r commander
TRANSCRIPT


2
Entorno
3
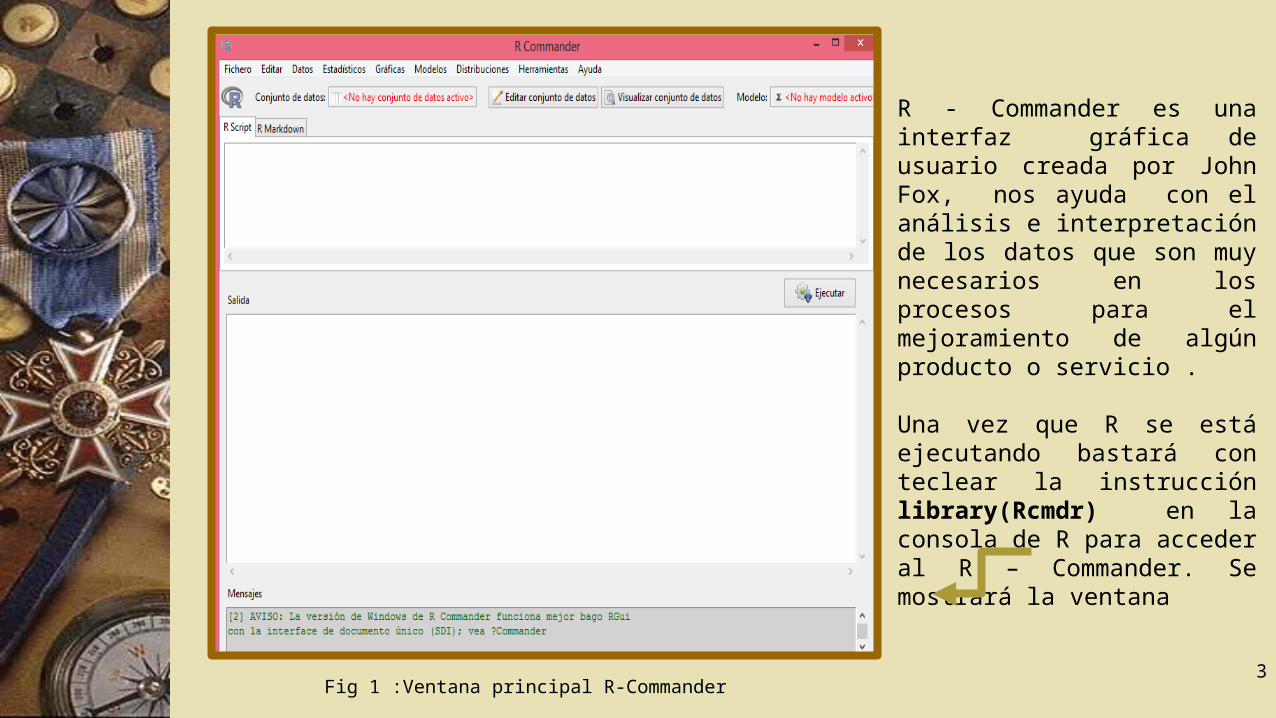
R - Commander es una interfaz gráfica de usuario creada por John Fox, nos ayuda con el análisis e interpretación de los datos que son muy necesarios en los procesos para el mejoramiento de algún producto o servicio .
Una vez que R se está ejecutando bastará con teclear la instrucción library(Rcmdr) en la consola de R para acceder al R – Commander. Se mostrará la ventana
Fig 1 :Ventana principal R-Commander

4
Opciones del R-Commander
Fichero: Permite abrir ficheros con instrucciones a ejecutar, o para guardar datos, resultados, sintaxis, etc.
Editar: Opciones para cortar, pegar, borrar, etc. Datos: Utilidades para la gestión de datos (creación de datos, importación desde otros
programas, recodificación de variables, etc.). Estadísticos: Ejecución de procedimientos propiamente estadísticos. Gráficas: Barras, sectores y puntos. Modelos: Definición y uso de modelos específicos para el análisis de datos. Distribuciones: Probabilidades, cuantiles y gráficos de las distribuciones de probabilidad más
habituales (Normal, t de Student, F de Fisher, binomial, etc.) Herramientas: Carga de librerías y definición del entorno.

