trabajo distribucion normal
TRANSCRIPT

DISTRIBUCION NORMAL
¿Cómo Determinar Si Una Serie De Datos Tiene
Distribución Normal?
ESTADISTICA
LEÓN GONZALO TAMAYO VÁSQUEZ Profesor (a)
Geiner Romero Zapata Alumno
UNIVERSIDAD AUTÓNOMA LATINOAMERICANA “UNAULA”
CONTADURÍA PÚBLICA CUARTO SEMESTRE
GRUPO 4B Medellín, Mayo de 2011

DISTRIBUCION NORMAL
La distribución normal fue reconocida por primera vez por el francés Abraham
de Moivre (1667-1754). Posteriormente, Carl Friedrich Gauss (1777-1855)
elaboró desarrollos más profundos y formuló la ecuación de la curva; de ahí que
también se la conozca, más comúnmente, como la "campana de Gauss". La
distribución de una variable normal está completamente determinada por dos
parámetros, su media y su desviación estándar, denotadas generalmente por µ
y σ. Con esta notación, la densidad de la normal viene dada por la ecuación:
que determina la curva en forma de campana que tan bien conocemos (Figura
2). Así, se dice que una característica X sigue una distribución normal de media
µ y varianza σ2, y se denota como X≈N (µ,σ), si su función de densidad
viene dada por la Ecuación 1.
Al igual que ocurría con un histograma, en el que el área de cada rectángulo es
proporcional al número de datos en el rango de valores correspondiente si, tal y
como se muestra en la Figura 2, en el eje horizontal se levantan
perpendiculares en dos puntos a y b, el área bajo la curva delimitada por esas
líneas indica la probabilidad de que la variable de interés, X, tome un valor
cualquiera en ese intervalo. Puesto que la curva alcanza su mayor altura en
torno a la media, mientras que sus "ramas" se extienden asintóticamente hacia
los ejes, cuando una variable siga una distribución normal, será mucho más
probable observar un dato cercano al valor medio que uno que se encuentre
muy alejado de éste.
Propiedades de la distribución normal:
La distribución normal posee ciertas propiedades importantes que conviene
destacar:
ü Tiene una única moda, que coincide con su media y su mediana.
ü La curva normal es asintótica al eje de abscisas. Por ello, cualquier valor
entre -∞ y +∞ es teóricamente posible. El área total bajo la curva es,
por tanto, igual a 1.

ü Es simétrica con respecto a su media µ. Según esto, para este tipo de
variables existe una probabilidad de un 50% de observar un dato mayor
que la media, y un 50% de observar un dato menor.
ü La distancia entre la línea trazada en la media y el punto de inflexión de
la curva es igual a una desviación típica (σ). Cuanto mayor sea σ, más
aplanada será la curva de la densidad.
ü El área bajo la curva comprendida entre los valores situados
aproximadamente a dos desviaciones estándar de la media es igual a
0.95. En concreto, existe un 95% de posibilidades de observar un valor
comprendido en el intervalo (� − � . � � � ; � + � . � � � )
ü La forma de la campana de Gauss depende de los parámetros µ y σ
(Figura 3). La media indica la posición de la campana, de modo que para
diferentes valores de µ la gráfica es desplazada a lo largo del eje
horizontal. Por otra parte, la desviación estándar determina el grado de
apuntamiento de la curva. Cuanto mayor sea el valor de σ, más se
dispersarán los datos en torno a la media y la curva será más plana. Un
valor pequeño de este parámetro indica, por tanto, una gran
probabilidad de obtener datos cercanos al valor medio de la distribución.

Métodos para determinar la Normalidad
Existen varios métodos para determinar si los datos de una muestra provienen
de una población normal, para así poder aplicar técnicas que se basan en el
supuesto de que la población presenta una distribución normal aproximada.
A continuación daré a conocer algunos de estos:
ü Histograma.
ü Cálculo IQR/S
ü Gráfico de probabilidad normal

Histograma
En este apartado dibujaremos el histograma de una muestra de una población
con distribución desconocida. Para ilustrar el procedimiento que determina si
esta muestra proviene de una distribución normal trabajaremos con el
siguiente supuesto:
“Los valores sobre las longitudes en micras de 50 filamentos de la producción
de una máquina son los siguientes:”
Esta es la primera prueba que realizamos para comprobar si los datos proceden
de una distribución normal. Si los datos son aproximadamente normales, la
forma de la gráfica será similar a la de la curva normal superpuesta (esto es,
con forma de joroba y simétrica alrededor de la media). En nuestro caso hay un
cierto parecido, por lo que en principio, aunque no podemos afirmar con
rotundidad que la muestra proviene de una población normal a la espera de
otros resultados, podemos concluir que se asemeja a la curva normal teórica.

