ingenieria estadistica - druida software &...
TRANSCRIPT


INGENIERIA ESTADISTICA
CONTENIDOS INGENIERIA ESTADISTICA ........................................................................................... 1
Estadística Avanzada en el marco del SGI ................................................................... 3
IDENTIFICACION Y SEGUIMIENTO DE PROYECTOS.......................................................... 9
La hoja de inicio del proyecto .................................................................................. 14
TIPOS DE ESTADISTICA, OBSERVACION Y EXPERIMENTACION, HOMOGENEIDAD. ............ 19
DIAGRAMA CAUSA Y EFECTO - AMFE ........................................................................... 32
ESTADISTICA DESCRIPTIVA, NORMALIDAD Y CAPACIDAD ............................................. 39
Estadística Descriptiva ............................................................................................ 39
Normalidad............................................................................................................ 43
Capacidad de Procesos ............................................................................................ 49
INTRODUCCION AL SPAC FL ....................................................................................... 56
Importación y Set de Datos ..................................................................................... 56
Funcionalidad ........................................................................................................ 62
TEST DE HIPOTESIS .................................................................................................. 69
Prueba T para diferencia de medias .......................................................................... 77
Alternativa No Paramétrica – Mann Whitney .............................................................. 83
Intervalos de Confianza .......................................................................................... 84
Tamaño de la muestra ............................................................................................ 95
GRAFICO MULTIVARI ................................................................................................. 99
EVALUACION DE SISTEMAS DE MEDICION .................................................................. 102
MSA para Variables ............................................................................................... 106
MSA para Atributos ............................................................................................... 112
ANALISIS DE LA VARIANCIA ONE WAY ....................................................................... 116
Kruskal-Wallis ....................................................................................................... 120
Bloqueo ............................................................................................................... 122
ANALISIS DE REGRESION ......................................................................................... 124
Regresión Multiple ................................................................................................. 129
Regresión Logística ................................................................................................ 131
DISEÑO DE EXPERIMENTOS ...................................................................................... 134
Variabilidad .......................................................................................................... 137
DOE 2k ................................................................................................................ 139
DOE 2k-p ............................................................................................................. 147
Superficie de Respuesta ......................................................................................... 155

ESTADÍSTICA AVANZADA EN EL MARCO DEL SGI


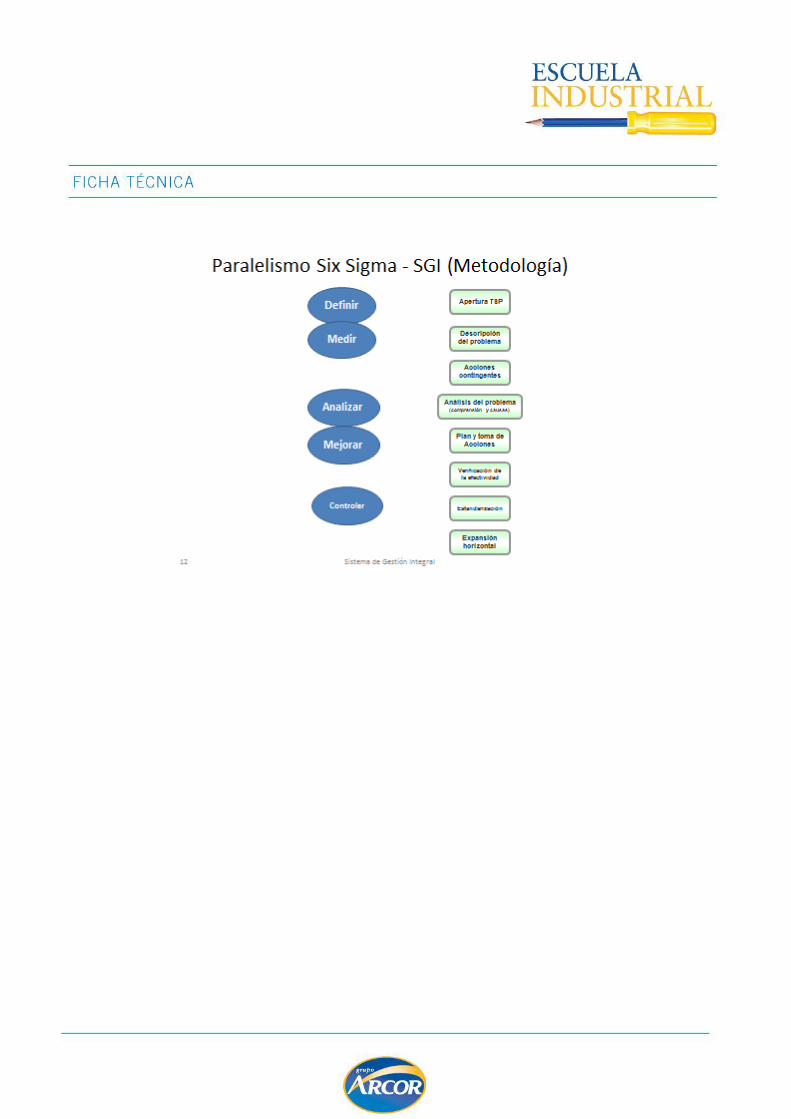

IDENTIFICACION Y SEGUIMIENTO DE PROYECTOS
Antes de comenzar cualquier proyecto, tenemos que tener un proyecto! Y la selección
del mismo exige tener en cuenta ciertos criterios.
¿Cómo seleccionar proyectos de alto valor? Existen dos fuentes posibles:
- El árbol de pérdidas, donde los procesos/problemas que impactan más negativamente
se transforman en proyectos de mejora.
- Los reclamos de clientes y análisis de tipo QFD, donde a partir de reclamos o
sugerencias se descubren oportunidades de mejora que se transforman en proyectos.

El esquema sugiere un modelo general que parte de tres fuentes informativas:
- Procesos QFD
- Reclamos de Consumidores / Clientes
- Comentarios, Felicitaciones y Sugerencias de Mejora
Con lo cual se identifican las características funcionales relevantes, que en muchos casos corresponden a atributos pasa - no pasa o variables de respuesta difícilmente medibles.
En el caso de atributos, estos pueden relacionarse con modos de falla que pueden estudiarse mediante herramientas como AMFE. La ocurrencia de estas fallas puede estar asociada a dos principios causales:
- Incumplimiento o inefectividad de condiciones estándares.
- Variabilidad de Variables de Proceso
En el caso de incumplimiento de estándares, la solución del inconveniente consiste en volver el proceso a trabajar bajo estándar. En estas situaciones el análisis no termina
en un proyecto de mejora sino en acciones concretas para asegurar que se cumpla el estándar.
Para el caso de variables de proceso, el análisis de todas las potenciales variables a través de métodos estadísticos permite extraer un modelo de variables relevantes (es
decir, de alto poder explicativo para la ocurrencia de la falla en cuestión).
Estas variables criticas de proceso, identificadas mediante métodos Fuera de Linea
(experimentación, estudios observacionales, etc.), son luego controladas estadísticamente utilizando métodos en línea, como los gráficos de control.
Finalmente estas variables relevantes forman parte de un índice de calidad que evalúa su performance a través del Cpk o Ppk.

El primer paso corresponde a la selección del proyecto, y los métodos por los cuales se eligió este proyecto y no otro. Un proyecto debe elegirse de tal manera que la causa
no sea bien clara, que represente un problema susceptible de ser analizado estadísticamente. Por ejemplo, no es recomendable un proceso donde el problema se resuelve con un setup más rápido de la máquina via SMED, o un proceso muy global que trata de solucionar el “hambre del mundo”.
El cuaderno de proyecto es un documento que refleja la información de base sobre la cual se lanza el proyecto.
El impacto económico del proyecto debe calcularse de la manera más objetiva posible, buscando los ahorros o ganancias netas que se podrían obtener si se cumple el objetivo del proyecto. Muchas veces es necesario contactar al contralor de la organización para que valide y verifique el impacto económico.
Contactar a los potenciales involucrados en el proyecto es una tarea que debe realizarse bien temprano, identificando actores que eventualmente se relacionaran con el proyecto. Los stakeholders o involucrados deben saber que el proyecto se realiza y
contactarlos tempranamente ayuda a lograr su apoyo en etapas posteriores.
La definición clara de la variable Y de respuesta es fundamental para facilitar la búsqueda de causas. Una variable Y muy genérica, como “eficiencia de Linea 2”, tiene dentro de sí tantos factores que dificulta mucho la identificación de causas. Es importante trabajar sobre esta “super Y” para determinar que factores influyen en la eficiencia, luego armar un Pareto e identificar los factores más significativos como
potenciales Y del proceso. Otro ejemplo: se intenta minimizar el decomiso en una
línea. Para desagregar esta super Y se debe armar un Pareto de las distintas causales de decomiso, y estudiar aquellas causales de mayor magnitud (por ejemplo tipos de defectos o problemas que generan el decomiso). Estas causas se convertirán en las Y del proceso.

La Y debe ser una variable cuantitativa numérica de ser posible, porque esto permite el uso de herramientas estadísticas más potentes a la hora de identificar causas. Si la variable es un atributo, por ejemplo producto con el defecto X, se debe buscar la
forma de encontrar variables Xi cuantitativas que estén relacionadas con la ocurrencia del defecto.
Una vez identificada la Y y asociada al objetivo del proyecto, se debe testear el sistema de medición de la Y, verificando si está garantizada una precisión y exactitud adecuadas para el proyecto. No se puede aceptar el sistema de medición por razones históricas o de creencia, se debe ser escéptico y validar el sistema incluso en casos
simples.
Si la Y esta definida correctamente y podemos medirla, se puede establecer la foto de situación actual. Es importante identificar cual es la capacidad del proceso a través de índices de capacidad como Cp,Cpk, Pp, Ppk, y el estado de control estadístico del proceso. Esto genera la vara de medida con la cual se podrá contrastar posteriormente los resultados de las mejoras implantadas.
La explosión de causas posibles se hace a través de herramientas como diagrama de
flujo, Ishikawa, Tormenta de Ideas, Estudios observacionales sobre datos históricos del proceso, discrepancias entre producto conforme y no conforme con métodos Shainin, etc. En esta etapa es fundamental incluir stakeholders que puedan enriquecer la lista
de causas que pueden impactar en la Y.
Se recomienda trabajar hasta tener una lista de 30 a 50 causas posibles, que deben priorizarse de alguna manera. Existen distintos métodos para priorizar causas:
- Utilizar el análisis de modo de falla y sus efectos (AMFE) para priorizar de acuerdo a la
severidad, grado de ocurrencia y probabilidad de detección.
- Agrupar usando diagramas de afinidad las causas que se refieren a un tema común.
- Utilizar “dinero virtual” haciendo que cada integrante del equipo tenga una cantidad
de dinero que puede apostar en la lista de causas y luego armar un Pareto del dinero
total apostado por las distintas causas.
- Validar midiendo en el proceso las diferentes causas y analizando la relación entre
estas causas y la variable Y, via regresión múltiple, multivari, etc.
Esta priorización permite detectar la/las causas raices que determinan la ocurrencia del problema. Se debe validar siempre las causas raices utilizando métodos
estadísticos. Nunca debe considerarse que se encontró la causa raíz sólo estudiando datos históricos sin una validación posterior.
Una vez identificada la causa raíz, surge la necesidad de encontrar soluciones posibles que eliminen o controlen la causa raíz. Para esto se utilizan métodos similares para abrir la lista de soluciones.
La lista de soluciones identificada también debe ser priorizada, teniendo cuenta el esfuerzo necesario para llevarlas a cabo y el beneficio que se obtendría de su
aplicación.
Una vez identificada la solución óptima, es fundamental realizar pruebas piloto que validen la solución antes de su implantación definitiva. Es común encontrar escollos o
problemas prácticos durante el piloto, que facilitan la programación de la implantación definitiva.
Si las pruebas piloto permiten validar la solución propuesta, el próximo paso es
establecer el plan de acciones concreto para implantar la solución y los mecanismos de enclavamiento que evitan la vuelta a la situación previa.

Finalmente, la expansión horizontal consiste en difundir los logros y la información sobre el proyecto, de manera tal que otros equipos en la organización puedan utilizar el aprendizaje en otros proyectos.
El diagrama SIPOC es utilizado para identificar todas las entradas y salidas del proceso
estudiado. El punto medio (P) se grafica como un diagrama de bloques de las
principales etapas que atraviesa el proceso. El nivel de detalle del diagrama debe corresponderse con el alcance del proyecto. Por ejemplo: un proyecto que trabaja sobre toda una línea de producción utilizará un diagrama de bloques cubriendo todas las etapas de proceso, mientras que si el proyecto sólo se aboca a una máquina o una etapa, el diagrama será un nivel más detallado de los pasos en esa máquina o etapa particular.
S (supliers - proveedores-) aquellos que proporcionan los insumos necesarios para que
el proceso comience. Estos insumos pueden ser físico y/o información. Ejemplos: 1)materia prima.-un agricultor que proporciona cereal para producir etanol 2) información.- el cliente que nos llama para hacer un pedido I (input -entradas/insumos-) las materias primas y/o información que desencadenan el proceso. Ejemplos: 1) materia prima.-el cereal para producir etanol 2) información.- el
pedido.
P (process -procesos-) el conjunto de tareas que realizamos para procesar el cereal hasta convertirlo en etanol. Esta descripción se hace a alto nivel (aprox. en 6 ó 7 pasos).

O (output -salida/producto-) es lo que entregamos según el pedido que entró. En el ejemplo sería el Etanol.
C (costumer - cliente-) Para quién hemos fabricado el etanol. En el ejemplo, el cliente que nos hizo el pedido.
La planilla de análisis de stakeholders es fundamental para identificar tempranamente quienes pueden ayudarnos o entorpecer la tarea, permitiendo establecer estrategias para lidiar con las posibles resistencias que se encuentren.
Los proyectos requieren recursos, ya sea monetarios, humanos, de tiempo, etc. Y los
stakeholders son los individuos que pueden eventualmente brindar los recursos necesarios para que el proyecto avance en sus etapas. La comunicación temprana de los objetivos del proyecto y el logro de compromiso ayudan a que estos individuos colaboren activa o pasivamente.
LA HOJA DE INICIO DEL PROYECTO
La hoja de Inicio de proyecto es un documento que comunica claramente:
- porqué se hace este proyecto (caso de negocio, problema y situación actual)
- que se espera lograr con este proyecto (objetivo y ganancias esperadas)
- a quienes impacta el proyecto y como.
- quienes participarán colaborando con el proyecto, aparte del lider del proyecto.
- en qué tiempos se trabajará.

Esta hoja también es la piedra de base sobre la que se edifica el proyecto.
Sugerencia: varios de los campos de la hoja de inicio se relacionan con aspectos
económicos. Sugiero que se validen estos campos con personas adecuadas (en muchas implementaciones de Seis Sigma esto lo hace formalmente gente de finanzas).
Las primeras reuniones del equipo en sí o del equipo con el responsable de apoyo y seguimiento, deben girar alrededor del contenido de la Hoja de Inicio.
Explicación de los campos:
Lider de Proyecto Negocio Unidad operativa
El lider del proyecto es la persona que lleva a cargo el proyecto (en el caso actual, los participantes del curso)
Nombre del proyecto:
El nombre debe ser una descripción corta, de menos de un renglón, que permite al lector darse una idea del proyecto.
Producto Proceso
Problema/Oportunidad
El problema es una descripción concisa y corta de lo que “esta mal”, el “dolor” causado
por el problema o la oportunidad que debe ser aprovechada (algunos usan la expresión “la plataforma hirviente” o “burning platform” que nos empuja a saltar y embarcarnos
en el proyecto).
Una vez escrito el problema, pueden validarlo con las siguientes preguntas:
1- ¿me permite entender porqué este proyecto es necesario?
2- ¿todos los involucrados más cercanos (miembros de equipo, o referentes que necesito
como ayudantes/soporte) están de acuerdo con el problema?
3- En la forma escrita, es algo manejable? recordar que un buen proyecto no debe ser ni
demasiado chico (porque no va a justificar la inversión en tiempo y recursos), ni
demasiado grande (no alcanzará el tiempo ni los recursos, y es mejor desde el
arranque separarlo en sub-proyectos)
4- Así descrito el problema, ¿me da pistas sobre donde buscar datos e información sobre
el mismo? (no hablamos de detalle, sino de orientación)
5- ¿Me permite establecer una línea de base, o una situación actual, a partir de la cual
mejorar? (puede ser que las métricas todavía no estén disponibles, y el problema
deberá ser completado más tarde en el avance del proyecto).

Tamaño recomendado: dos o tres oraciones máximo. Luego se podrá detallar más el problema con las métricas de la sección “situación actual”.
Objetivo
El objetivo está muy relacionado con el problema. Si el problema dice lo que “duele”,
el objetivo me dice cuánto se va a “aliviar” el problema mediante este proyecto, usando una métrica determinada.
Verificar que el objetivo sea SMART:
1. S : específico (usar verbos como reducir, incrementar, etc., no usar mejorar,
ayudar, etc.).
2. M: cuantificable o medible
3. A : agresivo pero lograble
4. R : relevante para el cliente interno o externo
5. T : unido a tiempos (el tiempo del proyecto puede indicarse en los campos
correspondientes de la segunda hoja, como el “tiempo previsto de finalización”)
Tamaño recomendado: una oración (p.ej.: reducir un 30% las pérdidas por retrabajo en la línea X)
Tanto el problema como el objetivo van a delimitar el proyecto, y en algunos casos se refinarán y completarán a medida que avance el proyecto.
Impacto en
Impacto
Cliente externo:
Aquí se debe indicar qué efectos tendrá el proyecto sobre el o los clientes externos, si lo hubiese (tanto distribuidores, consumidores finales, etc.)
Cliente interno Idem para clientes internos del proceso: aguas abajo en el proceso, otros sectores o departamentos que se benefician con
este proyecto, etc.
Resultados operativos (Valor Presente Neto)
Impacto financiero del proyecto. Si se calculó el valor presente neto, estimando determinados flujos de salida, y la recuperación (flujos de entrada), se debe indicar aquí. Este Valor presente neto podrá ser revisado a medida que el
proyecto avanza y se posea más información
Comunidad Efectos del proyecto a nivel comunidad.
Personal Efectos del proyecto sobre los empleados.
Situación inicial (Gráfico de Evolución/Tabla)
Lo mejor es insertar gráficos que indican la evolución en el tiempo de los indicadores o métricas más importantes del proyectos (CTQ: características críticas para la calidad).
En este caso, también se debe indicar en el gráfico el objetivo que se desea lograr.
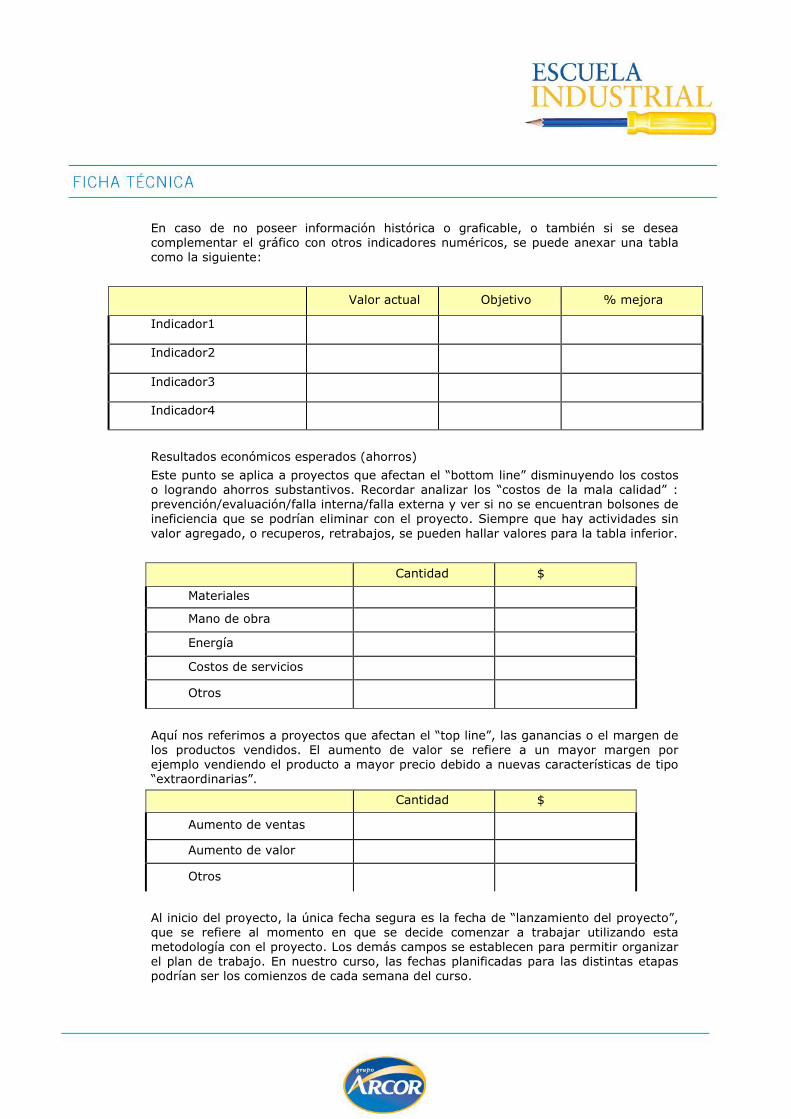
En caso de no poseer información histórica o graficable, o también si se desea complementar el gráfico con otros indicadores numéricos, se puede anexar una tabla como la siguiente:
Valor actual Objetivo % mejora
Indicador1
Indicador2
Indicador3
Indicador4
Resultados económicos esperados (ahorros)
Este punto se aplica a proyectos que afectan el “bottom line” disminuyendo los costos o logrando ahorros substantivos. Recordar analizar los “costos de la mala calidad” : prevención/evaluación/falla interna/falla externa y ver si no se encuentran bolsones de
ineficiencia que se podrían eliminar con el proyecto. Siempre que hay actividades sin
valor agregado, o recuperos, retrabajos, se pueden hallar valores para la tabla inferior.
Cantidad $
Materiales
Mano de obra
Energía
Costos de servicios
Otros
Aquí nos referimos a proyectos que afectan el “top line”, las ganancias o el margen de los productos vendidos. El aumento de valor se refiere a un mayor margen por ejemplo vendiendo el producto a mayor precio debido a nuevas características de tipo “extraordinarias”.
Cantidad $
Aumento de ventas
Aumento de valor
Otros
Al inicio del proyecto, la única fecha segura es la fecha de “lanzamiento del proyecto”,
que se refiere al momento en que se decide comenzar a trabajar utilizando esta metodología con el proyecto. Los demás campos se establecen para permitir organizar el plan de trabajo. En nuestro curso, las fechas planificadas para las distintas etapas podrían ser los comienzos de cada semana del curso.
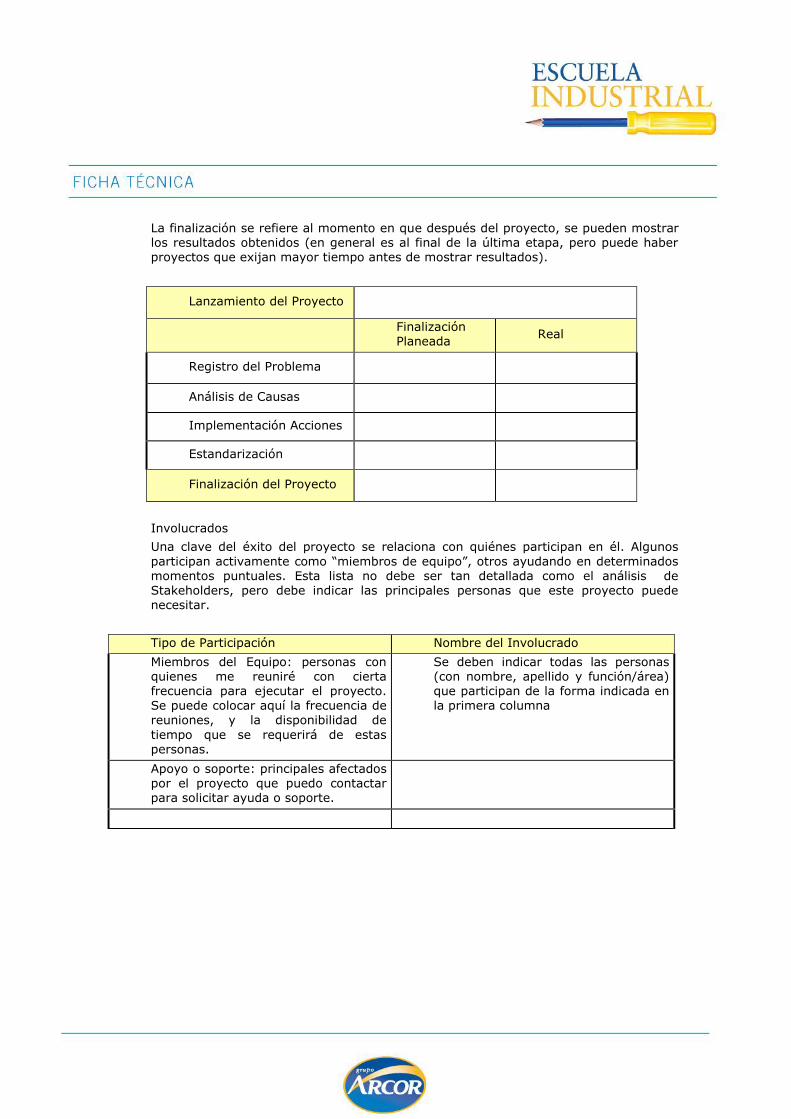
La finalización se refiere al momento en que después del proyecto, se pueden mostrar los resultados obtenidos (en general es al final de la última etapa, pero puede haber proyectos que exijan mayor tiempo antes de mostrar resultados).
Lanzamiento del Proyecto
Finalización Planeada
Real
Registro del Problema
Análisis de Causas
Implementación Acciones
Estandarización
Finalización del Proyecto
Involucrados
Una clave del éxito del proyecto se relaciona con quiénes participan en él. Algunos
participan activamente como “miembros de equipo”, otros ayudando en determinados momentos puntuales. Esta lista no debe ser tan detallada como el análisis de Stakeholders, pero debe indicar las principales personas que este proyecto puede necesitar.
Tipo de Participación Nombre del Involucrado
Miembros del Equipo: personas con quienes me reuniré con cierta frecuencia para ejecutar el proyecto. Se puede colocar aquí la frecuencia de
reuniones, y la disponibilidad de
tiempo que se requerirá de estas personas.
Se deben indicar todas las personas (con nombre, apellido y función/área) que participan de la forma indicada en la primera columna
Apoyo o soporte: principales afectados por el proyecto que puedo contactar para solicitar ayuda o soporte.

TIPOS DE ESTADISTICA, OBSERVACION Y EXPERIMENTACION, HOMOGENEIDAD.
Al referirnos a estadística, debemos comprender la diferencia entre “estadística descriptiva” y “estadística inferencial”. La estadística descriptiva da cuenta de información ya recolectada y cierta, para poder obtener conclusiones claras y
resumidas sobre un determinado fenómeno. A este tipo de estadística pertenecen, por ejemplo, los censos de población.
Escenario típico donde surge la necesidad de estadística descriptiva:
“Tengo un grupo de 200 mediciones en una tabla, ¿cuál es la mejor manera de resumir estos números, para que se conviertan en información comprensible y clara?”
Hay que tener en cuenta que la estadística descriptiva resume datos, pero no los analiza, es ciega a su contenido e interpretación… por ejemplo, puedo calcular el promedio de los números de la guía telefónica.
A diferencia de la estadística descriptiva, donde poseemos toda la información
necesaria para tomar decisiones, muchos problemas estadísticos trabajan con información parcial, y a partir de esta información parcial se deben tomar decisiones; este es el dominio de la estadística inferencial: nunca podremos estar absolutamente seguros de nuestras conclusiones en este terreno. Estamos condenados a aceptar un riesgo de equivocarnos.
Escenario típico donde surge la necesidad de estadística inferencial:

“Tomé una muestra de 30 pollos en la granja, y medí su peso. Si considero que todos los 500 pollos de la granja son representados por la muestra ¿qué puedo decir sobre el total de pollos de la granja?”
Hay otros dos conceptos que todo analista de datos debe comprender bien: la Teoría de Probabilidades y la Homogeneidad de Datos.
La teoría de probabilidades nos brinda instrumentos matemáticos que permiten, a partir de un determinado modelo teórico, deducir probabilidades e incertidumbres. Es decir: el cálculo de probabilidades supone el conocimiento cierto del modelo puro e ideal que da origen a nuestras especulaciones.
Asumiendo que nuestra población se adecua a cierto modelo teórico, la teoría de probabilidades me permite deducir las chances de obtener una muestra de determinadas características; por ejemplo, si poseo una caja con 1000 tiras de papel bien mezcladas con números diferentes, puedo deducir que existe una probabilidad exactamente igual a 0,001 de obtener el número 43 cuando saco una tira al azar de la caja.
Escenario típico donde surge la necesidad de Teoría de Probabilidades:
“Tengo una urna con 500 bolas blancas y 100 bolas rojas, ¿cuál es la probabilidad de
tener 4 bolas rojas en una muestra de 10 bolas extraídas al azar?”
La Teoría de Probabilidades nos ayuda a asignar probabilidades y cuantificar algunos resultados en la práctica, y tiene un aura de rigurosidad debido a su dependencia en conceptos matemáticos. Sin embargo, no es necesario ser experto en este campo para analizar datos de manera rigurosa. Veremos herramientas que nos permiten sacar
conclusiones valederas sin tener que adentrarnos en las complejidades del cálculo de probabilidades.
Por otro lado, la Teoría de Probabilidades es puramente deductiva, y supone que conocemos fehacientemente las características del modelo teórico que gobierna la realidad que analizamos. Esta suposición no siempre es sostenible, y se cae en el engaño de confiar en números retornados por el software sin verificar la validez de la
herramienta para la situación específica que estamos analizando.
Los tres conceptos que mencionamos (estadística descriptiva, inferencial y probabilidades), exigen un universo de datos del cuál tomamos muestras. La pregunta
que surge naturalmente es: ¿cómo sé que un grupo de datos conforma un único universo? Aquí entra en juego el último concepto fundamental: el análisis de Homogeneidad de los Datos.
Si el universo o población que estudiamos no es homogénea, no podremos obtener
información clara utilizando estadística descriptiva. Por ejemplo, supongamos que en un proceso de estampado, al ingresar el operario del turno tarde, comienza a modificar el proceso actuando sobre los controles y cambiando radicalmente la salida de nuestro proceso. En esta situación, si al definir nuestra población incluimos el turno mañana y el turno tarde, los datos involucrados tendrán una mezcla de dos procesos muy distintos, debido a los cambios introducidos por el segundo operador; la falta de homogeneidad nos impide aplicar la inferencia estadística o calcular probabilidades,
porque la población no es consistente ni representa un único universo.
En resumen: la homogeneidad de los datos es la condición que posibilita el uso de
estadística descriptiva, inferencial y teoría de las probabilidades. Podemos asumir ciegamente esta homogeneidad, pero corremos serios riesgos de errar en nuestros análisis. Alternativamente podemos utilizar una herramienta específicamente diseñada para cerciorarnos de esta homogeneidad: el Gráfico de Control o gráfico del
comportamiento del Proceso, que discutiremos más adelante.
Escenario típico donde surge la necesidad de verificar Homogeneidad:

“Tengo una serie de mediciones de temperatura de un horno, tomadas durante esta semana. ¿Es razonable asumir que estas mediciones forman parte de un mismo universo o población, o hay evidencia que las mediciones provienen de múltiples
universos?”
Cuando encontramos evidencia de un universo cambiando constantemente no podremos aprender nada mediante estadística descriptiva. La falta de homogeneidad
nos advierte que algo está sucediendo, una causa fuera de lo común actúa, y hasta
que no la identifiquemos no podremos utilizar descripción, probabilidad o inferencia estadística. Los cálculos no pueden solucionar el problema de la falta de homogeneidad, solo la acción lo puede hacer.
A veces al explicar métodos de análisis estadístico se demonizan los puntos alejados, o “outliers”, y simplemente se los elimina del set de datos analizado. En verdad, en muchas ocaciones estos “outliers” brindan información valiosísima para detectar causas de falta de homogeneidad en el proceso. Es recomendable prestar doble
atención a estos datos “extraños” para ver cuál puede ser su origen.
La principal herramienta para detectar falta de homogeneidad es el gráfico de control. Procedemos primero considerando que el proceso es homogéneo (como en un proceso penal: siempre asumimos que el acusado es inocente), y calculamos los límites de control. Cualquier señal de causa especial nos hace rechazar nuestra suposición (es decir, tenemos pruebas suficientes para considerar culpable al acusado).
Si podemos asumir la homogeneidad de los datos, entonces podremos utilizar las
técnicas de inferencia estadística para caracterizar el universo, determinar parámetros y distribuciones teóricas consistentes con los datos, y a partir de ellos calcular probabilidades y predicciones.
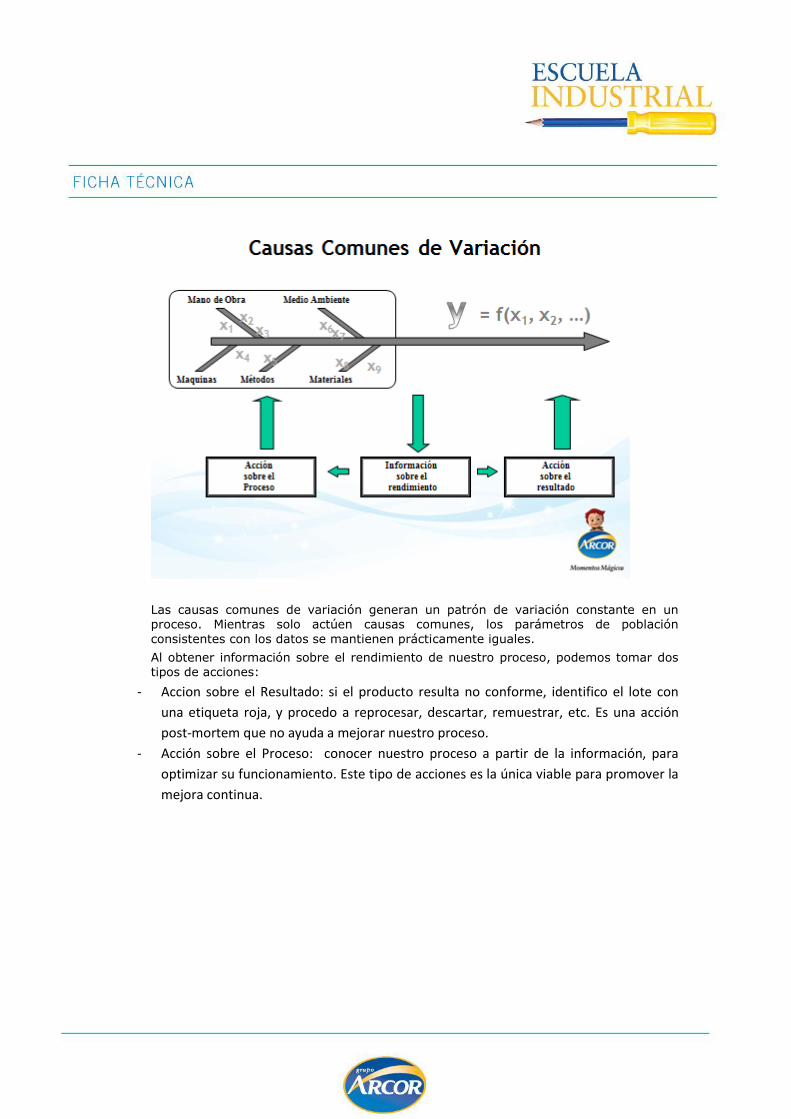
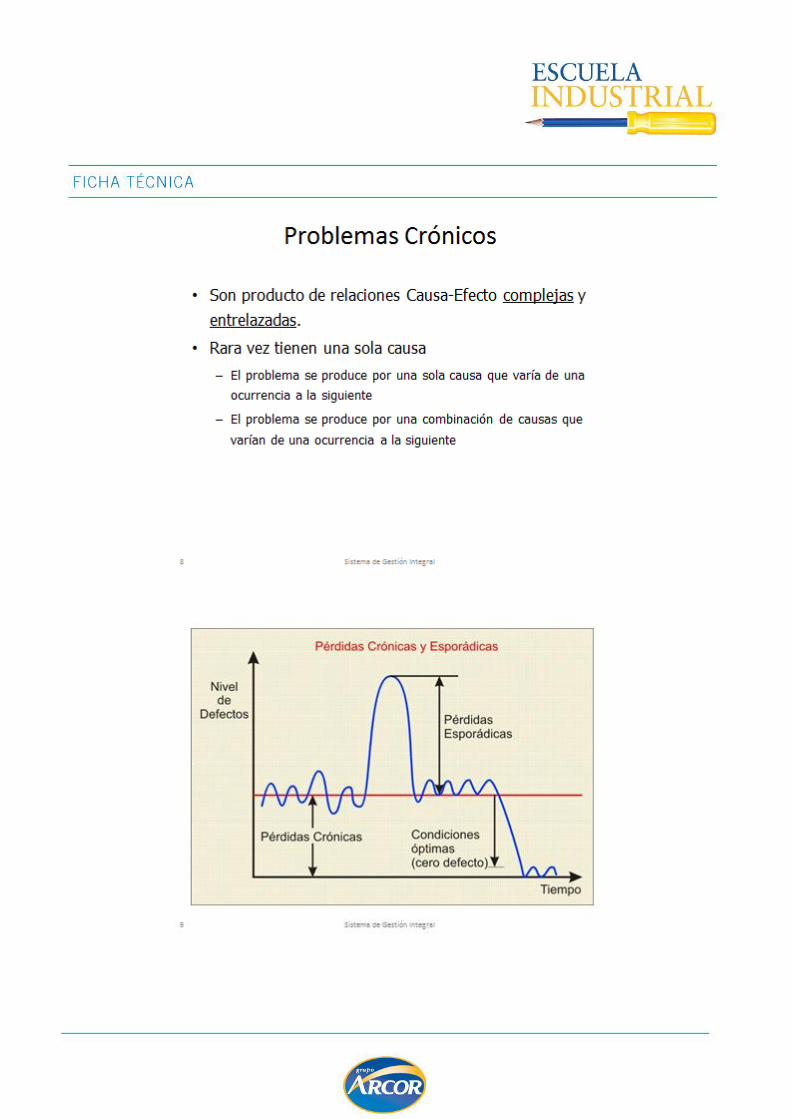
Las causas comunes de variación generan un patrón de variación constante en un proceso. Mientras solo actúen causas comunes, los parámetros de población
consistentes con los datos se mantienen prácticamente iguales.
Al obtener información sobre el rendimiento de nuestro proceso, podemos tomar dos tipos de acciones:
- Accion sobre el Resultado: si el producto resulta no conforme, identifico el lote con
una etiqueta roja, y procedo a reprocesar, descartar, remuestrar, etc. Es una acción
post-mortem que no ayuda a mejorar nuestro proceso.
- Acción sobre el Proceso: conocer nuestro proceso a partir de la información, para
optimizar su funcionamiento. Este tipo de acciones es la única viable para promover la
mejora continua.

Muchísimos factores producen efectos sobre el proceso, de manera tal que no hay dos productos exactamente iguales. Las fuentes de variabilidad son incontables; algunas
actúan inmediatamente (como la cantidad de baño depositado), otras lentamente (como el desgaste de una envasadora).
Desde el punto de vista de la especificación que nosotros fijamos sobre el producto, se considera la variabilidad total, sin importar la fuente de variación: las piezas que están dentro de límites se aceptan, las que no se rechazan. Pero para controlar un proceso de manufactura, debemos relacionar la variabilidad con sus fuentes. Debemos conocer
el proceso, en el sentido de darnos cuenta que tipo de causas actúan en un determinado momento.
Las causas comunes de variación son un sistema de fuentes de variabilidad aleatorias estabilizado en el tiempo. Cuando en un proceso actúan sólo causas comunes, la distribución de las características medidas será predecible en el tiempo.
Normalmente, cuando se produce un fallo en un sistema, suponemos que siempre es atribuible a alguien o se relaciona con algún hecho en particular. Sin embargo, la
mayoría de los problemas en los servicios o en la fabricación residen en el sistema, basados en causas comunes de variación.
Las causas especiales de variación son aquellas que producen variaciones no controladas, es decir, no predecibles. Cuando en un proceso actúan causas especiales además de las comunes, no podemos suponer la forma de la distribución en el momento T+1, sabiendo la distribución en el momento T.
Decimos que un proceso está bajo control estadístico, cuando las únicas fuentes de variabilidad que actúan son causas comunes de variación.

Uno de los objetivos más importantes del control estadístico de procesos es determinar cuándo actúan causas comunes y cuándo causas especiales de variación. La herramienta más útil para esta determinación es el Gráfico de Control, que aparece
históricamente en la década de 1930, gracias al trabajo de Walter Shewhart.
Shewhart llamo inicialmente “causas asignables” a las causas especiales, para dejar
claro que representan shocks o disrupciones del proceso, fácilmente distinguibles de la variación inherente, y que pueden ser identificadas y eliminadas (si son nocivas).
Otros autores definen control estadístico, como la situación en que la distribución de probabilidades que representa la característica de calidad se mantiene constante a
través del tiempo, y “fuera de control” cuando hay algún cambio en esta distribución.

Todos los gráficos de Control están basados en el mismo principio básico: determinar los carriles naturales de variación del proceso, para permitirnos identificar causas
especiales de variación.
Recordemos que para determinar la variabilidad local, tomábamos una serie de muestras, y calculábamos el rango de cada una, luego dividiendo por el factor d2. En base a esta variabilidad, podemos identificar el ancho natural de variación, que nos dicta los límites de control de proceso.
Al tomar una muestra de varias unidades, estoy midiendo una estimación de la
variabilidad local. NUNCA debemos utilizar la variabilidad global (juntando todos los datos y calculando el s con toda la información)
La escuela probabilística de Gráficos de Control asigna probabilidades exactas para determinar los límites; en cambio la escuela empírica de Shewhart utiliza como argumento que los límites 3 sigma son los que desde el punto de vista práctico me resultan en un funcionamiento óptimo del proceso.
El gráfico de control es la herramienta para mantener el proceso bajo control
estadístico.
Este gráfico muestra la evolución de una característica de calidad, identificando una línea central y dos líneas extremas (superior e inferior), que identifican las fronteras de variación natural del proceso, es decir, la gran mayoría de los puntos graficados se encuentran dentro de los limites superior e inferior de control, si el proceso está bajo control estadístico.
Cuando las características son variables numéricas continuas, se acostumbra graficar
dos cartas de control; la carta superior muestra la posición central de las muestras (que puede ser el promedio, la mediana, o el dato individual si las muestras son de una unidad). Este gráfico de promedios permite evaluar y controlar el centrado del proceso. La carta inferior muestra el estimador de la dispersión (que puede ser el

desvío estándar, el rango o rango móvil) y ayuda a detectar causas especiales que modifican la variabilidad de los datos.
Esta es una función crítica del gráfico de control, indicarnos el tipo de causa actuante
(común o especial) para evitar reacción sin causa, o inacción ante causas especiales. La distinción entre causas comunes y especiales depende en cierta medida del
contexto: una causa especial es aquella que tiene un impacto económico y práctico suficiente para merecer una acción del operador del proceso.
En este ejemplo, vemos que en el proceso durante el período A actúaron causas comunes que determinaban una cierta distribución de los datos. Esto se verifica en el gráfico de control con todos los puntos dentro de los límites naturales de variación.
A las 16:40 actúo una causa especial que modificó el centro del proceso, disminuyendo la media de los datos.
Vemos como las muestras tomadas posteriormente, correspondientes al período B, indican rápidamente la causa especial con puntos fuera de los límites de control.
Si no existieran los límites de control, es muy fácil pensar que un punto es una señal de variación especial cuando en realidad proviene de la acción de causas comunes. Cuando esto pasa, el operador actúa incorrectamente sobre el proceso, y esta perturbación genera mayor dispersión sobre el mismo. Esta perturbación del proceso sin necesidad lleva el nombre de “sobrecontrol”.

Caso de Estudio: Problemas de Fechado en Linea 3.
Resumen de las minutas de Reunión del Equipo de Mejora 121.
Problema: alta cantidad de defectos de fechado (estampado de la fecha sobre el producto) en línea 3 (línea de alta velocidad)
Reunión 1: Se conforma el equipo de mejora, se define claramente el problema, y se excluyen los defectos de fechados en otras líneas, decidiéndose concentrar en la línea 3 donde se producen los productos “estrella” de la compañía.
Reunión 2: El equipo está formado por expertos de la línea, operarios de
mantenimiento y personal de calidad. Se discute el problema; cada persona opina sobre las causas involucradas. Se esboza un árbol de causas y luego de una votación se determina la causa más probable: mala alineación de las unidades en la cinta transportadora, que determina errores al estampar la fecha.
Reunión 3: Se analizan distintos modos de corregir el problema de alineación. Luego de una tormenta de ideas se llega a dos soluciones posibles. Una solución exige una inversión significativa comprando alineadores especiales e instalándolos aguas arriba
en la línea productiva. La segunda solución propuesta consiste en aplicar “elementos redirectores” diseñados internamente por la gente de mantenimiento. Esta última solución no requiere inversión alguna y es fácil de implementar, pero no estamos tan seguros que vaya a funcionar.
Reunion 4: Se decide realizar un estudio confirmatorio para verificar si la solución “barata” es efectiva. Se realizará el siguiente experimento:
Con la línea trabajando a régimen constante en uno de los productos que mayores
defectos genera, se medirá la ocurrencia de defectos de fechado cada 1000 unidades. La prueba se realizará durante tres turnos. Cada turno funcionará las primeras 4 horas sin cambios, tomando muestras, y en las segundas 4 hrs. se instalarán los elementos redirectores tomando nuevas muestras.

Reunion 5: Luego de realizado el experimento, se analizan estadísticamente los datos recolectados, y lamentablemente estos no arrojan un resultado positivo: el nivel de defectos no disminuyó significativamente al colocar los elementos redirectores (con un
nivel de confianza del 95%). Se decide implantar la segunda solución: se solicita la aprobación del gasto y se inician las gestiones para realizar la inversión.
Reunión 6: Tema de la reunión: ¿porqué a pesar de haber instalado los nuevos alineadores, sigue habiendo un nivel altísimo de defectos de fechado?
Pregunta: ¿Dónde ve usted un problema en el recorrido que siguió este equipo de
Mejora?
Respuesta: Al final del Capítulo.
En el marco de metodologías de resolución de problemas – como el ciclo PDCA, el modelo DMAIC, etc.- es crítico entender la diferencia entre análisis exploratorios y confirmatorios.
En general, todo problema que amerite un tratamiento estructurado como DMAIC
puede estudiarse como un sistema donde actúan causas (Xs) y efectos (Ys). Una condición base para resolver el problema consiste en descubrir aquellas causas que
tienen mayor influencia sobre las variables críticas de salida.
Pero antes de poder experimentar para verificar si ciertos factores causales son críticos, es necesario identificar estos factores candidatos. Un experimento es por definición un estudio acotado donde se trata de mantener el contexto bien constante (ceteris paribus como dicen los economistas) y variando sólo los factores que me
interesan1. Pero esta coerción del contexto elimina grados de libertad que actúan durante el normal desempeño del proceso; es decir, en un experimento estamos restringiendo el funcionamiento del proceso para verificar o confirmar una hipótesis. Para que esto sea lógico, tenemos que estar seguros que los factores que dejamos fijos no tienen un efecto significativo (o sí lo tienen pero conscientemente decidimos dejarlos aparte del experimento).
A diferencia de un experimento, que es el ámbito de la confirmación o la verificación de hipótesis, en estudios exploratorios u observacionales analizamos el proceso en su ambiente natural, dejando que varíe libremente para que los factores
influyentes salgan a la luz como características salientes en el set de datos.
Los estudios confirmatorios requieren que tengamos hipótesis a comprobar. Estas hipótesis pueden surgir de distinto modo:
1) A partir de “corazonadas” o ideas preconcebidas.
2) Luego de un proceso de análisis deductivo por parte de expertos en el problema.
3) Como resultado de características salientes encontradas en un estudio exploratorio.
La metodología DMAIC utilizada en Seis Sigma nos impide caer en el error de considerar solamente el método (1). Sin la guía del DMAIC corremos el riesgo de usar preconceptos o ideas previas, intentando aplicar “pseudosoluciones” al problema sin suficiente análisis científico.
¿Qué es una hipótesis? Es una conjetura que aventuramos basada en nuestro
conocimiento del problema e información recolectada.
1 Como es imposible dejar todo el resto de factores constantes, la única solución posible es aceptar que hay
variación no controlada, pero eliminarla utilizando el procedimiento de aleatorización, donde la forma de realizar el experimento asegura que los factores no considerados se promedian entre sí y no contaminan los resultados del experimento.

Los estudios exploratorios buscan identificar variables dependientes (Y) e independientes (X) que pueden resultar de interés para comprender o resolver un problema bajo estudio. Estos estudios no siguen reglas fijas codificadas, son más
flexibles y especulativos; sin embargo, siempre parten de información recopilada sobre el problema en cuestión, y atraviesan tres etapas:
1) Gráficar la información
2) Determinar características salientes
3) Interpretar las características salientes.
El principal objetivo de estos estudios es explorar con un espíritu abierto, buscando detalles inesperado sobre el set de datos y tratando de desentrañar la estructura
escondida en el mar de números. Por esa razón las herramientas más utilizadas son gráficas, aprovechando la asombrosa capacidad de reconocimiento de patrones que todos tenemos. ,
En los estudios confirmatorios en general imponemos modelos sobre los datos, en base a nuestro conocimiento del problema, y estos modelos nos permiten estimar que error cometemos al sacar conclusiones. Esto agrega ciertas restricciones que deben
ser verificadas; por ejemplo, en análisis como ANOVA se asume que las discrepancias
respecto al modelo se distribuyen normalmente. Si esta suposición no se verifica, las conclusiones pierden validez estadística.
En pocas palabras, los estudios exploratorios generan hipótesis sobre el problema, los estudios confirmatorios confirman estas hipótesis.
Luego de un estudio Confirmatorio puedo decir:
“En base a mi análisis, puedo concluir que el Factor “temperatura del horno” es
significativo, con un 95% de confianza”
Luego de un estudio Observatorio puedo decir:
“En base a mi análisis, considero que el Factor “temperatura del horno” puede ser una causa importante para comprender mi problema.”
Leyendo ambos tipos de conclusión vemos que los estudios exploratorios carecen del rigor y objetividad que encontramos en los estudios confirmatorios, pero lo suplantan con mayor libertad de opciones y apertura a diferentes interpretaciones. Las
discusiones entre expertos y cruce de opiniones protagonizan el análisis exploratorio!
Como dice Wheeler: “Un estudio observacional es como prestar atención a un león en su hábitat salvaje en vez de investigarlo encerrados en una jaula… aunque podemos aprender ciertas cosas observando al león enjaulado, nuestro conocimiento puede ser mucho más completo si los observamos en libertad” 2
En un estudio observacional o exploratorio, es importante estudiar detalladamente los
datos ordenados cronológicamente, para descubrir señales que nos hablen de ciclos o comportamientos tendenciosos en las variables estudiadas. Posteriormente, cuando realicemos estudios confirmatorios, nos interesa que el tiempo no juegue un papel preponderante, porque no es un factor que podemos controlar en el proceso3.
Es importante recalcar que sólo podemos identificar efectos de factores que midamos y hayan variado durante el proceso de recolección de datos. Por esta razón en la fase
2 http://www.spcpress.com/pdf/ExpRandoObs.pdf
3 por eso se presta tanta atención al análisis de residuos ordenados en función del tiempo al analizar
resultados de experimentos. Cuando vemos una tendencia en los residuos, significa que algún factor no controlado afectó a nuestro proceso a medida que el tiempo pasaba, y deberemos examinar que influencias externas pueden haber causado esta tendencia.

exploratoria es fundamental dejar libre el proceso e incluir con cada medición la mayor información posible sobre variables controlables y no controlables del contexto.
En el flujo DMAIC, los estudios exploratorios surgen en la etapa M (Medir) y se
extienden sobre la etapa A (Análisis). En muchos proyectos se da un proceso iterativo de ida y vuelta entre estas dos etapas, dado que el análisis puede conducir a nuevas
mediciones y recopilación de información observacional que sugiere nuevos factores a tener en cuenta.
En la etapa de análisis se produce el pasaje del estadio exploratorio al confirmatorio; cuando se han identificado factores candidatos, los estudios confirmatorios asociados
frecuentemente a experimentos nos permitirán mensurar el efecto que estos factores tienen y descartar aquellos que no impactan significativamente.
Cuando el número de factores es muy grande incluso después del proceso exploratorio, técnicas como el diseño experimental factorial fraccional del tipo 2 k-p son herramienta valiosísimas para descartar factores de poca influencia.
En procesos transaccionales y servicios no disponemos generalmente de factores cuantitativos mensurables o susceptibles de experimentación. En estos casos cuando
la exploración descubre muchos factores candidatos, algunas opciones son:
- Volver a la definición del problema, puede ser que el proceso involucrado sea muy
complejo y debe ser subdividido en subprocesos acotados que nos permitan
acercarnos a la solución en forma gradual.
- Priorizar los factores utilizando mecanismos más cualitativos como tormenta de ideas,
votación, método Delphi, etc.
- Confirmar mediante pruebas pilotos donde se varían controladamente algunos
factores causales.
Las herramientas gráficas más utilizadas en los estudios exploratorios son:
- Gráfico Multivari para estratificar los datos siguiendo diferentes criterios. El objetivo
es buscar patrones de distribución que salten a la vista.
- Histograma: para ver si la distribución es unimodal o aparenta ser una mezcla de dos o
más poblaciones identificables.
- Gráfico de Control: cuando los datos pueden ordenarse temporalmente, permite
desentrañar tendencias o mediciones producidas por causas especiales de variación).
Permite también verificar la homogeneidad del set de datos.
- Gráfico probabilístico Normal: permite identificar desviaciones respecto a la curva
normal.
- Diagrama de dispersión, para analizar la relación entre dos variables.
- Box Plot, para determinar la influencia distintiva de distintos niveles de un factor sobre
una variable.
El Dr. De Mast4, en un reciente artículo sobre el tema (DeMast, 2007), recomienda prestar particular atención a desvíos de la normalidad al investigar datos de estudios exploratorios. Veamos porque…
4 El Dr. Jeroe De Mast trabaja en el Inst. de Negocios y Estadística Industrial de la Univ. De Amsterdam. La
siguiente entrevista (en inglés) puede resultar interesante, sobre todo a aquellos que trabajan en empresas

Si un proceso es el resultado de una serie de varios factores de similar importancia, la acción simultánea de estos factores produce un resultado aditivo cuya distribución es normal. Es decir que la suma de efectos disuelve los efectos individuales, generando
una respuesta con forma de campana de Gauss donde es imposible individualizar los factores intervinientes.
Invirtiendo el razonamiento, cuando la distribución observada es normal, no nos brinda información sobre los efectos individuales actuantes. Por otro lado, la falta de normalidad habla de factores con diferente preponderancia actuando sobre el proceso. Esta es la razón por la cual se sugiere en estudios exploratorios buscar desvíos
respecto a la normalidad.
Una vez identificadas características salientes, cosa que puede hacer un experto en estadística, es necesario interpretarlas para aventurar hipótesis. Esta interpretación exige el conocimiento del contexto en que se manifiesta el proceso. Por lo tanto, a la hora de entresacar hipótesis de estudios exploratorios, necesitamos incorporar en el análisis la mayor cantidad de expertos en el proceso involucrado, que nos permitan interpretar las características salientes descubiertas, y a partir de allí aventurar
hipótesis a confirmar posteriormente.
En conclusión, es importante conocer técnicas estadísticas: gráficos de control, ANOVA, DOE, etc. Pero aún más importante es saber aplicarlas sabiamente a un
problema determinado. Mucho dinero y tiempo se pierde cuando salteamos la etapa exploratoria pasando directamente a tratar de confirmar nuestras corazonadas.
La próxima vez que mires un set de datos que te muestra un analista, la primera pregunta que tiene que surgir es : ¿Corresponde a un estudio exploratorio o
confirmatorio? Porque las conclusiones y análisis que puedas hacer dependen de cómo fue obtenida la información que tienes ante tus ojos.
Referencias:
De Mast, J. & Trip, A. (2007): Exploratory Data Analysis in Quality-Improvement Projects. Journal of Quality Technology. Vol 39. No 4. Artículo del mes pasado donde el autor propone un camino para realizar studios exploratorios (particularmente cuando
las variables son cuantitativas)
Tukey, John (1977), Exploratory Data Analysis, Addison-Wesley. J. Tukey es reconocido como el fundador de la línea de análisis exploratorio (EDA: Exploratory
Data Analysis), como camino para construir hipótesis para testear.
NIST/Sematech (2004): NIST Handbook: http://www.itl.nist.gov/div898/handbook Un recurso gratuito con documentación exhaustiva sobre las técnicas de análisis exploratorio.
Respuesta al Caso 1: El inconveniente se debe a que la hipótesis sobre la causa del problema surge sólo a partir del conocimiento de expertos. No se realizaron estudios observacionales, que permitirían entresacar otras hipótesis posibles; descubrir incidencias mayores en determinados períodos de tiempo, efectos diferentes sobre distintos productos, etc. Podrían haber conducido a nuevas hipótesis causales que se deberían corroborar antes de saltar al proceso de buscar la acción
correctiva/preventiva. Esto originó una pérdida de tiempo, dinero y motivación, y a fin de cuentas se debe volver a pensar en la causa del problema después de la reunión 6, a la que sólo asisten la mitad de los integrantes del equipo, no hay posibilidad de pedir
más dinero para solucionar este problema, y hay tres proyectos más en marcha simultáneos.
de Servicios o áreas transaccionales de empresas Manufactureras: http://www.onesixsigma.com/lean-six-sigma-community/interviews/jeroen-de-mast

DIAGRAMA CAUSA Y EFECTO - AMFE
Este diagrama fue ideado por Kaouru Ishikawa, y por eso muchas veces se lo llama diagrama de Ishikawa.El efecto o evento que uno quiere analizar se ubica a la derecha y forma la “cabeza del pez”, desde la cual se desprende un eje principal como “columna vertebral”.
A este eje horizontal van llegando líneas oblicuas -como las espinas de un pez- que representan las causas valoradas como tales por las personas participantes en el
análisis del problema. A su vez, cada una de estas líneas que representa una posible causa, recibe otras líneas perpendiculares que representan las causas secundarias. Cada grupo formado por una posible causa primaria y las causas secundarias que se le relacionan forman un grupo de causas con naturaleza común.
El diagrama causa y efecto se utiliza en la etapa de exploración de causas del proyecto:
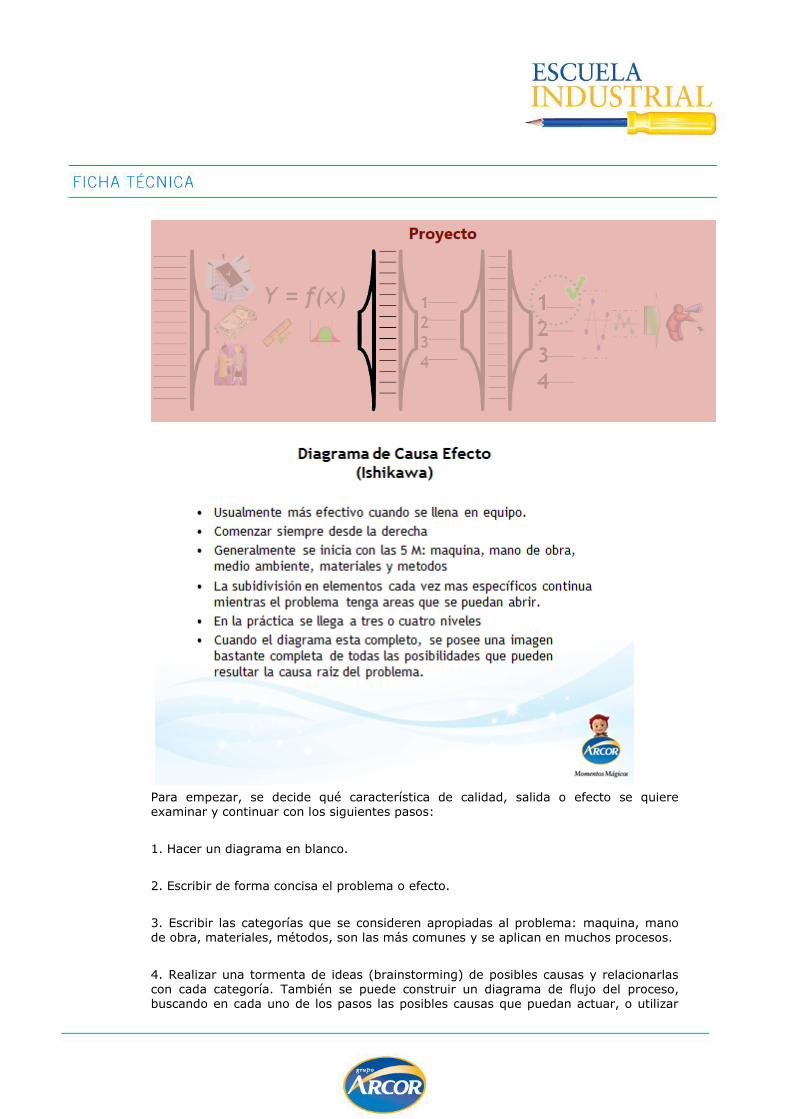
Para empezar, se decide qué característica de calidad, salida o efecto se quiere examinar y continuar con los siguientes pasos:
1. Hacer un diagrama en blanco.
2. Escribir de forma concisa el problema o efecto.
3. Escribir las categorías que se consideren apropiadas al problema: maquina, mano
de obra, materiales, métodos, son las más comunes y se aplican en muchos procesos.
4. Realizar una tormenta de ideas (brainstorming) de posibles causas y relacionarlas con cada categoría. También se puede construir un diagrama de flujo del proceso, buscando en cada uno de los pasos las posibles causas que puedan actuar, o utilizar

información histórica de reclamos, datos de SPAC, etc. Es muy importante involucrar a los stakeholders expertos en el tema, y ser muy creativos a la hora de buscar causas, dejando que cualquier sugerencia se plasme en una causa posible.
5. Preguntarse ¿por qué? a cada causa, no más de dos o tres veces. ¿Por qué no se
dispone de tiempo necesario?. ¿Por qué no se dispone de tiempo para estudiar las características de cada producto?.
Un análisis modal de fallos y efectos (AMFE) es un procedimiento de análisis de fallos potenciales en un sistema de clasificación determinado por la gravedad o por el efecto de los fallos en el sistema.
En los años 70 Ford introdujo el sistema AMFE en la industria del automóvil para mejorar la seguridad, la producción y el diseño, tras el escándalo del Ford Pinto.
El Ford Pinto, diseñado en muy poco tiempo y con criterios de economía muy estrictos, tenía dos defectos de seguridad pasiva:
El depósito de combustible estaba por detrás del eje trasero, con lo cual el coche
explotaba con mucha facilidad en caso de colisión por alcance.
La carrocería era muy endeble, con lo cual en caso de colisión por alcance el coche se
deformaba y las puertas quedaban bloqueadas, atrapando a sus ocupantes en un
coche en llamas.
Se cree que Ford estaba al tanto de ese problema, pero comparó el costo de agregar un refuerzo de 11 dolares a cada auto comparado con el costo de las vidas humanas perdidas por accidentes.

