compresiÓn digital - abcradiotel · para evitar este problema se modera el factor de compresión...
TRANSCRIPT

COMPRESIÓN DIGITAL
CAPITULO 4
4.1 PRINCIPIOS
En un sistema digital PCM la velocidad de bit (bit rate) es el producto de la
frecuencia de muestreo por el número de bits en cada muestra. Este último
generalmente es constante. Se debe tener en cuenta que la velocidad de
información (information rate) de una señal real varía constantemente.
En el lado opuesto, se ubican las señales impredecibles como, por ejemplo, el
A la diferencia entre la velocidad de bit (bit rate) y la velocidad de información
(informatión rate) se la conoce como redundancia. Los sistemas de compresión
son diseñados para eliminar la redundancia. Una manera de hacerlo es utilizando
predicciones estadísticas en las señales. La información contenida en una muestra
o entropía es una función de lo diferente que es ésta del valor predecible. Muchas
señales poseen algún grado de predicción. Un ejemplo de ello es la onda seno, una
señal altamente predecible debido a la uniformidad de sus ciclos. Cualquier señal
totalmente predecible carece de información, es representada por una simple
frecuencia y, por lo tanto, no tiene ancho de banda.
84

ruido. Los codecs (Compresor - Expansor) no pueden trabajar con señales
ruidosas. Esto obedece a que en su diseño se utilizan estadísticas de material real
que no podrían ser probados con ruido aleatorio dado que este es un elemento
impredecible. Otro problema podría ocurrir si un codec que se desempeña
correctamente con material limpio lo hace en forma errónea al trabajar con un
material que contenga ruido. Por lo expuesto, las unidades de compresión
requerirán de un proceso previo a la etapa de compresión. Una apropiada
reducción del ruido se podría incorporar en esta etapa previa, si las señales
ruidosas son anticipadas. Otro requerimiento será limitar el grado de compresión
aplicada a las señales ruidosas.
En un compresor (coder) ideal se extraería exclusivamente la forma de la entropía
para ser transmitida y se podría obtener la información original con un expansor
(decoder) ideal. A este sistema ideal es posible aproximarse, pero esto originará el
Cualquier señal real puede ubicarse en algún lugar entre los extremos de ser
predecible o impredecible. Si empleamos el ancho de banda (fijado por la
frecuencia de muestreo) y el rango dinámico (fijado por la longitud de palabra) de
un sistema de transmisión para denotar un área. Esta fija un límite en la capacidad
de información de un canal.
En la figura 4.54 se puede observar esta área y una señal real que sólo ocupa parte
de la misma. Esta señal no puede contener todas las frecuencias o no puede tener
un total dinamismo en ciertas frecuencias. La entropía es el área ocupada por la
señal y esta es el área que debe ser transmitida. El área remanente es llamada
redundancia dado que esta no se añade a la información transmitida.
85

Nivel dela señal
Figura 4.54
Entropia Entropia
Entropia
Codercon perdidas
Coder - Idealsin perdidas
Redundancia
frecuencia
86
aumento de la complejidad del compresor, además se tendría que contar con un
canal que aceptase cualquier entropía y si la capacidad del canal no fuese la
suficiente, el compresor descargaría parte de la entropía y con esto se eliminaría
información útil. Para evitar este problema se modera el factor de compresión
(coding gain) para que solamente se remueva la redundancia necesaria sin originar
elementos indeseables, lográndose un sistema subjetivamente sin pérdida
(subjectively lossless).
Cuando se convierte una señal de video analogica a digital utilizando PCM se
obtiene un gran flujo de datos (data rate) resultante. Este puede ser almacenado en
grabadoras digitales, pero cuando se trata de manipular este flujo de datos como en
el caso de los procesos de edición, postproducción y transmisión deberá
considerarse la forma de manipular esta cantidad de flujo de datos sin perder
información ni calidad. Para conseguirlo, se realiza el proceso de compresión
digital que nos permite comprimir este flujo de datos ( data rate) conservando la
calidad y cantidad necesaria de información.

87
La compresión nos permite además reducir costos, especialmente cuando se trata
de transmitir señales. En este proceso el costo está relacionado con la velocidad de
bit , por lo que al disminuir el flujo de datos (data rate) se aminora la velocidad de bit
(bit rate) y con éste los costos. Podríamos mencionar como ejemplo los equipos de
alta definición: estos requieren de un flujo de datos de aproximadamente cinco
veces más que la de un equipo de video convencional. En esta razón reside el hecho
de que la compresión en vídeo digital permita realizar algunos procesos que de
otra forma resultarían impracticables y ejecutar los ya conocidos de manera
económica. Los términos compresión, bit rate reduction y data reduction tienen el
mismo significado en este contexto.
La aplicación de la compresión en los equipos digitales de vídeo ha permitido que
estos se fabriquen para usos domésticos y también sea aprovechada en
computadoras gráficas, equipos de videoconferencia, videotelefónos, equipos
multimedia y de vídeo interactivo. Diferentes niveles de compresión serán
empleados en estos equipos acorde al requerimiento de calidad. Esta característica
nos permite afirmar que la técnica de compresión es flexible porque se puede variar
el rango la compresión y el grado de complejidad de la codificación (coding) de
acuerdo a la aplicación requerida.
Cuando se trata de postproducción de televisión el factor de compresión no puede
ser tan alto porque podría perderse parte de la entropía de la señal. No se puede
eliminar toda la redundancia de la señal, debido a que se necesitaría un algoritmo
perfecto que podría resultar extremadamente complejo. En la práctica, el factor de
compresión será mínimo y como consecuencia algoritmos simples podrán ser

88
adoptados. Este es el caso del sistema betacam digital de Sony que cuenta con un
factor de compresión de 2 a 1.
En otras aplicaciones, como en el de videoconferencia, la entropía es reducida y la
señal final no es la misma que la original. Para el caso de la editoras no-lineales
off-line, la entropía también es reducida porque las imágenes son utilizadas
solamente para tomar decisiones de edición. De esta forma, el producto acabado
será una lista final de edición (edit list), las grabaciones originales se conformarán
siguiendo esta lista final y la calidad será preservada.
Los sistemas de compresión presentan un número de requerimientos que no se
pueden cumplir con una simple solución. Por este motivo, en postproducción se
utiliza la compresión Intracuadro, que trabaja con un rango mínimo de
compresión y permite una máxima libertad de edición con insignificante
ocurrencia de errores. Los algoritmos de compresión que se utilizan para la
transmisión de imágenes fijas en otras aplicaciones pueden adaptarse a este tipo
de compresión. El Codec ISO-JPEG (Joint Photographic Experts Group) es uno
de estos algoritmos. Pueden aplicarse también los codecs basados en
transformadas Wavelet. Este tipo de compresión se utiliza en editoras no lineales
en las que, en algunos casos, el rango de compresión puede ser manipulado.
Cuando se requiera de grandes rangos de compresión y la libertad de edición no
sea una prioridad se puede utilizar la compresión Intercuadro. El Codec ISO
MPEG (Moving Picture Experts Group) utiliza este tipo de compresión, al igual
que el Codec MPEG-1. Este último presenta una menor velocidad de bit
(1.5Mbits/seg) y no reconoce el entrelazo con lo que reduce la entropía de la

89
señal. El Codec MPEG- 2 emplea también este tipo de compresión y posee una
gran velocidad de bit (bit rate) que lo hace lo suficientemente flexible tanto para
aceptar fuentes que emplean el entrelazado cuanto otras que no la emplean.
A continuación, veamos de una manera general el proceso de compresión. En la
figura 4.55a. Se observa cómo el flujo de datos (data rate) es reducido en la fuente
por un compresor (compressor). Los datos comprimidos son enviados por un
canal de comunicación hasta un expansor (expander) donde vuelve a su forma
original. La relación entre el flujo de datos (data rate) de la fuente y el flujo de
datos (data rate) del canal es conocida como factor de compresión (compression
factor). Se recurre también al término coding gain para definir esta relación. El
compresor puede ser referido como coder y el expansor como decoder y
finalmente nos podemos referir al par en serie como Codec. En comunicaciones el
costo del enlace para la comunicación de datos (data link) es proporcional al flujo
de datos (data rate) y, por este motivo, existe la presión económica para utilizar un
factor de compresión alto.
En la figura 4.55b se puede observar el empleo de un codec con una grabadora. El
uso de la compresión en aplicaciones de grabación es potente. El tiempo de
reproducción del medio es extenso en proporción al factor de compresión. En el
caso de cintas, el tiempo de acceso está perfeccionado porque la longitud de la
cinta necesaria para una grabación dada es reducida lo que implica que puede ser
rebobinada más rápidamente.
En Transmision digital; Radio y Televisión, la compresión es usada para reducir el
ancho de banda. En esta área de las telecomunicaciones existe un mercado masivo

