temas 20 y 21 introducción a la genómica estructural humana · temas 20 y 21 introducción a la...
TRANSCRIPT

Temas 20 y 21Temas 20 y 21Introducción a la genómicaIntroducción a la genómica
estructural humanaestructural humanaCurso de Genética Molecular
4º Ciencias BiológicasUniversidad de Jaén
Antonio Caruz ArcosDpto. Biología Experimental, Área de Genética
Universidad de Jaén
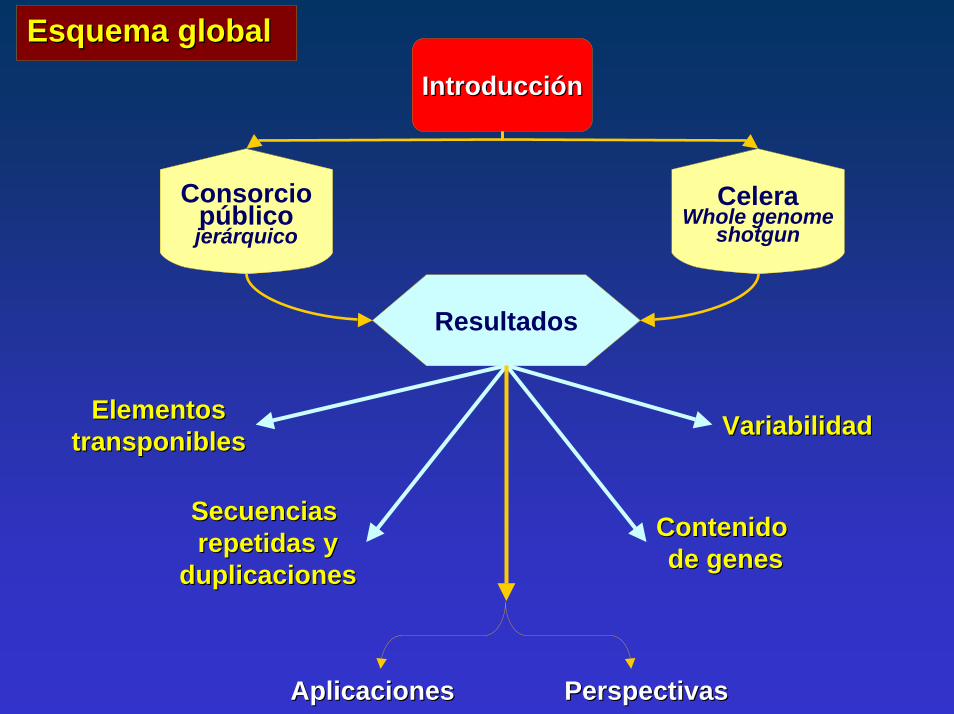
IntroducciónIntroducción
Resultados
Consorciopúblicojerárquico
CeleraWhole genome
shotgun
ElementosElementostransponiblestransponibles
Secuencias Secuencias repetidas yrepetidas y
duplicacionesduplicaciones
Contenido Contenido de genesde genes
VariabilidadVariabilidad
AplicacionesAplicaciones PerspectivasPerspectivas
Esquema global Esquema global

Proyecto Genoma HumanoProyecto Genoma HumanoIntroducción
Estrategias de secuenciación del genoma

Base tecnológicaBase tecnológica
19771977 SangerSanger descubre un método para la descubre un método para la secuenciación de ADN utilizando secuenciación de ADN utilizando ddNTPsddNTPs
19781978 El primer gen humano es identificado y El primer gen humano es identificado y secuenciadosecuenciado
19791979 Secuenciación del virus SV40Secuenciación del virus SV401981 Secuenciación del ADN 1981 Secuenciación del ADN mitocondrial mitocondrial
humanohumano1982 Secuenciación del bacteriófago lambda1982 Secuenciación del bacteriófago lambda1983 Descubrimiento del método 1983 Descubrimiento del método shotgunshotgun1991 Desarrollo de bancos de 1991 Desarrollo de bancos de ESTsESTs
1980 Mapas genéticos de levadura, nematodo y humano para clonación posicional

Avances técnicos imprescindiblesAvances técnicos imprescindibles
BiorobotsBiorobots Secuenciación Secuenciación automáticaautomática
BioinformáticaBioinformática
1990-2000 Secuenciación de varios
genomas completos
industrialización de la genética
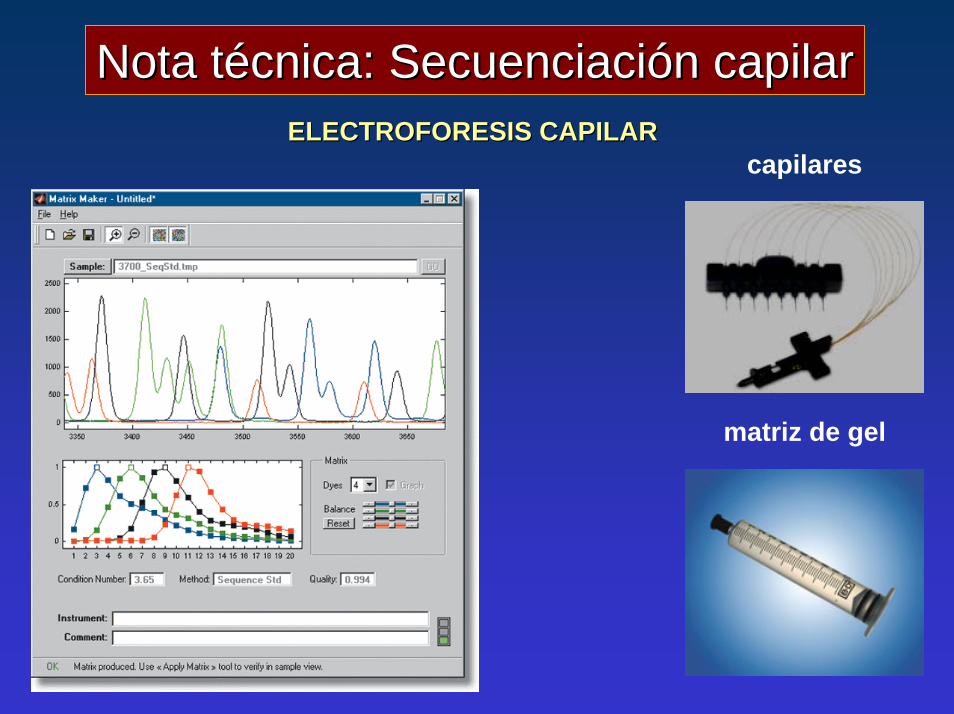
Nota técnica: Secuenciación capilarNota técnica: Secuenciación capilarELECTROFORESIS CAPILARELECTROFORESIS CAPILAR
capilares
matriz de gel
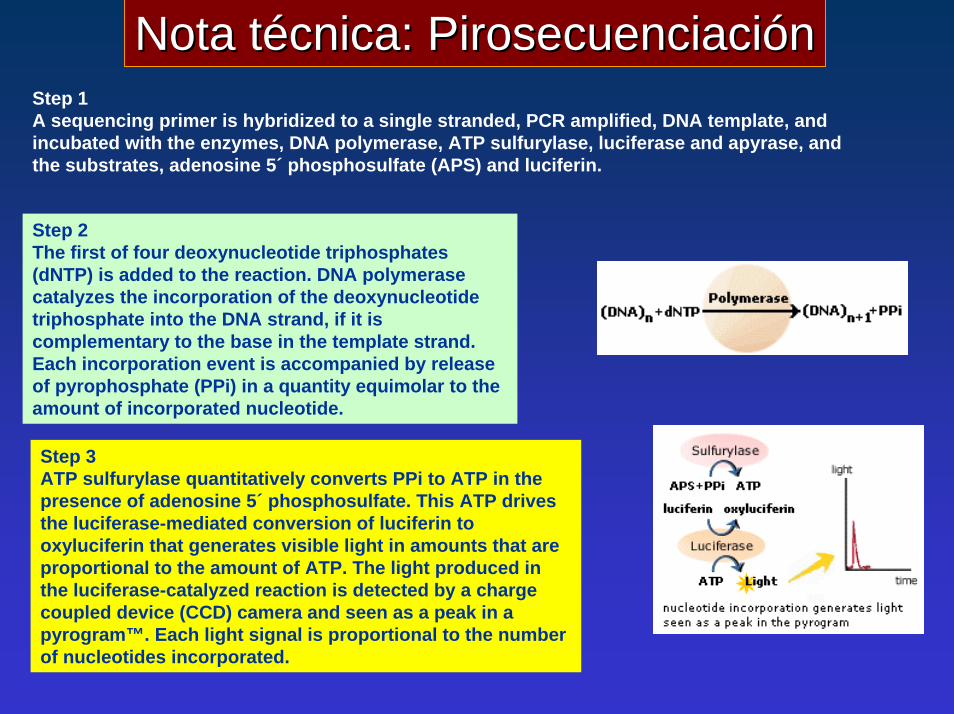
Nota técnica: PirosecuenciaciónNota técnica: PirosecuenciaciónStep 1A sequencing primer is hybridized to a single stranded, PCR amplified, DNA template, andincubated with the enzymes, DNA polymerase, ATP sulfurylase, luciferase and apyrase, and the substrates, adenosine 5´ phosphosulfate (APS) and luciferin.
Step 2The first of four deoxynucleotide triphosphates(dNTP) is added to the reaction. DNA polymerasecatalyzes the incorporation of the deoxynucleotide triphosphate into the DNA strand, if it is complementary to the base in the template strand.Each incorporation event is accompanied by release of pyrophosphate (PPi) in a quantity equimolar to theamount of incorporated nucleotide.
Step 3ATP sulfurylase quantitatively converts PPi to ATP in thepresence of adenosine 5´ phosphosulfate. This ATP drivesthe luciferase-mediated conversion of luciferin to oxyluciferin that generates visible light in amounts that areproportional to the amount of ATP. The light produced in the luciferase-catalyzed reaction is detected by a charge coupled device (CCD) camera and seen as a peak in apyrogram™. Each light signal is proportional to the number of nucleotides incorporated.
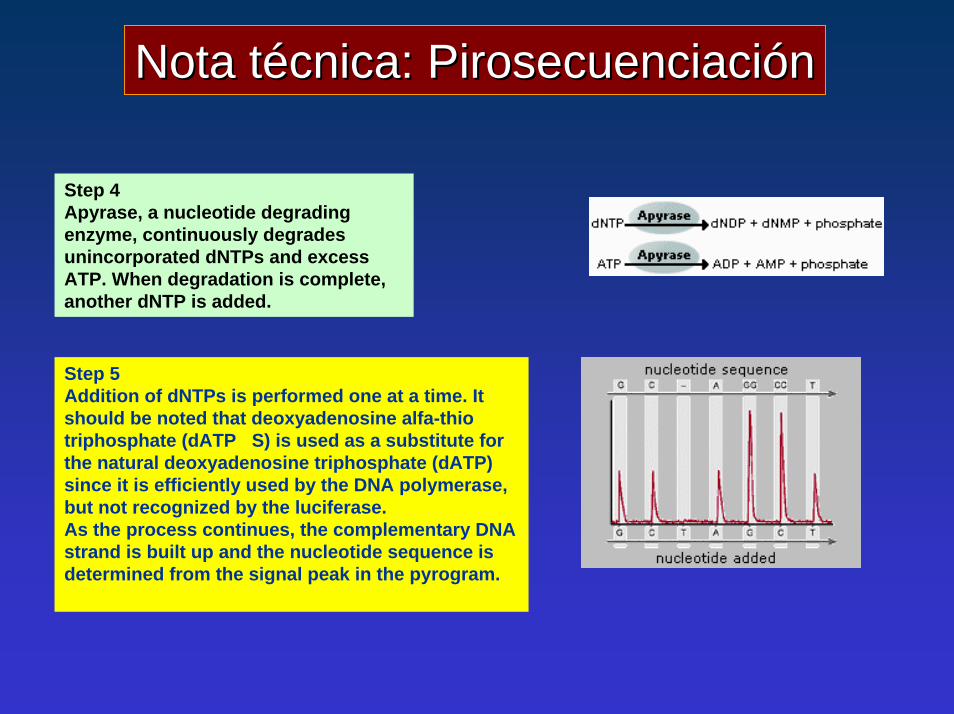
Nota técnica: PirosecuenciaciónNota técnica: Pirosecuenciación
Step 4Apyrase, a nucleotide degrading enzyme, continuously degradesunincorporated dNTPs and excessATP. When degradation is complete,another dNTP is added.
Step 5Addition of dNTPs is performed one at a time. It should be noted that deoxyadenosine alfa-thio triphosphate (dATP S) is used as a substitute forthe natural deoxyadenosine triphosphate (dATP)since it is efficiently used by the DNA polymerase,but not recognized by the luciferase.As the process continues, the complementary DNAstrand is built up and the nucleotide sequence is determined from the signal peak in the pyrogram.

19841984--86 (US 86 (US National Research CouncilNational Research Council))
La visión global del genoma permitirá acelerar la La visión global del genoma permitirá acelerar la investigación biomédica permitiendo a los investigadores investigación biomédica permitiendo a los investigadores abordar los problemas con una visión amplia no sesgada.abordar los problemas con una visión amplia no sesgada.
Necesitaría un esfuerzo global en Necesitaría un esfuerzo global en infraestructura y división de tareas.infraestructura y división de tareas.
3000 millones de dólares de presupuesto inicial3000 millones de dólares de presupuesto inicial
(AVE Madrid(AVE Madrid--Lleida Lleida 4.200 ME, presupuesto ministerio de 4.200 ME, presupuesto ministerio de defensa español 6.300 ME, reconstrucción defensa español 6.300 ME, reconstrucción
de Irak 20.000 ME)de Irak 20.000 ME)
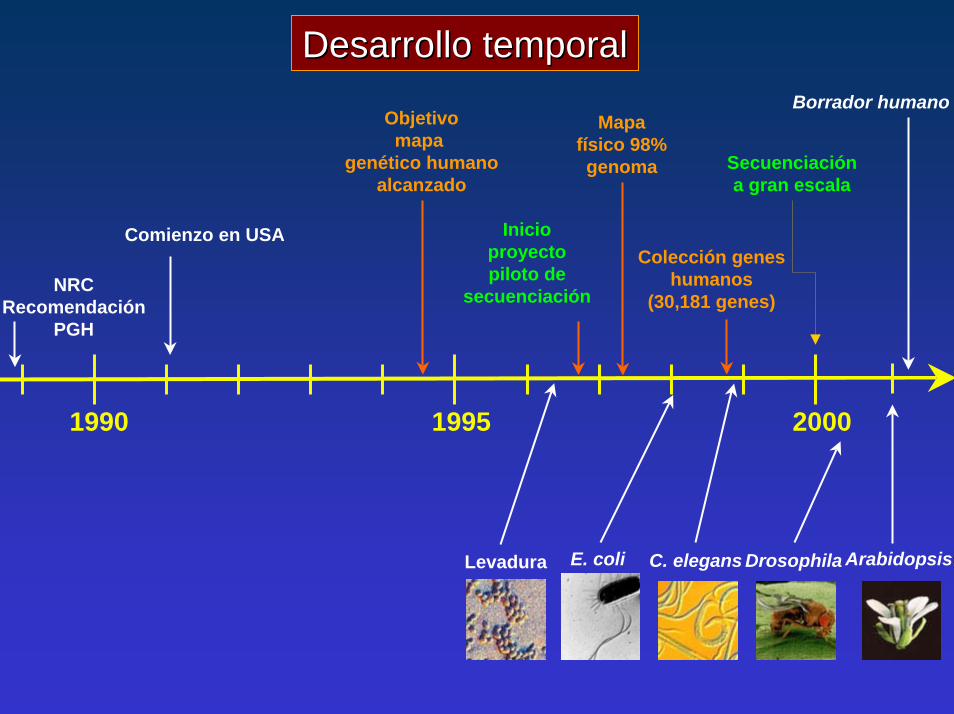
Desarrollo temporalDesarrollo temporal
Comienzo en USAColección genes
humanos(30,181 genes)
Objetivomapa
genético humanoalcanzado
Mapafísico 98%genoma
Inicioproyectopiloto de
secuenciaciónNRCRecomendación
PGH
1990 1995 2000
Borrador humano
Levadura E. coli C. elegans Drosophila Arabidopsis
Secuenciacióna gran escala

