01 introduccion a la mineria de datos 29 copia
TRANSCRIPT

Introducción a la minería de datos
MSc. Carlos Alberto Cobos Lozada
http://www.unicauca.edu.co/~ccobos
Grupo de I+D en Tecnologías de la Información
Departamento de Sistemas
Facultad de Ingeniería Electrónica y Telecomunicaciones
Universidad del Cauca

Definición
Gartner Group (www.gartner.com): es el proceso de descubrir nuevas y significantes correlaciones, patrones y tendencias en grandes cantidades de datos almacenados en repositorios usando tecnologías de reconocimiento de patrones así como técnicas estadísticas y matemáticas
MIT Technology Review (enero 2001) la selecciona como una de las 10 tecnologías emergentes que cambiarán al mundo, ejemplo: Boston Celtis (basketball) en Septiembre-Diciembre de 2003 busca experto en DM
Witten & Frank (2000): es la extracción de información implícita, previamente desconocida y potencialmente útil desde los datos
Fayyad (1997): es la aplicación de algoritmos para extraer patrones de los datos, siendo esto una parte del descubrimiento de conocimiento

Definición
Información
Conocimiento
Sabiduría
Datos Entendimiento
Conexión
Entender las relaciones
Entender los patrones
Entender los principios
Datos: símbolos Información: datos que son
procesados para que sean útiles; proveen respuestas a preguntas del tipo “quién”, “qué”, “dónde” y “cuándo”
Conocimiento: aplicación de datos e información a preguntas del tipo “cómo” o “por qué”
Sabiduría: la comprensión de los principios
http://www.systems-thinking.org/dikw/dikw.htm

Justificación
John Naisbitt: “estamos ahogándonos en información pero hambrientos de conocimiento”
Explosión en recolección de datos: ventas en supermercados Las bodegas de datos como almacenamiento global y confiable El incremento en el acceso a los datos desde la web El incremento en la competencia en una economía global El desarrollo de herramientas comerciales y académicas de
minería de datos: Clementine, Insightful Miner, WEKA, CART, PolyAnalyst, SAS
El gran crecimiento en la capacidad de computo y almacenamiento
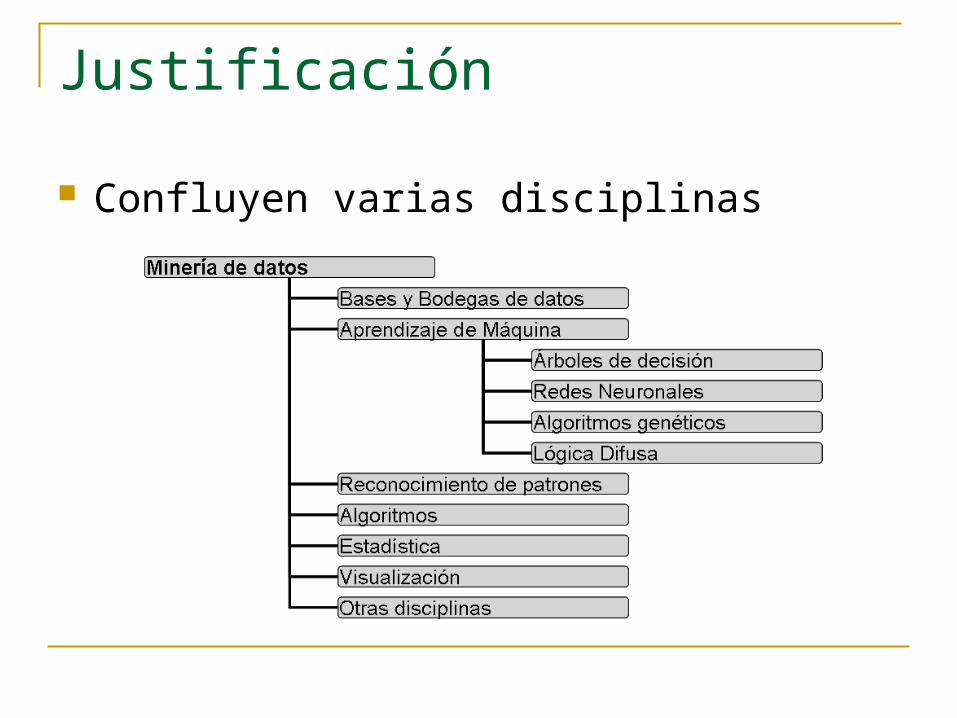
Justificación
Confluyen varias disciplinas