90
para decoders, y estos puedan ser implementados a bajo costo. En cambio, como
son pocos los encoders que se utilizan, no interesa si son caros.
Otro ejemplo de aplicación de la compresión lo encontramos en los sistemas no
lineales de edición de audio y vídeo. En ellos, el material se almacena en discos
duros de alta capacidad y rápido acceso. El factor de compresión de estos equipos
aminora sus costos. Los sistemas de edición no lineales que no comprimen
resultan los más costosos.
Fuente dela data
Fuente dela data
Datarecuperado
Datarecuperado
Canal deTransmisiónCompresor
ocoder
Compresoro
coder
Expansoro
decoder
Expansoro
decoder
Dispositivode
almace-namiento:
Cinta, RAM,disco, etc...
(a)
(b)
Figura 4.55

91
4.2 ALGORITMOS DE COMPRESIÓN
Existen dos tipos de algoritmos de compresión: los que no tienen pérdidas
(lossless) y los que sí la tienen (lossy). Estos sugestivos nombres nos indican la
principal característica de cada uno de ellos.
Otra técnica de algoritmo de compresión lossless se asemeja al código Morse
pues en ella se utilizan códigos de longitud variable. Esto es posible aplicando
análisis estadístico en la frecuencia con la que son utilizadas determinadas letras.
Así, cuando se trata de letras de uso frecuente se emplean códigos cortos mientras
los códigos largos se reservan para representar letras con poca frecuencia de uso.
El código Huffman utiliza este principio: la probabilidad con la que un código es
transmitido es estudiada y los códigos más repetidos son organizados para ser
transmitidos mediante símbolos de longitud de palabra corta. A los códigos
menos frecuentes se les permitirá longitudes de palabra largas. Este código es
usado en conjunción con un número de técnicas de compresión.
Los conocidos como lossless son aquellos que al reproducir a su forma original
los datos mediante la descompresión, lo hacen bit por bit. El factor de compresión
de estos algoritmos es bajo, del orden de 2 a 1. Una técnica común en un algoritmo
de compresión lossless es codificar en series (Run length encoding). En esta, las
series del mismo valor de data son comprimidas para transmitirlas en un codigo
pre-ordenado en líneas de unos o líneas de ceros seguidas por un número con la
longitud de la línea.
Los algoritmos de compresión lossy usan técnicas lossless cuando es posible,

92
pero su característica principal es la de poder obviar información. Para este fin, la
imagen es procesada o transformada en dos grupos de datos. Un grupo que
contiene idealmente toda la información importante y el otro toda la información
irrelevante. Únicamente los datos importantes necesitan ser mantenidos y
transmitidos. Este tipo de algoritmo de compresión es muy utilizado en
aplicaciones de audio y vídeo ya que permite grandes factores de compresión.
En los codecs que emplean algoritmos lossy, las diferencias son arregladas de tal
manera que se hacen subjetivamente no detectables a los sentidos humanos de
oído y visión. Este tipo de codecs se basan en comprender cómo trabaja la
percepción psicoacústica y psicovisual del ser humano. Por esta razón se les
conoce como códigos de percepción (perceptive codes). Una aplicación de este
tipo de codificación es la generación de las señales diferencia de color RGB en
vídeo. La visión humana no percibe el cambio en la calidad cuando el ancho de
banda de las señales diferencia de color se reduce.
Los codecs que utilizan algoritmos lossy también explotan la disminución en
nuestra habilidad para percibir detalles después de un cambio de imagen, en la
diagonal o en objetos en movimiento.
Este tipo de codecs no puede ser utilizado en los sistemas de prueba bit-error-rate,
debido a que la señal reconstruida de un código de percepción no es exactamente
bit a bit.

93
4.3 TÉCNICAS DE COMPRESION EN VIDEO DIGITAL
4.3.1 COMPRESION INTRACUADRO
Se puede dividir la técnica de compresión en vídeo digital en espacial y temporal.
Cuando la técnica de compresión ( bit rate reduction) está basada íntegramente
en la redundancia existente dentro de la imagen que está siendo comprimida se la
denomina compresión Intracuadro (intraframe).
Si la técnica de compresión ( bit rate reduction) se basa en la redundancia de la
información en un grupo de imágenes continuas, la llamaremos compresión
Intercuadro (interframe).
Este tipo de compresión se aplica a imágenes fijas como en el caso de la fotografía y
busca aprovechar la redundancia en éstas, conocidas también como redundancia
espacial. En virtud de que el vídeo es una sucesión de imágenes fijas, la compresión
intracuadro es aplicable a los cuadros de una secuencia de video. El Codec M-JPEG
es el más utilizado en la compresión de vídeo cuando se emplea la compresión
intracuadro. Esto obedece a su bajo costo de implementación y a las facilidades que
brinda en la edición al permitir el acceso a cada cuadro. Este Codec fue inicialmente
el más empleado por la mayoría de los sistemas de edición no lineales.
En este tipo de compresión se recurre, principalmente, a las transformadas
discretas del coseno - DCT, aunque también se utiliza transformadas Wavelet.
Las transformadas DCT son las mas empleadas por los siguientes codecs que
trabajan con la compresión intraframe; JPEG, M-JPEG y MPEG y por los

94
formatos de videograbadoras; betacam digital, digital-S, DV, DVCAM y
DVCPRO.
La compresión intracuadro es un proceso de conversión de imagen que consiste en
transformar una imagen del dominio espacial al dominio de frecuencia. Como la
transformación de una imagen podría resultar muy compleja, esta es usualmente
separada en pequeños bloques cuadrados de píxeles (4x4, 8x8 ó 16x16) y luego
cada bloque es codificado separadamente. Cuando la transformada discreta del
coseno es aplicada al bloque, la data de las muestras son transformadas del dominio
espacial al dominio de la frecuencia. Los coeficientes DCT resultantes son
ordenados de acuerdo con el espectro que contienen las muestras, representando al
bloque como una matriz de coeficientes. En la fig.4.56 se puede observar cómo la
muestra de información ha sido reordenada en el dominio de la frecuencia. La
esquina superior izquierda de la matriz de coeficientes contiene el coeficiente DC:
este es el valor promedio de todo el bloque y es el único coeficiente requerido para
representar un bloque sólido de luminancia o de información de color. El valor de
este coeficiente es unipolar (positivo) en el caso de la luminancia y será el valor más
grande del bloque. El coeficiente de la esquina inferior derecha representa la
frecuencia espectral más elevada dentro de la matriz. Los demás coeficientes DCT
se encuentran distribuidos entre estos dos. A la derecha del coeficiente DC
encontraremos coeficientes que difieren de éste debido al incremento de la
frecuencia horizontal que contienen. Si nos movemos hacia abajo encontraremos
incrementos en la frecuencia vertical. Todos estos coeficientes son bipolares y la
polaridad de cada uno de ellos indicará si la forma de onda original fue invertida en

95
Figura 4.56
c
c00
c10
c20
30…
…
…
…
…
c11
c01 c02 c03
Incrementa los detalles horizontales
Incre
menta
los d
eta
lles v
ertic
ale
s
= Coeficiente DCC 00

96
esa frecuencia. Grandes diferencias revelan la presencia de altas frecuencias en el
borde de la información dentro del bloque. En tanto, pequeñas diferencias son
indicadores de cambios graduales como en el caso del cielo en el que se produce un
desplazamiento sutil en la luminancia o en el color. A la luz de estos hechos,
podemos inferir que las pequeñas diferencias son más difíciles de tratar que las
grandes.
Con la aplicación de las transformadas DCT es posible cuantificar coeficientes en
una base selectiva. Los detalles en alta frecuencia pueden ser preservados para
muchas escenas. La calidad en las imágenes resultantes dependerá de dos factores:
la información completa contenida en la imagen y el bit rate seleccionado. Si el
nivel de cuantificación es constante, la velocidad de bit ( bit rate) del flujo de la
imagen comprimida variará basándose en el contenido de la información. Si la
velocidad de bit ( bit rate) es constante, el nivel de cuantificación tendrá que variar
para compensar los cambios en el contenido de la información de las imágenes.
En el sistema NTSC se emplean técnicas de filtrado para limitar la frecuencia
máxima de la luminancia y de las componentes de color de la señal de vídeo.
Basándonos en el espectro contenido en una imagen de vídeo, y sin considerar la
cantidad total de la información de una imagen, encontraremos porciones
significativas en la señal NTSC que contienen poca o ninguna información. Si
añadimos a esto las porciones de la señal que contienen información de
sincronización para las pantallas de TRC, se observará que hay mucho espacio a la
izquierda de la señal. En esta zona se acumula más información acerca de la imagen
incluyendo detalles de alta frecuencia removidos por los filtros pasa banda.