EstrategiaEstrategias des de secuenciación genoma humanosecuenciación genoma humano
Proyecto Público: Proyecto Público: Shotgun Shotgun jerárquico clones BACjerárquico clones BAC
Proyecto Genoma (HGO):
1. Clones derivados de 8 genotecas de BACs y PACs obtenidas por digestión parcial con enzimas de restricción de 8 hombres (sangre y semen)
2. Representan un muestreo del genoma con una redundancia de 65 veces.
3. DNA obtenido de donantes anónimos de varios orígenes.
Etapas básicas del Proyecto Genoma (HGO):
•Obtención de una genoteca genómica.
•Elaboración de un mapa físico y genético.
•Obtención de la secuencia primaria y ensamblaje a partir de los mapas anteriores.
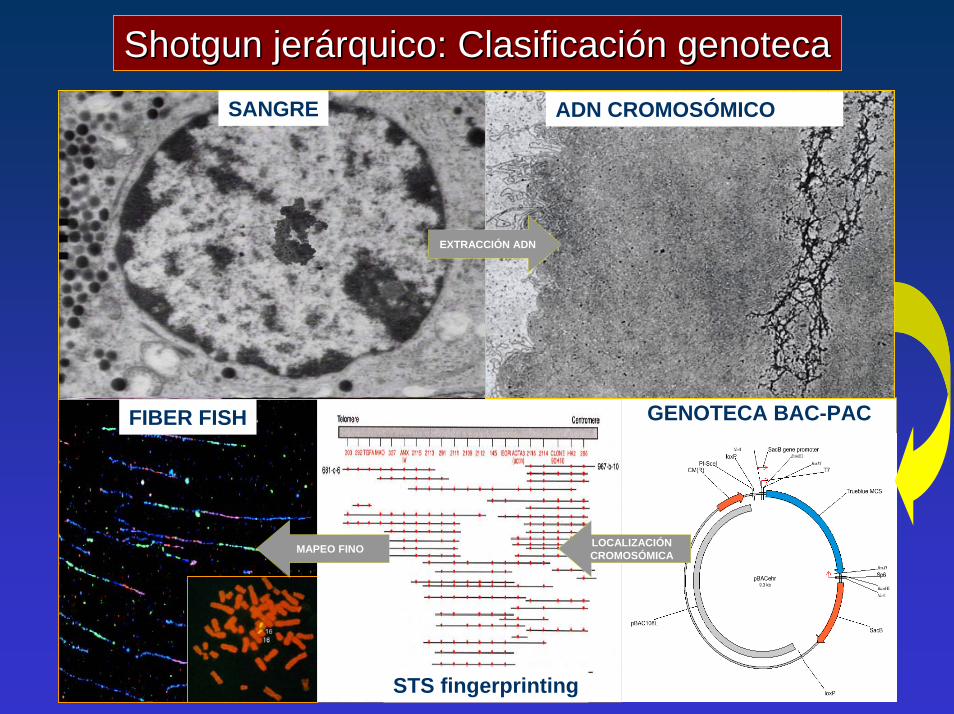
Shotgun Shotgun jerárquico: Clasificación genotecajerárquico: Clasificación genoteca
GENOTECA BAC-PAC
SANGRE ADN CROMOSÓMICO
EXTRACCIÓN ADN
FIBER FISH
STS fingerprinting
MAPEO FINO LOCALIZACIÓNCROMOSÓMICA

La tecnología de los cromosomas artificiales de La tecnología de los cromosomas artificiales de bacterias fueron desarrollados a principios de bacterias fueron desarrollados a principios de los 90los 90
Presenta las siguientes ventajas:Presenta las siguientes ventajas:
1.1. Mayores tamaños (50Mayores tamaños (50--300 300 KbKb))
2.2. Más estables que los Más estables que los YACs YACs (1(1--2 copias por 2 copias por célula), presentan baja tasa de recombinación y célula), presentan baja tasa de recombinación y reorganizaciones en casos de tramos altamente reorganizaciones en casos de tramos altamente repetitivos.repetitivos.
3.3. Crecen más deprisa que los Crecen más deprisa que los YACsYACs
4.4. Más fácil preparación del ADNMás fácil preparación del ADN
5.5. Permite un eficaz escrutinio mediante Permite un eficaz escrutinio mediante hibridación o PCR.hibridación o PCR.
6.6. Posibilidad de selección por color de clones Posibilidad de selección por color de clones recombinantesrecombinantes
7.7. Sitio de clonación múltiple muy completoSitio de clonación múltiple muy completo
Plásmidos Plásmidos BAC: imprescindiblesBAC: imprescindibles
Kim, U. J. et al. Construction and characterization of a human bacterial artificial chromosome library. Genomics 34, 213-218 (1996).

Plásmidos Plásmidos BAC: control de calidadBAC: control de calidad
Marra, M. A. et al. High throughput fingerprint analysis of large-insert clones. Genome Res. 7, 1072-1084 (1997).
38 Kpb
500 pb

Regulación replicación Regulación replicación BACsBACs y y PACsPACs
Unión DNA-A
Unión Rep-ARegión AT
Gen Rep-A Unión Rep-A
Ori PromotorRep-A
PAC
Proteína Rep-E
necesaria replicación
Unión DNA-A
Unión Rep-ERegión AT
Gen Rep-E Unión Rep-E
Ori PromotorRep-E
BAC
-+
Kornberg A. DNA replication. 2ndedition (1991).
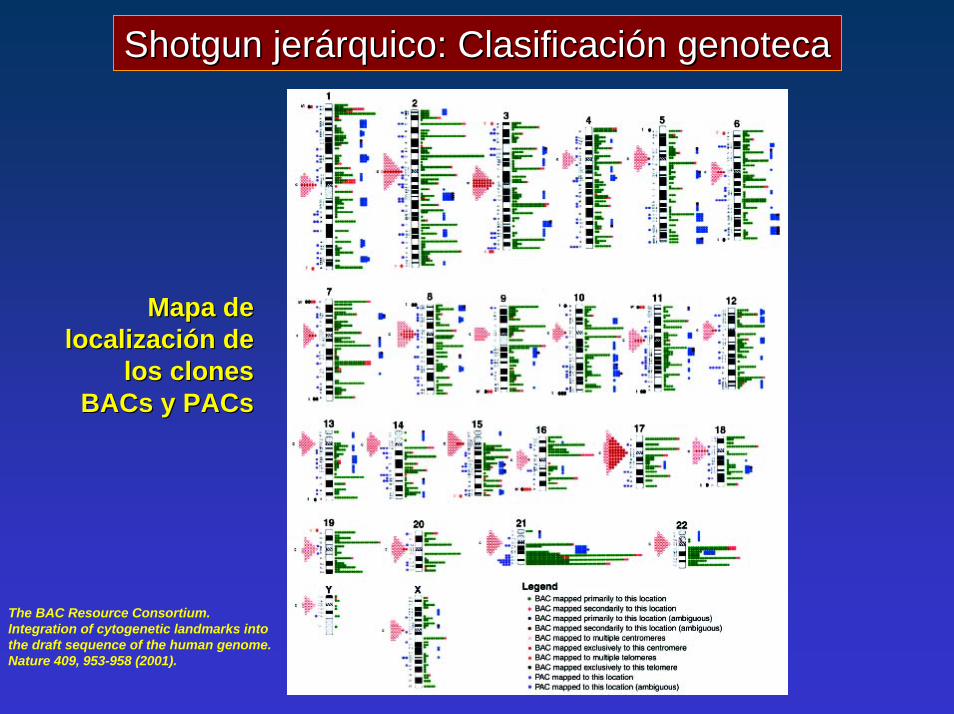
Shotgun Shotgun jerárquico: Clasificación genotecajerárquico: Clasificación genoteca
Mapa de Mapa de localización de localización de
los clones los clones BACsBACs y y PACsPACs
The BAC Resource Consortium. Integration of cytogenetic landmarks intothe draft sequence of the human genome. Nature 409, 953-958 (2001).

ShotShot--gun, BACs, Contings y Scaffoldsgun, BACs, Contings y Scaffolds
Muchas secuenciacionescon redundancia
Detectar homologías Fusionar
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).

Whole genome shotgunWhole genome shotgun: CELERA: CELERAROBOTIZACIÓNDEL TRABAJO
Construcción de la genoteca
2 europeos, 1 hispanoamericano (mexicano), 1 chino, 1 afroamericano (2 hombres y 3 mujeres)
Genoteca de 2 Genoteca de 2 KbKb Genoteca de 10 Genoteca de 10 KbKb Genoteca de 50 Genoteca de 50 KbKb

Whole genome shotgunWhole genome shotgun: CELERA: CELERA
La maquinaria de CELERA:La maquinaria de CELERA:150 150 secuenciadoressecuenciadores ABI 3700, 65 técnicos y ABI 3700, 65 técnicos y
175.000 secuenciaciones diarias (media 650 pb)175.000 secuenciaciones diarias (media 650 pb)durante 9 mesesdurante 9 meses
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).

Whole genome shotgunWhole genome shotgun: CELERA: CELERA
The The overlapper overlapper (desarrollado para el proyecto Drosophila)(desarrollado para el proyecto Drosophila)
busca solapamiento de al menos 40 pb<6% diferenciasbusca solapamiento de al menos 40 pb<6% diferencias
40 ordenadores 4 GB RAM durante 5 días (360 ordenadores convenci40 ordenadores 4 GB RAM durante 5 días (360 ordenadores convencionales)onales)
Correcciones con los datos públicos ordenados en Correcciones con los datos públicos ordenados en BACsBACs
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).

Proyecto Genoma HumanoProyecto Genoma HumanoResultados
Elementos repetidos en el genoma
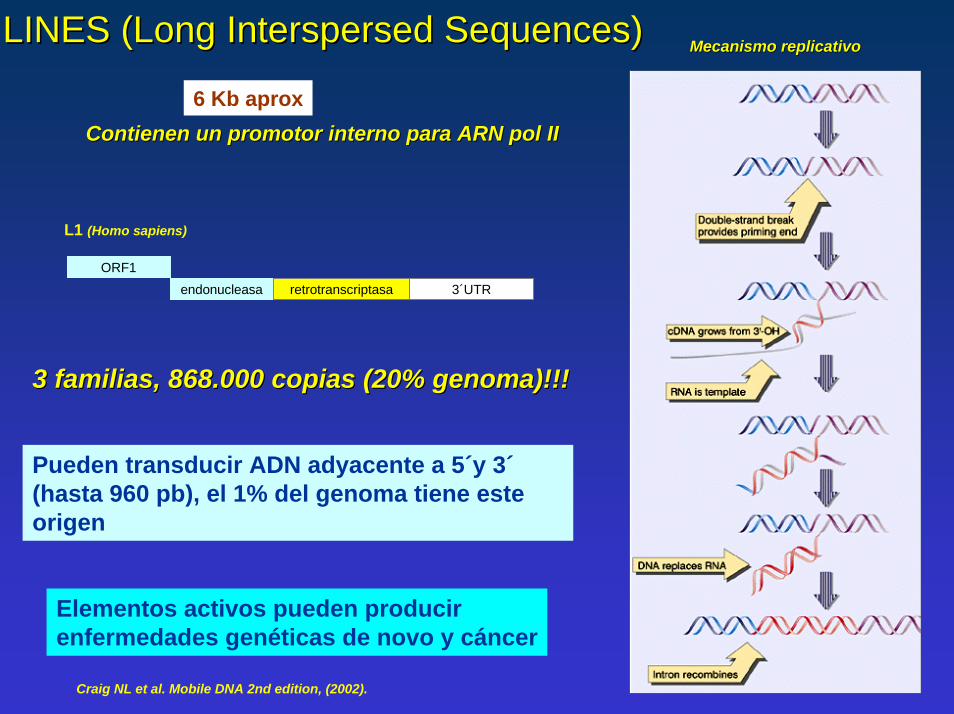
LINES (LINES (Long Interspersed SequencesLong Interspersed Sequences)) Mecanismo replicativoMecanismo replicativo
6 Kb aproxContienen un promotor interno para ARN Contienen un promotor interno para ARN pol pol IIII
ORF1endonucleasa retrotranscriptasa 3´UTR
L1 (Homo sapiens)
3 familias, 868.000 copias (20% genoma)!!!3 familias, 868.000 copias (20% genoma)!!!
Pueden transducir ADN adyacente a 5´y 3´ (hasta 960 pb), el 1% del genoma tiene este origen
Elementos activos pueden producir enfermedades genéticas de novo y cáncer
Craig NL et al. Mobile DNA 2nd edition, (2002).
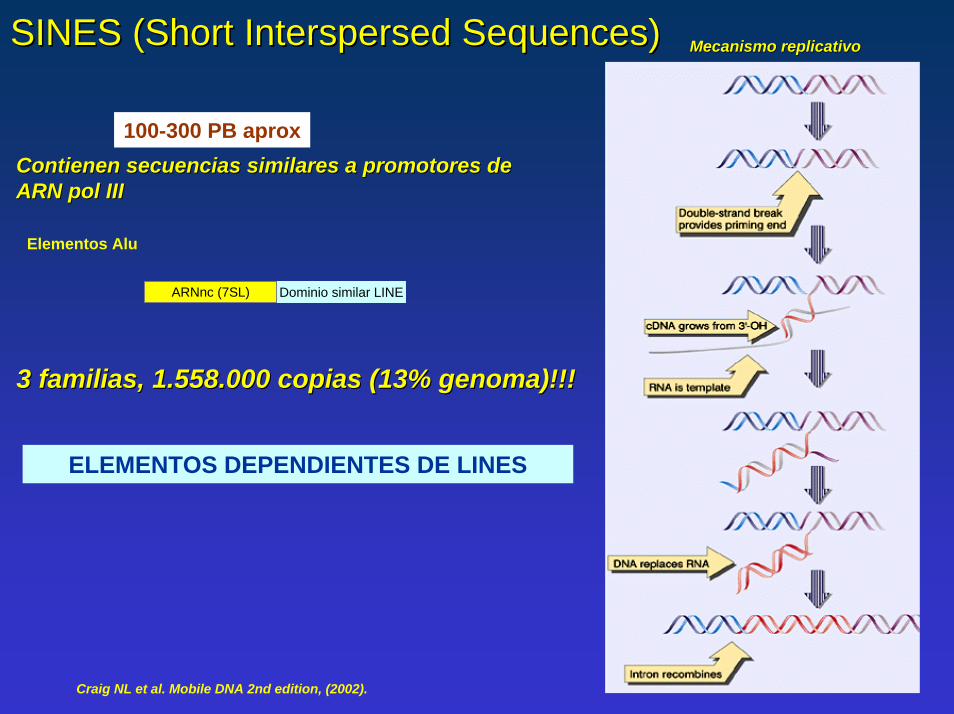
SINES (Short SINES (Short Interspersed SequencesInterspersed Sequences)) Mecanismo replicativoMecanismo replicativo
100-300 PB aproxContienen secuencias similares a promotores de Contienen secuencias similares a promotores de ARN ARN pol pol IIIIII
Elementos Alu
ARNnc (7SL) Dominio similar LINE
3 familias, 1.558.000 copias (13% genoma)!!!3 familias, 1.558.000 copias (13% genoma)!!!
ELEMENTOS DEPENDIENTES DE LINES
Craig NL et al. Mobile DNA 2nd edition, (2002).

