editorial universidad manuela beltrán · editorial universidad manuela beltrán autores miguel...
TRANSCRIPT

o


Editorial Universidad Manuela Beltrán
Fundamentos de Inteligencia Artificial
2018


Fundamentos de Inteligencia Artificial
Autores
Miguel García Torres Carlos Augusto Sánchez Martelo
Henry Leonardo Avendaño Delgado Manuel Antonio Sierra Rodríguez
Carlos Andrés Collazos Morales Domingo Alirio Montaño Arias
Breed Yeet Alfonso Corredor José Daniel Rodríguez Munca

6

Edición Editorial Universidad Manuela Beltrán Autores
Miguel García Torres Dr. En Ciencias de la Computación e Inteligencia Artificial, Investigador Postdoctoral en el Instituto Nacional de Técnica Aeroespacial, Magíster en
Informática, Físico.
Carlos Augusto Sanchez Martelo Dr. (c) en Pensamiento Complejo, Maestría en Diseño, Gestión y Dirección de Proyectos, Ingeniero de sistemas, Certificado
Internacionalmente en ITIL Foundation v3, Procesos en Desarrollo de Software y TIC
Henry Leonardo Avendaño Delgado Dr. (c) en Educación línea de investigación Tecnologías de la Información y Comunicación para la inclusión, Magister en
Educación, Especialista en Gerencia de Telecomunicaciones, Ingeniero Electrónico.
Manuel Antonio Sierra Rodríguez Dr. (c) en Proyectos en la línea de investigación en Tecnologías de la Información y Comunicación, Magíster en Software Libre, Especialista en
Seguridad en Redes, Ingeniero de Sistemas, Consultor en Seguridad de la Información y Comunicaciones.
Domingo Alirio Montaño Arias Dr. En Genética, Magister en Biología, Biólogo, Investigador Asociado, Universidad Manuela Beltrán, BSc, MSc, PhD Intereses de investigación en Neurociencias, Genética y TIC Aplicadas a la Educación.
Miembro comité editorial revista Journal of Science Educations. Miembro fundador de la Sociedad Iberoamericana de Biología Evolutiva.
Carlos Andres Collazos Morales Postdoctorado en Ciencia y Tecnología Avanzada, Dr. en Ciencias, Magister en Ingeniería Electrónica y Computadores, Físico.
Breed Yeet Alfonso Corredor Dr. (c) en Proyectos, Magister en Educación, Especialista en Desarrollo e Implementación de Herramientas Telemáticas, Ingeniera Electrónica, Directora Académica y
Calidad, Consultora Nacional e Internacional Académica de Educación Superior.
José Daniel Rodríguez Munca Magister en Ciencias de la Educación, Master en Estrategias y Tecnologías para el Desarrollo, Especialista en docencia mediada por las TIC e
Ingeniero Electrónico. Daniela Suarez Porras Corrección de estilo (Editor secundario) Diagramación: Cesar Augusto Ricaurte Diseño de portada: Cesar Augusto Ricaurte Publicado en Diciembre de 2018 Formato digital PDF (Portable Document Format) Editorial Universidad Manuela Beltrán Avenida Circunvalar Nº 60-00 Bogotá – Colombia Tel. (57-1) 5460600

8

Miguel García Torres, Carlos Augusto Sánchez Martelo, Henry Leonardo Avendaño Delgado, Manuel Antonio Sierra Rodríguez,
Carlos Andrés Collazos Morales, Domingo Alirio Montaño Arias, Breed Yeet Alfonso Corredor, José Daniel Rodríguez Munca
Fundamentos de Inteligencia Artificial, Bogotá, UMB
© Miguel García Torres, Carlos Augusto Sánchez Martelo, Henry Leonardo Avendaño Delgado, Manuel Antonio Sierra Rodríguez,
Carlos Andrés Collazos Morales, Domingo Alirio Montaño Arias, Breed Yeet Alfonso Corredor, José Daniel Rodríguez Munca
© Universidad Manuela Beltrán
Bogotá, Colombia http:// www.umb.edu.co
Queda prohibida la reproducción total o parcial de este libro por cualquier proceso gráfico o fónico, particularmente por fotocopia,
Ley 23 de 1982
Fundamentos de Inteligencia Artificial. / Miguel García Torres… (y otros 7) - Bogotá: Universidad Manuela Beltrán, 2018. 128 p.: ilustraciones, gráficas, tablas; [versión electrónica] Incluye bibliografía ISBN: 978-958-5467-27-9 1. Inteligencia artificial 2. Aprendizaje automático 3. Sistemas expertos (computadores). i. Sánchez Martelo, Carlos Augusto. ii. Avendaño Delgado, Henry Leonardo. iii. Sierra Rodríguez, Manuel Antonio. iv. Collazos Morales, Carlos Andrés. v. Montaño Arias, Domingo Alirio. vi. Alfonso Corredor, Breed Yeet. vii. Rodríguez Munca, José Daniel. 006.3 cd 23 ed. CO-BoFUM
Catalogación en la Publicación – Universidad Manuela Beltrán


Autoridades Administrativas
Gerente Juan Carlos Beltrán Gómez
Secretario General Juan Carlos Tafur Herrera
Autoridades Académicas
Rectora Alejandra Acosta Henríquez
Vicerrectoría de Investigaciones
Fredy Alberto Sanz Ramírez
Vicerrectoría Académica Claudia Milena Combita López
Vicerrectoría de Calidad Hugo Malaver Guzman
ISBN: 978-958-5467-27-9


13
TABLA DE CONTENIDO
Fundamentos de Inteligencia Artificial
Contenido PRÓLOGO................................................................................................................................. 15
INTRODUCCIÓN ...................................................................................................................... 17
Capítulo 1: Introducción y Búsqueda ................................................................................. 21
1. Introducción y Búsqueda de Datos ............................................................................. 21
1.1. Introducción .................................................................................................................. 21
1.2. Marco Conceptual ........................................................................................................ 22 1.2.1. Introducción a la Inteligencia Artificial ............................................................................ 22 1.2.2 Historia de la Inteligencia Artificial ................................................................................... 23 1.2.3 Agentes Inteligentes ............................................................................................................ 24
1.3. Ejemplos ........................................................................................................................ 32
1.4. Ejercicios de reflexión ................................................................................................ 36
1.5. Búsqueda de Datos ..................................................................................................... 40 1.5.1. Introducción ......................................................................................................................... 40 1.5.2. Búsquedas no Informadas ................................................................................................. 43 1.5.3. Búsquedas informadas ...................................................................................................... 46 1.5.4. Ejemplos ............................................................................................................................... 49 1.5.5. Ejercicios de Reflexión ....................................................................................................... 54
Capítulo 2: Aprendizaje Automático y Juegos .................................................................. 57
2. Aprendizaje Automático y Juegos ............................................................................... 57
2.1. Introducción .................................................................................................................. 57
2.2. Ejemplos ........................................................................................................................ 75
2.3. Ejercicios de reflexión ................................................................................................ 76
2.4. Conclusiones ................................................................................................................ 77
2.5. Teoría de Juegos ......................................................................................................... 78
2.6. Los Juegos Como un Problema de Búsqueda ...................................................... 81
2.7. Poda Alfa-Beta .............................................................................................................. 85
2.8. Ejemplos ........................................................................................................................ 87
2.9. Ejercicios de Reflexión ............................................................................................... 89
Capítulo 3: Problema de Satisfacción de Restricciones y Lógica ................................. 93

14
2. Problemas de Satisfacción de Restricciones y Lógica ........................................... 93
2.1. Introducción .................................................................................................................. 93
2.2. Modelización de Problemas de Satisfacción de Restricciones .......................... 95
2.3 Técnicas de Resolución de PSR ................................................................................ 98
5.3. Ejemplos ...................................................................................................................... 100
5.5. Conclusiones .............................................................................................................. 102
5.6. Conocimiento Racional ............................................................................................ 102
5.7. Representación del Conocimiento y Razonamiento ........................................... 103
5.8. Lógica .......................................................................................................................... 107
5.9. Tipos de lógica ........................................................................................................... 108
5.10. Ejemplos .................................................................................................................... 114
5.11. Ejercicios de reflexión ............................................................................................ 116

15
PRÓLOGO
La inteligencia artificial (IA) es una de las disciplinas computacionales más
demandadas que afectan, sin darnos cuenta, nuestro día a día. Tareas como
realizar una búsqueda en internet, filtrar nuestro correo electrónico o enfocar las
caras con las cámaras digitales están dotadas de IA para realizar dichos trabajos,
de modo que parezca que hay un cierto grado de inteligencia para realizarlos.
El objetivo de la IA no es reemplazar al humano sino mejorar la calidad de vida
de este asumiendo trabajos que hasta ahora solo podían ser realizados si hay una
inteligencia detrás que lo lleve a cabo. Sin embargo, el desconocimiento que aún
se tiene del cerebro hace que todavía estemos lejos de diseñar un software que
actúe de forma inteligente en aplicaciones diversas teniendo que poner el foco en
mejorar la realización de tareas específicas. A la par que se van produciendo
mejoras es inevitable que surjan cuestiones éticas y morales sobre el objetivo de
simular o reproducir un ser inteligente.
Miguel García Torres

16

17
INTRODUCCIÓN
La resolución de problemas es uno de los procesos básicos del razonamiento
que la IA trata de abordar. El objetivo es conseguir que un agente encuentre una
solución a un determinado problema de una forma equiparable o superior a como
lo haría un humano.
Esta unidad introduce la resolución de problemas como un proceso de
búsqueda en el espacio de posibles estados en los que puede encontrarse la
solución. Esta área está bastante ligada a las matemáticas y no requiere usar
mecanismos de la mente para abordarlo; por tanto, es una de las primeras áreas
de la IA que empezó a desarrollarse.
A lo largo de esta unidad se verá cómo se plantean este tipo de problemas.
También se expondrán las distintas estrategias que hay para abordar estos
problemas en función de la información que tengan las estrategias del problema
en cuestión.
El aprendizaje automático es una rama de la IA que tiene el objetivo de
desarrollar técnicas que le permitan a las computadoras aprender. Generalmente
se lleva a cabo mediante un proceso de inducción del conocimiento en el que se
pretende generalizar reglas a partir de ejemplos concretos.
A lo largo de este libro se abordará el aprendizaje supervisado y el no
supervisado. En el aprendizaje supervisado se persigue aprender una función que
establezca una correspondencia entre las entradas que recibe el algoritmo y la
salida deseada. En el no supervisado, en cambio, el objetivo es reconocer
patrones que ayuden a describir los datos de entrada. Las posibles aplicaciones
del aprendizaje automático son muy diversas y algunas de ellas precisamente son
los motores de búsqueda, el diagnóstico médico, detección de fraude en el uso de

18
las tarjetas de crédito, reconocimiento del habla, clasificación de secuencia de
ADN, etc.
La modelización de un problema como un problema de satisfacción de
restricciones (PSR) es una metodología utilizada para la descripción y posterior
resolución efectiva de cierto tipo de problemas, típicamente combinatorios y de
optimización. Las principales aplicaciones de este tipo de problema son
planificación, razonamiento temporal, diseño en la ingeniería, problemas de
empaquetamiento, criptografía, diagnóstico, toma de decisiones, etc.
Los primeros trabajos relacionados con la programación de restricciones datan
de los años 60 y 70 en el campo de la inteligencia artificial. La importancia de esta
área radica en que muchas decisiones que se toman diariamente están sujetas a
restricciones, como planificar un viaje, concertar una cita para el médico, comprar
una casa, etc.
19
Capítulo I
Intr
oduc
ción
y B
úsqu
eda
Introducción y Búsqueda de Datos
Marco Conceptual
Ejemplos
Ejercicios de Reflexión
Introducción y Búsqueda

20

21
CAPÍTULO 1: INTRODUCCIÓN Y BÚSQUEDA
Los conceptos básicos que se verán en la primera unidad permitirán entender
qué es y en qué consiste la IA. Además, se verán los distintos planteamientos que
hay para abordar la simulación de la conciencia por la importancia que tiene desde
un punto de vista filosófico, ético y moral. Finalmente, se abordará la IA desde el
paradigma de agentes.
La segunda unidad aborda un tipo de agentes basados en objetivos que plantea
la resolución de problemas como una búsqueda de la secuencia de acciones que
llevan desde un estado inicial a otro final deseado. También se abordarán dos
tipos de técnicas de búsquedas (informadas y no informadas) cuya principal
diferencia radica en la información que tiene cada aproximación del problema a
resolver.
1. Introducción y Búsqueda de Datos 1.1. Introducción
La inteligencia artificial es un área multidisciplinaria que estudia la creación y el
diseño de sistemas computacionales para realizar tareas intelectuales. Es una de
las ciencias más recientes que abarca una gran variedad de subcampos, que van
desde áreas de propósito general, como el aprendizaje y la percepción, a otras
áreas más específicas, como el ajedrez y la demostración de teoremas.
A lo largo de este libro se dará una visión global de la IA presentando los
conceptos básicos e introduciendo el contexto histórico y cultural en el que se
desarrolla esta nueva ciencia. Finalmente, se continuará con el concepto de
agente, inherente al campo de la IA.

22
1.2. Marco Conceptual
1.2.1. Introducción a la Inteligencia Artificial ¿Qué es la inteligencia artificial? La inteligencia artificial es una de las disciplinas más nuevas que evoluciona a
gran celeridad, motivada por su propia inmadurez. Esto ha llevado a que abarque
un gran número de áreas que permite que pueda ser aplicada a una gran cantidad
y variedad de disciplinas científicas. Esto se debe a que la IA puede aplicarse en
cualquier ámbito que se requiera el intelecto humano.
Desde un punto de vista etimológico, el término inteligencia proviene de las
palabras latinas inter (entre) y legere (escoger), es decir, la facultad de saber
elegir. Sin embargo, no basta con acumular información para saber, sino que se
requiere aprender de la información que ha sido percibida. Por tanto, para poder
considerar que un ser (de cualquier tipo) tiene inteligencia se requiere que capaz
de tomar decisiones en entornos nuevos o desconocidos, con base a una serie de
observaciones y/o aprendizajes previos sobre experiencias pasadas.
Actualmente no existe una única definición de IA aceptada en la comunidad sino
que hay varias propuestas que hacen énfasis en algunos de los aspectos que han
sido identificados como parte de la misma. Para el propósito de esta asignatura se
entenderá la IA como una disciplina que trata de desarrollar sistemas capaces de
adoptar comportamientos que, si fuesen realizados por humanos, no dudaríamos
en calificar de inteligentes.
Formas de hacer inteligencia artificial Existen distintas aproximaciones de cara a la simulación de la conciencia por un
ordenador:
IA fuerte: toda actividad mental puede simularse.

23
IA débil: toda propiedad física del cerebro puede simularse pero la
conciencia es una característica del cerebro a la que no puede llegarse
por computación.
Nueva física: piensa que hace falta desarrollar una nueva física para explicar la mente humana, de modo que con los conocimientos actuales
no es posible simular la mente humana.
Mística: en esta postura se defiende que la conciencia no puede ser explicada física ni computacionalmente. No puede entenderse a través de
ningún método científico debido a que pertenece a la esfera espiritual.
Aquellos que se posicionan por las dos primeras posturas creen que la
conciencia es un proceso físico que emerge del cerebro, explicable con la ciencia
actual, aunque aún se desconozca. Los que defienden la IA débil consideran que
sus modelos son representaciones simbólicas de los sistemas biológicos, y que
las máquinas pueden programarse para exhibir comportamiento inteligente. Sin
embargo, los que defienden la IA fuerte afirman que las máquinas pueden
programarse para poseer inteligencia y tener consciencia reproduciendo las
características básicas de los seres vivos.
La tercera postura, defendida principalmente por R. Penrose, afirma que hay
hechos que no pueden ser simulados computacionalmente. Por último, la cuarta
postura podría parecer la más próxima a la religión. No obstante, cualquiera de las
tres anteriores también puede ser compatible con la religión. Si bien es verdad que
la ciencia podrá responder, en un futuro, la pregunta de cómo funciona la mente,
nunca podrá responder la pregunta de por qué existe la mente o cuál es su fin
último.
1.2.2 Historia de la Inteligencia Artificial Desde un punto de vista histórico, el ser humano ha expresado su anhelo por
replicar la inteligencia humana a través de mitos y leyendas. La filosofía también

24
ha abordado el estudio de la inteligencia, pero desde un punto de vista de
modelización más que de replicación.
Los primeros trabajos que forman parte del origen de la IA moderna datan de la
década de los 40 del siglo XX. Sin embargo, no fue sino hasta 1950 que dicha
disciplina empezó a suscitar mayor interés gracias a Alan Turing. En 1956, en la
conferencia de Dartmouth, esta nueva disciplina se bautizó como inteligencia
artificial. En la década de los 50 hubo un gran optimismo debido a los éxitos
cosechados previamente. Sin embargo, la década siguiente sirvió para empezar a
conocer las limitaciones que había. Si en estos primeros años el enfoque era el
desarrollo de mecanismos de búsqueda de propósito general, en los 70 se amplió
el enfoque al desarrollo de sistemas que abarcaran problemas específicos
haciendo uso de conocimiento específico del dominio. Esto motivó que la IA
pasara a ser parte del tejido industrial a partir de los años 80. A finales de esta
década se produjo una revolución tanto en el contenido como en la metodología
de trabajo. A lo largo de los años la IA se ha ido aproximando a todos los ámbitos
de nuestra vida y está presente en nuestro día a día sin que seamos conscientes.
1.2.3 Agentes Inteligentes En la IA ha surgido un nuevo paradigma conocido como paradigma de agente
inteligente, el cual aborda el desarrollo de entidades que puedan actuar de forma
autónoma y razonada. De acuerdo a este nuevo paradigma la IA se puede
considerar como una disciplina orientada a la construcción de agentes inteligentes.
La definición de agente inteligente está aún abierta a debate debido a que dicha
definición varía en función del contexto o la aplicación. Una definición sencilla que
se puede adoptar es la de Russell y Norvig (2008), que consideran un agente
como “una entidad que percibe y actúa sobre un entorno”. La Figura 1 ilustra esta
idea. En dicha figura, el término percepción se utiliza para indicar que el agente
puede recibir entradas en cualquier momento. El historial completo de todas las

25
entradas forma una secuencia de percepciones y el agente toma una decisión en
función de la secuencia completa de percepciones. El agente es capaz de percibir
su medioambiente mediante la ayuda de sensores y es capaz de actuar a través
de actuadores. En este contexto, actuador hace referencia al elemento que
reacciona a un estímulo realizando una acción.
Otra definición bastante aceptada es aquella que ve a un agente como “un
sistema de computación capaz de actuar de forma autónoma y flexible en un
entorno” (Wooldridge & Jennings, 1995). En dicha definición, la flexibilidad se
identifica con una serie de características que deberían tener los agentes:
Reactivo. El agente debe ser capaz de responder a cambios en el entorno
en el que se encuentran.
Pro-activo. El agente debe ser capaz de intentar cumplir sus propios planes u objetivos.
Social. Un agente debe poder comunicarse con otros agentes a través de algún tipo de lenguaje.
Figura 1. Abstracción de un agente a partir de su interacción con el medio ambiente. Fuente: Russell & Norvig (2008).

