unidad 01 regresiòn lineal
DESCRIPTION
Estadística InferencialTRANSCRIPT

Regresión Lineal Simple y Correlación
Si tenemos 2 datos “x” y “y” se pueden graficar en un sistema coordenado y así obtener su
representación gráfica y a esta representación se le llama
diagrama de dispersión.

x y
5 10
7 15
11 20
15 25
20 30
25 35
30 40
35 45
40 50
Ejemplo:


Errores comunes en regresión
a) Extrapolación más allá del rango de los datos observados.
b) Causa y efecto.
c) Uso de tendencias anteriores para estimar tendencias futuras.
d) Interpretación errónea de los coeficientes de correlación y determinación.
e) Descubrimiento de relaciones cuando no existen.

Extrapolación más allá del rango de los datos observados
Un error común es suponer que la línea de estimación puede aplicarse en cualquier intervalo de valores. Una ecuación de estimación es válida sólo para el mismo rango dentro del cual se tomó la muestra inicialmente.

Causa y efecto
Los análisis de regresión y correlación no pueden, de ninguna manera, determinar
la causa y el efecto.

Uso de tendencias anteriores para estimar tendencias futuras
Debemos reevaluar los datos históricos que se usarán para estimar la ecuación de
regresión. Las condiciones pueden cambiar y violar una o más de las
suposiciones de las cuales depende nuestro análisis de regresión. En muchas situaciones, sin embargo, esta varianza
cambia de un año a otro.

Interpretación errónea de los coeficientes de correlación y determinación
El coeficiente de determinación se malinterpreta si usamos r2 para describir el porcentaje de cambio en la variable dependiente ocasionado por un cambio en la variable independiente. Esto es incorrecto porque r2 es una medida sólo de qué tan bien una variable describe a la otra, no de qué tanto cambio en una variable es originado por la otra variable. También se debe distinguir r y r2.

Descubrimiento de relaciones cuando no existen
Al aplicar el análisis de regresión, en ocasiones se encuentra una relación entre dos variables que, de hecho, no tienen un vínculo común o sentido. A este respecto, si uno tuviera que desarrollar un gran número de regresiones entre muchos pares de variables, probablemente sería posible obtener algunas “relaciones” sugeridas bastante interesantes. Se requiere tener el conocimiento, de las limitaciones inherentes a la técnica que se está empleando, además de sentido común para evitar llegar a conclusiones injustificadas.

Modelo de regresión simple
El análisis de la regresión puede ser lineal o no lineal (curvilíneo), y puede ser lineal simple o lineal múltiple. El lineal simple se ocupa sólo de 2 variables y el lineal múltiple de 3 o más variables.

Modelo de regresión simple
El objetivo de este modelo es explicar el comportamiento de una variable cuantitativa de interés Y (consumo en un supermercado, temperatura del aire) como función de otra variable cuantitativa X observable (ofertas, altura a la que se toma la temperatura).

Modelo de regresión simple
En el modelo de regresión lineal simple, se expresa yi como función lineal de xi.
yi = β0 + β1xi + εi
donde:
yi = valor pronosticado de y para la observación i.
β0 = Ordenada en yi para la población, representa el valor promedio de yi cuando xi es igual a 0.
β1 = Pendiente para la población, representa el cambio esperado en yi por unidad de cambio en x.
εi = Error aleatorio en Y para la observación i.

Variables de regresión
Las variables de regresión independientes son las que representamos como los
valores que graficamos en el eje horizontal (x).
Las variables de regresión dependientes son las que representamos como los
valores que graficamos en el eje vertical (y).

Diagramas de Dispersión
Consiste en representar los pares de valores (xi , yi) como puntos en un sistema de ejes cartesianos X y Y .

Diagramas de Dispersión
Relación Lineal Positiva

Diagramas de Dispersión
Relación Lineal Negativa

Diagramas de Dispersión
Relación Parabólica

Diagramas de Dispersión
Relación Potencial (Fracciones)

Diagramas de Dispersión
Relación Potencial

Diagramas de Dispersión
Relación Exponencial

Diagramas de Dispersión
Sin relación

Suposiciones para el Modelo de Regresión Lineal
1. Linealidad.
2. Independencia de errores.
3. Normalidad.
4. Igual varianza (Homoscedasticidad).

Linealidad
La primera suposición, linealidad, establece que la relación entre variables es lineal. Las relaciones entre variables pueden ser no lineales o sin relación.

Independencia de errores
La segunda suposición, independencia de errores, requiere que los errores sean
independientes unos de otros. Esta suposición, es en especial importante
cuando los datos se recolectan los datos a lo largo de un periodo de tiempo. En
esas situaciones, los errores para un periodo específico con frecuencia se
relacionan con los del periodo anterior.

