generador semiautomático de perfiles de usuario mediante owl
DESCRIPTION
La identificación de las preferencias del usuario en función de su perfil (su edad, gustos, nivel socioeconómico, nivel cultural, y de conocimientos en un área específica), permitirá a la siguiente generación de aplicaciones Web 3.0 y de sistemas de recomendación contextuales, por un lado, personalizar los contenidos Web de acuerdo al perfil del usuario y por otro, presentar resultados pertinentes para el mismo. Los perfiles de usuarios son una importante herramienta para personalizar respuestas y entornos. Por lo anterior, en este documento se presenta una metodología innovadora basada en el uso de ontologías definidas con lenguaje OWL y agrupamientos de secciones de información en clústeres y mecanismos de deducción que minimizan de manera significativa el atosigamiento e intrusión en el proceso de extracción de información personal del usuario. Esta metodología permite identificar, clasificar y agrupar componentes del perfil del usuario en una base de datos semántica que permitirá a diversas aplicaciones explotar esta información para la personalización de contenidos Web. Además, esta base de datos semántica también podrá ser utilizada para la selección de resultados pertinentes en búsquedas contextuales de servicios.TRANSCRIPT

Rojas, Christian i
cenidet
Centro Nacional de Investigación y Desarrollo Tecnológico
Departamento de Ciencias Computacionales
TESIS DE MAESTRÍA EN CIENCIAS EN CIENCIAS DE LA COMPUTACIÓN
Generador semiautomático de perfiles de usuario mediante OWL
presentada por
Christian Eloy Rojas Roldán Ing. en Sistemas Computacionales por el I. T. de Acapulco
como requisito para la obtención del grado de:
Maestría en Ciencias en Ciencias de la Computación
Director de tesis: Dr. Juan Gabriel González Serna
Jurado:
Dr. Javier Ortiz Hernández – Presidente Dra. Azucena Montes Rendón – Secretario
M.C. Hugo Estrada Esquivel – Vocal Dr. Juan Gabriel González Serna – Vocal Suplente
Cuernavaca, Morelos, México. 15 de Septiembre de 2009

Rojas, Christian ii
DEDICATORIA
A Dios, por todas las bendiciones otorgadas
A mis padres: Dr. Eloy Mario Rojas Nava y Dra. Aida Roldán Monroy, como
insignificante retribución a todo lo que sin reparos me han puesto en las manos.
A mi novia Xiomara, por todo el apoyo y alegría.
A mi hermano, por apoyarme en lo que necesité, este triunfo
también es tuyo.

Rojas, Christian iii
AGRADECIMIENTOS
A Dios. Siempre primero. A mis padres, por tanta paciencia, apoyo, y por enseñarme con amor y ejemplo que todo es posible cuando te lo propones. A mi hermano que nunca dijo un no, cuando lo necesité. Sin ellos nunca lo hubiera logrado. A mi novia Xiomara, que con su sonrisa alegró cada día desde el principio hasta el fin. Por contagiarme de su paciencia y ser mi compañera. Al Centro Nacional de Investigación y Desarrollo Tecnológico por permitirme un lugar entre sus alumnos y obtener mis estudios de maestría. Al Consejo Nacional de Ciencia y Tecnología por la beca para manutención otorgada y por permitirme conocer el viejo continente con excelente compañía. A mi director de tesis Dr. Juan Gabriel González Serna, por haberme elegido como su tesista, por todas esas horas de paciencia otorgadas, por la amabilidad y respetuosidad que lo caracterizan y sobre todo por ser un buen amigo. A mis revisores de tesis: Dr. Hugo Estrada Esquivel, Dra. Azucena Montes Rendón, Dr. Javier Ortíz Hernández, por todas las recomendaciones, apoyo y tiempo dedicado A mi gente de Acapulco, abuelos, tíos, primos, amigos, que siempre me obsequiaron ánimos, oraciones, suerte y bienestar cada vez que partía de regreso a mis labores. A esos compañeros de generación que ahora son amigos: Israel, Rubi, Omar, Yanet, Jose Luis e Itzel por todos los buenos ratos que pasamos juntos y en especial por haber mitigado la tristeza de no pasar navidad y fin de año con la familia, cuando España fue nuestro hogar. Aunque me resulta imposible agradecer en solo este espacio a todas esas personas que hicieron posible éste logro. A todos ellos:

Rojas, Christian iv
RESUMEN
La identificación de las preferencias del usuario en función de su perfil (su edad,
gustos, nivel socioeconómico, nivel cultural, y de conocimientos en un área
específica), permitirá a la siguiente generación de aplicaciones Web 3.0 y de
sistemas de recomendación contextuales, por un lado, personalizar los contenidos
Web de acuerdo al perfil del usuario y por otro, presentar resultados pertinentes
para el mismo.
Los perfiles de usuarios son una importante herramienta para personalizar
respuestas y entornos. Por lo anterior, en este documento se presenta una
metodología innovadora basada en el uso de ontologías definidas con lenguaje
OWL y agrupamientos de secciones de información en clústeres y mecanismos de
deducción que minimizan de manera significativa el atosigamiento e intrusión en
el proceso de extracción de información personal del usuario.
Esta metodología permite identificar, clasificar y agrupar componentes del perfil
del usuario en una base de datos semántica que permitirá a diversas aplicaciones
explotar esta información para la personalización de contenidos Web.
Además, esta base de datos semántica también podrá ser utilizada para la
selección de resultados pertinentes en búsquedas contextuales de servicios.

Rojas, Christian v
ÍNDICE
Lista de figuras ................................................................................................................................. ix
Lista de tablas.................................................................................................................................... x
Lista de Gráficos ............................................................................................................................... x
Glosario de términos y siglas ......................................................................................................... xi
1. Capítulo I. Introducción ............................................................................................................ 1
1.1 Introducción ......................................................................................................................... 2
1.2 Descripción del problema .................................................................................................... 2
1.3 Objetivo ............................................................................................................................... 3
1.4 Justificación ......................................................................................................................... 4
1.5 Beneficios ............................................................................................................................ 8
1.6 Trabajos relacionados ......................................................................................................... 8
1.6.1 Principios de marketing ............................................................................................... 8
1.6.2 Improving Ontology-Based User Profiles .................................................................... 9
1.6.3 Learning implicit user interest hierarchy for context in personalization ..................... 10
1.6.4 Need for Context-Aware Topographic Maps in Mobile Devices................................ 11
1.6.5 Matching User's Semantics with Data Semantics in Location-Based Services ........ 11
1.6.5.1 Perfil de usuario ..................................................................................................................................11
1.6.5.2 Perfiles de datos .................................................................................................................................12
1.6.6 Exploiting Hierarchical Relationships in Conceptual search ..................................... 12
1.6.7 SOUPA: Standard ontology for ubiquitous and pervasive applications .................... 12
1.6.7.1 SOUPA Core. ......................................................................................................................................13
1.6.7.2 SOUPA Extensión ...............................................................................................................................13
1.6.8 A MDD strategy for developing context-aware pervasive systems ........................... 13
1.6.9 Categorizaciones independientes de un Usuario. ..................................................... 14
1.6.9.1 GEEK ..................................................................................................................................................14
1.6.9.2 AKTORS .............................................................................................................................................15
1.6.9.3 Amigo de un amigo (FOAF: FRIEND Of A Friend) ...............................................................................15
1.7 Alcance del proyecto de tesis ............................................................................................ 17
1.8 Organización del documento ............................................................................................. 17
Capítulo II. Marco teórico ............................................................................................................... 18
2.1 Conceptos semánticos ...................................................................................................... 20
2.1.1 OWL........................................................................................................................... 20
2.1.2 RDF ........................................................................................................................... 20
2.1.3 W3C ........................................................................................................................... 21
2.1.4 Ontología ................................................................................................................... 21
2.2 Conceptos generales ........................................................................................................ 22
2.2.1 XSD ........................................................................................................................... 22

Rojas, Christian vi
3. Capítulo III. Análisis y diseño ................................................................................................. 23
3.1 Análisis .............................................................................................................................. 24
3.1.1 Análisis de operación con clases .............................................................................. 25
3.1.2 Estructura de URI´s (Uniform Resource Indicator). .................................................. 37
3.1.2.1 Árbol de abstracción de nombres ........................................................................................................38
3.1.3 Manejo de tipos ......................................................................................................... 40
3.1.4 Análisis de la interfaz ................................................................................................. 42
3.1.4.1 Dominio Básico. ..................................................................................................................................43
3.1.4.2 Dominio Médico ..................................................................................................................................43
3.1.4.3 Dominio Familiar .................................................................................................................................43
3.1.4.4 Dominio Profesional ............................................................................................................................44
3.1.4.5 Dominio Educativo ..............................................................................................................................44
3.2 Diseño ............................................................................................................................... 44
3.2.1 Actividades del proyecto............................................................................................ 48
3.2.1.1 Conexión con ontología.......................................................................................................................48
3.2.1.2 Usuario nuevo .....................................................................................................................................49
3.2.1.3 Usuario existente ................................................................................................................................50
3.2.1.4 Guardado en ontología........................................................................................................................51
3.2.1.5 Modificar en ontología .........................................................................................................................53
3.2.1.6 Eliminado de ontología ........................................................................................................................54
3.2.1.7 Elección de dominio ............................................................................................................................55
3.2.1.8 Elección de operación en ontología .....................................................................................................55
4. Capítulo IV. Desarrollo de la solución ................................................................................... 55
4.1 Recopilación, discriminación e integración de datos ........................................................ 58
4.2 Estructura de la ontología ................................................................................................. 61
4.2.1 Núcleo........................................................................................................................ 62
4.2.2 Extensibilidad ............................................................................................................ 62
4.2.2.1 Extensibilidad satelital .........................................................................................................................63
4.2.2.1.1 Ejemplo .......................................................................................................... 64
4.2.2.1.2 Formalización de extensibilidad satelital........................................................ 65
4.2.2.2 Extensibilidad parcial ..........................................................................................................................66
4.2.2.2.1 Ejemplo .......................................................................................................... 67
4.2.2.2.2 Formalización de extensibilidad parcial ......................................................... 69
4.2.2.3 Extensibilidad nuclear .........................................................................................................................70
4.2.2.3.1 Ejemplo .......................................................................................................... 71
4.2.2.3.2 Formalización de extensibilidad nuclear. ....................................................... 72
5. Capítulo V. Implementación ................................................................................................... 75
5.1 Conexión con ontología ..................................................................................................... 76
5.2 Usuario nuevo y usuario existente .................................................................................... 77

Rojas, Christian vii
5.3 Volcado de ontología ......................................................................................................... 79
5.4 Guardado de ontología ...................................................................................................... 80
5.5 Lectura y modificación de ontología .................................................................................. 82
5.6 Eliminar ontología .............................................................................................................. 82
6. Capítulo VI. Pruebas................................................................................................................ 85
6.1 Introducción ....................................................................................................................... 86
6.2 Descripción del Plan .......................................................................................................... 86
6.2.1 Características a ser probadas ................................................................................. 86
6.2.2 Características excluidas de las pruebas .................................................................. 87
6.2.3 Enfoque ..................................................................................................................... 87
6.2.4 Criterio pasa/ no pasa de casos de prueba. ............................................................. 87
6.2.5 Criterios de suspensión y requerimientos de reanudación. ...................................... 87
6.2.6 Tareas de pruebas. ................................................................................................... 87
6.2.7 Liberación de pruebas. .............................................................................................. 88
6.2.8 Requisitos ambientales. ............................................................................................ 88
6.2.9 Responsabilidades. ................................................................................................... 88
6.2.10 Riesgos y contingencias. ........................................................................................... 88
6.3 Casos de Pruebas. ............................................................................................................ 89
6.3.1 Características a probar ............................................................................................ 89
6.3.2 Grupos de pruebas .................................................................................................... 89
6.3.2.1 Operación con la ontología .................................................................................................................89
6.3.2.2 Estructuración ontológica ....................................................................................................................89
6.3.2.3 Enlace con ontología ...........................................................................................................................89
6.3.2.4 Elección de dominio de la aplicación ...................................................................................................89
6.3.3 Procedimiento de Pruebas ........................................................................................ 89
6.4 USOG-101 Pruebas de operación con la ontología .......................................................... 90
6.4.1 Propósito ................................................................................................................... 90
6.4.2 Entorno de prueba. .................................................................................................... 90
6.4.3 USOG-101-001 Lectura de la ontología .................................................................... 90
6.4.3.1 Propósito .............................................................................................................................................90
6.4.3.2 Entorno de prueba. .............................................................................................................................90
6.4.3.3 Proceso...............................................................................................................................................90
6.4.3.4 Resultado esperado. ...........................................................................................................................90
6.4.4 USOG-101-002 Escritura en ontología ..................................................................... 91
6.4.4.1 Propósito .............................................................................................................................................91
6.4.4.2 Entorno de prueba. .............................................................................................................................91
6.4.4.3 Proceso...............................................................................................................................................91
6.4.4.4 Resultado esperado. ...........................................................................................................................91
6.4.5 USOG-101-003 Eliminado de la ontología ................................................................ 91

Rojas, Christian viii
6.4.5.1 Propósito .............................................................................................................................................91
6.4.5.2 Entorno de prueba. .............................................................................................................................91
6.4.5.3 Proceso...............................................................................................................................................91
6.4.5.4 Resultado esperado. ...........................................................................................................................91
6.4.6 USOG-201 Pruebas de estructuración ontológica .................................................... 91
6.4.6.1 Propósito .............................................................................................................................................91
6.4.6.2 Entorno de prueba. .............................................................................................................................92
6.4.7 USOG-201-001 Estructuración de individualizaciones ............................................. 92
6.4.7.1 Propósito .............................................................................................................................................92
6.4.7.2 Entorno de prueba. .............................................................................................................................92
6.4.7.3 Proceso...............................................................................................................................................92
6.4.7.4 Resultado esperado. ...........................................................................................................................92
6.4.8 USOG-301 Prueba de enlace con ontología ............................................................. 92
6.4.8.1 Propósito .............................................................................................................................................92
6.4.8.2 Entorno de prueba. .............................................................................................................................92
6.4.9 USOG-301-001 Conexión con ontología................................................................... 93
6.4.9.1 Propósito .............................................................................................................................................93
6.4.9.2 Entorno de prueba. .............................................................................................................................93
6.4.9.3 Proceso...............................................................................................................................................93
6.4.9.4 Resultado esperado. ...........................................................................................................................93
6.4.10 USOG-401 Prueba de elección del dominio de la aplicación ............................... 93
6.4.10.1 Propósito .............................................................................................................................................93
6.4.10.2 Entorno de prueba. .............................................................................................................................93
6.4.11 USOG-401-001 Elección del dominio de la aplicación ............................................. 93
6.4.11.1 Propósito .............................................................................................................................................93
6.4.11.2 Entorno de prueba. .............................................................................................................................93
6.4.11.3 Proceso...............................................................................................................................................94
6.4.11.4 Resultado esperado. ...........................................................................................................................94
6.5 Pruebas ............................................................................................................................. 94
6.4.1 Pruebas Funcionales ................................................................................................. 95
6.4.2 Pruebas operativas .................................................................................................. 106
6.5 Observaciones generales ................................................................................................ 136
Capítulo VII. Conclusiones ........................................................................................................... 139
7.1 Conclusiones ................................................................................................................... 140
7.2 Aportaciones .................................................................................................................... 141
7.3 Trabajos futuros ............................................................................................................... 142
7.4 Publicaciones .................................................................................................................. 143
Bibliografía ..................................................................................................................................... 144
Anexo 1 ........................................................................................................................................... 147
Anexo 2 ........................................................................................................................................... 148

Rojas, Christian ix
LISTA DE FIGURAS
Figura 1.1 Perspectiva de SOUPA + CoBrA para modelar a un usuario. ........................................... 4
Figura 1.2 Perspectiva de GEEK para modelar a un usuario ............................................................. 5
Figura 1.3 Perspectiva de AKTORS para modelar a un usuario ........................................................ 6
Figura 1.4 Perspectiva de FOAF para modelar a un usuario ............................................................. 7
Figura 1.5 Mapa del comportamiento del comprador ......................................................................... 9
Figura 1.6 Ontologías integrantes de SOUPA .................................................................................. 13
Figura 3.1 Diagrama de bloques del proceso general del proyecto ................................................. 24
Figura 3.2 Diagrama general de casos de uso ................................................................................. 25
Figura 3.3 Diagrama de casos de uso de Operar con la ontología .................................................. 26
Figura 3.4 Diagrama de actividad del caso de uso CU-1 Operar con la ontología ........................... 28
Figura 3.5 Diagrama de actividad del caso de uso Elegir operación de altas, bajas y consultas .... 30
Figura 3.6 Diagrama de actividad del caso de uso Elegir dominio de aplicación ............................. 32
Figura 3.7 Diagrama de actividad del caso de uso Enlazar con la ontología ................................... 34
Figura 3.8 Diagrama de casos de uso de Estructuración ontológica................................................ 35
Figura 3.9 Diagrama de actividad del caso de uso Estructuración ontológica ................................. 36
Figura 3.10 Identificador del atributo “nombre” de la ontología en protégé ...................................... 37
Figura 3.11 Árbol de elementos de la ontología ............................................................................... 39
Figura 3.12 Árbol de elementos de la ontología ............................................................................... 39
Figura 3.13 Resultado del método para nombrar individualizaciones .............................................. 40
Figura 3.14 Esquema de manejo de los tipos de datos .................................................................... 41
Figura 3.15 Diagrama de clases del proyecto ................................................................................... 44
Figura 3.16 Diagrama de clases del paquete mx.edu.cenidet.userontology.axiomsinference ......... 45
Figura 3.17 Diagrama de clases del paquete mx.edu.cenidet.userontology.Front ........................... 47
Figura 3.18 Diagrama de secuencias para la Conexión con la ontología ........................................ 49
Figura 3.19 Diagrama de secuencias para ingresar al sistema como usuario nuevo ...................... 50
Figura 3.20 Diagrama de secuencias para ingresar al sistema como usuario existente.................. 51
Figura 3.21 Diagrama de secuencias del proceso Guardar ontología.............................................. 53
Figura 3.22 Diagrama de secuencias del proceso Modificación de ontología .................................. 54
Figura 3.23 Diagrama de secuencias del proceso Eliminación de la ontología ............................... 54
Figura 4.1. Estructura ontológica ...................................................................................................... 60
Figura 4.2. Enfermedades crónico-degenerativas en México ........................................................... 61
Figura 4.3. Estructura de la clase “Minusvalía”. ................................................................................ 64
Figura 4.4. Estructura de la clase “Ayuda_tecnica” .......................................................................... 64
Figura 4.5. Esquema de “Extensibilidad satelital” ............................................................................. 65
Figura 4.6. Esquema de extensibilidad parcial ................................................................................ 67
Figura 4.7. Estructura de la clase “Contacto” .................................................................................... 68
Figura 4.8. Estructura de la clase “Nivel_computo” .......................................................................... 68
Figura 4.9. Relación y cobertura entre las clases “Nivel_computo” y “Contacto” ............................. 69
Figura 4.10. Estructura de la clase “Personales” .............................................................................. 71
Figura 4.11. Estructura de la clase “Origen” ..................................................................................... 71
Figura 4.12. Esquema de extensibilidad nuclear .............................................................................. 72
Figura 5.1. Conexión con ontología .................................................................................................. 77
Figura 5.2. Autenticación de usuario.1 .............................................................................................. 77
Figura 5.3. Autenticación de usuario.2 .............................................................................................. 78
Figura 5.4. Autenticación de usuario.3 .............................................................................................. 79
Figura 5.5. Volcado de datos a la ontología ...................................................................................... 80
Figura 5.6. Relación de elementos en la ontología ........................................................................... 81
Figura 5.7. Lectura de datos desde la ontología ............................................................................... 82
Figura 5.8. Eliminación de datos en la ontología .............................................................................. 83
Figura 6.1. Datos de la ontología en protégé .................................................................................... 95
Figura 6.2. Autenticación invalida ..................................................................................................... 95
Figura 6.3. Autenticación válida y elección de operación con ontología .......................................... 95

Rojas, Christian x
Figura 6.4. Datos de la ontología en protégé .................................................................................... 96
Figura 6.5. Creación de nuevo usuario y elección del dominio de aplicación .................................. 96
Figura 6.6. Introducción de datos en el perfil .................................................................................... 97
Figura 6.7. Datos en la ontología después de la operación .............................................................. 97
Figura 6.8. Contenido de la instancia de la clase miembro en la ontología ..................................... 98
Figura 6.9. Eliminación de un individuals en la ontología ................................................................. 99
Figura 6.10. Resultado en la ontología después de la operación ..................................................... 99
Figura 6.11. Guardado de datos ontológicos. ................................................................................. 100
Figura 6.12. Árbol de abstracción de nombres de la ontología creada. ......................................... 100
Figura 6.13. Estructuración ontológica de la ontología en protégé................................................. 101
Figura 6.14. Contenido de password en la clase personales de la ontología ................................ 101
Figura 6.15. Autenticación en la ontología existente ...................................................................... 102
Figura 6.16. Cambio de contraseña en la ontología ....................................................................... 102
Figura 6.17. Valores ontológicos posteriores a la operación. ......................................................... 103
Figura 6.18. Autenticación y visualización de clases organizadas según el dominio de aplicación Hospital ............................................................................................................................................ 104
Figura 6.19. Dominio de aplicación antes de la operación ............................................................. 104
Figura 6.20. Dominio de aplicación después de la operación ........................................................ 105
Figura 6.21. visualización de clases organizadas según el dominio de aplicación Universidad .... 105
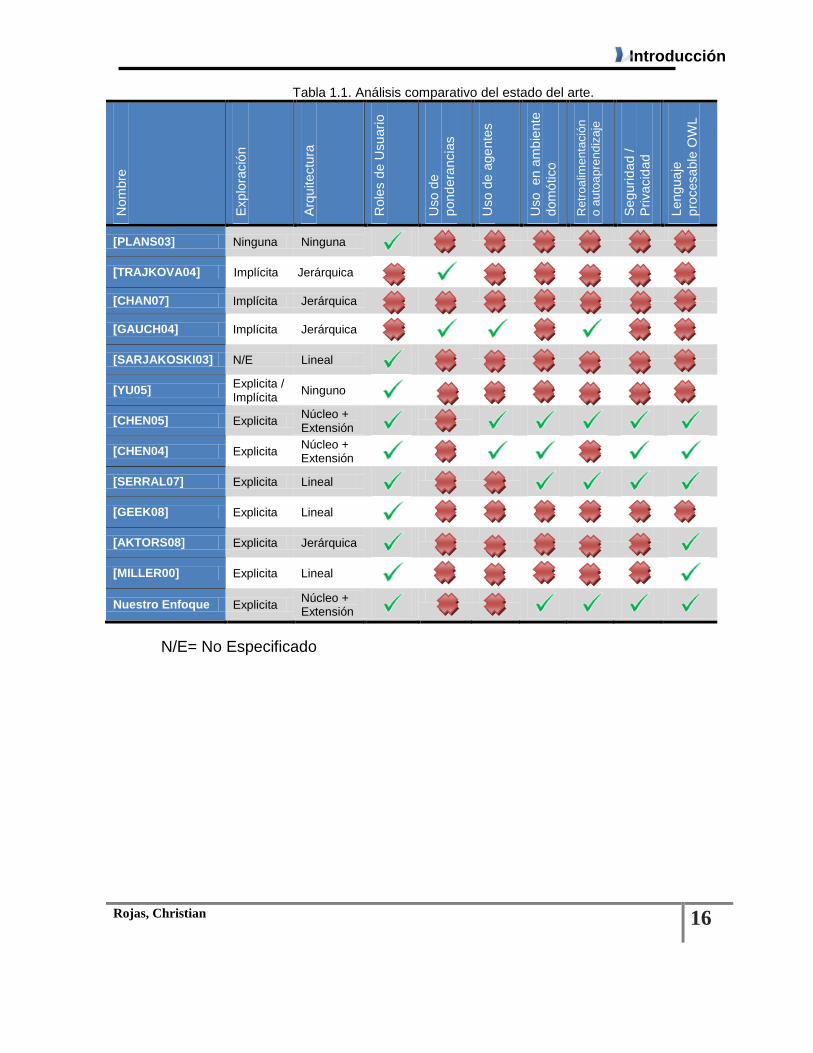
LISTA DE TABLAS Tabla 1.1. Análisis comparativo del estado del arte.......................................................................... 16
Tabla 3.1 Descripción del caso de uso Operar con la ontología ...................................................... 26
Tabla 3.2 Descripción del caso de uso Elegir operación de altas, bajas y consultas ....................... 28
Tabla 3.3 Descripción del caso de uso Elegir dominio de aplicación ............................................... 31
Tabla 3.4 Descripción del caso de uso Enlazar con la ontología ..................................................... 32
Tabla 3.5 Descripción del caso de uso Estructuración ontológica .................................................... 35
Tabla 4.1. Recopilación de atributos pertinentes para perfilar a un usuario. .................................... 58
Tabla 6.1 Tareas a desarrollar a las pruebas ................................................................................... 87
Tabla 6.2. Caso de prueba: Lectura de la ontología ......................................................................... 95
Tabla 6.3 Caso de prueba: Escritura en ontología............................................................................ 96
Tabla 6.4 Caso de prueba: Eliminado de la ontología ...................................................................... 98
Tabla 6.5 Caso De Prueba: Estructuración De Individualizaciones ................................................ 100
Tabla 6.6 Caso De Prueba: Estructuración De Individualizaciones ................................................ 101
Tabla 6.7 Caso De Prueba: Estructuración De Individualizaciones ................................................ 103
LISTA DE GRÁFICOS Grafico 1 Clases Accedidas Por El Grupo De Prueba .................................................................... 137
Grafico 2 Estadística de salida ........................................................................................................ 138

Rojas, Christian xi
GLOSARIO DE TÉRMINOS Y SIGLAS IEEE Institute of Electrical and Electronics Engineers (IEEE). Instituto de
Ingenieros Eléctricos y Electrónicos, una asociación técnico-profesional mundial dedicada a la estandarización, entre otras cosas. Es la mayor asociación internacional sin fines de lucro formada por profesionales de las nuevas tecnologías, como ingenieros de telecomunicaciones, ingenieros electrónicos, ingenieros en informática e Ingenieros en computación.
URI Un URI es una cadena corta de caracteres que identifica
inequívocamente un recurso (servicio, página, documento, dirección de correo electrónico, enciclopedia, etc.). Normalmente estos recursos son accesibles en una red o sistema.
Todas las definiciones se tomaron de [wiki09].

1. CAPÍTULO I. INTRODUCCIÓN
En este capítulo se presenta la descripción del problema que dio origen al presente trabajo de tesis, su objetivo, justificación y beneficios. También los trabajos relacionados. Y por último la organización del documento.

Introducción
Rojas, Christian 2
1.1 INTRODUCCIÓN
Debido a la inexactitud de los sistemas y estudios actuales para perfilar o modelar a un usuario real, se ha visto la necesidad de analizar las posibles categorizaciones del mismo, basadas en áreas como la mercadotecnia, psicología, y computación. Esto con la finalidad de obtener un conjunto de datos que permitan perfilar de un modo eficiente a un usuario en cuestión. Un simple documento legible por una persona y una lista de datos no son suficientes, por lo que se necesita un entorno de diseño en algún lenguaje procesable como lo puede ser (OWL/RDF) y alguna interfaz que permita la captura de estos datos. Uno de los principales intereses de este proyecto es entonces obtener una ontología que permita modelar a un usuario, así como sus costumbres, deficiencias, roles cotidianos y características, y poblarla mediante alguna interfaz gráfica de un ambiente de desarrollo para poder instanciarla y explotarla. Debido a que la información obtenida del usuario será proporcionada de manera explícita, es decir, directamente por el usuario, se investigarán e implementarán una serie de técnicas para evitar en la medida de lo posible la intrusión excesiva de sus datos, y por consiguiente obtener sólo los necesarios para un cierto dominio de aplicación, sin menoscabar la pertinencia de los mismos.
1.2 DESCRIPCIÓN DEL PROBLEMA
Los perfiles de usuarios son una importante herramienta para personalizar respuestas, entornos y evitar la intrusión excesiva de datos secundarios, así como para minimizar costos por manejo de datos impertinentes. En el mercado se pueden encontrar distintas categorizaciones de usuario [Geek09] [Akt08] [Miller00], sin embargo aunque cada una de ellas comparte en gran medida su conjunto de datos básico (nombre, edad, sexo, etc.), también poseen datos especializados, que sólo poseerán aquellos usuarios que estén en el dominio de aplicación de esa categorización. Es entonces necesaria, una depuración de los datos de un usuario, dispuestos por Web sociales, servicios independientes y estudios de áreas como la computación, mercadotecnia y psicología. [Yu05] [Plans03] [Trajkova04] [Chan07] [Gauch04] [Nivala03] Así como la adición de elementos considerados pertinentes. [Issste02] [Cif00] [Icf08] [Disc08] [Croja08] [Gzlez08] [Disca08]

Introducción
Rojas, Christian 3
Un simple documento legible por una persona y una lista de datos no son suficientes, por lo que se necesita un entorno de diseño en algún lenguaje procesable como lo puede ser OWL/RDF (Ontology Web Language/Resource Description Framework) [W3C04] y una interfaz amigable que permita la captura de estos datos. La necesidad objetiva de este proyecto es entonces obtener una ontología que cumpla con las características citadas, modelando a un usuario y tomando en cuenta sus costumbres, deficiencias, roles cotidianos y características, y poblarla mediante una interfaz gráfica para poder instanciarla y explotarla. Debido a que la información para perfilar al usuario deberá ser directamente introducida por el mismo, se investigaron e implementaron una serie de técnicas para evitar, en la medida de lo posible, la intrusión excesiva de datos del usuario, y por consiguiente obtener sólo los necesarios para un cierto dominio de aplicación, sin menoscabar la pertinencia de los mismos. Una de las problemáticas inmersas en el uso de ontologías es nombrar semánticamente de forma unívoca a los elementos en la ontología, como lo son atributos, clases e individuals (instancia de una clase); los cuales son representados mediante una URI (Uniform Resource Indicator) siguiendo un mismo patrón. [W3C04] [Protege09]. Esto ocasiona que no pueda ser identificado un elemento a partir de su URI, y en el peor de los casos esta nomenclatura arbitraria ocasionará que se tengan que implementar heurísticas más complejas para la recuperación de elementos a partir de un conjunto de identificadores conceptuales unívocos. Para resolver estos problemas, en esta tesis se propone una técnica para el tratamiento de los identificadores conceptuales mediante la generación de un árbol de abstracción de nombres a partir de un conjunto de reglas.
1.3 OBJETIVO
Obtener una ontología que modele a un usuario, tomando en cuenta sus costumbres, deficiencias, roles cotidianos y características, y poblarla mediante una interfaz gráfica para poder instanciarla y explotarla.

