1 descriptiva
TRANSCRIPT

1
"ESTADÍSTICA DESCRIPTIVA"
1.1 Parte básica

2
1.1.1 Introducción a la Estadística
1.1.1.1 Concepto de Estadística y Estadísticas
La primera acepción del término "Estadística", que tiene origen histórico, hace referencia a una determinada información numérica; esta acepción se encuentra cada día más arraigada en nuestra sociedad debido al abultado conjunto de números y cifras en el que se encuentra inmersa: P. I. B., índices de precios, tasas de inflación, evolución del paro, cotizaciones bursátiles, accidentes de circulación, porcentajes de votantes, porcentajes de personas que padecen una determinada enfermedad, etc.
Una segunda acepción entiende la estadística como una ciencia que facilita los métodos precisos para la obtención de información numérica, y que también proporciona métodos de análisis de esa información recogida y métodos de investigación aplicables al resto de las Ciencias. La primera se corresponde básicamente con la estadística descriptiva y la segunda con la estadística inferencial.
1.1.1.2 Etapas del análisis estadístico
Las diversas fases por las que atraviesa el análisis estadístico son:
a) Recogida de datos, que no por ser elemental, está exenta de dificultades e indicaciones que hay que observar, ya que una recogida mal efectuada puede ocasionar un sesgo de la información y del posterior análisis, por lo que el objeto de la investigación debe plantearse de una manera minuciosa, así como la organización del trabajo de campo necesario para la recogida de datos. b) Ordenación y presentación de los datos, y que suele presentarse mediante unas tablas de simple o de doble entrada. c) Resumen de la información, para tratar de describir las características más relevantes que pueden tener los datos, y que se realiza mediante la determinación de parámetros estadísticos que intentan resumir toda la información que aporte el conjunto de datos.

3
d) Análisis estadístico, a través de métodos facilitados por la Estadística Matemática, para tratar de verificar hipótesis sobre regularidades que pueden detectarse en las etapas previas.
1.1.1.3 Población y muestra
Recibe el nombre de Población, Colectivo o Universo, todo conjunto de individuos o elementos que tienen unas características comunes.
Dado que no siempre es posible estudiar todos los elementos de la población, ya sea por razones económicas, de rapidez de obtención de la información, o porque los elementos se destruyen en el proceso de la investigación, con frecuencia es necesario examinar sólo una parte de la población, que se denomina muestra; para que una muestra sea válida como objeto de estudio, ha de ser representativa de la población, es decir ha de tener las mismas características, en los caracteres estudiados, que la población.
1.1.1.4 Caracteres de una población
Llamaremos variable al carácter objeto de estudio, que puede tomar distintos valores.
Las variables pueden ser cuantitativa o cualitativas, según que tomen, o no, valores cuantificables.
Las variables de tipo cuantitativo, que estudian caracteres cuantificables, pueden clasificarse de diversas formas: variables discretas o continuas, según que sólo puedan tomar valores aislados o, por el contrario, todos los valores de un intervalo.
1.1.1.5 Tipos de escalas
En determinado tipo de estudios, quizá tenga mayor relevancia diferenciar las variables según el tipo de escala utilizada, distinguiendo:
Escala nominal: el carácter estudiado se clasifica en categorías no numéricas, sin que puedan establecerse ninguna relación de orden entre ellas,

4
por ejemplo: las profesiones laborales, el estado civil, la ideología política, el sexo, etc. Escala ordinal: el carácter estudiado es de tipo no numérico, pero se pueden establecer algún tipo de orden entre las distintas categorías. Este es el caso del nivel de estudios (primarios, medios, superiores), los tipos de clases sociales (baja, media, alta),etc. Escala de intervalo: puede establecerse alguna unidad de medida y cuantificar numéricamente la distancia existente entre dos observaciones. Es la escala cuantitativa, encontrándose en este caso gran número de variables entre ellas, como por ejemplo: salarios, presupuestos, gastos, etc. Escala de proporción: son aquellas variables en las que además de una unidad de medida, se fija un punto origen, que marca el cero. En este tipo pueden considerarse la edad, el peso, el número de unidades en stock en un inventario, etc.

5
1.1.2 Variables estadísticas unidimensionales
1.1.2.1 Distribución de frecuencias. Clases.
Vamos a tratar ahora de estructurar y ordenar los conjuntos numéricos de los datos obtenidos en la observación de una muestra o población para así poder proceder con más facilidad a su estudio.
Empezaremos estudiando las frecuencias en sus diversas clases: Frecuencia absoluta: es el número de veces que se repite cada valor de la
variable en el conjunto de todas las observaciones de la misma. En general la frecuencia absoluta del dato xi se representa por f i
Frecuencia relativa: es el cociente entre la frecuencia absoluta y el número total de datos u observaciones. El número total de datos lo representamos por n, y la frecuencia relativa del dato xi se representa por hi
Se verifica por lo tanto: hi = fi/n
Frecuencia absoluta acumulada: es la suma de las frecuencias absolutas de
los valores inferiores o iguales al considerado. Evidentemente los valores de la variable deben de estar ordenados en forma creciente.
En general, la frecuencia absoluta acumulada del dato xi se representa por Fi
Evidentemente, la última frecuencia absoluta acumulada coincide con el tamaño de la muestra.
Se verifica pues: Fi = f jj=1
i
!
Frecuencia relativa acumulada: es el cociente entre la frecuencia absoluta
acumulada y el número total de datos u observaciones. Análogamente a la anterior, los valores de la variable deben de estar ordenados en forma creciente, es decir, la escala debe de ser numérica o, al menos, ordinal.

6
La última frecuencia relativa acumulada es 1. Generalmente la frecuencia relativa acumulada del dato xi de la variable se representa por Fi, y verifica:
Hi =Fi
n=
f jj=1
i
!
n
1.1.2.2 Propiedades de las frecuencias
1ª La suma de las frecuencias absolutas coincide con tamaño de la muestra:
fii
! = n
2ª Todas las frecuencias absolutas son positivas y menores o iguales que n .
0 ≤ fi ≤ n 3ª La suma de las frecuencias relativas es 1:
hii
! =1
4ª Todas las frecuencias relativas son positivas y menores o iguales que 1:
0 ≤ hi ≤ n
5ª La frecuencia absoluta acumulada correspondiente a un valor de la variable se obtiene sumando la frecuencia absoluta acumulada del valor anterior, con la frecuencia absoluta del dato.
DISTRIBUCIÓN DE FRECUENCIAS
Llamaremos distribución de frecuencias al conjunto de los valores que toma una variable, junto con sus frecuencias correspondientes. Así pues, para determinar una distribución de frecuencias debemos conocer todos los valores xi de la variable y
cualquiera de las columnas de frecuencias (pues el paso de una a otra es inmediato).

7
Distinguiremos dos tipos fundamentales de distribución de frecuencias: las no agrupadas en intervalos y las agrupadas en intervalos.
La distribución de frecuencias no está agrupada en intervalos cuando cada valor de la variable tiene asociado su frecuencia. Pero ocurre frecuentemente, sobre todo en variables de tipo continuo, que el número de valores distintos que toma la variable es demasiado grande; en este caso, para mayor comodidad en el tratamiento de la información, parece aconsejable agrupar esos valores en intervalos, teniendo en cuenta que lo que ganamos en manejabilidad lo perdemos en información de la distribución.
En la agrupación en intervalos hay que tener en cuenta tres aspectos:
a) Que el máximo de información se obtiene en la recogida de datos y que ésta se pierde al agrupar en intervalos.
b) Las distribuciones agrupadas en intervalos no se presentan realmente así, sino que es el investigador el que las agrupa para manejar mejor los datos.
c) Al agrupar hay que tener en cuenta las frecuencias.
Un intervalo queda determinado por sus extremos y, en general, el intervalo i-ésimo se representa por [Li-1,Li), donde Li es el extremo superior del intervalo y Li-1 el
extremo inferior del mismo.
Llamaremos amplitud del intervalo, ai, a la diferencia entre sus extremos superior e inferior: ai = Li - Li-1
Esta amplitud puede ser constante para todos los intervalos, o variable, aunque es más cómodo que sea constante.
Cuando un investigador decide agrupar los datos en intervalos se encuentra con dos cuestiones iniciales:
1ª.- ¿Cómo se debe tomar la amplitud, constante o variable? 2ª.- ¿Cuántos intervalos conviene tomar ?
La respuesta a estas pregunta depende de la naturaleza del problema, y aunque
hay muchas reglas escritas en los textos de estadística, en la práctica suelen resultar estériles.

8
Posteriormente se hace un recuento de los datos que corresponden a cada
intervalo, para determinar la frecuencia de cada uno de ellos. Aparece un problema cuando un dato coincide con alguno de los extremos de los intervalos; como regla general, se toman los intervalos cerrados por la izquierda y abiertos por la derecha [Li-
1,Li), es decir, se incluirán dentro del intervalo los datos que coincidan con el extremo
inferior del mismo, y se excluirán de éste los que coincidan con su extremo superior, incluidos, por lo tanto, en el intervalo posterior. Para evitar este problema de incluir o no incluir los datos en los intervalos, los extremos se suelen tomar con un decimal más que los de los datos, siendo, normalmente este decimal un 5.
Por último cabe destacar que tomaremos como representante de cada intervalo su
punto medio, que denominaremos marca de clase, y designaremos por ci. Así la marca de clase del intervalo [Li-1,Li) será:
ci =
Li!1 + Li
2
EJEMPLO 1.1:
Investigados los precios por habitación de 50 hoteles de una ciudad, se han obtenido los siguientes resultados:
7000 3000 5000 4000 5000 7000 4000 7500 8000 5000 5000 500 3000 7000 10000 15000 5000 7500 12000 8000 4000 5000 3000 5000
10000 3000 4000 5000 7000 5000 3000 4000 7000 4000 7000 5000 4000 7000 10000 7500 7000 8000 7500 7000 7500 8000 7000 7000
12000 8000
Determinar la distribución de precios: a) Sin agrupar en intervalos. b) Agrupadas en 5 intervalos de amplitud constante.
Solución: a)
Precio (xi) en miles 3 4 5 7 7.5 8 10 12 15 Nº de hoteles (fi) 5 7 10 11 6 5 3 2 1

9
b)
Precio en intervalos marca de clase (xi) Nº de hoteles (fi) [3000, 5500) [5500, 8000)
[8000, 10500) [10500, 13000) [13000, 15500)
4250 6750 9250
11750 14250
22 17 8 2 1

10
1.1.3 Representaciones gráficas La información proporcionada por las tablas de distribución de frecuencias es
bastante completa, pero tiene la dificultad de que su lectura requiere un cierto tiempo y capacidad de comparación para relativizar la información de unas clases respecto de las otras. Además, en la experiencia del lector, al comenzar a leer un determinado artículo (científico o no), su vista se dirige primero al título, luego a los gráficos y, finalmente, a las tablas.
Así pues, las representaciones gráficas constituyen uno de los principales y más sencillos métodos de exponer la información, por su capacidad de impactar al lector con muy poco esfuerzo por su parte, dando una información rápida y global de los datos, siendo útiles incluso al investigador, pues le permiten tener una idea general de los resultados y, a veces, sugerir nuevas hipótesis.
1.1.3.1 Tipos de representaciones gráficas
Los diversos tipos de gráficos utilizados son:
1º DIAGRAMAS DE BARRAS PARA DISTRIBUCIONES DE FRECUENCIAS NO AGRUPADAS:
En un sistema de ejes de coordenadas cartesianas, se representan en el eje de abscisas los valores de la variable, y en el de ordenadas las frecuencias. Posteriormente, sobre cada valor de la variable se levanta una barra vertical de altura proporcional a la frecuencia, ya sea absoluta o relativa.
Sobre el eje de abscisas la escala de medida puede ser cualquiera y no coincidir
con la escala del eje de ordenadas. Incluso el cero del eje de abscisas no tiene porque coincidir con el cero de la medida utilizada.
EJEMPLO 1.2:
Supongamos una variable X que presenta los siguientes valores : xi = { a, e, i, o, u }
con las siguientes frecuencias: f1 = 1 f2 = 2 f3 =1 f4 = 3 f5 = 3,
correspondientes a las veces que aparecen dichas vocales en una frase.

11
Construya el diagrama de barras correspondiente y el diagrama de barras
acumulado, o diagrama de escalera.
Solución:
Podemos presentar entonces la siguiente tabla:
xi fi Fi hi Hi a 1 1 0,1 0,1 e 2 3 0,2 0,3 i 1 4 0,1 0,4 o 3 7 0,3 0,7 u 3 10 0,3 1
El diagrama de barras correspondiente aparece en la figura 1.1:
.
0
1
2
3
4
VOCALES
a e o ui
FRECUENCIAS
Figura 1.1: Diagrama de brarras Si lo que queremos representar son las frecuencias acumuladas, se procede igual
que en el caso anterior con los ejes cartesianos y levantando sobre cada valor de la variable, una altura proporcional (igual) a la frecuencia acumulada, uniendo mediante trazos horizontales el extremo de cada coordenada con el siguiente; este diagrama recibe el nombre de diagrama de escalera (ver figura 1.2).

12
Figura 1.2: Diagrama de barras acumulado. (Diagrama de escalera) Los gráficos de diagrama de barras y de escalera suelen utilizarse en variables de
tipo cualitativo, o en las de tipo cuantitativo discretas.
2º POLÍGONOS DE FRECUENCIAS PARA DISTRIBUCIONES DE FRECUENCIAS NO AGRUPADAS EN INTERVALOS:
Sobre unos ejes cartesianos, análogos a los anteriores, se levanta en cada valor de la variable una ordenada de altura igual a la frecuencia absoluta (o relativa) de dicho valor, uniendo a continuación con una poligonal dichas ordenadas. La primera ordenada se une con el cero del eje de abscisas, teniendo en cuenta que si hay algún valor de la variable con frecuencia cero también ha de ser considerado y unir dicho dato con los anteriores.
Veamos el polígono de frecuencias del ejemplo anterior (ver figura 1.3):

13
Figura 1.3: Polígono de frecuencias.
Análogamente se procedería con las frecuencias acumuladas (ver figura 1.4).
.
VOCALES
FR
EC
UE
NC
IAS
AC
UM
UL
AD
AS
5
10
a e i o u
Figura 1.4.: Polígono de frecuencias acumulado.
Estos polígonos de frecuencias se utilizan cuando la variable es de tipo cualitativo
o cuando es de tipo cuantitativo discreta. 3º HISTOGRAMA PARA DISTRIBUCIONES DE FRECUENCIAS AGRUPADAS EN INTERVALOS
Se construyen levantando, sobre cada intervalo de la variable, un rectángulo de área proporcional a la frecuencia absoluta de dicho intervalo. Si los intervalos son de amplitud constante, las alturas de los rectángulos serán iguales a las frecuencias absolutas respectivas, pues al ser las bases iguales las áreas son proporcionales a las alturas; pero si las amplitudes de los intervalos son diferentes, las alturas de los rectángulos deben calcularse dividiendo la frecuencia absoluta por la longitud del intervalo; ésta se puede representar por ai y vale pues:
ai =
fi
ci
y de esta forma, el área del rectángulo coincide con la frecuencia:
Si = ai ci =fi
ci
ci = f i

14
La altura ai correspondería a la frecuencia correspondiente a cada unidad de
medida de la variable en cada intervalo, y se le conoce a veces, con el nombre de densidad de frecuencia del intervalo.
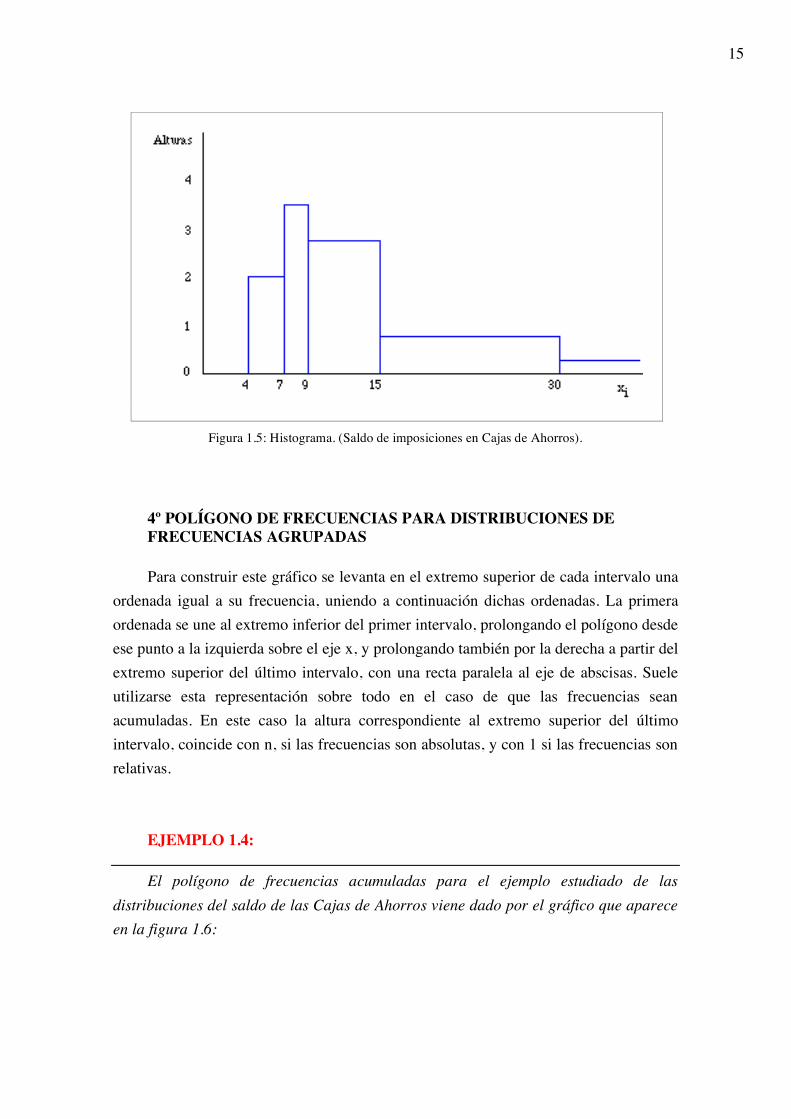
EJEMPLO 1.3:
La distribución del saldo de imposiciones en las Cajas de Ahorros viene dada en la tabla siguiente:
Saldo Nº provincias 4-6,9 7-8,9
9-14,9 15-29,9 30-59,9 60-99,9 ≥100
6 7 17 13 4 2 1
Representar el histograma correspondiente
Solución:
Como los intervalos son de amplitud no constante, hay que calcular las alturas de los mismos, obteniéndose la siguiente tabla: intervalos fi alturas Fi hi Hi Grados
4 -6.9 6 2 6 0.12 0.12 43.2 7 -8.9 7 3.5 13 0.14 0.26 50.4
9 -14.9 17 2.8 30 0.34 0.60 122.4 15 -29.9 13 0.8 43 0.26 0.86 93.6 30 -59.9 4 0.1 47 0.08 0.94 28.8 60 -99.9 2 0.05 49 0.04 0.98 14.4 ≥ 100 1 0 50 0.02 1.00 7.2 Total 50 1.00 360.0
que da lugar al histograma de la figura 1.5:
15
Figura 1.5: Histograma. (Saldo de imposiciones en Cajas de Ahorros).
4º POLÍGONO DE FRECUENCIAS PARA DISTRIBUCIONES DE FRECUENCIAS AGRUPADAS
Para construir este gráfico se levanta en el extremo superior de cada intervalo una ordenada igual a su frecuencia, uniendo a continuación dichas ordenadas. La primera ordenada se une al extremo inferior del primer intervalo, prolongando el polígono desde ese punto a la izquierda sobre el eje x, y prolongando también por la derecha a partir del extremo superior del último intervalo, con una recta paralela al eje de abscisas. Suele utilizarse esta representación sobre todo en el caso de que las frecuencias sean acumuladas. En este caso la altura correspondiente al extremo superior del último intervalo, coincide con n, si las frecuencias son absolutas, y con 1 si las frecuencias son relativas.
EJEMPLO 1.4:
El polígono de frecuencias acumuladas para el ejemplo estudiado de las distribuciones del saldo de las Cajas de Ahorros viene dado por el gráfico que aparece en la figura 1.6:

