generacion y analisis_de_secuencias_caot
TRANSCRIPT

UNIVERSIDAD POLITÉCNICA DE MADRID
ESCUELA UNIVERSITARIA DE INGENIERÍA TÉCNICA DE
TELECOMUNICACIÓN
PROYECTO FIN DE CARRERA
“GENERACIÓN DE SECUENCIAS CAÓTICAS
PARA CDMA”
AUTOR: SERGIO VALCÁRCEL MACUA
PROFESOR TUTOR: MIGUEL ÁNGEL DEL CASAR TENORIO
NOVIEMBRE 2003

A Ángeles y Horacio
GRACIAS por traerme al Mundo y disfrutarlo conmigo
Gracias por vuestra confianza inquebrantable
A Marta, Gracias por enseñarme la coherencia
A Ángel, me enseñas sin darte cuenta
A Sara, me das sin darte cuenta
A Cho, te Quiero, siempre juntos
Al Mundo y al Universo
A Todos JUNTOS
Gracias

INDICE
INTRODUCCIÓN
1. INTRODUCCIÓN AL CAOS
1.1. Preámbulo
1.2. Introducción a los Sistemas Dinámicos
1.2.1. Conceptos básicos de dinámica discreta
1.2.2. Teoría general de la dinámica continua
1.3. EL CAOS Y SUS MANIFESTACIONES
1.3.1. Sistema dinámico caótico
1.4. EJEMPLOS DE SISTEMAS DINÁMICOS CAÓTICOS DISCRETOS
DE UNA VARIABLE
1.4.1. Conjugación topológica
1.4.2. Función R-ádica
1.4.3. Tienda de Campaña
1.4.4. Curva Logística
1.4.5. Bended Up-Down
1.5. ATRACTORES EXTRAÑOS EN DINÁMICA
MULTIDIMENSIONAL
1.5.1. Conjuntos Invariantes y Atractores
1.5.2. Atractor de Henon
1.5.3. Atractor de Lorenz
1.5.4. Atractor de Rössler
2. EXPONENTES DE LYAPUNOV
2.1. CUANTIFICACIÓN DE LA DINÁMICA CAÓTICA
2.1.1. Exponentes de Lyapunov
2.1.2. Espectro de Lyapunov
2.1.3. Flujos no lineales. Análisis local mediante la matriz Jacobiana
2.2. ALGORITMO PARA LA EXTRACCIÓN DE LOS EXPONENTES
DE LYAPUNOV DE UN SISTEMA DINÁMICO DISCRETO O
CONTINUO, DEFINIDO POR SERIES
2.2.1. Presentación del problema
1
5
6
6
7
8
8
13
13
13
15
16
19
20
21
22
23
24
26
27
30
33
35
35

2.2.2. Presentación del algoritmo
2.2.3. Valores de entrada
2.2.4. Diagrama de bloques del algoritmo propuesto
2.2.5. Desarrollo de cada bloque
2.2.6. Análisis de los Resultados
2.2.7. Eficiencia Computacional
2.2.8. Aplicación Gráfica
2.2.9. Tablas con Pruebas
3. ESTUDIO DEL CAOS CON DENSIDADES DE PROBABILIDAD
3.1. ESTADO DEL ARTE
3.1.1. Espectro Ensanchado (Spread Spectrum)
3.1.2. Acceso Múltiple por División de Código (CDMA)
3.1.3. Secuencias de ensanchamiento en DS-CDMA
3.1.4. Secuencias caóticas
3.1.5. Necesidad de utilizar secuencias con unas propiedades
estadísticas determinadas
3.2. ESTUDIO DEL CAOS CON DENSIDADES DE PROBABILIDAD
3.2.1. Una aproximación alternativa para estudiar el caos
3.2.2. Introducción intuitiva a la evolución de densidades
3.2.3. Comentarios intuitivos sobre la evolución de densidades
3.2.4. Sistemas ergódicos –I–. La medida natural
3.2.5. Convenciones de notación
3.2.6. Herramienta para el estudio de la evolución de densidades
3.2.7. Operador Perron-Frobenius. Definición
3.2.8. Operador Perron-Frobenius. Propiedades y Ventajas
3.2.9. Consideraciones sobre los comentarios relativos a la evolución de
densidades
3.2.10. Mapas Ergódicos –II–
3.2.11. Mapas de mezcla
3.2.12. Mapas exactos
3.2.13. Inestabilidades numéricas en MATLAB
3.2.14. Estudio del Periodo de la secuencia en función del número de
decimales
35
36
37
38
49
52
53
54
61
62
62
62
63
63
64
65
65
66
77
78
79
79
81
83
84
85
88
92
93
94

4. DINÁMICA SIMBÓLICA
4.1. PRSENTACIÓN DEL PROBLEMA
4.1.1. Obtención de secuencias binarias a partir de órbitas reales de un
sistema
4.2. ESTUDIO DE LA CAOTICIDAD Y COMPLEJIDAD DE LA
SECUENCIA BINARIA
4.2.1. Varios intentos de algoritmos que extraigan los exponentes de
Lyapunov a partir de la Secuencia Binaria. Métodos y conclusiones
4.2.2. Reconstrucción del Atractor de partir de la Secuencia Binaria
4.2.3. Reconstrucción del atractor agrupando los bits en símbolos y
transformándolos a valores reales
4.2.4. Una trampa durante la reconstrucción del atractor
4.2.5. Test de evaluación de la aleatoriedad de una secuencia simbólica
5. CONCLUSIONES
6. ANEXOS
6.1.1. ANEXO 1. DESCOMPOSICIÓN QR
6.1.2. ANEXO 2. MANUAL DE USUARIO
6.1.3. ANEXO 3. PARTICIONES DE MARKOV
7. BIBLIOGRAFÍA
8. PRESUPUESTO
97
98
99
99
106
107
110
114
118
122
123
125
131
134
140

1
INTRODUCCIÓN

1
INTRODUCCIÓN
La Teoría del Caos ha abierto un nuevo mundo a la matemática aplicada. Unos
pocos conceptos que permiten, por primera vez, acercarse a la dinámica No Lineal. La
No Linealidad es una característica que se encuentra por todas partes en la Naturaleza.
De ahí que el campo de aplicación de la Teoría del Caos es muy extenso.
En ese campo de aplicación, la Teoría del Caos se puede utilizar bien para
analizar y modelar sistemas, o bien para diseñarlos y sintetizarlos.
En este proyecto vamos a enfocar la aplicación de la Teoría desde los dos puntos
de vista.
La idea de utilizar el Caos en comunicaciones seguras tiene ya unos cuantos
años. Pero es ahora cuando puede integrarse directamente como solución comercial y
tener un explosivo desarrollo. Nos estamos refiriendo al caso de las comunicaciones
inalámbricas de Acceso Múltiple por División de Código (CDMA). Las redes CDMA
van a ser fruto de una gran explotación durante la presente década, tanto en telefonía
móvil (UMTS) como en redes de área local inalámbricas (W-CDMA). El problema que
tienen es que los códigos que asignan a cada usuario deben tener unas propiedades
estadísticas determinadas para evitar interferencias. Comúnmente, las propiedades
estadísticas deseadas implican una autocovarianza tipo δ y una covarianza cruzada nula.
Hasta el momento se han estado utilizando unas secuencias generadas mediante códigos
algebraicos (polinomios generadores). Dichas secuencias son limitadas y adolecen de
ciertos problemas de seguridad. Comparados con los métodos convencionales, el
número de secuencias caóticas discretas es casi infinito ya que existen un grandísimo
número de sistemas dinámicos caóticos, condiciones iniciales posibles y funciones de
cuantificación.
El proyecto se organiza de la siguiente manera:
En el capítulo 1, titulado “Introducción al Caos”, se exponen las nociones
básicas sobre sistemas dinámicos caóticos, las manifestaciones del caos y algunos
sistemas caóticos a los que haremos referencia en posteriores capítulos.
En el capítulo 2, titulado “Exponentes de Lyapunov”, abordamos la tarea de
detectar si una señal observada es o no caótica. Lo hacemos midiendo una de las más

2
claras manifestaciones del caos, la sensibilidad a las condiciones iniciales. Dicha
manifestación la vamos a medir extrayendo los exponentes de Lyapunov de la serie.
Para ello hemos desarrollado un algoritmo y lo hemos implementado en MATLAB. El
algoritmo estima un modelo del sistema mediante funciones localmente lineales.
Una nueva forma de enfocar el caos, que además tiene una aplicación directa
para la generación de secuencias de tipo aleatorio, es estudiar la dinámica de un sistema
mediante funciones de densidad que miden la probabilidad de que, siguiendo una
trayectoria cualquiera del sistema, la órbita caiga en determinadas zonas del espacio de
fases. En el capítulo 3, llamado “Estudio del Caos con Densidades de Probabilidad”,
analizamos esta metodología. Presentamos las herramientas matemáticas necesarias y
exponemos su utilidad y aplicación.
En un sistema de comunicaciones basado en Caos, es fundamental que el
receptor conozca de antemano todos los parámetros asociados a la secuencia caótica de
transmisión. Por eso cuando no se conocen, el caos dota al sistema de un alto grado de
seguridad. Esta es la razón de que en criptografía también se estén utilizando
generadores caóticos de secuencias binarias. En el capítulo 4, “Dinámica Simbólica”,
abordamos la ardua tarea de extraer información a partir de una secuencia binaria
caótica. Lo hacemos desde dos puntos diferentes, intentamos extraer los exponentes de
Lyapunov de dicha secuencia e intentamos reconstruir el atractor al que pertenece la
órbita con la que ha sido generada.
Para terminar, incluimos unos anexos en los que tratamos de esclarecer algunas
cuestiones teóricas a las que se hace referencia durante la exposición.
Sergio Valcárcel Macua
Madrid, Noviembre de 2003

3
Introducción al Caos
Capítulo 1

4
1.1.- PREÁMBULO.
“Desde el campo de la matemática aplicada, una de las aportaciones que ha
irrumpido con fuerza en el panorama matemático del último tercio de siglo es la que se
centra en el estudio del movimiento: la teoría de los sistemas dinámicos. Los procesos
realizados en esta área, cuyos orígenes se remontan a la teoría de las ecuaciones
diferenciales, iniciada por Newton y Leibnitz, permiten hoy en día comenzar a entender
la conducta de sistemas dinámicos con conducta caótica, es decir, que prosiguen
perpetuamente en un movimiento sin pauta aparente.
Desde el Renacimiento se respeta a las matemáticas por ser capaces de
capturar la esencia del movimiento de los astros e incluso de predecirlo. Las
vibraciones de las cuerdas de un violín o de una membrana elástica, el movimiento de
los resortes mecánicos, la oscilación de las corrientes eléctricas en los circuitos, son
formas de movimiento cuya descripción matemática -conocida desde hace tiempo- ha
resultado clave en el desarrollo cultural y tecnológico de nuestro mundo.
¿ Pueden sin embargo las matemáticas “capturar” el complejo movimiento
atmosférico, la turbulencia de una explosión o la forma con la que un pintor mezcla
colores básicos para obtener en su paleta el tono que desea? ¿Puede el hombre, con
ayuda de algún formidable aparato matemático, despejar la bruma del futuro
prediciendo la evolución en los sistemas sometidos a leyes físicas o biológicas, por
azarosas que estas sean? ¿O por el contrario, en los sistemas en que un número de
variables muy elevado interactúa es completamente imposible cualquier predicción,
hasta el punto de que el leve aleteo de una mariposa en la selva amazónica pueda
alterar a los pocos dias el curso de un huracán? A tales preguntas se asoma, sin
respuestas acabadas, con el paso parsimonioso pero sólido que caracteriza siempre al
avance del saber matemático, la moderna teoría del caos, desarrollada a lo largo del
último tercio del siglo XX.”
Miguel A. Martín, Manuel Morán y Miguel Reyes
[I1]

5
1.2.- INTRODUCCIÓN A LOS SISTEMAS DINÁMICOS
1.2.1.- Conceptos básicos de dinámica discreta
Un sistema dinámico discreto es simplemente, desde un punto de vista
matemático, una ecuación de la forma
)(1 kk xfx , ...2,1,0k
donde f es una aplicación XXf : definida en cierto conjunto X , que recibe el
nombre de espacio de fases o espacio de estados.
Las variables que describen un sistema, se llaman variables de estado. Se
agrupan en un vector que se conoce como vector de estado, y que almacena la
información completa acerca del estado del sistema. El espacio de fases es entonces el
conjunto de todos los posibles vectores de estado del sistema.
La ecuación de un sistema dinámico puede interpretarse de la siguiente forma: si
el sistema adopta en un instante k un estado descrito a través de un cierto elemento
Xxk , entonces en el instante 1k el estado del sistema será )(1 kk xfx . La
aplicación f representa por consiguiente la ley de evolución del sistema dinámico, que
transforma cada estado en el siguiente estado que el sistema adopta. Si el sistema se
encuentra en un estado inicial 0x , su evolución temporal corresponde a la sucesión
,...,, 210 xxx , también llamada solución con condición inicial 0x . Se obtiene
recursivamente )( 01 xfx , )()( 0
2
12 xfxfx , y en general
)( 0xfx k
k
La sencilla expresión
)()( xfk k
k
es la solución general o flujo de los sistemas dinámicos discretos. Permite conocer el
estado del sistema en cualquier instante a partir de su posición inicial. El conjunto de
valores
),...}(),(),(,{)( 32 xfxfxfxxO
recibe el nombre de órbita de x (se diferencia de la solución )(),...,(),(, 2 xfxfxfx k en
que ésta última es una sucesión ordenada cuyos términos son los elementos de la
órbita).

6
1.2.2.- Teoría general de la dinámica continua
En los sistemas discretos se trata al tiempo como una magnitud discreta que se
incrementa por unidades enteras. Para muchos problemas la discretización del tiempo
resulta la solución más natural. Sin embargo las matemáticas disponen del lenguaje del
cálculo diferencial para describir de forma mucho más precisa el movimiento cuando se
desea tratar el tiempo como una magnitud continua.
Exponemos esta teoría en el espacio bidimensional por razones de sencillez,
pero todo lo que sigue vale para cualquier número de dimensiones.
Un sistema dinámico en tiempo continuo es una ecuación de la forma
))(()( txvtx
donde 22: RRUv es un campo vectorial definido en cierta región abierta U de
2R . Se entiende por solución de tal ecuación una función 2: RRI definida en
un intervalo abierto I que verifica la ecuación, es decir, tal que
))(()(
tvdt
td
Si I0 y x)0( se dice que f es una solución con condición inicial x. Tal
solución se denota )(tx .
La región U juega el papel de espacio de fases o espacio de los estados. El
estado del sistema en un instante t está caracterizado por un vector de estado Utx )( .
Las coordenadas del vector de estado )(),( 21 txtx , en el instante t son las variables de
estado. La ecuación del sistema dinámico puede desglosarse en las ecuaciones
))(),(()(
))(),(()(
2122
2111
txtxvtx
txtxvtx
De esta forma, un sistema dinámico en tiempo continuo especifica una pauta de
evolución de ciertas variables de estado, determinando los ritmos de variación de cada
una de ellas –sus derivadas– en función de los valores que las variables toman.

7
Teorema.
Sea la ecuación ))(()( txvtx
donde 22: RRUv admite derivadas
parciales continuas de primer orden en cada punto del conjunto abierto
U. Entonces, dado un punto cualquiera Ux , existe una única solución
de la ecuación con condición inicial x ( )(tx ).
Este teorema establece que la ecuación de un sistema dinámico define una ley de
evolución del sistema: fijados unos valores de las variables de estado en un instante, si
éstas evolucionan según la ecuación del sistema, quedan únicamente determinadas en
todo un intervalo temporal posterior y anterior al instante dado.
El sistema de todas las soluciones UI xx : es el llamado flujo generado por
el sistema dinámico. Contiene toda la información acerca de todas las posibles formas
de evolución del sistema, desde todas las posibles condiciones iniciales.
1.3.- EL CAOS Y SUS MANIFESTACIONES
Las pautas complejas de evolución, tan extendidas en el Universo, no son
consecuencia, como se creía, de la interdependencia entre un número elevado de
variables; la complejidad puede derivar simplemente de la no linealidad incluso en
sistemas caracterizados por una única variable, como es el caso del modelo de May.
1.3.1.- Sistema dinámico Caótico
Definición
Un sistema dinámico ),( fX se dice que es caótico si verifica las tres
propiedades siguientes:
1. Los puntos periódicos de f son densos en X .
2. Es sensible a las condiciones iniciales.
3. Tiene la propiedad de mezcla (o es topológicamente transitivo).

8
Esta definición de caos fue dada por R. Devaney en 1989. Posteriormente J.
Banks y otros autores probaron [I4] que las propiedades (1) y (3) implican la propiedad
(2). Además, M. Vellekoop y R. Berglund han probado [I5] que, cuando f es continua
y RX es un intervalo (no necesariamente finito) entonces la propiedad (3) implica
las propiedades (1) y (2).
Puntos periódicos densos
Dado un punto cualquiera Xy , existen puntos periódicos de f tan próximos
como se quiera a y, lo que es equivalente a probar que existe una sucesión de puntos
periódicos que convergen a y.
Sensibilidad a las condiciones iniciales
En el invierno de 1961 el metereólogo Edward Lorenz, con el objeto de predecir
el tiempo, estaba iterando un complejo sistema dinámico en su ordenador para ver como
se comportaba durante un largo periodo de tiempo. En vez de esperar varias horas, paró
su ordenador y anotó los valores de la órbita en un instante intermedio de lo que ya
había realizado, con la intención de volver a ponerlo a funcionar en otro momento.
Un tiempo después puso de nuevo a funcionar su ordenador, para seguir
calculando la órbita, con los datos iniciales que había tomado en aquel instante
intermedio. Lo que él esperaba que ocurriese es lo siguiente: la máquina repetiría la
segunda mitad de la ejecución original, y luego seguiría a partir de allí. La repetición
servía como una comprobación útil, pero ahorrándose la primera mitad.
Cuando Lorenz regresó, encontró que la nueva ejecución no había repetido la
segunda mitad de la original. Empezaba de la misma manera pero lentamente las dos
ejecuciones divergían, hasta que al final no guardaban ningún parecido la una con la
otra. [I2]
Lo que había sucedido es que en la memoria del ordenador se almacenaban seis
cifras decimales, mientras que en la impresión, para ahorrar espacio, sólo aparecían tres.

9
Lorenz había introducido los números redondeados suponiendo que la diferencia (una
parte entre mil) no tendría consecuencias. [I3]
Definición
Dado un sistema dinámico )(1 kk xfx , con espacio de fases x , y un
valor inicial Xx 0 , entonces la órbita de 0x es
,...},,,,{)( 432100 xxxxxxO
donde
)())))((...(()( 0
1
01 xfxffffxfx k
kk
para cada 0k .
La órbita de un punto 0x en el sistema dinámico ),( fX , interpretada como una
sucesión de pares
0)},{( kkxk se suele llamar serie temporal del sistema dinámico
),( fX con punto inicial 0x , y a la gráfica obtenida al trazar la poligonal que une
puntos consecutivos se le suele llamar gráfico de la serie temporal.
Podemos revivir la experiencia vivida por Lorenz iterando en el ordenador el
sistema dinámico asociado a la curva logística ( )1()( xxxf ) con parámetro 4 :
)1(4)( xxxf ó )1(41 kkk xxx
Si representamos en un gráfico las series temporales asociadas a las órbitas de
dos puntos muy próximos, 2360.352322530 x e 2370.352322530 y cuya distancia
es 12
00 10 yx , en el sistema dinámico )1(4)( xxxf nos encontramos con el
resultado de la (1.1). Se puede observar que las órbitas comienzan siendo muy
próximas, para ir separándose paulatinamente y llegar a realizar un recorrido
absolutamente independiente la una de la otra. Las órbitas se acercan y se alejan sin
ningún tipo de control.

10
Si elegimos otros valores iniciales, el resultado habría sido idéntico y, por
ocurrir este fenómeno, diremos que el sistema dinámico )1(4)( xxxf es sensible a
las condiciones iniciales.
Definición
Un sistema dinámico ),( fX se dice sensible a las condiciones iniciales
si existe un número positivo tal que para cualquier Xx y 0
existen Xy y 0n verificando que
yx y )()( yfxf nn
es decir, si existe un número positivo tal que todo punto inicial del espacio de
fases tiene puntos tan cerca como se quiera con órbitas que se separan en algún
momento de la órbita del punto inicial una distancia mayor que .
Conviene resaltar que la definición de sensibilidad a las condiciones iniciales no
exige que las órbitas de todos los puntos próximos a uno dado se separen de la órbita de
éste, sino que en cualquier entorno del punto dado haya algún punto cuya órbita se
separe de la de él.
Figura 1.1. Sensibilidad a las condiciones iniciales
11
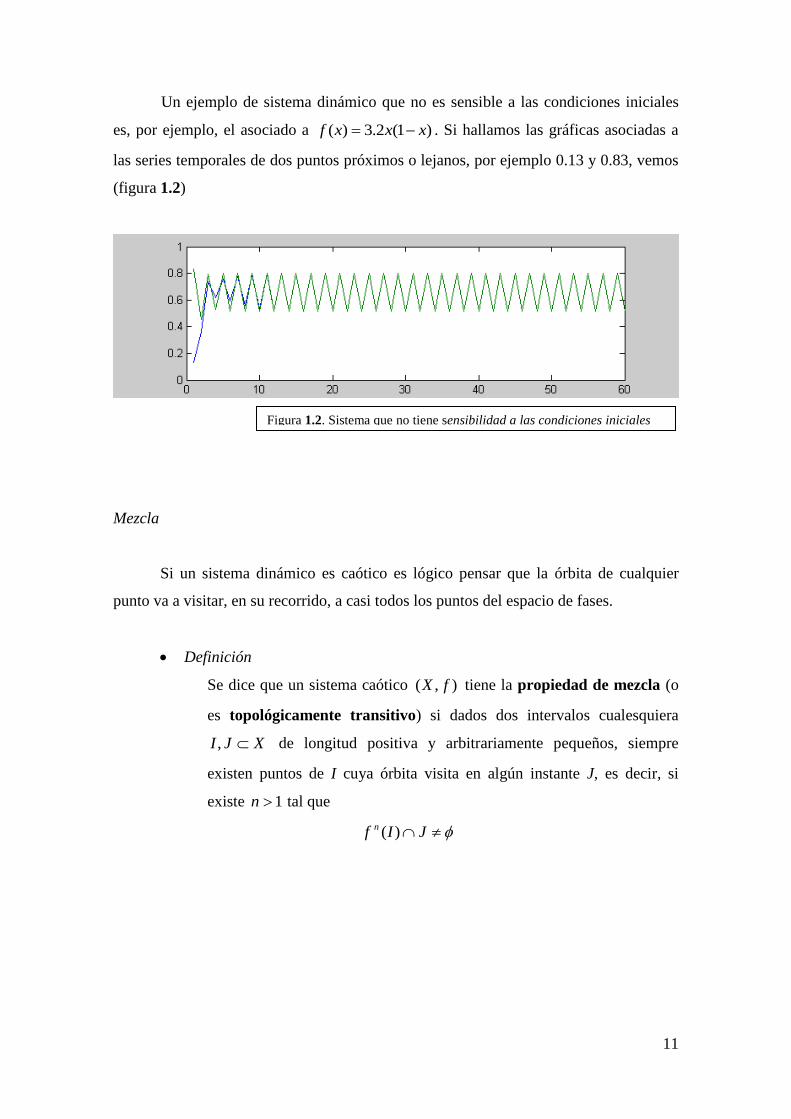
Un ejemplo de sistema dinámico que no es sensible a las condiciones iniciales
es, por ejemplo, el asociado a )1(2.3)( xxxf . Si hallamos las gráficas asociadas a
las series temporales de dos puntos próximos o lejanos, por ejemplo 0.13 y 0.83, vemos
(figura 1.2)
Mezcla
Si un sistema dinámico es caótico es lógico pensar que la órbita de cualquier
punto va a visitar, en su recorrido, a casi todos los puntos del espacio de fases.
Definición
Se dice que un sistema caótico ),( fX tiene la propiedad de mezcla (o
es topológicamente transitivo) si dados dos intervalos cualesquiera
XJI , de longitud positiva y arbitrariamente pequeños, siempre
existen puntos de I cuya órbita visita en algún instante J, es decir, si
existe 1n tal que
JIf n )(
Figura 1.2. Sistema que no tiene sensibilidad a las condiciones iniciales

12
1.4.- EJEMPLOS DE SISTEMAS DINÁMICOS CAÓTICOS DISCRETOS DE
UNA VARIABLE.
En esta sección vamos a describir tres sistemas dinámicos de tiempo discreto
que describen su movimiento sobre una dimensión (también llamados mapas), que,
como se verá cuando estudiemos el caos a partir de densidades de probabilidad, serán de
mucho interés por su aplicación práctica. Dichos sistemas son la función R-ádica, la
función tienda de campaña y la parábola logística.
1.4.1.- Conjugación topológica
Definición
Dados nRBA , , y dos aplicaciones AAf : y BBg : , se dice
que f y g son topológicamente conjugadas, si existe un
homeomorfismo BAh : (h es continua y tiene inversa 1h también
continua) tal que
hgfh
Dos aplicaciones topológicamente conjugadas son equivalentes en
cuanto al tipo de dinámica que generan.
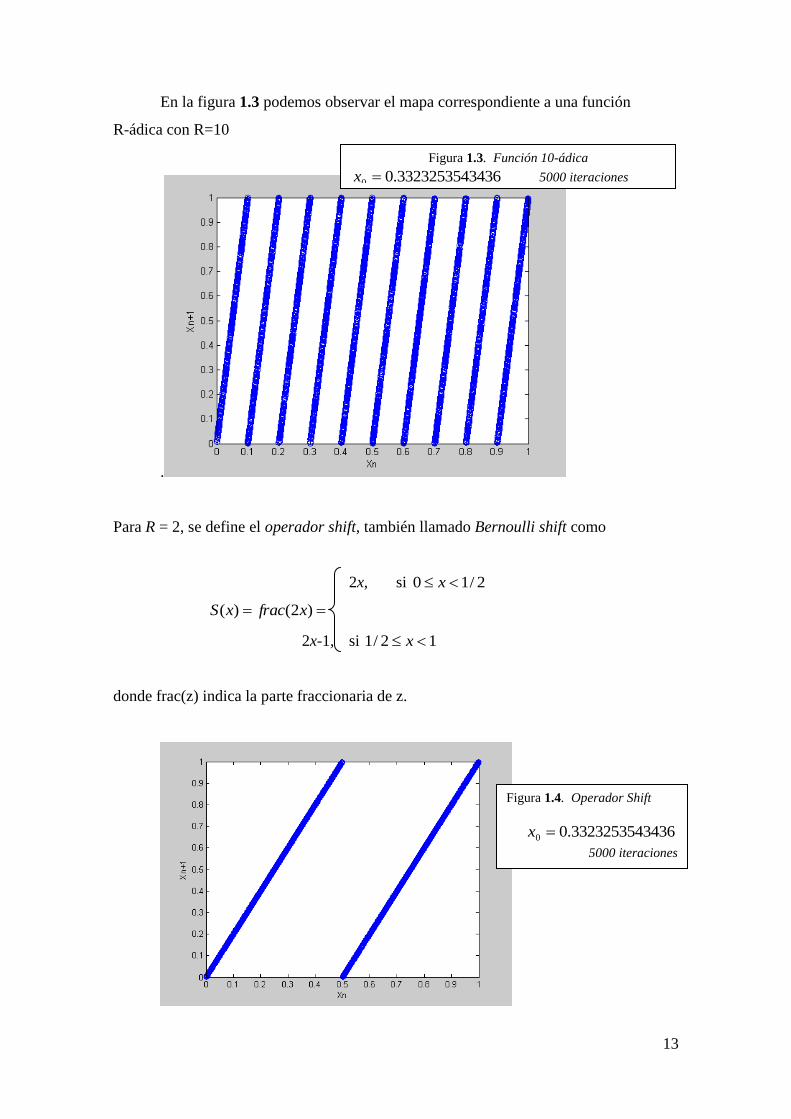
1.4.2.- Función R-ádica
Es una aplicación )1,0[)1,0[: R definida por
Rx, si Rx /10
Rx –R+1, si RxR /2/1
R(x) =
…… ……
Rx-R+(R-1) si 11
xR
R
13
En la figura 1.3 podemos observar el mapa correspondiente a una función
R-ádica con R=10
.
Para R = 2, se define el operador shift, también llamado Bernoulli shift como
2x, si 2/10 x
)2()( xfracxS
2x-1, si 12/1 x
donde frac(z) indica la parte fraccionaria de z.
Figura 1.3. Función 10-ádica
434360.332325350 x 5000 iteraciones
Figura 1.4. Operador Shift
434360.332325350 x
5000 iteraciones
14
Teorema
El sistema dinámico )),1,0([ S asociado al operador shift es un sistema
dinámico caótico.
Para una demostración del comportamiento caótico del sistema, en los términos de la
definición de R. Devaney, ver [I1] páginas 168-174.
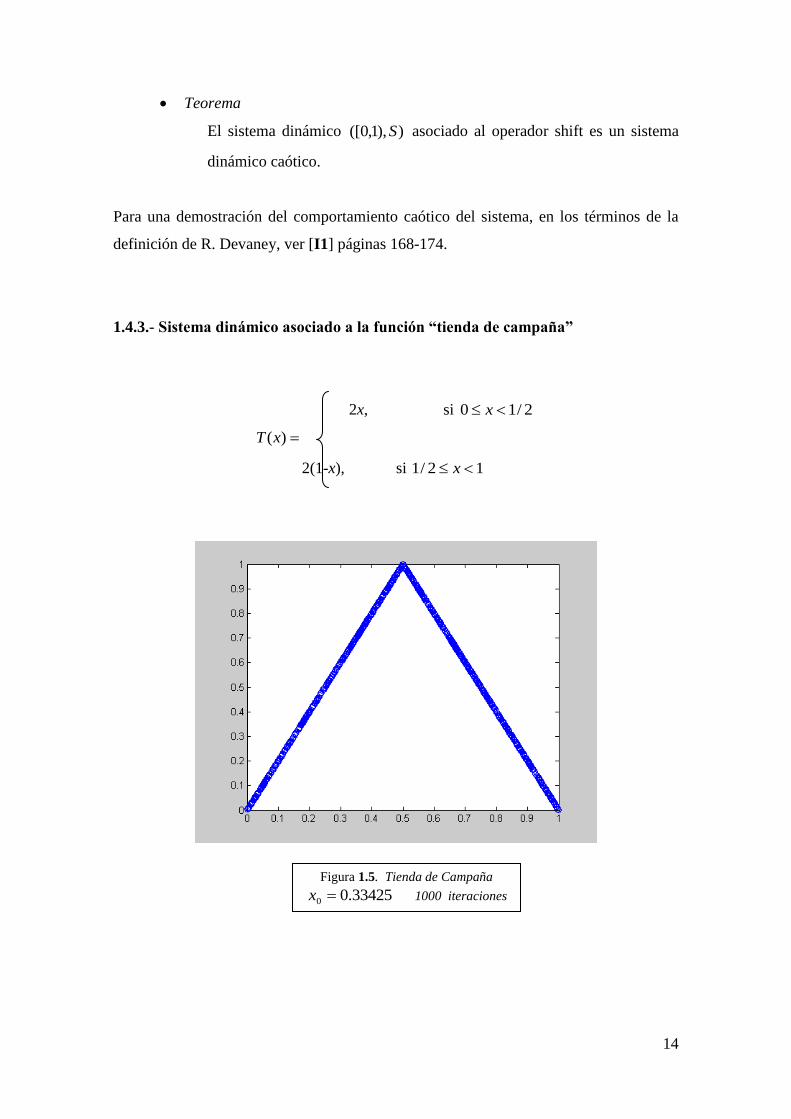
1.4.3.- Sistema dinámico asociado a la función “tienda de campaña”
2x, si 2/10 x
)(xT
2(1-x), si 12/1 x
Figura 1.5. Tienda de Campaña
0.334250 x 1000 iteraciones

