sociedad de la informacion - eduinnova · 2011. 5. 31. · 2. desarrollo de los sistemas...
TRANSCRIPT

1
Historia de la sociedad de la información y el
conocimiento.
Autora: Patricia Chia Serrano
DNI: 28818700E
ISBN: 978-84-615-0504-3
Depósito Legal: SE 3915-2011

2
Índice
1. SOCIEDAD DE LA INFORMACIÓN Y LA COMUNICACIÓN.... ...................................... 4
2. DESARROLLO DE LOS SISTEMAS INFORMACIÓN........................................................ 7
3. SISTEMAS INFORMÁTICOS ................................................................................................ 11
3.1. Estructura............................................................................................................................ 13
4. ORIGEN Y EVOLUCIÓN DEL HARDWARE ..................................................................... 17
4.1.HISTORIA DE LOS COMPUTADORES ........................................................................ 18
4.2. MODIFICACIONES DE LA ARQUITECTURA DE UN ORDENA DOR................... 21
4.4. EVOLUCIÓN DE CARACTERÍSTICAS DE LOS ORDENADORE S DIGITALES. 23
5. ORIGEN Y EVOLUCIÓN DEL SOFTWARE BASE ........................................................... 30
5.1. EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS...................................................... 34
5.1.1. Primera etapa (1943 – 1955). ...................................................................................... 34
5.1.2. SEGUNDA etapa (1956 – 1963). ................................................................................. 35
5.1.3. TERCERA etapa (1963 – 1979). ................................................................................. 36
5.1.4. CUARTA etapa (1980 – actualidad). ......................................................................... 39
5.2. Evolución de los sistemas operativos de mayor difusión................................................. 41
5.2.1. Sistemas operativos de Microsoft. .............................................................................. 42
5.2.2. UNIX y GNU/Linux. .................................................................................................... 44
5.2.3. Otros sistemas operativos............................................................................................ 46
6. ALGORITMIA, PROGRAMACIÓN Y APLICACIONES ......... ......................................... 47
6.1. HISTORIA DE LA INGENIERÍA DEL SOFTWARE........ ........................................... 51
6.2. DESARROLLO DE APLICACIONES Y ESTANDARIZACIÓN D E FORMATOS . 54
6.2.1. APLICACIONES......................................................................................................... 54
6.2.2. FORMATOS ................................................................................................................ 59
7. DESARROLLO DEL ALMACENAMIENTO DE LA INFORMACIÓN. .......................... 65
7.1. APLICACIONES DE GESTIÓN DE LA INFORMACIÓN EN L A EMPRESA ........ 66
8. COMUNICACIÓN Y REDES.................................................................................................. 71
8. COMUNICACIÓN Y REDES.................................................................................................. 71
8.1. EVOLUCIÓN HISTÓRICA DE LAS REDES. ............................................................... 72
8.2. Modelos de distribución del procesamiento y la información ........................................ 74
9. FUTURO: INTELIGENCIA ARTIFICIAL ................. .......................................................... 77
9.1. Sistemas basados en el conocimiento. .......................................................................... 77

3
9.2. Aplicaciones de la IA. .................................................................................................... 79
9.3. TIPOS DE SISTEMAS EXPERTOS. .......................................................................... 79
9.4. HISTORIA RECIENTE DE LOS SISTEMAS EXPERTOS. ................................... 81
10. REVOLUCIÓN MULTIMEDIA............................................................................................ 84
BIBLIOGRAFÍA............................................................................................................................ 90

4
1. SOCIEDAD DE LA INFORMACIÓN Y LA COMUNICACIÓN
Actualmente la irrupción y desarrollo de las nuevas tecnologías están conformando una serie
de cambios estructurales, a nivel económico, laboral, social, educativo, político, de relaciones. En
definitiva, se está configurando la emergencia de una nueva forma de entender la cultura. En esta
coyuntura, la información aparece como el elemento clave, aglutinador, estructurador... de este
tipo de sociedad.
Fue en la década de los setenta cuando se comienza a hablar de la "sociedad de la
información". Aparece la información como la panacea, el eslogan de "la información es poder"
vino a abanderar toda una serie de cambios que iban a configurar nuevas pautas sociales,
motivadas por el auge del sector servicios. Ya no se trata de desarrollar bienes tangibles, como se
venían desarrollando hasta ahora en una sociedad industrial. Se destinará a "producir" bienes
ligados a la educación, la salud, la información, el medio ambiente, el ocio, etc. Y que configuran a
grandes rasgos lo que se ha dado en llamar sociedad postindustrial.
Esta "sociedad de la información" se va a definir en relación a mecanismos como la
producción, el tratamiento y la distribución de la información. Va a exigir desde un punto de vista
técnico, la infraestructura necesaria para su utilización en todos los ámbitos de la economía y de la
vida social. Haciendo que muchas de nuestras acciones se conformen en torno a ésta.
Hoy día, en la sociedad occidental en la cual estamos inmersos se nos "vende" la información
como un elemento accesible, que se puede poseer, que da poder, que da conocimiento. La
información se ha convertido en un culto, en un mito, algo que otorga autoridad, ventajas,
superioridad, dominio,... Sin embargo, no se considera que la información tenga carácter
informativo, por el simple hecho de ser poseída; o de poder ser asimilada por un sujeto. Se ha
producido un cambio en el concepto de la información.
La información con las nuevas tecnologías, se independiza de los sujetos. Las personas son
despojadas de la posesión, de ser la fuente y manantial de la información. En último término, no es
la información para los sujetos y gracias a ellos, sino que los sujetos son para la información y, al
final, serán los productos de la misma. Es decir,
"el mundo físico ha dejado de ser el destinatario básico de la transformación. El destinatario
ahora, es la totalidad de lo real, los seres humanos incluidos".

5
Al mismo tiempo, la información ha pasado a ser un bien de consumo. Pero no sólo este
producto entra dentro de esta categoría sino que los modos de vida de las personas de los países
más desarrollados se han transformado de una manera radical. Asistimos al nacimiento de una
nueva sociedad donde la calidad, la gestión y la velocidad de la información se convierten en
factor clave de la competitividad tanto para el conjunto de los oferentes como para los
demandantes. Las tecnologías de la información y comunicación condicionan la economía en todas
sus etapas. Por todo ello la información, es controlada por las condiciones del mercado. Éstas
determinan por un lado, quienes tienen acceso a ella y por otro, qué o quiénes controlan su
creación y su disposición.
La información se toma o se ha tomado a veces como equivalente a saber o conocimiento.
Sin embargo, hay muchas diferencias entre información y conocimiento. La identificación entre
ambos va a surgir en la década de los cuarenta, desde las teorías de la información y la cibernética.
Desde estos postulados, la mente humana, se va a concebir como una máquina capaz de adquirir y
manipular información, de forma que pensar se va a reducir a procesar esa información.
¿Es cierto que tener información sobre determinados temas equivale a poseer conocimiento a
cerca del mismo? Nosotras coincidiendo con múltiples autores, opinamos que no es así. Esta teoría
es un tanto reduccionista, y no tiene en cuenta otras muchas variables que confluyen. Ya que
conocer y pensar no es simplemente almacenar, tratar y comunicar datos. Serán procesos de
generalización de distinto tipo y sus resultados, los que nos determinarán el saber cómo actuar
sobre algo en una situación dada. El desarrollar procesos de pensamiento alternativos, creativos e
idiosincrásicos. La información no es en sí conocimiento. El acceso a ella no garantiza en absoluto
desarrollar procesos originales de pensamiento.
A pesar de que el conocimiento se basa en la información, ésta por sí sola no genera
conocimiento.
La promesa que, insistentemente se nos hace de acceso global y factible a grandes volúmenes
de información desde las nuevas tecnologías no va a ser garantía de mayor conocimiento, ni de
mayor educación.
Para que esta información se convierta en conocimiento es necesario la puesta en marcha,
desarrollo y mantenimiento de una serie de estrategias. En primer lugar, tendremos que discriminar
aquella información relevante para nuestro interés. Tras haber seleccionado la información,
debemos analizarla desde una postura reflexiva, intentando profundizar en cada uno de los

6
elementos, deconstruyendo el mensaje, para construirlo desde nuestra propia realidad. Es decir en
el proceso de deconstrucción vamos a desmontar, comprender, entender las variables, partes,
objetivos, elementos, axiomas del mensaje. En el proceso de construcción realizamos el
procedimiento inverso. A partir de variables, axiomas, elementos, etc., volvemos a componer el
mensaje, desde nuestra realidad personal, social, histórica, cultural y vital. Es decir, desde nuestra
perspectiva global del conocimiento y la persona. Sólo y no perdiendo esta perspectiva podemos
afrontar y enfrentarnos a la evolución y el progreso de las nuevas tecnologías de tal forma que nos
lleve en un futuro a crear una sociedad más humana y justa donde lo tecnológico y lo humano se
integren al igual que los distintos puntos de mira de las distintas culturas conformando el crisol de
la realidad en la que estamos sumergidos.
A lo largo de los siguientes apartados veremos una revisión de los principales hitos históricos
que han posibilitado el auge de la sociedad de la información y el conocimiento.

7
2. DESARROLLO DE LOS SISTEMAS INFORMACIÓN
La palabra “sistema” tiene muchas acepciones, una de ella: Conjunto de elementos
interrelacionados que trabajan juntos para obtener un resultado deseado, operando sobre
información, sobre energía o materia u organismos para producir como salida información o
energía o materia u organismos. Un sistema de información se define como un conjunto de
funciones o componentes interrelacionados que forman un todo, es decir, obtiene, procesa,
almacena y distribuye información (datos manipulados) para apoyar la toma de decisiones y el
control en una organización. Igualmente apoya la coordinación, análisis de problemas,
visualización de aspectos complejos, entre otros aspectos.
El estudio de las empresas como sistemas de información es muy interesante para poder
tener una visión global de las mismas. Es un primer paso antes de informatizar. La mayoría de las
empresas son parecidas desde el punto de vista de la información que manejan y cómo la procesan.
Ello ha hecho que aparezcan herramientas genéricas adaptables a cualquier empresa, y cuya
popularidad es cada día mayor.
Actualmente, las empresas se enfrentan a un entorno comercial que progresivamente se
hace más complejo y difícil. El mercado requiere respuestas cada vez más rápidas en un mundo
donde los cambios resultan impredecibles, las situaciones evolucionan con mucha velocidad, los
problemas requieren un conocimiento mayor de una cantidad elevada de factores que se
interrelacionan entre sí de forma compleja, etc. Ante esto, la compañía debe adaptarse creando
organizaciones más eficaces. Los directivos de las empresas buscan el tipo de organización que
resulta más apropiada para los objetivos que se quieren lograr. La eficacia de una empresa depende
de su capacidad para que todos sus elementos funcionen de manera coordinada para la consecución
de los objetivos fijados. En un mercado como el actual en el que la competitividad y la rapidez de
maniobra es esencial para el éxito, hay que contar con la información adecuada para actuar y
tomar las mejores decisiones. Por ello, las organizaciones crean sistemas de información que
ayuden a lograr los objetivos de la compañía.
Toda empresa, grande o pequeña, necesita una infraestructura para poder desarrollar sus
actividades. Esta estructura organizativa suele descansar en una red de relaciones que hay que
desarrollar y que, entre otras, incluye a las siguientes:

8
• Controlar y gestionar el empleo de los recursos financieros, del dinero, a través de la
función (o sistema) contable y de gestión económica.
• Comercializar de manera óptima los productos o servicios en los que la empresa
basa su negocio: la actividad comercial y de ventas.
• Fabricar productos o crear servicios que vender en el mercado: se trata de la función
o departamento de producción.
Pero es muy difícil que todas estas funciones y actividades se puedan realizar con eficacia
sin coordinarse entre sí mediante la gestión y la intercomunicación de información de buena
calidad. Por ello, las organizaciones incluyen una infraestructura para coordinar los flujos y los
registros de información necesarios para desarrollar sus actividades de acuerdo a su
planteamiento o estrategia de negocio. El sistema dedicado a este cometido es el que se
denomina sistema de información de la empresa. Este sistema es tan necesario como cualquiera
de los otros nombrados anteriormente (ventas, comercialización, producción, etc.).
Hoy en día, cuando se piensa en un sistema de información, la mayoría de las personas
suele concebir una imagen repleta de ordenadores, programas e instrumentos sofisticados
pertenecientes a lo que se suele llamar tecnologías de la información (conocidas por las siglas
TI). Sin embargo, los sistemas de información existen desde el mismo día en el que se creó la
primera organización humana: una estructura compuesta por un conjunto de personas distribuidas
en departamentos o funciones con arreglo a ciertos criterios de división del trabajo y coordinación.
Cuando a principios del siglo XIX la Revolución Industrial cambió el concepto existente de
trabajo basado en la artesanía (cada empleado fabricaba un producto desde el principio al final) por
la especialización y la división del trabajo (cada empleado construye la parte del producto en cuyo
desarrollo está especializado), las empresas tuvieron que organizar un sistema para que los
distintos departamentos o especialistas se coordinaran entre sí mediante el intercambio de
información. En esos tiempos la gestión de la información sólo podía apoyarse en herramientas
elementales como el papel, el lápiz y los archivadores.
A principios del siglo XX, el tamaño y la complejidad de las empresas hizo que la gestión
de la información tuviera que apoyarse en sistemas que contaban con una multitud de “oficinistas”
o “administrativos” que manejaban ingentes cantidades de impresos, fichas, correspondencia, etc.
sin mayor ayuda que algunos medios manuales (considerados los más sofisticados de la época:

9
máquinas de escribir, calculadoras mecánicas, perforadoras de papel, etc.) y rígidos
procedimientos que simplificaban el trabajo repetitivo y permitían controlar el flujo y el
almacenamiento de información. Es la típica imagen de los empleados con manguitos realizando
sobre papel multitud de tareas repetitivas de contabilidad o administración. Todos estos elementos
constituían auténticos sistemas de información y formaron la infraestructura administrativa
sobre la que se edificaron muchas de las grandes empresas y organizaciones actuales.
Por lo tanto, la implementación actual de sistemas de información de las empresas
mediante el empleo de tecnologías de la información (TI) sofisticadas no debe hacernos olvidar
el concepto original que subyace en ellas. Sin embargo, no es tan sencillo ofrecer una definición
totalmente satisfactoria de sistema de información. En este sentido, una de las definiciones más
completas es la ofrecida por R. Andreu. Inspirados en ella podemos decir que un SI es:
Un conjunto formal de procesos que, operando sobre una colección de datos estructurada
según las necesidades de la empresa, recopilan, elaboran y distribuyen la información (o parte de
ella) necesaria para las operaciones de dicha empresa y para las actividades de dirección y
control correspondientes (decisiones) para desempeñar su actividad de acuerdo a su estrategia de
negocio.
Los sistemas de información pueden ser manuales o automatizados. Hasta ahora hemos
trabajado con la noción de SI independientemente de la tecnología empleada para darle soporte. Ya
sabemos que pueden existir sistemas de soporte puramente manuales, con herramientas
rudimentarias (papel, lápiz, ele.) y empleando personas para realizar todas las actividades de
procesamiento y almacenamiento de información.
Evidentemente, las empresas han ido incorporando nuevas tecnologías a lo largo del siglo
XX para mejorar el rendimiento y la eficacia de los SI. Se comenzó con máquinas de escribir,
calculadoras mecánicas, teléfonos, cintas de papel perforado, etc. y se han llegado ya a utilizar
tecnologías sofisticadas de tratamiento y comunicación de información: fax, informática,
ofimática, etc. a las que se ha denominado genéricamente tecnologías de la información (TI). En
nuestro caso, nos centraremos especialmente en la informática como TI que podemos aplicar a la
automatización de los SI, pero sin olvidar que otras tecnologías pueden complementar su acción.
Debemos recordar que, cuando los directivos de una empresa deciden mejorar el
rendimiento de su SI incorporando medios informáticos, se debe realizar un estudio minucioso de
lo que resulta más eficaz para cada caso. En general, la solución óptima consiste en un SI que

10
cuenta con una mezcla de actividades, con algunas partes o subsistemas automatizados y otras
funciones que se siguen realizando manualmente. Por lo tanto, podemos distinguir entre lo que es
el SI total y lo que es el SIA o Sistema Información Automatizado (véase la figura).
Por otra parte, el SIA deberá contar con un soporte informático para poder funcionar. En
este sentido, la informática constituye sólo una herramienta más o menos sofisticada y completa
para implementar lo que está incluido en el SIA. Por lo tanto, no debe confundirse informática y
SI. Esto implica que los informáticos son simples técnicos que deben aportar soluciones para
proporcionar porte a lo que los directivos de la empresa conciben como estructura óptima de
formación de su empresa. Tampoco debemos confundir el SIA con el simple soporte físico o
sistema informático asociado constituido por el hardware, el software base y las aplicaciones.
FIGURA. RELACIÓN ENTRE SI Y SIA

11
3. SISTEMAS INFORMÁTICOS
Un sistema informático es la síntesis de hardware, software y de un soporte humano. Un
sistema informático típico emplea un ordenador que usa dispositivos programables para almacenar,
recuperar y procesar datos. El ordenador personal o PC, junto con la persona que lo maneja y los
periféricos que los envuelven, resultan de por sí un ejemplo de un sistema informático.
Incluso el ordenador más sencillo se clasifica como un sistema informático, porque al
menos dos componentes (hardware y software) tienen que trabajar unidos. Pero el genuino
significado de “sistema informático” viene mediante la interconexión. La interconexión de
sistemas informáticos puede tornarse difícil debido a las incompatibilidades entre los mismos. A
veces estas dificultades ocurren entre hardware incompatible, mientras que en otras ocasiones se
dan entre programas informáticos que no se entienden entre sí.
Todo sistema, se puede contemplar desde 2 aspectos: cómo es físicamente, partes que lo
componen, interconexión de las mismas, etc, es decir una descripción física del mismo; por otro
lado se puede contemplar desde el punto de vista del funcionamiento, qué funciones desempeñan
sus constituyentes y cómo afectan dichas funciones al funcionamiento de otros. En un sistema
informático se puede establecer esta división, atendiendo a su estructura física y a la estructura
funcional.
Para facilitar el diseño y análisis de los sistemas informáticos, se describen distintos niveles
conceptuales. La distinción entre niveles más sencilla es la que existe entre software asociado a la
descripción funcional y hardware asociado a la descripción física del sistema. Una distinción
más detallada se muestra a continuación.

12
Figura. Niveles conceptuales de descripción de un computador
A lo largo del apartado veremos principalmente con más detalle las características de:
• Estructura física de los sistemas informáticos, asociada usualmente al soporte
físico, o hardware de un computador. Veremos con más detalle las arquitecturas de
organización que existen a nivel hardware en los sistemas informáticos.
• Estructura funcional, asociada al software o soporte lógico de un computador,
conjunto de programas (del sistema operativo, de utilidades y de los usuarios)
ejecutables por el computador y su organización. Veremos con más detalle las
arquitecturas de organización de los sistemas informáticos, desde el punto de vista
de ejecución de aplicaciones.
Por tanto un sistema informático es un conjunto de dispositivos constituido por, al
menos, una Unidad Central de Proceso (UCP), estando física y lógicamente conectados entre sí
todos los dispositivos que lo integran, ya sea a través de canales -en local- o mediante líneas de
telecomunicación. Representa la concreción e infraestructura física y lógica que sirve de soporte al
proceso, almacenamiento, entrada y salida de los datos, textos y gráficos que forman parte de un
sistema de información general o específico.