Introducción
Rojas, Christian 4
1.4 JUSTIFICACIÓN Una gran cantidad de interpretaciones para categorizar a un usuario están disponibles en el mercado, sin embargo, la mayoría de estas, contemplan una estructura influenciada por el domino hacia el cual intencionalmente fueron creadas, es decir, que los datos que consideran capturar son divergentes, debido a que cada categorización especializa los datos a sus intereses. Aunque muchas de estas categorizaciones son similares en sus datos básicos (datos personales), existe la variabilidad en su formato, es decir, estos conjuntos de datos están dispuestos en diferentes formas como por ejemplo: texto plano, bases de datos, lenguaje procesable (OWL), etc. En las siguientes figuras se muestran distintas apreciaciones para categorizar a un usuario. En la figura 1.1 se muestra una perspectiva de acuerdo a SOUPA + CoBrA [Chen04], la cual toma en cuenta datos generales y algunos basados en contacto.
Figura 1.1 Perspectiva de SOUPA + CoBrA para modelar a un usuario.
• Nombre
• Género
• Edad
• Fecha de nacimiento
Información básica de perfil
• Correo
• Dirección
• Página personal
• Número telefónico
• Mensajería instantanea
• Id. de chat
Información de contacto
• Amigos
• Dependientes de organizacion
Profesional y social
Perspectiva SOUPA + CoBrA

Introducción
Rojas, Christian 5
En la figura 1.2, se aprecia una perspectiva de GEEK [Geek09], en la que se enfatiza sobre las preferencias del usuario.
Figura 1.2 Perspectiva de GEEK para modelar a un usuario
La siguiente lista muestra los detalles de algunos elementos marcados con la letra asignada en la figura anterior.
A. Pretty Good Privacy o PGP (privacidad bastante buena) es un programa desarrollado por Phil Zimmermann y cuya finalidad es proteger la información distribuida a través de Internet mediante el uso de criptografía de clave pública, así como facilitar la autenticación de documentos gracias a firmas digitales. Fuente: Wikipedia.
B. Interesado en otros códigos GEEKS [Geek09], y habido de memorizarlos.
En la figura 1.3, se aprecia la perspectiva de AKTORS para perfilar a un usuario, tomando en cuenta datos referentes a su ubicación y preferencias del mismo. [Akt08]

Introducción
Rojas, Christian 6
Figura 1.3 Perspectiva de AKTORS para modelar a un usuario
La siguiente lista muestra los detalles de algunos elementos marcados con la letra asignada en la figura 1.3.
A. Refiere a la ubicación geográfica según el uso horario (GMT) B. Referente al origen de la persona. (Lugar natal) C. Indica cómo le gusta a la persona ser llamada (parte de su nombre) D. Indica el título de la persona en sociedad preferido por la persona (Ing. Sr.
Srita. Dr. Lic. etc.) E. Indica bajo qué tipo de contratación trabaja en su dependencia (Honorarios,
Confianza, Base, Contrato, Sindicalizado, etc.) F. Indica el tipo de trabajo de la persona de entre una lista proporcionada por
AKTORS (Administrador, diseñador multimedia, desarrollador, diseñador grafico, secretario, empleado educacional, soporte académico, interés en investigación, etc.)
En la figura 1.4 se muestra la perspectiva de Friend of a Friend (FOAF), para perfilar a un usuario tomando en cuenta que estos datos están inclinados a cuestiones de contacto debido a la naturaleza del proyecto en el que está inmerso, la cual toma como base los microformatos [Miller00].

Introducción
Rojas, Christian 7
Figura 1.4 Perspectiva de FOAF para modelar a un usuario
La siguiente lista muestra los detalles de algunos elementos marcados con la letra asignada en la figura 1.4. A. Organización fundada por un proyecto o persona B. Una imagen utilizada para representar algo en específico C. Documento que representa un tema principal D. Algo que fue hecho o fabricado por esta persona E. Algún agente que hizo algo F. Liga a las publicaciones de esta persona G. Una muestra en imagen de algo interesante.
Como se puede apreciar en las figuras anteriores, las categorizaciones para un usuario son dedicadas a cierto dominio y en algunos casos de gran tamaño, estas se justifican así mismas en su contenido, y son muy útiles para el contexto de investigación, pero tienen el inconveniente de no ser del mismo formato de operación, esto es, que el caso de GEEK, corresponde a un formato de texto plano, mientras que las demás categorizaciones corresponden a ontologías en lenguaje procesable (OWL), ocasionando una incompatibilidad en la explotación integral de al menos, estas categorías.

Introducción
Rojas, Christian 8
1.5 BENEFICIOS El principal beneficio que se obtuvo de esta tesis es una herramienta que permite modelar usuarios basándose en el contexto propio, mediante el uso de ontologías en lenguaje procesable, utilizando una interfaz gráfica. Las aplicaciones que pueden realizarse con esta herramienta son:
Captura personalizada de los datos del usuario. Una interfaz gráfica que permite la captura de datos pertinentes de acuerdo al usuario en cuestión, tomando en cuenta características, atributos, preferencias, y datos almacenados en el perfil.
Un esquema ontológico basado en núcleo + extensiones. Este tipo de estructura, permitirá el crecimiento de la ontología dependiendo del contexto del usuario en cuestión.
Explotación y reutilización de la ontología resultante. Debido a que el resultado (perfil de usuario) estará dispuesto en un formato liviano bajo un lenguaje procesable (OWL), permitirá a otras aplicaciones o servicios consumidores hacer uso de la información obtenida de manera más intuitiva y ordenada.
Detallado de reglas para la obtención de un mapa ontológico. Un método que define un conjunto de reglas bajo un algoritmo específico, que permitirá estandarizar los identificadores conceptuales generados por la ontología y también permitirá presentar el resultado obtenido. De esta manera es posible la explotación de la ontología de una manera más efectiva ya que el mapa generado manualmente a partir de las reglas mencionadas hace innecesario el conocimiento de lenguaje de consultas para la exploración puntual de un elemento en la estructuración de la ontología.
1.6 TRABAJOS RELACIONADOS
En primera instancia se describe un estudio del área mercadotécnica, en el cual se perfila a un usuario, denominado técnicamente como “comprador”. Posteriormente se muestra un conjunto de artículos asociados al tema, y por último dos tesis (doctorales y de maestría) involucradas por igual
1.6.1 Principios de marketing Este trabajo representa un estudio basado en la mercadotecnia, el cual maneja el concepto de cliente (sinónimo con usuario para fines del proyecto de tesis) Aquí se definen dos conceptos muy distintos entre sí, pero que aparentan una similitud, estos son: “Cliente” y “Consumidor”, pero contempla no sólo productos sino servicios por igual en estas definiciones. Debido a esta separación de definiciones,

Introducción
Rojas, Christian 9
consideran necesarias las categorizaciones de los comportamientos de estos dos actores, fijando la atención en el comprador (cliente). Véase figura 1.5.
Figura 1.5 Mapa del comportamiento del comprador
Se especifican también los roles de compra que son diferentes métricas adoptadas según la(s) rutina(s) en las que se desenvuelve el usuario, así como los tipos de comportamiento del comprador y demás estudios relacionados con el tema. Como se puede apreciar, el tipo de categorización realizada hacia el usuario (denominado comprador) se realiza de modo vectorial, es decir, sin subclasificaciones de datos. De modo que al no explayarse los datos internos de las categorías, solo los grupos, dejan espacio a ambigüedades. [Plans03]
1.6.2 Improving Ontology-Based User Profiles Intenta clasificar intereses del usuario, siendo su principal objetivo investigar técnicas que implican la construcción de perfiles de usuario basados en ontologías. La idea es construir perfiles sin interacción humana, esto es, de manera automática, con el simple monitoreo de los hábitos del usuario. Toma mucha importancia el definir los conceptos más importantes en la construcción o categorización de estos usuarios al igual que involucran estos conceptos o características de un modo jerárquico y cuestionan firmemente la cantidad de niveles necesarios para categorizar al usuario.

Introducción
Rojas, Christian 10
Sin embargo las principales problemáticas se basan en la elección de los elementos pertinentes para la elaboración de dicho perfil y cómo proyectar estos datos en el mismo, ya que se explayan dos técnicas para obtener estos datos, las cuales son implícitas (observación y exploración de su actividad) y explicitas (preguntas directas). Direccionando la metodología de este proyecto hacia la explotación implícita. Referente a la alimentación del perfil, esta se lleva a cabo de manera jerárquica y no vectorial, esto es, aplicando niveles de abstracción con cierta ponderación. [Trajkova04]
1.6.3 Learning implicit user interest hierarchy for context in personalization
El contenido de este documento presenta una visión de la categorización de un usuario a partir de sus intereses, analizada a partir de la navegación Web del mismo. Utilizan un método de estructuración basado en jerarquías para la creación de un perfil, tomando los niveles de la misma como niveles de abstracción de los conceptos, de modo que si un usuario en diferentes consultas o navegaciones toca temáticas muy distintas entre sí, puede darse el caso que en un nivel de abstracción no tengan relación, sin embargo, si se eleva el nivel de abstracción de esas navegaciones, se hace que pertenezcan al mismo concepto. Este artículo utiliza para la generación de un perfil de usuario una estructura jerárquica, denominada por ellos como: UIH (jerarquía de intereses del usuario por sus siglas en inglés). Se propone que la alimentación de las jerarquías y de los conceptos inmersos en ellas sean por un medio automático, esto es, dinámicamente, por medio de la navegación Web del usuario, usando la lógica de que los intereses se contemplan como pasivos cuando el nivel de abstracción es más alto y más activos cuando el nivel de abstracción es más bajo, es decir, de más genérico a más específico. La alimentación de la jerarquía utilizada es dinámica al defender el hecho de que los perfiles son constantemente actualizados por el usuario, y no es práctico el definir un perfil como estático ya sea en su contenido o incluso en su estructura. Según este artículo, la manipulación de los intereses de un modo jerárquico es más precisa que una realizada de un modo vectorial o lineal, sobre todo por cuestiones ontológicas. [Chan07]

Introducción
Rojas, Christian 11
1.6.4 Need for Context-Aware Topographic Maps in Mobile Devices Este trabajo se especializa en servicios que facilitan mapas cartográficos a usuarios, y uno de sus principales factores a tomar en cuenta es la capacidad que se tiene o no para darle al usuario algo en específico que cumpla con sus expectativas, todo esto con el fin de hacer los productos más usables y comerciales.
Los mapas no son un medio de comunicación, pero si, un medio de aproximación para localización de detalles vía espacial, (esto debido a que aplican ontologías para la solución de los mismos) y por lo tanto la exactitud de estos debe de ser por demás precisa, tomando en cuenta todos los detalles que conlleva.
Para la eficiente provisión de los mapas solicitados se emplean las siguientes categorías de acuerdo al momento de la solicitud de los mismos:
Contexto de cómputo
Contexto del usuario: Refiere a habilidades físicas, habilidades perceptuales y cognitivas, y diferentes personalidades del usuario en cuestión.
Contexto Físico
Contexto de tiempo.
Contexto de historia Sin embargo, debido a que el destino final de estos mapas son los dispositivos móviles, estos términos cambian con base en adaptabilidad. [Nivala03]
1.6.5 Matching User's Semantics with Data Semantics in Location-Based Services
Relación de semántica de usuarios con semántica de datos en LBS Propone cierta flexibilidad a los servicios de información para que puedan entender correctamente lo que está siendo solicitado por el usuario, y como seleccionar la información que esa relevante para esta solicitud, tomando en cuenta la gestión, el diseño y los factores humanos. En este artículo se definen los siguientes conceptos:
1.6.5.1 Perfil de usuario Son dinámicos. Dos usuarios en las mismas condiciones, en la misma ubicación y haciendo la misma petición pueden tener resultados distintos (polimorfismo) de acuerdo a su perfil. Se definen también los perfiles de usuario de tipo estático (explicito), y de tipo dinámico (implícito), es decir, alimentados por preguntas directas acerca de sus características, hábitos o comportamiento, y alimentada por el análisis constante de su comportamiento mediante su navegación u otro método, respectivamente.

Introducción
Rojas, Christian 12
1.6.5.2 Perfiles de datos Los perfiles de datos describen servicios de datos. Del mismo modo en que un esquema describe una base de datos, un perfil de datos proporciona información acerca de los datos provistos por un servicio. [Yu05]
1.6.6 Exploiting Hierarchical Relationships in Conceptual search Debido al constante crecimiento de sitios Web, la pertinencia de muchas de las respuestas arrojadas hacia un usuario que los consulta, dependen de una cierta personalización, la cual, no existe al momento, porque a pesar de que los mecanismos son más novedosos en cuestiones de navegación y búsqueda, los principios son los mismos, utilizando palabras clave para hacer sus búsquedas. El problema en la actualidad es que si dos usuarios realizan una consulta utilizando la misma palabra de búsqueda, el motor de búsqueda arroja como resultado el mismo conjunto de respuestas, siendo que es muy probable que cada uno de ellos se haya referido a un contexto distinto. [Gauch04] La herramienta que ellos desarrollaron denominada KeyConcept toma en cuenta tanto estas palabras clave como los conceptos o temas relacionados de su consulta directa y automáticamente de Open Directory. [Odp08] Este artículo entonces, utiliza una estructuración de tipo jerárquica para poder realizar la alimentación de una ontología adoptando los beneficios de este tipo de estructuración en contraste con una de tipo vectorial, además de que toma en cuenta un mejoramiento iterativo, refinándose la jerarquía automáticamente.
1.6.7 SOUPA: Standard ontology for ubiquitous and pervasive applications
En este artículo se explica a detalle el SOUPA, ésta ontología se diseñó para modelar y soportar aplicaciones de cómputo pervasivo.
Esta ontología está definida en lenguaje OWL, la cual incluye un componente modular de vocabulario para representar agentes inteligentes asociados a intenciones, deseos, creencias, perfiles de usuario, información de contexto, acciones y políticas de seguridad y privacidad, y además se explica cómo puede ser extendida y usada para soportar aplicaciones de CoBrA [Chen2005] para la construcción de cuartos inteligentes (habitaciones con sensores de radio frecuencia); y MoGATU, un gestor de datos peer-to-peer para ambientes pervasivos. [Chen04]
A continuación se definen los componentes de las ontologías integrantes de SOUPA:

Introducción
Rojas, Christian 13
Figura 1.6 Ontologías integrantes de SOUPA
1.6.7.1 SOUPA Core. Define el vocabulario genérico y universal para la construcción de aplicaciones de computo pervasivas. Este conjunto de ontologías consiste en vocabularios para expresar conceptos que son asociados con personas, agentes, intenciones, deseos y creencias; acciones políticas, tiempo, espacio y eventos. Véase figura 1.6
1.6.7.2 SOUPA Extensión Se extiende de SOUPA Core. Define vocabulario adicional para el soporte de tipos específicos de aplicaciones y ejemplos provenientes de la definición de nuevas extensiones de ontología. figura arriba Estas ontologías son definidas con dos propósitos: o Definir y extender el conjunto de vocabularios para soportar tipos específicos de
dominios y aplicaciones pervasivas. o Demostrar cómo definir nuevas ontologías por medio de la extensión de las
ontologías SOUPA Core.
1.6.8 A MDD strategy for developing context-aware pervasive systems Esta tesis propone un enfoque metodológico al desarrollo de sistemas pervasivos conscientes de los contextos basados en ontologías y normas del MDD (Model-Driven Development), y ofrece las siguientes contribuciones:
1. Un conjunto de modelos para la captura de datos del contexto en tiempo de modelado.
2. Una ontología de contexto y un repositorio contextual OWL basado en esta ontología para capturar datos del contexto en tiempo de ejecución.

Introducción
Rojas, Christian 14
3. Un framework para almacenamiento automático, gestión y procesamiento de información del contexto en tiempo de ejecución.
4. Una infraestructura para la adaptación del sistema pervasivo con la finalidad de mejorar la vida del usuario
Estos sistemas no solo deben capturar información del contexto, también deben entenderlo y adaptar su comportamiento acorde a éste a partir de las preferencias del usuario. En esta tesis se define una ontología de contexto y un repositorio contextual OWL como un sistema capaz de almacenar en una máquina de lenguaje procesable tanto la información contextual actual como la información contextual histórica. Este framework automáticamente actualiza el repositorio contextual OWL de acuerdo a los cambios producidos en la información contextual al tiempo de ejecución. Para poder gestionar la localización del usuario se requiere que cada uno de ellos tenga un dispositivo de localización (por ejemplo, un brazalete de identificación por radio frecuencia) para ser identificados por los propios sensores. [Serral07]
1.6.9 Categorizaciones independientes de un Usuario.
1.6.9.1 GEEK Un geek es una persona hábil para la informática, la electrónica y la tecnología, y además tiene interés por los gadgets1 y accesorios digitales y/o novedosos. Tanta fama ha cobrado este término que aquellos que se consideran GEEKS, han desarrollado un código para poder distinguirse de entre las personas que no lo son. Este código carente de sentido a simple vista contiene caracteres que identifican y describen no sólo los conocimientos de la persona sobre los temas arriba mostrados, sino también, de ciertas características físicas, de intereses socio-político-económicos, de entretenimiento y más. Cabe mencionar que cada una de las categorías y de las opciones operadas por esta categorización tiene asignado un símbolo univoco (conjunto de caracteres carentes de sentido en un contexto habitual), y formando una concatenación de acuerdo al orden de petición, es como se forma el código geek, cuyo análisis y ejemplo cae fuera de los intereses de este documento. 1. Gadget (Gizmo)
Obtenido de: http://es.wikipedia.org/wiki/Gadget ; Ultima consulta: Julio 2009 Es un dispositivo que tiene un propósito y una función específica, generalmente de pequeñas proporciones, práctico y a la vez novedoso. Los gadgets suelen tener un diseño más ingenioso que el de la tecnología corriente.

Introducción
Rojas, Christian 15
1.6.9.2 AKTORS AKTORS es una ontología creada por AKT (Advanced Kwnoledge Technologies), el cual es fundado en EPSCR (Engineering and Physical Sciences Research Council) el cual tienen como objetivo desarrollar y extender un rango de tecnologías provenientes de métodos y servicios integrados de captura, modelado, publicación, rehúso y gestión del conocimiento. [Akt08] Ellos han creado una ontología para modelar a un usuario tomando en cuenta en gran medida su ubicación física y los datos de geolocalización.
1.6.9.3 Amigo de un amigo (FOAF: FRIEND Of A Friend) FOAF es un proyecto para la Web semántica que se inició en el año 2000, utilizando tecnologías desarrolladas dentro de la Web semántica para describir relaciones mediante RDF que puedan ser procesadas fácilmente por máquinas. La idea detrás de FOAF es simple: la Web trata de realizar todas las conexiones entre las cosas. FOAF proporciona algunos mecanismos básicos para que nos ayuden a decirle a la agentes sobre las conexiones entre las cosas que interesan a los usuarios finales. FOAF es una tecnología sencilla que facilita el compartir y utilizar la información sobre las personas y sus actividades (por ejemplo, fotos, calendarios, diarios), para transferir información entre los sitios Web, y para extender automáticamente, fusionar y re-usar en línea. [Miller00] Para representar el lenguaje FOAF se ha descrito una especificación con diccionarios de nombres, propiedades y clases usando tecnología RDF de W3C. En la tabla 1, se muestra el análisis sintético de cada uno de los elementos estudiados anteriormente, reflejando los parámetros más importantes.
Introducción
Rojas, Christian 16
Tabla 1.1. Análisis comparativo del estado del arte.
Nom
bre
Explo
ració
n
Arq
uitectu
ra
Role
s d
e U
su
ario
Uso d
e
pond
era
ncia
s
Uso d
e a
ge
nte
s
Uso en a
mb
iente
dom
ótico
Re
tro
alim
en
tació
n
o a
uto
ap
ren
diz
aje
Seg
urid
ad /
Privacid
ad
Leng
ua
je
pro
cesable
OW
L
[PLANS03] Ninguna Ninguna
[TRAJKOVA04] Implícita Jerárquica
[CHAN07] Implícita Jerárquica
[GAUCH04] Implícita Jerárquica
[SARJAKOSKI03] N/E Lineal
[YU05] Explicita / Implícita
Ninguno
[CHEN05] Explicita Núcleo + Extensión
[CHEN04] Explicita Núcleo + Extensión
[SERRAL07] Explicita Lineal
[GEEK08] Explicita Lineal
[AKTORS08] Explicita Jerárquica
[MILLER00] Explicita Lineal
Nuestro Enfoque Explicita Núcleo + Extensión
N/E= No Especificado

Introducción
Rojas, Christian 17
1.7 ALCANCE DEL PROYECTO DE TESIS
El proyecto de tesis que se dispone en este documento, se conforma de acuerdo a 5 puntos importantes:
Los perfiles generados serán definidos en un lenguaje procesable (OWL).
Los perfiles generados responderán a un árbol de abstracción de nombres para su explotación posterior (Véase 3.1.2)
La interfaz gráfica resultante tendrá módulos dinámicos que responderán de acuerdo al contexto de los datos capturados al momento de la operación de dichos módulos.
La ontología resultante en cada perfil corresponderá en su tamaño de acuerdo con los datos capturados por el usuario correspondiente, conteniendo el núcleo más las extensiones pertinentes y acordes a cada perfil.
La ontología resultante de cada perfil tendrá una correspondencia directa en las clases y datos contenidos de acuerdo a un cierto dominio de aplicación. (Véase 3.1.2.3.1)
1.8 ORGANIZACIÓN DEL DOCUMENTO Este documento de tesis ésta estructurado de la siguiente manera: En el capítulo 2 se presentan los conceptos sobre las tecnologías involucradas en el desarrollo de la tesis. En el capítulo 3, se muestran los casos de uso, escenarios, diagramas de actividad, clases y secuencia que representan el análisis y diseño del proyecto realizado. En el capítulo 4, se detalla el procedimiento seguido para la obtención del prototipo. En el capítulo 5, se explica el uso de la aplicación así como segmentos de código importantes. En el capítulo 6, se presentan los resultados de las pruebas. En el capítulo 7, se presentan las aportaciones de la tesis, los trabajos futuros y las publicaciones realizadas durante el desarrollo de la tesis.

Introducción
Rojas, Christian 18

CAPÍTULO II. MARCO TEÓRICO
En este capítulo se presenta la teoría relacionada con el tema semántico aplicado en éste trabajo de tesis. Se inicia describiendo los conceptos relacionados con el proyecto en el ámbito semántico y continúa con los conceptos generales que se utilizaran en el transcurso de este documento.

Marco teórico
Rojas, Christian 20
2.1 CONCEPTOS SEMÁNTICOS
2.1.1 OWL El Lenguaje de Ontologías Web (OWL) está diseñado para ser usado en aplicaciones que necesitan procesar el contenido de la información en lugar de únicamente representar información para los humanos. OWL facilita un mecanismo de interoperabilidad de contenido Web más eficiente que los mecanismos admitidos por XML, RDF, y esquema RDF (RDF-S) proporcionando vocabulario adicional junto con una semántica formal. OWL tiene tres sub-lenguajes, con un nivel de expresividad creciente: OWL Lite, OWL DL, y OWL Full. La Web semántica se basará en la capacidad de XML para definir esquemas de etiquetas a medida y en la aproximación flexible de RDF para representar datos. El primer nivel requerido por encima de RDF para la Web semántica es un lenguaje de ontologías que pueda describir formalmente el significado de la terminología usada en los documentos Web. OWL añade más vocabulario para describir propiedades y clases: entre otros, relaciones entre clases (por ejemplo, desunión), cardinalidad (por ejemplo, "uno exacto"), igualdad, más tipos de propiedades, características de propiedades (por ejemplo, simetría), y clases enumeradas. [OWL09]
2.1.2 RDF El fundamento o base de RDF es un modelo para representar propiedades designadas y valores de propiedades. El modelo RDF se basa en principios perfectamente establecidos de varias comunidades de representación de datos. Las propiedades RDF pueden recordar a atributos de recursos y en este sentido corresponden con los tradicionales pares de atributo-valor. Las propiedades RDF representan también la relación entre recursos y por lo tanto, un modelo RDF puede parecer un diagrama entidad-relación. (De forma más precisa, los esquemas RDF que son objetos específicos de la categoría del modelo de datos RDF) son diagramas ER (Entidad Relación). En la terminología del diseño orientado a objetos, los recursos corresponden con objetos y las propiedades corresponden con objetos específicos y variables de una categoría. El modelo de datos de RDF es una forma de sintaxis-neutral para representar expresiones RDF. La representación del modelo de datos se usa para evaluar la equivalencia en significado. Dos expresiones RDF son equivalentes si y sólo si sus representaciones del modelo de datos son las mismas. Esta definición de equivalencia permite algunas variaciones sintácticas en expresiones sin alterar el significado. El modelo de datos básico consiste en tres tipos de objetos:

Marco teórico
Rojas, Christian 21
Recursos Todas las cosas descritas por expresiones RDF se denominan recursos. Un recursos puede ser una página Web completa; tal como el documento HTML "http://www.w3.org/Overview.html" por ejemplo. Un recurso puede ser una parte de una página Web. Un recurso puede ser también una colección completa de páginas o un objeto que no sea directamente accesible vía Web.
Propiedades Una propiedad es un aspecto específico, característica, atributo, o relación utilizado para describir un recurso. Cada propiedad tiene un significado específico, define sus valores permitidos, los tipos de recursos que puede describir, y sus relaciones con otras propiedades.
Sentencias [declaraciones, enunciados]
Un recurso específico junto con una propiedad denominada, más el valor de dicha propiedad para ese recurso es una sentencia RDF [RDF statement]. Estas tres partes individuales de una sentencia se denominan, respectivamente, sujeto, predicado y objeto. El objeto de una sentencia (es decir, el valor de la propiedad) puede ser otro recurso o pude ser un literal; es decir, un recurso (especificado por un URI) o una cadena simple de caracteres [string] u otros tipos de datos primitivos definidos por XML. [RDF09]
2.1.3 W3C Es un consorcio que tiene como visión la de guiar la Web a su potencialidad máxima a modo de foro de información, comercio, comunicación y conocimiento colectivo, mediante tecnologías inter-operativas, especificaciones, líneas maestras, software y herramientas. [W3C04]
2.1.4 Ontología Existen varias definiciones sobre éste concepto, entre ellas se encuentran: Una ontología constituye "Una especificación formal y explicita de una conceptualización compartida”. En esta definición, convertida ya en estándar, conceptualización se refiere a un modelo abstracto de algún fenómeno del mundo del que se identifican los conceptos que son relevantes; hace referencia a la necesidad de especificar de forma consciente los distintos conceptos que conforman una ontología. [Gruber] “Una ontología es una base de datos que describe los conceptos en el mundo y algunos dominios, algunas de sus propiedades y como los conceptos se relacionan unos con otros”. [Weigand]

Marco teórico
Rojas, Christian 22
Ontología describe una cierta realidad con un vocabulario específico, usando un conjunto de premisas de acuerdo con un sentido intencional de palabras del vocabulario. [Guarino]
2.2 CONCEPTOS GENERALES
2.2.1 XSD XML Schema es un lenguaje de esquema utilizado para describir la estructura y las restricciones de los contenidos de los documentos XML de una forma muy precisa, más allá de las normas sintácticas impuestas por el propio lenguaje XML. Se consigue así una percepción del tipo de documento con un nivel alto de abstracción. Fue desarrollado por el World Wide Web Consortium (W3C) y alcanzó el nivel de recomendación en mayo de 2001. [XSD09]

3. CAPÍTULO III. ANÁLISIS Y DISEÑO En este capítulo se presentan los diagramas de caso de uso, la definición de escenarios y los diagramas de actividad que corresponden a la fase de análisis. Así mismo se presenta los diagramas de clase y de secuencia correspondiente a la etapa del diseño.
Análisis y diseño
Rojas, Christian 24
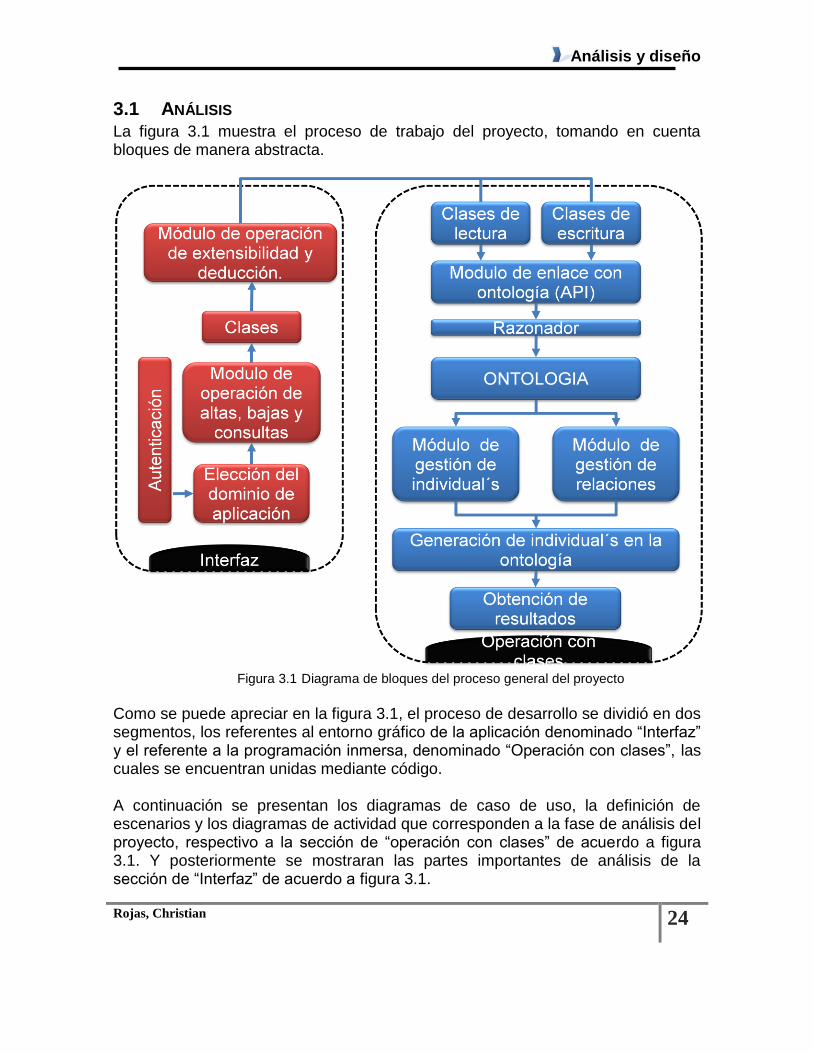
3.1 ANÁLISIS La figura 3.1 muestra el proceso de trabajo del proyecto, tomando en cuenta bloques de manera abstracta.
Figura 3.1 Diagrama de bloques del proceso general del proyecto
Como se puede apreciar en la figura 3.1, el proceso de desarrollo se dividió en dos segmentos, los referentes al entorno gráfico de la aplicación denominado “Interfaz” y el referente a la programación inmersa, denominado “Operación con clases”, las cuales se encuentran unidas mediante código. A continuación se presentan los diagramas de caso de uso, la definición de escenarios y los diagramas de actividad que corresponden a la fase de análisis del proyecto, respectivo a la sección de “operación con clases” de acuerdo a figura 3.1. Y posteriormente se mostraran las partes importantes de análisis de la sección de “Interfaz” de acuerdo a figura 3.1.

