universidad de los andes facultad de ciencias...
TRANSCRIPT

Universidad de Los AndesFacultad de Ciencias Forestales y AmbientalesEscuela de Ingeniería ForestalDepartamento Manejo de BosquesCátedra de Biometría ForestalAsignatura: ESTADISTICA Y BIOMETRIAProfesor Argenis Mora Garcés
GUÍA TEÓRICA TEMAS 1 Y 2.
Definición y tipos de variables aleatorias. Escalas de medición usadas en la investigación forestal. Métodos estadísticos descriptivos: Representación gráfica de datos y propiedades de las variables.
En ciencias Forestales las estadísticas son usadas para resumir las alturas de los
árboles, diámetros de los fustes (tallo aprovechable para madera), volumen de madera,
tasa de sobrevivencia de árboles, árboles infestados por patógenos microscópicos, etc.
En aserraderos, por ejemplo, cuadros y gráficas se construyen para indicar la calidad de
los productos generados en estas industrias, tales como la distribución de tableros por
clases o categorías, la dureza de los tableros y otras características importantes de
calidad.
Conceptualmente, se dará dos definiciones de Estadística: 1) Como la ciencia de colectar,
organizar, analizar e interpretar la información (en este caso Estadística es singular), 2)
Son números calculados a partir de la información numérica (en este caso Estadísticas
puede ser dicha en plural o singular).
El estudio de la Estadística generalmente se subdivide en dos campos diferentes:
a) Estadística descriptiva y b) Estadística inferencial. Considérese una lista enorme de
5.000 mediciones de altura de árboles colectadas en una unidad de manejo forestal. Por
lo común, es imposible tratar de extraer conclusiones a partir de la “lectura” de esta
enorme lista. Si usamos estadísticas descriptivas, podríamos describir esta información
con cuadros, números o valores resumen y gráficas. De esta manera, una persona puede
fácilmente caracterizar, resumir y comunicar los atributos de la unidad de manejo
forestal siendo estudiada. Por tanto, tratar de resumir y graficar la información es una
1

destreza que debe tener un Ingeniero Forestal.
Estadística descriptiva trata con la recolección, organización y la presentación de
la información y el cálculo de algunas medidas (Estadísticas) que describen dicha
información. La Estadística inferencial o Inferencia Estadística utiliza la información
contenida en una muestra para extraer conclusiones sobre una o más características de
la población completa. Esta generalización sobre la población implica estimación de
parámetros, probar hipótesis, determinar relaciones y predecir valores futuros.
Una población es la colección completa de individuos, elementos o items que
poseen ciertas características comunes sobre la cual la información está siendo
requerida. Las características de una población se denominan parámetros y se les
denota o escriben con letras griegas (α, β, γ, δ, ρ). Una muestra es una porción o
subconjunto de la población. Las características de una muestra se llaman Estadísticos y
se les escriben con letras romanas (x, y, y, etc). Así, es deseable registrar la información
deseada a partir de la muestra; pero tratar de generalizar sobre la población a partir de
una porción de ella tiene cierta cantidad de riesgo en equivocarnos. Algunas teorías
básicas de probabilidad ayudarán a entender y cuantificar ese riesgo de equivocarnos o
no.
El cuadro 1 muestra un ejemplo de un conjunto de datos, el cual contiene
información registrada a partir de 50 árboles. Los árboles aquí son los elementos, items,
o individuos sobre el cual los datos fueron registrados (medidos, observados, etc). Una
variable es una característica de un elemento (por ejemplo: árbol, parcela, hoja, finca,
etc) que nosotros queremos estudiar. Siete variables fueron registradas en este conjunto
de datos: 1) número de identificación de cada árbol, 2) fecha de medición, 3) especie, 4)
clases de copa, 5) número de árboles vecinos (crecidos dentro de un radio de 5 m) , 6)
diámetro a la altura de pecho (DAP, cm) y 7) altura total (m). Por lo general, una
variable toma diferentes valores de un individuo a otro, de allí su nombre de variable.
Una variable cuyos valores son determinados por medio de un experimento aleatorio se
2

llaman variable aleatoria. Un conjunto de mediciones (como las siete variables del
cuadro 1) registradas para un elemento, item o individuo se denomina observación, así
el cuadro 1 tiene 50 observaciones.
TIPOS DE VARIABLES
las variables pueden ser clasificadas como cualitativas o cuantitativas. V. cualitativas
se conocen también como variables categóricas ya que ellas contienen diferentes clases
de acuerdo a alguna característica. Especies y clases de copas son variables cualitativas
en el cuadro 1. Otros ejemplos de v. cualitativas incluyen género, tipo de bosque, nivel de
ataque de insecto (bajo, medio y completo) y nivel educativo. En cambio, las variables
cuantitativas son aquellas que pueden generar valores numéricos, por ejemplo, aquellas
“medidas” sobre los árboles como diámetro del fuste, la altura total del árbol, el peso
hojas, la temperatura del suelo, ingreso familiar, etc. así mismo, se reconoce también
como v. cuantitativa aquellas cuyos valores son producto de un conteo: número de
árboles con fustes bifurcados, número de árboles vecinos (cuadro 1), número de tableros
defectuosos, etc. De esta manera, se puede clasificar a su vez a las variables cuantitativas
como discretas (las que producen valores enteros o de conteo) y continuas (aquellas que
pueden tomar cualquier valor posible sobre un intervalo especifico y que son
generalmente medidos con algún instrumento).
ESCALAS DE MEDICION
Cuando se tienen que analizar a las variables, sean cualitativas o cuantitativas, es
importante conocer la escala sobre la cual esta variable fue “medida” o “registrada” y se
refiere a la cantidad de información contenida dentro de la variable; llevándonos al tipo
de análisis estadístico a aplicar apropiadamente. En general, se tienen cuatro tipos de
escalas de medición conocidas: nominal, ordinal, intervalo y razón.
Datos con una escala nominal puede ser cuantitativo y son utilizados
principalmente con el propósito de identificación y clasificación de individuos, items o
3

elementos. Como ejemplos se tienen los números que identifican a cada uno de los
árboles en el cuadro 1, el número escrito sobre una camiseta de un jugador de futbol o
beisbol, el número telefónico, etc. Es de hacer notar que a estos valores no tiene ningún
sentido aplicarles operaciones aritméticas o algún ordenamiento. Los del tipo
cualitativo tenemos como ejemplos: las diferentes especies identificadas en el cuadro 1,
género, estado civil, presencia o ausencia de un atributo en particular. La escala ordinal
es similar a la nominal, pero los registros que estas generan pueden tener un criterio de
orden o jerarquia. Así, clases de copa tiene registros cuyas clases tienen un sentido de
orden, pues por ejemplo, la clase D (dominante) son más altos que aquellos árboles con
el registro C (codominante), estos a su vez lo son mas que los I (intermedios) y los más
pequeños son los S (suprimidos). La calidad de fuste es una variable cuyos registros
también genera una jerarquía u orden se tiene por ejemplo calidad buena, media y mala.
Los niveles de daño causados por un ataque de insectos o algún microorganismo, sueles
registrarse a través de una escala arbitraria de orden 0 (sin ataque), 1 (con menos del 25
% de hojas dañadas), 2 ( hoja con mas del 25 % y menos del 50%), 3 (con mas del 50 % de
daño pero menos de 75 %) y 4 (con más del 75 % dañada). Al igual que para la escala
nominal, operaciones aritméticas no son apropiadas en las escalas nominales. La escala
de Intervalo registra siempre valores cuantitativos y diferencias entre los valores
producidos tienen sentido o puede tener alguna interpretación lógica. Ejemplos la
temperatura, fechas de medición, las calificaciones. En esta escala el valor “cero” no
indica una ausencia de la medida. Ejemplo, cero grados centígrados de temperatura
significa que el punto de congelamiento dentro de esta escala de grados Celsius y NO
una ausencia de temperatura. Por otra parte, si la temperatura en Mérida es de 16 °C y
en Barinas de 32 °C, la diferencia de 16 °C tiene un significado importante respecto al
clima, pero no significa que Barinas es dos veces más caliente que Mérida. Finalmente,
en la escala de razón el cero tiene el significado de “nada”, así mismo, la razón entre dos
variables cuantitativas tiene un significado relevante. Ejemplos como los mostrados en
el cuadro 1 se tiene la altura total, diámetro a la altura de pecho y el número de árboles
4