16
Figura 1.6: Polígono de frecuencias acumuladas. (Saldo de imposiciones en Cajas de Ahorros). En el caso de representar las frecuencias no acumuladas se procede de diferente
forma, uniendo los puntos medios de los lados superiores de los rectángulos del histograma y prolongando por los extremos hasta cortar al eje X en los puntos medios de las bases del primer y del último rectángulo (ver figura 1.7).
5
4
3
2
1
2010 30 40 50 60 70 80 90 100
xi
Alturas
Figura 1.7: Polígono de frecuencias. (Saldo de imposiciones en Cajas de Ahorros).
El área del polígono cerrado resultante es igual al área de los rectángulos
formados mediante el histograma.

17
A veces se representan en el mismo gráfico el histograma y el polígono de frecuencias.
5º DIAGRAMA DE SECTORES
Este caso, en una circunferencia se representan sectores circulares cuyo ángulo central coincida con la frecuencia absoluta (no se puede utilizar para acumuladas) o relativa del elemento, representando, mediante colores o incluyendo dentro de dicho sector el nombre de la clase o elemento a representar. Vale tanto para frecuencias agrupadas, como no agrupadas.
Previamente hay que calcular los grados que corresponde a cada elemento
multiplicando la frecuencia correspondiente a cada dato por el cociente entre 360º y el total de datos:
gi = f i
360°
n
EJEMPLO 1.5:
Obtener el gráfico de sectores correspondiente a los datos anteriores de las cajas de ahorros:
Solución:
intervalos fi alturas Fi hi Hi Grados 4 -6.9 6 2 6 0.12 0.12 43.2 7 -8.9 7 3.5 13 0.14 0.26 50.4 9 -14.9 17 2.8 30 0.34 0.60 122.4
15 -29.9 13 0.8 43 0.26 0.86 93.6 30 -59.9 4 0.1 47 0.08 0.94 28.8 60 -99.9 2 0.05 49 0.04 0.98 14.4 ≥ 100 1 0 50 0.02 1.00 7.2 Total 50 1.00 360.0
y su representación en sectores en la figura 1.8:
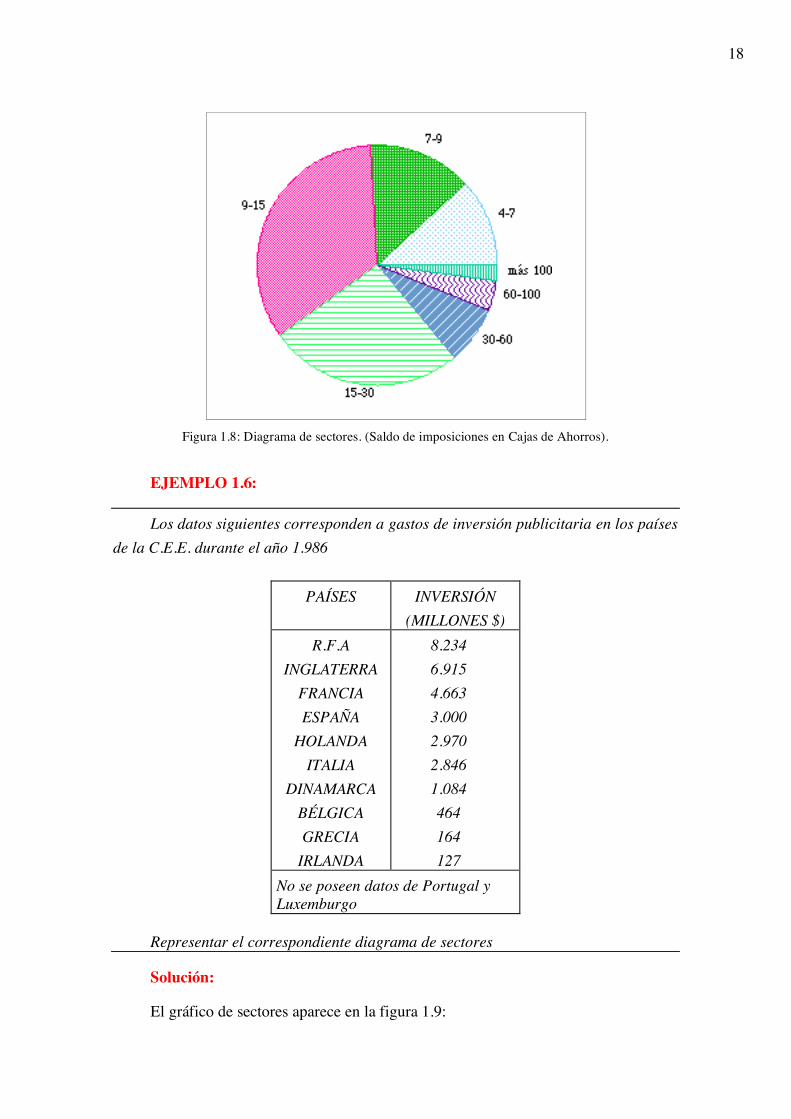
18
Figura 1.8: Diagrama de sectores. (Saldo de imposiciones en Cajas de Ahorros). EJEMPLO 1.6:
Los datos siguientes corresponden a gastos de inversión publicitaria en los países de la C.E.E. durante el año 1.986
PAÍSES INVERSIÓN (MILLONES $)
R.F.A INGLATERRA
FRANCIA ESPAÑA
HOLANDA ITALIA
DINAMARCA BÉLGICA GRECIA
IRLANDA
8.234 6.915 4.663 3.000 2.970 2.846 1.084 464 164 127
No se poseen datos de Portugal y Luxemburgo
Representar el correspondiente diagrama de sectores
Solución:
El gráfico de sectores aparece en la figura 1.9:

19
INGLATERRA
FRANCIA
ESPA ÑA
HOLANDA
ITALIA
DINAMARCA
IRLANDA
BELGICA
GRECIA
R.F.A
Figura 1.9: Diagrama de Sectores. Inversión publicitaria en la C.E. (datos de 1.986)
En este gráfico se observa que cuando ciertos datos presentan una frecuencia baja,
en relación con los demás, su sector circular seria no detectable visualmente, por lo que se une con otros de frecuencias también bajas, dándole el nombre de "otros", o bien, si es posible, indicando todos los elementos que lo forman.
6º PICTOGRAMAS
Son dibujos alusivos a la distribución que se pretende estudiar y que mediante su forma, tamaño, etc., ofrecen una descripción, lo más expresiva posible, de la misma. Consideremos el siguiente ejemplo:
EJEMPLO 1.7:
Representar el pictograma correspondiente a la tabla de datos siuiente:
PAÍSES INVERSIÓN (MILLONES $)
BRASIL MÉJICO
ARGENTINA VENEZUELA
CHILE PERU
COLOMBIA ECUADOR URUGUAY BOLIVIA
PARAGUAY
101.750 100.000 50.300 35.880 20.690 14.300 13.430 7.540 4.990 3.340 1.890

20
Solución:
BRASIL MEXICO ARGENTINA VENEZUELA CHILE PERU ECUADOR URUGUAUBOLIVIA PARAGUAY
DEUDA EXTERNADE AMERICA LATINA (Diciembre 1986)
COLOMBIA Figura 1.10: Pictograma (Deuda externa de América Latina)
En el caso anterior, el área de la figura debe de ser proporcional a la frecuencia,
aunque existe también la posibilidad de que una figura represente un número determinado de frecuencias, y entonces contenga este dato.
Este tipo de representación suele utilizarse en las distribuciones cualitativas, como
por ejemplo en la siguiente: EJEMPLO 1.8:
El censo ganadero español, en el mes de Septiembre de 1.977, según fuentes del Ministerio de Agricultura, era:
GANADO Nº DE CABEZAS
(EN MILES) BOVINO OVINO
CAPRINO PORCINO EQUINO
4.538 14.539 2.206 9.804 762
TOTAL 31.846 Represente el correspondiente pictograma

21
Solución:
El correspondiente pictograma sería de la forma que aparece en la figura 1.11:
Figura 1.11: Pictograma (Censo ganadero español) 7º CARTOGRAMAS
Son los gráficos realizados sobre mapas, representando el carácter estudiado en ciertas regiones, señalando las zonas con distintos colores o tramas, poniendo de manifiesto las diferencias existentes entre las regiones del plano. Se suelen utilizar para representar densidades demográficas de una nación, la renta per capita, índices de lluvia, etc.
8º DIAGRAMAS DE PERFIL RADIAL:
Se toma un punto de partida y se trazan tantos radios como modalidades tenga la variable estudiada y después, sobre estos radios, se toma una distancia al centro proporcional a la frecuencia de cada modalidad. Uniendo los puntos extremos de cada radio se obtiene un polígono cerrado, que es el perfil radial.
En el ejemplo del censo ganadero en Septiembre de 1977 seria (ver figura 1.12):

22
Equino
Caprino
Bovino
Porcino
Ovino
0 5000 10000
Figura 1.12: Perfil radial (Censo ganadero español) 9º DIAGRAMAS LINEALES
Se utilizan para mostrar las fluctuaciones de un determinado carácter estadístico con el paso del tiempo. Interesa únicamente la altura de la línea, referida a la base del diagrama, que se levanta con una longitud proporcional al valor del carácter estudiado en dicho mes.
Con frecuencia se aprovecha para representar sobre la misma escala varios
diagramas lineales muy relacionados entre sí. Por ejemplo, ingresos y gastos, nacimientos y defunciones, etc.
ENEROFEBRERO
MARZOABRIL
MAYOJUNIO
JULIO AGOSTO
SEPTIEMBRE
EVOLUCION DE LATASA DE INFLACION
6'06'3 6'2
5'8
4'9 4'94'5 4'4
0'7 1'1
1'7
21'9 1'9
2'9 2'9
3'8
6'0
EVOLUCION DEL IPC(Acumulado en 1987)
Figura 1.13: Diagrama lineal

23
El gráfico anterior (figura 1.13) reproduce un diagrama aparecido en DIARIO 16,
que expresa la evolución del IPC y la tasa de inflación durante los nueve primeros meses del año 1.987.
A veces se unen en un mismo gráfico varios grupos para considerarlos
conjuntamente, compararles y observar donde las distribuciones coinciden o se separan, permitiendo así un análisis gráfico comparativo.
Así, el gráfico siguiente (figura 1.14) muestra los polígonos de frecuencias
porcentuales correspondientes a las distribuciones de ingresos en familias de población blanca y negra en los Estados Unidos.
Población
negra
Población
blanca
Indice de
integración=0'71
0
2'0
4'0
6'0
8'0
10'0
12'0
14'0
1000$ 2000$ 5000$ 10000$ 15000$ 25000$ 50000$
%
Figura 1.14: Polígonos de frecuencias porcentuales

24
1.1.4 Medidas de tendencia central Las tablas de distribuciones de frecuencia ofrecen toda la información disponible,
pero a veces, debido a su extensión nos encontramos con dificultades a la hora de su interpretación, por lo que interesa resumirla con el fin de facilitar, tanto su análisis como la comparación entre distintas muestras o poblaciones. En este proceso de síntesis se buscan valores que determinen el comportamiento global del fenómeno estudiado
Las medidas de síntesis de la distribución se consideran operativas cuando:
a) Intervienen todos y cada uno de los elementos en su formación. b) Es siempre calculable. c) Es única para cada distribución de frecuencias.
Estos valores se denominan medidas de posición, en general son promedios de los
valores y pueden ser de tendencia central o no. Sólo tienen sentido si la variable es cuantitativa.
Entre las más importantes están la media aritmética, la mediana, la moda y los
cuantiles; además de éstos, también estudiaremos la media geométrica, la media armónica, la media cuadrática y la media aritmética ponderada.
1.1.4.1 Media aritmética
Se define como la suma de todos los valores de la distribución, dividida por el nº total de datos. Si designamos por xi al valor de la variable X, que se repite fi veces, la
media aritmética será:
x =x1
nf1 +
x2
nf2 +!+
xk
nf k =
xif i
i=1
k
!
n=
xif i
ni=1
n
! = xihi
i=1
k
!

25
EJEMPLO 1.9:
Por ejemplo, sea la variable X que representa los pesos en kilogramos de 10 estudiantes y que presenta los valores:
xi={ 54, 59, 63, 64 } con las siguientes frecuencias fi={ 2, 3, 4, 1 }. Calcular la media aritmética.
Solución:
La media aritmética vendrá dada por:
x =54.2 + 59.3 + 63.4 + 64.1
10=
108 +177 + 252 + 64
10=
601
10= 60.1 Kg
En el caso de que las variables estuvieran agrupadas en intervalos no se podría
utilizar dicha expresión, por no saber el valor exacto de la variable, usándose en este caso como xi la marca de clase del intervalo.
Veámoslo con el siguiente ejemplo:
EJEMPLO 1.10:
Consideraremos la siguiente tabla de distribución de frecuencias:
Intervalo fi Marca de clase 30-40 40-50 50-60
3 2 5
35 45 55
Total 10 Calcular la media aritmética de los datos
Solución:
Resultará, según la definición dada, que
x =xifi
n! =
35.3 + 45.2 + 55.5
10= 47

26
No obstante, y dado que la media aritmética está muy influenciada por los valores extremos de las observaciones, no siempre sirve para representar lo que ocurre en cada una de éstas, tal y como puede observarse en el siguiente ejemplo:
EJEMPLO 1.11:
La tabla siguiente recoge el número total de goles marcados en los ocho primeros campeonatos de liga de primera división correspondientes a las temporadas en que han participado en el mismo 20 equipos:
Temporada Número de goles
87-88 909 88-89 868 89-90 921 90-91 822 91-92 913 92-93 954 93-94 989 94-95 966
Calcular e interpretar la media aritmética.
Solución:
Calculada la media aritmética se observa que es 917,75; no obstante, este valor es poco representativo de lo ocurrido en cada temporada, puesto que solamente en los años 89-90 y 91-92 se obtuvo un número de goles próximo a dicho valor, mientras que en el resto de temporadas se obtuvieron bastantes más ( 92-93, 93-94 y 94-95 ) o bastantes menos ( 87- 88, 88-89, 90-91).
Por otro lado ¿qué sentido tiene decir que se marcaron 917,75 goles?, ¿acaso hubo
alguna ocasión en la que solamente penetró en la portería el 75% del balón?.

27
PROPIEDADES DE LA MEDIA ARITMÉTICA:
1ª. La suma de las desviaciones de los valores de la variable respecto a su media es 0.
xi ! x ( )f i
i=1
k
" = xif i
i=1
k
" ! x f i
i=1
k
" = n
xifi
i=1
k
"
n! x n = nx ! x n = 0
2ª. Si a todos los valores de la variable les sumamos una constante k, la media aritmética queda aumentada en esa constante. Si consideramos la distribución ( xi + k, fi ) su media será:
x'= xi
' fi
ni=1
k
! = xi + k( )f i
ni=1
k
! = xi
fi
ni=1
k
! + kf i
ni=1
k
! = x + k
3ª. Si a todos los valores de la variable los multiplicamos por una constante k, su media aritmética queda multiplicada por esa constante.
Para demostrar esta propiedad basta considerar la distribución ( xik , fi ), su media
será:
x ' ' = xi
' ' f i
ni=1
k
! = xik( )fi
ni=1
k
! = k xi
fi
ni=1
k
! = kx
4ª. Si a una variable X le efectuamos una transformación lineal de la forma Y = aX + b, con a y b constantes, la media de la nueva variable queda afectada por dicha transformación lineal:
y = ax + b
La demostración es consecuencia inmediata de las propiedades 2ª y 3ª de la
media.