15
Lema
Si consideramos al operador shift definido en 1x como 1)1( S ,
entonces, para 1k , se cumple que
kk STT 1
es decir, que
))(()(1 xSTxT kk
para todo 1,0x y 1k .
Teorema
El sistema dinámico T,1,0 asociado a la función tienda de campaña es
un sistema dinámico caótico.
Una demostración del lema y del teorema anterior se puede encontrar en [I1] (páginas
174-181).
1.4.4.- Curva logística
El sistema dinámico asociado a la curva logística
)1(4)( xxxf
con espacio de fases en 1,0 se puede ver en la gráfica 1.7.
Vamos a establecer una relación entre este sistema dinámico f,1,0 y el
sistema dinámico T,1,0 asociado a la función tienda de campaña. Esta relación nos
va a permitir deducir las propiedades del sistema dinámico logístico a partir de las del
sistema dinámico de la tienda de campaña, se va a establecer por medio de la función
1,01,0: h definida por
xsenxhy
2)( 2
(ver figura 1.6)
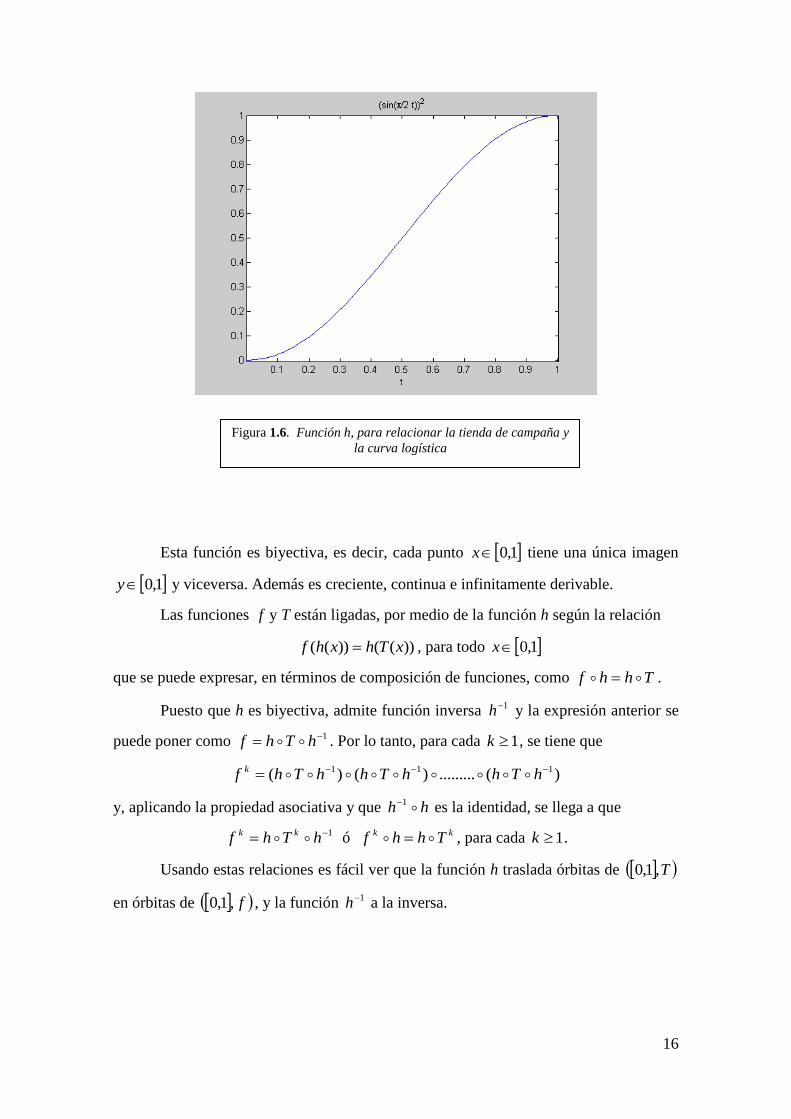
16
Esta función es biyectiva, es decir, cada punto 1,0x tiene una única imagen
1,0y y viceversa. Además es creciente, continua e infinitamente derivable.
Las funciones f y T están ligadas, por medio de la función h según la relación
))(())(( xThxhf , para todo 1,0x
que se puede expresar, en términos de composición de funciones, como Thhf .
Puesto que h es biyectiva, admite función inversa 1h y la expresión anterior se
puede poner como 1 hThf . Por lo tanto, para cada 1k , se tiene que
)(.........)()( 111 hThhThhThf k
y, aplicando la propiedad asociativa y que hh 1 es la identidad, se llega a que
1 hThf kk ó kk Thhf , para cada 1k .
Usando estas relaciones es fácil ver que la función h traslada órbitas de T,1,0
en órbitas de f,1,0 , y la función 1h a la inversa.
Figura 1.6. Función h, para relacionar la tienda de campaña y
la curva logística

17
Lema
Si ,...,,)( 2100 xxxxO es la órbita de 0x en T,1,0 , entonces
),...(),(),())(( 2100 xhxhxhxhO
es la órbita de )( 0xh en f,1,0 .
Inversamente, si ,...,,)( 2100 yyyyO es la órbita de 0y en f,1,0 ,
entonces
),...(),(),())(( 2
1
1
1
0
1
0
1 yhyhyhyhO
es la órbita de )( 0
1 yh en T,1,0
Teorema
El sistema dinámico f,1,0 , asociado a la curva logística )1(4)( xxxf ,
es un sistema dinámico caótico.
En realidad la familia de curvas logísticas )1()( xxxf se comporta de
forma caótica, sólo a partir de un determinado valor del parámetro .
Figura 1.7. Curva Logística
)1(41 nnn xxx
0.35230 x
600 iteraciones

18
El valor de que sirve de frontera, entre la zona donde se producen fenómenos
de duplicación de periodo y la zona de caos lo vamos a representar por y recibe el
nombre de punto de Feigenbaum o punto de entrada al caos.
Fue Feigenbaum el que determinó dicho valor para la familia de sistemas
dinámicos asociados a la curva logística
...5699456.3
A partir de dicho punto se puede evaluar la constante de Feigenbaum o
constante del caos para esta familia de sistemas dinámicos:
...0296692016091.4
que es interesante presentar por su universalidad (es idéntica para una amplia familia de
sistemas dinámicos) y por la importancia futura que se le augura.
Hemos definido por tanto tres sistemas dinámicos caóticos de tiempo discreto,
comprobando como la tienda de campaña y la curva logística surgen como conjugación
topológica a partir del operador shift. Vamos a definir otro sistema del que hablaremos
más en el capítulo 3.
1.4.5.- Bended Up-Down
Está definido por la función 1,01,0: f .
325
819937
152933
31332
9
)(
x
xx
xx
xx
x
xf
1119
11953
5331
310
x
x
x
x
Figura 1.8. Mapa Bended Up-Down
0.133523250 x
2000 iteraciones

19
1.5.- ATRACTORES EXTRAÑOS EN DINÁMICA MULTIDIMENSIONAL
Ligados a los sistemas dinámicos caóticos surgen conjuntos geométricos que
tienen estructura fractal [I1] [I6]. Esa complejidad geométrica ha sido detectada antes
por medio de la simulación de sistemas dinámicos de más de una variable que modelen
aspectos de la naturaleza (figura 1.9), que por el estudio matemático propiamente dicho.
Atractores extraños: Estructuras asintóticas hacia donde evolucionan las
órbitas de ciertos sistemas dinámicos, que están presentes en la dinámica de los más
insospechados procesos de la naturaleza. Siempre son procesos que en su evolución
“gastan energía”, es decir, son sistemas disipativos, y además, las leyes que los
gobiernan son no lineales.
En realidad ambos hechos, la no linealidad y la disipación, están relacionados,
aunque no de forma directa, ya que un sistema lineal también puede ser disipativo. La
disispación de energía desde un punto de vista matemático, significa que el espacio de
fases que el sistema dinámico n-dimensional, discreto o continuo, va transformando con
el tiempo, va contrayéndose y disminuyendo de volumen de tal forma, que la región del
espacio hacia donde evolucionan las órbitas del sistema, el atractor, tiene volumen n-
dimensional nulo. Lo que añade la no linealidad, es la forma particular de lograr esa
contracción del espacio de estados, la cual puede provocar, por una parte, una dinámica
caótica, y por otra, una estructura geométrica compleja en el atractor.
Podríamos decir que un atractor extraño, desde el punto de vista geométrico, es
fractal, y desde el punto de vista dinámico, es caótico.
Chua Duffing Lorenz Rössler
(Circuitos electrónicos) (Osciladores no lineales) (Convección atmosférica) (Cinética química)
Figura 1.9 Atractores extraños en diferentes modelos de la naturaleza

20
1.5.1.- Conjuntos invariantes y atractores
Definición
Consideremos un sistema dinámico
)(1 kk xfx
siendo kx un vector de estado perteneciente al espacio de fases X, que
supondremos es un subconjunto de nR y XXf : una aplicación.
Diremos que un conjunto XA es un atractor si existe un
conjunto abierto AC verificando que para Cx las órbitas )(xf k
convergen al conjunto A, es decir, para Cx
0)),(( Axfd k Cuando k
El atractor, por tanto, puede ser visto como la región del plano o
del espacio hacia donde viajan las órbitas del conjunto C, denominado
cuenca de atracción de A.
Además, las órbitas de los puntos del atractor ya han llegado a su
destino, por lo que habrá de ocurrir que AAf )( , esto es, el atractor es
un conjunto invariante.
Aunque el atractor como conjunto se transforma en sí mismo, las órbitas de sus
puntos no son necesariamente simples. Más bien, suele ocurrir lo contrario, es decir, que
la dinámica de los puntos del atractor suele ser caótica, esto es:
a) Existe al menos algún punto Ax tal que su órbita )(xf k es densa en A
(que es otra forma de expresar la propiedad de mezcla)
b) El conjunto de puntos periódicos de f en A es denso en A
c) Tiene sensibilidad a las condiciones iniciales.
Un atractor que verifica estas condiciones suele ser denominado un atractor
extraño.
La primera propiedad implica que el atractor no puede ser descompuesto en dos
atractores diferentes.
Aunque no existe una definición matemática formal del término atractor, en la
práctica el término suele implicar una complejidad geométrica de tipo fractal, que se

21
caracteriza por tener volumen n-dimensional nulo, y una microestructura particular
generalmente de tipo cantoriano.
1.5.2.- Atractor de Henon
Propuesto originalmente por Henon y Pomeau (1976) para explicar el
movimiento de ciertos cuerpos espaciales y presenta la cualidad de ser un sistema de
ecuaciones muy simple en el que la única componente no lineal es el 2x de la primera
ecuación.
Es un sistema dinámico bidimensional dependiente de dos parámetros.
2
1 1 kkk axyx
kk bxy 1
Si llamamos ),1(),( 2 bxaxyyxH a la transformación que define dicho
sistema, podemos estudiar - a partir del determinante de la matriz jacobiana ),( yxDH -
para qué valores de los parámetros a y b la transformación contrae áreas (es disipativa),
es decir, para qué valores de a y b es ),( yxDH <1.
En particular los valores a = 1.4 y b = 0.3 generan una dinámica caótica.
Figura 1.10 Atractor de Henon
(2000 iteraciones)

22
En contraste con lo que ocurre en sistemas discretos no lineales, los sistemas
continuos de dimensión 1 y 2 no dan lugar a una dinámica caótica. La propiedad de que
dos trayectorias soluciones no se pueden cortar [I1 página 89] tiene como consecuencia
el conocido teorema de Poincaré-Benedixon que establece que, en un sistema dinámico
continuo definido por funciones con cierto grado de regularidad (por ejemplo con
derivadas parciales continuas), las soluciones, o escapan al infinito (cuando el tiempo t
evoluciona, esto es t ) o convergen a un punto, o a una estructura recurrente (ciclo
límite). En otras palabras, parece que no existen sistemas dinámicos caóticos en
dimensión 1 y 2.
Vamos a presentar por tanto dos sistemas dinámicos de dimensión 3 que exhiben
comportamiento caótico y que en una sección posterior nos serán útiles para probar
nuestro algoritmo de extracción de los exponentes de Lyapunov.
1.5.3.- Atractor de Lorenz
Edward Lorenz (1963) estudió numéricamente el sistema.
yxx
yzyRxy
xyBzz
con , R y B constantes positivas.
El sistema proviene de un modelo matemático del problema de convección
térmica, y tiene una gran importancia para la predicción del tiempo atmosférico. [I7]
Figura 1.11
Atractor de Lorenz
Td= 0.005
Total=75
(Td = Intervalo de Integración)
23
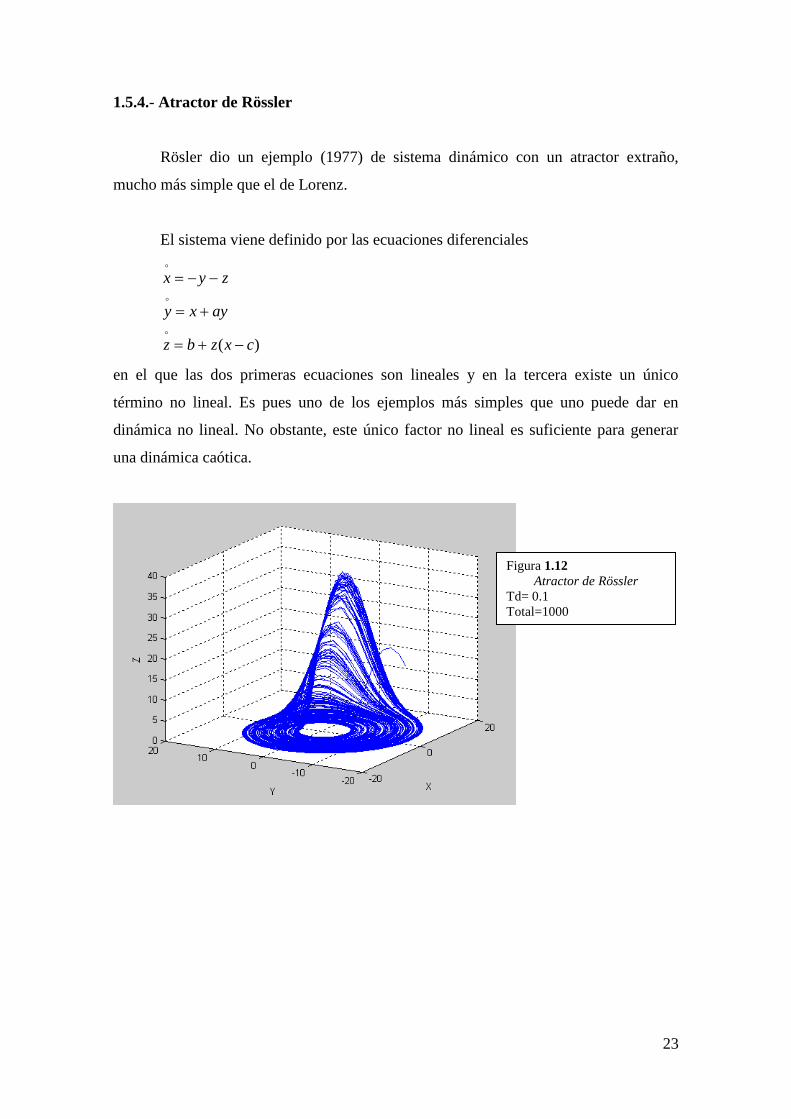
1.5.4.- Atractor de Rössler
Rösler dio un ejemplo (1977) de sistema dinámico con un atractor extraño,
mucho más simple que el de Lorenz.
El sistema viene definido por las ecuaciones diferenciales
)( cxzbz
ayxy
zyx
en el que las dos primeras ecuaciones son lineales y en la tercera existe un único
término no lineal. Es pues uno de los ejemplos más simples que uno puede dar en
dinámica no lineal. No obstante, este único factor no lineal es suficiente para generar
una dinámica caótica.
Figura 1.12
Atractor de Rössler
Td= 0.1
Total=1000

24
Exponentes de Lyapunov
Capítulo 2
“El movimiento de una simple ala de mariposa en
China, hoy produce un diminuto cambio en el estado de la
atmósfera. Después de un cierto periodo de tiempo, el
comportamiento de la atmósfera diverge del que debería haber
tenido. Así que, en el periodo de un mes, un tornado que habría
devastado la costa de América no se forma. O quizá se forma
uno que no se iba a formar.”
Edward Lorenz
[I1]

25
2.1.- CUANTIFICACIÓN DE LA DINÁMICA CAÓTICA
En un sistema caótico, por muy precisa que sea la medida efectuada del estado
actual ( 0x ), puesto que el conocimiento del valor exacto 0x es imposible, la sensibilidad
a las condiciones iniciales, presente siempre en dinámica caótica, determina una
impredicibilidad de los estados futuros. Por otra parte también determina una
incertidumbre respecto al pasado debido a que las aplicaciones caóticas no pueden
ser inyectivas.
El problema que nos planteamos es cómo cuantificar esos grados de
incertidumbre, junto con otros parámetros dinámicos y geométricos, que nos midan el
grado de “extrañeza” del atractor y, con ello, el conocimiento de la evolución del
sistema.
La dinámica caótica desarrolla una doble acción de estirado y plegado sobre el
espacio de fases [I1].
La operación de estirado tiene como consecuencia la sensibilidad a las
condiciones inicales, ya que dicha operación provoca que puntos inicialmente próximos
vean separados sus futuros. Esta característica de los sistemas dinámicos es una firma
inequívoca de comportamiento caótico. La tasa de divergencia media de órbitas de
puntos, que inicialmente están infinitesimalmente próximos, nos va a cuantificar esta
propiedad esencial del caos. Esta cuantificación se plasma en unos parámetros
numéricos denominados exponentes de Lyapunov, también llamados exponentes
característicos.
La entropía de un sistema dinámico es la pérdida de información que, en
promedio sobre el número de iteraciones, tiene lugar cuando el sistema evoluciona. Este
promedio de información perdida es proporcional a los exponentes de Lyapunov.
Otra característica que hemos constatado en los atractores extraños es la
fractalidad. La mencionada doble acción de estirado y plegado, repetida una y otra vez,
va “disipando”,es decir, contrayendo el espacio de fases, dando lugar a que el atractor

26
tenga una estructura cantoriana y su volumen n-dimensional sea nulo. Puesto que el
volumen del atractor es nulo, procede cuantificar su medida como conjunto geométrico.
Ello se consigue mediante la dimensión fractal que sirve para diferenciar, en medida, a
los conjuntos que, a pesar de tener volumen n-dimensional nulo, pueden tener un
tamaño muy variable. La idea intuitiva del concepto de dimensión fractal es medir cómo
escalan ciertos parámetros, que uno espera estén relacionados directamente con el
tamaño del conjunto, cuando observamos el mismo a una escala cada vez más pequeña.
El exponente de escalamiento será la dimensión fractal.
La dimensión de información nos da la pauta con que recibimos información
de la dinámica del atractor al pasar a escalas más pequeñas de observación.
Existen además un gran número de dimensiones cuantificables sobre el atractor,
que son: dimensión de auto-similaridad (self-similarity dimension), dimensión de
capacidad (capacity dimension), dimensión de Hausdorff, dimensión de correlación
(correlation dimension), dimensión de Lyapunov, dimensión de Minkowski-Bouligand
y un largo etc. Para más información sobre algunas de ellas consultar [L1] [L5] e [I6].
2.1.1.- Exponentes de Lyapunov
En un sistema dinámico la sensibilidad a las condiciones iniciales la vamos a
medir mediante un exponente que nos determine la tasa de divergencia exponencial de
órbitas adyacentes infinitamente próximas, o como la definen Eckmann y Ruelle [L5],
la razón exponencial a la que una perturbación en el estado inicial de una serie crece o
disminuye.
Lyapunov definió el exponente característico para cuantificar el grado de
estabilidad de un sistema, estableciendo que,dado un sistema de ecuaciones
diferenciales, una solución x(t) será estable si soluciones que empiezan próximas a ella
continúan estándolo con el paso del tiempo.
Si estudiamos un sistema lineal de ecuaciones diferenciales encontraremos una
solución general en la forma de
i
t
iieCtx
)( .

27
Para estudiar la estabilidad de esta solución bastará con estudiar el signo de sus
exponentes característicos i . La presencia de exponentes negativos supone que la
solución es estable. Si aparecen exponentes positivos estaremos ante una solución
inestable.
Para el caso de sistemas de ecuaciones diferenciales no lineales, su significado
no es idéntico, pues la presencia de exponentes positivos no indica inestabilidad, sino
comportamiento caótico.
Supongamos que
)(1 nn xfx
es un sistema dinámico unidimensional y que f es derivable salvo, a lo sumo, en un
número finito de puntos.
Imaginemos dos puntos próximos 0x y 0x ; después de N iteraciones se han
convertido en )( 0xf N y )( 0 xf N respectivamente.
Supongamos que ambos puntos están a una distancia
)(
000)()(
xNNN exfxf
es decir, que la separación inicial se ha multiplicado por un número que crece
exponencialmente con el número de iteraciones N y que, además, viene caracterizado
por un exponente )( 0x dependiente del punto 0x en el que estamos analizando la
sensibilidad a las condiciones iniciales.
Tomando logaritmos y límites cuando 0 y N en la expresión
anterior, obtnenemos
)()(log
1limlim)( 00
00
xfxf
Nx
NN
N
0
0 )(log
1lim
dx
xdf
N
N
N
siendo
0
0 )(
dx
xdf N
la derivada de la función )( 0xf N en 0xx .

28
Con la regla de la cadena para la derivación de funciones compuestas llegamos
a obtener que
1
0
0 )('log1
lim)(N
i
iN
xfN
x
Los exponentes de Lyapunov también se pueden expresar a partir de los
números de Lyapunov. Para un n-ciclo periódico atractivo (repulsivo) el ritmo con el
que las órbitas cercanas se acercaban (alejaban) del ciclo está regulado por la derivada
de nf en cualquier punto del ciclo. Además, si el ciclo es },...,,,{ 321 nxxxx , entonces
tras n iteraciones sobre un punto cercano la distancia de éste al ciclo se habrá
multiplicado por
)()'(...)()'()()'()()'()()'(...)()'( 3211 nn
nn xfxfxfxfxfxf
y la variación media tras cada iteración será
nnxfxfxfxf )('...)(')(')(' 321
En principio no hay ninguna razón para tener que restringirnos a ciclos. Si
tenemos una órbita },...,,,{ 321 nxxxx , no periódica podemos considerar el valor
nn
nxfxfxfxfxL )('...)(')(')('lim)( 3211
A )( 1xL se le llama número de Lyapunov de la órbita },...,,,{ 321 nxxxx , y es el
mismo para todos los elementos de la órbita. El número de Lyapunov mide la
contracción (expansión) local asintótica en cada iteración en la proximidad de una
órbita.
El exponente de Lyapunov es el valor ))(log()( 11 xLx [L2]
Si el exponente de Lyapunov de 1x es negativo, las órbitas de puntos cercanos a
1x serán atraídas por la de 1x , mientras que si es positivo tenderán a separarse.
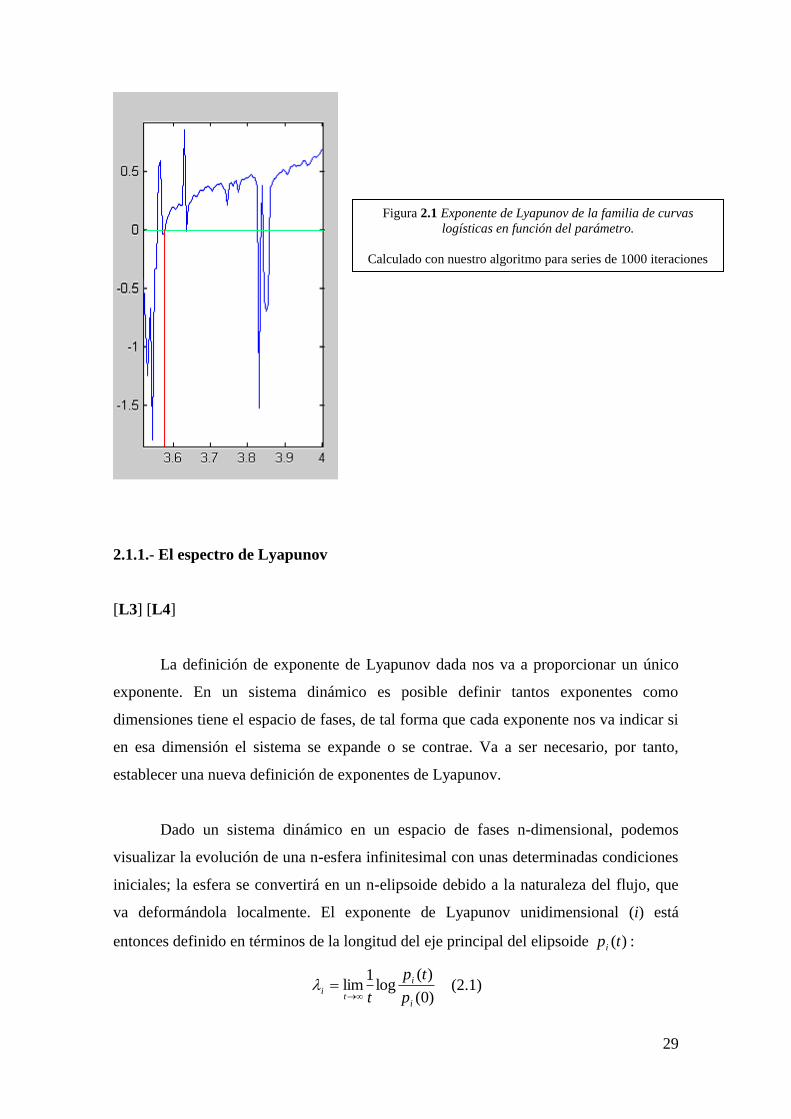
A modo de ejemplo, para la familia logística, representamos en la figura (2.1) el
exponente de Lyapunov del punto inicial 0.8087325, en función del parámetro μ. Puede
observarse cómo, a partir del punto de Feigenbaum ( ...5699456.3 ), el exponente
se vuelve positivo, corroborando dicho punto como punto de entrada al caos (véase
capítulo.1 Introducción a la dinámica caótica).
29
2.1.1.- El espectro de Lyapunov
[L3] [L4]
La definición de exponente de Lyapunov dada nos va a proporcionar un único
exponente. En un sistema dinámico es posible definir tantos exponentes como
dimensiones tiene el espacio de fases, de tal forma que cada exponente nos va indicar si
en esa dimensión el sistema se expande o se contrae. Va a ser necesario, por tanto,
establecer una nueva definición de exponentes de Lyapunov.
Dado un sistema dinámico en un espacio de fases n-dimensional, podemos
visualizar la evolución de una n-esfera infinitesimal con unas determinadas condiciones
iniciales; la esfera se convertirá en un n-elipsoide debido a la naturaleza del flujo, que
va deformándola localmente. El exponente de Lyapunov unidimensional (i) está
entonces definido en términos de la longitud del eje principal del elipsoide )(tpi :
)0(
)(log
1lim
i
i
ti
p
tp
t (2.1)
Figura 2.1 Exponente de Lyapunov de la familia de curvas
logísticas en función del parámetro.
Calculado con nuestro algoritmo para series de 1000 iteraciones

30
El espectro de Lyapunov viene definido por los i ordenados de mayor a menor
....321 n
Para nosotros, los exponentes de Lyapunov están relacionados con la naturaleza
que se expande o contrae de las diferentes direcciones en el espacio de fases. Debido a
que la orientación del elipsoide cambia continuamente cuando evoluciona, las
direcciones asociadas con un exponente dado varían de una forma muy complicada a
través del atractor. No podemos, por tanto, hablar de una dirección claramente definida
asociada con un exponente dado, sino de unas direcciones dependientes del flujo del
sistema denominadas direcciones de Lyapunov.
Observamos que la extensión lineal del elipsoide crece como t
e 1 , el área
definida por los dos primeros ejes principales crece como t
e)( 21
, el volumen definido
por los tres primeros ejes principales crece como t
e)( 321
y así sucesivamente.
Esta propiedad nos conduce a otra definición del espectro de exponentes: la
velocidad de crecimiento exponencial a largo plazo de un elemento de j-volumen
define la suma de los j primeros exponentes.
Los ejes que se expanden se corresponden con exponentes positivos y los que se
contraen con negativos. La suma de todos los exponentes de Lyapunov es el promedio,
en el tiempo, de la tasa de divergencia del espacio de fases. Por lo tanto un sistema
dinámico disipativo tendrá, por lo menos, un exponente negativo, y el movimiento de
las trayectorias, tras un intervalo de tiempo transitorio, sucederá sobre un conjunto
límite de volumen nulo, es decir, un atractor. Un atractor de un sistema disipativo con
uno o más exponentes de Lyapunov positivo es un atractor extraño.
El hecho conjunto de que un sistema tenga tanto exponentes positivos como
negativos, y que a la vez el espacio de fases se esté contrayendo, se puede observar
gráficamente en la figura 2.2. En esta figura se considera inicialmente una
circunferencia, que con el paso del tiempo evoluciona y se deforma, transformándose en
una elipse.

31
Se puede intuir que la magnitud de los exponentes de Lyapunov cuantifica la
dinámica de un atractor en términos teóricos de información. De hecho, Wolf y sus
colegas [L4] cuantifican los exponentes en unidades de bits/órbita ó bits/iteración
(definen la ecuación 2.1 como 2log en vez de Ln).
Obsérvese que la información creada por el sistema está representada como un
cambio en el volumen definido por los ejes principales, que se están expandiendo. La
suma de los correspondientes exponentes, es decir, los exponentes positivos, es igual a
la entropía de Kolmogorov (K) o tasa principal de ganancia de información [L5]:
0i
iK
El espectro de Lyapunov está también muy relacionado con la dimensión de
información del atractor extraño asociado al sistema. Existe la conjetura de Kaplan y
Yorke de que la dimensión de información fd se relaciona con el espectro de Lyapunov
según la ecuación
1
1
j
j
i i
f jd
donde j está definida por la condición
j
i
i
1
0 y que
1
1
0j
i
i
Figura 2.2. Divergencia y contracción.

32
2.1.2.- Flujos no lineales. Análisis local mediante la matriz Jacobiana
Un sistema dinámico continuo es una ecuación de la forma
))(()( tXVtx
Siendo V un campo vectorial definido en una región nRU que opera como
espacio de fases. Dicha ecuación también se puede escribir de la forma
))(),.......,(),(()(
....................................................
))(),.......,(),(()(
))(),.......,(),(()(
21
2122
2111
txtxtxvtx
txtxtxvtx
txtxtxvtx
nnn
n
n
Una solución de la ecuación es una función
))(),...,(),(()( 21 txtxtxt n
cuyas funciones componentes )(txi verifican el anterior sistema de ecuaciones.
Un punto o estado de equilibrio viene dado por la condición
0)( txi
, para i = 1,2,…, n
Si ))(,),...((),...,( 0011 txtxxxx nn
es uno de tales estados, el análisis de la
estabilidad del mismo ha de hacerse investigando las propiedades del sistema en un
punto “próximo”.
Ello se consigue estudiando el sistema lineal hAhL )( , siendo
),......,( 11 nn hxhxhx
y A la matriz jacobiana de V
n
nnn
n
x
v
x
v
x
v
x
v
x
v
x
v
VJA
......
............
............
......
)(
21
1
2
1
1
1
Este nuevo sistema nos da el comportamiento del sistema ante pequeñas
fluctuaciones en torno al punto de equilibrio.