vecinos. Otros ejemplos, el peso, distancia, costos, etc. A todas las variables anteriores es
apropiado aplicarles operaciones aritméticas. Aquí si podemos interpretar que un árbol
de 20 m es dos veces más alto que uno de 10 m.
EJERCICIOS
1.- Dos estudiantes son enviados a medir DAP y Altura en 75 árboles seleccionados
aleatoriamente en una plantación experimental, cada uno de los 10.753 árboles han
sido etiquetados con un número. Se tomaron 75 números entre 1 y 10.753 para indicar
los arboles a medir. Se pide:
a.- Describir la población,
b.- Describir la muestra,
c.- ¿En el estudio se puede utilizar estadística descriptiva, inferencial o ambos?
2.- Un estudiante trabaja en una fábrica de tableros de partículas, se le pide medir el
espesor de un tablero cada 15 minutos cuando estas salen de la línea de producción.
Estas observaciones serán utilizadas para estudiar la calidad de la producción de
tableros a través de un control estadístico de calidad.
a.- Describir la población
b.- Describir la muestra
c.- ¿Se estará utilizando la estadística descriptiva e inferencial en este estudio?
3.- Clasificar cada una de las variables como cualitativa o cuantitativa:
a.- Numero de arboles por ha
b.- Color de las flores
c.- Numero de hojas en una plantula de Cordia alliodora
d.- Diámetro de corteza externa de la teca a la altura de pecho
e.- Clasificación de riesgo de incendio (Bajo, Moderado o Grave)
f.- Espesor de madera contra enchapada
5

g.- categoría de tablas aserradas (calidad 1, calidad 2 o defectuosos)
h.- Longitud de un trozo de tabla
i.- Edad del pino ponderosa a través del número de anillos anuales
j.- Especies
k.- Temperaturas altas y bajas diarias en grados Celsius.
l.- Salario anual percibido por 20 técnicos forestales de una compañía (BsF)
m.- Número telefónico de los 20 técnicos forestales
n.- Fecha de ingreso en la empresa de cada uno de los técnicos forestales
4.-Clasifique cada una de las variables listadas en el ejercicio anterior de acuerdo a su
escala de medición (nominal, ordinal, intervalo, razón).
6

CUADRO 1. Conjunto de datos de 50 árboles.
Fecha clase de número Árbol medición especie copa vecinos DAP (cm) Altura (m)
especies: C: Cordia, F: Fresno, H: Teca. Clases de copa: D: dominante, C: codominante, I:
intermedio, S: suprimido
7

ESTADISTICA DESCRIPTIVA: “Leyendo e interpretando los datos”
Para poder monitorear y realizar planes de manejo de los recursos naturales, es
necesario colectar, registrar o medir muchos datos. Los datos descritos en el cuadro 1 se
denominan datos “crudos”; aun cuando se tuviera una sola variable en ese cuadro, sería
imposible evaluar la lista de 50 valores. Una de las vías más simple de organizar
variables es “ordenarlas” en orden ascendente. Esta técnica simple no reduce el tamaño
de los datos, de hecho, se recomienda para conjuntos de datos “pequeños”. Una
herramienta mucho más práctica cuando el número de datos es “grande” es organizar la
información a través de tablas o cuadros de distribución de frecuencias para cada
variable. Esta técnica consiste en agrupar todas las observaciones en “clases” y las
frecuencias o el conteo de las observaciones se ubica en cada clase y mostrados en
cuadros o tablas. Dependiendo del tipo de variable, estas tablas de distribución de
frecuencias pueden ser a) por categorías, b) no agrupados y c) agrupados.
Las tablas de distribución de frecuencias (de ahora en adelante las
mencionaremos como T.D.F por sus iniciales) por categorías son usadas para variables
que han sido medidas en escalas nominal u ordinal. El cuadro 2 muestra la frecuencia de
árboles por clases de copa (información tomada del cuadro 1).
Cuadro 2. Distribución de frecuencias por categorías para el total de 50 árboles por
clases de copa.
Clases de CopaFa
(frecuencia absoluta)Fr
(frecuencia relativa)
Dominante (D) 9 0,18
Codominante (C) 14 0,28
Intermedio (I) 19 0,38
Suprimido (S) 8 0,16
Total 50 1,00
8

Debido a que “clases de copa” es una variable categórica y, además, ésta variable tiene
cuatro clases o categorías (Dominante, Codominante, Intermedio y Suprimido), se
contabiliza el número de observaciones (de ese total que son n = 50) que corresponde a
cada categoría o clase, llamándose a ese conteo la frecuencia absoluta (Fa); así, la suma
de todas las frecuencias absolutas debe ser igual al número de observaciones (n). Luego
podemos realizar algunos cálculos complementarios que nos ayudaría a comprender
mejor las características de una variable estudiada; la frecuencia relativa (Fr) de cada
clase se obtiene dividiendo el número de observaciones en cada clase o frecuencia
absoluta entre el número total de observaciones de esa variable; para esta frecuencia la
suma de todas ellas debe ser igual a 1. Con frecuencia suele ser útil expresar la
frecuencia relativa en porcentaje, para ello simplemente se multiplica por 100 y se
inserta una nueva columna al cuadro de distribución de frecuencias.
Cuadro 3. Distribución de frecuencias no agrupada para el total de 50 árboles por
Número de árboles vecinos.
Número de árboles vecinos
Fa (frecuencia absoluta)
Fr (frecuencia relativa)
0 3 0,06
1 4 0,08
2 6 0,12
3 13 0,26
4 13 0,26
5 6 0,12
6 5 0,1
Total 50 1,00
9

