capitulo ii marco teÓrico sobre la arquitectura de...
TRANSCRIPT

13
CAPITULO II
MARCO TEÓRICO SOBRE LA ARQUITECTURA DE CLUSTER
2.1 GENERALIDADES
En la actualidad debido a la gran demanda de servicios de Internet y la
transferencia de información de todo tipo, es incuestionable la importancia que los
sistemas informáticos puedan funcionar de forma ininterrumpida y sin errores los
365 días al año.
Muchas empresas reconocidas a nivel mundial han decidido implementar
servidores de Clústers (Google, Microsoft, etc.) para poder hacer frente a la
demanda de la información y el tiempo en el que dicha información se necesita
procesar.
Es así como han surgido proyectos que han llevado a la creación de soluciones
informáticas que vienen a solventar esta demanda de procesamiento. Estas
soluciones se pueden encontrar tanto en software de Código Abierto (Open
Source) como software propietario.
Es por ello que la existencia de los Clústers juega un papel muy importante en la
solución de problemas de las ciencias, las ingenierías y en el desarrollo y
ejecución de muchas aplicaciones comerciales, la utilización de componentes de
hardware comunes, software libre e interconexión de redes de alta velocidad lo
hace muy atractivo.
El presente proyecto pretende exponer y desarrollar el tema bajo un enfoque
académico orientándolo a las necesidades de una institución educativa del país,
incluyendo: arquitectura de hardware, sistema operativo, lenguajes de
programación y las aplicaciones necesarias para su configuración.

14
2.2 HISTORIA DE CLUSTER.
El comienzo del término y del uso de este tipo de tecnología es desconocido pero
se puede considerar que comenzó a finales de los años 50 y principios de los años
60.
La base formal de la ingeniería informática de la categoría como un medio de
hacer trabajos paralelos de cualquier tipo fue posiblemente inventado por Gene
Amdahl de IBM, que en 1967 publicó lo que ha llegado ser considerado como el
papel inicial de procesamiento paralelo: la Ley de Amdahl que describe
matemáticamente lo que se puede esperar paralelizando cualquier otra serie de
tareas realizadas en una arquitectura paralela.
La historia de los primeros grupos de computadoras es más o menos directamente
ligado a la historia de principios de las redes, como una de las principales
motivaciones para el desarrollo de una red para enlazar los recursos de
computación, de hecho la creación de un Clúster de computadoras. Las redes de
conmutación de paquetes fueron conceptualmente inventados por la corporación
RAND en 1962.
Utilizando el concepto de una red de conmutación de paquetes, el proyecto
ARPANET logró crear en 1969 lo que fue posiblemente la primera red de
computadoras básico basadas en el Clúster de computadoras por cuatro tipos de
centros informáticos (cada una de las cuales fue algo similar a un "Clúster" pero
no un "comodity cluster" como hoy en día lo entendemos.
El primer producto comercial de tipo Clúster fue ARCnet, desarrollada en 1977 por
Datapoint pero no obtuvo un éxito comercial y los Clústers no consiguieron tener
éxito hasta que en 1984.

15
2.3 FUNDAMENTOS GENERALES DE CLUSTERS.
2.3.1 DEFINICIÓN DE CLÚSTER
Un Clúster es un grupo de equipos independientes que cooperan para la ejecución
de una serie de aplicaciones de forma conjunta se que comportan ante clientes
como un solo sistema. Los Clúster permiten aumentar la escalabilidad,
disponibilidad y fiabilidad de múltiples niveles de red.
Un Clúster está formado por dos o más servidores independientes pero
interconectados. Algunos están configurados de modo tal que puedan proveer alta
disponibilidad permitiendo que la carga de trabajo sea transferida a un nodo
secundario si el nodo principal deja de funcionar. Otros Clúster están diseñados
para proveer escalabilidad permitiendo que los usuarios o carga se distribuya
entre los nodos. Ambas configuraciones son consideradas Clúster.
Una característica importante es que se presentan a las aplicaciones como si
fueran un solo servidor. Es deseable que la administración de los diversos nodos
sea lo más parecida posible a la administración de una configuración de un solo
nodo. El software de administración del Clúster debería proveer este nivel de
transparencia.
Los supercomputadores tradicionales poseen costos excesivamente elevados
cuya capacidad de procesamiento puede ser fácilmente reemplazada con un
Clúster. Los Clústers son una buena solución cuando lo que se busca es mejorar
la velocidad, fiabilidad y escalabilidad a un precio razonable.

16
Ejemplo claro de un Clúster de Hardware es la siguiente imagen:
2.3.2 CLASIFICACION DE CLUSTER
Los Clústers pueden ser clasificado según su orígen: a nivel de software y a nivel
de hardware.
A nivel de Software. Mediante el uso de un sistema operativo que brinde
las herramientas necesarias para la creación de un Clúster, tal es el caso
de un kernel Linux modificado, compiladores y aplicaciones especiales, los
cuales permitan que los programas que se ejecutan en el sistema exploten
todas las ventajas del Clúster.
A nivel de Hardware. Mediante la interconexión entre máquinas (nodos)
del Clúster, las cuales se juntan utilizando redes dedicadas de alta
velocidad como por ejemplo Gigabit Ethernet.
Figura No.1 Ejemplo de Clúster

17
Cuando se trata de brindar balanceo de carga mediante un Clúster el hardware y
software trabajan conjuntamente para distribuir la carga de tráfico a los nodos,
para de ésta manera poder atender eficientemente las subtareas encomendadas y
con ello la tarea general asignada al Clúster.
Un servicio de alta disponibilidad en el Clúster normalmente no distribuye la carga
de tráfico a los nodos (balanceo de carga) ni comparte la carga de procesamiento
(alto rendimiento) sino más bien su función es la de estar preparado para entrar
inmediatamente en funcionamiento en caso de que falle algún otro servidor .
2.3.3 CARACTERÍSTICAS DE LOS CLÚSTER
Un Clúster debe cumplir con algunos requisitos o características que se detallan a
continuación:
Los nodos de un Clúster están conectados entre sí por al menos un medio
de comunicación.
Los Clústers necesitan software de control especializado. Para tener un
funcionamiento correcto de un Clúster, el diseño y modelado del mismo
depende del tipo de Clúster utilizado. El software y las máquinas conforman
el Clúster.
Software de control para gestión del Clúster. Control que se refiere a la
configuración del Clúster, el cual depende del tipo de Clúster y de la manera
en que se conectan los nodos. El control puede ser de dos tipos según sea
el caso:
Control centralizado. El cual consta de un nodo maestro o director, con
el que se puede configurar todo el sistema.

18
Control descentralizado. Control en el que cada nodo se administra y
gestiona individualmente.
Homogeneidad de un Clúster. Caracterizado por estar formado de nodos
con arquitecturas y recursos similares. Este tipo de Clúster son implementados
a nivel de sistema.
Heterogeneidad de un Clúster. Clústers caracterizados por tener diferencias
a nivel de tiempos de acceso, arquitecturas, sistemas operativos, estas dos
últimas conllevan a tener bibliotecas de carácter general las cuales van a ser
utilizadas como interfaz para poder formar un sistema conjunto entre los
nodos. Este tipo de Clústers son implementados a nivel de aplicación.
Entre las características de funcionalidad que presentan los Clústers se
mencionan:
2.3.3.1 ESCALABILIDAD
Los Clúster permiten agregar nuevos componentes para aumentar el nivel de
prestaciones sin necesidad de eliminar los elementos ya existentes.
El balanceo de carga (LB) ofrece escalabilidad: la distribución de peticiones en
varios servidores. LB consiste en el reenvío de paquetes y en el conocimiento del
servicio cuya carga va a balancearse. Se basa en un monitor externo que recoge
las estadísticas de carga de los servidores físicos para decidir donde se deben
enviar los paquetes.
La escalabilidad es la capacidad de un equipo para hacer frente a volúmenes de
trabajo cada vez mayores sin, por ello, dejar de prestar un nivel de rendimiento
aceptable. Existen dos tipos de escalabilidad:

19
Escalabilidad del hardware (también denominada «escalamiento
vertical»). Se basa en la utilización de un gran equipo cuya capacidad se
aumenta a medida que lo exige la carga de trabajo existente.
Escalabilidad del software (también denominada «escalamiento
horizontal»). Se basa, en la utilización de un Clúster compuesto de
varios equipos de mediana potencia que funcionan en tándem de forma
muy parecida a como lo hacen las unidades de un RAID (Array
redundante de discos de bajo coste). Se utilizan el término RAC (Array
redundante de equipos) para referirse a los Clústers de escalamiento
horizontal. Del mismo modo que se añaden discos a un array RAID para
aumentar su rendimiento, se pueden añadir nodos a un Clúster para
aumentar también su rendimiento.
2.3.3.2 DISPONIBILIDAD
Existe redundancia natural, cada nodo posee sus propios componentes: bus,
memoria, procesador. Se pueden implementar políticas para el reemplazo rápido
en caso de falla del servidor maestro.
La alta disponibilidad (HA) ofrece fiabilidad: mantiene los servicios ejecutándose.
Se basa en servidores redundantes, intercambio de mensajes del tipo “Estoy vivo”,
y un procedimiento para que en caso de fallos se sustituya el servidor donde se
produjo el error por otro. El beneficio de éste diseño es el de proveer disponibilidad
y confiabilidad. La confiabilidad se provee mediante software que detectan fallos y
permiten recuperarse frente a los mismos, mientras que en hardware se evita
tener un único punto de fallo.

20
2.3.3.3 RENDIMIENTO
En principio las aplicaciones paralelas son más rápidas. Entre los factores que
influyen se encuentran:
Comportamiento del programa.
Carga de la red.
En éste diseño se ejecutan tareas que requieren de gran capacidad
computacional, grandes cantidades de memoria, o ambos a la vez. El llevar a cabo
éstas tareas puede comprometer lo recursos del Clúster por largos períodos de
tiempo.
El objetivo principal de un Clúster de Alto Rendimiento ó HPCC "High Performance
Computing Cluster" es alcanzar el mayor rendimiento en la velocidad de proceso
de datos. Este tipo de tecnología nos permite que un conjunto de computadoras
trabajen en paralelo, dividiendo el trabajo en varias tareas más pequeñas las
cuales se pueden desarrollar de forma paralela.
21
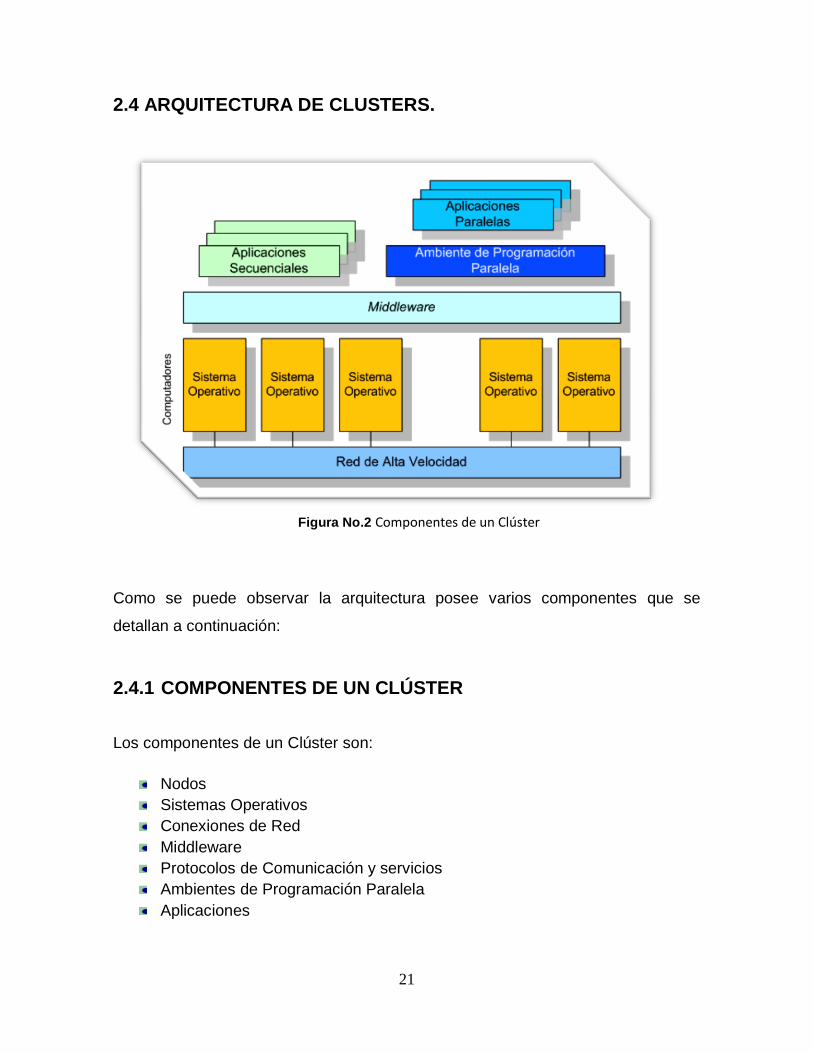
2.4 ARQUITECTURA DE CLUSTERS.
Como se puede observar la arquitectura posee varios componentes que se
detallan a continuación:
2.4.1 COMPONENTES DE UN CLÚSTER
Los componentes de un Clúster son:
Nodos
Sistemas Operativos
Conexiones de Red
Middleware
Protocolos de Comunicación y servicios
Ambientes de Programación Paralela
Aplicaciones
Figura No.2 Componentes de un Clúster

22
2.4.1.1 NODOS
Pueden ser simples ordenadores, sistemas multiprocesador o estaciones de
trabajo (Workstation). En informática de forma muy general, un nodo es un punto
de intersección o unión de varios elementos que confluyen en el mismo lugar.
En redes de computadoras cada una de las máquinas es un nodo, y si la red es
Internet, cada servidor constituye también un nodo. En un Clúster con nodos
dedicados, los nodos no disponen de teclado, mouse ni monitor y su uso está
exclusivamente dedicado a realizar tareas relacionadas con el Clúster. Mientras
que, en un Clúster con nodos no dedicados, los nodos disponen de teclado,
mouse y monitor y su uso no está exclusivamente dedicado a realizar tareas
relacionadas con el Clúster.
Los nodos de cómputo están conformados a nivel de hardware por diferentes
dispositivos los cuales permiten su funcionamiento individual y dentro del Clúster:
procesadores, memoria, caché, dispositivos de entrada/salida y buses de
comunicación.
Procesadores. Estos proveen la capacidad computacional del nodo.
Pueden ser de diferentes fabricantes: Intel con sus familias Pentium 3, 4,
Itanium y Xeon, HP y Compaq con su familia Alpha, dispositivos AMD
(Athlon) entre otros.
Memoria RAM (Random Access Memory). Es la memoria principal del
computador la cual almacena los datos que está utilizando en ese instante.
Esta memoria se actualiza constantemente mientras el ordenador está en
uso y pierde todos los datos cuando el sistema se apaga.

