serie apuntes de clase f&e n° 02 octubre de 2020
TRANSCRIPT

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
ECONOMETRIA DE DATOS DE
PANEL CON APLICACIONES
EN R STUDIO
Rafael Bustamante [email protected]
La Serie Apuntes de Finance and Econometrics Group S.A.C. tiene por objetivo difundir los materiales de enseñanza generados por los docentes que tienen a su cargo el desarrollo de las asignaturas de la empresa. Estos documentos buscan proporcionar a los estudiantes una explicación de algunos temas específicos que son abordados en su formación profesional.
Serie Apuntes de Clase F&E N° 02
Octubre de 2020

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
ECONOMETRÍA DE DATOS DE
PANEL: APLICACIONES EN EN R
STUDIO
Rafael Bustamante Romaní
RESUMEN
El aumento de bases de datos, junto con el progreso en las técnicas econométricas, ha facilitado el
perfeccionamiento de estudios cada vez más sofisticados de los fenómenos económicos, permitiendo asesorar
más acertadamente a los responsables de la elaboración de las políticas públicas y a los hombres de negocios.
Sin embargo, estas herramientas se han tornado cada vez más complejas, demandando un alto grado de
conocimiento teórico y práctico para poder implementarlas. La metodología de Datos de Panel es una de las
más usadas en los últimos tiempos en el ámbito de la economía, las finanzas y los negocios. Su riqueza radica
en que permite trabajar simultáneamente varios periodos de tiempo y los efectos individuales, y a su vez, tratar
el problema de la endogeneidad. A pesar de las ventajas de esta técnica, existen diversos obstáculos para su
implementación, tanto metodológicos como operativos. Esta guía intenta ayudar a los alumnos, investigadores
y profesionales que buscan llevar a cabo estudios utilizando Datos de Panel, ofreciendo una pauta para manejar
y analizar datos, en forma conjunta con revisar sus fundamentos.
Palabras Claves: Econometría de datos de Panel, especificaciones, Efectos Fijos, Efectos aleatorio
Clasificación JEL: C2, C25
Estudios de Doctorado en Economía, Universidad Autónoma de México. Maestría en Economía con mención en
Finanzas, MBA CENTRUM Pontificia Universidad Católica del Perú. B. Sc. Economía, Universidad Nacional Mayor de San
Marcos. Profesor del Departamento de Economía de UNMSM. Investigador asociado al Instituto de Investigaciones
FCE – UNMSM. Investiga. Contacto: [email protected]

Contenido
1. Introducción ...................................................................................................................... 1
2. Metodología ...................................................................................................................... 8
2.1 Desventajas del uso de los datos de panel ......................................................................13
2.2 Efectos Fijos versus efectos Aleatorios ...........................................................................24
2.3 Nuestro marco de análisis y los estimadores alternativos ..................................................26
2.4 Estimador Within ........................................................................................................27
2.5 Estimador Between .....................................................................................................29
2.6 Estimador de mínimos cuadrados generalizados ..............................................................31
2.7 Mínimos cuadrados generalizados factibles ....................................................................34
2.8 Estimador a usar .........................................................................................................36
2.9 Efectos no observados .................................................................................................36
2.10 Existe correlación entre los efectos no observados y los Regresores ...................................38
3. Aplicaciones......................................................................................................................40
3.1. Explorando el Panel Data ..........................................................................................42
3.2. Uso de ExPanD para la exploración de datos de panel ...................................................45
3.3. Inicio de ExPanD para cargar un archivo local que contiene datos del panel .....................46
3.4. Modelo de Efectos Fijos: Modelo de covarianza, estimador Within, modelo de variable
Dummy individual, modelo de variable Dummy de mínimos cuadrados .....................................50
4. Bibliografía .......................................................................................................................76

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
1. Introducción
Si se dispone de información de corte transversal para un conjunto de N individuos las
ganancias de que se tienen de tener información sobre cada uno de los individuos para
distintos períodos de tiempo se pueden expresar en:
➢ Primero es que logramos expandir el tamaño de nuestra base de datos, y, con esto,
dispondremos de más grados de libertad.
➢ Segundo es el hecho de contar con información referida a varios individuos
contribuye a reducir la colinealidad que es usual encontrar en un modelo de series
de tiempo. Todo esto contribuye a incrementar la precisión de nuestros estimados;
es decir, a reducir su varianza (Beltran & Castro, 2010).
➢ Un conjunto de datos panel (o longitudinales) consta de una serie temporal para
cada miembro del corte transversal en el conjunto de datos. Como ejemplo,
suponga que se tienen las variables de salario, educación , nivel de crédito, acceso a
educación y experiencia de un grupo de individuos a los que se les hace
seguimiento por varios años. De igual forma es posible recopilar información en
unidades geográficas. Por ejemplos, datos de los gobiernos regionales de un país
sobre impuestos, salarios, nivel de ejecución del gasto público, niveles de
educación, entre otros.
La característica principal de los datos panel, que los diferencian de las combinaciones de
cortes transversales, es el hecho de que se da un seguimiento a las mismas unidades

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
transversales ya sean individuos, países, regiones, entre otros, durante cierto período de
tiempo (Software Shop, 2013).
Como los datos de panel exigen la repetición de las mismas unidades con el tiempo, los
conjuntos de estos datos, en particular de los individuos, hogares y empresas, son más
difíciles de conseguir que en las combinaciones de corte transversales. La ventaja es que
al tener las mismas unidades es posible controlar ciertas características inobservadas de
individuos, empresas, países, bancos, etc.
Es decir, es posible capturar inferencias causales que no es posible capturar con los cortes
transversales. La segunda ventaja de los datos panel es que permite estudiar la
importancia de los rezagos en el comportamiento o el resultado de tomar una decisión.
Esta información puede ser significativa, puesto que es de esperar que muchas políticas
económicas tengan efecto sólo al paso del tiempo.
La idea del panel es poder capturar esos factores inobservables, por ejemplo, lo que
influye en el salario de un individuo en 1990 también influirá en el mismo individuo en
1991, ese factor inobservable puede ser la capacidad o habilidades.
Ahora bien, si además explotamos el hecho de que estamos observando cómo cambia el
comportamiento de cada individuo a lo largo del tiempo, estaremos en capacidad de
construir y validar hipótesis más complejas. Al respecto, recordemos que en el análisis de
regresión nuestros esfuerzos por aislar el efecto de determinada variable sobre otra
dependen de cómo estas varían a lo largo de la muestra consideradas. Si disponemos de
una muestra de corte transversal y queremos medir el impacto de determinada
característica, lo que haremos es comparar la respuesta de un individuo que tiene la
característica con la respuesta de otro que no la tiene. Si la muestra es de series de tiempo,

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
lo que haremos es comparar la respuesta de un mismo individuo antes y después de
exhibir la característica (Beltran & Castro,2010).
Puesta de esta manera, nuestra técnica puede ser duramente criticada: muchos otros
elementos que influyen sobre la respuesta pueden ser distintos entre un agente y otro, o
haber cambiado a lo largo del tiempo y nosotros, erróneamente, se los estamos
atribuyendo a la variable de interés. La ausencia de experimentación controlada está
conspirando contra la posibilidad de aislar los efectos de una variable de interés. Frente
a esto, y utilizando regresiones particionadas, podríamos responder que para eso están
los controles y que por eso hay un conjunto amplio de determinantes incluidos en nuestra
regresión.
Sabemos, no obstante, que difícilmente podremos informar de todos los determinantes y
que, sobre todo cuando hablamos del comportamiento de agentes individuales, el riesgo
de que el fenómeno en estudio dependa de variables no observables es alto. Si
disponemos de una base de datos de panel, en lugar de indagar si determinado agente
está mejor que su vecino o mejor que en el pasado, lo que podemos hacer es preguntar
qué tan distinta es la mejora experimentada por el agente respecto a la mejora
experimentada por su vecino. Es decir, en lugar de evaluar: ( )i jy y− (corte transversal)
o ( )t sy y− (Serie de tiempo), los datos de panel nos posibilita comparar
( ) ( )it is jt jsy y y y− − − o, más específicamente,_ _
it i jt jy y y y
− − −
. En la expresión
anterior _
iy y _
jy se refieren a los promedios de la variable dependiente tomados sobre
las T observaciones en el tiempo para el i-ésimo y j-ésimo agente, respectivamente. Esta
suerte de "diferencia en diferencia" solo es posible si tenemos datos que varían tanto a
través del espacio como a lo largo del tiempo y nos permitiría, en principio, limpiar

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
aquellos efectos que influyen sobre el fenómeno bajo análisis y no tienen que ver con la
característica que se busca evaluar (Beltran & Castro, 2010).
Con respecto a esto y a la presencia de variables no observables, sabemos que la omisión
de una variable relevante conlleva la lidiar con la presencia de estimadores sesgados. Para
muestras grandes esto no debería ser un problema, excepto cuando esta omisión ocasiona
también un problema de no consistencia en nuestro estimador. Antes de preocuparnos
por la estructura de varianzas-covarianzas del error, debemos analizar la posible
presencia un regresor estocástico. Y por "regresor estocástico" no solamente hacemos
referencia a aquellos que se determinan de manera simultánea con la variable
dependiente como es el caso de un sistema de ecuaciones simultáneas, sino que hacemos
referencia a aquellos regresores que se encuentran correlacionados contemporáneamente
con el término de error a través de la relación que tienen con las variables no observables
omitidas en el modelo.
La omisión de una variable puede conducir a la obtención de estimadores no consistentes
y esto se debe, precisamente, a que esta variable no observable omitida, está usualmente
correlacionada de manera contemporánea con los regresores incluidos en el modelo. Esto
trae como consecuencia la correlación contemporánea entre el regresor y el término de
error, lo que ocasiona que el estimador de mínimos cuadrados no converja en
probabilidad al verdadero parámetro (Beltran & Castro, 2010).
Ante la sospecha de que estamos frente a una situación como esta, el camino "clásico"
pasa por la búsqueda de variables instrumentales y la construcción del estimador
respectivo, con el consabido costo en términos de pérdida de información y precisión.
Una base de datos con estructura de panel, sin embargo, nos ofrece un camino alternativo
que implica, precisamente, trabajar con los desvíos presentados líneas arriba. Si bien esto
será discutido formalmente en las secciones siguientes, no es difícil darse cuenta de que

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
al trabajar con un desvío como _
.i jy y
−
se le está removiendo a cada observación del
i-ésimo agente cualquier efecto no observable que se mantenga constante en el tiempo; es
decir, cualquier característica especial que este agente tiene y que no es posible capturar
a partir del conjunto de regresores propuesto.
Al tener observaciones que varían tanto a lo largo del tiempo como a través del espacio,
es posible evaluar diferencias entre las diferencias de comportamiento, lo que permite
"limpiar" las observaciones de efectos difíciles de capturar que, de otro modo, hubiesen
resultado en estimados inexactos incluso en muestras grandes (Beltran & Castro, 2010).
En el análisis de la información (económica, social, empresarial, comercial, etc.) pueden
existir diferentes dimensiones sobre las cuales interesa obtener conclusiones derivadas
de la estimación de modelos que traten de extraer relaciones de causalidad o de
comportamiento entre diferentes tipos de variables, a partir de los datos disponibles. Una
de estas dimensiones la constituye el análisis de series de tiempo, la cual incorpora
información de variables y/o unidades individuales de estudio durante un período
determinado de tiempo (dimensión temporal). En este caso, cada período de tiempo
constituye el elemento poblacional y/o muestral. Ejemplo de este tipo de datos lo
constituyen las series del PIB y de tasas de interés de un país o el número de llamadas
telefónicas de una familia a lo largo de un período determinado de tiempo.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Finalmente podemos resumir que un modelo de datos de panel es, según la definición
más extendida, un modelo que utiliza muestras recogidas a individuos a lo largo de
instantes de tiempo. Los modelos de datos de panel incluyen así información de una
muestra de agentes económicos (individuos, empresas, bancos, ciudades, países, etc.)
durante un período determinado de tiempo, combinando, por tanto, la dimensión
temporal y estructural de los datos (Rodríguez, 2016).
Los modelos de datos de panel se aplican a conjuntos o bases de datos de series de tiempo
agregadas para los mismos individuos; estos conjuntos de datos suelen tener un número
relativamente grande de individuos y pocas observaciones en el tiempo, o por el contrario
podemos tener datos para un número grande de periodos, pero para un número pequeño
de individuos. Un ejemplo de este tipo de bases de datos es el panel de hogares de la
Unión Europea (70.000 hogares en la UE), las encuestas de opiniones empresariales del
Ministerio de Industria (3.000 empresas), los índices Nielsen (5.000 hogares en España)
para medir la audiencia televisiva, etc. Estos conjuntos de datos que son conocidos como
datos de panel o datos longitudinales hay que diferenciarlos de las encuestas
transversales que son repetidas en el tiempo, pero no a los mismos individuos (por
ejemplo, la Encuesta de Población Activa)1.
1 En los paneles de datos a veces también hay que sustituir individuos por falta de respuesta, pero no es el caso de las encuestas transversales en donde la muestra se renueva de forma sistemática, de manera que, a un periodo de tiempo determinado, por ejemplo, un año, los hogares de la muestra sean diferentes a los del año anterior. La falta de respuesta en los datos de panel como en otro tipo de encuesta a al momento de los análisis estadísticos deben de purificarse, bien eliminando todos los datos del individuo con falta de respuesta o eliminando únicamente los individuos con falta de respuesta en cada variable analizada.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
El principal objetivo que busca al agrupar y estudiar los datos en panel es capturar la
heterogeneidad no observable entre los agentes económicos como entre periodos
temporales.
Dado que esta heterogeneidad no se puede detectar exclusivamente con estudios de
series temporales, ni tampoco con estudios de corte transversal, hay que realizar un
análisis más dinámico incorporando a los estudios de corte transversal la dimensión
temporal de los datos.
Esta modalidad de analizar la información es muy usual en estudios de naturaleza
empresarial, ya que los efectos individuales específicos de cada empresa y los efectos
temporales del medio son determinantes cuando se trabaja con este tipo de información.
Los efectos individuales específicos se definen como aquellos que afectan de manera
desigual a cada uno de los agentes de estudio contenidos en la muestra (individuos,
empresas, bancos (Rodríguez, 2016)).
Estos efectos son invariables en el tiempo y se supone que afectan de manera directa a las
decisiones que toman dichas unidades. Usualmente, se identifica este tipo de efectos con
cuestiones de capacidad empresarial, eficiencia operativa , el “saber-hacer” (Know-
how), acceso a la tecnología, etc.
Por su parte, los efectos temporales son aquellos que afectan por igual a todas las
unidades individuales del estudio y que, además, varían en el tiempo. Este tipo de efectos
suele asociarse, por ejemplo, a shocks macroeconómicos que afectan por igual a todas las
empresas o unidades de estudio (una subida de los tipos de interés, un incremento de los
precios de la energía, un aumento de la inflación, etc.), o a cambios en la regulación de
mercados (ampliación de la Unión Europea, reducción de tarifas arancelarias, aumento
de la imposición indirecta, etc.) (Rodríguez, 2016).