La T.D.F no agrupados se utiliza para las variables cuantitativas discretas, como
ejemplo, se tiene el número de árboles vecinos dado en el cuadro 1. En este caso, las
clases en que se ha de agrupar las observaciones son cada uno de los valores de conteo,
es decir, 0, 1, 2, 3, 4, 5 y 6 árboles vecinos, como se muestra en el cuadro 3. Para resumir
datos que son variables continuas (escala de razón), la T.D.F usada es del tipo agrupado.
En este caso, se hace necesario crear clases basados en un intervalo de clase, y los límites
tanto inferior como el superior dentro de cada clase. A continuación, usando los datos
de DAP del cuadro 1, se explicará el procedimiento:
1.- Calcular la amplitud o rango de datos que llamaremos A,
A=Valor máximo – Valor mínimo
A = 22,7 – 7,7 = 15 cm
2.- Determinar el número de clases de acuerdo a la siguiente fórmula o regla de Sturges:
c = 3,3*log10(n)+1
donde n es el numero de observaciones, así tenemos que:
c = 3,3*log10(50)+1= 6,607 ≈ 7 clases
3.- Determinar la amplitud de cada una de las clases, para ello dividiendo el rango o
amplitud de los datos entre el número de clases:
a.c = A/c = 15/7 = 2,143 cm
como la variable original fue medida con un decimal, se recomienda dejar el mismo
número de decimales en la amplitud de clases, en nuestro ejemplo 2,1 cm
4.- Determinar los límites de cada clase:
recordemos que debemos construir nuestro cuadro con 7 clases, así, la primera clase
tendrá como límite inferior el valor mínimo, es decir 7,7 y el límite superior se obtiene
sumando este valor mínimo a la amplitud de clase: 7,7 + 2,1 = 9,8; por tanto nuestra
primera clase está comprendida entre 7,7 y 9,8. luego para la segunda clase, el límite
inferior debe comenzar por el siguiente valor seguido del límite superior de la clase
anterior; es decir 9,9 y el límite superior 9,9 + 2,1 = 12,0. En el cuadro 4 contiene en la
primera columna ya las 7 clases con sus respectivos límites inferiores y superiores.
10
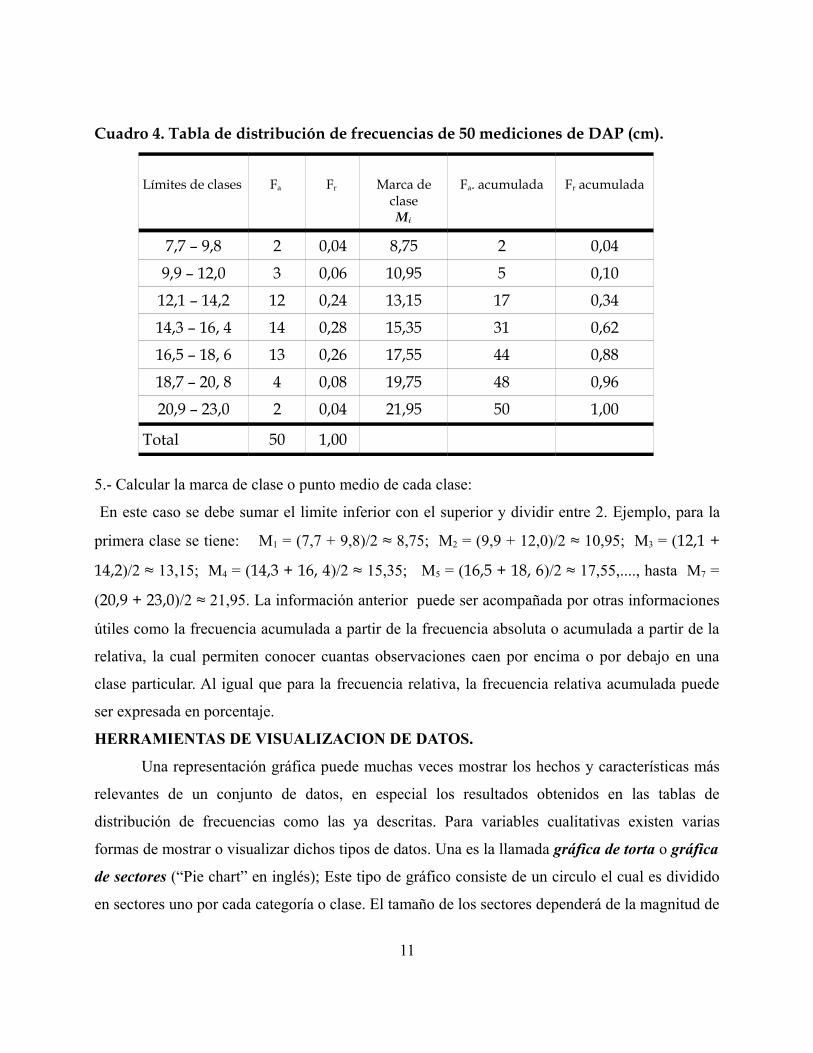
Cuadro 4. Tabla de distribución de frecuencias de 50 mediciones de DAP (cm).
Límites de clases Fa Fr Marca de claseMi
Fa. acumulada Fr acumulada
7,7 – 9,8 2 0,04 8,75 2 0,04
9,9 – 12,0 3 0,06 10,95 5 0,10
12,1 – 14,2 12 0,24 13,15 17 0,34
14,3 – 16, 4 14 0,28 15,35 31 0,62
16,5 – 18, 6 13 0,26 17,55 44 0,88
18,7 – 20, 8 4 0,08 19,75 48 0,96
20,9 – 23,0 2 0,04 21,95 50 1,00
Total 50 1,00
5.- Calcular la marca de clase o punto medio de cada clase:
En este caso se debe sumar el limite inferior con el superior y dividir entre 2. Ejemplo, para la
primera clase se tiene: M1 = (7,7 + 9,8)/2 ≈ 8,75; M2 = (9,9 + 12,0)/2 ≈ 10,95; M3 = (12,1 +
14,2)/2 ≈ 13,15; M4 = (14,3 + 16, 4)/2 ≈ 15,35; M5 = (16,5 + 18, 6)/2 ≈ 17,55,...., hasta M7 =
(20,9 + 23,0)/2 ≈ 21,95. La información anterior puede ser acompañada por otras informaciones
útiles como la frecuencia acumulada a partir de la frecuencia absoluta o acumulada a partir de la
relativa, la cual permiten conocer cuantas observaciones caen por encima o por debajo en una
clase particular. Al igual que para la frecuencia relativa, la frecuencia relativa acumulada puede
ser expresada en porcentaje.
HERRAMIENTAS DE VISUALIZACION DE DATOS.
Una representación gráfica puede muchas veces mostrar los hechos y características más
relevantes de un conjunto de datos, en especial los resultados obtenidos en las tablas de
distribución de frecuencias como las ya descritas. Para variables cualitativas existen varias
formas de mostrar o visualizar dichos tipos de datos. Una es la llamada gráfica de torta o gráfica
de sectores (“Pie chart” en inglés); Este tipo de gráfico consiste de un circulo el cual es dividido
en sectores uno por cada categoría o clase. El tamaño de los sectores dependerá de la magnitud de
11