33
Para calcular los exponentes de Lyapunov, uno está obligado a medir la
separación de las órbitas a lo largo de las direcciones de Lyapunov. Estas direcciones de
Lyapunov son dependientes del flujo del sistema y están definidas por su matriz
Jacobiana, es decir, la proyección tangente en cada punto de interés a lo largo del flujo
[L5]. Por lo tanto estamos obligados a preservar la correcta orientación del espacio de
fases mediante una conveniente aproximación de dicha proyección tangente.
Si suponemos que existe una medida ergódica del sistema, entonces el “teorema
ergódico multiplicativo” de Oseledec [L6] justifica el uso de unas direcciones
arbitrarias del espacio de fases cuando calculamos los exponentes de Lyapunov de
sistemas dinámicos con variaciones suaves [L7]. En la figura 2.2 se puede observar el
efecto del teorema de Oseledec: En un instante inicial encontramos los vectores
ortonormales 1v y 2v , el sistema los transforma en los vectores ortonormales 1w y 2w a
lo largo de los ejes de la elipse. Para largos periodos de evolución del sistema, los iv
son independientes del tiempo y la longitud de los ejes de la elipse varía de acuerdo a
los exponentes de Lyapunov.
Consideremos una órbita observada x(t), la cual puede ser considerada como
una solución de cierto sistema dinámico:
)(xFx (1)
definido en un espacio n-dimensional. Por otro lado, la evolución de un vector tangente
ξ en un espacio tangente a )(tx se obtiene linealizando la ecuación (1) que define al
sistema,
))(( txT (2),
donde
x
FDFT
es la matriz Jacobiana de F.
La solución de la ecuación (2) puede ser obtenida como
)0()( tAt (3),
donde tA es el operador lineal que proyecta la tangente desde el vector ξ(0) a ξ(t).
Este es el sistema lineal en el que hemos transformado el sistema no lineal. Nuestro
objetivo va a ser calcular los exponentes del sistema lineal.

34
El exponente de Lyapunov, o tasa de divergencia del vector tangente ξ se define
como
)0(
)(ln
1lim))0(),0((
t
tx
t
2.2.- ALGORITMO PARA LA EXTRACCIÓN DE LOS EXPONENTES DE
LYAPUNOV DE UN SISTEMA DINÁMICO DISCRETO O CONTINUO,
DEFINIDO POR SERIES.
2.2.1.- Presentación del problema.
Antes de detallar el funcionamiento del algoritmo, vamos a exponer brevemente
la situación de partida. Se obtiene una serie temporal, a partir de la observación en la
Naturaleza, en el laboratorio o mediante la simulación en computadora, y suponemos
que dicha serie puede ser obtenida como la solución de un sistema dinámico (continuo o
discreto) definido por ecuaciones diferenciales sobre un espacio de fases de,
posiblemente, infinitas dimensiones. Deseamos obtener el espectro de Lyapunov
correspondiente al comportamiento a largo plazo del sistema. Dicho más formalmente,
el comportamiento a largo plazo del sistema define una medida ergódica de la evolución
temporal en el espacio de fases; nosotros estamos interesados en los correspondientes
exponentes de Lyapunov de esa medida ergódica.
2.2.2.- Presentación del algoritmo.
Para resolver el problema proponemos un método basado principalmente en dos
anteriores, el de Sano y Sawada [L8] y el de Eckmann, Oliffson, Ruelle y Ciliberto
[L9], que son prácticamente iguales entre sí.
Incluimos una característica del método de Rosenstein [L10] que nos ha
permitido reducir la longitud de la serie necesaria para un resultado del algoritmo
satisfactorio; es la condición de que la separación entre los vecinos encontrados y el
punto orbital analizado sea mayor que el periodo principal de la serie (ver Buscar
Vecinos del Desarrollo de cada bloque).

35
Añadimos una característica más (no hemos encontrado una clara referencia
anterior, más bien lo contrario) que obliga a que sólo se analicen un total de puntos
igual a la longitud de la serie partido de τ, es decir, obligamos a que se utilicen como
puntos orbitales bajo estudio aquellos puntos de la serie que están separados τ
posiciones. Estudiamos qué parámetros influyen en el resultado. Y, finalmente,
comparamos los resultados obtenidos con los de anteriores contribuciones.
2.2.3.- Valores de entrada:
Serie de tiempo (Time Serie) de la que queremos extraer los exponentes.
dE = dimensión de inmersión (Embedding Dimesion). En la práctica hay que
elegir el valor correspondiente al número de variables de estado que definan al
sistema o, lo que es lo mismo, el número de exponentes de Lyapunov que hay
que calcular.
τ es el retardo utilizado para la reconstrucción del atractor. Tiene que ser un
número entero y representa el número de posiciones de la serie que hay que
retardar. Para un sistema continuo, el retardo en unidades temporales se
obtendría como
)()( stsretardo .
t es el intervalo de integración o de observación, con el que se han tomado las
muestras de la serie, y que las separa en el tiempo.

36
Inicializar
Estimar periodo principal de la serie
PARA cada punto j de la
serie, cogidos de τ en τ
Buscar Vecinos del
punto en una concha
de radios r y minr
Reconstruir órbita dE-dimensional
perteneciente al atractor
Hallar Vectores Desplazamiento entre
cada vecino y el punto orbital analizado
iy
Hallar Vectores Desplazamiento entre la
evolución de cada vecino y la evolución
del punto orbital analizado iz
Calcular jA (tal que i
j
i yAz ),
mediante un algoritmo de mínimos
cuadrados
Descomposición QR
n-ésima de 1 nj QA
Calcular exponentes para este punto orbital
y ponderar con todos
los calculados
FIN
2.2.4.- Diagrama de bloques del algoritmo propuesto.

37
2.2.5.- Desarrollo de cada bloque.
N: número de muestra máximo para analizar
N = n-dE*τ-1.
L: longitud del atractor. Es del orden de la máxima separación entre puntos del
atractor [L11]. Para asegurar que los puntos, donde medimos la separación,
pertenecen al atractor proponemos buscar los valores máximo y mínimo a partir
de una posición (p) determinada de la serie
pjixxL jMAXi ,min
.
r: radio exterior de la concha dE-dimensional ( Lr 05.0 ). Hay que establecer
un compromiso al elegir r. Tiene que ser lo suficientemente pequeña, para no
notar el efecto de las no linealidades, y lo suficientemente grande para que
incluya un número de vecinos mayor que dE.
rmin: radio interior de la concha dE-dimensional ( Lr 01.0min ). El peor efecto
del ruido se da en los vectores de desplazamiento pequeños. Introduciendo
0min r atenuamos el efecto del ruido.
nMinVec: número mínimo de vecinos. Al asegurar que el punto de estudio tiene
un número elevado de vecinos evitamos que la descomposición QR dé como
resultado matrices singulares.
Q: primera matriz ortogonal. En realidad la matriz Q representa una base
vectorial con las direcciones sobre las que vamos a calcular los exponentes de
Lyapunov. Elegimos por comodidad que la primera base ( 1Q ) sea la matriz
identidad1.
1 Gracias al teorema ergódico multiplicativo de Osedelec podemos elegir direcciones arbitrarias al
calcular los exponentes de Lyapunov.
Inicializar

38
Hacemos la FFT de la serie y hallamos el periodo principal como el recíproco
de la frecuencia principal del espectro de potencias.
Buscamos puntos dentro de la serie que estén incluidos en la concha de radio
interior minr , y de radio exterior r, centrada en el punto orbital bajo estudio; y que
además estén separados por un intervalo temporal mayor que el periodo principal de la
serie. Que estén incluidos en una bola de radio r muy pequeño, nos permite la
aproximación lineal del flujo tangente. Que estén separados por un intervalo temporal
mayor que el periodo principal (T) de la serie, nos permite considerar cada par de
vecinos como unas condiciones iniciales cercanas, pero pertenecientes a diferentes
trayectorias.
Tjirxxrxx jiiki min|
Para considerar que el punto es válido establecemos un número mínimo de
vecinos encontrados. En principio, con asegurar que el número de vecinos era mayor
que el número de dimensiones del espacio de fases reconstruido, ya obtendríamos
matrices no singulares. Aumentamos el número mínimo de vecinos, por encima de dE,
para mejorar el resultado. En los comentarios de las tablas 2.5 – 2.8 se puede observar
como varían los resultados, en función del número de vecinos, para los diferentes
sistemas.
Cuando el número de vecinos que encontramos es menor que el número mínimo
de vecinos que habíamos establecido tenemos dos opciones (A y B):
Estimar periodo principal de la serie
PARA cada punto j de la
serie, cogidos de τ en τ
Buscar Vecinos del
punto en una concha
de radios r y minr

39
La reconstrucción se hará mediante el método de retardo de coordenadas
propuesto por Takens [L7].
En nuestro análisis partimos de una serie temporal que suponemos obtenida
como solución de un sistema dinámico del que desconocemos sus características.
Existen toda una serie de medidas (la dimensión de correlación, los exponentes de
Lyapunov o la entropía de Kolmogorov) que requieren para su aplicación la
reconstrucción de ese sistema original.
Para comprobar si un proceso presenta un comportamiento caótico tendremos
que analizar la evolución de la órbita del sistema. La órbita viene dada por un conjunto
de vectores como los definidos en
)}(|{ 1tt
nt xfxRx . En el caso de que el sistema
sea caótico, el vector x en el momento t depende de forma completamente determinista
de ese mismo vector x en el periodo anterior. Si el sistema es estocástico esta función
será aleatoria.
Nº Vecinos
Encontrados
< Nº Mínimo
Abandonar el punto
orbital bajo estudio.
Aumentar la concha (r, rmin)
Reconstruir órbita dE-dimensional perteneciente al atractor
A B
40
Para conocer la órbita tendríamos que conocer la evolución de todos los
componentes del vector. Por desgracia, en la mayoría de las ocasiones no sólo
desconocemos la función f, sino cuáles son las variables que intervienen en el sistema e
incluso cuántas variables hay. Sólo disponemos de una serie temporal de escalares que,
suponemos, proceden de ese vector, es decir
RRn
)}({}{ ttt xyyx
.
Takens [L6] demostró que en la mayoría de los casos, la transformación
mRR
)},...,,{(}{ )1( mtttt yyyy
conserva las propiedades topológicas de la órbita original siempre que m>2n+1.
Mediante la transformación propuesta por Takens, conocida como “reconstrucción
mediante el retardo de coordenadas”, de los escalares observados ty pasamos a
vectores de dimensión m, cuantía que se denomina dimensión de inmersión. A los
vectores así formados también se les llama m-historias. Estos vectores tienen una
estructura que dibuja una trayectoria similar a la que poseía la órbita original.
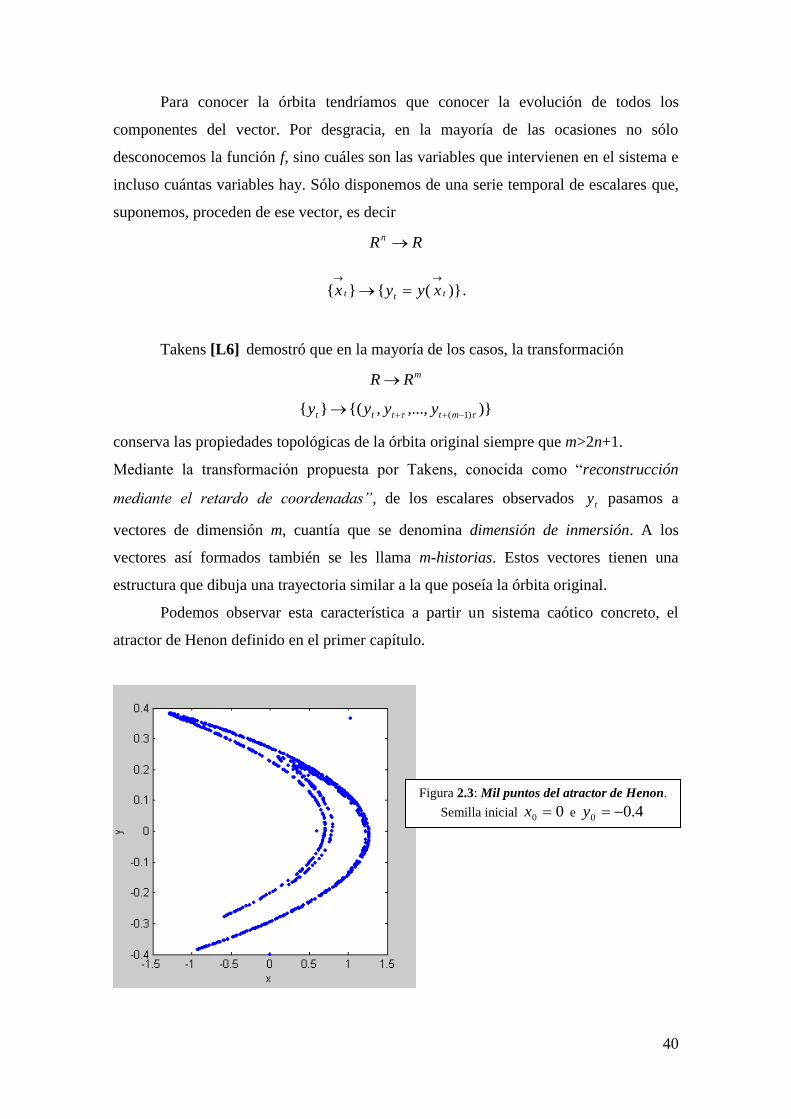
Podemos observar esta característica a partir un sistema caótico concreto, el
atractor de Henon definido en el primer capítulo.
Figura 2.3: Mil puntos del atractor de Henon.
Semilla inicial 00 x e 4.00 y
41
Para hacer la transformación de Takens es necesario determinar el valor de dos
parámetros: τ y m. El tamaño del vector va a venir determinado por m, mientras que τ
nos indica el tiempo que debe pasar entre observación y observación dentro de la misma
m-historia.
Si partimos de una serie temporal escalar, desconociendo todo lo que hace
referencia al sistema de partida, no vamos a tener pistas sobre qué valores dar a m y τ.
La primera alternativa sería ir dando distintos valores a m y τ, a la hora de
implementar el algoritmo de extracción de los exponentes de Lyapunov. A posteriori, a
la vista de los resultados, decidir cuáles son los valores que debemos dar a estos
parámetros. Esta forma de actuación es la que con más frecuencia se utiliza, pero tiene
como inconveniente que hace crecer de forma explosiva el tiempo de cálculo, ya de por
sí elevado, a la vez que complica la posterior interpretación de los resultados.
Aunque se escapa del contenido de este proyecto, existe una revisión completa
de los métodos [Buzug y Pfister, 1992] que tratan de darnos unos valores óptimos para
m y τ. De entre ellos es interesante resaltar “la información mutua”, que proporciona
unos resultados aceptables en unos plazos de tiempo moderados.
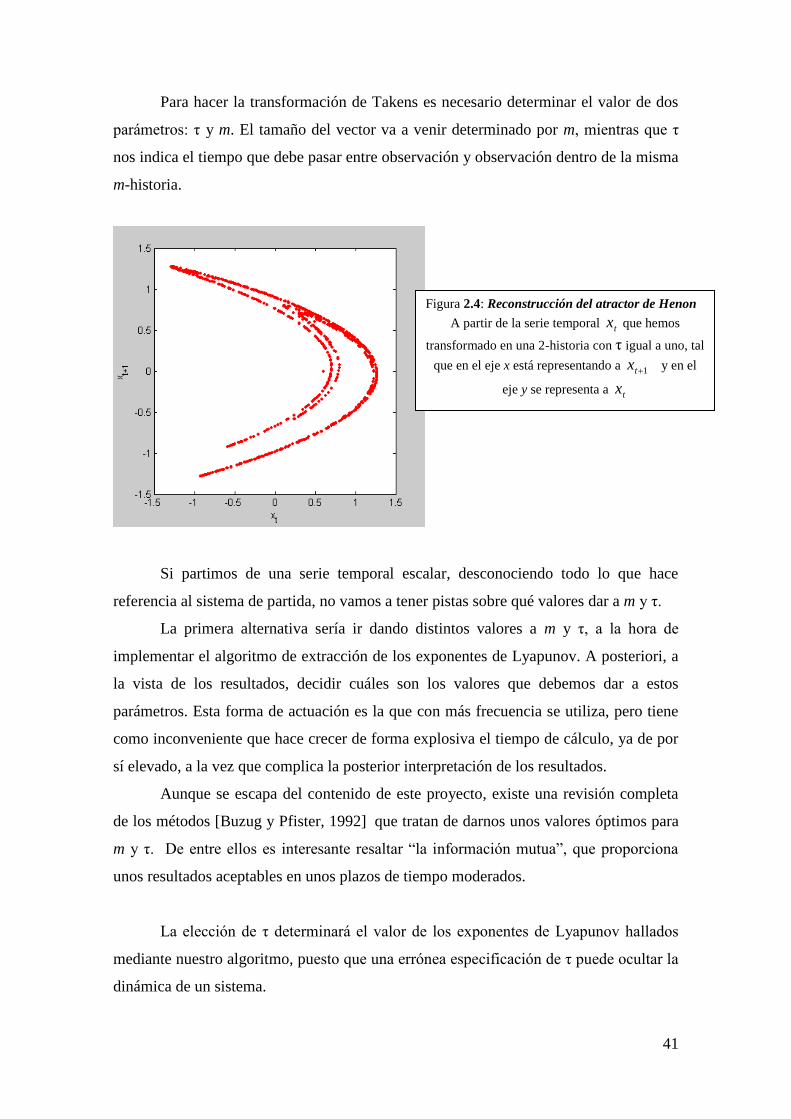
La elección de τ determinará el valor de los exponentes de Lyapunov hallados
mediante nuestro algoritmo, puesto que una errónea especificación de τ puede ocultar la
dinámica de un sistema.
Figura 2.4: Reconstrucción del atractor de Henon
A partir de la serie temporal tx que hemos
transformado en una 2-historia con τ igual a uno, tal
que en el eje x está representando a 1tx y en el
eje y se representa a tx

42
Las figuras 2.4 y 2.5 contienen varios ejemplos de reconstrucción de los
atractores de Lorenz y Rössler para diferentes valores de τ. En dichas figuras se ha
obtenido una serie a partir del sistema y luego se ha intentado reconstruirlo con distintos
valores de τ.
Para el sistema de Lorenz, con valores de τ demasiado pequeños, los puntos
parecen concentrarse en torno a la bisectriz. Para τ igual a 8 (0.08 segundos) se consigue
una reconstrucción óptima del atractor, pero para valores de τ superiores a 10 la
estructura comienza a diluirse y no resulta posible reconocer el sistema.
En el sistema de Rössler, la reconstrucción óptima se consigue para τ igual a 10.
Hallamos una matriz de vectores de desplazamiento para cada vecino incluido en
la concha ),...,2,1}({ numVecixik , es decir
})(|{}{ min Tjkrxxrxxy ijkjk
i
ii
siendo T el periodo principal.
Para un vector ),...,,( 21 dEwwww usamos la norma Euclídea
2122
2
2
1 ),...,,( dEwwww
Tras un intervalo tretardo , el punto orbital que estamos analizando jx
evoluciona a jx y sus puntos vecinos }{ kx a }{ kx . El vector desplazamiento
jki xxyi evoluciona por tanto al vector iz
rxxrxxz jkjk
i
ii min|
Hallar Vectores Desplazamiento entre la
evolución de cada vecino y la evolución
del punto orbital analizado iz
Hallar Vectores Desplazamiento entre
cada vecino y el punto orbital analizado
iy

43
Figura 2.4. Reconstrucción del atractor de Lorenz, mediante el método de
retardo de coordenadas, para diferentes valores de τ
Primero se ha determinado una serie de 10000 valores con un intervalo de
integración 0.01s.
La reconstrucción se hace a partir de la serie escalar correspondiente a la
coordenada x.
Se ilustra una proyección sobre las coordenadas x e y.

44
Figura 2.5. Reconstrucción del atractor de Rössler, mediante el método de
retardo de coordenadas, para diferentes valores de τ
Serie de 10000 valores con un intervalo de integración 0.1s.
La reconstrucción se hace a partir de la serie escalar correspondiente a la
coordenada x.
A diferencia de la figura 2.4 en esta figura las gráficas son en 3D

45
Si el radio exterior de la concha es suficientemente pequeño para que los
vectores de desplazamiento iy y iz sean considerados una buena aproximación de
vectores tangentes en el espacio tangente, la evolución de iy a iz puede ser
representada por alguna matriz jA , tal que
i
j
i yAz
La matriz jA es una aproximación de la proyección del flujo tangente a jx de la
ecuación (3)2. Así, las trayectorias de puntos en la superficie de la bola (o concha en
nuestro caso al hacer 0min r ) están definidas por la acción de las ecuaciones de
movimiento linealizadas sobre puntos infinitesimalmente separados de la trayectoria
original.
Para una estimación óptima de la proyección del flujo linealizado jA a partir de los
conjuntos de vectores iy y iz , utilizamos un algoritmo de mínimos cuadrados
(least-square-error [L8]):
N
i
i
j
i
AAyAz
NS
jj 1
21minmin
Llamando a la componente (k,l) de la matriz jA por )( jakl y aplicando la condición
anterior, se obtienen dEdE ecuaciones para solucionar 0)(
jaS
kl
. Podemos
hallar la siguiente expresión para jA :
CVA j ,
N
i
ilik
kl yyN
V1
1)(
N
i
ilik
kl yzN
C1
1)(
2 Véase el apartado Flujos no lineales. Análisis local.
Calcular jA (tal que i
j
i yAz ),
mediante un algoritmo de mínimos
cuadrados

46
donde V y C son matrices dEdE , llamadas matrices de covarianza, e iky y ikz son
las componentes k de los vectores iy y iz respectivamente.
La matriz jA será del tipo:
dE
j
aaaa
A
...
1...000
...............
0...100
0...010
321
Algunos ejemplos durante el cálculo en MATLAB de los exponentes del sistema de
Lorenz son:
4139830.334173390788460.18716901-0525570.95731143-
0000001.000000000000000.000000000000000.00000000-
00000001.000000000000000.00000000
jA
9078965.836316362654136.60980566-2708675.42932210
9453880.999999990635910.000000000632270.00000000
0546120.000000009364090.999999990632270.00000000
jA
Se puede observar que algunas veces no se halla exactamente un valor 0, aunque
el error, de producirse, es siempre menor que 810 .
Los principales ejes de la bola (concha) están definidos por la evolución
mediante las ecuaciones linealizadas de una base inicialmente ortonormal. Hay que
calcular la aproximación lineal definiendo una base cualquiera para cada punto de la
serie.
Descomposición QR
n-ésima de 1 nj QA

47
Cada eje de la base diverge en magnitud, en principio esto es sólo un problema
debido el limitado rango de almacenamiento de las computadoras, pero además, y más
grave, está el proceso de doblado del espacio de fases sobre los ejes definidos por la
base, que nos evita percibir el proceso de estirado que determinará la sensibilidad a las
condiciones iniciales.
En un sistema caótico se presenta un problema adicional: cada vector tiende a
caer a lo largo de la dirección local de más rápido crecimiento. Debido a la finita
precisión de cálculos de las computadoras actuales, el colapso - respecto a una dirección
común - provoca que la orientación de todos los ejes se vuelva indistinguible en el
espacio de fases.
Estos dos problemas se solucionan mediante un procedimiento de
reortonormalización.
La base ortonormal define matrices ortogonales y, por tanto, podemos efectuar
sucesivas descomposiciones QR para reortonormalizar. En la iteración n hacemos una
descomposición QR de la matriz que resulta de 1 nj QA . Este principio ha sido el
usado, entre otros, por [L3], [L8], [L9], [L12]. Para esta descomposición existen varios
métodos que describimos en el Apéndice A. En varios artículos analizados ([L3], [L8],
y [L14]) distinguen los resultados obtenidos según el método de descomposición QR
utilizado; anuncian que el clásico Gram-Schmidt conduce a errores estadísticos y que el
Gram-Schmidt y la transformación Householder los solucionan, siendo este último
método el que da unos resultados óptimos. En cambio, con el método aquí propuesto,
hemos llegado a la conclusión de que el clásico de Gram-Schmidt, el Gram-Schmidt
modificado, la transformación Householder y la descomposición QR de la función “qr”
de MATLAB, prácticamente siempre, producen el mismo resultado. Elegimos la
función “qr” de MATLAB, que, al estar ya optimizada, reduce el coste computacional.

48
Ahora que tenemos la ecuación del movimiento en el espacio tangente a lo largo
de las órbitas obtenidas experimentalmente, los exponentes de Lyapunov pueden ser
calculados como
N
j
iijN
i RtN 1
)(ln1
lim
donde iijR es la posición i de la diagonal de la matriz jR y jR es la matriz triangular
superior obtenida mediante la descomposición QR de 1 jj QA , es decir,
1, jjjj QAqrRQ .
Cuando j + τ > longitud de la serie finaliza el bucle PARA y, por tanto, finaliza
el algoritmo.
2.2.6.- Análisis de los Resultados.
Hay que tener en cuenta que todos los resultados obtenidos son dependientes de
las condiciones iniciales.
Si comparamos los resultados obtenidos mediante nuestro algoritmo con los
resultados obtenidos en otros artículos ([L4], [L8], [L9] y [L12]) vemos que hemos
mejorado respecto a todos los anteriores. Y lo hemos hecho tanto en la precisión del
cálculo, como en las exigencias en cuanto a la longitud de la serie.
Es interesante ver qué factores influyen en los resultados y cómo lo hacen.
Calcular exponentes para este punto orbital
y ponderar con todos
los calculados
FIN

49
Para ello, primero que vamos a hacer es analizar la longitud y calidad necesarias
de la serie para obtener un resultado satisfactorio. Lo siguiente será estudiar el efecto de
los diferentes parámetros del algoritmo.
Análisis de la LONGITUD de la serie.
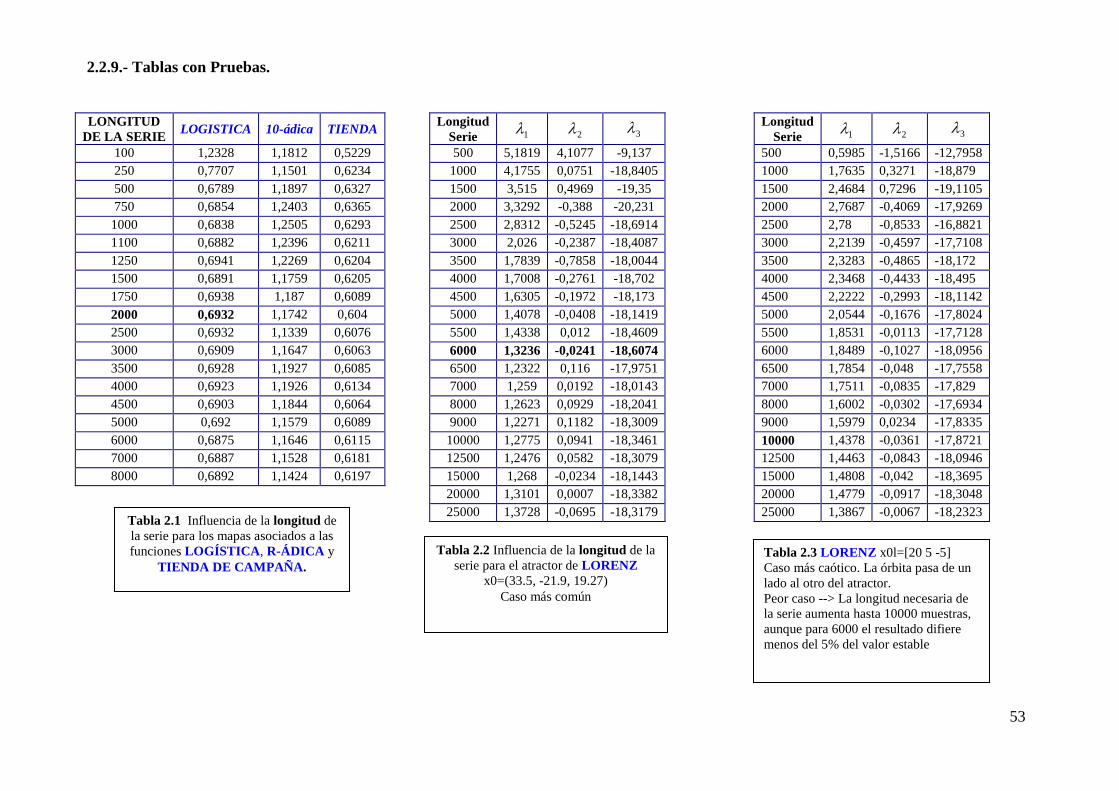
En la tabla 2.1 podemos observar cómo varía la longitud necesaria de los
sistemas discretos a los continuos. En los sistemas discretos, con 500 muestras, se
consigue un error menor del 10% y, con 2000, se consiguen los resultados óptimos.
Mientras que en los continuos es necesaria una serie con una longitud mínima del orden
de 5000 muestras, consiguiéndose los resultados óptimos a partir de 10000.
Hay que tener en cuenta que los resultados dependen de las condiciones iniciales
a partir de las cuales se hayan determinado las órbitas y, por tanto, habrá órbitas de las
que se obtendrá un resultado satisfactorio con muchas menos muestras que otras. A
modo de ejemplo se pueden contrastar las tablas 2.2 y 2.3 ambas correspondientes al
sistema de Lorenz, pero con condiciones iniciales muy diferentes.
Análisis de la CALIDAD de la serie.
Analizamos los efectos del ruido añadido y de la precisión en la observación.
Para ello, sumamos una señal de igual longitud con una función de densidad de
probabilidad Uniforme ponderada por un coeficiente.
Observando la tabla 2.19 comprobamos que el ruido modifica los resultados
llegando a enmascarar la caoticidad de la serie para un coeficiente del 40%.
En las tablas 2.20, 2.21 y 2.22 comprobamos lo robusto que se muestra nuestro
algoritmo frente a la precisión durante la observación y obtención de la serie. Para los
sistemas continuos se obtienen resultados muy buenos a partir de 1 decimal, mientras
que para los discretos es necesario una precisión de 2 decimales.
Análisis del efecto de los PARÁMETROS del algoritmo.
Número mínimo de vecinos.
Todos los autores estudiados ([L4], [L8], [L9], [L12] y [L13]) señalan que para
considerar válido el análisis de un punto orbital, es necesario que dicho punto tenga un
número mínimo de vecinos. Esta indicación se hace para evitar que el análisis nos
conduzca a matrices singulares durante la descomposición QR, o bien, para mejorar el
resultado estadístico del cálculo de los exponentes.

50
En nuestro caso hemos podido comprobar que el número de vecinos influye en
relación con la longitud de la serie. Si la serie es pequeña, el requisito de un número
mínimo de vecinos muy elevado evitaría analizar muchos puntos de la serie y eso nos
conduciría a errores (tablas 2.6 y 2.7). En una serie muy larga no se degenera el
resultado (tabla 2.8).
Durante nuestro análisis no hemos tenido ningún problema con los mapas 1-D
respecto a un número de vecinos pequeño (tabla 2.5).
De hecho, podemos asegurar que con un número mínimo de vecinos mayor o
igual al número de exponentes que calculamos los resultados son perfectamente válidos.
Hay que considerar que hemos calculado los exponentes de sistemas bien
conocidos, si analizáramos series de tiempo observadas en la naturaleza, el resultado
podría acusar el número mínimo de vecinos establecido.
r y minr
En la tabla 2.9 se observa cómo la influencia del radio (exterior, ya que medimos
su influencia con 0min r ) de la bola r, varía en función del tipo de sistema. En el
mapa Logístico apenas influye, mientras que en el mapa 10-ádico es capaz de hacer
alternar el signo del exponente. La explicación se debe a que según la propia dinámica
del sistema, es decir, como distribuye los puntos en el espacio de fases, una bola de
radio grande puede coger puntos suficientemente lejanos cuyas trayectorias pueden
converger hacia la misma zona. En este caso, no podemos utilizar la aproximación de
flujo tangente, corazón de nuestro algoritmo.
En las tablas 2.12 – 2.14 se aprecia cómo minr ayuda a calcular los exponentes
con más precisión.
51
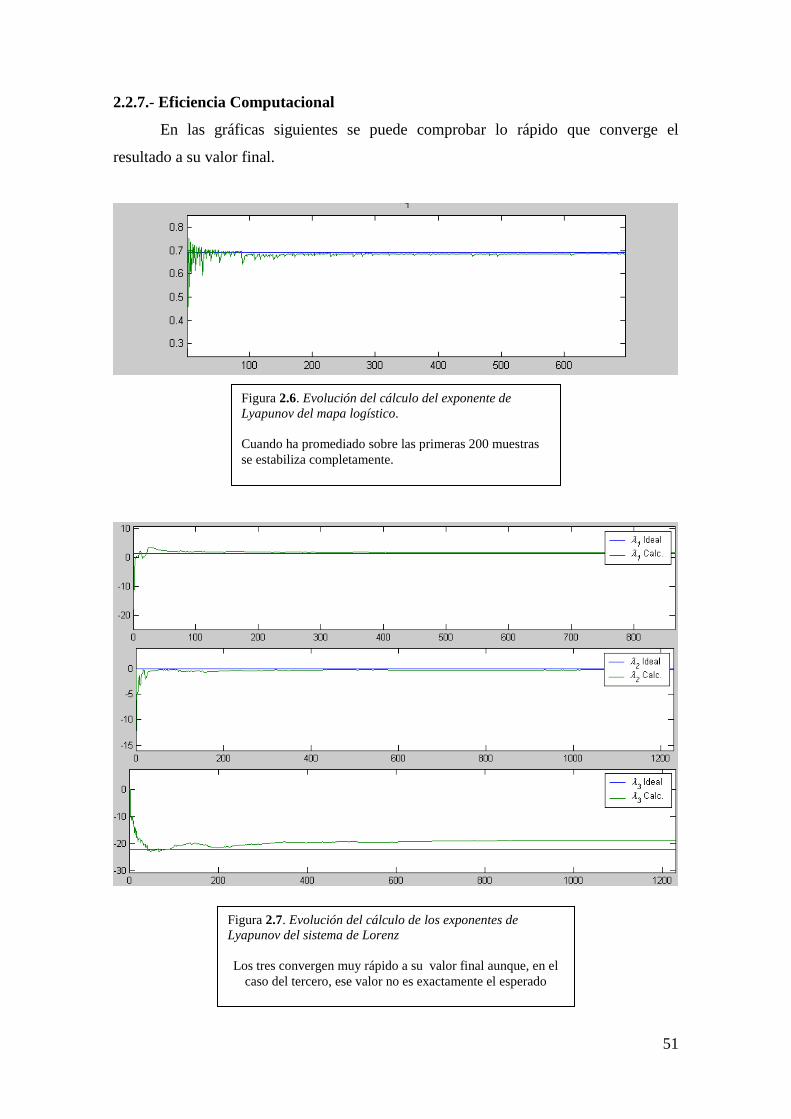
Figura 2.6. Evolución del cálculo del exponente de
Lyapunov del mapa logístico.
Cuando ha promediado sobre las primeras 200 muestras
se estabiliza completamente.
Figura 2.7. Evolución del cálculo de los exponentes de
Lyapunov del sistema de Lorenz
Los tres convergen muy rápido a su valor final aunque, en el
caso del tercero, ese valor no es exactamente el esperado
2.2.7.- Eficiencia Computacional
En las gráficas siguientes se puede comprobar lo rápido que converge el
resultado a su valor final.