Análisis y diseño
Rojas, Christian 25
3.1.1 Análisis de operación con clases En la figura 3.2 se muestra el diagrama general de casos de uso del proyecto y se muestran las funciones principales que ofrece.
Figura 3.2 Diagrama general de casos de uso
En la figura 3.2 el usuario accede o crea su ontología previa autenticación y realiza modificaciones en ella mediante el uso de la interfaz. Una vez que se ha autenticado y definido si se creará, modificará o eliminará su ontología, el usuario elegirá cual será el dominio de la aplicación hacia la cual se inclinaran los datos de la captura. Este caso de uso contempla el paquete: mx.edu.cenidet.userontology.axiomsInference y mx.edu.cenidet.userontology.front

Análisis y diseño
Rojas, Christian 26
Figura 3.3 Diagrama de casos de uso de Operar con la ontología
Como se puede apreciar en la figura 3.3, se introdujeron dos actores más, denominados “API de conexión” referida a OWL API la cual fue únicamente consumida por el proyecto y como su nombre lo indica, tiene como funcionalidad la de ofrecer un repositorio hábil para el manejo de una ontología definida; y “Ontología” la cual es operada por la aplicación o creada si es que no existe, en la cual recaerán todas las operaciones realizadas en el proyecto.
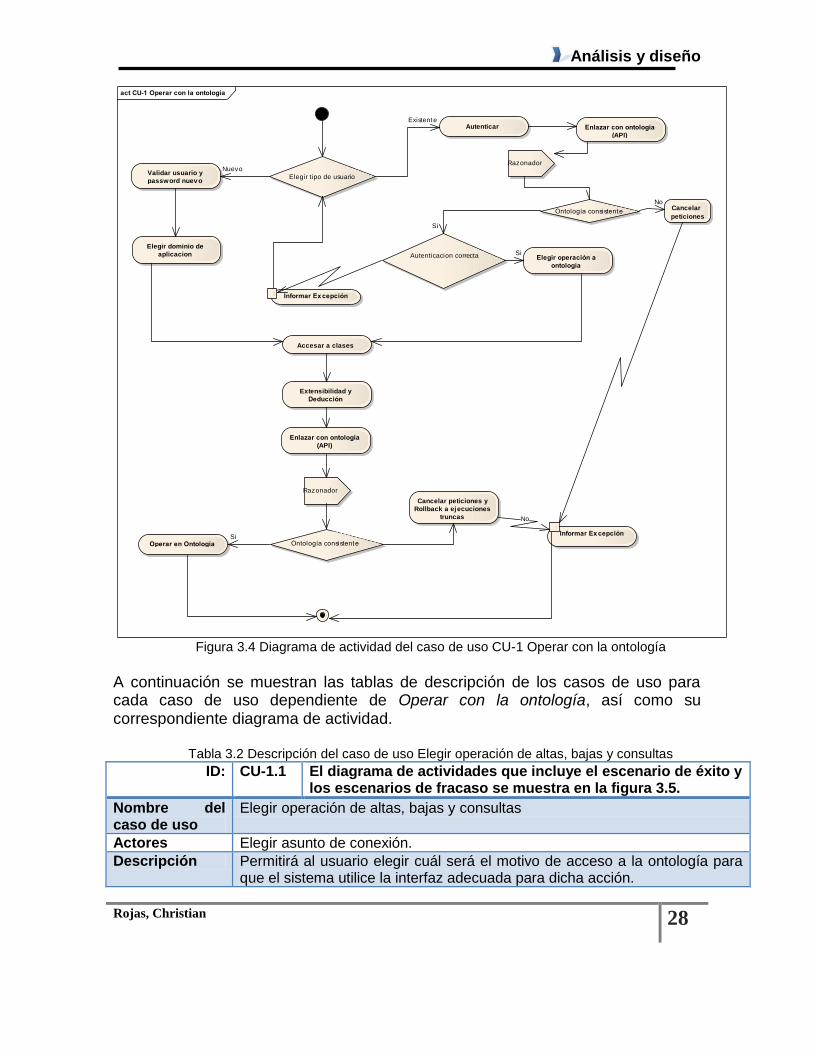
Tabla 3.1 Descripción del caso de uso Operar con la ontología
ID: CU-1 El diagrama de actividades que incluye el escenario de éxito y los escenarios de fracaso se muestra en la figura 3.4
Nombre del caso de uso
Operar con la ontología
Actores Usuario, API de conexión, Ontología
Descripción Permite al usuario realizar operaciones sobre la ontología, como lo son agregar, modificar y eliminar tanto de manera global como detallada.
Precondiciones Requisitos mínimos del sistema comunes para cualquier aplicación.
Poscondiciones Se obtendrá la ontología del usuario para poder ser reutilizada
Escenario de éxito 1
1. El usuario ingresa al sistema para crear una nueva ontología 2. El proceso de autenticación es univoco y se comienza la captura de
datos 3. Se elige el dominio de la aplicación para la captura 4. La ontología es creada
Escenario de éxito 2
1. El usuario ingresa al sistema para modificar su ontología 2. El proceso de autenticación es correcto 3. Se realizan las modificaciones pertinentes apropiadamente 4. La ontología es guardada
Escenario de éxito 3
1. El usuario ingresa al sistema para borrar su ontología 2. El proceso de autenticación es correcto

Análisis y diseño
Rojas, Christian 27
3. Se realiza el borrado de la ontología
Escenario de fracaso 1
1. El usuario ingresa al sistema para realizar un agregado, modificación o borrado de su ontología.
2. El proceso de autenticación no es univoco y se lanza una excepción controlada.
Escenario de fracaso 1
1. El usuario ingresa al sistema para realizar un agregado, modificación o borrado de su ontología.
2. El proceso de autenticación es correcto. 3. El usuario elije incorrectamente el dominio de la aplicación 4. Es necesario reiniciar el proceso de elección.
Incluye CU-1.1 Elegir operación de altas, bajas y consultas, CU-1.2 Elegir dominio de aplicación, CU-1.1 Enlazar con ontología
Suposiciones Se supone que la aplicación importa la librería en donde se encuentra la API
Análisis y diseño
Rojas, Christian 28
Figura 3.4 Diagrama de actividad del caso de uso CU-1 Operar con la ontología
A continuación se muestran las tablas de descripción de los casos de uso para cada caso de uso dependiente de Operar con la ontología, así como su correspondiente diagrama de actividad.
Tabla 3.2 Descripción del caso de uso Elegir operación de altas, bajas y consultas
ID: CU-1.1 El diagrama de actividades que incluye el escenario de éxito y los escenarios de fracaso se muestra en la figura 3.5.
Nombre del caso de uso
Elegir operación de altas, bajas y consultas
Actores Elegir asunto de conexión.
Descripción Permitirá al usuario elegir cuál será el motivo de acceso a la ontología para que el sistema utilice la interfaz adecuada para dicha acción.
act CU-1 Operar con la ontología
Elegir tipo de usuarioValidar usuario y
password nuev o
Autenticacion correcta
Elegir dominio de
aplicacion
Accesar a clases
Elegir operación a
ontología
Extensibilidad y
Deducción
Enlazar con ontología
(API)
Informar Ex cepción
Razonador
Ontología consistenteOperar en Ontología
Informar Ex cepción
Autenticar Enlazar con ontología
(API)
Ontología consistenteCancelar
peticiones
Cancelar peticiones y
Rollback a ejecuciones
truncas
Razonador
Si
Nuevo
Existente
Si
No
No
Si

Análisis y diseño
Rojas, Christian 29
Precondiciones 1. El usuario deberá haber pasado el proceso de autenticación correctamente.
2. Deberá haberse seleccionado ya la ontología a utilizar ya sea nueva o existente.
Poscondiciones 1. El usuario accederá a la interfaz pre programada para la operación con las clases.
Escenario de éxito 1
1. El usuario se autentica correctamente. 2. El usuario elige la operación a realizar. 3. La ontología es creada, modificada o eliminada correctamente. 4. La ontología es guardada.
Escenario de fracaso 1
1. El usuario ingresa al sistema para realizar un agregado, modificación o borrado de su ontología.
2. La ontología es inconsistente por cuestiones ajenas a la aplicación y es detectada por el razonador.
3. Actuación del manejador de la excepción generada.
Incluye
Suposiciones Se supone que la aplicación importa la librería en donde se encuentra la API
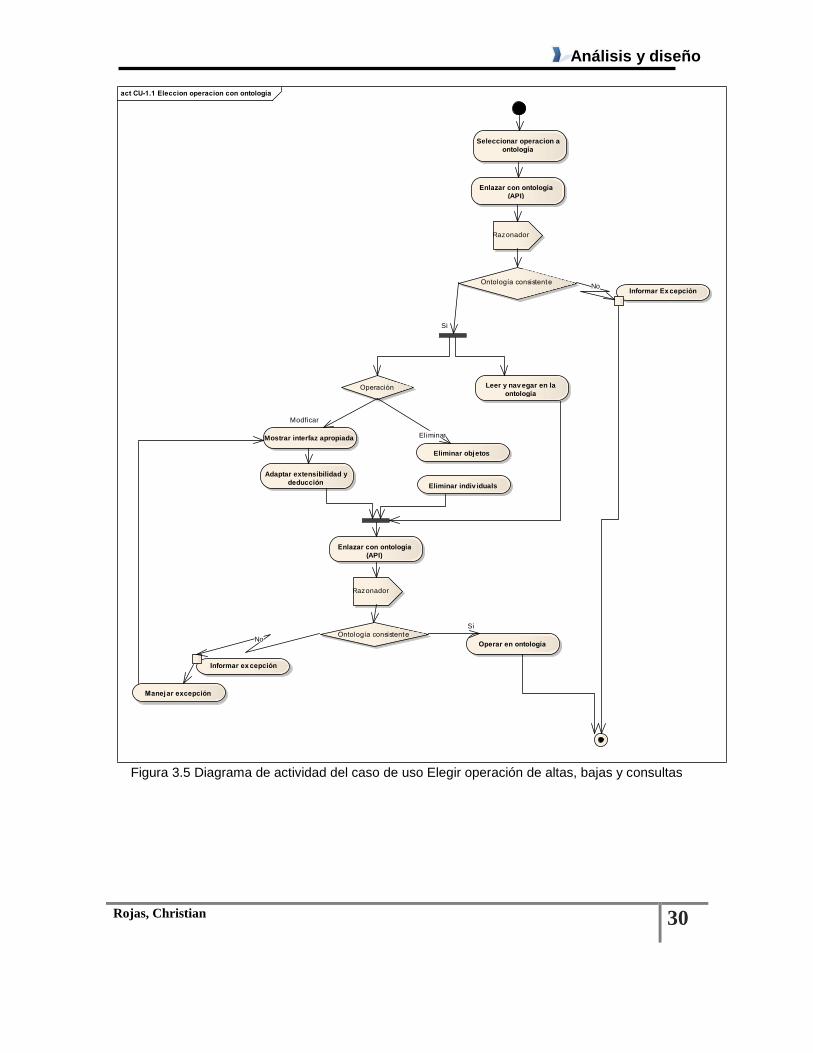
Análisis y diseño
Rojas, Christian 30
Figura 3.5 Diagrama de actividad del caso de uso Elegir operación de altas, bajas y consultas
act CU-1.1 Eleccion operacion con ontología
Seleccionar operacion a
ontología
Operación Leer y nav egar en la
ontología
Enlazar con ontología
(API)
Razonador
Ontología consistente
Informar Ex cepción
Adaptar extensibilidad y
deducción
Mostrar interfaz apropiada
Eliminar objetos
Eliminar indiv iduals
Enlazar con ontología
(API)
Razonador
Ontología consistente
Informar ex cepción
Operar en ontología
Manejar excepción
No
Si
Modficar
No
Si
Eliminar

Análisis y diseño
Rojas, Christian 31
Tabla 3.3 Descripción del caso de uso Elegir dominio de aplicación
ID: CU-1.2 El diagrama de actividades que incluye el escenario de éxito y los escenarios de fracaso se muestra en la figura 3.6
Nombre del caso de uso
Elegir dominio de aplicación
Actores Elegir modo de captura
Descripción Permitirá al usuario elegir cuál será la inclinación del proceso de captura, para que el sistema haga distinguir visualmente cuales son los campos recomendados y los optativos para el usuario de este dominio.
Precondiciones 1. El usuario deberá haber pasado el proceso de autenticación correctamente.
2. Deberá haberse seleccionado la opción de una ontología nueva.
Poscondiciones 1. Las clases disponibles para la captura estarán distribuidas de acuerdo al dominio de la aplicación elegido.
Escenario de éxito 1
1. El usuario se autentica correctamente. 2. El usuario elige crear una ontología, y elige el dominio de la
aplicación. 3. El usuario captura los datos en una o varias corridas de la aplicación.
Escenario de fracaso 1
1. El usuario se autentica correctamente. 2. El usuario elige crear una ontología, y elige el dominio de la
aplicación. 3. Debido a un error en la captura, la ontología se vuelve inconsistente y
es notada por el razonador. 4. Se lanza una excepción
Incluye
Suposiciones Se supone que la aplicación importa la librería en donde se encuentra la API
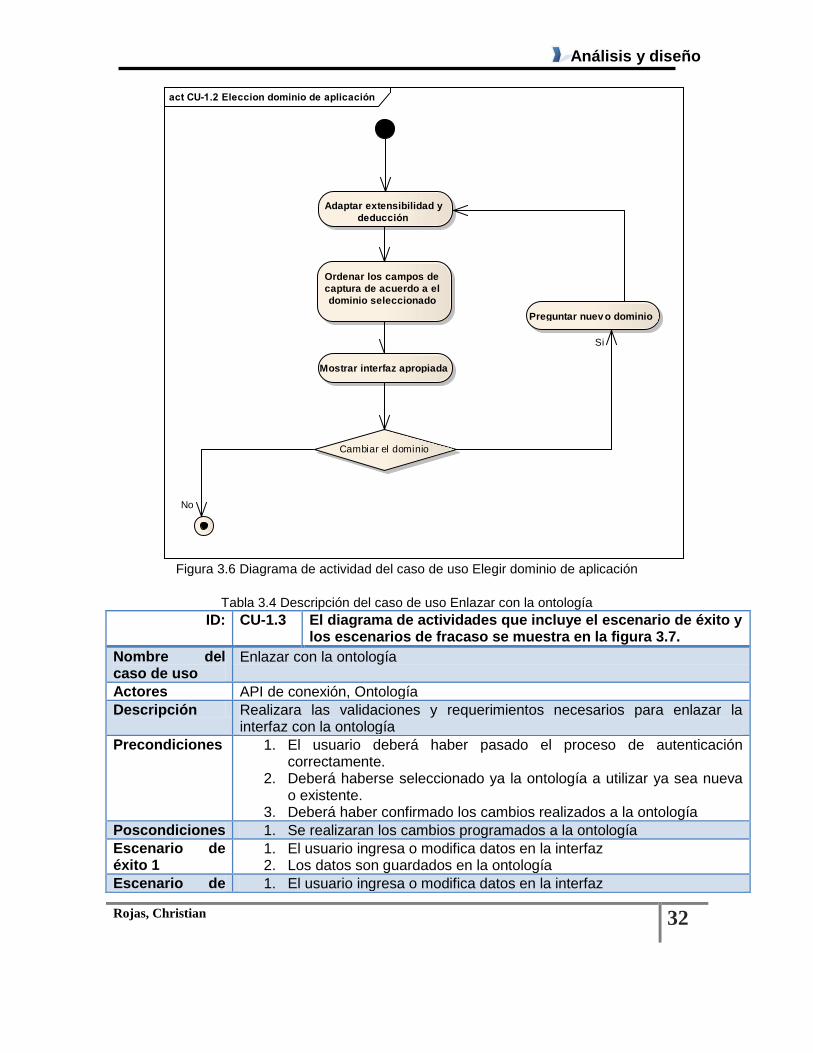
Análisis y diseño
Rojas, Christian 32
Figura 3.6 Diagrama de actividad del caso de uso Elegir dominio de aplicación
Tabla 3.4 Descripción del caso de uso Enlazar con la ontología
ID: CU-1.3 El diagrama de actividades que incluye el escenario de éxito y los escenarios de fracaso se muestra en la figura 3.7.
Nombre del caso de uso
Enlazar con la ontología
Actores API de conexión, Ontología
Descripción Realizara las validaciones y requerimientos necesarios para enlazar la interfaz con la ontología
Precondiciones 1. El usuario deberá haber pasado el proceso de autenticación correctamente.
2. Deberá haberse seleccionado ya la ontología a utilizar ya sea nueva o existente.
3. Deberá haber confirmado los cambios realizados a la ontología
Poscondiciones 1. Se realizaran los cambios programados a la ontología
Escenario de éxito 1
1. El usuario ingresa o modifica datos en la interfaz 2. Los datos son guardados en la ontología
Escenario de 1. El usuario ingresa o modifica datos en la interfaz
act CU-1.2 Eleccion dominio de aplicación
Adaptar extensibilidad y
deducción
Mostrar interfaz apropiada
Ordenar los campos de
captura de acuerdo a el
dominio seleccionado
Cambiar el dominio
Preguntar nuev o dominio
Si
No

Análisis y diseño
Rojas, Christian 33
fracaso 1 2. Existe un error provocando una inconsistencia en la ontología que es detectada por el razonador.
3. Se lanza una excepción.
Escenario de fracaso 2
1. El usuario ingresa o modifica datos en la interfaz 2. La ontología es modificada simultáneamente causando una
inconsistencia en los datos que es detectada por el razonador. 3. Se lanza una excepción.
Incluye
Suposiciones Se supone que la aplicación importa la librería en donde se encuentra la API
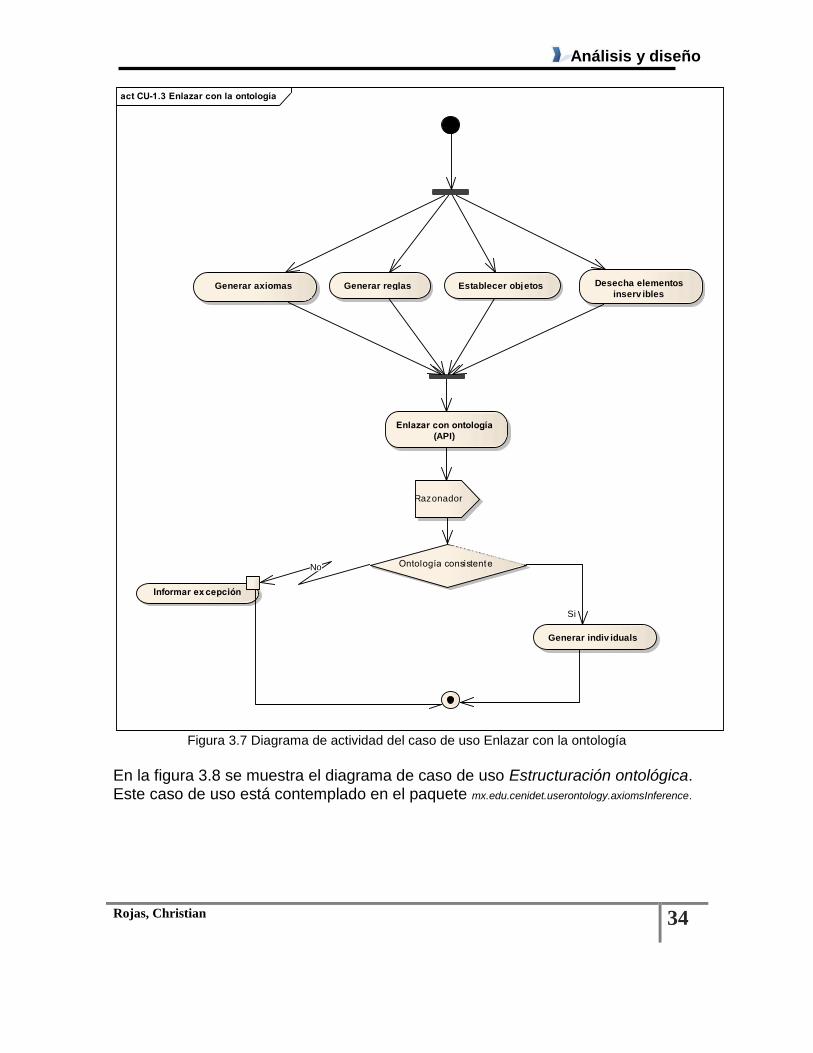
Análisis y diseño
Rojas, Christian 34
Figura 3.7 Diagrama de actividad del caso de uso Enlazar con la ontología
En la figura 3.8 se muestra el diagrama de caso de uso Estructuración ontológica. Este caso de uso está contemplado en el paquete mx.edu.cenidet.userontology.axiomsInference.
act CU-1.3 Enlazar con la ontología
Generar axiomas Generar reglas Establecer objetos
Enlazar con ontología
(API)
Razonador
Ontología consistente
Desecha elementos
inserv ibles
Informar ex cepción
Generar indiv iduals
Si
No

Análisis y diseño
Rojas, Christian 35
Figura 3.8 Diagrama de casos de uso de Estructuración ontológica
Tabla 3.5 Descripción del caso de uso Estructuración ontológica
ID: CU-2 El diagrama de actividades que incluye el escenario de éxito y los escenarios de fracaso se muestra en la figura 3.9.
Nombre del caso de uso
Estructuración ontológica
Actores Ontología
Descripción Permite estructurar la ontología de tal modo que se estandaricen sus identificadores conceptuales y pueda ser reutilizada de un modo más sencillo y elocuente. Véase 3.1.2
Precondiciones 1. La ontología debe de ser consistente (confirmada por el razonador)
Poscondiciones 1. Si la estructura no existe este será creada sin importar el nivel de granularidad.
2. Se obtendrá una ontología estructurada con relaciones.
Escenario de éxito 1
1. El usuario ingresa o modifica datos en la interfaz 2. Se generan las individualizaciones para cada clase utilizada. 3. Se generan las relaciones entre estas individualizaciones. 4. Se genera un individual en la clase principal para elevar el nivel de
abstracción 5. Se aplican las relaciones como atributos de la clase principal.
Escenario de fracaso 1
4. El usuario ingresa o modifica datos en la interfaz 5. Existe un error provocando una inconsistencia en la ontología que es
detectada por el razonador. 6. Se lanza una excepción.
Escenario de fracaso 2
4. El usuario ingresa o modifica datos en la interfaz 5. La ontología es modificada simultáneamente causando una
inconsistencia en los datos que es detectada por el razonador. 6. Se lanza una excepción.
Incluye
Suposiciones Se supone que la aplicación importa la librería en donde se encuentra la API
uc CU-2 Estructuracion ontológica
Ontología
Generar indiv iduals
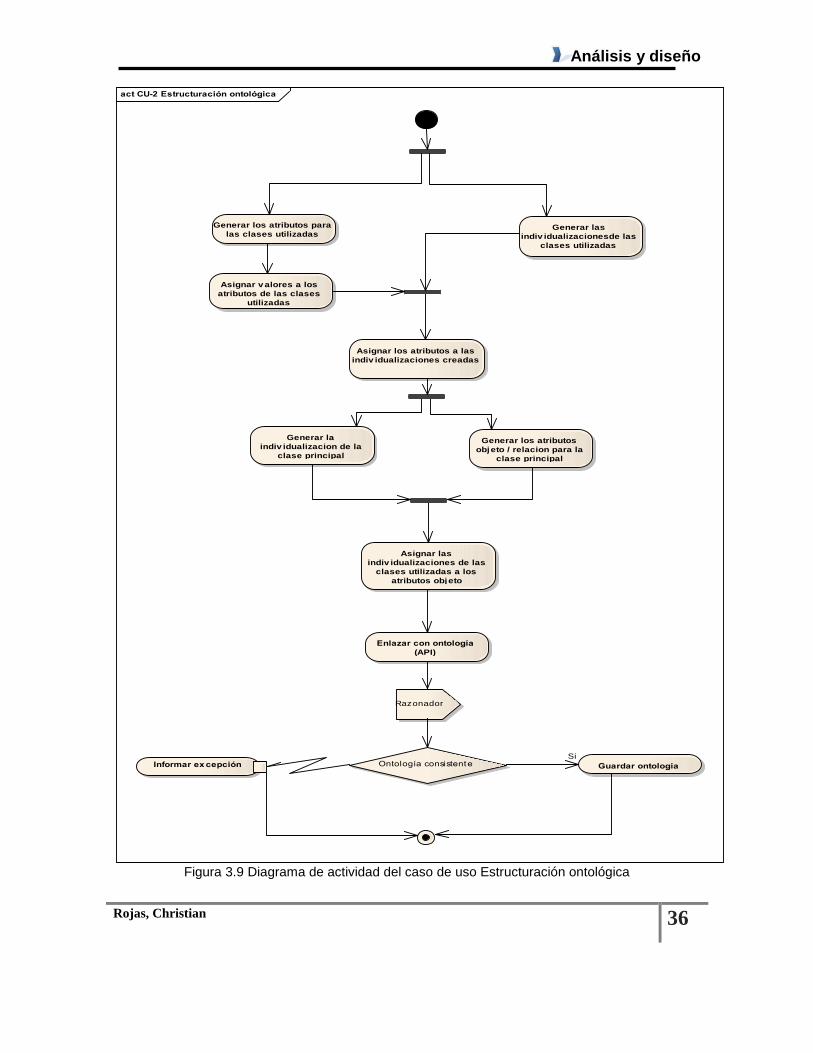
Análisis y diseño
Rojas, Christian 36
Figura 3.9 Diagrama de actividad del caso de uso Estructuración ontológica
act CU-2 Estructuración ontológica
Generar las
indiv idualizacionesde las
clases utilizadas
Generar la
indiv idualizacion de la
clase principal
Generar los atributos
objeto / relacion para la
clase principal
Generar los atributos para
las clases utilizadas
Asignar v alores a los
atributos de las clases
utilizadas
Asignar los atributos a las
indiv idualizaciones creadas
Asignar las
indiv idualizaciones de las
clases utilizadas a los
atributos objeto
Guardar ontología
Enlazar con ontología
(API)
Razonador
Ontología consistenteInformar ex cepciónSi

Análisis y diseño
Rojas, Christian 37
3.1.2 Estructura de URI´s (Uniform Resource Indicator). El método para identificar, atributos y propiedades en las ontologías es mediante identificadores conceptuales, denominados URI´s, los cuales están formadas en la primera parte por un identificador de la ontología, seguido por un símbolo “#” y por último el identificador del elemento en la ontología [Protege09]. Por ejemplo, el atributo “nombre”, que tiene como dominio a la clase “Personales” correspondiente a la ontología con la URI “http://www.cenidet.edu.mx/user_ontology.owl”, se identificara unívocamente de la siguiente manera:
http://www.cenidet.edu.mx/user_ontology.owl#nombre Tal y como se muestra en la figura 3.10:
Figura 3.10 Identificador del atributo “nombre” de la ontología en protégé
Sin embargo, cada elemento en la ontología es identificado siguiendo el mismo patrón y debido a que la aplicación a la que apunta este proyecto deberá generar automáticamente los datos en la ontología, se deducen las siguientes dificultades:
Los nombres son unívocos, por tanto deberá haber reglas de nomenclatura para almacenar y recuperar datos de la ontología.
No se pueden identificar mediante la URI de un elemento, la naturaleza de éste, es decir, la URI señalada como (http://www.cenidet.edu.mx/user_ontology.owl#nombre) podría referirse a un atributo, un objeto, una individualización, una clase, etc.
Referente a las dificultades anteriormente mencionadas, se diseñó un método para poder generar un árbol de abstracción, en el cual la referencia a un elemento tiene coherencia y propiedad con respecto al que está contiguo (ancestro o hijo en el árbol), con la finalidad de poder estandarizar estos identificadores conceptuales, y recuperarlos en cualquier momento. Dicho método se detalla a continuación:

Análisis y diseño
Rojas, Christian 38
3.1.2.1 Árbol de abstracción de nombres Algunas de las restricciones para los identificadores aplicables a los elementos de una ontología se enlistan a continuación en las siguientes reglas generales:
No es posible usar caracteres especiales.
Los nombres deben ser únicos (distinción entre mayúsculas y minúsculas).
Los identificadores de las clases comenzaran siempre con una letra mayúscula.
Los identificadores de las propiedades „datatype‟ y „object‟ serán con minúsculas, y si está conformada por más de una palabra, entonces estarán separadas por un símbolo “_”.
Los identificadores de propiedades “object” terminaran con un carácter en mayúscula, p.ej. “O”.
Como se aprecia en las primeras dos reglas generales, debido a la flexibilidad para nombrar un elemento, es muy sencillo entrar en ambigüedades de nomenclatura, tal vez influenciadas por el contexto, el horario, costumbres o incluso el humor del diseñador, lo que da razón a las últimas 3 reglas anteriores. Cabe mencionar que el dominio de este método son las individualizaciones de la ontología, ya que las reglas para nomenclatura de los elementos de la misma están aplicadas por el entorno de diseño utilizado y explicadas en las primeras dos reglas de la lista anterior. A continuación se enlistan las reglas específicas:
Para diferenciar a identificadores de clases y de atributos, se omitirá la opción de poner símbolos “_” en el caso de identificadores con más de una palabra para las clases, (por ejemplo, si una clase es llamada Ayuda Técnica, en lugar de nombrarse como „Ayuda_tecnica‟, se dispondrá como „AyudaTecnica‟, con la inicial de cada palabra en mayúscula)
Sera determinada una clase principal que será aquella por la cual haya más relaciones con respecto a las demás clases. A la cual se nombrará con un término determinado por el diseñador (primera letra en mayúscula) que servirá como identificador univoco respecto a otras individualizaciones de la misma ontología, y que formará el primer nivel jerárquico en el árbol de abstracción generado.
Cada nomenclatura definida por las reglas anteriores (excepto la que refiere al primer nivel jerárquico del árbol de abstracción a generar), deberá ir antecedida por el identificador inmediato superior completo, sin espacios y siguiendo las reglas para la nomenclatura de clases (primera letra de cada palabra en mayúscula).

