regresi6n multiple - biblio3.url.edu.gtbiblio3.url.edu.gt/libros/2012/esta-ae/13.pdfesta capitulo...
TRANSCRIPT

Regresi6n multiple
Esquema del capitulo
13.1. EJ modele de regresion multiple Especificaci6n del modele Desarrollo del modele Graficos tridimensionales
13.2. Estimaci6n de coeficienles Metoda de minimos cuadrados
13.3. Poder explicativo de una ecuaci6n de regresi6n multiple 13.4. Intervalos de confianza y conlrastes de hip6tesis de coeficientes de regresion
individuales Intervalos de confianza Contrastes de hip6tesis
1 3.5. Contrastes de los coeficientes de regresi6n Contrastes de lodos los coeficientes Contraste de un conjunto de coeficientes de regresi6n Comparaci6n de los contrastes F y t
13.6. Predicci6n 13.7. Transformaciones de modelos de regresion no lineales
Transformaciones de modelos cuadralicos Transformaciones logaritmicas
13.8. Utilizaci6n de variables fict icias en modelos de regresi6n Diferencias entre las pendientes
13.9. Metodo de aplicaci6n del analisis de regresi6n multiple Especificaci6n del modelo Regresi6n multiple Efecto de la eliminaci6n de una variable estadfsticamente significativa Analisis de los residuos
Introducci6n En el Capitulo 12 presentamos el metodo de regresi6n simple para obtener una ecuaci6n lineal que predice una variable dependiente 0 end6gena en funci6n de una unica variable independiente 0 ex6gena; por ejemplo, el numero total de art fculos vendidos en funci6n del precio. Sin embargo. en muchas situaciones, varias variables independientes influyen conjuntamente en una variable dependiente. La regresi6n multiple nos permite averiguar el efecto simultaneo de varias variables independientes en una variable dependiente utilizando el principio de los minimos cuadrados.

488 Estadfstica para administraci6n y economfa
Existen muchas aplicaciones importantes de la regresion multiple en al mundo de la emprasa y an la eeonomia. Entre estas aplicaciones se encuentran las siguientes:
1. La cantidad vendida de bianes es una funcion del precio, la renta, la publicidad, el precio de los bienes sustitutivos y otras variables.
2. Existe inversion de capital cuando un empresario cree que puede obtaner un beneficia. Par 10 tanto, la inversion de capital es una tuncion de variables relacionadas can las posibilidades de obtener beneficios, entre las que se encuenlran el tipo de interes, el producto interior bruto, las expectativas de los consumidores, la renta disponible y el nivel tecnol6gica.
3. EI salano es una funcion de la experiencia, la educacion, la edad y el puesto de trabaja.
4. Las grandes empresas del comercio al par menor y Ja hostelerfa deciden Ja localizacion de los nuevas establecimientos basandose en los ingresos previstos por ventas y/o en la rentabilidad. Utilizanda datos de localizaciones anteriores que han tenido exito y que no 10 han tenido, los analistas pueden construir modelos que predicen las vantas a los beneficios de una nueva 10calizaci6n posible.
EI analisis eeonomico y empresarial liene algunas caracterfsticas unicas en comparaci6n can el analisis de olras disciplinas. Los cientificos naturales trabajan en un laboratorio en el que es posible controlar muchas variables, pero no todas. En cambia, eJ laboratorio del economista y del directiva as el mundo y las cond iciones no pueden controlarse. Por 10 tanto, necesitan instrumentos como la regresion multiple para eslimar el afeelo simultaneo de varias variables. La regresion mUltiple como «instrumenta de labarataria» as muy importante para el trabajo de los directivos y de los economistas. En esta capitulo veremos muchas aplicaciones especificas en los ejemplos y los ejercicios.
Los metodos para ajustar modelos de regresion multiple se basan en el mismo principia de los minimos cuadrados que aprendimos en el Capitu lo 12 y, par 10 tanto, las ideas presentadas en ese cap itulo se axtenderan directamente a la regresi6n multiple. Sin embargo, se intraducen algunas complejidades debido a las relaeiones entre las distintas variables ex6genas. Estas requieren nuevas ideas que se desarrollan en este capitulo.
13.1. EI modelo de regresion multi Ie Nuestro objetivo es aprender a utilizar la regresi6n multiple para crear y analizar model os. Por 10 lanto, aprendemos como funciona la regresi6n multiple y algunas directrices para inlerpretaria. Comprendiendo perfectamente la regresi6n multip le, es posible reso lver una umplia variedad de problemas aplicac1os. Este estudio de los metodos de regresi6n m(lItiple es paralelo al de la rcgresi6n simple. El primer paso para desarrol1ar un modele es la cspeeifieaci6n de ese modelo, que consistc en la selecei6n de las variables del modelo y de 13 forma del modelo. A conlinuaci6n, se estudia el metoda de millimos euadrados y se allali ~
za la variabilidad para identificar los efeetos de cada una de las variables de predicci6n . Despues se eswdia 13 estimacion, los inLervalos de confianza y cl contraste de hi potesis. Se uti l izan frecuentemenle aplicae iones informalicas para indicar como se apl ica la leOrla a problemas real istas. EI estud io de este capItulo sera mas facil si se ponen ell relaci6n sus ideas COil las que presenlamos en el CapItulo 12.
Especificacion del modelo Comenzamos con una ap licac i6n que ill/stm la importante tarea de la espec ificaci6n del modele de regresi6n. La especi fi caci6n del modelo cons iste en la selecc i6n de las variables ex6gcnas y la forma funcional del mode 10.

Capitulo 13. Regresi6n multiple 489
EJEMPLO 13.1. Proceso de produccion (especificacion del modelo de regresion)
EI director de produccion de CircuilOs Flexibles. S.A., Ie ha pedido aYllda para estlldiar un proceso de produccion. Los circlli tos flexibles se producen con un rollo continuo de resina flexible que lleva adherida a su superficie una Fina peifcll la de materia l conductor hecho de cobrc. El cobre se adhiere a la resina pasando la res ina por una solucion de cobre. EI grosor del cobre es fu ndamenta l para que los circuilos sean de buena calidad. Depende en parte de In temperatura de la soluci6n de cobre, de la velocidad de la [fnea de produccion, de la densi.dad de la soluc i6n Y del grosor de la resina flexib le. Para controlar el grosor del cebre adheride a la superficie, el director de producci6n necesi ta saber que efecto produce cada una de estas variables. Le ha pedido ayuda para desarrollar un modele de regresion mu ltiple.
Solucion
La regres ion multiple puede uti lizarsc para hacer cstimaciones de l efecto que produce cada variable en combinacion con las demas. El desan·ollo del modelo comienza con un ana l isis detenido del contexto del problema. El primer paso en este ejemplo serfa una extensa conversacion con los ingenieros responsab les del disefio del producto Y de la produccion, con el fin de comprender detalladamente el proceso de l que se pretende desarrollar un modelo. En algunos casos, se estudiarfa la literatura existente sabre el proceso. Este debe ser comprendido y aceptado per todos los interesados antes de poder desarrellar Ull modelo util ut ilizando el anal is is de regresion mUltiple. En eSle ejemplo, la variable dependiente, Y, es el greso!" del cobrc. Las valiables independientes son la temperatura de 1a solucion de cobre. XI: la velocidad de la lfnea de produccion, X2; la dcnsidad de la solucion, XJ• y el grosor de la res ina flexible, X4 . Los ingenieros y los cientfficos que comprendfan la tecnologfa de l proceso de recubrimiento identificaron estas variables como posibles predictores del grosor del cobre, Y. Basandose en el estudio del proceso, la especificacion del modele resu ltante es
y ~ flo + {!,X, + {!2X, + P3X, + fi,X,
En el modelo lineal anterior, las Ii; son coeficienles lineales conSlanles de las Xj que indican el efecto condicionado de cada variable independienle en la determinacion de la variable dependieme, Y, en la poblacion. Por 10 tanIo, las P; son parametros en el modelo de regres i6n Itneal. A continuacion, se producirfa una serie de lotes para haccr mediciones de distintas combi naciones de las variables independientes y la variable dependicnte (vcasc el anaJisis del diseno experimental en el apartado 14.2).
EJEMPLO 13.2. Localizac ion de las l iendas (especificacion del modelo)
El director de plani ficaci6n de una gran cadena dt{ comercio al por menor estaba insatisfecho con su experiencia en la apel1ura de nuevas tiendas. En los cuatro ult imos afios, el 25 por ciento de las nuevas tiendas no habfa conseguido las ventas previstas en e1 periodo de pmeba de dos afios y se habfa ccrrado con cuantiosas perdidas econ6mkas. El director querfa desarro llar mejores crilerios para elegir el empiazamiento de las tiendas y llego a la conclusion de que debfa estudiarse la experiencia hi st6rica de las tiendas que habfan tenido exi to y las que habfan fracasado.

490 Esladfslica para adminislraci6n y economia
Solucion
Hablando con un consultor, lIeg6 a la conclusi6n de que podian uti li zarse los datos de las tiendas que habfan conseguido las venlas que estaball previstas y los datos de las que no las habfan conseguido para desarrollar un modelo de regresion multiple. El con~
suItor sugirio que debra lltil izarse como variable dependiente, y, las ventas del segundo ailo. Se emplearfa un modele de regresion para predecir las venlas del segundo ailo en funcion de varias variables illdependienles que dcfinen la zona que rodea a la tiencla . Solo se abrirfan tiendas en los lugares en los que las ventas predichas superaran un ni~ vel minima. EI modelo tambien indicarfa como afec tan varias variables independientes a las ventas.
Tras hablar largo y tendido con personas de la empresa, el consultor recomend6 las siguienles variables independ icntcs:
1. Xl = lamano de la tienda 2. X2 = vol umen de trMico de la calle en la que se encuentra la tienda 3. X] = aperlura de la tienda sola a en un centro comercial 4. X4 = exislencia de una tienda rival a menos de 500 metros 5. X 5 = renLa per capita de la poblaci6n residente a menos de 8 kilometros 6. X6 = mitnero total de personas que residen a menos de 8 kjlometros 7. X7 = renta per capita de la poblacion que res ide a menos de 15 kilometros 8. Xl'. = ntimero total de personas que res iden a menos de 15 ki lometros
Se uti lizQ la regresi6n multiple para esli mar los coeficienles del modelo de predi c~ cion de las ventas a partir de datos recog idos en lodas las liendas abiertas en los ocho 6ltimos anos. En el conjunto de datos habra tiendas que segufan abiertas y tiendas que se habfan cerrado. Se desarro1l6 un modele que podfa utilizarse para predecir las ventas del segundo ano. Este modele contenfa estimadores, b), de los para metros del modelo, p). Para ap licar el modelo
g
Yi = bo + L bj xji j = l
se hicieron mediciones de las variables independienles de cada nueva localizaci6n pro~ pLlesta y se calcu laron las ventas predichas de cada local izacion. Se uti liz6 cJ nivel pre~
dicho de ven tas , junto con eJ cri terio de los anal istas de marketing y de un comite de directores de tiendas de ex iLo, para elegir el lugar en el que se abrirfan [iendas.
En la estralegia para especificar un modelo influyen los objetivos de l modelo. Uno de los objetivos cs la prediccion de una variable dependiente 0 «de resultado» . Entre las apli ~
caciones se encuentran la prediccion de las ventas, de la producci6n, del consumo total, de la invers ion total y otros muchos criterios de los resultados empresariales y economicos. EI segundo objetivo es estimar el efecto marginal de cada variable independiente. Los econo~ mi stas y los di recti vos necesilan saber como cambian las medidas de los resultados cuando varian las variables independicntes, Xj' donde j = I, .. . , K. Por ejemplo:
L l,Como varfan las ventas como consecllencia de una subida del precio y de los gastos pllblicitarios?
2. i..Como varia la producci6n cuando se alteran las cantidades de trabajo y de capi tal? 3. i.. Disminuye la mortalidad infantil cuando se illcremenlan los gastos en asistencia
sanitaria y en servicios de saneamiento?

Capitulo 13. Regresi6n multiple 491
Objetivos de la regresi6n
La regresi6n multiple permite obtener dos importantes resultados:
1. Una ecuaci6n lineal estimada que predice la variable dependiente, Y, en funci6n de K variables independientes observadas, xi' donde j = 1, ...• K.
donde i = 1, "" n observaciones. 2. La variaci6n marginal de la variable dependiente, Y, provocada por las variacionas de
las variables independienles, que se eslima por medio de los coeficientes, bj. En la regresi6n multiple, estos coeficientes dependen de que otras variables se incluyan en al modelo. EI coeficiente b
j indica la variaci6n de Y, dada una variaci6n unitaria de X;, des
contando al mismo tiempo el efecto simultaneo de las demas variables independlentes.
En algunos problemas, ambos resultados son igual de importantes. Sin embargo, normalmente predomina uno de ellos (por ejemplo, la predicci6n de las ventas de las tiendas, y, en el ejemplo de la localizaci6n de las liendas).
La variaci6n margina l es mas diffei l de estimar porque las variables independientes csHi.n relac ionadas no s610 con las variables dependienles sino lam bien entre Sl. Si dos variubles independientes 0 mas varian en una re lac i6n lineal directa entre sf, es dificil averiguar cI efecto que produce cada variable independienle en la variable dependiente.
Examinaremos delalladamente el modelo del ejemplo 13.2. EI coeficiente de XI ---es decir, b J- indica la variaci6n que experimentan las ventas del segundo ana por cada variaci6n unitaria del tamano de la tienda. EI coeficiente de Xj indica la variaci6n que experi mentan las ventas por cada variaci6n unitaria de la rcnta per capita de la poblaci6n que reside a menos de 8 ki l6metros, miell(ras que la de X7 indica la variaci6n de las ventas por cada variaci6n de la renla per capita de la poblaci6n que res ide a menos de 15 ki l6metros. Es probable, pOI' supuesto, que las variables Xs Y X7 esten correlacionadas. Par 10 tanto, en la medida en que estas variables varfen am bas al mismo tiempo, es diffcil averiguar la contribucion de cada una de elias a la variacion de los ingresos generados por las ventas de las tiendas. Esta correlaci6n entre variables independientes complica el modelo. Es importanle comprendcr que el modelo predice los ingresos generados por las ventas de las tiendas ulilizando la combinaci6n de variables que contielle el modelo. El efecto de una variable de prediccion es e l efecto que produce esa variab le cuando se combina con las demas. POI' 10 tanto, en general, el coeficiente de una vari ab le no indica el efecto que produce esa variable en todas las condiciones. Estas complcj idades se anal izanln mas delen idamenle cuando se dcsarrolle el modelo de rcgresi6n mUltiple.
Desarrollo del modelo
Cuando aplicamos la regresi6n mUltiple, construimos un modelo para explicar la variabilidad de la variable dependiente. Para eso queremos incluir las influencias simultaneas e in* dividuales de varias variables independientes. Supongamos, por ejemplo, que queremos desarrollar un modelo que prediga el margen anua l de beneficios de las sociedades de ahorra y cn!dilO inmobiliari o ulili zando los dalos recog idos durante un periodo de anos. Una especificaci6n inicial del modelo indicaba que el margen anual de beneficios eslaba relac ionado can los ingresos netos pOl' dolar depositado y el nLimero de oncinas. Se espera que el ingreso neta aumente el margen anua! de benefic ios y se preve que el nllmero de ofic in<ls

492 Estadfstica para adminislraci6n y economia
Savings and Loan
red llc ini el margen an ual de benericios dcbido al aumenlO de la competencia. Eso nos lie. varia a especificar lin modele de regrcs i6n poblacional
Y = flo + li,X, + (J,X, + c
donde
Y = margen anual de beneficios XI = ingresos anuales netos por d61ar depos itado X2 = numcro de ofi cinas existentes ese anD
LIl Tabla 13. 1 y cl Fichera de dalos Savings and Loan cont iencJ1 25 observaciones por ano de eS{as variables. Utili zaremos estos datos para desarralJar un modele li neal que prediga el margen anunl de beneficios en funci6n de los ingresos por d61ar deposilado y del numero de ofi cinas (vease la referencia bibliografica 4).
Tabla 13.1. Datos de las asociaciones de ahorro y credito inmobitiario.
Ingresos Nlimero Mllrgen de lngresos Numero Margen de Ano por d611l r de oficinas beneficios Ano por d61a r de olieinas henelicios
I 3,92 7.298 0,75 14 3,78 6.672 0,84 2 3,6 1 6.855 0,7 1 15 3,82 6.890 0,79
3 3,,2 6.636 0,66 16 3,97 7. 115 0,7 4 3,07 6.506 0,6 1 17 4.07 7.327 0,68 5 3,06 6.450 0,7 18 4,25 7.546 0,72
6 3, 11 6.402 0,72 19 4.4 1 7.93 1 0,55
7 3,2 1 6.368 0,77 20 4.49 8.097 0,63 8 3,26 6.340 0,74 21 4,70 8.468 0,56 9 3,42 6.349 0,9 22 4,58 8.7 17 0,41
!O 3,42 6.352 0,82 23 4.69 8,99 1 0.5 1 II 3,45 6.361 0 ,75 24 4.71 9. 179 0,47 12 3.58 6.369 0.77 25 4.78 9.318 0,32
13 3,66 6.546 0,78
Pero antes de poder estimar el modelo, es necesario desarrollar y comprender el me· todo de regres i6n multiple. Para comenzar, examinemos el rnodelo general de regres i6n multiple y observemos sus diferencias CO il el modele de regresi6n simple. EI modelo de regres i6n mUltiple es
donde f'.; es e l tt~ rmi no de error aleatorio que tiene la media 0 y la varianza (J2, Y las /lj son los coefic ientes 0 efectos marginales de las variables independientes 0 cx6genas, Xj .
donde j = I, .. . , K, dados los efeclOs de las demas variables independientcs. Las i indio can las observacioncs, siendo i = I, ... , 1/.. Uti lizamos las minusculas Xji para indicar los va lores especfficos de la variable Xj en la obscrvac i6n i. Suponemos que las 8i son inde· pendientes de Jas Xj y entre sf para que las estimaciones de los coefi c ientes y sus va· rianzas sean correctas. En el Capitulo 14 explicamos que ocurre cuando se abandon an estos su puestos.

Capitulo 13. Regresi6n multiple 493
EI modelo mucstra l estimado es
don de e; es cl residuo 0 diferencia entre el valor observado de Y y el valor estimado de Y obtenido utili zando los coeficientes cstimados, bi' donde j = I, ... , K. EI metodo de regresi6n obl iene estimaciones simultaneas, bi' de los coeficientes del modelo poblac ional , /Jj' utili zando el metodo de minimos cuadrados.
En nuestro ejempJo de las asoc iaciones de ahorro y credi to inmobiliario , el modelo poblacional para los puntos de datos indi viduales es
Este modelo reducido con dos variab les de prediccion solamente brinda la oportunidad de comprender mejor el metodo de regresi6n. La funcion de regres i6n puede representarse gnificBmente en Ires dimensiones, como muesLra la Figura 13. 1. La funci6n de regresi6n se representa mediante un plano en el que los valores de Y son una funci6n de los va lores de la variables independientcs Xl Y X2. Para cada par pos ible, Xl;, X2i, el valor esperado de la variable dependienle, Yi. se encuentra en el plano. La Figura 13.2 ilustra especff"icamentc cl ejemplo de las asociaciones de ahorro y credilo jnmobiliario. Un aumento de Xl provoca un aumento del valor esperado de Y, condicionado al cfeclo de X2• Asimismo, un aumento de X2 provoca una disminucion del valor esperado de Y, condicionada al efeclo de X I.
Para complelar nuestro modelo, anadimos un (ermino de error I:. Este termino de en·or reconoce que no se cumpli ra exaClamenle ninguna relaci6n postu lada y que es probable que haya Olras variables que tambien aFeclen al valor observado de Y. Por 10 tanto, cuando aplicamos ei modelo, observamos el valor esperado de la variable dependiente, Y - representado por el plano en 101 Figura 13.2-, mas un {e rmi no de error alealorio, 1-:, que representa 1a parte de Y no inc\uida en eI valor esperado. Como conseCUCllcia, cI mode lo de datos liene la forma
y
Figura 13.1. EI plano es el valor esperado de Y en funci6n de XI Y X2.
y
.-
x,
Figura 13.2. Comparaci6n del valor obselVado y el esperado de Yen funci6n de dos variables independienles.

494 Estadistica para administraci6n yeconomia
EI modele de reg res ion poblacional multiple EI modelo de regresi6n poblacional multiple define la relaci6n entre una variable dependien!e 0 end6gena, Y, y un conjunto de variables independien!es 0 ex6genas, xi' donde j == 1,
... , K. Se supone que las xji son numeros fijos; Yes una variable aleatoria definida para cada obselVaci6n, i, donde i == 1, .. . , n, y n es el numero de obselVaciones. EI modele se define de la forma siguiente:
(13.1)
donde las Pj son coeficientes constantes y las I: son variables alealorias de 0 y varianza a2.
En el ejemplo de las asociaciones de ahorro y credito inrnobiliario, con dos variables independientes, el modelo de regres i6n poblacional es
Dados valores especfricos de los ingresos netos, Xli' y el numero de oric inas, XZi' el margen de benericios observado, Yi' es la suma de dos partes: el va lor esperado, flo + {JIXli + fJ-zX2i' y el tennino de error aleatorio, f.i . EI termi no de error aleatorio puede concebi rse como In combinaci6n de los efeclos de oLros muchos factores sin iden tificar que afecLan a los margenes de beneric ios. La Figura 13.2 ilustra e l modele; el plano indica el valor esperado de vadas combinaciones de las vari ables independientes y la E; es la desviaci6n entre el plano --el va lor esperado--- y cI valor observado de Y - marcado con un punto grande- de un punto de dato especffico. En general, los val ores observados de Y no se Cneuentran en el plano sino po r encima 0 por debajo de el, debiclo a los lerminos de error positivos 0 negatiVOS, l:i'
La regres i6n simple, presentada en el capftulo anterior, no es mas que un caso especial de la regres i6n multiple con una (mica variable de prediec i6n y, por 10 tanto, el plano se reduce a una Hnea. Asf pues, la teorla y eI anali sis que hemos desarrollaclo para ta regresi6n simple tambien se aplican a la regres i6n multi ple. Si ll embargo, existen algunas interprctaciones mas que desarrollaremos en nuestro eSludio de la regresi6n multiple. Una de eli as se ilustra en el siguiente anali sis de los grafieos trid imensionales.
Gnificos tridimensionales
Tal vez sea mas fUeil eomprender el metodo de regres i6n multiple mediante una imagen grMica simplificada. Observe el rinc6n de la habitacion en la que esta sentado. Las Hneas formadas pOI' las dos paredes y el suelo representan los ejes de dos vari ables independientes, X I Y X2 . La esquina que forman las dos paredes es el eje de la variable dependiente, Y. Para estimar una recta de regresi6n, relln imos conjllntos de punlOs (x l i. X2i e yJ
Representemos ahora estos puntos en su habitac i6n utili zando las esquinas de las paredes y el slle lo como los tres ejcs. Con estos puntos suspendidos en su habi tae i6n, buscamos un plano en el espacio que se aproxi me a todos ell os. Este plano es la fo rma geometrica de la ecuaci6n de mfnimos cuadrados. Con estes PUlltos en el espacio, ahora subimos y bajaIllOS un plano y 10 hacemos girar en dos direcciones: todos estos movimientos los hacemos simultaneamente hasta que tenemos Lin plano que esta «cerea» de lodos los puntos. Recuerdese que en el Capitulo 12 hieimos esto con una Ifnea recta en dos dimens iones para obtener una ecuaci6n

Capitulo 13. Regresion multiple 495
A continuacion, extendemos esa idea a tres dimensioncs para oblener una ecu<1ciun
Este proceso cs, par supuesto, mas complicado que en el caso de In rcgresi6n simple. Perc los problemas reales son complicados y la regres i6n permite analiza!" mcjor In complejidad de estos problemas. Querernos saber c6mo varfa Y cuando varfaX !. Pero sabemos que en estas variaciones influye, a su vez, la forma en que varfaX2. Y si XI Y Xz siempre varfan a la vez, no podernos saber cuanto contribuye cada variable a las variaciones de Y.
"" INTERPRETACION Las interpretaciones geomelricas de la regresion multiple son cada vez mas complejas
a medida que aumenta el numcro de variables independientes. Si n embargo, la analog fa con la regresion simple cs ex traordinari amente uti !. Estimamos los coeficientes minimizando la suma de los cuadrados de las desviaciones de la dimension Yen torno a una fu nc ian lineal de las variables independ ientes. En la regres ion simple, la fu nci6n es una linea recta en un grafi co bid imensional. Con dos variables independientcs, la funcion es un plano en un espacio tridimensional. Cuando consideramos mas de dos variables independientes, (enemos varios hiperplanos complejos que son imposibles de visualizar.
EJERCICIOS
Ejercicios basicos
13.1. Dado el modelo lineal eSli mado
y = 10 + 3xI + 2x2 + 4xJ
a) Calcule.V cuando XI = 20, X2 = II y.\") = 10. b) Calcule Y cliando XI = 15, x 2 = 14 Y x3 = 20. c) Calculc y cuando Xl = 35. x 2 = 19 Y X3 = 25. d) Calc ule y cuando X l = 10, X2 = 17 Y x] = 30.
13.2. Dado el modelo lineal CSlimado
y = 10 + 5Xl + 4x2 + 2x]
a) Calcule.V cuanda XI = 20. X2 = 11 Y x] = 10. b) Ca\Cule y cuando XI = 15, X2 = 14 Y x3 = 20. c) Calcule y cuando XI = 35, X2 = 19 Y X3 = 25. d) Calcule y cuando Xl = 10, x 2 = 17 Y x) = 30.
13.3. Dado el modelo lineal eSl imado
y = 10 + 4-1 + 12x2 + 8X3
a) Calcule y cuundo XI = 20. X2 = 11 Y x3 = 10. b) Ca1cule y cuanda XI = 15, x2 = 24 Y X3 = 20. c) Ca1cule y cuando XI = 20. x 2 = 19 Y x) = 25. d) Calcuie y cuundo XI = 1O'.\"2 = 9 Y X3 = 30.
13.4. Dado el modelo lineal esti mado
y = 10 + lxl + 12t2 + 8x3
a) l,Cuai es la variaci6n de y cuando Xl aumenta en 4?
b) l,Cual es In variaci6n de y cuanda xJ aumenla en I?
c) l,Cuai es la variaeion de y cuando x2 aumenla en 2'1
13.5. Dado el modelo lineal estimado
y= 1O -2x1- 14x2+&3
a) l,Cual es la variacion de y cualldo x] aumenta cn 4?
b) l,Cual es la variacion de y cuanda X3 disminuye cn I?
c) l,Cmil es la variac ion de y cuando X2 disminuye en 2?
Ejercicios aplicados
13.6. Una empresa acromiulica querfa predeeir e\ numcro de horas de trabajo necesario para aeabar el diseno de un nuevo avi6n. Se pensaba que las variables cxplicativas relevantes eran la velocidad m[lxima del avian. Sli peso y el numero de piezas que lenia en comun can olms modelos construidos por 1a cmprcsa. Se tom6 una muestra de 27 aviones de la empresu y se esti mo el Sl
guienle modelo:
Yi = Pu + Pl-\·Ii + fizX2i + {3Y:3j + e,. donde
y,. = esfuerzo de disefio en millones de horas de trabajo
Xli = veloeidad maxima del avi6n, en kil6mctros par hora
X2i = peso del avion, en loneladas

496 Estadistica para administracion y economia
X 3" = numcro porccnlual de piews en camLin con atros modelos
Los coeficientes de regresi6n estimados cran
h j = 0,661 6, ~ 0.065 6, ~ - 0,018
Interprete estas estimacioncs.
13.7. En un estud io de la influencia de [as instiwciones fInancieras en los tipos de interes de los bonos alemanes, se anal izaron datos trimestrales de un periodo de 12 aiios. EI modelo postlilado era
Yi = flo + fllx li + fJ?'x 2, + e,. dondc
Yi = variaci6n de los tipos de inten::-" de los bonos en el trimcstre
Xli = variaci6n de las compras de bonos pOl' parle de las instituciones financieras en el trimestre
X2,. = variacion de las ventas de oonos POI' paJ1C
de las instituciones financieras en cI trimestre
Los eoeficientes de rcgrcs ion parcial estimados eran
b, ~ 0,057 b, ~ -0,065
Interprete estas estimaciones .
13.8. Se aj llst6 el siguiente modelo a una muestra de 30 fam Uias para explicnr el consumo de leche por familia :
Y i = Po + PIX I ; + P2X2i + 8,
dande
Yi = consumo de leche, en li tros a In seman a
13.2. Estimacion de coeficientes
Xl = rentn semana[ en ciemos de d61ures X2 = lamano de la familia
Las cstimaeiones de los panimetros de la regrcsi6n par mlnimos cuadrados eran
bo = ~ 0,025 b l = 0,052
a) Interprete las estimaciones b J Y b2.
b) j,Es posible hacer una interpretaei6n de la estimacion bo que tenga senti do?
13.9. Se ajust6 eI slguienle modelo a una muestra de 2S estudiantes utilizando datos obtenidos a! final de su primer ano de universidad. El objcl ivo era explicar el aumento de peso de los esrudiantes.
Yi = Po + PIXI,. + fliX2; + P:y'<3iC,. donde
y,. = aumento de peso en kilos durante el primer ano
Xli = numero media de comidas a la semana X2i = numero medio de horns de ejercicio a la se
mana X3i = numero medio de cerveZ<lS consumidas a la
semana
Las estimaciones de los para metros de la regresi6n pOl' mlnimos cuadrados eran
bo = 7,35
b2 = ~ 1 ,345
b l = 0,653
b3 = 0,613
a) Interprete las estimaciones hi' b2 Y b3.
b) t,Es posib le haecr una interpretaci6n de la estimnci6n bo que tenga sentido?
Los coeficientes de regres i6n mul tiple se ca lculan utilizando estimadores oblenidos mediante el melodo de mfnimos cuadrados. Este metodo de minimos cuadrados es similar al que presenlamos en el Capitulo 12 para la regresi6n simple. S in embargo, los estimadores son complicados debido a las relaciones entre las vari ables independicntes Xj que ocurren simultaneamente con las re laciones entre las vari ables independ ientes y la variable depend iente. Por ejemplo, si dos variables indepcndientes aumcntan 0 dismin uycn al mismo tiempo -corrcl aci6n pos it iva 0 negativa- mientras que al mismo tiempo la variable dcpendiente aumenta 0 dismin uye, no podemos saber que variab le independienle esta relac ionada rea hn ente con la variaci6n de la variable dependiente. Como consec uenc ia, observamos que los coeficientes de regresi6n estimados son menos fiables si hay estrcchas correlac iones entre dos variables independicntcs 0 mas. Las estimaciones de los cocfic ientes y sus varianzas sicmprc sc obtienen por computador. Si n embargo, ded icaremos bastanles esfuerzos a eSlud iar el algebra y las rormas de calcular la regresi6n pOl' mfnimos cuadrados. Estos esfuerzos permi tin.lll comprender el metoda y averi guar c6mo influyen las d ife rentes pautas de los datos en los resultados. Come nzamos con los supuestos habituales del modelo de regres i6n multi ple.

Capitulo 13. Regresion multiple 497
Supuestos habituales de la regresi6n multiple
El modelo de regresion poblacional multiple es
y; = fio + fi,Xt; + fJ2-''( 2i + ... + fJKXKi + t;
y suponemos que se dispone de n conjuntos de observaciones. Se postulan los siguienles supuestos habituales para el modelo.
1. Las X/I son 0 bien numeros fijos, 0 bien realizaciones de variables aleatorias, XI' que son independientes de los terminos de error, cr En el segundo caso, la inferencia se realiza condicionada a los valores observados de las xj ,
2. EI valor esperado de la variable aleatoria Yes una juncian lineal de las variables independientes ~.
3. Los terminos de error son variables alealorias cuya media es 0 y que tienen la misma varianza, t? Este ultimo supuesto se denomina homocedasticidad a varianza uniforme.
y Ell;lJ = ([2 para (i = t , .. . , /1)
4. Los terminos de error aleatorios, c" no eslim correlacionados entre sf, por 10 que
para todo i = j
5. No es posible hallar un conjunlo de numeros que no sean iguales a cera, co' c1
' ••• , cK' tal que
Esta es la propiedad de la ausencia de relacion lineal entre las Xl
Los cuatro primeros supuestos son esencialmente iguales que los que postulamos en el caso de la regresi6n simple. Sin embargo, el supuesto 5 excluye algunos casos en los que existen relaciones lineales entre las variables de prediccion. Supongamos, pOl' ejemplo, que lenemos interes en expl icar la variab il idad de las tarifas que se cobran par cI envlo de mafz. Una variable expl icativa evidenle serfa la distancia a la que se envfa el maiz. La distancia podrfa medirse en diferentes unidades como millas 0 kil6metros. Pero no tendrfa sentido uti lizar como variables de predicci6n tanto la distancia en millas como la dislancia en kilometros. Estas dos medidas son funciones lineales una de la olra y no satisfarfan el supuesto 5. Ademas, serfa una tonterfa tratar de evaillar sus efectos independientes. Como veremos, las ecuaciones para calcular las eslimaciones de los coeficientes y los program as informaticos no funcionan si no se satisface el supuesto 5. En la mayorla de los casos, la especificaci6n adecuada del modelo evi tara que se viole ese supuesto.
Metodo de mfnimos cuadrados
EI metoda de mfnimos cuadrados para la regresi6n multiple calcula los coeficientes estimados para min i mizar la suma de los clladrados de los residuos. Recuerdese que el residuo es

498 Estadfstica para administraci6n y economia
donde Yi es el valor observado de Ye Yi es el valor de Y predicho a partir de la regres iun. En terminos formales , minimizamos SCE:
" seE ~ L e; ;=1
" ~ L (y; - y;)'
;=1
" = L (y; - (bo + b,x, ; + ... + bKxd)'
i"" I
Esta minimizaci6n eonsiste en hallar el plano que mejor represente un eonjunto de puntas en el espacio, como hemos visto en nuestro analisis de los graficos tridimensionales, Para rea lizar el proeeso formal mente, utili zamos deri vadas pare ia les para desarrollar un eonjunto de eeuacioncs normales simuitaneas que se resuelve para obtener los estimadores de los coeficien tes. Para los que tcngan buenos conocimientos de matematicas, en el apendice de l capitulo presentamos algunos de los detalles del proceso, S in embargo, se pueden extracr importantes concJusioncs dandose cucnta de que queremos enconlrar 1<1 ecuaci6n que mejor re presente los datos observados. Afortunadamente, en las aplicaciones estudiadas en este libra, los complejos calcul os siemprc se rcalizan utili zando un paquete cstadfstico como Minitab, SAS 0 SPSS. Nuestro objetivo es comprender c6mo se interprelan los resu ltados de las regresioncs y utilizarlos para resolver pro blemas. Lo haremos examinando algunos de los resultados algebraicos inlennedios para ayudar a comprender los efectos que producen di stintas paUl as de datos en los estimadores de los cocri cientes.
Estimaci6n por minimos cuadrados y regresi6n muestral multiple Comenzamos can una muestra de n observaclones (XI" X2i, "" xKo' y~ donde i = 1, ,." n) medidas para un proceso cuyo modelo de regresi6n pobJacional multiple es
Las estimaciones par minimos cuadrados de los coeficientes fJl' fJ2, ,." fJK son los valores bo' b
l, ... , bK para los que la suma de los cuadrados de las desviaciones
" SCE = L (Yi - bo - blXli - b2!2i - ... - bKxKi (13 .2)
; - 1
es la menor posible. La ecuaci6n resultante
(13.3)
es la regresi6n muestral multiple de Yean respecto a XI' X2 , ... , XI('
Consideremos de nuevo el modelo de regresi6n COil dos variables de predicci6n sola· mente.