En un AMFE, se otorga una prioridad a los fallos dependiendo de cuan serias sean sus consecuencias, la frecuencia con la que ocurren y con qué dificultad pueden ser
localizadas. Un AMFE también documenta el conocimiento existente y las acciones sobre riesgos o fallos que deben ser utilizadas para lograr una mejora continua. El AMFE se utiliza durante la fase de diseño para evitar fallos futuros. Posteriormente es utilizado en las fases de control de procesos, antes y durante estos procesos. Idealmente, un AMFE empieza durante los primeros niveles conceptuales del proyecto y continúa a lo largo de la vida del producto o servicio.
La finalidad de un AMFE es eliminar o reducir los fallos, comenzando por aquellos con una prioridad más alta. Puede ser también utilizado para evaluar las prioridades de la gestión del riesgo. El AMFE ayuda a seleccionar soluciones que reducen los impactos acumulativos de las consecuencias del ciclo de vida (riesgos) del fallo de un sistema (fallo).
Cada modo de fallo se analiza de acuerdo a tres criterios:
Gravedad del Fallo o Severidad
Probabilidad de Ocurrencia o Incidencia
Posilibidad de No Detección
Severidad
Es importante tener en cuenta que un fallo en un componente puede llevar a un fallo
en otro componente. Los modos de fallos debe ser listado en términos técnicos y por función, y el efecto final de cada modo de fallo debe tenerse en cuenta. Un efecto de

fallo se define como el resultado de un modo de fallo en la función del sistema percibida por el usuario.
Por lo tanto es necesario dejar constancia por escrito de estos efectos tal como los
verá o experimentará el usuario. Ejemplos de efectos de fallos son: rendimiento bajo, ruido y daños a un usuario o consumidor.
Cada efecto recibe un número de severidad (S) que van desde el 1 (sin peligro) a 10 (crítico). Estos números ayudarán a los ingenieros a priorizar los modos de fallo y sus efectos. Si la severidad de un efecto tiene un grado 9 o 10, se debe considerar cambiar el diseño eliminando el modo de fallo o protegiendo al usuario de su efecto.
Incidencia
Es necesario observar la causa del fallo y determinar con qué frecuencia ocurre. Esto puede lograrse mediante la observación de productos o procesos similares y la documentación de sus fallos. La causa de un fallo está vista como un punto débil del diseño. Todas las causas potenciales de modo de fallos deben ser identificadas y
documentadas utilizando terminología técnica.
Un modo de fallos recibe un número de probabilidad (O) que puede ir del 1 al 10. Las acciones deben ser desarrollarse si la incidencia es alta (>4 para fallos no relacionados con la seguridad y >1 cuando el número de severidad del paso 1 es de 9 o 10).
La incidencia puede ser definida también como un porcentaje. Si un problema no relacionado con la seguridad tiene una incidencia de menos del 1% se le puede dar
una cifra de 1; dependiendo del producto y las especificaciones de usuario.
Detección
Cuando las acciones adecuadas se han determinado, es necesario comprobar su eficiencia y realizar una verificación del diseño. Debe seleccionarse el método de
inspección adecuado. En primer lugar un ingeniero debe observar los controles actuales del sistema que impidan los modos de fallos o bien que lo detecten antes de
que alcance al consumidor.
Posteriormente deben identificarse técnicas de testeo, análisis y monitorización que hayan sido utilizadas en sistemas similares para detectar fallos. De estos controles, un ingeniero puede conocer que posibilidad hay de que ocurran fallos y como detectarlos.
Cada combinación de los dos pasos anteriores recibe un número de detección (D). Este número representa la capacidad de los tests planificados y las inspecciones de eliminar los defectos y detectar modos de fallos.
Finalmente se calculan los números de prioridad del riesgo (RPN), como el producto de los tres factores.


Siempre que la gravedad sea 9 ó 10, y que la frecuencia y detección sean superiores a 1, consideraremos el fallo y las características que le corresponden como críticas.
Estas
características, que pueden ser una cota o una especificación, se identificarán con un triángulo invertido u otro signo en el documento de AMFE, en el plan de control y en el plano si le
corresponde. Aunque el NPR resultante sea menor que el especificado como límite,
conviene actuar sobre estos modos de fallo.

ESTADISTICA DESCRIPTIVA, NORMALIDAD Y CAPACIDAD
ESTADÍSTICA DESCRIPTIVA

Al afrontar un problema estadístico, el primer paso es definir la población que estamos estudiando. En general, cualquier conjunto de datos puede llamarse una población si
está constituido por todos los valores de interés. Por ejemplo: todos los pesos de bombón en la etapa de proceso “Relleno”, todos los valores de Gluten Húmedo de la

harina adquirida a un determinado proveedor, todas las ventas mensuales del producto X, etc.
Examinar una tabla con los valores de todos los individuos de nuestra población es un
poco incómodo, y se hace cada vez más difícil entender lo que pasa con los datos a medida que crece la población. Por esta razón se inventaron números que nos
permiten decir algo sobre la población sin tener que mirar todos los datos individuales.
Llamaremos a estos números parámetros y en general los identificaremos con letras griegas, como mu (µ), sigma (σ), etc. Por ejemplo, un parámetro que distingue la población de “todos los valores de humedad de la masa de galletita” es el “promedio
de humedad de la masa de galletita”; con este parámetro describimos la tendencia central de la población estudiada. Otro parámetro importante se llama desvío estándar, y nos ayuda a ver qué tan dispersos o alejados entre sí están los datos: evalúa la variabilidad de la población.
Medidas de posición central
Hay tres números que pueden ser usados para representar la posición central de un grupo de datos: la media, la moda y la mediana.
La moda es el valor que aparece el mayor número de veces (el de mayor frecuencia). Si graficamos un histograma de nuestra población, la moda se ubicará en la clase más
alta. Si sólo hay una clase más alta decimos que el histograma es unimodal; mientras que si el histograma presenta dos clases más altas, como dos montañas adyacentes,
hablamos de un histograma bimodal. En la práctica esto generalmente sucede cuando mezclamos dos poblaciones unimodales.
La mediana es el valor central en un conjunto de números ordenados según su magnitud. Cuando el número de datos es par, hay dos valores centrales, y se define la mediana como el número que está a mitad de camino entre estos dos valores. Así, la mediana de seis valores esta en medio de los números tercero y cuarto.
La media o promedio de un conjunto de números no es más que la suma de todos los
valores considerados, dividida por el número total de valores del conjunto.
x x x x
N
N1 2 3 ... (Media Poblacional)
En la fórmula, N (con mayúsculas) representa el número total de unidades en la
población.
Medidas de dispersión
Las medidas de posición central no son suficientes para conocer una población, porque no dicen nada sobre el grado de dispersión de los datos. Imaginemos que sólo usamos la posición central, nos podríamos comparar con una persona que, teniendo la cabeza metida en un refrigerador, y los pies en un horno, dijera: “en promedio, me siento muy bien”.
Las medidas de dispersión más comunes son el rango y el desvío estándar.
El rango se define sencillamente como la diferencia entre el valor más alto y el más bajo del conjunto de datos. Es fácil de calcular, pero tiene la desventaja que sólo tiene en cuenta dos valores de la población (el extremo superior y el inferior).
El desvío estándar utiliza la distancia entre cada dato y el promedio, pero elevando esta distancia al cuadrado (para que siempre sea positiva), luego calcula un promedio de estas distancias:
1 2
1N
xi
i
N
( ) (Desvío estándar poblacional)
En la práctica, el rango es una medida más fácil de calcular e interpretar, pero a medida que aumentan los datos involucrados, cada vez corre más riesgo de medir
incorrectamente la dispersión, dado que sólo incorpora los dos valores extremos sin considerar los demás datos. En general, para menos de 10 datos se puede utilizar el rango, y cuando los datos superan las 10 unidades se recomienda el uso del desvío
estándar.
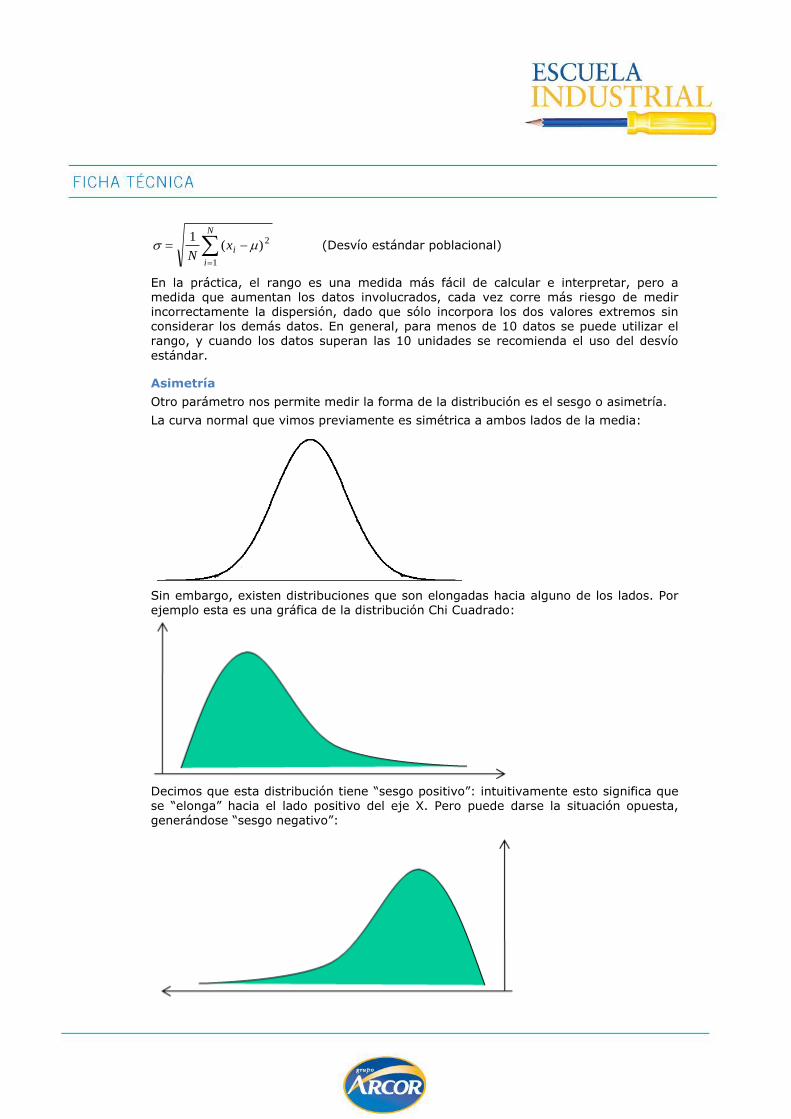
Asimetría
Otro parámetro nos permite medir la forma de la distribución es el sesgo o asimetría.
La curva normal que vimos previamente es simétrica a ambos lados de la media:
Sin embargo, existen distribuciones que son elongadas hacia alguno de los lados. Por ejemplo esta es una gráfica de la distribución Chi Cuadrado:
Decimos que esta distribución tiene “sesgo positivo”: intuitivamente esto significa que se “elonga” hacia el lado positivo del eje X. Pero puede darse la situación opuesta, generándose “sesgo negativo”:

Gráficamente se ve fácil, pero a veces es bueno encontrar un número que nos permita medir la asimetría. Un parámetro numérico que nos permite evaluar cuantitativamente la asimetría de la población es el siguiente:
3
1
3
1)(
N
xN
ii
Denominado “sesgo poblacional”, que vale cero si la curva es simétrica, y positivo o negativo según el sentido del sesgo.
No es la única medida de sesgo. Karl Pearson sugirió algunas medidas más simples, como:
)(3 MedianaMediaSesgo
ModaMediaSesgo
¿Cuánto se utiliza este parámetro en la práctica?… no mucho. Es bueno saber que existe, y a veces nos permitirá ver que tan lejos están nuestros datos de una curva simétrica como la normal, pero no se encuentran muchas aplicaciones en entornos industriales para el parámetro sesgo poblacional.
Curtosis.
Este parámetro no es muy utilizado en problemas prácticos. Sin embargo, dado que el parámetro existe y el lector puede llegar a escucharlo, lo describiré.
La curtosis mide el grado de achatamiento o apuntalamiento de la curva. Numéricamente se calcula mediante la siguiente fórmula:
∑
Se resta el número 3 al final para que cuando los datos tengan una distribución normal, la curtosis valga cero. De acuerdo a los valores hallados, la curva será más
punteaguda (leptocúrtica, curtosis mayor que cero) o achatada (platicúrtica, curtosis menor que cero)
NORMALIDAD

¿Por qué es normal la curva normal? Su nombre deviene de encontrarse en muchos procesos naturales: cuando una característica resulta de la acción conjunta muchas causas independientes de magnitud similar, donde ninguna causa es mucho más
influyente que otra, se distribuirá siguiendo una curva de forma gaussiana o normal.
En una planta, muchas variables de proceso resultan de la acción de un sinnúmero de causas diferentes y de magnitud similar; en estos casos la distribución normal será un modelo adecuado para caracterizar el proceso.
Dada su popularidad, varios procedimientos estadísticos (ANOVA, Regresión Lineal, etc.) presuponen que los datos o la variabilidad subyacente (residuos) se distribuyen
normalmente. Por fortuna, en muchos casos estos mismos procedimientos pueden utilizarse incluso con leves diferencias respecto de la distribución de Gauss.
Una distribución normal posee las siguientes características:
La distribución es simétrica a ambos lados de la media.
La media es igual a la moda y a la mediana.
Entre la media y un desvío estándar hacia cada lado se encuentra el 68 % de los datos.
Entre la media y dos desvíos hacia ambos lados se encuentran el 95% de los datos.
Entre la media y tres desvíos hacia ambos lados se encuentran el 99,7% de los datos.

Dado que generalmente no puedo acceder al total de los datos, debo realizar una muestra de la población, y calcular ciertos números, llamados estadísticos, para luego
intentar estimar los valores correspondientes a la población.

Utilizamos la inferencia estadística para sacar conclusiones sobre la población a partir de la muestra, mediante un proceso de inducción. En contraste, los problemas de probabilidad nos permiten sacar conclusiones sobre datos que extraemos de una
población que conocemos, mediante un proceso de deducción a partir de los parámetros de la población.
En toda situación real partimos del proceso inductivo, observando datos y realizando inferencias; la teoría de probabilidades será una idealización matemática, es decir, no real, que usamos porque no hay remedio.
El tipo de muestreo que realizamos determinará la confianza que tendremos en los
resultados obtenidos. Un requisito indispensable es que la muestra sea representativa de la población que estudiamos, y el mecanismo para recolectar muestras se denomina muestreo aleatorio simple.
El muestreo aleatorio simple implica que todos los elementos de la población tienen la misma oportunidad de ser escogidos para formar parte de la muestra.
Los números que calcularemos a partir de las muestras se llaman estadísticos muestrales, y cada parámetro poblacional tiene su correspondiente estadístico
muestral. Así tendremos un promedio muestral, un desvío estándar muestral, etc.
Los números que calcularemos a partir de las muestras se llaman estadísticos
muestrales, y cada parámetro poblacional tiene su correspondiente estadístico muestral. Así tendremos un promedio muestral, un desvío estándar muestral, etc.
Para no confundir estadístico muestral con parámetro poblacional, convengamos en los siguientes símbolos:
Característica Población
Muestra
Promedio Xm
Desvío estándar
s
Numero de unidades
N n
Para obtener una medida de la posición central de la muestra, usamos el promedio Xm:
n
xXm
i
Recordemos la fórmula del desvío estándar de la población:
1 2
1N
xi
i
N
( )
Si conociésemos , usaríamos ese valor en el numerador calcular el desvío estándar la
muestra. En la práctica, la mayoría de las veces no lo conocemos, ¿que nos queda? lo único que podemos usar el promedio muestral (Xm).
La fórmula para el desvío estándar muestral es:
n
i
i Xmxn
s1
2)(1
1

Cada grupo de tres círculos verdes corresponde a una muestra tomada en un momento determinado. Supongamos que obtuvimos 20 muestras, y a cada una
podemos calcularle los parámetros Xm (promedio muestral) y R (rango).
Al final tendremos un grupo de valores de Xm que podremos promediar, para obtener un “promedio de los promedios” (k es el número de muestras, no la cantidad de observaciones por muestra):
∑
Xmm también se lo expresa con X con dos rayas:
Uno se puede tentar a decir: “la media de la población es...” y nombrar a Xmm. Falso ! En realidad, Xmm solo es un estimador de ; para saber el verdadero valor de la
media de la población deberíamos tener todos los datos, no sólo un conjunto de muestras.
El símbolo se utiliza para mostrar que Xmm no es exactamente igual a :
En otros libros se usa un símbolo de mu con un sombrerito encima: para indicar que
estamos ante un “estimador” del promedio poblacional, y no del valor real. Así esta en la diapositiva:
Pasando a la dispersión, vamos a evaluar dos modos diferentes de estimar el desvío
estándar de la población.
El primer método consiste en incluir el total de observaciones y calcular el desvío estándar muestral del conjunto de datos:

N
i
ig XmmxN
s1
2)(1
1
Este valor fue obtenido en base a las muestras, para pasar al valor de la población ,
se necesita dividir por un coeficiente llamado c4, que depende del número de unidades
utilizado para calcular el desvío estándar (N). Para más de 20 unidades, el valor de c4 es casi 1 y puede obviarse an la mayoría de las aplicaciones prácticas, usando la
fórmula:
Usamos el subíndice g para indicar que calculamos la variabilidad con el total de los datos sin tener en cuenta a qué muestra pertenece cada dato; esto nos da una idea de la variación global.
Podemos usar un segundo método para estimar el desvío estándar: calcular el
promedio de todos los rangos muestrales (Rm). A partir de este promedio podemos obtener un estimador del desvío estándar poblacional (σ):
)(/ˆ2 ndRl
El factor d2 depende del número de unidades en la muestra (5 en nuestro caso) y se
puede buscar en la tabla adjunta al final de este texto.
Usamos el subíndice l (local) para indicar que calculamos la variabilidad con el total de los datos analizando información calculada dentro de cada muestra (local a cada subgrupo).
Si en vez de calcular los rangos, calculamos los desvíos estándar (s) de cada muestra, el desvío poblacional se estima como:
)()(
ˆ4
1
4
nck
s
ncs
n
i
i
ll
Un proceso estable varía de la misma forma a nivel local y global, o a “corto plazo” y
“largo plazo”, por lo tanto si el proceso tiene un similar al , hablamos de un
proceso estable. Un proceso inestable puede tener baja variabilidad local, pero a largo plazo presenta alta dispersión. En general .

CAPACIDAD DE PROCESOS
Una forma de determinar la capacidad de un proceso es graficando un histograma y viendo el acople entre los datos que el proceso me brinda (clases del histograma) y la especificación del cliente. Sin embargo, cuando tenemos gran cantidad de productos y características medidas, es poco práctico generar tantos histogramas.
En estas situaciones es más útil calcular ciertos números que nos resumen la capacidad de cada proceso, llamamos a estos números índices de Capacidad o
Performance de procesos.
No caigamos en la tiranía de los índices de capacidad, a veces no nos reflejan la realidad. Por ejemplo, un proceso donde se presenta una tendencia creciente, si dibujamos el histograma puede ser que los datos se encuadren dentro de los límites especificados. Pero dado que existe una tendencia, esta situación es sólo temporaria, y en un futuro próximo el proceso comenzará a generar producto defectuoso.
La capacidad se refiere al Corto Plazo, al uso de la variabilidad instantánea o local para calcular índices, llamados índices de Capacidad de Proceso.
La performance se relaciona con la variabilidad a Largo Plazo, tomando todos los valores e incluyendo causas especiales si las hubiese. Llamamos a estos índices índices de Performance del Proceso.
En un proceso fuera de control estadístico, no podemos hablar de una única capacidad, porque está continuamente fluctuando, la capacidad será distinta según cuándo realizo
mi medición.
El proceso debe encontrarse bajo control estadístico para determinar su capacidad.
Para el cálculo del Cp, notemos que se divide siempre por el desvío estándar de corto plazo o local. Lo que nos da la aptitud del proceso bajo la acción de causas comunes de variación.

Recordemos que 6 sigmas en una distribución normal cubre el 99.7% de los datos de la población. Al dividir por seis sigma, estamos dividiendo por el ancho natural del proceso.
Un Cp superior a 1 es considerado apto, cuanto mayor es el valor del Cp, más posibilidades tiene mi proceso de cumplir con las especificaciones.
Hay dos problemas con el Cp:
Sólo puede calcularse cuando existen ambos límites de especificación.
No tiene en cuenta el centrado del proceso, solo la variación.
Para evitar estos problemas se creo el índice Cpk, que se construye analizando independientemente la capacidad respecto a cada uno de los límites de especificación.
Así como en el Cp-Cpk dividíamos por el sigma local, para los índices de Performance (Pp, Ppk) utilizamos el sigma global, teniendo en cuenta todos los datos sin importar los subgrupos.
En un proceso fuera de Control Estadístico, los índices de Performance serán mucho menores que los índices de Capacidad.
Cuando el proceso se encuentra bajo la acción de causas comunes exclusivamente,
ambos índices serán similares.
Recordemos lo comentado sobre gráficos de control; antes de poder extender los límites de control para controlar nuestros procesos (lo que se llama Fase II del control estadístico de procesos), es importante verificar la capacidad de proceso a través de
los índices de Capacidad.

Desde el punto de vista de la Capacidad, cada una de estas dimensiones puede encontrarse en uno de dos estados:

La dimensión “producto” puede estar en el estado “El 100% del producto es
Conforme”, o en el estado “Hay producto No Conforme”. El cliente puede fácilmente
determinar el estado del producto que le entregamos, o nosotros podemos realizar
inspecciones a la salida de la máquina para determinar los porcentajes no conformes y
ver si tenemos o no problemas con el producto.
La dimensión “proceso” se refiere al continuo operar de nuestro proceso productivo.
En este sentido podemos, por un lado, encontrar el proceso operando de manera
estable, en el estado que llamaremos “Bajo Control Estadístico”, donde existe cierta
variabilidad acotada entre límites naturales de variación. La estabilidad u
homogeneidad de salida permite que el proceso sea predecible. En el otro extremo, el
proceso puede ser “impredecible”, con causas actuantes que generan fluctuaciones
esporádicas, saltos sin ton ni son, impidiendo establecer límites de variación natural.
Esta segunda situación recibe el nombre de “Ausencia de Control Estadístico”.
Resumiendo, podemos estudiar nuestro proceso desde dos ejes de análisis: un eje del producto, donde distinguimos si se está generando producto conforme o no conforme, y un eje del proceso, mediante el cual identificamos si el proceso es predecible (bajo control estadístico) o impredecible (fuera de control estadístico). Estos dos ejes definen la siguiente matriz Proceso/Producto, que nos permite clasificar cualquier situación operativa:


Lo que Wheeler llama el “círculo de la desilusión “(circle of despair) se produce cuando ante una situación de “caos” (hay no conforme y el proceso es inestable) el analista opera sobre el proceso para llevarlo a una situación de “caos inminente” (100% Ok con proceso inestable), a la que considera “sin problemas” en circunstancias ordinarias.
Una vez aplicado este parche, los analistas van a trabajar a otro problema, dejando que la acción de la entropía empuje al proceso inicial indefectiblemente hacia el estado de caos. La única manera de escapar de este círculo es a través del uso de gráficos de control, asegurando la estabilidad del proceso en el estado Óptimo.
Por otro lado, no es recomendable comenzar proyectos de Mejora (Six Sigma, PDCA, 8 pasos, etc.) cuando el proceso todavía está en los estados “inferiores” (Caos o Caos Inminente). En estos estados no conocemos la verdadera capacidad de nuestro proceso; ¿Por qué primero no recolectamos las “frutas maduras” eliminando causas especiales? Así determinaremos dónde nos hallamos en el eje del producto, y por ende si es realmente necesario emprender un proyecto de mejora.
Por supuesto que hay contadas ocasiones en las cuales comenzaremos proyectos de mejora sobre un proceso Fuera de Control. Tengamos bien claro que entonces no tendremos una concreta “línea de base” sobre la cual contrastar nuestros resultados y mejoras implementadas, lo que dificultará la redacción del cuaderno del proyecto –Project Charter- y afectará sobre todo en la etapa de Medición (M) del ciclo DMAIC.

La misma recomendación de estabilidad como prerrequisito vale para proyectos Lean (manufactura esbelta). Sin embargo, dado que Lean es una serie de principios que muchas veces redefinen enteramente el proceso, es más factible que se descarte el proceso actual, haciendo “borrón y cuenta nueva” y rediseñando el flujo de valor con un esquema “Pull” o de “tracción”.
Resumiendo las opciones para nuestro proceso, podemos terminar graficando la matriz Wheeler de Proceso-Producto:

INTRODUCCION AL SPAC FL
IMPORTACIÓN Y SET DE DATOS
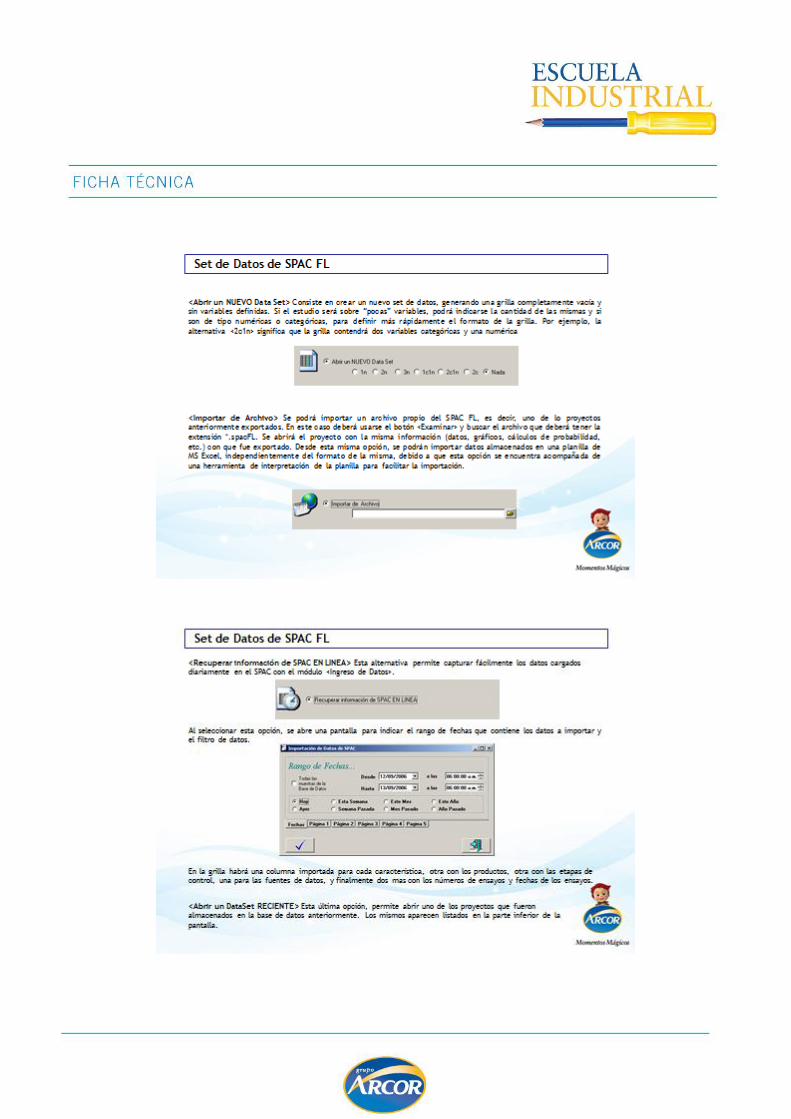
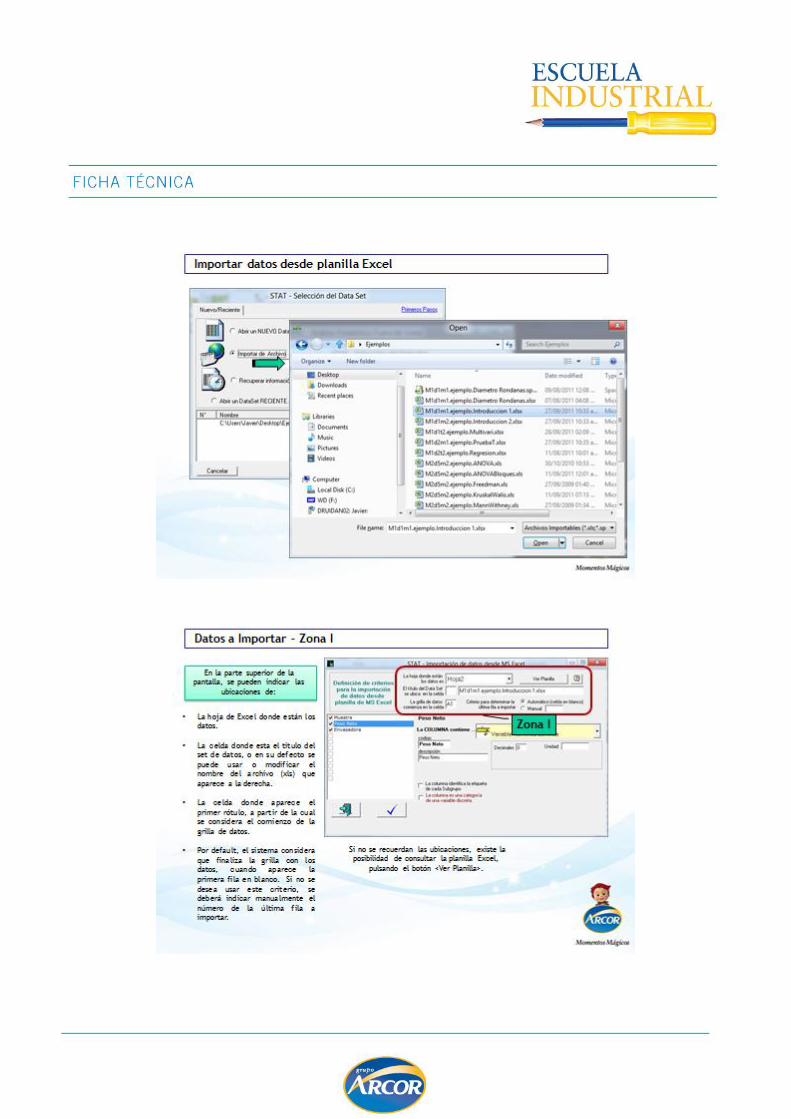
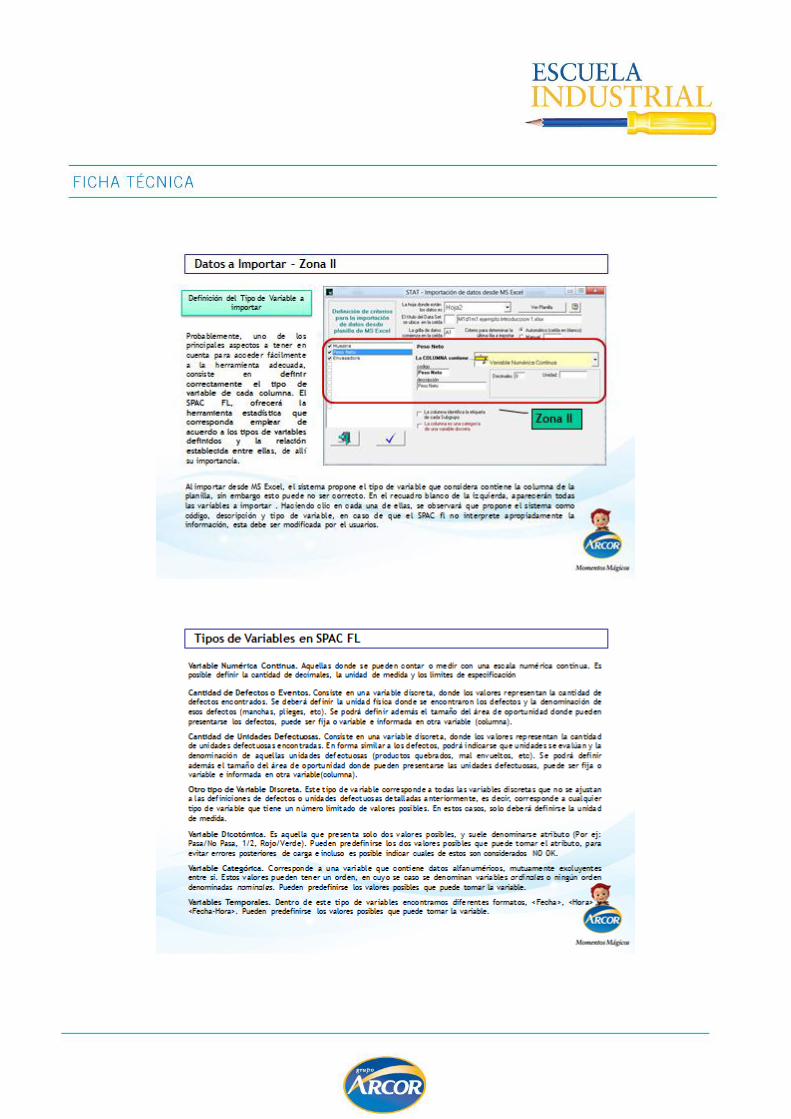
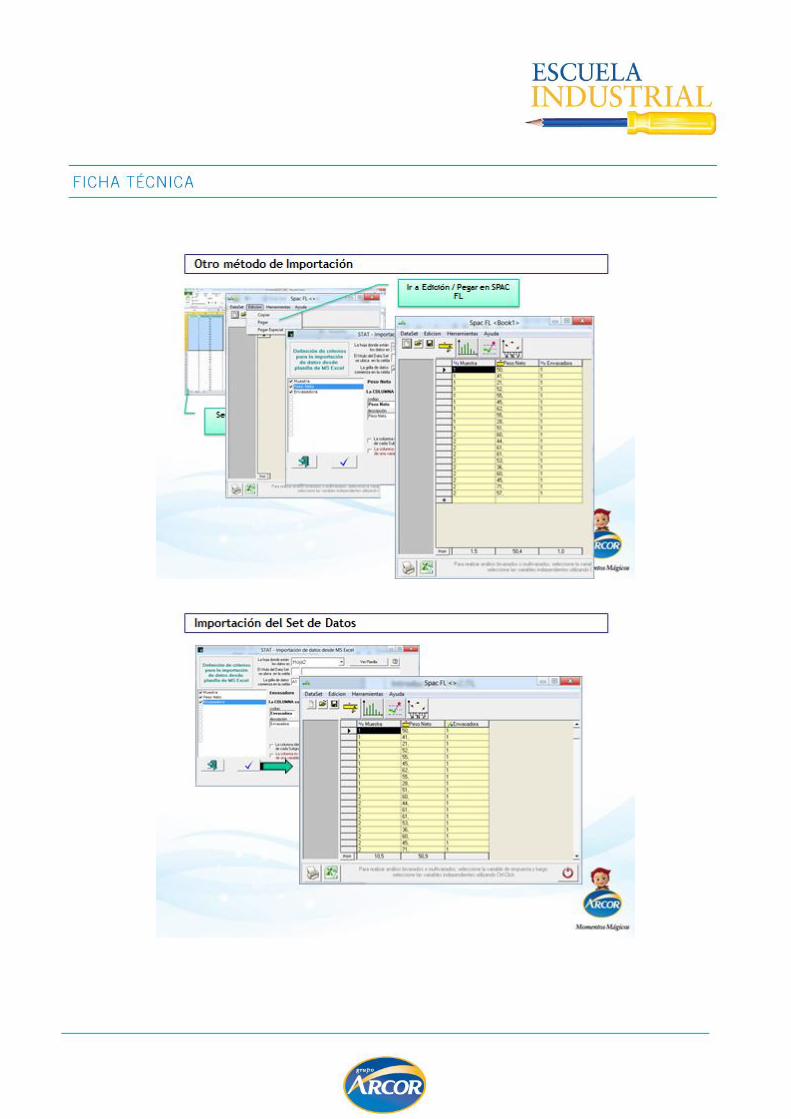
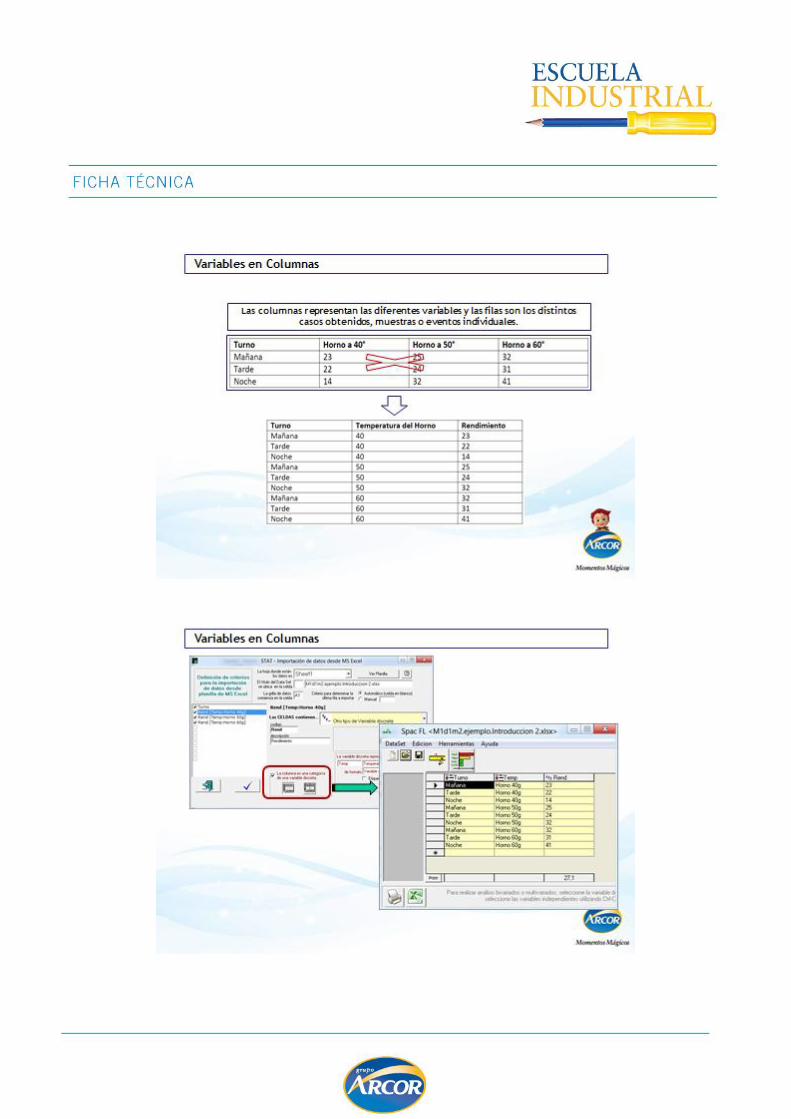
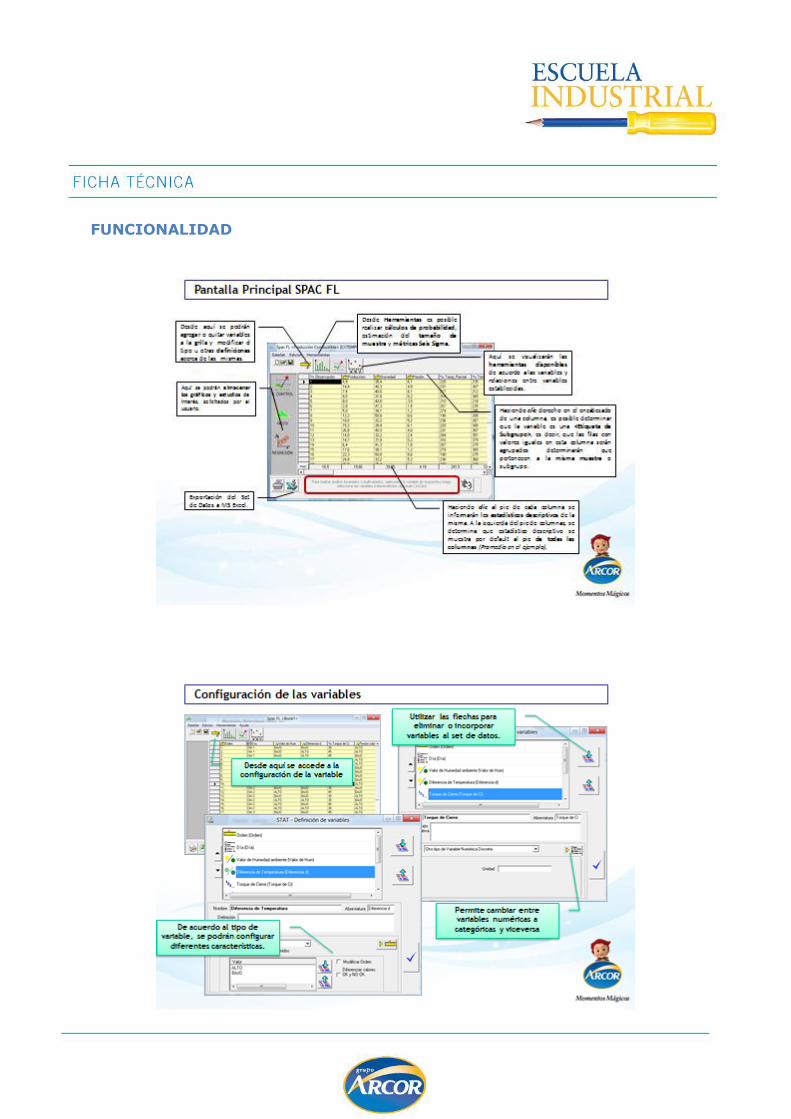
FUNCIONALIDAD

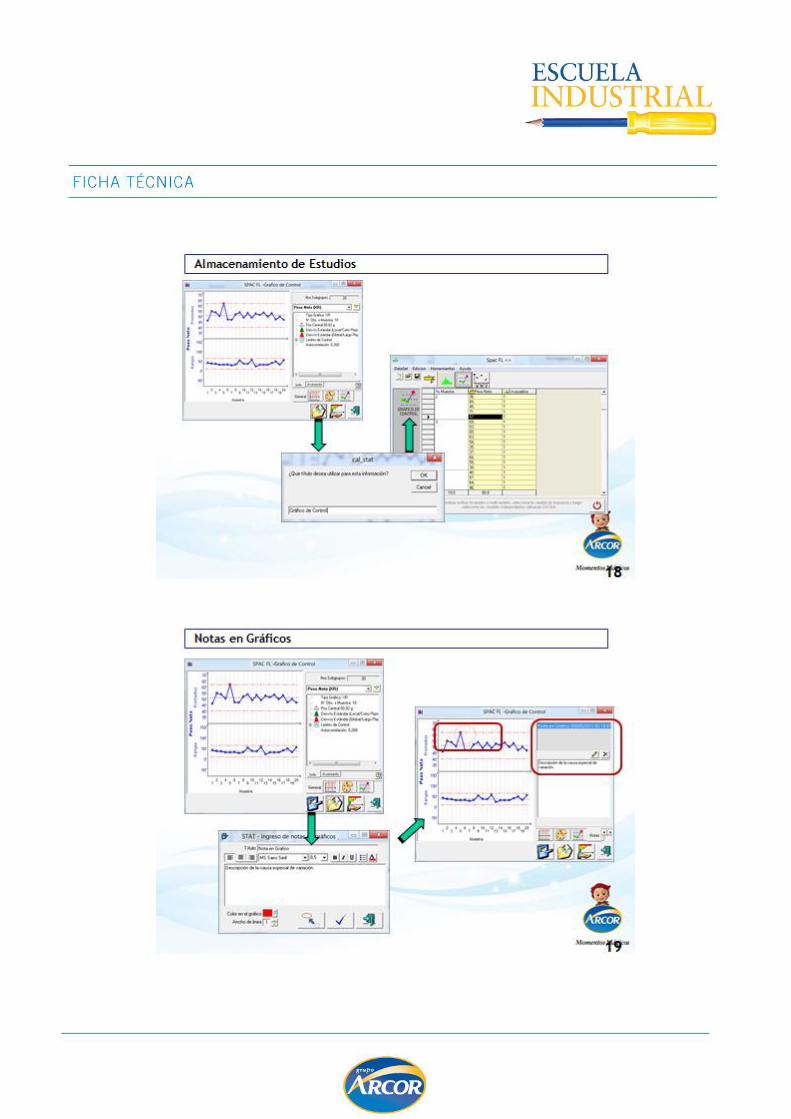
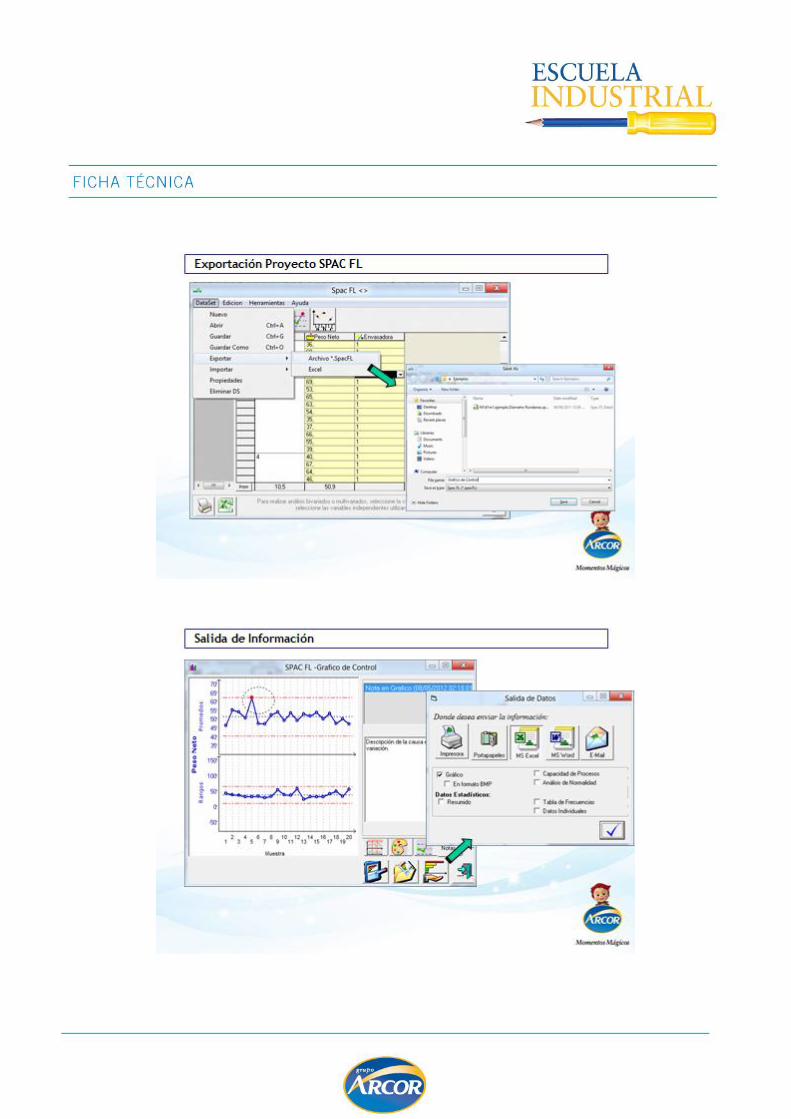

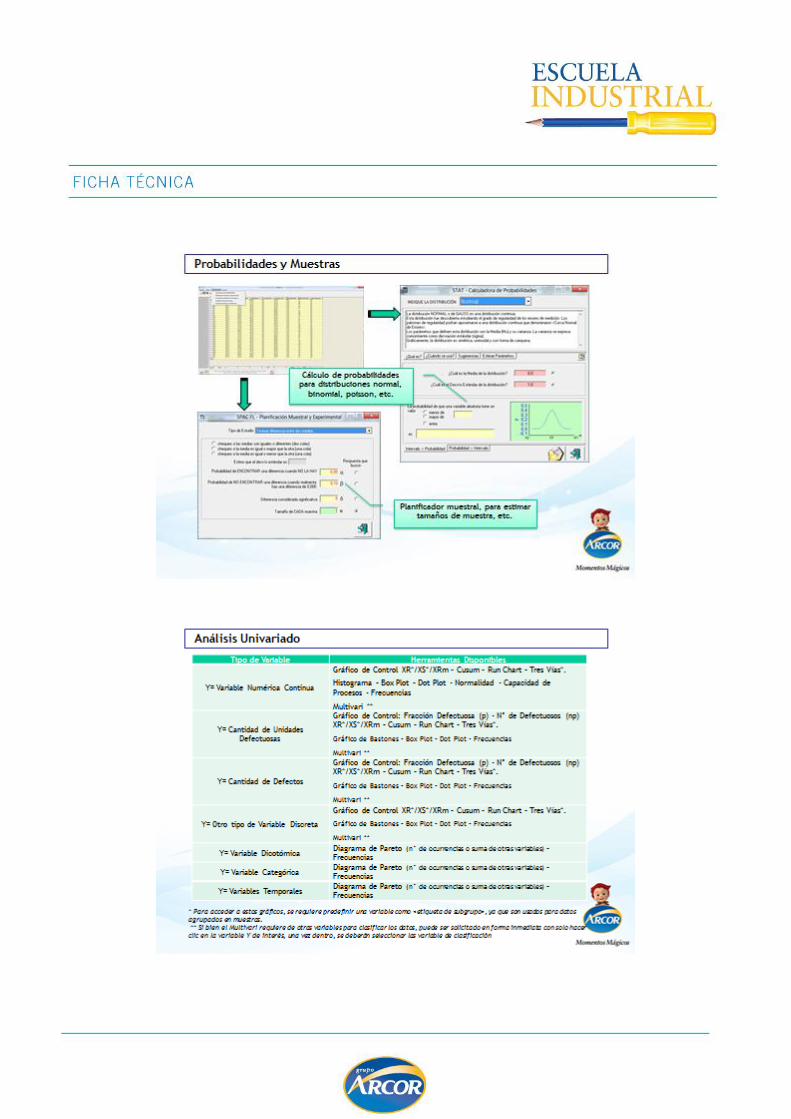


TEST DE HIPOTESIS
Los test de hipótesis son herramientas estadísticas que buscan verificar una determinada hipótesis (llamada hipótesis nula) a partir de evidencia estadística; si rechazamos esta hipótesis, se deberá aceptar una hipótesis alternativa.
Por ejemplo, un típico test de hipótesis es el siguiente: tengo un proceso cuya
característica pH varía continuamente, y creo que la variación se produce alrededor de un valor medio de 6.00; mi hipótesis nula será que el promedio del pH del proceso es 6.00, mi hipótesis alternativa será que el promedio es diferente de 6.00.
Continuando con el test, tomo una muestra de varias observaciones, evalúo el pH de estas observaciones y decido si con una suficiente confianza (por ejemplo 95%), la muestra es consistente con una población cuyo promedio es 6.00, es decir con la
hipótesis nula.
Si el pH resultante de la muestra esta estadísticamente muy alejado de 6.00, tendré
que rechazar la hipótesis de pH = 6.00 (con un nivel de confianza del 95%).

Hay que destacar que nunca estamos aceptando o rechazando nuestro planteo con 100% de certeza. Cuando acepto un nivel de confianza del 95%, significa que hay un
5% de riesgo asociado con esa decisión. Hay un 5% de riesgo de cometer el error y decir que rechazo la hipótesis nula (en el ejemplo, decir que el pH es distinto de 6.00), cuando en realidad la hipótesis nula era cierta (y el pH de la población es realmente 6.00). Este riesgo se denomina error de tipo I o riesgo Alfa.

Hay otro tipo de error posible, que por ahora no trataremos: el error de no rechazar la hipótesis nula (pH=6) cuando en realidad la población sí es diferente. Este error, llamado error Beta, depende de cuán lejos está el verdadero valor poblacional
de nuestra hipótesis. Si la verdadera situación es que el pH es 14, el Beta será muy bajo, pero si el pH es 6.01, el Beta puede ser muy alto, porque es muy difícil al tomar una muestra distinguir si el promedio poblacional es 6.00 o 6.01.
En resumen, de acuerdo a lo que pasa en la realidad y la desición que tomamos, se puede construir la siguiente tabla:

En el ejemplo planteado, nuestro interés era caracterizar la salida de un proceso. Otro uso de los test de hipótesis es para comparar dos condiciones para ver si son realmente diferentes. Ejemplos:
i. Tengo dos proveedores, ¿puedo decir que ambos entregan
producto o servicio similar?
ii. Estoy terminando un proceso de mejora, ¿puedo decir que estoy
mejor que cuando comencé?

Como estamos tomando datos de la realidad, siempre habrá muchas causas de variación actuando, y los test o pruebas de hipótesis nos permiten saber si entre toda
la variación existente, podemos determinar objetivamente que hubo un cambio en el proceso (ejemplo ii), o que los dos proveedores son realmente diferentes (ejemplo i).
Los datos que medimos, si usamos un buen instrumento de medición y definimos bien la variable medida, representan nuestra mejor aproximación a la realidad. A partir de
estos datos usamos estadística inferencial para “inferir” las características de la
población que dio origen a estos datos, y luego usamos teoría de probabilidades para ver si hay alguna señal identificable o no.
Hablar de variación, señales identificables, etc. nos sugiere que esto puede tener algo que ver con los conceptos de causas comunes y especiales que vimos al evaluar la Voz del Proceso. Veremos que hay una relación muy íntima entre ambos conceptos. Pero ahora volvamos a la estimación.
Al calcular un promedio, en realidad estamos estimando el valor de la población, es decir que tenemos cierta incertidumbre sobre lo cercano o lejano que esta este valor medido del verdadero promedio poblacional.
Recordemos que nos es imposible conocer el verdadero valor de , y sólo podremos
acercarnos mediante un estimador , calculado mediante promedios de muestras.
De la misma manera, no podemos conocer el valor exacto de un índice de capacidad (Cp, Pp, etc.), y sólo podremos aproximarnos tomando una muestra finita que siempre nos brindará un estimador; este estimador se aproximará al valor de la población cuanto mayor sea el número de datos involucrados en el cálculo.

Si pensamos en la estimación del promedio de la población - -. Dado que tenemos
una muestra, siempre habrá una incertidumbre asociada a su valor, una forma de cuantificar esta incertidumbre es utilizando su intervalo de confianza.
Para construir un intervalo de confianza, se obtienen datos y se calcula un estadístico (como el promedio, o el desvío estándar muestral). Luego se pasa al terreno teórico de los modelos probabilísticos, y usando la supuesta distribución probabilística de las
muestras tomadas, se determina un intervalo para el valor del parámetro poblacional, usando cierto coeficiente de verosimilitud denotado generalmente como 100*(1-α) %, donde la letra griega alfa se denomina “nivel de significación”.
En un proceso homogéneo, bajo control, podemos considerar que los datos son consistentes con cierta población subyacente, entonces podemos intentar estimar valores de posición central de esta población y su variabilidad. Si el proceso está fuera
de control, hay causas especiales que implican cambios en la población subyacente; esto impide hablar de un único valor central o una única variabilidad de nuestro proceso.
Incluso si el proceso es homogéneo, es importante que la muestra que tomemos para caracterizarlo sea aleatoria y representativa de la población, es decir, que cualquier
elemento tenga igual oportunidad de ser elegido. Esta suposición muchas veces no se cumple: imaginemos que recibimos un lote de materia prima y para estudiar una característica, tomamos las unidades de la muestra sólo de la parte superior del pallet recibido. La generación de esta muestra no puede considerarse aleatoria (seleccionando individuos al azar de cualquier lugar del pallet) ni representativa de todo el pallet. En definitiva, no debemos considerar que el muestreo es aleatorio o representativo por ley natural, sino que exige una cuidadosa planeación del muestreo.

En el ejemplo, si realizamos un test de hipótesis para comparar Linea 1 versus Linea 2 en Argentina y Canada, observaremos que en Argentina el test rechazará la hipótesis nula de igualdad de las linas, y me confirmará que las líneas son diferentes. En el caso
de Canadá, el test me dirá que no puedo rechazar la igualdad de las líneas. Es decir, en Argentina hay una diferencia estadísticamente significativa. Pero si miramos los histogramas, nos damos cuenta que el proceso de línea 1 y línea 2 en canada es mucho peor que en Argentina, del punto de vista práctico, la diferencia entre las líneas en argentina, a pesar de existir, no reviste importancia, porque ambas líneas tienen alta capacidad para cumplir con las especificaciones.

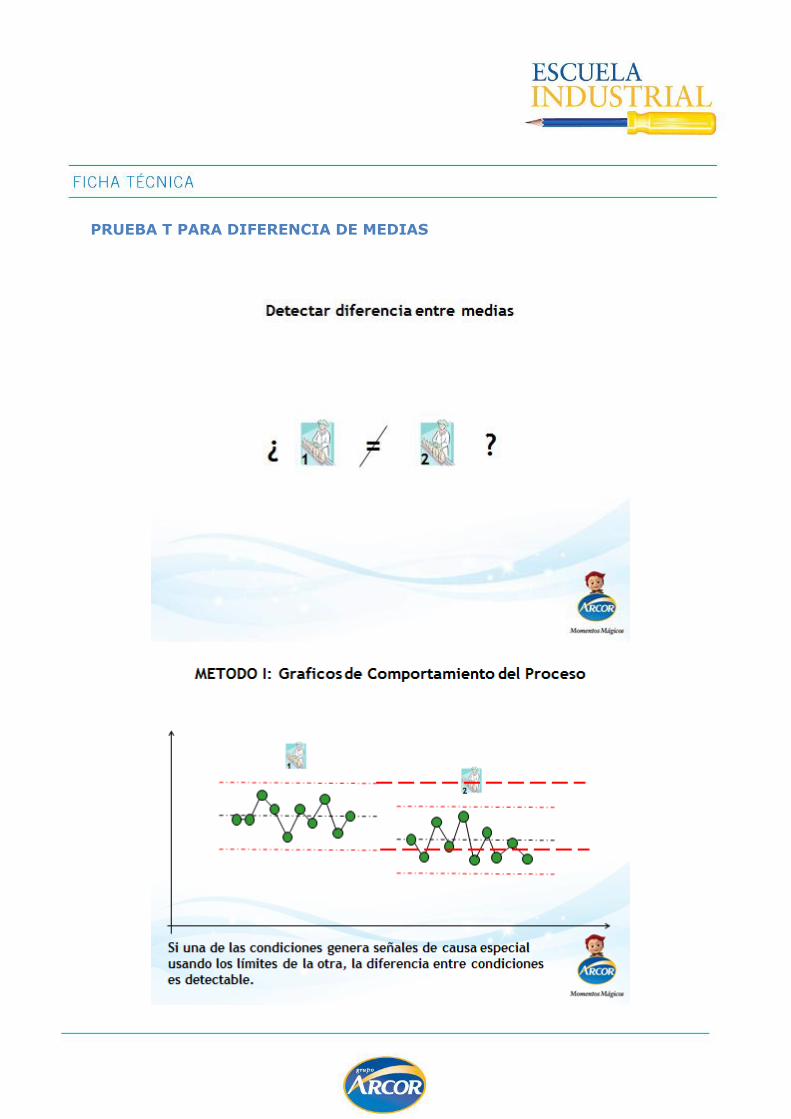
PRUEBA T PARA DIFERENCIA DE MEDIAS
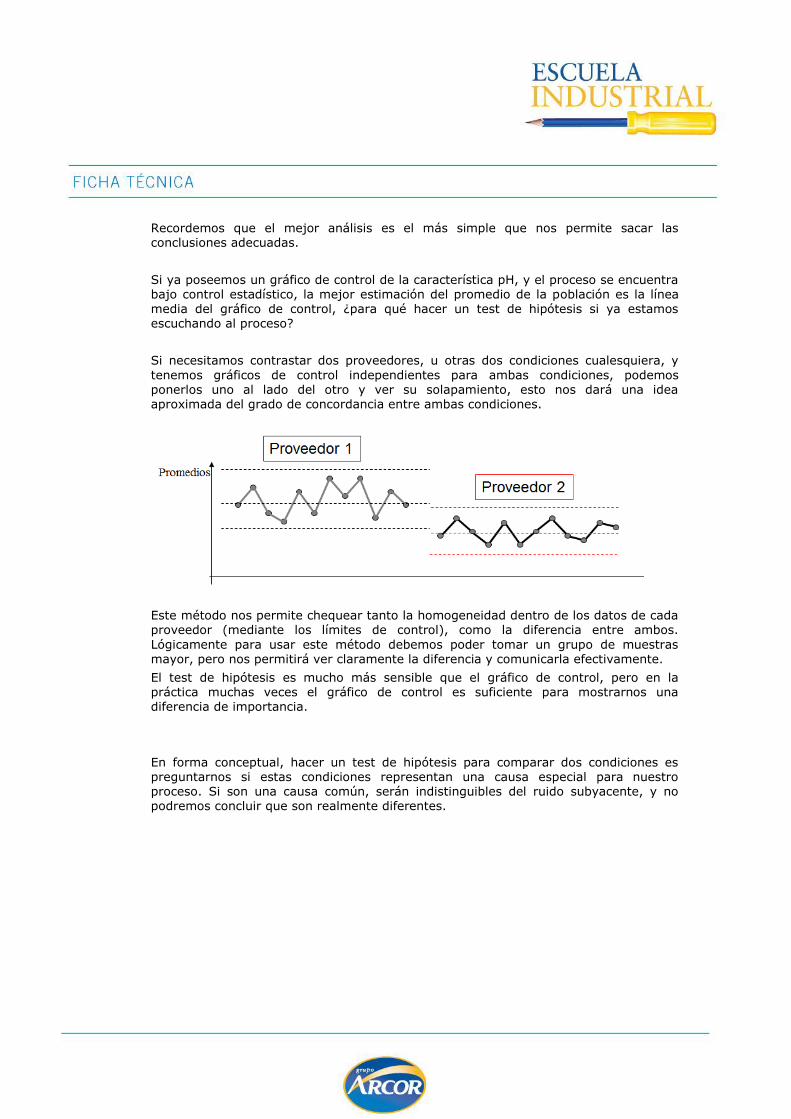
Recordemos que el mejor análisis es el más simple que nos permite sacar las conclusiones adecuadas.
Si ya poseemos un gráfico de control de la característica pH, y el proceso se encuentra bajo control estadístico, la mejor estimación del promedio de la población es la línea
media del gráfico de control, ¿para qué hacer un test de hipótesis si ya estamos escuchando al proceso?
Si necesitamos contrastar dos proveedores, u otras dos condiciones cualesquiera, y
tenemos gráficos de control independientes para ambas condiciones, podemos ponerlos uno al lado del otro y ver su solapamiento, esto nos dará una idea aproximada del grado de concordancia entre ambas condiciones.
Este método nos permite chequear tanto la homogeneidad dentro de los datos de cada proveedor (mediante los límites de control), como la diferencia entre ambos.
Lógicamente para usar este método debemos poder tomar un grupo de muestras mayor, pero nos permitirá ver claramente la diferencia y comunicarla efectivamente.
El test de hipótesis es mucho más sensible que el gráfico de control, pero en la práctica muchas veces el gráfico de control es suficiente para mostrarnos una diferencia de importancia.
En forma conceptual, hacer un test de hipótesis para comparar dos condiciones es preguntarnos si estas condiciones representan una causa especial para nuestro proceso. Si son una causa común, serán indistinguibles del ruido subyacente, y no podremos concluir que son realmente diferentes.

