t rabajo de fin de máster desarrollo de un sistema … filehabla poquito, cuando me abraza se me...
TRANSCRIPT

Trabajo de Fin de Máster
Desarrollo de un sistema para lagestión de plani�caciones de unaagencia de publicidad de radio ydespliegue en un entorno en la
nube.Sara Báez García
Madrid, 12 de julio de 2016

D. Francisco Serradilla García, profesor de la Escuela Técnica Superiorde Ingeniería en Sistemas Informáticos adscrito al Departamento de InteligenciaArti�cial de la Universidad Politécnica de Madrid, como tutor.
D. Alberto Díaz Álvarez, doctorando de la Universidad de La Laguna, comocotutor.
C E R T I F I C A N
Que la presente memoria titulada:
�Desarrollo de un sistema para la gestión de plani�caciones de una agencia depublicidad de radio y despliegue en un entorno en la nube.�
ha sido realizada bajo su dirección por D. Sara Báez García, con N.I.F. 78.647.701-Y.
Y para que así conste, en cumplimiento de la legislación vigente y a los efectosoportunos �rman la presente en Madrid a 12 de julio de 2016

Agradecimientos
A Paco, mi tutor, por darme la oportunidad de aprender y deconocer a tan buena gente en AICU. Y por la paciencia. A Barty,por la idea loca, sus chistes y por hacerme imaginar una croqueta
con monóculo.
Muchas gracias, a la gente del laboratorio, por la acogida y porayudarme a aprender. Y por cerrar la puerta al salir. A Alan y aIvan, sin tilde. Y en especial a Nacho, por aguantarme(nos) y por
alentar mi consumismo, por Ana, y por los bolos.
Gracias Ewawo por tener ganas de seguir aguantándome, inclusodespués de cuatro años. Y por seguir haciéndome esperar por ti.Por compartir la aventura madrileña, contigo fue todo más fácil.
Ojalá a tu edad me conserve tan bien...Gracias a Álvarro, que como le parecen una tontería los
agradecimientos, no me alargo.
A mi familia, a mi familia, a mi familia, a mi familia... A mamá y apapá. A ellos que me empujaron a venir a Madrid, aunque antes de
irme ya querían que volviera. Por la paciencia in�nita que tienenconmigo y por dármelo todo. A la niña de mis ojos, que aunque
habla poquito, cuando me abraza se me pasa todo. A mis abuelos.
Y a Raúl. Por ser conmigo y dejarme ser con él. Lo mereces todo.

Resumen
El objetivo de este trabajo ha sido el desarrollo de un sistema para la gestiónde plani�caciones para una agencia de publicidad de radio. Los servicios queintervienen en su funcionamiento han sido distribuidos haciendo uso del modelocloud computing.
Para el acceso a la aplicación, se ha desarrollado una API REST de tal maneraque permite trabajar con la lógica del sistema desde diferentes agentes. Y a �n deilustrar la comunicación con la API se desarrolla una aplicación web que conectacon dicho sistema.
Se pretende maximizar la disponibilidad, la calidad del servicio y la e�cienciadel mismo.
En los capítulos que componen este documento, se detalla cada uno de lospuntos que se han seguido hasta obtener el resultado �nal. Asimismo, se incluyeun apartado de resultados, conclusiones y posibles líneas de trabajo futuras.
Palabras clave: Servicio, nube, aplicación, API REST, interfaz, desarrollo, cloudcomputing.

Abstract
The main goal of this project has been the development of a service whichallows the plani�cation management for a radio publicity agency. The web servicewill be distributed following the cloud computing model.
Development of an API REST to access the service from di�erent devices, anddevelopment also of an user interface.
The whole system will be implemented in a way that availability, quality ande�ciency were the highest.
In the chapters on this document it is detailed every step which has beenfollowed in order to achieve the �nal result. Furthermore, it is included a results,conclusions and, future works sections.
Keywords: Service, cloud computing, application, API REST, interface, develop-ment.

Tabla de contenidos
1. Introducción 11.1. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2. Motivación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3. Estructura del documento . . . . . . . . . . . . . . . . . . . . . . . 3
2. Estado del arte 52.1. Antecedentes, origen del cloud computing . . . . . . . . . . . . . . 52.2. Concepto de cloud computing . . . . . . . . . . . . . . . . . . . . . 72.3. Tipos de cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1. Según el modelo de desarrollo . . . . . . . . . . . . . . . . . 92.3.2. Según el modelo de servicio . . . . . . . . . . . . . . . . . . 11
2.4. Soluciones tecnológicas actuales . . . . . . . . . . . . . . . . . . . 112.4.1. Amazon Web Services . . . . . . . . . . . . . . . . . . . . . 122.4.2. Google Cloud Platform . . . . . . . . . . . . . . . . . . . . 132.4.3. Microsoft Azure . . . . . . . . . . . . . . . . . . . . . . . . 142.4.4. IBM Cloud . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.5. Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3. Metodologías y tecnologías 173.1. Metodologías . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.1. Scrum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.1.2. Sprints realizados . . . . . . . . . . . . . . . . . . . . . . . 19
3.2. Tecnologías . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.2.1. Amazon EC2 - Infraestructura . . . . . . . . . . . . . . . . 223.2.2. Amazon S3 - Estáticos . . . . . . . . . . . . . . . . . . . . 223.2.3. Amazon RDS - Base de datos . . . . . . . . . . . . . . . . . 233.2.4. Amazon ElastiCache - Caché . . . . . . . . . . . . . . . . . 233.2.5. Amazon CloudWatch - Monitorización . . . . . . . . . . . . 233.2.6. Herramientas . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2.6.1. Python/Django . . . . . . . . . . . . . . . . . . . 233.2.6.2. Django REST framework . . . . . . . . . . . . . . 243.2.6.3. ReactJS . . . . . . . . . . . . . . . . . . . . . . . 243.2.6.4. HTML5 y CSS3 . . . . . . . . . . . . . . . . . . . 243.2.6.5. MySQL . . . . . . . . . . . . . . . . . . . . . . . 24
i

ii
4. Requisitos 254.1. Requisitos funcionales . . . . . . . . . . . . . . . . . . . . . . . . . 254.2. Requisitos no funcionales . . . . . . . . . . . . . . . . . . . . . . . 26
5. Diseño y desarrollo e implementación 285.1. Diseño . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.1.1. Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . . 285.1.2. Modelo de base de datos . . . . . . . . . . . . . . . . . . . 34
5.2. Desarrollo e implementación . . . . . . . . . . . . . . . . . . . . . 445.2.1. Creación de la base de datos . . . . . . . . . . . . . . . . . 445.2.2. Con�guración del entorno de desarrollo . . . . . . . . . . . 445.2.3. Con�guración del proyecto . . . . . . . . . . . . . . . . . . 455.2.4. Codi�cación . . . . . . . . . . . . . . . . . . . . . . . . . . 465.2.5. Pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
6. Despliegue 486.1. Separación de servicios . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1.1. Instancia EC2 . . . . . . . . . . . . . . . . . . . . . . . . . 506.1.2. Instancia RDS . . . . . . . . . . . . . . . . . . . . . . . . . 546.1.3. Bucket S3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 556.1.4. ElastiCache - Redis . . . . . . . . . . . . . . . . . . . . . . 55
7. Resultados 577.1. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
8. Conclusiones 588.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
9. Trabajos futuros 599.1. Mejoras en la aplicación . . . . . . . . . . . . . . . . . . . . . . . . 59
9.1.1. Mejora en los tests . . . . . . . . . . . . . . . . . . . . . . . 599.1.2. Mejora en la complejidad del código . . . . . . . . . . . . . 599.1.3. Tests en el frontend . . . . . . . . . . . . . . . . . . . . . . 609.1.4. Redux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
9.2. Mejoras generales . . . . . . . . . . . . . . . . . . . . . . . . . . . 609.2.1. Añadir fase de QA . . . . . . . . . . . . . . . . . . . . . . . 609.2.2. Seguridad . . . . . . . . . . . . . . . . . . . . . . . . . . . 619.2.3. Compatibilidad en navegadores . . . . . . . . . . . . . . . . 619.2.4. Desarrollo de aplicación móvil . . . . . . . . . . . . . . . . 61
9.3. Mejoras en la infraestructura . . . . . . . . . . . . . . . . . . . . . 619.3.1. Monitorización del sistema . . . . . . . . . . . . . . . . . . 61
A. Otras tecnologías 63A.1. Git . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63

iii
A.2. Gulp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64A.3. Ubuntu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64A.4. PyCharm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65A.5. LaTeX . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65A.6. Nginx . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66A.7. uWSGI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Bibliografía 66

Índice de �guras
2.1. Evolución de las arquitecturas y la tecnología hasta el cloud com-puting. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2. Sistema informático: hardware, software y usuarios. . . . . . . . . . 82.3. Tipos de nube según su modelo de desarrollo: privada, híbrida,
comunitaria y pública. . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.1. Ciclo básico de Scrum. . . . . . . . . . . . . . . . . . . . . . . . . 19
5.1. Esquema del patrón MVC. . . . . . . . . . . . . . . . . . . . . . . 295.2. Esquema del patrón Flux. . . . . . . . . . . . . . . . . . . . . . . . 305.3. Esquema del patrón Flux añadiendo acciones nuevas. . . . . . . . . 315.4. Esquema de API REST. . . . . . . . . . . . . . . . . . . . . . . . 325.5. Arquitectura del modelo de la aplicación. . . . . . . . . . . . . . . 335.6. Esquema de la base de datos. . . . . . . . . . . . . . . . . . . . . . 43
6.1. Arquitectura del sistema desplegado. . . . . . . . . . . . . . . . . . 486.2. VPC e instancias de EC2 y RDS. . . . . . . . . . . . . . . . . . . . 50
iv

Índice de tablas
5.1. Tabla AdType . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.2. Tabla Agency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.3. Tabla Announcer . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.4. Tabla Budget . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.5. Tabla Customer . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365.6. Tabla Delegation . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.7. Tabla Network . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 375.8. Tabla Order . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.9. Tabla Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.10. Tabla Product . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.11. Tabla Program . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395.12. Tabla Rate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 405.13. Tabla Schedule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.14. Tabla Station . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.15. Tabla User . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
v

Capítulo 1
Introducción
El cloud computing o computación en la nube es un paradigma que ofrece tantoa usuarios individuales, como a empresas y entidades públicas, una nueva formade prestación de los servicios de tratamiento de la información, y es válido paracualquier tipo de usuario.
Las soluciones y servicios del cloud computing aportan nuevas ventajas que nose consiguen con los sistemas tradicionales de las tecnologías de la información.Sobre todo, podemos destacar el ahorro en costes y la facilidad para escalar losrecursos.
Desde �nales de los años noventa, la mayoría de los negocios tradicionales sehan visto en la necesidad de actualizar su modelo de negocio, para orientarlo asíal uso de las nuevas tecnologías y poder sacar ventaja de ello. Este es el claroejemplo de las agencias de publicidad de radio, que es el tipo que empresa quenos incumbe.
Las agencias de publicidad de radio son un intermediario entre las emisoras ocadenas de radio y las empresas que desean publicitarse en ellas. Son las encar-gadas de negociar los precios y de generar las plani�caciones de anuncios que lascadenas van a emitir.
Estas tareas de plani�cación y negociación, se suelen realizar de forma manual,mediante llamadas de teléfono, envío de correos electrónicos, etc., hasta conseguirque ambas partes estén de acuerdo con la plani�cación y el contrato negociado.Debido a esto, se ha pensado realizar un sistema que permita automatizar estastareas de gestión de la agencia de publicidad de radio.
Debido a la naturaleza de este negocio, el sistema tendrá periodos de menordemanda de la infraestructura, y otros en los que se haga un mayor uso de ella.Por ejemplo, los primeros días del mes, la demanda será mayor, ya que es enesta fecha cuando se actualizan los contratos, se realizan nuevas negociaciones, secargan y actualizan los datos de los proveedores, etc., mientras que en los díascentrales del mes, la demanda se reduce drásticamente.
1

Introducción 2
La idea es disponer de una plataforma en la que la agencia pueda almacenarlos datos, tanto de clientes de publicidad como de las emisoras y cadenas deradio, además de la información relacionada con el horario de los programas y lastarifas para emitir anuncios en ellos. Todo esto con el �n de poder realizar lasplani�caciones de una manera sencilla y automática.
1.1. Objetivos
El objetivo del presente trabajo de �n de máster, como hemos dicho anterior-mente, es desarrollar e implementar un sistema web, cuya temática es la gestiónde plani�caciones para una agencia de publicidad de radio. Otro de los objetivoses ser capaz de realizar el despliegue en un sistema distribuido, a �n de aprovechartodas las ventajas que este nos proporciona. Es decir, saber sacar provecho a lascaracterísticas que nos ofrece el paradigma del cloud computing.
Como objetivos generales del proyecto se de�nen los siguientes:
Desarrollo de un servicio web.
Distribución del servicio desarrollado en múltiples máquinas (infraestructu-ra en la nube).
Implementación de tácticas para obtener una alta disponibilidad de servicio.
Implementación de una API de acceso para independizar el núcleo del sis-tema de su presentación.
Desarrollo de una interfaz para la interacción con la API REST.
Una vez �jados los objetivos generales del proyecto y utilizándolos como base,podemos ahondar más en lo que se quiere conseguir. Para ello se han de�nido lossiguientes objetivos especí�cos:
Implementación de la API REST en servicios de cómputo en la nube
Separación de responsabilidades en servicios en la nube:
• Amazon EC2 para la gestión de las máquinas virtuales.
• Amazon S3 como almacenamiento y servicio de estáticos.
• Base de datos RDS, de AWS.
• ElastiCache (Redis) para la gestión ligera de las cachés de usuario.
• CloudWatch para monitorización y la gestión de alarmas.
Para todo ello, se adoptará una nueva forma de trabajar y de gestionar elproyecto. Se utilizarán técnicas de metodologías ágiles. Todo esto se explicará enlos sucesivos capítulos del documento.