, Savings and Loan
Capitulo 13. Regresi6n multiple 499
Los estimadores de los eoeficientes pueden resolverse utilizando las fonnas s iguientes:
donde
I~\ I)' = correlaci6n muestral entre XI Y Y r.l:2.l' = correlaci6n muestral en tre Xz e Y
I':<IXl = correlaci6n muestral entre X I Y X2
SXI = desviacion tlpica muestral de X I ... ~> = desviaci6n Llpica muestrru de X2 s; = desviaci6n tfpica muestrru de Y
(13.4)
(13.5)
(13.6)
En las ecuaciones de los estimadores de los coeficientes , vemos que la est imaci6n del cocficiente de la pendiente, bl, no s610 depcnde de la correlac i6n entre Y Y XI sino que tam bien la afec(a la correlaci6n en tre X I Y Xl Y la correlaci6n entre Xl e Y. Si la cOlTelaci6n entre XI Y X2 es igual a 0, los estimadores de los coefieientes, hi Y b2• senln iguales que los eSLimadores de los eoeficienles que se obtendrfan en las regres iones simples correspondiemes: debemos sei'iaJar que eslO raras veces ocurre en el anal isis empresari al Y eeon6mico. Y a 1a inversa, si la correlac i6n entre las variables independientes es igual a I, los estimadores de los coeficientes seran indefinidos, pero eso se debenl unicamente a que la cspeciFicaci6 n del modelo es incorrccta Y violan'i el supuesto 5 de la regresi6n multiple. Si las variab les independientcs estrin correlacionadas perfecLamcnte, ambas experimentan variaciones relativas silTIllhiineas. Vemos que en ese caso no es posib le saber que variable predice la variaci6n de Y. En el ejemplo 13.3 vemos el efeclo de las correlaciones en tre las variables independienles examinando el problema de las asociaciones de ahorro y eredito inmobiliario, cuyos datos se muesLran en la Tabla 13.1.
EJEMPLO 13.3. Margenes de beneficios de las asociaciones de ahorro y credito in mobilia rio (estimacion de los coeficientes de regresion)
EI presidente de la confederacion de asoc iaciones de ahorro y credito inmobi liario Ie ha pedido que ident ifiqllc las variables que afeclan al margen porcentual de beneficios.
Soluci6n
En primer Jugar, desarrollamos una especificaci6n del modelo de regresi6n multiple que predice los beneficios como una fllnci6n lineal del porcentaje de ingresos netos por d6-lar depositado y el numero de ofi cinas. Util izando los datos de la Tabla 13. 1 que se encuentran en el fichero de datos Savings and Loan, hemos eSlimado un modele de regres i6n multiple, que se observa en las Salidas Minitab y Excel de la Figura 13.3.
Los coeficientes esti mados se identifican en la salida de los programas informaticos. Vemos que cada aumento unitario de los ingresos, Xl' provoca un all menlo de los beneFi cios porcentuaJes de 0,237 -si la olm variable no varfa- y un aumento unitario del
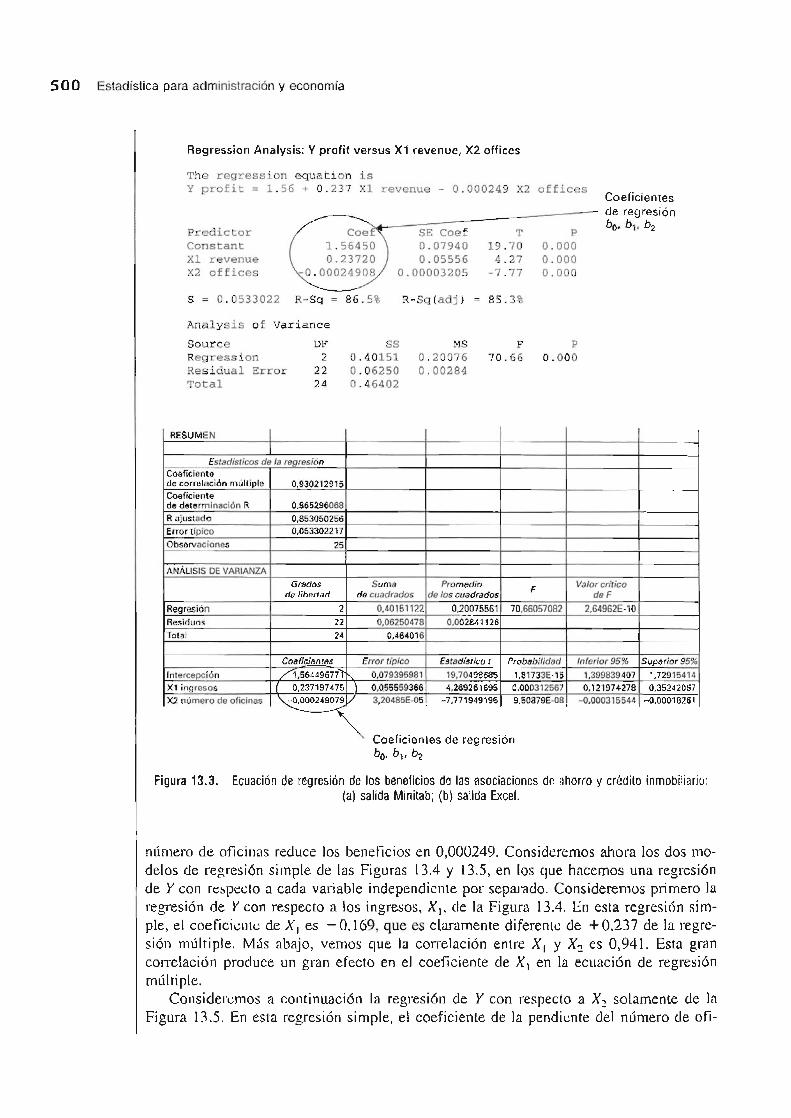
500 Eslad istica para administraci6n y economia
, ,
Regression Analysis: Y profit versus X1 revenue, X2 offices
The regression e quati on is Y profit = 1 . 56 ~ 0 . 23 7 Xl revenue - 0 . 000 24 9 X2 offices
Coeficientes
__ -;:~..-_ _ -;:;;--;:=;-_ _ --:- ---:- de regresion
Predictor / boo b,. b,
Coe SE Coef T p
Con stan t 1 . 564 50 0.079 4 0 19 . 70 Xl r e v e nue 0.23720 0 . 05556 4 . 27 x 2 of f ices 0 . 00024908 0 . 00003205 - 7 . 77
S = 0 . 0533022 R- Sq = 86 . 5% R-Sq (ad j) = 85 . 3%
Ana lys i s of Va ria n ce
Source OF Re g r e ssion 2 Residua l Err o r 22 Total 24
., ; , , R
~ ;
G",,",
, .
;;;;-" ... ,,, .. "
SS MS F 0 . 40151 0 . 2007 6 70 . 66 0 . 0 6250 0 . 00 2 8 4 0 .4 64 02
s~
~ . . ..
CoeflClentes de regreslOn boo b,. b,
0 . 000 0 . 000 0 . 000
P 0 . 000
F v.,,;;-::"'" ~ . .
,,, ,
Figura 13.3. Ecuaci6n de regresi6n de los beneficios de las asociaciones de ahorro y credito inmobiliario: (a) salida Minitab; (b) salida Excel.
numero de ofic inas reduce los beneficios en 0,000249. Consideremos ahora los dos mode los de regresi6n simple de las Figuras 13.4 y 13.5, en los que hacemos una regresi6n de Y con respeclo a cada variable independienle por separado. Consideremos primero la regresi6n de Y con respecto a los ingresos. Xl ' de la Figura 13.4. En eSla regresi6n simple, el coeficienle de Xl es -0,169, que es ciaramenle diferente de + 0.237 de la regresian mu l! iple. M,ls abajo, vemos que la correlaci6n entre X I Y X2 es 0,941. Esta gran correlac i6n produce un gran efecto en el coefi ciente de Xl en la ecuaci6n de regres i6n multiple.
Consideremos a conlinuaci6n In regresi6n de Y con respecto a X2 solamenle de la Figura 13.5. En esla regres ian simple, el coeficiente de la pendiente del numero de ofi ~

Regression Analysis: V profit versus Xl revenue
The regression equation is Y profit = 1.33 - 0.169 xl revenue
Predictor Coef Const-ant 1.3262 Xl revenue ~ ... 5 . 0 . 100891 R-Sq = 49 . 5%
Analysis of variance
Source Regression Residual Error Total
DF 1
23 24
S5 0.22990 0.23412 0 . 46402
SE Coef 0.1386
0.03559
R-Sq (adj)
M5 0.22990 0 . 01018
Capitulo 13. Regresi6n multiple 501
T p
9.51 0 . 000 - 4.15 0.000
Coeficiente
" 41.4% de regresion b 1
F P 22 . 59 0 . 000
Figura 13.4. Regresi6n de los beneficios de las asociaCiones de ahorro y cr~dito inmobiliario con respecto a los ingresos.
Regression Analysis: Y profit versus X2 revenue
The regression equation is Y profit = 1.55 - 0 . 000120 x2 offices
Predictor Coef SE Coef T P Constant 1 .54 60 0.1048 14 . 15 0.000 x2 offices ~. 000120Il> ~0 . 00001434 -8 . 39 0 . 000
Coeficiente 5 • 0 . 0104911 R-Sq '" 75 . 4% R-Sq(adj) . 14.3% de regresion ~
Analysis of variance
Source DF 55 M5 F P Reg r ession 1 0.34913 0 .34913 10 . 38 0. 000 Residual Error 23 0 . 11429 0.00491 Total 24 0 .4 6402
Figura 13.5. Regresi6n de los oeneficios de las asociaciones de ahorro y cr~dito inmobiliario con respecto a! numero de oficinas.
cinas, X2, es - 0 ,1XXl120, mientras que en 1a regres i6n multiple es - 0,000249. Este cambio de los coefic icntes, aunque no es Ian grande como en el caso del coeficiente de X I_ tambie n se debe a la eslrecha correlaci6n ·entre las variables independientes.
Las correlaciones entre las Ires variables son
Xl lngresos X2 Oficinas
Y Beneficios
- 0,704 - 0,868
Xl lngresos
0 ,94 1
Vcmos que la corrclaci6n entre XI Y X2 cs 0,941. Por 10 tanio , las dos variables tiendcn a variaI' a la vcz y no es sorprendente que los coeficienles de la regresi6n multiple sean difercnles de los coeficientes de la regresi6n simple. Debemos senalar que los coeficientes de la regresi6 n multiple son coejiciel1tes cOlldiciol/ados; es dec ir, el coeficienLc est imado

502 Esladislica para adminislracion y economia
I~I),)I )
8000
7000
0.'
0 .•
0.4
,
hi depende de las demas variables incJuidas en e l modelo. Eso sicmpre es aSI en la regre. si6n multiple, a menos que dos variables indcpcndientes tengan una correlaci6n 1lluestral de ccm, algo que es l11uy improbable.
Estas rc laciones tam bien puedcn eSludiarse uli li zando un IlgrMico malricial» de Mini . tab, como e l que muestra la Figura 13.6. No existen grafi cos de este tipo en Excel. Obser. vese que la relaci6n simple entre Y y X2 es claramente lineal. mientras que la relacion simple entre Y Y XI es algo curvilfnea. Esta relac ion no lineal entre XI e Yexplica en parte por que e l coeficienle de Xl de la regresi6n simple es ran distinto del de la regrcsion multiple. Vemos en este ejemplo que las correlaciones entre variables independientes pueden inOuir considerablcmenle en los coeficientes estimados. Por 10 taniO, si es posible clegir, deben cvitarse las variables independicntes muy correlac ionadas. Pero en mochos casos no es posib le clcgi r. Las estimaciones de los coefi cientes de regres ion sicmpre dependen de las demas vari ables de predicci6n del modelo. En este ejemplo, los beneficios aumentan en funci6n de los ingresos porcentuales por dolar depositado. Sin embargo, e l uumento simultaneo del numero de oficinas -que redujo los beneficios- ocultarfa el aumento de los beneficios si se utilizara un analisis de regres i6n simple. Por 10 lanlo, es muy importanle especificm correctamente el modelo, es decir, la elecci6n de las variables de predicci6n. Para especificar cl modelo es necesario comprender el contexto del problema Y la teoria.
Matrix Plot of X1 revenue, X2 offices, V profit Xl' .... v .... nue
Instrucciones de Minitab .' 1. Pulsar Graph • • 2. Seleccionar Matrix plot • 3. Seleccionar Simple • • 4. Seleccionar Matrix options
• X2 offices 5. Seleccionar lower Left •• • • • • • • .. ~ • • • • • • • •
'. · .' • I' • • • ". • • , • • • • • '. • • • • • • • • • Y profit
• • • • • •
• • , 4 , 7000 8000 9COO
Figura 13.6. Graficos matricia!es de las variables de las asociaciones de ahorro y crMito inmobiliario.
EJERCICIOS
Ejercicios basicos a) rx ,y = 0,60; rxlY = 0,70; rX • T , = 0,50; sx, = 200; SXI = 100: Sy = 400
13.10. Calcule los coeficicntes b l Y b2 del modelo de rcgrcsi6n
dados los siguientes eSladfsticos sinteticos:
b) Tx ,}, = - 0,60: TX1:1 = 0,70; ,-x .... , = - 0,50; S = 200· s = 100' S = 400 x, ' .~, ' y
c) Tx,y = 0,40; ':'1:1 = 0,450; ':.,x, = 0,80; S = 200' s = 100's =400 x, ' x, ' y
d) ':'oY = 0,60; rx,y = - 0,50; ,-x .... , = - 0,60; .~ = 20C},.' = 100' S = 400 x, ' .<, ' y

:jercicios aplicados
13.11. Considere las ccullciones de regrcsi6n lineal eslimadas
Y = no + alX I
y = bo+ blXI + "zX2
a) Mucstre dctaJladamente los estimadores de los coeficientes de a l Y hi cuando la cOiTelaci6n entre X I Y X 2 es igual a O.
b) Muestre detalladnmcnte los estimadores de los coefic ientes de (Jj Y bl cuundo la correiaci6n entre X I Y Xz es igual n I.
Se recomienda que los siguientes ejercicios se resue lvan con lu ay uda de un computador.
13.12. f 1 Amalgamated Power Inc. Ie ha pedido que eSlime una ecuaci6n de rcgresi6n para averiguar c6mo afeclan algunas variables de predicci6n ,I
101 demanda de ventas de electricidad. Realiza una serie de estimaciones de regrcsi6n Y anali za sus resultados uti lizando los dalos trimestrales de las ventas de electricidad de los 17 dltimos afios que se encuen tran en el fichero de datos I)ower Demand.
a) Estime una ccuHci6n de regresi6n utilizando las ventas de elcctricidad como variable dependicnte y el ndmero de clientes y cl precio como variables de predieei6n. Interprete los eocfieientes.
b) Estimc una eeuaei6n de regresi6n (venlas de electricidad) utili zando solumente cl numero de clientes como variable de predicci6n. Interprete el cacficiente y compare e1 resultado con cl del apartado (a).
e) Estime una ecuaci6n de regrcsi6n (ventas de electricidad) uti lizando el precio Y los gmdos-dfas como variables de predicci6n. Interprcte los coeficiel1(es. Compare cl cocficien le del precio con el que ha obten ido en cJ apartado (a).
d) Est"ime una ecuaci6n de regresi6n (ventas de electricidad) utili zando Ia renta y [os gradosdfas como variables de predicci6n. Intcrprele los coeficienles.
13.13. , f Transportation Research Inc. Ie ha pcdido que fonnule algunas ecuaeiones de regresi6n multiple para estimar cl efeclo de algunas variables en el ahorro de combustible. Los dalos para este estudio se Cllcuenlran en el fichcro de datos Motors y In variable dependiente son las millas por gal6n -milpgal- can forme a la certi ficaci6n del Departamento de Transparte.
Capflulo 13. Regresi6n multiple 503
a) Formulc una ecuaci6n de regresi6n que utilice la patencia de los vehiculos - horsepower- y el peso de los veh fculos - weightcomo variables indepcndientes. Intcrprctc los cocficientes.
b) Formule una segunda ecuaci6n de regresi6n que anada cl numero de cilindros --cylinder- como variable indcpendiente " la ccuaci6n del npartado (a). Interprete los caeficientcs.
c) Formule una ecunci6n de regresi6n que ulilice el nllmero de cilindros y el peso del vehfculo como variables independienles. Interprete los coeficientes y compare los resultados con los de los apanados (a) y (b).
d) Formule una ecuacion de regresi6n que uliliee la palencia de los vehCculos, el peso de los vehlcu los y el precio como variables de predicci6n. Interprete los coeficientes.
e) Escriba un breve infonne que resuma sus resultados.
13.14. ' . Transportat ion Rcsearch Inc. Ie ha pedido que fo rmule a!gunas ecuaciones de regresi6n multiple para estimar el efecto de algullas variables en la palencia de los vchCcu los. Los datos para este estudio se enCllcnlran en el fichero de datos Motors y la variab le depcndiente es la potencia -horsepower- conforme a la certifi caci6n del Depanamento de Transporte.
a) Formu!e una eCllaci6n de regresi6n que uti lice el peso de los vehCcu los - weight- y las pu lgadas ciibicas de desplazamiento de los cilindros --displacement- como variables de prcdicci6n. Inlcrprete los coeficientcs.
b) Formule una ecuacion de regresi6n que lltilice el peso de los vehfcu los, el desplazamicnto de los cilindros y el niimero de cilindros --<:ylinder- como variables de prcdicci6n. I nterprelc los cocficientes y compare los resuhados con los del apartudo (a).
e) Formulc unCI ecuaci6n de regresi6n que ut ilice el peso de los vehfculos. el desplazamicnto de los cil indros y las millas por gal6n - milpgal- como variables de predicci6n. Interprete [os cocficientes y compare los resultados con los del apartado (a).
d) Formule una ecuaci6n de regresion que util ice el peso de los vehfculos, cl desplazamienlo de los cilindros. las millas por gal6n y el precio como variables de prcdicci6n. Interprete los coeficientes y compare los resul tados con los dcl apartado (c).
c) Escriba un brevc informe que presellle los resultados de su ana l isis de esle problcma.


Capitulo 13. Regresi6n multiple 505
Restando In media muestral de la variable dependiente de ambos micmbros, tenemos que
que puede expresarse de Ja siguiemc manera:
De~v iaci 6 n observada con respecto a Ja media muestral
desviaci6n predicha con respecto a la media muestraJ + res iduo
A continuaci6n, elevando <II cuadrado los dos miembros y sumando con respecto al Indice, i , tenemos q lie
" " " ::-.' " -::-.2 • 2 L. (y, - y,. = L. (y , - y, + (y, - y,) i - I
" " = I <y,-Y)'+ I e;
i _ I
que es la descomposici6n de la suma de los cuadrados present ada en el Capitulo 12.
STC = SCR + SCE
Suma tolal de los cuadrados = suma de In
de los cuadrados regresi6n
+ suma de los cuadrados de los errores
Esla descomposici6n simplificada se debe 1:1 que )' e; son independientes Yl por 10 tanto.
Descomposicion de la suma de los cuadrados y coeficiente de determinacion Comenzamos con el model0 de regresi6n multiple ajustado mediante minimos cuadrados
donde las b, son las estimaciones par minimos euadrados de los coeficientes del modelo de regresi6n poblacional y las e son los residuos del modelo de regresi6n estimado.
La variabilidad del modelo puede dividirse en los componentes
STC = SCR + SCE (13.7)
donde estos componentes se definen de la forma siguiente. Suma total de los cuadrados:
" STC = I (y, - Y)' (13.8)
" " (13.9)

506 Estadistica para administraci6n y economfa
Suma de los cuadrados de los errores:
" " SCE = I (y, - y,)' = I ei (13.10)
Suma de los cuadrados de la regresi6n :
" SCR = I tY, - Yl' (13.11)
i-I
Esla descomposicion puede interpretarse de la forma siguiente:
Variabilidad muestral total = variabilidad explicada + variabilidad no explicada
EI caeficiante de determinaciOn, R2, de la regresi6n ajustada es la proporcion de la variabilidad muestral total explicada par la regresf6n
, SCR SCE R-= - = --
STC STC (13.12)
y se deduce que
La suma de los cuadrados de los errores tambien se utili za para calcular la eSlimaci6n de la varianza de los en·ores del model a poblacional, como muestra la ecuaci6n 13.1 3. AI igual que ocurre en 11.1 regres ion simple, la varianza de los errores poblacionales se utiliza para la inferencia estadfstica de la regresi6n multip le.
Estimacion de la varianza de los errores Dado el modelo de regresi6n poblacional multiple
y, = /io + /i ,x" + /i,,,-, + ... + PKXK1 + e,
Y los supuestos habituales de la regresi6n, sea q2 18 varianza comun del fermi no de error, I!r Entonces, una estimaci6n insesgada de esa varianza es
" L e; s' = -,',,--,-' __ = _,-SC,-E-,--_ " II - K- I/ - K -
(13.13)
donde K es el numera de variables independientes en el modelo de regresi6n . La raiz cuadrada de la varianza, s", tambien se llama error tiplco de la estimacion.
Uegados a este punta, tambien podemos calcular el cuadrado medio de la regresi6n de la forma siguientc:
SCR CMR=
K
Ulilizamos el CMR como medida de la variabi lidad explicada ajustada para tener en cuenta e l numcro de variables independicnles.

Capitulo 13. Regresi6n multiple 507
La media muestral de la variable dependicnte de los beneficios de las asociaciones de ahorro y eredito inmobiliario es y = 0,674, y hemos uti lizado cstc valor para calcular las dos ultimas eolumnas de la Tabla 13.2. Utilizando los datos de esta labIa y los componen~
tes, podemos demostrar que
SCE ~ 0,0625 STC ~ 0,4640 R' ~ 0,87
En estos resultados, vemos que en esta muestra cl 87 por eicnto de la variabilidad de los beneficios de las asociaciones de ahorro y credito inmobilia rio es expl icado por las relaciones lineales con los ingresos netos y el numero de oficinas. Observese que tambien podrfamos calcular la suma de los cuadrados de la regres ion a parlir de la identidad
SCR ~ STC - SCE ~ 0,4640 - 0,0625 ~ 0,40 15
Tambicn podemos calcular una estimac i6n de la varianza de los errores a2 utilizando la ecuaci6n 13. 13:
" I ei ? ; ... \ s- = f! II-K-
SCE 0,0625 25 - 2 - 1 ~ 0,0284 II-K-
La Figura 13.7 presenta la salidu Mini tub y Excel del aml li sis de regresi6n correspondiente al prob lema de las asoc iaciones de ahorro y credito inmobi liario e indica las distintas sumas de los cuadrados calculadas. Los paquetes estadisticos calcu lan habitualmcntc cstas cantidades; incluimos los deLalles de la Tabla 13.2 Cmicamente para indicar c6mo sc ca1cuIan las sumas de los cuadrados. A partir de ahora, suponemos que las sumas de los cuadrados se ealculan mediante un paquete estadistico.
Los componcntes de la variabilidad tienen sus correspondientes grados de li bertad. La cantidad STC tiene 1/ - 1 grados de libel1ad porque se neeesita la media de Y para eaJcularla. EI eomponente SCR tiene K grados de li bcnad pOl·que los coefieientes K se neces itan para ealcularla. Por ultimo, el componente SCE tiene 1/. - K - 1 grados de li bertad porque se neeesitan los K coeficientes y la media para eaJcularJ a. Observese que en 1a Figura 13.7 se incluyen los grados de libertad (DF) eOlTespondienLes a cada componente.
Utilizamos cI coefic ien te de determinaei6n, R2, habitual mente como es tadistico descriptivo para describi r la fuerza de la relaci6n lineal entre las variab les independientes X y la variable dependienle, Y. Es importante haecr hincapic en que R2 s610 puede utilizarse para comparar modelos de regres i6n que tienen el mismo conj un to de observacioncs mucstrales de Yi, siendo i = 1, ... , Il. Este res ullado se observa en la forma de la ecuaci6n
SCE 1 -
STC
Vemos, pues, que el va lor de R2 pllede scr alto bien porq lle SCE es pequefia - 10 que indi ca que los pun tos observados estan eerea de los pun tos prediehos- , bicn porque STC es grande. Hemos visto que SCE y s; indican la eereanfa de los puntos observados a los puntos prcd iehos. Cuando dos 0 lTlaS eCllaciones de regresi6n tienen la misma STC, R2 es una medidu comparable de la bondad del aj uste de las ecuaciones.
La ulili zaci6n de R2 como medida global de la calidad de una ecuaci6n ajustada puede plantear un problema. Cuando se afiaden vari ab les independientcs a un modelo de regre-

508 Estadistica para adminiSlracion y economia
Regression Analvsis: V profit versus Xl revenue, X2 offices
The ~e9~ession equation is Y profit 1 . 56 + 0 . 237 Xl revenue - 0 . 000249 x2 offices
e-------- - - --- - Coeficientes • bo, b" '" -Predictor Coe SE Coef T P
Constant 1 . 56 450 0 . 07940 19 . 70 0 . 000 Xl revenue 0 . 23720 0 . 05556 4 . 27 0.000 x2 offices 0 . 00024908 0 . 00003205 - 7 . 77 0 . 000 Error tlpico
7~~~;~~~::==========~~~=~ de la estimacion 5e
....... Coeficiente E 0 . 0 53~6 = 86y ""' R- SQ( adjj = 85 . 3% dedelerminaci6nRz
Ana ly s i s o f Variance
Sou rce Regres s ion Resid ual Erro r Tota l 24
Source Xl revenus X2 offices
i i
Coeficientes
boo b" '"
DF 1 1
Figura 13.1.
Seq SS 0 . 22990 0 . 17161
______ CMR ;: SCRjK
MS~ P ~ 70 66 0 000 Varianza de ~_ 5~
Error tipico
SCR . O,401S1 SCE = 0,06250 STC "" 0,46402
Numero de variables independientes (Xl = K
la estimaci6n 5"
SCR= 0, 40 151 SCE .. 0,06250 S TC = 0,46402
Coeficiente
Numero de I
ind ependientes (X) '" K
CMR : SCR K
Salida Minilab (a) y salida Exce l (b) del analisis de regresl6n correspondiente al problema de las asociaciones de ahorro y credilo inmobiliario.

Capitulo 13. Regresi6n multiple 509
si6n multiple -en casi lodas las siluacioncs ap licadas- , la suma explicada de los cuad rudos, seR, aumenta aunque la variable indepenclicnle adicional no sea una variable de predicci6n importante. Por 10 tanto, podrfamos enconlrarnos con que R'! ha aumentado espuriamentc dcspues de que se ha anad ido una 0 mas variables de predicc i6n poco importantes al modelo de regresi6n multiple. En esc caso, el aumentQ del vnlor de J?'! se rfa enganoso. Para ev itar cste problema, el coeficienle de dete rminac i6n aj ustado puede calcularse como mueSlra la ecuac i6n 13.14.
Coeficiente de determinacion ajustado
EI coeficiente de determinacion ajustado, R2, se define de la forma siguiente:
SCE/(n - K - I )
STC/(n - I ) (13.14)
Utilizamos esta medida para tener en cuenta el hecho de que las variables independientes irrelevantes provocan una pequefla reducci6n de la suma de los cuadrados de los errores. Por 10 tanto, el R2 ajustado permite comparar mejor los modelos de regresi6n multiple que tienen diferentes numeros de variables independientes.
Volviendo a nuestro ejemplo de las asociac iones de ahorro y cn!dito inmobiliario, vemos que
1/ = 25 SCE ~ 0,0625 STC ~ 0,4640
y, por 10 tanto, el coe fic iente ajustado de determinacion es
iP-= 0.0625 /22
1 - 0,4640/24 ~ 0,853
En cste ejemplo, la diferencia entre R2 y iF no es muy grande. Sin embargo, si e l modelo de regresi6n hubiera cOlltenido algunas vari ables independientes que no fueran importantes predictores condicionados, la diferencia serra grande. Olra medida de la relac ion en la rcgresi6n multi ple es e l coeficiente de correlac i6 n multiple.
Coeficiente de correlacion multiple
EI coeficiente de correlaci6n multiple es la correlaci6n entre el valor predicho y el valor observado de la variable dependiente
- In'i R ~ f(Y,y) ~ y R- (13.15)
y es igual a la ra fz cuadrada del coeliciente multiple de determinaci6n. Utilizamos R como olra medida de la fuerza de la relaei6n entre la variable dependiente y las variables independientes. Par 10 tanto, as comparable a la correlaci6n entre Y y X en la regresi6n simple.

510 Estadfstica para administraci6n y economia
EJERCICIOS
Ejercicios basicos
13.15. Un am'il isis de regresi6n ha producido la siguiente labia del amllisis de la varianza:
13.16.
Analysis of Variance
Sou r ce Of' 5S MS
Regres~ion 3 4500 Res i dual Error 26 500
a) Calcule SI: Y s;. b) Calcule STC. c) Calcllie R2 Y eI coeficiente ajustado de de
terminacion.
Un analisis de regresi6n ha prodllcido guiente tabla del an5lisis de la varianza: Analysis of vari anc e
Sour ce Re g ression Resid ua l Error
u) Calcule s~ y s;. b) Calcule STC.
OF 2
29
5S MS
7000 2500
la s\-
c) Ca1cu le R2 y cI cocficiente ajustado de determinacion.
13.17. Un an5lisis de regresi6n ha prodllCido la si guicntc tabla del amilisis de la varianza: Analys i s o[ Vari ance
Source Re gress i on Res i dual Err or
a) Calcu1c s" y s;. b) Ca1cule src.
OF , 45
SS 40000 10000
MS
c) CaJcule R2 y cI coericiente ajuslado de detcrminaci6n.
13.18. Un an5lisis de rcgresi6n ha producido la siguiente tabla del alllliisis de la varianza: Analys i s of varianc e
Source Regres sion Re sidua l Er ror
a) Ca1cule se y s;. b) Ca1cu le STC.
OF 5
200
SS MS
80000 15000
c) Calcule R2 y cI coeficiente ajustado de detenninaci6n.
Ejercicios aplicados
13.19. En el estudio del ejercicio 13.6, en el que las est imaciones por mfn imos cuadrados se basaban en 27 conjuntos de observaciones mueslrales, la
suma total de los cuadrados y la suma de lo~
cuadrados de la regresi6n Crall
STC ~ 3.881 y SCR ~ 3,549
a) Halle e imcrprc(c el coeficiente de determi_ nacion.
b) Halle la slima de los clladrados de los errores.
c) Halle el coeficiente ajustado de dClermina_ ci6n .
d) Halle e intcrprctc cl coefieiente de corrcla_ ci6n mu.lti ple.
13.20. En el estudio del eJerclcio 13.8, en el que las estimaciones pOl' mfnimos cuadrados se basaball en 30 eonjllntos de observaciones mucslrales. !a suma lotal de los clladrados y la sllma de los cuadrados de la regresi6n eran
13.21.
STC ~ 162.1 y SCR ~ 88.2
a) Hall e e interprete el coeficiente de delermi naci6n.
b) Halle el cocficiente de determinaci6n ajustado. c) Halle e inlerprete el coeficiente de correla-
ci6n mu ltiple.
En eI estudio del ejercicio 13.9, se utilizaron 25 observaciones para calcular las estimaciones pOl' mfnimos cuadrados. La suma de los cuadrados de la regresion y la suma de los cuadrados de los errores eran
SCR ~ 79.2 y SCE ~ 45,9
a) Halle e interprele el coeficiente de determinacion.
b) Halle el cocficientc de detel1llinaci6n ajustado. c) Halle e interprete el coeficiente de correla
cion mu.ltiple.
13.22. Vuelva a los datos de las asociaciones de ahorro y credito inmobiliario de la Tabla 13. 1.
a) Estime por mfnimos cuadrados la regrcsion del margen de beneficios con respecto al numera de ofici nas.
b) Estime por mfnimos cuadrados la regresi6n de los ingresos nelOS con respecto al numel'O de oficinas.
c) Estime por mlnimos cuadrados la regresi6n del margen de beneficios con respecto a los ingresos nelos.
d) Estime por mfn imos cuadrados la regresion del numero de ofic inas con respeclo a los ingresos nelos.

