proyecto de simulacion
TRANSCRIPT

1
Simulación aplicada a la teoría
de colas
15/05/2015
Ing. Eugenio Heriberto Martínez Castellanos

2
INTEGRANTES:
HERNANDEZ HERNANDEZ YARI MARIA
HERNANDEZ PALMA TANIA GUADALUPE
LEON APARICIO MARIA GUADALUPE
SEGURA PEREZ YADIS MARIA
ALATRISTE DE LA ROSA SANDRA

3
Índice
Introducción: .......................................................................................................................................................... 5
HISTORIA ............................................................................................................................................................. 6
DRECCIÓN DE LA EMPRESA: ........................................................................................................................ 6
PLANTEAMIENTO DEL PROBLEMA: ............................................................................................................. 7
OBJETIVO GENERAL: ....................................................................................................................................... 8
OBJETIVO ESPECIFICO ................................................................................................................................... 8
TAREAS: ............................................................................................................................................................... 8
JUSTIFICACION........................................................................................................................................................ 9
CAPÍTULO 1: ESTADO DEL ARTE (MARCO TEÓRICO Y CONCEPTUAL) ......................................... 11
1.1.- Teoría de Colas: ................................................................................................................................... 11
1.2 HISTORIA ................................................................................................................................................ 12
1.3 DEFINICIONES INÍCIALES: ........................................................................................................................... 12
1.4 CARACTERÍSTICAS DE LOS SISTEMAS DE COLAS .................................................................. 13
1.5 Estructura Básica de los Modelos de Colas: ..................................................................................... 15
1.6 El Proceso de Colas Elemental: ........................................................................................................... 21
1.7 Notación básica ....................................................................................................................................... 22
1.8 Terminología: ........................................................................................................................................... 36
1.9 Proceso de nacimiento y muerte: ......................................................................................................... 37
1.10 Aplicación de la teoría de colas .......................................................................................................... 38
Capítulo 2: PROCESO DE SIMULACIÓN DE EVENTOS DISCRETOS .................................................... 40
Capítulo 2. PROCESO DE SIMULACIÓN DE EVENTOS DISCRETOS..................................................................... 41
2.1.- Papel de la Simulación en los Estudios de Investigación de............................................................... 41
Operaciones: .................................................................................................................................................... 41
2.2.- Simulación de Eventos Discretos Versus Continuos: ................................................................................ 43
2.3.- ¿Cuándo Simular?: ................................................................................................................................... 43
2.4.- Ventajas de la simulación: ....................................................................................................................... 45
2.5.- Desventajas de la simulación: .................................................................................................................. 45
2.6.- Etapas de un Proyecto de Simulación: ..................................................................................................... 46

4
CAPITUL 3: DISEÑO DEL EXPERIMENTO Y ANALISIS DE RESULTADO ................................................................... 34
3.1 Método de Simulación aplicado al Banco Santander Serfín. ............................................................. 35
3.2 Permisos ..................................................................................................................................................... 36
3.3 Recolección de datos .................................................................................................................................. 37
3.4 Tratamiento de Datos en StatGraphics. .................................................................................................... 41
3.5 Simulación de Caso base en Promodel. ..................................................................................................... 44
3.6 INTERPRETACION DE RESULTADOS (CASO BASE: 2 SERVIDORES) ............................................................ 52
.............................................................................................................................................................................. 53
RECOMENDACIONES ............................................................................................................................................ 56
BIBLIOGRAFÍA ................................................................................................................................................... 57
ANEXOS ................................................................................................................................................................ 58
DIAGRAMA DE GANTT ...................................................................................................................................... 58
FOTOS ............................................................................................................................................................... 59

5
Introducción:
El presente proyecto se elaboró con el propósito de conocer, aplicar y comprender todo el
marco conceptual de la asignatura de “SIMULACIÓN”, en el siguiente trabajo se mostrara
como por medio de software es más fácil, sencillo y económico el poder representar el
tiempo de operaciones de un sistema, en este caso los tiempos de operación en el banco
Santander Serfin.
En cada capítulo se irá desarrollando este proyecto en el que se podrá observar de manera
detallada que tan productivo es el uso de software de simulación sin necesidad de gastar ni
un solo peso.
En el capítulo uno se podrán ver de forma detallada la información de dicha empresa que
abastece de dinero en efectivo a la población, en el capítulo dos se mostrará los conceptos
básico de la teoría de colas y del proceso de simulación con variables aleatorias, el capítulo
número tres resalta de entre todos, porque reflejará el desarrollo del proyecto, conformado
desde el proceso de recolección de datos, hasta el de simulación y el de las
recomendaciones que se elaboraron tras haber simulado con cantidades diferentes de
servidores, pues como equipo se pudo comprender de que este sería el factor que alteraría
significativamente el exceso de colas en el banco.
Para finalizar este proyecto usted observara las conclusiones y los anexos; tales como fotos
tomadas de evidencia, para certificar que el proceso de toma de tiempos fue hecho
correctamente y realizado por los propios alumnos del curso de simulación.

6
HISTORIA
Grupo Financiero Santander
La historia del Grupo Financiero Santander tiene su origen más remoto en la creación del
Banco de Londres, México y Sudamérica en el año de 1864.
El 22 de septiembre de 1932 nace el Banco Mexicano. En 1941 surge la Sociedad Mexicana
de Crédito Industrial, la que toma acciones de Banco Mexicano en 1955. Para 1958 se
fusionan Banco Mexicano y el Banco Español, nacido para atender las necesidades de una
amplia generación de empresarios españoles en México. Antes de ser Banco Español, tenía
como nombre Banco Fiduciario.
En 1970 el Banco de Londres y México se sumó a la Compañía General de Aceptaciones
para que de la operación surgiera Banca Serfin y en 1992 se crea el Grupo Financiero Serfin
luego de la compra que realizara Operadora de Bolsa de Banca Serfin. Transcurre el tiempo
hasta que en 1979 se conforma Banco Mexicano Somex ya en calidad de banca múltiple
que tuvo en su seno a 114 empresas industriales. Para el 11 de marzo de 1992 Banco
Mexicano Somex es vendido al Grupo Inverméxico como parte del proceso de privatización
bancaria, adquiriendo el nombre de Banco Mexicano.
DRECCIÓN DE LA EMPRESA:
Reforma 216, 86300 Comalcalco, TAB, México
NÚMERO TELEFÓNICO: 01 933 334 200
ANTECEDENTES DEL PROBLEMA
En la sucursal de Santander ubicado en el municipio de Comalcalco se presenta la
problemática de la saturación de las ventanillas de las diversas operaciones bancarias
(pagos, depósitos, cobro de cheques, etc.), el banco Santander maneja la nómina de ciertas

7
empresas que junto y a los clientes habituales y sumando a los educandos del Instituto
superior de Comalcalco el banco se ve superado en sus servicios, generando largas filas y
se generan así tiempo de espera largo y la inconformidad de los clientes quienes se ven
afectado.
PLANTEAMIENTO DEL PROBLEMA:
Durante nuestras visitas al banco podemos observar que suscitan muchos inconvenientes al
momento de recibir el servicio. Hay una tasa de llegada que se prolonga dependiendo la
hora del día en que se atiende al cliente. La fila se va generando muy rápido. Los clientes
tardan en el servicio un tiempo impredecible, debido a que hay clientes en exceso los
operadores no se dan abasto. Este problema genera desde luego una gran fila y el agobio
de los clientes al tardar tanto tiempo en la cola por ello muchos de ellos deciden abandonar
el lugar sin recibir el servicio.

8
OBJETIVO GENERAL:
Como ingenieros industriales nos dimos la tarea de estudiar a fondo el proceso en cuestión,
obtener un caso base del sistema, y simular las posibles soluciones de este., puesto que a
simple vista se observa que este sistema se encuentra fuera de control por ello se busca
tratar de resolver este problema sugiriendo posibles soluciones que ayuden a la eficiencia y
eficacia de este ya que el primordial objetivo de la empresa es atender a la mayor cantidad
de clientes en el menor tiempo que sea posible.
OBJETIVO ESPECIFICO
El objetivo de la simulación es buscar la reducción de los tiempos de espera que se
generan en las diversas operaciones bancarias, mejorando la calidad del servicio en el
banco al optimizar los tiempos de los clientes.
TAREAS:
Para la solución de este problema haremos uso de softwares estadísticos como Excel,
Statgraphics, que nos servirán de apoyo para el estudio de nuestros datos y así encontrar a
que distribución se ajustan. Posteriormente por medio del Software de simulación
PROMODEL podremos encontrar las posibles causas que generan el exceso de colas en
el Banco Santander y estudiar más a fondo que factores son los que el sistema necesita.
Con apoyo de estos softwares trataremos de dar las posibles soluciones que el sistema
pueda tener, para cumplir con nuestro objetivo.

9
JUSTIFICACION
Cualquier análisis puede ser hecho manualmente, sin embargo cuando la complejidad
aumenta, la necesidad de usar una herramienta basada en computadora también aumenta.
Una hoja de cálculo puede ser utilizada para hacer muchos cálculos complejos, para
determinar el estatus operacional de cualquier sistema bajo estudio. La limitación de la hoja
de cálculo es su falta de habilidad para incluir la aleatoriedad que ocurre en el modelo, así
como las interdependencias que los recursos y las entidades moviéndose en el modelo
tienen unos contra otras y viceversa. Los análisis de qué pasa si? pueden ser análisis
hechos a través de muchas corridas de los cálculos, sin embargo, los números promedio
que son utilizados en una hoja de cálculo como la tasa de llegadas telefónicas, o la duración
de las actividades (como la atención de la llamada) y la inesperada falla en la disponibilidad
de los recursos (turnos, descansos, etc.), no representan la realidad. La Simulación captura
la aleatoriedad y las interdependencias de la realidad, y permite utilizar distribuciones de
probabilidad en lugar de promedios.

10
Capítulo 1: ESTADO DEL ARTE
(MARCO TEÓRICO Y
CONCEPTUAL)

11
CAPÍTULO 1: ESTADO DEL ARTE (MARCO TEÓRICO Y CONCEPTUAL)
1.1.- Teoría de Colas:
Las colas (líneas de espera) son parte de la vida diaria. Todos compramos en colas para
poder comprar un boleto para el cine, hacer un depósito en el banco, pagar en el súper
mercado, enviar un paquete por correo, obtener comida en la cafetería, subir a un juego en
la feria, etc. Nos hemos acostumbrados a una cantidad de esperas, pero todavía nos
molesta cuando estas son demasiado largas.
Sin embargo, tener que esperar no solo es una molestia personal. El tiempo que la
población de un país pierde al esperar en las colas es un factor importante tanto de la
calidad de vida como de la eficiencia de su economía.
También ocurren grandes ineficiencias debido a otros tipos de espera que no son personas
en una cola. Por ejemplo, cuando las máquinas esperan ser reparadas pueden provocarse
pérdidas de producción. Los vehículos (incluso barcos y camiones) que deben esperar
su descarga pueden retrasar envíos subsecuentes. Los aviones que esperan despegar
o aterrizar pueden desorganizar la programación posterior de vuelos. Los retrasos de
las transmisiones de telecomunicaciones por saturación de líneas pueden causar fallas
inesperadas en los datos. Cuando los trabajos de manufactura esperan su proceso se
puede perturbar el proceso de producción. El retraso de los trabajos de servicio respecto de
su fecha de entrega es una causa de pérdidas de negocios futuros.
La teoría de colas es el estudio de la espera en las distintas modalidades. Utiliza los
modelos de colas para representar los tipos de sistemas de líneas de espera (sistemas que
involucran colas de algún tipo) que surgen en la práctica. Las fórmulas de cada modelo

12
indican cuál debe ser el desempeño del sistema correspondiente y señalan la
cantidad promedio de espera que ocurrirá en diversas circunstancias.
Por lo tanto, estos modelos de líneas de espera son muy útiles para determinar cómo
operar un sistema de colas de la manera más eficaz. Proporcionar demasiada
capacidad de para operar el sistema implica costos excesivos; pero si no se cuenta con
suficiente capacidad de servicio surgen esperas excesivas con todas sus desafortunadas
consecuencias. Los modelos permiten encontrar un balance adecuado entre el costo de
servicio y la cantidad de espera.
1.2 HISTORIA
La teoría de colas fue originariamente un trabajo práctico. La primera aplicación de la que se
tiene noticia es del matemático danés Agner Krarup Erlang (trabajador de la Copenhagen
Telephone Exchange), sobre conversaciones telefónicas en 1909, para el cálculo de tamaño
de centralitas. Después se convirtió en un concepto teórico que consiguió un gran desarrollo,
y desde hace unos años se vuelve a hablar de un concepto aplicado aunque exige un
importante trabajo de análisis para convertir las fórmulas en realidades, o viceversa.
1.3 DEFINICIONES INÍCIALES:
► La teoría de colas es el estudio matemático del comportamiento de líneas de
espera. Esta se presenta, cuando los “clientes” llegan a un “lugar” demandando un
servicio a un “servidor”, el cual tiene una cierta capacidad de atención. Si el servidor
no está disponible inmediatamente y el cliente decide esperar, entonces se forma la
línea de espera.
► Una cola es una línea de espera y la teoría
de colas es una colección de modelos
matemáticos que describen sistemas de línea
de espera particulares o sistemas de colas.
Los modelos sirven para encontrar un buen compromiso entre costes del sistema y
los tiempos promedio de la línea de espera para un sistema dado.

13
► Los sistemas de colas son modelos de sistemas que proporcionan servicio. Como
modelo, pueden representar cualquier sistema en donde los trabajos o clientes
llegan buscando un servicio de algún tipo y salen después de que dicho servicio
haya sido atendido.
1.4 CARACTERÍSTICAS DE LOS SISTEMAS DE COLAS
Seis son las características básicas que se deben utilizar para describir adecuadamente un
sistema de colas:
a) Patrón de llegada de los clientes
b) Patrón de servicio de los servidores
c) Disciplina de cola
d) Capacidad del sistema
e) Número de canales de servicio
f) Número de etapas de servicio
Algunos autores incluyen una séptima característica que es la población de posibles
clientes.
► Patrón de llegada de los clientes
En situaciones de cola habituales, la llegada es estocástica, es decir la llegada depende de
una cierta variable aleatoria, en este caso es necesario conocer la distribución probabilística
entre dos llegadas de cliente sucesivas. Además habría que tener en cuenta si los clientes
llegan independiente o simultáneamente. En este segundo caso (es decir, si llegan lotes)
habría que definir la distribución probabilística de éstos. También es posible que los clientes
sean “impacientes”. Es decir, que lleguen a la cola y si es demasiado larga se vayan, o que
tras esperar mucho rato en la cola decidan abandonar. Por último es posible que el patrón
de llegada varíe con el tiempo. Si se mantiene constante le llamamos estacionario, si por
ejemplo varía con las horas del día es no-estacionario.