Análisis y diseño
Rojas, Christian 39
A continuación se muestra un ejemplo de cómo se ha empleado este método para la nomenclatura estandarizada de las individualizaciones: Tomando en cuenta las clases que se muestran en la figura 3.11, se han aplicado las reglas generales para identificarlas unívocamente, tal como se muestra en la figura 3.12
Figura 3.11 Árbol de elementos de la ontología
Figura 3.12 Árbol de elementos de la ontología
Como se puede apreciar en la figura 3.12, las nomenclaturas de las clases y sus atributos, son similares (en la medida de lo posible) con respecto a su nombre contextual (de acuerdo a la lógica) de la figura 3.11 y siguiendo las reglas básicas de nomenclatura de clases explicada anteriormente, recordando también que cada identificador irá precedido de la URI que identifica la ontología y del símbolo “#”, como fue explicado al inicio de este subtema. Cabe mencionar que las individualizaciones se realizan solamente sobre clases, y no sobre atributos y/o propiedades, por tanto la figura 3.13 muestra las clases a las cuales se les puede realizar individualizaciones y por tanto se les referirá un identificador contextual ya operado por las reglas anteriores.
Persona
Enfermedades
Transmisibles
SIDA Tuberculosis
No Transmisibles
Cáncer
Personales
Nombre
Persona
Enfermedades
Transmisibles
sida tuberculosis
NoTransmisibles
cancer
Personales
nombre

Análisis y diseño
Rojas, Christian 40
Figura 3.13 Resultado del método para nombrar individualizaciones
En la figura 3.13 se muestra el resultado del método explicado en esta sección. En el resultado se aprecia que cualquier elemento tiene referencia en su nomenclatura al elemento contiguo.
3.1.3 Manejo de tipos Una de las limitantes hacia las cuales se vio influenciado este proyecto, fue a la operación de los atributos de la ontología, respetando los tipos de datos comunes (float, int, bool, string, etc), ya que durante el proceso de poblado de la ontología mediante la API (OWLAPI), no fue posible especificar el tipo de dato del atributo a operar, ya que internamente, todos estos, se manejan como datos de tipo cadena de caracteres (esto último con la finalidad de operar mediante un nivel de abstracción superior), la conversión para obtener los tipos necesarios se realiza mediante el uso de constantes predefinidas que representan a los tipos de datos citados. Dichas constantes no son más que URI´s estandarizadas y aprobadas por OWL [Protege09], las cuales realizan un mapeo funcional con respecto a el tipo de dato citado, especificándole al entorno de diseño de ontologías (protégé) que interprete el dato conforme al tipo asociado, utilizando para ello un esquema utilizado por el estándar XML para el manejo de tipos de dato (XSD) [W3C, 2009]. El proceso se muestra en la figura 3.14 Aunque ya existe solución a esta problemática, del proceso requiere que se procese dato por dato, por este motivo se ha estructurado un método para poder realizar esta operación de manera parametrizada, respetando las siguientes reglas:
Debe haberse especificado la URI (Identificador contextual) de la individualización a operar, dispuesta en algún sector de la memoria principal.
Debe haberse especificado también la conexión con la ontología, así como la definición del razonador y su validación de consistencia.
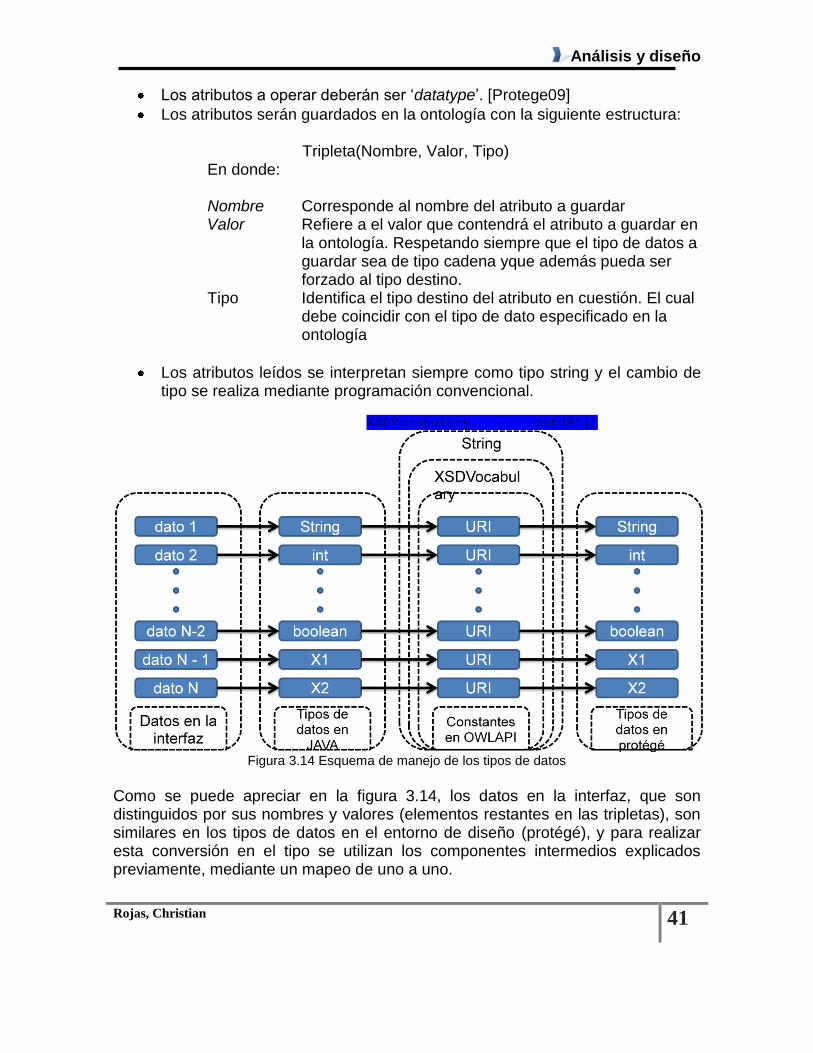
Análisis y diseño
Rojas, Christian 41
Los atributos a operar deberán ser „datatype‟. [Protege09]
Los atributos serán guardados en la ontología con la siguiente estructura: Tripleta(Nombre, Valor, Tipo)
En donde: Nombre Corresponde al nombre del atributo a guardar
Valor Refiere a el valor que contendrá el atributo a guardar en la ontología. Respetando siempre que el tipo de datos a guardar sea de tipo cadena yque además pueda ser forzado al tipo destino.
Tipo Identifica el tipo destino del atributo en cuestión. El cual debe coincidir con el tipo de dato especificado en la ontología
Los atributos leídos se interpretan siempre como tipo string y el cambio de tipo se realiza mediante programación convencional.
XSDVocabulary.STRING.getURI()
Figura 3.14 Esquema de manejo de los tipos de datos
Como se puede apreciar en la figura 3.14, los datos en la interfaz, que son distinguidos por sus nombres y valores (elementos restantes en las tripletas), son similares en los tipos de datos en el entorno de diseño (protégé), y para realizar esta conversión en el tipo se utilizan los componentes intermedios explicados previamente, mediante un mapeo de uno a uno.

Análisis y diseño
Rojas, Christian 42
3.1.4 Análisis de la interfaz Para la implementación de la interfaz se definieron los siguientes requerimientos:
Adaptación dinámica de clases. Deberá ser adaptativa al usuario, es decir, deberá cuestionar al usuario sólo los datos que le interesan y/o los que sean pertinentes de acuerdo a deducciones o a los mismos datos que el usuario haya ingresado, utilizando para ello los elementos específicos en la ontología, denominados extensiones, los cuales se explican en detalle en Extensiones. En otras palabras, ser eficiente en ¿Qué preguntar?
Deducción de atributos pertinentes. Debe adaptar los atributos a considerar para perfilar a un usuario, de acuerdo a los datos que haya o esté ingresando de manera dinámica, ocultando aquellos que no sean pertinentes de acuerdo a la naturaleza del usuario, procurando mostrar la menor cantidad de campos a rellenar en cada pantalla.
Deducción de solicitud de datos. La interfaz debe de organizar la solicitud de datos de acuerdo al dominio de la aplicación, la cual debe de ser elegida en algún momento del proceso de operación con la ontología usada o creada. Esta operación dividirá los datos a capturar en dos grupos: “recomendados” y “optativos”, distinguiéndolos visualmente.
Para cubrir los requerimientos anteriores, se implementó una interfaz en un lenguaje de programación Open Source2. La aplicación, tendrá como objetivo primordial:
Poblar la ontología adaptando sus elementos y requerimientos dinámicamente de acuerdo a la información almacenada tanto previamente, como al momento por parte del usuario, para evitar la intrusión, procurando “asegurar que el usuario rellene por lo menos los datos indispensables”.
De acuerdo a un consenso se determinaron los siguientes dominios de aplicación, tratando de abarcar los grupos de datos más relevantes y con mayor diferencia contextual entre ellas.
2. Open source (Código abierto) Obtenido de: http://es.wikipedia.org/wiki/Código_abierto; Ultima consulta: Julio 2009 Término con el que se conoce al software distribuido y desarrollado libremente.

Análisis y diseño
Rojas, Christian 43
3.1.4.1 Dominio Básico. Este dominio se encuentra implícito (no es manejable de manera selectiva visual), ya que comprenderá todos aquellos atributos considerados pertinentes para cualquier usuario y de conocimiento elemental (calificados visualmente como Recomendados), como lo son los datos personales, datos relacionados a su origen y dirección, y ciertas preguntas que permitirán o no, acceder a ciertos campos si es que el usuario desea algún perfil en especifico orientado a cierto dominio. La interfaz contempla un área recomendada y un área optativa, para los atributos de cada clase e incluso entre las mismas clases, las cuales como su nombre lo indica, son obligatorias u opcionales de capturar, categorizándolas de acuerdo a el dominio de la aplicación elegido y a las dependencias con otras capturas posteriores, es decir, el área obligatoria contendrá aquellos datos que no tengan dependencia de el valor almacenado en otros atributos de otras clases y aquellos atributos que sean parámetros (el acceso a otras capturas depende de este valor), tomando en cuenta siempre la relevancia de este dato y procurando en todo momento la requisición mínima necesaria de datos hacia el usuario. En esta interfaz se plantea el uso de dominios de la aplicación que identifican que conjuntos de datos de la ontología son pertinentes y necesarios para esa área. El conjunto de todas las áreas concederán la completitud de la ontología, el cual sería el escenario del peor caso para cuestiones de tiempo y dedicación por parte del usuario. Se han contemplado los siguientes dominios:
3.1.4.2 Dominio Médico Este dominio fue concertado para poder contemplar atributos del usuario tales como enfermedades, minusvalías, discapacidades y ayuda técnica que pudiese utilizar el usuario, tales como: muletas, silla de ruedas, bastón, etc. Las cuales se consideran elementos importantes a considerar de un usuario siempre y cuando el interés esté orientado a un dominio medico.
3.1.4.3 Dominio Familiar Este dominio ha sido acordado para aquellos usuarios cuya principal actividad sea discordante con el ámbito organizacional y educativo, en el cual, se distinguen atributos como lo son las preferencias del usuario y los gustos referidos a programación televisiva, actividades recreativas y demás.

Análisis y diseño
Rojas, Christian 44
3.1.4.4 Dominio Profesional Se contempló este dominio para poder categorizar usuarios que sean dependientes de una empresa u organización y cuyos datos relacionados sean de interés especifico, como lo son el nombre del puesto, el proyecto en el que se encuentre trabajando y en el que estuvo trabajando previamente, el número de empleados que tiene a su cargo, etc.
3.1.4.5 Dominio Educativo Este dominio fue concertado para atribuir elementos específicos de esta área como lo son datos acerca de la matriculación del usuario en la institución en la que estudia, el horario y demás.
3.2 DISEÑO
El proyecto consta de los siguientes elementos:
Una ontología que puede ser poblada y reutilizada.
Un área operativa que tiene como finalidad poblar y recuperar la ontología.
Una interfaz para el manejo del prototipo de manera transparente. Los paquetes que componen los elementos para el área operativa y la interfaz son los siguientes:
mx.edu.cenidet.userontology.front para el manejo de la interfaz gráfica.
mx.edu.cenidet.userontology.axiomsInference para las operaciones con la ontología. El nombre de los paquetes se asignó siguiendo las recomendaciones descritas en el artículo Estructura de paquetes [ITA09] Todas las clases obtienen datos de la clase DATA que se encuentra en el paquete, la cual contiene elementos de configuración para el proyecto, como lo son rutas físicas para los elementos que se necesitan, variables globales de control de extensibilidad, etc. En la figura 3.15 se muestra el diagrama de paquetes del proyecto.
Figura 3.15 Diagrama de clases del proyecto
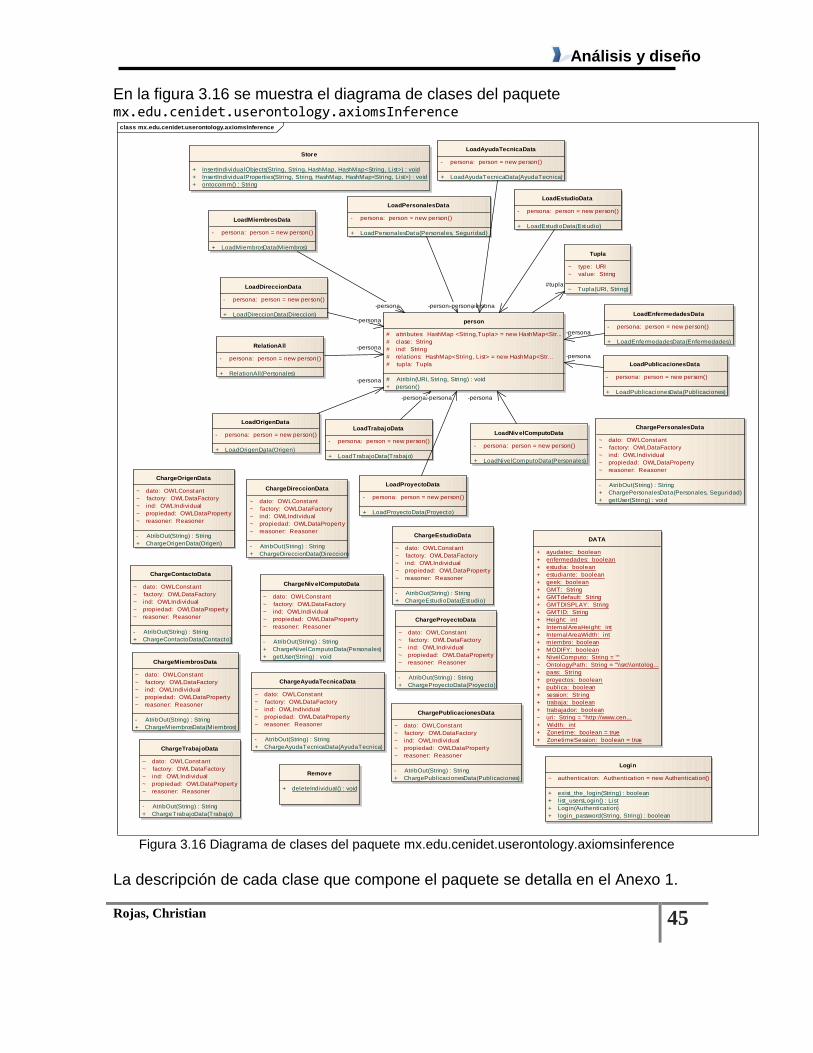
Análisis y diseño
Rojas, Christian 45
En la figura 3.16 se muestra el diagrama de clases del paquete mx.edu.cenidet.userontology.axiomsInference
Figura 3.16 Diagrama de clases del paquete mx.edu.cenidet.userontology.axiomsinference
La descripción de cada clase que compone el paquete se detalla en el Anexo 1.
class mx.edu.cenidet.userontology.axiomsInference
LoadEstudioData
- persona: person = new person()
+ LoadEstudioData(Estudio)
ChargeAyudaTecnicaData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeAyudaTecnicaData(AyudaTecnica)
ChargeDireccionData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeDireccionData(Direccion)
ChargeEstudioData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeEstudioData(Estudio)
ChargeMiembrosData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeMiembrosData(Miembros)
ChargeNiv elComputoData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeNivelComputoData(Personales)
+ getUser(String) : void
ChargeOrigenData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeOrigenData(Origen)
ChargePersonalesData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargePersonalesData(Personales, Seguridad)
+ getUser(String) : void
ChargeProyectoData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeProyectoData(Proyecto)
ChargePublicacionesData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargePublicacionesData(Publicaciones)
ChargeTrabajoData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeTrabajoData(Trabajo)
DATA
+ ayudatec: boolean
+ enfermedades: boolean
+ estudia: boolean
+ estudiante: boolean
+ geek: boolean
+ GMT: String
+ GMTdefault: String
+ GMTDISPLAY: String
+ GMTID: String
+ Height: int
+ InternalAreaHeight: int
+ InternalAreaWidth: int
+ miembro: boolean
+ MODIFY: boolean
+ NivelComputo: String = ""
~ OntologyPath: String = "\\src\\ontolog...
+ pass: String
+ proyectos: boolean
+ publica: boolean
+ session: String
+ trabaja: boolean
+ trabajador: boolean
~ uri: String = "http://www.cen...
+ Width: int
+ Zonetime: boolean = true
+ ZonetimeSession: boolean = true
LoadAyudaTecnicaData
- persona: person = new person()
+ LoadAyudaTecnicaData(AyudaTecnica)
Store
+ InsertIndividualObjects(String, String, HashMap, HashMap<String, List>) : void
+ InsertIndividualProperties(String, String, HashMap, HashMap<String, List>) : void
+ ontocomm() : String
LoadEnfermedadesData
- persona: person = new person()
+ LoadEnfermedadesData(Enfermedades)
Tupla
~ type: URI
~ value: String
~ Tupla(URI, String)
LoadMiembrosData
- persona: person = new person()
+ LoadMiembrosData(Miembros)
LoadNiv elComputoData
- persona: person = new person()
+ LoadNivelComputoData(Personales)
LoadOrigenData
- persona: person = new person()
+ LoadOrigenData(Origen)
LoadPersonalesData
- persona: person = new person()
+ LoadPersonalesData(Personales, Seguridad)
LoadProyectoData
- persona: person = new person()
+ LoadProyectoData(Proyecto)
LoadPublicacionesData
- persona: person = new person()
+ LoadPublicacionesData(Publicaciones)
LoadTrabajoData
- persona: person = new person()
+ LoadTrabajoData(Trabajo)
Login
~ authentication: Authentication = new Authentication()
+ exist_the_login(String) : boolean
+ list_usersLogin() : List
+ Login(Authentication)
+ login_password(String, String) : boolean
person
# attributes: HashMap <String,Tupla> = new HashMap<Str...
# clase: String
# ind: String
# relations: HashMap<String, List> = new HashMap<Str...
# tupla: Tupla
# AtribIn(URI, String, String) : void
+ person()
RelationAll
- persona: person = new person()
+ RelationAll(Personales)
Remov e
+ deleteIndividual() : void
LoadDireccionData
- persona: person = new person()
+ LoadDireccionData(Direccion)
ChargeContactoData
~ dato: OWLConstant
~ factory: OWLDataFactory
~ ind: OWLIndividual
~ propiedad: OWLDataProperty
~ reasoner: Reasoner
- AtribOut(String) : String
+ ChargeContactoData(Contacto)
-persona
#tupla
-persona
-persona
-persona
-persona
-persona
-persona
-persona -persona
-persona
-persona
-persona

Análisis y diseño
Rojas, Christian 46
En la figura 3.17 se muestra el diagrama de clases del paquete mx.edu.cenidet.userontology.Front
class mx.edu.cenidet.userontology.Front
JInternalFrame
Apariencia
- jContentPane: JPanel = null
- LabelAtletico: JLabel = null
- LabelDelgado: JLabel = null
- LabelEstetica: JLabel = null
- LabelMucho: JLabel = null
- LabelMuyDelgado: JLabel = null
- LabelObeso: JLabel = null
- LabelPoco: JLabel = null
- LabelRegular: JLabel = null
- LabelRegularVestuario: JLabel = null
- LabelVestuario: JLabel = null
- RadioAtletico: JRadioButton = null
- RadioDelgado: JRadioButton = null
- RadioMucho: JRadioButton = null
- RadioMuyDelgado: JRadioButton = null
- RadioObeso: JRadioButton = null
- RadioPoco: JRadioButton = null
- RadioRegular: JRadioButton = null
- RadioRegularVestuario: JRadioButton = null
+ Apariencia()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getRadioAtletico() : JRadioButton
- getRadioDelgado() : JRadioButton
- getRadioMucho() : JRadioButton
- getRadioMuyDelgado() : JRadioButton
- getRadioObeso() : JRadioButton
- getRadioPoco() : JRadioButton
- getRadioRegular() : JRadioButton
- getRadioRegularVestuario() : JRadioButton
JDialog
Authentication
- ButtonAceptar: JButton = null
- ButtonAceptarNew: JButton = null
- ButtonCancel: JButton = null
- ButtonCancelNew: JButton = null
- ButtonNuevo: JButton = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- LabelConfirme: JLabel = null
- LabelPassword: JLabel = null
- LabelUser: JLabel = null
- TextPassword: JPasswordField = null
- TextPasswordNew: JPasswordField = null
- TextUser: JTextField = null
+ Authentication()
+ Authentication(String, Interfaz)
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getButtonAceptar() : JButton
- getButtonAceptarNew() : JButton
- getButtonCancel() : JButton
- getButtonCancelNew() : JButton
- getButtonNuevo() : JButton
- getTextPassword() : JPasswordField
- getTextPasswordNew() : JPasswordField
- getTextUser() : JTextField
JInternalFrame
AyudaTecnica
+ CheckAndadera: JCheckBox = null
+ CheckBaston: JCheckBox = null
+ CheckMuletas: JCheckBox = null
+ CheckOtros: JCheckBox = null
+ CheckSilla: JCheckBox = null
- jContentPane: JPanel = null
- LabelAndadera: JLabel = null
- LabelBaston: JLabel = null
- LabelEspecifique: JLabel = null
- LabelMuletas: JLabel = null
- LabelOtro: JLabel = null
- Labelseleccioneayuda: JLabel = null
- LabelSillaruedas: JLabel = null
+ TextOtros: JTextField = null
+ AyudaTecnica()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getCheckAndadera() : JCheckBox
- getCheckBaston() : JCheckBox
- getCheckMuletas() : JCheckBox
- getCheckOtros() : JCheckBox
- getCheckSilla() : JCheckBox
- getTextOtros() : JTextField
JInternalFrame
ChooseDomain
- ButtonHogar: JButton = null
- ButtonHospital: JButton = null
- ButtonOrganizacion: JButton = null
- ButtonRegresar: JButton = null
- ButtonSalir: JButton = null
- ButtonUniversidad: JButton = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- LabelHogar: JLabel = null
- LabelHospital: JLabel = null
- LabelOrganizacion: JLabel = null
- LabelSelecccioneDominio: JLabel = null
- LabelUniversidad: JLabel = null
+ ChooseDomain()
+ ChooseDomain(String, Interfaz)
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getButtonHogar() : JButton
- getButtonHospital() : JButton
- getButtonOrganizacion() : JButton
- getButtonRegresar() : JButton
- getButtonSalir() : JButton
- getButtonUniversidad() : JButton
JInternalFrame
Clase s
- ButtonApariencia: JButton = null
- ButtonAyudaTecnica: JButton = null
- ButtonContacto: JButton = null
- ButtonDireccion: JButton = null
- ButtonEnfermedades: JButton = null
- ButtonEstiloVida: JButton = null
- ButtonEstudio: JButton = null
- ButtonGEEK: JButton = null
- Buttonintereses: JButton = null
- ButtonMiembros: JButton = null
- ButtonOrigen: JButton = null
- ButtonProyecto: JButton = null
- ButtonPublicaciones: JButton = null
- ButtonSeguridad: JButton = null
- ButtonTrabajo: JButton = null
- ButttonPersonales: JButton = null
- interfaz: Interfaz
- PanelOrganizacion: JPanel = null
- pos: int
- posOp: int
- ProgressDH: JProgressBar = null
+ Clases()
+ Clases(String, Interfaz)
- initialize() : void
«property get»
- getButtonApariencia() : JButton
- getButtonAyudaTecnica() : JButton
- getButtonContacto() : JButton
- getButtonDireccion() : JButton
- getButtonEnfermedades() : JButton
- getButtonEstiloVida() : JButton
- getButtonEstudio() : JButton
- getButtonGEEK() : JButton
- getButtonintereses() : JButton
- getButtonMiembros() : JButton
- getButtonOrigen() : JButton
- getButtonProyecto() : JButton
- getButtonPublicaciones() : JButton
- getButtonSeguridad() : JButton
- getButtonTrabajo() : JButton
- getButttonPersonales() : JButton
- getPanelOrganizacion() : JPanel
- getProgressDH() : JProgressBar
JInternalFrame
Direccion
+ ButtonCambiarZoneTime: JButton = null
+ ComboRegion: JComboBox = null
- jContentPane: JPanel = null
- LabelColonia: JLabel = null
- LabelCP: JLabel = null
- LabelDireccion: JLabel = null
- LabelDireccion1: JLabel = null
- LabelDistritoLocal: JLabel = null
- LabelExt: JLabel = null
- LabelInt: JLabel = null
- LabelMunicipioDir: JLabel = null
- LabelNum: JLabel = null
- LabelPiso: JLabel = null
- LabelPuerta: JLabel = null
- LabelRegion: JLabel = null
+ LabelRegionG: JLabel = null
- PanelDireccion: JPanel = null
- PanelDireccionOptativo: JPanel = null
+ TextColonia: JTextField = null
+ TextCP: JTextField = null
+ TextDireccion: JTextField = null
+ TextDistritoLocal: JTextField = null
+ TextExt: JTextField = null
+ TextInt: JTextField = null
+ TextMunicipioDir: JTextField = null
+ TextPiso: JTextField = null
+ TextPuerta: JTextField = null
+ Direccion()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getButtonCambiarZoneTime() : JButton
- getComboRegion() : JComboBox
- getPanelDireccion() : JPanel
- getPanelDireccionOptativo() : JPanel
- getTextColonia() : JTextField
- getTextCP() : JTextField
- getTextDireccion() : JTextField
- getTextDistritoLocal() : JTextField
- getTextExt() : JTextField
- getTextInt() : JTextField
- getTextMunicipioDir() : JTextField
- getTextPiso() : JTextField
- getTextPuerta() : JTextField
JInternalFrame
Enfermedade s
+ CheckCancer: JCheckBox = null
+ CheckCardiopatia: JCheckBox = null
+ CheckCerebo: JCheckBox = null
+ CheckDiabetes: JCheckBox = null
+ CheckHipertension: JCheckBox = null
+ CheckIntestinales: JCheckBox = null
+ CheckNeumonia: JCheckBox = null
+ checkSIDA: JCheckBox = null
+ CheckTuberculosis: JCheckBox = null
+ ComboPerinatales: JComboBox = null
- jContentPane: JPanel = null
- LabelCancer: JLabel = null
- LabelCardiopatia: JLabel = null
- LabelCerebro: JLabel = null
- LabelDiabetes: JLabel = null
- LabelEnferemedadesPerinatales: JLabel = null
- LabelEnfermedadesContagiosas: JLabel = null
- LabelEnfermedadesNoContagiosas: JLabel = null
- LabelHipertension: JLabel = null
- LabelInfeccionesIntestinales: JLabel = null
- LabelNeumonia: JLabel = null
- LabelOtraContagiosa: JLabel = null
- LabelOtraNoContagiosa: JLabel = null
- LabelSeleccione: JLabel = null
- LabelSIDA: JLabel = null
- LabelTuberculosis: JLabel = null
- PanelEnfermedades: JPanel = null
+ TextOtraContagiosa: JTextField = null
+ TextOtraNoContagiosa: JTextField = null
+ Enfermedades()
- getCheckSIDA() : JCheckBox
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getCheckCancer() : JCheckBox
- getCheckCardiopatia() : JCheckBox
- getCheckCerebo() : JCheckBox
- getCheckDiabetes() : JCheckBox
- getCheckHipertension() : JCheckBox
- getCheckIntestinales() : JCheckBox
- getCheckNeumonia() : JCheckBox
- getCheckTuberculosis() : JCheckBox
- getComboPerinatales() : JComboBox
- getPanelEnfermedades() : JPanel
- getTextOtraContagiosa() : JTextField
- getTextOtraNoContagiosa() : JTextField
JInternalFrame
EstiloV ida
- CheckMuchoHogareno: JCheckBox = null
- CheckMuchoSociable: JCheckBox = null
- CheckNadaHogareno: JCheckBox = null
- CheckNadaSociable: JCheckBox = null
- CheckPocoHogareno: JCheckBox = null
- CheckPocoSociable: JCheckBox = null
- CheckRegularHogareno: JCheckBox = null
- CheckRegularSociable: JCheckBox = null
- jContentPane: JPanel = null
- LabelHogareno: JLabel = null
- LabelMucho: JLabel = null
- LabelMuchoRelaciones: JLabel = null
- LabelNadaHogareno: JLabel = null
- LabelNadaRelaciones: JLabel = null
- LabelPoco: JLabel = null
- LabelPocoRelaciones: JLabel = null
- LabelRegular: JLabel = null
- LabelRegularRelaciones: JLabel = null
- LabelRelaciones: JLabel = null
+ EstiloVida()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getCheckMuchoHogareno() : JCheckBox
- getCheckMuchoSociable() : JCheckBox
- getCheckNadaHogareno() : JCheckBox
- getCheckNadaSociable() : JCheckBox
- getCheckPocoHogareno() : JCheckBox
- getCheckPocoSociable() : JCheckBox
- getCheckRegularHogareno() : JCheckBox
- getCheckRegularSociable() : JCheckBox
JInternalFrame
GEEK
- jContentPane: JPanel = null
- LabelOtroGEEK: JLabel = null
- LableCodigoGEEK: JLabel = null
- TextGEEK: JTextField = null
- TextGEEKOtro: JTextField = null
+ GEEK()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getTextGEEK() : JTextField
- getTextGEEKOtro() : JTextField
JFrame
Interfa z
+ apariencia: Apariencia = new Apariencia()
+ ayudatecnica: AyudaTecnica = new AyudaTecnica()
+ contacto: Contacto = new Contacto()
+ direccion: Direccion = new Direccion()
+ door: Clases = new Clases("DAT...
+ enfermedad: Enfermedades = new Enfermedades()
+ estilovida: EstiloVida = new EstiloVida()
+ estudio: Estudio = new Estudio(this)
+ geeko: GEEK = new GEEK()
+ intereses: Intereses = new Intereses()
- jContentPane: JPanel = null
+ miembros: Miembros = new Miembros()
+ origen: Origen = new Origen()
- PanelAreaTrabajo: JDesktopPane = null
+ personales: Personales = new Personales(this)
+ proyecto: Proyecto = new Proyecto()
+ publicaciones: Publicaciones = new Publicaciones()
~ saver: Saver = new Saver(this)
+ seguridad: Seguridad = new Seguridad()
- serialVersionUID: long = 1L {readOnly}
+ trabajo: Trabajo = new Trabajo(this)
- getJContentPane() : JPanel
+ initialize() : void
+ Interfaz()
+ LoadInternalFrames() : void
+ main(String[]) : void
+ rebootClases() : void
# RebootInternalFrame() : void
- SetInvisibleElementsContacto() : void
+ showApariencia() : void
+ showAuthentication() : void
+ showAyudaTecnica() : void
+ ShowChooseDomain() : void
+ showClases() : void
+ showContacto() : void
+ showDireccion() : void
+ showEnfermedades() : void
+ showEstiloVida() : void
+ showEstudio() : void
+ showGEEK() : void
+ showIntereses() : void
+ showMiembros() : void
+ showOrigen() : void
+ showPersonales() : void
+ showProyecto() : void
+ showPublicaciones() : void
+ showSaver() : void
+ showSeguridad() : void
+ showTaskChoice() : void
+ showTrabajo() : void
«property get»
- getPanelAreaTrabajo() : JDesktopPane
JInternalFrame
Publicacione s
- jContentPane: JPanel = null
- LabelPublicaciones: JLabel = null
+ TextPublicaciones: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Publicaciones()
«property get»
- getTextPublicaciones() : JTextField
JDialog
ZoneTime
- ButtonCambia: JButton = null
- ButtonDejar: JButton = null
- direccion: Direccion
- jContentPane: JPanel = null
- LabelZoneTime1: JLabel = null
- LabelZoneTime2: JLabel = null
- LabelZoneTime3: JLabel = null
- RadioDespues: JRadioButton = null
- RadioNunca: JRadioButton = null
- getJContentPane() : JPanel
- initialize() : void
+ ZoneTime()
+ ZoneTime(Direccion)
«property get»
- getButtonCambia() : JButton
- getButtonDejar() : JButton
- getRadioDespues() : JRadioButton
- getRadioNunca() : JRadioButton
-interfaz
-interfaz
+apariencia
+ayudatecnica
+direccion
+door
+enfermedad
+estilovida
-interfaz
-direccion
+publicaciones
+geeko

