estadísticas - marco alfaro
TRANSCRIPT

ESTADISTICA
por
Marco Antonio Alfaro Sironvalle
Ingeniero Civil de Minas, Universidad de Chile
Doctor en Geoestadística, Escuela de Minas de París. Profesor de Estadística, Probabilidades y Procesos Estocásticos, Universidad De Chile
Profesor de Evaluación de Yacimientos en la Universidad de Santiago de Chile
Junio, 2000

1
0. INTRODUCCIÓN A LA ESTADÍSTICA. La palabra Estadística se usa para caracterizar hechos numéricos reunidos sistemáticamente en cualquier campo, ya sea de observación o experimental. La Estadística se puede dividir en tres grandes capítulos: a) Estadística Descriptiva : Se ocupa del estudio de datos, los cuales se disponen en la forma más conveniente para su análisis o inspección. b) Teoría de Probabilidades : Se ocupa del estudio de un modelo matemático, que formaliza ciertos elementos de regularidad que sugieren leyes. Estas leyes se expresan en forma de axiomas lógicos, desarrollando las consecuencias de los axiomas, produciendo así un conjunto de teoremas o proposiciones. c) Inferencia Estadística : Se ocupa de las relaciones entre el modelo matemático y la practica, constituyendo, en cierta forma, la rama aplicada de la estadística.

2
I. ESTADÍSTICA DESCRIPTIVA. I.1. DEFINICIONES. a) Fenómenos Aleatorios : Desde hace algunos años se ha comenzado a estudiar, de manera científica, los fenómenos aleatorios, que son aquellos en que las mismas causas dan lugar resultados diferentes. b) Experimentos Aleatorios : Se llama experimento aleatorio a una experiencia cuyo resultado depende del azar, es decir, puede variar cuando esta se repite en condiciones supuestas idénticas, ejemplos. - tirar un dado y ver el número que aparece. - medir las horas de duración de una ampolleta. c) Resultado : Es la información aportada por la realización de una experiencia. el conjunto de todos los resultados posibles de un experimento se llama espacio muestral y se designa por la letra Ω, ejemplos: - Ω = 1, 2, 3, 4, 5, 6 , para el lanzamiento de un dado. - Ω = x : x ≥ 0 , si se mide la estatura de un individuo. I.2. PRESENTACIÓN DE RESULTADOS EXPERIMENTALES a) Variable estadística asociada a un experimento : Si a cada resultado se le asocia un número perteneciente a un cierto conjunto, se dice que este número es una variable estadística. Se utilizan letras mayúsculas para representar las variables estadísticas, ejemplos: - X = estatura de un individuo. - X= resultado de tirar un dado. - X = temperatura a las 12 horas en un punto dado. b) Muestra de n resultados : Es el conjunto de valores tomados por una variable estadística durante n experimentos, ejemplo: - M = 6, 2, 3, 3, 4, 5, 6, 3, 1, 1 si se tira 10 veces un dado. - M = 0.96; 1.02; 0.50; 030; 0.89 si se analizan 5 muestras por cobre dentro de un yacimiento. En general : M = x1, x2, ..., xn . I.3. CASO DE UNA VARIABLE DISCRETA. Una Variable estadística es Discreta, si el conjunto de valores posibles se puede poner en la forma
R = a1, a2, ... , ak
en que k es el número de valores diferentes que puede tomar la muestra. Sea una muestra de tamaño n y sea ri el número de repeticiones del valor ai en la serie de n
experimentos. Se tiene la relación ∑=
=k
1inri
En donde ri es la frecuencia absoluta del valor ai. Se define la frecuencia relativa del valor ai como:

3
nrfi i=
se tiene entonces la relación :
1fik
1i
=∑=
Ejemplo: Sea la muestra M = 0, 3, 1, 1, 2, 1, 2, 2 , n = 8 a1 = 0 , a2 = 1 , a3 = 2 , a4 = 3 , k = 4 r1 = 1 , r2 = 3 , r3 = 3 , r4 = 1 f1 = 1/8 , f2 = 3/8 , f3 = 3/8 , f4 = 1/8 En el caso general se puede construir la siguiente tabla:
X a1 a2 ........... ak ri r1 r2 ........... rk fi f1 f2 ........... fk
y dibujar un diagrama de frecuencias:
I.4. CASO DE UNA VARIABLE CONTINUA. Una variable estadística es continua si toma sus valores en un conjunto continuo, es decir, un intervalo del eje real. Para reducir una muestra M = x1, x2, ... , xn de una variable continua, se definen clases, que son intervalos disjuntos que cubren el dominio de definición de la variable, Ejemplo : Leyes de Cu de un conjunto de testigos, eligiendo clases iguales de magnitud 0.1
X 0 ≤ x < 0.1 0.1 ≤ x < 0.2 0.2 ≤ x < 0.3 ............... ri r1 r2 r3 ............... fi f1 f2 f3 ............... ci c1 c2 c3 ...............
Se define, análogamente : ri = numero de datos de la muestra que caen en la clase ci fi = frecuencia relativa de la clase ci ( ci = ri / n) ci = magnitud de la clase ci La representación gráfica de la tabla anterior se llama histograma ( k = número de clases )
f1
f2
fk
a1 a2 ak

4
Para construir un histograma, se recomienda, en Estadística, un mínimo de 8 clases, para lo cual se requiere un mínimo también de 30 datos. En el caso continuo también son válidas las relaciones:
1f,nrk
1ii
k
1ii == ∑∑
==
I.5. EL DIAGRAMA ACUMULADO Para caracterizar una variable estadística se utiliza también el diagrama acumulado F(x) que representa la frecuencia relativa acumulada en el histograma hasta el punto x. La figura 2 nos muestra como se construye el diagrama acumulado a partir del histograma.
Fig.1
Histograma
f1
f2
fi
fk
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
c1 c2 ci ck
0 1 2 3 4 5 6 7 x
1.0
0.8
0.6Fig.2
0.4
0.2
0 1 2 3 4 5 6 7 x
0.050.10
0.20
0.30
0.20
0.100.05
0.85
0.65
0.35
0.150.05
F(x)

5
En términos intuitivos F(x) representa el porcentaje de valores de la muestra que la muestra que son inferiores a x. I.6. PARÁMETROS DE UNA DISTRIBUCIÓN ESTADÍSTICA. Además del histograma y del diagrama acumulado, existen varios parámetros que caracterizan el comportamiento de una muestra. a) Parámetros de Tendencia Central : Los parámetros de tendencia más importantes son la media y la mediana. i) La Media Aritmética : Sea la muestra M = x1, x2, ..., xn la medida típica más comúnmente utilizada es la media, definida simplemente por:
∑=
⋅=+++
=n
1ii
n21 xn1
nx....xxx
En el caso en que los datos se han agrupado en un diagrama de frecuencias o un histograma, se tendrá lo siguiente: • Si la variable es discreta, se calcula por :
∑=
⋅=k
1iii fax
• Si la variable es continua, se calcula, aproximadamente por :
∑=
⋅=k
1iii fxx
en que xi es el punto medio de la clase ci. ii) La Mediana : Supongamos que la muestra M = x1, x2, ..., xn ha sido ordenada de menor a mayor obteniéndose la muestra ordenada M´ = y1, y2, ..., yn con y1 ≤ y2 ≤......≤ yn , se define la mediana por : • Si n es impar :
21nyM +=
• Si n es par :
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ +=
+
2
yyM 2
2n2n
Ejemplo : Se dispone de la muestra, con datos de leyes de Cu siguientes : M = 0.95 , 1.02 , 0.90 , 4.03 , 1.10 ⇒ M´ = 0.90 , 0.95 , 1.02 , 1.10 , 4.03 = y1, y2, y3, y4, y5 luego la mediana es M = y3 = 1.02. La mediana tiene la propiedad siguiente : el 50 % de los datos es menor que M y el 50% de los datos es mayor que M, es decir M divide la muestra en dos partes iguales. La mediana esta menos afectada por valores extremadamente altos ( o extremadamente pequeños ) que la media, en el ejemplo anterior la media es : 60.1=x valor muy afectado por el dato 4.03 La mediana se puede determinar gráficamente utilizando el diagrama acumulado F(x). Según lo anterior la mediana es el valor xM para el cual se cumple la relación F(xM) = 0.5

6
b) Parámetros de dispersión : Además de poder encontrar la media de una muestra, resulta importante medir la variación de los datos con respecto a este valor central. La variación de los datos con respecto a la media esta caracterizada por las diferencias :
).x(x),.....,x(x),x(x n21 −−− Para encontrar un indicador de la variación, se pueden promediar estas diferencias :
n
xx....xxxx n21 −++−+−=ε , pero
0xn
x....xx n21 =−+++
=ε
Luego la desviación promedio es siempre nula. Esto proviene del hecho que las desviaciones positivas se cancelan con las desviaciones negativas. Para definir una medida de la variación se
toman entonces las diferencias elevadas al cuadrado : 2,.......,2,21 )()()( 2 xxxxxx n −−− .
Tenemos entonces la definición siguiente : Se llama Varianza de la muestra M = x1, x2, ..., xn a :
( ) ( ) ( )n
xxxxxx n22
22
12 −++−+−=σ
o bien : ∑=
−=n
1i
2i
2 )x(xn1σ
La varianza constituye una medida de dispersión con respecto a la media y es un número ≥ 0, en el único caso en que σ2 = 0 , es aquel de una muestra del tipo M = a , a ,..., a con a = cte., es decir una muestra sin variación. Debido a que la varianza es una suma de cuadrados, la unidad de σ2 es igual a la unidad de la muestra elevada al cuadrado, es decir si X se mide en % de Cu, σ2 se mide en (% de Cu)2. Por esta razón se define la desviación típica σ como :
2σσ =
F(x) 1.0
0.8
0.6Fig.3
0.4
0.2
0.50
XM X

7
La desviación típica está expresada en las mismas unidades de la variable estadística, también constituye una medida de dispersión. c) Otras Medidas de Dispersión. Existen otras medidas de dispersión basadas en los cuartiles o percentiles de orden α. Se llama percentil de orden α ( 0 < α < 1 ), al valor xα tal que f(xα) = α . Este valor se puede obtener gráficamente utilizando la función F(x).
El percentil xα divide la muestra de datos en dos partes : el α % de los valores es menor que xα y el ( 1 - α )% de los valores es mayor que xα. Existen tres percentiles importantes llamados cuartiles : X0.25 → se llama primer cuartil. X0.50 → se llama segundo cuartil ( y es la mediana ). X0.75 → se llama tercer cuartil. Como medida de dispersión de la muestra se utiliza el recorrido intercuartílico, definido por :
R = x0.75 – x0.25
La magnitud de R nos da una medida de la dispersión de la muestra ( ver figura 5 )
F(x)
Fig.4
Percentil de orden 0.8
x0.8 x0
1.0
0.8

8
Observación : otros autores utilizan como medida de dispersión el recorrido siguiente : R’ = x0.90 – x0.10
Otras medidas que se utilizan para caracterizar el comportamiento de una muestra son el Coeficiente de Simetría y el Coeficiente de Kurtosis.
d) El Coeficiente de Simetría γ.
El coeficiente de simetría γ, sirve para caracterizar comportamientos tales como :
El Coeficiente de Simetría se define por :
33
σ
µγ =
En que : 3n
1iin
1 )x(x −= ∑=
3µ
Fig.5
Histograma con poca dispersión Histograma con mayor dispersión
x x
F(x) F(x)
1 1
0.750.75
0.250.25
0 x 0 xR R
Recorrido pequeño Recorrido mayor
Fig.6
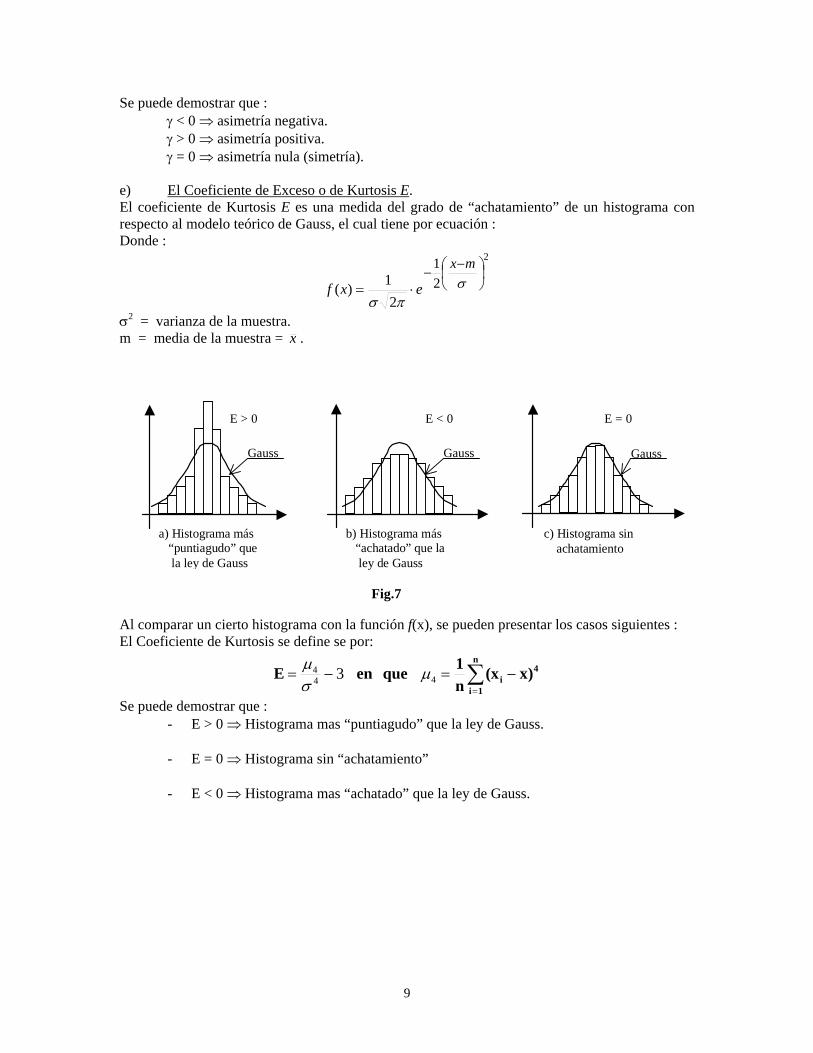
γ < 0 γ > 0 γ = 0
a) Asimetría Negativa b) Asimetría Positiva c) Simetría
9
Se puede demostrar que : γ < 0 ⇒ asimetría negativa. γ > 0 ⇒ asimetría positiva. γ = 0 ⇒ asimetría nula (simetría). e) El Coeficiente de Exceso o de Kurtosis E. El coeficiente de Kurtosis E es una medida del grado de “achatamiento” de un histograma con respecto al modelo teórico de Gauss, el cual tiene por ecuación : Donde :
2
21
21)(
⎟⎠⎞
⎜⎝⎛ −
−⋅= σ
πσ
mx
exf
σ2 = varianza de la muestra. m = media de la muestra = x .
Al comparar un cierto histograma con la función f(x), se pueden presentar los casos siguientes : El Coeficiente de Kurtosis se define se por:
∑=
−=−=n
1i
4i )x(x
n1queenE 44
4 3 µσµ
Se puede demostrar que : - E > 0 ⇒ Histograma mas “puntiagudo” que la ley de Gauss.
- E = 0 ⇒ Histograma sin “achatamiento”
- E < 0 ⇒ Histograma mas “achatado” que la ley de Gauss.
Fig.7
GaussGaussGauss
E > 0 E < 0 E = 0
a) Histograma más “puntiagudo” que la ley de Gauss
b) Histograma más “achatado” que la ley de Gauss
c) Histograma sin achatamiento

10
II. VARIABLES ESTADISTICAS BIDIMENSIONALES. A menudo se realizan experimentos cuyos resultados dan lugar a un par de números o a una serie de números. Ejemplo : ( X , Y ) , en que X = ley de Cu , Y = ley de S. O bien : ( X , Y , Z ) , en que X = ley de Pb , Y = ley de Zn , y Z = ley de Au En el caso bidimensional, una muestra de n observaciones es de la forma : M = (x1 , y1), (x2 , y2), ..., (xn , yn) La agrupación de la muestra se hace mediante una tabla del tipo tabla de contingencia : Y X b0 ≤ x < b1 b1 ≤ x < b2 .......... bk-1 ≤ x < bk
a0 ≤ y < a1 r11 r12 .......... r1k a1 ≤ y < a2 r21 r22 .......... r2k
ap-1 ≤ y < ap rp1 rp2 .......... rpk
y un histograma en el espacio seria de la forma :
Un método más simple para ilustrar los datos bidimencionales es el Diagrama de Dispersión o Nube de Puntos. Las dos medidas ( xi , yi ) se consideran como un par ordenado, que puede representarse como un punto en el sistema de coordenadas rectangulares; la muestra : M = (x1 , y1), (x2 , y2), ..., (xn , yn) Constituye entonces una nube de puntos.
Fig.8
y
x
11
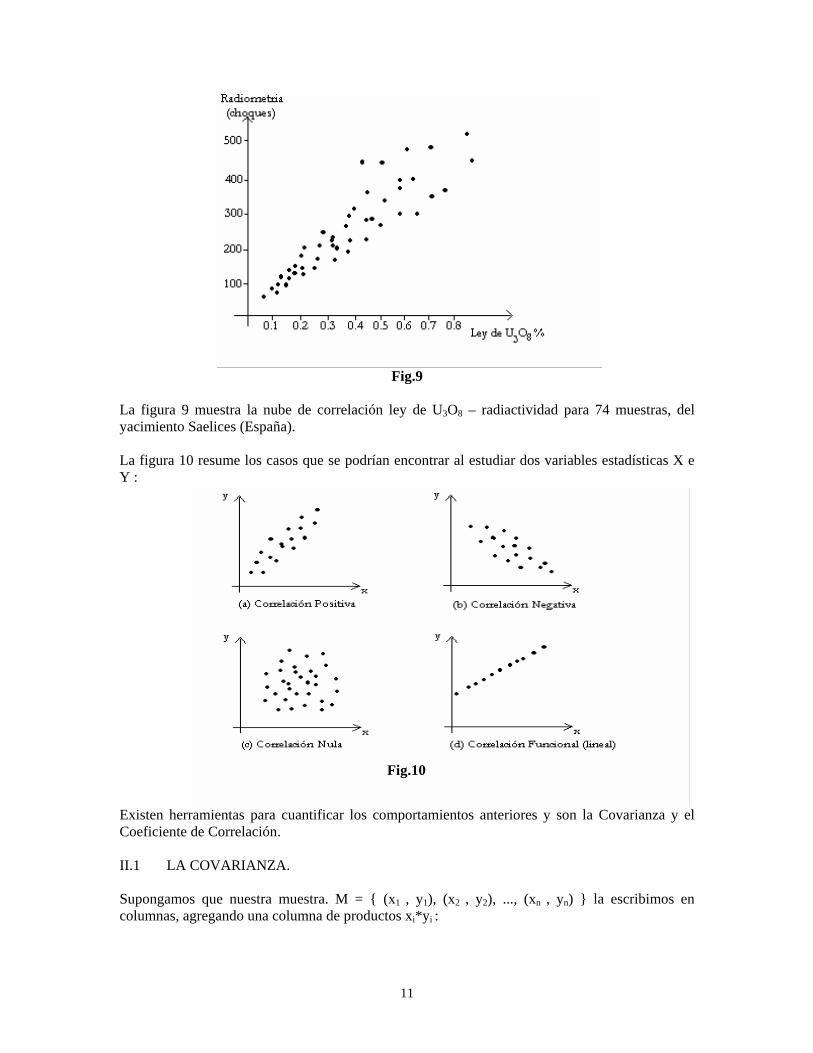
Fig.9 La figura 9 muestra la nube de correlación ley de U3O8 – radiactividad para 74 muestras, del yacimiento Saelices (España). La figura 10 resume los casos que se podrían encontrar al estudiar dos variables estadísticas X e Y :
Existen herramientas para cuantificar los comportamientos anteriores y son la Covarianza y el Coeficiente de Correlación. II.1 LA COVARIANZA. Supongamos que nuestra muestra. M = (x1 , y1), (x2 , y2), ..., (xn , yn) la escribimos en columnas, agregando una columna de productos xi*yi :
Fig.10

12
X Y X*Y x1 y1 x1*y1 x2 y2 x2*y2
xn yn xn*yn
Promedio X Promedio Y Promedio X*Y
Se define la Covarianza entre x e y por : yxxycxy ⋅−=
Lo cual se puede escribir también como :
⎟⎟⎠
⎞⎜⎜⎝
⎛∑=
⎟⎟⎠
⎞⎜⎜⎝
⎛∑=
−∑=
=n
1i iyn1n
1i ixn1n
1i iyixn1
xyc
Se puede demostrar que : i) Si la correlación es positiva : Cxy > 0 ii) Si la correlación es negativa : Cxy < 0 iii) Si la correlación es nula : Cxy = 0
Ejemplo : calcular Cxy en el caso de la muestra M = (1,1) , (2,2) , (2,3) , (3,4)
X Y X*Y 1 1 1 2 2 4 2 3 6 3 4 12
2=x 5.2=y 75.5=yx
Cxy = 5.75 – 2*2.5 = 0.75 > 0 La unidad de la covarianza es (unidad de x)*(unidad de y), debido a lo anterior se prefiere usar una cantidad adimencional, que es el Coeficiente de Correlación, definido por :
yx
xyCσσ
ρ =
en que : ∑∑==
−=−=n
1i
2i
2y
n
1i
2ix )y(y
n1)x(x
nσσ ,12
ρ es un número sin dimensión que verifica las propiedades siguientes :
i) –1 ≤ ρ ≤ 1 ii) Si la correlación es positiva : 0 < ρ ≤ 1

13
iii) Si la correlación es negativa : -1 ≤ ρ < 0 iv) Si la correlación es nula : ρ = 0 v) Si ρ = 1, entonces y = α x + β , con α > 0 vi) Si ρ = -1, entonces y = - α x + β , con α > 0
Cuando ρ cae en el intervalo achurado, se puede considerar que la correlación (positiva o negativa) es significativa :
II.1 LA CURVA DE REGRESIÓN. La curva de regresión y = m(x) representan el promedio de la variable y para un valor dado de x. El valor numérico de m(x0) se puede hallar gráficamente al promediar todos los valores que caen en una franja cercana a x0 (fig. 11) :
En general m(x) es una función de x. Si esta función es una recta se dice que la regresión es lineal (ver fig.12a ). Cuando no existe correlación entre x e y, la curva de regresión es una constante. (ver fig. 12b )
Fig.11
(a) (b)
Fig.12
Correlación significativa
Correlación debil
- 1.0 - 0.50 0.5 1.0

14
III. CALCULO DE PROBABILIDADES. En los párrafos anteriores hemos estudiado las situaciones aleatorias desde un punto de vista descriptivo. Se hace necesario introducir un modelo matemático. La exposición axiomática moderna es el único método riguroso para construir la teoría del cálculo de probabilidades. Antes de enunciar los axiomas de las probabilidades necesitamos introducir el concepto de sucesos o eventos aleatorios : Sucesos : Sea ε un experimento aleatorio. Se llama espacio muestral al conjunto de todos los resultados posibles. Se designa por la letra Ω. Ejemplos : (i) al tirar un dado Ω = 1, 2, 3, 4, 5, 6 (ii) al tirar una moneda Ω = cara, sello Se llama suceso a cualquier subconjunto del espacio muestral Ejemplo : A = “tirar un dado y sacar un número impar” = 1, 3, 5 , es un suceso ya que es subconjunto de Ω = 1, 2, 3, 4, 5, 6 Sea ε un experimento aleatorio y sea A un suceso, entonces al hacer un experimento solo caben dos alternativas : • Ocurre el suceso A. • No ocurre el suceso A. De acuerdo a lo anterior se definen otros tipos de sucesos : a) Suceso Seguro : Es aquel que siempre ocurre. Es fácil ver que suceso seguro y espacio muestral son lo mismo. Lo designaremos con la letra Ω. b) Suceso Imposible : Es aquel que nunca ocurre. Lo representaremos por la letra φ . Por ejemplo al tirar un dado φ = “sacar el número 7 ” c) Suceso Contrario : A es el suceso contrario de A, si ocurre cuando no ocurre A. Ejemplo: Si al tirar un dado A = 2, 4, 6 , entonces A = 1, 3, 5 . Se tiene las siguientes relaciones lógicas :
Ω==Ω= φφ ;;AA
d) Suceso Intersección : Sean A y B sucesos, se define la intersección de A y B como el suceso C que ocurre cuando A y B ocurren simultáneamente. Escribamos C = A ∩ B.
Ejemplo: Si A = 1, 2 , B = 2, 4, 6 , entonces A ∩ B = 2 . e) Sucesos iIncompatible : Dos sucesos A y B se dicen incompatibles si no pueden ocurrir simultáneamente. En este caso, según la definición : A ∩ B = ∅.