23
Caché. La memoria caché es pequeña y de alta velocidad de acceso que
sirve de búfer para aquellos datos de uso frecuente. La caché está
conectada a la memoria principal la cual tiene una velocidad de acceso
menor.
Dispositivos de entrada/salida (I/O). Dispositivos de mucha utilidad para un
computador, por medio de dispositivos de entrada puede escribirse en
memoria desde el exterior, ubicándose junto con los datos sobre los cuales
va a operar, de igual manera debe existir dispositivos de salida para
conocer los resultados de la ejecución de los programas. Los dispositivos
de entrada/salida (I/O) permiten la comunicación entre el
computador(memoria) y el mundo exterior (periféricos), dentro de
dispositivos periféricos que pueden interactuar con un computador se tiene:
Dispositivos de presentación de datos. Dentro de este grupo están
periféricos como el teclado, pantalla, ratón e impresora. Dispositivos
que interactúan directamente con el usuario.
Dispositivos de almacenamiento de datos. Dispositivos que
interactúan con la máquina, dentro de estos se encuentran las cintas
magnéticas y discos magnéticos.
Dispositivos de comunicación con otros procesadores. Comunicación
con otros procesadores remotos ya sea a través de una red LAN
(Local Area Networks) , una red WAN (Wide Area Networks) o el bus
de interconexión.
Bus del sistema. Periférico utilizado para transmisión de datos entre
los diferentes dispositivos del computador con el procesador y la
memoria.
24
2.4.1.2 SISTEMAS OPERATIVOS
Un nodo en un Clúster (no siempre) es una entidad de cómputo autónoma
completa y que posee su propio sistema operativo. Los Clústers Beowulf explotan
las características sofisticadas de los sistemas operativos modernos para la
administración de los recursos de los nodos y para la comunicación con los otros
nodos a través de la red de interconexión.
Pueden utilizarse sistemas operativos modernos entre los que se tiene a Linux,
Unix, Windows entre otros. Estos sistemas operativos son multitarea lo cual
permite compartir recursos entre usuarios, dividir el trabajo entre procesos, asignar
recursos cada proceso (memoria y ciclos de procesador) y tener al menos un hilo
de ejecución.
Ejemplos:
SISTEMA OPERATIVO DISTRIBUCIONES
GNU/Linux
o OpenMosix o Rocks o Kerrighed
Unix
o Solaris o HP-Ux o Aix
Windows
o NT o 2000 Server o 2003 Server o 2008 Server
Mac OS X
o Puma o Jaguar o Panther o Tiger o Leopard o Snow Leopard
Solaris
o Solaris 10 o Solaris 2.6
FreeBSD o
Cuadro No.1 Ejemplos de sistemas operativos y sus distribuciones
e

25
2.4.1.3 CONEXIONES DE RED
Existen diferentes redes de alta velocidad utilizadas en un Clúster. Se puede citar
algunas: Ethernet, ATM, SCI, cLAN, Myrinet, Infinibad y QsNet.
Ethernet, Fast Ethernet y Gigabit Ethernet. Tecnologías muy utilizadas en el
ámbito local, ethernet ofrece un ancho de banda de 10 Mbps, el cual en la
actualidad es pequeño para soportar nuevas aplicaciones de gran demanda
de acceso, es por ello que aparecieron las tecnologías fast ethernet, que
brinda un ancho de banda de 100 Mbps y Gigabit Ethernet, que ofrece un
ancho de banda de 1 Gbps.
Modo de Transferencia Asíncrono (ATM-Asyncronous Transfer Mode).
Tecnología desarrollada para hacer frente a la gran demanda de capacidad
de transmisión para servicios y aplicaciones. Tecnología de alta velocidad
basada en la conmutación de celdas o paquetes. ATM es una tecnología
utilizada en ámbitos LAN y WAN, de vital importancia para aplicaciones en
tiempo real como voz y vídeo, las cuales requieren garantía en la entrega
de información, es decir necesitan de un protocolo orientado a conexión.
cLAN Tecnología creada por Gigante (hoy adquirida por Emulex ) ofrece un
alto rendimiento para redes de alta velocidad, posee adaptadores PCI y
switches de 8 y 30 puertos, ofreciendo velocidades de 1.25 Gbps por puerto
(2.5 Gbps bidireccional). Es una tecnología muy utilizada en la
interconexión de los diferentes dispositivos pertenecientes a un Clúster.
Myrinet. Tecnología de alta velocidad diseñada por Myricom en Noviembre
de 1998. El ancho de banda que maneja cada adaptador de red y los switch
ha incrementado desde 640 Mbps hasta los 2.4 Gbps, teniendo tiempos de
entrega de paquetes que fluctúan entre los 7 y 10 micro segundos. Cada
nodo posee una tarjeta de red PCI-X con una o dos conexiones, las cuales

26
pueden manejar velocidades 2 Gbps o 10 Gbps bidireccionales, estas
tarjetas se interconectan a través de un cable Myrinet (fibra óptica) a un
switch Myrinet de hasta 128 puertos. Esta tecnología posee un software el
cual detecta automáticamente a la red Myrinet sin necesidad de configurar
el conmutador o switch.
Infiniband. El estándar InfiniBand es un bus de comunicaciones de alta
velocidad, diseñado tanto para conexiones internas como externas. Para la
comunicación utiliza un bus bidireccional con lo cual ofrece dos canales de
transmisión independientes. El ancho de banda básico de un enlace simple
QsNet. Igual que las tecnologías myrinet e infiband, QsNet está conformada
de dos partes, la interfaz de red Elan y el switch Elite, el cual dispone de 16
a 128 puertos, este switch posee dos canales virtuales bidireccionales por
enlace, es decir cada enlace posee dos puertos de entrada/salida con una
tasa de transferencia teórica de 400 Mbyte/s en cada dirección. El switch
provee también dos niveles de prioridad, los cuales son de gran ayuda en la
entrega de paquetes de mayor importancia en el menor tiempo posible.
2.4.1.4 MIDDLEWARE
El middleware es un software que generalmente actúa entre el sistema operativo y
las aplicaciones con la finalidad de proveer a un Clúster lo siguiente:
Una interfaz única de acceso al sistema, denominada SSI(Single System
Image), la cual genera la sensación al usuario de que utiliza un único
ordenador muy potente;

27
Herramientas para la optimización y mantenimiento del sistema: migración
de procesos, checkpoint-restart (congelar uno o varios procesos, mudarlos
de servidor y continuar su funcionamiento en el nuevo host), balanceo de
carga, tolerancia a fallos, etc.
Escalabilidad: debe poder detectar automáticamente nuevos servidores
conectados al Clúster para proceder a su utilización.
El middleware recibe los trabajos entrantes al Clúster y los redistribuye de manera
que el proceso se ejecute más rápido y el sistema no sufra sobrecargas en un
servidor. Esto se realiza mediante políticas definidas en el sistema
(automáticamente o por un administrador) que le indican dónde y cómo debe
distribuir los procesos, por un sistema de monitorización, el cual controla la carga
de cada CPU y la cantidad de procesos en él.
El middleware también debe poder migrar procesos entre servidores con distintas
finalidades:
Balancear la carga: si un servidor está muy cargado de procesos y otro está
ocioso, pueden transferirse procesos a este último para liberar de carga al
primero y optimizar el funcionamiento;
Mantenimiento de servidores: si hay procesos corriendo en un servidor que
necesita mantenimiento o una actualización, es posible migrar los procesos
a otro servidor y proceder a desconectar del Clúster al primero;
Priorización de trabajos: en caso de tener varios procesos corriendo en el
Clúster, pero uno de ellos de mayor importancia que los demás, puede
migrarse este proceso a los servidores que posean más o mejores recursos
para acelerar su procesamiento.

28
El usuario no necesita conocer donde se ejecutan las aplicaciones.
El usuario puede conectarse al Clúster como un sistema único, sin
necesidad de hacerlo de manera individual a cada nodo como es el caso de
un sistema distribuido.
Escalabilidad del sistema, ya que los Clústers pueden ampliarse fácilmente
añadiendo nuevos nodos, las aplicaciones deben ser capaces de ejecutarse
de forma eficiente en un amplio rango de tamaños de máquinas.
Es importante la disponibilidad del sistema para soportar las aplicaciones
de los usuarios, por medio de técnicas de tolerancia a fallos y recuperación
automática sin afectar a las aplicaciones de los usuarios.
2.4.1.5 PROTOCOLOS DE COMUNICACIÓN
Los protocolos son reglas de comunicación que permiten el flujo de información
entre computadoras distintas que manejan lenguajes distintos, por ejemplo, dos
computadores conectados en la misma red pero con protocolos diferentes no
podrían comunicarse jamás, para ello, es necesario que ambas "hablen" el mismo
idioma, por tal sentido, el protocolo TCP/IP fue creado para las comunicaciones en
Internet. Para que cualquier computador que se conecte a Internet, es necesario
que tenga instalado este protocolo de comunicación.
29
AL
MA
CE
NA
MIE
NT
O
TAREA
1
TAREA
2
TAREA
3
PL
AN
IFIC
AC
IÓNSesión
del
Usuario 1
Sesión
del
Usuario 2
Internet
o
Intranet
Usuario 1
Usuario 2
Nodos Maestros
Limite del Cluster
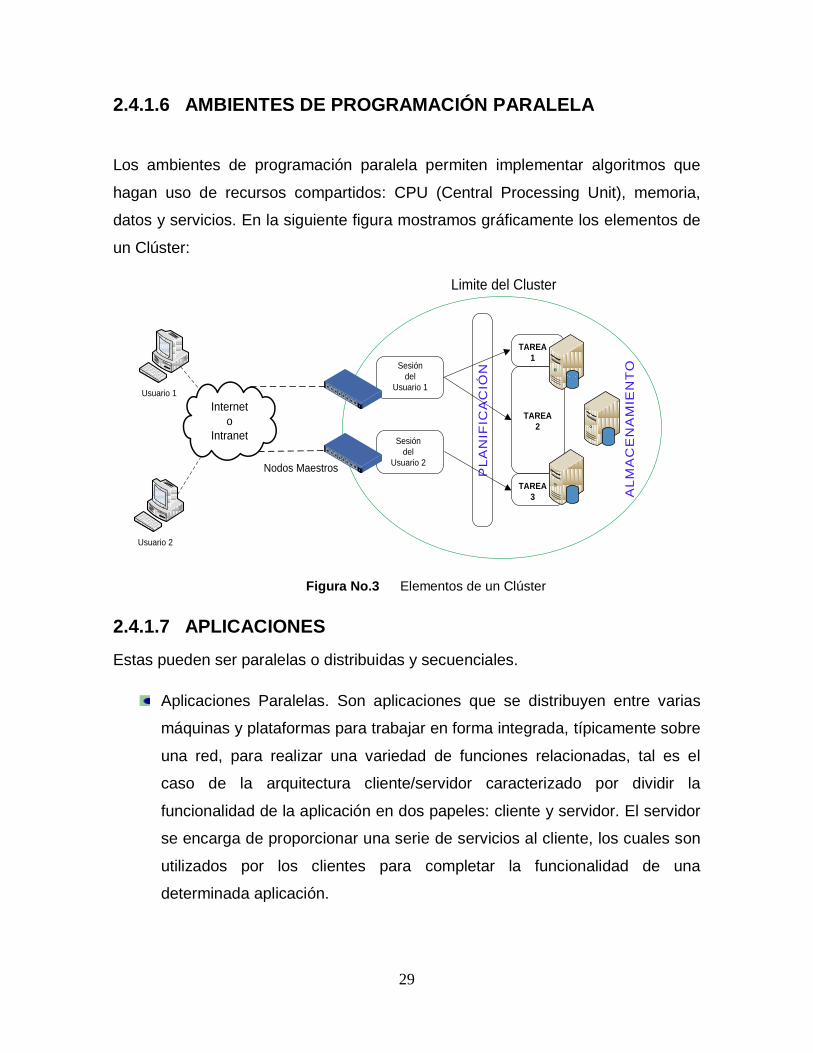
Figura No.3 Elementos de un Clúster
e
2.4.1.6 AMBIENTES DE PROGRAMACIÓN PARALELA
Los ambientes de programación paralela permiten implementar algoritmos que
hagan uso de recursos compartidos: CPU (Central Processing Unit), memoria,
datos y servicios. En la siguiente figura mostramos gráficamente los elementos de
un Clúster:
2.4.1.7 APLICACIONES
Estas pueden ser paralelas o distribuidas y secuenciales.
Aplicaciones Paralelas. Son aplicaciones que se distribuyen entre varias
máquinas y plataformas para trabajar en forma integrada, típicamente sobre
una red, para realizar una variedad de funciones relacionadas, tal es el
caso de la arquitectura cliente/servidor caracterizado por dividir la
funcionalidad de la aplicación en dos papeles: cliente y servidor. El servidor
se encarga de proporcionar una serie de servicios al cliente, los cuales son
utilizados por los clientes para completar la funcionalidad de una
determinada aplicación.

30
Aplicaciones Secuenciales. Es aquella en la que una acción (instrucción)
sigue a otra en secuencia. Las tareas se suceden de tal modo que la salida
de una es la entrada de la siguiente y así sucesivamente hasta el fin del
proceso.
2.5 TIPOS DE CLÚSTER
Los Clústers dependiendo de su aplicabilidad pueden clasificarse de diferentes
maneras. La clasificación más generalizada es la que se presenta a continuación:
Alto rendimiento (HP, high performance)
Alta disponibilidad (HA, high availability)
Balanceo de Carga (Load Balancing)
Tolerantes a fallos
Alta Confiabilidad (HR, high reliability).
2.5.1 CLÚSTER DE ALTO RENDIMIENTO
Los Clústers de alto rendimiento han sido creados
para compartir el recurso más valioso de un
ordenador, es decir, el tiempo de proceso.
Cualquier operación que necesite altos tiempos de
CPU puede ser utilizada en un Clúster de alto
rendimiento, siempre que se encuentre un algoritmo
que sea paralelizable.
Existen Clústers que pueden ser denominados de
alto rendimiento tanto a nivel de sistema como a
nivel de aplicación.

