universidad de guayaquil facultad de...
TRANSCRIPT

UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES
Análisis y Creación del modelo de Base de Datos para la gestión de las variables
que definen los modelos de contaminación ambiental en el aire, agua, tierra y
especies vivas dentro del proyecto de definición de escenarios de la
contaminación petrolera en Ecuador del programa MONOIL
PROYECTO DE TITULACIÓN
Previa a la obtención del Título de:
INGENIERO EN NETWORKING Y TELECOMUNICACIONES
AUTOR (ES):
PEDRO VILLAFUERTE YAGUAL
TUTOR:
ING. CHRISTIAN ANTÓN CEDEÑO
GUAYAQUIL – ECUADOR
2016

REPOSITORIO NACIONAL EN CIENCIAS Y TECNOLOGÍA
FICHA DE REGISTRO DE TESIS
TÍTULO “Análisis y Creación del modelo de Base de Datos para la gestión de las variables que
definen los modelos de contaminación ambiental en el aire, agua, tierra y especies vivas dentro
del proyecto de definición de escenarios de la contaminación petrolera en Ecuador del programa
MONOIL”
REVISORES:
Ing. Adiel Castaño Méndez, M.Sc
Ing. Marjorie Arias Domínguez, M.sc
INSTITUCIÓN: Universidad de Guayaquil FACULTAD: Ciencias Matemáticas y
Físicas
CARRERA: Ingeniería en Networking y Telecomunicaciones
FECHA DE PUBLICACIÓN: N° DE PÁGS.:
151
ÁREA TEMÁTICA: BASE DE DATOS PETROLERA
PALABRAS CLAVES: BASES DE DATOS CIENTÍFICAS, GESTIÓN DE CONOCIMIENTO,
PATRONES DE DISEÑO, SCRUM, CONTAMINACIÓN AMBIENTAL.
RESUMEN: El proyecto consiste es brindar una estructura unificada elaborada en el gestor de base
de datos libre PostgreSQL que contenga las variables de contaminación ambiental petrolera. Variables
brindadas por los indicadores de la CEPAL y OMS analizadas mediante la investigación sobre datos
petroleras utilizando sistemas libres.
N° DE REGISTRO (en base de datos): N° DE CLASIFICACIÓN:
Nº
DIRECCIÓN URL (tesis en la web):
ADJUNTO PDF X
SI NO
CONTACTO CON AUTOR:
Pedro Xavier Villafuerte yagual Teléfono:
0967350943
E-mail:
CONTACTO DE LA INSTITUCIÓN Nombre: SECRETARIA
Teléfono: 042565297

II
CARTA DE APROBACIÓN DEL TUTOR
En mi calidad de Tutor del trabajo de investigación, “Análisis y Creación del modelo
de Base de Datos para la gestión de las variables que definen los modelos de
contaminación ambiental en el aire, agua, tierra y especies vivas dentro del
proyecto de definición de escenarios de la contaminación petrolera en Ecuador del
programa MONOIL“ elaborado por el Sr. PEDRO VILLAFUERTE YAGUAL
Alumno no titulado de la Carrera de Ingeniería en Networking y
Telecomunicaciones de la Facultad de Ciencias Matemáticas y Físicas de la
Universidad de Guayaquil, previo a la obtención del Título de Ingeniero en
Networking y Telecomunicaciones, me permito declarar que luego de haber
orientado, estudiado y revisado, la Apruebo en todas sus partes.
ING. CHRISTIAN ANTÓN CEDEÑO
TUTOR

III
DEDICATORIA
Dedico esta tesis, a mis padres que siempre me han apoyado en
todo momento y gracias a sus esfuerzos he salido adelante, a mi
hijo por ser una pieza importante que me motiva a crecer
profesionalmente, y a todas aquellas personas que de alguna
manera me han brindado su apoyo.

IV
AGRADECIMIENTO
Agradezco a Dios por permitirme cumplir esta meta tan importante en
mi vida, a mi familia que me han apoyado en todo este tiempo para
poder culminar mi carrera Universitaria, a mis maestros por sus
enseñanzas y consejos durante mi etapa estudiantil.

V
TRIBUNAL PROYECTO DE TITULACIÓN
Ing. Eduardo Santos Baquerizo, M.Sc.
DECANO DE LA FACULTAD
CIENCIAS MATEMÁTICAS Y FÍSICAS
Ing. Harry Luna Aveiga, M.Sc.
DIRECTOR
CARRERA DE INGENIERÍA EN NETWORKING Y
TELECOMUNICACIONES
Ing. Christian Picón Farah, M.Sc. PROFESOR REVISOR DEL ÁREA
TRIBUNAL
Ing. Lorenzo Cevallos Torres, M.Sc.
PROFESOR REVISOR DEL ÁREA TRIBUNAL
Ing. Christian Antón Cedeño, M.Sc.
PROFESOR DIRECTOR DEL PROYECTO
DE TITULACIÓN
Ab. Juan Chávez Atocha, Esp.
SECRETARIO

VI
DECLARACIÓN EXPRESA
“La responsabilidad del contenido de este Proyecto de Titulación, me
corresponden exclusivamente; y el patrimonio intelectual de la misma a la
UNIVERSIDAD DE GUAYAQUIL”
PEDRO XAVIER VILLAFUERTE YAGUAL

VII
.
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES
ANÁLISIS Y CREACIÓN DEL MODELO DE BASE DE DATOS PARA LA
GESTIÓN DE LAS VARIABLES QUE DEFINEN LOS MODELOS DE
CONTAMINACIÓN AMBIENTAL EN EL AIRE, AGUA, TIERRA Y
ESPECIES VIVAS DENTRO DEL PROYECTO DE DEFINICIÓN
DE ESCENARIOS DE LA CONTAMINACIÓN PETROLERA
EN ECUADOR DEL PROGRAMA MONOIL
Proyecto de Titulación que se presenta como requisito para optar por el título de
INGENIERO en NETWORKING Y TELECOMUNICACIONES
Autor/a: PEDRO VILLAFUERTE YAGUAL
C.I: 0925281743
Tutor: ING. CHRISTIAN ANTÓN CEDEÑO
Guayaquil, diciembre del 2016

VIII
CERTIFICADO DE ACEPTACIÓN DEL TUTOR
En mi calidad de Tutor del proyecto de titulación, nombrado por el Consejo
Directivo de la Facultad de Ciencias Matemáticas y Físicas de la Universidad de
Guayaquil.
CERTIFICO:
Que he analizado el Proyecto de Titulación presentado por el/la estudiante
PEDRO XAVIER VILLAFUERTE YAGUAL, como requisito previo para optar por
el título de Ingeniero en Networking y Telecomunicaciones cuyo tema es:
“ANÁLISIS Y CREACIÓN DEL MODELO DE BASE DE DATOS PARA LA
GESTIÓN DE LAS VARIABLES QUE DEFINEN LOS MODELOS DE
CONTAMINACIÓN AMBIENTAL EN EL AIRE, AGUA, TIERRA Y ESPECIES
VIVAS DENTRO DEL PROYECTO DE DEFINICIÓN DE ESCENARIOS DE LA
CONTAMINACIÓN PETROLERA EN ECUADOR DEL PROGRAMA MONOIL”
Considero aprobado el trabajo en su totalidad.
Presentado por:
VILLAFUERTE YAGUAL PEDRO XAVIER 0925281743
Tutor: ING. CHRISTIAN ANTÓN CEDEÑO
Guayaquil, diciembre del 2016

IX
UNIVERSIDAD DE GUAYAQUIL
FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS
CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES
Autorización para Publicación de Proyecto de Titulación en Formato
Digital
1. Identificación del Proyecto de Titulación
Nombre Alumno: Pedro Xavier Villafuerte Yagual
Dirección: Urb. Paraísos del Rio 2 Mz. 3059 V. 12
Teléfono:
0967350943
E-mail:
Facultad: Matemáticas y Físicas
Carrera: Ingeniería en Networking y Telecomunicaciones
Título al que opta: Ingeniero en Networking y Telecomunicaciones
Profesor guía: Ing. Christian Antón Cedeño
Título del proyecto de Investigación: “Análisis y Creación del modelo de Base
de Datos para la gestión de las variables que definen los modelos de
contaminación ambiental en el aire, agua, tierra y especies vivas dentro del
proyecto de definición de escenarios de la contaminación petrolera en Ecuador
del programa MONOIL”.
Tema del Proyecto de Titulación: Implementación de la base de datos
científica en los modelos de contaminación ambiental del programa MONOIL. 2. Autorización de Publicación de Versión Electrónica del Proyecto de
Titulación
A través de este medio autorizo a la Biblioteca de la Universidad de Guayaquil y a
la Facultad de Ciencias Matemáticas y Físicas a publicar la versión electrónica de
este Proyecto de titulación.
Publicación electrónica:
Inmediata X Después de 1 año
Firma Alumno:
3. Forma de envío:
El texto del proyecto de titulación debe ser enviado en formato Word, como
archivo .Doc. O .RTF y. Puf para PC. Las imágenes que la acompañen pueden
ser: .gif, .jpg o .TIFF.
DVDROM
CDROM X

X
ÍNDICE GENERAL
CARTA DE APROBACIÓN DEL TUTOR ..................................................................... II
DEDICATORIA ............................................................................................................ III
AGRADECIMIENTO .................................................................................................... IV
TRIBUNAL PROYECTO DE TITULACIÓN .................. ¡Error! Marcador no definido.
DECLARACIÓN EXPRESA ......................................................................................... VI
CERTIFICADO DE ACEPTACIÓN DEL TUTOR ...................................................... VIII
Autorización para Publicación de Proyecto de Titulación en Formato Digital ............ IX
ÍNDICE GENERAL ....................................................................................................... X
ABREVIATURAS ........................................................................................................ XII
SIMBOLOGÍA ............................................................................................................ XIII
ÍNDICE DE CUADROS .............................................................................................. XIV
ÍNDICE DE GRÁFICOS ............................................................................................. XVI
Resumen ................................................................................................................... XVII
Abstract ...................................................................................................................... XIX
INTRODUCCIÓN .......................................................................................................... 0
CAPÍTULO I .................................................................................................................. 2
EL PROBLEMA ............................................................................................................ 2
PLANTEAMIENTO DEL PROBLEMA .......................................................................... 2
Ubicación del problema en un contexto ....................................................................... 2
Situación Conflicto Nudos Críticos ............................................................................... 4
Causas y Consecuencias del Problema ....................................................................... 5
Delimitación del Problema ............................................................................................ 6
Formulación del Problema ............................................................................................ 7
Evaluación del Problema .............................................................................................. 7
OBJETIVOS DE LA INVESTIGACIÓN ......................................................................... 8
Objetivo general ............................................................................................................ 8
Objetivos específicos .................................................................................................... 8
Alcances del Problema ................................................................................................. 9
JUSTIFICACIÓN E IMPORTANCIA DE LA INVESTIGACIÓN .................................. 10
CAPÍTULO II ............................................................................................................... 12
MARCO TEÓRICO ..................................................................................................... 12
ANTECEDENTES DEL ESTUDIO ............................................................................. 12
FUNDAMENTACIÓN TEÓRICA ................................................................................. 15

XI
FUNDAMENTACIÓN SOCIAL ................................................................................... 42
FUNDAMENTACIÓN LEGAL ..................................................................................... 43
HIPÓTESIS DE LA INVESTIGACIÓN DOCUMENTAL ............................................. 50
Variables de la Investigación ...................................................................................... 51
DEFINICIONES CONCEPTUALES............................................................................ 51
CAPÍTULO III .............................................................................................................. 54
METODOLOGÍA DE LA INVESTIGACIÓN ................................................................ 54
DISEÑO DE LA INVESTIGACIÓN ............................................................................. 54
Modalidad de la Investigación .................................................................................... 54
TIPOS DE INVESTIGACIÓN ...................................................................................... 55
MÉTODOS DE INVESTIGACIÓN .............................................................................. 56
POBLACIÓN Y MUESTRA ......................................................................................... 60
Instrumentos de recolección de datos ........................................................................ 61
Recolección de la Información ................................................................................... 64
Procesamiento y Análisis ........................................................................................... 64
Validación de la Hipótesis .......................................................................................... 72
CAPÍTULO IV.............................................................................................................. 73
PROPUESTA TECNOLÓGICA .................................................................................. 73
Análisis de Factibilidad ............................................................................................... 73
Factibilidad Operacional ............................................................................................. 74
Factibilidad Técnica .................................................................................................... 75
Factibilidad Legal ........................................................................................................ 76
Factibilidad Económica ............................................................................................... 77
Etapas de la metodología del proyecto ...................................................................... 81
Entregables del proyecto .......................................................................................... 120
Criterios de validación de la propuesta .................................................................... 121
Criterios de aceptación del Producto o Servicio ...................................................... 122
CONCLUSIONES Y RECOMENDACIONES ........................................................... 124
BIBLIOGRAFÍA ......................................................................................................... 126
ANEXO 1 .................................................................................................................. 129
ANEXO 2 .................................................................................................................. 131
ANEXO 3 .................................................................................................................. 148

XII
ABREVIATURAS
SQL Lenguaje de Consultas Estructuradas
UG Universidad de Guayaquil
CEPAL Comisión Económica para América Latina.
OMS Organización Mundial de la Salud.
BD Base de Datos.
Http Protocolo de transferencia de Hyper Texto
Ing. Ingeniero.
CC.MM. FF Facultad de Ciencias Matemáticas y Físicas
www World Wide Web (red mundial)
SGBD Sistema Gestor de Base de Datos.
GPL Licencia Publica General.
S. O Sistema Operativo.
HAP’S Hidrocarburos Policíclicos Aromáticos.
V.I Variable Independiente.
V.D Variable Dependiente.
E/R Entidad – Relación.

XIII
SIMBOLOGÍA
B/C Costo Beneficio
VAI Valor Actual de Ingresos
VAC Valor Actual de Costos de Inversión.
F Frecuencia Relativa.
C Modalidad.
N Frecuencia Absoluta.
N Población.

XIV
ÍNDICE DE CUADROS
Pág.
Cuadro #1: Causas y Consecuencias ...................................................................... 5 Cuadro #2: Versiones de PostgreSQL ................................................................... 29 Cuadro #3: Notación Húngara como estándar de una base de datos ................ 36 Cuadro #4: Catálogos de PostgreSQL ................................................................... 41 Cuadro #5: Matriz de Operacionalización de Variables Dependientes e
Independientes del proyecto. .................................................................................. 61 Cuadro #6: Variables Cualitativas I usado en entrevistas ................................... 65 Cuadro #7: Variables Cualitativas II usado en entrevistas .................................. 65 Cuadro #8: Variables Cualitativas III usado en entrevistas ................................. 65 Cuadro #9: Frecuencia variable Edad .................................................................... 66 Cuadro #10: Información Documentada en proyecto – pregunta 1 .................... 67 Cuadro #11: Trabajo realizado en unificación de base de datos – pregunta
2 .................................................................................................................................. 68 Cuadro #12: Entendimiento modelo E/R – pregunta 3 ......................................... 69 Cuadro #13: Entendimiento estructura MONOIL – pregunta 4 ............................ 70 Cuadro #14: Uso de esquemas en base de datos – pregunta 5 .......................... 71 Cuadro #15: Comparativo de ingresos y egresos en el proyecto. ...................... 77 Cuadro #16: Concepto de egresos en el proyecto ............................................... 78 Cuadro #17: Presupuesto estimado actual MONOIL ............................................ 80 Cuadro #18: Costo estimado actual MONOIL ........................................................ 80 Cuadro #19: Análisis FODA ..................................................................................... 82 Cuadro #20: Estándar de la base de datos ............................................................ 96 Cuadro #21: Creación de la estructura del BD ...................................................... 97 Cuadro #22: Identificación variables de contaminación petrolera ..................... 97 Cuadro #23: Identificación de variables de la CEPAL .......................................... 97 Cuadro #24: Identificación de variables OMS ....................................................... 98 Cuadro #25: Análisis de variables contaminación con investigadores del
proyecto MONOIL ..................................................................................................... 98 Cuadro #26: Análisis de variables de la CEPAL y OMS con
desarrolladores WS .................................................................................................. 99 Cuadro #27: Creación de estructura para BD de contaminación petrolera ....... 99 Cuadro #28: Creación de estructura para BS de las API CEPAL y OMS ......... 100 Cuadro #29: Unificación de esquemas ................................................................ 100 Cuadro #30: Análisis de propuesta de un sistema de monitoreo en
servidor de BD PostgreSQL .................................................................................. 101 Cuadro #31: Reunión de planeación del proyecto .............................................. 101 Cuadro #32: Sprint MONOIL .................................................................................. 103 Cuadro #33: Historia de Usuario 1 ........................................................................ 104 Cuadro #34: Historia de Usuario 2 ........................................................................ 104 Cuadro #35: Historia de Usuario 3 ........................................................................ 105 Cuadro #36: Historia de Usuario 4 ........................................................................ 108

XV
Cuadro #37: Historia de Usuario 5 ........................................................................ 108 Cuadro #38: Historia de Usuario 6 ........................................................................ 109 Cuadro #39: Historia de Usuario 7 ........................................................................ 113 Cuadro #40: Historia de Usuario 8 ........................................................................ 113 Cuadro #41: Historia de Usuario 9 ........................................................................ 114 Cuadro #42: Historia de usuario 10 ...................................................................... 118 Cuadro #43: Historia de Usuario 11 ...................................................................... 118 Cuadro #44: Matriz de aceptación ........................................................................ 122

XVI
ÍNDICE DE GRÁFICOS
Pág.
Grafico # 1: Fases de la Industria Petrolera .......................................................... 16 Grafico # 2: Sistema de Gestión en una Base de Datos ...................................... 22 Grafico # 3: Componentes del Sistema PostgreSQL ........................................... 26 Grafico # 4: Funcionamiento del optimizador de Consultas ............................... 37 Gráfico # 5: Representación de Pregunta 1 ........................................................... 67 Gráfico # 6: Representación de Pregunta 2 ........................................................... 68 Gráfico # 7: Representación de Pregunta 3 ........................................................... 69 Gráfico # 8: Representación de Pregunta 4 ........................................................... 70 Gráfico # 9: Representación de Pregunta 5 ........................................................... 71 Grafico # 10: Análisis de factibilidad de un problema ......................................... 74 Grafico # 11: Esquema Conexión Cliente/Servidor .............................................. 76 Grafico # 12: Egresos del Proyecto ........................................................................ 78 Grafico # 13: Diagrama de Causa – Efecto ............................................................ 84 Grafico # 14: Análisis Estándar BD ........................................................................ 87 Grafico # 15: Análisis Esquema CEPAL ................................................................. 88 Grafico # 16: Análisis Esquema OMS ..................................................................... 89 Grafico # 17: Análisis Esquema Contaminación ................................................... 90 Grafico # 18: Análisis Unificación de Esquemas .................................................. 91 Grafico # 19: Historia de Usuario 1 – Estándar BD ............................................. 105 Grafico # 20: Historia de Usuario 2 – Creación Esquemas ................................ 106 Grafico # 21: Historia de Usuario 3 – Esquema General .................................... 107 Grafico # 22: Historia de Usuario 4 – Definición Variables ................................ 109 Grafico # 23: Historia de Usuario 5 – Validación de Variables .......................... 110 Grafico # 24: Historia de Usuario 5 – Generación dinámica de tablas ............. 111 Grafico # 25: Historia de Usuario 6 – Ejecución de Job ..................................... 111 Grafico # 26: Historia de Usuario 6 – Esquema CAM ......................................... 112 Grafico # 27: Historia de Usuario 7 – Validación de datos ................................ 115 Grafico # 28: Historia de Usuario 8 – Análisis de variables............................... 116 Grafico # 29: Historia de Usuario 9 – Esquema API ........................................... 117 Gráfico # 30: Historia de Usuario 10 ..................................................................... 119 Gráfico # 31: Historia de Usuario 11 ..................................................................... 120

XVII
UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y
FÍSICAS CARRERA DE INGENIERÍA EN NETWORKING Y
TELECOMUNICACIONES
ANÁLISIS Y CREACIÓN DEL MODELO DE BASE DE DATOS PARA LA
GESTIÓN DE LAS VARIABLES QUE DEFINEN LOS MODELOS DE
CONTAMINACIÓN AMBIENTAL EN EL AIRE, AGUA, TIERRA Y
ESPECIES VIVAS DENTRO DEL PROYECTO DE DEFINICIÓN
DE ESCENARIOS DE LA CONTAMINACIÓN PETROLERA
EN ECUADOR DEL PROGRAMA MONOIL
Autor: Pedro Villafuerte Yagual Tutor: Ing. Christian Antón Cedeño
Resumen
Actualmente existen diversos repositorios de bases de datos dedicados a la
contaminación ambiental en todo el mundo, pero no existe un repositorio que
tenga información sobre los problemas ocasionados por el petróleo en el aire,
agua, tierra, especies vivas sobre las áreas cercanas a la Amazonia Ecuatoriana,
la parroquia Dayuma ubicados en la misma región amazónica y sobre los
indicadores socioeconómicos en el mundo que brinda la CEPAL y OMS. El
objetivo de este proyecto es brindar una estructura unificada elaborada en el
gestor de base de datos libre PostgreSQL que contenga las variables de
contaminación ambiental petrolera. Variables brindadas por los indicadores de la
CEPAL y OMS analizadas mediante la investigación sobre datos petroleras
utilizando sistemas libres. Información documentada mediante revistas o libros
para posterior a eso ser proporcionada al proyecto bi-nacional entre los gobiernos

XVIII
de Francia/Ecuador MONOIL (Monitoreo ambiental, salud, sociedad y petróleo en
el Ecuador) para que puedan ser usados por sus investigadores. El objetivo es
entregar un proyecto que cumpla con los principios de normalización y
estandarización de bases de datos. Junto con los modelos lógicos y de Entidad
Relación se proporcionará una estructura factible y viable haciendo uso de la
metodología SCRUM por el marco de trabajo elaborado entre investigadores e
desarrolladores miembros del proyecto.
Palabras clave: Base de datos científica, Gestión de conocimiento, Patrones de
diseño, SCRUM, Contaminación Petrolera.

XIX
UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y
FÍSICAS CARRERA DE INGENIERÍA EN NETWORKING Y
TELECOMUNICACIONES
ANÁLISIS Y CREACIÓN DEL MODELO DE BASE DE DATOS PARA LA
GESTIÓN DE LAS VARIABLES QUE DEFINEN LOS MODELOS DE
CONTAMINACIÓN AMBIENTAL EN EL AIRE, AGUA, TIERRA Y
ESPECIES VIVAS DENTRO DEL PROYECTO DE DEFINICIÓN
DE ESCENARIOS DE LA CONTAMINACIÓN PETROLERA
EN ECUADOR DEL PROGRAMA MONOIL
Autor: Pedro Villafuerte Yagual Tutor: Ing. Christian Antón Cedeño
Abstract
Currently, there are several database repositories dedicated to environmental
pollution worldwide, but there is no repository that has information about the
problems caused by oil in the air, water, soil, living species in the areas near the
Ecuadorian Amazon, the Dayuma parish (located in the same Amazon region),
and the economic indicators in the world provided by the CEPAL and the OMS.
The purpose of this project is to provide a unified structure, developed in
PostgreSQL open database which contains the variables of the oil pollution.
Variables provided by the CEPAL and the OMS indicators and analyzed the
investigation of the oil data using open source systems. The documented
information was done through magazines or books so that after that, be provided
to the bi-national project between the governments of France / Ecuador MONOIL
(environmental monitoring, health, society and oil in Ecuador) so they can be used

XX
by their researchers. The aim is to deliver a project that meets the principles of
standardization of databases. Along with logic models, and Entity Relationship, a
feasible and viable structure will be provided using the SCRUM methodology
developed by the members of the project who are all researchers and developers.
Key words: scientific database, knowledge management, design patterns,
SCRUM, Oil Pollution.

INTRODUCCIÓN
Las industrias petroleras durante la última década han mantenido y aumentado
una serie de trabajos constantes ya sea estas por perforaciones de pozos, análisis
de infraestructuras, producción de materiales pétreos y el constante uso de
químicos necesarios para la explotación petrolera, este conjunto de labores ha
permitido cambios en el ambiente natural, actualmente existen muchos
repositorios de Bases de datos que almacenan toda esta información sobre las
problemáticas ocasionadas por las industrias petroleras y sus derivados. Pero no
existe un repositorio de datos general que contenga información de varias
organizaciones socioeconómicas (área petróleo), organizaciones ambientales y
organizaciones privadas dedicadas a analizar la Amazonia Ecuatoriana.
Mediante censos se han logrado determinar las variables primarias de aquellos
indicadores que son parte de la afectación de la contaminación petrolera como lo
son los Censos Nacionales, sistemas de encuestas de condiciones de vida y
ciertos mecanismos Administrativos. (Bustamante & Jarrín, 2011).
En ciertos países como en México se construyó una base de datos que integre
toda la información obtenida sobre los contaminantes Orgánicos “COP” y lograr
definir mecanismos de coordinación factibles a nivel nacional y disminuir los
riesgos (Gavilán & Martínez, 2004). Debido a la gran cantidad de información que
se puede llegar a procesar respecto a los problemas ambientales en ciertas
empresas se desarrollan módulos de gestores de datos usando algoritmos
precisos que optimizan el rendimiento de la herramienta PostgreSQL (Robles
Aranda & R. Sotolongo, INTEGRACIÓN DE LOS ALGORITMOS DE MINERÍA DE
DATOS 1R, PRISM E ID3 A POSTGRESQL, 2013).
En base a los problemas ambientales ocasionados por el petróleo y con toda la
información recopilada en base a estos contaminantes, y la información que
brindan organizaciones sin fines de lucro como la CEPAL y OMS que publican su
base de datos libre para que sean utilizadas por otras empresas, nace el proyecto
bi-nacional entre los gobiernos de Francia y Ecuador denominado MONOIL donde

1
uno de sus objetivos es centralizar en un solo repositorio de datos toda la
información de daños ambientales petroleros y de indicadores socioeconómicos
haciendo uso de las mejores técnicas de optimización en el manejo de scripts
SQL. Se hará más fácil realizar consultas y obtener información por parte de
investigadores ambientales sobre los problemas ocasionados por el petróleo en el
agua, aire, tierra y especies vivas en la Amazonia Ecuatoriana y sobre la parroquia
Dayuma. Con este repositorio podemos tener un control estadístico de aquellos
elementos que afectan a los pobladores de la región producidos netamente por el
petróleo. Mediante las respectivas técnicas de optimización y afinamiento en base
de datos estos podrán ser consumidos por entidades públicas o privadas con un
tiempo de respuesta moderado para evitar afectaciones futuras. Este proyecto se
realiza en conjunto con miembros investigadores y desarrolladores pertenecientes
al proyecto MONOIL en donde se evalúa las variables de contaminación obtenidas
durante el proyecto de titulación.
A continuación, se detallan los 4 capítulos que constan en este trabajo.
En el Capítulo I, incluye el problema en la investigación y el beneficio que traerá
hacia MONOIL, se detallan los procesos tecnológicos, delimitación, planteamiento
al problema, conflictos, los objetivos y la importancia.
En el Capítulo II, se incluyen las variables utilizadas en la investigación para crear
el modelado de la BD, se detallas las fundamentaciones teóricas, legal y social,
así como las definiciones conceptuales.
En el Capítulo III, se detalla la metodología AGIL:SCRUM que es la usada en el
proyecto así como los tipos y métodos de investigación usados.
En el capítulo IV, se analiza detalladamente la metodología usada y la factibilidad
de usar el modelado de la base de datos usando los esquemas de la CEPAL, OMS
y de Contaminación ambiental.

2
CAPÍTULO I
EL PROBLEMA
PLANTEAMIENTO DEL PROBLEMA
Ubicación del problema en un contexto
Desde la década de 1960 se viene intensificando la explotación de petróleo en la
región amazónica ecuatoriana afectando severamente a el ecosistema y el medio
ambiente y a los pobladores de manera socioeconómica y sanitaria, teniendo un
estimado de perjuicios económicos superiores al 50% superando lo mas de 10
millones de galones en derrame producido en Alaska en 1989 (Almeida y Proaño
2008), a esto se suma la falta de conocimiento de los pobladores sobre el daño
sanitario provocado por los HAPS(Hidrocarburos Aromáticos Poli cíclicos) y los
metales pesados producidos por la actividad petrolera.
Entre la diversidad de metales pesados con una mayor densidad tóxica o
venenosa en concentraciones bajas tenemos varios como el mercurio(Hg), cadmio
(Cd), arsénico (As), cromo (Cr), plomo (Pb) entre otros. También tenemos una
diversidad de metales pesados sumamente esenciales para el correcto
funcionamiento en el metabolismo sobre el ser humano como el Cobre (Cu), zinc
(Zn) o selenio (Se), tomando en consideración que deben estar presentes en
pequeñas cantidades ya que en concentraciones muy altas puede provocar
envenenamiento.
Estos metales pueden incorporarse al agua a través de los residuos dejados en
ríos por las empresas petroleras sin utilizar algún tipo de tratamiento residual, en
la tierra también existen este tipo de metales los cuales son beneficiosos para la
fertilidad de la tierra Silicio (Si), Aluminio (Al), Hierro (Fe), Calcio (Ca), Potasio(K),
Magnesio (Mg) (Mahler, 2003). Pero si los contenidos de estos superan los límites
permitidos, afectan considerablemente la sostenibilidad de los suelos (Martin,
2000).