Análisis y diseño
Rojas, Christian 47
Figura 3.17 Diagrama De Clases De El Paquete mx.edu.cenidet.userontology.Front
class mx.edu.cenidet.userontology.Front
JInternalFrame
Sav er
- ButtonCancel: JButton = null
- ButtonExit: JButton = null
- ButtonSave: JButton = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- ProgressSave: JProgressBar = null
- getJContentPane() : JPanel
- initialize() : void
+ Saver()
+ Saver(Interfaz)
«property get»
- getButtonCancel() : JButton
- getButtonExit() : JButton
- getButtonSave() : JButton
- getProgressSave() : JProgressBar
JInternalFrame
Interese s
- CheckPunk: JCheckBox = null
- jContentPane: JPanel = null
- LabelCyberPunk: JLabel = null
- LabelEconomia: JLabel = null
- LabelFrecuenteEconomia: JLabel = null
- LabelFrecuentePolitica: JLabel = null
- LabelFrecuenteSociales: JLabel = null
- LabelMuyEconomia: JLabel = null
- LabelMuyPGP: JLabel = null
- LabelMuyPolitica: JLabel = null
- LabelMuySociales: JLabel = null
- LabelNingunEconomia: JLabel = null
- LabelNingunPGP: JLabel = null
- LabelNingunPolitica: JLabel = null
- LabelNingunSociales: JLabel = null
- LabelPolitica: JLabel = null
- LabelRegularPGP: JLabel = null
- LabelSinEconomia: JLabel = null
- LabelSinPolitica: JLabel = null
- LabelSinSociales: JLabel = null
- LabelSociales: JLabel = null
- LabePGP: JLabel = null
- RadioFrecuenteEconomia: JRadioButton = null
- RadioFrecuentePolitica: JRadioButton = null
- RadioFrecuenteSociales: JRadioButton = null
- RadioMuyEconomia: JRadioButton = null
- RadioMuyPGP: JRadioButton = null
- RadioMuyPolitica: JRadioButton = null
- RadioMuySociales: JRadioButton = null
- RadioNingunEconomia: JRadioButton = null
- RadioNingunPGP: JRadioButton = null
- RadioNingunPolitica: JRadioButton = null
- RadioNingunSociales: JRadioButton = null
- RadioRegularPGP: JRadioButton = null
- RadioSinEconomia: JRadioButton = null
- RadioSinPolitica: JRadioButton = null
- RadioSinSociales: JRadioButton = null
- getJContentPane() : JPanel
- initialize() : void
+ Intereses()
«property get»
- getCheckPunk() : JCheckBox
- getRadioFrecuenteEconomia() : JRadioButton
- getRadioFrecuentePolitica() : JRadioButton
- getRadioFrecuenteSociales() : JRadioButton
- getRadioMuyEconomia() : JRadioButton
- getRadioMuyPGP() : JRadioButton
- getRadioMuyPolitica() : JRadioButton
- getRadioMuySociales() : JRadioButton
- getRadioNingunEconomia() : JRadioButton
- getRadioNingunPGP() : JRadioButton
- getRadioNingunPolitica() : JRadioButton
- getRadioNingunSociales() : JRadioButton
- getRadioRegularPGP() : JRadioButton
- getRadioSinEconomia() : JRadioButton
- getRadioSinPolitica() : JRadioButton
- getRadioSinSociales() : JRadioButton
JFrame
Interfa z
+ apariencia: Apariencia = new Apariencia()
+ ayudatecnica: AyudaTecnica = new AyudaTecnica()
+ contacto: Contacto = new Contacto()
+ direccion: Direccion = new Direccion()
+ door: Clases = new Clases("DAT...
+ enfermedad: Enfermedades = new Enfermedades()
+ estilovida: EstiloVida = new EstiloVida()
+ estudio: Estudio = new Estudio(this)
+ geeko: GEEK = new GEEK()
+ intereses: Intereses = new Intereses()
- jContentPane: JPanel = null
+ miembros: Miembros = new Miembros()
+ origen: Origen = new Origen()
- PanelAreaTrabajo: JDesktopPane = null
+ personales: Personales = new Personales(this)
+ proyecto: Proyecto = new Proyecto()
+ publicaciones: Publicaciones = new Publicaciones()
~ saver: Saver = new Saver(this)
+ seguridad: Seguridad = new Seguridad()
- serialVersionUID: long = 1L {readOnly}
+ trabajo: Trabajo = new Trabajo(this)
- getJContentPane() : JPanel
+ initialize() : void
+ Interfaz()
+ LoadInternalFrames() : void
+ main(String[]) : void
+ rebootClases() : void
# RebootInternalFrame() : void
- SetInvisibleElementsContacto() : void
+ showApariencia() : void
+ showAuthentication() : void
+ showAyudaTecnica() : void
+ ShowChooseDomain() : void
+ showClases() : void
+ showContacto() : void
+ showDireccion() : void
+ showEnfermedades() : void
+ showEstiloVida() : void
+ showEstudio() : void
+ showGEEK() : void
+ showIntereses() : void
+ showMiembros() : void
+ showOrigen() : void
+ showPersonales() : void
+ showProyecto() : void
+ showPublicaciones() : void
+ showSaver() : void
+ showSeguridad() : void
+ showTaskChoice() : void
+ showTrabajo() : void
«property get»
- getPanelAreaTrabajo() : JDesktopPane
JInternalFrame
Miembros
- jContentPane: JPanel = null
- Label1: JLabel = null
- Label2: JLabel = null
- Label3: JLabel = null
- LabelNombreClub: JLabel = null
- LabelnombresMiembros: JLabel = null
+ TextMiembro1: JTextField = null
+ TextMiembro2: JTextField = null
+ TextMiembro3: JTextField = null
+ TextNombreClub: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Miembros()
«property get»
- getTextMiembro1() : JTextField
- getTextMiembro2() : JTextField
- getTextMiembro3() : JTextField
- getTextNombreClub() : JTextField
JInternalFrame
Orige n
- ButtonNivelComputo: JButton = null
- jContentPane: JPanel = null
- LabelCiudad: JLabel = null
- LabelDistrito: JLabel = null
- LabelGobierno: JLabel = null
- LabelLocalidad: JLabel = null
- LabelMoneda: JLabel = null
- LabelMunicipio: JLabel = null
- LabelOrigen: JLabel = null
- LabelPais: JLabel = null
- Origen: JPanel = null
- PanelOrigenOptativo: JPanel = null
+ TextCiudad: JTextField = null
+ TextDistrito: JTextField = null
+ TextGobierno: JTextField = null
+ TextLocalidad: JTextField = null
+ TextMoneda: JTextField = null
+ TextMunicipio: JTextField = null
+ TextPais: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Origen()
«property get»
- getOrigen() : JPanel
- getPanelOrigenOptativo() : JPanel
- getTextCiudad() : JTextField
- getTextDistrito() : JTextField
- getTextGobierno() : JTextField
- getTextLocalidad() : JTextField
- getTextMoneda() : JTextField
- getTextMunicipio() : JTextField
- getTextPais() : JTextField
JInternalFrame
Proyecto
- jContentPane: JPanel = null
- jPanel1: JPanel = null
- LabelPoyecto: JLabel = null
- LabelProyectoActual: JLabel = null
- LabelProyetoAnteriorl: JLabel = null
+ TextProyectoActual: JTextField = null
+ TextProyectoAnterior: JTextField = null
- getJContentPane() : JPanel
- getJPanel1() : JPanel
- initialize() : void
+ Proyecto()
«property get»
- getTextProyectoActual() : JTextField
- getTextProyectoAnterior() : JTextField
JInternalFrame
Trabajo
+ ComboHorario: JComboBox = null
+ ComboTipoContratacion: JComboBox = null
+ ComboTipoTrabajo: JComboBox = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- LabelDependientes: JLabel = null
- LabelHorario: JLabel = null
- LabelNombreEmpresa: JLabel = null
- LabelPersonasUnidad: JLabel = null
- LabelPuesto: JLabel = null
- LabelTipo: JLabel = null
- LabelTipoContratacion: JLabel = null
- PanelTrabajo: JPanel = null
- PanelTrabajoOptativo: JPanel = null
+ TextDependientes: JTextField = null
+ TextNombreEmpresa: JTextField = null
+ TextPersonasUnidad: JTextField = null
+ TextPuesto: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Trabajo()
+ Trabajo(Interfaz)
«property get»
- getComboHorario() : JComboBox
- getComboTipoContratacion() : JComboBox
- getComboTipoTrabajo() : JComboBox
- getPanelTrabajo() : JPanel
- getPanelTrabajoOptativo() : JPanel
- getTextDependientes() : JTextField
- getTextNombreEmpresa() : JTextField
- getTextPersonasUnidad() : JTextField
- getTextPuesto() : JTextField
JInternalFrame
Contacto
- jContentPane: JPanel = null
+ LabelChat: JLabel = null
+ LabelEmail: JLabel = null
+ LabelHomePage: JLabel = null
+ LabelICQ: JLabel = null
+ LabelJabber: JLabel = null
+ LabelMensajeriaInstantanea: JLabel = null
+ LabelMSN: JLabel = null
+ LabelOpenID: JLabel = null
+ LabelWebLog: JLabel = null
+ LabelYahoo: JLabel = null
- loc: int
- loclabels: int
+ PanelContacto: JPanel = null
+ TextChat: JTextField = null
+ TextEmail: JTextField = null
+ TextICQ: JTextField = null
+ TextJabber: JTextField = null
+ TextMensajeriaInstantanea: JTextField = null
+ TextMSN: JTextField = null
+ TextOpenID: JTextField = null
+ TextPaginaPersonal: JTextField = null
+ TextWebLog: JTextField = null
+ TextYahoo: JTextField = null
+ Contacto()
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getPanelContacto() : JPanel
- getTextChat() : JTextField
- getTextEmail() : JTextField
- getTextICQ() : JTextField
- getTextJabber() : JTextField
- getTextMensajeriaInstantanea() : JTextField
- getTextMSN() : JTextField
- getTextOpenID() : JTextField
- getTextPaginaPersonal() : JTextField
- getTextWebLog() : JTextField
- getTextYahoo() : JTextField
JInternalFrame
Estudio
+ ComboNivelEducativo: JComboBox = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- LabelInstitucion: JLabel = null
- LabelMatricula: JLabel = null
- LabelNivelEducativo: JLabel = null
- LabelSupervisor: JLabel = null
- PanelEstudio: JPanel = null
- PanelEstudiosOptativo: JPanel = null
+ TextInstitucion: JTextField = null
+ TextMatricula: JTextField = null
+ TextSupervisor: JTextField = null
+ Estudio()
+ Estudio(Interfaz)
- getJContentPane() : JPanel
- initialize() : void
«property get»
- getComboNivelEducativo() : JComboBox
- getPanelEstudio() : JPanel
- getPanelEstudiosOptativo() : JPanel
- getTextInstitucion() : JTextField
- getTextMatricula() : JTextField
- getTextSupervisor() : JTextField
JInternalFrame
Task Choice
- ButtonBack: JButton = null
- ButtonDrop: JButton = null
- ButtonModify: JButton = null
- caja: JTextArea = new JTextArea()
- interfaz: Interfaz
- jContentPane: JPanel = null
- Label: JLabel = null
- getJContentPane() : JPanel
- initialize() : void
+ TaskChoice()
+ TaskChoice(Interfaz)
«property get»
- getButtonBack() : JButton
- getButtonDrop() : JButton
- getButtonModify() : JButton
JInternalFrame
Personale s
+ BoxMiembro: JCheckBox = null
+ CheckEnfermedad: JCheckBox = null
+ CheckMinusvalia: JCheckBox = null
+ ComboComputo: JComboBox = null
+ ComboDedicacion: JComboBox = null
+ ComboSexo: JComboBox = null
- interfaz: Interfaz
- jContentPane: JPanel = null
- LabelAgenteLegal: JLabel = null
- LabelApellido: JLabel = null
- LabelDD: JLabel = null
- LabelDedicacion: JLabel = null
- LabelEdoCivil: JLabel = null
- LabelEnfermedad: JLabel = null
- LabelFechanac: JLabel = null
- LabelFijo: JLabel = null
- LabelLevel: JLabel = null
- LabelMiembro: JLabel = null
- LabelMinusvalia: JLabel = null
- LabelMinusvalidos: JLabel = null
- LabelMM: JLabel = null
- LabelMovil: JLabel = null
- LabelNick: JLabel = null
- Labelnick1: JLabel = null
- LabelNivelComputo: JLabel = null
- LabelNombre: JLabel = null
- LabelNombrePref: JLabel = null
- LabelPersonal: JLabel = null
- LabelSexo: JLabel = null
- LabelSlash: JLabel = null
- LabelSlash1: JLabel = null
- LabelTelefono: JLabel = null
- LabelTitulo: JLabel = null
- LabelYYYY: JLabel = null
- PanelEnfermedades: JPanel = null
- PanelNivelComputo: JPanel = null
- PanelPersonales: JPanel = null
- PanelPersonalesOptativo: JPanel = null
+ PasswordNuevoDos: JPasswordField = null
+ TextAgenteLegal: JTextField = null
+ TextApellido: JTextField = null
+ TextDia: JTextField = null
+ TextEdoCivil: JTextField = null
+ TextFijo: JTextField = null
+ TextMM: JTextField = null
+ TextMovil: JTextField = null
+ TextNickUser: JTextField = null
+ TextNombre: JTextField = null
+ TextNombrePref: JTextField = null
+ TextTitulo: JTextField = null
+ TextYYYY: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Personales()
+ Personales(Interfaz)
«property get»
- getBoxMiembro() : JCheckBox
- getCheckEnfermedad() : JCheckBox
- getCheckMinusvalia() : JCheckBox
- getComboComputo() : JComboBox
- getComboDedicacion() : JComboBox
- getComboSexo() : JComboBox
- getPanelEnfermedades() : JPanel
- getPanelNivelComputo() : JPanel
- getPanelPersonales() : JPanel
- getPanelPersonalesOptativo() : JPanel
- getTextAgenteLegal() : JTextField
- getTextApellido() : JTextField
- getTextDia() : JTextField
- getTextEdoCivil() : JTextField
- getTextFijo() : JTextField
- getTextMM() : JTextField
- getTextMovil() : JTextField
- getTextNickUser() : JTextField
- getTextNombre() : JTextField
- getTextNombrePref() : JTextField
- getTextTitulo() : JTextField
- getTextYYYY() : JTextField
JInternalFrame
Segurida d
- jContentPane: JPanel = null
- LabelOldPass: JLabel = null
- LabelPasswordDos: JLabel = null
- LabelPasswordUno: JLabel = null
- PanelSeguridad: JPanel = null
+ PasswordNuevoDos: JPasswordField = null
- PasswordNuevoUno: JPasswordField = null
+ PasswordViejo: JPasswordField = null
+ Textpass: JTextField = null
- getJContentPane() : JPanel
- initialize() : void
+ Seguridad()
«property get»
- getPanelSeguridad() : JPanel
- getPasswordNuevoDos() : JPasswordField
- getPasswordNuevoUno() : JPasswordField
- getPasswordViejo() : JPasswordField
- getTextpass() : JTextField
+seguridad
+personales
-interfaz-interfaz
+interfaz
-interfaz
-interfaz
+trabajo
~saver
+proyecto
+origen
+miembros
+intereses
+estudio
+contacto

Análisis y diseño
Rojas, Christian 48
La descripción de cada clase que compone el paquete se detalla en el Anexo 2.
3.2.1 Actividades del proyecto En esta sección se muestran las principales tareas que se realizan en este proyecto, con sus detalles y respectivos diagramas de secuencias para explicar las actividades desarrolladas. El proceso lo inicia la aplicación Interfaz desde la cual se invocan los métodos de las demás clases, la cual instancia a una clase llamada DATA que contiene los elementos genéricos y de configuración de la aplicación que permitirán realizar operaciones con la ontología. Para poder realizar cualquiera de las operaciones hacia o desde la ontología, es necesaria una conexión con la ontología. El proceso de conexión detallado se muestra en el diagrama de secuencias de la figura 3.18.
3.2.1.1 Conexión con ontología Para la conexión con la ontología, son necesarios los siguientes elementos:
API de conexión (OWLAPI). Este elemento permitirá mediante sus métodos y clases, el enlace con la ontología y la inserción, modificación o eliminación de individualizaciones, propiedades, axiomas y demás. “Manager” y “Factory” son dependientes de “OWLAPI” y son descritas a continuación:
o Manager. Se encargara de manejar la ontología a partir de su ubicación física como una entidad lógica y así operar localmente en ella. [Sforge09]
o Factory. Es una clase que implementa métodos para estandarizar los identificadores conceptuales para los elementos de la ontología, como lo son las individualizaciones, las propiedades, las relaciones y demás. [Sforge09]
Razonador (PELLET). Permitirá verificar la integridad y consistencia de la ontología de acuerdo a sus elementos guardados. Asegurando la coherencia de los tipos de datos guardados con los permitidos o especificados.
Para el proceso de conexión con la ontología, primero se instancia la clase Store, mediante el método ontocomm(), la cual solicita la dirección física de la ontología, que deberá encontrarse almacenada en la clase DATA, obteniéndose así una dirección absoluta que permitirá que la API maneje los identificadores conceptuales para los elementos de la ontología.

Análisis y diseño
Rojas, Christian 49
Posteriormente, se iniciarán los servicios referidos anteriormente, los cuales son “Manager”, “Factory” y el “Razonador”, y se devolverán por parte de la API de conexión “OWLAPI”, los identificadores de estos servicios.
Figura 3.18 Diagrama de secuencias para la Conexión con la ontología
Cabe mencionar que esta conexión no requiere un cierre al terminar de utilizarla, por este motivo será necesaria una conexión por cada acceso a los datos de la ontología. A continuación se describen los métodos involucrados en el ingreso al sistema por parte del usuario en sus opciones de usuario nuevo o existente.
3.2.1.2 Usuario nuevo Mediante una instanciación de la clase Authentication por medio del método ShowAuthentication(), se solicita al usuario un nombre de usuario y una contraseña (la cual debe ser requerida dos veces para verificar congruencia en esta), y verificará la disponibilidad de el nombre de usuario elegido mediante la invocación del método exist_the_login() de la clase Login, el cual le envía como parámetro el nombre de usuario elegido y recuperara de la invocación dicha validación. Una vez realizado esto, y siendo satisfactoria la validación de un nuevo usuario, se mostrará en pantalla la interfaz para la elección del dominio de la aplicación hacia la cual se inclinará la información mostrada. El diagrama de secuencia para este proceso se muestra en la figura 3.19

Análisis y diseño
Rojas, Christian 50
Figura 3.19 Diagrama de secuencias para ingresar al sistema como usuario nuevo
Una vez mostrada la pantalla para la elección del dominio de la aplicación se termina el proceso de autenticación para un usuario nuevo y continúa el proceso de elección del dominio de la aplicación. (Véase Elección del dominio de aplicación)
3.2.1.3 Usuario existente En esta actividad, se realiza una instanciación de la clase interfaz para mostrar en pantalla el panel base sobre el cual se invocarán los métodos a utilizar en el transcurso de la aplicación. Se instancia entonces la clase Authentication mediante el método showAuthentication(),el cual, solicitará al usuario un nombre de usuario y una contraseña, la cual deberá existir registrada en la ontología, para ello hace uso de un método dentro de la clase Login, invocándolo mediante login_password, enviando como parámetros el nombre de usuario y la contraseña proporcionada, la cual invocará a sí misma, los métodos: exist_the_login() que recibirá como parámetro el nombre de usuario en cuestión y list_usersLogin() la cual se encargará de verificar esta existencia.

Análisis y diseño
Rojas, Christian 51
Una vez realizado esto, y siendo satisfactoria la validación del usuario registrado, se mostrará en pantalla la interfaz para la elección de la operación a realizar con la ontología relacionada a el usuario dispuesto. El diagrama de secuencia para este proceso se muestra en la figura 3.20
Figura 3.20 Diagrama de secuencias para ingresar al sistema como usuario existente
Una vez terminado el proceso de autenticación para un usuario registrado, se muestra un mensaje de éxito, y continúa el proceso de elección de la operación a realizar en la ontología. (Véase 3.2.1.8) Para poder realizar las operaciones de guardado de datos en la ontología, es necesario explicar primero el procedimiento para procesar el volcado de estos datos en la ontología, es decir, haciendo uso de la API (OWLAPI), del razonador y de las clases pertinentes.
3.2.1.4 Guardado en ontología Este proceso es efectuado después de que el usuario realiza algún cambio en sus datos y desea verlos reflejados en la ontología o cuando el usuario guarda por primera vez sus datos.

Análisis y diseño
Rojas, Christian 52
Se comienza con la instanciación de la clase Remove, mediante la llamada deleteIndividual() (véase 3.2.1.6), la cual se encargará de eliminar todas las individualizaciones operadas por la interfaz, utilizando para ello la conexión con la ontología (véase 3.2.1.1), una vez devuelto el mensaje de éxito de la remoción de individualizaciones pertinentes, se procede al volcado de los datos desde las pantallas de interfaz respectivas hacia las clases en la ontología cuyo proceso involucra la obtención de los datos desde las casillas de la interfaz y la ubicación de estos en los campos respectivos en la ontología. A continuación se procede a relacionar las individualizaciones, mediante la clase RelationAll, la cual verificará si se encuentran datos cuyo valor sea necesario, dentro de la clase DATA, y posteriormente se crearán las relaciones a las individualizaciones de manera iterativa una a una. Posteriormente agrupará todas las relaciones y las empaquetará para enviarlas como parámetros (clase a operar, identificador conceptual actual, conjunto de atributos a insertar y conjunto de relaciones a insertar) en el método InsertIndividualObjects que invocará la clase STORE, la cual entablará una conexión con la ontología (véase 3.2.1.1). Para finalmente retornar un mensaje de éxito. EL diagrama de secuencias que describe este proceso se muestra en la figura 3.21

Análisis y diseño
Rojas, Christian 53
Figura 3.21 Diagrama de secuencias del proceso Guardar ontología
A continuación se describirá el proceso de modificación de la ontología, el cual lleva implícito el proceso de lectura de la misma y del vaciado de estos datos en las casillas y elementos respectivos de la interfaz apropiada.
3.2.1.5 Modificar en ontología Este método se encarga de obtener los datos de la ontología y asignarlos a los elementos respectivos en la interfaz. Primero se realiza una invocación de la lectura de ontología, la cual se encarga de leer los datos respectivos de la ontología uno a uno, para posteriormente asignar esos datos a las clases de la interfaz adecuada. Una vez terminado este proceso se muestra en pantalla dichas clases de la interfaz con los datos recuperados de la ontología. Este proceso se encuentra detallado en el diagrama de secuencias de la figura 3.22

Análisis y diseño
Rojas, Christian 54
Figura 3.22 Diagrama de secuencias del proceso Modificación de ontología
3.2.1.6 Eliminado de ontología En esta actividad de la aplicación se eliminarán las individualizaciones pertinentes (utilizadas) por la misma aplicación, dejando intactas cualquier otra relación, individualización o atributo encontrado en la ontología extras. EL proceso inicia instanciando la clase Remove mediante el método deleteIndividual(), el cual realizará iterativamente una conexión con la ontología (véase 3.2.1.1) y una eliminación de la individualización respectiva a la iteración. Por último se obtendrá como resultado un mensaje de éxito de la eliminación de los elementos en la ontología. EL proceso detallado se muestra en el diagrama de secuencias en la figura 3.23
Figura 3.23 Diagrama de secuencias del proceso Eliminación de la ontología

Análisis y diseño
Rojas, Christian 55
3.2.1.7 Elección de dominio Esta actividad de la aplicación funciona como un menú para poder acceder a cualquiera de los dominios dispuestos, los cuales se encargarán de inclinar la captura de los datos del usuario dentro de la interfaz, disponiendo estos en dos categorías, “Recomendados” y “Opcionales”. Véase Tabla 1.3
3.2.1.8 Elección de operación en ontología Este proceso se muestra en pantalla como un menú, después de haberse autenticado el usuario dependiendo de si es un usuario nuevo o existente en los registros de la ontología, y permitirá acceder a las clases correspondientes para realizar la operación pertinente, como lo son: modificar, eliminar o agregar datos.

Análisis y diseño
Rojas, Christian 56

4. CAPÍTULO IV. DESARROLLO DE LA SOLUCIÓN En este capítulo se presenta un análisis de la metodología a seguir para la construcción de la ontología, así como una aproximación de la misma. Se muestra también en detalle la formalización de las características propuestas para la ontología.

Desarrollo de la solución
Rojas, Christian 58
A continuación, se describe el procedimiento para la obtención de la ontología, involucrando elementos y restricciones además de la metodología para la obtención de la interfaz gráfica, que servirá para la población, explotación y uso de restricciones propuestas.
4.1 RECOPILACIÓN, DISCRIMINACIÓN E INTEGRACIÓN DE DATOS Para el desarrollo de esta primera fase del proyecto fue necesario analizar las posibles categorizaciones de un usuario, tanto en el tema de mercadotecnia, como otras áreas de estudio incluyendo algunas ontologías disponibles ya fundamentadas para un propósito similar. Las ontologías relacionadas que se analizaron fueron: Aktors, FOAF y SOUPA entre otras, las cuales se muestran a detalle en el estado del arte. De entre todas estas se extrajeron los atributos que se muestran en la tabla 7
Tabla 4.1. Recopilación de atributos pertinentes para perfilar a un usuario.
Clase Atributos datatype Atributos object
Apariencia Ayuda Técnica Contacto Dirección Enfermedades
Transmisibles No transmisibles
Estilo de vida Estudio GEEK
Forma Vestuario Tipo ayuda E_mail Weblog Icq Id_chat Jabber Mensajeria msn openid perfiles yahoo calle código postal municipio numero numero int piso puerta región geo tipos transmisibles tipos no transmisibles Hogareño? Relaciones? institución Matricula Nivel educativo Supervisor Código geek

Desarrollo de la solución
Rojas, Christian 59
Intereses Miembro Nivel Cómputo Origen Persona Personales Preferencias Proyecto Publicaciones Trabajo
Otros geek Cyberpunk Economía Pgp(pretty good privacy)
Política Temas sociales Nombre club Miembros Conocimiento computo Ciudad Distrito local Gobierno Localidad Moneda Municipio País Agente legal Apellido Dedicación Edo civil Fecha_nac Tel fijo Tel móvil Nick Nombre Nombre pref. Password Sexo Teléfono Titulo Hobbies Tipo_comida Dominio aplic. Zona horaria Lugares_favoritos_viaje Otra_dedicacion Habilidades Vehiculos_motorizados Peliculas_al_mes Genero_peliculas Reality_shows Programas_noticias Horario_dormir Mascotas Periodico Anterior Actual Link publicaciones Dependientes Horario Nombre empresa Personal depto. Puesto Tipo Tipo contratación
TODAS las clases

Desarrollo de la solución
Rojas, Christian 60
En la tabla 4.1 se muestra una cantidad considerable de atributos para poder categorizar a un usuario, tomando en cuenta datos de interés específico como es el conocimiento de cómputo, enfermedades contagiosas, el uso de aparatos técnicos necesarios por alguna minusvalía, etc. La ontología comprende el conjunto de todas las clases mostradas en la Tabla 4.1, tal como se muestra en la figura 4.1.
Figura 4.1. Estructura ontológica
Para poder disponer los datos en algún lenguaje procesable y además tener las ventajas de la reutilización y compartición se diseño una ontología, utilizando la herramienta “protégé” [Protege09]. Esta herramienta permite además de poner los datos bajo clases y atributos, estipular las relaciones y reglas, aunque cabe mencionar que las restricciones de llenado con base en el valor de otros atributos se realizaron en la fase de diseño, lo cual se explicará a detalle más adelante. Cabe mencionar que también se analizaron los diferentes enfoques para categorizar a las minusvalías, discapacidades, etc., y todas aquellas problemáticas humanas que afecten al rendimiento diario de una persona, además de las enfermedades que esta posea sin la intención de ser tan explícitos en este aspecto, simplemente de disponer de aquellas que son más comunes y que afecten en alguna medida la alimentación y o relación social entre otros factores inmersos. [Isssste02] Para el caso de las enfermedades, se llego a la conclusión de disponer de un pequeño catalogo de enfermedades crónico-degenerativas más comunes y así contemplarlas dentro de la ontología en forma de caja de verificación o con un simple valor booleano.