31
Este tipo de Clúster lo que busca es suplir las necesidades de súper computación
para resolver problemas de determinadas aplicaciones que requieren un alto
procesamiento, esto se logra mediante la utilización de un grupo de máquinas
individuales las cuales son interconectadas entre sí a través de redes de alta
velocidad y de esta manera se obtiene un sistema de gran rendimiento que actúa
como uno solo.
La utilidad principal de este tipo de Clúster es principalmente en aplicaciones en
las que se requieren gran capacidad de procesamiento computacional, la cual
soluciona problemas de alto procesamiento mediante la utilización de técnicas
necesarias para la paralelización de la aplicación, distribución de los datos a los
nodos, la obtención y presentación de resultados finales.
Generalmente estos problemas de cómputo suelen estar ligados a:
Estado del tiempo.
Cifrado y descifrado de códigos.
Compresión de datos.
Astronomía.
Simulación Militar.
2.5.2 CLÚSTER DE ALTA DISPONIBILIDAD(HA, HIGH AVAILABILITY).
Los Clústers de alta disponibilidad
pretenden dar servicios 7/24 de cualquier
tipo, son Clústers donde la principal
funcionalidad es estar controlando y
actuando para que un servicio o varios se
encuentren activos durante el máximo
periodo de tiempo posible.

32
El brindar alta disponibilidad no hace referencia a conseguir una gran capacidad
de cálculo, si no lograr que una colección de máquinas funcionen en conjunto y
que todas realicen la misma función que se les encomendó. La característica
principal de éste Clúster es que ante la existencia de algún problema o fallo de
uno de los nodos, el resto asumen ese fallo y con ello las tareas del nodo con
problemas. Estos mecanismos de alta disponibilidad lo brindan de forma
transparente y rápida para el usuario.
La escalabilidad en un Clúster de alta disponibilidad se traduce en redundancia lo
cual garantiza una pronta recuperación ante cualquier fallo.
La flexibilidad y robustez que poseen este tipo de Clúster los hacen necesario en
sistemas cuya funcionalidad principal es el intercambio masivo de información y el
almacenamiento de datos sensibles, dónde se requiere que el servicio esté
presente sin interrupciones.
El mantenimiento es otra de las ventajas que ofrece. El mantenimiento se puede
realizar de manera individual a cada máquina que compone el conglomerado
evitando comprometer los servicios que este brinda.
Existen dos tipos de configuraciones aplicables a estos Clústers:
Configuración activo-pasivo: Esta configuración tiene dos actividades en los
nodos que componen el Clúster, los activos son aquellos que se encargan de
ejecutar las aplicaciones encomendadas, mientras que los nodos restantes actúan
como respaldos redundantes para los servicios ofrecidos.
Configuración activo - activo: En este caso, todos los nodos actúan como
servidores activos de una o más aplicaciones y potencialmente como respaldos
para las aplicaciones que se ejecutan en otros nodos. Cuando un nodo falla las
aplicaciones que se ejecutaban en él migran a uno de los nodos de respaldo.

33
2.5.2.1 CARACTERISTICAS Y FUNCIONAMIENTO DE ALTA
DISPONIBILIDAD.
Los sistemas de alta disponibilidad, involucra el tener servidores que actúan entre
ellos como respaldos vivos de la información que sirven. Este tipo de Clústers se
les conoce también como Clúster de redundancia.
En los últimos años la idea de alta disponibilidad y de tolerancia a fallos se ha ido
acercando, con el surgimiento de nuevas tecnologías y el abaratamiento del
hardware se ha logrado que con la idea de alta disponibilidad se logre tener un
sistema tolerante a fallos a bajo precio.
2.5.2.2 SPOF ( Single Point of Failure ó Punto Simple de Fallo).
SPOF hace referencia a la tenencia de un elemento no replicado que puede estar
sujeto a fallos, logrando con esto la suspensión del servicio que se está brindando.
Es por ello la importancia de evitar tener un SPOF en los subsistemas del sistema
general, ya que con ello se pondría en peligro la prestación continua de servicios
del sistema.
En sistemas de alta disponibilidad a mas de tener redundancia en sus servidores,
es importante tenerla en otros dispositivos que componen el Clúster, tal es el caso
de dispositivos de interconexión, red de comunicación de servidores; etc. Esto con
la finalidad de evitar el tener un SPOF a nivel de subsistemas y sistemas como tal
que conforman el Clúster que se está implementando.

34
2.5.2.3 SERVICIO DE DATOS.
El servicio de datos hace referencia al servicio y sus respectivos recursos que se
estén brindando a un cliente. En entornos de alta disponibilidad al servicio
brindado y al grupo de recursos se denominan logical host o software package.
Los recursos que se estén utilizando deben tener mecanismos necesarios que
permitan la suplantación y conmutación física entre los nodos cuando uno de
estos falle, logrando de esta manera que el servicio de datos ofrecido falle en su
funcionamiento. De esta manera la única afección que el sistema tendrá es en el
tiempo de conmutación en la puesta en marca del servicio de datos.
2.5.2.4 DINAMICA DE ALTA DISPONIBILIDAD (HA)
Dinámica que hace referencia a las reconfiguraciones que el Clúster debe hacer
para garantizar la máxima disponibilidad de un determinado sistema; va orientada
a los nodos que conforman el Clúster y la forma de cómo éste responde. Existen
diferentes maneras de cómo el sistema responde ante la presencia de un fallo,
entre las cuales se tiene:
Tolerancia a fallos (failover). Se da cuando un nodo falla y otro debe asumir
sus responsabilidades. Para ello el nodo entrante debe importar los
recursos del nodo con fallo y habilitar los servicios de datos.
Toma de control o tolerancia a fallos automático (takeover). Se produce
cuando el servicio de datos falla y se detecta por un determinado, a éste
nodo se lo considera nodo fallido y se ve forzado a ceder sus servicios y
recursos. En este caso se requiere una monitorización continua del servicio
de datos.

35
Tolerancia a fallos manual (switchover o giveaway). Se caracteriza por
ceder los recursos y servicios de datos de un nodo a otro. Se utiliza cuando
se realizan tareas de mantenimiento y administración a un nodo.
División de cerebros (splitbrain). Mecanismo utilizado cuando el proceso de
gestión de un Clúster HA (High Availavility) falla. Esta falla se da debido a
problemas en la comunicación y verificación de los nodos existentes.
Debido a que los nodos no conocen de la existencia de sus vecinos y
asumen que son los únicos en el sistema, por tal motivo cada nodo
intentará apropiarse de todos los recursos del sistema incluyendo el servicio
de datos y tener el control total del Clúster. El splitbrain es un caso especial
del failover.
El splitbrain puede dejar a un sistema fuera de funcionamiento. Se puede
evitar utilizando dos métodos. El primero es actuar de forma prudente ante
esta falla, utilizando los recursos compartidos como señal de estar activos,
luego de que un nodo constata el problema debe reservar un recurso
compartido llamado quórum, este recurso debe ser reservado por un solo
nodo y el nodo que llegue tarde a la reserva entiende que debe abandonar
el Clúster y ceder todos sus recursos. El recurso quórum únicamente es
utilizado como método de decisión para abandonar o no un Clúster. El
segundo método consiste en tratar de dejar afuera o apagar al nodo con
fallo una vez detectado el problema, el primer nodo que lo haga toma el
control del Clúster y con ello el control de todos los recursos.
.

36
2.5.2.5 GRUPOS DE RECURSOS DE UN SERVICIO DE DATOS
Al trabajar con un Clúster de alta disponibilidad se tienen diferentes tipos de
recursos que son fundamentales para su funcionamiento y que se listan a
continuación:
Recursos Computacionales. Son aquellos que permiten alojar y ejecutar el
servicio de datos brindado. Estos recursos se consideran a nivel de CPU y
el Clúster. En alta disponibilidad se tienen recursos a nivel de Clúster donde
cada nodo que lo conforma debe tener una copia en memoria del programa
de servicio de datos.
Los recursos computacionales pueden ser considerados a nivel de CPU, nodo o
Clúster. Son los recursos que permiten que el programa que se encarga de ofrecer
servicio de datos pueda ser ejecutado. Si tenemos varias CPU, varios nodos o
varios Clústers estos deberán tener una copia del programa del servicio de datos
en memoria.
En la HA para Linux este recurso se considera a nivel de nodo, donde el servicio
de datos va a estar situado en un nodo determinado (como máster del servicio). El
software de alta disponibilidad es quien decide que nodo va a alojar que servicio
de datos dependiendo del estado del Clúster.
Recursos de Comunicaciones. Recursos utilizados para brindar el acceso al
servicio de datos mediante una red de comunicaciones.
Normalmente el servicio de datos va a ser accedido mediante una red de
comunicaciones. Las interfaces de red así como la pila de protocolos de red,
deben ser capaces de responder a varias direcciones de red con el fin de dar
flexibilidad al servicio de datos es decir virtualizar el servicio. En el caso de redes

37
TCP/IP el servicio de datos será accedido mediante una dirección IP y un puerto;
para que el servicio de datos pueda residir físicamente en cualquier nodo se debe
utilizar IP’s virtuales (IP aliasing) para que esto sea posible.
Recursos de Almacenamiento. Son los recursos más críticos en alta
disponibilidad. Se debe garantizar la integridad y confiabilidad de los datos
almacenados en los discos de los nodos o servidores. La falla de estos
dispositivos hace que los datos se corrompan y con ello se tenga efectos
irreversibles que afecten el rendimiento del sistema.
El almacenamiento de los datos del servicio de datos es quizás uno de los puntos
más delicados de la alta disponibilidad. Pues en ellos tendremos la aplicación que
se usará para el servicio de datos junto con los datos.
El almacenamiento suele ser el recurso más complicado de virtualizar en
configuraciones clásicas; ya que suele ser un medio SCSI compartido con muchos
discos y muchos elementos candidatos a SPOF. En configuraciones hardware
más modernas no hay tanta problemática; las arquitecturas SAN (storage área
network) permiten que los recursos de computación accedan por red SAN a los
recursos de almacenamiento. Los recursos de almacenamiento suelen ser
servidores de archivos en con discos en RAID y backup integrado con interfaz
FiberChannel. Al estar en un entorno SAN permite acceder a estos recursos a más
de un nodo de forma muy flexible.
El recurso de almacenamiento además de ser flexible debe ser independiente para
las necesidades de cada servicio de datos. Surge el concepto de grupos de
volúmenes; un grupo de volúmenes es un conjunto de volúmenes que pertenecen
a un servicio de datos en concreto. Cada volumen es un espacio de
almacenamiento que el servicio de datos utilizará para sus propósitos con
independencia de otros volúmenes.

38
Es vital que el recurso de almacenamiento sea capaz de mantener la integridad de
los datos y el tiempo de recuperación ante un fallo sea mínimo. Ante estos
problemas surgen las técnicas de journaling para la gestión de los datos.
2.5.3 CLUSTER DE BALANCEO DE CARGA.
Técnica muy utilizada para lograr que un conjunto de servidores de red compartan
la carga de trabajo y con ello el tráfico de sus clientes. Este proceso de dividir la
carga de trabajo entre los servidores reales permite obtener un mejor tiempo de
acceso a las aplicaciones y con ellos tener una mejor confiabilidad del sistema.
Además como es un conjunto de servidores el que atiende el trabajo, la falla de
uno de ellos no ocasiona una falla total del sistema ya que las funciones de uno,
las puede suplir el resto.
2.5.3.1 BALANCEO DE CARGA ( LOAD BALANCING).
El balanceo de carga permite suplir las necesidades del inminente crecimiento del
tráfico en Internet. Existen dos alternativas para manipular el crecimiento del
tráfico en internet: la primera permite usar una máquina de grandes características
y de alto precio que probablemente a futuro quede obsoleta; la segunda alternativa
consiste en utilizar un conjunto de servidores virtuales o granja de servidores de
bajo costo que trabajan en conjunto para balancear la carga entre ellos.
El balanceo de carga consiste en compartir la carga de trabajo y tráfico de los
clientes que éstos acceden. Al grupo de servidores que prestan este servicio se
los conoce como servidores virtuales.
Al balancear la carga se mejora el tiempo de respuesta, acceso y confiabilidad. La
caída de un servidor no influye en el funcionamiento de todo el Clúster ya que las
funciones de éste son asumidas por el resto de servidores virtuales. Cuando la

39
carga de trabajo sea mayor se pueden añadir más servidores al Clúster y escalar
este sistema para garantizar el balanceo de carga.
Existen diferentes métodos de distribución de carga que se detallan a
continuación.
2.5.3.2 BALANCEO DE CARGA POR SISTEMA DE NOMBRES DE
DOMINIO O DNS.
Este proceso consiste en crear un dominio DNS1 al cual se le asigna diferentes
direcciones IP2 pertenecientes a los servidores que están funcionando. A esta
configuración no se le considera un Clúster debido a que en la caché del
explorador de Internet de los clientes se almacena la dirección IP del servidor que
en ese momento lo atendió. Los clientes automáticamente redireccionan las
peticiones refiriéndose a la dirección del servidor de la caché cuando un nuevo
requerimiento se produce. El balanceo de carga no se realiza por completo ya que
un servidor puede atender solicitudes de gran procesamiento, mientras otros
servidores pueden atender solicitudes más sencillas, esto se debe a que carecen
de un dispositivo que controle y redireccione equitativamente el trabajo a los
servidores, la falta de este dispositivo hace que la repartición de carga no sea
equitativa y ello conlleva a tener un desigual funcionamiento de los servidores.
Cuando un servidor cae, los clientes que eran atendidos por este van a continuar
enviando requerimientos sin que sus peticiones sean cumplidas, quedando sin
atención hasta el momento en que su caché se actualice y aprenda la dirección de
un servidor operativo.
1 Sistema de Nombre de Dominio DNS (Domain Name System): El sistema de nombre de dominio es un estándar de internet. El propósito de DNS es crear un sistema que permita realizar búsquedas en una base de datos tipo árbol. Estas búsquedas se realizan para la obtención de la dirección IP p del nombre de host que pertenece a un nodo que se encuentra en el sistema de nombre de dominio. 2 IP: Internet Protocol, protocolo de comunicaciones de la capa de red de la arquitectura TCP/IP.