15
f) Suceso Unión : Sean A y B sucesos, se define la unión de A y B como el suceso D que ocurre cuando A ó B ó ambos a la vez. Se escribe D = A ∪ B.
Ejemplo: Si A = 1, 2 , B = 2, 4, 6 entonces A ∪ B = 1, 2, 4, 6 .
Se tiene la relacione lógica : ∪ Ω=AA Los conceptos anteriores pueden visualizarse mediante los diagramas de Venn de la teoría de conjuntos :
III.1 DEFINICION AXIOMATICA DE LA PROBABILIDAD Se llama probabilidad de un suceso A a un numero real P(A) que satisface los axiomas siguientes: Axioma 1 : P(A) ≥ 0 Axioma 2 : P(Ω) = 1 Axioma 3 : Si A y B son sucesos incompatibles, es decir A ∩ B = ∅, entonces : P(A ∪ B) = P(A) + P(B) Observación : El sistema de axiomas anteriores es incompleto; no nos dice como se calcula una probabilidad, de modo que se puede adoptar la definición de probabilidad al fenómeno que se quiere estudiar. Dependiendo de las condiciones del problema, se calculara la probabilidad de un suceso A por :
i) nkAP =)( = Nº de casos favorables a A / Nº de casos totales
ii) n
n
nlimAP A
∞→=)(
En que nA es el numero de veces que ocurre A en una serie de n repeticiones del experimento.
A B
Ω
A A A ∩ B A ∪ B A ∩ B = ∅
Fig.13
AA
B
A A
B
A
B

16
iii) En los casos de probabilidades geométricas, se calcula P(A) como una razón de longitudes, de áreas o de volúmenes. Ejemplo: Si se tira en S un punto al azar ( es decir sin apuntar ), la probabilidad S de que impacte en s es : P(A) = s / S Las tres maneras de calcular una probabilidad que hemos visto satisface los axiomas. III.2 CONSECUENCIAS DE LOS AXIOMAS Las propiedades siguientes resultan como consecuencia inmediata de los axiomas : - Propiedad 1 : P( ∅ ) = 0 - Propiedad 2 : P ( A ) = 1 – P( A ) - Propiedad 3 : P( A ∪ B ) = P( A ) + P( B ) – P( A ∩ B ) ; ( A ∩ B ≠ ∅ ) III.3 PROBABILIDAD CONDICIONAL Sea B un suceso del cual sabemos que ha ocurrido. La probabilidad condicional de un suceso A dado que ha ocurrido B, escrita P( A ⎜B ), se define por :
)(
)()(BP
BAPBAP ∩= (1)
Y se llama probabilidad condicional de A dado B. La probabilidad condicional De B dado A se define por :
)(
)()(AP
BAPABP ∩= (2)
Regla de la multiplicación : De (1) y (2) se deduce que : )()()()()( BAPBPABPAPBAP ⋅=⋅=∩ (3) Ejemplo : Se sacan 2 cartas consecutivamente ( sin devolución ) de una baraja. Sean : A = La primera carta es un as B = La segunda carta es un as
P( A ∩ B ) = P( A )*P( B ⎜A ) = (4 / 52)*(3 / 51) = 0,0045
La formula (3) se puede generalizar para más sucesos, por ejemplo, con tres sucesos A, B, C : P( A ∩ B ∩ C ) = P( A )*P( B ⎜A )*P( C ⎜A ∩ B ) (4)
s
A B

17
Y para n sucesos A1, A2,....., An : P(A1∩A2∩....∩An) = P(A1)*P(A2 ⎜ A1)*P(A3 ⎜ A1∩ A2)*.....*P(An ⎜ A1∩ A2∩....∩ An-1) (5) Ejemplo : Se sacan 4 cartas consecutivamente ( sin devolución ) de una baraja. Sean : A1 = La primera es un as ; A2 = La segunda es un as A3 = La tercera es un as ; A4 = La cuarta es un as : P(A1∩A2∩A3∩A4) = (4 / 52)*(3 / 51)*(2 / 50)*(1 / 49) = 0,0000037 III.4 SUCESOS INDEPENDIENTES En términos intuitivos dos sucesos A y B son independientes si la ocurrencia de B no afecta la ocurrencia de A. En términos formales tendremos la definición siguiente : Definición :Dos sucesos A y B son independientes si :
P( A ⎜B ) = P( A ) (6)
Al introducir la ecuación (6) en la ecuación (3), se tiene que si A y B son independientes, entonces:
P( A ∩ B ) = P( A )*P( B ) (7) Al introducir (7) en (2), se tiene :
P( B ⎜A ) = P( B ) Ejemplo : Se ponen al azar en una fila 3 personas A, B y C. Sean los sucesos : S = “ A esta a la izquierda de B ” T = “ C esta a la izquierda de B ” Encontrar P( S ), P( T ), P(S ∩ T ), P( S ⎜T ), ¿ Son independientes S y T ? Solución : Ω = ABC, ACB, BAC, BCA, CAB, CBA S = ABC, ACB, CAB T = ACB, CAB, CBA S ∩ T = ACB, CAB Luego : P( S ) = 3/6 = 1/2 = P( T ) P(S ∩ T ) = 2/6 = 1/3
P( S ⎜T ) = P(S ∩ T ) / P( T ) = (1/3) / (1/2) = 2 / 3 Luego S y T no son independientes porque P( S ⎜T ) ≠ P( S ).

18
IV. VARIABLES ALEATORIAS Se llama variable aleatoria al resultado de un experimento aleatorio cuando este resultado se puede expresar por un numero. Se utilizan letras mayúsculas para describir las variables aleatorias. Ejemplos: a) X = resultado de tirar un dado b) Y = estatura de un individuo elegido al azar c) Z = resultado de tirar una moneda. Z no es una variable aleatoria porque su resultado (C
ó S) no es un numero. Se puede observar que una variable aleatoria es la transposición teórica de una variable estadística. Rango de una Variable Aleatoria : Se llama rango R de una variable aleatoria X al conjunto de todos los valores que puede tomar X. Ejemplo: a) X = resultado de tirar un dado ⇒ R = 1, 2, 3, 4, 5, 6 b) X = terminación de la lotería ⇒ R = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 c) X = duración de una ampolleta ⇒ R = t : t ≥ 0 Tipos de Variables Aleatorias : Existen dos tipos de variables aleatorias : a) Variable Aleatoria Discreta : es aquella en la cual el rango R es de la forma : R = x1, x2, x3,......, xn b) Variable Aleatoria Continua : es aquella en la cual el rango R es de la forma : R = x : a ≤ x ≤ b ( a y b pueden ser eventualmente - ∞ y +∞ ). IV.1 DESCRIPCION PROBABILISTICA DE UNA VARIABLE ALEATORIA
a) 0)( ≥ixp b) ∑ =⇔=++++
iii21 1)p(x1....)p(x....)p(x)p(x
(p(xi) se llama función de probabilidad ) Ejemplo :Se tiran 3 monedas diferentes al aire. Sea X = “ numero de caras ”. Encontrar R y p(xi).
x1 x2 xi
x
a b x
Definición 1 : Sea X una variable aleatoria discreta, a cada valor posible xi le asociamos un valor p(xi) = P( X = xi ), llamado probabilidad de xi el cual satisface :
19
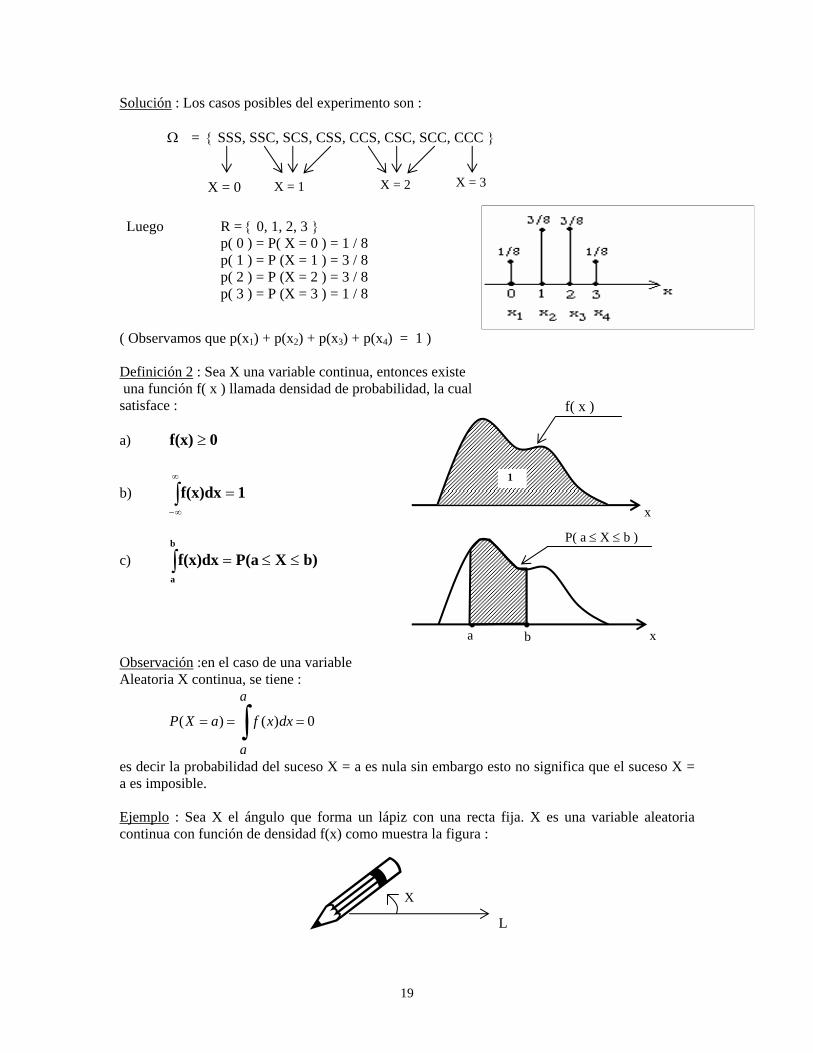
Solución : Los casos posibles del experimento son :
Ω = SSS, SSC, SCS, CSS, CCS, CSC, SCC, CCC
( Observamos que p(x1) + p(x2) + p(x3) + p(x4) = 1 ) Definición 2 : Sea X una variable continua, entonces existe una función f( x ) llamada densidad de probabilidad, la cual satisface : a) 0f(x) ≥
b) ∫∞
∞−
= 1f(x)dx
c) ∫ ≤≤=b
a
b)XP(af(x)dx
Observación :en el caso de una variable Aleatoria X continua, se tiene :
∫ ===
a
a
dxxfaXP 0)()(
es decir la probabilidad del suceso X = a es nula sin embargo esto no significa que el suceso X = a es imposible. Ejemplo : Sea X el ángulo que forma un lápiz con una recta fija. X es una variable aleatoria continua con función de densidad f(x) como muestra la figura :
L
X = 0 X = 1 X = 2 X = 3
Luego R = 0, 1, 2, 3 p( 0 ) = P( X = 0 ) = 1 / 8 p( 1 ) = P (X = 1 ) = 3 / 8 p( 2 ) = P (X = 2 ) = 3 / 8 p( 3 ) = P (X = 3 ) = 1 / 8
f( x )
x
P( a ≤ X ≤ b )
a b x
X
1

20
calculamos P( π/4 ≤ X ≤ π/2 ) :
81
21)24(
2/
4/
==≤≤ ∫ dxπ
π πππ XP
La función de Distribución de Probabilidades. Otra herramienta que sirve para caracterizar probabilisticamente a una variable aleatoria X es la función de distribución de probabilidades, definida por
F( x ) = P( X ≤ x ) Observación : F( x ) es la transposición teórica del diagrama acumulado ( ver pagina 4 ). Si X es continua, según la formula ( c ) de la pagina 22, se tiene :
∫∞−
=x
dxf(x)F(x) , lo que implica :
xF(x)f(x)d
d=
Propiedades de F( x ) : F( x ) satisface las propiedades siguientes : a) F( - ∞ ) = P( X ≤ - ∞ ) = P( ∅ ) = 0 b) F( + ∞ ) = P( X ≤ + ∞ ) = P( Ω ) = 1 c) F( x ) es una función que no decrece, es decir : si a ≤ b, entonces F( a ) ≤ F( b )
IV.2 EL VALOR ESPERADO O ESPERANZA MATEMATICA DE UNA VARIABLE ALEATORIA. La significación intuitiva de la esperanza matemática de una variable aleatoria X es la siguiente : es un valor medio de la variable X, en que todos los valores que X puede tomar están ponderados por su probabilidad respectiva. Se utiliza la notación E(X) para representar la esperanza matemática.
f(x)
2π
1/2π
0 x
Fig.14
F(x)
1
0x

21
Ejemplo : Sea X = resultado de tirar un dado. E(X) = 1*1/6 + 2*1/6 + 3*1/6 + 4*1/6 + 5*1/6 + 6*1/6 E(X) = 3.5 La significación de este resultado es la siguiente : si se repite un numero n grande de veces el experimento de tirar un dado y se registran las observaciones de X en una muestra, se obtendrá, por ejemplo : M = 6, 3, 5, 5, ....., 2 , y en condiciones ideales debería tenerse :
x = 6 + 3 + 5 + 5 + ......+ 2 = 3.5 n
O sea que la esperanza matemática es un promedio teórico de la variable X. La definición formal de esperanza matemática de una variable aleatoria es la siguiente : Definición : a) Sea X una variable aleatoria discreta, en la cual p( xi ) = P( X = xi ), se define la esperanza matemática de X como : )xip(x)E(X i ⋅= ∑
i
b) Sea X una variable aleatoria continua, con función de densidad f(x), se define la esperanza matemática de X como :
∫∞
∞−
⋅= xf(x)xE(X) d
Observación : si la variable aleatoria X es continua, E( X ) representa la abscisa del centro de gravedad de la masa ubicada bajo la curva f( x ) :
E(X)xf(x)
xf(x)x=
⋅=
∫
∫∞
∞−
∞
∞−
d
dxG
Ejemplo : sea f( x ) como en la figura 19,
G
1/6
1 2 3 4 5 6 x
Fig.15
E(X)
p(xi)
x1 x2 xi x
Fig.16
f(x)
x
Fig.17
E(x) = xG
f(x)
Centro de Gravedad
es igual a 1
Fig.18

22
Entonces :
∫ ∫⋅−
=−
⋅=b
a
b
a
dd xxab
1xab
1xE(X)
2
aba)2(b
ab2x
ab1E(X)
22b
a
2 +=
−−
=⎥⎦
⎤⎢⎣
⎡⋅
−=
Esperanza Matemática de una Función de X Sea H( X ) una función de X, se define la esperanza de H( X ) por : a) Si X es discreta : [ ] ∑ ⋅=
i
)p(x)H(xH(X)E ii
b) Si X es continua : [ ] ∫∞
∞−
⋅= dxf(x)H(x)H(X)E
Ejemplo : En el caso anterior encontrar E( X2 ), ( H( X ) = X2 )
dxdb
a
b
a∫∫ ⋅
−=
−⋅= 22 x
abx
ab1xE(X 1) 2
3)a2abb2(
a)(b3)a2abb2(a)(b
a)(b3a3b3
3x
ab1)X2E(
3 ++=
−⋅++⋅−
=−⋅
−=⎥
⎦
⎤⎢⎣
⎡⋅
−=
b
a
Propiedades de la Esperanza Matemática. Las siguientes son las propiedades de la esperanza matemática, las cuales se pueden probar apartir de la definición :
• Propiedad 1 : E( C ) = C
• Propiedad 2 : E( X + C ) = E( X ) + C
• Propiedad 3 : E( X * C ) = C * E( X ) Las propiedades 2 y 3 se generalizan de la siguiente forma :
βαβα +⋅=+⋅ ))( E(XXE ( α y β = cte. )
La Esperanza matemática constituye una medida de tendencia central de una distribución teórica de probabilidades. Por analogía de lo que vimos en Estadística Descriptiva, definiremos una medida de dispersión teórica : La Varianza. IV.3 LA VARIANZA DE UNA VARIABLE ALEATORIA. Definición : Se llama varianza de una variable aleatoria X a la cantidad :
1/(b-a)
f(x)
a b E(x)
Fig.19
23
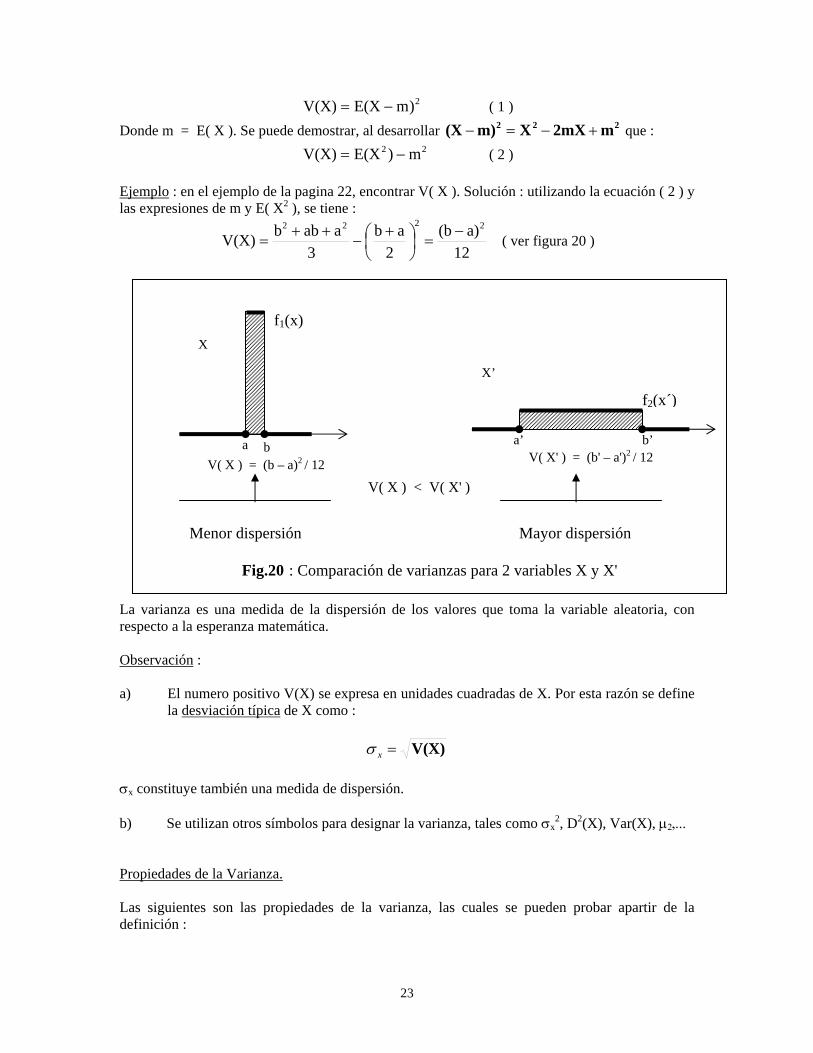
2)mE(XV(X) −= ( 1 ) Donde m = E( X ). Se puede demostrar, al desarrollar 222 m2mXXm)(X +−=− que :
22 m)E(XV(X) −= ( 2 ) Ejemplo : en el ejemplo de la pagina 22, encontrar V( X ). Solución : utilizando la ecuación ( 2 ) y las expresiones de m y E( X2 ), se tiene :
12a)(b
2ab
3aabbV(X)
2222 −=⎟
⎠⎞
⎜⎝⎛ +
−++
= ( ver figura 20 )
La varianza es una medida de la dispersión de los valores que toma la variable aleatoria, con respecto a la esperanza matemática. Observación : a) El numero positivo V(X) se expresa en unidades cuadradas de X. Por esta razón se define
la desviación típica de X como :
V(X)=xσ
σx constituye también una medida de dispersión. b) Se utilizan otros símbolos para designar la varianza, tales como σx
2, D2(X), Var(X), µ2,... Propiedades de la Varianza. Las siguientes son las propiedades de la varianza, las cuales se pueden probar apartir de la definición :
Menor dispersión Mayor dispersión
Fig.20 : Comparación de varianzas para 2 variables X y X'
f1(x)
f2(x´)
X
X’
a b a’ b’
V( X ) = (b – a)2 / 12 V( X' ) = (b' – a')2 / 12
V( X ) < V( X' )

