,250 89,6
18

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
8.587 1989 I 1.921 17.273 2.159,125 89,0 8.686 II 2.343 17.450 2.181,250 107,4 8.764 III 2.514 17.441 2.180,125 115,3 8.677 IV 1.986 17.165 2.145,625 92,6 8.488 1990 I 1.834 16.560 2.070,000 88,6 8.072 II 2.154 15.957 1.994,625 108,0 7.885 III 2.098 15.773 1.971,625 106,4 7.888 IV 1.799 15.647 1.955,875 92,0 7.759 1991 I 1.837 15.724 1.965,500 93,5 7.965 II 2.025 16.096 2.012,000 100,6 8.131 III 2.304 16.498 2.062,250 111,7 8.367 IV 1.965 17.123 2.140,375 91,8 8.756 1992 I 2.073 17.547 2.193,375 94,5 8.791
II 2.414 17.584 2.198,000 109,8 8.793 III 2.339 IV 1.967
Una vez obtenidos los índices estacionales, estos se organizan por trimestres según se indica más abajo Tabla 1.4.2.2: Organización de los índices estacionales obtenidos en tabla 1.4.2.1
TRIMESTRE Año I II III IV 1988 114,8 89,61989 89,0 107,4 115,3 92,6 1990 88,6 108,0 106,4 92,0 1991 93,5 100,6 111,7 91,8 1992 94,5 109,8
Observar que la tabla 1.4.2.2 muestra cuatro índices estacionales para cada trimestre. Para el trimestre I los valores son 89,0, 88,6, 93,5 y 94,5.
19