Introducción 3
1.2. Motivación
Anteriormente, hemos comentado la necesidad actual de las empresas de mo-dernizarse y de hacer uso de las nuevas tecnologías para modi�car su modelo denegocio y poder sacar ventaja de ello. Ya que en caso de no hacerlo, el resto deempresas del sector conseguirán la ventaja en el mercado.
En los negocios tradicionales, el volumen de datos disponible era reducido y seencontraba en formato analógico en su mayoría, pero tras la llegada de Internet ylas nuevas tecnologías derivadas de este, esto ha cambiado. Actualmente los datoso información disponible en la red son de un volumen muchísimo mayor, por lo quese hace inviable utilizar métodos analógicos para su análisis o almacenamiento.
El tipo de empresas en la que se ha detectado este problema, en nuestro casoen particular, son las agencias de publicidad de radio. Estas almacenaban grandescantidades de datos tanto de empresas anunciadoras como de emisoras y cadenasde radio. Para luego realizar de manera manual las plani�caciones y las negocia-ciones con ambas partes.
Por eso surge la idea de realizar este proyecto, para conseguir que este tipo deempresas mejoren su e�ciencia y e�cacia. Haciendo uso de una plataforma quepermite almacenar y cargar los datos de forma sencilla, además de su análisispara la realización de las plani�caciones.
Recordemos que debido a la naturaleza del negocio, la demanda del serviciosufre �uctuaciones a lo largo de un mes, por ejemplo. Teniendo su pico de uso en losprimeros días de cada mes, y reduciéndose de manera muy considerable a medidaque avanza el mismo. La forma de despliegue elegida (los sistemas distribuidos)se adaptan perfectamente a esta característica, ya que nos permite escalar losrecursos de manera muy sencilla.
1.3. Estructura del documento
En esta sección se detalla el contenido de los capítulos desarrollados en estedocumento.
Capítulo 1: Introducción. El presente capítulo, donde se realiza unapequeña introducción, a modo de toma de contacto, sobre el tema principaldel proyecto y exponemos los objetivos a alcanzar.
Capítulo 2: Estado del arte. En este capítulo se exponen las bases histó-ricas y aspectos teóricos sobre el paradigma a utilizar, el cloud computing.Además de describir algunas de las soluciones actuales disponibles en elmercado.

Introducción 4
Capítulo 3: Metodología y tecnologías. Descripción de la metodologíautilizada para el desarrollo del proyecto, así como algunas de las iteracionesrealizadas durante el mismo. Explicación de las tecnologías y herramientasempleadas.
Capítulo 4: Requisitos. En este capítulo se describen los requisitos quedebe cumplir el sistema para quedar acabado y cubriendo las necesidades delcliente. Se especi�can los requisitos tanto funcionales como no funcionales.
Capítulo 5: Diseño, desarrollo e implementación. Lo primero de loque se habla en el capítulo es del diseño del proyecto, incluyendo la arqui-tectura, modelos de datos, etc. En la segunda parte del mismo, se describecómo se ha realizar el desarrollo del mismo.
Capítulo 6: Despliegue. En este capítulo se describe la arquitectura delsistema completo, una vez desplegado. Además de esto, se describe como seha realizado la separación en servicios.
Capítulo 7: Resultados. Análisis de los resultados obtenidos en base alos objetivos y requisitos iniciales.
Capítulo 8: Conclusiones. Capítulo dedicado al resumen y a las conclu-siones obtenidas después del desarrollo y las pruebas de todas las partes delsistema.
Capítulo 9: Trabajos futuros. En este capítulo se detallan algunas líneasde trabajo futuras que se podrían desarrollar para completar o mejorar elproducto obtenido.
Por último se expone la bibliografía consultada (y recomendada) para la ela-boración de este proyecto.

Capítulo 2
Estado del arte
En este capítulo se introducen los aspectos necesarios para la comprensión delproyecto y sus objetivos. De esta forma, se describen varios términos, como compu-tación en la nube y las tecnologías disponibles para hacer uso de ella. Asimismo,se hace un recorrido desde los orígenes del cloud computing hasta las solucionesactuales.Además, se describe el estado actual de las tecnologías para el desarrollo de
sistemas web.
2.1. Antecedentes, origen del cloud computing
Actualmente y desde los últimos años, nos encontramos ante un proceso dedeslocalización e internacionalización de las grandes empresas. Su necesidad decómputo y su procesamiento de datos ha aumentado más rápido que la capacidadde cómputo de la que disponen los ordenadores personales. Esto ha hecho que lasarquitecturas de cálculo hayan tenido que evolucionar hacia métodos de ejecuciónsimultánea y colaborativa entre varios equipos informáticos.
Gracias a la creación de Internet, ha sido posible la aparición de muchos para-digmas cuya �nalidad es ofrecer la tecnología como un servicio. Internet permitela descentralización, que equipos individuales puedan conectarse con otros que seencuentran en un lugar del mundo diferente. Esta forma de interconexión haceque podamos obtener una mayor cantidad de recursos computacionales y de alma-cenamiento de forma distribuida. Los nuevos paradigmas, tales como la Web 2.0,computación P2P, data centers, clúster, grid, computación ubicua, etc, pretendenexplotar todo este potencial.
Sin embargo y para centrarnos más en el origen de lo que hoy conocemos comocloud computing, vamos a detenernos solo en las de�niciones de dos paradigmasde computación bastante usados o estudiados, como son la computación en clústery en grid.
Greg P�ster (gurú en clusters) de�ne un clúster como un tipo de sistema pa-
5

Estado del arte 6
ralelo que consiste en la interconexión de equipos individuales para actuar comouno solo [1]. Considera que un equipo individual es aquel que es independiente ypuede funcionar por sí mismo, es lo que se conoce como un nodo. Por lo tanto,un clúster es una con�guración de un grupo de nodos, que aparecen en la redcomo una sola máquina y actúan como tal. Puede ser administrado como un solosistema y además esta diseñado para tolerar fallos en los componentes, de maneraque si uno falla, el usuario no se percate de ello. Además, existen varios tiposde clúster; puede ser que todos los equipos sean similares en cuanto a hardwarey software, por lo que estaremos hablando de clúster homogéneo; si di�eren enrendimiento pero tienen similitudes, se trata de un clúster semi-homogéneo y encambio, si tanto el hardware como el software es diferente, se conoce como clústerheterogéneo. Este último tipo es el más sencillo y económico.
Podemos considerar un grid como una especialización de un clúster, los centrosde investigación y las universidades que disponían de estos sistemas clúster, co-menzaron a ofrecer los servicios de cálculo y almacenamiento a terceros, a travésde protocolos estándar, dando lugar a la que hoy en día se denomina computacióngrid. Por lo tanto, la computación grid, o también conocida como computacióndistribuida, consiste en un gran número de equipos organizados en clústeres yconectados mediante una red de comunicaciones. Está orientada al procesamientoen paralelo y al almacenamiento de grandes cantidades de información. Permitecompartir una amplia variedad de recursos que están distribuidos geográ�camente.Entre estos recursos se pueden encontrar supercomputadoras, sistemas de alma-cenamiento, etc.
A pesar de que este tipo de computación ofrece muchas ventajas, tales comola potencia, escalabilidad, integración de sistemas heterogéneos, etc, solo tuvie-ron éxito dentro del ámbito académico y de investigación. Esto fue debido a lacomplejidad para utilizar la infraestructura y los problemas de portabilidad entregrids.
El siguiente paso tras los clústeres y la computación en grid, fue la virtualiza-ción. Esta nueva tecnología consiste en la creación virtual de algún recurso, quepuede ser un sistema operativo, un servidor, un dispositivo de almacenamiento,recursos de red, etc. Esto tiene muchas ventajas, debido a que es posible replicarun entorno sin necesidad de instalar y con�gurar todo el software que requierenlas aplicaciones. La virtualización simula una plataforma de hardware autónomay ejecuta el software como si este estuviera instalado.
Esta nueva tecnología permite distribuir la carga de trabajo de una manera mu-cho más sencilla que en la computación grid. Y también permite, como la anterior,la integración de entornos heterogéneos. Así es como surge el nuevo paradigma decomputación, el cloud computing. Las plataformas de cloud computing tienen ca-racterísticas de ambas tecnologías, los clústeres y los grids, pero añade sus propiasventajas.

Estado del arte 7
Figura 2.1: Evolución de las arquitecturas y la tecnología hasta el cloud computing.
2.2. Concepto de cloud computing
La computación en la nube también se conoce como: cloud computing o sim-plemente, the cloud, es un nuevo paradigma de computación, una nueva forma deprestación de servicios. Pero previamente, antes de de�nir la computación en lanube, debemos conocer algunos conceptos como los que se describen a continua-ción.
Un sistema informático es un conjunto de partes interrelacionadas que per-miten almacenar y procesar información. Las partes que conforman un sistemainformático son las siguientes: el hardware, el software y los usuarios.
El hardware proporciona los recursos computacionales del sistema.
El software, que a su vez lo podemos dividir en el sistema operativo y enlos programas de aplicación.
- El sistema operativo se encarga de controlar y coordinar el uso delhardware por parte de las diferentes aplicaciones. Proporciona un en-torno adecuado para que los programas puedan realizar un trabajoútil.

Estado del arte 8
- Los programas de aplicación de�nen las diferentes formas en las quelos recursos de un sistema son utilizados, de manera que sean capacesde resolver los problemas de los usuarios.
Los usuarios son el conjunto tanto de los administradores, desarrolladores,etc, como de los usuarios �nales.
Figura 2.2: Sistema informático: hardware, software y usuarios.
Una vez de�nido el concepto de sistema informático, podemos pensar en lacomputación en la nube, como un sistema informático como servicio. Es un tipode computación que se basa en Internet para ofrecer diferentes servicios. Se tratade un modelo de pay-per-use o bajo demanda, en el que el usuario solo paga porlos servicios que necesita.
Según el NIST (National Institute of Standards and Technology)[2], el cloudcomputing se de�ne como un modelo tecnológico que permite el acceso ubicuo,adaptado y bajo demanda en red a un conjunto compartido de recursos de compu-tación con�gurables, tales como redes, servidores, equipos de almacenamiento,aplicaciones y servicios, que pueden ser rápidamente aprovisionados y liberadoscon un esfuerzo de gestión reducido o interacción mínima con el proveedor delservicio.
Una nube es un tipo de sistema paralelo y distribuido que consiste en la colecciónde equipos interconectados y virtualizados de tal forma que representan una solamáquina o un conjunto de recursos computacionales uni�cados. Las característicasson establecidas entre el proveedor de servicios y el consumidor.
Las principales características de la computación en la nube son las siguientes:

Estado del arte 9
Pago bajo demanda por el servicio, lo que hace posible que el usuario puedaampliar o reducir los recursos que necesita de manera rápida y automática ysin necesidad de negociar con el proveedor de servicios. Esto conlleva a unareducción de costos, ya que únicamente se paga por los servicios utilizados.
Accesibilidad a los recursos a través de la red, tanto desde mecanismosestándares como desde plataformas heterogéneas tales como dispositivosmóviles, ordenadores portátiles, tablets, etc.
Escalabilidad y elasticidad, los recursos pueden ser rápidamente liberadoso adquiridos según la demanda, de esta forma se escala hacia adentro ohacia afuera de manera automática. Se puede decir que podemos disponerde recursos ilimitados.
Medición del servicio. Con estos sistemas es posible controlar y optimizarautomáticamente el uso de los recursos, como por ejemplo el ancho de banda,la cantidad de almacenamiento, etc.
Resource pooling, es decir, que los recursos de los proveedores están com-partidos de manera que varios consumidores puedan acceder a ellos. Esteacceso se hará dependiendo de las asignaciones de cada consumidor segúnsu demanda. El consumidor no conoce la localización física de los recursosque está utilizando, pero puede especi�car una zona, como por ejemplo unpaís, una ciudad o un centro de datos.
2.3. Tipos de cloud
Las soluciones actuales de computación en la nube se pueden clasi�car en variosgrupos, dependiendo siempre del parámetro que elijamos para realizar la clasi�-cación.
2.3.1. Según el modelo de desarrollo
Una de las clasi�caciones que se puede realizar se hace atendiendo a la privaci-dad. De esta manera, encontramos cuatro modelos de desarrollo para la compu-tación en la nube: nube privada, pública, comunitaria e híbrida.
Nube privada: una sola organización hace la gestión y la administración desus servicios en la nube, esta organización puede ser el mismo proveedor deservicios, la empresa contratante o un tercero. En caso de que se trate deun tercero, este actuará bajo las necesidades de la organización.
Normalmente se elige este tipo de nube cuando la información es crítica,se necesita centralizar los recursos informáticos y además se quiere tener

Estado del arte 10
�exibilidad a la hora de disponer de los mismos. Esto es posible ya que lasolución adquirida está adaptada a las necesidades de la empresa contratantey se puede realizar el control y la supervisión de la seguridad y la protecciónde la información.
Nube pública: en este tipo de nube, no se conoce la ubicación de la infor-mación. El proveedor de servicios ofrece sus recursos de forma gratuita adiferentes entidades. No se debe pensar que una nube pública es una nubeinsegura.
En este tipo de nube se dispone de plazos de tiempo reducidos para ladisponibilidad del servicio. Además de que los costes por su uso, en caso deque los haya, son bastante bajos.
Nube comunitaria (community cloud): los servicios se comparten en unacomunidad cerrada de entidades que tienen los mismos objetivos, de maneraque colaboran entre ellas. En este caso la nube es gestionada y administradapor una o más entidades de la comunidad.
Nube híbrida: estas nubes pueden estar formadas por dos o más tipos denubes de los que ya hemos hablado: pública, privada o comunitaria. Algunosservicios se ofrecen de manera pública, como por ejemplo las herramientasde desarrollo, y otros de manera privada, como es el caso, por ejemplo de lainfraestructura.
Una entidad que opte por esta solución puede bene�ciarse de las ventajasque el resto de nubes tenían por separado. Por ejemplo, se dispone de unagran �exibilidad a la hora de adquirir servicios, pero además es posible tenercontrol sobre ellos.
Figura 2.3: Tipos de nube según su modelo de desarrollo: privada, híbrida, comu-nitaria y pública.