14
► Patrones de servicio de los servidores
Los servidores pueden tener un tiempo de servicio variable, en cuyo caso hay que asociarle,
para definirlo, una función de probabilidad. También pueden atender en lotes o de modo
individual. El tiempo de servicio también puede variar con el número de clientes en la cola,
trabajando más rápido o más lento, y en este caso se llama patrones de servicio
dependientes. Al igual que el patrón de llegadas el patrón de servicio puede ser no-
estacionario, variando con el tiempo transcurrido.
► Disciplina de cola
La disciplina de cola es la manera en que los clientes se ordenan en el momento de ser
servidos de entre los de la cola. Cuando se piensa en colas se
admite que la disciplina de cola normal es FIFO (atender
primero a quien llegó primero) Sin embargo en muchas colas
es habitual el uso de la disciplina LIFO (atender primero al
último). También es posible encontrar reglas de secuencia con
prioridades, como por ejemplo secuenciar primero las
tareas con menor duración o según tipos de clientes.
► Capacidad del sistema
En algunos sistemas existe una limitación respecto al número de clientes que pueden
esperar en la cola. A estos casos se les denomina situaciones de cola finitas. Esta limitación
puede ser considerada como una simplificación en la modelización de la impaciencia de los
clientes.
► Número de canales del servicio
Es evidente que es preferible utilizar sistemas multiservidor con una única línea de espera
para todos que con una cola por servidor. Por tanto, cuando se habla de canales de servicio
paralelos, se habla generalmente de una cola que alimenta a varios servidores mientras que
el caso de colas independientes se asemeja a múltiples sistemas con sólo un servidor.

15
► Etapas de servicio
Un sistema de colas puede ser unietapa o multietapa. En los sistemas multietapa el cliente
puede pasar por un número de etapas mayor que uno. Una peluquería es un sistema
unietapa, salvo que haya diferentes servicios (manicura, maquillaje) y cada uno de estos
servicios sea desarrollado por un servidor diferente.
En algunos sistemas multietapa se puede admitir la vuelta atrás o “reciclado”, esto es
habitual en sistemas productivos como controles de calidad y reprocesos.
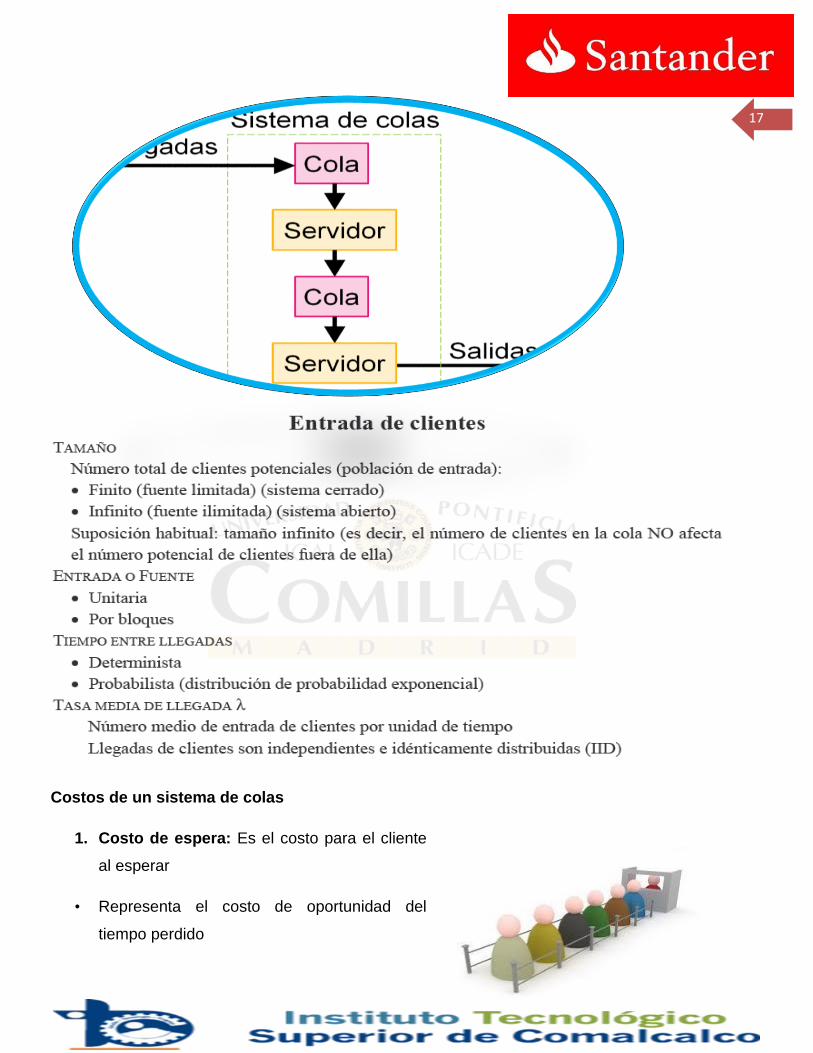
1.5 Estructura Básica de los Modelos de Colas:
Estructuras típicas de las colas:
Una línea, un servidor

16
Una línea, múltiples servidores
Varias líneas, múltiples servidores
servidores secuenciales
17
Costos de un sistema de colas
1. Costo de espera: Es el costo para el cliente
al esperar
• Representa el costo de oportunidad del
tiempo perdido

18
• Un sistema con un bajo costo de espera es una fuente importante de competitividad
2. Costo de servicio: Es el costo de operación del servicio brindado
• Es más fácil de estimar
– El objetivo de un sistema de colas es encontrar el sistema del costo total
mínimo
Proceso básico de colas
El proceso básico supuesto por la mayoría de los modelos de colas es el siguiente.
Los clientes que requieren un servicio se generan en el tiempo en una fuente de entrada.
Luego, entran al sistema y se unen a una cola. En determinado momento se selecciona un
miembro de la cola para proporcionarle el servicio mediante alguna regla conocida como
disciplina de cola. Se lleva a cabo el servicio que el cliente requiere mediante un
mecanismo de servicio, y después el cliente sale del sistema de colas. Se pueden hacer
muchos supuestos sobre los distintos elementos del proceso de colas que se analizarán a
continuación.
Fuente de entrada (población potencial)
Una característica de la fuente de entrada es su tamaño. El tamaño es el número total de
clientes que pueden requerir servicio en determinado momento, es decir, el número total de
clientes potenciales. Esta población a partir de la cual surgen las unidades que llegan se
conoce como población de entrada. Puede suponerse que el tamaño es infinito o finito (de
modo que también se dice que la fuente de entrada es ilimitada o limitada). Debido a

19
que los cálculos son mucho más sencillos en el caso del tamaño infinito, este supuesto
se hace a menudo aun cuando el tamaño real sea un número fijo relativamente grande, y
debe tomarse como un supuesto implícito en cualquier modelo en el que no se establezca
otra cosa. Desde una perspectiva analítica, el caso finito es más complejo puesto que el
número de clientes que conforman la cola afecta al número potencial de clientes fuera del
sistema en cualquier momento; pero debe hacerse este supuesto de finitud si la tasa a la
que la fuente de entrada genera clientes nuevos es afectada en forma significativa por el
número de clientes existentes el sistema de líneas de espera.
También se debe especificar el patrón estadístico mediante el cual se generan los clientes
en el tiempo. El supuesto normal es el que se generan de acuerdo con un proceso Poisson;
es decir, el número de clientes que llega hasta un momento específico tiene una distribución
de Poisson. Este caso corresponde a aquel cuyas llegadas al sistema ocurren de manera
aleatoria pero con cierta tasa media fija y sin que importe cuántos clientes están ya ahí (por
lo que el tamaño de la fuente de entrada es infinito). Un supuesto equivalente es que la
distribución de probabilidad del tiempo que transcurre entre dos llegadas consecutivas
es exponencial. Se hace referencia al tiempo que transcurre entre dos llegadas
consecutivas como tiempo entre llegadas.
También debe especificarse cualquier otro supuesto no usual sobre el comportamiento
de los clientes. Un ejemplo sería cuando se pierde un cliente porque desiste o se rehúsa a
entrar al sistema porque la cola es demasiado larga.
Cola
La cola es donde los clientes esperan antes de recibir el servicio. Una cola se caracteriza
por el número máximo permisible de clientes que puede admitir. Las colas pueden ser finitas
o infinitas según si dicho número es finito o infinito. El supuesto de una cola infinita es el
estándar de la mayoría de los modelos, incluso en situaciones en las que en realidad existe
una cota superior (relativamente grande) sobre el número permitido de clientes, puesto que
manejar una cota así puede ser un factor que complique el análisis. En los sistemas de colas
en los que la cota superior es tan pequeña que se llega a ella con cierta frecuencia, es
necesario suponer una cola finita.

20
Disciplina de cola
La disciplina de cola se refiere al orden en el que sus miembros se seleccionan para recibir
el servicio. Por ejemplo, puede ser: primero en entrar, primero en salir; aleatoria; de acuerdo
con algún procedimiento de prioridad o con algún otro orden. En los modelos de cola se
supone como normal a la disciplina de primero en entrar, primero en salir, a menos que se
establezca de otra manera. Existen dos formas como se puede establecer la disciplina de
cola:
FIFO: (First in, first out), primero en entrar primero en salir.
LIFO: (Last in, last out), último en entrar primero en salir.
Mecanismo de servicio
El mecanismo de servicio consiste en una o más estaciones de servicio. Cada una de ellas
con uno o más canales de servicio paralelos, llamados servidores. Si existe una o más
estación de servicio, el cliente puede recibirlo de una secuencia de ellas (canales de servicio
en serie). En una estación dada, el cliente entra en uno de estos canales y el servidor le
presta el servicio completo. Los modelos de colas deben de especificar el arreglo de las
estaciones y el número de servidores (Canales paralelos) en cada una de ellas. Los modelos
más elementales suponen una estación, ya sea con un servidor o con un número finito de
servidores.
El tiempo que transcurre desde el inicio del servicio para un cliente hasta su terminación en
una estación se llama tiempo de servicio (o duración del servicio).
Un modelo de un sistema. De colas determinado debe especificar la distribución de
probabilidad de los tiempos de servicio de cada servidor (y tal vez de los tipos de clientes),
aunque es común suponer la misma distribución para todos los servidores. La
distribución del tiempo del servicio que más se usa en la práctica (por ser más manejable
que cualquier otra) es la distribución exponencial. Otras distribuciones de tempos de
servicios importantes son la distribución degenerada (tiempos de servicio constantes) y la
distribución Erlang (gamma).

21
1.6 El Proceso de Colas Elemental:
Como ya se ha señalado, la teoría de colas se aplica a muchos diferentes tipos de
situaciones. El tipo que prevalece es el siguiente: una sola línea de espera (que a veces
puede estar vacía) se forma frente a una estación de servicio, dentro de la cual se encuentra
uno o más servidores. Cada cliente generado por una fuente de entrada recibe el recibe el
servicio de uno de los servidores, quizá después de esperar un poco en la cola (línea de
espera).
Un servidor no tiene que ser un solo individuo; puede ser un grupo de personas, por ejemplo
una cuadrilla de reparación que combina fuerzas para realizar, de manera simultánea, el
servicio que solicita el cliente. Aún más. Los servidores ni siquiera tienen que ser personas.
En muchos puede ser una máquina, un vehículo, un dispositivo electrónico, etc. En esta
misma línea de ideas, los clientes que conforman la cola no tienen que ser personas. Por
ejemplo poder ser unidades que esperan ser procesadas en cierto tipo de máquina, o
automóviles que deben pasar por una caseta de cobro.
En realidad, no es necesario que se forme una línea de espera física delante de una
estructura material que constituye la estación de servicio. Los miembros de la cola pueden
estar dispersos en un área mientras esperan que el servidor venga a ellos, como las
máquinas que esperan reparación. El servidor o grupo de servidores asignados a un
área constituyen la estación de servicio de esa área. De todas maneras, la teoría de colas
proporciona, entre otros, un número promedio de clientes en espera –el tiempo promedio
de espera-, puesto que es irrelevante si los clientes esperan en grupo o no.