Capitulo 13. Regresi6n multiple 511
13.4. Intervalos de confianza y contrastes de hipotesis de coeficientes de regresion individuales
En el apartado 13.2 hcmos dcsarrollado y anali zado los est imadorcs puntuales de los para.~ metros del modelo de regresi6n multiple
A continuaeion, desarrollamos intervalos de confianza y contrastes de hipotes is de los eoeficie ntes de regresi6n est imados. Estos interva los de confian za y contrastes de hipotesis dependell de la . varianza de los coefieientes y de la di stribucion de probabilidad de los coeficielltes . En el apartado 12.5 mostramos que el coeficiente de regres ion simple es una funcion lineaL de la variable dependiente, Y. Los coeficicntes de regresi6n multiple, bj ,
tam bien son funciones lineales de la variable depcndiente, Y, pero el algebra es algo mas compleja y no se presentara aqul. En la ecuac i6n de reg res ion mCiltipie anterior, vemos que la variable dependiente, Y, es una funci6n lineal de las variables X mas el error aleatorio /;:. Para un conjunlo dado de variables X, la funcion
es en realidad una constante. Tambiell vimos en los Capftulos 5 y 6 que sumando una eon stante a una variable aleatoria <.: se obtiene la vari ab le aleatoria Y que tiene la misma di stribucion de probabilidad y la misma varianza que la variable alcatoria original £. Como consecuencia, la variable dependien le, Y, sigue la misma distribuci61l normal y liene la misma varianza que el termino de error, e. Se deduce, pues, que los coerieientes de regresion, bj - que son funci ones lineales de Y-, tambien siguen una dist ribuc i6n normal y su varianza puede obtenerse utili zando la relaci6n li neal entre los coeficientes de regresion y la variab le dependiente. Este ctilculo se rea lizarfa siguiendo los mismos pasos que en el caso de la regresion simple del apartado 12.5, pero el algebra es mas complcja.
Basandonos en la relac i6n lineal entre los coeficientes e Y, sabemos que las estimaciones de los cocficientes siguen una distribuci6n normal si cl error del Illodelo, G, sigue una di stribuc i6n normal. Como consecueneia del teorema del Ifmite central, genera l mente observamos que las eSlimaciones de los coefic ientes siguen aproximadamente una di stribucion normal, aunque f. no la siga. Por 10 tanto, los contrastes de hipotesis y los intervalos de confianza que desarrollamos no son afectados seriamente por las desviaciones con respecto a la normalidad en la di stribuci6n de los terminos de error.
Podemos considerar que el termjno de error, e, del modelo de regresion poblacional incluye las influencias conj ulllas en la variable dependiente de multitud de faetores no inciuidos en la lista de variables independientes. Estos factores pueden 110 tener por separado una gran influencia, pero su efecto eonjunto puede ser importanle. EI hecho de que el ter~ mino de error este formado par un gran numero de eomponentes cuyos efeetos son aleatorios es un argumento in tuitivo para suponer que los errores de los coeficientes tambien siguen una distribuei6n normal.
Como hemos visto antes, los estimadores de los coeficientes, hj' son funeiones lineales de Y, y el valor predicho de Y es una funcion lineal de los estimadores de los coefic ientcs de regres ion. EI computador realiza los ca.lculos resultantes de las complejas relaciones. Sin embargo, estas relaciones a veees pueden plantear problemas de interpretaci6n, por 10 que dedicamos algun tiempo a explicar la forma de calcular las varial1zas. Sj no compren-

512 Estadislica para adminislraci6n y economia
demos c6mo se calculan las varianzas, no podl"cmos comprendcr perfectamenle los conIrastes de hip6tes is y los intervalos de con rianza.
La varianza de una est imaci6n de un coeri cienle dcpende del lamano de la mues!ra. de la dispcrsi6n de las variables X, de las correlaciones en tre las vari ables independientcs y del termino de error del modelo. Por 10 tanto, estas correlaciones afectan tanto a los intcrval os de confianza como a los contrastes de hi p6tesis. Antes hemos visto que las cOITcla_ ciones entre las vari ables indepcndien tes influyen en los estimadores de los coeficiemes. Eslas correJaciones entre variables independienles tambien aumentan la vari anza de los estimadores de los coeficienles. Una imporlame conclusi6n es que la varianza de los estimadores de los coeficientes, ademas de los estimadores de los coeficientes. depende de todo el conjunlo de variables independientes del modelo de regresi6n.
El aml li sis anterior de los gn'ifi cos tridimens ionales hacia hincapie en los complejos efeclos que producen varias variab les en la varianza de los coeficienles. A medida que Son estrechas las relaciones entre las vari ables indcpendicntes, las cstimaciones de los coeficientes son mas inestnbles, es decir, tienen una vuri anza mayor. A continuac ion, presentamos un amilisis mas formal de estas complcjidades. Para oblcner buenas estimaciones de los coeficientes --eslimaciones que tengan una baja varianza- debemos buscar un umplio rango para las variables indepcndienles, elegir vari"bJes independ ientes que no esten eSlrccham~nte rclacionadas entre sf y buscar un modele que este cerca de lodos los puntos de datos. En la pn'ictica, cuando se rea li zan estud ios estadfslicos aplicados en cI mundo de la empresa y la economfa. a menudo hay que utilizar datos que di stan de ser idcales. como los de l ejemplo de Jas asociaciones de ahorro y eredilo inmobiliario. Pero conociendo los efectos aqu f analizudos. podcmos con tal" con elementos para detcnninar en que medida son aplicables nuestros modelos.
Para comprender algo el efeclo de las correlaciones de variables independientes, e)(<1-minamos los estimadores de las vari anzas a partir del modelo de regresi6n multiple estimado con dos variables de predicci6n:
Los estimadores de las vari anzas de los coeficientes son
s' s;, = e (/I - I )s~/I
(13.16)
(13.17)
y las rafces cuadradas de estos estimadorcs de las varianzas, Sb , Y Sb2, se denominan errores
'(picos de los coejiciellfes. La varianza de los est imadores de los coeficientes aumenta direClamente con la di slan
cia a Ia que se encuentran los puntos de la Ifneu, medida por s;, la varianza de los en'orcs eSlimudos. Ademfis. una dispersi6n mayor de los valores de las variables independientes - Illcdida por s;, 0 por s.~!- reduce la varianza de los cocfic ientes. Recuerdese que eSlOS resultados tambien se aplican a los estimadores de los coeficicntes de regres i6n simple. Talllb ien vemos que la varianza de los estimadores de los coeficientes aumenta con los aumentos de la correluci6n entre Ins variables indepcndientes del modelo. A medida que aumenla la correlaci6n entre dos vari ables independientes, es mas diffei! separar el efeclo de cada una de las variables para predeci r las variables dependientes. Cuando aumenta cl

Capitulo 13. Aegresion multiple 51 3
numero de. variables indcpendienles en un modelo, las influeneias en la varianza de los eoefieientcs eontinuan siendo importantes, pero la estruet ura algebraiea se vuelve muy eomplcja y no se presenta aqul. EI efeeto de las corre laciones haee que los esti madorcs de las varianzas de los coeficientes dependan de las demas variables inclepenciienles del mode lo. Recuerdese que los estimadores efectivos de los coeficientes lambien dependen de las demas variables inclependientes del modelo, una vez mas debido al efecto de las correlaciones entre las variables independientes.
A continuaei6n, resumimos la base para la inrerencia de los coeficientes de la regresion poblaciona1. Normal mentc, nos interesan mas los coeficientes de regresi6n f3j que la constante u ordenada en cI origen f3o. Por 10 tanto, centraremos la atencion en los primcros, sciialando que la inferencia sobre la segunda se reali za de una mancra parccida.
Base para la inferencia de los parametros de la regresion poblacional
Sea el modelo de regresi6n poblacional
Sean bo' b1
, .. • , bK
las estimaciones par minimos cuadrados de los parametros poblacionales y s/:()' so,' .. . , Sb las desviaciones tfpicas estimadas de los estimadores por minimos cuadrados. Entonces, si te cumplen los supuestos habituales de la regresi6n y si los terminos de error, 1:1,
siguen una distribucion normal,
(13.18)
se distribuye como una distribuci6n t de Student con (n - K ~ 1) grados de libertad.
Intervalos de confianza
Pueden obtenerse intervalos de confianza de los Pj utilizando la ecuaci6n 13. 19.
Intervalos de confianza de los coeficientes de regresion
Si los errores de la regresi6n poblacional, £;1' siguen una distribucion normal y se cumplen los supuestos habituales de la reg resion , los intervalos de confianza bilaterales al 100(1 - (1:)% de los coeficientes de regresi6n, Pi' son
donde t,, _K_ 1.<>12 es el numero para el que
" P(t,, -K- I > t,, - K -1.a/2) = 2"
(13.19)
y la variable aleatoria t,, _K_l sigue una distribuci6n t de Student con (n - K - 1) grados de libertad.

514 Estadistica para administraci6n y economia
EJEMPLO 13.4. Desarrollo del modelo de las asociaciones de ahorro y credito inmobiliario (estimaclon de intervalos de confianza)
Se nos ha pedido que culculemos intcrva los de confianza de los cocficientes del mOdelo de regres i6n de las asociaciones de ahorro y credilO inmobi liario presenlado en e1 ejem. plo 13.3.
Soluci6n
La Figura 13.8 nluestra la sal ida Minitab del am'ilisis de regres i6n correspondiente al modelo de regresi6n de las asociaciones de ahOJTO y credito inmobi liario. Los est imado.
Regression Analvsis: V profit versus X1 revenue, X2 offices
The regression equation is Y profit = 1.56 + 0 . 237 Xl revenu e - 0 . 000249 X2
Predictor Constant Xl revenue X2 offices
1. Coef
S " 0.0533022 R-Sq 86.5' R- .) "
Analysis of vari ance
Sou r ce DF SS MS Regression 2 0 .4 0151 0 . 20076 Residual Error 22 0 . 06250 0 . 00284 Total 24 0 . 46402
Source OF Seq SS
Xl r evenue 1 0 . 22990 X2 o f fices 1 0 . 17161
(,)
."
(b)
F 70 . 66
offices b,
'b,
tb,
. 000
.000
tb,
0 . 000
Figura 13.8. Regresi6n de problema de las asociaciones de ahorro y credito inmobiliario (salidas Minitab y Excel).

Capitulo 13. Regresi6n multiple 515
res de los coefic ientes y sus desviaciones tfpicas cOITespondientes a las variables de prediccion de los ingresos, hi' y el numero de oficinas, b2• son
b, ~ 0,2372 s'" ~ 0,05556; b, ~ - 0,000249 Sb, ~ 0,00003205
Vemos, pues, que la desviac i6n tfpica de la di slribuci6n en el muestreo del estimador por minimos cuadrados de [11 se estima en 0,05556 y la de [J2 se eslima en 0,00003205.
Para obtener intervalos de confianza a1 99 por ciento de [1 I Y [12' utilizamos el valor t de Student de la Tabla 8 del apendice.
'II - K - J. r.r:!2 = (22.0.005 = 2,8 19
Basandonos en estos resultados, observamos que e1 intervalo de confianza al 99 por ciento de [J I es
0,237 - (2,8 19)(0,05556) < p, < 0,237 + (2,819)(0,05556) o sea,
0,080 < p, < 0,394
Por 10 tanto, el intervalo de cOllfianza al 99 par ciento del aumento esperado del margen de beneficios de las asociaciones de ahorro y cn':dito inmobiliario provocado pOl' un aumento de los ingresos nelos de I unidad, dado un numero rljo de otic inas , va de 0,080 a 0,394. El intervalo de confiunza al 99 por cienlO de [12 es
- 0,000249 - (2 ,8 19)(0,0000320) < {3, - 0,000249 + (2,819)(0,0000320) o sea
- 0,000339 < fl, < - 0,000 159
Vemos, pues, que el intervalo de confianza al 99 por ciellto de la disminuci6n espcrada del margen de beneficios provocada par un aumenlo de 1.000 oricinas, dado un ni vel fijo de ingresos netas, va de 0,159 a 0,339.
Contrastes de hip6tesis
Pueden desarrollarsc contrastes de hipolesis de los coeficientes de regrcsi6n utili zando las estimaciones de las varianzas de los coefic ientes. Especialmcntc intcrcsante es e l contraste de hipotcsis
que se utili za frecuentemente para averiguar si una variable independiente especffica es importante en un modelo de regresi6n mUltiple.
Contrastes de hip6tesis de los coeficientes de regresi6n Si 105 errores de la regresi6n, [;i' siguen una distribuci6n normal y se cumplen los supuestos habituales del analisis de regresi6n, los siguientes contrastes de hip6tesis tienen el nivel de significaci6n IX:
1. Para contrastar cualquiera de las dos hip6tesis nulas

516 Estadfstica para administraci6n y economia
"'" INTlRPRHACION
frente a la hip6tesis alternativa
la regia de decisi6n es
Rechazar Ho si (13.20)
2. Para contrastar cualquiera de las dos hip6tesis nutas
Ho: Pj = P* 0
frente a la hip6tesis alternativa
H ,: Pj < P*
la regia de decision es
Rechazar Ho si (13.21 )
3. Para contrastar la hipotesis nula
flo: lij = /i*
frente a la hip6tesis alternativa bilateral
H, :Pj # fI*
la regia de decision es
Rechazar Ho si o (13.22)
Muchos analistas sostiencn que si no podemos rechazar la hip6tesis condicionada de que cI coeficiente es 0, debemos concluir que la variable no debe incluirse en el modelo de regresi6n. EI estadfstico f de Student de esle contraste normal mente se ca lcula en la mayorfa de los programas de regresi6n y se indica al lado de la eSlimaci6n de la varianza de los coeficientes: ademas, normahnenle se induye el p-valor del contrasle de hip6tcs is. Estos se muestran en la salida Minirab de la Figura 13.8(a). Utili zando el estadfstico t de Student indicado 0 e l p-valor, podemos saber inmediatamcnte si una variable de predicci6n es significativa, dadas las dcmas variables del modelo de regresi6n.
Exislen ciaramenle olros mclodos para decidir si una variable independiente debe inc1uirse en un modele de regresi6n. Vemos que el metodo de selecci6n anlerior no liene en cuenta e l error de Tipo II: el coeficiente poblacionai no es igual a 0, pero no rechazamos la hip6tesis nu la de que es igual a 0. ESle es un problema importanle cuando un modelo basado en la leoria eeon6mica 0 en otra teoria y cspccificado con cuidado incluye eierlas va riables independienles. En esc caso, debido a un gran error, c, y/o a las correlaciones en tre variables independientes, no podemos rechazar la hi p6lcsis de que el coeficiente es O. En este caso, muchos analistas incluiran la variable independicnte en el modelo porque creen que debe primar la especificaci6n original del modelo basada en la leoria 0 la experiencia

Capitulo 13. Regresi6n multiple 517
econ6m icas. Se trata de una cuesti6n diffcil que exige haecr una buena valoracion basandose tanto en los resultados cstadisticos como en la tcoria economica sobre la relacion subyacente analizada.
EJEMPLO 13,5, Desarrollo del modele de las asociaciones de ahorro y cn3dito inmobiliario (contrastes de hipotesis de coeficientesj
Se nos ha pedido que averiguemos si los coeficielltes del modele de regres i6n de las asociaciones de ahorro y eredito inmobi liario son predictores significat ivos de los beneficios .
Solucion
En el contraste de hipotesis para esta cuesti6n uti lizaremos los resul tados de la regrcsi6n real izada con el programa Minitab moslrados en la Figura 13.8(a). En plimer lugar, queremos averigllar si los ingresos (Olales aumentan significativamente los beneficios dado el efecto del numero de oficinas, es decir, descontando la infillencia de este. La hipotesis nula es
frente a la hip6tesis alternativa
H,:[J, >0
EI contraste puede reaJizarse ca lculando el estadfstico 1 de Student del coeficiente, dado Ho:
0,237 - 0 --'cc,..,-,-"..,- = 4 27 0,05556 '
En la Tabla 8 de la t de Student del apendice podemos ver que el valor crftieo del estadfstico t de Student es
t 22•0.OO5 = 2,819
La Figura 13.8(a) tam bien indica que el p-valor del contraste de hip6tesis es inferior a 0,005. Basandonos en esta evidencia, rechazamos Ho Y aceptamos HI y conclui mos que los ingresos totales son un predictor estadfsticamente significativo del aumento de los beneficios de las asoc iac iones de ahorro y credito inmobiliario, dado que hemos ten ido en cuenta el efecto del numero de oficinas.
Tambien podemos averiguar si cl numero total de oficinas reduce significativamente los margenes de beneficios. La hip6tes is nula es
Ho: Ii, = 0
frente a la hip6tesis alternativa
H, : Ii, < 0

518 Estadistica para adminislraci6n y economia
EI contruste puede reali zarse calculando e l estadfst ico t de Student del coefici cnte, dudo Ho:
- 0,000249 - ° = - 7,77
0,0000320
En la Tabla 8 del apendice podemos ver que el valor crftico del estadfstico 1 de Student es
122.0.005 = 2,8 19
La Figura 13.8(a) lambien indica que el p-valor del contraste de hip6resis es in fe rior a 0,005. Basandol1os en esto evidencia, rechazamos Ho Y uccptumos HI y concluimos que el numero de ofic inas es un predictor estadfst ieamente significativo de la reducci6n de los beneficios de las asociaciones de ahorro y ered ilo inmobil iario, dado que hemos tenido en CLienta el efeelo de los ingresos tolales.
Es importanle hacer hineapie en que los dos contrates de hip6tes is se basan en el conjunlo de vari ables incluidas en el mode lo de regresi6n. Por ejemplo, si se incluyeran mas variab les de predicci6n, estos conlrastes ya no serfan v~lidos. Con mas variables en el modelo, las esti maciones de los coeficientes y sus desviaciones tfpicas estimadas serfan diferenles y, pOI' 10 lanto, tambien 10 serfa el estadfsl ico t de Student.
Observcse que en la sa lida Minilab del amllisis de regresi6n mostrada en la Figura 13.8(a). el eSLadfstico t de Student de la hip6tesis nula -Ho: fJj = 0- es eI cotiente entre el coeficiente eSlimado y e1 error tfpico de l coeficiel1le estimado. que se encuentra en las dos col umnas siLuadas a la izquierda de l estHdistico r de Student. Tambien se muestra la probabi lidad 0 p-valor de l contrasle de hip6tesis de dos colas: H/ Pj -::j::. 0. Por 10 tunto. cualquier analista puede realizar estos contrastes de hip6tesis directamente examinando la salida del aml li sis de regresion multiple. El estadistico t de Student y el pvalor se ca lculan en todos los paquetes eSLadfsticos modernos. La mayorfa de los anal istas buscan estos resultados habitualmente cliando examinan la salida del anal isis de regresi6n de un progrHma estadfstico.
EJEMPLO 13,6. faclores que afeclan al Ii po del impueslo sobre bienes inmuebles (amilisis de los coeficienles de regresi6n)
Un ayunta miento encarg6 un estudio para averiguar los ractores que influyen en los impuestos urbanos sobre los bicnes inmuebles de las ciudades de 100.000-200.000 habi tHntes.
Solucion
Uti lizando una muestra de 20 ciudades de Estados Unidos, se est im6 el siguiente mode-10 de regresi6n:
y = 1,79 + Q,000567x, + 0,0 1 83x2 - 0,OOO 191x, (0.000 139) (0.0082) (0.000446)
R2= 0,7 1 11 = 20 donde
y = lipo efecti vo del impuesto de bienes inmuebles (impuestos efectivos di vid idos pOl' el valor de mercado de la base imposiriva)
XI = numero de viviendas por kil6metro cuadrado

Capitulo 13. Aegresi6n multiple 519
X 2 = porccntajc de los ingresos lTIunicipales lotales represcnlado por las ayudas procedentcs de las administraciones de los estados y de In adrninistraci6n federal
x) = renta personal per capita mediana en d61ares
Los numeros entre purentesis que se encuentran debajo de los coeficienles son los errores lfpicos de los coeficientes eslimados.
La presenlacion anterior constituye un buen fonnato para mostrar los resultados de un modelo de regresi6n. Los resultados indican que las estimaciones condicionadas de los efeclOs de las tres vmi ables de predicci6n son las siguientes:
1. Un 3l1mento de una vivienda pOl' kilometro cuadrado eleva el tipo erectivo del impueslo sobre bienes inmuebles en 0,000567. Observese que los tipos del impuesto sobre bienes inmuebles l10rmalmente se expl'esan en d61ares pOl' cada 1.000 $ de valor catastral de la propiedad. Asf, un aumento de 0,000567 indica que los tipos del impuesto sobre bienes inmuebles son 0,567 $ mas altos por 1.000 $ de valor catastral de la propiedad.
2. Un aumento de los ingresos municipales totales de un 1 par dento procedenle de las ayudas de las administraciolles de los estados y de la administraci6n federal eleva el tipo impositivo erectivo en 0,0 183.
3. Un aumenlO de la renta personal per capita mediana de 1 $ provoca una dismi!luci6n esperada del tipo impositivo efectivo de 0,000191.
Hacemos de nuevo hincapie en que estas estimaciones de los coeficientes 5610 son validas en un modelo que incluya las tres variables de predicci6n an leriores.
Para comprender mejor la eXDclilud de eSlOs efectos, constnliremos intervalos de confianza al 95 por dento condicionados. En el modelo de regres i6n estimado, el error tiene (20 - 3 - I) = 16 grados de libertad. Por 10 tanto, el estadistico I de Student para calcular los intervalos de con l'i anza es, como se observa en el apendice, t I6. 0 .02.'i = 2,12. EI fonnato del interva lo de confianza es
bj - tn - K - !'~b) < fij < bj + f/l -K-I.rs.r-sbJ
Por 10 tanto, el coeficiente del numero de viviendas por kil6metro cuadrado tiene un intervalo de confianza al 95 por ciento de
0,000567 - (2,12)(0,000139) < p, < 0,000567 + (2, 12)(0,000139) 0,000272 < II, < 0,000862
EI coefi cienle del porcelltaje de ingresos representados pOI' las ayudas tiene un intervalo de confianza al 95 por cienlo de
0,0 183 - (2,12)(0,0082) < II, < 0,0183 + (2, 12)(0,0082) 0,0009 < #, < 0,0357
Par ultimo, el coefi ciente de la renla personal per capita mediana {iene un interval a de confianza al 95 par dento de
- 0,000 19 1 - (2, 12)(0,000446) < Ii, < - 0,00019 1 + (2, 12)(0,000446) - 0,0011 37 < p, < 0,000755
Una vez m6s hacernos hincapie en que estos intervalos dependen de que se incluyan las tres variables de predicci6n en el modelo.

520 Esladislica para administraci6n y economfa
Citydat
Vemos que el illlervalo de confi anza 31 95 por cienlo de fi3 incluye 0 y, por 10 tanto, podriamos no rechazar la hip61esis de dos colas de que este coeficiente es O. Bas{mdo_ nos en eSle intervalo de confianza. conc1 uimos que X) no es una variable de predicci6n estadisticamente signiricaliva en el modelo de regresi6n mult iple. Sin embargo. los intervalos de confianza de las otras dos variables no incluyen 0 y, por 10 tanto, conclui mos que eslas son estadfslicarnen te significat ivas.
EJEMPLO 13.7. Efeclos de los faclores fiscales en los precios de la vivienda (estimaclon de los coefic ienles del modelo de regresi6n)
Northern Ci ty (Minnesota) tenfa interes en saber c6mo afeclaba la promoci6n inmobiliaria local al precio de mercado de las viviendas de la ci lldad. Northern City es una de las numerosas ciudadcs no metropolitanas pequenas del Medio Oeste de Estados Unidos cuya poblaci6n osc ila entre 6.000 y 40.000 habitantes. Uno de los objeti vos era averiguar c6mo influiria un aumento de la canlidad de locales comerciales en e l valor de las viviendas locales. Los dalos se encuenl ran en e l fichero de dalos Citydat.
Solucion
Para responder a esta pregunta. se recogieron datos de algunas ciudades y se utilizaron para construi r un modelo de regresi6n que est ima el efecio de vari:lb les clave en e l pre· cio de 13 vivienda. Para este estudio se obtuvieron las siguienles variables de cada ciudnd:
Y (hseval) = precio medio de mercado de las viviendas de 13 ciudad XI (s izchse) = numero medio de habitaciones de las vivielldas X2 (incom72) = rcnta media de los hogares Xl (tax rate) = tipo imposilivo por mil d61ares de valor catastra l de las viviendas X4 (comper) = porcenlaje de propiedades inmobiliarias imponi bles que son comer-
ciales
La Figura 13.9 mllcslra los resultados de la regrcsi6n multi ple, obtcnidos por medio de l programa Mini tab. EI coeficiente del numero medio de habitaciones de las viviendas es 7,878 y 1a desviaci6n Ifp ica del coeficiente es 1,809. En esle estudio, los valores de las viviendas se expresan en unidades de 1.000 $ Y la media de todas las ciudadcs es de 2 1.000 $. As!, por ejempio, si e l numero medio de habitaciones de las viv iendas de una c iuclad es mayor en 1,0, el precio medio es mayor en 7.878 $. EI estadfs lico I de Student resu ltante es 4,35 y el p-valor es 0,000. Par 10 Ian to, se rechaza la hip61es is condicionada de que este cocficiente es igllal a 0. Se obliene eI misl110 resultado en e l caSD de las variables de la renla y del tipo impos il ivo. Ln variable «incom72» esta expresada en unidades de d61ares y, POI' 10 tanIO, si In renla media de una ciudad es mayor en 1.000 $, el coeficiente de 0,003666 indica que el prec io medio de la vivienda es 3.666 $ mayor. Si e l tipo imposilivo aumcnta un I por ciento, el precio medio de la vivienda se reduce en 1.720 $. Vemos que el an ~li sis de regres i6n Beva a la conclusion de que cada lI na de estas tres variables es un importante predictor del precio medio de la vivienda de las ciudades inclu idas en eSle estudio. Sin embargo, vemos que el coeficienle del porcenLaje de locales comerciales , «comper», es - 10,6 14 y la desviaci6n (ipica del coefi ciente es 6,491, 10 que da un estadfstico t de Student igual a - 1,64. Observese que esle resul lado permitc establecer una importante concl ll si6n. EI cocficiente tendria un p-valor de

Capitulo 13. Regresi6n multiple 521
Regression Analysis: hseval versus sizehse, income72, taxrate, Comper
The regression equation is hseval = -28 1 + 7.88 sizehse + 0.000367 incom72 - 172 taxrate -10.6 Comper
Predictor Coef SE Coef T p
Constant -28.075 9.766 -2.87 0.005 Sizehse 7.878 1.809 4.35 0 . 000 incom72 0.003666 0.001344 2 . 73 0 . 008 taxrate -171.80 43.09 -3 . 99 0.000 Comper -10.614 6 .4 91 -1 . 64 0.106
S . 3 . 67686 R-Sq " 47.4% R-SQ(adj) ~ 45.0%
Analysis of variance
Source Regression Residual Error Total
OF 5S 4 1037.49
85 1149 . 14 89 2186 . 63
M5 F P 259.37 19.19 0.000
13 . 52
Figura 13.9. Modelo de regresi6n del precio de la vivienda (salida Minitab).
una cola de 0,053 0 un p-valor de dos colas de 0,106. Por 10 tanto, parece que reduce algo el precio medio de las viviendas. Dado que se han incluido los efectos del tamano de las viv iendas, la renta y el tipo impositivQ en el precio de mercado de las viviendas, vemos que el porcentaje de locales comerciales no eleva los predos de la vivienda. POI'
10 tanto. este analis is no apoya el argumento de que el valor de mercado de las viviendas aumentanl si se construyen mas locales comerciales. Esa conclusi6n s610 es ciel1a en un modelo que incluya estas cuatro variables de predicci6n. Observese tambien que los valores de R 2 = 47,4 por ciento y Sr (error tfpico de In regresi6n) = 3,677 estan inc1uidos en la salida del anulis is de regresi6n.
Los defensores de Ull aumento de In promoci6n de locales comerciales tambien 505-
tenlan que cI aumento de la canlidad de locales comerciales reducirfa los impuestos pagados por lus viviendas ocupadas POI' sus propietarios. Esta tesis se contrast6 utilizando los resultados de la regresi6n de la Figura 13.10 obtenidos con el program a Excel. Se indican los estimadores de los coeficientes y sus errores tfpicos. Los estadfst icos 1 de Student de los coelicientes del tamano de la vivienda y el tipo impositivo son 2,65 y 6,36, 10 cual indica que estas variables son importantes predictores. EI estadfsti co r de Student de la rcnta es 1,83 con un p·valor de 0,07 para un contraste de dos colas. POl' 10 tanto, la renla tiene alguna influencia como predictor, perc su efecto no es tan fuerte como el de las dos vari ables anteriores. Vemos de nuevo que hay margen para extraer conclusiones s6l idas. La hip6tesis condicionada de que un aumento de los locales co· merciales reduce los impuestos sobre las viv iendas ocupadas por sus propietarios puede contrastarse utili zando el estadfsti co t de Student de la vari ~lble «com per» en los resultados de la regresi6n. E1 estadfstico I de Student es - 1,03 con un p-valor de 0,308. POl' 10 tanto, la hip6tesis de que un aumento de los locales comerciales no reduce los impuestos sobre la vivienda no puede rechazarse. No existen pmebas en eSle ana li sis de que los impuestos sobre las viviendas disminuirian si se conslruyeran mas locales comerciales.
Basandose en los ana l isis de regres i6n real izados en este estudio, los consultores lIegarotl a la conclusi6n de que no existfan pruebas de que un allmento de los locales comerciales elevaria el valor de mercado de las viviendas 0 reducirfa los impuestos sabre bienes inl1lllebles de las viviendas.

