fundamentos de matematicas - inicioantonio/industriales/apuntes_17-18/... · tenemos de nidas unas...
TRANSCRIPT

Sede Francisco Mendizabal
Dpto. de Matematica Aplicada
Escuela de Ingenierıas industriales
FUNDAMENTOS de MATEMATICAS
APUNTES PARA LA ASIGNATURA
Curso 2017–2018
Grado de Ingenierıa en Diseno Industrial y Desarrollo de producto
[Profesor : Jose Antonio Abia Vian
]

ii – Fundamentos de Matematicas : Contenidos
Indice de contenidos
Preliminares vi
0 Preliminares 10.1 ¿Un Curso 0? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
0.1.1 Numeros, conjuntos y lenguaje matematico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10.1.1.1 Conjuntos y lenguaje matematico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10.1.1.2 Logica y Teoremas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
0.1.2 Funciones elementales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30.1.2.1 Trigonometrıa y funciones trigonometricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30.1.2.2 Exponenciales y logaritmos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30.1.2.3 Funciones hiperbolicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
0.1.3 Conicas y cuadricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.1.3.1 Conicas en el plano R2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50.1.3.2 Cuadricas en el espacio R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
0.1.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80.2 Numeros Complejos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
0.2.1 Unidad imaginaria y forma binomica de un numero complejo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90.2.1.1 Construccion formal del plano complejo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
0.2.2 Propiedades de los complejos. Conjugado y modulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100.2.2.1 Conjugado de un numero complejo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100.2.2.2 Modulo de un numero complejo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
0.2.3 Forma polar de un numero complejo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110.2.4 Raices complejas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
0.2.4.1 La exponencial compleja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120.2.5 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
0.3 Polinomios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130.3.1 Introduccion. Nociones basicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
0.3.1.1 Operaciones en K[X] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140.3.2 Division euclıdea de polinomios. Divisibilidad y factorizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
0.3.2.1 Division entera o euclıdea de polinomios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160.3.2.2 Raız de un polinomio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160.3.2.3 Factorizacion de polinomios de coeficientes complejos . . . . . . . . . . . . . . . . . . . . . . . . . . . 170.3.2.4 Factorizacion de polinomios en R[X] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170.3.2.5 Factorizacion de polinomios de coeficientes racionales . . . . . . . . . . . . . . . . . . . . . . . . . . . 180.3.2.6 Descomposicion en fracciones simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
0.3.3 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Anexo 0: Preliminares 22
I Calculo diferencial en R 25
1 Funciones, lımites y continuidad 261.1 La recta real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
1.1.1 Los numeros reales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.1.2 Valor absoluto de un numero real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.1.3 Intervalos y entornos en R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271.1.4 Algunas operaciones con numeros reales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
1.1.4.1 Potencias racionales y reales de un numero real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281.1.4.2 Exponencial real de base e . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281.1.4.3 Logaritmo neperiano real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
1.2 Funciones reales de variable real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281.2.1 Monotonıa. Funciones inversas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
1.3 Lımite y continuidad de una funcion en un punto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 311.3.1 Algunos resultados interesantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
1.3.1.1 Lımites y continuidad con las operaciones basicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 331.3.1.2 Lımites laterales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
1.3.2 Lımites con infinito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351.3.3 Infinitesimos e infinitos equivalentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 371.3.4 Asıntotas de una funcion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
1.4 Teoremas del lımite y de continuidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391.4.1 Teoremas de continuidad en intervalos cerrados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
1.5 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

iii – Fundamentos de Matematicas : Contenidos INDICE DE CONTENIDOS
2 Funciones derivables 432.1 Derivada de una funcion en un punto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2.1.1 Aplicaciones de la derivada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452.1.1.1 Crecimiento de una funcion en un punto. Extremos locales . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.2 Teoremas de derivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472.2.1 Teorema de la funcion inversa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492.2.2 Representacion grafica de funciones (1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.2.2.1 Monotonıa y extremos locales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502.2.2.2 Concavidad y convexidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 512.2.2.3 Paridad y periodicidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.3 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3 Polinomios de Taylor 553.1 Polinomios de Taylor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.1.1 Formula de Taylor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 573.2 Representacion de funciones (2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.2.1 Representacion de funciones en forma explıcita: y = f(x) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.3 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Anexo 1: Calculo diferencial 62
II Calculo integral en R 74
4 Calculo de primitivas 754.1 Primitiva de una funcion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.1.1 Tabla de integrales inmediatas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 754.2 Metodos de integracion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.2.1 Metodo de sustitucion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.2.1.1 Tabla de integrales casi–inmediatas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.2.2 Cambio de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 764.2.3 Integracion por partes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.3 Integracion segun el tipo de funcion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.3.1 Integrales racionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.3.1.1 Descomposicion en fracciones simples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 774.3.1.2 Integracion de funciones racionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.3.2 Integracion de funciones trigonometricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 794.3.3 Integracion de funciones exponenciales e hiperbolicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.3.4 Integrales con raıces o irracionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.3.4.1 Integrales binomias∗ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 814.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5 Integral de Riemann 845.1 Sumas inferiores y superiores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.1.1 Particiones de un intervalo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 845.1.2 Sumas inferiores y superiores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.2 Integral de una funcion real de variable real . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 855.2.1 Sumas de Riemann∗ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 865.2.2 Otras propiedades de la integral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 875.2.3 Algunas funciones integrables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5.3 Integracion y derivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.4 Integrales impropias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.4.1 Integrales impropias de primera especie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 905.4.2 Criterios de comparacion para funciones no negativas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 915.4.3 Convergencia absoluta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 935.4.4 Integrales impropias de segunda especie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5.5 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6 Aplicaciones de la integral 986.1 Areas de superficies planas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
6.1.1 Funciones negativas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 986.1.2 Area entre dos funciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
6.2 Volumenes de cuerpos solidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1006.2.1 Volumenes de revolucion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.3 Otras aplicaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1026.3.1 Longitudes de arcos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1026.3.2 Area de una superficie de revolucion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
6.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
Anexo 2: Calculo integral 106
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

iv – Fundamentos de Matematicas : Contenidos INDICE DE CONTENIDOS
III Ecuaciones Diferenciales Ordinarias 114
7 Ecuaciones Diferenciales Ordinarias 1157.1 Introduccion, conceptos e ideas basicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.1.1 Ecuaciones diferenciales ordinarias de primer orden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1167.2 Metodos de resolucion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.2.1 Ecuaciones diferenciales separables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1177.2.2 Ecuaciones diferenciales exactas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1177.2.3 Factores integrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
7.2.3.1 Factores integrales de la forma µ(x) o µ(y) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1197.2.4 Ecuaciones lineales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1207.2.5 Ecuaciones un poco especiales * . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
7.2.5.1 Ecuaciones de Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1207.2.5.2 Ecuaciones reducibles a separables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
7.3 Aplicaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1217.3.1 Trayectorias ortogonales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
7.3.1.1 Trayectorias de angulo β . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1227.3.2 Modelado de problemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
7.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
IV Algebra Lineal 124
8 Matrices y sistemas de ecuaciones lineales 1258.1 Definiciones basicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8.1.1 Operaciones con las matrices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1258.1.2 Matriz transpuesta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
8.2 Sistemas de ecuaciones lineales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1268.2.1 Matrices elementales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1278.2.2 Metodo de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
8.2.2.1 Sistemas homogeneos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1298.2.2.2 Metodo de Gauss-Jordan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
8.2.3 Rango de una matriz y Teorema de Rouche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1308.3 Matrices cuadradas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.3.1 Matrices inversibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1318.4 Determinante de una matriz cuadrada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
8.4.1 Determinantes y operaciones elementales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1338.4.1.1 Calculo de determinantes por reduccion a la forma escalonada . . . . . . . . . . . . . . . . . . . . . . . 134
8.4.2 Otras propiedades del determinante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1348.4.3 Desarrollo por cofactores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1348.4.4 Rango de una matriz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
8.5 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
9 Espacios vectoriales reales 1409.1 Espacios vectoriales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1409.2 Subespacios vectoriales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1409.3 Base y dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
9.3.1 Coordenadas en una base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1429.3.2 Espacios de las filas y las columnas de una matriz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143
9.4 Cambios de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1449.5 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
10 Espacios vectoriales con producto escalar 14710.1 Producto escalar. Norma. Distancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
10.1.1 Matriz del producto escalar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14810.1.2 El espacio euclıdeo n -dimensional Rn . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
10.2 Ortogonalidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14910.2.1 Angulos y ortogonalidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14910.2.2 Bases ortonormales. Proyeccion ortogonal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
10.2.2.1 Teorema y ortonormalizacion de Gram-Schmidt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15010.2.2.2 Base ortonormal mediante diagonalizacion congruente . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
10.3 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
11 Aplicaciones lineales 15411.1 Definicion. Nucleo e imagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15411.2 Matrices de una aplicacion lineal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
11.2.1 Composicion de aplicaciones lineales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15711.3 Teorema de Semejanza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15811.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

v – Fundamentos de Matematicas : Contenidos INDICE DE CONTENIDOS
12 Diagonalizacion 16212.1 Valores y vectores propios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16212.2 Diagonalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16312.3 Diagonalizacion ortogonal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16412.4 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
13 Formas cuadraticas 16913.1 Diagonalizacion de una forma cuadratica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
13.1.1 Diagonalizacion ortogonal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17013.1.2 Diagonalizacion mediante operaciones elementales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
13.2 Rango y signatura de una forma cuadratica. Clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17113.2.1 Clasificacion de las formas cuadraticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
13.3 Ejercicios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
Anexo 3: Algebra lineal 175
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

vi – Fundamentos de Matematicas
Unidad 0
Preliminares
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

1 – Fundamentos de Matematicas : Preliminares
Capıtulo 0
Preliminares
0.1 ¿Un Curso 0?
Se pretende establecer un estandar de notaciones y significados comunes, sobre los objetos, operaciones, resul-tados, etc, ya conocidos en mayor o menor medida. Y alguna cosita mas . . .
0.1.1 Numeros, conjuntos y lenguaje matematico
Conocemos y manejamos diversos conjuntos de numeros, como son los conjuntos de los
numeros naturales N ={
0, 1, 2, 3, 4, 5, . . .}
numeros enteros Z ={. . . ,−3,−2,−1, 0, 1, 2, 3, . . .
}numeros racionales Q =
{ zn
: z ∈ Z y n ∈ Z−{0}}
y el conjunto de los numeros reales R (o de los decimales, que rellena los “huecos” entre los racionales. Ver laNota de mas abajo). Y ademas sabemos que se cumple la cadena de contenciones. . . N ⊂ Z ⊂ Q ⊂ R .
La creacion o el “descubrimiento” de estos conjuntos tuvo lugar por las necesidades tecnicas y practicas(pero tambien teoricas) de los cientıficos del momento, y que nosotros vamos a recordar a continuacion perocon un toque matematico mas actual. Tenemos definidas unas operaciones de suma y de producto en cada unode estos conjuntos que son operaciones internas (suma o producto de naturales es natural, suma o productode enteros es entero, etc,) sin embargo no tienen en cada conjunto las mismas propiedades:
? en N ni para la suma ni para el producto existe inverso (ni la resta ni la division de naturales tiene porqueser un natural),
? en Z existe el inverso para la suma pero no para el producto (la resta de enteros es un numero entero,pero no lo es la division en general)
? y tanto en Q como en R podemos restar y tambien dividir por valores distintos de cero
La otra operacion o manipulacion basica entre numeros, la potencia (una generalizacion del producto), diferencia
claramente estos dos ultimos conjuntos. Ası 2 ∈ Q (luego tambien a R), pero 212 =
√2 /∈ Q , aunque sı se
cumple que 212 =√
2 = 1.4142135623 · · · ∈ R .
Nota: El conjunto R –o recta real– se completa anadiendo a los numeros racionales los numeros irracionalesR = Q ∪ I , teniendo en cuenta que cualquier numero real puede describirse en la forma z.d1d2d3 . . . dn . . .(un numero entero seguido de infinitos decimales): si a partir de uno de ellos, los decimales se repitenperiodicamente o son cero, el numero es racional y en caso contrario se dice que es irracional. Ası, los numeros
13 = 0.
︷︷3 = 0.33333 · · · y 5
4 = 1.25 = 1.24︷︷9 = 1.2499999 · · · son racionales, mientras que los numeros
√2,
π o este 55.0270027000270000270000027 · · · son irracionales.
0.1.1.1 Conjuntos y lenguaje matematico
En el apartado anterior aparecen sımbolos para expresar los conjuntos de numeros y las relaciones entre ellos.Esta simbologıa matematica debe conocerse, pues es parte esencial de las matematicas, no por hacer mas concisau oculta la escritura de los enunciados, sino porque los hace mas precisos, mas exactos y verdaderos.
Unas llaves “{ }
” indican un conjunto que esta formado por elementos, y que puede ser descrito por suspropios elementos, {0, 1, 2} (o A = {0, 1, 2} si queremos darle nombre), o por alguna condicion que queremosque cumplan los elementos de ese conjunto, A =
{n ∈ N : n < 3
}. Esta notacion habitual se lee: A es el
conjunto (“{ }
”) formado por los numeros naturales (“n ∈ N”) tales que (“:”) son menores que 3 (“n < 3”).
Los elementos estan en el conjunto o pertenecen al conjunto, 0 ∈ A , y un conjunto puede estar contenidoo incluido en otro, A ⊆ B (A esta contenido en B si todos los elementos de A pertenecen tambien a B ) ytambien de dice que A es un subconjunto de B . Se usa B ⊇ A para indicar que B contiene a A .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

2 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
Se distingue entre contenido o igual “⊆” y contenido y distinto “⊂”, aunque en general solo se usa el ultimosımbolo cuando quiere ponerse de manifiesto la no igualdad.
Cuando se manejan conjuntos estamos tratando con sus elementos y, o bien por algo que les sucede oqueremos que cumplan todos ellos o bien observamos que hay algunos a los que no les sucede o no cumplen loque deseamos, por lo que hay dos sımbolos que aparecen comunmente:
• ∀ que significa para todo elemento o para cada elemento y
• ∃ que significa existe algun elemento o existe al menos un elemento
ya hemos visto el “todo” cuando definıamos la contencion y basta negar el “todo” para tener el “existe algun”
? A ⊆ B , si todo elemento de A pertenece tambien a B → A ⊆ B , si ∀x ∈ A se cumple que x ∈ B
? A 6⊆ B , si existe algun elemento de A que no esta en B → A 6⊆ B , si ∃x ∈ A tal que x /∈ B
Atencion, negar que todos cumplan algo no es que todos cumplan lo contrario sino que alguno no lo cumple.Por ejemplo negar que “todos los hombres son tontos” no es “todos los hombres son listos”, sino que “hay almenos un hombre que no es tonto”.
Estos significados exactos que representan estos sımbolos aparecen en las definiciones de la mayorıa de losconceptos matematicos, como lımites, derivabilidad, espacios vectoriales, . . . , y formando parte esencial ellas.No tienen sentido muchas de esas definiciones sin ellos.
Tambien entre los conjuntos encontramos una especie de operaciones, las mas basicas son la interseccion“∩”, union “∪” y eliminacion o resta entre conjuntos:
A ∩B ={x : x ∈ A y x ∈ B
}A ∪B =
{x : x ∈ A o x ∈ B
}A−B =
{x ∈ A : x /∈ B
}Si A y B tienen interseccion vacıa (sin elementos comunes), A∩B = ∅ , se dice que son conjuntos disjuntos.
Muy habitualmente los conjuntos que se usan son todos subconjuntos de uno mas grande (el universo), con-juntos de numeros reales, conjuntos de vectores, . . . , y en ese caso conviene tener en cuenta, el complementariode un conjunto, A =
{x : x /∈ A
}. Ası, para A =
{n ∈ N : n < 3
}, es A =
{n ∈ N : n ≥ 3
}0.1.1.2 Logica y Teoremas
Cuando construimos las herramientas matematicas es necesario que tengamos la seguridad de su funcionamiento,no la posibilidad sino la certeza. Para ello se usan los procesos logicos que nos permiten construir teoremas logicos(los teoremas, lemas, proposiciones,. . . que se ven en matematicas), resultados que son siempre siempre ciertos.
La estructura basica de un teorema logico es siempre la misma:
Se escribe P =⇒ Q , y se lee P implica Q , significando: si se cumple P , entonces se cumple tambien Q
Hay otras lecturas usuales de esa implicacion: “si se cumple P necesariamente se cumple tambien Q” o“que se cumpla Q es una condicion necesaria para que se cumpla P ” o “Q se deduce o infiere de P ”
El enunciado P se denomina la hipotesis del teorema y Q la tesis, por lo que estamos diciendo que: siempreque se cumpla la hipotesis tiene que cumplirse la tesis. Como ocurre en el teorema siguiente:
“Si un numero natural es multiplo de 4, entonces es un numero par”
Si P =⇒ Q y Q =⇒ P se pone P ⇐⇒ Q y se lee “P si y solo si Q” o tambien que “P y Q son equivalentes”
“Un numero natural es multiplo de 10 si y solo si la ultima cifra es 0”
A ⊆ B y B ⊆ A ⇐⇒ A = B
Cuando antes dijimos que si P =⇒ Q , el enunciado Q es una condicion necesaria para P , estamos dando unaexpresion equivalente a esa implicacion. Es decir, estamos construyendo el siguiente teorema
Teorema 1.- Si P y Q son dos enunciados o proposiciones logicas,
P =⇒ Q ⇐⇒ no Q =⇒ no P
Cierto: si cuando P es cierta Q tambien lo es, cuando Q no sea cierta necesariamente P tampoco lo sera, yaque si lo fuera Q tendrıa que ser cierta.
Esta implicacion no Q =⇒ no P se dice que es la contrarrecıproca o contrapositiva de P =⇒ Q . (DeQ =⇒ P se dice la recıproca). Ası tenemos el teorema siguiente, contrarrecıproco de uno anterior:
“Si un numero natural no es par, entonces no es un multiplo de 4”
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

3 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
0.1.2 Funciones elementales
0.1.2.1 Trigonometrıa y funciones trigonometricas
Unos de los conceptos que aparece mas a menudo es la trigonometrıa, tanto en su version de proporcionesgeometricas, como en version de funciones analıticas para Calculo. Las razones trigonometricas basicas de unangulo, seno, coseno y tangente, se definen mediante los angulos de un triangulo rectangulo:
sen θ =y
hcos θ =
x
htg θ =
y
x=
sen θ
cos �
�����
��
θ
y
x
h ���
r���r @
@@r@@@r
θ
θθsen θ = sen θ
cos θ = −cos θ
(cos θ, sen θ) = (x, y)
sen θ = −sen θcos θ = −cos θ θ
1
tg θ = tg θ
sen θ = −sen θcos θ = cos θtg θ = −tg θtg θ = tg θ
Cuando la hipotenusa es 1 (ver circunferencia goniometrica a la derecha del dibujo anterior), los valores delpunto (x, y) coinciden con (cos θ, sen θ), no solo en valor sino tambien en signo (si 90o < θ < 270o es cos θ < 0).Pero los angulos se usan en mas contextos con un sentido de recorrido, lo que les proporciona un signo y nose expresan en grados sino en radianes (amplitud del angulo θ cuyo arco en la circunferencia unidad tienelongitud 1, ası 180o son π radianes y 360o son 2π radianes) que son numeros reales, lo que convierte estasrazones en funciones reales extendidas a todos los numeros reales. Se cumplen las propiedades siguientes:
sen(−x) = − senx cos(−x) = cosx cos2 x+ sen2 x = 11
cos2 x= 1 + tg2 x
sen(x+ y) = senx cos y + cosx sen y cos(x+ y) = cosx cos y − senx sen y tg(x+ y) =tg x+ tg y
1− tg x tg y
que cuando y = x , nos proporcionan las formulas del angulo doble y las del angulo mitad
sen(2x)=2 senx cosx cos(2x)=cos2 x− sen2 x tg(2x)=2 tg x
1−tg2 x
sen2 x=1−cos(2x)
2cos2 x=
1+cos(2x)
2
Nota: El cuadro de la derecha recoge una regla nemotecnica muy sencillapara recordar los valores de seno y coseno de los angulos habituales delprimer cuadrante (30, 45, 60 y 90o ), que con las propiedades y formulasanteriores permite conocer de manera facil las razones de muchos otros.
θ 0 π6
π4
π3
π2
sen θ√
02
√1
2
√2
2
√3
2
√4
2
cos θ√
42
√3
2
√2
2
√1
2
√0
2
Para cada funcion trigonometrica se ha construido una funcion inversa, respondiendo a preguntas como¿para que angulo su seno vale 1
2 ? Ası se tienen las funciones inversas, arcoseno, arcocoseno y arcotangente:
• arcsen(x) = el angulo cuyo seno vale x ,
• arccos(x) = el angulo cuyo coseno vale x y
• arctg(x) = el angulo cuya tangente vale x
Naturalmente responder a esa pregunta –¿para que angulo su seno vale 12 ?– significa que sen(arcsen( 1
2 )) = 12 .
Y como para todas las funciones inversas (ver su estudio en la seccion 1.2.1) se cumple que
arcsen(sen(a)) = a y sen(arcsen(b)) = b
Lo mismo ocurre para coseno y arcocoseno, y tangente y arcotangente.
Estas son las funciones inversas (inversas para la composicion), y no deben confundirse con las obtenidas“invirtiendo el valor de las funciones respecto al producto”:
cosecante : cosecx = 1sen x secante : secx = 1
cos x y cotangente : cotg x = 1tg x
Observacion El uso de radianes en las funciones trigonometricas reales no es opcional, es necesario para que
se cumplan muchas de las propiedades conocidas. Ası, lımx→0
sen(x)x = 1 o sen′(x) = cos(x), ¡si x es en radianes!
0.1.2.2 Exponenciales y logaritmos
Ademas de las funciones trigonometricas se manejan mas funciones elementales, como la funcion exponencialy su inversa el logaritmo.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

4 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
La exponencial proviene de las potencias de los numeros (−2)3 , 512 , . . . que dan lugar a los polinomios x3
y las raıces x12 =√x cuando el exponente esta fijo, y a las exponenciales cuando es la base la que se mantiene
fija: 10x , 2x−1 , . . . . Aunque la mas interesante es la de base e , “la exponencial” inversa del logaritmo natural.Algunas de sus propiedades son (cualquier exponencial ax tambien las cumple),
• e0 = 1 y ex+y = exey de donde enx = (ex)n y e−x = 1ex
• 0 < ex y ex < ey cuando x < y
Los logaritmos, inversos de las exponenciales, tambien estan asociados a una base: “logaritmo en base 10 dex es el numero al que hay que elevar 10 para que nos de x , log10(x)”. Todos funcionan de manera similar yestan ıntimamente relacionados (como con las exponenciales), pero el mas significativo de todos es el logaritmode base e , el logaritmo natural (o neperiano): loge(1) = ln(1) = 0
Sus propiedades son “parejas invertidas” a las de la exponencial:
• ln(xy) = ln(x) + ln(y) de donde ln(xn) = n ln(x), ln( 1x ) = − ln(x) y ln(xy ) = ln(x)− ln(y)
• ln(x) < ln(y) cuando x < y
Tambien los logaritmos en bases de exponencial distintas de e , cumplen esas propiedades, pues loga(x) = ln(x)ln(a) .
Nota: El uso como “natural” de e tambien se justifica porque es la unica base que cumple f ′(x) = f(x).
f(x) = ex
1
1
f(x) = ln(x)
1
sh(x)ch(x)
th(x)
1
ππ2
tg(x)
sen(x)
cos(x)
0.1.2.3 Funciones hiperbolicas
Paralelas a las funciones trigonometricas (ver la exponencial compleja 0.2.4.1 y la forma polar 0.2.3) se cons-truyen las funciones hiperbolicas:
• seno hiperbolico: senh(x) = sh(x) =ex − e−x
2
• coseno hiperbolico: cosh(x) = ch(x) =ex + e−x
2
• tangente hiperbolica: tanh(x) = th(x) =sh(x)
ch(x)=e2x − 1
e2x + 1
que cumplen las propiedades siguientes, similares tambien a las de las funciones trigonometricas:
sh(−x) = − shx ch(−x) = chx ch2 x− sh2 x = 11
ch2 x= 1− th2 x
sh(x+ y) = shx ch y + chx sh y ch(x+ y) = chx ch y + shx sh y th(x+ y) =thx+ th y
1 + thx th y
que cuando y = x , proporcionan analogas expresiones de las formulas
sh(2x)=2 shx chx ch(2x)=ch2 x+ sh2 x th(2x)=2 thx
1+th2 xsh2 x=
ch(2x)−1
2ch2 x=
ch(2x)+1
2
Las funciones inversas correspondientes, suelen denominarse argumentos de (en lugar de arcos de)
• argumento del seno hiperbolico, argsh(x) = ln(x+√x2 + 1)
• argumento del coseno hiperbolico, argch(x) = ln(x+√x2 − 1)
• argumento de la tangente hiperbolica, argth(x) = 12 ln
(1+x1−x
)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
5 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
0.1.3 Conicas y cuadricas
Entre las curvas y recintos del plano son muy habituales las conicas y entre las superficies y volumenes del espaciolas cuadricas. Veremos aquı un pequeno estudio sobre las conicas del plano, repasando sobretodo lo conocidopero proporcionando mas variaciones y posobilidades, y un solo breve resumen recordatorio e informativo sobrelas cuadricas
0.1.3.1 Conicas en el plano R2
Muchas de las figuras planas que suelen aparecer son especıficas por sus caracterısticas o comportamientos yque generalmente se corresponden con propiedades metricas y geometricas concretas. Una de las familias mashabituales de estas figuras son las conicas: circunferencias, elipses, parabolas e hiperbolas.
Es evidente que cuando hay un giro tenemos una circunferencia (la omnipresente “rueda”) puesto que es ellugar geometrico de los puntos que equidistan de uno dado. los puntos de (x− x0)2 + (y − y0)2 = r2 estana distancia r del “centro” (x0, y0).
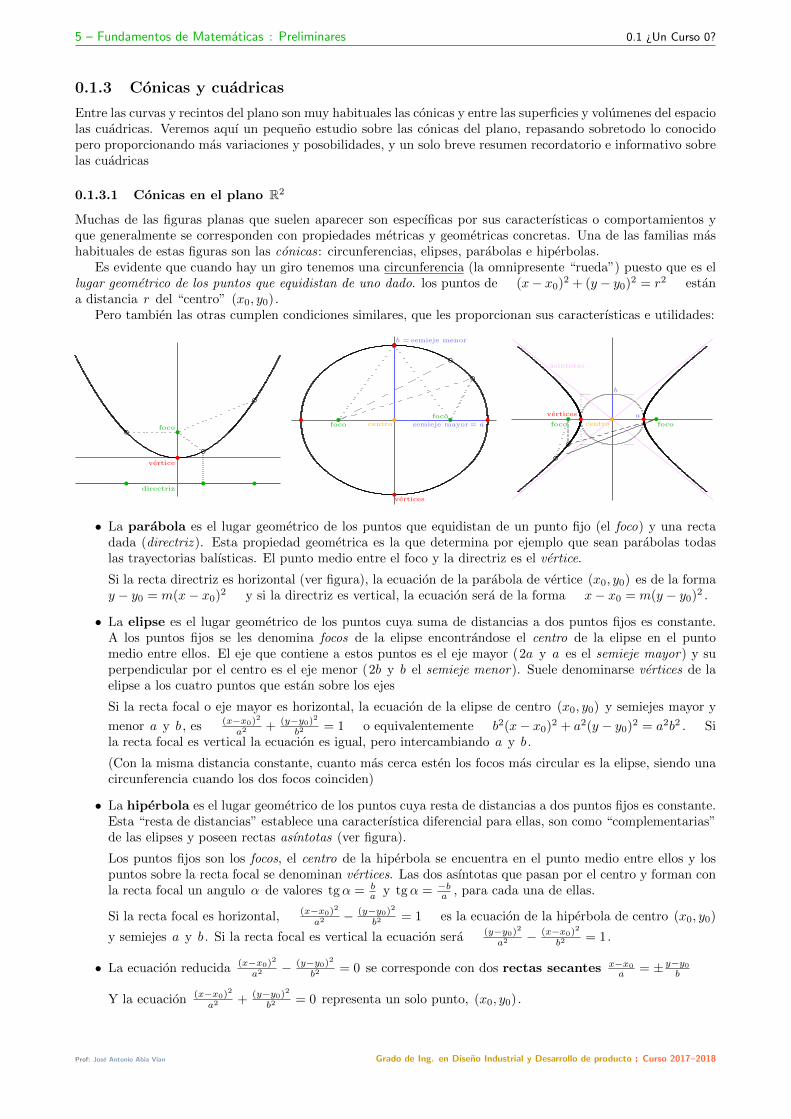
Pero tambien las otras cumplen condiciones similares, que les proporcionan sus caracterısticas e utilidades:
bbb r
vertice
rr r r
foco
directriz
b b bsemieje mayor= a
b =semieje menor
rcentro
rrfoco
foco r
r
r
rvertices
########
cccccccc
###
###
##
ccc
ccc
cc
asıntotas
b ba
brcentro
rrfoco foco
rrvertices
• La parabola es el lugar geometrico de los puntos que equidistan de un punto fijo (el foco) y una rectadada (directriz ). Esta propiedad geometrica es la que determina por ejemplo que sean parabolas todaslas trayectorias balısticas. El punto medio entre el foco y la directriz es el vertice.
Si la recta directriz es horizontal (ver figura), la ecuacion de la parabola de vertice (x0, y0) es de la formay − y0 = m(x− x0)2 y si la directriz es vertical, la ecuacion sera de la forma x− x0 = m(y − y0)2 .
• La elipse es el lugar geometrico de los puntos cuya suma de distancias a dos puntos fijos es constante.A los puntos fijos se les denomina focos de la elipse encontrandose el centro de la elipse en el puntomedio entre ellos. El eje que contiene a estos puntos es el eje mayor (2a y a es el semieje mayor) y superpendicular por el centro es el eje menor (2b y b el semieje menor). Suele denominarse vertices de laelipse a los cuatro puntos que estan sobre los ejes
Si la recta focal o eje mayor es horizontal, la ecuacion de la elipse de centro (x0, y0) y semiejes mayor y
menor a y b , es (x−x0)2
a2 + (y−y0)2
b2 = 1 o equivalentemente b2(x− x0)2 + a2(y − y0)2 = a2b2 . Sila recta focal es vertical la ecuacion es igual, pero intercambiando a y b .
(Con la misma distancia constante, cuanto mas cerca esten los focos mas circular es la elipse, siendo unacircunferencia cuando los dos focos coinciden)
• La hiperbola es el lugar geometrico de los puntos cuya resta de distancias a dos puntos fijos es constante.Esta “resta de distancias” establece una caracterıstica diferencial para ellas, son como “complementarias”de las elipses y poseen rectas asıntotas (ver figura).
Los puntos fijos son los focos, el centro de la hiperbola se encuentra en el punto medio entre ellos y lospuntos sobre la recta focal se denominan vertices. Las dos asıntotas que pasan por el centro y forman conla recta focal un angulo α de valores tgα = b
a y tgα = −ba , para cada una de ellas.
Si la recta focal es horizontal, (x−x0)2
a2 − (y−y0)2
b2 = 1 es la ecuacion de la hiperbola de centro (x0, y0)
y semiejes a y b . Si la recta focal es vertical la ecuacion sera (y−y0)2
a2 − (x−x0)2
b2 = 1.
• La ecuacion reducida (x−x0)2
a2 − (y−y0)2
b2 = 0 se corresponde con dos rectas secantes x−x0
a = ±y−y0
b
Y la ecuacion (x−x0)2
a2 + (y−y0)2
b2 = 0 representa un solo punto, (x0, y0).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

6 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
En las ecuaciones que hemos visto, la directriz o las rectas focales son siempre horizontales o verticales, peropueden construirse para cualesquiera puntos foco y cualquier recta directriz, por lo que las conicas tendran lamisma forma pero giradas sobre el plano, ası x2 +y2 + 2xy−x+y = 0 es una parabola y 3x2 + 2xy+ 3y2 = 2una elipse aunque sus ecuaciones no se ajusten a ninguna de las expuestas arriba.
Por ser las conicas lugares geometricos y sus ecuaciones reducidas funciones en x e y con algun termino deltipo x2 o y2 o xy , todas las conicas se pueden describir mediante una ecuacion del tipo:
Definicion 2.- Se define conica en R2 como el lugar geometrico de los puntos (x, y) que verifican una ecuacionde la forma:
a00 + a01 x+ a02 y + a11 x2 + a12 xy + a22 y
2 = 0
siempre que a11 , a12 y a22 no sean nulos simultaneamente
• Si el coeficiente a12 = 0 (no hay termino en xy ) la conica tiene la directriz o los ejes focales horizontaleso verticales y basta “completar cuadrados” para obtener la ecuacion reducida:
0 = x2 − y2 + 4x+ 2y − 1 = (x2+4x)− (y2−2y)− 1= (x2 + 4x+ 4− 4)− (y2 − 2y + 1− 1)− 1 = (x+2)2 − (y−1)2 − 4
• Si son cero los coeficientes a11 = a22 = 0 (el unico termino de grado 2 es xy ) se obtiene una conica giradaque sı aparece de manera habitual: las hiperbolas con ecuacion del tipo (x− x0)(y − y0) = m ; con unaasıntota vertical y otra horizontal. Piensese en el caso mas sencillo y muy conocido de y = 1
x .
En el caso m = 0, (x− x0)(y − y0) = 0, se tienen las rectas secantes x = x0 e y = y0
Genericamente se denominan conicas por que todasellas son secciones de un cono recto, es decir, se obtienenpor el corte de un cono tridimensional con un plano. De-pendiendo de que el plano sea: paralelo a la generatrizdel cono (se obtine una parabola), perpendicular al eje(una circunferencia), otro que solo corte una de los “em-budos” del cono (una elipse) o paralelo al eje del cono(una hiperbola). En el dibujo de la derecha, obtenidoen internet, pueden observarse esas circunstancias.
0.1.3.2 Cuadricas en el espacio R3
Damos entrada directamente a ellas con esta definicion general, pero el resto sera tipologıa y muy concreta:
Definicion 3.- Una cuadrica en R3 es el lugar geometrico de los puntos (x, y, z) cumpliendo una ecuacion:
a00 + a01 x+ a02 y + a03 z + a11 x2 + a12 xy + a22, y
2 + a13 xz + a23 yz + a33 z2 = 0
donde a11 , a12 , a13 , a22 , a23 y a33 no son simultaneamente nulos.
Bajo estas ecuaciones se esconden todas las cuadricas conocidas y no tan conocidas: esferas, elipsoides,paraboloides e hiperboloides. Un par de apuntes, a tener en cuenta:
• Para hacer el resumen lo mas sencillo posible vamos a usar en las ecuaciones reducidas siempre comocentro o vertice el punto cero = (0, 0, 0), pero teniendo en cuenta que cuando ese centro o vertice seaotro punto (x0, y0, z0) basta con sustituir x por x− x0 , y por y − y0 y z por z − z0
• De la misma manera se escribiran las ecuaciones con constante no nula 1 y sin otras constantes anadidas.Para generalizar todas las posibilidades de constantes bastara con sustituir x por x
a , y por yb y z por z
c
• Por ultimo, solo vamos a relatar las ecuaciones de las conicas que, por ası decir, siguen la direccion deleje z (el cono o el paraboloide van abriendose en el eje z ). Basta intercambiar las variables para tenerlas cuadrıcas “siguiendo la direccion” de otro eje, por ejempo si cambiamos x por z se sigue el eje x
Para recordar y comprender mejor como son las cuadricas, hay que tener en cuenta que su nombre tiene muchoque ver con las tipologıa de las secciones que se producen al cortar la superficie cuadrica con planos en lasdirecciones perpendiculares a los ejes –los planos coordenados o paralelos a ellos– (no es la razon del nombre,pero sı coincide en ser una consecuencia). Ası en un elipsoide todos los cortes son elipses, mientras que en un
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
7 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
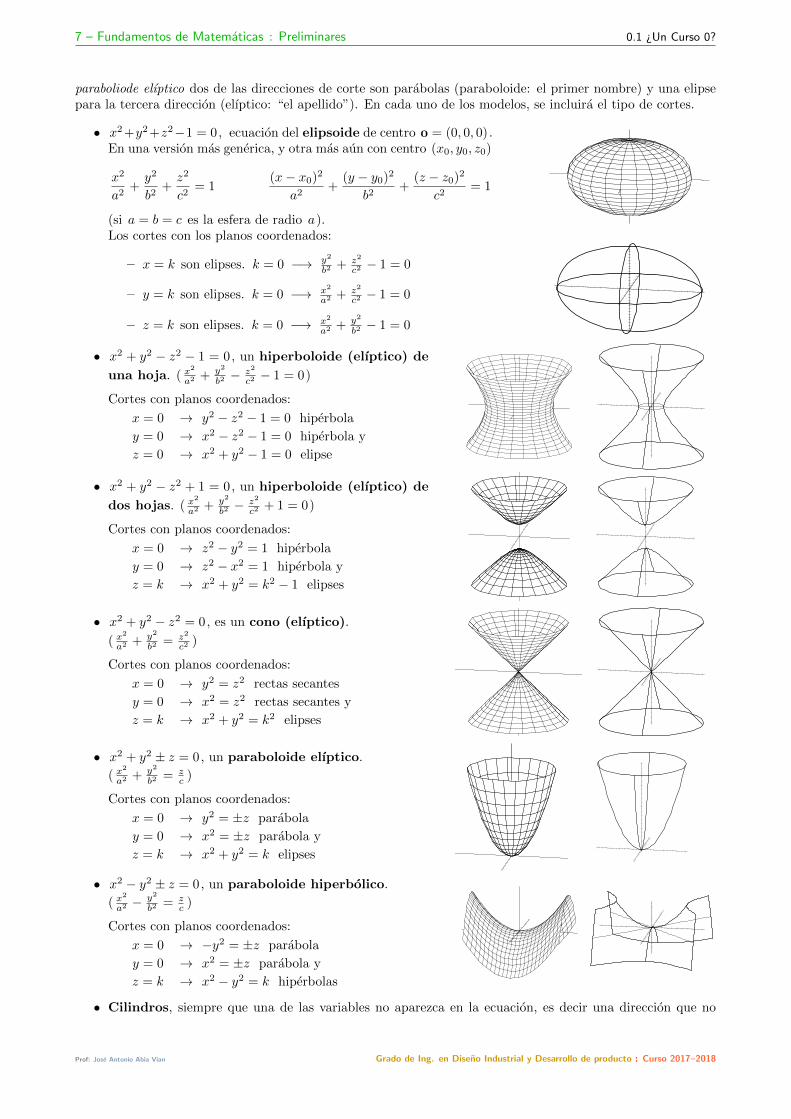
paraboliode elıptico dos de las direcciones de corte son parabolas (paraboloide: el primer nombre) y una elipsepara la tercera direccion (elıptico: “el apellido”). En cada uno de los modelos, se incluira el tipo de cortes.
• x2 +y2 +z2−1 = 0, ecuacion del elipsoide de centro = (0, 0, 0).En una version mas generica, y otra mas aun con centro (x0, y0, z0)
x2
a2+y2
b2+z2
c2= 1
(x− x0)2
a2+
(y − y0)2
b2+
(z − z0)2
c2= 1
(si a = b = c es la esfera de radio a).Los cortes con los planos coordenados:
– x = k son elipses. k = 0 −→ y2
b2 + z2
c2 − 1 = 0
– y = k son elipses. k = 0 −→ x2
a2 + z2
c2 − 1 = 0
– z = k son elipses. k = 0 −→ x2
a2 + y2
b2 − 1 = 0
• x2 + y2 − z2 − 1 = 0, un hiperboloide (elıptico) de
una hoja. ( x2
a2 + y2
b2 −z2
c2 − 1 = 0)
Cortes con planos coordenados:
x = 0 → y2 − z2 − 1 = 0 hiperbola
y = 0 → x2 − z2 − 1 = 0 hiperbola y
z = 0 → x2 + y2 − 1 = 0 elipse
• x2 + y2 − z2 + 1 = 0, un hiperboloide (elıptico) de
dos hojas. ( x2
a2 + y2
b2 −z2
c2 + 1 = 0)
Cortes con planos coordenados:
x = 0 → z2 − y2 = 1 hiperbola
y = 0 → z2 − x2 = 1 hiperbola y
z = k → x2 + y2 = k2 − 1 elipses
• x2 + y2 − z2 = 0, es un cono (elıptico).
( x2
a2 + y2
b2 = z2
c2 )
Cortes con planos coordenados:
x = 0 → y2 = z2 rectas secantes
y = 0 → x2 = z2 rectas secantes y
z = k → x2 + y2 = k2 elipses
• x2 + y2 ± z = 0, un paraboloide elıptico.
( x2
a2 + y2
b2 = zc )
Cortes con planos coordenados:
x = 0 → y2 = ±z parabola
y = 0 → x2 = ±z parabola y
z = k → x2 + y2 = k elipses
• x2 − y2 ± z = 0, un paraboloide hiperbolico.
( x2
a2 − y2
b2 = zc )
Cortes con planos coordenados:
x = 0 → −y2 = ±z parabola
y = 0 → x2 = ±z parabola y
z = k → x2 − y2 = k hiperbolas
• Cilindros, siempre que una de las variables no aparezca en la ecuacion, es decir una direccion que no
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

8 – Fundamentos de Matematicas : Preliminares 0.1 ¿Un Curso 0?
tenga que cumplir ninguna restriccion. Ası el apellido dependera de la conica determinada por las otrasvariables:
a) x2 + y2 − 1 = 0, un cilindro elıptico. ( x2
a2 + y2
b2 = 1, unaelipse que se repite indefinidamente en la direccion de z )
b) x2−y2±1 = 0, un cilindro hiperbolico. ( x2
a2 − y2
b2 = ±1, unahiperbola que existe para cualquier valor de z )
c) x2 ± y = 0, es un cilindro parabolico. ( x2
a2 = yb , una
parabola que se repite en cada valor de z )
• Los planos, como un caso especial
a) x2 − y2 = 0, planos secantes (xa −yb )(xa + y
b ) = 0
b) x2 − 1 = 0, planos paralelos (xa − 1)(xa + 1) = 0
c) x2 = 0, planos coincidentes.
Nota: Analogamente al caso de las conicas, cuando los coeficientes a12 = a13 = a23 = 0 (no haya terminos dexy , ni xz , ni yz ), bastara con “completar cuadrados” para obtener las ecuaciones reducidas.
0.1.4 Ejercicios
0.1 Hallar, usando las propiedades de las razones trigonometricas, los valores siguientes:
a) tg π3 b) sen(π2 − x) c) cos(π − x) d) sen π
12e) tg π
8 f) cos(π3 + π4 ) g) sen(3x) h) sen(x4 )
0.2 Resolver las siguientes ecuaciones exponenciales y logarıtmicas
a) 3e1−x = 9e2 b) ex − 2ex+1 + 4e2 = 2 c) e2x − 2ex − 3 = 0
d) ln(x2)− lnx = ln 1e e) − 3
2 − ln(x+ 1) = ln√e f)
{lnx+ ln y = 2ex = ee · ey
0.3 Usa las definiciones de sh, ch, th y argth, para comprobar que se cumplen las propiedades:
a) chx+ shx = ex b) ch2 x− sh2 x = 1 c) 1ch2 x
= 1− th2 x
d) th(2x) = 2 th x1+th2 x
e) ch(x+ y) = chx ch y + shx sh y f) argth(th(x)) = x
0.4 Comprobar que la conica 1− 4x− 4y + x2 + y2 = 0 es una circunferencia de centro (2,−2) ¿y radio?
0.5 Completar los cuadrados para hallar la ecuacion reducida e identificar las conicas siguientes:
a) 6x+ 6y + 3y2 = 2 b) x2 + 2x+ y2 = 0 c) 2x2 + 8x+ y − y2 − 2 = 0d) x2 − 2y + x+ 2y2 = 3
2 e) 2xy − 4x+ 3y = 5 f) y2 + 2x+ y + 3x2 = 32
g) y2 + 2x+ y − 2x2 = 32 h) x2 + 2x = y2 − 2y i) 2x2 − 5x+
√2(y − 1) = 3
√2
Indicar el centro o vertice y los semiejes y asıntotas de haberlos
0.6 Completar los cuadrados para hallar la ecuacion reducida e identificar las cuadricas siguientes:
a) x2 + y2 + 2z2 + 2z = 0 b) 2y2 − 3z2 + x2 + 2x = −2 c) 2z2 − 2x+ 2y2 = 0d) x2 − 2y2 − 3z2 = x+ y + z e) x2 − 2y2 + z2 = 2x− 4y − 2z f) 2y2 + 2x− 2z2 = 0
Indicar el tipo de los cortes y la “direccion” de la cuadrica
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

9 – Fundamentos de Matematicas : Preliminares 0.2 Numeros Complejos
0.2 Numeros Complejos
Este tema de numeros complejos es mas informativo que recordatorio, siendo el uso explıcito de los complejospracticamente nulo en las asignaturas de Matematicas del Grado. Sin embargo conocer su existencia e inter-relacion con los reales es muy util para la descomposicion y busqueda de raıces de polinomios, o en la resolucionde ecuaciones diferenciales; ademas en otras asignaturas mas tecnicas podrıan hacer uso de ellos.
Hemos visto y conocido las diferencias entre los numeros enteros, racionales y reales, y la manera en quecada conjunto va mejorando o completando alguna carencia del anterior, N ⊂ Z ⊂ Q ⊂ R .
Pero tambien los reales presentan algun “problemilla” a la hora de operar: como que no hay raıces cuadradasde numeros negativos. En realidad este fallo es mucho mas general: es cierto en R que si x e y son reales conx ≥ 0, entonces xy ∈ R ; pero esto no se cumple cuando x < 0. Para resolver este “defecto” se contruyen losnumeros complejos: un conjunto C que contenga a R , que sus operaciones suma y producto permitan restary dividir y sean coherentes con las operaciones de los subconjuntos, y que para la potencia se verifique ademasque si z, w ∈ C , entonces zw ∈ C .
0.2.1 Unidad imaginaria y forma binomica de un numero complejo
La ecuacion x2 = −b2 no tiene solucion para valores reales, pero sı la tiene compleja definiendo i =√−1 o
i2 = −1, pues ası x2 = −b2 tiene por solucion x = ±√−1√b2 = ±ib . Y en general las soluciones complejas
de las ecuaciones de grado dos, (x− a)2 = −b2 , son de la forma x = a±√−b2 = a± ib .
Los valores a y b reales forman los complejos de la forma a+ ib , que se conoce como forma binomica delnumero complejo. Del elemento i se dice que es la unidad imaginaria.
Suele describirse el conjunto de los numeros complejos por C = {a+ ib : a, b ∈ R} (a veces C = R + iR) yse denotan los elementos de C por z = a+ ib . Se representan en el plano R2 que se denomina entonces planocomplejo, al eje se abcisas se le denomina eje real y al de ordenadas eje imaginario.
Definicion 4.- Si z = a + ib es un numero complejo, al valor real a se le llama se llama parte real de z ,Re(z) = a , y al valor real b la parte imaginaria, Im(z) = b , es decir, z = Re(z) + i Im(z).
Si la parte imaginaria de z es cero, el complejo es un numero real y, suele indicarse con z ∈ R . Si la partereal de z es cero se dice que es imaginario puro y, suele indicarse con z ∈ iR .
El cero en C es el cero real 0 = 0 + i0.
Se tienen en C las operaciones internas suma y producto, siguientes:
z + w= (a+ib) + (c+id) = (a+ c) + i(b+ d)
z · w= (a+ib)(c+id) = ac+ iad+ icb+ i2bd = (ac−bd) + i(ad+cb)
con las propiedades habituales de asociatividad, conmutatividad y distributividad del producto respecto a lasuma.
0.2.1.1 Construccion formal del plano complejo
En realidad el plano complejo no se construye como hemos relatado antes, sino en la forma que describimos eneste apartado:
Consideremos el conjunto R2 y contruyamos en el unas operaciones suma y producto que funcionen comodeseamos. Sobre R2 tenemos definida una operacion suma que sı es interna:
(a1, b1) ∈ R2, (a2, b2) ∈ R2, y (a1, b1) + (a2, b2) = (a1 + a2, b1 + b2) ∈ R2,
con operacion inversa la resta (suma de opuestos) y una operacion producto escalar, que no es interna,
(a1, b1) ∈ R2, (a2, b2) ∈ R2, y (a1, b1) · (a2, b2) = a1a2 + b1b2 ∈ Ry no admite una operacion inversa. Dotar a R2 de una operacion “producto” interna, con un funcionamientoanalogo al funcionamiento del producto en R crea esa nueva estructura conocida como el conjunto de losnumeros complejos y tambien como plano complejo o cuerpo complejo.
Esta operacion producto “∗” se define de la forma siguiente:
(a1, b1) ∗ (a2, b2) = (a1a2 − b1b2, a1b2 + b1a2).
Ası, el conjunto de los numeros complejos, C , esta formado por R2 con dos operaciones basicas: suma “+”(la suma de R2 ) y el producto complejo “∗” (definido arriba). Es decir, C = (R2,+, ∗).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

10 – Fundamentos de Matematicas : Preliminares 0.2 Numeros Complejos
El producto (complejo) tiene por elemento neutro (1, 0), pues
(1, 0) ∗ (a, b) = (a, b) ∗ (1, 0) = (1a− 0b, 0a+ 1b) = (1a, 1b) = (a, b).
De hecho, para cualquier real λ , se tiene que (λ, 0) ∗ (a, b) = (λa − 0b, 0a + λb) = (λa, λb); como en R2
tambien sabemos que λ(a, b) = (λa, λb), pueden identificarse los elementos (λ, 0) con los numeros reales λ , esdecir, en C podemos decir que (λ, 0) = λ a todos los efectos.
Como (a, b) = (a, 0) + (0, b) = a + (0, b) = a + b(0, 1), haciendo (0, 1) = i el numero complejo se escribe(a, b) = a + ib , en la denominada forma binomica del numero complejo. La unidad imaginaria i cumple enefcto que i2 = ii = (0, 1) ∗ (0, 1) = (−1, 0) = −1.
Y tambien el producto en la forma binomica coincide con el definido pues:
(a+ib)(c+id) = ac+ iad+ icb+ i2bd = (ac−bd) + i(ad+cb) = (ac−bd, ad+cb) = (a, b) ∗ (c, d)
0.2.2 Propiedades de los complejos. Conjugado y modulo
Proposicion 5.- Sea z ∈ C− {0} , entonces existe un unico w ∈ C tal que zw = 1.
Demostracion:En efecto, con z = a + ib y w = x + iy , zw = ax − by + i(ay + bx) y zw = 1 = 1 + i0 ⇐⇒ el sistema{ax− by = 1bx+ ay = 0
tiene solucion unica. Que es cierto, con x = aa2+b2 e y = −b
a2+b2 (a2 + b2 6= 0 pues z 6= 0).
Si z = a+ ib , el inverso se denota por z−1 = 1z y viene dado por la expresion z−1 = a
a2+b2 + i −ba2+b2 = a−ib
a2+b2 .
0.2.2.1 Conjugado de un numero complejo
Definicion 6.- Sea z = a+ib un complejo, se llama conjugado de z al numero complejo z = a+i(−b) = a−ib .
Nota: Con la notacion de R2 , el conjugado de (a, b) es (a,−b) y son simetricos respecto al eje real (de abcisas).
Propiedades 7.- Sean z, w ∈ C , entonces
a) z = z ; z + w = z + w ; zw = z w ; z−1 = (z)−1 .
b) z = z ⇐⇒ z = a+ i0 ∈ R ; z = −z ⇐⇒ z = 0 + ib ∈ iR .
c) z + z = 2 Re(z); z − z = i2 Im(z). .
0.2.2.2 Modulo de un numero complejo
Definicion 8.- Sea z = a+ ib ∈ C . Se denomina modulo (o norma) de z al valor real |z| = +√a2 + b2 .
Se llama distancia entre z y w al valor real d(z, w) = |z − w| .
Nota: Evidentemente, el modulo de un complejo es su distancia al origen; y si z es real, z = a + i0 = a , setiene que |z| = +
√a2 + 02 = +
√a2 = |a| , es decir, el modulo complejo coincide con el valor absoluto real.
Propiedades 9.- Sean z, w ∈ C , entonces
a) |z| ≥ 0; |z| = 0⇐⇒ z = 0.
b) |Re(z)| ≤ |z| ; |Im(z)| ≤ |z| ; |z| ≤ |Re(z)|+ |Im(z)| .
c) |z| = |z| : |z|2 = zz ; 1z = z
zz = z|z|2 .
d) |z + w| ≤ |z|+ |w| ; |z − w| ≥∣∣∣ |z| − |w| ∣∣∣ .
e) |zw| = |z| |w| ;∣∣z−1
∣∣ = |z|−1. .
Del modulo, son inmediatas las propiedades de la distancia:
a) d(z, w) ≥ 0; d(z, w) = 0⇐⇒ z = w . b) d(z, w) ≤ d(z, t) + d(t, w), ∀ t ∈ C .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

11 – Fundamentos de Matematicas : Preliminares 0.2 Numeros Complejos
0.2.3 Forma polar de un numero complejo
Sea z = a+ ib = (a, b). Un punto de R2 queda perfectamente determinado mediante su distancia al origen |z|y el angulo θ que forma con el eje polar (el semieje real positivo).
Definicion 10.- Sea z = x + iy un numero complejo no nulo. Se llama argumento de z y se designa porarg(z) a cualquier numero real θ que verifique que
z = x+ iy = |z| cos θ + i |z| sen θ = |z| (cos θ + i sen θ).
Se dice entonces que z esta en forma polar (o modulo argumental) y denotarse por z = |z|θ .
Como las funciones seno y coseno son periodicas de perıodo 2π , arg(z) esta determinado salvo multiplos de2π ; es decir, hay infinidad de argumentos de z , pero dos cualesquiera de ellos difieren en multiplos de 2π . Sifijamos como argumento preferido el arg(z) ∈ (−π, π] , puede obtenerse de
(arg(z) ∈ (−π, π]
)=
{π, si x < 0 e y = 0
2 arctg yx+|z| , si x ≥ 0 o y 6= 0
2 arctgy
x+|z|
π
Al argumento que se encuentra dentro del intervalo de tamano 2π elegido como preferente suele denominarseargumento principal y denotarse por Arg(z). Con este concepto, todos los argumentos de z se pueden describirmediante: arg(z) = Arg(z) + 2kπ , ∀ k ∈ Z .
Aunque estamos habituados a manejar el angulo en el intervalo [0, 2π) o (0, 2π] , es mas usual tomar elintervalo (−π, π] o el [−π, π) como preferente debido sobre todo a:
Operaciones multiplicativas en forma polar 11.- Si z = |z|θ y w = |w|δ , se cumple que:
a) z = |z|(−θ) b) z−1 = (|z|−1)(−θ) c) zw = (|z| |w|)θ+δ d) z
w =(|z||w|
)θ−δ
e) zn = (|z|n)nθ .
0.2.4 Raices complejas
Proposicion 12.- Un complejo z 6= 0 tiene n raıces n -esimas distintas. Si θ es un argumento de z , sonprecisamente
z1n = (|z|
1n ) θ
n+ 2kπn, para k = 0, . . . , n− 1 .
Demostracion:Un complejo w es la raız n -esima de z , si se verifica que wn = z ; es decir, si |w|n = |z| y n arg(w) = arg(z) =
θ+2kπ (alguno de los argumentos de z ). Luego |w| = |z|1n y arg(w) = θ+2kπ
n , con k ∈ Z ; pero con todos estosargumentos solo se obtienen n numeros complejos distintos, los mismos que se obtienen tomando los n valoresde k = 0, 1, . . . , n− 1. Es decir, existen n , y solo n , complejos distintos que son raıces n -esimas de z , que son
z1n = |z|
1n(cos θ+2kπ
n + i sen θ+2kπn
), con k = 0, . . . , n− 1.
Observacion 13.- Es claro de la prueba anterior que lasraıces n -esimas de un complejo estan distribuidas re-gularmente en una circunferencia de radio n
√|z| . Por
ejemplo, las raıces quintas de z = rπ3
, son los 5 numeroscomplejos:
(i) z0 = 5√r π
15 + 2π05
= 5√r π
15.
(ii) z1 = 5√r π
15 + 2π15
= 5√r 7π
15.
(iii) z2 = 5√r π
15 + 2π25
= 5√r 13π
15.
(iv) z3 = 5√r π
15 + 2π35
= 5√r 19π
15= 5√r−11π
15.
(v) z4 = 5√r π
15 + 2π45
= 5√r 25π
15= 5√r−5π
15.
que quedan distribuidos como en la figura aneja.
z=rπ3
z0 = 5√r π
15
z1 = 5√r 7π
15
z2 = 5√r 13π
15
z3 = 5√r 19π
15 z4 = 5√r 25π
15
s
s
ss
s s
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

12 – Fundamentos de Matematicas : Preliminares 0.2 Numeros Complejos
0.2.4.1 La exponencial compleja
Definicion 14.- Si z = a+ ib , se define la exponencial compleja por ez = ea(cos b+ i sen b)
Proposicion 15.- Se verifican las siguientes propiedades:
a) Si z = a ∈ R , entonces ez = ea+i0 = ea(cos 0 + i sen 0) = ea y la exponencial compleja coincide con laexponencial real.
b) Si z = ib ∈ iR , entonces eib = e0+ib = e0(cos y + i sen y) = cos y + i sen y .
Entonces, si z = a+ ib , se tiene que ez = eaeib .
c) |ez| = |ea| |eiy| = ea |cos y + i sen y| = ea√
cos2 y + sen2 y = ea .
De donde ez 6= 0, para todo z ∈ C .
d) ez = ez , (ez)−1 = e−z y ez+w = ezew , para todo z, w ∈ C .
e) ez es periodica de perıodo 2πi y si ez = ew , entonces z − w = 2kπi , con k ∈ Z .
Nota: Si z 6= 0, puede escribirse como z = |z| eiArg(z) = |z| eiθ que se denomina forma exponencial de z .
Definicion 16.- Sea z un numero complejo no nulo. Se dice que un numero complejo w es un logaritmo dez , y se escribe w = log z , cuando ew = z .
Proposicion 17.- Sea z un numero complejo no nulo, los logaritmos de z son todos los numeros complejos
log(z) = ln |z|+ i arg(z) (uno por cada argumento de z )
Al valor Log(z) = ln |z|+iArg(z) que se le llama logaritmo principal de z y cualquiera de los otros logaritmosde z se obtienen de: log(z) = Log(z) + 2kπi , ∀ k ∈ Z .
0.2.5 Ejercicios
0.7 Efectuar las siguientes operaciones, expresando el resultado en forma binomica:
i−1;
√2 + i
2i;
2− i
1 + i+ i;
5
(1− i)(2− i)(i− 3); i344 + (−i)231;
(1 + i)5 + 1
(1− i)5 − 1;
0.8 Usar, cuando sea posible, las propiedades del modulo para calcular:
∣∣i−1∣∣ ; ∣∣∣∣∣
√2 + i
2i
∣∣∣∣∣ ;∣∣∣∣2− i
1 + i+ i
∣∣∣∣ ; ∣∣∣∣ 5
(1− i)(2− i)(i− 3)
∣∣∣∣ ; ∣∣i344(−i)231∣∣ ; ∣∣∣∣i(1 + i)5
2(1− i)5
∣∣∣∣ ;0.9 Expresar en forma exponencial, z = |z| ei arg(z) , los complejos siguientes:
a) −8 b) −1− i c) (−√
3+i2 )3 d)
[4 cos(π2 ) + 4i sen(π2 )
]−2
0.10 Expresar en forma binomica los complejos siguientes (tomar Arg(z) ∈ (−π, π]):
a)√
2 eiπ b) e1−iπ2 c) iei7π4 d) Log(i3) e) Log(2e1+iπ3 )
0.11 Hallar todos los valores complejos de:
a) i12 b) 8
16 c) (−1)
13 d) (−
√3 + i)
35 e)
[4 cos( 2π
3 ) + 4i sen( 2π3 )]− 3
4
0.12 Si se sabe que 1 + i es una raız cubica de z , hallar z y las demas raıces.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

13 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
0.13 Describir geometricamente las regiones del plano complejo:
a) |z − i| = 1 b)∣∣z2∣∣ = 4 c) 0 ≤ Arg z ≤ π
2 d) z = z
e) z = −z f) Im(z) ≤ 0 g) Re(z) > 2 h) Re(z) + Im(z) = 1
0.14 ¿Que valores de z verifican que |z + 1| < |z − i|?
0.15 Resolver las ecuaciones:
a) z4 + 2 = 0 b) z2 + 2z − i = 0 c) z3
2 + (i + 1)z2 − (2− i)z = 0
d) z3 = −1 e) z6 = iz f) z4 + (3− 2i)z2 = 6i
0.16 Hallar los z para los que
a) ez∈R b) Re(ez)=0 c) |e−iz|<1 d) ez=−1 e) e2z=i f) ez=e−z
0.17 Resolver la ecuacion z4 = z .
0.18 Probar que son ciertas las siguientes desigualdades: |a+ bi| ≤ |a|+ |b| ≤√
2 |a+ bi| .
0.19 Probar las propiedades de la exponencial compleja dadas en c) y d) de la proposicion 15.
0.3 Polinomios
0.3.1 Introduccion. Nociones basicas
Los conjuntos de numeros Q , R y C , verifican que la suma y el producto son operaciones internas, es decir lasuma o producto de racionales es racional, de reales es real y de complejos es compleja. Ademas, en ellos existeinverso para la suma y para el producto (resta y division tambien internas).
A los conjuntos con este tipo de caracterısticas se les denomina cuerpos (a los conjuntos de arriba se lesdice cuerpos conmutativos pues el producto es conmutativo, ab = ba) y se usan como conjuntos de numeros (oescalares) asociados a otros elementos: los polinomios, las matrices, los vectores, . . . .
En esta seccion, formalizaremos los conocidos polinomios e investigaremos algunas de sus propiedades ytambien entenderemos el significado del cuerpo asociado.
Definicion 18.- Se llama polinomio en la indeterminada X y con coeficientes en un cuerpo conmutativo K ,a toda expresion formal del tipo siguiente:
a0 + a1X + a2X2 + ...+ anX
n, siendo a0 , a1 , . . . , an elementos de K
Los numeros a0 , . . . , an son los coeficientes del polinomio, y de cada sumando aiXi se dice el termino de
grado i o monomio de grado i del polinomio. Al conjunto de todos los polinomios en la indeterminada X concoeficientes en K lo denotamos por K[X] :
K[X] ={a0 + a1X + · · ·+ anX
n : ∀ i, ai ∈ K}
Nosotros trabajaremos generalmente con K = R o K = C (y alguna vez con K = Q). Ası:
R[X] ={a0 + a1X+ · · ·+ anX
n : ai ∈ R}
es el conjunto de los polinomios reales (con coeficientes reales),
C[X] ={a0 + a1X+ · · ·+ anX
n : ai ∈ C}
es el de los polinomios complejos (con coeficientes complejos),
Q[X]={a0+a1X+· · ·+anXn : ai ∈ Q
}es el de los polinomios con coeficientes racionales, . . .
Notar que por ser Q ⊆ R ⊆ C tambien Q[X] ⊆ R[X] ⊆ C[X] .
La letra X no representa ningun valor, no es una variable ni una incognita: es un mero soporte para el ex-ponente (recordemos, polinomio=expresion formal). En otras palabras lo realmente significativo del polinomio,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

14 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
es la sucesion ordenada de sus coeficientes. Ası:
3 + 8X− 9X2 ≡ (3, 8,−9, 0, 0, . . .)8X− 9X2 + 3 ≡ (3, 8,−9, 0, 0, . . .)
3 + 8X2 − 9X5 ≡ (3, 0, 8, 0, 0,−9, 0, 0, . . .)X ≡ (0, 1, 0, 0, 0, . . .)
12 ≡ (12, 0, 0, 0, 0, . . .)
Es util abreviar la escritura de todos los terminos usando la notacion del sumatorio
P (X) = a0 + a1X + ...+ anXn =
n∑i=0
aiXi (por convenio, X0 = 1)
Definicion 19.- Sea P (X) =n∑i=0
aiXi un polinomio. Si an 6= 0, diremos que P (X) tiene grado n , Es decir, el
mayor exponente de X que tenga coeficiente no nulo. Y lo denotaremos por gr(P ) = n .Los polinomios de grado cero son de la forma P (X) = c , con c ∈ K y c 6= 0. Al polinomio cero, P (X) = 0,
no se le asigna ningun grado.
Definicion 20.- Diremos que dos polinomios son iguales si tienen el mismo grado y los coeficientes de cada
termino son iguales. Es decir, si P (X) =n∑i=0
aiXi y Q(X) =
m∑i=0
biXi , entonces:
P (X) = Q(X) ⇐⇒ n = m y ∀ i, ai = bi .
Expresiones tales como X2−12 = X+5 son pues absurdas, como lo serıa escribir 5 = 18, ya que ambos polinomiosson distintos.
Ejemplo 21 Encontrar a , b , c , tales que 3X + 5X2 + 12X4 = (a+ 1)X + 5X2 + 2cX4 + (2a+ b)X6 .Para que coincidan deben tener la misma sucesion de coeficientes, es decir,
3X + 5X2 + 12X4 ≡ (0, 3 , 5, 0, 12, 0, 0 , 0, . . ., 0, . . .),(a+ 1)X + 5X2 + 2cX4 + (2a+ b)X6 ≡ (0, a+ 1, 5, 0, 2c, 0, 2a+ b, 0, . . ., 0, . . .),
deben ser iguales. Igualando coeficiente a coeficiente se obtiene el sistema de ecuaciones:
0 = 03 = a+ 15 = 50 = 0
12 = 2c0 = 2a+ b0 = 0· · ·
=⇒
3 = a+ 1
12 = 2c0 = 2a+ b
=⇒
a = 2c = 6b = −2a
=⇒
a = 2c = 6b = −4
4
0.3.1.1 Operaciones en K[X]
Sean P (X) =n∑i=0
aiXi y Q(X) =
m∑i=0
biXi polinomios de K[X]
Definicion 22.- Llamaremos suma de los polinomios P y Q al polinomio P +Q , obtenido de:
P (X) +Q(X) =
(n∑i=0
aiXi
)+
(m∑i=0
biXi
)=
max{n,m}∑i=0
(ai + bi)Xi
Si, m > n , entonces an+1 = an+2 = · · · = am = 0, es decir, completamos con coeficientes cero.
Nota: gr(P +Q) ≤ max{gr(P ), gr(Q)}
Ejemplo Para P (X) = 3 + 6X2 − 5X4 y Q(X) = 2− 8X− 6X2 + 7X6 , se tiene
P +Q=(
3 + 6x2 − 5X4)
+(
2− 8X− 6X2 + 7X6)
=(
3 + 0X + 6X2 + 0X3 − 5X4 + 0X5 + 0X6)
+(
2− 8X− 6X2 + 0X3 + 0X4 + 0X5 + 7X6)
= (3 + 2) + (0− 8)X + (6− 6)X2 + (0 + 0)X3 + (−5 + 0)X4 + (0 + 0)X5 + (0 + 7)X6
= 5− 8X + 0X2 + 0X3 − 5X4 + 0X5 + 7X6 = 5− 8X− 5X4 + 7X6.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

15 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
y podemos comprobar que gr(P +Q) ≤ max{gr(P ), gr(Q)} = max{4, 6} = 6.
Definicion 23.- Llamaremos producto de los polinomios P y Q al polinomio P ·Q , obtenido de:
P (X) ·Q(X) =
(n∑i=0
aiXi
)(m∑i=0
biXi
)=
n+m∑i=0
ciXi, donde ci =
i∑k=0
akbi−k
Nota: gr(P ·Q) = gr(P ) + gr(Q).
Observaciones:• El neutro de la suma es el polinomio cero P (X) = 0 y del producto el polinomio 1, P (X) = 1.
• El inverso para la suma: de P (X) es (−1)P (X) = −P (X).
• No hay inversos para el producto: si el polinomio P (X) = X tuviera un inverso Q(X), tendrıa que ocurrirque P (X)Q(X) = 1. Pero entonces 0 = gr(1) = gr(P ·Q) = 1 + gr(Q) ≥ 1.
• Se cumplen las propiedades asociativas y distributivas.
• Si P (X) 6= 0 y P (X)Q(X) = 0, entonces Q(X) = 0.
En efecto, si fuera gr(Q) = 0 con Q(X) = k 6= 0, entonces P (X)Q(X) = kP (X) 6= 0 (absurdo); y sigr(Q) > 0, entonces gr(PQ) > 0 y P (X)Q(X) 6= 0 (tambien absurdo), luego Q(X) = 0.
• Si P (X) 6= 0 y P (X)Q(X) = P (X)R(X), entonces Q(X) = R(X). (Inmediata de la anterior.)
0.3.2 Division euclıdea de polinomios. Divisibilidad y factorizacion
El conjunto de polinomios K[X] tiene en muchos aspectos una profunda semejanza con el conjunto Z de losenteros (algebraicamente tienen la misma estructura, ambos son anillos conmutativos). Repasamos brevementealgunos hechos basicos que ocurren en Z , para despues hacer el estudio paralelo en K[X] .
? Dados a, b ∈ Z , b 6= 0 existen q, r ∈ Z unicos tal que a = qb + r con 0 ≤ r < |b| (la division entera oeuclıdea, con q y r el cociente y el resto).
? Dados a, b ∈ Z , se dice que ”b divide a a” (o que ”a es multiplo de b”) si existe c ∈ Z tal que a = bc .Se escribe b | a y significa que el resto de la division entera de a entre b es 0.
? Un elemento p ∈ Z se dice irreducible si los unicos enteros que lo dividen son 1, −1, p y −p . A losenteros irreducibles positivos se los llama numeros primos. El 1 no suele considerarse primo.
? Todo numero entero n admite una descomposicion unica (salvo el orden de los factores) de la forman = (±1)pt11 p
t22 · · · ptrr con pi numero primo ∀ i .
? Si a, b ∈ Z , se llama maximo comun divisor de a y b , mcd(a, b), a un entero d tal que: d | a y d | b y esel mayor, es decir, para cualquier otro δ ∈ Z tal que δ | a y δ | b entonces δ | d .
? El Algorıtmo de Euclides permite calcular el mcd(a, b) sin necesidad de utilizar la descomposicion dea y b en factores.
La realizacion practica del algoritmo se dispone ası:
q1 q2 q3 · · · · · · qn−1 qn qn+1
a b r1 r2 · · · · · · rn−2 rn−1 rnr1 r2 r3 · · · · · · rn−1 rn 0
a = bq1 + r1
b = r1q2 + r2
r1 = r2q3 + r3
· · ·rn−1 = rnqn+1 + 0
donde qi y ri son respectivamente los cocientes y restos de las divisiones, y rn = mcd(a, b).
La conclusion es correcta, pues por ser a = q1b+ r1 y d un divisor de a y b , a y b se descomponen ena = da1 y b = db1 , luego r1 = a − bq1 = da1 − db1q1 = d(a1 − b1q1) y d divide a r1 . Luego cualquierdivisor de a y b lo es tambien de b y r1 . Analogamente b = q2r1 + r2 y por el mismo proceso losdivisores de b y r1 tambien lo son de r1 y r2 . El proceso es mcd(a, b) = mcd(b, r1) = mcd(r1, r2) =· · · = mcd(rn−1, rn) = rn pues rn | rn−1 y rn | rn .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

16 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
? Si a, b ∈ Z , se llama mınimo comun multiplo de a y b , mcm(a, b), a un entero m tal que: a |m y b |my es el menor, es decir, para cualquier otro µ ∈ Z tal que a |µ y b |µ entonces m |µ .
? mcd(a, b) = mcd(±a,±b) = mcd(b, a) (igual para el mcm). Ademas, ab = mcd(a, b) ·mcm(a, b)
Ejemplo El mcd(711, 243) = 9 y el mcd(−300, 432) = 12 pues
2 1 12 2711 243 225 18 225 18 9 0
−1 3 3 1 2−300 432 132 36 24 132 36 24 12 0
0.3.2.1 Division entera o euclıdea de polinomios
Regresemos de nuevo a K[X] , y veamos que podemos encontrar resultados bastante analogos:
Definicion 24.- Dados P (X) y Q(X) con Q(X) 6= 0, existen dos unicos polinomios C(X) y R(X) tales que:
P (X) = C(X) ·Q(X) +R(X), siendo R(X) = 0 o gr(R) < gr(Q).
Si R(X) = 0, se dice que Q(X) divide a P (X) y se escribe Q(X) |P (X). Tambien se dice que Q(X) es un factorde P (X) (de P (X) = C(X) ·Q(X), claramente).
Nota: El metodo de division de polinomios es el conocido por los alumnos. Los polinomios constantes, de gradocero, dividen a todos los polinomios y el polinomio cero es multiplo de cualquiera.
Definicion 25.- Se dice que D(X) es un maximo comun divisor de P (X) y Q(X) si se verifica que D(X) |P (X)y D(X) |Q(X) y es el mayor, es decir, si para cualquier otro ∆(X) ∈ K[X] tal que ∆(X) |P (X) y ∆(X) |Q(X)entonces ∆(X) |D(X).
El mcd de dos polinomios esta determinado salvo un factor constante. En particular, puede elegirse unmcd monico (coeficiente del termino de mayor grado 1) que con esta condicion adicional es unico.
Definicion 26.- Un polinomio P (X) de grado n > 0 se dice reducible en K[X] si existen Q(X) y C(X)polinomios no constantes de K[X] tales que P (X) = Q(X)C(X).
Si no es reducible en K[X] , se dice irreducible en K[X] .
Observaciones:
• Si Q(X) y C(X) reducen a P (X), entonces 0 < gr(Q) < gr(P ) y 0 < gr(C) < gr(P ).
• En consecuencia, los polinomios de grado 1 son siempre irreducibles.
• Las constantes no se consideran irreducibles.
• Un polinomio es o no irreducible en K[X] . Ası, X2 + 1 es irreducible en R[X] mientras que no lo es enC[X] , pues X2 + 1 = (X− i)(X + i).
• Si Q(X) |P (X), entonces kQ(X) |P (X), para todo k∈K . Por ello suele trabajarse con divisores monicos.
• El Algoritmo de Euclides es valido en K[X] para obtener el maximo comun divisor de dos polinomios.
Teorema 27.- Todo polinomio P (X) ∈ K[X] admite en K[X] una descomposicion unica en la forma
P (X) = k(Q1(X)
)m1(Q2(X)
)m2
· · ·(Qr(X)
)mrdonde k ∈ K y los Qi(X) son polinomios irreducibles monicos.
0.3.2.2 Raız de un polinomio
Dado un polinomio P (X) = a0 + a1X + · · · + anXn ∈ K[X] y α ∈ K , denotaremos por P (α) al resultado de
efectuar en K los calculos: a0 + a1α+ · · ·+ anαn .
Definicion 28.- Se dice que α ∈ K es una raız del polinomio P (X) ∈ K[X] si P (α) = 0.
Teorema 29.- α ∈ K es raız de P (X) ⇐⇒ (X− α) |P (X).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

17 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
Demostracion:Siempre podemos dividir P (X) entre X−α y su division entera es P (X) = C(X) · (X−α) +R(X) donde R(X) = 0o gr(R(X)) < gr(X − α) = 1, es decir R(X) es cero o es una constante distinta de cero luego R(X) = k ∈ K ytenemos que: P (X) = C(X) · (X − α) + k , luego P (α) = C(α) · (α − α) + k = k . Como P (α) = k se puedeconcluir que
P (α) = 0⇐⇒ r = 0⇐⇒ P (X) = C(X) · (X− α)⇐⇒ (X− α) |P (X)
Corolario 30.- Un polinomio, de grado mayor que 1, irreducible en K[X] no tiene raıces en K .
Nota: El resultado inverso “si no tiene raıces en K entonces es irreducible en K[X]” no es cierto. Por ejemplo,en R[X] , el polinomio X4 + 5X2 + 4 = (X2 + 1)(X2 + 4) es reducible, pero no tiene raıces en R .
La condicion “de grado mayor que 1” es obvia, pues los polinomios de grado uno aX + b son siempreirreducibles y siempre tienen una raız.
Definicion 31.- Diremos que α ∈ K es una raız de multiplicidad m del polinomio P (X) ∈ K[X] , si se cumpleque P (X) = (X− α)m ·Q(X), con Q(α) 6= 0.
Lema 32.- Sea P (X) = Q(X)R(X). Si α ∈ K es raız de P (X) con multiplicidad m y Q(α) 6= 0 (no es raız deQ(X)), entonces α es raız de R(X) con multiplicidad m . .
Teorema 33.- Un polinomio de grado n posee, a lo mas, n raıces (contadas con sus multiplicidades).
Demostracion:En efecto, si P (X) tiene r raıces α1 , α2 , . . . , αr , de multiplicidades respectivas m1 , m2 , . . . , mr , en-tonces P (X) = (X − α1)m1(X − α2)m2 · · · (X − αr)
mrQ(X), por el Lema 32 anterior. Luego n = gr(P (X)) =m1 +m2 + · · ·+mr + gr(Q(X)), por lo que el numero de raices, m1 +m2 + · · ·+mr , es a lo mas n .
Corolario 34.- Un polinomio de grado n con n+ 1 raıces es el polinomio 0.
0.3.2.3 Factorizacion de polinomios de coeficientes complejos
El siguiente resultado (que no es elemental) aporta la informacion necesaria:
Teorema fundamental del Algebra 35.- Todo polinomio con coeficientes complejos, de grado mayor o igualque uno posee al menos una raiz compleja.
Corolario 36.- En C[X] :
• Un polinomio de grado n tiene n raıces (contadas con sus multiplicidades).
• Todo polinomio de grado n ≥ 1 se descompone en producto de n factores de grado 1.
• Los unicos polinomios irreducibles son los de grado 1.
Ejemplos
• 4X2 − 8X + 13 = 4(X− (1 + 3
2i))(
X− (1− 32i))
• 12X
4 + 8 = 12 (X4 + 16) = 1
2 (X− 2eiπ4 )(X− 2ei
3π4 )(X− 2e−i
3π4 )(X− 2e−i
π4 ) 4
0.3.2.4 Factorizacion de polinomios en R[X]
Puesto que R ⊆ C , un polinomio de R[X] puede mirarse como perteneciente a C[X] , y se descompone en factoreslineales en C[X] . Ahora bien, estos factores puede que no pertenezcan todos ellos a R[X] .
Lema 37.- Sea P (X) =n∑i=0
aiXi ∈ R[X] . Si α es una raız compleja (y no real) de P (X), entonces α tambien es
raız de P (X), y con la misma multiplicidad que α . .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

18 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
Nota: Los polinomios de grado 2 formados como en la demostracion del lema anterior (por (X− α)(X− α) conα no real), son irreducibles en R[X] .
Teorema 38.- Todo polinomio de coeficientes reales y grado mayor o igual que 1 se descompone en R[X] comoproducto de factores irreducibles de grado 1 o de grado 2.
Nota: La factorizacion del polinomio ası obtenida es unica (por la unicidad de la factorizacion compleja):
P (X) = an(X− α1)m1 · · · (X− αr)mr (X2 + c1X + d1)n1 · · · (X2 + ctX + dt)nt
donde αi ∈ R son las raıces reales, y los coeficientes reales de los polinomios de grado 2 se obtienen concj = −(βj + βj) y dj = βjβj , de las raıces βj y βj complejas de P (X).
Corolario 39.- Un polinomio real de grado impar tiene al menos una raız real.
0.3.2.5 Factorizacion de polinomios de coeficientes racionales
Sea P (X) =n∑i=0
miniXi un polinomio de Q[X] . Entonces, si m∗ es el mınimo comun multiplo de los denominadores
ni , el polinomio P∗(X) = m∗P (X) tiene todos sus coeficientes enteros, y las mismas raıces que P (X).En consecuencia, basta estudiar las raıces de un polinomio de coeficientes enteros:
Teorema 40.- Sea P (X) = a0 + a1X + · · ·+ an−1Xn−1 + anX
n un polinomio con ai ∈ Z , ∀ i . Entonces,
1.- Si P (X) posee una raız α ∈ Z , entonces α | a0 .
2.- Si P (X) posee una raız α = pq ∈ Q , entonces p | a0 y q | an .
(La expresion de α = pq debe estar simplificada al maximo, es decir, mcd(p, q) = 1.) .
Nota: La utilidad del teorema estriba en que se puede construir una lista de candidatos a raıces y bastacomprobar si cada uno de ellos es o no raız del polinomio.
Ejemplo Hallar las raıces racionales del polinomio P (X) = 7X4 + 954 X3 + 41
4 X2 − 20X− 3.Buscamos las raıces racionales de Q(X) = 4P (X) = 28X4 + 95X3 + 41X2 − 80X− 12.
• Como 12 = 223, sus divisores son 1, 2, 3, 4 (22 ), 6 (2 · 3) y 12 (223) y los negativos −1, −2, −3, −4,−6 y −12.
Comprobamos si Q(1) = 0, si Q(2) = 0, si Q(−1) = 0, etc. Si lo hacemos usando la division por Ruffini,tenemos ademas la descomposicion del polinomio
28 95 41 −80 −12−2 + −56 −78 74 12
28 39 −37 −6 0= Q(−2)y se tiene Q(X) = (X + 2)(28X3 + 39X2 − 37X− 6)
Buscamos ahora las raıces de Q1(X) = 28X3 + 39X2 − 37X − 6, y la lista de candidatos se reduce a ±1,±2, ±3 y ±6 (desaparecen ±4 y ±12)
28 39 −37 −6−2 + −56 34 6
28 −17 −3 0= Q1(−2)y se tiene Q(X) = (X + 2)2(28X2 − 17X− 3)
Buscamos ahora las raıces de Q2(X) = 28X2 − 17X − 3, y la lista de candidatos se reduce a ±1 y ±3.Ninguno de ellos es raız, por lo que buscamos las raıces fraccionarias:
• Como 28 = 227, sus divisores positivos son 1, 2, 7, 4, 14 y 28. Las posibles raıces racionales de Q2 son:±12 , ±1
4 , ±17 , ±1
14 , ±128 , ±3
2 , ±34 , ±3
7 , ±314 y ±3
28 (son todas distintas y estan simplificadas al maximo).
28 −17 −3− 1
7 + −4 328 −21 0= Q2(−1
7 )y se tiene Q(X) = (X + 2)2(X + 1
7 )(28X− 21)
Luego la descomposicion final es: Q(X) = 28(X + 2)2(X + 17 )(X− 3
4 ).(Por supuesto, como el polinomio Q2 es de grado 2, es mas facil y sencillo obtener sus raıces de la manera
habitual α =17±√
(−17)2−4(−3)28
2·28 .)
4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

19 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
Nota: Para evaluar un polinomio real a mano o con calculadora, es muy util reescribirlo de manera que sepueda hacer con sumas y productos sucesivos, sin almacenaje. Por ejemplo,
P (X) = a4X4 + a3X
3 + a2X2 + a1X + a0 = (a4X
3 + a3X2 + a2X + a1)X + a0
= ((a4X2 + a3X + a2)X + a1)X + a0 = (((a4X + a3)X + a2)X + a1)X + a0
y basta realizar las operaciones, sucesivamente de dentro a fuera.
0.3.2.6 Descomposicion en fracciones simples
Dados P (X), Q(X) ∈ K[X] , se considera la fraccion racional P (X)Q(X) . Se dice que esta simplificada, si P (X) y Q(X) no
tienen divisores comunes (salvo las constantes), es decir, considerando los divisores monicos, mcd(P (X), Q(X)) =1.
Las fracciones racionales reales y complejas admiten una expresion equivalente que es suma de fraccionesracionales mas simples que simplifican su manejo. El proceso para encontrar dicha expresion se denomina de-scomposicion en fracciones simples (de esta manera se usa en integracion, series de potencias, variable compleja,etc.).
Supondremos que la fraccion P (X)Q(X) esta simplificada y gr(P (X)) < gr(Q(X)). De no ser ası, podremos hacer:
• Si P (X)Q(X) y mcd(P (X), Q(X)) = D(X) 6= 1, la expresion equivalente P (X)/D(X)
Q(X)/D(X) esta simplificada.
• Si gr(P (X)) ≥ gr(Q(X)), entonces P (X)Q(X) = C(X) + R(X)
Q(X) , con gr(R(X)) < gr(Q(X)).
y obtener una fraccion que sı lo cumple.Consideremos la descomposicion de Q (eliminamos el soporte X del nombre de los polinomios, por como-
didad) en producto de polinomios monicos irreducibles: Q = Qm11 Qm2
2 · · ·Qmrr . En C[X] , todos los polinomiosirreducibles son de grado 1 luego los Qi son de grado 1, es decir, Qi(X) = X − αi . Pero en R[X] , los poli-nomios irreducibles pueden ser de grado 1 o de grado 2, es decir, de la forma Qi(X) = X − ai o de la formaQi(X) = X2 + biX + ci .
Se plantea entonces la fraccion PQ como suma de un cierto numero de fracciones: por cada factor Qi se
tendran mi sumandos, en la forma
· · ·+ Ti1Qi
+Ti2Q2i
+ · · ·+ Tij
Qji+ · · ·+ Timi
Qmii+ · · ·
donde gr(Tij) < gr(Qi). Entonces,
• En C[X] , todos los numeradores son Tij(X) = tij ∈ C .
• En R[X] , los numeradores son Tij(X) = tij ∈ R si Qi(X) = X − ai (si Qi es de grado 1) y de la formaTij(X) = pijX + qij ∈ R[X] si Qi(X) = X2 + biX + ci (de grado 2).
Para determinar los coeficientes de los numeradores se realiza la suma indicada, poniendo como denominadorcomun Qm1
1 · · ·Qmrr , es decir, Q . El polinomio obtenido en el numerador, se iguala a P y, de esta igualdad depolinomios, se extrae el sistema de ecuaciones que nos permite obtener los valores concretos: este sistema tienesiempre solucion unica.
El numero de incognitas es siempre igual al gr(Q) y como el polinomio obtenido en el numerador al sumares (inicialmente) de grado gr(Q) − 1 tambien tiene gr(Q) coeficientes. Luego el sistema de ecuaciones tienegr(Q) ecuaciones y gr(Q) incognitas. (Ver ejercicio 21)
Ejemplo 41 Sea P (X)Q(X) = X3+X2+3
X3(X−1)(X2+1)2 .
En R[X] , Q(X) = X3(X− 1)(X2 + 1)2 , pero en C[X] , Q(X) = X3(X− 1)(X− i)2(X + i)2 . Luego
X3 + X2 + 3
X3(X− 1)(X2 + 1)2=
t11
X+t12
X2+t13
X3+
t21
X− 1+
p31X + q31
X2 + 1+p32X + q32
(X2 + 1)2
en R[X] , siendo tij , pij , qij ∈ R . Y en C[X] , con los valores tij ∈ C , se tiene
X3 + X2 + 3
X3(X− 1)(X− i)2(X + i)2=
t11
X+t12
X2+t13
X3+
t21
X− 1+
t31
X− i+
t32
(X− i)2+
t41
X + i+
t42
(X + i)2
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