13
Para llevar a cabo su cometido un ordenador ha de dotarse de una serie de recursos. Estos
recursos pueden variar según el destino que le demos al ordenador. Así, un ordenador que se
destine a un proceso de investigación, tendrá que contar con grandes elementos de cálculo que le
permitan realizar operaciones completas en el mínimo tiempo, mientras que un ordenador
destinado al tratamiento de gran cantidad de datos, dispondrá de una gran memoria en donde
almacenar los datos para su tratamiento.
Sin embargo, estas variaciones en la concepción del ordenador no son más que
modificaciones de tipo cuantitativo pues cualitativamente todos los ordenadores deben disponer de
dos elementos básicos: Un sistema físico y un sistema lógico. A estos dos elementos hay que
añadir un tercero que, sin pertenecer a la estructura física no se puede pensar en un sistema sin él:
los Recursos Humanos.
3.1. Estructura.
Los elementos que componen un sistema informático son:
• Hardware, dispositivos electrónicos y electromecánicos, que proporcionan
capacidad de cálculos y funciones rápidas, exactas y efectivas (Computadoras,
sensores, maquinarias, bombas, lectores, etc.), que proporcionan una función
externa dentro de los sistemas.
• Software, que son programas de ordenador, con estructuras de datos y su
documentación de forma que hagan efectiva la metodología o controles de
requerimientos para los que fueron ideados.
• Personal, son los operadores o usuarios directos del sistema informático, y los
profesionales que lo diseñan, programan, configuran y mantienen.
• Base de Datos, colección de informaciones organizadas y enlazadas al sistema a las
que se accede por medio del software, en su fase de explotación.
• Documentación, Manuales, formularios, y otra información descriptiva que detalla
o da instrucciones sobre el empleo y operación del sistema y procedimientos de uso
del sistema.
• Procedimientos, o pasos que definen el uso especifico de cada uno de los
elementos o componentes del sistema y las reglas de su manejo y mantenimiento.

14
A continuación describiremos cada uno de los tres principales subsistemas que componen
un sistema informático.
• Subsistema físico. Es el conjunto de elementos tangibles necesarios para el
tratamiento eficaz de la información. El subsistema físico se conoce con el nombre
de hardware y se compone habitualmente a su vez de varios elementos: la unidad
central de proceso, la memoria auxiliar y los dispositivos de entrada/salida o
periféricos.
Recordar que la unidad central de proceso, como ya sabemos, está formada por la
unidad de control, por la unidad aritmético-lógica y por la memoria central. En
cuanto a la memoria auxiliar, decir que son los dispositivos que sirven para
almacenar de forma permanente datos y programas. Los periféricos, ya sabemos que
son elementos que comunican al ordenador con el exterior.
• Subsistema lógico. El subsistema físico por sí sólo es inerte, algo pasivo que
necesita elementos que le pongan en marcha. El subsistema lógico es el conjunto de
recursos lógicos necesarios para que el sistema físico se encuentre en condiciones
de realizar todos los trabajos que se le vayan a encomendar. Al subsistema lógico se
le conoce con el nombre de software.
Mediante el software un ordenador es capaz de realizar las operaciones y cálculos
de cualquier tipo. Este software se divide en dos tipos de programas: los llamados
programas del sistema, que manejan los recursos lógicos para que opere el propio
ordenador, y los llamados programas de aplicación, que son los que resuelven los
problemas de los usuarios.
Algunos de los programas del sistema residen en el hardware del ordenador (me-
moria o cableado) y se conocen con el nombre de firmware. Tales programas
suelen grabarse en el momento de la fabricación del propio ordenador. Otros
programas sin embargo residen en memorias externas y son cargados en la memoria
central o principal cuando se pone en marcha el ordenador o cuando se requiera
alguno de sus ellos.

15
• Subsistema de Recursos Humanos. Con la aparición de la informática surge un
nuevo colectivo de profesionales que trata de abarcar todos los conocimientos que
de esta nueva ciencia se derivan.
Pero no todo el mundo que utiliza los ordenadores es un profesional de la
informática; existe otro tipo de personas, los usuarios, que aprovechan las
prestaciones de los ordenadores. Por lo tanto, la informática es utilizada por dos
tipos de personas: los usuarios y los informáticos profesionales.
➥ Los usuarios: son los destinatarios finales de cualquier software. El usuario
es aquella persona que, sin necesidad de grandes conocimientos de infor-
mática, es capaz de realizar su trabajo utilizando un ordenador. Sus nociones
de informática, en general, son básicas, pero suele tener un gran cono-
cimiento de las posibilidades de los programas que usa.
➥ Los informáticos: son el colectivo de personas dedicado a la investigación,
el desarrollo, la explotación de los programas y la formación de los usuarios.
Los informáticos profesionales, según el tipo de trabajo que desarrollan, se
pueden clasificar por grupos o categorías:
➫ Analista: persona dedicada al análisis del problema y a encontrar el
algoritmo correcto para solucionarlo.
➫ Programador: persona que se encarga de transcribir los pasos descri-
tos por el analista para solucionar el problema, en un lenguaje
comprensible por el ordenador.
➫ Administrador del sistema: a su cargo está la administración de los
recursos que posee el sistema informática, así como el
establecimiento de los niveles necesarios para mantener la seguridad
de los datos.
➫ Planificador de trabajos informáticos: encargado de la instalación,
pruebas, mantenimiento y explotación de los programas que lleguen a
sus manos.

16
➫ Operador: notifica al ordenador los procesos que debe realizar,
estando a cargo de introducir o retirar los soportes donde se
encuentran los datos y la información.
➫ Formadores, informadores, comerciales y otros encargados de trans-
mitir conocimientos informáticos a los usuarios para su correcto
aprovechamiento.

17
4. ORIGEN Y EVOLUCIÓN DEL HARDWARE
En sentido general, un ordenador es todo aparato o máquina destinada a procesar
información, entendiéndose por proceso las sucesivas fases, manipulaciones o transformaciones
que sufre la información para resolver un problema determinado.
La palabra computador hace referencia a las aplicaciones exclusivamente numéricas para
las que se diseñaron los primeros ordenadores. Por tanto, el término francés “ordenateur”,
(introducido con motivo de la presentación en Europa del IBM 701), completa al término
anglosajón “computer”, aunque hay autores que los emplean indistintamente refiriéndose a
ordenadores. Desde este punto de vista general, no se presupone la tecnología en que se ha de
construir el computador, ni la forma en que se ha de representar la información para su proceso, ni
de cómo se realiza éste.
En sus orígenes, los ordenadores se basaban en las tecnologías mecánica y electromecánica.
Sin embargo, hoy en día, la tecnología mayoritariamente empleada es la electrónica, aunque ciertas
partes del ordenador, como son los periféricos, aún contienen una gran parte mecánica. Por otro
lado la tecnología óptica apunta como la tecnología del futuro de los ordenadores, aunque de
momento su mayor aplicación está en las comunicaciones y en algunos dispositivos de
almacenamiento de información.
Desde el punto de vista de la forma en que se representa la información en un computador,
existen dos alternativas muy diferentes, que dan lugar a dos clases de computadores perfectamente
diferenciados, esto es, a:
• Los computadores digitales.
• Los computadores analógicos.
En los computadores digitales (y, en general, en los ordenadores) la información está
representada mediante un sistema digital binario, esto es, un sistema que sólo reconoce dos estados
distintos, que suelen denominarse “1” y “0”. Cada uno de los dígitos de esta representación binaria
recibe el nombre de bit - binary digit y puede tomar los valores de “1” ó “0”.
En los computadores digitales se pueden emplear cadenas de bits de la longitud que se
desee y de la codificación que se quiera, lo que permite representar y manipular tanto números

18
como letras y símbolos. Cuando se consideran exclusivamente números se dice que la información
es numérica. Cuando se trata de números y texto se dice que es alfanumérica.
En contraposición, los computadores analógicos sólo pueden representar números,
estando determinada su magnitud por el valor de una tensión eléctrica, en el caso más frecuente de
estar construidos con circuitos electrónicos. La precisión del computador analógico está limitada,
también por razones constructivas, a las menores variaciones de tensión que es capaz de manejar
correctamente.
La superioridad de los ordenadores digitales frente a las computadoras analógicas es
patente en cuanto a:
• Facilidad y capacidad de almacenamiento de información.
• Precisión de la representación numérica, limitada, solamente, por la longitud de las
cadenas de bits empleadas y no por la calidad de los circuitos electrónicos.
• Comodidad de uso.
• Posibilidad de tratar información no numérica.
Por todo ello hoy en día se ha impuesto el ordenador digital, y por ello el título de este tema
lo menciona explícitamente.
4.1.HISTORIA DE LOS COMPUTADORES
Comenzaremos por la clasificación según hechos relevantes y generaciones del computador
digital actual:

19
El predecesor de las actuales computadoras personales y progenitor de la plataforma IBM
PC compatible, fue lanzado en agosto de 1981. El modelo original fue llamado "IBM 5150". Su
éxito comercial fue tal que el uso de ordenadores para particulares se extendió muy rápidamente
debido a sus bajos precios. El desarrollo exitoso del PC tardó cerca de un año. Para lograrlo,
primero decidieron construir la máquina con partes disponibles en el mercado de una variedad
de distintos fabricantes. Anteriormente IBM había desarrollado sus propios componentes. Luego
diseñaron una arquitectura abierta para que otros fabricantes pudieran producir y vender máquinas
compatibles (las compatibles con IBM PC ), así que la especificación de la ROM BIOS fue
publicada. IBM esperaba mantener su posición en el mercado al tener los derechos de licencia de
la BIOS, y manteniéndose delante de la competencia.
Desafortunadamente para IBM, otros fabricantes rápidamente hicieron ingeniería inversa de
la BIOS y produjeron sus propias versiones sin pagar derechos de uso a IBM. (Compaq Computer
Corporation fabricó el primer clon compatible de la IBM PC en 1983).
Una vez que el IBM PC se convirtió en un éxito comercial, el producto PC dejó de estar
bajo el control de un grupo especial dentro de IBM para pasar a diversificarse el mercado con otros
fabricantes hasta hoy en día en el cual el número de empresas que se dedican a desarrollar
componentes y a ensamblar ordenadores es incontable.
En la actualidad, y como muestra la gráfica de la figura, los ordenadores de tipo PC cubren
la mayor parte del mercado. Ello justifica que el presente tema se centre en los PC.
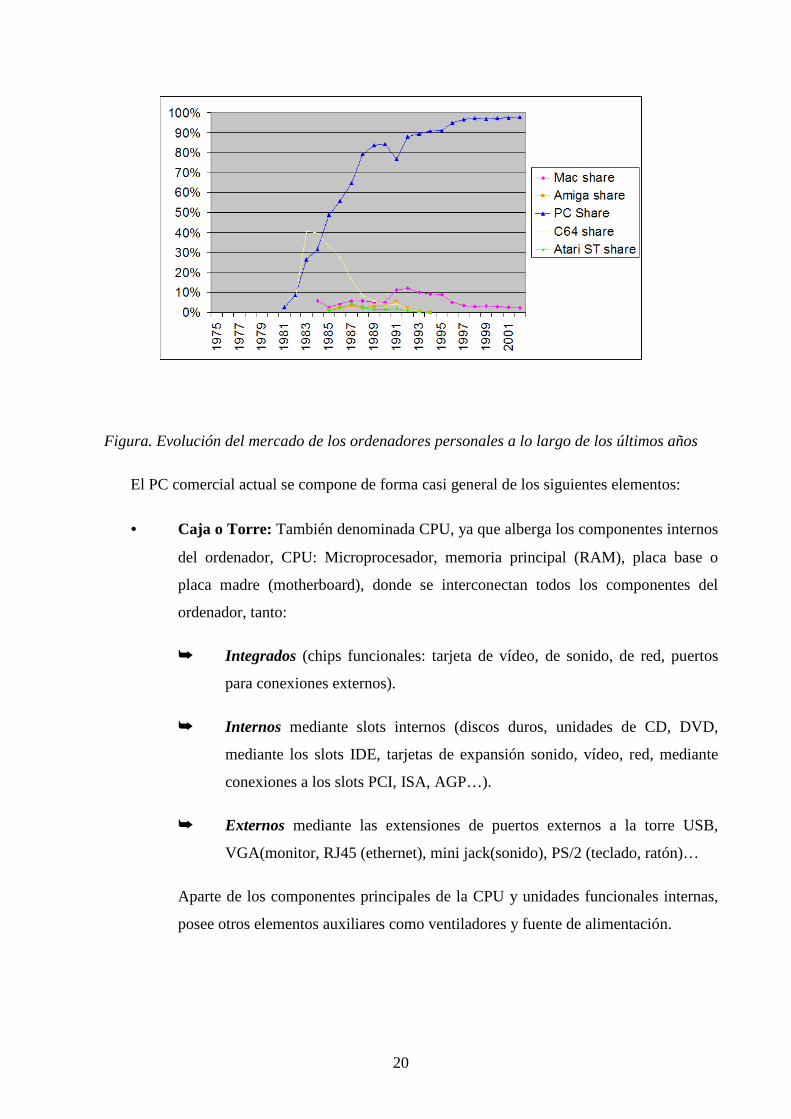
20
Figura. Evolución del mercado de los ordenadores personales a lo largo de los últimos años
El PC comercial actual se compone de forma casi general de los siguientes elementos:
• Caja o Torre: También denominada CPU, ya que alberga los componentes internos
del ordenador, CPU: Microprocesador, memoria principal (RAM), placa base o
placa madre (motherboard), donde se interconectan todos los componentes del
ordenador, tanto:
➥ Integrados (chips funcionales: tarjeta de vídeo, de sonido, de red, puertos
para conexiones externos).
➥ Internos mediante slots internos (discos duros, unidades de CD, DVD,
mediante los slots IDE, tarjetas de expansión sonido, vídeo, red, mediante
conexiones a los slots PCI, ISA, AGP…).
➥ Externos mediante las extensiones de puertos externos a la torre USB,
VGA(monitor, RJ45 (ethernet), mini jack(sonido), PS/2 (teclado, ratón)…
Aparte de los componentes principales de la CPU y unidades funcionales internas,
posee otros elementos auxiliares como ventiladores y fuente de alimentación.

21
• Periféricos externos: Como hemos mencionado el PC actual se compone de los
componentes internos a la torre y de periféricos que permiten la interacción exterior
con el hombre. Estos periféricos son típicamente de:
➥ Entrada: ratón, teclado, escáner, micrófono…,
➥ Salida: monitor, altavoces, impresora…
➥ Entrada/salida: módem, multifunciones…
➥ Almacenamiento externo: Memorias USB, disco duros externos…
4.2. MODIFICACIONES DE LA ARQUITECTURA DE UN ORDENA DOR
La arquitectura de un ordenador define su comportamiento funcional. El modelo básico de
arquitectura empleada en los ordenadores digitales fue establecido en 1945 por Von Neumann
(Budapest 1903- Washington 1957). Esta arquitectura es todavía la que emplean la gran mayoría
de los fabricantes.

22
La figura muestra la estructura general de un ordenador tipo Von Neumann. Esta máquina
es capaz de ejecutar una serie de instrucciones u órdenes elementales llamadas instrucciones de
máquina, que deben estar almacenadas en la memoria principal (programa almacenado) para poder
ser leídas y ejecutadas. El poder ejecutar distintos programas hace que el modelo de máquina de
von Neumann sea de propósito general. Puede observarse de la figura que esta máquina está
compuesta por las siguientes unidades:
Registros
UNIDADARITMÉTICO-LÓGICA
MEMORIAPRINCIPAL
UNIDAD DE CONTROL Puntero
UN
IDA
D D
EE
NTR
AD
A/S
ALI
DA
Periférico
Periférico
Periférico
Periférico
UNIDAD CENTRAL DE PROCESO (CPU)
Figura. Modelo de von Neumann
• La Memoria Principal está compuesta por un conjunto de celdas idénticas, esto es,
que tienen el mismo tamaño (mismo número de bits). En un instante determinado se
puede seleccionar una de estas celdas, para lo que se emplea una dirección que la
identifica. Sobre la celda seleccionada se puede realizar una operación de lectura,
que permite conocer el valor almacenado previamente en la celda, o de escritura,
que permite almacenar un nuevo valor. Estas celdas se emplean tanto para
almacenar los datos como las instrucciones de máquina.
• La Unidad Aritmético-Lógica (ALU) permite una serie de operaciones elementales
tales como suma, resta, AND, OR, etc. Los datos sobre los que opera esta unidad

23
provienen de la memoria principal, y pueden estar almacenados de forma temporal
en algunos registros de la propia unidad aritmética.
• La Unidad de Control se encarga de leer, una tras otra, las instrucciones de
máquina almacenadas en la memoria principal, y de generar las señales de control
necesarias para que todo el computador funcione y ejecute las instrucciones leídas.
La figura anterior indica estas señales mediante flechas de trazos. Para conocer en
todo momento la posición de memoria en la que está almacenada la instrucción que
corresponde ejecutar, existe un registro apuntador llamado contador de programa
que contiene esta información.
• La Unidad de Entrada/Salida (E/S) realiza la transferencia de información con
unas unidades exteriores llamadas periféricos, lo que permite, entre otras cosas,
cargar datos y programas en la memoria principal y sacar resultados impresos.
Se denomina Unidad Central de Proceso (CPU, Central Processing Unit) al conjunto de
la unidad de control, los registros y la unidad aritmética de un ordenador, esto es, al bloque que
ejecuta las instrucciones. Para formar un ordenador hay que añadir la memoria principal, la unidad
o unidades de entrada/salida y los periféricas. Con frecuencia se denomina procesador a una CPU,
aunque a veces se extrapole este término de procesador al conjunto formado por una CPU y una
pequeña memoria, como, por ejemplo, cuando se habla de un procesador de entrada/salida.
Entre los periféricos se podrían mencionar los siguientes:
• Impresoras, para producir texto.
• Discos, para almacenar información.
• Terminales, para que los usuarios se comuniquen con el ordenador
4.4. EVOLUCIÓN DE CARACTERÍSTICAS DE LOS ORDENADORE S DIGITALES
Caracterizar las prestaciones de los ordenadores digitales es una tarea muy compleja,
puesto que éstas dependen de muchos factores, entre los que hay que destacar el entorno en el que
se usen, las instrucciones de máquina que tienen, el grado de utilización efectiva que permiten, etc.

24
Sin embargo, se emplean con frecuencia una serie de parámetros para especificar sus
características.
1. Palabra. Es el conjunto de de bits que forma una dirección, instrucción u operando.
2. Ancho o longitud de palabra. Expresa el número de bits que maneja en paralelo el
ordenador. En general, mientras mayor sea el ancho de palabra mayor será su
potencia de cálculo. Tamaños típicos de los primeros microprocesadores fueron los
de 8 bits y 16. Hoy en día el tamaño más normal es el de 32 bits, pero son cada vez
más corrientes las máquinas de 64 bits.
3. Capacidad de almacenamiento. Se refiere a las posibilidades de una unidad para
almacenar datos o instrucciones de forma temporal o fija. La unidad generalmente
empleada es el octeto (formado por 8 bits), también denominado byte, y sus
múltiplos:
a) Octeto. 1 octeto = 8 bits
b) Kiloocteto. 1Kocteto = 1024 octetos
c) Megaocteto. 1 Mocteto = 1024 koctetos
d) Gigaocteto. 1 Gocteto = 1024 Moctetos
e) Teraocteto. 1 Tocteto = 1024 Goctetos
f) Petaocteto. 1 Pocteto = 1024 Toctetos
Internacionalmente se utiliza la letra “b” (minúscula) para indicar bit, y “B”
(mayúscula) para el byte u octeto. Conviene, por tanto, no confundir Kb, Mb, Gb,
Tb y Pb, que se refieren a bits, con KB, MB, GB, TB y PB, que se refieren a octetos
o bytes.
4. Tiempo de acceso. En una unidad de memoria es el intervalo de tiempo que
transcurre desde el instante en que se proporciona a la misma, la posición o
dirección concreta del dato o instrucción que se quiere leer o escribir, y el instante
en que se obtiene (lee) o graba (escribe) el mismo.

