1.5 medidas descriptivas
DESCRIPTION
1.5 Medidas DescriptivasTRANSCRIPT

Vázquez, H. 2009 1
1. ESTADÍSTICA DESCRIPTIVA
1.5. Medidas Descriptivas
1.5.1. Medidas de centralización
1.5.2. Medidas de Dispersión
1.5.3. Medidas de Posición
1.5.4. Medidas de Forma
1.5.5. Ejercicios
1.5.5.1. Resueltos
1.5.5.2. Propuestos
1.5. Medidas Descriptivas
Las medidas descriptivas, como su nombre lo dice, se encargan de describir el
comportamiento general de una población, ya que a través de éstas podemos
definir la tendencia de los datos, así como el grado en que varían éstos.
Generalmente se definen las medidas ya sea para datos no agrupados y para datos
agrupados, aunque en este curso sólo nos enfocaremos a revisar las medidas para
datos no agrupados y para datos agrupados se calcularán Media aritmética x y
desviación estándar (S) con el apoyo de la calculadora.
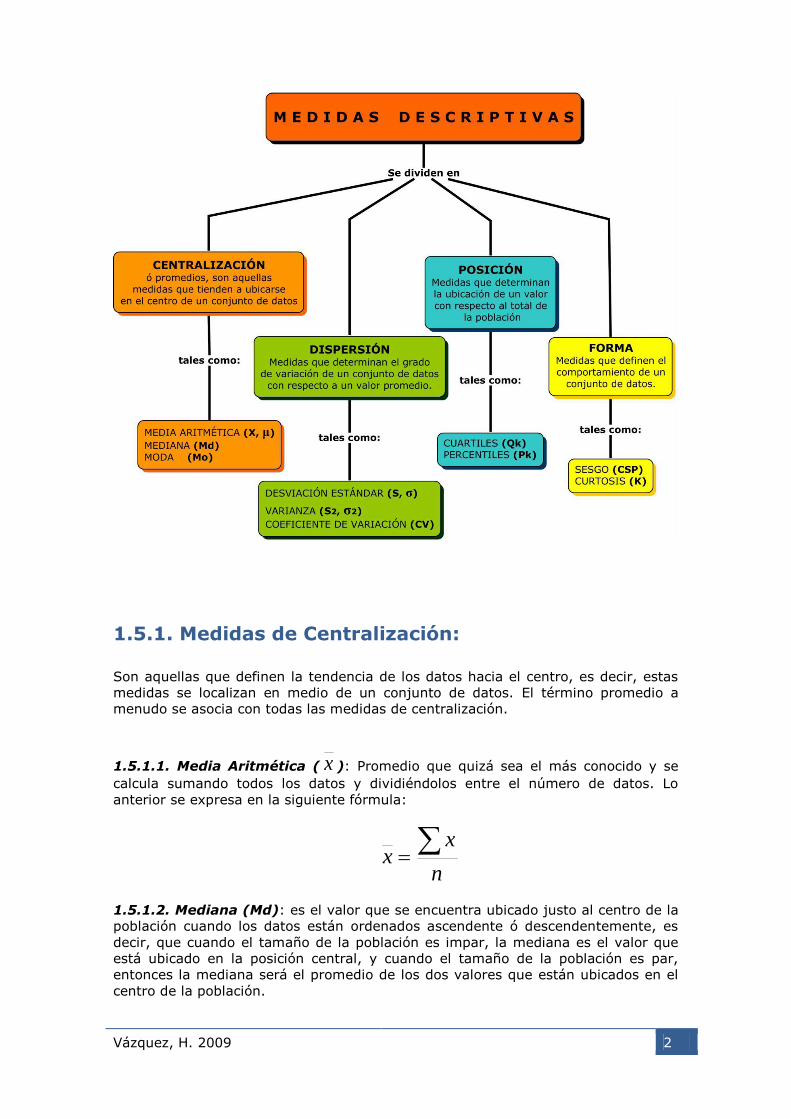
En el siguiente cuadro se muestra la clasificación y las medidas que se verán en el
curso:
Vázquez, H. 2009 2
1.5.1. Medidas de Centralización:
Son aquellas que definen la tendencia de los datos hacia el centro, es decir, estas
medidas se localizan en medio de un conjunto de datos. El término promedio a
menudo se asocia con todas las medidas de centralización.