20 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
Para calcular los coeficientes en el caso de R[X] , hacemos:
P
Q=a
X+
b
X2+
c
X3+
d
X− 1+eX + f
X2 + 1+
gX + h
(X2 + 1)2=aX2+bX+c
X3+
d
X− 1+eX3 + fX2 + (e+g)X + f+h
(X2 + 1)2
=(aX2+bX+c)(X−1)(X2+1)2 + dX3(X2+1)2 + (eX3+fX2+(e+g)X+f+h)(X−1)X3
X3(X− 1)(X2 + 1)2
[=C(X)
Q(X)
]= (a+d+e)X7+(b−a+f−e)X6+(c−b+2a+2d+e+g−f)X5+(2b−2a−c+f+h−e−g)X4+(a−2b+2c+d−f−h)X3+(b−a−2c)X2+(c−b)X−c
X3(X−1)(X2+1)2
e igualando los coeficientes de P (X) = 0X7 + 0X6 + 0X5 + 0X4 + X3 + X2 + 0X+ 3 con los del polinomio construidoC(X), se obtiene el sistema (1) de 8 ecuaciones y 8 incognitas con solucion unica.
Tambien puede construirse un sistema equivalente obligando a que ambos polinomios coincidan en 8 valores(uno mas que el grado), pues si P (αi) = C(αi) para α1, . . . , α8 todas distintas, el polinomio P (X)−C(X) tiene8 raıces y, por el corolario 34, es el polinomio 0; luego P (X) = C(X). Por ejemplo, podemos construir un sistemaa partir de (2):
(1)
0 = a+ d+ e0 = b− a+ f − e0 = c− b+ 2a+ 2d+ e+ g − f0 = 2b− 2a− c+ f + h− e− g1 = a− 2b+ 2c+ d− f − h1 = b− a− 2c0 = c− b3 = −c
(2)
3=P (0) =C(0)5=P (1) =C(1)3=P (−1)=C(−1)
15=P (2) =C(2)−1=P (−2)=C(−2)39=P (3) =C(3)−15=P (−3)=C(−3)
83=P (4) =C(4)4
0.3.3 Ejercicios
0.20 Encontrar las raıces de P (X) = X3 − 2X2 − 5X + 6 y Q(X) = 2X5 − 5X3 + 2X en R[X] , y sus expresionesfactorizadas. Hacerlo tambien en Q[X] .
0.21 Probar que el polinomio X2 + 2X + 2 divide a P (X) = X4 + 4, y obtener de ello todas las raıces de P (X)en C[X] , ası como su expresion factorizada en R[X] .
0.22 Sean P (X) = X5 + 3X4 + 3X3 + 3X2 + 2X y Q(X) = X3 − 3X2 + X− 3 dos polinomios de coeficientes reales.
a) Usar el algoritmo de Euclides para hallar su maximo comun divisor.
b) Encontrar su mınimo comun multiplo.
c) Factorizar ambos polinomios en R[X] .
d) ¿Cuales son sus factorizaciones en C[X]?
0.23 Calcular el polinomio real monico, maximo comun divisor de X19 − 9X18 + 21X17 + X16 − 30X15 yX4 − 6X3 − 16X2 + 54X + 63
¿Que raıces tienen en comun? ¿Podemos usar esto para obtener todas las raıces de ambos polinomios?¿Son todas sus raıces reales?
0.24 ¿Cuantos polinomios reales de grado 2 que tengan por raıces el 0 y el 1 hay? ¿Cual es su expresion?
0.25 El polinomio, P (X), de coeficientes reales y grado 3, tiene a 1 y −1 por raıces. ¿Puede asegurarse que latercera raız es tambien real?
Si P (0) = 1, ¿cual serıa la tercera raız de P ?
0.26 Probar que todo polinomio real de grado 2, P (X) = aX2 +bX+c , puede escribirse en la forma a(X−β)2 +γ .¿Como son sus raıces segun el valor de γ ?
0.27 Comprobar que si z = a+ bi el polinomio (X− z)(X− z) es de coeficientes reales.
0.28 Resolver la ecuacion 2x4 − x3 − 4x2 + 10x− 4 = 0 sabiendo que 1− i es una de las raıces del polinomioasociado.
0.29 Probar que si α es una raız de multiplicidad 5 del polinomio P , entonces α es una raız de multiplicidad4 de P ′ (el polinomio derivado de P ).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

21 – Fundamentos de Matematicas : Preliminares 0.3 Polinomios
0.30 Encontrar la multiplicidad de la raız r :
a) r = 2, en X5 − 5X4 + 7X3 − 2X2 + 4X− 8.
b) r = −2, en X5 + 7X4 + 16X3 + 8X2 − 16X− 16.
c) r = 1, en X5 − 5X4 + 7X3 − 2X2 + 4X− 5.
0.31 Sea P (X) = (1 − X)(X(X + a)(X − 1 − b) − (a + X)(a − aX + ba)
). Hallar todas las raıces y estudiar su
multiplicidad en funcion de los valores de los parametros a y b .
0.32 Sea la matriz A =
a −a 0−a a 0b 0 2b
. Encontrar las raıces, y su multiplicidad en funcion de los valores de
los parametros a y b , del polinomio P (X) = det(XI −A). (Nota: I es la matriz identidad)
0.33 Expresar como suma de fracciones simples los cocientes siguientes, sin hallar los valores de los coeficientes:
a) X2+1X4−6X3−16X2+54X+63 b) X−5
(X−1)(X3−1) c) X+52X4−X3−4X2+10X−4
d) X2+2X5+7X4+16X3+8X2−16X−16 e) X3−3X2+X−3
X5+3X4+3X3+3X2+2X f) X5+3X4+3X3+3X2+2X(X3−3X2+X−3)3
(Nota: Todos los polinomios de este ejercicio aparecen en alguno de los anteriores.)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

22 – Fundamentos de Matematicas : Preliminares
Anexo 0: Demostraciones
PreliminaresNumeros complejos
Demostracion de: Propiedades 7 de la pagina 10
Propiedades 7.- Sean z, w ∈ C , entonces
a) z = z ; z + w = z + w ; zw = z w ; z−1 = (z)−1 .
b) z = z ⇐⇒ z = a+ i0 ∈ R ; z = −z ⇐⇒ z = 0 + ib ∈ iR .
c) z + z = 2 Re(z); z − z = i2 Im(z).
Demostracion:Si z = a+ ib y w = c+ id , se tiene que:
a) z = a− ib = a+ ib = z .
z + w = (a− ib) + (c− id) = (a+ c)− i(b+ c) = z + w ;
z w = (a− ib)(c− id) = (ac− (−b)(−d)) + i(−bc− ad) = (ac− bd)− i(bc+ ad) = zw ;
(z)−1 = (a− ib)−1 = aa2+(−b)2 − i −b
a2+(−b)2 = aa2+b2 + i b
a2+b2 = aa2+b2 − i b
a2+b2 = z−1 .
b) z = z ⇐⇒ a− ib = a+ ib⇐⇒{a=a−b=b ⇐⇒ b = 0⇐⇒ z = a ;
z = −z ⇐⇒ a− ib = −a− ib⇐⇒{a=−a−b=−b ⇐⇒ a = 0⇐⇒ z = ib .
c) z + z = (a+ ib) + (a− ib) = 2a = 2 Re(z);
z − z = (a+ ib)− (a− ib) = i2b = i2 Im(z).
Demostracion de: Propiedades 9 de la pagina 10
Propiedades 9.- Sean z, w ∈ C , entonces
a) |z| ≥ 0; |z| = 0⇐⇒ z = 0.
b) |Re(z)| ≤ |z| ; |Im(z)| ≤ |z| ; |z| ≤ |Re(z)|+ |Im(z)| .
c) |z| = |z| : |z|2 = zz ; 1z = z
zz = z|z|2 .
d) |z + w| ≤ |z|+ |w| ; |z − w| ≥∣∣∣ |z| − |w| ∣∣∣ .
e) |zw| = |z| |w| ;∣∣z−1
∣∣ = |z|−1.
Demostracion:
a) |z| = +√a2 + b2 ≥ 0;
|z| = 0 ⇐⇒ |z|2 = 0 ⇐⇒ a2 + b2 = 0 ⇐⇒ a = b = 0 ⇐⇒ z = 0.
b) Como todos los modulos son valores reales positivos, basta probar las desigualdades para sus cuadrados:
|Re(z)|2 = |a|2 = a2 ≤ a2 + b2 = |z|2 y tambien |Im(z)|2 = |b|2 = b2 ≤ a2 + b2 = |z|2 .
(|Re(z)|+ |Im(z)|)2 = (|a|+ |b|)2 = |a|2 + |b|2 + 2 |a| |b| = a2 + b2 + 2 |a| |b| = |z|2 + 2 |a| |b| ≥ |z|2 .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

23 – Fundamentos de Matematicas : Preliminares Anexo 0
c) |z| = |a− ib| =√a2 + (−b)2 =
√a2 + b2 = |z| .
zz = (a+ ib)(a− ib) = a2 − (−b2) + i(−ab+ ab) = a2 + b2 = |z|2 .
d) |z + w|2 = (z + w)(z + w) = (z + w)(z + w) = zz + ww + zw + zw = |z|2 + |w|2 + zw + zw
= |z|2 + |w|2 + 2 Re(zw) ≤ |z|2 + |w|2 + 2 |Re(zw)| ≤ |z|2 + |w|2 + 2 |zw|= |z|2 + |w|2 + 2 |z| |w| = |z|2 + |w|2 + 2 |z| |w| = (|z|+ |w|)2
Como |z| = |z − w + w| ≤ |z − w|+ |w|=⇒ |z − w| ≥ |z| − |w||w| = |w − z + z| ≤ |w − z|+ |z| = |z − w|+ |z|=⇒ |z − w| ≥ |w| − |z|
se tiene la otra desigualdad propuesta |z − w| ≥∣∣∣ |z| − |w| ∣∣∣ .
e) |zw|2 = (ac− bd)2 + (ad+ bc)2 = a2c2 + b2d2 + a2d2 + b2c2 = (a2 + b2)(c2 + d2) = |z|2 |w|2 ;
|z|∣∣z−1
∣∣ =∣∣zz−1
∣∣ = |1| = 1.
Demostracion de: Operaciones multiplicativas en forma polar 11 de la pagina 11
Operaciones multiplicativas en forma polar 11.- Si z = |z|θ y w = |w|δ , se cumple que:
a) z = |z|(−θ) ; z−1 = (|z|−1)(−θ) .
b) zw = (|z| |w|)θ+δ ; zw = ( |z||w| )θ−δ .
c) zn = (|z|n)nθ .
Demostracion:Las pruebas son sencillas usando que z = |z| (cos θ + i sen θ) y que
(cos θ + i sen θ)(cos δ + i sen δ) = cos θ cos δ − sen θ sen δ + i(sen θ cos δ + cos θ sen δ)
= cos(θ + δ) + i sen(θ + δ).
a) z = |z| (cos θ + i sen θ) = |z| (cos θ − i sen θ) = |z|(
cos(−θ) + i sen(−θ))
= |z|−θ .
z−1 = 1z = z
|z|2 =|z|(
cos(−θ)+i sen(−θ))
|z|2 = 1|z|
(cos(−θ) + i sen(−θ)
)= ( 1|z| )−θ = (|z|−1
)−θ .
b) zw = |z| (cos θ + i sen θ) |w| (cos δ + i sen δ) = |z| |w|(
cos(θ + δ) + i sen(θ + δ))
= |zw|θ+θ′ .
zw = zw−1 = |z|θ ( 1
|w| )−δ = ( |z||w| )θ−δ .
c) zn = |z|θ |z|θn)· · · |z|θ = (|z|n)
θ+n)···+θ
= (|z|n)nθ .
En particular se verifica la formula de Moivre: (cos θ + i sen θ)n = cosnθ + i sennθ.
Polinomios
Demostracion de: Lema 32 de la pagina 17
Lema 32.- Sea P (X) = Q(X)R(X). Si α ∈ K es raız de P (X) con multiplicidad m y Q(α) 6= 0 (no es raız deQ(X)), entonces α es raız de R(X) con multiplicidad m .
Demostracion:Si P (α) = 0, como P (α) = Q(α)R(α) y Q(α) 6= 0, entonces R(α) = 0 y α es raız de R(X). De dondeR(X) = (X− α)R1(X) y P (X) = Q(X)(X− α)R1(X).
Como P (X) = (X − α)mC(X), con C(α) 6= 0, se tiene que P (X) = (X − α)mC(X) = Q(X)(X − α)R1(X), de
donde 0 = (X− α)mC(X)−Q(X)(X− α)R1(X) = (X− α)(
(X− α)mC(X)−Q(X)R1(X))
y como X− α 6= 0 tiene
que ser (X− α)m−1C(X) = Q(X)R1(X) = P1(X) tiene en α una raız de multiplicidad m− 1.Luego el polinomio P1(X) = Q(X)R1(X) tiene una raız en α que no lo es de Q(X), luego es raız de R1(X),
por lo que R1(X) = (X − α)R2(X) y, como antes se puede construir el polinomio P2(X) = (X − α)m−2C(X) =
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

24 – Fundamentos de Matematicas : Preliminares Anexo 0
Q(X)R2(X), con R(X) = (X − α)R2(X). Repitiendo el proceso de manera sucesiva, se llega a un polinomioPm−1(X) = (X− α)C(X) = Q(X)Rm−1(X), con R(X) = (X− α)m−1Rm−1(X).
Y ahora, como α tiene que ser raız de Rm−1(X), Rm−1(X) = (X − α)Rm(X) y C(X) = Q(X)Rm(X). ComoC(α) = Q(α)Rm(α) y C(α) 6= 0 y Q(α) 6= 0, necesariamente Rm(α) 6= 0 y, por tanto R(X) = (X−α)mRm(X),con Rm(α) 6= 0, de donde α es una raız de R(X) de multiplicidad m .
Demostracion de: Lema 37 de la pagina 17
Lema 37.- Sea P (X) =n∑i=0
aiXi ∈ R[X] . Si α es una raız compleja (y no real) de P (X), entonces α tambien es
raız de P (X), y con la misma multiplicidad que α .
Demostracion:Veamos que α es tambien raız de P (X). Teniendo en cuenta que ai ∈ R y que entonces ai = ai ,
P (α) =
n∑i=0
aiαi =
n∑i=0
aiαi =
n∑i=0
aiαi =
n∑i=0
aiαi =
n∑i=0
aiαi = P (α) = 0 = 0
Entonces, en la descomposicion de P (X) aparecen los factores X − α y X − α , pero como su producto (X −α)(X − α) = X2 − (α + α)X + αα = X2 − 2 Re(α)X + |α|2 ∈ R[X] , se descompone en R[X] en la forma P (X) =
(X2 − 2 Re(α)X + |α|2)P1(X). En consecuencia, si la multiplicidad de α es m > 1, el polinomio P1(X) ∈ R[X]tiene a α como raız de multiplicidad m− 1. Y repitiendo el proceso hasta sacar todas las raices, se obtiene queα y α tienen la misma multiplicidad.
Demostracion de: Teorema 40 de la pagina 18
Teorema 40.- Sea P (X) = a0 + a1X + · · ·+ an−1Xn−1 + anX
n un polinomio con ai ∈ Z , ∀ i . Entonces,
1.- Si P (X) posee una raız α ∈ Z , entonces α | a0 .
2.- Si P (X) posee una raız α = pq ∈ Q , entonces p | a0 y q | an .
(La expresion de α = pq debe estar simplificada al maximo, es decir, mcd(p, q) = 1.)
Demostracion:Si α ∈ Z es raız de P : 0 = a0 + a1α + · · · + an−1α
n−1 + anαn = a0 + α(a1 + · · · + an−1α
n−2 + anαn−1) y
−a0 = α(a1 + · · · + an−1αn−2 + anα
n−1); de donde el entero −a0 se descompone en dos factores α ∈ Z ya1 + · · ·+ an−1α
n−2 + anαn−1 ∈ Z (por ser suma y producto de enteros), luego α divide a a0 .
Si α = pq ∈ Q es raız de P : 0 = a0 + a1
pq + · · ·+ an−1
pn−1
qn−1 + anpn
qn = a0qn+a1pq
n−1+···+an−1pn−1q+anp
n
qn de dondeel numerador debe ser cero. Como antes, sacando primero p factor comun y luego q , se llega a:
• −a0qn = p(a1q
n−1 + · · ·+ an−1pn−2q + anp
n−1) luego p | a0qn pero como no divide a q , entonces p | a0
• −anpn = q(a0qn−1 + a1pq
n−2 + · · ·+ an−1pn−1) luego q | anpn pero como no divide a p , entonces q | an
(Los factores de las ultimas igualdades son todos enteros, pues p ∈ Z , q ∈ Z y los ai ∈ Z .)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

25 – Fundamentos de Matematicas
Unidad I
Calculo diferencial en R
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

26 – Fundamentos de Matematicas : Calculo diferencial en R
Capıtulo 1
Funciones, lımites y continuidad
1.1 La recta real
1.1.1 Los numeros reales
Los numeros reales son de sobra conocidos, sus operaciones basicas ası como su identificacion con los puntos de“la recta real”, por lo que solo vamos a mencionar aquı algunas de sus propiedades (la mayorıa conocidas) queson imprescindibles en el desarrollo de este tema.
Propiedades de orden 42.- Denotaremos por R+ = {x ∈ R : x > 0} y R− = {x ∈ R : x < 0}
1.- Antisimetrica: Si x ≤ y e y ≤ x =⇒ x = y .
2.- Transitiva: Si x ≤ y e y ≤ z =⇒ x ≤ z .
3.- Total : Para cualesquiera x, y ∈ R : o bien x ≤ y , o bien y ≤ x .
4.- Si x ≤ y , entonces x+ z ≤ y + z para todo z ∈ R (si x < y =⇒ x+ z < y + z ).
5.- Si x ≤ y , entonces x · z ≤ y · z para todo z ∈ R+ (si x < y =⇒ x · z < y · z ).
6.- Si x ≤ y , entonces x · z ≥ y · z para todo z ∈ R− (si x < y =⇒ x · z > y · z ).
7.- Si 0 < x < y , entonces 0 < 1y <
1x .
Las propiedades de acotacion siguientes garantizan que los numeros reales “llenan” la recta real, lo que nospermite decir que recorremos de manera continua un subconjunto de R .
Definicion 43.- Sea A ⊆ R , diremos que el conjunto A esta acotado superiormente si existe algun K ∈ Rtal que x ≤ K , para todo x ∈ A ; es decir, todos los elementos de A son menores que K . Del valor K diremosque es una cota superior de A .
Analogamente, A esta acotado inferiormente si existe k ∈ R tal que k ≤ x , para todo x ∈ A y diremosque k es una cota inferior de A . Diremos que A esta acotado si lo esta superior e inferiormente.
Propiedad del extremo superior 44.- Todo subconjunto no vacıo A ⊆ R y acotado superiormente admite unacota superior mınima, es decir, ∃Γ ∈ R tal que:
a) x ≤ Γ; ∀x ∈ A b) Si K < Γ, entonces ∃x ∈ A verificando que K < x ≤ Γ.
Se dice que Γ es el extremo superior o supremo de A y se denota por supA o ext supA . Si Γ pertenecea A , se dice que Γ es el maximo de A , y escribiremos maxA = Γ.
Propiedad del extremo inferior 45.- Todo subconjunto no vacıo A ⊆ R acotado inferiormente admite unacota inferior maxima, es decir, ∃ γ ∈ R tal que:
a) γ ≤ x ; ∀x ∈ A b) Si γ < k , entonces ∃x ∈ A verificando que γ ≤ x < k .
Se dice que γ es el extremo inferior o ınfimo de A y se denota por inf A o ext infA . Si γ pertenece a A ,se dice que γ es el mınimo de A , y escribiremos minA = γ .
Nota: Que Γ = supA es equivalente a que para cada ε > 0 existe x ∈ A con Γ − ε < x ≤ Γ. Es decir, quepara cualquier valor mas pequeno que el superior hay algun elemento del conjunto mas grande que el.
Analogamente, γ = inf A ⇐⇒ para cada ε > 0 existe x ∈ A con γ ≤ x < γ + ε .
Ejemplo El conjunto A ={
1n : n ∈ N
}={
1, 12 ,
13 ,
14 , . . .
}esta acotado superior e inferiormente.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

27 – Fundamentos de Matematicas : Calculo diferencial en R 1.1 La recta real
En efecto, 1n ≤ 1 < 2 para todo n , luego 2 es una cota superior del conjunto (de hecho, cualquier numero
mayor o igual a 1 lo es). Tambien esta acotado inferiormente, pues 1n es positivo luego 0 < 1
n para todo n y 0es una cota inferior de A (cualquier numero negativo es tambien una cota inferior).
Luego A es un conjunto acotado y tiene supremo e ınfimo: como el supremo es la mınima cota superior,supA = 1, pues 1 es una cota superior y si K < 1, existe el 1 ∈ A tal que K < 1 ≤ supA = 1 luego K no esuna cota y 1 es la mas pequena.
Como el ınfimo es la maxima cota inferior, inf A = 0, pues es una cota y para cualquier k > 0, puedoencontrar un n suficientemente grande para que 0 < 1
n < k (por ejemplo, para k = 0.00001, se tiene que0 < 1
100001 <1
100000 = k ).
Ademas, supA = 1 ∈ A luego maxA = 1; lo que no ocurre con el ınfimo, pues inf A = 0 /∈ A , luego6 ∃ minA . 4
1.1.2 Valor absoluto de un numero real
Definicion 46.- Sea a ∈ R , se llama valor absoluto de a , y se representa por |a| , al numero real dado por
|a| = +√a2 =
{a, si a ≥ 0−a, si a < 0
Propiedades del valor absoluto 47.-
a) |a| ≥ 0, ∀ a y |a| = 0 ⇐⇒ a = 0 b) |ab| = |a| |b| c)∣∣a−1
∣∣ = |a|−1
d) |a| ≤ k ⇐⇒ −k ≤ a ≤ k e) |a+ b| ≤ |a|+ |b| f)∣∣∣ |a| − |b| ∣∣∣ ≤ |a− b| .
El valor absoluto y su uso como distancia es clave en las definiciones de conjuntos y conceptos como el lımitey la continudad, la derivacion e integracion.
Nota: Con el valor absoluto, diremos que A es acotado ⇐⇒ existe K > 0 tal que |x| ≤ K , ∀x ∈ A .
Ejemplo El conjunto A ={
1, 12 ,
13 ,
14 , . . .
}del ejemplo anterior esta acotado pues
∣∣ 1n
∣∣ ≤ 1 para todo n .
1.1.3 Intervalos y entornos en RLos subconjuntos de R , estan formados por puntos separados o por intervalos (“trozos”) de la recta real o poruniones de ellos; pero no solo eso, sino que la validez de algunos resultados depende del tipo de intervalo usado.Pero ademas, los intervalos centrados en un punto (que llamaremos entornos) son basicos en la construccion dela mayorıa de los conceptos del Calculo.
Definicion 48.- Dados los numeros reales a y b con a ≤ b , se llama intervalo abierto de extremos a y b , yse representa por (a, b), al conjunto:
(a, b) = {x ∈ R : a < x < b} .
Se llama intervalo cerrado de extremos a y b , y se representa por [a, b] , al conjunto:
[a, b] = {x ∈ R : a ≤ x ≤ b} .
Analogamente se definen: (a, b] = {x ∈ R : a < x ≤ b} y [a, b) = {x ∈ R : a ≤ x < b}y los intervalos no acotados: (a,+∞) = {x ∈ R : a < x} y [a,+∞) = {x ∈ R : a ≤ x}
(−∞, b) = {x ∈ R : x < b} y (−∞, b] = {x ∈ R : x ≤ b}
En los intervalos cerrados, inf[a, b] = min[a, b] = a y sup[a, b] = max[a, b] = b , mientras que en los abiertosinf{(a, b)} = a y sup{(a, b)} = b pero no tiene ni maximo ni mınimo.
En los no acotados, como [a,+∞), se tiene inf[a,+∞) = min[a,+∞) = a pero no existe el superior (a vecesse escribe supA = +∞ , para indicar que el conjunto no esta acotado superiomente).
Naturalmente, R es tambien un intervalo R = (−∞,+∞). Y, [a, a] = {a} pero (a, a) = (a, a] = [a, a) = ∅ .
Definicion 49.- Llamaremos entorno de centro a y radio ε > 0, y escribiremos E(a, ε), al conjunto:
E(a, ε) = {x ∈ R : |x− a| < ε} = {x ∈ R : a− ε < x < a+ ε} = (a− ε, a+ ε).
Llamaremos entorno reducido de centro a y radio ε > 0, E∗(a, ε), al conjunto
E∗(a, ε) = E(a, ε)− {a} = {x ∈ R : 0 < |x− a| < ε} .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

28 – Fundamentos de Matematicas : Calculo diferencial en R 1.2 Funciones reales de variable real
1.1.4 Algunas operaciones con numeros reales
1.1.4.1 Potencias racionales y reales de un numero real
Las potencias racionales, xr , se definen paulatinamente a partir de las potencias naturales:
• para n ∈ N y x ∈ R , definimos xn = x · xn)· · · x .
• para z ∈ Z y x ∈ R− {0} , definimos x0 = 1 y si z < 0, xz = (x−1)−z .
• para n ∈ N y x ∈ R+ , definimos x1n = n
√x como el α ∈ R tal que αn = x
• para r = zn , con z ∈ Z y n ∈ N , y x ∈ R+ , definimos x
zn = n
√xz .
y se verifican las siguientes propiedades:
(1) xryr = (xy)r (2) xrxs = xr+s (3) (xr)s = xrs
(4) Si 0 < x < y , entonces 0 < xr < yr si r > 0 y 0 < yr < xr si r < 0
(5) Si r < s se tiene que xr < xs cuando x > 1 y xs < xr cuando 0 < x < 1.
Antes de terminar, un pequeno apunte sobre las raices n -esimas, n√x para x ≥ 0: si n es impar, existe un
unico numero real α > 0 tal que αn = x ; y si n es par, existe un unico numero real α > 0 tal que αn = x y(−α)n = x . Por ello, si n es par siempre se escribe n
√x > 0 y − n
√x < 0 para distinguir entre el valor positivo
y el negativo.
Potencias reales.- Las potencias reales de un numero real, xα , con x > 0 y α ∈ R se extienden de lasracionales (aunque no de manera sencilla) y verifican las mismas propiedades de (1) a (5) que las potenciasracionales.
1.1.4.2 Exponencial real de base e
La exponencial de base e que a cada x ∈ R le asigna el numero real ex . Las propiedades de las potencias,establecen la validez de:
(1) ex+y = exey (2) Si x < y se tiene que ex < ey (3) ex > 0
(Genericamente, tenemos exponenciales de base a , para cualquier a > 0, con propiedades similares.)
1.1.4.3 Logaritmo neperiano real
Para cada x ∈ (0,+∞), se define el logaritmo neperiano, lnx como el valor real α tal que eα = x ; es decir, laoperacion recıproca a la exponencial.
(1) ln(xy) = lnx+ ln y (2) ln(xy) = y lnx (3) Si 0 < x < y se tiene lnx < ln y
(Genericamente, para cada exponencial ax , tenemos el logaritmo en base a , loga x .)
1.2 Funciones reales de variable real
Definicion 50.- Llamaremos funcion real de variable real, a cualquier aplicacion f :A −→ R , donde A ⊆ R .Al conjunto A lo denominaremos dominio de f y escribiremos A = Dom(f).
Si x ∈ A escribiremos y = f(x) para indicar que y ∈ R es la imagen de x por medio de f .
El recorrido o conjunto imagen de f , que suele denotarse por f(A), sera:
f(A) ={f(x) ∈ R : x ∈ A
}={y ∈ R : ∃x ∈ A con y = f(x)
}= Img f
Nota: Si la funcion viene dada solo por la expresion y = f(x), sobreentenderemos que el dominio es el maximosubconjunto de R para el cual f(x) ∈ R , es decir, Dom(f) = {x ∈ R : f(x) ∈ R}
Ejemplo Sea f : [−1, 1] −→ R dada por f(x) =√
1− x2 . Se tiene que:
Dom(f) = [−1, 1]: pues x ∈ [−1, 1] =⇒ 0 ≤ x2 ≤ 1 =⇒ 1− x2 ≥ 0 =⇒√
1− x2 = f(x) ∈ R .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

29 – Fundamentos de Matematicas : Calculo diferencial en R 1.2 Funciones reales de variable real
f([−1, 1]) ⊆ [0, 1], ya que x∈ [−1, 1] =⇒ 0≤x2≤1 =⇒ −1≤ −x2≤0 =⇒ 0 ≤ 1−x2 ≤ 1 =⇒ 0 ≤√
1−x2 ≤ 1 y,si k ∈ [0, 1], se tiene k = f
(√1− k2
); luego f([−1, 1]) = [0, 1].
Para f dada por f(x) = 11−x2 , su dominio se obtendra de:
f(x) ∈ R ⇐⇒ 1
1− x2∈ R ⇐⇒ 1− x2 6= 0 ⇐⇒ x2 6= 1 ⇐⇒ x 6= ±1
luego Dom(f) = R− {1,−1} = (−∞,−1) ∪ (−1, 1) ∪ (1,+∞). Ademas, Img(f) = R− [0, 1). 4
Definicion 51.- Llamaremos grafica de la funcion dadapor y = f(x), y lo denotaremos por graf(f), al subcon-junto de R2
graf(f) ={
(x, y) ∈ R2 : x∈Dom(f) e y=f(x)}
={
(x, f(x)) ∈ R2 : x∈Dom(f)}
rr
r
a b c
f(a)
f(c)
f(b)
(a, f(a))
(b, f(b))
(c, f(c))
graf(f)�
���
x
y
Definicion 52 (Operaciones con funciones).- Sea f y g funciones reales de variable real. Entonces sonfunciones reales de variable real las siguientes:
1.- (Suma) (f+g)(x) = f(x) + g(x) 2.- (Producto) (fg)(x) = f(x) · g(x)
3.- (Cociente)(fg
)(x) = f(x)
g(x) 4.- (Composicion) (g ◦ f)(x) = g(f(x))
en los conjunto donde tenga sentido. Es decir:
Dom(f+g) = Dom(f) ∩Dom(g) Dom(f/g) =(
Dom(f) ∩Dom(g))− {x : g(x) = 0}
Dom(fg) = Dom(f) ∩Dom(g) Dom(g ◦ f) ={x ∈ Dom(f) : f(x) ∈ Dom(g)
}Ejemplo Sean f(x) =
√2− x y g(x) =
√x2 − 1. Se tiene que
Dom f = {x ∈ R : 2− x ≥ 0} = {x ∈ R : 2 ≥ x} = (−∞, 2]
Dom g = {x ∈ R : x2 − 1 ≥ 0} = {x ∈ R : x2 ≥ 1} = (−∞,−1] ∪ [1,+∞) = R− (−1, 1)
Luego el dominio de (f + g)(x) =√
2− x+√x2 − 1 es
Dom(f + g) = Dom f ∩Dom g = (−∞, 2] ∩(
(−∞,−1] ∪ [1,+∞))
= (−∞,−1] ∪ [1, 2]
que coincide con el de (fg)(x) =√
2− x√x2 − 1.
Para el dominio de ( fg )(x) =√
2−x√x2−1
, como g(x) = 0 si x2 − 1 = 0, es decir, si x = ±1,
Dom(fg
)= (Dom f ∩Dom g)− {−1, 1} =
((−∞,−1] ∪ [1, 2]
)− {−1, 1} = (−∞,−1) ∪ (1, 2]
y, finalmente el dominio de (g ◦ f)(x) =√
(√
2− x)2 − 1 =√
1− x sera
Dom(g ◦ f) ={x ∈ (−∞, 2] :
√2− x ∈ Dom g
} (1)={x ∈ (−∞, 2] :
√2− x ≥ 1
}= {x ∈ (−∞, 2] : 2− x ≥ 1} = {x ∈ (−∞, 2] : 1 ≥ x} = (−∞, 1]
(1) como√
2− x ≥ 0, se tiene√
2− x ∈ Dom g si√
2− x ∈ [1,+∞) , es decir, si√
2− x ≥ 1. 4
Dominio de algunas funciones elementales 53.-
• Raız: f(x) = n√x y Dom f = [0,+∞). Con n
√x = 0 ⇐⇒ x = 0.
• Potencia real: f(x) = xα y Dom f = (0,+∞). Con xα > 0 para todo x .
• Exponencial: f(x) = ex y Dom f = R . Con ex > 0 para todo x .
• Logaritmo neperiano: f(x) = ln(x) y Dom f = (0,+∞). Con lnx = 0 ⇐⇒ x = 1.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

30 – Fundamentos de Matematicas : Calculo diferencial en R 1.2 Funciones reales de variable real
• Seno: f(x) = sen(x) y Dom f = R . Con senx = 0 ⇐⇒ x = kπ con k ∈ Z ,
• Coseno: f(x) = cos(x) y Dom f = R . Con cosx = 0 ⇐⇒ x = π2 + kπ con k ∈ Z .
• Tangente: f(x) = tg(x) = sen xcos x y Dom f = R− {π2 + kπ : k ∈ Z} = dk∈Z(−π2 + kπ, π2 + kπ).
• Seno hiperbolico: f(x) = sh(x) = ex−e−x2 y Dom f = R . Con shx = 0 ⇐⇒ x = 0.
• Coseno hiperbolico: f(x) = ch(x) = ex+e−x
2 y Dom f = R . Con chx ≥ 1 para todo x .
• Tangente hiperbolica: f(x) = th(x) = sh xch x y Dom f = R .
f(x) = ex
1
1
f(x) = ln(x)
f(x) = xα1
1
α>1
���������
α=1
0<α<1
α<−1
−1<α<0
1
sh(x)ch(x)
th(x)
1
ππ2
tg(x)
sen(x)
cos(x)
Fig. 1.1. Graficas de algunas funciones elementales.
Definicion 54.- Sea f :A −→ R , con A ⊆ R . Diremos que f es una funcion acotada si el conjunto imagenf(A) esta acotado. Es decir, si existe K > 0 tal que |f(x)| ≤ K para todo x ∈ A .
Ejemplo ? El seno y el coseno estan acotadas en R , pues |senx| ≤ 1 y |cosx| ≤ 1 para todo x ∈ R .
• La funcion f :R−{0} −→ R , con f(x) = x|x| , esta acotada en su dominio pues para todo x ∈ R , se tiene
− |x| ≤ x ≤ |x| , y para todo x 6= 0, −1 ≤ x|x| ≤ 1. (De hecho, |f(x)| = 1, ∀x 6= 0.)
• La funcion th(x) esta acotada en R . En efecto, si x ≥ 0, se cumple que ex ≥ 1 ≥ 1ex = e−x , luego
0 ≤ ex − e−x < ex + e−x y entonces 0 ≤ ex−e−xex+e−x < 1. Como th(−x) = − th(x) (comprobarlo), cuando
x < 0, se tiene −1 < th(x) < 0, por lo que |th(x)| < 1, para todo x ∈ R . 4
1.2.1 Monotonıa. Funciones inversas
Definicion 55.- Sea f :A −→ R diremos que f es creciente o monotona creciente en el conjunto A , sipara cualesquiera x, y ∈ A , con x < y , se verifica que f(x) ≤ f(y).
Diremos que f es decreciente o monotona decreciente en el conjunto A , si para cualesquiera x, y ∈A , con x < y , se verifica que f(x) ≥ f(y).
Diremos que f es creciente (resp. decreciente) en el punto a ∈ A , si existe un entorno E(a, δ) tal que∀x, y ∈ E(a, δ) con x < a < y se cumple f(x) ≤ f(a) ≤ f(y) (resp. f(x) ≥ f(a) ≥ f(y)).
Nota: Si las desigualdades son estrictas, diremos estrictamente creciente y estrictamente decreciente.
Ejemplo Por las propiedades enunciadas anteriormente, las funciones ex , lnx y xα con α > 0 son estricta-mente crecientes en sus dominios; y si α < 0, xα decrece estrictamente en (0,+∞) (ver graficas arriba).
La funcion f(x) = 1x es estrictamente decreciente en cada punto de su dominio R−{0} , pero no es monotona
decreciente en el conjunto (ya que −1 < 1 pero f(−1) = −1 < f(1) = 1.) 4
Definicion 56.- Se dice que f :A −→ R es inyectiva en A si f(x) 6= f(y) para todo x, y ∈ A , con x 6= y .
Ejemplo Las funciones estrictamente crecientes o estrictamente decrecientes en un conjunto son inyectivas.
La funcion f(x) = x2 es inyectiva en [0, 1] y tambien en [−1, 0], pero no lo es en el conjunto [−1, 1] puestoque f(−1) = 1 = f(1) con 1 6= −1.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

31 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
Definicion 57.- Sean f :A −→ R y B = f(A). Si f es inyectiva en A , llamaremos funcion inversa de f enA , y la denotaremos por f−1 , a la funcion f−1:B −→ A tal que f−1(f(x)) = x , para todo x ∈ A .
Ejemplo 58 ? La funcion f : [0,∞) −→ R con f(x) = x2 , tiene inversa en ese conjunto (es estrictamente
creciente en el) y es f−1: [0,∞) −→ [0,∞) dada por f−1(y) =√y . [ f−1(f(x)) =
√x2 = |x| = x ]
• La funcion f : (−∞, 0] −→ R con f(x) = x2 , tiene inversa en ese conjunto (es estrictamente decreciente
en el), que es f−1: [0,∞) −→ (−∞, 0] dada por f−1(y) = −√y . [ f−1(f(x)) = −√x2 = − |x| = x ]
• La funcion f : (0,+∞) −→ R con f(x) = xα , tiene inversa en el conjunto (es estr. creciente si α > 0 y
decreciente si α < 0), que es f−1: (0,∞) −→ R dada por f−1(y) = y1α . [ f−1(f(x)) = (xα)
1α = x1 = x ]
• La funcion f :R −→ (0,∞) con f(x) = ex , tiene inversa en R (es estrictamente creciente en el), que esf−1: (0,∞) −→ R dada por f−1(y) = ln y . [ f−1(f(x)) = ln(ex) = x ln(e) = x ]
• La funcion f(x) = senx , tiene inversa en el conjunto [−π2 ,π2 ] (es estrictamente creciente en el), la funcion
f−1: [−1, 1] −→ [−π2 ,π2 ] que llamaremos arcoseno y denotaremos f−1(y) = arcsen y .
(El seno no tiene inversa en [0, 2π] , pues no es inyectiva en ese conjunto)
• La funcion f(x) = cosx , tiene inversa en el conjunto [0, π] (es estrictamente decreciente en el), la funcionf−1: [−1, 1] −→ [0, π] que llamaremos arcocoseno y denotaremos f−1(y) = arccos y .
• La funcion f(x) = tg x , tiene inversa en el conjunto [−π2 ,π2 ] (es estrictamente creciente en el), la funcion
f−1:R −→ [−π2 ,π2 ] que llamaremos arcotangente y denotaremos f−1(y) = arctg y .
• La funcion f(x) = shx , f :R −→ R , tiene inversa en R (es estrictamente creciente en el), la funcion
f−1:R −→ R que llamaremos argumento del sh y denotaremos f−1(y) = argsh y = ln(y +√y2 + 1).
• La funcion f(x) = chx , tiene inversa en [0,∞) (estrictamente creciente), la funcion f−1: [1,∞) −→ [0,∞)
que llamaremos argumento del ch y denotaremos f−1(y) = argch y = ln(−y +√y2 + 1).
• La funcion th:R −→ (−1, 1), tiene inversa en R (estrictamente creciente), la funcion f−1: (−1,−1) −→ Rque llamaremos argumento de la th y denotaremos f−1(y) = argth y = ln
√y+1y−1 . 4
Nota: La grafica de f−1 es simetrica, respecto de la bisectriz del primer cuadrante, a la grafica de f .En efecto, si (x, y) ∈ graf(f) con y = f(x), entonces, el punto (y, f−1(y)) ∈ graf(f−1) es de la forma(y, f−1(y)) = (y, f−1(f(x))) = (y, x).
Puede observarse esto en la figura 1.1 de la pagina 30, para ex y su inversa ln(x) y xα y su inversa x1α .
1.3 Lımite y continuidad de una funcion en un punto
Definicion 59.- Un punto x0 ∈ R se dice punto de acumulacion de un conjunto A si, y solo si, para cadaε > 0 se tiene que E∗(x0, ε) ∩ A 6= ∅ . Es decir, x0 es un punto de acumulacion de un conjunto A si en cadaentorno de x0 hay otros puntos de A .
De los puntos de A que no son de acumulacion, se dice que son puntos aislados de A .
Nota: Es decir, x0 es punto de acumulacion de A si “cerca” de x0 siempre hay (otros) puntos de A , porpequeno que hagamos el cırculo de cercanıa; en consecuencia, a un punto de acumulacion de un conjuntosiempre podremos acercarnos con puntos del conjunto. Solo ası tiene sentido la definicion del lımite siguiente.
Definicion 60.- Sea f :A −→ R y sea x0 ∈ R un punto de acumulacion de A . Se dice que el lımite de lafuncion f(x) cuando x tiende a x0 es L , y se representa por
lımx→x0
f(x) = L, (tambien con f −→ L, cuando x→ x0)
si, y solo si, para cada ε > 0 existe δ > 0 tal que si x ∈ A y 0 < |x− x0| < δ , entonces |f(x)− L| < ε .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
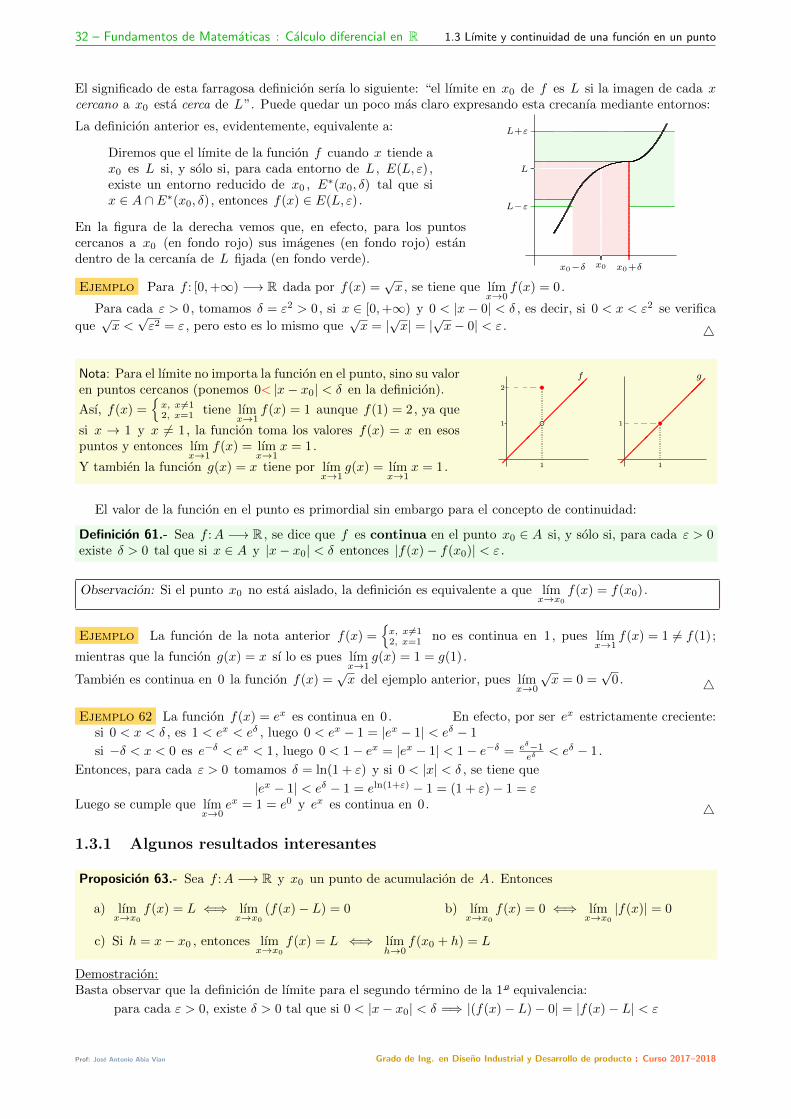
32 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
El significado de esta farragosa definicion serıa lo siguiente: “el lımite en x0 de f es L si la imagen de cada xcercano a x0 esta cerca de L”. Puede quedar un poco mas claro expresando esta crecanıa mediante entornos:
La definicion anterior es, evidentemente, equivalente a:
Diremos que el lımite de la funcion f cuando x tiende ax0 es L si, y solo si, para cada entorno de L , E(L, ε),existe un entorno reducido de x0 , E∗(x0, δ) tal que six ∈ A ∩ E∗(x0, δ), entonces f(x) ∈ E(L, ε).
En la figura de la derecha vemos que, en efecto, para los puntoscercanos a x0 (en fondo rojo) sus imagenes (en fondo rojo) estandentro de la cercanıa de L fijada (en fondo verde).
L+ε
L
L−ε
x0x0−δ x0+δ
Ejemplo Para f : [0,+∞) −→ R dada por f(x) =√x , se tiene que lım
x→0f(x) = 0.
Para cada ε > 0, tomamos δ = ε2 > 0, si x ∈ [0,+∞) y 0 < |x− 0| < δ , es decir, si 0 < x < ε2 se verifica
que√x <√ε2 = ε , pero esto es lo mismo que
√x = |
√x| = |
√x− 0| < ε . 4
Nota: Para el lımite no importa la funcion en el punto, sino su valoren puntos cercanos (ponemos 0< |x− x0| < δ en la definicion).
Ası, f(x) ={x, x 6=12, x=1 tiene lım
x→1f(x) = 1 aunque f(1) = 2, ya que
si x → 1 y x 6= 1, la funcion toma los valores f(x) = x en esospuntos y entonces lım
x→1f(x) = lım
x→1x = 1.
Y tambien la funcion g(x) = x tiene por lımx→1
g(x) = lımx→1
x = 1.
b2
1
1
f
���
����
r1
1
g
���
����
r
El valor de la funcion en el punto es primordial sin embargo para el concepto de continuidad:
Definicion 61.- Sea f :A −→ R , se dice que f es continua en el punto x0 ∈ A si, y solo si, para cada ε > 0existe δ > 0 tal que si x ∈ A y |x− x0| < δ entonces |f(x)− f(x0)| < ε .
Observacion: Si el punto x0 no esta aislado, la definicion es equivalente a que lımx→x0
f(x) = f(x0).
Ejemplo La funcion de la nota anterior f(x) ={x, x 6=12, x=1 no es continua en 1, pues lım
x→1f(x) = 1 6= f(1);
mientras que la funcion g(x) = x sı lo es pues lımx→1
g(x) = 1 = g(1).
Tambien es continua en 0 la funcion f(x) =√x del ejemplo anterior, pues lım
x→0
√x = 0 =
√0. 4
Ejemplo 62 La funcion f(x) = ex es continua en 0. En efecto, por ser ex estrictamente creciente:si 0 < x < δ , es 1 < ex < eδ , luego 0 < ex − 1 = |ex − 1| < eδ − 1
si −δ < x < 0 es e−δ < ex < 1, luego 0 < 1− ex = |ex − 1| < 1− e−δ = eδ−1eδ
< eδ − 1.
Entonces, para cada ε > 0 tomamos δ = ln(1 + ε) y si 0 < |x| < δ , se tiene que
|ex − 1| < eδ − 1 = eln(1+ε) − 1 = (1 + ε)− 1 = εLuego se cumple que lım
x→0ex = 1 = e0 y ex es continua en 0. 4
1.3.1 Algunos resultados interesantes
Proposicion 63.- Sea f :A −→ R y x0 un punto de acumulacion de A . Entonces
a) lımx→x0
f(x) = L ⇐⇒ lımx→x0
(f(x)− L) = 0 b) lımx→x0
f(x) = 0 ⇐⇒ lımx→x0
|f(x)| = 0
c) Si h = x− x0 , entonces lımx→x0
f(x) = L ⇐⇒ lımh→0
f(x0 + h) = L
Demostracion:Basta observar que la definicion de lımite para el segundo termino de la 1a equivalencia:
para cada ε > 0, existe δ > 0 tal que si 0 < |x− x0| < δ =⇒ |(f(x)− L)− 0| = |f(x)− L| < ε
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

33 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
para el segundo termino de la 2a equivalencia:
para cada ε > 0, existe δ > 0 tal que si 0 < |x− x0| < δ =⇒ ||f(x)| − 0| = |f(x)| < ε
y para el segundo termino de la 3a equivalencia:
para cada ε > 0, existe δ > 0 tal que si 0 < |h| = |x− x0| < δ =⇒ |f(x0 + h)− L| = |f(x)− L| < ε
coinciden con la definicion de los lımites para los respectivos primeros terminos de la equivalencias.
Los resultados a) y c) anteriores deben considerarse definiciones equivalentes de la definicion de lımite ynos permiten transformar un lımite en un lımite de valor 0 o a un lımite en el punto 0. Con el apartado b)cambiamos la funcion por otra “acotable”, lo que cobra interes tras los resultados siguientes:
Proposicion 64.- Sean f, g, h:A −→ R y x0 un punto de acumulacion de A .
1.- Si f(x) ≤ g(x) ≤ h(x) en A y lımx→x0
f(x) = L = lımx→x0
h(x), entonces lımx→x0
g(x) = L
2.- Si g esta acotada en A y lımx→x0
f(x) = 0, entonces lımx→x0
g(x) · f(x) = 0 .
Ejemplo El lımx→0
x sen 1x = 0, pues lım
x→0x = 0 y el seno esta acotado ( |sen y| ≤ 1, para cualquier y ∈ R). 4
1.3.1.1 Lımites y continuidad con las operaciones basicas
El calculo de los lımites y, por tanto el estudio de la continuidad, se extiende ampliamente y de manera sencillamediante las operaciones basicas de las funciones:
Propiedades 65.- Si lımx→x0
f(x) = L1 ∈ R y lımx→x0
g(x) = L2 ∈ R , entonces:
a) lımx→x0
[f(x) + g(x)] = lımx→x0
f(x) + lımx→x0
g(x) = L1 + L2 .
b) lımx→x0
[f(x) · g(x)] = lımx→x0
f(x) · lımx→x0
g(x) = L1 · L2 .
c) lımx→x0
f(x)g(x) =
lımx→x0
f(x)
lımx→x0
g(x) = L1
L2, siempre que L2 6= 0. .
Corolario 66.- Sean f y g funciones continuas en un punto x0 ∈ A , entonces:
1.- f + g es continua en el punto x0 .
2.- fg es continua en el punto x0 .
3.- fg es continua en el punto x0 siempre que g(x0) 6= 0.
Ejemplos
• La funcion f(x) = xn es continua en R : lımx→x0
xn = ( lımx→x0
x)n)· · · ( lım
x→x0
x) =(
lımx→x0
x)n
= xn0
• En general, si P (X) es un polinomio, lımx→x0
P (x) = P (x0), luego continuo en todo R .
• Y una funcion racional, f(x) = P (x)Q(x) , sera continua en los puntos de su dominio (salvo en aquellos a con
Q(a) = 0, pero esos no pertenecen al dominio) y en todos ellos lımx→x0
P (x)Q(x) = P (x0)
Q(x0) .
• f(x) = ex es continua en R , pues lo es en 0 (Ejemplo 62) y, para los demas puntos, se tiene
lımx→x0
ex = lımh→0
ex0+h = lımh→0
ex0eh = ex0 lımh→0
eh = ex0e0 = ex0
4
Teorema 67.- Sean f :A −→ R y g: f(A) −→ R . Si lımx→a
f(x) = b y g es continua en b , entonces
lımx→a
g(f(x)) = g(b) = g(
lımx→a
f(x)). .
Corolario 68.- Si f es continua en a y g continua en f(a), entonces g ◦ f es continua en a .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

34 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
Ejemplo La funcion f(x) = x − 1 es continua en 1 por ser polinomica; la funcion g(x) = |x| es continuaen 0 = f(1), pues lım
x→0x = 0 =⇒ lım
x→0|x| = 0 = |0| ; y h(x) =
√x es continua en 0 = g(0). Entonces, la
composicion (h ◦ g ◦ f)(x) = h(g(f(x))) =√|x− 1| es continua en 1.
Ademas, lımx→1
√|x− 1| =
√lımx→1|x− 1| =
√∣∣∣ lımx→1
(x− 1)∣∣∣ =
√|0| = 0. 4
Imponiendo condiciones sobre la funcion f , podemos dar una variante del teorema 67 anterior que prescindede la condicion de continuidad de g :
Proposicion 69 (Convergencia propia).- Sean f :A −→ R y g: f(A) −→ R . Si lımx→a
f(x) = b , con f(x) 6= b
para todos los x de un entorno reducido E∗(a, δ0) de a , entonces
lımx→a
(g ◦ f)(x) = lımf(x)→b
g(f(x)) = lımy→b
g(y). .
Ejemplo Sea g(y) =
{y, si y 6= 12, si y = 1
, no continua en 1. Para f(x) = ex se cumple la condicion pedida, pues
lımx→0
f(x) = 1 6= ex = f(x) si x 6= 0 (es est. creciente), luego lımx→0
g(f(x)) = lımy→1
g(y) = 1. (En efecto, como
g(f(x)) = g(ex) = ex si ex 6= 1, se tiene lımx→0
g(f(x)) = lımx→0
ex = 1).
Sin embargo, si tomamos la funcion f(x) =
{1, si x 6= 00, si x = 0
, que no verifica la condicion de la proposicion
( lımx→0
f(x) = 1 = f(x) si x 6= 0), se tiene que: lımx→0
g(f(x)) = lımx→0
g(1) = 2 6= lımy→1
g(y) = 1. 4
1.3.1.2 Lımites laterales
Definicion 70.- Sean a < c < b y f : (a, c) ∪ (c, b) −→ R .
• Diremos que L1 es el lımite por la izquierda de f en c , si para cada ε > 0 existe δ > 0 tal quecuando x < c y 0 < |x− c| < δ , se tiene que |f(x)− L1| < ε .
• Diremos que L2 es el lımite por la derecha de f en c , si para cada ε > 0 existe δ > 0 tal que cuandox > c y 0 < |x− c| < δ , se tiene que |f(x)− L2| < ε .
Los representaremos, respectivamente, por
lımx→cx<c
f(x) = lımx→c−
f(x) = L1 y lımx→cx>c
f(x) = lımx→c+
f(x) = L2
Proposicion 71 (Lımites laterales).- Sean a < c < b y f : (a, c) ∪ (c, b) −→ R . Entonces
lımx→c
f(x) = L ⇐⇒ lımx→c−
f(x) = lımx→c+
f(x) = L .
Ejemplo Sea f(x) = |x| ={
x, si x ≥ 0−x, si x < 0
. Entonces
lımx→0−
|x| = lımx→0−
−x = 0 y lımx→0+
|x| = lımx→0+
x = 0 =⇒ lımx→0|x| = 0 4
Nota: Si solo hay funcion en un lado, el lımite coincide con el lımite lateral. Por ejemplo, lımx→0
√x = lım
x→0+
√x ,
pues en los puntos a la izquierda de 0 no esta definida la funcion.
Definicion 72.- Si f no es continua en un punto x0 , pero se cumple que lımx→x−0
f(x) = f(x0) o que lımx→x+
0
f(x) =
f(x0), se dice que f es continua por la izquierda o continua por la derecha en x0 .
Ejemplo Todas son funciones discontinuas en 1, la tercera es continua por la derecha y las dos ultimas soncontinuas por la izquierda.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

35 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
b1
r bb1
b1
r b1
r1
rLa discontinuidad de la primera funcion suele denominarse evitable (porque basta “rellenar el hueco” para hac-erla continua), de la quinta se dice de salto infinito y de las tres restantes de salto finito. 4
1.3.2 Lımites con infinito
De manera similar a como se definen los limites para valores reales, podemos definir lımites donde la variable seacerca a +∞ o a −∞ , o que sea la funcion la que pueda tomar valores cercanos a ellos (valores, tan grandes quesuperan cualquier cota K > 0, o tan pequenos que rebasan cualquier cota por abajo −K < 0). Las definicionesson analogas, sin mas que cambiar la aproximaciones a puntos reales por aproximaciones a ∞ :
Definicion 73.- Si f es una funcion real de variable real, se tienen las siguientes definiciones:
lımx→x0
f(x) = +∞ si, para cada K > 0, existe δ > 0 tal que si 0 < |x− x0| < δ =⇒ f(x) > K
lımx→−∞
f(x) = L si, para cada ε > 0, existe M > 0 tal que si x < −M =⇒ |f(x)− L| < ε
lımx→+∞
f(x) = −∞ si, para cada K > 0, existe M > 0 tal que si x > M =⇒ f(x) < −K
Analogamente: lımx→x0
f(x) = −∞ , lımx→+∞
f(x) = L , lımx→+∞
f(x) = +∞ , lımx→−∞
f(x) = +∞ y lımx→−∞
f(x) = −∞ .
Ejemplo Para a > 0, lımx→+∞
ax = +∞ y lımx→0−
1x = −∞ . En efecto:
? para cada K > 0 tomamos M = Ka > 0 y si x > M , entonces f(x) = ax > aM = aKa = K
? para cada K > 0 tomamos δ = 1K > 0 y si −δ < x < 0, entonces f(x) = 1
x <1−δ = −K 4
Las operaciones del resultado Propiedades 65 son validas tambien cuando tenemos lımites en el infinito o convalor infinito, aunque aparecen situaciones cuyo resultado no puede determinarse usando las reglas generales.
Si lımx→x0
f(x) = a y lımx→x0
g(x) = b , donde tanto x0 como a y b pueden ser ±∞ , el valor del lımite para las
funciones f + g , f · g , fg y fg , se obtiene de las siguientes tablas:
f + g b = −∞ b ∈ R b = +∞a = −∞ −∞ −∞a ∈ R −∞ a+ b +∞
a = +∞ +∞ +∞
fg
b = −∞ b < 0 b = 0− b = 0 b = 0+ b > 0 b = +∞a = −∞ +∞ +∞ |∞| −∞ −∞a < 0 0 a
b+∞ |∞| −∞ a
b0
a = 0 0 0 0 0
a > 0 0 ab
−∞ |∞| +∞ ab
0
a = +∞ −∞ −∞ |∞| +∞ +∞
f · g b = −∞ b < 0 b = 0 b > 0 b = +∞a = −∞ +∞ +∞ −∞ −∞a < 0 +∞ ab 0 ab −∞a = 0 0 0 0
a > 0 −∞ ab 0 ab +∞a = +∞ −∞ −∞ +∞ +∞
fg b = −∞ b < 0 b = 0 b > 0 b = +∞a = 0 +∞ +∞ 0 0
0 < a < 1 +∞ ab 1 ab 0
a = 1 1 1 1
a > 1 0 ab 1 ab +∞a = +∞ 0 0 +∞ +∞
|∞| En estos casos, no se garantiza la existencia del lımite, pero sı que se tiene∣∣∣ fg ∣∣∣ −→ +∞ .
Hay siete indeterminaciones clasicas, indicadas con (que en el fondo se reducen a dos (i) e (ii)):
(i) ∞−∞ (ii) 0 · ∞ (iii) ∞∞ (iv) 0
0 (v) 1∞ (vi) 00 (vii) ∞0
Nota: Teniendo en cuenta que ab = eb ln a , las indeterminaciones (v), (vi) y (vii) se reducen a 0 · ∞ .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

36 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
Ejemplo 74 lımx→+∞
x2+2x+13x−2x2 = (+∞
−∞ ) = −12 .
lımx→+∞
x2 + 2x+ 1
3x− 2x2= lımx→+∞
x2+2x+1x2
3x−2x2
x2
= lımx→+∞
1 + 2x + 1
x2
3x − 2
=1 + 0 + 0
0− 2=−1
2 4
Ejemplo 75 lımx→0
x3−3x+2x2
3x3−2x = ( 00 ) = 3
2 .
lımx→0
x3 − 3x+ 2x2
3x3 − 2x= lımx→0
x(x2 − 3 + 2x)
x(3x2 − 2)= lımx→0
x2 − 3 + 2x
3x2 − 2=
0− 3 + 0
0− 2=−3
−2=
3
2 4
Ejemplo 76 lımx→+∞
2xx+√x2+2x
= (+∞+∞ ) = 1.
lımx→+∞
2x
x+√x2+2x
= lımx→+∞
2xx
xx +
√x2+2xx
= lımx→+∞
2
1 +√x2+2x√x2
= lımx→+∞
2
1 +√
1+ 2x
= 2√1+0+1
= 1
teniendo en cuenta que cuando x→ +∞ , sera x > 0 y por tanto x = |x| =√x2 . 4
Ejemplo 77 lımx→+∞
√x2 + 2x− x = (∞−∞) = 1.
lımx→+∞
√x2 + 2x− x= lım
x→+∞
(√x2 + 2x− x)(
√x2 + 2x+ x)√
x2 + 2x+ x= lımx→+∞
(√x2 + 2x)2 − x2
√x2 + 2x+ x
= lımx→+∞
x2 + 2x− x2
√x2 + 2x+ x
= lımx→+∞
2x√x2 + 2x+ x
= 1 4
Ejemplo 78 lımx→+∞
(1 + 1x )x = e
Por definicion, e = lımn→+∞
(1 + 1n )n y para cada x > 0, existe n ∈ N con n < x ≤ n + 1, luego con
1n+1 ≤
1x <
1n de donde 1 + 1
n+1 ≤ 1 + 1x < 1 + 1
n . De esta desigualdad y de n < x ≤ n+ 1, tenemos que:
(1 +
1
n+ 1
)n≤(
1 +1
x
)x<(
1 +1
n
)n+1
=⇒(1 + 1
n+1 )n+1
1 + 1n+1
≤(
1 +1
x
)x<(
1 +1
n
)(1 +
1
n
)n=⇒ n+ 1
n+ 2
(1 +
1
n+ 1
)n+1
≤(
1 +1
x
)x<n+ 1
n
(1 +
1
n
)nsi x→ +∞ , entonces n y n+1→ +∞ , por lo que se cumple que e ≤ lım
x→+∞(1 + 1
x )x ≤ e . 4
Nota: La Proposicion 69 de convergencia propia cobra nuevo interes con los lımites con infinitos (para los quetambien es valida), pues la condicion de continuidad no es aplicable en muchos de estos casos. Ademas, lacondicion de convergencia propia, que cuando f(x)→∞ sea f(x) 6=∞ se cumple de manera obvia.
Ejemplo Consideremos y = −x en (1), y z = h(y) = y − 1 en (2) entonces
lımx→−∞
(1 + 1x )x
(1)= lım
y→+∞(1− 1
y )−y = lımy→+∞
(y−1y )−y = lım
y→+∞( yy−1 )y = lım
y→+∞(1 + 1
y−1 )y
= lımy→+∞
(1 + 1y−1 )(1 + 1
y−1 )y−1 (2)= lım
y→+∞(1 + 1
y−1 ) lımz→+∞
(1 + 1z )z = 1 · e = e 4
Continuidad de algunas funciones elementales 79.- (Ver sus graficas en la figura 1.1 de la pagina 30.)
• f(x) = ex es continua en R y lımx→−∞
ex = 0 y lımx→+∞
ex = +∞ .
• f(x) = lnx es continua en (0,+∞) y lımx→0+
lnx = −∞ y lımx→+∞
lnx = +∞ .
• f(x) = xα continua en (0,∞) y lımx→0+
xα=0 y lımx→+∞
xα=∞ si α>0 (resp. ∞ y 0 si α<0).
• f(x) = shx es continua en R y lımx→−∞
shx = −∞ y lımx→+∞
shx = +∞ .
• f(x) = chx es continua en R y lımx→−∞
chx =∞ y lımx→+∞
chx = +∞ .
• f(x) = thx es continua en R y lımx→−∞
thx = −1 y lımx→+∞
thx = 1.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

37 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
• f(x) = senx y f(x) = cosx son de periodicas de periodo 2π , continuas en R y 6 ∃ lımx→±∞
f(x).
• f(x) = tg x es de periodo π , continua en su dominio y lımx→−π2
+tg x = −∞ y lım
x→π2−
tg x =∞ . .
1.3.3 Infinitesimos e infinitos equivalentes
Definicion 80.- Se dice que una funcion f es un infinitesimo en x0 si lımx→x0
f(x) = 0.
Una funcion f(x) se dice que es un infinito en x0 si lımx→x0
f(x) = +∞ (o −∞).
Definicion 81.- Dos infinitesimos en x0 , f y g , se dicen equivalentes en x0 si lımx→x0
f(x)g(x) = 1.
Dos infinitos en x0 , f y g , se dicen equivalentes en x0 si lımx→x0
f(x)g(x) = 1.
Proposicion 82.- Si g(x) y h(x) son infinitesimos (o infinitos) equivalentes en x0 , entonces
lımx→x0
g(x)f(x) = lımx→x0
h(x)f(x) y lımx→x0
f(x)
g(x)= lımx→x0
f(x)
h(x),
siempre que los segundos lımites existan.
Demostracion:
Si existe lımx→x0
f(x)h(x) y lımx→x0
g(x)h(x) = 1, entonces:
lımx→x0
h(x)f(x) = lımx→x0
g(x)h(x) · lım
x→x0
h(x)f(x) = lımx→x0
g(x)h(x)f(x)h(x) = lım
x→x0
g(x)f(x)
Analogamente para el otro caso.
Algunos infinitos e infinitesimos conocidos 83.- Usaremos la notacion f ∼ g para indicar que f y g soninfinitos o infinitesimos equivalentes:
anxn + · · ·+ a1x+ a0 ∼ anx
n cuando x→ ±∞ anxn + · · ·+ a1x ∼ a1x cuando x→ 0
sen(x) ∼ x cuando x→ 0 tg(x) ∼ x cuando x→ 0
sen 1x ∼
1x cuando x→ ±∞ 1− cos(x) ∼ x2
2 cuando x→ 0
ln(1 + x) ∼ x cuando x→ 0 ex − 1 ∼ x cuando x→ 0
sh(x) ∼ x cuando x→ 0 ch(x)− 1 ∼ x2
2 cuando x→ 0 .
Ejemplos lımx→1
ln(x)x−1 = 1. En efecto, lım
x→1
ln(x)x−1 = lım
x−1→0
ln(x)x−1 = lım
t→0
ln(1+t)t = lım
t→0
tt = 1
lımx→0
x sen( x2 )
ex2−1=
{x→ 0⇒ x
2 → 0sen(x2 ) ∼ x
2
}= lımx→0
x x2ex2−1
=
{x→ 0⇒ x2 → 0
ex2 − 1 ∼ x2
}= lımx→0
x x2x2 = 1
2
lımx→+∞
2x sen( 1x ) =
{x→ +∞⇒ 1
x → 0sen( 1
x ) ∼ 1x
}= lımx→+∞
2x 1x = 2 4
Nota: La hipotesis de la Proposicion, en el sentido de que los infinitesimos (o infinitos) sean factores o divisoresde la funcion, deben tenerse muy presentes pues solo ası garantizaremos el resultado. El ejemplo siguientemuestra como al sustituir un sumando por otro se falsea el resultado.
Sabemos que senx y x son infinitesimos equivalentes en x = 0, pero senx no puede ser sustituido por xen el lımite: lım
x→0
sen x−xx3 , pues si lo hacemos obtendrıamos como lımite 0 cuando su valor correcto es −1
6 .
Los infinitesimos o infinitos equivalentes son funciones que tienen un comportamiento “similar” en el lımite,pero no igual. Por ello, si los usamos en sumas o restas podemos eliminar esa diferencia (como ocurre en ellımite anterior) y dejar sin sentido el lımite.
Al sustituir senx por x en la resta de arriba estamos asumiendo que son iguales, pues sutituimos senx−xpor 0, lo que no es cierto (es senx− x 6= 0 si x 6= 0); de hecho, el seno es mas parecido a senx ≈ x− x3
6 con
lo que la deferencia es mas parecida a senx− x ≈ −x3
6 que a 0.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

38 – Fundamentos de Matematicas : Calculo diferencial en R 1.3 Lımite y continuidad de una funcion en un punto
1.3.4 Asıntotas de una funcion
Una buena ayuda para la representacion de la grafica de las funciones son las asıntotas. La grafica de f esuna representacion en el plano R2 formada por los puntos (x, y) con la condicion y = f(x) luego de la forma(x, f(x)); por consiguiente, la grafica puede tener puntos que se alejan hacia el infinito. Basta tener en cuentaque si el dominio es R , cuando x→ +∞ los puntos de la grafica se alejan hacia
(+∞, lım
x→+∞f(x)
).
Estos alejamientos de la grafica se llaman ramas infinitas de la funcion, y puede ocurrir que la funcion se“parezca” a una recta en estas ramas infinitas. Las rectas cumpliendo que la distancia de los puntos de unarama infinita a esa recta tienda hacia 0 a medida que se alejan, se denominan asıntotas de la funcion.
Dado que en R2 , los puntos se alejan en la forma (x,∞), (∞, y) o (∞,∞) (aquı, ∞ puede ser tanto +∞como −∞), buscaremos tres tipos de asıntotas: verticales, horizontales e inclinadas.
Asıntotas verticales
Si lımx→x−0
f(x) = ±∞ tenemos una rama infinita a la izquierda del punto x0 y la recta x = x0 es una asıntota
vertical de esa rama (el signo del lımite +∞ o −∞ , nos indicara el comportamiento de la rama infinita).Si lım
x→x+0
f(x) = ±∞ hay rama infinita a la derecha de x0 y la recta x = x0 es asıntota vertical de esa rama.
Asıntotas horizontales e inclinadas Aunque la busqueda de asıntotas horizontales e inclinadas puedenverse como procesos distintos, en ambos casos la variable x se aleja hacia el infinito (x, f(x))→
(∞, lım
x→∞f(x)
)y tambien, la recta es de la forma y = mx+ n (con m = 0 para las horizontales).
Si buscamos una recta y = mx + n cumpliendo que f(x) − (mx + n) −→ 0 cuando x → +∞ , tambien se
cumplira que f(x)−mx−nx −→ 0, de donde f(x)
x −m−nx −→ 0 luego se tendra que m = lım
x→+∞f(x)x . Y conocido
m , se tendra f(x)− (mx+ n) −→ 0 ⇐⇒ f(x)−mx −→ n , de donde n = lımx→+∞
f(x)−mx .
En consecuencia, existira asıntota cuando x→ +∞ (o en +∞), si existen y son reales los valores de los
lımites m = lımx→+∞
f(x)x y n = lım
x→+∞f(x)−mx , siendo y = mx+n es la asıntota buscada. (Analogo en −∞).
Ejemplo La funcion f(x) = (x−1)(x+2)|x|√(x2−1)(x−3)2
, tiene por dominio, Dom(f) = (−∞,−1) ∪ (1, 3) ∪ (3,+∞).
Como el numerador, es continuo en R , las asıntotas verticales (si existen) estaran en los puntos donde se anuleel denominador, es decir, −1, 1 y 3.
lımx→−1−
f(x) = lımx→−1−
(x− 1)(x+ 2) |x|√(x2 − 1)(x− 3)2
=
((−2) · 1 · |−1|
0+
)= −∞
lımx→1+
f(x) = lımx→1+
(x− 1)(x+ 2) |x|√(x2 − 1)(x− 3)2
= lımx→1+
(x+ 2) |x|√(x− 3)2
· lımx→1+
x− 1√x2 − 1
=3
2· lımx→1+
x− 1√x2 − 1
= 0
lımx→3−
f(x) = lımx→3−
(x− 1)(x+ 2) |x|√(x2 − 1)(x− 3)2
=
(30
0+
)= +∞ lım
x→3+f(x) =
( 30
0+
)= +∞
Luego las asıntotas verticales son x = −1 (cuando x → −1− , f(x) → −∞) y x = 3 (cuando x → 3− ,f(x)→ +∞ y cuando x→ 3+ , f(x)→ +∞).
Estudiamos las asıntotas en +∞ ,
m= lımx→+∞
f(x)
x= lımx→+∞
(x− 1)(x+ 2)√(x2 − 1)(x− 3)2
lımx→+∞
|x|x
= 1 · 1 = 1
n= lımx→+∞
f(x)− x = lımx→+∞
(x− 1)(x+ 2)x− x√
(x2 − 1)(x− 3)2√(x2 − 1)(x− 3)2
= lımx→+∞
x(x−1)(8x2−3x−13)√(x2−1)(x−3)2
((x−1)(x+2) +
√(x2−1)(x−3)2
) = 4
luego y = x+4 es asıntota de f cuando x→ +∞ . Analogamente,se obtiene que y = −x− 4 es asıntota cuando x→ −∞ . 4
x = 3
x=−1y=−x−4
y=x+4�����
@@@
@@
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

39 – Fundamentos de Matematicas : Calculo diferencial en R 1.4 Teoremas del lımite y de continuidad
1.4 Teoremas del lımite y de continuidad
Teorema 84 (de acotacion y del signo para lımites).- Sean f :A ⊆ R −→ R y x0 un punto de acumu-lacion de A . Si lım
x→x0
f(x) = L ∈ R , existe un entorno E(x0, δ) tal que f esta acotada en E∗(x0, δ) ∩A .
Ademas, si L 6= 0, los valores de f(x) tienen el mismo signo que L
Demostracion:Sea ε > 0 fijo, entonces existe E∗(x0, δ) tal que |f(x) − L| < ε , luego L − ε < f(x) < L + ε , para todox ∈ E∗(x0, δ). En consecuencia, f esta acotada en dicho entorno reducido.
Para la segunda parte, basta tomar ε tal que 0<L−ε<f(x) si L>0, o tal que f(x)<L+ε<0, si L<0.
Corolario 85.- Si f :A −→ R es continua en x0 , entonces f esta acotada en algun entorno de x0 .
Ademas, si f(x0) 6= 0, el valor de f(x) tiene el mismo signo que f(x0).
1.4.1 Teoremas de continuidad en intervalos cerrados
Teorema de Bolzano 86.- Sea f una funcion continua en el intervalo [a, b] y que toma valores de signo opuestoen a y b (es decir, f(a)f(b) < 0) entonces ∃c ∈ (a, b) tal que f(c) = 0. .
Teorema de los valores intermedios 87.- Si f : [a, b] −→ R es continua en [a, b] y f(a) 6= f(b), entonces paracada k entre f(a) y f(b), existe c ∈ (a, b) tal que f(c) = k .
Demostracion:Supongamos f(a)<f(b), y sea f(a)<k<f(b). La funcion g: [a, b] −→ R dada por g(x)=f(x)−k es continuaen [a, b] y verifica que g(a) = f(a)−k < 0 y g(b) = f(b)−k > 0, luego por el Teorema de Bolzano (86) existec ∈ (a, b) tal que g(c) = f(c)− k = 0, es decir, con f(c) = k . Analogamente si f(b) < f(a).
Corolario 88.- Sea I un intervalo de R y f : I −→ R continua en I , entonces f(I) es un intervalo de R . .
Teorema de acotacion 89.- Sea f una funcion continua en el intervalo cerrado [a, b] , entonces f esta acotadaen dicho intervalo. Es decir, existe M > 0 tal que |f(x)| ≤M , para todo x ∈ [a, b] . .
Teorema de Weierstrass 90.- Si f es una funcion continua en el intervalo [a, b] , entonces f alcanza unmaximo y un mınimo en [a, b] . Es decir, ∃α, β ∈ [a, b] tal que f(α) ≤ f(x) ≤ f(β), ∀x ∈ [a, b] . .
Corolario 91.- Si f es continua en (a, b) y lımx→a+
f(x) = l1 ∈ R y lımx→b−
f(x) = l2 ∈ R , la funcion f esta
acotada en (a, b). (Tambien es cierto cuando a es −∞ y cuando b es +∞ .) .
1.5 Ejercicios
1.34 Usar las Propiedades del orden 42 y las de las operaciones descritas en el apartado 1.1.4, para probar que:
a) si 0 < x < y , entonces 0 < x2 < y2 b) si y < x < 0, entonces 0 < x2 < y2
c) si 0 < x < y , entonces 0 < |x| < |y| d) si y < x < 0, entonces 0 < |x| < |y|e) si 0 < x < 1, entonces 0 < x2 < x f) si 1 < x , entonces 1 < x < x2
g) si y < x < 0, entonces 1x <
1y < 0 h) si y < x < 0, entonces 0 < 1
|y| <1|x|
i) si 0 < x < y , entonces 0 <√x <√y j) si 0 < x < y , entonces −√y < −
√x < 0
1.35 Expresar los siguientes conjuntos con intervalos y decir, para cada uno de ellos, si esta acotado, acotadosuperiormente y acotado inferiormente:
A={x ∈ R : 10− 3x ≥ 31
}B={x ∈ R :
∣∣x2 − 4∣∣ > 3
}C={x ∈ R :
∣∣x2 − 4∣∣ < 4
}D={x ∈ R :
∣∣x2 − 4∣∣ ≥ 5
}E={x ∈ R :
∣∣x2 − 4∣∣ ≤ 0
}F={x ∈ R : 3x2 + 13x < x3 + 15
}G={x ∈ R : 1 ≤ 2−x < 8
}H={x ∈ R : 1− |lnx| < 0
}I={x ∈ R : senx ≥ 1
2
}
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

40 – Fundamentos de Matematicas : Calculo diferencial en R 1.5 Ejercicios
1.36 Hallar el dominio de las funciones reales de variable real dadas por:
(i) f1(x) =√x2 − 2x (ii) f2(x) = −
√|x| − x (iii) f3(x) =
√x−1x+1
(iv) f4(x) = ln |x| (v) f5(x) = ln√x (vi) f6(x) = ln(2− x2)
(vii) f1(x) + f2(x) (viii) f3(x)− f1(x) (ix) 1f2(x) + 1
f3(x)
(x) f7(x) =√x−1√x+1
(xi) f8(x) = ln(f6(x)) (xii) f9(x) =√
x−1√x+1
(xiii) f3(x) · f3(x) (xiv) f9(x) · f7(x) (xv) f6(x)f1(x) + f1(x)
f6(x)
(xvi) f4(x)+f5(x)f8(x) (xvii) (f5 ◦ f8)(x) (xviii) (f1 ◦ f4 ◦ f2)(x)
a) Expresar la funciones f2 y f4 como funciones definidas a trozos.
b) ¿Por que los dominios de f3 y de f7 son distintos?
c) ¿Cual sera el dominio de la funcion f2 ◦ f2 ? Obtener su expresion.
1.37 Sean f y g dos funciones reales de variable real monotonas. Probar que:
a) Si f es (estrictamente) creciente, las funciones f(−x) y −f(x) son (estric.) decrecientes.
b) Si f es (estrictamente) decreciente, las funciones f(−x) y −f(x) son (estric.) crecientes.
c) Si f es (estric.) creciente y positiva, la funcion 1f(x) es (estric.) decreciente.
d) Si f es (estric.) decreciente y positiva, la funcion 1f(x) es (estric.) creciente. ¿Que ocurrira en este
caso y en el anterior si la funcion f es negativa?
e) Si f y g son crecientes (decrecientes), f + g es creciente (decreciente).
f) Buscar una funcion f creciente y una g decreciente tales que f + g sea creciente; y otras para quef + g sea decreciente.
g) Si g es creciente y f es creciente (decreciente), g ◦ f es creciente (decreciente).
h) Si g es decreciente y f es creciente (decreciente), g ◦ f es decreciente (creciente). ¿Que ocurrira sila monotonıa de g es estricta? ¿Y si lo es la de f ? ¿Y si lo son ambas?
1.38 Usar los resultados del ejercicio anterior, para probar lo siguente:
a) Probar que f(x) = 1x2+1 es creciente en (−∞, 0) y decreciente en (0,+∞).
b) Sabiendo que ex es esctirtamente creciente en R y que x = eln x , probar que sh(x) y ln(x) soncrecientes.
c) Probar que f(x) = x2−1x2+1 es creciente en (0,+∞) y usarlo para probar que th(x) es creciente en R .
1.39 Sea f :R −→ R , se dice que f es par si f(−x) = f(x), y que es impar si f(−x) = −f(x).
a) Comprobar si senx , cosx , tg x , shx , chx , thx y xn , para n = 0,±1,±2, . . . , son pares o impares.
b) Si f es par y creciente en (0,+∞), ¿sera tambien creciente en (−∞, 0)?
c) Si f es impar y creciente en (0,+∞), ¿sera tambien creciente en (−∞, 0)?
d) ¿Que caracterıstica especial cumplen las graficas de las funciones pares? ¿Y las de las funcionesimpares? Justificar la respuesta
1.40 Para las funciones que aparecen en el Ejemplo 58 anterior, pag. 31, dibujar su grafica y la de su inversa
en los dominios indicados.
Si una funcion f :A −→ B es creciente (decreciente) en A , ¿dirıas que su inversa f−1:B −→ A tambienes creciente (decreciente) en B ?
Probarlo en el caso de creer que es cierto, o en el caso de creer que es falso, justificarlo con un ejemplo.
1.41 Sean las funciones f , g y h , funciones reales definidas por:
f(x) =
{1, si x ≤ 0−1, si x > 0
; g(x) =
2x2 − 1
2 , si x ∈ (−∞,−1]1− x
2 , si x ∈ (−1, 0)3
1−x2 , si x ∈ [0,∞); h(x) =
{ −x3−12−x2 , si |x+ 1| ≤ 1
x2+22x+4 , si |x+ 1| > 1
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

41 – Fundamentos de Matematicas : Calculo diferencial en R 1.5 Ejercicios
a) Describir la casuıstica de f y h mediante la pertenencia de x a intervalos (como la funcion g )
b) Describir la casuıstica de g y h mediante desigualdades de x (como la funcion f )
c) Obtener su dominio y el de las funciones |f | , |g| , f+g y f ·h .
d) Hallar las expresiones de |f | , |g| , f+g y f ·h , como funciones definidas a trozos.
e) Encontrar el dominio y la expresion de las funciones compuestas f(x2) y g(2− x).
f) Encontrar el dominio y la expresion de las funciones g ◦ f y f ◦ g .
1.42 Calcular los siguientes lımites:
a) lımx→−∞
7x3+4x3x−x2−2x3 b) lım
x→∞7x3+4x
3x−x2−2x3 c) lımx→0
7x3+4x3x−x2−2x3
d) lımx→−2
x2−4x2(2+x) e) lım
x→∞
√1+4x2
4+x f) lımx→∞
sen2 xx2
g) lımx→∞
√x2 + 3x− 1− x h) lım
x→0(2− x2)2x i) lım
x→+∞(x2 + 2)
2xx−10
j) lımx→−1
2
+
√1−4x2
2x+1 k) lımx→0−
√|x|−x√x2−2x
l) lımx→1+
(1√x2−x −
√x+1x−1
)
1.43 Usar lımites laterales para verificar la existencia o no de los siguientes lımites:
a) lımx→1
√(1−x)2
x−1 b) lımx→0
x|x| c) lım
x→0
(1x −
1|x|
)d) lım
x→0
(|x|x − 1
)x
1.44 Probar, razonadamente, que los siguientes lımites valen 0:
a) lımx→1
(√x− 1) ex
2+2 b) lımx→0
x2 sen 1x c) lım
x→a(x−a)
43
|x−a|
1.45 Usar la continuidad de las funciones, para hallar:
a) lımx→0
ln√
3 + (1−x)2
x2+1 b) lımx→0
tg(ln(cos(e−1x ))) c) lım
x→π
√1 + cos2(π th( 1
|x−π| ))
1.46 Calcular, si existe, el valor de:
a) lımx→0
ln(cos x)x2 b) lım
x→0
sen2 x+ex−1th(2x) c) lım
x→∞x3 sen( 1
x3+x ) d) lımx→0
7x tg(x3−x5)(cos(2x)−1)2
1.47 Encontrar infinitesimos e infinitos equivalentes a:
a) sen2√
1− x2, cuando x→ −1+ b)√
1 + x2 + 2x4, cuando x→∞c) 1− cos((2− x2)2), cuando x→
√2 d) ln(1− 1
x ), cuando x→ −∞e)
√1−x
3x3+12x2 , cuando x→ 0 f) cos(x), cuando x→ π2
g) ln(x2), cuando x→ 1 h) 1− e2x5
, cuando x→ 0i) sen(x), cuando x→ 2π j) tg(−x6), cuando x→ 0
1.48 a) Si f y g son ifinitesimos cuando x → a y lımx→a
f(x)g(x) = L 6= 0, probar que f(x) y L · g(x) son
infinitesimos equivalentes cuando x→ a .
b) Si β es una raız de multiplicidad m del polinomio P (x) = anxn + · · ·+ a1x+ a0 , probar que P (x)
y k(x− β)m son infinitesimos equivalentes cuando x→ β , para algun valor k 6= 0.
1.49 Usar el resultado lımx→a
f(x) = lımh→0
f(a+ h) para calcular
a) lımx→1
ln(x2)x−1 b) lım
x→−2
x3+23
x+2 c) lımx→π−
3 sen(π+x)√1−cos(x−π)
d) lımx→π
2
cos x2x−π
1.50 Usar el logaritmo neperiano, para probar que lımx→+∞
(1 + 1x )x = e y que lım
x→−∞(1 + 1
x )x = e .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