40
2.5.3.3 BALANCEO DE CARGA MEDIANTE UN NODO DIRECTOR.
Mecanismo basado en la utilización de un nodo director. El nodo director recibe
todas las peticiones de los clientes, balancea la carga y redirecciona a los
servidores del Clúster.
El nodo director reenruta las peticiones a los nodos que posean menor carga para
que atiendan el requerimiento solicitado, una vez procesada la petición los
servidores virtuales devuelven el resultado al nodo director para que este entregue
los resultados al cliente. Existen variaciones donde los nodos o servidores
virtuales pueden entregar el resultado al cliente directamente.
Existen tres tipos de reenvío de paquetes que el nodo director hace en los
servidores que conforman el Clúster:
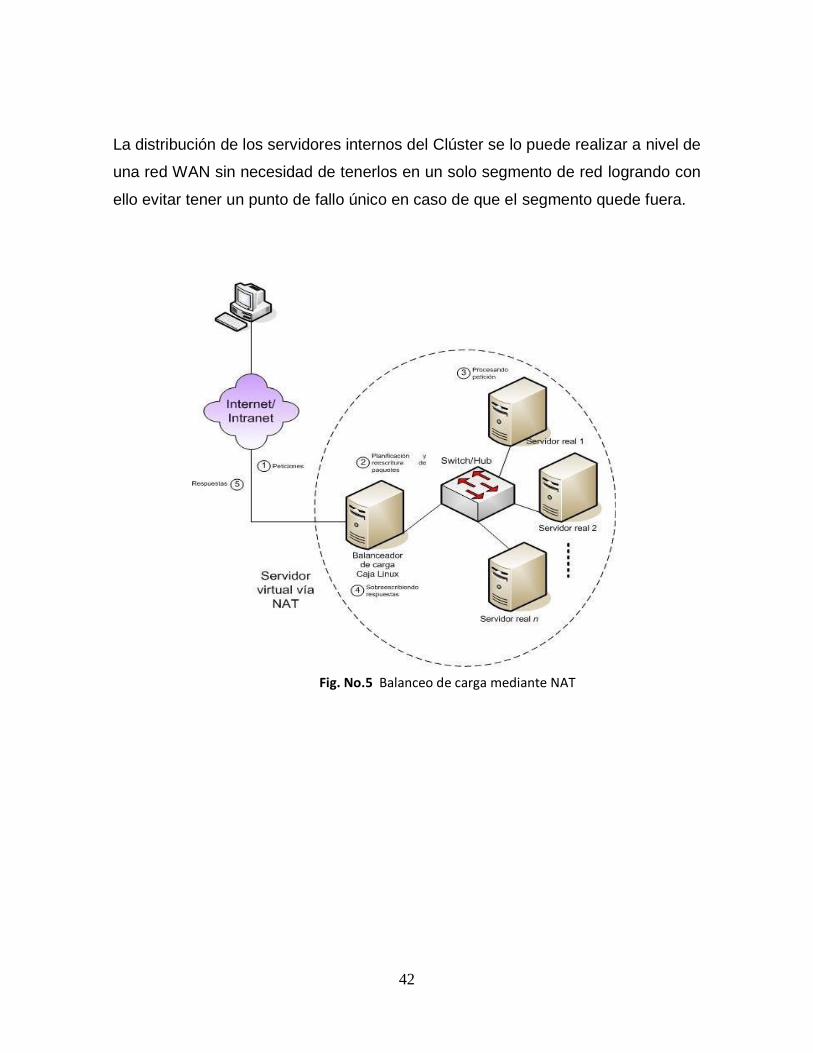
Balanceo por NAT (Network Address Traslation). Mecanismo basado en
trasladar las direcciones IP origen/destino de los paquetes que llegan al
nodo director y los reenvía a uno de los servidores reales disponibles.
Luego de que los servidores internos procesan el paquete recibido lo
reenvían al nodo director. El único mecanismo para que todos los
servidores del Clúster puedan salir a internet es a través del nodo director.
Fig. No.4 Balanceo de Carga mediante un nodo director.

41
Balanceo por encapsulado IP. Mecanismo basado en el encapsulamiento IP
(IP tunneling). La unidad de datos TCP/IP que llega al nodo director es
encapsulada dentro de otra unidad de datos manteniendo las direcciones
origen/destino intactas. Esta nueva unidad de datos contiene los datos
originales del cliente que genera la petición, posee la dirección origen del
nodo director y la destino del servidor disponible para atender el
requerimiento.
El servidor que atiende el requerimiento desencapsula la unidad de datos que le
envió el nodo director. Los servidores virtuales tienen configurada en una de sus
interfaces de red la misma dirección pública del nodo director con la finalidad de
poder aceptar la unidad de datos original y servir la petición requerida.
Luego de procesar las peticiones se las reenvía al cliente directamente utilizando
la dirección pública del Clúster, y así evitar reenrutar el resultado al nodo director
para que este la entregue al cliente que originó la petición. Así se logra evitar un
cuello de botella en el nodo director, haciendo más fácil el proceso de atención de
peticiones.
FALTA NOMBRE DE FIGURA
42
La distribución de los servidores internos del Clúster se lo puede realizar a nivel de
una red WAN sin necesidad de tenerlos en un solo segmento de red logrando con
ello evitar tener un punto de fallo único en caso de que el segmento quede fuera.
Fig. No.5 Balanceo de carga mediante NAT

43
2.5.4 CLUSTER TOLERANTE A FALLOS
En un sistema tolerante a fallos,
cuando se produce un fallo
hardware, el hardware asociado a
este tipo de sistema es capaz de
detectar el subsistema que falla y
obrar en consecuencia para
restablecer el servicio en
segundos (o incluso décimas de
segundo).
2.5.5 CLUSTER DE ALTA CONFIABILIDAD (HR, high reliability)
Clúster caracterizado por ofrecer una alta confiabilidad al sistema. La idea es
obtener respuestas eficientes del sistema a pesar de tener una sobrecarga de las
capacidades de un servidor. Estos Clústers se caracterizan por ejecutar un mayor
número de tareas en el menor tiempo posible.
2.6 VENTAJAS Y DESVENTAJAS DE CLUSTERS.
2.6.1 VENTAJAS
Mayor velocidad de computación, al interactuar un gran número de
computadoras como si se tratase de una sola. " Procesamiento en paralelo"
Mayor disponibilidad, evita la no disponibilidad de un servicio web, servicio
de correo electrónico, sitios web, etc. por la caída de uno de sus servidores
al direccionar su contenido directamente a otro servidor.

44
Ahorro en infraestructura en el caso de actualización de los equipos.
Permite en muchas ocasiones el aprovechamiento de viejos computadores,
que al estar conectados en paralelo son capaces de funcionar con sistemas
operativos de última generación con cierta velocidad de procesamiento.
Uso de las bondades del software libre.
2.6.2 DESVENTAJAS
En muchos casos, para alcanzar capacidades de procesamiento similares a
las de equipos actuales se requiere un gran espacio para el elevado
número de computadoras.
Existen muchos programas los cuales son incompatibles para procesar en
paralelo, o no son capaces de migrar el 100% de los procesos.
2.7 PLANIFICACION Y ADMINISTRACIÓN DE CLUSTERS.
2.7.1 ADMINISTRACIÓN
Luego del proceso de instalación del hardware, configuración del Clúster, se
necesita que estos recursos sean administrados para tener un control de
rendimiento y funcionamiento del Clúster.
La administración de un Clúster es de mucha importancia en el funcionamiento del
mismo, ya que es fundamental administrar adecuadamente los recursos del
Clúster y con ello poder detectar fallos a nivel de software y hardware, además
poder monitorear el rendimiento de cada servidor con la finalidad de constatar su
correcto funcionamiento y en caso de tener algún inconveniente poder tomar
medidas preventivas y evitar que estos colapsen.

45
Para poder lograr una administración adecuada de un Clúster se debe considerar
los siguientes aspectos:
Registro de eventos (logging)
Falla y Recuperación de Hardware.
Falla de Software
Falla y Recuperación del Sistema de archivos.
Encolamiento (Queing)
Planificación (Scheduling)
Monitoreo (Monitoring)
Contabilidad (Accounting)
Existe una relación entre usuarios, recursos y las actividades involucradas en la
administración del Clúster. El software de administración se ubica entre los
usuarios y los recursos (servidores reales y director) del Clúster. En primera
instancia los usuarios envían sus peticiones a una cola que almacena los trabajos
que se van a llevar a cabo (el usuario puede en cualquier momento pedir
información sobre el estado de ese trabajo). Los trabajos esperan en la cola hasta
el momento en que ingresan al Clúster para ser atendidos. Mientras todo está
ocurriendo, el sistema de administración esta monitoreando el estado de los
recursos del sistema y cuáles usuarios los están utilizando.
A continuación se va analizar con más detalle las actividades que se deben llevar
a cabo en un sistema de administración:

46
2.7.1.1 REGISTRO DE EVENTOS (logging)
El registro de eventos es el proceso por el cual todos los aspectos relacionados al
funcionamiento de una máquina y operación del Clúster se guardan en un archivo
de registro (logs) el cual puede ser usado para futuras consultas.
El administrador de un sistema Linux tiene a su disposición un programa de
generación de registros que monitoriza todos los eventos que se producen en el
mismo. Syslog guarda, analiza y procesa todos los archivos de registro sin requerir
apenas intervención por parte del administrador. La ubicación del directorio donde
se almacenarán los registros depende del servicio instalado, por lo general el
directorio donde se almacena es el /var/log.
2.7.1.2 FALLA Y RECUPERACIÓN DE HARDWARE.
Una de las principales responsabilidades de la administración de un Clúster es la
falla a nivel de hardware. El impacto que ocasiona la falla del hardware puede
conllevar a tener todo el sistema inoperante. Estos impactos pueden ocasionar
pérdidas de los servidores de archivos, servidores de red, dispositivos de
ínterconectividad, entre otros, siendo importante la necesidad de tener
monitoreado el funcionamiento de estos y a la vez tomar medidas de prevención.
Se debe tener presente que muchos fallos a nivel de hardware que se presentan
no afectan mucho al rendimiento general del Clúster, como es el caso de la falla
del disco de un servidor, éste dejaría de operar y afectaría únicamente a los
cliente que a él se conectan, pero en términos generales no afectarían a todo el
sistema ya que el Clúster de por si se encarga de suplir ese fallo, pero a fin de
cuentas esa falla si afecta al rendimiento del sistema, en especial al tiempo de
respuesta de los servidores operativos en el Clúster.
Para evitar un gran impacto de estos inconvenientes y poder tener una
recuperación ante fallos del hardware, la administración debe considerar varios

47
aspectos como el aislar el componente fallido con la finalidad de que puedan
interferir con el funcionamiento del resto de componentes del Clúster, tener
respaldos (backups) a nivel de hardware para poder suplantar de manera rápida el
componente fallido y así poder garantizar la disponibilidad del sistema.
2.7.1.3 FALLA DE SOFTWARE.
La falla ocasionada por el software al igual que los fallos a nivel de hardware son
críticos debido a que pueden dejar inoperante al Clúster, pero a la vez estas fallas
involucran otros aspectos que deben ser tomados en cuenta. Las fallas de
software muchas veces tienen arreglo, otras veces no, pero es de vital importancia
detectarlas, para poder analizar las posibilidades de evitar que vuelvan a ocurrir,
por lo general el Linux los errores se los evita con los denominados parches del
sistema, los cuales vienen a suplir las fallas del sistema a nivel de software.
Para que el sistema tenga un funcionamiento adecuado y a su vez poder evitar
los problemas de indisponibilidad que cada falla acarrea, se debe tomar en
consideración varios aspectos tales como: la actualización del sistema debe
hacérsela de manera continua, una vez que algún parche actualizado haya sido
desarrollado. Realizar pruebas de funcionamiento del sistema posterior a la
actualización del mismo, para poder de esta manera constatar las debilidades que
mencionada actualización trajo al sistema y si no las resuelve, tener la posibilidad
de volver a las versiones de software anteriores.
2.7.1.4 FALLA Y RECUPERACIÓN DEL SISTEMA DE ARCHIVOS.
La falla en un sistema de archivos es muy crítica, se podría decir que es la pérdida
que mayor daño ocasionaría a un sistema, ya que se perdería toda la información
almacenada por varios meses o años, en especial se perdería los datos de usuario
y de las aplicaciones que hacen uso de éste.

48
Por ello es de vital importancia tomar medidas preventivas que logren evitar tener
un punto de fallo en el sistema de archivos, teniendo sistemas de archivos
redundantes mediante el uso de técnicas como RAID, poseer un sistema de
archivos con journaling el cual permita recuperar rápidamente los datos en caso
de existir alguna falla inesperada en el sistema, poseer un sistema de archivos
paralelo, con lo cual la pérdida de un servidor de archivos no influya de manera
total al funcionamiento general del sistema ya que la existencia de otros servidores
de archivos podrían suplir su ausencia.
2.7.1.5 ENCOLAMIENTO (QUEING)
Un aspecto a tomar en cuenta en la administración de un Clúster es el
encolamiento (Queing) que consiste en el proceso de acumular los trabajos para
que sean ejecutados por el conjunto de recursos disponibles. Las tareas y los
trabajos que los usuarios desean realizar, son presentados por el sistema de
administración como un conjunto llamado grupo de trabajo.
Este grupo de trabajo para ser ejecutado necesita dos aspectos fundamentales
que el sistema debe proveer, en primer lugar proveer los recursos necesarios
(como la cantidad de memoria o CPU´s necesitados), y en segundo lugar una
descripción de las tareas a ser ejecutadas (archivo a ejecutar, datos requeridos
para procesar cualquier petición; entre otros).
El grupo de trabajo luego de presentado al sistema de administración, es colocado
en una cola hasta que el sistema provea los recursos necesarios (por ejemplo: la
cantidad correcta de memoria y CPU requerido) para procesar cualquier trabajo
encomendado. El tiempo de espera para que los trabajos se ejecuten depende
exclusivamente del tiempo de ocupación de los recursos.

49
2.7.1.6 MONITOREO (MONITORING).
El monitoreo involucra el observar que el rendimiento y funcionamiento del Clúster
sea correcto. Una operación correcta implica tener a todos los recursos de
hardware y software monitoreados y con ello constatar que el funcionamiento sea
el esperado.
El tener monitorizado un sistema es muy importante en el proceso de
administración del Clúster ya que mediante los datos que arroje dicho monitoreo
se puede prever cual es el comportamiento de un determinado dispositivo que
compone el Clúster, y con ello poder tomar los correctivos necesarios para evitar
una caída del sistema.
Es indispensable chequear parámetros de los equipos cuando estén en
funcionamiento, parámetros como: arquitectura y frecuencia del CPU, tipo y
versión del sistema operativo, memoria total, número de CPU´s en cada servidor,
tiempo de actividad, porcentajes de uso de CPU, utilización de disco, memoria
disponible, actividad de procesos, entro otros; y de esta manera constatar su
correcta operación.
2.7.1.7 CONTABILIDAD (ACCOUNTING).
Mecanismo utilizado para la recolección de datos de cada grupo de trabajo que se
ejecuta en el Clúster, el accounting es una herramienta muy importante que
permite generar información útil para el proceso de planificación de tareas, esta
herramienta puede ser utilizada para varios propósitos tales como:
Elaboración semanal de reportes de utilización del sistema.
Elaboración de reportes de utilización mensual de recursos por usuario.
Elaboración de un cronograma de políticas de planeamiento.
Prever requerimientos computacionales futuros.
Determinar áreas que deben ser mejoradas dentro del sistema.