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
2. Metodología
El objetivo de esta sección es familiarizar al lector con la estructura de la base de datos,
así como con el álgebra matricial asociada a la construcción de los distintos estimadores.
Aquí se muestra un aspecto de la generalización del álgebra de mínimos cuadrados
ordinarios aplicada a un contexto en el que se dispone de información que varía tanto a
través del espacio como a lo largo del tiempo (Beltran & Castro, 2010).
Al respecto se sugiere, la generalización que aquí discutimos se refiere al rol del
intercepto. Si disponemos de información que varía solo en una dimensión (y en ausencia
de un problema de quiebre estructural), solo tiene sentido "desviar" o "controlar" con
respecto a un promedio: aquel tomado usando toda la información disponible, ya sea a
lo largo del tiempo o a través del espacio. Conviene recordar que estos desvíos respecto
a la media son provistos, precisamente, por el intercepto2. Así, es fácil darnos cuenta de
qué está detrás de la recomendación general de incluir siempre un intercepto en el
modelo: recomendar la inclusión de un intercepto equivale a remover la influencia de la
media muestral. Sobre el fenómeno bajo análisis. Dicho de otra forma, en un modelo con
intercepto la pendiente (o "beta") asociada al i-ésimo regresor nos indicará cuánto cambia
la variable dependiente respecto a su valor medio por cada unidad que el regresar se
desvíe con respecto a su valor medio. En el contexto de un panel de datos, la información
presenta variabilidad en ambas dimensiones. Por lo mismo, será necesario decidir con
respecto a qué media controlar: (i) la media de todas las observaciones; (ii) la media
tomada a lo largo del tiempo, de cada uno de los N agentes; (iii) la media tomada a través
del espacio de cada uno de T momentos del tiempo. En lo que sigue, se discute esto
2 ¡El lector recordará la clásica demostración donde se verifica que las pendientes en un modelo con
intercepto son idénticas a las que se obtendrían si antes desviamos (o restamos) cada dato de su media o
promedio muestra! De hecho, este es un caso particular del resultado de una regresión particionada.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
formalmente sin perder de vista una interpretación intuitiva basada en el rol que tiene el
intercepto. Antes de proceder a la formalización del modelo, veamos algunas definiciones
de los datos de panel:
➢ Panel Data es mezclar información de corte transversal e información temporal.
Como en el corte transversal, se recoge información de individuos y se observa
cada individuo, como en el análisis de series de tiempo, a través del tiempo. Esto
permite estudiar los efectos dinámicos y de comportamiento individual de los
problemas.
➢ Son observaciones repetidas sobre el mismo conjunto de unidades de sección
cruzada o dicho de otra forma se tiene el mismo número de observaciones en cada
unidad de sección cruzada es decir es una mezcla de ambas en la cual se recoge
información entre individuos y se observa cada individuo como el análisis de
series de tiempo, a través del tiempo.
➢ En los paneles microeconómicos, el investigador está interesado en analizar como
varía el comportamiento de los agentes económicos individuales frente a
cuestiones como sus hábitos de consumo, su situación laboral, su nivel de estudios,
etc. Estas son decisiones que dependerán de una lista de características
socioeconómicas que el analista debe especificar como variables explicativas del
modelo. Sin embargo, no todos los agentes toman sus decisiones de igual modo:
diferentes agentes, incluso si comparten las mismas características observables,
toman decisiones distintas. Ello obliga a contemplar la existencia de efectos no
observables, específicos de cada agente encuestado, generalmente constantes en el
tiempo, que inciden sobre el modo en que esta toma sus decisiones. Si estos efectos
latentes existen y no se recogen explícitamente en el modelo, se producirá un

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
problema de variables omitidas: los coeficientes estimados de las variables
explicativas incluidas estarán sesgados, por recoger parcialmente los efectos
individuales no observables (Greene, William, 1999).
Para entender mejor esta metodología veamos algunos aspectos matriciales.
1
2
1
1, 2,3,...
...,
.
i
i
i
iT TX
Y
Y
Para todo t
Y
TY
=
=
(1)
1 2 1
1 1 1 1
1 2 1
2 2 2 2
1 2 1
1 1 1 1
1 2 1
. . .
. . .
. . . . . . .
. . . . . . .
. . . . . . .
. . .
. . .
K k
i i i i
K K
i i i i
i
K K
iT iT iT iT
K K
iT iT iT iT TxK
X X X X
X X X X
X
X X X X
X X X X
−
−
−
− − − −
−
=
(2)
Además, los errores del modelo y la variable explicativa se expresan:
1 1
2 2
1 1
1 1
. .
: . .
. .
i
i
i
iT N
iT NTX NTX
Ademas
− −
= =
1
2
1
1
.
.
.
N
N NTX
Y
Y
Y
Y
Y
−
=
(3)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
1
2
1
1, 2, 3, 1, 2, 3, .....,
.
.
.
N
N NTXK
t T i
X
N
X
X
X
X
−
=
= =
(4)
El modelo totalmente apilado es:
Y = X + (5)
jitX : Es el valor Jth de una variable explicativa i. Para todo t = 0 1, 2, 3, T.
Si existen K variables explicativas el vector de variables explicativas se puede denotar
como:
1
2
1
.
.
.
K
K
−
=
(6)
En base a lo anotado podemos afirmar que metodología de datos de panel lo que hace es
utilizar procedimientos adecuados para el manejo de las observaciones con una
dimensión de sección cruzada grande, con el objeto de estimar modelos econométricos
que incluyan entre las variables explicativas los efectos individuales no observables.
El disponer de un número reducido, T, de observaciones de cada uno de los N individuos
de la muestra, podría pensarse en estimar un modelo econométrico con cada una de las

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
T secciones cruzadas para luego comparar la evolución de los coeficientes del modelo a
lo largo del tiempo.
Las ventajas de modelos econométricos con información en panel, son las siguientes
(Greene, William, 1999):
• Se dispone de un gran número de datos (a través de individuos y a través del tiempo).
Por esta razón aumentan los grados de libertad y, al utilizar las diferencias
individuales en los valores de las variables explicativas, se reduce la colinealidad entre
las variables explicativas, mejorando de esta forma la eficiencia de los estimadores.
• Evita los sesgos de agregación con datos macroeconómicos.
• En general, es posible obtener estimaciones consistentes para N→ y T fijo. No
obstante, dada la creciente existencia de bases de datos longitudinales con períodos
muéstrales prolongados, existen trabajos recientes en que se consideran propiedades
asintóticas para N→ y T→ .
• La disponibilidad de datos longitudinales permite a los investigadores analizar una
variedad de importantes interrogantes económicas, que no se pueden analizar
utilizando solo información de corte transversal o sólo información de series de
tiempo.
• Permite construir y testear modelos de comportamiento más sofisticados que los
modelos econométricos estándar de series de tiempo o de corte transversal.
• Proporciona un método para resolver o reducir la magnitud de un problema
econométrico clave que siempre surge en los trabajos empíricos: siempre se señala
que la verdadera razón de porque se encuentra (o no se encuentran) ciertos efectos es

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
producto de la omisión de variables- debido a problemas de medición o porque ciertas
variables no son observadas – que están correlacionadas con las variables explicativas.
• Permite estudiar de una mejor manera la dinámica de los procesos de ajuste. Esto es
fundamentalmente cierto en estudios sobre el grado de duración y permanencia de
ciertos niveles de condición económica (desempleo, pobreza, riqueza).
• Permite elaborar y probar modelos relativamente complejos de comportamiento en
comparación con los análisis de series de tiempo y de corte transversal. Un ejemplo
claro de este tipo de modelos, son los que se refieren a los que tratan de medir niveles
de eficiencia técnica por parte de unidades económicas individuales (empresas,
bancos, etc.) (Beltrán, 2003).
• Permite al investigador mucha más flexibilidad para modelizar las diferencias de
comportamientos entre los individuos. Tal y como se mencionó anteriormente, la
técnica permite capturar la heterogeneidad no observable ya sea entre unidades
individuales de estudio como en el tiempo. Con base en lo anterior, la técnica permite
aplicar una serie de pruebas de hipótesis para confirmar o rechazar dicha
heterogeneidad y cómo capturarla.
2.1 Desventajas del uso de los datos de panel
• Sesgo de heterogeneidad:
Muchos paneles de datos provienen de procesos muy complicados que exigen el
comportamiento diario. Cuando se analiza series de corte transversal el supuesto típico
es que una variable económica ty es generada por una distribución de probabilidad

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
paramétrica del tipo ( )f y/θ , donde θ es un vector real de dimensión k “idéntico para
todos los individuos en todo instante de tiempo”. Este supuesto puede no ser realista en
el caso de datos de panel; es más ignorar la heterogeneidad en los intercepto y/o en las
pendientes es una que puede ser errada.
• Sesgo de selección:
Otra fuente de sesgo que se encuentra con frecuencia en datos de corte transversal y de
paneles de datos es que la muestra puede no haber sido extraída de manera aleatoria de
una población lo cual es poco frecuente en series de tiempo. Como consecuencia de ello
se puede tener (de Arce & Mahía, 2007):
• Amplificación del efecto de errores de medida asociados a datos de encuestas.
• Falta de representatividad de la muestra debido a:
✓ Desgaste muestral
✓ No aleatoriedad de las observaciones
Ejemplos de este tipo de limitaciones se encuentran en: La cobertura de la población de
interés, porcentajes de respuesta, preguntas confusas, distorsión deliberada de las
respuestas, etc.
'
1,2,... ; 1,2,...
it it it itY X U
i N t T
+
= = (7)
Donde i,tβ mide el efecto marginal de itx (es decir, el efecto marginal de las variables
x en el momento t para la i-ésima unidad). Este modelo es general y es necesario imponer
cierta estructura en los coeficientes; es decir, es necesario suponer que los agentes en
cuestión responden a un patrón de comportamiento generalizable a lo largo del tiempo

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
y/o a través del espacio. El supuesto estándar es que ,i t es constante para todo i y t,
deja abierta la posibilidad de que haya un intercepto distinto para cada agente ( )i . Esto
implica dejar abierta la posibilidad de que cada agente tenga un "comportamiento
promedio" distinto respecto del cual conviene controlar. Con consecuencia a lo anterior
si re especifiquemos nuestro modelo de la siguiente manera (Barco & Castro, 2010):
'11 1
12
1
21
( 1) ( ) ( )
2
1 0 0
1 0 0
. . . .
. . . .
. . . .
0 1 0
0 1 0
. ;D ;. . .
. . . .
. . . .
0 1 . . . 0
. . . .
. . . .
. . . .
0 0 1
T
NTx NTxN NTxK
T
NT
y x
y
y
y
y X
y
y
= = =
111
'1212
'11
'2121
( 1)
'22
'
..
..
..
;u . ;.
..
..
..
..
..
TT
NTx
TT
NTNT
u
ux
ux
ux
ux
ux
=
(8)
De la expresión anterior, es la matriz D (o matriz de dummies) la que nos permitirá
acomodar la presencia de hasta N interceptas distintos. Observar que esta matriz puede
expresarse como: N rD I i=
; donde NI es una matriz identidad de N x N, mientras que