24
• Propiedad 1 : V( C ) = 0 ,en que C es una constante ( en otras palabras, una constante no tiene dispersión )
• Propiedad 2 : V( X + C ) = V( X ) ( al sumar una constante la varianza no
varia , ver figura 21 )
• Propiedad 3 : V( C*X ) = C2 * V( X ) ( ver figura 22 )
Las propiedades 2 y 3 se generalizan en la siguiente forma :
V(X)2)X(V ⋅=+⋅ αβα ( α y β = ctes. )
Fig.21
Densidad de X Densidad de Y = X + 2
0 1 2 3E(X) E(X+2)x
Ley de X Ley de Y = 4*X
10.25
0 1 40
V( X ) = 1/12 V( Y ) = 16*V( X ) = 16/12 = 4/3
Fig.22

25
IV.4 VARIABLES ALEATORIAS MULTIDIMENSIONALES Estudiaremos principalmente el caso bidimensional; la generalización a n dimensiones es inmediata. Para describir probabilisticamente una variable aleatoria bidimencional ( X , Y ) tendremos la definición siguiente :
a) Sea ( X , Y ) una variable aleatoria bidimensional continua (es decir ambas son
continuas), entonces existe una función f(x , y) llamada densidad de probabilidad conjunta que satisface las condiciones :
i) 0y)f(x, ≥
ii) ∫ ∫∞
∞−
∞
∞−
= 1) yxyf(x, dd
iii) ∫∫=∈ ))D
D yxy)f(x,YP((X, dd
Definición :
a) Sea ( X , Y ) una variable bidimensional discreta ( es decir ambas son discretas ), a cadaresultado posible ( xi , yj ) le asociamos un valor :
p( xi , yj ) = P( X = xi , Y = yj )
el cual satisface :
∑∑ =i j
1)y,p(x ji p( xi , yj )
xi
yj
x
y
Fig.23

26
Ejemplo 1: Se tiran 3 monedas. Sea X = “ numero de caras ”, Y = ⎟Nº cara – Nº sellos⎟. Encontrar p( xi , yj ). Solución : los casos totales y su par ( xi , yj ) asociado son :
Ω = SSS, SSC, SCS, CSS, CCS, CSC, SCC, CCC Luego : p(0,3) = 1/8 ; p(1,1) = 3/8 p(2,1) = 3/8 ; p(3,3) = 1/8
Ejemplo 2 : Dos personas deciden juntarse entre las 0 hrs y 1 hrs. Cada una decide no esperar más de 10 minutos a la otra. Si estas personas llegan al azar entre las 0 h y 1 h ¿ cual es la probabilidad de que se encuentren ?
(0,3) (1,1) (2,1) (3,3)
Fig.24
DD
f ( x,y) f ( x,y )
Volumen
0
x y xy
Volumen bajo lafunción f(x,y) es igual a1.
(b)
∫∫D
dxdyyxf ),( representa la
probabilidad de que el resultado caiga enuna zona D del plano.
(c)
⇔
Fig.25
x1 x2 x3 x4
XY 0 1 2 3
1
3
0
1/8
3/8
0
3/8
0
0
1/8
y1
y2
3/8
3/8
1/8
1/8
01
23
3
1
y
x

27
Solución : Sea X = instante en que llega la 1ª persona Y = instante en que llega la 2ª persona Variación de X : 0 ≤ x ≤ 60´ Variación de Y : 0 ≤ y ≤ 60´ La densidad de la variable ( X , Y ) es f (x,y) = cte. Porque la personas llegan al azar :
Los casos favorables son aquellos definidos por la desigualdades :
x – y ≤ 10 y y – x ≤ 10
estas desigualdades determinan la zona DD en la cual se encuentran las personas ( figura 27 ) :
Probabilidad = Area de D * 1/3600 = 3611
360025003600
=−
La altura h vale 1/3600porque el volumen bajof ( x , y ) es 1.
f (x , y) = 1 / 360
Conjunto de resultados posibles
h
60
60
x
y
Fig.26
Fig.27
y = x + 10
y = x - 10
D
volumen
60
100 10 60
f(x,y)
60
60
1/3600
x
y
D

28
IV.1. LEYES MARGINALES DE PROBABILIDAD a) Sea ( X ,Y ) una variable aleatoria bidimensional discreta. Supongamos que conocemos
p(xi , yi ) y deseamos conocer p(xi) = P( X = xi ). Se tiene :
( X = xi ) = ( X = xi , Y = y1) ∪ ( X = xi , Y = y2) ∪......... tomando probabilidades :
)...... ∑=++=j
jy,p(x)y,xp()y,xp()xp( i2i1ii
∑=j
)y,p(xxip( ji)
se llama función de probabilidad marginal de X. Análogamente :
∑===i
)) jijj y,p(xyP(Y)yq(
se llama función de probabilidad marginal de Y. b) Sea ( X ,Y ) continua, en este caso se definen las densidades marginales por :
∫∞
∞−
= yyf(x,f(x) d) ⇒ densidad marginal de X.
∫∞
∞−
= xyf(x,g(y d)) ⇒ densidad marginal de Y.
IV.2. VARIABLES ALEATORIAS INDEPENDIENTES En términos intuitivos, dos variables aleatorias son independientes si el resultado de una no influye sobre el resultado de la otra. En términos formales, tendremos la definición siguiente ( ver pagina 17 formula 7 ) :
a) Se dice que las variables aleatorias discretas X e Y son independientes si se tiene (para todo xi , yi) :
P( X = xi , Y = yj) = P( X = xi )*P( Y = yj ) ⇔ p(xi , yj) = p(xi)*q(yj)
b) Se dice que las variables aleatorias continuas X e Y son independientes si se tiene
(para todo x , y)
g(y)f(x)y)f(x, ⋅=
Ejemplo : estudiar si las variables X e Y del ejemplo 1 de la pagina 26 son independientes : Solución : Veamos el cuadro :

29
x y
x1 0
x2 1
x3 2
x4 3
q(yj)
y1 1 0
3 8
3 8 0
6 8
y2 3
1 8 0 0
1 8
2 8
p(xi) 1 8
3 8
3 8
1 8
Se tiene : P( X = 1 , Y = 1 ) = 3/8 P( X = 1 ) = 1/8 , P( Y = 1 ) = 6/8 = 3/4 Como P( X = 1 , Y = 1 ) ≠ P( X = 1 ) * P( Y = 1 ), entonces X e Y no son independientes. IV.3. ESPERANZA MATEMATICA DE UNA FUNCION DE DOS VARIABLES X e Y. Sea H( X,Y ) una función de X y de Y. Se define la esperanza matemática de H( X ,Y ) por :
[ ] )( ji y,p(x)yj,xiHY)H(X,E ⋅= ∑∑i j
si ( X , Y ) es discreta
[ ] ∫ ∫∞
∞−
∞
∞−
⋅= yxy,f(x)y,H(xY)H(X,E jiji dd) si ( X , Y ) es continua
Utilizando esta definición se pueden establecer los dos teoremas siguientes : • Teorema 1 : E(Y)E(X)Y)E(X +=+
• Teorema 2 : Si las variables aleatorias X e Y son independientes, entonces :
E(Y)E(X)Y)E(X ⋅=⋅
Como un ejemplo veamos la demostración del teorema 2 en el caso que ( X ,Y ) es continua :
∫ ∫ ∫ ∫∞
∞−
∞
∞−
∞
∞−
∞
∞−
⋅⋅⋅=⋅⋅=⋅ yxg(yf(x)yxyxy)f(x,yxY)E(X dddd )
∫ ∫∞
∞−
∞
∞−
⋅=⋅⋅⋅=⋅ )) E(YE(X)yg(y)yxf(x)xYE(X dd
IV.4. LA COVARIANZA DE DOS VARIABLES ALEATORIAS x e y Definiremos a continuación una nueva cantidad que nos dará, en cierto sentido, una medida de la dependencia entre dos variables aleatorias X e Y. Definición : se llama covarianza de X e Y a la cantidad :

30
E(Y)E(X)E(XY)Cxy ⋅−=
( a veces se utilizan otras notaciones para la covarianza, tales como : cov(x,y), µxy, σxy, kxy ) Propiedades de la Covarianza. a) Como consecuencia inmediata del teorema 2, pagina 29, se tiene que :
Si X e Y son independientes, entonces : Cxy = 0
b) Se tiene la relación siguiente, cuando X = Y
[ ] V(X)E(X))E(XC 22xx =−= ( ver formula 2, pag. 23 )
c) Se puede demostrar que si ( en promedio ) X crece, Y también crece, entonces Cxy > 0 y
que si ( en promedio ) al crecer X, Y decrece, entonces Cxy < 0.
Fig.28
Varianza de una suma de variables aleatorias Deseamos encontrar una expresión para la varianza de la suma de variables aleatorias : Z = X+Y: [ ]22 Y)E(XY)E(XY)V(XV(Z) +−+=+=
[ ] [ ] [ ]E(Y)E(X)E(XY)2E(Y))E(YE(X))E(X 2222 ⋅−⋅+−+−= lo que implica que :
xyC2V(Y)V(X)Y)V(X ⋅++=+ (1) Si X e Y son independientes, entonces Cxy = 0, luego :
V( X + Y ) = V( X ) + V( Y ) (2)
La propiedad (2) se puede generalizar para n variables X1, X2, ......., Xn independientes entre ellas:
V( X1 + X2 +.......+ Xn ) = V( X1 ) + V( X2 ) +.......+ V( Xn ) (3)

31
El coeficiente de correlación entre dos variables aleatorias X e Y. El coeficiente de correlación constituye otra medida de la dependencia entre dos variables aleatorias X e Y. Definición : Se llama coeficiente de correlación lineal al cuociente :
V(Y)V(X)Cxy
xy ⋅=ρ
Se puede observar que ρxy esta íntimamente relacionado con la covarianza, sin embargo ρxy es un numero sin dimensión. Propiedades de ρxy :
• Propiedad 1 : Si X e Y son independientes, entonces :
ρxy = 0
• Propiedad 2 : Se tiene la desigualdad siguiente :
-1 ≤ ρxy ≤ 1
• Propiedad 3 : Si ρxy = 1, entonces Y = α*X + β con α > 0 Si ρxy = -1, entonces Y = - α*X + β con α > 0
En la figura 30 se pueden observar distintas situaciones y el ρxy asociado :
Fig.29
y y
xxρxy = 1 ρxy = -1

32
Fig.30

33
V. MODELOS PROBABILISTICOS. Estudiaremos a continuación una serie de modelos de variables aleatorias unidimensionales : binomiales, Poisson, exponencial, Gauss, etc.,.... Comenzaremos por el estudio de los modelos de variables aleatorias discretas : A. Modelos de variables aleatorias discretas. A.1. Variable aleatoria de Bernulli. La variable aleatoria de Bernulli es una de las mas simples. Por definición X es una variable de Bernulli ( ó X sigue la ley de Bernulli ) si X toma solamente dos valores a y b, con probabilidades
respectivamente 1 – p y p ( 0 ≤ p ≤ 1 ) : Se puede probar que : pbp)(1aE(X) ⋅+−⋅=
p)(1pa)(bV(X) 2 −⋅⋅−= Ejemplo : se tira una moneda y sea X = 0 si sale cara, X = 1 si sale sello :
A.2. Variable aleatoria geométrica. El experimento que conduce a una variable aleatoria geométrica es el siguiente : Supongamos un experimento que se repite de manera independiente un numero indefinido de veces. En cada repetición solo caben dos alternativas :
i) Ocurre un suceso A con probabilidad p.
ii) Ocurre un suceso con probabilidad 1 – p. El experimento se detiene cuando ocurre por primera vez el suceso A. Sea X = “ numero de repeticiones necesarias ”. El conjunto de resultados posibles es :
Ω = A , BA , BBA , BBBA ,...... X = 1 X = 2 X = 3 X = 4 ,....
Fig.31
a b x
1 - p
p
Fig.321/2 1/2
0 1x

34
Las probabilidades asociadas son : P( X = 1 ) = P( A ) = p P( X = 2 ) = P( BA ) = P( B ) * P( A ) = (1 – p)*p ( por la independencia ) P( X = 3 ) = P( BBA ) = P( B ) * P( B ) * P( A ) = (1 – p)2*p.
Se puede demostrar que :
p1E(X) =
pp1V(X) 2
−=
Ejemplo : se tira una moneda hasta que aparezca por primera vez cara. Entonces X = “ numero de lanzamientos necesarios ” sigue una ley geométrica con parámetros p = ½ . En particular E( X ) = 2.
A.3 La variable aleatoria Binomial. El experimento que conduce a una variable binomial es el siguiente : Supongamos un experimento que se repite de manera independiente n veces. En cada repetición solo caben dos alternativas : i) Ocurre un suceso A con probabilidad p ii) Ocurre un suceso B con probabilidad 1- p
1/2
pp)(1k)P(X 1k ⋅−== −Fig.33
p(1 – p)
p(1 – p)2
0 1 2 3 4 x
Fig.34
1 2 3 4 5 x
1/4
1/81/16
1/32

35
El espacio muestral asociado al experimento es :
Ω = BB...B, ABB...B, BAB...B,....,....,....,AAA...A X = 0 X = 1 X = 1 X = n Sea X = “ numero de veces que aparece A en las n repeticiones ”. Para deducir una formula general estudiemos los casos n = 1, 2, 3 : i) n = 1 ⇒ Ω = B, A P( X = 0 ) = 1 – p Los términos corresponden al desarrollo de [ (1 – p) + p ]1
P( X = 1) = p ii) n = 2 ⇒ Ω = BB, AB, BA, AA P( X = 0 ) = P( BB ) = P(B)*P(B) = (1 - p)2 P( X = 1 ) = P( AB, BA ) = P(AB)*P(BA) = 2p*(1 - p) P( X = 2 ) = P( AA ) = p2 iii) n = 3 ⇒ Ω = BBB, ABB, BAB, BBA, AAB, ABA, BAA, AAA P( X = 0 ) = (1 – p)3 P( X = 1 ) = 3p(1 – p)2
P( X = 2 ) = 3p2(1 – p) P( X = 3 ) = p3 iii) Para un valor de n más general, se tiene la formula siguiente, deducida del teorema del
binomio :
knp)(1pkn
kk)P(XPk
−−⋅⋅⎟⎟
⎠
⎞
⎜⎜
⎝
⎛=== k = 0, 1, ...., n
en particular : P0 = P( X = 0 ) = (1 – p)n
Pn = P( X = n ) = pn
Se puede probar que si X sigue una ley binomial con parámetros n y p, entonces :
n n n n
X = 0 X = 1
X = 0 X = 1 X = 2
Los términos corresponden al desarrollo de [(1 – p) + p]2
X = 0 X = 1 X = 2 X = 3
Los términos corresponden al desarrollo de [(1 – p) + p]3

36
pnE(X) ⋅= p)(1pnV(X) −⋅⋅=
Ejemplo : Sea una familia de n = 4 hijos, entonces X = “ numero de hijos varones ” es una variable binomial de parámetros n = 4 , p = 0.5. Además : P( X = 4) = (0.5)4 = 1 / 16 La esperanza matemática de X es : E(X) = n*p = 4*1/2 = 2, resultado que corresponde a la intuición.
En la formula knp)(1pkn
kk)P(XPk
−−⋅⋅⎟⎟
⎠
⎞
⎜⎜
⎝
⎛=== , el valor de ⎟
⎠⎞
⎜⎝⎛ n
k se calcula por :
k)!(nk!n!n
k −=⎟
⎠⎞
⎜⎝⎛
con : k.....321k! ⋅⋅⋅⋅= y 0! = 1 ( por definición ) Ejemplo : Se sabe que la probabilidad de que un camión este averiado a la entrada de un turno es p = 0.1. Si la empresa dispone de 30 camiones ¿ cual es la probabilidad de que haya exactamente 5 camiones averiados ? Sea X = “ numero de camiones averiados ”
102.0)9.0()1.0()5( 25530
5=⋅⋅⎟
⎠⎞
⎜⎝⎛==XP
( Observar que E(X) = n*p = 3 ) A.4. La variable aleatoria de Poisson. Es frecuente encontrar en la practica situaciones en que se aplica la Ley Binomial con p muy pequeño y n muy grande. Por ejemplo, se ha determinado que la probabilidad de que aparezca una pieza defectuosa es p = 0.01 y se reúnen las piezas en cajas de 200 piezas, la probabilidad de que en la caja existan r piezas defectuosas es :
r200r200
r(0.99)(0.01)r)P(X −⋅⋅⎟
⎠⎞
⎜⎝⎛==
Este valor se puede calcular de manera exacta o bien se puede calcular de manera aproximada utilizando el siguiente teorema :
!kep)(1p
kknk
n
knnp
λλ
λ
−−
∞→
⋅=−⋅⎟
⎠⎞
⎜⎝⎛
=lim

37
El limite anterior significa que n tiende a infinito manteniendo constante e igual a λ el producto n*p ( esto implica que p debe ser pequeño ). Se tiene entonces :
!ke)kP(XP
k
k
λλ −⋅=== k = 0, 1, 2,.....
Estas probabilidades Pk, limites de las probabilidades binomiales cuando n→∞ y n*p = λ = constante, constituyen la llamada Ley de Poisson.
Lo anterior significa que la Ley de Poisson aproxima bien a la binomial cuando n es grande y p pequeño; se considera que la aproximación es buena si p < 0.1 y si n*p < 5. Ejemplo : en el caso anterior de las piezas defectuosas :
1813.0)99.0()01.0()3P(X 1973200
3=⋅⋅⎟
⎠⎞
⎜⎝⎛==
utilizando Poisson, con 20.01200pn =⋅=⋅=λ :
1805.03!e23)P(X
23
=⋅
≅=−
Esperanza matemática y varianza : Se puede demostrar que la esperanza matemática y la varianza de la Ley de Poisson están dadas por :
E( X ) = λ V( X ) = λ
A.5. La Ley Hipergeometrica. El experimento que conduce a la ley hipergeometrica es el siguiente : Sea un lote de N piezas, de las cuales D = p*N son defectuosas (luego N – D = N – p*N =N(1- p) son aceptables) Se sacan al azar, una a una y sin devolver al lote, n piezas :
Fig.35P0
P2
P1
0 1 32 x

38
Sea X = “ numero de piezas defectuosas en la muestra de n piezas ”. Los valores que toma X son los que define la desigualdad :
Máximo entre 0 y D – N + n ≤ x ≤ Mínimo entre n y D
Se puede demostrar que :
a)
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛ −
−⋅
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
==N
n
DN
kn
D
kk)P(X
b) pnE(X) ⋅=
c) 1N
n)(Np)p(1nV(X)−
−⋅−⋅=
Ejemplo : en un estanque hay 20 peces de los cuales 8 son coloreados. Se pescan 10 peces, calcular la probabilidad de que existan 5 peces coloreados. Solución : N = 20 ; n = 10 ; D = 8 ; p = 0.8 ; X = “ numero de peces coloreados ”
24.020
10
820
510
8
55)P(X 20
10
12
5
8
5 =⎟⎠⎞
⎜⎝⎛
⎟⎠⎞
⎜⎝⎛⋅⎟
⎠⎞
⎜⎝⎛
=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛ −
−⋅
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
==
( En este caso E(X) = n*p = 10 * 0.4 = 4 ) B. Modelos de variables aleatorias continuas. B.1. La variable Aleatoria Uniforme. Sea X una variable aleatoria continua. Se dice que X sigue una ley uniforme si su densidad f(x) esta dada por :
p*N defectuosas N – p*N no defectuosas
? ( n ≤ N ) Muestreo
sin reemplazamiento
N piezas n piezas Fig.36

39
ab
1−
si x ∈ [a , b]
0 si x ∉ [a , b]
Ejemplo : Sea X el ángulo que forma un lápiz arrojado al azar con una recta fija ( ver pagina 19 ) entonces X sigue una ley uniforme en el intervalo [0 , 2π]. Se puede demostrar que si X sigue una ley uniforme :
2abE(X) +
=
( )12
abV(X)2−
=
B.2. La Ley Exponencial con parámetros λ ( λ > 0 ). Se dice que X sigue una ley exponencial con parámetros λ si su densidad esta dada por : xe ⋅−⋅ λλ si x > 0 0 si x ≤ 0
Se puede demostrar que :
λ1E(X) =
21)V(Xλ
=
f(x) =
f(x) =
Fig.37
ab1−
f(x)
E(x)a b
x
Fig.38
0 x
f(x)
λ

40
B.3. La variable aleatoria Gamma. Se define en Matemáticas la función gamma Γ( p ) como la integral :
∫∞
−− ⋅=Γ0
1px xxe)p( d
la cual presenta la propiedad, siendo p un entero > 0 :
Γ( p ) = ( p – 1 )!
Se dice que una variable aleatoria X sigue una ley Gamma con parámetros a y p si su densidad es :
)p(yea 1paxp
Γ⋅⋅ −−
si x > 0
0 si x ≤ 0 ( p > 0 , a > 0 ).
Se puede demostrar que :
apE(X) =
2apV(X) =
B.4. La variable aleatoria Beta. Se define en Matemáticas la función Beta B(p,q) como :
∫ −− −=+ΓΓ⋅Γ
=1
0
1q1p xx)(1x)q(p)q()p(q)B(p, d
Se dice que una variable aleatoria X sigue una ley Beta con parámetros p y q si su densidad es :
f ( x ) =
Gráfico de f(x) para p > 2
Fig.39
0 x

41
q)B(p,x)(1x 1q1p −− −⋅
si 0 < x < 1
0 si x ≤ 0 ó x ≥ 1 ( p > 0 , q > 0 ) Se puede demostrar que :
qppE(X)+
=
1)q(pq)(ppV(X) 2 ++⋅+
=
B.5. La variable aleatoria normal o gaussiana. Definición: se da el nombre de variable aleatoria normal ( o gaussiana ) a toda variable definida en el eje ( -∞ , +∞ ) y que tiene la densidad :
2
21
21)
⎟⎠⎞
⎜⎝⎛ −
−⋅
⋅= σ
πσ
mx
ef(x
Se puede demostrar que :
E(X) = m V(X) = σ2
El parámetro m no influye en la forma de la curva f(x), su variación conduce a un desplazamiento de la curva a lo largo del eje x. En cambio, al variar σ se altera la forma de la curva ; en efecto, es fácil de ver que el máximo de f(x) es igual a :
πσ 21
⋅ , en el punto x = m
o sea que si disminuye σ, aumenta el máximo de f(x) :
f ( x ) =