25
5. Ancho de banda. Expresa el caudal de información que es capaz de transmitir un
bus o una unidad de entrada/salida, o el caudal de información que es capaz de tratar
un aunidad. Se suele expresar en Kbits/segundo (Kb/s), Mbits/segundo (Mb/s),
Koctetos/segundo o Kbytes/segundo (KB/s) o Moctetos/segundo o Mbytes/segundo
(MB/s).
6. MIPS (millones de instrucciones por segundo). Expresa la velocidad de ejecución
de las instrucciones de máquina.
7. MFLOPS (millones de operaciones en punto flotante por segundo). Expresa la
potencia de cálculo científico de un ordenador. Dado que las operaciones en punto
flotante son las más complejas y largas de ejecutar, la tasa de MFLOPS de un
ordenador suele ser menor que su tasa de MIPS (sin embargo, los ordenadores
vectoriales ejecutan más de una operación de punto flotante por instrucción, por lo
que permiten obtener una tasa de MFLOPS mayor que su tasa de MIPS).
8. Vectores por segundo. Expresa la potencia de cálculo en la generación de gráficos.
Se suele aplicar a los coprocesadores gráficos de las estaciones de trabajo. Se puede
dar la medida en vectores 2D (en un plano) o en vectores 3D (en el espacio).
9. Tests sintéticos. Dado que las medidas en MIPS o MFLOPS no permiten una
comparación clara entre las máquinas de los distintos fabricantes, cada vez son más
utilizados los tests sintéticos. Estos tests consisten en programas que caracterizan
algunas de las aplicaciones típicas, por lo que la velocidad a la que se ejecutan dan
una medida de la velocidad del ordenador. Dado que suelen estar escritos en
lenguajes de alto nivel, en realidad miden la eficacia del conjunto compilador-CPU.
Entre los más empleados están el Linpack y los SPEC de System Performance
and Evaluation Cooperative. El resultado de estos tests puede expresarse en valor
absoluto como el tiempo que se tarda en ejecutar el test o como el número de veces
que se ejecuta el test en un segundo. También es muy frecuente expresar los
resultados con relación a la velocidad de ejecución en una máquina específica. Así,
los SPECint92 (enteros) y SPECfp92 (punto flotante) estaban referidos al VAX-
11/780 de DEC, mientras que los SPECint95 y SPECfp95 están referidos al
SparcStation 10 de 40 MHz de Sun. Una máquina de 10 SPECint95 es 10 veces más
rápida que la mencionada SparcStation10.

26
Figura. Medida de MIPS y MFLOPS

27
Figura. SPECint95
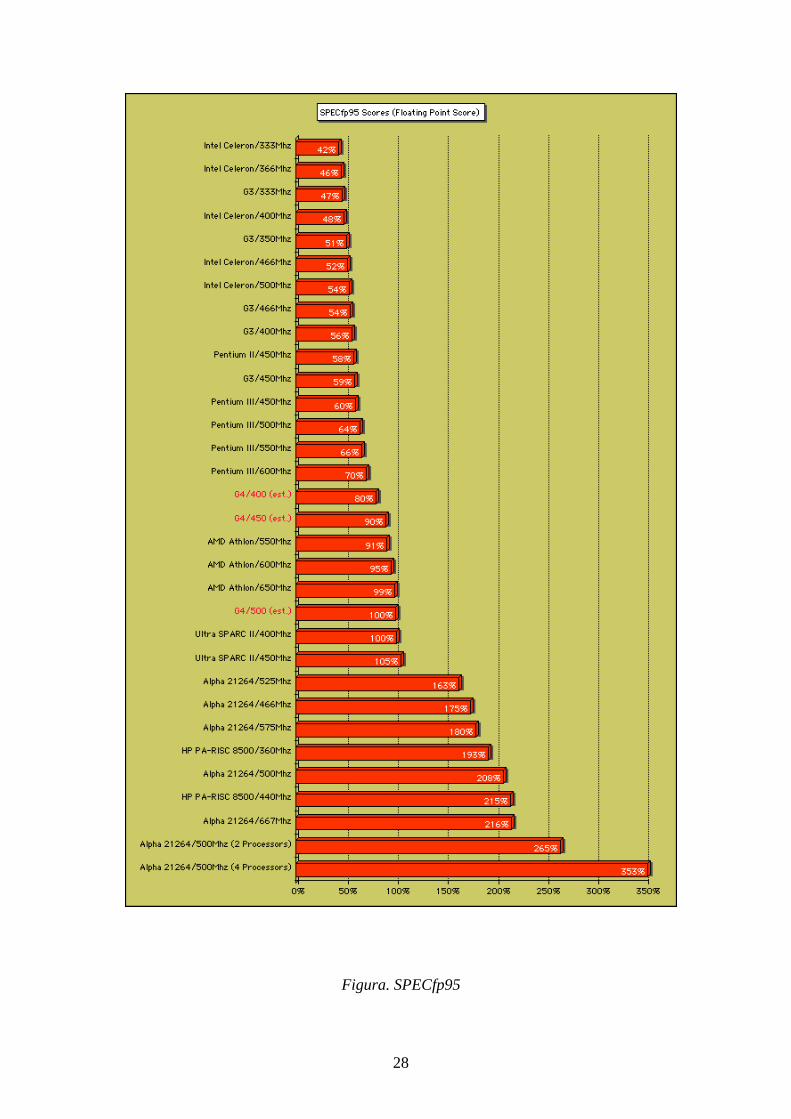
28
Figura. SPECfp95

29
Las “máquinas de cómputo” no han sido siempre iguales. Las arquitecturas fueron
evolucionando hasta el modelo de Von Neumann, que se ha convertido en el estándar de facto.
Desde un punto de vista esquemático, se puede concluir que la evolución de los ordenadores no ha
sido muy grande en las últimas décadas, al contrario de la opinión generalizada.
Al fin y al cabo, todos cuentan con los mismos bloques constitutivos: CPU, unidades de
E/S, memoria... Lo que sí ha presentado una evolución acelerada son precisamente esos bloques,
que son el objeto de estudio de los temas siguientes.

30
5. ORIGEN Y EVOLUCIÓN DEL SOFTWARE BASE
Los ordenadores por sí solos no pueden realizar ninguna función, necesitan recibir órdenes
que les dirijan y controlen. Estas órdenes o instrucciones son dadas por el programador, y
agrupadas forman los programas o parte lógica de los sistemas informáticos, junto a los datos.
Estos programas que controlan la actuación del ordenador son los que conforman el software de
un sistema informático. El software se puede clasificar en 2 grandes grupos: el software de
sistema y el software de aplicación:
• El Software de sistema, software básico o sistema operativo: Constituido por el
conjunto de programas que controlan el funcionamiento del ordenador junto con sus
recursos y del resto de los programas, proporcionando al usuario una interfaz
cómoda en su comunicación con el ordenador.
➥ El sistema operativo es lo que constituye este software de control y tiene
dos funciones básicas que lo hacen indispensable:

31
➫ Administrador de recursos del sistema.
➫ Interfaz entre el usuario y la máquina, facilitando su uso y ocultando
sus características físicas.
➥ Los programas de servicio o de proceso lo constituyen los programas o
utilidades que permiten la construcción de programas, incluyendo
herramientas como editores de texto, traductores, etc. En la actualidad,
existen entornos integrados de desarrollo (IDE) que contienen todas las
herramientas necesarias para la construcción de proyectos, desde
herramientas para el desarrollo y la documentación, como para el diseño
visual de formularios e informes, incluso herramientas de gestión del sistema
operativo. Existen en la actualidad herramientas especialmente diseñadas
para el desarrollo de software en todo su ciclo de vida, se les denomina
herramientas CASE (ingeniería del software asistida por ordenador).
• Software de aplicación: Dentro de este grupo se distinguen dos tipos de software
de aplicación, los verticales y los horizontales.
➥ Como software de aplicación horizontal se denominan a las aplicaciones
que, como los procesadores de texto o las hojas de cálculo, pueden aplicarse
a distintos usos. Cuando varios programas de este tipo se diseñan para
trabajar perfectamente coordinados reciben el nombre de paquete integrado.
También pertenecen a este tipo de software los programas que permiten la
comunicación entre ordenadores.
➥ El software vertical estaría constituido por los programas realizados a la
medida de las necesidades de un usuario. En este ámbito encontramos
soluciones software de gestión empresarial.
La estructura funcional más simple es la que conforma un sistema informático aislado que
no se relaciona con otros sistemas, y que es autónomo para realizar un completo funcionamiento
del mismo. Para un sistema asilado su estructura funcional estará compuesta por un sistema
operativo que administre los recuros, y disponga al usuario de un interfaz sencillo para poder
utilizar el hardware, junto con un conjunto de porgramas de aplicación.

32
El sistema operativo es el conjunto de programas del sistema informático que controla los
recursos hardware del ordenador y sirve de base para la ejecución de los programas de aplicación,
actúa por tanto de intermediario entre el hardware y los usuarios del mismo.
El sistema operativo es el software básico y fundamental de un sistema informático. Sin su
existencia, el elemento hardware sólo sería una entidad física sin utilidad, ya que no podríamos
asignarle ningún tipo de tarea. Por consiguiente, se trata de una de las partes más fundamentales de
un sistema informático y es importante conocerlo. De hecho, algunas empresas de software
desarrollan sus productos sólo para ciertos tipos de sistemas operativos.
Una primera aproximación nos presentaría al sistema operativo como un tipo de software
que controla el funcionamiento del sistema físico (hardware), ocultando sus detalles al usuario,
permitiéndole así trabajar con el ordenador de una forma fácil y segura.
El sistema operativo enmascara los recursos físicos, permitiendo un manejo sencillo y
flexible de los mismos, y proporciona determinados servicios de alto nivel al usuario que no están
directamente presentes en el hardware subyacente. En este sentido, hace posible la ejecución y uso
de aplicaciones por parte del usuario. De esta forma, el sistema operativo junto con el hardware
(máquina física) definen una máquina virtual que puede ser utilizada sin conocer las
características concretas de los dispositivos hardware.
El sistema operativo actúa como un programa (o conjunto de programas) de control que
tiene por objeto facilitar el uso del ordenador y conseguir que éste se utilice eficientemente.
Es un programa de control, ya que se encarga de gestionar y asignar los recursos
hardware a los usuarios. Controla los programas de los usuarios y los dispositivos de E/S. Los
recursos hardware son:
• El procesador (CPU): Dado que es el lugar donde se ejecutan las instrucciones de
los programas de aplicación, se debe controlar la forma en que se ejecutan dichos
programas.
• La memoria principal: Dado que es el dispositivo donde residirán los datos a
procesar y los programas a ejecutar, es necesario regular su uso y ocupación.

33
• Los dispositivos periféricos: Estas unidades permiten la comunicación de los
programas con el exterior, y debe asegurarse su adecuado direccionamiento y
control.
El sistema operativo facilita el uso del ordenador. Contiene módulos de gestión de
entradas/salidas que evitan a los usuarios tener que incluir esas instrucciones cada vez que
realizan una operación de ese tipo. Se puede decir que esos módulos del sistema operativo hacen
“transparente” al usuario las características hardware concretas de los dispositivos.
El sistema operativo también hace que el ordenador se utilice eficientemente. Por ejemplo,
en los sistemas de multiprogramación hace que, cuando un programa esté dedicado a una
operación de entrada o salida, la CPU pase a atender a otro programa.
En el desarrollo de este tema veremos los componentes que lo integran: núcleo, servicios y
el intérprete de mandatos o shell; distinguiremos los sistemas operativos con estructuras
monolíticas de los que son propiamente estructurados; veremos las funciones clásicas del sistema
operativo, se pueden agrupar en las tres siguientes: gestión de los recursos de la computadora,
ejecución de servicios para los programas, ejecución de los mandatos de los usuarios. Por último
haremos una revisión histórica de la evolución de los sitemas operativos, permitiéndonos
clasificarlos adecuadamente.
Los sistemas operativos se pueden clasificar según distintos criterios fundamentales:
• Administración de tareas:
➥ Monotarea: Solamente puede ejecutar un proceso (aparte de los procesos del
propio S.O.) en un momento dado. Una vez que empieza a ejecutar un
proceso, continuará haciéndolo hasta su finalización o interrupción.
➥ Multitarea: Es capaz de ejecutar varios procesos al mismo tiempo. Este tipo
de S.O. normalmente asigna los recursos disponibles (CPU, memoria,
periféricos) de forma alternada a los procesos que los solicitan, de manera
que el usuario percibe que todos funcionan a la vez, de forma concurrente.
• Administración de usuarios:

34
➥ Monousuario: Si sólo permite ejecutar los programas de un usuario al
mismo tiempo.
➥ Multiusuario: Si permite que varios usuarios ejecuten simultáneamente sus
programas, accediendo a la vez a los recursos de la computadora.
Normalmente estos sistemas operativos utilizan métodos de protección de
datos, de manera que un programa no pueda usar o cambiar los datos de otro
usuario.
• Manejo de recursos:
➥ Centralizado: Si permite utilizar los recursos de una sola computadora.
➥ Distribuido: Si permite utilizar los recursos (memoria, CPU, disco,
periféricos...) de más de una computadora al mismo tiempo.
El sistema operativo lo forman un conjunto de programas que ayudan a los usuarios en la
explotación de una computadora, simplificando, por un lado, su uso, y permitiendo, por otro,
obtener un buen rendimiento de la máquina. Es difícil tratar de dar una definición precisa de
sistema operativo, puesto que existen muchos tipos, según sea la aplicación deseada, el tamaño de
la computadora usada y el énfasis que se dé a su explotación. Por ello se va a realizar un bosquejo
de la evolución histórica de los sistemas operativos, ya que así quedará plasmada la finalidad que
se les ha ido atribuyendo.
5.1. EVOLUCIÓN DE LOS SISTEMAS OPERATIVOS
Se pueden encontrar los siguientes tipos de sistemas operativos, durante las cuatro
generaciones de evolución de los sistemas operativos.
5.1.1. Primera etapa (1943 – 1955).
Durante esta etapa, se construyen las primeras computadoras. Como ejemplo de
computadoras de esta época se pueden citar el ENIAC (Electronic Numerical Integrator Analyzer
and Computer), financiado por el Laboratorio de Investigación Balística de los Estados Unidos. El
ENIAC era una máquina enorme con un peso de 30 toneladas, que era capaz de realizar 5.000

35
sumas por segundo, 457 multiplicaciones por segundo y 38 divisiones por segundo. Otra
computadora de esta época fue el EDVAC (Electronic Discrete Variable Automatic Computer).
En esta etapa no existían sistemas operativos. El usuario debía codificar su programa a
mano y en instrucciones máquina, y debía introducirlo personalmente en la computadora, mediante
conmutadores o tarjetas perforadas. Las salidas se imprimían o se perforaban en cinta de papel
para su posterior impresión. En caso de errores en la ejecución de los programas, el usuario tenía
que depurarlos examinando el contenido de la memoria y los registros de la computadora.
En esta primera etapa todos los trabajos se realizaban en serie. Se introducía un programa
en la computadora, se ejecutaba y se imprimían los resultados y se repetía este proceso con otros
programas. Otro aspecto importante de esta época es que se requería mucho tiempo para preparar y
ejecutar un programa, ya que el programador debía encargarse de codificar todo el programa e
introducirlo en la computadora de forma manual.
5.1.2. SEGUNDA etapa (1956 – 1963).
Sistemas operativos por lotes: con la aparición de la primera generación de computadoras
(50’s) se hace necesario racionalizar su explotación, puesto que ya empieza a haber una base
mayor de usuarios. El tipo de operación seguía siendo serie como en el caso anterior, esto es, se
trataba un trabajo detrás de otro, teniendo cada trabajo las fases siguientes:
• Instalación de cintas o fichas perforadas en los dispositivos periféricos. En su caso,
instalación del papel en la impresora.
• Lectura mediante un programa cargador del programa a ejecutar y de sus datos.
• Ejecución del programa.
• Impresión o grabación de los resultados.
• Retirada de cintas, fichas y papel.
La realización de la primera fase se denominaba montar el trabajo.
El problema básico que abordaban estos sistemas operativos primitivos era optimizar el
flujo de trabajos, minimizando el tiempo empleado en retirar un trabajo y montar el siguiente.

36
También empezaron a abordar el problema de la E/S, facilitando al usuario paquetes de rutinas de
E/S, para simplificar la programación de estas operaciones, apareciendo así los primeros
manejadores de dispositivos. Se introdujo también el concepto de system file name, que empleaba
un nombre o número simbólico para referirse a los periféricos, haciendo que su manipulación fuera
mucho más flexible que mediante las direcciones físicas.
Para minimizar el tiempo de montaje de los trabajos, éstos se agrupaban en lotes (batch) del
mismo tipo (p. ej.: programas Fortran, programas Cobol, etc.), lo que evitaba tener que montar y
desmontar las cintas de los compiladores y montadores, aumentando el rendimiento.
En las grandes instalaciones se utilizaban computadoras auxiliares, o satélites, para realizar
las funciones de montar y retirar los trabajos. Así se mejoraba el rendimiento de la computadora
principal, puesto que se le suministraban los trabajos montados en cinta magnética y éste se
limitaba a procesarlos y a grabar los resultados también en cinta magnética. En este caso se decía
que la E/S se hacía fuera de línea (off-line).
Los sistemas operativos de las grandes instalaciones tenían las siguientes características:
• Procesaban un único flujo de trabajos en lotes.
• Disponían de un conjunto de rutinas de E/S.
• Usaban mecanismos rápidos para pasar de un trabajo al siguiente.
• Permitían la recuperación del sistema si un trabajo acababa en error.
• Tenían un lenguaje de control de trabajos que permitía especificar los recursos a
utilizar y las operaciones a realizar por cada trabajo.
Como ejemplos de sistemas operativos de esta época se pueden citar el FMS (Fortran
Monitor System) e IBYSS, el sistema operativo de la IBM 7094.
5.1.3. TERCERA etapa (1963 – 1979).
Sistemas operativos de multiprogramación: con la aparición de la segunda generación
de computadoras (60’s) se hizo más necesario, dada la mayor competencia entre los fabricantes,
mejorar la explotación de estas máquinas de altos precios. La multiprogramación se impuso en
sistemas de lotes como una forma de aprovechar el tiempo empleado en las operaciones de E/S. La

37
base de estos sistemas reside en la gran diferencia que existe entre las velocidades de los
periféricos y de la UCP, por lo que esta última, en las operaciones de E/S, se pasa mucho tiempo
esperando a los periféricos. Una forma de aprovechar ese tiempo consiste en mantener varios
trabajos simultáneamente en memoria principal (técnica llamada de multiprogramación), y
en realizar las operaciones de E/S por acceso directo a memoria. Cuando un trabajo necesita una
operación de E/S la solicita al sistema operativo que se encarga de:
• Congelar el trabajo solicitante.
• Iniciar la mencionada operación de E/S por DMA.
• Pasar a realizar otro trabajo residente en memoria. Estas operaciones las realiza el
sistema operativo multiprogramado de forma transparente al usuario.
Sistemas operativos de tiempo compartido: También en la segunda generación de
computadoras comienzan a desarrollarse los sistemas de tiempo compartido o timesharing. Estos
sistemas, a los que estamos muy acostumbrados en la actualidad, permiten que varios usuarios
trabajen de forma interactiva o conversacional con la computadora desde terminales, que en
aquellos días eran teletipos electromecánicos. El sistema operativo se encarga de repartir el tiempo
de la UCP entre los distintos usuarios, asignando de forma rotativa pequeños intervalos de tiempo
de UCP denominadas rodajas (time slice). En sistemas bien dimensionados, cada usuario tiene la
impresión de que la computadora le atiende exclusivamente a él, respondiendo rápidamente a sus
órdenes. Aparecen así los primeros planificadores. El CTSS, desarrollado en el MIT fue el primer
sistema de tiempo compartido.
Sistemas operativos en tiempo real: los primeros sistemas de tiempo real datan también
de los años sesenta, pertenecientes por tanto a la segunda generación de computadoras. Se trata de
aplicaciones militares, en concreto para detección de ataques aéreos. En este caso, la computadora
está conectada a un sistema externo y debe responder velozmente a las necesidades de ese sistema
externo. En este tipo de sistemas las respuestas deben producirse en períodos de tiempo
previamente especificados, que en la mayoría de los casos son pequeños. Los primeros sistemas de
este tipo se construían en ensamblador y ejecutaban sobre máquina desnuda, lo que hacía de estas
aplicaciones sistemas muy complejos.