Desarrollo de la solución
Rojas, Christian 61
Las categorías encontradas y propuestas en la ontología, se muestran en la figura 4.2.
Figura 4.2. Enfermedades crónico-degenerativas en México
Para cuestiones de organización se distribuyeron estas últimas en las clases “Enfermedades contagiosas” y “Enfermedades no contagiosas”, refiriéndose a enfermedades infecto contagiosas o no, e incluyendo en el primer clúster el SIDA/VIH. Después de analizar los diferentes enfoques (Véase capítulo II) para categorizar a un usuario, siendo algunas de ellas basadas en lenguaje procesable (OWL/RDF), y otras simplemente dispuestas en clúster disjuntos, se llego a la conclusión de que el mejor método para poder categorizar a un usuario es uniendo varias técnicas, y representarlas como se define a continuación.
4.2 ESTRUCTURA DE LA ONTOLOGÍA En primera instancia, la estructura de la información será alimentada de un modo explicito y se formará de un tipo “Nuclear + extensiones”, es decir, existirá un núcleo (conjunto de clases con sus respectivos atributos), que será legible y podrá poblarse por cualquier usuario, ya que contendrá todos aquellos datos que son de interés general y/o de uso común. A partir de los datos que contenga este núcleo, será posible acceder a otras clases y/o atributos que estarán fuera del mismo, denominadas “Extensiones”, de tal suerte que estas últimas contengan información referente a datos de interés

Desarrollo de la solución
Rojas, Christian 62
específico, y que sean cuestionables y/o accesibles a un usuario siempre y cuando cumpla una condición especificada en los datos “nucleares”. La ontología contemplará entonces el núcleo más todas las extensiones, aunque cabe mencionar que es improbable que un usuario cumpla o tenga en su perfil, acceso a todas las extensiones, incluyendo el núcleo, por la gran cantidad de información manejada. A continuación se definen los siguientes conceptos, generados a partir de la metodología de solución manejada.
4.2.1 Núcleo Refiere al conjunto de clases con sus respectivos atributos que son disjuntos entre sí pero que en unión se contextualizan como todos aquellos datos de uso común y/o información en general. El núcleo puede ser usado para perfilar a cualquier usuario real, sin notar detalles y características de uso específico. El núcleo será tomado como una ontología por sí misma, y será gestionada mediante un lenguaje procesable (OWL/RDF), la cual será instanciable por medio de alguna interfaz gráfica diseñada por algún lenguaje de programación (Open Source), para las pruebas pertinentes.
4.2.2 Extensibilidad Este proyecto propone tres tipos de extensibilidad: 1) Extensibilidad satelital que consiste en una clase que es completamente disjunta al núcleo, por lo que no se solapan ni comparten ningún elemento y que será añadida al núcleo de acuerdo a alguna(s) condición(es); 2) La Extensibilidad parcial, la cual consiste en una clase que es incompletamente integrante al núcleo y que lo extenderá a partir de algún parámetro y la 3) Extensibilidad nuclear, que refiere a un conjunto de parámetros integrantes del núcleo que serán habilitados o agregados mientras que otros son deshabilitados de acuerdo a cierta(s) condición(es). Este enfoque fue diseñado para evitar la intrusión excesiva a los datos del usuario preguntando todas las posibles clases a capturar, los cuales incluso en muchos casos pudiesen ser impertinentes y/o no aplicables. El resultado esperado es que estos datos serán accesibles para su captura explicita a aquellos usuarios que en realidad puedan perfilarse mejor con la utilización de estos.

Desarrollo de la solución
Rojas, Christian 63
Para lograr este resultado se han aplicado una serie de parámetros dispuestos como atributos de alguna clase integrante del núcleo, los cuales tendrán un dominio explicito en las extensiones (para todos los tipos), y cuyo valor restringirá (en tiempo de ejecución), a la accesibilidad en las mismas. A nivel de ontología, estos atributos serán propiedades “datatype”, que serán de tipo bool, o string y cuyo valor permitirá o no, el acceso a las extensiones. Las relaciones entre la superclase “Persona” la cual contendrá a todas las clases que conforman el núcleo, y las clases que formaran a las extensiones serán propiedades de tipo “object”, con dominio en la superclase “Persona” y rango en la extensión relacionada. Cabe mencionar que existirá una propiedad objeto para cada extensión, y aunque exista el caso de una sub-extensión, se asignará una propiedad objeto por cada hijo de la extensión, pero para efectos didácticos la extensión padre y las hijas serán referidas como una misma entidad en este documento. Además se especificarán en la ontología las restricciones mediante otras propiedades de tipo objeto, que permitirán enlazar las clases extendidas con el núcleo, únicamente a través de las clases que contengan el parámetro de extensión apropiado, lo cual se explicará a detalle más adelante. Los tipos de extensibilidad propuestos se explicarán a detalle a continuación:
4.2.2.1 Extensibilidad satelital Refiere a un tipo de extensibilidad para el núcleo de la ontología, en el cual, una clase disjunta3 al mismo, diseñada en un lenguaje procesable (OWL/RDF), contiene ciertos atributos de carácter específico y que en un contexto simple no son siempre necesarios. Estos serán accesibles para su población, mediante alguna interfaz gráfica diseñada en algún lenguaje de programación de código abierto, siempre y cuando los parámetros relacionados cumplan con cierto valor. Estos parámetros comprometerán el acceso a las extensiones, y una vez que esta sea realizada, la relación entre el núcleo y la extensión será de tipo débil, es decir, que la existencia de la extensión dependerá completamente del valor del parámetro dado. 3. Conjunto Disjunto Obtenido de: http://es.wikipedia.org/wiki/Conjuntos_disjuntos Ultima consulta: Julio 2009 Se dice que dos conjuntos son disjuntos si no tienen elementos en común

Desarrollo de la solución
Rojas, Christian 64
Minusvalía
Minusvalías
Física Psíquica Sensorial Asociada Ignorado Periodo
Ayuda_tecnica
Tipo_ayuda_tecnica
MuletasSilla de ruedas
Bastón Andadera Otro
4.2.2.1.1 Ejemplo Para poder mostrar de un modo más claro este tipo de extensión se desarrolló un caso de estudio sencillo. Como se puede apreciar en la Tabla 4.1, una de las clases que conforman el núcleo, es la de minusvalía, la cual está estructurada como se muestra en la figura 4.3. Esta clase tiene permite especificar si el usuario tiene alguna minusvalía y de ser así, especificar a qué tipo pertenece [Issste02], y en el caso de que el usuario no lo sepa o no esté de acuerdo con esta clasificación, éste podrá especificar el tipo según su criterio, y permite un dato temporal en el caso de que su minusvalía haya sido ocasionada por algún incidente que temporalmente ocasione este hecho. Nótese en la figura 4.1 que existe también una clase llamada “Ayuda_tecnica”. Esta clase está fuera del núcleo, es decir, es una extensión. Y tiene una estructura similar a la mostrada en la figura 4.4. El objetivo de esta clase es especificar si a partir de una minusvalía del usuario, éste necesita de ayuda técnica como lo son las muletas, silla de ruedas, etc., y permite especificar el nombre de alguna que no esté en esta lista de ayuda técnica común. Cabe hacer notar que esta clase no formar parte del núcleo, es decir, no es algo cuestionable a cualquier usuario a menos de que posea alguna minusvalía.
Atributos
Clase
Figura 4.3. Estructura de la clase “Minusvalía”.
Clase
Atributos
Valores
atributos
Figura 4.4. Estructura de la clase “Ayuda_tecnica”

Desarrollo de la solución
Rojas, Christian 65
Por tanto existe el problema de hacer valida la clase de “Ayuda_tecnica” siempre y cuando la necesite y para resolver esta problemática se hará uso de una extensibilidad de tipo satelital, de la siguiente manera. Se toma como atributo a la clase “Minusvalía”, de modo que si uno de sus elementos tiene un valor valido, es decir, que el usuario haya especificado el tener algún tipo de minusvalía mediante los valores booleanos o enteros de los atributos de la misma entonces y solo entonces podrá acceder al contenido de la clase “Ayuda_tecnica”. Aunque la restricción al acceso a la clase Ayuda_tecnica se realiza bajo programación, en la ontología, esta clase tomará forma por medio de la utilización de un atributo “objeto” el cual enlaza a la clase “Ayuda_tecnica” al núcleo, a través de la clase “minusvalía”, por medio de su definición con dominio en la clase “Minusvalía” y rango en la clase “Ayuda técnica.” Creando así un esquema de relación débil como se muestra en la figura 4.5.
Figura 4.5. Esquema de “Extensibilidad satelital”
Como se puede apreciar en la figura 4.5, se da una relación débil entre la clase minusvalía y la clase ayuda técnica, de modo que la clase ayuda técnica existe siempre y cuando la clase minusvalía lo haga.
4.2.2.1.2 Formalización de extensibilidad satelital A continuación se muestra la formalización para este tipo de extensión con la finalidad de eliminar ambigüedades en la misma. Sea
A = Núcleo de la ontología
B = Clases fuera del núcleo de la ontología.
C = Conjunto de valores validos para un parámetro

Desarrollo de la solución
Rojas, Christian 66
D = Conjunto de parámetros
x = Atributo de alguna clase que está disponible para capturar por el usuario.
Tomando en cuenta que C A y que D A.
Se definen ahora los casos con extensión y sin ésta:
Sin extensión
{x:x A x B}
Extendido
{x:x A x B}
Por tanto las condiciones para la extensión son entonces:
x !C|C A C D C C y Tiene rango en B x|x A x B
De otro modo con cualquier otra condición:
x | x A x B
4.2.2.2 Extensibilidad parcial Es otro tipo de extensibilidad propuesta en este proyecto en la que una clase es incompletamente integrante del núcleo, y la totalidad de esta será accesible únicamente si algún parámetro del núcleo (o de alguna clase que integre al núcleo) que tenga dominio en la clase a extender, tenga también un valor determinado. Los elementos denominados “Parámetros” que permitirán acceder a algunas clases encontradas en alguna extensión o a partes de clases que no pertenezcan al núcleo, se identifican en la ontología como parámetros de clases de tipo
A B
C D

Desarrollo de la solución
Rojas, Christian 67
N + (E)
N + (E-1L)
N + (E-2L)
N
booleano y que permiten el acceso dependiendo de si su valor es válido, o, parámetros de clases de tipo cadena con ciertos valores predeterminados. Para tipo de extensión, los valores predeterminados definirán el nivel de acceso en proporción a una clase de tipo “extensión”, esto es, que no sólo existirán dos tipos de cobertura (núcleo + extensión VS núcleo sin extensión) sino que pueden existir n niveles de cobertura (núcleo + (n elementos de la extensión)). Tal como se muestra en la figura 4.6. Como se puede apreciar en la figura 4.6, el núcleo sigue siendo integro, pero la cobertura hacia la extensión varía según un índice denominado nivel, el cual integra ciertos parámetros al núcleo en cada uno de ellos. La cantidad de niveles se proporciona por las mismas reglas dispuestas a nivel de programación. Cabe mencionar que el acceso a estos niveles será definido a partir de los valores que tengan los parámetros asignados, de modo que un mismo parámetro tendrá diferentes opciones a los valores asignados por defecto y la elección de uno de ellos definirá que nivel de acceso a la extensión es válido y pertinente para el usuario en cuestión.
4.2.2.2.1 Ejemplo Se mostrará ahora un caso de estudio para poder visualizar de un modo más claro esta extensibilidad. Como se puede apreciar en la Tabla 4.1, existe una clase denominada “Contacto” que tiene una estructura como la mostrada en la figura 4.7.
Siendo: N Núcleo E Extensión L Nivel
Figura 4.6. Esquema de extensibilidad parcial

Desarrollo de la solución
Rojas, Christian 68
La clase anterior tiene como objetivo el establecer todos los datos disponibles de contacto para cualquier usuario, adaptándose a su nivel de conocimiento de cómputo, para evitar la intrusión excesiva. Cabe hacer notar que esta clase no es nuclear, es decir, es disjunta a las clases que conforman el núcleo, y tiene la característica de que sus atributos serán accesibles de distinto modo entre ellos, como se explica a continuación. Al igual que la extensión anterior, este tipo de restricción dependerá de un parámetro encontrado en otra clase, en este caso la clase “Nivel_computo” la cual tiene una estructura como se muestra en la figura 4.8. Esta clase tiene un conjunto de valores disponibles para el usuario al igual que otras clases y atributos que se forman como “Parámetros”. La diferencia ocurre por el hecho de que los valores de estos atributos asignaran ciertos sectores de la clase a extender, (cubrirán cierta parte de esta). Como se muestra en la Tabla 4.7 el problema radica en que los atributos de la clase contacto son accedidos siempre y cuando se cumplan uno de los valores de la clase Nivel_computo a la vez. Esta relación se muestra más clara en la figura 4.9.
Figura 4.7. Estructura de la clase “Contacto”
Nivel_computo
Conocimiento_computo
Nulo Bajo/Medio Medio/Alto Experto
Atributos
Clase
Figura 4.8. Estructura de la clase “Nivel_computo”

Desarrollo de la solución
Rojas, Christian 69
Figura 4.9. Relación y cobertura entre las clases “Nivel_computo” y “Contacto”
Como se puede apreciar en la figura 4.9, dependiendo del nivel de cómputo se accederán o no a ciertos niveles de la extensión, permitiendo lógicamente el llenado de los datos que dependan del conocimiento de cómputo inferior. Es decir, el usuario con un nivel “Medio/Alto” podrá capturar los datos asignados a este nivel más los datos de los niveles “Bajo/Medio” y “Nulo”. Cabe hacer mención que el valor del nivel de cómputo nulo es indistinto ya que de cualquier manera está incluido en el núcleo de la ontología, y se sobreentenderá que el usuario tiene al menos un nivel de cómputo nulo, aunque está definido para mantener el contexto opcional.
4.2.2.2.2 Formalización de extensibilidad parcial A continuación se muestra la formalización para este tipo de extensión con el fin de eliminar ambigüedades en la misma. Sea
A = Núcleo de la ontología.
B = Clases parcialmente fuera del núcleo de la ontología.
C = Conjunto de valores validos para un parámetro.
D = Conjunto de parámetros.
E = Cobertura de la extensión.
x = Atributo de alguna clase que está disponible para capturar por el usuario.
E = Cobertura de la extensión

Desarrollo de la solución
Rojas, Christian 70
Tomando en cuenta que C A y que D A y A
Se definen ahora los casos con extensión y sin ésta:
Sin extensión
{x | x A x (A B E)} para E=(A B); B
Extendido
{ x | x A x (B E) x (A B E)} para E ; B
Por tanto las condiciones para la extensión son entonces:
x !C|C A C D C C y Tiene rango en B x|x A x (B E) x (A B E);
para C con rango en E; y (A B) E
De otro modo con cualquier otra condición:
{ x | x A x (A B E)} para E=(A B); B
4.2.2.3 Extensibilidad nuclear Es el último tipo de extensibilidad propuesta en este proyecto, en la que existen ciertos atributos en el núcleo que son pertinentes hacia un usuario mientras que otros no. Al igual que las extensiones anteriores existen ciertas clases con sus respectivos atributos que son pertinentes a cierto usuario mientras que otros no lo son y la elección y/o acceso a cada uno de ellos será definido a través de un parámetro encontrado en el núcleo. La diferencia radica entonces en que estas dos clases (o atributos de una misma clase), son nucleares en su totalidad, es decir, son subconjuntos del núcleo, pero tienen la propiedad de ser conjuntamente exclusivos, es decir, de entre dos grupos de atributos que son nucleares unos serán habilitados mientras los otros se mantendrán deshabilitados a partir del valor de cierto parámetro.
A B
D C A B E
E

Desarrollo de la solución
Rojas, Christian 71
Personales
First_name Middle_name Last_name Nombre …
Origen
Ciudad Distrito_local_origen Gobierno Localidad Moneda Municipio_origen Pais
Esta funcionalidad es parte de extensibilidad por el hecho de que, no solamente existe el caso de que sean dos grupos similares (en número y tipo), sino que la elección de uno de ellos pudiese involucrar la agregación de “n” parámetros a ese subconjunto.
4.2.2.3.1 Ejemplo Se mostrará a continuación un caso de estudio para esclarecer este tipo de extensibilidad. Como se aprecia en la Tabla 4.1, existe una clase llamada “Personales”, la cual es una de las clases principales de la ontología e integrante del núcleo, y presenta la siguiente estructura. La estructura original contiene más atributos, aunque para efectos didácticos sólo se mostraron los relevantes para el ejemplo de este tipo de extensibilidad. La finalidad de esta clase es muy clara, y trata de definir las cualidades y atributos de un usuario cualquiera contemplando sus datos personales básicos, contemplando su nacionalidad. Al igual que los otros tipos de extensibilidad, esta será accesible a través de un parámetro encontrado en el atributo de otra clase; en este caso será la clase “Origen”, la cual tiene una estructura como se muestra en la figura 4.11.
Atributos
Clase
Figura 4.10. Estructura de la clase “Personales”
Atributos
Clase
Figura 4.11. Estructura de la clase “Origen”

Desarrollo de la solución
Rojas, Christian 72
La finalidad de esta clase es definir la ubicación geográfica de origen de la persona, incluyendo datos específicos como tipo de moneda y gobierno, y por consiguiente a partir de su origen (País) se definirá como se le referenciara al nombre de esa persona. Tal como se muestra en la figura 4.12.
Figura 4.12. Esquema de extensibilidad nuclear
A partir de la figura anterior se puede hace notar que el atributo país encontrado en la clase origen condicionara cual de los dos grupos de atributos serán puestos a disponibilidad del usuario. Es importante notar que los dos grupos son disjuntos exclusivos (uno u otro pero no ambos) y además son asimétricos, es decir, aunque los datos en los dos grupos refieren al mismo contexto, no tienen la misma cantidad de atributos, por tanto además de la elección existe una pequeña agregación a partir de una condición. Este tipo de extensibilidad es útil para aquellos casos en que el uso de algunas variables involucren la cancelación de otras, como por ejemplo (Casado/Soltero), (Hombre/Mujer), etc., ya que estas elecciones desencadenarían o limitarían ciertas cuestiones como “embarazo” la cual es oportuno siempre y cuando el valor de género sea femenino.
4.2.2.3.2 Formalización de extensibilidad nuclear. Para evitar ambigüedades a continuación se realizó una formalización para condicionar este tipo de extensibilidad.
Sea
A = Núcleo de la ontología.
B = Conjunto de atributos condicionados
C = Conjunto de atributos condicionados
D = Conjunto de valores validos para un parámetro.
E = Conjunto de parámetros pertinentes.
x = Atributo de alguna clase que está disponible para capturar por el usuario.

Desarrollo de la solución
Rojas, Christian 73
Tomando en cuenta que B C; D A; E A y A ;
Por tanto las condiciones para la extensión B son entonces:
x !D|D A D D D E Tiene rango en B x|x C (x A x B)
Por tanto las condiciones para la extensión C son entonces:
x !D|D A D D D E Tiene rango en C x|x B (x A x C)
Para los dos casos: {x D} y {x E}
En general el uso de los parámetros puede ser interpretado para distintos dominios, asegurando una adaptación y/o aproximación de la ontología y de sus atributos al uso y contexto deseado.
A
E
D B C

Desarrollo de la solución
Rojas, Christian 74

5. CAPÍTULO V. IMPLEMENTACIÓN En este capítulo se presenta la forma en que será operada la aplicación, así como segmentos de código y descripciones a nivel operativo que precisaran los procedimientos manejados.

Implementación
Rojas, Christian 76
En este capítulo se muestran segmentos de código que explican el uso de la aplicación, los códigos completos se encuentran en el Anexo B. Para el desarrollo de la aplicación se utilizó el entorno de programación ECLIPSE, y Visual Editor como gestor grafico. La conexión con la ontología se realizó mediante la API “OWLAPI”, y PROTÉGÉ como entorno de diseño de la ontología. A continuación se muestran algunos segmentos de código correspondientes a las diferentes actividades que representan la aplicación, las cuales se enlistan a continuación:
1. Conexión con ontología 2. Usuario nuevo 3. Usuario existente 4. Volcado de ontología 5. Guardado de ontología 6. Lectura de ontología 7. Modificar en ontología 8. Eliminar ontología 9. Elección de dominio de aplicación 10. Elección de operación en ontología
5.1 CONEXIÓN CON ONTOLOGÍA Como se mencionó en el capitulo anterior, esta actividad en la aplicación, tiene como finalidad la de realizar la conexión pertinente entre la interfaz y la ontología manejada por protégé, mediante la API de conexión (OWLAPI). Cabe mencionar que esta actividad es frecuentemente invocada debido a que la conexión ontológica es no persistente. La principal clase involucrada en esta actividad es STORE, la cual, entre otros, contiene el método ontocomm(), el cual realiza la conexión con la ontología, direccionada mediante una ruta física y un identificador conceptual que la precisa. Este método devuelve la dirección absoluta de la ontología para poder utilizar el método factory encontrado en la API de conexión y realizar las operaciones pertinentes a la ontología de acuerdo a la actividad elegida.

Implementación
Rojas, Christian 77
Figura 5.1. Conexión con ontología
Como se puede apreciar en la figura 5.1, en la línea 3, se hace referencia a un elemento encontrado en otra clase “DATA”, la cual contiene además, ciertos datos que permitirán definir el comportamiento dinámico de la aplicación, así como datos de configuración generales.
5.2 USUARIO NUEVO Y USUARIO EXISTENTE
Esta actividad implica la utilización de la conexión a la ontología como es obvio, y además otros métodos de autenticación encontrados casi en su totalidad en la clase LOGIN, ya que la interfaz gráfica que se encuentra en la clase Authentication, que representa esta actividad, no maneja el área operativa y por tanto, se excluye de este apartado. Dentro de la clase Login existen 3 métodos que son fundamentales para la autenticación de un usuario nuevo y uno existente como se muestra a continuación:
Figura 5.2. Autenticación de usuario.1

Implementación
Rojas, Christian 78
Como se puede apreciar en la figura 5.2, este método se encarga de verificar la existencia de un login y u password en cierta clase en una ontología, y por consiguiente la correspondencia de estos. Este método devuelve como resultado un valor booleano que será verdadero si existe dicha correspondencia entre el usuario y el password, y negativo de no serla. Para la primera tarea de este método (verificar la existencia del login) es necesario hacer uso de otros métodos como se muestra a continuación.
Figura 5.3. Autenticación de usuario.2
Como se puede apreciar en el segmento de código de la figura 5.3, este método se encarga de obtener una lista de los nombres de usuario registrados en la ontología (mediante el método de la figura 5.2), para posteriormente hacer un barrido uno a uno y compararlo con el heredado de el método mostrado en la figura 5.4.

Implementación
Rojas, Christian 79
Figura 5.4. Autenticación de usuario.3
El segmento de código mostrado en la figura 5.4, Se obtiene una lista de todos los nombres de usuario registrados en la ontología, posteriormente los devuelve en un arreglo de tipo List. Para el caso de un usuario existente será necesario el proceso completo, y para un usuario nuevo, debido a que solo es necesario verificar la existencia del login, entonces solamente se realizarán los últimos dos métodos, recibiendo como parámetro el mismo nombre de usuario y devolviendo un valor booleano referente al resultado del análisis.
5.3 VOLCADO DE ONTOLOGÍA
Esta actividad dentro del proyecto se enfoca a leer los datos desde las interfaces y grabarlos en la ontología, de acuerdo a la correspondencia lógica entre ellos. Esta actividad es muy utilizada durante el proceso de guardado de la ontología y de sus elementos, ya que es operada para cada interfaz y cada clase, con sus respectivas diferencias referentes a los elementos visuales que conformen las clases. Por este motivo y para simplificar la redacción del documento, se explicará una de las clases involucradas solamente, ejemplificando con esta, todas las demás.

Implementación
Rojas, Christian 80
Figura 5.5. Volcado de datos a la ontología
EL código mostrado en la figura 5.5, corresponde a la clase LoadOrigenData, la cual tiene como objetivo específico el de volcar los datos contenidos en el formulario interfaz Origen y grabarlos en la clase Origen en la ontología. Como se puede apreciar en las líneas (9-15), es necesario el uso del esquema XSD para poder alinear los tipos de datos entre JAVA -> Protégé, utilizando la API de conexión, así como el nombre del elemento a guardar y su valor (formando la tripleta de datos), véase 3.1.3
5.4 GUARDADO DE ONTOLOGÍA
Esta actividad dentro del proyecto realiza el proceso de guardado en la ontología respetando el siguiente algoritmo:
Eliminar ontología (solo los datos alterados)
Volcado de ontología
Generación de las relaciones entre los elementos creados. Debido a que la primera instrucción corresponde a una actividad individual del proyecto, y la última refiere a una actividad ya explicada, nos enfocaremos a la segunda instrucción, la cual se encarga de guardar un elemento en cada atributo de tipo object dentro de la clase principal, con la finalidad de crear un árbol de abstracción, véase 3.1.2

Implementación
Rojas, Christian 81
Figura 5.6. Relación de elementos en la ontología
Como se aprecia en la figura 5.6, se identifica la clase principal, la cual contiene los atributos de tipo object hacia los cuales se realizará el guardado de los identificadores de los elementos creados. Como se aprecia en las líneas (10,13,16,20,24,27), se especifican los elementos creados por el proceso de guardado de datos en la ontología. Entre la línea 24 y 25, se omitieron (reducción de espacio) los elementos que aunque también fueron creados por el proceso de guardado, presentan el mismo comportamiento que los mostrados. En la línea 29 se aprecia la llamada al método InsertIndividualObjects que se encarga del grabado de datos en la ontología siguiendo la forma de tripleta descrita anteriormente.

Implementación
Rojas, Christian 82
5.5 LECTURA Y MODIFICACIÓN DE ONTOLOGÍA
Esta actividad en el proyecto es la encargada de realizar el proceso contrario al volcado de datos a la ontología, ya que realiza una lectura de los datos desde la ontología y los dispone en las interfaces correspondientes de acuerdo a una plantilla de escritura.
Figura 5.7. Lectura de datos desde la ontología
En la figura 5.7 se muestra el proceso de lectura de datos desde la ontología para la clase Origen, en la cual se muestran en las líneas (20-26), los procesos para asignación de valores.
5.6 ELIMINAR ONTOLOGÍA
Tal y como su nombre lo indica, esta actividad se encarga de eliminar las individualizaciones prudentes en la ontología. La decisión sobre dejar o eliminar una individualización se realiza con base en banderas actividades ante una modificación previa en dicha clase.

Implementación
Rojas, Christian 83
Figura 5.8. Eliminación de datos en la ontología

Implementación
Rojas, Christian 84

6. CAPÍTULO VI. PRUEBAS
En este capítulo se presenta el plan de pruebas correspondiente a los casos de uso analizados en el capítulo de Análisis y diseño.