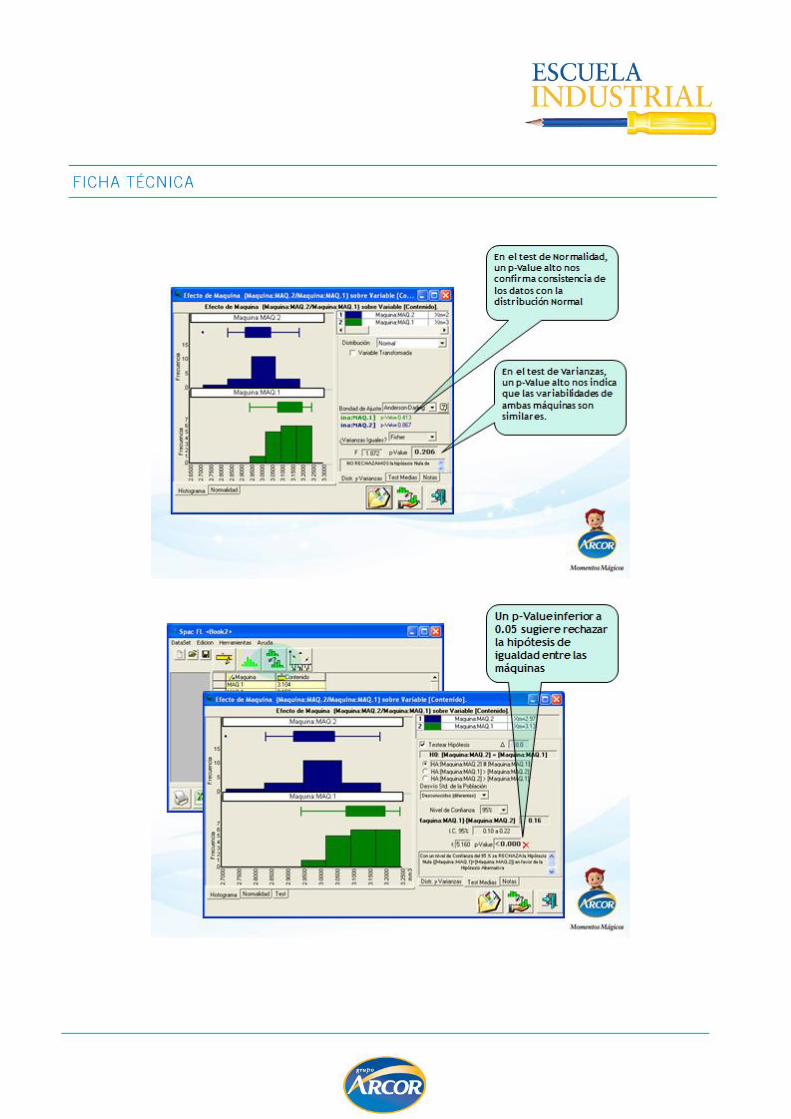


ALTERNATIVA NO PARAMÉTRICA – MANN WHITNEY
Si no se cumplen los supuestos de normalidad e igualdad de variancias, o se tienen pocos datos, se puede recurrir a la alternativa no paramétrica de la prueba t para comparar dos medias, en este caso, el test de Mann Whitney.
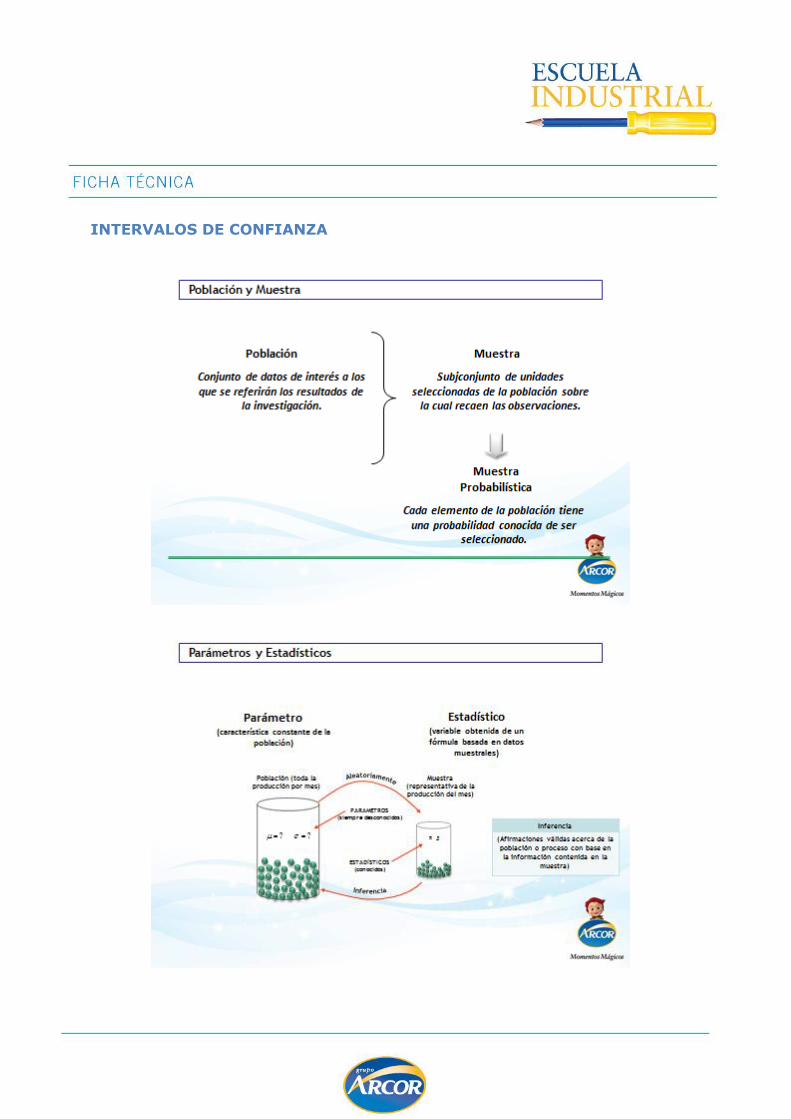
INTERVALOS DE CONFIANZA
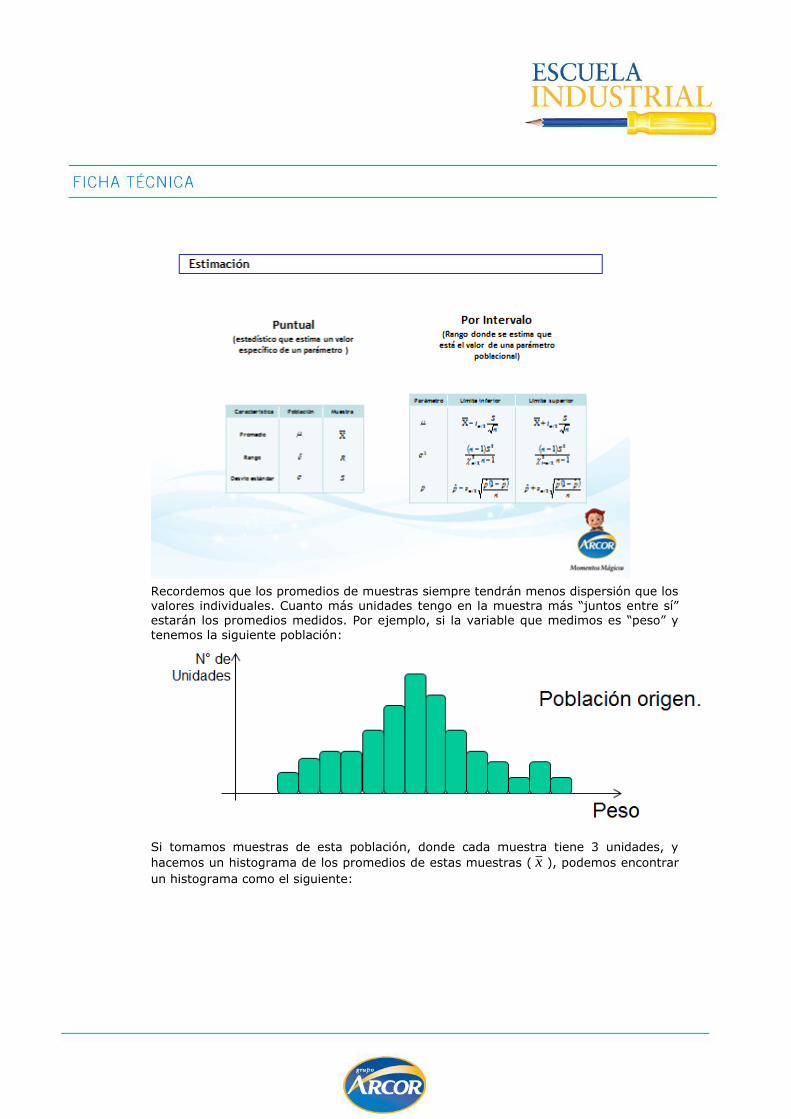
Recordemos que los promedios de muestras siempre tendrán menos dispersión que los valores individuales. Cuanto más unidades tengo en la muestra más “juntos entre sí” estarán los promedios medidos. Por ejemplo, si la variable que medimos es “peso” y
tenemos la siguiente población:
Si tomamos muestras de esta población, donde cada muestra tiene 3 unidades, y
hacemos un histograma de los promedios de estas muestras ( x ), podemos encontrar
un histograma como el siguiente:

Si luego en vez de muestras de 3 unidades, tomamos muestras de 10 unidades, calculando el promedio de cada una, el histograma será todavía más angosto alrededor del valor promedio .
El factor de achicamiento del histograma de los promedios es igual a la raíz cuadrada del número de unidades en la muestra. Es decir, que el histograma de los promedios
de muestras de tres unidades es 3 veces más angosto que el de datos individuales, y
el histograma con promedios de muestras de 10 unidades es 10 veces más angosto.
Volvamos ahora a cómo construir el intervalo de confianza para el promedio. Imaginemos que tenemos una población madre con una distribución normal y cuya posición central es , y tomamos muestras de n observaciones, calculando el
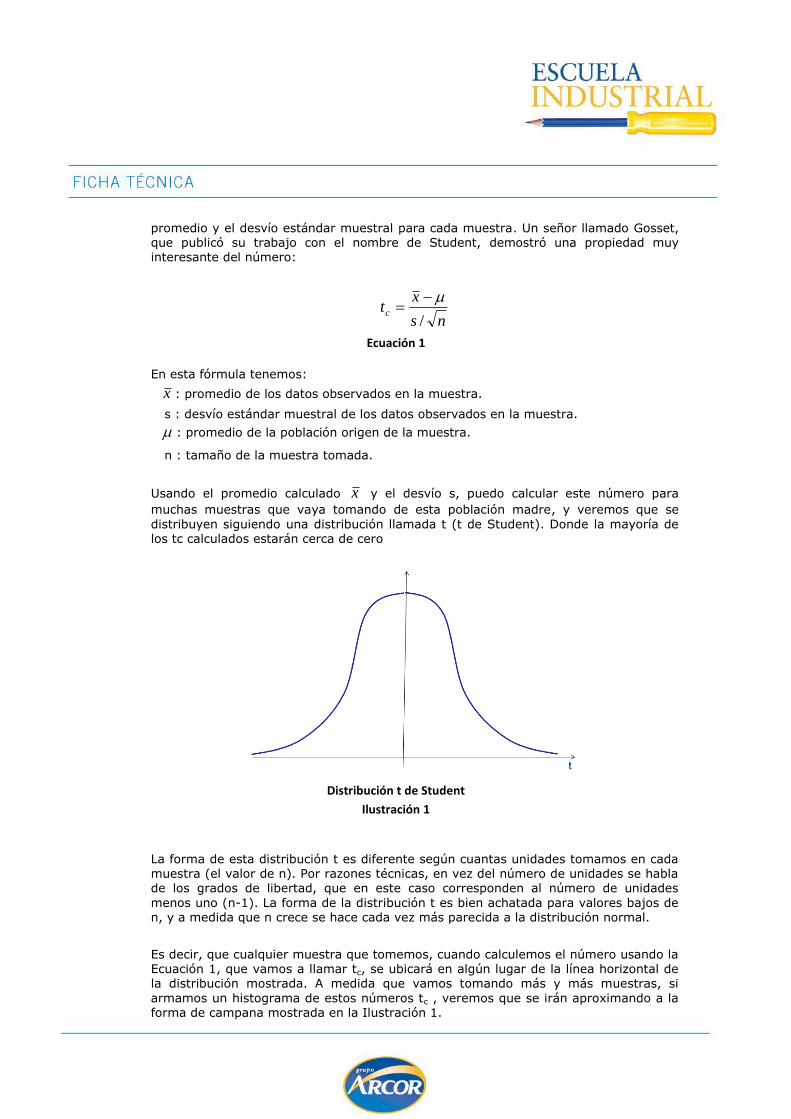
promedio y el desvío estándar muestral para cada muestra. Un señor llamado Gosset, que publicó su trabajo con el nombre de Student, demostró una propiedad muy interesante del número:
ns
xtc
/
Ecuación 1
En esta fórmula tenemos:
x : promedio de los datos observados en la muestra.
s : desvío estándar muestral de los datos observados en la muestra.
: promedio de la población origen de la muestra.
n : tamaño de la muestra tomada.
Usando el promedio calculado x y el desvío s, puedo calcular este número para
muchas muestras que vaya tomando de esta población madre, y veremos que se
distribuyen siguiendo una distribución llamada t (t de Student). Donde la mayoría de los tc calculados estarán cerca de cero
Distribución t de Student
Ilustración 1
La forma de esta distribución t es diferente según cuantas unidades tomamos en cada muestra (el valor de n). Por razones técnicas, en vez del número de unidades se habla de los grados de libertad, que en este caso corresponden al número de unidades
menos uno (n-1). La forma de la distribución t es bien achatada para valores bajos de n, y a medida que n crece se hace cada vez más parecida a la distribución normal.
Es decir, que cualquier muestra que tomemos, cuando calculemos el número usando la Ecuación 1, que vamos a llamar tc, se ubicará en algún lugar de la línea horizontal de la distribución mostrada. A medida que vamos tomando más y más muestras, si
armamos un histograma de estos números tc , veremos que se irán aproximando a la forma de campana mostrada en la Ilustración 1.

Es lógico que al tomar una muestra cualquiera, va a ser más factible que su valor se encuentre en el área abultada de la curva, cerca del centro, y menos probable que se
encuentre en alguna de las colas (pero no imposible). Lo que si podemos estar seguros es que este valor de t se encontrará en algún lugar de la línea continua, y como a los
estadísticos les gusta exagerar, podemos decir que el valor obtenido se encontrará entre menos infinito y más infinito:
%1001/
ns
xp
Ecuación 2
En esta fórmula p() significa probabilidad, es un valor que va entre cero (imposible) y 1 (certeza absoluta)
¿cómo se lee esta ecuación? Nos dice que un valor cualquiera calculado de tc=ns
x
/
va a estar ubicado en cualquier lugar de la distribución t de Student con probabilidad 1, es decir, con certeza. Bueno, ustedes me dirán, este conocimiento no es realmente muy útil. Entonces, vamos a disminuir un poco nuestra pretensión de certidumbre,
conformándonos con tener el 90% de certeza, tendremos:
%9090.0/
95.0,105.0,1
nn t
ns
xtp
Ecuación 3
¿Qué significa este resultado?: que si tomo una muestra de una población con media
μ, hay una probabilidad del 90% de que el valor ns
x
/
este en el intervalo entre los
dos valores de t. Dando vuelta el concepto: es muy raro que calculando (ns
x
/
),
obtengamos un valor fuera de ese intervalo.
Estos dos valores de t ( 05.0,1nt y 95.0,1nt ) corresponden a la distribución en los
siguientes puntos:
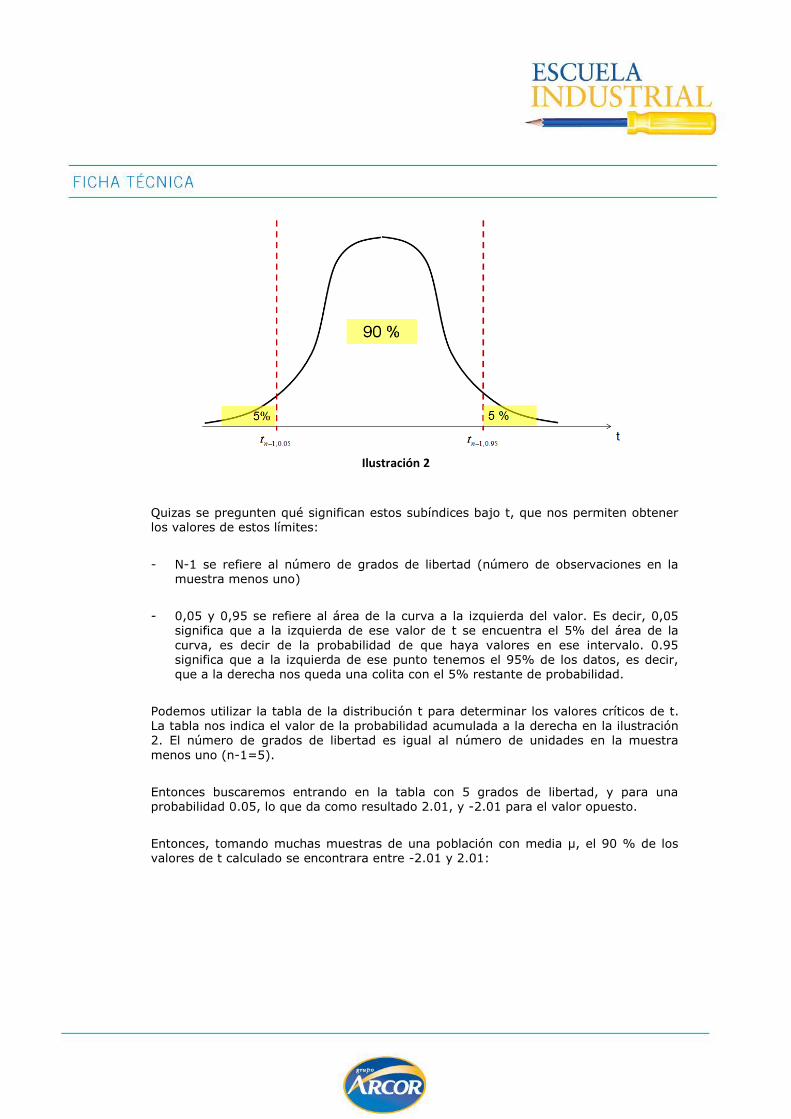
Ilustración 2
Quizas se pregunten qué significan estos subíndices bajo t, que nos permiten obtener los valores de estos límites:
- N-1 se refiere al número de grados de libertad (número de observaciones en la muestra menos uno)
- 0,05 y 0,95 se refiere al área de la curva a la izquierda del valor. Es decir, 0,05 significa que a la izquierda de ese valor de t se encuentra el 5% del área de la
curva, es decir de la probabilidad de que haya valores en ese intervalo. 0.95 significa que a la izquierda de ese punto tenemos el 95% de los datos, es decir, que a la derecha nos queda una colita con el 5% restante de probabilidad.
Podemos utilizar la tabla de la distribución t para determinar los valores críticos de t.
La tabla nos indica el valor de la probabilidad acumulada a la derecha en la ilustración 2. El número de grados de libertad es igual al número de unidades en la muestra
menos uno (n-1=5).
Entonces buscaremos entrando en la tabla con 5 grados de libertad, y para una probabilidad 0.05, lo que da como resultado 2.01, y -2.01 para el valor opuesto.
Entonces, tomando muchas muestras de una población con media µ, el 90 % de los valores de t calculado se encontrara entre -2.01 y 2.01:

Ilustración 3
Volvamos a la ecuación:
%9090.0/
95.0,105.0,1
nn t
ns
xtp
Operando dentro de los paréntesis, podemos llegar a:
%9090.095.0,105.0,1
n
stx
n
stxp nn
Ecuación 4
Que podemos leer en forma aproximada como: la probabilidad de que µ se encuentre entre esos dos valores calculados es 90%.
Entonces, si en una muestra de 6 unidades, el promedio que medimos resultó 3 y el
desvío estándar calculado fue de 2, tendremos:
%9090.06
201.23
6
201.23
p
%9090.064.435.1 p
Por fin, hemos llegado al intervalo de confianza 90% de , podemos decir que
el promedio de la población, con un 90% de confianza, se encuentra entre 1.35 y 4.645.
5 Recordemos siempre que esta es una lectura aproximada. La verdadera interpretación es que tomando
muchas muestras, en un 90% de ellas el verdadero parámetro estará en el intervalo seleccionado.

Resumiendo, si tenemos estimada la media y la variabilidad de cualquier proceso, podríamos calcular un intervalo de confianza para la media del mismo, a través de la
fórmula:
g
v
g
v
n
t
n
t
ˆˆˆˆ
2/,2/,
Ecuación 5
Expliquemos cada uno de los elementos de la ecuación:
: es el promedio estimado a través de los datos que observamos.
n : es el número de unidades que observamos en la muestra.
g : es el desvío estándar global. Estamos suponiendo que los datos son homogéneos,
pertenecen a una población, en ese caso la variabilidad global y local son iguales.
v : son los grados de libertad, se calculan en esta fórmula como el número de unidades en la muestra (n) menos uno: v= n-1
: (alfa) es el nivel de significación. Podemos pensar en este número como el nivel
de riesgo que queremos asumir, en forma porcentual. Por ejemplo, si usamos =
10% obtendremos un intervalo A asumiendo un 10% de riesgo; si queremos estar mas seguros, y sólo asumir un riesgo del 1%, el intervalos será más ancho que A.
2/,vt : es el valor absoluto (es decir positivo) de la distribución t para v grados de
libertad y probabilidad acumulada a la izquierda igual a 2/

Esta fórmula supone que para calcular el promedio estimado se tomó una muestra de tamaño n. Si en cambio tomamos k muestras de n unidades, la fórmula es
g
v
g
v
kn
t
kn
t
ˆˆˆˆ
2/1,2/,
Ecuación 6
Donde los grados de libertad v se calculan como (kn-1)
En algunos casos nos interesa saber lo más certeramente posible cual es la variabilidad de un proceso. ¿Cómo medíamos esta variabilidad? Usando el desvío estándar. Si tomamos muestras del proceso, cada muestra tendrá un valor de desvío estándar diferente, y nos gustaría conocer cuál es el intervalo de confianza para el
desvío estándar de la población origen.
Recordemos que la distribución t nos permitía hallar el intervalo de confianza para el
promedio; en el caso del desvío estándar, la distribución que nos ayuda a construir el
intervalo de confianza se llama Chi Cuadrado y se simboliza como 2
, v (los subíndices
representan el número de grados de libertad v , y el nivel de significación alfa).
La fórmula para determinar el intervalo de confianza para el desvío estándar es:
g
v
g
v
vv
ˆˆ2
2/1,
2
2/,
Ecuación 7
En este caso v es el número de grados de libertad, que para el desvío estándar
corresponde al número de datos en la muestra menos 1 (n-1), y 2
1, v corresponde al
valor tabulado de la distribución Chi-cuadrado para una probabilidad acumulada igual al valor indicado, que se puede buscar en tablas o usando Excel.
Dado que la distribución no es simétrica, debemos buscar ambos valores: alfa/2 para el valor superior y 1-alfa/2 para el valor inferior.
Ejemplo: tomamos una muestra de 6 unidades en un proceso y medimos la longitud, hallando que el desvío estándar de la muestra es 2 mm. Queremos calcular el intervalo de confianza 90% para el desvío estándar de la población origen.
El intervalo de confianza de 90% nos indica que el alfa usado es 10% (o sea 0.1). La mitad de alfa es 0.05. Dado que tenemos 6 unidades, el número de grados de libertad es 5. Buscamos los valores correspondientes de Chi cuadrado:
Valor critico INFERIOR para 5 grados de libertad , p=0.05 = 1.14

Valor critico SUPERIOR para 5 grados de libertad y p=0.95 = 11.07
Y utilizando la fórmula:
214.1
52
07.11
5
18.434.1
Es decir que la población varía con un desvío estándar cuyo intervalo de confianza del 90% está entre 1.34 y 4.18.
¿Qué hacer en la práctica, cual nivel de significación utilizar? El intervalo del 90% podemos asumir que es nuestra mejor aproximación al valor del parámetro. Supongamos que determinamos para nuestro proceso un intervalo del 90% entre 5.0 y 6.0. Este intervalo nos habla de la incertidumbre de base sobre ese parámetro de nuestro proceso.
El intervalo del 90%, correspondiente a un alfa del 10% representa el rango de valores para el parámetro más claramente soportados por nuestros datos.
Por otro lado, si usamos un alfa de 1%, es decir un intervalo de confianza del 99%, esto nos genera una confianza muy grande sobre la ubicación del parámetro.
Supongamos en estamos estudiando mediciones de materia grasa de una materia
prima entregada por un proveedor A, y en base a un muestreo de recepción

obtenemos que el intervalo de confianza del 99% el promedio de materia grasa está entre 2.5% y 2.7%.
Este rango entre 2.5 y 2.7 nos habla del rango que con seguridad se encuentra el
promedio de materia grasa entregada por nuestro proveedor. Imaginemos ahora que aparece un potencial nuevo proveedor B, y queremos verificar si la materia grasa del
nuevo proveedor es similar a lo que nos entrega el proveedor A.
Si tomamos una muestra del nuevo proveedor y el promedio estimado resulta fuera del intervalo 2.5 a 2.7, tenemos amplia evidencia para afirmar que el nuevo proveedor
entrega un porcentaje de materia grasa significativamente diferente del proveedor A.
En resumen, el intervalo del 90% nos habla de la incertidumbre básica sobre nuestro estimador, y el intervalo del 99% nos muestra el limite a partir del
cual tenemos que considerar que los datos vienen de una población diferente.
Entre medio tenemos los intervalos entre 90% y 99%. ¿Qué pasa si la medición hecha
sobre los datos del proveedor Bestá dentro de este intervalo? Esta región corresponde a posibilidades remotas pero factibles, entonces no podemos tomar una decisión
absoluta diciendo que el nuevo proveedor es diferente, pero existe el riesgo concreto de que lo sea. En este caso la mejor solución es tomar nuevas muestras confirmativas para poder confirmar o refutar que haya un cambio significativo.
Lo que llamamos test de hipótesis corresponde a esta toma de decisiones. Volvamos al
principio del capítulo.
… tengo un proceso cuya característica pH varía continuamente, y creo que la variación se produce alrededor de un valor medio de 6.00; mi hipótesis nula será que el promedio del pH del proceso es 6.00, mi hipótesis alternativa será que el promedio es diferente de 6.00
Tomo una serie de datos y calculo tc, luego utilizando la Ecuación 5 determino el intervalo de confianza con alfa = 1% (es decir, el interval del 99%). ¿qué representa este intervalo? Nos habla del rango de valores donde casi con absoluta seguridad se encontrará el centro del proceso. Pueden pasar dos cosas:
1) El intervalo calculado contiene el valor 6.00 (por ejemplo el intervalo resulta
entre 4.1 y 8.5). En este caso los datos medidos son consistentes con nuestra hipótesis nula, no podemos rechazarla y decir “6.00 NO ES el promedio de la población”
2) El intervalo no contiene nuestra propuesta (por ejemplo resulta entre 1.1 y 2.1). Entonces si podemos decir que tenemos evidencia para rechazar que el promedio de la población sea 6.00.
Cuando calculamos índices de capacidad o performance, ellos también son estimadores de un valor poblacional (si tomamos otra serie de mediciones de la misma población, los índices que calcularemos son seguramente levemente diferentes). Sin embargo, es muy común desestimar el concepto de variabilidad inherente a estos índices, presentando en los reportes sólo el estimador puntual, incluso cuando este fue
calculado con un número muy bajo de observaciones, es decir, con bastante

incertidumbre. Esto conduce a sospechar de los índices obtenidos, y finalmente del concepto mismo de índices de capacidad. En los textos de la bibliografía de la clase 4 se indican los cálculos necesarios para determinar los intervalos de confianza para los
índices de capacidad más comunes.
TAMAÑO DE LA MUESTRA
A continuación presentamos un método para estimar el tamaño de la muestra para un lote de cierta cantidad de unidades, suponiendo que la característica que medimos es una variable y se distribuye normalmente.
Supongamos que nos hallamos frente a un lote de producto, compuesto por unas 1000 unidades, y queremos verificar la hipótesis de que el peso promedio corresponde al objetivo que fijamos (valor target u objetivo de Peso).
La primera pregunta que surge es ¿cuántas unidades debo pesar? Es obvio que para tener total certeza necesito medir las 1000 unidades, pero esto es muy costoso en tiempo y dinero. Por lo tanto debemos recurrir a analizar un grupo de unidades tomadas al azar, pero... ¿cuantas?.
Vamos a suponer lo siguiente:
1- En base a los histogramas, gráfico de probabilidad y test de normalidad que vemos en SPAC, podemos decir que la característica peso tiene una distribución normal.

2- Podemos hacer una estimación de los limites de variación del proceso. Quizas a partir del desvío estándar que vemos en SPAC, o a través de un límite máximo y mínimo para el proceso
6.
Siempre que tomamos una muestra, estamos aceptando un riesgo de equivocarnos en las conclusiones. Entonces, antes de decidir cuál es el tamaño de la muestra, debemos decidir cuanta incertidumbre aceptamos en nuestra decisión, y cuál es el máximo error admisible para el promedio estimado. Si no queremos aceptar un margen de incertidumbre, tendremos que inspeccionar toda la población.
Hay tres cantidades que debemos definir antes de calcular el tamaño de la muestra:
1- El máximo error admisible (E o delta) es la máxima diferencia entre el valor del promedio hallado y el promedio real de la población (µ). Muchas veces podemos arreglarnos estableciendo que el máximo error sea un determinado porcentaje de la dispersión, por ejemplo E=0.5 σ (como veremos, si elegimos esta forma del error admisible, no necesitaremos el valor de σ en la fórmula).
2- Cuando tomemos la decisión, podemos cometer dos tipos de errores:
2.1: Decir que el peso es igual al Target, aunque en realidad el peso es distinto (riesgo beta). Este riesgo se llama generalmente Riesgo del Consumidor, porque nos hace aceptar el lote, aunque esta defectuoso.
2.2: Decir que el peso es distinto del Target, aunque realmente el peso promedio es igual al target (riesgo alfa). Este riesgo se llama riesgo del Productor, porque le rechazamos el lote, siendo que en realidad deberíamos aceptarlo.
Valores que generalmente se asumen en la practica son 1.005.0 y , pero cada
situación requiere evaluar el riesgo que uno aceptaría. Cuanto mayor riesgo, más pequeña la muestra.
Siguiendo con nuestro ejemplo, supongamos que el desvío estándar obtenido observando los datos en SPAC es de 4.00 g, y el máximo error admisible para el
promedio obtenido sea de 2g, es decir E = 2g.
La fórmula para hallar el número de unidades en la muestra si conocemos es7:
2
2/ )(
E
zzn
6 Por ejemplo, si decimos que el peso varia entre 100g y 140g, una aproximación práctica es considerar el
desvío estándar como Rango dividido 4, o sea 40g / 4 = 10g. 7 Fórmula presentada en Breyfogle: “Implementing Six Sigma”, Wiley IS, 2001, y Diamond, “Practical
Experiment Designs for Engineers and Scientists”. Van N.Reinhold, NY 1989

Donde:
2/z : El valor de Z para un intervalo de confianza %100).2/1( Este valor
es de 1.96 para un intervalo del 95%. En Excel la fórmula que provee este valor
es NORMINV( 2/ ,0,1); en nuestro ejemplo, usando 0.05 para tendremos
NORMINV(0.025,0,1)= -1.959961082
z : El valor de Z para un intervalo de confianza %100).1( Este valor es
de 1.28 para un intervalo del 95%. En Excel, usando 0.10 para tendremos
NORMINV(0.1,0,1)= -1.28
: El desvío estándar estimado.
E : El semi-ancho del intervalo.
Calculándolo en nuestro ejemplo:
4299.412
00.4)28.196.1(2
g
gn
Es interesante observar que si usamos para el Error E un valor relativo a la desviación estándar, como E =0.5 , la fórmula se transforma en
2
2/
2
2/
5.0
)(
5.0
)(
zzzzn
Lo que nos evita estimar el desvío estándar.
Es fundamental que las n unidades sean representativas, es decir, que cada unidad del lote tenga exactamente la misma probabilidad de ser incorporada en la muestra.
Cuando la muestra es muy grande respecto del tamaño de la población, por ejemplo, si la muestra es mayor del 5% de la población, es necesario realizar una corrección para muestras finitas, usando un factor llamado FPC (Finite Population Correction factor), obteniendo la siguiente fórmula para el tamaño muestral corregido:
Nn
nn
1
*
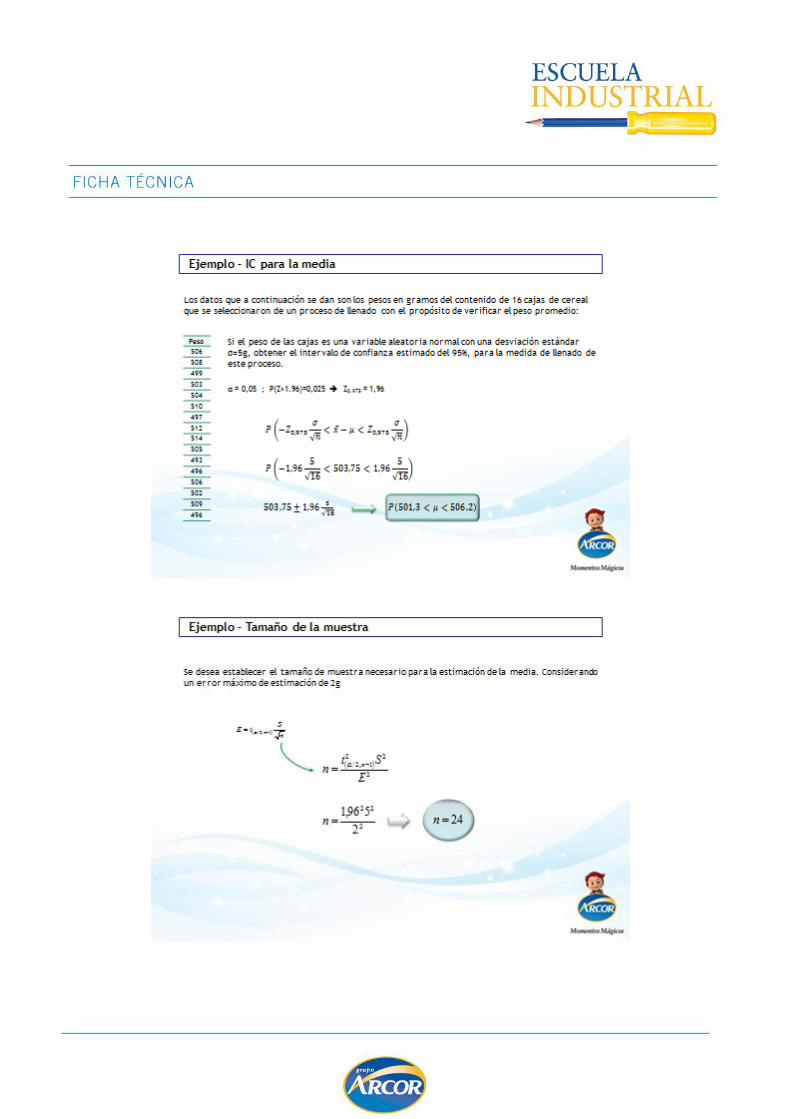