26
Estas características, identificadas como básicas de un agente, no son las únicas. Otras características que también se les suele atribuir a los
agentes para resolver problemas, según Franklin y Graesser (1996) y
Nwana (1996), son:
Autonomía. El agente inteligente actúa sin intervención humana directa y
tiene control de sus propios actos. Es capaz de actuar basándose en la
experiencia y de adaptarse aunque el entorno cambie.
Movilidad. Está relacionado con la capacidad, del agente, de cambiar de
entorno en caso de necesidad.
Veracidad. Se asume que el agente no comunica información falsa a
propósito.
BDI (Belief, Desire, Intentions). Esta característica hace referencia a las creencias, los deseos y las intenciones del agente. Las creencias hacen
referencia al conocimiento a priori den entorno y las responsabilidades.
Los deseos son las metas a realizar y las intenciones el plan que se
desarrollará para alcanzar dichos objetivos.
A pesar de que no está claro el grado de importancia de cada propiedad, este
conjunto de propiedades son las que distinguen a los agentes de meros
programas.
Racionalidad Los agentes actúan de forma racional en su entorno. Esto equivale a decir que
hacen lo correcto y para ello es necesario alguna forma de medir el éxito. La
racionalidad en un momento determinado se basa en la información disponible por
el agente y depende de los siguientes factores:
Medida de rendimiento, que define el grado de éxito del agente.
Conocimiento a priori del medio en el que habita el agente.
Acciones que el agente puede llevar a cabo.

27
Secuencia de percepciones, que representan la experiencia del agente.
En este contexto se puede afirmar que el comportamiento de un agente es
racional si el agente, partiendo de una secuencia de percepciones, así como del
conocimiento del entorno, elige el conjunto de acciones que optimicen la
medida de rendimiento.
Entorno de trabajo El entorno de trabajo de un agente se refiere al conjunto de componentes que
conforman el problema a resolver por el agente. Hace referencia al ambiente
o medio en el que el agente va a desenvolverse. El entorno de trabajo está
conformado por los cuatro factores que determinan la racionalidad de un agente:
Rendimiento. Hace referencia a las cualidades deseables para el agente,
así como los objetivos y metas que tiene. En este componente se asocian
las medidas de rendimiento.
Entorno. Se refiere al ambiente o mundo en el cual el agente actuará.
Actuadores. Se refiere al conjunto de herramientas o elementos para
efectuar el trabajo o el conjunto de acciones a realizar.
Sensores. Hace referencia a las percepciones del agente del ambiente y los sensores con los que percibe.
Por regla general suele referirse a dichos factores por el acrónimo REAS y para
poder diseñar un agente hay que especificar los componentes del entorno de
trabajo. Una cuestión importante de cara al diseño es que no importa si un entorno
es real o virtual sino la complejidad de la relación entre el comportamiento del
agente, la secuencia de percepción generada por el medio y la medida de
rendimiento.

28
Es importante identificar las propiedades del entorno en el que se va a trabajar
para que el diseño del agente se adecúe a dicho entorno. Algunas de estas
propiedades son:
Totalmente observable vs. parcialmente observable. Un estado de trabajo
totalmente observable es aquel al que se tiene acceso al estado completo
del medio en cada momento mediante los sensores. En este caso el
agente no necesita mantener ningún estado interno para percibir cómo
está el entorno. La parcialidad del entorno puede deberse al ruido y/o
problemas con los sensores por su precisión o por recibir información
parcial.
Determinista vs. estocástico. Un entorno es determinista si el estado del
medio depende del estado anterior y de la acción que llevó a cabo el
agente. Un medio determinista puede parecer estocástico si es
parcialmente observable. Debido a esto suele considerarse un medio
determinista o estocástico desde el punto de vista del agente.
Estático vs. dinámico. Un entorno se dice dinámico si este puede cambiar
mientras el agente adopta una decisión sobre la acción. En caso contrario
es estático. En entornos estáticos no es necesario preocuparse por el
paso del tiempo mientras que en los dinámicos sí y hay que estar
preguntando al agente constantemente qué acción llevar a cabo.
Agente individual vs. multiagente. Que un sistema sea o no multiagente dependerá de si identificando otras entidades como agentes mejora o no
el rendimiento del agente. Por ejemplo, se pueden encontrar entornos
multiagente competitivo en caso de juegos como el ajedrez, multiagente
parcialmente colaborativo como en caso de conducción autónoma, etc.
Estructura de los agentes La estructura de un agente se caracteriza por los siguientes componentes:

29
Agente = arquitectura + programa
La arquitectura hace referencia al computador que tiene asociado una serie de
sensores físicos y actuadores. El programa, sin embargo, hace referencia al
software que determina el comportamiento del agente e implementa la función
percepción-acción. La IA se encarga de diseñar el programa del agente.
Los cuatro tipos básicos de programas para agentes son:
Agentes reactivos simples. Representa el tipo de agentes más sencillo y
en él, el proceso del agente es un ciclo percepción-acción que reacciona a
la evolución del entorno.
Agentes reactivos basados en modelos. El agente crea un modelo del
entorno basándose en las percepciones y acciones previas.
Agentes basados en objetivos. Este tipo se da para casos en los que se
requiere, además de la descripción del estado actual, algún tipo de
información sobre el objetivo perseguido que describa las situaciones
deseables. En cada estado se evalúan las acciones y se elige la que
permite alcanzar la meta. En este caso el conocimiento que soporta la
acción está representado explícitamente y puede modificarse.
Agentes basados en utilidad. En este caso se usa una función que asocia
un número real a un estado (o conjunto de estados). Dicho valor
representa un nivel de éxito. Además, a diferencia del caso anterior,
permite adoptar decisiones antes dos tipos de casos en los que las metas
no son adecuadas:
Objetivos conflictivos. En estos caso solo son alcanzables algunos de los objetivos y la función de utilidad determina el equilibrio adecuado de la
acción a realizar.
Varios objetivos y no hay certeza de alcanzar ninguna de ellas. La función de utilidad sirve para ponderar la posibilidad de tener éxito considerando
la importancia de cada meta.

30
Agentes reactivos simples
Este tipo de agentes toman decisiones con base a las percepciones actuales sin
atender al pasado a través de históricos ni al futuro mediante la planificación. Por
tanto, el conocimiento puede representarse como una tabla en la que a cada
percepción se le asocia una acción. La estructura de este tipo de programas se
muestra en la Figura 2. Estos agentes trabajan con un conjunto de reglas de tipo
condición-acción que asocian la percepción con un conjunto de acciones.
El programa del agente se muestra en la Figura 3. La función INTERPRETAR-
ENTRADA genera una descripción abstracta del estado actual del entorno a partir
de lo que perciben los sensores. A continuación, REGLA-COINCIDENCIA busca
de entre el conjunto de reglas que hay, la primera que coincide con el estado
actual. Finalmente, con dicha regla, REGLA-ACCIÓN devuelve la acción que
llevará a cabo el agente.
Figura 2. Esquema de agente reactivo simple. Fuente: adaptado por el autor.

31
Agentes reactivos basados en modelos Estos agentes asocian a cada situación del entorno (formado por las
percepciones y los datos históricos) una acción, de modo que una misma
percepción puede dar lugar a acciones distintas. Para ello, mantiene un estado
interno con información pasada y no observable del estado actual. La percepción
actual se interpreta a partir del estado anterior usando información sobre cómo
evoluciona el entorno (independientemente del agente) y cómo influyen en el
mundo las acciones llevadas a cabo por el agente.
función AGENTE-REACTIVO-SIMPLE(percepción) devuelve un acción
estático: reglas, un conjunto de reglas condición-acción
estado → INTERPRETAR-ENTRADA(percepción)
regla → REGLA-COINCIDENCIA(estado, reglas) acción → REGLA-ACCIÓN[regla]
devolver acción Figura 3. Programa de un agente reactivo simple. Fuente: adaptado por el autor.
Figura 4. Estructura de un agente reactivo basado en modelo. Fuente: adaptado por el autor.

32
La estructura de un agente reactivo basado en modelos se muestra en la Figura
4. En este caso la percepción actual se combina con datos del estado interno para
poder actualizar el estado actual. El programa (ver Figura 5) tiene ahora la función
ACTUALIZA-ESTADO, que es la que actualiza la descripción del estado interno
del agente con base al estado actual, el conocimiento sobre cómo evoluciona el
medio y el efecto que tienen las acciones sobre dicho medio. Como en el caso
anterior, la función REGLA-COINCIDENCIA busca la regla que coincida con el
estado actual y llevar a cabo la acción a través de la función REGLA-ACCIÓN.
1.3. Ejemplos Se va a estudiar cómo resolver mediante un agente reactivo simple un problema
de limpieza con una aspiradora. Para ello se diseñará un agente aspiradora. Tal y
como se puede ver en la Figura 6, el entorno está compuesto por dos
localizaciones: cuadrícula A y B. La aspiradora es capaz de percibir en qué
cuadrícula está y el estado de la cuadrícula (sucio o limpio). Las acciones que
puede realizar son moverse hacia la derecha o izquierda, aspirar la suciedad o no
hacer nada. Tal y como se ha visto, para poder desarrollar un agente aspiradora
que sea racional, habrá que considerar cómo se ajustan los cuatro factores de los
que dependen la racionalidad del agente, que en este caso en concreto son:
función AGENTE-REACTIVO-CON-ESTADO(percepción) devuelve un acción estático: estado, una descripción actual del estado del entorno
reglas, un conjunto de reglas condición-acción acción, la acción más reciente, inicialmente ninguna
estado → ACTUALIZA-ESTADO(estado,acción,percepción)
regla → REGLA-COINCIDENCIA(estado, reglas) acción → REGLA-ACCIÓN[regla]
devolver acción
Figura 5. Programa de una agente reactivo basado en modelo. Fuente: adaptado por el autor.

33
La medida de rendimiento de la aspiradora debe premiar al agente
por limpiar la suciedad de cada recuadro en un tiempo de terminado.
El medio en el que se ubica el agente son dos cuadrículas aunque no
cómo se distribuye la suciedad.
El conjunto de acciones permitidas son:
◦ Movimiento: izquierda, derecha
◦ Tarea: aspirar, no hacer nada.sdsd
El agente puede percibir:
◦ Ubicación: cuadrículo A, cuadrícula B.
◦ Estado: cuadrícula sucia, cuadrícula limpia.
Considerando lo anterior, el programa del agente sería de la forma que puede
verse en la Figura 7. El agente es capaz de percibir el estado de la cuadrícula y su
ubicación. Primero revisa el estado de la cuadrícula y, en caso de estar sucio,
procede a pasar a la acción de aspirar. En caso contrario, se desplaza de una
cuadrícula a otra.
Figura 6. Ejemplo de agente relacionado con el mundo de la aspiradora. Fuente: adaptado por el autor.
función AGENTE-ASPIRADORA(localización, estado) devuelve un acción
si estado = Sucio, entonces devolver Aspirar de otra forma, si localización = A entonces devolver Derecha
de otra forma, si localización = B entonces devolver Izquierda Figura 7. Programa del agente aspiradora. Fuente: adaptado por el autor.

34
Si se representa mediante una tabla cómo relacionar la percepción con cada
acción, se tendría
Percepción Acción [A, limpio] Derecha [A, sucio] Aspirar [B, limpio] Izquierda [B, sucio] Aspirar [A, limpio], [A, sucio] Aspirar … ...
A continuación se procederá a crear un programa agente aspiradora usando la
biblioteca Russel y Norvig (Russel y Norvig 2008). Para ello hay que descargar
dicha biblioteca de http://aima.cs.berkeley.edu/code.html y descargar la versión en
Java (aima-java). Una vez descargada, se puede proceder a crear el archivo jar
con Netbeans. Una vez hecho, se puede crear un proyecto nuevo y poner dicho
archivo (aima-core-0.11.1.jar) como biblioteca de este proyecto.
import aima.core.environment.vacuum.ReflexVacuumAgent; import aima.core.environment.vacuum.VacuumEnvironment; import aima.core.environment.vacuum.VacuumEnvironmentViewActionTracker;
public class AgenteReactivoSimple { public static void main(String[] args) throws Exception { StringBuilder envChanges = new StringBuilder(“”); ReflexVacuumAgent agent = new ReflexVacuumAgent(); VacuumEnvironment environment = new VacuumEnvironment( VacuumEnvironment.LocationState.Dirty, VacuumEnvironment.LocationState.Dirty); environment.addAgent(agent, VacuumEnvironment.LOCATION_A); environment.addEnvironmentView(new VacuumEnvironmentViewActionTracker(envChanges));
System.out.println(“Step #0 => status: ” + environment.getCurrentState());
int n = 5; for (int i = 0; i < n; i++) { environment.step();
System.out.println(“Step #” + (i + 1) + “ action: ” + envChanges + “ => status: ” + environment.getCurrentState()); envChanges = new StringBuilder(“”); environment.addEnvironmentView(new VacuumEnvironmentViewActionTracker(envChanges));

35
Una vez hecho esto se procede a crear la clase AgenteReactivoSimple tal y
como se ve en la Figura 8. La clase ReflexVacuumAgent crea una agente
aspiradora de tipo agente reactivo simple. El entorno de la aspiradora es creado
instanciado una clase de tipo VacuumEnvironment. A dicho entorno se le asocia
el agente anteriormente creado y se pone el estado de cada cuadrícula.
Finalmente la actualización de cada estado es escrita en una clase de tipo
StringBuilder. Inicialmente se ve el estado del entorno y, posteriormente, tras cada
etapa, se visualizará la acción a realizar y el estado del agente.
Si se ejecuta dicho código para 5 pasos( = 5), se tendrá una salida como la que
se ve en la Figura 9. Inicialmente se parte con ambas cuadrículas sucias y se sitúa
al agente en la cuadrícula A. Tras percibir que dicha cuadrícula está sucia, lleva a
cabo la acción de aspirar. Una vez limpia la cuadrícula, la acción que lleva a cabo
es desplazarse a la otra cuadrícula, donde, en la siguiente etapa, percibe que está
sucia y procede a aspirar. Una vez que está limpia, la acción del agente será
moverse de una cuadrícula a otra.
step #0=> status: {A=Dirty, B=Dirty}
step #1 action: Action[name==Suck] => status: {A=Clean, B=Dirty}
step #2 action: Action[name==Right] => status: {A=Clean, B=Dirty}
step #3 action: Action[name==Suck] => status: {A=Clean, B=Clean}
step #4 action: Action[name==Left] => status: {A=Clean, B=Clean}
step #5 action: Action[name==Right] => status: {A=Clean, B=Clean}
Figura 9. Salida del programa agente aspiradora. Fuente: elaboración propia.

