sistema basado en web para el seguimiento y evaluación de...
TRANSCRIPT

ESCUELA TÉCNICA SUPERIOR EN INGENIERÍA INFORMÁTICA
INGENIERÍA TÉCNICA DE INFORMÁTICA DE GESTIÓN
Sistema basado en Web para el seguimiento y
evaluación de pacientes con Hemofilia en la
provincia de Málaga
Realizado por:
DOLORES JIMÉNEZ COBOS
Dirigido por:
DR. OSWALDO TRELLES SALAZAR
ING. MAXIMILIANO GARCÍA OLIVER
UNIVERSIDAD DE MÁLAGA ARQUITECTURA DE
COMPUTADORES
MÁLAGA, FEBRERO 2008

UNIVERSIDAD DE MÁLAGA
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA INFORMÁTICA
INGENIERÍA TÉCNICA DE INFORMÁTICA DE GESTIÓN
Reunido el tribunal examinador en el día de la fecha, constituido por:
Presidente Dº/Dª.________________________________________________________
Secretario Dº/Dª._________________________________________________________
Vocal Dº/Dª.____________________________________________________________
para juzgar el proyecto Fin de Carrera titulado:
SISTEMA BASADO EN WEB PARA EL SEGUIMIENTO Y EVALUACIÓN DE
PACIENTES CON HEMOFILIA EN LA PROVINCIA DE MÁLAGA
del alumno Dº/Dª. Dolores Jiménez Cobos
dirigido por Dº/Dª. Dr. Oswaldo Trelles Salazar, Ing. Maximiliano García Oliver
ACORDÓ POR __________________ OTORGAR LA CALIFICACIÓN DE:
______________________
Y PARA QUE CONSTE, SE EXTIENDE FIRMADA POR LOS COMPARECIENTES DEL
TRIBUNAL, LA PRESENTE DILIGENCIA.
Málaga, a de del 200__
El Presidente El Secretario El Vocal

A mi familia, porque a ellos se lo debo todo.
A Juanma por su ayuda, por apoyarme en todo momento y por ser tan especial en mi vida.
A mis amigos, en especial a Belén, Godino, Almudena, Gabriel, Víctor, Rita, Carlos y Alex por compartir conmigo tantos buenos momentos.
A Mª Eva por pensar en mi para este proyecto.
A Oswaldo y a Max por su ayuda y por confiar en mí.

ÍNDICE
Capítulo 1: Introducción…………………………………………………...………... 1
1.1 Motivación………………………………………………………………………… 2
1.2 Objetivos…………………………………………………………………………... 4
1.3 Métodos y fases de trabajo……………………………………………………….... 5
1.4 Base de datos………………………………………………………………………. 6
1.5 Aplicación HemoGest……………………………………………………………... 7
1.6 Descripción de la memoria………………………………………………................10
Capítulo 2: Fundamentos Tecnológicos………………………………………….… 11
2.1 Introducción……………………………………………………………………..… 12
2.2 Base de datos……………………………………………………………………… 12
2.3 Programación en PHP………………………………………………………….…. 17
2.3.1 Introducción…………………………………………………………............. 17
2.3.2 Tareas principales…………………………………………………………… 17
2.3.3 Sintaxis PHP………………………………………………………………... 18
2.4 Programación en Javascript………………………………………………………. 23
2.4.1 Introducción………………………………………………………………… 23
2.4.2 Sintaxis Javascript…………………………………………………………... 24
2.5 Hojas de estilos……………………………………………………………………. 29
2.5.1 Introducción…………………………………………………………………. 29
2.5.2 Sintaxis……………………………………………………………………… 30
2.6 Ejemplos de ejecución…………………………………………………………….. 35
2.6.1 PHP………………………………………………………………………….. 35
2.6.2 Javascript……………………………………………………………………. 39
2.6.3 CSS…………………………………………………………......................... 42
Capítulo 3: Análisis. Lenguaje de Modelamiento Unificado……………………... 45
3.1 Introducción……………………………………………………………………….. 46
3.2 Casos de uso………………………………………………………………………. 46
3.2.1 Descripción de la técnica…………………………………………………… 46
3.2.2 Diagramas de casos de uso del proyecto……………………………………. 48

3.3 Diagramas de clases…………………………………………………………….… 53
3.3.1 Descripción de la técnica……………………………………………………. 53
3.3.2 Diagramas de clases del proyecto…………………………………………… 54
3.4 Diagramas de interacción…………………………………………………………. 69
3.4.1 Descripción de la técnica……………………………………………………. 69
3.4.2 Diagramas de secuencia del proyecto……………………………………….. 71
3.5 Diagramas de transición de estados……………………………………………….. 77
3.5.1 Descripción de la técnica……………………………………………………. 77
3.5.2 Diagramas de transición de estados del proyecto…………………………… 80
Capítulo 4: Diseño. Modelo E/R en MySQL ……..................................................... 83
4.1 Introducción……………………………………………………………………….. 84
4.2 Modelo Entidad-Relación…………………………………………………………. 84
4.2.1 Conceptos modelo entidad-relación………………………………………… 84
4.2.2 Modelo Entidad-Relación…………………………………………………… 85
4.3 Acceso a la Base de Datos………………………………………………………… 90
4.3.1 Modelo de acceso………………………………………….………………... 90
4.3.2 Clase CMySQL……………………………………………………………... 91
4.3.3 Transacciones e integridad referencial……………..……………………….. 92
Capítulo 5: Implementación Aplicación Web…………………………………….. 95
5.1 Introducción……………………………………………………………………… 96
5.2 Sistema de autenticación…………………………………………………………. 96
5.3 Nociones básicas…………………………………………………………………. 97
5.4 Zona administración…………………………………………………………….... 99
5.4.1 Usuarios……………………………………………………………………. 99
5.4.2 Sistema……………………………………………………………………... 102
5.4.3 Tratamientos……………………………………………………………….. 103
5.5 Zona usuarios…………………………………………………………………….. 105
5.5.1 Nuevo paciente…………………………………………………………….. 107
5.5.2 Modificar paciente…………………………………………………………. 108
5.5.3 Buscar pacientes…………………………………………………………… 109
5.5.4 Estadísticas…………………………………………………………………. 110
5.5.5 General……………………………………………………………………... 112

5.5.6 Tratamientos……………………………………………………………….. 113
5.5.7 Análisis…………………………………………………………………….. 116
5.5.8 Articulaciones……………………………………………………………… 119
5.5.9 Inhibidores…………………………………………………………………. 122
5.5.10 Inmunotolerancias………………………………………………………… 125
5.5.11 Cuestionarios……………………………………………………………... 128
5.5.12 Informes…………………………………………………………………... 131
Capítulo 6: Conclusiones…........................................................................................ 133
6.1 Resultados y conclusiones……………………………………………………….. 134
6.2 Trabajos futuros………………………………………………………………….. 137
ANEXOS….................................................................................................................. 138
Anexo I. Instalación de la Aplicación………………………………………………... 139
Anexo II. Terminología básica de la hemofilia……………………………………… 142
Anexo III. Desarrollo con UML……………………………………………………... 145
Anexo IV. Tablas de la Base de Datos………………………………………………. 153
Bibliografía…………………………………………………………………………. 166


Introducción
1
CAPÍTULO 1:
INTRODUCCIÓN 1.1 Motivación
1.2 Objetivos
1.3 Métodos y fases de trabajo
1.4 Base de Datos
1.5 Aplicación Hemogest
1.6 Descripción de la memoria

Introducción
2
1.1 MOTIVACIÓN
La Hemofilia es una coagulopatía -enfermedad relacionada con la coagulación- por
déficit de FVIIII o FVIX, con un patrón de herencia recesivo ligado al cromosoma X. Su
frecuencia es de 1 por cada 5000-10000 varones, lo que la encuadrada entre las enfermedades
llamadas raras. Su abordaje resulta complicado por la dificultad de agrupar y homogeneizar
las evaluaciones y tratamientos entre pacientes de distintos centros, único sistema para la
consecución del número suficiente de casos a estudiar que permita inferir relaciones entre
datos. Pese a ello, el impacto socio-sanitario de enfermedades como el SIDA que ha diezmado
a esta población y la repercusión económica del tratamiento de la Hemofilia en los Sistemas
de Salud, hacen que los estudios sobre esta patología sean de crucial importancia.
Aunque se han realizado numerosos estudios, aún quedan múltiples interrogantes por
resolver en el manejo diario de estos pacientes. Entre ellos:
� Existen discrepancias entre los métodos de estudio fármaco-cinéticos de los
concentrados, dependiendo de la tecnología utilizada; siendo necesario abrir nuevas
líneas de investigación en este ámbito que permiten optimizar estrategias de
tratamiento.
� Es necesario disponer y perfeccionar un patrón estandarizado internacional para los
concentrados de los factores usados que permita normalizar los datos a estudiar.
� Existe una gran variedad y continua evolución de los distintos tipos de concentrado de
factor. Para elegir y manejar unos u otros preparados hay que realizar diversos
estudios sobre farmacocinética, eficacia, seguridad, desarrollo de inhibidores, etc.,
siendo aún amplio el camino por recorrer.
� No existen datos sobre la eficacia de las terapias sustitutivas (a demanda o en
profilaxis) con indicación de las dosis, horarios, etc, lo que precisa de nuevas
investigaciones para mejorar los tratamientos reduciendo los efectos secundarios y
optimizando los recursos económicos.
� No se conocen los mecanismos de aparición de inhibidores y factores pronósticos que
interfieren con la función proteica, por lo que es necesaria la valoración de factores
endógenos (tipo de mutación, raza, agrupación familiar, HLA) y medioambientales
(tipo de factor, cambio de producto, dosis, vía de administración, edad de la primera

Introducción
3
exposición, lactancia materna, enfermedad inflamatoria-infecciosa concomitante a la
infusión de factor, etc) que determinen o influencien la aparición de inhibidores.
� No se dispone de información sobre las pautas de tolerancia inmunológica a pesar que
existen muy diversas posibilidades.
� Es necesario disponer de información que permita la valoración global del resultado
obtenido con los tratamientos aplicados de una forma clínica objetiva.
Se trata pues de una vieja patología en la que aún quedan por definir un gran número de
aspectos y en la que apremia el diseño y desarrollo de estudios que permitan analizar los
resultados clínicos obtenidos e incluyan aspectos fármaco-económicos, permitiendo definir
Políticas de Salud sostenibles cumpliendo las expectativas y necesidades de los pacientes con
costes adecuados para el Sistema de Salud implicado.
Las respuestas a estos problemas de tratamiento e interpretación de grandes cantidades de
información con métodos específicos pero a su vez relacionados, nos las proporcionan entre
otras, la organización en bases de datos, los motores de búsqueda bases de datos que
proporcionan acceso a los datos, y el software específico del campo de trabajo con sus
diversos algoritmos y en particular con el tratamiento estadístico poblacional de los datos
mediante su disponibilidad en medios electrónicos y la posibilidad de integrarlos con
conjuntos externos para dar mayor solidez a las conclusiones.
Las bases de datos son una herramienta necesaria para el almacenamiento y la
organización de datos de diverso tipo, permitiendo manipularlos de distintas formas y
relacionarlos entre sí. Hoy en día, ocupan un lugar determinante en cualquier área del
quehacer humano, comercial, y tecnológico. No sólo las personas que trabajan en el área de
Informática, sino todas las personas administrativas, técnicas y con mayor razón los
profesionales de cualquier carrera, deben de tener los conocimientos necesarios para poder
usar las bases de datos.

Introducción
4
1.2 OBJETIVOS
El objetivo de este proyecto es el diseño, desarrollo e implantación de un sistema de
gestión de bases de datos que permita el almacenamiento, tratamiento y gestión de datos para
dar soporte a la evaluación de pacientes con hemofilia en el área sanitaria de la provincia de
Málaga. El sistema será implantado en el Hospital Carlos Haya (SAS).
Los principales objetivos de este proyecto son:
� Creación de un registro actualizado de los pacientes con hemofilia en el área sanitaria
de Málaga (pero igualmente utilizable en otras zonas geográficas).
� Diseño de una evaluación sistemática de resultados clínicos de estos pacientes que
permita el seguimiento homogeno de los mismos y la comparación de sus evoluciones,
facilitando la optimización de tratamientos, estudios de efectos adversos y
complicaciones, etc.
� Aplicar un cuestionario estadarizado de estudio de calidad de vida a dichos pacientes
para conocer su situación y plantear un abordaje de sus espectativas de forma global.
� Crear un soporte en formato electrónico de esta información, de fácil manejo para los
profesionales, que permita una intervención estadistica avanzada de los mismos.
� Familiarizarse con la terminología propia en la evaluación de pacientes con hemofilia.
(Ver anexo).
Ello permitirá, entre otro tipo de aplicaciones, las siguientes:
� Valoración farmacoeconomica de las pautas de tratamiento utilizadas para optimizar el
consumo de recursos.
� Desarrollo de una guía básica de tratamiento y manejo (cirugia, rehabilitación,
odontología, etc) de estos pacientes en nuestro medio, conforme a lo establecido en la
actualidad por las principales referencias científicas.
� Farmacovigilancia: Control sistemático sobre seroconversión, desarrollo de
inhibidores y reacciones anafilácticas.
� El soporte en formato electrónico de esta información deberá facilitar el manejo y la
gestión del colectivo de hemofilia por parte de los profesionales de la salud y aplicar
sobre estos datos las herramientas de procesamiento estadístico que se decida.