Estado del arte 11
2.3.2. Según el modelo de servicio
Si atendemos al modelo de servicio ofrecido, encontramos tres familias, que hoyen día son las que se conocen como XaaS(que signi�ca anything as a service), osimplemente como As a service. A pesar de que hoy en día las soluciones que seofrecen suelen ser mixtas, es decir, combinando varios modelos de servicio, vamosa realizar la siguiente clasi�cación para entender mejor los conceptos.
Software as a Service (SaaS): en este grupo lo que se ofrecen son productos�nales como un servicio, de manera que la entidad pueda disponer de estasaplicaciones para el desarrollo de su propia actividad. Se puede acceder a lasaplicaciones desde diferentes dispositivos y lo pueden hacer varios clientesa la vez.
Se provee al cliente con las licencias necesarias para el uso de un softwarecomo demanda. Además, puede hacerse de dos formas: el proveedor disponede las aplicaciones en sus servidores y el cliente accede por el navegador, ose instala la aplicación en los sistemas del cliente y la licencia expira cuandoacabe el periodo contratado.
Platform as a Service (PaaS): este modelo de servicio consiste en ofrecer alusuario herramientas con las que pueda desarrollar, hacer el testeo, desplie-gue, mantenimiento y hosting de sus propias aplicaciones informáticas, sinla necesidad de que tenga que instalarlas en sus equipos locales. Las grandesventajas de este modelo son que el usuario no tiene que pagar las licenciasde las herramientas y además está exento del mantenimiento y actualizaciónde las mismas.
Infrastructure as a Service (IaaS): se caracteriza porque provee capacidadde almacenamiento, y recursos computacionales que el usuario utilizará paradesarrollar su propio software. Es decir, se pone a disposición del cliente eluso de una infraestructura informática como servicio.
Se elige este método como alternativa para no tener que adquirir todos losservidores, el espacio de almacenamiento y los equipos de red necesariospara desarrollar la actividad del cliente.
Otros ejemplos de XaaS: además de las tres soluciones detalladas ante-riormente, también es posible disponer como servicio de las comunicaciones(CaaS), el almacenamiento (SaaS), la red (NaaS), la monitorización (MaaS),el escritorio (DaaS), etc.
2.4. Soluciones tecnológicas actuales
En apartados anteriores hemos hablado de la clasi�cación de los diferentes ti-pos de nube que existen hoy en día atendiendo a diferentes parámetros. Por lo

Estado del arte 12
tanto, las soluciones tecnológicas actuales van a pertenecer a uno de estos tiposo, de forma más real, van a pertenecer a varios de ellos a la vez. Si hacemos unrecorrido general por cada uno de los tipos de cloud según su modelo de servicio,encontramos algunas soluciones generales como las que se listan a continuación:
SaaS:
• Paquetes de software de o�cina
• Gestión de proyectos y porfolios
• Mensajería
• Gestión de contenidos
• ...
PaaS:
• Integración de datos
• Sistemas de gestión de bases de datos
• Aplicaciones de seguridad
• Portales de aplicaciones
• ...
IaaS:
• Servicios de computación
• Servicios de almacenamiento
• Servicios de copia de seguridad
• Hosting
Para ser más especí�cos vamos a nombrar y explicar alguna de las solucionesactuales propuestas por grandes empresas. Estas empresas han sabido adaptarseal nuevo paradigma que es el cloud computing y cada una de ellas ofrece algunassoluciones cloud, tanto PaaS, como IaaS y SaaS.
2.4.1. Amazon Web Services
Amazon fue la empresa pionera en esta nueva tecnología, ofrece sus propiosservidores a los clientes, para que estos puedan aprovechar los recursos de los quedispone la empresa. Así en el año 2006 surge Amazon Web Services. Las solucio-nes que ofrecen son tanto plataforma, como infraestructura, como servicio. Lasempresas que lo contraten pueden modi�car la potencia informática, la cantidad

Estado del arte 13
de almacenamiento, etc. Dispone de una gran �exibilidad, ya que se puede utilizarcualquier plataforma o modelo de programación.
Tiene varios centros de datos repartidos por el mundo, de manera que los usua-rios cercanos a cada unas de las regiones mantienen sus datos y recursos en esazona en concreto.
Además de esto, dispone de servicios adicionales que se pueden incorporar a lasaplicaciones existentes o simplemente utilizarse de forma independiente. La ma-yoría de estos servicios no están expuestos directamente a los usuarios �nales, yaque su �n es que sean utilizados para que los clientes puedan desarrollar software,que sí será el que esté pensado para ser utilizado por usuarios �nales. A estosservicios se accede mediante HTTP haciendo uso de protocolos REST y SOAP yen todos ellos se paga por uso.
Amazon EC2 o Amazon Elastic Cloud Compute es una de las partes centralesde AWS. Con este servicio, los usuarios pueden pagar por equipos virtuales paraalojar sus aplicaciones en vez de tener que comprar, o alquilar por meses o años,equipos dedicados. Esta plataforma se basa en el principio de la virtualización, deeste modo, es posible utilizar diferentes sistemas operativos y personalizarlos segúnlas necesidades especí�cas de cada usuario. Además de todas las característicasbásicas que ofrece el cloud computing, de las cuales hemos hablado anteriormente,Amazon EC2 dispone de herramientas de recuperación de datos y proporciona ungran aislamiento frente al resto de procesos que se realizan en sus máquinas.
Esta plataforma funciona con lo que se conocen como instancias y dependiendode las características, rendimiento, capacidad de cómputo, etc, el usuario puedeelegir entre todos los tipos de instancia existentes. Por ejemplo, hay instanciasde uso general, optimizadas para memoria o almacenamiento, instancias de GPU,etc.
El usuario pagará la instancia por horas de servicio activo, por eso se utilizael término elástico para referirse a la plataforma. Además, es posible elegir lalocalización geográ�ca de la instancia para controlar aspectos como la latencia yla redundancia.
La con�guración y el arranque en AWS se realiza mediante su interfaz de ser-vicios web, que está diseñada para facilitar el control sobre los recursos y parareducir el tiempo de arranque.
2.4.2. Google Cloud Platform
Google Cloud Platform es la plataforma de cloud computing que ofrece Googlea sus clientes y se trata de un servicio tanto de PaaS como de IaaS. Esta misma

Estado del arte 14
infraestructura es la utilizada internamente por Google para algunos de sus pro-ductos, como Google Search y Youtube. En esta plataforma, los usuarios puedendesarrollar y alojar sus aplicaciones haciendo uso de un amplio rango de progra-mas que permiten crear desde sencillos sitios web hasta complejas aplicaciones.
Esta plataforma es un conjunto de servicios modulares basados en la nube conmúltiples herramientas de desarrollo. Encontramos servicios de hosting y compu-tación, de almacenamiento en la nube, big data y APIs especí�cas, como porejemplo de traducción y predicción. Cada uno de estos productos dispone de unainterfaz web, herramienta para línea de comandos y de una REST API. Los pro-ductos que ofrecen actualmente son los siguientes: App Engine, Compute Engine yContainer Engine, es decir, disponen tanto de plataforma como de infraestructura.Como servicios de almacenamiento disponen de Cloud Storage, Cloud Datastore,Cloud SQL y Bigtable. Además ofrecen múltiples herramientas de Big Data yAPIs de traducción y predicción como habíamos nombrado anteriormente.
La plataforma como servicio, o PaaS de Google, es conocida como Google AppEngine y gracias a ella y a las herramientas de las que dispone, es posible crear unSaaS y alojarlo en esta misma plataforma. Tiene soporte para múltiples lenguajesde programación y frameworks. Además, es posible desarrollar de manera local laaplicación, gracias al SDK que tiene disponible cada lenguaje.
App Engine permite a los usuarios no tener que preocuparse por la administra-ción, ni por la con�guración, ni por el balanceo, etc, de sus servidores o bases dedatos. Incluso es posible comparar varias versiones de la misma aplicación.
2.4.3. Microsoft Azure
Microsoft Azure es tanto la plataforma como la infraestructura como servicioque ofrece Microsoft a sus clientes. Anteriormente era conocida como WindowsAzure o como Azure Services Platform. Esta plataforma se encuentra en los cen-tros de datos de la empresa, en concreto dispone de nodos en 24 países diferentes,repartidos por todo el mundo. Dispone tanto de alojamiento para aplicaciones,como de servicios propios e incluso comunicaciones seguras. Según lo describen enMicrosoft, Windows Azure es una capa en la nube, que se encuentra funcionandosobre servidores Windows Server. Esta capa es la que se encarga de escalar losrecursos y manejar la información de la aplicación web del usuario, de maneraque le pueda asignar la memoria necesaria, entre otras cosas.
La plataforma también dispone de un sistema de copias de seguridad automá-tico, para así proteger la información de usuario en caso de pérdidas. Las copiasde seguridad se almacenan de forma cifrada y el usuario puede acceder a ellaspara recuperarlas. En Windows Azure están soportados algunos lenguajes de pro-gramación y frameworks , así como bases de datos relacionales y no relacionales,

Estado del arte 15
blobs y colas de mensajes, entre otras muchas funcionalidades. Además, es posi-ble desplegar máquinas virtuales tanto con Windows Server como máquinas condistribuciones de Linux.
Al igual que las plataformas de las que hemos hablado anteriormente, WindowsAzure está formada por una serie de componentes, que proporcionan: capacidad decómputo, almacenamiento, bases de datos, servicios para las aplicaciones, mercadode aplicaciones, etc.
2.4.4. IBM Cloud
IBM, la multinacional estadounidense de tecnología y consultoría también sesumó a las empresas que proporcionan servicios en la nube.
Dispone tanto de infraestructura, con IBM SoftLayer, de plataforma y de soft-ware, con IBM Bluemix. Además lo ofrece como nube pública, privada o híbrida,de forma que hace que sea muy interesante para los usuarios.
La empresa dispone de tres grandes pilares:
Foundation. Consiste en la infraestructura, hardware, gestión, integracióny seguridad que se ofrecen como nube privada o híbrida.
Services. PaaS, IaaS y servicios de copias de seguridad.
Solutions. Aplicaciones SaaS de analíticas, marketing, etc.
Asimismo, hace unos años, decidió integrar servicios big data, testeo de softwarey almacenamiento en la nube.
2.5. Docker
Docker signi�ca contenedor y es una plataforma abierta para construir, em-paquetar y lanzar aplicaciones distribuidas de forma automática. El concepto,como su nombre indica, es empaquetar las aplicaciones con todas sus dependen-cias dentro de un contenedor. Esta plataforma empezó como un framework, unaherramienta de alto nivel de LXC, pero ahora dispone de una librería propia,llamada libcontainer.
Es una herramienta que está pensada tanto para programadores como paraadministradores de sistemas, debido a que ofrece muchas ventajas, tales como quepermite lanzar las aplicaciones tanto en entornos Linux, OS X y Windows, sinque importe el lenguaje utilizado, ya que crea una capa de abstracción del sistemaoperativo, eliminando los problemas derivados de dependencias y versiones.

Estado del arte 16
Docker implementa una API de alto nivel, la diferencia principal de Dockerfrente a cualquier máquina virtual, es que no necesita de la inclusión de un sistemaoperativo, sino que se basa en las funcionalidades del kernel y aísla los recursostales como la CPU, la memoria, los dispositivos de entrada/salida, la red, etc.Gracias al uso de los contenedores, los recursos pueden ser aislados, restringir losservicios y además, se puede hacer que los procesos tengan una vista privada delsistema operativo. Los contenedores pueden compartir el mismo kernel, pero cadauno de ellos estará restringido a usar cierta cantidad de recursos.
La plataforma es fácilmente integrable con multitud de infraestructuras, talescomo Amazon Web Services, Google Cloud Platform, Jenkins, Puppet y Vagrant,entre otras muchas.
A pesar de que Docker no se incluye en ninguno de los tipos de as-a-servicenombrados en la sección 2.4, se trata de una tecnología innovadora que está ad-quiriendo mucha presencia a la hora de realizar los despliegues. Esta herramientase está haciendo muy popular entre los administradores de sistemas, ya que agilizael trabajo. Por este motivo, parece relevante incluirla en este capítulo.

Capítulo 3
Metodologías y tecnologías
En este capítulo hablaremos de la metodología utilizada para la realización delproyecto. Una vez seleccionada la misma desglosaremos las fases en las que seha dividido el desarrollo y el despliegue; desde la obtención de los objetivos yrequisitos, hasta la implementación y las pruebas, para obtener el producto �nal.
Asimismo, detallaremos las tecnologías utilizadas para el desarrollo del proyectocomo la función que desempeña cada una de ellas dentro del sistema.
3.1. Metodologías
En ingeniería del software existen in�nidad de metodologías para desarrollarsoftware. Todas ellas se dividen en diferentes etapas que se van desarrollandodurante el ciclo de vida del producto, normalmente de forma iterativa.
Los modelos clásicos o tradicionales nos enfrentan a varios problemas, comopuede ser el separar demasiado el proceso de desarrollo de los clientes, crear unagran cantidad de documentación y procesos burocráticos, plani�car el ciclo de vidade principio a �n y así di�cultar la inclusión de nuevos cambios. En de�nitiva,ralentizan el proceso de desarrollo de software. Aunque, sin embargo, generan unadocumentación completa y son muy maduros.Algunos de estos paradigmas o metodologías son los siguientes:
Modelo en cascada
Modelo en espiral
Modelo de prototipos
...
En el caso de nuestro sistema, se ha optado por la utilización de una metodologíade desarrollo ágil. Pertenece a un tipo de metodología que ha ido creciendo enpopularidad desde �nales de los años 90 hasta ahora.
17

Metodologías y tecnologías 18
Las metodologías ágiles se enmarcan bajo lo que se conoce como Mani�estoÁgil [3], que fue escrito en el año 2001 por un grupo de diecisiete expertos en lamejora del desarrollo de software.Los pilares de este mani�esto, citados textualmente, son los siguientes:
Individuos e interacciones sobre procesos y herramientas
Software que funciona sobre documentación exhaustiva
Colaboración con el cliente sobre negociación de contratos
Responder ante el cambio sobre seguimiento de un plan
Tras esto aparecen las metodologías ágiles, con el �n de aprender y solucionarlas carencias de las metodologías tradicionales. De esta forma somos capaces decrear soluciones rápidamente a problemas y de mostrar resultados al cliente enpoco tiempo. Además, involucrando al cliente, es posible detectar problemas onuevas funcionalidades antes de �nalizar por completo el producto. Por lo tanto,se dice que estas metodologías están orientadas a las personas y no a los procesos.
Hoy en día existen muchas metodologías ágiles, algunas de ellas son las siguien-tes:
Extreme Programming
Scrum
Mobile-D
Adaptive Software Development (ASD)
Crystal
...
3.1.1. Scrum
Para el desarrollo del sistema se ha optado por utilizar la metodología de desa-rrollo Scrum, adaptándola a las necesidades especí�cas del proyecto. Como curio-sidad, cabe destacar que Scrum es el término para Melee en rugby, donde todoslos miembros se coordinan para avanzar sobre el contrario.
Se trata de metodología ágil enfocada hacia la gestión de proyectos, sin entraren detalle de qué prácticas de desarrollo hay que llevar a cabo. El objetivo deScrum es maximizar la productividad del equipo que desarrolla un producto,centrándose en crear software funcional con valor en iteraciones de entre dos y

Metodologías y tecnologías 19
Figura 3.1: Ciclo básico de Scrum.
cuatro semanas, conocidas como sprints. El equipo de desarrollo es el encargadode realizar la estimación de las tareas y de auto-organizarse.
En la �gura anterior podemos observar el �ujo de trabajo en un proyecto gestio-nado con Scrum. El propietario del producto nos indica qué tareas hay que hacery las prioriza. Esto es lo que va a conformar el product backlog. De este listado detareas, el equipo de desarrollo escoge las historias que va a de desarrollar en laiteración (sprint backlog), y los descompone en tareas para su posterior desarrollo.
Una vez ha �nalizado el tiempo del sprint, que normalmente son quince días,este se cierra y se hace un sprint review. En esta reunión se valora el trabajorealizado hasta el momento y el punto en el que nos encontramos del proyecto.Además de esto, se plani�ca el siguiente sprint.
3.1.2. Sprints realizados
En este apartado se describe a grandes rasgos, las fases realizadas en el proyecto,cada una de estas fases tiene una duración aproximada de quince días, y vamos aconsiderar que el trabajo es realizado por un equipo de cuatro personas.
Lo que se describe a continuación no son historias de usuario, sino tareas, en sumayoría verticales, a menos que se especi�que lo contrario. Es decir, que abarcandesde la creación del modelo, hasta la lógica de negocio y el frontend asociado aesa entidad.