3
Estos contaminantes pesados provocan efectos tanto leves como graves en la
salud humana al ser consumidos por una variedad de medios como lo pueden ser
el agua, aire o tierra. Se considera agudo cuando el organismo humano puede
combatir estos contaminantes microbianos como si fuese un germen, pero si la
cantidad es elevada sobrepasando el máximo permitido se la considera crónico
ya que es capaz de provocar cáncer, daños en riñones, hígado o problemas en la
reproducción. Se considera que el Cadmio (Cd) es el mineral que más problemas
ha causado en la salud humana (WHO, 1992).
Toda esta información se encuentra almacenada en diversos repositorios de datos
en el mundo que se encargan de analizar los daños ambientales producidos por
el petróleo inclusive almacenan datos sobre los problemas socioeconómicos y
ambientales. Sistemas que son actualizados y monitoreados constantemente para
su libre uso por parte de investigadores, entidades públicas, privadas y
gubernamentales.
Los investigadores son las personas que se encargan de analizar detalladamente
los resultados de nuevas investigaciones y constatar si es idóneo ser almacenado
en los repositorios de datos de cada entidad gubernamental.
Entre las entidades gubernamentales tenemos a la CEPAL (LA COMISIÓN
ECONÓMICA PARA AMÉRICA LATINA Y EL CARIBE), OMS (LA
ORGANIZACIÓN MUNDIAL DE LA SALUD), ITOPF (THE INTERNATIONAL
TANKER OWNERS POLLUTION FEDERATION LIMITED) que se encargan de
publicar todas sus investigaciones sobre salud, economía, daños ambientales
provocados por el petróleo, fenómenos naturales y otros indicadores para el
beneficio y conocimiento de la población.
En base a estos resultados se ha logrado generar reportes, informes estadísticos,
porcentaje de vulnerabilidades, métricas de afectación (tierra, agua, aire, especies
vivas), indicadores periódicos, perfiles regionales o nacionales, información que
es actualizada constantemente por lo tanto sus datos son reales.

4
Gran parte de los repositorios de base de datos se centran en una problemática
en general es decir por países o regiones, pero no en una fuente de información
a profundidad sobre determinadas zonas como la amazonia ecuatoriana, en base
a este requerimiento surge MONOIL (MONITOREO AMBIENTAL, SALUD,
SOCIEDAD Y PETROLEO EN ECUADOR), proyecto de investigación
interdisciplinaria binacional Francia/Ecuador entidad que se encarga de medir,
monitorear, reducir y prevenir la contaminación petrolera y medioambiental en la
amazonia y Costa Pacífica.
Este proyecto tiene como premisa tener un solo repositorio de datos que contenga
la información de varias entidades (incluyendo la CEPAL Y OMS) en uno solo y
que sea capaz de retroalimentarse con la información que sea almacenada por
los investigadores y/o científicos.
Situación Conflicto Nudos Críticos
Existen repositorios de base de datos globales que toman en cuenta las siguientes
características:
1. Se enfrascan en la información de determinadas regiones, países o
continentes.
2. Mezclan los datos socioeconómicos, ambientales, políticos, etc.
3. Sus datos solo pueden ser actualizados por investigadores acreditados.
4. Los datos no son compartidos entre las organizaciones gubernamentales.
Características que permiten determinar cómo las bases de datos son usadas
para el manejo de información acorde a sus necesidades como los repositorios de
las entidades gubernamentales como la CEPAL, OMS, ITOPF, etc. Esta tarea
implica que cuando se desee consultar una base se deba evaluar los repositorios
que se acoplen a nuestro requerimiento.

5
A pesar de toda la información que se dispone, no existe un repositorio dedicado
netamente a la amazonia ecuatoriana y los problemas de contaminación causado
por el petróleo o sus derivados (Metales pesados).
Causas y Consecuencias del Problema
Cuadro #1: Causas y Consecuencias
Causas Consecuencias
1. La falta de estándares para la
manipulación de datos permitiendo
que cada organización maneje su
propia base de datos.
Varias fuentes de información
existentes, pero ninguna nos muestra
el resultado esperado.
2. La falta de un esquema de base de
datos que represente netamente
los problemas de contaminación
en la amazonia ecuatoriana.
Consumir repositorio de datos
externos para generar reportes
propios.
3. El investigador no tiene algún lugar
digital donde almacenar su
información.
El desgaste hacia los investigadores o
científicos provocado por la
corrección, clasificación, verificación y
archivado de la información.
4. La falta de conocimiento sobre
bases de datos.
La transformación de la data obtenida
debe ser manejada cuidadosamente,
para no cambiar el contenido de
origen de la información que ingresa.
5. Al depender de otros repositorios
puede existir la probabilidad de
una base de datos desactualizada.
Divulgar información retrasada.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

6
Delimitación del Problema
Una vez realizado el análisis del diseño de la base de datos del proyecto MONOIL
se debe establecer la estructura general para luego ser modelado, diseñado e
implementado. El diseño debe estar esquematizado de la mejor forma posible para
evitar reajustes en caso se quiera acoplar a otros proyectos.
También debemos tomar en cuenta los siguientes puntos.
1. El repositorio de base de datos MONOIL, es usado y actualizado por
investigadores públicos, científicos, entidades gubernamentales.
2. Es capaz de migrar la información de los repositorios de la CEPAL y OMS
a la base de datos de MONOIL.
3. La actualización es constante.
4. Tiene una estructura capaz de almacenar información sobre los problemas
ocasionados por el Petróleo en el oriente ecuatoriano en base a
investigaciones científicas.
5. Respecto a la base de datos se maneja los esquemas para optimizar las
consultas por parte de los usuarios.
6. Reducir tiempos de respuesta en generación de reportes o consultas de
base de datos.
7. Manejar roles para el uso de la base de datos, así poder utilizar el mínimo
de recursos de memoria.

7
Formulación del Problema
¿Será factible realizar un modelo de base de datos que almacene toda clase de
información relacionada a la contaminación ambiental ocasionada por el petróleo,
sus derivados e información sobre los indicadores socioeconómicos de entidades
como la CEPAL, OMS, y se acople a cualquier proyecto investigativo sin afectar
la calidad de sus registros?
Evaluación del Problema
Evidente: Durante el traspaso de información se pueden presentar problemas por
los tipos de datos a migrar, para ello se debe realizar el monitoreo sobre el
modelado de base de datos, mediante esta técnica podemos encontrar la
necesidad de la transformación de los datos para evitar afectaciones futuras.
Relevante: Este proyecto optimiza los tiempos de búsqueda de información por
parte de investigadores, científicos o cualquier entidad gubernamental haciendo
uso de esta base de datos lo suficientemente robusta, este cambio también
disminuiría en gastos económicos ya que se reduce el tiempo de investigación.
Original: en la región no existe una base de datos dedicada a los problemas
causados por la contaminación petrolera y sus derivados, este es un teman poco
explorado en el país por lo tanto se debe monitorear la correcta creación del
modelado de base de datos por ser una de las estructuras principales del proyecto.
Contextual: El proyecto también puede ser utilizado en el ámbito académico,
brindando un aporte de manera significativa, ya que en si es otra alternativa como
fuente de información local y a la vez global, con información actualizada de
manera constante.
Factible: Este proyecto es sumamente factible ya que la migración de los datos
de la CEPAL, OMS u otro repositorio de datos es perfectamente realizable dado
que se trata de un estudio extenso tomando en cuenta todas las variables actuales
y las que se pueden presentar en un futuro.

8
Identifica los productos esperados: Por medio de este proyecto no solo se
demuestra la interacción de nuestra base con la información ingresada por los
investigadores, también se demuestra la integridad con otras bases a nivel global.
OBJETIVOS DE LA INVESTIGACIÓN
Objetivo general
Realizar el análisis y modelamiento SQL de los distintos medios de contaminación
ambiental producidos por el petróleo en el aire, agua, tierra, especies vivas sobre
la amazonia ecuatoriana y la parroquia Dayuma utilizando como base de datos
PostgreSQL para crear un repositorio General capaz de integrar los modelos de
base de datos de los Investigadores de MONOIL, base de datos de la CEPAL y
OMS, permitiendo facilitar el trabajo de búsqueda de información y tener
información precisa sobre la contaminación petrolera en la amazonia Ecuatoriana.
Objetivos específicos
Realizar un estudio sobre el modelamiento de bases de datos SQL sobre
contaminación ambiental, para lograr una estructura acorde a los estándares
de desarrollo actual y se pueda acoplar a la base de datos de otros
repositorios de datos públicos.
Identificar los requerimientos de los investigadores del proyecto MONOIL,
para esquematizar por completo el modelado de la base de datos en base a
los resultados obtenidos.
Realizar el desarrollo del modelo lógico para tener una correcta
normalización de la base de datos y sus esquemas.
Crear el modelo E/R y funciones del proyecto MONOIL para que sean
consumidos desde las interfaces principales tanto para la lectura o escritura
sobre los registros que estarán en el repositorio de base de datos SQL.

9
Alcances del Problema
Se analiza los repositorios libres de la OMS, CEPAL, ITOPF, CEPALSTAT
para identificar la estructura en común y evaluar la información obtenida.
Se determina las variables adicionales que brinda los estudios obtenidos
sobre la contaminación petrolera en el Ecuador.
Junto a los investigadores del proyecto MONOIL se realiza un análisis de
aquellas variables tanto locales como globales que se producen por la
afectación del petróleo sobre el agua, tierra, aire y especies vivas.
Se realiza el Esquema Macro en la herramienta Excel con todas las variables
encontradas.
Se utiliza el simulador del Modelo Lógico utilizando la herramienta Navicat
para PostgreSQL (tomar versión de pruebas).
Para obtener una correcta normalización de la base de datos se utiliza el
procedimiento de programación Pascal Casing usado frecuentemente para
las Nomenclaturas en Java, Sql server.
Se realiza sobre la Herramienta PostgreSQL 9.3 en donde se manejarán
roles y permisos hacia las tablas para tener controles a nivel de seguridad.
Se utiliza la Herramienta Navicat para elaborar el Modelo de E/R de la base
de datos en el proyecto MONOIL.

10
JUSTIFICACIÓN E IMPORTANCIA DE LA INVESTIGACIÓN
La elaboración de una estructura correcta de base de datos brinda una gran
ventaja para los investigadores por la manera en la que se pueden cruzar varios
temas y se encuentran en un mismo lugar de almacenamiento, estas bases de
datos netamente ambientales guardan un alto grado de homogeneidad debido a
la existencia de normas internacionales las cuales en conjunto con una variedad
de criterios creados permiten una mejor clasificación por cada tipo de información
ingresada (Gil Rivera, 1994).
Mediante el proyecto se hace uso de información real sobre cuáles son esos
factores del petróleo que afectan al medio ambiente en la región amazónica y
podremos obtener reportes, datos estadísticos por cada uno de las variables
encontradas para el agua, aire, tierra, y especies vivas, posteriormente son
analizadas junto con los miembros investigadores del proyecto de titulación
MONOIL.
Lo novedoso de este proyecto es la creación de un estándar en la estructura de
una base de datos ambiental que integre varios repositorios de base de datos en
una sola base, y como el software Libre en este caso PostgreSQL es muy útil para
el diseño, creación y manipulación de información de forma segura.
Actualmente los investigadores de MONOIL no tienen un solo lugar de
almacenamiento muchas veces son guardados en sus respectivos PC o en algún
lugar físico sin el respectivo cuidado que es necesario, para realizar consultas de
información en ocasiones se las realizaba a entidades externas, implementando
el proyecto de modelamiento de la base de datos los beneficios para MONOIL
traerá beneficios referente a gastos financieros ya que ahorraran más tiempo en
investigaciones y en el almacenamiento de información.

11
BENEFICIOS
Mejoras en el procesamiento de los datos
Agilidad en las consultas realizadas.
Ahorro de costos en software al ser base libre y flexible.
Competitividad y seguridad en la data de la institución.
Optimización de gastos operativos

12
CAPÍTULO II
MARCO TEÓRICO
ANTECEDENTES DEL ESTUDIO
Generalmente, durante las expropiaciones petroleras se produce un alto grado de
contaminación en zonas donde existen comunidades cercanas produciendo
catástrofes que conducen inevitablemente al deterioro gradual del ambiente que
lo rodea en forma directa como puede ser al suelo, agua, aire, y especies vivas de
la amazonia ecuatoriana y a sectores de la parroquia Dayuma de la provincia de
Orellana.
Dentro del programa de investigación interdisciplinario MONOIL (Monitoreo
ambiental, salud, sociedad y petróleo en Ecuador), no se cuenta con una Base de
Datos la cual ayude a los centros de investigación a almacenar la información y
minimizar costos al realizar nuevas investigaciones sobre la problemática de la
contaminación petrolera y de los indicadores socioeconómicos que provee la
CEPAL y OMS. El proyecto realizado es de mucha ayuda para los investigadores,
científicos o cualquier entidad gubernamental ya que podrán acceder a la
información de forma rápida y eficiente.
Los repositorios de datos han permitido mejorar las líneas de investigación y
oportunidades de desarrollo en base a los componentes del petróleo, en Cuba se
han utilizado software como Procite, Viscvery Somine, Ucinet y Microsoft Excel,
demostrando grandes proyecciones en etapa de investigación como la
recuperación mejorada del petróleo, la obtención de biogás y biodiesel y la
eliminación de metales pesados en el petróleo causado por los microorganismos,
considerándolo como un gran desarrollo con el propósito de mejorar la salud
humana, animal y los componentes del aire y agua. (Bonell Rosabal, 2009).
En el Ecuador existen repositorios de datos sobre el medio ambiente capaz de ser
actualizados anualmente permitiendo ser los únicos elementos que aborden los
temas principales como la pobreza, la salud, factores económicos, variables que
son desagregadas a nivel parroquial y provincial, zonas urbanas y rurales por
regiones. Con estos resultados se ha logrado determinar que la región amazonia

13
refleja una importante desventaja a nivel estructural sean por las viviendas o la
calidad de vida, si tomamos en cuenta la educación tienen un amplio avance
respecto a los últimos 10 años, en salud y en pobreza se acerca se acercan a los
índices promedios nacionales. (Bustamante & Jarrín, 2004).
En base a la gran cantidad de información que se procesa en base a las
investigaciones y la proveniente de otros repositorios de información como los
provistos por la CEPAL, y OMS se necesita un Gestor de base de datos potente y
que brinde la máxima prestación y escalabilidad posible, gran parte de los SGBD
(Sistemas Gestores de Base de Datos) cumplen con el paradigma relacional e
integran el lenguaje SQL(Structured Query Language) para la manipulación y
almacenamiento de los datos, con esta consigna estos sistemas no permiten la
consulta de datos definidos en base al paradigma temporal de base de datos,
ocupan más memoria y espacio físico que a lo largo del tiempo pude ocasionar
problemas de lentitud en el servidor donde repose la base de datos, el lenguaje
PostgreSQL es capar de incluir extensiones como el modelo TSQL2, TSQL
(Temporal Structured Query Language) y el 2 por tomar una parte del lenguaje
SQL2, en si es una extensión de este lenguaje de manipulación de datos. TSQL2
en el núcleo de PostgreSQL lo convierte en una arquitectura con una excelente
evaluación funcional, utilizando métodos de frecuencias sobre los datos
optimizando los tiempos de respuesta de manipulación. (Aguilera F. & Garcia M.,
2011).
El repositorio de base de datos por la cantidad de información que tiene y el
recurso que se toma por parte del servidor puede tener una serie de sistemas de
monitoreo de base de datos ya que escalable a cualquier sistema y lengua de
programación. Utilizando las correctas herramientas de monitoreo el administrador
puede no solo detectar problemas antes de que afecte al servidor durante la
operación, es decir puede prevenir a que ocurran estando en línea.
Existe el sistema de recopilación de datos y gráficos “Munin” enfocado
especialmente en el uso del gestor de base de datos PostgreSQL por su

14
flexibilidad y facilidad a la cual los desarrolladores y administradores pueden
agregar plugin específicos para el monitoreo de las necesidades y requerimientos
especiales de quien lo utilice, monitorea el servidor y genera estadísticas sobre el
funcionamiento como la memoria RAM, el disco duro y otros servicios, aparte de
ser una instalación muy simple plug and play y a la vez facilitando y optimizando
los recolectores de información. (Wolf Iszaevich, 2011)
PostgreSQL por la gran cantidad de información que se puede procesar y
consumir diariamente utiliza mecanismos, técnicas de minería de datos y de reglas
de inducción capaz de ser integrados en su núcleo aprovechando las ventajas de
ser un módulo completamente libre así se puede suplir cualquier deficiencia
respecto a su rendimiento, estos algoritmos pueden mejorar los tiempos de
respuesta de los datos en las consultas realizadas hacia la base de datos.
La minería de datos consiste en una técnica que obtiene los patrones o modelos
de datos a partir de una gran recopilación de información siendo capaz de ser
utilizado en cualquier entorno como en sistemas de educación, sistemas
financieros, procesos, políticas, ciencias sociales, estadísticas, es decir el
aprendizaje automático se aplican dependiendo del negocio al cual se aplica la
aplicación.
Entre las variedades de herramientas usadas en la base de datos existe un
método llamado minería de datos en donde podemos encontramos Weka
(Waikato Environment for Knowledge Analysis), un sistema multiplataforma fácil
de usar debido a sus herramientas gráfica, soporta diversas técnicas de minería
de datos como el agrupamiento, clasificación, visualización y selección logrando
obtener buenos resultados y un mejor análisis del conocimiento permitiendo
brindar una mejor comprensión de los datos. (Robles Aranda & R. Sotolongo,
INTEGRACIÓN DE LOS ALGORITMOS DE MINERÍA DE DATOS 1R, PRISM E
ID3 A POSTGRESQL, 2013).

15
FUNDAMENTACIÓN TEÓRICA
La protección a la Amazonía ecuatoriana es esencial para los pobladores
cercanos a esta región aumentando su tiempo de vida libres de enfermedades o
cualquier mal que ocasionen los desperdicios del petróleo o sus minerales,
aplicando oportunamente métodos sistémicos y apropiados podemos obtener los
diferentes factores que intervienen y afectan en la contaminación resolviendo los
problemas oportunamente, tomando en cuenta que hasta hace unos 5 años la
fuente esencial para la economía del país fue la exportación de crudo y sus
derivados, hasta aproximadamente una década las exportaciones del petróleo
eran de hasta un 66%.
A pesar de la bonanza que se mantuvo con el petróleo no se aplicaron las medidas
necesarias para el bienestar de los pobladores de la amazonia y de los
ecosistemas naturales esto ha durado casi 40 años, cuando se tuvo conocimiento
de los yacimientos en el ecuador especialmente en su amazonia en el país se
mencionaba que esto traería nuevos modelos tecnológicos, financieros y una
variedad de ingresos económicos que ayudarían con las deudas que contaba el
país. El inconveniente surgió cuando a pesar de la gran cantidad de exportaciones
siendo estas en gran volumen las divisas no ingresaban correctamente al país el
motivo es que la empresa encargada de la producción petrolera fue Texaco quien
se encargó de extraer gran parte de petróleo de los pozos con mayor índices de
exportación, pero estos contratos firmados y sin un ente regulador no beneficiaban
al país motivo que aprovecho Texaco para beneficiarse a sí mismo
económicamente y cometer irregularidades tanto legal como financieramente
posible por lo que actualmente sigue demandado en la corte de Sucumbíos, entre
los daños están el derramamiento de petróleo, contaminación en la selva
ecuatoriana, enfermedades graves hacia los pobladores cercanos.
A pesar de que estas empresas petroleras han aportado con tecnologías que
mejoren la extracción de este mineral, el país también se ha visto beneficiado de
regalías, impuestos a la renta, inversión social, infraestructura, los gobiernos
locales no contemplaron los efectos colaterales que conllevaron a estos índices

16
altos de afectación petrolera como el desplazamiento de los pobladores cercanos,
la contaminación al aire, tierra y a la salud.
A continuación, se detallan las fases de la industria petrolera:
Grafico # 1: Fases de la Industria Petrolera
Fuente: Fases de la industria Petrolera Elaboración por: Pedro Villafuerte Y.
Frente a las afectaciones producidas por las empresas petroleras en la selva
amazónica ecuatoriana surge el programa MONOIL cuyo objetivo es mejorar y
bajar a gran escala mediante el uso de estrategias en base a la recolección de
información utilizada los medios contaminantes de petróleo, realizar mediciones
constantes para mitigarlos, para realizar esta evaluación se toma en cuenta los
siguientes puntos de control:
Analizar los problemas socioeconómicos ocasionados por el petróleo sobre
las poblaciones cercanas a la selva ecuatoriana.
Análisis sociales para obtener las vulnerabilidades a niveles nacionales,
regionales, parroquiales y familiares.
En base a los resultados obtenidos implementar soluciones que hagan frente
a los impactos ocasionados.
Con la problemática presentada y el afán de tener un repositorio de datos del cual
se pueda saber cuáles son aquellos minerales contaminantes producidos por el
petróleo y sus derivados permitiendo obtener resultados idóneos y faciliten el
trabajo de los investigadores, así como de las encuestas o métodos estadísticos
más concretos y seguros con datos reales y que se puedan actualizar

17
constantemente. Se crea el repositorio de base de datos del proyecto MONOIL el
cual es elaborado en el Gestor de base de datos PostgreSQL por la gran potencia
que posee al momento de ser consumido por otros sistemas.
El objetivo del proyecto es construir una base de datos física funcional, así como
existen bases de datos para aplicaciones médicas, financieras, estudiantiles, de
control, petroleras, que logre gestionar los datos enviados o requeridos por los
investigadores del proyecto MONOIL. Gestor que pueda realizar en un
determinado tiempo todas las máximas consultas a la base de datos y a la vez se
pueda tener conocimiento del tiempo de respuesta desde y hacia su invocación a
la vez que no consuma tantos recursos por parte del servidor beneficiando a los
investigadores en el factor tiempo. (Díaz Silvera & Martínez Silva, 2010)
MONOIL (MONITOREO AMBIENTAL, SALUD, SOCIEDAD Y PETROLEO EN
ECUADOR)
Es un proyecto netamente investigativo entre Francia-Ecuador, cuyo principal
objetivo es analizar los impactos sean ambientales o socioeconómicos
ocasionados por la contaminación petrolera en el ecuador especialmente en su
amazonia ecuatoriana.
Entre sus objetivos se encuentran los siguientes:
1. Realizar cartografías de las zonas petroleras identificando las
vulnerabilidades/capacidades respecto a la contaminación ambiental.
2. Medición de los impactos ocasionados por los químicos presentes en los
Hap’s, metales pesados y todos esos contaminantes sobre el agua, tierra,
aire y especies vivas.
3. Analizar y entender los reglamentos referentes a las actividades petroleras
y ambientales.
4. Entender el funcionamiento de los contaminantes desde la afectación
ocasionada por los compuestos hasta los ocasionados en los humanos.

18
5. La implementación de un sistema innovador referente a la
descontaminación hacia el agua para el consumo humano.
MONOIL cuenta con una serie de procesos colectivos los que pueden contar con
encuestadores, sociólogos, médicos, economistas, modeladores. En el tiempo de
duración del proyecto se dictan una serie de seminarios hacia los pobladores de
las zonas afectadas para lograr hacer conciencia sobre los problemas
socioeconómicos y ambientales que produce la contaminación petrolera hacia sus
comunidades. (MONOIL, 2016).
SCRUM
Es un conjunto de procesos en el que se aplican una serie de buenas prácticas de
forma regular en el que se debe trabajar colaborada mente en equipo para obtener
los mejores resultados en el proyecto que se esté planteando. Con estas prácticas
el trabajo diario se vuelve más productivo.
Al aplicar esta metodología se deben realizar estrategias parciales y demostrar lo
aprendido durante cada etapa para lograr obtener las experiencias positivas o
negativas encontradas. También es usada en los entornos pequeños donde la
entrega de los proyectos debe ser en un corto periodo de tiempo y cuyos requisitos
sean cambiantes y altamente productivos. (Proyectos Agiles.org, 2016)
Se define a SCRUM como la colección de ciertos procesos para la correcta gestión
de proyectos de cualquier índole, permitiendo centrarse en una correcta entrega
del producto hacia el cliente y potenciar al equipo para lograr los objetivos
esperados en su máxima eficiencia utilizando un esquema de mejora continua
(Díaz, 2009).

19
Etapas de SCRUM
Planeamiento del Sprint/Sprint Planning. - Todos los miembros del
proyecto se reúnen para definir los sprint (Unidad básica de trabajo) a utilizar
en el proyecto, y asignar un tiempo estimado.
Reunión del equipo del SCRUM. - Reuniones diarias con un máximo de 15
minutos en donde se deben compartir experiencias de lo elaborado.
Refinamiento del Backlog. - El dueño del proyecto revisa las tareas con el
fin de darles un peso y resolver cualquier duda presentada.
Revisión del Sprint. - todos los miembros del equipo se reúnen para
demostrar cada tarea resuelta.
Retrospectiva del Sprint. - Reunión entre el dueño, líderes y equipo de
trabajo para tratar los eventos ocurridos en cada Sprint.
Base de Datos
Base de datos es un sistema en el cual se pueden almacenar gran cantidad de
datos en disco para luego ser gestionada, consultada fácilmente mediante
diferentes usuarios o programas sin que existe algún problema de sobrecarga. En
sí es el uso de cualquier mecanismo que almacena información en equipos
remotos y permite compartir datos en la red.
Las bases de datos se conforman de una o varias tablas que almacenan un
conjunto de datos. Estas tablas contienen columnas y filas que conforman los
registros, conjuntos de datos son explotados por los sistemas de información de
las empresas.
Características de una Base de datos
Control en redundancia
Manejo de Concurrencia por la cantidad de usuarios que acceden al servidor.
Independencia entre los datos.

20
Optimización en las consultas realizadas, llegando a ser complejas y no
complejas.
Tablas de Auditoria y Control de Acceso.
Uso de un lenguaje estándar para gran parte de sistemas gestores de base
de datos SQL.
Normalización de una Base de datos
Es un conjunto de procesos en el cual datos complejos se estructuran para
convertirse en datos más pequeños para que sean más simples y fáciles de
acceder. Estas técnicas o reglas son usadas por los diseñadores de bases de
datos para tener como resultado final un esquema físico que minimice los
problemas de lógica presentados y no presente errores de manipulación de datos.
Una base de datos no normalizada termina ocupando más espacio que una no
normalizada por la cantidad de datos redundantes que suele utilizar provocando
más lectura sobre el disco y mayor uso de memoria (mysql-hispano, 2003).
Para el uso de estas reglas es necesario el uso de cada una de estas existen 5
normas, pero las más utilizadas son las 3 primeras.
1. Primera Forma Normal (1FN)
2. Segunda Forma Normal (2FN)
3. Tercera Forma Normal (3FN)
4. Cuarta Forma Normal (4FN)
5. Quinta Forma Normal (5FN)
Primera Forma Normal (1FN)
Elimina aquellos grupos de datos repetitivos de cada tabla presente en el
modelo relacional.

21
Creación de tablas separadas por los grupos relacionales presentes.
Identificar cada grupo relacional con claves primarias.
Segunda Forma Normal (2FN)
Si en una tabla existen registros en varias columnas que cumplen la misma
funcionalidad es recomendable crear varias tablas.
Estas tablas divididas se las debe relacionar con una clave externa.
Tercera Forma Normal (3FN)
En caso de existir campos dentro de la tabla con datos que no dependan
en gran parte de la clave única es recomendable eliminarlos.
Se debe eliminar toda clase de dependencia transitiva en caso de ser
necesario.
Cuarta Forma Normal (4FN)
Se generan las relaciones externas usando otras tablas.
Entidades independientes de relaciones varios a varios no puedes estar
coexistiendo en la misma tabla.
Quinta Forma Normal (5FN)
Muchas veces se la llega a representa como una cuarta forma normal e
indica que toda dependencia join debe estar implicada por claves
primarias.
El uso de los procesos de normalización hacia la base de datos nos brinda
modelos más robustos, flexibles ante cualquier cambio en la lógica de negocio que
se vaya utilizar, favoreciendo las etapas transitivas de diseño hacia la de

22
implementación. También contribuye con un tiempo de desarrollo más corto en los
sistemas que lo vayan a consumir por la gran cantidad de información a procesar.
“La integración del proceso de normalización con los SGBD permite desarrollar
modelos robustos, eficientes, con mayor nivel de flexibilidad ante cambios
introducidos en el negocio” (Espinal Martín & Puebla Martínez, 2010).
Modelo Estrella de una base de datos
El modelo utilizado para la creación de estas estructuras de base de datos es el
de Estrella, “constituido especialmente por un conjunto de tablas llamadas
dimensiones y asocian toda su información a una tabla de hechos” (Fuentes Tapia,
2010). Los datos obtenidos deben alimentar constantemente a su estructura
principal esta será la de mayor carga transaccional de esta manera alivia el uso
de datos por acceso a múltiples tablas evita la cardinalidad y los cuellos de botella,
el uso de estos modelos también aplica para la migración de catálogos.
Sistema de Gestión de Base de Datos
Los SGBD son un tipo de Software que permiten la manipulación, creación entre
el usuario o software y la base de datos, para esto se hacen valer de algún
lenguaje informático que permita la manipulación de datos, así como el de
consultas.
Grafico # 2: Sistema de Gestión en una Base de Datos
SGBD
Modelo Relacional
Estructura de datos
Se compone
Se basa
Fuente: Sistema de Gestión de BD. Elaboración por: Pedro Villafuerte Y

23
Ventajas sobre la gestión de la base de datos.
Control sobre la redundancia de datos.
Consistencia de datos.
Compartir datos.
Mantenimiento de estándares.
Mejora en la integridad de datos.
Mejora en la seguridad.
Mejora en la accesibilidad a los datos.
Mejora en la productividad.
Mejora en el mantenimiento.
Aumento de la concurrencia.
Mejoras en servicios de copias de seguridad.
Desventajas de un SGBD
Complejidad.
Coste de equipamiento adicional.
Vulnerable a los fallos.
Modelos Entidad-Relación en una base de datos
Denominado por sus siglas ERD “Diagram Entity Relationship” es un diagrama
que mediante el modelado de datos junto con relaciones establecidas de un
sistema muestran el comportamiento de un conjunto de datos, permiten expresas
entidades relevantes e inter-relaciones, en base a este modelo podemos definir el
esquema adecuado para el gestor de base de datos.

24
Elementos del modelo Entidad-Relación
Entidad: Son las representaciones que se les da a los objetos utilizados, los
cuales tendrán cierta información necesaria para mantener las relaciones
establecidas, en representaciones gráficas se lo hace mediante un
rectángulo.
Atributos: Definen o identifican a la entidad, cada una de estas puede llegar
a tener distintos atributos. Cada entidad puede llegar a tener distintos
atributos, de esta manera es como logra ser identificada, están
representados mediante círculos y se puede mostrar solo las entidades
importantes. Los atributos están asociados a los tipos de clave que
describimos a continuación:
Clave Primaria: son aplicados a un único atributo que identifica a la
entidad.
Clave Foránea: se forma utilizando la clave primaria de otra entidad.
Súper Clave: se crea cuando un conjunto de atributos forma un único
atributo clave.
Relación: Indica la relación que se puede dar entre una o varias entidades
que tengan determinados atributos en común, las relaciones que se utilizan
en un esquema de base de datos están detalladas de la siguiente manera:
Relación uno a uno: una instancia de la tabla X se relaciona con una
instancia de la tabla Y.
Relación de uno a muchos: una instancia de la tabla X se relaciona con
varias instancias de la tabla Y.
Relación muchos a muchos: cualquier instancia de la tabla X se
relaciona con cualquier instancia de la tabla Y.