Proceso de desarrollo
CRISP-DM (Cross – Industry Standard Process for Data Mining)
SEMMA (Sample, Explore, Modify, Model, Assess): más orientado a las características técnicas del desarrollo del proyecto, propietario
Comprensión del negocio
Análisis de los datos
Preparación de los datos
ModelamientoEvaluación
Despliegue Datos

Falacias de la minería de datos1. Existen herramientas de minería de datos que
podemos soltar sobre nuestros datos y nos resolverán nuestras problemas
2. El proceso de minería de datos es autónomo requiriendo muy poca intervención humana
3. La inversión en procesos de minería de datos se paga por si misma y rápidamente

Falacias de la minería de datos4. Las herramientas o paquetes de minería de
datos son intuitivos y fáciles de usar
5. La minería de datos identifica las causas de nuestros problemas de negocios o de investigación
6. Con minería de datos se limpiaran y ordenaran automáticamente nuestras bases de datos

Tareas de la minería de datos
Descripción Clasificación
Estimación Predicción
Agrupación por similitud (Clustering)
Asociación

Tareas de la minería de datos
Descripción Sugerir posibles explicaciones para ciertos patrones y
tendencias
Los modelos de minería de datos deben ser lo más transparentes posibles. Árboles de decisión vs. Redes Neuronales
Técnicas estadísticas (media, moda, mediana, desviación estándar, mínimo , máximo, rango, correlaciones) y gráficas, algoritmos genéticos

Demo 1 con Weka
En Weka Explicación general del entorno partiendo del archivo
clasificacion-drug.arff Se visualizan los datos en la cuadricula Se visualizan los datos en el formato arff Se explorar la pestaña de pre-procesamiento: atributos, medidas
y gráficas

Tareas de la minería de datos
Clasificación Establecer a que valor
categórico pertenece un registro
Clasifica los ingresos (altos, medios, bajos) basado en la edad, genero, ocupación
Determinar si una operación especifica con tarjeta de crédito es fraudulenta
Ubicar a un estudiante en un “track” especifico de cursos de acuerdo con sus habilidades
Determinar si otorgar una hipoteca es una buen o mala decisión (riesgo)
Determinar si una enfermedad particular esta presente
Identificar si un determinado estado financiero indica una amenaza de terrorismo
Determinar el tipo de medicina más adecuada para un paciente
Redes neuronales, árboles de decisión (C4.5, C5.0, CART), k-vecino más cercano
Tomado de [1] para uso educativo

Demo 2 con Weka
En Weka Uso de la pestaña de clasificación con el ejemplo de
clasificacion-drug.arff Uso del árbol de decisión J48 Visualización del árbol y explicación de los resultados Matriz de confusión Instancias correctamente clasificadas Optimización basada en costos, ejemplo de túnel metacarpiano y
el costo de falsos positivos y falsos negativos Importancia de los expertos: nuevo atributo a5/a6