22
1.7 Notación básica
Nomenclatura
= Número de llegadas por unidad de tiempo
= Número de servicios por unidad de tiempo si el servidor está ocupado
c= Número de servidores en paralelo
Congestión de un sistema con parámetros: (,, c)
N(t): Número de clientes en el sistema en el instante t
Nq(t): Número de clientes en la cola en el instante t
Ns(t): Número de clientes en servicio en el instante t
Pn(t): Probabilidad que haya n clientes en el sistema en el instante t=Pr{N(t)=n}
N: Número de clientes en el sistema en el estado estable
Pn: Probabilidad de que haya n clientes en estado estable Pn= Pr {N=n}
L: Número medio de clientes en el sistema
Lq: Número medio de clientes en la cola

23
Tq: Representa el tiempo que un cliente invierte en la cola
S: Representa el tiempo de servicio
T = Tq+S: Representa el tiempo total que un cliente invierte en el sistema
Wq= E [Tq]: Tiempo medio de espera de los clientes en la cola
W= E [T]: Tiempo medio de estancia de los clientes en el sistema
r: número medio de clientes que se atienden por término medio
Pb: probabilidad de que cualquier servidor esté ocupado
Con el paso del tiempo se ha implantado una notación para representar los problemas de
colas que constan de 5 símbolos separados por barras.
A / B / X /Y / Z
A: indica la distribución de tiempo entre llegadas consecutivas
B: alude al patrón de servicio de servidores
X: es el número de canales de servicio
Y: es la restricción en la capacidad del sistema
Z: es la disciplina de cola
El símbolo G representa una distribución general de probabilidad, es decir, que el modelo

24
presentado y sus resultados son aplicables a cualquier distribución estadística (siempre que
sean Variables IID- Independientes e Idénticamente Distribuidas).
Si no existe restricción de capacidad (Y = 00) y la política de servicio es FIFO, no se suelen
incorporar dichos símbolos en la notación así:
M/D/3 es equivalente a M/D/3/ /FIFO
Y significa que los clientes entran según una distribución exponencial, se sirven de manera
determinista con tres servidores sin limitación de capacidad en el sistema y siguiendo una
estrategia FIFO de servicio.
Sistemas de colas: Las llegadas – Distribución exponencial
• La forma algebraica de la distribución exponencial es:
• Donde t representa una cantidad expresada en de tiempo unidades de tiempo (horas,
minutos, etc.)
La distribución exponencial supone una mayor probabilidad para tiempos entre
llegadas pequeños
• En general, se considera que las llegadas son aleatorias
• La última llegada no influye en la probabilidad de llegada de la siguiente
Sistemas de colas: Las llegadas - Distribución de Poisson
tetserviciodetiempoP 1)(

25
Es una distribución discreta empleada con mucha frecuencia para describir el patrón
de las llegadas a un sistema de colas
Para tasas medias de llegadas pequeñas es asimétrica y se hace más simétrica y se
aproxima a la binomial para tasas de llegadas altas
Su forma algebraica es:
Dónde:
P (k): probabilidad de k llegadas por unidad de tiempo
: Tasa media de llegadas
e = 2,7182818
Sistemas de colas: La cola
• El número de clientes en la cola es el número de clientes que esperan el servicio
!)(
k
ekP
k

26
• El número de clientes en el sistema es el número de clientes que esperan en la cola
más el número de clientes que actualmente reciben el servicio
• La capacidad de la cola es el número máximo de clientes que pueden estar en la cola
• Generalmente se supone que la cola es infinita
• Aunque también la cola puede ser finita
• La disciplina de la cola se refiere al orden en que se seleccionan los miembros de la
cola para comenzar el servicio
• La más común es PEPS: primero en llegar, primero en servicio
• Puede darse: selección aleatoria, prioridades, UEPS, entre otras.
Sistemas de colas: El servicio
• El servicio puede ser brindado por un servidor o por servidores múltiples
• El tiempo de servicio varía de cliente a cliente
• El tiempo esperado de servicio depende de la tasa media de servicio ()
• El tiempo esperado de servicio equivale a 1/
• Por ejemplo, si la tasa media de servicio es de 25 clientes por hora
• Entonces el tiempo esperado de servicio es 1/ = 1/25 = 0.04 horas, o 2.4 minutos
• Es necesario seleccionar una distribución de probabilidad para los tiempos de servicio
• Hay dos distribuciones que representarían puntos extremos:
• La distribución exponencial (=media)
• Tiempos de servicio constantes (=0)
• Una distribución intermedia es la distribución Erlang
• Esta distribución posee un parámetro de forma k que determina su desviación
estándar:
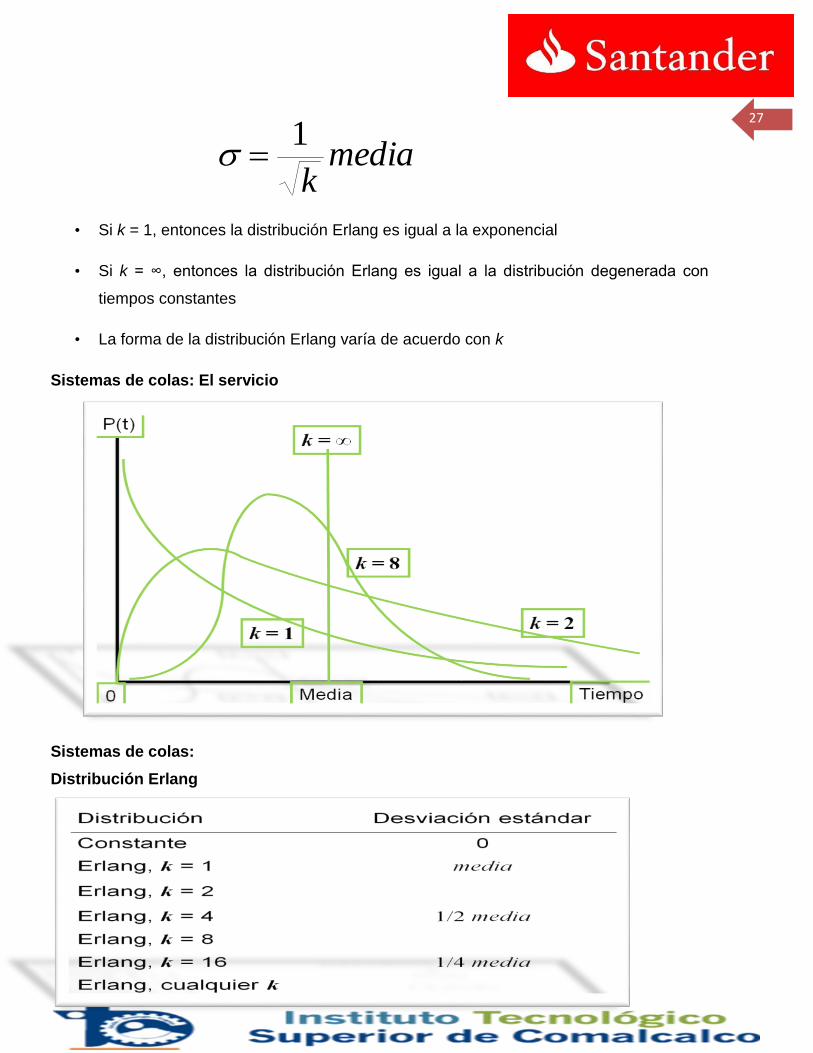
27
• Si k = 1, entonces la distribución Erlang es igual a la exponencial
• Si k = ∞, entonces la distribución Erlang es igual a la distribución degenerada con
tiempos constantes
• La forma de la distribución Erlang varía de acuerdo con k
Sistemas de colas: El servicio
Sistemas de colas:
Distribución Erlang
mediak
1

28
Sistemas de colas: Etiquetas para distintos modelos
Notación de Kendall: A/B/c
• A: Distribución de tiempos entre llegadas
• B: Distribución de tiempos de servicio
– M: distribución exponencial
– D: distribución degenerada
– Ek: distribución Erlang
• c: Número de servidores
Estado del sistema de colas
• En principio el sistema está en un estado inicial
• Se supone que el sistema de colas llega a una condición de estado estable (nivel
normal de operación)
• Existen otras condiciones anormales (horas pico, etc.)
• Lo que interesa es el estado estable
Desempeño del sistema de colas
• Para evaluar el desempeño se busca conocer dos factores principales:
1. El número de clientes que esperan en la cola
2. El tiempo que los clientes esperan en la cola y en el sistema
Medidas del desempeño del sistema de colas
1. Número esperado de clientes en la cola Lq
2. Número esperado de clientes en el sistema Ls

29
3. Tiempo esperado de espera en la cola Wq
4. Tiempo esperado de espera en el sistema Ws
Medidas del desempeño del sistema de colas: fórmulas generales
Medidas del desempeño del sistema de colas: ejemplo
• Suponga una estación de gasolina a la cual llegan en promedio 45 clientes por hora
• Se tiene capacidad para atender en promedio a 60 clientes por hora
• Se sabe que los clientes esperan en promedio 3 minutos en la cola
• La tasa media de llegadas es 45 clientes por hora o 45/60 = 0.75 clientes por
minuto
• La tasa media de servicio es 60 clientes por hora o 60/60 = 1 cliente por minuto
qs
ss
qs
LL
WL
WL
WW1
clientesWL
clientesWL
WW
W
ss
qs
q
25.2375.0
3475.0
min41
13
1
min3

30
Modelos de una cola y un servidor
• M/M/1: Un servidor con llegadas de Poisson y tiempos de servicio exponenciales
• M/G/1: Un servidor con tiempos entre llegadas exponenciales y una distribución
general de tiempos de servicio
• M/D/1: Un servidor con tiempos entre llegadas exponenciales y una distribución
degenerada de tiempos de servicio
• M/Ek/1: Un servidor con tiempos entre llegadas exponenciales y una distribución
Erlang de tiempos de servicio
Modelo M/M/1
Modelo M/M/1: ejemplo
• Un lava carro puede atender un auto cada 5 minutos y la tasa media de llegadas es
de 9 autos por hora
• Obtenga las medidas de desempeño de acuerdo con el modelo M/M/1
• Además la probabilidad de tener 0 clientes en el sistema, la probabilidad de tener una
cola de más de 3 clientes y la probabilidad de esperar más de 30 min. en la cola y en
el sistema
1,0
)()(
)()1(
)(
1
)(
)1()1(
1
2
t
etWPetWP
nLPP
WW
LL
t
q
t
s
n
s
n
n
qs
qs
17.0)60/30(
22.0)60/30(
32.0)3(25.0)1(
min1525.0)(
min2033.01
25.2)(
3
75.012
9,12,9
)1(
)1(
130
0
2
t
q
t
s
s
q
s
qs
eWP
eWP
LPP
hrsW
hrsW
clientesLclientesL

31
Modelo M/G/1
Modelo M/G/1: ejemplo
• Un lava carro puede atender un auto cada 5 min. y la tasa media de llegadas es de 9
autos/hora, = 2 min.
• Obtenga las medidas de desempeño de acuerdo con el modelo M/G/1
1
1
1
)1(2
0
222
w
q
qqs
qqs
PP
LWWW
LLL

32
Además la probabilidad de tener 0 clientes en el sistema y la probabilidad de que un cliente
tenga que esperar
75.025.01
min7.8145.0
min7.13228.01
31.1)1(2
06.275.31.1
0
222
w
q
q
qs
q
qs
PP
hrsL
W
hrsWW
clientesL
clientesLL

33
Modelo M/D/1
Modelo M/D/1: ejemplo
• Un lava carro puede atender un auto cada 5 min.
• La tasa media de llegadas es de 9 autos/hora.
• Obtenga las medidas de desempeño de acuerdo con el modelo M/D/1
1
1
)1(2
2
q
qqs
qss
LWWW
LWL
min5.7125.0
min5.1221.01
125.1)1(2
875.1
2
hrsL
W
hrsWW
clientesL
clientesWL
q
q
qs
q
ss

34
Modelo M/Ek/1
Modelo M/Ek/1: ejemplo
• Un lava carro puede atender un auto cada 5 min.
• La tasa media de llegadas es de 9 autos/hora. Suponga = 3.5 min (aprox.)
• Obtenga las medidas de desempeño de acuerdo con el modelo M/Ek/1
1
1
)1(2
)1(2
q
qqs
qss
LWWW
k
kLWL
min25.111875.0
min25.162708.01
6875.1)1(2
)1(
437.2
2
hrsL
W
hrsWW
clientesk
kL
clientesWL
q
q
qs
q
ss

35
Modelos de varios servidores
• M/M/s: s servidores con llegadas de Poisson y tiempos de servicio exponenciales
• M/D/s: s servidores con tiempos entre llegadas exponenciales y una distribución
degenerada de tiempos de servicio
• M/Ek/s: s servidores con tiempos entre llegadas exponenciales y una distribución
Erlang de tiempos de servicio
M/M/s, una línea de espera
00
0
02
1
0
0
!
1,
!
,!
1
)()!1(
!!
1
Ps
s
sPknsiP
ssP
knsiPn
PWW
LWLLP
ssL
ns
s
s
P
s
wsn
n
n
n
nqs
q
qqs
s
q
s
n
ns
)46)(3(
3
4
2
2
4
2
3
q
q
L
sSi
L
sSi

36
Análisis económico de líneas de espera
1.8 Terminología:
A menos que se establezca otra cosa se utilizará la siguiente terminología estándar:
** Estado del sistema = número de clientes en el sistema.
** Longitud de la cola = número de clientes que esperan servicio.
= estado del sistema menos número de clientes a quienes
se les da el servicio.
** N (t) = número de clientes en el sistema de colas en el tiempo t (t=0).
**(t) = probabilidad de que exactamente n clientes estén en el sistema en el tiempo t,
dado el número en el tiempo 0.
** s= número de servidores (canales de servicio en paralelo) en el sistema de colas.
*=tasa media de llegadas (número esperado de llegadas por unidad de tiempo) de
nuevos clientes cuando hay n clientes en el sistema.
** = tasa media de servicio en todo el sistema (número esperado de clientes que

37
completan su servicio por unidad de tiempo) cuando hay n clientes en el sistema. Nota:
representa la tasa combinada a la que todos los servidores ocupados (aquellos
que están sirviendo a un cliente) logran terminar sus servicios.
1.9 Proceso de nacimiento y muerte:
La mayor parte de los modelos elementales suponen que las entradas (llegadas de clientes)
y la salida (clientes que se van) el sistema ocurren de acuerdo con un proceso de
nacimiento y muerte. Este importante proceso de teoría de probabilidad tiene
aplicaciones en varias áreas. Sin embargo, en el contexto de la teoría de colas, el término
nacimiento se refiere a la llegada de un nuevo cliente al sistema de colas, mientras que el
término muerte se refiere a la salida del cliente servido. El estado del sistema en el tiempo t
(t 0), denotado por N (t), es el número de clientes que hay en el sistema de colas en el
tiempo t. El proceso de nacimiento y muerte describe en términos probabilísticos como
cambia N (t) al aumentar t. En general, sostiene que los nacimientos y muertes
individuales ocurren de manera aleatoria, y que sus tasas medias de ocurrencia dependen
del estado actual del sistema de manera más precisa, los supuestos del proceso de
nacimiento y muerte son los siguientes:
Supuesto 1. Dado N (t) = n, la distribución de probabilidad actual del tiempo que falta para el
próximo nacimiento (llegada) es exponencial con parámetro (n= 0,1, 2,….
Supuesto 2. Dado N (t) = n, la distribución de probabilidad actual del tiempo que falta para
la próxima muerte (terminación de servicio) es exponencial con parámetro = 1, 2, …
Supuesto 3. La variable aleatoria del supuesto 1 (el tiempo que falta hasta el próximo
nacimiento) y la variable aleatoria del supuesto 2 (el tiempo que falta hasta la siguiente
muerte) son mutuamente independientes. La siguiente transición del estado es:
n → n + 1 (un solo nacimiento)
n → n – 1 (una sola muerte)
Lo que depende de cuál de las dos variables es más pequeña.