25
Características de una base de datos
Controla la redundancia de datos: controla que los datos no se repitan, sean
consistentes y no desperdicien memoria, de esta manera no tiene datos
duplicados, pero si con alguna relación.
Integridad de los datos: creación de reglas que impida datos erróneos.
Seguridad: Se define la gestión de los roles necesarios para controlar los
usuarios sin los privilegios necesarios hacia la base de datos.
Accesibilidad: gestiona la cantidad de usuarios que acceden a la base de
datos de forma continua, evita que se formen cuellos de botella.
Respaldo y Recuperación: Respaldos y Backup constantes sobre la base de
datos como estándar se pide que sea de cada 3 meses, con esto se evita
futuras pérdidas de información.
PostgreSQL y su funcionalidad
PostgreSQL es actualmente uno de los mejores gestores de base de datos de
código abierto en la actualidad, trabaja basándose en el modelo objeto-relación y
se encuentra distribuido bajo licencia BSD permitiendo que su código fuente sea
libremente distribuido, debido a sus constantes actualizaciones y la seguridad
implementada es utilizada para el desarrollo de sistemas comerciales.
Gracias a su página wiki al cual se realizan publicaciones constantemente
evidencia la gran cantidad de usuarios, organizaciones y compañías que lo utilizan
a nivel global, desde sus inicios hasta la actualidad PostgreSQL lleva 20 años en
el mercado demostrando solvencia y sobretodo madurez en su desarrollo.
PostgreSQL maneja un Core que iguala y hasta supera en características,
funcionalidades, seguridad, estabilidad y potencia a otros gestores de base de
datos privados y gratis.
El nivel estructural que utiliza PostgreSQL es cliente/servidor utilizando
multiprocesos para evitar fallo alguno en cada proceso que puede estar

26
ejecutando de esta forma evita el daño de información y puede seguir teniendo
continuidad.
Grafico # 3: Componentes del Sistema PostgreSQL
Aplicación cliente: Es el cliente que se conecta a la base de datos y puede
gestionar, administrar su contenido, la conexión la logra mediante varios medios
como el TDP/IP.
Demonio postmaster: Es el proceso principal encargado de escuchar las
peticiones de los clientes utilizando un puerto seguro de conexión a la vez crea
procesos capaces de validar estas peticiones, las gestiona y las consulta para
devolver el resultado hacia el cliente.
Fuente: Componentes del sistema PostgreSQL Elaboración por: Pedro Villafuerte Y.
Aplicación
Cliente
Conexión Inicial
Administrador
de
Almacenamient
Autenticación,
Consultas y resultados
Administrador de
Correos Servidor de PostgreSQL
a nivel Backend.
Compartición de Buffer
Disco

27
PostgreSQL share buffer cache: Es la memoria que se utiliza para almacenar
los datos en la cache del servidor y agilitar las consultas a la base de datos.
Disco: Es la unidad física donde se almacena la información gestionada y los
datos por default necesarios para el correcto funcionamiento de PostgreSQL.
El comienzo de PostgreSQL
IBM en la década de los 70 mantenía la idea de la potencia que podría brindar las
bases de datos relacionales. Así nació el primer lenguaje estructurado SQL
(Structured Query Language) bajo el nombre del proyecto “System R”, su diseño,
características, algoritmos fueron la influencia de otros gestores de base de datos.
Uno de esos gestores de datos denominado Ingres (Interactive Graphics Retrieval
System) el cual aportaba con la idea de la potencia de las bases de datos
relacionales y que sea de código libre para darle más escalabilidad y se
implementen mejoras, incluso en la década de los 80 su evolución le permitió ser
el origen para otras bases de datos como NonStop, Sql, Sybase, Informix.
En los años 85 el creador de Ingres Michael Stonebraker lidero un proyecto en la
Universidad de Berkeley al cual lo llamo Postgres el cual tenía el apoyo de la
grandes organizaciones públicas y privadas de EEUU, con la experiencia obtenida
de Ingres y su afán de obtener un sistema capaz de superar a su primera creación,
pero con un nuevo enfoque y libre del código fuente anterior se planteó los
siguientes objetivos.
Brindar un mejor soporte.
Brindar métodos de acceso, operadores y tipos de datos más robustos.
Creación de tipos de datos autoejecutables.
La implementación de funcionalidades capaz de auto sustentar la base de
datos frente a una caída y que esta no afecte los datos, mejoro los sistemas de
backup.

28
La implementación de un lenguaje de consulta mucho mejor a Ingres
denominado POSTQUEL.
Postgres95 en el mundo Open Source
Ya en la década del 94 en la versión 4.2 de Postgres se empezó a trabajar en el
código quitando muchos objetos los cuales no eran necesarios, se quitaron los
errores y se hicieron mejoras volviéndolo más rentable.
Se mejoró la interfaz Objeto-Relación.
Se utilizó un mejor interpretador del lenguaje POSTQUEL.
Se implementaron las funciones capaces de ser interpretadas por el lenguaje
SQL.
Se implementó un pequeño manual para hacer más fácil la interpretación por
los usuarios y se pueda distribuir su información.
Fue publicado en la GNU Make.
Esta versión la 1.0 fue publicado 1 año después de su creación fue desarrollado
en ANSI C superando hasta en un 50% a Postgres convirtiéndolo en un gestor
potente, publicado bajo la licencia BSD y al ser libre nacieron más colaboradores
con el proyecto y su popularidad creció aún más.
PostgreSQL 1996 En la Actualidad.
Debido a la falta de tiempo de los creadores de Postgres95 los usuarios con más
conocimiento de este gestor tomaron la batuta del proyecto y crearon un grupo al
cual llamaron “Postgres95 Global Development Team”, este grupo de
colaboradores de aproximadamente 6 miembros decidieron cambiar el nombre del
proyecto a PostgreSQL lanzándolo en el año 1997 convirtiéndolo en la versión 6.0,
proyecto al cual le añadieron muchas funciones al grupo las cuales incluían:
Planificación en la liberación de los códigos actualizados.
Se convirtieron en los responsables únicos de las actualizaciones o novedades
de PostgreSQL, o algún tipo de anuncio político.

29
Se dividieron las responsabilidades como los permisos de las consultas SQL,
cambios en la estructura, modificaciones en el código fuente, etc.
Las actualizaciones o publicaciones nuevas eran supervisadas y discutidas
para validar si eran necesarias o no.
Este grupo ha crecido considerablemente en los últimos años colaborando con
numerosas ideas relacionadas al proyecto, brindando soluciones que alivien los
problemas, la carga de información que rentabilice los servicios de PostgreSQL,
verifican el funcionamiento realizando test, control de versiones en los servidores
y mantienen discusiones sobre las nuevas funcionalidades a implementar,
también alimentan la base de conocimiento para ser distribuido libremente y
aumentar la cantidad de participantes, la forma en como este proyecto está a flote
es gracias a la cantidad de empresas públicas y privadas que colaboran
económicamente con la mejora de PostgreSQL ya que esto también los beneficia
a ellos por el costo que lleva tener un gestor de base de datos licenciado, es por
eso que en los últimos años este gestor se ha dedicado a mejorar su velocidad de
procesamiento que es lo más esencial en una empresa.
Versiones de PostgreSQL
Cuadro #2: Versiones de PostgreSQL
Fecha de Lanzamiento Versión
1995/05/01 1.0
1997/01/29 6.0
1997/06/08 6.1
1997/10/02 6.2
1998/03/01 6.3
1998/10/30 6.4
1999/06/09 6.5
2000/05/08 7.0
2001/04/13 7.1
2002/02/04 7.2
2002/11/27 7.3
2003/11/17 7.4
2005/01/19 8.0
2005/11/08 8.1
2006/12/05 8.2
2008/02/04 8.3

30
2009/07/01 8.4
2010/09/20 9.0
2011/09/12 9.1
2012/09/10 9.2
2013/09/09 9.3
2014/12/20 9.4
2016/02/10 9.5
Fuente: https://2ndquadrant.com/es/postgresql Elaborado por: Pedro Villafuerte Yagual
Estabilidad de PostgreSQL
Actualmente PostgreSQL tiene disponible la versión beta 9.6 pero la más rentable
y escalable de la actualidad es la versión 9.5 el cual muchos usuarios y
desarrolladores la describen como la más potente de la actualidad cumpliendo con
los estándares de una base de datos comercial global, en las últimas versiones se
han ido mejorando el uso de funciones que aumente la rentabilidad de las
consultas a la base de datos y que estas respuestas se ejecuten en el mínimo
tiempo posible, entre los estándares actuales están la creación de índices,
particiones de tablas, particiones por fechas, Funciones, tablas de auditoria, tablas
de rendimiento, diccionario de datos, mejoras de cobertura, rendimiento,
desempeño, fácil al momento de ser invocado por otros lenguajes de
programación y soporte nativo para JSON.
Características
Las características principales de PostgreSQL en la actualidad son las siguientes:
Permite la concurrencia evitando bloqueos al momento de realizar consultas
desde varias instancias.
Actualización constante en base al estándar SQL.
Actualización y creación de nuevos drivers para el manejo del esquema
Cliente/Servidor.

31
Mejoras en el rendimiento para las consultas pesadas utilizadas por grandes
empresas.
Capaz de incluir en su Core nuevos plugins que mejoren su escalabilidad.
Capaz de ser usado en muchos tipos de aplicaciones sin importar su lenguaje
de programación.
Creación de funciones de Compatibilidad que permita la importación de otros
gestores de base de datos.
Optimización en índices y en las funciones de agregación.
Fácil configuración y gran rendimiento para varias aplicaciones.
Actualización constante en los drivers de conexión a Java, Python, php, etc.
Manejo de alta Disponibilidad.
Actualización en los tipos de datos utilizados, capaz de ser usados para
informaciones geográficas, petroleras, estudiantiles, medicinales.
Uso de Exclusión por Restricciones o Particionamiento de Tablas para evitar
el recorrido de varias tablas.
Inclusión de los roles de base de datos.
Rendimiento y escalabilidad mejorados
PostgreSQL no se queda atrás en el uso de las nuevas técnicas de desarrollo en
las bases de datos, uso de índices, gestión y análisis sobre tablas ya usadas,
particiones, optimización en la escritura de los datos, técnicas que optimizan los
recursos disponibles en los servidores, estas ventajas y mejoras en cuestión de
rendimiento permiten que la sobrecarga de información sea en volúmenes muy
altos, se puede tomar en cuenta los siguientes detalles:
Capaz de ajustarse al número de procesadores y a la memoria que posean
estos servidores, este nivel de arquitectura le permite soportar múltiples
peticiones en forma simultánea.

32
Funcionamientos en cascada para tablas de mayor carga transaccional
escalados horizontalmente.
Las consultas a los datos se realizan mediante el uso de índices.
Puede llegar a realizar 350.000 lecturas sobre la base por cada segundo.
Ahorro de energía por parte del servidor al no disponer de tantos servicios
inservibles.
Soporta hasta 2 Terabytes de RAM en equipos de 64 bits.
Mejoras en el GiST (Árbol de Búsqueda Generalizado), permitiendo
concurrencia, rendimiento y velocidad.
Empresas que lo usan.
Existen un sin número de empresas que utilizan PostgreSQL por su flexibilidad y
robustez como lo son: American Chemical Society, NASA, University of Alabama,
University of California, University of Sydney, Laboratorio Nacional de Física de la
India, LAMP, Safeway, Apple, Skype, Cisco, Red Hat, etc.
El Core libre disponible de PostgreSQL permite que muchos desarrolladores
implementen aplicaciones sencillas, financieras, políticas, es algo que otros
gestores de base no lo utilizan.
Ventajas de PostgreSQL
Al ser un sistema estable con altos índices de prestaciones y rendimiento capaz
de funcionar en la mayoría de los sistemas operativos e integrarse fácilmente, con
esta particularidad se puede acoplar a cualquier sistema generado por los
desarrolladores, entre el sinnúmero de ventajas detallamos las siguientes:
Posee una instalación ilimitada en cuanto al número de servidores que la
utilicen.
Rentabilidad al momento de ser ejecutado vía Web.
Fácil de Administrar.

33
Soporte disponible constantemente para las empresas.
Posee una interfaz amigable
Multiplataforma.
Capacidades de replicación de datos.
Desventajas
Se abortan las transacciones ante el fallo en la ejecución de fuentes o tablas
en PostgreSQL, internamente se crean puntos de restauración en la base,
pero esto provoca lentitud en los servidores.
PostgreSQL es más lento en comparación con MySQL.
No tiene un soporte oficial en línea, los documentos o ayudas son parte de
los colaboradores.
PostgreSQL consume más recursos que el gestor de base MySQL.
Sintaxis de comandos no tan amigables.
Estándares para el desarrollo de la Base de datos
Los estándares de desarrollo son un conjunto de reglas proporcionadas hacia los
sistemas más usados permitiendo dar un orden y entendimiento más explícito
sobre lo desarrollado, para esta definición se puede tomar en cuenta los siguientes
aspectos:
Fácil interacción entre la aplicación y el desarrollador.
Optimización del código elaborado permitiendo al desarrollador saber en qué
parte del desarrollo elaborado se encuentra, y detectar los problemas
fácilmente.
Permite la elaboración de una correcta estructura, así como la optimización
de los componentes en caso de prestarse a actualizaciones constantes.

34
Cumplimiento de normas permitiendo dar un toque más elegante al código
elaborado.
Identificar los aspectos visuales, diseño, código fuente entre diferentes
gestores de base de datos.
“Tomando en cuenta estas definiciones se pueden obtener un sistema óptimo y
escalable y la interacción con el desarrollador o los usuarios sea más elegante sin
contradicciones o pérdidas de tiempo”. (Greguas Navarro & Hernández Claro,
2010).
Para PostgreSQL no existe un conjunto de estándares que permitan interpretar y
elaborar su código fuente para brindar una experiencia más atractiva hacia los
usuarios, para evitar estos inconvenientes se usan las anotaciones las cuales
pueden ser utilizada para el desarrollo tanto de sistemas informáticos como de la
base de datos entre las más populares se encuentran:
Notación de Pascal (Pascal Case).
Notación Camello (Camel Case).
Notación Húngara.
Notación de Pascal (Pascal Case)
Esta anotación nos indica que las variables pertenecientes a la base de datos
deben tener como identificador la primera letra en mayúscula seguido de las
letras en minúscula.
Pais, Alumnos
Si la palabra es compuesta la primera letra de cada palabra debe ir en
Mayúscula.
RegionPais, PaisAlumnos
Deben ser nombres claros.

35
En caso de la base de datos estos detalles aplican para los nombres de las
tablas, campos, procesos, funciones, vistas, triggers.
Fn_ActualizaRegionPais, Fn_IngresaPaisAlumnos
Notación de Camello (Camel Case)
Esta anotación nos indica que las variables pertenecientes a la base de datos
deben tener como identificador la primera letra en Minúscula seguido de las
letras en minúscula.
Si la palabra es compuesta la primera letra de la primera palabra debe ir en
minúscula y las primeras letras de las siguientes palabras deben ir en
Mayúsculas.
regionPais, nombreProfesor
Deben ser nombres claros.
En caso de la base de datos estos detalles aplican para los nombres de las
tablas, campos, procesos, funciones, vistas, triggers.
Fn_actualizaRegionPais, Fn_ingresaPaisAlumnos
Notación Húngara
Este estándar se lo utiliza con más frecuencia para la identificación de las variables
en determinados proyectos, para su identificación se toman en cuenta los
siguientes puntos:
Consiste en un prefijo que se le asigna a cada tipo de dato de la variable, el
prefijo debe estar en minúscula y la variable debe comenzar con mayúscula y
las demás letras en minúscula.
Si es palabra compuesta, cada palabra debe comenzar en mayúscula.

36
Cuadro #3: Notación Húngara como estándar de una base de datos
Tipo de Dato Prefijo Ejemplo
Integer int intCodigoPais
Boolean bln blnExiste
Character Chr chrBandera
Date dt dtFechaIngreso
Fuente: Notación Húngara como estándar de una base de datos Elaborado por: Pedro Villafuerte Yagual
“Estos estándares también aplican para las variables internas del proyecto es decir
para aquellas usadas en funciones, vistas, triggers, aplicando estas
recomendaciones podemos mejorar la legibilidad de un proyecto, logrando
identificar los componentes y diferenciarlos rápidamente optimizando tiempo y
recursos.” (López Takeyas, 2016)
Para nuestro desarrollo vamos a considerar la Notación de Pascal ya que es una
de la más utilizada para las bases de datos SQL, de esta manera brindaremos un
código más limpio, entendible y ordenado.
Optimización y Rendimiento en PostgreSQL
Dada la cantidad de transacción que se puede llegar a generar en un determinado
tiempo afectando con la performance del servidor de base de datos. Se crean los
métodos de optimización y rendimiento que facilitan las consultas realizadas sobre
la base de datos, la optimización consiste en el sistema de evaluación sobre las
consultas a la base de datos para encontrar las estrategias posibles que vuelva
más eficiente su costo y convertirlo en otra subrutina dada.
Utilizando algoritmos relacionales intenta obtener una expresión equivalente
de la expresión dada.
En base a las estrategias se obtiene la más acorde a nuestra base de datos.
Selección del algoritmo más acorde a la operación.
Análisis y uso de los índices necesarios a utilizar.

37
Grafico # 4: Funcionamiento del optimizador de Consultas
Grafico 4. Funcionamiento del optimizador de Consultas Elaboración: Pedro Villafuerte Y.
En la selección del costo más óptimo para nuestros procesos se debe tomar en
cuenta que los índices cambian su plan de ejecución a medida que la tabla usada
aumente su tamaño, recomendables es hacer un análisis de estos tipos de tablas
cada 500000 registros nuevos.
Estimación de estadísticas
El costo usado en cada consulta puede depender también de cada su consulta ya
que pueden ser los causantes del aumento de las estadísticas. Se podría decir
que de una expresión “x=(y=z)” para obtener una estimación de su costo se debe
primero evaluar la expresión “(y= z)” optimizar esta consulta y con este resultado
agregarlo a la expresión “x”.
El costo de una consulta hacia la base de datos depende ciertos factores:
Tiempo de acceso al sistema E/S
Volumen de datos.
Organización Física.
Sentencia SQL
Estandarización
Optimización
Compilación
Rutina de acceso a datos
Resultados

38
Tamaño de buffers en memoria.
Tiempo de procesamiento del CPU
Para bajar el costo a las consultas se debe tomar en cuenta los siguientes factores.
Reducción al sistema de E/S
Reducir los accesos intermedios.
Acceso por los atributos indexados.
Reducción de los procesamientos del CPU
Ahorrar tiempo de procesamiento en la selección de expresiones.
Simplificación de expresiones usando algoritmos matemáticos.
Las expresiones matemáticas nos permiten identificar las consultas enviadas, en
el cual mediante suposiciones se puede alterar la consulta para reducir su costo.
Simplificando la expresión después del Where quedaría:
X ˅ Y~ ˄ (Y ˅ Z) ˄ Z~ = X ˅ ((Y~ ˄ Y) ˅ (Y~ ˄ Z)) ˄ Z~
X ˅ (Y~ ˅ Z) ˄ Z~ = X ˅ ((Y~ ˄ Z~) ˄ (Z ˄ Z~)) = 0
Select ciudad from vendedores Where nombre = ‘PEDRO’ -> variable X Or not (ciudad = ‘QUITO’) -> variable Y And (ciudad = ‘QUITO’ or ciudad = ‘AMBATO’) -> variable Z And not (ciudad = ‘AMBATO’);

39
La expresión quedaría de la siguiente manera:
Entre las equivalencias lógicas tenemos:
Conjunciones y Negaciones
a ˄ ¬a = falso a ˅ ¬a = cierto a ˄ falso = falso a ˅ falso = a a ˄ cierto = a a ˅ cierto = cierto
Leyes de Morgan
¬ (a ˄ b) = ¬a ˅ ¬b ¬ (a ˅ b) = ¬a ˄ ¬b
Implicación
A -> b = ¬a ˅ b
Cuantificadores
∀𝑥 ∙ 𝑃 𝑥 ≡ ∄𝑥 ∙ ¬𝑃 𝑥 ∀𝑥 ∙ ¬𝑃 𝑥 ≡ ∄𝑥 ∙ 𝑃 (𝑥)
Equivalencias en Algebra relacional
Distribución de la selección sobre el Join
𝜎𝑐r∧ 𝑐s (𝑅 ⋈ 𝑆) ≡ 𝜎𝑐r(𝑅) ⋈ 𝜎𝑐s(𝑆) Donde cr sólo incluye atributos de R y cs sólo de S. Distribución de la proyección sobre el Join
Π𝐴r∪𝐴s (𝑅 ⋈ 𝑆) ≡ Π𝐴r∪𝐴s (Π𝐴r∪𝐴⋈ (𝑅) ⋈ Π𝐴s∪𝐴⋈ (S)) Donde AR sólo incluye atributos de R, AS sólo de S y A ⋈ los atributos sobre los que se realiza el join.
Mediante estas proyecciones y operaciones matemáticas minimizamos el impacto
de las consultas vs el coste que pueden tomar, así como los siguientes puntos:
Reducción de impacto en operaciones en el uso de los joins.
Eliminar resultados redundantes, aplicando proyecciones en cascada.
Restricción en el uso de distinct, not in, not exists (evita resultados iguales).
Select ciudad from vendedores Where nombre = ‘PEDRO’;

40
Información del catálogo del SGDB
Toda la información descriptiva, completa que se genere de la estructura de una
base de datos es usada por el SGBD en donde lo almacena como un catálogo o
diccionario de datos, puede llegar a almacenar:
Los tipos de datos y sus elementos
Mapeo relacional entre los esquemas
Información sobre el archivo y sus propiedades.
Detalla la información almacenada.
Detalla la información de los usuarios creados junto con sus roles.
Toda información descriptiva almacenada se denomina meta datos, cuyo fin es
saber que datos ya existen en la base y poder acceder a ellos de una forma más
rápida, se podría decir que es la memoria cache de una base de datos.
Entonces cada vez que se requiera hacer una consulta sobre una tabla del DBMS
realiza una secuencia de pasos:
Verifica el catálogo del sistema para ver si tiene una estructura similar a la
que se está enviando.
El catalogo le indica en donde se puede encontrar la consulta (valida la
cantidad de byte que tenga la información).
Con los datos obtenidos accede al fichero o su información, realizando una
consulta más rápida.

41
Cuadro #4: Catálogos de PostgreSQL
Nombre Catalogo Propósito
Pg_aggregate funciones de agregado
Pg_am métodos de acceso de índice
Pg_amop operadores del método de acceso
Pg_amproc Procedimientos de soporte del método de acceso.
Pg_attrdef los valores por defecto de columna
Pg_attribute columnas de tablas (“Atributos”)
Pg_authid identificadores de autorización (“Roles”)
Pg_auth_members relaciones de miembros identificadores de autorización
Pg_cast conversión (conversiones de tipos de datos)
Pg_class tablas, índices, secuencias, vistas (relaciones)
Pg_collation colaciones (información de localización)
Pg_constraint restricciones de comprobación, restricciones únicas, restricciones de clave principal, las restricciones extranjeras
Fuente: https://www.postgresql.org/docs/9.3/static/catalogs.html
Elaborado por: Pedro Villafuerte Yagual
Los catálogos en PostgreSQL son tablas que pueden ser modificadas, eliminadas,
actualizadas, este gestor utiliza comandos especiales SQL en caso no se quiera
acceder a de forma manual a estos catálogos, un ejemplo es el comando CREATE
DATABASE que se encarga de insertar filas en el catálogo pg_database, también
los crea físicamente.
Esquemas en Base de Datos.
Un esquema es un contenedor de tablas, vistas, procesos, funciones y objetos
usados en una base de datos, los almacena en un espacio físico dentro del
servidor para ser exportado a otros equipos de ser necesarios, esto facilita la
subida de objetos a otros ambientes como desarrollo o producción. Un esquema
de una base de datos contiene una o más bases asociadas, incluso distintos
usuarios y esquemas pueden acceder entre sí. Los objetos que se encuentran
dentro de cada esquema pueden llevar el mismo nombre sin afectar a los modelos
de E/R.

42
Gran parte de los gestores de bases de datos mantienen una estructura relacional
en la cual almacenan gran cantidad de información esencial para las empresas,
ante esta necesidad se crea el paradigma de transformación de esquemas el cual
aún es un tema de investigación para los administradores de BD, a pesar de las
variedad de herramientas que se crean día a día para optimizar estos procesos se
mantienen ciertos problemas en cuestión de rendimiento, para estos problemas
se utilizan modelos matemáticos que optimicen el uso de los esquemas, lograr
que los usuarios que accedan al esquema mediante varios caminos puedan tener
la información de la manera más rápida posible. (Desiré Atangana & Sepúlveda
Lima, 2007)
Entre las razones por las que utilizamos esquemas tenemos las siguientes:
Múltiples usuarios puedan trabajar en sus propios modelos de E/R sin afectar
los datos de otros usuarios.
Organizar los objetos del modelo E/R en grupos, subcarpetas que puedan ser
manipulados en otros ambientes.
Evitar interferencias entre las aplicaciones que quieran acceder a la base de
datos
Se guardan en direcciones físicas en el servidor, es decir no pueden anidarse
en el Sistema Operativo.
FUNDAMENTACIÓN SOCIAL
MONOIL es un proyecto que tiene como objetivo restituir los derechos a las
sociedades impactadas por las actividades petroleras y reducir los daños sociales
y ambientales como lo ampara la Constitución Política.
Tratará de evaluar la contaminación ambiental en la Amazonia ecuatoriana, así
como en los sitios de la refinería cercanos a estas zonas, el impacto positivo o
negativo de la actividad petrolera en el desarrollo de los territorios ocupados y las
vulnerabilidades y disposiciones sociales que hay que enfrentar a diferentes
niveles de acción (nacional, regional, parroquial, familiar).

43
Los levantamientos de la información para elaborar estos informes no son
resguardados en una Base de Datos segura, con el proyecto que se presenta se
ayudara a los organismos involucrados dentro del proyecto MONOIL a acceder de
manera rápida a la información que necesiten para las diferentes investigaciones.
(Monoil / IRD - Monoil, 2016).
FUNDAMENTACIÓN LEGAL
El presente proyecto se fundamenta en los siguientes artículos los cuales se
encuentran especificados en la Constitución de la República del Ecuador y en el
Convenio de Colaboración e investigación entre el IRD, Ministerio del Ambiente y
PRAS para la realización conjunta de un estudio llamado MONOIL.
El Estado Ecuatoriano garantiza, apoya y promueve, en los estudiantes de
educación superior, la investigación científica y tecnológica y así promover
soluciones para los diferentes problemas del país. Se detallan en los siguientes
artículos:
Decreto 1014
Sobre el uso del software libre
En base al uso del software libre las políticas actuales decretadas por el gobierno
de la republica del ecuador se mencionan los siguientes artículos. (Secretaria
Nacional de la Administracion Publica, 2016)
Art. 1: Establecer como política pública para las entidades de administración
Pública central la utilización del Software Libre en sus sistemas y equipamientos
informáticos.
Art. 2: Se entiende por software libre, a los programas de computación que se
pueden utilizar y distribuir sin restricción alguna, que permitan el acceso a los
códigos fuentes y que sus aplicaciones puedan ser mejoradas.
Estos programas de computación tienen las siguientes libertades:

44
Utilización de programa con cualquier propósito de uso común.
Distribución de copias sin restricción alguna.
Estudio y modificación de programa (Requisito: código fuente disponible)
Publicación del programa mejorado (Requisito: código fuente disponible)
Art. 3: Las entidades de la administración pública central previa a la instalación
del software libre en sus equipos, deberán verificar la existencia de capacidad
técnica que brinde el soporte necesario para este tipo de software.
Art. 4: Se faculta la utilización de software propietario (no libre) únicamente
cuando no exista una solución de software libre que supla las necesidades
requeridas, o cuando esté en riesgo de seguridad nacional, o cuando el proyecto
informático se encuentre en un punto de no retorno.
Art. 5: Tanto para software libre como software propietario, siempre y cuando se
satisfagan los requerimientos.
Art. 6: La subsecretaría de Informática como órgano regulador y ejecutor de las
políticas y proyectos informáticos en las entidades de Gobierno Central deberá
realizar el control y seguimiento de este Decreto.
Art. 7: Encargue de la ejecución de este decreto los señores Ministros
Coordinadores y el señor Secretario General de la Administración Pública y
Comunicación.
Ley Orgánica de Educación Superior
Art. 32.- Programas informáticos. - Las empresas que distribuyan programas
informáticos tienen la obligación de conceder tarifas preferenciales para el uso de
las licencias obligatorias de los respectivos programas, a favor de las instituciones

45
de educación superior, para fines académicos. Las instituciones de educación
superior obligatoriamente incorporarán el uso de programas informáticos con
software libre (Consejo de Educacion Superior, 2016).
Reglamento de régimen académico título 1 ámbito y objetivos
Artículo 1.- Ámbito. - El presente reglamento regula y orienta el quehacer
académico de las instituciones de educación superior (IES) en sus diversos
niveles de formación, incluyendo sus modalidades de aprendizaje o estudio y la
organización de los aprendizajes, en el marco de Jo dispuesto en la Ley Orgánica
de Educación Superior.
Artículo 2.- Objetivos. - Los objetivos del régimen académico son: (Sistema
Nacional de Nivelacion y Admision, 2016)
a. Garantizar una formación de alta calidad que propenda a la excelencia y
pertinencia del Sistema de Educación Superior, mediante su articulación a
las necesidades de la transformación y participación social, fundamentales
para alcanzar el Buen Vivir.
b. Regular la gestión académica-formativa en todos los niveles de formación
y modalidades de aprendizaje de la educación superior, con miras a
fortalecer la investigación, la formación académica y profesional, y la
vinculación con la sociedad.
c. Promover la diversidad, integralidad y flexibilidad de los itinerarios
académicos, entendiendo a éstos como la secuencia de niveles y
contenidos en el aprendizaje y la investigación.
d. Articular la formación académica y profesional, la investigación científica,
tecnológica y social, y la vinculación con la colectividad, en un marco de
calidad, innovación y pertinencia.
e. Favorecer la movilidad nacional e internacional de profesores,
investigadores, profesionales y estudiantes con miras a la integración de
la comunidad académica ecuatoriana en la dinámica del conocimiento a
nivel regional y mundial.