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
El paso siguiente a esta organización de los índices estacionales es combinar estos valores en un solo índice por trimestre, para ello calculamos un promedio por trimestre.
Para que este promedio sea representativo del trimestre correspondiente, es conveniente eliminar los valores extremos, para ello existen varios procedimientos estadísticos que permiten la detección de estos valores, como por ejemplo el gráfico de caja y bigote. También esta la comparación de la media con la mediana. También se puede obtener el coeficiente de variación.
Veamos estos resultados para el ejemplo anterior. Tabla 1.4.2.3: Estadísticos descriptivos por trimestre
Año I II III IV1988 114.8 89.61989 89.0 107.4 115.3 92.61990 88.6 108.0 106.4 92.01991 93.5 100.6 111.7 91.81992 94.5 109.8
Promedio 91.4 106.45 112.05 91.5Mediana 91.25 107.7 113.25 91.9Desv. Estand 3.03 4.03 4.09 1.31Coef. Var. 3.32 3.79 3.65 1.43
Trimestre
De los resultados obtenidos observamos que la media no es fuertemente diferente de la mediana, por lo que ya el promedio es un buen representante del centro. Además, el coeficiente de variación es bastante pequeño (<4%), lo que indica que cada serie es bastante homogénea. De esta forma podemos considerar al promedio como índice estacional de cada trimestre. Los valores de los índices estacionales obtenidos en la tabla 1.4.2.1, todavía contienen las componentes cíclica e irregular de la variación de la serie de tiempo. Al eliminar los valores extremos de cada trimestre reducimos las variaciones cíclica e irregular extremas. Cuando promediamos los valores restantes, suavizamos aún más estas componentes. Las variaciones cíclicas e irregular tienden a ser eliminadas mediante este proceso, de modo que la media es un índice de la componente estacional. Al sumar los cuatro nuevos índices de la tabla 1.4.2.3 (91,4+106,45+112,05+91,5) dan por resultado 401,4, sin embargo, la base de un índice siempre es 100. Por consiguiente, los cuatro índices trimestrales deben dar un total de 400 y su media debe ser de 100. Para corregir este error, multiplicamos cada uno de los índices trimestrales por una constante de ajuste. Este número se encuentra dividiendo la suma deseada de los índices (400) entre la suma real (401,4), siendo en este caso la constante de ajuste igual a 0,99651.
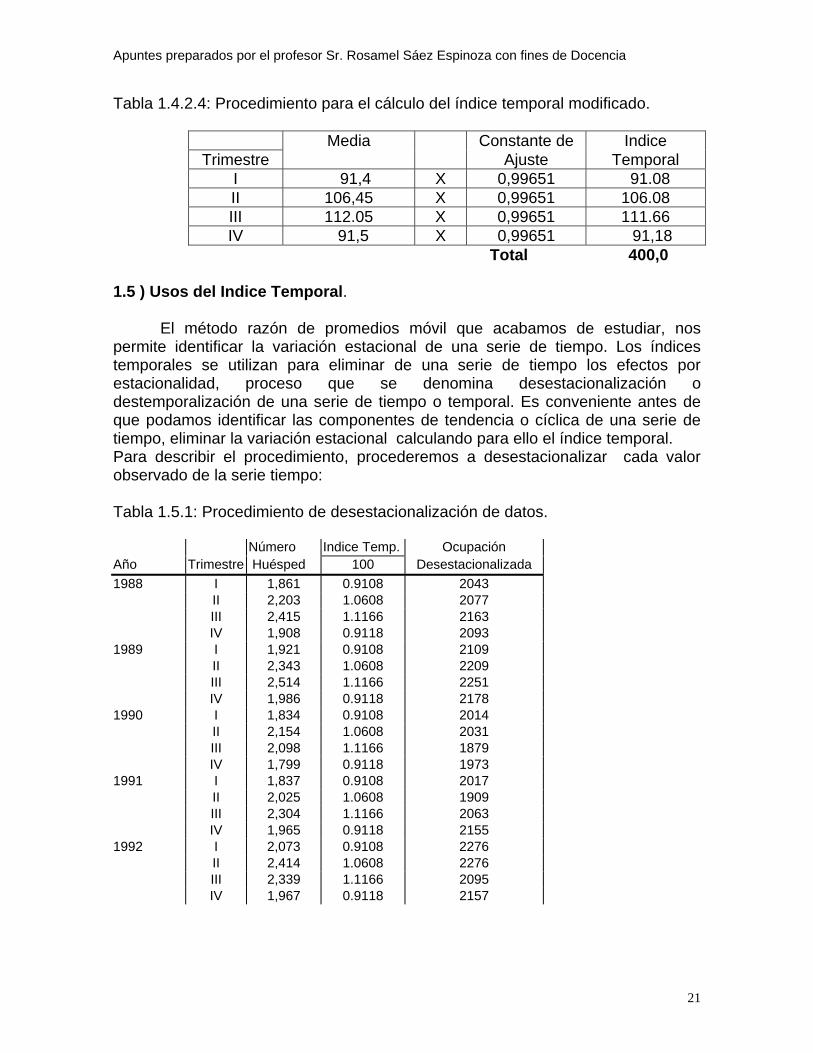
A continuación mostramos el cálculo del índice temporal por trimestre, donde el índice temporal = media modificada x constante de ajuste, así:
20
Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Tabla 1.4.2.4: Procedimiento para el cálculo del índice temporal modificado.
Media Constante de Indice Trimestre Ajuste Temporal
I 91,4 X 0,99651 91.08 II 106,45 X 0,99651 106.08 III 112.05 X 0,99651 111.66 IV 91,5 X 0,99651 91,18
Total 400,0 1.5 ) Usos del Indice Temporal. El método razón de promedios móvil que acabamos de estudiar, nos permite identificar la variación estacional de una serie de tiempo. Los índices temporales se utilizan para eliminar de una serie de tiempo los efectos por estacionalidad, proceso que se denomina desestacionalización o destemporalización de una serie de tiempo o temporal. Es conveniente antes de que podamos identificar las componentes de tendencia o cíclica de una serie de tiempo, eliminar la variación estacional calculando para ello el índice temporal. Para describir el procedimiento, procederemos a desestacionalizar cada valor observado de la serie tiempo: Tabla 1.5.1: Procedimiento de desestacionalización de datos.
Número Indice Temp. Ocupación Año Trimestre Huésped 100 Desestacionalizada 1988 I 1,861 0.9108 2043 II 2,203 1.0608 2077 III 2,415 1.1166 2163 IV 1,908 0.9118 2093 1989 I 1,921 0.9108 2109 II 2,343 1.0608 2209 III 2,514 1.1166 2251 IV 1,986 0.9118 2178 1990 I 1,834 0.9108 2014 II 2,154 1.0608 2031 III 2,098 1.1166 1879 IV 1,799 0.9118 1973 1991 I 1,837 0.9108 2017 II 2,025 1.0608 1909 III 2,304 1.1166 2063 IV 1,965 0.9118 2155 1992 I 2,073 0.9108 2276
II 2,414 1.0608 2276 III 2,339 1.1166 2095 IV 1,967 0.9118 2157
21