42 – Fundamentos de Matematicas : Calculo diferencial en R 1.5 Ejercicios
1.51 Calcular, si existe, el valor de:
a) lımx→∞
(1− 1
x
)xb) lım
x→∞
(3−x1−x
)2−xc) lım
x→1
(2
x+1
) 3−x1−x
d) lımx→π
2
(1 + cosx)3
cos x
1.52 Considerar las funciones reales de variable real dadas por f(x) =√x2−3x+1 y g(x) = x−1√
3−x2.
Estudiar la continuidad de f y g en sus dominios de definicion (indıquese tambien la continuidad lateral,si ha lugar). ¿Tienen alguna asıntota?
1.53 Estudiar la continuidad de las siguientes funciones en su dominio:
a) f(x) =
{sen xx , si x 6= 0
1, si x = 0b) f(x) =
{x2−4
x2(2+x) , si x 6= −2
0, si x = −2
c) f(x) =
{ √x2+x−
√2
x−1 , si x 6= 13√
24 , si x = 1
d) f(x) =
{x, si |x| > 1x3, si |x| ≤ 1
1.54 ¿Para que valores de las constantes a y b , f(x) =
ax+ 1, si x < 3a+ b, si x = 3
bx2 − 2, si x > 3es continua en R?
1.55 Sean las funciones f, g, h:R −→ R , definidas a trozos mediante:
f(x) =
{1, si x ≤ 0−1, si x > 0
; g(x) =
2x2 − 1
2 , si x ≤ −11− x
2 , si − 1 < x < 03
1+x2 , si x ≥ 0; h(x) =
{ −x3−12+x2 , si |x+ 1| ≤ 1
x2+22x+4 , si |x+ 1| > 1
a) Estudiar la continuidad de cada una de ellas (indıquese tambien la continuidad lateral).
b) Estudiar la continuidad de las funciones |f | , |g| , f+g y f ·h . ¿Que ocurre en los casos donde nopuede aplicarse la regla general?
c) Estudiar la continuidad de las funciones g ◦ f y f ◦ h
1.56 Estudiar el dominio, la continuidad y las existencia de asıntotas de las funciones
a) f(x) = 2(1−x2)|x|(x+3)2(|x|−1) b) g(x) = (x−1)(x−3)√
(x2−5)2−16c) h(x) =
{g(x), si x ∈ Dom(g)
1− x, si x /∈ Dom(g)
1.57 Estudiar la continuidad de las siguientes funciones segun los valores del parametro a :
a) fa(x) =
{a− x, si x ≤ a
x(a2−x2)a2+x2 , si x > a
b) fa(x) =
x2aa2+x2 , si x < a
x2 , si x = a
a2xa2+x2 , si x > a
1.58 Probar que las graficas de las funciones f(x) = ex y g(x) = 3x , se cortan al menos en dos puntos delintervalo [0, 2].
1.59 Estudiar si las funciones del ejercicio 1.53 estan acotadas superior e inferiormente.
1.60 Comprobar que las siguientes funciones tienen inversa en sus dominios (son inyectivas) y representarlas.Obtener la expresion de la inversa, indicando los dominios y recorridos, y representarlas.
(i) f(x) = 1x − 1 (ii) f(x) =
{2− x, si x ∈ (−2, 0]x− 2, si x ∈ (0, 2]
(iii) f(x) =
2x+3, si x ≤ −1ex+1, si −1 < x < 0
3+x2, si x ≥ 0
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

43 – Fundamentos de Matematicas : Calculo diferencial en R
Capıtulo 2
Funciones derivables
2.1 Derivada de una funcion en un punto
Definicion 92.- Se dice que f : (a, b) −→ R es derivable en el punto x0 ∈ (a, b) si
lımx→x0
f(x)− f(x0)
x− x0= L ∈ R
es decir, si existe y es finito ese lımite (o el lımite equivalente, lımh→0
f(x+h)−f(x)h ).
Al valor de dicho lımite se lo denomina derivada de f en el punto x0 y se representa por f ′(x0) o dfdx (x0).
La derivada nos indica lo que “crece” la funcion alrededor delpunto, puesto que en el cociente usado para definirla nos apareceel incremento f(x)− f(x0) de la funcion en relacion con el incre-mento x− x0 de la variable.El valor del cociente f(x)−f(x0)
x−x0, para cada x , es la pendiente
de la cuerda entre los puntos (x0, f(x0)) y (x, f(x)) (ver figuraaneja), por lo que en el lımite se obtendra la pendiente de la rectatangente a la grafica de la funcion en el punto. Es decir, la rectay = f(x0) + f ′(x0)(x− x0) resulta ser la recta tangente a lagrafica de f en el punto (x0, f(x0)).
rry = f(x0) + f ′(x0)(x− x0)
f(x0)
x0 ← ← x
f(x)
α
f(x)−f(x0)x−x0
= tgα
︸ ︷︷ ︸x−x0
f(x)− f(x0)
Diremos que f :A −→ R es derivable en un conjunto A1 ⊆ A , si lo es en cada punto de A1 . Entonces, sepuede construir la funcion que asocia a cada punto x ∈ A1 la derivada de la funcion f en el punto x ; A estafuncion se le llama funcion derivada de f y se le representa por f ′ , donde f ′:A1 −→ R .
Si a su vez, f ′:A1 −→ R es derivable en un conjunto A2 ⊆ A1 , se puede construir la derivada de la funcionf ′ en cada punto x ∈ A2 . A esta funcion se le llama funcion derivada segunda de f y se le representa por(f ′)′ = f ′′ , donde f ′′:A2 −→ R . Analogamente se tienen la derivadas de ordenes superiores, f ′′′ , . . . , fn) .
Ejemplo ? La funcion constante f :R −→ R , con f(x) = k , es derivable en cada punto de su dominio:
lımx→x0
f(x)−f(x0)x−x0
= lımx→x0
k−kx−x0
= lımx→x0
0x−x0
= 0 = f ′(x0); con lo que f ′(x) = 0 para todo x ∈ R .
• La funcion identidad f :R −→ R , con f(x) = x , es derivable en cada punto de R :
lımh→0
f(x0+h)−f(x0)h = lım
h→0
x0+h−x0
h = lımh→0
1 = 1 = f ′(x0), y f ′(x) = 1 para todo x ∈ R .
• La funcion polinomica f :R −→ R dada por f(x) = x2 es derivable en cada punto de su dominio pues
lımx→x0
f(x)−f(x0)x−x0
= lımx→x0
x2−x20
x−x0= lımx→x0
(x−x0)(x+x0)x−x0
= lımx→x0
x+ x0 = 2x0 = f ′(x0), y f ′(x) = 2x en R .
• La exponencial f(x) = ex es derivable en cada punto de R y f ′(x) = ex , pues
lımh→0
ex+h−exh = lım
h→0
ex(eh−1)h = lım
h→0ex( e
h−1h ) = ex lım
h→0
eh−1h = ex · 1 = ex = f ′(x).
• f(x) = lnx , es derivable en (0,+∞) y f ′(x) = 1x
lımh→0
ln(x+h)−ln(x)h = lım
h→0
ln( x+hx )
h = lımh→0
ln(1+hx )
xhx= 1
x lımh→0
ln(1+hx )
hx
= 1x = f ′(x).
• La funcion f(x) = senx es derivable en cada punto de R y f ′(x) = cosx
lımh→0
sen(x+h)−sen(x)h
(1)= lım
h→0
2 sen(h2 ) cos(x+h2 )
h = lımh→0
cos(x+ h2 )
sen(h2 )h2
= cos(x) · 1 = cosx = f ′(x).
(1) sen x−sen y = sen( x+y2 + x−y
2 )− sen( x+y2 − x−y
2 )
= sen( x+y2 ) cos( x−y2 ) + cos( x+y
2 ) sen( x−y2 )−(
sen( x+y2 ) cos( x−y2 )− cos( x+y
2 ) sen( x−y2 ))
= 2 cos( x+y2 ) sen( x−y2 )
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

44 – Fundamentos de Matematicas : Calculo diferencial en R 2.1 Derivada de una funcion en un punto
• La funcion f(x) = cosx es derivable en cada punto de R y f ′(x) = − senx
lımh→0
cos(x+h)−cos(x)h
(2)= lım
h→0
−2 sen(h2 ) sen(x+h2 )
h = lımh→0− sen(x+ h
2 )sen(h2 )
h2
= − sen(x) = f ′(x).
(2) Analogamente al caso del seno, cos x− cos y = cos( x+y2 + x−y
2 )− cos( x+y2 − x−y
2 ) = −2 sen( x+y2 ) sen( x−y2 )
• La recta y = cos 0 − sen 0(x − 0) = 1 es la recta tangente a cos(x) en el punto 0. Analogamente, larecta y = sen 0 + cos 0(x− 0) = x es la tangente a sen(x) en el 0. 4
Para que una funcion sea derivable, debe existir lımx→x0
f(x)−f(x0)x−x0
. Ahora bien, el denominador siempre
tiende hacia 0, por lo que solo puede existir el lımite si el lımite del denominador tambien es cero; puesto que
si f(x)− f(x0) 6→ 0 entonces∣∣∣ f(x)−f(x0)
x−x0
∣∣∣ −→∞ o no existe. Luego debe cumplirse que lımx→x0
f(x) = f(x0), es
decir que f sea continua en x0 :
Teorema 93.- Si f es derivable en un punto x0 entonces f es continua en dicho punto.
Demostracion:Veamos que lım
x→x0
f(x) = f(x0). Para cada x 6= x0 , la funcion f(x) puede escribirse en la forma
f(x) = f(x)− f(x0) + f(x0) = f(x)−f(x0)x−x0
(x− x0) + f(x0),
y tomando lımites se prueba la continudad de f en x0 , ya que:
lımx→x0
f(x) = lımx→x0
f(x)− f(x0)
x− x0· lımx→x0
(x− x0) + lımx→x0
f(x0) = f ′(x0) · 0 + f(x0) = f(x0).
Nota: Como consecuencia de este resultado una funcion solo puede ser derivable en los puntos de continuidad.
Pero la continuidad no garantiza la derivacion:
Ejemplo La funcion f(x) = |x| es continua pero no derivable en 0, ya que
lımx→0+
f(x)−f(0)x−0 = lım
x→0+
|x|x = lım
x→0+
xx = 1 y lım
x→0−
f(x)−f(0)x−0 = lım
x→0−
|x|x = lım
x→0−
−xx = −1 4
Como para los lımites y la continuidad, la derivabilidad se extiende bien mediante las operaciones confunciones:
Propiedades 94.- Sean f y g funciones derivables en un punto x0 , entonces:
a) f + g es derivable en x0 y (f + g)′(x0) = f ′(x0) + g′(x0).
b) fg es derivable en x0 y (fg)′(x0) = f ′(x0)g(x0) + f(x0)g′(x0).
c) f/g es derivable en x0 , si g(x0) 6= 0, y (f/g)′(x0) =f ′(x0)g(x0)− f(x0)g′(x0)(
g(x0))2 . .
Ejemplos ? Si g derivable en x0 y k una constante, f(x) = k g(x) es derivable en x0 y f ′(x0) = k g′(x0).En efecto, basta aplicar la formula del producto, f ′(x0) = 0g(x0) + k g′(x0) = k g′(x0).
• La funcion f(x) = x3 es derivable en cada x ∈ R , por ser producto de funciones derivables.f(x) = x3 = x2x = g(x)h(x), y f ′(x) = (gh)′(x) = g′(x)h(x) + g(x)h′(x) = 2x · x+ x2 · 1 = 3x2 .
En general, f(x) = xn es derivable en R con f ′(x) = nxn−1 y los polinomios son derivables en R .
• f(x) = x2−1x , cociente de derivables, es derivable en su dominio y f ′(x) = (2x)(x)−(x2−1)(1)
x2 = x2+1x2 . 4
Regla de la cadena 95.- Sea f derivable en x0 y g derivable en f(x0), entonces la funcion compuesta g ◦ fes derivable en x0 y ademas:
(g ◦ f)′(x0) = g′(f(x0)
)f ′(x0). .
Ejemplo f(x) = xα es derivable en (0,+∞), pues f(x) = xα = eα ln(x) donde g(x) = ex y h(x) = α lnxson derivables en sus dominios. Ademas, f ′(x) = g′(h(x))h′(x) = eα ln x(α 1
x ) = xα αx = αxα−1 . 4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

45 – Fundamentos de Matematicas : Calculo diferencial en R 2.1 Derivada de una funcion en un punto
2.1.1 Aplicaciones de la derivada
Regla simple de L’Hopital 96.- Si f(x0) = g(x0) = 0 y f y g son derivables en x0 con g′(x0) 6= 0. Entonces,
lımx→x0
f(x)
g(x)=f ′(x0)
g′(x0).
Demostracion:Por ser f y g derivables en x0 , y f(x0) = g(x0) = 0, se tiene
lımx→x0
f(x)
g(x)= lımx→x0
f(x)− f(x0)
g(x)− g(x0)= lımx→x0
f(x)−f(x0)x−x0
g(x)−g(x0)x−x0
=lımx→x0
f(x)−f(x0)x−x0
lımx→x0
g(x)−g(x0)x−x0
=f ′(x0)
g′(x0)
Ejemplo lımx→0
sen xx = 1 pues f(x) = senx y g(x) = x , verifican las condiciones del resultado, f(0) = g(0) = 0,
f ′(0) = cos(0) y g′(0) = 1. Luego lımx→0
sen xx = cos(0)
1 = 1 4
Ejemplo Calcular el valor del lımite lımx→1
ln xcos(πx)+e1−x2 .
La funcion f(x) = lnx verifica que f(1) = 0 y derivable en 1 con f ′(x) = 1x y f ′(1) = 1.
La funcion g(x) = cos(πx) + e1−x2
verifica que g(1) = cos(π) + e0 = −1 + 1 = 0 y derivable en 1 con
g′(x) = −π sen(πx) + e1−x2
(−2x) y g′(1) = −π sen(π) + e0(−2) = −2 6= 0.
Luego lımx→1
ln xcos(πx)+e1−x2 = 1
−2 4
Nota: La derivacion es una potente herramienta para el calculo de lımites, no solo por el resultado anteriorsino por la mas util Regla General de L’Hopital 107 y los polinomios de Taylor, que veremos mas adelante.
2.1.1.1 Crecimiento de una funcion en un punto. Extremos locales
El significado de la derivada como lo que crece la funcion cerca del punto, queda de manifiento con el siguienteresultado:
Teorema 97.- Sea f : (a, b) −→ R derivable en el punto x0 ∈ (a, b). Entonces, si f ′(x0) > 0 (resp. f ′(x0) < 0)la funcion f es estrictamente creciente (resp. decreciente) en x0 .
Demostracion:
Si f ′(x0) > 0, como f ′(x0) = lımx→x0
f(x)−f(x0)x−x0
, se tiene que f(x)−f(x0)x−x0
> 0 para los x cercanos a x0 . Entonces
• si x0 < x , como x− x0 > 0, necesariamente f(x)− f(x0) > 0 de donde f(x0) < f(x)
• y si x < x0 , es x− x0 < 0 y debe ser f(x)− f(x0) < 0 de donde f(x) < f(x0)
Analogamente, para f ′(x0) < 0.
Definicion 98.- Sea f : (a, b) −→ R , se dice que f alcanza un maximo local en el punto x0 ∈ (a, b) (o quef(x0) es un maximo local de f ) si f(x) ≤ f(x0) para todos los x de algun entorno E(x0, δ) de x0 .
Se dice f alcanza un mınimo local en x0 si f(x0) ≤ f(x) para todos los x del entorno.
Nota: Diremos extremo local para referirnos indistintamente a un maximo o un mınimo local.
Proposicion 99.- Sea f : [a, b] −→ R continua y c ∈ (a, b). Si f es decreciente en cada x ∈ [a, c) y crecienteen cada x ∈ (c, b] , entonces f(c) es un mınimo local de f .
Si f es creciente en cada x ∈ [a, c) y decreciente en cada x ∈ (c, b] , f(c) es un maximo local de f .
Demostracion:En efecto, en el primer caso, por ser f continua en [a, b] existe el mınimo de f en el conjunto, pero no se puedealcanzar en un punto de [a, c) ya que todos los puntos son decrecientes (el valor de f en el punto es mayor quelos cercanos de su derecha); y no puede alcanzarse en (c, b] ya que todos los puntos son crecientes (el valor de f
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

46 – Fundamentos de Matematicas : Calculo diferencial en R 2.1 Derivada de una funcion en un punto
en el punto es mayor que los cercanos de su izquierda). Luego necesariamente, el mınimo tiene que alcanzarseen c . Analogamente, para el caso del maximo.
Ejemplo La funcion f(x) = |x| presenta un mınimo local en 0, pues es continua enR (luego en cualquier intervalo cerrado como [−1, 1]), decreciente a la izquierda de 0(f(x) = −x) y creciente a la derecha (f(x) = x). 4
rNota: La hipotesis de continuidad de la funcion es imprescindible paraasegurar el resultado. En la figura aneja pueden observarse distintassituaciones en las que sin continuidad no hay los extremos esperados:en los dos primeros casos la funcion no alcanza el maximo esperado y nohay extremo local; en el tercero, no se tiene el maximo esperado aunquesı un extremo ya que se alcanza un mınimo local en el punto.
Con la continuidad, si f es creciente (o decreciente) en los puntosa derecha e izquierda de c , tambien se garantiza la no existencia deextremo. Pero sin continuidad, a pesar de ser creciente antes del puntoy creciente despues del punto puede existir extremo, como en la cuartasituacion de la figura donde tenemos un maximo local.
rb rbb
br rbCorolario 100.- Sea f : [a, b] −→ R continua en [a,b] y derivable en (a, b). Si f ′(x) < 0 (resp. f ′(x) > 0) paracada x ∈ (a, c) y f ′(x) > 0 (resp. f ′(x) < 0) en cada x ∈ (c, b), la funcion f alcanza en c un mınimo local(resp. maximo local).
Ejemplo La funcion f(x) = e−x2
, continua y derivable en R , presenta un maximo local en 0, pues su
derivada f ′(x) = e−x2
(−2x) es positiva si x < 0 y negativa si x > 0. 4
Teorema 101 (Condicion necesaria de extremo).- Sea f : (a, b) −→ R . Si f es derivable en el puntoc ∈ (a, b) y f alcanza un extremo local en c , entonces f ′(c) = 0.
Demostracion:
Si f es derivable en c , existe f ′(c) = lımx→c
f(x)−f(c)x−c = lım
x→cx<c
f(x)−f(c)x−c = lım
x→cx>c
f(x)−f(c)x−c . Entonces
• si f(c) es un maximo local, se verifica que f(x)− f(c) ≤ 0 para los x cercanos a c , luego
f ′(c) = lımx→cx<c
f(x)− f(c)
x− c=(≤ 0
≤ 0
)≥ 0 y f ′(c) = lım
x→cx>c
f(x)− f(c)
x− c=(≤ 0
≥ 0
)≤ 0 =⇒ f ′(c) = 0
• Analogamente, si f(c) es mınimo local, f(x)− f(c) ≥ 0, luego
f ′(c) = lımx→cx<c
f(x)− f(c)
x− c≤ 0 y f ′(c) = lım
x→cx>c
f(x)− f(c)
x− c≥ 0 =⇒ f ′(c) = 0
Ejemplo La funcion f(x) = e−x2
del ejemplo anterior, es derivable en 0 y presenta un maximo local en 0.
Y ciertamente se verifica que f ′(0) = e−02
(−2 · 0) = 0. 4
La condicion anterior es solo una condicion necesaria, bajo la hipotesis de derivacion, pero no es suficientepara asegurar la existencia de extremo. Es decir, de los puntos donde la funcion sea derivable puede alcanzarseextremo unicamente en aquellos donde la derivada se anule, pero tambien puede no alcanzarse extremo enellos. Son, de entre los puntos derivables, los unicos puntos candidados a albergar extremo.
En consecuencia, para encontar los extremos locales de una funcion, basta con buscarlos entre los puntosdonde sea derivable, con derivada cero, y los puntos donde la funcion no sea derivable.
De todos estos puntos candidatos se suele decir tambien que son los puntos crıticos de la funcion.
Ejemplo La funcion f(x) = x3 es derivable en R y f ′(x) = 3x2 se anula en x = 0, pero no tiene extremolocal en el punto.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

47 – Fundamentos de Matematicas : Calculo diferencial en R 2.2 Teoremas de derivacion
Ejemplo La funcion f(x) = 3x4−8x3
16 es continua en [−1, 3] y derivable en
(−1, 3); su derivada en (−1, 3) es f ′(x) = 3x2(x−2)4 y se anula (f ′(x) = 0)
en los puntos x = 0 y x = 2. Entonces los unicos puntos “candidatos”a albergar un extremo local son x = 0 y x = 2 (donde existe la derivaday se anula), pero tambien los puntos x = −1 y x = 3 donde la funcionno es derivable (por ser extremos del intervalo de definicion). De hecho,el los extremos del intervalo se alcanza extremo local (f(−1) y f(3) sonmaximos locales) y tambien en el punto interior x = 2 (f(2) es mınimolocal); mientras que el otro “candidato” x = 0 no alberga extremo. 4
r
r
r
r
Una definicion usada cuando se manejan funciones derivadas, derivadas segundas y de ordenes superiores es:
Definicion 102.- Se dice que f es una funcion de clase 1 (o que es C1 ) en x0 si es derivable en el punto ysu derivada es continua en el punto. En general, se dice de clase m (o Cm ) en x0 si admite derivada hastaorden m en x0 y son todas continuas en x0 .
Si admite derivadas de cualquier orden y todas son continuas, se dice de clase ∞ (C∞ ).
Ejemplos ? f(x) = ex es continua y derivable en R y su derivada es f ′(x) = ex continua en R , luego esC1 en R . Como su derivada es ella misma, vuelve a ser derivable y su derivada continua y, sucesivamente,es en realidad de C∞ .
• Los polimonies son de clase ∞ es R . En efecto, son continuos y derivables, y su derivada es un polinomio,que vuelve a ser continua y derivable, etc.
• Las funciones seno y coseno son C∞ , pues salvo signos una es la derivada de la otra y son continuas yderivables. 4
2.2 Teoremas de derivacion
Los tres teoremas siguientes son basicos para pasar los resultados de derivacion sobre puntos a todo un intervalo,lo que nos servira ademas para contruir mejores herramientas de trabajo.
Teorema de Rolle 103.- Sea f : [a, b] −→ R tal que f es continua en [a, b] y derivable en (a, b) y ademasf(a) = f(b), entonces ∃ c ∈ (a, b) tal que f ′(c) = 0.
Demostracion:Por ser f continua en [a, b] , el Teorema de Weierstrass (90) garantiza que se alcanzan el maximo y el mınimoen el conjunto. Entonces,
• si se alcanza uno de los extremos en algun c ∈ (a, b), por ser f derivable en (a, b), se cumple que f ′(c) = 0
• si los extremos se alcanzan en a y b , por ser f(a) = f(b), el maximo y el mınimo deben coincidir, por loque la funcion es constante en [a, b] y f ′(c) = 0 para todo c ∈ (a, b).
Ejemplo La funcion polinomica f(x) = x4 − 4x2 se anula en x = 0 y x = 2, luego f(0) = 0 = f(2) y escontinua y derivable en [0, 2]. Entonces, el polinomio f ′(x) = 4x3 − 8x tiene alguna raız entre 0 y 2. 4
Nota: Si la funcion no es constante, el teorema de Rolle tiene otra lectura: se asegura la existencia de al menosun extremo en el intervalo. Geometricamente, el teorema de Rolle significa que existe un punto con tangentehorizontal.
El teorema siguiente, conocido como de losincrementos finitos o del valor medio de La-grange, generaliza el Teorema de Rolle. Y, ensentido geometrico, significa que hay un puntocuya recta tangente tiene la misma pendienteque la cuerda que une los puntos extremos de
la grafica f(b)−f(a)b−a = f ′(c).
f ′(c) = 0
a c b
f(a) = f(b)
Teorema de Rolle
rq q
f ′(c) =f(b)−f(a)
b−a
a c b
f(a)
f(b)
Teorema de Lagrange
rq q
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

48 – Fundamentos de Matematicas : Calculo diferencial en R 2.2 Teoremas de derivacion
Teorema del valor medio de Lagrange 104.- Sea f : [a, b] −→ R tal que f es continua en [a, b] y derivable en(a, b), entonces ∃c ∈ (a, b) tal que:
f(b)− f(a) = f ′(c)(b− a)
Demostracion:
Como a 6= b , podemos escribir f ′(c) = f(b)−f(a)b−a , es decir, buscamos un c ∈ (a, b) tal que f ′(c) sea la pendiente
de la cuerda entre los puntos (a, f(a)) y (b, f(b)) que tiene por ecuacion y = f(a) + f(b)−f(a)b−a (x− a).
Consideremos entonces la funcion g(x) = f(x) −(f(a) + f(b)−f(a)
b−a (x − a))
(la funcion menos la cuerda)para llevar el problema a las condiciones del teorema de Rolle. En efecto, g: [a, b] −→ R es continua en [a, b] y
derivable en (a, b) por ser suma de continuas y derivables, ademas, g(a) = f(a)−(f(a) + f(b)−f(a)
b−a (a− a))
= 0
y g(b) = f(b)−(f(a) + f(b)−f(a)
b−a (b− a))
= 0.
Entonces, existe c ∈ (a, b) tal que g′(c) = 0; y como g′(x) = f ′(x)− f(b)−f(a)b−a , se tiene la igualdad propuesta
ya que 0 = f ′(c)− f(b)−f(a)b−a .
El ultimo de los teoremas y mas general es el teorema de Cauchy. Aunque graficamente no tiene un significadoclaro, es muy util para la extension de la teorıa:
Teorema del valor medio de Cauchy 105.- Sean f y g funciones continuas en [a, b] y derivables en (a, b).Si g′(x) 6= 0, ∀x ∈ (a, b), entonces ∃ c ∈ (a, b) tal que:
f(b)− f(a)
g(b)− g(a)=f ′(c)
g′(c) .
Con los teoremas anteriores y la derivacion, ya se puede asegurar la monotonıa por intervalos:
Proposicion 106.- Si f es un funcion continua en [a, b] y derivable en (a, b) y f ′(x) > 0, ∀x ∈ (a, b), entoncesf es estrictamente creciente en [a, b] .
Si f es una funcion continua en [a, b] y derivable en (a, b) y f ′(x) < 0, ∀x ∈ (a, b), entonces f esestrictamente decreciente en [a, b] .
Demostracion:Para cualesquiera x1, x2 ∈ [a, b] , con x1 < x2 , consideremos el intervalo [x1, x2] . Podemos aplicar el teoremadel valor medio de Lagrange en este intervalo, luego ∃ c ∈ (x1, x2) tal que f(x2) − f(x1) = f ′(c)(x2 − x1).Entonces,
• si f ′ > 0 en (a, b), tambien f ′(c) > 0 y se tiene que f(x2) − f(x1) = f ′(c)(x2 − x1) > 0 por lo quef(x1) < f(x2) y, en consecuencia, f es estrictamente creciente en [a, b] .
• si f ′ < 0 en (a, b), tambien f ′(c) < 0 y se tiene que f(x2) − f(x1) = f ′(c)(x2 − x1) < 0 por lo quef(x1) > f(x2) y, en consecuencia, f es estrictamente decreciente en [a, b] .
Y tambien podemos obtener el resultado de la Regla General de L’Hopital para el calculo de lımites:
Regla General de L’Hopital 107.- Sean f y g funciones derivables en un entorno reducido de x0 , E∗(x0, δ),con g(x) 6= 0 y g′(x) 6= 0, ∀x ∈ E∗(x0, δ) y lım
x→x0
f(x) = 0 = lımx→x0
g(x). Entonces,
si existe lımx→x0
f ′(x)g′(x) se cumple que lım
x→x0
f(x)g(x) = lım
x→x0
f ′(x)g′(x) . .
Nota: Esta regla es tambien valida en los casos en que x0 sea +∞ o −∞ y cuando lımx→x0
f(x) = +∞ o −∞y lımx→x0
g(x) = +∞ o −∞ , (tambien en este caso x0 puede ser +∞ o −∞) sin mas que traducir las hipotesis
de f y g a entornos de +∞ o −∞ .
Ejemplo Calcular el lımx→0
sen(x)−xx3 . Las funciones f(x) = sen(x) − x y g(x) = x3 son derivables en R ,
con f(0) = 0 = g(0); y sus derivadas son f ′(x) = cos(x)− 1 y g′(x) = 3x2 . Entonces, por L’Hopital, el lımiteinicial existe si existe el del cociente de las derivadas, por lo que hemos trasladado el problema al calculo de un
nuevo lımite lımx→0
cos(x)−13x2 . Como tambien es indeterminado y las derivadas son derivables, podemos aplicar de
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

49 – Fundamentos de Matematicas : Calculo diferencial en R 2.2 Teoremas de derivacion
nuevo L’Hopital para resolver este lımite. Sucesivamente, tendremos que
lımx→0
sen(x)− xx3
= lımx→0
cos(x)− 1
3x2= lımx→0
− sen(x)
6x=−1
6lımx→0
sen(x)
x=−1
6
La existencia del ultimo lımite garantiza la cadena de igualdades. 4
Ejemplo Calcular lımx→0+
tg(π2−x)
ln x .
Como las funciones del cociente son derivables cerca de 0+ , ytg(π2−x)
ln x → +∞−∞ , aplicando l’Hopital
lımx→0+
tg(π2−x)
ln x = lımx→0+
−1
cos2(π2−x)
1x
= lımx→0+
−xcos2(π2−x) =
(0−
0+
)= lımx→0+
−12 cos(π2−x)(− sen(π2−x))(−1) = (−1
0+ ) = −∞ 4
Ejemplo Sabemos que lımx→+∞
x2−xx2+3x = 1, y usando l’Hopital lım
x→+∞x2−xx2+3x = lım
x→+∞2x−12x+3 = lım
x→+∞22 = 1 4
Anadamos un resultado que puede parecer irrelevante, pero que resulta de utilidad para las funcionesdefinidas a trozos:
Proposicion 108.- Sea f : (a, b) −→ R tal que f es continua en x0 ∈ (a, b), f es derivable en un entornoreducido de x0 , y existen los lım
x→x+0
f ′(x) y lımx→x−0
f ′(x). Entonces:
f es de derivable en x0 si y solo si lımx→x+
0
f ′(x) = lımx→x−0
f ′(x).
Demostracion:Por ser f continua en x0 , f(x) → f(x0) cuando x → x0 y, por ser derivable, puede aplicarse la Regla deL’Hopital para obtener las igualdades de lımites siguientes:
lımx→x+
0
f(x)− f(x0)
x− x0= lımx→x+
0
f ′(x)
1= lımx→x+
0
f ′(x) lımx→x−0
f(x)− f(x0)
x− x0= lımx→x−0
f ′(x)
1= lımx→x−0
f ′(x)
Entonces, si f es derivable en x0 , f ′(x0) = lımx→x−0
f(x)−f(x0)x−x0
= lımx→x+
0
f(x)−f(x0)x−x0
y lımx→x+
0
f ′(x) = lımx→x−0
f ′(x).
Recıprocamente, si lımx→x+
0
f ′(x) = lımx→x−0
f ′(x), entonces lımx→x−0
f(x)−f(x0)x−x0
= lımx→x+
0
f(x)−f(x0)x−x0
y existe el lımite
global, por lo que f es derivable en x0 y f ′(x0) = lımx→x+
0
f ′(x) = lımx→x−0
f ′(x).
Ejemplos ? La funcion f(x) = |x| ={
x, si x ≥ 0−x, si x < 0
no es derivable en x = 0. En efecto, es continua en
x = 0 y derivable en R−{0} , y como lımx→0+
f ′(x) = lımx→0+
1 = 1 6= lımx→0−
f ′(x) = lımx→0−
−1 = −1, la funcion
no es derivable en el punto.
• La funcion f(x) =
{x2, si x ≥ 0−x2, si x < 0
es derivable en x = 0. En efecto, es continua en x = 0 y derivable en
R − {0} , y como lımx→0+
f ′(x) = lımx→0+
2x = 0 = lımx→0−
f ′(x) = lımx→0−
−2x = 0, la funcion es derivable en el
punto y f ′(0) = 0. 4
2.2.1 Teorema de la funcion inversa
El siguiente teorema garantiza de modo sencillo la existencia de funcion inversa en un conjunto y procura unmetodo para obtener las derivadas de la inversa aunque no conozcamos su expresion.
Teorema de la funcion inversa 109.- Sea f : [a, b] −→ R continua en [a, b] y derivable en (a, b), con f ′ > 0 of ′ < 0 en (a, b). Entonces f admite funcion inversa derivable en (a, b) y (f−1)′
(f(x)
)= 1
f ′(x) . .
Corolario 110.- Si f es estrictamente creciente (resp. estrictamente decreciente), su inversa f−1 es estricta-mente creciente (resp. estrictamente decreciente)
Demostracion:Como (f−1)′
(f(x)
)= 1
f ′(x) , su signo es el mismo que el de f ′ .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

50 – Fundamentos de Matematicas : Calculo diferencial en R 2.2 Teoremas de derivacion
Corolario 111.- Si f ′ es continua, entonces la derivada de la inversa es tambien continua.
Ejemplo La funcion f(x) = tg x es continua y derivable en (−π2 ,π2 ), con f ′(x) = 1 + tg2 x que es mayor que
cero en cada punto. Luego f es estrictamente creciente en el intervalo y su funcion inversa arctg:R −→ (−π2 ,π2 )
es tambien estrictamente creciente y (f−1)′(tg(x)) = 11+tg2 x luego haciendo y = tg x , se obtiene que
(f−1)′(y) = (arctg y)′ =1
1 + y2 4
Ejemplo La funcion f(x) = sh(x) es continua y derivable en R , con f ′(c) = ch(x) que es continua y mayorque cero en el conjunto. Luego admite inversa en R y su funcion inversa argsh:R −→ R tiene tambien derivadacontinua. Como (f−1)′(sh(x)) = 1
ch(x) haciendo y = sh(x) y usando que ch2 x− sh2 x = 1, se tiene
(f−1)′(y) = (argsh y)′ =1√
1 + y2 4
Inversas de las demas funciones trigonometricas e hiperbolicasf(x) = senx tiene por inversa en [−π2 ,
π2 ] a arcsen: [−1, 1] −→ [−π2 ,
π2 ] y (arcsen y)′ = 1√
1−y2
f(x) = cosx tiene por inversa en [0, π] a arccos: [−1, 1] −→ [0, π] y (arccos y)′ = −1√1−y2
f(x) = chx tiene por inversa en [0,+∞) a argch: [1,+∞) −→ [0,+∞) y (argch y)′ = 1√y2−1
f(x) = thx tiene por inversa en R a argth: (−1, 1) −→ R y (argth y)′ = 11−y2
2.2.2 Representacion grafica de funciones (1)
A lo largo de este tema (y tambien en el anterior) hemos obtenido resultados sobre el comportamiento de lafuncion: continuidad, monotonıa, extremos, . . . . Resultados que tambien se reflejan en la grafica de la funcion,y que vamos a utilizar, para realizar un esbozo de la misma. La representacion grafica sera mas completa trasel tema siguiente sobre las derivadas de ordenes superiores.
2.2.2.1 Monotonıa y extremos locales
Basta para ello reunir algunos de los resultados ya obtenidos, en particular: uso del signo de la derivada parael crecimiento de la funcion, la condicion necesaria de extremos locales, la condicion suficiente de extremo quese da en la Proposicion 99.
Para el estudio del signo de la funcion derivada, si esta es continua, puede resultar util el Teorema de Bolzano.
Si f ′(c) = 0 y f ′(d) = 0, f ′ continua en [c, d] y no se anula en ningun otro punto, el signo def ′(x) es el mismo para todos los x ∈ (c, d).
En efecto, si dos puntos de (c, d), x1 y x2 , con x1 < x2 , verifican que f ′ tiene signos distintos, por sercontinua, tendrıa que existir un punto x0 ∈ (x1, x2) en el que f ′(x0) = 0 en contra de que no se anula enningun punto mas del conjunto. Luego todos tienen el mismo signo y para conocerlo basta con calcularlo enuno de los puntos.
Ejemplo La funcion f(x) = 3x4−8x3
16 es continua en [−1, 3] y derivable en
(−1, 3); su derivada en (−1, 3) es f ′(x) = 3x2(x−2)4 y se anula unicamente
en x = 0 y x = 2. Como la funcion derivada f ′(x) = 34x
2(x−2) es continuaen (−1, 3) y en (−1, 0] solo se anula en 0, tiene el mismo signo en todos lospuntos de (-1,0); como f ′(−1
2 ) = −1532 < 0 en (−1, 0) es siempre negativa y
la funcion f es decreciente en (−1, 0).f ′(x) es continua en [0, 2] y solo se anula en los extremos, luego tiene elmismo signo en (0, 2). Como f ′(1) = −3
4 < 0 es siempre negativa y f esdecreciente en (0, 2).
r
r
r
r
f ′(x) es continua en [2, 3) y solo se anula en 2, luego tiene el mismo signo en (2, 3). Como f ′( 52 ) = 75
32 > 0 essiempre positiva y f es creciente en (2, 3).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

51 – Fundamentos de Matematicas : Calculo diferencial en R 2.2 Teoremas de derivacion
Los unicos puntos “candidatos” a albergar un extremo local son x = 0 y x = 2 (donde existe la derivada yse anula), y los puntos x = −1 y x = 3 donde la funcion no es derivable por ser extremos del dominio.
Como f es continua en −1 y es decreciente en (−1, 0), f(−1) es un maximo local. Como f es continuaen 0 y es decreciente en (−1, 0) y decreciente en (0, 2), f(0) no es un extremo. Como f es continua en 2 y esdecreciente en (0, 2) y creciente en (2, 3), f(2) es un mınimo local. Como f es continua en 3 y es creciente en(2, 3), f(3) es un maximo local. 4
2.2.2.2 Concavidad y convexidad
Hemos visto en la condicion necesaria de extremo local como, cuando es derivable, la derivada en el punto escero; o lo que es lo mismo, la recta tangente a la grafica en el punto es horizontal. Si el extremo es un maximo,para valores cercanos al punto los valores de la funcion son menores que el maximo local luego, graficamente,los puntos de la grafica estan por debajo de la recta tangente; y si es un mınimo los puntos de la grafica estanpor encima de la recta tangente. Pero, tambien eso puede ocurre en cualquier otro punto (ver la grafica queilustra los teoremas de Rolle y del valor medio de Lagrange en pag 48) y nos lleva a las definiciones de funcionconcava y convexa.
Aunque pueden darse definiciones para las que no es necesaria la derivacion (mejores y menos restrictivas queestas), las que damos a continuacion son sencillas de introducir y mas que suficientes para el uso que haremosde los conceptos, pero tambien incorporann herramientas para una facil manipulacion.
Definicion 112.- Diremos que una funcion f : (a, b) −→ R , derivable en x0 ∈ (a, b) es convexa en el punto x0
si f(x) ≤ f(x0) + f ′(x0)(x− x0) para los x de algun entorno de x0 .
Diremos que es concava en x0 si f(x) ≥ f(x0) + f ′(x0)(x− x0) para los x de algun entorno de x0 .
Diremos que es concava o convexa es un intervalo si lo es en cada punto.
Un punto de continuidad se dice de inflexion si la funcion cambia de concavidad en el.
Nota: En otras palabras, diremos que es convexa (concava) en x0 si, cerca de x0 , la grafica de la funcion estapor debajo (encima) de la recta tangente en el punto. Con los comentarios hechos en la introduccion de esteapartado, en los maximos donde la funcion sea derivable la funcion es convexa y en los mınimos concava.
Ejemplo La funcion f(x) = x2 es concava en cada punto de R . Como es derivable en cada punto x = a yf ′(x) = 2x , se cumple que f(x)−
(f(a) + f ′(a)(x− a)
)= x2 − a2 − 2a(x− a) = x2 − 2ax+ a2 = (x− a)2 ≥ 0
para todo x , luego f(x) ≥ f(a) + f ′(a)(x− a) y es concava en cada punto.
Ejemplo La funcion f(x) = x2(x − 3), es convexa en x = 0, concava en x = 3 y presenta un punto deinflexion en x = 1.
En efecto, consideremos la funcion ga(x) = f(x) − (f(a) + f ′(a)(x − a)) entonces, si ga(x) ≥ 0 en algunentorno de a es concava en a , si ga(x) ≤ 0 en algun entorno de a es convexa en a y si ga(x) cambia de signoen a es un punto de inflexion. Como ga(a) = 0 y es derivable (pues f lo es), veamos como se comporta cercade cada uno de los puntos indicados:
• En x = 0, se tiene g′0(x) = 3x(x− 2), por lo que es positiva antesde 0 y negativa depues (y g0 es creciente antes de 0 y decrecientedepues) luego g0(x) ≤ g0(0) = 0 en algun entorno de 0.
• En x = 3, se tiene g′3(x) = 3(x+ 1)(x− 3), por lo que es negativaantes de 3 y positiva depues (y g3 es decreciente antes de 3 ycreciente depues) luego g3(x) ≥ g3(3) = 0 en algun entorno de 3.
• En x = 1, se tiene g′1(x) = 3(x− 1)2 , por lo que es positiva antesde 1 y tambien depues (y g1 es creciente antes de 1 y crecientedepues) luego g1(x) ≤ g1(1) = 0 para los x menores que 1 yg1(x) ≥ 0 para los x mayores que 1.
q
Luego es convexa en x = 0, concava en x = 3 y tiene un punto de inflexion en x = 1. 4
2.2.2.3 Paridad y periodicidad
Las simetrıas, par e impar, y la periodicidad son muy utiles para reducir y simplificar los calculos, y preveralgunos de los resultados que conseguiremos sobre la grafica y su comportamiento.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

52 – Fundamentos de Matematicas : Calculo diferencial en R 2.3 Ejercicios
Definicion 113.- Una funcion f se dice par si f(−x) = f(x) (f simetrica respecto al eje OY ).Una funcion f se dice impar si f(−x) = −f(x) (f simetrica respecto al origen (0, 0)).
Definicion 114.- Una funcion f se dice periodica de periodo T , si T es el menor numero real tal quef(x+ T ) = f(x), ∀x .
2.3 Ejercicios
2.61 Aplicar las reglas de derivacion, para encontrar la expresion de f ′ en:
a) f(x) =√x−1√x+1
b) f(x) =√
x−1x+1 c) f(x) =
√x−1√x+1
d) f(x) = ln√x e) f(x) = ln(senx) f) f(x) = (ln(2− x2))−1
g) f(x) = arctg 2+xx2 h) f(x) = ln(arccos(tg(x2))) i) f(x) =
(x−1√x+1
)−53
Indicar en cada caso el dominio de f y de f ′ .
2.62 Encontar la expresion de las funciones derivadas, indicando el conjunto donde tienen validez:
a) f(x) = 1√x
b) f(x) = x√x
x2+1 c) f(x) = x45
(x+1)3
d) f(x) =√x2 − 2x e) f(x) = ln |x| f) f(x) = −
√|x| − x
2.63 Hallar la recta tangente a las graficas de las funciones siguientes en los puntos que se indican:
a) f(x) = x3 − x , en x = 0 y en x = 1.
b) f(x) = e1x2 , en x = −1 y en x = 0.
c) f(x) =√
2− x2 , en x = 1 y en x = −√
2+
.
2.64 Probar que la parabola y = (x+ 1)2 + 1 tiene recta tangente en todos sus puntos.
¿En que puntos la recta tangente pasa por (0, 0)?
2.65 Usar la regla de L’Hopital, para calcular
a) lımx→−2
x2−4x2(2+x) b) lım
x→−2
x3+23
x+2 c) lımx→0
7x3+4x3x−x2−2x3
d) lımx→∞
7x3+4x3x−x2−2x3 e) lım
x→0
ln(cos x)x2 f) lım
x→0
sen2 x+ex−1arctg x
g) lımx→1
ln(x2)x−1 h) lım
x→π2
cos x2x−π i) lım
x→∞(x+ 1)(π2 − arctg(2x))
j) lımx→∞
ex
x6 k) lımx→0
xα ln |x| α ∈ R l) lımx→∞
ln xxα α ∈ R
m) lımx→1
(1
ln x −1
x−1
)n) lım
x→0+xsen x o) lım
x→∞(x2 + 1)
−1
x2
2.66 Estudiar la derivabilidad y obtener las derivadas, de las funciones del ejercicio 1.53.
2.67 Obtener las asıntotas de las funciones del ejercicio 1.53.
2.68 Estudiar la continuidad y derivabilidad de la funcion f(x) =
{arctg 1+4x
4x2 , si x 6= 0π2 , si x = 0
, e indicar sus intervalos
de crecimiento y decrecimiento. ¿Tiene asıntotas?
2.69 Para las funciones f , g y h del ejercicio 1.55:
a) Estudiar su derivabilidad en los puntos del dominio.
b) Dar la expresion de las funciones derivadas.
c) Obtener los intervalos de monotonıa.
d) Estudiar la existencia de extremos locales.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

53 – Fundamentos de Matematicas : Calculo diferencial en R 2.3 Ejercicios
e) Estudiar la existencia de asıntotas.
f) Estudiar la continuidad y derivabilidad de las funciones f ′ , g′ y h′ .
2.70 Hallar los extremos locales y globales de f(x) = x√x
x2+1 en [1, 3] y en [0,+∞).
2.71 Estudiar la monotonıa de f(x) = x− senx en [0, π] y deducir de ello que x ≥ senx en [0, π] .
2.72 Probar que:
a) Si f es una funcion estrictamente creciente, entoncesf ◦ g alcanza un maximo/mınimo en a ⇐⇒ h alcanza un maximo/mınimo en a
b) Si f es una funcion estrictamente decreciente, entoncesf ◦ g alcanza un maximo/mınimo en a ⇐⇒ g alcanza un mınimo/maximo en a
2.73 Usar los resultados del ejercicio 2.72, para encontrar los extremos locales de las funciones
a) f(x) = ex+1
x2+3 b) f(x) = 1√(x2−5)2+x2
2.74 Si f es par y alcanza un extremo en x = a , ¿alcanzara tambien un extremo en x = −a?
¿Que ocurrira si f es impar? ¿Y si es periodica de periodo T ?
2.75 Problema: Con una cuerda atamos una vaca al exterior de un edificio de planta cuadrada situado en el
centro de un prado. Si la longitud de la cuerda es la misma que el lado del edificio, ¿en que punto debemosatar la vaca para que tenga la mayor area posible de pasto? ¿y la menor?
Modelado del problema: Representamos el edificio por un cuadrado de lado L , por ejemplo el de vertices(0, 0), (L, 0), (L,L) y (0, L).Como el edificio es cuadrado, ocurre lo mismo en cada lado, por lo que basta estudiar uno de los lados,por ejemplo el lado inferior (el segmento {(x, 0) : x ∈ [0, L]}).Luego, para cada x ∈ [0, L] , debemos encontrar un funcion f que asigne a cada x el area buscado, esdecir, tal que f(x) = area-abarcado-atando-en-x .
La solucion del problema se obtiene encontrando los puntos donde de alcancen el maximo y el mınimoglobal de f en el intervalo [0, L] .
a) Resolver el problema planteado.
b) Repetir el problema para una cuerda de longitud la mitad del perımetro del edificio.
2.76 Descomponer 100 en dos sumandos tales que el cuadruplo del primero mas el cuadrado del segundo sea
mınimo.
2.77 Hallar dos numeros cuya suma sea a , de modo que la suma de la cuarta potencia de uno, mas el cuadrado
del otro, sea maxima.
2.78 Entre todos los rectangulos de area 50, ¿cual es el de perımetro mınimo? ¿y maximo?
2.79 Sean los triangulos rectangulos que tienen la suma de los catetos constante (e igual a k ). ¿Cual de ellos
tiene area maxima?
2.80 Dado un triangulo isosceles de base 8 cm y altura 5 cm, hallar las dimensiones de un rectangulo inscritoen el de area maxima.
2.81 Un prisma de 15 cm de altura tiene como base un triangulo rectangulo de hipotenusa igual a 10 cm.Calcular las longitudes de los catetos para que el volumen sea maximo.
2.82 De entre todos los cilindros con volumen 100π cm3 , escoger el de area lateral maxima. ¿Cual es el dearea total maxima?
2.83 Hallar las distancias mınima y maxima del punto (1, 1) a la circunferencia (x− 2)2 + (y − 2)2 = 9.
2.84 Hallar, las dimensiones del cilindro de volumen maximo inscrito en una esfera de radio R
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

54 – Fundamentos de Matematicas : Calculo diferencial en R 2.3 Ejercicios
2.85 Hallar, las dimensiones del cilindro de area total maxima inscrito en una esfera de radio R
2.86 Un pescador en bote de remos se encuentra, mar adentro, a una distancia de 2 km. del punto mas cercanode una playa recta y desea llegar a otro punto de la playa a 6 km. del primero. Suponiendo que se puederemar a una velocidad de 3 km/h. y caminar a 5 km/h, ¿que trayectoria debe seguir para llegar a sudestino en el menor tiempo posible? Si tiene una lancha que viaja a 15 km/h, ¿que trayectoria debe seguirahora?
2.87 Hay que cortar un hilo de longitud L en dos trozos. Con uno de ellos se forma un cırculo, y con el otro
un cuadrado. ¿Como hay que cortar el hilo para que la suma de las areas sea maxima? ¿Y para que seamınima?.
2.88 Un camion ha de recorrer 300 kms en una carretera llana a una velocidad constante de x km/h. Las leyesde circulacion prescriben para la velocidad un maximo de 60 km/h y un mınimo de 30 km/h. Se supone
que el carburante cuesta 3 duros/litro y que el consumo es de 10+ x2
120 litros por hora. El conductor cobra10 duros por hora. Teniendo en cuenta que la empresa paga al conductor y el carburante, a que velocidadtendra que viajar el camion para que el dinero desembolsado por la empresa sea mınimo.
2.89 Sea f(x) una funcion derivable en todo R , cuya grafica es simetrica respecto al eje OY .
a) Estudiar la paridad (simetrıa) de f ′(x).
b) Determinar, si es posible, f ′(0).
2.90 Sea f una funcion de clase 1 (derivable con derivada continua) en la recta real R . Supongamos que ftiene exactamente un punto crıtico x0 que es un mınimo local estricto de f . Demostrar que x0 tambienes un mınimo absoluto para f .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

55 – Fundamentos de Matematicas : Calculo diferencial en R
Capıtulo 3
Polinomios de TaylorHemos visto el uso de la derivada como aproximacion de la funcion (la recta tangente) y como indicadora delcomportamiento de la funcion (monotonıa). En este tema veremos las derivadas de ordenes superiores paramejorar estos usos.
3.1 Polinomios de Taylor
Cuando en el calculo de lımites usamos L’Hopital o algunos infinitesimos, estamos sustituyendo el compor-tamiento de la funcion cerca del punto por el de su recta tangente. Esta aproximacion que usamos, coincidecon la funcion en su valor y el valor de la derivada en el punto; los polinomios de Taylor que construiremos acontinuacion se toman para que coincida con la funcion en todas las derivadas.
Definicion 115.- Lamaremos polinomio de Taylor de orden n para la funcion f en el punto a , y lodenotaremos por Pn,a , al polinomio:
Pn,a(x) = f(a) +f ′(a)
1!(x− a) +
f ′′(a)
2!(x− a)2 + · · ·+ f (n)(a)
n!(x− a)n =
n∑k=0
f (k)(a)
k!(x− a)k
Los polinomios de Taylor en el punto a = 0, suelen denominarse polinomios de McLaurin.
Nota: Observamos que el polinomio de orden 1, P1,a(x) =
f(a) + f ′(a)1! (x− a) es la recta tangente a f en el punto a ,
de manera que los polinomios de Taylor seran una especiede “polinomios tangentes” a la funcion en el punto. Altener mayor grado que la recta tangente se espera que separezcan mas a la funcion que esta, aunque dado que parasu construccion unicamente usamos los valores de f y susderivadas en el punto a , sera una aproximacion local (cercade a).
rf(x) = sen(x)P
1, 2π3
(x)
P2, 2π
3(x)
P3, 2π
3(x)
P4, 2π
3(x)
En efecto, para todo k = 1, . . . , n , se cumple que P(k)n,a(a) = f (k)(a):
Pn,a(x) = f(a) + f ′(a)1! (x− a)1 + f ′′(a)
2! (x− a)2 + f ′′′(a)3! (x− a)3 + · · ·+ f(n−1)(a)
(n−1)! (x− a)n−1 + f(n)(a)n! (x− a)n
P ′n,a(x) = f ′(a) + f ′′(a)1! (x− a)1 + f ′′′(a)
2! (x− a)2 + · · ·+ f(n−1)(a)(n−2)! (x− a)n−2 + f(n)(a)
(n−1)! (x− a)n−1
P ′′n,a(x) = f ′′(a) + f ′′′(a)1! (x− a)1 + · · ·+ f(n−1)(a)
(n−3)! (x− a)n−3 + f(n)(a)(n−2)! (x− a)n−2
P ′′′n,a(x) = f ′′′(a) + · · ·+ f(n−1)(a)(n−4)! (x− a)n−4 + f(n)(a)
(n−3)! (x− a)n−3
· · · · · ·P
(n−1)n,a (x) = f (n−1)(a) + f(n)(a)
1! (x− a)1
P(n)n,a (x) = f (n)(a)
Y sustituyendo, se ve que P(k)n,a(a) = f (k)(a), para todo k .
Ejemplo La funcion f(x) = senx es C∞ en R , y sus derivadas son f ′(x) = cosx , f ′′(x) = − senx ,f (3)(x) = − cosx y f (4)(x) = senx = f(x) de nuevo, luego f(0) = 0, f ′(0) = 1, f ′′(0) = 0, f (3)(0) = −1 y serepiten f (4)(0) = f(0) = 0, f (5)(0) = f ′(0) = 1, etc. Por lo que
P7,0(x) = 0+ 11! (x−0)+ 0
2! (x−0)2+−13! (x−0)3+ 0
4! (x−0)4+ 15! (x−0)5+ 0
6! (x−0)6+−17! (x−0)7 = x
1!−x3
3! + x5
5! −x7
7!
es su polinomio de Taylor de orden 7 en x = 0. 4
Por la propia contruccion de los polinomios de Taylor, resulta evidente el siguiente resultado
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

56 – Fundamentos de Matematicas : Calculo diferencial en R 3.1 Polinomios de Taylor
Proposicion 116.- Si P (x) es el polinomio de Taylor de orden n de f en a , entonces P ′(x) es el polinomiode Taylor de orden n− 1 de f ′ en a .
Ejemplo La funcion f(x) = cosx es la derivada del seno y el polinomio de Taylor de g(x) = senx en 0 de
orden 7 es P (x) = x1! −
x3
3! + x5
5! −x7
7! . Entonces, el polinomio de MacLaurin de orden 6 de f(x) = cosx en 0,
es P6,0 = P ′(x) = 1− x2
2! + x4
4! −x6
6! . 4
Como es habitual, la obtencion de polinomios de Taylor se amplia con las operaciones algebraicas basicas:
Propiedades 117.- Sean f y g dos funciones y Pn,a y Qn,a los polinomios de Taylor de orden n en arespectivos. Se tiene
1.- El polinomio de Taylor de orden n para f + g en a es Pn,a +Qn,a
2.- El polinomio de Taylor de orden n para fg en a es la parte hasta grado n del polinomio producto dePn,a y Qn,a .
3.- El polinomio de Taylor de orden n para f/g en a se obtiene dividiendo el polinomio Pn,a entre elpolinomio Qn,a , pero ordenados de la potencia menor a la potencia mayor, hasta llegar al grado n en elcociente.
Proposicion 118.- Si Pn,a es el polinomio de Taylor de orden n para f en a y Qn,f(a) es el polinomio deTaylor de orden n para g en f(a), entonces el polinomio de Taylor de orden n para g ◦ f en a se obtienetomando la parte hasta el grado n del polinomio Qn,f(a)[Pn,a(x)] , composicion de los de f y g .
Nota: La division entre polinomios comenzando por losterminos de menor grado a que se hace referencia en elresultado anterior, la vemos ejemplificada a la derecha,dividiendo 1+2x entre 1+x2 . Nos hemos detenido trasobtener 4 terminos del cociente, pero se puede dividirtanto como se quiera, mientras el resto no se anule.Puede comprobarse que es cierto que
1 + 2x
1 + x2= 1 + 2x− x2 − 2x3 +
x4 + 2x5
1 + x2
1 +2x 1 + x2
−1 −x2 1 + 2x− x2 − 2x3
2x−x2
−2x −2x3
−x2 −2x3
x2 +x4
−2x3 +x4
2x3 +2x5
x4 +2x5
Ejemplo Obtener el polinomio de Taylor de orden 3 en 0 de f(x) = senx + cosx , g(x) = senx cosx y
h(x) = tg x = sen xcos x . Como el polinomio de McLaurin de orden 3 de senx es P (x) = x − x3
3! y el de cosx es
Q(x) = 1− x2
2! , se tiene
• P (x) +Q(x) = 1 + x− x2
2! −x3
3! es el polinomio de McLaurin de orden 3 de f .
• P (x)Q(x) = x− x3
3! −x3
2! + x5
2!3! , luego x− 4x3
3! es el polinomio de McLaurin de orden 3 de g .
• P (x)Q(x) =
x− x3
6
1− x2
2
= x +x3
3
1− x2
2
= x + x3
3 +x5
6
1− x2
2
= x + x3
3 + x5
6 +x7
12
1− x2
2
, luego x + x3
3 es el polinomio de
McLaurin de orden 3 de h . 4
Ejemplo El polinomio de Taylor de orden 4 de f(x) = x2 en 0 es P (x) = x2 y el polinomio de Taylor de
orden 4 de g(x) = ex en f(0) = 0 es Q(x) = 1 + x1! + x2
2! + x3
3! + x4
4! , luego el polinomio de Taylor de orden 4
de (g ◦ f)(x) = ex2
sera: la parte hasta grado 4 del polinomio Q(P (x)) = 1 + x2
1! + x4
2! + x6
3! + x8
4! , es decir, el
polinomio 1 + x2
1! + x4
2! . 4
Un primer resultado en el sentido de que el polinomio de Taylor es una buena aproximacion de la funcion fen un entorno del punto:
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

57 – Fundamentos de Matematicas : Calculo diferencial en R 3.1 Polinomios de Taylor
Proposicion 119.- Sea f es una funcion de clase Cn−1 en un entorno de a y existe f (n)(a). Sea Pn,a(x) elpolinomio de Taylor de orden n para la funcion f en el punto a , entonces:
lımx→a
f(x)− Pn,a(x)
(x− a)n= 0
Demostracion:Basta aplicar L’Hopital sucesivamente al lımite siguiente (n − 1 veces, que es aplicable por tener la funcion yel polinomio de Taylor las mismas derivadas en el punto), y tener en cuenta que existe f (n)(a):
lımx→a
f(x)− Pn,a(x)
(x− a)n= lımx→a
f ′(x)− P ′n,a(x)
n(x− a)n−1= lımx→a
f ′′(x)− P ′′n,a(x)
n(n− 1)(x− a)n−2= · · ·
= lımx→a
f (n−1)(x)− P (n−1)n,a (x)
n · · · 2(x− a)= lımx→a
f (n−1)(x)−(f (n−1)(a) + f(n)(a)
1! (x− a))
n · · · 2(x− a)
=1
n!lımx→a
(f (n−1)(x)− f (n−1)(a)
x− a− f (n)(a)
)=
1
n!
(f (n)(a)− f (n)(a)
)= 0
Nota: El resultado nos indica que la diferencia entre f(x) y Pn,a(x) se hace pequena cuando x es cercano aa incluso en comparacion con (x− a)n , con lo que los polinomios de Taylor aproximan muy bien a la funcion,casi puede decirse que “reproducen” la funcion cerca del punto. Por ello, el uso de los polinomios de Taylor eneste sentido, es uno de los metodos mas sencilos para evaluar funciones de forma aproximada.
Es obvio, que si aumentamos el orden del polinomio seproduce una mejor aproximacion, no solo porque el valordel polinomio en un punto sea mas cercano al valor realde la funcion (“mejor” aproximacion) sino tambien porquepueden aumentar los puntos para los cuales la aproximaciones “buena”. No obstante esto no es lineal, es decir, no poraumentar mucho el orden del polinomio vamos a conseguiruna buena aproximacion en todo el dominio.
rf(x) = 1
1+x2P0,0(x) = 1
P2,0(x) = 1− x2
P4,0(x) = 1− x2 + x4
P6,0(x) = 1− x2 + x4 − x6
P8,0(x) = 1− x2 + x4 − x6 + x8
En la figura aneja, podemos ver un ejemplo de lo que estamos diciendo, por mucho que aumentemos el ordende los polinomios de Taylor en x = 0 la funcion f(x) = 1
x2+1 no puede aproximarse para los valores de x fuerade (−1, 1). Por ello, decimos que las aproximaciones de Taylor son aproximaciones locales.
3.1.1 Formula de Taylor.
Todas estas ideas y comentarios sobre la aproximacion de funciones con polinomios quedan de manifiesto conla obtencion de la Formula de Taylor, que relaciona con igualdad la funcion y el polinomio de Taylor:
Formula de Taylor 120.- Si para una funcion f existen f ′ , f ′′ , . . . , f (n) y f (n+1) sobre el intervalo [a, x] .Entonces,
f(x)− Pn,a(x) =f (n+1)(c)
(n+ 1)!(x− a)n+1 para un cierto c ∈ (a, x),
llamado resto de Lagrange, o tambien
f(x)− Pn,a(x) =f (n+1)(c)
n!(x− c)n(x− a) para un cierto c ∈ (a, x),
que se denomina resto de Cauchy. .
Corolario 121.- Cualquier polinomio de grado n , P (x) = a0 + a1x+ · · ·+ anxn , se puede escribir como
P (x) = P (a) +P ′(a)
1!(x− a) + · · ·+ P (n)(a)
n!(x− a)n ∀ a ∈ R
La Formula de Taylor y el hecho de que la derivada de orden n + 1 para un polinomio de grado n es cero,garantiza la igualdad de los dos polinomios del corolario. Pero tambien, la igualdad propuesta por la Formulade Taylor, nos permitira sustituir la funcion por el polinomio de Taylor en el calculo de lımites; esta sustitucionamplıa el uso de los infinitesimos equivalentes (que son casos simples de los polinomios de Taylor) eliminandola restriccion de su uso a los productos y cocientes.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

58 – Fundamentos de Matematicas : Calculo diferencial en R 3.2 Representacion de funciones (2)
Ejemplo lımx→0
sen x−xx3 = lım
x→0
(x− x3
3! +sen(c)x4
4! )−xx3 = lım
x→0
− x3
3! +sen(c)x4
4!
x3 = lımx→0− 1
3! + sen(c)x4! = −1
6 4
Cuando aproximamos el valor real de una funcion en un punto cercano a a usando el polinomio de Taylorde la funcion en a , con la Formula de Taylor podemos buscar una cota del error cometido. En efecto, al tomar
como valor de la funcion el del polinomio, el error cometido sera f(x) − Pn,a(x) = f(n+1)(c)(n+1)! (x − a)n+1 , para
algun c entre a y x , y aunque no conocemos el valor c , sı que podemos intentar acotar el valor del resto∣∣∣ f(n+1)(c)(n+1)! (x− a)n+1
∣∣∣ = |x−a|n+1
(n+1)|∣∣f (n+1)(c)
∣∣ .Ejemplo Sabemos que sen(x) = x − x3
3! + sen(c)x4
4! cerca de a = 0, entonces si decimos que el valor de
sen(0.4) ≈ (0.4)− (0.4)3
3! = 0.389333 el error cometido lo podemos acotar con |sen(c)||0.4|44! ≤ 1·|0.4|4
24 = 0.00106.Como sabemos que senx < x , y como c ∈ (0, 0.4), es mejor aproximacion sen(c) < c < 0.4 que sen(c) ≤ 1,
luego |sen(c)| |0.4|4
4! < |0.4| |0.4|4
24 = 0.000426 es una cota del error cometido (el error real cometido es menor que0.0001). 4
3.2 Representacion de funciones (2)
Monotonıa y extremos locales El siguiente resultado nos ofrece una condicion suficiente que caracterizaextremos locales, generalizada al uso de las derivadas de ordenes superiores:
Proposicion 122.- Sea f una funcion de clase Cn−1 en un entorno del punto a , para la que se cumple quef ′(a) = f ′′(a) = · · · = f (n−1)(a) = 0, y ademas existe f (n)(a) 6= 0. Entonces:
a) Si n es par y f (n)(a) > 0, f presenta un mınimo local en a .
b) Si n es par y f (n)(a) < 0, f presenta un maximo local en a .
c) Si n es impar y f (n)(a) > 0, f es estrictamente creciente en a .
d) Si n es impar y f (n)(a) < 0, f es estrictamente decreciente en a . .
Ejemplo La funcion f(x) = x4 presenta un mınimo local en 0, pues f ′(0) = f ′′(0) = f ′′′(0) = 0 y f (4)(0) =24 > 0 siendo n = 4 par. Mientras que f(x) = x3 es estrictamente creciente en 0, pues f ′(0) = f ′′(0) = 0 yf ′′′(0) = 6 > 0 siendo n = 3 impar. 4
Concavidad y convexidadCon la Formula de Taylor, la derivada segunda se convierte en la herramienta para el estudio de la concavidad
y convexidad:
Proposicion 123.- Sea f : (a, b) −→ R .
a) Si f ′′(x) < 0, ∀x ∈ (a, b), entonces f(x) es convexa en (a, b).
b) Si f ′′(x) > 0, ∀x ∈ (a, b), entonces f(x) es concava en (a, b).
Demostracion:
Sea x0 ∈ (a, b), entonces: f(x) = f(x0) + f ′(x0)(x− x0) + f ′′(t)2! (x− x0)2 para un cierto t entre x y x0 . Por
tanto, si f ′′ < 0 en (a, b),
f(x)− [f(x0) + f ′(x0)(x− x0)] = f ′′(t)(x− x0)2
2!≤ 0
luego f es convexa ya que esto se dara para todo x, x0 ∈ (a, b), y significa que todos los puntos de la curvaestan por debajo de la tangente a la curva en cualquier punto x0 ∈ (a, b).
Analogamente, sera concava si f ′′ > 0 en (a, b).
Ejemplo La funcion f(x) = x2 es concava en todos los puntos, pues f ′′(x) = 2 > 0. Analogamente,f(x) = −x2 es convexa en todo R . 4
Corolario 124.- Si f ′′(x) existe en un entorno de x0 y es continua en x0 , entonces una condicion necesariapara que x0 sea un punto de inflexion de f es que f ′′(x0) = 0.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

59 – Fundamentos de Matematicas : Calculo diferencial en R 3.3 Ejercicios
Demostracion:Si x0 es un punto de inflexion de f , entonces:
Si f es concava a la derecha de x0 (luego f ′′(x) > 0 en (x0, b)), sera convexa a la izquierda de x0
(luego f ′′(x) < 0 en (a, x0)), y viceversa.
Como f ′′ es continua en x0 , se tiene que lımx→x0
f ′′(x) = f ′′(x0) de donde puede concluirse que f ′′(x0) = 0.
Ejemplo f(x) = x3 presenta un punto de inflexion en x = 0, pues es C2 es R y f ′′(x) = 6x se anula enx = 0, por lo que verifica la condicion necesaria. Como es continua en 0 y f ′′ < 0 en (−∞, 0) y f ′′ > 0 en(0,∞) es punto de inflexion. 4
3.2.1 Representacion de funciones en forma explıcita: y = f(x)
Dada una funcion y = f(x), nos proponemos hacer su estudio y representacion grafica. Para ello se debenestudiar en terminos generales los siguientes aspectos:
1.- Dominio y continuidad de la funcion.
2.- Simetrıas (par e impar) y periodicidad.
3.- Comportamiento asintotico.
4.- Derivabilidad de la funcion.
5.- Intervalos de crecimiento y decrecimiento.
6.- Extremos locales y globales.
Generalmente, al estudiar una funcion f sobre un conjunto A va a interesar conocer los valores masextremos que puede tomar f en la totalidad del conjunto A , es decir, el maximo global y el mınimoglobal. Estos extremos globales (tambien llamados extremos absolutos) pueden existir o no, segun seanf y A ; sin embargo el teorema de Weierstrass (Th. 90) garantiza, bajo ciertas condiciones su existencia.
Es claro que los extremos globales han de buscarse entre los extremos locales y los posibles valores de fen la frontera de A .
7.- Intervalos de concavidad y convexidad.
8.- Puntos de inflexion.
3.3 Ejercicios
3.91 Escribir cada uno de los polinomios P (x) = x3 − 2x2 + 3x + 5 y Q(x) = 2x3 − 6x2 + 8 en potencias dex− 2 y en potencias de x+ 1.
3.92 Construir un polinomio de grado menor o igual que 10 que verifique: P (7) = 1, P ′(7) = 2, P ′′(7) = −3,
P (3)(7) = · · · = P (8)(7) = 0, P (9)(7) = −1, P (10)(7) = 5. Hallar la ecuacion de la recta tangente a lagrafica de P (x) en el punto de abscisa x = 9.
3.93 Probar que β es una raız de multiplicidad m del polinomio P (x) = anxn + · · · + a1x + a0 si, y solo si
P (β) = P ′(β) = P ′′(β) = · · · = Pm−1)(β) = 0 y Pm)(β) 6= 0.
3.94 Hallar los polinomios de Taylor de orden 4 de las funciones siguientes en los puntos indicados:
a) f(x) = 23−x en α = 1 b) f(x) = cosx en α = π
2 c) f(x) = lnx en α = 1
d) f(x) = ex en α = −1 e) f(x) = tg x en α = 0 f) f(x) = x34 en α = 1
3.95 Construir la formula de Taylor para el polinomipo de orden 4 de f(x) =√
3 + x en el punto 1 y obtener
una cota del error cometido al aproximar el valor√
5 mediante el polinomio de Taylor de orden 4.
3.96 Construir la formula de MacLaurin de f(x) = ex . Si aproximo el valor de e−1 mediante un polinomiode MacLaurin ¿que orden tendra que tener al menos, para que el error cometido sea menor que unadiezmilesima (10−4 )?
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

60 – Fundamentos de Matematicas : Calculo diferencial en R 3.3 Ejercicios
3.97 Construir la formula de Taylor de f(x) = lnx en el punto 1. Dar el valor aproximado de ln 32 , con un
error menor que una diezmilesima.
3.98 Considerar los polinomios de MacLaurin de orden 4 de las funciones ex , senx , cosx , x(1−x),√
1 + x yln(1 + x). Usar las operaciones con los polinomios de Taylor, para calcular los polinomios de MacLaurinde orden 4 de:
a) senx+ cosx b) ex ln(1 + x) c) x(1− x) ln(1 + x) d) x(1− x) + ex
e) 1√1+x
f) x(1−x)√1+x
g) sen xex + ln(1 + x) h) sen2 x√
1+x+ cos2 x
ex
3.99 Usar los desarrollos limitados (polinomios de Taylor) de las funciones f y g en los puntos que se indican,para encontrar los polinomios de Taylor de la composicion pedidos:
a) f(x) = x2 en α = 0 y g(y) = ey en β = 0, hallar el de g ◦ f en α = 0 de orden 8.
b) f(x) = 1− x en α = 1 y g(y) = ln(1− y) en β = 0, hallar el de g ◦ f en α = 1 de orden 5.
c) f(x) = 2x en α = 0 y g(y) = sen y en β = 0, hallar el de g ◦ f en α = 0 de orden 7.
d) f(x) = x2 en α = 0 y g(y) = (1 + y)12 en β = 0, hallar el de g ◦ f en α = 0 de orden 6.
e) f(x) = x2 + 4x+ 5 en α = −2 y g(y) = ln y en β = 1, hallar el de g ◦ f en α = −2 de orden 6.
3.100 Hallar los 4 primeros terminos (no nulos) de los polinomios de Taylor de:
a)√
2 + x2 en α = 0 b) 1x(1+x) en α = 1 c) ln
(1+x1−x
)en α = 0
3.101 Probar que si Pn(x) es el polinomio de Taylor de orden n de f en α , entonces f(x)−f(α) y Pn(x)−f(α)son infinitesimos equivalentes cuando x→ α .
[Nota: De hecho, para los infinitesimos conocidos se ha tomado el termino de menor grado de Pn(x)− f(α) ]
3.102 Hallar polinomios que sean infinitesimos equivalentes de las funciones:
a)√
1−x− 1 cuando x→ 0 b) 1−senx cuando x→ π2 c) 1
x−1 cuando x→ 1
3.103 Usar los polinomios de Taylor del orden necesario para calcular:
a) lımx→0
x(2+cos x)−3 sen xx5 b) lım
x→0
arctg x−tg xx3 c) lım
x→0
(1x + 2(1−ch x)
x3
)3.104 ¿Para que valores de a y de b es finito el lımite: lım
x→0
x(1+a cos x)−b sen xx3 ?
3.105 Hallar n ∈ N tal que lımx→0
arctg x−tg xxn = k 6= 0 y finito.
3.106 Encontrar a y b para que lımx→0
ex− 1+ax1+bx
x3 sea finito.
3.107 Encontrar a y b para que ln( 1+x1−x )− x(2+ax2)
1+bx2 sea equivalente a 8x7
175 cuando x tiende a cero.
3.108 Encontrar una funcion equivalente, cuando x → 0, a la funcion: g(x) = ex+e−x−2x2 − 1 y deducir que
lımx→0
g(x) = 0.
3.109 Encontrar una funcion equivalente a la funcion f(x) =√x+2−2√x+7−3
− 32 cuando x tiende a 2.
3.110 Probar que P (x) = x4 + 2x3 − 3x2 − 4x+ 5 no tiene ninguna raız real.
3.111 Se considera la funcion f(x) =x lnx
x2 − 1definida en los intervalos (0, 1) y (1,∞).
a) Probar que se pueden dar valores a f(0) y a f(1) para que la funcion sea continua en 0 a la derechay para que f sea continua y derivable en 1.
b) ¿Que vale en 0 la derivada por la derecha supuesto dado a f(0) el valor del apartado anterior?.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
61 – Fundamentos de Matematicas : Calculo diferencial en R 3.3 Ejercicios
3.112 Dada la funcion f(x) = xex
|ex−1| .
a) Definir la funcion f en el punto x = 0 de forma que f sea continua en dicho punto, si ello es posible.
b) Hallar las asıntotas de f .
3.113 Para las siguientes funciones, encuentra todas sus asıntotas e indica, mediante un esbozo grafico, como seaproxima la funcion a ellas.
a) f(x) = x−1(x2+4x)2 b) f(x) = (2x2−2
√2 x+1)2
x3−x c) f(x) = 1x −
1x−1
d) f(x) = x3
3x2−2 −1x e) f(x) = sen x
x f) f(x) = x tg x
3.114 Encuentra todas las asıntotas de las funciones siguientes:
a) f(x) = x+1√x2−1
b) f(x) = 42−ln(x2−
√2 x+ 1
2 )c) f(x) = x2+2x√
x2−1d) f(x) = sen x
1−cos x
3.115 Estudia las simetrıas y periodicidad de las funciones de los ejercicios 3.113 y 3.114 anteriores.
3.116 Sea f : [0, 9] −→ R continua. Si f ′: (0, 8)∪(8, 9) −→ R viene dada por la grafica de abajo,
b
b2 4
6 7 8 9
31 5
3
2
1
0
-1
-2
Estudiar: intervalos de monotonıa yconcavidad, puntos crıticos y de in-flexion de la funcion f (supondremosque existe f ′′ en los puntos donde loparece).
Representar aproximadamente lagrafica de f suponiendo f(x) ≥ 0.
¿Cual es el dominio de f ′′ y que sepuede decir de ella?
3.117 Estudiar las funciones siguientes y construir sus graficas
a) f(x) = (x− 1)2(x− 2) b) f(x) = 23
√8 + 2x− x2 c) f(x) = 4− x2(x+ 2)2
d) f(x) = x− 2 arctg x e) f(x) = x2√x+ 1 f) f(x) = 3
√x2 − x
g) f(x) = x5−10x3+20x2−15x+432 h) f(x) = 3+x4
x3 i) f(x) = 2x2+3x−4x2
j) f(x) = xln x k) f(x) = x2
2 − lnx l) f(x) = x2
2 ln |x|m) f(x) = sen(3x)− 3 senx n) f(x) = sen3 x+ cos3 x o) f(x) = e−2x sen(2x)
3.118 Estudiar la funcion f(x) = 3
√(x−1)5
(x+1)2 y construir su grafica.
3.119 Dada la funcion f(x) = arcsen x+1√2(x2+1)
, se pide:
a) Dominio y continuidad de f .
b) ¿Tiene asıntotas?
c) Ver que f no es derivable en x = 1. Hallar la derivada a la derecha y a la izquierda del punto x = 1.
d) Estudiar crecimiento y decrecimiento, extremos locales y globales de f .
e) Estudiar concavidad y los puntos de inflexion de f .
f) Representacion grafica de f y de f ′ .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

62 – Fundamentos de Matematicas : Calculo diferencial en R
Anexo 1: Demostraciones
Calculo diferencial en RFunciones, lımites y continuidad
Demostracion de: Propiedades del valor absoluto 47 de la pagina 27
Propiedades del valor absoluto 47.-
a) |a| ≥ 0, ∀ a y |a| = 0 ⇐⇒ a = 0 b) |ab| = |a| |b| c)∣∣a−1
∣∣ = |a|−1
d) |a| ≤ k ⇐⇒ −k ≤ a ≤ k e) |a+ b| ≤ |a|+ |b| f)∣∣∣ |a| − |b| ∣∣∣ ≤ |a− b|
Demostracion:
a) |a| ≥ 0 por la definicion. Para la segunda parte, si |a| = 0, o bien a = |a| = 0, o bien a = − |a| = 0,luego necesariamente a = 0; la otra implicacion es obvia pues |0| = 0.
b) Consideremos los casos: si a ≥ 0 y b ≥ 0 se tiene |ab| = ab = |a| |b| ; si a ≤ 0 y b ≤ 0 se tiene|ab| = ab = (−a)(−b) = |a| |b| ; y si a ≤ 0 y b ≥ 0, entonces |ab| = −ab = (−a)b = |a| |b| .
c) De 1 = |1| =∣∣a−1a
∣∣ =∣∣a−1
∣∣ |a| , se obtiene el resultado.
d) Si |a| ≤ k , o a = |a| ≤ k que cumple la segunda desigualdad o −a = |a| ≤ k , pero entonces −k ≤ a y secumple la primera. Si −k ≤ a ≤ k , se tiene k ≥ −a ≥ −k , por lo que −k ≤ |a| ≤ k .
e) Como ∀x , x ≤ |x| , o |a+ b| = a+ b ≤ |a|+ |b| , o bien |a+ b| = −a− b ≤ |−a|+ |−b| = |a|+ |b| .
f) |a| = |a− b+ b| ≤ |a− b| + |b| , luego |a| − |b| ≤ |a− b| ; y con b se tiene |b| − |a| ≤ |b− a| . Luego− |a− b| = − |b− a| ≤ −(|b| − |a|) = |a| − |b| ≤ |a− b| y por d) se concluye la prueba
Lımites y continuidad
Demostracion de: Proposicion 64 de la pagina 33
Proposicion 64.- Sean f, g, h:A −→ R y x0 un punto de acumulacion de A .
1.- Si f(x) ≤ g(x) ≤ h(x) en A y lımx→x0
f(x) = L = lımx→x0
h(x), entonces lımx→x0
g(x) = L
2.- Si g esta acotada en A y lımx→x0
f(x) = 0, entonces lımx→x0
g(x) · f(x) = 0
Demostracion:
1.- Si lımx→x0
f(x) = L = lımx→x0
h(x), entonces para cada ε > 0:
existe δ1 tal que si 0 < |x− x0| < δ1 , entonces L− ε < f(x) < L+ ε
existe δ2 tal que si 0 < |x− x0| < δ2 , entonces L− ε < h(x) < L+ ε
luego tomado δ = min{δ1, δ2} , si 0 < |x− x0| < δ , entonces L− ε < h(x) ≤ g(x) ≤ f(x) < L+ ε .
2.- Si g esta acotada, existe K > 0 tal que |g(x)| ≤ K , para todo x , luego se verifica que
0 ≤ |g(x)f(x)| ≤ K |f(x)| , para todo x
Por el apartado anterior, si probamos que lımx→x0
K |f(x)| = 0, entonces lımx→x0
|g(x)f(x)| = 0 y se tiene que
lımx→x0
g(x)f(x) = 0 (por la proposicion 63).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

63 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Como lımx→x0
f(x) = 0 ⇐⇒ lımx→x0
|f(x)| = 0, para cada ε > 0 existe δ > 0, tal que si 0 < |x− x0| < δ se
verifica que |f(x)| < εK . Entonces, si 0 < |x− x0| < δ se tiene que
|K |f(x)| − 0| = K |f(x)| < Kε
K= ε
lo que concluye la prueba.
Demostracion de: Propiedades 65 de la pagina 33
Propiedades 65.- Si lımx→x0
f(x) = L1 ∈ R y lımx→x0
g(x) = L2 ∈ R , entonces:
a) lımx→x0
[f(x) + g(x)] = lımx→x0
f(x) + lımx→x0
g(x) = L1 + L2 .
b) lımx→x0
[f(x) · g(x)] = lımx→x0
f(x) · lımx→x0
g(x) = L1 · L2 .
c) lımx→x0
f(x)g(x) =
lımx→x0
f(x)
lımx→x0
g(x) = L1
L2, siempre que L2 6= 0.
Demostracion:
1.- Por la definicion de lımite, tenemos que
lımx→x0
f(x) = L1 ⇐⇒ para cada ε > 0, ∃ δ1 > 0 tal que si 0 < |x− x0| < δ1 =⇒ |f(x)− L1| < ε2
lımx→x0
g(x) = L2 ⇐⇒ para cada ε > 0, ∃ δ2 > 0 tal que si 0 < |x− x0| < δ2 =⇒ |g(x)− L2| < ε2
luego tomando δ = min{δ1, δ2} , tenemos que: para cada ε > 0 existe δ = min{δ1, δ2} > 0 tal que si0 < |x− x0| < δ (luego menor que δ1 y menor que δ2 ), entonces
|(f(x) + g(x))− (L1 + L2)| = |f(x)− L1 + g(x)− L2| ≤ |f(x)− L1|+ |g(x)− L2| <ε
2+ε
2= ε
2.- Como lımx→x0
f(x)g(x) = L1L2 ⇐⇒ lımx→x0
(f(x)g(x)− L1L2
)= 0, veamos esto ultimo. Pero
f(x)g(x)− L1L2 = f(x)g(x)− L2f(x) + L2f(x)− L1L2 = f(x)(g(x)− L2) + L2(f(x)− L1)
y sabemos que lımx→x0
(f(x)−L1) = 0, lımx→x0
(g(x)−L2) = 0, f(x) esta acotada en algun entorno de x0 (Th
de acotacion) y L2 es constante. Por el segundo resultado de la Proposicion 64, lımx→x0
f(x)(g(x)−L2) = 0
y lımx→x0
L2(f(x)− L1) = 0, luego lımx→x0
(f(x)g(x)− L1L2
)= 0 + 0 = 0.
3.- Por ser f(x)g(x) = f(x) · 1
g(x) , por el apartado anterior, basta probar que lımx→x0
1g(x) = 1
L2.
Como 1g(x) −
1L2
= L2−g(x)g(x)L2
= 1g(x)L2
(L2− g(x)), lımx→x0
(g(x)−L2) = 0 y L2 es constante, si probamos que
la funcion 1g(x) esta acotada en un entorno de x0 , por la Proposicion 64 tendremos que lım
x→x0
1g(x)L2
(L2−
g(x)) = lımx→x0
(1
g(x) −1L2
)= 0, lo que prueba el resultado.
En efecto, si L2 6= 0, por el teorema del signo, o bien −K < g(x) < −k < 0 si L2 < 0, o bien0 < k < g(x) < K si L2 > 0. Entonces, 0 < k < |g(x)| < K y, por tanto, 0 < 1
K < 1|g(x)| <
1k , luego 1
g(x)
esta acotada.
Demostracion de: Teorema 67 de la pagina 33
Teorema 67.- Sean f :A −→ R y g: f(A) −→ R . Si lımx→a
f(x) = b y g es continua en b , entonces
lımx→a
g(f(x)) = g(b) = g(
lımx→a
f(x)).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