97
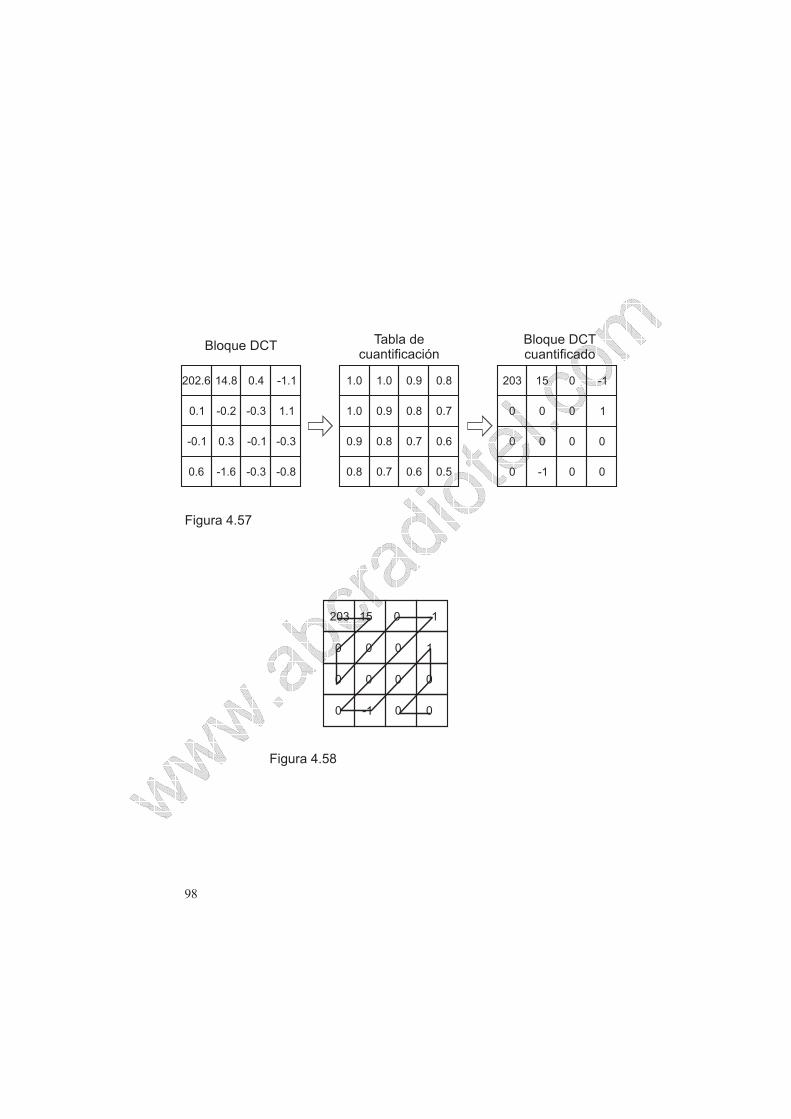
La cuantificación de los coeficientes DCT se realiza dividiendo los coeficientes
entre valores contenidos en una tabla de cuantificación. La función de esta
ponderación es adaptar la significación de los coeficientes individuales al sistema
visual humano. Dado que este es poco sensible a detalles de alta resolución, a los
coeficientes de alta frecuencia se le asignan factores de ponderación menores que 1;
a continuación, los coeficientes ponderados se redondean, dando como resultado
una matriz de transformadas DCT cuantificada, un ejemplo de esta aplicación se
observa en la figura 4.57.
A la combinación de ponderación y redondeo se la puede denominar cuantificación
de los coeficientes DCT. En esta matriz se distingue que un gran número de
coeficientes son iguales a cero y que varios coeficientes de este valor se encuentran
agrupados. Estos coeficientes 0 son eliminados aplicando una codificación de
longitud variable (Run Length Coding). Estos valores son leídos en zigzag para
maximizar la longitud (Run Lengths) de los coeficientes 0, como se observa en la
figura 4.58.
La división entre 1 deja un coeficiente invariable: la división entre un número más
grande reduce las diferencias entre coeficientes. Así decrece el número de
coeficientes diferentes y, como secuela, se mejora la eficiencia de la compresión.
El Código Huffman es aplicado a los coeficientes resultantes (entropía de la señal)
con el objetivo de reducir aun más la data. La aplicación de las transformadas DCT y
la compresión de la entropía no originan pérdida de la información de la imagen.
Como el contenido de la información varía de escena a escena, la cantidad de data
que es producida por cada cuadro al aplicarse las transformadas DCT también varía
98
203 15 0
0
0
0
0
0
0
0
0
0
0
1
-1
-1
1.0
1.0
1.0
0.9
0.9
0.9 0.8
0.8
0.8
0.8
0.7
0.7
0.7
0.6
0.6 0.5
202.6
0.1
0.6 -1.6
-0.1 -0.1
-0.2 -0.3
-0.3 -0.8
-0.30.3
14.8 0.4 -1.1
1.1
Bloque DCTTabla de
cuantificaciónBloque DCTcuantificado
Figura 4.57
Figura 4.58
203 15 0
0
0
0
0
0
0
0
0
0
0
1
-1
-1

99
con el contenido de la escena. En la mayoría de imágenes de vídeo, a las cuales se les
aplica las transformadas DCT, la compresión promedio producida es de 2 a 1.
Como muchos sistemas de edición no lineal tienen la capacidad necesaria para la
compresión 2 a 1, pueden utilizar los algoritmos sin pérdida (lossless) en los codecs
M-JPEG.
La tabla de cuantificación puede ser variada con el fin de alcanzar determinados
niveles de compresión o para especificar el tipo de información de la imagen.
Los codecs JPEG y M-JPEG se valen de la misma tabla de cuantificación para
todos los bloques DCT (8x8 píxeles) de una imagen. En DV y cuando se aplica un
codec MPEG se permite que las tablas de cuantificación sean ajustadas para cada
macrobloque de la imagen. Un macrobloque es un pequeño grupo de bloques DCT,
frecuentemente conformado por bloques ordenados en forma cuadrada o
rectangular.
Basándose en las estadísticas de una imagen, obtenidas de la aplicación de las
transformadas DCT a ésta, el nivel de cuantificación puede ser ajustado para cada
macrobloque asignando mayor cantidad de bits a la región de mayor demanda de
la imagen.
La gran selectividad en el proceso de cuantificación ubica a los bits codificados en
las frecuencias en las que nuestro sistema visual es más sensitivo. Si se usa con
moderación, la cuantificación de los coeficientes DCT resulta una efectiva
técnica de compresión.
La presencia de transiciones en altas frecuencias dentro de un bloque codificado
DCT, como las que se presentan en textos y gráficos, influye totalmente en los

100
coeficientes del bloque. En una correcta descompresión de imagen, cada
coeficiente debe ser restaurado a su valor original. Si muchos coeficientes fueron
modificados en el proceso de cuantificación, el resultado es una alteración
periódica de los píxeles que se encuentran alrededor de las transiciones en alta
frecuencia. Estas alteraciones se conocen como errores de cuantificación.
Una señal analógica de video componente de buena calidad, cuando es convertida
a digital a una frecuencia de muestreo acorde a la Norma ITU-R 601, puede ser
codificada con un factor de compresión en el rango de 2 :1 a 5:1, sin que se
aprecien pérdidas en la calidad de la imagen. Si el nivel se incrementa, se podrá
ver el ruido alrededor de los bordes de las altas frecuencias.
Otro defecto del proceso de cuantificación de los coeficientes DCT más notorios
que el ruido de cuantificación de las altas frecuencias, ocurre cuando se presentan
cambios sutiles dentro de una región de la imagen, como en el ejemplo del cielo o
de una pendiente lisa. Grandes niveles de cuantificación en los coeficientes DCT
eliminarán las pequeñas diferencias originando que todo el bloque se convierta en
sólido más que en variable. Como resultado, la región tomará una apariencia
acolchada.Ysi nos referimos a toda la imagen, ésta aparecerá como “pixeleada”.
Este codec se desarrolló a partir del estándar JPEG muy utilizado en la
compresión de imágenes estáticas. Se hizo muy popular en los sistemas no-
lineales, pero desafortunadamente no fue estandarizado lo que motivó que se
desarrollaran versiones incompatibles, hecho que impidió el intercambio de
4.3.2 M-JPEG

101
archivos entre sistemas. En la actualidad esta técnica es poco utilizada.
M-JPEG utiliza la transformada DCT en bloques y limita la compresión al
dominio espacial bidimensional. No hace uso de compresión temporal fuera de
los límites del fotograma. La herramienta principal de esta técnica para lograr la
compresión es la cuantificación de los coeficientes DCT.
La compresión es efectuada por un codificador de longitud variable, un proceso
en el que no tiene lugar pérdida alguna y que es absolutamente reversible.
Tras la cuantificación, la probabilidad de equivaler a cero es mucho mayor en los
coeficientes que representan frecuencias espectrales elevadas. El proceso de
codificación de longitud variable suministra menos bits (o una menor velocidad
de datos) para los coeficientes con menor probabilidad de equivaler a cero y más
bits para los coeficientes con mayor probabilidad de ser cero. En el dominio
digital los datos son, unos y ceros. Este tipo de codificación es un complejo
método matemático orientado a ganar eficiencia. Si se ordena cuidadosamente la
secuencia o jerarquía de los coeficientes, el codificador de longitud variable
intenta evitar el desperdicio de bits en la transmisión de coeficientes de valor cero.
La velocidad de datos de salida no es constante, sino que depende del contenido
de la escena y de la granulosidad seleccionada del cuantificado.
El sistema de compresión M-JPEG permite una gran variedad de parámetros de
diseño. El ajuste de cuantificación se realiza seleccionando y aplicando una tabla
de cuantificación específica. Esta selección ofrece la posibilidad de adaptar la
velocidad de datos y la calidad de imagen de la señal comprimida para una
aplicación específica.