42
Conviene recordar las siguientes áreas bajo la curva de la ley de Gauss ( Fig.41 ) :
Fig.41
En símbolos, si X sigue una ley de Gauss, con parámetros m y σ :
P( m-σ ≤ X ≤ m+σ ) = 0,68 P( m-2σ ≤ X ≤ m+2σ ) = 0,95
P( m-3σ ≤ X ≤ m+3σ ) = 0,997 Las variables aleatorias normales aparecen con gran frecuencia en Estadística. Por ejemplo los errores de mediciones siguen como regla una variable aleatoria normal. Un método mecánico para generar una variable aleatoria gaussiana consiste en la maquina de Galton, compuesta por un conjunto de bolillas que son desviadas en su trayectoria por una serie de clavos, depositándose en los recipientes inferiores ( Fig.42 )
Fig.40
σ = 1.0
σ = 0.5
mx
68 % 95 %
m - σ m + σ m - 2σ m + 2σ
99.7 %
m -3σ m + 3σ

43
Fig.42
B.6. La variable aleatoria Lognormal. Definición : Se dice que una variable aleatoria X sigue una Ley Lognormal si su logaritmo (neperiano, en base e) sigue una ley normal. A partir de esta definición se puede demostrar que la función de densidad tiene por expresión :
2mlnx
21
e2x
1)f(x⎟⎠⎞
⎜⎝⎛ −
−⋅
⋅=
πσ si x > 0
0)f(x = si x ≤ 0

44
La ley lognormal se presenta con frecuencia en el estudio de histogramas asociados con leyes de muestras provenientes de yacimientos mineros. Se puede demostrar que :
22)( σ+== meXEM
⎟⎠⎞
⎜⎝⎛ −⋅==∑ 1)(
222 σeMXV
Fig.43f(x)
0x

45
VI. LA LEY DE LOS GRANDES NUMEROS Y EL TEOREMA DEL LIMITE CENTRAL La ley de Los grandes números y el teorema del limite central constituyen uno de los resultados más importantes del calculo de probabilidades. A) La ley de Los grandes números. Sea X1, X2,......, Xn una sucesión de variables aleatorias independientes tales que E(X1) = E(X2) = .....=E(Xn) = m, entonces cuando n tiende a infinito, se tiene :
0,1.....21 ⎯→⎯⎟
⎠
⎞⎜⎝
⎛=
+++m
nXXX
P n
o sea que si n es grande, la probabilidad de que el promedio de las variables sea igual a la esperanza matemática m es muy próxima a 1,0. B) El teorema del limite central. Este teorema pone de manifiesto la importancia que la ley de Gauss : Teorema : Sea X1, X2,......, Xn una sucesión de variables aleatorias independientes tales que :
E(Xi) = mi , V(Xi) = σ2i
Entonces, si n es grande, la variable aleatoria :
Z = X1 + X2 +.....+ Xn sigue aproximadamente una ley de Gauss con esperanza matemática E( Z ) = m1 + m2 +.....+ mn y con varianza V( Z ) = σ2
1 + σ22 +.....+ σ2
n El grado de aproximación entre la variable Z y la ley de Gauss depende evidentemente de n y de la ley de probabilidad de Los Xi. En la figura 43 hemos representado el caso en que todos Los Xi siguen una ley uniforme en el intervalo [ 0 , 1 ], también hemos dibujado la densidad de la ley normal de igual esperanza y varianza.
Ejemplo : Supongamos que se tiene una sucesión X1, X2,......, Xn de variables aleatorias independientes tales que cada Xi sigue la ley de probabilidad siguiente :
Fig.44: Densidades de X1 , X1+X2 y X1+X2+X3
n = 1
n = 1
n = 2
n = 2
n = 3
n = 3
0 1 2 3 x

46
Es fácil de ver que la variable aleatoria Z = X1 + X2 +.....+ Xn toma los valores 0, 1, 2,....., n con probabilidades :
nn
kk kXPp ⎟
⎠⎞
⎜⎝⎛⋅⎟
⎟⎠
⎞⎜⎜⎝
⎛===
21)( k = 0, 1, 2,..., n
El gráfico de pk para n = 10 es :
Como puede observarse el Teorema del Limite Central explica porqué en tantas aplicaciones aparecen distribuciones normales, ya que expresa que la suma de variables aleatorias, en condiciones muy generales, tienden hacia la ley de Gauss. El ejemplo más clásico e importante es el de Los errores de medida, en que, al suponerse que el error total resulta de la suma de un gran numero de errores, explica que la ley de Gauss aparezca naturalmente para la representación de tales errores. El Teorema del Limite Central explica también porqué en la máquina de Galton las bolillas se depositan según una ley de Gauss.
½ ½
0 1
Fig.45
200 210
100 210
0 1 2 3 4 5 6 7 8 9 10

47
VII. LA INFERENCIA ESTADÍSTICA. Teoría de Muestras Para utilizar Los modelos probabilístico que hemos presentado en Los capítulos anteriores es necesario entrar en el mundo empírico y hacer algunas mediciones. Por ejemplo, en muchos casos es apropiado hacer hipótesis acerca de una variable aleatoria X, lo que conduce a un tipo determinado de distribución : normal, lognormal, gamma,...Sabemos que cada una de estas leyes de probabilidad depende de uno o más parámetros desconocidos, luego debemos obtener algunos valores experimentales de X y después utilizar estos valores de alguna manera apropiada para estimar estos parámetros. Formalicemos ahora la noción importante de muestra aleatoria : Definición : Sea X una variable aleatoria con una ley de probabilidad. Sean X1, X2,......, Xn , n variables aleatorias independientes en que cada una de ellas tiene la misma ley de probabilidad que X. Llamaremos a ( X1, X2,......, Xn ) una muestra aleatoria de tamaño n de la variable aleatoria X. Observaciones : en términos intuitivos una muestra aleatoria de tamaño n de una variable X corresponde a n mediciones repetidas de X, hechas básicamente bajo las mismas condiciones (para garantizar la independencia). Las variables X1, X2,......, Xn son independientes de manera que el resultado Xi no influya sobre el resultado Xj ( en caso contrario el muestreo de la variable estaría dirigido ). La muestra aleatoria es un conjunto de variables aleatorias ( X1, X2,......, Xn ) y no es un conjunto de números o datos. En otras palabras la muestra aleatoria es un ente teórico que se considera antes de hacer las mediciones para obtener Los datos. Por ejemplo sea Xi = resultado de un dado ( X1, X2,......, Xn ) ( 6, 2,...., 5 )
Experimento : “ Tirar n veces el dado ”
Muestra aleatoria de tamaño n
TEORIA Antes de realizar las mediciones
Muestra numérica de tamaño n o realización de la muestra aleatoria
PRACTICA Después de realizar
las mediciones

48
En general, Los valores numéricos tomados por la muestra ( X1, X2,......, Xn ) se denotarán por (x1, x2,......, xn). Estadísticos : una vez definidos Los valores x1, x2,......, xn de la muestra, los utilizaremos de alguna manera para hacer alguna inferencia acerca de la variable aleatoria X. En la práctica se trata de resumir este conjunto de valores por características más simples ( por ejemplo su promedio aritmético, valor más grande, valor más pequeño, etc...). Se llama estadístico a una función H( X1, X2,......, Xn ) de la muestra aleatoria X1, X2,......, Xn Observación : Un estadístico es una función de X1, X2,......, Xn , por consiguiente : Z = H( X1, X2,......, Xn ) es una variable aleatoria que toma el valor z = H(x1, x2,......, xn) una vez realizado el experimento. En general conviene estudiar Z y no z dado que este último es un número, mientras que Z es una variable aleatoria que puede tomar muchos valores y tiene en particular una esperanza matemática E(Z) y una varianza V(Z). Como ejemplo de estadísticos tenemos los siguientes :
Experimento mediciones
a) n
XXXX n+++
=...21
nxxx
x n+++=
...21
b) 2
1
12 )( XXSn
iin
−⋅= ∑=
2
1
12 )( xxsn
iin
−⋅= ∑=
c) K = Mín( X1, X2,......, Xn ) k = Mín( x1, x2,......, xn ) d) M = Máx( X1, X2,......, Xn ) m = Máx( x1, x2,......, xn )
TEORIA :
VARIABLES ALEATORIAS PRACTICA :
NUMEROS

49
X se llama promedio muestral, S2 varianza muestral, K valor más pequeño observado o mínimo, M valor más grande o máximo.

50
VIII. ESTUDIO DE ALGUNOS ESTADISTICOS. a) El estadístico X Se define la media muestral por :
∑=
⋅=n
iiX
nX
1
1
Las propiedades más importantes de X son las siguientes, en este caso de una muestra aleatoria (X1, X2,...., Xn) tal que E(X1) = E(X2) =....= E(Xn) = m , V(X1) = V(X2) =....= V(Xn) = σ2 : i) mXE =)(
ii) n
XV2
)( σ=
iv) Para n grande, la variable nmXZ
σ−
= sigue una ley de Gauss de esperanza 0 y varianza
1. Las relaciones ( i ) y ( ii ) resultan de las propiedades de la esperanza matemática y de la varianza. La relación ( iii ) se deduce por aplicación directa del teorema del limite central. b) El estadístico S2
n Se define la varianza muestral S2
n por :
∑=
−⋅=n
iin XX
nS
1
22 )(1
Las propiedades más importantes de S2
n son :
i) 22 1)( σ⋅−=
nnSE n
ii) 2
1
22 )()(1 mXmXn
Sn
iin −−−⋅= ∑
=
Observación : La propiedad ( i ) se obtiene al tomar esperanza matemática en ( ii ). Esta propiedad expresa que la esperanza matemática de S2
n no es igual a σ2 sino que es igual a 21
σ⋅−
n
n . Por esta razón se prefiere utilizar el estadístico S2n-1, definido por :

51
∑=
− −⋅−
=⋅−
=n
iinn XX
nS
nnS
1
2212 )(1
11
este estadístico presenta la propiedad : 212 )( σ=−nSE . Sin embargo cuando n es grande
(n≥100): 11
≅−nn y da lo mismo utilizar S2
n ó S2n-1 .

52
IX. LA ESTIMACION PUNTUAL. En este párrafo consideraremos el problema de estimar uno o más parámetros desconocidos asociados con una ley de probabilidad de una variable aleatoria X, a partir de una muestra aleatoria de X. Supongamos que la ley de probabilidad de X depende del parámetro desconocido θ. Queremos utilizar de alguna manera la muestra ( X1, X2,....., Xn ) con el objeto de estimar el valor de θ. Por ejemplo, supongamos que queremos estimar la esperanza matemática m de una variable X. Se pueden definir muchos estimadores del valor de m desconocido :
i) ∑=
⋅=n
iiX
nm
1
1ˆ
ii) )(21
ˆ 1 nXXm +⋅=
iii) )(21
ˆ KMm += ( M y K son el valor máximo y el mínimo de la muestra )
iv) nXXXm +++= .....ˆ 21 Observaciones : a) Es evidente que al proponer m como estimador del valor verdadero m, no esperamos que
m sea exactamente igual a m. Recordemos que m es una variable aleatoria y por lo tanto puede tomar muchos valores, luego m tendrá una cierta distribución de probabilidades y en particular una esperanza y una varianza.
b) Parece evidente que el estimador ( iv ) es un mal estimador, en el sentido de que siempre
proporciona un valor numérico alejado del valor verdadero m. Por otra parte parece intuitivo que el estimador ( i ) es mejor que el estimador ( ii ) porque el segundo no utiliza toda la información.
c) Veamos los valores numéricos que toman estos cuatro estimadores en una muestra de
tamaño 12 obtenida al tirar un dado no cargado :
( X1, X2,....., X12 ) (1, 3, 1, 1, 2, 1, 2, 5, 4, 2, 6, 2)
i).- 5,21230
ˆ ==om
ii).- 5,1)21(21
ˆ =+⋅=om

53
iii).- 5,3)16(21
ˆ =+⋅=om
iv).- 30ˆ =om En este ejemplo particular, debido a que el valor teórico es m = 3,5, el mejor estimador de la esperanza resulta ser (M + K)/2, pero este resultado podría deberse al azar; sin embargo el lector puede repetir muchas veces el experimento ( tirar 12 veces un dado ) y comprobar que en promedio, el estimador que más se acerca al valor verdadero es om = (M + K )/2. d) El ejemplo anterior de origen a las siguientes e importantes preguntas : • ¿Qué características queremos que posea un “ buen ” estimador ? • ¿Cómo decidimos que un estimador es mejor que otro ? • Dado un parámetro desconocido θ ¿Cuál es el estimador óptimo? En adelante trataremos de precisar los conceptos que hemos discutido y resolver estas interrogantes. IX.1. CRITERIOS PARA LOS ESTIMADORES Definición: Sea X una variable aleatoria con una distribución de probabilidades la cual depende de un parámetro desconocido θ. Sea (X1, X2,..., Xn) una muestra aleatoria de X y sean (x1, x2,..., xn) los valores muestrales correspondientes. Llamaremos estimador de θ a una función θ de la muestra :
θ = H(X1, X2,..., Xn)
y llamaremos estimación de θ al valor numérico de esta función para los valores x1, x2,..., xn , es decir :
oθ = H(x1, x2,..., xn)
Según esta definición, vemos que un estimador es un estadístico, luego es una variable aleatoria. Definición: Sea θ un estimador de un parámetro desconocido θ. Entonces diremos que θ es insesgado ( o centrado, o sin desviación sistemática ) si :
E(θ ) = θ Ejemplo: en el ejemplo de la pagina 55, el estimador de la esperanza matemática m, definido por :
m = X1 + X2 +....+ Xn no es insesgado ( se dice que es sesgado ). En efecto :
E( m ) = E(X1) + E(X2) +.....+ E(Xn) = n*m ≠ m En términos intuitivos, un estimador es insesgado si al repetir un numero N grande de veces el experimento de obtener los valores ( x1, x2, ...., xn ), el promedio de las estimaciones obtenidas es muy próximo al valor desconocido θ.

54
Fig.46
Tenemos entonces un primer criterio para los estimadores : restringirse a estimadores insesgados. Definición : Sea *θ un estimador insesgado del parámetro θ. Diremos que *θ es un estimador insesgado de varianza mínima si para cualquier otro estimador insesgado θ , se tiene :
V( *θ ) ≤ V(θ ) es decir, entre todos los estimadores insesgados, *θ es aquel que tiene varianza mínima.
E( *θ ) = E(θ ) = θ
Fig.47 Observación : Sabemos que la varianza de una variable aleatoria mide su variabilidad respecto a su valor esperado. Por lo tanto es intuitivamente atractivo exigir que un estimador insesgado tenga varianza pequeña porque de esta manera la variable aleatoria tiende a aproximarse a su valor esperado θ. Luego si *θ y θ son dos estimadores insesgados con funciones de densidad
como la figura 47, preferimos *θ a θ porque V( *θ ) < V(θ ).
θ 2 θ 1
θ θ β
E( 1θ ) = θ E( 2θ ) = β ≠ θ
Ley de probabilidad de un estimador insesgado.
Ley de probabilidad de un estimador sesgado.
V( *θ ) < V(θ )
θ
*θ
θ
valores de *θ
valores que toma θ
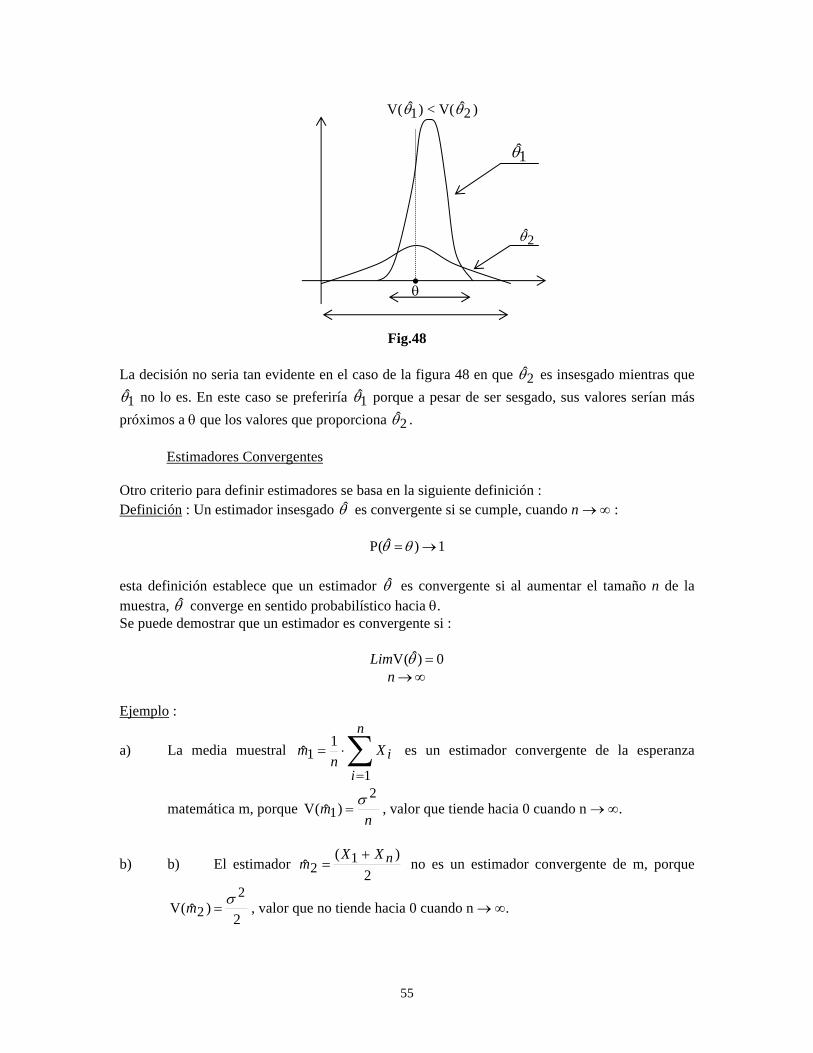
55
Fig.48 La decisión no seria tan evidente en el caso de la figura 48 en que 2θ es insesgado mientras que
1θ no lo es. En este caso se preferiría 1θ porque a pesar de ser sesgado, sus valores serían más próximos a θ que los valores que proporciona 2θ . Estimadores Convergentes Otro criterio para definir estimadores se basa en la siguiente definición : Definición : Un estimador insesgado θ es convergente si se cumple, cuando n → ∞ :
1)ˆ(P →=θθ
esta definición establece que un estimador θ es convergente si al aumentar el tamaño n de la muestra, θ converge en sentido probabilístico hacia θ. Se puede demostrar que un estimador es convergente si :
0)ˆ(V =∞→
θLimn
Ejemplo :
a) La media muestral ∑=
⋅=n
iiX
nm
11
1ˆ es un estimador convergente de la esperanza
matemática m, porque n
m2
1)ˆ(V σ= , valor que tiende hacia 0 cuando n → ∞.
b) b) El estimador 2
)(ˆ 1
2nXX
m+
= no es un estimador convergente de m, porque
2)ˆ(V
22
σ=m , valor que no tiende hacia 0 cuando n → ∞.
V( 1θ ) < V( 2θ )
1θ
2θ
θ

56
IX.2 METODOS PARA CONSTRUIR ESTIMADORES Hasta ahora solo hemos considerado criterios con los cuales podemos juzgar un estimador; es decir dado un estimador podemos verificar si es insesgado, convergente, calcular su varianza y comparar con otros estimadores. Sin embargo no disponemos de un método que proporcione estimadores. Existen varios procedimientos para obtener estimadores, uno de ellos es el método de los momentos que consiste en estimar el parámetro desconocido por el momento muestral asociado. Ejemplo: i) Esperanza matemática :
m = E(X) ∑=
⋅=n
iiX
nm
1
1ˆ
ii) Varianza :
σ2 = V(X) ∑=
−⋅=n
ii XX
n1
22 )(1σ
iii) Momento de orden k :
µk = E(Xk) ∑=
⋅=n
i
kik X
n1
1µ
Se puede demostrar que el método de los momentos proporciona estimadores convergentes que no siempre son insesgado y que no siempre son óptimos. Uno de los métodos más utilizados en Estadística es el método de la máxima verosimilitud el cual proporciona, bajo condiciones generales, estimadores óptimos. El método de la máxima verosimilitud. Antes de explicar este método estudiaremos un ejemplo introductorio : Ejemplo : En una urna hay 4 fichas que pueden ser blancas o negras pero se desconoce la proporción : no se conoce el parámetro p = ( número de fichas blancas )/4. Supongamos que hacemos dos extracciones con devolución y que obtenemos la primera blanca y la segunda negra. Con estos datos estimar el valor de p. Sea A el suceso que ocurrió : A = “ La primera es blanca y la segunda es negra ”. La probabilidad de A varía con p. El cuadro siguiente resume las diferentes alternativas :
Proporción p
p = 0 0 B 4 N
p = ¼ 1 B 3 N
p = ½ 2 B 2 N
p = ¾ 3 B 1 N
p = 1 4 B 0 N
Probabilidad del suceso que ocurrió : P(A)
0
¼ * ¾ = 3/16
2/4 * 2/4 = 4/16
¾ * ¼ = 3/16
0

57
Estimaremos el valor de p por 21
ˆ =op porque este valor maximiza la probabilidad del suceso que
ocurrió, esto equivale a admitir que lo que ocurrió era lo más probable. En el caso general supongamos una muestra aleatoria ( X1, X2,..., Xn ) la cual una vez realizado el experimento toma el valor ( x1, x2,..., xn ). La probabilidad del suceso que ocurrió es ( suponiendo que la variable es discreta ) :
= P( X1 = x1, X2 = x2,...., Xn = xn ) = p(x1) * p(x2) *....*p(xn)
en que p(xi) = P( Xi = xi ). Tendremos así la definición siguiente : Definición : Se llama estimador de máxima verosimilitud a aquel valor θ que máximiza la función siguiente, llamada función de verosimilitud. p(x1) * p(x2) *....*p(xn) si Xi es discreta f(x1) * f(x2) *....*f(xn) si Xi es continua
en términos matemáticos, se toma como estimación de θ la solución de la ecuación 0=∂∂
θ, sin
embargo resulta más simple ( lo cual es equivalente ) de resolver la ecuación :
( ) 0=∂
∂θ
Ln
Ejemplo 1 : En la ley de Poisson : !
)(xexp
x λλ −⋅= estimar el parámetro λ :
!....!2!1!
.....!2
2
!1
1
nxxx
xine
nxenx
xex
xex
⋅⋅⋅
∑⋅−=
−⋅⋅⋅
−⋅⋅
−⋅=
λλλλλλλλ
( ) ( )!....!! 21 nxxxLnLnixnLn ⋅⋅⋅−∑+−= λλ
⇒ ( ) 0=∑
+−=∂
∂λθ
ixnLn ⇒ ∑
=
⋅=n
iio x
n1
1λ ⇒ X=λ
Ejemplo 2 : En la ley exponencial : xexf λλ −⋅=)( estimar el parámetro λ :
∑⋅=⋅⋅⋅⋅⋅⋅= −−−− ixeeee nxxx n λλλλ λλλλ ....21
∑⋅−⋅= ixLnnLn λλ ⇒ 0=∑−=∂
∂ixnLn
λλ
=