38
1.10 Aplicación de la teoría de colas
Debido al valor de la información que proporciona la teoría de colas, ésta se usa con
amplitud para dirigir el diseño (o rediseño) de sistemas de líneas de espera. A continuación
se explicará cómo se aplica para este fin.
Las decisiones más comunes que deben tomarse cuando se diseña un sistema de colas son
cuántos servidores se deben proporcionar. Sin embargo hay otra serie de decisiones que
también pueden ser necesitadas. Las posibles decisiones incluyen:
1. Número de servidores en cada instalación de servicio.
2. Eficiencia de los servidores.
3. Número de instalaciones de servicio.
4. Cantidad de espacio para espera en la cola.
5. Algunas prioridades para diferentes categorías de clientes.
De manera típica, las dos consideraciones primordiales cuando se deben tomar estos tipos
de decisiones son 1) el costo en el que se incurre al dar el servicio y 2) las consecuencias de
hacer que los clientes esperen en el sistema de colas. Si se proporciona demasiada
capacidad de servicio se ocasiona costos excesivos. Si se proporciona una cantidad muy
limitada se producen esperas excesivas. En este contexto la meta es encontrar un trueque
adecuado entre el costo del servicio y el tamaño de la espera.
Existen dos enfoques básicos para realizar la búsqueda de este equilibrio. El primero es
establecer uno o más criterios para lograr un nivel satisfactorio del servicio en términos de
cuánta espera serían aceptables. Por ejemplo, un criterio posible podría ser no exceder
cierto número de minutos. Otro podría ser que al menos 95% de los clientes no deben de
esperar más de determinado número de minutos. También se pueden utilizar criterios
similares en términos del número esperado de clientes en el sistema (o la distribución de
probabilidad de esta cantidad). El criterio también puede establecerse en términos del
tiempo de espera o del número de clientes en la cola en lugar de en el sistema. Una vez que
se ha seleccionado el criterio o los criterios, por lo general es sencillo utilizar prueba y error

39
para encontrar el diseño menos costoso del sistema de colas que satisface todos los
criterios.
El otro criterio básico para buscar la mejor compensación implica evaluar los costos
asociados con la consecuencia de hacer esperar a los clientes. Por ejemplo, suponga
que el sistema de colases un sistema de servicio interno donde los clientes son los
empleados de una empresa comercial. Si se hace que éstos esperen en el sistema de colas,
se ocasiona una pérdida de productividad, lo que provoca pérdidas monetarias. Esta pérdida
es el costo de espera asociado con el sistema de líneas de espera. Al expresar este costo
de líneas de espera como una función del tamaño de la espera, el problema de determinar el
mejor diseño del sistema de colas se puede definir como la minimización del costo total
esperado (costo del servicio más costo de espera) por unidad de tiempo.

40
Capítulo 2:
PROCESO DE
SIMULACIÓN DE
EVENTOS
DISCRETOS

41
Capítulo 2. PROCESO DE SIMULACIÓN DE EVENTOS DISCRETOS
En el segundo capítulo observaremos a la última técnica importante de investigación de
operaciones. La simulación se clasifica en un escalón muy alto entre las técnicas que más
se usan. Aún más, debido a que es una herramienta tan flexible, poderosa e
intuitiva, sus aplicaciones crecen con rapidez de manera continua.
Esta técnica involucra el uso de una computadora para imitar (simular) la operación de un
proceso o sistema complejo. Por ejemplo, a menudo se usa simulación para realizar un
análisis de riesgo de procesos financieros mediante la imitación repetida de la evolución de
las transacciones necesarias para generar un perfil de los resultados posibles. También se
utiliza ampliamente en el análisis de sistemas estocásticos que continuarán en operación
indefinidamente. En el caso de este tipo de sistemas, la computadora genera y registra las
ocurrencias de los eventos que impulsan el sistema como si en realidad estuviera en
operación física. Debido a su velocidad, la computadora puede simular incluso años de
operación en cuestión de segundos. El registro del desempeño de la operación simulada
del sistema de varias alternativas de diseño o procedimientos de operación permite evaluar
y comparar estas alternativas antes de elegir una
2.1.- Papel de la Simulación en los Estudios de Investigación de
Operaciones: En esencia, la simulación tiene el mismo papel en muchos estudios de IO. No obstante,
en lugar de diseñar un avión, el equipo de IO se dedica a desarrollar un diseño o un
procedimiento de operación para algún sistema estocástico (que opera en forma
probabilística a través del tiempo). El desempeño del sistema real se imita mediante
distribuciones de probabilidad para generar aleatoriamente los

42
distintos eventos que ocurren en el sistema. Por todo esto, un modelo de
simulación sintetiza el sistema con su construcción de cada componente y de cada
evento. Después, el modelo corre el sistema simulado para obtener observaciones
estadísticas del desempeño del sistema como resultado de los diferentes eventos
generados de manera aleatoria. Debido a que las corridas de simulación, por lo
general, requieren la generación y el procesado de una gran cantidad de datos, es
inevitable que estos experimentos estadísticos simulados se lleven a cabo en una
computadora.
Cuando es necesario usar simulación como parte de un estudio de IO, es común
que vaya precedida y seguida de los mismos pasos que se describieron antes
para diseñar un avión. En particular primero se hace un análisis teórico preliminar
(quizá con modelos matemáticos aproximados) para desarrollar un diseño básico
del sistema (que incluye sus procedimientos de operación). Después se usa una
simulación para experimentar con los diseños específicos con el fin de estimar el
desempeño real. Una vez desarrollado y elegido el diseño detallado, se prueba el
21 sistema real para ajustar los últimos detalles del diseño final.
Para preparar la simulación de un sistema complejo, es necesario contar con un
modelo de simulación detallado para formular y describir la operación del sistema
y cómo debe simularse, el cual costa de varios bloques de construcción básicos:
1. Definir el estado del sistema (como el número de clientes en un sistema de
colas).
2. Identificar los estados posibles del sistema que pueden ocurrir.
3. Identificar los eventos posibles (como las llegadas y terminaciones de servicio
en un sistema de colas) que cambian el estado del sistema.
4. Contar con un reloj de simulación, localizado en alguna dirección del programa
de simulación, que registrará el paso del tiempo (simulado)
5. Un método para generar los eventos de manera aleatoria de los distintos tipos.
6. Una fórmula para identificar las transiciones de los estados que generan los
diferentes tipos de eventos.

43
2.2.- Simulación de Eventos Discretos Versus Continuos:
Las dos grandes categorías de simulación son la de eventos discretos y eventos
continuos.
Cuando se recurre a una simulación de eventos discretos, los cambios en el
estado del sistema ocurren de manera instantánea en puntos aleatorios del tiempo
como resultado de la ocurrencia de eventos discretos. Por ejemplo, en un sistema
de colas donde el estado del sistema es el número de clientes en él, los eventos
discretos que cambian este estado son la llegada de un cliente o su salida cuando
termina su servicio. En la práctica, la mayoría de las aplicaciones de simulación
son simulaciones de eventos discretos.
En una simulación continua los cambios en el estado del sistema ocurren
continuamente en el tiempo. Por ejemplo, si el sistema de interés es un avión en
vuelo y su estado se define como la posición actual, el estado cambia de manera
continua en el tiempo. Algunas aplicaciones de simulación ocurren en los estudios
de diseños de sistemas de ingeniería de este tipo.
Las simulaciones continuas suelen requerir ecuaciones diferenciales para describir
22 la tasa de cambio de las variables de estado, por lo que el análisis tiende a ser
complejo.
En ocasiones es posible aproximar los cambios continuos en el estado del sistema
mediante cambios discretos, para usar una simulación de eventos discretos que
aproxime el comportamiento de un sistema continuo, circunstancia que tiende a
simplificar mucho el análisis.
2.3.- ¿Cuándo Simular?:

44
Como regla general, es apropiada cuando:
Desarrollamos un modelo estocástico es muy difícil o quizás aún imposible.
El sistema tiene una o más variables aleatorias relacionadas.
La Dinámica del sistema es extremadamente compleja.
El objetivo es observar el comportamiento del sistema sobre un período.
La habilidad de mostrar la animación es importante.

45
2.4.- Ventajas de la simulación:
Beneficio general de la simulación.
Laboratorio de aprendizaje-Fácil de modificar.
Algunos beneficios específicos. 23
Mejorar desempeño de los sistemas reales complejos.
Disminuir inversiones y gastos de operación.
Reducir el tiempo de desarrollo de un sistema.
Asegurar que el sistema se comportará como se desea.
Conocer oportunamente hechos relevantes y efectuar cambios oportunamente.
A veces es lo único que se puede hacer para estudiar un sistema real (No
existe; Se destruye; Muy caro).
Flexibilidad para modelar las cosas tal como son (no importando si son enredadas y complicadas) modelado de sistemas complejos.
Evitan “buscar” sólo dónde hay luz: Cuento en dónde un “borrachito” busca las
llaves del auto cerca del farol porque ahí puede ver y no dónde se le cayeron
realmente porque está obscuro.
Permite Modelar la Incertidumbre y los procesos transcienden. La
única cosa segura es que nada es seguro. Peligro de ignorar la variabilidad
y la incertidumbre. Validez del Modelo.
2.5.- Desventajas de la simulación:
Puede ser costosa y consumidora de tiempo inicialmente.
Algunas veces soluciones mejores y más fáciles son pasadas por alto.

46
Los resultados pueden ser mal interpretados. 24 Por lo general son ignorados los factores humanos y tecnológicos.
Peligro de poner demasiada confianza en los resultados de la simulación.
Es difícil verificar si los resultados son válidos. (Proceso de validación tema
de estudio)
2.6.- Etapas de un Proyecto de Simulación:
Definición del problema: Define el Problema a ser estudiado, incluyendo una
declaración escrita del objetivo.
Partir con supuestos adecuados
Trabajar en el Problema Correcto
Manejar expectativas
Preguntar Hábilmente
Escuchar sin Juzgar
Comunicar Abiertamente
Pronosticar la Solución
Conceptualización del modelo: Abstraer el sistema en un modelo describiendo
todos sus elementos, sus características y sus interacciones (gráficos).
-Partir de “atrás para delante”
-Fijar primero dónde se quiere llegar para señalar la partida
-Modelo se construye de “abajo-arriba”

47
25
Recolección de datos especificar y colectar datos en apoyo del modelo.
Una vez que la propuesta ha sido aceptada, se debería preparar
un programa de requerimiento de datos.
La conceptualización del modelo y la recolección de datos son
actividades que se realizan en paralelo.
La conceptualización indica el tipo de datos que se requieren y en
qué forma. Los datos recolectados permiten, a su vez, refinar y reforzar el
concepto del modelo.
Construcción del modelo: Traducir el modelo conceptualizado utilizando
los constructos de algún lenguaje de simulación.
El Modelo conceptual se traduce a un modelo computacional utilizando lenguajes de propósito general o bien paquetes de aplicación tales como Promodel, Arena, Extend, GPSS y otros.
Se debe tener en cuenta que un paquete de aplicación se ajusta mejor a los requerimientos del sistema real, considerando las particularidades de cada lenguaje de simulación (construir un modelo de simulación aportando “constructos” adecuados al sistema).
Foco en el Problema.
Construir el modelo no es la tarea principal; lo es encontrar la solución correcta.
Partir con un Modelo Simpl

48
Agregar el detalle; no partir con él.
Frenar la complejidad.
No permitir que el modelo se vuelva complicado compensando un mal
diseño, o tan complejo que va más allá de la posibilidad de implantarlo.
Mantener Momentum.
26 Es mejor muchos hitos intermedios que una fecha límite de término.
Revisiones.
Darse tiempo para realinear el proyecto.
Verificación y validación: Establecer si el modelo ejecuta lo que
postula y si existe una concordancia entre el modelo y el sistema real.
¿Verificado?
Verificación se refiere al modelo operacional. ¿Está funcionando
adecuadamente?; esto es, ¿está haciendo lo que se supone que
debería hacer?
¿Los datos son los apropiados?, ¿son razonables?; ¿el modelo
computacional refleja con exactitud el modelo conceptual?
No es razonable y altamente no recomendable esperar llegar al final
para hacer esta tarea. La construcción del modelo operacional o
simulador debe cumplir con todas las especificaciones de aseguramiento
de calidad del desarrollo de software.
¿Validado?
En la validación se debe determinar si el modelo conceptual es una
representación apropiada del sistema real; esto es, ¿refleja lo que se
supone que debe representar? ¿Puede el modelo substituir al sistema
real para propósitos de experimentación?
Esta actividad en realidad debe ser considerada como un proceso
continuo; cada etapa debe verificarse: ¿está el problema claramente
definido?; ¿el modelo conceptual es razonable?; ¿son los datos de
entrada representativos de la

49
realidad?
Concluir experimentos: Hacer corridas de simulación controladas.
Modificando
27 los niveles de una variable de control y manteniendo el resto
exactamente igual.
La variación en la salida se atribuye a estos
cambios.
Corridas de producción y análisis
Las Corridas de Producción y su
posterior análisis, se utilizan para estimar las medidas de
desempeño de los distintos escenarios que se están simulando.
¿Más corridas?:
• Basado en el análisis de las corridas que se han completado, se debe
determinar si se requieren corridas adicionales o si es necesario estudiar
otros escenarios.
• Se requieren más corridas, cuando los resultados estadísticos
no permiten aceptar o rechazar una hipótesis;
• Se requiere estudiar nuevos escenarios, para tener una mayor
comprensión del sistema bajo estudio lo que obliga a menudo a
estudiar otras situaciones.
Analizar resultados: Estudiar los resultados de la simulación para
inferir nueva información y hacer recomendaciones para la resolución
del problema.
Documentación y reportes: La documentación y reportes son
necesarios por varias razones obvias. Si el simulador se utilizará otra vez
con mayor o menor frecuencia por el mismo u otros analistas es
necesario saber qué hace y cómo lo hace. Lo mismo ocurre si el
simulador es un prototipo y debe ser modificado en el futuro.