Introducción
5
� El diseño de los procedimientos para la evaluación sistemática de los resultados
clínicos de estos pacientes que permita el seguimiento homogéneo de los mismos y su
comparación, facilitando la optimización de tratamientos, estudios de efectos adversos
y complicaciones.
� Llevar adelante una fármaco-vigilancia (sero-conversiones, inhibidores y reacciones
adversas).
1.3 MÉTODOS Y FASES DE TRABAJO
Se han identificado las siguientes etapas en la realización de este trabajo y que
gobernarán la organización y desarrollo del mismo:
1. Instalación del Sistema Operativo Linux (Distribución Fedora Core 4).
2. Instalación de un Servidor de Base de Datos (MySQL).
3. Instalación de Servidor Web con soporte para PHP (Apache 2.0.48).
4. Instalación de PHP versión 4.3.4.
5. Diseño del modelo de datos.
6. Desarrollo de los casos de uso que guiarán el diseño de la aplicación.
7. Diseño y utilización de una Base de Datos para la gestión de datos específicos del
proyecto.
8. Aprendizaje de PHP, JavaScript, CSS y creación de formularios para actualizar la
base de datos.
9. Realización de la memoria del proyecto.
Serán resultados finales del proyecto:
1. Estudio de la estructura de datos necesaria para describir los pacientes, tratamientos,
análisis, revisiones de las articulaciones, inhibidores, inmunotolerancias y cuestionarios.
2. Estudio de MySQL (Gestor de base de datos de dominio público, basado en SQL).
3. Diseño de la estructura de la base de datos utilizando un modelo Entidad-Relación.
Implementación utilizando el modelo relacional de MySQL.
4. Desarrollo de la aplicación de control y estadística de acceso.
5. Desarrollo de informes.

Introducción
6
1.4 BASE DE DATOS
Una Base de Datos es un conjunto de tablas que contienen información ordenada en
alguna estructura que facilita el acceso a esas tablas, permitiendo además ordenar y
seleccionar filas de las tablas según criterios específicos.
Los principales objetivos de los Sistemas Gestores de Bases de Datos (SGBD) son:
1. Independencia lógica y física de los datos. Capacidad de modificar una definición de
esquema en un nivel de la arquitectura sin que esta modificación afecte al nivel
inmediatamente superior. Para ello un registro externo en un esquema externo no tiene
por qué ser igual a su registro correspondiente en el esquema conceptual.
2. Redundancia mínima. Se trata de usar la base de datos como repositorio común de
datos para distintas aplicaciones.
3. Acceso concurrente por parte de múltiples usuarios. Control de concurrencia mediante
técnicas de bloqueo o cerrado de datos accedidos.
4. Distribución espacial de los datos. La independencia lógica y física facilita la
posibilidad de sistemas de bases de datos distribuidas. Los datos pueden encontrarse
en otra habitación, otro edificio e incluso otro país. El usuario no tiene por qué
preocuparse de la localización espacial de los datos a los que accede.
5. Integridad de los datos. Se refiere a las medidas de seguridad que impiden que se
introduzcan datos erróneos. Esto puede suceder tanto por motivos físicos (defectos de
hardware, actualización incompleta debido a causas externas), como de operación
(introducción de datos incoherentes). Para permitir el uso de transacciones completas,
evitando perdida de información, hemos utilizado las transacciones de MySql.
COMMIT se utiliza cuando se ha realizado una inserción o eliminación en la base de
datos y queremos que estos cambios sean permanentes. ROLLBACK se utiliza para
cancelar los cambios que han sido realizados por las consultas hechas hasta el
momento.
6. Consultas complejas optimizadas. La optimización de consultas permite la rápida
ejecución de las mismas.
7. Seguridad de acceso y auditoría. Derecho de acceso a los datos contenidos en la base
de datos por parte de personas y organismos. El sistema de auditoría mantiene el
control de acceso a la base de datos, con el objeto de saber qué o quién realizó una
determinada modificación y en qué momento.

Introducción
7
8. Respaldo y recuperación. Capacidad de un sistema de base de datos de recuperar su
estado en un momento previo a la pérdida de datos.
9. Acceso a través de lenguajes de programación estándar. Posibilidad de acceder a los
datos de una base de datos mediante lenguajes de programación ajenos al sistema de
base de datos propiamente dicho.
Nuestro primer cometido será el diseño e implementación de una Base de Datos de tipo
Relacional generada a partir del SGBD MySQL. En dicha Base de datos almacenaremos
información referente a pacientes con hemofilia. Dentro del modelo controlaremos los datos
de cada uno de los pacientes además de los relacionados a los usuarios que acceden al mismo.
1.5 APLICACIÓN HEMOGEST
El objetivo de este proyecto es el diseño y desarrollo de una Aplicación Web para la
gestión de pacientes con Hemofilia. El sistema gestionará los datos médicos referentes a sus
tratamientos, análisis, revisiones de las articulaciones, inhibidores, inmunotolerancias y
cuestionarios. La aplicación también permitirá realizar informes y estadísticas.
Para la implementación de nuestra aplicación usaremos código HTML (HyperText
Markup Language, Lenguaje de hipertexto estándar usado para el desarrollo de páginas web)
con partes escritas en PHP (Acrónimo recursivo de Hypertext Preprocessor) y en Javascript.
PHP es un lenguaje script, su interpretación y ejecución se da en el servidor, en el cual se
encuentra almacenado el script, y el cliente sólo recibe el resultado de la ejecución. Cuando el
cliente hace una petición al servidor para que le envíe una página web, generada por un script
PHP, el servidor ejecuta el intérprete de PHP, el cual procesa el script solicitado que generará
el contenido de manera dinámica, pudiendo modificar el contenido a enviar, y regresa el
resultado al servidor, el cual se encarga de regresárselo al cliente.

Introducción
8
Figura 1.1
Javascript se inserta en documentos HTML, de forma que su código queda reflejado en la
propia página y no es llamado o cargado de ninguna fuente externa. Se trata de un lenguaje
interpretado puro (ni compilación, ni generación de intermedios codificados de ningún tipo).
Sirve principalmente para mejorar la gestión de la interfaz cliente/servidor. Un script
JavaScript insertado en un documento HTML permite reconocer y tratar localmente, es decir,
en el cliente, los eventos generados por el usuario.
Para definir la presentación de los documentos escritos en HTML hemos utilizado CSS
(Cascading Style Sheets, Hojas de estilos en cascada). Una hoja de estilos es un conjunto de
especificaciones de formato que se aplican a los elementos HTML. La idea que se encuentra
detrás del desarrollo de CSS, es separar la estructura de un documento de su presentación.
La interacción de todos los componentes es sencilla, tenemos toda nuestra información en
la Base de Datos MySQL y el código de nuestra aplicación en el servidor Apache, con el
motor de PHP integrado como módulo del mismo para ejecutar sus partes de código. Cuando
ejecutamos alguna consulta en lenguaje SQL usando las instrucciones pertinentes en PHP,
este código accede a través del servidor Web a la Base de Datos, para después mostrar la
información en las páginas HTML. JavaScript es utilizado para controlar las ventanas del
navegador, capturar los eventos generados por el usuario y responder a ellos sin salir a
Internet y comprobar los datos que el usuario introduce en un formulario antes de enviarlos.

Introducción
9
Nuestra aplicación constará de 3 módulos principales:
� Una página principal, donde se encuentra el sistema de autenticación.
� La zona de Administrador, restringida a uso único del mismo, donde se encuentra la
gestión de los usuarios, el mantenimiento de algunas de las tablas de la base de datos y
la importación de datos del diario de tratamientos de la AMH (Asociación Malagueña
de Hemofilia).
� La zona de Usuarios, donde se encuentran la información de los pacientes, su acceso
también es restringido.
Se ha diseñado un sistema con autenticación de usuarios, para los cuáles se definen los
siguientes permisos:
� Permiso de lectura. Podrán acceder a la información de los pacientes, así como podrán
realizar estadísticas e informes, pero no podrán insertar, ni modificar, ni eliminar
datos de la base de datos.
� Permiso de escritura. Además de los privilegios del usuario con permiso de lectura,
tiene la capacidad de insertar, modificar y eliminar en la base de datos.
� Permiso de Administración. Accederá a la zona de gestión de los usuarios y de
mantenimiento de las base de datos, teniendo permiso de lectura y escritura de la
misma.

Introducción
10
1.6 DESCRIPCIÓN DE LA MEMORIA
La memoria se ha organizado en seis capítulos. A continuación veremos cuáles son y una
breve descripción de cada uno para tener una idea general de los contenidos de este proyecto
� Capítulo 1: Introducción. En este capítulo se describen los motivos y objetivos del
desarrollo del proyecto.
� Capítulo 2: Fundamentos Tecnológicos. En este capítulo, se realizará una breve
introducción a las Bases de Datos, a continuación trataremos los aspectos más
destacados de los lenguajes de programación utilizados y por último mostraremos
algunos ejemplos de ejecución.
� Capítulo 3: Análisis: Lenguaje de Modelamiento Unificado (UML - Unified
Modeling Language). A través de UML se lleva a cabo el análisis del sistema.
� Capítulo 4: Diseño: Modelo E/R en MySQL. Detallaremos paso a paso la
elaboración de la base de datos.
� Capítulo 5: Implementación Aplicación. Describiremos como ha sido desarrollada la
aplicación web, comentando su funcionamiento.
� Capítulo 6: Conclusiones. En este capítulo comentaremos las conclusiones que
hemos obtenidos durante el desarrollo del Proyecto, objetivos cumplidos y futuros
trabajos para ampliar el mismo.
� Anexos. Indicaremos los pasos necesarios para instalación de la aplicación en un
servidor Web, definimos la terminología básica de la hemofilia y explicamos con
detalle algunos diagramas UML.
� Bibliografía: Referencias a toda la documentación usada durante la elaboración del
proyecto.

Fundamentos tecnológicos
11
CAPÍTULO 2:
FUNDAMENTOS TECNOLÓGICOS 2.1 Introducción
2.2 Base de Datos
2.3 Programación en PHP
2.4 Programación en Javascript
2.5 Hoja de estilos
2.6 Ejemplos de ejecución

Fundamentos tecnológicos
12
2.1 INTRODUCCIÓN
En este capítulo, se realizará una breve introducción a las Bases de Datos, a continuación
trataremos los aspectos más destacados de los lenguajes de programación utilizados y por
último mostraremos algunos ejemplos de ejecución.
2.2 BASE DE DATOS
Para la elaboración de la Base de datos el gestor que utilizaremos es MySQL.
MySQL es un sistema de administración relacional de bases de datos. Una base de datos
relacional archiva datos en tablas separadas en vez de colocar todos los datos en un gran
archivo. Esto permite velocidad y flexibilidad. Las tablas están conectadas por relaciones
definidas que hacen posible combinar datos de diferentes tablas.
Es necesario la utilización de claves o indentificadores de cada entidad que permita
distinguir sin ningún tipo de ambigüedad cada uno de los elementos del conjunto de
entidades. Dos o más entidades se pueden relacionar entre sí, y a este hecho y su implicación
conceptual se le conoce on el nombre de relación.
La sintaxis de SQL de las operaciones más básicas:
� Crear una tabla
CREATE TABLE nombre_tabla (
nombre_columna tipo_columna [ cláusula_defecto ] [ vínculos_de_columna ]
[ , nombre_columna tipo_columna [ cláusula_defecto ] [vínculos_de_columna ]
... ]
[ , [ vínculo_de tabla] ... ]
)
- nombre_columna: es el nombre de la columan que compone la tabla.
- tipo_columna: es la indicación del tipo de dato que la columna podrá contener.
- cláusula_defecto: indica el valor por defecto que tomará la columna si no se le
asigna uno explícitamente en el momento en que se crea la línea. La sintaxis que
hay que usar es la siguiente: DEFAULT {valor | NULL}, donde valor es un valor
válido para el tipo con el que la columna se ha definido.

Fundamentos tecnológicos
13
- vínculos_de_columna: son vínculos de integridad que se aplican a cada atributo
concreto. Son:
o NOT NULL, que indica que la columna no puede tomar el valor NULL.
o PRIMARY KEY, que indica que la columna es la llave primaria de la tabla.
o Una definición de referencia con la que se indica que la columna es una llave
externa hacia la tabla y los campos indicados en la definición. La sintaxis es la
siguiente:
REFERENCES nombre_tabla [ ( columna1 [ , columna2 ... ] ) ]
[ ON DELETE { CASCADE | SET DEFAULT | SET NULL } ]
[ ON UPDATE { CASCADE | SET DEFAULT | SET NULL } ]
Las cláusulas ON DELETE y ON UPDATE indican qué acción hay que
ejecutar en el caso en que una tupla en la tabla referenciada sea eliminada o
actualizada. De hecho, en dichos casos en la columna referenciante (que es la
que se está definiendo) podría haber valores inconsistentes. Las acciones
pueden ser:
CASCADE: eliminar la tupla que contiene la columna referenciante (en el caso
de ON DELETE) o también actualizar la columna referenciante (en el caso de
ON UPDATE).
SET DEFAULT: asignar a la columna referenziante su valor de defecto.
SET NULL: asignar a la columna referenciante el valor NULL.
o Un control de valor, con el que se permite o no asignar un valor a la columna
en función del resultado de una expresión. La sintaxis que se usa es:
CHECK(expresión_condicional)
donde expresión_condicional es una expresión que ofrece verdadero o falso.
- vínculos_de_tabla: son vínculos de integridad que se pueden referir a más
columnas de la tabla. Son:
o La definición de la llave primaria:
PRIMARY KEY ( columna1 [ , columna2 ... ] )
o Las definiciones de las llaves externas:
FOREIGN KEY ( columna1 [ , columna2 ... ] )

Fundamentos tecnológicos
14
� Insertar una nueva línea en la tabla:
INSERT INTO nombre_tabla [ ( lista_campos ) ]
VALUES ( lista_valores )
- nombre_tabla es el nombre de la tabla en la que se tiene que incluir la nueva línea.
- lista_campos es la lista de los nombres de los campos a los que hay que asignar un
valor, separados entre sí por una coma. Los campos no incluidos en la lista
tomarán su valor por defecto o NULL si no lo tienen por defecto. Es un error no
incluir en la lista un campo que no tenga un valor por defecto y que no pueda
tomar el valor NULL. En el caso en que no se especifique la lista, habrá que
especificar los valores de todos los campos de la tabla.
- lista_valores es la lista de los valores que se les darán a los campos de la tabla en
el orden y número especificados por la lista_campos o en la de la definición de la
tabla (si no se especifica lista_campos). Los valores pueden ser una expresión
escalar del tipo apropiado para el campo o las keywords DEFAULT o NULL, si el
campo prevé un valor por defecto o admite el valor NULL.
� Modificar líneas de la tabla:
UPDATE nombre_tabla
SET lista_asignaciones
[ WHERE expresión_condicional ]
La instrucción UPDATE actualiza las columnas de la tabla que se han especificado
en la cláusula SET, utilizando los valores que son calculados por las correspondientes
expresiones escalares. Si se expresa también la cláusula WHERE, se actualizan sólo
las líneas que satisfacen la expresión condicional.
� Eliminar líneas de la tabla:
DELETE FROM nombre_tabla
[ WHERE expresión_condicional ]
La instrucción delete elimina de una tabla todas las líneas que satisfacen la
expresión condicional de la cláusula WHERE. Si WHERE no se especifica, se
cancelan todas las líneas de la tabla.