la frecuencia absoluta que contenga cada clase. Como ejemplo, tenemos la gráfica 1, la cual esta
acompañada por dos elementos importantes, el color en cada sector que identifica a cada clase y
la frecuencia relativa expresada en porcentaje.
Otra vía de mostrar datos categóricos es con las llamadas gráficas de barras como aquella
mostrada en la gráfica 2. Aqui cada barra muestra la frecuencia absoluta o relativa de cada clase
o categoría puediendose agregar sobre cada barra el procentaje respectivo.
12
Grafica 1
Dom inante (D) 18%
Codominante (C) 28%Interm edio (I) 38%
Suprimido (S) 16%
Grafica 2
c d i s
Clases de Copa
Fre
cuen
cia
abso
luta
05
1015
20
0 1 2 3 4 5 6
Número de árboles vecinos
Fre
cuen
cia
abs
olu
ta
02
46
810
1214
Grafica 3
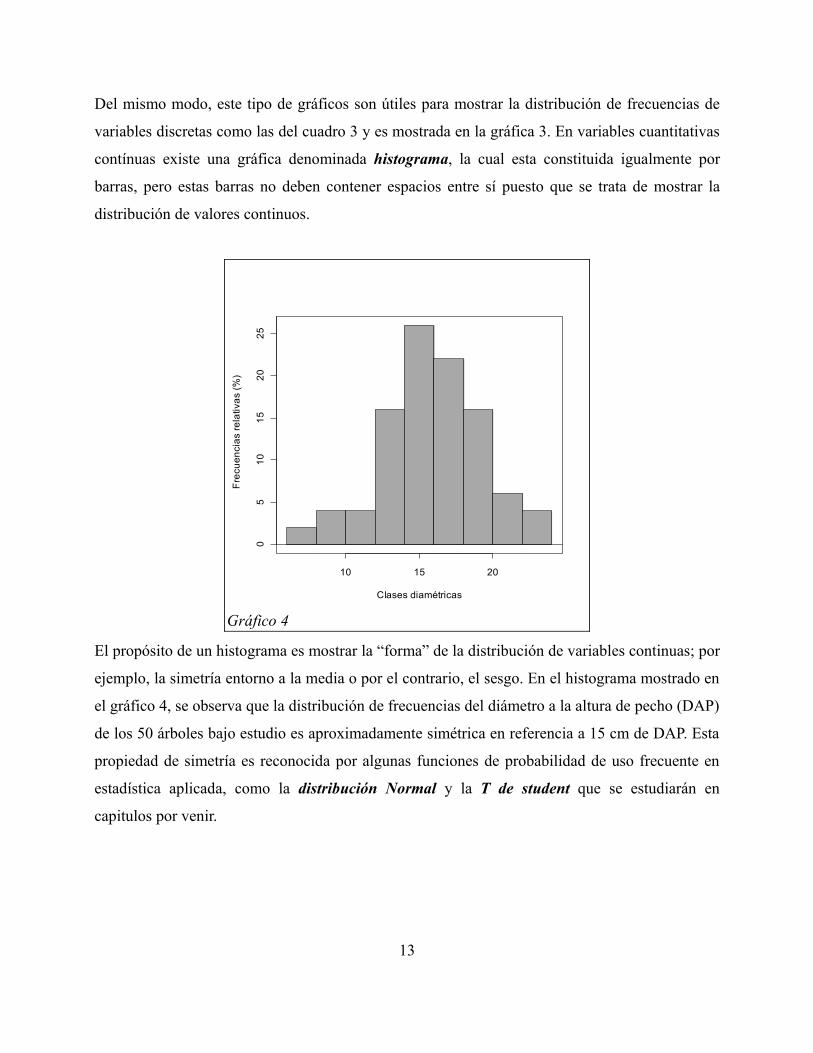
Del mismo modo, este tipo de gráficos son útiles para mostrar la distribución de frecuencias de
variables discretas como las del cuadro 3 y es mostrada en la gráfica 3. En variables cuantitativas
contínuas existe una gráfica denominada histograma, la cual esta constituida igualmente por
barras, pero estas barras no deben contener espacios entre sí puesto que se trata de mostrar la
distribución de valores continuos.
El propósito de un histograma es mostrar la “forma” de la distribución de variables continuas; por
ejemplo, la simetría entorno a la media o por el contrario, el sesgo. En el histograma mostrado en
el gráfico 4, se observa que la distribución de frecuencias del diámetro a la altura de pecho (DAP)
de los 50 árboles bajo estudio es aproximadamente simétrica en referencia a 15 cm de DAP. Esta
propiedad de simetría es reconocida por algunas funciones de probabilidad de uso frecuente en
estadística aplicada, como la distribución Normal y la T de student que se estudiarán en
capitulos por venir.
13
Gráfico 4
Clases diamétricas
Frec
uenc
ias
rela
tivas
(%)
10 15 20
05
1015
2025

ESTADISTICAS DESCRIPTIVAS
a) MEDIDAS DE TENDENCIA CENTRAL
Describiremos las principales estadisticas que permiten definir con un valor o número “el centro”
de un conjunto de mediciones u observaciones. Comenzaremos por definir la media o también
conocido como el promedio aritmético; este se obtiene dividiendo la suma de las observaciones
entre el número total de ellos, como se ilustrará a continuación,
la media se identifica con un equis mayúscula y una barra encima de ésta. La media para el DAP
será:
por tanto el promedio aritmético del DAP de los 50 árboles evaluados es de 15,79 cm. A medida
de tendencia central es la media ponderada:
en este caso, cada observación es “ponderado” o se le dará un “peso” en particular; el ejemplo
típico donde es necesario aplicar la media ponderada es cuando se trata de determinar el índice
académico de un estudiante. Sí un estudiante ha cursado y aprobado 5 asignaturas en un semestre
y las calificaciones fueron: 14, 16, 12, 20 y 10 puntos; luego, en ese mismo orden cada una de
esas asignaturas tienen las siguientes unidades créditos: 3, 4, 3, 6 y 3. por tanto, el promedio
ponderado o media ponderada de esas calificaciones será
14
nx....xxx
n
xX n321
n
1ii ++++==
∑=
79,1550
9,20....2,188,173,15n
xX
n
1ii
=++++==∑
=
n321
nn332211n
1ii
n
1ii*i
p p....pppxp....xpxpxp
p
xpX̂
++++++++==
∑
∑
=
=
95,1436343
10*320*612*314*414*3
p
xpX̂ n
1ii
n
1ii*i
p =++++
++++==∑
∑
=
=

la cual difiere mucho de un promedio aritmético (14,00), nótese que el peso viene dado por el
número de unidades créditos que tiene cada asignatura y por tanto cada calificación
correspondiente, así, aquella asignatura que tiene 6 unidades crédito le dará mayor peso a la
calificación, en este caso la calificación 20 tendrá un importante efecto sobre ese promedio
ponderado. Otra medida de tendecia central útil cuando se tiene pocos datos y cuya distribución
de los mismos es asimétrica es la Mediana la cual a continuación se muestra su cálculo:
a) cuando el número datos es pares, n = 6, se tiene el siguiente conjunto de datos 1, 10, 3, 8, 9, 5
se ordenan los datos de menor a mayor 1,3,5,8,9,10 y se seleccionan los dos valores centrales,
en este caso el 5 y 8 y se determina el promedio de estos dos valores, asi
la Mediana = (5+8)/2= 6.5
b) cuando el número de datos de impar, n= 7, por ejemplo 1, 10, 3, 8, 9, 5, 5
igualmente se ordenan los datos de menor a mayor 1, 3, 5, 5, 8,9,10 seleccionamos aquel valor
que está en el centro de esta distribución ordenad, es decir la Mediana = 5.Como puede notarse
la mediana divide en dos partes o porciones iguales la distribución ordenada de los datos, así que
por encima y por debajo de la mediana se ubicará el 50 % de los datos. Otra medida simple de
tendencia central es la moda, esta no requiere fórmula alguna para calcularla, sólo se determina
aquel valor que con mayor frecuencia se repite en un conjunto de datos; si existen dos o más
valores que se repiten con igual frecuencia se dice que los datos son multimodales.
b) MEDIDAS DE POSICION
Estas medidas o estadísticos permiten dividir un conjunto de datos ordenados en diferentes
porciones o partes en referencia a un valor de esa variable ubicada en una posición relativa. Uno
de estos es el llamado percentil, el cual un valor ubicado en el percentil 10 indica que por debajo
de éste valor se encuentra el 10 % de los datos, un percentil 75 indicaría que por debajo de ese
valor se ubica el 75 % de los datos, y así sucesivamente. Por ejemplo, para el conjunto de datos
de DAP del cuadro 1, aplicaremos el siguiente procedimiento
1.- Primero ordenamos las valores de menor a mayor y le asignamos su orden o posición K, como
sigue
15