50
Es importante documentar cada etapa del esfuerzo de simulación
junto con su ejecución; con esto se asegura que nada quedará en el
tintero. La otra razón es entregar al cliente informes de avance en cada
etapa y obtener su aprobación, especialmente en la definición del
problema.
Dossier de documentos formales a entregar debe contener a lo menos:
Definición de Objetivos y Metas. Plan de trabajo: (carta Gantt o pert Supuestos para el modelo Modelo conceptual Registro de cambios Modelo operacional Datos de prueba

51
SIMULACIÓN CON PROMODEL Generalidades
Para hacer una simulación con ProModel® se deben cumplir dos eventos:
1. Los elementos que conforman el modelo han de estar correctamente definidos, porque el programa antes de hacer la simulación comprueba la corrección en la definición del modelo.
2. El modelo debe contener al menos los siguientes elementos: Locaciones, entidades, arribos y proceso.
La simulación en promodel es la forma como se animan las iteraciones entre los elementos (locaciones, entidades ...) y la lógica definida. En la figura, se presenta un esquema de las interacciones de los elementos del software ProModel® y el modelador.

Las locaciones representan los lugares fijos en el sistema a dónde se dirigen las entidades por procesar, el almacenamiento, o alguna otra actividad o fabricación. Deben usarse locaciones para modelar los elementos como las máquinas, áreas de espera, estaciones de trabajo, colas, y bandas transportadoras.
Para acceder al Editor de locaciones: clic "Build>Locations" o Crtl+L.
Editor de locaciones
El Editor de locaciones consiste en tres ventanas: la ventana de Gráficos ubicada hacia la esquina inferior izquierda de la pantalla, la tabla de edición de locaciones a lo largo de la parte superior de la pantalla, y la ventana de Layout (Esquema) ubicada hacia la esquina inferior derecha de la pantalla. Estas ventanas pueden moverse y ajustar su tamaño usando el ratón.

La ventana de gráficos de locación provee un medio gráfico para crear las locaciones y cambiar sus iconos.
Iconos agregados al esquema representarán una nueva locación o se agregaran al icono de una locación ya existente esto dependerá de la caja de la opción New, si se encuentra activa o no; estos dos modos se describen a continuación.
NewActivo
Permite crear un nuevo registro de locación cada vez que se sitúe un nuevo gráfico de locación en el esquema. A la nueva locación se le da un nombre predefinido que puede cambiarse si se desea. Para activar la opción New el campo a la izquierda en la parte superior de la ventana de herramientas gráficas debe contener una equis [X].
New inactivo
Permite agregar gráficos adicionales a una locación existente, como una etiqueta de texto, un sitio para entidad, o una luz de estado. Una locación con múltiples gráficos se encerrara con una caja. Este modo se selecciona sin comprobar [] el cuadro adjunto a New en el cuadro de herramientas gráficas.
Botón Edit.
Despliega el cuadro de dialogo de la Librería Grafica que se usa para cambiar el color, dimensiones, y orientación del gráfico de la locación.
Botón Erase
Borra el gráfico de la locación seleccionada en la ventana del Esquema sin anular el registro correspondiente en la Tabla de edición de locaciones.
Botón View
Muestra la locación seleccionada en la tabla de edición de locaciones dentro de la ventana del Esquema.
Gráficos de locación

Una locación puede tener cualquiera, uno o más de los gráficos seleccionados de la ventana de gráficos de locación.
Contador
Representa el número actual de entidades en una locación.
Medidor
Barra corrediza vertical u horizontal que muestra los volúmenes actuales de la locación durante la simulación (como un porcentaje de la capacidad). Este gráfico constantemente se actualizará durante la simulación.
Tanque
Barra corrediza vertical u horizontal que muestra el flujo continúo de líquidos y otras substancias en y fuera de tanques o vasos similares. Esta capacidad de modelado continuo puede combinarse con la simulación de eventos discretos para modelar el intercambio entre el material continuo y las entidades discretas como cuando un líquido se pone en los contenedores. También se puede usar para modelar una alta tasa de partes discretas en manufactura.
Transportadores / Colas
Símbolo que representa una banda transportadora o una cola.
Etiqueta
Texto usado para describir la locación. La etiqueta es sincronizada inicialmente con el nombre de la locación y cambia siempre que el nombre de la locación cambie. El contenido, tamaño, y color del texto pueden ser cambiados con un doble clic en la etiqueta o seleccionándola y pulsando el botón de editar de las herramientas gráficas. Una vez el nombre en una etiqueta se edita ya no se cambiará automáticamente cuando el nombre de la locación se cambia.
Luz de estado
Círculo que cambia de color durante la simulación mostrará el estado de la locación. Para una locación de capacidad simple, los estados desplegados son:

desocupado/vacío, en funcionamiento, bloqueado, abajo, y en arreglo o mantenimiento. Para las locaciones de multi-capacidad, los estados desplegados son arriba (operando) y abajo (fuera de turno, en descanso, fuera de servicio).
Sitio de entidad
Sitio asignado sobre el esquema dónde la entidad o las entidades aparecerán mientras están en la locación.
Región
Límite usado para representar el área de una locación. Una región puede ponerse en el esquema encima de un fondo importado por ejemplo un dibujo de AutoCAD para representar una máquina u otra locación. Esta técnica permite a los elementos del fondo importado, trabajar como locaciones.
Biblioteca Gráfica
Cualquiera de los gráficos que aparecen en la biblioteca en el menú gráfico. la barra del despliegue ubicada en su parte baja sirve para ver todos los gráficos disponibles. Pueden crearse los gráficos de la biblioteca o pueden modificarse a través del Editor Gráfico.
Tabla de edición de locaciones
(Seleccionar una columna de la tabla para ver su descripción.)

Las características de una locación pueden modificarse con la Tabla de edición de locaciones.
La tabla de edición de locaciones contiene campos para mostrar el icono gráfico, el nombre de la locación y define otras características para cada locación. Cada uno de estos casos es explicado a continuación.
Se puede editar el cuadro deseado directamente en cualquier caso, o por selección de una fila y clic en la etiqueta o título de la columna del cuadro deseado.
"Icon" (Icono)
Icono gráfico usado para representar la locación.
Cambios en el gráfico de la locación se hacen usando las herramientas de la ventana gráficos de locación.
Si una locación ha sido definida usando múltiples gráficos, el primer gráfico usado se muestra aquí.
Clic en la etiqueta de icono muestra la gráfica de la locación seleccionada dentro de la ventana del esquema.
"Name" (Nombre)
Nombre de cada locación.
Los nombres pueden ser de hasta 80 caracteres de largo y deben empezar con una mayúscula. Un nombre de locación puede ser editado en este campo.
"Cap. “Capacidad de la locación se refiere al número de entidades que la locación puede sostener o puede procesar a la vez. La capacidad máxima de una locación es
999999. Entrando INF o INFINITE se ajustará la capacidad al valor aceptable máximo. La capacidad de una locación no variará durante la simulación.

En general, se usan locaciones de multi-capacidad para modelar las locaciones como colas, almacenes, líneas de espera, hornos, procesos de curando, o cualquier otro tipo de locación dónde pueden mantenerse múltiples entidades o pueden procesarse concurridamente.
"Units" (Unidades)
Número de unidades de una locación es hasta 999. Una unidad locativa se define como una máquina o estación de operación independiente.
Cuando varias locaciones o estaciones operan independientemente para cumplir la misma operación y son intercambiables, ellas forman una multi-unidad de locaciones.
Una multi-unidad de locaciones trabaja como varias locaciones con características comunes.
"DTs . . ." (Tiempos fuera de servicio de la locación)
"Stats . . ." (Estadísticas)
Clic en el botón del encabezado para especificar el nivel de detalle estadístico que será recogido para la locación. (Para ver las estadísticas de una locación después de correr la simulación, escoja "View statistics" del menú "Output".)
Se dispone de tres niveles que son:
None Ninguna estadística se recoge.
Basic Sólo la utilización y el tiempo promedio en la locación se recogerá.
Time Series Recoge las estadísticas básicas y series de tiempo que rastrean los volúmenes de la locación con el tiempo.
"Rules . . ." (Reglas)
"Notes . . ." (Notas)
Este campo es para escribir cualquier nota optativa sobre una locación, o clic en el botón del título de la columna para abrir una ventana de notas más grande.
Dts...
Un tiempo fuera de servicio detiene una locación o recurso de su operación. Los tiempos fuera de servicio pueden representar las interrupciones fijadas como

cambios, descansos o mantenimientos. O pueden representar los no programados, como interrupciones por el azar ó fallas del equipo.
Para locaciones de capacidad simple, los tiempos fuera de servicio pueden ser basados en tiempo de reloj, tiempo de uso, número de entidades procesadas, o un cambio en el tipo de entidad. Las locaciones de multi-capacidad tienen un único tiempo fuera por reloj. Al seleccionar el botón en la etiqueta o título se definen los tiempos fuera de servicio de la locación.
Clock...
Son usados para modelar tiempos fuera de servicio que ocurren dependiendo de el tiempo transcurrido de la simulación, como cuando un tiempo de fuera de servicio ocurre cada varias horas, sin importar cuantas entidades ha procesado cada locación.
El editor de los tiempos fuera consiste de la tabla de edición . Para acceder a ella seleccione Clock después de seleccionar el botón de encabezado DTs... .
(Seleccione una columna de la tabla siguiente para ver su descripción.)
Frequency
tiempo entre ocurrencias de tiempos fuera de servicio sucesivos. Esta opción puede ser una expresión.
Este campo se evaluara con el progreso de la simulación, por eso el tiempo entre tiempos fuera puede variar.
First Time
Tiempo en el que el primer tiempo fuera ocurrirá. Si este campo es dejado en blanco el primer tiempo fuera ocurrirá según el cuadro de Frecuencia.}
Frequency Priority
La prioridad (0-999) de la ocurrencia de tiempo fuera de servicio. La prioridad predefinida es 99.
Scheduled...

Seleccione YES si el tiempo fuera de servicio será contado como un tiempo fijado. Seleccione NO si el tiempo fuera de servicio será contado como un tiempo fuera de servicio No-fijado.
Logic
Entre cualquier estamento lógico a ser procesado cuando el tiempo fuera de servicio ocurre. Cuando la lógica se ha completado, la locación se pone a disposición. En el caso más simple, la lógica es simplemente un estamento WAIT (ESPERA) con un valor de tiempo o expresión que representan la duración del tiempo fuera de servicio.
Disable
Seleccione SÍ para desactivar el tiempo fuera de servicio temporalmente sin anularlo de la tabla.
Entry...
Sirve para modelar los tiempos fuera de servicio cuando una locación necesita ser reparada después de procesar un cierto número de entidades. Por ejemplo, si una máquina que pinta automóviles necesita ser tanqueada después de pintar 100, entonces debería definirse un tiempo fuera de servicio por entradas. El tiempo fuera de servicio ocurre después de que la entidad que lo activa deja la locación.
El editor de tiempos fuera por entradas consiste en una tabla de edición (ver figura
2.9); para acceder a el seleccione Entry... del menú que aparece luego de seleccionar el encabezado DTs....
(Seleccione una columna para ir a su descripción.)
Frequency.
El número de entidades a ser procesadas entre ocurrencias de tiempo fuera de servicio. Este puede ser un valor constante o una expresión numérica y es evaluado durante la simulación.
First Occurrence.
El número de entidades a ser procesadas antes del primer tiempo fuera de servicio. Éste puede ser un valor o una expresión numérica. Si el espacio es dejado en blanco, el primer tiempo fuera de servicio será basado en la frecuencia entrada.

Logic.
Cualquier estamento lógico para ejecutarse cuando el tiempo fuera de servicio ocurre. Normalmente, esta lógica simplemente es una expresión que determinará la duración del tiempo fuera de servicio.
Disable.
Seleccione YES para desactivar el tiempo fuera de servicio temporalmente sin anularlo de la mesa.
Usage...
Se usa para modelar tiempos fuera de servicio cuando ha ocurrido una cantidad de tiempo. La diferencia con el tiempo fuera por reloj es que al modelar por uso el tiempo fuera se basa en la operación neta de la locación. El editor de tiempos fuera por uso consiste en una tabla de edición ; para acceder al seleccione Usage... del menú que aparece luego de seleccionar el encabezado DTs....
Frequency.
Tiempo de uso entre tiempos fuera.
First Time.
Tiempo de uso antes de que el primer tiempo fuera ocurra. Si se deja en blanco el primer tiempo es basado en la frecuencia entrada.
Priority.
La prioridad entre 0 y 999 de que el tiempo fuera ocurra.
Logic.
Cualquier estamento lógico a ser procesado mientras el tiempo fuera ocurre, usualmente este campo contiene un estamento que define la duración del tiempo fuera.
Disable.
Seleccionando YES se desactiva temporalmente sin eliminarlo de la tabla. Setup...
Puede ser usado para modelar locaciones donde se pueden procesar diferentes tipos de entidades pero necesita ser ajustada o preparada para hacerlo, como cuando una estación de taladrado procesa varios tipos de partes, cada una con

una herramienta adecuada. Estos tiempos fuera no se traslaparan o ocurrirán dos a la vez sobre la misma locación.
Un tiempo fuera por ajuste ocurrirá solo cuando una entidad arriba a la locación y es diferente de la entidad anterior que arribó a la locación. El editor de tiempos fuera por ajuste consiste en una tabla de edición; para acceder a el seleccione Setup del menú que aparece luego de seleccionar el encabezado DTs....
Entity.
Entidad entrante para que el ajuste ocurra.
Prior Entity.
Entidad precedente a la entidad por la cual el tiempo fuera por ajuste ocurrirá.
Logic.
Se entra cualquier estamento lógico para ser procesado cuando el tiempo fuera ocurra.
Disable.
Seleccionar YES para desactivar temporalmente el tiempo fuera por Setup sin borrarlo de la tabla.
Rules...
La caja de dialogo de reglas, se selecciona pulsando el botón de encabezado en la tabla de edición de locaciones, es usado para escoger la regla que ProModel® seguirá cuando toma las siguientes decisiones:
1. Seleccionar las entidades entrantes
2. Hacer cola para salir
3. Seleccionar una unidad
(Seleccione un cuadro para ir a su descripción.)