Elementos LTR (Elementos LTR (Long Long Terminal Terminal RepeatsRepeats))
δ gag envpol δ
LTR gag retrotranscriptasaintegrasa LTR
Copia (Drosophila melanogaster)
HERV (Homo sapiens)
Mecanismo replicativoMecanismo replicativo6-11 Kb aprox
4 familias, 443.000 copias 4 familias, 443.000 copias (8,3% genoma)!!!(8,3% genoma)!!!
Craig NL et al. Mobile DNA 2nd edition, (2002).
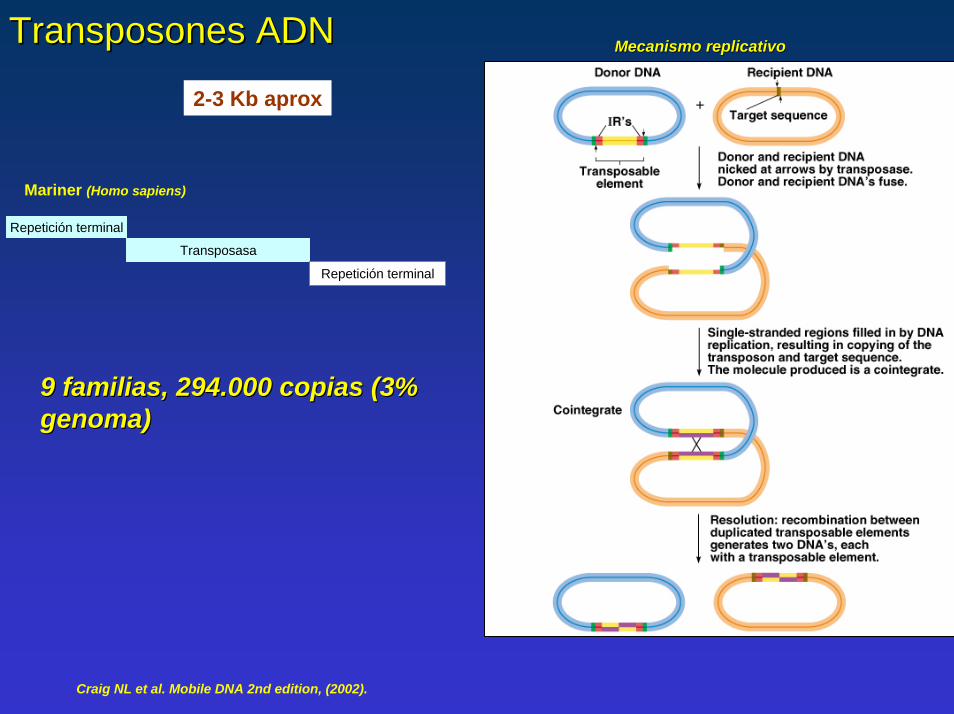
Transposones Transposones ADNADN Mecanismo replicativoMecanismo replicativo
2-3 Kb aprox
Mariner (Homo sapiens)
Repetición terminal
Transposasa
Repetición terminal
9 familias, 294.000 copias (3% 9 familias, 294.000 copias (3% genoma)genoma)
Craig NL et al. Mobile DNA 2nd edition, (2002).
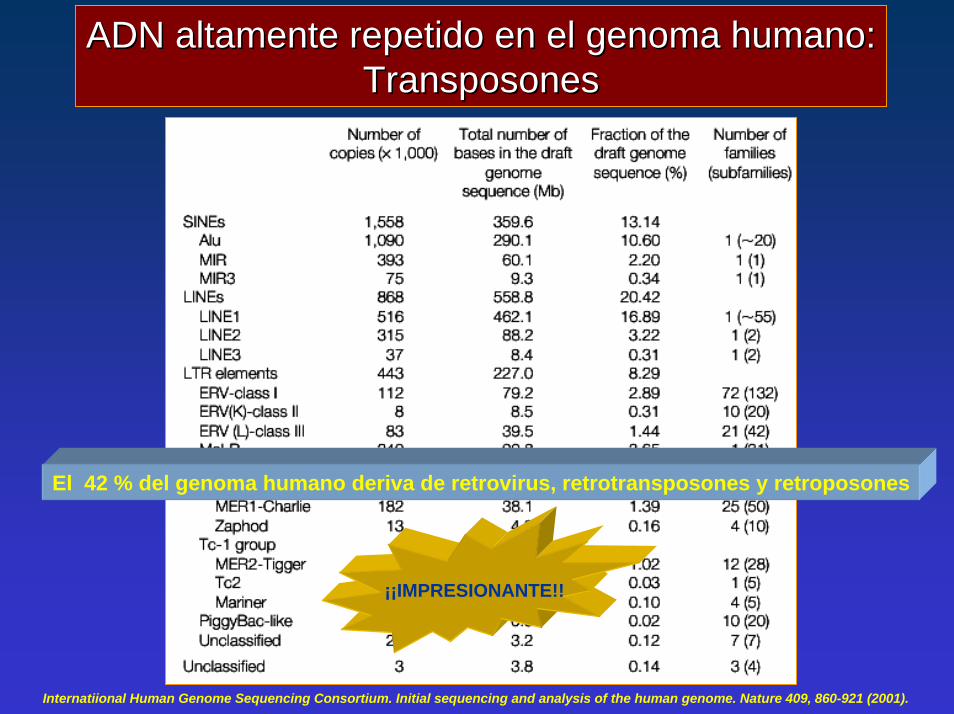
ADN altamente repetido en el genoma humano:ADN altamente repetido en el genoma humano:TransposonesTransposones
El 42 % del genoma humano deriva de retrovirus, retrotransposones y retroposones
¡¡IMPRESIONANTE!!
Internatiional Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).

Elementos móviles como fuerza evolutivaElementos móviles como fuerza evolutiva
TransposonesTransposones
RetrogenesRetrogenes
Nuevos genes
Nuevos genes
Agentes del caoscromosómico
Agentes del caoscromosómico
Brosius J. RNAs from all categories generate retrosequences that may be exapted as novel genes or regulatory elements. Gene 238 115–134, (1999).

Elementos móviles como fuerza evolutivaElementos móviles como fuerza evolutiva
Transcripción secuencias flanqueantes 3´ y transposición
Brosius J. RNAs from all categories generate retrosequences that may be exapted as novel genes or regulatory elements. Gene 238 115–134, (1999).

Elementos móviles como fuerza evolutivaElementos móviles como fuerza evolutivaORIGEN ELEMENTO GEN INFLUIDO SIRVE COMO REFERENCIA
ERV9 LTR ZNF80 zinc finger Promotor Di Cristofano et al. (1995)
HERV-E LTR Amilasa salival Promotor Samuelson et al. (1990)
HERV-E LTR Growth factor pleitropin (PTN)
Promotor específico de tejido
Schulte et al. (1996, 1998)
LINE Promotor apolipoprotein(a) Enhancer Yang et al. (1998)
MER11 LTR leptin Enhancer específico placenta
Bi et al. (1997)
LINE-2 ALF annexin VI, interleukin-4, protein kinase C-b
Silenciador específico de tejido
Donnelly et al. (1999)
THE-1 Gen específico
immunoglobulin heavy chain
Secuencia codificante
Hakim et al. (1994)
HERV-K LTR leptin receptor (OBRa)
Splicing alternativo
Kapitonov and Jurka (1999)
HERV-H LTR HHLA2 Señal de poliadenilación
Mager et. al. (1999)
HERV-H LTR HHLA3 Señal de poliadenilación
Mager et al. (1999)
ElementosEstructurales
de retrotransposonescon funciones
génicas
CARACTERÍSTICAS RETROGEN EXPRESIÓN
CROMOSOMA
GEN ORIGINAL EXPRESIÓN
CROMOSOMA Intrones - Poli-A Repeticiones directas
REFERENCIA
Fosfoglicerato kinasa
Pgk-1; constitutiva; chr X
+ (+) (+) Adra et al. (1988)
Piruvato deshidrogenasa (Pdha2); testículo
Pdha1; constitutiva; chr X
+ (+) (+) Fitzgerald et al. (1992)
NB-1 or CLP; tejido epitelial; chr 10
calmodulin CaMIII; ubícua; chr 2 + (+) Berchtold et
al. (1993)
Glutamato deshid. (GLUD2); retina, testículo, cerebro; X
GLUD1; ubícua; chr 10 + + + Shashidharan
et al. (1994)
Factor splicing pancreas, bazo, próstata; chr 11
PR264/SC35; timo, bazo, riñón, pulmón; chr 17
+ (+) + Soret et al. (1998)
CDY, chr 15 CDYL; ubícuo chr 13 + Lahn and
Page (1999)
Centrina, testículos; chr 18
Cetn2; testículo neonatal y oviducto; chr X
+ + Hart et al. (1999)
XAP-5-like (X5L); chr 6 XAP-5; chr X Sedlacek et al.
(1999)
ParálogosFuncionalessin intrones
Genes humanos
con hipotético origen en
transposones de ADN
1. Recombinasas RAG1 y RAG2
2. Proteína ppal. centromérica (CENPB)
3. Telomerasa4. Syncitina5. 11 factores de transcripción
(Zn finger) híbridos 6. Transposasa expresión
cerebral
Brosius J. RNAs from all categories generate retrosequences that may be exapted as novel genes or regulatory elements. Gene 238 115–134, (1999).

Elementos móviles como fuerza evolutivaElementos móviles como fuerza evolutiva
Reorganizaciones cromosómicasReorganizaciones cromosómicas
Inductores de translocaciones
Inductores de inversiones
Lim, J. K. & Simmons, M. J. Gross chromosome rearrangements mediated by transposable elements in Drosophila melanogaster. Bioessays 16, 269-275 (1994).
Zhang, J. & Peterson, T. Genome rearrangements by non-linear transposons in maize. Genetics 153, 1403-1410 (1999).

ADN altamente repetido en el genoma humano:ADN altamente repetido en el genoma humano:TransposonesTransposones
0
5
10
15
20
25
30
35
40
45
HOMO DROSOPHILA CAENORHABDITIS MUS
LINE/SINELTRDNATOTAL
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
Mouse Genome Sequencing Consortium. Initial sequencing and comparative analysis of the mouse genome. Nature 420, 520-562 (2002).
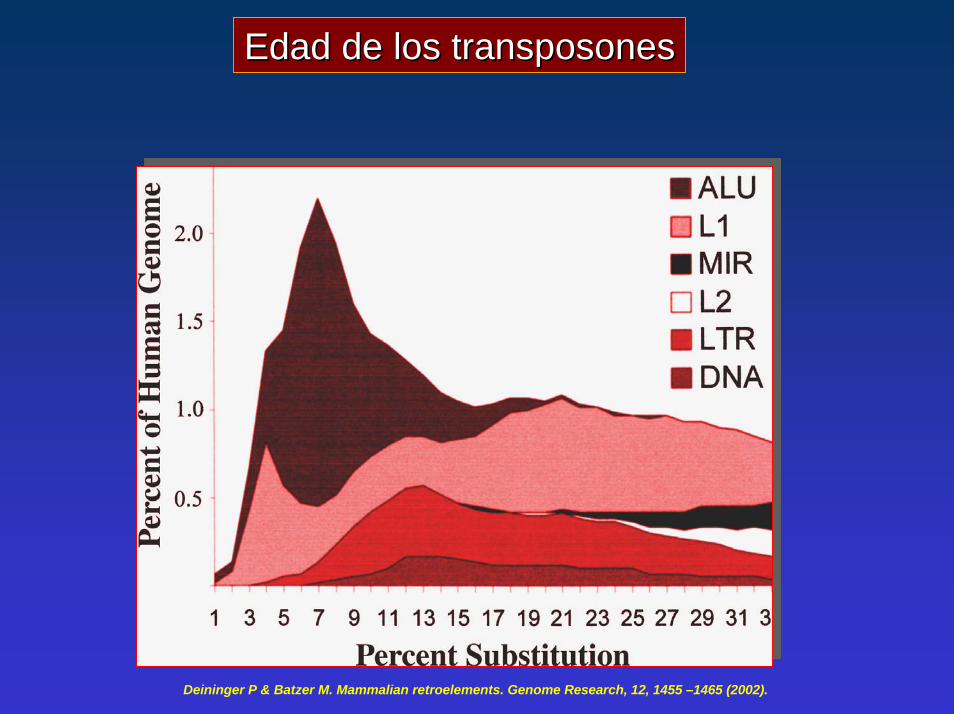
Edad de los tEdad de los transposonesransposones
Deininger P & Batzer M. Mammalian retroelements. Genome Research, 12, 1455 –1465 (2002).

TransposonesTransposones en el genoma:en el genoma:Historia de la humanidadHistoria de la humanidad
Ventajas LINES como herramientas Ventajas LINES como herramientas evolución humanidadevolución humanidad
1. Diagnóstico simple por PCR
2. Polimorfismos estables
3. La presencia indica identidad de antepasados (probababilidadcasi cero de identidad de inserción)
4. La ausencia indica el origen del árbol filogenético
5. Pueden ser incluso específicos de una sola familia
Población L1 freq
L2 freq
L3 freq
L4 freq
L5 freq
L6 freq
Negros americanos
0.08 0.02 0.07 0.38 0.17 0.13
Armenios 0.22 0.00 0.13 0.13 0.28 0.04 !Kung 0.00 0.01 0.00 0.00 0.04 0.06 Bantú 0.06 0.00 0.06 0.17 0.01 0.01 Sirios 0.17 0.01 0.05 0.28 0.22 0.04 Turcos 0.21 0.00 0.03 0.15 0.02 0.00 Franceses 0.22 0.00 0.08 0.22 0.01 0.06 EsquimalesAlaska
0.23 0.00 0.22 0.07 0.46 0.01
Esquimalesgroenlandia
0.27 0.00 0.12 0.02 0.53 0.00
Bretones 0.24 0.00 0.14 0.16 0.02 0.11 Alemanes 0.22 0.00 0.10 0.13 0.01 0.08 Suizos 0.38 0.02 0.08 0.15 0.10 0.02 Hispano-americanos
0.17 0.01 0.22 0.27 0.56 0.03
Europeos-americanos
0.24 0.02 0.05 0.32 0.19 0.08
Sheen F et al. Reading between the LINEs: Human Genomic Variation Induced by LINE-1 Retrotransposition. Genome Research, 10,1496-1508, (2000).

Distribución de Distribución de transposones transposones en el genoma:en el genoma:Identificación de grandes zonas reguladorasIdentificación de grandes zonas reguladoras
Variación en la distribución de las repeticiones
Genes Hox DGen Zfhx1bRatónHombre
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
Mouse Genome Sequencing Consortium. Initial sequencing and comparative analysis of the mouse genome. Nature 420, 520-562 (2002).
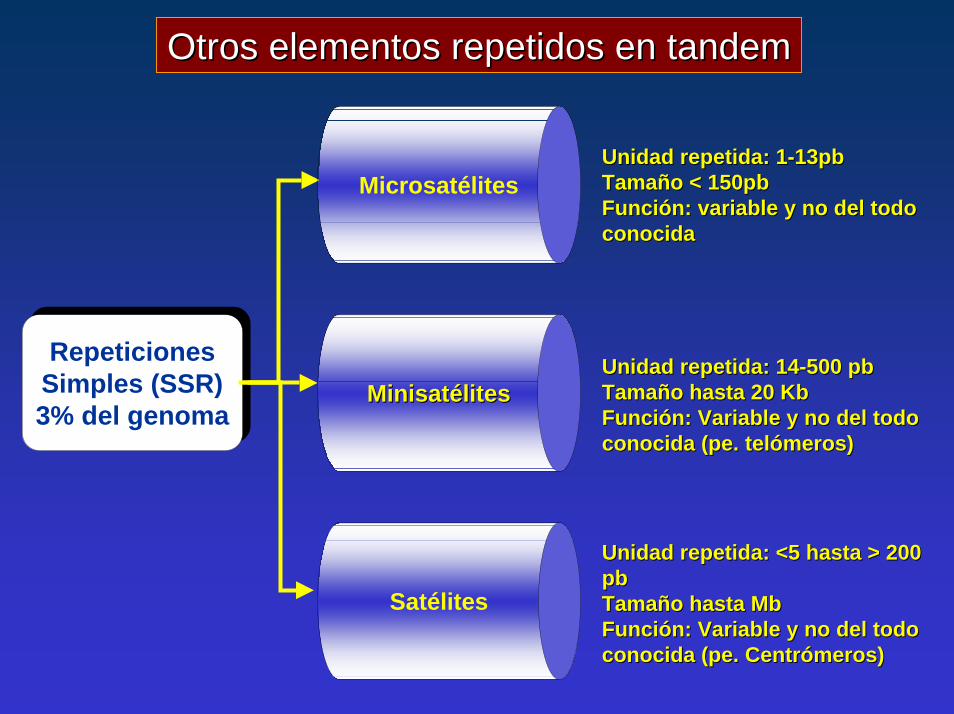
Unidad repetida: 1Unidad repetida: 1--13pb13pbTamaño < 150pbTamaño < 150pbFunción: variable y no del todo Función: variable y no del todo conocidaconocida
Unidad repetida: 14Unidad repetida: 14--500 pb500 pbTamaño hasta 20 Tamaño hasta 20 KbKbFunción: Variable y no del todo Función: Variable y no del todo conocida (pe. conocida (pe. telómerostelómeros))
Unidad repetida: <5 hasta > 200 Unidad repetida: <5 hasta > 200 pbpbTamaño hasta Tamaño hasta MbMbFunción: Variable y no del todo Función: Variable y no del todo conocida (pe. Centrómeros)conocida (pe. Centrómeros)
RepeticionesSimples (SSR)3% del genoma
RepeticionesSimples (SSR)3% del genoma
Microsatélites
MinisatélitesMinisatélites
Satélites
Otros elementos repetidos en Otros elementos repetidos en tandemtandem

Características secuencias repetidasCaracterísticas secuencias repetidas
El proyecto ha ampliado el nºEl proyecto ha ampliado el nº
1.1. Marcadores genéticos muy Marcadores genéticos muy polimórficos (genética forense)polimórficos (genética forense)
2.2. Asociados a enfermedades Asociados a enfermedades (síndrome X(síndrome X--frágil)frágil)
3.3. Importantísimos en clonación Importantísimos en clonación posicionalposicional
AC AT AG GC AAT AAC AGG AAG ATG CGG ACC AGC ACT ACG
0
5
10
15
20
25
30
Unidad repetida
Núm
ero
SSR
por
Mb
Genotipado Genotipado a gran escalaa gran escala((Applied BiosystemsApplied Biosystems))
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921
(2001).