2.- Ahora apliquemos la siguiente fórmula
(p*n)/100 + 0,5 = K, f
donde p es el percentil deseado, por ejemplo 10, 25, 50,75, etc. n es el número de datos; k es la
parte entera del resultado que se tomará como la posición u orden en los datos y f es la fracción
de ese resultado.
3.- Calculamos el valor correspondiente al percentil deseado
Vp = (Vk+1 – Vk)*f + Vk
donde Vk es el valor de la variable ubicado en el orden k y Vk+1 es el valor de la variable ubicado
en la posición u orden siguiente a la posición k.
Apliquemos este procedimiento para determinar los valores del DAP ubicados en los percentiles
10 y 25. Para hallar el percentil 10, tenemos que p = 10 y n = 50, entonces
(10*50)/100 + 0,5 = 5, 5
este resultado tenemos que K = 5 la parte entera y f = 0,5 la fracción del resultado. Luego
aplicamos la fórmula para hallar el valor del DAP ubicado en el percentil 10, así
V10 = (V6 – V5)*f + V5
es decir, V6 es el valor del DAP ubicado en la posición u orden 6, V6 = 12,4; V5 = 10,8 es el DAP
en la posición 5, por tanto
V10 = (12,4 – 10,8)*0,5 + 10,8 = (1,6)*0,5 + 10,8 = 11,6 cm
Para hallar el percentil 25, tenemos que p = 25 y n = 50, entonces
(25*50)/100 + 0,5 = 13, 0
este resultado tenemos que K = 13 la parte entera y f = 0,0 la fracción del resultado. Luego
16
orden DAP orden DAP orden DAP orden DAP orden DAP1 7,7 11 13,3 21 15,1 31 16,7 41 18,52 9,7 12 13,4 22 15,3 32 17,1 42 18,53 9,9 13 13,8 23 15,4 33 17,3 43 18,84 10,2 14 14,1 24 15,5 34 17,7 44 18,95 10,8 15 14,1 25 15,6 35 17,8 45 19,16 12,4 16 14,2 26 15,8 36 17,8 46 20,47 12,8 17 14,4 27 16,1 37 17,8 47 20,68 13 18 14,8 28 16,1 38 18,2 48 20,99 13 19 14,8 29 16,2 39 18,2 49 22,3

aplicamos la fórmula para hallar el valor del DAP ubicado en el percentil 10, así
V25 = (V14 – V13)*f + V13
es decir, V14 es el valor del DAP ubicado en la posición u orden 14, V14 = 14,1; V13 = 13,8 es el
DAP en la posición 13, por tanto
V25= (14,1 – 13,8)*0,0 + 13,8 = (0,3)*0,0 + 10,8 = 13,8 cm
como conclusión tenemos que por debajo de 11,6 cm se encuentra el 10 % de los datos de DAP
evaluados en los 50 árboles y por debajo de 13,8 cm se encuentra el 25 % de los datos de DAP
evaluados en los 50 árboles. Se debe mencionar que de acuerdo a nuestros objetivos de análisis
podemos dividir nuestro cuerpo de datos en cuartos o cuatro partes iguales; para ello
determinamos los “cuartiles”. El primer cuartil (Q1) sería aquel valor que por debajo de él se
ubica el 25 %, el segundo cuartil (Q2) divide la distribución de los datos en dos partes iguales o
por debajo de éste valor se ubicaría el 50 % de los datos y el tercer cuartil (Q3) me indicaría que
por debajo de éste se encuentra el 75 % de los datos. Nótese que el primer cuartil es el percentil
25, el segundo cuartil es el mismo percentil 50 y la mediana, y el tercer cuartil es el percentil 75.
C) MEDIDAS DE VARIACION
Una característica importante de los datos es que estos no son iguales entre sí, de allí que una
característica evaluada en una población se denomine variable, por que sus valores varían. Por
ejemplo, a continuación se tiene datos de DAP (cm) correspondientes a una especie forestal
tomada en dos condiciones o ecosistemas diferentes en bosque natural y en una plantación:
Bosque 12,4 14,5 15,2 17,8 19,1
Plantación 14,8 15,0 15,9 16,5 16,8
si calculamos la media en ambos sitios tenemos que tienen exactamente la misma media, 15,8
cm. Pero si inspeccionamos los datos tomados en el bosque notamos que los valores de DAP son
más dispersos o tienen una mayor variación que los DAP tomados en plantación. Si usted fuese
un ingeniero forestal a cargo de un aserradero, ¿cuáles árboles podrías preferir?. Para estar seguro
del grado de variación o dispersión de los datos en cada población se debe de utilizar algún
estadístico que permita “cuantificar” esa variación. Existen varios estadísticos o medidas de
variación que a continuación se describirán.
La amplitud o rango, como se habia descrito en la página 10, es una medida simple de variación
de un conjunto de datos y consiste de la diferencia entre el valor máximo y el valor mínimo
17

A = max(xi) – min(xi)
Consideremos los datos de DAP tomados en bosque y en planatción para una misma especie,
para bosque tenemos 19,1 – 12,4 = 6,7 cm de variación, mientras que para los datos de la
plantación 16,8 – 14,8 = 2,0 cm de variación. Estos números confirman que la variación del DAP
de la especie forestal, desde el punto de vista de la amplitud, es mayor en bosque natural que en
la plantación. Sin embargo, esta medida de dispersión como se puede notar sólo utiliza dos del
conjunto total n de datos, y eso puede ser inapropiado cuando se cuenta con muchos datos y
valores extremos. Una medida de variación que toma en cuenta todos los datos es la varianza y
se define así,
la definición de la varianza o S2 viene dada por las diferencias existente entre cada uno de los
datos respecto a la media; eso significa que para poder cuantificar la variación de un conjunto de
datos es necesario usar la media calculada previamente con estos mismo datos. La fórmula a la
derecha de la igualdad es para ser usada cuando se requiera de hacer los cálculos a mano.
Aplicando este estadístico a los datos anteriores tenemos
En bosque
luego,
18
1nn
)x(x
1n
)xx(S
2n
1iin
1i
2i
n
1i
2i
2
−
−=
−
−=
∑∑∑ =
==
∑=
=++++=++++=n
1in321i 791,198,172,155,144,12x...xxxx∑
==++++=++++=
n
1in321i 791,198,172,155,144,12x...xxxx
∑=
=++++=++++=n
1i
222222n
23
22
21
2i 7,12761,198,172,155,144,12x...xxxx
2
22
n
1iin
1i
2i
2 cm712515
5797,1276
1nn
)x(x
S =−
−=
−
−=
∑∑ =
=