52
2.2.8.- Aplicación Gráfica
Se ha desarrollado una aplicación que trata de mostrar al usuario todos los
aspectos relacionados con la extracción de los exponentes de Lyapunov de una serie
temporal. El usuario tiene posibilidad de variar los diferentes parámetros del algoritmo,
de visualizar el proceso de generación de una serie temporal, realizar el proceso de
reconstrucción del atractor o incluso, tiene oportunidad de ver la eficiencia
computacional del algoritmo en diferentes formatos.
Figura 2.8 Aplicación Gráfica
Se pueden apreciar la obtención de la serie mediante el sistema de
Rössler, la reconstrucción del atractor , los resultados, dos formas para
estudiar la eficiencia del algoritmo…
53
LONGITUD
DE LA SERIE LOGISTICA 10-ádica TIENDA
100 1,2328 1,1812 0,5229
250 0,7707 1,1501 0,6234
500 0,6789 1,1897 0,6327
750 0,6854 1,2403 0,6365
1000 0,6838 1,2505 0,6293
1100 0,6882 1,2396 0,6211
1250 0,6941 1,2269 0,6204
1500 0,6891 1,1759 0,6205
1750 0,6938 1,187 0,6089
2000 0,6932 1,1742 0,604
2500 0,6932 1,1339 0,6076
3000 0,6909 1,1647 0,6063
3500 0,6928 1,1927 0,6085
4000 0,6923 1,1926 0,6134
4500 0,6903 1,1844 0,6064
5000 0,692 1,1579 0,6089
6000 0,6875 1,1646 0,6115
7000 0,6887 1,1528 0,6181
8000 0,6892 1,1424 0,6197
Longitud
Serie 1 2 3
500 5,1819 4,1077 -9,137
1000 4,1755 0,0751 -18,8405
1500 3,515 0,4969 -19,35
2000 3,3292 -0,388 -20,231
2500 2,8312 -0,5245 -18,6914
3000 2,026 -0,2387 -18,4087
3500 1,7839 -0,7858 -18,0044
4000 1,7008 -0,2761 -18,702
4500 1,6305 -0,1972 -18,173
5000 1,4078 -0,0408 -18,1419
5500 1,4338 0,012 -18,4609
6000 1,3236 -0,0241 -18,6074
6500 1,2322 0,116 -17,9751
7000 1,259 0,0192 -18,0143
8000 1,2623 0,0929 -18,2041
9000 1,2271 0,1182 -18,3009
10000 1,2775 0,0941 -18,3461
12500 1,2476 0,0582 -18,3079
15000 1,268 -0,0234 -18,1443
20000 1,3101 0,0007 -18,3382
25000 1,3728 -0,0695 -18,3179
Longitud
Serie 1 2 3
500 0,5985 -1,5166 -12,7958
1000 1,7635 0,3271 -18,879
1500 2,4684 0,7296 -19,1105
2000 2,7687 -0,4069 -17,9269
2500 2,78 -0,8533 -16,8821
3000 2,2139 -0,4597 -17,7108
3500 2,3283 -0,4865 -18,172
4000 2,3468 -0,4433 -18,495
4500 2,2222 -0,2993 -18,1142
5000 2,0544 -0,1676 -17,8024
5500 1,8531 -0,0113 -17,7128
6000 1,8489 -0,1027 -18,0956
6500 1,7854 -0,048 -17,7558
7000 1,7511 -0,0835 -17,829
8000 1,6002 -0,0302 -17,6934
9000 1,5979 0,0234 -17,8335
10000 1,4378 -0,0361 -17,8721
12500 1,4463 -0,0843 -18,0946
15000 1,4808 -0,042 -18,3695
20000 1,4779 -0,0917 -18,3048
25000 1,3867 -0,0067 -18,2323
Tabla 2.2 Influencia de la longitud de la
serie para el atractor de LORENZ
x0=(33.5, -21.9, 19.27)
Caso más común
Tabla 2.3 LORENZ x0l=[20 5 -5]
Caso más caótico. La órbita pasa de un
lado al otro del atractor.
Peor caso --> La longitud necesaria de
la serie aumenta hasta 10000 muestras,
aunque para 6000 el resultado difiere
menos del 5% del valor estable
Tabla 2.1 Influencia de la longitud de
la serie para los mapas asociados a las
funciones LOGÍSTICA, R-ÁDICA y
TIENDA DE CAMPAÑA.
2.2.9.- Tablas con Pruebas.
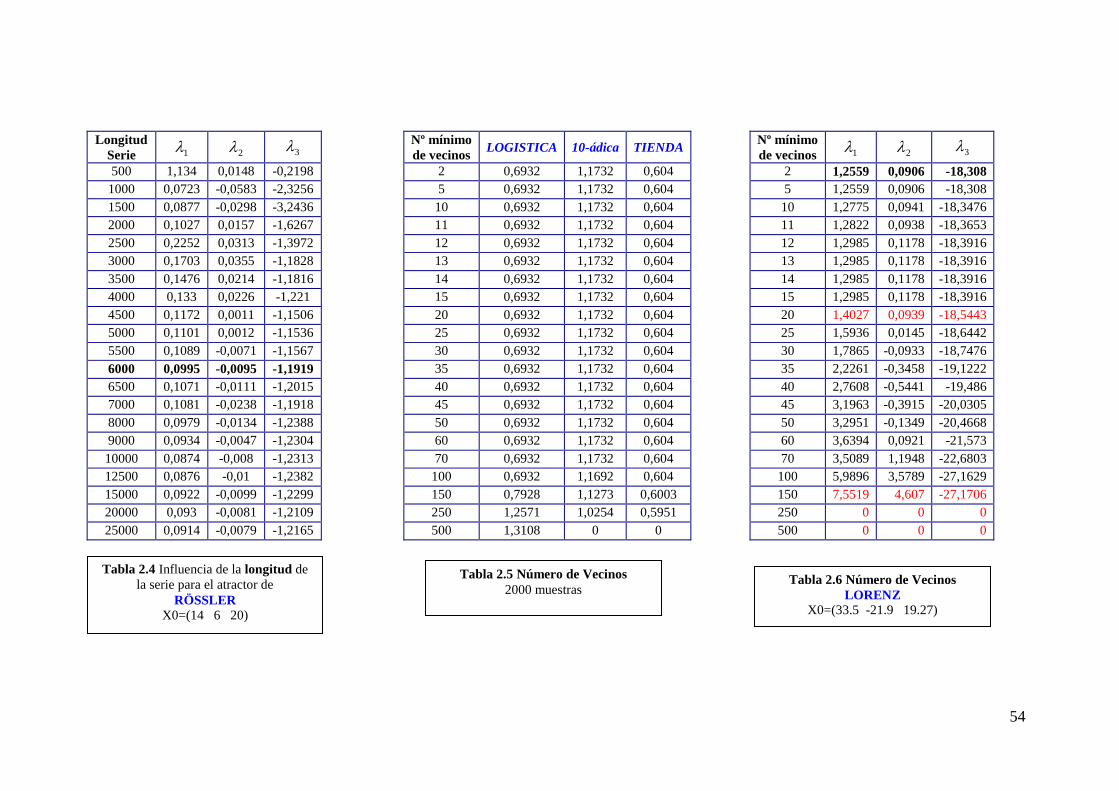
54
Longitud
Serie 1 2 3
500 1,134 0,0148 -0,2198
1000 0,0723 -0,0583 -2,3256
1500 0,0877 -0,0298 -3,2436
2000 0,1027 0,0157 -1,6267
2500 0,2252 0,0313 -1,3972
3000 0,1703 0,0355 -1,1828
3500 0,1476 0,0214 -1,1816
4000 0,133 0,0226 -1,221
4500 0,1172 0,0011 -1,1506
5000 0,1101 0,0012 -1,1536
5500 0,1089 -0,0071 -1,1567
6000 0,0995 -0,0095 -1,1919
6500 0,1071 -0,0111 -1,2015
7000 0,1081 -0,0238 -1,1918
8000 0,0979 -0,0134 -1,2388
9000 0,0934 -0,0047 -1,2304
10000 0,0874 -0,008 -1,2313
12500 0,0876 -0,01 -1,2382
15000 0,0922 -0,0099 -1,2299
20000 0,093 -0,0081 -1,2109
25000 0,0914 -0,0079 -1,2165
Nº mínimo
de vecinos LOGISTICA 10-ádica TIENDA
2 0,6932 1,1732 0,604
5 0,6932 1,1732 0,604
10 0,6932 1,1732 0,604
11 0,6932 1,1732 0,604
12 0,6932 1,1732 0,604
13 0,6932 1,1732 0,604
14 0,6932 1,1732 0,604
15 0,6932 1,1732 0,604
20 0,6932 1,1732 0,604
25 0,6932 1,1732 0,604
30 0,6932 1,1732 0,604
35 0,6932 1,1732 0,604
40 0,6932 1,1732 0,604
45 0,6932 1,1732 0,604
50 0,6932 1,1732 0,604
60 0,6932 1,1732 0,604
70 0,6932 1,1732 0,604
100 0,6932 1,1692 0,604
150 0,7928 1,1273 0,6003
250 1,2571 1,0254 0,5951
500 1,3108 0 0
Nº mínimo
de vecinos 1 2 3
2 1,2559 0,0906 -18,308
5 1,2559 0,0906 -18,308
10 1,2775 0,0941 -18,3476
11 1,2822 0,0938 -18,3653
12 1,2985 0,1178 -18,3916
13 1,2985 0,1178 -18,3916
14 1,2985 0,1178 -18,3916
15 1,2985 0,1178 -18,3916
20 1,4027 0,0939 -18,5443
25 1,5936 0,0145 -18,6442
30 1,7865 -0,0933 -18,7476
35 2,2261 -0,3458 -19,1222
40 2,7608 -0,5441 -19,486
45 3,1963 -0,3915 -20,0305
50 3,2951 -0,1349 -20,4668
60 3,6394 0,0921 -21,573
70 3,5089 1,1948 -22,6803
100 5,9896 3,5789 -27,1629
150 7,5519 4,607 -27,1706
250 0 0 0
500 0 0 0
Tabla 2.4 Influencia de la longitud de
la serie para el atractor de
RÖSSLER X0=(14 6 20)
Tabla 2.5 Número de Vecinos
2000 muestras Tabla 2.6 Número de Vecinos
LORENZ
X0=(33.5 -21.9 19.27)
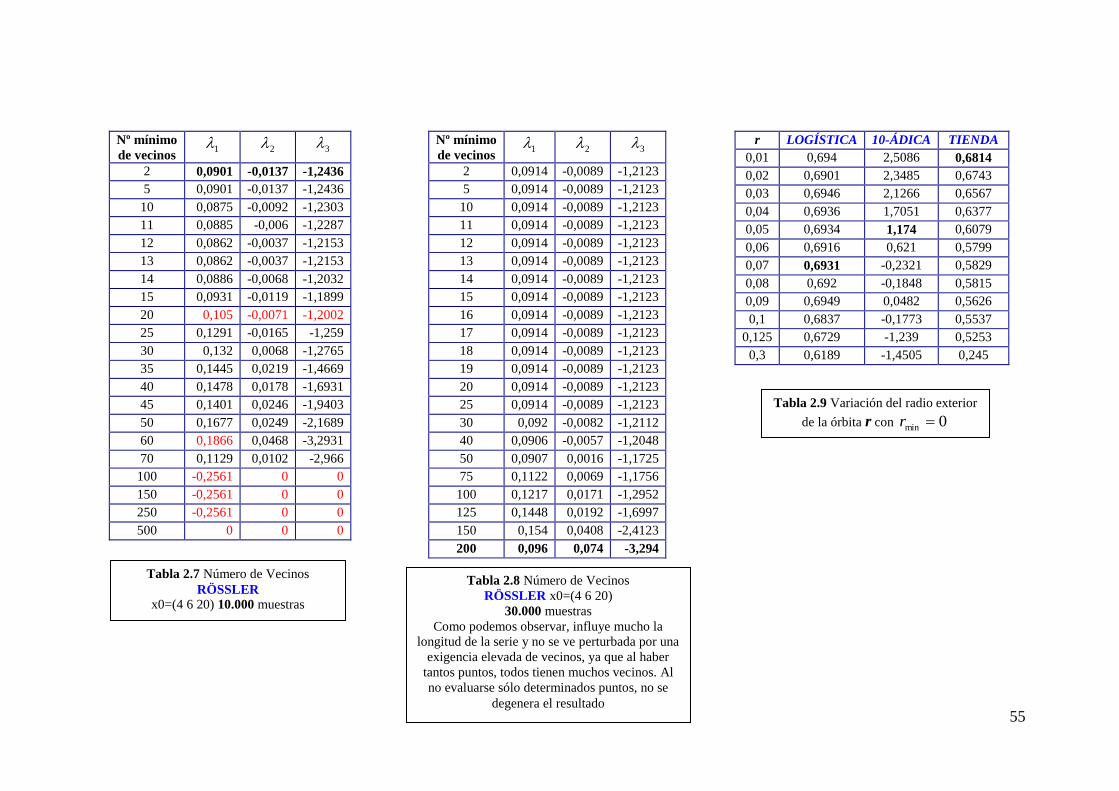
55
Nº mínimo
de vecinos 1 2 3
2 0,0901 -0,0137 -1,2436
5 0,0901 -0,0137 -1,2436
10 0,0875 -0,0092 -1,2303
11 0,0885 -0,006 -1,2287
12 0,0862 -0,0037 -1,2153
13 0,0862 -0,0037 -1,2153
14 0,0886 -0,0068 -1,2032
15 0,0931 -0,0119 -1,1899
20 0,105 -0,0071 -1,2002
25 0,1291 -0,0165 -1,259
30 0,132 0,0068 -1,2765
35 0,1445 0,0219 -1,4669
40 0,1478 0,0178 -1,6931
45 0,1401 0,0246 -1,9403
50 0,1677 0,0249 -2,1689
60 0,1866 0,0468 -3,2931
70 0,1129 0,0102 -2,966
100 -0,2561 0 0
150 -0,2561 0 0
250 -0,2561 0 0
500 0 0 0
Nº mínimo
de vecinos 1 2 3
2 0,0914 -0,0089 -1,2123
5 0,0914 -0,0089 -1,2123
10 0,0914 -0,0089 -1,2123
11 0,0914 -0,0089 -1,2123
12 0,0914 -0,0089 -1,2123
13 0,0914 -0,0089 -1,2123
14 0,0914 -0,0089 -1,2123
15 0,0914 -0,0089 -1,2123
16 0,0914 -0,0089 -1,2123
17 0,0914 -0,0089 -1,2123
18 0,0914 -0,0089 -1,2123
19 0,0914 -0,0089 -1,2123
20 0,0914 -0,0089 -1,2123
25 0,0914 -0,0089 -1,2123
30 0,092 -0,0082 -1,2112
40 0,0906 -0,0057 -1,2048
50 0,0907 0,0016 -1,1725
75 0,1122 0,0069 -1,1756
100 0,1217 0,0171 -1,2952
125 0,1448 0,0192 -1,6997
150 0,154 0,0408 -2,4123
200 0,096 0,074 -3,294
r LOGÍSTICA 10-ÁDICA TIENDA
0,01 0,694 2,5086 0,6814
0,02 0,6901 2,3485 0,6743
0,03 0,6946 2,1266 0,6567
0,04 0,6936 1,7051 0,6377
0,05 0,6934 1,174 0,6079
0,06 0,6916 0,621 0,5799
0,07 0,6931 -0,2321 0,5829
0,08 0,692 -0,1848 0,5815
0,09 0,6949 0,0482 0,5626
0,1 0,6837 -0,1773 0,5537
0,125 0,6729 -1,239 0,5253
0,3 0,6189 -1,4505 0,245
Tabla 2.7 Número de Vecinos
RÖSSLER
x0=(4 6 20) 10.000 muestras
Tabla 2.8 Número de Vecinos
RÖSSLER x0=(4 6 20)
30.000 muestras
Como podemos observar, influye mucho la
longitud de la serie y no se ve perturbada por una
exigencia elevada de vecinos, ya que al haber
tantos puntos, todos tienen muchos vecinos. Al
no evaluarse sólo determinados puntos, no se
degenera el resultado
Tabla 2.9 Variación del radio exterior
de la órbita r con 0min r
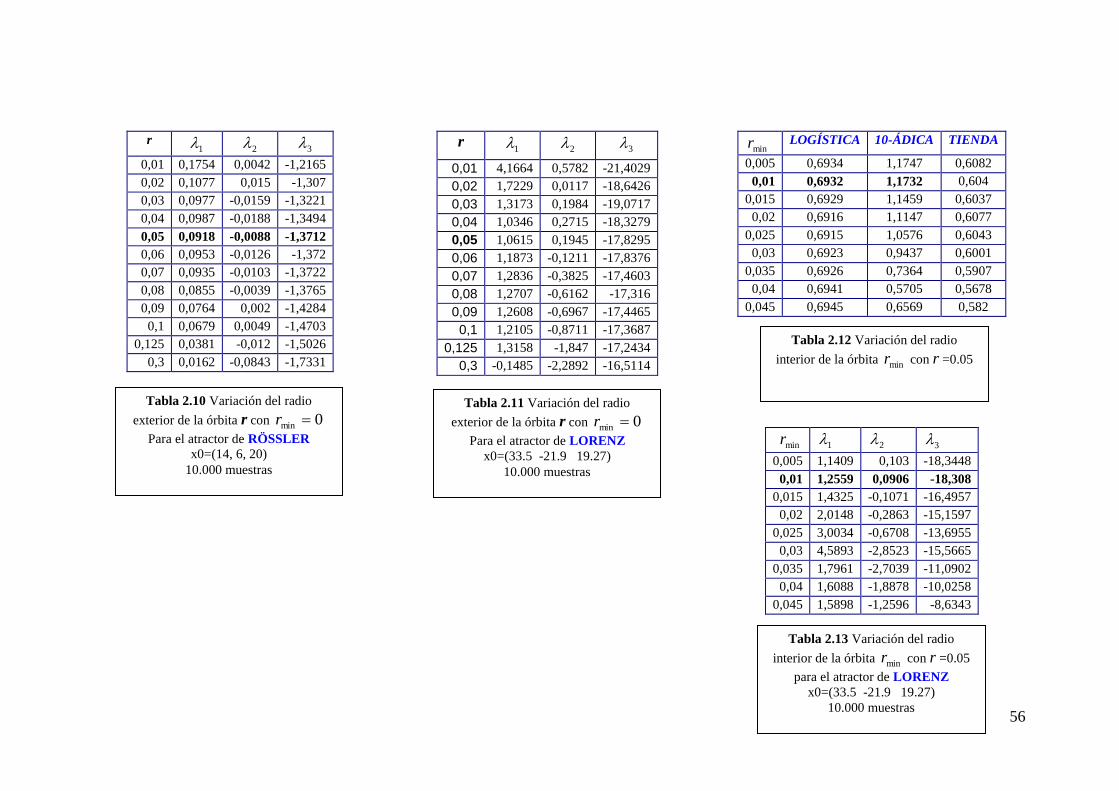
56
r
1 2 3
0,01 0,1754 0,0042 -1,2165
0,02 0,1077 0,015 -1,307
0,03 0,0977 -0,0159 -1,3221
0,04 0,0987 -0,0188 -1,3494
0,05 0,0918 -0,0088 -1,3712
0,06 0,0953 -0,0126 -1,372
0,07 0,0935 -0,0103 -1,3722
0,08 0,0855 -0,0039 -1,3765
0,09 0,0764 0,002 -1,4284
0,1 0,0679 0,0049 -1,4703
0,125 0,0381 -0,012 -1,5026
0,3 0,0162 -0,0843 -1,7331
r 1 2 3
0,01 4,1664 0,5782 -21,4029
0,02 1,7229 0,0117 -18,6426
0,03 1,3173 0,1984 -19,0717
0,04 1,0346 0,2715 -18,3279
0,05 1,0615 0,1945 -17,8295
0,06 1,1873 -0,1211 -17,8376
0,07 1,2836 -0,3825 -17,4603
0,08 1,2707 -0,6162 -17,316
0,09 1,2608 -0,6967 -17,4465
0,1 1,2105 -0,8711 -17,3687
0,125 1,3158 -1,847 -17,2434
0,3 -0,1485 -2,2892 -16,5114
minr LOGÍSTICA 10-ÁDICA TIENDA
0,005 0,6934 1,1747 0,6082
0,01 0,6932 1,1732 0,604
0,015 0,6929 1,1459 0,6037
0,02 0,6916 1,1147 0,6077
0,025 0,6915 1,0576 0,6043
0,03 0,6923 0,9437 0,6001
0,035 0,6926 0,7364 0,5907
0,04 0,6941 0,5705 0,5678
0,045 0,6945 0,6569 0,582
minr 1 2 3
0,005 1,1409 0,103 -18,3448
0,01 1,2559 0,0906 -18,308
0,015 1,4325 -0,1071 -16,4957
0,02 2,0148 -0,2863 -15,1597
0,025 3,0034 -0,6708 -13,6955
0,03 4,5893 -2,8523 -15,5665
0,035 1,7961 -2,7039 -11,0902
0,04 1,6088 -1,8878 -10,0258
0,045 1,5898 -1,2596 -8,6343
Tabla 2.11 Variación del radio
exterior de la órbita r con 0min r
Para el atractor de LORENZ
x0=(33.5 -21.9 19.27)
10.000 muestras
Tabla 2.12 Variación del radio
interior de la órbita minr con r =0.05
Tabla 2.13 Variación del radio
interior de la órbita minr con r =0.05
para el atractor de LORENZ
x0=(33.5 -21.9 19.27)
10.000 muestras
Tabla 2.10 Variación del radio
exterior de la órbita r con 0min r
Para el atractor de RÖSSLER
x0=(14, 6, 20)
10.000 muestras

57
minr 1 2 3
0,005 0,0895 -0,0086 -1,3169
0,01 0,0901 -0,0137 -1,2436
0,015 0,0832 -0,0096 -1,1828
0,02 0,1111 -0,0091 -1,1155
0,025 0,1097 -0,0024 -1,0607
0,03 0,2013 -0,024 -1,126
0,035 0,3113 -0,0575 -1,7021
0,04 0,6385 0,0433 -0,3317
0,045 0,5952 0,0325 -0,2221
Método QR
1 2 3
G-S clásico 1,2559 0,0906 -18,308
G-S modificado 1,2559 0,0906 -18,308
Householder Inf 0,1207 -18,308
qr MATLAB 1,2559 0,0906 -18,308
Método QR
1 2 3
G-S clásico 0,0901 -0,0137 -1,2436
G-S modificado 0,0901 -0,0137 -1,2436
Householder 0,0901 -0,0137 -1,2436
qr MATLAB 0,0901 -0,0137 -1,2436
Tabla 2.14 Variación del radio
interior de la órbita minr con r =0.05
para el atractor de RÖSSLER
x0=(14 6 20)
10.000 muestras
Tabla 2.15 Variación del método de
descomposición QR utilizado para el
atractor de LORENZ
x0=(33.5 -21.9 19.27)
10.000 muestras
r=0.05 - rmin=0.01 - nMinVec=5 -
τ=8
Hay que tener cuidado tonel método
de Householder puesto puede dar
como resultado matrices singulares.
Para solucionarlo, basta con no
calcular el punto es esos casos.
Tabla 2.16 Variación del método de
descomposición QR utilizado para el
atractor de RÖSSLER
x0=(14 6 20)
10.000 muestras
r=0.05 - rmin=0.01 - nMinVec=5 -
τ=8
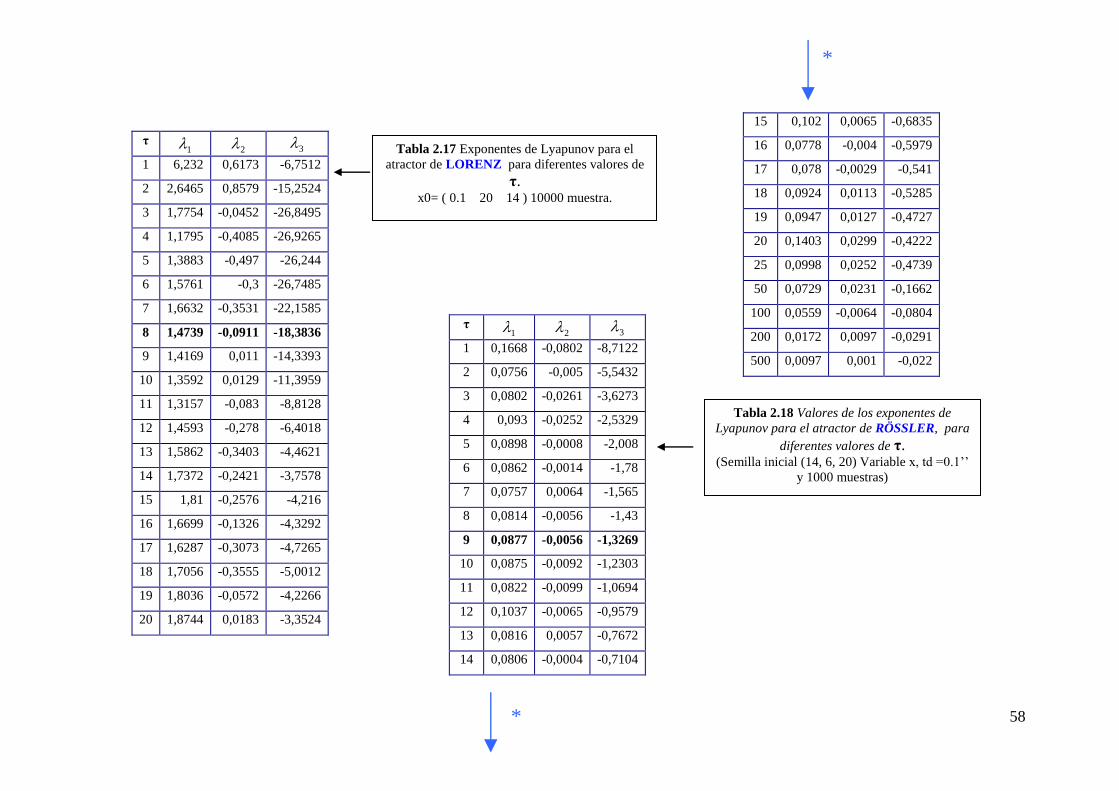
58
τ
1 2 3
1 6,232 0,6173 -6,7512
2 2,6465 0,8579 -15,2524
3 1,7754 -0,0452 -26,8495
4 1,1795 -0,4085 -26,9265
5 1,3883 -0,497 -26,244
6 1,5761 -0,3 -26,7485
7 1,6632 -0,3531 -22,1585
8 1,4739 -0,0911 -18,3836
9 1,4169 0,011 -14,3393
10 1,3592 0,0129 -11,3959
11 1,3157 -0,083 -8,8128
12 1,4593 -0,278 -6,4018
13 1,5862 -0,3403 -4,4621
14 1,7372 -0,2421 -3,7578
15 1,81 -0,2576 -4,216
16 1,6699 -0,1326 -4,3292
17 1,6287 -0,3073 -4,7265
18 1,7056 -0,3555 -5,0012
19 1,8036 -0,0572 -4,2266
20 1,8744 0,0183 -3,3524
τ
1 2 3
1 0,1668 -0,0802 -8,7122
2 0,0756 -0,005 -5,5432
3 0,0802 -0,0261 -3,6273
4 0,093 -0,0252 -2,5329
5 0,0898 -0,0008 -2,008
6 0,0862 -0,0014 -1,78
7 0,0757 0,0064 -1,565
8 0,0814 -0,0056 -1,43
9 0,0877 -0,0056 -1,3269
10 0,0875 -0,0092 -1,2303
11 0,0822 -0,0099 -1,0694
12 0,1037 -0,0065 -0,9579
13 0,0816 0,0057 -0,7672
14 0,0806 -0,0004 -0,7104
15 0,102 0,0065 -0,6835
16 0,0778 -0,004 -0,5979
17 0,078 -0,0029 -0,541
18 0,0924 0,0113 -0,5285
19 0,0947 0,0127 -0,4727
20 0,1403 0,0299 -0,4222
25 0,0998 0,0252 -0,4739
50 0,0729 0,0231 -0,1662
100 0,0559 -0,0064 -0,0804
200 0,0172 0,0097 -0,0291
500 0,0097 0,001 -0,022
Tabla 2.17 Exponentes de Lyapunov para el
atractor de LORENZ para diferentes valores de
τ. x0= ( 0.1 20 14 ) 10000 muestra.
Tabla 2.18 Valores de los exponentes de
Lyapunov para el atractor de RÖSSLER, para
diferentes valores de τ. (Semilla inicial (14, 6, 20) Variable x, td =0.1‟‟
y 1000 muestras)
*
*
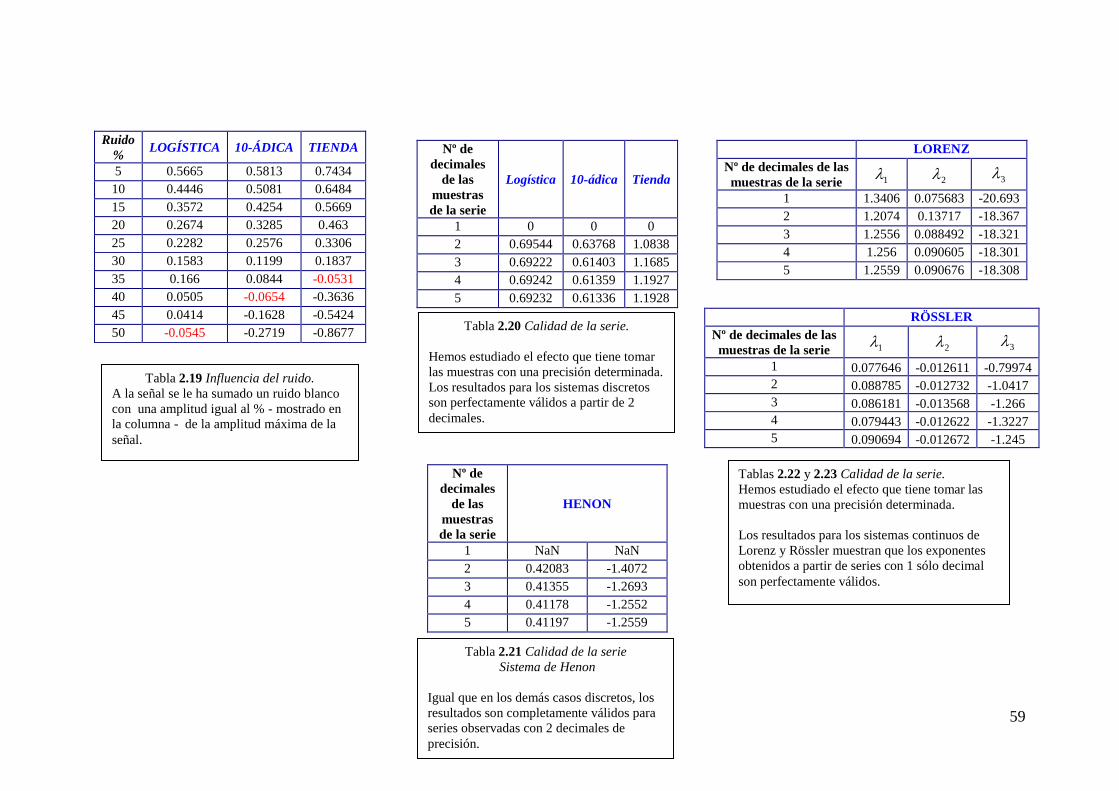
59
Ruido
% LOGÍSTICA 10-ÁDICA TIENDA
5 0.5665 0.5813 0.7434
10 0.4446 0.5081 0.6484
15 0.3572 0.4254 0.5669
20 0.2674 0.3285 0.463
25 0.2282 0.2576 0.3306
30 0.1583 0.1199 0.1837
35 0.166 0.0844 -0.0531
40 0.0505 -0.0654 -0.3636
45 0.0414 -0.1628 -0.5424
50 -0.0545 -0.2719 -0.8677
Nº de
decimales
de las
muestras
de la serie
Logística 10-ádica Tienda
1 0 0 0
2 0.69544 0.63768 1.0838
3 0.69222 0.61403 1.1685
4 0.69242 0.61359 1.1927
5 0.69232 0.61336 1.1928
Nº de
decimales
de las
muestras
de la serie
HENON
1 NaN NaN
2 0.42083 -1.4072
3 0.41355 -1.2693
4 0.41178 -1.2552
5 0.41197 -1.2559
LORENZ
Nº de decimales de las
muestras de la serie 1 2 3
1 1.3406 0.075683 -20.693
2 1.2074 0.13717 -18.367
3 1.2556 0.088492 -18.321
4 1.256 0.090605 -18.301
5 1.2559 0.090676 -18.308
RÖSSLER
Nº de decimales de las
muestras de la serie 1 2 3
1 0.077646 -0.012611 -0.79974
2 0.088785 -0.012732 -1.0417
3 0.086181 -0.013568 -1.266
4 0.079443 -0.012622 -1.3227
5 0.090694 -0.012672 -1.245
Tabla 2.19 Influencia del ruido.
A la señal se le ha sumado un ruido blanco
con una amplitud igual al % - mostrado en
la columna - de la amplitud máxima de la
señal.
Tabla 2.20 Calidad de la serie.
Hemos estudiado el efecto que tiene tomar
las muestras con una precisión determinada.
Los resultados para los sistemas discretos
son perfectamente válidos a partir de 2
decimales.
Tablas 2.22 y 2.23 Calidad de la serie.
Hemos estudiado el efecto que tiene tomar las
muestras con una precisión determinada.
Los resultados para los sistemas continuos de
Lorenz y Rössler muestran que los exponentes
obtenidos a partir de series con 1 sólo decimal
son perfectamente válidos.
Tabla 2.21 Calidad de la serie
Sistema de Henon
Igual que en los demás casos discretos, los
resultados son completamente válidos para
series observadas con 2 decimales de
precisión.