Tareas de la minería de datos
Estimación Similar a Clasificación, pero la
variable objetivo es numérica Estimar la presión de la sangre de
un paciente basado en la edad, genero, índice de masa corporal y los niveles de sodio en la sangre
Estimar la cantidad de dinero que una familia de cuatro personas seleccionada al azar gastara en las compras “de regreso al colegio”
Estimar el promedio de un estudiante de postgrado basado en su promedio en los resultados universitarios de pregrado
Técnicas estadísticas (ejemplo, regresión lineal simple, correlación, regresión múltiple), redes neuronales
Tomado de [1] para uso educativo
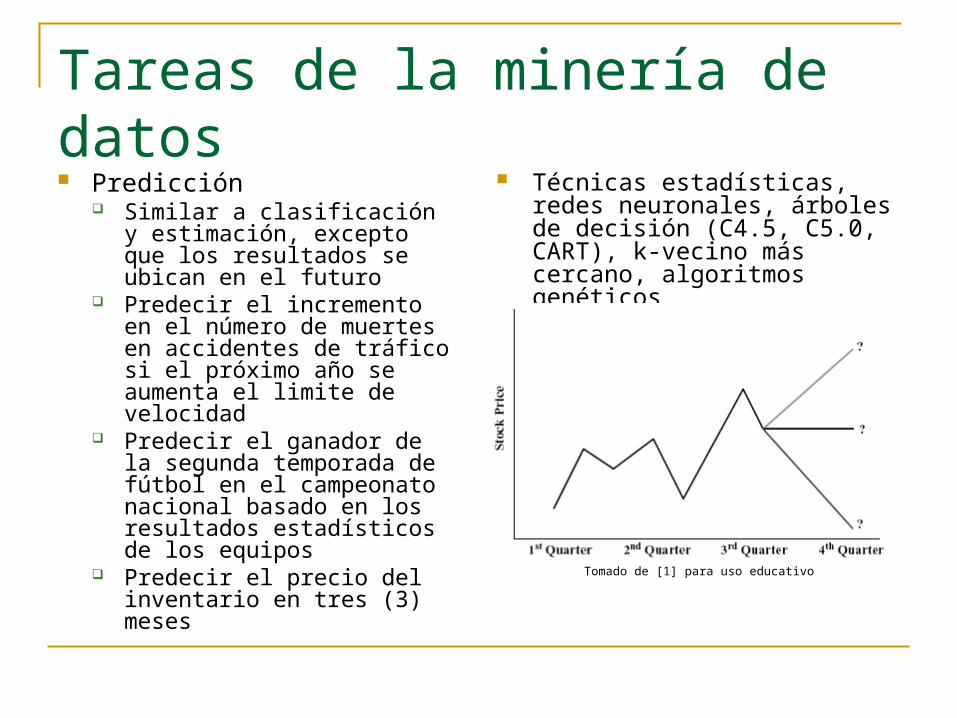
Tareas de la minería de datos
Predicción Similar a clasificación y
estimación, excepto que los resultados se ubican en el futuro
Predecir el incremento en el número de muertes en accidentes de tráfico si el próximo año se aumenta el limite de velocidad
Predecir el ganador de la segunda temporada de fútbol en el campeonato nacional basado en los resultados estadísticos de los equipos
Predecir el precio del inventario en tres (3) meses
Técnicas estadísticas, redes neuronales, árboles de decisión (C4.5, C5.0, CART), k-vecino más cercano, algoritmos genéticos
Tomado de [1] para uso educativo

Tareas de la minería de datos
Agrupación por similitud (Clustering) Generar clases que agrupen
instancias/objetos de características similares y se diferencien de los que están en otras clases
No hay variable objetivo Es a menudo un proceso
preliminar en el proceso de minería de datos
En auditoria, segmentar el comportamiento financiero entre benignas y sospechosas
Reducir el número de atributos a tratar en un DataSet
Agrupar los resultados de búsquedas en Internet
Agrupación Jerárquica, K-means, Red Kohonen, Fuzzy C-means
Tomado de [1] para uso educativo

Demo 3 con Weka
En Weka Uso de la pestaña de clustering con el archivo clustering-sencillo.arff La columna clase es sólo para introducir el ejemplo, pero en un
problema de clustering normalmente los datos no están pre-clasificados
Uso de la pestaña de Visualización para ver la distribución de las clases en cada uno de los atributos
Visualmente se definen cuales características son apropiadas (varianza-desviación en cada eje)
Uso de la pestaña de Selección de atributos para corroborar las dimensiones o características seleccionadas
Remover la clase en la pestaña de pre-procesamiento Ejecución de SimpleKmeans con 3 clusters Mostrar como hacer validación cuando se conoce la clase

Tareas de la minería de datos
Asociación Encontrar los atributos que
van juntos Conocido como análisis de
afinidad o análisis de la canasta de mercado
Si <antecedente> Entonces <consecuente>
Cuales ítems se compran juntos y cuales no
Establecer cuales situaciones degradan la red de telecomunicaciones
Determinar la proporción de casos en donde una nueva droga genera efectos secundarios peligrosos
Reglas de asociación con algoritmos A priori, GRI, FP Grow

Demo 4 con Weka
En Weka Uso de la pestaña de Asociación con el archivo Basket.arff Se usa información de la tarjeta Se deja información sólo de los productos comprados en cada
transacción Se usa el algoritmo apriori Explicación del soporte Explicación de la confianza