Secuencias repetidas simples y enfermedadesSecuencias repetidas simples y enfermedades
Ashley CT & Warren ST. Trinucleotide Repeat Expansion and Human Disease. Ann. Rev. Genetics, 29, 703-728 (1995).
Tres tipos de localización
Regiones 5´UTR
Regiones 3´UTR
Regiones codificantes
(poliglutamina)
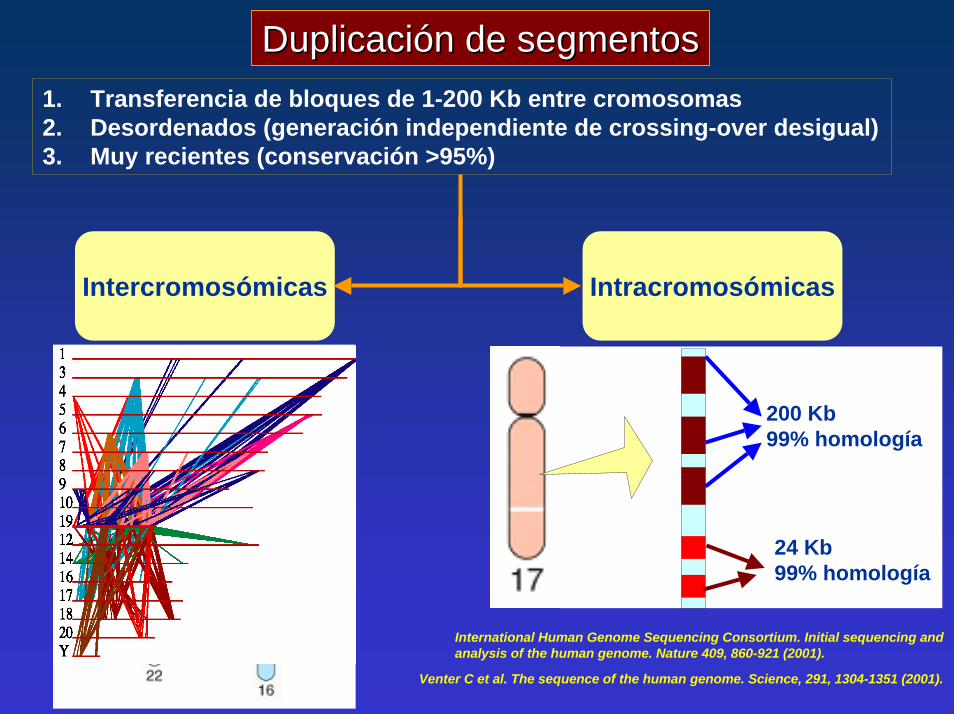
Duplicación de segmentosDuplicación de segmentos1. Transferencia de bloques de 1-200 Kb entre cromosomas2. Desordenados (generación independiente de crossing-over desigual)3. Muy recientes (conservación >95%)
9,5 Kb del locus ALD-X
IntracromosómicasIntercromosómicas
200 Kb 99% homología
24 Kb 99% homología
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).

Duplicación de segmentosDuplicación de segmentosOrigen de enfermedades por microdeleciones cromosómicas
1.1. Síndrome de Síndrome de delecióndeleción 22q11 22q11
2.2. Síndrome de Síndrome de Angelman Angelman
3.3. Síndrome Síndrome PraderPrader--Willi Willi
4.4. Síndrome de Síndrome de WilliamsWilliams
5.5. Síndrome de SmithSíndrome de Smith--MagenisMagenis
Shaffer LG & Lupski J. Molecular mechanisms for constitutional chromosomal Rearrangements in humans. Ann. Rev. Genetics, 34, 297-329 (2000).

Duplicación de segmentosDuplicación de segmentos
Plasticidad en las regiones pericentroméricas y subteloméricas
Chr.22: 5% del cromosoma (centrómero) contiene el 50% de las duplicaciones y la región subtelomérica está constituida sólo con duplicaciones de otros cromosomas
1. Las duplicaciones son muy recientes (95-100% homología)2. Diferentes duplicaciones separadas por minisatélites (ricos en AT ó GC)
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).

Duplicación de segmentosDuplicación de segmentos
Duplicaciones polimórficas en
poblaciones humanas

Proyecto Genoma HumanoProyecto Genoma HumanoResultados
Genes en el genoma

Número de genesNúmero de genesGen: fragmento de ácido nucleico que determina una función biolóGen: fragmento de ácido nucleico que determina una función biológicagica
LiLi y Grau (1991): un gen es una secuencia de ADN o ARN que es y Grau (1991): un gen es una secuencia de ADN o ARN que es esencial para una función específica, bien sea en el desarrollo esencial para una función específica, bien sea en el desarrollo o en el o en el
mantenimiento de la función fisiológica normal.mantenimiento de la función fisiológica normal.
La realización de esta función no requiere de la traducción del gen ni tan siquiera su transcripción:
1. Los genes que codifican para proteínas 2. ARNs específicos que solo se transcriben
3. Los genes reguladores sin transcriptos, tales como los inicios de replicación (que especifican el sitio de iniciación y terminación de la replicación del ADN)

Número de genesNúmero de genes
Muy controvertidoMuy controvertido
Incyte corporation (1999): datos de EST e islas G+C 142.634
Chaudhari et al (1993): EST del cerebro >100.000
Ewing y Green (2000): EST y extrapolación datos ch22 35.000
Roest et al. (2000): comparación con otros eucariotas 35.000
Identificación de genes individualesIdentificación de
genes individualesIdentificación de
la estructurade los genes
Identificación de la estructurade los genes
Dos problemasDos problemas