522 Estadistica para administraci6n y economia
--- - -----~ Mkr-osoft Excel· CITYDAT
l[) EOe ~dit I[JIe'N loser! F~mat 10015 Q.~ t~ :tiindo'N t!elo
D~!iI d :. ~ ~ ora. " . ~I @J (1) ~ "'" ~1 ... SUMMARY OUTPUT
. 10 .OI U I
Coeficiente multiple de determinaci6n R2
Coeficientes bo, b1, ~, ~, b.
SCR SCE STC
Estadisticos t Errores tipicos de Student de los coefic ientes
Figura 13.10. Modelo de regresi6n de los impuestos sabre las viviendas (salida Excel).
EJERCICIOS
Ejercicios basicos 13.23. Los resu ltados del and Usis de un modelo de rc
gresi6n son los siguientes:
y = 1,50 + 4,8x1 + 6,9x2 - 7,2x) (2, 1) (3.1) (2,8)
R2 = 0,71 II = 24
Los numeros entre parentesis situados debajo de las cstimaciones de los coeficientes son los errores tfpicos muestrales de las estimaciones de los coeficientes.
u) CaJcu lc intervalos de confianza al 95 par ciento bilaterales de los tres coeficientes de In pendiente de regrcsi6n.
b) Contrastc pam cada uno de los coeficientes de la pcndientc las hip61esis
Ho : Pj = 0 frente a
13.24. Los resultados del am'il isis de un modelo de rcgresi6n son los s iguicntes:
;; = 2.50 + 6,8x 1 + 6,9x2 - 7,2x) (3.1) (3.7) (3.2)
R2 = 0.85 II = 34
Los numeros entre parentesis s iluados debajo de las estimaciones de los coeficientes son los crrores tfpicos muestrales de las estim:lciones de los eoeficientcs.

a) Calcule imcrvalos de confianza al 95 por denlo bilaterales de los Ires coefieientes de la pendienle de regresi6n.
b) Conlrasle para cada uno de los coeficienles de la pendiente las hip6tesis
frente a H I : Ili > ° 13.25. Los resultados del anal isis de lin modelo de re
gresi6n son los siguientes:
y = - 101 ,50 + 34,8x, + 56,9x2 - 57,b:3 (12.1) (23.7) (32.S)
R2 = 0,71 II = 65
Los numeros entre parentesis situados debajo de las estimaciones de los coeficientes son los en-ores I{picos mueslrales de las estimaciones de los coeficientes.
a) Calculc intcrvalos dc confianza al 95 por ciento bilaterales de los Ires cocficientes de la pendiente de regresi6n.
b) Contraste para eada uno de los coefieientes de la pendiente las hip6tesi s
frentc a H j : fJj > 0
13.26. Los resultados del amilisis de un modelo de regresi6n son los siguientes:
y = - 9,50 + 17,8x j + 26,9x2 - 9,21:3 (7.1 ) (13 .7) n.8)
/I = 39
Los numeros entre parentesis situados debajo de las estimaciones de los coeficientes son los errores tfpicos muestrales de las estimaciones de los coefidcntes.
a) Calcule intervalos de eonfianza al 95 por cicnto bilatcralcs de los tres coeficientes de la pendiente de rcgresi6n.
b) Contraste para cada uno de los coeficientes de la pendiente las hip6tesis
flo:{Jj = 0 frente a HJ :/1) > 0
Ejercicios aplicados
13.27. En cI estudio del ejercicio 13.6, los errorcs tfpicos estimados eran
S;" = 0,099 S;" = 0,032
a) Hall e intervalos de eonfianza al 90 y el 95 por demo de fJ I'
b) Halle intervalos de confianza al 95 y el 99 par eiemo de #2'
Capitulo 13. Regresi6n multiple 523
c) Contraste la hip6tesis nub de que, man leniendose todo 10 demas constanle, el peso del avi6n no liene una intluencia lineal en su esfuerw de diseiio frente a la h ip6tesis alter· nativa bilateral.
d) La suma de los cuadrados de los en-ores de cSla rcgresi6n era 0.332. Utilizando los mismos datos, se aj usl6 una regresi6n lincal simple del esfuerzo de diseno can respecto al nlimero poreemual de piezas cornunes, 10 que dio una suma de los cuadrados de los errores de 3.311. Contraste al nivel del I par ciento la hip6tesis mila de que la velocidad maxima y el peso, considerados conjunta· mente, no contribuyen nada en un senti do li neal a la explicaci6n del esfuerz.o de diseno, dado quc cl numero porcentual de pi czas comimes tambicn se util iza como variable explieativa.
l3.28. En cI estudio del ejercicio 13.8, en cl que la regresi6n mueslral se basaba en 30 observaciones, los errores tfpicos eSli mados eran
S", = 0,023
a) Comraste la hip6lesis nul a de que, dado el tamano de la familia, el consumo de leche no depende lineal mente de la rema frenle a la hip6tesis a.lternativa unilateral adecuada.
b) Halle intervalos de eonfianza del 90, el 95 y el 99 por ciento de f32'
13.29. En el estudio de los ejercicios 13.9 y 13.21, en los que la regresi6n muestral se basaba en 25 observaciones, los errores t[picos estimados eran
Sb, = 0,189 Sb, = 0,565
a) Contraste la hip6tesis nula de que, manteniendose 10£10 10 dem.is conslanle, las horas de ejercicio no illtluyen lineal mente en el flumento de peso frente a la hip6tesis allernativa unilateral adecuada.
b) Conlrasle la hip6tesis nula de que, rnanteniendose todo 10 demas eonstante, el eonsu· rna de cerveza no in nuye lineal mente en el aumento de peso frente a la hip61esis alter· nativa unilateral adecuada.
c) Halle intervalos dc confianza del 90, el 95 y el 99 por ciento de fJI'
13.30. Vuelva a los datos del ejemplo 13.6.
a) Contraste la hip6tesis nula de que, manteniendose todo 10 dernas constante, la ren ta

524 Estadislica para adminislraci6n y economia
personal per capita mediana no InOuye en el ripo efcclivo del impuesto sobre bienes inmuebJes frente a una hipotesis alternativa bilateral.
h) Conlraste la hip61esis nula de que las tres variables independicntes, consideradas conjuntamente, no influyen linealmenle en d tipo erectivo del Impuesto sobre bienes 111-
muebles.
13.31. , ~ Vue!va a los datos del ejemplo 13.7 que se eneuentran en el fichero de datos Citydat.
a) Halle inrervalos de confianza al 95 y al 99 por cienlo de la variaci6n esperada del prccia de mercado de las viviendas provocada par un aumcnlo del numero medio de habitaeiones de I unidad cuando no varIan los valores de todas las demas variables independientes.
b) Contraste [a hip6tesis nula de que, manteniendose todo 10 demas constanle, 141 renla media de [as hogares no influye en el precio de mereado frente a la hip6tesis ahernativa de que cuanto mayor es la renta media de [os hogares, milS alto es el precio de mercado.
13.32. En Ull estudio de los ingresos gencrados pOl' las loterfas naciona[es, se ajust6 la siguiente ecuaci6n de regrcsi6n de 29 parses que tienen lorcrfas:
y= - 31 ,323 + O,04045xI + 0,8772r2 - 365,Olx3 - 9,929Kr4 (0.00755) (0.3t07) (263.88) (3.4520)
R2 = 0,51
donde y = d61ares de ingresos anua[es netos per capi
ta generados por la [olerfa XI = renta personal media per C<'ipita del pars X2 = numero de hOleles: motcles, hosta[es y aJ
bergues pOl' mil habitantcs del pars x ) = ingresos anua[es gastables per capita gene
rados por las apuestas, las carreras y otros juegos de azar legaJizados
X4 = porcentaje de la fronte ra nacional que limita con un pars 0 parses que licnen una loterfa
Los numeros entre parenlesis situados debajo de los coeficientes son los en'orcs t[picos de los coeficicntes estimados.
a) Inlcrprete el coefieiente estimado de Xl'
b) Halle e interprete eJ intervalo de con fianza al 95 por ciento del coeficienle de x2 en [a regresi6n poblacional.
13.33.
13.34.
c) Contraste la hipolcsis nula de que el cocficiente de x) en la regresi6n pobJaeiona[ es () frente a la hip6tesis alternativa de que eSlc cocficicnte cs ncgativo. Interprete sus resu[ _ tados.
Se realiz6 un estudio para averiguar si podfan ulilizarse algunas caracterfsticas para explic:n la variabil idad de los preeios de los homos. Se csrim6 para una muestra de 19 homos la siguienlc regresi6n:
.y = - 68,236 + 0,0023xl + 19,729x2 + 7,653Xl (0.005) (8.992) (3.082) .
R2 = 0.84
donde
y = prec io en d61ares x I = porencia del homo en BTU pOl' hora Xl = cocficicntc de eficienc ia energetica X3 = numero de posic iones
Los numeros entre parentesis situados debajo de los coeficientes son los errores tfpicos de los cocfieientcs estimados.
a) Halle el intervalo de confianza al 95 por cien lo de 141 subida esperada del preeio resultante de un aurnento de [as posiciones cllando los valores de la polencia y el fndice de eficiencia energetica se mantienen fijos.
b) Contraste 13 hip6tesis nula de que, mall1enicndosc todo 10 demas cOnstante, el fndice de eficiencia energetica de [os homos no afecta a su precio frente a la hip61esis alternativa de que cuanto mas a[lo es e[ rndiee de eficiencia energetica, mas alto cs cl precio.
En un estudio de [a demanda nigeriana de importac iones se ajust6 el siguiente mode[o a 19 ariaS de datos:
y= - 58,9+0,20x l - O,IOx2 if2 = 0,96 (0.0092) (0.084)
donde
y = cantidad de importaciones XI = gastos »crsonales de con sumo x 2 = preclo de las importaciones -:- precios
intcriorcs
Los numeros entre parentesis situados debajo de los coeficientes son Jos errores t(picos de los coeficientes estimados.
a) Halle el intervalo de con fi anza a[ 95 por dento de fJ l'
b) Contrastc la hipotcsis nula de que liz = 0 frente a la hip6tesis a[tcrnaliva un ilateral adecuada.

13.35. En un estud io de las tenenc ias extranjeras en bancos bril{micos., se o btu vo la siguientc rcgrc~
si6n muestra l, basada en 14 obscrvaciones an ualcs
y =
Capitulo 13. Regresi6n multiple 525
Iral , basada en datos de 39 eiudades de Mnryland:
- 0.00232 - 0,00024xl - Q,00002x2 + 0,00034x, (0,00010) (0,0000 18) (0,00012)-
y = - 3,248 + 0, 10 l xI - O,244x2 + 0,057x3 R2 = 0,93 + 0,48 122x4 + 0,04950x5 - 0,000 1Q."(6 + 0,00645x7 (0.77954) (0,0 11 72) (0.00005) (0.00306) (0,0023) (0,080) (0.00925)
donde
y = proporci6n de acti vQS a final del ano en filiales de bancos bri tani cos en manos de eXlranjcros en po rcentaj c de los activos 10-tales
X I = variaci6n anual , en miles de milloncs de libras, de la invers i6n cxtranjcra directa en Gran Bretafia (excluidos finanzas, seguros y bienes inmuebles)
Xl = relaci6n precio-benefi cios de los bancos x 3 = fndice del valor de cambia de In libra
Los ml mcros entre parentesis s ituados debajo de los coeficientes son los erfores tfpicas de los coeficientes cstimados .
a) Halle el intervalo de conllanza al 90 por ciento de /31 e interprele su resultado.
b) Contraste la hipotesis nula de que fh cs 0 frente a la hip6tesis alternati va de que es negati vo e interprete su resultado.
c) Contraste la hip6tesis nula de que /33 es ° frente a la hip6tcsis alternativa de que es posil ivo e interprete s u resultado.
13.36. En un estudio de las diferencias enlre los ni veles de demanda de bomberos par parte de las ciudades, se obtuvo la siguienle rcgrcsi6n mues-
ii' ~ 0.3572
donde
y = nLI1TIero de bomberos a tie mpo eompleto per c{ipila
X I = salario base maximo de los bamberos en miles de dol ares
X 2 = porcentaje de pablaci6n xJ = renta per capita estimada cn miles de d61ares X4 = densidad de poblaci6n X5 = can lidad de ayudas intergubernamencales
per capita en miles de d61ares X6 = numero de kil6melros de di slancia hasta la
capital de la region x7 = parcentaje de la poblaci6n que son varones
y lienen entre 12 y 2 1 aila:>
Los n(imcros entre parenlesis siluados debajo de los caeficientes son los errores tfpicos de los coeficienles estimados.
a) Hallc c intcrprcte el inlervalo de confianza al 99 por ciento de /3:; .
b) Contrasle la hip61esis nul a de que IJ4 es ° frente a la hip6rcsis ahcrnativa bilateral e interprete su resultado.
c) ContraSle In hip6tesis nuln de que #7 es ° frente a la hipotesis allernali va bilateral e illierprele su resultado.
13.5. Contrastes de los coeficientes de re resion
En el apartado anterior hemos moslrado como puede rea li zarse un contraste de hip6tesis cond ic ionado para averiguar si el coeficiente de una variable es pecffica es s igniricativo en un modelo de regresi6n. Existen, sin embargo, s ituac iones en las que no s inleresa saber cual e s e l efeclo de la combinaci6n de varias variables . POl' ejemplo, e n un modelo que predice la eanlidad ve nd ida, podrfa interesarnos saber e ua! es el e fecto eonjunto tanto del precio del vendedor como del precio del competidor. En olros casos, podrfa inte rcsarnos saber si la combinaci6n de lodas las variables es un util predicto r de la variable dcpendiente.
Contrastes de todos los coeficientes En primer lugar, presenlamos eontraste s de hip6tesis para averiguar s i los eonjuntos de varios coeficientes son lodos simultaneamente iguales a O. Consideremos de nuevo e l mode lo

526 Estadfslica para adminislracion y economfa
Comenzamos examinando la hip6tesis nula de que todos los cocficientes son simult u_ neamcnte iguales a cero:
La aceptac i6n de esta hip6tcsis nos lIevarfa a concluir que ni nguna de las variables de predicci6n del modelo de regresi6n es estadfsticamente significati va y, por 10 tanto, que no suministran ninguna informaci6n uti!. Si eso ocurriera, tendrfamos que volver al proceso de especificaci6n del modelo y desarrollar un nuevo conjunto de variables de prediccion. Afortunadamenle, en la mayorfa de los casos apl icados esta hip6tcsis se rechuza porque el proceso de especificacion normal mente lIeva a la identificaci6n de al menos una variable de predicci6n significativa.
Para contrastar la hipotesis anterior, podcmos utili zar la descomposic i6n de la variabilidad desarrol lada en el aparlado 13.3:
STC ~ SCR + SCE
Recuerdese que SCR es la cantidad de variabil idad exp licada por la regres ion y SCE es la cantidad de variabil idad no expl icada. Recuerdese tambien que la varianza del modelo de regresi6n puede estimarse utilizando
2 SCE s ~ ---=-='----, (II - K - 1)
Si la hi p6tesis nula de que todos los coefic ientes son iguales a 0 es verdadcra, entonees el
cuadrado medio de fa regresi6n
SCR CMR~
K
tam bien es una medida de l error con K grados de libertad. Como eonsccuencia, el cociente de
F ~ SCR/K SCE/(II - K - 1)
CMR 2
S,
sigue una distribucion F con K grados de libcrtad en el numerador y 11 - K - I grados de libertad en el denominador. Si la hi p6tesis nula es verdadera, lanto el numerador como el denominador son estimaciones de la varianza poblacional. Como sefialamos en eI apartado 11 .4, cI coeicnte entre las varianzas muestra les independientes de poblaciones que tienen varianzas poblacionales iguales sigue una distribuci6n F si las poblaciones siguen una distribuei6n normal. Se compara el valor ealculado de F con el valor critico de F de la Tabla 9 del apendice a un nivel de significaci6n GC Si el valor ealculado es mayor que el valor crftico de la tabla, reehazamos la hipolesis nula y concluimos que al menos uno de los cocficien tes no es igual a O. Este metoda de contraste se resume en la ecuaci6n 13.23.

Citydat
Capitulo 13. Regresi6n multiple 527
Contraste de todos los para metros de un modelo de regresi6n Consideremos el modelo de regresi6n multiple
Para contrastar la hip6tesis nula
frente 8 18 hi p6tesis alternativa
HI = Al menos un {Jj i=- 0
a un nivel de significaci6n a, u\ilizamos la regia de decision
CMR Rechazar Ho: si --,- > FK,, - K- l rt S . . ,
donde FK. n _ K _ 1." es el valor eritieo de F de la Tabla 9 del apendice para el que
P(FK.I1 - K- 1 > FK.n - K- l. rt) = rx
(13.23)
La variable aleatoria calculada F K. n - K - l sigue una distribueion F con K grados de libertad en el numerador y (n - K - 1) grados de libertad en el denominador.
EJEMPLO 13.8. Modelo de prediccion de los precios de la vivienda (contraste simultaneo de coeficientes)
Duranle el desarrollo del modelo de predicci6n de los precios de 1a vjvienda para NOfthem City, los analistas querfan saber si exjslian pruebas de que la combinaci6n de cuatro variables de predicci6n no era un predictor significativo de l precio de la vivienda. Es decir, querian contrastar la hip6tesis
Solucion
Esle metoda de contraste puede ilustrarse mediante la regresi6n de los precios de la vivienda de la Figura 13.9 realizada uti lizando el fichero de datos Citydat. En la tabla del ao.11isis de la varianza, el estadislico F calculado es 19,19 can 4 grados de I ibertad en el numerador y 85 grados de libeltad en el denominador. EI calculo de F es
259,37 F~ ~ 1919
13,52 •
Este valor es mas alto que el valor crftico de F = 3,6 para rx = 0,01 de la Tabla 9 del apendice. Observese, ademas, que el Minitab -y la mayoria de los paquetes estadfsticos- caJcula cI p-valor, que en este ejcmplo es igua1 a 0,000. Por 10 tanto, rechazarfa· mos la hip6tesis de que todos los coeficientes son iguales a cero.

528 Estadistica para administraci6n y economfa
Contraste de un subconjunto de coeficientes de regresion
En los apartados anteriores hemos desarrollado cOl1 trastes de hi p6tesis de panimetros de re~
grcs i6n indiv iduales y de todos los panimetros en conjunto. A continuaci6n, desarrollamos un contraste de hip6tesis de un subconjunto de panimetros de regresi6n, como el ejemplo del conjunlo de precios que acabamos de anal izar. Utilizamos estc contraste para averiguar si el efecto conjunto de varias variab les independientes es signi ficativo en un modelo de regresion.
Consideremos un modclo de regresion que contiene las variables indepencli enles Xj Y
La hipotesis nula que se contrasla es
j = 1, ... , K
Si Ho es verdadera, las variables Zj no deben inc\uirsc en el modelo de regresi6n porque 110
suministran ninguna informaci6n para explicar la conducta de la variable dependiente mas que la que sumini stran las variables Xj' EI metodo para reali zar este contrasle se resume en la ecuaci6n 13.24 y se analiza detalladamente a continuaci6n.
EI contraste se reali za comparando la suma de los cuadrados de los en'ores, SCE, del modelo de regresi6n completo, que incluye tanto las variables X como las variables Z, con la SCE(r) de un modelo restringido que s610 incluye las variables X. Primero realizamos una regres i6n con respecto al modele de regresi6n completo anterior y obtencmos la suma de los cuadrados de los errorcs, SCE. A continuacion realizamos la regresi6n restringida, que excluye las variables Z (obscrvese que en esta regres i6n se aplica la reslriccion de que los coefi cientes tY.j son iguales a 0):
A partir de esta regresi6n obtenemos la suma restringida de los cuadrados de los en'O~ res, SCE(r). A continuaci6n, calculamos cl estadfstico F con r grados de libertad en eI nu~
merador (r es el numero dc variables eliminadas simulliineamente del modele restringido) Y Il - K - r - I grados de libertad en el denominador (los grados de libertad del error en el. modelo que induye lanto las variables independienles X como Z). EI estadfstico F cs
F ~ (SC£(r) ~ SCEJ/r ~ 2
S,
donde s~ cs la varianza estimada del error del modelo completo. Este estadfstico sigue L1na distribucion F con r grados de libertad en el numerador y 11 - K - r - 1 grados de liber~ tad en el denominador. Si el valor de F calculado es mayor que cJ valor crflico de F, enlonces se rechaza la hip6lesis nula y concluimos que las variables Z como conjunto deben incluirse en el modelo. Obscrvcse que este contrasle no implica que las variables Z individuales no dcban exc\uirse, par ejemplo, utilizando el contraste f de Student antes anali za~
do. Ademus, el contraste para lodas las Z no implica que no pueda excluirse un subconjunto de las variab les Z utili zando este metodo de contraste con un subconj unto diferente de vari ables Z.

Capitulo 13. Regresi6n multiple 529
Contraste de un subconjunto de los parametros de regresi6n Dado un modele de regresion con la descomposicion de las variables independienles en los subconjuntos X y Z,
Para contrastar la hip61esis nula
Ho: IX] = 1X2 = ... = IX,. = 0
de que los parametros de regresi6n de un subconjunto son simullaneamente iguales a 0, frente a la hip61esis alternativa
HI: Al menos un IXj =f. 0 (j = I .... , r)
compararnos la surna de los cuadrados de los errares del modelo completo can la suma de los cuadrados de los errores del modelo restringido. Primero, hacemos una regresi6n para el mo~ delo complei0, que inciuye todas las variables independienles. y obtenernos la surna de los cuadrados de los errores, SeE. A continuaci6n, hacemos una regresion restringida, que excluye las variables Z cuyos coeficlenles son las a: el numero de variables excluidas es r. A parlir de esla regresion obtenemos la suma restringida de los cuadrados de los errares, SCE(i) . A continuacion, calculamos el estadfstico F y apHcamos la regia de declsi6n para el nivel de sig~ nificaci6n IX:
Rechazar Ho si (SCE(r) - SCEJ/r s: > F,..II - K- ,· - l .(l ,
(13.24)
Comparacion de los contrastes Fy t Si util izaramos la ecuaci6n 13.24 can r = I, podrfamos contrastar la hip6tcsis de que una {mica variable, Xj' no mejora la prediccion de la variable depend icntc, dadas las demas variables independientes del modelo. Por 10 tanto, tenemos cl contraste de hip6tesis
Ho : Pj ~ 0 I Ii, l' O,} l' I H,: Pj l' 0 111,1' O, } 1'1
Antes hemos visto que este contraste tambien podfa reali zarse util izando un contraste , de Student. Utilizando metodos que no presentamos en este libra. podemos demostrar que los contrastes F y f correspondienles pcrmiten lI egar exactamente a las mismas conclusiones sobre el contraste de hip6tesis de una unica variable. Ademas, el estadfstico I calculado para el coeficiente bj es igual a la raiz cuadrada del estadfstico F calculado correspondicnte. Es decir.
don de Fx. es el estadfslico F calculado utili zando la eCllacion 13.24 cuando se excluye la , variable Xj del modelo y, por 10 tanto, r = I. Demostramos este resultado numerico en el ejemplo 13.9.
La teoria estadfstica de la dislribucion tambicn dcmuestra que una variable aleatori a l' con 1 grado de libertad en el numerador es el cuadrado de una variable aleatoria t cuyos grados de libeltad son iguales al denominador de la variable aleatoria F. POI" 10 tanIO, los contrastes F y t siempre !levan a las mismas conclusiones sobre el contraste de hipo(es is de una unica variab le independiente en un modele de regres ion multiple.

530 Esladfslica para administraci6n y economia
EJEMPLO 13.9. Predicci6n del precio de la vivienda en las pequenas cludades (contrastes de hip6tesis de sUbconjuntos de coeficientes)
Los promorores del modelo de predieei6n del pree io de la vivienda del ejemplo 13.8 querfan ave riguar si el efeelo eonjullio del lipo imposili vQ y del poreentaje de locl.lles eomereiales contribuye a la prediee i6n despues de inc1ui r previamente los efeelos del tamano de la vivienda y de la renla.
Solucion
Continuando con eI problema de los ejemplos 13.7 y 13.8) tenemos un contraste condieionado de la hip6tesis de que dos variables no son predielores sign ifica livos, dado que las alras dos son prediclOres significativos:
ESle conlrasle se realiza uti lizando el metoda de la ecuaci6n 13.24. La Fig ura 13.9 presenLa la regresi6n del modelo eompleto can las cuatro variables de predicci6n. En esa regresi6n, SeE = 1.149, 14. En 13 Figura 13.11 tenemos 11.1 regresion reducida en la que las (micas variables de predicci6n son el tamano de la vivienda y la renta. En esa regresi6n, SeE = L.426,93. La hip6tesis se contrasta primero calculando el estadfsti co F euyo numerador es la suma de los euadrados de los errores del model a redueido [SCE(r )] menos la SCE del modelo completo.
(1.426,93 - 1.1 49,14)/2 F ~ ~ 10 27
13,52 '
Regression Analysis: hseval versus sizehse. income72
The regression equ~ tion is hseval = -42 . 2 + 91. 4 sizchse + 0 . 000393 i ncom72
Predictor Coef SE Coef l ' p
Cons tant - 42.208 9 . 810 - 4 . 30 0 . 000 Sizehse 9 . 135 1 . 940 4 . 71 0 . 000 i ncom72 0 . 003927 0 . 001473 2 . 67 0 . 009
S '" 4 . 04987 R-Sq :: 34 . 7% R-Sq(ad j) . 33 . 2%
Analysis of Vari~ncc
Source Regression Residua l Error Total
Source s i zehse i ncom72
OF 1 1
OF SS 2 759. 70
87 4 26 . 9 89 2186 . 63
Seq 55 643 . 12 116 . 58
MS F P 379 . 8 5 23.1 6 0 . 000
16 . 40
SCE(rl
Figura 13.11 . Regresion del precio de la vivienda: modelo reducido (salida Minitab).

Capitulo 13. Regresion multiple 531
EI estadfstico F liene 2 grados de libenad ---colTespondientes a las dos vari ab les conl"rastadas simultaneamente- en el numerador y 85 grados de libertad en el denominador. Observese que e l estimador de la varianza, s; = 13,52, se obliene a pm1ir del modele completo de la Figura 13.9, en la que el error tiene 85 gracias de libertad. Vemos en la Tabla 9 del apcndice que e l valor crilieo de F can IX = 0,01 Y 2 Y 85 grados de Iibertad es aproximadamente 4,9. Como el valor calculado de F es mayor que el va· lor critico, rechazamos la hip61esis nula de que el tipo imposilivo y el porcenlaje de 10· cales comerciales no estan en la combinaci6n significativa. EI efecto conjunto de estas dos variables si mejora el modele que predice el precio de la vivienda. POI' 10 tanto, el tipo imposit ivo y el porcentaje de locales comerciales deben incill irse en el modelo.
Tambicn hemos calculado esta regres i6n excluyendo la variable «compr» y hemos observado que 1a SeE resultante era
SCE(I) ~ 1.I 85,29
El estadfstico F calculado de esla variable era
(1.I85,29 - 1.149,14)/ 1 F ~ ~ 2 674
13,52 '
La rafz cuadrada de 2,674 es 1,64, que es el estadfstico I calculado para la variable «compo> en la salida del am'ilis is de regresi6n de la Figura 13 .9. Util izando cl estadfsti co F calclil ado 0 c l cstadfsti co 1 calculado, obtendrfamos este resultado para las hi p6tcsis de esta variable:
Ho : /3compr = ° I 111 oft 0, I #- compr
HI : /Jcompr #- 0 I /31 #- 0, I #- COl1lpr
EJERC1CIOS
Ejercicios basicos c) Analisis de Ia varianza
13.37. Suponga que ha estimado coelicientes para el siguiente modelo de regresi6n:
Contraste la hip6tesis de que las tres variables de predicci6n son igllales a 0, dadas las siguientes tablas del amilisis de la varianza.
a) Analisis de la varianza
b)
Source Regression Residual Error
OF 3
26
AmiUsis de la varianzu Source DF Regression 3 Residual Error "
5S MS 4500
SOD
SS MS 9780 2100
Source DF 55 M5 Regression 3 46000 Residual Error " 25000
d) Analisis de la varianza Source OF 5S MS Regression 3 87000 Residua l Error 26 48000
Ejercicios ap1icados
13.38. Vuelva al eSludio del esfucr7.0 de diseno de aYiones de los ejercicios 13.6 y 13.19.
u) Contraste la hip6tcsis nulu
b) Muestre la tabla del amllisis de la varianza.

532 Estadistica para administraci6n y economfa
13.39. Para el e.-audio de la intlucncia de Ins instituciones finaneieras en los precios de las aeciones del ejercicio 13.7, se utilizaron 48 observaciones lrimestrales y se observo que cl codicicnte cOlTegido de determinuci6n era R2 = 0,463. Contraste lu hip6tcsis nuia.
13.40. Vllelva al estudio del consumo de leche, deserito en los ejercicios 13.8, 13.20 Y 13.28.
a) Conrraste In hip6tesis nulo
Ho'~' ~ ~,~O
b) Mllestre In tabla del anMisis de la varianza.
13.41. Vllelva al estudio del numento de peso, descrilO en los ejercicios 13.9. 13.21 Y 13.29.
a) Contraste la hip6tesis nula
b) Muestre In tabla del analisis de la varianza.
13.42. Vuelva aJ ejercicio 13.32. Contraste la hip6tesis nula de que las cuatra variables independicnrcs. consideradas en conjunto, no inn uyen linealmente en los ingresos generados por las loterfas nacionales.
13.43. Vuelva al ejercicio 13.33. Contraste la hip61esis nula de que las tres variables independientes, consideradas en conjunto, 110 inlluyen linealmente en el precio de los hornos.
13.44. Vuclva al es\udio del cjercicio 13.34. Contraste la hip6tesis nula de que los gastos personales de eonsumo y el precio relativo de las importaeiones, eonsiderados en conjunto, no afectan linealmente a In demanda nigeriana de importac lones.
13.45. Vuelva al esludio de los delerminantes de la demanda de bomberos en una ciudad anal izado en el ejcrcicio 13.36. Contraste la hip6tesis nula
e interprete sus resultados.
13.46. Se realiza lIna regresi6n de una variable dependientc ·con respecto a K variables independienles utilizundo 11 conjuntos de observaciones muestra1cs. SeE es la sum a de los cuadrados de los errores y R2 es el coeficiente de detenni naci6n de esta rcgresi6n estimada. Queremos contrastar la hipiltesis nula de que KI de estas variables independientes, eonsideradas en conj unto, no afectan lineal mente a la variable
dependientc, dado que las de mas variables indcpendientes (K - KI ) lambien se ulilizan. Su. pongamos que se vllelve a estimar la regresi6n excluyendo las KI variables indepen<iicntes de interes. Sea SCE* la suma de los clladrados de los efrores y R*l el coeficiente de determinaci6n de esta regresi6n. Dernuestre que cI estudfslico para contrastar nuestra hip6tesis nula, introducido en el apartado 13.5, puede expresarse de la forma siguiente:
(SeE':' - SC£)/ K J R2 - R*2 II - K -
SCE/(n - K - I) I - R2 KI
13.47. En el estudio de los eJerclclos 13.8, 13.20 Y 13.28 sobre el consumo de leche, se ailadic. al modelo de regresi6n una tercera variable independiente: el mimero de ninos cn edad preescolar que habfu en el hogar. Cuando se estim6 esIe modelo ampliado. se observ6 que In suma de los cuadrados de los errores era 83,7. Contraste la hip6tesis nul a de que, manten h~ndose todo 10 demas constante, el numero de nifios en edad preescolar que hay en el hogar no afecta linealmente al consumo de leche.
13.48. Suponga que una variable dependiente est,! relacionada con K variables independientes a traves de un modelo de regresi6n multiple. Sea R2 el eoeficiente de delerminaci6n y iP el coefieiente cOlTegido. Suponga que se utilizan n conjunros de observaciones para ajustar la regresion.
a) Demuestre que
-2 (n - I )R2 -K R ~
n - K - I
b) Dcmuestre que -,
2 (II-K-I)R +K R ~
11-1
c) Demuestre que el estadfstico para contraslar la hi p6tesis nula de que todos los eocficienles de regresi6n son 0 puede expresnrse de la forma sigu iente:
SCRIK n - K- I ii2+A SeE/(n - K - I ) K R'
donde
K A ~-~
n-K - I

Capflulo 13. Regresi6n multiple 533
13.6. Prediccion
Una apl icaci6n imp0!1ante de los modelos de regresion es predecir los val ores de la variable dependiente, dados los valores de las variables independientes. Las prediccioncs pueden realizarse directamente a partir del modelo de regresion estimado utili zando las estimaciones de los cocficicntes de ese modelo, como mueSlra la eCllacion 13.25.
Predicciones a partir de los modelos de regresion multiple Dado que se cumple el modele de regresi6n poblacional
y que los supuestos habituales del ana.lisis de regresj6n son va.lidos, sean bo' b1, ••. , bK las estimaciones par mlnimos cuadrados de los co.eficientes del modelo, Pi' siendo j = 1, ... , K, basados en los puntos de datos Xl" >S" ••• , X Ki (/ = 1, ... , n). En tal caso, dada una nueva observa~i6n de un punta de datos, Xl, n + l' X2, n+ l' "', X K, n+ l' la mejor predieei6n lineal insesgada de Yn + 1 es
(13.25)
Es muy arriesgado haeer prediceiones que se basan en valores de X fuera del rango de los datos utillzados para eslimar los eoeficientes del modelo, ya que no tenemos pruebas que apoyen el modelo lineal en esos puntas.
Ademas de querer conocer el va lor predicho de Y para un conjunto de xj ' a menudo nos interesa calcular un intervalo de confianza 0 un intervalo de predicci6n. Como sefialamos en el apartado 12.6, el interva lo de confianza incluye el valor esperado de Y con la probabilidad 1 - 0:. En cambio, el intervalo de prediccion incluye los valores individua les prcdicllos: los valores esperados de Y mas el termino de error aleatorio. Para hallar estos intervalos, es necesario calcular estimaciones de las desviacioncs tfpicas del valor esperado de Y y los puntas individuales. Estos calculos son simi lares en la forma a los utilizados en la regresi6n simple, pem las ecuaciones de los esti madores son mucho mas complicadas. Las desviaciones tfpicas de los valores prediehos, .'ij' son L1na funei6n del error tfpico de la est imaci6n, se; la desviaci6n tfpica de las variables de predicci6n; las correlaciones entre las variables de predicci6n; y e! cuadrado de la distancia entre la media de las variables independientes y las X para la predicci6n. Esla desv iacion lfpica es similar a la desviaci6n tfpica de las prcdicciones de la regres i6n simple del Capitulo 12. Sin embargo, las ecuaciones de la regresi6n multiple son muy complejas y no se presentan aquf; [0 que hacemos es calcular los valores uti li zando el programa !y1initab. La mayorfa de los paquetes estadfsticos buenos calculan las desv iaciones tfpicas del intervalo de predicci6n y del intervalo de confianza y los correspondientes interval os. Excel no permite calcular la desv iaci6n tfpica de las variables predichas.
EJEMPLO 13.10. Prediccion del margen de beneficios de las asociaciones de ahorro y credito inmobiliario (predicciones del modelo de regresi6n)
Le han pedido que haga una predicei6n del margen de beneficios de las asoc iaciones de ahorro y cn:dito inmobiliario para un ano en el que e1 porcentaje de ingresos netos es

534 Estad{stica para administraci6n y economfa
Savings and Loan
4,50 Y hay 9.000 oficinas, ulilizando el modelo de regresion de las asociaciones de ahorro y credilO inmobiliario. Los datos se encuenlran en el lichero Savings and Loan.
Solucion
Utilizando la nolacion de la ecuaci6n 13.25. tenemos las variables
X I.,,+ I = 4,50 X2.,,+ I = 9.000
Uti lizando estos valores, observamos que nuestro predictor puntual del margen de beneficios es ,
)',, + 1 = bo + b IX I. II + 1 + b,;t·2.II + l
= 1,565 + (0,237)(4,50) - (0,000249)(9.000) = 0,39
Por 10 tanto, cn un ana en el que el porcentaje de ingresos netos por d61ar depositado es 4,50 y el numero de oficinas es 9.000, predecimos que el margen porcentual de benefitios de las asoc iaciones de ahorro y credito inmobiliario es 0.39.
Los valores predichos, los intervalos de confianza y los intervalos de predicci6n pueden calcularse directamente por medio del programa Minitab.
La Figura) 3. 12 muestro la salida del analisis de regresi6n. Se presenta el valor predicho, y = 0,39 y su desviaci6n tfpica, 0,0277, junto con el intervalo de confianza y el
Regression Analysis: Y profit versus Xl revenue, X2 offices
The regression equation is Y profit 2 1 . 56 + 0 . 237 Xl revenue - 0 . 000249 X2 offices
Predictor eoef SE Coef T P Constant 1 . 56450 0 . 07940 19 . 70 0.000 Xl revenue 0 . 23720 0.5556 4.27 0.000 X2 offices ~0.00024908 0.00003205 -7.77 0 . 000
S 0 . 0533022 R-Sq 86 . 5\ R-Sq(adj) = 85.3\
Analysis of variance
Sou rce OF 5S MS F P Regression 2 0.40151 0 . 20076 70 . 66 0.000 Residua l Error22 0 . 06250 0 . 00284 Total 24 0 . 46402
Instrucciones de Minitab 1. STAT> REGRESSION
> REGRESSION> OPTIONS 2. Pulsar New Observation
Values 3. Seleccionar Fits, Confidence
limits, Prediction limits
Valor predicho
pred:.~c~c~ed;;v~a~,;u~e~S;f;o~r;:N:e~W~O~b:,~e;r~v:;~::~~~~~~=-_ Error tfpico del valor predicho
95\ CI 95' PI .1.-- tntervalo 0 . 4476) 0.2656, 0 . S148y ~ __ ",,::::::~-:":::::::::=::::~ ___ de predicci6n
Intervalo Values of Predictor s for New Observations deconfianza
New x. Obs Xl revenue offices
1 4 . 509000 )<------Val ores de las variables de predicci6n
Figura 13.12. Predicciones e intervalos de predicci6n de la regresi6n multiple (salida Minitab).