28
VENTAJAS E INCONVENIENTES
Como ventajas de utilizar la media aritmética como un promedio para sintetizar los valores de la variable podemos citar las siguientes:
- Considera todos los valores de la distribución. - Es siempre calculable (en variable cuantitativa). - Es única. Como inconvenientes de la utilización de la media aritmética cabe citar que, a
veces, puede dar lugar a conclusiones erróneas, cuando la variable presenta valores muy extremos, que influyen mucho en la media, haciéndola poco representativa.
1.1.4.2 Media aritmética ponderada
Se calcula esta media aritmética cuando cada valor de la variable tiene asociado una ponderación o un peso, distinto de la frecuencia, y que le haga tener más o menos importancia en la distribución.
En este caso si el dato xi tiene un peso wi, su media ponderada sería:
x p =
xiwii=1
k
!
wii=1
k
!
Si cada dato presenta una frecuencia fi, la media ponderada sería:
x p =
xifiwii=1
k
!
fiw ii=1
k
!

29
EJEMPLO 1.12
Veamos un ejemplo de un estudiante que realiza tres exámenes de media hora, una hora y una hora y media respectivamente, obteniendo unas puntuaciones de 50, 80 y70.
Por la duración de los exámenes cabría atribuirles las ponderaciones de 1, 2 y 3
respectivamente.
xi 50 80 70 Ponderación 1 2 3
Calcular la puntuación media del alunno.
Solución:
Obtendríamos la siguiente media aritmética ponderada:
x =50.1 + 80.2 + 70.3
1 + 2 + 3=
420
6= 70
1.1.4.3 Media geométrica
Se define como la raíz n-ésima del producto de todos los n valores de la distribución:
G = x
1
f1x2
f2!x
k
fkn
Tomando logaritmos quedaría: logG =1
nfi logxi
i=1
k
!"
#
$ %
&
'
Es decir, el logaritmo de la media geométrica es la media aritmética de los logaritmos de los valores. En su cálculo se suele utilizar esta propiedad.
Veamos, por ejemplo, cómo calcular la renta media durante varios periodos de
tiempo.

30
EJEMPLO 1.13
Si invertimos 100.000 pts al 3% durante un año, al 5% durante otro año y al 8% durante un tercero, ¿cuál es la renta media a la que está invertido el dinero durante los tres años?.
Solución:
Cabría esperar que la solución fuera la media aritmética de las tres rentas, es decir el 5%, pero la realidad es otra; en efecto:
Teniendo en cuenta que:
C 1 + rm( )3=C 1 + r1( ) 1 + r2( ) 1 + r3( )
Se verificará que
1 + rm = 1 + r1( ) 1 + r2( ) 1+ r3( )3
Es decir, que 1+rm es la media geométrica de las rentas de cada anuales, expresadas en tanto por uno, más uno.
En nuestro problema: 1 + rm = 1.03!1.05!1.083 = 1.0497 es decir, el rédito medio
es del 4,97% ( media geométrica de los réditos anuales ), y no el 5% como parecía ser. Veamos otro ejemplo en el que interese utilizar logaritmos. EJEMPLO 1.14
Sea una clase de 22 niños, cuya talla se distribuye del modo siguiente:
Talla en cm. 100 120 125 140 Frecuencia 10 5 4 3
Calcular la talla media Solución: La media geométrica sería:
G = 100
10!120
5!125
4!140
322

31
Para calcular el valor de G tomaremos logaritmos, de manera que:
logG =1
2210 log100 + 5 log120 + 4 log125 + 3 log140( ) =
=1
2245.22193 = 2.05554
G = anti log 2.05554 = 113.6cm
La media geométrica tiene una ventaja sobre la media aritmética y es que es
menos sensible a los valores extremos. Como inconvenientes principales señalar que tiene un significado estadístico
menos intuitivo que la media aritmética, su cálculo es difícil y a veces no se puede calcular (si un valor de la variable es 0).
1.1.4.4 Media armónica
Se define como el inverso de la media aritmética de los inversos de los valores de la variable. Es decir:
A =
n
1
xi
fii=1
k
!
Como ventajas podemos mencionar que intervienen todos los valores de la
variable y que, en ciertos casos, es más representativa que la media aritmética. Como inconvenientes hay que citar la gran influencia de los valores pequeños y
que a veces no se puede calcular (si un valor de la variable es 0). Se suele utilizar para promediar velocidades, tiempos, etc.
EJEMPLO 1.15:
Supongamos un móvil que efectúa un recorrido de 100 km, en dos sentidos. En un sentido va a una velocidad constante v1 = 60 Km/h y en el otro también circula a una velocidad constante v2=70 Km/h y, por tanto, diferente de la anterior.

32
Calcular la velocidad media del recorrido total debemos calcular la media armónica.
Solución:
En este caso, si queremos calcular la velocidad media debemos calcular la media armónica.
v =espacio
timpo=
2s
t1 + t2
Pero
t1 =
s
v1
=100Km
60Km h
t2 =s
v2
=100Km
70Km h
Luego, sustituyendo, obtenemos que:
v =2s
t1 + t2
=200Km
100Km
60Km h+100Km
70Km h
=2Km
1
60 h+1
70h
= 64.62Km h
RELACION ENTRE LAS MEDIAS
La relación existente entre estas tres medias es:
H ! G ! x cuando las tres medias existen.
1.1.4.5 Mediana
Es el valor de la distribución que, una vez ordenados los valores de la variable de menor a mayor, deja igual número de frecuencias a su izquierda que a su derecha, es decir, el valor que ocupa el lugar central. Puede entenderse también como aquel valor cuya frecuencia absoluta acumulada es n/2.

33
DATOS SIN AGRUPAR
Nº impar de términos
Si la distribución está sin agrupar, y hay un nº impar de términos, la mediana será el que ocupa la posición central. Por ejemplo, si los valores de la variable son
{ 1 , 2 , 3 , 4 , 5 }
la mediana sería Me = 3
Nº par de términos
Pero si hay un nº par de términos habría dos términos centrales y se toma como mediana la media aritmética de ellos. Por ejemplo, si los valores de la variable son
{1 , 2 , 5 , 7 , 9 , 10 , 13 , 14}
La mediana seria: Me =7 + 9
2= 8
DATOS CON FRECUENCIAS
Variable discreta
Si los datos presentan diferentes frecuencias, el método más práctico es buscar en la columna de frecuencias acumuladas n/2.
EJEMPLO 1.16:
Si la distribución es:
xi fi Fi 1 3 3 2 4 7 5 9 16 7 10 26 10 7 33 13 2 35
Total 35 Calcular la mediana

34
Solución:
n
2=35
2=17.5
La mediana es Me = 7, puesto que desde el que ocupa el lugar 17 hasta el de lugar
26 todos los valores son 7. Es decir, si Fi-1 < n/2 < Fi, entonces, Me = xi
Variable continua o datos agrupados en intervalos
En el caso de estar la distribución agrupada en intervalos (sean o no de la misma amplitud) al buscar el valor que ocupa el lugar n/2 nos encontramos con un intervalo, el intervalo mediano, y no con un dato. Para determinar un único representante de dicho intervalo como mediana, determinaremos el elemento que en el polígono de frecuencias acumuladas toma de frecuencia n/2.
Figura 1.15: Polígono acumulativo de frecuencias para el cálculo de la Mediana

35
En el gráfico de la figura 1.15 se observa la forma de determinar la mediana. La mediana vale:
Me = Li-1 + m
Como los triángulos ABC Y AB'C' son semejantes, resulta que:
AC
AC'=BC
B' C'
es decir:
m
ci
=
n
2! Fi!1
Fi ! Fi!1
por lo tanto:
m =
n
2! Fi!1
fi
ci
De lo anterior se deduce que la Mediana se calcula de la siguiente forma:
Me = Li!1 +
n
2! Fi!1
fi
ci
VENTAJAS E INCONVENIENTES
Como ventajas de la mediana podemos citar que no está influida por los valores extremos como en el caso de la media, y además tiene sentido en casos de distribuciones en escala ordinal (datos que pueden ser ordenados), siendo la medida más representativa de estos por describir la tendencia central de los mismos.
Como inconvenientes puede ser la determinación de ésta en los casos de variables
agrupadas en intervalos.

36
EJEMPLO 1.17:
Sea la siguiente distribución de salarios y calculemos el salario mediano.
Clase Salario anual Nº de obreros Nº acumulado de obreros
1 2 3 4 5
20000 a 25000 25000 a 30000 30000 a 35000 35000 a 40000 40000 a 45000
100 150 200 180 41
------- 671
100 250 450 630 671
Solución:
Tenemos que n2=671
2= 335.5 , valor que nos indica que el salario anual mediano
pertenece a la tercera clase. La amplitud del tercer intervalo es ci = 5000, luego:
Me = 30000 +
335.5 ! 250
2005000 = 3000 + 2137.5
es decir, Me = 32137’5
1.1.4.6 Moda
Es el valor de la variable que más veces se repite en una distribución de frecuencias, es decir, el que tiene mayor frecuencia absoluta. Para calcular la moda, en el caso que la distribución no esté agrupada o esté agrupada en intervalos, se procede de forma diferente:
DISTRIBUCIÓN SIN AGRUPAR EN INTERVALOS DE CLASE
La moda es el valor ( o valores ) que presenten mayor frecuencia absoluta.

37
EJEMPLO 1.18:
Consideremos la siguiente distribución:
xi 1 2 5 7 10 13 fi 3 4 9 10 7 2
Observando la fila de frecuencias, se ve que Mo = 7
Puede ocurrir que una distribución presente más de una moda (bimodal, trimodal,
etc.), e incluso que presente una moda absoluta y alguna moda relativa. Las representaciones serian (ver figuras 1.16 y 1.17):
Figura 1.16: Representación de una distribución con una única moda y otra bimodal
Figura 1.17: Modas en una distribución bimodal

38
DISTRIBUCIÓN AGRUPADA EN INTERVALOS DE CLASE
Si la distribución está agrupada en intervalos, se procederá de forma diferente según que la amplitud sea constante o no.
Amplitud constante
Si la amplitud es constante, la máxima frecuencia nos determina un intervalo, el intervalo modal, pero hay que seleccionar un valor de ese intervalo que haga el papel de moda. En este caso hay varios criterios: unos seleccionan el extremo inferior del intervalo, otros el extremo superior y otros la marca de clase, pero habrá que tener en cuenta que la moda estará más cerca del intervalo contiguo de mayor frecuencia.
Figura 1.18: Histograma para el cálculo de la Moda
Es claro que Mo = Li-1 + m . Veamos la determinación de "m".
Dado que los triángulos OAA' y OBB' son semejantes por tener los ángulos
iguales, se puede establecer la proporción:
OQ
PO=BB'
AA'!OQ
PO+1 =
BB'
AA'+1!
OQ + PO
PO=BB' +AA'
AA'
invirtiéndola resulta:

39
PO
OQ + PO=
AA'
BB' +AA'!
m
ci "m( ) + m=
d1
d1 + d2
siendo d1, d2 las diferencias de frecuencias absolutas entre el intervalo modal y los
intervalos anterior y posterior respectivamente. Por lo tanto la moda valdría:
Mo = Li!1 +d1
d1 + d2
ci
EJEMPLO 1.19:
Calculemos la Moda de la siguiente distribución:
Intervalo Frecuencia 0 - 25 25 - 30 50 - 75 75 - 100
20 40
100 60
Total 220
Solución:
El intervalo modal es el 50 - 75, y como
d1 = 100 - 40 = 60 , d2 = 100 - 60 = 40
resulta que Mo = 50 + 60
60 + 4025 = 50 +15 = 65
Amplitud no constante
Si la amplitud de los intervalos es variable, teniendo en cuenta que la altura del rectángulo indica la densidad de frecuencia, el intervalo modal será el que tenga mayor densidad de frecuencia, es decir mayor altura.
EJEMPLO 1.20:
Calculemos la Moda de la siguiente distribución:

40
Intervalo fi ci ai
4 -7 7 - 9 9 - 15
15 - 30 30 - 60 60 - 100
más de 100
6 7 17 13 4 2 1
3 2 6
15 30 40 --
2 3,5 2,8 0,8 0,1 0,05 ---
Total 50
Solución:
Primero se procede a buscar la mayor altura:
ai = fi / ci
Se continúa como en el caso anterior sustituyendo la frecuencia por la altura. El intervalo modal es el 7-9, y por lo tanto:
d1 = 3,5 - 2 = 1,5 d2 = 3,5 - 2,8 = 0,7
Así la moda será:
Mo = 7 +1.5
1.5 + 0.725 = 7 +1.36 = 8.36
VENTAJAS E INCONVENIENTES
Como ventajas de la moda cabe citar que cuando la distribución es de escala nominal (no susceptible de ordenación) es la medida más representativa, pues no es posible hacer operaciones con sus observaciones, y por tanto no se pueden calcular las otras medidas. Además igual que la mediana, no viene influida por los valores extremos de la variable.
Como inconveniente cabe citar el modo de calcularla en los casos de variables
agrupadas en intervalos y el hecho de que utiliza un único dato de la distribución.

41
Calculemos en un ejemplo la media aritmética, la moda y la mediana de una distribución para hacernos una idea de cuál de ellas es la medida de centralización más representativa en la situación estudiada.
EJEMPLO 1.21:
El sueldo anual de los 25 trabajadores de una empresa viene expresado en la tabla siguiente:
Director 10.000.000 pts. Gerente 6.000.000 pts. Dos ingenieros 4.000.000 pts. cada uno. Tres peritos 2.500.000 pts. cada uno. Cinco encargados 2.000.000 pts. cada uno. Contable 1.800.000 pts. cada uno. Resto plantilla 1.300.000 pts. cada uno.
Calcular la media, la moda y la media y efectuar un estudio comparativo de los
resultados.
Solución:
Calculando la media aritmética de los sueldos vemos que es de 2.356.000 pts. cantidad que, además de no ser el sueldo de ningún empleado de la compañía, da una idea poco aproximada de la realidad, toda vez que la mayoría de los trabajadores ganan bastante menos de esa cantidad.
La moda, por su parte, vale 1.300.000 pts., mientras que la mediana es 1.800.000
pts. Estas dos medidas indican más claramente la situación en la empresa, siendo la moda la que mejor resume la situación.

42
1.1.5 Medidas de posición no centrales
Estos valores no reflejan ninguna tendencia central, sino una posición de la distribución, dividiéndola a ésta en partes iguales. Cabe citar entre los de uso más frecuente: cuartiles, deciles y percentiles.
1) Los cuartiles son tres valores que dividen a la distribución en cuatro partes
iguales, estando en cada una de ellas el 25% de sus observaciones. Se indican con Qi.
2) Los deciles son nueve valores que dividen a la distribución en diez partes
iguales, estando en cada una de ellas el 10% de las observaciones. Se indican por Di.
3) Los percentiles son noventa y nueve valores que dividen a la distribución en
cien partes iguales, dejando un 1% de las observaciones entre cada dos de ellos consecutivos. Se nombran por Pi.
Hay que tener en cuenta algunas relaciones entre ellos, como son:
Me = Q2 = D5 = P50 Q1 = P25 ; Q3 = P75 D1 = P10 ; D2 = P20 ; D3 = P30 ; D4 = P40 ; D6 = P60
Para el cálculo de todos los cuantiles el proceso es análogo al cálculo de la
mediana, sustituyendo n/2 por r.n/k, siendo r el orden del cuantil y k las partes en que dicho cuantil divide a la distribución. Así en los cuartiles k = 4 y r = 1, 2, 3 ; en los deciles k = 10 y r = 1, 2,....., 9, y en los percentiles k = 100 y r = 1, 2, 3,....., 99.
Se procede pues buscando en las frecuencias acumuladas el valor de rn/k, y si la
distribución está agrupada, el cuantil r/k será:
Cr k = Li!1 +
rn
k! Fi!1
f i
ci

43
VENTAJAS E INCONVENIENTES
Las ventajas e inconvenientes son las mismas que los de la mediana. EJEMPLO 1.22:
En el ejercicio de la distribución de salarios, calculemos Q1, Q3, D4, P88
Solución:
Para Q1: como 1.671/4 = 167,75 , el intervalo del primer cuartil es el 25000 - 30000
Q1 = 25000 +
671
4!100
1505000 = 25000 + 2258.3 = 27258.3
Para Q3: como 3.671/4 = 503,25 ,el intervalo del tercer cuartil es el 35000 - 40000
Q3 = 35000 +
3671
4! 450
1805000 = 35000 +1479.16 = 36479.16
Para D4: como 4.671/10 = 268’4 , el intervalo del cuarto decil es el 30000 - 35000
D4 = 30000 +
4671
4! 2500
2005000 = 30000 + 460 = 30460
Para P88: como 88.671/4 = 590,48, el intervalo del percentil ochenta y ocho es el 35000
- 40000
P88 = 35000 +
88671
4! 450
1805000 = 35000 + 3902.2 = 38902.2

44
1.1.6 Medidas de dispersión En el apartado anterior hemos definido una serie de medidas de tendencia central,
cuyo objetivo era tratar de sintetizar toda la información disponible, pero cabe preguntarse posteriormente si esa medida es o no representativa de la distribución de frecuencias.
Si consideramos dos variables X e Y con distribuciones:
xi 0 500 1000 yi 499 501 fi 1 1 1 fi 1 1
Las medias son :
x =
0 + 500 +1000
3= 500 y =
499 + 501
2= 500
Las dos medias son iguales y sin embargo las dos distribuciones son muy
diferentes pues los valores de X están mucho más dispersa que los de Y. Así pues, para intentar medir la representatividad de una determinada medida
debemos de cuantificar la separación de los valores de la distribución respecto de dicha medida. Así pues, resulta necesario que, para completar la información de un promedio (por ejemplo media aritmética), éste vaya acompañado de uno o varios coeficientes que nos midan el grado de dispersión de la distribución de la variable con respecto a él.
Distinguiremos dos tipos de medidas de dispersión: absolutas y relativas.
1.1.6.1 Medidas de dispersión absoluta
Cabe citar entre éstas el recorrido, el recorrido intercuartílico, la desviación media, la varianza y la desviación típica. Todas son referidas en general a un promedio.