1.5.1.1. Media Aritmética ( x ): Promedio que quizá sea el más conocido y se
calcula sumando todos los datos y dividiéndolos entre el número de datos. Lo
anterior se expresa en la siguiente fórmula:
n
xx
1.5.1.2. Mediana (Md): es el valor que se encuentra ubicado justo al centro de la
población cuando los datos están ordenados ascendente ó descendentemente, es
decir, que cuando el tamaño de la población es impar, la mediana es el valor que
está ubicado en la posición central, y cuando el tamaño de la población es par,
entonces la mediana será el promedio de los dos valores que están ubicados en el
centro de la población.

Vázquez, H. 2009 3
1.5.1.3. Moda (Mo): es el valor más común de la población, es decir, el valor que
más veces se repite.
En función del número de modas, la población se define como:
Población Amodal: que no tiene dato que más veces se repita.
Población Unimodal: que tiene sólo un dato que más veces se repite.
Población Bimodal: que tiene dos modas, ó dos datos que se repiten más
veces (mismo número de veces).
Población Multimodal: que tien más de dos modas ó más de dos datos
que se repiten más veces (mismo número de veces).
1.5.2. Medidas de Dispersión
Son aquellas que determinan el grado de variación de los datos con respecto a un
valor promedio ( x ). En otras palabras representan la variación promedio de los
datos con respecto a la media aritmética.
1.5.2.1. Desviación Estándar (S): es una medida absoluta, es decir, muestra la
variación de los datos en las unidades de la variable, se calcula como:
donde:
X: cada dato de la variable