Capitulo 13. Regresi6n multiple 535
intervalo de predicci6n. EI intervalo de confianza -Cl- es un intervalo del va lor esperado de Y en la funcion lineal defi nida por los val ores de las variables independientes. Este in tervalo es una funeion del elTor {ipieo del modele de regresion. la di slancia a la que se encuenlran los valores de Xj de sus medias muestrales individuales y la corre lacion entre las variables Xj uti lizadas para ajustar el modelo. El intervalo de prediccion -Pl- es un intervalo para un unieo valor observado. Por 10 tanto, incluye Ja variabilidad del valor esperado mas la variabilidad de un unico punlo en tome al valor predicho.
EJERCICIOS
Ejercicios basicos 13.49. Dada la ecuaci6n de regresi6n multiple estimada
y = 6 + 5xI + 4X2 + 7X3 + 8X4
calcular el valor predicho de Y cuando
a) XI = lO, x2 = 23 , x3= 9, x4= 12 b) XI = 23, X2= IS, X3 = lO, x4 = II c) XI = 10, -'"-2 = 23 , x)= 9, X4= 12 d) Xl = -10, X2 = 13, x 3 = - 8, X4 = - 16
Ejercicios aplicados
13.50. Utilizando In informaci6n del ejercicio 13.9. prediga el aumento de peso de un estud iante de primer ano que come una media de 20 comidas a la scmana, hace ejcrcicio durante una media de 10 horas a 1a semana y consume una media de 6 cervezas a la semana.
13.51. Utilizanda la informaci6n del ejercicio 13.8. prediga cl consumo semanal de lechc de una fami lia de cuatro personas que (iene una renta de 600 $ a la semana.
bo = 0,578
13.52, En la regresi6n del esfuerzo de diseno de aviones de! ejercicio 13.6, la ordenada en e! origen estimada era 2,0. Prediga el esfuerzo de diseno de un avi6n que iiene una velocidad maxima de mach I,D pesa 7 toncladas y tiene un 50 por ciento de piezas en comlin con otros modelos.
13.53. Una agencia inmobi li aria afi rma que en su ciudad el precio de venta de una vivienda en d61ares (y) ~epende de su lamana en metros cuadrados de superficie (Xl), el tamano del solar en metros cuadrados (~) , el numero de dormilorio~ (X.3 ) y cl numero de cuartos de bano (X4).
Basandosc en una muestra aleatoria de 20 vcnlas de vivicndas, sc obluvo el siguienle modela esti mado por minimos cuadrados:
y= 1.998,5 + 22,352x 1 + 1,468~+6.767,3x3 (2,5543) (1.4492) ( 1820,8)
+ 2.70 1,lX4 (1996.2) R2 = 0,9843
Los numeros entre parentesis situados debajo de los coeficientes son los errores t(picos de los coelicientes estimados.
a) Interprete en el contexto de este modelo el coeficiente estimado de x2.
b) Intcrpretc el cocficiente de determi nacion. c) Suponicndo que el modelo esta especificado
correctamente, contrasle al nivel del 5 por ciento la hipotesis Ilula de que. manteniendose todo 10 demas conS(antc, el precio de venta no depende del numero de cuartos de banD frente a la hip6tesis alternariva unilateral adecuada.
d) Estime el precio de venia de una vivienda de 1.250 metros cuadrados de superficie, un solar de 4.700 metros euadrados, 3 dormitorios y un cuarto de bano y medio.
13.7. Transformaciones de modelos de regresion no lineales
Hemos visto como puede utili zarse el anali sis de regresion para eSlimar relaciones lineales que predicen una variable dependiente en funcion de una 0 mas variables independientes. Estas aplicaciones son muy importanlcs. Sin embargo, hay, ademas, algunas relaciones economicas y empresariales que no son estrictamente lineales. En este apartado desalTolla-

536 Estadistica para administraci6n y economia
o -ri • " c • u
mos metodos para modificar algunos fonnatos de los lllodcJos no lineales con eI fin de poder utili zar los rnetodos de regrcs i6n mult iple para estimar los coeficientes del mocleln. POI' 10 tanto, eI objeli vo de los apartados 13.7 y 13.8 es am pliar la variedad de problemas que puedcn adaptarse a un amilisis de rcgresi6n. De esta forma vemos que el amilisis de regresi6n tiene aun mayores apl icaciones.
Examinando el algoritmo de mfn imos cuadrados. vcmos que maniplilando con ellidado los modelos no linea les, es posible ulili zar los mfnimos euadrados en un eonjulllO mas am. plio de problemas aplicados. Los supuestos sobre las variables independientes en la regresi6n multiple no son muy restrietivos. Las variables independientes definen puntos en los que medimos una variable aleatoria Y. Suponemos que hay una relaci6n li neal entre los ni veles de las vari ables independientes Xj , donde j = I, ... , K, y e l valor csperado de la variable dependiente Y. Podemos aproveehar eSla libertad para ampiiar el conjunto de modclos que pueden estimarse. POI' 10 tanto, podemos ir mas alia de los modelos lineales en nuestras apli cac iones del anal isis de regresi6n multiple. En la Figura 13. 13 se muestran Ires ejempJos:
(a) Las funeiones de of en a pueden no ser lineales. (b) EI aumenlo de la producei6n total con un au menlo del nu mero de trabajadorcs
puede ser cada vcz menor a medida que se anaden mas trabajadorcs. (c) EI eOSle medio pOl' unidad producida a menudo se minimiza en un ni vel de pro
dllcc i6n intermedio.
Precio, P (,I
>-C
:Q 0 0 , u 0 ~
~
Numero de trabajadores, Xl (b)
Figura 13.13. Ejemplos de funciones cuadraticas.
>--ri • u c , 0 ~
• " 0 u
Transformaciones de model os cuadraticos
Producci6n total, Xl (0)
Hemos dedieado bastante liempo al desarro llo del anali sis de regres ion para estimar eeuaciones lineales que rcprcsentan di versos procesos cmpresariales y econ6micos. Tambien hay muchos procesos que pueden representa rse mejor mediante ecuaciones no li neales. EI ingreso total tiene una re laci6n cuadralica con el prcc io y el ingreso maxi mo se obliene en un ni vel intermedin de precios si la funci6n de demanda tiene pendiente negativa. En muchos casos, el coste min imo de produec i6n pOl' unidad se obti ene en un nivel de producci6n inlermedio y cl coste por unidacl es decreciente a medida que nos aproximamos al coste mfnimo pa r unidad y despues aumenta a partir de ese coste minima par unidad. Podemos anali zar algun us de estas relaciones econ6micas y cmpresaria les utili zando un modela cuaddtico:
y = Po + p,X, + P,xi + ,

Production Cost
Capitulo 13. Regresi6n multiple 537
Para eslimar los coe ricientes de un modele clladratico para apl icac iones de este tipo, podemos transfonnar 0 modificar las variab les, como muestran las ec uHciones 13.26 y 13.27. De esta forma. un modelo cuadrat ico no li neal se convierte en un modele que es lineal en un conjunlo modifi cado de variables.
Transformaciones de modelos cuadraticos
La funci6n cuadratica
y ~ Po + /J,X, + p,X; + , (13.26)
puede transformarse en un modelo lineal de regresi6n multiple definiendo nuevas variables:
y despues especificando el modele
(13.27)
que es lineal en las variables transformadas. Las variables cuadraticas transformadas pueden combinarse can olras variables en un modelo de regresi6n multiple. Por 10 lanto, podemos ajustar una regresi6n cuadratica multiple ulilizando variables transfonnadas. EI objetivo es encontrar modelos que sean lineales en otras formas matematicas de una variable.
Transfonnando las variables. podemos estimar un modelo lineal de regresi6n multiple y utilizar los resultados como un mode lo no lineal. Los melodos de inferencia para los modclos elladdlicos transformados son los mismos que hemos desarrollado para los modelos lineales. De est a fo rma, evitamos la confusi6n que se tendr!a si se utili zaran llnos metodos eSladfslicos para los rnodelos lineales y oLres para los mode los cli adrat icos. Los coefic ientes dcben combinarse para poder interprctarlos. Asi, si tenemos un modelo cuadra Ii co, e l efeeto de una variable. X. es ind icado por los cocficientes tanlo de los tenninos lineales como de los termi nos cuadnitieos. Tambien realizamos un scncillo contraste de hi p6tesis para averi guar s i un modelo cuadralico es una mejora can respecto a un modelo !inc.1!. La variable ~ 0 xi no es mas que una variable ad icional cuyo coefic iente puede contrastarse - Ho: {J2 = 0-- utili zando la / de Student cond icionada 0 el estadfstico F. Si un modelo cuadratico se ajusta a los datos mejor que un modelo lineal , el coeficiente de la variable cuadratica -~ = xi- sera sign ificati vamen te diferente de O. EI melodo es e l mis mo si tenemos variables como 23 = X~ 0 24 = XTX2 .
EJEMPLO 13.11. Costes de produccion (estimaclon de un modelo cuadratico)
Arnold Sorenson, director de producc i6n de New Front iers Instruments Inc., tenia interes en estimar la relaci6 n matema.tica entre el numero de montajes eleetro nicos producidos en un tu rno de 8 horas y el coste medio pOl' montaje. Esta funci6n se utilizarfa despues para estimar el coste de varios pedidos de producci6n y averiguar el ni vel de producci6n que minimizaria el cosle med io. Los datos se encllentran en el fichere de datos Production Cost .

538 Estadistica para administraci6n yeconomfa
Solucion
Arnold recogi6 datos de nueve turnos duran te los cuales el numero de monlajes oscil6 enlre 100 y 900. Tambien obluvo en el departamento de contabilidad eJ coste medio pa r un idad en que se incuni6 durante esos dlas. Estos datos se presentan en un diagrama de puntos dispersos realizado por media del programa Excel y mostrado en la Figura 13.14. Sus estudios de economfa y su exper iencia 10 !levaron a sospechar que la funci6n podr!a ser cuadr.:itica can un coste media min ima intennedio. Diseii6 Sll amil isis para cOlls iderar tanto lIna funci6n de cosle media de producci6n lineal como lI na cuadratica.
La Figura 13.15 es la regresi6n simple del cosLe como una funci6n lineal del nume· ro de unidades. Vemos que la relaci6n lineal cs cas i plana, 10 que indica que no ex iste una relaci6n linea! entre el coste medio y e l numero de unidades producidas. Si Arno ld hubiera utili zado simplemente esta relaci6n, habr!a cometido graves errores en sus me· todos de estirnaci6n del coste.
La Figura 13.16 presenta la regresi6n cuadratica que muestra el coste media por unidad como una funci6n no lineal del numero de unidades producidas. Observese que b2 es diferente de 0 y, por 10 tanto, debe inclui rse en el modelo. Observese tambien que el R2 del modelo cuadriitico es 0,962. mientras que en el modelo lineal es 0,174. Utilizan· do eJ modelo cuadnitico, Arnold ha elaborado un modelo de coste media mucho mas uti!.
Numero de Coste medio 5,5 Unidades por unidad
~
100 5, 11 • 5 ~
• 210 4,42 c ,
" 4,5 290 4,07 0
0. • 415 3,52 0 '5 4
509 3,33 • E • •
• 613 3,44 • 3,5 ~ 697 3,77 0
" • 806 4,07 3
908 4,28 o 200 400 600 800 1.000
Numero de unidades
Figura 13.14. Coste media de producci6n en funci6n del numero de unidades.
Regression Analysis: Mean Cost per Unit versus Number of Units
The regress i on equation is Mean Co s t per Unit = 4 . 43 - 0 . 000 855 Number of Units
Pred ictor Cocf SI> Coe f T P Constant 4 . 4330 0 . 399 4 11.10 0 . 000 Number of Uni t s -0 . 0008547 0 . 0007029 -1.22 0 . 263
5 • 0.547614 R- Sq = 17 .4\ R-Sq( a dj) • 5.6\
Analysis of variance
Source DF 55 M5 F P Regression 1 0 .4433 0 . 4 433 1 .48 0 . 26 3 Res i d ua l Error 7 2 . 0992 0 . 299 9 Tota l 8 2.5425
Figura 13.15. Regresi6n linea! del coste medio en funci6n del numero de unidades (salida Minitab).

Capitulo 13. Regresi6n multiple 539
Regression Analysis: Mean Cost per Unit versus Number of Units, No Units Squared
The regression 0qu3tion is Mean Cost per Unit = 5 . 91 - 0.000884 Number of Units + 0 . 000008 No Units Squ3red
Predictor coef Const3nt 5.9084 Number of Units -0 .0088415 No Units Squared -0.00000793
S = 0 . 125875 R- Sq = 96.2\
Analysis o f Variance
Sourc e OF SS Regress ion , 2 .44 59 Residual Error 6 0 . 0955 Total 8 2.5425
SE Coef T P 0.1614 36 . 60 0.000
0 . 0007344 - 12 . 04 0.000 0 . 00000071 11 . 15 0.000
R-Sq(adj) 0 94 . 9%
MS F P 1 . 2230 75.97 O. 000 0 . 0151
Figura 13.16. Modelo cuadratico del coste media en juncian del numero de unidades (salida Minitab).
Transformaciones logarftmicas
Algunas relaciones econ6micas pueden anali zarse mediante fu nciones exponenciales. Por ejcmplo, si la variaci6n porcentual de la cantidad vend ida de bienes varfa linealmente en respuesta a las variaciones porcentuales del precio, la funci6n de demanda tendnl una forma exponencial:
donde Q es la cantidad demandada y P es el precio por unidad. Las funciones de demanda exponenciaies tienen elasticidad constante y, pOl' 10 tanto, una variaci6n del prccio de un 1 pm ciento provoca la misma variaci6n porcentual de la cantidad demandada en todos los niveles de precios. En cambio, los modelos lineales de demanda indican que una variac i6n unitaria de la variable del preeio provoea la misma variaci6n de la canlidad demandada en todos los nive les de precios. Los modelos exponenciales de demanda se ulilizan mucho en el amilisi s de la conducta del mercado. Una importante caracterfstica de estos modelos es que el coeficiente [lr es la c1asticidad constante, e, de la demanda Q con respecto al prec io P:
JQIQ e= -- =p, aplP
Este resultado se desarrol1a en la mayorfa de los iibros de texto de microeconomfa. Los coeficientes del modelo exponenciai se estiman utili zando transformaciones logarftmicas, como muestra la ecuac i6n 13.29.
La transformaci6n logarftmica supone que el tennillo de error aleatorio multi plica el verdadero valor de Y para obtener el va lor observado. Por 10 tan to, en el mode lo exponencial el error es un porcen taje del verdadero valor y la varianza de la distribuci6n de l error au menta cuando aumenta Y. Si este resu ltado no es cierto, la lrans rormacion logarft mica no es correcla. En ese caso, debe utili zarse una lecni ca de esti maci6n no lineal mucho rmis compleja. Estas tecni cas eSlan fuera del alcance de este li bro.

540 Esladislica para administracion y economia
Transformaciones de model os exponenciales Los coeficientes de los modelos exponenciales de la forma
(13.28)
pueden estimarse tomando primero el logaritmo de los dos miembros para obtener una ecuacion que es lineal en los logaritmos de las variables:
log (l') = log (Po) + fl, log (X,) + II, log (X, ) + log (,) (13.29)
Utilizando esla forma, podemos hacer una regresion del logaritmo de Y con respecto a los 10-garitmos de las dos variables X y obtener estimaciones de los coeficientes PI y IJ2 directamente del anal isis de regresi6n. Dado que los coeficientes son elasticidades, muchos economistas utilizan esla forma del modele en la que pueden suponer que las elasticidades son constantes en el rango de los datos. Observese que esle metoda de estimaci6n requiere que los errores alealorios sean multiplicativos en el modelo exponencial original. Par 10 tanto, el termino de error, c, sa 9xprasa como un aumento 0 una disminucion porcentual y no como la adici6n 0 la sustracci6n de un error aleatorio, como hemos vislo en los modelos lineales de regresi6n.
Otra importante aplicaci6n de los mode los exponenciales es la funci6n de producci6n Cobb-Douglas, que tiene la forma
donde Q es la cantidad producida, L es la cantidad utilizada de trabaja y K es la canLidad de capita l. PI Y P2 son las contribuciones relativas de las variaciones del tTabajo y de las variac iones del capital a las variaciones de la cant idad producida. En un caso especial, eorrespondiente a los rendimientos constan les de escala , sc plantea la restrieei6n de que la suma de los coefic ientes sea igual a I. En ese caso, 111 Y 112 son las conlribuciones porcentualcs del lrabajo y cl capilal al au mento de la produclividad.
La estimaci6n de los coeficientes cuando su suma cs iguaJ a I es un ejemplo de est imaci6n rcstringida en los modelos de regrcsi6n. La ecuaci6n 13.29 es modificada par la restricc i6n
fl, + #, = I
y, pOl' 10 tanto, se incluye la sust ituci6n de la fo rma
II, = I - fl,
y la nueva ecuae i6n de estimaci6n se convierte en
log(y) = log ({30) + /I,log(X,) + ( I - P,) log(X, ) + log (F.)
log(Y) - log (X, ) = log ({Io) + fl, [log(X,) -log(X, )] + log(")
log (;,) = log (Po) + p,log G:) + log (to) (13.30)
Vemos, pues, que el coeficiente PI se obticne haciendo una regres i6n de log (Y/X2) con respecto a log (X I/X2). A conlinuaci6n, se calcula 132 reSlando PI de 1,0.
Todos los buenos paquetes estadfsticos pucden calcular faci lmcnte las transformaciones necesarias de los 'datos para los modelos logarftmicos. En el ejemplo siguicntc utilizamos el programa Minitab, pero podrfan obtenerse resultados simi lares ulilizando olros muchos paquetes.

Capitulo 13. Regresi6n multiple 541
EJEMPLO 13.12. Funcion de produce ion de Minong Boat Works (estimacion del modelo exponencial)
Minong Boat Works comenz6 a producir pequcnos barcos de pesca a principios de la decada de 1970 para los pescadores del norte de Wisconsin. Sus propietarios desarro!Jaron un metoda de producci6n de bajo coste para producir barcos de cali dad. Como consecuencia, ha aumentado Sli demanda con el paso de los aoos. EI metoda de producci6n utili za una terminal de trabajo con un conjunlo de planlillas y herramientas electrieas que pueden ser manejadas por un numero variable de trabajadores. EI numero de tenn inales (unidades de capital) ha aumentado can cl paso de [os anos de 1 a 20 para sati sfaeer la demanda de barcos. Al mismo tiempo, la plantilla se ha incrementado de 2 trabajadores al ailo a 25. Ahara los propietarios estan eonsiderando la posibi lidad de aumentar sus ventas en olros mereados de Michigan y Minnesota. Por 10 tanto, neeesi[an saber cminto tienen que aumentar el numero de terminales y el numero de trabajadores para iograr diversos aumentos del nivel de producci6n.
Soluci6n
Su hija, licenciada en economfa, sugiere que estinien una funci6n de producci6n CobbDouglas restringida utili zando datos de alios antcriorcs. Explica que esta fu nci6n de produccion les permilira predecir el numero de barcos producidos can diferentes ni ve les de terminales y de trabajadores. Los propielarios estan de acuerdo en que esc anal isis es una buena idea y Ie piden que 10 realice. Comienza el amili sis recogiendo los datos hi s-
Boat tOl'icos de produccion de la empresa, que se encuentran en el fichero de datos Boat ProProdm:tion duction. Para estimar los coeficientes, primero debe transformar la especificaci6n origi
nal del model a en una forma que pueda estimarse mediante una regresion par mInimal' cuadrados. EI modelo de la runcion de producci6n Cobb-Douglas es
can la restricci6n
P2~ I - P,
donde Yes el numero de bareos producidos al ana, K es el numero de terminales (uni dades de capital) ulili zadas cada ano y L es e[ numero de trabajadores utili zados cada ana.
La funci6n de produccion Cobb-Douglas restringida se transforma en la forma de est imacio n:
para hacer una estimacion par mfnimos cuadrados. La est imaci6n del modelo de regresi6n se nluestra en la Figura 13.17 y la ecuacion
resullanle es:
log G) ~ 3,02 + 0,84510g (~) (13.31)
En este resultado, vemos que el coeficiente del modelo estimado, bb es 0,845. Por 10 tanto, b2 = 1 ~ 0.845 = 0, 155. Par Ultimo, log (bo) = 3,02. Este ana li sis muestra que el 84,5 pOl' ciento del valor de la produccion procede del trabajo y el 15,5 por ciento del

542 Estadistica para administraci6n y economia
The regression equation is logbotunit 3 . 02 ~ 0 . 845 logworunit
Predictor Constant logworun
Coef 3 . 02325 0 . 81\479
SE Coef 0 . 04387 0 . 09062
T 68.92 9.32
p 0 . 000 0 . 000
S " 0 . 1105 R- Sq", 79 . 8\ R-SQ(adj) '" 78.9t;
Analysis of Variance
Source Regression Residual Er r or Total
OF 1
22 23
SS 1 . 0618 0 . 2688 1.3306
MS F P 1 . 0618 86.90 0 . 000 0 . 0122
Figura 13.17. AnAlisis de regresi6n de la fu nci6n de producci6n restringida (salida Minitab).
capital. Tras rea lizar las oportunas transformaciones algebraicas, cl modele de la Fun~
ci6n de producci6n es Y - 20.49K"·'4> LO.,,, (13.32)
Esta Funci6n de producci6n puede util izarse para predecir la prod ucci6n esperada lItil i~
zando diversos niveles de capital y de tTabajo. La Figura 13. 18 muestra una comparaci6n del ntimero observado de barcos y el nil·
mere predicho de barcos a partir de Ia ecuaci6n de regres i6n transformada. EI numero predicho de barcos se ha calculado utili zando la ecuaci6n 13.32. Ese amllisis tambien indica que el R"l de In regresi6n del m1mero de barcos Con respecto al numero predicho de barcos es 0.973. Este R2 puede interpretarse exaclamente igual que el R2 de cualquier modelo de regresi6n lineal y, por 10 tanto, vemos que el mlmero predicho de barcos conslituye un buen ajuste de los datos observados sabre la producci6n de barcos. El R2 de los datos de la regresion transFormada de la Figura 13. 17 no puede interpretarse fucilmenle como un indicador de la relaci6n entre el numero de barcos producidos y las variables independientes del trabajo y el capital , ya que las unidades estan expresadas en logaritmos de cocientes.
Number of Boats = 11.82 + 1.199 Forecast Number of Boats
500 5 25.t9t6 : R·Sq 97.3%
R-5q(adj) 97.2%
400 •
~ • • • 300 .. • ~ • • • • • • ... 200 E
• , z •
100 •• •
0 0 100 200 300 400
Forecast Number of Boats
Figura 13.18. Comparaci6n de la producci6n observada y la predicha.

Capitulo 13, Regresi6n multiple 543
EJERCICIOS
Ejercicios basicos
13.54. Considcrc las dos ccuaeiones siguienles eslimadas utilizando los tnelodos desarrollados en eSle apartado.
i. Yi = 4x u ii. Yi = I + lxi + ~ Calcule los valores de y,. cuanda Xi = I , 2, 4, 6, 8, 10.
13.55. Considere las dos ecuaciancs siguientcs eSlimadas utilizando los mciodos desarrollados en este apanado.
i. Yi = 4xl.~ ii. Yi = I + 2rj +2xt Calcule los valores de Yi cuando xi = 1, 2, 4, 6, 8, 10.
13.56. Considcre las dos ecuaciones siguientes estimadas utilizando los melodos desarrollados en este apartado.
i. Yi = 4xu ii. Yi = 1 + lxi + 1,7x~
Ca1cule los valores de y,. cuando Xi = I, 2, 4, 6, 8, 10.
13.57. Considere las dos eeuaeiones siguientcs cSTimadas uti li zando los melodos desarrollados en este apartado.
i. Yi = 3Xl ,2
ii. Yi = 1 + 5Xi + 1,5x~ Calcu le los valorcs dc Yi cuando Xi = 1, 2, 4, 6, 8, 10.
Ejercicios aplicados
13.58. Describa un ejempJo ex trafdo de su experiencia en el que un modelo cuadn'it ico sea mejor que un modelo lineal.
13.59. Juan Sanchez. presidcnte de Estudios de Mercado, S.A. , Ie ha pedido que estime los eoeficienles del modelo
Y = {Jo + {J1Xl + {J2X~ + {J1X2
donde Y son las vcntas esperadas de sumi nistros de oficina de un gran distribuidor minorisla de suministros de ofieina, Xl es la renla total dispDnible de los residentes que viven a menos de 5 kil6metros de la tienda y X2 es eJ nutnero 10-
tal de personas cmpleadas en empresas euya actividad se basa en la informacion que se eneuentran a menos de 5 ki l6metros de la tienda.
Segun los esludios recientes de una consultora nacionaI. los eoefieientes del modelo deben lener la siguiente restricei6n:
fl, + ii, ~ 2
Dcscriba como eSlimarfa los coeficientes de! mode!o utilizando el metodo de minimos cuadrados.
13.60. En un estudio de los dctcrminanles de los gastos de los hogares en viajes de vacaciones, se obtuvieron datos de una muestra de 2.246 hogares (vease la refcrencia bibliografiea). EI mode-10 estimado era
logy = - 4,054+ 1,155610gxl -0,440Slogx2 (0.0546) (0.0490)
R' ~ 0,168
donde
Y = gasTo en viajes de vaeaciones XI = gasto total anual de eonsumo X 2 = numero de miembros del hogar
Los nutneros entre paremcsis que se encucnlran debajo de los eocficientes son los errores tfpicos de los eoefidcntcs csti mad os.
a) Interprete los coeficientes de regrcsi6n estimados.
b) imerprete el coeficiente de determinacion. c) Manteniendosc todo 10 demas eonstante, ha
lie el intervalo de confianza al 95 par demo del aumento poreentual de los gastos en viajes de vacacioncs provocado por un aumenlo del gasto anual tolal de consumo de un I por eiento.
d) Suponiendo que cl modelo eSla especificado correetamente, eonlraSle al nivel de significaei6n del I por ciento la hip6tesis nula de que, manteniendosc todo 10 demas constante, el numero de miembros de un hogar no afccta a los gastos en viajes de vacaciones frenle a In hipotesis alternaliva de que cuanto mayor es el numero de miembros del hogar, menor es el gasto en viajes de vaeaciones.
13.61. En lin estud io. se estim6 el siguiente modelo para una muestra de 322 supermcrcados de grandes zonas metropolitanas (vease la referencia bibliografica 3):
Logy = 2,921 + 0,680 logx (0.077)
f(2 = 0,19

544 Estadistica para adminlstracion y economia
donde
y = tamai\o de la tienda x = renta mediana del distrito poslal cn el que
se encuentm la tienda
Los numeros entre parenlesis que figurnn dcba~ jo de los coefic ienles son los errores Ifpicos de los coeficientes eSlimados.
a) interprcle el coeficienle estimado de log x. b) Contraslc la hip61csi s nula de que la renta
no infiuye en el tamano de In ticnda frcntc a la hip6Lcs is al lernaLiva de que un aurnento de la ['emu tiende a ir acompufiado de un aume nto del tamano de la tienda.
13.62. Un economisU\ agrfcola cree que la cantidad consumida de carne de vacuno (y) en toncladas al ano en Estados Unidos depende de su precio (XI) en d61ares por ki lo, del prccio de la carne de porci no (X2) en d61ares por kilo, del prccio del polio (x) en d61ares por kilo y de la renla por hagar (X4) en mi les de d6lares. Se ha oblenido la siguientc regrcsi6n muestrol POI' mfnimos cuadrados utili zando 30 observacioncs anuales:
Logy= - 0,024- 0,52910gx, + 0,217 logx2+ 0,193 logx3 (0.168) (0. 103) (0.\06)
+ O,416 10gx4 R2 = 0,683 (0. 163)
Los numerus entre parcntesis que se encuentran debajo de los cocficientes son los errores I{picos de los coeficientes estimados.
.1) Intcrprctc cI eocficiente de log XI '
b) Interprete el coefic iente de log x2'
c) Contraste al nivel de significac ion del I POI' d ento la hip61esis nula de que el coeficiente de logx4 en la regresi6n poblacional es 0 frente a la hip61esis altemativa de que e..<; positivo.
d ) Contrastc la hip61esis nul a de que las cuatro variables (logxl' logx2' log x), logx4 ) no liencn, en conjunto, ninguna influencia lineal en logy.
e) Al economisla lambicn Ic prcocupa que la crec ienle concienciaci6n de las consecucncias del consumo frecuente de came roja para la salud pueda haber influ ido en !a demanda de carne dc vacuno. Si eso es asf, loc6mo influ irfa en su opini6n sobre la regresi6n eslimada original?
13.63. Le han pedido que desarrolle una funci6n de produccion cxponenci al -forma Cobb-DoLL-
glas- que prediga el numero de microprocc~a_ dores producidos por un fabricante. Y. Cll fUIl _
ci6n de las unidades de capital. Xl: las unidade~ de trabajo, X2, y el numero de informaticos que rcu1i7..un investi gaci6n basica. X). Especifique la forma del modclo e indique con cuidado y exhausl ivamcntc c6mo estimarfa los coeficientes. Hugalo utilizando primcro un modelo sin rcstricciones y a conlinuaci6n incluyendo la restricci6n de que los cocficicntcs de las Ires vari ablcs deben sumar I.
13.64. Considere el sigui ente modelo no lineal COn crrores multiplicativos.
y = fJoXf'X~XglXh;
p, + p, ~ 1
113+P4 ~ 1
a) Muestre c6mo obrendria estimaciones de los cocficicnles. Deben satisfacerse las restricdalles de los coeficienles. Muestre lodo 10 que hace y explfq uelo.
b) loCual es la elasticidad constanle de Y con rcspecto a X4?
Sc rccom ienda que los siguiemcs cjercieios se resuelvan con la ayuda de un computador.
13.65. , j Angclica Chandra, presidenta de Benefi ts Rescarch Inc., Ie ha pedido que esludie la estructura snlnri al de su emprcsa. Benefits Research ofrece consu ltoria y gcsli6n de los programas de seguro medico y de jubi laci6n para los empleados. Sus cJienles son grandes y medianas cmprcsas. Primero Ie pide que desarrotlc Ull modclo de rcgrcsi6n que eSlime el salario es-. perado en funci6n de los anos de cxpcricncia en la empresa. Debe examinar modelos lineales. cuadraticos y cubicos y averiguar CUll l es mas adccuudo. Eslime modclos de regresi6n adecuados y cscriba un breve informe quc rccomiende el mejor modelo. Uli lice los dulOS del fi chero Benefi ts Research.
13.66. #. EI fichero de duloS German Im ports muesIra las importaciones real es alemanas (y). el consuillo privado real (XI) y el tipo de cambio rcal (x2) en d61ares estadouni dcnses pOl' marco de un periodo de 3 1 arios. Esli me el modelo
y escriba un informe sobre sus resultados .