64 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Demostracion:Como lım
x→af(x) = b ,
para cada ε1 > 0 existe δ > 0 tal que si 0 < |x− a| < δ entonces |f(x)− b| < ε1 .
Por otra parte, si g es continua en b se tiene que:
para cada ε > 0 existe δ1 > 0 tal que si |y − b| < δ1 entonces |g(y)− g(b)| < ε .
Entonces, haciendo ε1 = δ1 y reuniendo ambas conclusiones:
para cada ε > 0 existe δ > 0 tal que si 0 < |x− a| < δ se tiene |f(x)− b| < ε1 = δ2 y, por tanto,|g(f(x))− g(b)| < ε .
En consecuencia, lımx→a
g(f(x)) = g(b) = g(
lımx→a
f(x))
.
Demostracion de: Proposicion 69 de la pagina 34
Proposicion 69 (Convergencia propia).- Sean f :A −→ R y g: f(A) −→ R . Si lımx→a
f(x) = b , con f(x) 6= b
para todos los x de un entorno reducido E∗(a, δ0) de a , entonces
lımx→a
(g ◦ f)(x) = lımf(x)→b
g(f(x)) = lımy→b
g(y).
Demostracion:Como lım
x→af(x) = b , para cada ε1 > 0 existe δ1 > 0 tal que si 0 < |x − a| < δ1 entonces |f(x) − b| < ε1 , y
como f(x) 6= b en E∗(a, δ0), si tomamos δ = min{δ0, δ1} , se tiene que:
para cada ε1 > 0 existe δ > 0 tal que si 0 < |x− a| < δ entonces 0 < |f(x)− b| < ε1 .
Por otra parte, si L = lımy→b
g(y) se tiene que:
para cada ε > 0 existe δ2 > 0 tal que si 0 < |g(y)− L| < δ2 entonces |g(y)− L| < ε .
Entonces, haciendo ε1 = δ2 y reuniendo ambas conclusiones:
para cada ε > 0 existe δ > 0 tal que si 0 < |x − a| < δ se tiene 0 < |f(x) − b| < ε1 = δ2 y, portanto, |g(f(x))− L| < ε .
En consecuencia, lımx→a
g(f(x)) = L = lımy→b
g(y).
Demostracion de: Proposicion 71 de la pagina 34
Proposicion 71 (Lımites laterales).- Sean a < c < b y f : (a, c) ∪ (c, b) −→ R . Entonces
lımx→c
f(x) = L ⇐⇒ lımx→c−
f(x) = lımx→c+
f(x) = L
Demostracion:Si lım
x→cf(x) = L , para cada ε > 0 existe δ > 0 tal que si 0 < |x− c| < δ se tiene que |f(x)− L| < ε .
En particular, si 0 < |x−c| < δ y x < c se cumple, luego lımx→c−
f(x) = L y tambien si x > c , por lo que
lımx→c+
f(x) = L .
Recıprocamente, si lımx→c−
f(x) = lımx→c+
f(x) = L , se tiene que
para cada ε > 0 existe δ1 > 0 tal que si 0 < |x− c| < δ1 y x < c se tiene |f(x)− L| < ε
para cada ε > 0 existe δ2 > 0 tal que si 0 < |x− c| < δ2 y x > c se tiene |f(x)− L| < ε
tomando d = min{δ1, δ2} , para cada x con 0 < |x− c| < δ sea x < c o x > c se cuple la definicion de lımiteen c . Luego lım
x→cf(x) = L .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

65 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Demostracion de: Continuidad de algunas funciones elementales 79 de la pagina 36
Continuidad de algunas funciones elementales 79.-
• f(x) = ex es continua en R y lımx→−∞
ex = 0 y lımx→+∞
ex = +∞ .
• f(x) = lnx es continua en (0,+∞) y lımx→0+
lnx = −∞ y lımx→+∞
lnx = +∞ .
• f(x) = xα continua en (0,∞) y lımx→0+
xα=0 y lımx→+∞
xα=∞ si α>0 (resp. ∞ y 0 si α<0).
• f(x) = shx es continua en R y lımx→−∞
shx = −∞ y lımx→+∞
shx = +∞ .
• f(x) = chx es continua en R y lımx→−∞
chx =∞ y lımx→+∞
chx = +∞ .
• f(x) = thx es continua en R y lımx→−∞
thx = −1 y lımx→+∞
thx = 1.
• f(x) = senx es periodica de periodo 2π , continua en R y 6 ∃ lımx→±∞
senx .
• f(x) = cosx es de periodo 2π , continua en R y 6 ∃ lımx→±∞
cosx .
• f(x) = tg x es de periodo π , continua en su dominio y lımx→−π2
+tg x = −∞ y lım
x→π2−
tg x =∞ .
Demostracion:Ya hemos probado que ex es continua en R y sabemos que lım
x→+∞ex = +∞ (basta recordar que ex es creciente,
luego o esta acotada, o no lo esta y su lımite es +∞ , pero como 2n → +∞ y 2n < en , los valores en no estanacotados). Veamos lo demas:
• lımx→−∞
ex = lımx→+∞
e−x = lımx→+∞
1ex = 0
• Para cada a ∈ (0,∞), eln a = a = lımx→a
x = lımx→a
eln x = elımx→a
ln x; y como la exponencial es estrictamente
creciente, debe ser ln a = lımx→a
lnx . Luego ln es continua en a .
Como lnx es estrictamente creciente y continua, y +∞ = lımx→+∞
x = lımx→+∞
ln ex = lımex→+∞
ln(ex), no esta
acotada por lo que lımx→+∞
lnx = +∞ .
Analogamente, −∞ = lımx→−∞
x = lımx→−∞
ln ex = lımex→0+
ln(ex), no esta acotada inferiormente por lo que
lımx→0+
lnx = −∞ .
• Como xα = eα ln x es continua por ser composicion de continuas y si α > 0:lımx→0+
xα = lımx→0+
eα ln x = lımα ln x→−∞
eα ln x = 0 y lımx→∞
xα = lımx→∞
eα ln x = lımα ln x→∞
eα ln x = +∞
α<0: lımx→0+
xα= lımx→0+
eα ln x= lımα ln x→+∞
eα ln x=+∞ y lımx→∞
xα= lımx→∞
eα ln x= lımα ln x→−∞
eα ln x=0
• shx= ex−e−x2 , luego continua y lım
x→−∞ex−e−x
2 =( 0−∞2 )= −∞ y lım
x→+∞ex−e−x
2 =(∞−02 )= +∞ .
• chx= ex+e−x
2 , luego continua y lımx→−∞
ex+e−x
2 =( 0+∞2 )= +∞ y lım
x→+∞ex+e−x
2 =(∞+02 )= +∞ .
• thx= sh xch x = ex−e−x
ex+e−x , luego continua y como thx = ex−e−xex+e−x = e2x−1
e2x+1 = 1− 2e2x+1 :
lımx→−∞
thx = lımx→−∞
1− 2e2x+1 = 1− 2
0+1 = −1 y lımx→+∞
thx = lımx→+∞
1− 2e2x+1 = (1− 2
∞+1 )= 1
• De geometrıa sabemos ya que las funciones seno y coseno son periodicas deperiodo 2π .
Para la continuidad, veamos primero que sen(x) y cos(x) lo son en x = 0:
Por la construccion geometrica del seno, sabemos que en una circunferencia deradio 1, la longitud del arco recorrido coincide con la amplitud del angulo enradianes, luego si x ∈ (−π2 ,
π2 ), se cumple 0 ≤ |sen(x)| ≤ |x| (ver figura). Es
decir, que −x ≤ sen(x) ≤ x y como 0 = lımx→0−x ≤ lım
x→0sen(x) ≤ lım
x→0x = 0, se
cumple que lımx→0
sen(x) = 0 = sen(0). Luego el seno es continuo en x = 0.
sen x
xx > 0
sen x
xx < 0
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

66 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Para ver que lımx→0
cos(x) = cos(0) = 1, probemos que lımx→0
(1− cos(x)
)= 0:
lımx→0
(1− cos(x)
)= lımx→0
2 sen2(x2 ) = 2(
lımx→0
sen(x2 ))2
= 2 · 02 = 0
Veamos ahora que son continuas en todo punto x0 de R .
lımx→x0
sen(x) = lımh→0
sen(x0 + h) = lımh→0
(sen(x0) cos(h) + sen(h) cos(x0)
)= sen(x0)
(lımh→0
cos(h))
+(
lımh→0
sen(h))
cos(x0) = sen(x0) · 1 + 0 · cos(x0) = sen(x0)
lımx→x0
cos(x) = lımh→0
cos(x0 + h) = lımh→0
(cos(x0) cos(h)− sen(x0) sen(h)
)= cos(x0)
(lımh→0
cos(h))− sen(x0)
(lımh→0
sen(h))
= cos(x0) · 1 + sen(x0) · 0 = cos(x0)
La periodicidad de las funciones asegura que no existe el lımite lımx→+∞
senx , pues cuando n→∞ los puntos
x = 2πn y los puntos x = π2 +2πn se alejan hacia +∞ y sucede que lım
n→∞sen(π2 +n2π) = lım
n→∞sen(π2 ) = 1
y lımn→∞
sen(n2π) = lımn→∞
sen(0) = 0, que son valores distintos.
• Para la continuidad de la tangente bastan las propiedades del cociente tg x = sen xcos x .
Demostracion de: Algunos infinitos e infinitesimos conocidos 83 de la pagina 37
Algunos infinitos e infinitesimos conocidos 83.- Usaremos la notacion f ∼ g para indicar que f y g soninfinitos o infinitesimos equivalentes:
anxn + · · ·+ a1x+ a0 ∼ anx
n cuando x→ ±∞ anxn + · · ·+ a1x ∼ a1x cuando x→ 0
sen(x) ∼ x cuando x→ 0 tg(x) ∼ x cuando x→ 0
sen 1x ∼
1x cuando x→ ±∞ 1− cos(x) ∼ x2
2 cuando x→ 0
ln(1 + x) ∼ x cuando x→ 0 ex − 1 ∼ x cuando x→ 0
sh(x) ∼ x cuando x→ 0 ch(x)− 1 ∼ x2
2 cuando x→ 0
Demostracion:
• lımx→±∞
anxn+an−1x
n−1+···+a1x+a0
anxn= lımx→±∞
1 + an−1
an1x + · · ·+ a1
an1
xn−1 + a0
an1xn = 1 + 0 + · · ·+ 0 + 0 = 1
• lımx→0
anxn+an−1x
n−1+···+a2x2+a1x
a1x= lımx→0
ana1xn−1 + an−1
a1xn−2 + · · ·+ a2
a1x+ 1 = 0 + 0 + · · ·+ 0 + 1 = 1
• Veamos que lımx→0
sen xx = 1, con una pequena argucia geometrica (ver figura):
En una circunferencia de radio 1, la longitud del arco recorrido coincide con la ampli-tud del angulo (en radianes), luego si x ∈ (0, π2 ), se tiene que 0 < sen(x) < x < tg(x)de donde, dividiendo por sen(x), se tiene 1 < x
sen(x) <1
cos(x) y tomando lımites:
1 ≤ lımx→0+
xsen(x) ≤ lım
x→0+
1cos(x) = 1. Luego lım
x→0+
xsen(x) = 1.
Si x ∈ (−π2 , 0), se tiene que 0 > sen(x) > x > tg(x) de donde, dividiendo por sen(x)(que es negativo), se tiene 1 < x
sen(x) <1
cos(x) como antes. Luego lımx→0−
xsen(x) = 1.
sen x
tg xxx > 0
sen x
tg xxx < 0
• lımx→0
tg xx = lım
x→0
sen xx
1cos x = 1 · 1 = 1.
• Considerando y = g(x) = 1x , lım
x→+∞g(x) = 0+ con g(x) 6= 0 para todo x , luego por la proposicion 69 de
convergencia propia, se tiene: lımx→+∞
sen 1x
1x
= lımx→+∞
sen g(x)g(x) = lım
y→0+
sen yy = 1. (Idem si x→ −∞)
• lımx→0
1−cos xx2
2
= lımx→0
2 sen2( x2 )x2
2
= lımx→0
sen2( x2 )
( x2 )2 =(
lımx→0
sen( x2 )x2
)2 (1)=(
lımy→0
sen yy
)2
= 1. (1) Con y = g(x) = x2 .
• lımx→0+
ln(1+x)x = lım
x→0+
1x ln(1+x) = lım
x→0+ln(1+x)
1x = ln
(lımx→0+
(1+x)1x
)(1)= ln
(lım
y→+∞(1+ 1
y )y)
= ln(e) = 1
Considerando en (1) y = g(x) = 1x y luego el ejemplo 78. Analogamente, para x→ 0− :
lımx→0−
ln(1+x)x = ln
(lımx→0−
(1 + x)1x
)= ln
(lım
y→−∞(1 + 1
y )y)
= ln(e) = 1.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

67 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
• Para calcular lımx→0
ex−1x , consideramos y = g(x) = ex − 1, est. creciente y con lım
x→0g(x) = 0. Ademas
1 + y = ex y ln(1 + y) = x . Luego: lımx→0
ex−1x = lım
y→0
yln(1+y) = 1.
• lımx→0
sh xx = lım
x→0
ex−e−x2x = lım
x→0
e2x−1ex2x =
(lımx→0
1ex
)(lımx→0
e2x−12x
)(1)= 1 · lım
y→0
ey−1y = 1. (1) y = g(x) = 2x .
• lımx→0
ch(x)−1x2
2
= lımx→0
ex+e−x2 −1x2
2
= lımx→0
ex+e−x−2
2 x2
2
= lımx→0
e2x+1−2ex
exx2 = lımx→0
(ex−1)2
exx2 =(
lımx→0
1ex
)(lımx→0
ex−1x
)2
= 1.
Demostracion de: Teorema de Bolzano 86 de la pagina 39
Teorema de Bolzano 86.- Sea f una funcion continua en el intervalo [a, b] y que toma valores de signo opuestoen a y b (es decir, f(a)f(b) < 0) entonces ∃c ∈ (a, b) tal que f(c) = 0.
Demostracion:Podemos suponer que f(a) < 0 y f(b) > 0. Tomemos c0 = a+b
2 el punto medio entre a y b :
Si f(c0) = 0, como c = c0 ∈ (a, b), es el punto buscado. Si f(c0) 6= 0 pueden darse dos casos:
• si f(c0) > 0, como f(a) < 0 y f continua en [a, c0] , el teorema se reduce al intervalo [a, c0] ;
• si f(c0) < 0, como f(b) > 0 y f continua en [c0, b] , el teorema se reduce al intervalo [c0, b] .
En un caso u otro el teorema queda probado si lo hacemos en el intervalo [a1, b1] ⊂ [a, b] (bien [a, c0] o bien[c0, b]) de longitud b1 − a1 = b−a
2 , en el cual f es continua, f(a1) < 0 y f(b1) > 0.
En este intervalo, tomamos su punto medio c1 = a1+b12 . Si f(c1) = 0 es el punto buscado; si f(c1) 6= 0 se
puede, como hicimos antes, reducir el teorema al intervalo [a2, b2] ⊂ [a1, b1] de longitud b2 − a2 = b1−a1
2 = b−a22
en el cual f es continua, f(a2) < 0 y f(b2) > 0.Repitiendo sucesivamente el proceso anterior, y si ninguno de los puntos medios, cn , verifica que f(cn) = 0,
entonces hemos construido una sucesion de intervalos cerrados encajados
[a, b] ⊃ [a1, b1] ⊃ [a2, b2] ⊃ · · · ⊃ [an, bn] ⊃ · · · con bn − an = b−a2n , f(an) < 0 y f(bn) > 0.
Ademas, los puntos an extremos inferiores verifican que a ≤ a1 ≤ a2 ≤ · · · ≤ an ≤ · · · ≤ b,luego el conjunto A = {an : n ∈ N} esta acotado superiormente (por b) y, por tanto, existe c = supA ; comoa ≤ an ≤ b se cumple a ≤ c ≤ b luego c ∈ [a, b] . Por ser c = supA , para cada ε > 0 existe an0
∈ A conc− ε < an0
≤ c , y como an crece con n , para cada n ≥ n0 se tiene an0≤ an ≤ c . Luego
c− ε < an0≤ an ≤ c < c+ ε, ∀n ≥ n0 ⇐⇒ |an − c| < ε, ∀n ≥ n0 ⇐⇒ lım
n→∞an = c
Como lımn→∞
(bn − an) = lımn→∞
b−a2n = 0 y lım
n→∞an = c , entonces lım
n→∞bn = c y, por ser f continua en [a, b] ,
se tiene que 0 ≥ lımn→∞
f(an) = f(c) = lımn→∞
f(bn) ≥ 0, luego f(c) = 0. En consecuencia, existe c ∈ [a, b] con
f(c) = 0 y, como f(a) < 0 y f(b) > 0, c 6= a y c 6= b , luego c ∈ (a, b).
Demostracion de: Corolario 88 de la pagina 39
Corolario 88.- Sea I un intervalo de R y f : I −→ R continua en I , entonces f(I) es tambien un intervalo deR .
Demostracion:Supongamos primero que f(I) no esta acotado ni superior ni inferiormente. Entonces, para cada y ∈ R , existealgun valor mayor que el en f(I), y < f(b) ∈ f(I), y existe algun valor de f(I) menor que el, y > f(a) ∈ f(I),luego f(a) < y < f(b). Como a y b son del intervalo I , el intervalo [a, b] ⊆ I (o [b, a] ⊆ I ), luego por elteorema de los valores intermedios 87 existe c entre a y b tal que f(c) = y , luego y ∈ f(I) y f(I) = R .
Supongamos ahora que f(I) no esta acotado inferiormente pero sı superiormente, y sea Γ = sup f(I).Entonces, por ser extremo superior, para cada y < Γ, existe un punto f(b) ∈ f(I) tal que y < f(b) ≤ Γ y, porno estar f(I) acotado inferiormente, existe a ∈ I , tal que f(a) < y < f(b). Luego por el teorema 87 existe
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

68 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
c entre a y b tal que f(c) = y , luego y ∈ f(I) de donde (−∞,Γ) ⊆ f(I). Pero como Γ es el superior delconjunto, f(I) = (−∞,Γ) o f(I) = (−∞,Γ] (segun que el superior sea maximo o no lo sea).
La prueba, para los dos casos que restan, son enteramente analogas.
Demostracion de: Teorema de acotacion 89 de la pagina 39
Teorema de acotacion 89.- Sea f una funcion continua en el intervalo cerrado [a, b] , entonces f esta acotadaen dicho intervalo. Es decir, existe M > 0 tal que |f(x)| ≤M , para todo x ∈ [a, b] .
La prueba de este resultado se incluye en la prueba del siguiente; el Teorema de Weierstrass 90.
Demostracion de: Teorema de Weierstrass 90 de la pagina 39
Teorema de Weierstrass 90.- Si f es una funcion continua en el intervalo [a, b] , entonces f alcanza un maximoy un mınimo en [a, b] . Es decir, ∃α ∈ [a, b] tal que f(α) ≤ f(x), ∀x ∈ [a, b] y ∃β ∈ [a, b] tal que f(x) ≤ f(β),∀x ∈ [a, b] .
Demostracion:La demostracion de este resultado y del Teorema de acotacion 89 anterior, que vamos a exponer aquı no sontodo lo rigurosas que serıa de desear, por dos razones: la primera, que se hace uso del Teorema de Bolzano-Weierstrass (Un conjunto infinito y acotado de R , tiene al menos un punto de acumulacion) que no se incluyeen estos apuntes y, en segundo lugar, que simplificaremos del proceso (con una muy breve explicacion) en arasde entender el sentido de la prueba.
Por el Corolario 88, como J = [a, b] es un intervalo, su imagen f(J) es un intervalo de R .
Veamos primero, que el intervalo f(J) esta acotado. Supngamos que es un intervalo no acotado superiormente,en cuyo caso, el conjunto {n ∈ N} ⊆ f(J) y existen puntos xn ∈ [a, b] tales que f(xn) = n . Los puntos sondistintos, pues tienen imagenes distintas por la aplicacion f y son infinitos, luego el conjunto T = {xn : n ∈N} ⊆ [a, b] es infinito y acotado por lo que tiene al menos un punto de acumulacion l (Teorema de Bolzano-Weierstrass enunciado arriba). En aras de no complicar el proceso supondremos que es punto de acumulacionde todo el conjunto T , es decir, que lım
n→∞xn = l (ser punto de acumulacion, significa que nos podemos acercar
tanto como queramos al punto l con puntos del conjunto T ; luego que l es el lımite de los puntos de unsubconjunto infinito de T , por lo que tiene un funcionamiento similar a si fuera todo T –en cualquier estudiosobre sucesiones de numeros reales puede consultarse con mas detalle esta simplificacion–).
Como a ≤ xn ≤ b se tiene que a ≤ lımn→∞
xn ≤ b , luego que l ∈ [a, b] . Entonces, por ser f continua en [a, b] ,
lımn→∞
f(xn) = f(
lımn→∞
xn
)= f(l) ∈ R ; pero por su construccion, lım
n→∞f(xn) = lım
n→∞n = ∞ /∈ R , lo que es
absurdo. En consecuencia, f(J) tiene que estar acotado superiormente.Analogamente, se obtiene que f(J) esta acotado inferiormente, lo que prueba el Teorema de acotacion 89.
De lo anterior, f(J) es un intervalo acotado de R , luego de la forma [c, d] o [c, d) o (c, d] o (c, d).Veamos si d esta o no en el conjunto. Por ser d = sup f(J), para cada n ∈ N , existe xn ∈ [a, b] tal que
f(xn) = d− 1n < d , como las imagenes de los xn son distintas, tenemos un conjunto T = {xn : n ∈ N} infinito
y acotado que tiene un punto de acumulacion l . Con un razonamiento similar al de la parte anterior, sea
lımn→∞
xn = l ∈ [a, b] y se verifica que lımn→∞
f(xn) = f(
lımn→∞
xn
)= f(l) ∈ R por ser f continua y por otro lado,
lımn→∞
f(xn) = lımn→∞
d− 1n = d , luego d = f(l) y d ∈ f(J), por lo que d = max f(J).
Analogamente, se prueba que c = min f(J). Lo que concluye la prueba.
Demostracion de: Corolario 91 de la pagina 39
Corolario 91.- Si f es continua en (a, b) y lımx→a+
f(x) = l1 ∈ R y lımx→b−
f(x) = l2 ∈ R , la funcion f esta acotada
en (a, b). (Tambien es cierto cuando a es −∞ y cuando b es +∞ .)
Demostracion:Para que el resultado sea cierto no es necesario que exista el lımite en los extremos del intervalo, basta con quela funcion este acotada en algun entorno de ellos. La razon de poner el enunciado con lımites esta en que esuna manera comoda de asegurar la acotacion y suficiente en la mayorıa de los casos.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

69 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Si lımx→a+
f(x) = l1 ∈ R y lımx→b−
f(x) = l2 ∈ R , por el Teorema de acotacion para lımites 84, existe E(a, δ1)
y M1 > 0 tal que |f(x)| ≤M1 para todo x ∈ (a, a+ δ1) y existe E(b, δ2) y M2 > 0 tal que |f(x)| ≤M2 paratodo x ∈ (b− δ2, b). Entonces, (a, b) = (a, a+ δ1)∪ [a+ δ1, b− δ2]∪ (b− δ2, b) y al ser f continua en el intervalo[a+δ1, b−δ2] esta acotada en el (Th 89), luego existe M3 > 0, tal que |f(x)| ≤M3 para todo x ∈ [a+δ1, b−δ2] .En consecuencia, f esta acotada en cada uno de los tres trozos en que hemos dividido el intervalo, por lo queesta acotada; es decir, tomando M = max{M1,M2,M3} , para todo x ∈ (a, b), |f(x)| ≤M .
Si a = −∞ o b = +∞ , la prueba es identica, tomando entornos de −∞ o +∞ .
Funciones derivables
Demostracion de: Propiedades 94 de la pagina 44
Propiedades 94.- Sean f y g funciones derivables en un punto x0 , entonces:
a) f + g es derivable en el punto x0 y (f + g)′(x0) = f ′(x0) + g′(x0).
b) fg es derivable en el punto x0 y (fg)′(x0) = f ′(x0)g(x0) + f(x0)g′(x0).
c) f/g es derivable en el punto x0 , si g(x0) 6= 0, y (f/g)′(x0) =f ′(x0)g(x0)− f(x0)g′(x0)(
g(x0))2 .
Demostracion:
a) Es cierta, pues
(f + g)′(x0) = lımx→x0
(f + g)(x)− (f + g)(x0)
x− x0= lımx→x0
f(x) + g(x)− f(x0)− g(x0)
x− x0
= lımx→x0
f(x)− f(x0)
x− x0+ lımx→x0
g(x)− g(x0)
x− x0= f ′(x0) + g′(x0).
b) Basta tomar lımites, cuando x→ x0 , en la expresion
f(x)g(x)− f(x0)g(x0)
x− x0=f(x)g(x)− f(x0)g(x) + f(x0)g(x)− f(x0)g(x0)
x− x0
=f(x)− f(x0)
x− x0g(x) + f(x0)
g(x)− g(x0)
x− x0.
c) Teniendo en cuenta que la expresion
f(x)g(x) −
f(x0)g(x0)
x− x0=f(x)g(x0)− f(x0)g(x)
g(x)g(x0)(x− x0)
=1
g(x)g(x0)· f(x)g(x0)− f(x0)g(x0) + f(x0)g(x0)− f(x0)g(x)
x− x0
=1
g(x)g(x0)
(f(x)− f(x0)
x− x0g(x0)− f(x0)
g(x)− g(x0)
x− x0
)es valida en los valores de x proximos a x0 , y tomando lımites se obtiene el resultado.
Demostracion de: Regla de la cadena 95 de la pagina 44
Regla de la cadena 95.- Sea f derivable en x0 y g derivable en f(x0), entonces la funcion compuesta g ◦ fes derivable en x0 y ademas:
(g ◦ f)′(x0) = g′(f(x0)
)f ′(x0).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

70 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Demostracion:Si f(x) = f(x0) en un entorno de x0 , tambien se verifica que g(f(x)) = g(f(x0)) y, por tanto, f y g ◦ f sonconstantes en dicho entorno, luego g ◦ f es derivable en x0 y (g ◦ f)′(x0) = 0. Ademas, como f es constante,se tiene g′(f(x0))f ′(x0) = g′(f(x0)) · 0 = 0 obteniendose la igualdad propuesta.
Si f(x)− f(x0) 6= 0 en un entorno de x0 , podemos escribir
g(f(x))− g(f(x0))
x− x0=g(f(x))− g(f(x0))
x− x0· f(x)− f(x0)
f(x)− f(x0)=g(f(x))− g(f(x0))
f(x)− f(x0)· f(x)− f(x0)
x− x0.
Como y = f(x) 6= f(x0) = y0 y lımx→x0
f(x) = f(x0), por la proposicion 69, se tiene
(g ◦ f)′(x0) = lımx→x0
g(f(x))− g(f(x0))
x− x0= lımx→x0
g(f(x))− g(f(x0))
f(x)− f(x0)· lımx→x0
f(x)− f(x0)
x− x0
= lımy→y0
g(y)− g(y0)
y − y0· lımx→x0
f(x)− f(x0)
x− x0= g′(y0)f ′(x0) = g′
(f(x0)
)f ′(x0).
Demostracion de: Teorema del valor medio de Cauchy 105 de la pagina 48
Teorema del valor medio de Cauchy 105.- Sean f y g funciones continuas en [a, b] y derivables en (a, b). Sig′(x) 6= 0, ∀x ∈ (a, b), entonces ∃ c ∈ (a, b) tal que:
f(b)− f(a)
g(b)− g(a)=f ′(c)
g′(c)
Demostracion:Como en la demostracion del teorema del valor medio de Lagrage 104, construyamos una funcion para aplicarel teorema de Rolle. Sea h: [a, b] −→ R dada por h(x) =
(f(b)− f(a)
)g(x)−
(g(b)− g(a)
)f(x).
Entonces, h es continua en [a, b] y derivable en (a, b) por ser suma de funcines continuas y derivables, y
h(a) =(f(b)− f(a)
)g(a)−
(g(b)− g(a)
)f(a) = f(b)g(a)− g(b)f(a)
h(b) =(f(b)− f(a)
)g(b)−
(g(b)− g(a)
)f(b) = −f(a)g(b) + g(a)f(b).
Luego tambien se cumple que h(a) = h(b) y por el teorema de Rolle, existe c ∈ (a, b) tal que h′(c) = 0; es
decir, 0 =(f(b)− f(a)
)g′(c)−
(g(b)− g(a)
)f ′(c) de donde se obtiene el resultado f(b)−f(a)
g(b)−g(a) = f ′(c)g′(c) .
Notar, que al ser g′(x) 6= 0 para cada x ∈ (a, b), se tiene que g′(c) 6= 0 y g(b) 6= g(a).
Demostracion de: Regla General de L’Hopital 107 de la pagina 48
Regla General de L’Hopital 107.- Sean f y g funciones derivables en un entorno reducido de x0 , E∗(x0, δ),con g(x) 6= 0 y g′(x) 6= 0, ∀x ∈ E∗(x0, δ) y lım
x→x0
f(x) = 0 = lımx→x0
g(x). Entonces,
si existe lımx→x0
f ′(x)g′(x) se cumple que lım
x→x0
f(x)g(x) = lım
x→x0
f ′(x)g′(x) .
Demostracion:Por comodidad, denotaremos por E∗ = E∗(x0, δ) y por E = E(x0, δ).
Como lımx→x0
f(x) = 0 = lımx→x0
g(x), podemos ampliar estas funciones hasta E , con continuidad. En efecto,
sean F (x) =
{f(x), si x 6= x0
0, si x = x0y G(x) =
{g(x), si x 6= x0
0, si x = x0; que son continuas en E∗ por serlo f y g y continuas
en x0 por su contruccion ( lımx→x0
F (x) = lımx→x0
f(x) = 0 = F (x0) y lo mismo para G).
Para cada x ∈ E∗ con x < x0 , el intervalo [x, x0] ⊆ E , luego F y G son continuas en el y derivablesen (x, x0), donde se cumple que F ′ = f ′ y G′ = g′ . Entonces, por el teorema de Cauchy 105, existe ξx conx < ξx < x0 tal que
F (x)− F (x0)
G(x)−G(x0)=F ′(ξx)
G′(ξx, es decir, tal que
f(x)− 0
g(x)− 0=f ′(ξx)
g′(ξx)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

71 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Luego, como x < ξx < x0 , si x→ x−0 tambien ξx → x−0 y entonces,
lımx→x−0
f(x)
g(x)= lımx→x−0
f ′(ξx)
g′(ξx)= lımξx→x−0
f ′(ξx)
g′(ξx)= lımx→x−0
f ′(x)
g′(x)
siempre que este ultimo lımite exista. Analogamente, para los x > x0 , se tiene lımx→x+
0
f(x)g(x) = lım
x→x+0
f ′(x)g′(x) .
En consecuencia, si lımx→x0
f ′(x)g′(x) existe se tiene que lım
x→x0
f ′(x)g′(x) = lım
x→x−0
f ′(x)g′(x) = lım
x→x+0
f ′(x)g′(x) por lo que existe el
lımite lımx→x0
f(x)g(x) y coincide con el anterior.
Para la justificacion del funcionamiento de la Regla de L’Hopital en los demas casos, en que decimos quetambien funciona, solo indicamos como se obtendrıa esta o en que se basa:
Para el caso x0 = ±∞ , con el cambio x = 1t se tiene que las funciones F (t) = f( 1
t ) y G(t) = g( 1t ) verifican
que lımx→±∞
f(x)g(x) existe si y solo si lım
t→0±
F (t)G(t) existe, y si ocurre son iguales. Aplicando el caso anterior a estas
funciones se obtiene el resultado.
Para la indeterminacion lımx→x0
f(x)g(x) = ∞
∞ , se toma un punto y fijo y suficientemente cercano a x0 y entonces, el
cociente puede escribirse en la forma f(x)g(x) = f(y)−f(x)
g(y)−g(x) ·g(y)g(x)−1
f(y)f(x)−1
. Aplicando el Teorema de Cauchy 105 al primer
factor f(y)−f(x)g(y)−g(x) = f ′(ξx)
g′(ξx) y teniendo en cuenta, que al ser y fijo, lımx→x0
g(y)g(x)−1
f(y)f(x)−1
= 1, se observa que el resultado
sera cierto (la prueba exaustiva no es tan inmediata).
Demostracion de: Teorema de la funcion inversa 109 de la pagina 49
Teorema de la funcion inversa 109.- Sea f : [a, b] −→ R continua en [a, b] y derivable en (a, b), con f ′ > 0 of ′ < 0 en (a, b). Entonces f admite funcion inversa derivable en (a, b) y (f−1)′
(f(x)
)= 1
f ′(x) .
Demostracion:Por ser f ′ > 0 en (a, b) (resp. f ′ < 0 en (a, b)) la funcion f es estrictamente creciente (resp. estrictamentedecreciente) en [a, b] , luego es inyectiva y existe f−1: f([a, b]) −→ [a, b] tal que f−1(f(x)) = x para cadax ∈ [a, b] (recordar la definicion 57 y ver los ejemplos siguientes). De hecho, si f es estrictamente creciente,f([a, b]) = [f(a), f(b)] y si es estrictamente decreciente, f([a, b]) = [f(b), f(a)] .
Veamos primero, que si f es continua en x0 , entonces f−1 es continua en y0 = f(x0). Como f(x0) = y0 =
lımy→y0
y = lımy→y0
f(f−1(y))(1)= f
(lımy→b
f−1(y))
(1) por el resultado del Teorema 67luego, por la inyectividad, se tiene que lım
y→y0
f−1(y) = x0 = f−1(y0).
Veamos ahora que si f es derivable en x0 ∈ (a, b), entonces f−1 es derivable en y0 = f(x0), pero esto essencillo, pues si y 6= y0 ,
f−1(y)− f−1(y0)
y − y0=f−1(f(x))− f−1(f(x0))
f(x)− f(x0)=
x− x0
f(x)− f(x0)=
(f(x)− f(x0)
x− x0
)−1
Si y → y0 , x = f−1(y) tendera hacia x0 = f−1(y0) con x 6= x0 por ser f−1 inyectiva, en consecuencia,f(x)−f(x0)
x−x0→ f ′(x0) con lo que f−1 es derivable en y0 y su derivada es (f ′(x0))−1 .
Polinomios de Taylor
Demostracion de: Formula de Taylor 120 de la pagina 57
Formula de Taylor 120.- Sea una funcion f existen f ′ , f ′′ , . . . , f (n) y f (n+1) sobre el intervalo [a, x] . En-tonces,
f(x)− Pn,a(x) =f (n+1)(c)
(n+ 1)!(x− a)n+1 para un cierto c ∈ (a, x),
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

72 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
llamado resto de Lagrange, o tambien
f(x)− Pn,a(x) =f (n+1)(c)
n!(x− c)n(x− a) para un cierto c ∈ (a, x),
que se denomina resto de Cauchy. .
Demostracion:Consideremos la funcion G: [a, x] −→ R , definida por
G(t) = f(x)−[f(t) + f (1)(t)
(x− t)1
1!+ f (2)(t)
(x− t)2
2!+ f (3)(t)
(x− t)3
3!+ · · ·+ f (n−1)(t)
(x− t)n−1
(n− 1)!+ f (n)(t)
(x− t)n
n!
]La funcion G verifica que G(x) = 0 y G(a) = f(x)− Pn,a(x) y es derivable en [a, x] , por ser suma y productode derivables. Y su derivada es
G′(t) =−
[f (1)(t) +
(f (2)(t)
(x− t)1
1!+ f (1)(t)
1(x− t)0(−1)
1!
)+(f (3)(t)
(x− t)2
2!+ f (2)(t)
2(x− t)1(−1)
2!
)+(f (4)(t)
(x− t)3
3!+ f (3)(t)
3(x− t)2(−1)
3!
)+ · · ·+
(f (n)(t)
(x− t)n−1
(n− 1)!+ f (n−1)(t)
(n− 1)(x− t)n−2(−1)
(n− 2)!
)+(f (n+1)(t)
(x− t)n
n!+ f (n)(t)
n(x− t)n−1(−1)
(n− 1)!
)]
=−
[f (1)(t) +
(f (2)(t)
(x− t)1
1!− f (1)(t)
)+(f (3)(t)
(x− t)2
2!− f (2)(t)
(x− t)1
1!
)+(f (4)(t)
(x− t)3
3!− f (3)(t)
(x− t)2
2!
)+ · · ·+
(f (n)(t)
(x− t)n−1
(n− 1)!− f (n−1)(t)
(x− t)n−2
(n− 2)!
)+(f (n+1)(t)
(x− t)n
n!− f (n)(t)
(x− t)n−1
(n− 1)!
)]quitando los parentesis internos y cambiando el orden de los sustraendos, se tiene:
=−
[f (1)(t)− f (1)(t) + f (2)(t)
(x− t)1
1!− f (2)(t)
(x− t)1
1!+ f (3)(t)
(x− t)2
2!
−f (3)(t)(x− t)2
2!+ f (4)(t)
(x− t)3
3!+ · · · − f (n−1)(t)
(x− t)n−2
(n− 2)!+ f (n)(t)
(x− t)n−1
(n− 1)!
−f (n)(t)(x− t)n−1
(n− 1)!+ f (n+1)(t)
(x− t)n
n!
]y cada termino que resta se anula con el anterior, luego solo queda el ultimo termino:
=−f (n+1)(t)(x− t)n
n!.
Entonces:
• Por el teorema del valor medio de Lagrange, G(x)−G(a) = G′(c)(x− a), para algun c ∈ (a, x). Luego
G(x)−G(a) = −G(a) = −f (n+1)(c)(x− c)n
n!(x− a) =⇒ f(x)− Pn,a(x) =
f (n+1)(c)
n!(x− c)n(x− a)
• Tomando la funcion g(t) = (x − t)n+1 , continua en [a, x] y derivable en (a, x), por el teorema del valor
medio de Cauchy G(x)−G(a) = G′(c)g′c)
(g(x)− g(a)
), para algun c ∈ (a, x). Luego
−G(a) =−f(n+1)(c)(x−c)n
n!
(n+ 1)(x− c)n(−1)
(− (x− a)n+1
)=⇒ f(x)− Pn,a(x) =
f (n+1)(c)
(n+ 1)!(x− a)n+1
y hemos obtenido el resto de Cauchy, en el primer caso, y el de Lagrange en el segundo.
Demostracion de: Proposicion 122 de la pagina 58
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

73 – Fundamentos de Matematicas : Calculo diferencial en R Anexo 1
Proposicion 122.- Sea f una funcion de clase Cn−1 en un entorno del punto a , para la que se cumple quef ′(a) = f ′′(a) = · · · = f (n−1)(a) = 0, y ademas existe f (n)(a) 6= 0. Entonces:
a) Si n es par y f (n)(a) > 0, f presenta un mınimo local en a .
b) Si n es par y f (n)(a) < 0, f presenta un maximo local en a .
c) Si n es impar y f (n)(a) > 0, f es estrictamente creciente en a .
d) Si n es impar y f (n)(a) < 0, f es estrictamente decreciente en a .
Demostracion:Si f ′(a) = f ′′(a) = · · · = f (n−1)(a) = 0, el polinomio de Taylor de grado n de f en a se reduce al primer y
ultimo termino, Pn,a(x) = f(a) + f(n)(a)n! (x− a)n .
Por la proposicion 119 anterior, lımx→a
f(x)−Pn,a(x)(x−a)n = 0, luego
0 = lımx→a
f(x)−(f(a) + f(n)(a)
n! (x− a)n)
(x− a)n= lımx→a
f(x)− f(a)
(x− a)n− f (n)(a)
n!=⇒ lım
x→a
f(x)− f(a)
(x− a)n=f (n)(a)
n!
luego
• si f (n)(a) > 0, debe ser f(x)−f(a)(x−a)n > 0 para los x de un entorno de a , y
– si n es par, (x− a)n > 0 de donde f(x)− f(a) > 0 y f(x) ≥ f(a), por lo que f(a) es mınimo local.
– si n es impar, para los x < a se tiene que (x− a)n < 0 de donde f(x)− f(a) < 0 y f(x) < f(a); ypara los x > a se tiene que (x−a)n > 0 de donde f(x)− f(a) > 0 y f(x) > f(a). En consecuencia,f es estrictamente creciente en a .
Y se cumplen (a) y (c).
• si f (n)(a) < 0, debe ser f(x)−f(a)(x−a)n < 0 para los x de un entorno de a , y
– si n es par, (x−a)n > 0 de donde f(x)− f(a) < 0 y f(x) ≤ f(a), por lo que f(a) es maximo local.
– si n es impar, para los x < a se tiene que (x− a)n < 0 de donde f(x)− f(a) > 0 y f(x) > f(a); ypara los x > a se tiene que (x−a)n > 0 de donde f(x)− f(a) < 0 y f(x) < f(a). En consecuencia,f es estrictamente decreciente en a .
Y se cumplen (b) y (d).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

74 – Fundamentos de Matematicas
Unidad II
Calculo integral en R
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

75 – Fundamentos de Matematicas : Calculo integral en R
Capıtulo 4
Calculo de primitivas
4.1 Primitiva de una funcion
Definicion 125.- Diremos que la funcion F continua en [a, b] , es una primitiva de la funcion f en el intervalo[a, b] si y solo si F ′(x) = f(x), ∀x ∈ (a, b).
Teorema 126.- Si F y G son dos funciones primitivas de la funcion f en [a, b] , entonces F−G es una funcionconstante en [a, b] .
Demostracion:Para cada c ∈ (a, b), se tiene que (F −G)′(c) = F ′(c)−G′(c) = f(c)− f(c) = 0, luego tiene derivada nula.Por el Teorema del valor medio de Lagrange (teorema 104 de la pag 48), para cada x ∈ [a, b] ,(
F (x)−G(x))−(F (a)−G(a)
)= (F −G)′(c)(x− a) = 0,
luego F (x)−G(x) = F (a)−G(a) = k para todo x ∈ [a, b] .
Observacion: Como consecuencia del teorema anterior, se tiene que si F es una funcion primitiva de f en [a, b] ,entonces {F (x) + C : C ∈ R} es el conjunto formado por todas las funciones primitivas de f en [a, b] .
Definicion 127.- Llamaremos integral indefinida de f al conjunto de todas las primitivas de la funcion f ,
y lo denotaremos por
∫f(x) dx .
Si F es una funcion primitiva de f , escribiremos unicamente
∫f(x) dx = F (x) + C , con C ∈ R .
Propiedad 128.-
∫(λf + µg)(x) dx = λ
∫f(x) dx + µ
∫g(x) dx . Es decir, una primitiva de la suma y el
producto por escalares se obtiene como suma de primitivas y como primitivas por escalares.
Demostracion:Sean F ′(x) = f(x) y G′(x) = g(x). Entonces
((λF + µG)(x))′ = λF ′(x) + µG′(x) = λf(x) + µg(x) = (λf + µg)(x),
luego λF + µG es una primitiva de λf + µg .
4.1.1 Tabla de integrales inmediatas
Es usual manejar una tabla de primitivas inmediata, pero que en realidad se reduce a una tabla de derivadasconocidas:
∫xa dx= 1
a+1 xa+1 + C, a 6= −1
∫1x dx= ln |x|+ C
∫ax dx= 1
ln a ax + C∫
cosx dx= senx+ C
∫senx dx=− cosx+ C
∫1
cos2 x dx= tg x+ C∫dx
sen2 x =− cotg x+ C
∫1√
1−x2dx= arcsenx+ C
∫−1√1−x2
dx= arccosx+ C∫1
1+x2 dx= arctg x+ C
∫−1
1+x2 dx= arccotg x+ C
∫chx dx= shx+ C∫
shx dx= chx+ C
∫1
ch2 xdx= thx+ C
∫1√x2+1
dx= argshx = ln(x+√x2 + 1) + C
∫1
1−x2 dx= argthx = 12 ln 1+x
1−x + C
∫1√x2−1
dx= argchx = ln(x+√x2 − 1) + C
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

76 – Fundamentos de Matematicas : Calculo integral en R 4.2 Metodos de integracion
4.2 Metodos de integracion
4.2.1 Metodo de sustitucion
Si F (x) es una primitiva de f(x), entonces F (φ(x)) es una primitiva de la funcion f(φ(x))φ′(x), es decir,∫f(φ(x))φ′(x)dx = F (φ(x)) + C.
En efecto, por la Regla de la cadena (teorema 95 de la pag 44), (F (φ(x)))′ = f(φ(x))φ′(x).
Ejemplo Encontrar una expresion para
∫4(x2 + 1)32xdx .
Solucion:F (x) = x4 es una primitiva de f(x) = 4x3 y, si φ(x) = x2+1 se tiene φ′(x) = 2x . Luego F (φ(x)) = (x2+1)4
es una primitiva de f(φ(x))φ′(x) = 4(x2 + 1)32x . Es decir,∫4(x2 + 1)32xdx = (x2 + 1)4 + C. 4
Combinando este metodo con la tabla de integrales inmediatas, podemos componer toda una tabla deintegrales “casi inmediatas”:
4.2.1.1 Tabla de integrales casi–inmediatas
∫(v(x))av′(x)dx =
(v(x))a+1
a+ 1+ C, a 6= −1
∫1
v(x)v′(x)dx = ln |v(x)|+ C∫
av(x)v′(x)dx =av(x)
ln a+ C
∫cos(v(x))v′(x)dx = sen(v(x)) + C∫
sen(v(x))v′(x)dx = − cos(v(x)) + C
∫1
cos2(v(x))v′(x)dx = tg(v(x)) + C∫
1
sen2(v(x))v′(x)dx = − cotg(v(x)) + C
∫1√
1− (v(x))2v′(x)dx = arcsen(v(x)) + C∫
−1√1− (v(x))2
v′(x)dx = arccos(v(x)) + C
∫1
1 + (v(x))2v′(x)dx = arctg(v(x)) + C∫
−1
1 + (v(x))2v′(x)dx = arccotg(v(x)) + C
∫ch(v(x))v′(x)dx = sh(v(x)) + C∫
sh(v(x))v′(x)dx = ch(v(x)) + C
∫1
ch2(v(x))v′(x)dx = th(v(x)) + C∫
1√(v(x))2 + 1
v′(x)dx = argsh(v(x)) + C
∫1
1− (v(x))2v′(x)dx = argth(v(x)) + C∫
1√(v(x))2 − 1
v′(x)dx = argch(v(x)) + C.
4.2.2 Cambio de variable
Proposicion 129.- Sea
∫f(x)dx . Si x = φ(t), con φ derivable y existe φ−1 tambien derivable. Entonces
∫f(x)dx =
∫f(φ(t))φ′(t)dt.
Demostracion:
Sean
∫f(x)dx = F (x) + C1 y
∫f(φ(t))φ′(t)dt = G(t) + C2 . Como F (x) es una primitiva de f(x) se tiene
que F (φ(t)) es una primitiva de f(φ(t))φ′(t), luego F (φ(t)) = G(t) +C , y, por tanto, F (x) = F (φ(φ−1(x))) =G(φ−1(x)) + C
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

77 – Fundamentos de Matematicas : Calculo integral en R 4.3 Integracion segun el tipo de funcion
Se hace un cambio de variable x = φ(t) para transformar la integral de partida en otra mas sencilla oinmediata.
Ejemplo Hallar
∫3√
1 + xdx .
Solucion:Si tomamos 1 + x = t3 , es decir, x = φ(t) = t3 − 1, φ es derivable, existe φ−1 y es derivable. Entonces,
como dx = φ′(t)dt = 3t2dt , se tiene∫3√
1 + xdx =
∫3√t33t2dt =
∫3t3dt = 3
∫t3dt = 3
t4
4=
3
4
(3√
1 + x)4
+ C 4
4.2.3 Integracion por partes
En forma clasica, la derivada de un producto se escribe como d(uv) = udv + vdu , de donde udv =d(uv)− vdu . Entonces ∫
u dv = uv −∫v du
expresion conocida como formula de integracion por partes
Ejemplo Calcular
∫lnx dx .
Solucion:
Si tomamos
{u= lnxdv = dx
, se tiene
{du= 1
xdxv = x
, de donde
∫lnx dx = x lnx−
∫x
1
xdx = x lnx−
∫dx = x lnx− x+ C 4
4.3 Integracion segun el tipo de funcion
4.3.1 Integrales racionales
Resumen de resultados conocidos. Sea la ecuacion polinomica P (x) = a0 + a1x + . . . + anxn = 0, con
ai ∈ R .
• Si ai ∈ Z , para todo i , entonces toda raiz entera de P (x) es divisor del coeficiente a0 .
• Si ai ∈ Z , para todo i , el denominador de toda raiz fraccionaria de P (x) es divisor del coeficiente an yel numerador es divisor del coeficiente a0 .
• Si ai ∈ R , para todo i , y α+βi es una raiz compleja de P (x) entonces, tambien α−βi es raiz de P (x).
• Todo polinomio con coeficientes reales puede descomponerse en la forma
P (x) = an(x− r1)n1(x− r2)n2 · · · (x− rs)ns(x2 + p1x+ q1)m1 · · · (x2 + pkx+ qk)mk ,
donde n1 + · · ·+ns+2m1 + · · ·+2mk = n , los ri son las raices reales de P (x) y los terminos x2 +pjx+qjagrupan las raices complejas αj + βji y αj − βji (verifican por tanto que p2
j − 4qj < 0).
4.3.1.1 Descomposicion en fracciones simples
Sean Q y P funciones polinomicas reales y Q(x)P (x) la funcion racional cociente de ambas.
• Si el grado de P es mayor que el de Q se dice que es una fraccion propia, en cuyo caso, si P (x) se descompone
como en el punto anterior, Q(x)P (x) puede descomponerse de manera unica en la forma
Q(x)
P (x)=
1
an·[
A1
(x− r1)n1+
A2
(x− r1)n1−1+ · · ·+ An1
(x− r1)+
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

78 – Fundamentos de Matematicas : Calculo integral en R 4.3 Integracion segun el tipo de funcion
Q(x)
P (x)=
1
an+
B1
(x− r2)n2+
B2
(x− r2)n2−1+ · · ·+ Bn2
(x− r2)+
+ · · · · · · · · ·+
+L1
(x− rs)ns+
L2
(x− rs)ns−1+ · · ·+ Lns
(x− rs)+
+M1x+N1
(x2 + p1x+ q1)m1+
M2x+N2
(x2 + p1x+ q1)m1−1+ · · ·+ Mm1x+Nm1
x2 + p1x+ q1+
+ · · · · · · · · ·+
+E1x+ F1
(x2 + pkx+ pk)mk+
E2x+ F2
(x2 + pkx+ qk)mk−1+ · · ·+ Emkx+ Fmk
x2 + pkx+ qk
]Descomposicion que se denomina en fracciones simples (ver la subseccion 0.3.2.6 de Polinomios)
• Si el grado de Q es mayor que el grado de P , se dice que la fraccion es impropia, en cuyo caso, al dividirde forma entera el numerador por el denominador, se obtiene que
Q(x)
P (x)= M(x) +
R(x)
P (x),
donde M(x) es un polinomio y R(x)P (x) una fraccion propia.
Como P (x) es el polinomio denominador comun de los terminos de la descomposicion, el polinomio Q(x)debe coincidir con el polinomio que se obtiene en el numerador al sumar las fracciones simples. En consecuencialos nuevos coeficientes que aparecen en la descomposicion son aquellos que hacen iguales ambos polinomios.
4.3.1.2 Integracion de funciones racionales
Encontrar una primitiva de Q(x)P (x) , es resolver integrales de los tipos
a)
∫A
(x−r)k dx b)
∫Mx+N
(x2+px+q)kdx
a) Estas integrales son inmediatas, pues si k = 1,∫A
x− rdx = A ln |x− r|,
y si k > 1, ∫A
(x− r)kdx =
∫A(x− r)−kdx = A
(x− r)−k+1
−k + 1=
A
1− k1
(x− r)k−1.
b) Como 4q − p2 > 0, se tiene que
x2 + px+ q = (x+ p2 )2 + (q − p2
4 ) = (x− p2 )2 +R2 = R2(t2 + 1),
donde R =√q − p2
4 y t =x− p2R , luego haciendo el cambio x = Rt+ p
2 , con dx = Rdt , se tiene que∫Mx+N
(x2 + px+ q)kdx=
1
(R2)k
∫M ′t+N ′
(t2 + 1)kRdt =
1
R2k−1
(∫M ′t
(t2 + 1)kdt+
∫N ′
(t2 + 1)kdt
)=
1
R2k−1
(M ′
2
∫2t
(t2 + 1)kdt+N ′
∫1
(t2 + 1)kdt
)=
M ′
2R2k−1I ′k +
N ′
R2k−1Ik
integrales que se resuelven de forma inmediata en los siguientes casos:
• Si k = 1, I ′1 =
∫2tt2+1dt = ln |t2 + 1| , I1 =
∫1
t2+1dt = arctg t .
• Si k > 1, I ′k =
∫2t
(t2+1)kdt = 1
1−k1
(t2+1)k−1 .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

79 – Fundamentos de Matematicas : Calculo integral en R 4.3 Integracion segun el tipo de funcion
Para resolver Ik , se realiza un proceso que consiste en ir bajando sucesivamente la potencia k hasta quesea 1, de la forma siguiente
Ik =
∫1
(t2 + 1)kdt =
∫1− t2 + t2
(t2 + 1)kdt =
∫ (1 + t2
(t2 + 1)k− t2
(t2 + 1)k
)dt
=
∫1
(t2 + 1)k−1dt−
∫t2
(t2 + 1)kdt = Ik−1 − I
Haciendo en I integracion por partes,
{u= tdv = t
(1+t2)kdt
}se tiene
{du= dtv = 1
2(1−k)1
(1+t2)k−1
}, luego
Ik = Ik−1 −1
2(1− k)
t
(1 + t2)k−1+
1
2(1− k)
∫1
(1 + t2)k−1dt
=1
2(k − 1)
t
(1 + t2)k−1+
(1− 1
2(k − 1)
)Ik−1
Si k − 1 = 1, Ik−1 = I1 = arctg t . Si k − 1 > 1, se repite el proceso.
Ejemplo Calcular
∫1+x
x4+x3+x2 dx .
Solucion Como P (x) = x2(x2 + x+ 1), y x2 + x+ 1 no tiene raices reales, se tiene
1 + x
x2(x2 + x+ 1)=
A
x2+B
x+
Mx+N
x2 + x+ 1=A(x2 + x+ 1) +Bx(x2 + x+ 1) + (Mx+N)x2
x2(x2 + x+ 1)
de donde 1 + x = A+ (A+B)x+ (A+B +N)x2 + (B +M)x3 , es decir,
1 + x+ 0x2 + 0x3 = A+ (A+B)x+ (A+B +N)x2 + (B +M)x3 ,
obteniendose el sistema
1 =A1 =A+B0 =A+B +N0 =B +M
con soluciones
A= 1B = 0N =−1M = 0
. Entonces
∫dx
x2(x2 + x+ 1)=
∫dx
x2−∫
dx
x2 + x+ 1=−1
x− 4
3
∫dx
43 (x− 1
2 )2 + 1
=−1
x− 4
3
∫dx
( 2x−1√3
)2 + 1=−1
x− 4
3
∫ √3
2 dt
t2 + 1
=−1
x− 2√
3arctg t =
−1
x− 2√
3arctg
2x− 1√3
+ C 4
4.3.2 Integracion de funciones trigonometricas
Cambios de variable especıficos.
• Integrales de los tipos:∫sen(mx) cos(nx)dx
∫cos(mx) cos(nx)dx
∫sen(mx) sen(nx)dx.
se resuelven usando las relaciones
(1) + (2) : 2 senx cos y = sen(x+ y) + sen(x− y)(3) + (4) : 2 cosx cos y = cos(x+ y) + cos(x− y)(3)− (4) : −2 senx sen y = cos(x+ y)− cos(x− y)
obtenidas a partir de la formulas trigonometricas:
(1) sen(x+ y)=senx cos y + sen y cosx (3) cos(x+ y)=cosx cos y − senx sen y(2) sen(x− y)=senx cos y − sen y cosx (4) cos(x− y)=cosx cos y + senx sen y
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

80 – Fundamentos de Matematicas : Calculo integral en R 4.3 Integracion segun el tipo de funcion
• Integrales de la forma
∫senm x cosn xdx con m,n ∈ Z
– Si m es impar se resuelven usando el cambio t = cosx .
– Si n es impar con el cambio t = senx .
– Si m y n son pares positivos se resuelven utilizando las formulas del angulo mitad
sen2 x =1− cos(2x)
2cos2 x =
1 + cos(2x)
2senx cosx =
sen(2x)
2
– Si m y n son pares, no positivos ambos, se simplifican con tg2 x = 1cos2 x − 1 y cos2 x
sen2 x = 1sen2 x − 1
Ejemplo Hallar
∫sen2 x cos2 xdx .
∫sen4 x cos2 xdx=
∫ (1− cos 2x
2
)2(1 + cos 2x
2
)dx =
1
8
∫ (1− cos 2x− cos2 2x+ cos3 2x
)dx
=1
8
∫ (1− cos 2x−
(1 + cos 4x
2
)+ cos3 2x
)dx
=1
8
∫1
2dx− 1
8
∫cos 2xdx− 1
16
∫cos 4xdx+
1
8
∫cos3 2xdx
=x
16− sen 2x
16− sen 4x
64+
1
8
∫cos3 2xdx =
{t= sen 2xdt= 2 cos 2xdx
}=x− sen 2x
16− sen 4x
64+
1
8
∫(1− t2)
dt
2=x− sen 2x
16− sen 4x
64+
1
16(t− t3
3)
=x− sen 2x
16− sen 4x
64+
sen 2x
16− sen3 2x
48+ C
=x
16− sen 4x
64+− sen3 2x
48+ C 4
Cambios mas generales para las integrales trigonometricas.
Las integrales de la forma
∫R(senx, cosx)dx , siendo R(senx, cosx) una funcion racional en senx y cosx .
• Si se cumple R(senx, cosx) = R(− senx,− cosx) entonces la integral se puede reducir a una integralracional empleando el cambio t = tg x .
Es decir, x = arctg t −→ dx =dt
1 + t2.
Por otra parte 1 + tg2 x =1
cos2 x=⇒ cosx =
1√1 + t2
y por tanto senx =t√
1 + t2.
• En general, una integral del tipo
∫R(senx, cosx)dx se transforma en una integral racional utilizando el
cambio
t = tgx
2=⇒ x
2= arctg t −→ dx =
2dt
1 + t2, cosx =
1− t2
1 + t2y senx =
2t
1 + t2.
4.3.3 Integracion de funciones exponenciales e hiperbolicas∫R(ax)dx ; siendo R(ax) una funcion racional en ax .
El cambio t = ax convierte dicha integral en racional:
t = ax =⇒ dt = ax ln adx =⇒ dx =dt
t ln a
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

81 – Fundamentos de Matematicas : Calculo integral en R 4.3 Integracion segun el tipo de funcion
Dado que chx = ex+e−x
2 y shx = ex−e−x2 , resulta que entonces cualquier integral del tipo
∫R(shx, chx)dx
se puede resolver por el cambio anterior. Pero tambien existen unas relaciones entre las funciones hiperbolicasque hacen que su integracion sea similar a la de las funciones trigonometricas:
ch2 x− sh2 x = 1 sh2 x =ch 2x− 1
2ch2 x =
ch 2x+ 1
2
sh 2x = 2 shx chx 1− th2 x =1
ch2 x
De entre todos los casos que nos aparecen en la integracion de funciones racionales hiperbolicas destacamos:
• Cambio t = thx =⇒ dx = dt1−t2 chx = 1√
1−t2 shx = t√1−t2
• Cambio t = th(x2
)=⇒ dx = 2dt
1−t2 chx = 1+t2
1−t2 shx = 2t1−t2
Ejemplo Hallar
∫ex−1ex+1dx .
Solucion Con el cambio t = ex , se tiene dt = exdx = tdx , luego∫ex
ex + 1dx =
∫t− 1
t+ 1
dt
t=
∫ (2
t+ 1− 1
t
)dt = 2 ln |t+ 1| − ln |t| = ln
∣∣∣∣ (ex + 1)2
ex
∣∣∣∣+ C. 4
4.3.4 Integrales con raıces o irracionales
• Integrales de la forma
∫R
(x,(ax+bcx+d
) p1q1,(ax+bcx+d
) p2q2, . . . ,
(ax+bcx+d
) pkqk
)dx , siendo R una funcion racional
en esas variables y las fracciones p1
q1, p2
q2, . . . , pkqk irreducibles.
Sea n = mcm(q1, q2, . . . , qk), el cambio de variable tn = ax+bcx+d transforma la integral con raıces en una
racional. (Ver ejemplo 4.2.2.)
• Integrales del tipo
∫R(x,
√a2 − x2)dx
Se resuelven mediante alguno de los cambios: x = a sen t o x = a cos t o x = th t
• Integrales del tipo
∫R(x,
√a2 + x2)dx
Se resuelven mediante alguno de los cambios: x = a tg t o x = a sh t
• Integrales del tipo
∫R(x,
√x2 − a2)dx
Se resuelven mediante alguno de los cambios: x = a sec t o x = a ch t
Ejemplo Encontrar
∫ √1− x2dx .
Solucion Con el cambio x = sen t , dx = cos tdt . Entonces∫ √1− x2dx=
∫ √1− sen2 t cos tdt =
∫ √cos2 t cos tdt =
∫cos2 tdt
=1
2
∫(1− cos 2t)dt =
t
2− sen 2t
4=
arcsenx
2− sen(2 arcsenx)
4+ C 4
4.3.4.1 Integrales binomias∗
Las integrales binomias, son de la forma
∫xp(a+ bxq)rdx , con p, q, r ∈ Q .
Chebichev probo que es posible racionalizar la integral binomia cuando es entero uno de los tres numerossiguientes: r, p+1
q , p+1q + r .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

82 – Fundamentos de Matematicas : Calculo integral en R 4.4 Ejercicios
• Si r ∈ N , entonces se desarrolla (a+ bxq)r segun el binomio de Newton.
• Si r /∈ N , haremos el cambio: t = xq =⇒ dx = 1q t
1−qq dt , por tanto∫
xp(a+ bq)rdx =1
q
∫tp+1q −1(a+ bt)rdt.
– Si r ∈ Z , con r negativo, la integral siempre se va a poder convertir en una racional con el cambiou = t
1s siendo s ∈ N el denominador de la fraccion irreducible m
s = p+1q − 1.
– Si r /∈ Z , pero p+1q ∈ Z , la integral se ha convertido en un tipo ya estudiado. Si no
1
q
∫tp+1q −1(a+ bt)rdt =
1
q
∫tp+1q −1+r
(a+ bt
t
)rdt,
con lo que si p+1q + r ∈ Z la integral se ha convertido de nuevo en una del tipo anterior.
Ejemplo Hallar
∫x
12 (1 + x
13 )−
12 dx .
Solucion Como r = −12 /∈ N , hacemos el cambio t = xq = x
13 , luego x = t3 y dx = 3t2dt . Entonces∫
x12 (1 + x
13 )−
12 dx =
∫t
32 (1 + t)−
12 3t2dt =
∫3t
72 (1 + t)−
12 dt
Como 72 /∈ Z , multiplicamos y dividimos por t−
12 , obteniendo
∫3t
72 (1 + t)−
12 dt= 3
∫t
72−
12
(1 + t
t
)− 12
dt = 3
∫t3(
t
1 + t
) 12
dt ={u2 = t
1+t
}→
{t= u2
1−u2
dt= 2udu(1−u2)2
}
= 3
∫u6
(1− u2)3u
2udu
(1− u2)2= 6
∫u8
(1− u2)5du = 6
∫u8
(1− u)5(1 + u)5du
que es una integral racional en u . Se resuelve, y teniendo en cuenta que u =√
t1+t =
√x
13
1+x13
se obtiene el
resultado buscado. 4
4.4 Ejercicios
4.120 Manipular las expresiones para resolver de manera casi-inmediata las siguientes integrales indefinidas
1)
∫tg2 x dx 2)
∫x(3x2 + 1)4dx 3)
∫6x2+4
x3+2x+7dx
4)
∫e− sen x cosx dx 5)
∫x
1+x4 dx 6)
∫x(2x+ 5)10dx
7)
∫x2
x6+1dx 8)
∫sen2 x
6 dx 9)
∫dx
2+2x+x2
4.121 Usar los metodos de integracion por partes e integracion racional, segun convenga, para resolver:
10)
∫ln2 x dx 11)
∫x senx dx 12)
∫arctg x dx
13)
∫(x+ 1)2 cosxdx 14)
∫e2x sen(2x)dx 15)
∫x3+x−1(x2+2)2 dx
16)
∫x4−6x3+12x2+6x3−6x2+12x−8 dx 17)
∫dx
(x+1)(x2+x+2)2 18)
∫dx
(x+1)2(x2+1)
19)
∫x8
(1−x2)5 dx 20)
∫2x+2
(x2+1)2 dx 21)
∫dx
1+x4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

83 – Fundamentos de Matematicas : Calculo integral en R 4.4 Ejercicios
4.122 Usar los cambios de variable recomendados adecuados en cada caso para resolver:
22)
∫ √1− x2dx 23)
∫1+x
1+√xdx 24)
∫dx
x√x2−2
25)
∫dx√ex−1
26)
∫ln(2x)x ln(4x)dx 27)
∫ √2 + 2x+ x2dx
28)
∫cosx cos2(3x)dx 29)
∫cos x2 cos x3dx 30)
∫tg2(5x)dx
31)
∫ (tg3 x
4 + tg4 x4
)dx 32)
∫sen5 xdx 33)
∫sen3 x
2 cos5 x2dx
34)
∫cos5 xsen3 xdx 35)
∫cos6(3x)dx 36)
∫sen4 xdx
37)
∫dx
cos6 x 38)
∫cos2 xsen6 xdx 39)
∫dx
1+3 cos2 x
40)
∫3 sen x+2 cos x2 sen x+3 cos xdx 41)
∫dx
cos x+2 sen x+3 42)
∫dxex+1
43)
∫ch4 xdx 44)
∫sh3 x chxdx 45)
∫dx
sh2 x+ch2 x
46)
∫ √x+1+2
(x+1)2−√x+1
dx 47)
∫x√
x−1x+1dx 48)
∫dx
(2−x)√
1−x
49)
∫dx√x+ 3√x
50)
∫(x−1)dx
x(x+2)23
51)
∫x√x2−xdx
52)
∫x−4(1 + x2)
−12 dx 53)
∫dx
(x−2)√
5x−x2−454)
∫2x
3√1+x3dx
4.123 De la funcion f se sabe que f(1) = −1 y que f ′(x) = 1−2xx . ¿Que funcion es f ?
4.124 Encuentra todas las funciones que se anulen en x = 0 y tengan por derivada segunda, f ′′(x) = (2 +x)ex
4.125 Parece ser cierto que x5
5√
(1+x2)5− 50001 es una solucion de
∫x4 dx√(1+x2)7
a) Compruebese la veracidad de lo dicho
b) De entre estos tres cambios de variable x = sh t , x2 = t2−1 y x = tg t = sen tcos t , hay dos que
transforman la integral irracional en otra sin raıces
c) Resuelve cada una de las dos integrales no irracionales obtenidas con esos cambios
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

84 – Fundamentos de Matematicas : Calculo integral en R
Capıtulo 5
Integral de RiemannLa teorıa de la Integral de Riemann o Integral Definida, como tambien se denomina en contraposicion con elcalculo de primitivas o busqueda de “antiderivadas”, tiene su origen en el uso practico de la integral y es conuna aplicacion como se introduce y motiva su construccion. No es hasta que se obtienen los teoremas clave quepuede relacionarse esta integral con las primitivas.
Las funciones implicadas en ello deben cumplir dos preceptos para poder construir estas integrales: tenerun dominio acotado (o estar restringidas a uno) y ser funciones acotadas es ese dominio. Si una de las dosreglas se incumple no podremos hablar de integrales en el sentido que vamos a construir, y diremos de ellas queson integrales impropias y las trataremos sucintamente en la ultima seccion del tema.
5.1 Sumas inferiores y superiores
5.1.1 Particiones de un intervalo
Definicion 130.- Se llama particion de un intervalo [a, b] a un conjunto finito de puntos P = {x0, x1, . . . , xn}tales que a = x0 < x1 < · · · < xn = b . Una particion divide al intervalo en intervalos mas pequenos, es decir,
[a, b] = [a, x1] ∪ [x1, x2] ∪ · · · ∪ [xn−2, xn−1] ∪ [xn−1, b] =n∪i=1
[xi−1, xi]
La longitud de estos subintervalos se denomina incremento de xi y se representa por ∆xi = xi − xi−1 .
Denotaremos por P[a, b] al conjunto de todas las particiones del intervalo cerrado [a, b] . Considerando en elconjunto la relacion de orden de inclusion, diremos que P2 es mas fina que P1 , si P1 ⊆ P2 .
Como P2 tiene todos los puntos de P1 y quizas alguno mas, cada subintervalo obtenido con P2 estacontenido en alguno de los dados por P1 , es decir, la particion dada por P2 es mas fina que la dada por P1 .
Ejemplo En [0, 1], P ={
0, 14 ,
24 ,
34 , 1}
es una particion de [0, 1], que lo “parte” en 4 trozos [0, 1] =
[0, 14 ]∪ [ 1
4 ,24 ]∪ [ 2
4 ,34 ]∪ [ 3
4 , 1], de igual longitud ∆xi = 14 , para i = 1, 2, 3, 4. La particion P1 =
{0, 1
4 ,13 ,
24 ,
34 , 1}
es mas fina que P y la particion P2 ={
0, 24 , 1}
es menos fina que P . Es decir, P2 ⊆ P ⊆ P1 .
En [a, b] , la particion P ={a, a + b−a
n , a + 2(b−a)n , . . . , a + (n−1)(b−a)
n , b}
divide al intervalo [a, b] en n
subintervalos de longitud b−an : [a, b] =
n∪k=1
[a+ (k−1)(b−a)
n , a+ k(b−a)n
]. 4
5.1.2 Sumas inferiores y superiores
Definicion 131.- Sea f : [a, b] −→ R acotada y P ∈ P[a, b] . En cada [xi−1, xi] , considemos el inferior y el
superior de f en el: mi = inf{f(x) : xi−1 ≤ x ≤ xi
}y Mi = sup
{f(x) : x ∈ [xi−1, xi]
}.
Llamarenos suma inferior de f para la particion P al valor L(f, P ) =n∑i=1
mi(xi − xi−1) =n∑i=1
mi ∆xi
y llamaremos suma superior de f para la particion P a U(f, P ) =n∑i=1
Mi(xi − xi−1) =n∑i=1
Mi ∆xi.
Si la funcion es positiva, una suma inferior significa una cota pordefecto del valor del area que encierra la funcion con el eje deabcisas (suma de areas de rectangulos de base ∆xi y altura mi ),y una suma superior una cota por exceso del valor del area. Enla figura de la derecha, la suma inferior es el area de la zonagris oscuro y la suma superior el de dicha zona mas las areasde los rectangulos superiores. Puede observarse como en cadaintervalo la curva, y por tanto, el area que encierra, esta entreambos valores.
a b
m
M
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

85 – Fundamentos de Matematicas : Calculo integral en R 5.2 Integral de una funcion real de variable real
Ejemplo 132 Si tomamos f : [0, 1] −→ R donde f(x) = 2x , y la particion P ={
0, 13 ,
23 , 1}
, se tiene que
[0, 1] = [0, 13 ] ∪ [ 1
3 ,23 ] ∪ [ 2
3 , 1] y que ∆x1 = ∆x2 = ∆x3 = 13 . Luego
m1 = inf{2x : x ∈ [0, 13 ]} = 0 M1 = sup{2x : x ∈ [0, 1
3 ]} = 23
m2 = inf{2x : x ∈ [ 13 ,
23 ]} = 2
3 M2 = sup{2x : x ∈ [ 13 ,
23 ]} = 4
3
m3 = inf{2x : x ∈ [ 23 , 1]} = 4
3 M3 = sup{2x : x ∈ [ 23 , 1]} = 2
L(f, P ) = 0 · 13 + 2
3 ·13 + 4
3 ·13 = 2
3 U(f, P ) = 23 ·
13 + 4
3 ·13 + 2 · 1
3 = 43
Como el area encerrada por la funcion es 1 (es el area de un triangulo de altura 2 y base 1), se verifica queL(f, P ) = 2
3 ≤ 1 ≤ 43 = U(f, P ). 4
Propiedades 133.- Sea f : [a, b] −→ R una funcion acotada.
a) Para toda P ∈ P[a, b] , se verifica que L(f, P ) ≤ U(f, P ).
b) Para todas P1, P2 ∈ P[a, b] con P1 ⊆ P2 , se verifica que
L(f, P1) ≤ L(f, P2) y U(f, P2) ≤ U(f, P1).
c) Para cualesquiera P,Q ∈ P[a, b] , se verifica que L(f, P ) ≤ U(f,Q). .
De las propiedades a) y b) anteriores, es facil deducir que L(f, P1) ≤ L(f, P2) ≤ U(f, P2) ≤ U(f, P1),por lo que resulta evidente el siguiente corolario
Corolario 134.- Sean f : [a, b] −→ R una funcion acotada y P0 ∈ P[a, b] . Entonces, para toda P ∈ P[a, b] conP0 ⊆ P , se verifica que
0 ≤ U(f, P )− L(f, P ) ≤ U(f, P0)− L(f, P0)
5.2 Integral de una funcion real de variable real
Si tomamdo particiones mas finas las sumas inferiores van en aumento y las superiores en disminucion esrazonable desear que acaben encontrandose (cuando las sumas inferiores y superiores significan cotas por defectoy exceso del area encerrado, encontrarse significa precisamente el valor exacto de dicho area).
Pero para formalizar estos deseos con construcciones matematicas solidas, necesitamos expresar de maneramas rigurosa la situacion que describimos:
Si f : [a, b] −→ R esta acotada, los conjuntos de numeros reales
A ={L(f, P ) : P ∈ P[a, b]
}y B =
{U(f, P ) : P ∈ P[a, b]
}son no vacıos y, por la propiedad c) de 133, el conjunto A esta acotado superiormente (cualquier suma superiores cota superior de A) y el conjunto B esta acotado inferiormente (cualquier suma inferior es cota inferior deB ). En consecuencia, el conjunto de las suma inferiores tiene un extremo superior, que llamaremos integralinferior, I , y el conjunto de las sumas superiores tiene un extremo inferor, que llamaremos integral superior,I , y se cumple
supA = sup{L(f, P ) : P ∈ P[a, b]
}= I ≤ I = inf
{U(f, P ) : P ∈ P[a, b]
}= inf B
Lo que nos lleva a la siguiente definicion
Definicion 135.- Sea f : [a, b] −→ R una funcion acotada. Se dice que f es integrable si y solo si I = I .El valor I = I = I , se denomina integral de Riemann de la funcion f en [a, b] , y se representa por
I =
∫ b
a
f o I =
∫ b
a
f(x) dx (si se quiere poner enfasis en la variable usada)
Teorema 136.- (Condicion de integrabilidad de Riemann)Una funcion f : [a, b] −→ R acotada es integrable Riemann si, y solo si, para todo ε > 0 existe una particionPε ∈ P[a, b] tal que
U(f, Pε)− L(f, Pε) < ε .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
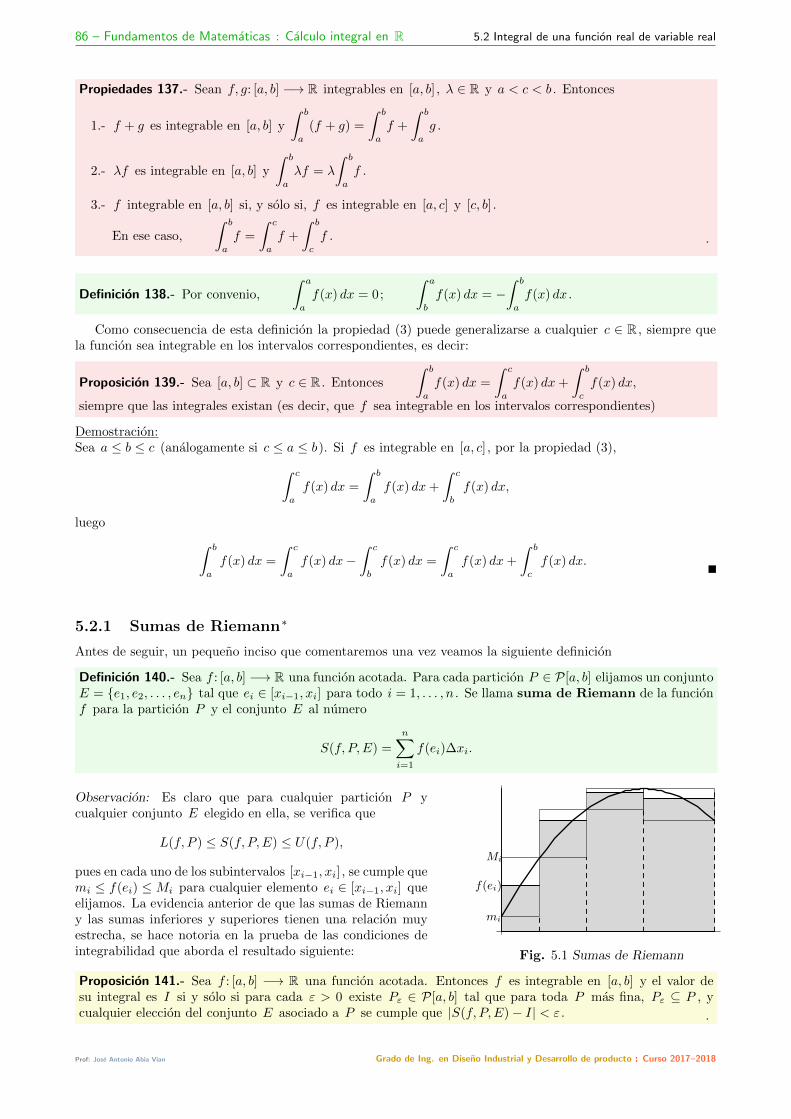
86 – Fundamentos de Matematicas : Calculo integral en R 5.2 Integral de una funcion real de variable real
Propiedades 137.- Sean f, g: [a, b] −→ R integrables en [a, b] , λ ∈ R y a < c < b . Entonces
1.- f + g es integrable en [a, b] y
∫ b
a
(f + g) =
∫ b
a
f +
∫ b
a
g .
2.- λf es integrable en [a, b] y
∫ b
a
λf = λ
∫ b
a
f .
3.- f integrable en [a, b] si, y solo si, f es integrable en [a, c] y [c, b] .
En ese caso,
∫ b
a
f =
∫ c
a
f +
∫ b
c
f . .
Definicion 138.- Por convenio,
∫ a
a
f(x) dx = 0;
∫ a
b
f(x) dx = −∫ b
a
f(x) dx .
Como consecuencia de esta definicion la propiedad (3) puede generalizarse a cualquier c ∈ R , siempre quela funcion sea integrable en los intervalos correspondientes, es decir:
Proposicion 139.- Sea [a, b] ⊂ R y c ∈ R . Entonces
∫ b
a
f(x) dx =
∫ c
a
f(x) dx+
∫ b
c
f(x) dx,
siempre que las integrales existan (es decir, que f sea integrable en los intervalos correspondientes)
Demostracion:Sea a ≤ b ≤ c (analogamente si c ≤ a ≤ b). Si f es integrable en [a, c] , por la propiedad (3),∫ c
a
f(x) dx =
∫ b
a
f(x) dx+
∫ c
b
f(x) dx,
luego ∫ b
a
f(x) dx =
∫ c
a
f(x) dx−∫ c
b
f(x) dx =
∫ c
a
f(x) dx+
∫ b
c
f(x) dx.
5.2.1 Sumas de Riemann∗
Antes de seguir, un pequeno inciso que comentaremos una vez veamos la siguiente definicion
Definicion 140.- Sea f : [a, b] −→ R una funcion acotada. Para cada particion P ∈ P[a, b] elijamos un conjuntoE = {e1, e2, . . . , en} tal que ei ∈ [xi−1, xi] para todo i = 1, . . . , n . Se llama suma de Riemann de la funcionf para la particion P y el conjunto E al numero
S(f, P,E) =
n∑i=1
f(ei)∆xi.
Observacion: Es claro que para cualquier particion P ycualquier conjunto E elegido en ella, se verifica que
L(f, P ) ≤ S(f, P,E) ≤ U(f, P ),
pues en cada uno de los subintervalos [xi−1, xi] , se cumple quemi ≤ f(ei) ≤Mi para cualquier elemento ei ∈ [xi−1, xi] queelijamos. La evidencia anterior de que las sumas de Riemanny las sumas inferiores y superiores tienen una relacion muyestrecha, se hace notoria en la prueba de las condiciones deintegrabilidad que aborda el resultado siguiente:
Mi
f(ei)
mi
Fig. 5.1 Sumas de Riemann
Proposicion 141.- Sea f : [a, b] −→ R una funcion acotada. Entonces f es integrable en [a, b] y el valor desu integral es I si y solo si para cada ε > 0 existe Pε ∈ P[a, b] tal que para toda P mas fina, Pε ⊆ P , ycualquier eleccion del conjunto E asociado a P se cumple que |S(f, P,E)− I| < ε . .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

87 – Fundamentos de Matematicas : Calculo integral en R 5.2 Integral de una funcion real de variable real
Este resultado nos indica que podemos definir la integral tanto con las sumas superiores e inferiores como conestas sumas de Riemann, y de manera bastante analoga. Sin embargo es mucho mas intuitiva la construccionpropuesta por Darboux que nosotros hemos hecho, que la construccion de Riemann asumiendo que el “parecido”de las sumas de Riemann con el area deben llevar necesariamente a la integracion.
No obstante, la construccion de Riemann es previa a la de Darboux y es de ella de quien deriva la notacion
usada: den∑i=1
f(ei)∆xi pasamos a
∫ b
a
f(x) dx si pensamos en que al final “dividimos” el intervalo en
trocitos unipuntuales, como expresa esta notacion.
5.2.2 Otras propiedades de la integral
Proposicion 142.- Sea f : [a, b] −→ R integrable en [a, b] y tal que f ≥ 0 en [a, b] , entonces
∫ b
a
f ≥ 0.
Demostracion:
Es claro, pues para cualquier P ∈ P[a, b] se tiene que 0 ≤ L(f, P ) ≤ I =
∫ b
a
f .
Corolario 143.- Sean f y g integrables en [a, b] tales que f ≤ g en [a, b] . Entonces
∫ b
a
f ≤∫ b
a
g.
Demostracion:
Como 0 ≤ (g − f), se tiene 0 ≤∫ b
a
(g − f) =
∫ b
a
g −∫ b
a
f . Luego
∫ b
a
f ≤∫ b
a
g .
Proposicion 144.- Sea f integrable en [a, b] , entonces |f | es integrable en [a, b] y se verifica que∣∣∣∣∣∫ b
a
f(x) dx
∣∣∣∣∣ ≤∫ b
a
|f(x)| dx . .
Corolario 145.- Sea f : [a, b] −→ R integrable en [a, b] . Para cualesquiera c, d ∈ [a, b] se verifica que∣∣∣∣∣∫ d
c
f(x) dx
∣∣∣∣∣ ≤∣∣∣∣∣∫ d
c
|f(x)| dx
∣∣∣∣∣Demostracion:En efecto, si c ≤ d es la proposicion 144. Si d ≤ c , se tiene
−∫ c
d
|f(x)| dx ≤∫ c
d
f(x) dx ≤∫ c
d
|f(x)| dx =⇒∫ d
c
|f(x)| dx ≤ −∫ d
c
f(x) dx ≤ −∫ d
c
|f(x)| dx,
luego
∣∣∣∣∣∫ d
c
f(x) dx
∣∣∣∣∣ ≤∣∣∣∣∣∫ d
c
|f(x)| dx
∣∣∣∣∣ .Proposicion 146.- Si f y g son integrables en [a, b] , entonces fg es integrable en [a, b] . .
5.2.3 Algunas funciones integrables
Proposicion 147.- Sea f : [a, b] −→ R una funcion monotona. Entonces f es integrable en [a, b] .
Demostracion:Supongamos que f es monotona creciente (analogo para decreciente). Entonces, para cualquier particionP ∈ P[a, b] se tiene que mi = f(xi−1) y Mi = f(xi), para todo i = 1, 2, . . . , n . En particular, si Pn es
Pn ={a, a+ b−a
n , a+ 2 b−an , . . . , a+ (n− 1) b−an , a+ n b−an = b}
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