60
Estudio del Caos con
Densidades de Probabilidad
Capítulo 3

61
3.1.- ESTADO DEL ARTE
3.1.1.- Espectro Ensanchado. (Spread Spectrum)
Una de las más importantes cuestiones de los sistemas inalámbricos es el
problema de garantizar acceso múltiple al medio de comunicación. Entre las posibles
estrategias que solucionan este problema, las técnicas de espectro ensanchado han sido
investigadas activamente durante las últimas dos décadas. Mediante el uso de esta
tecnología, todos los usuarios pueden transmitir al mismo tiempo ocupando el mismo
ancho de banda RF. Su principal característica es el ensanchamiento del ancho de
banda de la señal de información muy por encima del mínimo necesario para transmitir
el mensaje. Este ancho de banda está determinado principalmente por el método de
ensanchamiento y no por la información a transmitir.
3.1.2.- Acceso múltiple por división de código (CDMA).
Existen dos técnicas diferenciadas en CDMA, Frequency Hopping (Salto de
Frecuencia) y Direct Sequence (Secuencia Directa).
En FH-CDMA los usuarios transmiten en un gran ancho de banda cambiando la
frecuencia de la portadora a saltos, como su propio nombre indica. Para ello, los
usuarios deben saltar sin coincidir nunca en la misma frecuencia pues se interferirían. Se
intuye que la secuencia numérica que indica las frecuencias a las que tiene que saltar un
usuario, debe estar incorrelada con la misma secuencia de otro usuario. Dicha secuencia
debe ser de valores reales (normalizados o no) pues multiplicarán una frecuencia de
partida.
En DS-CDMA la transmisión es digital. Todos los usuarios comparten el mismo
ancho de banda simultáneamente. Para evitar la interferencia cocanal se le asigna a cada
usuario un código que tiene correlación cruzada nula con los de los demás usuarios.
Aunque las secuencias caóticas se pueden aplicar directamente a FH-CDMA, en
lo que sigue nos vamos a centrar en DS-CDMA

62
3.1.3.- Secuencias de ensanchamiento en DS-CDMA.
En DS-CDMA, durante la transmisión, al comenzar la conexión, se le asigna a
cada usuario un código determinístico diferente - llamado secuencia de ensanchamiento
-, conocido a priori por el receptor. Este código tiene un periodo de muestreo mucho
menor que el de la señal de información; al multiplicarlo por la secuencia de
información, ésta queda modulada y, al tener un periodo de muestreo menor, ensancha
el espectro de la forma de onda de la señal transmitida muy por encima del necesario
para transmitir la información.
En recepción, para demodular los datos, se calcula la correlación cruzada de la
señal de entrada con una copia local de la secuencia de ensanchamiento.
3.1.4.- Secuencias Caóticas
La idea de usar el caos en comunicaciones de espectro ensanchado viene de [C2]
y [C3], donde además primero se reivindicó la posibilidad de generar un infinito
número de secuencias de ensanchamiento para un acceso múltiple al medio por división
de código con secuencia directa (DS-CDMA). Un primer modelo del rendimiento de un
sistema DS-CDMA basado en caos fue [C4]. Esta contribución demostró con éxito el
potencial de usar las técnicas basadas en el caos en este campo. Dicho potencial se ha
seguido investigando [C5] hasta mostrar que la aplicación de la dinámica caótica para la
optimización del nivel de código de los sistemas DS-CDMA es un ejemplo claro donde
la solución basada en caos no sólo mejora el rendimiento de las clásicas
aproximaciones, sino que podría, además, ser la elección óptima cuando la interferencia
cocanal es la principal causa de fallos.
No es muy difícil obtener [C6] la probabilidad de bit erróneo cómo función de la
relación señal a interferencia. Esta relación es la figura de mérito que tratamos de
optimizar. Las variables que podemos modificar para dicha optimización son las
secuencias de ensanchamiento. Típicamente, se han elegido secuencias pseudoaleatorias
(secuencias Gold ó secuencias maximun-length), pero nuevos informes [C6] han
demostrado que las fuentes caóticas pueden utilizarse para generar secuencias de

63
ensanchamiento mejores que las aleatorias, en términos de la figura de mérito
estadística que antes mencionábamos.
3.1.5.- Necesidad de utilizar secuencias con unas propiedades estadísticas
determinadas.
Los sistemas DS-CDMA poseen tres ventajas características sobre otras técnicas
de acceso múltiple que son:
- robustez ante multitrayecto,
- una capacidad potencial elevada respecto al número de usuarios
- y una degradación suave del rendimiento.
Es interesante señalar que estas tres ventajas dependen de las propiedades
estadísticas de las secuencias de ensanchamiento; la robustez frente al multitrayecto se
deriva de las propiedades de autocorrelación del código de ensanchamiento, mientras
que la capacidad está relacionada con las propiedades de correlación cruzada de los
códigos de los diferentes usuarios.
Por tanto, la estadística de las secuencias de ensanchamiento juega un papel
fundamental en la determinación del rendimiento del sistema de comunicación. En la
teoría de los sistemas DS-CDMA comúnmente se asume [C1] que el rendimiento
máximo se obtiene usando códigos ortogonales, es decir, códigos caracterizados por
tener correlación cruzada nula. Sin embargo, si uno se refiere a un enlace CDMA up-
link, desde el transmisor móvil a una estación base fija, el medio puede ser considerado
asíncrono. Esto significa que, debido a que puede considerarse que el retardo absoluto y
la fase de la portadora varían de forma aleatoria de un usuario a otro, el tiempo de
transición de los símbolos de datos de diferentes usuarios no coincide en la recepción de
la estación base, incluso si cada receptor está sincronizado con la señal que tiene que
decodificar. Por tanto, el diseño de la secuencia de ensanchamiento es un problema
mucho más complicado que la simple determinación de un conjunto de secuencias con
correlación cruzada nula.

64
Según lo anterior, las propiedades estadísticas de los procesos generados por una
fuente caótica pueden ser unidas con la probabilidad de error en un sistema DS-CDMA
[C6]. De hecho, para caracterizar el rendimiento de un sistema DS-CDMA basado en
caos es necesario calcular los momentos de orden elevado. De hecho, la computación de
estadísticos de orden elevado de procesos generados por sistemas caóticos emerge como
un paso inevitable para la completa explotación del potencial de las técnicas basadas en
caos en las aplicaciones reales.
3.2.- ESTUDIO DEL CAOS CON DENSIDADES DE PROBABILIDAD
3.2.1.- Una aproximación alternativa para estudiar el caos.
Los sistemas dinámicos suelen exhibir comportamientos muy complicados, de
los cuales, el caos es el más espectacular. En el caso de la dinámica caótica, no se puede
caracterizar las propiedades del sistema de una manera sencilla. De hecho, la tradicional
y accesible teoría de sistemas, basada en la observación de las trayectorias a lo largo del
tiempo, muestra algunas limitaciones cuando la aplicamos a la compleja dinámica no
lineal y representa una dirección de análisis que no tiene mucha utilidad y, a veces,
resulta engañosa.
Aunque el comportamiento caótico puede emerger tanto de sistemas continuos
como discretos en el tiempo, en lo que sigue vamos a fijarnos en la elección más simple
posible, es decir, sistemas dinámicos caóticos discretos de 1-D, usualmente llamados
mapas. En particular, vamos a considerar un dominio normalizado X = [0,1] y una
función no lineal y no invertible XXM : . Ya que intentamos tratar con sistemas
que tienen memoria de sus estados pasados, al dominio X de M lo llamaremos espacio
de fases (Véase Capítulo 1).
Debido a la sensibilidad a las condiciones iniciales, cualquier error en el
conocimiento de un estado se amplificará durante la evolución del sistema, hasta llegar
a un punto donde será completamente imposible predecir la posición de la órbita en el
espacio de fases.
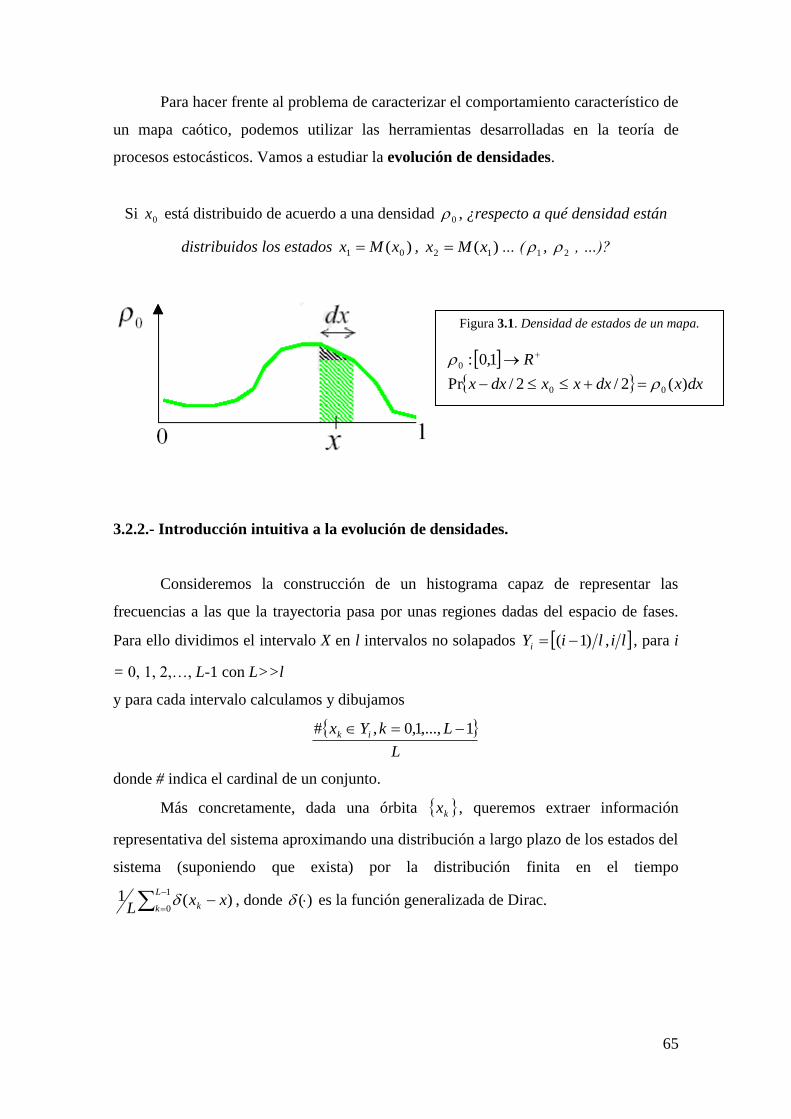
65
Para hacer frente al problema de caracterizar el comportamiento característico de
un mapa caótico, podemos utilizar las herramientas desarrolladas en la teoría de
procesos estocásticos. Vamos a estudiar la evolución de densidades.
Si 0x está distribuido de acuerdo a una densidad 0 , ¿respecto a qué densidad están
distribuidos los estados )( 01 xMx , )( 12 xMx … ( 1 , 2 , …)?
3.2.2.- Introducción intuitiva a la evolución de densidades.
Consideremos la construcción de un histograma capaz de representar las
frecuencias a las que la trayectoria pasa por unas regiones dadas del espacio de fases.
Para ello dividimos el intervalo X en l intervalos no solapados liliYi ,)1( , para i
= 0, 1, 2,…, L-1 con L>>l
y para cada intervalo calculamos y dibujamos
L
LkYx ik 1,...,1,0,#
donde # indica el cardinal de un conjunto.
Más concretamente, dada una órbita kx , queremos extraer información
representativa del sistema aproximando una distribución a largo plazo de los estados del
sistema (suponiendo que exista) por la distribución finita en el tiempo
)(1 1
0
L
k k xxL
, donde )( es la función generalizada de Dirac.
Figura 3.1. Densidad de estados de un mapa.
dxxdxxxdxx
R
)(2/2/Pr
1,0:
00
0

66
Figura 3.2 (a)
Histograma de densidades del
Mapa “Tienda de Campaña”
,1249.00 x
L = 5000 puntos de la órbita,
l = 32 intervalos.
Figura 3.2 (b)
Histograma de densidades del
Mapa “Logístico”
0.2412140 x
L = 5000 puntos de la órbita,
l = 32 intervalos.
Figura 3.2 (c)
Histograma de densidades del
Mapa “100-ádico”
0.241214,0 x
L = 5000 puntos de la órbita,
l = 32 intervalos.
Figura 3.2 (d)
Histograma de densidades del
Mapa “Bended Up-Down”
0.241,0 x
L = 5000 puntos de la órbita,
l = 32 intervalos.

67
En la figura 3.2 a, b, c y d aparece el resultado de este procedimiento para los
mapas Tienda, Logístico, 100-ádico y Bended Up-Down definidos en el Capítulo 1.
Hay una estructura sorprendente en el resultado, los estados están visiblemente
más concentrados cerca del centro de X, mientras que hay apreciables descensos cerca
del 1y, todavía mayor, cuando nos acercamos al 0.
Si repetimos el proceso para diferentes condiciones iniciales, en general, el
resultado es el mismo.
Por tanto, se puede concluir que la característica dependencia a las
condiciones iniciales del sistema no está reflejada en la distribución de los estados
por los que pasan sus trayectorias.
Aunque esta aproximación alumbra una importante regularidad, de alguna
manera falta conocimiento y contiene posibles inconvenientes. Podría ocurrir que,
comenzando a partir de unas determinadas condiciones iniciales, la órbita fuera
periódica (Figura 3.3) o cayera en un punto fijo. Obviamente, cualquier intento de
extraer características del sistema a partir de estas trayectorias está condenado al
fracaso. El peor aspecto de estos comportamientos excepcionales es que no hay un
camino claro para predecir qué estados nos conducirán a él.
Figura 3.3 Ciclo límite del mapa “bended up-down”
6.00 x

68
Una idea para superar el inconveniente anterior es considerar la evolución de
grandes conjuntos de trayectorias al mismo tiempo.
Supongamos que elegimos aleatoriamente un conjunto 0S de L condiciones
iniciales, que están repartidas siguiendo una determinada función de densidad de
probabilidad (fdp) RX:0 .
En la figura 3.4 se representa el histograma de tres conjuntos de condiciones
iniciales obtenidas mediante simulación en MATLAB3, para L = 5000 condiciones
iniciales y l = 32 intervalos. En la gráfica a las condiciones iniciales siguen una función
de densidad de probabilidad Uniforme ( 1
0S ), en la b siguen4 una Gaussiana con media
0.6 y varianza 0.1 ( 2
0S ), mientras que en la c siguen una Gaussiana de media 0.2 y
varianza 0.005 ( 3
0S ).
3 La generación de números aleatorios en MATLAB que sigan una distribución Gaussiana no es del todo
satisfactoria (Véase figura inferior). Por tanto, para que se distinga el efecto de las iteraciones sobre
diferentes distribuciones, nos hemos visto obligados a elegir conjuntos de varianza muy estrecha.
Media =0.6 y Varianza = 0.2 Media = 0.2 y Varianza = 0.1
Las figuras en azul ilustran los histogramas de frecuencias, de 2000 muestras cada uno, generadas por
MATLAB con la función “normrnd(Media, sqrt(Varianza) ,1,2000)”. Las figuras en rojo muestran la
función de densidad ideal para los mismos parámetros. Ambas figuras sólo incluyen el intervalo [0,1]
(Véase nota 2) 4 Se consideran sólo las condiciones iniciales que están dentro del intervalo [0,1], que es el espacio de
fases de las transformaciones que vamos a estudiar..
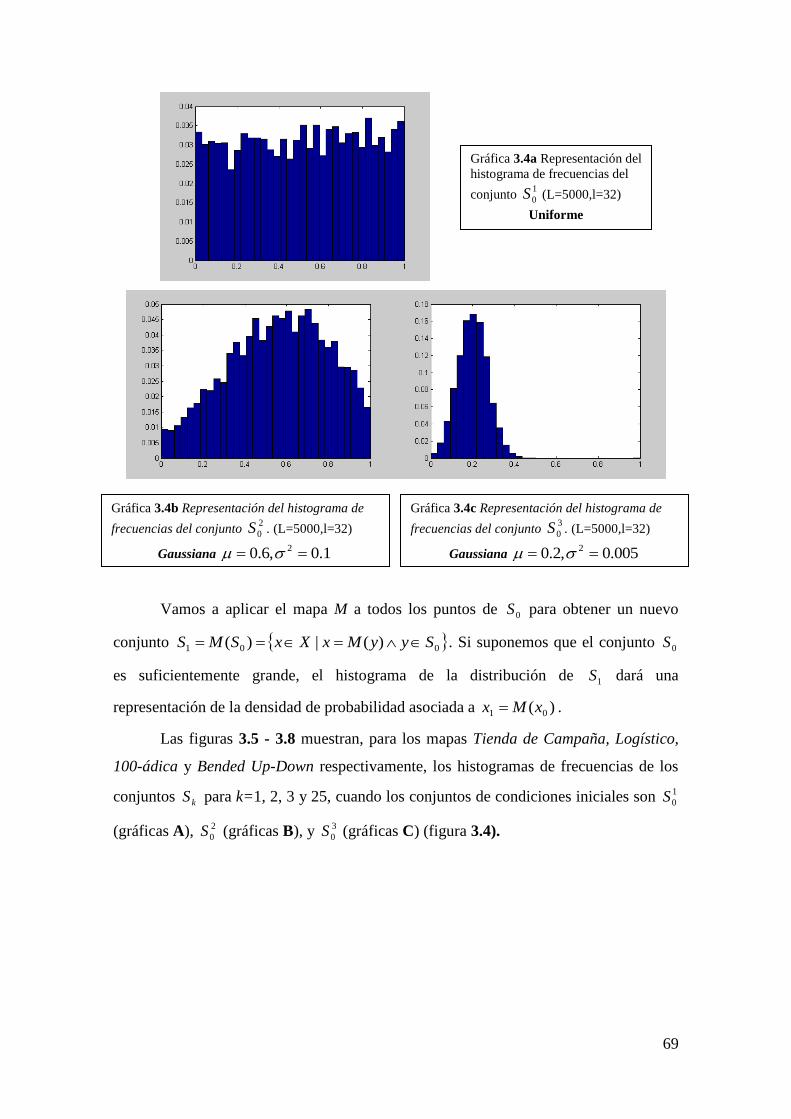
69
Vamos a aplicar el mapa M a todos los puntos de 0S para obtener un nuevo
conjunto 001 )(|)( SyyMxXxSMS . Si suponemos que el conjunto 0S
es suficientemente grande, el histograma de la distribución de 1S dará una
representación de la densidad de probabilidad asociada a )( 01 xMx .
Las figuras 3.5 - 3.8 muestran, para los mapas Tienda de Campaña, Logístico,
100-ádica y Bended Up-Down respectivamente, los histogramas de frecuencias de los
conjuntos kS para k=1, 2, 3 y 25, cuando los conjuntos de condiciones iniciales son 1
0S
(gráficas A), 2
0S (gráficas B), y 3
0S (gráficas C) (figura 3.4).
Gráfica 3.4b Representación del histograma de
frecuencias del conjunto 2
0S . (L=5000,l=32)
Gaussiana 1.0,6.0 2
Gráfica 3.4a Representación del
histograma de frecuencias del
conjunto 1
0S (L=5000,l=32)
Uniforme
Gráfica 3.4c Representación del histograma de
frecuencias del conjunto 3
0S . (L=5000,l=32)
Gaussiana 005.0,2.0 2

70
Figura 3.5B Representación de la evolución de histogramas cuando aplicamos el mapa TIENDA
a un conjunto inicial 2
0S (Figura 33b) , que sigue una GAUSSIANA 1.0,6.0 2 .
Para k =1 se ve cómo varía la densidad transformándose en una rampa. A partir de k =2 la densidad
se mantiene tipo Uniforme. Converge un poco más lentamente que la figura anterior.
Figura 3.5A Representación de la evolución de histogramas cuando aplicamos el mapa TIENDA a
un conjunto inicial 1
0S (Figura 3.3a), que sigue una distribución UNIFORME
Puede observarse como, desde la primera iteración, la distribución se mantiene Uniforme.
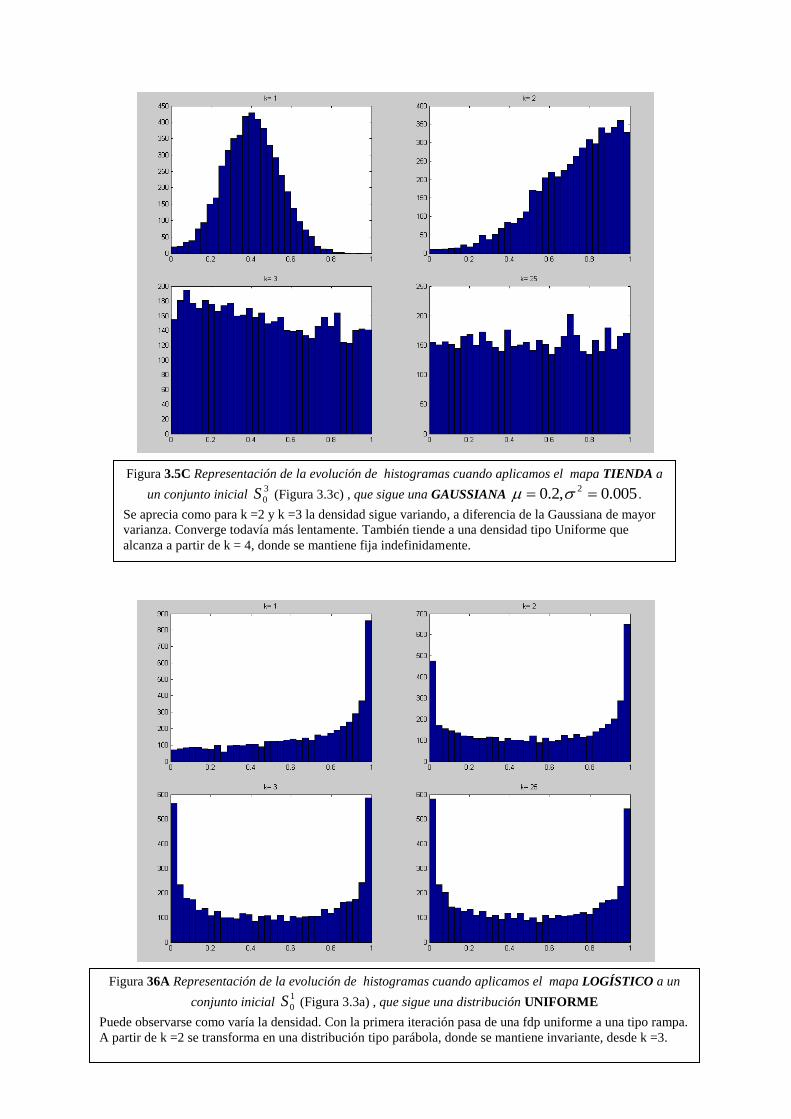
71
Figura 3.5C Representación de la evolución de histogramas cuando aplicamos el mapa TIENDA a
un conjunto inicial 3
0S (Figura 3.3c) , que sigue una GAUSSIANA 005.0,2.0 2 .
Se aprecia como para k =2 y k =3 la densidad sigue variando, a diferencia de la Gaussiana de mayor
varianza. Converge todavía más lentamente. También tiende a una densidad tipo Uniforme que
alcanza a partir de k = 4, donde se mantiene fija indefinidamente.
Figura 36A Representación de la evolución de histogramas cuando aplicamos el mapa LOGÍSTICO a un
conjunto inicial 1
0S (Figura 3.3a) , que sigue una distribución UNIFORME
Puede observarse como varía la densidad. Con la primera iteración pasa de una fdp uniforme a una tipo rampa.
A partir de k =2 se transforma en una distribución tipo parábola, donde se mantiene invariante, desde k =3.
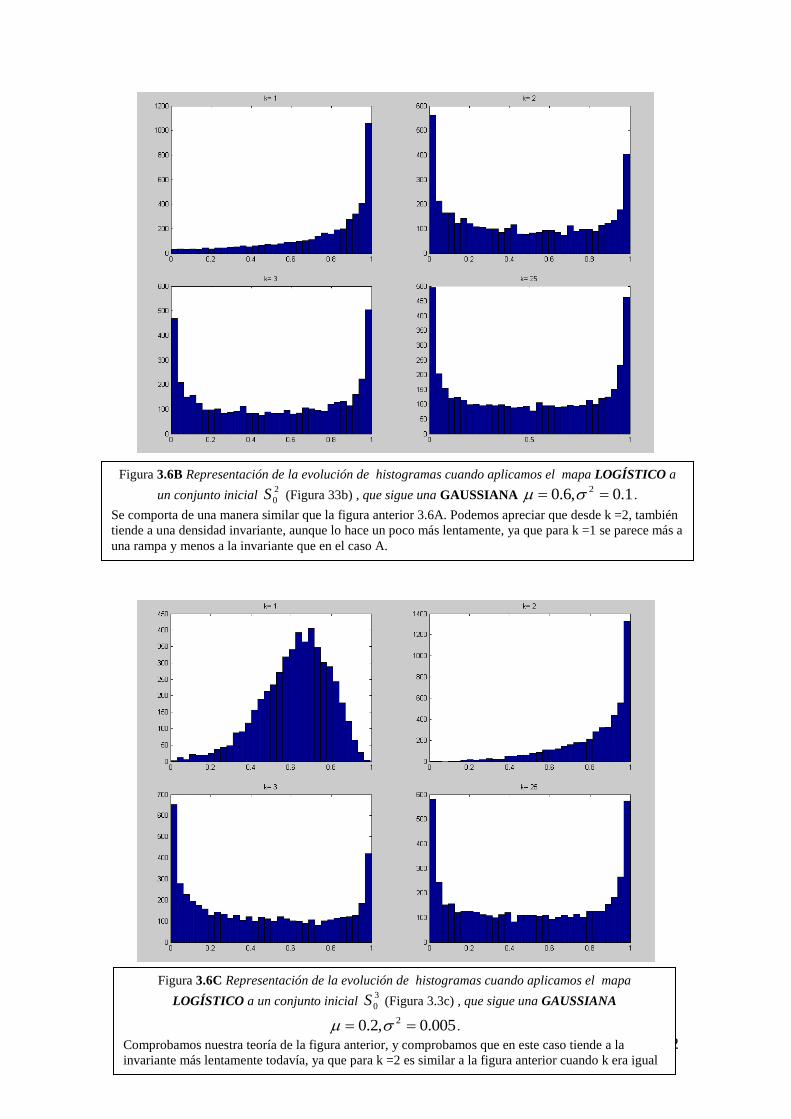
72
Figura 3.6B Representación de la evolución de histogramas cuando aplicamos el mapa LOGÍSTICO a
un conjunto inicial 2
0S (Figura 33b) , que sigue una GAUSSIANA 1.0,6.0 2 .
Se comporta de una manera similar que la figura anterior 3.6A. Podemos apreciar que desde k =2, también
tiende a una densidad invariante, aunque lo hace un poco más lentamente, ya que para k =1 se parece más a
una rampa y menos a la invariante que en el caso A.
Figura 3.6C Representación de la evolución de histogramas cuando aplicamos el mapa
LOGÍSTICO a un conjunto inicial 3
0S (Figura 3.3c) , que sigue una GAUSSIANA
005.0,2.0 2 .
Comprobamos nuestra teoría de la figura anterior, y comprobamos que en este caso tiende a la
invariante más lentamente todavía, ya que para k =2 es similar a la figura anterior cuando k era igual
a 1.
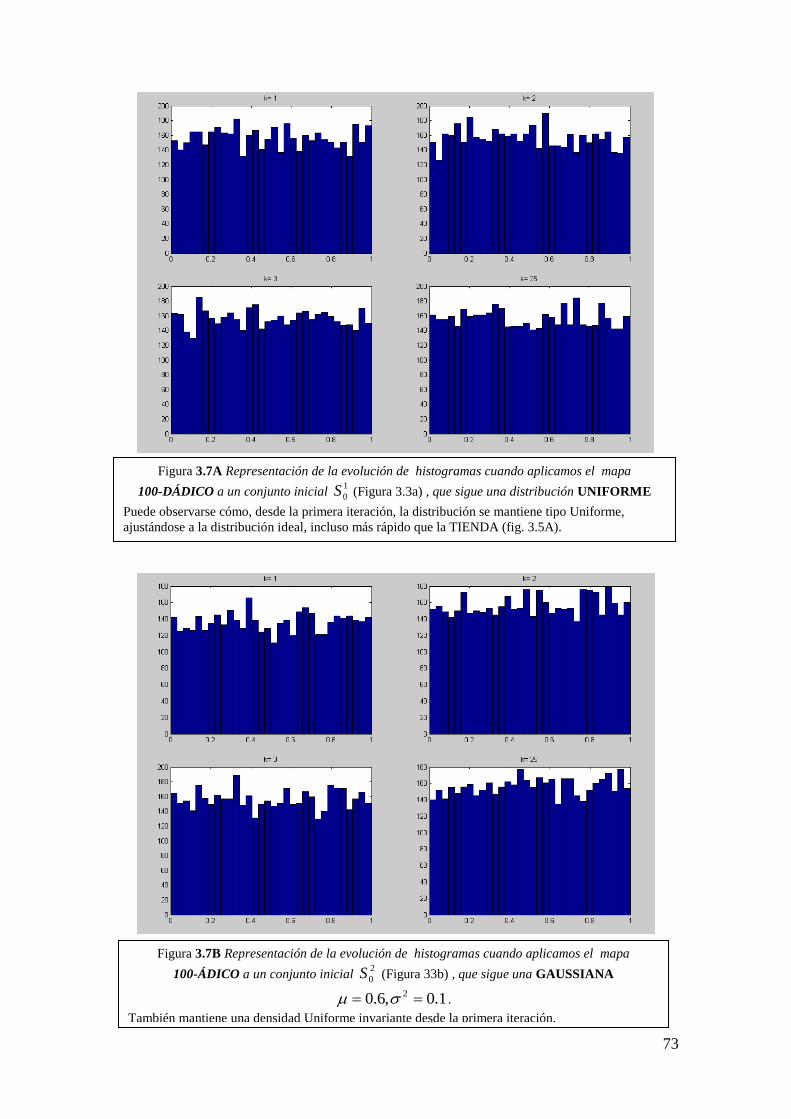
73
Figura 3.7A Representación de la evolución de histogramas cuando aplicamos el mapa
100-DÁDICO a un conjunto inicial 1
0S (Figura 3.3a) , que sigue una distribución UNIFORME
Puede observarse cómo, desde la primera iteración, la distribución se mantiene tipo Uniforme,
ajustándose a la distribución ideal, incluso más rápido que la TIENDA (fig. 3.5A).
Figura 3.7B Representación de la evolución de histogramas cuando aplicamos el mapa
100-ÁDICO a un conjunto inicial 2
0S (Figura 33b) , que sigue una GAUSSIANA
1.0,6.0 2 .
También mantiene una densidad Uniforme invariante desde la primera iteración.