Capitulo 13. Regresi6n multiple 545
13.8. Utilizacion de variables ficticias !In modelos de~gresion
Gender and Salary
En el amllis is de la regresi6n multiple, hemos supuesto hasta ahora que las variables independ ientes , xj , existfan en un rango y con ten fan muchos valorcs difcrcnles. Sin embargo, en los supuestos de ]a regres i6n multiple la unica restricc i6n a la que estan sujems las variab[es independientes es que son valores fijos. Por 10 Ian to, podrfamos tener una variable independiente que tamara solamente dos val ores: Xj = 0 Y .lj = [. Esta cstructura se denomina normalmcntc variable fieficia, y veremos que constituye un val ioso instrumento para aplicar la regresi6n multiple a situaciones en [as que hay variab les categ6ricas. Un importante ejemplo es una funci6 n lineal que varIa en respuesta a alguna innuencia. Consideremos primero una ecuaci6n de regresi6n simple:
y ~ (iu+ (i,X,
Supongamos ahora que introducimos una variable fictic ia, Xl' que toma los val ores 0 y I Y que la ecuaci6n resultante es
y ~ fJo + /J,X, + (i,X2
Cuando X2 = 0 en esla ecuaci6n, la constante es f3l), pero cuando X2 = 1, la constanle cs flo + fl2· Yemos, pues, que [a variable fict icia desplaza la relaci6n lineal entre Y y X] en el valor del coefic iente f32. De esta forma, podcmos representar el efecto de los desplazamienlOS en nuestra ecuaci6n de regresi6n. Las variables ficticias tambien se [Iaman variables de illdicador. Comenzamos nuestro ana lisis con un ejemplo de una importante aplicaci6n.
EJEMPLO 13.13. Amilisis de la discriminacion salarial (eslimacion de un modelo utilizando variables ficlicias)
EI pres idente de Investors LLd. quiere averiguar si existe alguna plUeba de la presencia de discriminaci6n salarial en los salarios de las mujeres y los hombres anali stas financieros. La Figura 13. 19 muestra un ejemplo de los salarios anuales de los analistas en relaci6n con sus anos de experiencia. Yease el fichero de datos Gender and Salary.
Solucion
Examinando los datos y el grMico, vemos dos subconjuntos diferentes de salarios y parece que los sa larios de los hombres son uniformemente mas attos cualesquiera que sean los anos de experiencia.
Este problema puede anali zarse estimando un modelo de regresi6n multiple del salario, Y, en funci6n de los anos de experiencia, Xl> con una segunda variable, X2, que lOrna dos valores:
o Mujeres analistas Hombres analistas
El modelo de regresi6n multiple resullante
puede analizarse ulili zando los metodos que hemos aprendido, senalando que el coeticiente b] es una estimaci6n del aUlllent.o anual esperado del salario par ana de experien-

546 Esladislica para administraci6n y economia
Scatterplot of Annual Salary (Y) vs Years Experience (Xl)
110000 """"" • (X2)
100000 O=fema le • i - Male
• • 0
)C 90000 • 1
~
i:" 80000 • .. • • • ., • 70000 , • < • <
'" 60000 • • 50000 •
• 40000
5.0 7.5 10.0 12.5 15.0 175 Yers Experience (Xl)
Figura 13.19. Ejemplo de una paula de datos que indica la existencia de discriminaci6n salarial.
cia y b2 cs el aumcnto que experimenta eI salario medio cuando el analisla es un hOIl1~ bre en Jugar de una mujer. Si b2 es positivo, eso indica que los salarios de los hombres SOil un iformemenle mas altos.
La Figura 13.20 presenta el anali sis de regresi6n multiple de Minitab para este pro~
blema. En este an6. li sis vemos que el coeficiente de Xl -gender- tiene un eSladfstico t de Student igual a 14,88 y un p-valor de 0, 10 que nos Ileva a rechazar la hi pOles is nula de que el codiciente es igual a O. Este resu hado indica que los salarios de los hombres son significati vamente mas altos. Tambien vemos que b2 = 4.076,5, 10 que indica que el valor esperado del aumento 8nual es 4.076,50 $ Y que b l = 14.638,7, 10 que indica que los salarios de los hombres son, en promedio, 14.683,70 $ m~1s altos. Este tipo de amilisis se ha util izado con exilo en algunos juicios sobre discriminaci6n salarial, por 10
que la mayoria de las empresas realizan anali sis parecidos a este para averiguar si existe alguna prueba de discriminaci6n sal aria!.
Esle tipo de ejemplos tiene numerosas apl icaciones en algunos problemas entre los que se encuenlran los siguientes:
1. Es probable que la relaci6n entre el numero de unidades vendidas y el precio se desplace si entra un nuevo competidor en el mercado.
2. La relaci6n entre el consumo agregado y la renia di sponible agregada puede desplazarse en tiempos de guerra 0 como consecuencia de algun otro gran acon~ tecimiento nacional.
3. La relaci6n entre la producci6n total y el numero de trabajadores puede desplazar~ se como consecuencia de la introducci6n de una nueva tecnologia de produccion.
4. La funci6n de demanda de un produclo puede variar como consecuencia de una nueva campana publicitaria 0 de la publicaci6n de una nOlicia relativa al producto.
Este anali sis ha inLroducido el concepto de regresi6n l1ti lizando variables ficticias como un metodo para ampliar nueslra capacidad de anal isis. El metodo se resume a continuaci6n.

Capitulo 13. Regresi6n multiple 547
The regression equation is Annual Salary (Y) = 23608 + 14684 Gender (X2) O=Fema l e l=Male
+ 4076 Years Experience (Xl)
Predictor Constant Gender (X2) O=Female l =Male Year Experience (Xl)
S = 1709.48 R-Sq = 99 . H
Analysis of Variance
Source DP
Coef S8 Coef T 23608 1434 16.46
14683 . 7 987 . 0 14.88 407 6 . 5 121.3 33 . 61
R-Sq (adj) = 99.2%
SS MS P Regression 2 39 4824096 1974120398 675 . 53 Residual Error 9 26300913 2922324 Total 11 3974541710
p
0 . 000 0 . 000 0 . 000
P 0 . 000
Figura 13.20. Analisis de regresion del ejemplo de la discriminacion salarial: salario anual en relacion can los anos de experiencia y el sexo (salida Minitab).
Analisis de regresi6n utilizando variables ficticias La relaci6n entre Y y X,
puede desplazarse en respuesta a un cambio de una determinada condicion. EI etecta del desplazamiento puede estimarse utilizando una variable ficticia que tiene el valor 0 (no se cum pie la condici6n) y 1 (se cumple la condicion). Como muestra la Figura 13.19, lodas las observaciones del conjunto superior de puntos de dalos lienen la variable ticlicia x2 = 1, Y las observaciones de los puntos inferiores tienen la variable ficlicia x
2 = O. En estos casos, la relaci6n en
tre Y y X, es especificada por el modelo de regresion multiple
(13.33)
EI coeficiente b2 represenla el desplazamiento de la funcion entre el conjunto de puntos inferior de la Figura 13.19 y el superior. Las funciones de cada conjunto de puntos son
y = bo + bXI cuando Xl = 0 y
cuando X2 = 1
En la primera funci6n, la constante es bo' mientras que en la segunda es bo + b2
• En el Capitulo 14 mostramos c6mo pueden utilizarse las variables ficticias para analizar problemas que lienen mas de dos categorfas discretas.
Esla sencilla especificaci6n del modelo de regresi6n lineal es un instrumento muy poderoso para resolver los problemas que implican un desplazamiento de la funci6n linea l provocado por factores discretos identificables. Ademas, la eSlruClura de regres i6n mUltiple es un metoda directo para realizar un contraste de hip6tcs is, como hemos hecho en el cjemplo 13.13. El contraste de hip6tesis es
Ho: p, ~ 0 III, '" 0 H,:P2",OIII, ,,, O

548 Esladfslica para adminislraci6n y econom(a
EI rechazo de la hipolesis nula, Ho, !leva a la conclusi6n de que la con stante de los dos subconjuntos de dalos es diferente. En el ejemplo 13. 13 hemos visto que esta difercncia entre las constantes lIevaba a la conclusion de que existia una diferencia sign ifica liva entre los salarios masculinos y los femeni nos una vez eliminado e l efecto de los ailos de expe~ riencia.
Diferencias entre las pendientes
Podemos utilizar variables ficticias para analiza!' y conlraSlar las diferenc ias entre las pen~ dientes aiiad iendo una variable de interacci6n . La Figura 13.21 muestra un ejemplo repre~ senlalivo. Para con trastar tanlo las diferencias enlre las constantes como las di ferencias en~
Ire las pendiellles, utili zamos un modelo de regres i6n mas complejo.
Gender (><2) Experience Years Annual Annual Salary vs Years of Experience
for Male and Female Engineers O=Female
l=Male 0 0 0 0 0 0 1 1 I I 1 I
times Experience Salary Gender (X I) (V)
0 5 $36,730 0 7 140,650 0 9 $46,820 0 10 150 ,149 0 14 $59,679 0 17 167,360 5 5 151,535 7 7 162,2ffi 9 9 172,486
10 10 175,022 14 14 193,379 17 17 $105,979
1120,OCXl
11 00 ,OCXl
~ 11:1 $00 ,(xx) ~
'" • -c c ..
160,000
540,000
520,000
10 o
• ••
• • • •
5 10 15
Years of Experience
Figura 13.21. Datos salariales anuales de Systems Inc.
Regresi6n utilizando variables ficticias para contrastar las diferencias entre las pendientes
•
• I
20
Para averiguar sl existen diferencias significativas entre las pendientes de dos condiciones discretas, hay que expandir nuestro modelo de regresi6n a una forma mas compleja:
(13,34)
Ahora vemos que la pendiente de x, conliene dos componentes, /3, Y fJaX2. Cuando X2 es igual a 0, la pendiente es el /1, habitual. Sin embargo, cuando X2 es igual a 1, la pendienle es igual a la suma algebraica de {Jl + {l3' Para estimar 81 modelo, necesitamos en realidad crear un nuevo conjunto de variables transformadas que sean lineales. Por 10 tanto, el modelo utilizado realmente para la estimacion es
(13,35)
Gender and Salary Increase
Capitulo 13. Regresion multiple 549
EI modelo de regresion resullanle ahora es lineal con Ires variables. La nueva variable, X1X2' a menudo se llama variable de interacci6n. Observese que cuando la variable ficticia x
2 = 0, esla
variable liene un valor de 0, pera cuando x2
= 1, esla variable Ilene el valor de Xl' EI coeficienIe b
3 es una eslimacion de la diferencia entre et coeficienle de X1 cuando x2 = 1 Y el coeficien
Ie de X1
cuando x2
= O. Por 10 lanlo, puede utitizarse el estadfslico t de Siudent de b3 para contrastar las hipotesis
Ho:{!, ~ Ol/!, #0. {!, # 0
H , : ii, '" 0 I {!, '" O. ii, '" 0
Si rechazamos la hipotesis nula, concluimos que existe una diferencia entre las pendientes de los dos subgrupos. En muchos casos, nos interesara tanto la diferencia entre las constantes como la diferencia entre las pendientes y contrastaremos las dos hip6tesis presentadas en esIe apartado.
EJEMPLO 13.14. Modelo de los salarios para Systems Inc. (estimacion de un modelo utilizando variables ficticias)
EI presidente de Systems Inc. esta interesado en saber si las subidas salariales anuales de las ingenieras de la empresa han sigo iguales que las de los ingenieros. Ha habido algunas quejas tanto de los ingenieros como de las ingenieras de que los salarios de cstas no han subido al mismo ritmo que los de aqucllos.
Solucion
La Figura 13.21 mueSlra los datos de ]a empresa y un diagrama de puntes disperses. EI diagrama sugiere que la pendiente es nuts a lta en el caso del subgrupo superior, que representa a los ingenieros. En la Figura 13.22 presentamos el amllisis de regresi6n multiple realizado con el programa Excel, que puede utilizarse para contrastar la hip6tesis de que las tasas de subida de los dos subgrupos de ingenieros son iguales. En este amilisis vemos que la experiencia multiplicada pOl' el sexo ticne un estadfstico I de Stu-
; ;
, Ii ;
i nmultip le 0,,""
; 0,,""
G"d., S"m, I,,;~; F " , d. F
, , ,
I ,
(
; , , Figura 13.22. Am'ilisis de regresi6n del salario anual en relaci6n con la experiencia y el sexo (salida Excel).

550 Esladislica para adminislracion y economia
dent de 14,20 Y Ull p-valor de O. Rechazamos la hip6tesis nu la de que, a medida que aumenta la experiencia, los salarios de los ingenieros y de las ingenieras han subido al mismo rilmo. Por 10 tanto, sera importante lomar medidas para abordar la discrimina_ ci6n salarial que es cvidenle en los dalos. Los datos se encueniran en el fichero Gender and Salary Increase.
EJERCICIOS
Ejercicios basicos 13.67. l,Cuul es la constante del modelo cuando la va
riable fictic ia es igual a I en las siguientes ecuacioncs, donde Xl es una variable continua y X2 es una variable fi cticia que toma un valor de 00 I?
a) ; = 4 + 8Xl + 3X2 b) Y = 7 + 6x 1 + 5x2 c) y = 4 + 8.Xl + 3x2 + 4X jX2
13.68. ;..Cm"il es la con sta nte del modele y el coeficienIe de la pendiente de Xj cuando la variable ficticia es igual a I en las siguientes ecuaciones, donde x. es una variable continua y X2 es una variable ficticia que toma un valor de 0 0 I?
a) Y = 4 + 9xj + 1,78x2 + 3 ,09xjX2
b) y= -3 + 7xl + 4,15x2+ 2,5Ix.X2 c) y = 10 + 5x. + 3,67x2 + 3,98x1X2
Ejercicios aplicados
13.69. EI siguiente modelo se ajusl6 a las obscrvaciones de 1972- 1979 en un intento de explicar la conducta de la fijaci6n de los prccios.
; = 37xI + 5,22t2
donde (0.029) (0.50)
y = diferencia entre el precio del ano actual y cl pretio del ano anterior en d61ares por barril
XJ = diferentia enlre el precio 01 contado en el ana actual y el precio al contado en el ano anterior
X2 = variable fic licia que lama el valor I en 1974 y 0 en los demas. para representar el cfcC10 cspecffico del embargo del petr6leo de esc ano
Los nlllneros entre parentesi.s situados dcbajo de los coeficientes son los errores tfpicas de los coc ficicntcs estimados.
Intcrprete vcrbal y grtificamente el coefi cieotc estimado de In variable fiC licia.
.13.70. Sc ha ajuslado cl siguiente modelo para expli car los precios de venta de los pisos de una muestra de 8 15 ventas.
13.71.
y = -1 .264 + 48,18xl + 3.382\"2 - 1.859x) (0.91) (S IS) (488)
+ 3.2 19x4 + 2.005xs (947) (768) ff2 = 0,86
donde
y = precio de venlu del piso, en d61ares Xl = melros cuudrados (itiles X2 = tamana del gamje en mlmero de autom6viles x ) = antiguedud del pi so en anos x" = variable fic ticia que toma e1 valor I SI el
piso tiene ch imenca y 0 en caso contrario Xs = variable fic licia que lorna el valor I si el
piso liene suelos de madern y 0 si liene suclos de vi Ili 10
a) lnlerprete el coeficiente estimado de X4'
b) Interprete el cocficiente estimado de Xs. c) Halle el interva lo de confianza al 95 por
cicnto del efecto de una chimenea en cl precio de venia, manteniendose todo 10 dcmas constante.
d) Contmste la hip6tcsis nula de que el tipo de sueIo no afecta al pretio de venta frente a la hip6tesis altcrnativa de que, manleniendosc todo 10 demas constantc, los pisos con suc lo de madera tienen un precio de venta mas al to que los pises con sue lo de vinila.
Se ha ajustado el siguietlte modele a datos sobre 32 compafifas de seguros.
; = 7,62 - 0,16x. + 1,23x2 R2 = 0,37 (0.008) (0.496)
donde
y = relaci6n preeio-beneficios Xl = volumcn de activos de las compafifus de
seguros, en miles de milloncs de d61ares x2 = variable fi cticiu que toma el valor 1 en el
caso de las companfas regionales y 0 cn c1 de las nacionales.

Los numeros en!re parcntesis siwados debajo de los coeficie ntes son los errores tfpicos de los coeficientcs estimados.
a) Interpretc el coeficicn lc estimado de la variable fieticia.
b) Contraste la hip6tesis nula de que el verdadero coeficiente de [a variable ficticia cs 0 frente a la hip6tcsis alternaLiva bilateral.
c) Contraste al nivel del 5 por ciento la hip6lesis nula #1 = (J2 = 0 e interprete su resultado.
13.72. EI deeano de una facultad de derecho querra eval uar la importancia de factores que podrfan ayudar a predecir el exito en los estudios de postgrado en dcrecho. Sc obtuvieron datos de una muestra aleatoria de 50 estudianles cuando lerminaron SLIS eswdios de poslgrado en derecho y se ajust6 el siguiente modelo:
SOURCE
MODEL ERROR
Yi = a + (J IX] i + {JzX2i + {J:'x3i + I:; donde
Yi = ealificaci6n que rdleja el rendimiento glo~ bal de los estudiantes en sus eSludios de postgrado en derecho
Xli = calificaci6n media de los estudios de grado X2i = ca[ ificac ion ell el examen de aceeso a la
universidad x3i = variable ficlicia que toma el valor I si las
cartas de recomendaci6n del eSLUdiante son excepcionalmente buenas y ° en caso contrario
Utilice la parte de la salida de la regresi6n esti· mada mostrada aquf para escribir un informe que resuma los resultados de este estudio.
SUMOF MEAN DF SQUARES SQUARE FVALUE R-SQUARE
3 641 . " 7.13.68 8.48 .356
" 1159 . 66 25.21 CORRECTED
TOTAL 49 1800 . 70
T FOR HO: STD. ERROR PARAMETER ESTIMATE PARAMETER '" 0 OF ESTIMATE
INTERCEPT 6 . 51.2 Xl 3 . 502 1. 45 2 . 419 X2 0 .4 91 , . 59 0 .1 07 x3 10 .3 27 2 . 45 4 . 213
13.73. EI siguiente modelo se ajust6 a datos de 50 estados de Estados Unidos.
y = 13.472 + 547xI + 5,48x2 + 493x3 + 32,7x4 + 5.793x5 (124.3) (1.858) (208.9) (234) (2.897)
- 3.IOOX6 R2 = 0,54 ( 1.761)
13.74.
Capitulo 13. Regresi6n multiple 551
donde
.y = sueldo anual del fiscal general del estado XI = sueldo anual medio de los abogados en
miles de d61ares X 2 = nlimero de leyes aprobadas en la [cgislalll
ra anterior .\"3 = numero de acluaciones de los tribunales de
los estados que dieron lugar a una anulaci6n de legislacion en los 40 anos anteriores
.\"4 = duraci6n del mandalo del fisca l general del estado
x~ = variable fieticia que lorna el valor I 5i los magistrados del tribunal supremo del esta~ do pueden ser cesados por el gobcrnador, par el consejo del poder judicial 0 mediante una votaci6n por mayorfa del tribunal supremo y 0 en casu conlrario
x6 = variable ficticia que lama el valor I si los magislrados del tribunal su premo son dcsignados tras unas elecciones en las que inLervienen los partidos poHticos y 0 en caso contra rio
Los numeros entre parcntcsis situados debajo de los coeficientcs son los errores tfpicos de los coeficienles estimados.
a) Interprete el coefi cienle esri mado de In variable ficticia X5.
b) Interprete el coeficiente estimado de la va· riable fie ticia x6.
c) Contraste al nivel del 5 pOI" cienlo la hi p6tesis nula de que el verdadero coeficientc de la variable ficlicia Xs es ° frente a la hipotesis alternativa de que es posilivo.
d) Controste al nive[ del 5 por cicnto la hi p6lesis nul a de qLle el verdadero coeficiente de la variabl e ficticia X6 es ° frente a la hip6te~ sis alternativa de que cs negativo.
c) Hall e e interprete un nivel de confianza del 95 por cienlo del para metro Pl .
Un grupo consultor ofreee cu rsos de gesti6n financiera para los ejecutivos. Al final de estos cursos, los participanles deben hacer una valoracion global del valor del curso. Se estim6 para una muestra de 25 cursos In siguiente regresian por mfnimos cuadrados .
y = 42,97 + 0,3&.1."] + O,52x2 - 0,08X3 + 6.21x4 (0.29) (0.21) (0.1 J) (0.359)
R2 = 0,569
donde
y = va loraci6n media realizada POI" los parlici panIcs en el curso

552 Esladfslica para administraci6n y economia
XI = porcentaje del tiempo de l curso dedicado a scsiones de discusi6n en grupo
xl = dinero, en d6larcs, par miembro del curso decl ieados a prcparnr el malerial del curso
x~ = dinero, en d6lares, por miembro del curso gaslado en comida y bcbida
X2 = variable fic ticia que toma el valor I 51 in lerviene en el curso un profesor vis itantc y 0 en caso contra rio.
Los mimeros entre parenlesis sllUados debajo de los coeficicntcs son los errores tfpicos de los coeficientcs eSli mados.
a) Interpretc cI cocficiente eSlimado de x4 .
b) Contraste la hip6tesis nu la de que el verdadero coeficiente de X4 cs 0 frenle a la hip6lesis alternativa de que es positi vo.
c) Interprete el coerieiente de determi naci6n y ulilfcelo para eontrastar la hip6tesis nula de que las cuatro variables indepcndientes. consideradas en conjunto. no influyen li nealmenle en la variable dependiente.
d) Halle e interprele el intervalo de con fi anza al 95 por ciento de P2'
13.75. En un estud io, se estimo un modelo de regresi6n para camparaI' el rcndimiento de los estudiantes que asistfan a un eurso de estadfslica para los negocios: un eurso normal de 14 $C
manas 0 un curso intensivo de 3 semanas. Se estim6 el siguienle modelo a parti r de las obscrvaciones sobre 350 cSludianles (vease la rcfereneia bi bJiografica 5):
y= - 0.7052 + 1.4170xI + 2, I 624x2 + 0.8680x) (0.4568) (0.3287) (0.4393)
+ 1,0845x4 + 0,4694xs + 0.OO38x6 + O.0484x7 (0.3766) (0,0628) (0.0094) (0,0776)
R2 = 0,344
donde
y = culi fi euci6n obtcnida en un examen norm(lliz(ldo sobre los conocimientos de cstadisliea despues de asisti r al curso
XI = variable fiClicia que lOrna el valor I s i se asisti6 a un curso de 3 sem.mas y 0 Sl se asisti6 a un curso de 14 semanas
X2 = calificaci6n media del estudiante Xl = variable fi eticia que toma el valor 0 0 I ,
dependiendo de ellal dc dos profesorcs imparliera el curso
.1"4 = variab le fi cticia que toma el valor I si el cstud iante es varon y 0 si es mujer
Xs = cali ficac i6n oblenida en un examen nor-
malizado sobre los conoci mienlos de matematieas antes de ;lsiSl ir al eurso
X6 = numero de creditos semcslrales que hubi:! completado el eSl udi unte
.1"7 = edad del estudiante
Los numeros entre parentcsis situados debajo de los coefieienles son los errores tfp icos de los coe ficientes eSlimados.
Escriba un infomle analizando 10 que pucdc aprenderse con csta regresi6n ajustada.
Se recom ienda que los sigu ientcs ejercieios se rcsuelvan con In ayuda de un compulUdor.
13.76. f .. En un estudio de 27 estudiantcs de la Universidad de lllinoi s sc obtu vieron resultados sobre la calificaci6n med ia 0'), c1 numero de horus scmanalcs dedi cadas a eSiudiar (XI), c l nuI11cro medio de horas dcdicadas a eSIt:d iar pura los examenes (X2), el numero de horas scmtlnaIcs pasadas en los b:lres (x)). el hecho de quc los CSludiantes tomcn nOlas 0 subrayen cuando Iccn los libras de texto (X4 = I si sf, 0 si no) y el numcro medio de ered itos realizados par semestre (xs) . Estime In rcgresi6n de la ca lifieaci6n media con rcspeclo a las cinco vari ables independicntcs y escriba un infonnc sabre sus resultados. Los dalOS se cncucnlran en el lichero de datos Student Perrormance de su disco de dmos.
13.77. ~ -t Lc han pediclo que desarrolle un modelo para anali zar los salarios de una gran empresa. Los datos para desarrollarlo se encuentran en el fichero llamado Salorg.
a) Utili zando los datos del fichero. desarrolle un modelo de regresi6n q ue prediga el salario en funei6n de las variables que se lecc ione. Ca1cule los eSladisricos F y t condicionudos del eoe lieienle de cada variable de predicci6n inc1 uid:l en el modelo. MuCSlre lotio 10 que hace y explfquelo minuciosamente.
b) Conrraste la hipOtcs is de que las mujcres tienell un salario anual mt'is bajo condieionado :I I:ls variables de su modclo. La v:lriable «Gendec I F» toma el valor I en el caso de las mujeres y 0 en el de los hombres.
c) Contrasle la hip6tesis de que la I:lsa de subida salafial de las mujeres ha sido mas baja condicionada a las variables del modelo desarrollado en el apanado (b).

13.9.
Cotton
Capitulo 13. Regresi6n multiple 553
M~todo de aplicacion del analisis de regresion multiple
En este apanado presentamos un extenso caso pn"ict ico que indica como se rea lizarfa un estudio estadfstico. EI eSludio detenido de este ejemplo pucde ayudar a utili zar muchos de los melodbs prescntados en este capitulo y en los anteriores.
EI objelivo de este estudio es desarrollar un Illodelo de regresion mult iple para predeci r las ventas de tejido de algodon. Los datos para el proyecto proceden del fichero de datos Cotton, que se encuentra en el disco de datos de estc libro. Las variables de l fichero de datos son
quarter year cottonq whoprice impfab exprab
Trimestre del ano ano de observacion canlidad de tejido de algod6n producida indice de precios al por mayor ean tidad de tej ido importado cantidad de tejido exportado
Especificacion del modelo EI pri mer paso para desarrollar el rnodelo es seleccionar Lln a tcoria cconomica adeeuada que sirva de base para el amll isis del modelo. Este proeeso de identi ficac ion de un eonjunto de variables de pred iccion probables y la rorma matematica del rnodelo se conoce call e l Ilombre de espec{{tcacion del mode/a. En este caso, la teorfa adecuada se basa en la de los modclos economieos de demanda. La teorfa economica indica que cl precio debe producir un importante efecto: una sub ida del preeio reduce la can tidad demandada. Es probable que tam bien haya Qt.-as variables que influyan en la eantidad demandada de algodon. Es de esperar quc la cantidad importada de tejido de algod6n redllzca la demanda de tejido interior y que la cant idad exportada de tejido de algodon aumente la demanda de tej ido in terior. En el lenguaje econ6mico, las importaciones y las exportaciones de tejido desplazan la runcion de demanda. Basandonos en este antil isis, nuestra especiricacion inicial incluye el preeia con un eoefie ien te negalivo, el tej ido exportado con un cocficientc posi tivo yel tej ido importado con un coet'iciente ncgativo. Se especifica inicialmente que todos los coeficientes tienen efeetos li neales. Por 10 tanto, e l modelo ticne la forma
da nde XI es el prec io al par mayor, Xl es la cant idad de tej ido importado y x 3 es la cantidad de tejido exportado.
Tambien existe la posih il idad de que la cantidad demandada vade con el tiempo, y, por 10 tanto, el modelo debe incl uir la posibi lidad de Ll na variable temporal para reducir la variabilidad no expl icada. Para este antilisis queremos uti lizar una variable que represente el tiempo. Como el tiempo es indicado por una combi naci6n de ano y trimestre, ut ilizamos la transformaci6n
Time = Year + O.2S*Quarter
para producir una nueva variable de l tiempo que sea eonlinuamenle creciente. EI paso siguiente en el amllisis es hacer una descri pci6n cstadfs tiea de las variables y
de sus relaciones. Excluimos el ano y el trimes tre de este anali sis porque han sido sustitu idos par el tiempo y Sll inclusion s610 introduci rfa confusion en el amilisis. Utili zamos cI

554 Esladislica para administraci6n y economia
programa Min itab para oblener medidas do la tendenoia central y de la dispersion y lalll. bien para oomprender algo la pauta de las observaciones. La Figll ra 13.23 contienc la sa li . da Minitab. E1 cxamen de la media, la desviacion tfpica y el mlnimo y el maximo indica la region pOlencial de apl icaoion del modelo. EI modele de regresi6n estimado siempre pasa por la media de las variables del modelo. Los valorcs predichos de la variable dependicnte, «cottonq», pueden utili zarse dentro del rango de las variables independientes.
EI paso siguicnte es examinar las rclaciones simples existentes entre las variables utili zando tanto la matriz de correlaciones como la opcion de los graJicos matriciales. Estes deben examinarse conjuntamente para averiguar la fuerza de las relaciones lineales (corre. laciones) y para averiguar la rorma de las re laciones (gn'ifico matricial ).
La Figura 13.24 contiene la matriz de correlaciones de las variables del estudio elabo. rada utili zundo Minitab. EI p-valor mostrado con cada correlaci6n indica la probabilidad de que la hip6tesis de la correlaci6n 0 entre las dos variab les sea verdadera. Utili zando nuestra regia de seleccion basada en el conlraste de hip6tesis, podemos conclui r que un p_ valor de menos de 0,05 es una prueba de la exislencia de una estrecha relaci6n lineal entre las dos variables. Examinando la primera columna, observamos que cxisten estrechas relndones lineales entre «cottonq}} y tanto «whoprice» como «time». L1 variable «expfab}} ti ene una posible relaci6n simple marginulmentc significativa. Una buena regia practica, mostrada en 01 apartado 12.1, para examinar los coeficientcs de correlac ion es que cl valor
Figura 13.23. Esladislicos descriplivos de las variables del mercado del algod6n (salida Minitab).
Results for : Cotton.MtW Descriptive Statistics: cottonq, w hoprice, impfab, expfab, time
Variable N N' Mean SR Mean StDev Minimum cottonq 28 0 1779.8 54 . 9 290 . 5 1277.0 whoprice 28 0 1 06 .81 1.16 6.11 98 . 00 impfab 28 0 7 . 52 1. 38 7 . 33 1.30 expfab 28 0 274 . 0 20 . 3 107 . 7 80 . 0
Q1 Median Q3 1535.3 1762 . 5 2035.0 100.45 107 .40 112.20
2.78 4 . 85 9 . 05 190.5 277 . 1 358.1
Figu ra 13.24. Correlaciones de las variables del mercado del algodon (salida Minitab).
time 28 0 69 . 625 0 . 389 2 . 056 66 . 250
Variable Maximum cottonq 2287 .0 whoprice 115.80 imp[ab 27.00 expfab 477.0 time 73.000
Correlations: cottonq, w hoprice, impfab, expfab, time
cottonq whoprice imp fab whop rice -0 . 950
0 . 000
i mpfab 0.291 - 0 .439 0.133 0 .019
expfab 0.3 70 - 0 . 285 0.181 0 . 052 0 . 142 0 . 357
time -0.950 0 . 992 -0 . 392 0 . 000 0 . 000 0 . 039
Cell Con tents : Pearson correlat i on P-Value
expfab
- 0 . 238 0 . 222
67.813 69 . 625 71.438

Capitulo 13. Regresion multiple 555
abso luto de la corre laci6n debe ser superior a 2 di vidido por la ralz cuadrada del tamano
de la muestra, II. En esle problema, cI valor de sclecei6n es 21fo = 0.38. La segunda tarea es averiguar si cx isten estrechas relaciones simples entre los pares de
variables de predicci6n posibles. Vemos una estreehfsima correlaci6n entre ~~Iime» y «whopricc» y relaciones significativas entre «impfab» y tanto «timc}) como «whopricc». Estas elevadas correlaciones hacen que la varian za de los estimadores de los coeficientes tanto de «lime) como de «whoprice» sea alta si se incl uyen ambos como variables de pre· dicci6n.
Tambien podemos cxaminar [as relaciones entre las variables utili zando [os gr<'ificos matriciales mostrados en la Figura 13.25. Los diagramas de puntas dispersos individuales mueslran simultancamente las relaciones entre d iFerentes variables. Constituyen, pues, un tipo de presentaei6n parecido a una matriz de correlae iones. La ventaja del diagrama de PUlltos dispersos radiea en que incluye todos los puntos de datos. Tambien se puede vel', pues, si cx iste una relaci6n no lineal simple entre las variables yJo si ex iste algun agrupa· miento ex lrano de obscrvaciones. Todas las variables, excepto «year» y «quartef», estan incluidas en el mismo orden que en In matriz de corre laciones , POI' 10 que hay una comparac i6n direcla entre la matriz de correlaciones y los gn'ificos matri cia1es.
Observese la eorrespondencia entre las eorrelaciol1es y los diagramas de puntos d ispersos. Tanto «whoprice» como (<lime» tienen estrechas relaciones linea les con «cononq». Sin embargo, la estrecha relaei6n li neal positiva entre «whoprice» y «time» tendra una gran influencia en los coeficientes estimados, como se muestra en el apanado 13.2, y en los errorcs tfpicos de los coeficientes, como se muestra en el apartado 13.4. No ex iste ninguna estrecha relaci6n simple entre las variables de predicci6n potenciales. Ni las importaciones ni las exportaciones estan correlacionadas con el precio a1 POI' mayor, con el tiempo 0 entre sf.
Figura 13.25. Graticos matriciales de las variables del estlJdio (salida Minilab).
cottonq
.. ~ 112 ....
." " .. .~ : . whoprice ...... ,, +-----,--'-~I-~~--~ • • 20 • •
•• • • 10 • • hlplab e· ... .. "-.~.=:~ .. ~~-'~!c-~',',-'r.'>c'~-~'~'~~=~'~'~'~'+-.. ---------.
i • e. e.. , • ... ••• •• - e -.. ._ " -.. _.. . ... .... . . .,.... . - . . ... ... .... .... ...
• • _. .. rxpfab
100 •• • •• • •• • . . -' ..... . .. 72 .'.. I.. · . .. . ~ ...... . . . . ..... ,,~.:. . . .... . ." . • 1'.... • . .. . . . . .. .. .. . .. . .. . . ~<---r--.--~'~'~'~~--~---.--~~'-"~-'~r---~-"'~~'~----i "
ISOO 1$00 2100 96 1M 112 0 10 20 100 300 500
Regresion multiple El paso sigui ente consiste en esti mar el primer modelo de regresi6n multiple. La tcorfa econ6mica para cste amllisis sug iere que la cantidad produeida de lejido de algod6n debe estnr relacionada in versamcnte con el precio y con la canlidad importada de tejido y relacionada directamente can la cantidad exportada de tejido. Ademas, la eslrecha correlaci6n

556 Estadisiica para administraci6n y economia
INTlRPRETACION
entre el tiempo y la producci6n de tej ido de algod6n indica que la producc i6n disminuyt> lineal mente con e l paso del liempo, pero que el precio a[ por mayor lambien subi6 lineal~
mente con el paso del tiempo. La estrecha correlaci6 n positiva resultante entre cI ticmJXl y cl precio a[ por mayor influye en ambos coeficicnles en una ecuaci6n de regresi6n rn(ih i~
pic. Seleccionamos «cQ((Qnq» como variab le depend iente y «wllOprice}}, «impfab», «exp~
rab» y «ti me», por ese orden, como variables independientes . E[ primer amili sis de rcgre~ si6n multiple sc muestra en In Figura 13.26.
EI aTUl li sis de los cstadfsticos de la regrcsi6n ind ica que e[ valor de R2 es alto y el error tfpico de [a estimaci6 n (5) es igual a 78,91 , en eomparaci6 n con la desv iaci6n tipica de 290,5 (Figura 13.23) de «cottonq», cuando se considera de forma ais lada. Las variables «irnpbaf;} y «expfnb» son ambas significativas y licncn s ignos que corresponden a In teoria econ6mica. Los pequeiios estadfsticos I de Student de «whoprice)} y «time» indican que, en realidad , existe un grave problema. Ambas variables no pueden incJuirse como predictorcs porque representan el mismo efecto.
Las reglas para eliminar variables se basan en una combinaci6n tanto de las teorras subyacentes al modelo como de indicadores estadfsticos. La regia estadfsti ca serfa eliminar 13 variable que tiene el menor t de Student absoluto, es deci r, «time». La teorra economica defenderfa la inclusi6n de una variable del precio en un modelo para predecir la cantidad producida 0 la cantidad demandada. Vemos que en este caso ambas reg las !levan a la mi srna conclusi6 n. No siempre oellrre asf, por 10 que cs muy importante va[orar bien los reSll l~
tados y tener daros los objetivos del modelo.
Figura 13.26. Modelo inicial de regresion multiple (salida Minitab) .
Regression Analvsis: cottonq versus whoprice, impfab, expfab, time
The regression equation is cottonq =8876 - 24.3 whoprice - 5 . 57 impfab + 0 . 376 expfab - 65 . 5 time
Predictor Coef SE Coef T • Constant 8876 2295 3.87 0.001 whoprice -24 . 31 24 . 45 - 0.99 0.331 impfab -5 . 565 2.527 - 2 .20 0.03 8 expfab 0.3758 0.1595 2.36 0.027 time -65 . 51 70.24 -0.99 0.361
S = 78.9141 R- Sq = 93.7\ R-Sq (adjJ ~ 92.6\
Analysis of Variance
Source DF SS MS F P
Regression 4 2134572 533643 85 . 69 0.001 Residual Error 23 143231 6227 Tota l 27 2277803
Nota ource DF Seq S5 Esta tabla indica
whoprice 1 2055110 la variabilidad explicada impfab 1 44905 co ndicionada de cada variable, expfab 1 29141 dado el orden de entrada time 1 5417 utilizado para esle analisis
de regresion. Unusual Observations
Obs Whoprice Cottonq Fit 5E Fit Residual se Resid 18 110 1810.0 1663.3 29.6 146.7 2.DOR
R denotes an observation with a large standardized residual .