Metodologías y tecnologías 20
Sprint 0Obtención de objetivos
De�nición de requisitos inicialesPreparación del entorno de trabajo
Creación de un proyecto basePreparación del proyecto para el uso de ReactDespliegue en preproducción y en producción
Sprint 1 - 50 puntosModelo y lógica para login y logout de usuariosCreación, modi�cación y listado de usuarios
Link de olvidar la contraseñaModelo y lógica de emisoras (station)
Modelo y carga de datos de comunidades autónomas, provincias ymunicipios
Sprint 2 - 120 puntosModelo y lógica de delegaciones (delegation)Modelo y lógica de anunciantes (announcers)Modelo y lógica de tipo de anuncio (ad type)
Modelo y lógica de productos (product)Modelo y lógica de programas (program)Modelo y lógica de clientes (customer)Modelo y lógica de agencias (agency)
Sprint 3 - 116 puntosModelo y lógica de tarifas (rate)Refactorización del frontend
Tablas responsivasMenú de �ltrado responsivoRefactorización de emisorasRefactorización de programasModelo y lógica de campañas

Metodologías y tecnologías 21
Sprint 4 - 97 puntosRefactorización de tarifas
Modelo y lógica de cadenas (network)Refactorización de tarifas
Refactorización de programasOptimización de peticiones a la base de datos
Sprint 5 - 72 puntosParser para la carga de datosMigración de datos de tarifas
Generar �cheros excel
Sprint 6 - 86 puntosReorganización de menús en el frontend
Modelo y lógica de plan (plan)Modelo y lógica de plani�cación (schedule)Eliminación de campañas y refactorizaciónCreación de modelo para orden (order)
Sprint 7 - 65 puntosModelo y lógica de presupuesto (budget)
Detalle de planGeneración de órdenes (order)

Metodologías y tecnologías 22
3.2. Tecnologías
Como ya hemos detallado en capítulos anteriores, el objetivo �nal de este pro-yecto es completar el desarrollo de un sistema y realizar un despliegue en siste-mas de cómputo distribuidos en la nube, con el �n de disponer de tácticas paragarantizar una alta disponibilidad del servicio. A continuación describiremos lainfraestructura utilizada para este propósito, así como las diferentes tecnologíasutilizadas para la separación de servicios.
3.2.1. Amazon EC2 - Infraestructura
La infraestructura sobre la que ha sido desplegado el sistema es Amazon EC2también conocida como Amazon Elastic Cloud Computing. Tal como hemos ade-lantado en el capítulo 2, se trata de la IaaS proporcionada por la empresa Amazon.
Se ha elegido esta infraestructura debido a muchos aspectos:
Madurez del servicio
Sistemas operativos soportados
Sistemas de bases de datos
Regiones disponibles
Servicios de análisis
Seguridad
...
EC2 es el encargado de alojar, servir, distribuir y gestionar el sistema desarro-llado. El servicio funciona con un sistema de instancias precon�guradas o persona-lizadas por el usuario. En estas instancias se instalan las herramientas necesariaspara que el sistema funcione.
3.2.2. Amazon S3 - Estáticos
Amazon Simple Storage Service (S3) es un servicio de almacenamiento incluidoen Amazon Web Services . Proporciona una infraestructura de almacenamientode datos, de gran escalabilidad, �able y de baja latencia a los usuarios.
Ya que permite almacenar cualquier tipo de datos, se ha utilizado para el al-macenamiento de los �cheros estáticos del sistema desarrollado, de manera que sepuede acceder a ellos de una forma muy rápida y sencilla.
Para comunicar un sistema desarrollado en Django con los buckets de AmazonS3, se utilizan las librerías django-storages y boto.

Metodologías y tecnologías 23
3.2.3. Amazon RDS - Base de datos
Este es el sistema de bases de datos relacional disponible en la plataforma AWS.Se trata de bases de datos en la nube, fácilmente gestionables y con�gurables. Esposible elegir entre varios motores de bases de datos.
El sistema desarrollado alojará sus datos en esta base de datos en la nube deforma que la información quede almacenada en sus tablas. Algunas de las tareashabituales como copias de seguridad, detección de errores, reparación, etc, quedanasí a cargo de Amazon RDS.
3.2.4. Amazon ElastiCache - Caché
Este es un servicio que facilita la implementación, el funcionamiento y el es-calado de una caché. Gracias a implementar este servicio, mejora el rendimientodel sistema, ya que se recupera la información desde el sistema de caché de unamanera más rápida.
ElastiCache soporta dos motores de almacenamiento en caché: memcached yRedis. En el despliegue se ha utilizado Redis, que es un sistema de código abierto,para el almacenamiento de claves y valores. Además está integrado con Cloud-Watch.
3.2.5. Amazon CloudWatch - Monitorización
La monitorización del sistema se realiza mediante CloudWatch. Se utiliza pararealizar el seguimiento de métricas y registros, además de permitir la creación dealarmas para reaccionar frente a sucesos de nuestro sistema.
3.2.6. Herramientas
Tras de�nir los requisitos del sistema a desarrollar y la plataforma cloud sobrela que se va a desplegar el mismo, es necesario escoger las herramientas que sevan a utilizar para la implementación. En la medida de lo posible se ha intentadoutilizar las últimas versiones de todas las herramientas que van a participar en eldesarrollo del sistema.
3.2.6.1. Python/Django
Python es un lenguaje de programación interpretado, open source, de propósitogeneral, multiplataforma, de tipado dinámico y multiparadigma. Lo que signi�caque permite tanto programación orientada a objetos, programación funcional yprogramación imperativa. Está diseñado con una �losofía que favorece a que seescriba código legible.

Metodologías y tecnologías 24
Para este lenguaje existen muchas implementaciones diferentes, así como fra-meworks, pero para el desarrollo de esta aplicación web se elige hacer uso deDjango.
El framework Django se utiliza para desarrollo web, es open sourcey sigue elpatrón de diseño de modelo-vista-controlador (MVC). Está pensado sobre todopara facilitar la creación de sitios o aplicaciones web muy complejos. Para elloutiliza una �losofía basada en la reutilización y la conectividad de componentes,el desarrollo rápido y el principio de no repetición (que viene del inglés "DRY",don't repeat yourself).
Para el desarrollo del sistema se han utilizado las versiones 3.4 de Python,siendo la última versión disponible en el momento de escritura, la versión 3.5 y1.9 de Django, estando en su última versión.
3.2.6.2. Django REST framework
Es una aplicación de Django que permite la implementación de Web APIs,bajo una arquitectura REST. Proporciona mecanismos para facilitar la creacióna los usuarios, además de las pruebas y envío de peticiones, gracias a su interfazadministrativa.
Esta aplicación se basa en el uso de las vistas genéricas de Django, para apro-vechar, de esta manera, las ventajas de la programación orientada a objetos.
3.2.6.3. ReactJS
ReactJS es una librería de JavaScript, no se trata de un framework . Y esutilizada normalmente para el desarrollo de frontend. Esta librería se encarga delrenderizado de las vistas de una aplicación web.
3.2.6.4. HTML5 y CSS3
Se han utilizado HTML como lenguaje de marcado para de�nir la semánticade las respuestas web y CSS para la aplicación de estilos a las respuestas HTMLgeneradas.
3.2.6.5. MySQL
MySQL es un sistema gestor de bases de datos relacional, multihilo y multi-usuario. Este sistema está disponible para una gran cantidad de plataformas y desistemas y además permite elegir entre diferentes mecanismos de almacenamien-to entre los que varía la velocidad de operación, las transacciones, etc. Permitereplicación e implementa un amplio subconjunto del lenguaje SQL.

Capítulo 4
Requisitos
En este capítulo, realizaremos un estudio sobre el proyecto, ya desde un puntode vista práctico. Se de�nen las características del proyecto, así como los requisitostanto funcionales como no funcionales, que debe cumplir.
Como ya hemos visto, la computación en la nube se puede clasi�car, según sumodelo de servicio, en SaaS, PaaS e IaaS; software, plataforma e infraestructura,respectivamente. En este desarrollo, lo que se pretende es implementar un sistema,y alojarlo en una infraestructura en la nube (IaaS). De esta manera seremoscapaces de analizar tanto las ventajas como las desventajas de optar por este tipode despliegue.
4.1. Requisitos funcionales
El capítulos anteriores, hemos especi�cado que el sistema a desarrollar será unsistema de gestión de plani�caciones para una agencia de publicidad de radio, porlo que se de�nen los requisitos que debe cumplir dicho sistema para que cumplacon las necesidades de la empresa.
La aplicación permitirá crear y modi�car cada una de las entidades presentesen el sistema. Estas entidades son las siguientes: usuarios, delegaciones,anunciantes, agencias, clientes, emisoras, cadenas, productos y programas.
Se podrán crear y modi�car elementos relacionados con la gestión de las en-tidades, tales como: tarifas, órdenes, planes, presupuestos y plani�caciones.
Listado y �ltrado de cada una de las entidades y elementos de gestión nom-brados en los puntos anteriores.
Separación de los usuarios por roles: rol de administrador o de usuario sinprivilegios especiales.
Creación de per�les de usuario por parte del usuario administrador.
25

Requisitos 26
Noti�cación al usuario creado mediante correo electrónico.
Carga de datos mediante hojas de cálculo.
Descarga de datos en hojas de cálculo.
Generación de plani�caciones y órdenes para la agencia.
4.2. Requisitos no funcionales
Para que el sistema se considere completo y correcto, se deben cumplir algunosrequisitos asociados al uso del sistema, su disponibilidad y otros muchos aspectosseparados de la funcionalidad del mismo. La norma ISO-25010:2011 [4] de�ne elmodelo de calidad de sistemas y de software. En base a esta norma, hemos de�nidola mayoría de los requisitos no funcionales que se listan a continuación.
Funcionalidad y usabilidad.
• Sistema usable con una sencilla interfaz de usuario.
• Sistema con interfaz siguiendo la �losofía de diseño de responsive de-sign.
• La interfaz debe ser totalmente operativa en navegadores Google Chro-me.
• Seguridad e integridad de la información.
• Privacidad y con�dencialidad de los usuarios y de los datos del sistema.
Fiabilidad.
• Disponibilidad continua del servicio.
• Tiempo de inactividad del servicio por debajo del 99
• Capacidad de recuperación del sistema ante fallos.
• Seguridad de la plataforma.
• Integridad para prevenir accesos o modi�caciones no autorizados.
• Registro de acciones para garantizar el no repudio.
E�ciencia.
• Respuesta rápida ante peticiones, no demorando más de 1,2 segundosen conexiones de 300Mbps.
Escalabilidad.

Requisitos 27
• Modularidad para permitir que los cambios en algún componente ten-gan un impacto mínimo sobre el resto.
• Facilidad para corregir los errores detectados en el sistema.

Capítulo 5
Diseño y desarrollo eimplementación
En los dos capítulos anteriores, capítulos 3 y 4 se de�ne tanto la metodologíaa seguir, como las herramientas y tecnologías que se van a utilizar, además de losrequerimientos que se deben cumplir para su correcta �nalización.
En este capítulo, se desarrollarán varias secciones para entender tanto el diseñocomo el desarrollo y la implementación del sistema �nal.
5.1. Diseño
En esta sección se de�ne la arquitectura software, módulos y datos del sistemadesarrollado. De manera que cumplamos todos los requisitos previamente de�ni-dos. La arquitectura hardware será especi�cada en el capítulo 6, ya que es dondese explica como ha sido el despliegue y como ha quedado distribuido el sistemaen los diferentes servicios.
5.1.1. Arquitectura
La organización global del sistema es lo que se conoce como arquitectura delsistema. Dependiendo del tipo de sistema a desarrollar existen algunos patronesarquitecturales de�nidos para aplicarlos a la solución.
El sistema �nal se divide en varias capas, cada una de las cuales tiene uncometido especí�co dentro del conjunto. En el proyecto se hace uso del patrón ar-quitectural de Modelo-Vista-Controlador (MVC), con el que se mantiene separadala presentación de la lógica de negocio.
En esta arquitectura participan tres componentes, como su nombre indica, mo-delo, vista y controlador, lo que signi�ca que por un lado se de�nen componentes
28

Diseño y desarrollo e implementación 29
encargados de la representación de la información y por otro lado, componentespara la interacción del usuario.
Es un patrón de arquitectura software basado en la reutilización de código yen la separación de conceptos, que son características que facilitan mucho lastareas de desarrollo de sistemas y su posterior mantenimiento. Suele utilizarse enel desarrollo de interfaces grá�cas de usuario.
En la subsección 3.2.6, de�nimos Python y Django como lenguaje de progra-mación y framework respectivamente, pues bien, esto va a hacer que nuestra ar-quitectura cambie ligeramente. Si bien es verdad que Django dice estar basado enla arquitectura MVC, dispone de algunas modi�caciones, pasando a ser conocidocomo MPV, o modelo-plantilla-vista (en inglés MTV, model-template-view). Enesta arquitectura, la plantilla se encarga de de�nir cómo se ven los datos, y lavista es la encargada de decir cuáles se ven.
A continuación, vamos a explicar muy a grandes rasgos, el papel que juega decada una de las entidades de este patrón de arquitectura, en nuestro sistema. Másadelante detallaremos en mayor profundidad cómo funciona realmente el �ujo delsistema y cada uno de los componentes que lo conforman.
En la Figura 5.1 se muestra un esquema del patrón de modelo-vista-controlador,indicando las acciones de las que encarga cada una de las entidades implicadas.
Figura 5.1: Esquema del patrón MVC.
Modelo
El modelo en la arquitectura que nos incumbe es la parte de los datos, es decir,los modelos en los que se apoya el sistema de plani�caciones, para almacenar,obtener y modi�car los datos. En nuestro proyecto se trata tanto de la base dedatos física como de las entidades de datos de�nidas en el sistema.
Vista

Diseño y desarrollo e implementación 30
Se re�ere a la parte de presentación, es decir, es la parte del sistema encargadade mostrar el resultado al usuario. En nuestro caso, la vista son las páginas HTML,las plantillas de Django, que serán las encargadas de llamar a nuestra aplicaciónen React.
Controlador
El controlador es la parte donde se encuentra la lógica de negocio, es el queestá situado entre la vista y el modelo. Busca los datos en el modelo, realizatransformaciones, si es necesario y se los sirve a la vista para que los muestre.
Realmente, el sistema desarrollado tiene una arquitectura más compleja que lade un MVC, debido a que disponemos de una API REST y que además, para rea-lizar la parte de la interfaz de usuario, se ha utilizado React, como adelantábamosen la sección 3.2.6 de herramientas. React se basa en el patrón de arquitecturaconocido como Flux.
Flux
Flux, es un patrón de arquitectura software, diseñado por la empresa Facebookpara utilizar con su librería React. Está enfocado en crear unos �ujos de datosexplícitos y entendibles, de manera que sea más sencillo seguir los cambios en elestado de la aplicación, y por lo tanto, identi�car más fácilmente los errores parapoder corregirlos.
Este patrón es bastante comparable al MVC, explicado anteriormente, en elque el controlador es el encargado de coordinar los cambios que se producen enuno o más modelos. Cuando los modelos cambian, se noti�ca a la vista, que leeny muestran los nuevos datos, de acuerdo con los cambios que ha realizado elcontrolador.
Figura 5.2: Esquema del patrón Flux.
Es lógico pensar, que a medida que la aplicación crece, se van añadiendo a lamisma nuevos controladores, modelos y vistas, de forma que las dependencias soncada vez más complejas. También se di�culta las tareas de depuración a �n deencontrar y solucionar errores.