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Ya que ha sido eliminado el efecto de las estaciones, los valores
desestacionalizados que quedan, solamente reflejan las componentes de tendencia, cíclica e irregular de la serie de tiempo.
Una vez que hemos eliminado la variación temporal, podemos determinar la tendencia desestacionalizada, que luego podemos proyectar hacia el futuro.
A continuación mostraremos los gráficos correspondiente a la serie observada junto al promedio móvil (figura 1.5.1) y a la serie observada junto a los valores desestacionalizados (figura 1.5.2) Figura 1.5.1: Gráfico promedio móvil para suavizar la serie de tiempo original
1,500
1,700
1,900
2,100
2,300
2,500
2,700
I II III IV I II III IV I II III IV I II III IV I II III IV
Serie1 Serie2La línea indicada como serie 1 en esta figura representa los valores observados, en cambio la línea punteada indicada como serie 2, representa los valores obtenidos por el método razón de promedios móvil para cada trimestre. La figura 1.5.1, muestra cómo el promedio móvil ha suavizado las cimas y valles de la serie de tiempo original.
22

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Figura 1.5.2: Gráfico comparación de la serie desestacionalizada junto a la serie original.
1500
1700
1900
2100
2300
2500
2700
I II III IV I II III IV I II III IV I II III IV I II III IV
Serie1 Serie2
La línea indicada como serie 1 en esta figura representa los valores observados, en cambio la línea punteada indicada como serie 2, representa los valores de la serie ya desestacionalizados. Procedamos ahora a estimar la línea de tendencia desestacionalizada, para ello aplicamos el método de mínimos cuadrados. Recordar codificar la variable tiempo, en este caso se codificó de 1 a 20 El modelo a ajustar es:
XˆˆY 10 β+β=donde representa los valores ajustados de la serie desestacionalizada Y y son los parámetros estimados del modelo. 0β 1β X es el periodo
23

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.08984655Coeficiente de determinación R^2 0.0080724R^2 ajustado -0.04703469Error típico 114.693274Observaciones 20
ANÁLISIS DE VARIANZA
Grados de libertad
Suma de cuadrados
Promedio de los
cuadrados FValor crítico
de FRegresión 1 1926.95338 1926.95338 0.14648573 0.7063986Residuos 18 236781.847 13154.547Total 19 238708.8
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior 95%Intercepción 2080.52632 53.2786334 39.0499189 7.4643E-19 1968.59197 2192.46066X 1.70225564 4.44761439 0.38273454 0.7063986 -7.64184268 11.046354
De esta salida excel vemos que el modelo de la tendencia desestacionalizada es: XY 7022152632080 ..ˆ += A partir de esta línea de tendencia podemos hacer proyecciones hacia el futuro, por ejemplo, realicemos un pronóstico para el cuarto trimestre de 1993, el cual corresponde a un tiempo de 24 de acuerdo a la variable codificada, así )(..ˆ 247022152632080 +=Y =2.121 personas Conocida esta predicción debemos tomar en consideración el efecto de las estaciones, para ello debemos multiplicar la ocupación promedio desestacionalizada predicha 2.121 por el índice temporal correspondiente al cuarto trimestre, expresado como fracción de 100, para obtener de este modo una estimación estacionalizada, así 2.121 x 0.9118=1.934 personas.
Veamos ahora un ejemplo completo que nos permitirá estudiar todas las componentes. Ejemplo: Suponga que deseamos predecir las ventas de una compañía que se
especializa en la producción de equipos para recreación. En la tabla 1.5.2 mostramos las ventas pasadas o históricas de esta compañía:
24