5
Manejo de datosA continuación se explicarán los formas básicas para abrir una base con R-Commander1.- Nuevo conjunto de datosEste comando permite crear a mano y activar un conjunto de datos. Una vez asignado un nombre a los datos se abrirá una tabla vacía, que el usuario tendrá que rellenar con sus propios datos.
1 2
3

6
2.- Cargar conjunto de datosEsta opción permite abrir un conjunto de datos ya existente, por ejemplo un fichero con el formato nativo de R (.rda). 3.- Importar datosR-Commander no solo permiten crear y trabajar sobre datos con formato nativo, sino que permiten también utilizar ficheros provenientes de otros programas. Los formatos de fichero soportados por R-Commander son : texto puro (en fichero, portapapeles o dirección URL). SPSS. Minitab STATA Excel Access.Como ejemplo, abramos el conjunto de datos sida.xlsx creado en Excel, siguiendo las instrucciones.

7
1
2
3

8
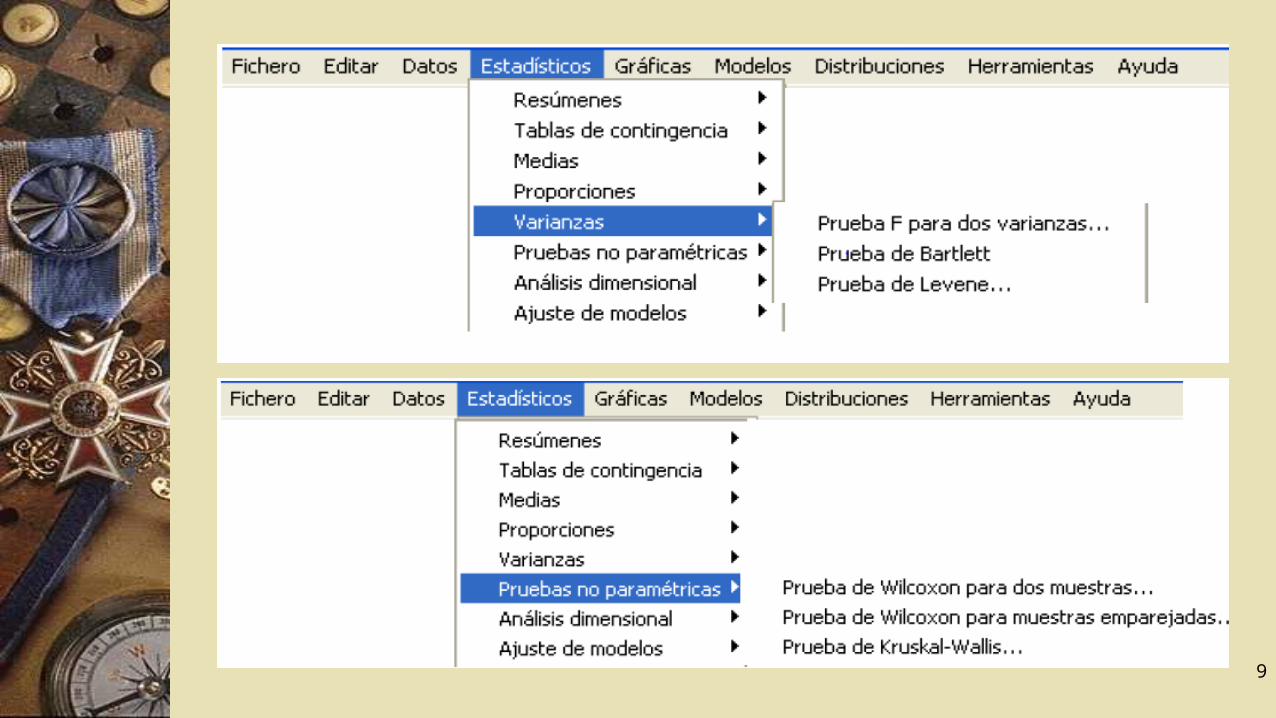
Contrastes de Hipótesis
9

10
En el contraste de hipótesis es preciso establecer procedimientos para aceptar o rechazar hipótesis estadísticas emitidas acerca de un parámetro u otra característica de la población. Vamos a ver como se realiza esto con ayuda del R – Commander a través de un ejemplo.
Prueba de hipótesis para la media de una distribución normal
Un agricultor quiere utilizar una forma nueva de fertilizante líquido para su cultivo de trigo. Se sabe que el rendimiento de una variedad de trigo, muy usada en la zona, utilizando un fertilizante granulado tradicional sigue una distribución normal de media de 2 t/ha y una desviación estándar de 0,2 t/ha. Se cuenta con los datos de rendimiento de 