x : Media aritmética
n: tamaño de la población
Nota: Observa que para el cálculo de la desviación estándar muestral, en la fórmula
se divide entre n-1, pero en el caso de calcular la desviación estándar población
simplemente se divide entre n.
1.5.2.2. Varianza ( S2 ): No es más que el cuadrado de la desviación estándar.
Vázquez, H. 2009 4
1.5.2.3. Coeficiente de Variación (CV): al igual que la desviación estándar,
muestra la variación de los datos con respecto a la media, pero en forma relativa,
es decir, el coeficiente es un valor adimensional, que se representa en forma
porcentual.
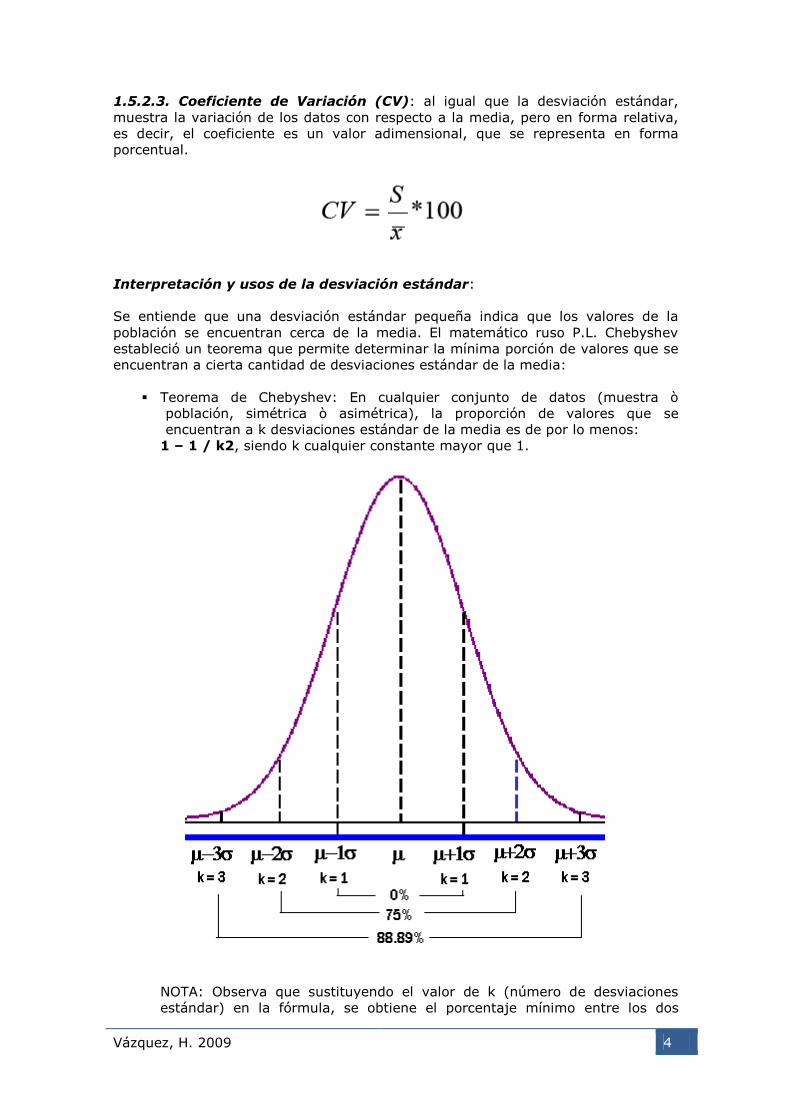
Interpretación y usos de la desviación estándar:
Se entiende que una desviación estándar pequeña indica que los valores de la
población se encuentran cerca de la media. El matemático ruso P.L. Chebyshev
estableció un teorema que permite determinar la mínima porción de valores que se
encuentran a cierta cantidad de desviaciones estándar de la media:
Teorema de Chebyshev: En cualquier conjunto de datos (muestra ò
población, simétrica ò asimétrica), la proporción de valores que se
encuentran a k desviaciones estándar de la media es de por lo menos:
1 – 1 / k2, siendo k cualquier constante mayor que 1.
NOTA: Observa que sustituyendo el valor de k (número de desviaciones
estándar) en la fórmula, se obtiene el porcentaje mínimo entre los dos
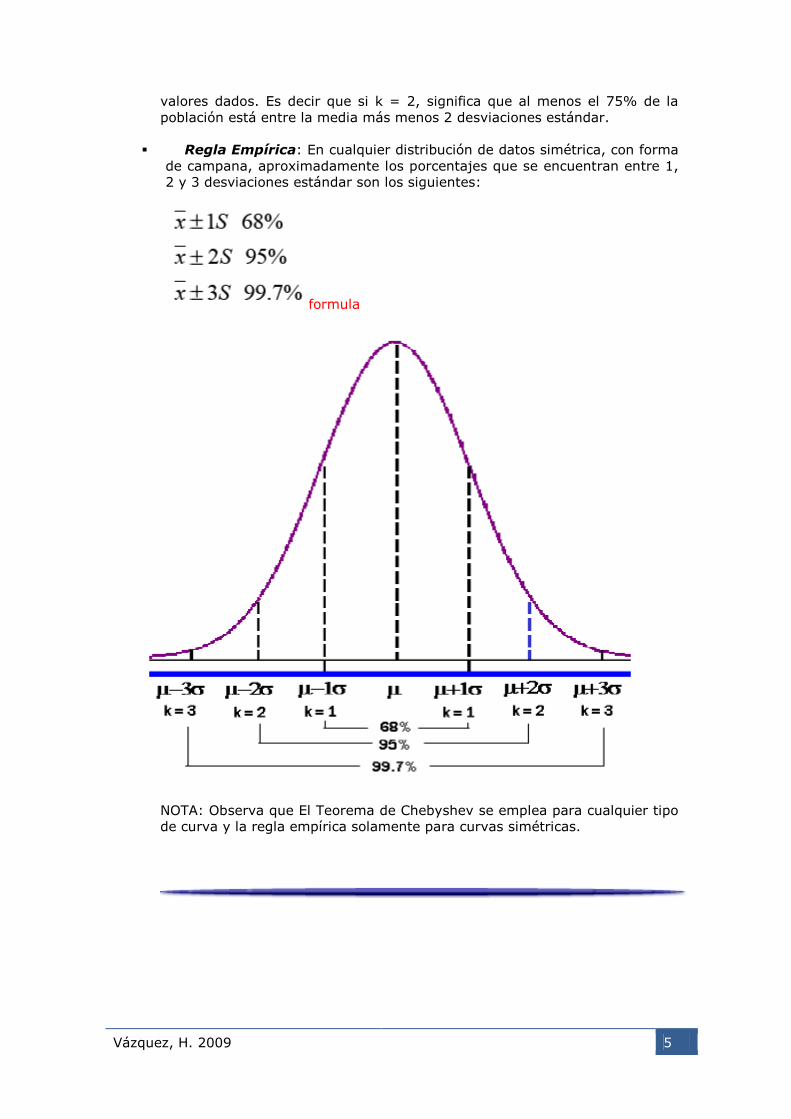
Vázquez, H. 2009 5
valores dados. Es decir que si k = 2, significa que al menos el 75% de la
población está entre la media más menos 2 desviaciones estándar.