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Tabla 1.5.2: Ventas trimestrales de equipos para recreación entre 1988 y 1992.
Ventas x Trimestre (x$1.000.000) Año I II III IV 1988 16 21 9 18 1989 15 20 10 18 1990 17 24 13 22 1991 17 25 11 21 1992 18 26 14 25
Como los datos de la tabla 1.5.2 están por trimestres, como primer paso
debemos desestacionalizar la serie temporal. Primero calculamos los promedios móviles por el método razón de promedio móvil, para luego obtener el índice estacional., estos se muestran en la tabla siguiente:
Tabla 1.5.3: Procedimiento para la determinación del índice estacional:
Total Móvil Total Móvil Promedio Índice Año Trimestre Ventas 4 trimestres de 8 trim. Móvil (1) Estacional 1988 I 16 II 21 64 III 9 127 15.875 56.7 63 IV 18 125 15.625 115.2 62 1989 I 15 125 15.625 96.0 63 II 20 126 15.750 127.0 63 III 10 128 16.000 62.5 65 IV 18 134 16.750 107.5 69 1990 I 17 141 17.625 96.5 72 II 24 148 18.500 129.7 76 III 13 152 19.000 68.4 76 IV 22 153 19.125 115.0 77 1991 I 17 152 19.000 89.5 75 II 25 149 18.625 134.2 74
25

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
III 11 149 18.625 59.1 75 IV 21 151 18.875 111.3 76 1992 I 18 155 19.375 92.9 79
II 26 162 20.250 128.4 83 III 14 IV 25
El paso siguiente consiste en organizar los índices obtenidos en la última columna de la tabla 5.3 y calcular la media modificada, con la cual obtenemos el nuevo índice temporal . Tabla 1.5.4 : Procedimiento para la obtención de la media modificada.
Año I II III IV 1988 56.7 115.2 1989 96 127 62.5 107.5 1990 96.5 129.7 68.4 115 1991 89.5 134.2 59.1 111.3 1992 92.9 128.4
Promedio 93.725 129.825 61.675 112.25 Mediana 94.45 129.05 60.8 113.15
Desv. Estándar 3.236 3.118 5.076 3.639 Coef. Var. 3.452 2.402 8.230 3.242
La suma de las medias modificadas es : 397,475, por lo que el factor de ajuste es
0063521475397
400 ,,
=
Tabla 5.5: Procedimiento para el cálculo del índice temporal modificado.
Media Constante de Indice Trimestre Modificada Ajuste Temporal
I 93,725 X 1,006352 94,32 II 129,825 X 1,006352 130,65 III 61.675 X 1,006352 62,07 IV 112.25 X 1,006352 112,96
Total 400
26