102
4.3.3 COMPRESION INTERCUADRO
Este tipo de compresión aprovecha la presencia de redundancia entre imágenes
contiguas para lograr grandes niveles de compresión y es aplicada sólo si se permite
el retardo de códigos largos y restricciones de edición. La compresión intercuadro
está basada en la técnica llamada Modulación Diferencial por Código de Pulsos
(DPCM - Diferencial Pulse Code Modulation). En la codificación diferencial
DPCM únicamente la diferencia entre dos imágenes necesita ser transmitida.
En un sistema de no entrelazado, la codificación DPCM se realiza insertando en
el sistema un fotograma de un periodo de retardo de modo tal que al compararlo
con el fotograma actual solamente se obtienen los píxeles diferentes para
transmisión. (Ver fig. 4.59a). Si el fotograma fuera fijo o tuviera un movimiento
lento, las imágenes sucesivas serían similares y, por lo tanto, las diferencias
serían pequeñas. Estas diferencias pueden ser transmitidas con palabras cortas
obteniéndose así una factor de compresión (coding gain).
Cuando se trata de un sistema de entrelazado, los píxeles de un campo no
coinciden espacialmente con los píxeles del campo previo. Es necesario, por ello,
interpolar el campo previo en sentido vertical para producir un campo de
referencia antes de que se calcule la diferencia de datos. En el decoder se
necesitará realizar una interpolación similar a fin de recrear la salida entrelazada.
Los datos que se envían son, la diferencia entre el campo de referencia y el campo
presente. Luego en el decoder se añaden los datos diferentes al campo de
referencia para obtener un campo de salida. Si el encoder y el decoder contienen
idénticos interpoladores lineales, ambos realizarán las mismas aproximaciones

103
Figura 4.59
EntradaPCM
(a)
Salida deDPCM
Retardo de imagen -
+
(b)
SalidaDPCM
Entradade uncampo
EntradaPCM
Retardo de imagenInterpolador
vertical
Campoprevio
X
X
X
X
X
X
X
X
X
X
Campointerpolado
-
+

104
en el cálculo del campo de referencia el cual se cancelará. (Ver fig.4.59b). De esta
manera, no habrá pérdida de calidad, pero el incremento de la diferencia de datos
reducirá el factor de compresión obtenido.
Los distintos valores de un arreglo de dos dimensiones pueden ser transformados
y codificados para lograr una factor de compresión adicional. Demasiada
redundancia espacial no se puede esperar en una imagen diferente. Las
estadísticas de las diferentes imágenes no son las mismas que las propias
imágenes. El proceso de diferenciación resulta enfatizando las altas frecuencias
espaciales en presencia de movimiento. Cuando volvemos a cuantificar los
coeficientes, podemos tomar en cuenta que el ruido en una imagen diferente
también será percibido de forma diferente al ruido en una imagen propia. En la
práctica, los movimientos reducen la similitud entre imágenes sucesivas y la
diferencia de datos se incrementa. Como resultado, los datos que fluyen en la
modulación DPCM subirán y bajarán con el contenido del fotograma y será
necesario almacenarlos para promediar la salida del flujo de datos (data rate).
Una manera de restaurar el factor de compresión (coding gain) es el uso de la
compensación de movimiento. Si es conocido el movimiento de una parte de la
imagen, de fotograma a fotograma, el encoder puede usar el vector de
movimiento para seleccionar el píxel de la imagen de referencia y moverlo para
crear una imagen (predictive image) que posteriormente será comparada con la
imagen que se presente.
La imagen es separada en macrobloques, los que a su vez serán múltiplos enteros
del tamaño de los bloques DCT. En la compresión intercuadro, el macrobloque se

105
define como el área de un cuadro en la cual se aplica un vector de movimiento. En
la figura 4.60 aparece un ejemplo de codificación de acuerdo a la Norma CCIR,
Resolución 723. En este ejemplo se enseña un macrobloque que consiste en dos
bloques situados lado a lado. El vector de movimiento tiene las componentes
horizontal y vertical. En la Resolución 273 se especifica que la componente
horizontal es un número complemento de dos de 6 bits y la componente vertical es
representada por 5 bits, esto debido a que el movimiento vertical se presenta menos
en las imágenes. La posición del macrobloque es fijada con respecto de la pantalla
y, por lo tanto, el mecanismo de compensación trabaja buscando valores de píxeles
desde algún lugar del fotograma de referencia hasta el macrobloque. Si el
movimiento estimado es exacto, la diferencia entre el bloque que se pronostica y el
que está presente será más pequeña que en un compresor diferencial. Si los
vectores de movimiento son transmitidos conjuntamente con los datos de
diferencia, el decoder puede usar los vectores para pronosticar sus propios
macrobloques en los que se incluye a los datos de diferencia. La diferencia entre
las imágenes pronosticadas y las presentes, puede ser tratadas también como
imágenes y, consecuentemente, ser comprimida por sistemas que se basan en DCT.
En la codificación DPCM también los coeficientes DCT llegan a ser cantidades
bipolares. El tamaño del macrobloque es un compromiso. Si los bloques son
pequeños pueden seguir movimientos complejos lográndose exactitud en la
predicción y un mayor factor de compresión (coding gain). La ganancia, sin
embargo, es compensada por la necesidad de transmitir más vectores. Partiendo
en dos el área del macrobloque se duplicara el número de vectores.

106
Parte dela imagenpeviaPixel
data
7.5pixels+-
+-
Vector demovimientovertical
Vector demovimientohorizontal
Macroblockde referencia
Figura 4.60
15.5 pixels

107
El desplazamiento de los contenidos de la memoria de la imagen de referencia para
pronosticar un macrobloque es fácil. Si los vectores de movimiento especifican
desplazamientos del orden igual a un píxel, son simplemente añadidos a la
dirección usada para leer la memoria de referencia. No obstante, los movimientos
reales no son de ese orden y pueden ser de una exactitud igual a un subpíxel. El
vector de movimiento real tendrá, entonces, una parte entera que modificará la
dirección real y una fraccional que controlará un interpolador para calcular los
valores entre píxeles. Este interpolador se encontrará dentro del codificador.
Esta técnica de codificación es usualmente empleada cuando se realiza transmisión
de señales comprimidas y cuando son requeridos altos niveles de compresión.
Este Codec utiliza la técnica intercuadro y su principal característica es la gran
asimetría existente entre los procesos de codificación y decodificación. Por esta
razón, se precisa un mayor esfuerzo en el procesamiento para codificar un flujo de
datos MPEG que para decodificarlo. Este codec presenta variantes de acuerdo a
su aplicación; MPEG-1, MPEG-2, MPEG-4 y MPEG-7.
MPEG-1 y MPEG-2 fueron desarrollados para modificar fotogramas en
movimiento con una variedad de de velocidad de bit (bit rate) que va desde 1.5
Mbps (calidad cercana a VHS) hasta 15 ó 30 Mbps, (similar a HDTV) MPEG-1
codifica los cuadros de vídeo con velocidades de bit (bit rates) que van de 1 a 3
Mbps; MPEG-2 puede codificar campos o cuadros de vídeo con velocidades de
bit (bit rates) que van de 3 a 10 Mbps para SDTV y de 15 a 30 Mbps para HDTV.
4.3.4 MPEG