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
ir se refiere a un vector unitario de Tx1. Con esto, podemos expresar el modelo en
términos matriciales de fa siguiente forma compacta:
y D X u = + + (9)
Donde y son los vectores que contienen los N interceptos y k pendientes,
respectivamente.
Para hallar las expresiones asociadas al estimador mínimo cuadrático de estos
intercepto y pendientes, basta con recordar lo que sabemos sobre el rol del intercepto y
el modelo en desviaciones: desviemos cada observación respecto de la media de cada
agente tomada sobre el tiempo, construyamos el estimador mínimo cuadrático de las
pendientes y utilicemos este último para hallar los N interceptos. Para el i-ésimo agente,
la media tomada sobre el tiempo T de la variable dependiente viene dada por
( )1
1/T
it
t
T y=
. Lo mismo aplica para el término de error y las variables explicativas.
Denotemos estas medias como, _ _ _
..., , iii
y u X respectivamente. Así, el modelo en
desviaciones y los respectivos estimadores pueden expresarse de la siguiente manera
(Barco & Castro, 2010):

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
'
'_ _ _
. ..
_ _ _'
. .
1_ _
'. .
'_ _
, ..
( )
( )( )
it i it it
i iii
i iit it iti
i iWithin it it
it
i Within i Withini
y x u
y x u
y y x x u u
x x x x
y x
−
= + +
= + +
− = − + −
= − −
= −
(10)
Nótese que hemos llamado Within a este estimador mínimo cuadrático de un modelo
desviado respecto a la media de cada agente. El término Within (o "intra", en castellano)
responde, precisamente, a que estamos explotando la variabilidad intraagente. Estamos
interesados en estimar cuánto cambia el comportamiento del agente respecto de su
comportamiento promedio, cuando alguno de los factores que lo explican ( )x , se desvía
en una unidad, respecto de lo que en promedio le ocurre al agente en cuestión. Al hacerlo,
estamos reconociendo que cada agente puede registrar un comportamiento promedio
distinto al del resto (Beltran &Castro,2010).
Pensemos ahora en términos de todas las observaciones y en la transformación matricial
requerida para desviar cada dato correspondiente al i-ésimo agente de su respectiva
media. Para esto, empecemos por darnos cuenta de que es necesario calcular N
promedios, y que un arreglo matricial como el siguiente es capaz de devolvernos los N
promedios que necesitamos.
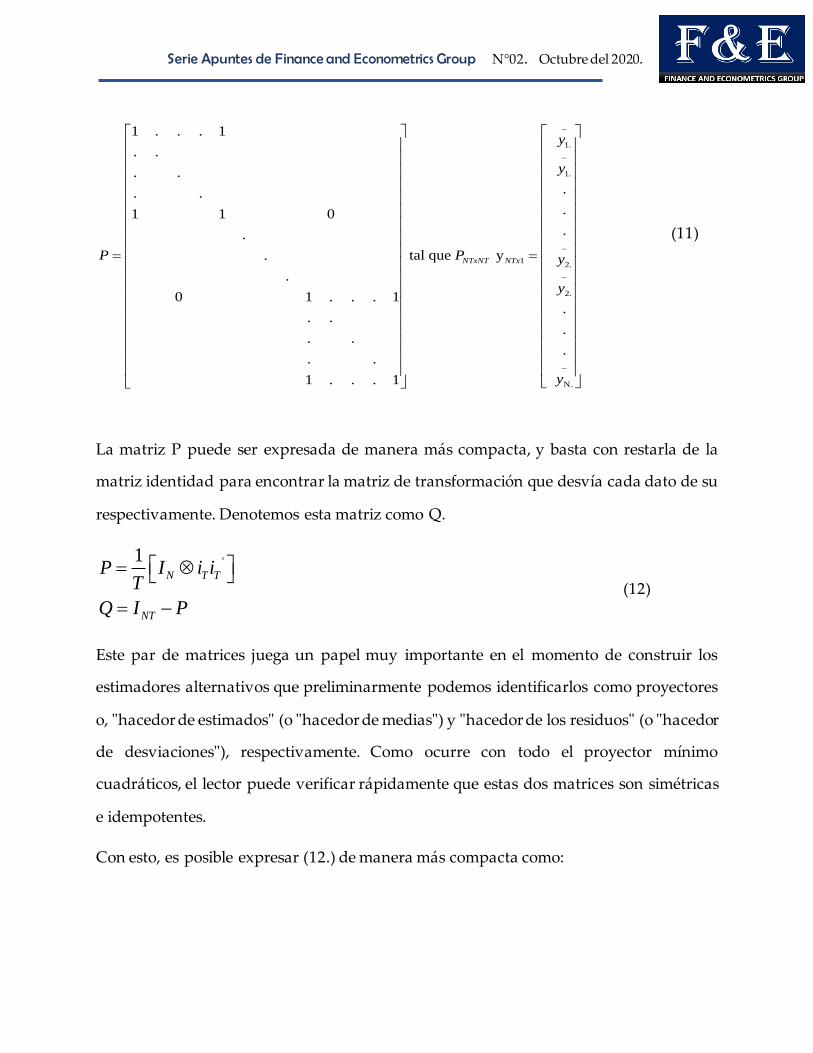
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
1.
1.
12.
2.
N.
1 . . . 1
. .
. .
.. .
.1 1 0
..
tal que y .
.
0 1 . . . 1.
. ..
. ..
. .
1 . . . 1
NTxNT NTx
y
y
P P y
y
y
−
−
−
−
−
= =
(11)
La matriz P puede ser expresada de manera más compacta, y basta con restarla de la
matriz identidad para encontrar la matriz de transformación que desvía cada dato de su
respectivamente. Denotemos esta matriz como Q.
'1N T T
NT
P I i iT
Q I P
=
= − (12)
Este par de matrices juega un papel muy importante en el momento de construir los
estimadores alternativos que preliminarmente podemos identificarlos como proyectores
o, "hacedor de estimados" (o "hacedor de medias") y "hacedor de los residuos" (o "hacedor
de desviaciones"), respectivamente. Como ocurre con todo el proyector mínimo
cuadráticos, el lector puede verificar rápidamente que estas dos matrices son simétricas
e idempotentes.
Con esto, es posible expresar (12.) de manera más compacta como:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
' 1 '
1
=
= (I i )
Qy = Q(I i ) Q Q
= Q Q
=(XQ QX) XQ Qy
=(XQX) XQy
N T
N T
Within
y D X u
X u
X u
X u
−
−
+ +
+ +
+ +
+ (13)
Ahora bien, si recordamos el resultado asociado al modelo en desviaciones, notaremos
que el resultado anterior debería ser equivalente al que obtendríamos si incluimos un
intercepto distinto para cada agente. Formalmente3:
' 1 '
' '
=
=(X M X) X M y
M ( )
Within D D
D NT
y D X u
I D D D D
−
+ +
= −
(14)
Las expresiones dadas en (12.) y (13.) no implican que se tenga dos maneras distintas de
expresar
Within
sino, más bien, implican que 4 MD Q= . Equivale a nuestra generalización
del resultado del modelo en desviaciones: estimar una regresión por mínimos cuadrados
ordinarios con un intercepto distinto para cada agente (resultado dado en [9.]). Equivale
a estimar una regresión con observaciones desviadas respecto del valor medio
correspondiente al agente en cuestión (resultado dado en la ecuación 14).
3 Esta expresión muestra de manera explícita cómo este acápite es una aplicación del resultado de regresión
particionada. Si partimos de un modelo general y X u= + y particionamos la matriz X en dos subconjuntos de
regresores de la forma, es posible demostrar que las pendientes estimadas del segundo grupo de regresores vienen
dadas por: ' 1 '
2 1 2 2 1(X M X ) X M y
−= , donde ' 1 '
1 1 1 1 1( )M I X X X X−= −
4 Esta igualdad se puede verificar fácilmente trabajando con las propiedades del producto Kronecker)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Hasta ahora, nuestra discusión se ha centrado en la segunda de las tres opciones
presentadas al inicio del párrafo cuando nos referíamos a que en un panel de datos
hay tres medias distintas que pueden servir como controles. ¿Es posible realizar un
análisis similar trabajando con la media (tomada a través del espacio) de cada uno de los
T momentos del tiempo? ¿Respecto de qué estaremos controlando en este caso?
Empezamos a responder estas preguntas planteando la posibilidad de que exista un
intercepto distinto para cada momento del tiempo. Definamos, para esto, como a
la media tomada sobre el espacio de la variable dependiente del t-ésimo momento
.
1
(1/ )N
itt
i
y N y−
=
= .
'
'_ _ _
.t .t.t
_ _ _'
.t .t.t
1_ _
'.t .t
' _ _
.tt, .t
( )
( )( )
it t it it
t
it it it
Within it it
it
Within Within
y x u
y x u
y y x x u u
x x x x
y x
−
= + +
= + +
− = − + −
= − −
= −
(15)
Nótese que también hemos llamado Within a este estimador. De hecho, le corresponde el
término "intra", solo que esta vez lo que buscamos es explotar la variabilidad
intratemporal.
-
.ty

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Nuestro interés recae en conocer cuánto cambia el comportamiento del agente respecto
del comportamiento promedio del grupo, cuando alguno de los factores que lo explican
( )itx experimenta un desvío, en una unidad, respecto del valor promedio del grupo. Al
hacerlo, estamos reconociendo que en cada momento del tiempo el grupo puede registrar
un promedio distinto.
En suma, los múltiples interceptos por agente nos permiten capturar qué tan distinta es
la respuesta de un agente respecto de su respuesta promedio, y comparar esto entre
agentes para un mismo momento del tiempo. Los múltiples interceptas de tiempo, por
su parte, nos permiten capturar qué tan distinta es la respuesta de un agente respecto de
la respuesta promedio del grupo, y comparar esto entre momentos del tiempo para un
mismo agente. En ambos casos se trata de una comparación de diferencias; de ahí la
"doble diferencia" a la que se hace referencia en el acápite introductorio.
La generalización de (14.) requiere introducir matrices de intercepto y desvíos distintos,
a las que llamaremos
y D Q , respectivamente. Formalmente (Barco & Castro, 2010):