58
⇒ Xn
iix
no
1ˆ
1
ˆ =⇒
∑=
= λλ
Propiedades de los estimadores de máxima verosimilitud. • Propiedad 1 : Los estimadores de máxima verosimilitud son convergentes. • Propiedad 2 : Los estimadores de máxima verosimilitud en el caso de ser insesgado son los
mejores estimadores posibles del parámetro θ. • Propiedad 3 : Si θ es un estimador de máxima verosimilitud de θ, entonces si n es grande, la
ley de probabilidad de θ es aproximadamente gaussiana con esperanza θ y varianza V(θ ). • Propiedad 4 : Si θ es un estimador de máxima verosimilitud de θ, entonces g(θ ) es el
estimador de máxima verosimilitud de g(θ). Ejemplos de estimadores máximo verosímiles Los ejemplos que se dan a continuación corresponden a los modelos de variables aleatorias estudiados anteriormente ( ver páginas 38 – 51 ) a.- Variable aleatoria de Bernulli : xp =ˆ b.- Variable aleatoria geométrica : xp 1ˆ =
c.- Variable aleatoria binomial con parámetros N y p :
Nxpppp kNkN
kk =⇒−⋅⋅⎟
⎟⎠
⎞⎜⎜⎝
⎛= − ˆ)1(
d.- Variable aleatoria de Poisson : x=λ e.- Variable aleatoria uniforme en [a , b] :
),....,,(ˆ,),....,,(ˆ 2121 nn XXXMáxbXXXMína ==
sin embargo estos estimadores son sesgados. Conviene utilizar los estimadores insesgados siguientes :
bn
nban
na ˆ1`ˆ,ˆ1
`ˆ ⋅+
=⋅+
=

59
f.- Ley exponencial con parámetro λ : x
1ˆ =λ
g.- Ley de Gauss con parámetros m y σ :
∑=
−⋅==n
ii xx
nxm
1
22 )(1ˆ,ˆ σ
sin embargo 2σ es sesgado; si n es pequeño conviene utilizar :
∑=
−⋅−
=n
ii xx
n1
221 )(
11σ , que es insesgado.
h.- Ley lognormal con parámetros m y σ :
2
1
2
1
)ˆ(ln1ˆ,ln1
ˆ ∑∑==
−⋅=⋅=n
ii
n
ii mX
nX
nm σ
y un estimador insesgado para σ2 es . 2
1
21 )ˆ(ln
11
ˆ ∑=
−⋅−
=n
ii mX
nσ

60
X. ESTIMACIÓN POR INTERVALOS DE CONFIANZA. Hasta ahora nos hemos ocupado de la estimación puntual de un parámetro desconocido θ, es decir la obtención de un valor oθ que estime de manera razonable el valor desconocido θ a partir de un conjunto de valores ( x1, x2,....,xn ). Somos conscientes de que en realidad oθ es una aproximación y aparece la pregunta siguiente : ¿ en qué medida el valor aproximado puede desviarse del valor verdadero θ ?. En particular nos preguntamos si es posible encontrar una magnitud d tal que se pueda afirmar con “ certeza ” ( es decir con una probabilidad cercana a la unidad ) que se verifica la desigualdad : oθ - d ≤ θ ≤ oθ + d Fig.49 Es decir la estimación se acompaña de un intervalo [ oθ - d , oθ + d ] junto a una medida de la probabilidad de que el parámetro verdadero θ sea interior a dicho intervalo. Precisemos estas ideas con un ejemplo intuitivo : Ejemplo :Supongamos que nos preguntan la edad E de una persona. Primero hacemos una estimación puntual, por ejemplo 32ˆ =oE años y luego hacemos afirmaciones del tipo : a) Creo que E verifica : 31 ≤ E ≤ 33 d = 1 b) Estoy seguro que : 27 ≤ E ≤ 37 d = 5 c) Estoy casi seguro que : 22 ≤ E ≤ 42 d = 10 Cada afirmación tiene una medida de la seguridad de que E esté comprendido en el intervalo. Al escribir 27 ≤ E ≤ 37 ( E = 32 ± 5 ) con seguridad 1-α diremos que 32ˆ =oE es el valor estimado de E y que d = 5 es el error asociado al nivel de seguridad 1-α. Para que nuestra afirmación sea buena, 1-α debe ser grande ( próximo a 1 ), sin embargo, a medida que 1-α crece, la magnitud del error ( d ) crece. Los estadísticos han convenido en aceptar una probabilidad de confianza de 1-α = 0.95. A. Intervalo de confianza para la esperanza matemática m de una ley de Gauss con σ conocido Sea X1, X2,...., Xn una muestra aleatoria de una variable X que sigue una ley normal de esperanza m desconocida y varianza σ2 conocida.
Confianza o Seguridad
Intervalo Error
d d
oθ - d oθ oθ + d

61
Se puede probar que la variable aleatoria :
n
mXZ σ−
=
sigue una ley de Gauss con esperanza 0 y varianza 1. Por propiedad de la ley de Gauss ( ver página 46 ) se tiene :
*95.0)2Z2(P =≤≤−
95.0)2n
mX2(P =≤−
≤− σ
mediante una transformación algebraica, llegamos a :
95.0)n
2Xmn
2XP( =+≤≤−σσ
La ultima relación nos dice que la probabilidad de que el intervalo ⎥⎦
⎤⎢⎣
⎡ +− n2X,n2X σσ
contenga el valor desconocido m es 0.95. A tal probabilidad la llamaremos probabilidad de confianza del intervalo. Otros intervalos de confianza, para otros niveles son :
⎥⎦
⎤⎢⎣
⎡ +− nX,nX σσ Intervalo del 68 % de confianza
⎥⎦
⎤⎢⎣
⎡ +− n64.1X,n64.1X σσ Intervalo del 90 % de confianza
⎥⎦
⎤⎢⎣
⎡ +− n3X,n3X σσ Intervalo del 99.7 % de confianza
Ejemplo : Se tiene una muestra aleatoria ( X1, X2, X3, X4 ) proveniente de una ley de Gauss con m=0 ( que se supone desconocido ) y σ2=1 ( que se supone conocido ). Los valores numéricos resultantes fueron : ( 0.9, -0.6, -0.4, 0.9 ). Encontrar el intervalo del 68 % de confianza y el del 95 % de confianza.
⎥⎦
⎤⎢⎣
⎡ +− nX,nX σσ ⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡+− 7.0,3.0412.0,412.0
= Intervalo del 68 % de confianza. * Observación : En forma más exacta, esta ecuación se escribe :P( -1.96 ≤ Z ≤ 1.96 ) = 0.95
-2 0 2 z
0.95 Ley de Z
Fig.50

62
⎥⎦
⎤⎢⎣
⎡ +− n2X,n2X σσ ⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡+− 2.1,8.0422.0,422.0
= Intervalo del 95 % de confianza. Repitamos unas veces más el experimento ( generación numérica de X1, X2, X3, X4 ) y obtengamos los intervalos asociados :
MUESTRA INTERVALO 1- α = 0.68
INTERVALO 1- α = 0.95
( -1.0, -0.4, -0.8, 0.1 ) [ -1.02 , -0.02 ] [ -1.52 , 0.47 ] I1 ( 0.3, 0.9, -1.0, 1.4 ) [ -0.10 , 0.90 ] [ -0.60 , 1.40 ] I2 ( 0.6, 0.8, 0.8, 1.7 ) [ 0.47 , 1.47 ] [ -0.02 , 1.97 ] I3
( -0.1, 0.0, 2.5, -0.9 ) [ -0.12 , 0.87 ] [ -0.62 , 1.37 ] I4 Representemos en un gráfico los intervalos obtenidos en las cuatro repeticiones del experimento :
En términos frecuenciales, si se repite el experimento 100 veces, se debería obtener que 95 intervalos ( del 95 % de confianza ) contienen el valor desconocido, mientras que 5 intervalos no lo contendrían. El intervalo de confianza que acabamos de estudiar está restringido al conocimiento de la varianza σ2. Sin embargo, en la práctica, este valor también es desconocido. Para encontrar el intervalo de confianza para m en una ley de Gauss con m y σ ( ó σ2 ) desconocidos, será necesario estudiar una nueva ley de probabilidad : La Ley de Student. B. La Ley de Student. Sean X0, X1,...., Xn , n +1 variables aleatorias gaussianas e independientes tales que E(Xi) = 0 , V(Xi) = σ2 . Se dice que la variable aleatoria :
Valor desconocido
Fig.51
68 %
95 %I1
I2
I3
I4
-2 -1 0 1 2

63
∑=
⋅=
n
i 1
2iX
n1
XoT
sigue una Ley de Student con parámetros n ( o con n grados de libertad ). Se demuestra que la densidad de T es :
21
1)
+−
⎟⎟⎠
⎞⎜⎜⎝
⎛+⋅
⎟⎠⎞
⎜⎝⎛Γ⋅
⎟⎠⎞
⎜⎝⎛ +
Γ=
n2
nt
2nn
21n
f(tπ
, -∞ < t < ∞
Se obtiene, a partir de esta densidad, que si n > 2 :
E(T) = 0 , V(T) = n/n-2
El gráfico de f(t) es cercano a la ley de Gauss con parámetros m = 0 , σ = 1. Si n ≥ 120 la ley de Student coincide con la ley de Gauss. La ley de Student se encuentra tabulada; en tablas figura el valor tα tal que :
P( - tα ≤ T ≤ tα ) = 1- α
Εn la página siguiente se tiene un extracto de una tabla de la ley de Student para 1- α = 0.95.
Fig.52
Gauss
Student
0 t

64
Tabla de la Ley de Student
1-α = 0.95
n tα 1 12.706 2 4.303 3 3.182 4 2.776 5 2.571 6 2.447 7 2.365 8 2.306 9 2.262
10 2.228 11 2.201 12 2.179 13 2.160 14 2.145 15 2.131 16 2.120 17 2.110 18 2.101 19 2.093 20 2.086 21 2.080 22 2.074 23 2.069 24 2.064 25 2.060 26 2.056 27 2.052 28 2.048 29 2.045 30 2.042 40 2.021 60 2.000
120 1.980 n > 120 1.960
P( -tα ≤ T ≤ tα ) = 0.95
0.95
-tα 0 tα

65
C. Intervalo de confianza para la esperanza matemática de una ley de Gauss en que σ es desconocido. En este caso m y σ son desconocidos. Se demuestra que la variable aleatoria :
nˆ
mX
)1(nn
)XX(
mXT
1
2i
σ−
=
−⋅
−
−=
∑=
n
i
( en que σ es el estimador : 1n
)XX(ˆ 1
2i
−
−=
∑=
n
iσ , ver página 59 )
sigue una ley de Student con n -1 grados de libertad. En las tablas de la ley de Student con n -1 grados de libertad encontramos el valor tα tal que ( ver página 64 ) :
P( - tα ≤ T ≤ tα ) = 0.95
⇒ P( - tα ≤
nˆ
mXσ
− ≤ tα ) = 0.95
después de una transformación en las desigualdades, se tiene :
95.0n
tXmn
t-XP =⎟⎠⎞
⎜⎝⎛ ⋅+≤≤⋅
σσα
⎥⎦
⎤⎢⎣
⎡ ⋅+⋅−nˆtX,
nˆtX σσ
es el intervalo del 95 % de confianza para m.
Ejemplo 1 : La resistencia a la rotura, expresada en kilos, de 5 ejemplares de cuerda son : 280, 240, 270, 285, 270. Estimar la resistencia media m utilizando un intervalo confidencial del 95 % ( suponiendo ley de Gauss ). Solución : n = 5 ⇒ de las tablas de la ley de Student con 4 grados de libertad encontramos tα = 2.776 ( página 64 ).
2695
270285270240280=
++++=x
64.174
)269270()269285()269270()269240()269280(ˆ
22222=
−+−+−+−+−=σ

66
El intervalo es ⎥⎥
⎦
⎤
⎢⎢
⎣
⎡ ⋅+
⋅−
564.17776.2269,
564.17776.2269
es decir [ 247.1 , 290.9 ] A veces se escribe lo anterior como : m = 269 ± 21.9 ( con 95 % de confianza ), con un error relativo : ε = 100*21.9/269 = 8.1 % Ejemplo 2 : Dos examinadores A y B efectuaron una corrección doble sobre 30 pruebas. Las notas figuran en la tabla siguiente :
A B A B A B 13 14 15 17 17 16 15 16 16 17 15 15 12 13 15 15 16 18 16 16 17 18 18 20 18 17 16 16 14 15 15 15 13 14 16 15 14 15 15 16 15 15 18 17 11 12 17 19 17 16 14 14 14 16 20 17 15 18 15 16
Encontrar el intervalo de confianza para la esperanza matemática de la variable Z = Nota de A - Nota de B, usando 1 - α = 0.95. Solución : A partir de los datos encontramos los valores numéricos de Z : (-1, -1, -1, 0, 1, ....., -1) = ( z1, z2,....., z30 ).
⇒ 253.1ˆ:57.1)zz(291
ˆ;53.030
1
2i
2 ==−⋅=−= ∑=
σσi
z
De las tablas de la ley de Student con n - 1 = 29 grados de libertad encontramos tα = 2.045, luego el intervalo de confianza para m = E(Z) es :
⎥⎥⎦
⎤
⎢⎢⎣
⎡−−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡⋅+−⋅−− 06.0,00.1
3025.1045.253.0,
3025.1045.253.0
Debido a que el valor 0 no pertenece al intervalo de confianza, podemos afirmar que el examinador A es más severo que el examinador B. Ejemplo 3 : La tabla siguiente muestra los resultados de análisis de oro ( en gr/ton ) para 10 muestras enviadas a dos laboratorios químicos diferentes :
21.9 21.9
247.1 269 290.9
0.47 0.47
-1.0 -0.53 -0.06

67
Laboratorio CIMM
6.5 5.6 6.6 6.1 5.8 6.0 6.1 6.3 6.1 6.6
Laboratorio Bondar
5.4 5.8 5.4 5.8 5.7 5.4 5.7 6.0 5.3 6.0
Diferencia Z
1.1 -0.2 1.2 0.3 0.1 0.6 0.4 0.3 0.8 0.6
Encontrar si estas diferencias son significativas.
Solución : Se tiene : 434.0ˆ,188.0ˆ,52.0z 2 === σσ , tα = 2.262 y el intervalo es :
⎥⎥⎦
⎤
⎢⎢⎣
⎡=
⎥⎥⎦
⎤
⎢⎢⎣
⎡⋅+⋅− 83.0,21.0
10434.0262.252.0,
10434.0262.252.0
Debido a que el valor 0 no pertenece al intervalo, podemos concluir que el laboratorio CIMM proporciona leyes significativamente más altas que las que proporciona el laboratorio Bondar. Para encontrar el intervalo de confianza para la varianza σ2 de una ley de Gauss, es necesario introducir otra ley de probabilidad. D. La ley de Chi-cuadrado. Sea X1, X2,....,Xn una sucesión de variables aleatorias independientes tales que cada Xi sigue una ley de Gauss con esperanza E(Xi) = 0 y varianza V(Xi) = 1. Se dice que una variable aleatoria : Z = X1
2 + X22 +.....+ Xn
2 sigue una ley de chi-cuadrado con parámetro n ( o con n grados de libertad ). Los métodos de calculo de probabilidad permiten demostrar que Z tiene la densidad siguiente :
⎟⎠⎞
⎜⎝⎛Γ⋅
⋅ −−
2n2
ez2n
2z12n
si z > 0
0 si z ≤ 0
0.31 0.31
0.21 0.52 0.83
(1) f(z) =

68
Utilizando (1) se obtiene : E(Z) = n , V(Z) = 2n Las áreas bajo la curva f(z) se encuentran tabuladas. A veces se utiliza la notación χ2
n para indicar la ley de chi-cuadrado con parámetro n. D. Intervalo de confianza para la varianza σ2 de una ley de Gauss Para encontrar el intervalo de confianza para σ2 se utiliza el resultado siguiente :
La variable aleatoria 21
2)XiX(T
σ
∑=
−
=
n
i sigue una ley de Chi-cuadrado con parámetro n – 1 (
o con n – 1 grados de libertad ). Para encontrar el intervalo del 95 % de confianza para σ2 determinamos dos números a y b en la ley χ2
n-1 tales que : P( a ≤ T ≤ b ) = 0.95 (fig.54)
⇒ 0.95b))X(XP(a 2
2i =≤∑ −
≤σ
después de una transformación simple se llega al intervalo del 95 % de confianza para σ2 :
95.0a
)X(X2b
)X(XP2
i2
i =⎟⎟⎠
⎞⎜⎜⎝
⎛ ∑ −≤≤∑ − σ
y el intervalo del 95 % de confianza para σ es :
95.0a
)X(Xb
)X(XP2
i2
i =⎟⎟⎠
⎞⎜⎜⎝
⎛ ∑ −≤≤∑ − σ
0.025
Fig.54
n = 1
0.95
0 a b
0.025
Fig.53
n = 2 n = 3 Gráfico den = 4
f(z)
n = 5
0z

69
Ley de χ2n
Valores de a y b para el intervalo de confianza para σ2
n a b 2 0.0506 7.3778 3 0.216 9.348 4 0.484 11.143 5 0.831 12.832 6 1.237 14.449 7 1.690 16.013 8 2.180 17.535 9 2.700 19.023
10 3.247 20.483 11 3.816 21.920 12 4.404 23.337 13 5.009 24.736 14 5.629 26.119 15 6.262 27.488 16 6.908 28.845
La tabla adjunta proporciona los valores de a y b. Ejemplo :Los valores siguientes provienen de una ley de Gauss. Encontrar el intervalo del 95 % de confianza para σ2 : M = ( 0.25, -0.74, 0.05, 1.13, 1.06, -0.86, -0.22, -1.12, 0.72, 0.95 )
⇒ 703.09327.6
ˆ,10n,327.6)x(x,122.0x10
1
2i ====−= ∑
=
σi
En la tabla anterior, con n – 1 = 9 encontramos : a = 2.70 , b = 19.02, el intervalo es : [ 6.327/19.02 , 6.327/2.70 ] = [ 0.33 , 2.34 ]
Hasta ahora todos los intervalo de confianza que hemos estudiado corresponden a parámetros de una ley de Gauss. En el caso de una variable no gaussiana, la solución es aproximada tal como veremos a continuación.
0.33 2.34
0 a b
0.025 0.0250 95

70
E. Intervalo de confianza para la esperanza matemática de una variable aleatoria no necesariamente gaussiana.
Según el teorema del límite central, deducimos que la variable aleatoria Z :
nmXZ
σ−
=
Sigue una ley de Gauss con esperanza 0 y varianza 1 cuando n → ∞. Entonces cuando n es grande, podemos afirmar que ( ver página 61 )
95.0n
2Xmn
2-XP ≅⎟⎠⎞
⎜⎝⎛ ⋅+≤≤⋅
σσ (1)
La diferencia con los casos anteriores es que los intervalos de confianza eran exactos mientras que en (1) se tiene una igualdad aproximada. a) Si σ es conocido y si la ley de X no es demasiado asimétrica, se puede aplicar (1)
cuando n ≥ 30.
b) Si σ es desconocido, se estima su valor por )1n(1
2)XiX(ˆ −⎟⎟⎠
⎞⎜⎜⎝
⎛∑=
−=n
iσ y se
puede aplicar (1) cuando n ≥ 100. F. Intervalo de confianza para parámetros estimados por el método de máxima
verosimilitud. Sea θ el estimador de máxima verosimilitud de θ entonces cuando n es grande, la variable aleatoria :
)ˆ(V
ˆZ
θθθ −
=
Sigue una ley de Gauss con esperanza 0 y varianza 1, luego :
95.0))ˆ(V2ˆ)ˆ(V2ˆ(P ≅⋅+≤≤⋅− θθθθθ Aproximación válida cuando n ≥ 100. Cuando )ˆ(V θ depende de parámetros desconocidos se utiliza )ˆ(V θ . Ejemplo : En la variable aleatoria de Bernulli, estimar el parámetro p mediante un intervalo del 95% de confianza. Sea X una variable de Bernulli, Entonces E(X) = p , V(X) = p(1 – p) El estimador máximo verosímil de p es :
Xp = ( ver página 62 ) el cual verifica : p)p(E = ,
n)x(1x
n)p(1p)p(V
np)p(1)pV( −
=−
=⇒−
= , luego el intervalo es :
p 1 - p
0 1

71
95.0n
)x-(1x2xpn
)x-(1x2-xP ≅⎟⎟⎠
⎞⎜⎜⎝
⎛⋅+≤≤⋅
Ejemplo numérico : en la propaganda televisiva se entrevistaron n = 1000 personas y 501 personas prefirieron Pepsi.
Entonces 501.01000501xp === ; el intervalo es :
[ ]533.0,469.01000
499.0501.02501.0,1000
499.0501.02501.0 =⎥⎥⎦
⎤
⎢⎢⎣
⎡ ⋅⋅+
⋅⋅−
O sea que la probabilidad p = probabilidad de que una persona prefiera Pepsi bien podría ser inferior a 0.5 !
0.469 0.533