Número de genesNúmero de genes
ARNm codificante proteínas
ARNm codificante proteínas
ARN no-codificante proteínas
ARN no-codificante proteínas
ARNtransferente
ARNtransferente
ARNsmall
nucleolar
ARNsmall
nucleolar
ARN7SL trans. proteínas
ARN7SL trans. proteínas
ARNsplicingARN
splicing
ARNmensajero
no-codificante
ARNmensajero
no-codificante
ARNribosómico
ARNribosómico
ARNTelomerasa
ARNTelomerasa
Transcripción (7SK)
Coactivador receptor esteroides (SRA)
Silenciamiento Ch X (XIST)
Imprinting (AIR)
Estabilidad ARNm (Ryhb de E. coli)
Traducción (Lin-4 de C. elegans)
Estabilidad de proteínas (ARNtm)
En ratónEn ratón
33.409 unidades de
33.409 unidades de transcripcióntranscripción
11.665 ARN no
11.665 ARN no codificantescodificantes!!!!!!
The The Phantom consortium
Phantom consortium, Nature 2002, Nature 2002
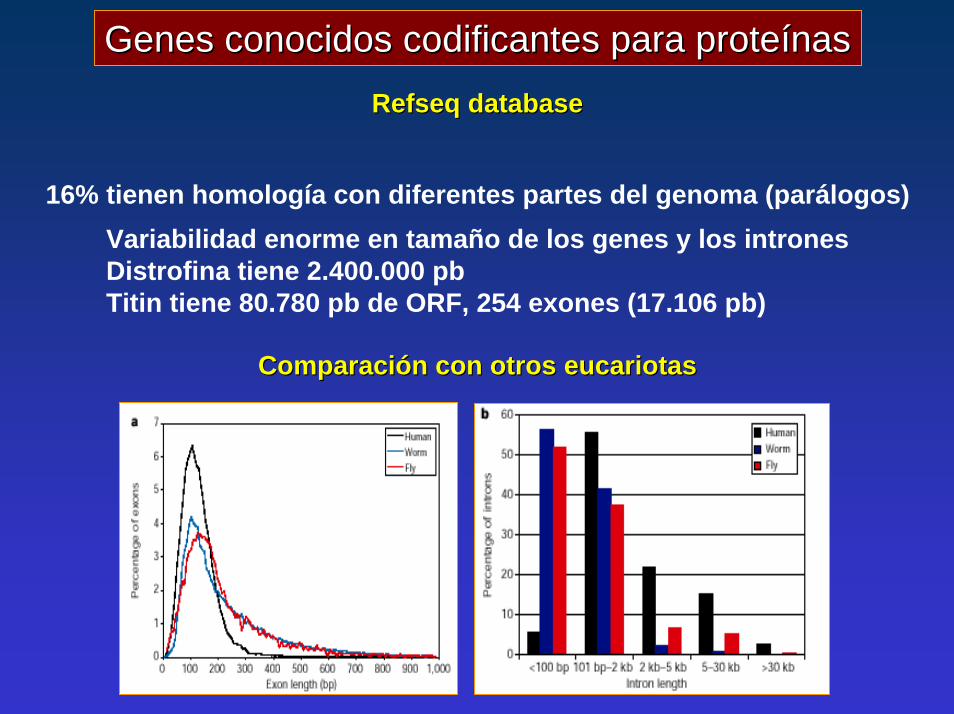
Genes conocidos Genes conocidos codificantescodificantes para proteínaspara proteínasRefseq databaseRefseq database
16% tienen homología con diferentes partes del genoma (parálogos)Variabilidad enorme en tamaño de los genes y los intronesDistrofina tiene 2.400.000 pbTitin tiene 80.780 pb de ORF, 254 exones (17.106 pb)
Comparación con otros Comparación con otros eucariotaseucariotas
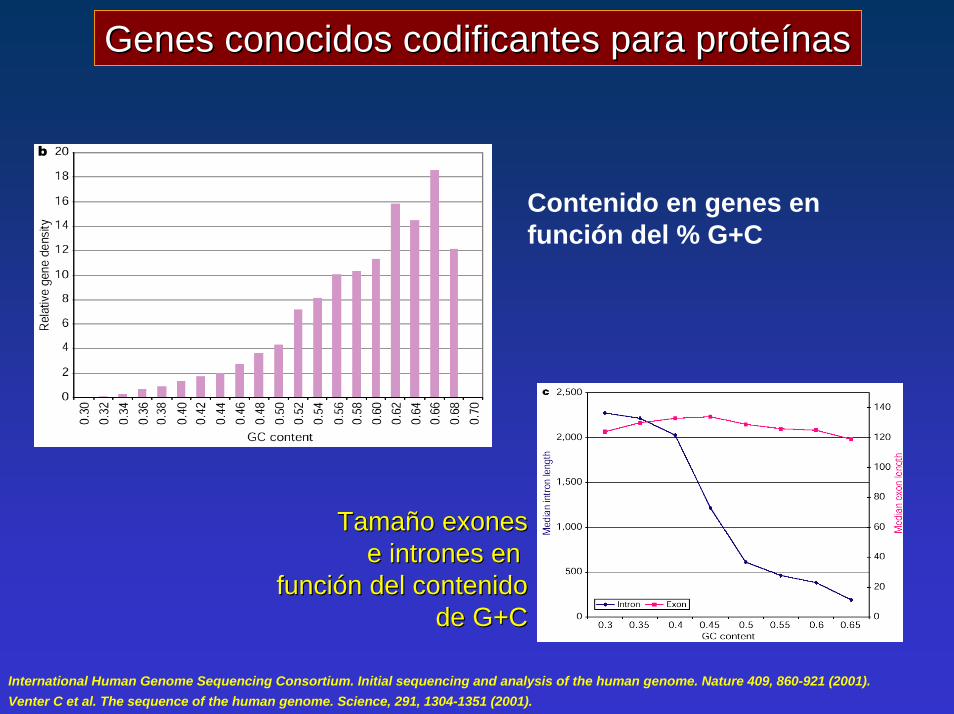
Genes conocidos Genes conocidos codificantescodificantes para proteínaspara proteínas
Contenido en genes en función del % G+C
Tamaño Tamaño exonesexonese e intrones intrones en en
función del contenidofunción del contenidode G+Cde G+C
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001). Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).
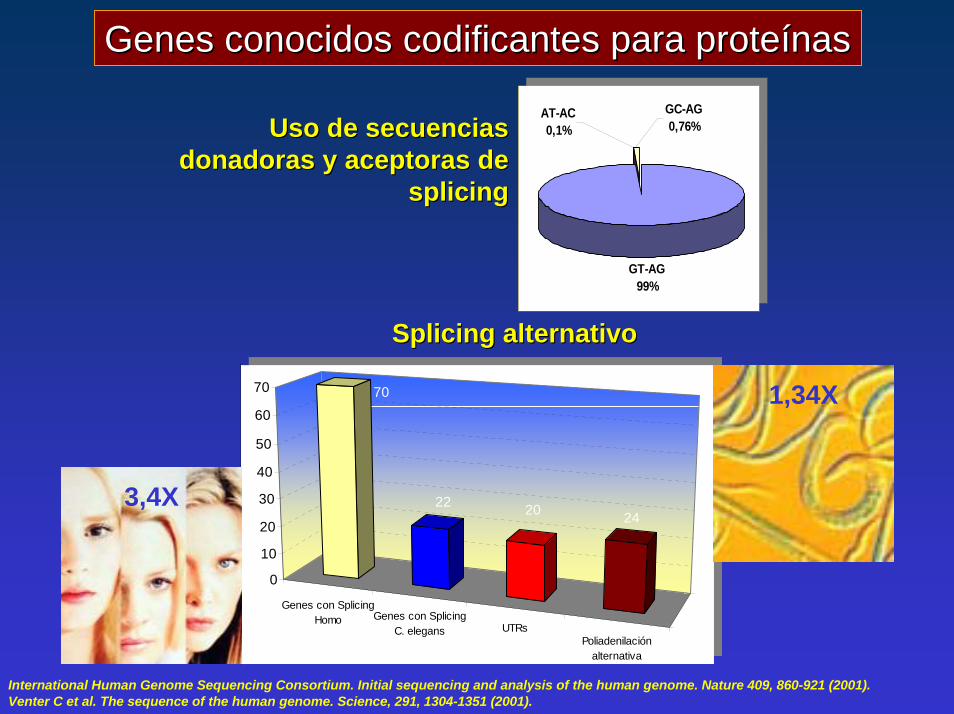
Genes conocidos Genes conocidos codificantescodificantes para proteínaspara proteínasGC-AG0,76%
AT-AC0,1%
GT-AG99%
GC-AG0,76%
AT-AC0,1%
GT-AG99%
Uso de secuencias Uso de secuencias donadoras y donadoras y aceptoras aceptoras de de
splicingsplicing
Splicing Splicing alternativoalternativo
Genes con SplicingHomo Genes con Splicing
C. elegans UTRsPoliadenilación
alternativa
C1
70
22 20 24
0
10
20
30
40
50
60
70
Genes con SplicingHomo Genes con Splicing
C. elegans UTRsPoliadenilación
alternativa
C1
70
22 20 24
0
10
20
30
40
50
60
70 1,34X
3,4X
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001). Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).
TCACAATTTAGACATCTAGTCTTCCACTTAAGCATATTTAGATTGTTTCCAGTTTTCAGCTTTTATGACTAAATCTTCTAAAATTGTTTTTCCCTAAATGTATATTTTAATTTGTCTCAGGAGTAGAATTTCTGAGTCATAAAGCGGTCATATGTATAAATTTTAGGTGCCTCATAGCTCTTCAAATAGTCATCCCATTTTATACATCCAGGCAATATATGAGAGTTCTTGGTGCTCCACATCTTAGCTAGGATTTGATGTCAACCAGTCTCTTTAATTTAGATATTCTAGTACATACAAAATAATACCTCAGTGTAACCTCTGTTTGTATTTCCCTTGATTAACTGATGCTGAGCACATCTTCATGTGCTTATTGACCATTAATTAGTCTTATTTGTTAAATGTCTCAAATATTTTATACAGTTTTACATTGTGTTATTCATTTTTTAAAAAATTCATTTTAGGTTATATGTATGTGTGTGTCAAAGTGTGTGTACATCTATTTGATATATGTATGTCTATATATTCTGGATACCATCTCTGTTTCATGCATTGCATATATATTTGCCTATTTAGTGGTTTATCTTTTCATTTTCTTTTGGTATCTTTTCATTAGAAATGTTATTTATTTTGAGTAAGTAACATTTAATATATTCTGTAACATTTAATGAATCATTTTATGTTATGTTTAGTATTAAATTTCTGAAAACATTCTATGTATTCTACTAGAATTGTCATAATTTTATCTTTTATATACATTGATATTTTTATGTCAAATATGTAGGTATGTGATATTATGCACATGGTTTTAATTCAGTTAATTGTTCTTCCAGATGTTTGTACCATTCCAACATCATTTAAATCATTAAATGAAAAGCCTTTCCTTACTAGCTAGCCAGCTTTGAAAATCCATTCATAGGGTTTGTGTTAATATATTTTTGTTCTTTTTTTTCCTTTCTACTGATCTCTTTATATTAATACCTACTGTGGCTTTATATGAAGTCATGGAATAATACGTAGTAAGCCCTCTAACACTGTTCTGTTACTGTTGTTATTGTTTTCTCAGGGTACTTTGAAATATTCGAGATTTTATTATTTTTTAGTAGCCTAGATTTCAAGATTGTTTTGACGATCAATTTTTGAATCAATTGTCAATATTTTTAGTAATAAAATGATGATTTTTGATTGGAAATACATTAAATCTATAAGCCAAATTGGAGATTATTGATATATTAACAAAAATGAGTTTTCCAGTCCATGAATGTATGCACATTATAAAATTCATTCTTAAGTATGTCATTTTTTAAGTTTTAGTTTCAGCAGTATATGTTTGTTACATAGGTAAACTCCTGTCATGGGGGTTAGTTGTACAGGTTATTTTATCATCCAGGCATAAAGCCCAGTACCCAGTAGTTATCTTTTCTGCTCCTCTCCCTCCTGTCACCCTCCACTCTCAAGTAGACCCCAGTTTCTGTTGTTCTCTTCTTTGCATTAATGACTTCTCATCATTTAGATTGCACTTGTAAGTGAGAACAGGACGTATGTGGTTTTCTACTCCTGTGTTAGTTTGCTAAGGATAACCACCTCCATCTCCATCCATGTTCCCACAAAAGACATGATCTCCTTTTTTATGGCTGCATATTATTCCATGGTATATATGTACCACATTTTCTTTATCCAATCTGTCATTGATGGACATTTAGGTTGTTTCCACATCATTGCCGTTGTAAATACTGCTGCAGTGAATATTCGTGTGTATGTCTTTATGGTAGAATGATTTATATTCCTCTGGGTATATTTCCAAGTAATGGGATGGTTGGGTCAAATGGTAATTCTGCTTTTAGCTTTTTGAGGAATTGCCATATTGCCTTTCACAACGGTTGAACTAATTTATACTCCCAAGAGTGTATAAGTTGTTCCTTTTTCTCTGCAACCTCGACATCACCTGTTATTTATGACTTTTATATAATAGCCATTCTGCTGGTCTGAGATGGTATCTCATTATGATTTTGATTTGCATTTCTCTAATGCTCAGTGATATTGAGCTTGGCTGCATATATGTCTTCTTTTAAAAATATCTGTTCATGTCCTTTGCCTAATTTATAACGGGGTTGTTTGTTTTTCTCTTGTAAATTTGTTTAAGTTCCTTATAGATTCTAGGTATTAAACCTTTTTTCAGAGGCGTGGCTTGCAAATATTTTCTCCCATTCTATAGGTTGTCTGTTTATTCTGTTGATAGTTTCCCTTGCTGTGCAGAAGCTCTTAACTTTAATTAGATCCGACTTGTCAATTTTTGCTTTGGTCGCAATTGCTTTTGATGTTATTGTCGTGAAATCTTTGCTAGTTCTTAGGTCCAGGATGATATTGCCCAAGTTGTCTTCCAGGGCTTTTATAATTTTGGATTTTACATTTAAGTCTTAATATATTTATTAAATTTGTTAGGGTTTCAGGATACAAGGACAATATAGCAGCAAACAATGTAAAAGTAAAATCTGAAAAATAATAGAAAACAGTTTAATTGAACACTTTACCATTATGTAATGCCCTTCTTTGTCTTTCCTGATCTTTGTTGGTTTGAAGTTCAAAAAAGACAAACTTAATGGTACAATAGGTATTGTAGATTTCAGGACTTTCTGTATAAAATATTTTGTATATATGAATAGATCATTTTTTATTTCCAGTCTTTAAACATTTTCTTAACATTTTCTTCTATTGCTTCACTTCACTCGCTAGGACCATCAGGACAGTGTTGAACAGAAATTGTCAGACTGATCATCACAACTTTTTCTAGATTTTAGAAGGAAATTTTTCTTTATTTCAACATAAAGCAGCATGTTAATGCCAAGTTTTAATATGTGTTATCAGATTGAAATTTTTTTGTATATTTCTACATTACCAAGAATTTTTAGCAAGAGTTTTTGTTGAGTTTTAATTTAAAAATCATTTGTTAATTTCATCTGATTTTTTTATTTCTCTTTTTACCTTAAGAGATTAAACTGACTACAGATTGAATATAAACAAACAAACAAACAAACAAAAACTCTAAAATGCTGTGGATCAACACCACTTAGTAATTTGTATACTTGGATTCAATTTGCTGAAATTTTGTTAGACATTTTTGCGTCGATATTTATGAGGGATGTTGATCTGTAAAAGTATTAAAATGCCTTTGACAGATTTTGATAGCAGTGTTATTCTGGCCTAATAAATCAAACTGAGGTATGATCCTTCCTTTTCTATTTCTTAATAGCATTTTTAAAATTGGTGGTTTTTTCCTTCCTTAGTGAAATTTACCAGCAAAGTAACAGGCCTTATATTTCTCTTGTGGAAATATTTTAATTTCAAATTAATGGTATTTTGTTCTTGTAGGGTGGTAATTTTCTCTGTGTTTGGTCTTAATGGACTCTTAGCTGATCACCCAGTTACTCAGCGAGGTCTCTTCACTCTGGAAGAGCTGGAACTCCAGTGTGTTTTAGTGCAGCATGACCACGGGTATTACCGTTCAACATTTAGGCTTTATCAGTGATAACTATTTGTCCTCATGGAGTTTTTGCCGCTGGGCCTACACAGTTTAGGCTTCAGCTTAGAACACATAATGAATTCTTATGCAGATTTCTGCCCACCTTTGACCTTTCATGATTTCCTCTTCTTGGGTAAGCTGCCTTATTAATCTGATACACTTCAGCAGTCCAGAACTACACTCTTTCCCTTCTCTGCTCTTGGAGATGACTCTTTTGTCTGAGATTCACTTTGCTGTGCTGAAAAAGAAAAGTGCTTCAAGGAAGATACCAAGGAAAATCACAGGGCTCATTTATGTATTTCTCTTCTTTCAAGGACTACAGCTTTGTGTTGCCTATGTTCAATTTCTGAAAATAATTAGAGCATATATACTCTGTGTGAGAAGGCAAATCCAGACAGTTAGTTTGTATGACTAGAAGCAGAAGTCTACATGGAGAATTTTACTTAACTGTGTTATAGTTTCTTTAATTATTTCAAGAGTATGTTTAATGTTCCACAGATCTCATTCTATAAATCTTTATCATCTTAGAGCTCTGATACTATTTAGAATTACTATTCCTTCAAATAAGAGATTAGAAACAGGGTTATATTTGGGGTAGGTTGACTTACTTTTCTGGGAACCAAAGCATATTAAATTGACCAGTTTTAACACACTTCTATGTATGCACAAAGATATATATTTACATTCTGCAAAATCATTCTTTCCTTTTTGAATTTGAAAAGGATCTTTGGTATACAGATATTCAATAGCCAGCCTGAAGATTCATTTGAATTCATTTAATGTTTAGATTCACTACATGAAATGATCCAGAAGAGAGTACTCAAATATAAGTATCTATAACGATGGAAATATACATCTCCACTGCCCAAGATGGTAGTCATGAGTCAATATTGATCATGTGAGACGTGGCAAGTGTTACTCAGGGTCTCAATATTTAAATGTATTAAGCTTTAATTAATGTAAATTTGAATTTAGCAAAACATGTATAGCTTGTGGTTACTGTTTTATTCAGTGCCAATATAGAACATTTCCATGATTACAGAAAGTTATCTTAGAATACTCAGTTCTGGACTATTTTATCTGGCTAAATTAAATGTTAAAATATTACAAATTCATCTTCAGGCTGGCTGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATCCCATTTTTATTCTTTTCATATTAATTTTATTGCCATGTATGAATGCTGTAGCATCCATGTTTAAATACTAGTTAACAAAATGCACTGGCATCAGATACAATAAGGATGAAATGAGATATAATTAGGACTCTGGTAACACACATAAAATTGGAAAGATACCCTGAAATTCAAGCCAAGAAGATATTTATCCAGCTTATTTTATTTTGAGACAGAGTCTTGCTCTCTCACTCAGGCTGGAGTGCAGTGGACCATTCTAGGCTCGCTCCAACCTCTGTCTCCCAAATTGAAGTAATTCTCGTGCCTCAATCTCCCGAGTAGCTGGGATTACAGGCATGTGTCACCAAGCCTGGCTGATTTTTGTAGTTTTAGTAGAGACGGGGTTTCACCATGATGGCCAGGCTGGTCTTGAACTCCTGGCCTCAAGTGACTGGAACACCTCGGCCTCCTAAAGTGCTGGGATTACAGACGAGAGCCACTGAACAGCTTTGATCCAACTTATTTGGATGAATGAGTTACATATTTTACATTAAATCTGTTATTGTGATAATTCTTCATGTTATTTTCCATGTATAGATTTATATATAATGTAATTTTAATTTTTTTTCACCGGAGAGTATAAACAACAATTATTTTATAAACAGGATAATAAAAATAAGACAAAAATTGTTGAAATGTCTTCATTTGACTACTAACTTTTTACATGTTTGTTACTTTGAAGCTGTTATCAATACTTGTGATGTATTACAATTAAGTAAAGATTTAAAGATGCCATTTTTAACTTATTATGACACAAAGTCTATAAATTCTTATATTTTGAGATTTGTATTTAAATAACTTGTGAAATTTAATTTTAAAATAAAATTTCTTCTATGGATTGGTCTTCAATCGAGGCATAAAAAGGAATATAACAGTGTGGCACTATAACTTCTATATTGAATTTCTATATTATTTAACACAATTATAATTTTGCTAATGAATTGTAATGTTTTTAAAAAGCTAGGTGAATTTTATTAAATTCATTACATGGCGATAACACAGAGAAAACATTTTGGGGATTCTTTTAAAATGGTATGTACAAAAGCTTAAAAGTTGTTATGTAGTGGCAGAGATAAAAAAGTAAAACAAAAAAAAGCTTAAAAGTTTGCTTTACTATTTATAGGCTCATAAGTGTAAGTGTGCCAGAAAATGAAAAAGAAAGGAGAGAAATTATAAATAACTGTGTGGAAAACACAGATAAAGCATAAAGATAGAATATAAAGATAGAAGCATTTTAATATGAGGCAGTGATGGCTTTTTGAAGAATCCCAACTAAGGACCTACTTTTAGTTAATAAATAATATGTTTCTAATCCCTATATTGTCCACAGCAACCTTTTTAGGACATGGAGCAGTGACTATGAGTGCCAGAAGGCAAGAGTAGAAGCAATTGTAAAATCATGAACACTAGTTTGTAAAATCCTCACTGAGATATAATATCTGTTTGCCTCTACCTTAGAATTATTAATGTCTTGAGGGCTGGGAGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATTAAAGTGTAATTTTAATTTTTTTTCACCGGAGAGTATAAACAACAATTATTTTATAAACAGGATAATAAAAATAAGACAAAAATTGTTGAAATGTCTTCATTTGACTACTAACTTTTTACATGTTTGTTACTTTGAAGCTGTTATCAATACTTGTGATGTATTACAATTAAGTAAAGATTTAAAGATGCCATTTTTAACTTATTATGACACAAAGTCTATAAATTCTTATATTTTGAGATTTGTATTTAAATAACTTGTGAAATTTAATTTTAAAATAAAATTTCTTCTATGGATTGGTCTTCAATCGAGGCATAAAAAGGAATATAACAGTGTGGCACTATAACTTCTATATTGAATTTCTATATTATTTAACACAATTATAATTTTGCTAATGAATTGTAATGTTTTTAAAAAGCTAGGTGAATTTTATTAAATTCATTACATGGCGATAACACAGAGAAAACATTTTGGGGATTCTTTTAAAATGGTATGTACAAAAGCTTAAAAGTTGTTATGTAGTGGCAGAGATAAAAAAGTAAAACAAAAAAAAGCTTAAAAGTTTGCTTTACTATTTATAGGCTCATAAGTGTAAGTGTGCCAGAAAATGAAAAAGAAAGGAGAGAAATTATAAATAACTGTGTGGAAAACACAGATAAAGCATAAAGATAGAATATAAAGATAGAAGCATTTTAATATGAGGCAGTGATGGCTTTTTGAAGAATCCCAACTAAGGACCTACTTTTAGTTAATAAATAATATGTTTCTAATCCCTATATTGTCCACAGCAACCTTTTTAGGACATGGAGCAGTGACTATGAGTGCCAGAAGGCAAGAGTAGAAGCAATTGTAAAATCATGAACACTAGTTTGTAAAATCCTCACTGAGATATAATATCTGTTTGCCTCTACCTTAGAATTATTAATGTCTTGAGGGCTGGGAGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATTAAA
TCACAATTTAGACATCTAGTCTTCCACTTAAGCATATTTAGATTGTTTCCAGTTTTCAGCTTTTATGACTAAATCTTCTAAAATTGTTTTTCCCTAAATGTATATTTTAATTTGTCTCAGGAGTAGAATTTCTGAGTCATAAAGCGGTCATATGTATAAATTTTAGGTGCCTCATAGCTCTTCAAATAGTCATCCCATTTTATACATCCAGGCAATATATGAGAGTTCTTGGTGCTCCACATCTTAGCTAGGATTTGATGTCAACCAGTCTCTTTAATTTAGATATTCTAGTACATACAAAATAATACCTCAGTGTAACCTCTGTTTGTATTTCCCTTGATTAACTGATGCTGAGCACATCTTCATGTGCTTATTGACCATTAATTAGTCTTATTTGTTAAATGTCTCAAATATTTTATACAGTTTTACATTGTGTTATTCATTTTTTAAAAAATTCATTTTAGGTTATATGTATGTGTGTGTCAAAGTGTGTGTACATCTATTTGATATATGTATGTCTATATATTCTGGATACCATCTCTGTTTCATGCATTGCATATATATTTGCCTATTTAGTGGTTTATCTTTTCATTTTCTTTTGGTATCTTTTCATTAGAAATGTTATTTATTTTGAGTAAGTAACATTTAATATATTCTGTAACATTTAATGAATCATTTTATGTTATGTTTAGTATTAAATTTCTGAAAACATTCTATGTATTCTACTAGAATTGTCATAATTTTATCTTTTATATACATTGATATTTTTATGTCAAATATGTAGGTATGTGATATTATGCACATGGTTTTAATTCAGTTAATTGTTCTTCCAGATGTTTGTACCATTCCAACATCATTTAAATCATTAAATGAAAAGCCTTTCCTTACTAGCTAGCCAGCTTTGAAAATCCATTCATAGGGTTTGTGTTAATATATTTTTGTTCTTTTTTTTCCTTTCTACTGATCTCTTTATATTAATACCTACTGTGGCTTTATATGAAGTCATGGAATAATACGTAGTAAGCCCTCTAACACTGTTCTGTTACTGTTGTTATTGTTTTCTCAGGGTACTTTGAAATATTCGAGATTTTATTATTTTTTAGTAGCCTAGATTTCAAGATTGTTTTGACGATCAATTTTTGAATCAATTGTCAATATTTTTAGTAATAAAATGATGATTTTTGATTGGAAATACATTAAATCTATAAGCCAAATTGGAGATTATTGATATATTAACAAAAATGAGTTTTCCAGTCCATGAATGTATGCACATTATAAAATTCATTCTTAAGTATGTCATTTTTTAAGTTTTAGTTTCAGCAGTATATGTTTGTTACATAGGTAAACTCCTGTCATGGGGGTTAGTTGTACAGGTTATTTTATCATCCAGGCATAAAGCCCAGTACCCAGTAGTTATCTTTTCTGCTCCTCTCCCTCCTGTCACCCTCCACTCTCAAGTAGACCCCAGTTTCTGTTGTTCTCTTCTTTGCATTAATGACTTCTCATCATTTAGATTGCACTTGTAAGTGAGAACAGGACGTATGTGGTTTTCTACTCCTGTGTTAGTTTGCTAAGGATAACCACCTCCATCTCCATCCATGTTCCCACAAAAGACATGATCTCCTTTTTTATGGCTGCATATTATTCCATGGTATATATGTACCACATTTTCTTTATCCAATCTGTCATTGATGGACATTTAGGTTGTTTCCACATCATTGCCGTTGTAAATACTGCTGCAGTGAATATTCGTGTGTATGTCTTTATGGTAGAATGATTTATATTCCTCTGGGTATATTTCCAAGTAATGGGATGGTTGGGTCAAATGGTAATTCTGCTTTTAGCTTTTTGAGGAATTGCCATATTGCCTTTCACAACGGTTGAACTAATTTATACTCCCAAGAGTGTATAAGTTGTTCCTTTTTCTCTGCAACCTCGACATCACCTGTTATTTATGACTTTTATATAATAGCCATTCTGCTGGTCTGAGATGGTATCTCATTATGATTTTGATTTGCATTTCTCTAATGCTCAGTGATATTGAGCTTGGCTGCATATATGTCTTCTTTTAAAAATATCTGTTCATGTCCTTTGCCTAATTTATAACGGGGTTGTTTGTTTTTCTCTTGTAAATTTGTTTAAGTTCCTTATAGATTCTAGGTATTAAACCTTTTTTCAGAGGCGTGGCTTGCAAATATTTTCTCCCATTCTATAGGTTGTCTGTTTATTCTGTTGATAGTTTCCCTTGCTGTGCAGAAGCTCTTAACTTTAATTAGATCCGACTTGTCAATTTTTGCTTTGGTCGCAATTGCTTTTGATGTTATTGTCGTGAAATCTTTGCTAGTTCTTAGGTCCAGGATGATATTGCCCAAGTTGTCTTCCAGGGCTTTTATAATTTTGGATTTTACATTTAAGTCTTAATATATTTATTAAATTTGTTAGGGTTTCAGGATACAAGGACAATATAGCAGCAAACAATGTAAAAGTAAAATCTGAAAAATAATAGAAAACAGTTTAATTGAACACTTTACCATTATGTAATGCCCTTCTTTGTCTTTCCTGATCTTTGTTGGTTTGAAGTTCAAAAAAGACAAACTTAATGGTACAATAGGTATTGTAGATTTCAGGACTTTCTGTATAAAATATTTTGTATATATGAATAGATCATTTTTTATTTCCAGTCTTTAAACATTTTCTTAACATTTTCTTCTATTGCTTCACTTCACTCGCTAGGACCATCAGGACAGTGTTGAACAGAAATTGTCAGACTGATCATCACAACTTTTTCTAGATTTTAGAAGGAAATTTTTCTTTATTTCAACATAAAGCAGCATGTTAATGCCAAGTTTTAATATGTGTTATCAGATTGAAATTTTTTTGTATATTTCTACATTACCAAGAATTTTTAGCAAGAGTTTTTGTTGAGTTTTAATTTAAAAATCATTTGTTAATTTCATCTGATTTTTTTATTTCTCTTTTTACCTTAAGAGATTAAACTGACTACAGATTGAATATAAACAAACAAACAAACAAACAAAAACTCTAAAATGCTGTGGATCAACACCACTTAGTAATTTGTATACTTGGATTCAATTTGCTGAAATTTTGTTAGACATTTTTGCGTCGATATTTATGAGGGATGTTGATCTGTAAAAGTATTAAAATGCCTTTGACAGATTTTGATAGCAGTGTTATTCTGGCCTAATAAATCAAACTGAGGTATGATCCTTCCTTTTCTATTTCTTAATAGCATTTTTAAAATTGGTGGTTTTTTCCTTCCTTAGTGAAATTTACCAGCAAAGTAACAGGCCTTATATTTCTCTTGTGGAAATATTTTAATTTCAAATTAATGGTATTTTGTTCTTGTAGGGTGGTAATTTTCTCTGTGTTTGGTCTTAATGGACTCTTAGCTGATCACCCAGTTACTCAGCGAGGTCTCTTCACTCTGGAAGAGCTGGAACTCCAGTGTGTTTTAGTGCAGCATGACCACGGGTATTACCGTTCAACATTTAGGCTTTATCAGTGATAACTATTTGTCCTCATGGAGTTTTTGCCGCTGGGCCTACACAGTTTAGGCTTCAGCTTAGAACACATAATGAATTCTTATGCAGATTTCTGCCCACCTTTGACCTTTCATGATTTCCTCTTCTTGGGTAAGCTGCCTTATTAATCTGATACACTTCAGCAGTCCAGAACTACACTCTTTCCCTTCTCTGCTCTTGGAGATGACTCTTTTGTCTGAGATTCACTTTGCTGTGCTGAAAAAGAAAAGTGCTTCAAGGAAGATACCAAGGAAAATCACAGGGCTCATTTATGTATTTCTCTTCTTTCAAGGACTACAGCTTTGTGTTGCCTATGTTCAATTTCTGAAAATAATTAGAGCATATATACTCTGTGTGAGAAGGCAAATCCAGACAGTTAGTTTGTATGACTAGAAGCAGAAGTCTACATGGAGAATTTTACTTAACTGTGTTATAGTTTCTTTAATTATTTCAAGAGTATGTTTAATGTTCCACAGATCTCATTCTATAAATCTTTATCATCTTAGAGCTCTGATACTATTTAGAATTACTATTCCTTCAAATAAGAGATTAGAAACAGGGTTATATTTGGGGTAGGTTGACTTACTTTTCTGGGAACCAAAGCATATTAAATTGACCAGTTTTAACACACTTCTATGTATGCACAAAGATATATATTTACATTCTGCAAAATCATTCTTTCCTTTTTGAATTTGAAAAGGATCTTTGGTATACAGATATTCAATAGCCAGCCTGAAGATTCATTTGAATTCATTTAATGTTTAGATTCACTACATGAAATGATCCAGAAGAGAGTACTCAAATATAAGTATCTATAACGATGGAAATATACATCTCCACTGCCCAAGATGGTAGTCATGAGTCAATATTGATCATGTGAGACGTGGCAAGTGTTACTCAGGGTCTCAATATTTAAATGTATTAAGCTTTAATTAATGTAAATTTGAATTTAGCAAAACATGTATAGCTTGTGGTTACTGTTTTATTCAGTGCCAATATAGAACATTTCCATGATTACAGAAAGTTATCTTAGAATACTCAGTTCTGGACTATTTTATCTGGCTAAATTAAATGTTAAAATATTACAAATTCATCTTCAGGCTGGCTGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATCCCATTTTTATTCTTTTCATATTAATTTTATTGCCATGTATGAATGCTGTAGCATCCATGTTTAAATACTAGTTAACAAAATGCACTGGCATCAGATACAATAAGGATGAAATGAGATATAATTAGGACTCTGGTAACACACATAAAATTGGAAAGATACCCTGAAATTCAAGCCAAGAAGATATTTATCCAGCTTATTTTATTTTGAGACAGAGTCTTGCTCTCTCACTCAGGCTGGAGTGCAGTGGACCATTCTAGGCTCGCTCCAACCTCTGTCTCCCAAATTGAAGTAATTCTCGTGCCTCAATCTCCCGAGTAGCTGGGATTACAGGCATGTGTCACCAAGCCTGGCTGATTTTTGTAGTTTTAGTAGAGACGGGGTTTCACCATGATGGCCAGGCTGGTCTTGAACTCCTGGCCTCAAGTGACTGGAACACCTCGGCCTCCTAAAGTGCTGGGATTACAGACGAGAGCCACTGAACAGCTTTGATCCAACTTATTTGGATGAATGAGTTACATATTTTACATTAAATCTGTTATTGTGATAATTCTTCATGTTATTTTCCATGTATAGATTTATATATAATGTAATTTTAATTTTTTTTCACCGGAGAGTATAAACAACAATTATTTTATAAACAGGATAATAAAAATAAGACAAAAATTGTTGAAATGTCTTCATTTGACTACTAACTTTTTACATGTTTGTTACTTTGAAGCTGTTATCAATACTTGTGATGTATTACAATTAAGTAAAGATTTAAAGATGCCATTTTTAACTTATTATGACACAAAGTCTATAAATTCTTATATTTTGAGATTTGTATTTAAATAACTTGTGAAATTTAATTTTAAAATAAAATTTCTTCTATGGATTGGTCTTCAATCGAGGCATAAAAAGGAATATAACAGTGTGGCACTATAACTTCTATATTGAATTTCTATATTATTTAACACAATTATAATTTTGCTAATGAATTGTAATGTTTTTAAAAAGCTAGGTGAATTTTATTAAATTCATTACATGGCGATAACACAGAGAAAACATTTTGGGGATTCTTTTAAAATGGTATGTACAAAAGCTTAAAAGTTGTTATGTAGTGGCAGAGATAAAAAAGTAAAACAAAAAAAAGCTTAAAAGTTTGCTTTACTATTTATAGGCTCATAAGTGTAAGTGTGCCAGAAAATGAAAAAGAAAGGAGAGAAATTATAAATAACTGTGTGGAAAACACAGATAAAGCATAAAGATAGAATATAAAGATAGAAGCATTTTAATATGAGGCAGTGATGGCTTTTTGAAGAATCCCAACTAAGGACCTACTTTTAGTTAATAAATAATATGTTTCTAATCCCTATATTGTCCACAGCAACCTTTTTAGGACATGGAGCAGTGACTATGAGTGCCAGAAGGCAAGAGTAGAAGCAATTGTAAAATCATGAACACTAGTTTGTAAAATCCTCACTGAGATATAATATCTGTTTGCCTCTACCTTAGAATTATTAATGTCTTGAGGGCTGGGAGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATTAAAGTGTAATTTTAATTTTTTTTCACCGGAGAGTATAAACAACAATTATTTTATAAACAGGATAATAAAAATAAGACAAAAATTGTTGAAATGTCTTCATTTGACTACTAACTTTTTACATGTTTGTTACTTTGAAGCTGTTATCAATACTTGTGATGTATTACAATTAAGTAAAGATTTAAAGATGCCATTTTTAACTTATTATGACACAAAGTCTATAAATTCTTATATTTTGAGATTTGTATTTAAATAACTTGTGAAATTTAATTTTAAAATAAAATTTCTTCTATGGATTGGTCTTCAATCGAGGCATAAAAAGGAATATAACAGTGTGGCACTATAACTTCTATATTGAATTTCTATATTATTTAACACAATTATAATTTTGCTAATGAATTGTAATGTTTTTAAAAAGCTAGGTGAATTTTATTAAATTCATTACATGGCGATAACACAGAGAAAACATTTTGGGGATTCTTTTAAAATGGTATGTACAAAAGCTTAAAAGTTGTTATGTAGTGGCAGAGATAAAAAAGTAAAACAAAAAAAAGCTTAAAAGTTTGCTTTACTATTTATAGGCTCATAAGTGTAAGTGTGCCAGAAAATGAAAAAGAAAGGAGAGAAATTATAAATAACTGTGTGGAAAACACAGATAAAGCATAAAGATAGAATATAAAGATAGAAGCATTTTAATATGAGGCAGTGATGGCTTTTTGAAGAATCCCAACTAAGGACCTACTTTTAGTTAATAAATAATATGTTTCTAATCCCTATATTGTCCACAGCAACCTTTTTAGGACATGGAGCAGTGACTATGAGTGCCAGAAGGCAAGAGTAGAAGCAATTGTAAAATCATGAACACTAGTTTGTAAAATCCTCACTGAGATATAATATCTGTTTGCCTCTACCTTAGAATTATTAATGTCTTGAGGGCTGGGAGTTGAATATTTTTATAGCAAAAGTCATTTATAAATTTAAAACTCAAATAATTATCTTTTTCAATATGTAAAATATGTCTTTACATATTCTACTCCCTTCTTACATACATATTCTGATGTAACATAGGTATTCTCTTATTCATGCACACTGAAATGACAACATAAATAATTTTACTAAGTGTCACCATATAAAAAACTTTGAACAAAATCAGATTATATCACTGTGGATATTTCTATTTTGAACTAACTTAGATGATAATTTTAATCTATATCCTAGATGAACTTTAAATCAATAAAATCTCTCAATGGTGTTATAAATCTCAAGCCATTAGCCACTGATTATTAAA
BIOINFORMÁTICASimilitud Similitud de de secuenciasecuencia::
1.1. BancosBancos de ESTde EST
2.2. Genes Genes conocidosconocidos
3.3. Umbral mínimo Umbral mínimo de de homologíahomología con con secuencias otros organismossecuencias otros organismos
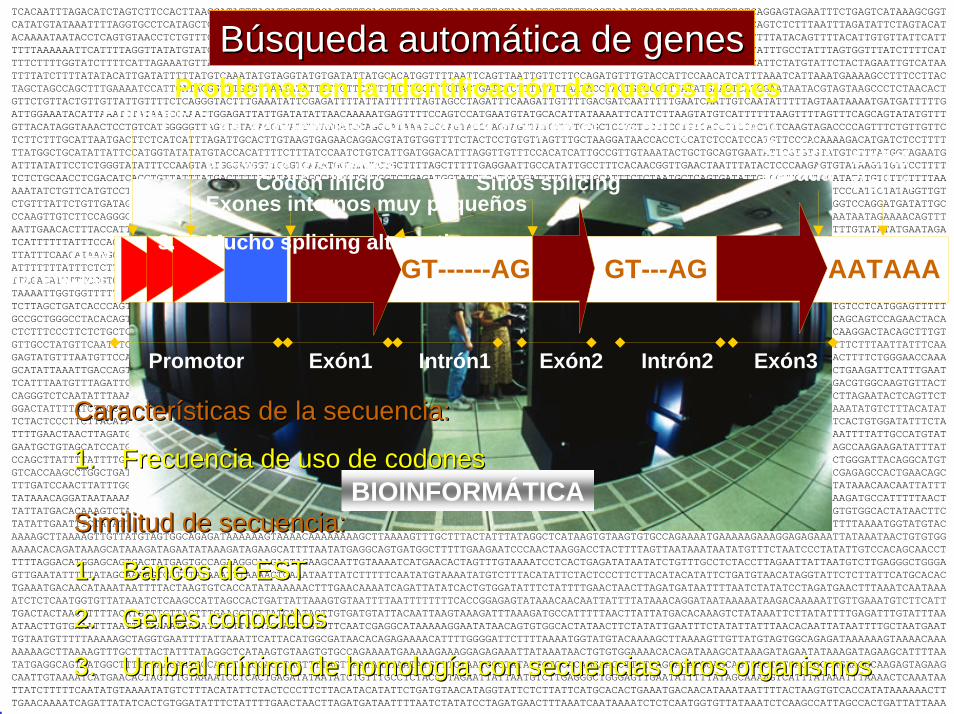
Enhancers
Codón inicio Sitios splicingCodónparada
Promotor
GENPOTENCIAL GT------AG GT---AG
Exón1 Exón2 Exón3
AATAAA
SeñalPoli-A
Intrón1 Intrón2
Búsqueda automática de genesBúsqueda automática de genesProblemas en la identificación de nuevos genes
1. Las secuencias codificantes ocupan el 1% del genoma y
el 5% de los genes
2. Exones internos muy pequeños
3. Mucho splicing alternativo
CaracterísticasCaracterísticas de la de la secuenciasecuencia::
1.1. FrecuenciaFrecuencia de de uso uso de de codonescodones