88 – Fundamentos de Matematicas : Calculo integral en R 5.3 Integracion y derivacion
son U(f, Pn) =n∑i=1
f(xi)∆xi y L(f, Pn) =n∑i=1
f(xi−1)∆xi , con xi = a+ i b−an y ∆xi = b−an , luego
U(f, Pn)− L(f, Pn) =
n∑i=1
(f(xi)− f(xi−1)
)b− an
=b− an
n∑i=1
(f(xi)− f(xi−1)
)=b− an
(f(b)− f(a)
).
Luego tomando n suficientemente grande para que b−an < ε
f(b)−f(a) , entonces
U(f, Pn)− L(f, Pn) =b− an
(f(b)− f(a)
)<
ε
f(b)− f(a)
(f(b)− f(a)
)= ε.
Teorema 148.- Sea f : [a, b] −→ R una funcion continua en [a, b] . Entonces f es integrable en [a, b] .
Teorema 149.- Sea f : [a, b] −→ R una funcion acotada en [a, b] y continua en [a, b] salvo acaso en una cantidadnumerable de puntos de dicho intervalo. Entonces f es integrable en [a, b] .
5.3 Integracion y derivacion
Teorema 150.- Sea f : [a, b] −→ R integrable en [a, b] , con a < b , y m ≤ f(x) ≤ M para todo x ∈ [a, b] .Entonces
m ≤ 1
b− a
∫ b
a
f(x) dx ≤M.
Demostracion:
Por ser m ≤ f(x) ≤M para todo x ∈ [a, b] , se tiene que
∫ b
a
mdx ≤∫ b
a
f(x) dx ≤∫ b
a
M dx, entonces (ver
ejercicio 5.126) m(b− a) ≤∫ b
a
f(x) dx ≤M(b− a), luego m ≤ 1b−a
∫ b
a
f(x) dx ≤M
Nota: Como 1b−a
∫ b
a
f(x) dx = 1a−b
∫ a
b
f(x) dx , tambien es cierto que m ≤ 1a−b
∫ a
b
f(x) dx ≤M .
Teorema de la media 151.- Sea f : [a, b] −→ R una funcion continua en [a, b] , entonces existe ξ ∈ [a, b] talque ∫ b
a
f(x) dx = f(ξ)(b− a).
Demostracion:Al ser f continua en [a, b] , alcanzara el mınimo y el maximo en [a, b] . Sean estos m y M respectivamente.
Por el teorema anterior 150, m ≤ 1b−a
∫ b
a
f(x) dx ≤ M y, por ser f continua, toma todos los valores entre el
mınimo y el maximo; por consiguiente, existe ξ ∈ [a, b] tal que f(ξ) = 1b−a
∫ b
a
f(x) dx.
Definicion 152.- Sea f : [a, b] −→ R integrable en [a, b] . La funcion F : [a, b] −→ R definida de la forma
F (x) =
∫ x
a
f(t) dt recibe el nombre de funcion integral de la funcion f .
Teorema 153.- Sea f : [a, b] −→ R integrable en [a, b] . Entonces su funcion integral es continua en [a, b] .
Demostracion:Como f esta acotada en [a, b] , existe M ∈ R tal que |f(x)| ≤M , para todo x ∈ [a, b] .
Sea entonces x ∈ [a, b] , la funcion F estara definida en todos los puntos de la forma x + h siempre quea < x+ h < b , luego
F (x+ h)− F (x) =
∫ x+h
a
f(t) dt−∫ x
a
f(t) dt =
∫ x+h
x
f(t) dt.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

89 – Fundamentos de Matematicas : Calculo integral en R 5.3 Integracion y derivacion
Como −M ≤ f(x) ≤M para todo x ∈ [a, b] , por el teorema 150 y la observacion posterior, se tiene que
−M ≤ 1
h
∫ x+h
x
f(t) dt ≤M, y, por tanto, |F (x+ h)− F (x)| = |h|
∣∣∣∣∣ 1h∫ x+h
x
f(t) dt
∣∣∣∣∣ ≤M |h| .Tomando lımites, cuando h→ 0, lım
h→0
(F (x+ h)− F (x)
)= 0 y F es continua en cada x ∈ [a, b] .
Teorema fundamental del Calculo Integral 154.- Sea f : [a, b] −→ R integrable y F (x) =
∫ x
a
f(t) dt su
funcion integral. Si f es continua en [a, b] , entonces
a) F es derivable en [a, b] .
b) F ′(x) = f(x), para todo x ∈ [a, b] .
Demostracion:Sea x ∈ (a, b). La funcion F estara definida en todos los puntos de la forma x+ h siempre que a < x+ h < b ,entonces
lımh→0
F (x+ h)− F (x)
h= lımh→0
∫ x+h
x
f(t) dt
h= lımh→0
f(ξ)h
h= lımh→0
f(ξ) = f(x),
ya que, por el teorema de la media 151, ξ es un punto comprendido entre x y x+ h ; y f es continua en [a, b] .Ası pues F es derivable para todo x ∈ (a, b) y F ′(x) = f(x).
Como F y f son continuas en [a, b] , F es derivable “por la derecha” en a y “por la izquierda” en b ,verificandose que F ′(a) = f(a) y F ′(b) = f(b).
Regla de Barrow 155.- Sea f : [a, b] −→ R integrable en [a, b] . Si G: [a, b] −→ R es una primitiva de f en[a, b] , entonces ∫ b
a
f(x) dx = G(b)−G(a) .
Ejemplo
∫ 3
0
2x dx es el area del triangulo de vertices (0, 0), (3, 0) y (3, 6), pero tambien, por la regla de
Barrow, puede calcularse como:
∫ 3
0
2x dx =(x2]3
0= 32 − 02 = 9 4
Teorema del Cambio de variable 156.- Sean f : [a, b] −→ R continua en [a, b] y x = φ(t) siendo φ(t) y φ′(t)funciones continuas en [α, β] (o [β, α]), con φ(α) = a y φ(β) = b . Entonces:∫ b
a
f(x) dx =
∫ β
α
f(φ(t))φ′(t) dt.
Demostracion:
f(φ(t))φ′(t) es tambien continua, luego las funciones F (x) =
∫ x
a
f(u) du y G(t) =
∫ t
α
f(φ(v))φ′(v) dv
son respectivamente primitivas de f(x) y f(φ(t))φ′(t).Ahora bien, como F es una primitiva de f , F (φ(t)) es tambien una primitiva de f(φ(t))φ′(t), luego
F (φ(t)) = G(t) + C , para todo t ∈ [α, β] .Para t = α se tiene F (φ(α)) = G(α) + C , y como F (φ(α)) = F (a) = 0 y G(α) = 0, entonces C = 0.Y para t = β se tiene F (φ(β)) = G(β), es decir,∫ b
a
f(x) dx =
∫ β
α
f(φ(t))φ′(t) dt.
Ejemplo Para calcular
∫ 7
0
3√
1 + x dx hacemos el cambio 1 + x = t3 , de donde 3√
1 + 0 = 1 y 3√
1 + 7 = 2,
y se tiene que
∫ 7
0
3√
1 + x dx =
∫ 2
1
3√t3 3t2 td =
∫ 2
1
3t3 =(
3t4
4
]21
= 34 (16− 1) = 45
4 4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

90 – Fundamentos de Matematicas : Calculo integral en R 5.4 Integrales impropias
5.4 Integrales impropias
En las secciones anteriores hemos construido la integral de Riemann con las premisas de acotacion
• Dom(f) = [a, b] es un conjunto acotado.
• f : [a, b] −→ R esta acotada en [a, b] .
Si no se cumple la primera, nos encontraremos con Integrales impropias de primera especie, y si la quefalla es la segunda hablaremos de integrales impropias de segunda especie.
5.4.1 Integrales impropias de primera especie
Definicion 157.- Sea f : [a,+∞) −→ R integrable en [a, t] , para todo t ≥ a . De∫ +∞
a
f(x) dx = lımt→+∞
∫ t
a
f(x) dx
se dice integral impropia de primera especie
De forma analoga se definen para funciones f : (−∞, b] −→ R integrables en [t, b] , para todo t ∈ R , por∫ b
−∞f(x) dx = lım
t→−∞
∫ b
t
f(x) dx
O, con el cambio x = −y , transformandola en una de las anteriores∫ b
−∞f(x) dx = lım
t→−∞
∫ b
t
f(x) dx = lımt→−∞
∫ −b−t−f(−y) dy = lım
t→−∞
∫ −t−b
f(−y) dy =
∫ +∞
−bf(−y) dy
Es evidente entonces que el estudio para las primeras tendra un espejo en las segundas, pero que no repetiremos.
Definicion 158.- Si lımt→+∞
∫ t
a
f(x) dx existe y es finito diremos que la integral impropia es convergente y
que lımt→+∞
∫ t
a
f(x) dx =
∫ +∞
a
f(x) dx es su valor.
Si el lımite anterior es infinito, a ∞ o −∞ , se dice que la integral impropia es divergente (hacia ∞ ohacia −∞), y si no existe el lımite se dice que es oscilante
Ejemplo La integral
∫ ∞1
x dx es divergente, pues lımt→+∞
∫ t
1
x dx = lımt→+∞
(x2
2
]t1
= lımt→+∞
t2
2 −12 = +∞ 4
Ejemplo
∫ ∞0
cosx dx es oscilante, pues lımt→+∞
∫ t
0
cosx dx = lımt→+∞
(senx]t0 = lım
t→+∞sen t que 6 ∃ 4
Ejemplo
∫ 0
−∞
11+x2 dx = π
2 , pues lımt→−∞
∫ 0
t
11+x2 dx = lım
t→−∞(arctg x]
0t = lım
t→−∞arctg 0− arctg t = −−π2 4
Ejemplo 159 Estudiar el caracter de
∫ ∞1
dxxα , para α ∈ R .
Como la funcion tiene primitivas distintas para α = 1 y α 6= 1, las estudiamos por separado:
Si α = 1, lımt→+∞
∫ t
1
1
xdx = lım
t→+∞
(lnx]t
1= lımt→+∞
(ln t− ln 1) = lımt→+∞
ln t = +∞, luego diverge
Si α 6= 1,
lımt→+∞
∫ t
1
x−αdx= lımt→+∞
(x−α+1
−α+ 1
]t1
= lımt→+∞
(t−α+1
−α+ 1− 1−α+1
−α+ 1
)= lımt→+∞
t1−α − 1
1− α=
{ −11−α , si α > 1
+∞, si α < 1
Resumiendo,
∫ ∞1
dxxα diverge si α ≤ 1 y converge si α > 1. En este ultimo caso,
∫ ∞1
dxxα = 1
α−1 . 4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

91 – Fundamentos de Matematicas : Calculo integral en R 5.4 Integrales impropias
Definicion 160.- Diremos que dos integrales impropias tienen el mismo caracter, y lo representaremos por“∼”, si son simultaneamente convergentes, divergentes u oscilantes.
Propiedades 161.- Sean f, g: [a,+∞) −→ R integrables en [a, t] para todo t ≥ a .
1.- Para cualquier b ≥ a , se tiene que
∫ +∞
a
f(x)dx ∼∫ +∞
b
f(x)dx
2.- Para cualquier λ ∈ R− {0} , se tiene que
∫ +∞
a
f(x) dx ∼∫ +∞
a
λf(x) dx
3.- Si
∫ +∞
a
f y
∫ +∞
a
g convergen, entonces converge
∫ +∞
a
f+g y
∫ +∞
a
f+g =
∫ +∞
a
f +
∫ +∞
a
g
Demostracion:
1.- Como
lımt→+∞
∫ t
a
f(x) dx = lımt→+∞
(∫ b
a
f(x) dx+
∫ t
b
f(x) dx
)=
∫ b
a
f(x) dx+ lımt→+∞
∫ t
b
f(x) dx
el lımite de la izquierda es finito, infinito o no existe si el lımite de la derecha es finito, infinito o no existerespectivamente. Y viceversa.
2.- Como lımt→+∞
∫ t
a
λf(x) dx = λ lımt→+∞
∫ t
a
f(x) dx , ambos son simultaneamente finitos, infinitos o no existen
3.- Cierto, pues lımt→+∞
∫ t
a
(f+g)(x) dx = lımt→+∞
∫ t
a
f(x) dx+ lımt→+∞
∫ t
a
g(x) dx , si los segundos lımites existen.
Ejemplo La integral
∫ ∞2
x+2x3 dx es convergente, ya que x+2
x3 = 1x2 + 2 1
x3 y por las propiedades 161 anteri-
ores,
∫ ∞2
1x2 dx
(P.1)∼∫ ∞
1
1x2 dx y
∫ ∞2
2 1x3 dx
(P.2)∼∫ ∞
2
1x3 dx
(P.1)∼∫ ∞
1
1x3 dx , que son ambas convergentes
(ejemplo 159). Luego por la propiedad (P.3) la integral
∫ ∞2
x+2x3 dx es convergente por ser suma de integrales
convergentes y
∫ ∞2
x+2x3 dx =
∫ ∞2
1x2 dx+
∫ ∞2
2 1x3 dx 4
Proposicion 162.- Sea f : [a,+∞) −→ R integrable en [a, t] para todo t ∈ [a,+∞). Si lımx→+∞
f(x) = L 6= 0
entonces
∫ ∞a
f(x) dx diverge. .
Observacion 163.- Como consecuencia de este resultado, si una funcion tiene lımite en +∞ , su integral solopuede ser convergente cuando el lımite es cero. (Si el lımite no existe no se puede asegurar nada.)
El recıproco de la proposicion 162 no es cierto, una integral puede ser divergente, aunque su lımite sea 0.
Contraejemplo
∫ ∞1
dxx diverge (ver ejemplo 159) y sin embargo, lım
x→+∞1x = 0.
5.4.2 Criterios de comparacion para funciones no negativas
Teorema 164.- Sea f : [a,+∞) −→ R integrable y no negativa en [a, t] , ∀t ∈ R .∫ +∞
a
f(x) dx es convergente ⇐⇒ F (t) =
∫ t
a
f(x) dx esta acotada superiormente. .
Nota: En consecuencia, para funciones no negativas,
∫ +∞
a
f(x) dx solo puede ser convergente o divergente.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

92 – Fundamentos de Matematicas : Calculo integral en R 5.4 Integrales impropias
Primer criterio de comparacion 165.- Sean f, g: [a,+∞) −→ R integrables en [a, t] para todo t ≥ a ysupongamos que existe b > a tal que 0 ≤ f(x) ≤ g(x) para todo x ≥ b . Entonces:
a) Si
∫ +∞
a
g(x) dx converge ⇒∫ +∞
a
f(x) dx tambien converge.
b) Si
∫ +∞
a
f(x) dx diverge ⇒∫ +∞
a
g(x) dx tambien diverge.
Demostracion:
Por la propiedad 1 de 161,
∫ +∞
a
f ∼∫ +∞
b
f y
∫ +∞
a
g ∼∫ +∞
b
g, luego basta probarlo en [b,+∞). Y
como 0 ≤ f(x) ≤ g(x), tambien se tendra F (t) =
∫ t
b
f(x) dx ≤∫ t
b
g(x) dx = G(t)
a) Si
∫ +∞
b
g converge, G(t) esta acotada superiormente y F (t) que es menor tambien; luego
∫ +∞
b
f converge
b) Si
∫ +∞
b
f diverge, F (t) no esta acotada superiormente y G(t) tampoco, luego
∫ +∞
b
g diverge
Ejemplo
∫ ∞1
1x2+1 dx es convergente, pues en [1,+∞), 0 < x2 < x2 + 1 de donde 0 < 1
1+x2 <1x2 . Luego∫ ∞
1
1x2+1 dx ≤
∫ ∞1
1x2 dx y como la mayor es convergente, la menor tambien. 4
Ejemplo
∫ ∞1
1x+1 dx es divergente, pues en [1,+∞), 0 < x+1 < x+x = 2x de donde 0 < 1
2x <1
x+1 . Luego∫ ∞1
12
1x dx ≤
∫ ∞1
1x+1 dx y como la menor es divergente, la mayor tambien lo es. 4
Segundo criterio de comparacion 166.- Sean f, g: [a,+∞) −→ R integrables en [a, t] , para todo t ≥ a y no
negativas. Supongamos que existe lımx→+∞
f(x)g(x) = L . Entonces:
a) Si 0 < L < +∞ =⇒∫ +∞
a
f(x) dx ∼∫ +∞
a
g(x) dx .
b) Si L = 0, se tiene:
[i] si
∫ +∞
a
g(x) dx converge =⇒∫ +∞
a
f(x) dx converge.
[ii] si
∫ +∞
a
f(x) dx diverge =⇒∫ +∞
a
g(x) dx diverge.
c) Si L = +∞ , se tiene:
[i] si
∫ +∞
a
f(x) dx converge =⇒∫ +∞
a
g(x) dx converge.
[ii] si
∫ +∞
a
g(x) dx diverge =⇒∫ +∞
a
f(x) dx diverge. .
Ejemplo
∫ ∞2
1x2−√xdx es convergente, pues [2,+∞) es positiva y lım
x→+∞
1x2−√x
1x2
= lımx→+∞
x2
x2−√x
= 1 6= 0.
Luego
∫ ∞2
1x2−√xdx ∼
∫ ∞2
1x2 dx que converge. 4
Observacion: Aunque los criterios dados son validos unicamente para funciones positivas en un entorno de +∞ ,
teniendo en cuenta que
∫ +∞
a
f ∼∫ +∞
a
−f , para las funciones negativas basta estudiar el caracter de
∫ +∞
a
− f .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

93 – Fundamentos de Matematicas : Calculo integral en R 5.4 Integrales impropias
5.4.3 Convergencia absoluta
Definicion 167.- Sea f : [a,+∞) −→ R integrable en [a, t] para todo t ≥ a . Diremos que
∫ +∞
a
f(x)dx es
absolutamente convergente si
∫ +∞
a
|f(x)|dx converge.
Teorema 168.- Sea f : [a,+∞) −→ R integrable en [a, t] para todo t ≥ a .
Si
∫ ∞a
|f(x)|dx converge, entonces
∫ +∞
a
f(x)dx converge.
En otras palabras, si una integral impropia converge absolutamente entonces converge.
Demostracion:Para todo x ∈ [a,+∞) se tiene −|f(x)| ≤ f(x) ≤ |f(x)| , luego 0 ≤ f(x) + |f(x)| ≤ 2|f(x)| . Entonces, si∫ +∞
a
|f(x)|dx converge se tiene que
∫ +∞
a
(|f(x)|+ f(x)) dx es convergente y, por tanto, aplicando al propiedad
3 de 161, se tiene que ∫ +∞
a
f(x)dx =
∫ +∞
a
(f(x) + |f(x)|) dx−∫ +∞
a
|f(x)|dx
converge.
Nota: El recıproco no es cierto, pues
∫ ∞π
sen xx dx es convergente pero no converge absolutamente
5.4.4 Integrales impropias de segunda especie
Cuando la funcion no esta acotada en el intervalo, tenemos estas integrales de segunda especie:
Definicion 169.- Sea f : (a, b] −→ R integrable en [t, b] , para todo t ∈ (a, b] , y no acotada. De∫ b
a+
f(x)dx = lımt→a+
∫ b
t
f(x) dx
se dice integral impropia de segunda especie
Analogamente se definen las integrales impropias de segunda especie en intervalos de la forma [a, b), para fun-ciones f : [a, b) −→ R integrables en [a, t] , ∀t ∈ [a, b) y no acotadas∫ b−
a
f(x)dx = lımt→b−
∫ t
a
f(x) dx o
∫ b−
a
f.
Observaciones 170.- Los distintos tipos de integrales impropias tienen, en realidad, el mismo comportamientoy cumplen condiciones similares
1.- En efecto, con el cambio x = a + b − t , se tiene que
∫ b−
a
f(x)dx =
∫ b
a+
f(a+b−t)dt y todas las
integrales de segunda especie pueden ser del mismo tipo
2.- pero tambien el cambio x = a + 1t , produce que
∫ b
a+
f(x)dx =
∫ +∞
1b−a
f( 1t+a)
t2 dt y que todas las
integrales impropias de segunda especie se transformen en una de primera especie
3.- Es claro por las definiciones y por estas observaciones anteriores, que las caracterizaciones de convergencia,divergencia y oscilancion sean identicas en las de segunda especie; lo mismo que el comportamiento delas integrales impropias para funciones no negativas, ası como en la convergencia absoluta
4.- De hecho los criterios de convergencia de integrales impropias de segunda especie para funciones nonegativas son identicos (pero acomomodados a estas) a los de primera especie:
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

94 – Fundamentos de Matematicas : Calculo integral en R 5.4 Integrales impropias
Primer criterio de comparacion 171.- Sean f, g: (a, b] −→ R integrables en [t, b] , para todo t ∈ (a, b] , y noacotadas. Supongamos que existe c ∈ (a, b] tal que 0 ≤ f(x) ≤ g(x), para todo x ∈ (a, c] , entonces
a) Si
∫ b
a+
g(x)dx converge =⇒∫ b
a+
f(x)dx tambien converge.
b) Si
∫ b
a+
f(x)dx diverge =⇒∫ b
a+
g(x)dx tambien diverge.
Segundo criterio de comparacion 172.- Sean f, g: (a, b] −→ R integrables en [t, b] , para todo t ∈ (a, b] , no
negativas y no acotadas. Supongamos que existe y es finito lımx→a+
f(x)g(x) = L . Entonces:
a) Si L 6= 0 entonces,
∫ b
a+
f(x)dx ∼∫ b
a+
g(x)dx .
b) Si L = 0, se tiene:
[i] Si
∫ b
a+
g(x)dx converge =⇒∫ b
a+
f(x)dx tambien converge.
[ii] Si
∫ b
a+
f(x)dx diverge =⇒∫ b
a+
g(x)dx tambien diverge.
Teorema 173.- (Convergencia absoluta.)Sea f : (a, b] −→ R integrable en [t, b] , ∀t ∈ (a, b] , y no acotada.
Si
∫ b
a+
|f(x)|dx convergente =⇒∫ b
a+
f(x)dx es convergente.
Para usar esos criterios son muy utiles las familias de integrales impropias de segunda especie siguientes:
Ejemplo 174 Estudiar el caracter de
∫ b
a+
dx(x−a)α y de
∫ b−
a
dx(b−x)α , para los α ∈ R .
Solucion:Si α = 1,
lımt→a+
∫ b
t
dx
x− a= lımt→a+
(ln |x− a|
]bt
= lımt→a+
(ln |b− a| − ln |t− a|
)= +∞
lımt→b−
∫ t
a
dx
b− x= lımt→b−
(− ln |b− x|
]ta
= lımt→b−
(ln |b− a| − ln |b− t|
)= +∞
Si α 6= 1,
lımt→a+
∫ b
t
dx
(x− a)α= lımt→a+
(1
1− α1
(x− a)α−1
]bt
= lımt→a+
1
1− α
(1
(b− a)α−1− 1
(t− a)α−1
)=
{ 1(1−α)(b−a)α−1 , si α < 1
+∞, si α > 1
lımt→bb
∫ t
a
dx
(b− x)α= lımt→b−
(−1
1− α1
(b− x)α−1
]ta
= lımt→b−
1
α− 1
(1
(b− t)α−1− 1
(b− a)α−1
)=
{ 1(1−α)(b−a)α−1 , si α < 1
+∞, si α > 1
luego converge si α < 1 y diverge si α ≥ 1.
Analogamente se hace la segunda, y se obtiene que
∫ b−
a
dx(b−x)α converge si α < 1 y diverge si α ≥ 1. 4
Cuando se reunen en una sola integral varias impropiedades, la unica manera de resolver el problema esseparar la integral en varias integrales impropias que tengan con una sola impropiedad. Esto es precisamentelo que aparece recogido en las siguientes definiciones:
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

95 – Fundamentos de Matematicas : Calculo integral en R 5.5 Ejercicios
Definicion 175.- Sea f :R −→ R integrable en todo intervalo cerrado [t1, t2] ⊂ R , diremos que
∫ +∞
−∞f(x) dx
es convergente si para algun c ∈ R las dos integrales
∫ c
−∞f y
∫ +∞
c
son convergentes.
Y en ese caso:
∫ +∞
−∞f(x) dx =
∫ c
−∞f(x) dx+
∫ +∞
c
f(x) dx
Definicion 176.- f : (a, b) −→ R integrable en cada [t1, t2] ⊂ (a, b). La
∫ b−
a+
f es convergente si para algun
c ∈ R las dos integrales
∫ c
a+
f y
∫ b−
c
f son convergentes. Y en ese caso
∫ b−
a+
f =
∫ c
a+
f +
∫ b−
c
f
Definicion 177.- f : (a,∞) −→ R integrable en cada [t1, t2] ⊂ (a,∞). La
∫ ∞a+
f es convergente si para algun
c ∈ R las dos integrales
∫ c
a+
f y
∫ ∞c
f son convergentes. Y en ese caso
∫ ∞a+
f =
∫ c
a+
f +
∫ ∞c
f
5.5 Ejercicios
5.126 Comprobar que la funcion f(x) = k , donde k es constante, es integrable en cualquier intervalo [a, b] deR y calcular el valor de la integral.
5.127 Comprobar que la funcion f(x) =
{1, si x ∈ [0, 1]2, si x ∈ (1, 2]
es integrable Riemann en [0, 2]. (Utilizar la condicion
de integrabilidad de Riemann.)
5.128 Justificar razonadamente la falsedad de las siguientes afirmaciones:
a) U(f, P1) = 4 para P1 = {0, 1, 32 , 2} y U(f, P2) = 5 para P2 = {0, 1
4 , 1,32 , 2} .
b) L(f, P1) = 5 para P1 = {0, 1, 32 , 2} y L(f, P2) = 4 para P2 = {0, 1
4 , 1,32 , 2} .
c) Tomando P ∈ P[−1, 1],
(i) L(f, P ) = 3 y U(f, P ) = 2.
(ii) L(f, P ) = 3 y U(f, P ) = 6 y
∫ 1
−1
f(x) dx = 2.
(iii) L(f, P ) = 3 y U(f, P ) = 6 y
∫ 1
−1
f(x) dx = 10.
5.129 Se sabe que
∫ 1
0
f(x) dx = 6,
∫ 2
0
f(x) dx = 4 y
∫ 5
2
f(x) dx = 1. Hallar el valor de cada una de las
siguientes integrales:
a)
∫ 5
0
f(x) dx b)
∫ 2
1
f(x) dx c)
∫ 5
1
f(x) dx.
5.130 Sean f derivable y F (x) =
∫ x
a
f(t) dt . ¿Es cierto que F ′(x) =
∫ x
a
f ′(t) dt? ¿Por que?
5.131 Sea f(x) =
∫ x
a
11+sen2 t dt . ¿Cual es su dominio? Calcular f ′(x) y f ′′(x), indicando sus dominios de
definicion.
5.132 Hallar f ′(x), indicando su dominio de definicion, para
a) f(x) =
∫ x3
a
11+sen2 tdt. b) f(x) =
(∫ x
a
11+sen2 tdt
)3
.
c) f(x) =
∫ sen x
a
11+sen2 tdt. d) f(x) =
∫ (∫ xa
11+sen2 t
dt)
a
11+sen2 tdt.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

96 – Fundamentos de Matematicas : Calculo integral en R 5.5 Ejercicios
5.133 Hallar el dominio y la expresion de f ′(x) para cada una de las siguientes funciones:
a) f(x) =
∫ 47
1x
1t dt b) f(x) =
∫ sec x
x2
1t dt c) f(x) =
∫ cos x
x3
sen(t2) dt
5.134 Si f es continua, calcular F ′(x), siendo F (x) =
∫ x
0
xf(t) dt .
5.135 Obtener el dominio y la expresion concreta de su funcion integral F (x) =
∫ x
a
f(t) dt , para cada una de
las funciones siguientes:
a) La funcion f(t) = t2 para a = −1. Repetirlo, tomando ahora a = 1, ¿porque son iguales/distintas?
b) La funcion f(t) =
{0, si t < 02, si t ≥ 0
y a = 0
c) La funcion f(t) = |t| y a = 0
d) La funcion f(t) =
{−2t, si t ≤ 1
1, si t > 1, para a = 1 y tambien para a = 0
Comprobar que se cumplen las tesis de los teoremas 153 y 154 anteriores.
5.136 Sea f :R −→ R estrictamente creciente y continua, con f(0) = 0. Calcular los extremos de la funcion∫ (x+3)(x−1)
0
f(t) dt .
5.137 Dada la funcion f estrictamente creciente en R , con f(0) = 0, y continua, estudiar el crecimiento,
decrecimiento y los extremos de F (x) =
∫ x3−2x2+x
1
f(t) dt .
5.138 Encontrar los valores de x para los que la funcion F (x) =
∫ x
0
te−t2
dt alcanza algun extremo.
5.139 Sea f : [a, b] −→ R de clase 1, tal que f(a) = f(b) = 0 y
∫ b
a
f2(x) dx = 1. Probar que
∫ b
a
xf(x)f ′(x) dx = −1
2.
5.140 Sean f y g funciones reales continuas en [a, b] que verifican que∫ b
a
f(x) dx =
∫ b
a
g(x) dx.
Demostrar que existe un punto c ∈ [a, b] tal que f(c) = g(c).
5.141 Calcular
∫ +∞
0
e−xdx e
∫ 0
−∞exdx
5.142 Calcular el valor de
∫ +∞
−∞
dx1+x2
5.143 Definicion: Si f es integrable en cualquier [a, b] de R , se llama valor principal de
∫ +∞
−∞f(x) al lımite
lımt→+∞
∫ t
−tf(x)dx y si la integral impropia es convergente el valor principal es el valor de la integral
Comprobar que el VP
∫ +∞
−∞
dx1+x2 coincide con el valor de la integral obtenido en el ejercicio anterior
5.144 Probar que
∫ +∞
−∞senx dx no es convergente, pero que sı existe el V P
∫ +∞
−∞senx dx?
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

97 – Fundamentos de Matematicas : Calculo integral en R 5.5 Ejercicios
5.145 Estudiar el caracter de
∫ +∞
−∞
2x−11+x2 dx y hallar V P
∫ +∞
−∞
2x−11+x2 dx .
5.146 Estudiar el caracter de las integrales siguientes:
a)
∫ ∞0
(2 + senx)dx b)
∫ ∞0
e2x(2x2−4x)dx c)
∫ ∞−∞
e−xdx d)
∫ ∞1
1ch xdx
e)
∫ ∞−∞
e−x2
dx f)
∫ 0
−∞e2x(2x2+4x)dx g)
∫ 0
−∞
x2+1x4+1dx h)
∫ ∞0
xe−x2
dx
i)
∫ ∞0
sen3 x1+cos x+ex dx j)
∫ ∞1
x1+x4 dx k)
∫ ∞0
dx√x
l)
∫ ∞0
x ln x(1+x2)2 dx
5.147 Estudiar el caracter de las integrales siguientes:
a)
∫ 0
−1
x−1(x+1)2 dx b)
∫ 1
0
dx√x(1−x)
c)
∫ 1
0
sen x+cos x√x(1−x)
dx
d)
∫ π
0
dx1−cos x e)
∫ 1
0
ex
ex−1dx f)
∫ π2
0
ex√sen x
dx
5.148 Probar que
∫ +∞
0
dxxα diverge para cualquier α ∈ R .
5.149 Estudiar el caracter de las siguientes integrales, segun los valores de α
a)
∫ +∞
α
sen2 xx2 dx b)
∫ +∞
α
dxln x , para α > 1
5.150 Estudiar el caracter de las integrales siguientes:
a)
∫ 1
0
sen xx2 dx b)
∫ π
0
sen2 2xx2 dx c)
∫ ∞1
ln xx4−x3−x2+xdx
d)
∫ √2
0
x
(x2−1)45dx e)
∫ 2
1
dxx ln x f)
∫ ∞0
dx
x+(x3+1)12
g)
∫ +∞
1
sen2 1xdx h)
∫ 1
0
lnx ln(x+ 1)dx i)
∫ ∞0
ex
ex+1dx.
5.151 Estudiar el caracter de las integrales siguientes:
a)
∫ π4
0
(1−tg x) sen x
(π4−x)32 x
32dx b)
∫ √2
2
0
π4−arcsen x
x12 ( 1√
2−x)
32dx c)
∫ ∞0
ex
ex+1 −ex
ex−1dx
d)
∫ ∞1
arctg(x−1)3√
(x−1)4dx e)
∫ 1
0
sen3(x−1)x ln3 x
dx f)
∫ ∞0
√x sen 1
x2
ln(1+x) dx
g)
∫ π4
0
(1−e−x
2
x2 cos x − 1)dx h)
∫ π2
π4
(1−e−x
2
x2 cos x − 1)dx i)
∫ π
0
1+ x2−
x2
8 −√
1+sen x
x72
dx
5.152 Encontrar los valores de β , para que las integrales siguientes sean convergentes.
a)
∫ π2
0
1−cos xxβ
dx b)
∫ ∞2
(βxx2+1 −
12x+1
)dx c)
∫ ∞0
1−e1√x
xβdx d)
∫ ∞0
x−sen xxβ
dx
e)
∫ ∞0
dxx1−β 3√1−x2
f)
∫ ∞0
(1√
1+2x2− β
x+1
)dx g)
∫ ∞β
sen2 xx2−1 dx h)
∫ ∞β
xβ
x4−1dx
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

98 – Fundamentos de Matematicas : Calculo integral en R
Capıtulo 6
Aplicaciones de la integral
6.1 Areas de superficies planas
A la vista del estudio de la integral definida realizado en el Tema 5, parece razonable la siguiente definicion:
Definicion 178.- Sea f : [a, b] −→ R una funcion continua y positiva, y consideremos la region R del planocuya frontera viene dada por las rectas x = a , x = b , el eje de abcisas y la grafica de f (ver figura debajo).Entonces el area de la region R esta definida por
A(R) =
∫ b
a
f(x) dx.
En efecto, en su momento hemos comentado como las sumas inferi-ores y sumas superiores nos ofrecen aproximaciones por “defecto” ypor “exceso” del area encerrado por la curva y = f(x), es decir, elvalor de ese area esta siempre entre el area calculado por defectoo yel calculado por exceso. Entonces, cuando la funcion es integrable,el inferior de las cotas superiores y el superior de las cotas inferiorescoinciden, y como el valor del area indicado por la funcion esta en-tre ambos valores, necesariamente debe conincidir con el valor de laintegral.
R
y = f(x)
a b
Ejemplo Calcular el area de la region limitada por la curva f(x) = x2
3 + 1, los ejes coordenados y la rectax = 3.Solucion:La funcion es positiva en todo R . En particular, lo es en el dominio deintegracion y, por tanto, el valor del area que buscamos vendra dado por
A(R) =
∫ 3
0
f(x) dx.
En nuestro caso, como F (x) = x3
9 + x es una primitiva de f en [0, 3],basta aplicar la regla de Barrow para obtener que
R
f(x)= x2
3 +1
x=3
1
A(R) =
∫ 3
0
(x2
3+ 1
)dx =
(x3
9+ x
)]3
0
= (3 + 3)− (0 + 0) = 6,
nos ofrece el area del recinto R de la figura. 4
6.1.1 Funciones negativas
R
R′
y = f(x)
y = −f(x)
a b
Cuando la funcion f : [a, b] −→ R que limita R , es continua y nega-tiva, es decir, f(x) ≤ 0 para todo x ∈ [a, b] , el valor de la integral sera∫ b
a
f(x) dx ≤ 0, por lo que no puede representar el valor del area de R
como magnitud de medida positiva. Sin embargo, es claro que el areade la region R coincide con el area de la region R′ determinada por lafuncion −f (ver figura a la izquierda), por lo que, teniendo en cuentalas propiedades de la integral, puede darse la siguiente definicion.
Definicion 179.- Sea f : [a, b] −→ R una funcion continua y negativa. Consideremos la region R del planocuya frontera viene dada por las rectas x = a , x = b , el eje de abcisas y la grafica de f . Entonces el area dela region R esta definida por
A(R) =
∫ b
a
−f(x) dx = −∫ b
a
f(x) dx.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
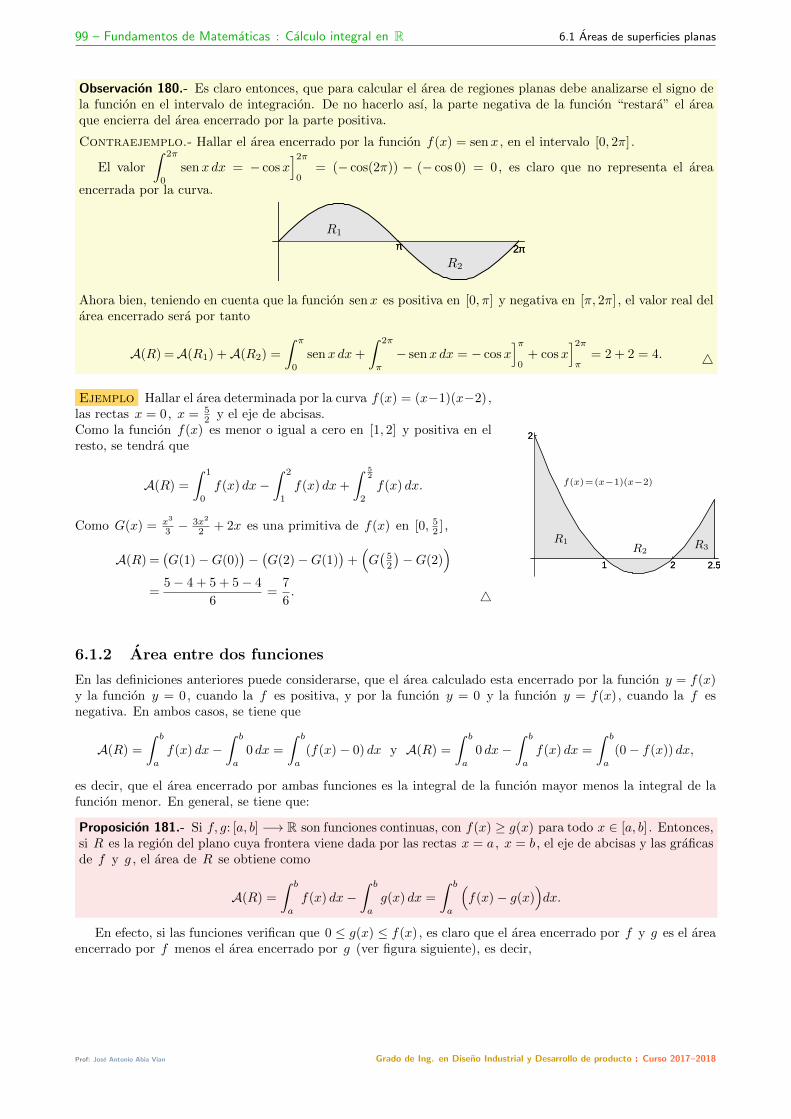
99 – Fundamentos de Matematicas : Calculo integral en R 6.1 Areas de superficies planas
Observacion 180.- Es claro entonces, que para calcular el area de regiones planas debe analizarse el signo dela funcion en el intervalo de integracion. De no hacerlo ası, la parte negativa de la funcion “restara” el areaque encierra del area encerrado por la parte positiva.
Contraejemplo.- Hallar el area encerrado por la funcion f(x) = senx , en el intervalo [0, 2π] .
El valor
∫ 2π
0
senx dx = − cosx]2π
0= (− cos(2π)) − (− cos 0) = 0, es claro que no representa el area
encerrada por la curva.
π 2ππ 2π
R1
R2
Ahora bien, teniendo en cuenta que la funcion senx es positiva en [0, π] y negativa en [π, 2π] , el valor real delarea encerrado sera por tanto
A(R) =A(R1) +A(R2) =
∫ π
0
senx dx+
∫ 2π
π
− senx dx = − cosx]π
0+ cosx
]2ππ
= 2 + 2 = 4. 4
Ejemplo Hallar el area determinada por la curva f(x) = (x−1)(x−2),las rectas x = 0, x = 5
2 y el eje de abcisas.Como la funcion f(x) es menor o igual a cero en [1, 2] y positiva en elresto, se tendra que
A(R) =
∫ 1
0
f(x) dx−∫ 2
1
f(x) dx+
∫ 52
2
f(x) dx.
Como G(x) = x3
3 −3x2
2 + 2x es una primitiva de f(x) en [0, 52 ] ,
A(R) =(G(1)−G(0)
)−(G(2)−G(1)
)+(G(
52
)−G(2)
)=
5− 4 + 5 + 5− 4
6=
7
6. 4
1 2 2.5
2
1 2 2.5
2
R1R2
R3
f(x)=(x−1)(x−2)
6.1.2 Area entre dos funciones
En las definiciones anteriores puede considerarse, que el area calculado esta encerrado por la funcion y = f(x)y la funcion y = 0, cuando la f es positiva, y por la funcion y = 0 y la funcion y = f(x), cuando la f esnegativa. En ambos casos, se tiene que
A(R) =
∫ b
a
f(x) dx−∫ b
a
0 dx =
∫ b
a
(f(x)− 0) dx y A(R) =
∫ b
a
0 dx−∫ b
a
f(x) dx =
∫ b
a
(0− f(x)) dx,
es decir, que el area encerrado por ambas funciones es la integral de la funcion mayor menos la integral de lafuncion menor. En general, se tiene que:
Proposicion 181.- Si f, g: [a, b] −→ R son funciones continuas, con f(x) ≥ g(x) para todo x ∈ [a, b] . Entonces,si R es la region del plano cuya frontera viene dada por las rectas x = a , x = b , el eje de abcisas y las graficasde f y g , el area de R se obtiene como
A(R) =
∫ b
a
f(x) dx−∫ b
a
g(x) dx =
∫ b
a
(f(x)− g(x)
)dx.
En efecto, si las funciones verifican que 0 ≤ g(x) ≤ f(x), es claro que el area encerrado por f y g es el areaencerrado por f menos el area encerrado por g (ver figura siguiente), es decir,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

100 – Fundamentos de Matematicas : Calculo integral en R 6.2 Volumenes de cuerpos solidos
A(Rf−g) = A(Rf )−A(Rg) =
∫ b
a
f(x) dx−∫ b
a
g(x) dx.
Si alguna de ellas toma valores negativos, el area entre ambas, R , es el mismoque si le sumamos a cada funcion una constante k que las haga positivas y,por tanto, el area R es el area R′ encerrado por f+k menos el area encerradopor g + k (ver figura), es decir,
A(Rf−g) =A(Rf+k)−A(Rg+k) =
∫ b
a
(f(x) + k) dx−∫ b
a
(g(x) + k) dx
=
∫ b
a
f(x) dx+
∫ b
a
k dx−∫ b
a
g(x) dx−∫ b
a
k dx
=
∫ b
a
f(x) dx−∫ b
a
g(x) dx.
R
y = f(x)
y = g(x)a b
R′y = f(x)+k
y = g(x)+k
Observacion 182.- De forma analoga, si la region esta limitada por funciones x = f(y), x = g(y) y las rectasy = c e y = d , siendo g(y) ≤ f(y) para todo y ∈ [c, d] , el area de la region puede encontrarse mediante laformula
A(R) =
∫ d
c
(f(y)− g(y)
)dy.
Ejemplo Calcular el area de la region acotada comprendida entre las parabolas de ecuaciones y2 + 8x = 16e y2 − 24x = 48.
Las parabolas pueden escribirse como funciones de y , de la forma
x = g(y) =16− y2
8y x = f(y) =
y2 − 48
24
Los puntos de corte de ambas parabolas son las soluciones de la ecuacion
16− y2
8=y2 − 48
24=⇒ y = ±
√24.
Como en el intervalo [−√
24,√
24] es f(y) ≤ g(y), se tiene que
A(R) =
∫ √24
−√
24
16−y2
8dy −
∫ √24
−√
24
y2−48
24dy=
∫ √24
−√
24
(4− y
2
6
)dy
=
(4y− y
3
18
)]√24
−√
24
=16
3
√24. 4
R
−√
24
√24
x=g(y)
x=f(y)
6.2 Volumenes de cuerpos solidos
Trataremos ahora de calcular el volumen de un solido S . Paraello supongamos que esta colocado en los ejes coordenados de R3
y que los extremos del solido en la direccion del eje de abcisasse toman en los valores x = a y x = b . Consideremos paracada x ∈ [a, b] que A(x) representa el area de la intersecciondel cuerpo con un plano perpendicular al eje de abcisas (verfigura).Entonces, para cada particion P = {a = x0, x1, ..., xn = b} delintervalo [a, b] , consideremos
mi = inf{A(x) : x1 ≤ x ≤ xi−1}Mi = sup{A(x) : x1 ≤ x ≤ xi−1} x=x1 x=x2 x=x3
A(x1)A(x2)
A(x3)
a
b
S
el inferior y el superior de los valores de las areas A(x) de las secciones del solido entre xi−1 y xi .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

101 – Fundamentos de Matematicas : Calculo integral en R 6.2 Volumenes de cuerpos solidos
Definimos suma superior e inferior asociadas al solido S y la particion P en la forma
U(A,P ) =
n∑i=1
Mi4xi y L(A,P ) =
n∑i=1
mi4xi,
donde cada termino de las sumas representa el volumen de un cuerpo con area de la base mi o Mi y alturaxi − xi−1 = 4xi .
Fig. 6.1. Volumenes por exceso y por defecto.
Por tanto, ambas sumas corresponden a volumenes que aproximan por exceso y por defecto, respectivamente,al verdadero volumen de S (fig 6.1).
Considerando todas las particiones de [a, b] y razonando de forma analoga a como se hizo en el Tema 5,para la construccion de la integral de Riemann, estamos en condiciones de dar la siguiente definicion:
Definicion 183.- Sea S un solido acotado comprendido entre los planos x = a y x = b . Para cada x ∈ [a, b] ,sea A(x) el area de la seccion que produce sobre S el plano perpendicular al eje de abcisas en el punto x . SiA(x) es continua en [a, b] definimos el volumen de S como
V(S) =
∫ b
a
A(x) dx.
Nota: Podemos dar definiciones analogas si tomamos secciones perpendiculares al eje y o al eje z .
Ejemplo Hallar el volumen del solido S ={
(x, y, z) ∈ R3 : x, y, z ≥ 0; x+ y + z ≤ 1}
.
El solido S es la parte del primer octante limitada por el plano x+y+z = 1, es decir, el tetraedro (piramidede base triangular) cuyas caras son los planos coordenados y el plano x+ y + z = 1.
Las secciones formadas por planos perpendiculares al eje x son
triangulos y su area, para cada x , es A(x) = base(x)×altura(x)2 .
Para cada x de [0, 1], la base del triangulo es la coordenada y de
la recta interseccion de los planos
{x+ y + z = 1z = 0
, luego base(x) =
y = 1 − x . La altura es la coordenada z de la recta interseccion de
los planos
{x+ y + z = 1y = 0
, luego altura(x) = z = 1− x . Por tanto,
A(x) = (1−x)(1−x)2 y
V (S) =
∫ 1
0
A(x) dx =
∫ 1
0
(1− x)2
2dx =
(− (1− x)3
6
)]1
0
=1
6 4
z=1−x
A(x)
y=1−x
1
1
1
6.2.1 Volumenes de revolucion
Un caso particular de gran importancia de la definicion anterior es el de los solidos de revolucion, es decir,solidos generados al girar respecto a un eje.
Supongamos dada una funcion f : [a, b] −→ R y consideremos la region limitada por la curva y = f(x) eleje de abcisas y las rectas x = a y x = b (como e la figura inical del tema). Una rotacion completa de estaalrededor del eje de abcisas produce un solido S para el cual, cada seccion es un cırculo de radio f(x) (o |f(x)|si la funcion es negativa, ver la figura anexa al ejemplo siguiente de la esfera) y por tanto, su area sera
A(x) = πf2(x).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

102 – Fundamentos de Matematicas : Calculo integral en R 6.3 Otras aplicaciones
En consecuencia, el volumen se obtendra de
V (S) =
∫ b
a
πf2(x) dx = π
∫ b
a
f2(x) dx.
Ejemplo Hallar el volumen de la esfera x2 + y2 + z2 ≤ 4.
La esfera es claramente un solido de revolucion, pues si gi-ramos el cırculo maximo se genera una esfera. De hecho,basta girar el cırculo maximo media vuelta para conseguirla,o dar una vuelta completa a uno de los semicırculos.
Como el circulo maximo, interseccion de la esfera con el planoy = 0, tiene por ecuacion (en el plano xz ) a x2 + z2 = 4,obtenemos la esfera al girar una rotacion completa la su-perficie encerrada por la semicircunferencia superior, z =√
4− x2 .Para cada x ∈ [−2, 2], el area de la seccion generada esA(x) = π(
√4− x2)2 = π(4 − x2), con lo que el volumen
sera
V (S) = π
∫ 2
−2
(4−x2) dx = π
(4x− x3
3
)]2
−2
= π32
3=
4
3π23,
como ya sabıamos. 4
Observaciones 184.- • Analogamente, si tenemos una funcion x = f(y) y hacemos rotar su grafica alrede-dor del eje de ordenadas, el volumen del solido sera
V (S) = π
∫ d
c
f2(y) dy.
donde c y d son los extremos de variacion de y .
• En el caso mas general, los volumenes de los cuerpos engendrados por la rotacion de una figura limitadapor las curvas continuas y = f(x), y = g(x) (donde 0 ≤ g(x) ≤ f(x) o f(x) ≤ g(x) ≤ 0) y por lasrectas x = a e x = b alrededor del eje de abcisas es
V (S) = π
∫ b
a
f2(x) dx− π∫ b
a
g2(x) dx = π
∫ b
a
(f2(x)− g2(x)
)dx.
Nota: Si sucede que g(x) ≤ 0 ≤ f(x), al girar alrededor del eje de abcisas la superficie comprendida entre
las graficas, debe tenerse en cuenta unicamente la superficie (por encima o por debajo del eje de giro) demayor radio de giro, pues el volumen que engendra al girar la parte mayor contiene al volumen engendradopor la parte menor. Es decir, si |g(x)| ≤ |f(x)| se gira solo la parte superior y si |g(x)| ≥ |f(x)| se giraunicamente la parte inferior.
6.3 Otras aplicaciones
6.3.1 Longitudes de arcos
La integral definida se puede usar tambien para encontrar la longitud de una curva dada por la grafica de unafuncion f(x) derivable y con derivada continua en [a, b] .
Definicion 185.- Sea f : [a, b] −→ R derivable y con derivada continua en [a, b] , entonces la longitud L de dela grafica de f , esta dada por
L =
∫ b
a
√1 + (f ′(x))2 dx.
Sin una justificacion completa, esta definicion se obtiene de lo siguiente: sea P = {a = x0, x1, ..., xn = b}una particion del intervalo [a, b] y denotemos por Pxi = (xi, f(xi)) al punto correspondiente de la grafica de f ,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
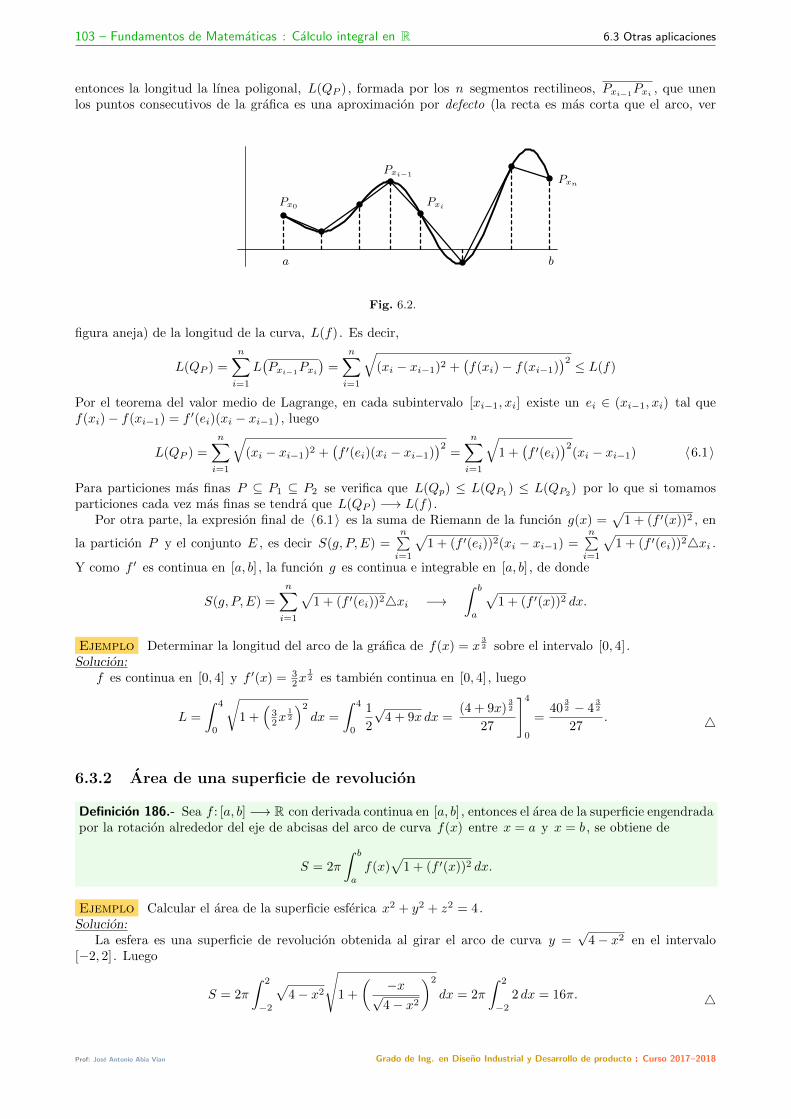
103 – Fundamentos de Matematicas : Calculo integral en R 6.3 Otras aplicaciones
entonces la longitud la lınea poligonal, L(QP ), formada por los n segmentos rectilineos, Pxi−1Pxi , que unenlos puntos consecutivos de la grafica es una aproximacion por defecto (la recta es mas corta que el arco, ver
Px0
Pxi−1
Pxi
Pxn
a b
Fig. 6.2.
figura aneja) de la longitud de la curva, L(f). Es decir,
L(QP ) =
n∑i=1
L(Pxi−1
Pxi)
=
n∑i=1
√(xi − xi−1)2 +
(f(xi)− f(xi−1)
)2 ≤ L(f)
Por el teorema del valor medio de Lagrange, en cada subintervalo [xi−1, xi] existe un ei ∈ (xi−1, xi) tal quef(xi)− f(xi−1) = f ′(ei)(xi − xi−1), luego
L(QP ) =
n∑i=1
√(xi − xi−1)2 +
(f ′(ei)(xi − xi−1)
)2=
n∑i=1
√1 +
(f ′(ei)
)2(xi − xi−1) 〈6.1〉
Para particiones mas finas P ⊆ P1 ⊆ P2 se verifica que L(Qp) ≤ L(QP1) ≤ L(QP2
) por lo que si tomamosparticiones cada vez mas finas se tendra que L(QP ) −→ L(f).
Por otra parte, la expresion final de 〈6.1〉 es la suma de Riemann de la funcion g(x) =√
1 + (f ′(x))2 , en
la particion P y el conjunto E , es decir S(g, P,E) =n∑i=1
√1 + (f ′(ei))2(xi − xi−1) =
n∑i=1
√1 + (f ′(ei))24xi .
Y como f ′ es continua en [a, b] , la funcion g es continua e integrable en [a, b] , de donde
S(g, P,E) =
n∑i=1
√1 + (f ′(ei))24xi −→
∫ b
a
√1 + (f ′(x))2 dx.
Ejemplo Determinar la longitud del arco de la grafica de f(x) = x32 sobre el intervalo [0, 4].
Solucion:f es continua en [0, 4] y f ′(x) = 3
2x12 es tambien continua en [0, 4], luego
L =
∫ 4
0
√1 +
(32x
12
)2
dx =
∫ 4
0
1
2
√4 + 9x dx =
(4 + 9x)32
27
]4
0
=40
32 − 4
32
27. 4
6.3.2 Area de una superficie de revolucion
Definicion 186.- Sea f : [a, b] −→ R con derivada continua en [a, b] , entonces el area de la superficie engendradapor la rotacion alrededor del eje de abcisas del arco de curva f(x) entre x = a y x = b , se obtiene de
S = 2π
∫ b
a
f(x)√
1 + (f ′(x))2 dx.
Ejemplo Calcular el area de la superficie esferica x2 + y2 + z2 = 4.Solucion:
La esfera es una superficie de revolucion obtenida al girar el arco de curva y =√
4− x2 en el intervalo[−2, 2]. Luego
S = 2π
∫ 2
−2
√4− x2
√1 +
(−x√
4− x2
)2
dx = 2π
∫ 2
−2
2 dx = 16π. 4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

104 – Fundamentos de Matematicas : Calculo integral en R 6.4 Ejercicios
6.4 Ejercicios
6.153 Hallar el area de la figura limitada por la curva y = x(x− 1)(x− 2) y el eje de abcisas.
6.154 Probar que el area encerrado por la curva f(x) = pxn , con x ∈ [0, a] , p ∈ R y n ∈ N es a|f(a)|n+1 .
6.155 Calcular el area de la figura limitada por la curva y = x3 , la recta y = 8, y el eje OY .
6.156 Calcular el area de la figura limitada por la curva y3 − y + 2 = x , la recta x = 8, y el eje OX .
6.157 Hallar el area encerrado por la elipse x2
a2 + y2
b2 = 1.
6.158 Hallar el area de la figura comprendida entre las parabolas y = x2 , y = x2
2 , y la recta y = 2x .
6.159 Calcular el area de las dos partes en que la parabola y2 = 2x divide al cırculo x2 + y2 = 8.
6.160 Calcular el area de la figura limitada por la hiperbola x2
a2 − y2
b2 = 1 y la recta x = 2a .
6.161 Calcular el area de cada una de las partes en que las curvas 2y = x2 y 2x = y2 dividen al cırculox2 + y2 ≤ 3.
6.162 Calcular el area limitada por las curvas f(x) = ex
1+ex y g(x) = 1(x+1)2+1) cuando x ∈ [0, 1].
6.163 Calcular el area encerrada por la curva y =√
1− x2 + arcsen√x y el eje de abcisas.
(Nota: Estudiar el dominio y el signo de la funcion.)
6.164 La curva que aparece en la figura de la derecha, llamada astroide, viene dada
por la ecuacionx
23 + y
23 = a
23
Hallar el area encerrada por la astroide.(Nota: Se sugiere el cambio x = a sen3 t o x = a cos3 t .)
6.165 Calcular el area de la figura limitada por la curva a2y2 = x2(a2 − x2).
a−a
x23 + y
23 = a
23
6.166 Calcular el area de la figura comprendida dentro de la curva (x5 )2 + (y4 )23 = 1.
6.167 Comprobar usando la integracion, que el volumen de una esfera de radio r es 43πr
3
6.168 Hallar el volumen del elipsoide x2
a2 + y2
b2 + z2
c2 = 1.
6.169 Considerar el solido V formado al cortar el cilindro x2 +y2 ≤ 22 por losplanos z = 0 e y+z = 2 (ver la figura de la derecha), que analıticamenteviene descrito por:
V ={
(x, y, z) : x2 + y2 ≤ 22; 0 ≤ z ≤ 2− y}
Describir y calcular el area de las secciones de V perpendiculares a cadauno de los ejes.Calcular el volumen de V mediante las secciones correspondientes a dosde los ejes.
6.170 Hallar el volumen encerrado por el paraboloide elıptico y2
4 + z2
6 = x y limitado por el plano x=5.
6.171 Hallar el volumen del elipsoide, engendrado por la rotacion de la elipse x2
a2 + y2
b2 = 1 alrededor del eje OX .
6.172 Hallar el volumen del cuerpo engendrado al girar alrededor del eje OY , la parte de la parabola y2 = 12x ,
que intercepta la recta x = 3.
6.173 Hallar volumen del toro engendrado por la rotacion del cırculo (x− b)2 + y2 ≤ a2 , con b > a , alrededor
del eje OY .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

105 – Fundamentos de Matematicas : Calculo integral en R 6.4 Ejercicios
6.174 La recta x = 2 divide al cırculo (x− 1)2 + y2 ≤ 4 en dos partes.
a) Calcular el volumen generado al girar alrededor de la recta y = 0 la parte de mayor area.
b) Calcular el volumen generado al girar alrededor de la recta x = 0 la parte de mayor area.
c) Calcular el volumen generado al girar alrededor de la recta x = 2 la parte de menor area.
6.175 Considerar las curvas y = sen(x) e y = sen(2x) en el intervalo [0, π] .
a) Hallar el area de la region encerrada entre las dos curvas.
b) Hallar el area de cada uno de los trozos en que la recta y = 12 divide a la region encerrada entre las
dos curvas.
c) Si giramos ambas curvas alrededor de la recta y = 12 , ¿cual de las dos engendrara mayor volumen?
6.176 Hallar el volumen de la parte del hiperboloide de una hoja S = {x2
a2 + y2
a2 − z2
c2 ≤ 1; 0 ≤ z ≤ h} .
6.177 Hallar el volumen del cono elıptico recto, de base una elipse de semiejes a y b y cuya altura es h .
6.178 Hallar el volumen del cuerpo limitado por la superficies de los cilindros
parabolicos z = x2 y z = 1 − y2 (ver figura de la derecha) a partir delas areas formadas al seccionar el cuerpo por planos paralelos al planoz = 0.
6.179 Hallar el volumen del cuerpo limitado por los cilindros: x2 + z2 = a2 e y2 + z2 = a2 .
6.180 Calcular el volumen de cada una de las partes en que queda dividido un cilindro circular recto de radio 2y de altura 8 por un plano que, conteniendo un diametro de una de las bases, es tangente a la otra base.
6.181 Sobre las cuerdas de la astroide x23 +y
23 = 2
23 , paralelas al eje OX , se han construido unos cuadrados, cuyos
lados son iguales a las longitudes de las cuerdas y los planos en que se encuentran son perpendiculares alplano XY . Hallar el volumen del cuerpo que forman estos cuadrados.
6.182 El plano de un triangulo movil permanece perpendicular al diametro fijode un cırculo de radio a . La base del triangulo es la cuerda correspon-diente de dicho cırculo, mientras que su vertice resbala por una rectaparalela al diametro fijo que se encuentra a una distancia h del planodel cırculo. Hallar el volumen del cuerpo (llamado “conoide”, ver figuraaneja) engendrado por el movimiento de este triangulo desde un extremodel diametro hasta el otro.
6.183 Un cırculo deformable se desplaza paralelamente al plano XZ de talforma, que uno de los puntos de su circunferencia descansa sobre el
eje OY y el centro recorre la elipse x2
a2 + y2
b2 = 1. Hallar el volumen delcuerpo engendrado por el desplazamiento de dicho cırculo.
6.184 Sea S el recinto del plano limitado por la parabola y = 4 − x2 y el eje de abscisas. Para cada p > 0
consideramos los dos recintos en que la parabola y = p x2 divide a S ,
A(p) = {(x, y) ∈ S : y ≥ p x2} y B(p) = {(x, y) ∈ S : y ≤ p x2}.
a) Hallar p para que las areas de A(p) y B(p) sean iguales
b) Hallar p para que al girar A(p) y B(p) alrededor del eje OY s obtengamos solidos de igual volumen
6.185 Hallar el perımetro de uno de los triangulos curvilıneos limitado por el eje de abscisas y las curvasy = ln | cosx| e y = ln | senx| .
6.186 Hallar la longitud del arco y = arcsen(e−x) desde x = 0 hasta x = 1.
6.187 Hallar el area de la superficie del toro engendrado por la rotacion de la circunferencia (x− b)2 + y2 = a2 ,
con b > a , alrededor del eje OY .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018
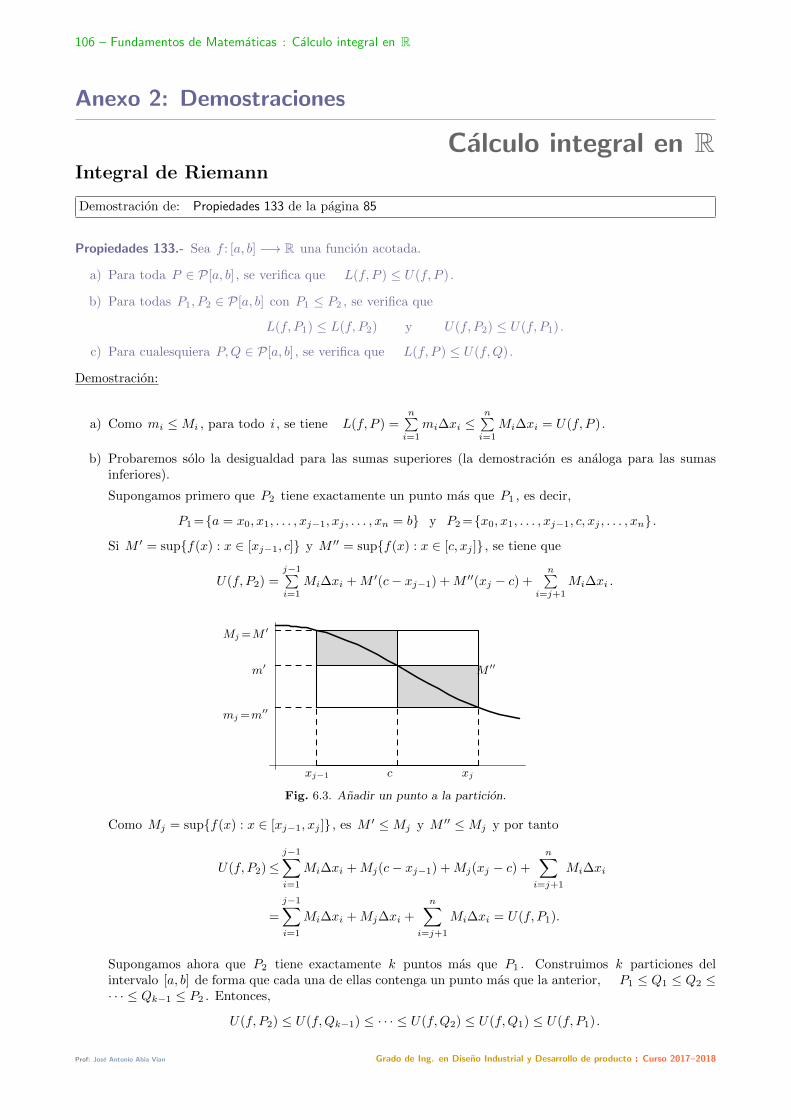
106 – Fundamentos de Matematicas : Calculo integral en R
Anexo 2: Demostraciones
Calculo integral en RIntegral de Riemann
Demostracion de: Propiedades 133 de la pagina 85
Propiedades 133.- Sea f : [a, b] −→ R una funcion acotada.
a) Para toda P ∈ P[a, b] , se verifica que L(f, P ) ≤ U(f, P ).
b) Para todas P1, P2 ∈ P[a, b] con P1 ≤ P2 , se verifica que
L(f, P1) ≤ L(f, P2) y U(f, P2) ≤ U(f, P1).
c) Para cualesquiera P,Q ∈ P[a, b] , se verifica que L(f, P ) ≤ U(f,Q).
Demostracion:
a) Como mi ≤Mi , para todo i , se tiene L(f, P ) =n∑i=1
mi∆xi ≤n∑i=1
Mi∆xi = U(f, P ).
b) Probaremos solo la desigualdad para las sumas superiores (la demostracion es analoga para las sumasinferiores).
Supongamos primero que P2 tiene exactamente un punto mas que P1 , es decir,
P1 ={a = x0, x1, . . . , xj−1, xj , . . . , xn = b} y P2 ={x0, x1, . . . , xj−1, c, xj , . . . , xn} .
Si M ′ = sup{f(x) : x ∈ [xj−1, c]} y M ′′ = sup{f(x) : x ∈ [c, xj ]} , se tiene que
U(f, P2) =j−1∑i=1
Mi∆xi +M ′(c− xj−1) +M ′′(xj − c) +n∑
i=j+1
Mi∆xi .
xj−1 c xj
Mj =M ′
m′ M ′′
mj =m′′
Fig. 6.3. Anadir un punto a la particion.
Como Mj = sup{f(x) : x ∈ [xj−1, xj ]} , es M ′ ≤Mj y M ′′ ≤Mj y por tanto
U(f, P2)≤j−1∑i=1
Mi∆xi +Mj(c− xj−1) +Mj(xj − c) +
n∑i=j+1
Mi∆xi
=
j−1∑i=1
Mi∆xi +Mj∆xi +
n∑i=j+1
Mi∆xi = U(f, P1).
Supongamos ahora que P2 tiene exactamente k puntos mas que P1 . Construimos k particiones delintervalo [a, b] de forma que cada una de ellas contenga un punto mas que la anterior, P1 ≤ Q1 ≤ Q2 ≤· · · ≤ Qk−1 ≤ P2 . Entonces,
U(f, P2) ≤ U(f,Qk−1) ≤ · · · ≤ U(f,Q2) ≤ U(f,Q1) ≤ U(f, P1).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

107 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
c) Si consideramos P∗ = P ∪Q , P∗ es una particion de [a, b] y se verifica que P ≤ P∗ y Q ≤ P∗ . Usandolas propiedades b), a) y b) en las desigualdades siguientes, se tiene
L(f, P ) ≤ L(f, P∗) ≤ U(f, P∗) ≤ U(f,Q).
Demostracion de: Teorema 136 de la pagina 85
Teorema 136.- (Condicion de integrabilidad de Riemann)Una funcion f : [a, b] −→ R acotada es integrable Riemann si, y solo si, para todo ε > 0 existe una particionPε ∈ P[a, b] tal que
U(f, Pε)− L(f, Pε) < ε.
Demostracion:=⇒c Sea f integrable Riemann y sea ε > 0. Como I = I es el inferior de las sumas superiores y I = I es elsuperior de las sumas inferiores, existe una particion P1 y existe una particion P2 , tales que
U(f, P1)− I < ε
2y I − L(f, P2) <
ε
2.
Tomando Pε = P1 ∪ P2 , se tiene que P1 ⊆ Pε y P2 ⊆ Pε y, por tanto,
U(f, Pε) ≤ U(f, P1) y L(f, P2) ≤ L(f, Pε).
Luego
U(f, Pε)− I ≤ U(f, P1)− I < ε2 y I − L(f, Pε) ≤ I − L(f, P2) < ε
2 ,
y sumando ambas desigualdades U(f, Pε)− L(f, Pε) < ε .
⇐=c Recıprocamente, supongamos que para cualquier ε > 0 existe una particion Pε ∈ P[a, b] tal queU(f, Pε)− L(f, Pε) < ε . Sabemos tambien que
I ≤ U(f, Pε) y L(f, Pε) ≤ I ,
restando entonces ambas expresiones obtenemos
0 ≤ I − I ≤ U(f, Pε)− L(f, Pε) < ε,
luego I = I .
Demostracion de: Propiedades 137 de la pagina 86
Propiedades 137.- Sean f, g: [a, b] −→ R integrables en [a, b] , λ ∈ R y a < c < b . Entonces
1.- f + g es integrable en [a, b] y
∫ b
a
(f + g) =
∫ b
a
f +
∫ b
a
g .
2.- λf es integrable en [a, b] y
∫ b
a
λf = λ
∫ b
a
f .
3.- f integrable en [a, b] si, y solo si, f es integrable en [a, c] y [c, b] .
En ese caso,
∫ b
a
f =
∫ c
a
f +
∫ b
c
f .
Demostracion:
1.- Como f y g son integrables en [a, b] , existen P1 y P2 particiones de [a, b] , tales que U(f, P1)−L(f, P1) <ε2 y U(g, P2)− L(g, P2) < ε
2 ; luego tomando Pε = P1 ∪ P2 , al ser mas fina que P1 y P2 , se verifica que
U(f, Pε)− L(f, Pε) =
n∑i=1
(M ′i −m′i)∆xi <ε
2U(g, Pε)− L(g, Pε) =
n∑i=1
(M ′′i −m′′i )∆xi <ε
2.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

108 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
Sea Pε = {x0 < x1 < · · · < xn} , y sean mi y Mi el inferior y superior de f + g en [xi−1, xi] . Entonces,como m′i ≤ f(x) ≤M ′i y m′′i ≤ g(x) ≤M ′′i , se tiene que m′i +m′′i ≤ f(x) + g(x) ≤M ′i +M ′′i , luego quem′i +m′′i ≤ mi ≤Mi ≤M ′i +M ′′i . En consecuencia,
U(f + g, Pε)− L(f + g, Pε) =
n∑i=1
(Mi −mi)∆xi ≤n∑i=1
((M ′i +M ′′i )− (m′i +m′′i )
)∆xi
=
n∑i=1
(M ′i −m′i)∆xi +
n∑i=1
(M ′′i −m′′i )∆xi <ε
2+ε
2= ε.
2.- Basta con tener en cuenta que U(λf, P )− L(λf, P ) = λ(U(f, P )− L(f, P )
)y usar que f es integrable.
3.- Sea ε > 0. Si f integrable en [a, b] existe Pε ∈ P[a, b] tal que U(f, Pε)− L(f, Pε) < ε .
Anadiendo, si no esta, el punto c a Pε obtenemos la particion de [a, b]
P = {a = x0, x1, . . . , xi−1, c, xi, . . . , xn = b}
mas fina que Pε , luego se verifica que U(f, P )− L(f, P ) ≤ U(f, Pε)− L(f, Pε) < ε .
Tomando P1 = {a, x1, . . . , xi−1, c} , particion de [a, c] y P2 = {c, xi, . . . , b} , particion de [c, b] , se verificaque
L(f, P ) = L(f, P1) + L(f, P2) y U(f, P ) = U(f, P1) + U(f, P2)
y, por tanto,U(f, P )− L(f, P ) = (U(f, P1)− L(f, P1)) + (U(f, P2)− L(f, P2)) < ε.
LuegoU(f, P1)− L(f, P1) < ε y U(f, P2)− L(f, P2) < ε.
Recıprocamente, si f es integrable en [a, c] y en [c, b] , existen P1 ∈ P[a, c] y P2 ∈ P[c, b] tales que
U(f, P1)− L(f, P1) < ε2 y U(f, P2)− L(f, P2) < ε
2 .
Tomando P = P1 ∪ P2 , se tiene que P ∈ P[a, b] y
U(f, P )− L(f, P ) = (U(f, P1)− L(f, P1)) + (U(f, P2)− L(f, P2)) < ε2 + ε
2 = ε ,
luego f es integrable en [a, b] .
Si denotamos por I1 =
∫ c
a
f(x) dx , I2 =
∫ b
c
f(x) dx e I =
∫ b
a
f(x) dx , se tiene que
L(f, P ) ≤ I ≤ U(f, P ) L(f, P1) ≤ I1 ≤ U(f, P1) L(f, P2) ≤ I2 ≤ U(f, P2)
y, por tanto,|I − (I1 + I2)| ≤ U(f, P )− L(f, P ) < ε, ∀ε > 0.
En consecuencia, I = I1 + I2 .
Demostracion de: Proposicion 141 de la pagina 86
Proposicion 141.- Sea f : [a, b] −→ R una funcion acotada. Entonces f es integrable en [a, b] y el valor de suintegral es I si y solo si para cada ε > 0 existe Pε ∈ P[a, b] tal que para toda P ≥ Pε y cualquier eleccion delconjunto E asociado a P se cumple que |S(f, P,E)− I| < ε .
Demostracion:Antes de la demostracion propiamente dicha un resultado necesario para la demostracion, pero que hacemosaparte para no perder el hilo
Lema.- Sean f : [a, b] −→ R acotada y P ∈ P[a, b] . Para cualquier ε > 0 es posible elegir dosconjuntos E1 y E2 asociados a P de forma que
S(f, P,E1)− L(f, P ) < ε y U(f, P )− S(f, P,E2) < ε
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

109 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
Demostracion:Sea ε > 0. Para cada i = 1, . . . , n , por ser mi = inf{f(x) : x ∈ [xi−1, xi]} existe ei ∈ [xi−1, xi] talque f(ei)−mi <
εb−a , y sea E1 el conjunto formado por estos ei . Entonces
S(f, P,E1)− L(f, P ) =
n∑i=1
(f(ei)−mi) ∆xi <
n∑i=1
ε
b− a∆xi =
ε
b− a
n∑i=1
∆xi = ε
Lo que prueba la existencia del primer conjunto. El segundo se prueba de forma analoga
=⇒c Si f integrable en [a, b] e I =
∫ b
a
f(x) dx , dado ε > 0 existe Pε ∈ P[a, b] tal que
U(f, Pε)− L(f, Pε) < ε.
Por otra parte, para cualesquiera P y E asociado a P , se cumple que
L(f, P ) ≤ S(f, P,E) ≤ U(f, P )
y queL(f, P ) ≤ I ≤ U(f, P ) o mejor − U(f, P ) ≤ −I ≤ −L(f, P ),
sumando ambas−(U(f, P )− L(f, P )) ≤ S(f, P,E)− I ≤ U(f, P )− L(f, P ),
de donde|S(f, P,E)− I| ≤ U(f, P )− L(f, P ), ∀P ∈ P[a, b].
En particular, si P ≥ Pε se tendra que
|S(f, P,E)− I| ≤ U(f, P )− L(f, P ) ≤ U(f, Pε)− L(f, Pε) < ε.
⇐=c Supongamos que dado ε > 0 existe Pε ∈ P[a, b] tal que para todo P ≥ Pε y cualquier eleccion de Easociado a P se tiene que |S(f, P,E)− I| < ε
4 .Aplicando el lema previo a la particion Pε , existiran dos conjuntos E1 y E2 asociados a la particion tales
que
S(f, Pε, E1)− L(f, Pε) <ε
4y U(f, Pε)− S(f, Pε, E2) <
ε
4,
entonces
|U(f, Pε)− L(f, Pε)| ≤ |U(f, Pε)− S(f, Pε, E2)|+ |S(f, Pε, E2)− I|++ |I − S(f, Pε, E1)|+ |S(f, Pε, E1)− L(f, Pε)|
<ε
4+ε
4+ε
4+ε
4= ε.
Luego f es integrable en [a, b] y existe el valor de
∫ b
a
f(x) dx . Veamos que
∫ b
a
f(x) dx = I .
Existe Pε tal que
U(f, Pε)− L(f, Pε) <ε
2〈6.2〉
y que
|S(f, Pε, E)− I| < ε
2〈6.3〉
(existen P1 y P2 verificando respectivamente 〈6.2〉 y 〈6.3〉 , luego Pε = P1∪P2 verifica a la vez 〈6.2〉 y 〈6.3〉).Como
L(f, Pε) ≤∫ b
a
f(x) dx ≤ U(f, Pε) y L(f, Pε) ≤ S(f, Pε, E) ≤ U(f, Pε)
se tiene que ∣∣∣∣∣∫ b
a
f(x) dx− S(f, Pε, E)
∣∣∣∣∣ ≤ U(f, Pε)− L(f, Pε) <ε
2
luego
−ε2<
∫ b
a
f(x) dx− S(f, Pε, E) <ε
2,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

110 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
y de 〈6.3〉 tenemos que
−ε2< S(f, Pε, E)− I < ε
2,
sumando ambas
−ε <∫ b
a
f(x) dx− I < ε
y, por tanto I =
∫ b
a
f(x) dx .
Demostracion de: Proposicion 144 de la pagina 87
Proposicion 144.- Sea f integrable en [a, b] , entonces |f | es integrable en [a, b] y se verifica que∣∣∣∣∣∫ b
a
f(x) dx
∣∣∣∣∣ ≤∫ b
a
|f(x)| dx .
Demostracion:
Como |f(x)| ={f(x), si f(x) ≥ 0−f(x), si f(x) < 0
, si tomamos las funciones definidas por
f+(x) =
{f(x), si f(x) ≥ 0
0, si f(x) < 0y f−(x) =
{0, si f(x) > 0
−f(x), si f(x) ≤ 0,
entonces |f | = f+ + f− y sera integrable si f+ y f− son integrables.
Veamos que f+ es integrable en [a, b] :
f es integrable, luego existe Pε tal que U(f, Pε)− L(f, Pε) =n∑i=1
(Mi −mi)∆xi < ε
y, para esa misma particion, U(f+, Pε)− L(f+, Pε) =n∑i=1
(M ′i −m′i)∆xi . Ahora bien:
• si 0 ≤ mi entonces 0 ≤ f = f+ en [xi−1, xi] y M ′i −m′i = Mi −mi .
• si Mi ≤ 0, entonces f ≤ 0 = f+ en [xi−1, xi] y M ′i −m′i = 0− 0 ≤Mi −mi .
• si mi < 0 < Mi , entonces mi < 0 = m′i ≤M ′i = Mi y M ′i −m′i ≤Mi −mi .
En consecuencia, U(f+, Pε)− L(f+, Pε) ≤ U(f, Pε)− L(f, Pε) < ε y f+ es integrable. en [a, b] .
Como es tambien f = f+−f− , se tiene que f− = f+−f es integrable en [a, b] por ser suma de integrablesy, por tanto, |f | es integrable en [a, b] .
Aplicando ahora el corolario 143 a la desigualdad − |f | ≤ f ≤ |f | , se tiene que
−∫ b
a
|f | ≤∫ b
a
f ≤∫ b
a
|f |
y, por tanto,
∣∣∣∣∣∫ b
a
f
∣∣∣∣∣ ≤∫ b
a
|f | .
Demostracion de: Proposicion 146 de la pagina 87
Proposicion 146.- Si f y g son integrables en [a, b] , entonces fg es integrable en [a, b] .
Demostracion:Como puede escribirse fg = 1
4
((f + g)2 − (f − g)2
)y las funciones f + g y f − g son integrables, basta probar
que el cuadrado de una funcion integrable es integrable.Sea entonces h integrable en [a, b] . Por ser acotada, existe K > 0 tal que |h(x)| < K , para todo x ∈ [a, b] ,
y por ser integrable, existe Pε ∈ P[a, b] tal que
U(h, Pε)− L(h, Pε) =
n∑i=1
(Mi −mi)∆xi <ε
2K.
Para esa particion y la funcion h2 , sea U(h2, Pε)− L(h2, Pε) =n∑i=1
(M ′i −m′i)∆xi,entonces,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

111 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
• si 0 ≤ mi ≤Mi , se tiene que M ′i = M2i y m′i = m2
i , de dondeM ′i −m′i = M2
i −m2i = (Mi +mi)(Mi −mi).
• si mi ≤Mi ≤ 0, se tiene que M ′i = m2i y m′i = M2
i , de dondeM ′i −m′i = −(M2
i −m2i ) = −(Mi +mi)(Mi −mi) = |Mi +mi| (Mi −mi).
• si mi < 0 < Mi , se tiene que M ′i = max{m2i ,M
2i } y m′i = min{m2
i ,M2i } , de donde (por las anteriores)
M ′i −m′i =∣∣M2
i −m2i
∣∣ = |Mi +mi| (Mi −mi).
Luegon∑i=1
(M ′i−m′i)∆xi =
n∑i=1
|Mi+mi| (Mi−mi)∆xi ≤n∑i=1
2K(Mi−mi)∆xi < 2Kε
2K=ε,
y h2 es integrable. En consecuencia fg es integrable en [a, b] .
Demostracion de: Regla de Barrow 155 de la pagina 89
Regla de Barrow 155.- Sea f : [a, b] −→ R integrable en [a, b] . Si G: [a, b] −→ R es una primitiva de f en[a, b] , entonces ∫ b
a
f(x) dx = G(b)−G(a)
Demostracion:Sea ε > 0. Por ser f integrable en [a, b] existe Pε ∈ P[a, b] , tal que U(f, Pε) − L(f, Pε) < ε . Aplicando elteorema del valor medio de Lagrange a la funcion G , para cada i = 1, 2, . . . , n existe ei ∈ (xi−1, xi) tal que
G(xi)−G(xi−1) = G′(ei)(xi − xi−1) = f(ei)(xi − xi−1).
Puesto que mi = inf{f(x) : xi−1 ≤ x ≤ xi} y Mi = sup{f(x) : xi−1 ≤ x ≤ xi} , se tiene que
mi ≤ f(ei) ≤Mi,
de dondemi(xi − xi−1) ≤ f(ei)(xi − xi−1) ≤Mi(xi − xi−1)
mi(xi − xi−1) ≤ G(xi)−G(xi−1) ≤Mi(xi − xi−1)
n∑i=1
mi∆xi ≤n∑i=1
(G(xi)−G(xi−1)
)≤
n∑i=1
Mi∆xi
L(f, Pε) ≤ G(b)−G(a) ≤ U(f, Pε).
Como tambien es L(f, Pε) ≤∫ b
a
f(x) dx ≤ U(f, Pε), se verifica que
∣∣∣∣∣∫ b
a
f(x) dx−(G(b)−G(a)
)∣∣∣∣∣ < ε
y, por tanto, ∫ b
a
f(x) dx = G(b)−G(a)
Integrales impropias
Demostracion de: Proposicion 162 de la pagina 91
Proposicion 162.- Sea f : [a,+∞) −→ R integrable en [a, t] para todo t ∈ [a,+∞). Si lımx→+∞
f(x) = L 6= 0
entonces
∫ ∞a
f(x) dx diverge
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