38
Sistemas operativos de propósito general o multimodo: La tercera generación (70’s) es
la época de los sistemas de propósito general y se caracteriza por la sistemas operativos
multimodo de operación, esto es, capaces de operar en lotes, en multiprogramación, en tiempo
real, en tiempo compartido y en modo multiprocesador. Estos sistemas operativa fueron
costosísimos de realizar e interpusieron entre el usuario y el hardware una gruesa capa de software,
de forma que éste sólo veía esta capa, sin tenerse que preocupar de los detalles de la circuitería.
Uno de los inconvenientes de estos sistemas operativos era su complejo lenguaje de control
que debían aprenderse los usuarios para preparar sus trabajos, puesto que era necesario especificar
multitud de detalles y opciones. Otro de los inconvenientes era el gran consumo de recursos que
ocasionaban, esto es, los grandes espacios de memoria principal y secundaria ocupados, así como
tiempo de UCP consumido, que en algunos casos superaba el 50 por 100 del tiempo total.
Esta década fue importante por la aparición de dos sistemas que tuvieron una gran difusión
UNIX y MVS de IBM. De especial importancia fue UNIX, desarrollado en los laboratorios Bell
para una PDP-7 en 1970. Pronto se transportó a una PDP-11, para cual se reescribió utilizando el
lenguaje de programación C. Esto fue algo muy importante en historia de los sistemas operativos,
ya que hasta la fecha ninguno se había escrito utilizando lenguaje de alto nivel, recurriendo para
ello a los lenguajes ensambladores propios de cada quitectura. Sólo una pequeña parte de UNIX,
aquella que accedía de forma directa al hardware siguió escribiéndose en ensamblador. La
programación de un sistema operativo utilizando un lenguaje de alto nivel como es C hace que un
sistema operativo sea fácilmente transportable a amplia gama de computadoras. En la actualidad,
prácticamente todos los sistemas operativos escriben en lenguajes de alto nivel, fundamentalmente
en C.
La primera versión ampliamente disponible de UNIX fue la versión 6 de los laboratorios
Bell que apareció en 1976. A ésta le siguió la versión 7 distribuida en 1978, antecesora de
prácticamente todas las versiones modernas de UNIX. En 1982 aparece una versión de UNIX
desarrollada por Universidad de California en Berkeley, la cual se distribuyó como la versión BSD
(Berkeley Ovare Distribution) de UNIX. Esta versión de UNIX introdujo mejoras importantes
como la inclusión de memoria virtual y la interfaz de sockets para la programación de aplicaciones
sobre protocolos TCP/IP.
Más tarde, AT&T (propietario de los laboratorios Bell) distribuyó la versión de UNIX
conocida como System V o RVS4. Desde entonces muchos han sido los fabricantes de

39
computadoras has adoptado a UNIX como sistema operativo de sus máquinas. Ejemplos de estas
versiones Solaris de SUN, HP UNIX, IRIX de SGI y AIX de IBM.
5.1.4. CUARTA etapa (1980 – actualidad).
Sistemas operativos orientados a usuarios finales: La cuarta generación se caracteriza
por una evolución de los sistemas operativos de propósito general de la tercera generación,
tendente a su especialización, a su simplificación y a dar más importancia a la productividad del
usuario que al rendimiento de la máquina.
Adquiere cada vez más importancia el tema de las redes de computadoras, tanto redes de
largo alcance como locales. En concreto, la disminución del coste del hardware hace que se
difunda el proceso distribuido, en contra de la tendencia centralizadora anterior. El proceso
distribuido consiste en disponer de varias computadoras, cada una situada en el lugar de trabajo de
las personas que la emplean, en lugar de una única central. Estas computadoras suelen estar unidas
mediante una red, de forma que puedan compartir información y periféricos.
Se difunde el concepto de máquina virtual , consistente en que una computadora X,
incluyendo su sistema operativo, sea simulada por otra computadora Y. Su ventaja es que permite
ejecutar, en la computadora Y, programas preparados para la computadora X, lo que posibilita el
empleo de software elaborado para la computadora X, sin necesidad de disponer de dicha
computadora.
Durante esta época, los sistemas de bases de datos sustituyen a los archivos en multitud de
aplicaciones. Estos sistemas se diferencian de un conjunto de archivos en que sus datos están
estructurados de tal forma que permiten acceder a la información de diversas maneras, evitar datos
redundantes y mantener su integridad y coherencia.
La difusión de las computadoras personales ha traído una humanización en los sistemas
informáticos. Aparecen los sistemas «amistosos» o ergonómicos, en los que se evita que el usuario
tenga que aprenderse complejos lenguajes de control, sustituyéndose éstos por los sistemas
dirigidos por menú, en los que la selección puede incluso hacerse mediante un manejados de
cursor. En estos sistemas, de orientación monousuario, el objetivo primario del sistema operativo
ya no es aumentar el rendimiento del sistema, sino la productividad del usuario. En este sentido, la
tendencia actual consiste en utilizar sistemas operativos multiprogramados sobre los que se añade

40
un gestor de ventanas, lo que permite que el usuario tenga activas, en cada momento, tantas tareas
como desee y que las distribuya a su antojo sobre la superficie del terminal.
Los sistemas operativos que dominaron el campo de las computadoras personales fueron
UNIX, MS-DOS y los sucesores de Microsoft para este sistema: Windows 95/98, Windows NT y
Windows 2000. La primera versión de Windows NT (versión 3.1) apareció en 1993 e incluía la
misma interfaz de usuario que Windows 3.1. En 1996 aparece la versión 4.0, que se caracterizó por
la inclusión dentro del ejecutivo de Windows NT de diversos componentes gráficos que ejecutaban
anteriormente en modo usuario. Durante el año 2000, Microsoft distribuye la versión denominada
Windows 2000. Posteriormente le han sucedido Windows XP y, para servidores, Windows 2003.
También ha tenido importancia durante esta época el desarrollo de Linux. Linux es un
sistema operativo similar a UNIX, desarrollado de forma desinteresada durante la década de los
noventa por miles de voluntarios conectados a Internet. Linux está creciendo fuertemente debido
sobre todo a su bajo coste y a su gran estabilidad, comparable a cualquier otro sistema UNIX. Una
de las principales características de Linux es que su código fuente está disponible, lo que le hace
especialmente atractivo para el estudio de la estructura interna de un sistema operativo. Su
aparición ha tenido también mucha importancia en el mercado del software ya que ha hecho que se
difunda el concepto de software libre.
Sistemas operativos distribuidos: A mediados de los ochenta aparecen los sistemas
operativos distribuidos. Un sistema operativo distribuido es un sistema operativo común utilizado
en una serie de computadoras conectadas por una red. Este tipo de sistemas aparece al usuario
como un único sistema operativo centralizado, haciendo por tanto más fácil el uso de una red de
computadoras. Un sistema operativo de este tipo sigue teniendo las mismas características que un
sistema operativo convencional pero aplicadas a un sistema distribuido. Como ejemplo de sistemas
operativos distribuidos se puede citar: Mach, Chorus y Amoeba.
Figura. Estructura de un sistema distribuido que utiliza un sistema operativo distribuido

41
Sistemas operativos con middleware: los sistemas operativos distribuidos han dejado de
tener importancia y han evolucionado durante la década de los noventa a lo que se conoce como
middleware. Un middleware es una capa de software que se ejecuta sobre un sistema operativo ya
existente y que se encarga de gestionar un sistema distribuido. En este sentido, presenta las mismas
funciones que un sistema operativo distribuido. La diferencia es que ejecuta sobre sistemas
operativos ya existentes que pueden ser además distintos, lo que hace más atractiva su utilización.
Dos de los middleware más importantes de esta década han sido DCE y CORBA. Microsoft
también ofrece su propio middleware conocido como DCOM.
Figura. Estructura de un sistema distribuido que emplea un middleware
5.2. Evolución de los sistemas operativos de mayor difusión.
Inicialmente cada fabricante de computadores (IBM, DEC, Data General, Apple, Sperry,
etc.) desarrollaba sus propios sistemas operativos, que incluso, dentro de la misma empresa,
podrían diferir de una serie de computadores a otra. Esto dificultaba considerablemente el trabajo
de los programadores y usuarios, en general, ya que, con gran frecuencia, al cambiar de
computador tenían que aprender un nuevo sistema operativo y realizar las adaptaciones oportunas
de todas las aplicaciones al nuevo equipo. Este panorama ha cambiado en la actualidad debido a
que en el mercado se han impuesto sistemas operativos que no son propietarios de un determinado
fabricante de computadores sino que son realizados por terceras personas o empresas
especializadas en software de forma que pueden ser utilizados en equipos muy diversos. Los más
relevantes son los siguientes:

42
5.2.1. Sistemas operativos de Microsoft.
Son los sistemas operativos dominantes en el mercado de microcomputadores. El primero
de ellos es el MS-DOS (Microsoft Disk Operating System) y debe su difusión a que fue adoptado
por IBM al inicio de la década de los 80 como el sistema operativo estándar para el IBM-PC. En la
Figura 15.8 se muestra un esquema de la evolución de este sistema operativo. El MS-DOS inicial
era un sistema operativo para microprocesadores de 16 bits (de Intel), monousuario y tenía una
interfaz de usuario de línea de órdenes. A inicios de los 90 se comercializó el Microsoft Windows
3.0 que disponía de una GUI con gestión de menús, y era capaz de cargar en memoria más de un
programa a la vez. En 1995 Microsoft comercializó el Windows 95, que contiene una GUI basada
en iconos, y es un sistema operativo de 16/32 bits con multiprogramación apropiativa (puede
suspender temporalmente la ejecución de un trabajo para ejecutar otro) y con memoria virtual.
Posteriormente se comercializaron las versiones Windows 98 y Windows ME (Milenium), en 1998
y en 2000, respectivamente. Conviene indicar que las denominaciones Windows en realidad hacen
referencia a la GUI: para identificar completamente a las nuevas versiones de Microsoft hay que
facilitar también la versión del sistema operativo propiamente dicho; por ejemplo, una versión
concreta es: Windows 98 MS-DOS 7.0.
Paralelamente al desarrollo de las versiones Windows, en 1993 Microsoft comercializó el
Windows NT (Windows New Technology), diseñado fundamentalmente para estaciones de trabajo
potentes y servidores de red con procesadores de 32 bits. En 2001 se disponían de tres alternativas:
• Windows 2000 professional: está orientado a estaciones de trabajo en red. Puede
utilizarse con diversos procesadores (Intel, Alpha y PowerPC). Es un sistema
operativo monousuario y multiprogramación. Su interfaz de usuario es muy
parecida a Windows 95, pero ofrece mucha más seguridad (identificación y
contabilidad de usuarios) y tolerante a fallos (aísla unos programas de otros, y
duplica en línea el contenido de los discos de forma que si falla uno,
automáticamente actúa el de respaldo).
• Windows NT Server (servidores): es una versión ampliada del Windows NT
Workstation, multiusuario y proyectada para actuar en servidores de archivos y de
impresoras, y otros sistemas, a los que se accede a través de redes de área local
(LAN) o internet. Incluye funciones de seguridad para grupos de usuario,

43
autentificación de usuarios y control de acceso a los recursos compartidos de la red.
Admite estructuras RAID de discos.
• Windows CE (Consumer Electronics): es una versión simplificada de las otras
versiones de Windows NT ideada para equipos informáticos miniaturizados, como
computadores móviles (asistentes digitales personales, computadores de bolsillo, or-
ganizadores personales, etc.), televisores conectables a internet, etc.
En el año 2001 se comercializó en Windows XP, que supuso la unificación de la línea
clásica de los sistemas operativos de Microsoft (Windows 3.1/95/98J98SE/ME) con la de
Windows NT (NT 3.1, 4.1 y Windows 2000), véase Figura 15.8. El Windows XP contiene el
núcleo del Windows NT y se comercializó en dos versiones: Home y Proffesional. Posteriormente
se lanzó al mercado el Windows 2003 y Vista.
Figura. Pasos más relevantes en la evoluciónde los sistemas operativos Microsoft.

44
5.2.2. UNIX y GNU/Linux.
El sistema operativo UNIX inicialmente se desarrolló en los Bell Labs de la AT&T y fue
comercializado en sus inicios por Honeywell y, a los comienzos de la década de los 90, por Novell.
En la siguiente figura 15.9 se incluye un esquema simplificado de la evolución de este sistema
operativo. Una de las versiones más conocidas es la desarrollada en el Campus de Berkeley de la
Universidad de California. Algunas de las principales características del UNIX son las siguientes:
• Desde un punto de vista técnico UNIX puede considerarse como un conjunto de
familias de sistemas operativos que comparten ciertos criterios de diseño e
interoperabilidad. Esta familia incluye más de 100 sistemas operativos desarrollados
a lo largo de 35 años. No obstante, es importante señalar que esta definición no
implica necesariamente que dichos sistemas operativos compartan código máquina
o cualquier propiedad intelectual.
• Puede funcionar en multitud de computadores, desde en los supercomputadores
Cray hasta en PC. Debido a ello puede considerarse como un auténtico sistema
operativo estándar y la columna vertebral de Internet. Su mayor uso se da en
estaciones de trabajo para usuarios CAD y CAM (estaciones de trabajo de Sun
Microsystems, Hewlett-Packard, IBM y Silicon Graphics).
• Es un sistema operativo de multiprogramación, multiusuario y multiprocesamiento,
pudiéndose utilizar también para procesamiento en tiempo real.
• A priori al poder configurar más parámetros del sistema operativo puede resultar
más difícil de aprender y de usar que los MS-Windows y Mac orientados
claramente a usuarios finales.

45
Figura. Pasos relevantes en la evolución del sistema operativo UNIX.
Un estudiante de informática de la Universidad de Helsinki (Finlandia) llamado Linus
Torvalls concluyó en 1991 (con 23 años de edad) un sistema operativo que denominó Linux,
versión 0.01. Este sistema operativo fue concebido como una versión PC compatible y
sustancialmente mejorada del sistema operativo Minix (muy parecido al UNIX), descrito por el
profesor Tanenbaum en sus primeros textos de sistemas operativos. Aunque Linux no es un
programa de dominio público, se distribuye con una licencia GPL (General Public Licence) de
GNU, de forma que los autores no han renunciado a sus derechos, pero la obtención de su licencia
es gratuita, y cualquiera puede disponer de todos los programas fuente, modificarlos y desarrollar
nuevas aplicaciones basadas en Linux, teniendo derecho a regalar éstas e incluso a venderlas. La
condición de la licencia radica en que nadie puede registrar como propiedad intelectual los
productos derivados de Linux y los usuarios que adquieran (por compra o gratuitamente) el código
modificado tienen derecho a disponer también del código fuente correspondiente. Linux hoy día
puede considerarse como un clónico de UNIX desarrollado por multitud de personas distribuidas
por todo el mundo.

46
5.2.3. Otros sistemas operativos.
Hay otros muchos sistemas operativos, entre los que se pueden destacar:
• MacOS, o sistema operativo de los Macintosh. Desarrollado a mediados de los 80,
es sin lugar a dudas el precursor de los sistemas operativos con interfaz gráfica,
siendo muy fácil de usar y el preferido por empresas de publicidad y de artes
gráficas, y realizadores de aplicaciones multimedia. Su principal inconveniente es
que sólo funciona en los PC tipo Macintosh y sus compatibles (microprocesadores
Motorola), no existiendo tanta disponibilidad de software como para los IBM-PC y
compatibles (microprocesadores Intel).
• OS/2, desarrollado a partir de 1982 inicialmente de forma conjunta por IBM e Intel,
es un sistema operativo monousuario y multiprogramación ideado para los
microprocesadores Intel. Actualmente sólo es comercializado y mantenido por IBM.
• MVS (Múltiple Virtual Storage), es uno de los sistemas operativos más sofisticados
desarrollado por IBM para grandes computadores, es de tipo multiprogramación,
multiusuario, funcionando tanto de forma interactiva como por lotes, y con memoria
virtual.
Los sistemas operativos son una parte fundamental de los sistemas informáticos, significan
mucho más que simplemente la interfaz de usuario. En el futuro próximo, la evolución de los
sistemas operativos se va a orientar hacia las plataformas distribuidas y la computación móvil.
Gran importancia tendrá la construcción de sistemas operativos y entornos que permitan utilizar
estaciones de trabajo heterogéneas (computadoras de diferentes fabricantes con sistemas
operativos distintos) conectadas por redes de interconexión, como una gran máquina centralizada,
lo que permitirá disponer de una mayor capacidad de cómputo y facilitará el trabajo cooperativo.

47
6. ALGORITMIA, PROGRAMACIÓN Y APLICACIONES
Los primeros algoritmos conocidos están fechados entre los años 3000 y 1500 antes de
Cristo. Fueron encontrados en la zona conocida como Mesopotamia (actualmente Irak) cerca de la
ciudad de Babilonia. Estos algoritmos no tenían ni condicionales, los expresaban escribiendo
diversas veces el algoritmo, extendían el algoritmo con tantos pasos como fuera necesario.
Algoritmo proviene de Mohammed al-KhoWârizmi, matemático persa que vivió durante el siglo
IX y alcanzó gran reputación por el enunciado de las reglas paso a paso para sumar, restar,
multiplicar y dividir números decimales; la traducción al latín del apellido en la palabra algorismus
derivó posteriormente en algoritmo. Euclides, el gran matemático griego (del siglo IV a.C.) que
inventó un método para encontrar el máximo común divisor de dos números, se considera con Al-
Khowârizmi el otro gran padre de la algoritmia (ciencia que trata de los algoritmos).
Más recientes fueron las aportaciones en este campo de Charles Babbage, quien entre los
años 1820 y 1850, diseñó dos máquinas para computar ninguna de las cuales fue terminada. La
más interesante, ya que se parecía a los computadores digitales modernos, fue la máquina
analítica. Los programas para este primer computador estaban escritos, básicamente, en lenguaje
máquina y utilizaban unas ciertas tarjetas de operación y tarjetas de variable (no se tenía la idea de
programas y datos residentes en memoria). Junto a Babbage trabajó Ada Augusta, condesa de
Lovelace, hija del famoso poeta Lord Byron. Recientemente ha sido reconocida como la primera
programadora (en su honor se llamó ADA al último lenguaje desarrollado bajo el auspicio del
Departamento de Defensa de los Estados Unidos).
Durante los años 1930 y 1940 surge un gran número de científicos con ideas sobre
notaciones para la programación. La mayoría eran puramente teóricas, es decir, no pretendían que
fueran usadas en máquinas reales. Algunos ejemplos son la máquma de Turing o el cálculo
lambda.
A principios de los años 1950 se empezaron a construir máquinas con cierta capacidad de
cálculo (aunque muy limitadas y costosas), que trabajaban con lenguajes tipo ensamblador.
Todos estos lenguajes eran muy parecidos y tuvieron un éxito muy limitado. Ejemplos de estos
lenguajes podrían ser AUTOCODER, SPS, BAL o EASYCODER.