46
f. Contribuir a la formación del talento humano y al desarrollo de
profesionales y ciudadanos críticos, creativos, deliberativos y éticos, que
desarrollen conocimientos científicos, tecnológicos y humanísticos,
comprometiéndose con las transformaciones de los entornos sociales y
naturales, y respetando la interculturalidad, igualdad de género y demás
derechos constitucionales.
g. Desarrollar una educación centrada en los sujetos educativos,
promoviendo el desarrollo de contextos pedagógico-curriculares
interactivos, creativos y de construcción innovadora del conocimiento y los
saberes.
h. Impulsar el conocimiento de carácter multi, inter y trans disciplinario en la
formación de grado y postgrado, la investigación y la vinculación con la
colectividad.
i. Propiciar la integración de redes académicas y de investigación, tanto
nacional como internacional, para el desarrollo de procesos de producción
del conocimiento y los aprendizajes profesionales.
j. Desarrollar la educación superior bajo la perspectiva del bien público
social, aportando a la democratización del conocimiento para la garantía
de derechos y la reducción de inequidades.
LEY DE PROPIEDAD INTELECTUAL
Esta ley promulga los siguientes artículos para las personas creadoras de algún
sistema informático para ordenadores y cuyos fines es la venta o cualquier otro
propósito comercial. (OMPI, 2016)
Parágrafo primero de los programas de ordenador
Art. 28. Los programas de ordenador se consideran obras literarias y se protegen
como tales. Dicha protección se otorga independientemente de que hayan sido
incorporados en un ordenador y cualquiera sea la forma en que estén expresados,

47
ya sea en forma legible por el hombre (código fuente) o en forma legible por
máquina (código objeto), ya sean programas operativos y programas aplicativos,
incluyendo diagramas de flujo, planos, manuales de uso, y en general, aquellos
elementos que conformen la estructura, secuencia y organización del programa.
Art. 29. Es titular de un programa de ordenador, el productor, esto es la persona
natural o jurídica que toma la iniciativa y responsabilidad de la realización de la
obra. Se considerará titular, salvo prueba en contrario, a la persona cuyo nombre
conste en la obra o sus copias de la forma usual.
Dicho titular está además legitimado para ejercer en nombre propio los derechos
morales sobre la obra, incluyendo la facultad para decidir sobre su divulgación.
El productor tendrá el derecho exclusivo de realizar, autorizar o prohibir la
realización de modificaciones o versiones sucesivas del programa, y de
programas derivados del mismo.
Las disposiciones del presente artículo podrán ser modificadas mediante acuerdo
entre los autores y el productor.
Art. 30. La adquisición de un ejemplar de un programa de ordenador que haya
circulado lícitamente, autoriza a su propietario a realizar exclusivamente:
Una copia de la versión del programa legible por máquina (código objeto) con
fines de seguridad o resguardo;
Fijar el programa en la memoria interna del aparato, ya sea que dicha fijación
desaparezca o no al apagarlo, con el único fin y en la medida necesaria para
utilizar el programa;
Salvo prohibición expresa, adaptar el programa para su exclusivo uso
personal, siempre que se limite al uso normal previsto en la licencia. El
adquirente no podrá transferir a ningún título el soporte que contenga el
programa así adaptado, ni podrá utilizarlo de ninguna otra forma sin
autorización expresa, según las reglas generales.

48
Se requerirá de autorización del titular de los derechos para cualquier otra
utilización, inclusive la reproducción para fines de uso personal o el
aprovechamiento del programa por varias personas, a través de redes u otros
sistemas análogos, conocidos o por conocerse.
Convenios de cooperación firmados para el proyecto MONOIL
Dentro del Convenio de Colaboración e investigación entre el IRD, Ministerio del
Ambiente y PRAS para la realización conjunta de un estudio llamado MONOIL, se
detallan las siguientes clausulas en las cuales se especifican las obligaciones que
adquieren cada una de las partes involucradas; además de los compromisos de
confidencialidad que debemos respetar con respecto a la información que se nos
brindara para la realización del proyecto. (MONOIL, 2016)
Clausula Tercera. - OBJETO DEL CONVENIO
El presente convenio tiene como objetivo definir las modalidades de colaboración
entre el PRAS-MAE y el IRD, para la realización conjunta de un Estudio
denominado MONOIL, “Monitoreo ambiental, salud, sociedad y petróleo en
Ecuador”.
Clausula sexta. - OBLIGACIONES DE LAS PARTES
El PRAS del Ministerio del Medio Ambiente del Ecuador se compromete a:
Asignar a los investigadores e ingenieros de su equipo para una participación
global en el Estudio, equivalente al menos a la participación de un investigador a
tiempo completo:
Co-dirigir tesis de Máster o Doctorado, relacionados con el Estudio;
Facilitar las relaciones de colaboración con los otros organismos públicos o
privados en el Ecuador;
Proporcionar el apoyo del personal técnico, y, en la medida de sus
posibilidades, las facilidades administrativas y otros apoyos institucionales

49
para la correcta ejecución del Estudio en particular para obtener datos
existentes en las instituciones y administraciones del Estado Ecuatoriano.
Clausula Décima Primera. - CONFIDENCIALIDAD – PUBLICACIONES
Confidencialidad
11.1.2.- Además de los compromisos recíprocos de reserva asumidos por las
partes conforme a las estipulaciones expuestas, cada parte se compromete a no
publicar ni divulgar sin el acuerdo escrito de la otra parte, y eso, de cualquier forma
que sea, las informaciones científicas, técnicas o comerciales distintas a aquellas
resultantes del Estudio, en particular los conocimientos anteriores que
pertenezcan a la otra Parte y de los cuales ella podría llegar a conocer con motivo
de la ejecución del presente convenio y ello, siempre que dichas informaciones no
hubieren estado protegidas o no fueren de dominio público.
Toda derogación a esta obligación de confidencialidad deberá ser realizada en
común acuerdo y sometida a la aprobación de los responsables científicos de cada
Parte.
Las Partes sin embargo podrán comunicar a terceros tales informaciones para
satisfacer sus propias necesidades de investigación o para la evaluación de los
agentes o programas, con la condición de que estos terceros respeten las mismas
condiciones de confidencialidad.
Clausula Décimo Segunda. - PROPIEDAD DE LOS RESULTADOS:
Conocimientos no resultantes del Estudio
Los conocimientos obtenidos por las Partes con anterioridad al Estudio, quedan
bajo su propiedad respectiva.
Los conocimientos que tratan incluso sobre el objetivo del Estudio, pero que no
son resultado directo de los trabajos ejecutados en el marco del presente
convenio, pertenecen a la Parte que las ha obtenido. Para el efecto se sujetarán
a lo que disponen los artículos 322, 400 y 402 de la Constitución de la República
del Ecuador y la Ley de Propiedad Intelectual.

50
La otra parte no recibe sobre las patentes y el saber hacer correspondiente ningún
derecho por causa del presente convenio, son perjuicio de aplicar lo que dispone
el Art. 322, 400 y 402 de la Constitución de la República del Ecuador y la Ley de
Propiedad Intelectual.
HIPÓTESIS DE LA INVESTIGACIÓN DOCUMENTAL
Por medio de la investigación y desarrollo del presente documento se establece
una Base de Datos que sirve para el almacenamiento de la información de los
diferentes indicadores de pasivos ambientales y sociales de las actividades
económicas que han generado daño ambiental además de implementar
mecanismos, instrumentos y estrategias para la reparación integral de las
pérdidas del patrimonio natural y las condiciones de vida de la población afectada,
que han sido causadas por el actividades hidrocarburíferas.
Se responderán las siguientes inquietudes:
Si estandarizo y valido los modelos de entidad-relación, entonces se podrá
verificar y por ende brindará un óptimo modelado del diseño de la base de
datos.
Si logramos sistematizar y optimizar los scripts de consultas realizadas a la
base de datos por medio de los múltiples usuarios, entonces se tiene un
menor tiempo de respuesta y por ende un menor consumo de recursos.
Si analizo las estadísticas de las consultas base de datos, entonces podremos
identificar los procesos que afecten al rendimiento y encontrar soluciones
antes de las afectaciones.
Si se implementa el sistema de monitoreo del gestor de base de datos,
entonces aseguramos la identificación de los procesos del servidor que
afecten al rendimiento de los servicios del gestor de base de datos.

51
Variables de la Investigación
Variable independiente
Validación de los estándares y del modelado de entidad-relación de la base de
datos.
Variable dependiente I
Optimización y sistematización de los scripts de consultas a la base de datos.
Variable dependiente II
Implementación de una estructura entendible para cualquier usuario.
Variable dependiente III
Implementación de esquemas de las distintas estructuras usadas en el
modelamiento de la base de datos.
DEFINICIONES CONCEPTUALES
Se detallan los conceptos básicos que son utilizados en esta investigación
Base de datos. – Es aquel centro de información que alberga una variedad de
datos de cualquier índole sea estadísticos, científicos, matemáticos, educativos,
etc. pudiéndolos re categorizarlos de varias maneras posibles, esta información
puede está relacionada entre si permitiendo hacer su búsqueda de manera más
fácil y sencilla.
Bases de datos objeto-relacional.- Es una extensión de la base tradicional, con
la diferencia de que tiene las características brindadas por la programación
orientada a objetos.

52
DBMS Database Management System. – Aplicación cuyo principal fin es brindar
la asistencia al usuario de gestionar sobre la base de datos ejecutando consultas
y obteniendo estadísticas del consumo hacia el servidor.
METADATOS. - Recolector de datos que permiten identificar otros datos
mediante la clasificación, identificación, análisis sobre el gestor de la base de
datos.
SQL. - (Structured Query Language) es un lenguaje nativo de consultas
estructuradas con acceso a una base de datos relacional que identifica las
distintas operaciones que se puede realizar sobre ella, aplicando algoritmos
matemáticos reduce los costos de las operaciones realizadas sean de consultas
o de actualizaciones sobre los datos.
BSD. - Licencias usadas para los sistemas BSD (Berkeley Software Distribution),
son menos restrictivas que las licencias GPL por esto son frecuentemente usadas
por el dominio público, también permiten el uso de código fuentes sobre software
no libre, actualmente en sus nuevas versiones son denominadas licencias
modificadas BSD.
TSQL2.- Extensiones usadas para el manejo del paradigma de bases de datos
temporales, bitemporales, de transacciones.
CEPALSTAT. - Base de datos de la CEPAL es de uso público y puede ser
invocado mediante el uso de Servicios Web.
WHO. - Base de datos de la OMS es de uso público y puede ser invocado
mediante el uso de Servicios Web.
ITOPF. - Empresa dedicada a la contingencia en caso de derrames petroleros.

53
ADIOS2. – Sistema simulador de derrames petroleros.
RED7 PROCESS. – Esquematiza los indicadores usados por la CEPAL.
WTO – EDB. – Base de datos de la OMC dedicada al medio ambiente solo permite
consultar las estadísticas socioeconómicas y ambientales.
OIL & GAS. – Revista dedicada a los indicadores petroleros en todo el mundo,
con una especialidad en las refinerías ubicadas en el pacifico.

54
CAPÍTULO III
METODOLOGÍA DE LA INVESTIGACIÓN
DISEÑO DE LA INVESTIGACIÓN
Modalidad de la Investigación
Para el presente proyecto tomando en cuenta la necesidad por tener un gestor de
base de datos robusto que almacena la información de aquellas variables
presentes en la contaminación petrolera y de las variables presentes en las bases
de datos públicas de la CEPAL y OMS, determinamos que este proyecto es
factible tomando en cuenta la información tomada un 15% de campo, 15 análisis
experimental, 20% de bibliografías, y un 50% en base a los análisis aplicados para
los modelos Entidad/Relación, métodos de optimización y métodos de consultas
de estadísticas.
Se ha optado por utilizar un tipo de investigación aplicada para lo cual son
necesarios los conocimientos previos de una investigación básica, como resultado
nos permitirá resolver un problema existente dentro de un proyecto ya establecido.
“La investigación aplicada se centra en la búsqueda de una solución original de
un problema, que mejore las soluciones disponibles si es que las hay. Los centros
donde se cultiva son los de investigación aplicada y su calidad es evaluada por el
cliente para quien se desarrolló la solución del problema y por los pares de
investigador. El criterio que se sigue es la eficacia y eficiencia de la solución
desarrollada.” (Casalet, 1998)

55
TIPOS DE INVESTIGACIÓN
En el presente capítulo se explican los tipos de investigación que se usan para el
desarrollo del proyecto de tesis planteado. La correcta selección del tipo de
investigación está estrechamente relacionada con el objetivo general del proyecto,
además esto nos permitirá determinar, con exacta precisión, hacia donde va
dirigida nuestro proyecto y la manera de como analizaremos los datos obtenidos,
por lo tanto, la investigación que usaremos determinara el enfoque que le daremos
a nuestro proyecto.
Investigación Documental
Es el tipo de investigación que nos indica los documentos que se usan para la
obtención de los datos necesarios; el subtipo elegido de esta investigación es la
archivista, pues utilizaremos los documentos ya archivados de una investigación
básica anteriormente realizada.
“Este tipo de investigación es la que se realiza, como su nombre lo indica,
apoyándose en fuentes de carácter documental, esto es, en documentos de
cualquier especie. Las técnicas de investigación documental se sirven de datos
extraídos a partir del análisis, revisión e interpretación de documentos que aportan
información relevante para la comprensión del fenómeno.” (Zwerg-Villegas &
Ramírez Atehortúa, 2012).
Investigación explicativa
Como no existe algún proyecto parecido al que hemos tomado como tema de
tesis, este tipo de investigación es el más adecuado ya que nos permitirá
determinar los factores del problema y la solución al mismo.
“La investigación explicativa es apropiada cuando se necesita definir el problema
con más precisión, identificar las acciones a seguir, establecer las preguntas o
hipótesis de investigación, aislar y clasificar las variables fundamentales como
dependientes o independientes” (Malhotra, 2004).

56
PROYECTO FACTIBLE
Podemos denominar a un proyecto factible como aquel que se basa en una
investigación y análisis para poder satisfacer alguna necesidad de la población o
resolver un problema de la misma, claro está, que dicho proyecto debe estar
sustentado en una investigación que demuestre su veracidad.
Por todo lo expresado podemos concluir que el proyecto presentado es factible y
aplicable dentro del Proyecto de Investigación MONOIL tomando en cuenta que,
de la investigación realizada sobre las variables de contaminación ambiental
petrolera, Dayuma, de la CEPAL y OMS se las analiza con miembros
investigadores del proyecto de titulación para determinar cuáles son las que
necesita nuestra estructura principal de la base de datos.
MÉTODOS DE INVESTIGACIÓN
Existen muchos métodos de investigación, para este proyecto hemos analizado y
escogido los siguientes:
Método lógico deductivo
Este método se centra en el análisis de fundamentos desconocidos, en base a
aquellos centros de información conocidos; es decir analizaremos las bases de
datos libres y publicadas de las organizaciones (CEPAL, OMS) y de sistemas no
libres como (ITOPF, ADIOS2, RED7 PROCESS, OIL & GAS, BELA, WTO - EDB)
para crear una Base de datos sobre los problemas ambientales ocasionados por
el petróleo, posterior a eso unificar estas bases para ayuda de los investigadores
ambientales de MONOIL.
Método lógico inductivo
Se define como la investigación que parte de elementos simples hacia una base
de conocimientos más profunda, permitiendo tomar como referencia la formación
de hipótesis y demostración de las leyes.

57
Método de concordancia
Usamos este método para comparar varios Bases de datos y definir lo que se
repite en ellas, en base a este análisis tomamos las variables que definirán el
modelado de la base de datos final que es la propuesta para este proyecto.
Método de variaciones concomitantes
Este método indica si Los cambios que se producen sobre un determinado
elemento por alguna circunstancia y lo afectan de manera proporcional, puede
afectar la semántica de otro elemento con iguales características, es decir si en la
base de datos de la CEPAL y OMS tienen algún cambio significativo en una de
sus variables este puede afectar en nuestro modelado de base de datos.
Método histórico
Este método se basa en el estudio histórico de los elementos relacionados al
proyecto usando métodos, técnicas y un sin número de procesos relevantes, con
esta técnica podemos conocer la evolución y desarrollo del proyecto MONOIL.
Método analítico
Consiste en el estudio por separado de las partes de un todo, para poder
analizarlas para así determinar lo que tengan en común y poder usarlo como
beneficio nuestro permitiéndonos conocer detalladamente del objeto de estudio y
su comportamiento.
Método sistémico
Este método usado más en la hipótesis del proyecto contiene procesos en el cual
se combinan casos aislados en primera instancia, al finalizar su análisis se
formulan las teorías de sus elementos, está orientado a modelar el objeto, así
como la relación entre ellos, dicha relación nos indicara la estructura y dinámica
del objeto.

58
CONCEPTOS
Población
Se define población como el total de personas que presentan similitudes en ciertos
elementos, esta población es la que forma parte de una investigación o proyecto.
“Llamamos población o universo al conjunto de los elementos que van a ser
observados en la realización de un experimento. Cada uno de los elementos que
componen la población es llamado individuo o unidad estadística” (Vargas
Sabadías, Estadística descriptiva e inferencial, 1995)
Variable cuantitativa.
La variable cuantitativa es aquella que se expresa mediante variables numéricas,
es decir con ella se pueden resolver problemas aritméticos. (Moore, 2000)
Comenta: “Una variable cuantitativa toma valores numéricos, para los que tiene
sentido hacer operaciones aritméticas como sumas y medias.”
Variable cualitativa.
Este tipo de variables no se mide con números, si no es la que mide las cualidades
de los objetos que son parte de la investigación. Tal como indica (Kuby, 2008) :
“De atributos, o de categoría, clasifica o describe a un elemento de una población.”
Frecuencia Absoluta
Es el elemento que se puede llegar a repetirse varias veces en un análisis
estadístico. (Vargas Sabadías, Estadística Descriptiva e Inferencial, 1995) Indica
“Se llama frecuencia absoluta n, de la modalidad C (característica), al número de
individuos que presentan dicha modalidad.”
Frecuencia Relativa
La representación más significativa de esta frecuencia es tomando su valor
absoluto y dividirlo para la cantidad de elementos de la población denominada N.
Indica (Vargas Sabadías, Estadística Descriptiva e Inferencial, 1995) “Se llama
frecuencia relativa f, de la modalidad C, al cociente de dividir su frecuencia
absoluta n, por el número total de individuos de la población N.”

59
Representaciones gráficas
Para explicar de mejor manera datos que son resultado de una investigación, se
utilizan las representaciones gráficas; esto nos ayuda a entender de manera clara
todo lo que se investigó.
Una de las representaciones que se usaran en este proyecto es el Diagrama de
Barras en donde por medio de barras de colores se explican los resultados de una
investigación, pero para mayor entendimiento se explica la interpretación de
dichas barras. (Vargas Sabadías, Estadística Descriptiva e Inferencial, 1995) Nos
dice: “Un despliegue gráfico proporciona una impresión de ayuda a clasificar la
variabilidad y simetría de la distribución que figura en la tabla de frecuencias.”
Distribución de Frecuencias
Es la representación y ordenamiento mediante graficas estadísticas a cierta
distribución de una frecuencia. (Vargas Sabadías, Estadística Descriptiva e
Inferencial, 1995) Comenta: “Es la clasificación de los datos de acuerdo a la
modalidad del carácter que pertenece cada uno de los individuos y se ordenan,
anotando sus resultados en una tabla.”
Media
Podemos definir como media a la suma de la información de muestra dividida para
la cantidad total, también se la llama promedio. (Gordas, Cardiel, & Zamorano,
2011) “La media se calcula sencillamente sumando los distintos valores de x y
dividiendo por el número de datos.”
Mediana
La mediana es el valor que está ubicado en la parte central de toda la población a
la cual realizaremos la investigación. (Vladimirovna Panteleeva, 2002) “La
mediana de un conjunto de datos es el valor medio de los datos cuando estos se
han ordenados en forma no decreciente en cuanto a su magnitud”

60
Histograma
Es la parte gráfica de las variables a usar en la investigación. (Triola, 2004) “Es un
gráfico de barras en donde la escala horizontal representa clases de valores de
datos y la escala vertical representa frecuencias”.
POBLACIÓN Y MUESTRA
Población
Una vez se tengan los objetivos principales a cumplir y tener las variables de
nuestro proyecto, se determina mediante estudios la población relacionada o la
más cercana a la problemática para tomarlos como referencia en nuestra
investigación.
Dentro de nuestro proyecto se considera como población a 5 docentes; de los
cuales 3 son miembros del equipo de líderes del proyecto MONOIL 60% y 2 como
miembros lo cual representa el 40% de la población.
En esta investigación documental se usan como unidades de análisis los
siguientes:
Observación documental
Base de datos en línea (Petroleras).
Software Administradores de Bases Petroleras.
Bases de datos Públicas de la CEPAL y OMS.
Enciclopedias y libros.
Publicaciones periódicas, como revistas académicas y científicas.
Recopilación de datos por parte de investigadores del proyecto.
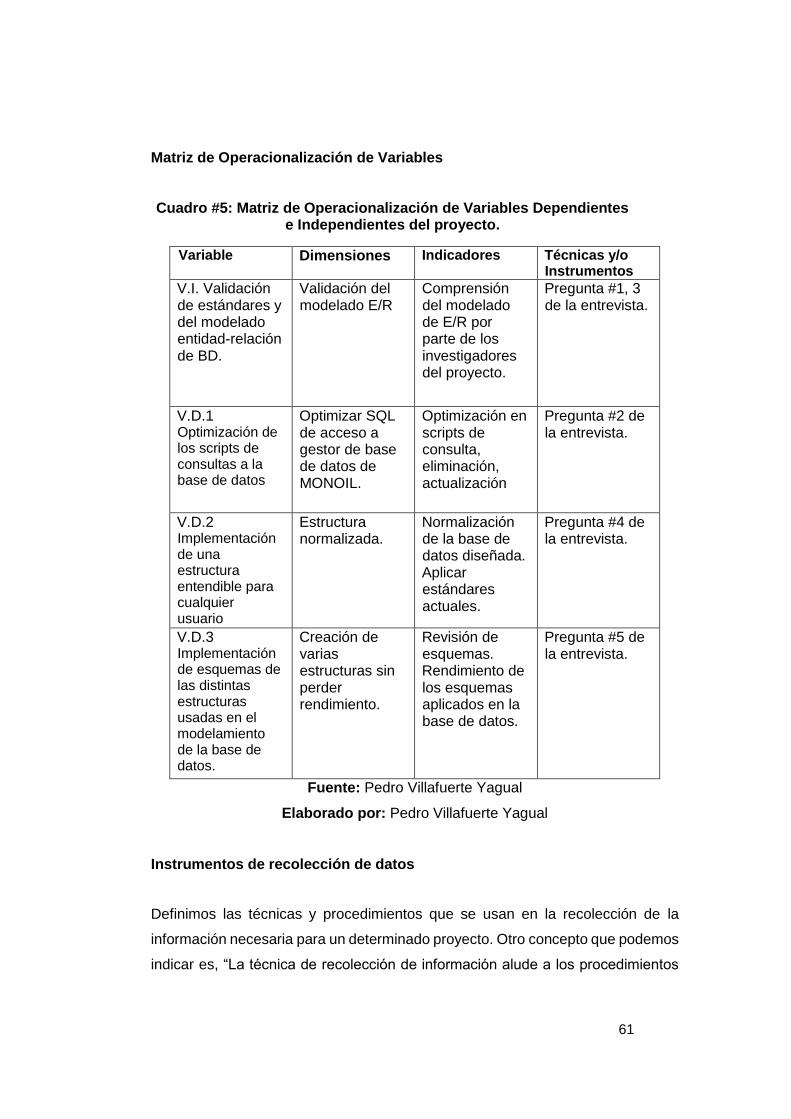
61
Matriz de Operacionalización de Variables
Cuadro #5: Matriz de Operacionalización de Variables Dependientes e Independientes del proyecto.
Variable Dimensiones Indicadores Técnicas y/o Instrumentos
V.I. Validación de estándares y del modelado entidad-relación de BD.
Validación del modelado E/R
Comprensión del modelado de E/R por parte de los investigadores del proyecto.
Pregunta #1, 3 de la entrevista.
V.D.1 Optimización de los scripts de consultas a la base de datos
Optimizar SQL de acceso a gestor de base de datos de MONOIL.
Optimización en scripts de consulta, eliminación, actualización
Pregunta #2 de la entrevista.
V.D.2 Implementación de una estructura entendible para cualquier usuario
Estructura normalizada.
Normalización de la base de datos diseñada. Aplicar estándares actuales.
Pregunta #4 de la entrevista.
V.D.3 Implementación de esquemas de las distintas estructuras usadas en el modelamiento de la base de datos.
Creación de varias estructuras sin perder rendimiento.
Revisión de esquemas. Rendimiento de los esquemas aplicados en la base de datos.
Pregunta #5 de la entrevista.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Instrumentos de recolección de datos
Definimos las técnicas y procedimientos que se usan en la recolección de la
información necesaria para un determinado proyecto. Otro concepto que podemos
indicar es, “La técnica de recolección de información alude a los procedimientos

62
mediante los cuales se generan informaciones válidas y confiables, para ser
utilizados como datos científicos.” (Yuni & Urbano, 2006)
Para la recolección de datos se usa un sinnúmero de instrumentos los cuales se
definen como la cantidad de recursos a usar por el investigador para la extracción
de datos necesarios para el proyecto que se tenga planteado.
Técnica
Las técnicas usadas para recopilar información necesaria en la realización de un
proyecto son:
Entrevistas
Observación
Entrevista
Podemos definir como entrevista a una conversación personal entre el
investigador y uno o más interesados en el proyecto, estas preguntas deben ser
concretas o similares a las utilizadas en una encuesta.
Observaciones
Las observaciones no requieren participación directa de los interesados en el
proyecto. El investigador obtiene los datos analizando las conductas diarias de los
participantes del proyecto, las observaciones pueden ser:
Observación directa. - Es cuando el investigador estudia directamente a los
involucrados en el estudio, se contacta directamente con el hecho a
investigar.

63
Observación indirecta. - Es el tipo de observación donde el investigador
utiliza herramientas realizadas por otra persona para lograr un mejor enfoque
del tema a investigar.
Observación Documental. - Se refiere al tipo de observación fundamentado
en libros, informes, biografías, revistas, etc. Las fichas bibliográficas es la
técnica más usada para este tipo de investigación, ya que sirve para citar y
tener presente la fuente utilizada en la investigación.
Observación estructurada. - En este tipo de observación el investigador
sabe de antemano lo que va a registrar y como lo realizará.
Por las definiciones dadas anteriormente para la recopilación de información en el
presente proyecto de tesis se consideró como más adecuada la observación
documental, ya que se necesita recopilar la información de varias fuentes y así
armar un solo repositorio que es de mucha ayuda para los interesados del
proyecto.
Entre los instrumentos usados en la recolección de la información, podemos
detallar las siguientes:
Bibliográficos
Repositorio de organizaciones como (CEPAL, OMS, petroleras) para así
unificar y armar una Base de datos necesaria para los investigadores del
proyecto MONOIL.
Los datos recolectados fueron analizados y ordenados a través de fichas y
hojas de cálculo y así lograr estudiar de forma detallada lo realmente
necesario para la investigación.
Con el uso de entrevistas se recolecto una gran cantidad de información referente
a la aceptación del proyecto ante los investigadores del proyecto MONOIL. Las
preguntas utilizadas en dicha entrevista fueron redactadas de tal manera que los

64
interesados en el proyecto puedan entender los términos que se usaron para
poder lograr una recopilación de información relevante
Recolección de la Información
La recopilación de la información tomada se basa en el análisis desarrollado hacia
las bases de datos de organizaciones como CEPAL, OMS y varias bases
petroleras.
Otra forma de recopilación de información fue también por medio de información
bibliográfica y artículos en revistas de educación ambiental.
Para la elaboración de la entrevista re hizo un análisis de las preguntas a
considerar tomando en cuenta el grupo hacia el cual iban dirigidas posterior a eso
se realizó el análisis y procesos de la información recolectada.
Procesamiento y Análisis
Para poder analizar la información se utiliza una encuesta documentada, esta
encuesta se desarrolla con un total de 6 preguntas. El siguiente paso, luego del
tiempo establecido para la resolución de la encuesta, fue el procesamiento de la
información el cual está representado en los cuadros y gráficos que se detallan a
continuación.