112 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
Demostracion:Supongamos que lım
x→+∞f(x) = L > 0. Entonces, para cualquier ε > 0 existe k > 0 tal que si x ≥ k se verifica
que |f(x)− L| < ε , es decir, L− ε < f(x) < L+ ε .En particular, tomando ε = L
2 > 0, si x ≥ k se verifica que L2 < f(x) < 3L
2 , luego 0 < L2 < f(x) para todo
x ∈ [k,+∞). Entonces,
lımt→+∞
∫ t
k
L
2dx ≤ lım
t→+∞
∫ t
k
f(x) dx
y como
lımt→+∞
∫ t
k
L
2dx = lım
t→+∞
L
2(x]
tk =
L
2lım
t→+∞t− k = +∞,
se tiene que lımt→+∞
∫ t
k
f(x) dx = +∞ y la integral
∫ ∞k
f(x) dx diverge, luego por la propiedad 1 de 161,∫ ∞a
f(x) dx diverge.
Supongamos ahora que lımx→+∞
f(x) = L < 0. Entonces lımx→+∞
−f(x) = −L > 0 y, por tanto,
∫ ∞a
− f(x) dx
diverge. Luego
∫ ∞a
f(x) dx diverge.
Demostracion de: Teorema 164 de la pagina 91
Teorema 164.- Sea f : [a,+∞) −→ R integrable y no negativa en [a, t] , ∀t ∈ R .∫ +∞
a
f(x) dx es convergente ⇐⇒ F (t) =
∫ t
a
f(x) dx esta acotada superiormente.
Demostracion:La prueba se basa en el hecho de que si f(x) ≥ 0 en [a,+∞), la funcion F debe ser creciente ya que se cumple
que F (t2)− F (t1) =
∫ t2
t1
f(x)dx ≥ 0, para cualesquiera t1 < t2 . Y ahora tenemos que:
Si
∫ ∞a
f(x) dx converge, entonces lımt→+∞
∫ t
a
f(x) dx = lımt→+∞
F (t) = L ∈ R . Pero como F (t) es creciente,
debe ser F (t) ≤ L y esta acotada superiormente.
Recıprocamente, si F (t) esta acotada superiormente existe sup{F (t) : t ∈ [a,+∞)
}= α ∈ R . Veamos que
α = lımt→+∞
F (t) y habremos probado que
∫ ∞a
f(x) dx es convergente.
Sea ε > 0. Entonces, por ser α un extremo superior, existe t′ ∈ [a,+∞) tal que α − ε < F (t′), luegosi t ≥ t′ , como F es creciente, se tiene que α − ε < F (t′) ≤ F (t). Ademas, para todo t , se verifica queF (t) ≤ α < α+ ε .
En consecuencia, para cualquier ε > 0 existe t′ tal que si t ≥ t′ , α−ε < F (t) < α+ε , es decir, |F (t)−α| < ε ,luego lım
t→+∞F (t) = α .
Demostracion de: Segundo criterio de comparacion 166 de la pagina 92
Segundo criterio de comparacion 166.- Sean f, g: [a,+∞) −→ R integrables en [a, t] , para todo t ≥ a y no
negativas. Supongamos que existe lımx→+∞
f(x)g(x) = L . Entonces:
a) Si 0 < L < +∞ =⇒∫ +∞
a
f(x) dx ∼∫ +∞
a
g(x) dx .
b) Si L = 0, se tiene:
[i] si
∫ +∞
a
g(x) dx converge =⇒∫ +∞
a
f(x) dx converge.
[ii] si
∫ +∞
a
f(x) dx diverge =⇒∫ +∞
a
g(x) dx diverge.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

113 – Fundamentos de Matematicas : Calculo integral en R Anexo 2
c) Si L = +∞ , se tiene:
[i] si
∫ +∞
a
f(x) dx converge =⇒∫ +∞
a
g(x) dx converge.
[ii] si
∫ +∞
a
g(x) dx diverge =⇒∫ +∞
a
f(x) dx diverge.
Demostracion:
1.- Si 0 < L < +∞ , tomamos ε = L2 , luego existe K > 0 tal que si x ≥ K se tiene que
∣∣∣ f(x)g(x) − L
∣∣∣ < L2 . De
donde
−L2
+ L <f(x)
g(x)<L
2+ L
y, como g(x) ≥ 0, se tieneL
2g(x) ≤ f(x) ≤ 3L
2g(x)
para todo x ≥ K . Basta aplicar 165, a los pares de funciones L2 g ≤ f(x) y f(x) ≤ 3L
2 g(x) y tener encuenta la propiedad 2 de 161.
2.- Si L = 0, tomando ε = 1, se tiene que existe K > 0 tal que si x ≥ K entonces 0 ≤ f(x) < g(x).
De nuevo, basta con aplicar 165.
3.- Si L = +∞ , entonces lımx→+∞
g(x)f(x) = 0 y recaemos en el caso anterior.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

114 – Fundamentos de Matematicas
Unidad III
Ecuaciones Diferenciales Ordinarias
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

115 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias
Capıtulo 7
Ecuaciones Diferenciales Ordinarias
7.1 Introduccion, conceptos e ideas basicas
Las ecuaciones diferenciales surgen en muchas aplicaciones de la ingenierıa como modelos matematicos dediversos sistemas fısicos y de otros tipos, y muchas de las leyes y relaciones se modelan matematicamente comoecuaciones diferenciales. Siempre que intervenga la razon de cambio de una funcion, como la velocidad, laaceleracion, la desintegracion, etc., se llegara a una ecuacion diferencial.
Definicion 187.- Una ecuacion diferencial ordinaria (EDO) es aquella que contiene una o varias derivadasde una funcion desconocida de una variable, y se quiere determinar a partir de la ecuacion
Suele denominarse por y = y(x) a esa funcion buscada y por x la variable sobre la que se deriva. Ası, porejemplo, (se usan indistintamente las notaciones y′ e dy
dx ):
• y′ = cosx
• d2ydx2 + 4y = dy
dx
• x2y′′′y′ + 2exy′′ = (x2 + 2)y2
El termino ordinarias las distinque de las ecuaciones diferenciales parciales en las que la solucion depende dedos o mas variables. El orden de una ecuacion diferencial es el orden de la derivada mas alta.
Definicion 188.- Una ecuacion diferencial ordinaria de orden n generica suele representarse mediante la ex-presion
F(x; y,
dy
dx, . . . ,
dny
dxn
)= F
(x; y, y′, . . . , yn)
)= 0
y se dice que una funcion y = f(x), definida en un intervalo I ⊆ R y con derivada n -esima en el inter-valo, es una solucion explıcita de la ecuacion diferencial si la verifica en cada punto de I . Es decir, siF (x; f(x), f ′(x), . . . , fn)(x)) = 0 para cada x ∈ I .
Se dice que g(x, y) = 0 es una solucion implıcita de la ecuacion diferencial si define implıcitamente a unafuncion f(x) que es una solucion explıcita de la ecuacion diferencial.
Ejemplo La ecuacion diferencial x + y y′ = 0 tiene a x2 + y2 − 25 = 0 como solucion implıcita en el
intervalo (−5, 5), que define implıcitamente la solucion explıcita y = f(x) =√
25− x2 .
En efecto, si y = y(x), derivando respecto a x la ecuacion implıcita x2+y2−25 = 0 se tiene 2x+2y(x) y′(x) = 0(derivacion en implıcitas) de donde se obtiene la ecuacion de partida x+ y y′ = 0.
Igualmente, para f(x) =√
25− x2 es f ′(x) = −x√25−x2
, y se cumple que es una solucion explıcita
x+ f(x) f ′(x) = x+√
25− x2 · −x√25− x2
= x− x = 0
Algunas ecuaciones resolubles Disponemos de algunas ecuaciones diferenciales que podemos resolver y yahemos resuelto, por ejemplo y′ = cos(x). Es evidente que la podemos resolver, pues
y′ = cos(x) =⇒ y =
∫cos(x)dx = sen(x) + C
No solo hemos encontrado una solucion sino que hemos encontrado todas las soluciones posibles. Para cadavalor concreto de la contante C tendremos una solucion particular de la ecuacion diferencial, y a la expresionparametrica que las define se le denomina solucion general.
Si lo que buscamos es una solucion concreta, que por ejemplo en x = 0 valga 5 (y(0) = 5), la solucionpedida sera la que cumpla ambas condiciones: en este caso, y = sen(x) + 5. Como la solucion general dependede un unico parametro, un unica condicion anadida determina su valor; incluir mas condiciones a cumplir queparametros a fijar supone que o bien hay condiciones superfluas o no hay solucion.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

116 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.1 Introduccion, conceptos e ideas basicas
Definicion 189.- Este tipo de ecuaciones diferenciales con condiciones adicionales que se refieren todas almismo punto, se denominan problemas de valores iniciales o problemas de Cauchy y se expresan en laforma {
y′ = f(x, y)y(x0) = y0
;
y′′ = f(x; y, y′)y(x0) = y0
y′(x0) = y1
; · · · · · · · · ·
Cuando las condiciones se refieren a mas de un punto se dicen Problemas de contorno (y que no trataremos).
Nota: En general, una ecuacion diferencial de orden n tiene soluciones dependientes de n parametros.
y′′ = cos(x) =⇒ y′ = sen(x) + C1 =⇒ y =
∫(senx+C1)dx = − cos(x) + C1x+ C2
7.1.1 Ecuaciones diferenciales ordinarias de primer orden
Antes de seguir buscando nuevos metodos de resolucion, fijemos notaciones, condiciones y recursos que nosaseguren soluciones y resultados. Para ello comencemos por las ¿mas sencillas?, las de primer orden:
Definicion 190.- Las ecuaciones diferenciales de primer orden pueden escribirse mediante las expresiones:
F (x; y, y′) = 0 y′ = f(x, y) M(x, y)dx+N(x, y)dy = 0
que suelen denominarse la forma general o implıcita, la forma normal y la forma diferencial, todas ellasvalidas y puede usarse una u otra segun interese en cada caso (ver nota siguiente)
Nota: La manipulacion de los terminos de la ecuacion diferencial para cambiar de una forma a otra que puedafacilitarnos la resolucion, no cambia el grueso de las soluciones, aunque sı puede eliminar alguna solucionconcreta o anadirla
Ejemplo Las exprersiones, y′ − xy 12 = 0, y′ = xy
12 y xdx− 1
y12dy = 0 son formas distintas de la misma
ecuacion diferencial, pero la funcion y(x) = 0 no puede ser una solucion en la forma diferencial y sı lo es de lasotras formas (ver el 2o ejemplo de la subseccion 7.2.1 de Ecuaciones diferenciales separables)
Teorema de existencia y unicidad 191.- Sea la ecuacion diferencial y′(x) = f(x, y). Si f es una funcioncontinua en un abierto y conexo D de R2 y si ∂f
∂y es tambien continua en D y (x0, y0) ∈ D , entonces existe
una unica funcion y = ϕ(x) definida en un entorno de x0 que es solucion del problema de Cauchy{y′ = f(x, y)
y(x0) = y0
(Muy burdamente, conexo significa un conjunto en un solo trozo). Es evidente que si no se cumplen las hipotesis,ni existencia ni unicidad esta garantizada (aunque puedan ocurrir) como en el siguiente ejemplo:
Ejemplo Para la ecuacion diferencial y′ = xy12 , se tiene que f(x, y) = xy
12 es continua en y ≥ 0 y ∂f
∂y
lo es en y > 0. Luego en (0, 0) no se cumplen las hipotesis del teorema, sin embargo tanto y1(x) = 0 como
y2(x) = x4
16 son soluciones del problema de Cauchy
{y′ = xy
12
y(0) = 0
Ambas verifican la condicion en el punto y como y121 = 0 e y′1 = 0 se tiene que 0 = y′1 = xy
121 = 0.
Identicamente, y122 = x2
4 e y′2 = x3
4 , luego x3
4 = xx2
4 tambien cumple la ecuacion.
Observacion Han aparecido aquı funciones de varias variables y conviene matizar un par de cosas sobre suuso, dado que no se han estudiado. Las funciones de las que hablamos son funciones reales que dependen devarias variables, pero se construye la continuidad de manera identica a como se hace en una variable, por lo quelas condiciones para la continudad son parecidas. Del mismo modo, la derivacion es distinta (bastante diferente)pero son clave las derivadas parciales, que no es mas que una derivada normal respecto a una variable dondesuponemos para derivar que las otras variables son constantes. Para enfatizarlo se escribe ∂
∂xf(x, y) o ddxf(x, y)
cuyo significado nos es mas conocido.Ası, para f(x, y) = x2y − 2xy3 + y es ∂
∂xf(x, y) = ddxf(x, y) = 2xy − 2y3 y ∂
∂yf(x, y) = x2 − 6xy2 + 1
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

117 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.2 Metodos de resolucion
7.2 Metodos de resolucion
La resolucion de estas ecuaciones diferenciales se basa en la busqueda de “primitivas” (en un sentido amplio),de funciones de una variable y de funciones de dos variables. Los dos primeros metodos que veremos marcanestas dos pautas de resolucion (y todos los demas han de reducirse a alguno de ellos)
7.2.1 Ecuaciones diferenciales separables
Definicion 192.- Si la ecuacion diferencial y′ = f(x, y) puede escribirse en la forma
g(y) y′ = f(x)(
o mejor g(y) dy = f(x) dx)
se denomina ecuacion diferencial separable o de variables separables
Y como parece indicar la segunda opcion, se resuelven mediante integraciones independientes en cada una delas ”variables” x e y :
Una solucion y(x) debe cumplir la ecuacion g(y(x)) y′(x) = f(x), luego ambos terminos seran funciones de x ,por lo que integrando en x ambos lados de la igualdad (y un sencillo cambio de variable)∫
g(y(x)) y′(x) dx =
∫f(x) dx−→
{y(x) = t
y′(x)dx = dt
}−→
∫g(t) dt =
∫f(x) dx
(que en el fondo es)−→{
y(x) = y
y′(x)dx = dy
}−→
∫g(y) dy =
∫f(x) dx
Luego, si denotamos por las mayusculas a sendas primitivas, se tiene que G(y) = F (x) + C . Por lo que lafuncion G(y)− F (x) = C es la solucion general implıcita de la ecuacion diferencial
Ejemplo La ecuacion diferencial x+ y dydx = 0 es separable pues y y′ = −x o
y dy = −x dx =⇒∫y dy =
∫−x dx =⇒ y2
2= −x
2
2+ C =⇒ x2 + y2 = 2C = K
que es la solucion general, con K ≥ 0.
Ejemplo La ecuacion diferencial y′ = xy12 (1) es separable, pues puede escribirse como y−
12dydx = x (2)∫
y−12 dy =
∫x dx =⇒ y
12
12
=x2
2+ C =⇒ y
12 =
x2
4+ 2C =⇒ y =
(x2
4+K
)2
y la solucion general de (2) es y(x) =(x2
4 +K)2
para todo K ∈ R .
Ahora bien, para obtener (2) hemos dividido (1) por y12 y, puesto que buscamos una solucion de la forma
y = y(x), la funcion constantemente 0 no puede ser solucion de (2), pero sı resulta ser una solucion de (1). Es
decir, todas las soluciones de la ecuacion inicial (1) son y(x) = 0 e y(x) =(x2
4 +K)2
, para cada K ∈ R .
Las soluciones, como esta y(x) = 0, que no aparecen incluidas en la expresion con parametros de la solucionsuelen denominarse soluciones singulares.
7.2.2 Ecuaciones diferenciales exactas
La existencia de una solucion implıcita, que es una funcion real de dos variables y cuya derivacion debe reconstruirla ecuacion diferencial, nos indica el metodo para la resolucion: buscar esa “primitiva” cuya derivada es laecuacion.
Una funcion ϕ(x, y) = C que define implıcitamente una funcion y(x), es tambien una solucion implıcitade la ecuacion diferencial. Derivando respecto a x , se tiene
∂ϕ
∂y· ∂y∂x
+∂ϕ
∂x· ∂x∂x
= 0 ⇐⇒ ∂ϕ
∂y· dydx
+∂ϕ
∂x= 0,
con expresiones mas comunes: f2(x, y) · y′ + f1(x, y) = 0 ⇐⇒ f1(x, y) dx+ f2(x, y) dy = 0
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

118 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.2 Metodos de resolucion
Definicion 193.- Una ecuacion de primer orden dada en la forma diferencial por
M(x, y) dx+N(x, y) dy = 0
se dice que es exacta en un abierto y conexo D si existe ϕ tal que
∂ϕ
∂x(x, y) = M(x, y)
∂ϕ
∂y(x, y) = N(x, y)
para cada (x, y) ∈ D . Entonces, ϕ(x, y) = C es la solucion general de la ecuacion diferencial.
Teorema 194.- Si se cumple que ∂M∂y (x, y) = ∂N
∂x (x, y) en cada punto de un abierto y convexo D , existe ϕ
tal que ∂ϕ∂x (x, y) = M(x, y) y ∂ϕ
∂y (x, y) = N(x, y) en cada punto de D .
Calculo de ϕ : Si sabemos que ϕ existe, podemos hacerlo sencillamente obligando a que cumpla lo que tieneque cumplir. Para ilustrar el metodo, consideremos el siguiente ejemplo de ecuacion diferencial exacta:
(y2+y cosx)dx+ (2xy+3y2+senx)dy = 0 ya que ∂∂y (y2+y cosx) = 2y+cosx = ∂
∂x (2xy+3y2+senx)
• ϕ debe verificar que ∂ϕ∂x (x, y) = M(x, y) = y2 +y cosx , luego considerando y como constante, ϕ debe
ser una primitiva de M , es decir,
ϕ(x, y) =
∫M(x, y) dx =
∫y2 + y cosx dx = xy2 + y senx+K(y)
siendo K(y) la constante de integracion, que sera constante respecto a x pero que podrıa contener algunaconstante y (recordad, en este punto consideramos y como constante)
• ϕ tambien debe verificar que ∂ϕ∂y (x, y) = N(x, y) = 2xy+3y2+senx , luego debe verificarse que
2xy+3y2+senx = ∂∂yϕ(x, y) = ∂
∂y (xy2 + y senx+K(y)) = 2xy + senx+K ′(y)
De donde, K ′(y) = 3y2 y por consiguiente
K(y) =
∫K ′(y)dy =
∫3y2dy = y3 + C
con C la constante de integracion. Luego hemos construido
ϕ(x, y) = xy2 + y senx+K(y) = xy2 + y senx+ y3 + C
y se tiene entonces que xy2 + y senx+ y3 + C = 0 es la solucion general implıcita de la ecuacion diferencial
Observaciones Unas consideraciones interesantes sobre este calculo y el metodo
1.- En el segundo paso, K ′(y) es una funcion de y , luego constante o con la variable y , pero en ningun casodebe tener la variable x . Si esto sucede, o bien hemos errado en los calculos o bien la ecuacion diferencialno es exacta
2.- Antes de intertar calcular la funcion ϕ , debe comprobarse que la ecuacion diferencial es exacta
3.- La construccion de ϕ puede hacerse tambien intercambiando las variables x e y en los dos pasos, es decir,comenzando por considerar ϕ una primitiva de N respecto a y . De hecho, conviene comenzar por la quetenga el calculo de la primitiva mas sencillo.
4.- Es evidente del planteamiento de este metodo, que se estan usando las variables x e y como independientes,y tambien es independiente el calculo de la funcion “primitiva”. El resultado es independiente de sibuscamos una solucion y = y(x) o una x = x(y); nosotros decidiremos de que tipo buscamos y nosaseguraremos entonces de que todas esas soluciones se encuentren.
Nota: La ecuaciones separables tambien son ecuaciones exactas, pues si g(y) y′ = f(x), entonces en la formadiferencial f(x) dx− g(y) dy = 0 se cumple obviamente la condicion anterior.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

119 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.2 Metodos de resolucion
7.2.3 Factores integrales
Desgraciadamente, las ecuaciones diferenciales no son habitualmente exactas, pero en ocasiones lo son si semultiplican por una funcion adecuada.
Definicion 195.- Se dice que la funcion µ(x, y) no nula en un abierto, es un factor integrante de la ecuacionM(x, y) dx+N(x, y) dy = 0 si la ecuacion diferencial
µ(x, y)(M(x, y) dx+N(x, y) dy
)= 0 ⇐⇒ µ(x, y)M(x, y) dx+ µ(x, y)N(x, y) dy = 0
es exacta.
Observar que si µ(x, y) es no nula, las soluciones de la nueva ecuacion solo pueden ser soluciones de la ecuacioninicial. En caso de no ser ası, deben comprobarse aquellas soluciones que provengan de µ(x, y) = 0.
Buscar factores integrantes cualesquiera no es tarea facil, pero no es excesivamente complejo si el factordepende de una sola variable:
7.2.3.1 Factores integrales de la forma µ(x) o µ(y)
Veamos las condiciones para admitir un factor integrante dependiente unicamente de la variable x . La funcionµ(x) es un factor integrante si cumple que
∂
∂y
(µ(x)M(x, y)
)=
∂
∂x
(µ(x)N(x, y)
)µ(x)
∂M(x, y)
∂y=N(x, y)
∂µ(x)
∂x+ µ(x)
∂N(x, y)
∂x
µ(x)
(∂M(x, y)
∂y− ∂N(x, y)
∂x
)=N(x, y)µ′(x)
∂M(x,y)∂y − ∂N(x,y)
∂x
N(x, y)=µ′(x)
µ(x)= f(x) =⇒
∫ ∂M(x,y)∂y − ∂N(x,y)
∂x
N(x, y)dx =
∫µ′(x)
µ(x)dx = ln
(µ(x)
)de donde µ(x) = exp
(∫∂M(x,y)
∂y − ∂N(x,y)∂x
N(x,y) dx
).
Analogamente, para un factor integrante de la forma µ(y) debe ser µ′(y)µ(y) =
∂M∂y −
∂N∂x
−M = f(y).
Ejemplo La ecuacion 2 sen(y2)dx+ xy cos(y2)dy = 0 admite un factor integrante µ(x).En efecto,
∂M
∂y− ∂N
∂x= 2 cos(y2)2y − y cos(y2) = 3y cos(y2)
y se eliminan todas las y si dividimos por N ,
∂M∂y −
∂N∂x
N=
2 cos(y2)2y − y cos(y2)
xy cos(y2)=
3y cos(y2)
xy cos(y2)=
3
x=µ′(x)
µ(x)
de donde ln(µ(x)
)=
∫3x dx = lnx3 =⇒ µ(x) = x3 . Luego es exacta la ecuacion:
2x3 sen(y2)dx+ x4y cos(y2)dy = 0 ←− ∂M
∂y− ∂N
∂x= 2x2 cos(y2)2y − 4x3y cos(y2) = 0
Resolviendo, ϕ(x, y) =
∫M(x, y)dx =
∫2x3 sen(y2)dx =
x4
2sen(y2) +K(y)
y como x4y cos(y2) = N(x, y) = ∂ϕ∂y = x4
2 cos(y2)2y +K ′(y) =⇒ K ′(y) = 0 =⇒ K(y) = C
de donde, x4
2 sen(y2) = C o x4 sen(y2) = C es la solucion general.Comprobar que tambien admite un factor integral de la forma µ(y) y resolverla.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

120 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.2 Metodos de resolucion
7.2.4 Ecuaciones lineales
Un caso de factor integrante son las ecuaciones lineales, que admiten siempre un factor µ(x). Pero que sonreconocibles por:
Definicion 196.- Se dice que una ecuacion diferencial de orden uno es lineal, si puede escribirse en la forma
dy
dx+ P (x) y = Q(x)
y su factor integral es, µ(x) = exp
(∫P (x)dx
)= e(
∫P (x)dx) .
En efecto, si(P (x)y −Q(x)
)dx + dy = 0 se tiene
∂M∂y −
∂N∂x
N=P (x)− 0
1= P (x) =
µ′(x)
µ(x)de donde
se llega al resultado ln(µ(x)) =
∫P (x)dx =⇒ µ(x) = e(
∫P (x)dx) . Entonces, como µ(x)P (x) = µ′(x), se tiene
µ(x)(y′ + P (x) y) = µ(x) y′ + µ(x)P (x) y = µ(x)Q(x)
µ(x) y′ + µ′(x) y = µ(x)Q(x)
(µ(x) y)′= µ(x)Q(x)
µ(x)y =
∫µ(x)Q(x) dx =⇒ y =
1
µ(x)
∫µ(x)Q(x) dx
Luego no solo estas ecuaciones lineales ofrecen una solucion alcanzable con un metodo sencillo, sino que ademasla solucion viene directamente dada de forma explıcita (algo no excesivamente habitual como hemos visto).
Las ecuaciones diferenciales lineales aparecen con mucha frecuencia en las aplicaciones practicas y, al igualque aquı, su generalizacion a ordenes superiores ofrece uno de los pocos tipos de ecuaciones resolubles pormetodos generales (siempre y cuando podamos encontrar las primitivas, ¡claro!).
Ejemplo La ecuacion x2y′ + x(x+ 2)y = ex es lineal, si la escribimos en la forma y′ + x+2x y = ex
x2 .
Ademas,
∫(1 + 2
x )dx = x + 2 ln |x| = x + ln(x2) y su factor integrante es µ(x) = ex+ln(x2) = exx2 . De
donde
x2exy′ + xex(x+ 2)y = e2x ⇐⇒ (x2exy)′ = e2x ⇐⇒ x2exy =
∫e2xdx =
e2x
2+ C
y =ex
2x2+ C
e−x
x2⇐⇒ y =
ex +Ke−x
2x2
7.2.5 Ecuaciones un poco especiales *
7.2.5.1 Ecuaciones de Bernoulli
Es una especie de generalizacion de la lineal, por lo que puede remitirse a una de ellas, pero tambien admite unfactor integrante que genariza el de la lineal
Definicion 197.- Se dice que una ecuacion diferencial de orden uno es de Bernoulli, si puede escribirse en laforma
dy
dx+ P (x) y = Q(x)yα (α ∈ R)
y que se convierte en lineal con el cambio ν = y1−α .
Ademas, directamente admite el factor integral µ(x, y) =1
yαexp
(∫(1−α)P (x)dx
)=e(1−α)(
∫P (x)dx)
yα
Ejercicio Comprobar que la ecuacion diferencial y′ = yx + xy3 es de Bernoulli, y obtener su solucion
x2
y2 (2 + x2y2) = C mediante el cambio a una lineal y tambien directamente con el factor de integracion.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

121 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.3 Aplicaciones
7.2.5.2 Ecuaciones reducibles a separables
Proposicion 198.- Si una ecuacion diferencial y′ = f(x, y) puede expresarse en la forma
y′ = f(x, y) = g(yx
)el cambio y = x z la convierte en una ecuacion de variables separables en x y z
Nota: Una caracterizacion sencilla para este tipo es comprobar si se cumple que−M(1, yx )
N(1, yx ) = −M(x,y)N(x,y) , pues
entonces obtenemos g( yx ) directamente. En particular, se obtiene rapidamente este resultado si M y N sonpolinomios cuyos monomios son todos del mismo grado (ver ejemplo siguiente).
Ejemplo La ecuacion (x2 − 3y2)dx+ 2xy dy = 0 es reducible a separables, pues
−M(x, y)
N(x, y)=−x2 + 3y2
2xy=
3y2−x2
x2
2xyx2
=3 y
2
x2 − 1
2 yx
Entonces haciendo el cambio y = zx , con dy = z dx+ x dz , se tiene
(x2 − 3y2)dx+ 2xy dy = 0⇐⇒ (x2 − 3(zx)2)dx+ 2x(zx)(z dx+ x dz) = 0
⇐⇒ x2(1− 3z2)dx+ 2x2z2dx+ 2x3z dz = 0
⇐⇒ x2(1− z2)dx+ 2x3z dz = 0 ⇐⇒ 2x3z dz = −x2(1− z2)dx
=⇒ 2z
1− z2dz = −x
2
x3dx =⇒
∫−2z
1− z2dz =
∫1
xdx
Luego ln∣∣1− z2
∣∣ = ln |x| + C (C ∈ R) =⇒ ln∣∣∣ 1−z2
x
∣∣∣ = lnK (K > 0) =⇒ x2−y2
x3 = C (C ∈ R) =⇒x2 − y2 = x3C con C ∈ R .
Las soluciones z = ±1 (dividimos por 1 − z2 ), es decir y = ±x han sido eliminadas, sin embargo estanincluidas en la solucion general con C = 0
Ejercicio Comprobar que, en el ejemplo, las soluciones y(x) = x e y(x) = −x lo son de la ecuaciondiferencial inicial y no contradicen el Teorema de existencia y unicidad para un problema de valores iniciales en(1, 1), ni en (1,−1) y tampoco en (0, 0)
7.3 Aplicaciones
Como ya hemos comentado que muchas de las leyes y relaciones cientıficas obtienen su expresion mediante estetipo de ecuaciones y, en particular, casi todas las expresiones de los sucesos con variaciones de magnitudesrelacionadas (variacion de la velocidad en funcion del tiempo, crecimiento de cultivos segun la temperatura, ...)
7.3.1 Trayectorias ortogonales
Un facil ejemplo del uso de las ecuaciones diferenciales lo encontramos en la busqueda de trayectorias ortogonales(curvas que intersecan a otras con angulos rectos), cuya dualidad aparece con frecuencia: meridianos y paralelosterraqueos, curvas de fuerza y lıneas equipotenciales de los campos electricos, ...
Dada una familia uniparametrica de curvas F (x, y, c) = 0 (para cada valor de c la ecuacion representauna curva en R2 ), puede representarse mediante una ecuacion diferencial de la forma
y′ = f(x, y)
derivando implıcitamente F (x, y, c) = 0 y eliminando el parametro entre ambas ecuaciones
Definicion 199.- Si una familia de curvas viene representada por y′ = f(x, y), entonces las trayectoriasortogonales de la familia deben cumplir la ecuacion diferencial
y′ =−1
f(x, y)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

122 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.4 Ejercicios
Nota: : Baste recordar que en una curva y = g(x), la pendiente en un punto x0 viene dada por m = g′(x0) y
la recta ortogonal tiene que tener de pendiente −1m
7.3.1.1 Trayectorias de angulo β
Estas trayectorias se puede generalizar a cualquier angulo, aunque no sea un angulo recto. Si buscamos lastrayectorias que formen un angulo β con la familia y′ = f(x, y), como esto significa que y′ = f(x, y) = tgα ,para que las curvas buscadas formen con ellas un angulo β deben cumplir la condicion y′ = tg(α+ β). Luego,al ser α = arctg(f(x, y)), se tiene que
y′ = tg(α+ β) =tgα+ tg β
1− tgα · tg β=
f(x, y) + tg β
1− f(x, y) · tg β
es la ecuacion a resolver.
7.3.2 Modelado de problemas
Hay muchos problemas que pueden modelarse como ecuaciones diferenciales: velocidad de caida de un para-caidista, desintegracion radiactiva, variaciones de temperatura, . . . o por ejemplo variaciones de las mezclas, quees el ejemplo que vamos a usar. Quiza sea la manera mas sencilla de verlo.
Ejemplo Un tanque contiene 200 l de agua en los que hay disueltos 40 kg de sal. Al tanque, le entran10 l/min cada uno de los cuales contiene 0′7 kg de sal disuelta y, la mezcla homogenea sale a razon de 5 l/min .Encontrar la cantidad de sal y(t) que hay en el tanque en cualquier tiempo t .
La variacion de sal en la unidad de tiempo, y′ = dydt , es por supuesto la cantidad entrante menos la saliente:
entran 10 l/min a 0′7Kg/l que suponen 10( lmin )× 0′7(kgl ) = 7 Kg
min y salen 5 l/min de una salmuera formadapor los y(t) kilos de sal que hay en este momento disueltos en los 200 + 10t− 5t litros actuales (en cada unidadde tiempo anadimos 10 litros y quitamos 5, por lo que aumentamos a razon de 5 litros por unidad de tiempo).Luego tenemos el problema de valores iniciales
y′(t) = 7− y(t)
200 + 5ty(0) = 40
puesto que incialmente (t = 0) existıan 40 kilos de sal en el agua.
7.4 Ejercicios
7.188 Probar que y(x) = ex2
∫ x
0
e−t2
dt es una solucion de la ecuacion y′ = 2xy + 1.
7.189 Para que valores de la constante m sera y = emx solucion de la ecuacion 2y′′′ + y′′ − 5y′ + 2y = 0
7.190 Comprobar que la ecuacion diferencial xyy′ = (x+ 1)(y + 1) es separable y encontrar la curva y(x)
solucion cumpliendo que y(1) = 0
7.191 Comprobar que las siguientes ecuaciones son exactas y resolverlas:
a) (3x2y + ey)dx+ (x3 + xey − 2y)dy = 0 b)(x2y3 − 1
1+9x2
)dxdy + x3y2 = 0
c) (ey2 − 1
sen y sen2 x )dx+ (2xyey2 − cos x cos y
sen x sen2 y )dy = 0 d) y dx+x dy1−x2y2 + x dx = 0
7.192 Para cada una de las ecuaciones diferenciales siguientes, comprobar si son separables y si son exactas o
admiten un factor de integracion de la forma µ(x) y µ(y). Resolverlas por esos metodos.
a) dydx = y−1xex+y2
b) y′ = xy+3x−(y+3)(x+4)(y−2)
c) exyy′ = e−y + e−2x−y d) (x4 + y4)dx− xy3dy = 0
e) 2(y2 + yx)dx− x2dy = 0 f) (x+ y)dy = (1− x− y)dx
g) xy − y = y2 dxdy h) y′ = y
x+y
i) (2x+ 3y − 1)dx− 4(x+ 1)dy = 0 j) (x2 + y2)dy + (y2 − 2xy)dx = 0
k) x sen( yx )y′ = y sen( yx ) + x l) (2xy2 + y)dx+ (2y3 − x)dy = 0
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

123 – Fundamentos de Matematicas : Ecuaciones Diferenciales Ordinarias 7.4 Ejercicios
7.193 Se sabe que la ecuacion P (x, y)dx + (x2 + yx )dy = 0 admite como factor integrante a µ(x) = x , que
ddxP (x, y) = 3y y que P (0, 1) = 0.Encontrar P (x, y) y hallar la solucion de la ecuacion que pasa por el punto (x0, y0) = (1, 1)
7.194 Comprobar que son lineales (en y o en x) y resolverlas:
a) x2y′ + x(x+ 2)y = ex b) y′ + y = 11+e2x c) y′ + y cosx = sen 2x
d) (y − 2xy − x2)dx+ x2dy = 0 e) x′ + x = ey f) dxdy + x
y + y−3 = 0
g) (1 + x4)y′ + 8x3y = x h) dydx = y+3
1−x i) y2dx+ (x+ xy − 1y )dy = 0
7.195 Resolver la ecuacion diferencial de orden dos y′′ + (y′)2 = 0
7.196 Resolver la ecuacion
∫ x
0
y(t)dt =x(y − x)
2
7.197 Probar que el cambio de variable z = g(y) convierte a la ecuacion g′(y)y′ + g(y)p(x) = f(x) en una
ecuacion lineal en z . Utilizar esto para resolver la ecuacion ey2
(2yy′ + 2x ) = 1
x2
7.198 Comprobar que el cambio de variable y = xz , con dy = zdx+ xdz , convierte la ecuacion
(x2 + 2xy − y2)dx+ (y2 + 2xy − x2)dy = 0en una separable en las variables x y z , y resolverla
7.199 Hallar las trayectorias ortogonales a la familia de curvas y2 = cex+x+1, con c una constante arbitraria.
7.200 Hallar la familia ortogonal de curvas a la familia de curvas dadas por la ecuacion y = ln(tg x+ c)
7.201 Encontrar la curva de la familia de trayectorias ortogonales a y(x3 + c) = 3 que pasa por el punto (3, 1)
7.202 Una curva arranca desde el origen por el primer cuadrante. El area bajo el arco de la curva entre (0, 0)
y (x, y) es un tercio del area del rectangulo que tiene a esos puntos como vertices opuestos. Hallar laecuacion de las curvas que cumplen dicha condicion y la familia de curvas ortogonales a ellas
7.203 Un gran deposito contiene 1000 litros de agua en la que estan disueltos 30 Kgs. de polvo de tinta. A
partir del instante t = 0 se introduce agua pura a razon de 3 l/min y la mezcla sale del deposito a razonde 2 l/min . Encontrar la funcion que rige la cantidad de tinta en cada momento
7.204 Un deposito tiene 200 Kg. de sal disueltos en 1000 litros de agua. A partir del instante t = 0 se introduce
agua pura a razon de 2 l/min y la salmuera (que se mantiene homogenea) sale del deposito a razon de 2l/min. ¿Cuanto tiempo se necesitara para reducir la cantidad de sal a la mitad?
7.205 En un deposito con 1 m3 de salmuera se comienza a introducir agua pura a razon de 3 litros por minuto
y la mezcla que se mantiene homogenea sale del deposito a razon de 2 l/min . Si al cabo de 1000 minutosquedan en la mezcla 20 kg de sal, ¿cuanta sal habıa en el momento de comenzar a echar el agua?
7.206 Un vino tinto se saca de la bodega a 10 grados centigrados y se deja reposar en un cuarto con temperatura
de 23 grados. Calcular la formula para la temperatura en funcion del tiempo, si el vino tarda 10 min.en alcanzar 13 grados. (Se supone que se verifica la ley de Newton: “la velocidad de enfriamiento de uncuerpo es directamente proporcional a la diferencia de temperaturas entre el y el medio que le rodea”).
7.207 Un torpedo se desplaza a una velocidad de 60 millas por hora en el momento en el que se le agota el
combustible. Si el agua se opone a su movimiento con una fuerza proporcional a la velocidad, y si en unamilla de recorrido reduce su velocidad a 30 millas por hora, ¿a que distancia se detendra?
7.208 Un tanque contiene 800 litros de salmuera en la que se han disuelto 8 kgs. de sal. A partir del instante
t=0 comienza a entrar salmuera, con una concentracion de 250 grs. de sal por litro, a razon de 4 litrospor minuto. La mezcla se mantiene homogenea y abandona el tanque a razon de 8 litros por minuto.
a) Hallar la cantidad de sal en el tanque al cabo de una hora.
b) Hallar la cantidad de sal en el tanque cuando solo quedan 200 litros de salmuera.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

124 – Fundamentos de Matematicas
Unidad IV
Algebra Lineal
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

125 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 8
Matrices y sistemas lineales
8.1 Definiciones basicas
Una matriz es una tabla rectangular de numeros, es decir, una distribucion ordenada de numeros. Losnumeros de la tabla se conocen con el nombre de elementos de la matriz. El tamano de una matrizse describe especificando el numero de filas y columnas que la forman. Si A es una matriz de m filas yn columnas, Am×n , se usara aij para denotar el elemento de la fila i y la columna j y, en general, serepresentara por
A = (aij) 1≤i≤m1≤j≤n
= (aij)m×n =
a11 a12 · · · a1n
a21 a22 · · · a2n
...... · · ·
...am1 am2 · · · amn
.
Dos matrices son iguales si tienen igual tamano y los elementos correspondientes de ambas matrices iguales.Una matriz An×n (o An ) se denomina matriz cuadrada de orden n y de los elementos de la forma a11 ,
a22 , . . . , ann se dice que forman la diagonal principal. De una matriz A1×n se dice que es una matriz filay de una matriz Am×1 que es una matriz columna.
8.1.1 Operaciones con las matrices
Las matrices con las que trabajaremos habitualmente seran matrices reales, sus elementos seran numeros reales(sin embargo, los resultados y definiciones dados aquı son validos para matrices de numeros complejos).
Suma: Si A y B son dos matrices del mismo tamano, m×n , la suma A+B es otra matriz de tamano m×ndonde el elemento ij de A+ B se obtiene sumando el elemento ij de A con el elemento ij de B . Es decir,si A = (aij)m×n y B = (bij)m×n , entonces A+B = (aij + bij)m×n .
El neutro de la suma es la matriz cero, 0, con todos sus elementos cero, y la matriz opuesta de A , sedesigna por −A , y es −A = (−aij)m×n .
Producto por escalares: Si A es una matriz m×n y k ∈ R un escalar, el producto kA es otra matriz delmismo tamano donde cada elemento de A aparece multiplicado por k . Es decir, kA = (kaij)m×n .
Evidentemente, −A = (−1)A y A−B = A+ (−B).
Producto de matrices: Si Am×n y Bn×p el producto AB es otra matriz de tamano m×p tal que, elelemento eij de AB se obtiene sumando los productos de cada elemento de la fila i de A por el elementocorrespondiente de la columna j de B . Es decir,
eij = FAi × CBj =(ai1 ai2 · · · ain
)b1jb2j...bnj
= ai1b1j + ai2b2j + · · ·+ ainbnj =
n∑k=1
aikbkj
(lo denotaremos por eABij = FAi × CBj cuando queramos significar la fila y columna que intervienen).
Nota: Esta definicion requiere el mismo numero de columnas en la primera matriz que de filas en la segunda: a11 a12 a13 a14
a21 a22 a23 a24
a31 a32 a33 a34
3×4
·
b11 b12 b13 b14 b15
b21 b22 b23 b24 b25
b31 b32 b33 b34 b35
b41 b42 b43 b44 b45
4×5
=
e11 e12 e13 e14 e15
e21 e22 e23 e24 e25
e31 e32 c33 e34 e35
3×5
puesto que para el calculo de eij ha de haber tantos elementos en la fila i de A (numero de columnas de A)como en la columna j de B (numero de filas de B ). En forma sinoptica con los tamanos (m×n)·(n×p) = (m×p).
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

126 – Fundamentos de Matematicas : Algebra Lineal 8.2 Sistemas de ecuaciones lineales
Observacion: Cada elemento de la matriz producto puede obtenerse de manera independiente, por lo que no esnecesario calcularlos todos si solo son necesarios unos pocos. Ası:
• eABij =FAi · CBj ? FABi =FAi ·B ? CABj =A · CBj ? eABCij =FAi · CBCj =FAi ·B · CCj
La matriz cuadrada I = In =
1 0 · · · 00 1 · · · 0...
.... . .
...0 0 · · · 1
, formada por ceros excepto en la diagonal principal que tiene
unos, de llama matriz identidad y es el neutro del producto de matrices (tomada del tamano adecuado). Esdecir, para toda Am×n se tiene que ImAm×n = Am×n y Am×nIn = Am×n .
Propiedades 200.- Suponiendo tamanos adecuados para que las operaciones sean posibles:
a) A+B = B +A (conmutativa de la suma).
b) A+ (B + C) = (A+B) + C ; A(BC) = (AB)C (asociativas de la suma y del producto).
c) A(B+C) = AB+AC ; (A+B)C = AC+BC (distributivas por la izquierda y por la derecha).
d) a(B + C) = aB + aC ; ∀a ∈ R .
e) (a+ b)C = aC + bC ; ∀a, b ∈ R .
f) a(BC) = (aB)C = B(aC); ∀a ∈ R .
En general, NO es cierto que:? AB = BA? Si AB = 0 tengan que ser A = 0 o B = 0? Si AB = AC necesariamente sea B = C
Ejemplo 201 Con A=
(0 10 2
), B=
(3 70 0
)y C=
(−1 −10 0
)tenemos AB=
(0 00 0
)6= BA=
(0 170 0
),
es decir AB 6= BA y AB = 0 con A 6= 0 y B 6= 0. Ademas AC = 0 = AB , pero B 6= C . 4
8.1.2 Matriz transpuesta
Definicion 202.- Si A es una matriz m×n llamamos matriz transpuesta de A a la matriz At de tamanon×m que tiene por filas las columnas de A y por columnas las filas de A . Es decir, el elemento ij de At
coincide con el elemento ji de A. (a11 a12 a13
a21 a22 a23
)t=
a11 a21
a12 a22
a13 a23
Proposicion 203.- Se verifican las siguientes propiedades:
a) (At)t = A . b) (A+B)t = At +Bt . c) (kA)t = kAt .
d) (AB)t = BtAt y, en general, (A1A2 · · ·An)t = Atn · · ·At2At1 .
Demostracion:Las tres primeras son claras. Veamos la cuarta: eB
tAt
ij = FBt
i × CAtj = CBi × FAj = FAj × CBi = eABji . LuegoBtAt = (AB)t .
8.2 Sistemas de ecuaciones lineales
Definicion 204.- Se denomina ecuacion lineal de n variables (o incognitas), xi , aquella ecuacion que puedeexpresarse en la forma: a1x1 + a2x2 + · · ·+ anxn = b , donde los ai , b ∈ R .
Una solucion de la ecuacion lineal es un conjunto ordenado de numeros reales (s1, s2, . . . , sn), tales quea1s1 + a2s2 + · · ·+ ansn = b .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

127 – Fundamentos de Matematicas : Algebra Lineal 8.2 Sistemas de ecuaciones lineales
Ejemplo Una ecuacion lineal de 2 incognitas, 2x + y = 3, es una representacion analıtica de una recta delplano pues las soluciones de la ecuacion son cada uno de los puntos de la recta y el conjunto solucion es todala recta, todos los puntos de la recta. Una ecuacion lineal de 3 incognitas representa un plano en el espacio.
En una ecuacion lineal no pueden aparecer productos, ni potencias, ni otras expresiones, . . . , de las variables.
Definicion 205.- Se denomina sistema de m ecuaciones lineales con n incognitas a la reunion de mecuaciones lineales sobre las mismas n incognitas, y se escribe en la forma:
a11x1 + a12x2 + · · ·+ a1nxn = b1a21x1 + a22x2 + · · ·+ a2nxn = b2
......
am1x1 + am2x2 + · · ·+ amnxn = bm
Una n -upla (s1, s2, . . . , sn) es solucion del sistema si es solucion de todas y cada una de las ecuaciones.
Ejemplo El par (−7, 9) es una solucion del sistema de ecuaciones
{x+ y = 2
2x+ y = −5, pues es solucion de cada
una de las 2 ecuaciones. De hecho, es el unico punto comun a esas dos rectas (ver la ejemplo anterior).Un sistema de ecuaciones lineales puede no tener solucion (con dos incognitas, las rectas paraleras no tienen
puntos en comun) o infinitas (las dos ecuaciones representan la misma recta).
Si un sistema no tiene solucion, suele decirse que es incompatible; si existe solucion y es unica compatibledeterminado y compatible indeterminado si tiene un conjunto infinito de soluciones.
Lenguaje matricial de los sistemas de ecuaciones Un sistema de ecuaciones lineales, tambien puedeescribirse como AX = B donde A = (aij)m×n , X = (xi)n×1 y B = (bj)m×1 .
AX =
a11 a12 a13 · · · a1n
a21 a22 a23 · · · a2n
· · · · · · · · · · · · · · ·am1 am2 am3 · · · amn
x1
x2
x3
...xn
=
b1b2...bm
= B
La matriz A se denomina matriz de los coeficientes, la matriz columna B se denomina matriz de los terminosindependientes y una S = (si)n×1 es solucion de sistema si verifica que AS = B .
Ejemplo Para el sistema del ejemplo anterior{x+ y = 2
2x+ y = −5←→
(1 12 1
)(xy
)=
(2−5
); (−7, 9) es solucion, pues
(1 12 1
)(−79
)=
(2−5
)4
8.2.1 Matrices elementales
Definicion 206.- Llamaremos operacion elemental en las filas de las matrices, a las siguientes:
a) Intercambiar la posicion de dos filas.
b) Multiplicar una fila por una constante distinta de cero.
c) Sumar a una fila un multiplo de otra fila.
Definicion 207.- Se dice que una matriz cuadrada En×n es una matriz elemental si se obtiene de efectuaruna sola operacion elemental sobre la matriz identidad In×n .
Teorema 208.- Si la matriz elemental Em×m resulta de efectuar cierta operacion elemental sobre las filas deIm y si Am×n es otra matriz, el producto EA es la matriz m×n que resulta de efectuar la misma operacionelemental sobre las filas de A . .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

128 – Fundamentos de Matematicas : Algebra Lineal 8.2 Sistemas de ecuaciones lineales
Ejemplo Son matrices elementales las matrices
E1 =
0 1 01 0 00 0 1
, E2 =
1 0 00 2 00 0 1
y E3 =
1 0 00 1 03 0 1
,
que se obtienen de I3 , intercambiando la primera con la segunda fila (F1 ↔ F2 ), multiplicando la segunda filapor 2 (2F2 ) y sumando a la tercera fila la primera fila multiplicada por 3 (F3 + 3F1 ), respectivamente. Y siA = (aij)3×4 , se tiene
E1A=
a21 a22 a23 a24
a11 a12 a13 a14
a31 a32 a33 a34
, E2A =
a11 a12 a13 a14
2a21 2a22 2a23 2a24
a31 a32 a33 a34
y
E3A=
a11 a12 a13 a14
a21 a22 a23 a24
a31+3a11 a32+3a12 a33+3a13 a34+3a14
. 4
Observacion 209.- Es claro, que una vez realizada una operacion elemental puede deshacerse mediante otraoperacion elemental: ası, si intercambiamos la fila i con la fila j , la operacion elemental que lo deshace esintercambiar de nuevo la fila i con la fila j ; si multiplicamos la fila i por k 6= 0 se deshace multiplicandolade nuevo por 1
k y si sumamos a la fila i la fila j multiplicada por k lo deshacemos restando a la fila i la filaj multiplicada por k (sumando la fila j multiplicada por −k ). Denotando por E∗1 , E∗2 y E∗1 a las matriceselementales que deshacen las operaciones elementales dadas por las matrices elementales E1 , E2 y E3 delejemplo anterior, tenemos que
E∗1 =
0 1 01 0 00 0 1
= E1, E∗2 =
1 0 00 1
2 00 0 1
y E∗3 =
1 0 00 1 0−3 0 1
.
Entonces, si E∗ es la matriz elemental que deshace la operacion realizada por E , se tiene que E∗(EA) = A .
Teorema 210.- Si E es una matriz elemental, los sistemas AX = B y (EA)X = EB tienen las mismassoluciones.
Demostracion:En efecto, si S es solucion del primer sistema, AS = B , luego (EA)S = E(AS) = EB y S es tambien soluciondel segundo. Y viceversa, si (EA)S = EB y E∗ es la matriz elemental que deshace E , multiplicando en laigualdad, se tiene: E∗(EA)S = E∗EB =⇒ AS = B .
8.2.2 Metodo de Gauss
El Teorema 210 anterior asegura que haciendo sobre el sistema AX = B unicamente operaciones elementalesllegamos a un sistema con las mismas soluciones (sistema equivalente). El siguiente proceso para obtener unsistema equivalente que da las soluciones de manera mas sencilla se conoce como metodo de Gauss.
Ademas, al operar en el sistema debemos hacer operaciones elementales sobre la matriz A de los coeficientesy, las mismas operaciones sobre B para que se mantenga la equivalencia. Luego esto nos lleva a:
Definicion 211.- En un sistema lineal AX = B , se llama matriz ampliada del sistema a la matriz (A|B)formada anadiendo a la matriz de coeficientes A la matriz columna de los terminos independientes B .
Mediante operaciones elementales, se hacen ceros en la matriz ampliada del sistema, para obtener una matrizescalonada, con ceros por debajo de la “escalera”. Esta matriz escalonada debe cumplir:
1.- Si una fila consta unicamente de ceros debe ir en la parte inferior de la matriz.
2.- Si dos filas seguidas no constan solo de ceros, el primer elemento distinto de cero de la fila inferior debeencontrarse mas a la derecha que el primer elemento distinto de cero de la fila superior.
El primer elemento distinto de cero de cada fila lo llamaremos elemento principal y las incognitas corres-pondientes a estos elementos incognitas principales. (Los elementos principales “marcan” la escalera.)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

129 – Fundamentos de Matematicas : Algebra Lineal 8.2 Sistemas de ecuaciones lineales
Ejemplo 2125x3 + 10x4 + 15x6 = 5
x1 + 3x2 − 2x3 + 2x5 = 02x1 + 6x2 − 5x3 − 2x4 + 4x5 − 3x6 = −1
2x1 + 6x2 + 8x4 + 4x5 + 18x6 = 6
Apliquemos el metodo a la matriz ampliada del sistema (A|B):
(A|B) =
0 0 5 10 0 15 51 3 −2 0 2 0 02 6 −5 −2 4 −3 −12 6 0 8 4 18 6
Por la operacion (a) cambiamos la fila 1 porla fila 2 (F1 ↔ F2)
1 3 −2 0 2 0 00 0 5 10 0 15 52 6 −5 −2 4 −3 −12 6 0 8 4 18 6
Por (b) hacemos cero el 2 de F3 (F3 − 2F1) yel de F4 (F4 − 2F1)
3 −2 0 2 0 00 0 5 10 0 15 50 0 −1 −2 0 −3 −10 0 4 8 0 18 6
Hacemos 0 el −1 de F3 (F3 + 15F2) y el 4 de
F4 (F4 − 45F2)
3 −2 0 2 0 00 0 10 0 15 50 0 0 0 0 0 00 0 0 0 0 6 2
Cambiamos F3 por F4 (F3 ↔ F4)
3 −2 0 2 0 00 0 10 0 15 50 0 0 0 0 20 0 0 0 0 0 0
Esta matriz es escalonada, y nos proporcionael sistema equivalente
x1 + 3x2 − 2x3 + 2x5 = 05x3 + 10x4 + 15x6 = 5
6x6 = 20 = 0
=⇒
x1 = −3x2 + 2x3 − 2x5
x3 = 5−10x4−15x6
5x6 = 2
6
cuyas soluciones se encuentran facilmente sustituyendo de abajo hacia arriba, obteniendose: x6 = 13 , x3 = −2x4 ,
x1 = −3x2 − 4x4 − 2x5 , donde x2 , x4 y x5 pueden tomar cualquier valor. Es decir, todas las soluciones son:(−3x2− 4x4− 2x5, x2, −2x4, x4, x5,
13 ) para cualquiera valores de x2 , x4 y x5 . 4
Si el ultimo elemento principal esta en la columna ampliada, el sistema no tiene solucion: claramente una delas ecuaciones equivalentes sera 0x1 + · · ·+ 0xn = k (con k 6= 0 por ser un elemento principal de la ampliada)y esta igualdad no se cumple para ningun valor posible de las incognitas.
Ejemplo
{2x+ y = 22x+ y = 5
⇔ (A|B)=
(2 1 22 1 5
)→(
2 1 20 0 5
)⇔{
2x+ y = 20 = 5
sist. equivalentesin solucion 4
Nota: Si el sistema tiene solucion, por ser los elementos principales no nulos se garantiza que las incognitasprincipales pueden despejarse (como valor concreto o en funcion de las incognitas no principales) y puedendespejarse tantas incognitas como elementos principales haya. Luego
• Si el numero de elementos principales es igual al numero de incognitas el sistema tiene solucion unica.
• Si el numero de elementos principales es menor que el numero de incognitas el sistema tiene infinitassoluciones. (Las soluciones quedan en funcion de las incognitas no despejadas. Ver ejemplo 212.)
8.2.2.1 Sistemas homogeneos
Definicion 213.- Un sistema de ecuaciones lineales se dice que es homogeneo si tiene todos los terminosindependientes cero; es decir, un sistema de la forma AX = 0.
Un sistema homogeneo siempre tiene solucion pues X = 0 es una solucion del sistema. A esta solucion suelellamarse la solucion trivial y de cualquier otra solucion distinta de esta se dice solucion no trivial.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

130 – Fundamentos de Matematicas : Algebra Lineal 8.2 Sistemas de ecuaciones lineales
8.2.2.2 Metodo de Gauss-Jordan
El metodo de Gauss-Jordan continua el metodo de Gauss, haciendo operaciones elementales para conseguiruna matriz escalonada reducida: los elementos principales son 1 y en las columnas de dichos unos todos losdemas elementos son cero; es decir, despeja las incognitas principales.
Ejemplo 214 Continuando con el sistema del ejemplo 212 (quitada la fila de ceros, que no interviene): 1 3 −2 0 2 0 00 0 5 10 0 15 50 0 0 0 0 6 2
Hacemos 1 los elementos principales multiplicando 15F2 y 1
6F3
1 3 −2 0 2 0 0
0 0 1 2 0 3 1
0 0 0 0 0 1 13
hay que hacer cero el 3 de F2 y C6 (a26): F2 − 3F3
1 3 −2 0 2 0 0
0 0 1 2 0 0 0
0 0 0 0 0 1 13
hay que hacer cero el −2 de F1 y C3 (a13): F1 + 2F2
1 3 0 4 2 0 0
0 0 1 2 0 0 0
0 0 0 0 0 1 13
luego
x1 = −3x2 − 4x4 − 2x5
x3 = −2x4
x6 = 13
obteniendose, naturalmente, las mismas soluciones que antes. 4
Nota: La reordenacion y simplificacion de las filas puede dar lugar a distintas matrices escalonadas, pero laescalonada reducida es unica (si no se cambian de orden las incognitas), puesto que se tiene la misma soluciondespejando las mismas incognitas
8.2.3 Rango de una matriz y Teorema de Rouche
Definicion 215 (1a definicion del rango).- Se llama rango de una matriz A y se denota por rg(A) alnumero de filas distintas de cero que aparecen en alguna de las formas escalonadas de la matriz A .
Teorema de Rouche 216.- Sea el sistema AX = B , sistema de m ecuaciones con n incognitas. EntoncesAX = B tiene solucion si, y solo si, rg(A) = rg(A|B).Si rg(A) = rg(A|B) = r , toda solucion puede expresarse en la forma X=V0+t1V1+t2V2+· · ·+tn−rVn−r , conV0 una solucion particular de AX = B y las n -uplas V1 , . . . , Vn−r soluciones del homogeneo AX = 0. .
Resumiendo: En un sistema AX = B de m ecuaciones con n incognitas,
• si r = rg(A) = rg(A|B) = r =⇒ Sist. Compatible (con sol.)
{r = n → Solucion unica.r < n → Infinitas soluciones.
• si r = rg(A) 6= rg(A|B) = r + 1 =⇒ Sist. Incompatible (no tiene solucion).
Ejemplo Tomemos la solucion obtenida en el ejemplo 212: (−3x2 − 4x4 − 2x5, x2, −2x4, x4, x5,13 ), para
todo x2 , x4 y x5 . Podemos escribirla en la formax1
x2
x3
x4
x5
x6
=
0− 3x2 − 4x4 − 2x5
0 + x2 + 0x4 + 0x5
0 + 0x2 − 2x4 + 0x5
0 + 0x2 + x4 + 0x5
0 + 0x2 + 0x4 + x513 + 0x2 + 0x4 + 0x5
=
0000013
+ x2
−310000
+ x4
−40−2100
+ x5
−200010
= V0 + t1V1 + t2V2 + t3V3
y X = V0 + t1V1 + t2V2 + t3V3 es solucion para todo t1 , t2 y t3 . Entonces, para t1 = t2 = t3 = 0, X = V0 essolucion del sistema luego AV0 = B ; para t1 = 1 y t2 = t3 = 0, X = V0 + V1 es solucion del sistema, luegoB = A(V0 + V1) = AV0 +AV1 = B +AV1 de donde AV1 = 0 por lo que V1 es solucion del sistema homogeneoAX = 0; y analogamente para V2 y V3 .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

131 – Fundamentos de Matematicas : Algebra Lineal 8.3 Matrices cuadradas
8.3 Matrices cuadradas
Una matriz cuadrada A se dice triangular superior, si todos los elementos por debajo de la diagonal principalson nulos, es decir: aij = 0, para cualquier ij tal que i > j . Una matriz cuadrada A se dice triangularinferior, si todos los elementos por encima de la diagonal principal son nulos, es decir, aij = 0, para cualquierij tal que i < j .
Una matriz cuadrada A se dice que es diagonal, si es triangular superior e inferior, es decir, si son cerotodos los elementos que no estan en la diagonal principal.
Una matriz cuadrada A se dice simetrica si A = At , es decir, si aij = aji para todo ij ; y se diceantisimetrica si A = −At , es decir si aij = −aji para todo ij .
8.3.1 Matrices inversibles
Definicion 217.- Si A es una matriz cuadrada de orden n , An×n , y existe Bn×n tal que AB = BA = I sedice que A es inversible y que B es inversa de A .
Nota: Es claro de la definicion que tambien B es inversible y A una inversa de B .Por definicion, se ha de verificar que AB = I y tambien que BA = I ; sin embargo es suficiente con que severifique una de ellas para que la otra tambien se verifique (se vera en el Corolario 226).
Proposicion 218.- Si una matriz cuadrada A tiene inversa, esta es unica. Y la denotaremos por A−1 .
Demostracion:Supongamos que B y C son inversas de A . Al ser B inversa de A es I = AB , multiplicando a esta igualdadpor C y teniendo en cuenta que C es inversa de A obtenemos que C = C(AB) = (CA)B = IB = B .
De los comentarios hechos en la Observacion 209, es claro el siguiente resultado para matrices elementales.
Proposicion 219.- Las matrices elementales son inversibles y sus inversas son tambien elementales:
• De intercambiar dos filas, intercambiarlas de nuevo.
• De multiplicar una fila por k 6= 0, multiplicar esa fila por 1/k .
• De sumar a una fila un multiplo de otra, restar a esa fila el multiplo sumado.
Teorema 220.- Si A y B son dos matrices inversibles, entonces AB es inversible y
(AB)−1 = B−1A−1. Y en general, (A1A2 · · ·Ak)−1 = A−1k · · ·A
−12 A−1
1
Demostracion:
Basta comprobarlo:
{(AB)(B−1A−1) = A(BB−1)A−1 = AIA−1 = AA−1 = I
(B−1A−1)(AB) = B−1(A−1A)B = B−1IB = B−1B = I.
Propiedades 221.- a) (A−1)−1 = A b) (An)−1 = (A−1)n c) (kA)−1 = 1kA−1
Definicion 222.- Una matriz cuadrada, A , se dice ortogonal si A−1 = At .
Teorema 223.- Sea A una matriz cuadrada de orden n . Son equivalentes:
a) A es inversible.
b) El sistema AX = B tiene solucion unica para todo Bn×1 .
c) El sistema homogeneo AX = 0 tiene solucion unica.
d) Por operaciones elementales en A puede llegarse a la identidad.
Demostracion:
a)⇒b) A es inversible, luego existe A−1 . Si se multiplica por A−1 en la igualdad AX = B se tiene queA−1AX = A−1B , luego X = A−1B es la solucion del sistema y es la unica.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

132 – Fundamentos de Matematicas : Algebra Lineal 8.4 Determinante de una matriz cuadrada.
b)⇒c) Es un caso particular.
c)⇒d) Como la solucion del sistema AX = 0 es unica, al aplicar el metodo de Gauss-Jordan a la matriz A laescalonada reducida tiene que ser, necesariamente I (ver observacion 224 siguiente).
d)⇒a) Si existen matrices elementales tales que Ek · · ·E2E1A = I , multiplicando sucesivamente en la igualdadpor sus inversas, se obtiene A = E−1
1 E−12 · · ·E
−1k I como producto de matrices inversibles y, por tanto, es
inversible. Ademas, A−1 = Ek · · ·E2E1 .
Observacion 224.- Para una matriz cuadrada, cualquier matriz escalonada obtenida de ella es triangularsuperior (tiene ceros por debajo de la diagonal), pues el elemento principal de la fila 1 esta en la posicion 11o mas a la derecha, luego el elemento principal de la fila 2 esta en la posicion 22 o mas a la derecha, y engeneral el elemento principal de la fila i esta en la posicion ii o mas a la derecha. Luego para toda fila i , loselementos aij con j < i son cero, que es la caracterizacion de matriz triangular superior.
Ası pues, una matriz escalonada cuadrada, o tiene elemento principal en cada fila (y en consecuencia estantodos en la diagonal principal de la matriz) o tiene al menos una fila de ceros.
Luego si es una matriz escalonada reducida, o es la matriz identidad o tiene al menos una fila de ceros.
Corolario 225.- Una matriz An×n , es inversible ⇐⇒ rg(A) = n
Corolario 226.- Sea A una matriz cuadrada. Entonces
a) Si existe B tal que BA = I , entonces A es inversible y B = A−1 .
b) Si existe B tal que AB = I , entonces A es inversible y B = A−1 .
Demostracion:Si BA = I , consideremos el sistema AX = 0. Multiplicando por B en ambos lados se tiene que BAX =B0 = 0, pero al ser BA = I , X = 0 es la unica solucion del sistema y, por tanto, A es inversible. Entonces,A−1 = IA−1 = BAA−1 = B . Analogamente, en b).
Corolario 227 (Calculo de A−1 por el metodo de Gauss-Jordan).- Si A es inversible, su matrizescalonada reducida es la identidad, I , luego aplicando Gauss-Jordan a la matriz A ampliada con I , se
obtendran I y la inversa A−1 :(A I
)−→ · · · −→
(I A−1
)Claramente, el metodo no hace mas que resolver n sistemas lineales con la misma matriz de coeficientes, A , ypor terminos independientes las n columnas de I .
Ejemplo Sea la matriz A =
1 0 −20 2 11 1 −1
. Encontremos A−1 :
(A|I) =
1 0 −2 1 0 00 2 1 0 1 01 1 −1 0 0 1
F3−F1−→
1 0 −2 1 0 00 2 1 0 1 00 1 1 −1 0 1
F2−F3−→
1 0 −2 1 0 00 1 0 1 1 −10 1 1 −1 0 1
F3−F2−→
F3−F2−→
1 0 −2 1 0 00 1 0 1 1 −10 0 1 −2 −1 2
F1+2F3−→
1 0 0 −3 −2 40 1 0 1 1 −10 0 1 −2 −1 2
= (I|A−1)
4
8.4 Determinante de una matriz cuadrada.
Definicion 228.- Sea A una matriz cuadrada de orden n . Llamaremos producto elemental en A al productoordenado de un elemento de cada fila, cada uno de los cuales pertenece a columnas distintas. Es decir, unaexpresion de la forma a1j1a2j2 · · · anjn con todos los jk distintos.
Llamaremos producto elemental con signo al valor (−1)Na1j1a2j2 · · · anjn donde el numero N , paracada producto elemental, es el numero de “inversiones del orden” en el conjunto de las columnas {j1, j2, . . . , jn} ,es decir, el numero de veces que cada ındice jk es menor que los anteriores a el.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

133 – Fundamentos de Matematicas : Algebra Lineal 8.4 Determinante de una matriz cuadrada.
Ejemplo 229 {2, 4, 1, 3} . Para calcular las inversiones tenemos que ver cuantas veces 4, 1 y 3 son menoresque sus anteriores. Para el 4, hay inversion cuando 4 < 2, no. Para el 1, cuando 1 < 2, si ; y cuando 1 < 4, si.Y para el 3, cuando 3 < 2, no; 3 < 4, si ; y 3 < 1, no. El conjunto presenta entonces tres inversiones, N = 3.
Definicion 230.- Definimos la funcion determinante en el conjunto de las matrices de orden n , como lafuncion que asigna a cada matriz A el numero real, que denotaremos por det(A) o detA o |A| , y cuyo valores la suma de todos los productos elementales con signo que se pueden formar en A :
det(A) = |A| =∑
(j1,j2,...,jn)
(−1)Na1j1a2j2 · · · anjn .
Expresion del determinante de las matrices de orden 1, 2 y 3. Los determinantes de las matrices delos primeros ordenes de magnitud se obtienen de la forma:
∣∣ a11
∣∣ = a11 y∣∣∣∣ a11 a12
a21 a22
∣∣∣∣= a11a22 − a12a21∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣= a11a22a33 + a12a23a31 + a13a21a32 − a13a22a31 − a12a21a33 − a11a23a32
Estas expresiones admiten una regla nemotecnica grafica para recordar la construccion de los productos ele-mentales y el signo, siguiendo las direcciones de las diagonales principal y secundaria (para matrices de orden3 se conoce como Regla de Sarrus):
ss
ss
@@@
���
sign( ) = +
sign( ) = −
sss
sss
sss
@@@@@@
@@@
@@@ s
ss
sss
sss
������
���
���
Observacion: Cada uno de los productos elementales consigno se corresponde con el determinante de una matrizque se forma haciendo cero todos los elementos que noestan en el producto. Es claro, pues cualquier otro producto
(−1)3a12a24a31a43 =
∣∣∣∣∣∣∣∣0 a12 0 00 0 0 a24
a31 0 0 00 0 a43 0
∣∣∣∣∣∣∣∣tendra alguno de sus factores distinto de estos y, en consecuencia, sera 0. De manera similar son inmediatoslos dos resultados recogidos en la proposicion siguiente.
Proposicion 231.-
1.- Si A es una matriz que tiene una fila o una columna de ceros, entonces |A| = 0.
2.- Si A es una matriz triangular superior o triangular inferior, |A| es el producto de los elementos de ladiagonal principal, es decir, |A| = a11a22 · · · ann . (En todos los demas productos elementales aparece almenos un 0: si hay algun elemento por encima de la diagonal, hay alguno por debajo.)
8.4.1 Determinantes y operaciones elementales
Teorema 232.- Sea An×n una matriz. Se tiene que:
a) si A′ es la matriz obtenida al multiplicar una fila de A por un valor λ 6= 0, entonces det(A′) = λ det(A)
b) si A′ es la matriz resultante de intercambiar dos filas de A , entonces det(A′) = −det(A)
c) si A′ es la matriz que resulta de sumar a la fila k un multiplo de la fila i , entonces det(A′) = det(A)
.
Corolario 233.- Una matriz con dos filas iguales tiene determinante cero.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

134 – Fundamentos de Matematicas : Algebra Lineal 8.4 Determinante de una matriz cuadrada.
Corolario 234.-
a) Si la matriz elemental E resulta de multiplicar una fila de I por k ∈ R , entonces det(E) = k det(I) = k
b) Si la matriz elemental E resulta de intercambiar dos filas de I , entonces det(E) = −det(I) = −1
c) Si E resulta de sumar a una fila k un multiplo de la fila i de I , entonces det(E) = det(I) = 1
8.4.1.1 Calculo de determinantes por reduccion a la forma escalonada
El teorema anterior nos ofrece la posibilidad de calcular el determinante de una matriz usando el metodo deGauss. Si tenemos que Ek · · ·E2E1A = R , donde R es la matriz escalonada que se obtiene al aplicar el metodode Gauss, se tiene que
det(R) = det(EkEk−1Ek−2 · · ·E1A) = δk det(Ek−1Ek−2 · · ·E1A)
= δkδk−1 det(Ek−2 · · ·E1A) = · · · = δkδk−1δk−2 · · · δ1 det(A),
donde δi es k , −1 o 1, segun la operacion elemental que represente Ei . Luego
det(A) = 1δ1· · · 1
δkdet(R) = 1
δ1· · · 1
δkr11r22 · · · rnn
pues R es una matriz triangular superior (recordar observacion 224 de pag. 132) y det(R) = r11r22 · · · rnn .
8.4.2 Otras propiedades del determinante
Teorema 235.- Si A y B son matrices cuadradas de orden n , entonces
det(AB) = det(A) · det(B) .
Teorema 236.- Sea An×n entonces, A es inversible ⇐⇒ det(A) 6= 0.
Demostracion:Si A es inversible I = AA−1 , luego det(I) = det(AA−1) = det(A) det(A−1), pero al ser det(I) = 1 6= 0,necesariamente ha de ser det(A) 6= 0.
Si A no es inversible, por la parte 3 de la demostracion del Teorema 235 (Anexo 0, pag. 177), se tiene quedet(AI) = 0 = det(A) det(I) y como det(I) = 1, debe ser det(A) = 0.
Corolario 237.- Si A es inversible,∣∣A−1
∣∣ = |A|−1.
Teorema 238.- Si A es una matriz cuadrada, entonces |At| = |A| . .
8.4.3 Desarrollo por cofactores
Definicion 239.- Sea A una matriz cuadrada, llamaremos menor del elemento aij , y lo denotaremos porMij , al determinante de la submatriz que se forma al suprimir en A la fila i y la columna j . Al numero(−1)i+jMij lo llamaremos cofactor del elemento aij y lo denotaremos por Cij .
Ejemplo A partir de la matriz A de abajo, construimos los cofactores C21 , eliminando la fila 2 y la columna1, y C34 , eliminando la fila 3 y columna 4:
A =
0 −1 2 51 2 0 −22 −1 1 30 2 4 −2
−→ C21 = (−1)2+1
∣∣∣∣∣∣∣∣0 − 1 2 0 −22 − 0 −
∣∣∣∣∣∣∣∣ C34 = (−1)3+4
∣∣∣∣∣∣∣∣ − 5 −22 −1 1 3 −2
∣∣∣∣∣∣∣∣
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

135 – Fundamentos de Matematicas : Algebra Lineal 8.4 Determinante de una matriz cuadrada.
Teorema 240.- El determinante de una matriz A se puede calcular multiplicando los elementos de una fila (ode una columna) por sus cofactores correspondientes y sumando todos los productos resultantes; es decir, paracada fila 1 ≤ i ≤ n y para cada columna 1 ≤ j ≤ n :
det(A) = ai1Ci1 + ai2Ci2 + · · ·+ ainCin y det(A) = a1jC1j + a2jC2j + · · ·+ anjCnj .
Ejemplo∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣= a21(−1)2+1
∣∣∣∣ a12 a13
a32 a33
∣∣∣∣+ a22(−1)2+2
∣∣∣∣ a11 a13
a31 a33
∣∣∣∣+ a23(−1)2+3
∣∣∣∣ a11 a12
a31 a32
∣∣∣∣= a13(−1)1+3
∣∣∣∣ a21 a22
a31 a32
∣∣∣∣+ a23(−1)2+3
∣∣∣∣ a11 a12
a31 a32
∣∣∣∣+ a33(−1)3+3
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣Corolario 241.- Si desarrollamos una fila de una matriz A por los cofactores de otra distinta, el resultado escero; es decir,
ai1Cj1 + ai2Cj2 + · · ·+ ainCjn = 0 , si i 6= j .Identico resultado para las columnas.
Demostracion:Es claro, pues si en A hacemos la fila j igual a la fila i , la matriz obtenida A′ tiene determinante cero y
0 = |A′| = a′j1C′j1 + a′j2C
′j2 + · · ·+ a′jnC
′jn = ai1Cj1 + ai2Cj2 + · · ·+ ainCjn
Definicion 242.- Dada una matriz A cuadrada de orden n , llamaremos matriz de cofactores de A a lamatriz que tiene por elementos los cofactores de A , C = (Cij), y llamaremos matriz adjunta de A a lamatriz de cofactores traspuesta, Adj(A) = Ct .
Nota: Tambien es usual utilizar las denominaciones de menor adjunto para el cofactor y matriz adjunta para lamatriz de cofactores (sin trasponer). En este caso, los resultados son identicos a los que aquı se presentan conla unica consideracion a tener en cuenta es que donde aparece Adj(A) tendra que aparecer Adj(A)t .
Teorema 243.- Si A es una matriz inversible, entonces A−1 = 1|A| Adj(A).
Demostracion:
Si probamos que A · Adj(A) = |A|I entonces, como |A| 6= 0, sera AAdj(A)|A| = I y A−1 = 1
|A| Adj(A). En
efecto, aplicando el teorema 240 y el corolario 241 anteriores,
A ·Adj(A) = ACt =
a11 a12 · · · a1n
a21 a22 · · · a2n
......
. . ....
an1 an2 · · · ann
C11 C21 · · · Cn1
C12 C22 · · · Cn2
......
. . ....
C1n C2n · · · Cnn
=
|A| 0 · · · 00 |A| · · · 0...
.... . .
...0 0 · · · |A|
= |A| · I
Ejemplo
A =
1 2 34 5 −4−3 −2 −1
; A−1 =1
|A|
∣∣∣∣ 5 −4−2 −1
∣∣∣∣ − ∣∣∣∣ 4 −4−3 −1
∣∣∣∣ ∣∣∣∣ 4 5−3 −2
∣∣∣∣−∣∣∣∣ 2 3−2 −1
∣∣∣∣ ∣∣∣∣ 1 3−3 −1
∣∣∣∣ − ∣∣∣∣ 1 2−3 −2
∣∣∣∣∣∣∣∣ 2 35 −4
∣∣∣∣ −∣∣∣∣ 1 3
4 −4
∣∣∣∣ ∣∣∣∣ 1 24 5
∣∣∣∣
t
=1
40
−13 −4 −2316 8 167 −4 −3
Regla de Cramer 244.- Sea AX = B , un sistema de n ecuaciones con n incognitas, tal que A es inversible,entonces el sistema tiene como unica solucion:
x1 =
∣∣∣∣∣∣∣∣∣b1 a12 · · · a1n
b2 a22 · · · a2n
......
. . ....
bn an2 · · · ann
∣∣∣∣∣∣∣∣∣|A|
, x2 =
∣∣∣∣∣∣∣∣∣a11 b1 · · · a1n
a21 b2 · · · a2n
......
. . ....
an1 bn · · · ann
∣∣∣∣∣∣∣∣∣|A|
, . . . , xn =
∣∣∣∣∣∣∣∣∣a11 a12 · · · b1a21 a22 · · · b2...
.... . .
...an1 an2 · · · bn
∣∣∣∣∣∣∣∣∣|A|
. .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

136 – Fundamentos de Matematicas : Algebra Lineal 8.4 Determinante de una matriz cuadrada.
8.4.4 Rango de una matriz
Definicion 245 (Segunda definicion del rango).- Se llama rango de una matriz Am×n , rang(A) o rg(A),al maximo orden que resulta de considerar todas las submatrices cuadradas que pueden formarse eliminandofilas y columnas completas de A y cuyo determinante sea distinto de cero.
Del determinante de una submatriz cuadrada de orden r de A , formada eliminando filas y columnas com-pletas, de suele decir que es un menor de orden r de A , por analogıa a la denominacion dada en la definicion239 a los menores de un elemento.
Resulta evidente que para Am×n , se tiene rg(A) ≤ min{m,n} . Esta nueva definicion de rango de una matrizes equivalente a la dada anteriormente:
“el rango de una matriz es el numero de filas distintas de cero que aparecen en alguna de las formasescalonadas de la matriz”,
puesto que el menor formado con las filas y columnas que contienen a los elementos principales de la matrizescalonada es distinto de 0, y cualquier menor de orden mayor es cero.
Corolario 246.- Si A es una matriz, rg(A) = rg(At).
Demostracion:De la nueva definicion de rango y de |M | = |M t| para cualquier submatriz cuadrada de A .
Proposicion 247.- Sea A una matriz m×n , entonces
a) Si existe un menor de orden r distinto de cero el rg(A) ≥ r .
b) Si todos los menores de orden r son cero el rg(A) < r .
Demostracion:
a) es claro, pues como r es el orden de un menor distinto de cero, el maximo de los ordenes de los menoresdistintos de cero es al menos r .
b) Si todos los menores de orden r son cero, como un menor de orden r + 1 puede descomponerse comosuma de menores de orden r por constantes, todos los menores de orden r+ 1 son cero y, tambien todoslos menores de orden mayor. Luego rg(A) < r
En una matriz m×n , el numero de menores de orden r que podemos formar puede ser muy alto, de hecho es(mr
)(nr
)=
m!
r!(m− r)!n!
r!(n− r)!,
es decir, todas las posibles elecciones de r filas de entre las m y de r columnas de entre las n . Por tanto, paraver que una matriz tiene rango menor que r usando los menores, hemos de comprobar que cada uno de los
m!r!(m−r)!
n!r!(n−r)! menores son cero. Sin embargo, el coste de la evaluacion por menores, puede reducirse usando
el siguiente resultado:
Orlado de menores 248.- Sea Am×n una matriz, y Mr×r una submatriz de A con determinante distinto decero. Entonces, si el determinante de todas las submatrices de orden r + 1 que se pueden conseguir en Aanadiendo una fila y una columna a M son cero, el rango de A es r . .
Este resultado nos indica el metodo –conocido como “orlado de menores”– para encontrar el rango de unamatriz usando los menores:
“Buscamos un menor de orden uno distinto de cero: si no existe rg(A) = 0; si existe M1 6= 0entonces rg(A) ≥ 1, y buscamos un menor de orden 2 distinto de cero de entre los que “orlan” alanterior : si todos ellos son cero, por el resultado anterior, el rg(A) = 1; si algun M2 6= 0 entoncesrg(A) ≥ 2, y buscamos un menor de orden 3 distinto de cero de entre los que orlan a M2 : si noexiste rg(A) = 2, y si existe M3 6= 0 entonces rg(A) ≥ 3, y buscamos . . . .”
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

137 – Fundamentos de Matematicas : Algebra Lineal 8.5 Ejercicios
8.5 Ejercicios
8.209 Sean las matrices
A=
3 0−1 21 1
B=
(4 −10 2
)C=
(1 4 23 1 5
)D=
1 5 2−1 0 13 2 4
E=
6 1 3−1 1 24 1 3
a) Calcular cuando se pueda: 3C − D , (AB)C , A(BC), ED , DE , (4B)C + CA y CA + B2 .
Indicar porque no es posible en los otros casos.
b) Calcular, haciendo el menor numero de operaciones posible, la fila 1 de CA , la columna 2 de CD ylos elementos 23 y 12 de la matriz CDE .
c) Hallar para cada una de ellas una matriz escalonada e indicar cual es su rango.
8.210 Encontrar las operaciones elementales en las filas que llevan la matriz
1 2 30 1 21 0 3
a una matriz escalonada.
Construir una matriz elemental para cada operacion y comprobar que al multiplicar por esas matrices(Teorema 208) se obtiene esa matriz escalonada
8.211 Considerar el sistemax+ 2y − z − t = 0
x+ z − t = −2−x+ 2y − 3z + t = 4
(1)
a) ¿(−2, 2, 2, 0) y (1, 0,−1, 2) son solucion del sistema (1)?
b) Encontar todas las soluciones de (1)
c) Encontar todas las soluciones del sistemax− y + z − t = −3
x+ 6y − 5z − t = 4
}(2)
d) ¿Que soluciones de (1) son tambien solucion de (2)? ¿Tiene (2) alguna solucion que no lo sea de (1)?
8.212 Escribir los sistemas como operaciones matriciales AX = B , estudiar si tienen solucion (Th. de Rouche 216)y resolverlos
a)
{2x+ 3y = −1−7x+ 4y = 47
b)
2x+ 4y = 184x+ 5y = 243x+ y = 4
c)
x+ 2y − z + t = 0−x+ 4y − 5z + 7t = 2
2x+ y + z − 2t = −1
d)
x+ y + z + t+ u = 1
x+ y + z = 2y − z = 1x+ 2y = 03t− u = 4
e)
x+ 2y − z = 22x+ y + z = −1
3x+ 3y + 2z = −1f)
x+ y + z = 3
2x+ 3z = 43x+ y + 4z = 75x+ y + 7z = 9
8.213 Expresar el sistema con operaciones de matrices AX = B
a) Usar el metodo de Guass para comprobar que rg(A) = rg(A|B) eindicar de cuantos parametros dependera la solucion
b) Completar el metodo de Gauss-Jordan para resolver el sistema
c) Expresar la solucion segun el Th de Rouche (216): X = V0 + t1V1
d) Comprobar que V0 es solucion de AX = B y que V1 lo es de AX = 0
x+ y + z + u = 1
x+ y + z = −1y − z = 1
2y + x = 03t− u = 4
8.214 Para los sistemas del ejercicio 8.212 con solucion, expresarla en la forma descrita por el Th de Rouche
8.215 Estudiar el rango de las matrices siguientes en funcion de los valores de su parametro:
a)
a 2 22 a 01 a a
b)
1 1 −1 02 1 −1 0−b 6 3− b 9− b
c)
c 1 −2 0−1 −1 c 11 1 1 c
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

138 – Fundamentos de Matematicas : Algebra Lineal 8.5 Ejercicios
8.216 Estudiar cada uno de los sistemas siguientes, segun los valores de los paramentros:
a)
x+ 2y − z = a2x+ y + z = 1− a
3x+ (1 + a)y + az = 1− ab)
x+ 2y + 4z = 1x+ 2y + 2az = 2ax+ 4y + 4az = 4a
c)
x+ y + z = a− 3ax+ y = 0
ax+ y + az = 0d)
5x− (a+ b)y + 7z = 8 + b
2x− ay + 3z = 4x+ y + z = 3
3x− 3y + 4z = 7
8.217 Estudiar y resolver los siguientes sistemas
a)2x+ 2y + 4z = 16−x− 2y + 3z = 13x− 7y + 4z = 10
b)2x+ 2y + 4z = 2−x− 2y + 3z = 03x− 7y + 4z = 26
c)2x+ 2y + 4z = −2−x− 2y + 3z = −23x− 7y + 4z = 0
8.218 Usar el metodo de Gauss para saber cuales de las siguientes matrices tienen inversa y calcularlas:
a)
1 1 33 4 1−1 −1 −1
b)
8 6 −66 −1 1−4 0 0
c)
1 −2 3 −4−2 3 4 −33 4 −3 2−4 −3 2 −1
d)
0 0 1 20 1 1 11 1 1 02 1 0 0
8.219 Hallar una matriz P tal que:
1 4−2 31 −2
P
(2 0 00 1 −1
)=
8 6 −66 −1 1−4 0 0
.
8.220 Considerar las matrices A =
1 5 2−1 0 13 2 4
y B =
1 2 −2−2 3 −31 −1 1
.
a) Hallar todas las matrices columna X3×1 que verifican la igualdad ABX = BAX .
b) ¿Los sistemas BX = 0 y BtX = 0 tienen las mismas soluciones? Justificar la respuesta.
8.221 Encontrar los coeficientes de las descomposiciones en fraciones simples del ejercicio 0.33 de polinomios:
a) X2+1X4−6X3−16X2+54X+63 b) X−5
(X−1)(X3−1) c) X+52X4−X3−4X2+10X−4
d) X2+2X5+7X4+16X3+8X2−16X−16 e) X3−3X2+X−3
X5+3X4+3X3+3X2+2X f) X5+3X4+3X3+3X2+2X(X3−3X2+X−3)3
8.222 Probar que si A es cuadrada, la matriz S = A+At es simetrica y la matriz T = A−At es antisimetrica
Probar que la diagonal principal de T esta formada unicamente por ceros
8.223 Sea A =
1 2 30 1 21 0 −1
.
a) Encontar todas las matrices B3×3 tales que AB = 0.
¿Que relacion tienen estas matrices con las soluciones del sistema AX = 0?
b) Encontar todas las matrices C3×3 tales que CA = 0.
c) Encontar todas las matrices D3×3 tales que AD −DA = 0.
8.224 Sean A y B matrices cuadradas tales que AB = 0. Demostrar que si A es inversible entonces B = 0
8.225 Sean A y B matrices cuadradas tales que AB = 0. Demostrar que si B 6= 0, entonces A no es inversible.
8.226 Sea A una matriz cuadrada y E una matriz elemental. Comprobar que AEt realiza sobre las columnasde A la misma operacion elemental que hace EA sobre las filas de A (ver el teorema 208 y el ejemplosiguiente de pag. 127)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