45
RECORRIDO O RANGO:
Hemos dicho ya que éste es la diferencia entre el mayor y el menor valor de la distribución:
Re = Max (xi) - Min (xi)
Si este recorrido es pequeño respecto al número de datos puede entenderse que
existe poca dispersión. Tiene el inconveniente de que se ve totalmente influenciado por los valores
extremos (con los que se calcula). RECORRIDO INTERCUARTÍLICO:
Es la diferencia existente entre el tercer y el primer cuartil
RI = Q3 - Q1
En esta medida se suprimen el 25% superior e inferior de la distribución, y por lo tanto no se ve influenciado por los valores extremos, y nos indica la longitud del intervalo en el que están el 50% central de los valores
En algunos casos se utiliza el recorrido semiintercuartílico que se define como
la mitad del recorrido intercuartílico.
RSI = (Q3 -Q1)/2
DESVIACIÓN MEDIA:
Esta medida de dispersión hace referencia a un promedio, cosa que no hacen las anteriores; puede entenderse como la media de las desviaciones de los datos de la variable respecto al promedio utilizado; no obstante, para evitar que las desviaciones positivas queden compensadas por las negativas y que esta desviación media resulte igual a 0, (que nos haría pensar que no hay dispersión) se utiliza el valor absoluto de la desviación de los datos respecto del promedio.
Así se definirá la desviación media respecto de la media como:

46
Dx = xi ! x fi
ni=1
k
"
También se puede utilizar la desviación media respecto de la mediana como:
DMe = xi !Mef i
ni=1
k
"
Las dos nos indicarían la dispersión de los datos respecto del promedio utilizado,
en el caso de que ésta fuera grande el promedio sería poco representativo. VARIANZA:
Se define como la media de los cuadrados de las desviaciones de los valores de la variable respecto de la media aritmética, es decir:
s2= xi ! x ( )
2 f i
n= xi ! x ( )
2hi
i=1
k
"i=1
k
"
Se utiliza el cuadrado para lograr que todas las desviaciones sean positivas; nos
indica la mayor o menor dispersión de los valores de la variable respecto de la media aritmética, y por lo tanto, su representatividad.
Tiene el inconveniente de no venir expresada en las mismas unidades que la
variable, sino en el cuadrado de las mismas, por ello se utiliza más la siguiente. DESVIACIÓN TÍPICA O ESTÁNDAR:
Se define como la raíz cuadrada positiva de la varianza, es decir:
s = xi ! x ( )2 fi
ni=1
k
" = xi ! x ( )2
hi
i=1
k
"
Al ser la raíz cuadrada de la varianza viene expresada en las mismas unidades que
la variable, lo que la hace más apta como medida de dispersión que la varianza, siendo en la actualidad la más utilizada.

47
A menudo, en lugar de dividir entre el tamaño de los datos, n, se divide entre n-1, obteniéndose la llamada cuasivarianza:
ˆ s 2= xi ! x ( )
2 fi
n !1i=1
k
"
y cuasidesviación típica:
ˆ s = xi ! x ( )2 f i
n !1i=1
k
"
Siendo la relación entre la varianza y la cuasivarianza la siguiente:
ˆ s 2=
n
n !1s2
PROPIEDADES DE LA VARIANZA Y DE LA DESVIACIÓN TÍPICA:
La varianza y la desviación típica no pueden ser negativas, por ser suma de cuadrados:
s2 ≥ 0, s ≥ 0
Si en una distribución le sumamos a todos los valores de la variable una constante, la varianza y la desviación típica no varían.
Si en la distribución (xi fi) de media x = xi
f i
ni=1
k
! , y de varianza
s2= xi ! x ( )
2 f i
ni=1
k
" sumamos a todos los elementos una constante k, obtenemos otra
distribución de variable x'i = xi + k .
Como, x ' = x + k resulta que la varianza de la nueva distribución será:

48
s'2 = xi
' ! x '( )2 fi
ni=1
k
" = xi + k( ) ! x ! k( )[ ]2 f i
ni=1
k
" =
= xi ! x ( )2 f i
ni=1
k
" = s2
es decir, que la varianza no varia, y por lo tanto, la desviación típica tampoco.
Si en una distribución multiplicamos a todos los valores de la variable por
una constante, la varianza queda multiplicada por el cuadrado de la constante y la desviación típica queda multiplicada por la constante.
En efecto: Si tomamos la distribución xi
''= kxi teniendo en cuenta que x ' = kx , resulta que
la varianza de la nueva distribución vale:
s' '2 = xi
' ' ! x ' '( )2 fi
ni=1
k
" = kxi + kx ( )f i
ni=1
k
" =
= k2
xi ! x ( )2 f i
ni=1
k
" = k2s2
y por ser la desviación típica la raíz cuadrada de la varianza queda:
s' '= s' '2= k
2s2= ks
CÁLCULO PRÁCTICO DE LA VARIANZA*
En la práctica, al calcular la varianza conviene tener en cuenta la siguiente expresión:
* La media, la varianza y la desviación típica las proporciona directamente cualquier calculadora de bolsillo, luego nomerece la pena hacer perder tiempo al alumno escribiendo tablas con xifi etc.

49
s2 = xi ! x ( )
2 f i
ni=1
k
" = xi2 ! 2xix + x
2( )f i
ni=1
k
" =
= xi2 fi
ni=1
k
" ! 2x xi
fi
ni=1
k
" + x 2 f i
ni=1
k
" = xi2 f i
ni=1
k
" ! 2x 2 + x
2 = x2 ! x
2
Veamos el cálculo de la varianza y desviación típica en los ejemplos 1.9 y 1.10:
xi fi 54 59 63 64
2 3 4 1
10
x = xifi
ni! = 60.1 Kg
s2 = s2= xi
2 fi
ni=1
k
! " x = 36247/10 -(60,1)2 = 3624,7 - 3612,01 = 12,69 Kg2
s = 12.69 = 3,5623 Kg.
En el ejemplo de datos agrupados en intervalos es:
Intervalo marca de clase
fi
30-40 40-50 50-60
35 45 55
3 2 5
10
x = 470/10 = 47 S2 = 22850/10 -(47)2 = 2285 - 2209 = 76 S = 76 = 8,718

50
1.1.6.2 Medidas de dispersión relativas
En el caso de intentar comparar la dispersión de dos distribuciones mediante alguna de las medidas de dispersión halladas antes, no podríamos efectuar tal comparación porque las distribuciones, en general, no vendrán dadas en las mismas unidades y tampoco porque los promedios en general también serán diferentes. Por ello, para poder comparar las dispersiones, es preciso definir medidas de dispersión adimensionales.
Entre éstas se encuentra el coeficiente de variación de Pearson. COEFICIENTE DE VARIACIÓN DE PEARSON:
Es el cociente entre la desviación típica y el valor absoluto de la media aritmética.
CV =s
x
Este coeficiente es adimensional luego permite comparar las dispersiones de dos
distribuciones diferentes. A menudo se le suele utilizar en forma de porcentaje, empleando CV =
s
x 100
Obviamente, a mayor CV menor es la representatividad de x , pues la desviación
típica será mayor comparada con la media.
1.1.7 Momentos Existen dos tipos de momentos:
1.1.7.1 Momentos centrales (respecto a la media aritmética)

51
Se define el momento central de orden r respecto de la media aritmética x como la media aritmética de las potencias de orden r de las desviaciones de los datos respecto de la media:
m r = xi ! x ( )r f i
ni=1
k
"
En particular, se verifica que: - El momento central de orden 0 vale 1:
m0 = xi ! x ( )0 fi
ni=1
k
" =fi
ni=1
k
" =n
n= 1
- El momento central de orden 1 vale 0:
m1 = xi ! x ( )1 f i
ni=1
k
" = xi
f i
ni=1
k
" ! x f i
ni=1
k
" = x ! x n
n= 0
- El momento de orden 2 es la varianza.
1.1.7.2 Momentos con respecto al origen
Se define el momento de orden r con respecto al origen como la media aritmética de las potencias de orden r de los datos de la variable:
ar = xir fi
ni=1
r
!
Como casos particulares cabe destacar: - El momento de orden 0 vale 1:
a0 = xi
0 fi
ni=1
k
! " x fi
ni=1
k
! = 1
- El momento de orden 1 es la media aritmética

52
Existe una relación entre los dos momentos, que nos da una forma reducida de calcular la varianza:
s2= m2 = xi ! x ( )
2 fi
ni=1
k
" = xi
2 fi
ni=1
k
" ! x 2= a2 ! a1
2

53
1.1.8 Medidas de forma Para tratar de conocer una distribución no basta con conocer sus medidas de
dispersión y de posición, sino que es necesario, en general, conocer algunos aspectos más de la misma.
Dado que la diversidad de comportamientos de las xi de la distribución se hacía
más patente al realizar la representación gráfica, vamos a tratar de determinar a continuación más medidas, según la "forma" de la representación; clasificaremos estas medidas en dos grupos: medidas de asimetría y medidas de curtosis o apuntamiento.
1.1.8.1 Medidas de asimetría
Tienen por objeto establecer el grado de simetría (o asimetría) de una distribución sin necesidad de realizar la representación gráfica.
Entenderemos la simetría respecto al eje determinado por la media aritmética, de
tal forma que diremos que una distribución es simétrica cuando los valores de la variable equidistantes de este valor central tengan la misma frecuencia, en caso contrario diremos que es asimétrica, siendo esta asimetría negativa o a izquierda si es más larga la rama de la izquierda, es decir, las frecuencias descienden más lentamente por la izquierda que por la derecha; analogamente llamaremos asimetría positiva o a derechas aquella en que la rama de la derecha es más larga, es decir las frecuencias descienden más lentamente por la derecha que por la izquierda.
COEFICIENTE DE ASIMETRÍA DE FISHER
Debemos buscar ahora una medida adimensional que recoja las desviaciones positivas y negativas de los valores respecto de la media.
La figura 1.19 nos muestra las distintas distribuciones:

54
Mo
g1
>0
x_
g = 01
Distribución simétrica Distribución asimétricaa la derecha
Mo
g <01
Distribución asimétricaa la izquierda
Figura 1.19: Distintos tipos e distribuciones según su simetria
Dado que
xi ! x ( )f i
ni=1
k
" = 0
hay que buscar una medida que venga influida por el signo; ésta será:
m3 = xi ! x ( )3 f i
ni=1
k
"
ya que
si la curva es simétrica m3 = 0 si la curva tiene asimetría positiva o a derechas, m3 > 0 si la curva tiene asimetría negativa o a izquierdas, m3 < 0
Para que no tenga dimensión debemos dividirla por una medida con las mismas
unidades (cúbicas), obteniéndose el coeficiente de asimetría de Fisher.

55
g1 =m3
s3 =
xi ! x ( )3 f i
ni =1
k
"
xi ! x ( )2 fi
ni=1
k
"#
$ %
&
' (
3
2
Siendo su interpretación:
Si g1 > 0 la distribución es asimétrica positiva o a derecha. Si g1 = 0 la distribución es simétrica. Si g1 < 0 la distribución es asimétrica negativa o a izquierda.
COEFICIENTE DE ASIMETRÍA DE PEARSON
Otra medida de asimetría es el coeficiente de asimetría de Pearson definido por:
Ap =x !Mo
s
Teniendo en cuenta que si la curva es simétrica, x = Me = Mo, si la distribución
es asimétrica positiva o a derechas x > Mo y si la distribución es asimétrica negativa o a izquierdas x < Mo, su interpretación será:
Ap = 0 la distribución es simétrica. Ap > 0 la distribución es asimétrica positiva (derechas) Ap < 0 la distribuciones asimétrica negativa (izquierdas)
Tiene el inconveniente de que no puede utilizarse en distribuciones bimodales, por
ello Pearson demostró empíricamente que
x ! Mo " 3 x !Me( ) por lo que algunos autores utilizan como coeficiente de asimetría de Pearson
Ap =3 x ! Me( )
s
Existen otros tipos de coeficientes de asimetría, pero son menos utilizados.

56
1.1.8.2 Medidas de curtosis o apuntamiento
Estas medidas, aplicadas a distribuciones unimodales simétricas o con ligera asimetría, tratan de estudiar la distribución de frecuencias en la zona central, dando lugar a distribuciones muy apuntadas, o poco apuntadas.
Para estudiar el apuntamiento, debemos hacer referencia a una distribución tipo
que consideraremos la distribución "Normal"; ésta corresponde a fenómenos muy corrientes en la naturaleza cuya representación gráfica es la campana de Gauss.
Si una distribución tiene mayor apuntamiento que la normal diremos que es
"leptocúrtica", si tiene menor apuntamiento que la normal la llamaremos "platicúrtica", y a las que tengan igual apuntamiento que la normal las llamaremos "mesocúrticas". Veamos esto en unas figuras 1.20a y b:
Figura 1.20: Diferentes distribuciones según su apuntamiento. Comparación con la Normal En la distribución normal m4 = 3.s4, por lo tanto utilizaremos como coeficiente de
apuntamiento o curtosis.
g2 =m 4
s4 =
xi ! x ( )4 f i
ni=1
k
"
xi ! x ( )2 fi
ni =1
k
"#
$ %
&
' (
2
siendo la interpretación la siguiente:

57
Si g2 > 3 la curva es más apuntada que la normal (leptocúrtica). Si g2 = 3 la curva tiene el mismo apuntamiento que la normal (mesocúrtica). Si g2 < 3 la curva es menos apuntada que la normal (platicúrtica).
A veces se utiliza como coeficiente de curtosis:
g2 =m4
s4 ! 3
y la comparación será con 0, obteniéndose:
g2 = 0 (mesocúrtica). g2 > 0 (leptocúrtica). g2 < 0 (platicúrtica)
NOTA: El cálculo de m3 y m4 es más práctico utilizando las fórmulas: m3 = a3 - 3a2a1 + 2a1
3
m4 = a4 - 4a3a1 + 6a2a12 - 3a1
4
siendo a1 = x .
1.1.9 Medidas de concentración Aunque "dispersión" y "concentración" tengan significados opuestos en el
lenguaje coloquial, en estadística no coincide el concepto de concentración con la acepción normal del vocablo.
La "dispersión" hace referencia a la variabilidad de los datos, a las diferencias
existentes entre ellos y la representatividad de los promedios. La "concentración", por su parte, se refiere al mayor o menor grado de igualdad
en el reparto de todos los valores de la variable. Estas medidas de concentración tienen especial aplicación a variables económicas
(rentas, salarios, etc.), pues lo que interesa es la mayor o menor igualdad en el reparto entre los componentes de la población, es decir, que esté equitativamente repartida.

58
Llamaremos, pues, concentración al grado de equidad en el reparto de la suma
total de la variable considerada. La concentración es máxima si uno solo de los elementos recibe el total de la
variable, mientras que la concentración será mínima o equidistribuida si todos los elementos perciben la misma cantidad.
Entre los índices de concentración que estudiaremos se encuentran el índice de
Gini y la curva de Lorenz.
1.1.9.1 Curva de Lorenz
Es una representación gráfica de la concentración. Llamando
ur = xif ii=1
r
! , pr =Fr
n100 , qr =
ur
n100
Si representamos los valores pr en el eje de abscisas y los valores qi en el eje de
ordenadas, dibujando en el cuadrado de lado 100 los puntos pi y qi, y uniéndolos, queda
determinada una poligonal llamada "curva de Lorenz". Veámoslo en un ejemplo económico (tengamos en cuenta que lo anterior no es
aplicable a todo tipo de variables): Supongamos que tenemos k trabajadores, con salarios x1 ≤ x2 ≤ ... ≤xk ordenados
en sentido creciente. Queremos saber como se reparte la suma total de salarios
S = xii=1
k
!
entre los k trabajadores. La concentración es máxima si x1 = x2 = ........= xk-1 = 0; xk = S es decir, un solo
trabajador recibe todo y el resto nada.