74
Figura 3.7C Representación de la evolución de histogramas cuando aplicamos el mapa
100-ÁDICO a un conjunto inicial 3
0S (Figura 3.3c) , que sigue una GAUSSIANA
005.0,2.0 2 .
Converge inmediatamente a la Uniforme. Ahora si podemos comparar la velocidad de convergencia
con la Tienda de Campaña, que para k =1,2 todavía estaba transformándose.
Figura 3.8A Representación de la evolución de histogramas cuando aplicamos el mapa BENDED
UP-DOWN a un conjunto inicial 1
0S (Figura 3.3a) , que sigue una distribución UNIFORME
Puede observarse como, desde la primera iteración, la distribución tiende a una forma determinada.
En k =1 se observa que el primer tramo (hasta 0.2) está muy levantado, y el final (0.8, 1) está plano.
Según sigue evolucionando el conjunto 1
kS el tramo inicial disminuye en amplitud y el final forma
una pequeña rampa.

75
Figura 3.8B Representación de la evolución de histogramas cuando aplicamos el mapa BENDED UP-
DOWN a un conjunto inicial 2
0S (Figura 3.4b) , que sigue una GAUSSIANA 1.0,6.0 2 .
Evoluciona muy rápidamente, pareciéndose a la invariante desde el principio. La única diferencia, respecto
a la figura anterior, e en el tramo intermedio
Figura 3.8C Representación de la evolución de histogramas cuando aplicamos el mapa BENDED UP-
DOWN a un conjunto inicial 3
0S (Figura 3.3c), que sigue una GAUSSIANA 005.0,2.0 2 .
Vemos que el histograma evoluciona hacia la misma densidad final que en las figuras anteriores, pero lo
hace de una forma más lenta. Para k =1, todavía no se parece nada a la densidad invariante.

76
3.2.3.- Comentarios intuitivos sobre la evolución de densidades.
Los resultados de estos sencillos experimentos numéricos revelan una estructura
sorprendentemente regular, que podemos resumir en los siguientes comentarios.
Comentario 1:
Para todos los mapas considerados, la representación del histograma
del conjunto kS se vuelve casi invariante después de unas pocas
iteraciones, y no parece depender de las condiciones iniciales.
En otras palabras, el comportamiento de un mapa caótico en términos de la
evolución de sus órbitas –el cuál no es sólo altamente irregular, sino también
dependiente de las condiciones iniciales– se corresponde con un comportamiento
aparentemente regular en términos de la evolución de un conjunto significativo de
trayectorias. Es fácil observar esto en las gráficas A, B y C de cada figura donde,
partiendo de tres conjuntos de condiciones iniciales ( iS0 ), después de k = 25 iteraciones
los resultados son prácticamente indistinguibles.
Comentario 2:
La distribución final obtenida depende del mapa analizado.
Se puede comprobar que, aunque la distribución final asociada a la tienda y a la
función R-ádica son parecidas (las dos tienden a la función de densidad uniforme), la
distribución final asociada al mapa bended up-down es muy diferente. Hay que señalar
que las distribuciones finales obtenidas en las figuras 3.5 - 3.8 son iguales a las
obtenidas a partir de una sola trayectoria de la figura 3.2.
Comentario 3:
La velocidad de convergencia hacia la distribución final depende del
mapa y de la fdp del conjunto de condiciones iniciales.
La dependencia de la fdp de las condiciones iniciales es fácilmente visible si
comparamos las figuras correspondientes a la Uniforme (figuras A) y las Gaussianas

77
(figuras B y C). La evolución del conjunto 1
0S (densidad uniforme) converge más
rápidamente que las Gaussianas. Esto cabía esperarse, ya que sabemos que los mapas
analizados son caóticos y, por tanto, van a mezclar los puntos en el espacio de fases. En
este caso, la densidad Uniforme tiene ventaja sobre las Gaussianas, ya que los puntos
iniciales están más mezclados.
Respecto a la dependencia del mapa, se puede observar cómo la fdp
correspondiente a la 100-ádica converge mucho más rápidamente que todas las demás
cuando se parte del mismo conjunto 3
0S (distribución Gaussiana de media 0.2 y varianza
0.005).
3.2.4.- Sistemas ergódicos –I–. La medida natural.
Aunque luego definiremos formalmente los sistemas ergódicos y sus
propiedades, vamos a dar una introducción intuitiva, que sirva de apoyo para seguir con
facilidad las definiciones formales.
Cuando representamos un atractor extraño (véase Cap.1) mediante una
computadora, lo que representamos en realidad, es parte de una órbita concreta del
correspondiente sistema dinámicos. Sin embargo, al hacer la órbita de otro punto
distinto, observamos que, si dichas órbitas generadas son largas, el aspecto de la
representación obtenida es muy parecido.
Uno puede preguntarse si una órbita es muy representativa de la geometría del
atractor, es decir, si existe fidelidad geométrica y dinámica entre una órbita del sistema
dinámico y el atractor del sistema, y en el caso de que dicha fidelidad tenga lugar para
determinadas órbitas, si éstas abundan, o los puntos que las generan son una excepción.
Por fidelidad dinámica habremos de entender que la frecuencia con que visitan
las órbitas del sistema una región B del atractor, tiene un valor estable para órbitas
suficientemente largas, y es independiente de la órbita elegida. Cuando tal fidelidad se
da, se dice que el sistema es ergódico.

78
La medida ergódica nos determina una medida de probabilidad, que debe ser
vista como la proporción de “masa” del atractor que cae dentro de B, o mejor, la
proporción de tiempo que las órbitas del sistema pasan en la región B.
3.2.5.- Convenciones de notación.
Para formalizar la aproximación estadística de los sistemas caóticos que hemos
introducido, es necesario establecer algunas convenciones de notación.
Sea kM la iteración número k del mapa M, tal que para algún conjunto XY ,
)(YM k es el conjunto YxxMyXy k )(| , y )(YM k es el conjunto
YyxMyXx k )(|
Ya que es necesario operar sobre conjuntos en los cuales hay una medida
definida, vamos a indicar por Ą una σ-álgebra de los subconjuntos de X y, con μ, una
medida sobre Ą. Además, si μ(x) = 1, entonces al triplete (X, Ą , μ) lo llamaremos
espacio de probabilidad.
Considerando un espacio de medida (X, Ą , μ), se dice que un mapa XXM :
1) es no singular, si 0))(( 1 YM para todos los conjuntos AY , tal
que 0)( Y ;
2) conserva la medida, si )())(( 1 YYM para cualquier conjunto
AY .
3.2.6.- Herramienta para el estudio de la evolución de densidades.
Para desarrollar un marco teórico que explique los comentarios 1-3, es necesario
introducir una herramienta matemática fundamental.

79
Para este propósito planteamos un ejemplo sencillo del que sacaremos
conclusiones generales.
Partimos de un mapa R-ádico y suponemos que su condición inicial 0x es una
variable aleatoria que sigue una función de densidad de probabilidad RX:0 .
Si iteramos el mapa, obtenemos una nueva variable aleatoria )( 01 xMx que
queremos describir estadísticamente a partir de la densidad 1 asociada a 0 .
Para solucionar el problema, uno puede, simplemente, considerar la restricción
de conservación de probabilidad impuesta por la naturaleza determinística del sistema.
Más exactamente, por1xI vamos a indicar un pequeño conjunto vecino de 1x y,
por 1x el conjunto previo que, cuando le aplicamos el mapa, se transforma en
1xI
(11
)(
x
xM
x I ) y escribimos
Prob
10x
11
xI
xIx Prob 00 xIx
que simplemente se corresponde con considerar todos los posibles eventos en el instante
k = 0 que conducen el estado del mapa al valor 1x en el instante k = 1.
Examinando la figura 3.9 5, se sigue inmediatamente que la restricción previa
puede ser expresada en términos de distribución de probabilidad como
x n
i
nx
ni
dd0
1
0
/)1(
01 )()(
),0(01
)(xM
d
así, si derivamos a ambos lados de la ecuación, se obtiene
),0(01 1
)()(xM
ddx
dx
que es la expresión analítica del operador que necesitamos.
5 Las Figuras 3.9, 3.10 y 3.11 están sacadas de [C7]

80
3.2.7.- Operador Perron-Frobenius. Definición.
Para desentrañar su uso y propiedades hay que proceder formalmente.
o Norma de Lebesgue X
dxxff )(
o Espacio de Lebesgue f Ł 11
RXf : y 1f
o Restringimos M a un dominio de densidades 0,1Ð ,1,0: R Ł 1
Figura 3.9.
Representación gráfica de la restricción de conservación de probabilidad, con la
que se define el PFO, para la tienda de campaña.
22
Prdy
yydy
y
22Pr
22Pr 2
222
21
111
1
dxxx
dxx
dxxx
dxx
Restricción de conservación de densidades de probabilidad
)('
)(
)('
)()(
)()()(
)()()(
2
2
1
1
1
222
111
22111
xM
x
xM
xy
dy
dxdxx
dy
dxxy
dxxdxxdyy
kk
k
kkk
kkk

81
Sea (X, Ą , μ) un espacio de medida, donde μ es la medida de Lebesgue.
Definición
Si M es un mapa no singular, el único operador P: Ł 1 Ł 1 definido por
XxMdxMd
dx
dx ))(()()()(
),0(1
es llamado operador Perron-Frobenius (PFO) correspondiente al mapa M.
Aplicando la definición anterior se obtiene, inmediatamente, la expresión del
PFO para la Tienda de Campaña:
1
)2(1
2
0
)()()(x
x
dddx
dx
y para la función R-ádica:
1
0
)(
1
)()(n
i
nix
n
ddx
dx
Siguiendo con la notación de la figura 3.9 el operador M del mapa M, para mapas con “muchas
ramas” sería
yxM
k
kMkxM
xyy
)(
1)('
)()()(
Para el mapa Tienda de Campaña: (véase Figura 3.9)
2/1 yx 2/12 yx 2
)2/1(
2
)2/()(2'
yyyM M
Para la función R-ádica: (véase Figura 3.10)
ninyxi /)1(/
n
l
Mn
ninyynM
1
)/)1(/()('

82
3.2.8.- Operador Perron-Frobenius. Propiedades y Ventajas.
Usando esta definición es sencillo mostrar que P es un operador lineal infinito-
dimensional caracterizado por las siguientes propiedades:
- P es positivo, es decir, P 0 , si 0 . (p1)
- P conserva , es decir, XX
dxxdxx )()( . (p2)
- El PFO correspondiente a kM es k
k . (p3)
Las propiedades (p1) y (p2) aseguran que el PFO mantiene las funciones de
densidad como funciones de densidad. Por tanto, en lo siguiente, vamos a considerar la
restricción de usar el PFO al conjunto Đ(x) de densidades de probabilidad definido
sobre X.
La propiedad (p3) asegura que el PFO asociado con la iteración número k del
mapa no es otra cosa que las sucesivas k aplicaciones del PFO asociado a dicho mapa.
Debido a esto, si la condición inicial del mapa, 0x , está elegida de acuerdo a una
Figura 3.10 Mapa R-ádico, también
llamado desplazamiento de Bernoulli n-
ramas.
nxxM )( mod 1

83
función de densidad inicial 0 , tras k iteraciones, su estado kx estará organizado de
acuerdo a la función de densidad
(1).
Si comparamos la ecuación anterior (1) con
)( 1 kk xMx (2),
podemos considerar a (1) como ecuación de estados de un sistema dinámico asociado a
M, cuyo estado representa como se regula la distribución de la densidad de estados del
mapa M.
La ventaja de estudiar el comportamiento del sistema, en términos de evolución
de densidades, es que el sistema (1) es lineal y, aparentemente, caracterizado por un
comportamiento muy regular, mientras que el mapa original es no lineal y muy difícil
de tratar.
Mediante estas últimas consideraciones podemos volver a considerar los
comentarios 1 - 3 de una forma más precisa.
3.2.9.- Consideraciones sobre los comentarios relativos a la evolución de
densidades.
El comentario 1 hacía referencia al hecho de que, para todos los mapas
considerados y para k suficientemente grande, la densidad 0 k
k converge a una
densidad final ~ , independientemente de 0 .
Merece la pena señalar que, cuando dicha densidad final existe para un mapa
determinado es, obligatoriamente, un punto fijo del PFO asociado, resultando ~~ .
Esto usualmente se expresa llamando a ~ la densidad invariante del mapa.
Adviértase además que para toda definición del PFO, se obtiene ~~ si, y
sólo si, la medida ~~ d es invariante bajo M; por esta razón, nos referimos a ~ como
la medida invariante del mapa.
01 k
kk

84
Con los argumentos introducidos hasta ahora se puede dar una explicación
teórica que justifique el comentario 2. De hecho, ya que la densidad de invariante ~ es
un punto fijo del PFO, cuya definición depende de M, obviamente ~ dependerá del
mapa.
Respecto al comentario 3, mediante la simple observación de la ecuación (1) se
llega a la conclusión de que la velocidad de convergencia de k a ~ está,
obligatoriamente, relacionada con el mapa y con la elección de la densidad inicial 0 .
Para dar una explicación teórica de los comentarios 1 y 3 hay que esclarecer la
unión entre las características de un mapa particular y las propiedades estadísticas del
sistema (2).
Lo vamos a hacer mediante los siguientes pasos:
Paso 1) Identificar las condiciones que aseguran que el PFO de un mapa
tiene un único punto fijo ~ .
Paso 2) Identificar las condiciones que aseguran que el ~lim 0
k
k
existe para algún 0 y es único.
Paso 3) Determinar a qué velocidad y con respecto a qué norma tiende
0~0 k
.
Para este propósito es necesario introducir una nueva clasificación de los mapas
que va a caracterizarlos por la creciente complejidad de su comportamiento.
3.2.10.- Mapas Ergódicos –II–
El hecho de que el PFO asociado a un mapa particular M tenga un punto fijo,
¿implica que la densidad invariante sea única? Si, si M es ergódico

85
Definición
Considera un espacio de medida (X, Ą, μ). Se dice que un mapa no
singular XXM : es ergódico si todo conjunto invariante Y Ą es un
subconjunto trivial de X, es decir, si se da que 0)( Y ó μ(X \Y) = 0.
En realidad, la medidad μ se define previamente sobre el espacio de fases como
una fdp, y la exigencia de que coincida con una densidad invariante para casi todo punto
0x del espacio de fases, es decir, casi todo excepto a lo sumo un conjunto de μ-medida
nula, es la condición de ergodicidad de dicha medida (o sistema). Se admite por tanto
que existan órbitas “no típicas”, pero éstas han de ser irrelevantes, en términos de la
medida de los puntos que las generan. Es decir, sea un sistema dinámico definido por
XXM : y μ una medida d probabilidad en X, se dice que μ es ergódica si para todo
conjunto (medible), existe el límite establecido como una fdp invariante, y es el mismo
para casi todo 0x perteneciente a X.
Los mapas bended up-down, tienda de campaña, R-ádico y
1mod10
2)(
xxM (Mapa 1)
6
son todos ergódicos.
Teorema 1
Sea (X, Ą, μ) un espacio de medida, XXM : un mapa no singular y
P el PFO asociado a M. Si M es ergódico, entonces, hay, como máximo,
una densidad invariante ~ de P. Además, si hay una única densidad
invariante ~ de P y 0~ se puede afirmar que M es ergódico.
Este teorema, que une la ergodicidad con la existencia de ~ , da una primera
respuesta al Paso 1.
6 Introducimos este mapa porque es ergódico pero, como veremos más adelante, no es de tipo “exacto”.
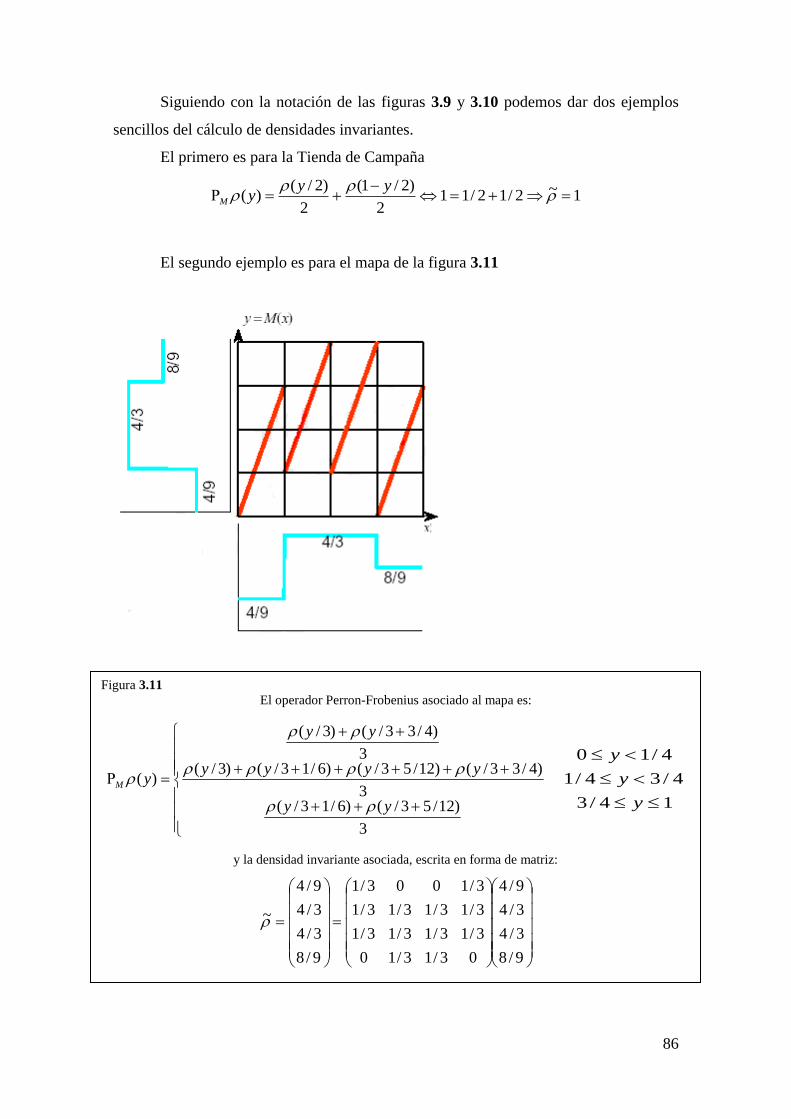
86
Siguiendo con la notación de las figuras 3.9 y 3.10 podemos dar dos ejemplos
sencillos del cálculo de densidades invariantes.
El primero es para la Tienda de Campaña
1~2/12/112
)2/1(
2
)2/()(
yy
yM
El segundo ejemplo es para el mapa de la figura 3.11
Figura 3.11
El operador Perron-Frobenius asociado al mapa es:
3
)12/53/()6/13/(3
)4/33/()12/53/()6/13/()3/(3
)4/33/()3/(
)(
yy
yyyy
yy
yM
14/3
4/34/1
4/10
y
y
y
y la densidad invariante asociada, escrita en forma de matriz:
9/8
3/4
3/4
9/4
03/13/10
3/13/13/13/1
3/13/13/13/1
3/1003/1
9/8
3/4
3/4
9/4
~

87
La importancia de los sistemas ergódicos radica además en que satisfacen el
“teorema ergódico individual” de Birkhoff [C8] [C9]; el cual se puede expresar de la
siguiente manera
Teorema 2
Sea (X, Ą, μ) un espacio de medida, XXM : un mapa que preserva
la medida y ergódico. Entonces para cualquier función Ł 1 , el
promedio en el tiempo de , a lo largo de la trayectoria de M, es igual a
la esperanza E [ ] de sobre X, nombrada como
X
L
k
k
LdxxxxM
L)(~)())((
1lim
1
0
0
Es muy interesante señalar la posibilidad de sustituir esperanzas estadísticas por
los promedios en el tiempo de una órbita observable a lo largo de una trayectoria típica.
3.2.11.- Mapas de mezcla
Hay que tener en cuenta que la dinámica de un mapa ergódico no tiene por que
ser excesivamente complicada. De hecho, podría ser inapropiado identificar el caos con
la ergodicidad. Vamos, por tanto, a introducir una descripción formal de algunos
comportamientos “más complicados”. Esto nos ayudará a encontrar una respuesta para
el Paso 2.
Definición
Considera un espacio de medida (X, Ą, μ) y una transformación
XXM : que preserva la medida. Decimos que el mapa M es de
mezcla si para cualquier 21,YY Ą se tiene que el
)()())((lim 2121 YYYMY n
n
A la vista de la definición anterior, podríamos decir que la transformación de
mezcla distribuye grupos de puntos de acuerdo a la medida μ.
De hecho, a partir de la definición anterior, si tomamos dos conjuntos 1Y e 2Y
tenemos que, para un mapa de mezcla,
)()())(( 1221 YYYMY n cuando n .

88
El primer término es la probabilidad (de acuerdo a μ) de que, tras n iteraciones,
una trayectoria típica del sistema que haya empezado en 2Y , llegue a 1Y .
El segundo término simplemente representa la probabilidad de que una
trayectoria típica esté en 1Y .
Aplicando la definición más común de independencia estadística entre dos
variables aleatorias, podemos suponer que, para valores de n elevados, los dos eventos
2Yx y 1)( YxM n se vuelven estadísticamente independientes. En otras palabras,
los mapas de mezcla generan muestras cuya independencia crece con el tiempo.
Es fácil mostrar que un mapa de mezcla es además ergódico.7
Los mapas de mezcla tienen un comportamiento más complejo que los ergódicos
y, en teoría de sistemas dinámicos es común indicar como caóticos sólo aquellos mapas
que, por lo menos, son de mezcla.
Los mapas bended up-down, tienda de campaña y R-ádico son todos de mezcla,
mientras que el (Mapa 1) no lo es.
La pérdida de dependencia estadística que caracteriza a las series temporales
generadas por un mapa de mezcla, se suele estudiar considerando la cantidad
E dxxxMxxx p
Xkpkk )(~))(()()()(
donde RX :, son funciones suaves [C10].
Si uno piensa que estas funciones son cantidades físicas y observables del
sistema, entonces dicha cantidad cuantifica la correlación entre las observaciones de
en el instante k y de en el instante k + p.
Para los mapas de mezcla genéricos, la computación exacta de E )()( pkk xx
es, casi, una tarea imposible. Uno suele estar restringido a calcular la velocidad
10 mixr de la convergencia geométrica de dicha correlación a su valor límite,
cuando p . A mixr se le suele llamar velocidad de mezcla [C6].
7 Se puede usar la medida invariante ~ en la definición de mezcla. [C10]

89
Formalmente, puede demostrarse que existe una constante 0 tal que
p
mixXX
kpkk rdxxxdxxxxx supsup)(~)()(~)()()( E
En otras palabras, la velocidad de mezcla es una cantidad muy representativa,
que proporciona información sobre la rapidez a la que el sistema tiende a un
comportamiento estadístico estable, y para nosotros, sobre la rapidez con que las
cantidades físicas observables se vuelven incorreladas.
Para el cálculo de mixr hay que introducir el concepto de espectro de autovalores
)(P del PFO, es decir, la colección de números complejos λ para los cuales existe, por
lo menos, una función Ł BV
8 tal que .
Siendo el PFO infinito-dimensional se puede esperar que exista una colección de
infinitos autovalores.
Teorema
El PFO P : Ł BV Ł BV es un operador casi-compacto.
Esto significa que su espectro tiene una parte esencial )(ess , contenida toda
ella en un disco de radio )(:sup essessr y dado por
k
kkess
Mdxdr
1
)(
1suplim
mientras los autovalores de P fuera del disco essrz z:C son aislados y con
autoespacios de dimensión finita.
Calcular essr es relativamente sencillo.
Además, P tiene un radio espectral unidad y hay l > 0 autovalores l ,..., 21 de
módulo 1, que se corresponden con autoespacios de dimensión finita lE,...,E,E 21 .
8 P transforma el conjunto Ł 1 en sí mismo. Para evitar posibles resultados incorrectos [C6], vamos a
imponer una condición al espacio de Lebesgue: que exista una constante σ > 0, tal que .
Entonces, identificamos por P el PFO restringido a Ł BV y escribimos P : Ł BV Ł BV [C6]

90
Por tanto, P sólo puede tener un número finito de autovalores aislados m ,...,, 21 con
autoespacios de dimensión finita, cuyo módulo está entre essr y 1.
Si el mapa es de mezcla l = 1 y 11 y, si además restringimos P a
Ł BV D(X), ~E1 .
La figura 3.12 muestra una posible reproducción del espectro de P de un mapa
de Mezcla, donde los puntos negros indican autovalores aislados y la región rellenada
en gris representa la parte esencial del espectro.
Si 1 es el autovalor aislado de mayor módulo y establecemos 1r se
deduce, a partir de la descomposición espectral, que essmix rrr ,max .
Merece la pena señalar que, aunque la definición es aparentemente muy sencilla,
debido a la presencia de r, mixr es una cantidad muy difícil de encontrar.
Junto a todo lo anterior, para un mapa de mezcla, el PFO podría descomponerse
[C6] como Q 11 , donde 1 es el operador proyección sobre 1E y Q un
operador lineal infinito-dimensional tal que 011 QQ . Por tanto, tenemos que
kk Q 1 , donde k
mix
k HrQ para una constante H > 0 elegida convenientemente.
Figura 3.12 Retrato de una posible
descomposición espectral del PFO
P : Ł BV Ł BV ,
para un mapa de mezcla

91
Con esto y la descomposción espectral del operador P, llegamos finalmente a
k
mix
k rH 00~
para cualquier densidad inicial 0 Ł BV .
Evidentemente, la ecuación superior responde a los pasos 2 y 3. En otras
palabras, sabemos que si elegimos aleatoriamente la condición inicial de un mapa de
mezcla M de acuerdo a una densidad 0 (de variación limitada), el estado kx se
distribuye según la densidad 0k , la cual converge a una densidad invariante con una
velocidad exponencial y limitada.
3.2.12.- Mapas exactos
Finalmente, es interesante señalar que algunas transformaciones no invertibles
pueden mostrar una forma de mezcla más fuerte; son los llamados mapas exactos.
Definición
Sea (X, Ą, μ) un espacio de medida y XXM : una transformación que
preserva la medida. M es llamado exacto si 1))((lim
YM n
n para cualquier
Y Ą con 0)( Y .
En otras palabras, la exactitud de un mapa viene a decir que, si comenzamos
con un grupo de puntos (con medidas positivas), bajo la iteración, el grupo se
expande hasta rellenar todo el espacio de fases.
Se puede demostrar que los mapas exactos son además de mezcla. Por tanto, los
mapas exactos exhiben un comportamiento mucho más complicado que los mapas de
mezcla.
Los mapas bended up-down, tienda de campaña y R-ádico son todos exactos.