Fundamentos tecnológicos
15
� Consultar la base de datos:
SELECT [ ALL | DISTINCT ] lista_elementos_selección
FROM lista_referencias_tabla
[ WHERE expresión_condicional ]
[ GROUP BY lista_columnas ]
[ HAVING expresión_condicional ]
[ ORDER BY lista_columnas ]
La instrucción SELECT produce una tabla que se obtiene aplicando el siguiente
procedimiento (por lo menos desde el punto de vista lógico, cada DBMS optimiza la
ejecución de las interrogaciones según las propias estrategias):
1. Produce una tabla que se obtiene como producto cartesiano de las tablas
especificadas en la cláusula FROM. Cada elemento de la lista_referencias_tabla
sigue la siguiente sintaxis: referencia tabla[ [ AS ] alias tabla]
La referencia puede ser el nombre de una tabla o una expresión (puesta entre
paréntesis) cuyo resultado es una tabla, y por lo tanto incluso otra SELECT. El
alias es un nombre que sirve para indicar brevemente una referencia de tabla. En el
caso en que la referencia de tabla sea una expresión, es obligatorio especificar un
alias.
2. De la tabla anterior elimina todas las líneas que no satisfacen la expresión
condicional (es decir las líneas por las cuales la expresión condicional devuelve
falso como resultado) de la cláusula WHERE.
3. (Si está presente la cláusula GROUP BY) las líneas de la tabla resultante del paso
2 se reagrupan según los valores presentes en las columnas especificadas en la
cláusula GROUP BY. Líneas con valores iguales se unen en una única línea. Las
columnas no comprendidas en la cláusula tienen que comprender expresiones con
funciones de agregación (como por ejemplo AVG, que calcula la media) que, por
tanto, se calculan produciendo un único valor para cada grupo.
4. (Si está presente la cláusula HAVING) del resultado del punto 3 se eliminan las
líneas que no satisfacen la expresión condicional de la cláusula HAVING.

Fundamentos tecnológicos
16
5. Se calculan las columnas presentes en la cláusula SELECT (las de la
lista_elementos_selección). En concreto, se calculan las columnas con las
funciones de agregación que derivan del reagrupamiento que se ha producido en el
punto 3. Cada elemento de la lista_elementos_selección sigue la siguiente sintaxis:
expresión_escalar [ [ AS ] alias_columna ]
Una expresión escalar es una expresión que produce como resultado un valor
escalar. Los tipos de datos escalares del lenguaje SQL son principalmente los
descritos en la lección 6 (Crear la base de datos), excepto INTERVAL, DATE,
TIME y TIMESTAMP.
Toda la lista de las columnas de una tabla puede especificarse usando el carácter
'*'.
6. (Si está presente la opción DISTINCT) se eliminan las líneas que resultan
duplicadas. En el caso en que no estén presentes ni ALL ni DISTINCT, se asume
ALL.
7. (Si está presente la cláusula ORDER BY) las líneas de la tabla se ordenan según
los valores presentes en las columnas especificadas en la cláusula. La sintaxis que
hay que usar es la siguiente:
ORDER BY nombre_columna [ ASC | DESC ] [ , nombre_columna [ ASC | DESC
] ... ]
Las principales características de este gestor de bases de datos son las siguientes:
1. Aprovecha la potencia de sistemas multiprocesador, gracias a su implementación
multihilo.
2. Soporta gran cantidad de tipos de datos para las columnas.
3. Dispone de API's en gran cantidad de lenguajes (C, C++, Java, PHP, etc).
4. Gran portabilidad entre sistemas.
5. Soporta hasta 32 índices por tabla.
6. Gestión de usuarios y passwords, manteniendo un muy buen nivel de seguridad en
los datos.
7. Software de código abierto. El código fuente se puede descargar y está accesible a
cualquiera, por otra parte, usa la licencia GPL para aplicaciones no comerciales.

Fundamentos tecnológicos
17
2.3 PROGRAMACION EN PHP
2.3.1 Introducción
PHP es un lenguaje creado por una gran comunidad de personas. El sistema fue
desarrollado originalmente en el año 1994 por Rasmus Lerdorf como un CGI (Common
Gateway Interface, norma para establecer comunicación entre un servidor web y un
programa) escrito en C que permitía la interpretación de un número limitado de comandos. El
sistema fue denominado Personal Home Page Tools y adquirió relativo éxito gracias a que
otras personas pidieron a Rasmus que les permitiese utilizar sus programas en sus propias
páginas. Dada la aceptación del primer PHP y de manera adicional, su creador diseñó un
sistema para procesar formularios al que le atribuyó el nombre de FI (Form Interpreter) y el
conjunto de estas dos herramientas, sería la primera versión compacta del lenguaje: PHP/FI.
La siguiente gran contribución al lenguaje se realizó a mediados del 97 cuando se volvió a
programar el analizador sintáctico, se incluyeron nuevas funcionalidades como el soporte a
nuevos protocolos de Internet y el soporte a la gran mayoría de las bases de datos
comerciales.
En el último año, el número de servidores que utilizan PHP se ha disparado, lo que le ha
convertido en una tecnología popular.
2.3.2 Tareas principales
Poco a poco el PHP se va convirtiendo en una herramienta que proporciona la
funcionalidad completa de un lenguaje de programación. En un principio diseñado para
realizar poco más que un contador y un libro de visitas, PHP ha experimentado en poco
tiempo una verdadera revolución y, a partir de sus funciones, en estos momentos se pueden
realizar una multitud de tareas útiles para el desarrollo del web:
� Gestión de bases de datos: Resulta difícil concebir un sitio actual, potente y rico en
contenido que no es gestionado por una base de datos. El lenguaje PHP ofrece
interfaces para el acceso a la mayoría de las bases de datos comerciales y por ODBC a

Fundamentos tecnológicos
18
todas las bases de datos posibles en sistemas Microsoft, a partir de las cuales
podremos editar el contenido de nuestro sitio con absoluta sencillez.
� Funciones de correo electrónico: Podemos enviar un e-mail a una persona o lista
parametrizando toda una serie de aspectos tales como el e-mail de procedencia,
asunto, persona a responder…
� Gestión de archivos: Crear, borrar, mover, modificar...cualquier tipo de operación más
o menos razonable que se nos pueda ocurrir puede ser realizada a partir de una amplia
librería de funciones para la gestión de archivos por PHP. También podemos transferir
archivos por FTP a partir de sentencias en nuestro código, protocolo para el cual PHP
ha previsto también gran cantidad de funciones.
� Tratamiento de imágenes: Puede parecer útil el crear botones dinámicos, es decir,
botones en los que utilizamos el mismo diseño y solo cambiamos el texto. Podremos
por ejemplo crear un botón haciendo una única llamada a una función en la que
introducimos el estilo del botón y el texto a introducir obteniendo automáticamente el
botón deseado. A partir de la librería de funciones graficas podemos hacer esto y
mucho más.
Muchas otras funciones pensadas para Internet (tratamiento de cookies, accesos
restringidos, comercio electrónico...) o para propósito general (funciones matemáticas,
explotación de cadenas, de fechas, corrección ortográfica, compresión de archivos...) son
realizadas por este lenguaje.
2.3.3 Sintaxis PHP
PHP se escribe dentro de la propia página web, junto con el código HTML y, como para
cualquier otro tipo de lenguaje incluido en un código HTML, en PHP necesitamos especificar
cuáles son las partes constitutivas del código escritas en este lenguaje. Esto se hace, como en
otros casos, delimitando nuestro código por etiquetas. Podemos utilizar distintos modelos de
etiquetas en función de nuestras preferencias y costumbres. Hay que tener sin embargo en
cuenta que no necesariamente todas están configuradas inicialmente y que otras, como es el
caso de que sólo están disponibles a partir de una determinada versión (3.0.4.).

Fundamentos tecnológicos
19
Estos modos de abrir y cerrar las etiquetas son:
1. <?código?>
2. <?php código ?>
3. <?script language=”php”> código </script>
4. <% código %>
El modo de funcionamiento de una página PHP, a grandes rasgos, no difiere del clásico
para una página dinámica de lado servidor: El servidor va a reconocer la extensión
correspondiente a la página PHP (phtml, php, php4,...) y antes de enviarla al navegador va a
encargarse de interpretar y ejecutar todo aquello que se encuentre entre las etiquetas
correspondientes al lenguaje PHP. El resto, lo enviara sin más ya que, asumirá que se trata de
código HTML absolutamente compresible por el navegador.
▪ Separación de instrucciones
Cada instrucción acaba con un punto y coma ";". Para la última expresión, la que va antes
del cierre de etiqueta, este formalismo no es necesario.
▪ Comentarios
PHP soporta comentarios tipo ‘C’, ‘C++’ y shell de Unix. La forma de incluir estos
comentarios es variable dependiendo si queremos escribir una línea o más. Si usamos doble
barra (//) o el símbolo # podemos introducir comentarios de una línea. Mediante /* y */
creamos comentarios multilínea. Por supuesto, nada nos impide de usar estos últimos en una
sola línea.
▪ Tipos
El tipo de una variable normalmente no lo indica el programador; en su lugar, lo decide
PHP en tiempo de ejecución dependiendo del contexto en el que se utilice esa variable. PHP
soporta los siguientes tipos de datos:
- Enteros, del tipo $a=1234, $a=-1234, $a=o123(octal, $a=ox123(hexadecimal).

Fundamentos tecnológicos
20
- Punto flotante, $a=1.234, $a=1.2e3.
- Cadenas de caracteres, se de limitan por dobles comillas “” o simples ‘ (con más
restricciones).
- Arrays, los crearemos usando las funciones list o array, o asignando los valores de
manera explícita ($a[0]=”abc”). También dispondremos de arrays multidimensionales.
- Objetos. Podremos instanciar objetos de una clase con la función new.
▪ Variables
Las variables son definidas anteponiendo el símbolo dólar ($) al nombre de la variable
que estábamos definiendo. El nombre de la variable es sensible a minúsculas y mayúsculas.
Las variables siempre se asignan por valor, lo cual significa que cuando se asigna una
expresión a una variable, el valor íntegro de la expresión original se copia en la variable
destino. A partir de PHP4 ofrece otra forma de asignar valores a las variables, asignar por
referencia, simplemente anteponiendo un ampersand (&) al comienzo de la variable.
Además de las variables que crean los usuarios, se crean por defecto otras variables, como
son las del servidor (Apache en nuestro caso, tales como SERVER,
NAME_DOCUMENT_ROOT, HTTP_HOST, etc…) variables de entorno que se importan
desde el entorno donde se este ejecutando el interprete de PHP, variables del propio PHP,
como HTTP_GET_VARS, HTTP_POST_VARS, PHP_SELF, etc…Mención aparte merecen
las variables externas a PHP, como son las de los formularios HTML (GET Y POST), que
pasan a estar disponibles en el Script de PHP cuando son enviadas.
▪ Constantes
Se puede definir una constante usando la función define(). Una vez definida, no puede
ser modificada ni eliminada. Solo se puede definir como constantes valores escalares
(boolean, integer, float y string ).
▪ Expresiones
En PHP, casi cualquier cosa que se escribe es una expresión. La forma más simple y
ajustada de definir una expresión es “cualquier cosa que tiene valor”. Sus formas más básicas
son las constantes y las variables. Se pueden escribir todas las expresiones típicas de un
lenguaje de programación, con sus operadores lógicos, aritméticos, funciones, etc…

Fundamentos tecnológicos
21
▪ Operadores
PHP pone a disposición del usuario todos los operadores típicos que se usan en la
construcción de expresiones:
- Aritméticos: +, - , * , / , %.
- Asignación: El operador básico de asignación es “=”, aunque se puede combinar con
otros operadores, como los aritméticos + y -, para realizar incrementos o decrementos.
- Operadores bit a bit, permiten activar o desactivar bits individuales de entero (&, |, ^,
<<, >>).
- Operadores de comparación: Permiten comparar dos valores (= =, !=, <, >, <=, >=).
- Operador de ejecución: Permiten ejecutar la instrucción contenida dentro de los
apóstrofes invertidos como si fuera un comando del shell.
- Operadores lógicos: and (o $$), oer (o ||), xor (o ¡).
- Operador de cadenas, es el operador de concatenación (‘.’), que devuelve el resultado
de concatenar su operando izquierdo y derecho.
▪ Sentencias de control
Las sentencias se pueden agrupar en grupos de sentencias encapsulándolas con llaves. Se
pueden usar todas las estructuras típicas de un lenguaje de programación:
- Aritméticos: +, - , * , / , %.
- IF (<expresión>) {<sentencias>) ELSE {<sentencias>} (la segunda parte del else es
opcional también podríamos usar ELSEIF(<expresión>)).
- WHILE (<expresión>){<sentencias>}.
- DO {<sentencias>} WHILE (<expresión>);
- FOR {<expresion1>,<expresion2>,<expresion3>){<sentencias>}.
- DO {<sentencias>} WHILE (<expresión>);
- FOR {<expresion1>, <expresion2>, <expresion3>) {<sentencias>}.
- SWITCH {<expresión>) {case <valor1>:<sentencias> break; case <valor2>:
<sentencias> break;…default:<sentencias>
- Require(), actúa igual que el #include de C, se sustituye por el archivo especificado
entre los paréntesis.
- Include() incluye y evalúa el archivo especificado.