Aplicaciones
Mejorar la eficiencia del marketing Identificar prospectos Escoger el canal de comunicación para alcanzar los
prospectos Crear mensajes apropiados para grupos de prospectos
Ejemplo: un mensaje en la página de deportes del periódico, otro distinto en la página de política
Ejemplo: un mensaje destacando el precio para usuarios sensibles al precio y otro destacando la conveniencia del producto (compras y/o pedidos nocturnos, dominicales y festivos)

Aplicaciones
Retener clientes rentables Evitar clientes de alto riesgo (hipotecas,
créditos) Prevenir fraudes Recuperar clientes Mejorar la satisfacción de los clientes Disminuir costos Incrementar ventas Mejorar la rentabilidad de sus clientes

Aplicaciones
venta cruzada (cross-selling) e incremento de venta (up-selling o venta sugestiva/mejorada)
Retener talento humano Definir líneas de capacitación y retención de
talento humano
Gestión de la cadena de suministro

Industrias donde aplica: Banca Seguros Telecomunicaciones Venta al por menor (e-commerce) Venta al por mayor Turismo Educación Salud …
Aplicaciones
Gente
Deptos. Administrativos
Auditoria
Deptos. Operativos
Productos
Otros
Proveedores
Clientes

Aplicaciones
En industrias manufactureras (vehículos), encontrar cuales situaciones generan la mayor cantidad de reclamos/garantías
En educación, encontrar relaciones entre tipos de estudios y origen de los estudiantes en una universidad
Predecir condiciones financieras especificas que llevan una empresa a la banca rota
Organizar una campaña de turismo interno para el departamento

Aplicaciones
Clasificación de datos estelares Diagnostico medico
Túnel carpiano Medicinas en tratamientos
Text Mining Web Mining
Contenido Estructura - Navegación Uso
Bio-Informática

Aplicaciones en GTI
Búsqueda en Internet BIM (2008): Ontologías, Resultado de los motores de búsqueda
(Google, Yahoo, MSN), Perfil del usuario, Minería de textos
DSS para viveros automatizados (2008) Bodegas de datos y OLAP Clasificación (C4.5, C5.0, CART)
CASE integrada basada en CRISP-DM (2009)

Aplicaciones en GTI
DSS para el repositorio de acceso público de objetos de aprendizaje (SPAR, 2009) Bodegas, OLAP y Minería Web (de contenidos)
Sistema de recomendación de patrones pedagógicos basado en ontologías y minería de datos (2009) Singular Value Decomposition, Frobenius, k-nn
Reconocimiento Balístico (2010) Procesamiento y Análisis de Imágenes, Algoritmos Genéticos,
los k vecinos más cercanos (k-nn) y validación cruzada

Aplicaciones en GTI
Búsqueda en Internet Clustering en general (Harmony Search, k-means) (2009) Web Document Clustering
Global-Best Harmony Search y Fp-growth (2010) Algoritmos meméticos con técnicas de niching (2010)
En proceso (2010 – 2011) Web Document Clustering basado en reglas de asociación y
frases de documentos Clustering usando Global-Best Harmony Search y modelos LEM

Referencias
1. Discovering knowledge in Data: An Introduction to Data Mining. Daniel T. Larose. John Wiley & Sons, Inc. 2005. ISBN 0-471-66657-2
2. Larose, Daniel T. Data Mining Methods and Models. Daniel T. Larose. ISBN: 0-471-75647-4. E-Book. 385 pages. February 2006, Wiley-IEEE Press.
3. Data Mining with SQL Server 2005. ZhaoHui Tang, Jamie Maclennan. Wiley Publishing, Indiana, 2005.
4. Kantardzic, Mehmed. Data Mining: Concepts, Models, Methods, and Algorithms, John Wiley & Sons 2003 (343 pages). ISBN: 0471228524.
5. Análisis y Extracción de Conocimiento en Sistemas de Información: Datawarehouse y Datamining. Departamento de Sistemas Informáticos y Computación. Universidad Politécnica de Valencia. http://www.dsic.upv.es/~jorallo/cursoDWDM.
6. Wang, John (Editor). Data Mining: Opportunities and Challenges. Hershey, PA, USA: Idea Group Inc., 2003.