72
XI. TEST DE HIPÓTESIS ESTADÍSTICAS. Ejemplos introductorios de hipótesis estadísticas a) Una fábrica de ampolletas eléctricas debe decidir cuál de dos métodos A ó B da una
vida mayor a las lámparas. b) Las estadísticas de la Polla chilena desde 1934 a la fecha dan los resultados siguientes
para las terminaciones ( n = 820 sorteos ) :
¿ Se puede afirmar que estos números son equiprobables ? El estadístico aborda este tipo de problemas de la manera siguiente : a) Considera una hipótesis Ho ( en el último ejemplo : H0 = “los números son
equiprobables” ) y una hipótesis alternativa H1 ( en el ejemplo : H1 = “los números no son equiprobables” ).
b) Se aplica un cierto número de experimentos ( en el ejemplo : obtención de 819 datos ) y
se define un cierto suceso S1 del cual sabemos que si H0 es cierta, S1 tiene una probabilidad muy pequeña ( por ejemplo 0.05 ).
Ω
P(S1) = α = nivel de significación Entonces si al aplicar el conjunto de experimentos se produce el suceso S1 rechazamos H0 y en consecuencia aceptamos H1. En caso contrario aceptamos H0.
Justificación de la regla Debemos concluír una de las dos alternativas siguientes :
i) O bien la hipótesis H0 es cierta y se ha producido un suceso S1 de probabilidad muy pequeña ( 0.05 ).
ii) O bien la hipótesis es falsa y debemos rechazarla. Parece natural no admitir lo primero, luego se admite lo segundo y se rechaza la hipótesis. Ejemplo : Un fabricante asegura que sus ampolletas tienen una vida media mo = 2400 horas. Se supone que σ es conocido y vale σ = 300 horas y que la duración de una ampolleta es gaussiana. Se toma una muestra de n = 200 ampolletas y esta muestra ha dado 2320x = horas. ¿ Se puede considerar este resultado compatible con la hipótesis que la vida de las lámparas tenga un valor medio mo = 2400 horas ? i) Se fija un nivel de significación α = 0.05.
S1
Fig.550 salió 71 veces1 salió 87 veces9 salió 88 veces
0 1 2 3 4 5 6 7 8 9
7187 83 88
7280
97
807884

73
ii) Se supone que H0 : m = mo = 2400 es verdadera, luego se cumple la relación (ver página 61 ) :
95.0n
2Xmn
2XP o =⎟⎠⎞
⎜⎝⎛ ⋅+≤≤⋅−
σσ
la cual es equivalente a :
95.0n
2mXn
2mP o =⎟⎠⎞
⎜⎝⎛ ⋅+≤≤⋅−
σσo
Utilizando los datos mo = 2400 , σ = 300 , n = 100, se tiene :
095)2460X2340(P =≤≤ Pero resultó 2320=x , por consiguiente se rechaza la hipótesis.
Estudiemos el problema desde el punto de vista de los intervalos de confianza : el intervalo del 95 % para el valor m desconocido es :
[ ] [ ]2380,2260602320,602320n
2X,n
2X =+−→⎥⎦⎤
⎢⎣⎡ +−
σσ
y debemos rechazar la hipótesis porque el valor mo = 2400 no pertenece al intervalo. El test de hipótesis que acabamos de estudiar se puede resumir en la receta siguiente : Test de hipótesis sobre la esperanza m de una ley de gauss con σ conocido. Se desea comprobar la hipótesis H0 : m = mo siendo H1 : m ≠ mo. (I) Elegir el nivel de significación α pequeño ( 0.05 ) (II) Si H0 es cierta, se elige un intervalo de aceptación I tal que : ( ) 95.0n2mXn2mP o =+≤≤− σσ o
I
2260 2320 2380
Fig.56
Ley de X cuando H0 es verdadera0.95
2340 2400 2460
Zona de rechazo Zona de Zona de rechazo aceptación

74
(III) Se procede a la extracción de la muestra ( X1, X2,....., Xn ) anotando el valor de x , realización de X . (IV) Conclusión : a) Si x ∈ I se acepta la hipótesis H0
b) Si x ∉ I se rechaza la hipótesis H0
Observación : i) No se deben invertir los pasos II y III, es decir el intervalo de aceptación debe ser fijado antes de hacer el experimento. ii) A menudo se elige un riesgo α = 0.05. iii) La decisión de un test de hipótesis no es nunca definitiva y puede ser puesta en tela de juicio luego de otra experiencia. iv) Al hacer un test de hipótesis se pueden cometer dos tipos de errores, tal como muestra la tabla siguiente :
Decisión → Aceptar Rechazar Hipótesis Verdadera
Decisión Correcta
Error Tipo I
Hipótesis Falsa
Error Tipo II
Decisión Correcta
Observación : En general, para un valor dado de n, disminuir la probabilidad de un tipo de error implica necesariamente un aumento en la probabilidad del otro tipo de error. El único medio para reducir ambos es aumentando n. En la práctica un tipo de error puede ser más serio que el otro : el problema específico dispondrá cuál necesita un control más estricto. v) La hipótesis H0 se llama hipótesis nula y H1 se llama hipótesis alternativa. Potencia de un test de hipótesis. Supongamos el caso del test anterior : comprobar la hipótesis H0 : m = mo. Se llama potencia del test a la probabilidad de rechazar la hipótesis H0 cuando el valor del parámetro es m.
m)IX(P)m( ∉=π
n2mo σ− n2mo σ+
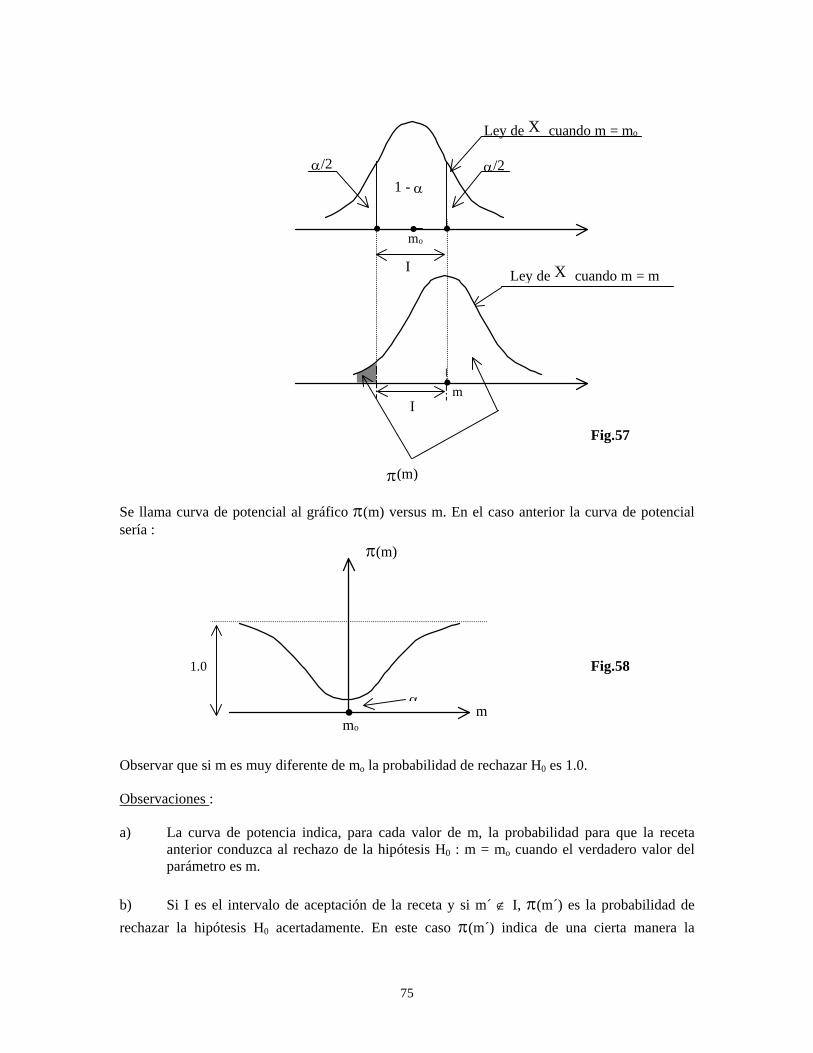
75
Se llama curva de potencial al gráfico π(m) versus m. En el caso anterior la curva de potencial sería :
Observar que si m es muy diferente de mo la probabilidad de rechazar H0 es 1.0. Observaciones : a) La curva de potencia indica, para cada valor de m, la probabilidad para que la receta anterior conduzca al rechazo de la hipótesis H0 : m = mo cuando el verdadero valor del parámetro es m. b) Si I es el intervalo de aceptación de la receta y si m´ ∉ I, π(m´) es la probabilidad de rechazar la hipótesis H0 acertadamente. En este caso π(m´) indica de una cierta manera la
π(m)
I
Fig.57
π(m)
Ley de X cuando m = m
mI
1 - α
Ley de X cuando m = mo
α/2α/2
mo
Fig.58
α
mom
1.0

76
potencia que tiene el test para descubrir la falsedad de la hipótesis H0. Luego la curva de potencia ideal sería:
c) Existen otros intervalos de aceptación ( dependiendo del problema ) :
El caso (a) se utiliza en los siguientes test : i) H0 : m = mo versus H1 : m < mo ii) H0 : m ≥ mo versus H1 : m < mo El caso (b) se utiliza en los siguientes test : i) H0 : m = mo versus H1 : m > mo ii) H0 : m ≤ mo versus H1 : m > mo Relación entre los intervalos de confianza y los test de hipótesis
El ejemplo anterior nos muestra que existe una íntima relación entre el intervalo de confianza para un parámetro y el test de una hipótesis relativa al mismo. En general, dada una variable aleatoria X cuya ley de probabilidad depende de un parámetro θ, encontramos dos funciones T1 y T2 ( las cuales dependen de X1, X2,....., Xn ; ver páginas 61 – 70 ) tales que :
P( T1 ≤ θ ≤ T2 ) = 1 - α
Entonces si al hacer la hipótesis H0 : θ = θο, una vez obtenida la muestra ( x1, x2,....., xn ), el intervalo :
[ t1 , t2 ] no cubre el valor del parámetro θo, debemos rechazar la hipótesis al nivel de significación α. Esto último permite obtener test de hipótesis a partir de los intervalos de confianza ya estudiados, lo cual proponemos como ejercicio al lector.
Fig.59
I
1.0 α
mo m
n64.1mo σ⋅− n64.1mo σ⋅+
Fig.60
mo mo
0.050.05
caso (a) caso (b)

77
La información que proporciona un intervalo de confianza tiene una analogía perfecta con la que da un test, como se ve en el siguiente cuadro :
INTERVALO DE CONFIANZA TEST DE HIPOTESIS a) No cubre al parámetro a) Error tipo I b) Cubre valores erróneos b) Error tipo II c) Extensión de la muestra para reducir la longitud del intervalo
c) Extensión de la muestra para aumentar la potencia del test
Existen otros test de hipótesis que no se refieren a parámetros de una ley de probabilidad, que son los test de bondad del ajuste, los cuales estudiaremos a continuación XI.1. TEST DE BONDAD DEL AJUSTE Los test de bondad del ajuste se refieren a la comparación de una observación de datos con una ley de probabilidad teórica. El ejemplo (b) de la página 61 referente a 820 terminaciones de la Polla nos proporciona un caso: supongamos que queremos comparar las frecuencias observadas con las frecuencias teóricas correspondientes al modelo siguiente :
np0 = np1 =.....= np9 = 82 es la frecuencia teórica de cada valor Se tiene así el cuadro siguiente :
Valor Frecuencia
observada Frecuencia
teórica 0 71 82 1 87 82 2 83 82 3 84 82 4 78 82 5 80 82 6 97 82 7 80 82 8 72 82 9 88 82
Total 820 820 La hipótesis a comprobar sería : H0 . “ Los valores son equiprobables ”. Existen dos test para comprobar este tipo de hipótesis que son el test de chi-cuadrado y el test de Kolmogorov-Smirnov.
n = 829P0 = P1 =.....= 0.1
0 1 2 3 4 5 6 7 8 9
Fig.61
P9P1P0

78
El test de Chi - cuadrado : χ2 Sean x1, x2,...., xn los resultados de n observaciones de una variable aleatoria X. Los datos se han agrupado de la manera siguiente :
Valor Frecuencia observada
Clase Frecuencia observada
a1 o1 c1 o1 a2 o2 c2 o2
ak ok ck ok
Total n Total n
Variable discreta Variable continua de la observación de esta agrupación y considerando otra información disponible sobre la variable en estudio, se infiere una ley de probabilidad para la variable aleatoria X ( si X es discreta se utiliza p(xi) = P(X = xi ) y si X es continua se utiliza su densidad f(x) ). Esta ley de probabilidad depende de parámetros desconocidos θ1, θ2,.....,θ los cuales se estiman por el método de la máxima verosimilitud. Una vez calculados los parámetros, se calculan las frecuencias teóricas asociadas : Ei = )p(an i⋅ i = 1, 2,...., k caso discreto
Ei = ∫⋅ic
f(x)dxn i = 1, 2,...., k caso continuo
El test de χ2 se basa en la comparación entre los valores observados oi y los valores teóricos Ei, utilizando el resultado siguiente : Teorema : La variable aleatoria
∑=
−=
k
1i
2
EiEi)(OiD (1)
sigue una ley de Chi - cuadrado con k - - 1 grados de libertad : χ2 k - - 1 *
D varía entre 0 y DMáximo con un 1 - α = 0.95 de probabilidad. Esto nos induce la siguiente regla de decisión : * Este teorema es valido si X sigue la ley inferida, es decir si la hipótesis a comprobar es verdadera; es el número de parámetros desconocidos.
Fig.62
χ2 k - l – 1 = Ley de D
0 DMáx d
0 95

79
Sea Do el valor numérico calculado según la formula (1), entonces : i) Si 0 ≤ Do ≤ Dmáx , entonces se acepta la hipótesis que la variable aleatoria X sigue la ley de probabilidad p(xi) ó f(x). ii) Si Do ≥ DMáx , entonces se rechaza la hipótesis. El valor de DMáximo se calcula según las tablas de la ley χ2 k - - 1. La tabla siguiente proporciona este valor para 1 - α = 0.95.
Ley χ2n
1 - α = 0.95
n Dmáx
1 3.841 2 5.991 3 7.815 4 9.488 5 11.070 6 12.592 7 14.067 8 15.507 9 16.919
10 18.307 Ejemplo 1 : Comprobar si las terminaciones de la Polla son equiprobables : Solución : El número de parámetros desconocidos es = 0, porque la hipótesis H0 nos proporciona el valor del parámetro p = 0.1. Además k = 10. En la tabla de χ2 10 - 0 - 1 = χ2
9 encontramos DMáx = 16.919. Ahora calculamos Do ( ver página 77 )
537.682
)8288(.......82
)8287(82
)8271(D222
0 =−
++−
+−
=
Conclusión : como D0 ≤ DMáx , se acepta la hipótesis que las terminaciones de la Polla son equiprobables, al nivel de significación α = 0.05.
Fig.63
0 DMáx

80
En algunos casos en que el dominio de la variable aleatoria X es infinito, se debe tomar un intervalo de agrupación extremo también infinito, tal como muestra el ejemplo siguiente. Ejemplo : Un barrio de Londres sufrió durante los bombardeos de la segunda guerra mundial 537 impactos. La zona ha sido dividida en 576 cuadrados de 500m x 500m. Se estudió la variable aleatoria X = “ número de impactos por cuadrado”, obteniéndose el cuadro :
Nº Impactos
Frec. Observada
0 229 1 211 2 93 3 35 4 7 5 7
Total 576 Lo anterior significa que de los n = 576 cuadrados : 229 recibieron 0 impactos, 211 recibieron exactamente 1 impacto,...., y 1 cuadrado recibió exactamente 5 impactos. Se pide comprobar si X sigue una ley de Poisson. Solución : La ley de Poisson toma los valores 0, 1, 2,....con probabilidades :
k!ek)P(Xp(k)
k λλ −⋅=== , k = 0, 1, 2,....
Existe un parámetro desconocido que es λ, el cual se estima por el promedio de los datos : x=λ ( ver página 58 ) :
929.0576)157435393221112290( =×+×+×+×+×+×=oλ Calculamos ahora las probabilidades y las frecuencias teóricas : p(0) = P( X = 0 ) = e-0.929 = 0.395 → np(0) = 227 p(1) = P( X = 1 ) = 0.929e-0.929 = 0.367 → np(1) = 211 p(2) = P( X = 2 ) = (0.929)2e-0.929/2 = 0.170 → np(2) = 98 p(3) = P( X = 3 ) = (0.929)3e-0.929/6 = 0.053 → np(3) = 31 p(4) = P( X = 4 ) = (0.929)4e-0.929/24 = 0.012 → np(4) = 7 p = P( X ≥ 5 ) = 1 - P( X < 5 ) = 0.003 → np = 2 Como la ley de Poisson puede tomar, en teoría, valores mayores que 5 hemos tomado un intervalo infinito al final ( de no ser así, la suma 227 + 211 + 98 +.... sería inferior a n = 576 ). Se tiene así el cuadro :

81
Nº Impactos
Frec. Observada
Frec. Teórica
0 229 227 1 211 211 2 93 98 3 35 31 4 7 7
5 ó más 1 2 Total 576 576
Por otra parte k = 6 , = 1. En la tabla χ2
6-1-1 = χ24 encontramos DMáx = 9.488. Ahora calculamos D0 :
289.12
)21(......211
)211211(227
)227229(Ei
Ei)(OiD222k
1i
20 =
−++
−+
−=
−= ∑
=
Conclusión : Se acepta la hipótesis que los datos provienen de una ley de Poisson, al nivel α = 0.05 porque D0 ≤ DMáx . Se puede demostrar la propiedad siguiente de la ley de Poisson : si los impactos son al azar ( es decir sin apuntar ), entonces la variable X = “ número de impactos por cuadrado ”, sigue una ley de Poisson. Al aceptar nuestra hipótesis concluimos que los bombardeos no apuntaban a zonas específicas dentro del barrio. El test de Kolmogorov - Smirnov. El test de Kolmogorov - Smirnov sirve para comprobar la hipótesis de que una variable aleatoria X sigue una ley de probabilidad especificada. El test se basa en la comparación de las funciones de distribución teórica y empírica ( ver páginas 3 - 4 y 15 - 16 ) : F*(x) = porcentaje de valores de la muestra que son ≤ x F (x) = P( X ≤ x ) F*(x) = función de distribución empírica F (x) = función de distribución teórica El test toma como medida de disconformidad de las distribuciones empíricas F*(x) al módulo de la mayor diferencia observada entre F*(x) y F(x) ( ver figura 64 ), es decir a :
D = Máx ⎜ F*(x) - F(x) ⎜

82
Fig.64
Se demuestra que si los datos observados corresponden a una variable aleatoria con función de distribución F(x), entonces D sigue una ley de Kolmogorov Kn :
Lo anterior nos induce la siguiente regla de decisión : i).- Aceptar la hipótesis si D0 ≤ DMáx ii).- Rechazar la hipótesis si D0 > DMáx La tabla siguiente nos proporciona el valor de DMáx para el nivel de confianza 1 - α = 0.95 :
Fig.65
Ley de D
0.95
0 DMáx d

83
Valor crítico para el test de Kolmogorov - Smirnov
1 - α = 0.95
Numero de datos n
DMáx
5 0.56 10 0.41 15 0.34 20 0.29 25 0.26 30 0.24 40 0.21
n > 40 n36.1 Ejemplo : Aplicar el test de Kolmogorov - Smirnov a las terminaciones de la Polla. Solución : Se tiene el cuadro siguiente :
Valor Frec. Observada
Frec. Teórica
F*(x) F(x) ⎜F*(x) - F(x)⎜
0 71 82 0.087 0.100 0.013 ← D0 1 87 82 0.193 0.200 0.007 2 83 82 0.293 0.300 0.007 3 84 82 0.396 0.400 0.004 4 78 82 0.491 0.500 0.009 5 80 82 0.589 0.600 0.011 6 97 82 0.707 0.700 0.007 7 80 82 0.805 0.800 0.005 8 72 82 0.893 0.900 0.007 9 88 82 1.000 1.000 0.000
Total 820 820 Se tiene entonces que D0 = 0.013. En la tabla anterior encontramos 0475.082036.1DMáx == Conclusión : como D0 ≤ Dmáx, aceptamos la hipótesis que los números son equiprobables. Aplicación del test de Chi - cuadrado a las tablas de contingencia. A veces un conjunto de datos se clasifica de acuerdo a características en un cuadro llamado tabla de contingencia. Ejemplo : En el año 1897 se produce una peste. De 127 personas no vacunadas, 10 contrajeron la peste. Sobre 147 personas vacunadas, 3 contrajeron la peste. Estos datos se pueden clasificar en la tabla siguiente :

84
A Contaminad.
B No Contam.
Total
C No Vacunad.
10 117 127 n = 274
D Vacunadas
3 144 147
Total 13 261 274 que es una tabla de contingencia de 2 x 2. Cuando se consideran estas características es interesante comprobar si son o no independientes. La hipótesis a comprobar sería : H0 : A y B son independientes de C y D versus H1 : A y B no son independientes de C y D Estas hipótesis se pueden escribir como : H0 : P( A ∩ C ) = P(A)*P(C) , P( A ∩ D ) = P(A)*P(D)
P( B ∩ C ) = P(B)*P(C) , P( B ∩ D ) = P(B)*P(D) versus H1 : Las relaciones anteriores no son verdaderas El número esperado de observaciones en las celdas es : n*P(A ∩ C), n*P(A ∩ D), n*P(B ∩ C),
n*P(B ∩ D) y según la hipótesis será : n*P(A)*P(C), n*P(A)*P(D), n*P(B)*P(C), n*P(B)*P(D). Como ninguna de estas probabilidades es conocida, deben ser estimadas a partir de los datos :
261/274(A)P1(B)P,13/274(A)P =−==
147/274(C)P1(D)P,127/274(C)P =−== la estimación de los números esperados en las celdas es
6.97(D)P(A)Pn,6.03(C)P(A)Pn =⋅⋅=⋅⋅
140.03(D)P(B)Pn,97.120(C)P(B)Pn =⋅⋅=⋅⋅
Tenemos entonces las tablas siguientes : * Observación : Solo se han estimado dos parámetros desconocidos : P(A) y P(C). Las otras : P(B) y P(D) fueron calculadas a partir de P(A) y P(C).
*