Fundamentos tecnológicos
22
▪ Funciones
Las funciones son segmentos de código que pueden ser invocados varias veces y que tras
su ejecución continua el flujo del programa desde el que fue llamado. Para definir una función
en PHP, hay que hacerlo antes de que se referencie en el código del programa. Una función se
define con las siguientes sintaxis:
function ejemplo($arg_1, $arg_2, . . . ,$arg_n){
echo “función ejemplo.\n”
return $retval;
}
▪ Clases
Una clase es una colección de variables y de funciones que acceden a esas variables. Una
clase se define con la siguiente sintaxis:
<?
class Caja{
var $alto;
var $ancho;
var $largo;
var $contenido;
var $color;
function introduce($valor){
$this->contenido = $valor;
}
function muestra_contenido(){
echo $this->contenido;
}
}
?>
Las clases solamente son definiciones. Si queremos utilizar la clase tenemos que crear un
ejemplar de dicha clase, lo que corrientemente se le llama instanciar un objeto de una clase.
$micaja = new Caja;
Con esto hemos creado, o mejor dicho, instanciado, un objeto de la clase Caja llamado

Fundamentos tecnológicos
23
$micaja.
$micaja->introduce($valor);
$micaja->muestra_contenido();
Con estas dos sentencias estamos introduciendo "algo" en la caja y luego estamos
mostrando ese contendido en el texto de la página. Nos fijamos que los métodos de un objeto
se llaman utilizando el código "->".
nombre_del_objeto->nombre_de_metodo()
Para acceder a los atributos de una clase también se accede con el código "->". De esta
forma:
nombre_del_objeto->nombre_del_atributo
2.4 PROGRAMACION EN JAVASCRIPT
2.4.1 Introducción
HTML no es suficiente para realizar todas las acciones que se pueden llegar a necesitar
en una página web. Esto es debido a que conforme fue creciendo el web y sus distintos usos
se fueron complicando las páginas y las acciones que se querían realizar a través de ellas. El
HTLM se había quedado corto para definir todas estas nuevas funcionalidades, ya que sólo
sirve para presentar el texto en una página, definir su estilo y poco más. El primer ayudante
para cubrir las necesidades que estaban surgiendo fue Java, a través de la tecnología de los
Applets, que son pequeños programas que se incrustan en las páginas web y que pueden
realizar las acciones asociadas a los programas de propósito general. La programación de
Applets fue un gran avance y Netscape, por aquel entonces el navegador más popular, había
roto la primera barrera del HTML al hacer posible la programación dentro de las páginas
web. No cabe duda que la aparición de los Applets supuso un gran avance en la historia
del web, pero no ha sido una tecnología definitiva y muchas otras han seguido
implementando el camino que comenzó con ellos.
Netscape, después de hacer sus navegadores compatibles con los applets, comenzó a
desarrollar un lenguaje de programación al que llamó LiveScript que permitiese crear
pequeños programas en las páginas y que fuese mucho más sencillo de utilizar que Java. De
modo que el primer Javascript se llamo LiveScript, pero no duró mucho ese nombre, pues

Fundamentos tecnológicos
24
antes de lanzar la primera versión del producto se forjó una alianza con Sun Microsystems,
creador de Java, para desarrollar en conjunto ese nuevo lenguaje.
La alianza hizo que Javascript se diseñara como un hermano pequeño de Java,
solamente útil dentro de las páginas web y mucho más fácil de utilizar. Además, para
programar Javascript no es necesario un kit de desarrollo, ni compilar los scripts, ni
realizarlos en ficheros externos al código HTML, como ocurría con los applets. Netscape 2.0
fue el primer navegador que entendía Javascript y su estela fue seguida por los navegadores
de la compañía Microsoft a partir de la versión 3.0.
2.4.2 Sintaxis Javascript
La programación de Javascript se realiza dentro del propio documento HTML. Hay dos
formas de colocar scripts en páginas web:
- Dentro del lenguaje que estamos utilizando:
La etiqueta <SCRIPT> tiene un atributo que sirve para indicar el lenguaje que estamos
utilizando, así como la versión de este. Por ejemplo, podemos indicar que estamos
programando en Javascript 1.2 o Visual Basic Script, que es otro lenguaje para programar
scripts en el navegador cliente que sólo es compatible con Internet Explorer. El atributo
en cuestión es language y lo más habitual es indicar simplemente el lenguaje con el que se
han programado los scripts. El lenguaje por defecto es Javascript, por lo que si no
utilizamos este atributo, el navegador entenderá que el lenguaje con el que se está
programando es Javascript.
<SCRIPT LANGUAGE=javascript>
- Ficheros externos de Javascript:
Otra manera de incluir scripts en páginas web, implementada a partir de Javascript 1.1,
es incluir archivos externos donde se pueden colocar muchas funciones que se utilicen en
la página. Los ficheros suelen tener extensión .js y se incluyen de esta manera.
<SCRIPT language=javascript src="archivo_externo.js">
//estoy incluyendo el fichero "archivo_externo.js"
</SCRIPT>

Fundamentos tecnológicos
25
▪ Separación de instrucciones
Javascript tiene dos maneras de separar instrucciones. La primera es a través del carácter
punto y coma (;) y la segunda es a través de un salto de línea.
▪ Comentarios
Existen dos tipos de comentarios en el lenguaje. Uno de ellos, la doble barra, sirve para
comentar una línea de código. El otro comentario lo podemos utilizar para comentar varias
líneas y se indica con los signos /* para empezar el comentario y */ para terminarlo.
▪ Tipos
En Javascript, al igual que ocurre en otros lenguajes como PHP, la definición de los tipos
de los datos se hace de forma dinámica, es decir, una variable no está limitada a contener el
tipo de dato que se indicó al declarar la variable, sino que puede contener primero un número
y mas tarde pasar a contener una cadena de texto.
Además de los tipos de datos básicos tenemos matrices, funciones y los objetos.
▪ Variables
Los nombres de las variables han de construirse con caracteres alfanuméricos y el
carácter subrayado (_). Aparte de esta, hay una serie de reglas adicionales para construir
nombres para variables. La más importante es que tienen que comenzar por un carácter
alfabético o el subrayado. No podemos utilizar caracteres raros como el signo +, un espacio o
un $. También hay que evitar utilizar nombres reservados como variables, por ejemplo no
podremos llamar a nuestra variable palabras como return o for, que ya veremos que son
utilizadas para estructuras del propio lenguaje.
Javascript se salta muchas reglas por ser un lenguaje un tanto libre a la hora de programar
y uno de los casos en los que otorga un poco de libertad es a la hora de declarar las variables,
ya que no estamos obligados a hacerlo, al contrario de lo que pasa en la mayoría de los
lenguajes de programación. De todos modos, es aconsejable declarar las variables, para ello
Javascript cuenta con la palabra var.

Fundamentos tecnológicos
26
▪ Constantes
Se trata de bloques de datos (cadenas, números) que JavaScript interpreta literalmente.
Las cadenas numéricas se escriben tal cual, mientras que las de cadenas se escriben entre
comillas dobles o sencillas. Por ejemplo: x = 25 a = "Hola, qué tal" .
▪ Operadores
Los operadores más comunes son:
- + adición( o concatenación en el caso de cadenas)
- -substracción
- * multiplicación
- / división
- = igual
- ++ incremento
- -- decremento
- > mayor que
- < menor que
- >= Mayor o igual que
- <= Menor o igual que
- = = igual a (comparar dos valores)
- ¡= distinto de (comparar dos valores)
- && y (une dos comparaciones)
- || o (una u otra comparación)
▪ Sentencias de control
Se pueden usar todas las estructuras típicas de un lenguaje de programación:
- If (<expresión>) {<sentencias>) else {<sentencias>}. Otra forma más esquemática
Variable = (condición) ? valor1 : valor2, . Lo que hace es evaluar la condición
(colocada entre paréntesis) y si es positiva asigna el valor1 a la variable y en caso
contrario le asigna el valor2.
- While (<expresión>){<sentencias>}.

Fundamentos tecnológicos
27
- Do {<sentencias>} while (<expresión>);
- For {<expresion1>,<expresion2>,<expresion3>){<sentencias>}.
- Do {<sentencias>} while (<expresión>);
- For {<expresion1>, <expresion2>, <expresion3>) {<sentencias>}.
- Switch {<expresión>) {case <valor1>:<sentencias> break; case <valor2>:
<sentencias> break;…default:<sentencias>.
▪ Función
Una función se define con la siguiente sintaxis:
function ejemplo($arg_1, $arg_2, . . . ,$arg_n){
document.write("<H1>Función ejemplo</H1>") }
▪ Objetos
Javascript es un lenguaje orientado a objetos, es decir, podrá manejar diferentes objetos,
tales como: la pantalla, la ventana, el documento, las etiquetas, los formularios.
Cada uno de estos objetos tiene una serie de características, a las que llamaremos
propiedades. Además cada objeto podrá realizar toda una serie de cosas, a las que llamaremos
métodos. Para hacer referencia a una propiedad se utiliza la sintaxis:
nombredeobjeto.propiedad y para hacer referencia un método se utiliza la misma sintaxis
aunque suele acabar con una apertura y cierre de paréntesis: nombredeobjeto.metodo().
- Objeto documento(document): Hace referencia a la página que esté visualizando en
ese momento. Algunas de sus propiedades son: bicolor (color del fondo), fgColor
(color del texto), linkColor, alinkColor y vlinkColor (color de los vínculos), location
(la URL del documento), lasModified (última modificación), title(título de la
página), links (enlaces del documento). Algunos de sus métodos son: clear, close,
open, write.
- Objeto cadena (string): La clase String sólo tiene una propiedad: length, que guarda el
número de caracteres del String. Algunos de sus métodos: Para formatear: bold, blink,
big, small, fontcolor, fontsize, italics, strike, sub, sup, toLowerCase, toUpperCase.
Otros: indexOf (contenido en la cadena), charAt(x) (representa el carácter número x de
la cadena).

Fundamentos tecnológicos
28
- Objeto fecha (date): No tiene propiedades y algunos de sus métodos son: getDate (sólo
la fecha), getDay (el día), getMonth, getHours, getMinutes, getSeconds.
- Objeto pantalla: Contiene la información sobre la pantalla que usa el navegador.
Algunas de sus propiedades son: colorDepth (número de bits de colores en uso),
height (altura de la pantalla en pixels), pixelDepth (número de bits por pixel), width
(anchura de la pantalla en pixels).
- Otros objetos:
o Ancla (anchor): contiene una lista de todas las señales (A NAME) de ese
documento. Objetos para formularios: botón (button), casilla de verificación
(checkbox), borrar (reset), enviar (submit), seleccionar (select), password.
o Formularios (forms): contiene una lista de todos los formularios de ese documento.
o Ventana (window): es el de más alto nivel y tiene numerosas propiedades y
métodos para trabajar con él. Algunos de sus métodos son:
open('nombre_página','nombre_ventana','propiedades:width, height, top, left, ...'),
close (para cerrar la ventana), print (para imprimir la ventana), ... Entre sus
propiedades tenemos: defaultStatus (para configurar el mensaje por defecto de la
barra de estado), status (mensajes en la barre de estado), ...
o Localización (location): contiene información sobre la URL de la página en uso en
ese momento.
o Historia (history): contiene una lista de todos los elementos del historial del
navegador. A través de los métodos Back, Forward y Go podremos desplazarnos
por ellos.
o Navegador (navigator): contiene información sobre el navegador que usamos para
ver la página, a través de propiedades como: appName, appVersion, ...
o Matemáticas (math): se trata de un objeto predifinido de JavaScript con numerosas
propiedades y métodos para manejar datos y funciones numéricas.
o Marco (frame): contiene una lista de todos los marcos que se muestran en ese
momento en la pantalla. Permite desplazarse por ellos, abrir nuevos, ...