Regla Empírica: En cualquier distribución de datos simétrica, con forma
de campana, aproximadamente los porcentajes que se encuentran entre 1,
2 y 3 desviaciones estándar son los siguientes:
formula
NOTA: Observa que El Teorema de Chebyshev se emplea para cualquier tipo
de curva y la regla empírica solamente para curvas simétricas.

Vázquez, H. 2009 6
1.5.3. Medidas de Posición (Qk, Pk)
Son medidas que determinan la ubicación de un valor con respecto al total de la
población, de otro modo se puede decir que son valores que dividen a la población
en partes iguales.
1.5.3.1. Cuartiles (Qk): son medidas que dividen a la población en 4 partes
iguales. Cuando el valor de k=1, representa el valor hasta el cuál está el 25% de la
población; Q2 representa el valor donde se acumula el 50% de la población, es
decir este valor coincide ó es el mismo valor que la mediana; y por último, el Q3
representa el valor hasta el cual se acumula el 75% de la población.
1.5.3.2. Percentiles (Pk): son aquellos valores que dividen a la población en 100
partes iguales, y al igual que los cuartiles el subíndice k representa la posición de
dicha medida, es decir, por ejemplo si k=15 la medida representa el valor hasta
donde se acumula el 15%. Significa que hay 99 percentiles, desde el P1 que
representa el 1% de la población hasta el P99 que represent el 99% de la población.
Existen otras medidas llamadas Deciles, que dividen a la población en 10 partes
iguales pero por coincidir con los percentiles en su cálculo no los comentaremos en
este curso.
Para el cálculo de las medidas de posición, como primer paso es requisito calcular la
posición de dicha medida empleando la siguiente fórmula:
Si el valor de la Posición es ENTERO, el valor del cuartil ó percentil es directamente
el dato que se encuentre en dicha posición; pero si el valor de la Posición NO ES
ENTERO, el valor del cuartil ó percentil se calculará con la siguiente fórmula de
INTERPOLACIÓN:
Qk , Pk = DPm + (DPM – DPm) ƒ Donde:
DPm: Dato de la Posición menor
DPM: Dato de la Posición mayor
ƒ : el decimal de la posición

Vázquez, H. 2009 7
Nota: Observa que para la interpretación de las medidas es recomendable que
analices cual es la porción menor en la que la medida de posición divide a la
población, pues con éste es más práctica su interpretación, por ejemplo, si
calculaste el Q3 es más representativo que se indique que a partir de este valor
está el 25% de los datos más altos, que decir que el 75% de la población son
menores a éste valor. Para el caso, por ejemplo del P90, es más simple decir que el
10% esta por encima de este valor, a decir que el 90% de la población está por
debajo de este valor.
1.5.4. Medidas de Forma
Son aquellas que describen el comportamiento de una población, en lo que se
refiere hacia donde tienden a acumularse, así como al grado de concentración de
los datos.
1.5.4.1. Sesgo (CSP): el Coeficiente de Sesgo de Pearson es el que determina el
sesgo de un conjunto de datos que se define como el grado de asimetría de la
población, ya que determina la fuerza con la que los datos pierden la simetría, es
decir, nos muestra con que grado los datos tienden a concentrarse fuera del centro
de la población; se puede decir que define hacia donde se desplazan la mayoría de
los datos, y en consecuencia se define el sesgo, es decir hacia donde tienden a
desplazarse algunos datos.