25 parcelas experimentales en las cuales se sembró la variedad de trigo y se aplicó el nuevo fertilizante ¿ Hay fuertes evidencias para decir que el nuevo fertilizante mejora el rendimiento con respecto al fertilizante tradicional?. Considere un nivel de significación del 5%.Los rendimientos obtenidos (t/ha) fueron:2,87 3,03 2,90 2,80 3,092,75 2,72 2,94 2,98 2,542,84 2,74 2,68 2,97 3,132,85 2,74 2,94 3,09 2,853,03 3,01 2,70 2,89 2,98
Ejemplo 1

11
Solución: En este caso, todos los datos corresponden solo a valores de rendimiento con el uso del nuevo fertilizante, por lo que el conjunto de datos que necesitamos para trabajar contendrán una única variable (rendimiento) y 25 observaciones. 1.- Utilizando la primera forma de ingreso de datos vamos a introducirlos.

12
Una vez creado el conjunto de datos procederemos a realizar la prueba de hipótesis de interés.En este ejemplo, el tipo de hipótesis que se desea probar es del tipo unilateral 1.- Planteamiento de la hipótesisH0 : µ ≤ 2 (La media poblacional del rendimiento del trigo con el nuevo fertilizante líquido es igual o inferior a 2 t/ha)H1 : µ > 2 (La media poblacional del rendimiento del trigo con el nuevo fertilizante líquido es superior a 2 t/ha)Nota: La prueba de hipótesis que se realizará depende de si se conoce o no la varianza poblacional del rendimiento de trigo con el nuevo fertilizante. En este caso dado que se conoce dicha varianza poblacional, se puede usar una prueba t de student, que utiliza el estadístico.
Donde:Es la media muestral.
µ0 Es el valor de la constante especificado en la hipótesis nula.S Es el desvío estándar muestral.n Es el tamaño de la muestra.