65
DESCRIPCIÓN DE VARIABLES
Tablas de Variables Cualitativas
Estas variables son las utilizadas en las entrevistas, permiten determinar su peso
para la realización de los diagramas de barras y el análisis.
Cuadro #6: Variables Cualitativas I usado en entrevistas
DESCRIPCION VALOR
Totalmente de acuerdo 5
Parcialmente de acuerdo 4
Indiferente 3
Parcialmente en desacuerdo 2
Totalmente en desacuerdo 1
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #7: Variables Cualitativas II usado en entrevistas
DESCRIPCION VALOR
Excelente trabajo 5
Buen trabajo 4
Faltan pocos detalles 3
Trabajo inconcluso 2
Pésimo trabajo 1
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #8: Variables Cualitativas III usado en entrevistas
DESCRIPCION VALOR
Completamente entendible 5
Fácil entendimiento 4
Se entiende a medias 3
Difícil entendimiento 2
No se entiende nada 1
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

66
Tablas de Variables de frecuencia Cuantitativas
Variable Edad
Para determinar la edad promedio de los entrevistados y determinar un nivel de
experiencia por parte de ellos.
Cuadro #9: Frecuencia variable Edad
Rango Edad Frecuencia Absoluta
Frecuencia Relativa
18-26 7 70%
26-36 3 30%
36-46 0 0%
Total 10 100% Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
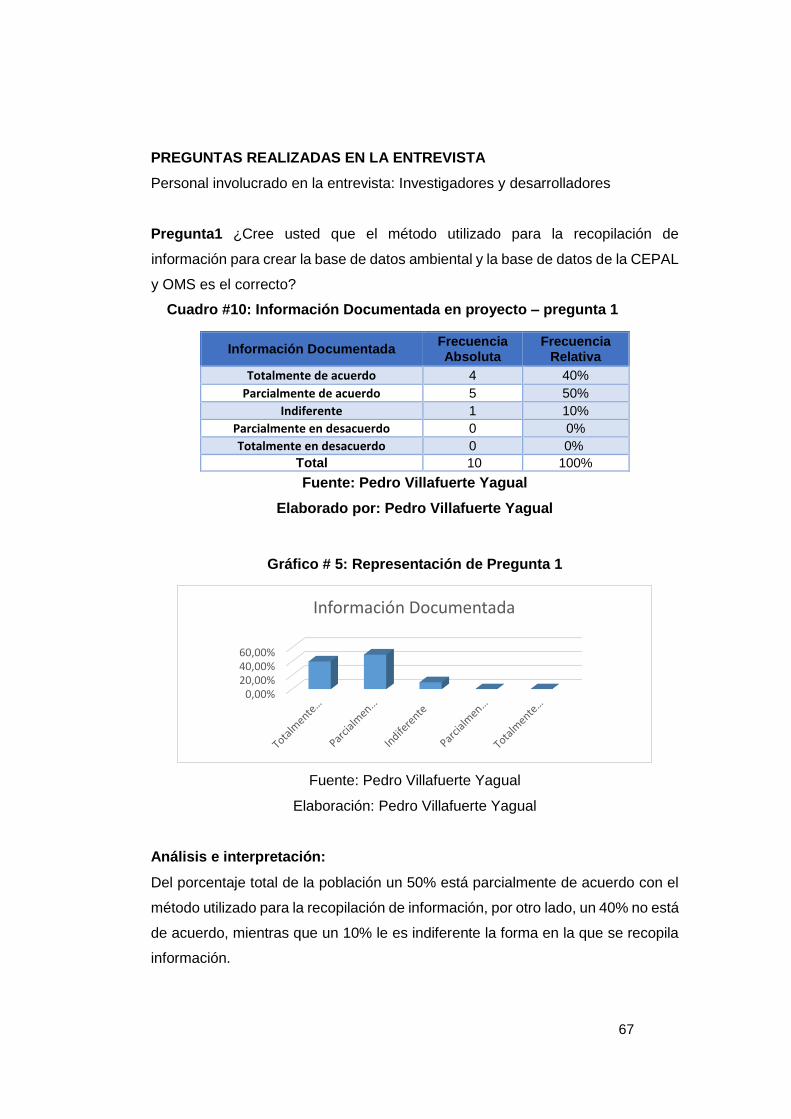
67
PREGUNTAS REALIZADAS EN LA ENTREVISTA
Personal involucrado en la entrevista: Investigadores y desarrolladores
Pregunta1 ¿Cree usted que el método utilizado para la recopilación de
información para crear la base de datos ambiental y la base de datos de la CEPAL
y OMS es el correcto?
Cuadro #10: Información Documentada en proyecto – pregunta 1
Información Documentada Frecuencia Absoluta
Frecuencia Relativa
Totalmente de acuerdo 4 40%
Parcialmente de acuerdo 5 50%
Indiferente 1 10%
Parcialmente en desacuerdo 0 0%
Totalmente en desacuerdo 0 0%
Total 10 100%
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Gráfico # 5: Representación de Pregunta 1
Fuente: Pedro Villafuerte Yagual
Elaboración: Pedro Villafuerte Yagual
Análisis e interpretación:
Del porcentaje total de la población un 50% está parcialmente de acuerdo con el
método utilizado para la recopilación de información, por otro lado, un 40% no está
de acuerdo, mientras que un 10% le es indiferente la forma en la que se recopila
información.
0,00%20,00%40,00%60,00%
Información Documentada

68
Pregunta 2. De lo analizado en la base de datos, ¿Cómo usted considera el
trabajo investigado para le realización de la unificación de las Base de datos
ambientales petroleras, CEPAL, OMS, y el tiempo de respuesta al ser consumidos
por otros sistemas?
Cuadro #11: Trabajo realizado en unificación de base de datos – pregunta 2
Trabajo realizado Frecuencia Absoluta
Frecuencia Relativa
Excelente trabajo 5 50%
Buen trabajo 4 40%
Faltan pocos detalles 1 10%
Trabajo inconcluso 0 00%
Pésimo trabajo 0 0%
Total 10 100%
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Gráfico # 6: Representación de Pregunta 2
Fuente: Pedro Villafuerte Yagual
Elaboración: Pedro Villafuerte Yagual
Análisis e interpretación:
Del total de la población entrevistada el 50% considera que es excelente la forma
en la que se ha investigado la información para el proyecto de tesis, un 40% de la
población considera que es un buen trabajo y un 10% indica que le faltan algunos
detalles.
0%
20%
40%
60%
Excelentetrabajo
Buentrabajo
Faltanpocos
detalles
Trabajoinconcluso
Pésimotrabajo
Trabajo investigativo
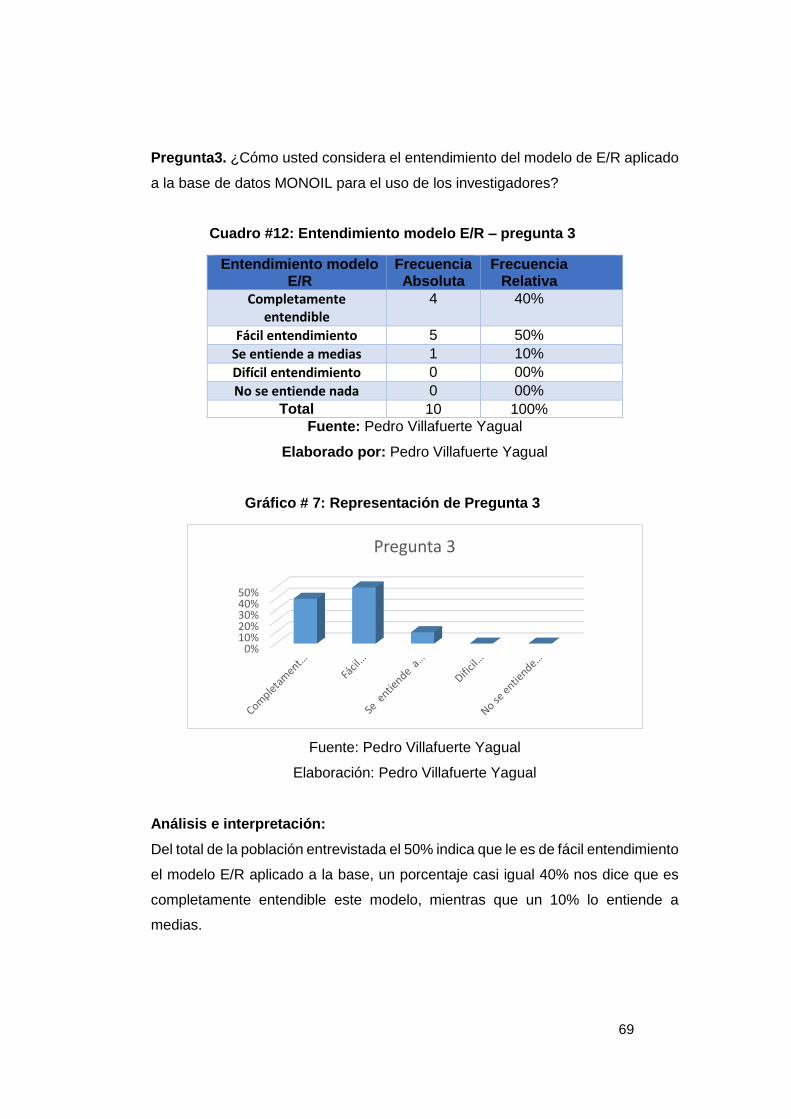
69
Pregunta3. ¿Cómo usted considera el entendimiento del modelo de E/R aplicado
a la base de datos MONOIL para el uso de los investigadores?
Cuadro #12: Entendimiento modelo E/R – pregunta 3
Entendimiento modelo E/R
Frecuencia Absoluta
Frecuencia Relativa
Completamente entendible
4 40%
Fácil entendimiento 5 50%
Se entiende a medias 1 10%
Difícil entendimiento 0 00%
No se entiende nada 0 00%
Total 10 100%
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Gráfico # 7: Representación de Pregunta 3
Fuente: Pedro Villafuerte Yagual
Elaboración: Pedro Villafuerte Yagual
Análisis e interpretación:
Del total de la población entrevistada el 50% indica que le es de fácil entendimiento
el modelo E/R aplicado a la base, un porcentaje casi igual 40% nos dice que es
completamente entendible este modelo, mientras que un 10% lo entiende a
medias.
0%10%20%30%40%50%
Pregunta 3
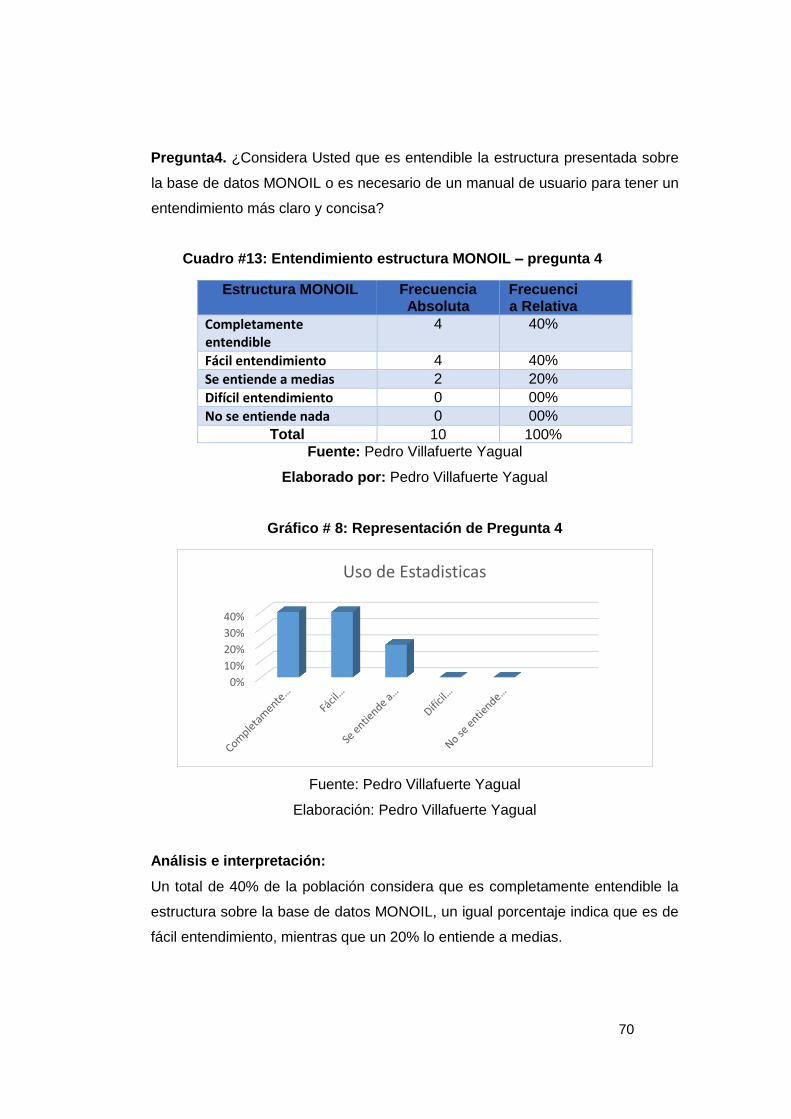
70
Pregunta4. ¿Considera Usted que es entendible la estructura presentada sobre
la base de datos MONOIL o es necesario de un manual de usuario para tener un
entendimiento más claro y concisa?
Cuadro #13: Entendimiento estructura MONOIL – pregunta 4
Estructura MONOIL Frecuencia Absoluta
Frecuencia Relativa
Completamente entendible
4 40%
Fácil entendimiento 4 40%
Se entiende a medias 2 20%
Difícil entendimiento 0 00%
No se entiende nada 0 00%
Total 10 100% Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Gráfico # 8: Representación de Pregunta 4
Fuente: Pedro Villafuerte Yagual
Elaboración: Pedro Villafuerte Yagual
Análisis e interpretación:
Un total de 40% de la población considera que es completamente entendible la
estructura sobre la base de datos MONOIL, un igual porcentaje indica que es de
fácil entendimiento, mientras que un 20% lo entiende a medias.
0%
10%
20%
30%
40%
Uso de Estadisticas
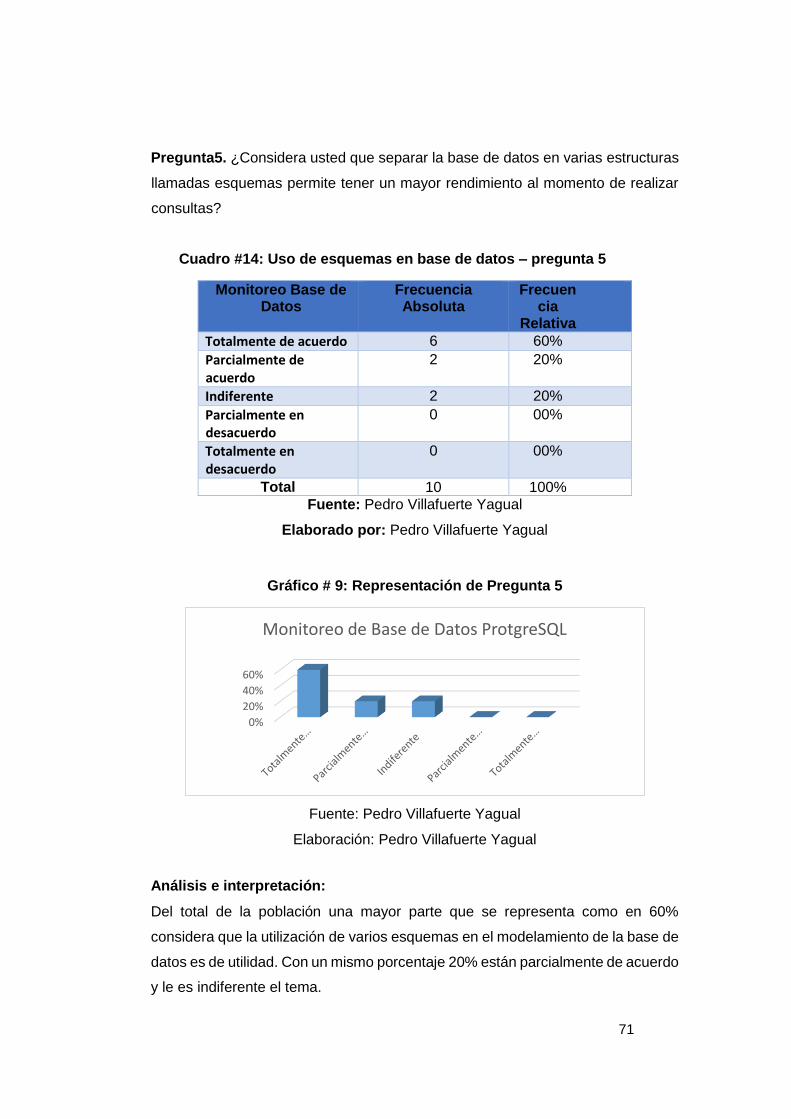
71
Pregunta5. ¿Considera usted que separar la base de datos en varias estructuras
llamadas esquemas permite tener un mayor rendimiento al momento de realizar
consultas?
Cuadro #14: Uso de esquemas en base de datos – pregunta 5
Monitoreo Base de Datos
Frecuencia Absoluta
Frecuencia
Relativa
Totalmente de acuerdo 6 60%
Parcialmente de acuerdo
2 20%
Indiferente 2 20%
Parcialmente en desacuerdo
0 00%
Totalmente en desacuerdo
0 00%
Total 10 100%
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Gráfico # 9: Representación de Pregunta 5
Fuente: Pedro Villafuerte Yagual
Elaboración: Pedro Villafuerte Yagual
Análisis e interpretación:
Del total de la población una mayor parte que se representa como en 60%
considera que la utilización de varios esquemas en el modelamiento de la base de
datos es de utilidad. Con un mismo porcentaje 20% están parcialmente de acuerdo
y le es indiferente el tema.
0%
20%
40%
60%
Monitoreo de Base de Datos ProtgreSQL

72
Validación de la Hipótesis
Luego de realizada el levantamiento de la información por medio de los métodos
que ya se explicaron anteriormente, se puede dar como resultado que es
necesaria la implementación de una base de datos que logre reunir la información
de varios repositorios, esto como ya hemos analizado le es de mucha ayuda para
los investigadores del proyecto MONOIL ya que les ahorrará tiempo, y costos
además de brindarles de forma rápida la información necesaria en sus actividades,
también se puede definir que esta Base de Datos resguardara de manera segura
toda la información confidencial que se enmarque dentro del proyecto en mención.

73
CAPÍTULO IV
PROPUESTA TECNOLÓGICA
Luego de haber investigado y analizado la problemática; se define la siguiente
propuesta tecnológica como solución al tema general objeto de este estudio.
Como propuesta general es la creación de una base de datos unificada en el
gestor PostgreSQL; la cual tomara información de repositorios que corresponden
a instituciones como CEPAL, OMS y datos correspondientes a la contaminación
ambiental producida por el petróleo.
Dichas instituciones cuentan con información muy amplia la cual es necesaria para
los investigadores, pero a la vez es tan extensa que se dificulta el estudio. Es por
este motivo que se presentó este proyecto de tesis, para así crear una base de
datos con información específica y netamente necesaria para los investigadores
las cuales les puede ahorrar tiempo y costos.
FACTIBILIDAD
Se toma en cuenta los siguientes puntos, los cuales son estudiados y analizados:
Control en redundancia
Factibilidad operacional
Factibilidad técnica
Factibilidad legal
Factibilidad económica
Análisis de Factibilidad
Después de haber analizado con los diferentes métodos de investigación la
problemática del estudio, se determina que la ejecución del tema de tesis
propuesto es factible para el éxito del proyecto.
Con el correcto análisis de la factibilidad se puede comprobar si el proyecto de
tesis planteado es viable para la realización. De no cumplir con los aspectos
fundamentales que comprueben su viabilidad entonces el proyecto se definiría

74
como abandonado o también se podría postergar, esto dependiendo del resultado
del análisis.
Grafico # 10: Análisis de factibilidad de un problema
Fuente: Pedro Villafuerte Yagual Elaboración: Pedro Villafuerte Yagual
Con el análisis de la encuesta realizada a la población se pudo detectar la
necesidad de este software y el impacto que este tendrá sobre la población
estudiada.
Factibilidad Operacional
El principal objetivo de la factibilidad operacional es lograr que el nuevo software
no sea complejo para los usuarios siendo un proyecto de fácil entendimiento y

75
amigable, para este procedimiento es necesario que se conozca del
funcionamiento del mismo y que se realicen constantes evaluaciones sobre los
integrantes del proyecto prevaleciendo el objetivo principal de tener un máximo
rendimiento.
El personal que usara la base de datos se encuentra totalmente interesados en la
realización del mismo ya que todos coinciden con la pronta necesidad del sistema.
Además de no estar de acuerdo con la forma en la que actualmente se recopila la
información y no tener un repositorio de los datos.
Es por este motivo que para el desarrollo del proyecto se analiza y considera todas
y cada una de las propuestas de los usuarios, las mismas que reflejaban sus
necesidades actuales, nuestro principal objetivo es dar solución a estas
necesidades y entregar un modelado de base de datos escalable.
Factibilidad Técnica
Para la tesis propuesta se evalúa la herramienta tecnológica que poseen los
interesados para poder comprobar la compatibilidad de los sistemas operativos.
Las necesidades de los equipos deben ser las siguientes:
Hardware
Servidor con sistema operativo Linux.
RAM de 8 GB
Disco Duro 500 GB
Software
Apache Tomcat.
Servidor de Base de datos PostgreSQL
IDE para PostgreSQL PGADMIN.

76
Nivel Técnico
Conocimientos técnicos en Modelamiento de Base de datos.
Conocimientos en Base de Datos
Conocimiento en Afinación de Scripts de consultas.
Grafico # 11: Esquema Conexión Cliente/Servidor
Fuente: Pedro Villafuerte Yagual Elaboración: Pedro Villafuerte Yagual
Factibilidad Legal
La factibilidad legal identifica si los requisitos del proyecto violan o atentan contra
alguna ley que sea acorde al proyecto.
Tal como se explica en el Capítulo II, donde se detalla los principios legales que
se tomaron en cuenta para la elaboración del presente proyecto de tesis; por lo
expuesto en ese punto podemos concluir que el tema propuesto es viable para la
ejecución ya que no infringe en ninguno de los artículos mencionados en el texto
anterior.
Entre los artículos que se tomaron en cuenta están los siguientes:
Decreto 1014
Establece reglas sobre el uso del software libre en servidores como ambientes de
producción o desarrollo.
Afinamiento de scripts Modelamiento BD

77
Ley Orgánica de Educación Superior.
Establece las normas para los costos de los programas informáticos o de sus
licencias en caso de que sea un sistema comercial.
Las instituciones de educación superior deben tener programas basados en
software libre.
Ley de la propiedad Intelectual.
Esta ley se aplica sobre los sistemas creados, ya sea un programa, manual,
diagrama de flujo, estructuras.
Factibilidad Económica
Mediante este estudio determinamos el costo/beneficio que se puede tener en el
modelado de datos, se analiza el recurso costo técnico y humano.
Para el estudio de la factibilidad económica se detallan los siguientes cuadros
donde se reflejan los costos del proyecto:
Cuadro #15: Comparativo de ingresos y egresos en el proyecto.
INGRESOS EGRESOS
Total, comparativo de ingresos y egresos 0,00 1820,00
Fuente: Datos de la investigación
Elaborado por: Pedro Villafuerte Yagual
Egresos del proyecto
Los egresos o gastos del proyecto se pueden puntualizar en el siguiente cuadro
el cual también se ha representado con un gráfico circular, para un mejor
entendimiento.

78
Cuadro #16: Concepto de egresos en el proyecto
CONCEPTO DE EGRESOS DÓLARES
Libros y documentos guías 30,00
Internet 80,00
Fotocopias 45,00
Suministros de oficina 85,00
Computadoras 900,00
Transporte 100,00
Comida 150,00
Impresiones de encuestas 25,00
Impresión de tesis y borrador 125,00
Anillado y empastado de tesis 60,00
Consumo Eléctrico 120,00
Varios 100,00
TOTAL 1820,00
Fuente: Datos de la investigación
Elaborado por: Pedro Villafuerte Yagual
Grafico # 12: Egresos del Proyecto
Fuente: Datos de la investigación
Elaboración: Pedro Villafuerte Yagual
2% 4%2%
5%
49%6%
8%
1%
7%
3%7%
6%
Libros y documentos guías
Internet
Fotocopias
Suministros de oficina
Computadoras
Transporte
Comida
Impresiones de encuestas
Impresión de tesis y borrador
Anillado y empastado de tesis
Consumo Eléctrico

79
Beneficios del proyecto
Los beneficios del proyecto los podemos dividir en dos grupos
Beneficios materiales
Base de datos con información oportuna y actualizada
Beneficios inmateriales
Conocimiento aprendido
Agilidad en las labores diarias de los interesados del proyecto
Análisis Costo-Beneficio
Un análisis costo-beneficio nos sirve para medir la rentabilidad financiera de un
proyecto; es decir con este resultado podemos concluir si la realización del
proyecto es viable o no.
La fórmula general para el cálculo es:
Donde el significado de las siglas es:
B/C: Relación Costo-Beneficio
VAI: Valor Actual de los Ingresos
VAC: Valor Actual de los Costos
El resultado de este análisis nos indicara lo siguiente:
Si B/C >1: Los beneficios superan los costos por lo tanto el proyecto es viable.
Si B/C <1: Los costos son mayores que los beneficios, el proyecto no se
considera.
Si B/C =1: Los beneficios son iguales a los costos, no hay ganancias con este
proyecto.
El presupuesto actual que maneja MONOIL por cada investigación asignada a una
persona es de aproximadamente $8750, desglosado de la siguiente manera:

80
Cuadro #17: Presupuesto estimado actual MONOIL
Descripción Costo 3 meses
Consumo Internet $150
Alimentos $500
Libros y Documentos guías $250
Transporte $1000
Impresiones $150
Varios $700
Sueldo $6000
Total, VAI $8750
Fuente: Datos de la investigación
Elaborado por: Pedro Villafuerte Yagual
Al utilizar como repositorio el gestor de base de datos y al realizar las consultas
directamente sobre la base el costo es menor:
Cuadro #18: Costo estimado actual MONOIL
Descripción Costo 3 meses
Consumo Internet $100
Alimentos $400
Libros y Documentos guías $150
Transporte $700
Impresiones $100
Varios $500
Sueldo $6000
Total, VAC $7950
Fuente: Datos de la investigación
Elaborado por: Pedro Villafuerte Yagual
B/C = VAI/VAC
B/C = 8750/7950
B/C = 1,10
Cumpliendo la condición:
Si B/C >1: Los beneficios superan los costos por lo tanto el proyecto es viable.

81
Etapas de la metodología del proyecto
Mejora Continua
Actualmente la forma de recopilación de información por parte de los
investigadores de MONOIL se evidencia una gran vulnerabilidad ya que no existe
un control adecuado en el proceso de la información sobre los contaminantes
petroleros en la región Amazónica del Ecuador. A la vez no cuentan con un
repositorio general para la búsqueda de información relacionada a problemas de
salud o de medidas poblacionales.
En la realización del proyecto se buscó las desventajas del proceso actual de
levantamiento de información para lo cual utilizamos el análisis FODA para
verificar la situación actual.
El análisis FODA consiste en realizar una evaluación de los factores fuertes
y débiles que, en su conjunto, diagnostican la situación interna de una
organización, así como su evaluación externa, es decir, las oportunidades y
amenazas. También es una herramienta que puede considerarse sencilla y que
permite obtener una perspectiva general de la situación estratégica de una
organización determinada. (Ponce Talancón, 2007)

82
Cuadro #19: Análisis FODA
Fortalezas Oportunidades
Acceso permitido solo hacia
los usuarios investigadores.
Cantidad de Información
recolectada sobre los
problemas ambientales.
Normalización sobre la
información.
Elaboración de una estrategia de
pruebas que analicen el
rendimiento de la información.
Recolección de información
capaz de aplicarse mejoras.
Análisis de estadísticas sobre la
información.
Debilidades Amenazas
No existe un control de acceso por
cada investigador.
No existe información relacionada
a la contaminación ambiental
petrolera.
No existe un sistema de
autogestión.
Robo o pérdida de información.
Mal uso de la disponibilidad de la
información.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
FORTALEZAS
La fortaleza principal del manejo de la información actual por parte de los
investigadores de MONOIL sobre la contaminación ambiental es el acceso
restringido hacia los usuarios investigadores ya que cada uno de ellos procesa la
información asignada, las cuales contempla varios temas incluyendo el análisis de
contaminación petrolera, salud, socio económico las cuales cumplen los
estándares de normalización propuesta por ellos para una mejor identificación de
los datos.

83
OPORTUNIDADES
Dentro de las oportunidades podemos constatar la elaboración de una estrategia
para identificar el actual rendimiento de la información procesada, analizando los
tiempos de respuesta para determinadas investigaciones sobre la contaminación
ambiental y poder compararlas con la información automatizada que tendrá la
base de datos de MONOIL, se podrá constatar las mejoras que se puedan aplicar
a la recolección de esta información, el análisis de las estadísticas en base a la
información recolectada también es una oportunidad ya que al aplicarse la mejora
con la base de datos se identificara esta información requerida sin necesidad de
una investigación exhaustiva.
DEBILIDADES
Actualmente se evidencia que no existe un control de acceso hacia cada
investigador, es decir, todos pueden acceder a la misma información a pesar del
nivel de conocimiento que presenten sobre dicha investigación. La data
recolectada por parte de sus investigadores sobre la contaminación ambiental es
en un plano general y no presentan un repositorio que respalde la información de
la contaminación petrolera en el amazonas ni las bases de datos de la CEPAL y
OMS. La actualización constante sobre estos datos se lo realiza de forma manual,
es decir no hay una auto gestión.
AMENAZAS
En base a las debilidades expuestas logramos evidenciar que la pérdida o robo
de información es uno de los procesos más críticos en la actualidad sobre la
búsqueda de la información de la contaminación ambiental, al no existir un
repositorio de datos con acceso restringido cualquier usuario puede hacer uso de
estos datos, esto también deja en evidencia el mal uso sobre la disponibilidad de
los datos recolectados.

84
Grafico # 13: Diagrama de Causa – Efecto
Investigadores
Diferentes fuentes de acceso. - Actualmente para la obtención de la información
los investigadores recurren a diversos medios de recopilación de información más
aun cuando la búsqueda es sobre los contaminantes ambientales, para esto con
la implementación de la base de datos tendrán un sistema en donde podrán buscar
la información relevante para ellos.
No existe repositorio de Información. – Al no existir un lugar donde se almacena
la data a buscar deben cumplir tareas más exhaustivas que alargan el tiempo
destinado a cierta investigación, con un repositorio la información es más concreta
y rápida.
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.

85
Base de Datos
Falta coordinación de la información. – No existe un control para la
coordinación de la información recolectada, los datos de la contaminación
ambiental petrolera pueden ser usada por varios investigadores, pero ellos
trataran la información acorde a sus necesidades.
Desconfianza en resguardo de información. – La desconfianza al guardar su
información en archivos propios se da por la falta de seguridad que esta puede
brindar, para esto el repositorio de la base de datos debe brindar la seguridad en
el resguardo de los registros que se vaya a almacenar.
Estándares
No se utilizan estándares de almacenamiento. - Al ser tratada por diferentes
medios no siempre se llega a un determinado fin, las investigaciones deben
cumplir con ciertas normas para fácil entendimiento por parte de los usuarios, al
estar en un repositorio de datos los investigadores deben cumplir las normas que
se aplican en esta sea cual sea la forma de procesar su información.
Falta de Control de Calidad. – El proceso manual de los datos puede ocasionar
una falta de estándares sobre los controles de calidad de las investigaciones, una
correcta estructura sobre la base de datos permite mejorar este proceso y se tiene
un determinado lineamiento sobre la información sea cual sea su medio.
Fuentes
Falta de datos sobre contaminación. – Actualmente no se encuentra con la
información correcta sobre la contaminación ambiental ocasionada por el petróleo
en la amazonia ecuatoriana, en base a las investigaciones realizadas se brinda de
esta base de datos que tomará como estructura las bases de datos de
contaminación petrolera mundial convirtiéndola en una base de datos
multiplataforma.