92
3.2.13.- Inestabilidades numéricas en MATLAB
Hemos detectado pequeñas inestabilidades al simular mapas caóticos discretos
en MATLAB.
Estas inestabilidades son debidas a un redondeo interno que el programa realiza
sobre el valor del estado del sistema en cada iteración. El efecto que produce este
redondeo es una función de densidad asociada al sistema dinámico errónea, es decir,
diferente de la esperada. Al redondear, se pierde una información que es determinante
para la órbita que describe el sistema.
Los estados tienden a acumularse en las zonas del espacio de fases
correspondientes a puntos periódicos del sistema, hasta que, tras un determinado
número de iteraciones, caen en un punto fijo.
El truncamiento automático depende de la naturaleza del número a redondear y,
por tanto, afecta más en aquellos sistemas cuyos puntos periódicos son racionales con
pocos decimales.
Para comprobar esta inestabilidad, independientemente de la condición inicial
elegida, hacemos uso del operador Perron Frobenius.
La primera vez que nos encontramos con este problema se nos presentó de dos
formas diferentes:
- Por un lado, cuando no especificábamos un número de decimales
determinado para los estados calculados en cada iteración, había muchas
condiciones iniciales para las que la órbita caía en un punto fijo tras
menos de 60 iteraciones. Pudimos comprobar como aumentando el
número de decimales de la condición inicial, la órbita aguantaba más
iteraciones.
- Por otro lado, cuando calculábamos la función de densidad invariante de
la función 10-ádica los puntos se acumulaban en ciertas regiones (Véase
Figura 3.13). Esta sorprendente situación se repetía con muchos de los
mapas asociados a la función R-ádica cuando R era par. En cambio,
cuando R era impar no aparecían comportamientos extraños.
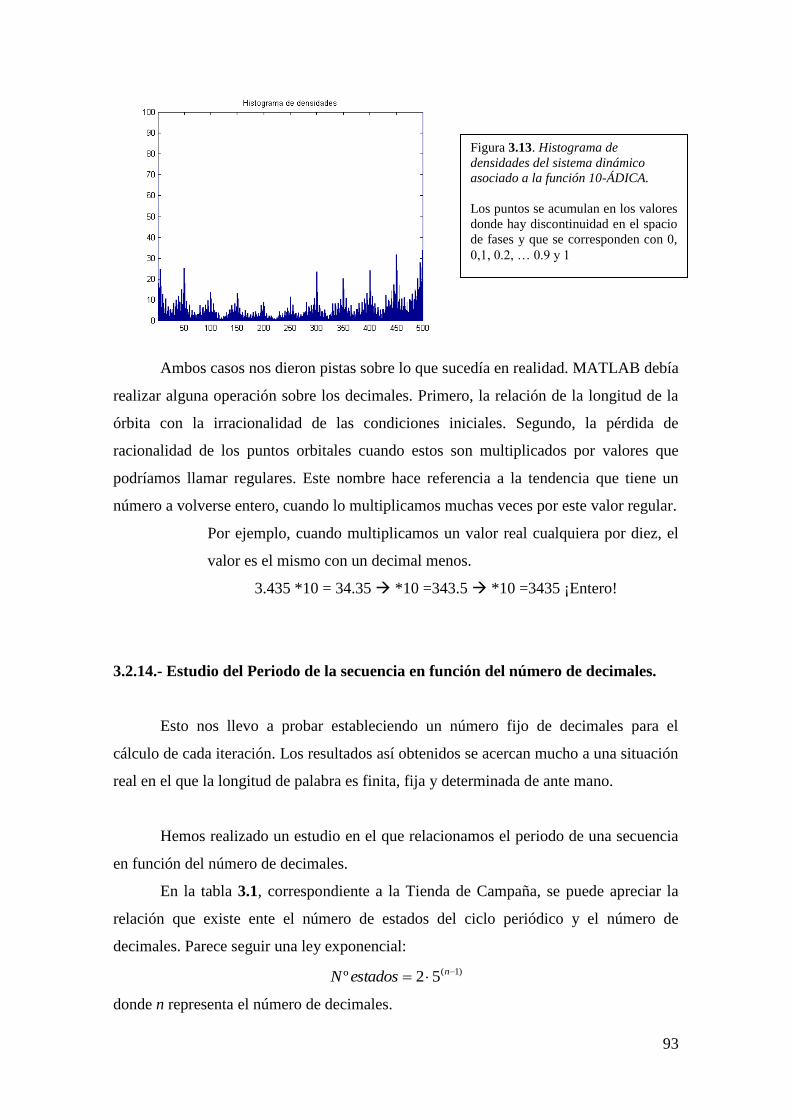
93
Ambos casos nos dieron pistas sobre lo que sucedía en realidad. MATLAB debía
realizar alguna operación sobre los decimales. Primero, la relación de la longitud de la
órbita con la irracionalidad de las condiciones iniciales. Segundo, la pérdida de
racionalidad de los puntos orbitales cuando estos son multiplicados por valores que
podríamos llamar regulares. Este nombre hace referencia a la tendencia que tiene un
número a volverse entero, cuando lo multiplicamos muchas veces por este valor regular.
Por ejemplo, cuando multiplicamos un valor real cualquiera por diez, el
valor es el mismo con un decimal menos.
3.435 *10 = 34.35 *10 =343.5 *10 =3435 ¡Entero!
3.2.14.- Estudio del Periodo de la secuencia en función del número de decimales.
Esto nos llevo a probar estableciendo un número fijo de decimales para el
cálculo de cada iteración. Los resultados así obtenidos se acercan mucho a una situación
real en el que la longitud de palabra es finita, fija y determinada de ante mano.
Hemos realizado un estudio en el que relacionamos el periodo de una secuencia
en función del número de decimales.
En la tabla 3.1, correspondiente a la Tienda de Campaña, se puede apreciar la
relación que existe ente el número de estados del ciclo periódico y el número de
decimales. Parece seguir una ley exponencial:
)1(52º nestadosN
donde n representa el número de decimales.
Figura 3.13. Histograma de
densidades del sistema dinámico
asociado a la función 10-ÁDICA.
Los puntos se acumulan en los valores
donde hay discontinuidad en el spacio
de fases y que se corresponden con 0,
0,1, 0.2, … 0.9 y 1

94
TIENDA DE CAMPAÑA
Resolución
n = (Nº decimales) Posición donde comienza el Ciclo Periódico Longitud del Periodo de la órbita
1 2 2
2 1,1,4,4, 10,10, 1 ,10
3 1,2,3,4 50
4 3,4,5,6 250
5 2,6,7 1250
6 1,2,3,4,8 6250
7 5,8,9 31250
8 8,10... 156250
LOGÍSTICA
Resolución
n = (Nº decimales) Posición donde comienza el Ciclo Periódico Longitud del Periodo de la órbita
1 4 1
2 9 3
3 25 1
4 5,12,23 97, 103, 97
5 69, 241, 248 227
6 195, 2, 688 155,85,155
7 2280, 2690, 3181 136
8 2471, 3039, 3227 2412
9 >30000 ?
Tabla 3.1. Relación entre el número de decimales y el comienzo y longitud
de un ciclo periódico para la TIENDA de CAMPAÑA
Los valores están calculados para muchas condiciones iniciales, de ahí que el
periodo comience en varias posiciones diferentes. La longitud del periodo
parece mantenerse igual, menos en los primeros casos.
Tabla 3.2. Relación entre el número de decimales y el comienzo y longitud
de un ciclo periódico para la PARÁBOLA LOGÍSTICA
Los valores están calculados para muchas condiciones iniciales, de ahí que el
periodo comience en varias posiciones diferentes. La longitud del periodo
parece mantenerse igual, menos en los primeros casos.

95
BENDED UP-DOWN
Resolución
n = (Nº decimales) Posición donde comienza el Ciclo Periódico Longitud del Periodo de la órbita
1 3 2
2 10, 37, 19, 21, 57, 6 2, 10, 10, 10, 10, 16
3 25, 2, 83, 108 3, 44, 21, 25
4 50, 25, 10, 11, 33 3, 64, 64, 64, 64
5 14, 158, 174, 341 241
6 120, 388, 998, 1084 682, 32, 682, 682
7 2331, 2667, 2777, 3342 471, 471, 781, 781, 1754
8 3762, 3714, 7946, 11824 649, 1718, 649, 1718
9 >50000
10-ÁDICA
Resolución
n = (Nº decimales) Posición donde comienza el Ciclo Periódico Longitud del Periodo de la órbita
1 2 1
2 3 1
3 4 1
4 5 1
... +1 ... +1 1
15 28,29,31... 1
16 >25000
Tabla 3.3. Relación entre el número de decimales y el comienzo y longitud
de un ciclo periódico para el mapa BENDED UP-DOWN
Los valores son mucho menos regulares que en los dos casos anteriores.
Dependiendo más de la condición inicial de partida.
Tabla 3.4. Relación entre el número de decimales y el comienzo y longitud
de un ciclo periódico para el 10-DESPLAZAMIENTO DE BERNOULLI ö
función 10-ÁDICA
Hasta una resolución de 15 decimales la función cae en un punto fijo. A
partir de 16 la longitud de la órbita antes de caer en un ciclo periódico crece
enromemente

96
Dinámica Simbólica
Capítulo 4

97
4.1.- PRESENTACIÓN DEL PROBLEMA
Una de las ventajas de utilizar el caos en comunicaciones es su implícito grado
de seguridad. Las condiciones iniciales y los parámetros del sistema no pueden ser
deducidos a partir de una longitud finita de la secuencia. Pero la simple reconstrucción
del atractor, bastaría para facilitar la tarea de sincronización entre la señal transmitida y
un receptor.
La secuencia binaria caótica es resultado de transformar una órbita, de valores
reales del espacio de fases, en una secuencia simbólica. Esta secuencia no se transmitirá
directamente, sino que modulará la información, a modo de código chip en DS-CDMA
ó de keystream en criptografía.
Por sencillez, vamos a centrarnos en intentar extraer información de la secuencia
binaria caótica, antes de que module a la información.
Hemos abordado la tarea desde tres puntos de vista:
- Extracción de los exponentes de Lyapunov de una secuencia binaria.
- Reconstrucción del atractor.
- Evaluación de la complejidad mediante el test de Lempel & Ziv.
4.1.1.- Obtención de secuencias binarias a partir de órbitas reales de un sistema.
Partimos de un valor 1,00 x y le aplicamos el mapa 1,0)( 0 xfx k
k
obteniendo una órbita )}(),...,(),(,{)( 00
2
000 xfxfxfxxO k .
Todos los métodos analizados en la literatura ([C5] y [B1] - [B4]), utilizan el
mismo procedimiento para generar una secuencia simbólica a partir de una órbita real.
Consiste en dividir el espacio de fases en intervalos de una cadena de Markov9, y
asignar a cada intervalo un símbolo. Así, si la órbita pasa por un intervalo determinado,
se le asignará el símbolo asociado a ese intervalo.
9 Véase Anexo 3 “Particiones de Markov”

98
La verdadera importancia de los métodos analizados radica en la posibilidad de
obtener propiedades estadísticas de las secuencias simbólicas con facilidad.
Khoda y Tsuneda [B1] han propuesto varios tipos de secuencias en función de la
forma de obtenerlas a partir de un mapa caótico. Además indican una metodología para
calcular los estadísticos de orden elevado de dichas secuencias, cuando han sido
obtenidas a partir de ciertos mapas caóticos que cumplan cierta condición
(“equidistributivity property”) respecto a la densidad invariante.
Más tarde, Sang, Wang y Yan [B2] propusieron una generalización del método
de Khoda y Tsuneda, extendiendo la posibilidad de calcular estadísticos de orden
elevados a secuencias obtenidas a partir de una amplia variedad de mapas, menos
restrictivos que en el caso anterior.
Por otro lado, Rovatti, Setti y Manzini [C5 - C7] han desarrollado un marco de
trabajo con matrices y tensores, de forma que pueden establecer parámetros de diseño,
basados en las propiedades de correlación de las secuencias, para un tipo de mapas
determinado (los mapas (n,t) - tailed shift, tipo al que pertenece la función R-ádica).
4.2.- ESTUDIO DE LA CAOTICIDAD Y COMPLEJIDAD DE LA SECUENCIA
BINARIA
4.2.1.- Varios intentos de algoritmos que extraigan los exponentes de Lyapunov a
partir de la Secuencia Binaria. Métodos y conclusiones.
Detectar si una secuencia binaria temporal, aparentemente aleatoria, tiene algún
exponente de Lyapunov positivo representa una primera aproximación para procesarla,
puesto que nos está indicando que es una secuencia caótica y, por tanto, determinística.
Una primera aproximación consiste en seguir directamente la definición de los
exponentes de Lyapunov. Para ello hay que estudiar si se puede obtener la distancia
entre puntos del espacio de fases a partir de los puntos de la serie simbólica.

99
Por simplicidad vamos a limitarnos a una cuantificación binaria, es decir,
dividimos el espacio de fases en dos intervalos, [0,u] y (u,1]. La separación de los
intervalos lo denominamos umbral de decisión, de tal forma que, si
0))((,0)( 00 xfSuxf iii , lo codificamos con un símbolo, y si
1))((1,)( 00 xfSuxf iii , lo codificamos con otro.
Obtenemos por tanto una secuencia binaria
))}(()),...,(()),((),({)( 00
2
000 xfSxfSxfSxSxB k
que cuantifica en qué región del espacio de fases se encuentra el punto orbital.
Escribiremos ))},...,,,{)( 2100 kbbbbxB por comodidad.
Para obtener la tabla 4.1 hemos procedido de la siguiente manera:
1) Definimos un conjunto de 50.000 condiciones iniciales {i
x0 },
repartidas aleatoriamente sobre todo el espacio de fases.
2) Hallamos la órbita )}(),...,(),(,{)( 00
2
000
ikiiiixfxfxfxxO para
cada condición inicial, aplicando el mapa Logístico.
3) Hallamos una órbita a partir de una condición inicial separada por
una distancia ε de cada una de las condiciones iniciales anteriores
)}(),...,(),(,{)( 00
2
000 ikiiiixfxfxfxxO
4) Obtenemos la secuencia binaria asociada a cada una de las dos órbitas
anteriores obtenidas para cada condición inicial, )( 0
ixB y )( 0
ixB .
5) Comparamos las dos secuencias binarias para ver en qué posición
dejan de ser iguales.
6) Realizamos el mismo experimento para diferentes distancias ε.
Se puede comprobar que un porcentaje elevado del conjunto de condiciones
iniciales se separa en la misma posición de las secuencias binarias. Estableciéndose
cierta relación probabilística entre la distancia de separación de las condiciones iniciales
y la posición de la secuencia binaria en la que dejan de ser iguales.
Mediante este sencillo experimento con los mapas 1-D presentados en el
Capítulo 1, se puede observar que hay una relación entre la distancia de puntos cercanos

100
en el espacio de fases real y la distancia, en número de pasos, a la que las órbitas de esos
puntos cercanos se mantienen iguales en el espacio simbólico.
Esto representa una cuestión muy importante. Por un lado nos da idea de que, aunque se
pierda mucha información al establecer las divisiones de Markov, por el otro se
mantiene cierto determinismo en la órbita. La explicación más sencilla podría hacer
referencia al “teorema ergódico individual” de Birkhoff [C8] [C9].
101
*
*
Número de Iteración donde las trayectorias dejan de ser iguales
Distancia de las
Condiciones
iniciales
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
110 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
210 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
310 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
410 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
510 13108 18404 3156 0 0 0 0 0 0 0 0 0 0 0 0 0
610 1552 3165 6090 11015 17275 9254 0 0 0 0 0 0 0 0 0 0
710 171 318 661 1280 2564 4919 9123 15460 15287 0 0 0 0 0 0 0
810 16 28 56 114 277 551 1070 2130 3998 7454 13137 18522 2584 0 0 0
910 1 3 4 11 21 49 129 217 450 876 1624 3153 6121 11121 17788 8382
Número de Iteración donde las trayectorias dejan de ser iguales
Distancia de las
Condiciones
Iniciales
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
110 4933 10011 17000 17526 382 76 14 7 1 0 0 0 0 0 0
210 485 1012 1965 3943 7341 12989 18481 3729 4 1 0 0 0 0 0
310 60 96 176 433 794 1635 3051 5898 10920 16965 9922 0 0 0 0
410 5 14 16 43 65 162 351 653 1246 2477 4903 8973 15124 15918 0
510 0 0 2 2 11 8 35 62 117 249 502 1009 2036 3866 7383
610 0 0 0 0 0 1 3 8 14 30 47 99 191 411 795
710 0 0 0 0 0 0 0 2 2 1 4 12 17 41 88
810 0 0 0 0 0 0 0 0 0 0 0 0 3 5 5
910 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Tabla 4.1 Relación entre órbitas simbólicas y la distancia que separaba, en espacio de fases
real, las condiciones iniciales a partir de las que se han originado

102
Para el mapa logístico se puede establecer una primera aproximación de esta relación:
kd 5.0 que comprobamos en la tabla 4.2, obtenida a partir de la 4.1.
Para cada k aparece un porcentaje
que representa el número de puntos del
espacio de fases, de los 50.000, cuyas
secuencias binarias, )( 0
ixB y )( 0
ixB ,
dejan de ser iguales en k o antes de k.
Para cada distancia inicial,
ii 10)E( , comparamos el valor k5.0
que hemos postulado.
Representamos en negrita las
mejores aproximaciones.
Animados por la regularidad de los resultados vistos en las tablas 4.1 y 4.2, nos
hemos centrado en intentar extraer los exponentes de la secuencia binaria, evaluando la
distancia de las condiciones iniciales como función del número de paso en el que las
órbitas simbólicas, de puntos inicialmente cercanos, dejan de ser iguales.
Hemos desarrollado varios algoritmos que, aprovechando la relación numérica
que hemos obtenido a partir de la tabla 4.2, extraigan los exponentes de Lyapunov a
partir de su definición, es decir
)()(log
1limlim)( 00
00
xfxf
Nx
NN
N
Un resumen de los pasos seguidos y las conclusiones obtenidas es el siguiente:
Distancia de
las C.I. de
las órbitas
Número de Iteración y
Porcentaje de C.I.
k=3 – 64% k=4 – 99%
E-1 0.125 0.0625
k=6 – 55% k=7 – 92.4%
E-2 0.015625 0.008
k=10 – 80% k=11 – 100%
E-3 0.00098 0.0005
k=13 – 68% k=14 – 100%
E-4 1.22E-04 6.10E-05
k=16 – 57% k=17 – 93.7%
E-5 1.50E-05 7.60E-06
k=20 – 81.5% k=21 – 100%
E-6 9.50E-07 4.80E-07
k=23 – 70% k=24 – 100%
E-7 1.19E-07 5.96E-08
k=26 – 58% k=27 – 95%
E-9 1.49E-08 7.45E-09

103
1º Buscar vecinos de un determinado punto 1,0)( jxS de la secuencia
binaria. Entendemos por vecinos aquellos puntos cuya órbita binaria )( vxB tiene un
determinado número de bits iguales a la órbita del punto que estamos analizando
))(( jxSB .
Cuando comparamos los vecinos obtenidos por este método con los vecinos
obtenidos midiendo la distancia de los puntos de la secuencia de valores reales, vemos
que ¡funciona! Todos los vecinos que encuentra en la secuencia binaria están también
en la secuencia de valores reales.
Este resultado parece muy alentador.
2º Evaluar la distancia entre el siguiente punto al que estoy evaluando jb y
el siguiente a su vecino vb .
La distancia la mide en número de bits de las órbitas, )( jbB y )( vbB que se
mantienen iguales.
Aquí nos encontramos el primer inconveniente: En un sistema discreto el retardo
para reconstruir el atractor debe valer uno ( 1 ), luego la distancia, en número de bits
iguales, entre el estado al que evoluciona el punto analizado ( jj bbB )( ) y el estado
al que evoluciona su vecino ( vv bbB )( ) será el mismo que hemos obtenido antes,
entre jb y vb , menos .
Para ilustrar este problema vamos a ver un ejemplo:
Si la distancia en bits iguales de las órbitas de vb y vb era igual a 7 (es
decir, de aproximadamente 0.01 según la tabla 4.1 y de 0.0078 según la
tabla 4.2) y 1 , la distancia, en número de bits iguales de las órbitas de
jb y vb será de 6 bits iguales, es decir mayor que la anterior (en
términos de la tabla 4.2 será de 0.0156)
Resultando en que siempre se obtendrá que el sistema tiene exponente de
Lyapunov positivo, sea cual sea la serie y, por tanto, diverge.

104
Así, aunque calcula un valor muy aproximado al valor real del exponente, no
distingue un sistema caótico de otro, por ejemplo, aleatorio (en nuestro caso generamos
la serie aleatoria con la función rand de MATLAB10
).
3º Probamos otro procedimiento.
Consiste en evaluar la distancia, en bits iguales, que hay entre las órbitas de
la secuencia binaria )( jbB y )( vbB respecto a la órbita de otro punto
intermedio )( ibB . Esta distancia la llamaremos
))(),(())(),(())(),(( ivbitijbitvjbit bBbBdbBbBdbBbBd .
Este punto intermedio ib es, obligatoriamente, diferente del punto original jb .
Una cuestión muy importante es saber la posición relativa del punto intermedio
en el espacio de fases ix , respecto a jx y vx . Es decir, necesitamos averiguar si el
punto intermedio se encuentra entre los dos puntos o fuera del intervalo que los une.
Si el punto intermedio cae dentro del intervalo que une a jx y vx , la
distancia entre dichos puntos será la suma de las distancias que hay entre cada punto y
el punto intermedio; y si está fuera del intervalo, la distancia entre ellos será la
diferencia de esas mismas distancias relativas, entre cada punto y el punto intermedio.
El resultado que obtenemos es muy parecido al del caso anterior. Consigue
calcular un valor muy aproximado del exponente de Lyapunov de un mapa caótico, pero
no puede distinguir si una secuencia aleatoria es o no caótica, puesto que siempre le
da un exponente de Lyapunov positivo, algo distinto del que extrae de la serie
caótica.
4º Como último intento, en vez de calcular la distancia entre jb y vb respecto
a un punto intermedio, que tenía que ser cercano a ellos, evalúo la distancia (en bits
10
Comprobamos que da exponentes de Lyapunov negativos o, según el número de variables de estado,
da siempre un sistema No-Disipativo.
Nº de variables
de estado
Exponentes de Lyapunov
de la función rand de MATLAB
1 -0.8579 0 0 0 0
2 0.9137 -0.4739 0 0 0
3 -0.0932 -0.2891 -0.5245 0 0
4 -0.0491 -0.1727 -0.2616 -0.4191 0
5 -0.0423 -0.1716 -0.2458 -0.316 -0.4309

105
iguales) hacia atrás. El primer problema es que las aplicaciones caóticas no son
inyectivas. Lógicamente este algoritmo calcula el exponente de la secuencia caótica
peor que en los casos anteriores. Y, además, tampoco consigue distinguir una secuencia
caótica de otra aleatoria.
CONCLUSIÓN: El algoritmo sólo funciona bien para mapas caóticos porque
presupone que la serie está obtenida a partir de un mapa caótico. Cuando busca vecinos,
lo hace correctamente, los vecinos que encontramos examinando la serie simbólica se
corresponden con vecinos reales en el espacio de fases.
El problema es que cuando busca vecinos en una serie no caótica, también los
encuentra, pero ahora no es cierto que se correspondan con vecinos en la secuencia real,
sino simplemente con palabras de código iguales. como es lógico, esas palabras de
código se repiten a lo largo de la serie y, por tanto, ¡falsean los datos!
Esta es una cuestión que todavía no he podido resolver.
Para posteriores investigaciones, es muy interesante recordar que existe la
posibilidad de sustituir esperanzas estadísticas por los promedios en el tiempo de una
órbita observable a lo largo de una trayectoria típica. Hay que señalar que esta
equivalencia puede ser aplicada para calcular cantidades significativas como los
exponentes de Lyapunov y la entropía [B5]
4.2.2.- Reconstrucción del Atractor de partir de la Secuencia Binaria.
¿Mantiene cierta relación la secuencia binaria caótica con la geometría del
atractor de la órbita real original? Y, si es así ¿se puede reconstruir el atractor?
El espacio de fases original era un espacio continuo.
Cuando realizamos los cálculos con el ordenador para reconstruir el atractor la
precisión es limitada; pero un número elevado de decimales asegura una buena fidelidad
al original (véase Capítulo 3). Esto es porque el número de valores que consideramos es
muy grande, del orden de diez elevado al número de decimales.

106
Cuando trabajamos con la secuencia binaria, el conjunto de valores que tenemos
para cada punto de la serie es muy reducido, igual al número de intervalos en los que
hayamos dividido el espacio de fases.
En nuestro caso consideramos una división en dos intervalos, luego para cada
punto de la serie sólo tenemos dos posiciones posibles.
Evidentemente, esta situación es insuficiente para poder reconstruir el atractor de
valores reales, puesto que estamos considerando un espacio de fases de sólo dos puntos.
Una primera idea para solucionar este problema es agrupar la secuencia binaria
en símbolos de n bits, mediante una conversión binario-decimal y ver qué información
se puede obtener de esta nueva secuencia.
El primer inconveniente es que disminuye la longitud de la serie en 1/n.
El segundo es que no podemos asegurar una correspondencia entre dicha
transformación y una conservación de la dinámica original del sistema, sin hacer un
estudio matemático preciso.
Nosotros nos hemos aventurado a intentar extraer algo de información de la
dinámica del sistema reconstruido mediante este método y, aprovechando las
herramientas ya desarrolladas, lo hemos hecho mediante los exponentes de Lyapunov.
Otra opción - que no hemos podido abordar - es buscar una relación, de carácter
estadístico, entre la serie original y la serie reconstruida, considerando los diferentes
parámetros que intervienen en el proceso, los umbrales que definen la división del
espacio de fases, el número de bits por símbolo utilizado, etc.
4.2.3.- Reconstrucción del atractor agrupando los bits en símbolos y
transformándolos a valores reales.
A la vista de la figura 4.1 se puede concluir que este método de reconstrucción
no proporciona mucha información sobre el atractor original. La desorganización en el
espacio de fases es la típica de un proceso aleatorio. Además la f.d.p. de la serie
transformada a partir de la secuencia binaria no tiene nada que ver con la original; se ha
vuelto uniforme, corroborando la apariencia de proceso estocástico.
Esta situación es buena, ya que da una idea de la seguridad de estas secuencias y
de la dificultad de reconstruirlas mediante su observación.

107
Una primera idea para comprobar que el umbral que separa los intervalos es una
buena elección consiste en ver si la secuencia binaria está equidistribuida, es decir, si
hay el mismo número de „1‟ que de „0‟.
Para obtener más información sobre este método de reconstrucción del atractor,
calculamos los exponentes de Lyapunov en función del número de bits por símbolo que
utilizamos.
En la Tabla 4.3 podemos observar que los resultados no varían de una forma
asintótica ni lineal, aunque sí hay cierta tendencia a pasar de signo negativo del
exponente a positivo cuando aumentamos el número de bits/símbolo. Cuestión que se
podía intuir, puesto que aumenta el número de puntos del espacio de fases y la
complejidad de la serie.
Figura 4.1 Reconstrucción del atractor a
partir de la Secuencia Binaria.
A partir de una serie de 100.000 valores y una
longitud de 29 bits/símbolo.
Figura 4.2 Función densidad de
probabilidad de la serie de la figura 4.1
Figura 4.3 Estudio del número de „1‟ y „0‟
de la serie de la figura 4.1
Se aprecia que son prácticamente el mismo

108
Bits/
Símbolo Logística
Tienda
Campaña R-ádica
6 -0.4906 -0.3857 -Inf
7 -0.3097 -0.3495 -0.3498
8 -0.3103 -0.1822 -0.1943
9 -0.2695 -0.1159 -0.1302
10 -0.2296 -0.1953 -0.027
11 -0.227 -0.2246 -0.1396
12 -0.4267 -0.128 0.0306
13 -0.1069 -0.1451 -0.0925
14 -0.0621 0.0968 -0.1031
15 0.0686 0.0103 -0.0681
16 -0.0133 -0.0145 -0.2376
17 0.03 0.026 0.2287
18 0.0751 0.0488 -0.0302
19 0.0012 0.2369 -0.0281
20 0.2358 0.2754 -0.1157
21 0.0419 0.0896 0.195
22 0.432 0.0532 0.2318
23 0.2153 0.2756 0.0721
24 0.1576 0.4649 0.1804
25 -0.2125 0.2677 0.2689
27 0.3163 0.2571 0.2753
28 0.3266 0.2548 0.029
29 0.2731 0.3219 0.4316
30 0.1574 0.2895 0.308
Hemos probado este procedimiento con el mapa de Henon (Capítulo 1), cuyo
espacio de fases es 2-D.
Hallamos la serie simbólica, asociada a la secuencia escalar de una de las dos
variables de estado del sistema, dividiendo el eje en dos intervalos; es decir, hacemos
una codificación binaria.
Aparece en la reconstrucción cierta regularidad (Figura 4.4) –recuerda a la
transformación del Panadero-. En cambio, cuando calculamos los exponentes de
Lyapunov de la secuencia binaria transformada en real obtenemos la tabla 4.4. En dicha
tabla podemos comprobar que, si bien el sistema parece caótico por tener el exponente
más alto positivo, el sistema es No-Disipativo, ya que la suma de los dos exponentes es
positiva.
A la vista de los resultados de la tabla 4.4 se deduce que este proceso de
reconstrucción, tal como lo hemos enfocado, no es válido.
símbolobits
1 2
11 1.6387 -0.1695
Tabla 4.3 Exponentes de Lyapunov de las secuencias de
valores reales. Estas secuencias han sido obtenidas
agrupando los bits de la secuencia binaria en símbolos
y luego pasados a notación decimal.

109
4.2.4.- Una trampa durante la reconstrucción del atractor.
Como ya hemos comentado, un inconveniente cuando transformamos una
secuencia binaria en una secuencia digital es el diezmado que supone agrupar los bits
para formar símbolos. Además, como necesitamos un elevado número de puntos para
reconstruir el espacio de fases, el número de bits por símbolo debe ser elevado,
disminuyendo considerablemente la longitud de la serie reconstruida.
Para evitarlo, la primera solución que estudiamos consistía en transformar la
secuencia binaria en decimal, pero sin despreciar ningún valor. Es decir, para cada uno
12 1.5758 -0.3211
13 NaN NaN
14 1.3648 -0.2664
15 NaN NaN
16 1.463 -0.3146
17 1.4773 -0.4802
18 1.5526 -0.3805
19 1.3937 -0.1513
20 1.4126 -0.13
21 1.4783 -0.3352
22 1.5191 -0.2388
23 1.3629 -0.1684
24 1.3005 -0.0092
25 1.3994 -0.2493
26 1.2718 -0.1932
27 1.5157 -0.1903
28 1.1554 -0.0727
29 1.4902 -0.3703
30 1.3167 -0.1816
Figura 4.4. Reconstrucción del atractor de Henon
transformando la secuencia binaria en una secuencia
real, mediante la asociación de varios bits en
símbolos y su posterior conversión a decimal
Tabla 4.4 Exponentes de Lyapunov del
atractor de Henon, en función del número de
bits/símbolo con que ha sido transformada la
serie binaria en otra de valores reales.
Tabla 4.5 Comprobación del número de „0‟ y „1‟ tras la
conversión de la serie original de Henon en una serie simbólica.
La división del espacio de fases se ha realizado con el umbral
que separa los intervalos igual a 0.1875

110
de los puntos de la serie binaria agrupar los bits siguientes en un símbolo, solapando por
tanto las cadenas de bits. Se ve más claro en el siguiente ejemplo:
1 0 0 1 1 0 0 1 0 0 1 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 1.1971
1 0 0 1 1 0 0 1 0 0 1 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 0.3942
Definimos una longitud de símbolo de 19 bits/símbolo y se analizan todos los bit, es
decir, un desplazamiento de 1 bit.
1 0 0 1 1 0 0 1 0 0 1 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 1.1971
1 0 0 1 1 0 0 1 0 0 1 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 1.1537
El número de bits/símbolo sigue siendo 19, pero ahora el desplazamiento es de 4 bit, es
decir, construimos la secuencia decimal analizando uno de cada seis puntos de la
secuencia binaria.
Cuando aplicamos esta solución a los mapas Logístico, Tienda y Bernoulli
obtenemos los valores de la tabla 4.5.
En la tabla 4.3 y sobretodo en la 4.5, la alternancia de signo y la falta de una
tendencia asintótica del resultado dejan entrever que la transformación utilizada no
responde a una mera cuestión trivial.
En una primera impresión, las figuras 4.4 y 4.6 parecen revelar una dinámica
tipo función R-ádica, que no contrastaría con la f.d.p. uniforme propia de este mapa.
El problema es cuando, a modo de prueba, hacemos el mismo proceso de
cuantificación y reconstrucción con una secuencia aleatoria (no determinística y
caótica). Los resultados que obtenemos son exactamente los mismos, invalidando, por
tanto, dicho proceso de reconstrucción.
En realidad, lo que estamos representando cuando el desplazamiento es igual a 1
es la función de autocorrelación de la serie.