48
A mediados de los años 50 comenzaron a aparecer máquinas con más capacidad de
cálculo y memoria, y se creó FORTRAN cuyo principal propósito era conseguir eficiencia. Entre
los anos 57 y 63 aparecen ALGOL (ALGOL6O), COBOL y LISP.
ALGOL fue un lenguaje diseñado por un colectivo mayoritariamente europeo. Sus
objetivos principales eran la claridad, la coherencia y la elegancia, pero no la eficiencia. Sólo se
usaba en las universidades, pero fue el más importante de la época. Para definir su sintaxis, se
utilizó por primera vez la notación BNF (Backus-Naur-Formalism) que fue utilizada
posteriormente en la definición de otros lenguajes. ALGOL introdujo nociones como la de tipo de
datos o de estructura de bloques, así corno ciertas instrucciones que después han sido muy
utilizadas (while, if, else, etc.) o el uso de la recursividad. Se le considera un lenguaje muy bien
diseñado.
COBOL, en cambio, fue un lenguaje diseñado por un comité bajo el auspicio del
Departamento de Defensa de EEUU para las necesidades, las áreas de problemas y los hábitos de
expresión de los programadores en el procesamiento de datos comerciales y bases de datos. Se
intentó obtener programas más legibles y aumentar la potencia en el tratamiento de ficheros.
LISP fue un lenguaje extraño en su momento, ya que no se parecía a ningún otro lenguaje
anterior. En LISP se pueden tener funciones que se aplican a ciertos datos, de aquí proviene el
nombre de lenguaje funcional con el que se denomina a éste y a otros lenguajes de estas
características. Como tipo de datos tenemos símbolos (tratamiento simbólico) o bien la estructura
de datos lista. Fue un lenguaje difícil de implementar.
Después de estos lenguajes aparecieron otros, todos orientados a resolver algún problema
concreto. Hacia el 1965 aparece BASIC, por motivos didácticos. Estaba orientado a computadores
pequeños. Es un lenguaje con pocas instrucciones y fácil de aprender. Durante la primera editad de
los años 60 se define lenguajes como SNOBOL (para el procesamiento de cadenas de caracteres,
es decir, tratamiento de textos) o APL (para el tratamiento de matrices).
Un resultado negativo de la proliferación de estos primeros lenguajes fue la división de la
programación en dos campos, las aplicaciones científicas y las comerciales. De hecho, el
problema venía de la creencia que programar consistía principalmente en codificar algoritmos en
un lenguaje específico. Entre el 1954 y 1957 se desarrolla PL/I, en un intento de crear un lenguaje
útil para resolver cualquier tipo de problema. El resultado fue un lenguaje demasiado grande,
difícil de aprender y de conocer, y a la vez poco fiable.

49
En 1967 se crea SIMULA, basado en ALGOL60, con la simulación como campo de
aplicación principal. Una de las características más importantes que se introducen en SIMULA es
el concepto de clase, donde un conjunto de declaraciones y procedimientos están agrupados y
tratados como una unidad. Se pueden generar objetos de una clase, que pueden ser usados fueraa
del bloque donde fueron creados. El concepto de clase es considerado el precusor de la abstracción
de datos.
ALGOL68 (1968) pretendía ser el sucesor de ALGOL60, es decir, una versión más
actualizada. Se intentó llegar a la máxima ortogonolidad (no poner ninguna restricción a los
componentes del lenguaje: instrucciones, estructuras de datos, etc.). Se quería conseguir un
lenguaje simple y ortogonal, y de esta forma, obtener un lenguaje potente y sencillo. El resultado,
en cambio, fue un lenguaje casi inimplementable. Fue el fracaso más grande de la historia de los
lenguajes de programación.
Después de la crisis del software, a principios de los 70, aparece Pascal, notablemente
influido por las nuevas técnicas: verificación de programas, programación estructurada, etc. Sigue
la línea de ALGOL60 con adquisiciones de otros lenguajes: el constructor tupla (COBOL y PL/I),
los tipos de datos, se mejoran los apuntadores (respecto a PL/I), se definen mejor los bloques. Es
un lenguaje bastante bien diseñado.
Tras Pascal (en la década de los 70) aparecen lenguajes de alto nivel diseñados para
programar en un cierto estilo, como CLU, ALPHARD, C, MODULA o EUCLID. Se introduce la
idea de programación paralela. Aparecen los programas concurrentes en nuevas versiones de
MODULA y en Pascal concurrente. En este periodo se crea el primer lenguaje de programación
lógica, PROLOG, cuyo dominio de aplicación se restringía a una parte de la lógica de primer
orden, la lógica clausal. Se basaba en la existencia de una cierta similitud entre teoremas y
programas, y entre demostración y ejecución. Posteriormente fue mejorado y se convirtió en un
lenguaje útil en diversos campos de la programación (principalmente científicos).
El lenguaje C fue inventado en los Laboratorios Bell en 1972 por Dennis Ritchie e
implementado sobre un DEC PDP-11 utilizando el sistema operativo UNIX. La idea de Ritchie era
crear un lenguaje de propósito general (al contrario de los lenguajs de propósito específico, como
es el caso de FORTRAN para el cálculo cinentífico) que facilitara la programación y realización de
muchas de las tareas anteriormente reservadas al lenguaje ensamblador. Inicialmente surgieron
varias versiones de C incompatibles entre sí, hasta que en 1983 ANSI lo estandarizó. Se ha usado

50
para el desarrollo de infinidad de herramientas de trabajo (sistemas operativos, compiladores,
procesadores de texto, sistemas gestores de bases de datos, etc.). La ventaja más destacable es la
transportabilidad o portabilidad, es decir, la posibilidad de utilizarlo en diversos sistemas y
máquinas. El lenguaje C es un lenguaje que por estas carcaterísticas se ha convertido en referencia
a nivel educativo a la hora de iniciarse en la programación, en escuelas técnicas y de formación
profesional, incluso por autodidactas, principalmente por la cantidad de documentación existente.
Con el proyecto de las máquinas de quinta generación (máquinas muntiprocesador con
paralelismo masivo), surgen nuevos lenguajes funcionales y se empiezan a usar los lenguajes
lógicos. Nace un nuevo tipo de lenguajes, los de flujo de datos: VAL, LAU, Id o Lucid. Son len-
guajes experimentales que se basan en el intento de hacer el máximo número de cálculos en
paralelo. También durante los últimos años han surgido los lenguajes orientarlos a objetos. que
tienen como principales representantes a Smalltalk y Eiffel.
Debido a la gran cantidad de lenguajes existentes, se intentó nuevamente diseñar un
lenguaje de gran abasto, esta vez con el auspicio del Departamento de Defensa de EEUU. El
resultado fue ADA, la versión definitiva del cual apareció en 1983. Para evitar que se hicieran
versiones de este lenguaje (con el mismo nombre) se registró la marca. Para obtener una
generalidad máxima, el compilador de ADA fue el primero que no daba directamente código en el
lenguaje máquina del computador en el que se estaba trabajando, sino que generaba un código
intermedio, que se pretendía que fuera único para todo tipo de máquina, y posteriormente se
pasaba al lenguaje máquina determinado. Así, la primera parte del compilador era común para
todas las máquinas que lo usaran. ADA se convirtió en un lenguaje para profesionales (con gran
capacidad de abstracción y conocimientos a nivel teórico), pues era un lenguaje muy complejo y
extenso. En ADA se mejoraron las construcciones modulares, las tuplas con partes variables, los
apuntadores, la forma de abordar la concurrencia, el tratamiento de excepciones (por ejemplo,
errores de ejecución) y apareció el concepto de sobrecarga (posibilidad de usar en un mismo
punto del programa el mismo identificador para denotar cosas distintas).
En la segunda mitad de los años 80 se han diseñado desde nuevos lenguajes funcionales
como Lazy ML (1984), Miranda (1985) o Standard ML (1986), hasta lenguajes que eran mejoras o
ampliaciones de otros ya conocidos, como es el caso de C++ (1986, en el que se incorpora el
concepto de clase) u Oberon (Wirth 1988, como mejora de MODULA).

51
Finalmente, durante los años 90 hasta la actualidad, han ido apareciendo los llamados
lenguajes de cuarta generación, que permiten, por ejemplo, acelerar el proceso de
automatización de las apliaciones mediante los entornos integrados de desarrollo o IDE,
integrated develpment environment, y reducir los costos de mantenimiento o permitir a los
usuarios finales solucionar directamente sus propios problemas. Muchos de estos lenguajes
dependen de bases de datos y diccionarios de datos, su acceso y ejecución es orientado a
entorno web y son multiplataforma, es decir ejecutables en distintos sistemas operativos. Pueden
incluir formatos de pantalla, formatos de informes, estructuras de diálogo, asociaciones entre
muchos datos, pruebas de validación, controles de seguridad, etc.
Una de las decisiones más importantes que se deben tomar al diseñar y construir un sistema
grande de software es la del lenguaje de programación que se va a utilizar en la aplicación del
sistema. Como la mayor parte de los costes de un sistema de software se producen en las fases de
prueba y mantenimiento del ciclo de vida, el empleo de una notación inapropiada para representar
el sistema puede ser la causa de dificultades en las etapas posteriores del ciclo de vida. La elección
de un lenguaje de programación apropiado reduce al mínimo las dificultades de codificar un
diseño, reduce la cantidad de pruebas de programas necesarias y hace al programa más legible y,
por tanto, más fácil de mantener.
La elección de un lenguaje de programación es muy importante y deben tenerse en cuenta
todos los factores al hacer tal elección. En la actualidad, no hay lenguajes que sean realmente
adecuados para todas las aplicaciones, y no es recomendable la estandarización rígida de un solo
lenguaje.
6.1. HISTORIA DE LA INGENIERÍA DEL SOFTWARE
A lo largo del desarrollo de un sistema software desde el estudio de requisitos hasta la
implementación y puesta en marcha del mismo, se contemplan una multitud de tareas complejas.
El software desde sus orígenes de desarrollo en los que se realizaban programas de forma poco
sistemática, casi artesanal, hasta hoy en día en el que existen metodologías de desarrollo muy
definidas, ha evolucionado en gran medida gracias a la ingeniería del software que pretende aplicar
los principios de la ingeniería al desarrollo de software de forma que se sistematice la producción
del mismo.

52
La crisis del software, término informático acuñado en 1968, en la primera conferencia
organizada por la OTAN sobre desarrollo de software, se refiere a la dificultad en escribir
programas libres de defectos, fácilmente comprensibles, y que sean verificables. Las causas son,
entre otras, la complejidad que supone la tarea de programar, y los cambios a los que se tiene que
ver sometido un programa para ser continuamente adaptado a las necesidades de los usuarios. Esta
conferencia supone un punto de inflexión en el desarrollo de software, ya que formalmente nace la
ingeniería del software.
Como pudiera esperarse, las organizaciones pequeñas de proceso de datos tienden a ser
relativamente informales: los proyectos de desarrollo de sistemas nacen de conversaciones entre el
usuario y el administrador del proyecto (que puede ser a la vez el analista, el programador, y el
operario) y el proyecto procede desde el análisis hasta el diseño e implantación sin mayor alboroto.
Sin embargo, en las organizaciones más grandes, las cosas se llevan a cabo de manera
mucho más formal. La comunicación entre los usuarios, la administración y el equipo del proyecto
suele ser por escrito, y todo mundo entiende que el proyecto pasará por diversas fases antes de
completarse. Aun así, es sorprendente ver la gran diferencia entre las maneras en que dos
directores afrontan sus respectivos proyectos. De hecho, a menudo se deja a discreción del
administrador determinar las fases y actividades de su proyecto, y cómo se llevarán a cabo.

53
Recientemente, sin embargo, ha empezado a cambiar el enfoque que se le da al desarrollo
de sistemas. Cada vez son más las organizaciones grandes y pequeñas que están adoptando un
ciclo de vida uniforme y único para sus proyectos. Esto a veces se conoce como el plan del
proyecto, la metodología del desarrollo del sistema o, simplemente, “la forma en la que hacemos
las cosas aquí”. (El manual del ciclo de vida del proyecto suele ser un libro tan voluminoso como
el compendio de normas, que yace, sobre escritorio de todo analista y programador).
El enfoque a la hora de desarrollar software puede ser casero o, como alternativa, pudiera
ser que la organización para el desarrollo de sistemas decida comprar un paquete de administración
de proyectos y ajustarlo a las necesidades de la compañía. Parece obvio que, aparte de darle
empleo a las personas que crean los manuales de ciclo de vida de los proyectos (y a aquellos que
escriben libros de texto al respecto), es conveniente la metodología del proyecto. ¿De qué sirve
entonces tener un ciclo de vida de un proyecto? Existen tres objetivos principales:
1. Definir las actividades a llevarse a cabo en un proyecto de desarrollo de sistemas.
2. Lograr congruencia entre la multitud de proyectos de desarrollo de sistemas en una
misma organización.
3. Proporcionar puntos de control y revisión administrativos de las decisiones sobre
continuar o no con un proyecto. El tercer objetivo de un ciclo de vida de proyecto
normal se refiere a la necesidad de la dirección de controlar un proyecto.
Como hemos visto anteriormente en la introducción, la crisis del software se fundamentó
en el tiempo de creación de software, ya que en la creación del mismo no se obtenían los
resultados deseados, además de un gran costo y poca flexibilidad.
Es un término informático acuñado en 1968, en la primera conferencia organizada por la
OTAN sobre desarrollo de software, de la cual nació formalmente la rama de la ingeniería de
software. El término se adjudica a F. L. Bauer, aunque previamente había sido utilizado por Edsger
Dijkstra en su obra The Humble Programmer.
Básicamente, la crisis del software se refiere a la dificultad en escribir programas libres de
defectos, fácilmente comprensibles, y que sean verificables. Las causas son, entre otras, la
complejidad que supone la tarea de programar, y los cambios a los que se tiene que ver sometido
un programa para ser continuamente adaptado a las necesidades de los usuarios.

54
Englobó a una serie de sucesos que se venían observando en los proyectos de desarrollo de
software:
• Los proyectos no terminaban en plazo.
• Los proyectos no se ajustaban al presupuesto inicial.
• Baja calidad del software generado.
• Software que no cumplía las especificaciones.
• Código inmantenible que dificultaba la gestión y evolución del proyecto.
Todo esto hizo replantear el enfoque y la metodología de desarrollo de los programas,
naciendo formalmente la ingeniería del software.
El autor de referencia Roger S. Pressman en su libro “Ingeniería del Software. Un enfoque
práctico” incluye la definición del IEEE de ingeniería del software: aplicación de un enfoque
sistemático, disciplinado y cuantificable hacia el desarrollo, operación y mantenimiento del
software.
Su objetivo es facilitar el mantenimiento del software y aumentar la calidad de éste. La
ingeniería del software por tanto estudiará el conjunto de procesos para el desarrollo de productos
software según un enfoque ingenieril, considerando, además de la programación, otras actividades
previas de análisis y diseño. Si se ignoran este tipo de actividades, en lugar de ingeniería del
software se está realizando “artesanía del software”.
Los sistemas informáticos son tan complejos y en su elaboración participan tantos
desarrolladores que se hace necesario planificar y organizar cuidadosamente los equipos y plazos.
La ingeniería del software se hace, por tanto, imprescindible en proyectos serios, si bien muchos la
ignoran, con los problemas que ello acarrea a medio y largo plazo.
6.2. DESARROLLO DE APLICACIONES Y ESTANDARIZACIÓN D E FORMATOS
6.2.1. APLICACIONES
Entre las aplicaciones de software horizontal encontramos las aplicaciones ofimáticas. El
término ofimática procede de la unión de oficina e informática y trata de la automatización de
oficinas y de los procesos del trabajo que se realizan en su seno. La ofimática en sus orígenes,

55
surge como la necesidad de mecanizar las tareas más repetitivas y costosas del trabajo propio de
una oficina y con este objetivo aparecieron las primeras máquinas de escribir y calculadoras. Con
el avance de la tecnología y durante los años 70 las oficinas se van dotando de máquinas de
tratamiento de textos, dedicadas a secretarias/os principalmente. Este concepto, hoy en día
completamente obsoleto, fue transformándose gracias a la entrada de los ordenadores personales
(PCs) en la oficina.
Las fases por las que ha ido evolucionando la ofimática son:
• Primera fase (1975 - 1980). La ofimática de una empresa se componía de
elementos aislados, es decir, un procesador de textos, una hoja de cálculo, etc.
Estos elementos no tenían interrelación entre sí, la formación era muy costosa y la
interfaz con el usuario árida. Esta incipiente ofimática estaba soportada por grandes
ordenadores corporativos.
• Segunda fase (1980 - 1990). Irrumpen los paquetes integrados, como conjunto de
herramientas que daban solución a la mayoría de las funcionalidades normalmente
requeridas. Presentaban el inconveniente de tener que adquirir todo el paquete
aunque se necesitase únicamente una o dos funciones del mismo y sobre todo, la
formación no sólo era imprescindible, sino costosa. La interfaz de usuario seguía
siendo orientada a carácter.
La ofimática en este punto sigue teniendo una importancia de segundo orden frente
a aplicaciones de mayor entidad dentro de la empresa, éstas aplicaciones estaban
centralizadas en un gran ordenador central del que dependían terminales sin
capacidad de proceso.
En los últimos años 80, como consecuencia de la experiencia adquirida por los
fabricantes del sector informático y debido al cambio de estrategia de éstos hacia la
fabricación de productos para ordenadores personales, se abaratan los costes y
aumentan las prestaciones tanto en soporte físico como lógico de forma
espectacular.
• Tercera fase (a partir de 1990). La ofimática moderna, está apoyada por
ordenadores personales con alta capacidad de proceso, monitores en color y soporte
lógico desarrollado con nuevas tecnologías de programación orientada a objetos

56
(OOP). A estos factores hay que añadir el auge experimentado por las diferentes
comunicaciones y a la creciente utilización de redes locales de ordenadores
personales.
El equipo lógico se compone de paquetes modulares con una completa interrelación
entre sí, productos que comparten información y procesos, pudiéndose adquirir
únicamente lo que se necesita.
Aparecen nuevos estándares de interfaz gráfica de usuario que permiten reducir el
tiempo de formación de usuarios al mínimo y surge el concepto de “Trabajo en
Grupo”.
La información fluye a través de las redes de área local y es compartida por todos
los miembros de un grupo de trabajo que no tienen que estar necesariamente en un
mismo edificio. Esta capacidad tecnológica de hacer “circular” la información sin la
necesidad de tener un soporte en papel lleva a pensar en el futuro: “la oficina sin
papel”.
En este punto surgen las suites como conjunto de aplicaciones que al ser utilizadas
conjuntamente ofrecen ventajas adicionales en cuanto a integración y facilidad de
uso, y cuyos distintos componentes se encuentran también disponibles en el
mercado como productos independientes. La auténtica ventaja de las suites es la
integración: la capacidad de las aplicaciones para compartir datos e interactuar entre
sí de una manera que sería imposible si funcionasen por separado. Una mayor
integración aumenta la productividad. La suite debe incluir un gestor centralizado
que supervise los programas que la componen, y ofrecer herramientas compartidas
para realizar las operaciones más habituales. Todas las aplicaciones componentes
deben poder intercambiar datos de forma transparente. La suites preponderantes en
el mercado son el paquete Office de Microsoft y OpenOffice de Sun Microsystems,
de licencia libre y multiplataforma.
Entre las principales tendencias actuales de los productos ofimáticos destacan las
siguientes:
➥ Trabajo en grupo. La compartición de información y recursos está
cimentada sobre una sólida plataforma tecnológica de redes de área local,

57
esta tendencia es ya un hecho en oficinas con un entorno ofimático
avanzado.
➥ Multimedia. El fenómeno multimedia representa una auténtica revolución
tanto en la presentación de la información como en la estructura misma de la
comunicación. Existen múltiples definiciones de multimedia puesto que se
trata de una tecnología en constante evolución. Se puede decir que
multimedia es la aplicación conjunta y en un sólo mensaje de texto, gráficos,
sonido e imágenes. El fuerte crecimiento de las prestaciones de los
ordenadores personales así como del software de aplicación y los precios
cada vez más asequibles, están propiciando la rápida entrada en el mercado
de esta tecnología.
➥ Herramientas multiplataforma. La evolución tecnológica en cuanto a
conectividad y la creciente necesidad de la integración de los diferentes
sistemas existentes, están propiciando el desarrollo de productos capaces de
trabajar en diferentes plataformas. De hecho, numerosos fabricantes se están
inclinando hacia la adaptación y desarrollo de sus productos ofimáticos
sobre por ejemplo Java estándar, como es el caso de OpenOffice. Esto hace
a sus aplicaciones independientes del sistema operativo o plataforma puesto
que teniendo instalada su “máquina virtual” (“virtual machine”) (Java
Virtual Machine JVM, la cual existe para la mayoría de las plataformas), es
posible interpretar el lenguaje Java .
➥ Integración de herramientas ofimáticas. Los fabricantes en su afán por
acaparar mercado están lanzando una serie de productos llamados suites, que
son grupos de aplicaciones que al ser utilizadas conjuntamente, ofrecen
según los fabricantes ventajas adicionales en cuanto a integración y facilidad
de uso. Un requisito imprescindible es que los distintos componentes de la
suite también se encuentren disponibles en el mercado como productos
independientes, y que éstos figuren en la élite de las aplicaciones ofimáticas
del momento. Uno de los atractivos de estos conjuntos de aplicaciones es
que el precio total del mismo suele ser muy inferior al de la suma de los
programas que la forman, aunuqe la tendencia actual es a diseñar paquetes
ofimáticos completos de licencia libre, y sin costes.