13
2.- Nivel de significanciaα = 0.053.- CriterioRechazar H0 si p-valor < α4.- CálculosElegimos la opción del menú: Estadísticos – Medias – Test t para una muestra
A continuación :- Debemos elegir una sola variable seleccionamos ( rendimiento).- Indicamos cual es la hipótesis alternativa (bilateral, unilateral a derecha y
unilateral a izquierda )En nuestro caso elegimos la tercera opción .- Especificamos el valor hipotético con el que estamos comparando la media,
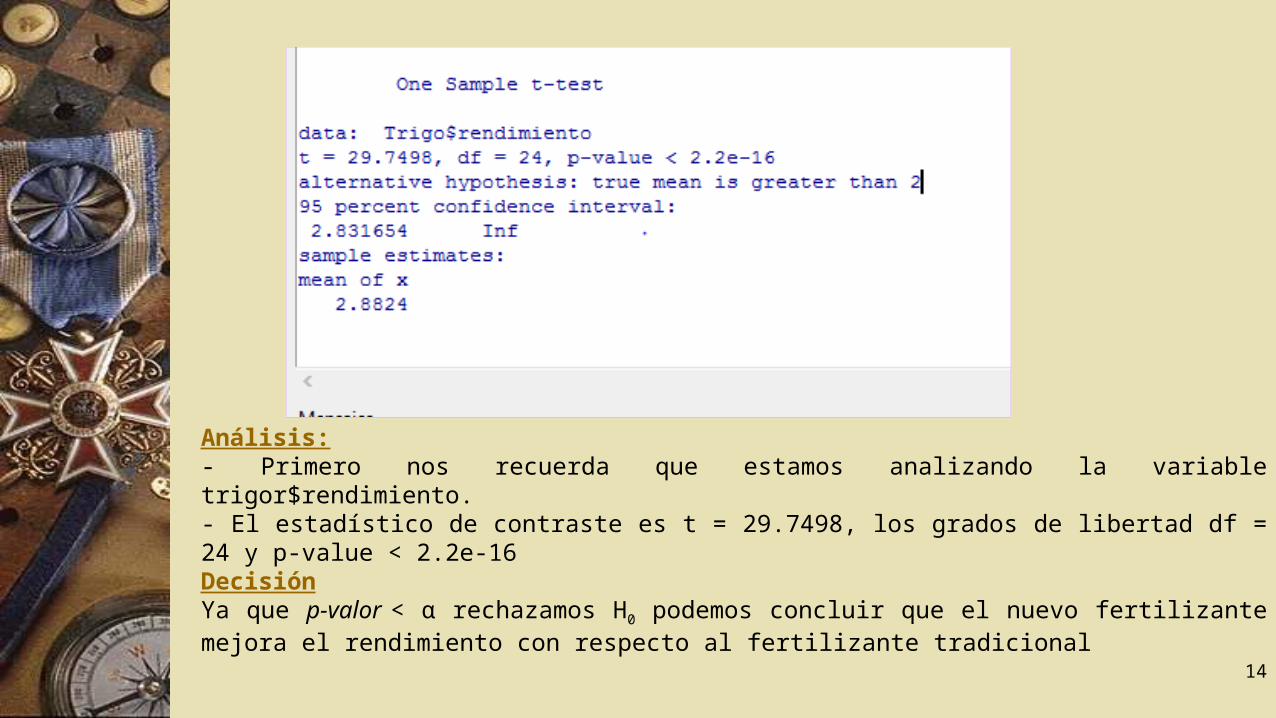
en nuestro caso 2.- Por último especificamos el nivel de confianza (0.95).- Hacemos clic en aceptar- Los resultados se muestran en la ventana de resultados.
14
Análisis:- Primero nos recuerda que estamos analizando la variable trigor$rendimiento.- El estadístico de contraste es t = 29.7498, los grados de libertad df = 24 y p-value < 2.2e-16 DecisiónYa que p-valor < α rechazamos H0 podemos concluir que el nuevo fertilizante mejora el rendimiento con respecto al fertilizante tradicional

15
Datos Emparejados.Para comparar dos materiales A y B para suela de zapatos deportivos, se eligen 10 niños al azar, y a cada uno se le proporciona un par de zapatos, uno con la suela del material A y el otro con la suela del material B. A fin de eliminar en lo posible la influencia de que un material vaya al pie derecho o al izquierdo, la asignación de orden dentro de cada par se hace al azar. AL cabo de 3 meses se mide una característica en cada zapato que refleja su comportamiento ante el uso, que se interpreta con que si la característica medida tiene mayor valor es porque ese tipo de material ofrece mejor calidad. Así resulta:
Ejemplo 2