Funciones de los genes Funciones de los genes codificantes codificantes para proteínaspara proteínas
¿Cuales son las proteínas que difieren de otros
eucariotas secuenciados?
¿Cuales son las funciones probables de los genes identificados y cómo se clasifican dentro de las
familias conocidas?
¿Cuales son las funciones comunes en los animales?

Funciones de los genes Funciones de los genes codificantes codificantes para proteínaspara proteínas
Metabolismo Metabolismo ADNADN
Factores de Factores de transcripcióntranscripción
Receptores,Receptores,quinasasquinasas,,
hidrolasashidrolasas
Transducción Transducción de señalesde señales
DesconocidasDesconocidas
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).
Conservación evolutiva de proteínasConservación evolutiva de proteínas

Propiedades de los genes codificantes Propiedades de los genes codificantes en eucariotas superioresen eucariotas superiores
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
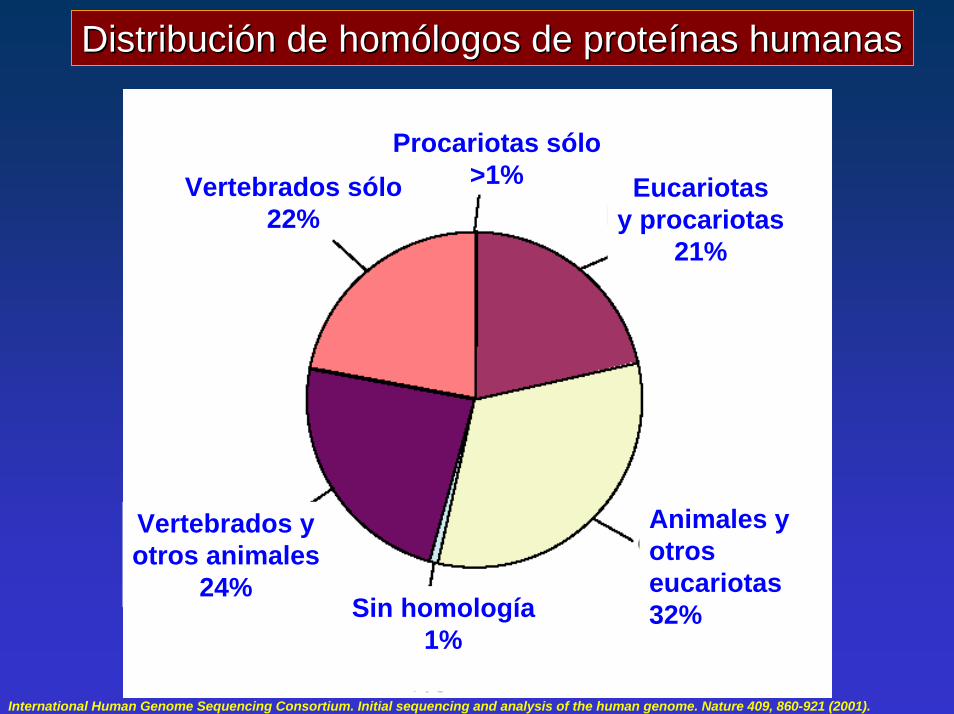
Distribución de homólogos de proteínas humanasDistribución de homólogos de proteínas humanas
Procariotas sólo>1% Eucariotas
y procariotas21%
Vertebrados sólo22%
Vertebrados yotros animales
24%Sin homología
1%
Animales yotros eucariotas32%
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
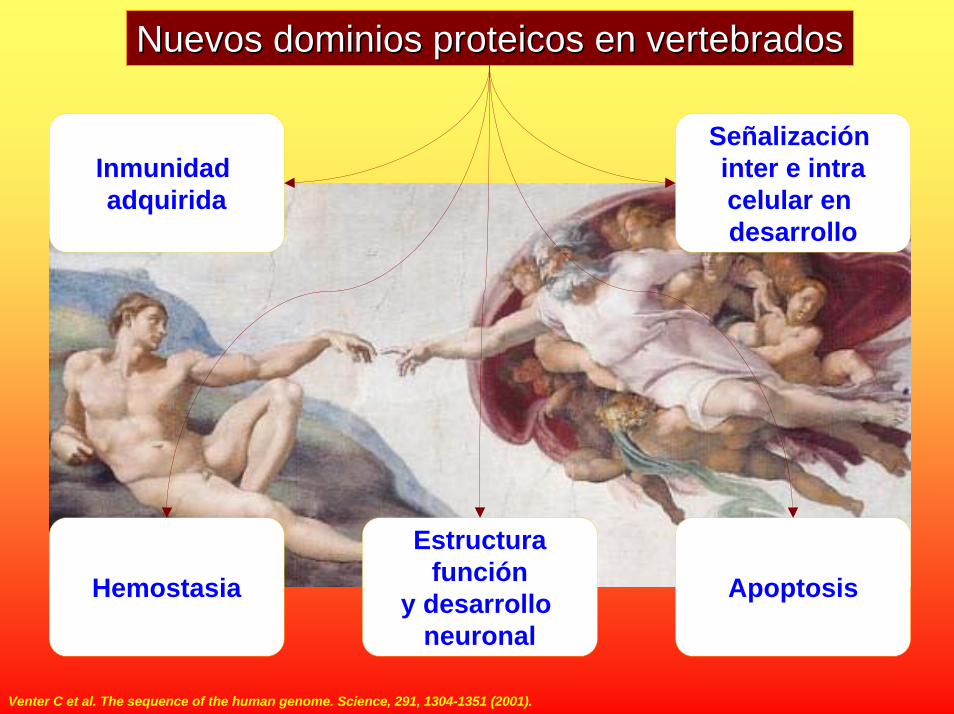
Nuevos dominios proteicos en vertebradosNuevos dominios proteicos en vertebrados
Inmunidad adquirida
Estructurafunción
y desarrollo neuronal
Señalización inter e intracelular en desarrollo
Hemostasia Apoptosis
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).
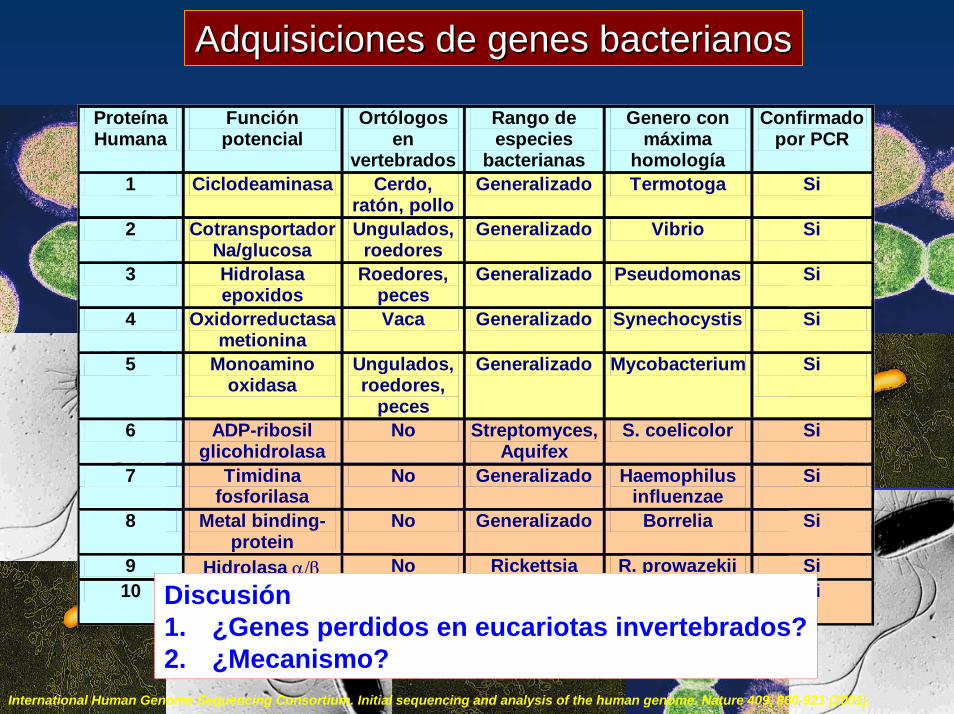
Adquisiciones de genes bacterianosAdquisiciones de genes bacterianos
Proteína Humana
Función potencial
Ortólogos en
vertebrados
Rango de especies
bacterianas
Genero con máxima
homología
Confirmado por PCR
1 Ciclodeaminasa Cerdo, ratón, pollo
Generalizado Termotoga Si
2 Cotransportador Na/glucosa
Ungulados, roedores
Generalizado Vibrio Si
3 Hidrolasa epoxidos
Roedores, peces
Generalizado Pseudomonas Si
4 Oxidorreductasa metionina
Vaca Generalizado Synechocystis Si
5 Monoamino oxidasa
Ungulados, roedores,
peces
Generalizado Mycobacterium Si
6 ADP-ribosil glicohidrolasa
No Streptomyces, Aquifex
S. coelicolor Si
7 Timidina fosforilasa
No Generalizado Haemophilus influenzae
Si
8 Metal binding-protein
No Generalizado Borrelia Si
9 Hidrolasa α/β No Rickettsia R. prowazekii Si 10 Histona M-2cA
fosfatasa No Thermotoga,
Alcaligenes T. marítima
Virus de ARN Si Discusión
1. ¿Genes perdidos en eucariotas invertebrados?2. ¿Mecanismo?
International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
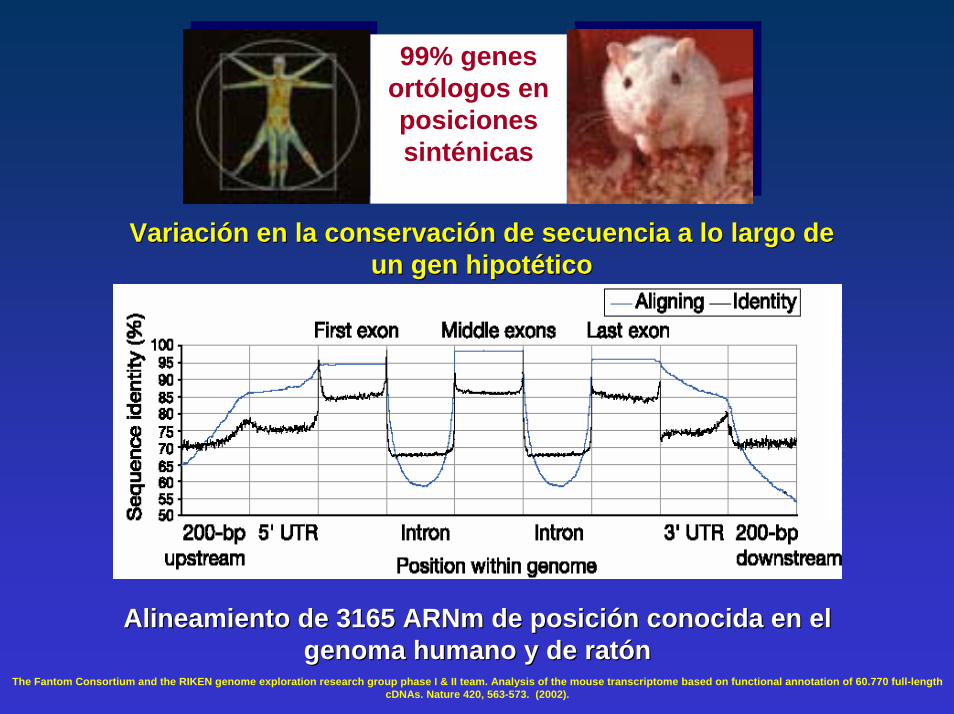
99% genes ortólogos en posiciones sinténicas
Variación en la conservación de secuencia a lo largo de Variación en la conservación de secuencia a lo largo de un gen hipotéticoun gen hipotético
Alineamiento de 3165 Alineamiento de 3165 ARNm ARNm de posición conocida en el de posición conocida en el genoma humano y de ratóngenoma humano y de ratón
The Fantom Consortium and the RIKEN genome exploration research group phase I & II team. Analysis of the mouse transcriptome based on functional annotation of 60.770 full-length cDNAs. Nature 420, 563-573. (2002).
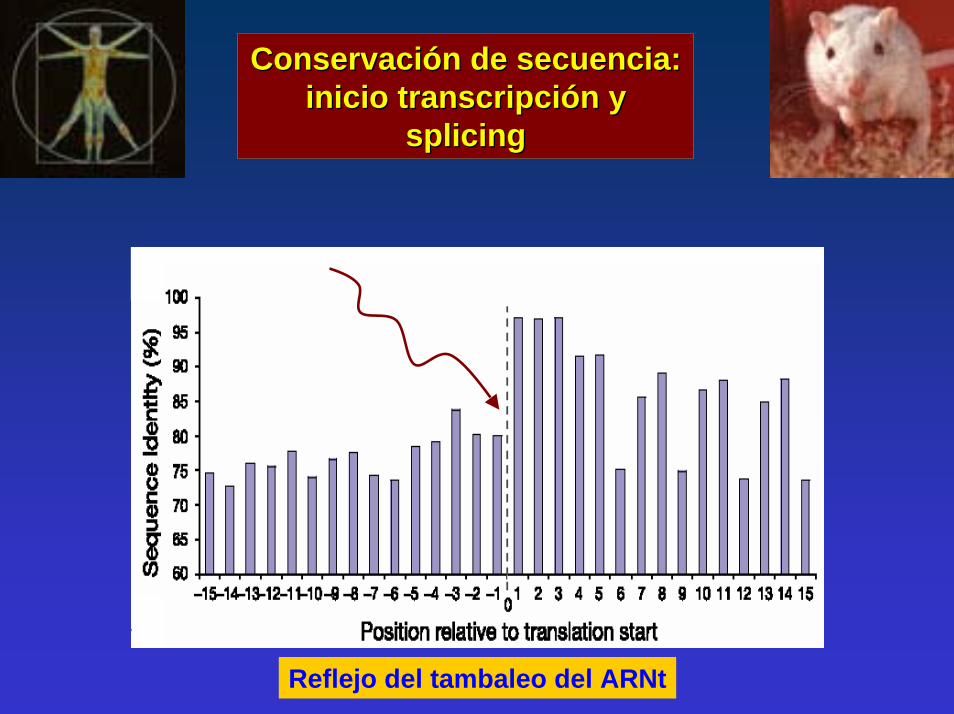
Conservación de secuencia:Conservación de secuencia:inicio inicio transcripción transcripción y y
splicing splicing
Reflejo del tambaleo del ARNt
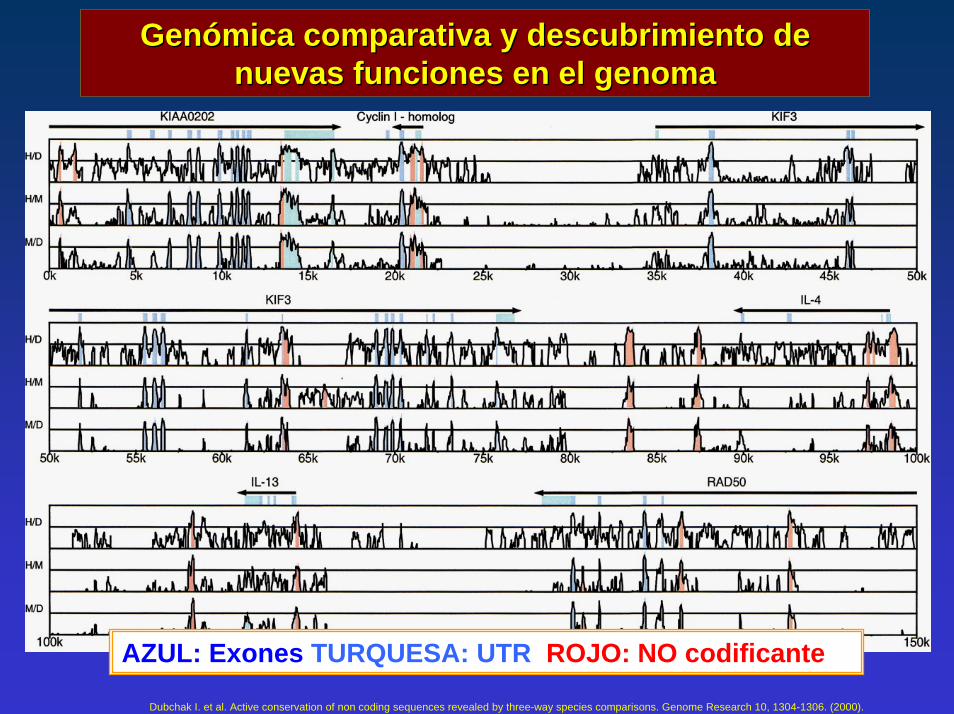
Genómica Genómica comparativa y descubrimiento de comparativa y descubrimiento de nuevas funciones en el genoma nuevas funciones en el genoma
AZUL: Exones TURQUESA: UTR ROJO: NO codificante
Dubchak I. et al. Active conservation of non coding sequences revealed by three-way species comparisons. Genome Research 10, 1304-1306. (2000).