139 – Fundamentos de Matematicas : Algebra Lineal 8.5 Ejercicios
8.227 Suponiendo que det(A) = 5, siendo A =
a b cd e fg h i
, calcular
a)
∣∣∣∣∣∣d e fg h ia b c
∣∣∣∣∣∣ b)
∣∣∣∣∣∣−a −b −c2d 2e 2f−g −h −i
∣∣∣∣∣∣ c)
∣∣∣∣∣∣a+d b+e c+fd e fg h i
∣∣∣∣∣∣ d)
∣∣∣∣∣∣a b c
d−3a e−3b f−3c2g 2h 2i
∣∣∣∣∣∣e)
∣∣∣∣∣∣a g hb h ec i f
∣∣∣∣∣∣ f)
∣∣∣∣∣∣2a− d d g2b− e e h2c− f f i
∣∣∣∣∣∣ g) det(3A) h) det(2A−1) i) det((2A)−1)
8.228 Hallar el valor exacto del determinante de la derecha:
a) Usando unicamente el metodo de Gauss
b) Mediante el desarrollo por cofactores
c) Aplicando simultaneamente ambas tecnicas para resolverlomas rapida y facilmente.
∣∣∣∣∣∣∣∣∣∣∣∣
0 −2 1 0 1 02 2 2 2 2 23 1 −1 4 −1 10 1 0 0 3 0−1 2 4 0 4 11 3 0 0 0 2
∣∣∣∣∣∣∣∣∣∣∣∣8.229 Desarrollar por cofactores para calcular el determinante de las matrices del ejercicio 8.218
8.230 Usar el metodo de Gauss para calcular el determinante de cada una de las matrices del ejercicio 8.218
8.231 Usar el orlado de menores para calcular el rango de
0 1 −2 0 1 0−2 2 2 −2 2 23 −1 0 4 −1 0−1 4 2 0 4 −10 6 2 2 6 1
8.232 Usar las propiedades y desarrollos del determinante para resolver las siguientes ecuaciones:
a)
∣∣∣∣∣∣x−2 0 0x+2 −1 2x−2 2 −1
∣∣∣∣∣∣=x b)
∣∣∣∣∣∣x x x
x+2 x−1 x+2x−2 x+2 x−1
∣∣∣∣∣∣=3 c)
∣∣∣∣∣∣x+1 0 0
2 x−1 2−2 2 x−1
∣∣∣∣∣∣=0 d)
∣∣∣∣∣∣∣∣x 1 0 00 x 1 00 0 x 11 0 0 x
∣∣∣∣∣∣∣∣=8
8.233 Sean A y B matrices de orden n tales que A 6=0, B 6=0 y AB=0. Probar que det(A)=det(B)=0.
8.234 Sea A una matriz antisimetrica de orden n impar. Demostrar que det(A) = 0
8.235 Sea A una matriz cuadrada de orden n tal que la suma de los elementos de cada fila es cero. Demostrarque A no es inversible
8.236 Calcular los posibles valores del determinante de una matriz ortogonal
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

140 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 9
Espacios vectoriales reales
9.1 Espacios vectoriales
Los conjuntos de vectores del plano, R2 , y del espacio, R3 , son conocidos y estamos acostumbrados a movernosen sus direcciones (ancho, largo y alto), manejar sus medidas y angulos. Pero todo eso es reflejo de su fun-cionamiento, mejor dicho, de la estructura que generan las pautas de su comportamiento y son estas pautas lasque vamos a extraer y fijar para exportar esta estructura tan comoda y fiable
Definicion 249.- Un espacio vectorial real V es un conjunto de elementos denominados vectores, juntocon dos operaciones, una que recibe el nombre de suma de vectores y otra que recibe el nombre de productopor escalares o producto de vectores por numeros reales, que verifican las siguientes propiedades:
(1) u + v ∈ V ; ∀u,v ∈ V
(2) u + v = v + u ; ∀u,v ∈ V
(3) u + (v + w) = (u + v) + w ; ∀u,v,w ∈ V
(4) Existe un vector, llamado vector cero y denotado por , tal que: + u = u + = u ; ∀u ∈ V
(5) Para cada u ∈ V , existe un vector de V , llamado opuesto de u y denotado −u , tal que u+ (−u) =
(6) ku ∈ V ; ∀ k ∈ R y ∀u ∈ V
(7) k(u + v) = ku + kv ; ∀ k ∈ R y ∀u,v ∈ V
(8) (k + l)u = ku + lu ; ∀ k, l ∈ R y ∀u ∈ V
(9) (kl)u = k(lu); ∀ k, l ∈ R y ∀u ∈ V
(10) 1u = u ; ∀u ∈ V
Ejemplo Los conjuntos Rn , los conjuntos de polinomios reales Rn[X] = {P (X) ∈ R[X] : gr(P ) ≤ n} y losconjuntos de matrices reales Mm×n = {matrices de tamano m×n} , con las operaciones usuales en cada unode ellos, son espacios vectoriales reales. Por ser los escalares de R se dicen espacios vectoriales reales
Propiedades 250.- Algunas propiedades que se deducen de las anteriores son:
(i) 0u = (ii) k = (iii) (−1)u = −u (iv) ku = ⇐⇒ k = 0 o u =
(v) El vector cero de un espacio vectorial es unico.
(vi) El vector opuesto de cada vector del espacio vectorial es unico. .
9.2 Subespacios vectoriales
Definicion 251.- Un subconjunto W de un espacio vectorial V se dice que es un subespacio vectorial deV , si W es un espacio vectorial con las operaciones definidas en V .
Como W ⊆ V , todos los vectores de W verifican las propiedades 2 a 5 y 7 a 10, por tanto es suficiente probarque las operaciones suma y producto por escalares son internas (se mantienen) en W , es decir
Proposicion 252.- W ⊆ V es un subespacio vectorial de V si se cumplen las propiedades
(1∗ ) u + v ∈W ; ∀u,v ∈W (6∗ ) ku ∈W ; ∀u ∈W y ∀ k ∈ R
Estas dos propiedades son equivalentes a la propiedad unica: ku + lv ∈W ; ∀u,v ∈W y ∀ k, l ∈ R
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

141 – Fundamentos de Matematicas : Algebra Lineal 9.3 Base y dimension
Nota: Es claro, que si W es un subespacio de V , entonces ∈W .
Ejemplo R2[X] es un subespacio de R4[X] , pues es un subconjunto suyo y si P (X), Q(X) ∈ R2[X] , el grado dekP (X) + lQ(X) es gr(kP + lQ) = max{gr(kP ), gr(lQ)} ≤ max{gr(P ), gr(Q)} ≤ 2, por lo que esta en R2[X] .
Sin embargo, {P (X) : gr(P ) = 2} no es un subespacio de R4[X] , por dos razones: primero, porque no contieneal polinomio cero; y segundo, no verifica la propiedad (1∗) ya que X2 y 2X − X2 son polinomios del conjuntopero su suma X2 + (2X− X2) = 2X es un polinomio de grado 1 que no esta en el conjunto. 4
Definicion 253.- Se dice que un vector v ∈ V es una combinacion lineal de los vectores v,v, . . . ,vn si,y solo si, ∃ c1, c2, . . . , cn ∈ R tales que v = c1v + c2v + · · ·+ cnvn .
Definicion 254.- Dado un conjunto de vectores S = {v,v, . . . ,vk} de un espacio vectorial V , llamaremossubespacio lineal generado por S y que denotaremos por linS o lin{v,v, . . . ,vk} , al conjunto de todaslas combinaciones lineales que se pueden formar con los vectores de S :
linS = lin{v,v, . . . ,vk} ={c1v + c2v + · · ·+ ckvk : ∀ ci ∈ R
}y se dira que S genera linS o que los vectores v,v, . . . ,vk generan linS .
Naturalmente linS es un subespacio vectorial de V , de hecho el mas pequeno que contiene a S (Ejer. 9.242)
Definicion 255.- Dado un conjunto S = {v,v, . . . ,vk} de vectores del espacio vectorial V , la ecuacionvectorial c1v + c2v + · · ·+ ckvk = tiene al menos una solucion, a saber: c1 = c2 = · · · = ck = 0. Si estasolucion es unica, entonces se dice que S es un conjunto linealmente independiente (o que los vectoresde S son linealmente independientes). Si existen otras soluciones, entonces se dice que S es linealmentedependiente (o que los vectores son linealmente dependientes).
Ejemplo El vector 2X− X2 de R2[X] esta generado por los vectores X− 1 y X2 − 2:
2X− X2 = λ(X− 1) + µ(X2 − 2) = λX− λ+ µX2 − 2µ = (−λ− 2µ) + λX + µX2 =⇒
−λ− 2µ= 0λ= 2µ=−1
luego 2X− X2 = 2(X− 1) + (−1)(X2 − 2).
Ejemplo Los polinomios X + 2 y X2 de R2[X] son linealmente independientes: si λ(X + 2) + µX2 = 0 (alpolinomio cero), se tiene que 0 = λ(X + 2) + µX2 = 2λ + λX + µX2 =⇒ 2λ = 0, λ = 0 y µ = 0, ya que loscoeficientes de ambos polinomios deben coincidir. 4
Nota: Si los vectores {v,v, . . . ,vk} son linealmente dependientes, al menos uno de ellos se puede escribir comouna combinacion lineal de los otros; y si son linealmente independientes ninguno de ellos puede ser generadopor los restantes. Tenemos ası la siguiente caracterizacion para la dependencia lineal (Ejer.o 9.243):
“Un conjunto de dos o mas vectores es linealmente dependiente si, y solo si, al menos unode los vectores es una combinacion lineal de los restantes.”
9.3 Base y dimension
Lema 256.- Si vn+ = c1v + · · ·+ cnvn , entonces lin{v, . . . , vn, vn+} = lin{v, . . . , vn} .
Es facil asumir que este resultado es cierto, ya que cualquier combinacion lineal de los n+ 1 vectores puedereconvertirse a una combinacion lineal de los n primeros, por simple sustitucion. En otras palabras, puedereducirse el numero de generadores mientras haya dependencia lineal, lo que nos lleva a:
Definicion 257.- Sean V un espacio vectorial y S un conjunto finito de vectores de V . Diremos que S esuna base de V si:
a) S es linealmente independiente y b) S genera a V
Observacion: El lema y comentario anteriores a esta definicion nos indican la manera de reducir un conjuntogenerador del espacio a una base.
Igualmente, podemos construir una base a partir de un conjunto linealmente independiente de vectores:si S es linealmente independiente y linS 6= V , tomando v ∈ V pero que v /∈ linS , el conjunto S ∪ {v} eslinealmente independiente (ver el Lema 258 siguiente); y ası, se anaden vectores a S hasta generar V .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

142 – Fundamentos de Matematicas : Algebra Lineal 9.3 Base y dimension
Lema 258.- Si S es un conjunto linealmente independiente de vectores de V y v ∈ V−linS , entonces S∪{v}es linealmente independiente. .
De cierta forma, estamos diciendo que una base tiene el menor numero posible de generadores y el mayornumero posible de vectores linealmente independientes (ver Lema 259 siguiente); luego ¿no tendra una base unnumero fijo de vectores? La respuesta la proporciona el Lema siguiente y se recoge en el Teorema de la base.
Lema 259.- Sean V un espacio vectorial y B una base de V formada por n vectores. Entonces cualquierconjunto {v,v, . . . ,vm} de vectores de V, con m > n , es linealmente dependiente. .
Teorema de la base 260.- Todas las bases de un espacio vectorial tienen el mismo numero de elementos
Demostracion:La demostracion es muy sencilla si tenemos en cuenta el Lema anterior, pues si B1 es una base de n elementosy B2 es una base de m elementos, por ser B1 base y B2 linealmente independiente, m 6> n y por ser B2 basey B1 linealmente independiente n 6> m , luego n = m .
Definicion 261.- En un espacio vectorial V se llama dimension de V , dimV , al numero de vectores que hayde cualquier base de V .
El espacio vectorial V = {} diremos que tiene dimension cero
Ejemplo R2[X] ={P (X) ∈ R[X] : gr(P ) ≤ 2
}tiene dimension 3, pues B = {1, X, X2} forman una base. En
general, dim(Rn[X]) = n+ 1 y B ={
1, X, . . . , Xn}
es una base suya.
Ejemplo 262 Los conjuntos Rn = R×R×· · ·×R ={
(x1, . . . , xn) : xi ∈ R, ∀ i}
con las operaciones habi-
tuales de suma y producto por escalares
x + y = (x1, . . . , xn) + (y1, . . . , yn) = (x1 + y1, . . . , xn + yn)
λx = λ(x1, . . . , xn) = (λx1, . . . , λxn)
son espacios vectoriales con dimRn = n , ya que cualquier vector x ∈ Rn puede escribirse de la forma
x = (x1, x2, . . . , xn) = x1(1, 0, . . . , 0) + x2(0, 1, . . . , 0) + · · ·+ xn(0, 0, . . . , 1)
y este conjunto de vectores
B ={e = (1, 0, . . . , 0), e = (0, 1, . . . , 0), . . . , en = (0, 0, . . . , 1)
}es linealmente independiente. A esta base se la denomina base canonica de Rn . 4
Conocer a priori la dimension de un espacio facilita la obtencion de bases:
Proposicion 263.- Si V es un espacio vectorial, con dimV = n . Entonces, un conjunto de n vectores de Ves base de V ,
a) si el conjunto es linealmente independiente, o b) si genera a V . .
9.3.1 Coordenadas en una base
Definicion 264.- Sean V un espacio vectorial de dimension finita y B = {v,v, . . . ,vn} una base de V . Paracada vector v ∈ V , se llaman coordenadas de v en la base B a los n unicos numeros reales c1, c2, . . . , cntales que v = c1v + c2v + · · ·+ cnvn .
Fijando un orden para los vectores de la base, el vector de Rn , de las coordenadas de v en B se denotapor (v)B = (c1, c2, . . . , cn) y mas usualmente por [v]B cuando lo escribimos como vector columna en lasoperaciones con matrices: [v]B = (c1, c2, . . . , cn)t .
Ejemplo Si B = {v, v, v} es una base de V y v = v − v + 2v , se tiene que
(v)B = (1,−1, 2) (v)B = (1, 0, 0) (v)B = (0, 1, 0) (v)B = (0, 0, 1)
o tambien
[v]B =
1−12
[v]B =
100
[v]B =
010
[v]B =
001
4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

143 – Fundamentos de Matematicas : Algebra Lineal 9.3 Base y dimension
Nota: Al usar vectores de coordenadas, es imprescindible mantener el orden de los vectores. Si, en el ejemplo an-terior, tomamos como base B1 = {v, v, v} , tenemos que (v)B1
= (−1, 2, 1) que es un vector de coordenadasdistinto de (v)B = (1,−1, 2).
Fijada una base, la unicidad de las coordenadas asigna a cada vector de V un unico vector de Rn , de maneraque disponer de las coordenadas es, en el fondo, disponer del vector. Ademas, se cumple (ver ejercicio 9.251):
[v+w]B = [v]B + [w]B y [λv]B = λ[v]B , luego [λ1v+· · ·+λnvn]B = λ1[v]B + · · ·+ λn[vn]B
y con esto, no es dificil probar que (ejer. 9.251):
v ∈ lin{v, . . . , vk} ⊆ V ⇐⇒ [v]B ∈ lin{[v]B , . . . , [vk]B} ⊆ Rn
{v, . . . , vk} lin. independiente en V ⇐⇒{[v]B , . . . , [vk]B} lin. independiente en Rn
{v, . . . , vn} base de V ⇐⇒{[v]B , . . . , [vn]B} base de Rn
por lo que se puede trabajar sobre las coordenadas en lugar de sobre los vectores.
9.3.2 Espacios de las filas y las columnas de una matriz
De lo anterior, tenemos que independientemente del espacio vectorial en que nos encontremos, fijada una base,podemos trasladar todo el trabajo operativo sobre los vectores de Rn ; por lo que resulta muy interesante conoceresta seccion.
Definicion 265.- Consideremos la matriz Am×n =
a11 a12 . . . a1n
a21 a22 . . . a2n
...... . . .
...am1 am2 . . . amn
.
Los m vectores de Rn : r = (a11, . . . , a1n), r = (a21, . . . , a2n), . . . , rm = (am1, . . . , amn), se denominanvectores fila de A y al subespacio lineal generado por ellos, Ef (A) = lin{r, r, . . . , rm} , espacio de lasfilas de A . Por supuesto Ef (A) ⊆ Rn .
Los n vectores de Rm : c = (a11, . . . , am1), c = (a12, . . . , am2), . . . , cn = (a1n, . . . , amn), se denominanvectores columna de A y el subespacio lineal generado por ellos, Ec(A) = lin{c, c, . . . , cn} , espacio delas columnas de A . Por supuesto Ec(A) ⊆ Rm .
Proposicion 266.- Si A es una matriz de tamano m×n , entonces las operaciones elementales sobre las filas(resp. columnas) de A no cambian el espacio de las filas (resp. columnas) de A .
Demostracion:Claro, puesto que hacer operaciones elementales es hacer combinaciones lineales de los vectores, y el subespaciolineal generado es el mismo (Ejer. 9.246)
Corolario 267.- Sea A una matriz, entonces:
a) Los vectores no nulos de una forma escalonada de la matriz A , forman una base de Ef (A).
b) Los vectores no nulos de una forma escalonada de la matriz At , forman una base de Ec(A).
Demostracion:Basta probar que los vectores no nulos de una forma escalonada son linealmente independientes, pero eso secomprueba facilmente ya que debajo de cada elemento principal solo hay ceros.
Teorema 268.- Sea A una matriz de tamano m×n , entonces: dim(Ef (A)) = dim(Ec(A)).
Demostracion:El resultado es inmediato, teniendo en cuenta que rg(A) = rg(At), y que el rango coincide con el numero devectores no nulos en la forma escalonada, ası como el resultado anterior.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

144 – Fundamentos de Matematicas : Algebra Lineal 9.4 Cambios de base
Estos resultados nos permiten usar el metodo de Gauss, y por lo tanto nos ofrecen un operativo sencillo, paracomprobar cuando un conjunto de vectores es linealmente independiente y para obtener bases.
Ejemplo ¿Los vectores X− 1, X + 1 y X2 − 1 de R2[X] son linealmente independientes?Tomemos la base B = {1, X, X2} de R2[X] , entonces formamos por filas la matriz:
A =
(X− 1)B(X + 1)B(X2 − 1)B
=
−1 1 01 1 0−1 0 1
F2+F1F3−F1−→
−1 1 00 2 00 −1 1
F3+ 12F2−→
−1 1 00 2 00 0 1
Por lo anterior, los vectores fila de la ultima matriz son linealmente independientes y dimEf (A) = 3. Enconsecuencia, los tres vectores fila de la matriz A inicial que generan Ef (A) son tambien base, luego linealmenteindependientes y los polinomios del enunciado tambien son linealmente independientes.
Ademas, forman una base de R2[X] (¿por que?). 4
9.4 Cambios de base
Puesto que las coordenadas estan referidas a una base, al cambiar la base de trabajo, habra que cambiar a lascoordenadas en la nueva base. Pero este proceso puede realizarse facilmente, teniendo en cuenta lo siguiente:
Definicion 269.- Sean B1 = {u,u, . . . ,un} y B2 = {v,v, . . . ,vn} son bases de un espacio vectorial V .Recibe el nombre de matriz de transicion o matriz de cambio de la base B1 a la base B2 , la matriz dedimensiones n×n , que por columnas es
P =
([u]B2 [u]B2 · · · [un]B2
),
es decir, la columna i-esima esta constituida por las coordenadas en la base B2 , del vector ui de la base B1 .
En otras palabras, la matriz de cambio de base tiene por columnas las coordenadas en la base de llegada delos vectores de la base de partida.
El porque la matriz de paso se contruye ası, puede observarse en la prueba de la proposicion siguiente:
Proposicion 270.- Sea P la matriz de paso de una base B1 en otra base B2 de un espacio V . Entonces:
1.- ∀x ∈ V se tiene que [x]B2= P · [x]B1
.
2.- P es inversible y su inversa, P−1 , es la matriz de paso de la base B2 a la base B1 .
Demostracion:
Sea B1 = {u, u, . . . , un} y sea x = c1u + c2u + · · ·+ cnun . Entonces, Apartado 1:
P [x]B1=
([u]B2
[u]B2· · · [un]B2
)c1c2...cn
= c1[u]B2
+ c2[u]B2+ · · ·+ cn[un]B2
= [c1u + c2u + · · ·+ cnun]B2= [x]B2
Apartado 2: como los vectores de la base B1 son linealmente independientes, sus vectores de coordenadas enla base B2 tambien lo son. Luego las columnas de P son vectores linealmente independientes y rg(P ) = n ,por lo que P es inversible.
Ademas, [x]B2 = P [x]B1 =⇒ P−1[x]B2 = P−1P [x]B1 =⇒ P−1[x]B2 = [x]B1 y P−1 es la matriz decambio de la base B2 en la base B1 .
Ejemplo Consideremos las bases B = {1, X, X2} y B1 = {X− 1, X + 1, X2 − 1} de R2[X] .La matriz de paso de la base B1 a la base B sera:
P =
([X− 1]B [X + 1]B [X2 − 1]B
)=
−1 1 −11 1 00 0 1
y P−1 =
−12
12−12
12
12
12
0 0 1
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

145 – Fundamentos de Matematicas : Algebra Lineal 9.5 Ejercicios
la matriz de paso de B a B1 .
Ejemplo Consideremos en R3 la base canonica Bc = {e = (1, 0, 0), e = (0, 1, 0), e = (0, 0, 1)} y la baseB1 = {v =(1, 0,−1), v =(2,−1, 1), v =(0,−1, 1)} .
Como v = 1(1, 0, 0) + 0(0, 1, 0)− 1(0, 0, 1) = e − e , se tiene que (v)Bc = (1, 0,−1); y lo mismo para losotros vectores, luego la matriz de paso de la base B1 a la base Bc sera:
P =
([v]Bc [v]Bc [v]Bc
)=
1 2 00 −1 −1−1 1 1
y P−1 =
1 2 00 −1 −1−1 1 1
−1
la matriz de paso de la base Bc a la base B1 . 4
Nota: A la vista del ejemplo anterior, obtener las coordenadas de un vector de Rn en la base canonica de Rnes inmediato, pues (x)Bc = x . Pero ¡ciudado!, al trabajar con vectores de Rn no hay que confundir el vectorcon las coordenadas en una base, pues la igualdad anterior unicamente es cierta en la base canonica.
9.5 Ejercicios
9.237 Determinar si son espacios vectoriales los siguientes conjuntos:
a) R2 con las operaciones: (x, y) + (x′, y′) = (x+ x′, y + y′) y k(x, y) = (2kx, 2ky).
b) A = {(x, 0) : x ∈ R} con las operaciones usuales de R2 .
c) R2 con las operaciones: (x, y) + (x′, y′) = (x+ x′ + 1, y + y′ + 1) y k(x, y) = (kx, ky).
d) El conjunto de los numeros reales estrıctamente positivos, R+−{0} , con las operaciones: x+x′ = xx′
y kx = xk .
9.238 ¿Cuales de los siguientes conjuntos son subespacios vectoriales de R3 o R4 ?
a) {(a, 1, 1) ∈ R3 : a ∈ R} ⊆ R3 b) {(a, b, c) ∈ R3 : b = a+ c} ⊆ R3
c) {(a, b, c, d) ∈ R4 : a+ 2d = 7} ⊆ R4 d) {(a, b, c, d) ∈ R4 : ba = 0} ⊆ R4
9.239 Sean v = (2, 1, 0, 3), v = (3,−1, 5, 2) y v = (−1, 0, 2, 1) vectores de R4 . ¿Cuales de los vectores(2, 3,−7, 3), (0, 0, 0, 0), (1, 1, 1, 1) y (−4, 6,−13, 4), estan en lin{v,v,v}?
9.240 ¿Para que valores reales de λ los vectores v = (λ, −12 ,−12 ) v = (−1
2 , λ,−12 ) y v = (−1
2 ,−12 , λ) forman
un conjunto linealmente dependiente en R3 ?
9.241 Dados tres vectores linealmente independientes u , v y w , demostrar que u + v , v + w y w + u son
tambien linealmente independientes.
9.242 Sea V un espacio vectorial y S = {v, . . . ,vk} un conjunto de vectores de V . Probar que:
a) linS es un subespacio vectorial de V .
b) Si W es un subespacio de V que contiene a los vectores de S , entonces linS ⊆W .
9.243 Probar que si los vectores v , . . . , vk son linealmente dependientes, al menos uno de ellos se puede
escribir como una combinacion lineal de los restantes.
9.244 Determinar la dimension de los siguientes subespacios de R4 :
a) Todos los vectores de la forma (a, b, c, 0).
b) Todos los vectores de la forma (a, b, c, d) con d = a+ b y c = a− b .
c) Todos los vectores de la forma (a, b, c, d) con a = b = c = d .
9.245 Probar que los vectores solucion de un sistema no homogeneo compatible, AX = B , de m ecuaciones con
n incognitas no forman un subespacio de Rn . ¿Que ocurre si el sistema es homogeneo, es decir, si B = 0?
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

146 – Fundamentos de Matematicas : Algebra Lineal 9.5 Ejercicios
9.246 Sea W = lin{v,v,v
}. Probar que, para λ 6= 0, se cumple:
a) lin{v + λv, v, v
}= W b) lin
{λv, v, v
}= W c) lin
{v, v, v
}= W
9.247 Sean E y F subespacios de un espacio V . Probar que: E ∩ F = {v ∈ V : v ∈ E y v ∈ F} es un
subespacio de V .
9.248 Considerar en R4 los conjuntos de vectores:
A = {(1, 2,−1, 3), (0, 1, 0, 3)} B = {(1,−1, 1, 0), (2, 3, 1, 2), (0, 0, 0, 1)}
a) Hallar las dimensiones de lin(A) y de lin(B), y encontrar una base
b) Hallar las ecuaciones parametricas de lin(A) y de lin(B).
c) Hallar las ecuaciones cartesianas de lin(A) y de lin(B).
d) Hallar la dimension de lin(A) ∩ lin(B).
9.249 Consideremos en el espacio vectorial R3 la base B = {u,u,u} . Sea E el subespacio engendrado por
los vectoresv = u + 3u , v = 2u − 3u + u , v = 4u − 3u + 7u .
Sea F el subespacio engendrado por los vectoresw = u + u + u , w = 2u + 3u + 4u , w = 3u + 4u + 5u .
Hallar una base de E , una base de F , el subespacio E ∩ F y una base de E ∩ F .
9.250 Sea M2×2 el espacio vectorial de las matrices cuadradas de orden 2 sobre R y sea E el subconjunto de
M2×2 formado por las matrices de la forma
(a b+ c
−b+ c a
)con a, b, c ∈ R .
a) Demostrar que E es un subespacio vectorial.
b) Probar que las matrices A1 =
(1 00 1
), A2 =
(0 1−1 0
)y A3 =
(0 11 0
), forman una base de E .
9.251 Sea B una base de un espacio vectorial V de dimension n . Demostrar que el conjunto {v,v, . . . ,vn}es una base de V si, y solo si el conjunto {[v]B , [v]B , . . . , [vn]B} es una base de Rn .
9.252 En una cierta base {u,u,u,u} de un espacio vectorial V , un vector w tiene por coordenadas(3, 1, 2, 6). Hallar las coordenadas de w en otra base {v,v,v,v} cuyos vectores verifican que v =u+u , v =2u−u , v =u−u y v =2u−u .
9.253 En R3 se consideran las bases B = {v = (2, 0, 0), v = (0,−1, 2), v = (0, 0,−3)} y la base canonicaBc = {e, e, e} . Hallar las coordenadas respecto de la base B del vector x = 4e + e − 5e .
9.254 Se consideran en R3 las bases B = {u,u,u} y B′ = {v,v,v} , siendo
u = (−3, 0,−3), u = (−3, 2,−1), u = (1, 6,−1) y
v = (−6,−6, 0), v = (−2,−6, 4), v = (−2,−3, 7).
a) Hallar la matriz de paso de B a B′ .
b) Calcular la matriz de coordenadas, [w]B , siendo w = (−5, 8,−5).
c) Calcular [w]B′ de dos formas diferentes
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

147 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 10
Espacios vectoriales con producto escalar
10.1 Producto escalar. Norma. Distancia
Definicion 271.- Un producto escalar o producto interior en un espacio vectorial real V es una funcion〈, 〉 que a cada par de vectores u,v ∈ V le asocia un numero real, que denotaremos por 〈u,v〉 , de tal maneraque se cumplen las siguientes propiedades:
1.- 〈u,v〉 = 〈v,u〉 ; ∀u,v ∈ V .
2.- 〈u + v,w〉 = 〈u,w〉+ 〈v,w〉 ; ∀u,v,w ∈ V .
3.- 〈ku,v〉 = k〈u,v〉 ; ∀u,v ∈ V y ∀ k ∈ R .
4.- 〈u,u〉 ≥ 0; ∀u ∈ V y 〈u,u〉 = 0 ⇐⇒ u = .
Otra propiedades que se deducen de las anteriores son:
1.- 〈,u〉 = 0 2.- 〈u,v + w〉 = 〈u,v〉+ 〈u,w〉 3.- 〈u, kv〉 = k〈u,v〉
Ejemplo Considerar en R2[X] , la funcion 〈p(X), q(X)〉 = p(1)q(1) + p′(1)q′(1) + p′′(1)q′′(1).
(1) 〈p(X), q(X)〉= p(1)q(1) + p′(1)q′(1) + p′′(1)q′′(1)= q(1)p(1) + q′(1)p′(1) + q′′(1)p′′(1) = 〈q(X), p(X)〉
(2) 〈p(X) + r(X), q(X)〉 =(p(1) + r(1)
)q(1) +
(p′(1) + r′(1)
)q′(1) +
(p′′(1) + r′′(1)
)q′′(1)
=(p(1)q(1)+p′(1)q′(1)+p′′(1)q′′(1)
)+(r(1)q(1)+r′(1)q′(1)+r′′(1)q′′(1)
)= 〈p(X), q(X)〉+ 〈r(X), q(X)〉
(3) 〈kp(X), q(X)〉= kp(1)q(1) + kp′(1)q′(1) + kp′′(1)q′′(1)
= k(p(1)q(1) + p′(1)q′(1) + p′′(1)q′′(1)
)= k〈p(X), q(X)〉
(4) 〈p(X), p(X)〉 = p(1)p(1) + p′(1)p′(1) + p′′(1)p′′(1) =(p(1)
)2
+(p′(1)
)2
+(p′′(1)
)2
≥ 0.
Y, se da la igualdad si y solo si, p(1) = p′(1) = p′′(1) = 0. Entonces, sea p(X) = a + bX + cX2 , de dondep′(X) = b+ 2cX y p′′(X) = 2c ; de las igualdades se tiene:
p(1) = p′(1) = p′′(1) = 0 ⇐⇒a+ b+ c = 0b+ 2c = 0
2c = 0
⇐⇒ a = b = c = 0 ⇐⇒ p(X) = 0.
Luego tenemos un producto escalar definido en R2[X] . 4
A partir de un producto escalar sobre un espacio V se definen los conceptos de norma, distancia y angulo.
Definicion 272.- Si V es un espacio vectorial con producto interior, entonces la norma (o longitud omodulo) de un vector v ∈ V se denota mediante ‖v‖ y se define como
‖v‖ = +√〈v,v〉.
La distancia entre dos vectores u y v de V se denota mediante d(u,v) y se define como
d(u,v) = ‖u− v‖ = +√〈u− v,u− v〉.
Desigualdad de Cauchy-Schwarz 273.- Para todo u,v ∈ V , espacio con producto escalar, se tiene
〈u,v〉2 ≤ ‖u‖2 ‖v‖2 o en la forma |〈u,v〉| ≤ ‖u‖ ‖v‖ . .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

148 – Fundamentos de Matematicas : Algebra Lineal 10.1 Producto escalar. Norma. Distancia
Propiedades basicas de la norma 274.-
1.- ‖u‖ ≥ 0; ∀u ∈ V
2.- ‖u‖ = 0 ⇐⇒ u =
3.- ‖ku‖= |k| ‖u‖ ; ∀u ∈ V y ∀ k ∈ R
4.- ‖u+v‖ ≤ ‖u‖+‖v‖ ; ∀u,v ∈ V
Propiedades basicas de la distancia 275.-
1.- d(u,v) ≥ 0; ∀u,v ∈ V
2.- d(u,v) = 0 ⇐⇒ u = v
3.- d(u,v) = d(v,u); ∀u,v ∈ V
4.- d(u,v) ≤ d(u,w)+d(w,v); ∀u,v,w ∈ V
La prueba de estas propiedades es analoga a la de Propiedades del modulo complejo 9.
10.1.1 Matriz del producto escalar
Observacion: Sean V un espacio con producto interior y B = {u, . . . ,un} una base de V . Tomemos dosvectores v = a1u + · · ·+ anun y w = b1u + · · ·+ bnun , entonces
〈v,w〉= 〈a1u + · · ·+ anun, w〉 = a1〈u,w〉+ · · ·+ an〈un,w〉= a1〈u, b1u + · · ·+ bnun〉+ · · ·+ an〈un, b1u + · · ·+ bnun〉= a1〈u,u〉b1 + · · ·+ a1〈u,un〉bn + · · ·+ an〈un,u〉b1 + · · ·+ an〈un,un〉bn
=(a1 · · · an
) 〈u,u〉 · · · 〈u,un〉...
. . ....
〈un,u〉 · · · 〈un,un〉
b1
...bn
= (v)B Q [w]B = [v]tB Q [w]B
luego, fijada una base, un producto interior se puede obtener a partir de las coordenadas en la base.
Definicion 276.- Sea B base de un espacio V con producto interior. Se llama matriz metrica (o de Gram)del producto escalar asociada a la base B , a la matriz Q tal que 〈u,v〉 = [u]tB Q [v]B para cada u,v ∈ V
Observaciones Por cumplise las propiedades 2a y 3a del producto escalar se puede construir la matriz Q ;por las propiedades 1 y 4 (1a parte), la matriz Q debe de ser simetrica y tener los elementos de la diagonalpositivos.
Y por la propiedad 4 (2a parte) debe cumplirse que 〈u,u〉 = [u]tB Q [u]B > 0 para todo u ∈ V −{} . Unamatriz simetrica compliendo esto ultimo se dice matriz definida positiva (ver Tema 13 de Formas cuadraticas).
Criterio de Sylvester 277.- Una matriz simetrica S es definida positiva si y solo si son positivos los menores
|s11| > 0
∣∣∣∣ s11 s12
s21 s22
∣∣∣∣ > 0 · · ·
∣∣∣∣∣∣∣s11 · · · s1k
.... . .
...sk1 · · · skk
∣∣∣∣∣∣∣ > 0 · · · |S| > 0
Nota: De lo anterior, para comprobar si una funcion dada 〈, 〉 es un producto escalar, basta comprobar quese cumplen las propiedades 2 y 3, construir la matriz Q referida a una base y comprobar si esta es simetrica, yen ese caso ver si es tambien definida positiva con el Criterio de Sylvester 277 anterior.
Proposicion 278.- Sea V un espacio con producto escalar. Si Q1 es la matriz metrica del producto escalar enla base B1 , Q2 la matriz metrica en la base B2 y P la matriz de paso de B2 a B1 , entonces: Q2 = P tQ1P
Demostracion:Sabemos que 〈x,y〉 = [x]tB1
Q1[y]B1 y P [v]B2 = [v]B1 , con lo que sustituyendo la tercera igualdad en laprimera
〈x,y〉 = [x]tB1Q1[y]B1
= (P [x]B2)tQ1(P [y]B2
) = [x]tB2P tQ1P [y]B2
∀x,y
pero como tambien se cumple 〈x,y〉 = [x]tB2Q2[y]B2 , debe ser Q2 = P tQ1P
Definicion 279.- Dos matrices simetricas A y A′ son congruentes, si existe P inversible tal que A′ = P tAP
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

149 – Fundamentos de Matematicas : Algebra Lineal 10.2 Ortogonalidad
10.1.2 El espacio euclıdeo n-dimensional Rn
Definicion 280.- En el espacio vectorial Rn , la funcion que a cada x,y ∈ Rn le asocia
〈x,y〉 = x · y = (x1, . . . , xn) · (y1, . . . , yn) = x1y1 + · · ·+ xnyn =n∑i=1
xiyi
es un producto interior que se conoce como producto escalar euclıdeo o producto euclıdeo (ya usado en R2
y R3 ). Que da lugar a la norma y distancia euclıdeas, ya conocidas:
‖x‖ =√x · x =
√x2
1 + · · ·+ x2n y d(x,y) = ‖x− y‖ =
√(x1 − y1)2 + · · ·+ (xn − yn)2
Y llamaremos espacio euclıdeo n-dimensional a Rn con el producto escalar euclıdeo.
Nota: Tambien se suele denominar de manera generica como Espacio euclıdeo a cualquier espacio vectorialcon un producto interior, pero como ya hemos dicho nosotros reservaremos esta denominacion para Rn con elproducto euclıdeo. Intentamos evitar cualquier tipo de dualidad.
De la misma manera reservamos la notacion x · y para el producto euclıdeo, remarcando ası con 〈x,y〉 quevamos a usar un producto escalar que no es el euclıdeo.
Observacion: En Rn con el producto euclıdeo, la matriz metrica en la base canonica es la identidad. Perotambien al reves, cuando la matriz metrica sea la identidad cualquier producto interior se reduce al productoeuclıdeo de las coordenadas; y esto ocurre precisamente para las bases ortonormales que se estudimos a contin-uacion
10.2 Ortogonalidad
10.2.1 Angulos y ortogonalidad
Definicion 281.- Si u y v son vectores distintos de cero de un espacio con producto interior, como consecuencia
de la desigualdad de Cauchy-Schwarz se tiene que −1 ≤ 〈u,v〉‖u‖‖v‖ ≤ 1 y, por tanto, existe un unico angulo, θ ,
tal que
cos θ =〈u,v〉‖u‖ ‖v‖
, con 0 ≤ θ ≤ π
Definicion 282.- En un espacio vectorial con producto interior, dos vectores u y v se dicen que son ortogo-nales si 〈u,v〉 = 0. Suele denotarse por u ⊥ v .
Si u es ortogonal a todos los vectores de un conjunto W , se dice que u es ortogonal a W .
Se dice que S = {v,v, . . . ,vk} es un conjunto ortogonal si los vectores son ortogonales dos a dos, esdecir, si vi ⊥ vj para todo i 6= j .
Ejemplo Los vectores de la base canonica de R3 con el producto escalar euclıdeo son ortogonales entre si,pero no lo son si el producto interior definido es: 〈v,w〉 = v1w1 + v1w2 + v2w1 + 2v2w2 + v3w3 . (Pruebeseque es un producto interior). En efecto: 〈e, e〉 = 〈(1, 0, 0), (0, 1, 0)〉 = 0 + 1 + 0 + 0 + 0 = 1 6= 0. 4
Nota: Si dos vectores son ortogonales, el angulo que forman es de π2 radianes (los famosos 90 grados). De hecho,
en Rn con el producto escalar euclıdeo, la ortogonalidad coincide con la perpendicularidad.
Una curiosidad:
Teorema general de Pitagoras 283.- Si u y v son dos vectores ortogonales de un espacio vectorial con pro-ducto interior, entonces
‖u + v‖2 = ‖u‖2 + ‖v‖2 .
Este resultado, de facil comprobacion, se reduce en R2 con el producto escalar al Teorema de Pitagoras.Tambien es sencillo probar el resultado siguiente (ver ejercicio 10.258):
Proposicion 284.- Si w ⊥ {v,v, . . . ,vk} , entonces w ⊥ lin{v,v, . . . ,vk} .
Mucho mas interesante es el siguiente, que relaciona ortogonalidad e independencia:
Teorema 285.- Si S = {v,v, . . . ,vk} un conjunto finito de vectores no nulos, ortogonales dos a dos, entoncesS es linealmente independiente. .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

150 – Fundamentos de Matematicas : Algebra Lineal 10.2 Ortogonalidad
10.2.2 Bases ortonormales. Proyeccion ortogonal
Definicion 286.- Sean V un espacio vectorial de dimension n con producto interior. Se dice que la baseB = {v,v, . . . ,vn} es una base ortonormal de V , si B es un conjunto ortogonal y ‖vi‖ = 1, ∀ i .
Ejemplo Las bases canonica y B1 ={(
1√2, 1√
2
),(−1√
2, 1√
2
)}son ortonormales en R2 con el producto escalar
euclıdeo. La base B2 = {(2, 0), (0,−√
2)} es ortonormal para el producto interior 〈x, y〉 = x1y1
4 + x2y2
2 . 4
Teorema 287.- Si B = {v,v, . . . ,vn} es una base ortonormal para un espacio V con producto escalar,
entonces ∀v ∈ V se tiene que (v)B =(〈v,v〉, 〈v,v〉, . . . , 〈v,vn〉
). Es decir,
v = 〈v,v〉v + 〈v,v〉v + · · ·+ 〈v,vn〉vn,
Demostracion:Si v = c1v + · · ·+ civi + · · ·+ cnvn , para cada i , se tiene que
〈v,vi〉= 〈c1v + · · ·+ civi + · · ·+ cnvn, vi〉= c1〈v,vi〉+ · · ·+ ci〈vi,vi〉+ · · ·+ cn〈vn,vi〉 = ci〈vi,vi〉 = ci ‖vi‖2 = ci
Es decir, en una base ortonormal, la obtencion de cordenadas es mas sencilla. Y no solo eso:
Teorema 288.- Si P es la matriz de paso de una base ortonormal B1 a otra base ortonormal B2 , entoncesP es una matriz ortogonal (es decir, P−1 = P t ).
La prueba es puramente operativa, con la definicion y el apartado b) del ejer. 10.261 (ver tambien ejer. 10.266).
Definicion 289.- Sean V un espacio con producto escalar, W subespacio de V y B = {w,w, . . . ,wk} baseortonormal de W . Para cada v ∈ V , llamaremos proyeccion ortogonal de v sobre W al vector de W
ProyW (v) = 〈v,w〉w + 〈v,w〉w + · · ·+ 〈v,wk〉wk.
Al vector v−ProyW (v) se le llama componente ortogonal de v sobre W .
La proyeccion ortogonal no depende la base ortonormal elegida, es decir, tomando otra se obtiene lo mismo. Laprueba puede encontrarse en el Anexo, pag. 150, tras la demostracion del Lema 290 siguiente.
Lema 290.- Sean V un espacio vectorial con producto interior y W subespacio de V , entonces para cadav ∈ V , el vector v− ProyW (v) es ortogonal a W . .
10.2.2.1 Teorema y ortonormalizacion de Gram-Schmidt
El siguiente teorema prueba la existencia de bases ortonormales para cualquier producto escalar, y no solo esosino que la prueba es un metodo de construccion de esa base ortonormal.
Proceso de ortonormalizacion de Gram-Schmidt 291.- Sean V un espacio vectorial con producto interior yde dimension n . Vamos a describir este proceso que construye a partir de una base B={v,v, . . . ,vn} unabase ortonormal B∗ = {u,u, . . . ,un} .
Demostracion:
1a etapa.- Como v 6= por ser de B , el vector u =v
‖v‖tiene norma 1 y lin{u} = lin{v} .
2a etapa.- Sea W1 = lin{u} , por el Lema anterior, el vector v−ProyW1(v) es ortogonal a W1 , en particular
a u , y es distinto del vector pues ProyW1(v) ∈W1 y v /∈W1 = lin{v} , entonces tiene que
u =v − ProyW1
(v)∥∥v − ProyW1(v)
∥∥ =v − 〈v,u〉u
‖v − 〈v,u〉u‖∈ lin{v,v}
es ortogonal a u y tiene norma 1. Ademas, lin{u,u} = lin{v,v} .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

151 – Fundamentos de Matematicas : Algebra Lineal 10.2 Ortogonalidad
3a etapa.- Sea ahora W2 = lin{u,u} , como antes, el vector v−ProyW2(v) es ortogonal a W2 , en particular
a u y u , y es distinto del vector , pues ProyW2(v) ∈W2 y v /∈W2 = lin{v,v} , entonces se tiene que
u =v − ProyW2
(v)∥∥v − ProyW2(v)
∥∥ =v − 〈v,u〉u − 〈v,u〉u
‖v − 〈v,u〉u − 〈v,u〉u‖∈ lin{v,v,v}
es ortogonal a u y u , y tiene norma 1. Ademas, lin{u,u,u} = lin{v,v,v} .
na etapa.- Con la repeticion del proceso se ha construido un conjunto ortonormal de n vectores no nulos,B∗ = {u,u, . . . ,un} , tal que linB∗ = linB = V . Luego B∗ es una base ortonormal de V .
Ejemplo En R4 con el producto euclıdeo, 〈x,y〉 = x · y , transformar
B={v =(1, 1, 1, 1), v =(−1,−1, 0, 2), v =(0, 1,−2, 1), v =(−1, 0, 1, 1)
}en una base ortonormal
• u = v
‖v‖ = ( 12 ,
12 ,
12 ,
12 ) y W1 = lin{u}
• u =v−ProyW1
(v)∥∥∥v−ProyW1(v)
∥∥∥ =v−(〈v,u〉u
)∥∥∥v−
(〈v,u〉u
)∥∥∥ = 1√6(−1,−1.0, 2) y W2 = lin{u,u}
• u =v−ProyW2
(v)∥∥∥v−ProyW2(v)
∥∥∥ =v−(〈v,u〉u+〈v,u〉u
)∥∥∥v−
(〈v,u〉u+〈v,u〉u
)∥∥∥ = 6√210
( 16 ,
76 ,−2, 4
6 ) y W3 = lin{u,u,u}
• u =v−ProyW3
(v)∥∥∥v−ProyW3(v)
∥∥∥ =v−(〈v,u〉u+〈v,u〉u+〈v,u〉u
)∥∥∥v−
(〈v,u〉u+〈v,u〉u+〈v,u〉u
)∥∥∥ = 12√
35(−9, 7, 3,−1) 4
Observacion El calculo de la base ortonormal mediante el proceso de Gram-Schmidt es simple, es algorıtmicoluego basta seguir los pasos indicados, pero muy laborioso.
Si buscamos solo dos o a lo sumo tres vectores ortogonales a veces puede hacerse por simple inspeccion uobligando a que cumplan las condiciones de ortogonalidad y resolviendo los sistemas resultantes; basta ahoracon normalizar los vectores para tener la base. Menos sistematico pero valido.
Hay otro proceso que tambien construye una base ortogonal a partir de otra dada, pero que usa las matricesmetricas. Consiste en obtener la matriz metrica identidad a partir de la matriz metrica de la base dada.
10.2.2.2 Base ortonormal mediante diagonalizacion congruente
Para un producto escalar dado, la matriz metrica referida a una base ortonormal es la identidad (referida auna base ortogonal es diagonal). Este hecho y la Proposicion 278 nos proporcionan la idea de buscar una baseortonormal buscando una matriz de cambio de base de manera que P tQP = I .
El proceso de que hablamos, se basa de nuevo en hacer operaciones elementales sobre la matriz. La idea delmetodo es la siguiente: haciendo operaciones elementales en las filas de la matriz podemos conseguir una matriztriangular inferior, pero como necesitamos que la matriz obtenida sea simetrica (debe ser congruente con laanterior, seguir siendo una matriz metrica), despues de cada operacion que hagamos en las filas repetiremos lamisma operacion sobre las columnas. Tras cada doble paso (operacion sobre las filas y misma operacion sobrelas columnas) la matriz obtenida seguira siendo simetrica y congruente con la inicial y, al final del proceso lamatriz obtenida sera diagonal.
La justificacion no es dificil de entender si usamos las matrices elementales que representan a cada operacion ele-mental (ver la subseccion 8.2.1 sobre matrices elementales en la pagina 127), pues: si E es una matriz elementalobtenida de realizar una aplicacion elemental sobre I , al multiplicar EA se tiene la matriz resultante de realizarla misma operacion elemental de E sobre las filas de A (Th.209) y si multiplicamos a la traspuesta de A , EAt
realiza la operacion sobre las columnas de A . Entonces: la matriz E(EA)t realiza la operacion sobre las colum-nas de la matriz en la que ya hemos realizado la operacion de las filas; pero como E(EA)t = EAtEt = EAEt
(por ser A simetrica), esta matriz es simetrica y congruente con A (pues E es inversible). Luego repitiendo elproceso hasta obtener una matriz diagonal y haciendo 1 los elementos de la diagonal:
I = EkEk−1 · · ·E1AEt1 · · ·Etk−1E
tk = (EkEk−1 · · ·E1)A (EkEk−1 · · ·E1)t = P tA(P t)t = P tAP
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

152 – Fundamentos de Matematicas : Algebra Lineal 10.3 Ejercicios
que sera congruente con A pues P es inversible al ser producto de inversibles.
Diagonalizacion congruente mediante operaciones elementales 292.- Ampliamos la matriz A con la iden-tidad, (A | I) y efectuamos en A y en I las operaciones elementales en las filas para escalonar A y repetimoscada operacion en las columnas de A , al cabo de un numero finito de pasos obtendremos (D | P t)
Nota: Construimos ası una matriz congruente diagonal, que se corresponde con una base ortogonal. Bastaahora con hacer 1 los elementos de la diagonal para obtener la base ortonormal.
Ejemplo 293 Sea 〈x,y〉 = 2x1y1 + 2x1y2 + 3x2y2 + 2x2y1 + x2y3 + x3y2 + 4x3y3 un producto escalar sobreR3 . Obtener una base ortonormal
La matriz metrica en la base canonica es S =
2 2 02 3 10 1 4
, luego para obtener una matriz congruente con S
que sea la identidad, hacemos el proceso de (S|I)→ (I|P t). Detallamos los pasos ha dar:
(S|I)=
2 2 0 1 0 02 3 1 0 1 00 1 4 0 0 1
F2−F1C2−C1−→
2 0 0 1 0 00 1 1 −1 1 00 1 4 0 0 1
F3−F2C3−C2−→
2 0 0 1 0 00 1 0 −1 1 00 0 3 1 −1 1
1√2F1
1√2C1
−→
1 0 0 1√2
0 0
0 1 0 −1 1 00 0 3 1 −1 1
1√3F3
1√3C3
−→
1 0 0 1√2
0 0
0 1 0 −1 1 00 0 1 1√
3− 1√
31√3
=(I|P t)
Tenemos entonces la matriz identidad y la matriz, P =
1√2−1 1√
3
0 1 − 1√3
0 0 1√3
, de paso de la base ortonormal
B∗={
( 1√2, 0, 0), (−1, 1, 0), ( 1√
3,− 1√
3, 1√
3)}
a la canonica, que verifican que P tSP = I . 4
10.3 Ejercicios
10.255 Sean u = (u1, u2, u3) y v = (v1, v2, v3). Determinar si 〈u,v〉 = u1v1 − u2v2 + u3v3 define un productointerior en R3 .
10.256 a) Encontrar dos vectores de R2 con norma euclıdea 1 y cuyo producto euclıdeo con (−2, 4) sea cero
b) Probar que hay infinitos x ∈ R3 con ‖x‖ = 1 y el producto euclıdeo x · (−1, 7, 2) = 0
10.257 Sean a = ( 1√5, −1√
5) y b = ( 2√
30, 3√
30). Demostrar que {a, b} es ortonormal si R2 tiene el producto interior
〈u,v〉 = 3u1v1 + 2u2v2 donde u = (u1, u2) y v = (v1, v2), y que no lo es si R2 tiene el producto euclıdeo
10.258 Sea V un espacio con producto interior. Probar que si un vector w es ortogonal a cada uno de los vectoresv,v, . . . ,vk entonces es ortogonal a todo el conjunto lin{v,v, . . . ,vk}
10.259 Considerar R3 con el producto interior euclideo. Utilizar tanto el proceso de Gram-Schmidt como ladiagonalizacion congruente para transformar, en cada caso, la base {u,u,u} en una base ortonormal.
a) u = (1, 1, 1), u = (−1, 1, 0), u = (1, 2, 1).
b) u = (1, 0, 0), u = (3, 7,−2), u = (0, 4, 1).
10.260 Sea R3 con el producto escalar 〈u,v〉 = u1v1 +2u2v2 +3u3v3 . Utilizar tanto el proceso de Gram-Schmidtcomo la diagonalizacion congruente para transformar la base formada por los vectores (1, 1, 1), (1, 1, 0) y(1, 0, 0) en una base ortonormal
10.261 Sea B = {v,v,v} una base ortonormal de un espacio V con producto interior. Comprobar que:
a) ‖w‖2 = 〈w,v〉2 + 〈w,v〉2 + 〈w,v〉2 ; ∀w ∈ V .
b) 〈u,w〉 = (u)B · (w)B = [u]tB [w]B ; ∀u,w ∈ V .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

153 – Fundamentos de Matematicas : Algebra Lineal 10.3 Ejercicios
10.262 Tomemos en R4 el producto interior euclideo. Expresar el vector w = (−1, 2, 6, 0) en la forma w =w+w donde, w este en el subespacio W generado por los vectores u = (−1, 0, 1, 2) y u = (0, 1, 0, 1),y w sea ortogonal a W .
10.263 Suponer que R4 tiene el producto interior euclideo.
a) Hallar un vector ortogonal a u = (1, 0, 0, 0) y u = (0, 0, 0, 1), y que forme angulos iguales con losvectores u = (0, 1, 0, 0) y u = (0, 0, 1, 0).
b) Hallar un vector x de longitud 1, ortogonal a u y a u , tal que el coseno del angulo entre x y u
sea el doble del coseno del angulo entre x y u .
10.264 Hallar la distancia del vector u = (1, 1, 1, 1) de R4 al subespacio generado por los vectores v = (1, 1, 1, 0)
y v = (1, 1, 0, 0).
10.265 Dados los vectores x = (x1, x2, x3) e y = (y1, y2, y3) de R3 , demostrar que la expresion 〈x,y〉 =2x1y1 + 2x2y2 + x3y3 + x1y2 + x2y1 define un producto interior.
Encontrar una base {u,u,u} ortonormal respecto al producto interior anterior tal que u y u tenganigual direccion y sentido que los vectores (0, 1, 0) y (0, 0, 1), respectivamente.
10.266 Probar que una matriz A de orden n es ortogonal si, y solo si sus vectores fila forman un conjuntoortonormal en Rn .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

154 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 11
Aplicaciones lineales
11.1 Definicion. Nucleo e imagen
Definicion 294.- Sea f :V −→ W una aplicacion entre los espacios vectoriales reales V y W . Se dice que fes una aplicacion lineal si:
(1) f(u + v) = f(u) + f(v); ∀u,v ∈ V, (2) f(ku) = kf(u); ∀u ∈ V y ∀ k ∈ R.
Estas dos propiedades se pueden reunir en:
f(ku + lv) = kf(u) + lf(v); ∀u,v ∈ V, ∀ k, l ∈ R.y, en general, se tiene:
f(k1u + k2u + · · ·+ krur) = k1f(u) + k2f(u) + · · ·+ krf(ur) ∀ui ∈ V, ∀ ki ∈ RSi V = W la aplicacion lineal tambien se dice que es un operador lineal.
Ejemplos 295 Las siguientes aplicaciones son aplicaciones lineales
1.- f :V −→ V definida por f(v) = 2v :
f(λv + µw) = 2(λv + µw) = λ2v + µ2w = λf(v) + µf(w)
2.- Dada A =
(0 −1 11 0 −1
), la aplicacion f :R3 −→ R2 con f(x) = Ax =
(0 1 11 0 −1
) x1
x2
x3
:
f(λx + µy) = A(λx + µy) = A(λx) +A(µy) = λAx + µAy = λf(x) + µf(y) 4
Proposicion 296.- Si f :V −→W es una aplicacion lineal, entonces:
a) f() = ; b) f(−v) = −f(v); ∀v ∈ V
Definicion 297.- Dada una aplicacion lineal f :V −→W , se define el nucleo o ker(nel) de f , que se denotapor ker(f) o ker f , como el conjunto:
ker f = {v ∈ V : f(v) = }
y se define la imagen de f , que se denota por Img(f) o Img f (a veces f(V )), como el conjunto
Img f = {w ∈W : ∃v ∈ V tal que w = f(v)}
El ker f es un subespacio vectorial de V y la Img f es subespacio vectorial de W (ver ejercicio 11.268).
Definicion 298.- Si f :V −→ W es una aplicacion lineal, entonces la dimension del nucleo se denomina lanulidad de f y la dimension de la imagen de f se denomina el rango de f .
Proposicion 299.- Sea f :V −→ W es una aplicacion lineal y B = {v,v, . . . ,vn} una base de V , entoncesImg f = lin{f(v), f(v), . . . , f(vn)}
Demostracion:En efecto, todo v ∈ V puede escribirse como v = k1v + k2v + · · ·+ knvn , luego
f(v) = f(k1v + k2v + · · ·+ knvn) = k1f(v) + k2f(v) + · · ·+ knf(vn)
En consecuencia, si w ∈ Img f , w = f(v) = k1f(v) + k2f(v) + · · ·+ knf(vn), para algun v .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

155 – Fundamentos de Matematicas : Algebra Lineal 11.2 Matrices de una aplicacion lineal
Ejemplo Tomemos el ejemplo 2) de los Ejemplos 295 anteriores:
ker f = {x ∈ R3 : f(x) = } = {x ∈ R3 : Ax = }luego son las soluciones del sitema de ecuaciones lineales AX = 0. Como son los vectores de la forma (z,−z, z),para cualquier valor de z ∈ R , se tiene que ker f = {(z,−z, z) ∈ R3 : z ∈ R} = lin{(1,−1, 1)} .
Para la imagen: tomemos en R3 la base canonica, entonces
Img f= lin{f(e), f(e), f(e)}= lin{Ae, Ae, Ae}= lin{(0, 1), (−1, 0), (1,−1)}= lin{(0, 1), (−1, 0)}=R2
pues (1,−1) = (−1)(0, 1) + (−1)(−1, 0). Se tiene ademas, que dim(ker f) = 1 y dim(Img f) = 2. 4
No por casualidad, sucede que dim(ker f) + dim(Img f) = 1 + 2 = 3 = dimR3 :
Teorema de la dimension 300.- Si f :V −→W es una aplicacion lineal entre espacios vectoriales,
dimV = dim(ker f) + dim(Img f)
Demostracion:Si la dim(ker f) = n = dimV , entonces ker f = V , y f(v) = ∀v ∈ V , luego Img f = {} que tiene dimensioncero, por lo que se cumple
dim(ker f) + dim(Img f) = dimV ( n + 0 = n )
Si la dim(ker f) = r < n , tomemos Bker = {u, . . . ,ur} una base del ker f ⊆ V que podemos completar conn− r vectores hasta una base de V , BV = {u, . . . ,ur,vr+, . . . ,vn} , y el conjunto imagen sera por tanto
Img f = lin{f(u), . . . , f(ur), f(vr+), . . . , f(vn)
}= lin
{, . . . ,, f(vr+), . . . , f(vn)
}= lin
{f(vr+), . . . , f(vn)
}Si probamos que el conjunto formado por esos n− r vectores es linealmente independiente, sera una base de laImg f y habremos probado que
dim(ker f) + dim(Img f) = dimV ( r + n− r = n )
como querıamos. Veamoslo: por ser f una aplicacion lineal,
λr+1f(vr+) + · · ·+ λnf(vn) = ⇐⇒ f(λr+1vr+ + · · ·+ λnvn) = ⇐⇒ λr+1vr+ + · · ·+ λnvn ∈ ker f
luego en la base Bker se expresa con λr+1vr+1 + · · ·+ λnvn = µ1u + · · ·+ µrur , para ciertos µi . Luego
−µ1u − · · · − µrur + λr+1vr+1 + · · ·+ λnvn =
y −µ1 = · · · = −µr = λr+1 = · · · = λn = 0 por formar esos vectores una base de V . En particular, conλr+1 = · · · = λn = 0 se prueba que el conjunto {f(vr+1), . . . , f(vn)} es un conjunto linealmente independientede vectores, que por ser tambien generador de la Img f es una base de ella.
11.2 Matrices de una aplicacion lineal
Teorema 301.- Sean V y W espacios vectoriales con dimV = n y dimW = m , y sea f :V −→ W , unaaplicacion lineal. Si B1 = {v,v, . . . ,vn} es una base de V y B2 = {w,w, . . . ,wm} una base de W ,entonces la matriz
Am×n =
([f(v)]B2 [f(v)]B2 · · · [f(vn)]B2
)es la unica matriz que verifica que [f(v)]B2
= A[v]B1, para cada v ∈ V .
Demostracion:Todo v ∈ V se escribe de forma unica como una combinacion lineal de los vectores de la base, v =k1v + k2v + · · ·+ knvn , luego su imagen f(v) = k1f(v) + k2f(v) + · · ·+ knf(vn).
Como los vectores f(v), f(v), . . . , f(vn) son de W , sean sus coordenadas en la base B2 :
(f(v)
)B2
= (a11, a21, . . . , am1)(f(v)
)B2
= (a12, a22, . . . , am2)
· · · · · · · · · · · · · · · · · · · · ·(f(vn)
)B2
= (a1n, a2n, . . . , amn)
⇐⇒
f(v) = a11w + a21w + · · ·+ am1wm
f(v) = a12w + a22w + · · ·+ am2wm
· · · · · · · · · · · · · · · · · · · · ·f(vn) = a1nw + a2nw + · · ·+ amnwm
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

156 – Fundamentos de Matematicas : Algebra Lineal 11.2 Matrices de una aplicacion lineal
Entonces, sustituyendo en f(v), se tiene
f(v) = k1(a11w + a21w + · · ·+ am1wm) + k2(a12w + a22w + · · ·+ am2wm)
+ · · · · · · · · · · · · · · · · · ·+ kn(a1nw + a2nw + · · ·+ amnwm)
= (k1a11 + k2a12 + · · ·+ kna1n)w + (k1a21 + k2a22 + · · ·+ kna2n)w
+ · · · · · · · · · · · · · · · · · ·+ (k1am1 + k2am2 + · · ·+ knamn)wm
por tanto, las coordenadas de f(v) en la base B2 son
[f(v)]B2=
k1a11 + k2a12 + · · ·+ kna1n
k1a21 + k2a22 + · · ·+ kna2n
· · · · · · · · · · · · · · ·k1am1 + k2am2 + · · ·+ knamn
=
a11 a12 · · · a1n
a21 a22 · · · a2n
...... · · ·
...am1 am2 · · · amn
k1
k2
...kn
= A[v]B1
y A , tiene por columnas las coordenadas en la base B2 de las imagenes de los vectores de la base B1 .
Definicion 302.- Sean B1 una base de V , B2 base de W y f :V −→ W una aplicacion lineal. A la unicamatriz A , tal que [f(v)]B2
= A[v]B1, para cada v ∈ V , se le llama matriz de f respecto de las bases B1
y B2 .Si f :V −→ V es un operador lineal y consideramos que tenemos la misma base B en el espacio de partida
y en el de llegada, entonces se habla de matriz de f respecto de la base B .
Ejemplo Sea f :R2[X] −→ R1[X] dada por f(P (X)) = P ′(X). Sean B1 = {1, X, X2} y B2 = {1, X} basesrespectivas de R2[X] y R1[X] . Entonces, como f(1) = 0, f(X) = 1 y f(X2) = 2X se tiene que
A =(
[f(1)]B2[f(X)]B2
[f(X2)]B2
)=
(0 1 00 0 2
)es la matriz de f asociada a B1 y B2 .
En efecto
f(a+ bX + cX2) = b+ 2cX y A[a+ bX + cX2]B1=
(0 1 00 0 2
) abc
=
(b2c
)= [b+ 2cX]B2 4
Observacion 303.- Si f :V −→W es una aplicacion lineal y A la matriz de f respecto de B1 y B2 , entonces
ker f ={v ∈ V : f(v) =
}={v ∈ V : [f(v)]B2 = []B2
}={v ∈ V : A[v]B1 =
}luego las coordenadas en la base B1 de los vectores del ker f son las soluciones del sistema homogeneo Ax = .
w ∈ Img f = lin{f(v), f(v), . . . , f(vn)
}⇐⇒ [w]B2
∈ lin{
[f(v)]B2, [f(v)]B2
, . . . , [f(vn)]B2
}luego el espacio de las columnas de la matriz A , Ec(A), esta compuesto por las coordenadas en la base B2 delos vectores de la Img f . En consecuencia, dim(Img f) = dimEc(A) = rg(A).
Ejemplo Sean B1 = {v,v,v} base de V , B2 = {w,w,w} base de W , f :V −→ W aplicacion lineal
y A =
1 0 1−1 1 11 1 3
la matriz de f asociada a B1 y B2 . Encontrar una base de ker f y otra de Img f .
Como A[v]B1= [f(v)]B2
, v ∈ ker f ⇐⇒ A[v]B1= 0, luego resolviendo el sistema AX = 0:
A =
1 0 1−1 1 11 1 3
−→ 1 0 1
0 1 20 1 2
−→ 1 0 1
0 1 20 0 0
=⇒
x = −zy = −2zz = z
=⇒ [v]B1 =
xyz
= z
−1−21
el vector (−1,−2, 1) genera las coordenadas en B1 de los vectores del ker f . Luego ker f= lin{−v−2v+v} .
Ademas, dim(ker f) = 1 luego dim(Img f) = 3 − 1 = 2 = rg(A). Y una base de la imagen se obtendra deuna base del espacio de las columnas de A (para operar sobre las columnas de A , operamos es las filas de At ):
At =
1 0 1−1 1 11 1 3
t
=
1 −1 10 1 11 1 3
−→ 1 −1 1
0 1 10 2 2
−→ 1 −1 1
0 1 10 0 0
luego los vectores (1,−1, 1) y (0, 1, 1) generan las coordenadas en la base B2 de los vectores de la Img f . Enconsecuencia, Img f = lin{w−w+w, w+w} . 4
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

157 – Fundamentos de Matematicas : Algebra Lineal 11.2 Matrices de una aplicacion lineal
Observacion 304.- Pueden obtenerse de una sola vez una base para ker(f) y otra para la Img(f). Basta paraello, tener en cuenta que las operaciones elementales realizadas sobre las columnas de la matriz, son operacionessobre los vectores imagen.
Ejemplo Sea A =
1 2 −1 1 0 1−1 1 −2 2 1 02 −1 −1 −1 1 −11 6 −9 7 4 0
la matriz de la aplicacion f :V −→ W , referida a las
bases B1 = {v,v,v,v,v,v} y B2 = {w,w,w,w} . Para obtener una base de la imagen, hacemosoperaciones elementales en las filas de At (en las columnas de A):
At =
1 −1 2 1 : C1
2 1 −1 6 : C2
−1 −2 −1 −9 : C3
1 2 −1 7 : C4
0 1 1 4 : C5
1 0 −1 1 : C6
F2−2F1F3+F1F4−F1F6−F1−→
1 −1 2 1 : C1
0 3 −5 4 : C2 − 2C1
0 −3 1 −8 : C3 + C1
0 3 −3 6 : C4 − C1
0 1 1 4 : C5
0 1 −3 0 : C6 − C1
F2↔F6−→
1 −1 2 1 : C1
0 1 −3 0 : C6−C1
0 −3 1 −8 : C3+C1
0 3 −3 6 : C4−C1
0 1 1 4 : C5
0 3 −5 4 : C2−2C1
F3+3F2F4−3F2F5−F2F6−3F2−→
1 −1 2 1 : C1
0 1 −3 0 : C6 − C1
0 0 −8 −8 : C3 + C1 + 3(C6 − C1)0 0 6 6 : C4 − C1 − 3(C6 − C1)0 0 4 4 : C5 − (C6 − C1)0 0 4 4 : C2 − 2C1 − 3(C6 − C1)
F3↔F5−→
1 −1 2 1 : C1
0 1 −3 0 : C6 − C1
0 0 4 4 : C5 − C6 + C1
0 0 6 6 : C4 + 2C1 − 3C6
0 0 −8 −8 : C3 − 2C1 + 3C6
0 0 4 4 : C2 + C1 − 3C6
F4−
32F3
F5+2F3F6−F3−→
1 −1 2 1 : C1
0 1 −3 0 : C6 − C1
0 0 4 4 : C5 − C6 + C1
0 0 0 0 : C4 + 12C1 − 3
2C6 − 32C5
0 0 0 0 : C3 + C6 + 2C5
0 0 0 0 : C2 − 2C6 − C5
La matriz final es escalonada, luego las tres primeras filas son linealmente independientes, pero estas en realidadson: C1 = [f(v)]B2
, C6−C1 = [f(v)]B2− [f(v)]B2
= [f(v−v)]B2y C5−C6 +C1 = [f(v−v +v)]B2
.
Por lo que{f(v), f(v − v), f(v − v + v)
}es base de Img(f) (rg(A) = dim(Img f) = 3).
Las tres filas restantes de la matriz son cero, en realidad:
= C4 + 12C1 − 3
2C6 − 32C5 = [f(v +
v − v −
v)]B2
= C3 + C6 + 2C5 = [f(v + v + v)]B2
= C2 − 2C6 − C5 = [f(v − v − v)]B2
luego los vectores v+ v−
v− v , v+v+v y v−v−v son vectores de ker(f). Como son
linealmente independientes (ver justificacion en Anexo 13.3, pag 183) y dim(ker f) = 6 − dim(Img f) = 3,forman una base del ker(f).
Definicion 305.- Si f :Rn −→ Rm es una aplicacion lineal, a la matriz de f asociada a las bases canonicas deRn y Rm , se le llama la matriz estandar.
Definicion 306.- Para cada matriz Am×n , la aplicacion f :Rn −→ Rm definida por f(x) = Ax es lineal y Aes la matriz estandar de f . Se dice que f es una aplicacion matricial.
11.2.1 Composicion de aplicaciones lineales
Aplicacion y funcion tienen el mismo significado (aunque esta ultima denominacion es la que suele usarse en lostemas de Calculo) por lo que la definicion siguiente no debe plantear sorpresas:
Definicion 307.- Sean f :V −→W y g:W −→ U aplicaciones lineales. Llamaremos aplicacion compuestade f y g , a la aplicacion g ◦ f :V −→ U definida por
(g ◦ f)(v) = g(f(v)), ∀v ∈ V.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

158 – Fundamentos de Matematicas : Algebra Lineal 11.3 Teorema de Semejanza
Proposicion 308.- Sean f :V −→ W y g:W −→ U aplicaciones lineales, con dimV = n , dimW = m ydimU = p , y sean B1 , B2 y B3 bases de V , W y U , respectivamente. Entonces:
a) g ◦ f es una aplicacion lineal.
b) Si Am×n es la matriz asociada a f respecto de las bases B1 y B2 , y Cp×m es la matriz asociada a grespecto de B2 y B3 , entonces CAp×n es la matriz asociada a g ◦ f respecto de las bases B1 y B3 .
Demostracion:
a) (g ◦ f)(λu + µv) = g(f(λu + µv)) = g(λf(u) + µf(v)) = λg(f(u)) + µg(f(v))= λ(g ◦ f)(u) + µ(g ◦ f)(v).
b) Teniendo en cuenta que [g(w)]B3= C[w]B2
y [f(v)]B2= A[v]B1
,
[(g ◦ f)(v)]B3 = [g(f(v))]B3 = C[f(v)]B2 = CA[v]B1 ; ∀v ∈ V.
11.3 Teorema de Semejanza
Proposicion 309.- Sea f :V −→ W una aplicacion lineal entre espacios vectoriales, B1 y B∗1 dos bases de Vy B2 y B∗2 dos bases de W . Si A1 es la matriz de f asociada a las bases B1 y B2 , P la matriz de cambiode base la base B∗1 a la base B1 y Q la matriz de cambio de base de B2 a B∗2 ; entonces la matriz, A∗ , de fasociada a las bases B∗1 y B∗2 viene dada por
A∗ = QAP
Demostracion:QAP [v]B∗1 = QA[v]B1 = Q[f(v)]B2 = [f(v)]B∗2 = A∗[v]B∗2 , ∀v ∈ V . Luego A∗ = QAP .
Teorema de semejanza 310.- Sean f :V −→ V , un operador lineal, A1 la matriz de f respecto de una baseB1 de V , A2 la matriz de f respecto de otra base B2 y P la matriz de paso de B2 a B1 . Entonces
A2 = P−1A1P
Observacion: Una manera de recordar bien este proceso es tener en cuenta los diagramas siguientes, donde laobtencion de las nuevas matrices se reduce a la busqueda de caminos alternativos:
A∗ = QAP
Vf−→ W
B1A−→ B2
↑ |P | ↓ Q
B∗1A∗−→ B∗2
Vf−→ V
B1A1−→ B1
↑ |P | ↓ P−1
B2A2−→ B2
A2 = P−1A1P
No hay que olvidar, que las matrices se operan en orden inverso (las matrices multiplican a los vectores por laizquierda, sucesivamente). Obviamente, el Teorema de Semejanza es un caso particular de la Proposicion 309.
Definicion 311.- Dadas dos matrices A y B de orden n , se dice que A y B son semejantes si existe unamatriz P inversible tal que B = P−1AP .
Corolario 312.- Dos matrices A y B son semejantes si y solo si representan al mismo operador lineal respectoa dos bases.
Corolario 313.- Si A y B son matrices semejantes, entonces tienen el mismo rango.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

159 – Fundamentos de Matematicas : Algebra Lineal 11.4 Ejercicios
11.4 Ejercicios
11.267 Determinar si las siguientes aplicaciones son o no lineales:
a) f :R2 −→ R2 definida por f(x, y) = ( 3√x, 3√y)
b) f :R3 −→ R2 definida por f(x, y, z) = (2x+ y, 3y − 4z).
c) f :M2×2 −→ R definida por f
(a bc d
)= a2 + b2 .
d) f :M2×2 −→ R4 definida por f
(a bc d
)= (a− b, b− c, c− d, d− a).
e) f :R2[X] −→ R3[X] definida por f(p(X)) = (X− 1) · p(X).
f) Si w ∈ V − {} , sea f :V −→ V definida por f(v) = v + w .
g) f :R4[X] −→ R5[X] definida por f(p(X)) =
∫ X
0
p(t) dt .
11.268 Sea f :V −→W una aplicacion lineal.
a) Probar que ker f es un subespacio de V
b) Probar que Img f es un subespacio de W
11.269 Sean V un espacio vectorial y T :V −→ V la aplicacion lineal tal que T (v) = 3v . ¿Cual es el nucleo deT ? ¿Cual es la imagen de T ?
11.270 Sea B = {v = (1, 2, 3), v = (2, 5, 3), v = (1, 0, 10)} una base de R3 y f :R3 −→ R2 una aplicacion
lineal para la que f(v) = (1, 0), f(v) = (0, 1) y f(v) = (0, 1).
a) Encontrar una matriz de la aplicacion f indicando las bases a las que esta asociada.
b) Calcular f(v − v − 2v) y f(1, 1, 1).
11.271 Sea T :R3 −→ R3 la aplicacion lineal dada por la formula T (x, y, z) =
1 3 43 4 7−2 2 0
xyz
.
a) Comprobar que el nucleo de T es una recta y encontrar sus ecuaciones parametricas
b) Comprobar que la imagen de T es un plano y hallar su ecuacion (cartesiana)
11.272 Obtener nucleo, imagen y una matriz de cada aplicacion lineal del ejercicio 11.267
11.273 Encontrar la matriz en las bases canonicas de cada una de las aplicaciones lineales f :Rn −→ Rm siguientes:
a) f
x1
x2
x3
=
x1 + 2x2 + x3
x1 + 5x2
x3
b) f
x1
x2
x3
x4
=
x4
x1
x3
x1 − x3
c) f
x1
x2
x3
x4
=
x4 − x1
x1 + x2
x2 − x3
Encontrar una base del nucleo y otra de la imagen, para cada una de ellas
11.274 Sea T :R3 −→W la proyeccion ortogonal de R3 sobre el plano W que tiene por ecuacion x+ y + z = 0.
a) Hallar una formula para T (x, y, z) y calcular T (3, 8, 4)
b) Encontar el nucleo y la imagen de T , y una base de cada uno de ellos
c) ¿Hay vectores que cumplan la igualdad T (v) = v?, ¿cuales?
11.275 Sea A una matriz de tamano 5× 7 con rango 4.
a) ¿Cual es la dimension del espacio de soluciones de Ax = ?
b) ¿Ax = b tiene solucion para todo b de R5 ? ¿Por que?
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

160 – Fundamentos de Matematicas : Algebra Lineal 11.4 Ejercicios
11.276 Se dice que una aplicacion lineal es inyectiva si a cada vector de la imagen le corresponde un unico
original (es decir, si f(u) = f(v) =⇒ u = v ). Demostrar que f es inyectiva si y solo si ker f = {} .
11.277 Sea T :R2 −→ R3 la transformacion lineal definida por T (x1, x2) = (x1 + 2x2, −x1, 0).
a) Encontrar la matriz de la aplicacion T en las bases:
B1 ={u =(1, 3), u =(−2, 4)
}y B2 =
{v =(1, 1, 1),v =(2, 2, 0),v =(3, 0, 0)
}.
b) Usar la matriz obtenida en el apartado anterior para calcular T (8, 3).
11.278 Sea f :M2×2 −→M2×2 definida por: f
(a11 a12
a21 a22
)=
(−1 20 1
)(a11 a12
a21 a22
)y sean las bases Bc
(hace el papel de la canonica) y B de M2×2 :
Bc =
{(1 00 0
),
(0 10 0
),
(0 01 0
),
(0 00 1
)}B =
{(1 00 0
),
(0 21 0
),
(0 12 0
),
(0 00 1
)}a) Demostrar que f es lineal.
b) ¿Cual sera el tamano de la matriz de f asociada a la base Bc ? Hallarla.
c) Hallar el nucleo y la imagen de f ası como sus dimensiones y bases.
d) Hallar la matriz de f respecto de la base B .
11.279 Sea A =
3 −2 1 01 6 2 1−3 0 7 1
la matriz de la aplicacion lineal T :R4 −→ R3 respecto de las bases:
B1 ={v = (0, 1, 1, 1),v = (2, 1,−1,−1),v = (1, 4, 1,−2),v = (6, 9, 4, 2)
}y
B2 ={w = (0, 8, 8),w = (−7, 8, 1),w = (−6, 9, 1)
}.
a) Hallar [T (v)]B2, [T (v)]B2
, [T (v)]B2y [T (v)]B2
b) Encontrar T (v), T (v), T (v) y T (v)
c) Hallar T (2, 2, 0, 0)
11.280 Sea T :R2 −→ R2 la aplicacion lineal definida por T
(x1
x2
)=
(x1 + 7x2
3x1 + 4x2
).
Hallar la matriz de T respecto de la base B1 y aplicar el teorema de semejanza para calcular la matrizde T respecto de la base B2 , siendo
B1 ={u = (2, 2),u = (4,−1)
}y B2 =
{v = (1, 3),v = (−1,−1)
}11.281 Dado el operador lineal T :R2[X] −→ R2[X] tal que [T (p)]B = A[p ]B siendo:
A =
−2 a 11 −2a 11 a −2
y B ={p = 1− X, p = X− X2, p = −1
}a) Calcular los subespacios ker(T ) y Img(T ) segun los valores de a
b) Hallar la matriz de T en la base B0 = {1, X, X2}c) Hallar la matriz de T respecto de las bases B0 y B y de las bases B y B0
11.282 Sea T :R3 −→ R3 la aplicacion lineal T =
x1
x2
x3
=
λx1 + µx2 + x3
x1 + λµx2 + x3
x1 + µx2 + λx3
. Se pide:
a) Encontrar los valores de λ y µ para los que Img(T ) = R3 , ¿quien es entonces el nucleo?
b) Para λ = 1, encontrar una base del nucleo
c) Sea λ = 1 y µ = 0. Se pide:
(c.1) Hallar la matriz de T respecto de la base B ={u =(−1, 0, 1), u =(0, 1, 0), u =(4, 1, 2)
}(c.2) Encontrar la matriz de paso de B a B1 =
{v =(1, 1, 2), v =(1, 1, 0), v =(−1, 1,−1)
}(c.3) Encontrar la matriz de T en la base B1 aplicando el teorema de semejanza
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

161 – Fundamentos de Matematicas : Algebra Lineal 11.4 Ejercicios
(c.4) Encontrar la matriz de T respecto de las bases B1 y B
(c.5) Obtener las matrices de T ◦ T : respecto de la base B , respecto de la base B1 , respecto de lasbases B y B1 y respecto de las bases B1 y B
11.283 Sean f :V −→W una aplicacion lineal. Probar que si f(v), f(v), . . . , f(vn) son linealmente indepen-dientes, entonces v , v , . . . , vn son linealmente independientes.
¿Es cierto el recıproco? Justificar la respuesta.
11.284 Sea T :R3 −→ R2 una aplicacion lineal tal que:
(i) ker(T ) =
{x+ 2y + z = 02x+ y + z = 0
(ii) T
001
=
(01
)(iii) T
101
=
(21
)a) Obtener una matriz asociada a T , indicando respecto a que bases.
b) Encontar la imagen del subespacio de R3 dado por x+ y + z = 0, y una base de ella
11.285 Sean Bp ={p,p,p,p
}una base de R3[X] , B1 =
{v = (0, 1, 0), v = (1, 1, 1), v = (0, 0, 1)
}una
base de R3 y f :R3[X] −→ R3 una aplicacion lineal verificando:
(i) f(p)=f(2p+p)=f(p−p) (ii) f(p)=v+v−v (iii) f(p)=(3, 3, 2)
a) Encontrar Ap1 la matriz de la aplicacion f en las bases Bp y B1 .
b) ¿Es
−1 1 01 0 0−1 0 1
la matriz de paso, Pc1 , de la base canonica de R3 a B1 ? Justificar la respuesta
y, en caso negativo, hallar Pc1 .
c) Sea Bq ={q =X−X3, q =X2−1, q =1−X, q =X2+X
}otra base de R3[X] para la cual, las matrices
Mqp =
2 0 0 01 3 2 0−1 −2 −1 00 0 0 −1
y Aq1 =
6 5 3 03 1 0 −33 3 2 1
son respectivamente, la matriz de paso de Bq
a Bp y la matriz de f en las bases Bq y B1 . Con estos nuevos datos, ¿como se puede comprobarque la matriz Ap1 calculada antes es la correcta?
d) Hallar bases de ker(f) e Img(f), obteniendo los vectores concretos que las forman.
e) Probar que B2 ={w = (−1, 2, 1), w = (0,−1,−1), w = (2, 1, 0)
}es base de R3 y obtener la
matriz de paso, P21 , de la base B2 en la base B1 .
f) A partir de las matrices anteriores, dar la expresion del calculo de las matrices:
• Ap2 de la aplicacion f en las bases Bp y B2
• Mpq de paso de la base Bp en la base Bq
• Aq2 de la aplicacion f en las bases Bq y B2
g) ¿Pueden conocerse los vectores que forman Bp ? ¿Como? de ser posible o ¿por que no?
11.286 Probar que si A y B son matrices semejantes entonces det(A) = det(B).
11.287 Probar que si A y B son matrices semejantes entonces A2 y B2 tambien lo son.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

162 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 12
Diagonalizacion
12.1 Valores y vectores propios
Problema general de diagonalizacion Dado un operador lineal f sobre un espacio vectorial V , nosplanteamos el problema de cuando es posible encontrar una base de V respecto de la cual la matriz de f seadiagonal.
Si A es la matriz del operador f con respecto a una determinada base B , el planteamiento anterior esequivalente a preguntarse cuando existe un cambio de base tal que la matriz del operador en la nueva base B∗sea diagonal. Esa nueva matriz viene dada por P−1AP , donde P es la matriz de paso de la nueva base B∗ ala base anterior B (Teorema de Semejanza). Podemos pues formular el problema en terminos de matrices:
Definicion 314.- Se dice que una matriz A cuadrada es diagonalizable si existe una matriz P inversible talque P−1AP es diagonal. En ese caso se dice que P diagonaliza a la matriz A .
Antes de seguir: en esta definicion y en el estudio que vamos a realizar, diagonalizaremos matrices independien-temente del operador lineal que aparece en el planteamiento inicial del problema. Sin embargo, las matrices deque hablamos son matrices de columnas de coordenadas por lo que todo sera valido y aplicable en terminos deloperador. En el Anexo 3, pag 183, pueden verse resultados identicos en terminos de operadores que lo justifican.
Supongamos que la matriz An×n es diagonalizable y sea D la matriz diagonal. Entonces:
∃P inversible tal que P−1AP = D o, equivalentemente, ∃P inversible tal que AP = PD
Si denotamos por p , p , . . . , pn a las columnas de P , las matrices son
AP = A
(p p · · · pn
)=
(Ap Ap · · · Apn
)
PD =
p11 p12 · · · p1np21 p22 · · · p2n...
.... . .
...pn1 pn2 · · · pnn
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
=
λ1p11 λ2p12 · · · λnp1nλ1p21 λ2p22 · · · λnp2n
......
. . ....
λ1pn1 λ2pn2 · · · λnpnn
=
(λ1p λ2p · · · λnpn
)
y, como son iguales: Api = λipi , para todo i = 1, . . . , n . Es decir, han de existir n vectores linealmenteindependientes pi (P es inversible) y n numeros λi que lo verifiquen.
Definicion 315.- Si A es una matriz de orden n , diremos que λ es un valor propio, valor caracterıstico,eigenvalor o autovalor de A si existe algun p ∈ Rn , p 6= , tal que Ap = λp .
Del vector p diremos que es un vector propio, vector caracterıstico, eigenvector o autovector de Acorrespondiente al valor propio λ .
Del comentario anterior, obtenemos la primera caracterizacion para la diagonalizacion de la matriz:
Teorema 316.- Sea A una matriz de orden n , entonces:
A es diagonalizable ⇐⇒ A tiene n vectores propios linealmente independientes
Demostracion:Por lo anterior, se tiene que: A es una matriz diagonalizable ⇐⇒⇐⇒ ∃P inversible y D diagonal tal que AP = PD
⇐⇒ ∃P inversible y D diagonal tal que
AP =
(Ap Ap · · · Apn
)=
(λ1p λ2p · · · λnpn
)= PD
⇐⇒ existen n vectores linealmente independientes tales que Ap = λ1p , . . . , Apn = λnpn
⇐⇒ A tiene n vectores propios linealmente independientes
En consecuencia, el problema de la diagonalizacion se reduce a la busqueda de los vectores propios de lamatriz, y comprobar si de entre ellos pueden tomarse n linealmente independientes.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