108
En MPEG-2, las herramientas de codificación de vídeo inter e intracuadros,
conjuntamente con las técnicas de codificacion de audio y protocolos de
transporte de data son parte de lo que se conoce como caja de herramientas
(toolbox). A las combinaciones específicas de herramientas, optimizadas para
diversas labores y aplicaciones requeridas, se las conoce como Perfiles (Profiles).
(Ver fig. 4.61).
Los Seis Perfiles MPEG-2 reúnen diferentes juegos de herramientas de
compresión dentro de un grupo de herramientas para diferentes aplicaciones. Los
Niveles (Levels) acomodan cuatro grados diferentes de vídeo de entrada, que van
desde una definición limitada similar a la de los de los equipos de consumo, hasta
llegar a la alta definición.
Los Niveles y Perfiles proporcionan demasiadas combinaciones prácticas. Las
que se eligen, por lo tanto, tienen que especificar los puntos de conformidad
dentro de toda la matriz. Así por ejemplo 12 puntos de conformidad han sido
definidos desde el Simple Profile at Main Level (SP@ ML) hasta el High Profile
at High level (HP@ HL). El Main Profile at Main Level (MP@ ML) es el que más
se aproxima, cuando se trata de calidad de vídeo para transmisión (Broadcast).
Cualquier decoder que esté certificado para un punto de conformidad tiene que
poder reconocer y decodificar las herramientas y resoluciones usadas en otro punto
de conformidad ubicado debajo de éste y a la izquierda. Por lo tanto, un decoder de
MP@ LL también puede decodificar un punto SP@ ML y MP@ LL. Un decoder
MP@ HLtiene que decodificar un MP@ H14L, MP@ ML, MP@ LLy SP@ ML.
Como con MP@H14L, no todos los puntos de conformidad han encontrado un

109
100M
b/s
80M
b/s
PR
OF
ILE
S
60M
b/s
40M
b/s H
IGH
MA
X. N
UM
BE
R
OF
SA
MP
LE
S
19
20
x1
08
0x
30
19
20
x1
15
2x
25
14
40
x1
08
0x
30
14
40
x1
15
2x
25
32
5x
24
0x
30
32
5x
28
8x
25
72
0x
48
0x
30
72
0x
57
6x
25
HIG
H
MP
@H
L
HP
@H
L
HP
@M
L
MP
@M
L MP
@L
L
4:2
:2P
@H
L 4:2
:2P
@H
14
L
MP
@H
14
L
HP
@H
14
LS
SP
@ H
14
L
SN
RP
@ M
L
SN
RP
@ L
L
SP @ M
L
LOW
MA
IN
SIM
PLE
MA
IN
HIG
H
4:2:
2S
NR
SC
ALA
BLE
SPA
TIA
LLY
SC
ALA
BLE
1440
20M
b/s
LE
VE
LS
MAX BITRATES
Figura 4.61

110
uso práctico. El que más se ha acercado a este objetivo es el MP@ML; y para
propósitos de sistemas HDTV, los contenidos dentro del punto MP@HL.
MP@ML soporta una frecuencia de muestreo para el área activa de la imagen de
vídeo de 10,4 muestras por segundo y se encuentra optimizado para manejar los
formatos existentes de vídeo digital basados en las especificaciones de muestreo
ITU-R 601. La diferencia en las frecuencias de muestreo (10,4 millones
versus13,5 millones) está relacionada con el tiempo que dura el muestreo de los
intervalos del blanking de vídeo.
MPEG especifica tres tipos de fotogramas que pueden ser codificados en un flujo
de data. Estos son:
MPEG también se basa en la modulación diferencial DPCM para eliminar la
redundancia temporal. Si podemos predecir cómo se verá un cuadro, las
diferencias serán significativamente más pequeñas que los cuadros mismos. En
imágenes fijas la diferencia consistirá en ruido o grano de película. Esta
proporciona un significativo refuerzo a la eficiencia de la compresión cuando la
comparamos con la técnica intracuadro.
(I) (Intra-coded picture): La imagen original es
codificada usando únicamente su propia información. Las técnicas de compresión
DCT son empleadas para codificar el cuadro de la imagen o los dos campos
entrelazados. Los fotogramas I proporcionan puntos de acceso a un grupo de datos.
este es un fotograma codificado
utilizando la predicción de la compensación de movimiento a partir de un
fotograma de referencia pasado. La diferencia entre la imagen actual y la imagen
Fotograma Intracodificado
Fotograma codificado de Predicción (P):

111
pronosticada es codificada utilizando técnicas de compresión DCT.
este es un fotograma
codificado utilizando la predicción de la compensación de movimiento a partir de
los fotogramas de referencia pasado y futuro. La diferencia entre la imagen actual
y la imagen pronosticada es codificada utilizando técnicas de compresión DCT.
Este no es un promedio del cuadro previo y futuro. Los fotogramas B
proporcionan la codificación más eficiente, sin embargo una tercera memoria de
almacenamiento es requerida para agregarla a los fotogramas almacenados de
referencia pasado y futuro (I y P). Los modos de búsqueda rápida son facilitados
ignorando los fotogramas B.
Los flujos MPEG pueden ser codificados usando solo cuadros I, cuadros I y P,
cuadros I y B o cuadros I, P, y B. La codificación de solo cuadros I es idéntica a la
técnica de codificación intracuadro.
Los Perfiles MPEG para distribución de programas utilizan muestreo 4:2:0, cuadro
IP o IPB. The MPEG-2 Studio Profile fue creado para la producción y contribuye a
la calidad de la codificación del vídeo. Este Perfil permite el uso del muestreo 4:2:2,
de cualquier combinación de los cuadros I, P y B; y de velocidades de bit (bit rates)
de hasta 50 Mbps. Por ejemplo, el formato Betacam SX de Sony emplea un
muestreo de 4:2:2, cuadros I y B y una velocodad de (bit rate) de 18 Mbps.
La sintaxis de un grupo de datos MPEG está constituida en una arquitectura de
capas. A continuación, detallaremos esta conformación empezando por el nivel
mínimo y avanzando hasta el superior.
Esta es la unidad básica y está formada por 8 líneas y 8 columnas
Fotograma codificado de Predicción Bidireccional (B):
Bloque (Block):

112
ortogonales de píxeles.Aesta unidad básica le son aplicadas las DCT.
Es la unidad básica adoptada para pronosticar la
compensación del movimiento. Está integrada por varios bloques dependiendo
del tipo de codificación que se utilice. Para el caso de MPEG-2, el macrobloque
consta de 4 bloques de data de luminancia de 8x8 píxeles (resultando un arreglo
de 16x16) y de dos bloques de data de las señales diferencia de color de 8x8
píxeles. Estos bloques cubren el área de la componente luminancia. En este caso
la frecuencia de muestreo para MPEG-2 será 4:2:0. (Ver fig. 4.62).
Compuesta por una serie de macrobloques, es la unidad básica
de sincronización para la reconstrucción de la data de la imagen y la forman todos
los bloques en un intervalo horizontal del cuadro (16 líneas del cuadro).
Es el origen de una imagen o los datos de reconstrucción
para un simple cuadro o dos campos entrelazados. Un fotograma consiste en tres
matrices rectangulares de números de 8 bits que representan a la señal luminancia
y a las dos señales diferencias de color.
Secuencia de fotogramas
que comienza con un cuadro I y continúa con un número variable de cuadros P y
B. (Ver fig.4.63).
El circuito de codificación MPEG requiere de uno o dos cuadros de una secuencia
de video almacenada en la memoria, que proporciona la imagen de referencia
para el pronóstico de la compensación del movimiento. Los cuadros
pronosticados requieren de una segunda o tercera memoria de almacenamiento.
En MPEG, la estimación del movimiento involucra un fuerte calculo
Macrobloque (Macroblock):
División (Slice):
Fotograma (Picture):
Grupo de Fotogramas (Group of Pictures-GOP):

113
Figura 4.62
Figura 4.63
4:x:xX:2:2
X:2:0
Macrobloque de luminancia
Bloques DCT de luminancia
Las muestras de las señales diferencia de color cubren la misma área de la imagencomo lo hace un macrobloque de luminancia.
Bloques DCT R-Y
Bloques DCT B-Y
Bloques DCT de las señales diferencia de color
I
Grupo de imagenesGOP
Formación pronosticada
NuevoGOP
Predicción bidireccional
BBPBBPBBPBBI

114
computarizado - cuando se busca la igualdad de un macrobloque en dos cuadros,
para determinar la dirección y la distancia que un macrobloque se ha movido entre
los cuadros (vector de movimiento).
El decoder utiliza los vectores de movimiento para reponer los macrobloques
desde una imagen de referencia, reuniéndolos en una memoria de
almacenamiento para pronosticar una imagen (P). El Encoder también contiene
un decoder, el cual es utilizado para producir la imagen P; esta predicción es
substraída del cuadro original sin comprimir, con la esperanza de dejar solo
pequeñas diferencias. Estas diferencias son codificadas usando la misma técnica
basada en transformadas DCT, utilizada para codificar los cuadros I.
El circuito de codificación MPEG es mas eficiente cuando se pueda ver que las
cosas lucen igual en el futuro. Cuando se comienza a codificar una nueva
secuencia de imágenes con un cuadro I, y hay presencia de movimiento de objetos
oscuros en el fondo de esta secuencia; no hay forma de predecir que estos pixels
del fondo luzcan iguales hasta que estos puedan ser vistos. Pero si saltamos
algunos cuadros hacia delante, se puede confirmar que los pixels que se muestran
se ven igual y a los vectores de movimiento de los objetos que se movieron.
Un encoder MPEG tiene que tener multiples cuadros de almacenamiento para
permitir el cambio en el orden en el cual las imágenes son codificadas. Aesto se
le conoce como orden de codificación (coding order). Con una memoria de
almacenamiento de un cuadro, la siguiente predicción puede ser usada para
crear el siguiente cuadro P. Con una memoria de almacenamiento de dos
cuadros, las predicciones bidireccionales pueden ser usadas para uno o más