GRAFICO MULTIVARI
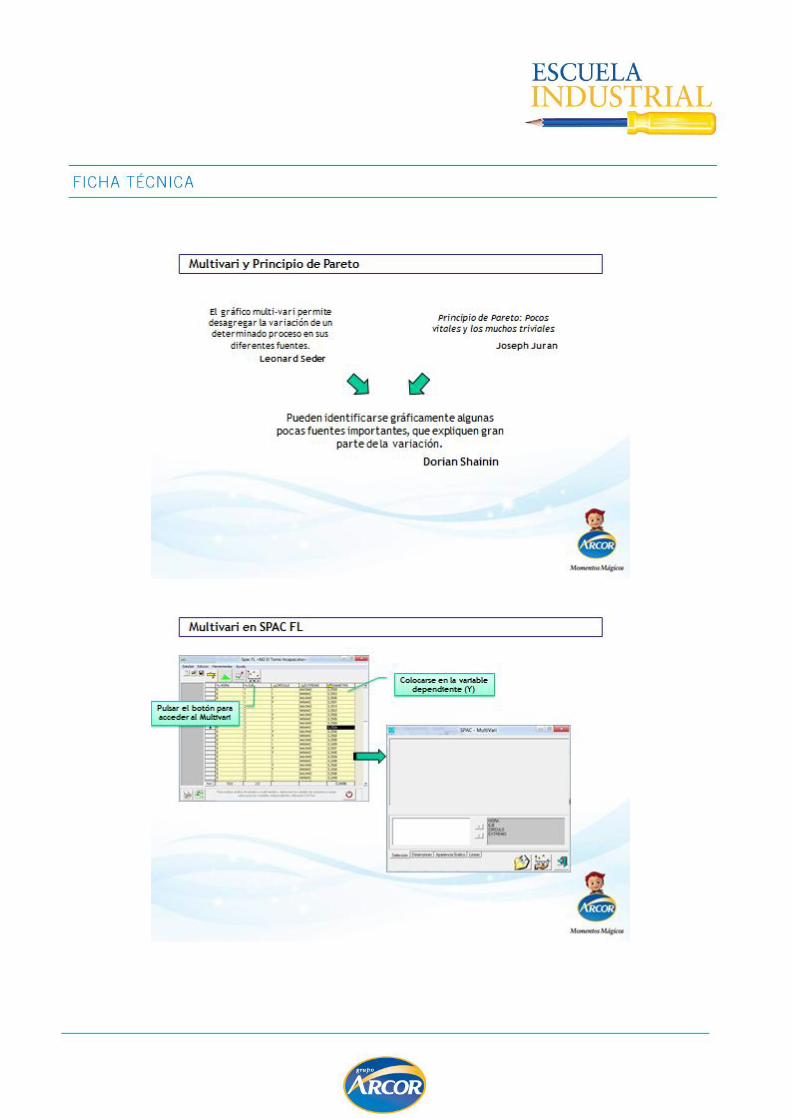


Podemos concluir entonces, en que la potencia del gráfico multi-vari, radica en la aplicación del principio de Pareto a las fuentes de variación de un proceso, de una
manera simple y escapando a la rigurosidad de la estadística analítica. Bien usado, permitirá al investigador eliminar muchas fuentes triviales de variación del proceso, delimitando la búsqueda de la causa raíz.
A lo largo del tiempo el gráfico multi-vari fue evolucionando e incorporando
herramientas complementarias que fueron aumentando su potencial. Por ejemplo, en lugar de comparar valores individuales o promedios entre los diferentes niveles de
cada fuente o factor de variación, podría compararse además la dispersión entre estos niveles, por ejemplo graficando box plots, lo que transformaría al gráfico prácticamente en una aproximación a la comparación de grupos, similar a un análisis de variancia.
En este caso al tratarse de una técnica de pre-experimentación, se transforma en un interesante aliado para realizar un análisis exploratorio, que a posteriori podría derivar en un diseño de experimentos para confirmar las sospechas observadas en el multi-
vari.
EVALUACION DE SISTEMAS DE MEDICION
Cuando medimos una serie de unidades, la variación que queremos identificar es la correspondiente a las unidades medidas. Pero dado que no existen mediciones perfectas, siempre habrá una variación o “ruido” incorporada por el proceso de
medición. Cuanto mayor es el ruido introducido por el sistema, más difícil es identificar claramente la señal de variación proveniente del producto.

Los principales objetivos de los estudios denominados GR&R son:
Determinar la magnitud de la variación observada en una serie de mediciones, debida al instrumento utilizado.
Identificar las fuentes de variación que influyen en el proceso de medición:
Variación debida a las unidades medidas.
Variación debida a que diferentes operadores han medido las unidades (u otras
condiciones).
Variación debida a la forma en que los operadores miden las distintas piezas. Nos referimos a cuando los distintos operadores miden de diferente forma las distintas piezas o unidades. Esta variación se denomina interacción operador-pieza en los estudios RyR, y es muy perniciosa.
Variación debida a los distintos valores reportados por el instrumento de medición.
Verificar la capacidad del instrumento para medir el mensurando.

El método recomendado para realizar estos estudios es el análisis de componentes de varianza 8. En este estudio se toma una serie de unidades, y se miden varias veces por un grupo de operadores. El análisis estadístico permite descomponer la varianza total en los componentes 2.a , 2.b, 2.c y 2.d, detellados anteriormente y así evaluar la adecuación del sistema de medicion.
Como conclusión, podemos decir entonces que analizando los resultados de un estudio GR&R podremos descubrir cuánta variabilidad es aportada por el sistema de medición.
Esta variabilidad comúnmente se divide en dos partes: variabilidad del instrumento
cuando mide bajo las mismas condiciones (mismo operador, misma pieza, mismo instrumento), llamada repetibilidad (2.d) , y variabilidad “entre diferentes condiciones” (por ejemplo entre operadores, entre laboratorios, etc.) llamada reproducibilidad (2.c + 2.b).
Un buen sistema de medición tiene baja variabilidad tanto respecto de la dispersión del proceso que debe medir (lo que se evalúa con un indicador llamado número de
distintas categorías, o NDC), como respecto de la tolerancia o especificación (medido generalmente por un indicador llamado PTR o precision to tolerance Ratio)
Los primeros métodos desarrollados para evaluar sistemas de medición utilizaban estimaciones de la variabilidad basadas en los rangos entre mediciones. Estos métodos (expuestos en los manuales de AIAG9) son actualmente desaconsejados, siendo preferible estimar la variabilidad utilizando el Análisis de Varianza (ANOVA) descrito previamente.
8 Varianza es un parámetro estadístico asociado a la dispersión. En este caso, la dispersión de los resultados de cada medición. En rigor, el método se denomina ANOVA de dos factores aleatorios, operadores y unidades o partes. 9 AIAG: Measurement System Analysis, 3rd Edition.

Suposiciones de los estudios GR&R
En todo R&R, hay una serie de suposiciones que se deben dar por ciertas para que
los resultados obtenidos sean válidos:
A) Constancia de Bias, tanto en el tiempo como en la escala.
Definimos bias (o error de justeza, o tendencia, o sesgo) como la diferencia entre el promedio de una gran cantidad de mediciones sobre una misma unidad, y el valor de referencia considerado verdadero. También se lo llama error sistemático de una
medición. Suponer constancia de Bias implica:
el error no cambia a lo largo de la escala de variación normal de los productos que medimos (linealidad). Por ejemplo, si una balanza mide el peso mostrando un valor 0.01 gr por encima del valor de referencia, esta diferencia o Bias sera igual tanto para un producto liviano como para un producto pesado.
el Bias es constante en mediciones en distintos momentos de tiempo (estabilidad).
B) Homogeneidad del error de medición.
La distribución del error de medición es constante para todas las unidades, es decir, el instrumento no tiene distinta variabilidad según que pieza mida. Si la balanza tiene una variación interna o repetibilidad de 0,1 g, este “ancho de variación” no cambia según el peso del producto que mide.
Si tenemos una sola medición de una pieza, es imposible estimar la variación. Por eso
estamos condenados a realizar una serie de mediciones y estimar la variación a partir de ellas. Ahora bien, para que estas distintas mediciones reflejen la variación del Sistema de Medición, es necesario hacer dos suposiciones más:
C) Estabilidad temporal de las mediciones.
El momento en que realizo la medición no afecta el resultado, esto me permite medir
varias veces en distintos momentos a las piezas, y seguir obteniendo un resultado válido para la variación del sistema de medición.
Es fácil comprender esto con un ejemplo: quiero hacer un GR&R de un termómetro para medir la temperatura del agua con que tomo mate (soy muy quisquilloso y quiero siempre cebar con agua en la temperatura ideal de 85°C +/- 2°C10). Para mi estudio tendré tres operadores (mi madre, mi hermana y yo, todos expertos cebadores), cuatro unidades (cuatro pavas de mate recién calentadas), y tres repeticiones (cada
operador mide tres veces la temperatura en cada pava). ¿Cual es la falla de este diseño? La pava se enfría con el tiempo, por lo tanto las variaciones de temperatura medida no se deben solo al termómetro o la habilidad para tomar la temperatura, sino a la inestabilidad temporal de las mediciones. Fallo de la suposición C.
D) Robustez a las mediciones.
Las mediciones consecutivas no modifican lo que estoy midiendo (el mensurando),
esto me permite medir varias veces la misma unidad, y considerar que todas estas
mediciones son equivalentes.
Esta suposición es mas problemática de lo que puede suponerse. Por ejemplo, si para medir la altura de un bizcochuelo utilizo un calibre, quizás hago presión excesiva con el
10 El autor no ha realizado un experimento controlado para detectar esta temperatura ideal. Si alguno de los lectores de este boletín lo ha hecho, seria interesante que comparta su experiencia, que será incluida en futuras ediciones.

calibre y modifico el mensurando, violando la suposición D. Los resultados evaluados incluirán no sólo la variación del calibre, sino también las modificaciones realizadas sobre el bizcochuelo.
MSA PARA VARIABLES


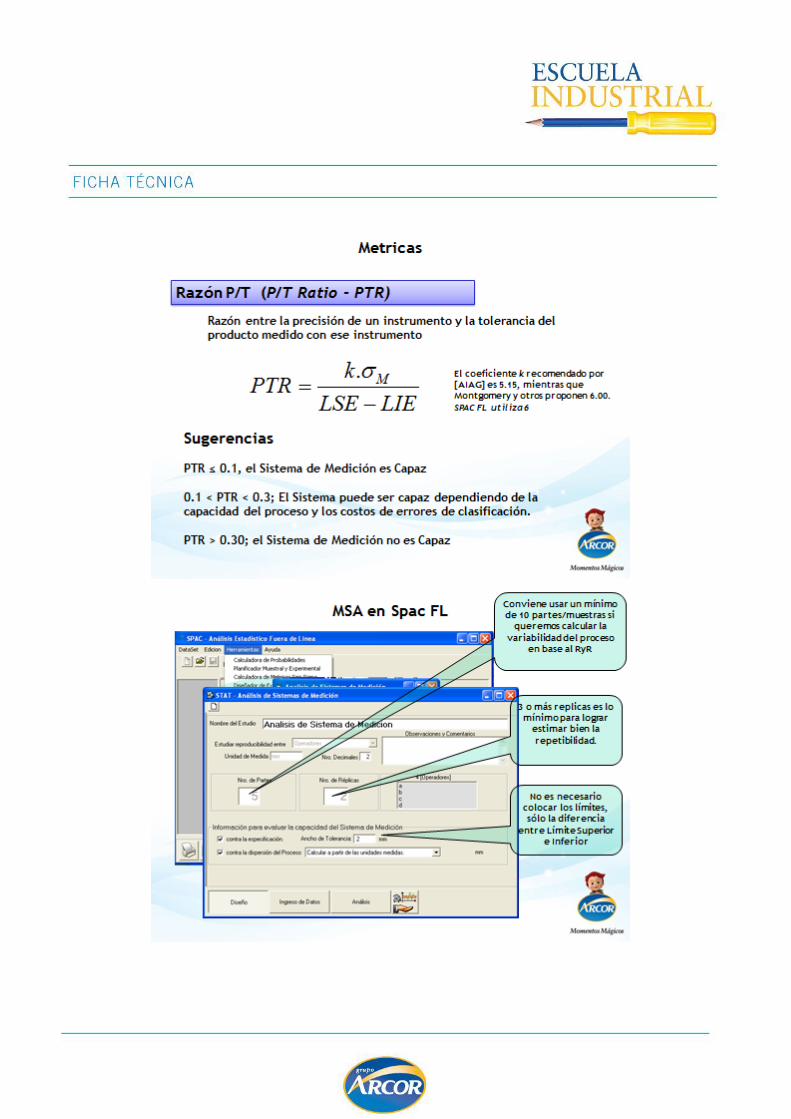
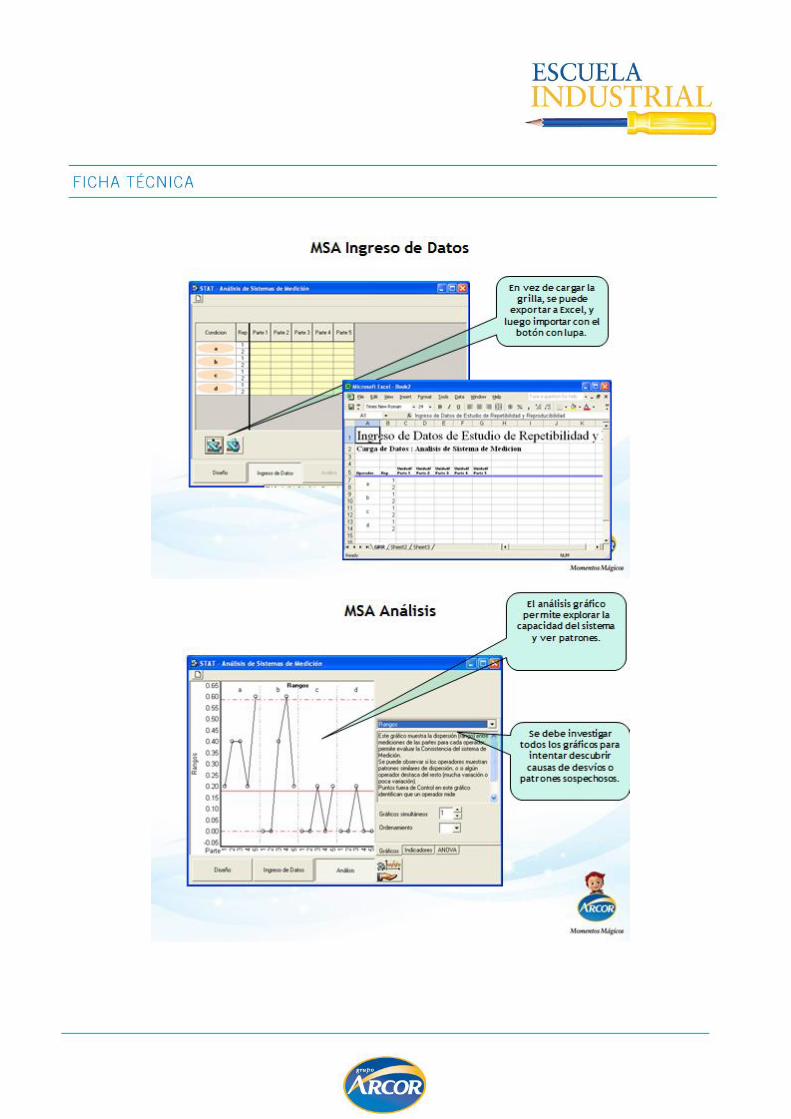
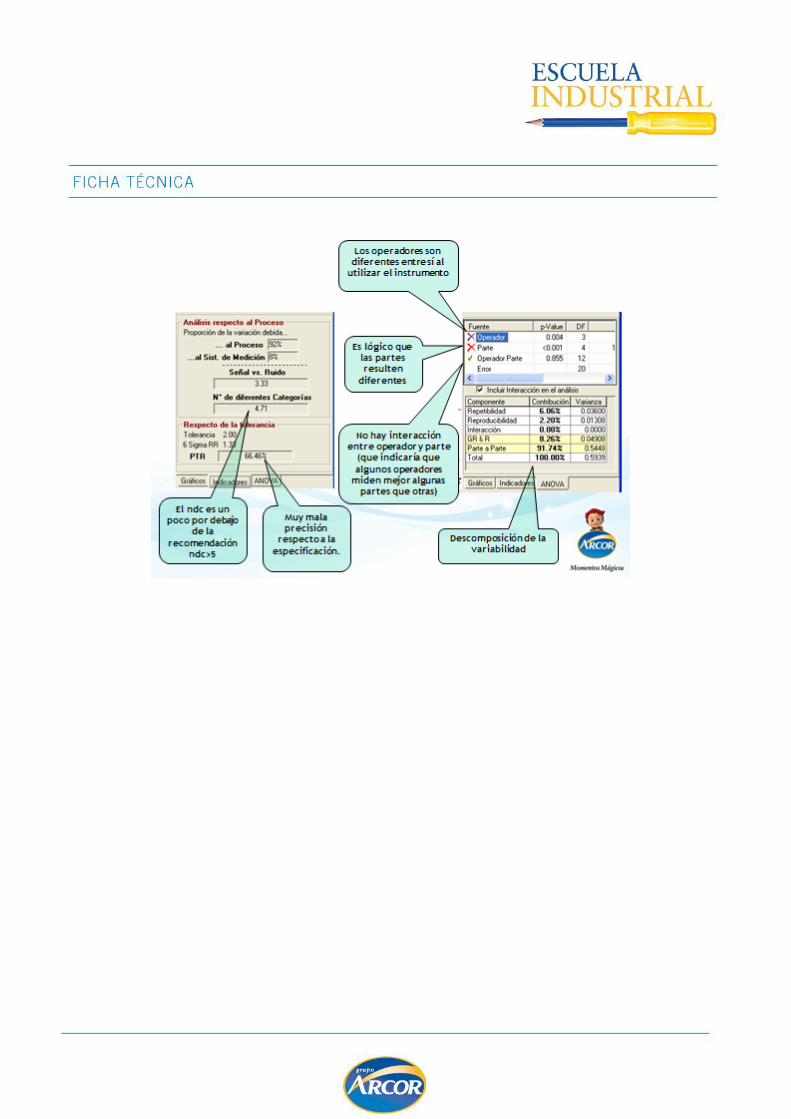

MSA PARA ATRIBUTOS
Como dijimos, los estudios GR&R buscan identificar cuánto “ruido” genera el sistema de
medición en lo que estamos midiendo. En mediciones cuantitativas, cuando el resultado es
un número, los métodos ANOVA nos permiten estudiar e identificar las distintas fuentes de variación. Sin embargo, existen muchas mediciones en donde el resultado solo puede expresarse como OK / NO OK, o Cumple/No Cumple, etc.
No existen hasta el momento métodos estándar y mayoritariamente aceptados para evaluar la capacidad de sistemas de medición cuando las características son de tipo Atributo.
Describiremos aquí tres métodos propuestos, y adjuntamos algunas planillas en el boletín para que los interesados puedan realizar estos cálculos.11
El factor más importante para asegurar la adecuación del sistema de medición es tener una clara definición operativa del atributo, es decir, el método para juzgar si el atributo observado esta OK, o NO OK.
Tanto la AIAG como el George Group utilizan el cálculo del coeficiente Kappa, generalmente
utilizado en análisis estadístico de datos categoriales dicotómicos.
Los pasos recomendados para el estudio son:
- Si solo hay dos categorías: OK y NO OK, se deben tener entre 20 y 50 unidades de cada tipo, tratando de tener 50% de cada tipo. Conviene elegir diferentes grados de OK y NO OK, cubriendo las situaciones que aparecen comunmente.
- Si hay mas de dos categorías, una de las cuales es OK y el resto son distintos modos de defectos, hacer el 50% OK y tener un mínimo de 10% de items en cada defecto, combinando algunos defectos como “otros”. (no puede haber solapamiento entre categorías)
- Hacer que cada evaluador evalúe la misma unidad al menos dos veces.
- Calcular el Kappa para cada evaluador,
- Calcular el Kappa entre evaluadores
- Interpretar los resultados:
o Si Kappa<0.7, el sistema de medición no es adecuado (0.75 en el caso de AIAG)
o Si Kappa >0.9 el sistema de medición es excelente
El coeficiente Kappa se define como:
chance
chanceobservado
P
PPK
1
Pobservado: proporción de unid. en que ambos evaluadores coinciden (tanto en que es
OK como NO OK).
11 Se adjuntan dos planillas, una confeccionada por el autor, la otra se puede bajar gratuitamente
desde http://www.isixsigma.com/st/msa/
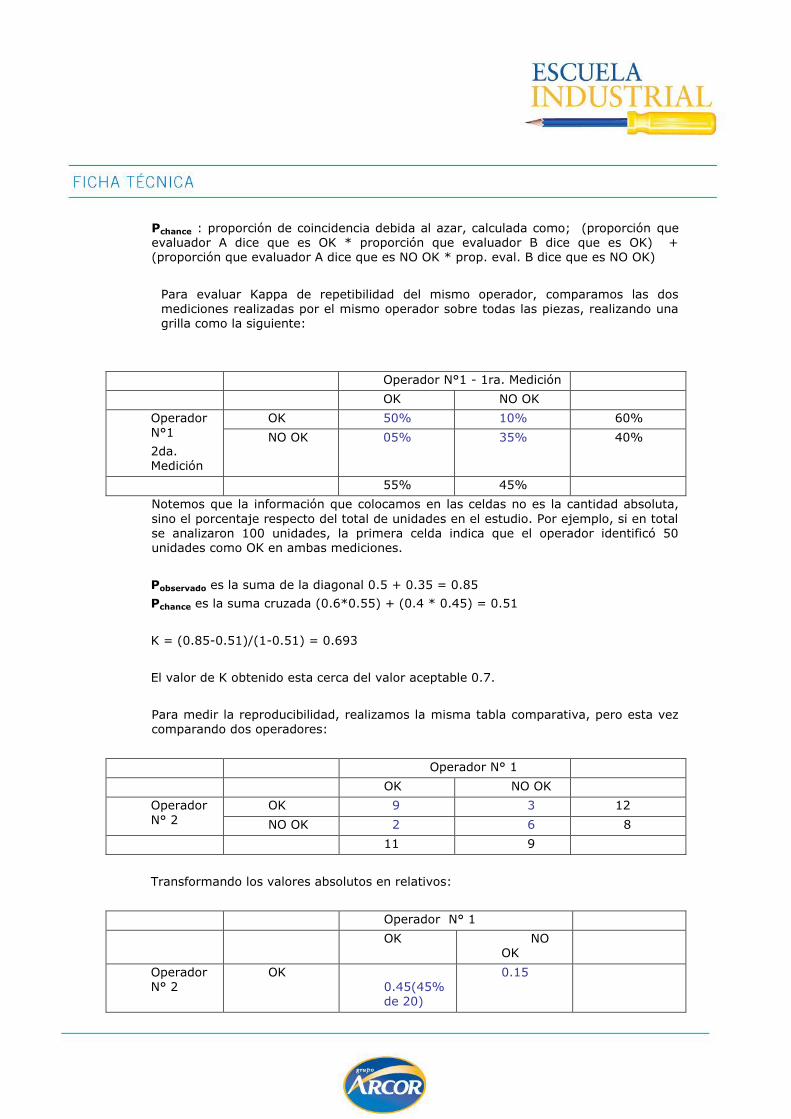
Pchance : proporción de coincidencia debida al azar, calculada como; (proporción que evaluador A dice que es OK * proporción que evaluador B dice que es OK) + (proporción que evaluador A dice que es NO OK * prop. eval. B dice que es NO OK)
Para evaluar Kappa de repetibilidad del mismo operador, comparamos las dos
mediciones realizadas por el mismo operador sobre todas las piezas, realizando una grilla como la siguiente:
Operador N°1 - 1ra. Medición
OK NO OK
Operador N°1
2da. Medición
OK 50% 10% 60%
NO OK 05% 35% 40%
55% 45%
Notemos que la información que colocamos en las celdas no es la cantidad absoluta,
sino el porcentaje respecto del total de unidades en el estudio. Por ejemplo, si en total se analizaron 100 unidades, la primera celda indica que el operador identificó 50 unidades como OK en ambas mediciones.
Pobservado es la suma de la diagonal 0.5 + 0.35 = 0.85
Pchance es la suma cruzada (0.6*0.55) + (0.4 * 0.45) = 0.51
K = (0.85-0.51)/(1-0.51) = 0.693
El valor de K obtenido esta cerca del valor aceptable 0.7.
Para medir la reproducibilidad, realizamos la misma tabla comparativa, pero esta vez
comparando dos operadores:
Operador N° 1
OK NO OK
Operador
N° 2
OK 9 3 12
NO OK 2 6 8
11 9
Transformando los valores absolutos en relativos:
Operador N° 1
OK NO OK
Operador N° 2
OK 0.45(45% de 20)
0.15
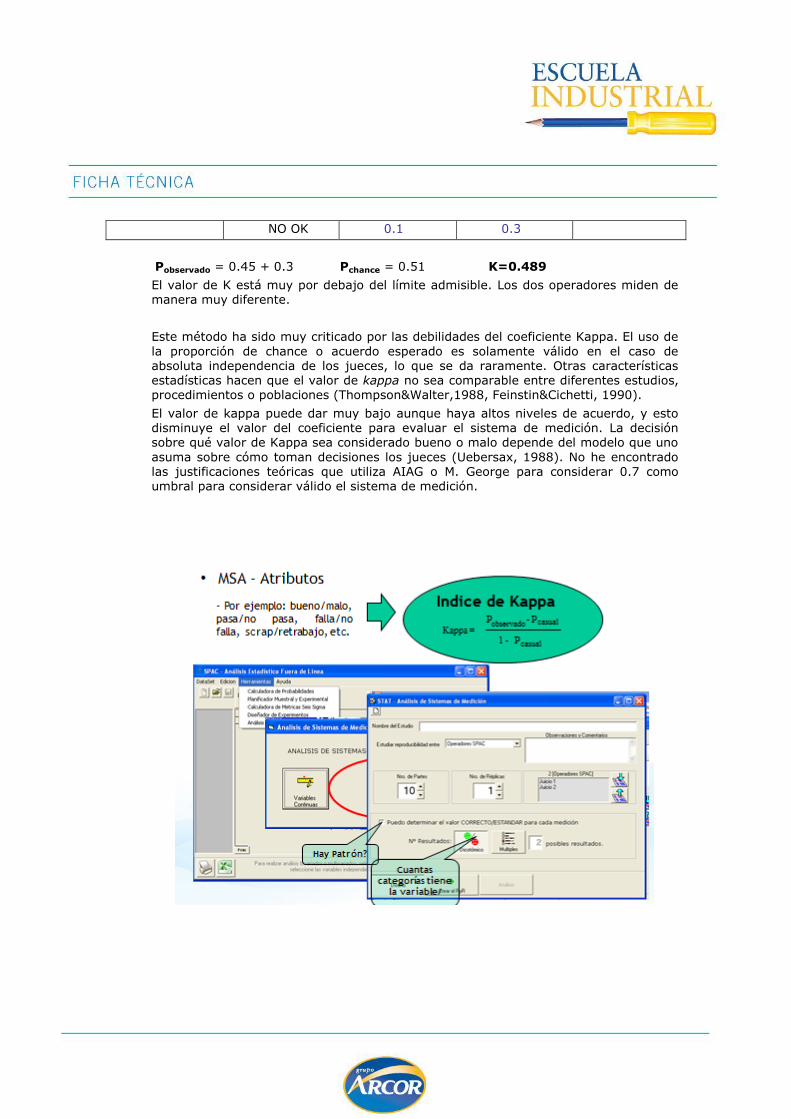
NO OK 0.1 0.3
Pobservado = 0.45 + 0.3 Pchance = 0.51 K=0.489
El valor de K está muy por debajo del límite admisible. Los dos operadores miden de manera muy diferente.
Este método ha sido muy criticado por las debilidades del coeficiente Kappa. El uso de
la proporción de chance o acuerdo esperado es solamente válido en el caso de absoluta independencia de los jueces, lo que se da raramente. Otras características estadísticas hacen que el valor de kappa no sea comparable entre diferentes estudios, procedimientos o poblaciones (Thompson&Walter,1988, Feinstin&Cichetti, 1990).
El valor de kappa puede dar muy bajo aunque haya altos niveles de acuerdo, y esto disminuye el valor del coeficiente para evaluar el sistema de medición. La decisión sobre qué valor de Kappa sea considerado bueno o malo depende del modelo que uno
asuma sobre cómo toman decisiones los jueces (Uebersax, 1988). No he encontrado las justificaciones teóricas que utiliza AIAG o M. George para considerar 0.7 como umbral para considerar válido el sistema de medición.
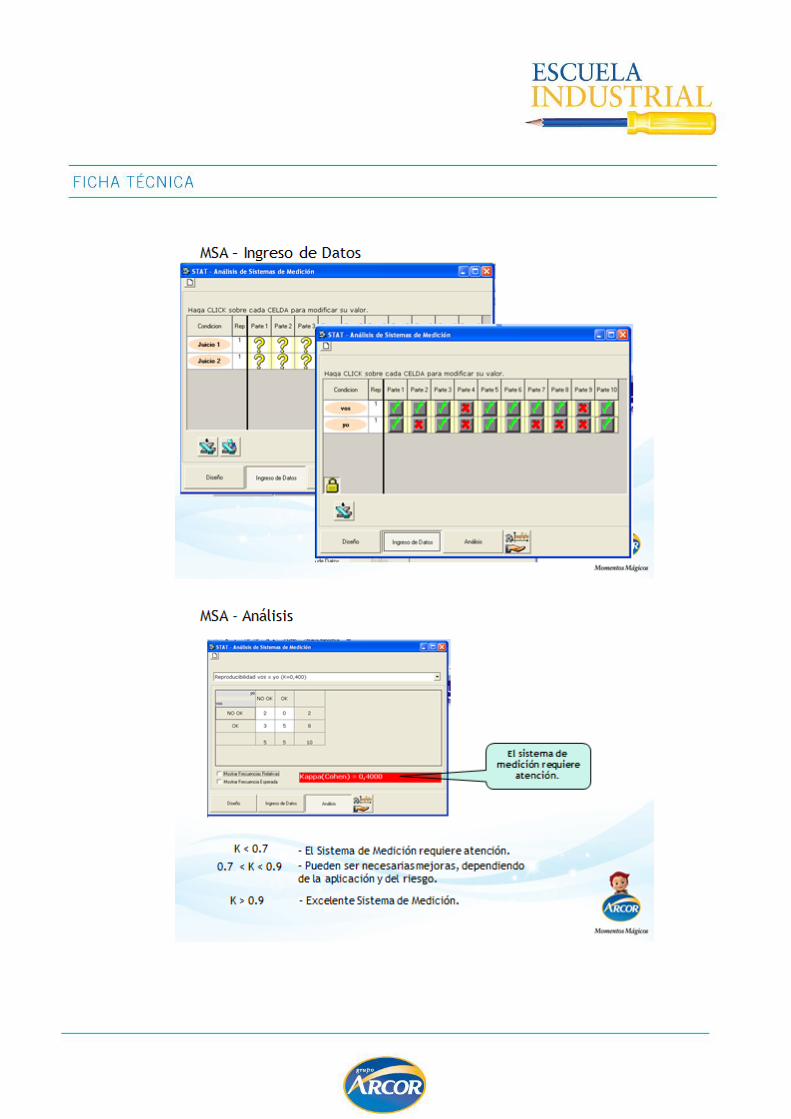