Proyecto Genoma HumanoProyecto Genoma HumanoResultados
Variabilidad en el genoma

Variaciones polimórficasVariaciones polimórficas
1. Polimorfismos de nucleótidosCambios de un solo nucleótidoInserciones o deleciones pequeñas
1. Polimorfismos de inserción de transposones2. Polimorfismos de duplicación de segmentos3. Polimorfismos de repetición (microsatélites y
minisatélites)
1. Polimorfismos de nucleótidosCambios de un solo nucleótidoInserciones o deleciones pequeñas
1. Polimorfismos de inserción de transposones2. Polimorfismos de duplicación de segmentos3. Polimorfismos de repetición (microsatélites y
minisatélites)

A - TC - GT - AT - AT - A
alelo T/A alelo C/G
“ La fuente más común de variación genética en el hombre son los polimorfismosde un solo nucleótido (SNPs)
Aravinda Chakravarti, Nature, 409 (Feb 2001), 822-823
Polimorfismos Polimorfismos de un solo de un solo nucleótidonucleótido Single Single nucleotide nucleotide polimorphismspolimorphisms ((SNPsSNPs))
Cromosoma de la persona A
Cromosoma de la persona B
A - TC - GC - GT - AT - A
Fenotipo = Fenotipo?
un cambio cada 1000 nucleótidos

Mutación versus polimorfismoMutación versus polimorfismoDefinición indefinida
Mutación (<1%) Polimorfismo (1%)
0.90 0.10,0010.999PolimorfismoMutación Población
generalPoblacióngeneral
AA 0.998AC 2x10-3
CC 10-6
AA 0.998AC 2x10-3
CC 10-6
GG 0.81GA 0.18AA 0.01
GG 0.81GA 0.18AA 0.01

Características de los Características de los SNPsSNPs
SNPs cromosoma SNPs cromosoma 11
1.1. Los Los humanoshumanos compartencomparten el 99,9% de la el 99,9% de la informacióninformación genéticagenética
2.2. Hay un SNP Hay un SNP por cada por cada 1000 pb 1000 pb aproximadamenteaproximadamente
3.3. 90% de la 90% de la variabilidad genética variabilidad genética se se corresponde corresponde con con SNPsSNPs
4.4. El El genomagenoma humanohumano contienecontiene másmás de 2 de 2 millonesmillones de de SNPsSNPs ~21,000 de ~21,000 de los cuales los cuales se se encuentran encuentran en en los los genesgenes
5.5. SNPs que cambian SNPs que cambian un un aminoácido aminoácido 0,17% de 0,17% de los cuales los cuales no no conservativos conservativos son son sólo sólo el 0,07%el 0,07%
¡¡FuncionalmenteFuncionalmente la la variabilidad humana es incluso menorvariabilidad humana es incluso menor!!International Human Genome Sequencing Consortium. Initial sequencing and analysis of the human genome. Nature 409, 860-921 (2001).
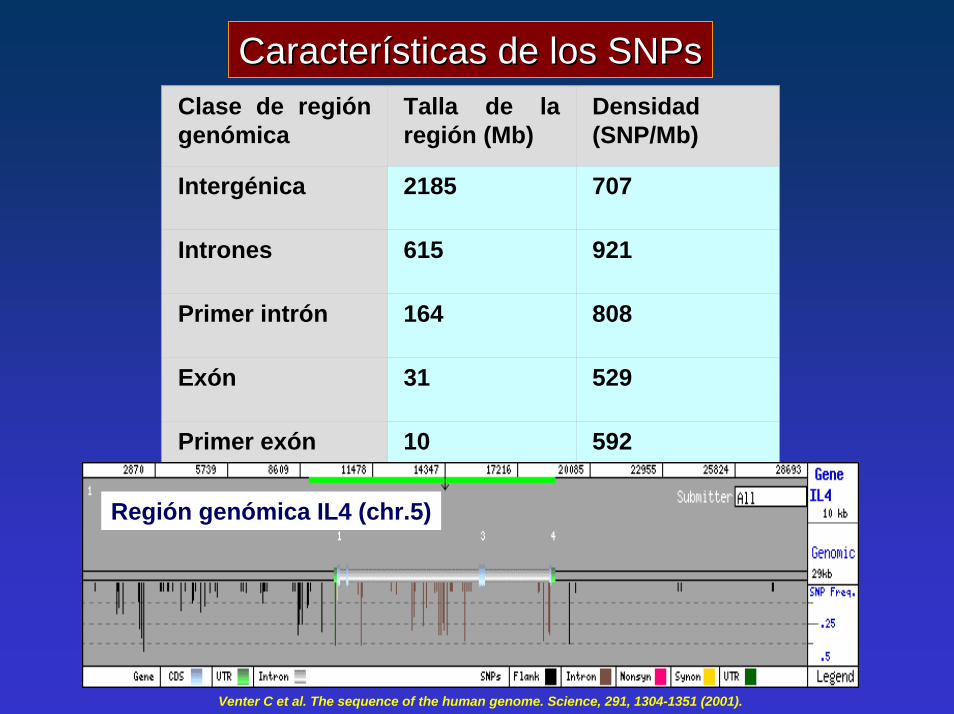
Características de los Características de los SNPsSNPsClase de región genómica
Talla de la región (Mb)
Densidad (SNP/Mb)
Intergénica 2185 707
Intrones 615 921
Primer intrón 164 808
Exón 31 529
Primer exón 10 592
Región genómica IL4 (chr.5)
Venter C et al. The sequence of the human genome. Science, 291, 1304-1351 (2001).

SNPs SNPs y fenotipoy fenotipo
SNPsSNPs1.1. Dentro Dentro de un de un exón codificanteexón codificante: : puede alterar puede alterar la la
estructura estructura de la de la proteínaproteína
2.2. En la En la regiregióón reguladoran reguladora PuedePuede afectarafectar la la expresiexpresióónncuantitativacuantitativa o o temporalmentetemporalmente
3.3. Regiones intergRegiones intergéénicas nicas no no reguladorasreguladoras Marcadores Marcadores gengenééticos para anticos para anáálisis lisis de de ligamiento ligamiento con con fenotipos fenotipos mutantes mutantes ((enfermedadesenfermedades))

Proyecto Genoma HumanoProyecto Genoma HumanoPerspectivas en
Biología y Medicina
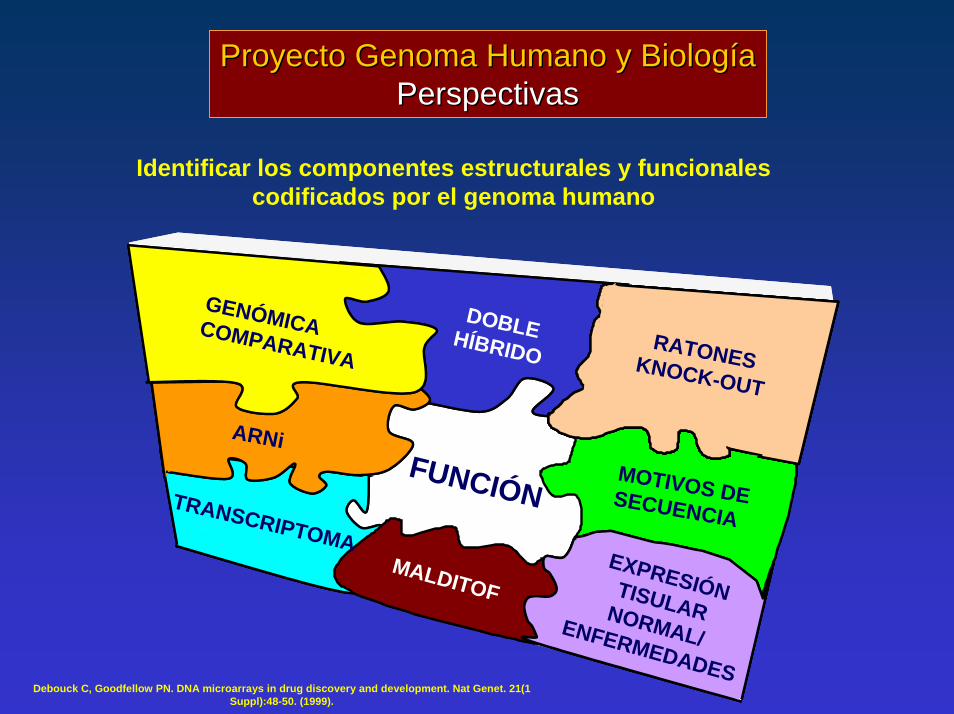
Proyecto Genoma Humano y BiologíaProyecto Genoma Humano y BiologíaPerspectivasPerspectivas
Identificar los componentes estructurales y funcionales codificados por el genoma humano
GENÓMICACOMPARATIVA
FUNCIÓN
DOBLEHÍBRIDO
MALDITOF
ARNi
EXPRESIÓNTISULAR NORMAL/ENFERMEDADES
TRANSCRIPTOMA
MOTIVOS DESECUENCIA
RATONESKNOCK-OUT
GENÓMICACOMPARATIVA
FUNCIÓN
DOBLEHÍBRIDO
MALDITOF
ARNi
EXPRESIÓNTISULAR NORMAL/ENFERMEDADES
TRANSCRIPTOMA
MOTIVOS DESECUENCIA
RATONESKNOCK-OUT
Debouck C, Goodfellow PN. DNA microarrays in drug discovery and development. Nat Genet. 21(1 Suppl):48-50. (1999).
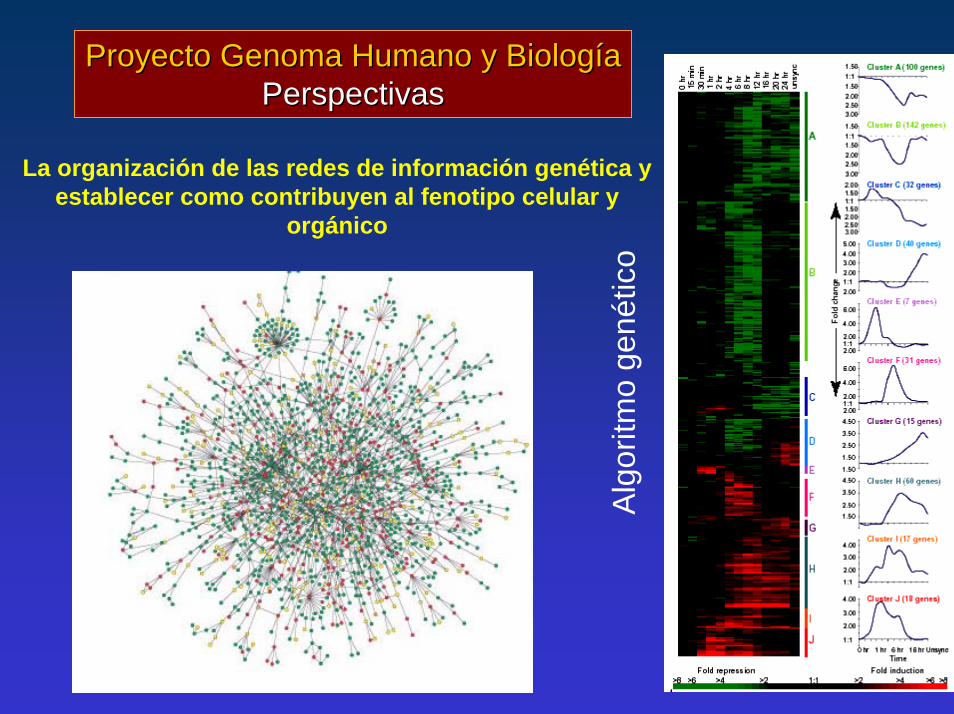
La organización de las redes de información genética y establecer como contribuyen al fenotipo celular y
orgánico
Proyecto Genoma Humano y BiologíaProyecto Genoma Humano y BiologíaPerspectivasPerspectivas
Alg
oritm
o ge
nétic
o

Proyecto Genoma Humano y BiologíaProyecto Genoma Humano y BiologíaPerspectivasPerspectivas
Catalogar toda la variabilidad genética de la humanidad
Determinar la base molecular del fenotipo, muchos SPNs se asocian a enfermedades, pero no se conoce porqué influyen en la expresión fenotípica

Proyecto Genoma Humano y BiologíaProyecto Genoma Humano y BiologíaPerspectivasPerspectivas
Comprender los mecanismos evolutivos
¿Qué nos hace humanos?

Proyecto Genoma Humano y MedicinaProyecto Genoma Humano y MedicinaPerspectivasPerspectivas
Desarrollar nuevas estrategias para la identificación de los componentes genéticos que contribuyen al desarrollo de
enfermedades y respuesta a drogas.

Proyecto Genoma Humano y MedicinaProyecto Genoma Humano y MedicinaPerspectivasPerspectivas
Desarrollo de nuevos fármacos contra dianas moleculares identificadas por su patrón de expresión génica.
De la función al genenzima/receptor
micropurificación ensayos funcionales
clonación gen
Del gen a la funcióngenotecas sustracción-específicas de tejido
microarrays identificación nuevas proteínas
knock-out ratónestructura proteína
diseño químico inhibidores
CLÁSICACLÁSICA
GENÉTICAGENÉTICA

Craig VenterCraig Venter, Science 2001, Science 2001
El desafío más importante de la biología humana, más allá del
objetivo de comprender cómo los genes controlan la construcción y
mantenimiento del mecanismo de nuestros cuerpos, está más allá:
Explicar cómo nuestras mentes han llegado a organizar los Explicar cómo nuestras mentes han llegado a organizar los
pensamientos suficientemente bien para investigar nuestra propiapensamientos suficientemente bien para investigar nuestra propia
existenciaexistencia