58
Hoy en día la industria ofimática se realimenta de las necesidades manifestadas por los
propios usuarios, y se desarrolla en función de las mismas. Dichas necesidades son las que tienen
una importancia más significativa a la hora de adquirir un producto ofimático y que se enumeran a
continuación:
• Fácil manejo:Interfaz de usuario amigable, personalizable y sensible al contexto.
Necesidad de formación mínima.
• Protección de la inversión exigiendo una trayectoria de adaptación a las nuevas
tecnologías y una estrategia de futuro que garantice la continuidad del producto.
Compatibilidad con los productos que ya se poseen.
• Soporte de distintas plataformas físicas y sistemas operativos. Interoperabilidad con
otras aplicaciones. Facilidad para las comunicaciones con otros entornos operativos.
• Seguridad de los datos.
• Soporte de los dispositivos requeridos.
• Manuales en la lengua mayoritaria de los usuarios, muy valorables las ayudas
embebidas en el producto.
Esta lista, general para todos los productos ofimáticos, podría disgregarse dando lugar a una
lista de características técnico-funcionales específicas que se deberían exigir a los diferentes
productos ofimáticos. Los productos ofimáticos se han acercado mucho unos a otros, debido a la
utilización de un estándar gráfico común y al alto grado de conocimiento de los fabricantes sobre
las necesidades de los usuarios. Esencialmente todos los productos, cada uno en su especialidad,
realizan las mismas funciones básicas.
En el siguiente apartado se verán algunos de los formatos de ficheros más desarrollados en
cuanto al intercambio directo entre aplicaciones y sistemas. Es importante resaltar la tendencia
actual a estandarizar los formatos internos de representación que emplean las distintas aplicaciones
de propósito general para sus ficheros o archivos, ya que se pretende que la mayor parte de las
plataformas y aplicaciones, y por tanto de los usuarios potenciales, los puedan abrir sin problemas
de compatibilidad.

59
6.2.2. FORMATOS
ODA/ODIF/ODF.
La Arquitectura de Documentos de Oficina (ODA, Office Document Architecture) empezó
a desarrollarse en 1982 en un principio por la Asociación Europea de Fabricantes de Ordenadores
(ECMA).
En 1985 el programa de investigación europea ESPRIT financió una implementación piloto
de ODA. En 1991 ODA recibió un fuerte impulso con la creación del Consorcio ODA, constituido
por Bull Corporation, DEC, IBM, ICL y Siemens AG.
Más adelante fue reconocida por la ITU-T (documentos T.411-T.424) y por la
Organización Internacional de Estandarización (ISO) en su norma ISO 8613 y pasó a denominarse
Open Document Architecture. El estándar se publicó finalmente en 1999.
ODA se diseñó como un formato de intercambio para documentos elaborados mediante
procesadores de textos, y estaba destinado más a la comunicación entre sistemas de software que al
uso directo por parte de usuarios humanos. Su objetivo era conseguir que los documentos, tanto
textuales como gráficos, pudieran ser transferidos, con todos sus atributos intactos, de un sistema a
otro para poder ser luego editados, procesados, almacenados, etc. Se pretendía, en definitiva,
solucionar el problema de comunicación entre formatos de procesadores de texto propietarios,
cuya proliferación se veía en aquellos momentos (más que ahora) como una dificultad para el
intercambio de documentos complejos.
ODA describe cómo debe ser la estructura de un documentos. Esa estructura se divide en
tres partes:
• Estructura lógica, que que consiste en una secuencia en orden lógico de los objetos
que componen el fichero. la estructura lógica permite dividir un documento en
capítulos, secciones, párrafos, notas a pie de página, etc. La estructura es semejante
a HTML.
• Diseño (layout), que define la colocación de los elementos en el texto impreso o en
la pantalla de visualización, en términos de páginas, columnas, márgenes, etc. La
función es semejante a la de las hojas de estilo de internet.

60
• Contenido: el texto en sí, las figuras vectoriales, y las imágenes.
No todos los ficheros ODA tienen esas 3 partes. De hecho, los ficheros ODA se pueden
clasificar en función de esto:
• Formateados: sólo constan del diseño y del contenido. Carecen de la estructura
lógica, no se pueden editar.
• Procesables: sólo constan del contenido y la estructura lógica, y son editables.
• Formateados procesables: tienen las 3 partes, y se pueden editar.
El formato de transporte binario de un fichero ODA se denomina ODIF (Open Document
Interchange Format), y está basado en una codificación ASN.1 (Abstract Syntax Notation One).
El formato ODA/ODIF ha caído en el olvido más absoluto durante unos años. La actividad
del Consorcio ODA cesó y el soporte y desarrollo de productos acordes con la norma también se
vieron paralizados. Quizá su complejidad fue una de las causas por las que ODA/ODIF no
consiguió alcanzar un nivel de aceptación suficiente entre los fabricantes de software. También es
verdad que el predominio logrado por Microsoft y sus aplicaciones de sobremesa en los últimos
años fueron los principales enemigos para su éxito.
Pero en los últimos años ha existido un resurgimiento de esta idea, el Formato de
Documento Abierto para Aplicaciones Ofimáticas de OASIS (en inglés, OASIS Open
Document Format for Office Applications), también referido como formato OpenDocument
(ODF). ODF es un formato de fichero estándar para el almacenamiento de documentos ofimáticos
tales como hojas de cálculo, memorandos, gráficas y presentaciones. Aunque las especificaciones
fueron inicialmente elaboradas por Sun, el estándar fue desarrollado por el comité técnico para
Open Office XML de la organización OASIS y está basado en un esquema XML, que veremos
posteriormente, inicialmente creado e implementado por la suite ofimática OpenOffice.org.
OpenDocument fue aprobado como un estándar OASIS el 1 de mayo de 2005. Asimismo
fue publicado el 30 de noviembre de 2006 por las organizaciones ISO/IEC como estándar
ISO/IEC 26300:2006 Open Document Format for Office Applications (OpenDocument) v1.0.

61
Por otra parte la versión 1.1 de la especificación fue aprobada el 25 de octubre de 2006 por el
comité de estandarización de OASIS.
El estándar fue desarrollado públicamente por un grupo de organizaciones, es de acceso
libre, y puede ser implementado por cualquiera sin restricción. Con ello, Open Document es el
primer estándar para documentos ofimáticos implementado por distintos competidores, visado por
organismos de estandarización independientes y susceptible de ser implementado por cualquier
proveedor.
PDF.
Ante el fracaso de ODA/ODIF, las empresas especializadas en software para la gestión de
documentos digitales se enzarzaron en una carrera para ver quién conseguía imponer como
estándar su propio formato de intercambio. Así surgió en 1993 Acrobat con su formato PDF
(Portable Document File) un sistema con el que Adobe ha facilitado la difusión de documentos
digitales entre sistemas software y hardware que son incompatibles entre sí. Haciendo uso de la
tecnología Acrobat es posible ver en la pantalla del ordenador o imprimir (con gran fidelidad a la
tipografía, estilo, gráficos y colores del original) documentos que pueden haber sido creados en un
sistema completamente incompatible.
Los documentos de réplica se crean mediante un proceso de conversión, utilizando un
software especial que actúa como un controlador (driver) de impresión. Para generar un
documento basta con imprimirlo desde la aplicación con la que se creó (Microsoft Word,
WordPerfect, QuarkXpress, FrameMaker, Excel, etc.) tras haber seleccionado el controlador
correspondiente desde el cuadro de diálogo que contiene las opciones de impresión.
El documento resultante mantiene las características tipográficas y el formateo del original,
y todos los objetos que lo componen se fusionan en un único archivo comprimido, con lo que se
minimiza el espacio de almacenamiento requerido y se facilita su transmisión a través de redes. El
formato también almacena información sobre las fuentes utilizadas en el documento original. En el
caso de que el ordenador desde el que se lee no disponga del tipo de letra utilizado al crearlo, el
software lector (Acrobat Reader) propietario pero gratuito, disponible en multitud de
plataformas y de pequeño tamaño, es capaz de emularla de forma razonablemente satisfactoria.
Tras la conversión es posible añadir al documento tablas de contenidos, crear índices en texto
completo, hiperenlaces, etc., así como indicar restricciones de seguridad. Esta edición se lleva a
cabo utilizando aplicaciones proporcionadas por el fabricante del formato. Para leer y editar los

62
documentos es necesario disponer de un. Ésta es una de las características más importantes de los
formatos de réplica.
Las posibilidades de edición disponibles con este tipo de formatos son muy limitadas
(eliminación e inserción de páginas extraídas de otro archivo en el mismo formato, creación de
notas e hiperenlaces, etc.) y no suelen estar disponibles en los lectores de libre distribución.
En 1998 Adobe Acrobat y PDF dejaron de tener competencia: Farallon abandonó la tarea
de desarrollar y comercializar Replica; Hummingbird había hecho pública su decisión de hacer lo
mismo con Common Ground en febrero de ese mismo año y Tumbleweed (encargada de
desarrollar Envoy) orientó su actividad hacia la distribución segura de documentos, recomendando
el uso de PDF, al que definió como estándar de facto en una nota de prensa publicada en octubre
de 1997, todos ellos intentos fallidos de conseguir un formato de documento universal.
Esto no debe interpretarse como una superioridad técnica del formato PDF frente al resto
de sus competidores. Simplemente se trata, nuevamente, de una mayor aceptación debida sobre
todo a la posición de superioridad que Adobe tenía en el mercado, gracias en buena parte a la
importante implantación del estándar de facto PostScript, que había sido lanzado por la compañía
en 1985.
SGML.
SGML (Standard Generalized Markup Language) es una norma ISO (ISO 8879) que data
de 1986 y que se derivó de una anterior (GML de IBM). SGML fue diseñado para permitir el
intercambio de información entre distintas plataformas, soportes físicos, lógicos y diferentes
sistemas de almacenamiento y presentación (bases de datos, edición electrónica, etc.), con
independencia de su grado de complejidad.
El estándar SGML utiliza un conjunto de caracteres basado en el estándar ASCII
(American Standard Coding for the Interchange of Information), reconocido de manera
prácticamente universal por cualquier tipo de plataforma y de sistema informático.
Los caracteres especiales, que no están contemplados en el conjunto de caracteres ASCII (propios
de sistemas de escritura distintos del inglés, símbolos matemáticos, etc.) se transforman en
representaciones ASCII y se denominan referencias de entidad.
Así se evitan otros caracteres especiales o de control.

63
Un documento SGML se marca con etiquetas de modo que no dice nada respecto a su
representación en la pantalla o en papel. Un programa de presentación debe unir el documento con
la información de estilo a fin de producir una copia impresa en la pantalla o en el papel.
En SGML, las etiquetas se distinguen del resto del texto mediante caracteres de
delimitación. Estos delimitadores permiten que el software reconozca qué caracteres deben ser
leídos en modo de ETIQUETA, y deben por ello traducirse al lenguaje concreto de composición o
tratarse de manera específica, y qué otros caracteres de CONTENIDO deberán ser transferidos
posteriormente a la aplicación para su procesamiento.
Los caracteres utilizados como delimitadores deben elegirse cuidadosamente, ya que no
han de aparecer con demasiada frecuencia como parte del contenido de un documento.
La norma ISO 8879 describe un conjunto de caracteres básicos entre los que se incluyen los
signos < y > de apertura y de cierre para destacar las etiquetas de inicio y el signo & seguido por
un nombre, y éste a su vez seguido de un punto y coma para representar entidades tales como
imágenes gráficas o caracteres especiales (por ejemplo, • para un redondelito negro).
Todos los procesadores de texto utilizan algún sistema de codificación interno para marcar
cuestiones como la negrita, la cursiva, el sangrado, el centrado, etc. Pero el problema con estos
códigos es que cada programa usa un sistema propio, sistemas que incluso cambian de una versión
a otra en un mismo programa. Aunque existen programas para convertir, los problemas que esta
disparidad ocasiona son considerables.
En las primeras reuniones del Comité que abordó la creación de SGML, una de las
principales cuestiones que se debatieron fue la codificación genérica, esto es, un sistema de
códigos universal e independiente de la aplicación, por medio del cual, por ejemplo <P>
significara siempre párrafo y <H1> indicara siempre un encabezado de primer nivel. La intención
inicial era lograr especificar un conjunto de etiquetas que fueran válidas para un elevado número
de documentos.
Sin embargo, a pesar de que el principio de la codificación genérica está bien fundado, la
variedad de documentos, así como la diversidad de elementos que contienen, lo hacen
prácticamente inabordable.
La solución que se adoptó es emplear una cabecera (heading) donde se definan las
etiquetas que se van a usar. De esta forma SGML no se quedó como un mero conjunto de códigos

64
normalizados, sino que se convirtió en un lenguaje con el que se podía crear una definición del
tipo de documento (DTD), mediante la que se definen con precisión aquellos elementos que son
necesarios en la elaboración de un documento o un grupo de documentos estructurados de manera
similar. Las definiciones de los elementos -formalmente denominadas declaraciones de
elementos- tienen dos funciones:
• Aportan el nombre “oficial” de las etiquetas (los nombres que aparecerán dentro de
los delimitadores, por ejemplo <chapter>).
• Describen lo que cada elemento puede contener, el modelo de contenido.
XML (eXtensible Markup Language) fue desarrollado por un Grupo de Trabajo XML
(originalmente conocido como “SGML Editorial Review Board”) formado bajo los auspicios del
Consorcio World Wide Web (W3C), en 1996. Fue presidido por Jon Bosak de Sun Microsystems
con la participación activa de un Grupo Especial de Interés en XML (previamente conocido como
Grupo de Trabajo SGML) también organizado en el W3C.
XML es un subconjunto de SGML cuyo objetivo es permitir que SGML sea servido,
recibido y procesado en la web de la misma forma que HTML. Se trata, por tanto, de posibilitar el
intercambio electrónico de datos (EDI), tanto estructurados como no estructurados, mediante la
tecnología web, hasta ahora reservada exclusivamente a los documentos HTML.
Relación entre HTML, XML y SGML
XML es un metalenguaje, como SGML. Los documentos XML válidos son, por definición,
documentos SGML válidos, pero los documentos XML tienen restricciones adicionales. Por
ejemplo, XML no admite el conector & de SGML. Por otra parte, la esencia de SGML, que es el
concepto de DTD, continúa estando presente en XML.

65
7. DESARROLLO DEL ALMACENAMIENTO DE LA INFORMACIÓN
Las bases de datos nacen para solucionar los problemas presentados a los programadores a
la hora de diseñar programas eficientes capaces de manipular grandes volúmenes de información.
Los pioneros de finales de los 50 y principios de los 60 desarrollaron muchas técnicas
nuevas para manipular los ficheros. Los ficheros se pueden manipular mediante lenguajes de
tercera generación convencionales empleando los servicios del sistema operativo. La complejidad
del trabajo de programación y la rigidez de las restricciones que imponía la tecnología de los
ordenadores en aspectos como la inserción de datos o la gestión de casos especiales, hacía arduo el
trabajo. De su evolución y necesidad de facilitar la tarea al programador surgen las bases de datos
como conjunto, colección o depósito de datos almacenados en un soporte informático no volátil. A
su vez alrededor de las bases de datos nacen los sistemas gestores de base de datos (SGBD)
(DBMS, DataBase Management System) conjunto de utilidades que permiten la implantación,
acceso y mantenimiento de una base de datos.
A lo largo de la historia los sistemas gestores de base de datos han ido evolucionando
ligados a los modelos de datos que pueden implementar, desde los años sesenta con bases de datos
estructurados de forma jerárquica y en red, hasta los actuales que permiten desarrollar aplicaciones
gráficas multiusuario y multiplataforma, en potentes sistemas en red, podemos distinguir una
evolución en la que se distinguen tres etapas o generaciones:
Primera generación de los SGBD: Los sistemas jerárquico y de red constituyen la primera
generación de los SGBD. El modelo jerárquico estructura los datos de manera escalonada,
existiendo una relación del tipo padre-hijo entre sus registros. La representación de la información
es similar a una estructura en árbol. El modelo en red, elimina la restricción del modelo
jerárquico, en el sentido de que un registro puede tener más de un padre, por lo que resulta más
flexible, dando lugar a una estructura de grafo. Pero estos sistemas presentan algunos
inconvenientes:
• Es necesario escribir complejos programas de aplicación para responder a cualquier
tipo de consulta de datos, por simple que ésta sea.
• La independencia de datos es mínima.
• No tienen un fundamento teórico.

66
Segunda generación de los SGBD: En 1970 Codd, de los laboratorios de investigación de
IBM, escribió un artículo presentando el modelo relacional. En este artículo, presentaba también
los inconvenientes de los sistemas previos, el jerárquico y el de red. Entonces, se comenzaron a
desarrollar muchos sistemas relacionales, apareciendo los primeros a finales de los setenta y
principios de los ochenta. Esto condujo a dos grandes desarrollos:
• El desarrollo de un lenguaje de consultas estructurado denominado SQL, que se
ha convertido en el lenguaje estándar de los sistemas relacionales.
• La producción de varios SGBD relacionales durante los años ochenta, como DB2
y SLQ/DS de IBM, y ORACLE de ORACLE Corporation.
Hoy en día, existen cientos de SGBD relacionales, tanto para microordenadores como para
sistemas multiusuario, aunque muchos no son completamente fieles al modelo relacional. Los
SGBD relacionales constituyen la segunda generación de los SGBD.
Tercera generación de los SGBD: Como respuesta a la creciente complejidad de las
aplicaciones que requieren bases de datos, han surgido nuevos modelos de datos y SGBD que los
soportan: el modelo de datos objeto-relacional y el modelo relacional extendido. Sin embargo,
a diferencia de los modelos que los preceden, la composición de estos modelos no está clara.
Las bases de datos son hoy en día el corazón de las empresas. Sin ellas se verían expulsadas
del mercado por la competencia. Todos los ciclos formativos de la familia profesional de
informática contemplan en sus temarios las bases de datos, lo que pone de relieve la gran
importancia de las mismas.
7.1. APLICACIONES DE GESTIÓN DE LA INFORMACIÓN EN L A EMPRESA
• WORKFLOW. Un sistema de workflow (“flujo de trabajo”) es un software de gestión
basado en reglas que dirige, coordina y monitoriza la ejecución de un conjunto interrelacionado de
tareas organizadas para formar un proceso de negocio. El propósito principal de los sistemas de
workflow es proporcionar a los empleados capacidad de seguimiento, enrutamiento, gestión de
documentos, y otras posibilidades diseñadas para mejorar los procesos de negocio.