Selecting Incoming Entities.
Cuando una locación está disponible y hay más de una entidad esperando para entrar, deberá ser tomada una decisión respecto a cuál admitir.
Selecting Incoming Entities>Oldest by Priority.
Selecciona la entidad que ha esperado más para asignarle la más alta prioridad de ruta.
Selecting Incoming Entities>Random.
Selecciona aleatoriamente la entidad siguiente con igual probabilidad del grupo de todas las entidades que esperan.
Selecting Incoming Entities>Least Available Capacity.
Selecciona la entidad que viene de la locación que tiene la menor capacidad disponible.
Selecting Incoming Entities>Last Selected Location.
Selecciona la entidad que viene de la locación que se seleccionó la última vez.
Selecting Incoming Entities>Highest Attribute Value.
Selecciona la entidad con el valor del atributo más alto de un atributo especificado.
Selecting Incoming Entities>Lowest Attribute Value.
Selecciona la entidad con el valor del atributo más bajo de un atributo especificado.
Queuing For Output.
Cuando una entidad ha finalizado su operación en una locación y otras que han finalizado adelante de ella no han partido. Una decisión debe tomarse, permitir a la entidad salir o esperar según alguna regla de formación de colas de espera.
Si no se especifica alguna de las reglas de formación de colas de espera, "Ninguna formación de colas de espera" será usada.
Queuing For Output.>No Queuing.

Entidades que han completado su proceso en la locación actual son libres de dirigirse a otras locaciones independientemente de otras entidades que han terminado su proceso. Si esta opción se selecciona no se despliega en la Caja de Reglas.
Queuing For Output>First In, First Out.
La primera entidad en completar el proceso debe salir para la próxima locación antes que la segunda en completar el proceso salga, y así.
Queuing For Output>Last In, First Out (LIFO).
Entidades que han finalizado su proceso esperan para salir con esta regla, la última que finaliza o completa el proceso es la primera en salir.
Queuing For Output>By Type.
Entidades que han finalizado esperan para salir FIFO, pero se tiene en cuenta el tipo de entidad para asignar su ruta especifica.
Queuing For Output>Highest Attibute Value.
Entidades que han completado su proceso hacen cola para salir de acuerdo con el más alto valor de un atributo especificado.
Queuing For Output>Lowest Attribute Value.
Entidades que han completado su proceso hacen cola para salir de acuerdo con el menor valor de un atributo especificado.
Selecting a Unit.
Si la locación tiene unidades múltiples, entonces las entidades entrantes deben asignarse a una unidad en particular. Una de las siguientes reglas deberá ser seleccionada. Las reglas de decisión aplican solo para locaciones de multi-unidad.
Selecting a Unit>First Available.
Selecciona la primera unidad disponible.
Selecting a Unit>By Turn.
Rota la selección entre las unidades disponibles.
Selecting a Unit>Most Available Capacity.
Selecciona la unidad que tiene la mayor capacidad disponible. Esta regla no tiene efecto con unidades de capacidad unitaria.
Selecting a Unit>Fewest Entries.
Selecciona una unidad disponible con la menor cantidad de entradas.
Selecting a Unit>Ramdom.
Selecciona una unidad disponible aleatoriamente.
Selecting a Unit>Longest Empty.
Selecciona la una unidad disponible que ha estado más tiempo vacía. Entidades
Todo lo que el sistema procesa es llamado "Entidad", también puede pensarse en ellas como las partes en los sistemas de manufactura, personas, papeles, tornillos, productos de toda clase.
Para acceder al Editor de Entidades, seleccione el menú Build y luego Entities; ó Ctrl+E .
Editor de Entidades
Las entidades son creadas o editadas con el editor de entidades. Consiste en una tabla de edición para especificar las propiedades de la entidad en el sistema, y una ventana grafica para seleccionar uno o más gráficos para representar la entidad.

Tabla de edición.
Cada campo de esta tabla es descrito a continuación:
Icon.
Muestra el grafico de la entidad.
Name.
Nombre de la entidad.
Speed.
Esta entrada es opcional y se aplica para entidades que se muevan por si mismas como los humanos. Su valor predefinido es de 50 metros por minuto, o 150 pies por minuto dependiendo de las unidades ingresadas en el cuadro de dialogo de Información General.
Stats.
El nivel de estadísticas que se coleccionaran de la entidad, hay tres niveles: None, Basic y Time Series.
Notes.
Cualquier información puede entrarse por ejemplo el material de la parte o entidad, la referencia, el proveedor, etc.
Path Networks
Se pueden conceptualizar como rutas, rieles o caminos fijos por los cuales se mueven los recursos (operarios, maquinas, etc.) para transportar entidades. Para acceder al editor de Path Networks, en el menú Build, seleccione Path Networks, ó Ctrl+N.

Editor de Path Networks
En ésta tabla se reúne la información básica de la "ruta", cada uno de sus campos se explica a continuación.
(Seleccione una columna para ver su descripción.)
Graphic.
Especifica el color de la red.
Name.
Nombre de la ruta.
Type.
Existen tres tipos de rutas; Passing, Non-Passing, Crane; Passing es un tipo de ruta en la que las entidades pueden pasar a otras entidades, es una forma de modelar algunas redes en las que los recursos se adelantan o se traslapan sin ningún inconveniente; Non-Passing es un tipo de ruta en la que las entidades no se adelantan unas a otras, como una carrilera para vagones o cualquier otro tipo de casos en los que físicamente los adelantos o traslapos no puedan darse, esta es la opción para modelarlos; Crane es especial para modelar grúas y puentes grúas.
T/S.

Se puede definir el movimiento en la ruta mediante dos tipos de unidades: Time, Speed & Distance.
Paths….
El numero de segmentos de ruta en la red, consta de una tabla de edición.
Paths…>From.
El nodo de comienzo del segmento de ruta.
Paths…>To.
El nodo de final del segmento de ruta.
Paths…>BI. Se ajusta con BI-direccional ó Uni-direccional dependiendo si el trafico puede darse en una o en las dos direcciones.
Paths…>Time.
Si el viaje a través de la ruta va ha ser medido más en términos del tiempo que de la distancia, entonces es el tiempo que un recurso o entidad tomara en recorrer el segmento de ruta.
Paths…>Distance.
Si el viaje a través de la ruta va ha ser medido en términos de la velocidad y distancia muestra la longitud del segmento de ruta, el tiempo de viaje entonces se determinara por la velocidad del recurso o la entidad.
Interfaces….
El numero de conexiones locación-nodo en la actual red.

Si una entidad será tomada o dejada por un recurso en una locación entonces deberá existir una interfaz entre el nodo y la locación.
Interfaces…>Node.
Nombre del Nodo
Interfaces…>Location.
Nombre de la locación o locaciones conectadas con el nodo, un nodo puede tener interfaz con varias locaciones pero una locación solo puede tener una interfaz con un nodo por ruta.
Mapping.…
Cuando hay varias rutas o segmentos que conecten un nodo de origen con un nodo de destino y deba tomarse una decisión acerca de cual camino seguir entonces ProModel® escogerá el más corto pero mediante esta tabla de edición se puede establecer explícitamente el camino que deberá seguirse.
Nodes….
Numero de nodos que conforman la ruta.

Tabla de edición de recursos.
(Seleccione una de sus columnas para ver la descripción.)
Dts.…
Dos tipos de detenciones están disponibles para los recursos: Clock y Usage. Con características muy similares a los ya explicados para las locaciones.
Stats.…
Las estadísticas deseadas. Las cuales pueden ser:
1. None No se recogen estadísticas.
2. Basic Promedio de utilización y tiempos de actividad.
3. By Unit Se recogen estadísticas para cada unidad de recurso.
Specs.…
Search.…
Si se ha asignado una ruta, seleccione este campo para acceder a las tablas de edición de Work Search (búsqueda de trabajo) y Park Search (búsqueda de buffer de parada), usadas para definir trabajos y buffers de parada opcionales.
Logic.…

Si se ha asignado una ruta, seleccione este campo para definir cualquier lógica opcional para ser ejecutada cuando un recurso entra o deja un nodo particular de la ruta.
Pts.…
Si se ha asignado una ruta, seleccione este campo para definir puntos del recurso, que son puntos auxiliares donde muchos recursos pueden aparecer gráficamente cuando se estacionan o en uso en un nodo de multi capacidad.
Notes.…
Para colocar cualquier nota en este campo.
Specifications
Abre el cuadro de dialogo de especificaciones del recurso, que se muestra a continuación.
(Seleccione un elemento de la figura para ver su descripción.)
Path Network.
Se selecciona la ruta por la cual el recurso viajará.
Home.
El nodo desde el cual el recurso comenzara en la simulación.
Return Home if Idle.

Al comprobar esta casilla el recurso vuelve al nodo HOME si está desocupado.
Off Shift.
Si a un recurso se le ha asignado una ruta y un turno, este es el nodo al cual el recurso va cuando esta fuera del turno.
Break.
Este es nodo al cual el recurso viaja cuando tiene un descanso.
Resource Search.
Cuando una entidad que necesita un recurso debe seleccionarlo entre varias unidades de recursos disponibles, debe especificarse una de las siguientes reglas (esto solo se aplica para recursos multi-unidad):
1. Closest Resource Recurso más cercano
2. Least Utilized Resource Recurso menos utilizado
3. Longest Idle Resource Recurso que ha estado más tiempo desocupado.
Entity Search.
Cuando dos o más entidades con la misma prioridad requieren un recurso al mismo tiempo, el recurso seguirá una de estas reglas:
1. Longest waiting entity (with highest priority)
Entidad que ha esperado más (con la más alta prioridad)
2. Closest Entity (with highest priority)
Entidad más cercana (con la más alta prioridad)
3. Entity with the minimum value of a specified attribute
Entidad con el mínimo valor de un atributo especificado
4. Entity with the maximum value of a specified attribute
Entidad con el máximo valor de un atributo especificado
Motion.
Si una ruta ha sido asignada al recurso, en estas casillas se especifica el movimiento.

1. Speed trávelin empty/full
Velocidad de viaje vacio/ocupado
2. Acceleration rate
Aceleración
3. Deceleration rate
Desaceleración
4. Pikup time
Tiempo para recoger
5. Deposit time
Tiempo para depositar
Proceso.
El menú de proceso define las rutas y las operaciones que se llevaran a cabo en
las locaciones para las entidades en su viaje por el sistema. También puede
decirse que generalmente se conocen o hacen parte de la información recolectada
del sistema, los diagramas de proceso o operación, estos se transcribirán al
computador para formar el proceso. Antes de crear el proceso es necesario definir
las entidades, locaciones, recursos y path networks. Para acceder al menú de
edición de proceso, en el menú Build, seleccione Processing; ó Ctrl+P.
Editor de Proceso.

El editor de proceso consta de cuatro ventanas que se despliegan simultáneamente.
(Seleccione una tabla o ventana para ver su descripción.)
Tools.
Ventana que
aparece abajo y
la izquierda, es
usada para definir
gráficamente
operaciones y
rutas.
Process.
Tabla de edición que está en la parte superior izquierda del editor de proceso y en
ella aparecen todas las operaciones realizadas en todas las locaciones a las
entidades. En ella se definen las condiciones de entrada al proceso.
Se usa para crear operaciones lógicas para cada tipo de entidad y cada locación en el sistema.

Entity.…
Tipo de entidad para las cuales el proceso es definido. Seleccione el botón de encabezado para abrir un cuadro con un listado de entidades.
(Cuadro de selección de entidades.)
Location.…
La locación en donde el proceso ocurre. Seleccione el botón de encabezado para abrir un cuadro con una lista de locaciones.
(Cuadro de selección de locaciones.)
Operation.…
Seleccione el botón de encabezado y se despliega un cuadro para crear o editar la operación. La operación lógica es opcional, pero típicamente contiene como

mínimo el estamento WAIT para asignar una cantidad de tiempo que la entidad deberá esperar en la locación. Otras operaciones comunes pueden ser, unir o agrupar entidades, realizar operaciones con variables, asignar tiempos, desplegar mensajes en pantalla.
(Ventana de edición de operación.)
Routing.
Aparece en la parte superior derecha del editor de proceso y en ella se define el destino de las entidades que han terminado su operación en una locación; ó en ella se define la salida del proceso.
Define las salidas de cada proceso asignado en la tabla de edición de proceso.
Blk.
Contiene el número del actual bloque de asignación de rutas.
Output…
Si una ruta es definida, debe entrarse el nombre de la entidad resultante de la operación.
Seleccione el botón de encabezado para abrir el cuadro con un listado de entidades, que es idéntico al que se despliega en la tabla de edición de proceso.
Destination.

Se define la locación a la cual las entidades se dirigen después de terminada la operación.
Seleccione el botón de encabezado para abrir un cuadro con un listado de locaciones que es idéntico al mostrado en la tabla de edición de proceso.
Rule.
En este campo de define la regla para seleccionar la ruta de destino.
Move logic.
Se define el método de movimiento hacia la próxima locación con estamentos lógicos, seleccione el botón de encabezado para abrir un cuadro de creación lógica como el mostrado en operación de la tabla de edición de proceso.
Arribos.
Al transcurrir la simulación nuevas entidades entran al sistema, esto es un arribo.
Un arribo puede consistir en personas, materia prima, información, los sistemas
necesitan una entrada para activar el funcionamiento de los procesos al interior de
ellos. Para acceder al editor de arribos, en el menú Build, seleccione Arrivals; ó
Ctrl+A.
El editor de arribos consta de tres ventanas que aparecen la pantalla juntas, la tabla de edición, la ventana de herramientas y ventana de layout ó esquema.