36
1.4. Ejercicios de reflexión 1. Considere que se quiere diseñar un agente taxista mediante conducción
autónoma. Especifique los distintos componentes REAS del entorno de trabajo en
el que se encontrará el taxi.
Agente Rendimiento Entorno Actuadores Sensores
Taxista
Seguro, rápido, legal, viaje confortable, maximización del beneficio
Carreteras, tráfico, peatones, clientes
Dirección acelerador, freno, señal, bocina, visualizador
Cámaras, sónares, velocímetro, GPS, tacómetro, visualizador de la aceleración, sensores del motor, teclado
2. Considere que se quiere diseñar un agente tutor interactivo de inglés.
Especifique los distintos componentes REAS del entorno de trabajo en el que se
encontrará el taxi.
Agente Rendimiento Entorno Actuadores Sensores
Tutor interactivo de inglés
Maximización de los resultados de los estudiantes en las pruebas de inglés rápido, legal, viaje confortable, maximización del beneficio
Conjunto de estudiantes
Pantalla (ejercicios, sugerencias, correcciones)
Teclado

37
3. Indicar las propiedades del entorno de los dos problemas planteados en los
ejercicios anteriores
Problema/
Tipo de entorno
Observable (totalmente o parcialmente)
Determinista (determinista o
estocástico)
Estático (est. o
dinámico)
Agentes (individual o multiagente)
Taxista Parcialmente Estocástico Dinámico Multiagente
Tutor interactivo de inglés
Parcialmente Estocástico Dinámico Multiagente
4. Haciendo uso de la biblioteca usada en la sección anterior, implemente un
agente aspiradora de tipo reactivo basado en modelo. ¿Qué diferencias encuentra
con el agente reactivo simple?
import aima.core.environment.vacuum.ModelBasedReflexVacuumAgent;
import aima.core.environment.vacuum.VacuumEnvironment;
import aima.core.environment.vacuum.VacuumEnvironmentViewActionTracker;
public class AgenteReactivoBasadoEnModelo {
public static void main(String[] args) throws Exception { StringBuilder envChanges = new StringBuilder(“”); ModelBasedReflexVacuumAgent agent = new ModelBasedReflexVacuumAgent();
VacuumEnvironment environment = new VacuumEnvironment( VacuumEnvironment.LocationState.Dirty, VacuumEnvironment.LocationState.Dirty);
environment.addAgent(agent, VacuumEnvironment.LOCATION_A); environment.addEnvironmentView(new VacuumEnvironmentViewActionTracker(envChanges));
environment.stepUntilDone();
System.out.println(“Actions: ” + environment);
}

38
1.5. Conclusiones Dentro del ámbito de las ciencias de la computación la IA es una de las áreas
que causan mayor expectación, tanto a nivel académico como en la sociedad en
general. Históricamente, esta área ha sido un vaivén de expectativas y
decepciones. Sin embargo, la incorporación de la IA en distintos los ámbitos de
nuestra vida ha crecido exponencialmente en los últimos años debido a la
creciente necesidad de analizar grandes volúmenes de datos de forma
automatizada (big data) en un tiempo razonable. Tareas cotidianas como
búsqueda de información en un buscador, la detección de correo basura (spam),
visualización de anuncios personalizados en función de los gustos del usuario en
una red social incorporan IA.
A pesar de los avances que se están produciendo, aún queda mucho por
desarrollar pues todavía no se conoce bien cómo funciona el cerebro. En la
actualidad se han identificado diversos tipos de inteligencia (matemática,
lingüística, visual, cinética, musical, interpersonal, intrapersonal y naturalista) que
son manejadas por el cerebro a la vez en cada instante. Sin embargo, la IA suele
enfocarse en algún tipo de inteligencia y/o en dar solución a algún problema
concreto (predicción, segmentación de clientes, etc.). Están surgiendo nuevos
paradigmas de programación (como map-reduce) que permiten manejar distintos
tipos de inteligencia a la vez. No obstante, aún queda mucho por recorrer pues no
se sabe cómo imitar las capacidades de imaginar e intuir; dos características que
marcan la diferencia entre la inteligencia humana y la artificial. La razón es que
dichas capacidades son las que permiten crear conceptos abstractos y crear
nuevos pensamientos.
Uno de los mayores logros de la IA es el de desarrollar técnicas que lleven a
cabo el análisis de datos de forma automatizada. Esto hace que los expertos
puedan dedicarse a tareas más reflexivas. A pesar de eso, aún queda mucho

39
camino para poder lograr que la IA sepa interpretar las preferencias de actuación
en función de dicho análisis.

40
1.5. Búsqueda de Datos 1.5.1. Introducción
Esta unidad describe un tipo de agente basado en objetivos, llamado agente
resolvente-problemas. Su principal característica es que buscan la secuencia de
acciones que conduzca a los estados deseables. Para ello elige un objetivo que
tratará de satisfacerlo y buscará la secuencia de acciones que conduzcan desde
un estado inicial a algún estado objetivo. De cara a poder resolver un problema de
búsqueda es necesario realizar los siguientes pasos:
Formulación del objetivo: este primer paso consiste en fijar las metas perseguidas en base a la situación actual y la medida de rendimiento
del agente. Este objetivo se considera un conjunto de estados que
satisfacen dicho objetivo.
Formulación del problema: tras fijar el objetivo, lo siguiente es decidir
qué acciones y estados tienen que ser considerados. Para ello habrá
que realizar un proceso de abstracción que elimine aquellos detalles
del problema que no aportan información útil y/o dificulten su
resolución.
Búsqueda: proceso que consiste en la estrategia que examina diferentes secuencias posibles de acciones para hallar aquella que
nos lleve al objetivo perseguido. Tiene como entrada un problema y,
como salida, una solución.
Ejecución: el conjunto de acciones recomendadas por la solución que son llevadas a cabo.
Por ejemplo, se puede considerar el siguiente problema de ruta. Suponga que estamos en Rumanía, en la ciudad de Arad. El avión
de vuelta sale de Bucarest. Las distintas etapas a seguir son:
Formulación del objetivo: llegar a Bucarest en el menor tiempo posible.

41
Formulación del problema: consideramos el conjunto de ciudades de
Rumanía conectadas por carretera y lo representamos como un
grafo. La Figura 10 muestra el mapa de carreteras de Rumanía que
puede interpretarse como un grafo de modo que cada nodo
representa una ciudad y las aristas indican las ciudades que están
conectadas. El peso asociado a cada arista indica la distancia, en
kilómetros, entre dos ciudades conectadas. En este caso un estado
representa estar en una ciudad mientras que una acción se asocia a
conducir de una ciudad a otra.
Búsqueda: encontrar la secuencia de ciudades que nos lleve desde
Arad a Bucarest por el camino más corto.
Ejecución: ir a Bucarest por la ruta encontrada.
Para formular un problema es necesario definir los siguientes componentes:
Estado inicial en el que comienza el agente.
Conjunto de acciones que puede llevar a cabo el agente. Para ello suele usarse una función sucesor que asocia, a cada estado, el par
acción y estado al que puede acceder el agente. El estado inicial
junto con la función sucesor definen el espacio de estados del
problema, que representa el conjunto de todos los estados
alcanzables desde el estado inicial.
Coste del camino( )es una función que asigna un coste numérico a
cada camino. Para ello deberá ser capaz de asociar, a cada acción,
un coste individual.
Test objetivo que determina si un estado es un estado objetivo.

42
Para el problema del viaje por Rumanía, los elementos del problema serían:
Estado inicial: ciudad de Arad.
Función sucesor: función que asocia, para cada ciudad, el conjunto de pares de acción desplazamiento y ciudad destino.
Coste del camino vendría representado por la distancia en kilómetros
entre el origen (Arad) y el destino (Bucarest).
El objetivo del agente es llegar a Bucarest.
Como se ha visto, resolver un problema consiste en buscar el conjunto de
acciones en el espacio de estados. Una solución no es más que un camino desde
un estado inicial a un estado objetivo. La calidad de dicha solución se mide a
través de la función de costo. Diremos que una solución es óptima si es aquella
que optimiza dicha función de costo. Sin embargo, existen diversas estrategias
Figura 10. Mapa de carreteras de Rumanía con las distancias entre ciudades conectadas en kilómetros. Fuente: adaptado por el autor.

43
para encontrar la solución. Para poder analizar la idoneidad de una estrategia a un
problema determinado, es necesario medir el rendimiento de la estrategia. Cuatro
factores que suelen usarse para medir los algoritmos son:
Completitud: hace referencia a si encuentra la solución en caso de que exista.
Optimalidad: si encuentra la mejor solución en caso de que haya varias.
Complejidad temporal: ¿cuánto tiempo tarda en encontrar la solución?
Complejidad espacial: ¿cuánta memoria utiliza durante la búsqueda?
1.5.2. Búsquedas no Informadas Este tipo de estrategias no dependen de la información propia del problema para
resolverlos. Basan la búsqueda en la estructura del espacio de estados y aplican
estrategias sistemáticas para su exploración. Por lo tanto, pueden aplicarse en
cualquier circunstancia. Son algoritmos exhaustivos que, en el peor de los casos,
recorren todos los nodos para encontrar la solución. Esto hace que su coste sea
prohibitivo para la mayoría de los problemas reales y solo puedan ser aplicado al
problema de tamaño pequeño. A continuación se describen las dos principales
estrategias de búsqueda: primero en anchura y primero en profundidad.
Primero en Anchura La idea que subyace en esta estrategia consiste en visitar todos los nodos que
haya a una profundidad antes de visitar aquellos que estén a profundidad + 1.
Partiendo del nodo raíz, esta estrategia visita todos los nodos del siguiente nivel, y
así sucesivamente hasta que no haya más nodos sucesores.
Esta búsqueda puede implementarse mediante un procedimiento FIFO (First
Input First Output) en el que los sucesores del nodo que se visita son
almacenados en una cola. La Figura 11 muestra un ejemplo de búsqueda en
anchura que parte del nodo A y almacena en la cola los nodos B y C. A

44
continuación, visitaría el nodo B, que sería eliminado de la cola, y sus sucesores
(D y E) serían almacenados en dicha cola a continuación de C.
Atendiendo a los criterios anteriormente mencionados, esta estrategia tiene las
siguientes características:
Completitud: es una estrategia completa si el factor de ramificación
es finito.
Optimización: no garantiza una solución óptima. El nodo objetivo más superficial no tiene por qué ser la solución óptima.
Complejidad: si cada nodo tiene sucesores y la solución está a
nivel ,en el peor de los casos tenemos que expandir todos menos el
último nodo del nivel .Tanto la complejidad espacial como temporal
es exponencial en :
= ( )
Figura 11. Ejemplo de búsqueda primero en anchura. La flecha indica el nodo a expandir en cada etapa. Fuente: adaptado por el autor.

45
Búsqueda primero en profundidad En esta estrategia, partiendo de un nodo determinado, se visitan los sucesores
de dicho nodo antes que los nodos del mismo nivel. La búsqueda tiende a subir
por las ramas del árbol hacia las hojas. Una vez llega a un nodo hoja, visita la
siguiente rama del árbol.
Esta estrategia puede implementarse mediante una estrategia LIFO (Last Input
First Output) haciendo uso de una pila. La Figura 12 muestra un ejemplo de
primero en profundidad. Parte del nodo A y añade a la pila el nodo B. A
continuación, visita dicho nodo y añade el nodo D a la pila. Al no tener sucesores
el nodo D, es eliminado de la pila y se añade el nodo E. Al ser este nodo de tipo
hoja también y no haber más ramificación por esta parte, se pasa a visitar el nodo
C y posteriormente el F. Esto sigue así hasta que se han recorrido todos los
nodos.
Las principales características de esta estrategia son:
Completitud: si hay ramas infinitas el proceso de búsqueda podría no terminar, aun teniendo una solución próxima a la raíz.
Optimización: no garantiza que la solución encontrada sea óptima.
Complejidad: si cada nodo tiene sucesores y es la profundidad
máxima del árbol. Entonces:
◦ Temporal: complejidad exponencial
( )
◦ Espacial: no es necesario almacenar las distintas ramas. Cada
vez que se llega a un nodo hoja, se puede eliminar dicha rama.
Por tanto, solo requiere almacenar + 1 nodos y su complejidad
es ( )

46
1.5.3. Búsquedas informadas Una estrategia para reducir el tiempo de búsqueda es guiar la búsqueda con
conocimiento adicional del problema a resolver. Aunque esto haga que la
estrategia no sea de aplicación general, permitirá que se aplique a problemas
reales de mayor tamaño por la disminución en la complejidad temporal.
Como en el caso de las búsquedas no informadas tenemos que definir qué se
entiende por búsqueda del óptimo mediante la asociación de alguna medida de
costo. Estas estrategias guiarán la búsqueda en base al coste de los caminos
explorados. De esta manera se pierde la sistematicidad en la búsqueda de las
estrategias no informadas.
Dado un nodo , la función de evaluación ( ) nos da la distancia desde ese
nodo a un nodo objetivo. A menor distancia, mayor será la calidad del nodo.
Desde este punto de vista se puede decir que las búsquedas informadas son
Figura 12. Ejemplo de búsqueda Primero en Profundidad. Fuente: adaptado por el autor.

47
aquellas que dirigen la búsqueda hacia los nodos con menor valor de ( ).Esta
función es un estimador y puede considerarse que ( ) = ( ) + ℎ( ) con:
( )el coste del mejor camino conocido para ir desde el nodo inicial
al nodo .
ℎ( )es la función heurística que estima el camino de menor coste
desde el nodo a un objetivo.
Con esto se pueden definir diversas funciones de evaluación:
( ) = ( )para el caso de las búsquedas no informadas.
( ) = ℎ( )para algoritmos como el voraz.
( ) = ( ) + ℎ( )para estrategias como el A*.
Algoritmo voraz Es un algoritmo heurístico o aproximado que selecciona el siguiente nodo en
función del coste inmediato. Esta decisión, localmente óptima, suele dirigir la
búsqueda hacia soluciones subóptimas. Desde el punto de vista de la
implementación, se puede ordenar la secuencia de nodos a probar mediante una
cola de prioridad.
Este algoritmo trabaja considerando un conjunto S de acciones seleccionadas
que inicialmente está vacía, y un conjunto C con una lista de acciones candidatas
identificadas y con una prioridad asociada. En cada iteración, se evalúa la
factibilidad de añadir el siguiente elemento de C a S. Si no es factible, se elimina
de S y de C. Si lo es, pasa a formar parte de S y se borra de C. Además se pasa a
evaluar si la solución actual es parcial o no. En caso de haber obtenido la solución,
el algoritmo para.
De cara a exponer como trabaja este algoritmo, hay que considerar el problema
de ruta de viajar a Arad a Bucarest que se expuso anteriormente en esta unidad.
Sin embargo, para aplicar este algoritmo, como función de evaluación, la distancia

48
en línea recta desde Bucarest al resto de ciudades y que se llamará ℎ . Los
valores de dicha distancia están en la siguiente tabla.
Arad 366
Lugoj 244
Rimnicu Vilcea 193
Craiova 160
Mehadia 241
Sibiu 253
Dobreta 242
Oradea 380
Timisoara 329
Fagaras 176
Pitesti 100
Zerind 374
Entonces, el algoritmo voraz parte del nodo Arad, y desde dicha ciudad sólo tiene
acceso a las ciudades Sibiu, Timisoara y Zerind que tienen una distancia (en línea
recta desde Bucarest ℎ ) de 253, 329 y 374 respectivamente. Por tanto, esta
estrategia selecciona Sibiu por ser la más próxima a Bucarest y, por tanto, dicho
nodo se expande. En la siguiente, la estrategia busca de entre todas las ciudades
accesibles desde Sibiu aquella que esté a menor distancia o, dicho de otra forma,
la que menor valor de ℎ tenga. En este caso las ciudades accesibles son Arad, Fagaras, Oradea y Rimnicu Vilcea con una distancia de 366, 176, 380 y 193. Por
tanto, el algoritmo selecciona Fagaras. Y así sucesivamente hasta llegar a
Bucarest. La secuencia completa de búsqueda puede verse en la Figura 13.
Las principales características de esta estrategia son:
No garantiza que la solución final sea óptima.
Suelen ser rápidos y fáciles de implementar.
Solo genera una de entre todas las posibles secuencias de
decisiones.

49
1.5.4. Ejemplos
El problema del puzzle 8 consiste en un tablero matricial de3 3de 9 posiciones
de las cuales 8 están ocupadas por fichas numeradas (del 1 al 8) más un espacio
vacío. Inicialmente las fichas están dispuestas de forma aleatoria y el objetivo del
juego es ordenar las fichas de modo que el hueco quede en el extremo inferior
derecha. Para ello habrá que mover el espacio vacío de forma horizontal o vertical.
Para poder definir este problema hay que definir el estado inicial, el test objetivo,
los operadores (conjunto de acciones) que se pueden realizar mediante la función
sucesor y el coste del camino ( ).
En este problema se definirá el estado inicial como cualquier estado que no
coincida con el estado final. La Figura 14 muestra el estado inicial del puzzle a la
izquierda y el estado final a la derecha. Tal y como se puede ver en la Figura 15,
Figura 13. Ejemplo de búsqueda de algoritmo voraz para el ejemplo de la ruta desde Arad a Bucarest. Fuente: adaptado por el autor.

50
en este caso se cuenta con cuatro operadores, arriba, izquierda, abajo y derecha,
que se corresponde con los movimientos que puede hacer el espacio vacío.
Finalmente, como coste del camino se puede considerar que cada movimiento del
espacio vacío tiene un coste de 1.
Este problema tiene un total de9! = 362.880estados distintos, siendo solo uno de
esos estados el objetivo. Cuando la casilla vacía está en el centro, tiene cuatro
posibles movimientos y en cualquier otra posición solo 2.
Figura 14. Estado inicial (izquierda) y final (derecha) del puzzle 8. Fuente: adaptado por el autor.
Figura 15. Operadores del problema del puzzle 8. Fuente: adaptado por el autor.