Pruebas
Rojas, Christian 86
6.1 INTRODUCCIÓN Descripción del identificador: US: User O: Ontology G: Generator
Este documento define el plan de pruebas basado en el estándar IEEE 829 para pruebas de software, que permitirá verificar la funcionalidad de la USOG que es una herramienta para la generación de ontologías de usuario basadas en contexto. La aplicación consta de dos módulos principales:
1. Interfaz: Se encarga de mostrar en pantalla todos los elementos para poder poblar la ontología de una manera ordenada y coherente tomando en cuenta deducciones de los datos almacenados.
2. Operación con ontología: Tiene como objetivo realizar las operaciones con la ontología
La hipótesis nula a probar es la siguiente: Las ontologías de usuario actuales no perfilan a un usuario de manera apropiada y completa, basándose en un dominio de la aplicación: La hipótesis alterna es: Las ontologías de usuario actuales no perfilan a un usuario de manera apropiada y completa, basándose en un dominio de la aplicación: A continuación se presentan los siguientes puntos además de la introducción:
Descripción del plan
Casos de Prueba
Procedimientos de Pruebas.
Resultado de Pruebas
6.2 DESCRIPCIÓN DEL PLAN
6.2.1 Características a ser probadas El presente plan de pruebas contiene la descripción de los casos de prueba definidos con el fin de validar y verificar que la aplicación cumple con los requisitos de herramienta para la generación de perfiles de usuario basadas en su contexto

Pruebas
Rojas, Christian 87
6.2.2 Características excluidas de las pruebas No se dará prioridad al diseño de interfaz de las aplicaciones que se utilicen para probar la API. No se dará prioridad al idioma de los usuarios, tomando como idioma principal el español latinoamericano.
6.2.3 Enfoque Debido a que las mediciones son principalmente de funcionalidad, la aplicación se probará con casos que la utilicen. Las cuales serán poblados de ontologías de usuario utilizando divergencia natural de los mismos. Ya que la aplicación toma en cuenta factores como la extensibilidad de sus elementos, estos se probaran con cuestiones como ¿Lo que se pregunta es pertinente? ¿Es suficiente lo que se pregunta?
6.2.4 Criterio pasa/ no pasa de casos de prueba. En la descripción de los casos de prueba, se detallarán los resultados esperados para cada uno de los casos. Se considerará que una prueba ha pasado con éxito cuando los resultados esperados coincidan con los descritos en el caso de prueba. En caso de no coincidencia, se analizarán las causas y se harán las modificaciones necesarias hasta que se cumplan con los resultados esperados.
6.2.5 Criterios de suspensión y requerimientos de reanudación. En ningún caso se suspenderán definitivamente las pruebas. Cada vez que se presente que el caso no pasa una prueba, inmediatamente se procederá a evaluar y corregir el error, permaneciendo en la prueba de este caso hasta que ya no se presenten dificultades con él.
6.2.6 Tareas de pruebas. Las tareas a desarrollar para preparar y aplicar las pruebas se muestran en la Tabla 6.1.
Tabla 6.1 Tareas a desarrollar a las pruebas Tarea Tarea Precedente Habilidades especiales Responsabilidad de
1. Preparación del plan de pruebas.
Terminación del análisis y diseño de la aplicación.
Conocimiento del leguaje OWL, ontologías de usuario y del IEEE Std. 829
Autor de tesis
2. Preparación del diseño de pruebas.
Tarea 1 Conocimiento sobre la estructura de la aplicación, sus clases y métodos y del IEEE Std. 829
Autor de tesis
3. Preparación de los casos de prueba.
Tarea 2 Conocimiento de las aplicaciones de ontologías de usuario.
Autor de tesis
4. Aplicación de pruebas. Tarea 3 Conocimiento del entorno y Autor de tesis

Pruebas
Rojas, Christian 88
preparación del sistema desarrollado para su ejecución.
5. Resolver los incidentes de pruebas.
Tarea 4 Conocimiento del lenguaje de programación J2EE
Autor de tesis
6. Evaluación de resultados.
Tarea 4 Tarea 5
Conocimiento de las preguntas de investigación, la hipótesis de prueba, y los objetivos de esta tesis.
Autor de tesis
6.2.7 Liberación de pruebas. La entrada especificada y la salida esperada en cada caso de prueba, serán suficientes para la comprobación del objetivo alcanzado y por lo tanto para la aceptación de las pruebas.
6.2.8 Requisitos ambientales. Las características y propiedades físicas y lógicas requeridas para el ambiente de pruebas, son las siguientes: Equipo
PC de Escritorio Procesador Intel P4 o superior.
512M de memoria RAM o superior.
30Mb libres en Disco duro.
Windows XP/VISTA/SEVEN Herramientas
Java (J2EE).
Eclipse, como entorno de programación.
Visual Editor, como entorno de desarrollo grafico.
Protégé, como gestor ontológico
OWLAPI, para conexión con ontología
PELLET, como razonador ontológico
6.2.9 Responsabilidades. Toda la responsabilidad de las pruebas recae en la autora de la tesis.
6.2.10 Riesgos y contingencias. Falta de tiempo: El tiempo es un factor importante que genera incertidumbre a la
hora de aplicar las pruebas, por lo que se tomarán como mínimo 6 casos de prueba, si el tiempo lo permite se extenderán las pruebas a otros casos.
Todas las fallas que se pudieran presentar en el transcurso del desarrollo de las pruebas deberán ir resolviéndose de manera iterativa por el responsable de esta tesis, hasta que la falla no produzca otras más.

Pruebas
Rojas, Christian 89
6.3 CASOS DE PRUEBAS.
6.3.1 Características a probar La siguiente lista define las características a ser probadas:
Guardado de datos a la ontología: Se verificará que las clases para el guardado de datos en la ontología funciones de manera adecuada.
Lectura de datos desde la ontología: Se verificará que las clases relacionadas con la lectura de datos desde la ontología funcionen adecuadamente.
Eliminado de datos de la ontología: Se verificará que las clases relacionadas con este proceso funcionen adecuadamente.
Elección del dominio de aplicación: Se verificara que las clases relacionadas con el proceso de elección del dominio hacia la cual se inclinará la captura en la aplicación funcionen de manera adecuada.
Enlazar con ontología: Se verificara que las clases relacionadas con el proceso de enlace con la ontología funcione
6.3.2 Grupos de pruebas En este apartado se mostraran y nombraran a las pruebas a realizar, tomando en cuenta la funcionalidad de la aplicación.
6.3.2.1 Operación con la ontología USOG-101 Pruebas de operación con la ontología USOG-101-001 Lectura de la ontología USOG-101-002 Escritura en ontología USOG-101-003 Eliminado de la ontología
6.3.2.2 Estructuración ontológica USOG-201 Prueba de estructuración ontológica USOG-201-001 Estructuración de individualizaciones
6.3.2.3 Enlace con ontología USOG-301 Prueba de enlace con la ontología USOG-301-001 Conexión con ontología
6.3.2.4 Elección de dominio de la aplicación USOG-401 Prueba de elección del dominio de la aplicación USOG-401-001 Elección del dominio de la aplicación
6.3.3 Procedimiento de Pruebas Este capítulo contiene la descripción de los procedimientos de pruebas correspondientes a los distintos casos de prueba que conforman el presente plan de pruebas. Los distintos casos de pruebas se encuentran organizados en grupos de pruebas cuyo objetivo es validar y verificar una determinada funcionalidad de

Pruebas
Rojas, Christian 90
las rutinas de transformación. Cada uno de los casos de pruebas está dirigido a la validación y verificación de una funcionalidad muy concreta. Para cada uno de los grupos de pruebas se describe el propósito del grupo de pruebas, el entorno de prueba necesario, los distintos conjuntos de pruebas que lo conforman. Para cada uno de los casos de prueba se describe el propósito del caso, el entorno necesario para la ejecución del caso, el procedimiento de la prueba y los resultados esperados.
6.4 USOG-101 PRUEBAS DE OPERACIÓN CON LA ONTOLOGÍA
6.4.1 Propósito Verificar que las clases relacionadas con la operación para/con la ontología funcionen correctamente.
6.4.2 Entorno de prueba. Para la ejecución de los casos de prueba contenidos en este grupo se utilizarán los elementos de la aplicación. Véase 3.28
6.4.3 USOG-101-001 Lectura de la ontología
6.4.3.1 Propósito Recuperar datos desde la ontología y ubicarlos en memoria principal
6.4.3.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Validada por el razonador, y operada por una acción detonadora.
6.4.3.3 Proceso 1. Actuar el proceso mediante una invocación o un detonador 2. Ver la consistencia de los datos con respecto a los almacenados en la
ontología. 3. Verificar la consistencia de la ontología al finalizar el proceso
6.4.3.4 Resultado esperado. Consistencia, completitud e integridad en los datos obtenidos.

Pruebas
Rojas, Christian 91
6.4.4 USOG-101-002 Escritura en ontología
6.4.4.1 Propósito Recuperar datos de memoria principal y ubicarlos adecuadamente en la ontología
6.4.4.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Validada por el razonador, y operada por una acción detonadora.
6.4.4.3 Proceso 7. Actuar el proceso mediante una invocación o un detonador 8. Ver la consistencia de los datos en la ontología con respecto a los
almacenados en la interfaz (memoria principal). 9. Verificar la consistencia de la ontología al finalizar el proceso
6.4.4.4 Resultado esperado. Consistencia, completitud e integridad en los datos escritos.
6.4.5 USOG-101-003 Eliminado de la ontología
6.4.5.1 Propósito Eliminación de datos involucrados con la aplicación, como lo son: individualizaciones, atributos y demás.
6.4.5.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Validada por el razonador, y operada por una acción detonadora, con datos ya ingresados previamente.
6.4.5.3 Proceso 1. Actuar el proceso mediante una invocación o un detonador 2. Verificar que la ontología aun existente no contiene ya, los datos operados
por la aplicación. 3. Verificar la consistencia de la ontología al finalizar el proceso
6.4.5.4 Resultado esperado. Consistencia, completitud e integridad en los datos exentos de la eliminación programada.
6.4.6 USOG-201 Pruebas de estructuración ontológica
6.4.6.1 Propósito Verificar que la generación automática de identificadores conceptuales esté funcionando correctamente.

Pruebas
Rojas, Christian 92
6.4.6.2 Entorno de prueba. Para la ejecución de los casos de prueba contenidos en este grupo se utilizarán los elementos de la aplicación. Véase Análisis de la interfaz, así como un árbol de abstracción de nombres. 3.1.2
6.4.7 USOG-201-001 Estructuración de individualizaciones
6.4.7.1 Propósito Generación de un árbol de abstracción de nombres (transparente), para la manipulación de identificadores conceptuales destinados a individualizaciones generadas por la aplicación.
6.4.7.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Comparando la estructura ontológica con un árbol de abstracción de nombres diseñado para la prueba.
6.4.7.3 Proceso 1. Operar la ontología mediante un guardado de datos completo (todas las
clases capturadas). 2. Comparación de la estructura ontológica con el árbol de abstracción de
nombres diseñado para la prueba. 3. Verificar la consistencia de la ontología al finalizar el proceso
6.4.7.4 Resultado esperado. Similitud de identificadores conceptuales entre el árbol de abstracción de nombres y la estructura ontológica generada automáticamente.
6.4.8 USOG-301 Prueba de enlace con ontología
6.4.8.1 Propósito Verificar que la conexión con la ontología sea exitosa y los posibles manejos de excepciones causados por inconsistencia sean adecuados.
6.4.8.2 Entorno de prueba. Para la ejecución de los casos de prueba contenidos en este grupo se utilizarán los elementos de la aplicación. Tomando en cuenta que los más importantes para este punto son las herramientas requeridas. Véase 6.2.8

Pruebas
Rojas, Christian 93
6.4.9 USOG-301-001 Conexión con ontología
6.4.9.1 Propósito Conexión con la ontología de un modo transparente para el usuario.
6.4.9.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Operada por una acción detonadora, con datos a procesar, mediante el uso de los métodos contenidos en la API de conexión (OWLAPI), y su respectivo verificador de consistencias (razonador, PELLET).
6.4.9.3 Proceso 1. Actuar el proceso mediante una invocación o un detonador 2. Revisar los servicios que se solicitan al realizar la conexión, como lo son
factory, manager y razonador 3. Verificar que cualquier inconsistencia que aparezca, tenga su respectivo
manejo 4. Verificar la consistencia de la ontología al finalizar el proceso
6.4.9.4 Resultado esperado. Consistencia, completitud e integridad en los datos exentos de la eliminación programada.
6.4.10 USOG-401 Prueba de elección del dominio de la aplicación
6.4.10.1 Propósito Revisar que la inclinación de la captura de los datos en la aplicación tengan coherencia con respecto al dominio elegido en el momento de la selección.
6.4.10.2 Entorno de prueba. Para la ejecución de los casos de prueba contenidos en este grupo se utilizarán los elementos de la aplicación. Véase Análisis de la aplicación, así como un dominio de aplicación seleccionado previa o actualmente.
6.4.11 USOG-401-001 Elección del dominio de la aplicación
6.4.11.1 Propósito Discriminación de los datos no apropiados de acuerdo al dominio de aplicación elegido, así como separación dinámica de los elementos de captura de acuerdo a una lógica de datos recomendados y optativos.
6.4.11.2 Entorno de prueba. La prueba se realizara con una ontología ya creada y consistente. Validada por el razonador, y operada por una acción detonadora, con datos ya ingresados previamente o una ontología nueva con un usuario de reciente ingreso al sistema,

Pruebas
Rojas, Christian 94
el cual ha solicitado la inclinación de la captura de su ontología de acuerdo a un dominio de aplicación especifico.
6.4.11.3 Proceso 1. Un dominio de aplicación elegido. 2. Verificar que los datos de captura hayan sido modificados posterior a la
elección. 3. Verificar la inserción de los datos de acuerdo a nuevas reglas definidas por
cambios realizados en el proceso de captura. 4. Verificación de la consistencia de la ontología en caso de que los datos
hayan sido guardados.
6.4.11.4 Resultado esperado. Modificación dinámica de los elementos de captura así como consistencia, completitud e integridad en los datos guardados en la ontología de ser el caso. A continuación se muestran las pruebas realizadas sobre el plan de pruebas descrito previamente y referentes a las pruebas funcionales, para después mostrar en detalle las pruebas operativas.
6.5 PRUEBAS
Las partes a probar fueron aquellas que conforman la aplicación:
1. Interfaz: Se encarga de mostrar en pantalla todos los elementos para poder poblar la ontología de una manera ordenada y coherente tomando en cuenta deducciones de los datos almacenados.
2. Operación con ontología: Tiene como objetivo realizar las operaciones con la ontología
Las pruebas se basaron en la utilización de la interfaz grafica, ya que al estar dividida la parte operativa de la parte grafica, al funcionar las funciones graficas se sobre entiende que funcionará la parte operativa de haberse invocado en sus métodos de manera individual.
A continuación se mostrará el desarrollo de las pruebas basadas en el plan de pruebas descrito anteriormente. Las pruebas que se muestran a continuación corresponden a la operación con la ontología, es decir, que los elementos en la interfaz llamaran a estos métodos para poder funcionar.

Pruebas
Rojas, Christian 95
6.4.1 Pruebas Funcionales Tabla 6.2. Caso de prueba: Lectura de la ontología
Caso de prueba USOG-101-001 Lectura de la ontología
Descripción: Recuperar datos desde la ontología y ubicarlos en memoria principal. La prueba se realizó tomando en cuenta la autenticación de un usuario existente, la cual necesita llamar los datos del usuario y su contraseña para poder entrar al sistema.
Resultado: La figura 6.1 muestra los datos de la ontología en el entorno de diseño ontológico, apreciándose en ésta, que el usuario debe ser XtianReds y la contraseña 0, para poder acceder a los datos del perfil.
Figura 6.1. Datos de la ontología en protégé
Al insertar datos incorrectos en el proceso de autenticación, se muestra un mensaje de error, tal como se muestra en la figura 6.2.
Figura 6.2. Autenticación invalida
Posteriormente al ingresar los datos validos se puede observar en la figura 6.3, el acceso a la elección de la operación en la ontología.
Observaciones: La autenticación de usuario es válida también para usuarios nuevos, tomando en cuenta que la interacciona de lectura con la ontología es durante la búsqueda de existencia previa del login elegido.
Figura 6.3. Autenticación válida y elección de operación con ontología

Pruebas
Rojas, Christian 96
Tabla 6.3 Caso de prueba: Escritura en ontología
Caso de prueba USOG-101-002 Escritura en ontología
Descripción: Recuperar datos de memoria principal y ubicarlos adecuadamente en la ontología. La prueba se realizó mediante la modificación de algún dato en la interfaz y la revisión de la integridad de éste con respecto al encontrado en la ontología.
Resultado: Como se puede apreciar en la figura 6.4, la ontología en protégé contiene solamente a un individual.
Figura 6.4. Datos de la ontología en protégé
Posteriormente se procede a crear un nuevo usuario “nueva ontología”, ingresando a la opción usuario nuevo para poder elegir el dominio de aplicación hacia el cual se inclinará la captura. Véase figura 6.5
Figura 6.5. Creación de nuevo usuario y elección del dominio de aplicación
Una vez elegido el dominio de la aplicación, se capturan los datos requeridos por la interfaz y se guardan con el respectivo botón asignado. Véase figura 6.6
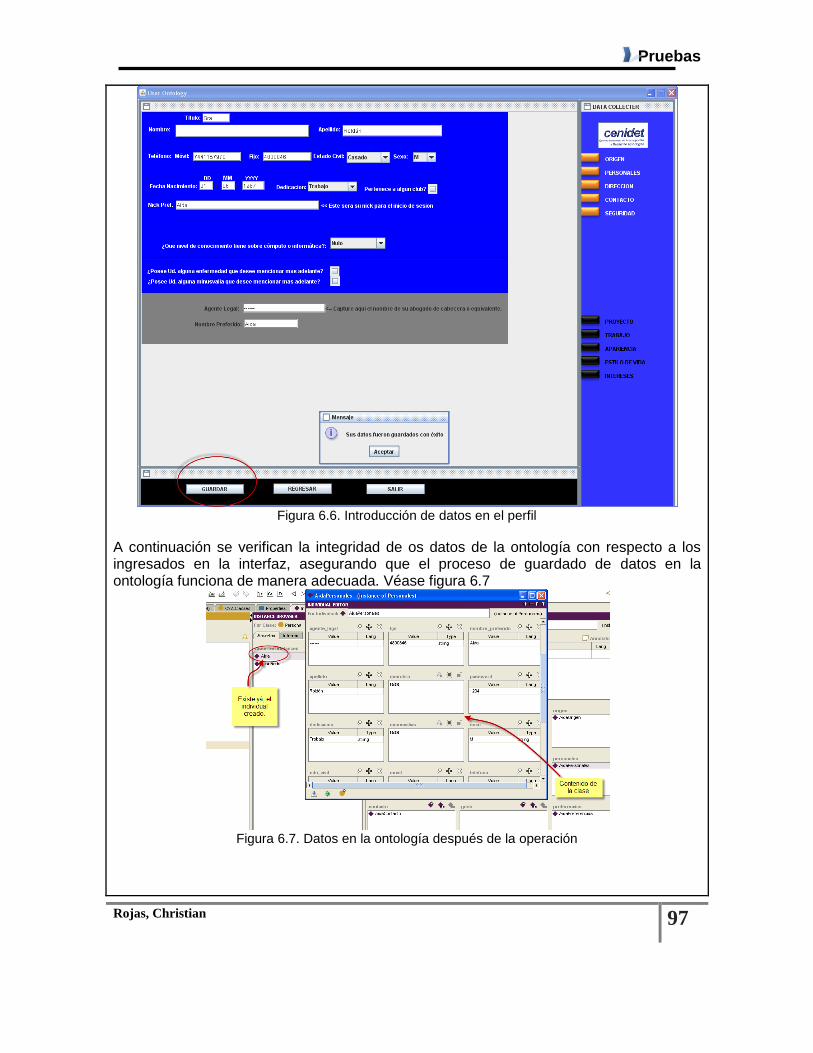
Pruebas
Rojas, Christian 97
Figura 6.6. Introducción de datos en el perfil
A continuación se verifican la integridad de os datos de la ontología con respecto a los ingresados en la interfaz, asegurando que el proceso de guardado de datos en la ontología funciona de manera adecuada. Véase figura 6.7
Figura 6.7. Datos en la ontología después de la operación

Pruebas
Rojas, Christian 98
Observaciones: Este procedimiento involucra varias acciones como lo son la conexión con la ontología, el proceso de volcado de datos, eliminación de datos de la ontología, los cuales serán explicados independientemente en los demás casos de prueba.
Tabla 6.4 Caso de prueba: Eliminado de la ontología
Caso de prueba USOG-101-003 Eliminado de la ontología
Descripción: Eliminación de datos involucrados con la aplicación, como lo son: individualizaciones, atributos y demás. La prueba se realizó eliminando un elemento al azar en un perfil ya guardado anteriormente y verificando su correspondencia en la ontología antes y después de la acción.
Resultado: En primer lugar se procede a revisar los datos de la ontología en protégé, para seleccionar un elemento a eliminarse en la interfaz.
Figura 6.8. Contenido de la instancia de la clase miembro en la ontología
Ahora, se realiza una autenticación en la interfaz (del usuario al cual se realizara la eliminación parcial o total), eligiendo la opción de Eliminar datos, lo cual nos mostrara una ventana tal como se muestra en la figura 6.9, en la cual se seleccionará únicamente la opción miembros y aceptando la eliminación de la clase.

Pruebas
Rojas, Christian 99
Figura 6.9. Eliminación de un individuals en la ontología
Una vez eliminados los datos se procede a revisar esta eliminación manualmente en la ontología mediante protégé.
Figura 6.10. Resultado en la ontología después de la operación
Como se puede apreciar en la figura 6.10, no existe ya, el individual correspondiente a la clase Miembros.
Observaciones: La interfaz está capacitada para ofrecer al usuario una eliminación parcial o total de la ontología, permitiendo la elección de estos elementos.
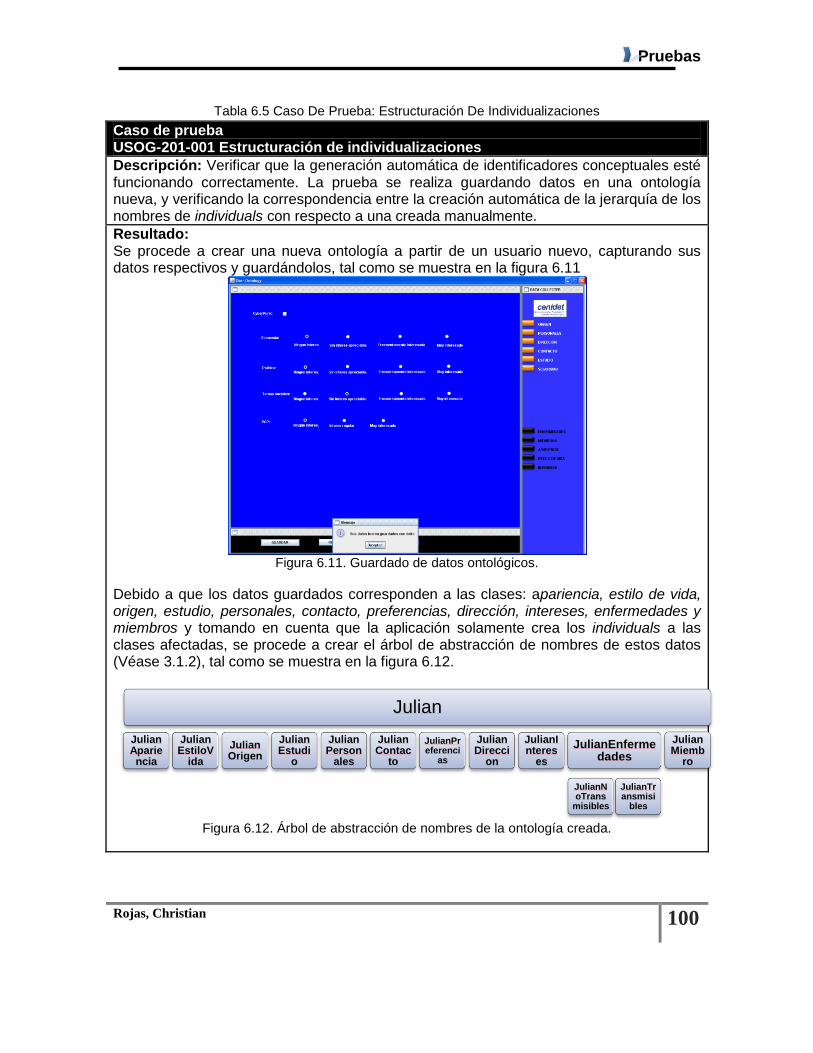
Pruebas
Rojas, Christian 100
Tabla 6.5 Caso De Prueba: Estructuración De Individualizaciones
Caso de prueba USOG-201-001 Estructuración de individualizaciones
Descripción: Verificar que la generación automática de identificadores conceptuales esté funcionando correctamente. La prueba se realiza guardando datos en una ontología nueva, y verificando la correspondencia entre la creación automática de la jerarquía de los nombres de individuals con respecto a una creada manualmente.
Resultado: Se procede a crear una nueva ontología a partir de un usuario nuevo, capturando sus datos respectivos y guardándolos, tal como se muestra en la figura 6.11
Figura 6.11. Guardado de datos ontológicos.
Debido a que los datos guardados corresponden a las clases: apariencia, estilo de vida, origen, estudio, personales, contacto, preferencias, dirección, intereses, enfermedades y miembros y tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos (Véase 3.1.2), tal como se muestra en la figura 6.12.
Figura 6.12. Árbol de abstracción de nombres de la ontología creada.
Julian
JulianApariencia
JulianEstiloV
ida
JulianOrigen
JulianEstudi
o
JulianPerson
ales
JulianContac
to
JulianPreferenci
as
JulianDirecci
on
JulianInteres
es
JulianEnfermedades
JulianNoTrans
misibles
JulianTransmisi
bles
JulianMiemb
ro

Pruebas
Rojas, Christian 101
Figura 6.13. Estructuración ontológica de la ontología en protégé
Como se puede apreciar en la figura 6.13, la correspondencia con el árbol de abstracción de nombres es directa, por tanto satisfactoria para esta prueba.
Observaciones: La generación de los elementos en la ontología es directamente proporcional a la cantidad de elementos operados en la interfaz, es decir, solo los elementos operados son manipulados.
Tabla 6.6 Caso De Prueba: Estructuración De Individualizaciones
Caso de prueba USOG-301-001 Conexión con ontología
Descripción: Conexión con la ontología de un modo transparente para el usuario. La prueba se realiza cambiando la contraseña de la cuenta mediante la interfaz en el apartado seguridad y verificando dicho cambio con respecto al contenido de la ontología.
Resultado: En primera instancia se verifica el valor de la contraseña actual para ingresar al sistema, tal como se muestra en la figura 6.14.
Figura 6.14. Contenido de password en la clase personales de la ontología

Pruebas
Rojas, Christian 102
Posteriormente se ingresa a la ontología con esta contraseña y se cambia en el apartado Seguridad (Respetando el procedimiento seguro para dicho cambio), y se guardan los datos, tal como se muestra en las figuras 6.15 y 6.16.
Figura 6.15. Autenticación en la ontología existente
Figura 6.16. Cambio de contraseña en la ontología
Una vez realizado el cambio de contraseña se procede a verificar la consistencia de estos datos en la ontología por medio de protégé, tal como se muestra en la figura 6.17.

Pruebas
Rojas, Christian 103
Figura 6.17. Valores ontológicos posteriores a la operación.
Como se puede apreciar en la figura 6.17, los valores cambiaron después de la operación con la interfaz, deduciendo una óptima conexión con la ontología.
Observaciones: Se eligió el procedimiento de cambio de contraseña para comprobar la conexión con la ontología, sin embargo, la mayoría de las actividades realizadas necesitan esta conexión.
Tabla 6.7 Caso De Prueba: Estructuración De Individualizaciones
Caso de prueba USOG-401-001 Elección del dominio de aplicación
Descripción: Revisar que la inclinación de la captura de los datos en la aplicación tengan coherencia con respecto al dominio elegido en el momento de la selección. La prueba se realiza tomando en cuenta la variación de los elementos requeridos, así como su distinción entre datos recomendados y optativos, con respecto a la misma ontología con otro dominio de aplicación.
Resultado: Para la prueba primero se autentica un usuario existente y se muestra su conjunto de datos con respecto al domino de aplicación actual (en este caso Hospital), tal como se muestra en la figura 6.18.

Pruebas
Rojas, Christian 104
Figura 6.18. Autenticación y visualización de clases organizadas según el dominio de aplicación Hospital
Posteriormente se ingresa nuevamente a la ontología del mismo usuario y se elige la opción Cambiar Dominio, mostrándose en pantalla un mensaje con el dominio actual para este usuario. Véase figura 6.19.
Figura 6.19. Dominio de aplicación antes de la operación
Se muestra ahora una pantalla de elección del dominio de aplicación nuevo. Cabe mencionar que los datos guardados previamente no se pierden, solamente cambian de organización recomendada/optativa en ciertos elementos. Una vez elegido el nuevo dominio de aplicación se muestra un mensaje de informe acerca de este cambio, como se muestra en la figura 6.20

Pruebas
Rojas, Christian 105
Figura 6.20. Dominio de aplicación después de la operación
Para poder verificar dicho cambio, se procede a mostrar la nueva disposición de los datos referente al nuevo domino de aplicación, tal como se muestra en la figura 6.21.
Figura 6.21. visualización de clases organizadas según el dominio de aplicación Universidad
Observaciones: El nuevo dominio de aplicación estará disponible a partir del momento del cambio sin necesidad de reiniciar la autenticación y será recordado por el sistema cada vez que se reingrese.

Pruebas
Rojas, Christian 106
6.4.2 Pruebas operativas A continuación se muestran las pruebas que enfatizan la operación de la aplicación al ingresar perfiles de usuario, y se sobreentiende que las pruebas funcionales son apropiadas y aprobatorias. Para estas pruebas fue necesaria la participación de la comunidad (familiares y amigos), para poder poblar la ontología con perfiles reales y así disponer de un conjunto de datos para poder realizar las operaciones pertinentes. Estas pruebas fueron realizadas bajo las siguientes condiciones:
La captura de los datos por los participantes fue personal, permitiendo la libre participación de los mismos, y la captura de los datos que consideraban apropiados y de pronta captura.
La aplicación genera un árbol de abstracción de nombres basado en los identificadores conceptuales de las clases instanciadas por cada usuario, tomando en cuenta las reglas para su nomenclatura (véase 3.1.2). Éste árbol se aprecia gráficamente utilizando un entorno de diseño ontológico (protégé).
Manualmente, siguiendo las mismas reglas para la nomenclatura de clases, se procede a realizar un árbol de abstracción de nombres de acuerdo al identificador de sesión capturado por los mismos usuarios.
Se comparan los arboles de abstracción (el generado manualmente VS el generado automáticamente por la aplicación), para verificar consistencia.
Este procedimiento es repetido para verificar todas las posibles combinaciones de clases, utilizando para ello el apoyo del usuario final.
Por último, se muestra una tabla comparativa de las clases capturadas por el usuario, así como el dominio de aplicación elegido.
Caso de prueba Estructuración de individualizaciones 1
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos (Véase 3.1.2), tal como se muestra en el siguiente árbol generado manualmente.

Pruebas
Rojas, Christian 107
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 2
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 108
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 3
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 109
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 4
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente
.

Pruebas
Rojas, Christian 110
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 5
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente
.

Pruebas
Rojas, Christian 111
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 6
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 112
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 7
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 113
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 8
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 114
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 9
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente.