Diseño y desarrollo e implementación 31
Esto es lo que Flux pretende solucionar, y lo hace utilizando un �ujo de datosque funciona en una sola dirección. Todas las acciones, o interacciones dentrode una vista llaman a un creador de acciones, y este a su vez llamará a undispatcher. Este dispatcher, se encarga de emitir los eventos de tipo acción a losque se subscriben los stores. Por último, los stores responden a la acción y seactualizan y actualizan también los componentes si es necesario.
En este sistema, se logra que al añadir nuevos stores y vistas, el �ujo no varíemucho. El dispatcher envía cada acción a todos los stores, pero no sabe los detallesde cómo se actualiza cada uno de ellos, ya que cada store tiene su propia lógica.
Figura 5.3: Esquema del patrón Flux añadiendo acciones nuevas.
La actualización de los stores produce un evento, ante el que reaccionan lasvistas para actualizar los componentes que forman la interfaz de usuario.
El siguiente componente del sistema que debemos conocer es la API REST, yaque es otro elemento que pertenece al conjunto, que, junto con React, hace quecambie un poco la arquitectura de nuestro desarrollo y sea un sistema con patrónde modelo-vista-controlador, pero con algunas peculiaridades.
API REST
Hoy en día existen in�nidad de frameworks y lenguajes para el desarrollo web,tanto del lado del servidor, o backend, como en el lado del cliente, o frontend .Es por esto que, la mayoría de aplicaciones webs están convergiendo hacia undesarrollo separado del frontend y el backend, utilizando un servicio REST comoAPI.
REST son las siglas de REpresentational State Transfer. Se trata de un esti-lo de arquitectura de software pensado sobre todo para sistemas distribuidos oaplicaciones web.
En la actualidad, el término REST se utiliza, en el sentido más amplio, paradenominar cualquier interfaz entre sistemas que utilice el protocolo HTTP. Nor-malmente, se utilizan los métodos de las peticiones HTTP más comunes como

Diseño y desarrollo e implementación 32
Figura 5.4: Esquema de API REST.
GET, POST, PUT, DELETE, equiparándolas a las operaciones CRUD (crear,obtener, borrar y actualizar) de base de datos. De esta forma, se puede tener unaAPI intuitiva que transforma las peticiones HTTP en verdaderas acciones en basede datos. Unido a esto, y utilizando códigos HTTP en las respuestas de dichasacciones, construir una aplicación web cliente sobre un servicio REST es cada díamás sencillo.
Las principales características y ventajas del uso de esta metodología a la horade desarrollar aplicaciones webs son:
Backend y frontend separados. Lo que ofrece mayor �exibilidad a la horade cambiar tecnologías. Por ejemplo, si se quiere cambiar de framework deJavaScript en el cliente, no haría falta cambiar ninguna línea de código enel servidor.
Al tratarse de una API, es posible que aplicaciones de terceros puedaninteractuar directamente con nuestra aplicación.
Posibilidad de desarrollar aplicaciones móviles que se comuniquen directa-mente con la API REST del servidor.
Stateless. Lo que quiere decir que entre dos llamadas, cualquiera que sean, nose almacena el contexto. Cada petición dispone de todos los datos necesariospara su correcta ejecución.
Los datos pueden estar en diferentes formatos (XML, JSON, etc).
Cada componente es un recurso y se accede a él a través de su URI 1.
1URI: uniform resource identi�er. Es una cadena de caracteres que identi�ca los recursos de forma unívoca
Diseño y desarrollo e implementación 33
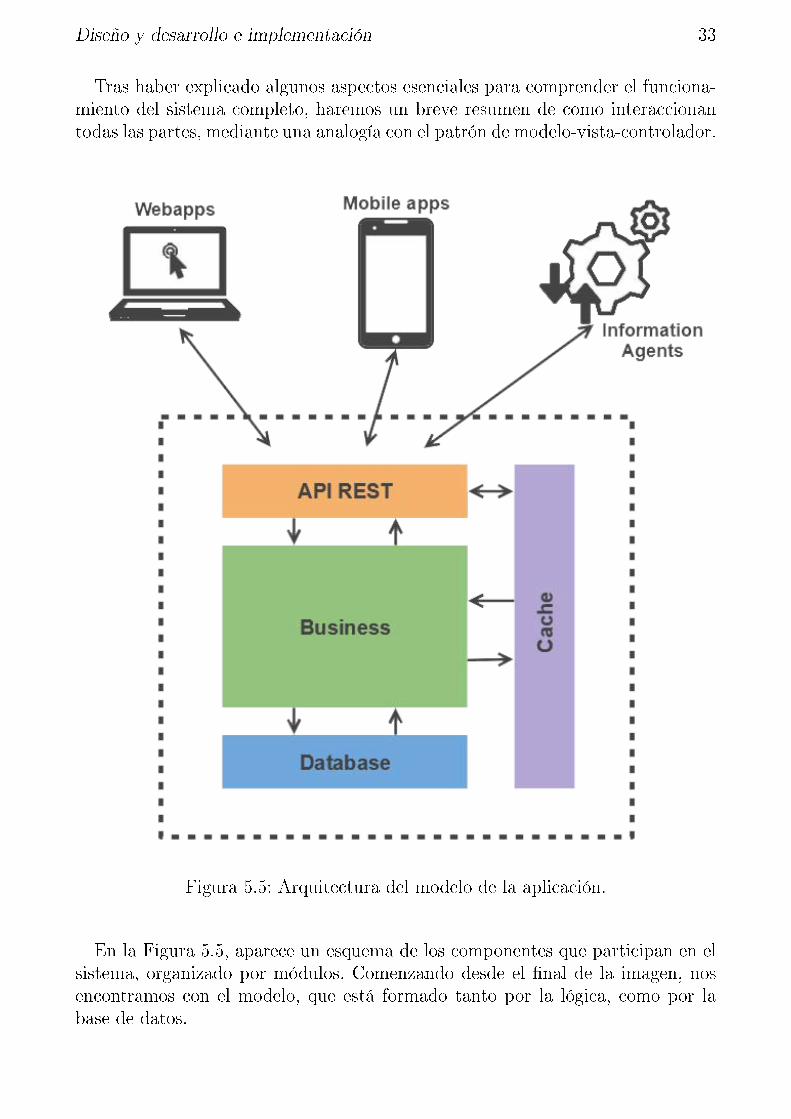
Tras haber explicado algunos aspectos esenciales para comprender el funciona-miento del sistema completo, haremos un breve resumen de como interaccionantodas las partes, mediante una analogía con el patrón de modelo-vista-controlador.
Figura 5.5: Arquitectura del modelo de la aplicación.
En la Figura 5.5, aparece un esquema de los componentes que participan en elsistema, organizado por módulos. Comenzando desde el �nal de la imagen, nosencontramos con el modelo, que está formado tanto por la lógica, como por labase de datos.

Diseño y desarrollo e implementación 34
Una vez hemos conocido el concepto de API REST, parece lógico decir que ennuestro desarrollo, va a actuar como controlador, junto con la lógica de negocio,ya que es el encargado de comunicar la base de datos con la interfaz de usuario. Ypor último, la vista, estará formada por nuestra aplicación de React, es decir, porla interfaz de usuario. La aplicación que se muestra a los dispositivos que haganpeticiones a la aplicación.
Entonces, poniendo un ejemplo que sirva de resumen: Los clientes a través dela interfaz, que es una aplicación en React, harán las peticiones a la API REST.Esta será la encargada de acceder a la base de datos para realizar la operaciónsolicitada, ya sea de modi�cación, creación o consulta. Una vez ha realizado sutarea, devuelve la respuesta, que será recibida por la interfaz, o aplicación React.Finalmente, si es necesario, la aplicación de React actualizará sus componentespara mostrar el resultado obtenido.
5.1.2. Modelo de base de datos
Este apartado va más allá de explicar simplemente el modelo entidad-relación,sino que se hace un análisis del tipo de datos usado e información sobre lo quesigni�ca cada tabla en la base de datos.
Se detallan las tablas, las relaciones que existen entre ellas, las relaciones mu-chos a muchos, los campos obligatorios y algunas peculiaridades especí�cas de lastablas. Todo esto con la �nalidad de entender de manera más precisa el sistemade plani�caciones desarrollado. Las tablas se muestran por orden alfabético, aexcepción de las tablas relacionadas con la localización.
AdType
Tabla que almacena los tipos de anuncios disponibles según las cadenas y emiso-ras de radio. Algunos ejemplos son: cuña de veinte y treinta segundos y mención.
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre del tipo de anuncio,
únicoSí
description VARCHAR(255) Descripción del tipo de anuncio Nois active BOOLEAN Estado del tipo de anuncio Sí
Tabla 5.1: Tabla AdType
Agency
Las agencias son las encargadas de realizar la gestión de los anunciantes, enalgunos casos, la agencia puede ser la misma que el cliente. Se establece unarelación N:M con la tabla de clientes (Customer).

Diseño y desarrollo e implementación 35
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre de la agencia, único Sícustomer INTEGER Clave foránea a cliente Nois active BOOLEAN Estado de la agencia Sí
Tabla 5.2: Tabla Agency
Announcer
Esta tabla re�eja a las entidades que quieren vender, o, valga la redundan-cia, anunciar su producto. Estos anunciantes están gestionados por cero o másagencias. Hay una relación N:M establecida con agencias y otra relación N:M es-tablecida con productos (Product). Ya que un anunciante puede tener cero o másproductos para promocionar.
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre de anunciante Síagency INTEGER Clave foránea a agencia Nois active BOOLEAN Estado de anunciante Sí
Tabla 5.3: Tabla Announcer
Budget
Un presupuesto es una colección de plani�caciones (Schedules), es decir, en unpresupuesto se recoge la información relacionada con: el usuario y la delegaciónque ha creado el presupuesto, el plan al que pertenece, el periodo de aplicacióndel mismo y algunos valores de comisiones.

Diseño y desarrollo e implementación 36
Campo Tipo Descripción Oblig.name VARCHAR(255) Nombre del presupuesto Nobudget num INTEGER Número del presupuesto, valor
únicoSí
user INTEGER Clave foránea a usuario Sídelegation INTEGER Clave foránea a delegación Sípurchase co-mission
DOUBLE Comisión de compra aplicable No
customercomission
DOUBLE Comisión del cliente No
month INTEGER Mes del presupuesto Síyear INTEGER Año del presupuesto Síplan INTEGER Clave foránea a plan Síis active BOOLEAN Estado del tipo del presupuesto Sí
Tabla 5.4: Tabla Budget
Customer
Los clientes son las personas o entidades que contratan el servicio a la agenciade publicidad de radio. Un cliente puede gestionar cero o más agencias, a veces elcliente y la agencia se re�eren a la misma persona o entidad. Por lo tanto existeuna relación N:M entre clientes (Customer) y agencias (Agency). Además, uncliente debe estar adscrito a un municipio.
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre del cliente, único Sícif VARCHAR(9) Número de identi�ación �scal Noaddress VARCHAR(150) Dirección Nomunicipality INTEGER Clave foránea a municipio Sítelephone VARCHAR(9) Teléfono Nopostal code VARCHAR(5) Código postal Noemail VARCHAR(60) Email de contacto, valor único Nois active BOOLEAN Estado del cliente Sí
Tabla 5.5: Tabla Customer
Delegation
Una delegación no es más que cada una de las sedes que pueda tener la agenciade publicidad que esté usando el sistema. Se recogen datos como el número deidenti�cación �scal, datos de contacto y una persona responsable de la misma.

Diseño y desarrollo e implementación 37
Campo Tipo Descripción Oblig.name VARCHAR(64) Nombre de la delegación, único Sícif VARCHAR(9) Número de identi�ación �scal,
valor únicoNo
address VARCHAR(255) Dirección Sítelephone VARCHAR(9) Teléfono Símanager VARCHAR(64) Responsable de la delegación Síis active BOOLEAN Estado de la delegación Sí
Tabla 5.6: Tabla Delegation
Network
Esta tabla se re�ere a las cadenas de radio. Una cadena de radio, normalmentetiene muchas emisoras repartidas en diferentes comunidades autónomas o pro-vincias. Por poner un ejemplo: Onda Cero, tiene Onda Cero Madrid, Onda CeroAragón, Onda Cero Barcelona, etc. En este caso Onda Cero sería la cadena, y elresto se consideran emisoras en nuestro sistema.
Entonces, la cadena tendrá cero o más emisoras hijas, por lo que en caso de quese de de baja una cadena, también serán dadas de baja sus emisoras asociadas.Del mismo modo ocurre con los programas adscritos a esta cadena.
Campo Tipo Descripción Oblig.name VARCHAR(64) Nombre de la cadena, valor úni-
coSí
address VARCHAR(255) Dirección Sítelephone VARCHAR(9) Teléfono Sífax VARCHAR(9) Fax Nois active BOOLEAN Estado de la cadena Sí
Tabla 5.7: Tabla Network
Order
Las órdenes se pueden considerar el contrato que envía la agencia de publicidada las emisoras y/o cadenas de radio. Es la relación sobre los anuncios que se haacordado emitir y el precio negociado entre ambas partes, o sea, que es el acuerdoque ha conseguido la agencia de publicidad de radio entre los clientes y las cadenas.
Una orden estará compuesta por una o más plani�caciones, y la suma de suprecio será el valor �nal de la orden. Tiene atributos como la persona negociadora,el comprador, el método de pago y la fecha de creación. Su estado puede ser: a

Diseño y desarrollo e implementación 38
Campo Tipo Descripción Oblig.name VARCHAR(64) Nombre de la orden Noorder num INTEGER Número de la orden, valor único Sícreated at DATE Fecha de creación Sípaymentmethod
VARCHAR(2) Forma de pago Sí
dealer VARCHAR(128) Negociado con Nobuyer VARCHAR(128) Comprador Nofootnotes VARCHAR(255) Comentarios adicionales Nostatus VARCHAR(2) Estado de la orden Sí
Tabla 5.8: Tabla Order
enviar, enviada, anulada, �nalizada, facturada y pagada. Además es posible incluirnotas sobre la orden.
Plan
La tabla de planes, o campañas, incluye la información asociada a los clientes,anunciantes y/o agencias que participan en los mismos. Es decir, tiene una relacióncon cada una de estas tablas, pero solo puede pertenecer a una instancia de cadatabla. Además, incluye una fecha de inicio y de �n de la campaña.
Los estados de la campaña pueden ser varios: activada, no activada, �nalizadao cancelada, y dependiendo en el estado en el que se encuentre ocurrirán unasacciones u otras.
En términos de modelo de negocio, una campaña, o plan es un conjunto deuno o más presupuestos (Budget). Están asociadas a algún cliente, anunciante yagencia, para promocionar cierto producto. Todo esto en un periodo de tiempoconcreto.
Campo Tipo Descripción Oblig.name VARCHAR(64) Nombre del plan Síproduct INTEGER Clave foránea a producto Síannouncer INTEGER Clave foránea a anunciante Síagency INTEGER Clave foránea a agencia Sícustomer INTEGER Clave foránea a cliente Síbegin date DATE Fecha de inicio del plan Síend date DATE Fecha de �n del plan Sístatus VARCHAR(2) Estado del plan Sí
Tabla 5.9: Tabla Plan