115
cuadros B entre la imagen de referencia I y los cuadros P.
Un encoder que trabaja a menos de la velocidad de tiempo real no tiene problema
en
imágenes, a las que codifica fuera de orden. En función de observar hacia el futuro,
un encoder MPEG de tiempo real tiene que introducir un periodo de confusión
entre el periodo actual de un evento y el periodo en que uno lo ve- la confusión es
igual al numero de cuadros de retardo instalados en el encoder.
Si un Encoder que trabaja en tiempo no- real ejecuta una difícil secuencia
codificada, este puede hacerla mas lenta y así realizar un mejor trabajo en el
calculo del movimiento. Pero un encoder MPEG de tiempo real tiene una
cantidad finita de tiempo para realizar decisiones de codificación y de esta modo
se puede hacer algunos compromisos- como el de permitir elementos indeseables
en la imagen o el de una gran velocidad de data para alguna imagen de calidad.
El Decoder MPEG utiliza la data de las imágenes I y P y el vector de movimiento
para reconstruir las imágenes B. La diferencia de información se añade luego a las
predicciones para reconstruir las imágenes que serán mostradas.
Los Encoders de tiempo real pueden aprovechar del nivel de la división (Slice) de
la sintaxis MPEG que separa la imagen en secciones que pueden ser codificadas
en paralelo. Cada pedazo de la imagen es codificada utilizando un procesador
distinto y varios procesadores adicionales son utilizados para seguir la
información que se esta moviendo entre los pedazos. Los primeros encoders de
tiempo real MP @ML utilizaban como máximo 14 procesadores en paralelo para
codificar una imagen.
trasgredir tiempo. Este llena sus memorias de almacenamiento con un grupo de

116
La codificación de imágenes entrelazadas requiere de una adicional capa de
sofisticación, debido al oblicuidad (skewing) temporal entre los campos que
conforman cada cuadro. Si los campos están combinados, la oblicuidad entre las
muestras interfiere con la normal correlación entre las muestras.
Para solucionar este problema, primero se aplica la codificación basada en el
campo/cuadro a nivel macrobloque. Como un macrobloque MPEG contiene
cuatro bloques de codificación DCT. Si se detecta una significativa oblicuidad
dentro de los bloques DCT. Las muestras de un campo son movidas a los dos
bloques superiores, mientras que las muestras del otro campo se mueven a los
bloques inferiores. De este modo se mejora la correlación de los datos de la
imagen y significativamente es mejorada la eficiencia de codificación de cada
bloque DCT. La combinación de la cuantificación a nivel de macrobloque con la
codificación del macrobloque basado en el campo/caudro, en promedio, permite
a la codificación intraframe MPEG-2 una mejora 2:1 en eficiencia de compresión
si la comparamos con la codificación M-JPEG. Esto permite el uso de los cuadros
I codificados en MPEG-2, en ediciones de video.
La segunda técnica, añadida en MPEG-2 para tratar con el entrelazado, consiste
en adoptar la predicción del movimiento basada en el campo/cuadro. Esto
complementa el uso de la aplicación de la codificación de bloque basada en el
campo/cuadro permitiendo generar distintos vectores de movimiento para los
bloques que conforman cada campo.
MPEG tiene problemas cuando se trabaja con ciertos efectos en producción de
video, como por ejemplo; en las disolvencias entre imagenes y la disolvencia a

117
negro. Durante estos efectos, cada muestra esta cambiando con cada nuevo
campo o cuadro: hay una pequeña redundancia por eliminar. La disolvencia entre
dos imágenes se complica por la co-ubicación de dos imágenes con objetos
moviéndose en diferentes direcciones.
Otro Codec que se utiliza en la actualidad es el MPEG- 4. Esta norma tiene una
serie de herramientas que pueden ser agrupadas en Perfiles (Profiles) y Niveles
(Levels) para diferentes aplicaciones de video. El kit de herramientas de esta
norma permitirá a los futuros autores de multimedia y usuarios; almacenar,
acceder, manipular y presentar a la data de los audiovisuales en una forma que
cubra sus necesidades individuales en el momento, sin tener que ver por los
detalles subalternos. Esta norma se utiliza en las paginas web, los CD, los
videoteléfonos y en la transmisión de televisión.
En MPEG-4, la estructura de codificación de video comienza con un núcleo de
video que tiene muy baja velocidad de bit (VLBV- Very low bit rate video) en el
que se incluyen algoritmos y herramientas para una velocidad de datos (data rate)
que varia de 5Kilobits/seg hasta 65Kbit/seg. Trabajando con muy bajas
velocidades de bits (bit rate) la compresión del movimiento, el enmascaramiento
y las correcciones de errores han sido mejoradas, las velocidades de refresco se
mantienen bajas (entre 0 y 15 cuadros/seg) y la resolución es limitada a un rango
de unos poco pixels por linea hasta un formato intermedio común (CIF- Common
Intermedia Format) (352x288).
MPEG-4 no tiene que ver directamente con la protección a errores que se necesita
en canales específicos como en el caso de radio celular, pero ha permitido mejorar

118
la forma en que los bits de carga útil son ordenados de este modo la recuperación
será mas fuerte.
Si se cuenta con un canal que permita una velocidad que va de 64 Kb/seg a
2Mb/seg, MPEG-4 tiene una alta velocidad de bit para un modo de video
(HBV- High bit rate Video mode) que soporta resoluciones y velocidades de
cuadro permitidas por la norma ITU-R 601. Las herramientas y los algoritmos son
esencialmente los mismos como en el caso de VLBV, mas algunos adicionales
unos que sirven para manipular fuentes entrelazadas.
Este nuevo MPEG suena igual que el antiguo MPEG con unos pocos arreglos para
el ruido en canales de baja velocidad de bit (bit rate). Lo que lo diferencia
sustancialmente de los esquemas de codificación anteriores son sus herramientas
para codificar objetos de video. No realiza solamente la codificación convencional
de imágenes rectangulares, porque tiene un grupo de herramientas para codificar
formas arbitrarias.
Algunos ejemplos de aplicación de MPEG-4 los tenemos en los siguientes casos ;
la codificación de una noticia separada de su fondo estático, y la codificación de un
jugador de tenis independientemente de la cancha de juego. Una vez que los
objetos de una escena han sido codificados discretamente, el usuario puede
interactuar con estos individualmente. Los Objetos pueden ser agregados y
extraídos, se les puede variar de tamaño y moverlos en la escena. Además la
eficiencia de codificación puede ser mejorada enviando la información de un fondo
estático como un simple cuadro. Luego se necesitara enviar solo los objetos
móviles, sus relaciones con el fondo y como estos podrían conformar la escena

119
final. Los fondos estáticos son llamados “Sprites”. Estos pueden tener dimensiones
mas grandes que las que se verían en cualquier cuadro simple. Un sistema de
coordenadas es proporcionado para posesionar los objetos en relación a otros y a
los “Sprites”.
La capacidad de descripción de una escena en MPEG-4 ha sido fuertemente
influenciada por un trabajo previo que fue realizado por la comunidad de Internet
en el Virtual Reality Modeling Language (VRML) e incluye muchas de sus
herramientas.
La codificación y la manipulación arbitraria de las formas de los objetos es una
cosa. Extraerlos de su escena natural es completamente diferente y no es fácil.
Demostraciones de MPEG-4 han requerido de mucha mano de obra en el lado del
procesamiento de la entrada, los beneficiarios inmediatos de la nueva técnica de
codificación de objetos son los juegos, los programas basados en imágenes
sintéticas y las separaciones de Chroma key.
Los Encoders y decoders en MPEG-4 son mas complejos y mas caros que en las
normas MPEG-1 y MPEG-2.