85
A Cont.
B No Cont.
Total A Cont.
B No Cont.
Total
C No Vac.
10 117 127 C No Vac.
6.03 120.97 127
D Vac.
3 144 147 D Vac.
6.97 140.03 147
Total 13 261 274 Total 13 261 274 Para comprobar la hipótesis H0, se utiliza la variable aleatoria :
BD
2BDBD
BC
2BCBC
AD
2ADAD
AC
2ACAC
E)E(O
E)E(O
E)E(O
E)E(O
D−
+−
+−
+−
=
la cual sigue una ley de chi-cuadrado con k - - 1 = 1, grado de libertad ( porque : k = 4 , = número de parámetros desconocidos = 2 ).
Se tiene entonces ( ver página 79 ) : P( D ≤ 3.841 ) = 0.95 ; lo que nos induce la regla de decisión siguiente : i).- Aceptar H0 ( A y B son independientes de C y D ) si : D0 ≤ DMáx = 3.841 ii).- Rechazar H0 si : D0 > DMáx = 3.841 En el ejemplo anterior, se tiene :
12.5140.03
)03.401(1446.97
)97.6(3120.97
)97.201(1176.03
)03.6(10D2222
o =−
+−
+−
+−
=
Conclusión : Como D0 > DMáx se rechaza la hipótesis H0, lo que equivale a aceptar que A y B dependen de C y D, es decir la vacuna produce resultados significativos. Generalización : El esquema anterior se generaliza al caso de una tabla de contingencia q x r :
Tabla Observada Tabla Teórica
Fig.66 1 - α = 0.95
0 95
Ley χ21
0 DMáx = 3.841 d
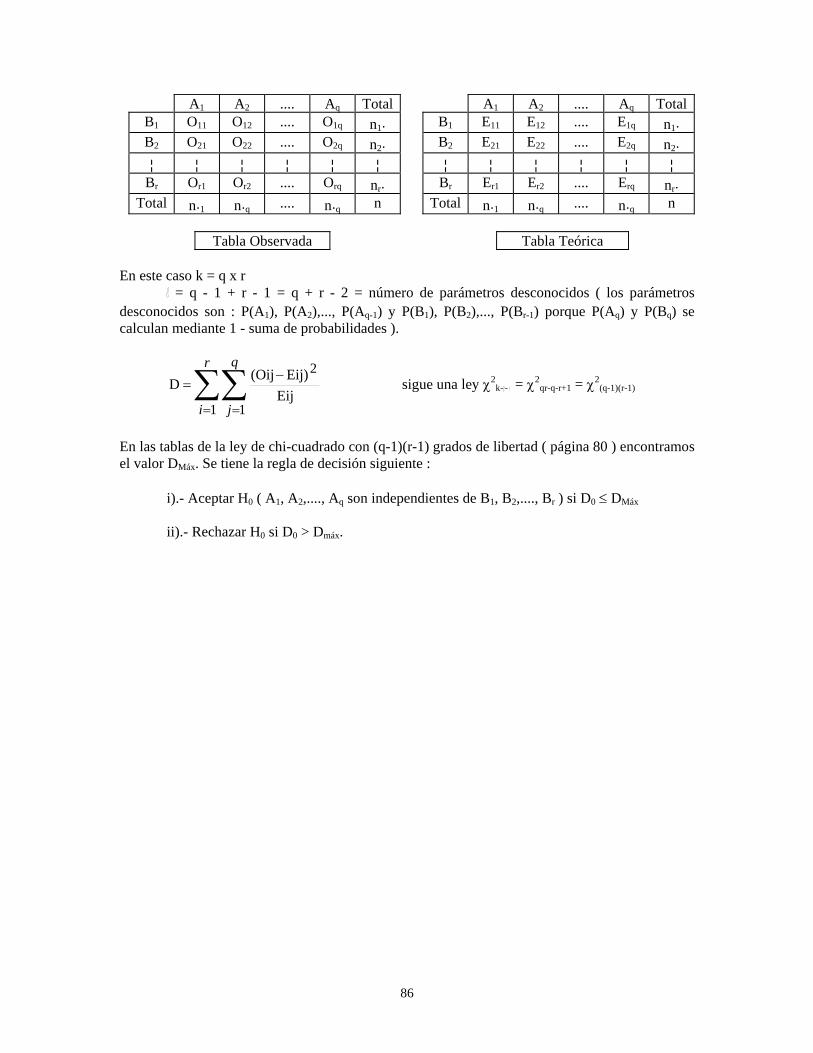
86
A1 A2 .... Aq Total A1 A2 .... Aq TotalB1 O11 O12 .... O1q n1• B1 E11 E12 .... E1q n1• B2 O21 O22 .... O2q n2• B2 E21 E22 .... E2q n2• ¦ ¦ ¦ ¦ ¦ ¦ ¦ ¦ ¦ ¦ ¦ ¦ Br Or1 Or2 .... Orq nr• Br Er1 Er2 .... Erq nr•
Total n•1 n•q .... n•q n Total n•1 n•q .... n•q n
Tabla Observada Tabla Teórica En este caso k = q x r = q - 1 + r - 1 = q + r - 2 = número de parámetros desconocidos ( los parámetros desconocidos son : P(A1), P(A2),..., P(Aq-1) y P(B1), P(B2),..., P(Br-1) porque P(Aq) y P(Bq) se calculan mediante 1 - suma de probabilidades ).
∑∑= =
−=
r
i
q
j1 1
2
EijEij)(OijD sigue una ley χ2
k- - = χ2qr-q-r+1 = χ2
(q-1)(r-1)
En las tablas de la ley de chi-cuadrado con (q-1)(r-1) grados de libertad ( página 80 ) encontramos el valor DMáx. Se tiene la regla de decisión siguiente : i).- Aceptar H0 ( A1, A2,...., Aq son independientes de B1, B2,...., Br ) si D0 ≤ DMáx ii).- Rechazar H0 si D0 > Dmáx.

87
XII. ANALISIS DE LA VARIANZA. El análisis de la varianza se ocupa de las técnicas estadísticas para estudiar inferencias respecto de medias de dos o más muestras. Supongamos que tenemos r muestras aleatorias y queremos comprobar la hipótesis : H0 : m1 = m2 =....= mr versus H1 : no todas las esperanzas son iguales Notaciones . Sea xij el dato I de la muestra Mj. Las r muestras aleatorias se pueden ordenar en la tabla siguiente:
Muestras
M1 M2 ..... Mr x11 x12 ..... x1r x21 x22 ..... x2r xn
11 xn
22 ..... xn
rr
Promedios 1x• 2x •
..... rx•
N = n1 + n2 +.....+ nr
r1
2r11
n.....nxn.....xnx
++⋅++⋅
= ••
Ejemplo : En una parte de un yacimiento con tres tipos de rocas R1, R2, R3 se han tomado 3, 4, 5 muestras respectivamente.
Fig.67
las leyes se dan en el cuadro siguiente :

88
Tipo de Roca R1 R2 R3
0.56 0.70 0.77 0.53 0.61 0.73 0.68 0.67 0.63
0.62 0.74 0.68
r = 3
1x• = 0.59 2x• = 0.71 3x• = 0.71
n1 = 3 n2 = 4 n3 = 5
66.0x = N = 12
Se tiene además : numero total de datos : N = 12 Promedio de todas las observaciones : 66.0x = En este ejemplo estaríamos interesados en comprobar : H0 : m1 = m2 = m3 versus H1 : “no todas las esperanzas son iguales” Para comprobar este tipo de hipótesis se utiliza el resultado siguiente : si las r muestras son muestras aleatorias de una misma variable X gaussiana, entonces la variable aleatoria :
∑∑
∑∑
= =
•
= =
•
=r
j
n
ii
r
j
n
ij
j
1 1
2jj
1 1
2j
r)-(N)x-x(
1)-(r)x-x(
D (1)
sigue una ley F(r-1 , N-r) llamada ley de F de Snedecor con (r-1 , N-r) grados de libertad.
Tenemos entonces la siguiente regla de decisión :
Leyes de Cobre
1 - α = 0.95
Fig.68
Ley de D = F(r-1 , N-r)
0.95
0 DMáx d

89
i).- Aceptar H0 ( m1 = m2 =.....= mr ) si D0 ≤ DMáx. ii).- Rechazar H0 si D0 > DMáx. Esta regla se justifica porque si la Hipótesis es verdadera, entonces debería tenerse que
xxxx r ≅≅≅≅ ••• .....21 luego el numerador de la expresión (1) sería pequeño. En el caso de ser falsa la hipótesis, el numerador sería grande. La tabla siguiente proporciona los valores de DMáximo en función de n1 y n2 correspondientes a la ley F(n1 , n2) para 1 - α =0.95.
Valores de DMáximo ( 1 - α =0.95 ) Ley de F de Snedecor
n2 n1 1 2 3 4 5
1 161 200 216 225 230 2 18.51 19.00 19.16 19.25 19.30 3 10.13 9.55 9.28 9.12 9.01 4 7.71 6.94 6.59 6.39 6.26 5 6.61 5.79 5.41 5.19 5.05 6 5.99 5.14 4.76 4.53 4.39 7 5.59 4.74 4.35 4.12 3.97 8 5.32 4.46 4.07 3.84 3.69 9 5.12 4.26 3.86 3.63 3.48
10 4.96 4.10 3.71 3.48 3.33 Ejemplo : En el caso anterior, comprobar la hipótesis : H0 : m1 = m2 = m3 Calculemos primero DMáx. Debemos utilizar la tabla anterior : F(r–1 , N–r) = F(2 , 9) = F(n1 , n2) ⇒ DMáx = 4.26. Calculemos D0 según la fórmula (1). Encontremos el denominador :
Denominador = ∑∑= =
• −−r
j
n
i
j
1 1
2jij r)(N)xx(
= [ (0.56 – 0.59)² + (0.53 – 0.59)² + (0.68 – 0.59)² + (0.70 – 0.65)² + (0.61 – 0.65)² + (0.67 – 0.65)² + (0.62 – 0.65)² + (0.77 – 0.71)² + (0.73 – 0.71)² + (0.63 –0.71)² + (0.74 – 0.71)² + (0.68 – 0.71)² ]/9 = 0.00336
Fig.69
F(n1 , n2)
0.95
0 DMáx d

90
Numerador = ∑∑= =
•
r
j
n
i
j
1 1
2j 1)-(r)x-x(
= [ (0.59 – 0.66)² + (0.59 – 0.66)² + (0.59 – 0.66)² + (0.65 - 0.66)² + (0.65 – 0.66)² + (0.65 – 0.66)² + (0.65 – 0.66)² + (0.71 – 0.66)² + (0.71 – 0.66)² + (0.71 –0.66)² + (0.71 – 0.66)² + (0.71 – 0.66)² ]/2 = 0.01380 ∴ D0 = 4.11 Conclusión : Debemos aceptar H0 porque resultó D0 ≤ DMáx sin embargo el valor de D0 es muy próximo a DMáx.
Consideremos ahora la cantidad : ∑∑= =
−r
j
n
i
j
1 1
2ij )xx(
= [ ] 2
1 1jjij )xx()xx(∑∑
= =•• −+−
r
j
n
i
j
= ∑∑∑∑∑∑= =
••= =
•= =
• −⋅−⋅+−+−r
j
n
i
r
j
n
i
r
j
n
i
jjj
1 1jjj
1 1
2j
1 1
2jij )xx()xxi(2)xx()x(x
es fácil de ver que : 0)xx()xxi(21 1
jjj =−⋅−∑∑= =
••
r
j
n
i
j
El término ∑∑= =
−r
j
n
i
j
1 1
2ij )xx( se llama suma total de cuadrados ( abreviado : SST ). El termino
∑∑= =
•−r
j
n
i
j
1 1
2jij )xx( se llama suma de cuadrados entre grupos ( abreviado : SSW ). El término
∑∑= =
• −r
j
n
i
j
1 1
2j )xx( se llama suma de cuadrados entre grupos. Luego tenemos que :
SST = SSA + SSW
Luego la ecuación (1) se puede escribir como :
r)(NSSW1)(rSSAD
−−
=

91
XIII. LA REGRESIÓN. A menudo estamos interesados en una posible relación entre dos o más variables. Podemos sospechar que cuando una de las variables cambia, la otra también cambia de manera previsible. Es importante expresar tal relación mediante una ecuación matemática que relacione las variables. Esta ecuación nos servirá para predecir el valor de una variable partiendo del valor de la(s) otra(s) variable(s). Regresión Lineal Simple. Si la relación que existe entre la variable x y la variable y es una línea recta, las variables están relacionadas por :
y = αx + β En una situación no determinística es razonable postular que esta relación está afectada por errores experimentales o perturbaciones aleatorias. De acuerdo a lo anterior podemos formular el siguiente modelo estadístico : Modelo estadístico : Se asume que Yi está relacionado con Xi por :
Yi = α + βXi + ei , i = 1, 2,....,n
en que : (a).- x1, x2,....,xn son los valores de la variable x que han sido tomados para el estudio. (b).- e1, e2,...., e3 son los errores aleatorios de la relación lineal. Estos errores son desconocidos y se asume que son variables aleatorias independientes, gaussianas, con esperanza nula y varianza desconocida σ2. (c).- Los parámetros α y β son desconocidos. El Método de los Mínimos Cuadrados : Si asumimos en forma tentativa que la formulación del modelo es correcta, se puede proceder a la estimación de los parámetros α y β. El método de los mínimos cuadrados constituye un método eficiente para estimar los parámetros de la regresión. Supongamos que se ha graficado la recta y = a + bx. En el punto xi, el valor que predice la recta para y es a + bxi, mientras que el valor observado es yi. La discrepancia es di = yi –a –bxi. Al considerar todas las discrepancias, se toma :
∑∑==
−−==n
1i
2ii
n
1i
2i )bxa(ydD (1)

92
como medida de la discrepancia global. Si el ajuste es bueno, D debería ser pequeño. El principio del método de los mínimos cuadrados es entonces : determinar los parámetros desconocidos de manera de minimizar D. Los valores encontrados se denotan α y β .
Fig.70
Antes de encontrar las expresiones para α y β veamos las notaciones que utilizaremos :
∑∑ == ii yn1y,x
n1x
∑ ∑∑ ∑ −=−=−=−= 22i
2i
2y
22i
2i
2x yny)y(yS,xnx)x(xS
∑ ∑ ⋅⋅−⋅=−−= nyxyx)y)(yx(xS iiiixy
Escribiendo D en la forma :
∑ ∑ −−+−−−=−−= 2ii
2ii ))xbay()xb(x)y((y)bxa(yD
después de una transformación algebraica se llega a :
( )2
2x
2xy2
y
2
x
xyx
2
SS
SSS
SbxbaynD ⎟⎟⎠
⎞⎜⎜⎝
⎛−+⎟⎟
⎠
⎞⎜⎜⎝
⎛−⋅+−−⋅= (1)
Lo cual es mínimo si : 0SS
bS,0xbayx
xyx =−=−−
Luego : xyˆ,SSˆ
2x
xy ⋅−== βαβ (2)
Ejemplo : en una empresa minera se dispone de los datos siguientes : x = Producción en toneladas , y = Costo de producción. Hallar la recta de regresión :

93
Producción x
Costo y
1.5 2.5 2.0 3.1 3.0 3.8 1.5 2.1 3.5 4.3 3.0 3.2 4.5 4.8 4.0 3.9 4.0 4.4 2.5 3.0
Nota : Tanto la producción como el costo han sido multiplicados por constantes. La primera etapa lógica es dibujar los datos. Este gráfico nos indicara si el modelo lineal es adecuado.
Fig.71
Al hacer los cálculos, se tiene :
13.5y,2.95x ==
56.8S,10.23S 2y
2x == ⇒
24.9501.277.051.3ˆ
77.023.1091.7ˆ
⋅−=
==
α
β
91.7Sxy = ∴ x0.771.24y ⋅+=
Volvamos a las ecuaciones de la página anterior. El valor mínimo de D es : 2x
2xy2
y SS
SDMin −=
y utilizando la expresión (2) para β : 2x
22y SˆSDMin ⋅−= β

94
se llama suma de cuadrados debida al error a :
∑=
−−=⋅−=n
iiiy
1
22x
22y )xˆˆ(SˆSSSE βαβ
En el ejemplo anterior : 785.023.10)77.0(85.6SSE 2 =⋅−=
Propiedades de los estimadores de mínimos cuadrados
A) los estimadores βα ˆyˆ son óptimos, es decir son insesgados : ββαα == )ˆ(E,)ˆ(E y tienen varianza mínima.
B) 2n
SSES2−
= es un estimador insesgado de σ2.
C) S
)ˆ(SZ x ββ −
= sigue una ley de Student con n – 2 grados de libertad.
D)
⎟⎟⎠
⎞⎜⎜⎝
⎛+⋅
−=
2x
2
Sx
n1S
ˆT αα sigue una ley de Student con n – 2 grados de libertad.
E)
⎟⎟⎠
⎞⎜⎜⎝
⎛ −+⋅
++=
∗
∗
2x
2
S)x(x
n1S
x)(-xˆˆW βαβα sigue una ley de Student con n – 2 grados de libertad.
Estas propiedades nos sirven para establecer algunas inferencias respecto del modelo lineal.
i) Inferencia respecto de la pendiente β ii)
El intervalo del 95 % de confianza para β, deducido de la propiedad (C) es :
xSSt ⋅± αβ
en que tα se obtiene de las tablas de la ley de Student con parámetro n – 2 ( ver página 64 ). Ejemplo : En el ejemplo anterior, comprobar la hipótesis H0 : β = 0. Solución : Encontremos el intervalo de confianza para β :
3.2010.23S;0.77ˆ x ===β
S2 = 0.785/8 = 0.098 ; S = 0.313
En la tabla de la ley de Student con n – 2 = 8 grados de libertad encontramos tα = 2.306 (página 64); luego el intervalo es : 0.77 ± 0.23 ⇒ 0.54 0.77 1.00 Conclusión : se rechaza H0. ii) Inferencias respecto de α. El intervalo del 95 % de confianza para α, deducido de la propiedad (D) es :

95
⎟⎟⎠
⎞⎜⎜⎝
⎛+⋅⋅± 2
x
2
Sx
n1Stˆ αα
en que tα se obtiene de las tablas de la ley de Student con parámetro n – 2. Ejemplo : En el caso anterior encontrar el intervalo del 95 % de confianza para α.
Solución : 306.2t;24.1ˆ;2.95x;10n;0.313S;10.23S2x ====== αα ; luego el
intervalo es : 1.24 ± 0.70 ⇒ 0.54 1.24 1.94 iii) Predicción de la respuesta media para x = x* El objetivo más importante en un estudio de regresión es el de estimar el valor esperado de Y para un valor específico x = x* : para estimar E(Y⎥ x*) = α + βx* se utiliza el estimador *ˆˆ x⋅+ βα con el siguiente intervalo de confianza, deducido de la propiedad (E) :
⎟⎟⎠
⎞⎜⎜⎝
⎛ −+⋅±⋅+ 2
x
2
S)x*(x
n1St*xˆˆ βα
en que tα se obtiene de las tablas de la ley de Student con parámetros n – 2. Ejemplo : En el caso anterior x0.771.24y ⋅+= ; la estimación para x* = 3.5 es 94.3y = y el intervalo del 95 % de confianza es :
26.094.323.10
)95.25.3(101313.0306.2394
2
±→⎟⎟⎠
⎞⎜⎜⎝
⎛ −+⋅±
Observación Importante : Se debe tener mucho cuidado al utilizar el modelo lineal para valores x* que están fuera del rango de valores x observados. La figura 72 ilustra esta situación :
3.68 3.94 4.20

96
XIII.1 VALIDACION DEL MODELO LINEAL Recordemos las hipótesis del modelo lineal : a) La relación subyacente es lineal. b) Independencia de los errores. c) Varianza constante. d) Distribución normal. Estudio de Residuos. Una de las técnicas más importantes para criticar el modelo es el estudio de los residuos, definidos por :
iyye ii −= i = 1, 2,...,n.
Ejemplo : En el caso anterior, se tiene el cuadro siguiente. Para validar el modelo sería necesario hacer un test sobre la normalidad de los ie . Sin embargo resulta más simple estudiar el gráfico residuo – valor de predicción, es decir ie versus iy , el cual, en el ejemplo, es el que aparece en la figura 73.
xi
yi iy ie
1.5 2.5 2.40 -0.10 2.0 3.1 2.78 -0.32 3.0 3.8 3.55 -0.25 1.5 2.1 2.40 0.30 3.5 4.3 3.94 -0.36 3.0 3.2 3.55 0.35 4.5 4.8 4.71 -0.09 4.0 3.9 4.32 0.42 4.0 4.4 4.32 -0.08 2.5 3.0 3.17 0.17
yxˆˆy ⋅+= βα
Fig.72Relación verdadera
Dominio de validez del modelo
0 1 5 8 x
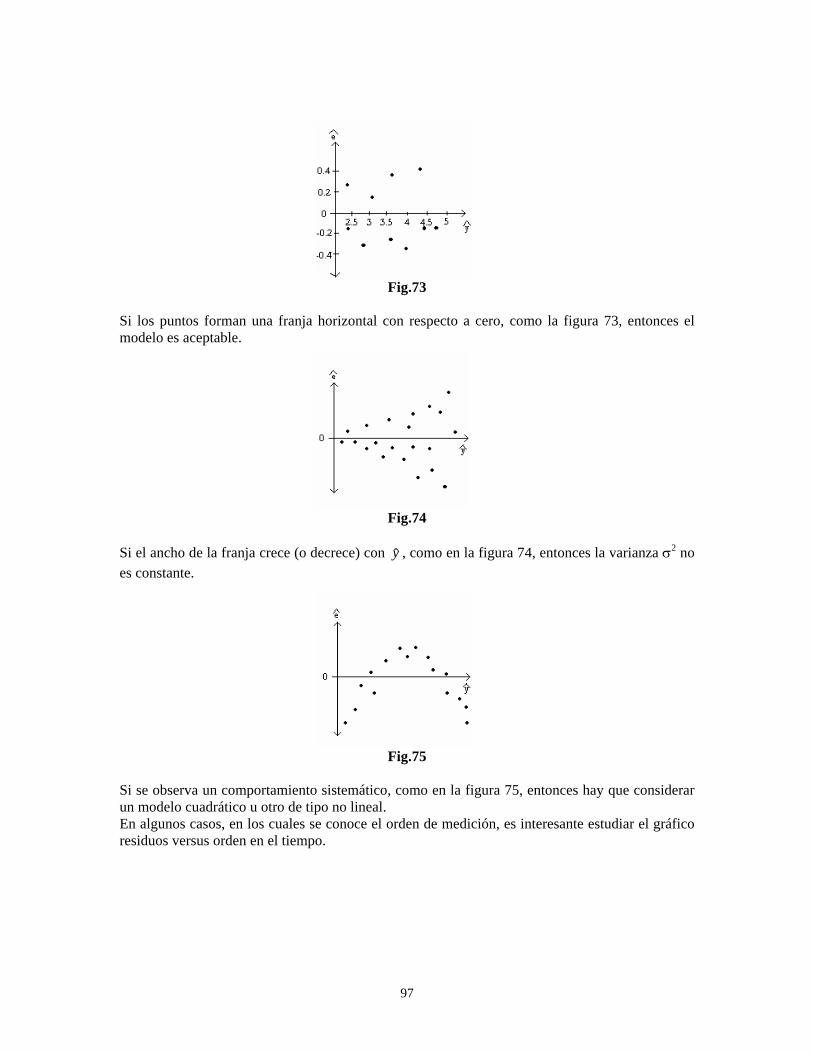
97
Fig.73 Si los puntos forman una franja horizontal con respecto a cero, como la figura 73, entonces el modelo es aceptable.
Fig.74 Si el ancho de la franja crece (o decrece) con y , como en la figura 74, entonces la varianza σ2 no es constante.
Fig.75 Si se observa un comportamiento sistemático, como en la figura 75, entonces hay que considerar un modelo cuadrático u otro de tipo no lineal. En algunos casos, en los cuales se conoce el orden de medición, es interesante estudiar el gráfico residuos versus orden en el tiempo.