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
'
' ' 1
1
1
=
y =
=
=(X X) X y
=(X X) X y
N T
NT N N T
Within
D i I
Q I i i IN
y D X u
Q Q D Q X Qu
Q X Qu
Q Q Q Q
Q Q
−
−
=
= −
+ +
+ +
+ (16)
Ahora solo nos queda una de las opciones pendiente: la media de todas las observaciones.
Como se verá a continuación, es necesario introducir esta media "total" si es que se desea
trabajar con interceptas distintos para agente y tiempo, simultáneamente. Partamos de
una especificación general:
'
it i t it ity x u = + + + (17)
Y démonos cuenta de que al remover (o desviar respecto de) las medias por agente y
tiempo, todavía están presentes los valores promedio de estos interceptas. Formalmente:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
' _ _
. ..
' _ _ _
.t .t.t
' _ _ _ _ _ _ _ _
. . . .t. .t
(1/ )
(1/ N)
( )
i ii ti
i t
i t iit it iti
Ty x u
y x u
y y y x x x u u u
= + + +
= + + +
− − = − − + − − + − −
(18)
Donde: = = __ __1 1
,t i
it itNT NT;. Esto último implica que es posible eliminar estos
términos constantes (para proceder con la estimación de las pendientes) si sumamos el
promedio total a la ecuación dada en (17.). Este promedio total viene dado por:
_ _
y x u = = =
= + + + (19)
' _ _ _ _ _ _ _ _
. . . .t. .t( ) i t iit it iti
y y y y x x x x u u u u = = =
− − + = − − + − − + + − − +
(20)
Al regresionar _ _
. .tit iy y y y=
− − +
sobre
_ _
. .i titx x x x=
− − +
obtenemos Whitin y, con
esto, es posible hallar los estimadores de los efectos individuales y temporales:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
_ _
, ..
_ _
.tt, .t
i Within iWithini
Within Within
y y x x
y y x x
= =
= =
= − − −
= − − −
(21)
Por último, el lector puede verificar que la transformación asociada pasa por pre
multiplicar el modelo por la matriz Q, la cual viene dada por:
' '1 1 1NT N T T N N TQ I I i i i i I J
T N NT
= − − + (22)
Donde J es una matriz unitaria de (NT x NT).
2.2 Efectos Fijos versus efectos Aleatorios
A partir de lo expuesto el problema radica en la estimación de N o T (o si se desea de NT)
interceptos distintos. Esto involucra suponer que iα ; ( )t
o γ son un conjunto
considerable de parámetros desconocidos. Pero que implica la estimación de un conjunto
demasiado grande de parámetros. Concentrémonos en i; y pensemos en un panel de
datos con un número bastante grande de observaciones de corte transversal (N), como en
el caso de un panel construido con encuestas de hogares realizada por los institutos de
estadísticas de los países. Dada la marcada heterogeneidad a través del espacio, de hecho,
tiene más sentido suponer que los distintos valores de i; son (al igual que la información
contenida en x) la realización de un proceso estocástico subyacente.
La distinción anterior es la que ha originado que, en algunos casos, se bosqueje una
aparente dicotomía entre un "modelo de efectos fijos" y un "modelo de efectos aleatorios''.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
En el primero, se sugiere que los i ; son parámetros, mientras que en el segundo se trata
a i ; como una variable aleatoria. Sin embargo, esto puede conducir a una interpretación
errónea del rol del i , así como de los resultados de algunas de las pruebas que
advertiremos más adelante. Por lo mismo, aquí no haremos esta distinción y
supondremos que i ; recoge efectos no observables, atribuibles al i-ésimo agente y que
no varían en el tiempo. Esto no implica que más adelante no experimentemos saber más
sobre la naturaleza de i , o que no hagamos referencia a los estimadores de efectos fijos
y aleatorios.
Nuestro interés sobre la naturaleza de i , no obstante, se centrará en determinar si está
o no correlacionado con las variables explicativas del modelo. Nuestra distinción entre
"efectos fijos y "efectos aleatorios", por su parte, se referirá a la técnica de estimación por
emplear y no a la naturaleza de i .
No es difícil suponer que, en el momento de modelar las decisiones individuales de un
grupo amplio de agentes, las respuestas dependan de un conjunto también amplio de
factores, muchos de ellos no observables5.
En un modelo de corte transversal no queda más que dejar que esta heterogeneidad no
observable sea capturada por el error, y confiar en que no esté correlacionada
contemporáneamente con alguno de los regresores incluidos6. El panel, sin embargo,
ofrece una alternativa distinta, ya que hace posible controlar por esta fuente de
heterogeneidad no observable.
5 Factores como la "habilidad" o la "motivación" son sin duda determinantes de variables como la decisión de
matricularse en la educación superior o del salario por hora, pero difícilmente observables. 6 Tal como se discutió en el acápite introductorio, esta correlación contemporánea llevaría a que el estimador mínimo
cuadrático deje de exhibir la propiedad de consistencia. Una alternativa para esto es el uso del estimador de variables
instrumentales, con la subsecuente pérdida de información que su uso implica.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
En lo que sigue, formalizaremos nuestros supuestos sobre la naturaleza de la data
partiendo de que i ; recoge esta heterogeneidad que no es observable pero que, sin duda,
afecta las decisiones de los agentes bajo análisis (Barco & Castro, 2010)
2.3 Nuestro marco de análisis y los estimadores alternativos
En las páginas que siguen empezaremos planteando un conjunto de supuestos sobre el
proceso generador de datos, para luego analizar las propiedades de distintos estimadores
con el objetivo de determinar cuál de ellos es el más apropiado. Como siempre, las
propiedades que privilegiaremos serán el insesgamiento y eficiencia, para muestras
pequeñas; y la consistencia para muestras grandes.
De acuerdo con nuestra discusión anterior, supongamos que la información contenida en
nuestro panel de datos puede representarse de la siguiente manera (Barco & Castro,
2010):
'
2
2
. . (0, )
. . (0, )
it it it
it i it
i
it u
y x v
v u
i i d
u i i d
= + +
= +
(23)
Es decir, supongamos que el error asociado a la observación del i-ésimo agente en el t-
ésimo momento del tiempo está compuesto de dos partes: un término que no varía a lo
largo del tiempo y recoge la heterogeneidad no observable atribuible al i-ésimo agente
( )i , que se distribuye de manera idéntica e independiente con media igual a cero y

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
varianza igual a 2
, y un término que registra realizaciones distintas tanto a lo largo del
tiempo como a través del espacio ( )itu que distribuye de manera idéntica e independiente
con media igual a cero y varianza igual a 2
u .
La forma compuesta que hemos supuesto para el error implica que, si bien este es
homocedástico en los residuos, exhiben correlación serial cuando se trata de un propio
agente. Formalmente: lo expresamos en la ecuación 24.
2 2
2
( )
Cov( , ) t s
it u
it is
Var v
v v
= +
= (24)
También podemos expresar el modelo y su estructura de varianzas y covarianzas del
error en términos matriciales. Formalmente: lo expresamos en la ecuación 25.
' '
' 2 2 ' 2 2
; W= ,
( )
NT
u NT N T T u NT
y W v i X
W vv I I i i I TP
= + =
= = = + = + (25)
2.4 Estimador Within
Este estimador que ya fue presentado anteriormente y, como sabemos, implica
transformar el modelo premultiplicándolo por un proyector. A diferencia de lo indicado
en la ecuación 14, aquí estamos asumiendo que solo existe un intercepto común ( ) por
estimar y que el término a; corresponde al error. Nótese que, en términos prácticos, no
existe ninguna diferencia en la expresión asociada a la estimación de las pendientes.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Como ya es usual, expresamos el estimador tanto en términos matriciales (Barco &
Castro, 2010):
−= ' 1 '( )Whitin WQW WQy (26)
Lo que equivale a regresionar:
'
'_ '
.
1_ _ _ _
' '. . . .
' =
t,
( )( ) ( )(y )
− −
−
=
= + + +
− = − + + −
= − − − −
= −
it it i it
iit it i it ii
i i iWithin it it it it i
it it
Within Within
y x u
y y x x u u
x x x x x x y
y x
(27)
En este punto cabe destacar la forma que adopta el error del modelo transformado. Al
remover de cada observación la media correspondiente al agente en cuestión (haciendo
uso del proyector Q ), el nuevo término de error, al que denominamos v resulta:
= − = −_ _
. .v v vit i iit it (28)
El nuevo término de error está "libre" de la heterogeneidad no observable asociada al
agente.
Este resultado es clave para garantizar una propiedad importante del estimador, tal como
será discutido más adelante. Por lo pronto, démonos cuenta de que este nuevo error
tampoco exhibe una matriz de varianzas-covarianzas escalar debido a la existencia de
correlación serial entre errores correspondientes a un mismo agente. Formalmente:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
− = − = − + =
= − − = − + = −
_2 2 2 2 2
.
_ _2 2 2
. .
1(v ) (u u ) (2 / T) (1 / )
(v ,v ) (u u ) (u u ) (2 / ) (1 / ) (1 / )
it it i u u u u
it is it i st i u u u
TVar E T
T
Cov E T T T
(29)
O de manera compacta:
= = + =
' ' 2 2 2( v v ) (Qvv Q) Qu NT u
E E I TP Q Q (30)
Al igual que el estimador mínimo cuadrático, el estimador Within es insesgado. El
resultado dado en (27.) (y, en particular, la existencia de correlación serial en los errores)
implica que el estimador Within no es eficiente, excepto si =2 0u
o T tiende a infinito
( )→T .
2.5 Estimador Between
Así como existe un estimador Within que aprovecha la variabilidad intra agentes, es
posible construir un estimador Between que tome en cuenta la variabilidad inter agentes.
Para esto basta con tomar los promedios para cada agente y utilizar esta información
como si se tratase de una base de datos de corte transversal. Como sabemos, estos
promedios son tomados por el proyector P, por lo que:
= ' -1 '(W PW) W QyBetween (31)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Lo que equivale a regresionar
'_ _ _
..
1_ _ _ _
' '. . . .
' =
( )( ) ( )( )
Between Between
it iii
i i iBetween i
i i
y x u
x x x x x x y y
y x
− = = = =
=
= + + +
= − − − −
= −
(32)
Al igual que sus predecesores (y siempre y cuando el error sea independiente en media
de los regresores: =(v / ) 0E X el estimador Between es insesgado. Asimismo, tampoco es
eficiente. De hecho, el término de error del modelo transformado = +_ _
it .v ii también
exhibe autocorrelación.
= = + = +
2 _ _ _ __
2 2it isit
1Var(v) (v ,v ) ii u u
Cov E uT (33)
O, en términos más compactos:
= = + = +
_ _' 2 2 2 2( v v ) E(PvvP) P ( )P
u NT uE I TP P
(34)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
2.6 Estimador de mínimos cuadrados generalizados
Ninguno de los tres estimadores presentados anteriormente son eficientes. Para
garantizar esto, es preciso convertir el modelo de modo que el “nuevo” error del modelo
exhiba una matriz de varianzas-covarianzas escalar. Ninguna de las tres
transformaciones consideradas hasta ahora lo consigue5.
Definamos como R a la matriz que transforma al modelo de modo que el nuevo error
tenga una estructura de varianzas-covarianzas escalar. Esto implica que R debe ser tal
que:
' 1R R c −= (35)
Donde c es un escalar positivo. Es posible demostrar que la forma de esta matriz viene
dada por:
2
2 2
(1 )NT
u
u
R I P Q P
= − = +
=+
(36)
Es decir que la transformación que garantiza un estimador eficiente es aquella que
remueve de cada observación una proporción (1 )− de su media, donde es función de
las varianzas de los dos componentes del error. De hecho, no es difícil demostrar que la
estructura de varianzas-covarianzas del error transformado Rv es escalar:
' ' 2 2 2 2( ) ( ) ( )u NT u uE RVV R Q I TP Q P Q P I = + + + = + = (37)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Lo anterior garantiza que el estimador asociado sea eficiente, y, por lo mismo, pertenece
a la clase de estimadores de mínimos cuadrados generalizados (MCG).
' 1 ' 1 1 1( ) ( )MCG WR RW WR Ry W W W y
− − − −= = (38)
Lo que equivale a regresionar
_
.(1 )it i
y y− − sobre una constante y _
.(1 ) iitx x− −
1_ _ _ _
. . . .(x (1 ) x )(x (1 ) x ) (x (1 ) x )(y (1 ) )i i iMCG it it it it i
it it
x x x y y
− = = = =
= − − − − − − − − − − − − (39)
De manera compacta podemos escribirlo:
' '_ _ _ _
' 2 ' 2. . . .
'
x x xi i iMCG i
i i
MCG MCG
X QX x x X QX x y y
y x
= = = =
= =
= + − − + − −
−
(40)
La expresión anterior nos sugiere que el estimador MCG combina la información
contenida en los estimadores7 withinβ y Betwenβ .No debe extrañarnos, por tanto, que se trate
7 De hecho, es posible demostrar que el estimador MCG es un promedio ponderado de los estimadores Within y
Between:
(1 )B W
= + − , donde: 1
' _ _
2 '1 i iXQX x x x x X QX
−= =
− = − − −