50
2.7.2 PLANIFICACIÓN DE TAREAS.
La planificación de tareas es una actividad de mucha utilidad en la administración
de un Clúster, ya que permite programar un conjunto de actividades que se
ejecutarán de acuerdo al tiempo, necesidad y circunstancia que un determinado
sistema así lo requiera. Al hablar de tarea se hace referencia a un programa
ejecutable que realiza determinadas funciones. Un proceso consiste en un número
de tareas con cierta independencia que se coordinan para cumplir funciones
lógicas.
Un planificador de tareas debe garantizar tres aspectos fundamentales:
Rendimiento. Optimizar la ejecución del número de tareas y procesos.
Tiempo de respuesta. Conseguir que el tiempo de ejecución de un
determinado proceso sea mínimo
.Optimización de CPU. Optimización constante de la carga de proceso de la
CPU.
Este tipo de herramientas permiten la ejecución automática de tareas, esto
mediante la ejecución de comandos los cuales se ejecutarán dependiendo del
tiempo y las necesidades que se presenten, en Linux hay tres formas de
especificar tiempos y comandos:
at. el comando se inicia en un tiempo determinado (por ejemplo: at [-f file]
time [date])
batch. el comando se inicia una vez como la carga de una función del
sistema (por ejemplo: batch [archivo])
crontab. al igual que at especifica el tiempo al cual se ejecutará un
programa script.
En el caso de la planificación de tareas multiplataforma (desde Linux pasando por
Unix o Windows), el principal objetivo es gestionar tantas tareas como sea posible
de manera más rápida posible y con el menor número de anomalías.

51
Una solución de planificación de tareas debe ser capaz de interrumpir, parar o
reiniciar tareas, así como el poder asignar prioridades a la ejecución de las
mismas. También es importante la existencia de puntos de verificación, los cuales
van a proporcionar una imagen del estado actual de la tarea en ejecución, de igual
manera la tarea puede continuar su ejecución desde el punto de verificación.
Los planificadores de tareas completos y modernos pueden combinar múltiples
tareas en grupos cuando lo necesitan y procesarlo como una única unidad cuyo
resultado será utilizado como condición de inicio para otras tareas o grupos de
tareas.
2.8 SOLUCIONES DE ALTA DISPONIBILIDAD (HA) PARA LINUX.
De un tiempo a esta parte han ido surgiendo proyectos y soluciones de alta
disponibilidad para Linux, en las cuales algunas destacan su elegancia y sencillez
en comparación con sistemas comerciales. En esta sección se va a comentar los
más conocidos y los más utilizados. Se está recibiendo mucha cooperación de
distribuciones como VA, SuSE, Red Hat o Conectiva y los esfuerzos de Debian no
se quedan atrás.
2.9.1 HEARTBEAT3
Heartbeat es un software que tiene la habilidad de reubicar un recurso
sobrecargado o con fallas de una computadora hacia otra.
Con la arquitectura de heartbeat, podemos definir acciones que se realizan
cuando hay un cambio en el estado (vivo o muerto) de las máquinas servidores.
Una vez instalado, heartbeat lanza un demonio en cada máquina y los demonios
se conectaran entre ellos para detectar el estado de los servidores.
3 http://www.linux-ha.org/

52
A Heartbeat se le indica que computadora es el servidor primario y la otra
computadora será el servidor de backup (de respaldo). Posteriormente se
configura el "demonio" (un programa o proceso que se ejecuta en el trasfondo de
manera pasiva hasta que es invocado para realizar su tarea; se activa únicamente
cuando es necesario, sin ser invocado por el usuario) de Heartbeat, este se
ejecutara en el servidor de respaldo para que escuche los "latidos de corazón"
provenientes del servidor primario. Si el servidor de respaldo no escucha los
"latidos de corazón" del servidor primario, este inicia el proceso a prueba de falla y
toma posesión del recurso.
El programa Heartbeat corriendo en el servidor de respaldo puede chequear los
"latidos de corazón" provenientes del servidor primario sobre una conexión de red
normal Ethernet, aunque normalmente Heartbeat es configurado para que trabaje
sobre una conexión física entre dos servidores. Esta conexión física separada
puede ser ya sea un cable serial u otra conexión de red Ethernet (a través de un
cable cruzado o minihub, por ejemplo). Un cable cruzado es más simple y más
confiable que un minihub porque no requiere poder externo.
Heartbeat trabajara sobre una o más de estas conexiones físicas al mismo tiempo
y considerara el nodo primario activo mientras se encuentre recibiendo los latidos
de corazón al menos en una de las conexiones físicas.
2.9.2 CYRUS4
Cyrus es un sistema de correo empresarial altamente escalable para utilizarse en
ambientes empresariales de varios tamaños utilizando tecnologías basadas en
estándares. La tecnología de Cyrus va desde el uso independiente en
departamentos de correo hasta sistemas centralizados administrados en
empresas de gran tamaño.
4 http://cyrusimap.web.cmu.edu/generalinfo.html

53
2.9.3 RSYNC5
Rsync es una aplicación para sistemas de tipo Unix que ofrece transmisión
eficiente de datos incrementales comprimidos y cifrados. Mediante una técnica de
codificación llamada "codificación delta", permite sincronizar archivos y directorios
entre dos máquinas de una red o entre dos ubicaciones en una misma máquina,
minimizando el volumen de datos transferidos.
Algoritmo utilizado para realizar copias entre dos servidores, este proceso se
caracteriza por sincronizar archivos y directorios sobre los cuales se transfieren
únicamente las modificaciones que a éstos se hayan realizado, con ello se logra
tener al día copias idénticas de los directorios del sistema de archivos presentes
en los servidores que lo conforman. Con el algoritmo rsync se pueden realizar
varias actividades tales como:
Copiar en su totalidad ficheros, directorios, sistemas de archivos
manteniendo una sincronización adecuada mediante la cual se puede
realizar copias únicamente de los cambios realizados.
Realizar la copia de datos de manera segura, ya que puede utilizar ssh6,
algoritmo para cifrar el tráfico de datos.
Los principales usos de rsync incluyen mirroring (espejado) o Respaldo de
múltiples clientes Unix dentro de un servidor Unix central. Habitualmente se lo
ejecuta mediante herramientas de scheduling como cron, para automatizar
procesos de sincronización.
5 http://rsync.samba.org./ 6 SSH (Secure Shell) es una técnica de cifrado que hacen que la información que viaja por el medio de comunicación vaya de manera no legible y ninguna tercera persona pueda descubrir el usuario y contraseña de la conexión ni lo que se escribe durante toda la sesión (http://web.mit.edu/rhel-doc/4/RH-DOCS/rhel-rg-es-4/ch-ssh.html.)

54
2.9.4 NFS7
El sistema de archivos de red (NFS- Network File System) fue creado por SUN y
publicado en el año de 1985, es un sistema que ofrece soluciones de seguridad,
alto rendimiento acceso transparente al sistema de archivos. NFS es un estándar
abierto basado en la arquitectura Cliente/Servidor, la cual es útil para compartir
archivos por red independientemente del sistema operativo del cliente o del
servidor y, a la vez puede instalarse en cualquier plataforma.
El uso de NFS ofrece varias ventajas como:
La existencia de archivos a los se pueden acceder de manera simultánea
por varios clientes a través de la red.
Reduce costos de almacenamiento debido a que tiene los archivos
compartidos en la red y no necesita de espacio en disco local.
Realiza el montaje de los sistemas de archivos a los usuarios de manera
transparente.
El acceso a los archivos es transparente para el usuario.
Soporta ambientes heterogéneos, es decir que se puede instalar en
aquellas infraestructuras que no disponen de arquitecturas de iguales o
similares características.
NFS consta de un programa cliente y servidor. El programa servidor comparte los
archivos mediante el proceso de exportación, mientras que el cliente accede al
sistema de archivos compartidos añadiéndolos a su sistema local mediante el
proceso de montaje. Los protocolos8 de NFS proporcionan el medio de
comunicación entre los procesos de exportación y montaje sobre la red.
7 http://www.freebsd.org/doc/en/books/handbook/network-nfs.html 8 Los protocolos de NFS utilizan llamadas a procedimientos remotos RPC (Remote Procedure Call) que a su vez se basan en IPC (Inter Process Comunication), que no es sino la capacidad del sistema operativo para permitir la comunicación entre procesos, sea que éstos se ejecuten de manera local o remota.

55
En el servidor para realizar el proceso de exportación se debe editar un archivo de
configuración (/etc/exports ) el cual consta de tres partes:
Ruta completa del archivo a exportar.
Máquinas que son autorizadas para acceder al archivo exportado.
Restricciones de acceso.
Cuando el servidor arranca el sistema, este archivo de configuración es leído y se
informa al Kernel de los tres aspectos que conlleva la exportación de un archivo.
El cliente es encargado de montar un sistema de archivos remoto, no hace una
copia de este, sino realiza un montaje por medio de una serie de llamadas de
procedimiento remoto con el que se habilita al cliente el acceso al sistema de
archivos. El cliente NFS tiene la característica de montar o desmontar el sistema
de archivos de acuerdo a las necesidades, pero todo el proceso se realiza de
manera transparente para el usuario.
2.9.5 LDIRECTORD Y LVS (Linux Virtual Server)
LVS permite crear un Clúster de balanceo de carga, en el cual hay un nodo que se
encarga de gestionar y repartir las conexiones (nodo máster LVS) entre todos los
nodos slave del Clúster. El servicio de datos debe residir en todos los nodos slave.
LVS puede llegar a soportar sin problemas hasta 200 nodos slave.
Ldirectord Es un demonio que monitorea y administra a los servidores reales que
son parte de un Clúster de carga balanceada. Usualmente es usado en conjunto
con heartbeat, aunque puede funcionar con otro detector de servicios.

56
2.9.6 ROUND ROBIN DNS9
Es una técnica en la cual el balanceo de carga es realizada por un servidor DNS
en lugar de una máquina estrictamente dedicada. Esta técnica se suele usarse en
grandes redes o redes IRC.
Round robin funciona respondiendo a las peticiones DNS con una lista de
direcciones IP en lugar de una sola (todas ellas deberían hospedar el mismo
contenido). El orden con el cual las direcciones IP de la lista son retornadas es la
base del round robin, actuando en ciclos.
Round robin DNS se usa generalmente para balancear la carga de servidores web
distribuidos geográficamente, donde cada usuario que accede es enviado a la
siguiente dirección IP de manera cíclica.
Hay que tener en cuenta que NO es la mejor opción para balanceo de carga ya
que simplemente alterna el orden de los registros de direcciones cada vez que
llega una petición a un servidor de nombres. No se toma en consideración el
tiempo de transacción, carga del servidor, congestión de la red, etc. Por ello en
servidores con recursos no homogéneos diríamos que tan solo hace distribución
de la carga.
2.9.7 HAPROXY10
Es una solución gratis, confiable y muy rápida ofreciendo alta disponibilidad,
balanceo de carga y el uso de un proxy para aplicaciones basadas en TCP y
HTTP.
Es una solución gratis, confiable y muy rápida y el uso de un proxy para
aplicaciones basadas en TCP y HTTP.
9 http://bytecoders.homelinux.com/content/balanceo-de-carga-round-robin-dns.html 10 http://haproxy.1wt.eu/

57
2.9.8 PIRAHNA
Es el nombre que RedHat ha dado a su solución basada en LVS, el añadido es
una interfaz para configurarlo.
Ofrece un conjunto de herramientas para implementar Clústers de alta
disponibilidad y balanceo de carga.
2.9.9 ULTRAMONKEY11
Es una solución creada por VA Linux que se basa en LVS y Heartbeat para ofrecer
Clústers de alta disponibilidad y balanceo de carga. El nodo máster LVS se pone
en alta disponibilidad ya que es el único SPOF. Además incorpora una interfaz
para configurar el Clúster.
2.9.10 KIMBERLITE12
Creada por Mission Critical Linux, es una solución que soporta un Clúster de 2
nodos. Permite fácilmente, definir un dispositivo de quórum, monitorizar los
servicios de datos, así como gestionarlo. Una solución completa bajo GPL.
2.10 EL MODELO OSI13
En sus inicios, el desarrollo de redes sucedió con desorden en muchos sentidos. A
principios de la década de 1980 se produjo un enorme crecimiento en la cantidad y
el tamaño de las redes. A medida que las empresas tomaron conciencia de las
ventajas de usar tecnología de networking, las redes se agregaban o expandían a
casi la misma velocidad a la que se introducían las nuevas tecnologías de red.
Para poder simplificar el estudio y la implementación de la arquitectura necesaria,
la ISO (Organización Internacional de Normas) creó el modelo de referencia OSI
para lograr una estandarización internacional de los protocolos. Este modelo se
11 http://www.ultramonkey.org/ 12 http://www.missioncriticallinux.com/projects/kimberlite/ 13 Cisco Networking Academy Program CCNA Land2. Versión 3.1

58
ocupa de la Interconexión de Sistemas Abiertos a la comunicación y está divido en
7 capas, entendiéndose por "capa" una entidad que realiza de por sí una función
específica.
A continuación la explicación de cada una de las capas del modelo OSI:
CAPA NOMBRE DESCRIPCIÓN
7 APLICACIÓN Se entiende directamente con el usuario final, al proporcionarle el servicio de información distribuida para soportar las aplicaciones y administrar las
comunicaciones por parte de la capa de presentación.
6 PRESENTACIÓ
N
Permite a la capa de aplicación interpretar el significado de la información que se intercambia. Esta realiza las conversiones de formato mediante las
cuales se logra la comunicación de dispositivos.
5 SESIÓN Administra el diálogo entre las dos aplicaciones en cooperación mediante el
suministro de los servicios que se necesitan para establecer la comunicación, flujo de datos y conclusión de la conexión.
4 TRANSPORTE
Esta capa proporciona el control de extremo a extremo y el intercambio de información con el nivel que requiere el usuario. Representa el corazón de la jerarquía de los protocolos que permite realizar el transporte de los datos en
forma segura y económica.
3 RED Proporciona los medios para establecer, mantener y concluir las conexiones conmutadas entre los sistemas del usuario final. Por lo tanto, la capa de red
es la más baja, que se ocupa de la transmisión de extremo a extremo.
2 ENLACE Asegura con confiabilidad del medio de transmisión, ya que realiza la
verificación de errores, retransmisión, control fuera del flujo y la secuenciación de la capacidad que se utilizan en la capa de red.
1 FISICO Se encarga de las características eléctricas, mecánicas, funcionales y de procedimiento que se requieren para mover los bits de datos entre cada
extremo del enlace de la comunicación.
Cuadro No.2 Capas del Modelo OSI
e
Figura No.6 Modelo OSI
e