En plantación
luego
A raíz de estos resultados se puede apreciar que el grado de variación del DAP es
considerablemente mayor en el bosque que en la planatción. Nótese que estos resultados estan
expresados en la unidades de la variable DAP pero al cuadrado. Una manera de expresar esa
variación pero en la misma unidades de la variable es calculando la desviación estándar que
llamaremos S.
Eso significa que la desviación estandar del DAP es 2,67 cm y 0,89 cm para bosque y planatción,
respectivamente. Así podemos interpretar que en plantación la mayoría de los valores del DAP
medidos en los árboles son similares entorno a la media. Otra medida de variación útil cuando
queremos comparar no sólo grupos de datos de una misma variable, si no de diferentes variables
medidas bajo diferentes unidades se cuenta con el coeficiente de variación (CV)
el cual es una medida estandarizada de la variación de un grupo de datos. Aplicando a los datos
de DAP tenemos que para bosque es 17% y plantacion 5,6 %. En este caso se puede interpretar
que el porcentaje de variación de los valores de DAP respecto a la media fue mayor en bosque
que en plantaciones. El uso del CV tiene sus limitaciones, sobre todo en los siguientes casos:
a) Sí el valor de una media es cercano a cero
b) No debe usarse en datos expresados en porcentaje
19
∑=
=++++=++++=n
1in321i 798,165,169,150,158,14x...xxxx
∑=
=++++=++++=n
1i
222222n
23
22
21
2i 34,12518,165,169,150,158,14x...xxxx
2
22
n
1iin
1i
2i
2 cm785,015
57934,1251
1nn
)x(x
S =−
−=
−
−=
∑∑ =
=
2SS =
100*xSCV =

EJERCICIOS
1.- El número de accidentes por mes en los últimos 20 meses en un aserradero es de:
0 1 0 2 2 1 4 3 0 1
5 1 2 3 4 0 1 1 3 4
Construya una tabla de frecuencia y calcule la frecuencia relativa
2.- Las especies de árboles fueron identificadas en parcelas de muestreo permanente en
una región en particular cuyos códigos utilizados fueron (F= Fresno, H=Teca,
C=Terminalia y A=Abarema)
F H F C F A H F
H C A C F H H H
F H A C F H H F
Construya una tabla de frecuencia y calcule la frecuencia relativa para cada una de las especies.
3. – Construya una tabla de frecuencia usando las 50 mediciones de la altura total
mostrada en el cuadro 1. Mostrar los límites de clases, punto medio de clase, frecuencias
relativas, frecuencia relativa acumulada y frecuencia absoluta acumulada.
4. – Las siguientes cantidades son compuestos de nitrógeno, parte de millón (ppm),
encontrados en 60 muestras de suelo:
3.6 3.2 3.3 3.6 2.7 3.4 4.5 3.3 2.8 5.4
6.1 3.4 2.9 2.7 4.1 4.7 5.1 4.7 3.2 3.6
5.1 2.6 3.6 3.8 3.8 3.1 3.7 5.5 3.2 3.7
4.2 4.5 4.3 3.7 3.6 3.9 3.5 4.4 2.8 3.3
3.9 4.4 5.1 4.6 3.4 2.6 4.5 3.1 2.5 3.1
3.7 3.4 4.1 2.7 5.7 3.5 4.7 4.4 4.4 5.0
a)construya una tabla de frecuencia y limites de clases, punto medio de clase, frecuencia relativa, frecuencia relativa acumulada y frecuencia absoluta acumulada.
b) Determine los percentiles 25, 50 y 75
20

5.- A la siguiente distribución de frecuencias de arboles:
Limites de Clases Frecuencia
12,1 - 14,0 6
14,1 - 16,0 23
16,1 - 18,0 44
18,1 -20,0 27
20,1 – 22,0 4
Construir un histograma de frecuencias.
6.- El peso específico (densidad, g/cm3) de cada uno de las 8 especies de coníferas se midió de la siguiente manera:
0,682 0,357 0,412 0,582 0,556 0,576 0,368 0,381
Encontrar la media, mediana y moda del peso específico.
7.-Las siguientes son las temperaturas mínimas de 7 ciudades de Canadá del 14 de enero de 2006.
-12 -5 2 2 0 -3 5
a) Calcular la media, mediana y moda de las temperaturas.
b) La amplitud, varianza y coeficiente de variación.
8.- Encontrar la media, mediana, moda, la varianza, desviación estandar y coeficiente de variación para los datos de los ejercicios 1 y 4.
9.- A partir de los datos del cuadro 1, calcular la media del DAP por especie.
10.-Asumir que un bloque consta de tres tipos de bosques, A, B y C, y sus áreas son 420, 350 y 210 ha, respectivamente. Si el volumen por ha para cada uno de los 3 tipos de bosques es de 450, 480 y 620 m3, respectivamente, ¿Cual es el volumen promedio del bloque? Utilice la media ponderada.
21

Variables Aleatorias y Distribuciones de Probabilidad:
Resultados de Experimentos AleatoriosObjetivos de este tema
1. Demostrar como los resultados de experimentos aleatorios pueden ser descritos en términos numéricos reales
2. Como las probabilidades pueden ser asignadas a estos valores o números reales.1. Variables Aleatorias
Algunos experimentos aleatorios producen resultados que pueden ser descritos por
letras, símbolos, o simples descripciones generales. Otros experimentos producen
resultados en términos numéricos, como por ejemplo, el número de “cara” que pueden
ocurrir cuando se lanza una moneda varias veces; el número de puntos observados
cuando se lanza un par de dados; el número de plantas en un área de 100 m2; o el
número de semillas que germinan en un semillero. Una variable aleatoria (de ahora en
adelante la abreviamos como V.A) es una descripción bien definida de los resultados en
el espacio muestral de un experimento aleatorio. Se escribirá a las variables aleatorias
con las letras mayúsculas “X”, “Y” y “Z”; mientras que sus respectivos valores o
resultados con sus respectivas letras minúsculas: “x”, “y” y “z”. Este espacio muestral
asociado con un experimento aleatorio puede ser clasificado en dos tipos: discreto y
continuo.
El espacio muestral discreto es aquel que contiene un numero finito de elementos y/o
no finito pero contable. Ejemplos: i) el número de hogares con servicios públicos
deficientes, ii) el número de accidentes por mes, iii) el número de lanzamientos
necesarios hasta que la “cara” aparezca, iv) número de votantes entre 18 y 20 años de
edad.
El espacio muestral continuo contiene un infinito e incontable número de resultados.
Cualquier V.A o característica obtenida por medición, como por ejemplo, el tiempo
necesario para que las semillas germinen, el peso de personas que viven en una región
determinada, la distancia entre comunidades dependientes de un centro de acopio de
productos agrícolas, etc., todas en teoría pudieran tomar cualquier valor en un intervalo
22

de medición. Por ejemplo, dependiendo de la precisión del instrumento de medición, se
podría obtener un caudal de un río en 3.1 m3/minuto ó 3.2 m3/minuto; pero también es
posible que este caudal tome el valor de 3.17.
2. Distribuciones de Probabilidad de V.A.
2.1 Probabilidades de V.A discretas.
Una V.A discreta puede ser descrita por medio de probabilidades de que cada valor
individual ocurra cuando un experimento aleatorio se realice. La lista de todos los
resultados numéricos posibles y sus probabilidades asociadas a cada resultado se llama
la distribución de probabilidad de una V.A. Aquí tenemos el ejemplo clásico del
lanzamiento de una moneda: Sí la lanzamos tres veces (este hecho es el experimento
aleatorio) la moneda y solo nos interesa saber el número de veces en que caiga el lado de
la “cara”, entonces la “característica” o la variable aleatoria que nos interesa estudiar es
el número de cara y la denotamos como X. Ahora bien, los resultados posibles dentro
del espacio muestral ya definido serian: 0, 1, 2, y 3 veces que caiga “cara”. Estos valores
serán denominados como x. Formalmente, podemos escribir este resultado en una tabla
o cuadro como sigue:
xi 0 1 2 3
P(X = xi) 1/8 3/8 3/8 1/8
Pero ¿de dónde “salieron” esas fracciones?, primero que nada veamos que el número de
veces que lanzaremos la moneda es la base para el conteo de “el número de veces en
que caiga el lado de la “cara”. ¿Cuales serian los posibles resultados para esta variable
aleatoria? Es posible que al lanzar tres veces la moneda surjan varios resultados teóricos
y debemos considerar el orden en que estos resultados se produzcan, veamos la
siguiente tabla o cuadro. Llamamos E para escudo y C para cara.
23