Fundamentos tecnológicos
29
▪ Eventos
Es la forma de decirle a JavaScript cuándo tiene que llevar a cabo una acción:
- onClick: Se ejecuta cuando se pulsa con el botón izquierdo del ratón.
- onChange: Se ejecuta cuando se modifica el contenido de un input en un formulario.
- onFocus: Se ejecuta cuando se sitúa el cursor de inserción dentro de un elemento de un
formulario.
- onBlur: Se ejecuta cuando se sitúa el cursor de inserción fuera de un elemento de un
formulario.
- onMouseOver: Se ejecuta cuando se pone el puntero del ratón sobre él (sin apretar).
- onMouseOut: Se ejecuta cuando el puntero del ratón nos lo llevamos de una zona
sensible (por ejemplo, un enlace).
- onSelect: Se ejecuta cuando se selecciona un elemento de una lista en un formulario.
- onSubmit: Se ejecuta cuando se hace clic sobre el botón de enviar en un formulario.
- onLoad: Se ejecuta cuando se abre por primera vez una página.
- onUnLoad: Se ejecuta cuando se sale de la página activa.
- HREF:javascript: Se ejecuta cuando se hace clic sobre un enlace, pudiendo poner una
referencia a una función o expresión de javascript .
2.5 HOJAS DE ESTILOS
2.5.1 Introducción
Hojas de Estilo en Cascada (Cascading Style Sheets), es un mecanismo simple que
describe cómo se va a mostrar un documento en la pantalla, o cómo se va a imprimir. Esta
forma de descripción de estilos ofrece a los desarrolladores el control total sobre estilo y
formato de sus documentos.
CSS se utiliza para dar estilo a documentos HTML y XML, separando el contenido de la
presentación. Cualquier cambio en el estilo marcado para un elemento en la CSS afectará a
todas las páginas vinculadas a esa CSS en las que aparezca ese elemento.
CSS funciona a base de reglas, es decir, declaraciones sobre el estilo de uno o más
elementos. Las hojas de estilos están compuestas por una o más de esas reglas aplicadas a un

Fundamentos tecnológicos
30
documento HTML o XML. La regla tiene dos partes: un selector y la declaración. A su vez la
declaración está compuesta por una propiedad y el valor que se le asigne
h1 {color: red;}
- h1 es el selector
- {color: red;} es la declaración
El selector funciona como enlace entre el documento y el estilo, especificando los
elementos que se van a ver afectados por esa declaración. La declaración es la parte de la
regla que establece cuál será el efecto. En el ejemplo anterior, el selector h1 indica que
todos los elementos h1 se verán afectados por la declaración donde se establece que la
propiedad color va a tener el valor red (rojo) para todos los elementos h1 del documento o
documentos que estén vinculados a esa hoja de estilos.
2.5.2 Sintaxis
▪ Inclusión en HTML
Las tres formas más conocidas de dar estilo a un documento son las siguientes:
1. Utilizando una hoja de estilo externa que estará vinculada a un documento a través
del elemento <link>, el cual debe ir situado en la sección <head>.
<LINK REL=”stylesheet” TYPE=”text/css” HREF=”URL_Hoja.css>
2.- Utilizando el elemento <style>, en el interior del documento al que se le quiere dar
estilo, y que generalmente se situaría en la sección <head>. De esta forma los estilos
serán reconocidos antes de que la página se cargue por completo.
<STYLE TYPE=”text/css”>
Etiqueta1, Etiqueta2: {propiedad1:valor}
Etiqueta3: {propiedad1: valor;…; propiedadS: valor}

Fundamentos tecnológicos
31
………
.Clase1: {propiedad1_valor;…;propiedadT:valor}
</STYLE>
3.- Utilizando estilos directamente sobre aquellos elementos que lo permiten a través del
atributo <style> dentro de <body>. Pero este tipo de estilo pierde las ventajas que ofrecen
las hojas de estilo al mezclarse el contenido con la presentación.
<etiqueta style=”propiedad1:valor; … ; propiedadn: valor”>…</etiqueta>
▪ Clases
Una clase es una definición de un estilo que en principio no está asociado a alguna
etiqueta HTML, pero que podemos asociar, en el documento, a etiquetas concretas.
Para ello, en primer lugar definimos la clase (en el bloque de estilos o en la hoja
externa) como un estilo más, de esta forma:
.Nombre_de_la_clase {propiedad1:valor; propiedad2:valor…..;propiedadN:valorN}
Para aplicar el estilo de una clase a una etiqueta concreta, utilizaremos el parámetro
CLASS como sigue:
<etiqueta CLASS=”Nombre_de_la_Clase”> … </etiqueta>
▪ Pseudoclases
Hay ocasiones en las que HTML da a algunas etiquetas un estilo propio: por ejemplo, los
enlaces aparecen por defecto de otro color y subrayados. Estos elementos son las
pseudoclases. Por ahora, sólo están definidas para la etiqueta <A>.
La forma de definir un estilo para una pseudoclase es la siguiente:

Fundamentos tecnológicos
32
etiqueta: pseudoclase {propiedad1:valor;…;propiedadN:valorN}
pseudoclases:
- link: Estilo de un enlace que no ha sido visitado.
- visited: Estilo de un enlace que ha sido visitado.
- active: Estilo de un enlace que está siendo pulsado.
- hover: Estilo de un enlace sobre el que está pasando el ratón.
▪ Atributos
- Aributo "font-family": Es uno de los principales atributos de texto para una página. Por
ejemplo, queremos aplicar una fuente tipo "Verdana" a todo el documento.
Pondríamos:
<STYLE>
BODY{font-family:verdana}
</STYLE>
- Aributos de márgenes y alineación: Se trata de cuatro atributos que intervienen en la
distancia entre la caja y los componentes internos que tiene esa caja, respecto a los
cuatro márgenes: margin-left, margin-right, margin-top, margin-bottom.
<STYLE>
BODY {margin-top: 15px; margin-right; 15px; margin-bottom: 15px;
margin-left:15px}
</STYLE>
padding-top, padding-bottom, padding-right, padding-left: Estos atributos indican la
distancia entre los lados de la caja de texto y los elementos que están en su interior.
Es posible usar las medidas estándar (pulgadas, centímetros, puntos, pixel, etc.)
o valores porcentuales:
- Atributos para los bordes: Se trata de cuatro atributos: border-top, border-bottom,
border-right, border-left; estos atributos definen el estilo y el color de cada elemento

Fundamentos tecnológicos
33
<STYLE>
BODY { border-top: green; border-left: none; border-right: blue;
border-bottom: red }
</STYLE>
Se pueden definir los colores de los cuatro bordes a la vez, como por ejemplo:
<STYLE>
BODY { border-color: red }
</STYLE>
border-style: Define el estilo de los bordes a la vez,
<STYLE>
BODY { border-style: groove }
</STYLE>
- Aributo font-size: Este atributo establece el tamaño del texto. Mientras el HTML es
estándar prevé tan sólo 7 niveles predefinidos para el tamaño del texto (de font size=1
a font size=7), las hojas de estilo permiten un control mucho más preciso y elástico,
sin limitaciones.
Este atributo indica el estilo para la fuente. Es posible aplicar distintos valores:
<STYLE>
BODY { font-style:normal }
</STYLE>
- Atributo font-variant: Asigna un estilo todo en mayúsculas. Si no está disponible en el
ordenador del usuario, el estilo usará las mayúsculas adaptándose a las medidas. Los
valores que hay que asignar son "normal" y "small-caps"
<STYLE>
BODY { font-variant: small-caps }
</STYLE>

Fundamentos tecnológicos
34
- Atributo font-weight: El atributo font-weight establece el grosor de las fuentes como
“BOLD". Es posible asignar a este atributo valores diferentes: bold, extra-light, demi-
light, medium, extra-bold, etc
<STYLE>
BODY { font-weight: bold }
</STYLE>
- Atributo text-decoration: Permite decorar el texto con subrayados y otros efectos.
Puede tener varios valores: none, underline, italic y line-height, etc
<STYLE>
BODY { text-decoration: none }
</STYLE>
- Atributo color: El atributo color define el color del texto del documento (no se debe
confundir con el color de background) tanto mediante los nombres de los colores en
inglés: black, silver, gray, white, red, blue, etc) y con los códigos hexadecimales.
- Atributo background-color , background-imagen: Este atributo de background-color
determina el color de fondo, el atributo background-image, tiene una función similar
al background="imagen.gif" de HTML clásico, invocando una imágen en formato GIF
o JPG cargada en la css.

Fundamentos tecnológicos
35
2.6 EJEMPLOS DE EJECUCIÓN
2.6.1 PHP
Lo que se muestra a continuación es parte del código de la clase CMySQL, clase que
utilizamos para el acceso a la base de datos.
<?
class CMySQL {
//variables de conexión
var $BaseDatos;
var $Servidor;
var $Usuario;
var $Clave;
//identificador de conexión y consulta
var $Conexion_ID = 0;
var $Consulta_ID = 0;
//número de error y texto error
var $Errno = 0;
var $Error = "";
/*Método Constructor: Cada vez que creemos una variable
de esta clase, se ejecutará esta función*/
function CMySQL($bd = "", $host = "localhost", $user = "nobody", $pass = "") {
$this->BaseDatos = $bd;
$this->Servidor = $host;
$this->Usuario = $user;
$this->Clave = $pass;

Fundamentos tecnológicos
36
}
/*Conexión a la base de datos*/
function Conectar($bd, $host, $user, $pass){
if ($bd != "") $this->BaseDatos = $bd;
if ($host != "") $this->Servidor = $host;
if ($user != "") $this->Usuario = $user;
if ($pass != "") $this->Clave = $pass;
//Conectamos al servidor
$this->Conexion_ID = mysql_connect ($this->Servidor, $this->Usuario,
$this->Clave);
if (!$this->Conexion_ID) {
$this->Error = "Ha fallado la conexión.";
return 0;
}
//seleccionamos la base de datos
if (!@mysql_select_db($this->BaseDatos, $this->Conexion_ID)) {
$this->Error = "Imposible abrir ".$this->BaseDatos ;
return 0;
}
//Si hemos tenido éxito en la consulta devuelve
//el identificador de la conexión, sino devuelve 0
return $this->Conexion_ID;
}
/* Ejecuta un consulta */
function Consulta($sql = ""){

Fundamentos tecnológicos
37
if ($sql == "") {
$this->Error = "No ha especificado una consulta SQL";
return 0;
}
//ejecutamos la consulta
$this->Consulta_ID = @mysql_query($sql, $this->Conexion_ID);
if (!$this->Consulta_ID) {
$this->Errno = mysql_errno();
$this->Error = mysql_error();
}
//Si hemos tenido éxito en la consulta devuelve
//el identificador de la conexión, sino devuelve 0
return $this->Consulta_ID;
}
/*Devuelve el número de campos de una consulta*/
function NumCampos() {
return mysql_num_fields($this->Consulta_ID);
}
/* Devuelve el número de registros de una consulta*/
function NumRegistros(){
return mysql_num_rows($this->Consulta_ID);
}
/*Libera resultados a consultas anteriores*/
function LiberaResultado() {

Fundamentos tecnológicos
38
mysql_free_result($this->Consulta_ID);
}
/*Cierra sesiones de conexión*/
function Cerrar() {
mysql_free_result($this->Consulta_ID);
mysql_close($this->Conexion_ID);
}
/*Devuelve el primer registro del objeto consulta*/
function PrimerRegistro() {
$registro = mysql_fetch_object($this->Consulta_ID);
return $registro;
}
/*Devuelve el ultimo registro del objeto consulta*/
function UltimoRegistro() {
while ($registro = mysql_fetch_object($this->Consulta_ID) ) {
}
return $registro;
}
/*Recorre resultados de una consulta*/
function Mover() {
return mysql_fetch_object($this->Consulta_ID);
}
/*Esta función comienza una transaccion en MySQL*/
function Iniciar_Transaccion() {
mysql_query("BEGIN", $this->Conexion_ID);

Fundamentos tecnológicos
39
}
/*Esta función termina la transaccion con éxito*/
function Commitar() {
mysql_query("COMMIT", $this->Conexion_ID);
}
/*Esta función acaba la transacción como si no hubiera cambios*/
function RollBack() {
mysql_query("ROLLBACK", $this->Conexion_ID);
}
}
?>
2.6.2 JAVASCRIPT
▪ Función que comprueba si una cadena es un dni válido:
function tipoDNI(nif){
letras = new Array();
letras[0] = "T", letras[1] = "R", letras[2] = "W", letras[3] = "A", letras[4] = "G",
letras[5] = "M", letras[6] = "Y", letras[7] = "F", letras[8] = "P", letras[9] = "D",
letras[10] = "X", letras[11] = "B", letras[12] = "N", letras[13] = "J", letras[14] = "Z",
letras[15] = "S", letras[16] = "Q", letras[17] = "V", letras[18] = "H", letras[19] = "L",
letras[20] = "C", letras[21] = "K", letras[22] = "E";
txtError = "";
ok = true;
dni=nif.substring(0,nif.length-1);

Fundamentos tecnológicos
40
dni=parseInt(dni);
letra=nif.charAt(9);
letraCorrecta = letras[ dni % 23];
if (dni > 99999999){ //si tienes mas de 8 cifras
ok = false;
} else if(letra!=letraCorrecta) {//si la letra es correcta
ok = false;
}
return !ok;
}
▪ Función que comprueba si una cadena es un número entero.
function tipoInteger(oTxt){
var checkOK = "0123456789";
var checkStr = oTxt;
var allValid = true;
var decPoints = 0;
var allNum = "";
for (i = 0; i < checkStr.length; i++) {
ch = checkStr.charAt(i);
for (j = 0; j < checkOK.length; j++)
if (ch == checkOK.charAt(j))
break;
if (j == checkOK.length) {
allValid = false;