59
La concentración es mínima si x1 = x2 = .........= xk, es decir, todos los
trabajadores reciben lo mismo. Para determinar el índice de concentración se forman las columnas siguientes:
1º- xifi que denota el salario recibido por los ni trabajadores.
2º- Fi columna de frecuencia absolutas acumuladas.
3º- ur, acumulador de la primera columna que denota el salario total recibido
por los Fr primeros trabajadores, siendo su valor ur = xif ii=1
r
!
4º- pr, que es la frecuencia relativa acumulada en tantos por 100:
pr =Fr
n100
5º- qr, que es el porcentaje del salario total que reciben los Ni primeros trabajadores:
qr =ur
n100
Si la concentración fuese mínima, pr = qr igualmente repartida. Si la concentración fuese máxima, q1 = q2 =..........= qk-1 = 0, qk = 100
La representación de la curva de Lorenz sería:

60
Figura 1.21: Curva de Lorenz
Los casos extremos nos darían las siguientes gráficas (figura 1.22 y b):
pi %
qi %
Distribución de concentración mínima pi %
qi %
Distribución de concentración máxima
(a) (b)
Figura 1.22: Casos extremos de concetración
Como propiedades de esta curva de Lorenz pueden citarse las siguientes:
- La curva es siempre creciente, pues la ordenación de salarios es de menor a mayor. - La curva empezará en el origen O = (0,0) y terminará en el (100,100)B - La curva está siempre situada por debajo de la diagonal. - La concentración será menor cuanto más próxima esté la curva de Lorenz a la diagonal.
1.1.9.2 Índice de Gini
Se define el índice de concentración de Gini por :
IG =
pi ! qi( )i=1
k!1
"
pii=1
k!1
"
61
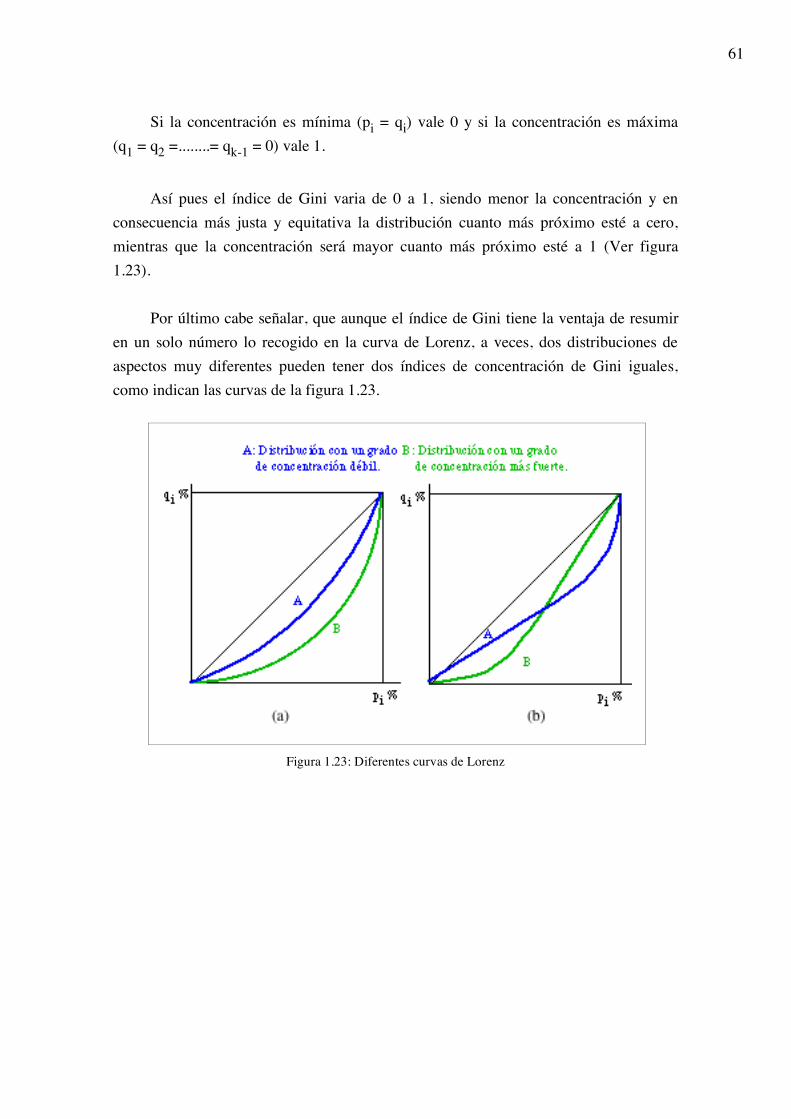
Si la concentración es mínima (pi = qi) vale 0 y si la concentración es máxima (q1 = q2 =........= qk-1 = 0) vale 1.
Así pues el índice de Gini varia de 0 a 1, siendo menor la concentración y en
consecuencia más justa y equitativa la distribución cuanto más próximo esté a cero, mientras que la concentración será mayor cuanto más próximo esté a 1 (Ver figura 1.23).
Por último cabe señalar, que aunque el índice de Gini tiene la ventaja de resumir
en un solo número lo recogido en la curva de Lorenz, a veces, dos distribuciones de aspectos muy diferentes pueden tener dos índices de concentración de Gini iguales, como indican las curvas de la figura 1.23.
Figura 1.23: Diferentes curvas de Lorenz

62
"REPRESENTACIONES GRAFICAS"
1.2 Ampliación

63
Quizás fuese interesante, presentar el tema de las representaciones gráficas al alumno, mediante una introducción desde la perspectiva del lenguaje gráfico y de su utilidad y difusión en el mundo que nos rodea. Sería una buena forma de motivarle para que prestase atención sobre la importancia de saber leer de forma correcta los gráficos más usuales.
1.2.1 El lenguaje gráfico El lenguaje gráfico es el "conjunto de símbolos y convenios que permiten comunicar una información cuantitativa de la manera más eficiente posible" (GETE-ALONSO y del BARRIO, 1990).
Este lenguaje se sirve de numerosos signos y símbolos que han evolucionado con
el tiempo y que encontramos en casi todas las manifestaciones de la actividad humana, empleándose para expresar de manera rápida y sucinta ideas, objetos y situaciones, en muchas ocasiones con significado universal.
1.2.1.1 El lenguaje gráfico en la vida cotidiana
Si nos detenemos un momento a pensar en el mundo que nos rodea vemos como el lenguaje gráfico se utiliza en absolutamente todo nuestro entorno (figura 1.24).
Lo encontramos en las instrucciones de lavado de cualquier prenda de vestir, en la información sobre los transportes metropolitanos de cualquier ciudad, en las teclas que hacen funcionar los electrodomésticos, en los mapas de carreteras, en la información acerca de la calidad y categoría de restaurantes y hoteles, en las señales que regulan el tráfico, en el parte diario acerca del estado del tiempo, en los emblemas y distintivos de organizaciones y sociedades, etc. etc.

64
Figura 1.24.- Importancia y actualidad del lenguaje gráfico
(Tomada de AVILA-ZARZA, 1993)
1.2.1.2 El lenguaje gráfico como herramienta de comunicación social
Hace ya tiempo que las representaciones gráficas abandonaron las publicaciones especializadas, en las que se utilizan como herramienta de comunicación y análisis de datos estadísticos, para pasar a formar parte de las herramientas de comunicación social (televisión, prensa, propaganda...).
La generalizada utilización de las representaciones gráficas es sin duda
sorprendente. Podemos encontrarlas en billetes, como el de diez Marcos alemanes de la figura
1.25, en el que aparece representada la curva normal de Gauss.
65
Figura 1.25: Billete de diez marcos alemanes, en el que está impresa
la Curva Normal de Gauss
También es posible encontrarlas ya en obras dirigidas al gran público, cuya única intención es entretener. Así ocurre, por ejemplo, con la conocida novela de ficción "Parque Jurásico" (CRICHTON, M. 1990-92) en la que un Diagrama de perfil - (ver figura 1.26) sirve de base argumental.
Figura 1.26.
Esto se debe a que sin duda, y cada vez con mayor intensidad, nos vemos inmersos en una "sociedad estadística", entendiendo como tal aquélla en la que los ciudadanos piensan, razonan y toman decisiones en base a análisis estadísticos de datos.

66
Aunque en España la Estadística dista aún de ocupar un lugar como el que, por ejemplo, tiene en un país como Japón, donde los periódicos de mayor difusión e importancia incluyen los viernes una sección dedicada al control estadístico de calidad y en el que, por ejemplo, el diagrama horario del tren de Tokio se presenta mediante un clásico Steam and Leaf (ROMERO, 1991)* , somos en la actualidad espectadores de un cambio significativo.
Cada vez en mayor medida se recurre a datos y análisis estadísticos para transmitir
la información, siendo los Métodos Gráficos de carácter descriptivo la herramienta de la que no se puede prescindir** .
Un claro ejemplo de esta situación de transición, se produjo a raíz de las
elecciones generales realizadas en los dos últimos comicios en nuestro país, donde no sólo los resultados de las encuestas, sino también los aspectos relacionados con aquéllas eran objeto de análisis estadístico, siendo los métodos gráficos las auténticas estrellas en la transmisión de la información.
1.2.2 El poder de los métodos gráficos "Una imagen vale más que mil palabras"*** . No sólo el lenguaje gráfico es importante; el poder de las representaciones gráficas es un hecho. La visión es la modalidad sensorial dominante del ser humano; nuestro cerebro
está altamente capacitado para el manejo de información visual, siendo capaz de reconocer y procesar imágenes gráficas con una simple inspección ocular.
Así, está comúnmente aceptado por la comunidad científica que, en general, una
representación gráfica proporciona mayor información acerca de las características y patrones de los datos, que un texto o una presentación tabular de los mismos.
* Nos preguntamos, ¿cuántos lectores en España, sin y con conocimientos estadísticos básicos podrían ser capaces de interpretar uno similar...?. ** Todo ello ha motivado no sacrificar en el apartado de métodos gráficos la inclusión de aquéllos, que aún no siendo históricamente recientes, son aún "grandes desconocidos". *** Provervio Chino

67
1.2.2.1 Los riesgos del Análisis de Datos sin la utilización de gráficos
LOS DIAGRAMAS DE ANSCOMBE
El peligro de llevar a cabo análisis de datos sin la utilización de gráficos puede ponerse de manifiesto con los conocidos Diagramas de Anscombe (ANSCOMBE, 1973) (ver figura 6.19), los cuales evidencian cómo cuatro grupos de datos que producen idénticas rectas de Regresión (incluida la ordenada en el origen y la pendiente), idénticos coeficientes de correlación e idénticos errores estándar, corresponden en realidad a casos muy diferentes.
Como señala TUKEY (1962), gran parte del poder e importancia de los Métodos Gráficos, es que nos permiten percibir aquello que nunca esperábamos ver.
1.2.2.2 Los gráficos como herramienta de engaño
ESPACIO PERCEPTIVO Y ESPACIO MATEMÁTICO EUCLÍDEO
A pesar de la reconocida importancia y poder del lenguaje gráfico, el proceso perceptivo y cognoscitivo que se produce durante la inspección de un gráfico no es del todo conocido.
En las Matemáticas los espacios se construyen a partir de unos axiomas, y se
describen y definen por una geometría. Hay varios tipos de espacios matemáticos, definidos por sus correspondientes geometrías (topológico, proyectivo, afín, euclídeo...). El más conocido y utilizado, es el Espacio Euclídeo.
El espacio físico en el que vivimos, puede considerarse aproximadamente, y
teniendo en cuenta el alcance de nuestra percepción, como un espacio matemático euclídeo. Admitir que el espacio físico es euclídeo no equivale a que el perceptual lo sea, y así, aun no está claro que la idea subjetiva de distancia, por ejemplo, coincida con la distancia física definida en relación con las coordenadas rectangulares. Según VURPILLOT (1979), el espacio visual binocular es un espacio de curvatura negativa al que la geometría hiperbólica de Lobatchefsky describíría de forma más adecuada.

68
Sin embargo, y a pesar de esta controversia acerca de si el espacio perceptivo coincide con en el espacio matemático euclídeo, es éste -por aproximación al espacio físico- el que generalmente utilizamos para representar el mundo.
No obstante, representadas en un espacio Euclídeo, las cosas no son siempre
aquello que parecen ser. Como señala PINILLOS (1973 ) "En realidad, lo que ocurre es que la mente
humana funciona como una totalidad, y no son los sentidos, sino el sujeto, quien percibe".
ILUSIONES GEOMÉTRICAS
Lo que acabamos de comentar se pone especialmente de manifiesto en las conocidas distorsiones perceptivas o ilusiones geométricas. (Ver figura 1.27a y b)
Fig. 1.27 (a): Ilusión de Müller-Lyer (dos rectas de igual longitud, parecen de diferente tamaño
(b): Ilusión de PoggendorfLas líneas oblicuas son colineales
Estas distorsiones perceptivas, conocidas ya a principios de siglo, deberían ser tenidas en cuenta en el contexto de los Métodos Gráficos. Son sin embargo pocos los estudios experimentales realizados que examinan el papel de las distorsiones perceptivas (ilusiones geométricas) en relación con la utilización de los gráficos, y la mayoría de ellos no son conocidos por el usuario medio, como afirman SPENCE & LEWANDOWSKY (1990).
POULTON (1985) ha investigado ilusiones similares a la clásica de Poggendorf,
mediante experimentos que sugieren que las relaciones de líneas inclinadas sobre los ejes vertical y horizontal de los gráficos pueden producir errores de lectura, que se incrementan a medida que aumenta la distancia a los ejes.

69
SOLUCIONES PARA MITIGAR LAS ILUSIONES GEOMETRICAS
POULTON (1985) propone: que los todos los gráficos muestren los cuatro ejes. que todos los ejes estén graduados.
INCONVENIENTES DE LAS REPRESENTACIONES GRÁFICAS
Las representaciones gráficas tienen ventajas, pero también sus inconvenientes. La frase "una imagen vale más que mil palabras" podría cambiarse por esta otra "una imagen miente más que 1000 números" (SWOBODA, 1975).
Las representaciones gráficas deberían proporcionar con una sola mirada aquella idea del material estadístico que venía dada por la comparación de muchos números y datos. Pero... no siempre es así. Los errores y malentendidos surgen cuando el lector es
distraído o no está suficientemente preparado y adquiere una idea que no se corresponde con los datos originales.
10000
9000
8000
7000
6000
I II III IV(a)
9500
9000
8500
8000
7500
I II III IV
(b)
I/II II/III III/IV
9%
8%
7%
6%
5%
(c)
Figura 1.28: La ascensión lenta de la curva (a) pone de manifiesto un crecimiento moderado. Los mismos datos pueden expresar un crecimiento explosivo y optimista (b). Se puede obtener una curva ascendente primero, y
descendente después si se toman los índices de crecimiento de uno a otro período en lugar de los números absolutos (c). (Adaptada de SWOBODA, 1975).

70
No se pueden juzgar nunca las imágenes solas, sino que siempre deben considerarse también los números y las escalas.
1.2.3 Representaciones gráficas más usuales
1.2.3.1 Introducción
El artículo publicado por TUKEY en 1962, "The Future of Data Analysis", fue el germen que proporcionó un inusitado auge de Métodos Gráficos en la Estadística, inaugurando una nueva era en este campo, al otorgarles un papel central en análisis exploratorios.
Sin embargo, la importancia y protagonismo que entonces se preveía, no llegó a
hacerse realidad hasta más tarde. Fue en la década de los 70 cuando aparecen publicaciones sobre el tema, tanto históricas (ROYSTON, 1970), como de recapitulación (FIENBERG, 1977), o de carácter novedoso (CHERNOFF, 1973; TUKEY, 1977). Incluso tiene lugar un Simposio sobre el tema (WANG & LAKE,1978).
La aparición, desarrollo y generalizada utilización de los ordenadores fue y es, sin
duda, la causa fundamental.
1.2.3.2 Clasificación
Existen diversos criterios para clasificar los métodos de representación gráfica: SNEE & PFEIFER (1985), siguiendo el criterio del propósito del método, realizan
una clasificación de los distintos métodos gráficos en tres grandes grupos:
-Gráficos utilizados en Análisis Exploratorios. -Gráficos usados en Análisis Confirmatorios. -Gráficos para la Comunicación y/o Presentación de los resultados.

71
Esta clasificación de los Métodos Gráficos, resulta de un gran atractivo por su sencillez y didáctica.
En la figura 1.29 podemos ver un esquema sobre de las fases del método científico
en donde tienen cabida las representaciones gráficas.
Figura 1.29: Posible implementación de los métodos gráficos en el proceso del Análisis de Datos, según NAGEL & DOBBERKAU (1988)
ALONSO (1982) realiza una clasificación en función de la finalidad estadística y
las características técnicas de los distintos métodos gráficos. En ella, éstos son clasificados en cuatro grupos de técnicas.
-Técnicas de Representación Gráfica de la distribución de Probabilidad, para una o varias variables.
-Técnicas que proporcionan el Perfil (o evolución) a lo largo del tiempo, o del espacio, etc., de una o varias variables, bien para individuos, bien para poblaciones.
-Técnicas que presentan las proximidades entre individuos y poblaciones, de acuerdo con los valores que toman para varias variables.
-Técnicas que permiten obtener grupos jerarquizados de individuos o poblaciones, en base a los valores que toman para varias variables.

72
En base al procedimiento gráfico y la técnica estadística subyacente, en el Análisis Multivariante pueden distinguirse claramente dos grandes grupos de técnicas gráficas:
Métodos Multivariantes Gráficos (MMG). Métodos Gráficos Multivariantes (MGM).
Los Métodos Multivariantes Gráficos son potentes herramientas de diagnosis basadas en el análisis de grandes matrices de datos, que mediante complejos procesos algebraicos asentados sobre métodos numéricos, permiten representar la información del hiperespacio de partida en un subespacio de dimensiones reducidas.
Evidentemente se trata de procedimientos sumamente interesantes, pero que
escapan al contenido del presente capítulo.
Los Métodos Gráficos Multivariantes sólo exigen efectuar una transcripción geométrica de los datos correspondientes a un conjunto de variables, en una representación gráfica.
Este tipo de métodos permiten resumir la información, y constituyen directamente
un procedimiento gráfico descriptivo. Entre ellos tenemos: Diagramas de Dispersión Múltiple. Figuras de Representación (Gráficos Pictoriales o Iconos). Curvas de Andrews. Estos métodos serán tratados con mayor profundidad más adelante. (Ver figura
1.30)
1.2.3.3 Representaciones gráficas en el análisis multivariante
MÉTODOS GRÁFICOS UNIVARIANTES MULTIPLES
Muchas de las representaciones utilizadas en análisis multivariante no son en sí mismas multidimensionales ya que, a pesar de ser un conjunto de gráficas que forman una representación unitaria, cada una de ellas por separado sólo muestra una dimensión (o a lo sumo dos) de los datos referidos a varias variables o dimensiones. Desde ellas no

73
se puede mostrar una variación común. Son por ello Métodos Gráficos Univariantes Múltiples, más que multivariantes.
Evidentemente, son muchas las posibilidades que permiten las representaciones
univariantes en el análisis de los datos correspondientes a varias variables. Sin embargo, estas representaciones no difieren en sus características de los métodos gráficos univariantes pero debido a su importancia, popularidad y utilización en todos los ámbitos, merece la pena hacer referencia a tres técnicas:
Stem & leaf, Box-plot * Diagrama de dispersión** .
Curvas de Andrews Mapas Estadísticos
Gráficos Pictoriales
o Figurativos
Diagrama de Dispersion
Múltiple
• ••••
• • •••
•••••
•• •••
••••
••••••••
•• ••••
• •••••••••••
Figura 1.30: Algunos Métodos Gráficos Multivariantes (Tomado de AVILA-ZARZA (1993) con permiso del autor)
Stem & leaf
* Ambos son métodos gráficos de gran utilidad en la comparación de dos o más series de datos, de ahí su importancia dentro del análisis multivariante ** Mediante esta representación gráfica es como generalmente se presentan los resultados en la mayoría de los métodos multivariantes gráficos (MGM).