Se calcula como sigue:
formula
Entonces, de acuerdo a la asimetría, una población puede ser:
Simétrica: si su sesgo es cero (CSP=0)
Asimétrica positiva: ó con sesgo a la derecha, si su sesgo es mayor que cero
(CSP>0).
Asimétrica negativa: ó con sesgo a la izquierda, si su sesgo es menor que
cero (CSP<0).
NOTA: Observa que en la figura anterior, el eje de simetría es la mediana de la
población.
Vázquez, H. 2009 8
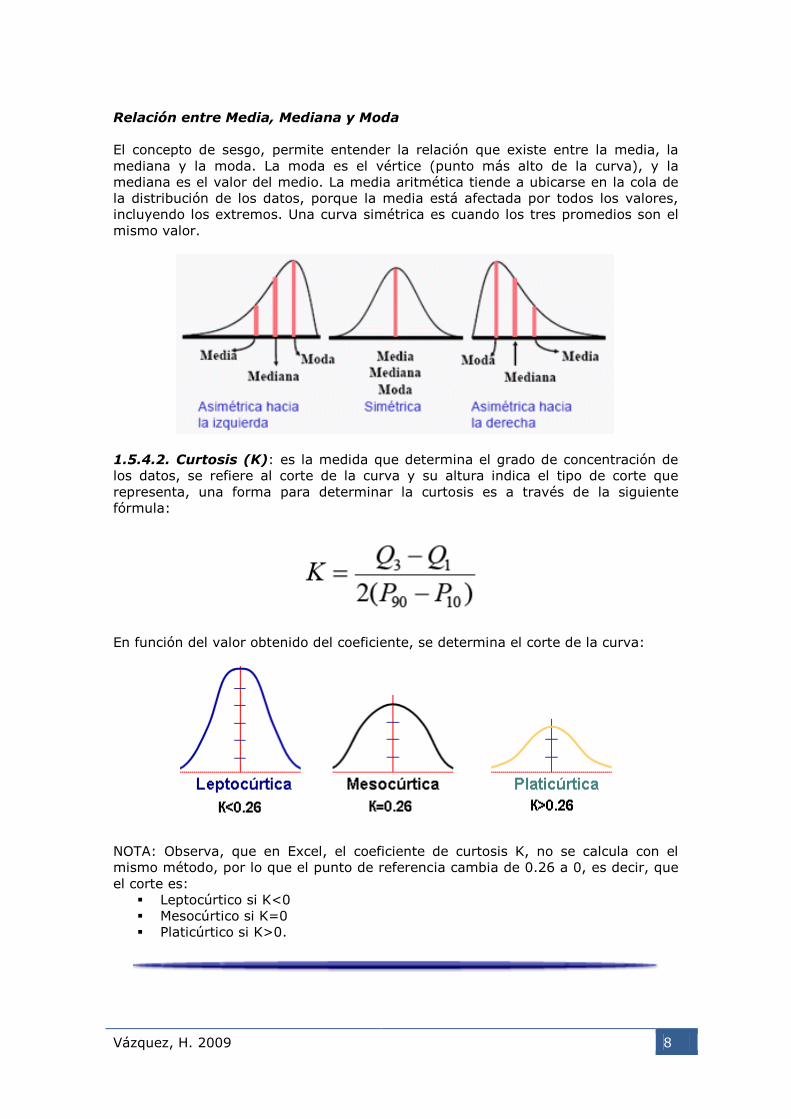
Relación entre Media, Mediana y Moda
El concepto de sesgo, permite entender la relación que existe entre la media, la
mediana y la moda. La moda es el vértice (punto más alto de la curva), y la
mediana es el valor del medio. La media aritmética tiende a ubicarse en la cola de
la distribución de los datos, porque la media está afectada por todos los valores,
incluyendo los extremos. Una curva simétrica es cuando los tres promedios son el
mismo valor.