Fundamentos tecnológicos
41
break;
}
allNum += ch;
}
if (!allValid) {
allValid=false;
}
return !allValid;
}
▪ Función que carga la pantalla principal.
function cargarPrincipal(){
if (top.location != self.location)top.location = self.location;
parent.location.href="index.php";
}
▪ Función que comprueba si los datos usuario y password son correctos.
function comprobarValores(error,usuario,password,obligatorio){
error1=false;
error2=false;
mensaje=”Error en:”+"\n";
if(document.form_presentacion.login.value.length==0){
mensaje=mensaje+"- Usuario obligatorio \n";
document.form_presentacion.login.focus()
error1=true;

Fundamentos tecnológicos
42
}
if(document.form_presentacion.pass.value.length==0){
mensaje=mensaje+- Password obligatorio \n”;
error2=true;
if (!error1){
document.form_presentacion.pass.focus()
}
}
if ((!error1)&&(!error2)){ //Datos correctos
document.form_presentacion.submit();
return true;
}else{ //Error->Mostrar error
alert(mensaje);
return false;
}
}
2.6.3 CSS
▪ Estilo para el texto:
.texto_oscuro {
font-family: Arial, Helvetica, sans-serif;
font-size: 12px;
font-weight: bold;
color: #005075;
}
.texto_claro {
font-family: Arial, Helvetica, sans-serif;

Fundamentos tecnológicos
43
font-size: 11px;
font-weight: bold;
color: #E6ECEB;
}
▪ Estilo para los input:
input {
font-family: Arial, Helvetica, sans-serif;
font-size: 12px;
}
▪ Estilo para los hipervínculos visitados y no visitados:
A:link, A:visited {
font-family: Arial, Helvetica, sans-serif;
font-size: 12px;
font-weight: bold;
color: #E6ECEB;
text-decoration: none;
}
▪ Estilo para los hipervínculos cuando se pasa el ratón por encima:
A:hover{
font-family: Arial, Helvetica, sans-serif;
font-size: 13px;
font-weight: bold;

Fundamentos tecnológicos
44
color: #E6ECEB;
text-decoration: none;
}
▪ Estilos para el color de las capas:
.capa_oscura{
background-color:#006d95;
}
.capa_clara{
background-color:#4892b5;
}
▪ Estilos para las tablas:
TABLE { border-style: hidden }
td{ padding:0px 0px 0px 2px;}

Análisis
45
CAPÍTULO 3:
ANÁLISIS: LENGUAJE DE
MODELAMIENTO UNIFICADO (UML) 3.1 Introducción
3.2 Casos de usos
3.3 Diagramas de clases
3.4 Diagramas de interacción
3.5 Diagramas de transición de estados

Análisis
46
3.1 INTRODUCCIÓN
En este capítulo se detallará la fase de análisis de la aplicación por medio de UML
(Lenguaje unificado de modelado).
UML es un lenguaje que permite modelar, construir y documentar los elementos que
forman un sistema software, para lo que cuenta con varios tipos de diagramas, los cuales
muestran diferentes aspectos de las entidades representadas.
Sus objetivos principales son los siguientes:
� Expresan de una forma gráfica un sistema de manera que otro lo puede entender.
� Especifica cuáles son las características de un sistema antes de su construcción.
� Construir a partir de los modelos especificados los sistemas diseñados.
� Los propios elementos gráficos forman parte de la documentación del sistema para su
mantenimiento.
3.2 CASOS DE USO
3.2.1 Descripción de la técnica
A continuación se realiza una breve explicación de los casos de uso, para mayor
información ver anexo al final de la memoria.
Un diagrama de casos de uso es un grafo constituido por actores, casos de uso y
relaciones que se establecen entre ellos. Cada diagrama constituye un escenario, donde se
describen los distintos requisitos funcionales del sistema.
Los elementos que constituyen un diagrama de casos de uso son los siguientes:
� Actores: Usuarios del sistema u otros sistemas externos.
� Casos de uso: Representa un requisito funcional del sistema.
� Escenarios: Diferentes caminos que pueden darse en un caso de uso.
� Paquetes: Los paquetes se emplean en los diagramas de casos de uso para la
organización de éstos.
� Relaciones: Existen distintos tipos de relaciones entre los elementos anteriores:
- Actor-Actor: La relación que pueden mantener dos actores es la relación de
generalización. En esta relación el actor hijo hereda el comportamiento de un

Análisis
47
actor padre, además de poder definir los atributos propios que los diferencia de
los demás.
- Actor-Caso de uso: La relación que puede tener un actor con un caso de uso
es una relación de comunicación, está puede tener una o dos direcciones.
- Casos de uso-Caso de uso: Las relaciones que se pueden dar entre los casos
de uso son tres, generalización/especificación, inclusión y extensión.
1. Generalización / Especificación: Un caso de uso hijo hereda el
comportamiento y el significado de otro caso de uso padre. El caso de
uso hijo puede añadir información el comportamiento o bien
redefinirlo.
2. Inclusión: La inclusión se presenta cuando existe un comportamiento
común entre varios casos de uso. <<include>>
3. Extensión: Representa un comportamiento opcional de un caso de uso.
<<extend>>

Análisis
48
3.2.2 Diagramas de casos de uso del proyecto
A continuación se muestran los diferentes diagramas de casos de uso generados durante el
proceso de análisis del proyecto.
Figura 3.1 Diagrama Principal de los Casos de Uso
Como se puede observar en el diagrama principal de los casos de uso, intervienen dos
actores: administrador y usuario. Cada actor podrá acceder a un conjunto de acciones
distintas, dichas acciones se han agrupado en paquetes para su mejor compresión. De esta
forma las acciones que puede realizar el actor Administrador se encuentran en el paquete
Administración y las acciones que puede realizar el actor Usuario se encuentran en el paquete
Gestión de Pacientes.
El actor usuario puede tener dos tipos de permisos:
� Permiso de lectura. Podrán acceder al paquete Gestión de pacientes pero no podrán
acceder a los casos de usos que realicen inserción, modificación o eliminación en la
base de datos.
� Permiso de escritura. Los usuarios con este tipo de permiso podrán acceder a todos los
casos de usos del paquete Gestión de pacientes.
A continuación se desarrollarán los distintos paquetes.

Análisis
49
Figura 3.2 Diagrama de Casos de Uso del paquete Administración
Este diagrama representa las acciones que puede realizar el administrador. Las
operaciones principales son:
� Gestión de usuarios: En esta zona el administrador podrá dar de alta, editar o dar de
baja a los usuarios de la aplicación.
� Gestión de la base de datos: En esta zona el administrador podrá dar de alta, editar o
dar de baja registros en determinadas tablas de la base de datos.
� Carga de tratamientos por medio de un archivo XML: En esta zona el administrador
podrá añadir mediante la carga de un archivo de formato XML tratamientos recogidos
desde el diario de episodio/tratamientos de AMH.

Análisis
50
Figura 3.3 Diagrama de Casos de Uso del paquete Gestión de pacientes
En este diagrama se muestran las distintas operaciones que se pueden realizar desde la
pantalla principal del usuario, desde aquí se podrá acceder a cualquier información del
paciente, así como realizar informes y estadísticas.
A continuación se desarrollarán cada uno de los paquetes en los que se divide este
diagrama.

Análisis
51
Figura 3.4 Diagrama de Casos de Uso del paquete General
Cuando se selecciona un paciente determinado se mostrará la información general de
dicho paciente, esta información es un resumen de todos los datos que se encuentran
almacenados, de esta forma el usuario podrá obtener una visión global de la situación del
paciente. Dentro de esta información se encuentran el listado de la profilaxis y de los porta-a-
cath.
Figura 3.5 Diagrama de Casos de Uso del paquete Tratamientos

Análisis
52
La acción principal de este paquete es mostrar todos los tratamientos de un determinado
paciente, que se encuentran almacenados en la base de datos. A partir de ahí se podrán
realizar las operaciones que muestra el diagrama.
Los paquetes análisis, articulaciones, cuestionarios e inmunotolerancias no se han
desarrollado. Son muy similares al paquete tratamientos, con la única diferencia que en estos
paquetes no se encuentra el caso de uso Añadir Concentrado/Dosis.
Figura 3.6 Diagrama de Casos de Uso del paquete Inhibidores
Figura 3.7 Diagrama de Casos de Uso del paquete Informes
Existen dos casos de uso más: Ayuda y Salir. A estos casos de uso se puede acceder desde
cualquier otro.

Análisis
53
3.3 DIAGRAMAS DE CLASES
3.3.1 Descripción de la técnica
Igual que en el apartado anterior, se realiza una explicación breve de los diagramas de
clases, para mayor información ver anexo al final de la memoria.
El objetivo principal de los diagramas de clases es la representación de los aspectos
estáticos del sistema, utilizando para ello diversos mecanismos de abstracción como son la
clasificación, generalización y agregación. Los diagramas de clases identifican las clases,
relaciones, atributos y operaciones que se utilizarán en el sistema de información. Debido a su
carácter estático es mucho más fácil de entender que los modelos dinámicos. El diagrama de
clases está compuesto por varios tipos de componentes que se describen a continuación.
� Clases: Las clases agrupan o abstraen objetos con atributos, relaciones y operaciones
comunes y con la misma semántica y comportamiento.
� Objetos: Un objeto de una clase es la instancia de esa clase.
� Atributos: Propiedad de una clase compartida por todos sus objetos.
� Operaciones: Representan el comportamiento de los objetos de una clase.
La visibilidad tanto de los atributos como de las operaciones se descompone en tres
tipos:
+ público
- privado
# protegido
� Relaciones: Las relaciones son las conexiones que pueden tener los distintos
elementos.
Existen varios tipos de relaciones:
- Asociación: La asociación es una relación estructural que especifica que los
objetos de un elemento están conectados con los objetos de otro.
Multiplicidad:
Cero a 1. 0..1
Muchos. 0..n ó 0..n
Uno o más. 1..n ó 1..*
Número exacto. 7
Combinaciones. 0..1, 3..4, 6..*

Análisis
54
- Agregación: La agregación es un caso particular de la asociación, parte de la
relación jerárquica entre un objeto que representa la totalidad de ese objeto y
las partes que lo componen.
- Dependencia: La relación de dependencia representa que una clase requiere de
otra para proporcionar alguno de sus servicios.
- Generalización o herencia: Es el mecanismo que permite a una clase de
objetos añadir atributos y métodos de otra clase, incorporándolos a los que ya
tiene.
- Paquete: Los paquetes se usan para dividir el modelo de clases del sistema de
información agrupando clases u otros paquetes.
3.3.2 Diagramas de clases del proyecto
La implementación de la aplicación Web no ha seguido una estructura de programación
orientada a objetos. Se establece una clase de acceso a la BD MySQL para gestionar los datos,
siendo esta la única clase propiamente dicha de la aplicación. PHP dispone de funcionalidad
para trabajar con clases desde su versión 3, pero ya que la Programación Orientada a Objetos,
a parte de las clases, se basa en otros conceptos como la herencia, interfaces, polimorfismo,
etc., las cuales no se implementan en la versión que hemos utilizado durante el desarrollo de
la aplicación, proponemos este diseño en diagrama de clases como trabajo futuro de
refactoriación de código.
Figura 3.8 Diagramas de clases principal

Análisis
55
Los diagramas de clases están distribuidos en tres carpetas principales:
� Dominio del problema: Reconoce el problema y determina las necesidades y
objetivos.
� Interfaz de usuario: Comprende todos los puntos de contacto entre el usuario y la
aplicación.
� Gestión de datos: Desarrollo y ejecución de arquitecturas, políticas, prácticas y
procedimientos que gestionan apropiadamente las necesidades del ciclo de vida
completo de los datos.

Análisis
56
Figura 3.9 Dominio del problema

Análisis
57
Figura 3.10 Dominio del problema (continuación)

Análisis
58
Las clases del dominio del problema no contienen todos sus atributos, se han omitido por
una mayor claridad en el diagrama.
La gestión de datos no se muestra en este apartado, ya que el capítulo siguiente esta
dedicado exclusivamente a ello.
� Interfaz de usuario
Figura 3.11 Diagrama principal de clases del Interfaz de Usuario.
La ventana de control de usuario aparece cuando se inicia la aplicación, a partir de ella
podremos acceder a la aplicación dependiendo si nos encontramos registrados o no en el
sistema. Los usuarios registrados se encuentran en la tabla Usuarios de la base de datos, cada
usuario contiene una password para entrar en el sistema, dicha password está encriptada para
mayor seguridad.
El diagrama principal del interfaz de usuario está dividido en dos paquetes:
Administración si accedemos como administrador y Gestión de pacientes si accedemos como
usuario. A continuación se desarrollarán cada uno de ellos.
Todas las clases utilizan la tabla Etiquetas, pero se ha omitido para una mayor claridad en
los diagramas.

Análisis
59
- Paquete administración
Figura 3.12 Diagrama de clases del paquete Administración
Este diagrama contiene las distintas operaciones que puede realizar un usuario de tipo
administrador. Esta parte de la aplicación se divide en tres pestañas: Usuarios, Sistema y
Tratamientos.

Análisis
60
Figura 3.13 Diagrama de clases del paquete Pestaña Sistema

Análisis
61
En este paquete se controlan todos los registros el sistema. Los registros de análisis y
cuestionario pueden activar o desactivarse, de esta forma en la interfaz se mostrará solo los
registros que están activos en ese momento.
- Paquete listado tratamientos de la AMH
Figura 3.14 Diagrama de clases del paquete Tratamientos de la AMH
El objetivo de este paquete es automatizar la carga de tratamientos de pacientes obtenidos
del diario episodios/tratamientos proporcionado por la Asociación Malagueña de Hemofilia
(AMH). Estos tratamientos se proporcionan en un archivo con formato XML para facilitar su
carga, y que permanece encriptado para salvaguardar la privacidad de los datos.