120
4.4 COMPENSACIÓN DE MOVIMIENTO
La compresión en vídeo digital depende de la eliminación de la información
redundante en una señal. En consecuencia, grandes factores de compresión se
pueden alcanzar eliminando los datos comunes en imágenes sucesivas y
transmitiendo solo los datos diferentes.
Un movimiento origina que la imagen se mueva con respecto a la red de muestreo
provocando que todos los valores de muestra en un área de movimiento cambien y
se preparen para una reducción efectiva. Mediante el cálculo del movimiento, la
imagen en movimiento puede ser cancelada porque la comparación puede ser hecha
a lo largo del eje de movimiento en lugar de utilizar el eje del tiempo. Por lo tanto,
un gran factor de reducción se puede lograr porque solo será necesario enviar los
parámetros del movimiento y un pequeño número de diferentes imágenes genuinas.
En imágenes en movimiento también debemos considerar el ruido aleatorio que se
podría presentar. La reducción de ruido en señales de vídeo se logra por la
combinación de cuadros sucesivos en el eje del tiempo de modo tal que el
contenido de la imagen de la señal se refuerza fuertemente mientras que esto no lo
puede hacer el elemento aleatorio en la señal debido al ruido. La reducción del
ruido aumenta con el número de cuadros sobre los cuales el ruido está integrado,
pero el movimiento de imagen previene de una simple combinación de cuadros.
Si se dispone del cálculo del movimiento, la imagen de un objeto en movimiento en
un cuadro particular puede ser compuesta a partir de las imágenes en diferentes
cuadros, los cuales han sido sobrepuestos en el mismo lugar de la pantalla por los

121
desplazamientos derivados de la medición del movimiento. Como resultado es
posible una gran reducción de ruido.
diferentes
4.5 TÉCNICAS DE ESTIMACIÓN DE MOVIMIENTO
4.5.1 IGUALDAD DE BLOQUE
A continuación, explicaremos los dos principales métodos para el cálculo de un
movimiento: igualdad de bloque (block matching) y correlación de fase (phase
correlation).
En este método, en una imagen dada, un bloque de píxeles es seleccionado y
almacenado como referencia. Si el bloque seleccionado es parte de un objeto en
movimiento, un bloque similar existirá en la siguiente imagen, pero no en el
mismo lugar. Este método consiste en mover el bloque de referencia por toda la
segunda imagen buscando iguales valores de píxeles. Cuando una igualdad de
bloque es encontrada, el desplazamiento realizado es utilizado como una base
para un vector de movimiento.(Ver fig. 4.64)
Esta técnica requiere de un enorme cálculo computarizado debido a que cada
posible movimiento tiene que ser probado sobre un rango asumido. Por ejemplo,
si asumimos que un objeto se ha movido sobre un rango de 16 píxeles será
necesario probar 16 desplazamientos horizontales en cada una de las 16
posiciones, resultando más de 65,000 posiciones (16*16*16*16). La posición de
cada píxel en el bloque tiene que ser comparada con cada píxel de la segunda

122
Areabuscada
Figura 4.64
El bloque se mueve endirección vertical yhorizontal y la correlación semide en cada dirección
Areade imagen

123
imagen. Un típico movimiento en el cual la imagen se repite se puede observar en
los eventos deportivos.
Una forma de reducir la cantidad de cálculos es el de comparar si hay igualdad por
etapas. La primera etapa es inexacta, pero cubre un largo rango de movimiento; la
última es exacta, porque cubre un pequeño rango.
La primera etapa se realiza en una imagen excesivamente filtrada y muestreada que
contiene pocos píxeles. Cuando una igualdad es encontrada, el desplazamiento es
usado como base para una segunda etapa, la cual es llevada a cabo con menos
exceso en el filtrado de la imagen. Este tipo de aproximación puede reducir los
cálculos requeridos, pero sufre de un problema: puede hacer desaparecer objetos
pequeños debido al excesivo filtrado producido en la primera etapa ya que dichos
objetos no se podrán encontrar en las etapas posteriores si están moviéndose con
respecto a su fondo. Este tipo de problemas se presenta en los eventos deportivos en
los que surge la presencia de objetos pequeños moviéndose a gran velocidad.
Como el proceso de igualdad incluye encontrar similares valores de luminancia,
este puede ser víctima de confusión por causa de objetos que se mueven en la
sombra o se desvanecen.
Mediante esta técnica pueden ser calculados movimientos hacia los píxels cercanos.
Sin embargo, si se requiere de mayor exactitud será necesario interpolar,
especialmente cuando se trata de desplazar imágenes a distancias iguales a subpíxel
antes de intentar encontrar una igualdad. En sistemas de compresión, una exactitud
de medio píxel es suficiente para muchos propósitos.

124
4.5.2 CORRELACIÓN DE FASE
Este método utiliza como herramienta la transformada discreta de fourier (DCT),
y se aplica a dos campos sucesivos para luego substraer todo lo referente a las
fases de los componentes espectrales. A las diferencias de fases se les aplica la
transformada inversa y el resultado de estas revela los picos, cuyas posiciones
corresponden a movimientos entre los campos.
Como a partir del uso de la transformada podemos medir exactamente la distancia y
dirección del movimiento pero no el área en la cual se realiza, en sistemas prácticos
la correlación de fase es seguida por una etapa de igualdad (matchingstage). Esta no
es distinta del proceso de igualdad de bloque (block matching), sin embargo el
proceso de igualdad es guiado por los movimientos de la correlación de fase y, por lo
tanto, no habrá necesidad de buscar la igualdad en todas las posibles direcciones.
Como corolario, el proceso de igualdad se realiza con gran eficiencia.
El uso de transformadas de fourier en este método permite separar una imagen en
sus componentes de frecuencias espaciales, mientras que en paralelo se realiza la
estructuración jerárquica de la igualdad de bloques en varias resoluciones. De esta
forma, los pequeños objetos no se pierden porque estos generan componentes de
alta frecuencia en la transformación.
La eliminación de la información de las amplitudes en el proceso de correlación
de fase permite continuar calculando el movimiento en el caso de disolvencias,
objetos moviéndose en la oscuridad o disparos de armas.
A continuación, veamos un ejemplo de la aplicación de este método.
Consideremos una línea de luminancia, la cual consiste de una serie de muestras

125
en el dominio digital y es una función del brillo con respecto de la distancia a lo
largo de la pantalla: la transformada de fourier convierte esta función en un
espectro de frecuencias espaciales (unidad de ciclos por ancho de imagen) y fases.
Como toda señal de vídeo tiene que ser manipulada en un sistema de fase lineal, si
una señal de video pasa por un dispositivo que carece de esta característica, los
componentes de varias frecuencias de los bordes serán desplazados a los largo de
la pantalla.
En la figura 4.65 se observa un sistema de fase lineal. Si se considera fijo el lado
izquierdo del eje de frecuencia, el lado derecho puede ser rotado para indicar un
cambio de posición a lo largo de la pantalla, se observara que cuando el eje es
doblado uniformemente el resultado es un desplazamiento de fase proporcional a
la frecuencia. Un sistema que posea esta característica tiene una fase lineal.
En el dominio espacial, un desplazamiento de fase corresponde a un movimiento
físico (Ver fig. 4.66). Aquí se observa que si entre los campos, una forma de onda
se mueve a lo largo de la línea, en la frecuencia más baja de la transformada de
fourier se produce un desplazamiento de fase: el doble de esta frecuencia sufrirá el
doble de desplazamiento y así sucesivamente. Por lo tanto, será posible medir
movimiento entre dos campos consecutivos si analizamos las diferencias de fase
entre los espectros de fourier.
El resultado del método de correlación de fases es un conjunto de componentes de
frecuencia que poseen la misma amplitud, pero tienen fases que corresponden a
las diferencias entre dos campos. Los coeficientes resultantes forman la señal de
entrada cuando se realiza una transformada inversa (Ver fig. 4.67a). Si los dos

126
Figura 4.65
Figura 4.66
0
0
F
Fase
Frecuencia
2F
3F
4F
5F6F
7F
8F
8F
Desplazamiento
Señal devideo
Fcia. Fundamental
3er. Armónico5to. Armónico
0°
1 Ciclo = 360°
3 Ciclos = 1080°
5 Ciclos = 1800°
El desplazamientode fase esproporcional aldesplazamientopor frecuencia