74
La representación Stem & Leaf*** es una representación intermedia entre una tabla y un gráfico. Muestra los valores con cifras, aunque su perfil es el de un histograma. Este tipo de representación se debe a TUKEY (1977). (Ver figura 1.31). Construcción de un diagrama Steam & Leaf
1º.- Se debe escribir a la izquierda de una línea vertical, de arriba hacia abajo, todos los posibles dígitos principales del conjunto de datos.
2º.- Luego se representa cada dato a la derecha de la línea, escribiendo sus dígitos secundarios en la fila apropiada.
Lectura del gráfico
La longitud de cada fila nos muestra el número de valores en cada intervalo, por lo que representa esencialmente un histograma lateral, solventando una limitación del histograma, ya que permite identificar los valores originales de cada intervalo.
La figura siguiente (figura 1.31) muestra el gráfico Stem & leaf de los 50 estados de Estados Unidos ordenados según la variable "voto medioambiental", cuyos datos aparecen en la tabla 1.1. Esta variable mide cómo la delegación congresista de cada estado votó en relación a temas de medioambiente durante el año 1984. Refleja el porcentaje de veces que sus votos estuvieron de acuerdo con las recomendaciones del grupo "The League of Conservation Voters". Así el valor de Idaho, 12, significa que el voto de sus representantes estuvo de acuerdo con la liga en el 12% de las ocasiones.
1 267 2 6 3 33345699 4 01477779 5 123456667799 6 224999 7 02222499 8 26 9 6
Figura 1.31: Representación Stem & leaf de la tabla 1.1
*** Literalmente traducido, diagrama de tallo y hojas

75
Se observa claramente cómo el rango del porcentaje varía desde 12 hasta 96. También puede apreciarse como la distribución es aproximadamente simétrica de modo que el valor mediano (siendo este valor 55%) se encuentra en el intervalo de 50 a 60 (opcionalmente puede indicarse poniendo entre paréntesis el tallo correspondiente).

76
Estado Porcentaje
de voto medioamb.
Estado
Porcentaje de voto
medioamb. Idaho 12 S. Dakota 55 Utah 16 Illinois 56
Alaska 17 Montana 56 Wyoming 26 Missouri 56 Alabama 33 Ohio 57
Mississippi 33 Washington 57 Virinia 33 California 59
Nebraska 34 N. Dakota 59 Arizona 35 Maryland 62
Arkansas 36 Pnnsylvania 62 Texas 39 Hawaii 64 Kansas 39 Delaware 69
Louisiana 40 Michigan 69 Kentucky 41 W. Virginia 69
N. Carolina 47 Minnesota 70 Tennessee 45 New York 72
New Mexido 47 Wisconsin 72 Nevada 47 New Hampsh. 72
S. Carolina 47 New Jersey 72 Colorado 47 Iowa 74 Georgia 49 Maine 79 Florida 51 Connecticut 79
Oclahoma 52 Massachusetts 82 Oregon 53 Rhode Island 86 Indiana 54 Vermont 96
Tabla 1.1: Lista ordenada de los votos al congreso de los 50 Estados de EE.UU. en 1984:
Porcentaje de acuerdo con "The League of Conservation Voters". (Tomado de HAMILTON, 1990)
Este método también es de gran utilidad para la comparación de dos o más series
de datos, como hemos dicho con anterioridad, representando un diagrama steam & leaf para cada serie.
Box-plot Esta representación gráfica, también debida a TUKEY (1977), puede ser traducida
como Caja con Bigotes o Representación Caja, aunque se conoce usualmente con el nombre de Box-plot o bien Box and Whiskers plot.
Es un método gráfico simple para resumir la información, proporcionando una rápida impresión de las características más importantes de una distribución.
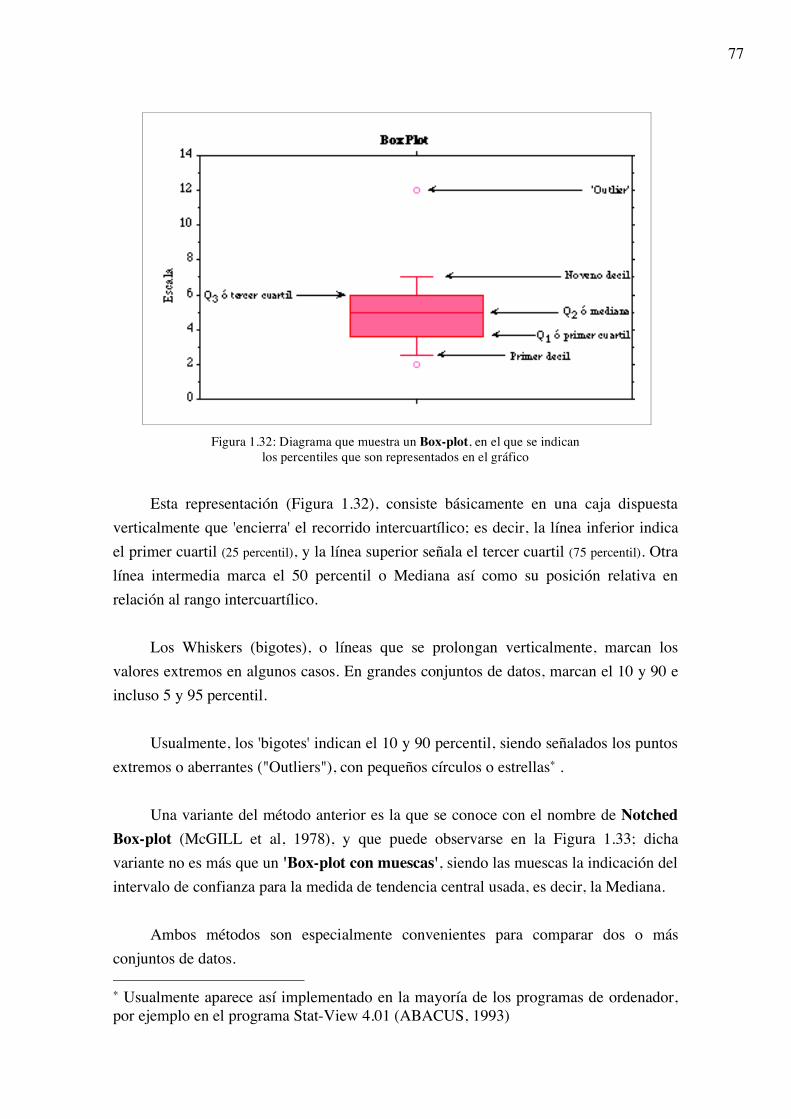
77
Figura 1.32: Diagrama que muestra un Box-plot, en el que se indican los percentiles que son representados en el gráfico
Esta representación (Figura 1.32), consiste básicamente en una caja dispuesta
verticalmente que 'encierra' el recorrido intercuartílico; es decir, la línea inferior indica el primer cuartil (25 percentil), y la línea superior señala el tercer cuartil (75 percentil). Otra línea intermedia marca el 50 percentil o Mediana así como su posición relativa en relación al rango intercuartílico.
Los Whiskers (bigotes), o líneas que se prolongan verticalmente, marcan los valores extremos en algunos casos. En grandes conjuntos de datos, marcan el 10 y 90 e incluso 5 y 95 percentil.
Usualmente, los 'bigotes' indican el 10 y 90 percentil, siendo señalados los puntos
extremos o aberrantes ("Outliers"), con pequeños círculos o estrellas* . Una variante del método anterior es la que se conoce con el nombre de Notched
Box-plot (McGILL et al, 1978), y que puede observarse en la Figura 1.33; dicha variante no es más que un 'Box-plot con muescas', siendo las muescas la indicación del intervalo de confianza para la medida de tendencia central usada, es decir, la Mediana.
Ambos métodos son especialmente convenientes para comparar dos o más conjuntos de datos. * Usualmente aparece así implementado en la mayoría de los programas de ordenador, por ejemplo en el programa Stat-View 4.01 (ABACUS, 1993)
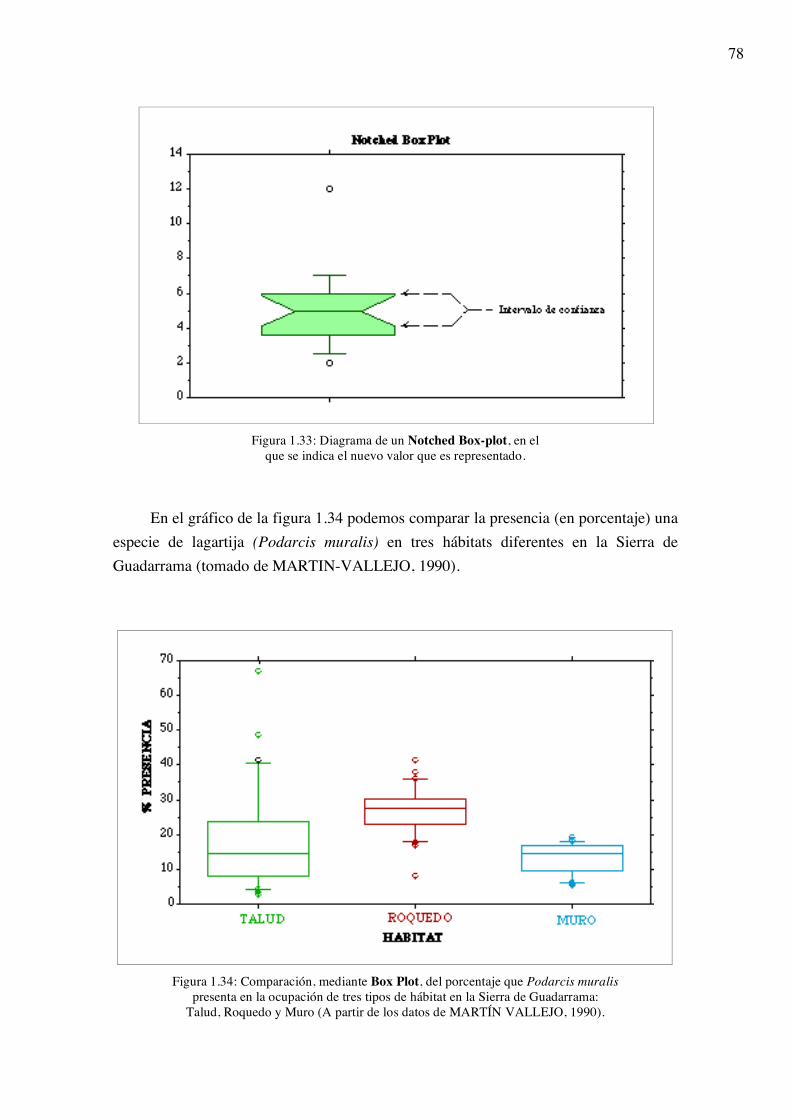
78
Figura 1.33: Diagrama de un Notched Box-plot, en el que se indica el nuevo valor que es representado.
En el gráfico de la figura 1.34 podemos comparar la presencia (en porcentaje) una especie de lagartija (Podarcis muralis) en tres hábitats diferentes en la Sierra de Guadarrama (tomado de MARTIN-VALLEJO, 1990).
Figura 1.34: Comparación, mediante Box Plot, del porcentaje que Podarcis muralis presenta en la ocupación de tres tipos de hábitat en la Sierra de Guadarrama:
Talud, Roquedo y Muro (A partir de los datos de MARTÍN VALLEJO, 1990).

79
Incluso en algunos programas combinan información en un mismo gráfico, como puede observarse en el siguiente (figura 1.35) realizado con el JMP (SAS Institute Inc. 1989-94), en el cual además de un Box-plot aparece la información sobre la media y su intervalo de confianza.*
Figura 1.35: Gráfico obtenido con el programa JMP. Además de un Box-plot aparece información sobre la media aritmética y su intervalo de confianza.
Diagramas de dispersión
Un Diagrama de puntos, más conocido como Diagrama de Dispersión, es un método simple pero eficiente para ilustrar un determinado comportamiento o bien analizar una distribución en particular; su finalidad puede ser la de poner de manifiesto una relación entre variables, analizar proximidades entre individuos y/o poblaciones, localizar outliers...
Por ser un método suficientemente conocido, no se realizará un estudio detallado
de dicha representación, si bien -dada su importancia- se comentarán algunas de las posibilidades que permite en el estudio de datos multivariantes.
La información visual de un diagrama de dispersión puede ser incrementada
mediante varias herramientas adicionales (CHAMBERS & KLEINER, 1982); por ejemplo, mediante un Box-plot paralelo marginal para cada variable. (Ver figura 1.36).
* Ver el apartado 4.1.3 relativo a intervalos de confianza

80
.
25
20
15
10
5
0
100 20 30
SA
AV
SG
LE
SO
P
BU
VA
ZA
BARBECHO
PASTIZAL
Figura 1.36: Diagrama de Dispersión, con Box Plot paralelo marginal, de la superficie de cultivo dedicada a Barbecho y Pastizal, en las provincias de Castilla y León.
(A partir de los datos del Anuario de Estadística Agraria, 1990)
Para representar las relaciones entre más de dos variables, una posibilidad es añadir una tercera, obteniendo así un Diagrama de Dispersión Tridimensional, como se muestra en la figura 1.37.
Figura 1.37: Diagrama de Dispersión Tridimensional, de la superficie de cultivo dedicada a Barbecho, Prado y Herbáceo en las provincias de Castilla y León.
(A partir de los datos del Anuario de Estadística Agraria, 1990)

81
Existen sistemas gráficos de ordenador (SYSTAT, JMP, SPSS), que permiten -
mediante la opción denominada 'SPIN'- la 'exploración multivariante' de estas representaciones tridimensionales, al rotar la nube de puntos alrededor de cualquier eje en la pantalla, y visualizar de este modo todos los puntos, y sus posiciones relativas. El resultado puede llegar a ser realmente espectacular con el uso del color en la representación.
De acuerdo con los modernos Analistas de Datos (GABRIEL (1971) entre otros),
esta importante innovación gráfica constituye una de las más potentes técnicas de análisis visual de datos multivariantes existentes en la actualidad.
Quizás sea ésta la razón por la cual todos los nuevos 'paquetes gráficos' que salen
al mercado, incluyan esta opción. Opción, por otra parte, que ha sido posible por el desarrollo que en los últimos tiempos han sufrido los ordenadores; el movimiento en tiempo real de la nube tridimensional exige operar con una gran cantidad de datos con potencia y rapidez.
Matriz de Diagramas de Dispersión
Otra forma de representar relaciones entre más de dos variables, es dibujando pares de variables mediante diagramas de dispersión, que son ordenados en una Scatterplot Matrix , o Matriz de Diagramas de Dispersión (figura 1.38), proporcionando de este modo, en una única imagen visual, todos los pares posibles; todas las variables.
Aunque cada diagrama por separado muestra tan sólo dos dimensiones de los
datos (no es posible detectar una variación común), en ocasiones esta representación univariante múltiple puede ser efectiva en la detección de 'outliers', o patrones de los datos.
Los Diagramas de Dispersión Múltiples, nombre con el cual también se conoce
a este tipo de representación, son análogos gráficos de las matrices de covarianzas o correlaciones utilizadas en la mayor parte de las técnicas gráficas multivariantes. En este sentido podrían considerarse técnicas gráficas multivariantes.

82
Figura 1.38: Matriz de diagramas de dispersión de la superficie de cultivo dedicada a Barbecho, Prado, Herbáceo y Pastizal en las provincias de Castilla y León.
(A partir de los datos del Anuario de Estadística Agraria, 1990)
MÉTODOS GRÁFICOS MULTIVARIANTES (MGM)
Los Métodos Gráficos Multivariantes, como hemos apuntado con anterioridad, son métodos que simplemente exigen efectuar una transcripción geométrica de los datos (correspondientes a un conjunto de n variables, n>2 ), en una representación gráfica. Constituyen directamente por ello un procedimiento descriptivo.
¿Cómo podemos representar gráficamente valores de más de tres variables
en una representación gráfica? Cuando los datos tienen más de dos o tres dimensiones, la representación gráfica
se hace complicada: las dimensiones del plano no son capaces de acoger un mayor número de variables que los que acoge la representación cartesiana convencional, o la tridimensional; por lo tanto se requiere otro tipo de representación.
Existen diferentes métodos para representar datos multivariantes, prácticamente
tantos como autores se han ocupado del tema. No se realizará por ello una revisión exhaustiva ni una descripción detallada de los MGM; solamente se enumerarán algunas de las técnicas existentes en la actualidad, y únicamente se expondrán con cierto detalle las más importantes y actuales que permiten la representación gráfica de entidades definidas por varias variables, como son las Caras de Chernoff (CHERNOFF, 1973), y las Curvas de Andrews (ANDREWS, 1972), o las Gotas de Fourier.

83
Como en todo Análisis Multivariante, se parte de una matriz de datos que contiene la información de los valores que los individuos toman para cada una de las variables a estudiar, que será la que se representará de forma gráfica.
Antes de representar dicha matriz pictóricamente, debe cuestionarse cual será el
uso que se dará a dicha representación, y el objetivo final de la misma; teniendo en cuenta, además, que por lo general serán los individuos las entidades representadas. Todo ello en base a elegir el método de representación más adecuado.
La práctica totalidad de los Métodos Gráficos Multivariantes que se conocen, no son otra cosa que 'constructos pictóricos', (también conocidos como gráficos pictoriales o figurativos, o simplemente 'Iconos'), formados por elementos geométricos (puntos, rectas, curvas, triángulos, círculos...) que varían en función de los valores que toman las variables en los individuos a los que representan. Algunos de los muchos MGM existentes, son los que aparecen esquematizados en
la figura 1.39. (Tomada de AVILA-ZARZA, 1993).
Entre los métodos representados en esta figura, unos se caracterizan porque las variables se representan como longitudes de las componentes gráficas; es el caso de los Polígonos o Estrellas (rayos circulares emanando de un origen común), o los Glifos, (segmentos
que se extienden desde un círculo); otros -es el caso de las Caras de Chernoff- representan las variables mediante características faciales (excentricidad de la cara, la curvatura de la boca o
la inclinación de los ojos...), etc.. La mayoría de las técnicas se encuentran ya informatizadas, de modo que el
investigador tan sólo deberá determinar el orden de asignación de las variables para su construcción.