1.5.4.2. Curtosis (K): es la medida que determina el grado de concentración de
los datos, se refiere al corte de la curva y su altura indica el tipo de corte que
representa, una forma para determinar la curtosis es a través de la siguiente
fórmula:
En función del valor obtenido del coeficiente, se determina el corte de la curva:
NOTA: Observa, que en Excel, el coeficiente de curtosis K, no se calcula con el
mismo método, por lo que el punto de referencia cambia de 0.26 a 0, es decir, que
el corte es:
Leptocúrtico si K<0
Mesocúrtico si K=0
Platicúrtico si K>0.

Vázquez, H. 2009 9
1.5.5. Ejercicios
1.5.5.1. Ejercicios Resueltos:
1. Los datos representan el monto de las ventas mensuales (en miles de pesos) de
un agente de ventas en los últimos 12 meses:
16 28 29 13 17 20
11 34 32 27 19 18
a) Calcular las medidas de centralización.
Solución:
+ Para el cálculo de la media aritmética, tenemos que:
x = (16+28+29+13+17+20+11+34+32+27+19+18)/12
x = 22 es decir, el promedio de ventas
del agente es de $ 22,000 mensuales.
+ Para el cálculo de la mediana, es necesario ordenar los datos, de
preferencia, ascendentemente:
11 13 16 17 18 19 20 27 28 29 32 34
Ya ordenados, podemos observar que por tratarse de un tamaño de la
población par, los datos que están ubicados al centro son 2: el 19 y 20,
por lo que la mediana será el promedio de estos dos valores:
Md = (19+20)/2
Md = 19.5 es decir, el promedio de $19,500
Mensuales es el valor ubicado justo al centro
de todos los datos de la población.
+ Para el cálculo de la moda, simplemente es buscar el dato ó datos
que más se repite, y del conjunto de datos podemos observar que no
hay dato que se repita más veces, por lo que podemos decir que NO
HAY MODA, y por lo tanto hablamos de una Población AMODAL.

Vázquez, H. 2009 10
b) Calcular las medidas de dispersión.
Solución: + Para el cálculo de la desviación estándar, tenemos:
X X - X (X – X)2
11
13
16
17
18
19
20
27
28
29
32
34
11 - 22 = -11
13 - 22 = -9
16 - 22 = -6
17 - 22 = -5
18 - 22 = -4
19 - 22 = -3
20 - 22 = -2
27 - 22 = 5
28 - 22 = 6
29 - 22 = 7
32 - 22 = 10
34 – 22 = 12
(-11)2 = 121
(-9)2 = 81
(-6)2 = 36
(-5)2 = 25
(-4)2 = 16
(-3)2 = 9
(-2)2 = 4
(5)2 = 25
(6)2 = 36
(7)2 = 49
(10)2 = 100
(12)2 = 144
SUMA 646
S = 7.663 es decir, que las ventas mensuales del agente
varían en promedio $7,663 con respecto a la media aritmética
+ Para el cálculo de la varianza simplemente es el cuadrado de la
desviación estándar, por lo que:
S= 58.727 representa también la variabilidad de los datos,
como el cuadrado de la desviación estándar.

Vázquez, H. 2009 11
+ Para el cálculo del coeficiente de variación, simplemente es
sustituir las medidas en la fórmula, por lo que tenemos:
CV=34.83% al igual que la desviación estándar, indica que las ventas
mensuales del agente varían en promedio el 34.83% con respecto a
la media aritmética.
NOTA IMPORTANTE: la desviación estándar es una medida absoluta
(sus unidades son las de los datos) y el Coeficiente de variación es
una medida relativa (es adimensional) su aplicación principal es
cuando se desea comparar la variabilidad de varios grupos cuando las
unidades de los datos no son las mismas.
c) Calcular los coeficientes de sesgo y de curtosis
Solución:
+ Para el cálculo del coeficiente de sesgo de Pearson tenemos que:
CSP=0.979, como el valor de CSP >0, significa que la curva es
asimétrica con sesgo a la derecha.