Capitulo 13. Regresion multiple 557
Es importante fonnular claramente las razones por las que se seleccionan las vari ables antes de examinar los resultados. En los modelos eeon6micos de demanda 0 de oferta como el que examinamos aquf, desearfamos fervienlemente seguir la teorla eeon6mica e in clui r cI preeio, a menos que los resultados estad fsticos fueran mlly contrarios a esa decisi6n previa. POI' ejemplo, s i eI va lor absoluto de l eSladfslico 1 de Student del liempo ruera superior a 2,5 0 3 y el valor absoluto del estadfstico f de Student del prccio al pa r mayor fuera inferior a I, habrfa prucbas contundentes en contra de la teorla de que el prec io es una importante variab le.
Basandose en este anali sis, se estima un segundo moclelo de regresi6n , mostrado en la Figura 13.27, en eI que se excluye el liempo como variable de prediceion. Ahara vemos que la variable «whopricc» cs muy significaliva y que los estadfsti cos s y R2 son esencial mente iguales que los del primer Hllalisis de regresi6n (Figura 13.26). Observese tambiell que 1a suma de los cuadrados de la regres i6n explicada (SCR) y 1a suma de los cuadrados de los errores residua les (SCE) son esencialmente iguales. La dcsviac i6n tfpica del coefi ciente de ({whoprice» ha disminu ido de 24,45 a 2,835 y, como consecuencia, la t de Student es considerab lemenre mayor. Como hemos vista en el apartaelo 13.4, euando exislen eorrelaciones estrechas entre variables independientes , las varianzas de los estimadores de los coeficientes son mucho mayores. Vemos aquf ese efecto. Observesc tambien que en este modelo de regresi6n, la estimaci6n del coeficien te del precio al por mayor cambia de - 24,31 a - 46,956. En cI apartado 13.2 hemos visto que las correlaciones entre variables de pred icci6n producen un complejo cfccto en las estirnaciones de los coe ficientes, par 10
Figura 13.27. Modelo final del an<llisis de regresi6n (salida Minitab).
Regres~ion Analy~i~: cottonq ver~u~ whoprice, impfab. expfab. time
The regression equation is
Predictor Coef SE Coef T P
Constan t 6757 . 0 322 . 2 20 . 97 0 . 000 whoprice -16 . 956 2.835 -16 . 56 0 . 000 impfab -6 . 5 1 7 2 . 306 -2 . 83 0 . 009 expfab 0 . 3190 0 . 1471 2 . 17 0.040
5 . 78 . 6998 R-Sq 93 . 5% R-Sq(adj) • 92 . 7%
Analysis of Variance
Source OF 55 MS F P
Regression 3 2129156 709719 111 . 59 0 . 000
Residual Error 24 148648 6194
Total 27 2277803
Source wh oprice impfab expfab
OF Seq 55 1 2055110 1 44905 1 29141
Unusual Observations
Nota Estas sucesivas sumas de los
, -------1 cuadrados explicadas 14 condicionadas son iguales
que las de la regresi6n de la Figura 13.26. que incluian el tiempo como variable de prediccion.
Obs Whoprice Cottonq Fit SE Fit Residual St. Res i d 18 110 1810 . 0 1642 . 0 18.7 168 . 0 2 . 20R
R denotes an observat ion wi th a large standardized residual.

558 Esladislica para administraci6n yeconomfa
que no siempre ex iSle una direrencia tan grande. Sin embargo, Ins correlnciones enlre variables independientes sicmpre aumentnn el e rror tfpico de los coeficicnte5. Los errores Ifpicos de los Olros dos coeficientes no han cmnbiado significati va rnente, debido a que las correlac iones con el tiempo no eran grandcs.
EI programa Minitab tambien contiene una lista de observaciones con residuos extremos. Vemos en la observaci6n 18 que eI valor observado de ( cottonq» es muy superior al valor que predice la ecuacion. En estc caso, podrfamos decidir volver a los datos originales y tratar de averi guar 5i hay un error en los dalos del fi chero. Esa investigacion tam bien podrfa ayudar a cornprender el proceso estudiado utilizando la regres i6n multip le.
Efecto de la eliminacion de una variable estadisticamente significativa
En este apartado examinamos el decLo de la eliminaci6n de una vari able significativa del modelo de regresi6n. En la Figura 13.27 hemos visto que «cxpfnb» es una predictor estadfsticamente significati vo de la canlidnd producida de algod6n. Si ll embargo, el ami.li sis de regresi6n de la Figura 13.28 ha eli minado «cxpfab» del modelo de regresi6n de la Figura 13.27.
Observese que, como consccuencia de la eliminac i6n de «cxpfab», eI error tfpico de In estimaci6n ha aumcntado de 78,70 a 84,33 y R2 ha disminuido del 93,5 al 92,2 por ciento. Estos res ultados indican que el termino de error del modelo ahora es mayor y, por 10 tanto, ha empeorado la calidad del mOOelo.
~ EI cstadfstico F cond icionado de (exprah» puede calcularse uli li z..1ndo las tablas del INTERPRETACION anal isis de la varianza de los modelos de las Figuras 13.27 y 13.28. En la sigui ente eeua
ci6n, definimos la regresi6n lineal a partir de la Figura 13.27 como modelo 1 y la regresi6n de la Figura 13.28, eliminado «exprab», como modelo 2. Ut il izando estas convenciones, cI estadfsti co F condicionada de la variable «expfab}) , X3, en la hip6les is nula de que su coeficiente es 0, puede calcularse de la forma siguientc:
Figura 13.28. Ana!isis de regresi6n con la eliminaciOn de! tejido exportado (salida Minitab).
SCR, - SCR, (2. 129. 156 - 2. 100.0 15) I' = = = 4705
.1) s; 6.194 '
Regress ion Analysis: cottonq versus whoprice, impfab, expfab, time
'I'he regression equation is cottonq = 5995 - 48.4 whoprice - 6 . 20 impfab
Predictor Coef SE Coef T p
Constant 6994 . 8 324 . 6 21 55 0 . 000 whoprice - 48.388 2 . 955 -16.38 0.000 impfab -6.195 2 .465 -2.51 0.0 19
S = 84.3299 R-Sq = 92 . 2\ R- Sq(adjJ = 91.6\
An"lysis of Variance
Source OF SS MS F P Regress ion , 2100015 1050007 147 65 0.000 Residual Error 25 177788 7112 Total 27 2277803

Capitulo 13. Regresi6n multiple 559
Tambien podcmos calcular cl cSlad fsti co I de Student condicionado de la variable x ] 10-
mando la ralz cuadrada de la F~-.1 condic ionada:
IX) = J4,705 = 2,169
y, natural mente, vemos que es igual que el estadfstico ( de Student de la vari able «expfab» (x3) de la Figura 13.27. EI contrasle F condicionado de una unica variable independiente siempre es exaetamente igual que el F eondieionado, ya que una F con I grado de libertad en el numerador es exactamente igual a ,2.
Analisis de los residuos
Despues de aj ustar el modelo de regresi6n, cs util examinar los residuos para avcriguar e6-. mo se aj usta real mente el modelo a los datos y los supuestos de la regresi6n. En ·el apanado 12.7, examinamos el anal isis de los casas atfpicos y los puntas extremos en la regres ion simple. Esas ideas tambien se aplican direclame nle a la regres ion mult iple y deben formar parte del anal isis de los residuos . Recuerdese que los res iduos se calculan de la forma siguiente:
ei = Yi - Yi
Con el programa Minitab 0 con eualquier olro buen paquetc estadfstico se puede calcular una variable que contenga los residuos de un anal isis de regres i6n. Se ha hecho para el modelo final de regresi6n de la F,igura 13.27. EI primer paso eonsiste en examinar la paUla de los residuos eonstruyendo un hi stograma, como el de 1a Figura 13.29. Vemos que la di stribuei6n de los rcsiduos es aprox imadamente simctrica. La di stribuei6n tambicn parcee alga uniforme. Observese que se debe en parte al pequeno tamano de la muestra utilizada para construir eI histograrria.
Figura 13.29. Histograma de los residuos del modelo final de reg resi6n .
t;'
9
8
7
6
~ 5 ~ .,. ~ 4
3
2
1
o
V V
-150 -100
Histogram of RESI1 Normal
II ~ \
-50 o RESI1
50
\ 100
~
'i--150
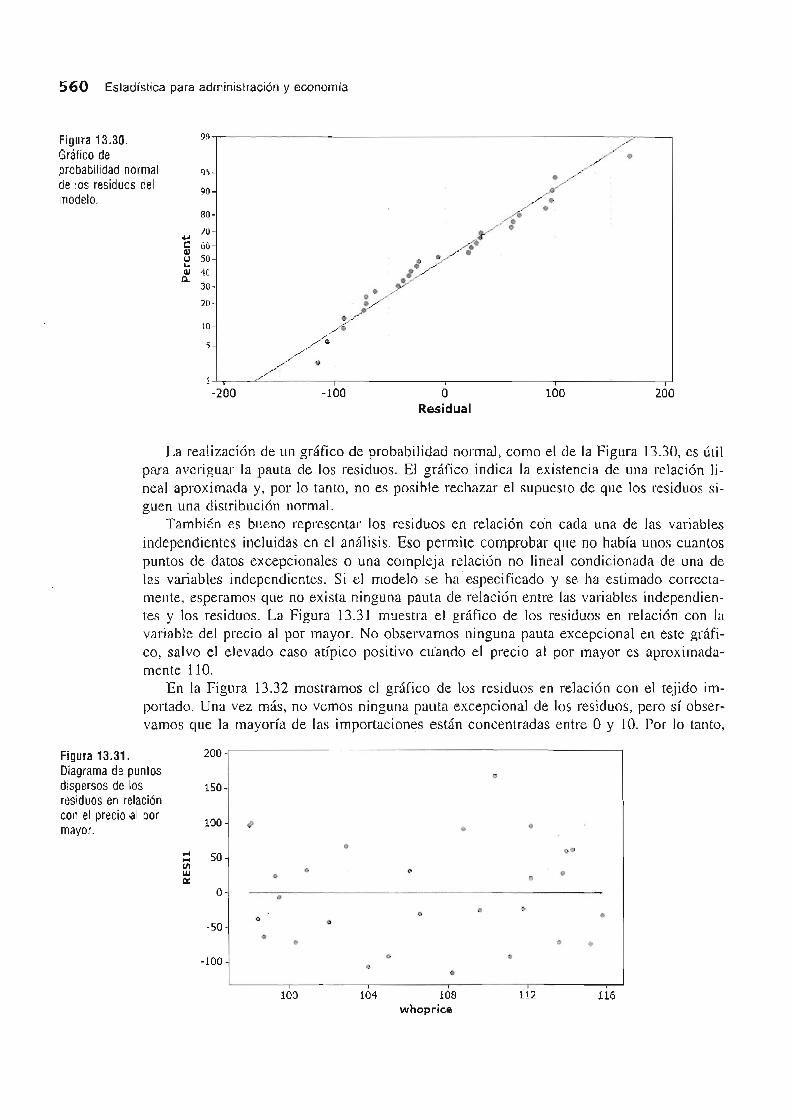
560 Esladfslica para adminislraci6n y economfa
Figura 13.30. " Gr.1fico de • probabilidad normal 95 • de los residuos del
90
/" modelo.
Figura 13.31.
BO -
lO • ~
C GO •• • • • u so • .,' • <0 "-
" • • 20 • •
'" 5 •
• 1 -200 -100 a 100 200
Residual
La realizaci6n de un gnlfico de probabjlidad normal , como el de la Figura 13.30, es util para averiguar la paula de los residuos. EI gn'ifico indica la existencia de una relaci6n lineal aproximada y, par 10 tan to, no es posib le rechazar cl supuesto de que los residuos sigucn una di stribuci6n normal.
Tambien es bueno representar los residuos en relaci6n co"n cada una de Jas variables independiemes incluidas en eJ anaiisis. Eso permite comprobar que 110 hab ra ullas cuan tos puntos de datos excepcionalcs 0 una campJeja re laci6n no lineal condicionada de una de las variab les independientes. Si el modelo se ha · especificado y se ha estimado correclamente, esperamos que no exisla ninguna pauta de relaci6n entre las variables independienles y los residuos. La Figura 13.31 muestra cI grMico de los residuos en relaci6n can la variable del prccio al por mayor. No observamos ninguna paura excepcional en estc gn'ifico, salvo el elevado caso atfp ico posi tivo cu:ando el precio al por mayor es aproximadamente 110.
En la Figura 13.32 moslramos el grMico de los residuos en relaci6n con el tejido importado. Una vez mas, no vemos ninguna paUla excepcional de los residuos, pero sf observamos que la mayorfa de las importaciones estan concentradas entre 0 y 10. Par 10 tan to,
200
Diagrama de puntos • dispersos de los ISO residuos en relaci6n con el precio.at por
100 # mayor.
• ~ SO ~
~ • w
" • a •
• • -50 • •
-100 •
100 104
•
•
•
• 108
whoprice
•
•
•
• ••
• •
• •
• •
112 116

Capitulo 13. Regresi6n multiple 561
Figura 13.32. 200
Diagrama de puntas • dispersos de los 150 residuos en relacion can el tejido importado.
Figura 13.33.
100 • • •
" • - 50 ~ • w • ~ •
a • .' •
-50 • •
" -100 • •
• 0 5
•
•
•
10
•
15 impfab
• •
•
•
20 2S 30
los valores mas altos del tej ido importado podrfan producir un gran efecto en el coeficiente de la pendienle de la recta de regresi6n. Por ul timo, en la Figura 13.33 vemos un gnirico de los residuos en relaci6n con cl tcj ido expollado. De nuevo, la paula de los residuos no sugiere L1n a alternativa a Ja relaci6n lineal.
EI ana l isis final de los residuos examin<l la relaci6n entre los res iduos y la variab le de· pendientc. Consideramos un grafico de los residuos en relaci6n con el valor observado de la variable dependienle en 'Ia Figura 13.34 y en re laci6n con el valor predicho de la varia· ble depcndiente en la 13.35. Podemos vcr en In 13.34 que existe una relaci6n positiva entre los residuos y el valor observado de «collonq». Hay mas residllos negativos en los valores bajos de «collonq» y mas res iduos positivos en los valores altos de «cottonq». Es posible demostrar m<ltematicamente que siempre existe una corrclaci6n positiva entre los residuos y los valores observados de la variable dependienle. Por 10 tanIO, un grMico de los residuos en relac i6n con e l va lor observado 110 suministra ninguna infonnaci6n {Itil. Sin embargo, siempre se deben representar los residuos en re laci6n con los va lorcs predichos 0 ajustados de la variable depend iente. De esa forma se averigua si los CITores del modelo son eslables en el rango de los val ores predichos. En estc ejemplo, observese que no existe ninguna relaci6n entre los res iduos y los valol"es predichos. POI' 10 tanto, los crrores del modclo son cstables en el rango.
200 Diagrama de puntas • dispersos de los 150 residuos en relaci6n can el tejldo
100 exportado. • , •
" so - • • • ~ • w ~
.' • • a •
-so • • • • • •
• • • • -100 • •
• •
100 200 300 400 SOO expfab

562 Estadislica para administraci6n y economfa
Figura 13.34. Diagrama de puntos dispersos de los residuos en relacion con el valor observado del algod6n.
200,------------------------------------------,
• 150
100 • • .. 50 • • •
• • • • • 0t-----------------------------------•• ----------1
• • -50
• • -100 •
• 1200 1400 1600
•
•
•
•
1800 cottonq
• • •
•
2000 2200 2400
Figura 13.35. Diagrama de puntas dispersos de los residuos en relaci6n can el valor predicho del algodon.
200 ,-------------------------------------------, •
150
100 • • .. 50 • • •
• • • • • 0t---------------------------------------•• ------~
• • • -50
• • -100 •
1400 1600
•
• • •
1800 Fitted Va lue
• • • •
2000 2200
En el Capftulo 14 ulili zaremos el anal isis de los res iduos para identificar dos situaciones del modelo de regresi6n, la heterocedasticidad y la aUlocorrelaci6n, que violan el supuesto del ana li sis de regresi6n de que la vari anza de los errores es la misma en el rango del modelo.
EJERCICIOS
Ejercicios basicos 13.78. Suponga que se incluyen dos variables indepen
di entes como variables de predicci6n en un amilisis de rcgrcsi6n multiple. l,C6mo cabe esperar que afecle a los cocficienles de la pendiente estimados cuando estas dos variables lienen una cOiTeluci6n igual a -
a) Q,78? b) 0,08? c) Q,94? d) D,33?
13.79. Considere un umilisis de regresi6n con II = 34 Y cualro variables independientes posibles. Suponga que una de las variables independientes liene una correlaci6n de 0,23 con la variable depcndicllIc. i,Impli ca eso qlle esta variable independi enle tendr:\ un estadfst icQ I de Student muy pequeno en el amilisis de regresi6n con las cuatro variables de predicti6n?
13.80. Considere un anal isis de regresi6n con II = 47 Y Ires variables independicnles posibles. Suponga que una de las variables independientes tiene

una correlaci6n de 0,95 con la variable dcpendienle. i,lmpliea eso que esta variable indepen diente tcndra un esladlslico f de Student muy grande en el amilisis de regresi6n con las tres variables de predicci6n?
13.81. Considere ll11 anal isis de regresion can 1/ = 49 y dos variables indepcndientcs posibles. Suponga que una de las variables independientes liene una correlaci6n de 0,56 con la variable dependiente. i,lmplica eso que eSla variable independienle lendni un estadfsli co t de Studenl muy pequeno en el amllisis de regresi6n con las dos variables de predicci6n?
Ejercicios aplicados
-1,3.82. Para averiguar c6mo influye en un eSlado el podel' econ6mico de una compafifa de seguras de accidentes en su poder polflico, se desarro1l6 cl siguiente modelo y sc ajust6 a los datos de los 50 estados de ESlados Unidos.
y= Po + P!Xl + fJ~ + pyX] + P.p4 + P.,xs + f'. donde
Y = cociente entre el pago de los impuesLos estatales y locales de la empresa, en miles de d6lares, y los ingresos fiscales eSlalales y locales totales en millones de d61ares
XI = coeficicnte de concentraci6n estatal de las companlas de seguras (que mide la concenrracion de los recursos bancarios)
x2 = renla per capita del eSlado en miles de d6-lares
x] = cociente entre la renla no agricola y la suma de la renta agrfcola y no agrfcola
x4 = cociente entre la reola neta despues de impuestos de la compafiia de seguras y las reservas de segura (multiplicado POl' 1.000)
Capitulo 13. Regresion multiple 563
13.83. Sc pidi6 a una mueSlra alealoria de 93 estudiantes universitarios de primer ario de la Universidad de Illinois que valoraran en una escala de r (baja) a 10 (alta) su opini6n general sobre la vi~ da en la residencia universitaria. Tambien se les pidi6 que valoraran su nivel de satisfaccion con los compaficros, con la planta, con la residencia y con el director de la residencia (se ObluvO informacion sobre la satisfacci6n con la habitacion. pero 6sta sc dcscano mas tarde, porque no sumi nistrnba mas informaci6n para explicar la opinion general). Se estim6 cl siguiente modelo:
y = Po + PIX! + P~2 + pyX] + PttX4 + G
donde
Y = opini6n general sobre la residencia Xl = satisfacci6n con los compafieros X2 = satis l~'lcci6n con la plama x3 = satisfaccion con la residencia X4 = sat isfaccion con cl director de la residen-
om Utilice la parte de la salida informatica de la regrcsion es(imada que se muestra a continuaci6n para realiwr un informe que resuma los resultados de este estudio.
DEPENDENT VARIABLE, Y OVl':RALL OPINION
SOURCE
MODEL ERROR TOTAL
PARAMETER
INTERCEP'l' Xl x2 x3
SUN OF DF SQUARES
4 37 . 016 88 81 . 780 92 118 . 79
ESTIMATE
3 . 950 0.106 0 122 0 . 092
~~
SOUAAE FVALUE R~SOUAAE
9.2540 9 958 0 . 312 0 . 9293
STUDENT'S t STD. FOR HO: ERROR OF
PARAMETER = 0 ESTIMATE
5 . 84 0 . 676 1. 69 0 .063 1. 70 o. 072 1.75 0 053
0 . 169 2.64 0 064 x., = media de las reservas de seguro (dividida X4 PO' lO'(JOO) "'------=-"-------'-------'---
AquI se muestra parte de ]a salida informatica de la regresi6n eSlimada. Realiee un infon.nc que resuma los resultados de cste cstudio.
«-SQUARE = 0.5L5
Student's t for HO: Std. Error
Parameter Estimate Parameter '= 0 of Estimate
Intercept 10.60 2.41 4.40
Xl -0.90 -0.69 1.3 1 X3 - 13.85 -2.83 4.1 8 X4 0.080 0.50 0.160
X5 O.tOO 5.00 0.020
13.84. En un estudio, se ajusl6 el siguiente modele a 47 obscrvaciones mensuales en un intento de ex plicar la diferencia entre los tipos de los certificados de dep6sito y los tipos del papel comercial:
y = Po + PIX! + P1h + e
donde
y ~ tipo de los cenificados de dep6sito mcnos tipo del papc1 comcrcial
XI = tiro del papel comercial X2 = cociente entre los prestamos y las invcrsio
nes y·el capital

564 Esladfslica para administracion y economfa
Utilicc la IXlrtc de la sa lida informatica de la rc~ gresi6n estimada que se muestra a continuaci6n para escribir un informe que resuma los resultados de este estudiu.
R-SQUARE - 0 .7 30
STUDENT'S t; STD. FOR HO: ERROR OF
PARAMETER ESTIMATE PARAMETER '" 0 ESTIMATE
INTERCEPT - 5.55 9 - 4 . 14 1. 343 Xl 0 . 186 5 . 64 0 . 0 33 X2 0 . 450 2 . 08 0 . 216
13.85. (i., Se Ie ha pcdido quc dcsarrolle un modelu de regresi6n multiple para predeci r el numero anual de muertes en carrctcra en Estados Unidos en funci6n del rotal de millas recorridas y de la velocidad media. EI fichcro de datos Trame Death Rate contiene 10 anos de datos anuales sabre las tasas de mortalidad pur 100 millones de millas-vchfculo (y), la distancia total reconida en miles de millones de millas-vehfculo (xd Y la velocidad media en millas por hora de todos los vehfculos (x2)' Ca1cu1c la regresi6n mu ltiple de y con respeclo a XI Y X1 Y rea lice un informe que anal ice sus resultados.
13.86. (i <t El fichero de datos Household Income cuntiene datos de los 50 est ados de Estados Vll idos. Las variables incluidas en el fichero son el porcentaje de mujeres que partieipan en la poblaci6n nctiva (y) , la mediana de la renin personal de los hugares (Xl), el nt' mero med io de anos de
estudios de las mujeres (x2) Y la lasa de dese m_ pleo de las mujercs (x)). Calcu[e la regresi6n multiple de y con respeeto a X I ' Xl Y X ) Y realiee Ull in forme sobre sus resultados.
13.87. ( ) Le han pedido que desarrolle un modelo de regresi6n multipl~ que prediga la of en a monetaria real de Alemania en funci6n de la rcnta y del tipo de interes. El fichero de datos Real Money eontiene 12 observaeiones anllales sobre cl dinero real pe r capita (y). la renta real per capita (X I) Y los lipos de interes (x2) de Alemania. Utilkc estos datos para desarrollar un modclo que prediga el dinero real per c:"ipita en funei6n de la renla per capita Y del tipo de interes y realice un informc sobre sus resultados.
13.88. ~ oj L"1s Naeiones Unidas Ie han conlralado como consultor para ayudar a identiticar Ius faetores que predigan el crecirniento dc [n industria manufacturera de los pafses en vias de desarrollo. Ha decidido utilizar una regresi6n multiple para desarrollar un modelo e identificar las variables importames que prediccn c[ credmiento. Ha rccugido los datos de 48 pafse~ en el Fichera de datos Developing Country. Las variables inclllidas son cl crecimiento porcentual de la in dustria manufactllrera (y), cl crccimiento agrfcola porcentual (XI ) ' el crecimicnto porcentual de las exportacioncs (x2) Y la tasa porcentual de intlaei6n (x)) de 48 pafses en vfas de desarrollo. Desarrolle un modelo de regresi6n multiple y escriba un informe sobre sus resultados .
RESUMEN
En este capftulo hemos sentado las bases necesarias para cornprender Y ap[icar los metodos de regresi6n multiple. Hemos cumenzado analizando delalladamente Ius supuestos del modelo y las consecuencias de esos supuestos. A partir de ahf, hemos presenlado el metodo de mfn imos cuadrados y los metodos para obtener estimaciones de los coeficientes. Con esas bases, hemos desarrollado metodos para averiguar e6mu se ajusta el tlludelo de regresi6n a los datos observados, 10 ellal nos ha llevado a desarrollar los melodos clasicos de inferencia para contraSfar hip6tesis sobre Ius eoeticientes Y para eonstruir intervalos de confianza. Eso nos ha llevado a presentar metodos para realizar predieciones de la variable (\t;pendiente a partir del modelo e inferencias sobre los valores predichos.
. Con estas bases y comprendiendo el modele basico,
hemos pllsadu a examinar algunas tecnieas impOrlanles. Hemos presentado mcrodos para transformar model os cuadn:lticos en funciones lineales. Tambien hemos desarrollado trans formaciones para modelos lineales logarftmicos. Por ultimo, hemos come{lzado a presentar metodos para utilizar varinb[es f"ieticias para represenlar variables de predicci6n categ6rieas. El capItulo termina can Ull extenso modelo de aplicaci6n que muestra c6mo rcalizarfa un analista todo el proceso de desarrollo del modelo de regresi6n. Este proceso eomienza can sencillos estadfsticos descriptivos, teenicas grufieas Y la aplicaci6n de metodos de rcgresi6n Y termina con un analisis de los residuos para cxaminar [a compatibilidad del modelo con los datos y los supuestos del modelo.