16
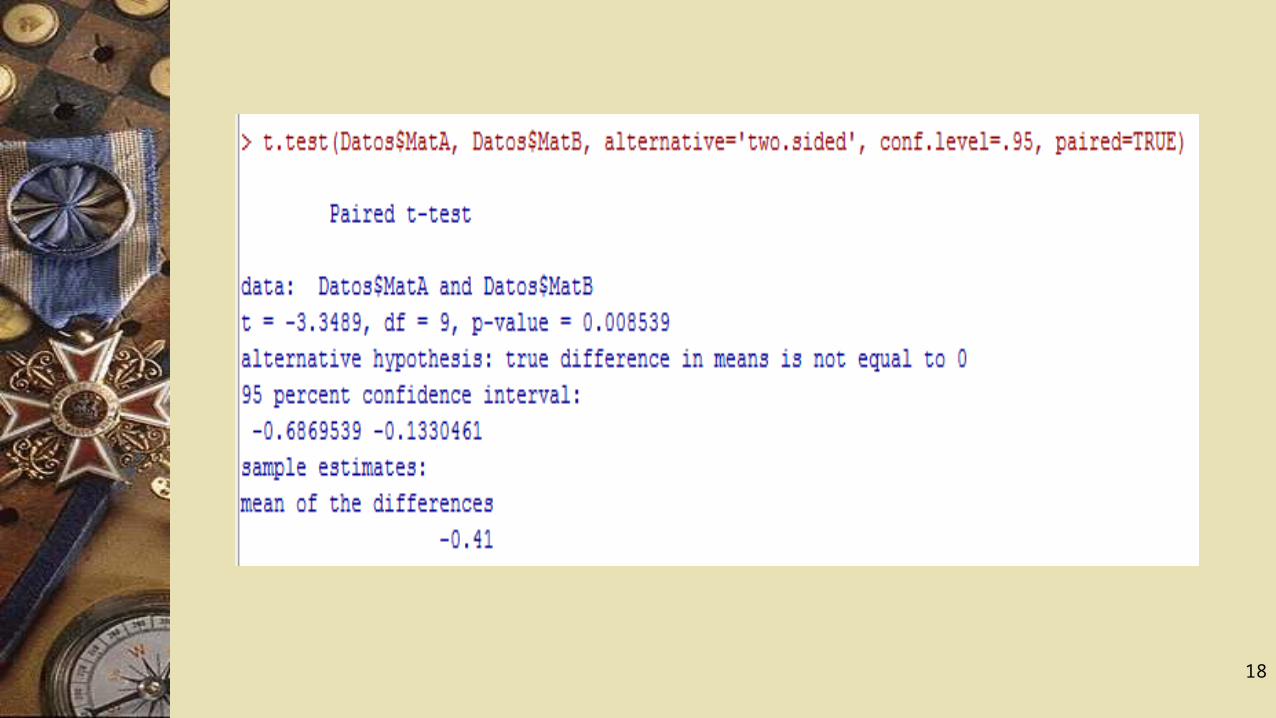
Considerando los datos de los desgastes en 10 pares de zapatos según el material A y B , efectuamos la comparación .