84
Gráficos de veleta
Polígonos o estrellas
Glifos
Gotas de Fourier
Caras de Chernoff
Figura 1.39: Algunos tipos de Métodos Gráficos Multivariantes
(tomada de AVILA-ZARZA, 1993)
Interpretación de las representaciones gráficas multivariantes
Cada elemento de un icono no puede ser convertido al valor numérico; las transformaciones que en general suelen realizarse, son lo suficientemente complejas para que nosotros podamos interpretar esos valores mentalmente con la simple observación visual de los mismos.
La correcta interpretación de estos métodos consiste, fundamentalmente, en buscar gráficos similares. Entidades con similares valores para las variables tendrán formas parecidas; y entidades con diferentes valores, presentaran formas diferentes. Esto nos permitirá encontrar patrones de variación similares, en contraposición
con otros tipos de patrón, y por tanto, por ejemplo, establecer grupos o 'Clusters'. Si se desea obtener información acerca de los valores de partida, deberá volverse sobre los datos originales y examinar los valores correspondientes, y cómo estos determinan los gráficos.

85
Veamos, de manera simplificada, alguno de estos métodos.
Polígonos o Estrellas
Determinan perfiles configurados por segmentos que parten de un origen común, y cuya longitud corresponde al valor que -para cada entidad- toma la variable a la cual dicho segmento representa. Las figuras 1.40 y 1.41, son un ejemplo de este tipo de representación
ASALTOS
ROBOS
ALLANAMIENTOS
DE MORADA
HURTOS
ROBOS DE
COCHES
ASESINATOS VIOLACIONES
Figura 1.40: Icono de estrella para la ciudad de New York mostrando la asignación de las
variables a cada segmento, para el ejemplo de la figura 1.41
Figura 1.41: Iconos de estrella representando los datos de la criminalidad en diversas ciudades de EE.UU. (datos originales de EVERITT, 1993).

86
Para hacer la representación más visible, los extremos de los segmentos pueden ser conectados entre si. El programa de ordenador SYSTAT (WILKINSON & EVANSTON, 1988), presenta los resultados (tras la aplicación de este método), mediante los polígonos que resultan de la conexión de estos segmentos, pero sin que los mismos aparezcan.
Como en otros gráficos figurativos, es conveniente ordenar las variables de tal
manera que aquellas que estén correlacionadas aparezcan próximas.
Gotas o Manchas de Fourier
Se trata de otro método de representación gráfica multivariante (Ver figura. 1.42)
Esta está determinada por la función de Fourier:
f(t) =y1
2+ y2sen(t) + y3 cos(t) + y4sen(2t) + y5 cos(2t)
donde y es una variable p-dimensional y t varía desde -3,14 hasta 3,14.
El resultado de esta transformación es un conjunto de formas onduladas hechas a
partir del seno y el coseno, que trasladadas a coordenadas polares, toman el parecido de manchas, gotas o amebas.
Cada individuo vendrá representado por una gota, de modo que podremos
encontrar clusters de individuos "parecidos" cuando las gotas que los representan tengan una forma similar. La forma de las gotas dependen del orden de introducción de las variables en la función de Fourier.
La información contenida en las gotas de Fourier es la misma que la de las curva
de Andrews (que veremos al final del capítulo) pero con la ventaja de que no se solapan y pueden ser utilizadas como símbolos en otro tipo de representaciones gráficas.

87
Avila Burgos Leon
Palencia Salamanca Segovia
Soria Valladolid Zamora
Figura 1.42: Gotas de Fourier representando las provincias de Castilla León en cuanto a diferentes variables de producción agraria.
(A partir de los datos del Anuario de Estadística Agraria, 1990)
Caras de Chernoff ¡No se ría!. Estas son las primeras palabras con las que se presenta a los lectores
este método de representación de datos multivariantes en el manual SYGRAPH, que trata de las representaciones gráficas que el programa estadístico para ordenador SYSTAT permite realizar. Quizás porque ésta suele ser la primera reacción de los que desconociendo el método, se encuentran de pronto con caras de rasgos caricaturizados en una ponencia o en un trabajo de investigación; quizás para contrarrestar la aparente falta de seriedad (argumento esgrimido por sus detractores), que puede inducir a más de uno a descartarlo sin haberlo tomado en consideración.
Figura 1.43: Caras de Chernoff correspondientes a las provincias de Salamanca y Valladolid, epresentando la variabilidad de cultivos. (Gráfica cedida por VICENTE TAVERA y cols., 1993)

88
El método original, aparecido en el trabajo "Using faces to represent points in k-dimensional space graphically", que fue publicado en 1973 en Journal of the American Statistical Association, se debe a H. CHERNOFF, al que no le causó trauma alguno enfrentarse al reparo psicológico que los investigadores pronto tuvieron con el mismo (ALONSO, 1982).
CHERNOFF (1982) comenta, que buscaba un método gráfico sencillo que
representara, de forma compacta, un número importante de variables, de forma que causase el máximo impacto en el observador, y permitiese un buen contraste y clasificación de las entidades representadas. De entre todas las posibilidades, eligió las caras para aprovechar la capacidad de reconocimiento del observador humano, que puede discriminar muchas caras diariamente, y por el impacto o reacción emocional que dichas caras provocan, lo que acentúa su poder de captación de atención y su carácter nemotécnico.
El principio heurístico de las caras de Chernoff está basado, pues, en la capacidad
del hombre para reconocer, comparar y agrupar caras. Este procedimiento gráfico, que requiere la utilización de un programa de
ordenador para ser realizado, concentra la información de cada individuo en un rostro humano caricaturizado, cuyos rasgos reflejan cada una de las variables o "descriptores" (Figura 1.43).
Originalmente, las caras estaban determinadas por 18 parámetros tales como la
longitud de la nariz, el tamaño de los ojos o la curvatura de la boca (CHERNOFF, 1973.). Los 18 parámetros o facciones que originalmente determinaban el dibujo de las Caras de CHERNOFF, son los que aparecen en la figura 1.44.
Estos 18 parámetros son los que se hacen variar, reflejando así el comportamiento de cada una de las variables en todas las entidades o individuos (caras) representados.
En la figura 1.45 se esquematiza la serie de parámetros que se hacen variar, lo que
permite representar hasta 18 variables.

89
1. Anchura de la cara. 2. Nivel de la oreja. 3. Altura de la cara. 4. Excentricidad de la elipse superior cara. 5. Excentricidad de la elipse inferior cara . 6. Longitud de la nariz . 7. Posición centro de la boca. 8. Curvatura de la boca. 9. Longitud de la boca. 10. Altura del centro de los ojos. 11. Separación de los ojos. 12. Inclinación de los ojos. 13. Excentricidad de los ojos . 14. Longitud ojo. 15. Posición de las pupilas. 16. Altura de la ceja. 17. Ángulo de la ceja. 18. Longitud de las cejas.
Figura 1.44: parámetros de las caras de Chernoff
Figura 1.45: Parámetros de los Rasgos faciales de las Caras de Chernoff, según BRUCKNER (1978). A.- Caras originales de CHERNOFF (1973). B.- Variante de DAVIS (1988), que incluye nariz y oreja
Las variaciones de los rasgos caricaturizados dan una apariencia concreta a la cara, que representa un punto en un espacio de 18 dimensiones. En espacios de dimensión menor, es decir, cuando el número de variables es menor que el de facciones, se asignan las variables a los primeros rasgos, tomando los rasgos restantes un valor constante para mantener la imagen facial completa (participan en las figuras sin variar), por ejemplo.

90
Cada variable estudiada se asigna a uno de los parámetros que controlan los rasgos, de forma que el valor del parámetro facial sea proporcional al valor que toma la variable en el individuo a representar. Para ello se deja variar el parámetro dentro de un rango de variabilidad preestablecido, de manera que la estructura global mantenga las características básicas de una cara. Algunos parámetros faciales varían libremente (diámetro de la oreja), pero la mayoría quedan supeditados a la exigencia anterior y dependen de otras características faciales.
La asignación de cada variable a cada parámetro facial es optativa. Hay usuarios
del método que prefieren efectuar una asignación al azar, mientras que otros establecen una correspondencia intencionada.
Existen otras variantes de caras.
La variante de Davis (BRUCKNER, 1978) añade dos variables más (anchura de nariz y diámetro de orejas). (Ver figura 1.45). EVERITT, en 1978 introduce pelo y boca bidimensional, quizás con la intención de que resulten menos caricaturescas. NEWTON (1978), dibuja sus caras con ojos rómbicos y nariz ganchuda, etc.
Un programa que permite representar la variante de Davis, es el programa CHER,
implementado por ALONSO en colaboración con M.A. Campos. Otros programas que implementan las Caras son:
◊ ASYM: Programa en Fortran. ◊ SCHÜPBACH (1984): Versión para IBM. PC. ◊ SAS-Macro con caras asimétricas.
Aplicaciones Algunas aplicaciones que se pueden encontrar en la literatura, abarcan casos tan
diversos como* :
* Caracterización de presas del Guadiana por sus variables ecológicas (ALONSO, 1982).
* Estudio de los resultados de las elecciones municipales en 27 poblaciones catalanas (ALONSO, 1982).
* Estudio sobre la política soviética en África (WANG & LAKE, 1978).
* Nos ha parecido apropiado incluir estas referencias para que el profesor tenga acceso a un material complementario al que se ofrece en este trabajo

91
* Estudio económico de las grandes compañías petrolíferas (BRUCKNER, 1978).
* Clasificación de tipos de enfermos mentales caracterizados por diversos test (MEZZICH & WORTHINGTON, op. cit.).
* Asignación de caras con distintas actitudes faciales a enfermedades mentales (JACOB, 78).
* Agrupación de distintas ciudades caracterizadas por variables demográficas y ambientales (HUFF & BLACK, 1978).
* Estudio de la policía secreta soviética (WANG & LAKE 1978).
* Estudio de los cráteres de la Luna (PIKE, 1974)
* Perfiles de la personalidad psiquiátrica (MEZZICH & WORTHINGTON, op. cit.)
* Variabilidad de Cultivos en la comunidad Castellano-Leonesa (VICENTE TAVERA y col., 1993). (Ver figura 1.46).
LEON
PALENCIABURGOS
VALLADOLID
ZAMORA
SALAMANCA
AVILA
SEGOVIA
SORIA
CACERESTOLEDO
MADRID
GUADALAJARA
RIOJA
ALAVA
VIZCAYA
CANTABRIA
ASTURIAS
LUGO
ORENSE
Figura 1.46: Cartograma con Caras de Chernoff, correspondiente a las provincias de Castilla-León, representando la variabilidad de cultivos. (Gráfica cedida por VICENTE TAVERA y cols. 1993).

92
Ventajas e inconvenientes.
Ventajas 1.- Facilidad de reconocimiento global de la información contenida en las caras; se trata de una característica de la percepción humana confirmada por diversos estudios experimentales. JACOB (1978) demostró que los sujetos sin preparación o conocimiento de las variables representadas, pueden juzgar con caras con razonable exactitud 2.- Los datos representados pueden ser heterogéneos y no se exige ninguna condición estadística. 3.- Con este método resulta sencillo efectuar agrupaciones por similitudes de rasgos. 4.- Es una Técnica que permite concentrar la información de todas las variables en una figura muy compacta. Tanto la asignación intencionada de rasgos, como la subjetividad al seleccionar
determinadas facciones para identificar similitudes, puede constituir una ventaja o una desventaja según las exigencias del trabajo y del observador, ya que otros métodos -aparentemente neutros- también presentan riesgos de subjetividad.
Diversos autores abogan por una estricta aleatoriedad en la asignación de rasgos
(ALONSO, 1982), así como efectuar diversas asignaciones para corroborar las agrupaciones, evitando así los posibles efectos subjetivos de la clasificación.
Otros, por el contrario, defienden la asignación intencionada y aprovechar dichos
factores subjetivos (HUFF & BLACK; 1978).
Inconvenientes 1.- Necesidad de un dispositivo gráfico y un programa. 2.- Pérdida de información directa de los valores concretos de las variables (común a la práctica totalidad de los MGM). 3.- Dificultad de reconocimiento, cuando se tiene un grupo muy numeroso de caras, o cuando existe un número elevado de variables. 4.- Interdependencia de los rasgos que hace que, cuando uno de ellos adopta un valor muy alto, puede modificar otros (que en principio deberían ser iguales a los presentados por otra cara no deformada por dicha interdependencia).

93
BRUCKNER (1978) sugiere la normalización de los rasgos (reducirlos a áreas limitadas) para evitarlo. 5.- Existencia de rasgos que destacan más que otros en la discriminación, por lo que HUFF & BLACK (1978) recomiendan efectuar un análisis de la varianza y asignar a los rasgos más significativos (boca, ojos, anchura cara, etc.) las variables con mayor varianza. Una variable puede ser portadora de mayor información, si se representa por la curvatura de la boca, que por el tamaño de las cejas. 6.- Debe tenerse precaución a la hora de asignar los rangos de los parámetros faciales, pues si se eligen muy amplios y las variables tienen poca variabilidad no se obtiene discriminación alguna . En cambio, si no se determinan correctamente los rangos de variabilidad de las variables, puede suceder que los rasgos se salgan de la cara. Curvas de Andrews. ANDREWS (1972) propone un técnica muy simple, conocida como "Curvas de
Andrews", para obtener una representación visual de datos multivariantes, donde cada punto es representado en una suma de funciones trigonométricas.
Este método, a caballo entre el perfil y la reducción de la dimensión, consiste en representar a cada individuo, que presenta los valores muestrales (x1, ..., xk) de las variables consideradas, mediante un grafo de la función periódica:
f( t) =x1
2+ x2sen(t) + x3 cos(t) + x4sen(2t) + x5 cos(2t)
para valores de t comprendidos entre - π< t < π. Este tipo de funciones son fácilmente trazables mediante un dispositivo gráfico y
un sencillo programa, obteniéndose, para los individuos considerados, series de curvas que permiten la interpretación posterior (Figura 1.47 y 1.48).
Los clusters y puntos aberrantes, son revelados por el hecho de que las distancias
entre dos funciones son concebidas proporcionales a la distancia euclídea de los objetos en el espacio p dimensional original, por la preservación de la media y la desviación.
Interpretación.

94
ANDREWS (1972), destaca el hecho de que cada curva recoge y resume información de todas las variables que afectan al individuo, de manera que las diferencias entre individuos para alguna de ellas debe resultar manifiesta en alguna parte de las respectivas curvas.
Figura 1.47: Curvas de Andrews de los porcentajes de nutrientes en distintos productos alimenticios. Recogidos por el Departamento de Agricultura de E.E. U.U.
.
-180 -90 0 90 180
0
1000
2000
3000
4000
GRADOS
-1000
-2000
CO
MP
ON
EN
TE
DE
FO
UR
IER
Figura 1.48: Curvas de Andrews obtenidos por EVERITT, 1993 sobre la criminalidad de dieciséis ciudades diferentes de EE.UU.
La conservación de las distancias euclídeas originales para las curvas permite, según el autor, afirmar que dos curvas similares a lo largo del recorrido de t corresponden a individuos próximos.

95
Por ello, al analizar un conjunto de curvas se deben buscar aquellos valores de t
que permiten identificar o discriminar al máximo algunos grupos de ellos y efectuar, si se cumplen las condiciones necesarias, un contraste para la significación de la agrupación.
Dado que la primera impresión de un conjunto numeroso de curvas (el autor
desaconseja superar las 10) puede resultar desconcertante (figura 1.48), suele realizarse una representación previa de varias curvas por separado (mejor si se tienen grupos de referencia), de forma que pueden identificarse dichos valores de t que permitan interpretar las proximidades de nuevas curvas que se vayan añadiendo.
Como hay variables que están asociadas a elementos cíclicos de la función con
distinta frecuencia y se discrimina mejor en las curvas las bajas frecuencias, es aconsejable colocar en los valores iniciales (x1, x2, ... ) aquellos correspondientes a las variables más importantes en la discriminación, es decir, las que reflejan más variabilidad.
Sin embargo, se carece de información acerca de la relación concreta de las
distintas crestas de la curva con los valores de las variables, al perderse toda la información directa. BIBLIOGRAFIA CITADA ABACUS (1993). StatView 4.01. Berkeley. ALONSO, G. (1982). 'Nuevos métodos de representación gráfica de datos multivariantes. Publicaciones de Bioestadística y Biomatemática. 5. Eunibar. Universidad de Barcelona. ANDREWS, D.F. (1972). 'Plots for high dimensional data'. Biometrika, 28: 125-136. ANSCOMBE, F.J. (1973). 'Graphs in statistical analysis'. American Statistician, 27: 17-21. ANUARIO DE ESTADISTICA AGRARIA (1990). Publicado por el Ministerio de Agricultura, Pesca y Alimentación. Datos correspondientes a 1987. AVILA-ZARZA, C. (1993). Métodos Gráficos Multivariantes y su Aplicación en las Ciencias de la Vida. Trabajo de Grado. Dpto. de Estadística y Matemática Aplicadas. Universidad de Salamanca. BRUCKNER, L.A. (1978). 'On Chernoff faces'. In Graphical Representation of Multivariate Data. (P.C.C. Wang, ed.). pp.: 93-121. Academic Press. CHAMBERS, J.M. & KLEINER, B. (1982). 'Graphical techniques for multivariate data & clustering'. In Handbook of Statistics. 2 (P.R. Krishnaiah, & L.N. Kanal, eds.) Nort-Holland P.C.