Capitulo 13. Regresi6n multiple 565
TERM IN OS CLAVE
anal isis de regresi6n utilizando variables fictic ias, 547
descomposici6n de la suma objctivos de la regresi6n, 49 [ prcdicci6n a part ir de modclos
base para ]a infel'enci[l sobre la de los cuadrados y coeficiente de detcrrninaci6n, 505 de rcgresi6n multiple, 533
rcgrcsi6n utilizando vari:,b[es ficticias para contraSlar las diferencias emre pendientes, 548
supuCSIOS habituales de [a
regresi6n pob[acional. 513 cocfi cientc de cOl"l'clacic'in Illultiple, 509 coefici ente de determinaci6n ajustado, 509 conlraste de un subconjunto de los
error tfpico de la estimaci6n. 506 est imaci6n JXlr millimos cuadrados
y regrcsi6n muestral multip[e, 498 estimaci6n de [a varianz[l
par:illletros de regresic'in, 529 contraste de todos los parametros
de un modele de regresi6n, 527 contrastes de hip6tesis de los
coeficientes de regresi6n, 515
de los errores, 506 regresi6n mUltiple, 497 transformaciones de modelos
cuadnllicos, 537 intervalos de confianza de los
coeficicntes de regres i6n, 5 [3 mode[o de regresi6n poblacional
multiple, 494 trans formac iones de mode[os
exponenciales, 540
EJERCICIOS V APLICACIONES DEL CAPiTULO
13.89. EI mctodo de mlnimos cuadrados se utili za mu~ cho mas a menudo que cllalquier Olro para esti~ mar los parfimelros de un modelo de regresi6n multiple. Explique la bast! de este metoda de estimrtei6n y explique por que se utili za tanto.
13.90. Es habitual caleular una labia de l amilisis de la varianza junto con una regresi6n multipl e est imada. Exptique detenidamente que informacion puede extraerse de esa tabla.
13.91. lndique si eada una de las afirmaeiones siguienles es verdadera 0 fa[ sa.
a) La suma de los cuadrados de los crrorcs debe ser menor que la suma de tos cuadrados de 1.1 regresi6n .
b) En lugar de realizar una regresi6n multiple, podemos obtener la mi sma informacion a partir de regresiones lineales simples de la variable dependiente con respccto a cada variable independiente.
c) EI coetieiente de determinaci6n no pucdc ser negativo.
d) EI coeficiente de determi naci6 n ajustado no puede seT negativo.
c) El coeficien~e de correlaci6n multip[e es la raiz euadrada del eoeficiente de determinac ion.
13.92. Si se aiiadc una variable independiente mas, por irrelevante que sea, a un modelo de regresi6n multiple, la suma de [os cuadrados de [os errores es menor. Expl ique por que y anatice las consecuencias para 1.1 intcrpretaci6n del coeficiente de determinaci6n.
13.93, Se haee una regresi6n de una variable dependiente can respecto a dos variables indcpcndientes. Es posib[e que no puedan rechazarse las hip6tesis Ho: [31 = 0 Y Ho: [32 = 0 a nive!es bajos de significac i6n y, sin embargo, pucda rcchazarse [a hipotesis No: PI = fl2 = 0 a un Il ivel muy bajo de significacion. i,En quc c ircunstan e ias podrfa darse este resultado?
13.94. [Para Iweer eSle ejereicio es necesario lIaber fefdo el apindice del capillllol Suponga que se esti ma el modelo de rcgrcs i6n por mfnimos (;uadrados:
YI = Po + PIXI; + {J~2; + C;
Dcmucstre que [os residuos, e;, del modele ~ustado suman O.
13.95. Se realizo un cscudio para evaluar [a influencia de algunos faetores en [a ereaci6n de nuevas empresas en [a industria de chips de computa.dor. Se estim6 el siguiente modelo para ull a mucstra de 70 paises :
y = - 59,31 + 4,983x, + 2,1 98x2 + 3,8 [6x3 - 0 ,3 [OX4 ( 1.156) (0.210) (2.063) (0,]]0)
- O,886x5 + 3,2 l5x6 + O,085X7 R2 = 0,766 (3,055) (1.568) (0.354)
dande
y = c rcaeion de nuevas empresas en la indus-tria
X l = poblacion en millones X2 = tamafio de 1.1 industria x) = medida de la calidad de vida econ6mica X4 = medida de 1.1 calidad de vida polftica

566 Estadfstica para administraci6n y economfa
Xs = medida dc la calidad dc vida medioambiental
x6 = Illcd ida de In calidad de vida san itaria y cd ucmiva
X1 = medida de la calidad de vida social
Los nUlllcros entre parentcsis s ituados debajo de los coeficientes son los errores tfpicos de los coeticicntcs estimados.
a) Interprete los cocfi cien tes de regresi6n estimados.
b) Interprele el coe fi cien tc de delenninaci6n . c) Halle cl intervalo de con fianza al 90 pur
dcnto del aumento de la ereaci6n de empre· sas provocudo por un aumenlO de la calidad de vida ccon6mica de I unidad, manteniendose toelas las dcmas variables constanles.
d) COlllrasle al nivel del 5 par ciento la hip6tesis nula de que, manteniendose todo 10 demas eonslantc, la caUdad de vida medioambienlal no innuye en la creac i6n dc cmpresas fren te a la hi p6tesis altcmati va bilateral.
e) Contraste al ni vel del 5 par dento 1a hip6tesis nulu de que. munleniendose todo 10 de· mas conSlanle, la ca lidad de vida sanitaria y
educuti va no innuye en la crcaci6n de empresas frentc a la hip6tesis alternali va bilateral.
f) Contrasle In hip61csis nula de que eSlas siCle 'll ilriables indepcndientes, considcradas en conjunto, no inn uyen en la creaci6n de empresns.
13.96. Una Cmprcsa de sondcos realiza habituahnente estudio~ sobre los ~ogaJ'es pOl' medio de cuesli onartos por correo y liene intcrcs en com>ccr los factores que innuycn en la tasa de respuesta. En un expcrimento, se cnviaron 30 jucgos de cueslionarios a posibles encuestados. EI modelo de rcgrcsi6n ajustado al conjunto de datos resultanles era
donde
Y = porcenlaje de respuestas rccibidas Xl = numero de preguntas realizadas X2 = longitud dcl cuestionario en numero de pa
labras
A continuuci6 n se muestra una parte de la salida del programa SAS de la regresi6n cstimada.
R-SQUARE - 0.637
STUDENT'S t STD. FOR HO: ERROR OF
PARAMETER ESTiMATE PARAMETER - 0 ESTIMATE INTERCEPT 7 L 3652 Xl - 1 . 6345 - 2.89 0 . 6349 X2 - 0.0162 -1 . 78 0 .0091
a) Interprelc los cocfic ientes de regresi6n cstimados.
b) Intcrpretc el coeficientc de determ inacion. c) Contrasle al nivcl de signifi caci6n del I par
cienlo lu hip6lcsis nula de que las dos variables indepcndic111es, consideradas en conjun. to, no innuyen lineal mente en la tasa de rcspuestu.
d) Halle e intcrpretc cl intervalo de confianza al 99 pOl' ciento de (ll '
e) Contrnste In hip6tcsis nula
frente a la hip6tesis alternativa
H I :(l2<O
e interprete sus resu ltados.
13.97. Una consultora ofrece cursos de gesti6n financiera para ejecutivos. AI final de estos cursos. se pide a los participanles que hagan una valo· racion global del valor de l curso. Para ver c6mo innuycn algunos factores en las valoraciones, se ajust6 el modelo
Y = Po + /JJxJ + {J~2 + P}-l:J + C
para 25 cursos, donde
Y = va loraci6n media realizada por los participantes en el curso
XI = po rccnluje del cursa dedicado a reulizar sesiones de di scusi6n en grupo
X2 = ell nlidnd de dinero (en d6lares) por asistetHe al curso ded icndo a la preparaci6n del material del curso
x) = cuntidad de dinero por asistente al cursa dcdicado a la provisi6n de material no reIndonado con el cursu (comida, bcbidas, e tc.)
A conlinuaci6n SC' mueslra una pane de la salida del progruma SAS dc la regresi6n ajustada.
R- SQUARE - 0.57 9
S'l'UDEN'l" S t s=. FOR HOI ERROR OF
ESTIMATE PARAM!:'l'!:R - 0 ESTiMATE
INTERCEPT Xl
42.9712 0 . 381 7 1. 69 0 . 2018
X2 X)
0.5112 2.64 0 1957 0 . 015 ) 1 . 09 0 0693
a) Interprete los coeficicntes de regresi6n estimados.
b) Interprete el coefi ciente de delerm inaci6n. c) Contraste al nivel de signifi caci6n del 5 par
dento la hip6tcsis nula de que las Ires variables indepcndicntes, considcradas en conj un-

10, no infillyell linealmenle en la valoraci6n de! clIrso.
d) Halle e inlerprele el inlervalo de confianza al 90 por cienlo de !JI'
c) COlltraste la hip6tesis nula
frente a la hip6tesis alternativa
H I :P2> O
e interprete su resullado.
f) Contraste al nivel del 10 por dento la hip6-tesis nllia
Ho:fh=O frente a la hip6tesis alternaliva
e interprete su resu ltado.
13.98. ,. Al final de las dases, los profesores sao evaluados por sus estudiantes en una escala de I (malo) a 5 (excelellte). Tambiell se les pregunta a los esludiantes que ealifieaci6n csperan oblener y eSlas se codifiean de la forma siguiente: A = 4, B = 3, etc. EI fichero de datos Teacher Rating coilliene las evaluaciones de los profesores, las calificaciones medias esperadas y el numero de estudiantes de las clases de una muestra aleatoria de 20 clases. Calcule la rcgresi6n multiple de la evaluaci6n con respecto a la califieaci6n esperada y eJllumero de estudiantes y real ice un informe sobre sus resultados.
13.99. Sistemas Informiiticos Voiadores, S.A., quiere saber c6mo afectan algullas variables a la eficiencia del Irabajo. Basandose en una muestra de 64 observaci ones, cstim6 ci siguicnlc mode-10 por mfnimos cuadrados:
y= - 16,528 + 28.729xl + 0,022X2 - 0,023x) - 0,054x4
- 0,077X5 +0,411-"'6 + 0,349x7+ 0,028x8 R2=0,467
donde
y = fndiee de efieiencia directa del trabajo en la planta de produeci6n
X l = eociente entre las homs extmordinarias y las horas ordinarias realizadas por todos los obreros
-"'2 = numero medio de trabajadores por hora en la planta
x ) = porcemaje dc asalariados que palticipan en algun programa de calidad de vida laboral
X4 = numero de reclamaciones recibidas por cada 100 trabajadores
Capitulo 13 Regresi6n multiple 567
-'"5 = tasa de accioncs disciplinarias .\"(, = lasa de absent ismo de los trabajadores
par hora x7 = attitudes de los trabajadores asalariados,
desde baja (in satisfechos) hasta alta, medidas par media de un cuestionnrio.
x8 = porcenlaje de (rabajadorcs par hom que haeen al menos una sugereneia en un ana al programa de sugerencias de la planta.
Tambien se obtuvo por mfllimos cuadrados un modelo ajustado a partir de estos datos:
y= 9,062 - 10,944xl + 0,320-"'2 +0,01 9X3 R2= 0,242
Las variables X4' -"'5' X6' X7 Y X8 son medidas de los resultados de un sistema de relacioncs laborales de la planta. Contraste al nivcl del I por eiento la hip6tesis nula de que no contribuyen a explicar la eficiencia dirccta del trabajo, dado que tambien se utili zan XI ' x2 Y x3-
13.100. Basandose en las calificaciones obtenidas por 107 esrudiantes en el pri mer examen de un eurso de estadfstica para los ncgocios, se esti m6 el siguiente modelo por minimos cuadrados:
y=2, 178+0,469x l + 3,369x2 + 3,054x3 (0.090) (0.456) (1.457)
donele
y = calificaci6n efectiva del estudiante en el examen
Xl = calificaci6n csperada por el estudiante en el examen
X2 = hams semana1es dedicadas a estudiar pa-ra el curso
xJ = ealifieaci6n media del estudianle
Los numeros entre parentesis situados debajo de los eoctieicnles son los errores t(picos de los eoeficientes estimados.
a) Interprete la estimaci6n de (JI' b) Halle e inlcrprcte el inlervalo de confianza
al 95 par ciento de P2' e) Contraste la hip6tesis nu la de que fh es 0
frellte a una hip6tesis altemati va bilateral e interprete Sll resultado.
d) Interprete el eoeficiente de detenninaci6n. e) Contraste la hip6tesis nula de que
f) Halle e interprete el coeficiente de correlaci6n multiple.
g) Prediga la califieaci6n de un estudiante que espera una calificaci6n de 80, estudia 8 horas a la semana y tiene una calificaci6n media de 3,0.

568 Esladislica para adminislracioo y economia
13.101. Basandose en 25 alios de datos aouales, se inlent6 cxplicar el uhorro en la India . EI modclo ajustado era
13.102.
Yi = {Jo + fJlXli + rJ~2j + f:i donde
y = variaci6n del tipo real de los dep6si tos XI = variaci6n de la renta real per capita X2 = variaci6n del ti po de intercs real
Las estimaciones de los para metros por mfnimos cuadrados (con los crrores tfpicos entre parentesis) eran (vease la referencia bibliognifica I)
b, ~ 0,0974(0,02 15) b, ~ 0.374(0,209)
El coeficiente de dcterminaci6n corrcgido era
iP = 0,9 1
a) Halle e interprete el intervalo de confianza al 99 POI" cicnto de [JI.
b) Contrasle la hip61esis nula de que P2 es ° frenle a la hip6tcsis alternativa de quc cs positivo.
c) Halle el coeficiente de delerminaci6n. d) Contrasle In hip6tesis nula de que
Ii, ~ p, ~ O. e) Halle e interprete el coeficicntc de cOlrela-
ei6n multiple.
Basandose en datos de 2.679 jugadorcs de balonceslo de centros de cnselianza secundaria, sc ajust6 el siguiente modclo:
Yj = {Jo + PIXI; + {J2-'f2i + ... + P9-'C91 + Cj
dondc
y = minutos jugados en 13 tcmporada XI = porcentaje de li ros de 2 puntos convertidos Xi = porecmaje de ti ros Iibres X3 = rebotes por minuto ..1."4 = puntos por minulo x~ = raltas por min u\o X6 = robos de bal6n por minuto X7 = lapones por mi nu to XII = perdidas de bal6n por minulo X9 = asistencias por minuto
Las eSli maciones de los panl.metros por mfni mos cuadrados (con los errores Ifpicos entre parcnlcsis) son
bo ~ 358,848 (44,695) b, ~ 0,2855 (0,0388) b, ~ 504,95 (43,26) b, ~ 480,04 (224,9)
b, ~ 0,6742 (0,0639) bJ ~ 303 ,8 1 (77,73) bs ~ - 3.923,5 (120.6) b, ~ 1.350,3 (2 12.3) b, ~ 722.95 (110,98) b, ~ -89 1,67 (180,87)
EI coef"icicnte de determinacion es
R2 = 0,5239
a) Halle e inlcrprcte el inrervalo de confianl.:t al 90 por cienlo de (J6.
b) Halle e interprete cl illlervalo de con fi :lIlz:I al 99 por ciento de (J7.
c) COlllraste la hip6tesis nula de que /18 es 0 frente a 1a hip6tesis alteOlativa de que es negativo. Interprctc Sll resultado.
d) Conlraste la hip6lcsis nula de que fi9 es 0 frente a b hip6tesis alLCrnativa de que e~ positivo. Intcrprete su resultado.
e) Interprele el eocfieiente de determinaci6n. f) Halle e interprete el cocficienle de cOlrelil
ci6n multiple.
13.103. Basandosc en datos de 63 regiones, se cstim6 el siguientc modelo por mfnimos cuadrados:
13,104,
y = 0,58 - 0,052x 1 - 0,005..1."2 RZ = 0.1 7 (0,U I9) (0.042)
donde
y = tasa de crec imienlo del produclo in terior bruto real
XI = renta real per capita X2 = lipo impositivo medio en porcentaje del
producto naciona l bruto
Los m"imeros entre parenlesis situados debajo de los coeficienles son los errores tfpicos de los coeficientcs est imados.
a) Contraste la hip6tesis nula de que PI es 0 frente a una hip6tesis alternativa bilatcral. Interprete Sll resultado.
b) Contraste la hip6lesis nu la de que (J2 es 0 frente a una hip6tesis alternati va bilateral. Interprete su resultado.
c) Inlerprete el cocficienle de determ inaci6n . d) Halle e interprctc cl coeficicntc de correla-
cion multiple .
En un cstudio, se ajust6 el siguicllte modelo de regresi6n a los datos de 60 golfi stas amateurs:
y= 164.683 +34 1, IOX I + 170,02xz+ 495,19x) -4,23x-I (10059) (167, t8) (305.48) (90.0)
- 136.04Oxs - 35.549x6 + 202,52x7 iP =0,5 16 (25.634) (16.240) (106.20)
donde
y = ganancias por torneo en d61arcs Xl = longitud med ia del golpe ..1."2 = porcentaje de veccs en que el golpe acu
ba en la pisla X3 = porccntajc de vcces en que se llega cn
buena posici6n al ((green» (<<regulation»)

x" = porcent[lje de veces en que se consigue e l par despues de haber cafdo en zona de arena
X j = niimero media de «putts» reali zados en los «greens» a los que se ha lIegado en buena posicion
.\"6 = numero medi o de «putLs» rcalizados en los «greens» a los que no se ha lIegado en buena posici6n
.\"7 = numcro dc anos quc lleva jugando c\ golfista amateur.
Los numeros entre pantntesi s situados debajo de los coefic ientes wn [Of; errores tfpicas de los coeficienles estimados.
Realice un infonne que reSllma 10 que ha aprcndido con CSIOS resultados.
13.105. f.1 EI Departamento de Economfa quiere desan'ollar un modelo de regresi6n multiple para predecir la calilicaci6n media (GPA) de los estudiantes en los cursos de economfa. El profesorado del departamento ha reunido datos de 112 licenciados, que contienen las variables CPA de economfa. SAT verbal, SAT de matcmaticas, ACT de ingles, ACT de cicncias 50-ciales y puesto oblenido en el bachillemto (I'allk). Los dato~ sc encuentmn en el fichero de datos llamado Student GPA de su disco de datos. El apendice conticne una descripci6n de las variables.
a) Uti lice las variables SAT y «rank» para averiguar eutil es el mcjor modclo de predicci6n. Elimine las variables independientes que no scan significativas . i,Cuales son los coeficientes, Sll estadfstico , de Student y el modelo?
b) Utilice las variables ACT y «rank» para avcriguar cwll es cl mejor modcl0 de prcdicci6n. Elimine las variables indcpcndientes que no scan sigll ifi cati vas. i,Cuales son los coeficientes. su cstadfstico I de Student y el modelo?
c) i.Que madelo predice mejor la GPA de economfa? Aporte pruebas para apoyar su conclusion .
13.106. ( ... EI fichero de datos Salary Model contiene una variable dependiente y siete variables independientes. Tiene que desarrollar el «mejol"» modelo de regresi6n que prediga Yen funei6n de las siete variables independientes. Los datos se encuentran en su disco de datos.
La variable dependi enle se llama {<y~) en el fichero y las variables independientes tambiCIl
Capitulo 13. Regresi6n multiple 569
tienen Sli propio nombre. Util iee un anal isis dc regresi6n para averi guar que variables dcbcn eslal" en el modelo final y para estimar los coeJi cientes. Mueslrc el conlraste P eondicionado y el contraSle t condicionada de cualquier variable eliminada. Analice los residuo.'> del modelo por medio dc grMicos. Mueslre SllS resul tados y anal ice SliS canclusiones. Transfonne las variables si los residuos indican una relaci6n no lineal. Presente claramente su modelo final , mOSlrando los coeficienles y los estadfslieos I de SllIdent de los coeficientes.
13.107. ~. I Uti lice los datos del fichero Citydat para estimar una ccuaci6n de rcgrcsion que pueda utilizarsc para avcriguar cI cfccto marginal que produce el porcentaje de locales comerciales cn c1 valor dc mcrcado por vivicnda ocupada por su propietario. IncJlIya en Sll eCllaci6n de regresi6n multiple el porcentaje de viviendas ocupadas por Sli propietario, cl porcentajc dc locales ind ustriales, el numero mediano de habitaciones par vivienda y la renta per capita como variables de predicci6n adicionales. Las variables estrin en Sll disco de datos y se describen en el apendice . Indique cuales son significativas. Sll eeuaci6n fina l debe incluir un icamente las variables significativas. Analice e inlerprele su modelo final de regresi6n e indique c6mo seleecionaria una ciudad para comprar Sll vivienda.
13.108. (0, Los rcsponsables de la National Hi ghway Traffic SafclY Administralion (NHTSA) de Estados Unidos quieren saber si los diferentes tipas de vehfculos de un estado tienen relaei6n con la (asa de mOltalidad en carretera del estado. Le han pedido quc dcsarrollc varios anal isis de regresi6 n multiple para averiguar si el peso medio de los vehfculos, el porcelllaje de vehfculos importados, el porcentaje de camiones ligeros y la antigiiedad media de los autom6viles estan relacionados con las muenes en accidente ocu rridas en autom6v iles y camionetas. Los datos del anatisis se encuentran en el fichero de datos Ilamado Crash. que esta en su disco de datos.
a) Prepare lIna malriz de correlaciones de las muertcs ell accidentc y las variables de prcdicci6n. Observe las rclaeioncs si mples entre las muertes en accidente y las variables de predicci6n. lndique ademas Tualquier problema posible de multicolinealidad entre las variables de predicei6n.

570 Estadfstica para administracion y economia
b) Realice un ,malisis de regrcsion multiple de las muertes en accidentc con rcspccto a las variables de prcdiccion posibles. Elimine en el modelo de regresi6n eualquier variable de prediccion no significativa, una dc cada vez. Indique su mejor modelo final.
c) Exponga las conclusiones de su anal isis y anal ice la importancia condi cionada dc las variables desde el punto de vista de su relacion COIl las muenes en accidente.
13.109. , If El Departamento de Transporte de Estados Unidos qui ere saher 5i los estados que tienen un porcentaje mayor de poblacion urbana tienen una lasa mas alia de rnuenes totales en accidente ocurridas en automoviles y camionetas. Tambien quiere saber si la vcloc idad media a la que se conduce par las CUlTeteras rurales 0 el porcentaje de carreteras rurales que esta asfaltado estan relacionados con las tasas de muertes en accidente, dado el porcenlaje de ]loblacion urbana. Los datos de este estudio se encuemran en el fichero de datos Crash almacenado en su disco de datos.
a) Prepare una malriz de conelaciones y estadfsticos descriptivos de las muertes en accidente y las variables de prediccion posi bles. Senale las relaciones y cualquier problema posib le de multicolinealidad.
b) Realice un anfilisis de regresion mulliple de las muertes en aceidcnle con respeeto a las variables de prediccion posibles . Averigiie euales de las variables deben mantenerse en el modelo de regresion porque tienen una relaci6n sign iricativa.
c) Muestre Ins resultados de su analisis desde el punta dc vista de su modelo rinal de regresion. Indique que variable ... son signifi cali vas.
13.110. ) Un economisia desea predecir el valor de mercado de las viviendas de pequenas ei udades del Media Oeste ocupadas por sus propietarios. Ha reunido un cooj uoto de datos de 45 pcquenas ciudades que se refieren a un periodo de dos anos y quiere que los utilice como fuente de datos para el antilisis. Los datos se encuentmn en el fiehero Citydat, que est:! en su disco de datos. Quiere que desarrolle una ecuacion de prediccion basada en una regresion multiple. Las variables de prediccion posibles son el tamano de la vivienda, el lipo itll positivo, eI porcentaje de loca les comerciales, la renta per capita y el gasto publico municipal total.
a) Caleule la matriz de carrelaciones y eSI<l_ dfsticos deseriptivos del valor de mcreado de las viviendas y las variables de predic_ cion posibles. Senale los problemas posibles de tllulticolinealidad. Defina el rango aproxi mado para su modele de rcgresion utilizando In regIa siguiente: medias de las variables ± 2 desv iaciones tfpicas.
b) Realice anal isis de regresi6n m(tltiple utilizando las variables de predicci6n. Elirninc las variables que no sean significativas. i,Que variable, el tamano de la vivienda a el tipo impositivo, tiene In relaeion condi eionadn mas cstrecha con c! valor de las vivicndas?
c) Un promotor industrial de un estado del Medio Oeste ha afirmado que los lipos de los impuestos locales sobre bienes inrnuebles de las pcquenas ciudades deben bajarse, ya que, de 10 contrario, nadie comprarfi una vivienda en estas ciudades. Basandose en su amllisis de este problema, eval (le la afirmacion del promotor.
13.111. f, Stuart Wainwright, vicepresidente de compms para una gran cadena nacionaJ de licndas de ESlados Unidos, Ie ha pedido que realice un anal isis de las ventas al por menor por estados. Quiere saber si el porcentaje de descmpJcados o la renla personal per capita esttin relacionados con las ventas al por menor per ca pila. Los datos para realizar este estudio se encuentran en cl fichero de datos Ilamada Retail, que esla almacenado en su disco de datos.
a) Prepare una matriz de correlaciones, calcuIe los estadfsticos descri ptivos y realice un anal isis de regresion de las vcntas al por menor per capila can rcspccto al porcentaje de desempleados y a la renta personal. Calcule intervalos de confianZil al 95 por cien\0 de los coericientes de la pendiente de cada ecuaci6n de regresi6n.
b) ,;,Cu{Ll es el erecto condieionado de una disminuci6n de la renta per capita de 1.000 $ en las venlas per capita?
c) i, Mejorarfa la ecuacion de prediccion aiiadiendo la poblacion de los estados como una variable de prediecion adicional?
13.112. i ~ Un importanle provecdor nacional de materiales de construccion para la construccion de vi viendas eSla prcocupado por las venta~
tolales del pr6ximo ano. Es bien sabido que las ventas de la empresa est{1Il relacionadas di rectamente con la inversion nacional total en

viviendu. Algunos banqueros de Nueva York estan prediciendo que los tipos de intcrcs subiran alredcdor de 2 puntos porccntuales el pr6-ximo ano. Le han pedido que realice un analisis de regresi6n para podcr predecir el cfecto de las vnl'iacioncs de los tipos de intcres en la inversi6n en viviendu. Usted cree que, adcmas del !ipo de interes, el PNB, In oferta monClaria, cl gnslo publico y el fndicc de precios de los bienes ucabados podrfall scr prediclores de la inversi6n en vivienda. por 10 que llega a la conclllsi6n dc que ncccsi!<l dos modclos de rcgrcsi6n multi pIc. Uno inclu ira el tipo de imcres preferencial y olras importantes variables. EI otro incluirii el tipo de interes dc los fondos federa les y OIras imponantes variables. Los datos de series (cmporales para reatizar cstc cstudio sc cncuentran en cl fichero de datos lIamado Macr02003, que esta almacenado en su di sco de dalOS y se describe en el apendice del CapItu lo 14.
a) Desarro llc dos modelos de rcgresi6n para predecir 1a inversi6n en vivienda util izando el tipo de inten!s prererencial para uno y el tipo de intercs de 1m: rondos federales para eI otro. Los modelos finales de regresi6n deben ineluir solamente variables de predicci6n que produzcan un ereclo condidonado significali vo. Analice los eSladfsticos de la regresi6n e indique que ecuacion hacc hIS mejorcs predicciones.
b) Hall e el inlervalo de eonfianza al 95 pOl' dento del coeficiente dc la pendiente del 111'0 de interes cn ambas ecuaciones de regresi6n.
13.113. t La Congrcssional Budget Office (eBO) de Estados Unidos tiene intercs en saber 5i las tasas de mortalidad infantil de los eslados esttUl relacionadas con el ni ve l de rec ursos medicos de que dispone cada uno. Los datos para el estudio se encuentran en el fi chero dc datos lIamado State, que esta almacenado en SlI disco de datos. L .... I medida de la mortalidad infantil SUIl las mucrtes de ninos de menos de I ario por cada tOO nacidos vivos. EI conjunto de variables de pred icci6n pasibles son los medicos por 100.000 habitantes. la renla personal per capita y los gastos totales de los hospitales (esta variable debe expresarse en magnitudes per capi ta dividicndo por la poblaci6n del estado).
a) Reulice un amilisis de rcgrcsi6n mutt iple y avcrigi.ie que variables de predicci6n deben incluirse en cI modelo de regresi6n multi -
Capitulo 13. Regresi6n multiple 571
pie. Interprete su modelo final de regrcsi6n y anal ice los cocficiente5, sus estudfsticos I
de Student. el error tfpieo de 1a cstimac i6n y cI R2.
b) JdenLitique dos variables mas que pod rian ser predictores adicionalcs si se anadieran al modelo de regresi6n multiple. Contraste su erecto en un anali sis de regresi6n multi ple e indique si sus sospcchas iniciales cran corrcctas.
13.114. f" Desarro lle un modelo de regresion multi ple para predccir cI salario en funci6n de otras variables independientes utilizando los datos del fichero Salary Model. que se encuentra en su disco de datos. Para eSle problema no utilice los :tfios de expcriencia sino la edad como sucedaneo de la experiencia.
a) Describa los pasos scguidos para obtcner el modclo final de regres i6n.
b) Contnlstc la hip6tcsis de que la lasa de variaci6n de los salarios femeninos en funci6n de la edad es menor que la lasa de variad6n de los salarios masculinos en rutlci6n de la edad. Debe formular su contraste de hip6tesi s de manera que aporte pruebas conlundemes de la ex istencia dc di scrimi naci6n de las mujeres [nora: las mujcres se indic:m mcdiante un <<I » en la variable «sexo» en 101 columna 5; el eontrasle debe realizarsc condicionado a las demas variables de predicci6n significa ti· vas del apartado (a)"I.
13.115. ( I Un grupo de activistas de Peaceful (Montana) cSla tratando de au mentar el desarrollo de su prfst ino enclave. que ha sido objelo de algun reconocimienlO nacional en el programa de tclevisi6n FOllr Dirty Old Mell. Sosticnen que un OIllmenlO del desarrollo comercial e indus\fial lraera mayor prospcridad e impllcstos mas bajos a Peaceful. Concrctamentc, sosticnen que un aumento del porcentaje de locales comcrciales e industri alcs rcducira el tipo del impuesto sobre bicnes inmuebles y aumentiln1 el valor de mercado de las viviendas ocupnctas por sus propietarios.
Le han contratado para analizar sus afirmaciones. Para ella ha ohtcnido eI fichero de datos Citydllt, que conliene dalos de 45 pcquenas ciudndes. Con estos datos, primero desalTOlla modclos de regresi6n quc prcdicen el valor medio de las vi viendas ocupadas por sus propietarios y el tipo del impuesto sobre bienes inmuebles. A continuaci6n, avcrigua si y c6mo la

572 Estadistica para administraci6n y economia
adici6n del porectltaje dc locales comerciales y del poreentaje de locales industriales afeeta a la variabil idad en estos modelos de regresi6n. EI modelo b:lsieo para predecir el valor de mcrcado de las viviendas (e 10) incluye como variables indcpcndientes el lamano de la vivicnda (c4), el tipo impositivo (e7), la renta per capita (e9) y el porcentajc de viviendas ocupadas por sus propietarios (e I2). EI modelo basico para predcc ir cl tipo imposi ti vo (e7) incluye como variables indepcndientes el valor cat:lstral (c6), los gaslos municipales actuales per capita (c5/c8) y el porcentaje de viviendas ocupadas por sus propielarios (e I2).
Averiglie si el porccnlaje de locales comerciales (cI4) y el porcentaje de locales industriales (e [5) mejoran la variabilidad explicada en cada uno de los tlos mOOclus. Realice Ull
contraste F condicionado de cada una de estas variables adicionales. Primero estime el cfeclo eondicionado del porcentajc de locales comerciales par 5i so lo y. a cont inuaci6n, el de locales industriales por sf solo. Explique delen idamente los resultados de su analisis. Incluya en su infonne una explicaci6n de por que cs importunte inc1uir todas las demas variables en el rnodelo de regresi6n en lugar de exmninar simplerncnte el efecto de la rclaci6n directa y s irnpic entre el poreentaje de locales comerciales y el de locales industriales en el tipo imposit ivo y en e[ valor de mcrcado de la vivienda.
13.116. f. Utiliee los datos del fi chcro de datos lIamado Student GJ'A. que se cncuentra en Sil
disco de dalos y se describe en el apend ice. a fin de desarrolluf un modelo para prcdecir In
calificaci6n media (O r A) de ecollornfa de un estudiantc. ComiCllcc con las variables «ACT scores», «gender» y «HSpcl».
Apendice
a) Ut il ice metodos cstadfsticos adecuados para elegir un subconjunlo de variables de prediccion cst:ldisticamente significlilivas. Describa su estrategia y defina minuciosamente su modelo final.
b) Explique c6mo podrfa utilizar la cornisi6n de adrnisiones de la un iversidad eSlc mode-10 para tamar sus decisiones.
13.117. Un economista estim6 para una mucstm aleatoria de 50 observaciones cl modelo de regresi6n
Log,V; = cr: + fJ1 logX 1i + IJ2 10gX21 + Ih log:r)/ + (J;J log X4i + f;i
donde
y = ingresos brutos generados pOl' una practiea medica
Xli = niirnero medio de horas trabajadas par los medicos en la praclica
X2i = numero de medicos en la praetica x )/ = niimero de personal sanitario auxiliar
(como cn fenneras) cmpleado en la praclica
X 41 = numero de habitaciones util izadas en la practica
Uti li ce In parte de In salida informatica mastrada aquf para realizar un informe sobre estos resultados.
R- SQUAR£ - 0 .927
STUDENT'S t STD.
FOR HOI ERROR OF
PARAMETER ESTUIATE PARAMETER ... 0 ESTIMATE
INTERCEI?'!' 2 . 347 LOG X, 0 .239 3.27 0.013
=" 0 . 673 8.31 0 . 081
LOG " 0.279 6 . 64 0.042
LOG x, 0.082 1.61 0.051
1. Obtencion de los estimadores por mfnimos cuadrados
Los esl imadorcs de los coeficientes de un mo de le con dos variab les de predicci6n sc obtienen de la forma sig uientc:

Sc minimiza
Capitulo 13. Regresion multiple 573
" seE ~ I [Vi - (bo + b,xli + b,x2,)12
i - I
Aplicando el calculo diferencial, obtenemos un conjunlo de Ires ecuaciones normales que pucdcn resol verse para hallar los eslimadores de los coe ricientes:
"
"
"
oseE --~ O
abo
2 I IYi - (bo + b,"1i + b,x,,)]( - 1) ~ 0 i '" I
"
"
"
"
"
oseE -- ~O
ob ,
"
"
2 I IYi - (bo + b,"1i + b,x2i)]( - Xli) ~ 0 i= J
"
" "
"
"
"
oseE --~O
8b,
"
" X liX2i = L X 2iYi
i - I
2 I [Yi - (bo + '"x li + b,",,)]( - X2,) ~ 0 i - I
" " "
" " /I /I
bo L. X2i + b, L X l i X 2i + b2 L '\~i = L X 2iYi i _ I i - I i - I i - I
Como consecuencia de la aplicacion del algoritmo de los minimos cuadrados, tenemos un sistema de tres ecuaciones lineales con tres incognilas, bo, hi Y h2:
" " " nbo + b l I Xli + b2 I X2i = I Yi
i - I i - I i - I
" " " " bo I Xli + hi I xt + b2 I X l i X 2i = I XliYi
;=1 ; = 1 i = 1 i '" I
" " " " bo L X2i + b l L X li X2i + b2 L. 4 = L X2iYi
i - I i - I i - I i - I

574 ESladistica para adminislraci6n y economia
Se rcs llclven las ecuaciones normales para obtencr los coeficientes deseados ea lcuJanclo pri mero los distintos clladrados de X e Y y los terminos que incluyen los productos entre eHas.
El tennino de la ordenada en el origen sc est ima de la forma siguiente:
2. Variabilidad total explicada EI termino SCR de la variabi lidad explicada en la regresi6n multiple es mas complejo que el terminG SCR caJculado en la regresi6n simple.
En el modele de regresi6n con dos variab les independientes
observamos que
" "' . "" SCR ~ L. (Yi - y, i - I
"
y ~ Po + /J,X, + p,X,
~ I [bo + b,xli + b,x" - (ho + h,;, + h,",,)J' i - I
Vemos que la variabil idad explicada tiene Ulla parte relacionada directamente con cada LI lla de [as variab les independienles y L1na parte relacionada con la correlaci6n entre las dos variables.
Bibliografia
I. Ghatak. S. y D. Deadman, «Money, Prices and Stabilization Policies in Some Developing Countries», Applied Economics. 21, 1989, pags. 853-865.
2. Hagermann. R. P., «The Determinants or Household Vacation Travel: Some Empirical Evidence», Applied Ecollomicl', 13, 198 1, pags. 225-234.
3. MacDonald, J . M. Y P. E. Nelson. «Do the Poor Still Pay More? Food Price Variations in Large Metropolitan Areas», loumal of Urban Economics, 30. 1991. pags. 344-359.
4. Spellman, L. J., «Entry and Profitabi lity in a Rnte·free Savings and Loan Markel), Quarterly Review oj Economics alld Business, 18. n." 2, 1978, pags. 87-95.
5. Van Scyoc, L. J. Y J. Gleason, «Traditional or Intensive Course Lcnghts? A Comparison of Outcomes in Economics Learning», 101/I'llal oj ECOllomic Educatioll, 24, 1993, pags. 15-22.