111
Desplazamiento
bits
Logística Tienda 2-ádica
1 0.7885 0.8056 0.7957
2 1.4396 1.4582 1.4146
3 1.4586 1.4695 1.4828
4 0.2341 0.3585 0.2233
5 -0.204 -0.0487 -0.171
6 -0.4767 -0.4516 -0.5337
7 -0.3796 -0.298 -0.435
8 -0.3092 -0.3312 -0.3919
9 -0.3198 -0.2089 -0.2266
10 -0.2455 -0.1356 -0.14
11 -0.2524 -0.1711 0.0036
12 -0.2298 -0.2226 -0.1222
13 -0.4389 -0.1254 0.0518
14 -0.0789 -0.123 -0.076
15 -0.0601 0.098 -0.0909
16 0.0722 0.0056 -0.0717
17 -0.0138 -0.0138 -0.2348
18 0.0208 0.0275 0.2366
19 0.0752 0.048 -0.0322
20 0.001 0.2368 -0.026
21 0.2357 0.2754 -0.1157
22 0.0317 0.1107 0.1844
23 0.4321 0.0533 0.2318
24 0.1999 0.2758 0.072
25 0.1576 0.4649 0.1804
26 -0.2125 0.2677 0.2689
27 0.3163 0.2571 0.2753
28 0.3266 0.2548 0.029
29 0.2731 0.3219 0.4316
Figura 4.4
Reconstrucción con un desplazamiento = 1
Serie original de 100.000 muestras
obtenidas mediante el mapa Logístico.
Figura 4.5 Función densidad de
probabilidad de la serie de la figura 4.3
Tabla 4.5. Exponentes de Lyapunov para los mapas
Logístico, Tienda y 2-ádico cuando variamos el
desplazamiento.
Los valores están calculados para una reconstrucción de
29 bits/símbolo que, según la tabla 4.3 se conseguían
buenos resultados en los tres mapas
112
Figura 4.6
Reconstrucción con un desplazamiento = 2
Serie original de 100.000 muestras
obtenidas mediante el mapa Logístico.
Figura 4.7 Función densidad de
probabilidad de la serie de la figura 4.5
Figura 4.8
Reconstrucción de una secuencia aleatoria y su f.d.p.
Serie original de 100.000 muestras obtenidas mediante la
función rand de MATLAB.
Las reconstrucciones son con 29 bits/símbolo y con
desplazamientos iguales a 1 (fig. superior) y 2 (fig. inferior)

113
A la vista de esta situación, se nos ocurrió probar de otra manera; consistía en
agrupar bits separados una determinada distancia en símbolos. Así lograríamos evitar la
autocorrelación. Este proceso tiene una justificación más intuitiva que matemática; se
basa en la reconstrucción del atractor mediante el retardo de coordenadas (Véase
Capítulo 3). Igual que en ese caso, cogemos los bits que vamos a agrupar retardándolos
un cierto número de pasos.
El resultado que obtuvimos es que la secuencia así reconstruida tenía una
completa apariencia estocástica, tanto por la ausencia de un atractor como por los
exponentes de Lyapunov negativos.
4.2.5.- Test de evaluación de la aleatoriedad de una secuencia simbólica.
Los generadores de secuencias pseudoaleatorias pueden utilizarse para construir
cifradores de flujo en criptografía, o como secuencias para otras aplicaciones tales como
CDMA, generación de números aleatorios, etc.
Antes de utilizarlos, es necesario evaluar sus prestaciones.
No existe ninguna herramienta matemática aplicable a todos los tipos de
cifradores. Siempre sería posible inventar un cifrador para el cual no se hubiera
descubierto todavía un análisis matemático.
Por tanto, ¿cómo se puede demostrar entonces que un generador en general es
bueno? De hecho, no se puede demostrar que es bueno, y éste es un concepto aplicable a
cualquier método criptográfico.
Lo que se debe demostrar es que, con los conocimientos actuales, no se conoce
ninguna pauta o método que permita romper el sistema fácilmente, al menos,
comparativamente, con menos esfuerzo que un ataque por fuerza bruta.
La única parte común a todos los generadores es la salida, la secuencia de
símbolos.
El análisis general forzosamente ha de tratar a cada generador como una caja
negra y debe analizar las propiedades de la secuencia.

114
La solución consiste en obtener algunos valores cuantitativos aplicando
algoritmos llamados "tests" a las secuencias de salida de dichos generadores.
Estos tests tienen que ser independientes del generador en particular empleado y
se deben poder aplicar siempre.
Estos tests miden la distancia entre la secuencia actual y una secuencia
verdaderamente aleatoria.
Los resultados de los tests a menudo son números que pueden variar dentro de
un rango continuo de valores. No siempre está claro cuándo una secuencia tiene que ser
rechazada. Algunas veces, los parámetros obtenidos no ofrecen ninguna información en
valor absoluto, aunque permiten comparar diferentes generadores entre sí para decidir
cuál de ellos es mejor.
Existen diversos tipos de tests: estadísticos, empíricos, teóricos,
complejidades,...
Se debe utilizar como mínimo uno de cada tipo para realizar una buena
evaluación de un generador de secuencias pseudoaleatorias.
Para las secuencias generadas, nos hemos limitado a estudiar los test
Equidistribuido y de la complejidad de Lempel-Ziv. Por tanto, sólo expondremos las
conclusiones obtenidas con ellos, mientras que nos limitaremos a enunciar brevemente
los demás.
Entre los principales test podemos destacar:
1.- Test Equidistribuido. Cuenta el número de unos y de ceros de la secuencia
binaria y comprueba que no haya grandes diferencias. Estas desviaciones se miden con
una chi-cuadrado ( 2 ) [B6]. Definimos que la secuencia pasa el test si la 2 estimada
cae dentro del intervalo de confianza al 95%.
Hemos podido comprobar que la elección del umbral es determinante si
queremos pasar el test. La elección del umbral a priori, es todavía una cuestión por
resolver, y seguramente esté relacionada con la densidad invariante del sistema y,
posiblemente con la geometría del atractor. Respecto a la elección de la condición
inicial, ésta se vuelve menos importante cuánto más grande es la órbita que evaluamos –
siempre, claro está, que no haya puntos fijos ni ciclos límites-.

115
2.- Test Serie. Agrupa los bits de la secuencia formando símbolos de t bits no
solapados, sobre los cuales evalúa su distribución contrastándola con la equidistribuida.
Como en el test anterior, se aplica una 2 (95%).
3.- Postulados de Golomb. El tercer Postulado de Golomb permite realizar la
autocorrelación de la secuencia y compara el valor del pico máximo con el valor en el
origen, la relación lóbulo principal - lóbulo secundario. El peor resultado de este test es
cuando hay un pico elevado (aunque los demás valores puedan ser cero), entre otros
razonamientos, debido al ataque por correlación. Es preferible tener muchos picos
razonablemente moderados que unos pocos picos elevados. El resultado del test
reflejará la relación lóbulo principal-secundario medido en dB.
4.- Test Universal de Entropía. Este test estima el valor de la entropía por bit de
la secuencia de acuerdo con el algoritmo propuesto debido a Maurer en 1990. El método
tiene tres parámetros: la memoria estimada de la secuencia original, la longitud del
periodo de transición y el número de pasos del test. Dado que la entropía calculada es
una estimación, se pueden originar valores mayores que la unidad.
5.- Test Espectral. Agrupando los bits en símbolos solapadamente, se calcula la
distribución de apariciones de dichos símbolos. Sobre esta distribución, se aplica una
transformada discreta de Fourier, obteniendo un espectro, lo que le confiere el nombre a
este test. Si la secuencia es aleatoria, el espectro debería exhibir un valor máximo „1‟ en
el origen y „0‟ en el resto de las componentes frecuenciales. La figura de mérito es la
denominada "distorsión cuadrática", que mide la energía de las componentes
frecuenciales no nulas y la compara con la energía de la componente constante.
2
2
)0(
)(_
F
kFECuadráticaDistorsión
A diferencia del tercer postulado de Golomb, aquí todos los picos son
importantes porque el aspecto principal es la la pérdida de energía , es decir, la
diferencia entre el resultado y los valores ideales, y no importa, en principio, si esta
pérdida de energía se ha dispersado uniformemente, o está concentrada únicamente en
una componente particular.

116
6.- Complejidad Lineal. Calcula la longitud mínima del LFSR capaz de sintetizar
la misma secuencia por medio del algoritmo de Massey-Berlekamp (de 1969). El
resultado de la complejidad se compara con el periodo de la secuencia. Cuanto más
cercanos sean los valores, mejor será el generador.
7.- Complejidad de Ziv-Lempel [B7], cuenta el número de patrones con
diferentes estructuras en la secuencia. A partir de la medida de esta complejidad se
puede estimar la entropía por bit de la secuencia como:
nnC
Hlog
donde C es la complejidad de Ziv-Lempel de la secuencia, y n su longitud.
Desde otro punto de vista, la compresión de Ziv-Lempel convierte cualquier
secuencia en otra, normalmente más pequeña. Suponiendo que esta compresión es la
mejor que se puede alcanzar, la secuencia no se puede reducir más allá, y por tanto, la
razón entre la longitud de la secuencia comprimida y la longitud original puede servir
como una estimación de la entropía.
Los resultados cuando calculamos la entropía basada en la complejidad de
Lempel- Ziv son irrelevantes porque todos los valores son muy similares y cercanos a la
unidad. Por esta razón, no suele resultar útil para remarcar las diferencias entre los
generadores.
Es importante comentar que cada test analiza y comprueba una característica
específica de la secuencia, características que son diferentes aunque no necesariamente
independientes y, tan pronto como se detecta una regularidad, hay evidencia de no-
aleatoriedad del generador y debe ser evitado su uso. Ya que en términos de seguridad,
esta regularidad puede ser aprovechada para atacar el esquema.

117
Conclusiones

118
CONCLUSIONES
Se ha realizado un estudio sobre la posibilidad de usar sistemas caóticos para la
generación de secuencias de tipo aleatorio.
El algoritmo desarrollado para la extracción de los exponentes de Lyapunov está
basado en dos algoritmos originales muy similares, el de Eckmann & Ruelle y el de
Sano & Sawada. Sobre ellos se han realizado modificaciones extraídas de muchos otros
métodos y, además, se ha añadido una mejora propia que permite trabajar con series de
longitud relativamente cortas. La integración de los algoritmos citados, las mejoras
aportadas y la cantidad de pruebas y conclusiones extraídas hacen de nuestro método
una aportación interesante a la tarea de detectar la no linealidad en series temporales.
Respecto al estudio del caos con densidades de probabilidad ha sido presentada
una metodología que puede ser usada para generar secuencias caóticas con unas
propiedades estadísticas conocidas a priori. Esta cuestión es de vital importancia al
analizar el rendimiento en una implementación real de un sistema CDMA.
Mediante la simulación de los sistemas dinámicos caóticos hemos podido
comprobar la importancia que tiene el efecto de una longitud de palabra finita. Esta
cuestión era de esperar por la sensibilidad a las condiciones iniciales presentes en estos
sistemas; por otro lado, resulta imprescindible tenerla en cuenta cuando tratemos de
generar secuencias caóticas para aplicaciones reales.
Durante los intentos de extraer información de la secuencia binaria nos hemos
dado cuenta de que el estudio directo de la evolución temporal de dicha secuencia es
infructuoso, por lo menos como nosotros lo hemos enfocado
Este trabajo queda como una introducción teórica y práctica desde la que
abordar futuros desafíos y líneas de investigación.

119
Posibles líneas futuras de investigación
Ha sido propuesto un método sencillo para la generación de secuencias
simbólicas, que consiste en dividir el espacio de fases de acuerdo a una cadena de
Markov. Gracias a esta característica división es posible obtener las propiedades de
correlación de las secuencias generadas por el sistema. La determinación óptima de
estos umbrales de decisión es todavía una cuestión abierta, por determinar, para cada
nuevo mapa con el que se trabaje. De hecho, para sistemas de más de una variable,
establecer una metodología para la división del espacio de fases (por ejemplo, basada en
secciones de Poincaré del atractor) puede provocar más de un dolor de cabeza.
Es necesario comprobar mediante simulación que las secuencias caóticas,
generadas con unas correlaciones determinadas, proporcionan una mejora real del
rendimiento y del número de usuarios del sistema. En dicha comprobación se deberían
tener en cuenta una gran cantidad de sistemas dinámicos caóticos generadores.
La posibilidad de que el transmisor envíe como clave de usuario una condición
inicial elegida aleatoriamente, en vez de asignar un código fijo entre un conjunto finito
de códigos, aumenta cualitativamente el grado de seguridad. Por tanto, una tarea
obligada, antes de la implementación física de un sistema CB-CDMA, es el estudio de
la sincronización de secuencias caóticas asíncronas, determinadas solamente por la
condición inicial. Dicho estudio puede ser utilizado también en criptografía.
Respecto al análisis de la seguridad del sistema queda un camino por recorrer; el
de aplicar el Teorema Ergódico Individual de Birkhof y tratar de extraer información de
la evolución temporal a partir de los promedios estadísticos. Mediante este enfoque
podría, además, ser viable relacionar cantidades significativas del sistema generador con
los test de complejidad y aleatoriedad de las secuencias.

120
Una cuestión muy interesante es estudiar la seguridad de un sistema FH-CDMA
(CDMA por Salto de Frecuencia) Basado en Caos (CB). En este sistema los saltos de
frecuencia estarán gobernados por una serie temporal obtenida directamente de una
trayectoria en el espacio de fases del sistema. Como dicho sistema utilizará un rango de
frecuencias fijo, la posibilidad de escanear la banda y anotar los saltos de frecuencias
permitiría estimar los exponentes de Lyapunov y reconstruir el atractor. Por tanto, sería
interesante estudiar qué posibilidades existen de enmascarar la órbita.

121
Anexos

122
ANEXO 1
COMPUTACIÓN DE LA DESCOMPOSICIÓN QR
A.1.- Ortonormalización de Gram-Schmidt.
Los vectores columna jQ de Q pueden ser determinados recursivamente por la
proyección ortogonal de los vectores columna jP de P sobre los vectores columna 1jQ
para kj 2 :
1
11 : PR ,
11
11 : RPQ ,
ji
ij PQR |: ,
1
1
:j
i
i
ij
jj QRPQ ,
j
jj QR : ,
jj
jj RQQ : , para 11 ji y kj 2 (A-1.1) Clásico Gram-Schmidt
Indicando por 21
|: xxx la norma Euclídea y por
m
i
ii yxxx1
:| el producto
interior de los vectores tr
mxxx ),...,(: 1 e mtr
m Ryyy ),...,(: 1 .
Figura A.1. Procedimiento Gram-Schmidt:
Los vectores ortonormales arbitrarios 1O y 2O se transformane en 1P y 2P que
luego son ortogonalizados mediante el Procedimiento Gramm-Schmidt de forma que
mantengan el área del paralelogramo.

123
Para vectores columna jP de P muy cerca de ser paralelos las longitudes jQ
de los vectores diferencia jQ ( kj 2 ) son muy pequeñas. Por tanto, la computación
de Q con el algoritmo (A-1) puede conducir a errores. Estos errores pueden ser evitados
con la siguiente modificación:
1
11 : PR ,
11
11 : RPQ ,
ji
ij PQR |: ,
1
1
:j
i
i
ij
jj QRPQ ,
jiij QQR |:~
,
1
1
~:
~ j
i
i
ij
jj QRQQ ,
ijijij RRR~
: ,
j
jj QR~
: ,
jj
jj RQQ~
: , para 11 ji y kj 2 (A-
1.2)
A este método lo denominamos Gram-Schmidt Modficado

124
A.2.- TRANSFORMACIÓN HOUSEHOLDER
Householder encontró en 1958 un procedimiento de descomposición QR
caracterizado por una gran estabilidad numérica.
La matriz )0(PP de grado km es transformada, con la ayuda de las
transformaciones ortogonales y simétricas - llamadas Transformaciones Household r -,
)()()( |2: jjj uuIH ,
)(
)()( :
j
jj
v
vu ,
j
jj
jj
trj
mj
j
jj
j ecPsignPPv )()1()1()1()( )(),...,,0,...,0(: ,
21
2)1()( )(:
m
ji
j
ij
j Pc , )11( kj
en la matriz triangular PHHPR kk )1()1()1( de grado km , donde
)1()()( jjj PHP para 11 kj .
La multiplicación explícita de las matrices )( jH ( 11 kj ) puede ser evitada
si aplicamos k-1 pasos Householder sobre la matriz aumentada de grado )( mkm
),(),(:),( SQRQSRQIP .
De esta manera se obtienen la matriz aumentada ),( SR de grado )( mkm y
una representación explícita para la matriz ortogonal Q de grado km :
kijij SRQ ,),( , donde mi 1 y kj 1 .
Sin embargo, la matriz R , calculada numéricamente, todavía contiene
elementos de la diagonal negativos. Por tanto, para alcanzar la unicidad de la
descomposición QR de P, se tienen que multiplicar Q y R por la matriz diagonal
))(),...,((:)( 11 kkRsignRsigndiagRSIGN , es decir,
)(: RSIGNQQ ,
RRSIGNR )(
Para más información consultar [L14], [A1]

125
ANEXO 2
MANUAL DE USUARIO DE LA APLICACIÓN
“Exponentes de Lyapunov”
Para ejecutar la aplicación deberemos abrir MATLAB y situarnos en el
directorio correspondiente (“cd PFC”), luego ejecutar el archivo “exponentes”.
La primera pantalla que nos encontramos es
El botón “Reconstruir Atractor” reconstruye el atractor del sistema dinámico,
con el que ha sido generada la serie temporal Para ello utiliza el método del retardo de
coordenadas (Véase Capítulo 2).
El botón “CALCULAR” calcula los exponentes de Lyapunov de la serie que
tenga cargada en memoria.
El icono azul “SIN DATOS” indica que no hay ninguna serie temporal cargada
en memoria.
Si intentamos calcular los exponentes o reconstruir el atractor cuando no hay
datos cargados aparecerá un cuadro de diálogo indicándonos el error.

126
Lo primero que tenemos que hacer es cargar en memoria la serie temporal que
queramos analizar. Para ello tenemos dos opciones, generar la serie o cargarla de un
fichero tipo ASCII. Ambas opciones se encuentran en el menú “Datos de la Serie
Temporal”. Cuando lo pulsamos aparece el siguiente submenú
En él se encuentran los sistemas que hemos descrito en el capítulo 1 y la opción
“Cargar Fichero”.
Si pulsamos sobre cualquiera de los sistemas ya conocidos aparecerá otra
ventana, donde se especifican los parámetros necesarios para generar la órbita que
vamos a utilizar como serie temporal.
Pulsando, por ejemplo, sobre “Atractor de Lorenz” se despliega la siguiente ventana
En ella aparecen por defecto unas condiciones iniciales aleatorias y valores para
el intervalo de integración, el tiempo total y la variable de salida (la serie temporal es

127
escalar). Podemos variar cualquiera de ellos o pulsar directamente sobre el botón
“Calcular”. Haciendo esto último se obtiene
La representación gráfica del atractor indica que la serie, correspondiente a la
“Variable de Salida” elegida, se ha calculado correctamente. Si queremos, podemos
grabar la serie obtenida con comodidad haciendo uso del menú “Archivo”. En ventana
hay además dos barras de scroll, “Azimut” y “Elevación”, con ellas podemos variar el
ángulo de visión desde el que observar la representación del atractor.
Inmediatamente después de calcularse la serie temporal, ésta ha sido cargada en
memoria y, por tanto, nuestra aplicación está lista para analizarla. Esta situación se
comunica al usuario mediante el icono verde “DATOS CARGADOS”
Como hemos generado la serie con un sistema conocido aparecen por defecto los
parámetros óptimos para su análisis.

128
Si la serie temporal la hubiéramos cargado desde un fichero tendríamos que
especificar todos los parámetros del análisis. Esta es la situación que nos encontramos
cuando analizamos una señal observada en la Naturaleza, para la cuál, no se sabe a
priori, qué parámetros serán los óptimos. En caso de que faltase alguno de los
parámetros cuando tratamos de analizar la serie se nos indicará un mensaje de error.
Los parámetros a los que nos referimos son:
- “Número de Exponentes” que queremos calcular.
- “Td”. Si hemos obtenido la serie integrando una serie de ecuaciones
diferenciales que definen el comportamiento de un sistema continuo
se refiere al intervalo de integración. Si hemos obtenido la serie
mediante la observación de muestras de una señal de la Naturaleza se
refiere al periodo muestreo. En el caso de que hallamos obtenido la
serie mediante la simulación de un sistema de tiempo discreto Td
debe valer la unidad.
- “tau”. Es el número de posiciones de la serie que tenemos que
retardar para reconstruir el atractor.
Una vez que tenemos cargada la serie temporal tenemos dos opciones,
reconstruir el atractor o calcular los exponentes de Lyapunov.
Si pulsamos sobre “Reconstruir Atractor” obtendremos una representación de
dicha reconstrucción para el retardo indicado (tau). En nuestro ejemplo hemos obtenido

129
Si pulsamos sobre “CALCULAR”, la aplicación se fijará en si chekboxes
“Calcular error” estaba o no activado
Si lo estaba, aparecerá otro cuadro de diálogo donde se nos preguntará por el
valor que esperamos obtener para cada exponente que queremos calcular. Esta opción es
interesante cuando queremos medir lo rápido que converge el valor calculado a un valor
esperado, es decir, cuando medimos la eficiencia computacional. En nuestro ejemplo
aparece
Una vez introducidos los valores deseados y pulsado “OK”, la aplicación
comenzará a calcular los exponentes, mostrando, en tiempo real, los valores que consiga

130
Una vez que ha terminado de analizar toda la serie, aparecen otras dos ventanas.
En una se presentan las gráficas que indican las oscilaciones que han sufrido los
exponentes durante su cálculo y cómo han ido convergiendo a un determinado valor.
También aparece una línea recta de otro color que representa el valor que esperábamos
obtener.
La otra ventana proyecta una animación de la que se extrae la misma
información. La evolución temporal la marca la propia animación y se representa una
figura geométrica (elipse o elipsoide según el número de exponentes sea 2 o 3) que se
transforma alrededor de otra figura fija. La figura que se transforma representa el valor
calculado por la aplicación y, la fija el valor que esperábamos obtener.

131
ANEXO 3
PARTICIONES DE MARKOV
Para simplificar el análisis de un sistema dinámico, comúnmente se estudia un
sistema topológicamente equivalene usando dinámica simbólica, que representa
trayectorias de longitud infinita usando un número finito de símbolos.
Para representar el espacio de fases de un sistema dinámico con un número finito de
símbolos, debemos dividirlo en un número finito de elementos y asignar un símbolo a
cada uno de ellos. En teoría de probabilidad, el término Markov significa “sin
memoria”. Es decir, la probabilidad de cada elemento, condicionada por toda su historia
previa, es igual a la condicionada sólo por el estado actual; no es necesaria la historia
previa. La misma idea puede ser adaptada a los sistemas dinámicos, significando que se
divide el espacio de fases de tal modo que la información del pasado de la secuencia
simbólica esté contenida en el símbolo actual, dando origen a una transformación de
Markov.
Transformaciones unidimensionales
En el caso especial, pero importante, de una transformación de Markov del
intervalo, la dinámica simbólica es presentada sencillamente como un gráfico de
transiciones (diagrama de estados).
Una transformación de Markov en 1R se define como sigue [C9]:
Definición
Sea dcI , y sea II : . Sea P una partición de I dada por los
puntos dcccc p ...10 . Para i = 1, … , p, sea ),( 11 ii ccI e
indicamos por i la restricción de τ a iI . Si i es un homeomorfismo de
iI a (onto11
) alguna unión de los intervalos de P , entonces se dice que τ
es una transformación de Markov. Y a la partición P se le llama una
partición de Markov respecto a la función τ.
11
“onto” se distingue de “into” en que transforma un intervalo en sí mismo y no en una parte de sí
mismo.

132
Ejemplo.
El mapa M1 (Figura 3.9a) es un mapa de Markov respecto a la partición
asociada 4321 ,,, IIII . La dinámica simbólica está captada en el gráfico de transición
(Figura 3.9b). Aunque el mapa M2 (Figura 3.9c) está definido por tramos lineales y,
lógicamente, está dividido por los mismos intervalos que en el mapa M1, la división no
es de Markov, porque el intervalo 2I no transforma sobre (onto) alguna unión de los
intervalos de la partición. Sin embargo, no podemos decir que el mapa M2 no es de
Markov. Puede haber alguna otra partición que satisfaga la condición de Markov. En
general, encontrar una partición de Markov o probar que partición no existe es un
problema difícil.
Aplicaciones de las particiones de Markov.
En un sistema dinámico solemos estar interesados en el comportamiento global
del mapa, que puede interpretarse como la evolución de un conjunto de condiciones
iniciales. Para describir esta evolución se usa el operador Perron-Frobenius. Cuando el
mapa es de Markov, dicho operador se reduce a una matriz de transición estocástica, de
dimensión finita. Siguiendo el mismo desarrollo que en teoría de probabilidad la
densidad invariante12
asociada a este mapa está descrita por el autovector de autovalor
1.
12
Si el sistema es ergódico, esta densidad reflejará el comportamiento, promediado en el tiempo,
del sistema.
Figura 3.11: (a) Mapa de Markov M1 con su espacio de fases dividido en elementos
iI . (b) El diagrama de estados, con las probabilidades asociadas a cada transición, para
el mapa M1. (c) Mapa M2. La partición no es de Markov, porque la imagen de 2I no es
igual a una unión de intervalos de la partición.

133
Bibliografía

134
INTRODUCCIÓN AL CAOS
[I1] M. A. Martín, M. Morán y M. Reyes, Iniciación al caos. Ed. Síntesis 1998.
[I2] I. Stewart, ¿Juega Dios a los dados?. Ed. Crítica 1991.
[I3] J. Gleik Caos. Ed. Seix Barral 1988.
[I4] J. Banks y otros autores, “On Devaney‟s definition of Chaos”. American
Mathematical Monthly, Vol. 99 páginas 332-334, 1992.
[I5] M. Vellekoop y R. Berglund, “On intervals, Transitivity = Chaos” American
Mathematical Monthly, Vol. 101, páginas 353-355.
[I6] B. Luque, “Fractales en la Red”, Material didáctico curso GATE-UPM.
[I 7] J. M. Thompson y H. B. Stewart, Nonlinear Dynamics and Chaos, New York, Ed.
Wiley, 1987.
EXPONENTES DE LYAPUNOV
[L1] J. D. Farmer, E. Ott y J. A. Yorke, “The Dimension of chaotic attractors”, Physica
7D páginas 153-180, 1983.
[L2] A. Giraldo y M. A. Sastre, Sistemas dinámicos discretos y caos : teoría, ejemplos y
algoritmos, Fundación General de la Universidad Politécnica de Madrid, 2002.
[L3] I. Shimada y T. Nagashima, “A Numerical Approach to Ergodic Problem of
dissipative Dynamical system”, Progress of Theoretical. Pysics, Vol. 61, No. 6,
páginas 1605-1616, 1979.

135
[L4] A. Wolf, J. B. Swift, H. L. Swinney Y J. A. Vastano, “Determining Lyapunov
exponents from a Time Series”, Physica 16D, páginas 285-317, 1985.
[L5] J. –P. Eckmann y D. Ruelle, “Ergodic theory of chaos and strange attractors”
Reviews of Modern Physics, Vol. 57, No.3, Part I, páginas 617-656, 1985.
[L6] V. I. Oseledec, “A multiplicative ergodic theorem. Lyapunov characteristic
exponents for dynamical systems”, Trudy Moskov. Mat. Obshch, 19, páginas. 197-231,
1968
[L7] F. Takens, “Detecting strange attractors in turbulence”, Lectures Notes in
Mathematics, Vol. 798, D.A., páginas 366-381, 1981.
[L8] M. Sano e Y. Sawada, “Measurement of the Lyapunov Spectrum from a Chaotic
Time Series”, Physical Review Letters, Vol. 55, No. 10, páginas 1082-1085, 1985.
[L9] Eckmann, S. O. Kamphorst, D. Ruelle y S. Ciliberto, “Lyapunov exponents from
time Series”, Physical Review A, Vol. 34, No. 6, páginas 4971-4979, 1986.
[L10] M. T. Rosenstein, J. J. Collins y C. J. De Luca, “A practical method for
calculating largest Lyapunov exponents from small data sets”, Physica D, 65, páginas
117-134, 1993.
[L11] N. B. Abraham, A.M. Albano, B. Das, G. De Guzman, S.Young, R.S. Gioggia,
G.P. Puccioni y J.R. Tredicce, “Calculating the dimension of attractors from small data
sets”, Phisics Letters, Vol. 114A, No. 5, páginas 217-221, 1986.
[L12] X. Zeng, R. Eykholt y R. A. Pielke, “Estimating the Lyapunov-Exponent
Spectrum from Short Time Series of Low Precision”, Physical Review Letters, Vol. 66,
No. 25, páginas 3229-3232, 1991.
[L13] H. Kantz, “A robust method to estimate the maximal Lyapunov exponent of a
time series”, Physics Letters A, 185, páginas 77-87, 1994.

136
[L14] K. Geist, U. Parlitz y W. Lauterborn, “Comparision of Different Methods for
Computing Lyapunov Exponents”, Progress of Theoretical Physics, Vol. 83, No. 5
páginas 875-893, 1990.
ESTUDIO DEL CAOS CON DENSIDADES DE PROBABILIDAD
[C1] J. G. Proakis, Digital Communications, McGraw Hill, 1983.
[C2] T. Khoda y A. Tsuneda, “Chaotic binary sequences by Chebysev maps and their
correlation properties”, en Proc. IEEE 2nd
Int. Symp. Spread Spectrum Techniques and
Applications, páginas 63-66, 1992.
[C3] T.Khoda y A. Tsuneda, “A chaotic direct-sequence spread spectrum
communication system”, IEEE Trans. Commun., Vol. 42, páginas 1524-1527, 1994.
[C4] T.Khoda y A. Tsuneda, “Explicit evaluation of correlation functions of Chebysev
binary and bit sequences based on Perron-Frobenius operator”, IEICE Trans. Fundam.,
Vol. E77-A, páginas 1794-1800, 1994.
[C5] M. P. Kennedy, R. Rovatti y G. Setti, Chaotic Electronics in Communications,
Boca Raton, 2000.
[C6] Gianluca Setti, Gianluca Mazzini, Ricardo Rovatti y Sergio Callegari,
“Statistical Modeling of Discrete-Time Chaotic Processes- Basic Finite-Dimensional
Tools and Applications”, Proceedings of the IEEE, Vol. 90, No.5, páginas 662-689,
2002.
[C7] Gianluca Setti, Gianluca Mazzini y Ricardo Rovatti, “Statistical Approach to
Discrete Statistical Approach to Discrete-time Chaotic Systems: time Chaotic
Systems:Theoretical Results and Application to Theoretical Results and Application to

137
DS DS-CDMA Communication and EMI Reduction CDMA communication and EMI
Reduction”, EPFL Summer Research Institute, 2002.
[C8] G. D. Birkhoff, “Proof of Ergodic Theorem”, Proc. Nat. Acad. Sci. USA, Vol. 17,
páginas 656-660, 1931.
[C9] A. Lasota y M. C. Mackey, Chaos, Fractals and Noise, Berlin, Germany:
Springer-Verlag, 1994.
[C10] V. Baladi, Positive Transfer Operator and Decay of Correlations. Singapore:
World Scientific, 2000.
DINÁMICA SIMBÓLICA
[B1] T. Kohda y A. Tsuneda, “Statistics of Chaotic Binary Sequences”, IEEE
Transactions on Information Theory, Vol. 43, No. 1, 1997.
[B2] T. Sang, R. Wang y Y. Yan, “Constructing Chaotic Discrete Sequences for Digital
communications Based on Correlation Analysis”, IEEE Transactions On Signal
Processing, Vol. 48, No. 9, páginas 2557-2565, 2000.
[B3] A. Tsuneda, “Design of Chaotic Binary Sequences with Good Statistical Properties
Based on Piecewise Linear Into Maps”,
[B4] A. Tsuneda, “On Auto-Correlation Properties of Chaotic Binary Sequences
Generated by One-Dimensional Maps”, 2000.
[B5] E. Ott, Chaos in dynamical systems. Cambridge, U.K.: Cambridge Univ. Press,
1993.

138
[B6] J.G. Kalbfleisch, Probabilidad e inferencia estadística, ISBN: 84-7288-126-1
(V.2), 1984.
[B7] A. Lempel y J. Ziv, “On the Complexity of Finite Sequences”, IEEE Transactions
On Information Theory, Vol. IT-22, No. 1, 1976.
ANEXOS
[A1] J. H. Wilkinson, The Algebraic Eigenvalue Problem, Oxford Science Publications.

139
Presupuesto

140
PRESUPUESTO
A) EJECUCIÓN DEL PROYECTO:
1. EJECUCIÓN MATERIAL: Para llevar a cabo el proyecto se ha
necesitado el siguiente equipo y herramientas software:
- Ordenador PC Pentium 4 Mobile 1.6 GHz
- Impresora HP Deskjet 720C
- Conexión a Internet
- Sistema Operativo Microsoft Windows XP– Home Edition
- Software de simulación MATLAB
- Procesador de textos Microsoft Word – Office XP
Total Ejecución Material _____________________________________ 3.300 €
2. GASTOS GENERALES:
16 % sobre Ejecución Material _______________________ 528 €
3. BENEFICIO INDUSTRIAL:
6 % sobre Ejecución Material _______________________ 198 €
4. MATERIAL FUNGIBLE:
- Papel DIN A4 280 mgr
- Fotocopias
- Cartucho tinta negro HP Deskjet 720C
- Cartucho tinta color HP Deskjet 720C
- Material diverso de oficina
- Encuadernación
Total Material Fungible ______________________________________ 120 €

141
B) HONORARIOS DEL PROYECTO:
- Honorarios como ingeniero: 820 h * 24 €/h = 19.200 €
- Honorarios como programador: 100 h * 20 €/h = 2.000 €
SUBTOTAL ___________________________________ 25.346 €
IVA. Aplicable 15% del subtotal del presupuesto ____________________ 3.801 €
TOTAL ___________ 29.148 €

142