Normalidad La tercera suposición, normalidad, requiere que los errores se distribuyan normalmente en cada valor de x, siempre que la distribución de los errores alrededor de la recta de regresión en cada nivel de x no sea en extremo diferente de una distribución normal, no habrá efectos serios en las inferencias acerca de la recta de regresión y los coeficientes de regresión.

Normalidad

Igual varianza La cuarta suposición, igual varianza o homoscedasticidad, requiere que la varianza de los errores sea constante para todos los valores de x, es importante para usar el método de mínimos cuadrados que determina los coeficientes de regresión. Si hay desviaciones serias de esta suposición, se pueden aplicar transformaciones de datos o métodos de mínimos cuadrados ponderados.

Análisis de residual Se utiliza para evaluar qué tan adecuado es el modelo de regresión ajustado a los
datos.
El residual o error del valor estimado ei es la diferencia entre los valores observados (yi) y los valores pronosticados (𝑦 𝑖) de la variable dependiente para un valor dado
de xi.

Análisis de residual
Gráficamente, aparece un residuo en el diagrama de dispersión como la distancia vertical entre un valor observado de y y la
línea de predicción.
𝑒𝑖 = 𝑦𝑖 − 𝑦 𝑖

Evaluación de las suposiciones Linealidad. Para evaluar la linealidad, se
debe graficar los residuos en el eje vertical contra los valores correspondientes de xi
de la variable independiente en el eje horizontal. Si el modelo lineal es
apropiado para los datos, no habría un patrón aparente de este gráfico. Sin embargo, si el modelo lineal no es
apropiado, habrá una relación entre los valores xi y los residuos ei.

Linealidad

Evaluación de las suposiciones Independencia. Dicha autocorrelación se
puede probar con el estadístico de Durbin-Watson.

Evaluación de las suposiciones Independencia.
Si está presente un efecto positivo de autocorrelación, habrá grupos de residuos con
el mismo signo y podrá detectarse rápidamente un patrón aparente. Si existe una
autocorrelación negativa, los residuos tenderán a saltar hacia atrás y hacia delante, de positivo a negativo, luego a positivo y así
sucesivamente. Este tipo de patrón se observa rara vez en los análisis de regresión.

Evaluación de las suposiciones Independencia.
El estadístico de Durbin-Watson mide la correlación entre cada residuo y el residuo para el periodo de tiempo inmediatamente anterior al periodo de interés.
Donde:
ei = Residuo en el periodo de tiempo i.
2
1
2
2
1
( )n
i i
in
i
i
e e
D
e

Evaluación de las suposiciones Independencia.
Cuando los residuos sucesivos están autocorrelacionados positivamente, el
valor de D se acercará a 0. Si los residuos no se correlacionan, el valor de D se
aproximará a 2.

Evaluación de las suposiciones Independencia.
(Si existe una autocorrelación negativa, D será mayor a 2 e incluso se podría acercar
a su máximo valor de 4)
En la tabla 8C (ITAM) se incluyen dos valores para cada combinación de α (nivel
de significancia), n (tamaño de la muestra), y k (número de variables
independientes en el modelo).

Evaluación de las suposiciones Independencia.
El primer valor, dL representa el valor crítico más bajo. Si D se encuentra por
debajo de dL, se concluye que existe evidencia de una autocorrelacion positiva entre los residuos. En tal circunstancia, el
método de los mínimos cuadrados es inapropiado, y debería recurrirse a
métodos alternativos.

Evaluación de las suposiciones Independencia.
El segundo valor, dU, representa el valor crítico superior a D, por encima del cual se concluiría que no existe evidencia de una
autocorrelación positiva entre los residuos. Si D se encuentra entre dL y dU,
no se podrá llegar a una conclusión definitiva.

Evaluación de las suposiciones Normalidad.
Se puede evaluar la suposición de normalidad en los errores agrupando los
residuos dentro de la distribución de frecuencias y mostrando los resultados en
un histograma. También es factible evaluarla comparando los valores reales
contra los valores teóricos de los residuos, o construyendo una gráfica de
probabilidad normal (Minitab), un

Evaluación de las suposiciones Normalidad.
diagrama de tallo y hojas o una gráfica de caja y bigote para los residuos. Es difícil evaluar la suposición de normalidad con
pocos datos.

Evaluación de las suposiciones Igual varianza o homoscedasticidad.
Para verificar si hay homoscedasticidad, los residuos (y – y ̂) se grafican contra los valores ajustados de “y” (y ̂) o también se
puede verificar en una gráfica de los residuos (y – y ̂) contra los valores x.