Diseño y desarrollo e implementación 39
Product
Los productos son el bien o servicio que del que disponen los anunciantes para supromoción en alguna cadena o emisora de radio. Por lo tanto, existe una relaciónN:M entre producto y anunciante (Announcer), debido a que el mismo productopuede ser gestionado por cero o más anunciantes.
Campo Tipo Descripción Oblig.name VARCHAR(64) Nombre del producto, valor úni-
coSí
announcer INTEGER Clave foránea a anunciante Nois active BOOLEAN Estado del producto Sí
Tabla 5.10: Tabla Product
Program
Un programa de radio debe pertenecer a una cadena. Dispone de una fechaorientativa de fecha de inicio y de �nalización del programa, a �n de identi�carla época en la que se emite.
Puede haber programas que dispongan del mismo nombre, puesto que la clavede esta tabla está formada tanto por la cadena como por el nombre del programa.De manera, que en una misma cadena, no puede haber dos programas con elmismo nombre.
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre del programa Sínetwork INTEGER Clave foránea a cadena Síbegin date DATE Fecha de inicio del programa Noend date DATE Fecha de �n del programa Nois active BOOLEAN Estado del programa Sí
Tabla 5.11: Tabla Program
Rate
El modelo tarifa es el encargado de relacionar los programas con las emisoras enlas que emite dicho programa. Se especi�ca también la tarifa a aplicar para cadauno de los tipos de anuncio, según la franja horaria en la que se emita. Ademásde esto, hay que tener en cuenta, la emisora concreta de radio en la que se va aemitir el anuncio.
Se trata de una tabla bastante compleja, en la que la clave primaria está formadapor muchos atributos de la tabla. Estos atributos son: hora de inicio y �n, horario

Diseño y desarrollo e implementación 40
semanal, tipo de anuncio, año, programa y emisora o cadena. Lo que con palabrasviene a representar el precio que costaría emitir un tipo de anuncio en concreto, enun programa especí�co de una emisora o cadena. En una franja horaria, horariosemanal y año, determinados.
Campo Tipo Descripción Oblig.ad type INTEGER Clave foránea a tipo de anuncio Síbegin time DATETIME Hora de inicio de la tarifa Síend time DATETIME Hora de �n de la tarifa Síamout DOUBLE Tarifa, precio Síweek sche-dule
VARCHAR(13) Horario Sí
program INTEGER Clave foránea a programa Sístation INTEGER Clave foránea a cadena Nois active BOOLEAN Estado de la tarifa Sí
Tabla 5.12: Tabla Rate
Schedule
Una plani�cación se puede considerar el desglose de un presupuesto, es decir,en una plani�cación se indican aspectos como la tarifa (Rate), el tipo de anuncio,su duración y cantidad, la emisora en la que han de ser reproducidos, el horario,etc.
Una plani�cación pertenece a un solo presupuesto y está dirigida a un programay emisora en concreto. En esta tabla también se añade la información referente alos descuentos aplicables.

Diseño y desarrollo e implementación 41
Campo Tipo Descripción Oblig.begin time DATETIME Hora de inicio de la plani�cación Síend time DATETIME Hora de �n de la plani�cación Síprogram INTEGER Clave foránea a programa Sístation INTEGER Clave foránea a cadena Síad type INTEGER Clave foránea a tipo de anuncio Síweek sche-dule
VARCHAR(13) Horario Sí
rate year INTEGER Año de la tarifa Sírate INTEGER Clave foránea a tarifa Síbudget INTEGER Clave foránea a presupuesto Sílength VARCHAR(128) Duración del anuncio Síad quantity INTEGER Número de anuncios Sínetwork dis-count
DOUBLE Descuento de la cadena Sí
networkagency dis-count
DOUBLE Descuento de la agencia por par-te de la cadena
Sí
customerdiscount
DOUBLE Descuento del cliente Sí
user agencydiscount
DOUBLE Descuento de la agencia por par-te del cliente
Sí
Tabla 5.13: Tabla Schedule
Station
Una emisora de radio debe pertenecer a una cadena. Además, tiene que estarsubscrita a una localización. Es decir, puede ser considerada una emisora regional(pertenece a una Comunidad Autónoma), provincial, o municipal. En estos casosexiste una relación con la tabla Region, Province o Municipality, respectivamente.
Puede haber emisoras que dispongan del mismo nombre, puesto que la clave deesta tabla está formada por varios campos: cadena, región, provincia, municipioy el nombre de la emisora.

Diseño y desarrollo e implementación 42
Campo Tipo Descripción Oblig.name VARCHAR(128) Nombre de la emisora Sídial VARCHAR(10) Dial Noaddress VARCHAR(255) Dirección Notelephone VARCHAR(9) Teléfono Nofax VARCHAR(9) Fax Nonetwork INTEGER Clave foránea a cadena Síregion INTEGER Clave foránea a comunidad au-
tónomaNo
province INTEGER Clave foránea a provincia Nominicipality INTEGER Clave foránea a municipio Nois active BOOLEAN Estado de la emisora Sí
Tabla 5.14: Tabla Station
User
Esta es la tabla que usa el sistema para almacenar a los usuarios registrados enel mismo. Se incluye la información personal de cada uno. Su nombre, apellidos,dirección de correo electrónico, imagen y un nombre de usuario. Asimismo, losusuarios pueden tener dos roles, el de administrador o el de usuario normal.
Campo Tipo Descripción Oblig.username VARCHAR(30) Nombre de usuario, valor único Sí�rst name VARCHAR(30) Nombre Nolast name VARCHAR(30) Apellido Noemail VARCHAR(30) Correo electrónico, valor único Síimage VARCHAR(255) Imagen de per�l Nodate joined DATETIME Fecha de registro Síis sta� BOOLEAN Es usuario administrador Síis active BOOLEAN Estado del usuario Sí
Tabla 5.15: Tabla User
Region, province, municipality
Estas tres tablas sirven para localizar algunas de las entidades en la geografíaespañola. La tabla Region contiene cada una de las Comunidades Autónomas yProvince y Municipality la las provincias y los municipios respectivamente.

Diseño y desarrollo e implementación 43
Figura 5.6: Esquema de la base de datos.

Diseño y desarrollo e implementación 44
5.2. Desarrollo e implementación
Una vez completadas las fases de plani�cación y diseño, comienza la fase dedesarrollo e implementación, en la que se codi�ca la solución para convertirla enun producto.
Es muy importante haber realizado de manera exhaustiva las fases anteriores, yaque de esta manera será más sencillo el desarrollo. Aunque no debemos olvidar,que las �uctuaciones o remodelaciones que aparezcan a lo largo de esta nuevafase, no van a ocasionar un gran problema, debido a que estamos trabajandocon metodologías ágiles. Con ellas es posible reajustar los parámetros que seannecesarios para aplicar los nuevos cambios.
El desarrollo se puede dividir en varios puntos para entender las tareas que hayque realizar en la etapa de desarrollo. Aunque en realidad, no podemos considerarlos puntos siguientes como fases realizadas secuencialmente. Esto es debido, porejemplo, a que a medida que vamos codi�cando, probamos el código que desa-rrollamos. O debido a que añadimos las tablas a la base de datos según vayamoscreando el modelo de las entidades. Igual ocurre con la instalación de dependen-cias, es posible que necesitemos instalar una dependencia más tarde.
5.2.1. Creación de la base de datos
Los primeros pasos son preparar las herramientas sobre las que vamos a tra-bajar, para ello comenzamos con�gurando la base de datos a utilizar. Como seespeci�ca en la sección 3.2.4, de herramientas, hemos utilizado MySQL como sis-tema gestor de bases de datos.
Creamos la base de datos y un usuario al que garantizamos permisos sobre lamisma. Debemos recordar estos datos porque los vamos a utilizar en la con�gu-ración del proyecto.
Además de esto, podemos hacer uso de la herramienta MySQL Workbench, yaque dispone de muchas utilidades que nos van a facilitar el trabajo y la depuraciónde nuestra base de datos y de sus entidades.
5.2.2. Con�guración del entorno de desarrollo
Para facilitar la gestión de las dependencias y mantener el entorno ordenado,vamos a utilizar una herramienta llamada virtualenv. Es un directorio en el quevamos a instalar las dependencias del proyecto y así no interferirán con los demásprogramas o paquetes que tengamos instalados en la máquina.
Debemos tener en cuenta, durante la creación del entorno virtual, de que debe-mos hacerlo con Python3.4, para que el resto de dependencias se instalen en base

Diseño y desarrollo e implementación 45
a esta versión. Una vez creado el entorno virtual, instalamos las dependencias quesabemos que vamos a necesitar para comenzar el desarrollo del proyecto, tales co-mo: Python, Django y el conector con la base de datos. A medida que avancemosen el desarrollo, instalaremos las dependencias necesarias.
El siguiente paso, es instalar el entorno de desarrollo a utilizar, PyCharm ennuestro caso. Una vez instalado, debemos realizar una serie de con�guraciones,todas ellas se pueden llevar a cabo desde la interfaz grá�ca del entorno.
Indicar el entorno virtual
Con�gurar el repositorio de control de versiones
Y con esto tendremos el entorno de desarrollo listo para comenzar a crear elproyecto.
5.2.3. Con�guración del proyecto
PyCharm es el entorno de desarrollo elegido para este proyecto, como descri-bimos en el Apéndice A.4. Podemos hacer uso de este IDE, para crear incluso elentorno virtual descrito en el apartado anterior.
El entorno nos permite seleccionar el tipo de proyecto que vamos a desarrollar,en nuestro caso seleccionaremos Django, y genera una estructura de �cheros basepara el desarrollo. Debemos añadir algunos parámetros al �chero de con�guración.Además, es una buena práctica disponer de un �chero de con�guración para elentorno de desarrollo y otro para producción.
En el �chero de con�guración debemos añadir:
Directorio de estáticos
Directorio de media
Parámetros de conexión con la base de datos
Aplicaciones instaladas
Parámetros de logging
La estructura general de un proyecto Django es la que se muestra en el siguienteárbol. Cabe destacar que no se han añadido todos los �cheros ni directorios quese crean, solo los más relevantes para la explicación.
Proyecto
aplicación1

Diseño y desarrollo e implementación 46
models py
views py
...
aplicación2
...
templates
config
settings py
urls py
wsgi py
...
manage py
El proyecto se organiza mediante aplicaciones, que van a ser cada uno delos módulos de los que está compuesto el sistema. Normalmente, podemostratar de relacionar un módulo con una entidad concreta de nuestro modelode datos, para hacer una mejor idea de cuántos módulos tendrá el proyecto.
settings.py es el �chero de con�guración.
manage.py una herramienta le línea de comandos para interactuar con Djan-go.
urls.py donde van las declaraciones URL del proyecto. Crea como una tablade contenidos para el sitio.
wsgi.py es el punto de acceso para servidores web.
En el directorio templates se localizan normalmente los �cheros estáticos.Suele incluir una jerarquía de directorios, por cada una de las aplicaciones.
5.2.4. Codi�cación
La codi�cación del código se ha llevado a cabo a partir del diseño previamentedescrito en la sección 5.1. Además el proceso que se ha seguido es el representadoaproximadamente en los sprints de Scrum, 3.1.2.
A medida que se generan las nuevas aplicaciones, se crean sus modelos y secrea también tanto el código de su controlador, y los endpoint de la API REST,como el la aplicación frontend. De forma que el desarrollo sea vertical, en el quedisponemos de funcionalidad completa en todo momento, desde el backend hastael frontend.

Diseño y desarrollo e implementación 47
5.2.5. Pruebas
En este apartado vamos a hablar del testeo de la aplicación siguiendo dos enfo-ques, el primero es el enfoque de pruebas por parte del cliente y el segundo, queestá basado en las pruebas realizadas por el equipo de desarrollo para crear unproducto robusto.
Una de las características de las metodologías ágiles es que el proceso de desa-rrollo es muy adaptable a los cambios que se introducen por ejemplo, por losclientes. Debido a que como el proyecto está en continua relación con el cliente,este puede indicar las modi�caciones o los fallos muy pronto, de manera que esmuy fácil solucionar el problema o cambiar la funcionalidad.
El tipo de prueba que implica al cliente, haciendo uso del producto, son muybuenas, debido a que simulan al usuario �nal utilizando la aplicación. Así nosllegan incidencias de malos funcionamientos, bugs, o posibles mejoras, que sepueden subsanar muy rápidamente.
Durante el proceso de desarrollo se ha querido probar el código a la vez quese desarrollaba. Esto se hace para evitar realizar desarrollos muy grandes, sinpruebas, en los que después sea una tarea casi imposible solucionar errores.
Además, durante el desarrollo del proyecto se ha seguido lo que se conoce comodesarrollo guiado por pruebas, TDD, que implica realizar el software en dosfases:
Primero el desarrollo de pruebas. Se suelen utilizar pruebas unitarias(unit tests), consiste en escribir la prueba y se comprueba que la pruebafalla.
Refactorización. Una vez escritas las pruebas y comprobado que fallan,se desarrolla el código necesario apara que la prueba pase de manera satis-factoria.
La idea de este tipo de desarrollo es que los requisitos se puedan traducir di-rectamente a pruebas unitarias, de manera que nos aseguramos que al �nal de laetapa, todos los requisitos que se habían de�nido están cumplidos. Así además secrea un código más limpio.