17
18

19
El intervalo de confianza (nivel del 95%) para la diferencia de medias en el Material A y en el B es (-0,687; -0,133), lo que indica que el valor de la característica de uso (por tanto la satisfacción) es mayor con el Material B que con el A. Desde la visión de contraste de hipótesis, el reducido valor del p-valor: 0,009, indica que la hipótesis de igualdad de medias se rechazaría con un nivel de significación del 5%, frente a la hipótesis de que los dos materiales son igualmente satisfactorios.
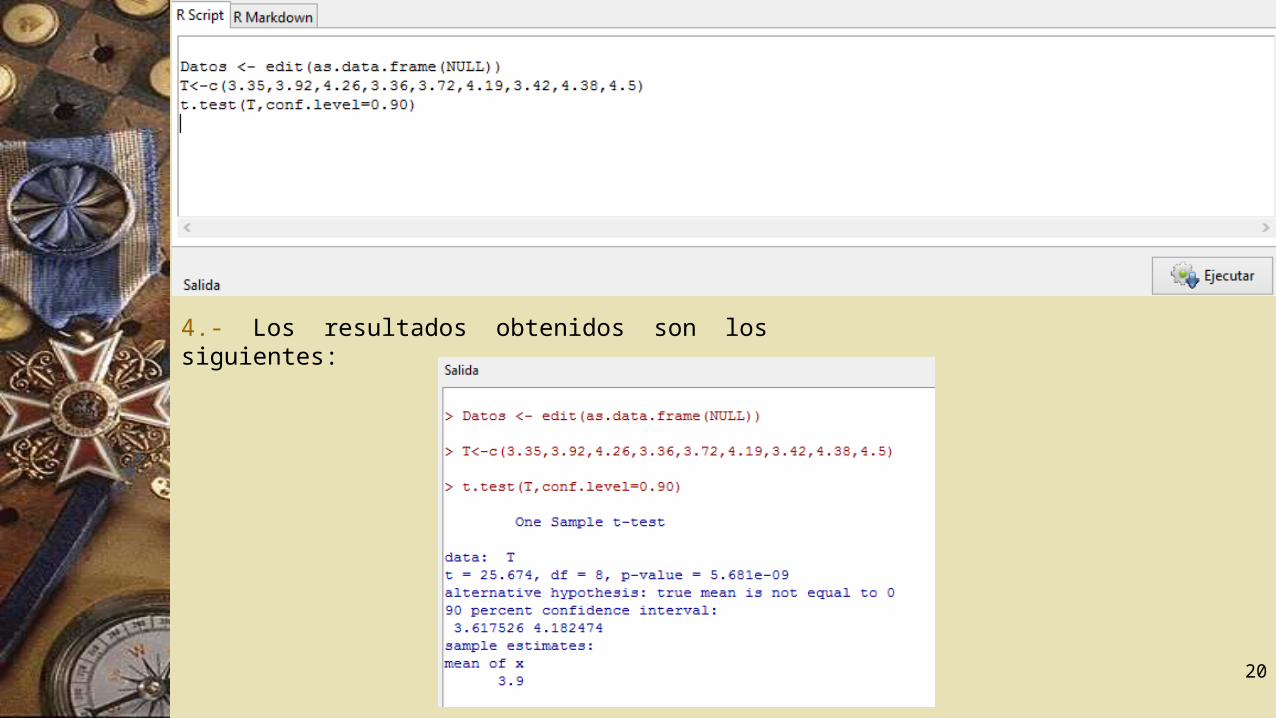
Los siguientes datos corresponden al rendimiento por hectárea de cierta nueva variedad de trigo, medido en 9 lotes experimentales: 3,35; 3,92; 4,26; 3,36; 3,72; 4,19, 3,42; 4,38; 4,5.Construya un intervalo de confianza al 90% de confianza para el rendimiento promedio de la nueva variedad de trigo si suponemos que el rendimiento por hectárea se distribuye aproximadamente normal.En el lenguaje R procedemos como sigue:1.- En la ventana de instrucciones ingresamos los datos.T<-c(3.35,3.92,4.26,3.36,3.72,4.19,3.42,4.38,4.5)2.- Para la construcción del intervalo de confianza digitamos la siguiente instrucciónt.test(T,conf.level=0.90)3.- Pulsamos Ejecutar.
Ejemplo 3
20
4.- Los resultados obtenidos son los siguientes:

21
El intervalo de confianza pedido es [3.6175; 4.1825]. Note que la salida entrega además la media con valor 3,9 y por defecto, el test de hipótesis H0 : µ=0 en contra de la hipótesis alternativa H1 : µ≠0 . Se rechaza la hipótesis nula ya que el valor de la prueba es p-value = 5.681e-09.