51
A continuación se mostrará cómo resolvería este problema la estrategia Primero
en Anchura. Para ello, hay que considerar que el estado inicial del puzzle es el
que se ve en la Figura 16, y que el orden de los movimientos a realizar son
izquierda, arriba, derecha y abajo.
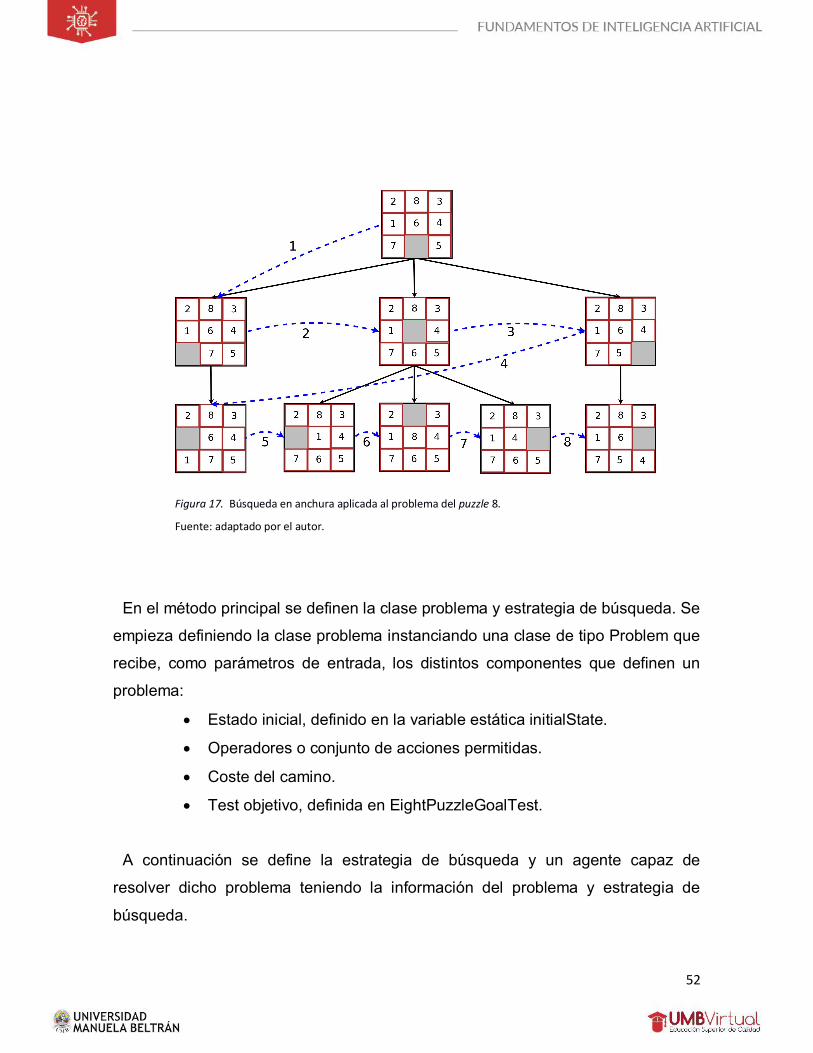
La Figura 17 muestra cómo procede el algoritmo para resolver este problema.
En el primer nivel el hueco solo podrá desplazarse en las posiciones izquierda,
arriba y derecha. La línea azul discontinua indica el orden de búsqueda. Tras
recorrer el primer nivel pasará al siguiente, y así sucesivamente. Haciendo uso de
la biblioteca introducida en la unidad anterior, se puede implementar un programa
que resuelva dicho problema.
La Figura 18 muestra dicho código. El código implementa mediante una variable
estática, el estado inicial del puzzle indicando la posición vacía con el valor 0.
Incluye dos métodos estáticos auxiliares para poder imprimir los avances de la
estrategia.
Figura 16. Estado inicial del puzzle a resolver. Fuente: adaptado por el autor.
52
En el método principal se definen la clase problema y estrategia de búsqueda. Se
empieza definiendo la clase problema instanciando una clase de tipo Problem que
recibe, como parámetros de entrada, los distintos componentes que definen un
problema:
Estado inicial, definido en la variable estática initialState.
Operadores o conjunto de acciones permitidas.
Coste del camino.
Test objetivo, definida en EightPuzzleGoalTest.
A continuación se define la estrategia de búsqueda y un agente capaz de
resolver dicho problema teniendo la información del problema y estrategia de
búsqueda.
Figura 17. Búsqueda en anchura aplicada al problema del puzzle 8. Fuente: adaptado por el autor.

53
import aima.core.agent.Action; import aima.core.environment.eightpuzzle.EightPuzzleBoard; import aima.core.environment.eightpuzzle.EightPuzzleFunctionFactory; import aima.core.environment.eightpuzzle.EightPuzzleGoalTest; import aima.core.search.framework.Search; import aima.core.search.framework.SearchAgent; import aima.core.search.framework.problem.Problem; import aima.core.search.uninformed.BreadthFirstSearch; import java.util.Iterator; import java.util.List; import java.util.Properties;
public class PrimeroEnAnchura { static EightPuzzleBoard initialState = new EightPuzzleBoard( new int[]{1, 4, 3, 7, 0, 6, 5, 8, 2}); private static void printActions(List<Action> actions) { for (int i = 0; i < actions.size(); i++) { String action = actions.get(i).toString();
System.out.println(action);
}
}
private static void printInstrumentation(Properties properties) { Iterator<Object> keys = properties.keySet().iterator();
while (keys.hasNext()) { String key = (String) keys.next();
String property = properties.getProperty(key);
System.out.println(key + " : " + property); }
}
public static void main(String[] args) throws Exception { Problem problem = new Problem(initialState, EightPuzzleFunctionFactory.getActionsFunction(),
EightPuzzleFunctionFactory.getResultFunction(),
new EightPuzzleGoalTest()); Search search = new BreadthFirstSearch(); SearchAgent agent = new SearchAgent(problem, search); printActions(agent.getActions());
printInstrumentation(agent.getInstrumentation());
} }
Figura 18. Código para resolver el problema del puzzle 8 mediante una estrategia Primero en Anchura. Fuente: elaboración propia.

54
1.5.5. Ejercicios de Reflexión
1. Considere el problema del puzzle 8. Siguiendo la Figura 17 como referencia,
dibuje el árbol de búsqueda de la estrategia primero en profundad. Solo es
necesario dibujar el árbol parcialmente explicando cómo procede la estrategia.
2. Implemente un programa, similar al de la Figura 18 pero con la estrategia
Primero en Profundidad.
3. Explique en qué consiste el problema de la mochila y, mediante un ejemplo,
indique cómo se resolvería mediante un Algoritmo Voraz.

55
Capítulo II
Apre
ndiz
aje
Auto
mát
ico
y Ju
egos
Aprendizaje Automático y Juegos
Introducción
Ejemplos
Ejercicios de Reflexión
Teoría de Jugos
Poda Alfa-Beta
Aprendizaje Automático y Juegos

56

57
CAPÍTULO 2: APRENDIZAJE AUTOMÁTICO Y
JUEGOS
2. Aprendizaje Automático y Juegos 2.1. Introducción
Existen diversos programas para que un agente pueda seleccionar las acciones
que se adecúan al entorno. Sin embargo, esto conlleva a que se programen todos
los posibles escenarios. A la dificultad de programar todos los posibles escenarios
se le añade la posibilidad de que el entorno varíe y haya que contemplarse nuevos
escenarios. Una forma de afrontar esto sería diseñar agentes con capacidad de
aprender. Esto permitiría al agente complementar y/o completar el conocimiento
inicial que tiene sobre el medio ambiente.
El modelo general de un agente con capacidad de aprender puede verse en la
Figura 1. Los componentes de este tipo de agentes son el elemento de actuación,
la crítica, el elemento de aprendizaje y el generador de problemas. El elemento de
actuación corresponde a un agente completo como el visto en la Unidad 2. Este
elemento recibe los estímulos del medio ambiente y determina las acciones a
realizar A continuación está el elemento crítica, encargado de evaluar el
rendimiento del agente en base a un estándar fijo y proveer el grado de éxito del
agente. El elemento de aprendizaje es el encargado de formular mejoras, con
base a la crítica, que modificarán el elemento de actuación incorporando esta
mejora. Por último, el generador de problemas se encarga de explorar situaciones
nuevas e informativas que pueden ayudar a mejorar el conocimiento del agente
del entorno.
A continuación es oportuno retomar el ejemplo del taxi automatizado de la
unidad 2 para ver cómo y en qué consistirían cada uno de los elementos del

58
agente. En este escenario, el elemento de actuación consiste en la colección de
conocimientos que hay predeterminados para seleccionar las acciones de
conducción. Por ejemplo, arrancar el coche, frenar, circular, etc. El elemento
crítico evalúa la conducción en función de lo que observa del entorno y
proporciona dicha evaluación al elemento de aprendizaje para que este formule
una mejora que sea incorporada en el elemento de actuación. Por ejemplo, si el
taxi no se aparta cuando se aproxima una ambulancia con las luces y la sirena
encendidas, otros conductores, incluida la ambulancia, reaccionan tocando el
claxon. La crítica evalúa estas reacciones y pasa la información al elemento de
aprendizaje que formula la regla de apartarse cuando se aproxime una ambulancia
con las luces y la sirena encendidas. Esta nueva regla se incorpora al elemento de
actuación. Finalmente el generador de problemas se encargaría de identificar qué
comportamientos durante la conducción deberían mejorarse y diseñar
experimentos que le conduzcan a dichas mejoras.
Figura 1. Modelo general de un agente que aprende. Fuente: adaptado por el autor.

59
Tipos de aprendizaje
Para poder producir un aprendizaje es necesario fijar una serie de conceptos y
definir métodos para medir el grado de éxito de un aprendizaje. En el contexto
computacional se considera que un programa aprende si mejora el desempeño de
una tarea a través de la experiencia. Es decir: “Un programa de ordenador se dice
que aprende de la experiencia con respecto a una tarea específica y una
medida de rendimiento , si su rendimiento en el desempeño de la tarea ,
medido según , mejora con la experiencia ”.
El tipo de retroalimentación disponible para el aprendizaje es el factor más
relevante para diferenciar los distintos tipos de aprendizaje a los que tiene que
enfrentarse un agente. Con base a la retroalimentación se distinguen el
aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por
refuerzo. El aprendizaje supervisado consiste en aprender una función que
relacione una entrada con una salida a partir de un conjunto de ejemplos. El
aprendizaje no supervisado solo parte de un conjunto de ejemplos con entrada y
ninguna salida. El objetivo es aprender patrones a partir de la entrada recibida. Por
último, el aprendizaje por refuerzo consiste en aprender haciendo uso de algún
tipo de recompensa.
En el diseño de un elemento de aprendizaje hay que considerar, principalmente,
los siguientes aspectos:
Qué retroalimentación está disponible para aprender dichos
componentes.
Qué elementos del elemento de acción tienen que aprenderse.
Qué tipo de representación se usa para los componentes.
Como se ha comentado anteriormente, el tipo de retroalimentación indica la
naturaleza del aprendizaje a la que se enfrenta el agente. Los elementos de un
agente señalan qué aspectos relacionados con este son candidatos a que puedan

60
mejorar mediante el aprendizaje. Atendiendo a los distintos tipos de agente que
hay, los componentes son:
Proyección de las condiciones del estado actual a las acciones a
llevar a cabo.
Método de inferencia de las propiedades del medio ambiente a partir
de una secuencia de percepciones.
Información de la evolución del mundo y de los resultados de las posibles acciones que el agente puede llevar a cabo.
Información de utilidad, que indica lo deseable que es un estado.
Información acción-valor, que señala lo deseable que son las
acciones.
Metas que describen las clases de estado que maximizan la utilidad
del agente.
Estos componentes son susceptibles a mejorar de acuerdo al aprendizaje. Por
ejemplo, en el primer punto el objetivo del agente es aprender las reglas
condición-acción de una determinada actividad. Retomando el caso del taxi,
considere que durante el aprendizaje del agente, cada vez que el instructor le
indica que pare, el agente aprende una regla de condición-acción que le indica en
qué condiciones debe frenar. Desde el punto de vista del aprendizaje equivale a
decir que aprende una función booleana que le indica cuándo parar de acuerdo a
las condiciones del estado actual. Otro ejemplo, con el segundo punto, del
aprendizaje de propiedades a partir de percepciones podría darse, en el caso del
taxi al querer identificar peatones a partir de imágenes durante la conducción.
Finalmente, hay que destacar la importancia que tiene la forma de representar
la información aprendida de cara al diseño del algoritmo de aprendizaje. Algunas
representaciones que se pueden encontrar son descripciones probabilísticas,
sentencias en lógica proposicional y de primer orden, polinomios para representar
la función de utilidad, etc.

61
3.2.2 Aprendizaje supervisado
El objetivo del aprendizaje supervisado es aprender una función que relacione
una entrada con una salida según un conjunto de ejemplos. Desde un punto de
vista formal, un ejemplo es un par , ( ) , donde es la entrada y ( ) es la
salida de la función aplicada a . Entonces dado un conjunto de ejemplos, el
aprendizaje inductivo consiste en aprender una función ℎ que se aproxime a .
La función ℎ recibe el nombre de hipótesis y debido a que la función es
desconocida, no se puede saber qué tan buena es la aproximación de ℎ. A pesar
de esto suele evaluarse la calidad de la hipótesis de acuerdo a su capacidad de
generalización y, por tanto, de predecir la salida de nuevos ejemplos.
Estimación del error de un algoritmo de aprendizaje
La evaluación de un algoritmo de aprendizaje (ℎ) permite, por un lado, estimar
el rendimiento de una hipótesis y, por otro, poder seleccionar entre varias hipótesis
aquella con mejor rendimiento. Sin embargo, el algoritmo solo cuenta con un
conjunto de ejemplos de entrenamiento limitado para aprender la función ℎ. Esto
hace que surjan dos dificultades para la estimación del error de ℎ: el sesgo y la
varianza.
El sesgo está asociado al error en la aproximación de la función ℎ con respecto
a la función . Este error no depende del tamaño del conjunto de ejemplos que se use para aprender dicha función pues se debe al error asociado a no poder
modelar correctamente la hipótesis. La varianza, por el contrario, sí depende del
tamaño muestral y decrece a medida que aumenta la muestra. Este error se
refiere a la diferencia que hay entre la hipótesis aprendida y el mejor posible de la
hipótesis. En la Figura 2 se puede ver visualmente en qué consiste el sesgo y la
varianza con un ejemplo con dianas y dardos. Hay cuatro dianas con distinta

62
combinación de sesgo y varianza alta y baja. La diana superior izquierda tiene una
baja varianza debido a que todos los dardos están muy próximos entre sí y un bajo
sesgo, de modo que están dispuestos en torno al centro. Sin embargo, la diana
que está a su derecha tiene una alta varianza debido a que los dardos están muy
dispersados. La diana inferior izquierda tiene todos los dardos muy próximos entre
sí, de modo que su varianza es baja, pero están dispuestos alejados del centro y,
por tanto, tiene un sesgo elevado. Por último, la diana inferior derecha tiene
valores altos en el sesgo y la varianza.
En caso de un sesgo elevado, suele darse el fenómeno de subajuste
(underfitting). Dicho fenómeno consiste en que con la muestra considerada, el
modelo aprendido es más simple que el real y, por lo mismo, a pesar de que
disminuye el error en la muestra considerada, la capacidad predictiva será menor
en futuros casos. Otro fenómeno que hay que tener en cuenta es el sobreajuste
(overfitting), el cual se da en caso de que la varianza sea elevada. En este caso la
hipótesis se ajusta tanto a la muestra que pierde su capacidad de generalizar. La
Figura 3 muestra estos fenómenos considerando el ajuste de una curva. Como
puede ver, en la figura de la izquierda, la curva no se ajusta adecuadamente a los
puntos, mientras que en la de la derecha la curva se ajusta en exceso a los
puntos.
Figura 2. Sesgo y varianza visualizado mediante un ejemplo con dianas.
Fuente: elaboración propia.

63
En el cálculo del error de una hipótesis ℎ hay que distinguir entre el error en la
muestra y el verdadero error. El error muestral se refiere a la tasa de error de la
hipótesis en la muestra de datos disponibles. El otro es el error de la hipótesis
sobre la distribución de los datos, que es desconocida. Por tanto, siempre que
se hable del error se hace referencia al error muestral.
Validación de un algoritmo de aprendizaje
Las técnicas de validación están motivadas por dos problemas fundamentales
en el aprendizaje automático: la selección del modelo y la estimación del
rendimiento del algoritmo de aprendizaje. De cara a la selección del modelo,
existen diversas técnicas de aprendizaje y cada una de ellas tiene una serie de
parámetros. ¿Cómo se selecciona el modelo adecuado o la combinación óptima
de parámetros? Una vez seleccionado el modelo, ¿qué medidas se usan para
estimar su rendimiento? El rendimiento debería medirse con base al error real.
Si se tuviera acceso a un número ilimitado de ejemplos, la respuesta a ambas
preguntas sería seleccionar aquel modelo que tenga el error más bajo. Sin
embargo, en aplicaciones reales solo se cuenta con un conjunto finito de ejemplos
Figura 3. Fenómeno del subajuste y sobreajuste. Fuente: elaboración propia.

64
y, por lo tanto, solo se tiene acceso al error muestral. Existen diversas técnicas de
validación en función del tamaño de la muestra:
Muestra grande
◦ Resustitución
◦ Holdout
Muestra pequeña
◦ Repeated holdout
◦ K-fold cross-validation
Resustitución Es el estimador más simple que hay y consiste en usar todo el conjunto de
datos como conjunto de entrenamiento y probar el clasificador en el mismo
conjunto de datos. Al haber sido el clasificador inducido en el mismo conjunto de
datos, la estimación del error es optimista pues el conjunto de reglas de
clasificación aprendidas se ajustan a dicho conjunto de datos. Además favorece
que el sobreajuste en el modelo inducido. El error de clasificación se estima del
siguiente modo:
=1
1 − , ( ), ∈
Donde es el número de ejemplos del conjunto de datos, es la muestra, , el
ejemplo a clasificar, la clase asociada a dicho ejemplo, y ( ) es la clase
predicha por el clasificador inducido.
Holdout Este método de estimación del error divide la muestra original etiquetado en un
conjunto de entrenamiento y otro de prueba. El conjunto de entrenamiento se

65
usará para que se induzca el clasificador mientras que con el conjunto de prueba
se mide la tasa de error que comete el clasificador.
La partición entre conjunto de entrenamiento y de prueba es aleatoria y de
normal suele adoptarse una proporción de 1/2 para cada conjunto o 2/3 para el
conjunto de entrenamiento y el restante 1/3 como conjunto de prueba. El error de
clasificación en el conjunto de prueba se calcula del siguiente modo:
=1
1 − , ( ), ∈
Donde corresponde al número de ejemplos en el conjunto de prueba, es el
conjunto de prueba, el ejemplo a clasificar, la clase asociada a dicho ejemplo,
y ( ) es la clase predicha por el clasificador inducido.
Repeated holdout Es una variante del holdout que consiste en repetir el procedimiento de
evaluación entrenamiento-prueba un número de veces. Se caracteriza porque el
error estimado tiene una varianza elevada pero un sesgo pequeño. El error
estimado ^ se promedia sobre las ejecuciones del siguiente modo:
^ =1
Con el error estimado de una ejecución.
K-fold cross validation Es un método muy popular debido a que tiene un sesgo pequeño (menor que el
repeated holdout) aunque sigue conservando una varianza alta. El método
consiste en dividir el conjunto de datos en subconjuntos disjuntos y se procede a

66
estimar el error de clasificación. Para ello se estima el error de clasificación
veces de modo que en cada ejecución se usan − 1 subconjuntos como conjunto
de entrenamiento y el que queda de prueba. Además, el conjunto de prueba varía
de una ejecución a otra de modo que al final de todas las ejecuciones se ha
estimado el error sobre uno de los subconjuntos disponibles.
Algoritmos de aprendizaje
Dentro del aprendizaje supervisado existen dos grandes tareas: la regresión y la
clasificación. En regresión la variable que se quiere predecir (variable de salida) es
continua; de modo que el objetivo es inducir, desde un conjunto de entrenamiento,
una función continua que se ajuste a los datos de entrada. Por el contrario, en
clasificación, la variable de salida es discreta y el objetivo es aprender un conjunto
de reglas que permita etiquetar futuros casos. La Figura 4 muestra un ejemplo de
cada una de estas tareas.
Figura 4. Tareas de regresión y clasificación. Fuente: elaboración propia.