Cálculo IQR/S
El segundo paso es el de calcular el intervalo intercuartiles, IQR, la desviación
estándar, s para la muestra y luego calcular el cociente IQR/S. Si los datos son
aproximadamente normales, IQR/S 1.3. Puede verse que esta propiedad se
cumple para las distribuciones normales si se observa que los valores z que
corresponden a los percentiles 75o. y 25o. son 0.67 y -0.67, respectivamente.
Puesto que σ = 1 para una distribución normal estándar (z),
IQR/σ = [.67- (-.67)]/1 = 1.34.
En esta segunda verificación debemos obtener el intervalo intercuartiles (es
decir la diferencia entre los percentiles 75º. Y 25º.) y la desviación estándar del
conjunto de datos.
Los resultados para nuestro ejemplo son:
Haciendo el cálculo obtenemos que IQR/S = (115.25-100.00) / 10.81 = 1.41.
Puesto que este valor es aproximadamente igual a 1.3, tenemos una
confirmación adicional de que los datos son aproximadamente normales.
Gráfico de probabilidad normal
Una tercera técnica descriptiva para comprobar la normalidad es la gráfica de
probabilidad normal. En una gráfica de probabilidad normal, las observaciones
de un conjunto de datos se ordenan y luego se grafican contra los valores
esperados estandarizados de las observaciones bajo el supuesto de que los datos
están distribuidos normalmente. Si los datos en verdad tienen una distribución
normal, una observación será aproximadamente igual a su valor esperado. Por
tanto, una tendencia lineal (de línea recta) en la gráfica de probabilidad normal
sugiere que los datos provienen de una distribución aproximadamente normal,
en tanto que una tendencia no lineal indica que los datos no son normales.
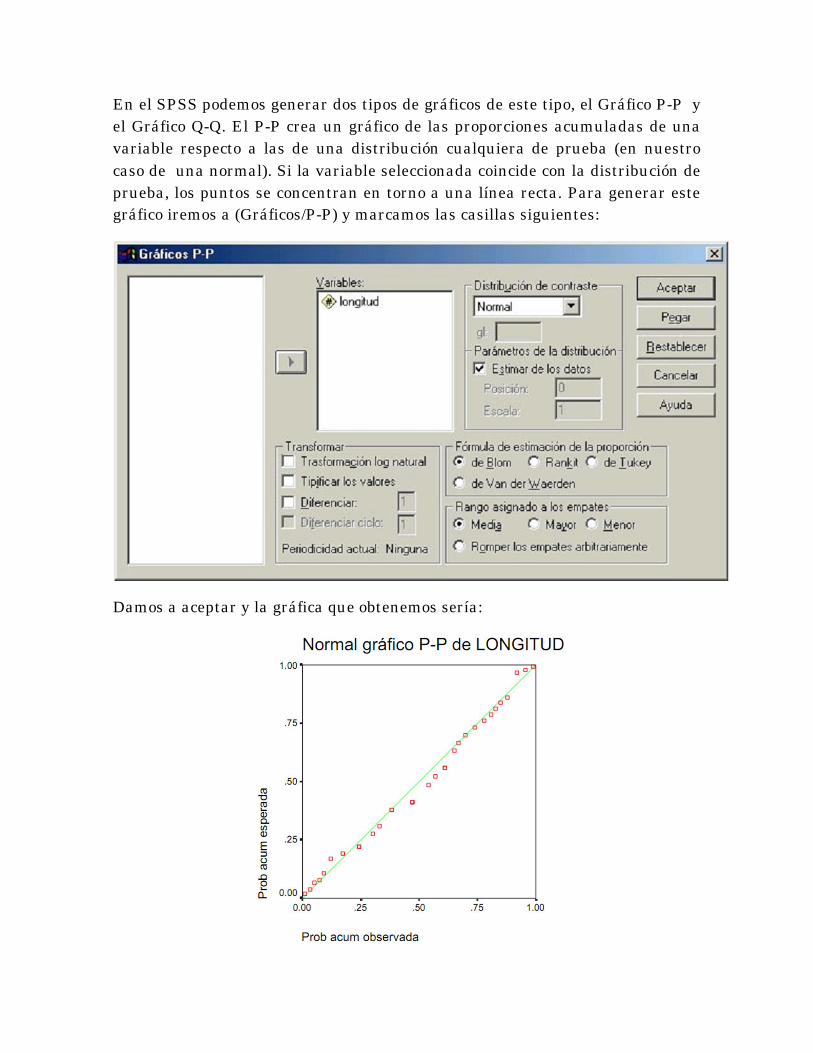
En el SPSS podemos generar dos tipos de gráficos de este tipo, el Gráfico P-P y
el Gráfico Q-Q. El P-P crea un gráfico de las proporciones acumuladas de una
variable respecto a las de una distribución cualquiera de prueba (en nuestro
caso de una normal). Si la variable seleccionada coincide con la distribución de
prueba, los puntos se concentran en torno a una línea recta. Para generar este
gráfico iremos a (Gráficos/P-P) y marcamos las casillas siguientes:
Damos a aceptar y la gráfica que obtenemos sería:

Observe que los puntos se ajustan relativamente bien a una línea recta. Por
tanto, la verificación 3 también sugiere que los datos probablemente tienen una
distribución normal.
El otro gráfico que genera el SPSS es el Gráfico Q-Q. La forma de obtener dicho
gráfico es similar al anterior únicamente que debemos seleccionar (Gráficos/Q-
Q). Este procedimiento crea un gráfico con los cuartiles de distribución de una
variable respecto a los cuartiles de cualquiera de varias distribuciones de
prueba (en nuestro caso de una normal). Si la variable seleccionada coincide
con la distribución de prueba, los puntos se concentran en torno a una línea
recta.
Existen otros métodos para probar la normalidad, los anteriores explicados son
los más comunes, a continuación veremos un listado de estos. Las pruebas de
normalidad se aplican a conjuntos de datos para determinar su similitud con
una distribución normal. La hipótesis nula es, en estos casos, si el conjunto de
datos es similar a una distribución normal, por lo que un P-valor
suficientemente pequeño indica datos no normales.
ü Prueba de Kolmogórov-Smirnov ü Test de Lilliefors ü Test de Anderson–Darling ü Test de Ryan–Joiner ü Test de Shapiro–Wilk ü Normal probability plot (rankit plot) ü Test de Jarque–Bera ü Test omnibús de Spiegelhalter

Bibliografia
ü www.google.com.co
ü http://www.virtual.unal.edu.co/cursos/ciencias/2001065/html/un2/metodo
s_descriptivos.html
ü http://webpages.ull.es/users/jjsalaza/MEI/
ü www.fisterra.com
ü www.uoc.edu