86
Falta de permisos a múltiples fuentes. – Para acceder a diversos sistemas
externos para consultar información, se necesita de diversos permisos y una serie
de medios para extraer la data y un lugar donde se almacene digitalmente, esta
falta de recursos limita los tiempos del planeamiento y análisis que necesitan los
investigadores.
PROCESO DE MEJORA
MAPA DE PROCESO
A continuación, se muestran los mapas de procesos a utilizar en la elaboración
del modelo E/R a utilizar en el proyecto de contaminación ambiental petrolera y la
unificación con las bases de datos de la CEPAL y OMS.

87
CREAR ESTANDAR DE BASE DE DATOS
Se crea un estándar sobre el desarrollo a la base de datos para que sea utilizado
por todos los integrantes del proyecto MONOIL, de esta manera se tendrá un
entendimiento más claro sobre la información que se resguardara sobre la base.
Grafico # 14: Análisis Estándar BD
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.
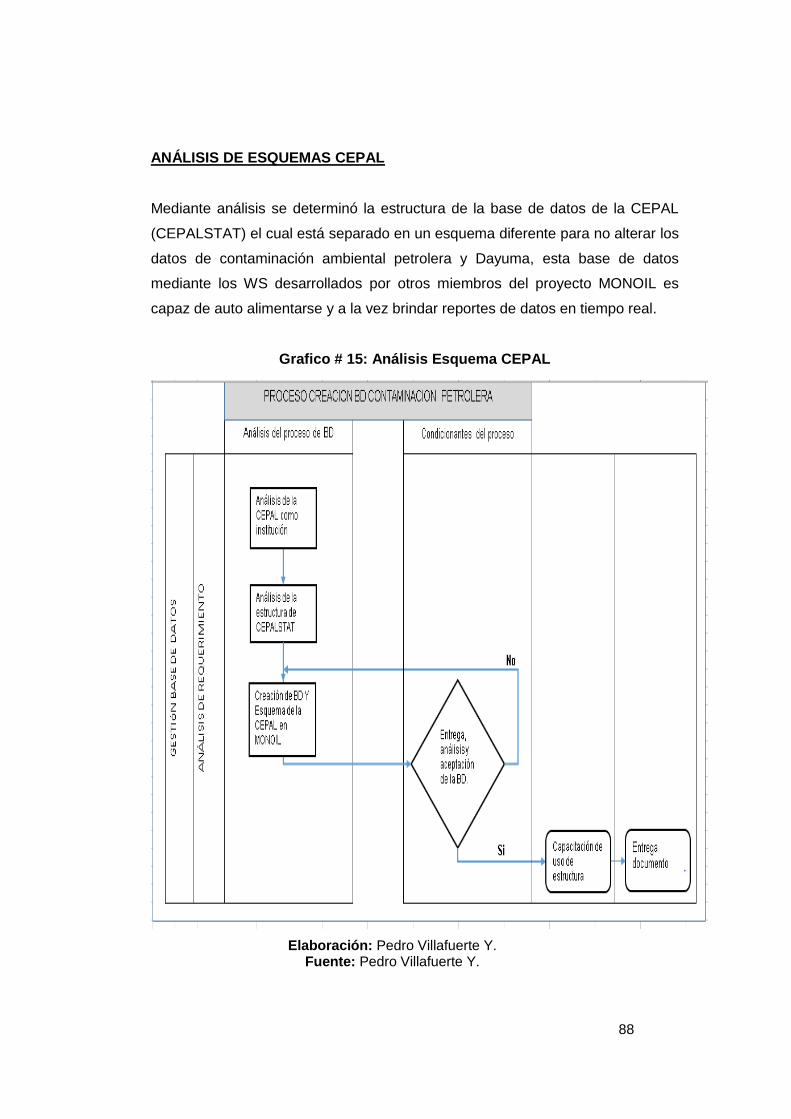
88
ANÁLISIS DE ESQUEMAS CEPAL
Mediante análisis se determinó la estructura de la base de datos de la CEPAL
(CEPALSTAT) el cual está separado en un esquema diferente para no alterar los
datos de contaminación ambiental petrolera y Dayuma, esta base de datos
mediante los WS desarrollados por otros miembros del proyecto MONOIL es
capaz de auto alimentarse y a la vez brindar reportes de datos en tiempo real.
Grafico # 15: Análisis Esquema CEPAL
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.

89
ANÁLISIS DE BD DE OMS
Mediante análisis se determina la estructura de la base de datos de la OMS (GHO
Database). La cual está separada en un esquema diferente para no alterar los
datos de contaminación ambiental petrolera y Dayuma. La base de datos mediante
los WS desarrollados por otros miembros del proyecto MONOIL es capaz de auto
alimentarse y a la vez brindar reportes y estadísticas de datos en tiempo real.
Grafico # 16: Análisis Esquema OMS
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.

90
ANÁLISIS DE BD CONTAMINACIÓN PETROLERA Y DAYUMA
Mediante análisis se determinó la estructura de la base de datos contaminación
ambiental petrolera y Dayuma. Las variables son analizadas con los grupos de
investigación del proyecto MONOIL para obtener la estructura más idónea, Se
utilizada posteriormente para la creación de los reportes que mostraran las
estadísticas utilizadas por los investigadores de MONOIL.
Grafico # 17: Análisis Esquema Contaminación
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.

91
UNIFICACIÓN DE ESQUEMAS
Se analizaron los esquemas construidos para determinar las tablas que generales
que son utilizadas en todos los módulos y construir un esquema que contengan
esas estructuras. La integridad de los datos se mantiene y no hay afectación
alguna en cada llamada por parte de agentes externos.
Grafico # 18: Análisis Unificación de Esquemas
Elaboración: Pedro Villafuerte Y. Fuente: Pedro Villafuerte Y.

92
Metodología de trabajo
En esta parte del documento describimos la implementación de la metodología
SCRUM que fue la utilizada para la creación de la base de datos de la
contaminación ambiental petrolera para el proyecto binacional MONOIL.
A continuación, se describirán los ciclos de vida que se usa en el proyecto, así
como los pasos para la gestión de las tareas sus requisitos, avances y
responsabilidades técnicas.
Propósito de la documentación
Facilita la información necesaria hacia los miembros implicados en esta parte del
proyecto MONOIL.
Alcance
Todos los procedimientos y miembros descritos en el desarrollo del proyecto
MONOIL.
Descripción General de la Metodología
Fundamentación
Entre las principales razones usadas en el ciclo de desarrollo usando la
Metodología SCRUM podemos definir las siguientes:
Las características que tiene la base de datos de contaminación ambiental del
proyecto MONOIL tiene un incremente en sus funcionalidades ya que se
deberá acoplar a cualquier otro sistema.
Frecuentemente se debe entregar al cliente los avances por cada módulo
terminado, para que exista un corto periodo de tiempo donde se aplique una
mejora continua, todos estos avances deben ser claros y bien detallados.
Posibles cambios entre los requisitos principales.

93
Estructura debe ser implementada orientándose a la necesidad de que el
sistema pueda implementar más funcionalidades que no fueron identificadas
anteriormente.
Durante la ejecución del proyecto frecuentemente se dan cambios que
modifican el orden de los requisitos iniciales, es decir puede existir un cambio
en las historias de usuarios.
Es difícil entender desde el inicio del proyecto la dimensión real que tiene el
sistema para lo cual las implementaciones de las historias de usuarios deben
ser en el tiempo indicado para evitar afectaciones futuras.
Valores de trabajo
Para que esta metodología tenga éxito se deben cumplir los siguientes valores
hacia los participantes del proyecto:
Dedicarse al proyecto
Respeto hacia los integrantes del proyecto
Responsabilidad, eficacia, disciplina
Atención netamente sobre la tarea.
Transparencia y efectividad sobre el proyecto.
Etapas de la metodología SCRUM usadas en el proyecto
A continuación, se describen las etapas usadas en la implementación del proyecto
en base a esta metodología.
1. Identificación de los requerimientos solicitados.
2. Análisis del proyecto por etapas.
3. Diseño y Ejecución.
4. Pruebas finales.

94
Identificación de Requerimientos solicitados
En base a reuniones iniciales con las personas involucradas netamente en el
proyecto se determinó la necesidad de una base de datos capaz de abarcar toda
la información referente a la contaminación petrolera en la amazonia ecuatoriana
especialmente en el aire, agua, tierra, especies vivas, Dayuma y que también
pueda abarcar información de los indicadores de salud y contaminación provistos
por la CEPAL y OMS.
Para cumplir con este requerimiento se debe analizar las afectaciones del petróleo
en cada uno de los componentes descritos anteriormente para saber que lo
provoco y cual fue o puede ser el método de remediación a implementar, para el
caso de las bases de datos de la CEPAL y OMS se debe analizar las estructuras
que estas proveen en sus estructuras a través de los servicios Web que estos
proveen.
REQUERIMIENTOS FUNCIONALES
R.F.1: Uso de un estándar aplicado a la base de datos PostgreSQL por todos los
miembros desarrolladores del proyecto MONOIL, para facilitar el uso y posterior
unificación de los esquemas creados.
R.F.2: Consultar en un esquema individual toda la estructura e información
referente a la contaminación ambiental petrolera en el aire, agua, tierra, especies
vivas y parroquia Dayuma para ser utilizados posteriormente por los
investigadores del proyecto MONOIL y para generación de reportes.
R.F.3: Consultar en un esquema individual toda la estructura e información
referente a los esquemas de base de datos de la CEPAL y OMS para la posterior
generación de reportes estadísticos.

95
REQUERIMIENTOS NO FUNCIONALES
R.N.F.1: Las estructuras creadas deben ser capaz de no afectar la información de
cada esquema creado.
R.N.F.2: El esquema de la CEPAL y OMS debe soportar la mayor
transaccionalidad posible por la cantidad de datos que puede albergar, esto sin
afectar el rendimiento de los demás esquemas.
R.N.F.3: Verificar la factibilidad de un sistema de monitoreo para verificar el
rendimiento del uso de base de datos PostgreSQL.
Estos requerimientos deben ser analizados con los involucrados en el proyecto
para revalidarlos y aplicar las respectivas mejoras en caso de ser necesario.
Análisis del proyecto por etapas.
Luego de haber obtenido los requerimientos de usuarios se realizó la creación de
las historias de usuarios por cada esquema creado y los análisis tomados de las
bases de datos libres, la OMS y la CEPAL.
Para el ambiente de desarrollo se utiliza una computadora HP con procesador i7,
8Gb de RAM, utilizando como gestor de base de datos se usó PostgreSQL y como
clientes pgAdmin III, Navicat.
Backlog de Producto
Roles
Administrador de Usuarios
Arquitectura de BD
Gestión de Esquemas
Lista de historias de usuario
1. Estándar de la base de datos.
2. Creación de la estructura del BD.

96
3. Identificación de variables de contaminación petrolera.
4. Identificación de variables de la CEPAL.
5. Identificación de variables de la OMS
6. Análisis de variables de contaminación con investigadores del proyecto
MONOIL.
7. Análisis de variables de la CEPAL y OMS con desarrolladores de los WS del
grupo MONOIL.
8. Creación de estructura para BD de contaminación.
9. Creación de estructura para BD de las API CEPAL y OMS
10. Unificación de esquemas.
11. Análisis de las estadísticas de rendimiento de la base de datos.
12. Análisis de la propuesta de un sistema open Source de monitorio en el
servidor de BD PostgreSQL.
Descripción de Historias de Usuario
Se debe considerar las historias de usuarios encontradas y determinar cuál sería
su peso y prioridad según el equipo de trabajo haciendo uso de la técnica de
planificación póquer, para esta parte se consideró el tiempo que puede llevar el
desarrollo de cada historia, a continuación, se detallan las historias de usuarios
creadas.
Cuadro #20: Estándar de la base de datos
Número 1
Título Estándares aplicada a BD en PostgreSQL
Descripción Yo como administrador, necesito de
estándares de BD para tener un control
sobre los fuentes y estructuras.
Importancia para la
Empresa:
7
Esfuerzo: 5
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
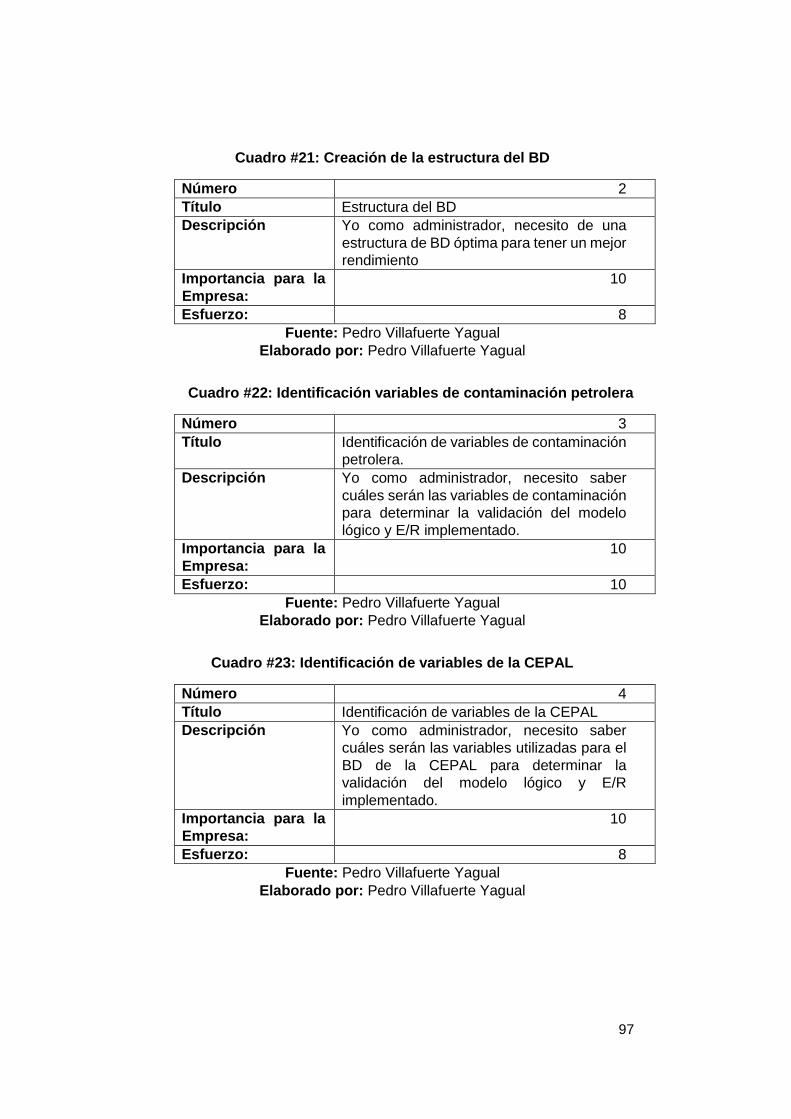
97
Cuadro #21: Creación de la estructura del BD
Número 2
Título Estructura del BD
Descripción Yo como administrador, necesito de una
estructura de BD óptima para tener un mejor
rendimiento
Importancia para la
Empresa:
10
Esfuerzo: 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #22: Identificación variables de contaminación petrolera
Número 3
Título Identificación de variables de contaminación
petrolera.
Descripción Yo como administrador, necesito saber
cuáles serán las variables de contaminación
para determinar la validación del modelo
lógico y E/R implementado.
Importancia para la
Empresa:
10
Esfuerzo: 10
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #23: Identificación de variables de la CEPAL
Número 4
Título Identificación de variables de la CEPAL
Descripción Yo como administrador, necesito saber
cuáles serán las variables utilizadas para el
BD de la CEPAL para determinar la
validación del modelo lógico y E/R
implementado.
Importancia para la
Empresa:
10
Esfuerzo: 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

98
Cuadro #24: Identificación de variables OMS
Número 5
Título Identificación de variables de la OMS
Descripción Yo como administrador, necesito saber
cuáles serán las variables utilizadas para el
BD de la OMS para determinar la validación
del modelo lógico y E/R implementado.
Importancia para la
Empresa:
10
Esfuerzo: 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #25: Análisis de variables contaminación con investigadores del proyecto MONOIL
Número 6
Título Análisis de variables de contaminación con
investigadores del proyecto MONOIL.
Descripción Yo como administrador, necesito saber si
las variables usadas en la base de datos de
Contaminación son las correctas para que
puedan ser usadas al 100% por los
investigadores de MONOIL.
Importancia para la
Empresa:
8
Esfuerzo: 7
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

99
Cuadro #26: Análisis de variables de la CEPAL y OMS con desarrolladores WS
Número 7
Título Análisis de variables de la CEPAL y OMS
con desarrolladores de los WS del grupo
MONOIL
Descripción Yo como administrador, necesito saber si
las variables usadas en la base de datos de
la CEPAL y OMS son las correctas para que
puedan ser usadas al 100% por los
desarrolladores de los WS.
Importancia para la
Empresa:
7
Esfuerzo: 6
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #27: Creación de estructura para BD de contaminación petrolera
Número 8
Título Creación de estructura para BD de
contaminación
Descripción Yo como administrador, necesito la
implementación de las variables de
contaminación sobre una base de datos,
para ser usada por los investigadores de
MONOIL.
Importancia para la
Empresa:
9
Esfuerzo: 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
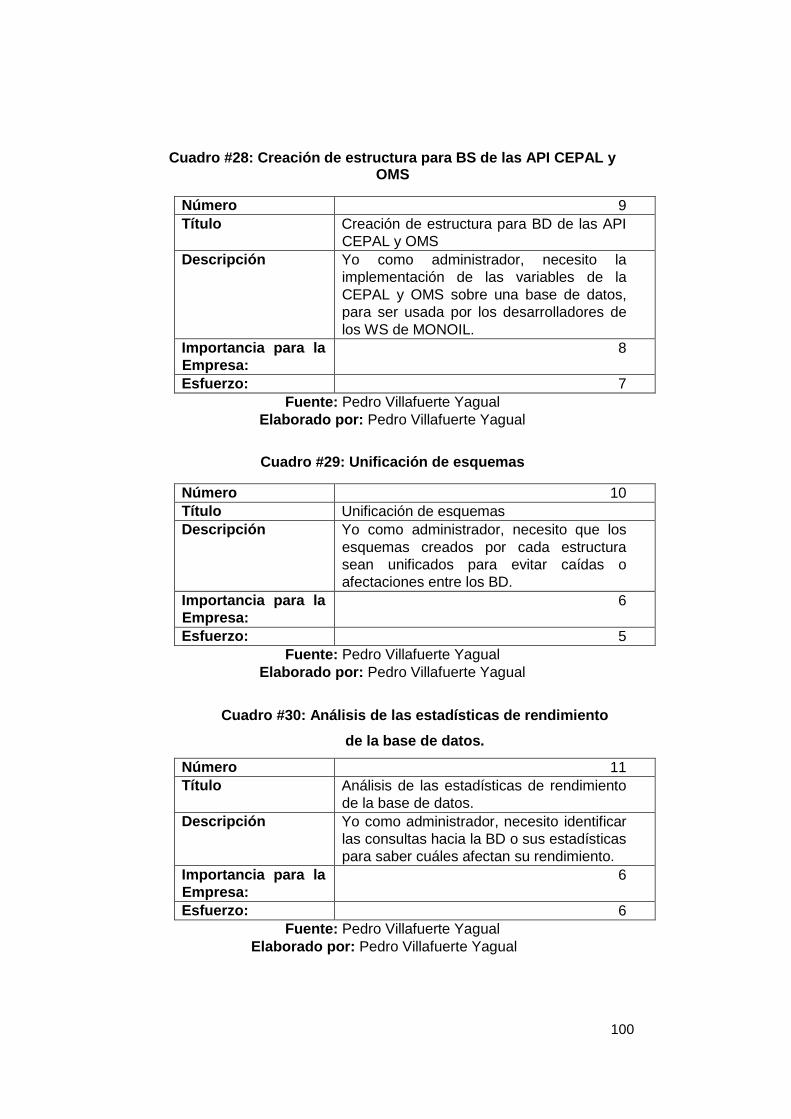
100
Cuadro #28: Creación de estructura para BS de las API CEPAL y OMS
Número 9
Título Creación de estructura para BD de las API
CEPAL y OMS
Descripción Yo como administrador, necesito la
implementación de las variables de la
CEPAL y OMS sobre una base de datos,
para ser usada por los desarrolladores de
los WS de MONOIL.
Importancia para la
Empresa:
8
Esfuerzo: 7
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #29: Unificación de esquemas
Número 10
Título Unificación de esquemas
Descripción Yo como administrador, necesito que los
esquemas creados por cada estructura
sean unificados para evitar caídas o
afectaciones entre los BD.
Importancia para la
Empresa:
6
Esfuerzo: 5
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #30: Análisis de las estadísticas de rendimiento
de la base de datos.
Número 11
Título Análisis de las estadísticas de rendimiento
de la base de datos.
Descripción Yo como administrador, necesito identificar
las consultas hacia la BD o sus estadísticas
para saber cuáles afectan su rendimiento.
Importancia para la
Empresa:
6
Esfuerzo: 6
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

101
Cuadro #30: Análisis de propuesta de un sistema de monitoreo en servidor de BD PostgreSQL
Número 12
Título Análisis de la propuesta de un sistema de
monitorio en el servidor de BD PostgreSQL
Descripción Yo como administrador, necesito saber si es
posible la futura implementación de un
sistema monitoreo de BD para analizar el
rendimiento y evitar afectaciones futuras.
Importancia para la
Empresa:
5
Esfuerzo: 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
REUNIÓN DE PLANEACIÓN DEL PROYECTO
Dentro de la metodología SCRUM existe la necesidad de agrupar las historias de
usuarios y desarrollar los Sprint para darle un orden de ejecución acorde a las
necesidades de los usuarios.
Cuadro #31: Reunión de planeación del proyecto
Historia de
usuario
Esfuerzo Importancia
para la
empresa
Esfuerzo
en horas
Sprint
Estándar base de
datos.
5 7 8 1
Creación de
estructura de BD.
8 10 6
Identificar variables
contaminación
petrolera.
10 10 72
Identificación de
variables CEPAL.
8 10 14
Identificación de
variables OMS
8 10 14

102
Análisis variables de
contaminación con
investigadores.
7 8 8
Análisis de variables
de la CEPAL y OMS
con desarrolladores
de los WS.
6 7 8
Creación de
estructura para BD
de contaminación.
8 9 48 2
Creación estructura
para BD de las API
CEPAL y OMS
7 8 32
Unificación de
esquemas.
5 6 8
Análisis de las
estadísticas de
rendimiento de la
base de datos.
6 6 10 3
Análisis de propuesta
de un sistema de
monitorio en servidor
de BD PostgreSQL.
8 5 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
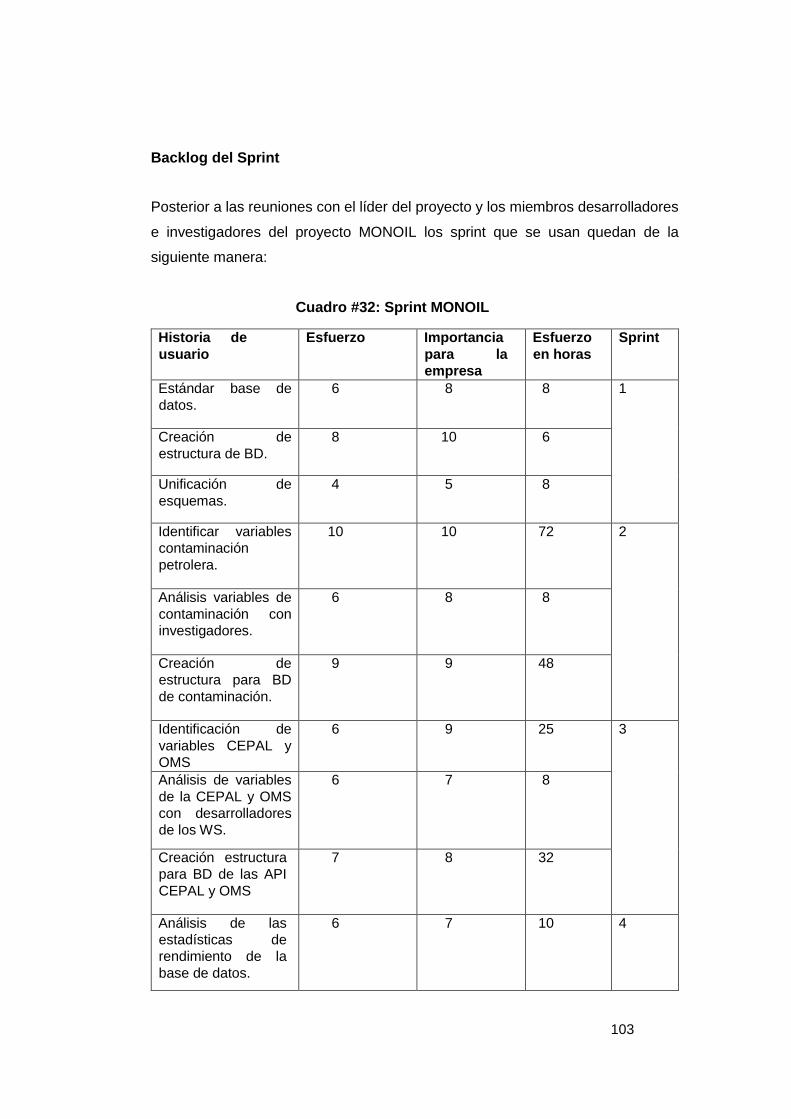
103
Backlog del Sprint
Posterior a las reuniones con el líder del proyecto y los miembros desarrolladores
e investigadores del proyecto MONOIL los sprint que se usan quedan de la
siguiente manera:
Cuadro #32: Sprint MONOIL
Historia de
usuario
Esfuerzo Importancia
para la
empresa
Esfuerzo
en horas
Sprint
Estándar base de
datos.
6 8 8 1
Creación de
estructura de BD.
8 10 6
Unificación de
esquemas.
4 5 8
Identificar variables
contaminación
petrolera.
10 10 72 2
Análisis variables de
contaminación con
investigadores.
6 8 8
Creación de
estructura para BD
de contaminación.
9 9 48
Identificación de
variables CEPAL y
OMS
6 9 25 3
Análisis de variables
de la CEPAL y OMS
con desarrolladores
de los WS.
6 7 8
Creación estructura
para BD de las API
CEPAL y OMS
7 8 32
Análisis de las
estadísticas de
rendimiento de la
base de datos.
6 7 10 4

104
Análisis de propuesta
de un sistema de
monitorio en servidor
de BD PostgreSQL.
8 5 8
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Diseño y Ejecución.
A continuación, se detalla la ejecución de cada Sprint usado en el proyecto.
Sprint 1
Cuadro #33: Historia de Usuario 1
Historia de
Usuario 1
Estándares aplicada a
BD en PostgreSQL
Esfuerzo en horas 6
Descripción Importancia para la
empresa
8
Yo como administrador, necesito de estándares de BD para tener un control
sobre los fuentes y estructuras.
Criterio de aceptación
Todas las estructuras creadas presentan el mismo estándar
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #34: Historia de Usuario 2
Historia de
Usuario 2
Estructura del BD Esfuerzo en horas 8
Descripción Importancia para la
empresa
10
Yo como administrador, necesito de una estructura de BD óptima para tener
un mejor rendimiento
Criterio de aceptación
La BD presenta la estructura cumpliendo con las reglas adecuadas de un
sistema actual.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

105
Cuadro #35: Historia de Usuario 3
Historia de
Usuario 3
Unificación de
esquemas
Esfuerzo en horas 4
Descripción Importancia para la
empresa
5
Yo como administrador, necesito que los esquemas creados por cada
estructura sean unificados para evitar caídas o afectaciones entre los BD.
Criterio de aceptación
La BD utiliza un esquema general utilizado por los demás esquemas del
proyecto MONOIL.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Demostración del Sprint 1
Grafico # 19: Historia de Usuario 1 – Estándar BD
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