67
En clasificación se puede diferenciar entre dos aproximaciones: modelos
discriminativos y modelos generativos. Los modelos discriminativos son aquellos
son aquellos que no intentan modelar los datos sino que basan las reglas de
clasificación en modelar las hipersuperficies de decisión. Los generativos, por el
contrario, modelan la distribución de las distintas clases que tiene el conjunto de
datos que se está tratando. A continuación se describirá el algoritmo de
clasificación Naive Bayes debido a su popularidad y los buenos resultados que
suele obtener en problemas de distintos dominios.
Naive Bayes Es un clasificador que se encuadra en los modelos generativos. Partiendo del
teorema de Bayes de probabilidad, a posteriori determina cuál es la hipótesis más
probable ℎ del espacio de hipótesis . Para ello considera que todas las variables
de entrada son independientes. Dado el teorema de Bayes:
(ℎ| ) =( |ℎ) (ℎ)
( )
Con (ℎ) la probabilidad a priori de la hipótesisℎ, ( ) es la probabilidad
marginal y corresponde a la probabilidad de que tengamos la muestra dada bajo
todas las posibles hipótesis, ( |ℎ) es la verosimilitud y es probabilidad de
observar la muestra dada la hipótesis ℎ, y, por último, (ℎ| ) es la probabilidad
a posteriori y s corresponde con la probabilidad de que la hipótesis sea ℎ teniendo
la muestra .
Entonces la hipótesis más probable será aquella con la máxima probabilidad a
posteriori ℎ
ℎ =∈
(ℎ| ) =∈
( |ℎ) (ℎ)( ) =
∈( |ℎ) (ℎ)

68
Como puede verse, ( ) puede eliminarse por ser constante para una muestra
dada. A pesar de su sencillez y de la consideración de independencia ente las
variables, es un algoritmo muy popular debido a los buenos resultados que obtiene
en datos de distintos dominios.
3.2.3 Aprendizaje no supervisado
El aprendizaje no supervisado tiene como objetivo inferir una función que
describa la estructura implícita de los datos. A diferencia del caso supervisado, en
este caso no se cuenta con una variable de salida y, por tanto, el modelo
aprendido no tiene asociado ningún error o medida de evaluación que nos indique
la calidad de dicho modelo.
Algunas de las tareas asociadas a este tipo de aprendizaje son:
Agrupamiento.
Detección de casos anómalos (outliers).
Extracción de características.
Reducción de la dimensionalidad.
El agrupamiento tiene como objetivo particionar el conjunto de datos de entrada
en distintos grupos en función de una propiedad. La detección de casos anómalos
tiene el objetivo de buscar ejemplos que añadan error al análisis de los datos. La
extracción de características busca una serie de variables pequeñas medidas a
partir del conjunto original de variables que suele ser mucho mayor. Dichas
características contendrán la información más relevante del conjunto de datos
original. Por último la reducción de la dimensionalidad pretende reducir el conjunto
de datos originales aplicando una transformación lineal o no lineal a las
características originales. A pesar de las diversas tareas asociadas a este tipo de
aprendizaje, el término aprendizaje no supervisado suele usarse habitualmente
para referirse al agrupamiento.

69
Agrupamiento (clustering) El agrupamiento es una tarea cuyo objetivo es dividir un conjunto de datos en
grupos en base a un criterio. Intuitivamente se buscan grupos de modo que
aquellas instancias que pertenezcan a un mismo grupo son más similares entre sí
que aquellas pertenecientes a grupos distintos.
Los dos propósitos que persigue el agrupamiento son la comprensión y
descubrimiento. En lo relativo a la comprensión, esta tarea tiene el propósito de
entender cómo se organizan los datos. En este contexto, el objetivo es el estudio
de técnicas que automáticamente encuentren los grupos, que pueden verse como
una clasificación natural de los datos. En lo relativo a la comprensión, el objetivo
es proveer una abstracción de los datos individuales mediante los grupos
obtenidos. Esto permite reducir el conjunto de datos a los prototipos
representativos de cada grupo encontrados. En este ámbito se persigue estudiar
el conjunto de técnicas que encuentren los prototipos de los grupos que mejor
describan los datos.
Para poder llevar a cabo esta tarea es necesario establecer tres componentes:
Medidas de proximidad.
Criterios de evaluación.
Algoritmos de agrupamiento.
Medidas de Proximidad La proximidad suele medirse con base a una medida de distancia. Para ello hay
que tener en cuenta el tipo de atributos que tienen los datos: numéricos, binarios y
categóricos. En caso de que todos los atributos sean numéricos, las distancias
más empleadas son:
Euclídea: es la distancia más popular y tiene la propiedad de que es invariante a las traslaciones. Se define del siguiente modo:

70
, = ( ) − ( )
Manhattan: es una distancia bastante popular porque ahorra tiempo
de cómputo respecto a la euclídea.
, = ( ) − ( )
Chebyshev: es una aproximación a la euclídea también más barata, computacionalmente hablando, que esta.
, = ( ) − ( )
Para el caso de que los atributos sean binarios, se puede calcular la proximidad
haciendo uso de una matriz de confusión. Suponiendo que se tienen dos vectores
de atributos binario y , entonces se puede representar el número de
combinaciones de valores al comparar los atributos de uno y otro vector del
siguiente modo:
punto
i\punto j
1 0
1 a b
0 c d
En este caso a representa el número de atributos que valen 1 en ambos
vectores, del número de atributos con valor 0 en ambos casos, b el número de
atributos con 1 en el vector y 0 en el y c el caso contrario. Atendiendo a esta matriz se puede definir un coeficiente de similitud basado en la proporción de
valores que no coinciden:
, =+
+ + +

71
Por último, en caso de atributos nominales con más de dos etiquetas, una
posible medida de distancia se correspondería con el número de atributos que
coindicen dividido por el total de atributos :
, =
Existen muchas otras distancias propuestas en la literatura. El motivo de la
multitud de propuesta se debe a que la idoneidad de una distancia no solo se basa
en el tipo de atributos sino también en las características de estos. Una dificultad
añadida es el caso en que se tengan atributos de distinto tipo pues habrá que
tener cuidado con el peso que tiene la medida en cada tipo de atributo.
Criterios de evaluación La evaluación de un agrupamiento no es una tarea bien definida como en el
caso del aprendizaje supervisado. Ha habido esfuerzos que intentan establecer un
criterio objetivo. Sin embargo, no existe ningún criterio universal debido a que
según el ámbito de aplicación habrá un criterio de evaluación distinto. Además, la
existencia de distintos tipos de grupos hace la tarea de evaluar más difícil aún.
En líneas generales está aceptado que se busca hacer un agrupamiento de
modo que los grupos sean lo más cohesionado posible y estos estén lo más
separados entre sí. La cohesión intragrupo mide lo compacto que son los grupos.
Una medida típica es WSS (within cluster sum of squares):
= ( − )∈
Donde representa una instancia perteneciente al grupo y es el centroide
o centro de masas asociado al grupo . La distancia intergrupo nos indica cuán

72
separados están los distintos grupos encontrados. Una medida típica usada es la
BSS (between cluster sum of squares):
= | | ( − )
Donde | | es el tamaño del grupo y es el centroide de todo el conjunto de
datos.
La mayor dificultad en el contexto de la evaluación del agrupamiento surge en
cómo evaluar objetivamente qué tan correctos son los grupos encontrados. Por
ejemplo, en la Figura 5 puede verse un conjunto de datos de 20 puntos que ha
sido agrupado considerando 2, 4 y 6 grupos. Sin embargo, no se encuentra
ninguna elección que sea más adecuada que otra. Si se conoce el contexto de los
datos se podrá dar un sentido a cada uno de estos resultados o, bien, saber
cuáles elecciones tienen sentido y cuáles no.
Figura 5. Subjetividad en la elección del número de grupos adecuado en un conjunto de datos. Fuente: adaptado por el autor.

73
El problema de conocer el número de grupos suele abordarse mediante dos
aproximaciones principalmente. La primera abarca a aquellos algoritmos de
agrupamiento en el que el número de grupos es un parámetro de entrada. En
estos casos se prueba con distintos valores de y se eligen la mejor solución o,
bien, se aplica, previo al agrupamiento, una técnica de estimación del número de
grupos. La segunda aproximación abarca aquellos algoritmos que en cuentran un
número variable de grupos en función del valor de los parámetros. En estos casos
se varía el valor de dichos parámetros para poder evaluar los distintos grupos
encontrados.
La comunidad científica sigue trabajando en encontrar criterios adecuados, de
modo que existen una gran diversidad de métodos de evaluación. Dependiendo
del campo de aplicación, unas medidas serán más populares que otras.
Algoritmos de agrupamiento Existen un gran número de técnicas que usan distintas aproximaciones para
agrupar. El principal motivo es que dependiendo del campo de aplicación
podremos encontrar tipos de grupos muy distintos. De esta forma un criterio que
va bien en un dominio puede ir mal en otro debido a las características asociadas
a los grupos. Algunos de los distintos tipos de grupos que el algoritmo de
agrupamiento puede encontrarse son mostrados en la Figura 6.
Grupos separables. Este es el caso más sencillo pues los puntos de
un grupo son más similares entre sí que puntos de distintos grupos.
Grupos basado en centroides. En este caso cada grupo está
representado por un centroide o un medoide. Un centroide es el
centro de masas del grupo mientras que un medoide es el punto más
representativo. En este caso los puntos de un grupo están más
próximo al punto representativo del grupo al que pertenecen que de
cualquiera de otro grupo.

74
Grupos basados en contigüidad. En este caso cualquier punto de un
grupo está más próximo a un subconjunto de puntos del mismo
grupo que de cualquier punto de otro grupo.
Grupos basados en densidad. Un grupo se caracteriza por ser una región del espacio con una alta densidad de puntos. Son adecuados
para los casos en los que los grupos son de forma irregular y cuando
hay ruido o casos anómalos en los datos.
Grupos conceptuales. Representan un tipo de grupos que comparten una propiedad que deriva del conjunto completo de puntos o que
representan un concepto particular.
Existen diversas técnicas para poder abordar los distintos tipos de grupos que
podemos encontrar. Tres de las aproximaciones más destacadas son:
Particionales. Son algoritmos que dividen los datos en grupos no solapados.
Jerárquicos. Este tipo de técnicas agrupa los puntos por niveles de modo que la partición se representa mediante un esquema de árbol denominado
Figura 7. Los distintos tipos de grupos que puede encontrarse una técnica de agrupamiento.

75
dendrograma. En función del nivel que se considere el algoritmo indicará un
número de grupos distintos. Tiene dos aproximaciones:
◦ Estrategia aglomerativa. Partiendo de que cada punto es un
grupo, en cada etapa se van fusionando los grupos más próximos
hasta que tenemos uno solo.
◦ Estrategia dividiva. Partiendo de un solo grupo, en cada etapa se
pasa a dividirlo en grupos de menor tamaño hasta que se tienen
tantos grupos como puntos.
Bayesianos. Esta aproximación aplica una aproximación bayesiana para
modelar los datos en distintas particiones.
2.2. Ejemplos En esta sección se estudiará cómo el algoritmo de clasificación Naive Bayes
induce un clasificador para el caso de análisis de sentimiento en Twitter. Hay que
considerar que se quiere ser capaz de predecir para cada tweet que contenga una
de las palabras claves o hashtag entre los sentimientos etiquetados como
, y .La probabilidad de que dado un tweet este sea
positivo según la regla de Bayes es:
( | ) =( | ) ( )
( )
Hay que recordar que siendo ( )constante, puede descartarse para
inducir la regla de clasificación porque no afecta a la decisión. Si considera que
cada uno de los tres posibles sentimientos son equiprobables se tendrá:
( ) = ( ) = ( ) = .
El término ( | ) se calcula a partir de un conjunto de tweets
etiquetados que se usan como conjunto de entrenamiento. Cada tweet se asociará
con una secuencia de símbolos (tokens). Si se considera que el tweet a analizar

76
tiene , ,. . . , símbolos o tokens, ( | ) se calculará del siguiente
modo:
( | ) = ( | ) ∗ ( | ) ∗. . .∗ ( | )
El término asociado a cada token se calcula mediante la expresión:
( | ) =
Con el número de ocurrencias del token en tweets etiquetados como
y el número total de tokens que fueron etiquetados . Por
ejemplo, si se considera que uno de los tokens es con los siguientes
números:
El número de veces que la palabra aparece en tweets
positivos: 455.
El número total de palabras que aparecen en tweets positivos: 1211.
Se tendrá ( | ) = 0.376. Este cálculo ha de repetirse para
cada palabra que aparece en el tweet a clasificar.
Una vez se calcule para el sentimiento positivo se continuará con los otros dos
sentimientos y se asociará el tweet al sentimiento que mayor probabilidad tenga.
De modo que la regla de clasificación se podrá expresar del siguiente modo:
ℎ =∈{ , , }
( |ℎ) (ℎ)
2.3. Ejercicios de reflexión 1. Describa los algoritmos de clasificación KNN (K-Nearest Neighbors) y C4.5.
Indique, para cada caso y mediante un ejemplo concreto, cómo se induce el

77
clasificador. Tome como referencia la descripción del algoritmo Naive Bayes de la
sección anterior.
2. Describa los algoritmos de agrupamiento K-means y Single-Linkage
Clustering. Indique, para cada caso y mediante un ejemplo concreto, cómo se
genera el modelo descriptivo de los datos.
3. Haciendo uso de la herramienta Weka, haga una experimentación en la que
quiera estudiarse el rendimiento de los clasificadores Naive Bayes, KNN
(denominado en Weka IbK) y C4.5 (denominado en Weka J48). Para el caso del
KNN pruebe con 1, 3 y 5 vecinos. Para la experimentación considere 10 conjuntos
de datos distintos y valide los resultados aplicando validación cruzada con K=10.
Para manejar la herramienta Weka puede usar el tutorial que está en la
bibliografía.
Describa la experimentación indicando, en los resultados, el error de
clasificación mediante una tabla en la que cada fila corresponde a los resultados
de un conjunto de datos y cada columna a los resultados con un clasificador.
Indique también el error promedio sobre todos los datos en la última fila. Resalte
en negrita el mejor resultado para cada conjunto de datos. En promedio, ¿qué
clasificador es mejor? ¿Es mejor en todos los datos? ¿Cuál de ellos obtiene las
reglas de clasificación más fáciles de entender? Comente cómo es la regla de
clasificación de cada uno de las técnicas.
2.4. Conclusiones El aprendizaje automático es un campo de la IA muy activo debido a la
creciente necesidad de analizar datos. Con las mejoras en las tecnologías de
recogida y almacenamiento de información, el volumen de datos almacenados por
parte de cualquier organización ha aumentado exponencialmente. A pesar de los
avances, las tareas de aprendizaje resuelven con éxito tareas muy específicas.
Sin embargo, no se ha podido diseñar un programa que imite el aprendizaje

78
humano debido a que diversos aspectos del cerebro aún son desconocidos. Esto
ha hecho que se creen equipos multidisciplinares que estudien el aprendizaje
desde distintos puntos de vista.
2.5. Teoría de Juegos La teoría de juegos aborda un tipo de problemas en la que hay un conflicto de
intereses entre varios agentes implicados. Este tipo de problemas son muy
frecuentes en el día a día y, por lo tanto, el ámbito de aplicación es muy amplio.
Por ejemplo, en el mundo empresarial, se puede abordar como juegos algunos
temas tan dispares como la guerra de precios, la introducción de nuevos
productos, pujas en contratos públicos, etc. Por regla general, las situaciones de
conflicto son difíciles de analizar y entender, pues interrelacionan diversos
aspectos de la actividad humana. La teoría de juegos nos da un marco conceptual
para estudiar este tipo de situaciones.
Esta unidad introduce el marco teórico de la teoría de juegos como un entorno
multiagente, donde cualquier agente (también denominado jugador) tomará una
serie de decisiones en función de las acciones llevadas a cabo por cualquier otro
agente. Se verá la estrategia minimax para resolver este tipo de problemas y se
extenderá para el caso de decisiones en tiempo real imperfectas. Finalmente se
abordará el caso en los que se introduce un elemento aleatorio y, por tanto, las
distintas posibilidades tendrán asociadas una serie de probabilidades que influirán
en la toma de decisiones.
Los fundamentos de la teoría de juegos fueron establecidos por el matemático
John von Neumann en 1928, y junto con el economista Oskar Morgenstern fueron
expuestos en el libro Theory of games and economic behaviour, publicado en
1944. Un juego puede definirse como un problema de decisión en el que hay
involucrados más de un agente (o jugador) de modo que las decisiones de un
agente tienen efectos sobre el resto de agentes. Cabe destacar que esta definición

79
contiene varios elementos interesantes. Por una parte se tienen varios agentes
implicados. De lo contrario, solo se tendría un agente decisor y se estaría frente a
un problema de análisis de decisiones y, probablemente, con cierta incertidumbre.
Por lo tanto, un problema de juegos se da si hay al menos dos agentes cuyas
decisiones varían en función de las acciones del otro agente. El segundo aspecto
a destacar es que debe haber algún conflicto de intereses. En caso de juegos en
los que los agentes cooperen, el conflicto se referiría a la coordinación que debe
haber entre los jugadores. La ausencia de conflicto haría el problema más sencillo
y no pertenecería al ámbito de los juegos.
Los juegos en IA han recibido una gran atención debido a sus principales
características:
Representan una tarea estructurada que requiere una forma de inteligencia.
Representa una competición entre dos o más oponentes.
Son fáciles de formalizar pues las reglas están definidas y la definición de éxito o fallo es clara.
Además, en IA suelen tratarse los juegos en el caso de información completa y
multijugadores. En general, los problemas de juegos pueden clasificarse en
función de diferentes factores:
Cooperación ◦ Cooperativos: los agentes deben asociarse para encontrar una
solución que maximice el beneficio de todos.
◦ Competitivos: los agentes luchan entre sí de modo que el
beneficio de uno implica el perjuicio de otro u otros agentes.
Número de jugadores
◦ Bipersonales: problemas con dos agentes y, por naturaleza,
suelen ser no cooperativos.