96
CHERNOFF, H. (1973). 'The use of faces to represent points in k-dimensional space graphically'. Journal of the American Statistical Association, 68: 361-368. CHERNOFF, H. (1982). 'Chernoff faces'. Encyclopedia of Statistical Sciences. I: 436-438. John Wiley & Sons. New York. CRICHTON, M. (1990-92). Parque Jurásico. Ed. Plaza y Janés. DAVIS, F. (1988). La Comunicación no Vergal. Alianza Editorial. Madrid. EVERITT, B.S. (1993). Cluster Analysis. (3rd. ed.). Halsted Press. New York. EVERITT, B.S. (1978). Graphical Techniques for Multivariate Data. Heinemann Educational Books. London. FIENBERG, S.E. (1977). 'Graphical methods in Statistics'. Tech. Report, 304. Dep. Appl. Statistics. University of Minnessota, 44. GABRIEL, K.R. (1971). 'The Biplot graphic display of matrices with applications to principal component analysis'. Biometrika, 58: 453-467. GETE-ALONSO, J.C. y BARRIO, V. del (1990). Lenguaje Gráfico. Alhambra. Madrid. HAMILTON, L.C. (1990). Modern Data Analysis. A First Course in Applied Statiscs. Brooks/Cole Publishing Company. California. HUFF, D.L. & BLACK, W. (1978). 'A multivariate graphic display for regional analysis'. In Graphical Representation of Multiaviate Data (P.C.C. Wang, ed.) pp.: 199-218. Academic Press. New York. JACOB, R.J.K. (1978). 'Facial representation of multivariate data'. In Graphical Representation of Multiaviate Data (P.C.C. Wang, ed.) pp.: 199-218. Academic Press. New York. JMP. (1989-94). SAS Institute Inc. MARTIN-VALLEJO, F.J. (1990). Uso del Espacio y del Tiempo en dos Especies Simpátridas del Genero Podarcis (Wagler, 1830). Tesina de Licenciatura. Universidad de Salamanca. MEZZICH, J.E. & WORTHINGTON, D.R.L. (1978). 'A comparation of grpahical representation of multidimensional psychiatric diagnostic data'. In Graphical Representation of Multivariate Data (P.C.C Wang, ed.) pp.: 123-142. Academic Press. New York. McGILL, R.; TUFEY, J.W. & LARSEN, W.A. (1978). 'Variations of Box-plots' Amer. Stat., 32: 12-36. NAGEL, M. & DOBBERKAY, H.J. (1988). 'Graphical methods of exploratory data analysis: An overview'. In Classification and Related Methods of Data Analysis. Elsevier Science P.B.V. Holland. NEWTON, C.M. (1978). In Graphical Representation of Multivariate Data. (Wang, ed.) Academic Press. New York. PIKE, J. (1974). 'Craters on Earth, Moon and Mars: Multivariate clasification and mode of origin'. Earth and Planetary Science Letters, 22: 245-255. PINILLOS, J.L. (1973). La Mente Humana. Salvat. Pamplona. POULTON, E.C. (1985). 'Geometric illusions in reading graphs'. Perceptions and Psichophisics. 37: 543-548. ROMERO-VILLAFRANCA, R. (1991). Estadística: Proyecto de Innovación Educativa. Dpto. de Estadística e Investigación Operativa. Universidad Politécnica de Valencia.

97
ROYSTON, E. (1970). 'Studies in the history of probability and Statistics. A note on the history of the graphical presentation of data'. Biometrika, 43 (3,4): 241; 247. SNEE, R.D. & PFEIFER, C.G. (1985). 'Graphical representation of data'. In Encyclopedia of Statistical Sciences. John Wiley & Sons. New York. SPENCE, I. & LEWANDOWSKY (1990). 'Graphical perception'. In Modern Methods of Data Analysis (J. Fox & J. Scott Long, eds.). Sage Publications. Newbury. SWOBODA, H. (1975). El Libro de la Estadística Moderna. Ediciones Omega. Barcelona. TUKEY, J.W. (1962). 'The future of data analysis'. Ann. Math. Statist. 33: 1. TUKEY, J.W. (1977). Exploratory Data Analysis. M.A. Adisson-Wesley. Reading. VICENTE,S.; GALINDO, M.P.; VICENTE-VILLARDON, J.L.; MARTIN, A.; BARRERA, I. y FERNANDEZ-GOMEZ, M.J. (1993). 'Análisis gráfico y descripción estructural de la variabilidad de cultivos en Castilla-León'. Investigación Agraria, Vol 8(3):315-329. VURPILLOT, E. (1979). 'Percepción del espacio'. En La Percepción (Fraisse & Piaget Eds.). Paidós. Buenos Aires. WANG, P.C.C. & LAKE, G.E. (1978). 'Application of grpahical multivariate techniques in poligy sciences'. In Graphical representation of multivariate data (P.C.C. Wang, ed.) pp: 15-38. Academic Press. New York. WILKISON, & EVANSTON (1988-91). SYSTAT. SYSTAT Inc.

98
"REPRESENTACIONES GRÁFICAS"
1.3 Trabajo de investigación

99
1.3.1 Objetivo En este trabajo se pretende aplicar los conceptos descritos en esta
unidad temática, utilizando para ello datos reales tomados de la evaluación del profesorado universitario durante el curso académico 1991-92. Está planteado de forma que pueda ser utilizado como ejercicio de prácticas para los alumnos, como recapitulación de las ideas de esta unidad.
1.3.2 Planteamiento del trabajo Durante el curso académico 1991-92 las autoridades de la Universidad de
Salamanca llevaron a cabo un estudio sobre la calidad de la docencia. Para ello se preparó un cuestionario con 28 preguntas relacionadas con seis áreas
diferentes de la tarea del Profesor: Apartado 1.- Consta de tres preguntas relativas al cumplimiento de las obligaciones docentes del Profesor. Apartado 2.- Tres preguntas relativas a la calidad y desarrollo del programa. Apartado 3.- Cinco preguntas relativas al dominio de la asignatura por parte del profesor que la imparte. Apartado 4.- Seis preguntas relativas a la interacción del profesor con los alumnos. Apartado 5.- Tres preguntas relativas a los exámenes. Apartado 6.- Tres preguntas relativas a la valoración global del profesor. Para cada uno de los profesores que imparte la asignatura, los alumnos deben
rellenar un cuestionario en el que a cada una de las preguntas se le debe asignar una valoración cuyo rango oscila entre 1 y 5; la puntuación 1 indica que el profesor no satisface en modo alguno el supuesto de la pregunta y la puntuación 5 que el profesor satisface plenamente el supuesto. La evaluación se realiza en horas de clase normal, pasando el cuestionario a los alumnos que en dicho momento se encuentren en clase.

100
Trabajaremos sobre tres preguntas que consideramos importantes:
La nº 3 del cuestionario: "¿El profesor está accesible para sus alumnos fuera del horario de clase?"
La nº 7: "El profesor parece dominar la asignatura que imparte"
La nº 26: "¿Piensa que el Profesor que imparte esta asignatura es un buen Profesor"
En este caso, vamos a trabajar sobre los resultados de la evaluación docente
obtenidos por un Profesor del Departamento de Estadística y Matemática Aplicadas de la Universidad de Salamanca, en las diferentes asignaturas que impartió durante el citado curso académico. A este profesor, le llamaremos de ahora en adelante "Mrs. X".
1.3.3 Desarrollo del trabajo Cuando se realiza un trabajo de investigación, deberemos tener en cuenta, en
primer lugar, cuál es la población en estudio. En este caso, podemos considerar 4 poblaciones. Cada población estará formada por los alumnos de cada una de las 4 asignaturas que impartió Mrs. X durante dicho curso.
Generalmente, no se analiza la población completa, sino que se elige un
subconjunto de la misma sobre la que se realiza el estudio, y que se denomina muestra. Obviamente la muestra elegida deberá ser representativa de la población de la que es extraída, es decir, los individuos de la muestra han de contener todas las características relevantes de la población, lo que podemos conseguir por ejemplo tomando una muestra aleatoria de la población (ver para más información, el capítulo sobre muestreo). En el estudio de la universidad se pasa el cuestionario a los alumnos que un día determinado se encuentran en clase.
La característica que se pretende estudiar -que se denomina variable- es en este
caso la opinión de los alumnos acerca de cada uno de los items que hemos citado con anterioridad. La variable en este caso es una variable ordinal, siendo los valores que puede tomar 1, 2, 3, 4 y 5. Obviamente, la elección de la escala no garantiza que dos alumnos que otorguen la misma puntuación al profesor, en una determinada pregunta, estén realmente realizando la misma valoración.

101
1.3.3.1 Tabulación de los resultados
Generalmente, al llevar a cabo un estudio estadístico, solemos encontrarnos con una gran cantidad de datos, cuya interpretación, y ni siquiera su presentación, es fácil. Es lo que ocurre en este caso. Por ello, en primer lugar necesitamos realizar un proceso que nos permita condensar la información de manera que podamos obtener los rasgos más sobresalientes. Por ello dispondremos los datos de manera ordenada y sistemática en una tabla de distribución de frecuencias.
A partir de los resultados obtenidos por "Mrs. X", en las asignaturas que impartió
durante el citado curso académico, se construyeron las correspondientes tablas de distribución de frecuencias. Así, para evitar presentar los datos brutos obtenidos en el análisis presentamos a continuación las tablas de distribución de frecuencias para cada uno de los ítems (variables) analizadas y para cada muestra (tablas 1.2, 1.3 y 1.4):
a) "El profesor está accesible para los alumnos"
Frecuencia Valor de la
variable Ampliación
Bioestadística Bioestadística
(Biología) Bioestadística
(Medicina) Análisis de Datos
1 4 17 11 0 2 6 23 14 3 3 2 19 29 5 4 4 18 17 7 5 0 26 30 8 ni 16 103 101 23
Tabla 1.2
b) "¿Domina la asignatura que imparte?"
Frecuencia Valor Ampliación
Bioestadística Bioestadística
(Biología) Bioestadística
(Medicina) Análisis de Datos
(Libre dispos.) 1 0 2 1 0 2 0 3 3 0 3 0 3 3 0 4 4 10 11 0 5 12 85 83 23 ni 16 103 101 23
Tabla 1.3

102
c) "¿Es un buen Profesor?"
Frecuencia Valor Ampliación
Bioestadística Bioestadística
(Biología) Bioestadística
(Medicina) Análisis de Datos
1 1 12 2 0 2 0 8 7 0 3 4 25 21 1 4 4 31 35 7 5 7 27 36 15 ni 16 103 101 23
Tabla 1.4
A partir de la información suministrada por las tablas anteriores vemos cuáles han
sido los tamaños de las muestras extraídas de cada una de las 4 poblaciones en estudio (denotadas con ni (i=1,...,4)).
1.3.3.2 Representaciones gráficas
La información proporcionada por las tablas puede ser bastante completa, pero tiene la dificultad de que su lectura requiere un cierto tiempo y capacidad de comparación para relativizar la información de unas clases respectos de las otras.
Las representaciones gráficas constituyen uno de los principales métodos de
exponer la información, siendo uno de los más sencillos, por su capacidad de impactar al lector con muy poco esfuerzo por su parte, (de modo que incluso los profanos en la materia pueden entenderlos). Por ejemplo, siempre que el lector se disponga a leer un determinado artículo (científico, divulgativo, o simplemente un artículo publicado en un periódico) su vista se dirige en primer término al título del mismo, para pasar luego a los gráficos y por último a las tablas.
Dado que de los gráficos obtenemos una información rápida y global de los
resultados, pasaremos en este punto a realizar diversas representaciones gráficas de los resultados anteriores.
Por ejemplo, podemos realizar, para la pregunta "El profesor está accesible para
los alumnos" el diagrama de barras para la opinión de los alumnos de la asignatura de Bioestadística sería el que se muestra en la figura 1.49:

103
Figura 1.49: Diagrama de barras para la asignatura Bioestadística de la Facultad de Biología Si quisiésemos comparar los resultados para las cuatro asignaturas, podríamos
presentar el gráfico siguiente (figura 1.50):
1 2 3 4 5
0
10
20
30
40
BIOESTAD.
BIOEST. MED.
AN. DATOS
AMP. BIOEST.
¿Está accesible para los alumnos?
PUNTUACION
frecuencia
Figura 1.50: Diagrama de barras comparativo para las cuatro asignaturas.
A simple vista, parece que es para los alumnos de las asignaturas de Análisis de

104
Datos y Ampliación de Bioestadística, para los que menos disponible está Mrs. X. Sin embargo, los gráficos, por dar una información más general que las tablas, son más susceptibles a alteraciones, conscientes o no, que pueden inducir a error. El lector, debe fijarse atentamente en el gráfico, y comprobará que en el eje de ordenadas se ha representado la frecuencia (número de alumnos que han dado una determinada puntuación al profesor en relación al ítem considerado). Esto nos hace observar, con más detenimiento, y teniendo en cuenta la información de las tablas de frecuencias, que el número de alumnos de cada muestra no es el mismo, por lo que la representación de las frecuencias absolutas, no nos permite realizar comparaciones aceptables en dichos casos.
Por lo tanto, sería más conveniente, si lo que quisiésemos es comparar las
respuestas en las diferentes asignaturas que utilizásemos frecuencias relativas o porcentajes.
Así, con la utilización de éstos últimos, el diagrama de barras correspondiente
sería el que se muestra a continuación (figura 1.51):
1 2 3 4 5
0
10
20
30
40
BIOESTAD.
BIOEST. MED.
AN. DATOS
AMP. BIOEST.
¿Está accesible para los alumnos?
PUNTUACION
porcentaje
Figura 1.51: Diagrama de barras comparativo para los porcentajes de cada asignatura
Fijémonos por ejemplo, en la puntuación de 2: En el gráfico de la figura 1.50, se observa que el mayor número absoluto de alumnos que dan dicha puntuación son los de Bioestadística de Biología. Sin embargo, si nos fijamos en el gráfico de la figura 1.51,

105
podemos observar cómo esa interpretación debe hacerse con cautela, ya que el tamaño de la muestra en cada caso es distinto, y así, son los alumnos de Ampliación de Bioestadística los que en términos relativos dan con mayor frecuencia esa puntuación. (23 de 103 alumnos de Bioestadística de Biología, dan una puntuación de 2, mientras que en ampliación de Bioestadística son 6 de 16).
1.3.3.3 Resumen de la información
El siguiente paso en un análisis consiste en encontrar unas cuántas medidas que nos permitan resumir o describir la información recogida, proporcionándonos una idea -lo más clara posible- de los resultados.
Deberemos, en primer lugar, averiguar la tendencia central, es decir, encontrar un
número con la propiedad de que la mayoría de los datos de la muestra estén agrupados en torno a él (lo cual ya lleva implícita la idea de variación, pues no tendría sentido promediar un carácter no variable). Esta medida de tendencia central va a sustituir al conjunto de observaciones, por lo tanto deberá ser representativa del mismo. Además deberá ir acompañada de una medida que nos indique la dispersión de los datos.
En las siguientes tablas (tablas 1.5, 1.6 y 1.7) aparece la descriptiva básica para
cada una de las preguntas analizadas. Se ha anotado, la media, la desviación típica (o estándar) el coeficiente de variación. También se señala cuál es el valor más frecuente (moda).
"El profesor está accesible para los alumnos"
Descriptiva básica Asignatura n Media Desviación
estándar Coeficiente de
variación Moda
Ampliación de Bioestadística 16 2,375 1,147 48,314 2
Bioestadística (Biología) 103 3,126 1,439 46,046 5
Bioestadística (Medicina) 101 3,406 1,336 39,211 5
Análisis de Datos 23 3,87 1,058 27,332 5
Tabla 1.5 Vemos cómo el valor medio de las puntuaciones obtenidas por Mrs. X es mayor

106
en la asignatura de análisis de datos, siendo el valor medio más pequeño el correspondiente a la asignatura de Ampliación de Bioestadística. Por lo tanto, parece que Mrs. X está más accesible para los alumnos de la asignatura Análisis de datos que para los de Ampliación de Bioestadística. La mayor variabilidad en la respuesta se da en los alumnos de Ampliación de Bioestadística (su coeficiente de variación es 48.314%) y la menor en la de Análisis de Datos. Excepto en la asignatura de Ampliación de Bioestadística, en la que la puntuación más frecuente ha sido 2, en el resto la puntuación modal ha sido 5.
"¿Domina la asignatura que imparte?"
Descriptiva básica Asignatura n Media Desviación
estándar Coeficiente de
variación Moda
Ampliación de Bioestadística 16 4,75 0,447 9,415 5
Bioestadística (Biología) 103 4,68 0,831 17,757 5
Bioestadística (Medicina) 101 4,703 0,756 16,066 5
Análisis de Datos 23 5 0 0 5
Tabla 1.6
El análisis de los resultados se haría de igual forma que en el caso anterior. En este caso, cabe destacar la opinión de los alumnos de la asignatura Análisis de Datos, ya que todos, sin excepción han dado la máxima puntuación al profesor Mrs. X. "¿Es un buen profesor?"
Descriptiva básica Asignatura n Media Desviación
estándar Coeficiente de
variación Moda
Ampliación de Bioestadística 16 4 1,155 28,868 5
Bioestadística (Biología) 103 3,515 1,282 36,486 4
Bioestadística (Medicina) 101 3,95 1,014 25,659 5
Análisis de Datos 23 4,609 0,583 12,651 5
Tabla 1.7

107
En el siguiente gráfico (figura 1.52), se han representado las puntuaciones medias para cada asignatura y para cada ítem analizado:
A la vista de los resultados obtenidos, tras el análisis descriptivo de los datos,
podemos observar cómo los alumnos de las cuatro asignaturas, dan a Mrs. X la mayor puntuación en el ítem de ¿Domina la asignatura? y la menor en el ítem ¿Está accesible?.
Figura 1.52
Como hemos apuntado con anterioridad, cualquier paquete estadístico estándar permite realizar una representación gráfica de tipo Box-plot.
La figura 1.53 representa los "Box-Plot" para la pregunta "¿Está accesible para
los alumnos?" . Aquí se ha representado un Box-Plot para cada asignatura.
108
,5
1
1,5
2
2,5
3
3,5
4
4,5
5
5,5
Bioestadística Bioest Medicina Análisis datos Ampliación Bioest.
Units
Figura 1.53: Box plot para los resultados a la pregunta ¿Está accesible a los alumnos?
NOTA: Tal como señalamos, se trata de datos reales, y el Profesor Mrs. X lleva
realmente el mismo sistema de atención para todos los alumnos. Refleja por tanto la "percepción del alumno", ya que no existían diferencias reales.