59
2.11 APLICACIONES EN LAS QUE SE HA UTILIZADO LA
ARQUITECTURA DE CLÚSTER.
2.11.1 CLÚSTER GOOGLE
Google necesitaría muchísima potencia para
abastecer los servicios de todos los usuarios del
mundo, una media de 40 millones de búsquedas
diarias. Para conseguir esta potencia Google
desarrolló varios servidores, cada uno de ellos
formado por un Clúster. Consiguiendo así la potencia
necesaria para todas las peticiones. Cada uno se
compone de 359 racks (estructura parecida a una
estantería para organizar los nodos), 31654 nodos,
63184 CPUs, 126.368 Ghz de potencia de
procesamiento, 63.184 Gbytes de RAM y 2.527
Tbytes de espacio en disco duro.
60
2.11.2 CLUSTER IMPLEMENTADOS A NIVEL NACIONAL (EN
EL SALVADOR).
EMPRESA TIPO DE CLUSTER TIPO DE SOTFWARE
BANCO CUSCATLÁN
Instalación de un Clúster de Web Server (IBM HttpServer 2.x) para Banco Cuscatlán.
GNU
BANCO
AGRÍCOLA
Instalación de dos Clúster para Banco Agrícola, un Clúster para IBM Edge Server -Servidor de load balancing y web caching proxy y segundo Clúster para IBM HttpServer 2.x
GNU
CORTE DE CUENTAS
Instalación de un Clúster de IBM HttpServer 2.x para la corte de Cuentas.
GNU
GRUPO SIMAN
Instalación de Clúster para Grupo Siman. Este Clúster es de mensajería y colaboración de Lotus Domino sobre RedHat Linux. Los servidores Linux fueron tuneados para soportar 2,400 usuarios concurrentemente.Esta es la solución de linux mas grande que hay en El Salvador, ya que comprende 2 servidores en Clúster RedHat Enterprise y 4 servidores adicionales RedHat Enterprise para los países Guatemala, El Salvador, Honduras y Nicaragua. De hecho estos son los servidores Linux con más demanda de carga que hay en el país y en Centro América.
GNU
DEL SUR
Instalación de Clúster de Mensajería y colaboración de Lotus Domino sobre RedHat Enterprise. Los servidores RedHat fueron configurados para soportar la carga de 400 usuarios concurrentemente.
GNU
2.11.3 EVOLUCIÓN DE LOS CLÚSTERS
La tecnología de Clúster ha evolucionado en apoyo de actividades que van desde
aplicaciones de supercómputo y software de misiones críticas, servidores Web y
comercio electrónico, hasta bases de datos de alto rendimiento, entre otros usos.
El cómputo con Clúster surge como resultado de la convergencia de varias
tendencias actuales que incluyen la disponibilidad de microprocesadores
económicos de alto rendimiento y redes de alta velocidad, el desarrollo de
herramientas de software para cómputo distribuido de alto rendimiento, así como
la creciente necesidad de potencia computacional para aplicaciones que la
requieran.
Cuadro No.3 Clústers implementados en El Salvador
61
14 Las condiciones que dieron origen al proyecto Beowulf fueron el éxito general de las computadoras personales, el
surgimiento de Linux como alternativa viable de sistema operativo tipo Unix para computadoras personales y la
estandarización de las prácticas comunes de programación paralela.
ORDEN NOMBRE DE
CLÚSTER DESCRIPCION IMAGEN
1 CLÚSTER
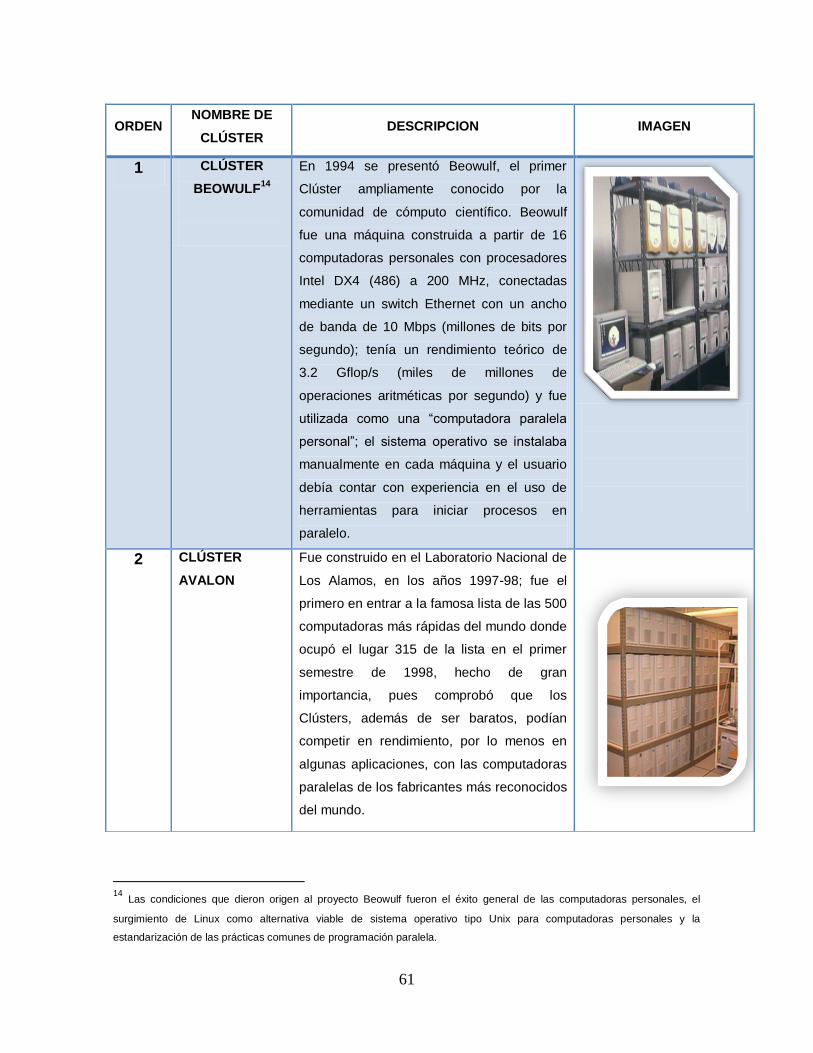
BEOWULF14
En 1994 se presentó Beowulf, el primer
Clúster ampliamente conocido por la
comunidad de cómputo científico. Beowulf
fue una máquina construida a partir de 16
computadoras personales con procesadores
Intel DX4 (486) a 200 MHz, conectadas
mediante un switch Ethernet con un ancho
de banda de 10 Mbps (millones de bits por
segundo); tenía un rendimiento teórico de
3.2 Gflop/s (miles de millones de
operaciones aritméticas por segundo) y fue
utilizada como una “computadora paralela
personal”; el sistema operativo se instalaba
manualmente en cada máquina y el usuario
debía contar con experiencia en el uso de
herramientas para iniciar procesos en
paralelo.
2 CLÚSTER
AVALON
Fue construido en el Laboratorio Nacional de
Los Alamos, en los años 1997-98; fue el
primero en entrar a la famosa lista de las 500
computadoras más rápidas del mundo donde
ocupó el lugar 315 de la lista en el primer
semestre de 1998, hecho de gran
importancia, pues comprobó que los
Clústers, además de ser baratos, podían
competir en rendimiento, por lo menos en
algunas aplicaciones, con las computadoras
paralelas de los fabricantes más reconocidos
del mundo.

62
3 CLÚSTER
CPLANT
Construido en el Laboratorio Nacional
Sandia, se dio un paso importante en la
evolución de los Clústers. Cplant no es
solamente un tipo de máquina paralela, sino
todo un proyecto que contempla la manera
en que un equipo de esta naturaleza puede
crecer y renovarse de manera continua.
Durante los últimos años, Cplant ha crecido
hasta los 1590 procesadores.
4 CLÚSTER
SCORE
Es otro Clúster relevante instalado en el
Centro de Investigación de Tsukuba, ya que
fue el primero con más de 1000
procesadores (1024) lo que lo llevó a ocupar
el lugar 36 en el Top500 del primer semestre
de 2001.
5 CLÚSTER X
En la actualidad, es el Clúster más grande del mundo, construido en el Tecnológico de Virginia en 2003. Este Clúster se compone de 2200 procesadores G5 a 2.0 GHz, conectados a través de dos redes diferentes: infiniband para las comunicaciones entre procesos y Gigabit Ethernet para la administración; esta computadora posee un total de 4 TeraBytes (más de cuatro mil GBytes) de RAM y más de 176 TeraBytes (176 mil Gbytes) de almacenamiento secundario. Es la tercera computadora más rápida del mundo y en el comunicado de prensa de su lanzamiento se enfatiza el hecho de que la instalación de los nodos fue realizada en su totalidad por estudiantes del Tecnológico de Virginia.

63
6 CLUSTER PS2
En el año 2004, en la Universidad de Illinois en Urbana-Champaign, Estados Unidos, se exploró el uso de consolas Play Station 2 (PS2) en cómputo científico y visualización de alta resolución. Se construyó un Clúster conformado por 70 PS2; utilizando Sony Linux Kit (basado en Linux Kondora y Linux Red Hat) y MPI.
7 CLÚSTER DE 1000 NODOS
Utilizado para la investigación de algoritmos
genéticos.
CLÚSTER BEOWULF PIRUN KASETSART UNIVERSITY, THAILAND
PIRUN=Piles of Inexpensive and Redundant Universal Nodes. Constituido por 72 nodos PIII 500 MHz, 128 MB Es utilizado en Cálculo intensivo en general y funciona como superservidor de internet.

64
2.12 GESTIÓN DE ALMACENAMIENTO EN DISCOS
El almacenamiento en disco puede consistir en una NAS, una SAN o
almacenamiento interno en el servidor. El protocolo más comúnmente utilizado es
NFS (Network File System), sistema de ficheros compartido entre servidor y los
nodos. Sin embargo existen sistemas de ficheros específicos para Clústers como
Lustre (CFS) y PVFS2.
Tecnologías en el soporte del almacenamiento en discos duros:
IDE (PATA, Parallel ATA): Anchos de banda (Bw) de 33, 66, 100 y
133MBps.
SATA I (SATA-150): Bw 150 MBps.
SATA II (SATA-300): Bw 300 MBps.
SCSI: Bw 160, 320, 640MBps. Proporciona altos rendimientos.
SAS (Serial Array SCSI): Aúna SATA II y SCSI. Bw 375MBps.
Las unidades de cinta (DLTs) son utilizadas para backups por su bajo
coste.
NAS (Network Attached Storage): es un dispositivo específico dedicado a
almacenamiento a través de red (normalmente TCP/IP) que hace uso de un S.O.
optimizado para dar acceso a través de protocolos CIFS, NFS, FTP o TFTP.
DAS (Direct Attached Storage): consiste en conectar unidades externas de
almacenamiento SCSI o a una SAN (Storage Area Network) a través de Fibre
Channel. Estas conexiones son dedicadas.
Mientras NAS permite compartir el almacenamiento, utilizar la red, y tiene una
gestión más sencilla, DAS proporciona mayor rendimiento y mayor fiabilidad al no
compartir el recurso.

65
ALMACENAMIENTO DE DISCO NAS VS. SAN
2.12.1 REDUNDANT ARRAY OF INDEPENDENT DISKS
(RAID)15
RAID son las siglas para Redundant Array of Inexpensive Disks, que traducido al
español significa Arreglo Redundante de Discos Económicos.
Un subsistema RAID nos va a permitir eliminar SPOF de los recursos de
almacenamiento. Actualmente el kernel de Linux soporta RAID 0, 1 y 5 con el
driver MD. Además de RAID software también soporta gran número de
controladoras SCSI y ATA100 que ofrecen volúmenes de RAID por hardware.
Compaq e IBM han colaborado mucho en este aspecto, creando drivers para sus
productos.
15 http://www.smdata.com/queesraid.htm
CATEGORIA NAS SAN
Cables Ethernet Fibre Channel
Protocolo CIFS, NFS, ó HTTP sobre TCP/IP
Encapsulated SCSI (iSCSI, cuando encapsula sobre TCP/IP, y FCP cuando encapsula directamente sobre Fibre Channel)
Manejo El NAS head gestiona el sistema de ficheros
Múltiples servidores manejan los datos
Acceso Permite acceder a un sistema de ficheros a través de TCP/IP usando CIFS (en el caso de Windows) ó NFS (en el caso de Unix/Linux
Es usada para acceder a almacenamiento en modo BLOQUE, a través de una red de fibra óptica con Fibre Channel (FC) utilizando el protocolo SCSI.
Solución adecuada para
Servidor de ficheros. Almacenamiento de
directorios de usuario. Almacenamiento de archivos
en general.
Bases de datos. Data warehouse. Backup (al no interferir en la red del
sistema). Cualquier aplicación que requiera
baja latencia y alto ancho de banda en el almacenamiento y recuperación de datos.
Cuadro No.4 Almacenamiento NAS vRs. SAN

66
2.12.2 ARREGLOS DE DISCOS DUROS
El objetivo de RAID es combinar varias platinas de disco económicas en una
unidad lógica o arreglo de discos que mejora el desempeño superando el de una
platina de alta velocidad mucho más cara. Además de mejorar el desempeño, los
arreglos de disco pueden proveer tolerancia a fallas de disco al almacenar la
información de manera redundante en diversas formas.
Existen muchas aplicaciones para los arreglos de discos, especialmente en los
ambientes corporativos donde hay necesidades más allá de lo que puede ser
satisfecho por un solo disco duro, sin importar su capacidad, desempeño o
calidad.
Muchas empresas y corporaciones no pueden tomarse el lujo de tener sus
sistemas abajo por al menos una hora en caso de una falla de disco; requieren
subsistemas de almacenamiento masivo con capacidades en terabytes, que
además sean resistentes a fallas a cualquier nivel posible.
Originalmente RAID era utilizado casi exclusivamente para las aplicaciones de alto
nivel en los negocios debido al alto costo de los equipos requeridos. Esta situación
cambió paulatinamente conforme los usuarios de alto nivel (power users) de todos
los niveles comenzaron a exigir mejor desempeño y mayor tiempo de operación.

67
2.12.3 NIVELES DE ARREGLOS.16
2.12.3.1 RAID 1: ESPEJO Y DUPLICACION
RAID nivel 1 requiere al menos dos platinas de disco para poder ser
implementado. Para mejor desempeño, el controlador debe de ser capaz de
realizar dos lecturas concurrentes independientes por par espejo o dos escrituras
duplicadas por par de discos en espejo.
Funcionamiento
RAID 1 implementa un arreglo de discos en espejo en donde los datos son leídos
y escritos de manera simultánea en dos discos distintos.
Ventajas
En esta configuración un arreglo de discos puede realizar una escritura o dos
lecturas por par en espejo, duplicando la tasa de transaccional de lectura de
discos simples con la misma tasa transaccional de escritura que los discos
tradicionales. Una redundancia total de datos significa que no es necesaria la
reconstrucción en caso de falla de algún disco, sino sólo una copia.
16 http://mx.geocities.com/pcmuseo/mecatronica/discoraidniveles.htm

68
La tasa de transferencia por bloques es la misma que en los discos
tradicionales.
Bajo ciertas circunstancias RAID 1 puede soportar fallas simultáneas
múltiples de discos.
Es el diseño RAID más simple.
Sencillez de implementación.
Desventajas
Es el que tiene mayor derroche de disco de todos los tipos de RAID, con el
100% de derroche.
Típicamente la función RAID es llevada a cabo por el software del sistema
cargando a la UCP ó al servidor, degradando el desempeño del mismo.
Probablemente no soporte cambio en caliente de un disco dañado cuando
se implementa por software.