80
◦ n-personales: implican más de dos jugadores y pueden ser
cooperativos, dando lugar a coaliciones.
Beneficio
◦ Suma nula: en este caso la suma del beneficio y pérdida de todos
los jugadores debe ser 0.
◦ Suma no nula: cualquier otro caso en el que la suma sea distinta
de 0.
Duración
◦ Finitos: tienen un final programado como, por ejemplo, un número
de jugadas, un tiempo de duración, etc.
◦ Infinitos: no tienen ningún final programado.
Información ◦ Información perfecta. Ambos jugadores tienen infomación
completa del estado del juego en cada instante.
◦ Información imperfecta. Ambos jugadores tienen información
parcial del estado del juego en cada momento.
Incertidumbre
◦ Deterministas: tiene predeterminado a qué estado se llega al
hacer un movimiento.
◦ Estocástico: hay componentes aleatorias que hacen que no se
conozca a qué estado se llegará al realizar un movimiento. En
ese caso se tendrá una serie de estados posibles a los que se
puede llegar y cada uno de estos estados tendrá asociada una
probabilidad.
Por ejemplo, atendiendo a la información que se maneja así como a la
incertidumbre asociada a cada movimiento, se podrá hacer una tabla de juegos
asociados:
Incertidumbre\Información Determinista Estocástico
Perfecta Ajedrez, damas, go Monopoly, backgammon

81
Imperfecta Batalla naval, tictactoe
Póker, scrabble, guerra nuclear
2.6. Los Juegos Como un Problema de Búsqueda Los juegos pueden ser abordados como un problema de búsqueda. Para ello se
requiere que la definición de juego cuente con los siguientes componentes:
Estado inicial. Incluye la posición del tablero e identifica al jugador al
que le toca mover.
Función sucesor. Proporciona una lista de pares (movimiento,
estado), indicando qué estado corresponde a un movimiento legal.
Test pro-prueba terminal. Determina cuándo se termina el juego. A
los estados en los que el juego concluye se les denomina estados
terminales.
Función de utilidad u objetivo. Se encarga de asignar un valor
numérico a los estados terminales. El tipo de valor así como su rango
dependerá del tipo de juego.
Conociendo el estado inicial y los movimientos legales se puede definir el árbol
de juegos, que no es más que una representación, en forma de árbol, de los
distintos estados posibles del juego. La Figura 7 muestra un árbol con los distintos
estados para el juego tres en línea. Como puede verse, para el primer movimiento
hay 9 posibilidades, y para cada uno de estos movimientos habrá varias
posibilidades para el adversario haciendo que el número de nodos del árbol crezca
rápidamente. En este juego hay tres posibles resultados: que gane el jugador de
las X, el de las O o que haya empate.

82
El crecimiento exponencial de los nodos hace que los juegos sean difíciles de
resolver, incluso para el caso de tamaños no muy grandes de tablero. Por ejemplo,
para el caso del ajedrez, la ramificación promedio es de 35 y a menudo cada
jugador hace una media de 50 movimientos, de modo que el árbol tiene en torno a
30 o 10 nodos aunque sólo 10 nodos son distintos. Por tanto, se requiere la
capacidad de adoptar una estrategia determinada cuando no es factible calcular la
óptima.
Estrategias óptimas
Hay que recordar que en un problema de búsqueda la solución óptima se
alcanza a través de una secuencia de movimientos que conducen a un estado
objetivo. Sin embargo, en un juego se cuenta con dos jugadores (MIN y MAX) y
ahora, a diferencia de un problema de búsqueda, se necesitará una estrategia
óptima que se adapte a las respuestas que vaya dando el oponente. Al igual que
en los problemas de búsquedas normales, encontrar la estrategia óptima deja de
ser factible incluso a partir de problemas no demasiado grandes.
Figura 7. Juego tres en raya. Fuente: adaptado por el autor.

83
Por ejemplo, considere un juego trivial con dos jugadores (MIN y MAX) que
permita mostrar todos los nodos. Los movimientos posibles para MAX se etiquetan
como a1, a2 y a3; y los de MIN como b1, b2, b3. El juego finaliza después de que
cada jugador realice un movimiento. La utilidad de los estados terminales varía de
2 a 14. El objetivo (para MAX) será seleccionar, en cada movimiento, el máximo
valor minimax. El valor minimax de un nodo es la utilidad (para MAX) de estar en
el estado correspondiente, asumiendo que ambos jugadores juegan de forma
óptima. La Figura 8 muestra el árbol de estados de dos capas.
Por lo mismo, la estrategia óptima puede determinarse a partir del valor
minimax de cada nodo, denominando Valor-Minimax(n). El valor asociado a un
nodo terminal será el de su utilidad. El jugador MAX, durante el desarrollo del
juego (en un estado intermedio del árbol), elegirá la opción (el nodo) que maximice
el valor mientras que MIN el que lo minimice. De esta forma el valor minimax
vendrá dado por la siguiente expresión:
Figura 8. Valor minimax de un juego trivial. Fuente: adaptado por el autor.

84
− ( )( )
∈ ( ) − ( )∈ ( ) − ( )
Considerando esta expresión y el árbol de juegos de la Figura 8, se puede ver
que el nodo raíz es un nodo MAX (le toca mover a MAX). Tiene tres sucesores con
valores 3, 2 y 2. El primer nodo MIN, con valor minimax 3, se accede tras ejecutar
MAX el movimiento etiquetado como a1. Dicho jugador tiene tres posibles
movimientos a su vez, que llevan a los nodos terminales. La estrategia óptima
para MAX será aquella que conduzca al valor minimax más alto. Por tanto, elegirá
la acción etiquetada como a1. En el caso de MIN, este también juega de forma
óptima, de modo que elegirá la acción b1. En caso de que MIN no juegue de forma
óptima entonces tendremos que MAX mejorará el valor de utilidad obtenido. En
caso de que MIN juegue de forma subóptima, existen otras estrategias que lo
hacen mejor que la minimax. Sin embargo, son peores para el caso en que MIN
juegue de forma óptima.
El Algoritmo Minimax
Es un método de decisión que tiene el objetivo de minimizar la pérdida máxima
esperada en juegos con adversarios e información perfecta. Esta estrategia se
caracteriza por elegir, para cada jugador, el mejor movimiento suponiendo que el
adversario elige el peor. Busca la solución óptima en el espacio de estados (árbol
de juegos) mediante una estrategia primero en profundidad completa. La Figura 9
muestra el pseudocódigo del algoritmo para el cálculo de decisiones minimax. Las
funciones Max-Valor y Min-Valor son las funciones asociadas al jugador MAX y
MIN respectivamente.
Esta estrategia suele implementarse mediante recursividad y la búsqueda la
hace del siguiente modo: considerando la Figura 8, el algoritmo parte del nodo raíz
y comienza a explorar una de las posibles acciones de MAX, por ejemplo a1. A
continuación, avanza desde el nodo MIN considerando la acción b1 y al llegar a un

85
nodo terminal almacena el valor obtenido por la función utilidad y retrocede para
explorar la siguiente acción de MIN. Esto se lleva a cabo hasta explorar todos los
nodos terminales.
Si el árbol de juego tiene una profundidad máxima de y el número de
movimientos de cada jugador es , entonces la complejidad temporal del algoritmo
es ( ). La complejidad espacial dependerá de si genera todos los sucesores a
la vez, que en ese caso sería ( ),o si los genera uno por uno, siendo en este
último caso ( ). El alto costo temporal de este algoritmo hace que no sea viable
para juegos reales.
2.7. Poda Alfa-Beta El problema del algoritmo minimax es que el número de estados a explorar
aumenta exponencialmente con el número de movimientos. Sin embargo, es
posible diseñar una estrategia completa sin necesidad de explorar todos los
función Decisión-Minimax(estado) devuelve una acción variables de entrada: estado, estado actual del juego ←Max-Valor(estado) devolver la acción de SUCESORES(estado) con valor función Max-Valor(estado) devuelve un valor utilidad si Test-Terminal(estado) entonces devolver Utilidad(estado) ← −∞ para un s en Sucesores(estado) hacer ←Max( , Min-Valor( )) devolver función Min-Valor(estado) devuelve un valor utilidad si Test-Terminal(estado) entonces devolver Utilidad(estado) ← +∞ para un s en Sucesores(estado) hacer ←Min( , Max-Valor( )) devolver
Figura 9. Pseudocódigo del algoritmo para calcular las decisiones minimax y de las funciones Max-Valor y Min-Valor. Fuente: adaptado por el autor.

86
estados posibles. Dicha estrategia, a pesar de seguir teniendo una complejidad
exponencial, el número de estados a explorar se reduce a la mitad ( ⁄ ). Esta
técnica, conocida como poda alfa-beta, devuelve el mismo valor que la estrategia
minimax.
Esta estrategia hace uso de los parámetros y , los cuales se usan como
referencia para los jugadores MAX y MIN respectivamente. hace referencia al
máximo valor encontrado a lo largo del camino e cualquier punto de la búsqueda
para MAX. De forma equivalente se asocia con el jugador MIN y almacena el
mínimo valor encontrado. La Figura 10 muestra el pseudocódigo de esta
función Búsqueda-Alfa-Beta(estado) devuelve una acción variables de entrada: estado, estado actual del juego ←Max-Valor(estado) devolver la acción de SUCESORES(estado) con valor función Max-Valor(estado, , ) devuelve un valor utilidad variables de entrada: estado, estado actual del juego ,mejor valor encontrado para MAX hasta estado. ,Mejor valor encontrado para MIN hasta estado. si Test-Terminal(estado) entonces devolver Utilidad(estado) ← −∞ para a, s en Sucesores(estado) hacer ←Max( , Min-Valor( , , )) si ⩾ entonces devolver ←Max( , ) devolver función Min-Valor(estado) devuelve un valor utilidad variables de entrada: estado, estado actual del juego ,mejor valor encontrado para MAX hasta estado. ,Mejor valor encontrado para MIN hasta estado. si Test-Terminal(estado) entonces devolver Utilidad(estado) ← +∞ para a, s en Sucesores(estado) hacer ←Min( , Max-Valor( , , )) si ⩽ entonces devolver ←Min( , ) devolver
Figura 10. Pseudocódigo del algoritmo para calcular las decisiones minimax y de las funciones Max-Valor y Min-Valor. Fuente: adaptado por el autor.

87
estrategia. Como puede verse, las rutinas son las mismas que la de minimax pero
incluye la posibilidad de poda en caso de que el jugador MAX analice un nodo
cuyo valor asociado sea menor que el menor encontrado . Del mismo modo para
MIN la poda se lleva a cabo en caso de que el valor asociado a un nodo sea
mayor que .A medida que avanza la búsqueda dichos valores se van
actualizando.
2.8. Ejemplos A continuación se propone un ejemplo de la técnica poda alfa-beta para
entender mejor cómo funciona. Para ello, se retomará el juego trivial que se
introdujo en la sección estrategias óptimas.
Figura 11. Estrategia de búsqueda de la técnica poda alfa-beta. Fuente: adaptado por el autor.

88
La Figura 11 muestra las etapas de la búsqueda de la decisión óptima en el
árbol de juego. A medida que se avanza en la búsqueda se irán mostrando el
rango de valores posibles para cada nodo. A) El nodo raíz examina el primer nodo
que tiene un valor asociado de 3. Al ser un nodo MIN, el valor 3 es el valor máximo
que puede tener. B) A continuación, retrocede y explora el siguiente nodom que
tiene un valor de 12. Al ser un nodo MIN, descarta este movimiento por tener un
valor mayor. C) Examinar la tercera acción de MIN, con un valor de 8. Como en el
caso anterior, dicho valor es descartado y ya se sabe que el mejor valor de MIN en
este nodo es exactamente 3, y el del nodo raíz, se sabe que es, al menos, 3. D) A
continuación la estrategia explora la segunda posible acción de MAX. En este
caso, la primera acción de MIN tiene asociado un valor de 2. Al ser el jugador MIN,
este valor será el valor máximo que pueda tener. Sin embargo, la primera acción
que llevó a cabo MAX le dio un valor mejor, 3; de modo que MAX nunca elegiría
esta acción. El motivo es que si MIN pudiera llevar a cabo una acción con un valor
menor en la función de utilidad, MAX descartaría llevar a cabo esta acción (a2).
Por el contrario, si el resto de acciones de MIN son mayores, entonces serán
descartadas pues este jugador elige la acción que minimice la función de utlidad.
E) En este caso, al explorar la última acción posible de MAX (a3), la técnica
examina la primera acción de MIN (d1). En este caso el valor es 14, de modo que
será el valor máximo de la acción de MIN. Esta alternativa es mejor que la que
encontró previamente (3); de modo que seguirá explorando. F) La segunda acción
(d2) tiene un valor 5 de modo que deberá seguir explorando. El último sucesor
tiene un valor 2 y, por lo tanto, este será el valor asociado a MIN. Otra forma de
ver esto, atendiendo a la fórmula Valor-Minimax sería considerar las siguientes
evaluaciones:
− ( ) = ( ), ( ), ( )
Con ( ) = (3,12,8), ( ) = (14,5,2)y ( ) = (2, , ). En
este último caso, sea el menor valor de los tres valores, entonces se sabe que

89
⩽ 2. Cualquier otro valor mayor no será considerado por el jugador MIN mientras
que cualquier otro valor menor que seleccione MIN será descartado por el jugador
MAX debido a que encontró, explorando una acción previa, un resultado más
favorable.
2.9. Ejercicios de Reflexión 1. Explicar las propiedades de la estrategia minimax (completitud, optimalidad,
complejidad espacial y temporal), y argumente la motivación de la poda alfa-beta.
2. Dado el siguiente árbol de juego, aplique la técnica poda alfa-beta indicando,
en cada etapa de la búsqueda, los valores de alfa y de beta.

90
91
Capítulo III
Prob
lem
a de
Sat
isfa
cció
n de
Re
stric
cion
es y
Lóg
ica
Aprendizaje Automático y Juegos
Introducción
Ejemplos
Ejercicios de Reflexión
Teoría de Jugos
Poda Alfa-Beta
Problema de Satisfacción de Restricciones y Lógica

92

93
CAPÍTULO 3: PROBLEMA DE SATISFACCIÓN
DE RESTRICCIONES Y LÓGICA Este capítulo aborda dos grandes temas: la resolución de problemas de
satisfacción de restricciones (PSR) y la lógica. El primero de ellos es ampliamente usado en problemas grandes y complejos y, principalmente, combinatorios. Se partirá de una introducción en la que se da una definición formal y se continuará presentando cómo se modelan varios problemas para resolverlos como un PSR. Finalmente, se presentará los tipos de técnicas que hay y se entrará en detalle con la estrategia vuelta atrás.
En el segundo tema se introduce la lógica, cuyo objetivo de estudio es el aprendizaje de las técnicas de demostración formales y sus aplicaciones en la resolución de problemas. Para ello es necesario llevar a cabo la formalización del conocimiento y aprender la manipulación del mismo. La formalización se hace mediante el lenguaje formal lógico. En este tema se introduce el lenguaje de la lógica de primer orden para aprender a formular proposiciones y razonamiento con dicho lenguaje.
2. Problemas de Satisfacción de Restricciones y Lógica 2.1. Introducción
Los problemas de satisfacción de restricciones (PSR) se caracterizan porque los estados y el test objetivo están representados de forma estructurada. Un estado está compuesto por variables que pueden tomar diferentes valores y un estado es de tipo meta si los valores que cumplen las variables implicadas (en dicho estado) cumplen una serie de restricciones.
Desde un punto de vista formal, un PSR se define como una tripleta ( , , )
donde: , , … , es un conjunto de variables. : → Es una función que asigna un dominio (conjunto de valores
de ) a cada variable. El dominio de una variable suele denotarse como y contiene los posibles valores que puede tomar la variable. La cardinalidad del dominio es = | |.