127
campos son los mismos, no hay diferencia de fases entre los dos y, por lo tanto, al
sumar todos los componentes de frecuencia se produce un simple pico en el centro
de la transformada inversa. Cuando se presenta un movimiento entre campos, tal
como un movimiento lateral, todos los componentes tienen fases diferentes y el
resultado es un pico desplazado del centro de la transformada inversa igual a la
distancia de movimiento. Así, la fase de correlación mide el movimiento entre
campos (Ver fig.4.67b).
Cuando la línea de vídeo cruza objetos en movimiento a diferentes velocidades, la
transformada inversa tendrá un pico correspondiente a la distancia del
movimiento de cada objeto (Ver fig. 4.67c).
Hasta ahora solamente se explicó cómo se realiza el método de correlación de fase
en una sola dimensión, pero para efectos prácticos la señal de vídeo está en dos
dimensiones. Para este caso se realiza el cálculo de una transformada de fourier en
dos dimensiones por cada campo, las fases se sustraen y se calcula una
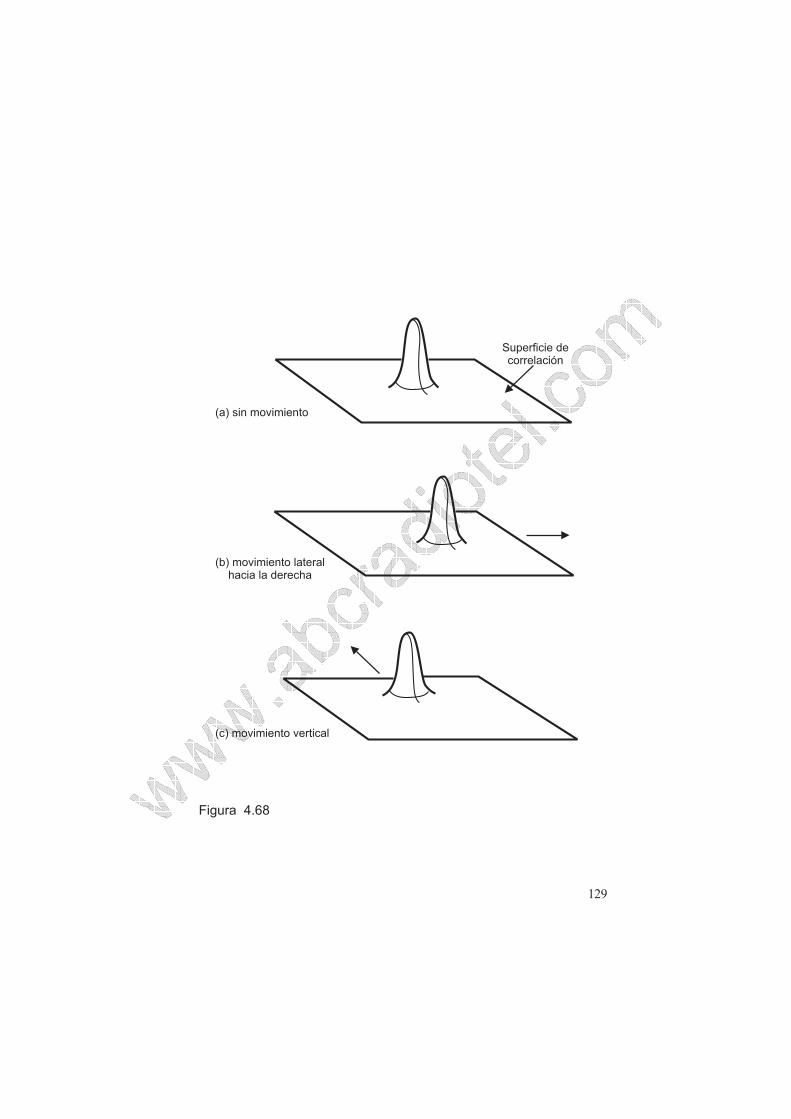
transformada inversa. El resultado de esta transformada inversa es un plano liso
del cual sobresale un pico de tres dimensiones. Este plano es conocido como una
superficie de correlación.
En la figura 4.68 se observa una superficie de correlación en la cual se presentan
los siguientes casos:
a.- No hay movimiento entre campos y por lo tanto solo hay un pico central.
b.- Existió un movimiento lateral y el pico se mueve a lo largo de la superficie.
c.- Existió un movimiento vertical y el pico se mueve hacia arriba.
Cuando se presentan movimientos complejos y quizás con diferentes objetos

128
f
f f
3f
3f
3f
Primeraimagen
Segundaimagen
45°f
135°3f
225°5f
Transformadainversa
Pico central= sin movimiento
El pico indica queel objeto se muevea la izquierda
Figura 4.67
El pico indica queel objeto se muevea la derecha
El desplazamiento de picomide el movimiento
(b)(a)
(c)
3f
3f
5f
5f
5f
5f 5f
f
f
129
Superficie decorrelación
(a) sin movimiento
(b) movimiento lateralhacia la derecha
(c) movimiento vertical
Figura 4.68

130
moviéndose en diferentes direcciones y a diferentes velocidades, un pico
aparecerá en la superficie de correlación por cada objeto.
Este método de correlación de fase desempeña un papel muy importante pues
mide y no simplemente estima, extrapola o busca la dirección y velocidad de un
movimiento. El movimiento puede ser medido con una exactitud de subpíxel sin
excesiva complejidad .
Dado que no especifica en qué lugar de la imagen se producen los movimientos,
este método se complementa con un proceso de igualdad capaz de cubrir esa
carencia.
4.6 COMPRESIÓN Y RECUANTIFICACIÓN
Los sistemas de compresión tiene como objetivo lograr una ganancia en el factor
de compresión (coding gain) mediante el cual y utilizando pocos bits se puede
representar la misma información.
El factor de compresión (coding gain) se obtiene acortando la longitud de palabra
de la data de modo tal que pocos bits sean necesarios. Esta data de palabras
pueden ser las muestras de la forma de onda de un sistema basado en sub-bandas o
los coeficientes de un sistema basado en transformadas. En ambos casos, la data
estará expresada en un formato complemento de dos con la finalidad de manejar
los valores positivos y negativos.
Un ejemplo se ofrece en la figura 4.69a.Aquí podemos observar varios niveles de
una señal en una codificación complemento de dos. En este caso, a medida de que

131
el nivel disminuye aparece un fenómeno denominado extensión de signo que se
presenta en más y más bits del final más significativo de la palabra (MSB)
simplemente copiando el bit de signo. El factor de compresión (códing gain) se
puede obtener eliminando la redundancia de los bits de extensión de signo que
aparece en los niveles inferiores. (Ver fig.4.69b).
Para eliminar los bits de extensión de signo del centro de la palabra será necesario
multiplicar la palabra por un factor dependiente del nivel. Si este es de potencia 2,
los bits útiles desplazarán hacia el lado superior izquierdo al bit de signo. Los
ceros del lado derecho son omitidos de la transmisión y en el decoder tendrá que
aplicarse una división de compensación . El factor de multiplicación tendrá que
ser transmitido conjuntamente con los datos comprimidos para que esta pueda ser
hecha. Si solamente se elimina en este proceso los bits de signo de extensión,
entonces es un proceso sin perdidas (lossless) porque la misma data estará
disponible en el decoder.
La razón de utilizar sub-bandas de filtrado (Ver fig. 4.70) y factor de compresión
(coding gain) en las transformadas se debe a que en señales reales, los niveles en
muchas sub-bandas y los valores de muchos coeficientes son considerablemente
menores que el nivel mas alto.
En muchos casos, el factor de compresión (coding gain) obtenido de esta forma no
es suficiente y la longitud de la palabra tiene que ser acortada aun más. Siguiendo
con la multiplicación, un gran número de bits son eliminados del final menos
significativo de la palabra. El resultado es que el mismo rango de señal es retenido
pero es expresado con menos exactitud como si la señal análoga original hubiera

132
EntradaX
Eliminaciónde filasde ceros
Data
Nivel
Figura 4.69
Detectorde nivel
(a)
(b)
X X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X X
X
X
X
X
X
X
X
X0
0000
0
0
0
Bit de signo
Picopositivo
Piconegativo
-6dB
-6dB
-12dB
-12dB
-18dB
Bits redundantes“de extensión de signo”
-18dB
etc.
0
0
0
0
0
01
1
1
1 1 1 1
1
1
1
1
1 1
1
X
X
X
X
X
X
X
X
X
X
X
X

133
sido convertida utilizando menos niveles de cuantificación. Expresado de otro
modo: se ha realizado una recuantificación.
Durante el proceso de decodificación, es necesario utilizar un cuantificador
inverso para convertir los valores comprimidos a su forma original. El proceso de
recuantificación y sus posibles aplicaciones ya fueron mencionados en un
capítulo anterior a este.
Si el parámetro que va a ser recuantificado es un coeficiente de transformación, el
resultado luego de la decodificación, es que la frecuencia reproducida tiene una
amplitud incorrecta debido al error de cuantificación. Si todos los coeficientes
que describen una señal son recuantificados con el mismo grado, el error estará
presente de forma uniforme en todas las frecuencias y el ruido será igual.
Si la data son muestras en el dominio del tiempo, como por ejemplo un compresor
de sub-banda, el resultado será diferente y para convertir el error de
cuantificación en ruido más que en distorsión, será preciso utilizar un dither
digital.
Sub-banda
0
Figura 4.70
FrecuenciaF 3F 2Fin in in

134
Bibliografía
“Sistemas electrónicos digitales”
“Sistemas de comunicación”
“La compresión digital”
“Image Compresión Using The discrete cosine Transform”
“Interframe and Intraframe Compression Techniques”
“Compression in Video and Audio”
“DV sampling, artifacts, tape dropout, generation loss, codecs”
“The Guide to Digital Television”
“Digital Video”
“Introduction to Digital filters”
Enrique Mandado.
B. P. Latí.
Panasonic.
Andrew B. Watson.
Colin E. Manning.
Jhon Watkinson.
Adam J. Wilt.
Michael Silbergleid.
Jhon Watkinson.
Digital Signal Processing.