ANALISIS DE LA VARIANCIA ONE WAY


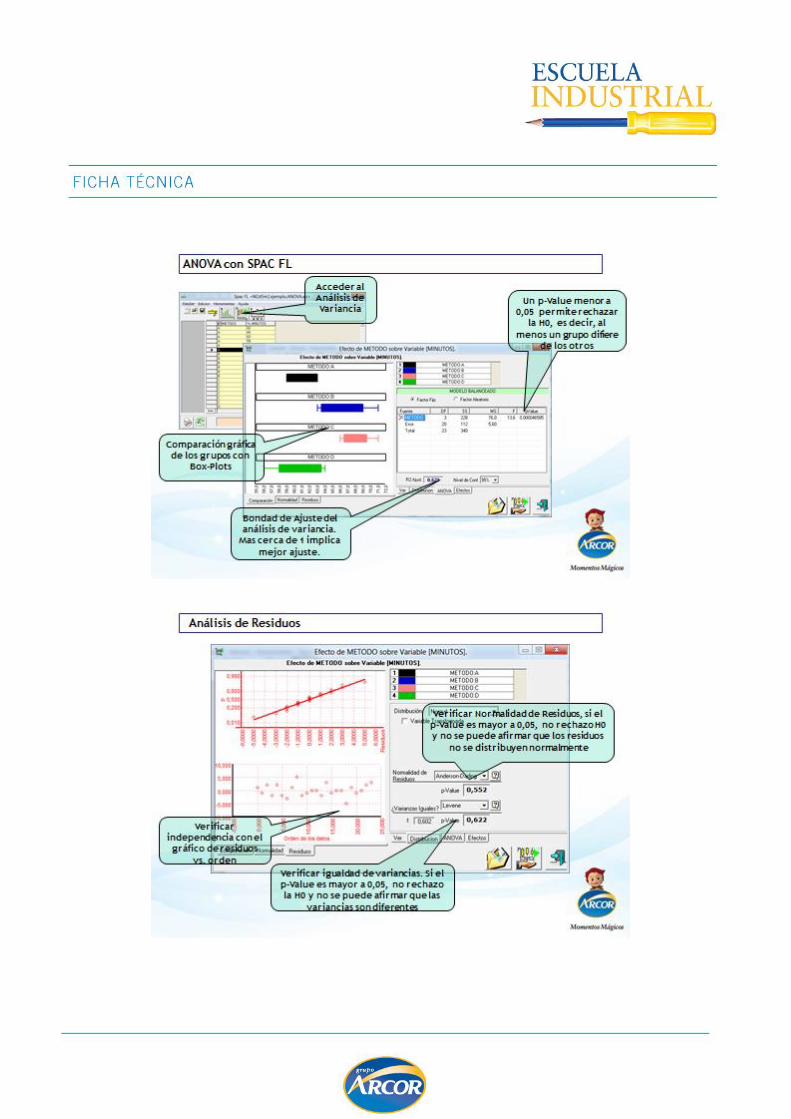
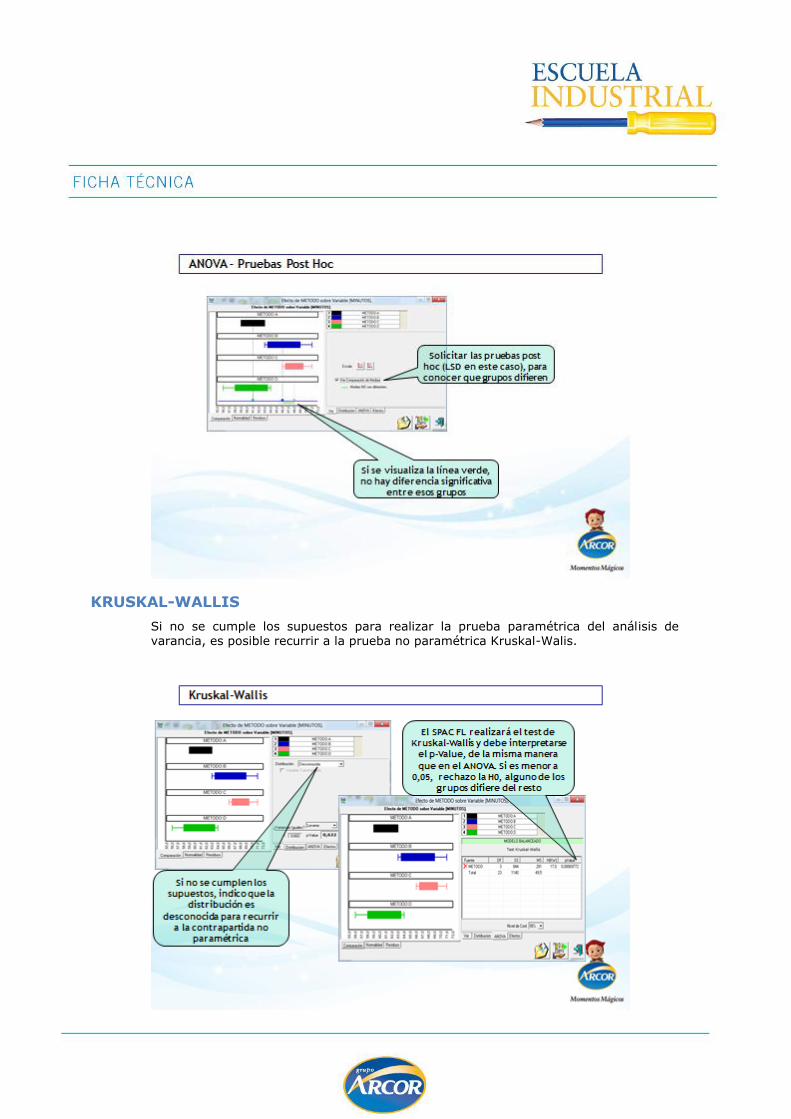
KRUSKAL-WALLIS
Si no se cumple los supuestos para realizar la prueba paramétrica del análisis de varancia, es posible recurrir a la prueba no paramétrica Kruskal-Walis.

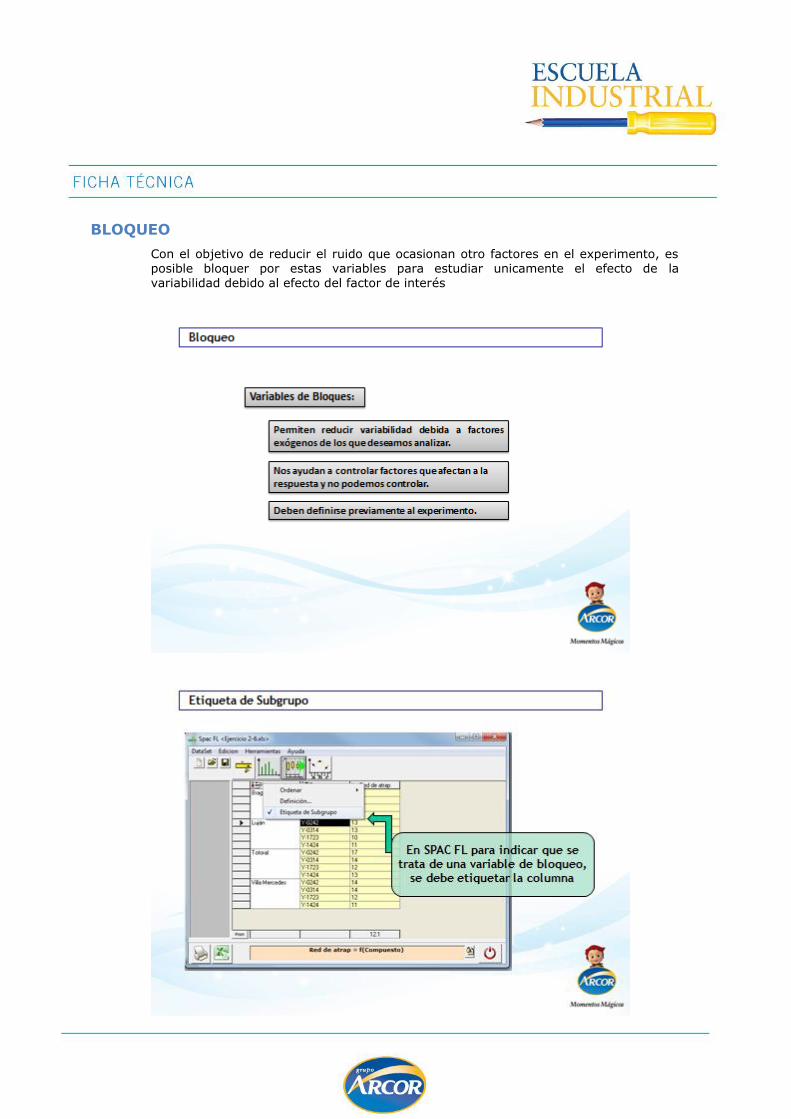
BLOQUEO
Con el objetivo de reducir el ruido que ocasionan otro factores en el experimento, es posible bloquer por estas variables para estudiar unicamente el efecto de la variabilidad debido al efecto del factor de interés
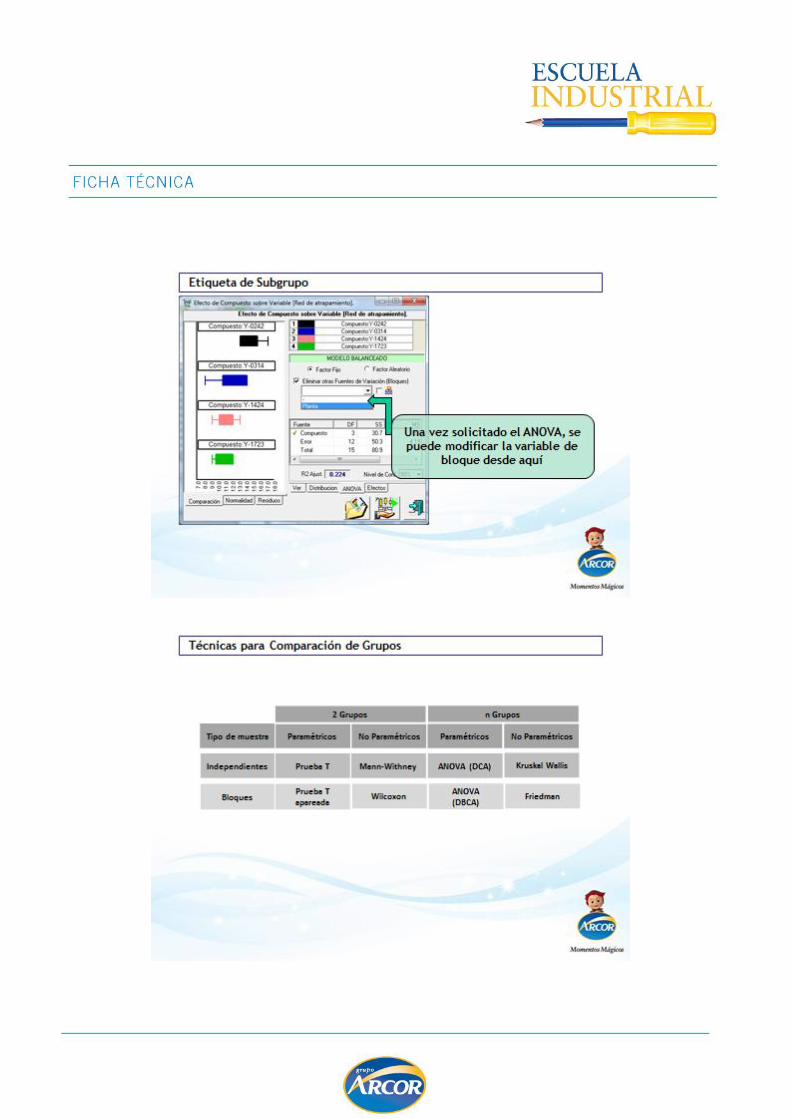

ANALISIS DE REGRESION
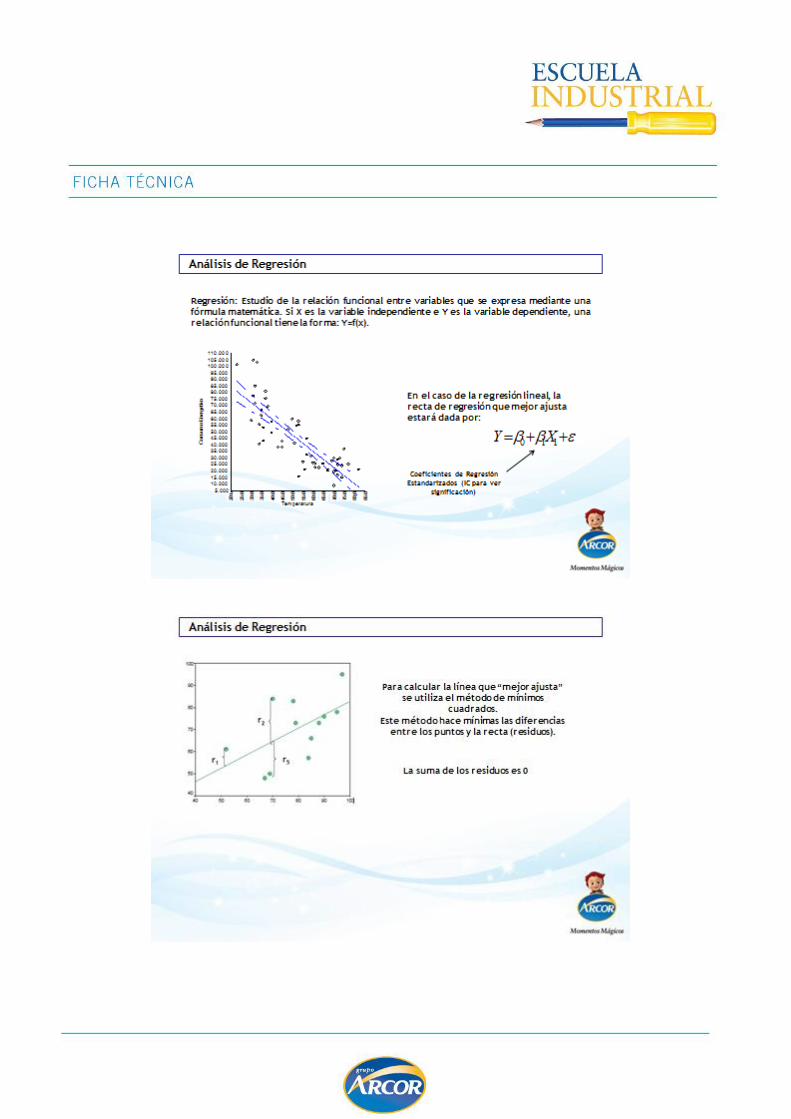



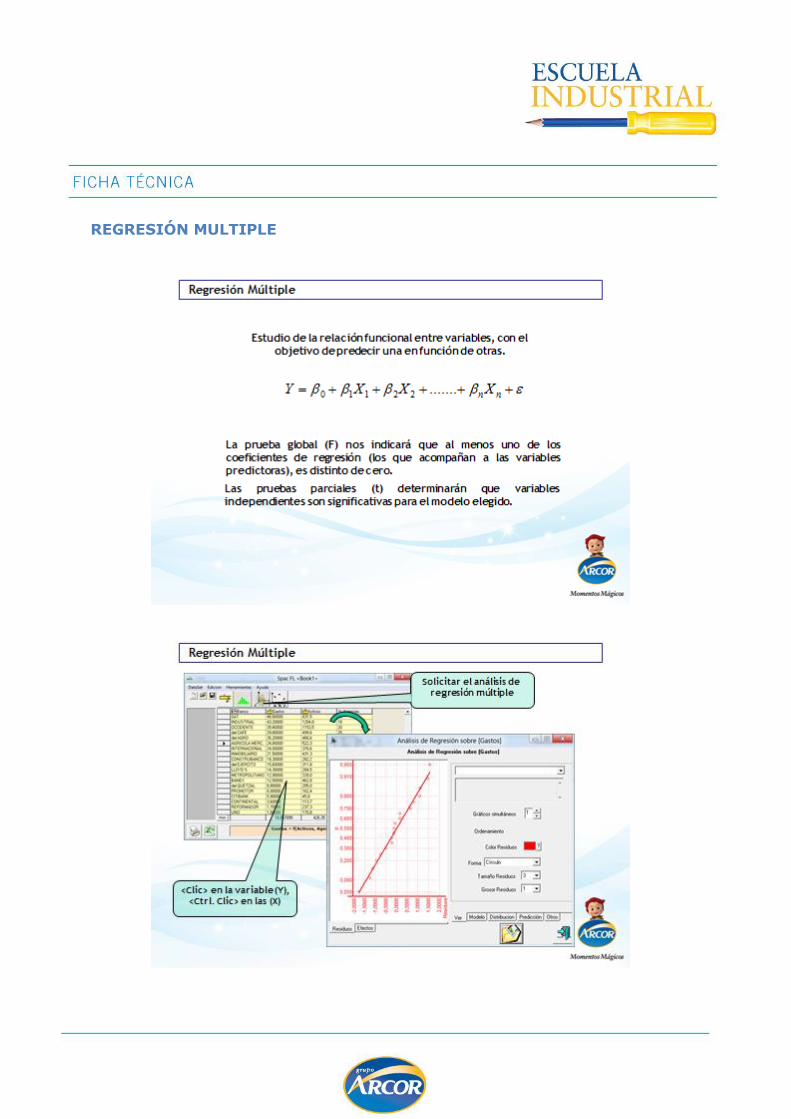
REGRESIÓN MULTIPLE
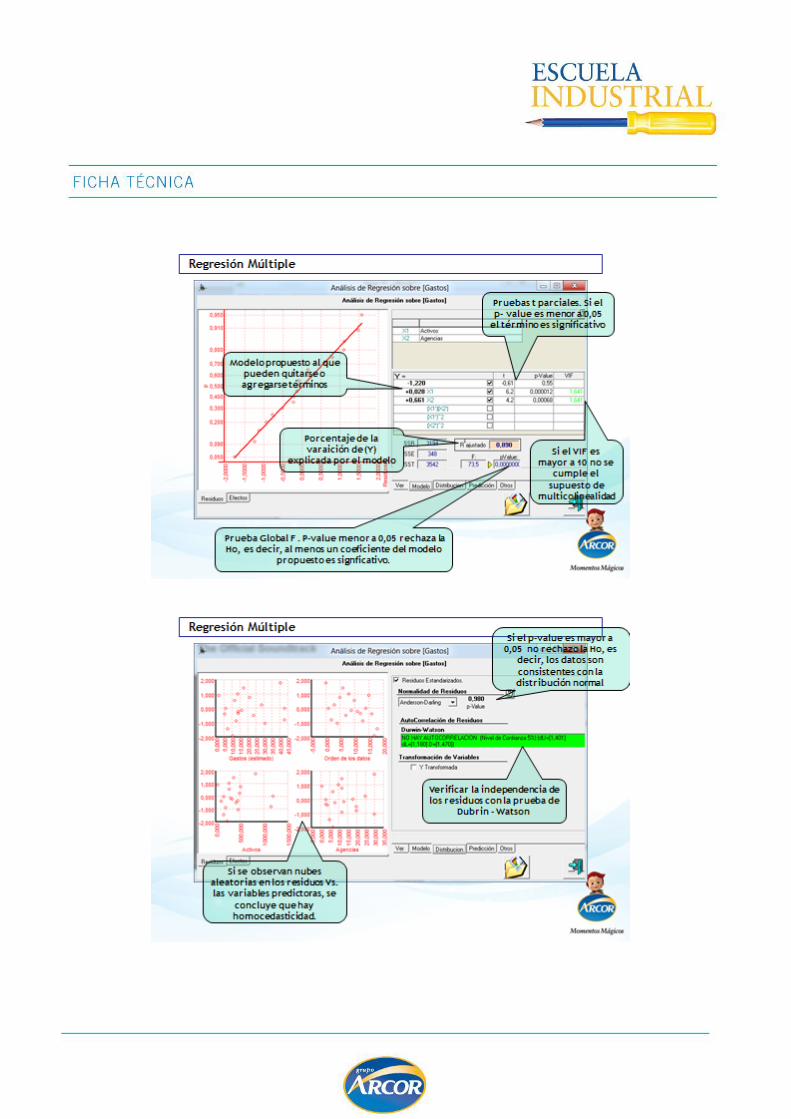
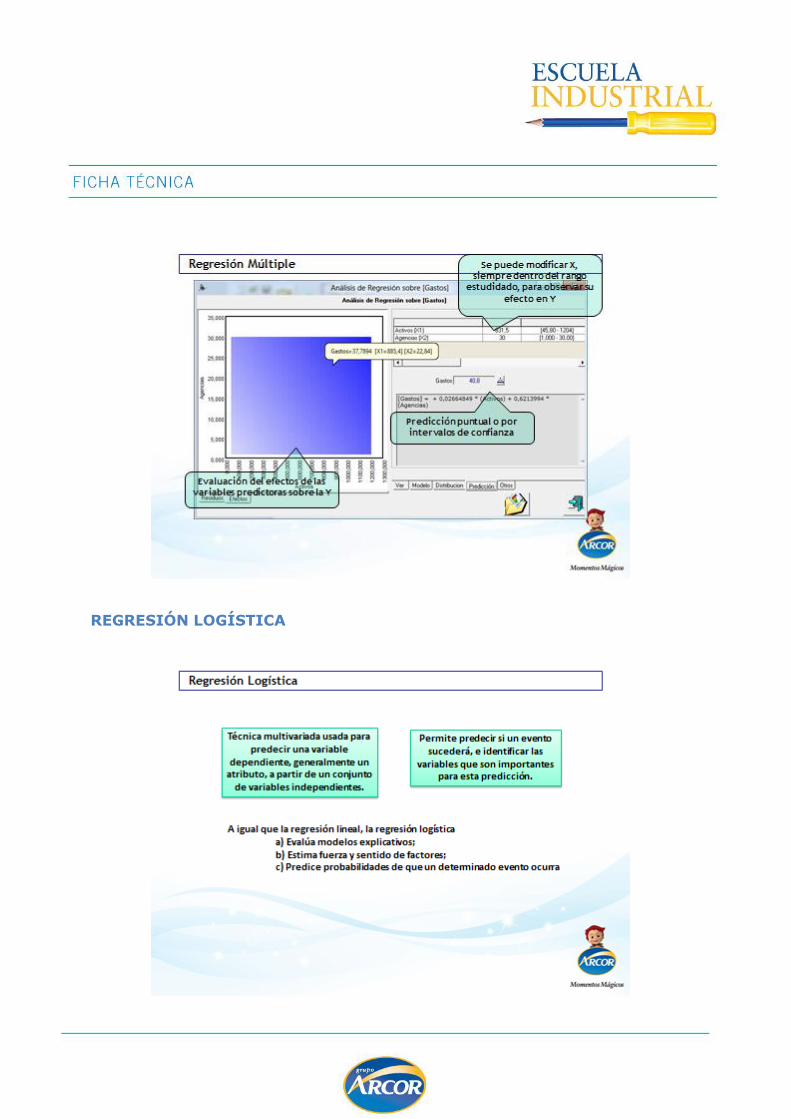
REGRESIÓN LOGÍSTICA



DISEÑO DE EXPERIMENTOS El diseño experimental no debe ser considerada la primera herramienta a utilizar para mejorar un proceso. Muchas veces herramientas más simples como gráficos de
control, paretos, histogramas y diagramas de flujo, etc. pueden dar indicaciones claras sobre cuáles son los factores responsables de los problemas o la variación excesiva de nuestro proceso.
Sin embargo, cuando existen muchos factores que pueden ser causantesy no podemos
identificar cuáles de ellos son más importantes. aparece la necesidad del diseño experimental.
También debemos experimentar si buscamos modelar el comportamiento del proceso de manera matemática, para buscar la combinación de factores que nos de como resultado una respuesta o respuestas óptimas.
Finalmente, la experimentación permite validar factores identificados como potenciales causas raíces de un determinado efecto. En general, la observación no es una estrategia de validación; nos ayuda a identificar hipótesis o sugerir mecanismos causales, pero la validación sólo se logra mediante la predicción o la cuidadosa
experimentación.
Estudios realizados sobre datos históricos pueden ocultar factores de importancia porque los niveles de estos factores varían tan poco que no se manifiestan en cambios significativos en la variable de respuesta, imposibilitando identificar estos factores en
análisis de regresión, ANOVA o multi-vari. En estos casos la herramienta utilizada debe ser el diseño experimental, donde se afecta el proceso con ciertas combinaciones de
factores para estudiar el comportamiento y su respuesta. El objetivo es detectar cómo responde el proceso a los factores estudiados y cuál es el camino para optimizar el proceso, a través de un modelo predictivo de la función de transferencia Y = f(X) que relaciona la respuesta Y con las variables de entrada X.
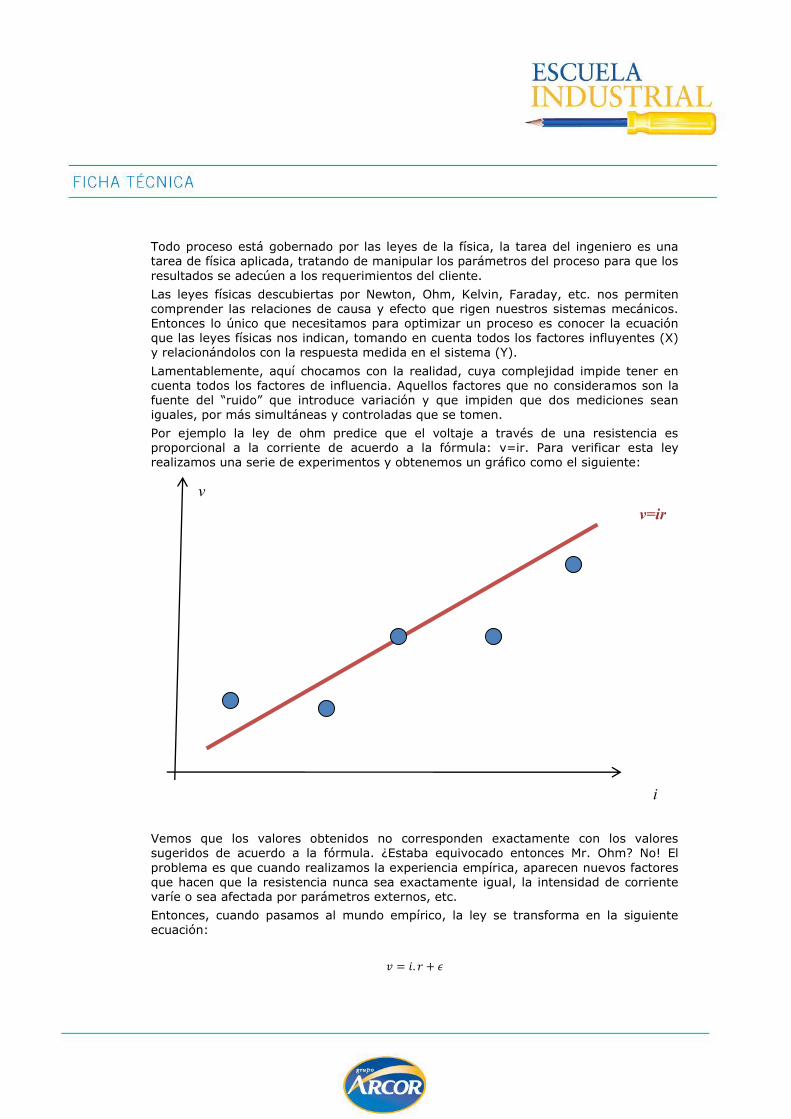
Todo proceso está gobernado por las leyes de la física, la tarea del ingeniero es una tarea de física aplicada, tratando de manipular los parámetros del proceso para que los
resultados se adecúen a los requerimientos del cliente.
Las leyes físicas descubiertas por Newton, Ohm, Kelvin, Faraday, etc. nos permiten
comprender las relaciones de causa y efecto que rigen nuestros sistemas mecánicos. Entonces lo único que necesitamos para optimizar un proceso es conocer la ecuación que las leyes físicas nos indican, tomando en cuenta todos los factores influyentes (X) y relacionándolos con la respuesta medida en el sistema (Y).
Lamentablemente, aquí chocamos con la realidad, cuya complejidad impide tener en cuenta todos los factores de influencia. Aquellos factores que no consideramos son la fuente del “ruido” que introduce variación y que impiden que dos mediciones sean iguales, por más simultáneas y controladas que se tomen.
Por ejemplo la ley de ohm predice que el voltaje a través de una resistencia es proporcional a la corriente de acuerdo a la fórmula: v=ir. Para verificar esta ley realizamos una serie de experimentos y obtenemos un gráfico como el siguiente:
Vemos que los valores obtenidos no corresponden exactamente con los valores sugeridos de acuerdo a la fórmula. ¿Estaba equivocado entonces Mr. Ohm? No! El
problema es que cuando realizamos la experiencia empírica, aparecen nuevos factores que hacen que la resistencia nunca sea exactamente igual, la intensidad de corriente varíe o sea afectada por parámetros externos, etc.
Entonces, cuando pasamos al mundo empírico, la ley se transforma en la siguiente
ecuación:
v
i
v=ir

Donde es un término que agrupa toda la variación que hace que el voltaje medido
sea diferente del voltaje predicho (temperatura, variación de humedad, auto-calentamiento, incertidumbre del sistema de medición, etc.)
El análisis de regresión nos permite estudiar estas relaciones entre X e Y como
funciones Y = f(X) + e,
En la práctica no tenemos la función exacta que relaciona las varias X’s con la Y que nos interesa. Si todos los factores fueran de influencia insignificante, nuestro modelo sería:
Donde es un valor constante de la respuesta y representa un sinnúmero de
pequeñas causas azarosas, donde ninguna tiene una importancia que destaque sobre las demás. Esta es una forma de definir un proceso bajo control estadístico.
El componente se lo asocia al ruido agregado por los factores no preponderantes;
cuanto más ruido, más diferentes entre sí serán los valores Y que medimos.
Si sospechamos que hay un factor preponderante, que sobresale entre las demás causas, la ecuación que representa nuestro sistema sería:
Aquí, la letra griega tau () representa el efecto apreciable de nuestro factor. Decimos
que este factor es una señal, que sobresale entre el ruido circundante (representado por ).
Una tarea del diseño experimental busca determinar si hay razones suficientes para concluir que podemos extraer de uno o más factores diferenciados e importantes de
entre las demás causas. O dicho de otro modo, si podemos separar las señales del
ruido.
Un experimento diseñado es una serie de experiencias en los cuales se han realizado
cambios a determinadas variables de entrada en forma predefinida, con el fin de observar las variaciones producidas en las variables de salida.
Todo proceso puede ser visualizado como una caja negra, en donde la acción de determinados materiales, máquinas, operarios, factores ambientales, etc. Generan una determinada salida. Algunas de las variables de entrada pueden estar bajo nuestro
control (la temperatura de un horno, la tensión aplicada en bornes), mientras que otras no pueden ser controladas (la humedad ambiente, el ruido de linea eléctrica).
Algunos de los objetivos que se pueden seguir a través del diseño experimental son:
Determinar cuáles son las variables que más afectan la salida del proceso.
Determinar los valores de las variables de entrada que minimizan la variabilidad de la variable de salida.
Minimizar la influencia de las variables incontrolables (ruido) a través de los valores fijados en las variables de entrada (es decir, lograr un proceso robusto).