94
= , , … , Es un conjunto finito de restricciones de modo que cada restricción implica algún subconjunto de variables y especifica las combinaciones aceptables de valores para ese subconjunto.
Una variable viene dada por el par variable-valor ( , ) que representa la
asignación del valor a la variable ( = ). De la misma firma un conjunto de variables viene dado por una tupla de pares ordenados, donde cada par ordenado ( , ) asigna el valor { ∈ } a la variable . Una tupla , , … , , se dice que es localmente consistente si satisface todas las restricciones formadas por las variables , … , . Por simplificación sustituiremos dicha tupla por
, … , . Un valor ∈ se dice que es un valor consistente para si existe al menos
una solución del PSR en la que = . Un estado del problema está definido por una asignación de valores a unas o todas las variables , … . A una asignación se le dice consistente si no viola ninguna restricción y es completa si todas las variables están representadas. De esta forma se puede definir una solución de un PSR como una asignación completa y consistente. Este tipo de problemas pueden tener asociados una función objetivo, de modo que se requiere que la solución encontrada maximice o minimice dicha función.
Un PSR puede modelarse como un grafo de restricciones, de modo que cada
nodo representa una variable y los arcos las restricciones. Esta modelización permite aplicar algoritmos de búsqueda sobre grafos. Además, un PSR se le puede dar una formulación incremental similar a la de un problema de búsqueda estándar:
Estado inicial: asignación vacía { }, en la que ninguna variable ha sido asignada.
Función sucesor: un valor se puede asignar a cualquier variable no asignada, siempre y cuando no viole ninguna restricción.
Test objetivo: la asignación actual es completa. Costo del camino: un coste constante para cada paso.
Cada solución debe ser una asignación completa, de modo que el árbol de
búsqueda tendrá una profundidad equivalente al número de variables .

95
2.2. Modelización de Problemas de Satisfacción de Restricciones
A continuación se introducirá un par de problemas y cómo se deslizan para ser
tratados como un PSR.
El Problema de las N-Reinas
Dado un tablero de ajedrez × , hay que colocar reinas de tal modo que
ninguna de ellas pueda ser alcanzada por otra con un movimiento. En otras
palabras, que ninguna reina pueda ser comida por otra con los movimientos que
tiene permitidos. Las restricciones, por tanto, son que dos reinas no pueden
coincidir en la misma fila o columna, y tampoco pueden estar en diagonal. Esto
hace que se pueda asociar cada reina con una columna distinta y se reduzcan las
variables a las filas de modo que su valor representa la fila en la que se coloca la
reina correspondiente a dicha variable. Desde el punto de vista de un PSR se
puede formular del siguiente modo:
Variables: { }, = 1, … , .
Dominio: {1, … , }, para todas las variables.
Restricciones (∀ , , ≠ ):
◦ ≠ No pueden estar en la misma fila.
◦ − ≠ | − | No pueden estar en la diagonal.

96
La Figura 1 muestra dos soluciones del problema para el caso = 4, que
tendría las siguientes restricciones:
| − | ≠ 1.
| − | ≠ 2.
| − | ≠ 3.
| − | ≠ 1.
| − | ≠ 2.
| − | ≠ 1.
Coloración de Mapas
Dado un conjunto de colores finitos y un mapa dividido en regiones, colorear
cada región de modo que las regiones adyacentes no pueden tener el mismo
color. En la formulación PSR se define una variable por cada región del mapa, y el
dominio de cada variable es el conjunto de colores disponibles. La restricción es
que las variables de dos regiones contiguas no pueden tener el mismo valor.
Figura 1. Dos soluciones del problema de la N Reinas para N=4. Fuente: elaboración propia.

97
Por ejemplo, la Figura 2 muestra un mapa de cuatro regiones , , , para ser
coloreadas con los colores rojo, verde y azul. La formulación PSR sería:
Variables: { , , , }
Dominio: { , , }
Restricciones: { ≠ , ≠ , ≠ , ≠ , ≠ }
Figura 2. Mapa con cuatro regiones a colorear. Fuente: elaboración propia.

98
La Figura 3 muestra la representación de este problema como un grafo de
restricciones en que cada nodo representa una región del mapa mientras que los
arcos son las restricciones entre las mismas. Por tanto, se tendrán 5 aristas. En
esta representación, todos los nodos adyacentes deben tener un valor distinto.
2.3 Técnicas de Resolución de PSR Al formularse el PSR como un problema de búsqueda, se puede aplicar
cualquier estrategia de búsqueda. Sin embargo, hay que tener en cuenta la
complejidad del algoritmo pues el árbol de búsqueda con muchas ramificaciones
que hacen que no pueda aplicarse algoritmos exhaustivos.
Las técnicas más usuales que se llevan a cabo para manejar un PSR se
pueden agrupar en tres tipos:
Figura 3. Grafo de restricciones del problema de coloreado de mapa. Fuente: adaptado por el autor.

99
Búsqueda sistemática: se centran en buscar en el espacio de
estados del problema. Este tipo de técnicas pueden ser completas, si
buscan en todo el espacio de estados o incompletas si solo buscan
en una región de este.
Técnicas inferenciales: tienen como objetivo deducir nuevas restricciones a partir de las planteadas de forma explícita en el
problema. Por lo general inducen restricciones implícitas entre
variables que hacen que se plantee un nuevo PSR equivalente al de
partida.
Técnicas híbridas: combinan las dos anteriores de modo que
mediante una técnica inferencia plantea un PSR más restringido y
equivalente al original. Esto permite acotar el espacio de búsqueda y
aplica, sobre este nuevo espacio, una estrategia de búsqueda.
Búsqueda con vuelta atrás (backtracking) Esta técnica es una estrategia primero en profundidad que en cada nivel del
árbol de búsqueda, asigna un valor a una variable y vuelve para atrás cuando no
hay opción de asignarle un valor consistente.
función Búsqueda-con-Vuelta-Atrás(psr) devuelve una solución o fallo devolver Vuelta-Atrás-Recursiva({}, psr) función Vuelta-Atrás-Recursiva(asignación, psr) devuelve una solución o fallo si ó es completa entonces devolver ó ←Selecciona-Variable-Noasignada(Variables[psr], ó ,psr) para cada valor en Orden-Valores-Dominio( , ó ,psr) hacer si es consistente con asignación de acuerdo a las Restricciones[psr] entonces añadir { = } a ó ←Vuelta-Atrás-Recursiva(asignación, psr) si ≠ entonces devolver borrar { = } de ó devolver Figura 4. Pseudocódigo del algoritmo Vuelta Atrás para problemas de satisfacción de restricciones. Fuente: adaptado por el autor.

100
La Figura 4 muestra el pseudocódigo de la Vuelta Atrás para el PSR. Como
puede verse, se modela sobre la estrategia de búsqueda Primero en Profundidad
recursiva.
5.3. Ejemplos En esta sección vamos a ver cómo se resolvería el problema de coloración del
mapa mediante la técnica de búsqueda Vuelta Atrás. Para ello consideraremos el
mapa de Australia, que está dividida, tal y como se ve en la Figura 5, en las
siguientes regiones:
Australia Occidental (AO)
Territorio del Norte (TN)
Australia del Sur (AS)
Queensland (Q)
Nueva Gales del Sur (NGS)
Victoria (V).
Tasmania (T)

101
La formulación del problema es:
Variables: { , , , , , , }
Dominio: { , , }
Restricciones: { ≠ , ≠ , ≠ , ≠ , ≠ ,
≠ , ≠ , ≠ , ≠ }
Haciendo uso de la librería AIMA, se puede resolver dicho problema con el
código que se muestra en la Figura 6.
5.4. Ejercicios de Reflexión
1. Representar el siguiente problema como problema de satisfacción de
restricciones (no es necesario resolverlo, solo plantear la representación).
Suponga el siguiente puzzle lógico: hay cinco casas de diferentes colores, en las
cuales viven personas de diferentes nacionalidades, con diferentes mascotas, que
gustan de diferentes bebidas y practican diferentes deportes, además se
consideran las siguientes restricciones:
El inglés vive en la casa roja.
El español tiene un perro.
El hombre de la casa verde bebe café.
El irlandés bebe té.
import aima.core.search.csp.Assignment; import aima.core.search.csp.BacktrackingStrategy; import aima.core.search.csp.MapCSP; public class VueltaAtras { public static void main(String[] args) throws Exception { MapCSP csp = new MapCSP(); BacktrackingStrategy strategy = new BacktrackingStrategy(); Assignment assignment = strategy.solve(csp); System.out.println(assignment); } }
Figura 6. Código en Java para resolver el problema de coloreado de las regiones del mapa de Australia con el algoritmo Vuelta Atrás usando la librería AIMA. Fuente: elaboración propia.

102
La casa verde está a la derecha de la casa marfil.
El jugador de go es dueño de caracoles.
El hombre de la casa amarilla juega cricket.
El hombre de la casa del medio bebe leche.
El nigeriano vive en la primera casa.
El jugador de judo vive cerca del hombre que tiene un lobo.
El jugador de cricket vive cerca del dueño del caballo.
El jugador de póker bebe jugo de naranja.
El japonés practica polo.
El nigeriano vive cerca de la casa azul.
2. Resuelva, manualmente, el problema anterior planteado de modo que pueda
responder a las siguientes preguntas: ¿quién es el dueño de la cebra? y ¿quién
bebe cerveza?
3. Diseñe una estrategia Vuelta Atrás que resuelva el problema de la cebra.
5.5. Conclusiones La modelización de un problema como un PSR permite que sea abordado
mediante un amplio número de estrategias. Los PSR han demostrado su utilidad
en ámbitos tan diversos como la investigación operativa, la bioinformática, las
telecomunicaciones, etc.
5.6. Conocimiento Racional No puede hablarse de inteligencia sin hablar de conocimiento. En IA todos los
agentes manejan conocimiento de una u otra forma. Sin embargo, el conocimiento
que manejan es muy específico de acuerdo al problema. En este sentido, los
agentes basados en conocimiento pueden aprovechar el conocimiento expresado

103
mediante alguna técnica de representación para combinar la información que
extraen y adaptarse a diversos propósitos.
El uso explícito que se hace en la IA del conocimiento es la diferencia
fundamental entre esta disciplina y la informática convencional. Desde este punto
de vista se puede decir que los objetivos que se persiguen son:
Estudiar técnicas generales de representación del conocimiento.
Estudiar nuevas estrategias de resolución de problemas.
En esta unidad se hará un énfasis en el primer objetivo mediante el uso de la
lógica como técnica de representación del conocimiento.
5.7. Representación del Conocimiento y Razonamiento El conocimiento y el razonamiento son dos conceptos centrales en el ámbito de
la IA. Para poder inferir a partir de un conocimiento previo es necesario encontrar
una forma de modelarlo. No obstante, los desafíos a los que se enfrenta son:
La representación del conocimiento del sentido común.
La habilidad para compensar la eficiencia computacional en busca de
inferencias precisas.
La habilidad de representar y manipular conocimiento e información
con incertidumbre.
La representación del conocimiento puede definirse como la transformación del
conocimiento de un dominio a un lenguaje simbólico. En este caso se hace un
planteamiento simbólico de resolución de problemas en el que cada elemento de
la representación (símbolo) se refiere a un objeto, hecho o relación de interés
perteneciente al dominio a representar. Este lenguaje de representación debe
definir dos aspectos:

104
La sintaxis: abarca las posibles formas de construir y combinar los
elementos del lenguaje para representar los hechos del dominio real.
Está centrada en la estructura formal del lenguaje.
La semántica: determina la relación entre los elementos del lenguaje y su interpretación en el dominio. Está centrada en las condiciones
de verdad de las oraciones.
La representación del conocimiento tiene una fase de codificación, encargada
de convertir los hechos reales en una representación interna, y otra de
decodificación, que vuelve a convertir en hechos del mundo real los resultados de
los procesos inferenciales realizados sobre la representación interna del
conocimiento. El instrumento para codificar el dominio real en otra representación
se denomina esquema de representación. Desde un punto de vista computacional
un esquema de representación puede ser descrito como una combinación de
estructuras de datos y procedimientos que representan la componente estática y
dinámica del esquema:
Parte estática:
◦ Formada por las estructuras que codifica el problema.
◦ Operaciones para crear, modificar y destruir elementos en la
estructura.
◦ Predicados que dan un mecanismo para consultar esta estructura
de datos.
◦ Semántica de la estructura: se necesita definir la relación entre la
realidad y la representación escogida.
Parte dinámica: ◦ Estructuras de datos que almacenan conocimiento referente al
entorno/dominio en el que se desarrolla el problema.
◦ Procedimientos que permiten:
▪ Interpretar los datos del problema (de la parte estática) a partir
del conocimiento del dominio (de la parte dinámica).

105
▪ Controlar el uso de los datos: estrategias de control.
▪ Adquirir nuevo conocimiento.
Además, todo esquema de representación debe presentar una serie de
propiedades:
Adecuación de la representación. Capacidad para poder representar de forma adecuada todo el conocimiento de un dominio, sobre todo el que se considere
relevante.
Adecuación inferencial. Posibilidad de manipular las estructuras de representación de forma que se puedan derivar nuevas estructuras asociadas
con nuevo conocimiento inferido a partir del antiguo.
Eficiencia inferencial. Posibilidad de mejorar la eficiencia del proceso inferencial mediante la inclusión de estrategias que agilicen dicho proceso.
Eficiencia adquisicional. Capacidad para incorporar nuevo conocimiento de forma sencilla.
En IA se usa la lógica como instrumento para la representación del
conocimiento. Los principales motivos para esta elección son:
Desde un punto de vista matemático son precisos, de modo que puede
conocerse sus limitaciones, sus propiedades, la complejidad de una inferencia,
etc.
Son lenguajes formales, de modo que los programas computacionales pueden
manipular sentencias en el propio lenguaje.
Presentan una sintaxis y una semántica.
Para manejar estos conceptos se introducen los agentes basados en
conocimiento debido a su capacidad para inferir aspectos ocultos del estado del
entorno a partir del conocimiento y las percepciones. Para ello requiere que el
agente sea capaz de razonar con el conocimiento que maneja.

106
Agentes basados en conocimientos
El principal componente de este tipo de agentes es su base de conocimiento
(BC). Informalmente, una BC es un conjunto de sentencias de modo que cada
sentencia se expresa en un lenguaje de representación del conocimiento y
representa alguna aserción acerca del mundo. Además, el agente debería estar
dotado de tres cualidades fundamentales:
Representar el conocimiento del mundo que le rodea.
Razonar para generar nuevo conocimiento a partir del conocimiento disponible.
Aprender nuevo conocimiento a partir de las observaciones que obtiene del entorno.
Adicionalmente, estos agentes deben tener la capacidad de aceptar nuevas
tareas, usar el conocimiento o inferir de forma eficiente y adaptarse a cambios en
el entorno. Para ello, deben contar con mecanismos para conocer el estado actual
del entorno, y cómo evoluciona a lo largo del tiempo. También necesita de algún
mecanismo para poder inferir a partir de propiedades no vistas.
La Figura 7 muestra el esquema general de un agente basado en conocimiento.
Como otros agentes, este recibe una percepción y devuelve una acción. El agente
mantiene una BC que contiene algún tipo de conocimiento de antecedentes. En
función AGENTE-BC(percepción) devuelve un acción variables estáticas: BC, una base de conocimiento t, un contador, inicializado a 0, que indica el tiempo DECIR(BC, CONSTRUIR-SENTENCIA-DE-PERCEPCIÓN(percepción, t)) acción ← PEGUNTAR(BC, PEDIR-ACCION(t)) DECIR(BC, CONSTRUIR-SENTENCIA-DE-ACCIÓN(acción, t)) t ← t + 1 devolver acción
Figura 7. Programa de un agente basado en conocimiento genérico. Fuente: adaptado por el autor.

107
dicho esquema los mecanismos para añadir sentencias nuevas a la BC y
preguntar qué sabe el agente de acuerdo a dicho BC vienen dadas por las tareas
DECIR y PREGUNTAR, respectivamente. Ambas tareas requieren realizar
inferencia. Cada vez que el agente es invocado realiza dos cosas: primero dice a
la BC lo que ha percibido y, a continuación, pregunta a la BC qué acción ejecutar.
Tras elegir la acción, el agente graba su elección mediante la tarea DECIR y
ejecuta la acción.
Las funciones CONSTRUIR-SENTENCIA-DE-PERCEPCIÓN y PEDIR-ACCION
ocultan los detalles del lenguaje de representación. La primera de ellas toma una
percepción en un instante de tiempo y devuelve una sentencia afirmando lo que el
agente ha percibido en dicho instante de tiempo. La segunda función toma un
instante de tiempo como entrada y devuelve una sentencia para preguntarle a la
BC qué acción se debe realizar en dicho instante de tiempo. En este esquema los
detalles de los mecanismos de inferencia (DECIR y PREGUNTAR) están ocultos.
5.8. Lógica En esta sección se expondrá la representación del conocimiento basado en
lógica. Como se dijo anteriormente, se caracteriza por tener una base teórica muy
sólida y porque los mecanismos de inferencia son potentes y conocidos. Además,
separa el conocimiento del razonamiento. La lógica, como mecanismo de
representación, consta de tres elementos:
Una sintaxis, que indica qué símbolos pueden usarse y cómo construir las sentencias legales.
Una semántica, que asocia los elementos del lenguaje con los elementos reales
del dominio. Da el significado de las sentencias lógicas.
Un conjunto de reglas de inferencia, que permiten inferir conocimiento nuevo a
partir del ya existente.