163 – Fundamentos de Matematicas : Algebra Lineal 12.2 Diagonalizacion
12.2 Diagonalizacion
La primer paso adelante en la busqueda se produce, no sobre los vectores propios, sino sobre los autovalores:
Teorema 317.- Si A es una matriz de orden n , las siguientes proposiciones son equivalentes:
a) λ es un valor propio de A .
b) El sistema de ecuaciones (λI −A)x = tiene soluciones distintas de la trivial.
c) det(λI −A) = 0.
Demostracion:λ es un valor propio de A ⇐⇒ existe un vector x ∈ Rn , x 6= , tal que Ax = λx ⇐⇒ el sistemaλx−Ax = (λI −A)x = tiene soluciones distintas de la trivial ⇐⇒ |λI −A| = 0
Definicion 318.- Sea A una matriz de orden n . P(λ) = |λI−A| es un polinomio en λ de grado n denominadopolinomio caracterıstico de la matriz A .
Si λ un valor propio de A , llamaremos espacio caracterıstico de A correspondiente a λ al conjunto
V (λ) ={x ∈ Rn : (λI − A)x =
}. Es decir, V (λ) es el conjunto formado por todos los vectores propios de
A correspondientes a λ , mas el vector cero.
Observaciones 319.- • Los valores propios son las raıces del polinomio caracterıstico y los vectores propios,los vectores no nulos de su espacio caracterıstico asociado
• V (λ) es un subespacio y dimV (λ) ≥ 1:
En efecto, es un subespacio por ser el conjunto de soluciones de un sistema homogeneo y como λ es valorpropio de A , existe x 6= en V (λ), luego lin{x} ⊆ V (λ) y 1 = dim(lin{x}) ≤ dimV (λ).
Ademas, dimV (λ) = dim{x ∈ Rn : (λI −A)x =
}= n− rg(λI −A).
Teorema 320.- Sean v , v , . . . , vk vectores propios de una matriz A asociados a los valores propios λ1 ,λ2 , . . . , λk respectivamente, siendo λi 6= λj , ∀ i 6= j . Entonces el conjunto de vectores {v,v, . . . ,vk} eslinealmente independiente. .
Corolario 321.- Una matriz de orden n con n autovalores distintos, es diagonalizable.
Demostracion:Si la matriz tiene n autovalores distintos λ1 , λ2 , . . . , λn y de cada espacio caracterıstico V (λk) podemostomar un vector propio vk 6= , tenemos n vectores propios, v , v , . . . , vn que son, por el resultado anterior,linealmente independientes.
Proposicion 322.- Sea A de orden n y λk un autovalor de A de multiplicidad mk . Entonces
1 ≤ dimV (λk) ≤ mk. .
Teorema de la diagonalizacion 323.- Sea A una matriz de orden n . Entonces A es diagonalizable si y solosi se cumplen las condiciones:
1.- |λI −A| = (λ− λ1)m1 · · · (λ− λk)mk , con m1 +m2 + · · ·+mk = n (es decir, tiene n raıces reales)
2.- Para cada espacio caracterıstico V (λi), se cumple que dimV (λi) = mi .
Aunque omitimos aquı la demostracion por ser demasiado tecnica (puede verse en el Anexo 3), en ella se aportael metodo para encontrar los n vectores propios linealmente independientes necesarios en la diagonalizacion:
Si dimV (λi) = mi para todo i = 1, . . . , k y m1 + · · · + mk = n , podemos tomar de cada V (λi) los mi
vectores de una base para conseguir el total de n vectores.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

164 – Fundamentos de Matematicas : Algebra Lineal 12.3 Diagonalizacion ortogonal
Ejemplo 324 Para la matriz A =
0 0 40 4 04 0 0
, su polinomio caracterıstico es:
P (λ) = |λI −A| =
∣∣∣∣∣∣λ 0 −40 λ− 4 0−4 0 λ
∣∣∣∣∣∣ = (λ− 4)
∣∣∣∣ λ −4−4 λ
∣∣∣∣ = (λ− 4)(λ2 − 42) = (λ− 4)2(λ+ 4)
luego los autovalores de A son λ1 = 4 con m1 = 2 y λ2 = −4 con m2 = 1. Como λ1, λ2 ∈ R y m1 + m2 =2 + 1 = 3 = n , se cumple la primera condicion del Teorema.
Veamos el punto 2: como 1 ≤ dimV (−4) ≤ m2 = 1 la condicion dimV (−4) = 1 se cumple de manerainmediata (y se cumple siempre para cualquier autovalor con multiplicidad 1). Para el otro autovalor, λ1 = 4:
dimV (4) = 3− rg(4I −A) = 3− rg
4 0 −40 0 0−4 0 4
= 3− rg
4 0 −40 0 00 0 0
= 3− 1 = 2 = m1
luego tambien se cumple y, en consecuencia, la matriz diagonaliza.
Como los elementos de V (4) son las soluciones del sistema homogeneo (4I − A)X = 0, tenemos queV (4) = lin{(1, 0, 1), (0, 1, 0)} ; y los elementos V (−4) las soluciones del sistema (−4I − A)X = 0, tenemosque V (−4) = lin{(1, 0,−1)} . En consecuencia, los tres vectores son autovectores y linealmente independientes,cumpliendose que:
P−1AP =
1 0 10 1 01 0 −1
−1 0 0 40 4 04 0 0
1 0 10 1 01 0 −1
=
4 0 00 4 00 0 −4
= D 4
Ejemplo La matriz A =
0 2 40 4 04 2 0
tiene por polinomio caracterıstico P (λ) = (λ− 4)2(λ+ 4), luego tiene
por autovalores λ1 = 4 con m1 = 2 y λ2 = −4 con m2 = 1.Como m1 + m2 = 2 + 1 = 3 se cumple el primer punto; y por ser m2 = 1, tambien se cumple que
dimV (−4) = 1. Veamos para el otro autovalor:
rg(4I−A) = rg
4 −2 −40 0 0−4 −2 4
= rg
4 −2 −40 0 00 −4 0
= 2 = 3−dimV (4) luego dimV (4) = 3−2 = 1 6= m1 = 2.
En consecuencia, la matriz A no diagonaliza.
(Si dimV (4) = 1 y dimV (−4) = 1 de cada uno de ellos podemos conseguir, a lo mas, un vector propio lineal-mente independiente; luego en total, podremos conseguir a lo mas dos autovectores linealmente independientes.No conseguimos los tres necesarios, luego no diagonaliza.) 4
12.3 Diagonalizacion ortogonal
Problema de la diagonalizacion ortogonal Dado un operador lineal f sobre un espacio vectorial V conproducto interior, nos planteamos el problema de cuando es posible encontrar una base ortonormal de V respectode la cual la matriz de f sea diagonal. Si V es un espacio con producto interior y las bases son ortonormalesentonces se tendra que P sera ortogonal, y el problema en terminos de matrices:
Definicion 325.- Si existe una matriz ortogonal P tal que P−1AP es diagonal, entonces se dice que A esdiagonalizable ortogonalmente y que P diagonaliza ortogonalmente a A .
Teorema 326.- Sea A una matriz de orden n , entonces son equivalentes:
1.- A es diagonalizable ortogonalmente
2.- A tiene un conjunto de n vectores propios ortonormales
Demostracion:A es una matriz diagonalizable ortogonalmente ⇐⇒ ∃P ortogonal con P tAP = D y D diagonal ⇐⇒
⇐⇒ ∃P ortogonal y D diagonal con AP =
(Ap Ap · · · Apn
)=
(λ1p λ2p · · · λnpn
)= PD
⇐⇒ ∃n vect. ortonormales con Ap = λ1p , . . . , Apn = λnpn ⇐⇒ A tiene n autovectores ortonormales
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

165 – Fundamentos de Matematicas : Algebra Lineal 12.4 Ejercicios
Lema 327.- Si A es diagonaliza ortogonalmente, entonces A es simetrica
Demostracion:D es simetrica por ser diagonal, luego: Si A es diagonalizable ortogonalmente =⇒=⇒ ∃P ortogonal y D diagonal tal que P tAP = D =⇒ ∃P ortogonal y D diagonal tal que A = PDP t =⇒=⇒ At = (PDP t)t = (P t)tDtP t = PDP t = A =⇒ A es simetrica
Lema 328.- Si A es simetrica, entonces los vectores propios asociados a autovalores distintos son ortogonales
Demostracion:Sean λ1 y λ2 valores propios distintos de una matriz simetrica A y sean u y v vectores propios correspondi-entes a λ1 y λ2 respectivamente. Veamos que utv = 0. (Notar que utAv es un escalar).Se tiene que utAv = (utAv)t = vtAu = vtλ1u = λ1v
tu = λ1utv ,
y por otra parte que utAv = utλ2v = λ2utv ,
por tanto λ1utv = λ2u
tv =⇒ (λ1 − λ2)utv = 0 y como λ1 − λ2 6= 0, entonces utv = 0
Teorema de la diagonalizacion ortogonal 329.- A diagonaliza ortogonalmente ⇐⇒ A es simetrica .
El Lema 328 y el resaltado que apostilla el Teorema de diagonalizacion 323 nos indican la manera de encontrarlos n vectores propios ortonormales linealmente independientes:
tomando en cada V (λi) una base ortonormal, conseguiremos el total de n vectores ortonormales
Ejemplo La matriz A =
0 0 40 4 04 0 0
del Ejemplo 324, es simetrica luego diagonaliza ortogonalmente y
V (4) = lin{(1, 0, 1), (0, 1, 0)} y V (−4) = lin{(1, 0,−1)} .Si tomamos una base ortonormal en cada uno de ellos, por ejemplo V (4) = lin{( 1√
2, 0, 1√
2), (0, 1, 0)} y
V (−4) = lin{( 1√2, 0, −1√
2)} , los tres vectores juntos forman un conjunto ortonormal, cumpliendose que:
P tAP =
1√2
0 1√2
0 1 01√2
0 −1√2
t 0 0 40 4 04 0 0
1√2
0 1√2
0 1 01√2
0 −1√2
=
4 0 00 4 00 0 −4
= D 4
12.4 Ejercicios
12.288 Hallar los polinomios caracterısticos, los valores propios y bases de los espacios caracterısticos de lassiguientes matrices:
a)
(−2 −71 2
)b)
5 6 20 −1 −81 0 −2
c)
4 0 1−2 1 0−2 0 1
12.289 Sea T :M2×2 −→M2×2 el operador lineal definido por:
T
(a bc d
)=
(2c a+ c
b− 2c d
)Hallar los valores propios de T y bases para los subespacios caracterısticos de T .
12.290 Estudiar si son o no diagonalizables las siguientes matrices y en caso de que lo sean hallar una matriz Ptal que P−1AP = D con D matriz diagonal:
a)
3 0 00 2 00 1 2
b)
(−14 12−20 17
)c)
−1 4 −2−3 4 0−3 1 3
12.291 Sea T :R3 −→ R3 el operador lineal T
x1
x2
x3
=
2x1 − x2 − x3
x1 − x3
−x1 + x2 + 2x3
. Hallar una base de R3 respecto
de la cual la matriz de T sea diagonal.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

166 – Fundamentos de Matematicas : Algebra Lineal 12.4 Ejercicios
12.292 Sea R1[X] el espacio vectorial de los polinomios de grado menor o igual a 1. Sea T :R1[X] −→ R1[X] eloperador lineal T (a0 + a1X) = a0 + (6a0 − a1)X . Hallar una base de R1[X] respecto de la cual la matrizde T sea diagonal.
12.293 Probar que si λ = 0 es un valor propio de una matriz A , entonces A es no inversible.Y recıprocamente, probar que si A no es inversible, entonces λ = 0 es un valor propio de A
12.294 Demostrar que si λ es un valor propio de A entonces λ2 es un valor propio de A2 .
12.295 Probar que el termino constante del polinomio caracterıstico P (λ) = |λI −A| de una matriz A de ordenn es (−1)n det(A).
12.296 Probar que si A y B son matrices semejantes, λI − A y λI − B tambien son semejantes. Y deducir deello que A y B tienen el mismo polinomio caracterıstico
12.297 Sean A cuadrada y P inversible. Comprobar que (P−1AP )k = P−1AkP , para k = 2 y k = 3; y
deducir una prueba de que es cierto para cualquier k ∈ N
12.298 Calcular A40 y M4000 siendo A =
(1 0−1 2
)y M =
(−3 4−2 3
)
12.299 Estudiar la diagonalizabilidad de la matriz A =
5 0 00 −1 a3 0 b
en funcion de los parametros a y b .
En los casos posibles hallar la matriz diagonal y la matriz P que la diagonaliza
12.300 Hallar P que diagonalice ortogonalmente a A y calcular P tAP para cada una de las matrices:
a) A =
(−7 2424 7
)b) A =
2 −1 −1−1 2 −1−1 −1 2
c) A =
5 −2 0 0−2 2 0 00 0 5 −20 0 −2 2
12.301 Sea A una matriz de orden n .
a) Probar que A y At tienen los mismos valores propios
b) Probar que si A es inversible, los valores propios de A−1 son los inversos de los valores propios de A
c) Probar que si A es ortogonal, los unicos valores propios de A son 1 o −1
12.302 Se sabe que (1, 0, 0), (1, 1, 0), (0, 1, 0) y (0, 0, 1) son vectores propios de una matriz de orden 3 y que hayvectores de R3 que no lo son. Calcular todos los vectores propios de la matriz.
12.303 Se dan las siguientes ecuaciones de recurrencia:
{un = 3un−1 + 3vn−1
vn = 5un−1 + vn−1. Utilizar la diagonalizacion para
calcular un y vn en funcion de n , sabiendo que u0 = v0 = 1.
12.304 Los dos primeros terminos de una sucesion son a0 = 0 y a1 = 1. Los terminos siguientes se generan a
partir de ak = 2ak−1 + ak−2; k ≥ 2. Hallar a127 .
12.305 Si a0 = 1 y a1 = 2, calcular a100 si se cumple que an = 3an−1 − 2an−2 , para cada n > 1
12.306 El propietario de una granja para la crıa de conejos observo en la reproduccion de estos que:
[i] Cada pareja adulta (con capacidad reproductora) tiene una pareja de conejos cada mes.
[ii] Una pareja recien nacida tarda dos meses en tener la primera descendencia.
Partiendo de 1 pareja adulta y siendo an el no de parejas nacidas en el n -esimo mes (a0 = 0), se pide:
a) Obtener una formula recurrente para an en funcion de terminos anteriores
b) Probar que an =(1 +
√5)n − (1−
√5)n
2n√
5
c) Calcular, si existe: lımn→∞
an+1
an
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

167 – Fundamentos de Matematicas : Algebra Lineal 12.4 Ejercicios
12.307 Sea el determinante n×n siguiente:
Dn =
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
3 1 0 0 · · · 0 01 3 1 0 · · · 0 00 1 3 1 · · · 0 00 0 1 3 · · · 0 0...
......
.... . .
......
0 0 0 0 · · · 3 10 0 0 0 · · · 1 3
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣Dar una expresion de Dn en funcion de los determinantes de tamano menor que n y obtener las ecuacionesde recurrencia para hallar su valor
12.308 Determinar para que valores de a , b y c son diagonalizables simultaneamente las matrices
A =
1 a b0 2 c0 0 2
y B =
1 a b0 1 c0 0 2
12.309 Estudiar para que valores de a , b y c es diagonalizable la matriz A =
c 2a 0b 0 a0 2b −c
12.310 Dada la matriz A =
a −a 0−a a 0b 0 2b
. Estudiar para que valores de a y b la matriz A es diagonalizable.
12.311 Sea f :R3 −→ R3 el operador lineal cuya matriz asociada a la base canonica es A =
m 0 00 m 11 n m
a) Determinar para que valores de m y n existe una base de R3 en la cual la matriz de f sea diagonal.
En los casos que f sea diagonalizable encontrar bases en las que diagonaliza la matriz de f
b) Si n = 0, observando la matriz A y sin hacer ningun calculo, determinar un valor propio y un vectorpropio asociado a dicho valor propio, razonando la respuesta.
12.312 Dada la matriz A =
−1 0 0 0a −1 0 0b d 1 1c e f 1
.
a) Encontrar para que valores de los parametros a, b, c, d, e, f ∈ R la matriz A es diagonalizable
b) Para esos valores, encontrar las matrices de paso P y diagonal D tales que P−1AP = D
c) Para los valores de los parametros que hacen a la matriz A diagonalizable ortogonalmente, encontrarlas matrices P y D tales que P tAP = D
12.313 Sean S={
(x1, x2, x3, x4) : x2−x4 =0}
, subconjunto de R4 y T :R4 −→ R4 el operador lineal que verifica:
[i] ker(T ) ={x ∈ R4 : 〈x,y〉 = 0, para cada y ∈ S
}[ii] T (1, 0, 0, 0) = (−1, 3, 1,−2) y T (1, 1, 1, 1) = (−3,m, n, p)
[iii] El subespacio solucion de
{x1 + x2 + x3 + x4 = 0x2 + 2x3 + 2x4 = 0
es el espacio caracterıstico correspondientes a
algun autovalor
Se pide:
a) Probar que S es un subespacio vectorial de R4 .
b) Hallar ker(T ).
c) Encontrar una base para el subespacio de vectores propios de la propiedad [iii].
d) Una matriz de T , indicando las bases de referencia.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

168 – Fundamentos de Matematicas : Algebra Lineal 12.4 Ejercicios
12.314 Sean f : R4 −→ R4 un operador lineal, y B = {e1, e2, e3, e4} la base canonica de R4 , verificando lo
siguiente:
(i) f(e1) ∈ H = {x ∈ R4 / x2 = 0}(ii) f(e2) ∈ S = {x ∈ R4 / x2 = 1 y x4 = 0}(iii) f(e3) = (α, β, 1,−2); f(e4) = (1, 0,−2, γ)
(iv) ker f es el conjunto de soluciones del sistema:
2x1 + x2 + 2x3 − 2x4 = 03x1 + 3x2 + x3 + x4 = 0x1 − x2 − x3 + 3x4 = 0
(v) Las ecuaciones implıcitas de la imagen de f son y1 − 2y3 − y4 = 0.
(vi) El operador f es diagonalizable.
Hallar una matriz de f , indicando las bases de referencia.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

169 – Fundamentos de Matematicas : Algebra Lineal
Capıtulo 13
Formas cuadraticasAunque, pueda parecernos que vamos a estudiar un nuevo concepto, un caso particular de las formas cudraticasya ha sido estudiado, pues el cuadrado de la norma de un vector no es mas que una forma cuadratica (comoveremos definida positiva). Aquı, las estudiaremos de forma general.
Definicion 330.- Sean V un espacio vectorial de dimension n y B una base V . Si (x1, . . . , xn) = [x ]tB yaij ∈ R , con 1≤ i, j≤n , se denomina forma cuadratica sobre V a toda funcion polinomica Q:V −→ R dela forma
Q(x) =
n∑i,j=1
aijxixj =(x1 x2 · · · xn
)a11 a12 · · · a1n
a21 a22 · · · a2n
......
. . ....
an1 an2 · · · ann
x1
x2
...xn
= [x ]tB A [x ]B
Es decir, una forma cuadratica es un polinomio homogeneo de grado 2 y n variables.
La escritura de Q en la forma Q(x) = [x]tB A [x]B se denomina expresion matricial de la forma cuadratica.De hecho, se puede expresar siempre mediante una matriz simetrica ya que
[x]tB A [x]B =
n∑i,j=1
aijxixj = [x]tBA+At
2 [x]B
y la matriz S = A+At
2 es simetrica (St = (A+At
2 )t = At+(At)t
2 = At+A2 = S). En efecto:
Si en la expresion de la forma cuadratica, Q(x) =
n∑i,j=1
aijxixj , consideramos los pares de sumandos de la
forma aijxixj y ajixjxi , se tiene que
aijxixj + ajixjxi = (aij + aji)xixj =aij + aji
2xixj +
aij + aji2
xjxi = sijxixj + sjixjxi
Luego hemos probado el siguiente resultado:
Proposicion 331.- Toda forma cuadratica Q sobre V , se puede expresar matricialmente como
Q(x) = [x ]tBA[x ]B
donde A es una matriz simetrica.
Definicion 332.- Es esa matriz simetrica A , la matriz asociada a la forma cuadratica Q en la base B
Ejemplo Para la forma cuadratica Q(x) = x2 + 2xy + 2y2 + 3yz + 5z2 tambien tenemos que
Q(x) = x2 + 2xy + 2y2 + 3yz + 5z2 = x2 + xy + yx+ 2y2 + 32yz + 3
2zy + 5z2
luego
Q(x) = (x, y, z)
1 2 00 2 30 0 5
xyz
= (x, y, z)
1 1 01 2 3
20 3
2 5
xyz
= [x]tB A [x]B
y la matriz simetrica A es la matriz de Q en la base B . 4
Teorema 333.- Sean B y B′ dos bases de V , P la matriz de paso de B′ a B y A la matriz simetrica de Qen la base B . Entonces, la matriz de Q en la base B′ , A′ , se obtiene de
A′ = P tAP
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

170 – Fundamentos de Matematicas : Algebra Lineal 13.1 Diagonalizacion de una forma cuadratica
Demostracion:Como P es matriz de cambio de base verifica que [x ]B = P [x ]B′ , y , sustituyendo en Q , tenemos que
Q(x) = [x ]tBA[x ]B = (P [x ]B′)tA(P [x ]B′) = [x ]tB′(P
tAP )[x ]B′ ∀x ∈ V
luego A′ = P tAP y es tambien simetrica A′t = (P tAP )t = P tAt(P t)t = P tAP = A′ .
Nota: Las matrices A y A′ son congruentes (ver Definicion 279 en pag.148) pero no son, en general,semejantes (solo coinciden congruencia y semejanza cuando la matriz P es ortogonal, P t = P−1 ).
13.1 Diagonalizacion de una forma cuadratica
La matriz asociada a una forma cuadratica es simetrica, y una matriz simetrica es diagonalizable ortogonalmente,luego siempre podemos asegurar que existe una matriz congruente con la inicial que es diagonal
13.1.1 Diagonalizacion ortogonal
Sea B una base de V y Q(x) = [x ]tB A [x ]B la expresion matricial de una forma cuadratica sobre V . Puestoque A es simetrica, existe una base B∗ tal que la matriz P de cambio de base de B∗ a B es ortogonal y
D = P−1AP = P tAP , con D diagonales decir, que D y A son congruentes (ademas de semejantes). Luego en B∗ , se tiene que
Q(x) = [x ]tB∗ PtAP [x ]B∗ = [x ]tB∗ D [x ]B∗ = λ1y
21 + . . .+ λny
2n
es decir, la forma cuadratica se expresara como una suma de cuadrados, donde (y1, . . . , yn) = [x ]tB∗ yλ1, . . . , λn son los valores propios de A .
Ejemplo 334 Reducir a suma de cuadrados la forma cuadratica Q(x) = xy + yz .
Q(x) = (x, y, z)
0 12 0
12 0 1
20 1
2 0
xyz
y |λI −A| =
∣∣∣∣∣∣λ − 1
2 0− 1
2 λ − 12
0 − 12 λ
∣∣∣∣∣∣ = (λ− 1√2)(λ+ 1√
2)λ
luego 1√2
, −1√2
y 0 son los valores propios de A . Entonces, A es congruente con D =
1√2
0 0
0 −1√2
0
0 0 0
, y existira,
por tanto, una base B∗ en la cual Q(x) = [x]tB∗D[x]B∗ = 1√2x2∗ − 1√
2y2∗. 4
13.1.2 Diagonalizacion mediante operaciones elementales
La diagonalizacion ortogonal, propuesta para hallar una matriz asociada a la forma cuadratica que sea diagonal,puede ser dificil de llevar a cabo (o imposible en ocasiones) pues supone encontrar las raıces de un polinomio.Sin embargo, como se buscan matrices diagonales congruentes y no es necesario que tambien sean semejantes, esposible disponer de otros metodos mas sencillos pero igualmente eficaces para obtener una matriz diagonal, comopor ejemplo la Diagonalizacion congruente mediante operaciones elementales 292 que usamos en la busquedade bases ortonormales.
Ejemplo 335 Se considera Q(x) = 2x2 + 2xy+ 2yz+ 3z2 una forma cuadratica sobre R3 , reducir Q a sumade cuadrados y hallar la matriz del cambio de base.
Solucion: Si x = (x, y, z), se tiene que A=
2 1 01 0 10 1 3
, es la matriz de Q en la base canonica. Para obtener
una matriz congruente con A que sea diagonal, hacemos el proceso de (A | I)→ (D |P t), detallando la primeravez como deben darse los pasos de efectuar cada operacion:
(A | I)=
2 1 0 1 0 01 0 1 0 1 00 1 3 0 0 1
→{FAI2 − 12FAI1
}→
2 1 0 1 0 00 −1
21 −1
21 0
0 1 3 0 0 1
→{CA2 − 12CA1}→
2 0 0 1 0 00 −1
21 −1
21 0
0 1 3 0 0 1
→{FA3 + 2FA2CA3 + 2CA2
}→
2 0 0 1 0 00 −1
20 −1
21 0
0 0 5 −1 2 1
=(D | P t)
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

171 – Fundamentos de Matematicas : Algebra Lineal 13.2 Rango y signatura de una forma cuadratica. Clasificacion
Tenemos entonces la matriz diagonal, D =
2 0 00 − 1
2 00 0 5
, y la matriz, P =
1 − 12 −1
0 1 20 0 1
, de paso de la base
B∗ ={
(1, 0, 0), (−12 , 1, 0), (−1, 2, 1)
}a la canonica, que verifican que P tAP = D . Por tanto, si (x∗, y∗, z∗) =
[x ]tB∗ , se tiene que Q(x) = 2x2∗ − 1
2y2∗ + 5z2
∗ . 4
13.2 Rango y signatura de una forma cuadratica. Clasificacion
Hemos visto distintos metodos de encontrar matrices diagonales asociadas a una forma cuadratica, por loque existiran tambien distintas matrices diagonales. Sin embargo, veremos que algunas cosas permaneceraninvariantes: mismo numero de elementos no nulos (mismo rango) y mismo numero de elementos positivos ynegativos en la diagonal (misma signatura); lo que nos permitira una clasificacion de las formas cuadraticas.
Teorema 336.- Dos matrices congruentes tienen el mismo rango.
Demostracion:Sea A una matriz simetrica de rango n y A′ = P tAP con P inversible. Consideremos la aplicacion linealf :Rn −→ Rn dada por f(x) = Ax , luego A es la matriz de f en la base canonica, Bc . Como P es inversible,sus columnas forman una base B′ de Rn y P es la matriz de cambio de base de B′ a Bc ; y como (P t)−1 esinversible, sus columnas forman una base B′′ de Rn y (P t)−1 es la matriz de cambio de base de B′′ a Bc , porlo que P t es la matriz de paso de Bc a B′′ .
Entonces, la matriz A′ = P tAP es la matriz de la aplicacion f asociada a las bases B′ y B′′ , pues
A′[x]B′ = P tAP [x]B′ = P tA[x]Bc = P t[f(x)]Bc = [f(x)]B′′
por lo que A′ y A son matrices asociadas a la misma aplicacion lineal, luego rg(A) = rg(A′).
Definicion 337.- Llamaremos rango de una forma cuadratica, al rango de cualquier matriz simetrica asociadaa la forma cuadratica en alguna base.
Observacion: Del teorema anterior, se deduce entonces que dos cualesquiera matrices diagonales asociadas ala misma forma cuadratica tienen el mismo numero de elementos en la diagonal distintos de cero, –pues estenumero es el rango de la matriz diagonal–.
Teorema de Sylvester o Ley de inercia 338.- Si una forma cuadratica se reduce a la suma de cuadrados endos bases diferentes, el numero de terminos que aparecen con coeficientes positivos, ası como el numero determinos con coeficientes negativos es el mismo en ambos casos. .
Definicion 339.- Sea Q una forma cuadratica y D una matriz diagonal asociada a Q . Se define comosignatura de Q al par Sig(Q) = (p, q) donde p es el numero de elementos positivos en la diagonal de D y qes el numero de elementos negativos de la misma.
13.2.1 Clasificacion de las formas cuadraticas
Definicion 340.- Se dice que una forma cuadratica Q es
a) Nula si Q(x) = 0 para todo x .
b) Definida positiva si Q(x) > 0, para todo x no nulo.
c) Semidefinida positiva si Q(x) ≥ 0, para todo x y Q no es nula ni definida positiva.
d) Definida negativa si Q(x) < 0, para todo x no nulo.
e) Semidefinida negativa si Q(x) ≤ 0, para todo x y Q no es nula ni definida negativa.
f) Indefinida si Q(x) alcanza tanto valores positivos como negativos, es decir, si ∃x 6= tal queQ(x) > 0 y ∃x 6= tal que Q(x) < 0.
Para las formas cuadraticas sobre R2 , podemos dar una representacion de ellas usando superficies en R3
asignando a z el valor de la forma cuadratica en (x, y), es decir, haciendo z = d1x2 +d2y
2 . Con estas premisas,hemos realizado la figura 13.1 siguiente.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

172 – Fundamentos de Matematicas : Algebra Lineal 13.2 Rango y signatura de una forma cuadratica. Clasificacion
Fig. 13.1. Graficas de las formas cuadraticas de R2 : definida positiva, definida negativa, indefinida, semidefinida positiva,semidefinida negativa y nula
Teorema de clasificacion 341.- Sea Q una forma cuadratica en un espacio vectorial de dimension n . Severifica:
a) Q es nula ⇐⇒ Sig(Q) = (0, 0)
b) Q es definida positiva ⇐⇒ Sig(Q) = (n, 0).
c) Q es semidefinida positiva ⇐⇒ Sig(Q) = (p, 0) con 0 < p < n .
d) Q es definida negativa ⇐⇒ Sig(Q) = (0, n).
e) Q es semidefinida negativa ⇐⇒ Sig(Q) = (0, q) con 0 < q < n .
f) Q es indefinida ⇐⇒ Sig(Q) = (p, q) con 0 < p, q . .
Ejemplo Las formas cuadraticas de los ejemplos 334 y 335 anteriores son ambas indefinidas, pues en elprimer ejemplo Q(x) = 1√
2x2∗ − 1√
2y2∗ en una base, luego Sig(Q) = (1, 1). En el segundo ejemplo, se escribe
Q(x) = 2x2∗ − 1
2y2∗ + 5z2
∗ en una base y Sig(Q) = (2, 1).
Un ejemplo de forma cuadratica definida positiva, lo tenemos con el cuadrado de la norma de un vector(ver la observacion de la pagina 148 sobre la expresion matricial de un producto interior), pues se verifica que
Q(v) = ‖v‖2 = 〈v,v〉 > 0 si v 6= . 4
Para finalizar –y aunque puede obtenerse sin mucho coste una matriz diagonal mediante operaciones elementales–recuperamos, mas completa y sin demostracion, una proposicion que puede ser util por su version practica, puesengloba varios resultados para clasificar una forma cuadratica usando la matriz inicial:
Proposicion 342.- Sea Q una forma cuadratica y A su matriz asociada. Denotemos por ∆k , el k -esimomenor principal de A , para cada 1 ≤ k ≤ n :
∆1 = |a11| ∆2 =
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ · · · ∆k =
∣∣∣∣∣∣∣a11 · · · a1k
.... . .
...ak1 · · · akk
∣∣∣∣∣∣∣ · · · ∆n = |A|
Entonces:
a) Q es definida positiva si, y solo si, ∆k > 0, para 1 ≤ k ≤ n .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

173 – Fundamentos de Matematicas : Algebra Lineal 13.3 Ejercicios
b) Q es definida negativa si, y solo si, (−1)k∆k > 0, para 1 ≤ k ≤ n .
c) Si ∆n = det(A) 6= 0 y no se esta en alguno de los casos anteriores, entonces Q es indefinida.
d) Si existe i tal que aii ≤ 0 (resp. aii ≥ 0 ), entonces Q no es definida positiva (resp. no es definidanegativa).
e) Si existen i y j , con i 6= j , tales que aii = 0 y aij 6= 0, entonces Q es indefinida.
13.3 Ejercicios
13.315 Clasificar cada una de las formas cuadraticas siguientes, y reducir a suma de cuadrados:
a) Q(x) = x2 + y2 + z2 − (xz + xy + yz).
b) Q(x) = x2 + y2 + z2 − 4(xz + xy + yz).
c) Q(x) = 8x2 + 6y2 + 3z2 + 4xy + 8xz + 4yz .
d) Q(x) = x2 + 2y2 + z2 + 2xy + xz .
e) Q(x) = x2 + 2xy + 3y2 + 4xz + 6yz + 5z2 .
f) Q(x) = 3x2 + 4y2 + 5z2 + 4xy − 4yz .
g) Q(x) = 2x2 + 5y2 + 5z2 + 4xy − 4yz − 8zx .
h) Q(x) = x2 + y2 + 2z(x cosα+ y senα).
13.316 Sean las formas cuadraticas Qi:Rn −→ R dadas por Qi(x) = xtAix , con x = (x1, . . . , xn), siendo
A1 =
1 1 01 0 1−1 0 0
A2 =
3 −2 11 6 2−3 0 7
A3 =
5 −2 0 −1−2 2 0 10 3 1 −20 0 −2 2
A4 =
2 0 0 01 3 2 0−1 −2 −1 00 0 0 −1
Obtener, para cada Qi , la matriz asociada a la base canonica del espacio correspondiente, una matrizdiagonal congruente y la base respecto de la que es diagonal.
13.317 Sean B1 y B2 bases respectivas de los espacios V y W y sea A =
6 5 3 03 1 0 −33 3 2 1
la matriz de una apli-
cacion lineal f :V −→W en las bases B1 y B2 . Tomemos Q:V −→ R dada por Q(v) = [f(v)]tB2[f(v)]B2
.
a) ¿Cuales son las dimensiones de V y W ?
b) Obtener la matriz de Q en la base B1 y comprobar que es una forma cuadratica.
c) ¿Cual es su clasificacion?
13.318 Clasificar, segun los valores de m , la familia de formas cuadraticas:
Q(x) = x2 + y2 + z2 + 2m(xy + xz).
13.319 Se considera la familia de formas cuadraticas Q(x) = x tAx , siendo A =
a 0 c0 a+ c 0c 0 a
. Utilizando
dos metodos diferentes, expresar Q como suma de cuadrados.
13.320 Sea A =
a 1 11 a 11 1 a
.
a) Para a = 3, encontrar P que diagonalice a A .
b) Para a = 3, calcular (5A)10 .
c) Sea Q(x) = x tAx , clasificar Q segun los valores de a .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

174 – Fundamentos de Matematicas : Algebra Lineal 13.3 Ejercicios
13.321 Sean A =
a b 0b a b0 b a
y B ={v =(1, 1, 1), v =(1,−1, 0), v =(0, 1,−1)
}. Se pide
a) Clasificar la forma cuadratica Q(x) = [x ]tBA[x ]B , segun los valores de a y b .
b) Para a = 0 y b = 1, hallar una base B′ tal que Q(x) = [x ]tB′D[x ]B′ , con D diagonal.
13.322 Sea A =
a 0 b0 a 0b 0 a
a) ¿Para que valores de a y de b es Q(x) = x tAx > 0, ∀ x 6= ?
b) Si a = −1 y ∀ b , reducir Q a suma de cuadrados.
c) Si a = −1, ¿para que valores de b es Q(x) < 0, ∀ x 6= ?
13.323 Sea Q:Rn −→ R una forma cuadratica no nula cuya matriz asociada en la base canonica es A .
a) Si λ ∈ R− {0} , probar que Q(x) y Q(λx) tienen el mismo signo.
b) Para que valores de λ ∈ R es cierto que Q(λx) = λQ(x).
c) Deducir de lo anterior, que en general no es cierta la igualdad Q(x + y) = Q(x) +Q(y).
d) Si la forma cuadratica Q′:Rn −→ R tiene a A′ como matriz en la base canonica, ¿cual sera la matrizde la forma cuadratica (Q+Q′)(x) = Q(x) +Q′(x)?
13.324 Sea A la matriz de orden n asociada a una forma cuadratica definida positiva y P una matriz n×n
a) Si P es inversible, probar que la matriz P tAP es definida positiva.
b) Si P es no inversible, probar que la matriz P tAP es semidefinida positiva.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

175 – Fundamentos de Matematicas : Algebra Lineal
Anexo 3: Demostraciones
Algebra linealMatrices, sistemas y determinantes
Demostracion de: Teorema 208 de la pagina 127
Teorema 208.- Si la matriz elemental Em×m resulta de efectuar cierta operacion elemental sobre las filas deIm y si Am×n es otra matriz, el producto EA es la matriz m×n que resulta de efectuar la misma operacionelemental sobre las filas de A .
Demostracion:Sean E1 la matriz elemental que tiene intercambiadas las filas i y j , E2 la matriz elemental de multiplicar lafila i por λ 6= 0 y E3 la matriz elemental obtenida de sumar a la fila i la fila j multplicada por λ . Entonces
• E = E1 :
eEAik = FEi · CAk = F Ij · CAk = eIAjk = eAjk, ∀ k =⇒ FEAi = FAj
eEAjk = FEj · CAk = F Ii · CAk = eIAik = eAik, ∀ k =⇒ FEAj = FAi
r 6= i, j eEArk = FEr · CAk = F Ir · CAk = eIArk = eArk, ∀ k =⇒ FEAr = FAr
• E = E2 :
{eEAik = FEi · CAk = λF Ii · CAk = λeIAik = λeAik, ∀ k =⇒ FEAi = λFAi
r 6= i eEArk = FEr · CAk = F Ir · CAk = eIArk = eArk, ∀ k =⇒ FEAr = FAr
• E = E3 : veamos que FEAi = FAi + λFAj , pues las demas no cambian:
eEAik = FEi · CAk = (F Ii + λF Ij ) · CAk = (F Ii · CAk ) + (λF Ij · CAk ) = eIAik + λeIAjk = eAik + λeAjk, ∀ k
Demostracion de: Teorema de Rouche 216 de la pagina 130
Teorema de Rouche 216.- Sea el sistema AX = B , sistema de m ecuaciones con n incognitas. EntoncesAX = B tiene solucion si, y solo si, rg(A) = rg(A|B).
En caso de tener solucion, si rg(A) = r , toda solucion del sistema puede expresarse en la forma X =V0 + t1V1 + t2V2 + · · ·+ tn−rVn−r , siendo V0 una solucion particular de AX = B y los vectores V1 , . . . , Vn−rsoluciones del sistema homogeneo asociado AX = 0.
Demostracion:Reduciendo la matriz ampliada del sistema por operaciones elementales segun el metodo de Gauss-Jordan,llegamos a una matriz escalonada reducida, que en la parte correspondiente a A , tiene r unos como elementosprincipales. Si reordenamos las columnas para juntar en las r primeras los elementos principales, la matrizampliada resultante sera:
1 0 · · · 0 a′1r+1 · · · a′1n b′10 1 · · · 0 a′2r+1 · · · a′2n b′2...
.... . .
...... · · ·
......
0 0 · · · 1 a′rr+1 · · · a′rn b′r0 0 · · · 0 0 · · · 0 b′r+1...
... · · ·...
... · · ·...
...0 0 · · · 0 0 · · · 0 b′m
En forma mas escueta indicando los tamanospodemos escribirla ası:(
Ir×r A′r×n−r B′r×1
0m−r×r 0m−r×n−r B′m−r×1
)
(Nota: Al intercambiar el orden de las columnas de la matriz A , solo cambiamos el orden de las incognitas. Esdecir, las soluciones seran las mismas pero en otro orden.)
Obviamente el rango de la matriz de los coeficientes es r y el sistema tendra solucion si y solo si b′r+1 =b′r+2 = · · · = b′m = 0, es decir si el rango de la ampliada tambien es r .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

176 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
En este caso, (asumiendo una posible reordenacion de las incognitas) el sistema resultante es:x1 = b′1 − xr+1a
′1r+1 − xr+2a
′1r+2 − · · · − xna′1n
x2 = b′2 − xr+1a′2r+1 − xr+2a
′2r+2 − · · · − xna′2n
...xr = b′r − xr+1a
′rr+1 − xr+2a
′rr+2 − · · · − xna′rn
y la solucion, usando parametros:
x1 = b′1 − t1a′1r+1 − t2a′1r+2 − · · · − tn−ra′1nx2 = b′2 − t1a′2r+1 − t2a′2r+2 − · · · − tn−ra′2n
...xr = b′r − t1a′rr+1 − t2a′rr+2 − · · · − tn−ra′rn
xr+1 = t1...
xn = tn−r
que tambien podemos escribir en forma matri-cial teniendo en cuenta que
xr+i = 0 + t1 · 0 + · · ·+ ti · 1 + · · ·+ tn−r · 0
x1
...xrxr+1
...xn
=
b′1...b′r0...0
+t1
−a′1r+1...
−a′rr+1
1...0
+· · ·+tn−r
−a′1n...−a′rn
0...1
y llamando Vi a las matricescolumna, podemos escribir
X = V0+ t1V1+ · · ·+ tn−rVn−r
como enunciabamos.
Fijandonos en las soluciones se observa que haciendo t1 = · · · = tn−r = 0, V0 es una solucion de AX = B .Si consideramos el sistema homogeneo asociado AX = 0, ha de ser V0 = 0 y como solucion generica
obtendremos X = t1V1 + · · ·+ tn−rVn−r . Luego haciendo ti = 1 y tk = 0, para k 6= i , vemos que X = Vi essolucion del sistema homogeneo AX = 0.
Demostracion de: Teorema 232 de la pagina 133
Teorema 232.- Sea An×n una matriz. Se tiene:
a) que si A′ es la matriz que resulta de multiplicar una fila de A por una constante λ 6= 0, entoncesdet(A′) = λ det(A).
b) que si A′ es la matriz que resulta de intercambiar dos filas de A , entonces det(A′) = −det(A).
c) que si A′ es la matriz que resulta de sumar a una fila k un multiplo de la fila i , entonces det(A′) = det(A).
Demostracion:
a) det(A′) =∑
(−1)Na1j1 · · ·λaiji · · · anjn = λ∑
(−1)Na1j1 · · · aiji · · · anjn = λ det(A)
b) Previamente necesitamos el siguiente resultado:
Lema.- Si en el conjunto {j1, . . . , jn} intercambiamos dos elementos el numero de inversionesde signo cambia de paridad (de par a impar, o viceversa).
Demostracion:Si intercambiamos los elementos consecutivos ji y ji+1 cambia la paridad, pues si antes eraji < ji+1 ahora es ji+1 > ji , produciendose una inversion donde antes no la habıa, y si eraji > ji+1 ahora ji+1 < ji , con lo que se elimina una inversion que antes habıa. Como con elresto de los elementos no se producen modificaciones, si tenıamos N inversiones ahora tendremosN + 1 o N − 1, luego se cambia de paridad.
Si intercambiamos los elementos ji y jk no consecutivos, podemos hacerlo repitiendo el procesocomentado arriba, yendo paso a paso intercambiando terminos consecutivos. Hacemos por lotanto k − i intercambios consecutivos para llevar el elemento ji a la posicion k y haremosk− i−1 intercambios para llevar jk (que ahora esta en la posicion k−1) a la posicion i . Luego
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

177 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
hay 2(k − i) − 1, un numero impar, de cambios de paridad y, por tanto, cambia la paridad alintercambiar dos elementos cualesquiera.
Con este resultado, para probar b) basta observar que los productos elementales que aparecen en eldet(A′) son los mismos que aparecen en el det(A), aunque intercambiadas las posiciones de los ele-mentos de las filas en cuestion, es decir, los productos elementales a1j1 · · · akjk · · · aiji · · · anjn de A′ ya1j1 · · · aiji · · · akjk · · · anjn de A son iguales. Pero como los ındices ji y jk aparecen intercambiando lasposiciones en el desarrollo de los determinantes, tendran signos contrarios, luego det(A′) = − det(A).
Corolario.- Una matriz con dos filas iguales tiene determinante cero.
Demostracion:Sea B una matriz cuadrada que tiene la fila i y la fila k iguales, entonces por la parte b)anterior, si intercambiamos las filas i y k que son iguales se obtiene que det(B) = −det(B) esdecir que det(B) = 0.
c) det(A′) =∑
(−1)Na1j1 · · · aiji · · · (akjk + kaijk) · · · anjn=∑
(−1)Na1j1 · · · aiji · · · akjk · · · anjn +∑
(−1)Na1j1 · · · aiji · · · kaijk · · · anjn= det(A) + k
∑(−1)Na1j1 · · · aiji · · · aijk · · · anjn .
Como este ultimo sumatorio, que es el determinante de una matriz que tiene la fila i y la fila k iguales,vale 0, se tiene que det(A′) = det(A).
Demostracion de: Teorema 235 de la pagina 134
Teorema 235.- Si A y B son matrices cuadradas de orden n , entonces
det(AB) = det(A) · det(B).
Demostracion:La demostracion se hace en tres pasos. Primero el caso particular en que A sea una matriz elemental y luegolos casos generales, que A sea una matriz inversible o que no lo sea.
1. Si A es una matriz elemental, por el teorema 232 y corolario 234 anteriores, se tiene que:
a) det(AB) = k det(B) = det(A) det(B)
b) det(AB) = −det(B) = (−1) det(B) = det(A) det(B)
c) det(AB) = det(B) = 1 det(B) = det(A) det(B)
segun el tipo de matriz elemental que sea A .
2. Si A es inversible es producto de matrices elementales (teorema 223) y por la parte 1,
det(AB) = det(EkEk−1 · · ·E1B) = det(Ek) det(Ek−1 · · ·E1B) = · · ·= det(Ek) · · · det(E2) det(E1) det(B) = det(Ek) · · · det(E2E1) det(B) = · · ·= det(Ek · · ·E1) det(B) = det(A) det(B).
3. Si A no es inversible, la matriz escalonada reducida, R , obtenida de Ek · · ·E1A = R no es la identidad, luegoA = E−1
1 · · ·E−1k R = E−1R donde E−1 es inversible (producto de inversibles) y R tiene al menos una fila
de ceros. Luego det(AB) = det(E−1RB) = det(E−1) det(RB) y det(A) det(B) = det(E−1R) det(B) =det(E−1) det(R) det(B). Como R tiene al menos una fila de ceros, RB tiene al menos una fila de cerosy det(R) = 0 = det(RB). Luego:
det(AB) = det(E−1) det(RB) = 0 = det(E−1) det(R) det(B) = det(A) det(B).
Demostracion de: Teorema 238 de la pagina 134
Teorema 238.- Si A es una matriz cuadrada, entonces |At| = |A| .
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

178 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Demostracion:Es claro que los productos elementales que aparecen en ambos determinantes son los mismos, luego basta probarque ademas tienen el mismo signo.
Si en la matriz A hacemos cero todos los elementos excepto los que intervienen en un producto elementaldado, obtenemos una matriz B cuyo determinante es precisamente ese producto elemental con signo, es decirdet(B) = (−1)Na1j1 · · · anjn ; si en At hacemos cero los elementos que no intervienen en ese mismo producto
elemental se obtiene precisamente Bt , y det(Bt) = (−1)N′a1j1 · · · anjn . Entonces,
|BBt|=
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
0 · · · 0 · · · a1j1 · · · 00 · · · 0 · · · 0 · · · a2j2
a3j3 · · · 0 · · · 0 · · · 0...
......
......
......
0 · · · anjn · · · 0 · · · 0
0 0 a3j3 · · · 0...
...... · · ·
...0 0 0 · · · anjn...
...... · · ·
...a1j1 0 0 · · · 0
......
... · · ·...
0 a2j2 0 · · · 0
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣=
∣∣∣∣∣∣∣∣∣∣∣
a21j1
0 0 · · · 00 a2
2j20 · · · 0
0 0 a23j3· · · 0
......
.... . .
...0 0 0 · · · a2
njn
∣∣∣∣∣∣∣∣∣∣∣= a2
1j1a22j2a
23j3 · · · a
2njn ≥ 0,
y, por tanto, det(B) det(Bt) = det(BBt) ≥ 0 y ambos factores tienen el mismo signo.
Demostracion de: Teorema 240 de la pagina 135
Teorema 240.- El determinante de una matriz A se puede calcular multiplicando los elementos de una fila (ode una columna) por sus cofactores correspondientes y sumando todos los productos resultantes; es decir, paracada 1 ≤ i ≤ n y para cada 1 ≤ j ≤ n :
det(A) = ai1Ci1 + ai2Ci2 + · · ·+ ainCin y det(A) = a1jC1j + a2jC2j + · · ·+ anjCnj
Demostracion:Sopongamos que desarrollamos por la fila 1. Si en det(A) agrupamos los terminos que involucran a cada a1k ,tenemos que
|A|=∑
(1,j2,...,jn)
(−1)Na11a2j2 · · · anjn + · · ·+∑
(n,j2,...,jn)
(−1)Na1na2j2 · · · anjn
=
n∑k=1
∑(k,j2,...,jn)
(−1)Na1ka2j2 · · · anjn
=
n∑k=1
a1k
∑(k,j2,...,jn)
(−1)Na2j2 · · · anjn
Por otra parte como C1k = (−1)1+kM1k = (−1)1+k
∑(j2,...,jn)ji 6=k
(−1)Nka2j2 · · · anjn , basta comprobar que este valor
coincide con el que aparece entre parentesis en el sumatorio anterior.Para cada k , en el conjunto {k, j2, . . . , jn} aparecen k − 1 inversiones mas que en {j2, . . . , jn} , pues estan
todas aquellas que se producen entre los ji mas las que se produzcan con el primer elemento k . En efecto, comoen el conjunto {j2, . . . , jn} aparecen los valores 1, 2, . . . , k − 1, y se tiene que k > 1, k > 2, . . . , k > k − 1,aparecen exactamente k − 1 inversiones mas. Es decir, (−1)N = (−1)k−1(−1)Nk , luego
|A|=n∑k=1
a1k
∑(k,j2,...,jn)
(−1)Na2j2 · · · anjn
=
n∑k=1
a1k
∑(j2,...,jn)
(−1)k−1(−1)Nka2j2 · · · anjn
=
n∑k=1
a1k(−1)k−1
∑(j2,...,jn)
(−1)Nka2j2 · · · anjn
=
n∑k=1
a1k(−1)k−1M1k
=
n∑k=1
a1k(−1)k+1M1k =
n∑k=1
a1kC1k
Para desarrollar por una fila k cualquiera, basta llevar esta a la fila 1 y aplicar lo anterior. En efecto, si vamosintercambiando la fila k con cada una de las anteriores, obtenemos una matriz A′ que tiene por fila 1 la fila k
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

179 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
de A , por fila 2 la fila 1 de A , . . . , por fila k la fila k − 1 de A , y las demas igual. Luego hemos hecho k − 1cambios de fila y, por tanto, |A| = (−1)k−1|A′| . Si desarrollamos det(A′) por la primera fila, tenemos que
|A|= (−1)k−1|A′| = (−1)k−1n∑j=1
a′1j(−1)1+jM ′1j = (−1)k−1n∑j=1
akj(−1)1+jMkj
=
n∑j=1
akj(−1)k−1(−1)1+jMkj =
n∑j=1
akj(−1)k+jMkj =
n∑j=1
akjCkj .
Para el desarrollo por columnas basta recordar que |A| = |At| .
Demostracion de: Regla de Cramer 244 de la pagina 135
Regla de Cramer 244.- Sea AX = B , un sistema de n ecuaciones con n incognitas, tal que A es inversible,entonces el sistema tiene como unica solucion:
x1 =
∣∣∣∣∣∣∣∣∣b1 a12 · · · a1n
b2 a22 · · · a2n
......
. . ....
bn an2 · · · ann
∣∣∣∣∣∣∣∣∣|A|
, x2 =
∣∣∣∣∣∣∣∣∣a11 b1 · · · a1n
a21 b2 · · · a2n
......
. . ....
an1 bn · · · ann
∣∣∣∣∣∣∣∣∣|A|
, . . . , xn =
∣∣∣∣∣∣∣∣∣a11 a12 · · · b1a21 a22 · · · b2...
.... . .
...an1 an2 · · · bn
∣∣∣∣∣∣∣∣∣|A|
.
Demostracion:Si A es inversible la solucion unica es X = A−1B =
Adj(A)
|A|B =
1
|A|
C11 C21 · · · Cn1
C12 C22 · · · Cn2
......
. . ....
a1n a2n · · · ann
b1b2...bn
=1
|A|
b1C11 + b2C21 + · · ·+ bnCn1
b1C12 + b2C22 + · · ·+ bnCn2
· · · · · · · · · · · ·b1C1n + b2C2n + · · ·+ bnCnn
luego cada xj =
b1C1j + b2C2j + · · ·+ bnCnj|A|
, como querıamos probar.
Demostracion de: Orlado de menores 248 de la pagina 136
Orlado de menores 248.- Sea Am×n una matriz, y Mr×r una submatriz de A con determinante distinto decero. Entonces, si el determinante de todas las submatrices de orden r + 1 que se pueden conseguir en Aanadiendo una fila y una columna a M son cero, el rango de A es r .
Demostracion:Supongamos, por simplicidad en la notacion, que M es el menor formado por las primeras r filas y columnas.Consideremos la matriz
a11 · · · a1r a1r+1 a1r+2 · · · a1n
.... . .
......
......
...ar1 · · · arr arr+1 arr+2 · · · arnar+11 · · · ar+1r ar+1r+1 ar+1r+2 · · · ar+1n
donde las lıneas verticales significan respectivamente M y este menor ampliado a la fila r + 1 y a cada una delas demas columnas de A . Si hacemos operaciones elementales en las filas, obtenemos
a′11 · · · a′1r a′1r+1 a′1r+2 · · · a′1n...
. . ....
......
......
0 · · · a′rr a′rr+1 a′rr+2 · · · a′rn0 · · · 0 a′r+1r+1 a′r+1r+2 · · · a′r+1n
y los menores que tenemos ahora son o no cero segun lo fueran o no antes. Como M es distinto de cero ha deser a′11a
′22 · · · a′rr 6= 0 y como cada uno de los menores ampliados son cero han de ser a′11a
′22 · · · a′rra′r+1r+1 = 0,
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

180 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
a′11a′22 · · · a′rra′r+1r+2 = 0, . . . , a′11a
′22 · · · a′rra′r+1n = 0. Luego, a′r+1r+1 = a′r+1r+2 = · · · = a′r+1n = 0 y la
matriz escalonada queda a′11 · · · a′1r a′1r+1 a′1r+2 · · · a′1n...
. . ....
......
......
0 · · · a′rr a′rr+1 a′rr+2 · · · a′rn0 · · · 0 0 0 · · · 0
.
Haciendo el mismo proceso para las filas r + 2 hasta m , tenemos que una forma escalonada de A serıa
a′11 · · · a′1r a′1r+1 a′1r+2 · · · a′1n...
. . ....
......
......
0 · · · a′rr a′rr+1 a′rr+2 · · · a′rn0 · · · 0 0 0 · · · 0...
......
......
......
0 · · · 0 0 0 · · · 0
y el rango de A es por tanto r .
Espacios vectoriales reales
Demostracion de: Propiedades 250 de la pagina 140
Propiedades 250.- Algunas propiedades que se deducen de las anteriores son:
(i) 0u = . (ii) k = . (iii) (−1)u = −u .
(iv) ku = ⇐⇒ k = 0 o u = .
(v) El vector cero de un espacio vectorial es unico.
(vi) El vector opuesto de cada vector del espacio vectorial es unico.
Demostracion:
(i) Como 0u = (0 + 0)u = 0u + 0u , si sumamos a cada lado de la igualdad el opuesto de 0u , tenemos que0u + (−0u) = 0u + 0u + (−0u) luego = 0u + = 0u .
(ii) Como k = k( + ) = k + k , si sumamos a cada lado de la igualdad el opuesto de k , tenemos quek + (−k) = k + k + (−k) luego = k + = k .
(v) Si w verifica que w + u = u , entonces w + u + (−u) = u + (−u) de donde w + = y w = . Enconsecuencia, el vector cero es unico.
(vi) Si w verifica que w +u = , entonces w +u+ (−u) = + (−u) de donde w + = −u y w = −u . Enconsecuencia, el vector opuesto es unico.
(iii) Veamos que (−1)u es el opuesto u : u + (−1)u = 1u + (−1)u = (1 + (−1))u = 0u = .
(iv) Si ku = y k 6= 0, entonces 1kku = 1
k = . Luego = 1kku = ( 1
kk)u = 1u = u .
La implicacion en el otro sentido es evidente por (i) y (ii).
Demostracion de: Lema 258 de la pagina 142
Lema 258.- Si S es un conjunto linealmente independiente de vectores de V y v ∈ V −linS , entonces S∪{v}es linealmente independiente.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

181 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Demostracion:Sea S = {u, u, . . . , ur} es un conjunto linealmente independiente de vectores V y sea v ∈ V que nopertenece a linS . Entonces, en la igualdad vectorial
λ1u + λ2u + · · ·+ λrur + λv = 〈13.1〉
el coeficiente λ debe ser cero, pues si no lo es, podemos despejar v = −λ1
λ u − λ2
λ u − · · · − λrλ ur y v
estarıa generado por los vectores de S , lo que no es cierto. Ahora bien, como λ = 0, la ecuacion 13.1 se reducea λ1u + λ2u + · · · + λrur = y en consecuencia, todos los λi son cero por ser los vectores ui linealmenteindependientes.
Demostracion de: Lema 259 de la pagina 142
Lema 259.- Sean V un espacio vectorial y B una base de V formada por n vectores. Entonces cualquierconjunto {v,v, . . . ,vm} de vectores de V , con m > n , es linealmente dependiente.
Demostracion:Sea B = {w, w, . . . , wn} la base de V . Cada vector vk del conjunto {v, v, . . . , vm} puede expresarsecomo combinacion lineal de los vectores de B , en la forma
vk = ak1w + ak2w + · · ·+ aknwn , para cada k = 1, . . . ,mEl conjunto es linealmente dependiente si la ecuacion λ1v + λ2v + · · ·+ λmvm = tiene multiples solu-
ciones. Sustituyendo:
= λ1(a11w + a12w + · · ·+ a1nwn) + λ2(a21w + a22w + · · ·+ a2nwn)
+ · · ·+ λm(am1w + am2w + · · ·+ amnwn)
= (λ1a11 + λ2a21 + · · ·+ λmam1)w + (λ1a12 + λ2a22 + · · ·+ λmam2)w
+ · · ·+ (λ1a1n + λ2a2n + · · ·+ λmamn)wn
Como B es un conjunto linealmente independiente de vectores, se tiene el sistema lineal
λ1a11 + λ2a21 + · · ·+ λmam1 = 0λ1a12 + λ2a22 + · · ·+ λmam2 = 0
· · · · · · = 0λ1a1n + λ2a2n + · · ·+ λmamn = 0
que tiene m incognitas (los λk ) y n ecuaciones, con m > n , por lo que no tiene solucion unica.
Demostracion de: Proposicion 263 de la pagina 142
Proposicion 263.- Si V es un espacio vectorial, con dimV = n . Entonces, un conjunto de n vectores de V esbase de V ,
a) si el conjunto es linealmente independiente, o b) si genera a V .
Demostracion:Sea S el conjunto de n vectores.
Si S es linealmente independiente, tiene que generar V , pues si no: podrıan anadirse vectores linealmenteindependientes con lo anteriores hasta formar una base de V (existirıa al menos un vector vn+ ∈ V − linS ,tal que S ∪ {vn+} es linealmente independiente, ver comentarios previos al Lema 259 anterior) que tendrıa almenos n+ 1 vectores, lo que es absurdo.
Analogamente si S genera V , tiene que ser linealmente independiente, pues si no: podrıan eliminarsevectores dependientes de S hasta conseguir una base que tendrıa menos de n vectores (Lema 256), lo quetambien es absurdo.
Espacios vectoriales con producto escalar
Demostracion de: Desigualdad de Cauchy-Schwarz 273 de la pagina 147
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

182 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Desigualdad de Cauchy-Schwarz 273.- Para todo u,v ∈ V, espacio con producto interior, se tiene
〈u,v〉2 ≤ ‖u‖2 ‖v‖2 o en la forma |〈u,v〉| ≤ ‖u‖ ‖v‖ .
Demostracion:Si v = , es claro que 0 = 〈u,〉2 ≤ ‖u‖2 ‖‖2 = 0, ∀u ∈ V .
Si v 6= , para todo k ∈ R , se verifica que
0 ≤ ‖u− kv‖2 = 〈u− kv, u− kv〉 = 〈u,u〉 − 2k〈u,v〉+ k2〈v,v〉
en particular, para k = 〈u , v 〉〈v , v 〉 . Luego
0 ≤ 〈u,u〉 − 2〈u,v〉〈v,v〉
〈u,v〉+〈u,v〉2
〈v,v〉2〈v,v〉= 〈u,u〉 − 2
〈u,v〉2
〈v,v〉+〈u,v〉2
〈v,v〉
= 〈u,u〉 − 〈u,v〉2
〈v,v〉= ‖u‖2 − 〈u,v〉
2
‖v‖2
de donde 〈u , v 〉2‖v ‖2 ≤ ‖u‖2 y por consiguiente 〈u , v 〉2 ≤ ‖u‖2 ‖v‖2 .
Demostracion de: Teorema 285 de la pagina 149
Teorema 285.- Si S = {v,v, . . . ,vk} un conjunto finito de vectores no nulos, ortogonales dos a dos, entoncesS es linealmente independiente.
Demostracion:Veamos que en la igualdad λ1v + · · ·+ λivi + · · ·+ λkvk = , cada λi tiene que ser cero:
0 = 〈vi,〉= 〈vi, λ1v + · · ·+ λivi + · · ·+ λkvk〉 = λ1〈vi,v〉+ · · ·+ λi〈vi,vi〉+ · · ·+ λk〈vi,vk〉= 0 + · · ·+ λi〈vi,vi〉+ · · ·+ 0 = λi ‖vi‖2
como vi 6= , su norma no es cero por lo que tiene que ser λi = 0.
Demostracion de: Lema 290 de la pagina 150
Lema 290.- Sean V un espacio vectorial con producto interior, W un subespacio de V y B una base ortonormalde W . Entonces para cada v ∈ V , el vector v−ProyW (v) es ortogonal a cada vector de W .
Demostracion:Por la Proposicion 284, para probar que un vector es ortogonal a todos los vectores de un subespacio, bastaprobarlo para los vectores de una base. Sea B = {w,w, . . . ,wk} , para cada wi de B , por ser B ortonormal,〈wi,wi〉 = 1 y 〈wi,wj〉 = 0, si i 6= j , entonces
〈v−ProyW (v), wi〉= 〈v − 〈v,w〉w − · · · − 〈v,wi〉wi − · · · − 〈v,wk〉wk, wi〉= 〈v,wi〉 − 〈v,w〉〈w,wi〉 − · · · − 〈v,wi〉〈wi,wi〉 − · · · − 〈v,wk〉〈wk, wi〉= 〈v,wi〉 − 0− · · · − 〈v,wi〉 · 1− · · · − 0 = 〈v,wi〉 − 〈v,wi〉 = 0
Luego es ortogonal a los vectores de B y, por consiguiente, a todos los vectores de W .
Unicidad de la proyeccion ortogonal.- Sea V un espacio con producto interior y W un subespacio de V . Paracada v ∈ V , la proyeccion ortogonal de v en W no depende de la base ortonormal elegida.
Es decir, si B1 = {u,u, . . . ,uk} y B2 = {v,v, . . . ,vk} son dos bases ortonormales de W , entonces,para cada v ∈ V , los vectores
Proy(1)W (v) = w = 〈v,u〉u + 〈v,u〉u + · · ·+ 〈v,uk〉uk
Proy(2)W (v) = w = 〈v,v〉v + 〈v,v〉v + · · ·+ 〈v,vk〉vk
son el mismo.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

183 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Demostracion:Como w es una proyeccion ortogonal de v sobre W , el vector w ∈W y el vector v−w es ortogonal a Wy, por la misma razon, el vector w ∈W y el vector v−w es ortogonal a W .
Entonces, el vector (v−w)− (v−w) = w−w cumple que: es ortogonal a todos los vectores de W porser diferencia de dos vectores ortogonales a W ; y tambien es un vector de W por ser diferencia de dos vectoresde W . En consecuencia, es ortogonal a si mismo y 〈w −w, w −w〉 = 0, luego es el vector ; por lo quew = w y la proyeccion ortogonal no depende de la base.
Aplicaciones lineales
Justificacion del metodo descrito en la Observacion 304, de la pagina 157
Usaremos en la justificacion el mismo ejercicio del ejemplo, pero la prueba es valida en cualquier caso.Haciendo las operaciones elementales sobre la matriz At , que tiene por filas las [f(vi)]B2 , hemos obtenido
la matriz que tiene por filas
[f(v)]B2
[f(v − v)]B2
[f(v − v + v)]B2
[f(v + v −
v − v)]B2
[f(v + v + v)]B2
[f(v − v − v)]B2
. Luego si repetimos las mismas operaciones
sobre la matriz J que tiene por filas
[v]B1
[v]B1
[v]B1
[v]B1
[v]B1
[v]B1
obtendrıamos K =
[v]B1
[v − v]B1
[v − v + v]B1
[v + v −
v − v]B1
[v + v + v]B1
[v − v − v]B1
.
Ahora bien, como la matriz J es la identidad, que tiene rango 6, la matriz K tambien tiene rango 6, por loque sus filas son linealmente independientes y en consecuencia los tres ultimos vectores (los vectores de ker(f))tambien son linealmente independientes.
Diagonalizacion
Justificacion de la observacion en Antes de seguir de la pagina 163
Definicion.- Sea f :V −→ V un operador lineal, diremos que un escalar λ es un valor propio de f si existeun vector v ∈ V , diferente de cero, tal que f(v ) = λv .
Al vector v se le denomina vector propio de f correspondiente a λ .
Teorema.- Sea f : V −→ V un operador lineal, siendo V un espacio vectorial de dimension n . Entonces,existe una base de V con respecto a la cual la matriz de f es diagonal si y solo si f tiene n vectores propioslinealmente independientes.
Demostracion:Si la matriz de f en la base B = {v, v, . . . , v} es D diagonal, los mismos vectores de la base son vectorespropios y son linealmente independientes, pues:
([f(v)]B [f(v)]B · · · [f(vn)]B
)= D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
=
(λ1[v]B λ2[v]B · · · λn[vn]B
)
Recıprocamente, si tenemos n vectores propios linealmente independientes, la matriz de f respecto de la baseformada con ellos es diagonal.
([f(v)]B [f(v)]B · · · [f(vn)]B
)=
(λ1[v]B λ2[v]B · · · λn[vn]B
)=
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

184 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Teorema.- Sean V un espacio vectorial de dimension n , f :V −→ V un operador lineal y A la matriz de f conrespecto a una base B = {v 1, v 2, . . . , vn} . Entonces:
a) Los valores propios de f son los valores propios de A
b) Un vector v ∈ V es un vector propio de f correspondiente al valor propio λ si y solo si su matriz decoordenadas [v ]B es un vector propio de A correspondiente a λ .
Demostracion:
a) Sea λ un valor propio de f , es decir, ∃v ∈ V , distinto de , tal que f(v ) = λv =⇒ [f(v )]B = [λv ]B=⇒ A[v ]B = λ[v ]B , luego λ es un valor propio de A al ser [v ]B 6= .
Sea λ un valor propio de A , entonces ∃x ∈ Rn , x 6= tal que Ax = λx . Si tomamos x∗ =x1v 1 + · · ·+xnvn , siendo x = (x1, . . . , xn), lo anterior quiere decir que A[x∗]B = λ[x∗]B ⇒ [f(x∗)]B =[λx∗]B ⇒ f(x∗) = λx∗ y λ es un valor propio de f ya que x∗ 6=
b) v es un vector propio de f correspondiente a λ si y solo sif(v ) = λv ⇐⇒ [f(v )]B = [λv ]B ⇐⇒ A[v ]B = λ[v ]B
si y solo si [v ]B es un vector propio de A correspondiente a λ .
Teorema.- Los vectores propios de f correspondientes al valor propio λ , son los vectores distintos de cero delnucleo de la aplicacion λId − f (denotamos por Id la aplicacion identidad, Id(v) = v ).
Llamaremos a dicho nucleo, espacio caracterıstico de f correspondiente al valor propio λ .
Demostracion:v un vector propio correspondiente a λ ⇐⇒ f(v ) = λv ⇐⇒ f(v ) = λId(v ) ⇐⇒ λId(v )− f(v ) = ⇐⇒(λId − f)(v ) = ⇐⇒ v ∈ ker(λId − f).
Demostracion de: Teorema 320 de la pagina 163
Teorema 320.- Sean v , v , . . . , vk vectores propios de una matriz A asociados a los valores propios λ1 ,λ2 , . . . , λk respectivamente, siendo λi 6= λj , ∀ i 6= j . Entonces el conjunto de vectores {v,v, . . . ,vk} eslinealmente independiente.
Demostracion:Supongamos que v,v, . . . ,vk son linealmente dependientes.
Por definicion, un vector propio es distinto de cero, luego el conjunto {v} es linealmente independiente.Sea r el maximo entero tal que {v,v, . . . ,vr} es linealmente independiente. Puesto que hemos supuestoque {v,v, . . . ,vk} es linealmente dependiente, r satisface que 1 ≤ r < k . Ademas, por la manera en quese definio r , {v,v, . . . ,vr,vr+} es linealmente dependiente. Por tanto, existen escalares c1, c2, . . . , cr+1 , almenos uno diferente de cero, tales que
c1v + c2v + · · ·+ cr+1vr+ = . 〈13.2〉
Multiplicando en ambos lados de la igualdad por A y haciendo las sustitucionesAv = λ1v, Av = λ2v, . . . , Avr+ = λr+1vr+
se obtienec1λ1v + c2λ2v + · · ·+ crλrvr + cr+1λr+1vr+ = 〈13.3〉
Multiplicando los dos lados de (13.2) por λr+1 y restandole a (13.3) la ecuacion resultante se obtendra
c1(λ1 − λr+1)v + c2(λ2 − λr+1)v + · · ·+ cr(λr − λr+1)vr = .
Y dado que los vectores v,v, . . . ,vr son linealmente independientes, necesariamentec1(λ1 − λr+1) = c2(λ2 − λr+1) = · · · = cr(λr − λr+1) = 0
Como los λ1, λ2, . . . , λr+1 son distintos entre si, se deduce que c1 = c2 = · · · = cr = 0.Sustituyendo estos valores en (13.2) resulta que cr+1vr+ = , y como vr+ 6= se deduce que cr+1 = 0,
lo que contradice el hecho de que al menos uno de los escalares c1, c2, . . . , cr+1 debıa de ser distinto de cero.Luego los vectores v,v, . . . ,vk han de ser linealmente independientes, que prueba el teorema.
Demostracion de: Proposicion 322 de la pagina 163
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

185 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Proposicion 322.- Sea A de orden n y λk un autovalor de A de multiplicidad mk . Entonces
1 ≤ dimV (λk) ≤ mk.
Demostracion:Como ya observamos anteriormente, dimV (λi) ≥ 1.
Supongamos que dimV (λk) = d , y consideremos el operador lineal f :Rn −→ Rn definido por f(v) = Av .Sea {v, . . . ,vd} una base del espacio caracterıstico V (λk), que podemos completar hasta obtener una base deRn , B = {v, . . . ,vd,vd+, . . . ,vn} . La matriz A′ , del operador en la base B , sera de la forma
A′ =
([f(v)]B · · · [f(vd)]B [f(vd+)]B · · · [f(vn)]B
)
=
(λk[v]B · · · λk[v]B [f(vd+)]B · · · [f(vn)]B
)=
λk · · · 0...
. . .... A′12
0 · · · λk0 · · · 0... · · ·
... A′220 · · · 0
de donden |λI −A′| = (λ− λk)d|λI −A′22| . Pero como A y A′ son matrices semejantes que tienen el mismopolinomio caracterıstico (Ejer. 12.296), (λ− λk)d|λI −A′22| = |λI −A′| = |λI −A| = (λ− λk)mkQ(λ), enconsecuencia tiene que ser d ≤ mk puesto que mk es la multiplicidad de la raız
Demostracion de: Teorema de la diagonalizacion 323 de la pagina 163
Teorema de la diagonalizacion 323.- Sea A una matriz de orden n . Entonces A es diagonalizable si y solo sise cumplen las condiciones:
1.- |λI −A| = (λ− λ1)m1 · · · (λ− λk)mk , con m1 +m2 + · · ·+mk = n (es decir, tiene n raıces reales)
2.- Para cada espacio caracterıstico V (λi), se cumple que dimV (λi) = mi
Demostracion:=⇒ Si A es diagonalizable, la matriz diagonal D y A son semejantes (D = P−1AP ) y por tanto poseen el
mismo polinomio caracterıstico (Ejer. 12.296), luego P (λ) = |λI − A| = |λI −D| = (λ− λ1)m1 · · · (λ− λk)mk ,donde los λi ∈ R son los valores de la diagonal de D y mi el numero de veces que se repite. Por tanto, P (λ)tiene todas sus raices reales y, por ser de grado n , m1 +m2 + · · ·+mk = n .
Ademas, por ser A y D matrices semejantes, tambien lo son λI − A y λI − D , para todo λ ∈ R , puesP−1(λI−A)P = λP−1IP −P−1AP = λI−D , de donde rg(λI−A) = rg(λI−D), para todo λ . Entonces, paracada autovalor λi se tiene que rg(λiI −A) = rg(λiI −D) = n−mi y, en consecuencia, que dimV (λi) = mi .
⇐= Si |λI − A| = (λ − λ1)m1 · · · (λ − λk)mk , con m1 + m2 + · · · + mk = n , y dimV (λi) = mi para cadai = 1, . . . , k , consideremos en cada V (λi) una base Bi , de la forma
B1 ={p11 , . . . , p1m1
}, B2 =
{p21 , . . . , p2m2
}, . . . , Bk =
{pk1 , . . . , pkmk
}Tomemos entonces B = B1∪B2∪· · ·∪Bk , un conjunto de n vectores propios de A , si vemos que son linealmenteindependientes, tendremos que A es diagonalizable.
Planteemos una combinacion lineal igualada a cero:
= β11p11 + · · ·+ β1m1p1m1 + β21p21 + · · ·+ β2m2
p2m2 + · · ·+ βk1pk1 + · · ·+ βkmkpkmk
= (β11p11 + · · ·+ β1m1p1m1) + (β21p21 + · · ·+ β2m2
p2m2) + · · ·+ (βk1pk1 + · · ·+ βkmkpkmk)
= v + v + · · ·+ vk
siendo vj = βj1pj1 + · · ·+ βjmj pjmj ∈ V (λj), para cada j = 1, . . . , k .Los vectores v , v , . . . , vk son vectores de espacios caracterısticos correspondientes, respectivamente, a
los valores propios distintos λ1 , λ2 , . . . , λk y por tanto, si no son cero, son linealmente independientes. Pero lacombinacion lineal v + v + · · ·+ vk = nos indicarıa que son dependientes, luego la unica forma de eliminaresa contradiccion es que vj = , ∀j = 1, 2, . . . , k ; de donde, si = vj = βj1pj1 + · · ·+ βjmj pjmj , han de sertodos βj1 = βj2 = · · · = βjmj = 0 por ser Bj una base. Como es cierto para cada j , se tiene que βji = 0,∀ i, j , con lo que B es linealmente independiente.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

186 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Demostracion de: Teorema de la diagonalizacion ortogonal 329 de la pagina 165
Teorema de la diagonalizacion ortogonal 329.- A diagonaliza ortogonalmente ⇐⇒ A es simetrica
Demostracion:=⇒ Es el Lema 327
⇐= Sea A simetrica, veamos que es diagonalizable. Primero, que todos los valores propios de A son reales:Sea λ ∈ C un valor propio de A , entonces existe x = (x1, . . . , xn) 6= (xj ∈ C) tal que Ax = λx . Por
ser A real, su polinomio caracterıstico es real y el conjugado de λ , λ , es tambien autovalor de A ; ademas,tomando conjugados en la igualdad anterior, se tiene que Ax = Ax = λx . Entonces, son iguales los valores
xtAx = xt(Ax) = xt(λx) = λxtx = λ
n∑j=1
xjxj = λ
n∑j=1
|xj |2
xtAx = (xtA)x = (xtAt)x = (Ax)tx = (λx)tx = λxtx = λ
n∑j=1
|xj |2
y, al ser x 6= ,n∑j=1
|xj |2 6= 0 por lo que λ = λ y λ ∈ R . En consecuencia, si todos los autovalores de A son
reales, el polinomio caracterıstico de A tiene las n raices reales.
Veamos ahora que para cada λj se verifica que dimV (λj) = mj .Sean dimV (λj) = d y Bj = {x, . . . ,xd} una base ortonormal de V (λj) que ampliamos hasta una base
ortonormal de Rn , B = {x, . . . ,xd,xd+, . . . ,xn} .Consideremos el operador lineal f :Rn −→ Rn dado por f(x) = Ax , luego A es la matriz de f en la base
canonica que es ortonormal y si A′ es la matriz de f en la base B y P la matriz de paso de B a la canonica,P es ortogonal y A′ = P tAP . Como A es simetrica, A′ tambien lo sera pues (A′)t = (P tAP )t = P tAt(P t)t =P tAP = A′ .
A′ =
([f(x)]B · · · [f(xd)]B [f(xd+)]B · · · [f(xn)]B
)
=
(λj [x]B · · · λj [x]B [f(xd+)]B · · · [f(xn)]B
)=
λj · · · 0...
. . .... A′12
0 · · · λj0 · · · 0... · · ·
... A′22
0 · · · 0
donde A′12 = 0, puesto que A′ es simetrica y A′22 cuadrada de orden n − d . Luego la matriz λjI − A′ nosqueda
λjI −A′ =
λj − λj · · · 0...
. . .... 0
0 · · · λj − λj0 · · · 0... · · ·
... λjI −A′22
0 · · · 0
=
0 · · · 0...
. . .... 0
0 · · · 00 · · · 0... · · ·
... λjI −A′22
0 · · · 0
por lo que rg(λjI−A′) = rg(λjI−A′22). Por ser A y A′ semejantes rg(λjI−A)=rg(λjI−A′) (ver demostraciondel Teorema 323), y se tiene que rg(λjI−A′22) = rg(λjI−A) = n−dimV (λj) = n−d por lo que |λjI −A′22| 6= 0.
Entonces, |λI −A| = |λI −A′| = (λ− λj)d |λI −A′22| , con |λjI −A′22| 6= 0, luego d = mj .
En resumen, A diagonaliza, y tomando una base ortonormal de cada uno de los espacios caracterısticos,tendremos n vectores propios de norma 1 y, que por el Lema 328, son ortogonales entre sı.
Formas cuadraticas
Demostracion de: Teorema de Sylvester o Ley de inercia 338 de la pagina 171
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

187 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
Teorema de Sylvester o Ley de inercia 338.- Si una forma cuadratica se reduce a la suma de cuadrados endos bases diferentes, el numero de terminos que aparecen con coeficientes positivos, ası como el numero determinos con coeficientes negativos es el mismo en ambos casos.
Demostracion:Supongamos que respecto a una base B1 = {b, b, . . . , bn} la matriz de la forma cuadratica Q es una matrizdiagonal y tiene p elementos positivos y s elementos negativos en su diagonal principal, luego la expresion dela forma cuadratica sera
Q(x) = a1x21 + · · ·+ apx
2p − ap+1x
2p+1 − · · · − ap+sx2
p+s
con ai > 0 para todo i , y (x1, . . . , xp, xp+1, . . . , xp+s, xp+s+1, . . . , xn) = [x]tB1; y que respecto a otra base
B2 = {d,d, . . . ,dn} la matriz de la forma cuadratica es tambien diagonal con q elementos positivos y rnegativos, por lo que Q se expresara en la forma
Q(x) = c1y21 + · · ·+ cqy
2q − cq+1y
2q+1 − · · · − cq+ry2
q+r
con ci > 0 para todo i , e (y1, . . . , yq, yq+1, . . . , yq+r, yq+r+1, . . . , yn) = [x]tB2.
Por el teorema 336 anterior, sabemos que las matrices congruentes tienen el mismo rango, luego tienen queser p+ s = q + r . Veamos que p = q , con lo que tendremos tambien que s = r .
Si p 6= q , uno de ellos es mayor que el otro, supongamos que es p > q y consideremos los conjuntos de vectores{b, . . . , bp} y {dq+, . . . ,dn} . Si p > q , el conjunto {b, . . . , bp,dq+, . . . ,dn} tiene p+(n−q) = n+(p−q) > nvectores y, por lo tanto, es un conjunto linealmente dependiente y en la igualdad
λ1b + · · ·+ λpbp + µq+1dq+ + · · ·+ µndn =
alguno de los coeficientes no es cero. Entonces, el vector
λ1b + · · ·+ λpbp = −µq+1dq+ − · · · − µndn = x
no es el cero (si es cero, todos los λi son cero por ser los bi de B1 , y todos los µj = 0 por ser los dj ∈ B2 ),con algun λi y algun µj distintos de cero. Tenemos ası que
[x]tB1= (λ1, . . . , λp, 0, . . . , 0) y [x]tB2
= (0, . . . , 0,−µq+1, . . . ,−µn)
pero calculando Q(x) respecto a las dos bases obtenemos
Q(x) = a1λ21 + · · ·+ apλ
2p − ap+10− · · · − ap+s0 = a1λ
21 + · · ·+ apλ
2p > 0
Q(x) = c10 + · · ·+ cq0− cq+1(−µq+1)2 − · · · − cq+r(−µq+r)2 + 0(−µq+r+1)2 + · · ·+ 0(−µn)2
=−cq+1(−µq+1)2 − · · · − cq+r(−µq+r)2 ≤ 0
lo que no puede ser. Por tanto deben ser p = q y s = r , es decir, las dos matrices diagonales tienen el mismonumero de elementos positivos y negativos.
Demostracion de: Teorema de clasificacion 341 de la pagina 172
Teorema de clasificacion 341.- Sea Q una forma cuadratica en un espacio de dimension n . Se verifica:
a) Q es nula ⇐⇒ Sig(Q) = (0, 0)
b) Q es definida positiva ⇐⇒ Sig(Q) = (n, 0).
c) Q es semidefinida positiva ⇐⇒ Sig(Q) = (p, 0) con 0 < p < n .
d) Q es definida negativa ⇐⇒ Sig(Q) = (0, n).
e) Q es semidefinida negativa ⇐⇒ Sig(Q) = (0, q) con 0 < q < n .
f) Q es indefinida ⇐⇒ Sig(Q) = (p, q) con 0 < p, q .
Demostracion:Sea B = {v, . . . ,vn} una base en la cual, la expresion de Q es Q(x) = d1x
21 + d2x
22 + · · ·+ dnx
2n
donde (x1, . . . , xn) = [x]tB . Luego, Q(vi) = di , para todo i = 1, . . . , n , ya que los vectores de B tiene porcoordenadas [v]tB = (1, 0, 0, . . . , 0), [v]tB = (0, 1, 0, . . . , 0), . . . , [vn]tB = (0, 0, 0, . . . , 1). Entonces:
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018

188 – Fundamentos de Matematicas : Algebra Lineal Anexo 3
a) Si Q(x) = 0, para todo x , se tiene que di = Q(vi) = 0, para todo i , luego Sig(Q) = (0, 0).
Reciprocamente, si di = 0 para todo i , entonces Q(x) = 0 para todo x .
b) Si Q(x) > 0 para todo x 6= , se tiene que di = Q(vi) > 0, para todo i , luego Sig(Q) = (n, 0).
Recıprocamente, si di > 0 para todo i , entonces Q(x) > 0 para todo x 6= .
c) Si Q(x) ≥ 0 para todo x 6= , es di = Q(vi) ≥ 0 para todo i . Como no es nula existe algun dj > 0 ycomo no es definida positiva existe algun dk = 0, luego Sig(Q) = (p, 0) con 0 < p < n .
Recıprocamente, si di ≥ 0 para todo i , con algun dj > 0 y algun dk = 0, se tiene que Q(x) ≥ 0 paratodo x , que Q(vj) = dj > 0, por lo que no es nula, y que Q(vk) = dk = 0, por lo que no es definidapositiva.
d) y e) Analogos a los casos de definida y semidefinida positiva.
f) Por ser indefinida, Q(x) 6≥ 0 para todo x , luego di 6≥ 0 para todo i , por lo que existira un dj < 0y Q(x) 6≤ 0 para todo x , luego di 6≤ 0 para todo i por lo que existira un dk > 0. En consecuencia,Sig(Q) = (p, q) con p, q > 0.
Recıprocamente, si existe dj < 0 y dk > 0, seran Q(vj) = dj < 0 y Q(vk) = dk > 0, luego es indefinida.
Prof: Jose Antonio Abia Vian Grado de Ing. en Diseno Industrial y Desarrollo de producto : Curso 2017–2018