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Tabla 1.5.6: Procedimiento de desestacionalización de datos.
Indice Temp. Ventas Año Trimestre Ventas 100 Desestacionalizada 1988 I 16 0.9432 16.96 II 21 1.3065 16.07 III 9 0.6207 14.50 IV 18 1.1296 15.93 1989 I 15 0.9432 15.90 II 20 1.3065 15.31 III 10 0.6207 16.11 IV 18 1.1296 15.93 1990 I 17 0.9432 18.02 II 24 1.3065 18.37 III 13 0.6207 20.94 IV 22 1.1296 19.48 1991 I 17 0.9432 18.02 II 25 1.3065 19.14 III 11 0.6207 17.72 IV 21 1.1296 18.59 1992 I 18 0.9432 19.08
II 26 1.3065 19.90 III 14 0.6207 22.56 IV 25 1.1296 22.13
Con las ventas desestacionalizada estamos ahora en condiciones de obtener la línea de tendencia desestacionalizada, para ello emplearemos excel
Estadísticas de la regresiónCoeficiente de correlación múltiple 0.83129099Coeficiente de determinación R^2 0.6910447R^2 ajustado 0.67388052Error típico 1.28463688Observaciones 20
ANÁLISIS DE VARIANZA
Grados de libertad
Suma de cuadrados
Promedio de los
cuadrados FValor crítico
de FRegresión 1 66.4421654 66.4421654 40.260856 5.6017E-06Residuos 18 29.7052546 1.65029192Total 19 96.14742
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior 95%Intercepción 14.7140526 0.59675424 24.6568044 2.5265E-15 13.4603175 15.9677877X 0.31609023 0.04981608 6.34514429 5.6017E-06 0.21143044 0.42075001
27

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
De la salida excel vemos que nuestro modelo estimado es: XY 3161071414 ,,ˆ += Supongamos ahora que deseamos realizar estimaciones de las ventas para todos los trimestres de 1993 ¿cuáles serían los pasos a seguir? 1.- Debemos determinar los valores desestacionalizados de las ventas para los
cuatro trimestres de 1993 mediante el uso de la ecuación de tendencia . Esto requiere obviamente de la codificación de los
cuatros trimestres de 1993. XY 3161071414 ,,ˆ +=
Como los trimestres históricos fueron codificados correlativamente de 1 a 20, entonces a los trimestres de 1993 le corresponden los códigos 21, 22, 23 y 24 respectivamente. Sustituyendo estos valores en la ecuación de la tendencia tenemos que:
352121316107141421 ,)(.,ˆ =+=Y
662122316107141422 ,)(.,ˆ =+=Y 982123316107141423 .)(.,ˆ =+=Y 302224316107141424 ,)(.,ˆ =+=Y
Cada uno de estos valores estimados de ventas para los cuatro trimestres del año 1993 se encuentran sobre la línea de tendencia.
2.- Ahora debemos estacionalizar esta estimación multiplicándola por el índice estacional correspondiente a cada trimestre, expresado como una fracción de 100, así los nuevos valores son:
21,35 x 0,9432 =20.14 21,66 x 1,3065= 28.30 21.98 x 0,6207 = 13.64 22,30 x 1,1296 = 25.19 Sobre la base de este análisis, la compañía estima que las ventas por trimestre para 1993 serán de $20.140.000, $28.300.000, $13.640.0000 y $25.190.000 respectivamente. A continuación en la figura 7 podemos apreciar la serie original junto a su proyección para cada trimestre de 1993.
28

Apuntes preparados por el profesor Sr. Rosamel Sáez Espinoza con fines de Docencia
Figura 1.5.7: Serie original junto a la proyección de ventas para 1993.
05
1015202530
I1988
III I1989
III I1990
III I1991
III I1992
III I1993
III
Ventas Estimación
Para finalizar con esta primera parte, se dejará el siguiente ejercicio para su análisis. Ejercicio: Los datos que a continuación se muestran corresponden a registros
mensuales de automóviles nuevos
1985 1986 1987 1988 1989 1990 1991 ene 781 913 800 774 733 619 599 feb 790 822 671 810 722 657 590 mar 927 848 829 919 833 773 669 abr 936 906 895 852 843 751 675 may 912 918 830 874 885 819 744 jun 923 1012 963 981 950 858 792 jul 949 934 899 883 830 779 755
ago 926 894 903 901 880 777 675 sep 1105 1149 955 937 956 825 737 oct 973 948 819 807 800 787 692 nov 828 719 718 764 666 683 610 dic 849 902 901 896 694 683 628
29