A continuación se explican las columnas que conforman la tabla de edición de arribos.
Entity.…
Entidad que arriba.
Location.…
Locación donde la entidad arriba.
Qty each.…
Número de entidades que arriban por cada intervalo de arribo.
First Time.
El tiempo del primer arribo. Dejado en blanco se tomara el tiempo consignado en el campo de Frequency.
Occurrences.
El número de arribos o ocurrencias de paquetes de entidades que se simularan, con la expresión INF se realizaran infinitos arribos en la simulación por lo cual el fin de esta será especificado por otros parámetros.
Frequency.
Tiempo entre arribos.
Logic.
Define cualquier lógica opcional de arribos, consiste de uno o más estamentos lógicos, para ser ejecutados por las entidades en sus arribos.
Información General.
Permite especificar información básica del modelo como el nombre; las unidades
por defecto de tiempo y distancia, así como la librería grafica de la cual se toman
las imágenes para crear locaciones, entidades, etc.
Para acceder al cuadro de dialogo General Information; en el menú File,
seleccione New; ó en el menú Build, seleccione General Information; ó Ctrl+I.

El cuadro de dialogo de información general se muestra a continuación. Atributos.
El atributo es una condición inicial, como una marca; puede ser que pertenezca a entidades o a locaciones, entre ellos pueden contarse el peso de un material, su dureza, o cualquier otra característica ya sea física, química o de cualquier otro tipo que se quiera asignar a una entidad o locación.
Para acceder a la tabla de edición de atributos, en el menú Build, seleccionar More
Elements, seleccionar Attributes; ó Ctrl+T.
La Tabla de edición de atributos, es el medio por el cual se crean o editan atributos, cada una de sus columnas es explicada a continuación.
ID.
Nombre del atributo
Type.
Tipo de atributo, real o entero.
Classification.…
Atributo de entidad ó atributo de locación.

Notes.
Campo para notas generales para describir el atributo.
Espacios y opciones de selección se explican a continuación.
Title.
Es opcional, da una descripción del modelo.
Time Units.
Unidad de tiempo en el modelo. Siempre que no existan otras unidades explicitas estas serán usadas por defecto.
Distance Units.
Unidades en pies o metros para todas las distancias especificadas en el modelo.
Model Notes.…
Despliega una ventana para especificar notas generales sobre el modelo.
Graphic Library File.
Abre un cuadro de dialogo para seleccionar el archivo de la librería grafica que se usará cuando se abra el modelo.
Initialization Logic...
Instrucciones que son ejecutadas para comenzar la simulación.
Termination Logic...
Instrucciones que se ejecutan cuando el modelo termina la simulación.
Atributos.

El atributo es una condición inicial, como una marca; puede ser que pertenezca a entidades o a locaciones, entre ellos pueden contarse el peso de un material, su dureza, o cualquier otra característica ya sea física, química o de cualquier otro tipo que se quiera asignar a una entidad o locación.
Para acceder a la tabla de edición de atributos, en el menú Build, seleccionar More
Elements, seleccionar Attributes; ó Ctrl+T.
La Tabla de edición de atributos, es el medio por el cual se crean o editan atributos, cada una de sus columnas es explicada a continuación.
ID.
Nombre del atributo
Type.
Tipo de atributo, real o entero.
Classification.…
Atributo de entidad ó atributo de locación.
Notes.
Campo para notas generales para describir el atributo. Variables.
Las variables pueden ser de tipo global o local. La variables son útiles para capturar y guardar información numérica, estas pueden ser números reales o enteros. Para acceder a la tabla de edición de variables, en el menú Build, deslizarse con el mouse hasta More Elements, se desplegara un menú, seleccionar Variables (global); ó Ctrl+B.

La Tabla de edición de variables, es el medio por el cual se crean o editan variables, cada una de sus columnas es
explicada a continuación.
Icon.
Este campo muestra "YES" si un icono para la variable aparece en la ventana de layout ó esquema, el cual es un contador que muestra el valor de la variable. Build>More Elements>Variables>ID.
Nombre de la variable.
Type.
Tipo de variable, real o entera.
Initial Value.
Valor inicial que toma la variable al comenzar la simulación.
Stats.
Se recogerán para la variable actual, estadísticas en tres niveles de detalle, None, Basic, and Time Series.
CONSTRUCCIÓN DE LA LOGICA.
Dentro de los elementos que conforman los modelos en ProModel®, existen cuadros o ventanas de lógica. Para facilitar la corrección en la sintaxis de los estamentos que conforman dicha lógica, ProModel® ha creado un ayudante (ver figura sigiente).
(Seleccione un elemento para ver su descipcion.)

Dicho ayudante se activa de la ventana de lógica seleccionando el icono que muestra un clavo y un martillo (ver figura siguiente).
A continuación se explican los componentes que conforman el constructor de lógica.
(Seleccione un elemento para ver su descripción.)

Cuadro de texto lógico.
Brinda una breve descripción del estamento o función seleccionada, que será pegado en la ventana de lógica.
Botones de parámetros.
Están ubicados en la parte inferior del cuadro de texto lógico, sirven para controlar los parámetros de un estamento o expresión.
Estos aparecen de acuerdo al estamento seleccionado e indican cuando son opcionales o no.
Casilla de entrada de parámetros.
Esta casilla editable sirve para ingresar los datos del parámetro.
Este solo aparece cuando el parámetro es requerido por el estamento.
Teclado numérico y botones lógicos.
Seleccione el botón "Keypad" para desplegar un arreglo de casillas con números (ver figura siguiente), con el cual se pueden ingresar números sin el teclado en la casilla de entrada de parámetros.

Category.
Este cuadro permite seleccionar el tipo de estamentos que aparecerán en la lista que se muestra en la ventana inferior, se puede seleccionar todos o algún tipo de estamentos.
Build Expresión button.
Este botón permite crear una única expresión. Una expresión consiste de una combinación de números, model elements, funciones and/or, pero no incluye estamentos.
Statement selection list.
Es un listado de estamentos válidos para la casilla de lógica que se está creando, de ella se pueden escoger los estamentos que se requieran.
Paste Button.
Es un botón que pega el texto del cuadro de texto lógico dentro de la venta o cuadro lógico seleccionado. Este solo funciona cuando el estamento o expresión a completado el mínimo de condiciones o requerimientos.
Clear button.
Este botón limpia cualquier expresión o estamento que se ha trabajado sin pegarlo a la ventana lógica y permite comenzar otra vez.
Close button.
Cierra el constructor de lógica sin pegar el actual texto en el cuadro de texto lógico.
Logic Elements.
Cuando se edita la casilla de entrada de parámetros, la lista de selección de estamentos es reemplazada por Elementos Lógicos (ver figura siguiente). Este es una lista de elementos lógicos y del modelo.
Help button.
Abre la ayuda con los temas del contexto.

CAPITUL 3:
DISEÑO DEL
EXPERIMENTO Y
ANALISIS DE
RESULTADO

3.1 Método de Simulación aplicado al Banco
Santander Serfín.
Elección del lugar para realizar el muestreo: Al ver el gran problema que evidentemente acompleja el Banco Santander Serfin decidimos hacer un estudio más a fondo y encontrar la causa raíz del caos provocado por el exceso de colas.
Toma de datos: Los datos tomados para realizar la simulación de colas en fueron registrados de acuerdo a la hora a la que llegaban los clientes al sistema, (la hora que tenían que esperar antes de recibir el servicio, así como el tiempo en que recibían su servicio y la hora de salida del sistema.
Procesamiento y validación de datos: Los datos obtenidos en segundos (tiempos de llegada, espera, servicio y los tiempos de salida) se ordenaron e insertaron en Excel para tener un registro de estos. Posteriormente todos los grupos de datos fueron tratados en el software StatGraphics con el fin de ajustarlos a una distribución estadística. Y posteriormente ingresarlos al simulador Promodel.
Obtener el modelo: Con el uso de los softwares mencionados anteriormente se obtuvo un modelo matemático con el que más adelante se realizó la simulación.
Hacer el caso base: En este punto, se insertaron la media y desviación estándar de cada grupo de datos para simular el proceso desde que llega el cliente hasta que sale del sistema.
Simular: Después de simular el caso base, se hicieron algunas modificaciones en la simulación, cambiando las variables del modelo, para encontrar el nivel óptimo del sistema. De esta forma, se observó el comportamiento que tuvo el sistema de colas al cambiar las variables determinadas.
Discutir resultados:
Se analizaron los resultados obtenidos en las corridas de simulación, y en base
a ellos se realizaron recomendaciones para este Banco.

3.2 Permisos
Antes de poder iniciar con nuestro estudio fue necesario asumir algunos de los
permisos para poder acceder sin problemas al sistema y así realizar
posteriormente la toma de datos.

3.3 Recolección de datos
La recolección de datos decidimos tomarla entre los días del 9 al 16 de marzo
teniendo en cuenta días de pago, por lo que nuestra tasa de llegadas se elevó
más de lo normal, debido a que en estos días, los clientes llegan aún más a recibir
el servicio.
Aquí observamos los datos obtenidos llegadas, espera y servicio; todos en
segundos.
Tiempos Obtenidos en el Banco Santander
Llegada Espera Servicio Salida
69 44 200 43
61 36 122 35
62 37 179 48
79 1632 213 53
60 1643 185 35
61 36 156 55
75 50 185 58
95 70 221 51
53 28 238 34
78 53 206 52
62 37 197 18
93 1820 161 18
85 60 219 19
68 43 158 19
63 38 228 19
55 30 215 22
58 1670 189 23
74 62 154 25
97 85 217 27
81 69 155 30
76 64 152 30
92 1690 201 34
189 177 192 34
153 141 172 34
160 1821 145 35
157 145 152 35
190 178 149 36
202 190 169 44
165 153 219 51
212 200 216 52
165 153 166 52

107 95 250 53
80 68 197 53
209 197 228 53
265 253 232 53
56 44 182 53
137 125 161 54
100 1650 163 55
119 107 222 55
123 111 168 55
100 88 208 56
103 1812 135 56
128 116 168 56
147 135 212 57
141 129 159 57
119 107 160 58
122 110 250 59
139 127 190 59
101 89 163 60
119 107 158 60
138 126 222 61
108 96 163 63
120 108 228 63
128 116 206 64
109 97 227 65
100 1840 194 67
141 129 219 67
122 1630 152 67
126 1625 191 68
141 1643 239 68
103 91 250 68
133 1630 158 76
107 95 210 68
119 107 175 69
103 91 218 40
193 181 142 45
167 155 138 72
194 182 160 25
185 173 207 70
161 149 155 73
138 126 209 65
145 133 139 74
158 1800 219 48
190 178 143 75
183 171 153 43
184 172 179 56
189 177 181 75
185 173 177 76
185 173 193 76
185 173 220 76
146 134 189 57

154 142 138 87
139 127 146 78
174 162 139 78
200 188 157 78
135 123 136 79
146 134 134 43
166 1614 149 58
154 142 157 65
196 184 139 80
170 158 179 51
178 166 158 82
155 143 136 84
155 143 182 85
167 155 218 54
186 174 172 86
160 148 187 86
154 126 198 87
176 148 147 63
150 122 172 77
167 139 189 88
55 27 134 47
157 129 144 89
51 23 133 63
187 159 145 50
50 22 215 58
152 124 188 90
285 257 173 91
89 61 152 91
211 183 197 59
216 1815 173 93
70 42 134 6
329 301 227 94
243 215 185 4
207 179 239 94
294 266 195 95
233 205 191 97
204 176 172 99
300 272 199 99
294 266 131 34
253 225 135 90
265 237 187 76
268 240 223 43
223 1645 181 103
226 198 182 95
274 246 224 45
231 203 240 65
271 243 199 73
223 1432 217 24
200 172 197 62
275 247 174 43

204 176 190 98
221 193 209 11
213 1817 199 67
234 206 167 64
243 215 193 12
226 198 187 54
200 172 181 34
243 215 198 38
232 204 187 54
228 200 173 38
231 203 226 24
282 254 209 39
287 259 153 40
281 253 199 42
244 216 211 42
288 260 136 43
285 257 126 44
260 232 218 38
211 183 131 78
216 188 224 56
257 229 163 55
292 264 214 39
243 215 140 14
207 179 172 13
294 266 186 45
233 205 172 45
204 176 199 31
300 272 183 67
294 266 193 32
119 91 178 59
55 27 166 50
185 157 193 12
92 64 173 13
123 95 181 23
60 32 173 45
152 124 189 33
55 27 176 54
61 33 244 6
145 117 191 32
50 22 161 15
158 130 228 6
223 195 156 3
93 65 163 12
253 225 198 17
287 259 195 4
243 215 178 30
119 91 116 28
50 22 195 26
74 46 187 35
178 150 161 21

265 237 199 32
167 139 200 31
103 75 156 26
107 79 175 28
167 139 153 34
204 176 177 50
152 124 171 38
53 25 174 29
213 185 164 18
185 157 173 22
223 195 241 30
55 27 202 10
221 193 208 12
119 101 245 21
55 37 203 59
243 225 214 22
221 203 161 42
285 267 211 55
92 74 180 24
3.4 Tratamiento de Datos en StatGraphics. Cada grupo de datos fue ingresado en el Software estadístico Statgraphics 5.1
para analizarlo y encontrar la distribución a la que se ajusta.
Resumen del Análisis
Datos: Tiempos de Entrada
200 valores comprendidos desde 50.0 hasta 329.0
Distribución normal ajustada:
Media = 164.335
Desviación típica = 70.9506

Resumen del Análisis
Datos: Tiempos de Espera
200 valores comprendidos desde 1432.0 hasta 2304.0
Distribución normal ajustada:
Media = 1962.44
Desviación típica = 166.142
Resumen del Análisis
Datos: Tiempos de Servicio
Histograma para Col_1
0 100 200 300 400
Col_1
0
10
20
30
40
50
frecue
ncia
Histograma para Tiempos de Espera
1300 1500 1700 1900 2100 2300 2500
Tiempos de Espera
0
20
40
60
80
frecue
ncia

200 valores comprendidos desde 116.0 hasta 250.0
Distribución normal ajustada:
Media = 183.3
Desviación típica = 30.2808
Resumen del Análisis
Datos: Tiempos de Salida
200 valores comprendidos desde 3.0 hasta 103.0
Distribución normal ajustada:
Media = 50.44
Desviación típica = 23.8733
Histograma para Tiempos de Servicio
100 140 180 220 260
Tiempos de Servicio
0
10
20
30
40
50
frecu
enci
a
Histograma para Tiempos de Salida
-10 10 30 50 70 90 110
Tiempos de Salida
0
10
20
30
40
50
frecu
enci
a

3.5 Simulación de Caso base en Promodel.
Al abrir el software de simulación Promodel presionamos la primera opción de la
Barra de Herramientas (FILE) y abrimos un nuevo documento (NEW).
Posteriormente nos apareceré una ventana donde pedirá ingresar datos como el
título del documento (TITLE) y las unidades de tiempo en las que están los datos,
(TIME UNITS) en este caso nuestros datos están en segundos y damos clic en
aceptar (OK).