67
• ERP. Un sistema ERP (Enterprise Resource Planning, planificación de recursos
empresariales) consta de un conjunto de programas integrados capaz de gestionar las operaciones
vitales de una empresa global que tenga multitud de sedes. Aunque el alcance de los sistemas ERP
puede variar de empresa a empresa, la mayoría proporcionan software integrado de soporte para
las funciones de finanzas y producción.
Los sistemas ERP típicamente manejan la producción, logística, distribución, inventario, envíos,
facturas y una contabilidad para la compañía de la Planificación de Recursos Empresariales o el
software ERP puede intervenir en el control de muchas actividades de negocios como ventas,
entregas, pagos, producción, administración de inventarios, calidad de administración y la
administración de recursos humanos.
Por ejemplo, los sistemas ERP son capaces de hacer predicciones de demanda, cotejar la
predicción con las existencias de inventario, y determinar las materias primas necesarias para
fabricar los productos que se prevén van a demandarse. La mayoría de los sistemas ERP también
incorporan la capacidad de realizar automáticamente los pedidos de esos materiales.
Además, se soportan e integran otras funciones como las relativas a la gestión de recursos
humanos, ventas y distribución.
Algunos productos ERP son:
➥ mySAP de SAP AG (la versión anterior de este ERP es SAP R/3). Es el líder en ERP.
➥ Oracle E-Business, de Oracle Co.
➥ SSA ERP de SSA Global.
➥ Peoplesoft de Peoplesoft (adquirida por Oracle).
➥ World de J.D. Edwards (adquirido por Peoplesoft).
• CRM. Del acrónimo inglés “Customer Relationship Management”, administración de la
relación con los clientes. Se trata de software en sistemas informáticos, de apoyo a la gestión de las
relaciones con los clientes, a la venta y al marketing. Con este significado CRM se refiere al Data
warehouse con la información de la gestión de ventas, y de los clientes de la empresa.

68
Las bases de datos de marketing tienen como finalidad cargar y almacenar perfiles de los clientes
con datos más subjetivos como, por ejemplo, qué le gusta hacer en su tiempo libre, qué tipo de
comida consume, etc., datos que están enfocados a poder desarrollar un perfil de cliente de modo
que podamos brindarle una oferta que esté realmente hecha para él. Por esto es que las estrategias
de marketing directo basadas en un desarrollo CRM tienen tanto éxito en todo el mundo.
La orientación al cliente es cada vez más importante. El objetivo es ofrecer al cliente aquello que
necesita y en el momento que lo necesita. El software CRM online es, según consultoras y
especialistas, el que en un futuro cercano mejor permitirá conocer al detalle, sus necesidades y
anticiparse a su demanda desde el lugar en que nos encontremos, compartiendo la información.
Uno de los mayores problemas para que las empresas exploten un producto CRM es el alto costo
de estos productos comerciales, licencias adicionales como un sistema operativo y mas aun el alto
costo de la su implantación y puesta en marcha.
• MIS. Un MIS (Management Information System, sistema de información para la dirección),
es una colección de personas, procedimientos, software, bases de datos y dispositivos usados para
proporcionar información rutinaria a los directivos. El objetivo de los MIS es la eficiencia en la
toma de decisiones operacionales. Estas decisiones se caracterizan por ser estructuradas. Es decir,
se adoptan conforme a una regla, un procedimiento o un método cuantitativo. Por ejemplo, decir
que se debe repoer el inventario cuando su nivel descienda a 100 unidades es una regla. Las
decisiones estructuradas son fáciles de programar.
Las diversas áreas empresariales (marketing, producción, finanzas, etc.) disponen de MIS dedicados,
que generan informes estándar a partir de los datos proporcionados por los sistemas de procesamiento
de transacciones, no sólo de su área, sino de todas. Para ello, se ha de usar una base de datos común a
todas las áreas.
Los informes que proporcionan los MIS sin fijos, con formatos estándar, si bien se permite a lo
usuarios elaborar informes a medida. Para su confección, los MIS hacen uso de la información
interna a la empresa, que reside en sus bases de datos. Algunos MIS usan fuentes externa de datos
sobre sus competidores, el mercado, etc. Internet se usa con frecuencia como una fuente de datos
externos.

69
• DSS. Un DSS (Decision Support System, sistema de ayuda a la decisión) es una colección
organizada de personas, procedimientos, software, bases de datos y dispositivos usados para servir
de ayuda en la toma de decisiones de problemas específicos. Estos problemas son poco
estructurados, es decir, las relaciones entre los datos no son siempre claras, los datos pueden estar
en una gran variedad de formatos, y pueden ser difíciles de obtener. Mientras que un MIS ayudan a
la empresa a “hacer correctamente las cosas”, un DSS ayuda a un directivo a “hacer la cosa
correcta”.
Los DSS asisten en todos los aspectos que se han de contemplar para adoptar decisiones relativas a
problemas específicos, extendiéndose más allá de lo que lo haría un MIS; los MIS tradicionales no
ayudan a resolver problemas complejos.
Los MIS tradicionales se usan raramente para resolver este tipo de problemas; un DSS puede
ayudar sugiriendo alternativas que faciliten la adopción de la solución final.
Los sistemas de apoyo a la decisión se usan cuando los problemas son complejos y la información
que se necesita para dar la mejor respuesta es difícil de obtener y usar. Entre los elementos
constitutivos de un DSS se encuentran los modelos empleados, y los hechos (datos) con los que se
han de alimentar esos modelos, así como una interfaz de usuario que permita interactuar con el
DSS, planteándole, por ejemplo, situaciones hipotéticas cuyas consecuencias habrán de simular
mediante los modelos. También se les puede proporcionar un objetivo (goal) para el que deben
determinar los datos de entrada que lo lograrían. Los DSS proporcionan maneras flexibles de
presentar la información, tanto gráfica como textualmente, y con distintos niveles de profundidad,
aunque son fáciles de usar y aprender.
Los DSS manejan grandes cantidades de información (almacenes de datos o data warehouses),
procedentes de diversas fuentes.
Encontramos 2 versiones o evoluciones de los sistemas software DSS:
➥ GDSS: Los sistemas de apoyo a la toma de decisión en grupo (GDSS, Group Decision
Support System), también denominados sistemas de trabajo colaborativo constan de la mayoría de
los elementos de los DSS, además del software necesario para facilitar el trabajo en grupo a
distancia (groupware).
➥ ESS: Los ejecutivos de más alto nivel necesitan un apoyo muy especializado que les ayude
a adoptar decisiones estratégicas. Este apoyo se lo brindan los sistemas de sistemas de apoyo para

70
ejecutivos (ESS, Executive Support System), también llamados sistemas de información para
ejecutivos (EIS, Executive Information System). Los ESS son un caso particular de DSS, aunque
presentan diferencias. Los DSS proporcionan herramientas de modelado y análisis que permiten a
los usuarios profundizar en los problemas a la busca de respuestas. Los ESS presentan información
sobre aspectos de la empresa que los ejecutivos consideran importantes; en otras palabras, les
facilitan la tarea de formular las preguntas oportunas.

71
8. COMUNICACIÓN Y REDES
Los tres últimos siglos han estado dominados, cada uno de ellos, por una tecnología.
El siglo XVIII fue la época de los grandes sistemas mecánicos que acompañaron a la
Revolución Industrial.
El siglo XIX fue la era de las máquinas de vapor.
En el siglo XX, la tecnología clave ha sido la obtención, procesamiento y distribución de
la información. Entre otros avances, hemos visto la instalación de redes telefónicas mundiales, la
invención del radio y la televisión, el nacimiento y crecimiento sin precedentes de la industria de
las computadoras y el lanzamiento de satélites de comunicación.
Debido al rápido progreso de la tecnología, estas áreas están convergiendo rápidamente, y
las diferencias entre juntar, transportar, almacenar y procesar información desaparecen con
rapidez. Las organizaciones con cientos de oficinas que se extienden sobre una amplia área
geográfica esperan ser capaces de examinar la situación, aun de sus más remotos puestos de
avanzada, oprimiendo un botón. Al crecer nuestra habilidad para obtener, procesar y distribuir
información, también crece la demanda de técnicas de procesamiento de información más
avanzadas.
El constante avance tecnológico en informática ha derivado no sólo en el avance en el
procesamiento de la información, sino en las necesidades de comunicar, compartir y divulgar dicha
información. En este sentido la tendencia actual es la compartición de datos, programas,
dispositivos hardware y todo tipo de recursos en general.
De la unión de la informática y las telecomunicaciones surge la ciencia de la Telemática o
Teleinformática, que estudia las técnicas necesarias para la transmisión de datos a través de redes
de telecomunicación.
Una red de comunicaciones es un conjunto de equipos y facilidades para el transporte de
información entre usuarios ubicados en varios puntos geográficos. Debido a las nuevas
necesidades aparecidas en los últimos años las redes de ordenadores han experimentado un
desarrollo veloz. En su libro “Redes de computadoras” el autor Andrew S. Tanenbaum define una
red de ordenadores, como “colección interconectada de computadoras autónomas”.

72
Los objetivos fundamentales de las redes en general y de la interconexión de ordenadores
en particular son:
• Disponer de medios de comunicación entre emplazamientos remotos.
• Compartir la información de forma casi instantánea.
• Compartir recursos sin importar la localización física y/o el entorno de trabajo.
• Compartir la carga de trabajo de procesamiento.
En este tema veremos una panorámica global de las redes, así como los principios básicos
de las mismas y los servicios que se soportan y prestan a los usuarios.
8.1. EVOLUCIÓN HISTÓRICA DE LAS REDES.
No es posible entender el estado actual de las telecomunicaciones y transmisión de datos
sin conocer cuál ha sido su evolución histórica y la sucesión avances tecnológicos en la materia. La
evolución de la tecnología ha posibilitado que la informática haya conseguido avances
espectaculares en un tiempo relativamente corto.
Las telecomunicaciones, comienzan en la primera mitad del siglo XIX, en 1844 Samuel
Morse inventó el telégrafo inalámbrico, que permitió el enviar mensajes cuyo contenido eran letras
y números.
Más tarde en 1876 Alexander Bell amplió las posibilidades del telégrafo, desarrollando el
teléfono, con el que fue posible comunicarse utilizando la voz, y posteriormente, la revolución de
la comunicación inalámbrica: las ondas de radio.
A principios del siglo XX aparece el teletipo que, utilizando el código Baudot, permitía
enviar texto en algo parecido a una máquina de escribir y también recibir texto, que era impreso
por tipos movidos por relés.
El término telecomunicación fue definido por primera vez en la reunión conjunta de la XIII
Conferencia de la UTI (Unión Telegráfica Internacional). La definición entonces aprobada del
término fue: "Telecomunicación es toda transmisión, emisión o recepción, de signos, señales,
escritos, imágenes, sonidos o informaciones de cualquier naturaleza por hilo, radioelectricidad,
medios ópticos u otros sistemas electromagnéticos".

73
El siguiente artefacto revolucionario en las telecomunicaciones fue el módem que hizo
posible la transmisión de datos entre computadoras y otros dispositivos. En los años 60's comienza
a ser utilizada la telecomunicación en el campo de la informática con el uso de satélites de
comunicación y las redes de conmutación de paquetes.
La década siguiente se caracterizó por la aparición de las redes de computadoras y los
protocolos y arquitecturas que servirían de base para las telecomunicaciones modernas (en estos
años aparece la ARPANET, que dio origen a la Internet). También en estos años comienza el auge
de la normalización de las redes de datos: el CCITT trabaja en la normalización de las redes de
conmutación de circuitos y de conmutación de paquetes y la Organización Internacional para la
Estandarización crea el modelo OSI. A finales de los años setenta aparecen las redes de área local
o LAN.
En los años 1980, cuando los ordenadores personales se volvieron populares, aparecen las
redes digitales. En la última década del siglo XX aparece Internet, que se expandió enormemente y
a principios del siglo XXI se están viviendo los comienzos de la interconexión total a la que
convergen las telecomunicaciones, a través de todo tipo de dispositivos que son cada vez más
rápidos, más compactos, más poderosos y multifuncionales
Entre 1983 y 1984 surgieron los primeros entornos servidores de ficheros para redes de
área local. Entre las compañías destacadas, cabe citar a Novell Inc., 3Com Corp., AT&T e IBM.
Aunque todas ellas diferían en la gestión e implementación, se trataba de entornos centralizados,
donde un ordenador hacía las veces de servidor (con el sistema operativo de red instalado en él y
los datos compartidos) y el resto de equipos funcionaban con una versión de un sistema operativo
más “ligero”, como MSDOS. Hacia 1990, este tipo de redes locales triunfó en el mundo de la
empresa y la industria de las redes creció a velocidades impresionantes.
Hoy en día, las redes de ordenadores son algo más que un entorno centralizado de gestión
de ficheros. El desarrollo de la tecnología en los medios físicos disponibles (cobre, coaxial, fibra
óptica, transmisores y receptores inalámbricos de alta velocidad) ha posibilitado el incremento en
velocidad de transmisión y fiabilidad, lo que ha supuesto una extensión en sus capacidades. La
principal tiene que ver con las redes de altas prestaciones, donde una aplicación compleja se
ejecuta de forma distribuida en los equipos de la red. La tendencia actual debido a las altas
velocidades, fiabilidad y capacidad de procesamiento en equipos dispuestos en red local, se orienta

74
hoy en día hacia las redes distribuidas (en lugar de centralizadas) donde cada ordenador es
cliente, pero también puede realizar procesamiento de las peticiones de otros clientes, siendo
servidor de datos o dispositivos compartidos.
8.2. Modelos de distribución del procesamiento y la información
Hace unos años los sistemas informáticos empresariales eran centralizados. Grandes
mainframes, también denominados hosts, concentraban toda la carga computacional. Se accedía a
ellos desde unos terminales, que eran poco más que un monitor de fósforo verde y un teclado.
Conforme los requisitos de las aplicaciones empresariales fueron aumentando, se fue haciendo
cada vez más patente que los sistemas centralizados no eran adecuados y resultaban caros. Las
empresas dependían de ellos, pero... ¿qué sucedía cuando el host se caía?: se paraba la actividad
empresarial.
El surgimiento de los ordenadores personales (PC), de coste cada vez más asequible,
propició su implantación progresiva en las empresas. Como su capacidad de cómputo crecía
rápidamente, parece lógico que se empezara a delegar parte del trabajo de los hosts en los PC. Del
mismo modo el desarrollo de los lenguajes de alto nivel como Visual Basic y con Oracle Forms
Developer, facilitó el desarrollo de aplicaciones de clientes en PC con acceso a servidores. De esa
forma, surgió la arquitectura de dos capas cliente/servidor. Esta arquitectura no estaba exenta
problemas, pero como habitualmente los sistemas no ocupaban más de una oficina, las ventajas
que aportaba la tecnología cliente/servidor superaban a sus inconvenientes.

75
A mediados de la década de los noventa, a medida que los sistemas empezaban a estar cada
vez más intercomunicados, los problemas se fueron haciendo progresivamente más patentes. Un
inconveniente muy fuerte de la arquitectura de dos capas (aunque no el único) es su administración
cuando la red se extiende más allá de un departamento u oficina. Piénsese en lo que supone migrar
a una nueva versión del cliente: reinstalar en muchísimas máquinas, parando el trabajo de todos los
empleados. Otro inconveniente, vinculado al anterior, es la elevada complejidad que habían
alcanzado los sistemas. Los clientes cada vez eran más “obesos”; debían utilizar más inteligencia.
Lo que antes era un host, ahora, cada vez más, se limitaba a un medio para compartir recursos,
como un sistema de ficheros, una impresora y, con frecuencia, una base de datos. Los problemas
de administración y desarrollo se agigantaban. Había que construir y administrar aplicaciones
diferentes para distintos departamentos.
Se hacía cada vez más necesaria una arquitectura que fuera escalable. Es decir, ampliable.
Surgen así las arquitecturas de tres capas, favorecidas por la explosión de Internet. Aun así los
sistemas centralizados siguen teniendo aplicación hoy en día.
La arquitectura de tres capas aleja la inteligencia del cliente. El cliente ahora es,
típicamente, un navegador web (browser), y sólo sirve como interfaz de usuario. Los datos siguen
residiendo en una base de datos, carente de “inteligencia”. Dicha “inteligencia” reside ahora en
programas que componen una capa intermedia.
El cliente emite su solicitud a los programas intermedios, que pedirán datos al servidor
mediante una consulta, procesándolos una vez obtenidos, y devolverán al cliente el resultado de
dicho proceso.
La arquitectura de tres capas es tremendamente flexible. Ampliar el sistema sólo supone
cambiar, en un único sitio, los componentes de la capa intermedia. Además, todos los
departamentos pueden acceder a dicha capa, y aunque posiblemente cada uno tenga su aplicación
allí, la administración se simplifica enormemente.
Además hay otras ventajas, como pueden ser:
• Mayor seguridad, derivada del hecho de no permitir a los clientes un acceso directo
a la base de datos.
• Soporte directo para acceso desde Internet a las aplicaciones empresariales.

76
• Elevada disponibilidad, puesto que se puede configurar una capa intermedia con
varias máquinas.
• Buen rendimiento, al dividir el sistema en partes que pueden residir en ordenadores
distintos.
Actualmente, la comunicación entre el usuario final y el programa de la capa intermedia se
suele hacer mediante páginas web (protocolo HTTP), empleando alguna de las tecnologías de
programación web (CGI, Servlets Java o Páginas de Servidor).
La comunicación entre la capa intermedia y el sistema gestor de bases de datos se lleva a
cabo mediante mensajes SQL con protocolos y arquitecturas de red propietarios como, por
ejemplo, NET8 de Oracle. La programación de la comunicación con el servidor se realiza
habitualmente con SQL embebido, ODBC o JDBC.

77
9. FUTURO: INTELIGENCIA ARTIFICIAL
Los sistemas basados en el conocimiento también denominados expertos son programas
que reproducen el proceso intelectual de un experto humano en un campo particular, pudiendo
mejorar su productividad, ahorrar tiempo y dinero, conservar sus valiosos conocimientos y
difundirlos más fácilmente.
Los sistemas expertos se pueden considerar como el primer producto verdaderamente
operacional de la inteligencia artificial. Son programas de ordenador diseñados para actuar como
un especialista humano en un dominio particular o área de conocimiento. En este sentido, pueden
considerarse como intermediarios entre el experto humano, que transmite su conocimiento al
sistema, y el usuario que lo utiliza para resolver un problema con la eficacia del especialista. El
sistema experto utilizará para ello el conocimiento que tenga almacenado y algunos métodos de
inferencia.
A la vez, el usuario puede aprender observando el comportamiento del sistema. Es decir,
los sistemas expertos se pueden considerar simultáneamente como un medio de ejecución y
transmisión del conocimiento.
Lo que se intenta, de esta manera, es representar los mecanismos heurísticos que
intervienen en un proceso de descubrimiento. Éstos mecanismos forman ese conocimiento difícil
de expresar que permite que los expertos humanos sean eficaces calculando lo menos posible. Los
sistemas expertos contienen ese “saber hacer”.
La característica fundamental de un sistema experto es que separa los conocimientos
almacenados (base de conocimiento) del programa que los controla (motor de inferencia). Los
datos propios de un determinado problema se almacenan en una base de datos aparte (base de
hechos).
Una característica adicional deseable, y a veces fundamental, es que el sistema sea capaz de
justificar su propia línea de razonamiento de forma inteligible por el usuario.
9.1. Sistemas basados en el conocimiento.
Como el conocimiento es el núcleo de los sistemas expertos, a menudo se les denomina
sistemas de conocimiento o sistemas basados en el conocimiento. El campo de los sistemas
expertos trata de las formas de adquirir conocimiento de los especialistas humanos y de representar

78
esos conocimientos en una forma compatible con un ordenador. Los ordenadores ejecutan una
forma de tratamiento del conocimiento cuando los usuarios lo solicitan.
¿Qué es el conocimiento? El conocimiento se puede considerar como la comprensión
adquirida. En muchas aplicaciones, el conocimiento heurístico adquirido mediante la experiencia
que proporciona el mundo real es el más adecuado para resolver los problemas.
¿Qué es la información? La información son hechos e imágenes. El conocimiento consiste
en entender esos hechos e imágenes.
Los sistemas expertos ayudan a manejar la sobrecarga de información a la que nos
enfrentamos traduciendo ésta en conocimiento utilizable.
Inteligencia artificial (IA). Los sistemas expertos son una de las aplicaciones de la
inteligencia artificial. Ahora que ya se sabe qué es y qué hace un sistema experto, es el momento
de volver la vista hacia la inteligencia artificial, el campo del que derivan los sistemas expertos.
La inteligencia artificial es esa “misteriosa” parte de la informática que intenta hacer
ordenadores más “inteligentes” y, por tanto, más útiles. El objeto de la IA no es reemplazar a los
humanos con ordenadores inteligentes, sino dotar a los ordenadores de “inteligencia” suficiente
para que resulten una herramienta más potente, más útil y de uso más variado.
Los sistemas expertos y otras formas de inteligencia artificial son paquetes de software que
se pueden hacer funcionar en casi todos los ordenadores.
Los dos componentes principales de cualquier programa de IA son: una base de
conocimientos y un programa de inferencia. Mediante el uso de símbolos se puede crear una
“base de conocimientos” que establezca diferentes hechos acerca de objetos, acciones o procesos,
y sus relaciones. Una vez creada la base de conocimiento se debe diseñar un método para
utilizarla. Básicamente, se necesita un programa que use el conocimiento para razonar y pensar en
cómo resolver un problema particular. Esta clase de programa se denomina generalmente
“programa de inferencia” o “máquina de inferencia”.
El enfoque básico para la resolución de problemas en inteligencia artificial son los procesos
de búsqueda y comparación de patrones, los veremos posteriormente.