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
de un estimador eficiente, en la medida en que explota la variabilidad tanto intra como
Inter agente.
Tan o más interesante es verificar bajo qué condiciones especiales el estimador MCG
coincide con el estimador Within o el mínimo cuadrático. Para el primer caso, recordemos
bajo qué circunstancias es el estimador Within eficiente 2 0u = o cuando T tienda a
infinito. En cualquier caso, desaparecería la correlación serial entre los errores del modelo
transformado con el proyector. Es fácil verificar que, bajo cualquiera de estas dos
situaciones, se cumple que
MCG Betwenβ =β
8 .
2
2
2 2
, 0 0
0
/ 0
R/ I
u
u
u
T
NT P Q
→ =
=
=+
=
= − = (41)
Regresemos ahora a la estructura de varianzas-covarianzas del error del modelo original
(dada en (20.)) y notemos que esta matriz sería escalar (garantizando la· eficiencia de
MICO
en caso
0MICO
= . También es fácil verificar que, en este caso, se cumple que
MCG MICOβ =β
·
8 Si
2 0u = , los efectos no observados son solo específicos del individuo, no hay generales, por lo que basta con
corregir por la presencia de a; para eliminar el problema de autocorrelación que presenta el modelo original.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
2
2
2 2
0
1
/ 1
R/
u
u
NT
T
I
=
=
=+
=
= (42)
2.7 Mínimos cuadrados generalizados factibles
¿Por qué no presentar únicamente al estimador eficiente? ¿Qué utilidad puede tener la
discusión de los estimadores
Whitin
y
Betwen
La respuesta a esta pregunta tiene dos partes.
En primer lugar, es necesario notar que para construir el proyector R es necesario conocer
las varianzas de los dos componentes del error de nuestro modelo. En la práctica, esto
difícilmente será posible, así que tendremos que utilizar un estimado de dichas varianzas.
Es para la estimación de estas varianzas que 1os estimadores
Whitin
y
Betwen
nos pueden
ser útiles.
En particular, es posible demostrar que la varianza estimada del error del modelo
transformado con el proyector ( ) itQ v es un estimador consistente de 2
u . Formalmente9
2_ _
'.2 2. Pr
(y y ) (x )
iit it Whithini obit
v u
x
NT N K
− − −
= →− −
(43)
9 Si
2 0 = , directamente se elimina el problema de autocorrelación del modelo original por lo que MICO es el
estimador eficiente.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Tal como se muestra en la expresión anterior, nuestro estimador consistente de 2
u no es
otra cosa que la suma de cuadrados residual de la estimación Within, corregida por el
número apropiado de grados de libertad (Barco & Castro, 2010)
Por otro lado, la varianza estimada del error del modelo transformado con el proyector P
( )itv también nos provee información valiosa. De hecho, es posible demostrar que,
conforme N tienda a infinito, dicha varianza converge en probabilidad a una suma
ponderada de 2
u y 2
. Formalmente:
2
_ _ '
..2 2 2Pr
(y y) ( )
1 +
1
i Betweni
it ob
v u
x x
N K T
= =
− − − = →
− −
(44)
Si combinamos los resultados indicados en (40) y (41), es posible construir estimados de
2
y 2
u , con esto, nuestro estimado de y del proyector R. Esto configura lo que se
conoce como "estimador de mínimos cuadrados generalizados factibles". En particular
2
v
, provee directamente un estimador consistente de 2
u , mientras que la resta
2 21
v v
T
− nos provee un estimador consistente de 2
. Formalmente:
2 2 Pr21 ob
v v
T
− → 10
10 Nótese que el resultado de esta resta podría ser negativo. En este caso, conviene reconsiderar el uso del estimador
de efectos aleatorios.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
2.8 Estimador a usar
La discusión anterior revela que hay dos preguntas claves que deben ser resueltas antes
de determinar cuál es el mejor estimador por utilizar. La primera pregunta está asociada
a la idoneidad del marco de análisis propuesto. La segunda, por su parte, se refiere a la
posibilidad de que exista correlación contemporánea entre los regresares y el término de
error.
2.9 Efectos no observados
Como se dijo, esta primera pregunta está relacionada con el marco de análisis propuesto
y, en particular, con la estructura del término de error. Al respecto, nótese que la ausencia
de efectos no observados específicos del individuo equivale a suponer que el error se
comporta de la siguiente manera: it itv u= . Dado que se asume que ( ) 0iE = , lo anterior
equivale a decir que 2 0 = .Para comprobar esta hipótesis se dispone del test de Breusch-
Pagan, cuyo estadístico (LM) se construye sobre la base de los residuos mínimo
cuadráticos (e) y, bajo la hipótesis nula, se distribuye chi-cuadrado con un grado de
libertad. Formalmente:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
= = =
= = = =
= =
+
− = − − −
2
0
22 2
_
.1 1 21
2 2
1 1 1 1
: v ( 0)
: v =
LM= 1 1 (1)2( 1) 2( 1)
it it
a it it i
N T N
it ii t i
N T N T
it iti t i t
H u
H u
e T eNT NT
T Te e
(45)
Si se rechaza la hipótesis nula, se concluye que la estructura supuesta para el error es la
correcta y que, por lo mismo, se aplica el análisis desarrollado en el acápite anterior. Es
decir, que es necesario construir el estimador de mínimos cuadrados generalizados si lo
que se busca es un estimador eficiente.
Si se acepta la hipótesis nula, por otro lado, bastará con estimar las pendientes a través
de mínimos cuadrados ordinarios. De hecho, cabe recordar que en caso de 2 0 = , el
proyector R es igual a la matriz identidad y el estimador eficiente es el mínimo cuadrático.
Una estimación como esta también se conoce como un POOL: se dispone solo de los datos
agrupados y, en el momento de hacer la estimación, no hay nada que identifique a la
información de un agente o momento del tiempo particular. La ganancia, en este caso, se
debe al hecho de contar con un significativo número de grados de libertad. Al respecto,
es posible evaluar la ganancia de ajuste asociada a la introducción de interceptas
múltiples (específicos ya sea a agentes o períodos de tiempo). Para esto, se puede utilizar

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
una típica prueba F11; y, de encontrarse una ganancia de ajuste significativa (si se rechaza
la prueba F), se preferiría el modelo de interceptas múltiples12
2.10 Existe correlación entre los efectos no observados y los Regresores
Como se dijo, si se acepta que el error tiene la estructura it i itv u= + la búsqueda de
eficiencia requiere la construcción del estimador de mínimos cuadrados generalizados.
No obstante, esto puede poner en riesgo la propiedad de consistencia si es que existe
correlación contemporánea entre la heterogeneidad individual no observable y el término
de error. Para verificar esto y decidir si trabajamos con el estimador de mínimos
cuadrados generalizados o el estimador Within, es posible construir una prueba de
Hausman.
De acuerdo con el planteamiento general de dicha prueba, se propone comparar dos
estimadores: uno eficiente pero solo consistente bajo la hipótesis nula, y otro no eficiente
pero consistente tanto bajo la hipótesis nula como bajo la alternativa. La hipótesis nula
por evaluar es la existencia de correlación entre el error y los regreso res. Por lo mismo, y
11 Nos referimos al típico contraste basado en pérdida de ajuste, el cual también puede ser expresado sobre la base de
los R-cuadrado:
2 2
2
( )( 1, )
(1 R ) / (NT N K)
SR Pool
SR
R RF F N NT N k
−= − − − −
− − − , donde
2R SR se refiere al R-cuadrado
del modelo con interceptas múltiples (sin restringir) y
2
PoolR, corresponde al R-cuadrado del modelo pool (restringido
a un solo intercepto común). 12 Cabe recordar que la estimación con interceptas múltiples es, en principio, equivalente a la construcción del
estimador Within. Nótese, sin embargo, que existe una diferencia en los objetivos. Cuando el error se comporta de
acuerdo con nuestro marco de análisis y construimos el estimador Within, nos interesa remover la heterogeneidad no
observable del término de error para garantizar consistencia. Para esto, desviamos cada observación de su media, y la
inclusión de un intercepto distinto para cada agente es una de las maneras de hacerlo. En el caso que aquí discutimos,
donde el error ya no es un error compuesto, nuestra motivación es la ganancia de ajuste: estamos interesados en estimar
un intercepto distinto para cada agente, y el hecho de que esto sea equivalente a desviar cada dato de su media podría
entenderse como un subproducto.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
de acuerdo con las propiedades discutidas hasta ahora, nuestros candidatos ideales
serían el estimador de mínimos cuadrados generalizados y el estimador Within.
El primero es eficiente pero solo consistente en ausencia de correlación, mientras que
Within no es eficiente, pero retiene la propiedad de consistencia incluso bajo la presencia
de correlación entre el término a; y los regresores.
La intuición detrás la prueba es clara: una diferencia significativa entre los estimadores
de mínimos cuadrados generalizados y Within, constituye evidencia en contra de la
consistencia del primero y esto, a su vez, constituye evidencia en contra de la ausencia de
correlación entre a; y los regresores. Por lo mismo, si se rechaza la hipótesis nula de esta
prueba, convendrá utilizar el estimador Within. Si se acepta la hipótesis nula, en tanto, se
privilegiará el uso del estimador de mínimos cuadrados generalizados13.
0
1
: ( ) 0
: ( ) 0
( )
( ) ( ) Var( )
i it
a i i it
MCG Whitin
MCG Whitin
H E x
H E x
S q Var q q
q
Var q Var
−
=
=
= −
= +
(46)
13 De hecho, cualquier combinación entre los estimadores Wíthín, Between o mínimos cuadrados generalizados
sería válida en la medida en que este último es un promedio ponderado de los dos primeros.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Antes de concluir, conviene destacar que esta no es una prueba para determinar si los
efectos individuales son "fijos" o "aleatorios''. Lo que sí es cierto es que, dependiendo de
sus resultados, se decidirá si utilizar el estimador de mínimos cuadrados generalizados
("efectos aleatorios") o el estimador Within ("efectos fijos"). Esta decisión, no obstante, no
responde a la posibilidad de que los efectos individuales no exhiban una naturaleza
aleatoria, sino a la posibilidad de que, siendo aleatorios, estén correlacionados con los
regresores (Barco & Castro, 2010)
3. Aplicaciones
Ejemplo 1.1 heterogeneidad individual: conjunto de datos de fatalidades
El conjunto de datos de Fatalities de Stock y Watson (2007) es un buen ejemplo de la
importancia de heterogeneidad individual y efectos de tiempo en un entorno de panel.
La pregunta de la investigación es si gravar a los alcohólicos puede reducir el número de
muertos en las carreteras. Lo básico La especificación relaciona la tasa de mortalidad en
la carretera con la tasa impositiva sobre la cerveza en un entorno de regresión clásico:
n i nfrate beertax = + + (47)
Los datos son de 1982 a 1988 para cada uno de los estados continentales de EE. UU. Los
elementos básicos de cualquier comando de estimación en R son una fórmula que
especifica el modelo diseño y un conjunto de datos, generalmente en forma de marco de
datos. Los conjuntos de datos de ejemplo pre empaquetados son la forma más sencilla de
importar datos, ya que solo necesita ser llamado por su nombre para recuperarlos. A

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
continuación, el modelo se especifica en su forma más simple, una relación bivariada
entre tasa de mortalidad y el impuesto a la cerveza.
El paso más básico es un análisis transversal de un solo año (aquí, 1982). Uno procede
primero creando un objeto modelo a través de una llamada a lm, luego mostrando un
summary. lm del mismo.
La impresión en pantalla se produce cuando se llama interactivamente a un objeto por
su nombre. Note que subconjunto se puede hacer dentro de la llamada a lm alimentando
una expresión que resuelva en un vector lógico al argumento de subconjunto: se
seleccionarán los puntos de datos correspondientes a VERDADEROS, se descartarán los
FALSOS.
data("Fatalities", package="AER")
Fatalities$frate <- with(Fatalities, fatal / pop * 10000)
fm <- frate ̃ beertax

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
3.1. Explorando el Panel Data
Datos de panel (también conocidos como datos de series de tiempo longitudinales o
transversales) es un conjunto de datos en el que el comportamiento de las entidades es
observado a lo largo del tiempo. Estas entidades pueden ser estados, empresas,
individuos, países, etc. Los datos del panel se ven así:

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
coplot(y ~ year|country, type="l", data=Panel) # Lines
coplot(y ~ year|country, type="b", data=Panel) # Points and lines
# Bars at top indicates corresponding graph (i.e. countries) from left to right
# starting on the bottom to (Muenchen/Hilbe:355)
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 1
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
library(car)
scatterplot (y~year|country, boxplots=FALSE, smooth=TRUE, reg.line=FALSE, data=Panel)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 2
3.2. Uso de ExPanD para la exploración de datos de panel
ExPanD es una aplicación brillante basada en las funciones del paquete ExPanDaR. Su
intención es hacer que la exploración de datos del panel sea entretenida y fácil. Con
ExPanD se puede explorar rápidamente los datos del panel, independientemente de su
origen, prototipo de diseños de prueba simples y verificarlos fuera de la muestra y brinde
a los usuarios la oportunidad de evaluar la solidez de sus hallazgos sin brindarles acceso
a los datos subyacentes.
Esta sección lo guiará a través del proceso de uso de ExPanD discutiendo tres casos de
uso. Mientras que los dos primeros utilizan datos macroeconómicos para explorar la
asociación de la Producción Interna Bruta (PIB) per cápita con la esperanza de vida al

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
nacer, el último caso de uso explora la asociación entre las medidas de desempeño
contable financiero y los rendimientos de las acciones concurrentes14.
3.3. Inicio de ExPanD para cargar un archivo local que contiene datos
del panel
La forma más fácil de comenzar a usar ExPanD es usarlo con un archivo de datos local
que contenga datos de panel. ExPanD admite formatos de archivo Stata, SAS, CSV, Excel
y R. Para usar ExPanD desde dentro de R, debe instalar el paquete ExPanDaR e iniciar
ExPanD.
Figura N º 3
14 Si no usa R, aún puede usar la aplicación ExPanD para explorar los datos del panel. En este caso, acceda
a la variante alojada de la aplicación ExPanD aquí y siga los consejos a continuación sobre cómo cargar un
archivo de datos de panel adecuado para la exploración en línea. No se preocupe: sus datos no se
almacenarán en el servidor y se eliminarán de la memoria una vez que se cierre la conexión al servidor.
devtools::install_github("joachim-gassen/ExPanDaR")
library(ExPanDaR)
ExPanD()
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Ahora necesitas un archivo para explorar. Siéntase libre de usar lo que quiera, pero para
nuestro primer caso de uso usaré el conocido conjunto de datos gapminder
proporcionado por el paquete gapminder.
library(gapminder)
# write.csv(gapminder, file = "gapminder.csv", row.names = FALSE)
head(gapminder, 10)
#> # A tibble: 10 x 6

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Para usar ExPanD, necesita lo siguiente:
• Un conjunto de datos de panel en formato largo con al menos dos variables
numéricas y sin observaciones duplicadas (identificadas por la dimensión
transversal y de serie temporal)
• Una variable o un vector de variables dentro de este conjunto de datos que
identifique la dimensión transversal
• Una variable que es coercible a un factor ordenado y que identifica (y ordena) la
dimensión de tiempo de su panel.
Como puede ver, el archivo gapminder contiene datos del año del país. Está organizado
en un formato largo utilizando el país como identificador transversal y el año como
identificador de serie temporal. Luego, cada una de las variables adicionales se almacena
en una columna separada. Tiene un factor (continente) y tres variables numéricas
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl> 1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
any(duplicated(gapminder[,c("country", "year")]))
#> [1] FALSE