106
Grafico # 20: Historia de Usuario 2 – Creación Esquemas
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

107
Grafico # 21: Historia de Usuario 3 – Esquema General
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
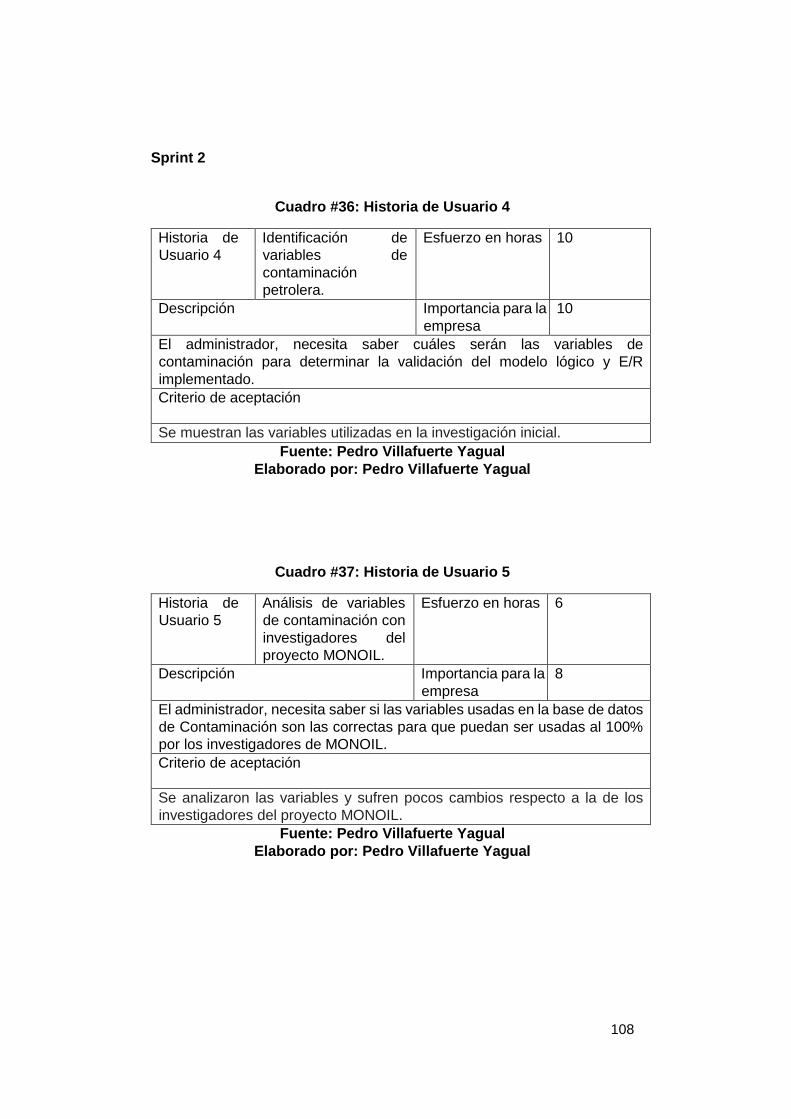
108
Sprint 2
Cuadro #36: Historia de Usuario 4
Historia de
Usuario 4
Identificación de
variables de
contaminación
petrolera.
Esfuerzo en horas 10
Descripción Importancia para la
empresa
10
El administrador, necesita saber cuáles serán las variables de
contaminación para determinar la validación del modelo lógico y E/R
implementado.
Criterio de aceptación
Se muestran las variables utilizadas en la investigación inicial.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #37: Historia de Usuario 5
Historia de
Usuario 5
Análisis de variables
de contaminación con
investigadores del
proyecto MONOIL.
Esfuerzo en horas 6
Descripción Importancia para la
empresa
8
El administrador, necesita saber si las variables usadas en la base de datos
de Contaminación son las correctas para que puedan ser usadas al 100%
por los investigadores de MONOIL.
Criterio de aceptación
Se analizaron las variables y sufren pocos cambios respecto a la de los
investigadores del proyecto MONOIL.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

109
Cuadro #38: Historia de Usuario 6
Historia de
Usuario 6
Creación de
estructura para BD de
contaminación
Esfuerzo en horas 9
Descripción Importancia para la
empresa
9
El administrador, necesita la implementación de las variables de
contaminación sobre una base de datos, para ser usada por los
investigadores de MONOIL.
Criterio de aceptación
Se muestra la estructura creada y si diagrama E/R.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Grafico # 22: Historia de Usuario 4 – Definición Variables
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

110
Grafico # 23: Historia de Usuario 5 – Validación de Variables
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
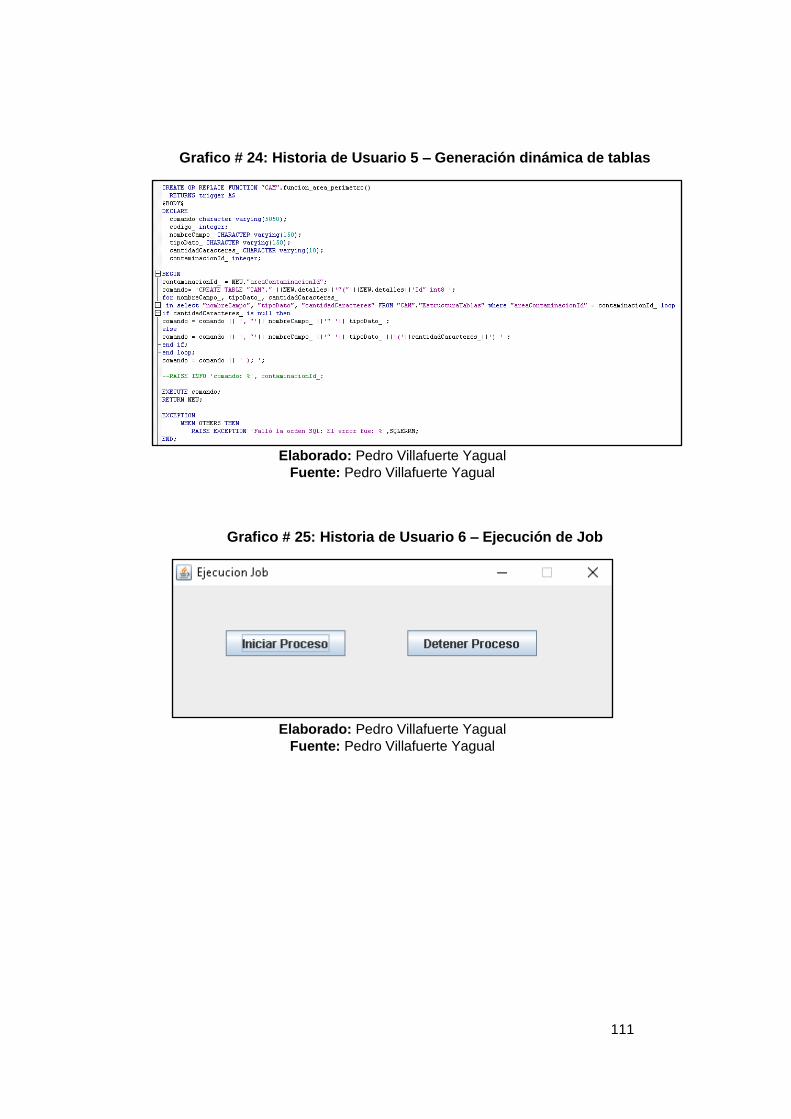
111
Grafico # 24: Historia de Usuario 5 – Generación dinámica de tablas
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
Grafico # 25: Historia de Usuario 6 – Ejecución de Job
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
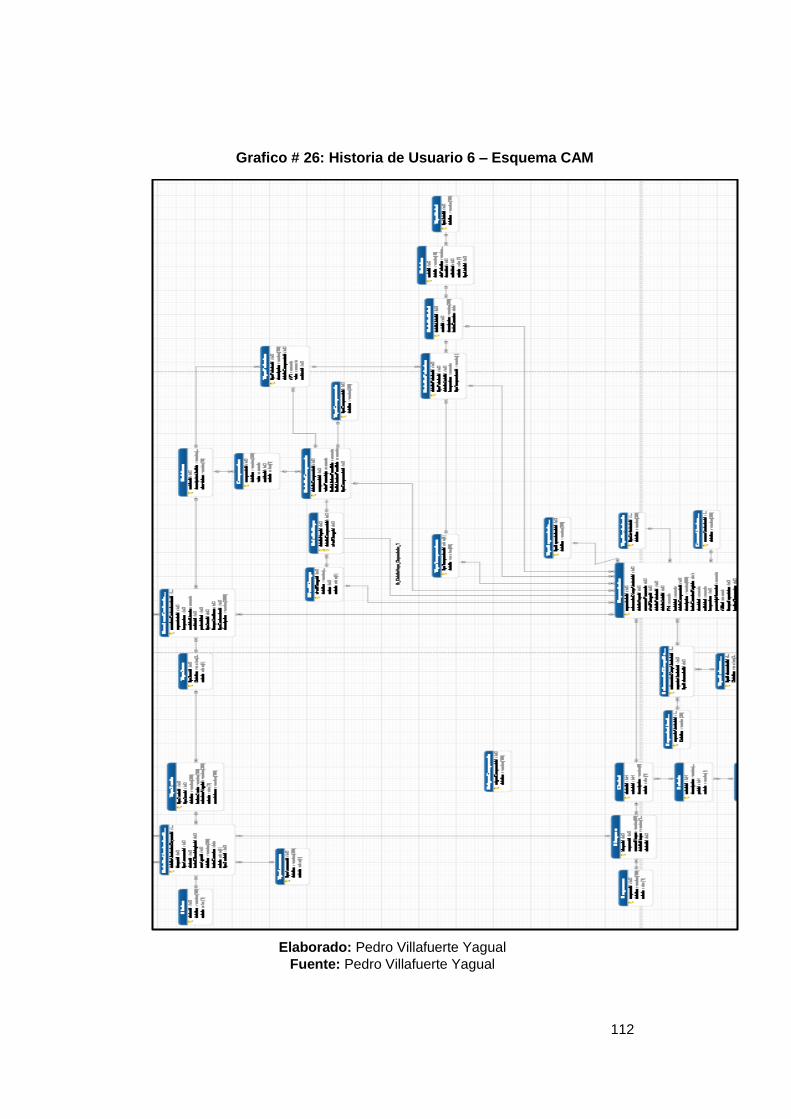
112
Grafico # 26: Historia de Usuario 6 – Esquema CAM
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

113
Sprint 3
Cuadro #39: Historia de Usuario 7
Historia de
Usuario 7
Identificación de
variables de la CEPAL
y OMS
Esfuerzo en horas 6
Descripción Importancia para la
empresa
9
El administrador, necesita saber cuáles serán las variables utilizadas para
el BD de la CEPAL y OMS para determinar la validación del modelo lógico
y E/R implementado.
Criterio de aceptación
Se muestran las variables utilizadas en la investigación inicial.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #40: Historia de Usuario 8
Historia de
Usuario 8
Análisis de variables
de la CEPAL y OMS
con desarrolladores
de los WS del grupo
MONOIL
Esfuerzo en horas 6
Descripción Importancia para la
empresa
7
El administrador, necesita saber si las variables usadas en la base de datos
de la CEPAL y OMS son las correctas para que puedan ser usadas al 100%
por los desarrolladores de los WS.
Criterio de aceptación
Se muestran las variables utilizadas en la investigación inicial.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

114
Cuadro #41: Historia de Usuario 9
Historia de
Usuario 9
Creación de
estructura para BD de
las API CEPAL y OMS
Esfuerzo en horas 7
Descripción Importancia para la
empresa
8
El administrador, necesita la implementación de las variables de la CEPAL
y OMS sobre una base de datos, para ser usada por los desarrolladores de
los WS de MONOIL.
Criterio de aceptación
Se muestra la estructura y el diagrama de E/R
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
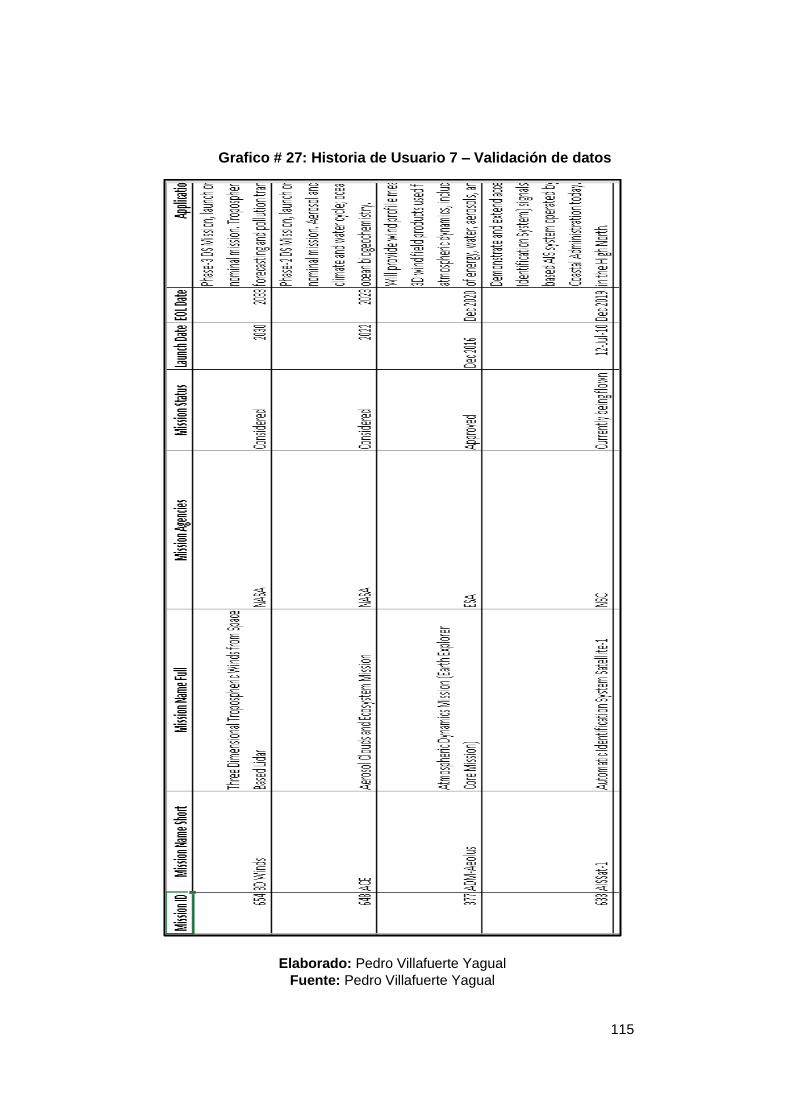
115
Grafico # 27: Historia de Usuario 7 – Validación de datos
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

116
Grafico # 28: Historia de Usuario 8 – Análisis de variables
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

117
Grafico # 29: Historia de Usuario 9 – Esquema API
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual

118
Sprint 4
Cuadro #42: Historia de usuario 10
Historia de
Usuario 10
Análisis de las
estadísticas de
rendimiento de la
base de datos.
Esfuerzo en horas 6
Descripción Importancia para la
empresa
7
El administrador, necesita identificar las consultas hacia la BD o sus
estadísticas para saber cuáles afectan su rendimiento.
Criterio de aceptación
Se muestra en la consola del servidor las estadísticas.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual
Cuadro #43: Historia de Usuario 11
Historia de
Usuario 11
Análisis de la
propuesta de un
sistema de monitorio
en el servidor de BD
PostgreSQL
Esfuerzo en horas 8
Descripción Importancia para la
empresa
5
El administrador, necesita saber si es posible la futura implementación de
un sistema monitoreo de BD para analizar el rendimiento y evitar
afectaciones futuras.
Criterio de aceptación
Se evidencia su funcionamiento.
Fuente: Pedro Villafuerte Yagual
Elaborado por: Pedro Villafuerte Yagual

119
Gráfico # 30: Historia de Usuario 10
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
Pruebas Finales
Culminada la creación de las estructuras creadas se las facilita a los
desarrolladores del proyecto MONOIL para el uso de los esquemas de las API de
la CEPAL y OMS, así como la base de datos a usar por los investigadores de
MONOIL y para la creación de reportes estadísticos dependiendo de las gráficas
que se quiera visualizar, cabe recalcar que esta base de datos albergar
información de contaminación mundial, datos socioeconómicos y de salud.
La implementación final de la base de datos es sobre los servidores de base de
datos que se encuentra en la carrera de Ing. en Networking y Telecomunicaciones
de la Universidad de Guayaquil.

120
Gráfico # 31: Historia de Usuario 11
Elaborado: Pedro Villafuerte Yagual
Fuente: Pedro Villafuerte Yagual
Entregables del proyecto
Basados en la metodología utilizada que es SCRUM los entregables son los
descritos a continuación:
Matriz de Pruebas, el cual detallara las pruebas realizadas en la creación del
modelado de datos.
Manual técnico, el cual describe los procesos de instalación de los
componentes utilizados y los respaldos de la base de datos creada
Manual de Usuario, el cual describe como debe ser el uso del modelado de
datos para un fácil entendimiento por parte del usuario final, se denota el uso
correcto hacia las bases de datos de la CEPAL, OMS y de Contaminación
Ambiental.

121
Criterios de validación de la propuesta
Las bases de datos relacionales permiten acoplar varios esquemas entre sí, sin la
necesidad de alterar la información que estas contengan ni afectar su rendimiento
a medida que exista transaccionalidad, utilizando los pasos para una correcta
normalización de base de datos se construye una estructura general que es de
gran ayuda para los investigadores y desarrolladores del proyecto MONOIL.
En base a las entrevistas realizadas se evidencia que más del %85 de los
entrevistados concuerdan en que los métodos utilizados para obtener y definir la
estructura de los modelos de contaminación petrolera, modelos de la CEPAL y
OMS han brindado los esquemas necesarios que se muestra en los diagramas
E/R físico y que son acordes a las necesidades planteadas por el proyecto
MONOIL.
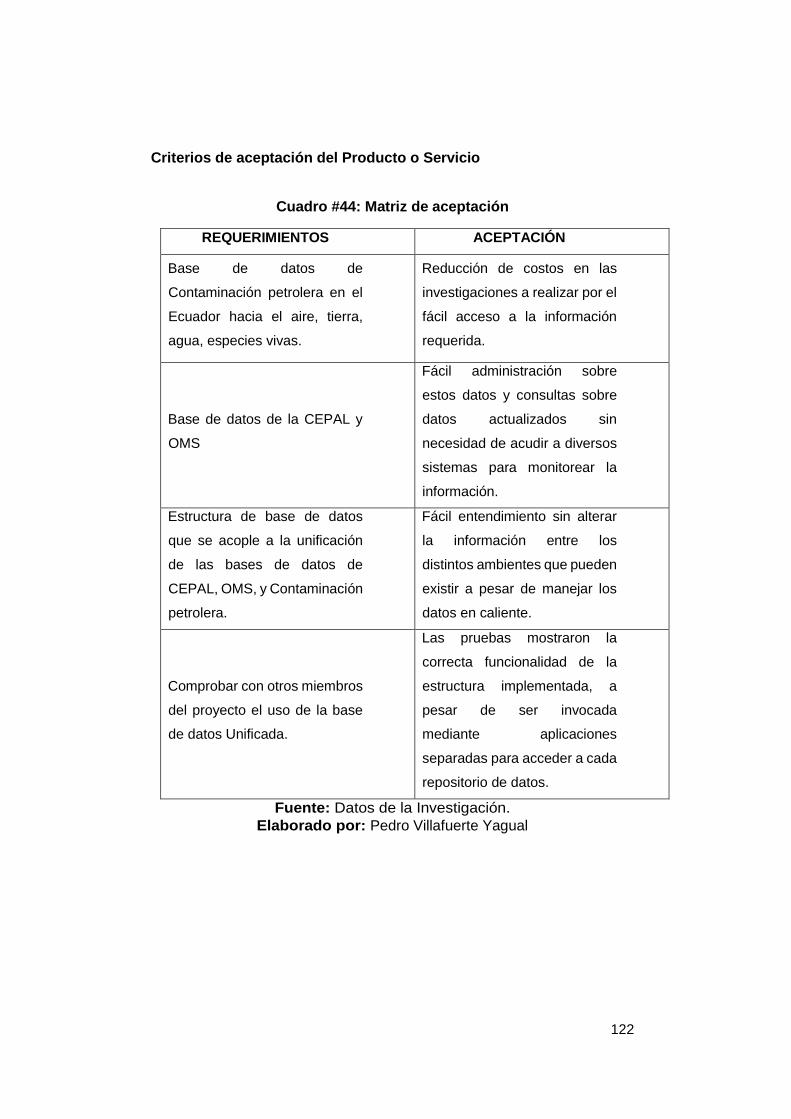
122
Criterios de aceptación del Producto o Servicio
Cuadro #44: Matriz de aceptación
REQUERIMIENTOS ACEPTACIÓN
Base de datos de
Contaminación petrolera en el
Ecuador hacia el aire, tierra,
agua, especies vivas.
Reducción de costos en las
investigaciones a realizar por el
fácil acceso a la información
requerida.
Base de datos de la CEPAL y
OMS
Fácil administración sobre
estos datos y consultas sobre
datos actualizados sin
necesidad de acudir a diversos
sistemas para monitorear la
información.
Estructura de base de datos
que se acople a la unificación
de las bases de datos de
CEPAL, OMS, y Contaminación
petrolera.
Fácil entendimiento sin alterar
la información entre los
distintos ambientes que pueden
existir a pesar de manejar los
datos en caliente.
Comprobar con otros miembros
del proyecto el uso de la base
de datos Unificada.
Las pruebas mostraron la
correcta funcionalidad de la
estructura implementada, a
pesar de ser invocada
mediante aplicaciones
separadas para acceder a cada
repositorio de datos.
Fuente: Datos de la Investigación.
Elaborado por: Pedro Villafuerte Yagual

123
Entre los informes de aseguramiento de calidad se detallan los siguientes puntos:
Documento de modelos de E/R de la base de datos de contaminación
petrolera, base de datos de la CEPAL y OMS.
Entrega de scripts de análisis y rendimiento del uso de la base de datos
Unificada.
Listado de índices utilizados para el correcto rendimiento de la base de datos
en momentos de mayor carga transaccional.

124
CONCLUSIONES Y RECOMENDACIONES
Conclusiones
La implementación del modelamiento de la BD incide positivamente a los
requerimientos de los investigadores de MONOIL por que permite definir una
estructura de fácil entendimiento capaz de acoplarse a diversas bases entre
la CEPAL, OMS, Contaminación petrolera hacia el aire, agua, tierra y
especies vivas.
Las variables definidas por los investigadores del proyecto MONOIL sobre
la contaminación petrolera en el aire, agua, tierra, especies vivas se
visualizan en el modelado de la base de datos creada se encuentra en una
estructura independiente para no afectar a los demás esquemas usados en
el proyecto MONOIL.
El modelo lógico implementado muestra la viabilidad de la estructura final
aplicada a la base de datos, permitiendo identificar el correcto uso de la
normalización aplicada.
El modelo entidad relación presenta una estructura legible que al ser
implementado no se ve afectada por la cantidad de registros que se ingresan
a la base de datos, lo evidenciado en la estructura indica que puede ser
expandible sin afectar a cada uno de los esquemas creados.

125
Recomendaciones
Al consumir esta base de datos es necesario que se analicen los datos que
se van a usar, en el caso de los sistemas externos de la CEPAL y OMS que
pueden brindar información irrelevante respecto a la contaminación
ambiental y que pueden afectar al rendimiento del gestor de base de datos.
Gestionar documentadamente las nuevas variables que se encuentren y no
perder el lineamiento que se ha estado siguiendo, si se crean módulos que
guarden relación con la base de datos MONOIL es preferible usar esquemas
individuales para liberar la carga transaccional.
Para futuras aplicaciones relacionados al proyecto MONOIL es preferible
mantener los usos de normalización para las nuevas estructuras de la base
de datos, pues mantener estos pasos permitirá brindar un modelo lógico
entendible en cada nueva estructura que se adicione en lo posterior.
A medida que aumente la data de las tablas de la base de datos del proyecto
MONOIL es recomendable hacer un análisis del diagrama entidad relación,
los índices creados y sus claves foráneas, es necesario hacer esta tarea ya
que la base de datos se puede volver pesada lo que afectara el rendimiento
de las consultas hacia la base de datos, y toda vez que las creaciones de
nuevas tablas pueden bajar los costes del uso a la base de datos.

126
BIBLIOGRAFÍA
Aguilera F., A., & Garcia M., L. D. (2011). RT-POSTGRESQL: EXTENSIÓN DE
POSTGRESQL PARA EL MANEJO DE DATOS CON FRECUENCIAS
TEMPORALES. scielo, 130-143. Bonell Rosabal, S. (2009). Petróleo y biotecnología: análisis del estado del arte
y tendenciasOil and biotechnology: analysis of the state of the art and
trends. Obtenido de scielo:
http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S1024-
94352009000100003&lng=es&tlng=es
Bustamante, T., & Jarrín, C. (2004). Indicadores sociales y petróleo en la
Amazonía. flacsoandes, 1-38.
Bustamante, T., & Jarrín, C. (2011). Indicadores sociales y petróleo en la
Amazonía. flacsoandes, 1-38.
Cáceres Hernández, J. (2007). Conceptos básicos de estadística para ciencias
sociale. Madrid.
Casalet, M. (01 de 01 de 1998). google books. Obtenido de
https://books.google.com.ec/books?id=SSqDGtPR7T0C&dq=investiga
cion+aplicada+concepto&hl=es&source=gbs_navlinks_s
Consejo de Educacion Superior. (10 de septiembre de 2016). CES. Obtenido
de
http://www.ces.gob.ec/index.php?option=com_phocadownload&view=
category&id=11:ley-organica-de-educacion-superior&Itemid=137
Desiré Atangana, M., & Sepúlveda Lima, R. (2007). TRANSFORMACIÓN DE
ESQUEMAS RELACIONALES ORIENTADOS A OBJETOS: UN
ENFOQUE BASADO EN EL OBJETO. Ingeniería Industrial 2007
XXVIII(1), 66-72.
Díaz Silvera, J., & Martínez Silva, J. (2010). INTERFAZ PARA LA GESTIÓN
DE BASES DE DATOS TEMPORALES (IGBDT) V 1.0. Ciencia en su
PC 2010 (1), 47-56.
Díaz, J. R. (2009). Las metodologías ágiles como garantía de calidad del
software. Revista Española de Innovación, Calidad e Ingeniería del
Software, 1-43.
Espinal Martín, Y., & Puebla Martínez, M. E. (2010). Sistema para la integración
del proceso de normalización de bases de datos relacionales con
gestores de bases de datos (SINORGES). Avances en Sistemas e
Informática, 17-25.
Fuentes Tapia, L. (2010). INCORPORACIÓN DE ELEMENTOS DE
INTELIGENCIA DE NEGOCIOS EN EL PROCESO DE ADMISIÓN Y
MATRÍCULA DE UNA UNIVERSIDAD CHILENA. Ingeniare. Revista
Chilena de Ingeniería, 383-394.
García Ferrando, M. (1993). El análisis de la realidad social. Métodos y
técnicas de investigación. Madrid-España: Alianza Universitaria.
Gavilán, A., & Martínez, M. Á. (2004). La investigación en México en materia
de compuestos orgánicos persistentes. Gaceta Ecológica, 5-20.
Gil Rivera, M. d. (1994).
Gordas, J., Cardiel, N., & Zamorano, J. (2011). Estadística Básica para
Estudiantes de Ciencias. Madrid.
Greguas Navarro, D., & Hernández Claro, R. L. (2010). Estándares de Diseño
Web. Ciencias de la Información, 69-71.

127
Kuby, J. (2008). Estadística Elemental. Gengage Learning.
López Takeyas, B. (30 de Abril de 2016). Apuntes y Prácticas de Programación
Orientada a Objetos (C#). Obtenido de
http://www.itnuevolaredo.edu.mx/takeyas/apuntes/poo/
Malhotra, N. K. (2004). Investigación de mercados: un enfoque aplicado. En N.
K. Malhotra, Investigación de mercados: un enfoque aplicado (pág.
713). Pearson Educación.
Monoil / IRD - Monoil. (12 de Agosto de 2016). Es.monoil.ird.fr. Obtenido de
http://es.monoil.ird.fr/
MONOIL. (10 de junio de 2016). MONOIL (Monitore ambiental, salud, sociedad
y petróleo en Ecuador). Obtenido de http://es.monoil.ird.fr/
MONOIL. (10 de septiembre de 2016). MONOIL, convenios de cooperacion
firmados para el proyecto MONOIL. Obtenido de
http://es.monoil.ird.fr/content/view/full/199826
Moore, D. S. (2000). Estadística Aplicada Básica. Barcelona: Manuel Girona,
61 - 08034.
mysql-hispano. (29 de mayo de 2003). Normalización de bases de datos.
Obtenido de
http://www.eet2mdp.edu.ar/alumnos/MATERIAL/MATERIAL/info/infon
orma.pdf
OMPI. (10 de septiembre de 2016). LEY DE PROPIEDAD INTELECTUAL.
Obtenido de http://www.wipo.int/wipolex/es/text.jsp?file_id=195678
Ponce Talancón, H. (2007). La matriz foda: alternativa de diagnóstico y
determinación de estrategias de intervención en diversas
organizaciones. Enseñanza e Investigación en Psicología., 113-130.
Proyectos Agiles.org. (10 de septiembre de 2016). METODOS AGILES.
Obtenido de https://proyectosagiles.org/que-es-scrum/
Robles Aranda, Y., & R. Sotolongo, A. (2013). INTEGRACIÓN DE LOS
ALGORITMOS DE MINERÍA DE DATOS 1R, PRISM E ID3 A
POSTGRESQL. JISTEM: Journal of Information Systems and
Technology Management, 389-406.
Robles Aranda, Y., & R. Sotolongo, A. (2013). INTEGRACIÓN DE LOS
ALGORITMOS DE MINERÍA DE DATOS 1R, PRISM E ID3 A
POSTGRESQL. JISTEM: Journal of Information Systems and
Technology Management, 389-406.
Secretaria Nacional de la Administracion Publica. (10 de septiembre de 2016).
Software Libre. Obtenido de
http://www.administracionpublica.gob.ec/wp-
content/uploads/downloads/2014/06/DecretoEjecutivo1014.pdf
Sistema Nacional de Nivelacion y Admision. (10 de septiembre de 2016).
SNNA. Obtenido de http://www.snna.gob.ec/wp-
content/themes/institucion/dw-
pages/Descargas/regimen_academico.pdf
Triola, M. F. (2004). Estadística Novena Edición. México: Pearson Educación.
Vargas Sabadías, A. (1995). Estadística descriptiva e inferencial. En A. Vargas
Sabadías, Estadística descriptiva e inferencial (pág. 576). Madrid:
Universidad de Castilla-La Mancha.
Vargas Sabadías, A. (1995). Estadística Descriptiva e Inferencial. Castilla-La
Mancha: Servicio de Publicaciones de la Universidad de Castilla-La
Mancha.

128
Vladimirovna Panteleeva, O. (2002). Fundamentos de Probabilidad y
Estadística. Toluca.
Wolf Iszaevich, G. E. (2011). Monitoreo de PostgreSQL con Munin. Revista
Cubana de Ciencias Informáticas, 1-8.
Yuni, J., & Urbano, A. (2006). Tecnicas Para Investigar 2. Editorial Brujas.
Zwerg-Villegas, A. M., & Ramírez Atehortúa, F. H. (2012). Metodología de la
investigación:más que una receta. AD-minister, 91-111.