Pruebas
Rojas, Christian 115
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 10
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 116
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 11
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 117
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 12
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 118
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 13
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 119
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 14
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 120
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 15
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 121
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 16
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 122
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 17
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 123
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 18
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 124
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 19
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 125
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 20
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 126
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 21
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 127
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 22
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 128
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 23
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 129
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 24
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 130
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 25
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 131
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 26
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 132
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 27
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 133
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 28
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 134
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 29
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente
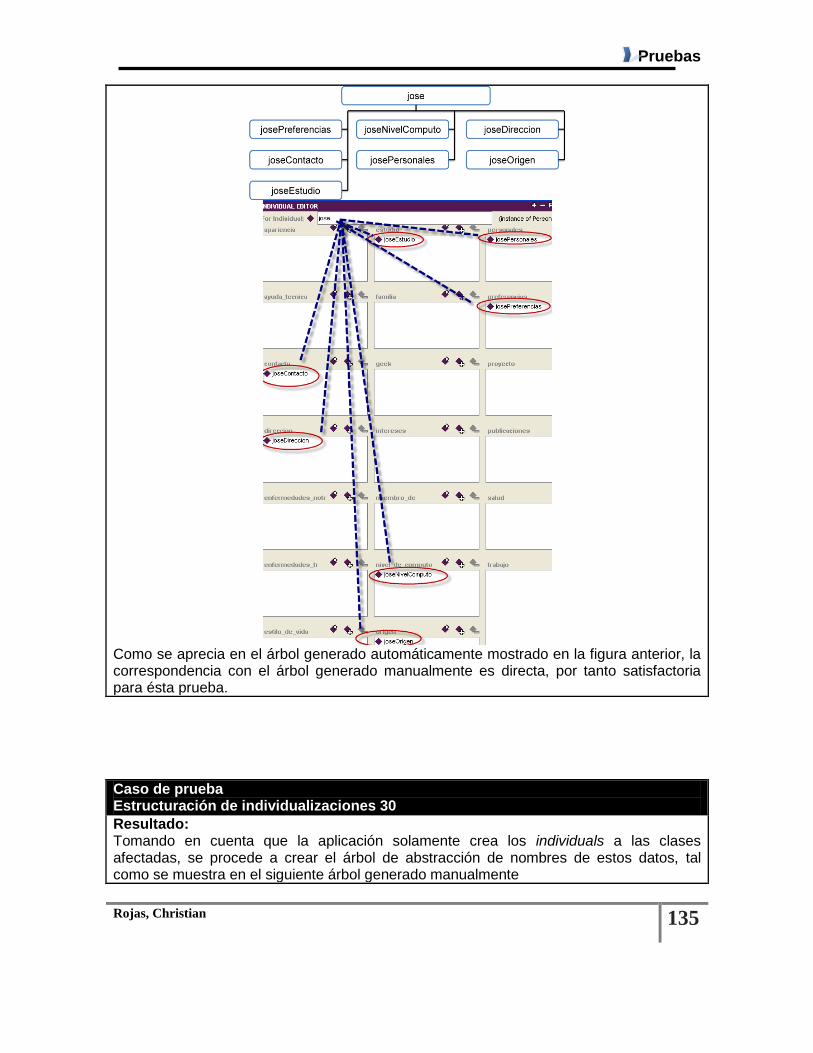
Pruebas
Rojas, Christian 135
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
Caso de prueba Estructuración de individualizaciones 30
Resultado: Tomando en cuenta que la aplicación solamente crea los individuals a las clases afectadas, se procede a crear el árbol de abstracción de nombres de estos datos, tal como se muestra en el siguiente árbol generado manualmente

Pruebas
Rojas, Christian 136
Como se aprecia en el árbol generado automáticamente mostrado en la figura anterior, la correspondencia con el árbol generado manualmente es directa, por tanto satisfactoria para ésta prueba.
6.5 OBSERVACIONES GENERALES Para todos los casos mostrados en las pruebas anteriores, la generación de los elementos en la ontología es directamente proporcional a la cantidad de elementos operados en la interfaz, es decir, solo los elementos operados son manipulados.
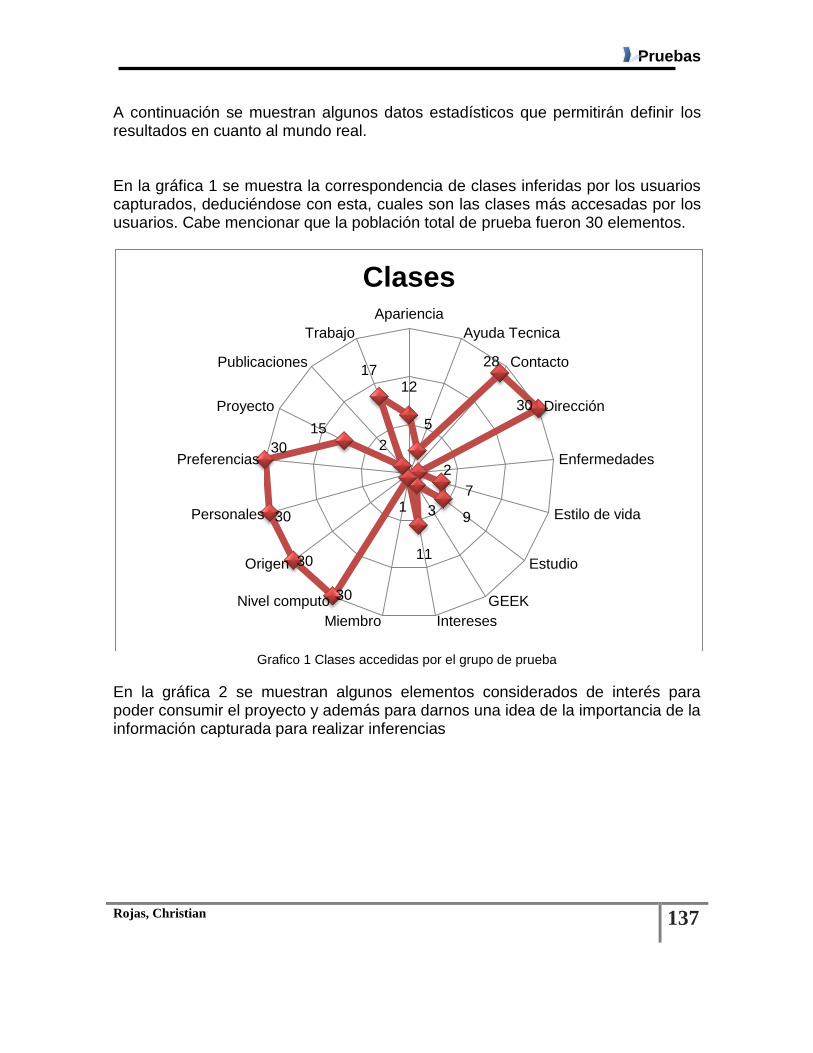
Pruebas
Rojas, Christian 137
A continuación se muestran algunos datos estadísticos que permitirán definir los resultados en cuanto al mundo real. En la gráfica 1 se muestra la correspondencia de clases inferidas por los usuarios capturados, deduciéndose con esta, cuales son las clases más accesadas por los usuarios. Cabe mencionar que la población total de prueba fueron 30 elementos.
Grafico 1 Clases accedidas por el grupo de prueba
En la gráfica 2 se muestran algunos elementos considerados de interés para poder consumir el proyecto y además para darnos una idea de la importancia de la información capturada para realizar inferencias
12
5
28
30
2
7
93
11
1
30
30
30
30
152
17
Apariencia
Ayuda Tecnica
Contacto
Dirección
Enfermedades
Estilo de vida
Estudio
GEEK
InteresesMiembro
Nivel computo
Origen
Personales
Preferencias
Proyecto
Publicaciones
Trabajo
Clases
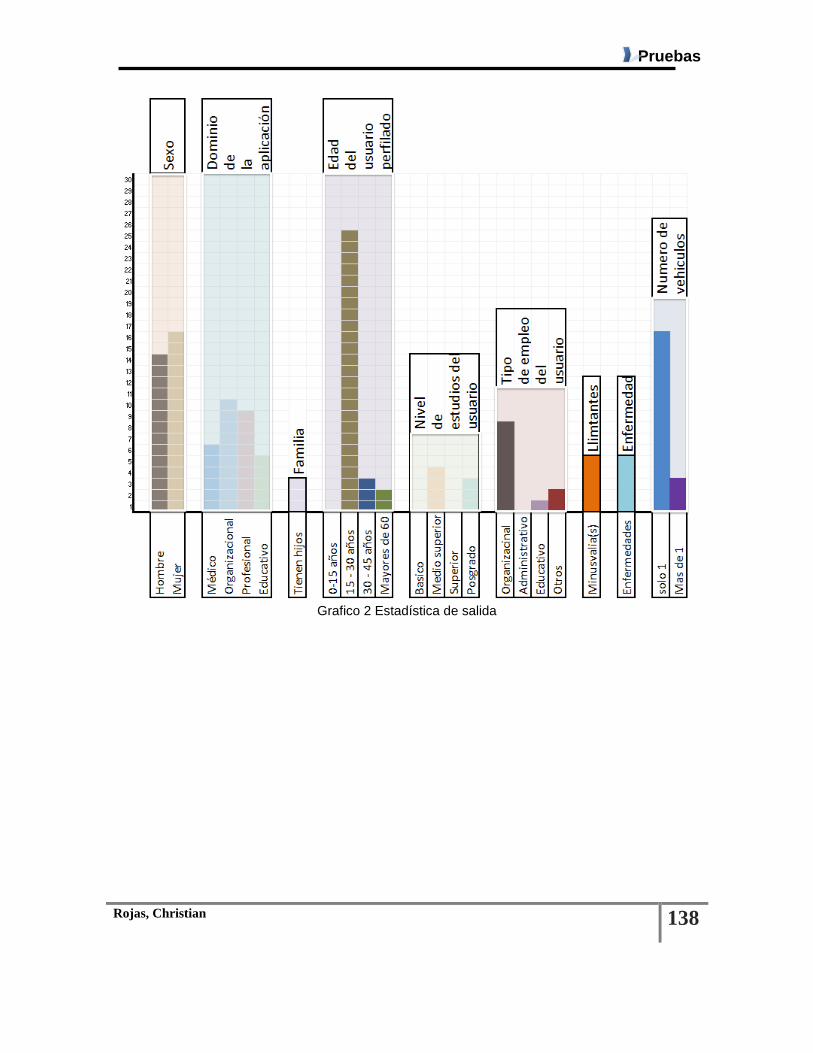
Pruebas
Rojas, Christian 138
Grafico 2 Estadística de salida

CAPÍTULO VII. CONCLUSIONES
En este capítulo se muestran las conclusiones aportaciones, trabajos futuros, publicaciones que se obtuvieron con el presente trabajo de tesis

Conclusiones
Rojas, Christian 140
7.1 CONCLUSIONES
Una de las pautas principales para la formación de la ontología es la estructura misma, ya que define la complejidad de la captura y la recuperación de los datos almacenados. Los principales conocimientos obtenidos a partir del logro de este proyecto fueron: el concepto de OWL, tomando en cuenta su lenguaje, estructura, comportamiento y limitantes; así como el manejo de la API de interacción “OWL API”. La interacción con la ontología tuvo una limitante muy pronunciada, basada en el manejo de los tipos de datos internos, ya que la API de interacción solo maneja el tipo de datos de cadena de caracteres, aunque para solucionar los demás tipos, basa su implementación en una tripleta (nombre, valor y tipo), causando que la programación se adapte a esta característica, usando para ello un esquema de definición de tipos XSD. La mayoría de las características que componen a la ontología resultante fueron consensuales por un grupo de personas de diversa índole, así como de diversas naciones, ya que algunas de las aportaciones ocurridas en la tesis aquí mostrada fueron iniciativa del personal de la Universidad Politécnica de Valencia, España, durante una estancia ocurrida en el desarrollo del mismo. Algunos de los resultados obtenidos en esta tesis, fueron una ontología con gran capacidad de explotación por parte de servicios o sitios con Web semántica que permitan la explotación de contenido a partir de una ontología. El proceso de captura o población de ésta, está definido mediante una interfaz centralizada y utilizando un entorno gráfico, sin embargo, debido a que el proyecto está dividido en su área operativa y el entorno gráfico de captura, este último puede ser reemplazado por alguna aplicación Web, móvil o algún método emergente. Otra de las resultantes de esta tesis fue un conjunto de datos estadísticos que permitirán tomas conclusiones y consideraciones para el posible emparejamiento con alguna otra ontología o servicio que requiera de datos de este tipo, como lo pueden ser los Servicios Basados en Localización (LBS). Un perfil de usuario en lenguaje procesable, estructurado bajo el estándar XML (etiquetado), y que puede ser operable por cualquier gestor ontológico como por ejemplo protégé. Este proyecto puede ser adaptable en su contenido, ya que pueden aplicarse técnicas para poder realizar retroalimentación por parte del usuario y así enriquecer el contenido de la misma.

Conclusiones
Rojas, Christian 141
También es posible modificar los dominios de aplicación predefinidos, y enfocar el proceso de captura a un área específica con la finalidad de reducir aún más los elementos recomendados de captura hacia el usuario. Es importante tomar en cuenta la experiencia obtenida en el guardado, recuperación y borrado de elementos ontológicos, ya que el tema ontologías se vislumbra como uno de los más importantes para la Web 3.0.
7.2 APORTACIONES
Una ontología que se caracteriza por:
Modelar perfiles de usuarios estructurados en un lenguaje procesable (OWL).
Generar un árbol de abstracción de nombres para cada perfil generado (Véase 3.1.2), que permitirá mapear la estructura de cada ontología generada para poder explotarla posteriormente de manera más eficiente y lógica.
Tener una correspondencia directa (en tamaño y número) con los elementos operados (pertinentes) para cada perfil de usuario generado.
Corresponder directamente en las clases y datos contenidos de acuerdo a un cierto dominio de aplicación. (Véase 3.1.2.3.1)
Una interfaz gráfica que se caracteriza por:
Contener módulos dinámicos que responderán de acuerdo al contexto de los datos capturados al momento de la operación de dichos módulos. Permitiendo personalizar dinámicamente la captura de los elementos, mostrando y requiriendo solo los pertinentes para cada usuario en cuestión.
Manejar de manera transparente todas las interacciones con la ontología, así como operaciones inmersas y estructuración de árboles de abstracción de nombres para cada perfil generado.
Una de las principales aportaciones a este proyecto es la facilidad de ser explotada por otros servicios, para poder dar cabida a una personalización de contenidos basada en las preferencias del usuario, así como su comportamiento e inclinaciones de decisión. Los sistemas de recomendación basados en contexto son también un punto hacia el cual esta tesis ofrece una aportación ya que el conjunto de datos resultantes de los perfiles de usuario obtenidos, contienen información relevante para los Servicios Basados en Localización (LBS). Este proyecto aporta en gran medida entonces una funcionalidad puntual a la Web 3.0 que aunque emergente, también es inminente.

Conclusiones
Rojas, Christian 142
7.3 TRABAJOS FUTUROS Los elementos de un perfil de usuario basado en ontologías que comprende el presente trabajo son: la propuesta de un conjunto de datos divididos en secciones que se justifican como todos los datos disponibles para capturar para cualquier usuario, una estructura ontológica basada en un núcleo más extensiones las cuales serán accesibles en la medida que sean pertinentes para el usuario en cuestión, la generación automática de un árbol de abstracción de nombres que permite mapear los elementos generados por la aplicación para cada perfil de usuario generado, una interfaz gráfica centralizada que permite realizar todas las operaciones tanto ontológicas como inmersas de sus funciones, en este orden surgen posibles trabajos futuros.
El conjunto de datos propuestos del proyecto puede crecer en la medida que se considere necesario, además de que podrán incluirse clases faltantes para algún propósito especifico.
Debido a que la ontología está estructurada de acuerdo a un núcleo más extensiones, el número de extensiones podrá crecer, generando más extensiones para casos de uso específicos de algún servicio o aplicación, además, también es posible aumentar la cantidad de atributos para cada extensión establecida.
En cuanto al árbol de abstracción de nombres refiere, es posible implementar un crecimiento o disminución de las reglas establecidas para su generación, con la finalidad de afinar los resultantes de estas.
Este proyecto involucra una interfaz gráfica centralizada, sin embargo, debido a que la distribución de las clases programadas han sido en un lenguaje de programación de código abierto y además divididas según la lógica de Struts (código por un lado y operación grafica por otro), es posible sustituir la interfaz gráfica por alguna aplicación web, móvil o en alguna tecnología emergente.
En cuanto a trabajos futuros propuestos, se proponen los siguientes:
Integración de datos de Webs sociales actuales en la ontología, por medio de RIA (Aplicaciones de internet enriquecidas), con la finalidad de facilitar más aún, el proceso de captura de datos por parte del usuario; formando así un integrador de perfiles de usuario.
Publicación del árbol de abstracción de nombres. Esta opción puede ser de gran ayuda ya que ayudara a los servicios consumidores a poder utilizar solo los datos que le sean pertinentes y además de explotar correctamente los dominios de aplicación, ya que al publicar el mapa de los nombres, es posible saber el contenido de la ontología sin la necesidad de adentrarse en la misma.
Generación de un middleware para el emparejamiento con algún servicio consumidor. Este software intermedio podría permitir la adaptación de la ontología hacia el sitio Web semántico, con la finalidad de discriminar o

Conclusiones
Rojas, Christian 143
perfeccionar el contenido del mismo a partir de los datos definidos en las preferencias del usuario.
7.4 PUBLICACIONES En el transcurso de los estudios de maestría fue lograda la publicación de un artículo que lleva por nombre: “Perfiles de usuario basados en contexto, utilizando ontologías”, en el congreso de ciindet, Junio 2009. Se obtuvo el 2° lugar en el XXIV Concurso nacional de creatividad 2009 en su fase local.

Rojas, Christian 144
BIBLIOGRAFÍA
[Plans03] Plans, J.I.; Trenzano, F.; Robinat, J.; (2003), “Principios de marketing “En El consumidor y el comprador, Universidad de Barcelona Virtual [en línea], disponible en: Bivitec: Mercadotecnia, recuperado: 09 de septiembre de 2008.
[Trajkova04] Joana Trajkova, Susan Gauch, (2004), “Improving Ontology-Based User Profiles”,
Electrical Engineering and Computer Science, University of Kansas [en línea], disponible en: “citeseer.uark.edu/publications/RIAO2004.pdf”, presentada en RIAO, Vaucluse, Francia (Abril, 2004), recuperado: 23 de septiembre de 2008.
[Chan07] Hyoung-Rae Kim, Philip K. Chan (2007).” Learning implicit user interest hierarchy
for context in personalization”, Springer Science+Business Media, LLC, Estados Unidos, publicada en línea: Junio 2007.
[Gauch04] Devanand Ravindran, Susan Gauch (2004).” Exploiting Hierarchical Relationships
in Conceptual Search”, presentada en CIKM (Conference on Information and Knowledge Management), Washington D.C., Estados Unidos de América (Noviembre, 2004)
[Sarjakoski03] Annu-Maaria Nivala, L.Tiina Sarjakoski (2003), “Need for Context-Aware
Topographic Maps in Mobile Devices”, Department of Geoinformatics and Cartography, Finnish Geodetic Institute, presentada en ScanGIS, ISBN: 951-22-6565-6, Masala, Finlandia (Mayo, 2003)
[Yu05] Shijun Yu, Lina Al-Jadir, Stefano Spaccapietra (2005), “Matching User's Semantics
with Data Semantics in Location-Based Services”, presentada en MCMP (First International Workshop on Managing Context Information in Mobile and Pervasive Environments), Vol-165, ISSN 1613-0073, Ayia Napa, Cyprus (Mayo, 2005)
[ODP08] Netscape, “DMOZ (Open Directory Project)”, Directorio [en línea], disponible en:
http://www.dmoz.org/, recuperado: 23 de septiembre de 2008.
[Yho08] [Chen05] [Chen04] [Serral07]
Yahoo, Yahoo! Directory, Directorio [en línea], disponible en: http://dir.yahoo.com/, recuperado: 23 de septiembre de 2008. Harry Chen, Tim Finin, y Anupam Joshi (2005), “The SOUPA Ontology for Pervasive Computing”, Ed. Birkhäuser Basel Dept. of CSEE, University of Maryland, Springer, ISBN: 978-3-7643-7237-8 (Print) 978-3-7643-7361-0 (Online), DOI: 0.1007/3-7643-7361-X_10, Baltimore County, USA(Marzo, 2006) Harry Chen, Filip Perich, Timothy W. Finin, Anupam Joshi (2004), “SOUPA: Standard Ontology for Ubiquitous and Pervasive Applications”, presentada en MobiQuitous (1st Annual International Conference on Mobile and Ubiquitous Systems, Networking and Services), ISB N0-7695-2208-4, Cambridge, MA, USA. IEEE Computer Society (2004) Estefanía Serral (2007), “A MDD strategy for developing context-aware pervasive systems”, Tesis de máster en Ingeniería del Software, Métodos Formales y Sistemas de Información, Universidad Politécnica de Valencia, Valencia, España.

Rojas, Christian 145
[GEEK, 2008] [Aktors08] [Miller00] [Muñoz08]
GEEK(1996), “The Code of the Geeks v3.12”, disponible en http://www.geekcode.com/geek.html, recuperado: 10 de Noviembre de 2008. AKT / CROSI, “Advanced Kwnoledge Technologies”, disponible en http://www.aktors.org/akt, recuperado: 10 de Noviembre de 2008. Miller, Libby; D., Brickley. (2000). FOAF PROJECT. (Foaf (friend of a friend)) Disponible en: www.foaf-project.org/you/index.html Última consulta: 30 de Noviembre de 2008 Javier Muñoz Ferrara, Vicente Pelechano Ferragud (2008), “Model Driven Development of Pervasive Systems. Building a Software Factory”, Tésis doctoral en sistemas de información y computación, Universidad Politécnica de Valencia, Valencia, España.
[Gomez07] Alberto Gómez. OWL, “Descripción de la ontología”, Universidad Rey Juan Carlos (2007). Disponible en: http://axel.deri.ie/~axepol/teaching/ri2007/alberto.pdf. Recuperado el 07 de diciembre de 2008.
[W3C04] [Escarza07]
Deborah L. McGuinness, Frank van Harmelen; “OWL Web Ontology Language Overview”, W3C Recommendation (Feb. 2004). Disponible en: http://www.w3.org/TR/owl-features/. Recuperado el 08 de diciembre de 2008 Sebastian Escarza, Silvia Castro, Sergio Martig; “Ontologías de visualización”, Universidad Nacional del Sur, Buenos Aires, Argentina (2007). Disponible en: http://www.ing.unp.edu.ar/wicc2007/trabajos/CGIV/057.pdf. Recuperado el 08 de diciembre de 2008.
[Issste02] Instituto de Seguridad y Servicios Sociales a los Trabajadores del Estado. Sector
Salud. Departamento Sanitario de Gobierno Mexicano. Disponible en: http://www.issste.gob.mx/aconseja. Recuperado el 06 de diciembre de 2008.
[Disweb00] Clasificación Internacional del Funcionamiento, de la Discapacidad y de la Salud,
CIF. Disponible en: http://usuarios.discapnet.es/disweb2000/cif/. Recuperado el 06 de diciembre de 2008.
[Who08] [Disc08] [Croja08] [Gzlez08] [Disca08]
World Healt Organization. “International Classification of Functioning, Disability and Health” (ICF). Disponible en: http://www.who.int/classifications/icf/en/. Recuperado el 06 de diciembre de 2008. Tipos de discapacidades. “Clasificación en línea”. Disponible en: http://es.geocities.com/mr_herraiz82/discapacidades.htm. Recuperado el 06 de diciembre de 2008. Tipos y grados de discapacidad. Cruz Roja. Disponible en: http://www.cruzroja.es/portal/page?_pageid=418,12398047&_dad=portal30&_schema=PORTAL30. Recuperado el 06 de diciembre de 2008. Gema González. “Las diferentes minusvalías y sus características”. Disponible en: http://www.efdeportes.com/efd104/minusvalias.htm. Recuperado el 06 de diciembre de 2008. Servicios Sociales. “Guía de recursos sobre discapacidad”. Disponible en: http://ayuntamiento.cieza.net/serviciosmunicipales/serviciossociales/discapacidad/tiposminusvalias.html. Recuperado el 06 de diciembre de 2008.

Rojas, Christian 146
[Protege09] [W3C09] [ITA09] [Sforge09]
Gestor ontológico. Stanford Center for Biomedical Informatics Research, disponible en: http://protege.stanford.edu/, recuperado: 17 de abril de 2009. Desarrollo de tecnologías de interoperación. World Wide Web Consortium, disponible en: http://www.w3.org/, recuperado: 17 de abril de 2009 I.T. de Apizaco. Nomenclatura de paquetes, disponible en: http://www.itapizaco.edu.mx/paginas/JavaTut/froufe/parte5/cap5-14.html, recuperado: 17 de abril de 2009 API Ontológica, SourceForge.net, disponible en: http://owlapi.sourceforge.net, recuperado: 17 de abril de 2009
[Wiki09] Wikipedia. La enciclopedia Libre Disponible en: www.wikipedia.org. Última consulta: Julio 2009.
[OWL09] Lenguaje de descripción de la Web. W3C. Disponible en : http://www.idg.es/pcworld/La-W3C-presenta-el-lenguaje-de-descripcion-de-la- W/art152601.htm. Última consulta: Julio 2009 [RDF09] RDF, Especificacion del módelo y sintaxis, recomendación de W3C. Disponible
en: http://www.sidar.org/recur/desdi/traduc/es/rdf/rdfesp.htm. Última consulta: Julio 2009
[XSD09] XML Schema, recomendación de W3C. Disponible en:
http://es.wikipedia.org/wiki/XML_Schema. Última consulta: Julio 2009 [API09] Definición API. Disponible en: http://es.wikipedia.org/wiki/API Última consulta:
Septiembre 2007. [Gruber95] GRUBER, T. R. "Toward Principles for the Design of Ontologies Used for
Knowledge Sharing" en International Journal of Human and Computer Studies, 43 (5-6), 1995, p.907-928
GRUBER, T. R. "What is an Ontology?" http://www-ksl.stanford.edu/kst/what-is-an-ontology.html. Última consulta: Julio 2009
[Guarino96] GUARINO, N. "Formal Ontology, Conceptual Analysis and Kwoledge
Representation" en International Journal of Human and Computer Studies, 43(5-6), 1995, p. 625-640

Rojas, Christian 147
ANEXO 1 Descripción de las clases del paquete mx.edu.cenidet.userontology.axiomsinference
Clases tipo Charge Se encargan de obtener los atributos pertenecientes a la clase instanciada y
correspondientes en la ontología, modificar el tipo de dato (siempre string) hacia el tipo de dato pertinente en la interfaz de la clase respectiva operada en la aplicación y rellenar las casillas gráficas en la interfaz con estos datos. Las clases que se contemplan en este grupo son: ChargePersonalesData, ChargeAyudaTecnicaData, ChargeContactoData, ChargeDireccionData, ChargeEstudioData, ChargeMiembrosData, ChargeNivelComputoData, ChargeOrigenData, ChargeProyectoData, ChargePublicacionesData, ChargeTrabajoData.
Clases tipo Load Este conjunto de clases tienen como función la de extraer los datos pertenecientes
a la interfaz respectiva de la clase que se está operando con los datos que el usuario introdujo o fueron deducidos por algún medio, y guardarlos en la ontología, mediante el uso de la API (OWLAPI). Las clases involucradas en este grupo son: LoadPersonalesData, LoadAyudaTecnicaData, LoadContactoData, LoadDireccionData, LoadEstudioData, LoadMiembrosData, LoadNivelComputoData, LoadOrigenData, LoadProyectoData, LoadPublicacionesData, LoadTrabajoData.
Store Esta clase contiene métodos para crear individualizaciones en la ontología y
atributos de tipo objeto para relacionarlos.
Person Contiene la estructura genérica para que un elemento pueda ser guardado en la
ontología, ya sea individualización o atributo de tipo objeto. Además contiene un método para parametrizar el guardado de un valor en un atributo en la ontología.
Tupla Define el valor y el tipo de los atributos a operar en la ontología.
Remove Se encarga de eliminar los individuals involucrados en la ontología. Dejando a un
lado aquellos que se encuentren en la ontología pero que no hayan sido operados por el proyecto.
DATA Contiene los datos genéricos para el manejo de la aplicación, así como banderas
para poder aplicar o no extensibilidades en las clases mostradas gráficamente.
Login Contiene métodos para poder autenticar a un usuario y marcar una bandera en
caso de validarlo.
RelationAll Los métodos que contiene permiten establecer las relaciones conceptuales entre
las individualizaciones operadas por la aplicación.

Rojas, Christian 148
ANEXO 2 Descripción de las clases del paquete mx.edu.cenidet.userontology.Front
Clases de grupos de datos Se encargan de mostrar en pantalla los elementos que intervienen en cada grupo
de datos respectivamente, conservando una coherencia y relación con aquellos atributos del entorno de desarrollo de la ontología (protégé), y los métodos internos se encargan de cambiar dinámicamente el contenido de dichas interfaces. Las clases involucradas son: Origen, Personales, Dirección, Proyecto, Contacto, Estudio, Trabajo, Enfermedades, AyudaTecnica, Miembros, Publicaciones, Apariencia, EstilodeVida, GEEK, Intereses.
Seguridad Esta clase contiene métodos para cambiar de contraseña de usuario,
asociándose internamente con la clase Personales, y métodos de validación de este cambio.
Authentication Esta clase posee métodos para comprobar o no la autenticación de un usuario
para acceder al sistema, además de modificar su comportamiento para un usuario nuevo o un usuario existente, asegura la validación del password para un usuario nuevo y un nombre de usuario univoco.
ChooseDomain Esta clase contiene una interfaz que permite definir el dominio de la aplicación
hacia la cual se inclinaran los campos solicitados al usuario en cuestión.
Clases Esta clase se encarga de mostrar gráficamente las clases disponibles para el
usuario en cuestión a partir de las deducciones dinámicas que se concluyan, así como de organizarlas de acuerdo al dominio de aplicación elegido.
Interfaz Es la clase principal de este paquete, y además la clase que tiene una función
principal. Tiene como finalidad el mostrar en pantalla el área de trabajo y organizar todos los paneles superiores que se vayan utilizando.
Saver Esta clase se encarga de almacenar en la ontología los datos que se encuentren
dispuestos en la interfaz respectiva.
TaskChoice Contiene métodos para dar una elección al usuario sobre su operación en la
ontología, como modificar, guardar o agregar datos en la ontología.
ZoneTime Esta clase funciona para dar opciones al usuario de modificar su zona horaria
“GMT”, y/o el manejo de la aparición de alertas en pantalla.