Análisis
62
- Paquete gestión de pacientes
Figura 3.15 Diagrama de clases del paquete Gestión de Pacientes

Análisis
63
Cuando entramos como usuario al sistema, se muestra la ventana principal de la Gestión
de Pacientes. A partir de aquí el usuario controla todos los datos de los pacientes. La
información de los pacientes está dividida en pestañas. La ventana que se muestra
inicialmente es la pestaña General.
Figura 3.16 Diagrama de clases del paquete Buscar Paciente
La búsqueda de pacientes se realiza por los datos principales del paciente. Una vez
introducido los datos de búsqueda y pulsado el botón buscar, aparecerá un listado de los
pacientes que cumple el criterio de búsqueda. Cada paciente aparecerá acompañado de un
botón que al pulsarlo cargará los datos de dicho paciente.

Análisis
64
Figura 3.17 Diagrama de clases del paquete Estadísticas
Mediante está opción, el usuario obtiene distintos listados de pacientes, filtrando los
resultados mediante unos criterios determinados.

Análisis
65
Figura 3.18 Diagrama de clase del paquete Profilaxis
Este paquete gestiona las profilaxis de los pacientes, llevando a cabo las operaciones
básicas: alta, baja y modificación.

Análisis
66
Figura 3.19 Diagrama de clases del paquete Tratamientos
El paquete tratamiento además de gestionar las operaciones básicas de alta, eliminación y
modificación, gestiona el seguimiento de cada tratamiento. Este seguimiento se realiza a
través de la clase “Añadir Concentrado/Dosis“, de esta forma queda por un lado la gestión del
tratamiento y por el otro la gestión del conjunto de “Concentrados/Dosis” aconsejado para
cada tratamiento.
Los paquetes análisis, articulaciones, cuestionarios e inmunotolerancias no se han
desarrollado. Presentan el mismo diagrama que el paquete tratamientos.

Análisis
67
Figura 3.20 Diagrama de clases del paquete Inhibidores
Su funcionalidad es parecida a la del paquete de tratamientos, interviniendo otras
entidades. El seguimiento de cada inhibidor, se realiza a través de la clase “Historial
Inhibidor”.

Análisis
68
Figura 3.21 Diagrama de clases del paquete Informes
Hay tres tipos de informes: informe de actividades, informes de viaje e informe de
minusvalía. Estos informes tienen un formato fijo, es decir, la estructura y el texto están
predeterminados.

Análisis
69
3.4 DIAGRAMAS DE INTERACCION
3.4.1 Descripción de la técnica
El objetivo de esta técnica es la descripción del comportamiento dinámico del sistema
mediante el intercambio de mensajes entre objetos del mismo. Representa un medio para
verificar la corrección del sistema mediante la validación con el modelo de clases. Cada
diagrama de interacción describe en detalle un determinado escenario de un caso de uso,
mostrando la interacción entre el conjunto de objetos que cooperan en la realización de dicho
escenario.
Los elementos que componen los diagramas de interacción son los siguientes:
- Objetos: Instancias de una determinada clase o de un actor.
- Mensajes: Es una comunicación entre dos objetos. El envío de un mensaje por parte
de un objeto (emisor) a otro (receptor) puede provocar que se ejecute una operación,
salte un evento o se cree o destruya un objeto.
Existen dos tipos de diagramas de interacción: diagramas de secuencia y diagramas de
colaboración, ambos tratan la misma información, pero cado uno enfatiza en aspectos
particulares de la forma de mostrarla. A continuación hacemos una pequeña descripción de
los diagramas de secuencia.
▪ Diagramas de Secuencia:
Muestran el comportamiento del sistema en términos de la secuencia de mensajes
intercambiados. Pone un mayor énfasis en la ordenación de los mensajes intercambiados por
los objetos. Lo que realmente interesa es el orden de producción de los mensajes. Tiene dos
dimensiones, el eje vertical representa el tiempo y el eje horizontal los diferentes objetos. El
tiempo avanza desde la parte superior del diagrama hacia la arte inferior.
Cada objeto tiene asociado una línea de vida y varios focos de control.
Los elementos que componen los diagramas de secuencia son los siguientes:
- Evento: Es un estímulo individual que llega a un objeto procedente de otro. Estos
eventos pueden tener parámetros, se trasladan en un solo sentido y la respuesta ha de
hacerse con otro evento.

Análisis
70
- Escenario: Secuencia de eventos que se produce durante una ejecución concreta de un
sistema.
- Objeto: Un objeto se representa por una línea vertical discontinua, llamada línea
de la vida.
- Línea de vida de un objeto: Período de tiempo en que existe el objeto. Si el objeto es
destruido durante la interacción que muestra el diagrama, la línea de vida termina en
ese punto, si no es eliminado en el tiempo que dura la interacción, su línea de vida se
prolonga hasta la parte inferior del diagrama.
- Foco de control: Muestra el período de tiempo en el cual el objeto se encuentra
ejecutando alguna operación, ya sea directamente o mediante un procedimiento
concurrente. Se representa como un rectángulo delgado superpuesto a la línea de vida
del objeto, la longitud de éste dependerá de la duración de la acción. La parte superior
del rectángulo indica el inicio de una acción ejecutada por el objeto y la parte inferior
su finalización.
- Mensaje: Se representa como una flecha horizontal entre las líneas de vida de los
objetos que intercambian los mensajes. La flecha tiene asociada una etiqueta con el
nombre del mensaje y los argumentos entre paréntesis. Los mensajes pueden ser
etiquetados con un número de secuencia. Un objeto puede mandarse un mensaje a sí
mismo. Hay que destacar que los mensajes pueden presentar condiciones e iteraciones.
Una condición se representa mediante una expresión booleana encerrada entre
corchetes junto a un mensaje, este mensaje solo será enviado en el caso que se cumpla
la condición booleana. Las iteraciones se representan con un asterisco y una expresión
entre corchetes, que indican el número de veces que se produce.

Análisis
71
3.4.2 Diagramas de secuencia del proyecto
A continuación se mostrarán algunos de los diagramas de secuencia del proyecto.
El caso normal es cuando todo es correcto y el caso excepción es cuando se ha producido
un error, en este caso se muestra un mensaje.
Figura 3.22 Diagrama de secuencia de Nuevo Análisis (caso normal)
En este diagrama, se puede observar como interactúa el usuario con en la interfaz de la
aplicación, para insertar un nuevo análisis en la base de datos. El funcionamiento es similar
para todas las operaciones de inserción. Primero se obtienen los datos de las entidades, para
mostrar el formulario que crea un nuevo registro. Una vez introducidos los datos en dicho
formulario, pulsar el botón guardar. Antes de insertar el nuevo registro en la base de datos, se
comprueba si todo es correcto.

Análisis
72
Figura 3.23 Diagrama de secuencia de Nuevo Análisis (caso excepción)
Este diagrama representa la secuencia cuando la comprobación de los datos no es
correcta. Mostrará un mensaje con los datos incorrectos.

Análisis
73
Figura 3.24 Diagrama de secuencia de Modificar Análisis (caso normal)
Este diagrama muestra la secuencia de operaciones que se realiza al modificar un
análisis. El funcionamiento es similar para todas las operaciones de modificación. Una vez
modificados los datos deseados, pulsar el botón guardar, a continuación se realizará la
comprobación de los datos.

Análisis
74
Figura 3.25 Diagrama de secuencia de Modificar Análisis (caso excepción)
Este diagrama muestra la secuencia cuando la comprobación de los datos no es correcta.

Análisis
75
Figura 3.26 Diagrama de secuencia de Eliminar Análisis (caso normal)
Cuando se pulsa el botón eliminar análisis, se mostrará un mensaje de confirmación. Este
diagrama, representa el comportamiento de la aplicación en el caso de que se confirme la
eliminación.
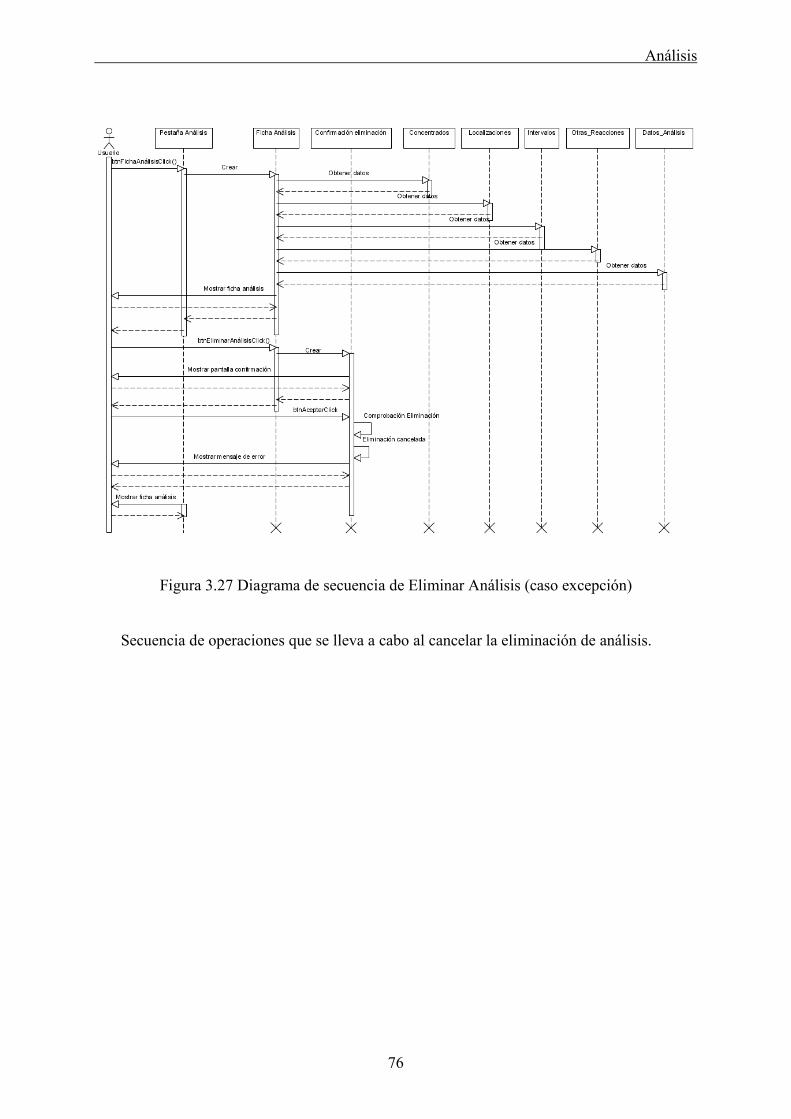
Análisis
76
Figura 3.27 Diagrama de secuencia de Eliminar Análisis (caso excepción)
Secuencia de operaciones que se lleva a cabo al cancelar la eliminación de análisis.

Análisis
77
3.5 DIAGRAMAS DE TRANSICION DE ESTADOS
3.5.1 Descripción de la técnica
El objetivo de estos diagramas es representar cambios de estado, es decir, mostrar los
diferentes estados que atraviesa un objeto debido su flujo de ejecución, indicando los eventos
que implican la transición de un estado a otro. Gráficamente los diagramas de estados se
representan con un grafo dirigido en el que sus nodos representan estados del elemento
descrito y sus arcos son transiciones, etiquetadas con nombres de eventos, entre dichos
estados.
Los elementos que componen los diagramas de transición de estados son los siguientes:
� Estados: Es una situación en la vida de un objeto en la que este satisface alguna
condición, realiza alguna acción y/o espera algún evento. Las condiciones que puede
cumplir un estado suele establecerse en valores de atributos y enlaces. Se caracteriza
por el valor de uno o varios atributos que lo definen en un momento dado.
Existen dos tipos de estados especiales que son:
- Estado Inicial: Marca el inicio de la vida del sistema u objeto especificado en el
diagrama. A lo sumo puede haber uno en cada diagrama de estados. A un estado
inicial no puede llegar ninguna transición.
- Estado Final: No hay estados posteriores a él, no hay ninguna transición que parta
de él y marca el fin de la vida del objeto especificado.
� Operación: Se define como la especificación de una sentencia ejecutable que
constituye una abstracción de un procedimiento. Las operaciones tienen acceso a los
parámetros del evento que dispara la acción, a las variables de estado y a otros
atributos del objeto. Las operaciones se expresan de la siguiente forma:
Etiqueta de operación/Expresión de operación
La expresión de la operación puede contener argumentos. La etiqueta de operación s
emplea para caracterizar el tipo de operación y el momento en que se ejecuta.
Tipos de operaciones:

Análisis
78
- Actividad: Es una operación con duración, que se ejecuta mientras que el
elemento permanece en el estado o hasta que termina el cómputo de la operación.
Una actividad puede ser interrumpida por una transición de salida del evento. La
etiqueta de operación correspondiente a las actividades es do.
- Acción: Se considera como una operación que constituye un bloque que no puede
ser interrumpido. Dentro de las acciones, se consideran varios subtipos.
� Acciones de entrada: Se ejecutan al entrar al estado al que están
asociadas. Se representan anteponiéndoles la etiqueta de operación entry.
� Acciones de salida: Se ejecutan al salir del estado al que están asociadas.
La etiqueta de la operación correspondiente es exit.
� Acciones internas: Están asociadas a las llamadas transiciones internas y
no producen un cambio de estado por el evento dado. Opcionalmente
pueden estar controladas por una condición de guarda. Cuando se produce
una transición interna no se ejecutan las acciones de entradas y de salida
del estado, ya que ni se sale ni se entra en él. Su representación es la
siguiente:
eventoInterno (argumento) [guarda/acciónInterna(argumentos)
Un mismo evento puede disparar varias acciones internas en el mismo
estado siempre que las condiciones de guarda sean excluyentes.
� Envío de eventos: Consiste en el envío de un evento a otro objeto. Los
envíos de eventos pueden realizarse a la entrada de un estado, a la
salida, o asociados a una transición de cualquier tipo. Se representan
mediante la siguiente expresión de operación.
send objetoDestino.evento (argumentos)
^objetoDestino.evento (argumentos)
Observaciones: Según la semántica de los diagramas de estados de UML,
un estado puede tener varias acciones internas y, a lo sumo, una actividad,
una acción de entrada y una acción de salida.
� Evento: Es un acontecimiento significativo y que puede constituir un estímulo que
dispare una transición de estados. Los eventos son sucesos atómicos que no pueden ser
interrumpidos. Los eventos sólo tienen un sentido, la respuesta es otro evento.