No Homocedasticidad

No Homocedasticidad

Homocedasticidad

Determinación de la ecuación de regresión
Método de Mínimos Cuadrados Para evitar el juicio individual en la construcción de rectas, parábolas, u otras curvas de aproximación en su ajuste a colecciones de datos es necesario obtener una definición de la mejor recta de ajuste o mejor parábola de ajuste, etc.
Para llegar a una posible definición considérese en la figura los puntos representativos de los
datos dados por (x1, y1), (x2, y2), ..., (xn, yn).
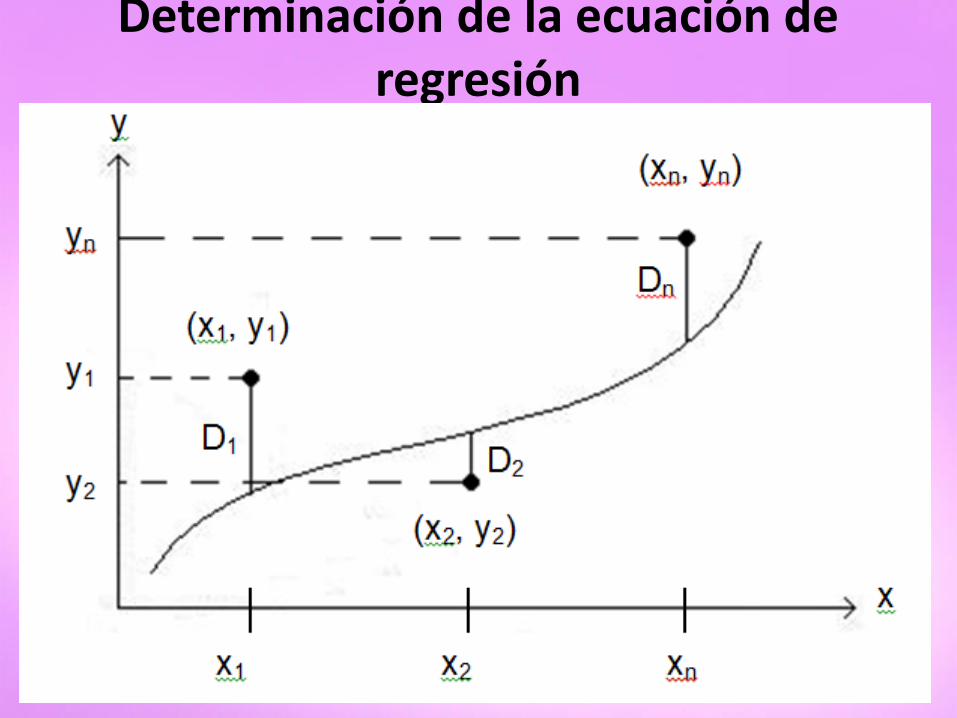
Determinación de la ecuación de regresión

Método de Mínimos Cuadrados Como se indica en la figura, para un valor dado de x por ejemplo: x1 habrá una diferencia entre el valor y1 y el correspondiente valor de la curva “C”, se denota esta diferencia por D1, que se conoce a veces como desviación, error o residuo y puede ser positivo, negativo o incluso 0 (cero). De la misma manera para los valores de x2 hasta xn se obtienen las desviaciones D2 hasta Dn .

Método de Mínimos Cuadrados Una medida de la bondad de ajuste de la
curva “C” a los datos dados viene suministrada por la cantidad:
D12 + D2
2 + D32 +... Dn
2
Definición: De todas las curvas de aproximación a una serie de datos
puntuales, la curva que tiene la propiedad de que la suma anterior es mínima se conoce como la mejor curva de ajuste.

Método de Mínimos Cuadrados D1
2 + D22 + D3
2 +... Dn2 = mínimo
Una curva que presente esta propiedad se dice que se ajusta a los datos por mínimos
cuadrados y se llama curva de mínimos cuadrados.
Así una recta con esta propiedad se llama recta de mínimos cuadrados, una parábola con esta propiedad se llama parábola de
mínimos cuadrados, etc.

Recta de Mínimos Cuadrados La recta de aproximación por mínimos
cuadrados de los puntos (x1, y1), (x2, y2), ..., (xn, yn) de nuestro conjunto de datos
tiene la ecuación:
𝑦 𝑖 = 𝑏0 + 𝑏1𝑥𝑖
Donde, 𝑦 𝑖es el valor pronosticado de y para la observación i, las constantes b0 y
b1 son coeficientes de regresión.

Recta de Mínimos Cuadrados Se determinan mediante el sistema de
ecuaciones:
(1)
(2)
n
i
i
n
i
i xbnby1
10
1
n
i
i
n
i
i
n
i
ii xbxbyx1
2
1
1
0
1