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
(lifeExp, pop y gdpPercap). Por lo tanto, cumple con los requisitos anteriores, asumiendo
que no tiene duplicados:
Utilice la llamada a la función write.csv () comentada anterior para guardar el archivo
CSV en su sistema y el cuadro de diálogo del archivo para cargarlo en ExPanD (si no está
utilizando R, puede descargar el archivo CSV aquí). Después de cargar el archivo,
aparecerán dos cuadros de diálogo pidiéndole que seleccione los identificadores
transversales y el identificador de serie temporal.
Figura N º 4
any(duplicated(gapminder[,c("country", "year")]))
#> [1] FALSE

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Seleccione el país como identificador transversal y el año como identificador de serie
temporal. ExPanD ahora procesará los datos para mostrarlos para que pueda comenzar
a explorar.
Iniciar ExPanD con un marco de datos que contiene datos de panel
Alternativamente, si está utilizando R, puede omitir el cuadro de diálogo de carga de
archivos especificando un marco de datos y sus identificadores transversales y de serie
temporal.
3.4. Modelo de Efectos Fijos: Modelo de covarianza, estimador Within,
modelo de variable Dummy individual, modelo de variable
Dummy de mínimos cuadrados
Efectos fijos: heterogeneidad entre países (o entidades)
Explorando los Datos
devtools::install_github("joachim-gassen/ExPanDaR")
library(ExPanDaR)
library(gapminder)
ExPanD(df = gapminder, cs_id = "country", ts_id = "year")
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
coplot(y ~ year|country, type="l", data=Panel) # Lines
coplot(y ~ year|country, type="b", data=Panel) # Points and lines
# Bars at top indicates corresponding graph (i.e. countries) from left to right starting on
the bottom row #(Muenchen/Hilbe:355)
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 5
Las barras en la parte superior indican el gráfico correspondiente (es decir, países) de izquierda
a derecha comenzando en la fila inferior # (Muenchen / Hilbe: 355)
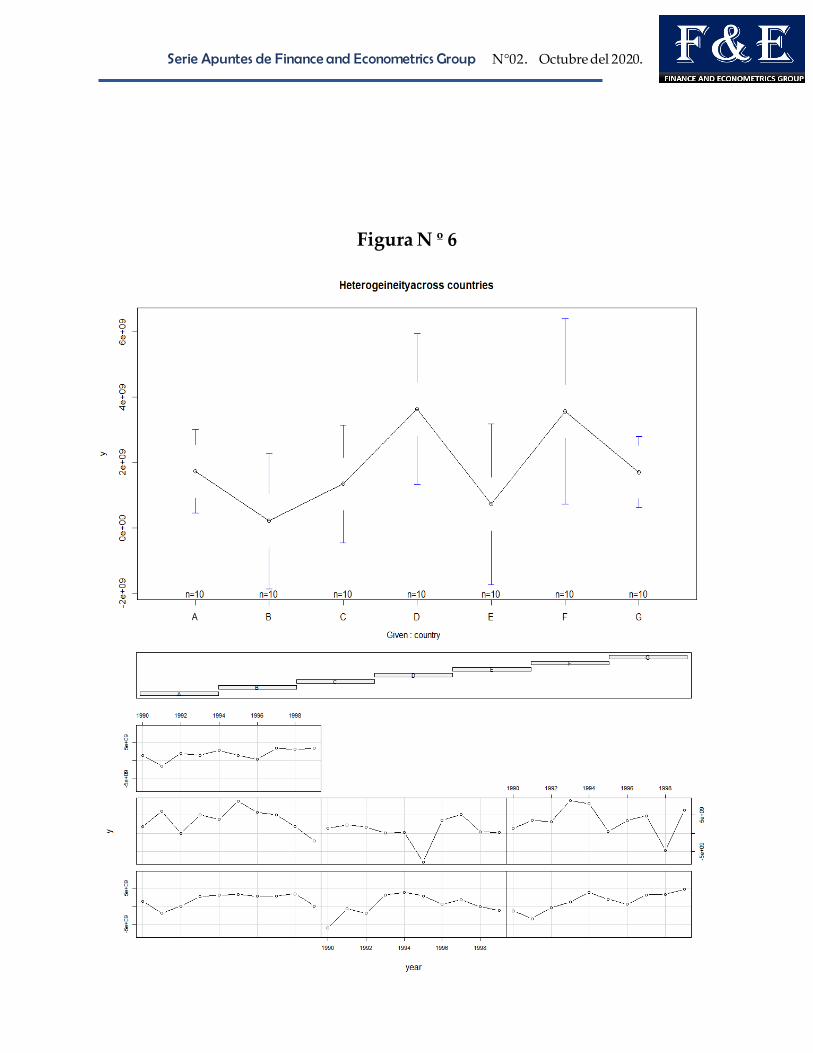
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 6
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
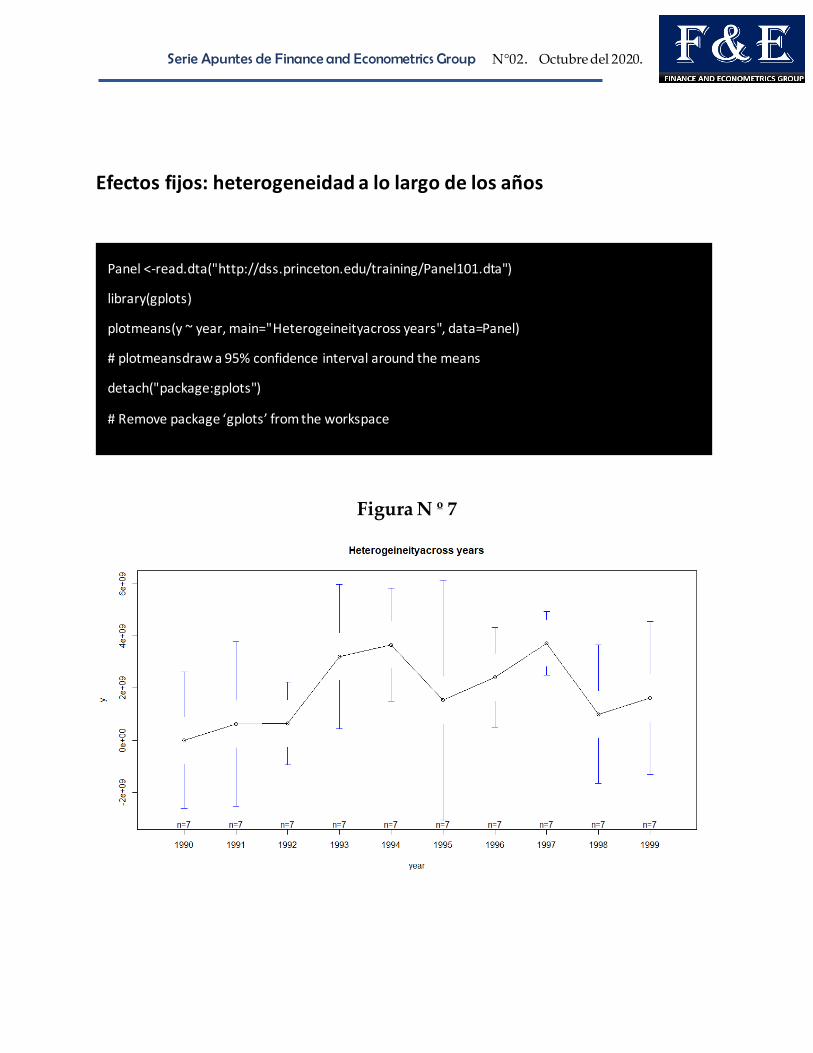
Efectos fijos: heterogeneidad a lo largo de los años
Figura N º 7
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
library(gplots)
plotmeans(y ~ year, main="Heterogeineityacross years", data=Panel)
# plotmeansdraw a 95% confidence interval around the means
detach("package:gplots")
# Remove package ‘gplots’ from the workspace