caso Resultados x: número de veces en que caiga el lado de la “cara”
Probabilidad de queX sea x
1 E, E, E 0 1 de 8 casos
2 C, E, E 13 de 8 casos
3 E, C, E 1
4 E, E, C 1
5 C, C, E 23 de 8 casos
6 C, E, C 2
7 E, C, C 2
8 C, C, C 1 1 de 8 casos
Interpretemos los resultados anteriores, sabemos que existen 8 casos posibles, pero solo
4 resultados:
1) ninguna salga cara (todas las tres veces fue “escudo”), por tanto el primer resultado
teórico es 0 “cara”, x = 0 de un total de 8 casos sólo se puede dar una vez.
2) sólo una vez de los tres lanzamientos es “cara”, x = 1 de un total de 8 casos, este
resultado se puede dar tres veces.
3) es posible que en dos oportunidades apareció “cara” x = 2 de un total de 8 casos, este
resultado se puede dar en tres casos.
4) que todas las veces cayó “cara”, es decir, tres veces en los tres lanzamientos x = 3 de
un total de 8 casos y este resultado es posible una sola vez.
Así, que los resultados posibles para la variable aleatoria, X, llamada el número de veces
en que caiga el lado de la “cara”, al lanzar una moneda tres veces, son x1=0 cara, x2=1
cara, x3=2 caras y, x4=3 caras, cuyas probabilidades de ocurrencia de cada resultado es
1/8, 3/8, 3/8 y 1/8, respectivamente. Como ahora se resume en la tabla o cuadro de la
distribución de probabilidades
24

xi 0 1 2 3
P(X = xi) 1/8 3/8 3/8 1/8
Con frecuencia es posible y hasta conveniente expresar los resultados y las
probabilidades a través de una ecuación denominada función de probabilidades;
algunas veces derivarlas no es muy obvia. En el caso del lanzamiento de una moneda si
es posible construir una función de probabilidad basándonos en el hecho de que al
lanzar una moneda se tendrán dos posibles resultados: cara o escudo, y sabemos el
número de posibles resultados (0, 1, 2, 3) cuando “cara” aparezca. Así tenemos que con
reglas de la “combinatoria” es posible hacerlo:
P X =x = fx=
n!x !∗n−1!
2L
Donde x se refiere a los posibles resultados de la variable aleatoria X, es decir,
x = 0, 1, 2, 3, 4, …, n. y “L” es el número de veces en que se lanza la moneda, aquí fue 3
veces.
Para el caso de nuestro ejemplo, tenemos que al lanzar la moneda tres veces, es decir n
veces, implica que se darán 2n casos donde aparecerá “cara”. Por tanto, nuestra función
de probabilidad para el número de veces en que cae “cara” al lanzar tres veces una
moneda es
Para los valores x = 0, 1, 2, 3 número de veces en que caiga el lado de la “cara”, al lanzar
una moneda tres veces. Con esta función de probabilidad podemos usarla para hallar
varias probabilidades de acuerdo a uno ó varios eventos de interés. Por ejemplo, La
probabilidad de que al lanzar la moneda tres veces, el número de caras esté entre 1 y 2;
esto se expresaría así P(1 ≤ X≤ 2) = P(X=1)+P(X=2)= 3/8 +3/8 =6/8, resultado que se
puede resolver bien sea con el cuadro de distribución de probabilidades o con la función
de probabilidad ya descritas anteriormente. Finalmente, se debe notar que las
25
P X =x = fx=
4 !x !∗4−1!
8

distribuciones de probabilidad discretas deben cumplir con dos condiciones:
a) Las probabilidades de cada uno de los resultados deben sumar 1.
b) Las probabilidades de los resultados individuales debe ser 0 ≤ P(X=x) ≤ 1; eso
significa que las probabilidades no pueden ser ni negativas ni mayor a 1.
También, la distribución de probabilidades de variables discretas puede ser visualizada a través de
un gráfico donde se expresa en el eje de las y los resultados de las probabilidades individuales de
cada valor de x mostrados en el eje de las X
2.2 Probabilidades de V.A. continuas
Respecto a las variables aleatorias continuas, la probabilidad de cualquier valor exacto
es siempre cero. Esto es debido a que es imposible construir una tabla o cuadro similar a
las de las variables discretas. Aunque un valor exacto puede tener una probabilidad de
cero, las probabilidades asociadas con intervalos si es posibles, así que para V.A
continuas solo es posible calcular probabilidades para intervalos, mayores o menores
que algún valor en particular: P(1.9 ≤ X ≤ 2.1); P(X ≤ 2.5) y P(X ≥ 3.3). Estas
probabilidades calculadas deben ser mayores o iguales a 0 y menores o iguales a 1.
Cuando las probabilidades son representadas en un gráfico para variables continuas,
esta reflejará una curva continua, y se denominará densidad de probabilidad. Como la
mostrada a continuación
26

-4 -2 0 2 4
0.0
00
.05
0.1
00
.15
0.2
00
.25
0.3
0
x
De esta manera, para hallar las probabilidades como las postuladas anteriormente se
obtienen hallando el área bajo la curva entre los dos límites, por lo que determinar P(1.9
≤ X ≤ 2.1) es igual que P(1.9 < X< 2.1).
Las probabilidades para variables aleatorias continuas con dominios bien definidos
tienen propiedades similares a las discretas:
1) El área total bajo la curva entre los resultados más bajos y más altos debe sumar
1.
2) Las probabilidades entre dos límites, x1 y x2, deben ser 0 ≤ P(x1 ≤ X≤ x2) ≤ 1.
La Media y Varianza de una Variable Aleatoria Discreta
La media de una V.A puede obtenerse a partir de la distribución de probabilidades que
esta tenga. Y se define como el promedio ponderado de todos los posibles resultados de
una V.A, donde los pesos o ponderaciones son las probabilidades asociadas a cada uno.
Por ejemplo, si retomamos el caso del lanzamiento de la moneda tres veces y deseamos
conocer el número promedio de veces en que aparezca “cara” se obtiene asi:
μ=0∗ 1
81∗ 3
82∗3
83∗1
8
18 3
83
8 1
8
=1,5
Debido a que la suma de las probabilidades debe sumar 1, el denominador siempre será
27