VARIABILIDAD
Durante mucho tiempo se creyó que la variabilidad era algo inherente a cualquier proceso natural; una carga que se debía soportar indefectiblemente en cada caso. Actualmente, sin embargo, la variación es vista como algo que puede ser reducido drásticamente a través de nuevas herramientas, como el Diseño de Experimentos,
disminuyendo costos e incrementando la satisfacción de los clientes.
La visión tradicional de la calidad se describe metafóricamente como “el poste del arco”, porque siempre y cuando las mediciones estén dentro de los limites
especificados (los dos postes del arco), la calidad del producto está garantizada. Sin embargo, lo único que realmente garantiza la calidad del producto es que los parámetros sean iguales al objetivo fijado en el diseño del mismo. Todo alejamiento del Valor Objetivo implica una variación que genera consecuencias indeseables en el proceso considerado.
El caso Ford <> Mazda
Este paradigma del poste se evidencia en el famoso caso de la transmisión automática
en los autos de Ford. Unos años atrás, Ford tenía graves problemas con su sistema de transmisión automática, era ruidoso, tenía problemas en el cambio de velocidades, y altos costos de garantía. A diferencia, los sistemas de transmisión de Mazda, a pesar de responder a los mismos planos mecánicos, funcionaban con niveles de ruido
mínimos y sin reclamos de clientes. El análisis de las dos transmisiones reveló que la diferencia estaba en el grado de adecuación a los objetivos definidos en el diseño. Los sistemas de Ford tenían todas las partes dentro de la especificación, pero su desvío estándar era muchas veces mayor que el correspondiente a las piezas de Mazda, cuyas partes estaban distribuidas siempre alrededor del valor objetivo especificado.
Causas de Variación
Entre los causantes de variación en los productos, encontramos:
Mal gerenciamiento
- Falta de una política de reducción de la variación.
- Visión “Poste de Arco” sobre las especificaciones.
- Falta de recursos asignados al Diseño de Experimentos.
- Escasa aceptación del DOE
Pobres especificaciones de proceso o producto
- No escuchar la voz del cliente.
- Tolerancias demasiado amplias.
- No poner la Fiabilidad como una especificación.
- No utilizar DOE en el test de sistemas.
Uso de herramientas de calidad inadecuadas
- ISO 9000, TQM y otras modas de calidad usadas inapropiadamente.

Malas prácticas de producción
- Operaciones estándar inadecuadas o imprácticas.
- Mantenimiento preventivo inadecuado.
- Metrología inadecuada.
Materias primas inadecuadas
- Demasiados proveedores.
- Control exclusivamente por precio.
- Control a través de AQL o tablas Mil Std 105.
Errores de Operador
- Instrucciones inadecuadas.
- Inspección externa.
- Sobrecontrol de parámetros del proceso.
Experimentación
¿por qué experimentar? supongamos que tenemos un proceso de manufactura generando un excesivo número de ítems no conformes, del cual tomamos frecuentemente muestras y realizamos ensayos ... , ¿no es suficiente con mirar los datos históricos archivados? en base a estos datos podríamos determinar las variables que afectaron el proceso y su magnitud relativa.
En realidad, los datos históricos nos pueden dar sugerencias, pero no nos permiten determinar relaciones causales, dado que puede haber muchas otras variables posibles actuando simultáneamente que no controlamos y que se hayan “colado” en nuestro análisis. Como no tuvimos en cuenta esas causas concurrentes, atribuimos incorrectamente las modificaciones a otros factores qué sí analizamos.
La experimentación permite un mayor grado de control, permitiéndonos corroborar si factores sospechosos son realmente causales de cambios en nuestro proceso. Lo
importante es detectar si los factores involucrados son señales, es decir si producen un cambio significativo en la respuesta. Por lo tanto la experimentación busca filtrar el
ruido para luego interpretar las diferencias como señales potenciales.
En general los experimentos en la práctica son de tipo comparativos. P.ej. comparar rendimientos, ver el cambio de una respuesta cuando cambiamos otro factor, etc. Y se busca arribar a una decisión luego del experimento; la estadística nos ayuda a tomar esta decisión.
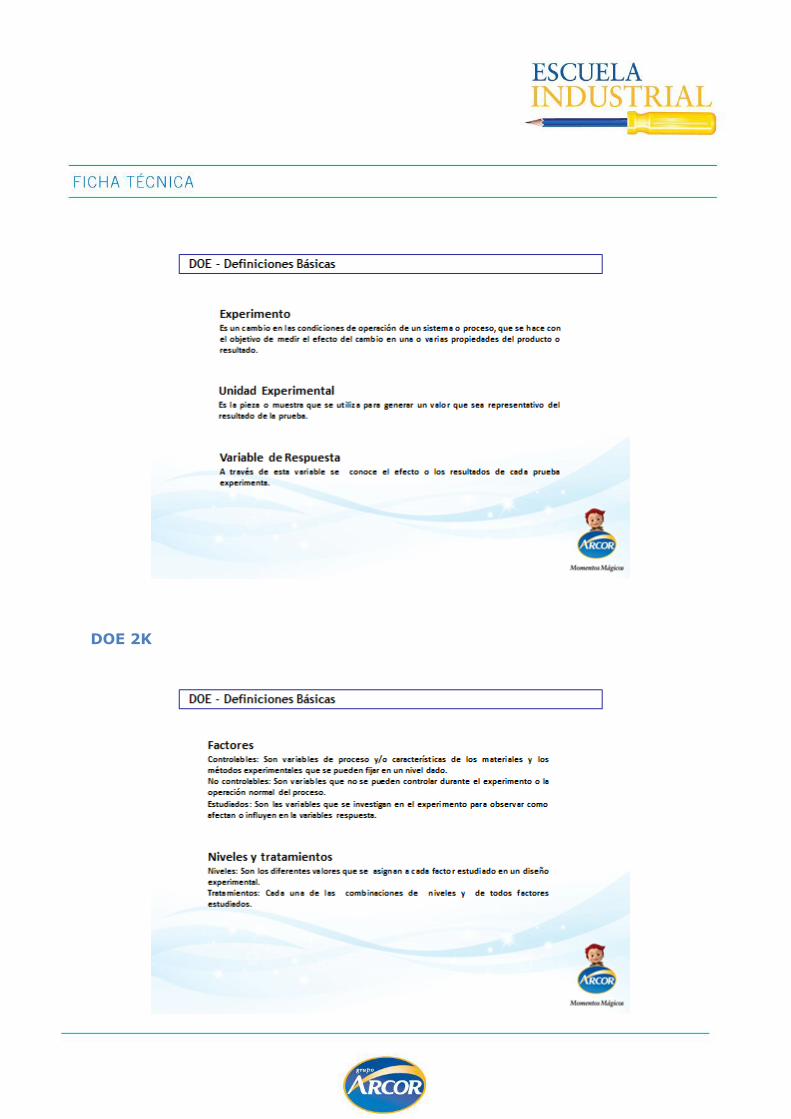
DOE 2K
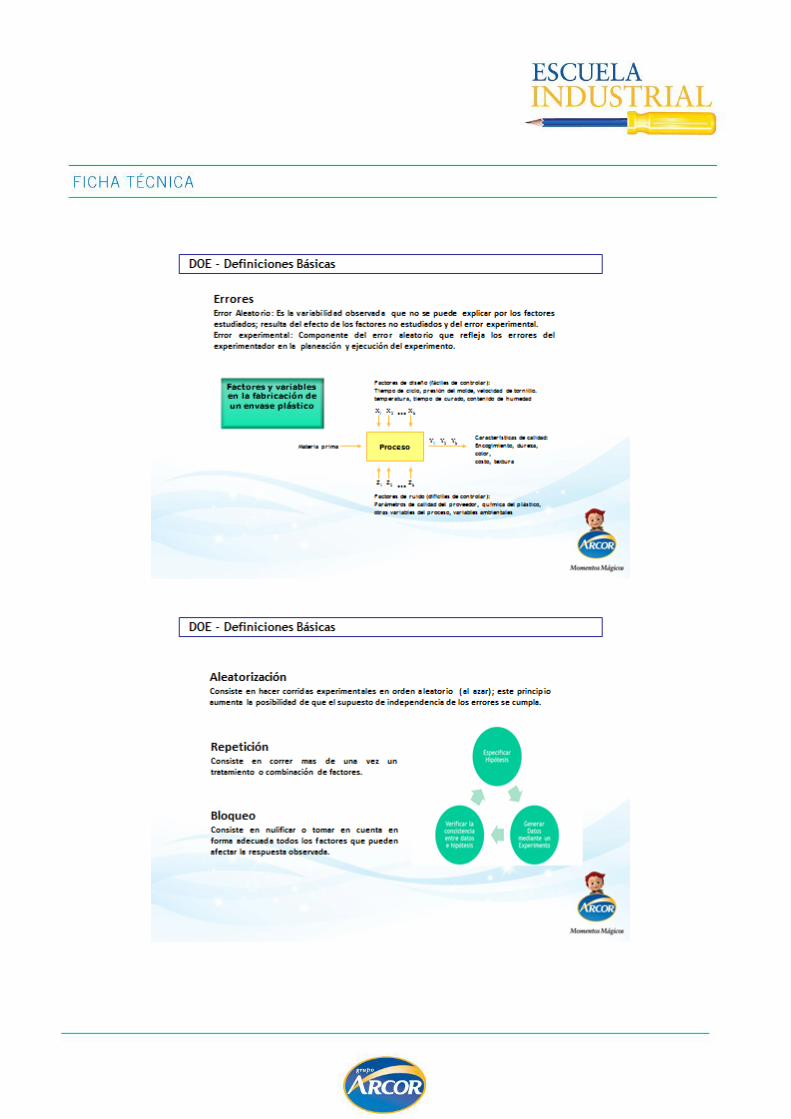

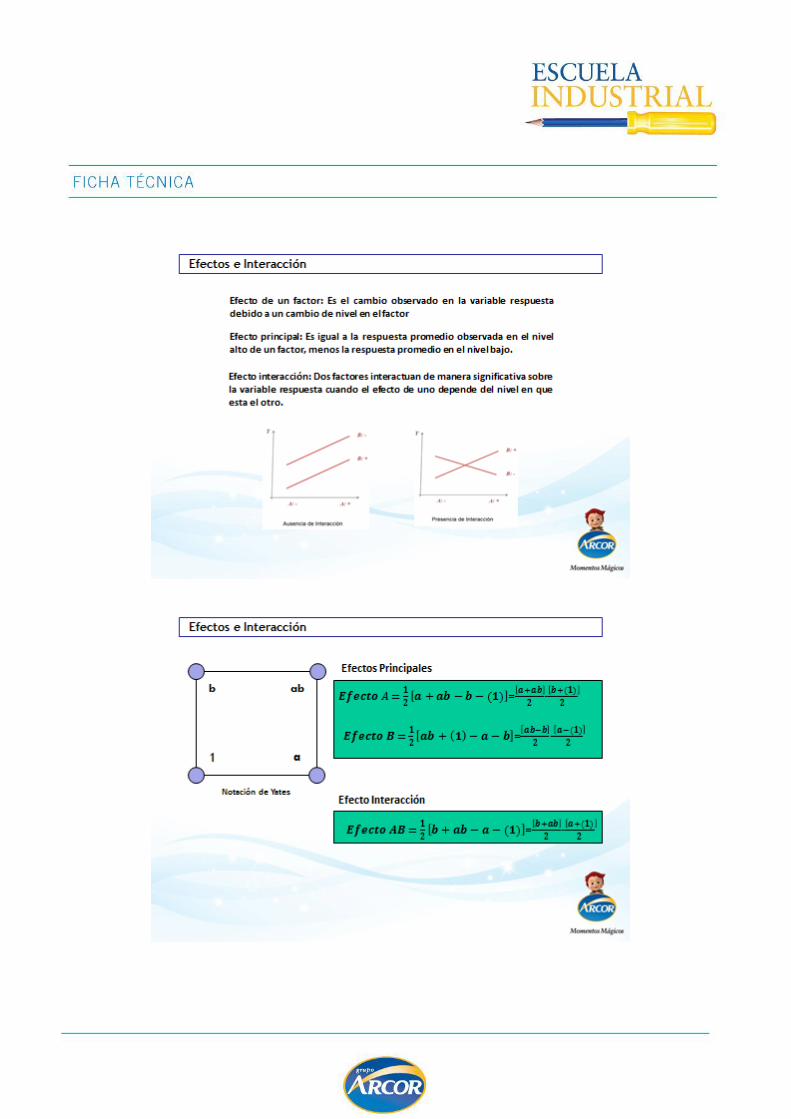

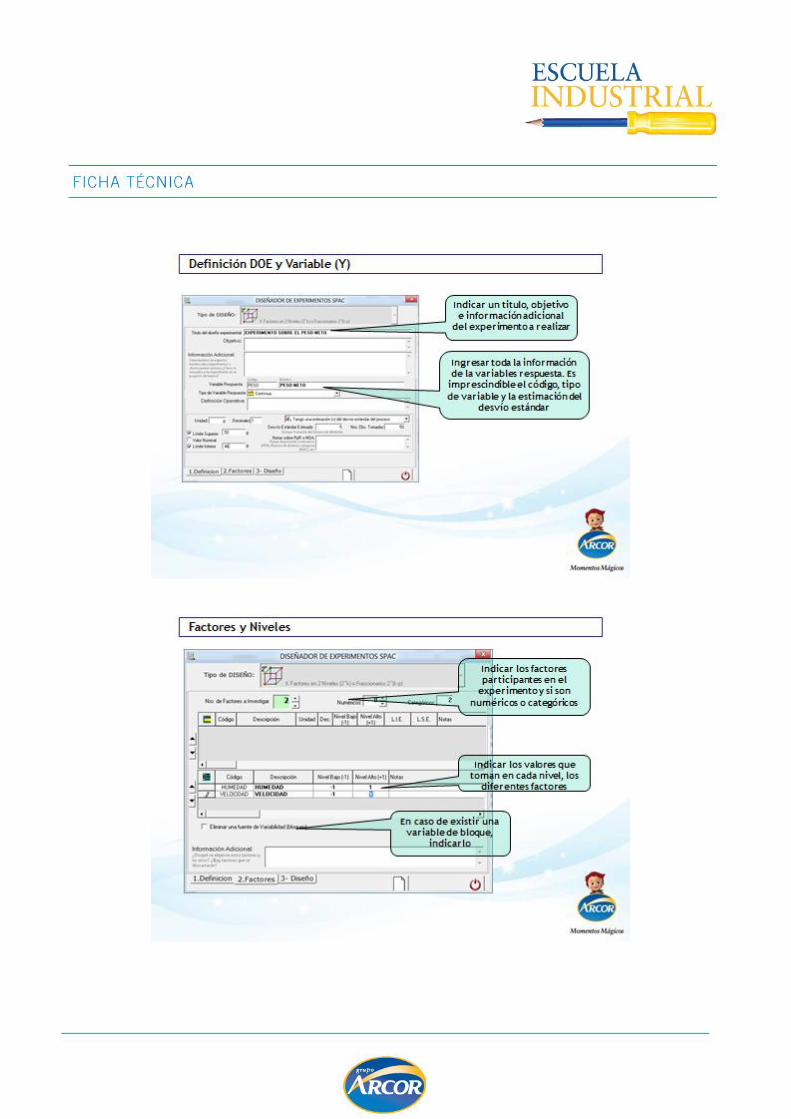
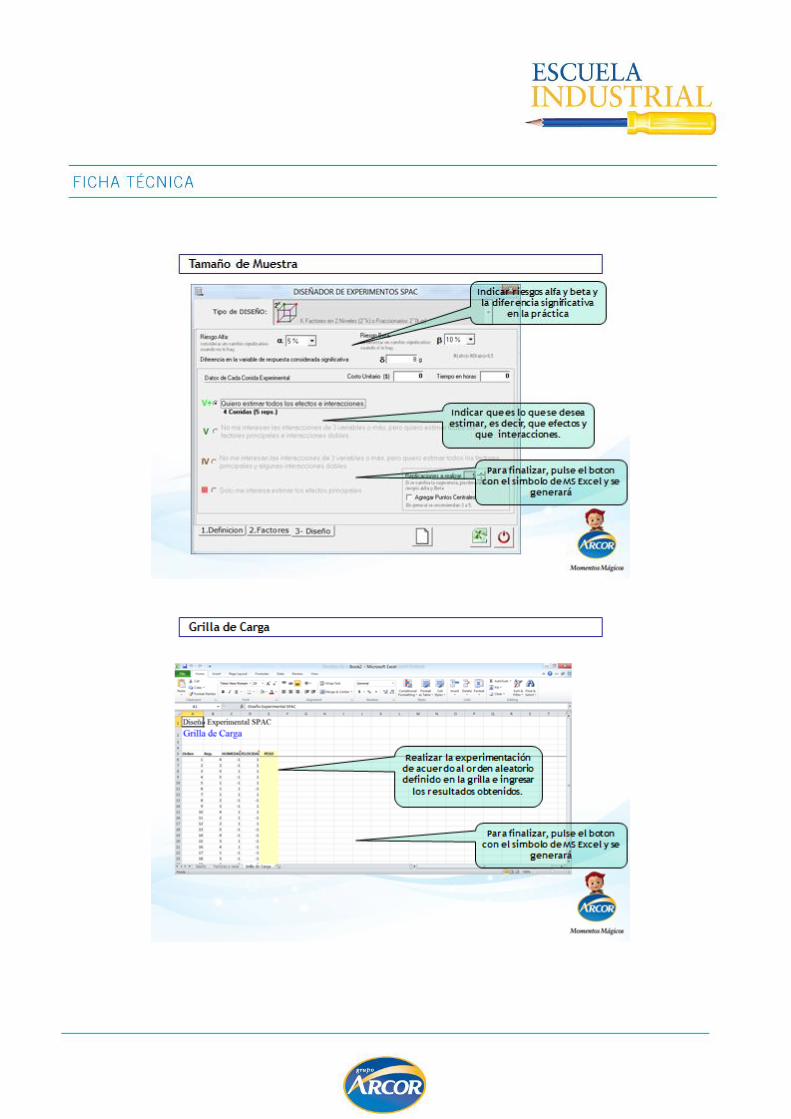


DOE 2K-P
Si no tenemos ninguna suposición sobre las causas que modifican la variable Y estudiada, podemos suponer que cada observación es igual a una constante K más cierto error. Este error representa la discrepancia entre cada valor medido y el valor constante de Y.
Este sería el modelo más simple posible, por eso se lo llama modelo Reducido. Solo un valor constante explica los valore de Y. Cada segmento identificado como e representa
un error entre el valor constante supuesto y el valor medido; la suma de todos los segmentos es el error total del modelo.
Sin embargo, supongamos que medimos cierta variable X cada vez que tomamos una observación de Y. Luego graficamos el valor de cada observación ubicándolo respecto al valor de X correspondiente, obteniendo le siguiente diagrama:
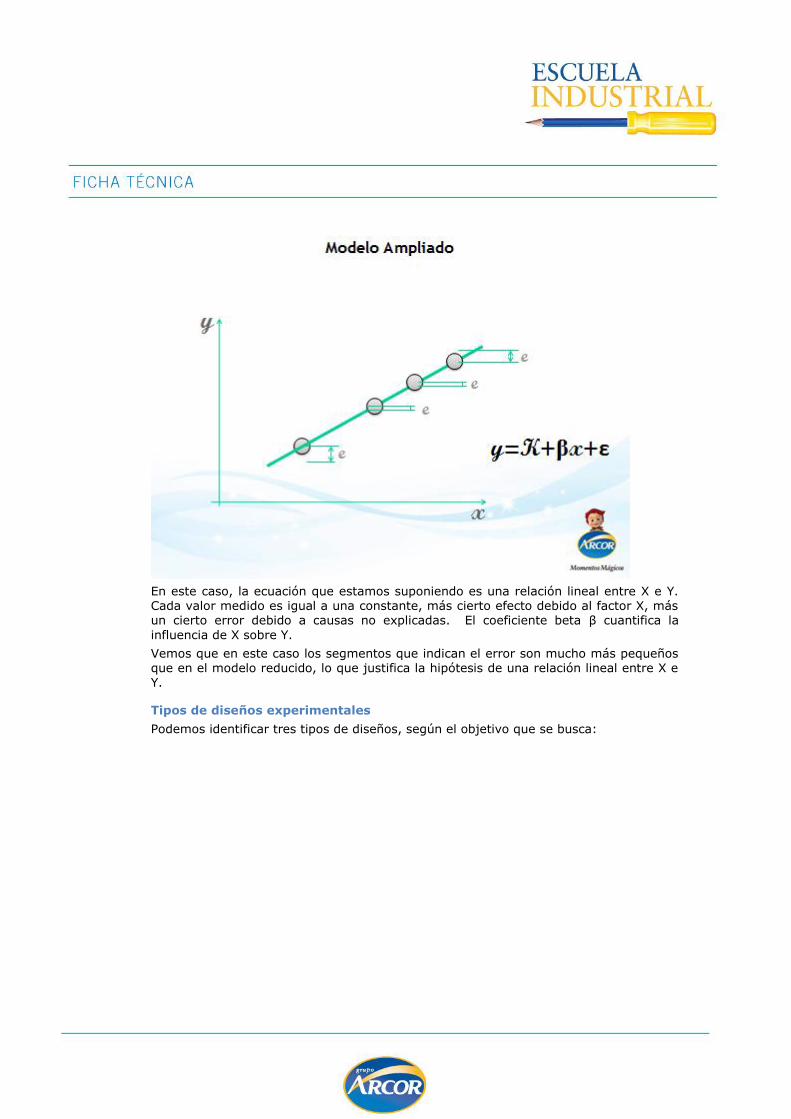
En este caso, la ecuación que estamos suponiendo es una relación lineal entre X e Y. Cada valor medido es igual a una constante, más cierto efecto debido al factor X, más un cierto error debido a causas no explicadas. El coeficiente beta β cuantifica la
influencia de X sobre Y.
Vemos que en este caso los segmentos que indican el error son mucho más pequeños que en el modelo reducido, lo que justifica la hipótesis de una relación lineal entre X e Y.
Tipos de diseños experimentales
Podemos identificar tres tipos de diseños, según el objetivo que se busca:

Los diseños de filtrado se utilizan para identificar aquellos factores que más afectan la variable Y.
En el gráfico se muestra a la izquierda la situación inicial, con una nube de factores sin
cualificar, y la situación luego de experimentar, con una serie de factores identificados como significativos.
Los diseños DOE 2k y DOE 2k-p se ubican en esta categoría.

Los diseños de superficie de respuesta permiten determinar la ecuación que relaciona los distintos valores de X con la respuesta Y. Muchas veces esta relación es lineal, pero puede ser que existan relaciones cuadráticas, exponenciales o de otro tipo.
Estos diseños en la práctica se utilizan una vez que se conocen las X críticas, para modelar la respuesta como una función matemática, que siempre tiene que tener en cuenta cierto error, debido a causas menos importantes actuantes sobre el proceso.

Finalmente, los diseños para incrementar la robustez se enfocan en crear un producto lo más insensible a las influencias no controlables (el ruido). Por ejemplo, diseñar un producto alimenticio robusto a cambios de temperatura ambiente.
Los métodos Taguchi, que quedan para un curso más avanzado, se ubican en esta categoría.
Fraccionamiento de diseños 2k
Los diseños DOE 2k crecen duplicando el número de corridas por cada factor adicional. Cuando hay muchos factores, el número de corridas se vuelve prohibitivo. Por otro lado, realizar todas las corridas permite calcular todas las interacciones entre factores. Sin embargo, es muy raro hallar interacciones de 3 factores o más, entonces se pierden corridas para estimar interacciones poco importantes. Los diseños fraccionarios permiten aprovechar esta situación para disminuir el número de corridas a costa de interacciones no relevantes.
El siguiente diagrama muestra todas las combinaciones de corridas que se deben realizar en un diseño con 6 factores en 2 niveles:
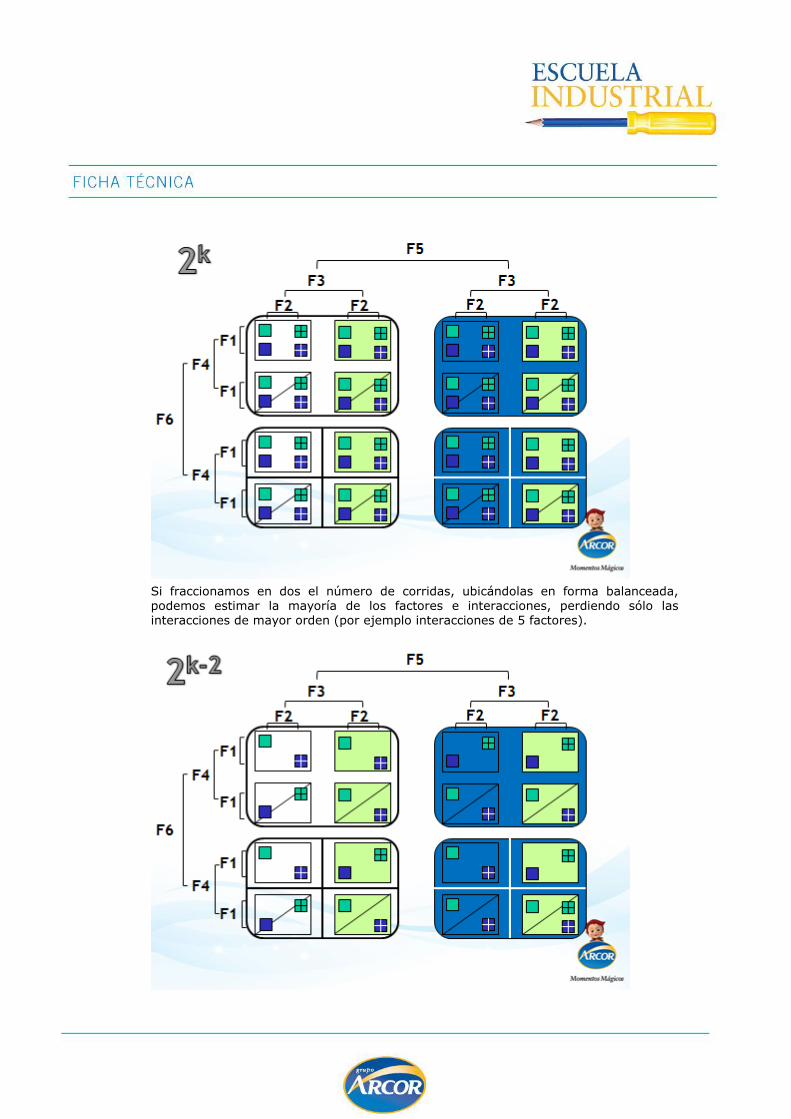
Si fraccionamos en dos el número de corridas, ubicándolas en forma balanceada, podemos estimar la mayoría de los factores e interacciones, perdiendo sólo las interacciones de mayor orden (por ejemplo interacciones de 5 factores).

El balanceo implica que sigue habiendo el mismo número de corridas para cada nivel del factor. Por ejemplo si contamos, veremos que a pesar de ser fraccionado, cada nivel del factor contiene 32 corridas.
Cuando fraccionamos, las barras del Pareto dejan de estar relacionadas con un solo factor o interacción. En cada barra puede haber más de un efecto “confundido”.
Por ejemplo, en la imagen previa, la primera barra incluye en su valor la suma de dos efectos:
- El efecto A (lo que se llama el efecto principal)
- La interacción B x C (una interacción doble)
Por ejemplo, si el valor del efecto es 80, puede ser que esto corresponda 100% al factor A, siendo nula la interacción BC; o podría ser que el factor A no sea importante, y el efecto corresponda totalmente a la interacción BC.
Por esta razón, cuando se diseña un fraccionario, se debe considerar que factores e interacciones estarán confundidos.
El grado de “confusión” se denomina la resolución del experimento. Cuanto mayor la resolución, menos confusión.
Los experimentos de resolución 5 o superior (la resolución se indica con números romanos, es decir que esto sería V+), son los completos, donde no existe confusión y cada barra del Pareto es uno y solo un efecto.
La resolución V permite asegurarse que no habrá ninguna barra donde se confunda más de un factor o factores principales con interacciones dobles.
Si bajamos a resolución IV, algunos factores principales estarán confundidos con interacciones dobles.
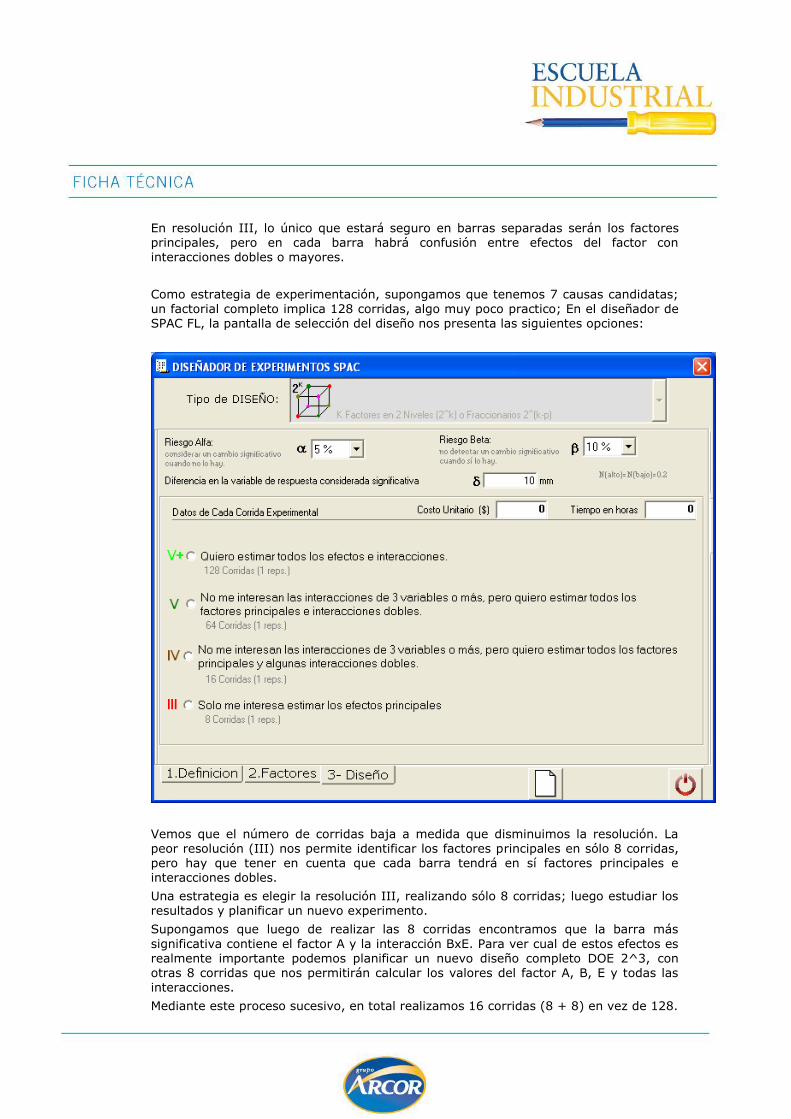
En resolución III, lo único que estará seguro en barras separadas serán los factores principales, pero en cada barra habrá confusión entre efectos del factor con interacciones dobles o mayores.
Como estrategia de experimentación, supongamos que tenemos 7 causas candidatas;
un factorial completo implica 128 corridas, algo muy poco practico; En el diseñador de SPAC FL, la pantalla de selección del diseño nos presenta las siguientes opciones:
Vemos que el número de corridas baja a medida que disminuimos la resolución. La peor resolución (III) nos permite identificar los factores principales en sólo 8 corridas, pero hay que tener en cuenta que cada barra tendrá en sí factores principales e interacciones dobles.
Una estrategia es elegir la resolución III, realizando sólo 8 corridas; luego estudiar los resultados y planificar un nuevo experimento.
Supongamos que luego de realizar las 8 corridas encontramos que la barra más
significativa contiene el factor A y la interacción BxE. Para ver cual de estos efectos es realmente importante podemos planificar un nuevo diseño completo DOE 2^3, con otras 8 corridas que nos permitirán calcular los valores del factor A, B, E y todas las interacciones.
Mediante este proceso sucesivo, en total realizamos 16 corridas (8 + 8) en vez de 128.

SUPERFICIE DE RESPUESTA
El Método de Superficies de Respuesta es una técnica que permite al experimentador encontrar el punto de rendimiento más alto (RMA) dados al menos dos factores significativos.