Vázquez, H. 2009 12
+ Para el cálculo de la curtosis, tenemos que calcular previamente los
cuartiles 1 y 3 y percentiles 10 y 90, para lo cual es necesario
manejar los datos ordenados ascendentemente, nota que se está
indicando la posición de cada uno de ellos:
1° 2° 3° 4° 5° 6° 7° 8° 9° 10° 11° 12°
11 13 16 17 18 19 20 27 28 29 32 34
++ Para el cálculo del Q1, primero determinamos la posición de dicho
valor:
Como el valor de la posición NO ES ENTERO, aplicamos la
interpolación, es decir, el valor del Q1 está ubicado entre la 3ª y 4ª
posición:
DPm es la 3ª posición: 16
DPM es la 4ª posición: 17
f: 0.75
por lo que la fórmula de interpolación queda:
Significa que el 25% de las ventas mensuales más bajas del
agente están por debajo de los $ 16,750.

Vázquez, H. 2009 13
++ Para el cálculo del Q3, P10 y P90 el procedimiento es el mismo:
Significa que hasta $28,250 están el 75% de las ventas del
agente, o dicho de otra manera, a partir de $28,250, están el
25% de las mejores ventas del agente.
Significa que el 10% de las ventas más bajas son menores de
$13,300.

Vázquez, H. 2009 14
Significa que el 90% de las ventas mensuales del agente son
menores a $31,700. De otra forma se puede decir que arriba
de $31,700 están el 10% de las mejores ventas mensuales del
agente.
Sustituyendo las medidas de posición en la fórmula de la
curtosis, tenemos:
K=0.313, como el valor de K>0.26, tenemos que la población
de los ventas mensuales del agente tiene un CORTE
PLATICÚRTICO.
d) Aplica la regla empírica ó Teorema de Chebyshev, según sea el
caso:
Se debe tomar en consideración la simetría de la población para
determinar cual es la regla que se aplica basados en que si es
simétrica, se aplica la Regla Empírica y si la población es Asimétrica,
se emplea el Teorema de Chebyshev. Para el caso de este ejercicio,
de acuerdo al coeficiente de sesgo podemos notar que la población es
asimétrica por lo que se aplicará el Teorema de Chebyshev:
Sabemos que la media aritmética es de 22 y la desviación estándar
es de 7.663, por lo que:
Si K=1, el intervalo queda como:
x ± S 22 ± 7.663
A = 1-1/k2
A = 1-1/1
A = 0%
Es decir, al menos el 0% de las ventas mensuales están entre
$14,337 y $29,663.

Vázquez, H. 2009 15
Si K=2, el intervalo queda como:
x ±2S 22 ± 2(7.663)=22 ± 15.326
A = 1-1/22
A = 1-1/4
A = 75%
Es decir, al menos el 75% de las ventas mensuales están entre
$6,674 y $37,326.
Si K=3, el intervalo queda como:
x ±3S 22 ± 3(7.663)=22 ± 22.989
A = 1-1/32
A = 1-1/9
A = 88.89%
Es decir, al menos el 88.89% de las ventas mensuales están
entre $ -989 y $44,989.
e) Aplicando el teorema de Chebyshev, ¿Qué porcentaje de las ventas
están entre los $14,000 y $30,000?
Se sabe que K es el número de veces que hay que sumar y restar la
desviación estándar a la media, por lo que los límites quedan como
sigue:
Significa que al menos el 8.25% de las ventas mensuales
están entre $14,000 y $30,000.
Nota: es importante que notes que la distancia en los intervalos a la
media aritmética necesariamente debe ser la misma para poder
aplicar este teorema.