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Regresión OLS
La regresión de MCO regular no considera la heterogeneidad entre grupos o
tiempo.
Call:
lm(formula = y ~ x1, data = Panel)
Residuals:
Min 1Q Median 3Q Max
-9.546e+09 -1.578e+09 1.554e+08 1.422e+09 7.183e+09
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.524e+09 6.211e+08 2.454 0.0167 *
x1 4.950e+08 7.789e+08 0.636 0.5272
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.028e+09 on 68 degrees of freedom
Multiple R-squared: 0.005905, Adjusted R-squared: -0.008714
F-statistic: 0.4039 on 1 and 68 DF, p-value: 0.5272
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
ols<-lm(y ~ x1, data=Panel)
summary(ols)
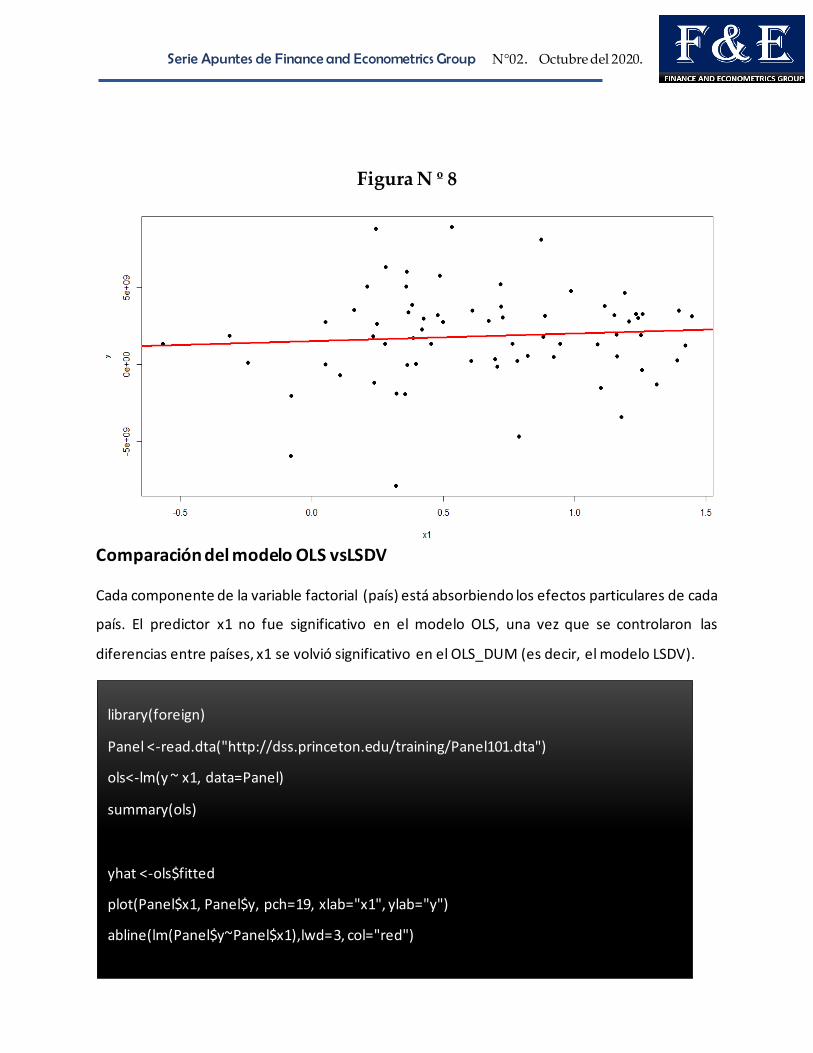
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 8
Comparación del modelo OLS vsLSDV
Cada componente de la variable factorial (país) está absorbiendo los efectos particulares de cada
país. El predictor x1 no fue significativo en el modelo OLS, una vez que se controlaron las
diferencias entre países, x1 se volvió significativo en el OLS_DUM (es decir, el modelo LSDV).
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
ols<-lm(y ~ x1, data=Panel)
summary(ols)
yhat <-ols$fitted
plot(Panel$x1, Panel$y, pch=19, xlab="x1", ylab="y")
abline(lm(Panel$y~Panel$x1),lwd=3, col="red")
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 9
yhat <-ols$fitted
plot(Panel$x1, Panel$y, pch=19, xlab="x1", ylab="y")
abline(lm(Panel$y~Panel$x1),lwd=3, col="red")
install.packages("apsrtable")
library(apsrtable)
apsrtable(ols,fixed.dum, model.names= c("OLS", "OLS_DUM"))
# Displays a table in Latex form
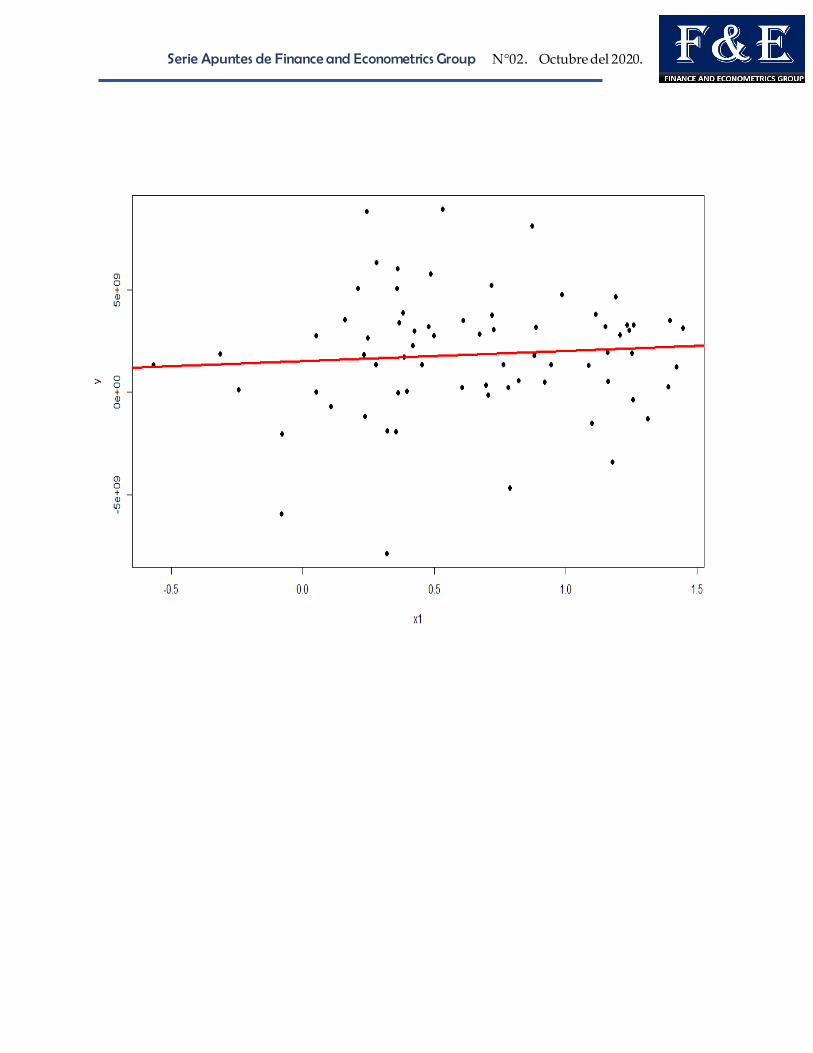
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Call:
lm(formula = y ~ x1, data = Panel)
Residuals:
Min 1Q Median 3Q Max
-9.546e+09 -1.578e+09 1.554e+08 1.422e+09 7.183e+09
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.524e+09 6.211e+08 2.454 0.0167 *
x1 4.950e+08 7.789e+08 0.636 0.5272
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.028e+09 on 68 degrees of freedom
Multiple R-squared: 0.005905, Adjusted R-squared: -0.008714
F-statistic: 0.4039 on 1 and 68 DF, p-value: 0.5272
library(foreign)
Panel <-read.dta("http://dss.princeton.edu/training/Panel101.dta")
fixed.dum <-lm(y ~ x1 + factor(country) -1, data=Panel)
summary(fixed.dum)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Call:
lm(formula = y ~ x1 + factor(country) - 1, data = Panel)
Residuals:
Min 1Q Median 3Q Max
-8.634e+09 -9.697e+08 5.405e+08 1.386e+09 5.612e+09
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 2.476e+09 1.107e+09 2.237 0.02889 *
factor(country)A 8.805e+08 9.618e+08 0.916 0.36347
factor(country)B -1.058e+09 1.051e+09 -1.006 0.31811
factor(country)C -1.723e+09 1.632e+09 -1.056 0.29508
factor(country)D 3.163e+09 9.095e+08 3.478 0.00093 ***
factor(country)E -6.026e+08 1.064e+09 -0.566 0.57329
factor(country)F 2.011e+09 1.123e+09 1.791 0.07821 .
factor(country)G -9.847e+08 1.493e+09 -0.660 0.51190
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.796e+09 on 62 degrees of freedom
Multiple R-squared: 0.4402, Adjusted R-squared: 0.368
F-statistic: 6.095 on 8 and 62 DF, p-value: 8.892e-06
yhat<-fixed.dum$fitted
library(car)
scatterplot(yhat~Panel$x1|Panel$country, boxplots=FALSE, xlab="x1",
ylab="yhat",smooth=FALSE)
abline(lm(Panel$y~Panel$x1),lwd=3, col="red")
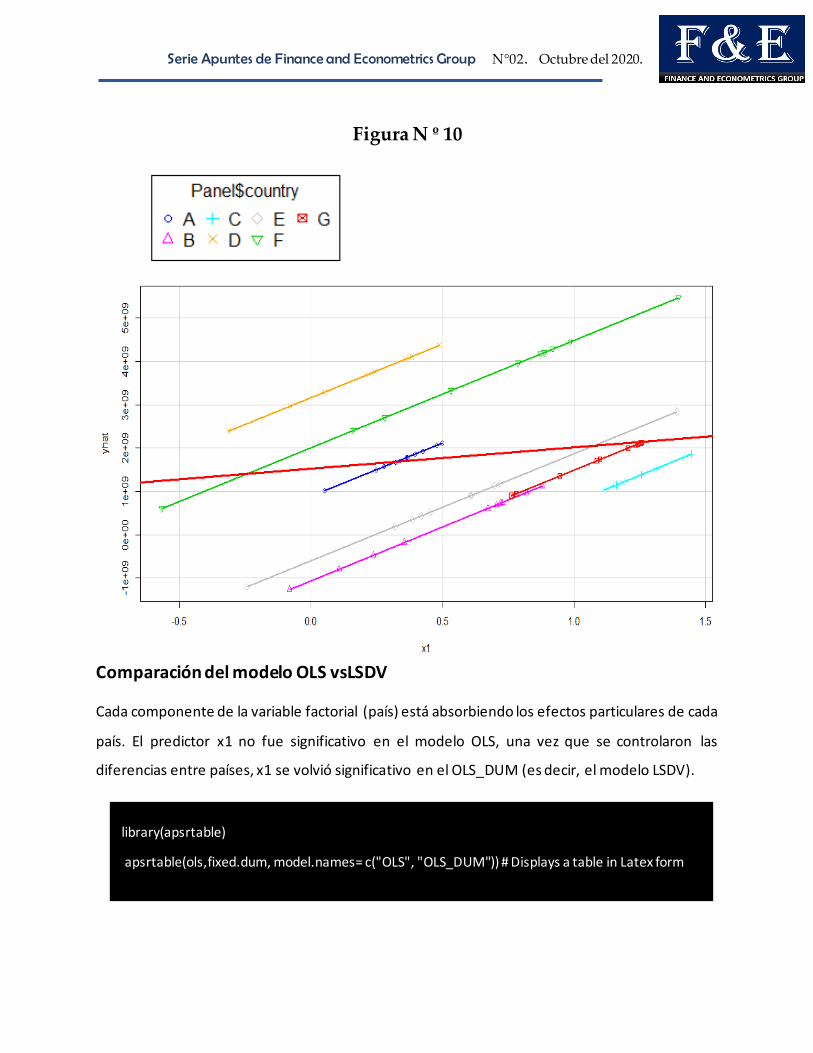
Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 10
Comparación del modelo OLS vsLSDV
Cada componente de la variable factorial (país) está absorbiendo los efectos particulares de cada
país. El predictor x1 no fue significativo en el modelo OLS, una vez que se controlaron las
diferencias entre países, x1 se volvió significativo en el OLS_DUM (es decir, el modelo LSDV).
library(apsrtable)
apsrtable(ols,fixed.dum, model.names= c("OLS", "OLS_DUM")) # Displays a table in Latex form

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 11
Efectos fijos: intersecciones específicas de la entidad (usando plm)
\begin{table}[!ht]
\caption{}
\label{}
\begin{tabular}{ l D{.}{.}{2}D{.}{.}{2} }
\hline
& \multicolumn{ 1 }{ c }{ OLS } & \multicolumn{ 1 }{ c }{ OLS_DUM } \\ \hline
% & OLS & OLS_DUM \\
(Intercept) & 1524319070.05 ^* & \\
& (621072623.86) & \\
x1 & 494988913.90 & 2475617827.10 ^*\\
& (778861260.95) & (1106675593.60) \\
factor(country)A & & 880542403.99 \\
& & (961807052.24) \\
factor(country)B & & -1057858363.16 \\
& & (1051067684.19) \\
factor(country)C & & -1722810754.55 \\
& & (1631513751.40) \\
factor(country)D & & 3162826897.32 ^*\\
& & (909459149.66) \\
factor(country)E & & -602622000.33 \\
& & (1064291684.41) \\
factor(country)F & & 2010731793.24 \\
& & (1122809097.35) \\
factor(country)G & & -984717493.45 \\
& & (1492723118.24) \\
$N$ & 70 & 70 \\
$R^2$ & 0.01 & 0.44 \\
adj. $R^2$ & -0.01 & 0.37 \\
Resid. sd & 3028276248.26 & 2795552570.60 \\ \hline
\multicolumn{3}{l}{\footnotesize{Standard errors in parentheses}}\\
\multicolumn{3}{l}{\footnotesize{$^*$ indicates significance at $p< 0.05 $}}
\end{tabular}
\end{table}
El coeficiente de x1
indica cuánto
cambia Y cuando X
aumenta en una
unidad. Observe
que x1 no es
significativo en el
modelo OLS
El coeficiente de x1
indica cuánto cambia Y
con el tiempo,
controlando por las
diferencias entre
países, cuando X
aumenta en una
unidad. Observe que x1
es significativo en el
modelo LSDV
library(plm)
fixed <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
summary(fixed)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 12

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
MODELO DE EFECTOS ALEATORIOS (Intercepción aleatoria, modelo de
agrupación parcial)
Oneway (individual) effect Random Effect Model
(Swamy-Arora's transformation)
Call:
plm(formula = y ~ x1, data = Panel.set, model = "random")
Balanced Panel: n = 7, T = 10, N = 70
Effects:
var std.dev share
idiosyncratic 7.815e+18 2.796e+09 0.873
individual 1.133e+18 1.065e+09 0.127
theta: 0.3611
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-8.94e+09 -1.51e+09 2.82e+08 0.00e+00 1.56e+09 6.63e+09
Coefficients:
Estimate Std. Error z-value Pr(>|z|)
(Intercept) 1037014284 790626206 1.3116 0.1896
x1 1247001782 902145601 1.3823 0.1669
Total Sum of Squares: 5.6595e+20
Residual Sum of Squares: 5.5048e+20
R-Squared: 0.02733
Adj. R-Squared: 0.013026
Chisq: 1.91065 on 1 DF, p-value: 0.16689

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Efectos Fijos versus efectos Aleatorios
Para decidir entre efectos fijos o aleatorios, se puede ejecutar el test de Hausman donde la
hipótesis nula es que el modelo preferido son los efectos aleatorios frente a la alternativa los
efectos fijos (ver Green, 2008, capítulo 9). Básicamente, prueba si los errores únicos ( )iu están
correlacionados con los regresores, la hipótesis nula es que no.
Se ejecuta un modelo de efectos fijos y se guardan las estimaciones, luego se ejecutan un modelo
de efectos aleatorios y se guardan las estimaciones, finalmente se realiza la prueba. Si el valor p
es significativo (por ejemplo, <0,05), utilice el modelo de efectos fijos, si no, utilice el modelo
efectos aleatorios.
Figura N º 13
Otras pruebas / diagnósticos
Prueba de efectos fijos en el tiempo
> phtest(fixed, random)
Hausman Test
data: y ~ x1
chisq = 3.674, df = 1, p-value = 0.05527
alternative hypothesis: one model is inconsistent
Si este número es <0,05, utilice el modelo de efectos fijos
library(plm)
fixed <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
fixed.time<-plm(y ~ x1 + factor(year), data=Panel, index=c("country", "year"), model="within")
summary(fixed.time)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 14
Oneway (individual) effect Within Model
Call:
plm(formula = y ~ x1 + factor(year), data = Panel, model = "within",
index = c("country", "year"))
Balanced Panel: n = 7, T = 10, N = 70
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-7.92e+09 -1.05e+09 -1.40e+08 0.00e+00 1.63e+09 5.49e+09
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
x1 1389050354 1319849567 1.0524 0.29738
factor(year)1991 296381559 1503368528 0.1971 0.84447
factor(year)1992 145369666 1547226548 0.0940 0.92550
factor(year)1993 2874386795 1503862554 1.9113 0.06138 .
factor(year)1994 2848156288 1661498927 1.7142 0.09233 .
factor(year)1995 973941306 1567245748 0.6214 0.53698
factor(year)1996 1672812557 1631539254 1.0253 0.30988
factor(year)1997 2991770063 1627062032 1.8388 0.07156 .
factor(year)1998 367463593 1587924445 0.2314 0.81789
factor(year)1999 1258751933 1512397632 0.8323 0.40898
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 5.2364e+20
Residual Sum of Squares: 4.0201e+20
R-Squared: 0.23229
Adj. R-Squared: 0.00052851
F-statistic: 1.60365 on 10 and 53 DF, p-value: 0.13113
pFtest(fixed.time, fixed)
plmtest(fixed, c("time"), type=("bp"))