Para iniciar a construir nuestro modelo presionamos la opción de Construir
(BUILD) y damos clic en el apartado de locaciones (LOCATIONS).
Una vez que nos aparece la ventanilla de iconos, vamos construyendo nuestro
modelo base.

Posteriormente en el recuadro de Locaciones (LOCATIONS) agregamos cada uno
de los nombres de los componentes de nuestro modelo.
En ese mismo recuadro seleccionamos las reglas (RULES) entre los arribos,
dando doble clic sobre la palabra. Nos aparecerá un recuadro nuevo en el que
seleccionaremos que las llegadas de entidades (SELECTING INCOMING
ENTITIES) serán aleatorias (RANDOM) y la disciplina para la cola (QUEUING
FOR OUTPUT) será el primero que llega, primero que sale (FIFO) y le damos clic
en aceptar (OK).

Después de definir esas reglas de arribos, seguimos construyendo nuestro
modelo, pero esta vez nos enfocaremos en nuestras entidades (ENTITIES).
Nos aparecerá un nuevo recuadro en el que seleccionaremos nuestra entidad, y
ajustaremos el tamaño y la posición de nuestro icono. Sin olvidar cambiar el
nombre del icono a cliente.
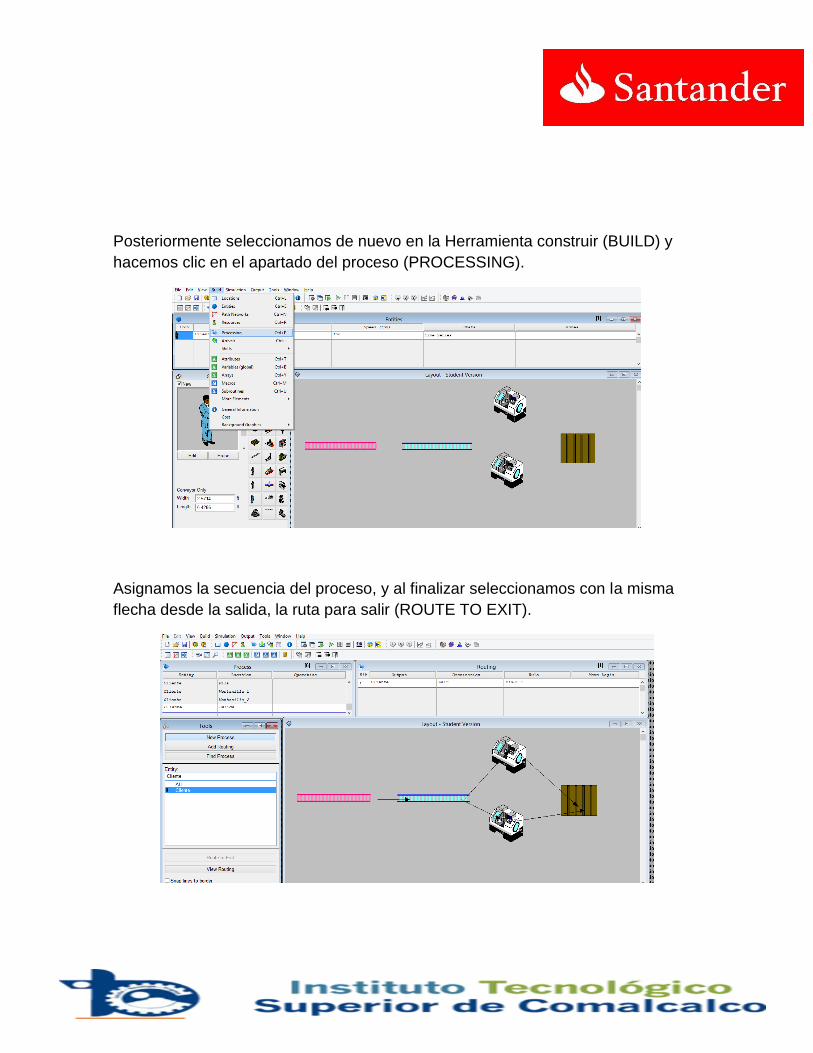
Posteriormente seleccionamos de nuevo en la Herramienta construir (BUILD) y
hacemos clic en el apartado del proceso (PROCESSING).
Asignamos la secuencia del proceso, y al finalizar seleccionamos con la misma
flecha desde la salida, la ruta para salir (ROUTE TO EXIT).

En el recuadro de Proceso (PROCESS) se asignan las operaciones a cada
entidad haciendo clic en la opción de Operación (OPERATION), aparecerá un
nuevo recuadro, y se selecciona el icono del martillo (BUILD).
Aparecerá un nuevo recuadro, llamado Constructor Lógico (LOGIC BUILDER) y en
la categoría, seleccionamos con doble clic la opción esperar (WAIT), en el
apartado de elementos lógicos (LOGIC ELEMENTS) se selecciona la opción de
todas las funciones (ALL FUNCTIONS) y se selecciona la distribución que sigue la
operación. En este caso todos nuestros grupos de datos se ajustan a una
distribución Normal. Se colocan los datos obtenidos en los análisis, en este caso,
la media y desviación estándar, se presiona la opción regresar (RETURN) se pega
en la operación (PASTE) y se cierra la ventana (CLOSE).
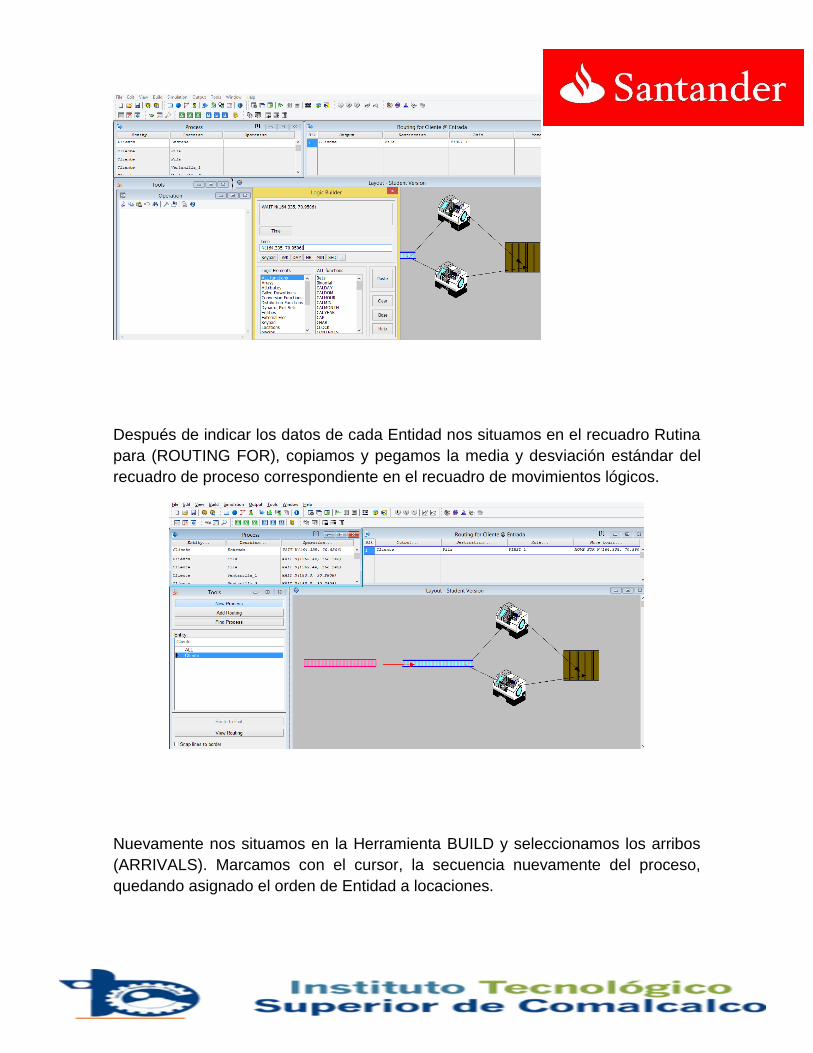
Después de indicar los datos de cada Entidad nos situamos en el recuadro Rutina
para (ROUTING FOR), copiamos y pegamos la media y desviación estándar del
recuadro de proceso correspondiente en el recuadro de movimientos lógicos.
Nuevamente nos situamos en la Herramienta BUILD y seleccionamos los arribos
(ARRIVALS). Marcamos con el cursor, la secuencia nuevamente del proceso,
quedando asignado el orden de Entidad a locaciones.

Finalmente en la Herramienta de Simulación, (SIMULATION) elegimos la opción
de guardar y correr nuestro modelo base (SAVE & RUN).
Finalmente se muestran los resultados de la simulación.

3.6 INTERPRETACION DE RESULTADOS (CASO BASE: 2 SERVIDORES)
General:
Como se muestra en la siguiente ficha, nuestro tiempo de simulación fueron 8
horas, que son los que normalmente se trabaja en na empresa de este tipo de
acuerdo a la LFT (Ley federal de Trabajo).
De acuerdo a nuestro caso base, la simulación arrojó que hubo exceso fracasos
en las llegadas debido a la insuficiente capacidad y a la deficiencia de los
empleados en cada ventanilla. La ficha marca que en esas ocho horas de trabajo
recibieron en total el servicio 140 entidades (Clientes). La ventanilla 1 logro
atender a la mayoría de los clientes (103) mientras que por ser una ventanilla
preferente la Ventanilla 2 solo atendió a 17 clientes. Los clientes que quedaron sin

recibir el servicio y en la cola de espera fueron un total de
31. Por lo que podemos concluir que el sistema se
encuentra en desbalance, por el poco número de Servidores. El porcentaje de
utilización de la ventanilla 1 fue de 20.88% y de la ventanilla 2 fue de 99.83%, es
decir que el empleado de la Ventanilla 1 tuvo más tiempo ocioso que el de la
ventanilla 2.
En la siguiente ficha, muestra que en el sistema siempre estuvieron llegando
clientes en exceso y este, salió fuera de control. Debido a que el 99.12 % de las
personas que entraron al sistema, en este caso, al banco, esperaban para recibir
el servicio mucho tiempo.
En el siguiente recuadro de abajo, se muestra que el 75.21% de los clientes fueron
atendidos satisfactoriamente y salieron del sistema, mientras que el 24.79% de
estos, se quedaron en la espera de recibir el servicio. También nos muestra que la
ventanilla 1 estuvo el 10.10% atendiendo clientes, 79.12 de tiempo de ocio y el
10.78% saturado de clientes. Mientras que la Ventanilla 2 estuvo el 64.36

atendiendo a clientes normalmente sin cuello de botella, el
0.17% de tiempo ocioso y el 35.47% saturadísimo de
clientes.
Debido al exceso de llegadas en el sistema, se presentaron un gran número de
arribos fallados, que fueron los que se muestran a continuación.
En el recuadro siguiente, se observa que un cliente pasaba en promedio 22.51
minutos en el sistema, cabe mencionar que solo en recibir el servicio.
Estos son los resultados ya en porcentajes de los movimientos del cliente.

CONCLUSIONES De acuerdo con la realización de este proyecto se logró descubrir una nueva forma de mejorar el servicio del “Banco Santander”, por medio del proceso de simulación se llegó a concluir lo siguiente:
De las largas filas que se forman dentro de la sucursal en Comalcalco del
“Banco Santander”, y con base a los datos que se tomaron, se puede identificar
que existe un problema al momento de atender a los clientes, ya que este sólo
cuenta con dos servidores.
En efecto aumenta el tiempo de espera de los clientes, generando así una
extensa fila l a cua l gene ra c ie r ta insa t i s f acc ión pa ra l os c l i en te s .
Y como se muestra que la fila es infinita, hace que disminuya poco el tiempo
en la misma fila y se obliga a espera aún más.
Otro punto el cual es causa de la deficiencia del servicio, es que los servidores
sólo pueden atender a un solo cliente, es decir, el tiempo de servicio depende de
la capacidad del servidor y del mismo servicio que el cliente requiera.
Por último, cabe mencionar que el porcentaje de utilización del cajero 2 es mayor
que el cajero 1, ya que el cajero 2 está disponible para los clientes en general,
es decir, en el cajero 1 se realiza un servicio más exclusivo, para clientes
Premium, lo que ocasiona que el cajero 2 se mantenga más tiempo ocupado,
puesto que hay más clientes generales, esto mismo genera la problemática
ya que no cualquier cliente puede ser atendido en el cajero 1. Siendo así el
descubrimiento de como poder mejorar el servicio que este banco ofrece a la
comunidad comalcalquense.

RECOMENDACIONES
La principal recomendación es la implementación de un tercer cajero, en el
cual se puede ofrecer el mismo tipo de servicio que se ofrece en el cajero 2.
Se requiere un tercer operario competente, para estar al frente de este
nuevo cajero.
Establecer tiempos de ocio (descanso) para cada operario, sin afectar el
rendimiento de los cajeros, evitando así la generación de una fila
demasiado larga.

BIBLIOGRAFÍA
HILLIER, Frederick S. y Gerald J. Lieberman. (2009). “Introducción a la
investigación de operaciones”. McGraw Hill.
personales.upv.es/jpgarcia/LinkedDocuments/Teoriadecolasdoc.pdf
www.ingenieria.unam.mx/javica1/ingsistemas2/Simulacion/COLAS.doc
www.iit.upcomillas.es/aramos/simio/transpa/t_qt_ar.pdf

ANEXOS
DIAGRAMA DE GANTT

FOTOS