Capítulo 6
Despliegue
Una vez realizado el desarrollo del sistema de gestión de plani�caciones, se pro-cede a realizar su despliegue en un sistema distribuido en la nube. En este capítulose narra el funcionamiento de la arquitectura distribuida, tanto en conjunto comoseparando por fases y componentes.
Figura 6.1: Arquitectura del sistema desplegado.
48

Despliegue 49
La arquitectura del sistema completo está formada por varios componentes enlos que se alojan los diferentes servicios de los que queremos disponer. En nuestrocaso, el sistema se compone de cuatro grandes grupos, que son los siguientes:
Instancia EC2.
Bucket S3.
Instancia RDS.
Clúster ElastiCache.
La arquitectura del sistema es la que se muestra en la Figura 6.1 y en ellapodemos ver los componentes que se citaban anteriormente.
A grandes rasgos, el funcionamiento es el descrito a continuación: un servidorweb atiende y sirve las peticiones que se hacen desde el exterior, de cualquiera quesea el dispositivo o medio cliente. La aplicación hace las llamadas pertinentes a labase de datos, tal y como describimos en el Capítulo 5. Además se añade cachépara la gestión de sesiones de usuario.
Se incluye otro tipo de servicios, por ejemplo, para servir los �cheros estáticosy los multimedia que sean necesarios. Asimismo, se realizan algunas tareas demonitorización con otra herramienta proporcionada por Amazon Web Services.
En la siguiente sección se describe cada uno de los servicios implementados enel sistema, así como una breve descripción de cómo se hace y de la función quetienen en el sistema �nal.
6.1. Separación de servicios
Los servicios utilizados para conformar la arquitectura �nal del despliegue estándescritos teóricamente y a grandes rasgos en la sección 3.2 de tecnologías. En lossiguientes apartados describiremos el funcionamiento de cada una de ellas en elsistema.
Normalmente debe de�nirse una VPC1, que es una nube privada virtual, enla que colocaremos todos los componentes que van a formar nuestro sistema,de manera que puedan comunicarse entre ellos y compartir la información. LaFigura 6.2 muestra la instancia de EC2 y la instancia de RDS, el escenario quecomentamos.
Una nube privada virtual es una red virtual que se parece mucho a las redestradicionales, con la ventaja de que es posible aprovechar la escalabilidad de lainfraestructura de la nube.
1VPC - Virtual Private Cloud

Despliegue 50
Figura 6.2: VPC e instancias de EC2 y RDS.
Creamos la VPC tanto con subred pública como privada, ya que, por ejemplola instancia de RDS, solo debe ser visible por el servidor web, por lo que debeestar colocada en la subred privada. En cambio, la instancia EC2 será alojadaen la subred pública, ya que es accedida por el exterior. La instancia EC2 podráconectarse con la instancia de RDS, debido a que se encuentran en la misma VPC,pero RDS no será accedida desde el exterior, para una mayor seguridad.
6.1.1. Instancia EC2
Lo primero es crear una instancia en Amazon EC2, que utilizaremos de servidorvirtual para servir, valga la redundancia, nuestra aplicación. Normalmente se partede una imagen base llamada Amazon Machine Image (AMI).
Además, a la vez que hacemos esto, debemos tener en cuenta la seguridad dela instancia, por lo que crearemos también grupos de seguridad (security groups)y un rol de identidad y de acceso (IAM2 role).
Grupo de seguridad
2IAM - Identity and Access Management

Despliegue 51
Los grupos de seguridad, van a actuar como un �rewall que controla en trá�copermitido para cada una de las instancias EC2. A cada una de las instancias sele puede asignar más de un grupo de seguridad.
Funcionan por reglas, y se pueden modi�car en cualquier momento, teniendoefecto de manera automática. Disponemos de reglas tanto de entrada como desalida, igual que si con�guráramos un �rewall.
Para nuestra instancia, hemos creado las siguientes reglas:
Inbound.
• Acceso HTTP desde cualquier dirección.
• Acceso HTTPS desde cualquier dirección.
• Trá�co SSH desde la dirección de los ordenadores de desarrollo, parapoder acceder a la instancia, con�gurarla, etc.
Outbound.
• Permitir todo el trá�co.
Rol IAM
Es necesario crear un rol de identidad y de acceso, debido a que todas las pe-ticiones que se hagan a AWS, deben estar �rmadas criptográ�camente utilizandocredenciales emitidas por el mismo AWS. De esta manera, necesitamos disponerde una forma de administrar estas credenciales para cada una de las instanciasEC2, y para eso existen los roles IAM.
Estos roles funcionan como usuarios, pero con la característica de que no dis-ponen de credenciales asociadas (claves de acceso o contraseñas). Son los usuariosasociados a estos roles los que proveerán las credenciales.
Con�guramos un rol IAM, otorgando los permisos que nuestro software va anecesitar. Para facilitarnos la tarea de con�guración de un rol, AWS, dispone depolíticas de permisos prede�nidas. En nuestro caso crearemos un rol con la políticaPowerUserAccess. Esta política nos garantiza acceso total a la instancia AWS.
La instancia
Una vez que hemos creado el grupo o grupos de seguridad y el rol IAM quevamos a aplicar a la instancia, debemos crearla.
Lo primero es seleccionar la imagen que vamos a utilizar en la instancia, laAMI3. Esto es una plantilla que contiene el software de con�guración, como puede
3AMI - Amazon Machine Image

Despliegue 52
ser el sistema operativo, la aplicación que vamos a utilizar como servidor y otrasaplicaciones. Podemos seleccionar una AMI proporcionada por AWS o una propia.
Para el desarrollo de nuestro sistema, hemos seleccionado una AMI con UbuntuServer 14.04 para una arquitectura de 64bits, como se describe en el Apéndice A.3.Después de esto, debemos seleccionar el tipo de instancia. AWS proporciona unaamplia selección de tipos para diferentes casos de uso. Por ejemplo, hay instan-cias de propósito genera, optimizadas para almacenamiento, instancias de GPU,optimizadas para memoria y optimizadas para computación. Cada uno de los ti-pos varía en CPU, memoria, almacenamiento y capacidad de red, de modo quetenemos la posibilidad de seleccionar la que más se adapte a nuestras necesidades.
Seleccionamos el tipo t2.micro. Este tipo de instancia tiene las siguientes ca-racterísticas:
Propósito general
Una CPU virtual
1 GiB de memoria
Almacenamiento en elastic block stores
En la con�guración de la instancia debemos indicar una serie de parámetros:
Las instancias deben ser desplegadas dentro de una subred, para asignar unadebemos tener creada previamente una VPC y asignar una de las subredes quepertenezcan a esta VPC. Asignamos entonces, tanto la VPC como la subred enla que se encuentra nuestra instancia.
Indicamos el número de instancias, la asignación automática de una direcciónIP, para obtener una IP pública para la instancia y un DNS público. Además esmuy importante añadir el rol IAM que creamos previamente, para así tener accesoa la misma.
Los grupos de seguridad también deben añadirse en esta fase del despliegue.Tras haber con�gurado correctamente nuestros grupos de seguridad, podemosañadirlos a la instancia que estamos creando.
Tras realizar estos pasos estamos en disposición de poner en funcionamiento lainstancia y comprobar que tenemos acceso a ella.
La aplicación
La aplicación va a estar disponible al exterior por medio de un servidor web, queserá el que atienda las peticiones al sistema. Las tecnologías que vamos a utilizarpara con�gurar este servidor web son las expuestas en el Apéndice A, Nginx

Despliegue 53
y uWSGI. uWSGI es el servidor de aplicaciones, el que va a tener disponiblenuestra aplicación. Nginx se encarga de atender las peticiones de los clientes yderivarlas a uWSGI para pedir la aplicación adecuada según la petición.
Debemos instalar ambas herramientas en la instancia de EC2 que acabamos decrear. Empezaremos descargando el código de la aplicación Django que tenemosen un repositorio de GitLab, en la ubicación en la que queramos tener la aplicacióny que luego debemos indicar al servidor de aplicaciones. Seguimos realizando lacon�guración del servidor de aplicaciones uWSGI. Para ello creamos un �cherode con�guración.
En este �chero, indicamos tanto los datos de nuestra aplicación Django, comolos datos para conectar uWSGI y Nginx a través de un socket de UNIX. Algunosde los datos a con�gurar en el �chero son los siguientes:
Nombre del proyecto
Ubicación del proyecto
Entorno virtual
Aplicación o módulo Django a servir
Fichero de logs
Número de procesos
Socket
Tras esto, debemos con�gurar uWSGI como servicio y además hacer que inicieal arranque del sistema, para no tener que entrar a la máquina para levantar elservicio cada vez que el sistema inicie.
Nginx se prepara mediante otro �chero de con�guración. En él indicamos losiguiente:
Puerto
Dominio del servidor
Ubicación de logs
Localización de la raíz
Localización de estáticos
Localización de �cheros media

Despliegue 54
El �chero debemos situarlo en el directorio de sitios habilitados de Nginx, ycrear un link con el directorio de sitios disponibles, para que el servidor, puedaver la aplicación.
Si hemos realizado las con�guraciones correctamente, podemos iniciar ambosservicios, Nginx y uWSGI y comprobar que se está sirviendo la aplicación correc-tamente.
6.1.2. Instancia RDS
Debemos crear la instancia que va a contener nuestro sistema gestor de basesde datos, y por lo tanto será el encargado de almacenar la información de laaplicación. Debe estar situada en la VPC que creamos previamente, pero solodebe ser accesible a través de la aplicación, es decir, desde la instancia EC2.
Para la instancia de RDS, seleccionamos MySQL como motor, tal como descri-bimos en el apartado de tecnologías, en el Capítulo 3. Además, debemos con�gurarotra serie de parámetros, algunos de ellos se indican a continuación:
Clase de la instancia
Tipo de almacenamiento
Tamaño de la instancia
Identi�cador de la instancia
Usuario máster y contraseña
VPC y subred
Nombre de la base de datos
Una vez realizada la con�guración, debemos esperar a que la instancia estédisponible para ver cual es el endpoint que se le asignado. Necesitamos este valorpara poder indicarlo en el �chero de con�guración de Django, en el apartado debase de datos. Aquí indicaremos dicho endpoint, el usuario máster y su contraseña,el puerto de conexión, etc.
Antes de realizar la migración es recomendable comprobar si la instancia deEC2 tiene acceso a la instancia que acabamos de crear de RDS. Esta prueba lapodemos realizar fácilmente a través de la herramienta MySQL Workbench.
Una vez hemos hecho la comprobación, solo debemos realizar la migración delas tablas a la base de datos de nuestra instancia.

Despliegue 55
6.1.3. Bucket S3
En el capítulo 3, en la sección de tecnologías, hablamos de que íbamos a utilizarun bucket de S3, para almacenar los estáticos y los �cheros media, y así liberar elservidor web de esta carga y tener un acceso más rápido a ellos.
Creamos el bucket, el cual debe tener un nombre único entre todos los existentesen Amazon S3. Este nombre será visible en la URL que apunta a cada uno de losobjetos almacenados en el bucket.
Es posible elegir una región de manera que optimicemos la latencia y minimi-cemos costos. Debemos tener en cuenta de que los objetos almacenados en unaregión, nunca la abandonan a menos que los trans�ramos explícitamente.
Una vez que hemos creado el bucket, podemos añadir objetos en él. Los objetospueden ser de cualquier tipo de �chero: �cheros de texto, imágenes, vídeos, etc.Además, podemos incluir metadatos junto con los �cheros y añadir permisos decontrol de acceso a cada uno de ellos.
En Django, debemos indicar, en el �chero de con�guración el nombre del bucketde S3 que vamos a utilizar. El otro parámetro que hay que con�gurar en Djangoes el backend que se va a utilizar para el almacenamiento de los estáticos. Estoes, como indicamos en el capítulo de tecnologías (que nombramos anteriormente),S3BotoStorage.
Si hemos realizado esto correctamente, solo nos queda hacer collectstatic, en elentorno de producción, y los �cheros serán alojados en el bucket. Se puede accedera ellos mediante el panel en AWS.
Asimismo, como queremos almacenar los �cheros media que vayamos teniendoen la aplicación, debemos indicar en el �chero de con�guración de Django laubicación por defecto para estos �cheros y la ruta para los �cheros media.
Lo mejor en este caso es crear dos buckets diferentes, y así almacenaremosen uno los estáticos y en otro los �cheros media. Adicionalmente tendremos quecrear una subclase en Django, para poder separar la ubicación de estos dos tiposde �cheros.
6.1.4. ElastiCache - Redis
Para poner a funcionar Redis en el sistema como sistema caché, utilizaremosElastiCache. Esta herramienta funciona por clústeres. Debemos crear un clústeren la VPC y crear un grupo de subredes.
Los pasos que debemos seguir son los siguientes:
Seleccionar el motor, en nuestro caso Redis

Despliegue 56
Deshabilitar la replicación
Nombre del clúster
El clúster será accedido únicamente desde la instancia EC2 que hemos con�-gurado para alojar nuestra aplicación. Para esto, debe encontrarse en la mismaVPC. Además, debemos permitir el acceso desde la instancia explícitamente.
Para garantizar el acceso desde la instancia hacia Redis, en nuestro caso, debe-mos modi�car las reglas de entrada del grupo de seguridad que teníamos creadopreviamente. Este grupo debe ser el que habíamos asignado para la VPC.
Entonces en las reglas de entrada de trá�co del grupo, debemos añadir unaregla con los siguientes parámetros:
Tipo: Regla personalizada de TCP
Protocolo: TCP
Puerto: 6379
Origen: Cualquiera
Tras realizar esta modi�cación, seremos capaces de acceder al clúster desde lainstancia EC2. El siguiente paso es conectarnos a un nodo del clúster y para ellodebemos conocer su endpoint.
Los clústeres de Redis, siempre tienen un único nodo. Si se trata de un clústerautónomo, como es nuestro caso, el endpoint se utilizará tanto para realizar laslecturas como las escrituras.
Para encontrar el endpoint lo haremos a través de la consola de administraciónde AWS. Debemos copiar el valor, para utilizarlo más delante en la conexión alnodo.
El último paso es con�gurar Django para que utilice este clúster Redis paralas sesiones de usuario. Para esto debemos añadir el endpoint en el �chero decon�guración de Django, seguido del puerto en el que se sirve Redis. Asimismo,hay que especi�car el motor para las sesiones.