1, por tanto la fórmula quedaría resumida y generalizada de la siguiente manera, para
una V.A discreta:
La letra griega µ (miu) es tratada como la media de la población de la variable aleatoria
X; y es la media teórica de una distribución de probabilidades y se refiere también como
el valor esperado o esperanza matemática de X, es decir E(X). El término valor esperado
o esperanza matemática es una medida ponderada del centro, o media ponderada de
todos los posibles valores de una V.A.
Como en el caso de la media, la varianza de una V.A discreta es el promedio ponderado
de las diferencias entre cada resultado de la V.A y la media elevadas al cuadrado, donde
los pesos o ponderaciones son las probabilidades de los resultados. Usemos los
resultados del ejemplo anterior
σ2=0-1,518+1-1,538+2-1,538+3-1,518=68=0,75
La notación σ (sigma) se utiliza para definir la varianza de la población de una V.A. en
general, la varianza de una V.A discreta viene dada como:
σ2=E(xi-μ)2=i=1n(xi-μ)2fxi,
Donde f(xi) es la probabilidad de xi. Con alguna manipulación algebraica la fórmula
anterior puede reescribirse de la siguiente manera:
σ2=i=1nxi2fxi-μ2,
La cual permitirá realizar los cálculos a mano. Al aplicar la raíz cuadrada del valor de la
varianza se obtendrá la desviación estándar y se denotará simplemente con la letra
griega σ.
La Media y Varianza de una Variable Aleatoria Continua
28
μ=E X =∑ i=ni=1
x i∗ f x i

Para el cálculo de la media de V.A continuas se debe utilizar la técnica del cálculo
integral. Y la ecuación general es
μ=EX=abxfxdx
Donde a ≤ x ≤ b. Esta integral lo que permite es determinar el área bajo la curva de una
densidad de probabilidades determinada. Afortunadamente, ya existen tablas de
probabilidades ya calculadas o software de computación (como en Excel) que pueden
ser usadas para algunas densidades de probabilidad teóricas ya conocidas en la
literatura estadística, como se verá en capítulos por venir. Como para la media, el
cálculo de la varianza para variables continuas requiere de un entendimiento del cálculo
integral. La ecuación se describirá a continuación, pero al igual que para la media, sólo
se hará para tenerla como referencia
σ2=E(X-μ)2=ab(x-μ)2fxdx
Donde a ≤ x ≤ b.
Algunas Distribuciones de Probabilidad de Variables Discretas.
La Distribución Uniforme
Esta distribución describe procesos en el cual las probabilidades de cada resultado es la
misma. Para un experimento con k posibles resultados, la función de probabilidad es
dada por:
fx;k=1k, para x = x1, x2, x3, …, xk
f(x;k) se interpreta que la función de probabilidad de los valores x observados depende
de un solo parámetro llamado k, el número de posibles resultados. Supóngase que
tenemos 8 piezas de madera dentro de una caja, enumeradas del 1 al 8. Seleccionamos 1
pieza aleatoriamente, entonces la probabilidad de seleccionar una pieza en particular
29

sigue una distribución uniforme con k = 8 y asi mismo la función de probabilidad es
fx;8=18, para x = 1, 2, 3, 4,…, 8
La siguiente gráfica muestra la función de probabilidad uniforme dada anteriormente,
La Distribución Binomial
Considérese un experimento con dos posibles resultados que es repetido varias veces. Por
ejemplo, queremos realizar una encuesta a tres (3) hogares dirigida al jefe de familia,
asuma que a partir de estudios previos se ha demostrado que la probabilidad de
entrevistar a un jefe de familia del sexo femenino (F) es de 0,2 y la probabilidad de que
este sea masculino (M) es de 0,8. Nosotros esperaríamos 8 posibles resultados con las
siguientes probabilidades
Resultados x Probabilidad
F F F 0 (0,2)*(0,2)*(0,2) = (0,2)3(0,8)0
M F F 1 (0,8)*(0,2)*(0,2) = (0,2)2(0,8)1
F M F 1 (0,2)*(0,8)*(0,2) = (0,2)2(0,8)1
F F M 1 (0,2)*(0,2)*(0,8) = (0,2)2(0,8)1
M M F 2 (0,8)*(0,8)*(0,2) = (0,2)1(0,8)2
M F M 2 (0,8)*(0,2)*(0,8) = (0,2)1(0,8)2
F M M 2 (0,2)*(0,8)*(0,8) = (0,2)1(0,8)2
M M M 3 (0,8)*(0,8)*(0,8) = (0,2)0(0,8)3
30

Si definimos la variable aleatoria, X, como el número de hogares cuyo jefe de familia es
del sexo masculino, la distribución de probabilidad de X es
x f(x)
0 (0,2)3(0,8)0
1 (3)(0,2)2(0,8)1
2 (3)(0,2)1(0,8)2
3 (0,2)0(0,8)3
En el proceso de obtener esta tabla de distribución de probabilidades se ha utilizado la
regla de la multiplicación, es decir, las probabilidades para un resultado dado, tal como
(F M M) es P(F)xP(M)xP(M) = (0,2)*(0,8)*(0,8). También de manera implícita se ha usado
la suma de probabilidades; veamos si requerimos encontrar la probabilidad de que al
aplicar una encuesta a tres hogares uno de los tres jefes de familia a encuestar sea del
sexo masculino, tenemos (M F F) + (F M F) + (F F M) = (0,2)2(0,8)1 + (0,2)2(0,8)1 +
(0,2)2(0,8)1 = 3 veces (0,2)2(0,8)1, o sea, (3)(0,2)2(0,8)1. Esto es posible porque cada resultado
es independiente uno del otro. A partir de las probabilidades derivadas anteriormente
se puede conformar una función generalizada de probabilidad para este experimento
como sigue:
fx;3;0,8=3x0,8x0,23-x=3!x!3-x!0,8x0,23-x, para x= 0,1,2,3.
En este caso, la función está definida por dos parámetros, en este ejemplo, 3 representa
el numero de experimentos (aquí concretamente es el número de encuestas) y 0,8
representa la probabilidad teórica de que el jefe de familia a entrevistar sea masculino.
Ya que sólo se tiene dos posibles resultados la probabilidad, por complemento, de que el
jefe de familia a entrevistar sea femenino es 1 – 0,8 = 0,2.
31

Este tipo de experimento se llama experimento binomial ya que se produce en él una
variable aleatoria binomial (dos resultados, masculino o femenino). Todos los
experimentos binomiales tienen las siguientes propiedades:
1- El experimento consiste de un número fijo de ensayos o experimentos,
simbolizado por n, donde estamos interesados en estudiar sólo uno de dos de
esos resultados (algunos textos estadísticos le llaman a esos dos posibles
resultados éxito y fracaso).
2- La probabilidad de ese resultado de interés (éxito) es la misma en cada
experimento o ensayo, y se simboliza como p; y se conoce a priori.
3- Cada experimento o ensayo es independiente uno del otro.
Por tanto, la función de distribución de probabilidades binomial tiene dos parámetros: n
el número de ensayos o experimentos y p la probabilidad teórica de éxito, por
complemento la probabilidad de fracaso es q =1 - p. Así, la variable aleatoria X es el
número de veces en que se presenta el éxito en un total de n ensayos o experimentos y
los valores que puede tomar esta variables es x = 0, 1, 2, 3,…, hasta n. A continuación la
función
fx;n;p=nxpxq3-x=n!x!n-x!pxq3-x, para x = 0,1,2,3, ..., n
Esta función de distribución de probabilidades tiene como todas las funciones de
probabilidad para variables discretas una media o valor esperado (µ) y una varianza
(σ2), que se definen a continuación:
µ = np y σ2 = npq
32