98
Fig.76 El gráfico de la figura 76 indica que los residuos consecutivos están correlacionedos. Otras Comprobaciones en el Modelo Lineal Se puede considerar que el valor observado yi es la suma de dos componentes :
)xˆˆy()xˆˆ(y iiii βαβα −−++=
En una situación ideal en la cual los puntos están exactamente en una recta, los residuos son nulos y la ecuación ixˆˆ βα + toma totalmente en cuenta los valores de y : se dice que la relación lineal explica los valores de y. Como medida global de la discrepancia respecto de la linealidad se utiliza la suma de cuadrados debida al error (ver página 94) :
∑=
−=−−=n
i 1
2x
22y
2ii SˆS)xˆˆ(ySSE ββα
en que : ∑=
−=n
i 1
2i
2y )y(yS es una suma de cuadrados que representa la variación total de los
valores y. Se puede escribir entonces :
SSESˆS 2x
22y += β (1)
El termino 2
x2Sβ se llama suma de cuadrados debida a la regresión lineal. Si la recta proporciona
un buen ajuste. entonces este término comprende la mayor parte de S2y y deja solo una pequeña
parte para SSE. En la situación ideal en que los puntos están en una recta, SSE es cero. Como índice del ajuste lineal se utiliza la cantidad :
Suma total de cuadrados de y
Valor explicado por la relación lineal
Residuo o desviación respecto de la relación lineal
Valor observado de y
Suma de cuadrados Explicados por la relación lineal
Suma de cuadrados De los residuos (no explicada)

99
2y
2x
2xy
2y
2x
22
SSS
SSˆ
r⋅
==β (se utilizó fórmula (2) página 92)
llamada Coeficiente de Determinación. Esta cantidad está relacionada con el coeficiente de correlación muestral entre x e y (ver página 12). En efecto : r = ρ. El coeficiente de determinación r2 sirve como medida de la linealidad de la regresión. Al introducir r2 la relación (1) queda :
2yS = r2 2
yS + SSE ⇒ SSE = 2yS (1 – r2)
Ejemplo : Encontrar r2 en el ejemplo anterior.
Solución : 2y
2x
2xy2
SSS
r⋅
=
2xyS = (7.91)2 = 62.57 , 2
xS = 10.23 , 2yS = 6.85
89.085.623.10
57.62r2 =⋅
=⇒
Esto significa que el 89 % de la variación de y es explicada por la relación lineal, lo cual hace satisfactorio al modelo en este aspecto. Cuando el valor de r2 es pequeño, se debe concluir que la relación lineal no constituye un buen ajuste para los datos. Esto puede deberse a dos causas : i) Hay muy poca relación entre las variables (Fig.77a) ii) La relación subyacente no es lineal (Fig.77b)
Fig.77

100
El Test F. Para comprobar la falta de ajuste (por ejemplo la situación (b) de la figura 77), se utiliza el test F el cual requiere disponer de varios valores de y para un mismo valor de x (ver figura 78).
Fig.78
En este caso los datos se ordenan según la tabla siguiente, similar a la tabla del análisis de la varianza :
Valores diferentes de x
Valores repetidos de y
Promedios
x1 y11 y12 ...... y1n1 1y x2 ...... y2n2 2y
xk yk1 yk2 ...... yknk ky
Se define la suma de cuadrados de errores SSP por :
∑∑= =
−=k
i
n
j
i
1 1
2iij )yy(SSP
Se demuestra entonces que la variable aleatoria
k)(nSSP2)(kSSP)(SSED
−−−
= (*)
sigue una ley F de Snedecor con (k – 2 , n – k) grados de libertad.
* Observación : si el ajuste es razonable, D debe ser pequeño.
Fig.790.95
0 DMáx d
Ley de D

101
Regla de decisión : i) Se acepta el ajuste si D0 ≤ DMáx. ii) Se rechaza el ajuste si D0 > DMáx. Ejemplo : En el conjunto de datos siguientes, efectuar el test F.
x 2 2 2 3 3 4 5 5 6 6 6 y 4 3 8 18 22 24 24 18 13 10 16
Reordenando los datos tenemos :
x y y SS 2 4, 3,8 5 14 3 18, 22 20 8 4 24 24 0 5 24, 18 21 18 6 13, 10, 16 13 18
SSP = 14 + 8 + 0 + 18 + 18 = 58
Por otra parte : 50S,571S,28S,14.55y,4x xy2y
2x =====
5k,11n,482SˆSSSE,406.7ˆ,786.1ˆ 2x
22y ===−===⇒ βαβ
62.14658
3)58482(k)(nSSP
2)(kSSP)(SSED0 =−
=−
−−=
En las tablas de la ley F(k –2 , n – k) = F(3 , 6) encontramos (ver página 89) :
DMáx = 4.76
Conclusión : se rechaza el ajuste lineal. Hay que considerar además que 156.0SSSr 2y
2x
2xy
2 =⋅= , que es un valor muy pequeño. En este ejemplo una relación cuadrática resulta mejor que una relación lineal (Fig.80.).
Fig.80
k = 5

102
XIII.2. RELACIONES NO LINEALES En la práctica existen muchos casos en los cuales no es posible ajustar una recta, esto puede detectarse por el gráfico de los valores observados y por el cálculo de un r2 pequeño. En el caso no lineal, los métodos estadísticos de ajuste son más complicados. Sin embargo, en algunos casos es posible transformar las variables de manera de obtener una relación aproximadamente lineal; el modelo lineal debe aplicarse entonces sobre las variables transformadas. Ejemplo : En 10 autos se midieron las variables siguientes : x : velocidad , y : distancia necesaria para detenerse al frenar. Se obtuvo : Velocidad x 40 40 60 60 60 80 80 100 100 120 Distancia y 16.3 26.7 39.2 63.5 51.3 98.4 65.7 104.1 155.6 217.2
Lo cual proporciona el gráfico siguiente :
Fig.81 La observación de la figura 81 nos sugiere utilizar las variables x’ = x , y’ = y :
x = x’ 40 40 60 60 60 80 80 100 100 120 y’ = y 4.04 5.17 6.26 7.97 7.16 9.92 8.11 10.20 12.47 14.74
Fig.82
Por otra parte :

103
2
2xy'
2y
2x
x)0.1190.206(yx0.1190.206'y
926.0r,206.0ˆ,119.0ˆ,766S,98.41S,6440S,8.60'y,74x'
⋅+−=⇒⋅+−=⇒
=−======= αβ
La tabla siguiente nos muestra algunos modelos no lineales y las transformaciones para obtener una relación lineal :
Modelo no Lineal
Transformación
bxeay ⋅= xx',lnyy' == bxay ⋅= lnxx',lnyy' ==
bxa1y
+= xx',y
1y' ==
2bx)(a1y
+= xx',
y1y' ==
x1ba
y1
++= x1
1x',y1y' +==
xbay ⋅+= xx',yy' == La Regresión Multivariable. Los conceptos estudiados es este capítulo pueden ser extendidos a situaciones en las cuales existe más de una variable independiente. Supongamos, que la variable y depende de las variables x’, x”, x’’’ ( la generalización a p variables es inmediata). Por analogía con el modelo lineal simple, se puede formular el modelo siguiente :
Yi = α + β1xi’ + β2xi” + β3xi’’’ + ei i = 1, 2,...,n En que xi’, xi”, xi’’’ son los valores de las variables independientes en el experimento i, siendo yi la respuesta correspondiente. Se asume que los errores ei son variables aleatorias gaussianas independientes, de esperanza nula y varianza σ2 desconocida. Las constantes α, β1, β2, β3 son desconocidas. Debido a la presencia de más de dos variables, este modelo se llama regresión lineal múltiple. Para estimar los parámetros α, β1, β2, β3 se utiliza el método de los mínimos cuadrados, minimizando la cantidad :
∑=
−−−−=n
i 1
2i3i2i1i )'''x"x'xy(D βββα
Al derivar parcialmente D con respecto a α, β1, β2, β3 se llega al sistema de ecuaciones siguiente, llamado sistema normal :

104
'''xˆ"xˆ'xˆˆ
SSˆSˆSˆ
SSˆSˆSˆ
SSˆSˆSˆ
321
y''x'2
''x'3''x'x"2''x'x'1
yx"''x'x"32x"2x"x'1
yx'''x'x'3x"x'22x'1
βββα
βββ
βββ
βββ
−−−=
=++
=++
=++
y
en que :
∑ ∑
∑ ∑
= =
= =
−⋅=−−=
−=−=
n
i
n
i
n
i
n
i
1 1iiiix"x'
1
2
1
2i
2i
2x'
"x'xn"x'x)"x")(x'x'x(S
'xn)'(x)'x'x(S
etc. Ejemplo : En la Oficina Salitrera de Pedro de Valdivia se observan durante 10 meses las variables siguientes, en la planta de concentración : y = Recuperación de la planta en %. x’ = Temperatura del proceso. x” = Porcentaje de caliche vaciado. x’’’= Porcentaje de material con granulometría > 0.5 pulgadas. Los datos figuran en la tabla siguiente :
Recuperación
y Temperatura
x’ % Caliche
x” Granulometría
x’’’ 60.2 35.33 76.22 3.7 55.0 34.37 77.41 3.9 56.2 35.10 77.04 4.1 60.9 39.53 77.98 3.7 64.6 40.03 77.99 3.7 64.1 40.03 77.51 3.6 62.2 39.77 77.84 4.0 63.1 40.70 77.44 3.6 59.1 40.17 77.32 4.1 59.4 39.87 76.40 4.1
En este caso, el sistema normal de ecuaciones proporciona la solución :
742.7ˆ,172.02ˆ,867.0ˆ,23.70ˆ 31 −=−=== βββα
y la ecuación : ''x'7.742x"0.172x'0.86770.23y ⋅−⋅−⋅+=
La ecuación de regresión nos indica que la única variable (de las consideradas) que hace subir la recuperación de la planta es la temperatura. Se pusieron calderas y se comprobó que la recuperación subió significativamente. Los residuos '''x"x'xyyy i3i2i1iii βββα −−−−=− son los que figuran en la tabla siguiente :

105
yi iy ei
60.2 59.10 1.10 55.0 56.52 -1.52 56.2 55.66 0.54 60.9 62.44 -1.54 64.6 62.87 1.73 64.1 63.73 0.37 62.2 60.35 1.85 63.1 64.32 -1.22 59.1 60.01 -0.91 59.4 59.91 -0.51
De manera análoga a la regresión simple, el estudio de los residuos sirve para validar el modelo. Ver páginas 99 – 101. En el caso multivariable, como índice del ajuste lineal, se utiliza el coeficiente de determinación r2, definido por :
2y
2y
2yy2
SS
Sr
⋅=
y se llama coeficiente de correlación múltiple a ρ = r. Si llamamos :
∑∑==
−=−−−−−−=n
i
n
i 1
2ii
1
2(p)ipi3i2i1i )y(y)x....'''x"x'xy(SSE ββββα
entonces se puede demostrar que : )r(1SSSE 22
y −=
y que : 1pn
SSES2
−−= es un estimador insesgado de σ2. (p = número de variables independientes)
S se llama desviación standard de estimación y representa, en cierto sentido, la magnitud de los errores ei. Ejemplo : Calcular r2, ρ, SSE, S2 y S en el caso de los datos de salitre.
Solución : 86.76yynyyS,77.45S,91.58S ii1
iiyy2y
2y =⋅⋅−=== ∑
=
n
i
⇒ r2 = 0.833 , ρ = 0.913 Utilizando la tabla anterior : SSE = (1.10)2 + (-1.52)2 +....+(-0.51)2 = 15.313 S2 = SSE/(10-4) = 2.552 , S = 1.598 Del análisis de los residuos ei y del valor de r2, concluimos en este caso que el modelo lineal múltiple es satisfactorio.

106
La Regresión Polinómica. En el caso en el cual se dispone de una variable independiente se puede suponer un modelo polinómico del tipo :
Yi = α + β1xi + β2xi2 +....+βpxi
p + ei
que es un caso particular del modelo lineal múltiple, con : x’ = x , x” = x2 ,......, x(p) = xp. Por ejemplo, si se desea ajustar la parábola α + β1x + β2x2,
∑=
−−−=n
i 1
22i2i1i )xx(yD ββα
lo cual es mínimo si se cumple el sistema :
∑=∑+∑+⋅
∑=∑+∑+∑
∑=∑+∑+∑
i2
i2i1
i2
i4
i23
i12
i
ii3
i22
i1i
yxˆxˆnˆ
yxxˆxˆxˆ
yxxˆxˆxˆ
ββα
ββα
ββα

107
XIV. ESTADISTICA NO PARAMETRICA. Casi todos los métodos estadísticos que hemos estudiado suponen que las variables que interesan son gaussianas. Estos métodos requieren, en general, el conocimiento de dos parámetros : la esperanza matemática y la varianza. Ahora consideremos situaciones en las cuales no podemos hacer suposiciones referentes a los parámetros de las variables, de aquí el término Estadística no Parámetrica. Aplicaremos los métodos no parámetricos en las ocasiones en las cuales no tenemos motivos para suponer que las variables son normales. Sin embargo como regla, los métodos no parámetricos tienen menor eficacia que los correspondientes métodos paramétricos. A. Criterio de Wilcoxon de verificación de la Homogeneidad de Dos Muestras. El criterio de Wilcoxon trata de responder la siguiente pregunta : ¿ se puede unir dos o más “porciones” de datos estadísticos para formar una muestra común, considerándola como una muestra homogénea ?. Si la respuesta es positiva, el investigador podrá realizar cálculos posteriores con una muestra más grande. El criterio de Wilcoxon solo se aplica a variables continuas. Existen una versión equivalente de este criterio, desarrollada por Mann y Whitney (1947). Sean : M1 = ( x1
(1), x2(1),....., xn1
(1) ) M2 = ( x1
(2), x2(2),....., xn2
(2) ) dos muestras, suponiendo que n1 ≤ n2 a) Se construye la muestra M = M1 ∪ M2 compuesta de n1 + n2 valores, ordenados en orden creciente. En esta muestra solo nos interesa el orden (rango) de los elementos de cada serie. b) Se calcula la suma de los rangos ri de los elementos de la muestra m1 : W = r1 + r2 +....+rn1 Ejemplo : Dos formaciones geológicas se comparan según la ley de oro en gr/ton. Se obtuvieron los datos siguientes : Datos Formación 1 : M1 = ( 4.7, 6.4, 4.1, 3.7, 3.9 ) Datos Formación 2 : M2 = ( 7.6, 11.1, 6.8, 9.8, 4.9, 6.1, 15.1 ) Se construye ahora la muestra ordenada M1 ∪ M2, identificando los valores que pertenecen a M1 y M2 :
M1 ∪ M2 3.7 3.9 4.1 4.7 4.9 6.1 6.4 6.8 7.6 9.8 11.1 15.1
Rango 1 2 3 4 5 6 7 8 9 10 11 12 Luego se tiene : Wo = 1+2+3+4+7 = 17 c) Regla de decisión : Si la primera muestra presenta una desviación sistemática hacia los “grandes valores”, entonces los valores xi
(1) de la muestra M1 estarán al final de la serie M1 ∪ M2 y el valor de W será anormalmente grande. Si la muestra M1 presenta una desviación sistemática hacia los “pequeños
Datos de M1

108
valores”, entonces los valores de la muestra M1 estarán al comienzo de la serie M1 ∪ M2 y el valor de W será anormalmente pequeño. En estos dos casos la hipótesis de homogeneidad de las muestras debe ser rechazada. En resumen la regla de decisión al nivel 1 - α es : i) Aceptar la hipótesis de homogeneidad si : WMín < Wo < WMáx ii) Rechazar la hipótesis en caso contrario La tabla siguiente proporciona los valores de WMín y WMáx para el nivel 1 - α = 0.95.
n1 n2 WMín WMáx
3 5 6 21 3 6 7 23 3 7 7 26 3 8 8 28 3 9 8 31 3 10 9 33 3 11 9 36 3 12 10 38 3 13 10 38 3 14 11 43 3 15 11 46 4 5 11 29 4 6 12 32 4 7 13 35 4 8 14 38 4 9 14 42 4 10 15 45 4 11 16 48 4 12 17 51 4 13 18 54 4 14 19 57 4 15 20 60 5 5 17 38 5 6 18 42 5 7 20 45 5 8 21 49 5 9 22 53 5 10 23 57 5 11 24 61 5 12 26 64 5 13 27 68 5 14 28 72 5 15 29 76
Ejemplo : Comprobar si los datos de las formaciones geológicas evidencian que la formación 2 es más rica que la formación 1.

109
Solución : n1 = 5 , n2 = 7 ⇒ WMín = 20 , WMáx = 45 (según tabla adjunta) y como Wo = 17, entonces se debe rechazar la hipótesis de que las muestras son homogéneas, luego la formación geológica 2 es más rica que la formación 1. B. El Test de los Signos. Un test no parámetrico excepcionalmente simple e intuitivo es el test de los signos. Este test requiere disponer de dos muestras M1 y M2 de igual extensión y tomadas de a pares. La hipótesis a comprobar es H0 : “Las dos muestras corresponden a la misma variable aleatoria”. Se comprueba que no existe diferencia entre ambas muestras al examinar los signos de las diferencias entre las parejas, los cuales deberían estar distribuidos uniformemente :
P( + ) = P( - ) = ½
Como regla de decisión se puede utilizar el test de χ2; por lo menos se necesitan 10 parejas de números para que la comprobación sea razonablemente sensitiva. Ejemplo : La tabla siguiente muestra al número de obreros ausentes en dos turnos de una empresa durante 16 días. Tenemos 15 parejas de datos : no consideramos el día 7 porque los dos valores coinciden.
Día Turno A Turno B Diferencia
A – B 1 8 7 + 2 6 7 - 3 5 7 - 4 0 2 - 5 5 3 + 6 2 3 - 7 4 4 8 3 5 - 9 9 8 +
10 6 8 - 11 11 12 - 12 8 7 + 13 5 6 - 14 8 9 - 15 10 7 + 16 3 5 -
Se tiene entonces que de las 15 diferencias, en teoría 7.5 serían ( + ) y 7.5 serían ( - ) :
Diferencias Observado Oi
Teórico Ei
+ 5 7.5 - 10 7.5
∑=
−=
k
ii
iiE
EOD
1
2)( sigue una ley χ2
1 : k = 2 , l = 0

110
de la tabla de la página 84 deducimos al nivel 0.95 que DMáx = 3.841. Por otra parte :
67.15.7
)5.710(5.7
)5.75( 220 =
−+
−=D
Conclusión : Los datos no justifican la inferencia de que existe una diferencia en el ausentismo de los dos turnos. C. El Coeficiente de Correlación de Rangos de Spearman. Supongamos n individuos ordenados con respecto a dos caracteres A y B. Sea di = diferencia de rangos del individuo i en ambas clasificaciones. Se define el coeficiente de correlación de rangos de Spearman por :
)1(1
261
2 −
∑=
⋅
−=nn
n
iid
τ
Ejemplo : Supongamos que tenemos 10 alumnos A, B, C,....,J clasificados por 2 profesores por orden de capacidad. Los resultados de la clasificación se presentan como sigue :
Alumno A B C D E F G H I J
Profesor 1 2 1 3 4 6 5 8 7 10 9 Profesor 2 3 2 1 4 6 7 5 9 10 8
di 1 1 -2 0 0 2 -3 2 0 -1 (lo anterior significa por ejemplo : para el profesor 1 el alumno A es el segundo en capacidad, mientras que para el profesor 2 es el tercero en capacidad).
Se tiene que ∑=
=−++−++=10
1
22222 24)1(.....)2(11
iid , n = 10
⇒ 85.099.1024.61 =−=τ
El coeficiente de correlación de rangos ha sido elaborado de manera que, en el caso de clasificaciones idénticas (di = 0), τ vale 1.0 y, en el caso de la clasificación más discordante posible (las clasificaciones son inversas), τ vale -1.0 (comprobarlo numéricamente en el ejemplo). Test de Hipótesis Respecto del Coeficiente de Correlación. En este párrafo nos hacemos la pregunta siguiente : ¿cómo verificar la significancia del coeficiente de correlación τ? Para responder esta pregunta se puede encontrar el intervalo del 95 % de confianza para τ el cual se determina según el ábaco del anexo.

111
Ejemplo : En el ejemplo anterior, con n = 10 encontrar τ0 = 0.855. Encontrar el intervalo de confianza.
Fig.83 En el ábaco del anexo, se entra con el valor 0.855 y en las curvas para n = 10 se determinan los puntos A y A’ los cuales proporcionan el intervalo del 95 % de confianza para τ : 0.45 ≤ τ ≤ 0.95. Podemos concluír que el grado de acuerdo entre los dos profesores es significativo. Observación : El ábaco del anexo también es aplicable al coeficiente de correlación ρ.

112
Anexo : Abaco para determinar el intervalo de confianza para el
coeficiente de correlación

113
Bibliografía
1.- Sixto Ríos : Métodos Estadísticos. Mc. Graw Hill,1967. 2.- G. Bhattacharyya : Statistical Concepts and Methods. Wiley, 1977. 3.- A. Rickmers : Introducción a la Estadística. CECSA, 1971. 4.- S. Aïvazian : Étude Statistique des Dépendances. MIR, 1970. 5.- J. Davis : Statistics and data Analysis in Geology. Wiley, 1972.