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 15
Prueba de efectos aleatorios: multiplicador de Breusch-
Pagan Lagrange (LM)
pFtest(fixed.time, fixed)
F test for individual effects
data: y ~ x1 + factor(year)
F = 1.209, df1 = 9, df2 = 53, p-value = 0.3094
alternative hypothesis: significant effects
> plmtest(fixed, c("time"), type=("bp"))
Lagrange Multiplier Test - time effects (Breusch-Pagan) for
balanced panels
data: y ~ x1
chisq = 0.16532, df = 1, p-value = 0.6843
alternative hypothesis: significant effects
Si este número es
<0,05, utilice efectos
de tiempo fijo. En
este ejemplo, no es
necesario utilizar
efectos de tiempo
fijo.
# Regular OLS (pooling model) using plm
pool <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="pooling")
summary(pool)

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 16
La prueba LM le ayuda a decidir entre una regresión de efectos aleatorios y una regresión OLS
simple.
La hipótesis nula en la prueba LM es que las varianzas entre entidades es cero. Es decir, no hay
diferencias significativas entre las unidades (es decir, sin efecto de panel).
Pooling Model
Call:
plm(formula = y ~ x1, data = Panel, model = "pooling",
index = c("country", "year"))
Balanced Panel: n = 7, T = 10, N = 70
Residuals:
Min. 1st Qu. Median Mean 3rd Qu. Max.
-9.55e+09 -1.58e+09 1.55e+08 0.00e+00 1.42e+09 7.18e+09
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 1524319070 621072624 2.4543 0.01668 *
x1 494988914 778861261 0.6355 0.52722
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 6.2729e+20
Residual Sum of Squares: 6.2359e+20
R-Squared: 0.0059046
Adj. R-Squared: -0.0087145
F-statistic: 0.403897 on 1 and 68 DF, p-value: 0.52722
# Breusch-Pagan Lagrange Multiplier for random effects.
# Null is no panel effect (i.e. OLS better).
plmtest(pool, type=c("bp"))

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 17
Prueba de dependencia transversal / correlación contemporánea:
utilizando la prueba de independencia Breusch-Pagan LM y la prueba CD
de Pasaran
Según Baltagi, la dependencia transversal es un problema en paneles macro con series de
tiempo largas. Esto no es un gran problema en los micropaneles (pocos años y gran
número de casos).
La hipótesis nula en las pruebas de independencia B-P / LM y Pasaran CD es que los
residuos entre entidades no están correlacionados. Las pruebas B-P / LM y Pasaran CD
(dependencia transversal) se utilizan para probar si los residuos están correlacionados
entre entidades *. La dependencia transversal puede conducir a sesgos en los resultados
de las pruebas (también llamada correlación contemporánea).
Lagrange Multiplier Test - (Breusch-Pagan) for balanced
panels
data: y ~ x1
chisq = 2.6692, df = 1, p-value = 0.1023
alternative hypothesis: significant effects
Aquí no podemos rechazar la hipótesis nula y concluir que los efectos aleatorios no son
apropiados. Esto es, no hay evidencia de diferencias significativas entre países, por lo tanto,
puede ejecutar una regresión OLS simple.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Prueba de correlación serial
Las pruebas de correlación en serie se aplican a paneles macro con series de tiempo largas.
No hay problema en micropaneles (con muy pocos años). La hipótesis nula es que no
hay correlación serial.
pcdtest(fixed, test = c("lm"))
Breusch-Pagan LM test for cross-sectional dependence in
panels
data: y ~ x1
chisq = 28.914, df = 21, p-value = 0.1161
alternative hypothesis: cross-sectional dependence
pcdtest(fixed, test = c("cd"))
Pesaran CD test for cross-sectional dependence in panels
data: y ~ x1
z = 1.1554, p-value = 0.2479
alternative hypothesis: cross-sectional dependence
fixed <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
pcdtest(fixed, test = c("lm"))
pcdtest(fixed, test = c("cd"))
Sin dependencia transversal

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Prueba de raíces unitarias / estacionariedad
La prueba de Dickey-Fuller para verificar las tendencias estocásticas. La hipótesis nula es
que la serie tiene una raíz unitaria (es decir, no estacionaria). Si la raíz unitaria está
presente, puede tomar la primera diferencia de la variable.
Breusch-Godfrey/Wooldridge test for serial correlation in
panel models
data: y ~ x1
chisq = 14.137, df = 10, p-value = 0.1668
alternative hypothesis: serial correlation in idiosyncratic errors
Augmented Dickey-Fuller Test
data: Panel.set$y
Dickey-Fuller = -3.9051, Lag order = 2, p-value = 0.0191
alternative hypothesis: stationary
pbgtest(fixed)
No existe Correlación Serial
Si el valor p <0.05, entonces no hay raíces unitarias
presentes.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Prueba de heterocedasticidad
La hipótesis nula para la prueba de Breusch-Pagan es la homocedasticidad.
Si se detecta hetersokedaticity, puede utilizar una matriz de covarianza robusta para dar
cuenta de ello. Consulte las páginas siguientes.
Control de heterocedasticidad: estimación de matriz de
covarianza robusta (estimador de sándwich)
La función --vcovHC – estima tres estimadores de covarianza consistentes con
heterocedasticidad:
• "white 1": para heterocedasticidad general, pero sin correlación serial.
Recomendado para efectos aleatorios.
• "white2" -es "white1" restringido a una variación común dentro de los grupos.
Recomendado para efectos aleatorios.
• "arellano" -tanto heterocedasticidad como correlación serial. Recomendado para
efectos fijos Se aplican las siguientes opciones *:
✓ HC0 -heteroscedasticidad consistente. El valor por defecto.
✓ HC1, HC2, HC3: recomendado para muestras pequeñas. HC3 da menos peso a las
observaciones influyentes.
✓ HC4: muestras pequeñas con observaciones influyentes
Breusch-Pagan test
data: y ~ x1 + factor(country)
BP = 14.606, df = 7, p-value = 0.04139
Presencia de
heterocedasticidad

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
✓ HAC -heteroscedasticidad y autocorrelación consistente (escriba? VcovHAC para
más detalles) Consulte las páginas siguientes para ver ejemplos
For more details see:
http://cran.r-project.org/web/packages/plm/vignettes/plm.pdf
http://cran.r-project.org/web/packages/sandwich/vignettes/sandwich.pdf (see page 4)
Stock and Watson 2006. *Kleiberand Zeileis, 2008.
Controlando la heterocedasticidad: efectos aleatorios
random <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="random")
coeftest(random) # Original coefficients
coeftest(random, vcovHC) # Heteroskedasticityconsistent coefficients
coeftest(random, vcovHC(random, type = "HC3")) # Heteroskedasticityconsistent coefficients,
type 3
# The following shows the HC standard errors of the coefficients
t(sapply(c("HC0", "HC1", "HC2", "HC3", "HC4"), function(x) sqrt(diag(vcovHC(random, type = x)))))

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 19
random <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="random")
coeftest(random) # Original coefficients
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1037014284 790626206 1.3116 0.1941
x1 1247001782 902145601 1.3823 0.1714
coeftest(random, vcovHC) # Heteroskedasticityconsistent coefficients
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1037014284 907983029 1.1421 0.2574
x1 1247001782 828970247 1.5043 0.1371
coeftest(random, vcovHC(random, type = "HC3")) # Heteroskedasticityconsistent coefficients, type 3
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1037014284 943438284 1.0992 0.2756
x1 1247001782 867137585 1.4381 0.1550
# The following shows the HC standard errors of the coefficients
t(sapply(c("HC0", "HC1", "HC2", "HC3", "HC4"), function(x) sqrt(diag(vcovHC(random, type = x)))))
(Intercept) x1
HC0 907983029 828970247
HC1 921238957 841072643
HC2 925403820 847733474
HC3 943438284 867137584
HC4 941376033 866024033
Errores estándar dan diferentes tipos de HC.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Controlar la heterocedasticidad: Efectos Fijos
fixed <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
coeftest(fixed) # Original coefficients
coeftest(fixed, vcovHC) # Heteroskedasticityconsistent coefficients
coeftest(fixed, vcovHC(fixed, method = "arellano")) # Heteroskedasticityconsistent coefficients (Arellano)
coeftest(fixed, vcovHC(fixed, type = "HC3")) # Heteroskedasticityconsistent coefficients, type 3
# The following shows the HC standard errors of the coefficients
t(sapply(c("HC0", "HC1", "HC2", "HC3", "HC4"), function(x) sqrt(diag(vcovHC(fixed, type = x)))))

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Figura N º 20
fixed <-plm(y ~ x1, data=Panel, index=c("country", "year"), model="within")
coeftest(fixed) # Original coefficients
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 2475617827 1106675594 2.237 0.02889 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
coeftest(fixed, vcovHC) # Heteroskedasticityconsistent coefficients
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 2475617827 1358388942 1.8225 0.07321 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
coeftest(fixed, vcovHC(fixed, method = "arellano")) # Heteroskedasticityconsistent coefficients (Arellano)
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 2475617827 1358388942 1.8225 0.07321 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
coeftest(fixed, vcovHC(fixed, type = "HC3")) # Heteroskedasticityconsistent coefficients, type 3
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 2475617827 1439083523 1.7203 0.09037 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
# The following shows the HC standard errors of the coefficients
t(sapply(c("HC0", "HC1", "HC2", "HC3", "HC4"), function(x) sqrt(diag(vcovHC(fixed, type = x)))))
HC0.x1 HC1.x1 HC2.x1 HC3.x1 HC4.x1
[1,] 1358388942 1368196931 1397037369 1439083523 1522166034
Errores estándar nos dan diferentes tipos de HC.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Referencias / Enlaces útiles
✓ DSS Online Training Section http://dss.princeton.edu/training/
✓ Princeton DSS Libguideshttp://libguides.princeton.edu/dss
✓ John Fox’s site http://socserv.mcmaster.ca/jfox/
✓ Quick-R http://www.statmethods.net/
✓ UCLA Resources to learn and use R http://www.ats.ucla.edu/stat/R/
✓ UCLA Resources to learn and use Stata http://www.ats.ucla.edu/stat/stata/
✓ DSS -Stata http://dss/online_help/stats_packages/stata/
✓ DSS -R http://dss.princeton.edu/online_help/stats_packages/r
✓ Panel Data Econometrics in R: theplmpackagehttp://cran.r-
project.org/web/packages/plm/vignettes/plm.pdf
✓ Econometric Computing with HC and HAC Covariance Matrix Estimators
✓ http://cran.r-project.org/web/packages/sandwich/vignettes/sandwich.pdf
4. Bibliografía
Colin Cameron , A., & Trivedi, P. (2005). Microeconometrics: Methods and
Applications. (C. U. Press, Ed.) New York.
Orihuela, A. (2011). Stata Avanzado Aplicado a la Investigación Económica. Grupo
Iddea, Lima.
Paradis, E. (2010). R para principiantes. Universit Montpellier II. París: Institut des
Sciences de l’E´volution.
Rivera Loredo, C. (2018). Elementos de Cálculo Actuarial con R. Centro
Universitario UAEM, Valle de México, Atizapán de Zaragoza.

Serie Apuntes de Finance and Econometrics Group N°02. Octubre del 2020.
Beltrán Barco, A. (2003). Econometría de series de tiempo. Lima: . Universidad del
Pacífico. Obtenido de
https://econometriaii.files.wordpress.com/2010/01/beltran.pdf
Beltran Barco, Arlette; Castro Carlin, Juan;. (2010). Modelos de datos de panel y
variables dependientes limitadas: teoría y práctica. (U. d. Pacífico, Ed.)
Bravo, D., & Vásquez, J. (2008). Microeconometria Aplicada. Notas de Clase,
Centro Micro Datos., Santiago. Obtenido de
http://www.academia.edu/9494003/MICROECONOMETR%C3%8DA_CON_
STATA
de Arce, R., & Mahía, R. (2007). Técnicas de Previsión de variables
financieras:Modelos Arima. (M. d. Citius, Ed.)
González, A., & González, S. (2000). Introdución al R. Notas sobre R: Un entorno de
programación para Análisis de Datos y Gráficos. cran.r-project.org.
Greene, W. (1997). Análisis Econometrico (Tercera ed.). Prentice Hall.
Greene, William. (1999). Análisis Econométrico. (S. &. Schuster, Trad.) Madrid:
Prentice Hall Iberia.
INFOPUC. (2011). Stata para Economistas. Pontificia Universidad Católica .
Rodríguez, F. P. (2016). Curso de Estadística con R. DOC. Nº 2/2016, Instituto
Canabro de Estadística, Servicio de Estadísticas Económicas y
Sociodemográficas.
Software Shop. (2013). Introducion al Stata 12: Ejercicios aplicados a la Economía
y Econometría Financiera.