Vázquez, H. 2009 16
1.5.5.2. Ejercicios Propuestos:
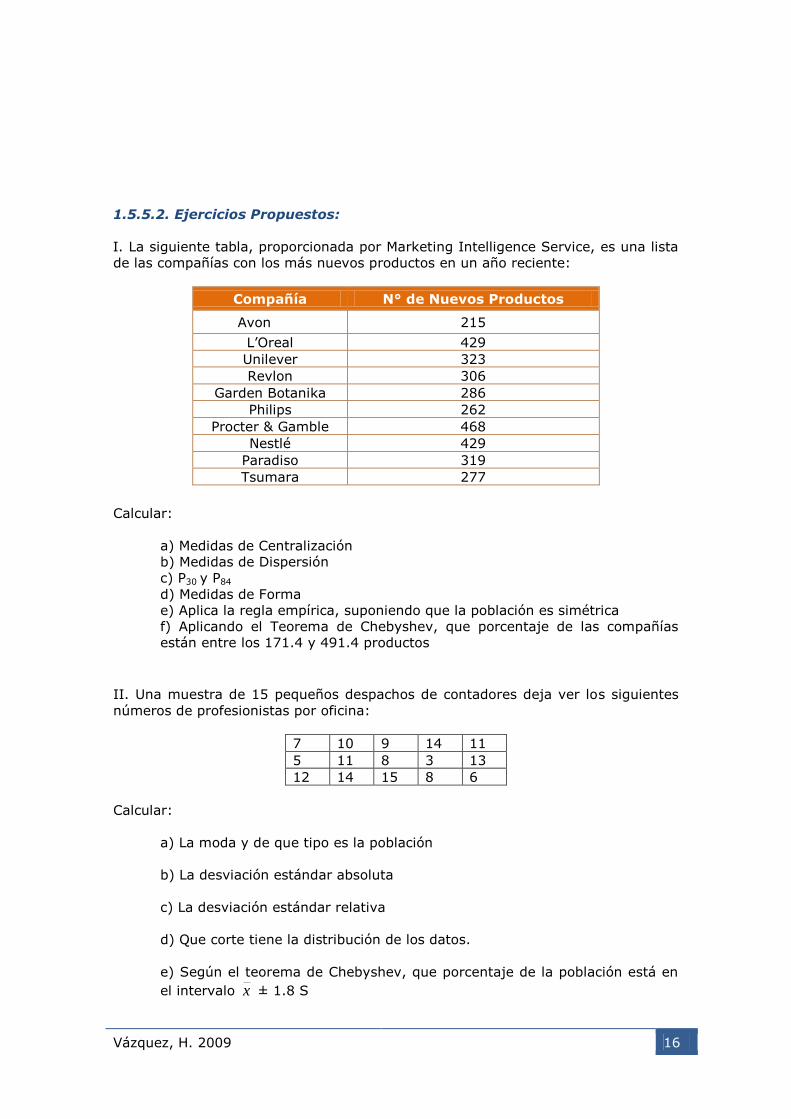
I. La siguiente tabla, proporcionada por Marketing Intelligence Service, es una lista
de las compañías con los más nuevos productos en un año reciente:
Compañía N° de Nuevos Productos
Avon 215
L’Oreal 429
Unilever 323
Revlon 306
Garden Botanika 286
Philips 262
Procter & Gamble 468
Nestlé 429
Paradiso 319
Tsumara 277
Calcular:
a) Medidas de Centralización
b) Medidas de Dispersión
c) P30 y P84
d) Medidas de Forma
e) Aplica la regla empírica, suponiendo que la población es simétrica
f) Aplicando el Teorema de Chebyshev, que porcentaje de las compañías
están entre los 171.4 y 491.4 productos
II. Una muestra de 15 pequeños despachos de contadores deja ver los siguientes
números de profesionistas por oficina:
7 10 9 14 11
5 11 8 3 13
12 14 15 8 6
Calcular:
a) La moda y de que tipo es la población
b) La desviación estándar absoluta
c) La desviación estándar relativa
d) Que corte tiene la distribución de los datos.
e) Según el teorema de Chebyshev, que porcentaje de la población está en
el intervalo x ± 1.8 S

Vázquez, H. 2009 17
III. Según el Teorema de Chebyshev, ¿Cuántas desviaciones estándar desde la
media incluirán por lo menos el 80% de los datos?
IV. Si un conjunto de datos se distribuye simétricamente, y la media es de 125 y la
desviación estándar es de 12, ¿entre cuáles números caería aproximadamente el
68% de los valores?, entre cuales dos números caería el 95% de los valores?,
¿entre cuales dos valores caería el 99.7% de los valores?.