108
La semántica del lenguaje define el valor de la verdad de cada sentencia
respecto al modelo. Dicho modelo no es más que una abstracción matemática de
un entorno real que permite definir la verdad o falsedad de una sentencia.
Razonamiento automático
En inferencia es importante poder representar estructuras con conocimiento
para poder caracterizar el nuevo conocimiento generado. Existen varios tipos de
razonamientos lógicos para inferir:
Razonamiento deductivo: razonamiento que pasa, a partir de un conocimiento general, a otro específico. El nuevo conocimiento generado es cierto si parte
de otro conocimiento cierto. Abarca las reglas de inferencias de la lógica (por
ejemplo, el Modus Ponens).
Razonamiento inductivo: se caracteriza por generalizar a partir de un
conocimiento más específico. Este es el mecanismo del aprendizaje
automático.
Razonamiento abductivo: este método de razonamiento parte de un
conocimiento (reglas y hechos observados) y genera un conjunto de
explicaciones posibles o hipótesis que harían, usando la deducción, coherente
el conocimiento de partida.
Estos métodos de inferencia deben caracterizarse por ser sólidos y completos.
Se dice que un método de inferencia es sólido o mantiene la verdad si solo deriva
conocimiento implicado y es completo si puede derivar cualquier conocimiento que
está implicado.
5.9. Tipos de lógica Los modelos lógicos más conocidos en IA son la lógica proposicional y la lógica
de predicados o de primer orden. Básicamente, se diferencian en que la primera
no admite argumentos en los predicados mientras que la segunda sí.

109
Lógica proposicional (orden 0) Es una lógica que representa hechos discretos del mundo real que pueden ser
ciertos o falsos. Está compuesto de proposiciones, que son afirmaciones (ciertas o
falsas) sobre un hecho único del dominio. De igual forma, estas proposiciones
pueden combinarse mediante conectores para expresar hechos más complejos.
Sin embargo, esta lógica padece de poca expresividad debido a la dificultad de
expresar un conjunto de hechos con características comunes pues una
proposición está asociada a un hecho y no permite la cuantificación.
Sintaxis y semántica
La sintaxis se compone de los siguientes elementos:
Sentencia atómica: representa los elementos sintácticos indivisibles que se
componen de un único símbolo proposicional.
◦ Constantes lógicas. Son dos símbolos proposicionales con
significado fijado: verdadero (V) y falso (F).
◦ Proposiciones lógicas. Son símbolos proposicionales que pueden
ser verdadera o falsa. Suelen usarse mayúsculas para denotar
estos símbolos: P, Q, R, etc.
Conectivas lógicas: permite construir sentencias complejas combinando
sentencias más simples. Existen cinco conectivas:
◦ ¬(no) se denomina negación.
◦ ∧(y) se denomina conjunción.
◦ ∨(o) se denomina disyunción.
◦ ⇒(implica) se denomina implicación y está compuesto por una
premisa o antecedente y una conclusión o consecuente. También
se les conoce como reglas si-entonces.
◦ ⇔(si y solo si) se denomina bicondicional.
Sentencias: son elementos sintácticos que se construyen a partir de átomos
y/o sentencias mediante conectivas lógicas.

110
Con el objetivo de evitar la ambigüedad, cada sentencia construida a partir de
conectivas binarias puede estar encerrada en paréntesis. Por ejemplo, se podría
poner ( ∧ ) ⇒ en vez de ∧ ⇒ .Sin embargo, con el objetivo de mejorar
la legibilidad suele omitirse dicho paréntesis atendiendo al siguiente orden de
precedencia descendente (de mayor a menor) de los símbolos: ¬,∧,∨,⇒y⇔. La
semántica, en cambio, define las reglas para asociar un valor de verdad (V o F) a
cada sentencia. La interpretación de las sentencias consistirá en asignar un valor
de verdad a cada proposición y habrá que considerar la correspondencia que haya
entre elementos del lenguaje y el mundo a representar.
Lógica de primer orden
La lógica proposicional tiene muchas limitaciones derivadas del uso exclusivo
de la proposición como construcción del lenguaje. Su lenguaje no permite
representar de forma precisa el conocimiento de entornos complejos. La lógica de
primer orden (LPO) extiende la lógica proposicional adoptando sus fundamentos,
es decir, adoptando una semántica composicional declarativa, que es
independiente del contexto y no ambigua. Además, construye una lógica más
expresiva basada en dicho fundamento y tomando prestada, de los lenguajes
naturales, su idea de la representación. La representación del conocimiento se
lleva a cabo considerando que en el lenguaje natural los nombres y las sentencias
nominales se refieren a objetos que tienen unas características distintivas
(propiedades). Por otro lado, están los verbos y las sentencias verbales que hacen
referencia a relaciones entre objetos. Algunas de estas relaciones son funciones,
las cuales son un tipo de relaciones que requieren una entrada determinada y
proporcionan una salida. Los siguientes son ejemplos de lo mencionado
anteriormente:
Objetos: gente, casas, números, colores,...
Propiedades: alto, rojo,..
Relaciones: hermano, más alto que,...

111
Funciones: padre de, tejado de,...
Así pues, la principal diferencia entre la lógica proposicional y la LPO es lo que
cada uno asume, que es la naturaleza de la realidad y lo que comprende el
compromiso ontológico de cada lenguaje. La lógica proposicional considera que
hay hechos que suceden o no en el mundo mientras que la LPO asume que el
mundo se compone de objetos con ciertas relaciones que suceden o no.
El compromiso epistemológico es otra caracterización posible de la lógica, la
cual se refiere a los posibles estados del conocimiento respecto a cada hecho que
la propia lógica permite. En este caso, ambas lógicas analizadas permiten que el
agente adopte tres posibles valores ante un hecho representado mediante una
sentencia: verdadero, falso o desconocido.
Sintaxis y semántica
Los elementos sintácticos básicos de la LPO son los símbolos que representan
los objetos, las relaciones y las funciones. Por lo tanto, los símbolos se agrupan en
tres tipos:
Símbolos de constante, que representan los objetos.
Símbolos de predicado, que representan las relaciones.
Símbolos de función, que representan funciones.
Cada símbolo de predicado y de función tiene una aridad que establece su
número de argumentos. Cada relación tiene una aridad mayor o igual a 0 mientras
que una función tiene una aridad mayor que 0. Por ejemplo, se puede representar
el lenguaje de la aritmética para representar los números naturales:
Símbolos de constantes:{0,1}.
Símbolos de función:
◦ Monaria: s (siguiente).
◦ Binarias:{+,∗}.

112
Símbolo de relaciones binaria:{ }.
Otros símbolos que usa la sintaxis de la LPO son:
Símbolos lógicos: ◦ Variables: x, y, z, etc.
◦ Conectivas: ¬,∧,∨,⇒y⇔.
◦ Cuantificadores: ∀, ∃.
◦ Símbolo de igualdad:.
Símbolos auxiliares:
◦ Los paréntesis: “(“, “)”.
◦ La coma: “,”.
A partir de los símbolos anteriormente descritos se pueden definir las siguientes
nociones:
Términos. Un término es una expresión lógica que se refiere a un objeto. Por
tanto abarca los símbolos de variable, constante y los de función. En este
último caso tendrá la forma , … , ,con haciendo referencia a un
símbolo de función, es la aridad y es un término. Siguiendo con el ejemplo
del lengiaje de la aritmética se tendría:
◦ Es un término que se suele escribir( ∗ 1) + ( ).
◦ , <∗ , ( )+
no es un término.
Sentencias atómicas. Representan hechos y están formados por un símbolo
de predicado seguido de una lista de términos entre paréntesis. Estas
sentencias pueden tener términos complejos. Una sentencia atómica es
verdadera en un modelo dado, y bajo una interpretación dada, si se cumple la
relación (símbolo de predicado) entre los objetos (argumentos). Continuando
con el ejemplo de la aritmética:
◦ ∗ ( , 1), ( ) es una sentencia atómica que se suele escribir como
∗ 1 < ( ).

113
◦ +( , ) =∗ ( , ) es una sentencia atómica que se suele escribir
como + = ∗ .
Sentencias compuestas. Las sentencias pueden hacerse más complejas
haciendo uso de las conectivas lógicas. La semántica es idéntica a la de la
lógica proposicional.
Cuantificadores. Para poder expresar propiedades de colecciones de objetos,
se puede hacer uso de los cuantificadores para no tener que enumerarlos
todos. La LPO tiene dos cuantificadores:
◦ Cuantificador universal( ).Hace referencia a todo objeto y se lee
“para todo...”.
◦ Cuantificador existencial ( ). Permite construir enunciados
indicando que de todos los objetos existe al menos uno sin
nombrarlo específicamente. Se lee “existe...”.
Igualdad. La LPO usa el símbolo de igualdad para construir enunciados
describiendo que dos términos se refieren al mismo objeto.
Uso de la LPO
Se parte de una BC a la que se irán añadiendo sentencias mediante DECIR,
que corresponde a una sentencia que se denomina aserción. Por ejemplo, se
puede afirmar que un rey es una persona mediante la siguiente sentencia
, ∀ ( ) ⇒ ( ) . Además, se puede preguntar a la BC
mediante PREGUNTAR. Por ejemplo, , ( ) . Esta
sentencia se denomina petición u objetivo. Estas dos interfaces permiten
interactuar con la BC.
A continuación se tratará, como ejemplo, el dominio de las relaciones familiares
o de parentesco. La modelización de este dominio se caracterizaría del siguiente
modo:
Objetos: personas
Propiedades: género → predicados unarios: masculino y femenino.

114
Relaciones (de parentesco): progenitor, descendiente, hijo, hija, cónyuge,
esposo, esposa,... → predicados binarios pprogenitor, descendiente, hijo, hija,
cónyuge, esposo, esposa,…
Funciones: padre y madre → funciones padre y madre
A partir de esto se pueden escribir algunas sentencias sobre lo que se sabe
acerca de los símbolos:
La madre de alguien es su progenitor femenino.
∀ , ( ) = ⇔ ( ) ∧ ( , )
El esposo de alguien es su cónyuge masculino.
∀ , ( , ) ⇔ ( ) ∧ ó ( , )
Masculino y femenino son géneros disjuntos.
∀ ( ) ⇔ ¬ ( )
Progenitor y descendiente son relaciones inversas.
Cada una de estas sentencias puede verse como un axioma del dominio de
parentesco. Sin embargo, no todas las sentencias son axiomas. Algunas son
teoremas pues son deducidas a parir de los axiomas. Desde el punto de vista
lógico, la BC solo necesita saber tener los axiomas de modo que todo el
conocimiento derivará en forma de teoremas y, por lo tanto, no es necesario
almacenarlos en la BC. Sin embargo, desde un punto de vista práctico, su
almacenamiento reducirá el coste computacional para derivar nuevo conocimiento
pues en caso de no almacenarlo siempre tendrá que empezar desde los axiomas.
5.10. Ejemplos A continuación se analizará el modelo de lógica de primer orden que se muestra
en la Figura 8. El modelo consta de:
Cinco objetos: Ricardo corazón de León, Juan, pierna izquierda de Ricardo, pierna izquierda de Juan y una corona.
Dos relaciones binarias: hermano y sobre la cabeza.

115
Tres relaciones unitarias: corona, rey y persona.
Una función unitaria: pierna izquierda.
Los símbolos de LPO del modelo son:
Símbolos de constante: Ricardo y Juan.
Símbolos de predicado: hermano, sobre la cabeza, persona, rey y corona.
Símbolo de función: pierna izquierda.
La semántica ayuda a interpretar qué objetos, relaciones y funciones son
referenciados mediante los símbolos anteriormente mencionados. Una posible
interpretación de este ejemplo podría ser:
Símbolos de constante:
◦ Ricardo se refiere a Ricardo Corazón de León.
◦ Juan se refiere al Rey Juan.
Símbolos de predicado:
◦ Hermano se refiere a la relación de hermandad entre dos personas.
Figura 8. Modelo sencillo en lógica de primer orden. Fuente: http://www.slideshare.net/rushdishams/first-order-logic-26695335

116
◦ Sobre la cabeza se refiere a la relación que hay entre el Rey Juan y la
corona que está sobre su cabeza.
◦ Persona, rey y corona hacen referencia a los conjuntos de objetos
que son una persona, un rey y una corona.
Símbolo de función pierna izquierda es una función que se refiere a la pierna
situada en dicha posición.
A partir de aquí se pueden considerar diversas sentencias que representarán
los axiomas de este modelo.
5.11. Ejercicios de reflexión 1. Considerando el dominio del parentesco para la LPO, indicar cómo se
escribirían las siguientes sentencias:
Padre e hijo son relaciones inversas.
Un abuelo es el padre del padre de uno.
Un hermano es otro hijo del padre de uno.
2. Considere una serie de bloques dispuestos como se muestra en la Figura X.
Modele su lenguaje dentro de la lógica de primer orden indicando qué tipo de
símbolo es cada cosa. Para el caso de los símbolos de predicado y función,
indique su aridad:
Tipos de símbolos:
constantes
predicado
función
- Símbolos a identificar: libre, a, superior, bajo, b, es_bloque, d, e, sobre_mesa,
pila, sobre, encima, tope y c.
3. En el lenguaje del mundo de los bloques indique:

117
Si es o no un término:
◦ Superior (superior(c)). [S]
◦ Libre (superior(c)). [N]
Si es o no una sentencia atómica:
◦ Libre (superior(c)) [S]
◦ Tope (c) = superior(b) [S]
4. Traduzca a lógica de primer orden:
El Everest es la montaña más alta de la tierra.
Hay al menos dos manzanas en el barril.
Elena se comió una seta que había seleccionado ella misma.
Ninguna rana amarilla es comestible.
Todos los estudiantes hornearon, al menos, dos bizcochos.

118
Conclusiones En IA la búsqueda es el núcleo de muchos procesos inteligentes como la
deducción, la planificación, prueba automática de teoremas, etc. Una de las claves
de su importancia radica en que es una técnica que permite encontrar una
solución a un problema cuando no se conoce una aproximación directa al
problema. Para ello abordan un problema reduciéndolo a una búsqueda en el
espacio de estados, y dicha búsqueda puede representarse mediante una
estructura de tipo árbol.

119
Considerando que el número de estados suele crecer exponencialmente a
medida que aumenta el tamaño del problema, se hace necesario estudiar la
eficacia y eficiencia de los distintos tipos de estrategias.
En IA los juegos han sido estudiados ampliamente ayudando al desarrollo de la
IA. Adoptar decisiones óptimas es intratable en la mayoría de los casos, de modo
que suelen tratarse mediante algoritmos aproximados que ayudan a buscar una
estrategia que se aproxime lo más posible a la óptima.
En el mundo de la industria esta temática ha tenido mucho éxito en el mundo
del videojuego pues ha permitido que los jugadores humanos puedan enfrentarse
a oponentes de calidad similar o superior en sus decisiones a las que tendría
cualquier otro jugador humano.
En el tercer capítulo, se vieron qué características hay que tener en cuenta para
representar el conocimiento. Además, se introdujeron los dos tipos de lógica más
usados (la lógica proposicional y la de primer orden) como lenguaje para poder
representar dicho conocimiento. El motivo por el que la LPO ha desbancado la
popularidad de la lógica proposicional se debe a las limitaciones de esta,
principalmente, en la expresividad. Sin embargo, la lógica proposicional es muy útil
para los casos en los que no importa el contenido de la proposición sino la
estructura de la información.

120
Glosario Agente inteligente: entidad con capacidad de percibir su entorno, procesar
dichas percepciones y responder o actuar sobre un entorno de manera racional,
es decir, correcta y maximizando el resultado esperado.
Inteligencia artificial (IA): disciplina de las ciencias de la computación que
trata de desarrollar sistemas capaces de adoptar comportamientos que, si fuesen
realizados por humanos, no dudaríamos en calificar como inteligentes.

121
Inteligencia artificial débil: corriente de la IA que adopta dos posibles posturas
respecto a la conciencia. La primera es que considera que la conciencia no se
puede atribuir a procesos puramente físicos y, por lo tanto, no es posible abordarlo
científicamente. La otra considera que, aunque la conciencia puede atribuirse a
procesos puramente físicos, su elevada complejidad hace que no pueda ser
entendido ni simulado.
Inteligencia artificial fuerte: corriente de la IA que sostiene que en un futuro
seremos capaces de comprender y simular los procesos que dan lugar a la
conciencia. De esta forma, una máquina que haya sido provisto con la suficiente
inteligencia podrá adquirir conciencia.

122
Bibliografía
Franklin, S., & Graesser, A. (1996). Is it an agent, or just a program? a taxonomy
for autonomous agents. Proceedings of the third International Workshop on
Agent Theories, Architectures, and Languages. New York: Springer-Verlag.
Nwana, H.S. (1996). Software agents: an overview. Knowledge Engineering
Review, 11 (3), p. 1-40.
Russel, S., Norvig, P. (2008). Inteligencia Artificial. Un enfoque moderno. Madrid:
Pearson Prentice Hall.

123
Wooldridge, M., & Jennings, N.R. (1995). Intelligent agents: theory and practice.
Knowledge Enginnering Review, 10 (2), p. 115-152.
García Morate, D. (2016). Manual de Weka. Obtenido de: http://sci2s.ugr.es/sites/default/files/files/Teaching/GraduatesCourses/InteligenciaDeNegocio/weka.pdf
Russel, S., Norvig, P., (2008). Inteligencia Artificial. Un enfoque moderno. Madrid:
Pearson Prentice Hall. Witten, I.H., Frank E. (2005). Data Mining. Practical Machine Learning Tools and
Techniques. San Francisco: Morgan Kaufmann.
Barber, F., & Salido, M. (2008). Problemas de Satisfacción de Restricciones (CSP). En Inteligencia Artificial: Técnicas, métodos y aplicaciones. México: McGraw-Hill, p. 385-432. Obtenido de: http://users.dsic.upv.es/~msalido/papers/capitulo.pdf
Russel, S., Norvig, P., (2008). Inteligencia Artificial. Un enfoque moderno. Madrid:
Pearson Prentice Hall.

124

125

126

127