Capítulo 7
Resultados
Tras haber pasado por todas las fases del proyecto en los capítulos anterioresde este documento. Fases como: obtención de requisitos, de�nición de objetivos,elección de herramientas y tecnologías. Así como: diseño de la aplicación y de labase de datos, desarrollo e implementación y �nalmente despliegue, pasamos adescribir los resultados obtenidos.
7.1. Resultados
Una �nalizado el proyecto, podemos comparar los resultados obtenidos conlos requisitos que teníamos adicionalmente, tanto los funcionales como los nofuncionales.
En el caso de la aplicación se han cumplido todos los requisitos de�nidos, deforma que podemos decir que la aplicación está terminada según las especi�cacio-nes.
Además de esto, la aplicación ha sido desplegada en un sistema en la nubepara ahorrar en recursos monetarios y en recursos hardware. La necesidad demantenimiento de las máquinas se reduce, y el tiempo de con�guración de cadauna de ellas es muy pequeño.
Separar la arquitectura en servicios permite aprovechar al máximo los recursos,porque cada uno de los servicios se encuentra en una instancia, bucket o clúster,diseñado para la tarea que desempeñan.
57

Capítulo 8
Conclusiones
En este capítulo se abordan las conclusiones obtenidas después de las fases dediseño, desarrollo e implementación y despliegue de la aplicación. Además de haberrealizado un análisis de los resultados que se sacan en claro tras la �nalización delproyecto.
8.1. Conclusiones
En general ha sido un proyecto bastante interesante de abordar. Lo principales que tiene una utilidad real una vez se ha terminado, y es posible continuarmejorándolo poco a poco.
Esta herramienta se desarrolló pensando en la necesidad que tienen las empresasde estar adaptadas a las nuevas tecnologías para poder conseguir ventaja en elmercado. Servirá para agilizar algunos procesos bastante comunes que costabanmucho tiempo y recursos para las empresas.
Aprovechando las características inherentes de la nube, ahorramos en tiempode con�guración y costo y tiempo de mantenimiento de la infraestructura. Asícomo añadimos seguridad a nuestras instancias y servicios.
Una de las cosas que ha permitido que este proyecto se haya desarrollado deuna manera rápida y ágil ha sido la elección de las tecnologías. Tanto en el ladodel servidor como del cliente. Se ha optado por frameworks limpios, muy rápidosde aprender y que necesitan de poco código para realizar las aplicaciones. A suvez, estos frameworks son completos y utilizados por muchas personas, lo quehace que sea fácil encontrar información, documentación y tutoriales al respecto.
Personalmente, el proyecto me ha servido para asentar conocimientos de algunasherramientas y tecnologías y aprender el manejo y uso de otras. Este proyecto haservido para tener una clara visión de cómo se desarrollan las aplicaciones webhoy en día, y la cantidad de frameworks que existen para el desarrollo web, sobretodo en el lado del frontend o cliente.
58

Capítulo 9
Trabajos futuros
Existe la posibilidad de implementar alguna serie de mejoras en cada una delas partes qe conforman la totalidad del proyecto. A lo largo de este capítulo sedescriben algunas de ellas, haciendo una separación entre: mejoras en la aplicación,mejoras generales y mejoras en la infraestructura.
9.1. Mejoras en la aplicación
Con el objetivo de reducir la posible deuda técnica del proyecto, se proponenlas siguientes mejoras. Además, se propone modi�car el modelo arquitectural dela aplicación de frontend, para hacerla más e�ciente.
9.1.1. Mejora en los tests
Aumentar la cobertura del código con los tests hace posible tener una aplicacióncon un código más robusto y con�able. De esta forma, los cambios introducidos enel futuro tendrán menos impacto sobre el funcionamiento actual de la aplicación,ya que se podrá controlar si alguno de los módulos deja de funcionar al introducirdichos cambios.
9.1.2. Mejora en la complejidad del código
Realizar un estudio sobre la complejidad ciclomática del código puede tambiénser una buena manera de tratar de reducir la deuda técnica. Un código complejose hace difícil de mantener y de depurar, por lo que es necesario mantener losniveles de complejidad en el mínimo posible, algunas técnicas para poder lograrlopueden ser:
Bucles anidados. Hay veces que se hace necesario anidar más de 2 buclesfor/while para conseguir la lógica deseada. Sin embargo, es poco recomen-dable hacer esto, no solamente por la complejidad de nivel exponencial quegenera, sino por la legibilidad del código y la mantenibilidad del mismo.
59

Trabajos futuros 60
Condicionales anidados. Además de reducir los niveles dentro de bucles, estambién recomendable no anidar más de dos veces los bloques if/else paratratar de hacer el código lo más legible y sencillo posible.
Número de líneas por función. Las funciones largas son a su vez, difíciles deentender y difíciles de refactorizar.
Reutilización de código. Siempre que sea posible, se debe identi�car losbloques que se van a repetir en el código para tratar de refactorizarlos y asípoder usarlos desde distintos sitios sin repetir ninguna línea.
9.1.3. Tests en el frontend
Mediante la inclusión de tests de funcionamiento, despliegue y unitarios en laparte cliente de la aplicación, será posible también anticiparse a posibles erroresen la interfaz. Esto es muy importante, ya que el frontend es lo primero que veun usuario al utilizar la aplicación.
9.1.4. Redux
En capítulos anteriores, en la sección 5.1.1 se ha hablado de la arquitecturaFlux que se utilizó para desarrollar la aplicación cliente. En los últimos mesestambién se ha puesto de moda la utilización de la herramienta Redux.
Gracias a ella, es posible desarrollar aplicaciones con React siguiendo la meto-dología Flux pero introduciendo algunos cambios. Por ejemplo, en vez de tenerdiferentes contenedores para los estados de nuestra aplicación, existe un únicoestado global. Esto hace que el desarrollo sea más fácil. Es más, el estado es in-mutable, y solo puede ser alterado mediante acciones que serán disparadas porlos componentes de React, lo que hace mucho más segura la edición del estadoglobal.
9.2. Mejoras generales
En esta sección hablamos de algunas posibles mejoras que realmente no tienenque ver con el código de la aplicación en sí misma, pero sí con su funcionamiento.
9.2.1. Añadir fase de QA
Hoy en día es muy usual complementar la fase de tests de cualquier aplicacióncon un tiempo destinado exclusivamente a probar la calidad de la misma. Paraello, existen muchas técnicas de detección de bugs o errores en software funcional.La más extendida es realizar una caza de bugs o bug hunting. Existen multitud de

Trabajos futuros 61
páginas webs y de empresas que se dedican a ofrecer este tipo de servicios, comointermediarios a trabajadores externos que cobran por cada uno de los errores queencuentran.
9.2.2. Seguridad
Debido a que se está enviando contenido sensible a través de la red (datosprivados, contraseñas, datos personales, etc), es imprescindible colocar algún tipode seguridad en las conexiones.
Una solución sería agregar un certi�cado SSL para que la información viaje porHTTPS en lugar de HTTP. De esta forma, todos los datos irán cifrados a travésde la red, añadiendo una robusta capa de seguridad.
9.2.3. Compatibilidad en navegadores
Hacer una aplicación compatible con distintos dispositivos y navegadores es unatarea bastante complicada. La forma en que los navegadores tienen de renderizarciertos componentes o funcionalidades de CSS o JavaScript puede ser distintaentre todos ellos.
Por ello, se hace imprescindible estar al tanto de los problemas que tiene laaplicación con el máximo número de combinaciones posibles de dispositivos y denavegadores para poder solucionarlos en un futuro.
9.2.4. Desarrollo de aplicación móvil
Actualmente, los dispositivos móviles son usados diariamente por los usuariosde Internet, y a pesar de que la aplicación desarrollada es accesible desde estosdispositivos, además de disponer de una interfaz responsiva, una mejora seríadesarrollar una aplicación especí�ca.
La creación de una aplicación nativa para las plataformas móviles más impor-tantes (Android e iOS), puede ser una línea futura de trabajo. Esto haría que lainterfaz de cada una se adaptara a los estándares y convenios de cada una de lasplataformas y la haría más user friendly. Esto es debido a que se adaptaría a lanaturaleza táctil de los dispositivos móviles actuales.
9.3. Mejoras en la infraestructura
9.3.1. Monitorización del sistema
Se propone la monitorización del sistema actual tanto en la fase de test comodespués del despliegue en producción. De esta manera, será posible determinar si

Trabajos futuros 62
la opción elegida para el despliegue ha sido la correcta, o es necesario cambiarlahacia otro enfoque que se ajuste más a las necesidades actuales de la aplicaciónen producción.

Apéndice A
Otras tecnologías
Además de las herramientas y tecnologías que se describen en el capítulo 3, sehan utilizado otras herramientas para la realización del proyecto. Sin embargo, alestas no ser estrictamente necesarias, las comentaremos en este apéndice.
A.1. Git
Git es un software de control de versiones open source, que se ha utilizado,integrado en el entorno de desarrollo. Esta herramienta fue pensada para mantenerlas versiones cuando se dispone de un gran número de archivos de código fuente.
Inicialmente, era un motor de bajo nivel sobre el que escribir la interfaz deusuario, pero hoy en día es un sistema de control de versiones de funcionalidadplena. Tanto es así, que por ejemplo es utilizado por el grupo de programacióndel núcleo de Linux para realizar el control de versiones del mismo.
Entre las características más importantes de Git, y por lo que lo hemos elegidocomo herramienta de control de versiones, se encuentran las siguientes:
Rapidez en la gestión de ramas y mezclado de versiones.
Gestión distribuida, haciendo uso de copia local de historial de desarrollocompleto.
La información se puede publicar por HTTP, FTP, rsync o algún protocolonativo, tanto por una conexión TCP/IP simple, o mediante cifrado SSH.
Gestión e�ciente de proyectos grandes.
Se guarda un histórico de cambios, así que se puede recuperar en cualquiermomento el estado anterior de cualquier �chero.
63

Otras tecnologías 64
La herramienta ha sido utilizada siguiendo los principios de buenas prácticasrecomendadas. Es decir, disponiendo de varios tipos de ramas para diferenciar enqué momento exacto del proyecto nos encontramos.
La organización de la ramas ha sido la siguiente:
Master es la rama principal y contienen el código que �nalmente se utilizaráen el entorno de producción.
Development es la rama de integración, todas las nuevas funcionalidadesse integran en esta rama primero, de manera que se realiza aquí la correcciónde errores. Una vez esté estable, es cuando se puede unir con la rama master.
Features se crea una rama nueva para cada una de las funcionalidades quese vaya a añadir al proyecto. Una vez la funcionalidad está terminada, seintegra la rama de la misma con la rama development.
GitLab es un servicio de hosting para repositorios Git. Se ha utilizado estaherramienta para compartir el código, debido a que da la posibilidad de disponerde repositorios privados.
A.2. Gulp
Gulp, o Gulp.js, es un sistema de construcción que permite automatizar lastareas comunes de desarrollo. Estas tareas son muchas, y hacerlas por separadopuede resultar un trabajo tedioso, para el que hay que instalar múltiples herra-mientas diferentes. Algunas de estas tareas son la mini�cación del código JavaS-cript, utilizado para el frontend, recarga del servidor, compresión de imágenes,validación de sintaxis, entre otras muchas.
Se trata de una herramienta construida con JavaScript, que funciona sobreNode.js, y además es open source. Y se ha decidido su utilización para agilizar eltrabajo.
Una de las directrices de la herramienta es que un plugin solo debe hacer unacosa, y debe hacerla bien, por este motivo es muy sencillo escribir tareas, para quecada una de ellas sea simple y cumpla una determinada función.
A.3. Ubuntu
Ubuntu es un sistema operativo que está basado en GNU/Linux, distribuidocomo software libre. Es uno de los sistemas Linux más utilizados, y cada vezaumenta su ratio de uso en servidores.

Otras tecnologías 65
Cada seis meses se publica una nueva versión de Ubuntu en el mercado, para laque se garantizan nueve meses de soporte, es decir, de actualizaciones de seguridad,parches para bugs, actualizaciones de programas, etc. Las versiones de largo plazose liberan cada dos años y estas reciben soporte durante cinco años, tanto parasistemas de escritorio como de servidor.
Este sistema operativo, actualmente soporta arquitecturas tanto de 32 bits comode 64, aunque extrao�cialmente ha sido portado a más arquitecturas.
Dispone de una gran comunidad de desarrolladores, que se encargan de darsoporte a las muchas derivaciones que han surgido de Ubuntu, con otros entornosgrá�cos.
Ubuntu es uno de los sistemas operativos disponibles en AWS, para instalaren sus instancias de EC2. Por lo tanto, gracias a la familiaridad con el mismo,sencillez de uso y disponibilidad de programas y paquetes software, es el sistemaoperativo instalado en la instancia EC2 utilizada para el despliegue del sistema.
A.4. PyCharm
PyCharm es un entorno de desarrollo integrado (IDE), y multiplataforma, usadopara desarrollar en el lenguaje Python. Al tratarse de un entorno de desarrollo,proporciona todas las herramientas necesarias en una sola, lo que facilita el trabajoal desarrollador.
Dispone de depurador, análisis de código, test unitarios e integración con controlde versiones, entre otras muchas facilidades. Además de esto soporta desarrollo conmuchos frameworks actuales, como Django, Google App Engine, Flask, Web2Py,y muchos otros. Además se puede utilizar en múltiples lenguajes.
Tiene disponibles varios tipos de licencia, comunitaria, profesional y licenciaspara uso educativo.
A.5. LaTeX
Por último, hemos usado LaTeX para la elaboración de la presente documenta-ción de nuestro proyecto. LaTeX es un sistema para la creación de documentaciónescrita, tal como documentos, libros y artículos, orientado sobre todo a la inclusiónde lenguaje matemático.
Es muy utilizado para elaborar documentación cientí�ca, libros técnicos y tesisporque, además de ser muy versátil, produce documentos con mucha calidad, quedan un resultado muy profesional, similar al de libros de editoriales técnicas ycientí�cas.

Otras tecnologías 66
Una de las cualidades más signi�cativas de LaTeX, y por la que nos hemosdecantado por su uso, es que su código fuente está escrito en texto plano y puedeser leído por cualquier procesador o editor. Esto ha permitido utilizar el controlde versiones para mantener la documentación y estar siempre al tanto de todoslos cambios hechos en la memoria.
A.6. Nginx
Nginx es un servidor web y un proxy inverso, ligero y de un rendimiento muyalto. Se trata de un producto open source y de software libre. Además es multi-plataforma, por lo que funciona en muchos tipos de sistemas.
En el proyecto será utilizado como servidor web, en la instancia EC2, y atenderálas peticiones de los clientes.
A.7. uWSGI
uWSGI es el servidor de aplicaciones que vamos a utilizar para disponer denuestra aplicación en Django. Las siglas WSGI, vienen del inglés Web ServerGateway Interface, lo que signi�ca que se trata de una interfaz simple y universalentre los servidores webs y las aplicaciones o los frameworks, para el lenguaje deprogramación Python.

Bibliografía
[1] Greg F. P�ster. In Search of Clusters. 1998.
[2] Peter Mell and Timothy Grance. The NIST de�nition of cloud computing.Special Publication 800-145, 2011.
[3] Mani�esto ágil. http://www.agilemanifesto.org/iso/es/.
[4] Norma ISO 25010 System and software quality models. http://www.iso.org/.
[5] Google Cloud Platform. https://cloud.google.com/.
[6] Amazon Web Services. http://aws.amazon.com/es/.
[7] Microsoft Azure. http://azure.microsoft.com/es-es/.
[8] IBM Cloud. https://www.ibm.com/cloud-computing/.
[9] Docker. https://www.docker.com/.
[10] Scrum. https://www.scrumalliance.org/.
[11] Flux. https://facebook.github.io/�ux/.
[12] Above the Clouds: A Berkeley View of Cloud Computing, UCB/EECS-2009-28. Technical report, 2009.
[13] Ian Marriot. Gartners 30 Leading Locations for O�shore Services. Gartner,2009.
[14] Forecast: Public Cloud Services, Worldwide and Regions, Industry Sectors,2010-2015. Technical report, 2011.
[15] Django. https://www.djangoproject.com/.
[16] Python. https://www.python.org/.
[17] MySQL. https://www.mysql.com/.
[18] PyCharm - JetBrains. https://www.jetbrains.com/pycharm/.
67

Otras tecnologías 68
[19] LaTeX. https://www.latex-project.org/.
[20] Ubuntu. http://www.ubuntu.com/.
[21] Git. https://git-scm.com/.
[22] React. https://facebook.github.io/react/.
[23] Gulp. http://gulpjs.com/.