79
9.2. Aplicaciones de la IA.
La inteligencia artificial se viene aplicando a multitud de campos, en algunos de los cuales
tiene una profunda evolución y maduración:
• Procesamiento del lenguaje natural (NLP). Las técnicas de procesamiento del
lenguaje natural permiten a los ordenadores comprender el lenguaje de los humanos.
• Reconocimiento de la voz. Los sistemas de reconocimiento de la voz imitan la
capacidad auditiva humana de reconocer e interpretar la voz.
• Visión por ordenador. Los sistemas de visión dotan a los ordenadores de
capacidad de percepción visual.
• Robótica. Un robot es a la inteligencia artificial lo que el cuerpo es a la mente
humana. Se puede crear un robot inteligente usando sensores para obtener retroali-
mentación y software de IA para modificar el programa de control.
• Aprendizaje del ordenador. Los investigadores están intentando encontrar formas
de hacer que los ordenadores aprendan de su experiencia o de los datos que reciben.
• Educación y en entrenamiento. Los métodos de la IA se están usando para crear
una nueva forma de enseñanza asistida por ordenador.
• Programación automática, en la que se aplican las técnicas de la inteligencia
artificial a la difícil tarea de crear software.
9.3. TIPOS DE SISTEMAS EXPERTOS.
• Sistemas de análisis e interpretación. Los sistemas expertos realizan un trabajo de
interpretación a partir de la información recibida desde un teclado, desde otro
programa del ordenador o desde sensores electrónicos. Una vez que la información
está disponible, los programas de inferencia utilizan esos datos junto con la
información contenida en una base de conocimientos para intentar comprender los
datos, y a continuación proporcionan una explicación para los datos o saca
conclusiones apropiadas.

80
• Sistemas de predicción. Los sistemas expertos son muy buenos para predecir
resultados futuros. Utilizando los datos de entrada acerca de una situación dada, un
sistema experto de predicción puede deducir consecuencias futuras o resultados a
partir del conocimiento que tiene. Los sistemas de predicción producen resultados
especialmente buenos a la hora de sugerir las consecuencias más probables de unas
determinadas condiciones. La base de conocimientos suelen contener las tendencias
de los datos y la información histórica, así como los patrones cíclicos apropiados.
• Sistemas de diagnóstico y depuración. Otra aplicación especialmente adecuada
para los sistemas expertos son los sistemas de diagnóstico y depuración. Ambas
técnicas se utilizan en la reparación y detección de fallos en equipos. También se
emplean mucho en medicina de diagnóstico. Un sistema experto de diagnóstico
recibe los datos acerca del comportamiento del dispositivo, sistema o individuo. De
hecho, la mayoría de los sistemas expertos formulan listas de preguntas en un
intento de acumular los datos necesarios para llegar a una conclusión. Estos datos de
entrada toman la forma de síntomas, características físicas, prestaciones registradas
e irregularidades o funciones indeseadas. Con esta información, el programa de
inferencia recorre la base de conocimientos para detectar los problemas. Mientras
que algunos sistemas expertos realizan sólo diagnósticos, otros también incluyen
características de depuración, lo que significa que recomiendan las acciones adecua-
das para corregir los problemas y deficiencias descubiertas.
• Sistemas de control. El control consiste fundamentalmente en observar los datos
que proporcionan los sensores. Se emplea una gran variedad de sensores para
transformar las variaciones de distintas magnitudes físicas en señales eléctricas que
pueden ser interpretadas por un ordenador. Se prepara un programa para determinar
cuáles de las señales controladas se encuentran dentro de los límites deseados. En
un sistema experto, la base de conocimientos contiene reglas para decidir qué hacer
con las magnitudes con valores fuera de límite. Si alguno de los sensores indica un
valor fuera de límite, se activa un programa de control en el ordenador para
devolver los datos a su nivel correcto. Este proceso de control generalmente emplea
técnicas de retroalimentación, es decir, información detectada en el sistema que se
está controlando, e informa el ordenador de lo que sucede. El ordenador continúa
controlando el sistema hasta que recibe información de que el sistema falla o llega a

81
alguna condición deseada. Denominados sistemas de control en bucle cerrado, éstos
permiten automatizar totalmente algunos procesos.
• Sistemas de diseño. Los sistemas CAD basados en sistemas expertos liberan a los
ingenieros o a los diseñadores para dedicarse a tareas más creativas.
• Sistemas de planificación. Los sistemas expertos ayudan a las personas a
establecer planes, de forma rápida, para realizar operaciones complejas.
• Sistemas de enseñanza. Un sistema experto puede utilizarse para la enseñanza em-
pleando el conocimiento que forma el núcleo del sistema. Un sistema experto
evalúa el nivel de conocimientos y comprensión de cada estudiante. Con esta
información se puede ajustar el proceso educativo a sus necesidades.
9.4. HISTORIA RECIENTE DE LOS SISTEMAS EXPERTOS.
Los sistemas expertos descritos a continuación son famosos por su impacto en la
inteligencia artificial. Se han empleado muchos años de investigación para desarrollar estos
primeros programas, que definen la forma y el sistema de funcionamiento de los sistemas expertos
actuales.
• Dendral. Muchos consideran que Dendral fue el primer sistema experto. Se
desarrolló en la Universidad de Stanford a mediados de los años setenta. El
desarrollo del programa y sus múltiples descendientes continuó durante la mayor
parte de los años setenta. Siendo uno de los sistemas expertos más estudiados, el
trabajo que se ha desarrollado sobre Dendral ha influido en el desarrollo de la
mayoría de los sistemas expertos.
La versión comercial de Dendral ayuda a los químicos a identificar la estructura
molecular de las sustancias desconocidas.
• Macsyma. Desarrollado en el MIT, Macsyma está diseñado para realizar
manipulaciones simbólicas de expresiones matemáticas. Macsyma se desarrolló a
principio de los años setenta y se siguió trabajando en él hasta principios de los años
ochenta. Capaz de realizar simbólicamente cálculo integral y diferencial, ayuda a los
científicos e ingenieros a resolver problemas complicados que habrían tardado días

82
e incluso meses en resolver manualmente. Macsyma también manipula expresiones
algebraicas complicadas y ayuda a reducirlas a su forma más simple.
• Mycin. Mycin es un sistema experto desarrollado en Stanford para el diagnóstico y
tratamiento de enfermedades infecciosas de la sangre. Es uno de los sistemas
expertos más estudiados por su gran éxito. Mycin fue uno de los primeros sistemas
expertos en emplear reglas de producción y métodos de inferencia con
encadenamiento regresivo.
Una de las características principales de Mycin es que su base de reglas está radical-
mente separada de su programa de inferencia. Esto permite eliminar completamente
la base de conocimientos, creando Mycin vacíos (llamados Emmycin). Emmycin es
el modelo a partir del cual se crearon los “shell” de los modernos sistemas expertos.
• Prospector. Prospector, construido sobre la tecnología de Mycin, es un sistema
experto diseñado para ayudar a los geólogos a encontrar yacimientos importantes.
Su base de conocimientos, que se complementa con reglas de producción y redes
semánticas, contiene información sobre los depósitos y sobre la clasificación de
distintos tipos de rocas y minerales. Dándole datos acerca de un área particular,
Prospector puede estimar las probabilidades de encontrar distintos tipos de
depósitos minerales. Prospector ha tenido un éxito poco usual en la localización de
grandes depósitos de minerales valiosos. Se desarrolló a principios de los años
setenta en SRI Internacional.
• Xcon. Xcon es un sistema experto diseñado para ayudar a los técnicos de Digital
Equipment Corporation (DEC) a configurar sistemas de miniordenadores. La
popular serie VAX de DEC se encuentra disponible en una amplia gama de modelos
con una gran cantidad de características y opciones que puede seleccionar el cliente.
Dado el gran número de posibles combinaciones, el personal de DEC tenía
problemas para configurar el sistema apropiado en el que todos los componentes
funcionaran en conjunto. Xcon genera automáticamente la configuración deseada a
partir de los requisitos del cliente.

83
Xcon se denominó originalmente R1 y fue desarrollado en la Universidad Carnegie
Mellon a finales de los años setenta, siendo revisado y actualizado en DEC a
principios de los años ochenta.

84
10. REVOLUCIÓN MULTIMEDIA
Multimedia es cualquier combinación de texto, sonido digital, música, imagen estática,
animación y vídeo que se expone por medio de un ordenador personal u otros medios electrónicos.
Multimedia se compone de los siguientes elementos:
• Texto.
• Sonido.
• Imagen.
• Animación.
• Vídeo.
Cuando un programa, además de utilizar los elementos anteriores de Multimedia, permite
que el usuario intervenga y controle su ejecución, entonces se habla de Multimedia interactiva.
Desde el punto de vista del diseño y construcción de interfaces gráficas de usuario, lo que
aporta Multimedia es una ampliación de las posibilidades existentes para comunicarse con el
usuario de una aplicación. Algunos ejemplos:
• Hacer que la aplicación emita un sonido de alarma cuando se produzca un error
importante, con lo que se consigue atraer la atención del usuario si éste está
pendiente de otra tarea.
• Utilizar síntesis de voz para facilitar el manejo del programa por parte de usuarios
con problemas de visión.
• Utilizar fragmentos de vídeo o animaciones en programas de enseñanza asistida por
ordenador, con el fin de mejorar las explicaciones proporcionadas al alumno.
Los sistemas de información que modelan la realidad incorporando la información de la
forma más natural posible y que ofrecen niveles de estímulo elevado tienen una respuesta
inmediata en el hombre. Este es el gran reto y también el gran éxito de la tecnología multimedia;
la utilización de “múltiples medios” de la forma más similar a como se percibe la vida real. Ello
implica que se tiene que trabajar con imágenes de vídeo dinámicas en tiempo real y en pantalla
completa, audio de alta fidelidad, gráficos, texto y animación en una sola plataforma con un

85
software como único soporte controlando toda la aplicación mediante comandos hablados o
dispositivos adicionales mediante simples gestos.
Pero, además, el cerebro procesa la información de forma aleatoria y multidireccional a
diferencia del ordenador que lo hace lineal y secuencialmente. Esto impone a multimedia una
servidumbre adicional: la interactividad, que significa que el usuario decide qué parte y en qué
secuencia desea recibir la información. Este entorno interactivo trata de involucrar al usuario a
través de un diálogo constante que reduzca la carga de información inútil y le haga el
conocimiento más accesible.
En este tema revisaremos los sistemas multimedia, revisando los elementos más
importantes, la imagen, el sonido y el vídeo, junto al hardware comercial correspondiente.
Desde el comienzo de la era informática los terminales de salida de información de los
ordenadores han ido mejorando considerablemente. Al principio sólo comprendían una simple
impresora, luego aparecieron las pantallas de visualización en las que los datos aparecían con
mucha mayor rapidez que en una impresora. Pero estos primeros sistemas de visualización
presentaban numerosos inconvenientes: el más grave consistía en lo largo y enojoso de examinar
en gran número de datos expresados en forma de palabras y frases, es decir, codificados en
caracteres alfabéticos y numéricos en continua sucesión temporal. Este sistema no es capaz de
aprovechar la extraordinaria capacidad que tiene la visión del ser humano para localizar
rápidamente algo especialmente interesante situado en un espacio de disposición compleja.
Hasta entonces, el sector de los sistemas de información habían dominado las modalidades
alfanuméricas. Pero la situación fue cambiando y aparecieron, sobre todo en el mundo
empresarial, planteamientos nuevos en los que se reclamaba ver “información” y no simplemente
“datos”; entendiendo por “información”, las curvas de tendencias o los gráficos de barras.
La posibilidad de utilizar pantallas de más resolución, así como la disponibilidad de
mejores programas de tratamiento de imagen permitieron nuevas formas de presentar la
información, por ejemplo con los interfaces gráficos de usuario o conmunmente denominados
GUI , con las que era posible que la pantalla del ordenador mostrara imágenes visualmente más
atractivas y representativas de la información que se quiere mostrar.

86
De esta forma se permitía una interacción persona-máquina más <natural>, en la que el
usuario <ve> el proceso que siguen los datos que maneja.
Ahora que las redes de telecomunicaciones son globales, los proveedores de información
y los propietarios de derechos de autor determinan el valor de sus productos y cuánto cobran por
ellos, los elementos de información se integrarán a sus desarrollos en línea como recursos
distribuidos en una autopista de datos, como una autopista de pago, donde se pagará por adquirir y
utilizar la información basada en multimedia.
Actualmente el desarrollo de internet posibilita un gran desarrollo multimedia por
ejemplo se tiene acceso a textos completos de libros y revistas, vía módem y enlaces electrónicos;
se proyectan películas en casa; se disponen de noticias casi en el momento que ocurran en
cualquier lugar de la Tierra,etc.
La tendencia actual es llevar al hogar la multimedia interactiva, proprocionando la
interacción y control de los distintos mecanismos y electrodomésticos de casa desde un sistema
informático.
El origen de la gran difusión multimedia también está promovido por el intento de
estandarización por parte de los fabricantes debido a los grandes problemas de compatibilidad
entre los diferentes componentes. En 1991 un grupo de fabricantes (AT&T, CompuAdd, NEC,
Tandy, Microsoft, Zenith, NCR, Olivetti, Philips, Media Vision, Video Seven y Creative Labs)
agrupados con la denominación The Multimedia PC Marketing Council, elaboró la primera
Norma Multimedia para Ordenadores Personales, o MPC, que definía los requisitos mínimos de
un sistema multimedia. Esta especificación estaba en consonancia con la tecnología y capacidad de
proceso del momento. Esta primera estandarización quedó obsoleta ya que las prestaciones
requeridas superaban la capacidad de proceso existente requerida por los escasos productos del
mercado (principalmente enciclopedias) y, en consecuencia, las expectativas de la mayoría de los
usuarios quedaron defraudadas. Tras estos primeros pasos, en la primavera de 1993, se elaboró una
segunda norma denominada MPC-II cuyos criterios eran más exigentes y se apoyaban en un
soporte físico ya disponible (en especial procesadores) más potente. Fue el inicio de las
aplicaciones y los ordenadores multimedia. A continuación se muestran dichas especificaciones.

87
Level 1 Level 2
------------------------------
RAM 2 MB 4 MB
Processor 386SX, 16 MHz 486SX, 25 MHz
Hard Drive 30 MB 160 MB
CD-ROM Drive 150 KB/sec. 300 KB/sec
Other CD-ROM XA ready,
Multisession capable
Sound 8-bit digital sound, 16-bit digital sound,
8-note synthesizer, 8-note synthesizer,
MIDI playback MIDI playback
Video Display 640 x 480, 16 colors 640 x 480, 65,536 colors
Ports MIDI I/O, joystick MIDI I/O, joystick
Aunque como podemos comprobar dichas especificaciones están obsoletas, marcaron un
hito de cara a compatibilizar y definir los componentes básicos multimedia de un PC, actualmente
se entiende por MPC un ordenador multimedia personal, estándar para los programas y hardware
multimedia en los ordenadores personales.
Por tanto podemos concluir que en los últimos años se está produciendo un auge del
concepto multimedia; este fenómeno está motivado, fundamentalmente, por las causas
siguientes:
• La continua bajada de precios, tanto de equipo lógico como de físico. Como
ejemplo se puede indicar el precio de un ordenador personal de características
similares que reduce su precio de año en año.
• El equipamiento físico disponible, que incrementa el rendimiento de los

88
ordenadores, la capacidad de los discos magnéticos y la aparición de la tecnología
de almacenamiento óptico, que permite el almacenamiento masivo a más bajo coste
que con la tecnología de discos magnéticos.
• La aparición de tecnologías como MMX en el diseño de microprocesadores, que
incorpora en su interior capacidades multimedia, y la puerta que, con ello, queda
abierta, para el futuro de dichos dispositivos, y su proyección en el entorno
multimedia.
• La presencia de herramientas software, que permiten la integración y el sencillo
acceso por parte de los usuarios a diferentes aplicaciones.
• La creciente demanda de los usuarios que cada vez solicitan más prestaciones a su
sistema informático como tratamiento de gráficos, imágenes, sonido, movimiento,
etc.
• La decisión internacional de digitalización de la TV, que supone tratamiento digital
homogéneo para todos los medios: datos, voz, imágen fija y en movimiento y TV,
así como la posibilidad de acceder a Internet a través de dicha tecnología, hecho que
abre un canal universal de entrada en la Red y a todas las posibilidades multimedia
que en ella se ofrecen.
• La convergencia entre TV digital y la tecnología Web, favorecida por el alto ancho
de banda proporcionado por las proveedoras de Internet en combinación con la
tecnología asociada a las operadoras de “cable”. La posibilidad de acceder, a través
de Internet, a “frames” de imágen en movimiento y sonido que crean la necesidad
de tener equipos multimedia por parte de los usuarios.
• La tendencia al aumento del ancho de banda en las redes de comunicaciones y la
utilización de ADSL, RDSI de banda ancha sobre fibra óptica.
• La convergencia de los servicios de telecomunicaciones con la informática
tradicional, así como el desarrollo de comunicaciones celulares y redes sin cable. La
aparición de TV que permite ejecutar aplicaciones, monitores de PC que están
adaptados para recibir y visualizar señales de TV. En resumen, la confluencia en un
solo dispositivo de terminales para proceso y TV.

89
• La evolución de las técnicas de compresión.
Hoy en día la evolución y presencia de multimedia podemos encontrarlas en multitud de
dispositivos de uso cotidiano como TV, portátiles, teléfonos móviles, reproductores de audio,
video, etc. integrando y estandarizando cada vez en mayor medida las opciones y calidad de
reproducción.

90
BIBLIOGRAFÍA
- INTRODUCCIÓN A LA INFORMÁTICA, A. Prieto Espinosa, A. Lloris Ruiz, J.C.
Torres Cantero, Ed. McGraw-Hill, 4ª Edición, 2006.
- FUNDAMENTOS DE LOS COMPUTADORES, P. De Miguel Anasagasti, Ed.
Paraninfo, 1999.
- SISTEMAS OPERATIVOS: UNA VISIÓN APLICADA, Jesús Carretero Pérez, Pedro
de Miguel Anasagasti, Félix García Carballeira y Fernando Pérez Costoya, McGraw
Hill, 2001.
- Sistemas operativos, Stallings, W. Prentice Hall, 2ed., 1997.
- Sistemas operativos: Diseño e implementación, Tanenbaum, Andrew S. Prentice Hall,
1990.
- Sistemas operativos Modernos, Tanenbaum, Andrew S. Prentice Hall, 1993.
- INGENIERÍA DEL SOFTWARE, 2ª Ed., Ian Sommerville, Addison Wesley, 1988.
- PROGRAMMING LANGUAGES: PRINCIPLES AND PARADIGMS, Allen Tucker y
Robert Nooan, McGraw Hill, 2002.
- Comunicaciones y redes de computadores. Stallings, William. Pearson Prentice Hall,
7ed. 2004
- ANÁLISIS Y DISEÑO DETALLADO DE APLICACIONES INFORMÁTICAS DE
GESTIÓN, Mario G. Piattini, José A. Calvo-Manzano, Joaquín Cercera y Luis
Fernández, Ra-Ma, 1996.