69
RAID 2: CODIGO DE CORRECCION DE ERRORES CON CODIGO
DE HAMMING
RAID nivel 2 requiere al menos dos platinas de disco para poder ser
implementado. Para mejor desempeño, el controlador debe de ser capaz de
realizar dos lecturas concurrentes independientes por par espejo o dos escrituras
duplicadas por par de discos en espejo.
Funcionamiento
Cada bit de cada palabra es escrito a un disco, 4 en el ejemplo gráfico. Cada
palabra tiene su Código Hamming de Corrección de Errores (CHCE) almacenada
en los discos CHCE. Durante la lectura el CHCE verifica y corrige los datos o
errores específicos en los discos.

70
Ventajas
En esta configuración un arreglo de discos puede realizar una escritura o dos
lecturas por par en espejo, duplicando la tasa de transaccional de lectura de
discos simples con la misma tasa transaccional de escritura que los discos
tradicionales. Una redundancia total de datos significa que no es necesaria la
reconstrucción en caso de falla de algún disco, sino sólo una copia.
Capacidad de corrección de errores al paso.
Es posible alcanzar tasas de transferencia muy altas.
A mayor tasa de transferencia requerida, es mejor la relación de los discos
de datos a los discos CHCE.
El diseño del controlador es relativamente simple comparado con los
niveles 3,4 y 5.
Desventajas
Puede tener una alta relación de los discos CHCE a los discos de datos con
tamaños de palabra pequeños, tornando el sistema ineficiente.
Costo de nivel de entrada muy alto, requiere de una muy alta tasa de
transferencia para justificarlo.
No existen implementaciones comerciales ya que comercialmente no es
viable.

71
2.12.3.2 RAID 3: TRANSFERENCIA EN PARALELO CON PARIDAD
RAID nivel 3 requiere cuando menos 3 discos para funcionar.
Funcionamiento
El bloque de datos es subdividido en bandas y escrito en los discos de datos. Las
bandas de paridad son generadas durante la escritura, almacenadas en los discos
de paridad y verificado durante la lectura.
Ventajas
Muy alta tasa de transferencia de lectura.
Muy alta tasa de transferencia de escritura.
La falla de un disco tiene impacto poco relevante para la capacidad de
transferencia.
Baja relación de discos de paridad contra los de datos, lo que aumenta la
eficiencia.

72
Desventajas
En el mejor de los casos la tasa de transacciones es la misma que en
configuraciones de un solo disco.
Diseño de controlador relativamente simple.
Muy complejo y demandante de recursos para implementarse por software.
2.12.3.3 RAID 4: DISCOS INDEPENDIENTES DE DATO CON DISCO
COMPARTIDO DE PARIDAD.
RAID nivel 4 requiere cuando menos 3 discos para funcionar.
Funcionamiento
Cada bloque completo es escrito en un disco de datos. La paridad para bloques
del mismo rango es generada durante las escrituras y almacenada en el disco de
paridad, y verificada durante las lecturas.

73
Ventajas
Muy alta tasa transaccional de lectura.
Baja relación de discos de paridad contra los de datos, lo que aumenta la
eficiencia.
Alta tasa de transferencia agregada para lectura.
Desventajas
Tiene la peor tasa transaccional de escritura así como para escritura
agregada.
Diseño muy complejo de controlador.
Reconstrucción de datos compleja e ineficiente en caso de falla de disco.
Tasa de transferencia en lectura por bloques igual a la de un disco simple.
2.12.3.4 RAID 5: DISCOS INDEPENDIENTES DE DATOS CON
BLOQUES DISTRIBUIDOS DE PARIDAD
RAID nivel 5 requiere cuando menos 3 discos para funcionar.

74
Funcionamiento
Cada bloque de datos completo es escrito en un disco de datos; la paridad para
los bloques en el mismo rango es generada durante las escrituras, almacenada en
locaciones distribuidas y verificada durante las lecturas.
Ventajas
Tiene la más alta tasa de transacciones de lectura.
Regular tasa de transacciones de escritura.
Baja relación entre los discos de paridad contra los discos de datos
ofreciendo una alta eficiencia.
Buena tasa de transferencia de agregado.
Es el nivel de RAID más versátil.
Desventajas
La falla de un disco tiene impacto sensible en el desempeño.
El diseño del controlador es el más complejo.
La reconstrucción de datos en caso de falla de un disco es compleja,
comparada con RAID 1.
Tasa de transferencia en bloques individuales de datos igual que la de un
disco sencillo.

75
2.12.3.5 RAID 6: DISCOS INDEPENDIENTES DE DATOS CON
ESQUEMAS INDEPENDIENTES DE PARIDAD
RAID nivel 6 requiere n+2 discos para funcionar.
Funcionamiento
Esencialmente RAID 6 es una extensión de RAID 5 que aumenta la tolerancia a
fallos utilizando bandas de paridad bidimensionales.
Las bandas de paridad bidimensionales consisten en la utilización de un segundo
esquema independiente de distribución de bandas de paridad.
Los datos son separados en bandas a nivel de bloques a través de todos los
discos, como en RAID 5, y un segundo conjunto de paridad es calculado y escrito
en todos los discos; RAID 6 provee una tolerancia a fallos extremadamente alta y
puede soportar múltiples fallas simultáneas de discos.
Ventajas
Muy alta tolerancia a fallos de disco.
Tolerancia a fallas de múltiples discos.

76
Desventajas
Diseño complejo del controlador.
Alta sobrecarga del controlador para calcular direcciones de paridad.
Pobre desempeño para la escritura.
Requiere de n+2 discos debido al esquema de paridad bidimensional.
2.12.4 DEFINICIÓN DE HOT SWAP17
Es la capacidad de algunos componentes esenciales que permiten instalarse o
sustituirse sin detener las operaciones normales de la computadora que los aloja.
Cuando no son componentes esenciales se denomina hot pluggin o conexión en
caliente.
Este tipo de componentes (y los sistemas operativos que lo permiten) suelen
utilizarse en servidores que necesitan estar en funcionamiento sin parar. Por
ejemplo, las fuentes de alimentación en los servidores suelen ser hot swap,
cuando una se rompe, es posible sustituirla sin detener el suministro eléctrico.
También un disco duro si se daña puede ser reemplazado sin afectar a los datos,
pues suelen utilizar varios discos duros con información espejada (RAID).
17
http://www.alegsa.com.ar/Dic/hot%20swap.php

77
2.12.5 CLUSTERS CON DISCOS DUROS
Los discos duros son los dispositivos donde se graban los datos. El fallo más
común en un servidor es el fallo de un disco duro. Si el servidor tiene solamente
un disco y este falla, fallara el servidor al completo y no se podrá acceder a los
datos contenidos en el mismo. Existen por ello técnicas que nos ayudan a
minimizar este problema y a que el servidor siga funcionando y no pierda datos
incluso cuando falle algún disco duro. Lo más normal también, es que se puedan
sustituir los discos que fallan sin necesidad de apagar el servidor (HotSwap)
La técnica más comunes la llamada RAID (redundant array of independent disks).
Con esta técnica creamos un conjunto de discos redundantes que nos pueden
ayudar, tanto a aumentar la velocidad y el rendimiento del sistema de
almacenamiento, como a que el sistema siga funcionando aunque algún disco
falle. Existen implementaciones por software y hardware y diferentes
configuraciones RAID, siendo las más comunes RAID1, RAID5 y RAID10.
2.12.6 LOGICAL VOLUME MANAGEMENT (LVM)
El software de gestión de volúmenes permite exportar los volúmenes de grupos de
discos para que el servicio de datos pueda hacer uso de él. Logical Volume
Management inicialmente adoptado por IBM luego por la OSF, está en desarrollo.
No sólo es capaz de cambiar el tamaño de discos lógicos sino también de
sistemas de ficheros ext2.

78
2.13 DIRECCIONES IP18
Las direcciones IP fueron creadas con la idea de asignar un numero único en las
maquinas para tener control sobre ellas e identificarlas en su momento.
2.13.1 CLASES DE IP´S
Internet Corporation for Assigned Names and Numbers - Corporación de Internet
para la Asignación de Nombres y Números. Organización sin fines de lucro creada
el 18 de septiembre de 1998 para encargarse de algunas tareas que realizaba la
IANA. Es manejada por el Departamento de Comercio de EE.UU., no permitiendo
a ningún organismo o empresa manejar dichas tareas.
Éstas tareas incluyen la gestión de la asignación de nombres de dominios de
primer nivel y direcciones IP. La Internet Corporation for Assigned Names and
Numbers (ICANN es la organización encargada de distribuir las direcciones IP.)
reconoce tres clases de direcciones IP:
Clase A:
En esta clase se reserva el primer grupo a la identificación de la red, quedando los
tres siguientes para identificar los diferentes host. Los rangos de esta clase están
comprendidos entre 1.0.0.0 y 127.255.255.255.
Clase B:
En esta clase se reservan los dos primeros grupos a la identificación de la red,
quedando los dos siguientes para identificar los diferentes host. Los rangos de
esta clase están comprendidos entre 128.0.0.0 y 191.255.255.255.
18 http://www.ibiblio.org/pub/Linux/docs/LuCaS/Manuales-LuCAS/GARL2/garl2/x-087-2-issues.ip-addresses.html

79
Cuadro No.5 Clases de IP´S
Clase C:
En esta clase se reservan los tres primeros grupos a la identificación de la red,
quedando el último para identificar los diferentes hosts. Los rangos de esta clase
están comprendidos entre 192.0.0.0 y 223.255.255.255.
2.13.2 IP's PUBLICAS
La IP pública sirve para establecer conexiones con los servidores que alojan las
páginas web, el correo, intercambio de P2P y todo lo que implique tener conexión
con otro Host o servidor fuera de nuestra LAN.
Las IP´s públicas generalmente las administran los proveedores de internet y otras
instituciones especializadas en el control de estas.
Al igual que las privadas, las públicas son un conjunto de cuatro números a partir
de cero hasta 255 separados por un punto. Ejemplo 200.85.0.104
La dirección IP es con la que nos identificamos al conectarnos a otras redes
(Internet). Esta IP nos la asigna nuestro proveedor ISP, y no tenemos control
sobre ella. A su vez puede ser de dos tipos diferentes:

80
IP estática
Es cuando tenemos una dirección IP fija asignada. Este tipo es poco utilizado,
carece de interés para el usuario doméstico y además los proveedores ISP suelen
cobrar un suplemento por ellas.
IP dinámica
Es la utilizada habitualmente. El ISP nos asigna al conectarnos a la red (Internet)
una dirección que tenga disponible en ese momento. Esta dirección cambia cada
vez que nos desconectamos de Internet y nos volvemos a conectar.
2.13.3 IP´s PRIVADAS
La IP privada es la que asignamos a las maquinas de nuestra casa, empresa o
pequeño negocio, con el fin de ahorrar en direcciones públicas, dar seguridad a
nuestra PC, ya que nadie puede entrar a una maquina usando una IP privada, y
permitirnos comunicación entre PC’s conectadas al mismo router o switch.
Las direcciones privadas responden al estándar RFC1918 que establece que las
IP’s privadas deben ser del rango
10.0.0.0 al 10.255.255.255
172.16.0.0 al 172.31.255.255
192.168.0.0 al 192.168.255.255

81
2.14 ELEMENTOS PARA CREAR UNA RED DE AREA LOCAL19
En una LAN existen elementos de hardware y software entre los cuales se pueden
destacar:
El servidor: es el elemento principal de procesamiento, contiene el
sistema operativo de red y se encarga de administrar todos los procesos
dentro de ella, controla también el acceso a los recursos comunes como
son las impresoras y las unidades de almacenamiento.
Las estaciones de trabajo: en ocasiones llamadas nodos, pueden ser
computadoras personales o cualquier terminal conectada a la red. De
esta manera trabaja con sus propios programas o aprovecha las
aplicaciones existentes en el servidor.
El sistema operativo de red: es el programa (software) que permite el
control de la red y reside en el servidor. Ejemplos de estos sistemas
operativos de red son: NetWare, LAN Manager, OS/2, LANtastic y
Appletalk.
Los protocolos de comunicación: son un conjunto de normas que
regulan la transmisión y recepción de datos dentro de la red.
La tarjeta de interface de red: proporciona la conectividad de la
terminal o usuario de la red física, ya que maneja los protocolos de
comunicación de cada topología especifica.
También se denominan NIC (Network Interface Card). Básicamente realiza la
función de intermediario entre el ordenador y la red de comunicación. En ella se
encuentran grabados los protocolos de comunicación de la red. La comunicación 19 Cisco Networking Academy Program CCNA Land2. Versión 3.1

82
con el ordenador se realiza normalmente a través de las ranuras de expansión que
éste dispone, ya sea ISA, PCI o PCMCIA. Aunque algunos equipos disponen de
este adaptador integrado directamente en la placa base.
La función de una NIC es conectar un dispositivo host al medio de red. Una NIC es
una placa de circuito impreso que se coloca en la ranura de expansión de un bus
de la motherboard o dispositivo periférico de un computador. La NIC también se
conoce como adaptador de red. En los computadores portátiles o de mano, una
NIC tiene el tamaño de una tarjeta de crédito.