129
ANEXO 1
ENTREVISTA PROYECTO MONOIL
Esta entrevista es dirigida hacia los miembros líderes del proyecto MONOIL y
docentes investigadores que validen la propuesta del proyecto de Titulación sobre
el Análisis y Creación del modelo de Base de Datos para la gestión de las variables
que definen los modelos de contaminación ambiental en el aire, agua, tierra y
especies vivas dentro del proyecto de definición de escenarios de la
contaminación petrolera en Ecuador del programa MONOIL
1. ¿Creé usted que el método utilizado para la recopilación de información para
crear la base de datos ambiental y la base de datos de la CEPAL y OMS es
el correcto?
Totalmente de acuerdo
Parcialmente de acuerdo
Indiferente
Parcialmente en desacuerdo
Totalmente en desacuerdo
2. ¿De lo analizado en la base de datos, ¿Cómo usted considera el trabajo
investigado para le realización de la unificación de las Base de datos
ambientales petroleras, CEPAL, OMS, y el tiempo de respuesta al ser
consumidos por otros sistemas?
Excelente trabajo
Buen trabajo
Faltan pocos detalles
Trabajo inconcluso
Pésimo trabajo

130
3. Como usted considera el entendimiento del modelo de E/R aplicado a la base
de datos MONOIL para el uso de los investigadores?
Completamente entendible
Fácil entendimiento
Se entiende a medias
Difícil entendimiento
No se entiende nada
4. ¿Considera Usted que es entendible la estructura presentada sobre la base
de datos MONOIL o es necesario de un manual de usuario para tener un
entendimiento más claro y concisa?
Completamente entendible
Fácil entendimiento
Se entiende a medias
Difícil entendimiento
No se entiende nada
5. ¿Considera usted que separar la base de datos en varias estructuras
llamadas esquemas permite tener un mayor rendimiento al momento de
realizar consultas?
Totalmente de acuerdo
Parcialmente de acuerdo
Indiferente
Parcialmente en desacuerdo
Totalmente en desacuerdo

131
ANEXO 2
MANUAL DE USUARIO
El presente documento indica el uso que se debe dar a los esquemas
creados en la base de datos PostgreSQL y el entendimiento del uso de
estas.
Esquema AMG
Este esquema es de uso general para toda la aplicación, los elementos que
se presentan son los siguientes:
Tablas:
Anio: Indica los años que se usaran para la generación de los reportes.
Anio
anioId Integer detalle Integer estado Character (1)
PK_ANIOS PRIMARY KEY(“anioId”)
Canal: utilizado por las tablas para identificar a que esquema pertenecen.
Canal
CanalId Character (3) Detalle Character
varying(50) estado Character (1)
PK_ANIOS PRIMARY KEY(“canalId”)

132
Ciudad: identifica las ciudades que se utilizaran en el módulo.
Ciudad
CiudadId Integer EstadoId Integer descripcion Character (1)
estado Character (1)
PK_CIUDAD PRIMARY KEY(“ciudadId”)
FK_ESTADO_CIUDAD FOREIGN KEY(“estadoId”)
Estado: identifica los estados asociados a las ciudades que se utilizaran
en el módulo.
Estado
EstadoId Integer Descripción Character varying
(50) PaisId Integer
estado Character varying (1)
PK_ESTADO PRIMARY KEY(“estadoId”) FK_PAIS_ESTADO FOREIGN KEY(“paisId”)
Idioma: identifica los idiomas que se pueden configurar para los modulos
utilizados en el proyecto.
Idioma
IdiomaId Character (3) Detalle Character varying
(15) Estado Character varying
(1)
PK_IDIOMA PRIMARY KEY(“idiomaId”)
País: identifica los países que se pueden configurar para los módulos
utilizados en el proyecto.
Pais
paisId Integer Descripción Character varying
(15) Estado Character varying
(1)
PK_PAIS PRIMARY KEY(“paisId”)

133
Usuario: identifica los usuarios que se pueden configurar para los módulos
utilizados en el proyecto.
Usuario
UsarioId Bigserial Identificación Character varying
(15) Apellidos Character varying
(100) Nombres Character varying
(100) Nacionalidad Character varying
PaisId Integer
EstadoId Integer
CiudadId Integer
Teléfono Character varying
Telefonotrabajo Character varying
Email1 Character varying
Email2 Character varying
fechaNacimiento Date
PK_USUARIO PRIMARY KEY(“usuarioId”)
FK_CIUDAD_USUARIO FOREIGN KEY (“ciudadId”)
FK_ESTADO_USUARIO FOREIGN KEY (“estadoId”)
FK_PAIS_USUARIO FOREIGN KEY (“paisId”)
RegistrosAuditoria: almacena los log sean por errores o por notificaciones
presentes en el sistema.
RegistrosAuditoria
registroAuditoriaId smaillint descripcion Character varying
(2000) nivelRiesgoId smaillint
fechaCreacion Date
canalId character varying (5)
PK_REGISTROSAUDITORIA PRIMARY KEY(“registroAuditoriaId”) FK_REGISTROSAUDITORIA_01 FOREIGN KEY (“canalId”)

134
Esquema API
Este esquema es de uso general para los servicios web usados por la
CEPAL y OMS.
Categoria: tabla usada por la OMS para sus indicadores.
categoriaId int2
Descripción varchar(150)
dimensionId int2
DetalleAcumuladoCategoria: usa los detalles que se agrupan por los
indicadores de la OMS
detalleAcumuladoCategoriald int2
acumuladoCategoriald int2
Valor varchar(250)
Factld varchar(100)
Published varchar(100)
Dataset varchar(100)
fechaIngreso int2
fechaCaducudad int2
AcumuladoCategoria: contiene el valor de los indicadores de la OMS.
acumuladoCategoriald int2
Dimensionld int2
Categoriald int2

135
Dimension: detalla las dimensiones usadas por la CEPAL y OMS.
Dimensionld int8
descripcionIdiona1 varchar(250)
descripcionIdioma2 varchar(250)
descripcionIdioma3 varchar(250)
Estado char1
Integradorld varchar(15
DetalleDimension: indica los detalles de las dimensiones que se utilizaran
en la CEPAL y OMS.
detalleDimensionld int8
Dimensionld int8
Orden int8
Estado char(1)
descripcionDetalleIdioma1 varchar(250)
descripcionDetalleIdioma2 varchar(250)
url varchar(250)
detalleDisplay varchar(250)
integradorld varchar(15)
ValorCategoriaDimension: es el valor que se mostraran en los reportes
se los agrupa por categoria y dimension usado generalmente por la OMS.
valorCategoriaDimensionld int2
detalleDimensionld int2
Categoriald int2
Valor varchar(500)
DetalleDisplay varchar(250)
IndicadorDetaDimension: asocia los indicadores con los detalles de las
dimensiones usado por la CEPAL.
indicadorDetaDimensionld int8
Indicadorld int8
detalleDimensionld int8
Indicador: se detallan los indicadores usados por la CEPAL.
Indicadorld int8
Estado char(1)
descripcionIdioma1 varchar(300)

136
descripcionIdioma2 varchar(300)
unidadIdioma1 varchar(100)
unidadIdioma2 varchar(100)
definicionUnidadIdioma1 varchar(300)
definicionUnidadIdioma2 varchar(300)
AreaIndicador: asocia las áreas con los indicadores usados por la CEPAL.
areaIndicadorld int8
Areald int8
Indicadorld int8
Notas: asocia las notas creadas por los investigadores de la CEPAL.
notald int8
descripcionIdioma1 varchar(100)
descripcionIdioma2 varchar(100)
DatoValorDimension: muestra los valores asociados a las dimensiones
utilizados por la CEPAL.
datoValorDimensionld int8
Fuenteld int8
Notald varchar(150)
nomenclaturaIso varchar(15)
indicadorDetaDimensionld int8
Valor varchar(250)
descripcionDatoIdioma1 varchar(150)
descripcionDatoIdioma2 varchar(150)
descripcionCalculoIdioma1 varchar(500)
descripcionCalculoIdioma2 varchar(500)
comentarioIdioma1 varchar(300)
comentarioIdioma2 varchar(300)
Aniold int4
Area: detalla las áreas que se asocian a los módulos de la CEPAL y agrupa
a los indicadores.
Areald int8
descripcionIdioma1 varchar(150)
descripcionIdioma2 varchar(150)

137
ArbolArea: agrupa las áreas para que puedan ser mostrados como árbol
por los reportes de la CEPAL.
ArbolAreald int8
Areald int8
subAreald int8
Estado char(1)
Temald int8
Fuente: Son las fuentes de dónde sacan la información los investigadores
de la CEPAL.
fuenteld int(8)
abreviatura varchar(10)
urlOrganizacion varchar(100)
urlPublicacion varchar(100)
organizacionIdioma1 varchar(250)
organizacionIdioma2 varchar(250)
descripcionPublicacionIdioma1 varchar(500)
descripcionPublicacionIdioma2 varchar(500)
ESQUEMA CAM
Este esquema alberga las variables investigadas para contaminación
ambiental.

138
UsoAgua: detalla los usos que se le pueden dar al agua sea contaminada
o pura.
usoAguald int2
Detalles varchar(150)
Estado char(1)
FactorClimatologico: factores que afectan al clima.
factorClimatologicoId int2
Detalles varchar(150)
Clima varchar(150)
Estado char(1)
Etnias: etnias que están presentes en las tierras afectadas por la
contaminación ambiental.
etniasId int2
Detalles varchar(100)
Estado char(1)
DetalleAfectacionDayuma: contiene los detalles que afectan a las tierras
de Dayuma.
detalleAfectacionDayumaId int8
bloqueId int2
tipoAmenazasId int2
etniasId int2
factorClimatologicoId int2
usoAguaId int2
Detalles varchar(250)
fechaCreacion date
Estado char(1)
tipoSueloId int2
TipoSuelo: los tipos de suelos afectados.
tipoSueloId int2
tipoZonaId int2
Detalles varchar(250)
texturaSuelo varchar(150)
coberturaVegetal varchar(250)

139
Estado char(1)
Ecosistema varchar(150)
TipoZona: Diferencia los tipos de zonas usados por los investigadores
tipoZonaId int2
Detalles varchar(250)
estado char(1)
TipoAmenaza: son los tipos de amenazas que presentan los derrames del
petróleo.
tipoAmenazaId int2
detalles verchar(250)
estado char(1)
OrigenCompuesto: indica el origen de los compuestos que se presentan.
origenCompuestoId int2
detalles varchar(150)
Empresa: las empresas presentes en las zonas de afectación de Dayuma.
empresaId int2
detalles varchar(150)
estado char(1)
Bloques: son las zonas de afectación por los cuales se separan en la
amazonia para la explotación petrolera.
bloqueId int2
empresaId int2
numeroBloque varchar(50)
detallesBloque varchar(150)
ciudadId int2
TipoContencion: son los tipos de contención para determinadas zonas.
tipoContencionId int2
detalles vechar(250)
MuestreContaminacion: Detalla las formas de contaminación.
muestreoContaminacionId int8
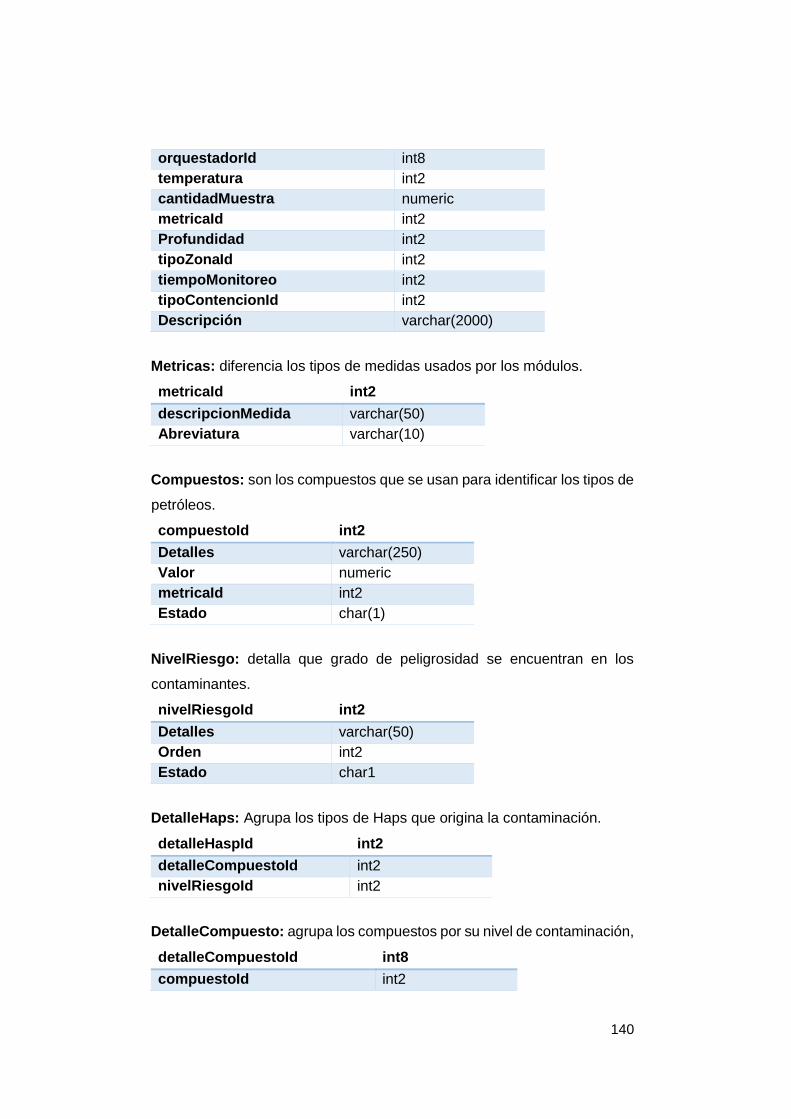
140
orquestadorId int8
temperatura int2
cantidadMuestra numeric
metricaId int2
Profundidad int2
tipoZonaId int2
tiempoMonitoreo int2
tipoContencionId int2
Descripción varchar(2000)
Metricas: diferencia los tipos de medidas usados por los módulos.
metricaId int2
descripcionMedida varchar(50)
Abreviatura varchar(10)
Compuestos: son los compuestos que se usan para identificar los tipos de
petróleos.
compuestoId int2
Detalles varchar(250)
Valor numeric
metricaId int2
Estado char(1)
NivelRiesgo: detalla que grado de peligrosidad se encuentran en los
contaminantes.
nivelRiesgoId int2
Detalles varchar(50)
Orden int2
Estado char1
DetalleHaps: Agrupa los tipos de Haps que origina la contaminación.
detalleHaspId int2
detalleCompuestoId int2
nivelRiesgoId int2
DetalleCompuesto: agrupa los compuestos por su nivel de contaminación,
detalleCompuestoId int8
compuestoId int2
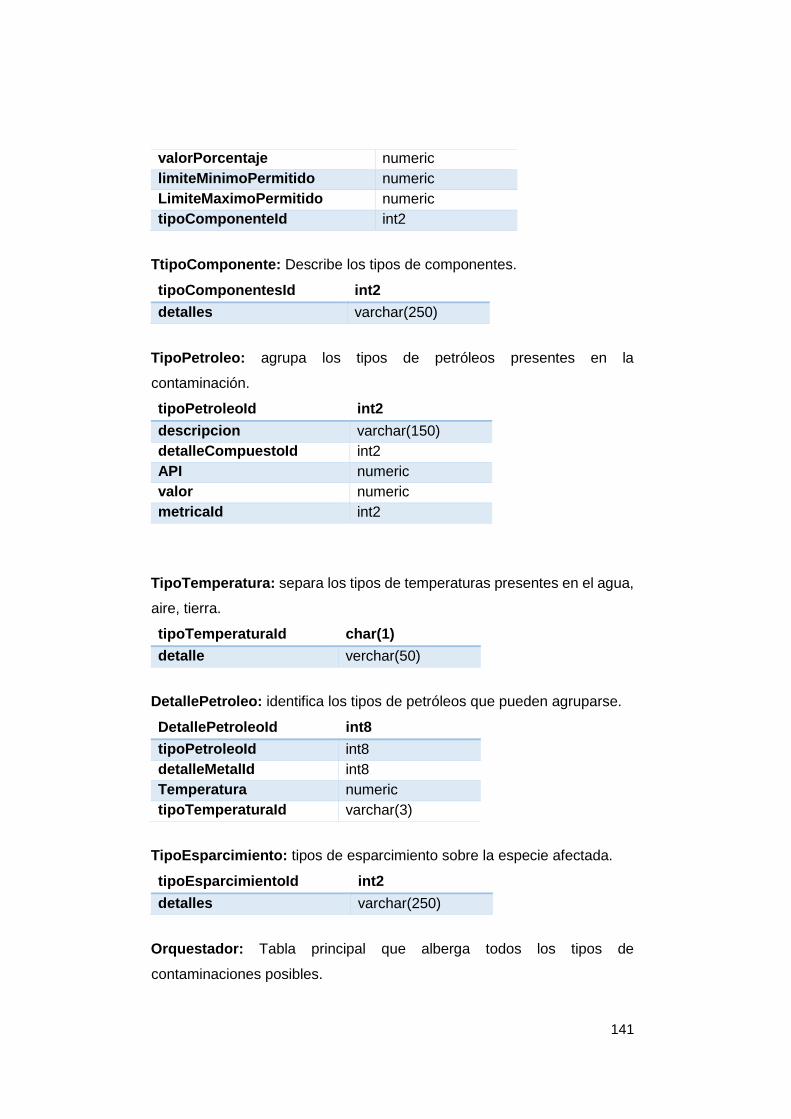
141
valorPorcentaje numeric
limiteMinimoPermitido numeric
LimiteMaximoPermitido numeric
tipoComponenteId int2
TtipoComponente: Describe los tipos de componentes.
tipoComponentesId int2
detalles varchar(250)
TipoPetroleo: agrupa los tipos de petróleos presentes en la
contaminación.
tipoPetroleoId int2
descripcion varchar(150)
detalleCompuestoId int2
API numeric
valor numeric
metricaId int2
TipoTemperatura: separa los tipos de temperaturas presentes en el agua,
aire, tierra.
tipoTemperaturaId char(1)
detalle verchar(50)
DetallePetroleo: identifica los tipos de petróleos que pueden agruparse.
DetallePetroleoId int8
tipoPetroleoId int8
detalleMetalId int8
Temperatura numeric
tipoTemperaturaId varchar(3)
TipoEsparcimiento: tipos de esparcimiento sobre la especie afectada.
tipoEsparcimientoId int2
detalles varchar(250)
Orquestador: Tabla principal que alberga todos los tipos de
contaminaciones posibles.

142
orquestadorId int2
enfermedadXespAfectadaId int2
detalleHaspId int2
semanasPresencia int2
nivelRiesgoId int2
detallePetroleoId int2
detalleMetalId int2
PH numeric
Toxidad numeric
detalleCompuestoId int2
Descripción varchar(500)
fechaCreacionRegistro date
Densidad numeric
Salinidad numeric
Temperatura int2
porcentajeHumedad numeric
Altitud numeric
tiempoExposicion int2
barrilesDerramados int8
velocidadViento int2
conductividadElectrica int2
tipoTemperaturaId varchar(3)
superficieAfectada numeric
porcEfectividadContencion numeric
ciudadId int2
areaContaminacionId int2
causaAfectacionId int2
tipoMovimientoId int2
tipoEsparcimientoId int2
TipoMovimiento: los tipos de movimientos que se presentan en las olas
tipoMovimientoId int2
Detalles varchar(250)
Metales: detalla los metales y su nivel de contaminación.
metalId int8
Detalle varchar(50)
abrPeriodica varchar(4)
Densidad int2
Salinidad int2

143
Estado char(1)
tipoMetalId int2
DetalleMetal: agrupa los contaminantes presentes por los metales.
detalleMetalId int2
metalId int2
Descrpcion varchar(250)
fechaCreacion date
TipoMetal: detalla los tipos de metales y su nivel de contaminación,
tipoMetalId int2
detalles varchar(150)
EspecieAfectada: indica las posibles especies afectadas por el nivel de
contaminación.
especieAfectadaId int2
Detalles verchar(250)
TipoEnfermedad: Detalla los tipos de enfermedades.
tipoEnfermedadId int2
Detalles varcgar(250)
CausaAfectacion: causas de la contaminación.
causaAfectacionId int2
detalles varchar(250)
AreaContaminacion: detalla el área de contaminación.
areaContaminacionId int2
detalles varchar(0)
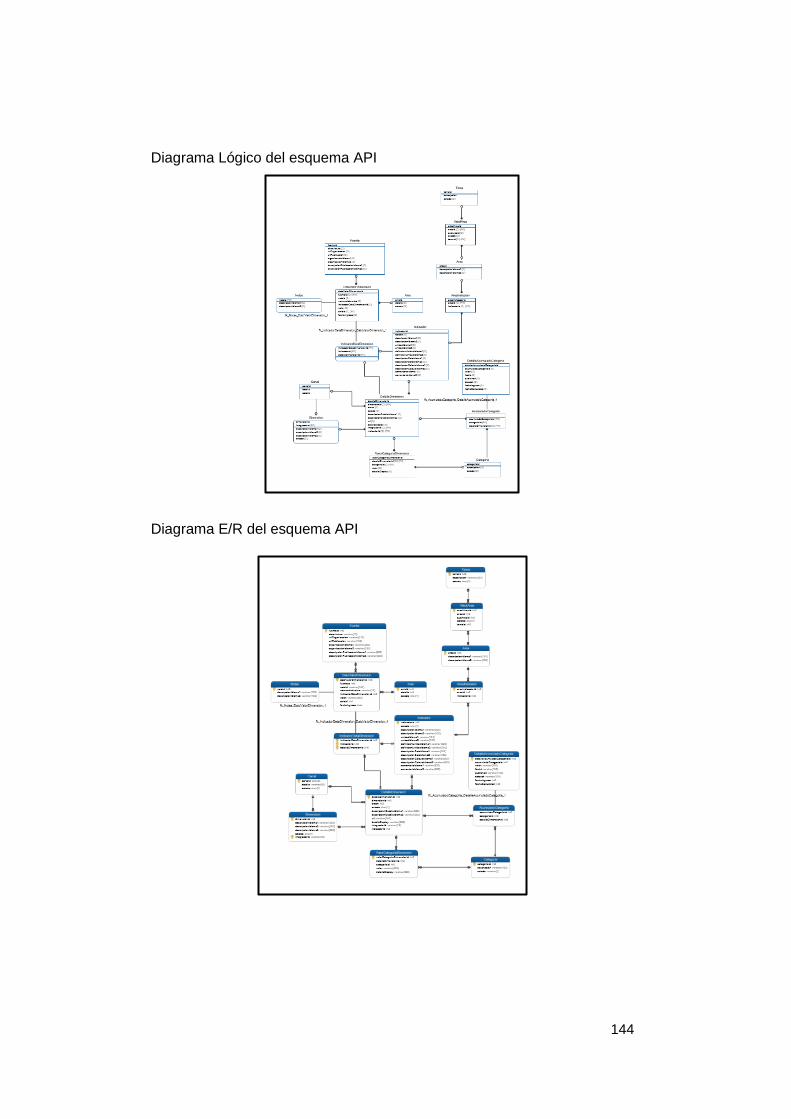
144
Diagrama Lógico del esquema API
Diagrama E/R del esquema API

145
Diagrama Lógico del esquema CAM

146
Diagrama E/R del esquema CAM

147
Diagrama Lógico del esquema AMG
Diagrama E/R del esquema AMG

148
ANEXO 3
MANUAL TECNICO
En el presente manual se indica cómo se debe instalar los esquemas a utilizar
para los módulos de contaminación ambiental petrolera, indicadores de la CEPAL
y OMS, módulos generales. Los siguientes pasos se los debe realizar en la
herramienta pgAdmin III, en caso de no existir la Base MONOIL se la debe crear
siguiendo los pasos a continuación:
1. Clic derecho en la opción Databases y seleccionar New Database.
2. Escribir MONOIL en la opción NAME.
3. Una vez creada la base seleccionarla, dar clic derecho y luego en Restore.
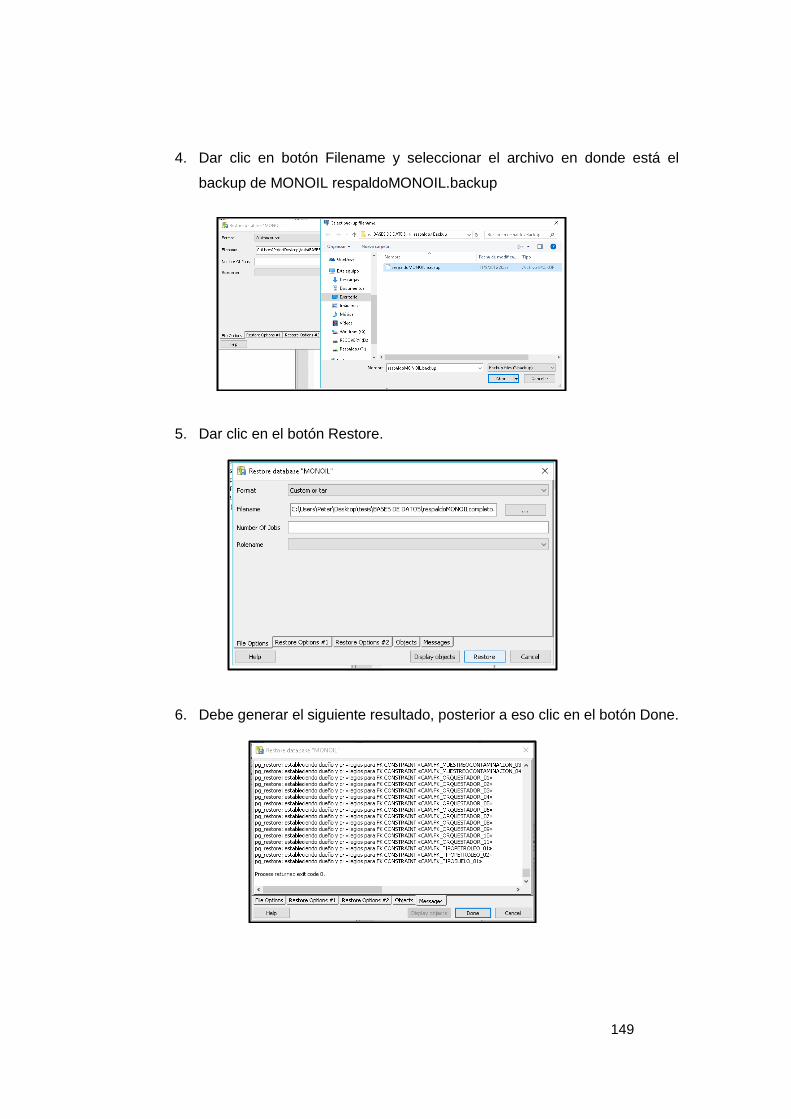
149
4. Dar clic en botón Filename y seleccionar el archivo en donde está el
backup de MONOIL respaldoMONOIL.backup
5. Dar clic en el botón Restore.
6. Debe generar el siguiente resultado, posterior a eso clic en el botón Done.
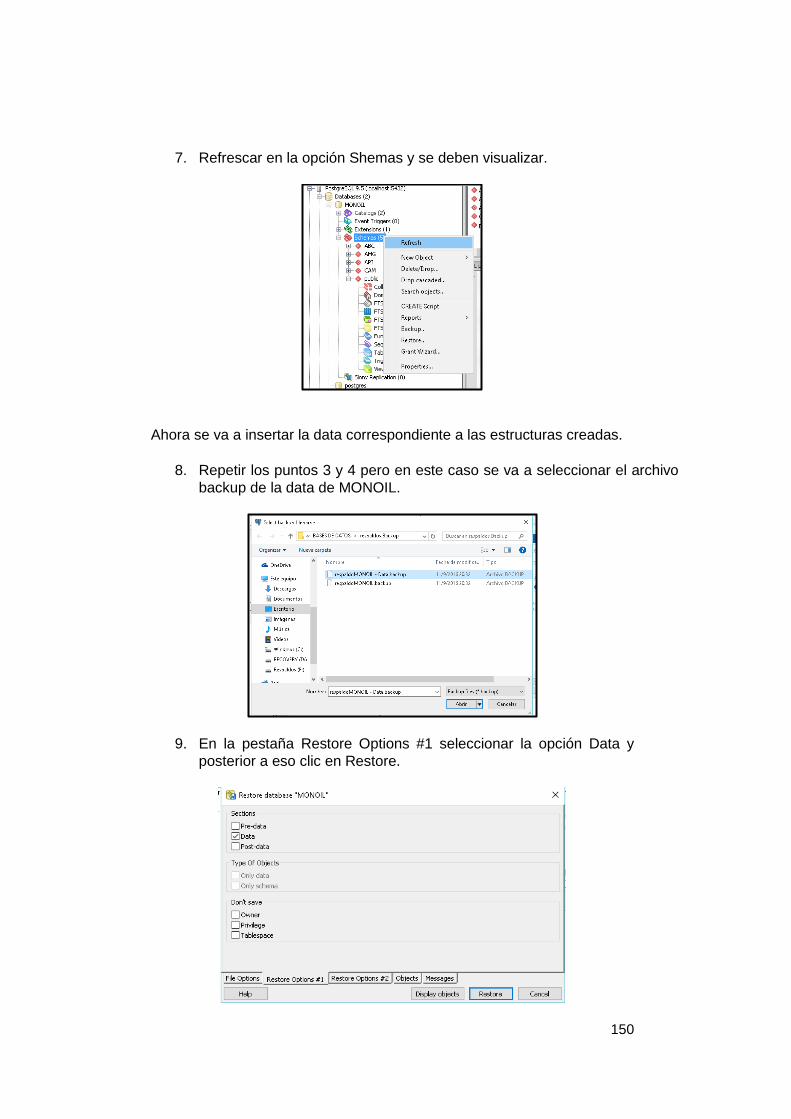
150
7. Refrescar en la opción Shemas y se deben visualizar.
Ahora se va a insertar la data correspondiente a las estructuras creadas.
8. Repetir los puntos 3 y 4 pero en este caso se va a seleccionar el archivo
backup de la data de MONOIL.
9. En la pestaña Restore Options #1 seleccionar la opción Data y
posterior a eso clic en Restore.

151
10. Se mostrará un mensaje como el indicado a continuación y con eso
terminará la inserción de datos sobre las tablas.
11. Crear una carpeta en la unidad D:\ de nombre “Archivos” y copiar los
archivos logs.txt y conexión.txt
12. Dentro del archivo conexión.txt actualizar las credenciales de conexión
a la base de datos.
13. Ejecutar el .jar entregado myejecucion.jar