83
2.15 TOPOLOGIAS DE RED20
El término topología se refiere a la forma en que está diseñada la red, bien
físicamente (rigiéndose de algunas características en su hardware) o bien
lógicamente (basándose en las características internas de su software).
La topología de red es la representación geométrica de la relación entre todos los
enlaces y los dispositivos que los enlazan entre sí (habitualmente denominados
nodos).
Entre las topologías de red de uso más común se encuentran: malla, estrella,
árbol, bus y anillo.
2.15.1 TOPOLOGÍA DE MALLA
En esta topología, cada dispositivo tiene un enlace
punto a punto y dedicado con cualquier otro
dispositivo. El término dedicado significa que el
enlace conduce el tráfico únicamente entre los dos
dispositivos que conecta.
20 Tomado de: http://www.bloginformatico.com/topologia-de-red.php
Fig. No.7 TOPOLOGIAS DE RED
Fig. No.8 TOPOLOGIAS DE MALLA

84
Por tanto, una red en malla completamente conectada necesita n(n-1)/2 canales
físicos para enlazar n dispositivos. Para acomodar tantos enlaces, cada dispositivo
de la red debe tener sus puertos de entrada/salida (E/S).
Una malla ofrece varias ventajas sobre otras topologías de red. En primer lugar, el
uso de los enlaces dedicados garantiza que cada conexión sólo debe transportar
la carga de datos propia de los dispositivos conectados, eliminando el problema
que surge cuando los enlaces son compartidos por varios dispositivos. En
segundo lugar, una topología en malla es robusta. Si un enlace falla, no inhabilita
todo el sistema.
Otra ventaja es la privacidad o la seguridad. Cuando un mensaje viaja a través de
una línea dedicada, solamente lo ve el receptor adecuado. Las fronteras físicas
evitan que otros usuarios puedan tener acceso a los mensajes.
2.15.2 TOPOLOGÍA DE ESTRELLA
En la topología en estrella cada dispositivo solamente tiene un enlace punto a
punto dedicado con el controlador central, habitualmente llamado concentrador.
Los dispositivos no están directamente enlazados entre sí.
A diferencia de la topología en malla, la topología en estrella no permite el tráfico
directo de dispositivos. El controlador actúa
como un intercambiador: si un dispositivo
quiere enviar datos a otro, envía los datos al
controlador, que los retransmite al dispositivo
final.
Una topología en estrella es más barata que
una topología en malla. En una red de estrella,
cada dispositivo necesita solamente un enlace Fig. No.9 TOPOLOGIAS DE ESTRELLA

85
y un puerto de entrada/salida para conectarse a cualquier número de dispositivos.
Este factor hace que también sea más fácil de instalar y reconfigurar. Además, es
necesario instalar menos cables, y la conexión, desconexión y traslado de
dispositivos afecta solamente a una conexión: la que existe entre el dispositivo y el
concentrador.
2.15.3 TOPOLOGÍA DE ÁRBOL
La topología de árbol es una variante de la de estrella. Como en la estrella, los
nodos del árbol están conectados a un concentrador central que controla el tráfico
de la red.
Sin embargo, no todos los dispositivos se conectan directamente al concentrador
central.
La mayoría de los dispositivos se conectan a un concentrador secundario que, a
su vez, se conecta al concentrador central.
El controlador central del árbol es un concentrador activo. Un concentrador activo
contiene un repetidor, es decir, un dispositivo hardware que regenera los patrones
de bits recibidos antes de retransmitidos.
Fig. No.10 TOPOLOGIAS DE ARBOL

86
Retransmitir las señales de esta forma amplifica su potencia e incrementa la
distancia a la que puede viajar la señal. Los concentradores secundarios pueden
ser activos o pasivos. Un concentrador pasivo proporciona solamente una
conexión física entre los dispositivos conectados.
2.15.4 TOPOLOGÍA DE BUS
Esta topología se caracteriza por tener un único canal de comunicaciones
(denominado bus, troncal o backbone) al cual se conectan los diferentes
dispositivos. De esta forma todos los dispositivos comparten el mismo canal de
comunicación entre sí.
Los nodos se conectan al bus mediante cables de conexión (y sondas). Un cable
de conexión es una conexión que va desde el dispositivo al cable principal. Una
sonda es un conector que, o bien se conecta al cable principal, o se pincha en el
cable para crear un contacto con el núcleo metálico.
Entre las ventajas de la topología de bus se incluye la sencillez de instalación.
El cable troncal puede tenderse por el camino más eficiente y, después, los nodos
se pueden conectar al mismo mediante líneas de conexión de longitud variable.
De esta forma se puede conseguir que un bus use menos cable que una malla,
una estrella o una topología en árbol.
Fig. No.11 TOPOLOGIAS DE BUS

87
2.15.5 TOPOLOGÍA DE ANILLO
En una topología en anillo cada dispositivo tiene una línea de conexión dedicada y
punto a punto solamente con los dos dispositivos que están a sus lados. La señal
pasa a lo largo del anillo en una dirección, o de dispositivo a dispositivo, hasta que
alcanza su destino. Cada dispositivo del anillo incorpora un repetidor.
Un anillo es relativamente fácil de instalar y
reconfigurar. Cada dispositivo está enlazado
solamente a sus vecinos inmediatos (bien
físicos o lógicos). Para añadir o quitar
dispositivos, solamente hay que mover dos
conexiones.
Las únicas restricciones están relacionadas
con aspectos del medio físico y el tráfico
(máxima longitud del anillo y número de
dispositivos). Además, los fallos se pueden aislar de forma sencilla. Generalmente,
en un anillo hay una señal en circulación continuamente.
PARES EN HUB
Fig. No.12 TOPOLOGIAS DE ANILLO
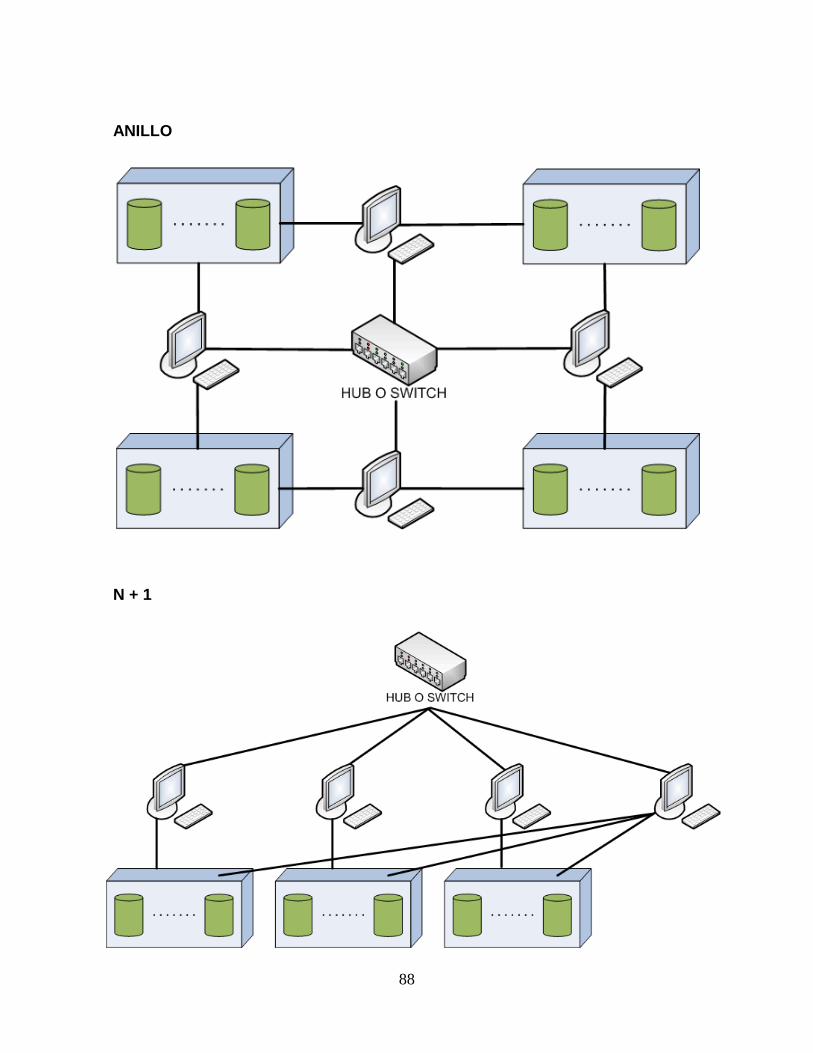
88
ANILLO
N + 1

89
2.16 LICENCIAMIENTO DE SOFTWARE
La licencia de software es una especie de contrato, en donde se especifican todas
las normas y clausulas que rigen el uso de un determinado programa,
principalmente se estipulan los alcances de uso, instalación, reproducción y copia
de estos productos.
2.16.1 LICENCIAR UN SOFTWARE
"Es el procedimiento de conceder a otra persona o entidad el derecho de usar un
software con fines industriales, comerciales o personales, de acuerdo a las
clausulas que en ella aparecen."
Es obtener la determinada licencia ó autorización que permita el uso legal de un
determinado programa, esta licencia es un documento electrónico, en papel
original ó número de serie autorizado por el autor. Se puede tener cualquier
cantidad de programas instalados, pero necesitará un documento ó número de
serie legal que le autorice su uso.
El software gratis como el sistema operativo Linux, el traductor Babylon, WinZip
para descomprimir archivos y muchos otros son considerados por el usuario
promedio, como programas para el 'uso y el abuso' por parte de este. Y los que
tienen alguna idea sobre las diferentes licencias que cobijan el software sin costo
pueden llegar a confundirse con las sutiles distinciones que existen entre los tipos
de licencias como GPL, Free Software, de dominio público y Open Source.

90
2.16.2 TIPOS DE LICENCIAS DE SOFTWARE LIBRE.21
2.16.2.1 FREE SOFTWARE
Según Richard Stallman, fundador del proyecto GNU, "el termino software libre ha
sido malinterpretado, pues no tiene nada que ver con el precio, tiene que ver con
libertad" (El Proyecto GNU es una campaña para difundir el Free Software. Fue
iniciada por Richard Stallman en 1984 y pretende implantar la tendencia hacia el
desarrollo de software sin limitantes de derechos de autor y bajo precio).
Explica Stallman que para que un software sea libre, este debe cumplir los
siguientes requisitos:
Que se pueda ejecutar sin importar el propósito.
Que el usuario lo pueda modificar para ajustarlo a sus necesidades. Para
lograrlo, este debe tener acceso al código fuente ya que si no se sabe el
código es muy difícil realizar cambios.
Que el usuario pueda redistribuir copias del programa, ya sea gratis o por
una suma determinada.
Que el usuario pueda distribuir versiones modificadas del programa siempre
y cuando se documenten los cambios al software.
2.16.2.2 OPEN SOURCE
Es necesario aclarar que Open Source y Free Software son esencialmente lo
mismo, la diferencia radica en que los defensores del Free Software no están
ciento por ciento de acuerdo con que las empresas disfruten y distribuyan Free
Software ya que, según ellos, el mercado corporativo antepone la utilidad a la
21 http://aceitunassinhueso.com/wiki/index.php/Patentes_y_tipos_de_Licencias_de_Software

91
libertad, a la comunidad y a los principios y por ende no va de la mano con la
filosofía pura detrás del Free Software.
Por otra parte, los seguidores del software Open Source sostienen que el proceso
normal de crecimiento de la tendencia debe llegar al mercado corporativo y no
seguir escondida bajo el manto de la oposición, sino que, por el contrario, están en
el deber de lanzar software potente y de excelente calidad. Para lograrlo, creen en
la necesidad de un software Open Source más confiable que el software
propietario ya que son más las personas que trabajan en el al mismo tiempo y
mayor la cantidad de 'ojos' que pueden detectar errores y corregirlos.
Open Source es pues, el software que puede ser compartido abiertamente entre
desarrolladores y usuarios finales de tal forma que todos aprendan de todos. Tal
es el caso de Linux, que espera juntar a desarrolladores de todo el mundo,
profesionales y aficionados a la espera del despegue definitivo de la tecnología
bajo licencia Open Source.
2.16.2.3 LICENCIA GPL (GENERAL PUBLIC LICENSE) Ó
'COPYLEFT'
La licencia GPL se aplica al software de la FSF (Free Software Foundation) y el
proyecto GNU y otorga al usuario la libertad de compartir el software y realizar
cambios en él. Dicho de otra forma, el usuario tiene derecho a usar el programa,
modificarlo y distribuir las versiones modificadas pero no tiene permiso de realizar
restricciones propias con respecto a la utilización de ese programa modificado.
La licencia GPL o copyleft (contrario a copyright) fue creada para mantener la
libertad del software y evitar que alguien quisiera apropiarse de la autoría
intelectual de un determinado programa. La licencia advierte que el software debe
ser gratuito y que el paquete final, también debe ser gratuito.

92
2.16.2.4 SOFTWARE DE DOMINIO PÚBLICO.
El software de dominio público no está protegido por las leyes de derechos de
autor y puede ser copiado por cualquiera sin costo alguno. Algunas veces los
programadores crean un programa y lo donan para su utilización por parte del
público en general. Lo anterior no quiere decir que en algún momento un usuario
lo pueda copiar, modificar y distribuir como si fuera software propietario. Así
mismo, existe software gratis protegido por leyes de derechos de autor que
permite al usuario publicar versiones modificadas como si fueran propiedad de
este último.
2.16.2.5 FREEWARE
Es software que el usuario final puede bajar totalmente gratis de Internet. La
diferencia con el Open Source es que el autor siempre es dueño de los derechos,
o sea que el usuario no puede realizar algo que no esté expresamente autorizado
por el autor del programa, como modificarlo o venderlo. Un ejemplo de este tipo de
software es el traductor Babylon, Quintessential, BSPlayer, etc.
2.16.2.6 SHAREWARE
Es software que se distribuye gratis y que el usuario puede utilizar durante algún
tiempo. El autor requiere que después de un tiempo de prueba el usuario pague
por el software, normalmente a un costo bastante bajo, para continuar usando el
programa. Algunas veces el programa no deja de funcionar si el usuario no paga,
pero se espera que este último cancele una suma de dinero y se registre como
usuario legal del software para que además del programa reciba soporte técnico y
actualizaciones. El usuario puede copiar el software y distribuirlo entre sus amigos.
El 'bajo costo' del shareware se debe a que el producto llega directamente al
cliente (Internet), evitando así los costos de empaque y transporte. A menudo el
software shareware es denominado como software de evaluación. Hay también
software shareware que dejan de funcionar después de un periodo de prueba, los
llamados Try Out.

93
2.16.2.7 ADWARE (ADVERTISING SPYWARE)
No son más que programas financiados con componentes publicitarios ocultos que
son instalados por algunos productos shareware, Es decir, el software es gratuito
en su uso a cambio de tener un banner de publicidad visible en todo momento
mientras utilizamos el programa. Se supone que éste es el único «precio» que
debemos pagar por usar este tipo de aplicaciones. Pero en ocasiones estos
programas aprovechan que tienen que estar conectados a la Red para
descargarse la publicidad y pueden enviar algunos datos personales.
El Adware, al igual que el Spyware son aplicaciones que instaladas del mismo
modo explicado anteriormente, permiten visualizar los banners publicitarios de
muchos programas gratuitos, mientras éstos son ejecutados. Es importante
mencionar que NO todos los programas gratuitos contienen archivos "espías" o
publicitarios.
2.16.3 ALGUNAS VENTAJAS DE UTILIZAR CÓDIGO
ABIERTO.22
Es gratuito o muy barato.
Es de libre distribución, cualquier persona puede regalarlo, venderlo o
prestarlo.
Es más seguro.
Permite ofrecer menores tiempos de desarrollo debido a la amplia
disponibilidad de herramientas y bibliotecas.
Se puede acceder a su código y aprender de él.
Se puede modificar, adaptándolo para realizar tareas específicas.
22 http://www.altavoz.net/prontus_altavoz/antialone.html?page=http://www.altavoz.net/prontus_altavoz/site/artic/20060304/pags/20060304151415.html