Análisis
79
� Transición: Es una relación entre dos estados que indica que si el elemento descrito en
el diagrama se encuentra en el primero de ellos y se produce un evento dado, el
elemento pasará al segundo estado. Las transiciones pueden tener acciones asociadas,
que se ejecutan durante el cambio de estado. Se representa gráficamente con una
flecha que parte del estado origen y finaliza en el de destino.
Transiciones con características especiales:
- Transición reflexiva: Transición que nos lleva al mismo estado.
- Transición automática: Transición que no tiene ningún evento asociado. Se
dispara al finalizar la actividad del estado que la origina. Si el estado no tiene
actividad, se dispara tras ejecutar las acciones de entrada y de salida.
Puede tener asociada una guarda, en cuyo caso la transición se dispara al
finalizar la actividad del estado si se verifica la condición de guarda.
� Acción: Es una operación atómica ejecutable por el elemento descrito en el diagrama.

Análisis
80
3.5.2 Diagramas de transición de estados del proyecto
A continuación se mostrarán algunos de los diagramas de estados del proyecto.
Figura 3.28 Diagrama de estado de Ficha Tratamiento
En la opción Ficha Tratamiento se muestra los datos del tratamiento seleccionado. A
partir de aquí, se podrá realizar las distintas operaciones que indica el diagrama.
Figura 3.29 Diagrama de estado de Nuevo Tratamiento

Análisis
81
Cuando se está realizando la operación de Nuevo Tratamiento, cualquier evento que no
sea el de btnGuardarClick o btnListadoTratamientoClick, produce un error. Esto ocurre
cuando se inserta cualquier registro a la base de datos.
Antes de añadir un nuevo registro a la base de datos, se comprueba si los datos son
correctos, en el caso de que no lo sean, se muestra un mensaje informando los campos
incorrectos.
Figura 3.30 Diagrama de estado de Modificar Tratamiento
Al pulsar la opción de Modificar Tratamiento, la primera acción que se realiza, es la de
editar los datos del tratamiento seleccionado. Una vez modificados los datos, al pulsar el
botón guardar, se comprobará si los datos son correctos, en el caso de que no lo sea se
mostrará un mensaje informando los campos incorrectos.

Análisis
82
Figura 3.31 Diagrama de estado de Eliminar Tratamiento
Antes de eliminar un tratamiento o cualquier registro de la base de datos, se muestra un
mensaje de confirmación. Si se confirma la acción, se comprueba si el registro puede ser
eliminado (consistencia de datos). En el caso de que el registro sea referenciado por otra tabla,
se muestra un mensaje de error.

Modelo Entidad-Relación en MySQL
83
CAPÍTULO 4:
DISEÑO: MODELO E/R EN MYSQL 4.1 Introducción
4.2 Modelo entidad relación
4.3 Acceso a la Base de Datos

Modelo Entidad-Relación en MySQL
84
4.1 INTRODUCCIÓN
En este capítulo exponemos la estructura de los datos o Modelo de Datos desarrollado, así
como la implementación del Modelo Relacional en el Sistema Gestor de Base de Datos
MySQL. También veremos la forma como PHP interactúa con la base de datos, junto a otras
características, como la integridad referencial o el uso de transacciones.
4.2 MODELO ENTIDAD-RELACION
En este punto vamos a desarrollar el modelo entidad-relación de la información que
vamos a almacenar en la base de datos. A partir del mismo implementaremos la base de datos
relacional en el SGBD MySQL. A continuación definimos formalmente los elementos que
comprenden el modelo.
4.2.1 Conceptos modelo entidad-relación
� Entidades. Se puede definir como entidad a cualquier objeto, real o abstracto, que existe
en un contexto determinado o puede llegar a existir y del cual deseamos guardar
información. Las entidades las podemos clasificar en entidades fuertes, son aquellas que no
necesitan de atributos de otras entidades para que existan ejemplares de ella, mientras que
las entidades débiles están definidas con atributos de otras tablas y sí los necesitan.
� Atributos. Las entidades se componen de atributos que son cada una de las propiedades
que lo caracterizan. Cada ejemplar de una misma entidad posee los mismos atributos, tanto
en nombre como en número, diferenciándose cada uno de los ejemplares por los valores
que toman dichos atributos. Existen distintos tipos, obligatorios, opcionales,
monoevaluados y multievaluados.
� Ejemplar. Si estuviéramos hablando de Clases, la entidad sería una clase y cada ejemplar
sería una instancia de esa clase. En nuestra base de datos, cada ejemplar se identificará con
una entrada de una tabla de la base de datos.

Modelo Entidad-Relación en MySQL
85
� Dominio. Se define dominio como un conjunto de valores que puede tomar un determinado
atributo dentro de una entidad. De forma casi inherente al término dominio aparece el
concepto restricción para un atributo.
� Clave. El modelo entidad-relación exige que cada entidad tenga un identificador, se trata
de un atributo o conjunto de atributos que identifican de forma única a cada uno de los
ejemplares de la entidad. De tal forma que ningún par de ejemplares de la entidad puedan
tener el mismo valor en ese identificador. A estos atributos se les llama indentificadores
principales o claves primarias, pudiendo darse el caso de que halla más de uno, quedando
los otros como identificadores candidatos.
� Relaciones. Se entiende por relación a la asociación, vinculación o correspondencia entre
entidades. En cada relación se debe establecer el número máximo y mínimo de ejemplares
de un tipo de entidad que pueden estar asociadas, mediante una determinada relación, con
un ejemplar de otra entidad. Los tres tipos de relaciones son:
- Uno a uno (1:1), donde para un ejemplar de una entidad existe una relación única con
otro ejemplar de otra entidad.
- Muchos a uno (m:1), varios ejemplares de una entidad se relacionan con el mismo
ejemplar de otra.
- Muchos a muchos (m:m), varios ejemplares se relacionan con varios de otra entidad.
4.2.2 Modelo Entidad-Relación
Ahora construiremos el modelo para nuestra base de datos Las entidades que conseguimos al aplicar el modelo a nuestros datos son las siguientes:
� Pacientes, guarda la información principal de todos pacientes.
� General, guarda datos médicos generales.
� Porta, aquí guardaremos la información correspondiente a los porta-a-cath del
paciente.

Modelo Entidad-Relación en MySQL
86
� Profilaxis, guarda la información de todas las profilaxis (tratamientos preventivo) del
paciente.
� Tratamientos, contiene información de todos los tratamientos. Hay dos tipos de
tratamientos: los tratamientos que recomienda el médico y las inyecciones que se pone
el paciente. Estos dos tipos de tratamientos lo diferencia el campo Operación que
valdrá “1” si el tratamiento ha sido recomendado por el médico y “2” en el otro caso.
� Historial_Tratamiento, contiene información del seguimiento de cada tratamiento.
Cada tratamiento tiene asociado un conjunto de concentrado/dosis.
� Analisis, contiene información de todos los análisis del paciente. El valor de cada uno
de los parámetros del análisis se encuentra en Datos_Analisis. Los parámetros que
pueden ser evaluados son los que están activo en ese momento, esto lo controla el
campo Activo de la entidad Etiquetas_Analisis.
� Etiquetas_Analisis, contiene las etiquetas de los parámetros del análisis. El campo
Activo de esta entidad indicará en cada momento si ese parámetro puede ser evaluado
en el análisis o no.
� Datos_Analisis, aquí guardaremos el valor correspondiente a cada parámetro evaluado
en el análisis.
� Revisiones_Articulaciones, guarda información de las revisiones de las articulaciones
del paciente.
� Inhibidores, contiene información de los inhibidores del paciente.
� Historial_Inhibidor, contiene información de los tratamientos la evolución de los
inhibidores del paciente.
� Inmunotolerancias, contiene información de los tratamientos de inmunotolerancias
asociadas a la eliminación de los inhibidores del paciente.

Modelo Entidad-Relación en MySQL
87
� Cuestionarios, guarda información de los cuestionarios realizados a los pacientes.
Dichos cuestionarios se evalúan por un conjunto de ítems, el valor de estos ítems se
encuentran en la entidad Datos_Cuestionarios. El campo Activo de la entidad
Etiquetas_Cuestionarios controla los ítems que pueden ser evaluados.
� Etiquetas_Cuestionarios, contiene los ítems del cuestionario. El campo Activo de esta
entidad indicará en cada momento si ese ítem puede ser evaluado en el cuestionario o
no.
� Datos_Cuestionarios, aquí guardaremos el valor correspondiente a cada ítem evaluado
en el cuestionario.
� Usuarios, contiene información de todos los usuarios que pueden acceder a la
aplicación.
� Etiquetas, aquí guardaremos todas las etiquetas de la aplicación. Cada registro de esta
entidad contiene las etiquetas en un idioma distinto, con el fin de mostrar la aplicación
en el idioma que se desee. Para añadir un nuevo idioma, solo hay que insertar un
nuevo registro en esta entidad.
� Articulaciones, Causas_Extraccion, Causas_Fallecimiento, Causas_Investigacion,
Cirugías, Concentrados, Defectos, Diagnosticos, Genotipovhc, Intervalos,
Localizaciones, Otras_Reacciones, Protocolos, Unidades_Titulos, Sangrados,
Tipo_Profilaxis son entidades fuertes que no guardan información de los pacientes, si
no que sirven para definir valores de campos de otras entidades.
Estas son las entidades que forman nuestro modelo. En la siguiente figura se muestra la
estructura del modelo entidad-relación, donde se ven las relaciones entre entidades. Las
relaciones se establecerán mediante líneas, donde el tipo de relación vendrá marcada de la
siguiente manera:
Representa una relación del tipo muchos a uno.
Representa una relación del tipo uno a uno.
Representa una relación del tipo muchos a muchos.

Modelo Entidad-Relación en MySQL
88
Figura 4.1 Modelo Entidad-Relación

Modelo Entidad-Relación en MySQL
89
Figura 4.2 Modelo Entidad-Relación (continuación)

Modelo Entidad-Relación en MySQL
90
4.3 ACCESO A LA BASE DE DATOS
4.3.1 Modelo de Acceso
Para acceder a la base de datos usaremos distintas funciones disponibles en PHP. Para
activar el acceso para esta base de datos, durante la instalación de PHP como módulo del
servidor Web Apache, debemos hacerla compilándolo con soporte para MySQL, usando la
opción de la configuración –with-mysql[DIR=]. A partir de PHP 4 esta opción está activada
por defecto.
En la mayoría de distribuciones de Sistemas Operativos tenemos la opción de instalar
el modulo con un gestor de paquetes propio del sistema (yum, apt-get, aptitude, synaptic,etc.),
instalando el módulo PHP del servidor Web correspondiente, en nuestro caso Apache, así
como el modulo de PHP necesario para la comunicación con el SGBD MySQL. En el caso de
instalar una versión fuente (source), se especifica donde está instalado MySQL y el servidor
Web, para que PHP pueda compilar los módulos que le son necesario. Para esto hace falta
tener las fuentes de MySQL instaladas también en el servidor.
En nuestro modelo de acceso, el software necesario para que nuestra aplicación acceda a
la base de datos recae totalmente sobre la máquina servidor. Para la máquina cliente, lo único
que se necesita es un navegador Web y un acceso a la red, para acceder a través del servidor
Web Apache al conjunto de páginas que forman la aplicación.
Figura 4.3 Modelo acceso Cliente-Servidor.

Modelo Entidad-Relación en MySQL
91
4.3.2 Clase CMySQL
Como interfaz de acceso al SGBD, hemos creado una Clase CMySQL, en la cual creamos una serie de métodos para acceder a la base de datos, iniciar transacciones, realizar consultas,
etc… y así disminuir el número de llamadas a funciones para realizar una sola consulta.
Pongamos por ejemplo que queremos hacer una conexión desde una de las páginas de nuestra
aplicación Web para insertar datos en la base de datos, todo ello desde dentro de una
transacción, para dar fiabilidad a la consulta.
� En primer lugar creamos una nueva instancia de nuestra clase con $conexion=new
CMySQL(); y empezamos a usar los métodos para conectarnos a la base de datos.
� Conectamos a la base de datos con $conexion->Conectar(“DATABASE”,
“HOSTNAME”, “USER”, “PASSWORD”); donde el primer parámetro del método es
el nombre de la base de datos, el segundo el Host, el tercero el nombre del usuario de
la base de datos y el último la contraseña de acceso.
� Iniciamos la transacción segura con $conexion->Iniciar_Transaccion();
� Realizamos la consulta, para ello en la variable de PHP $consulta introducimos una
cadena de texto con la consulta en el lenguaje SQL, y luego llamamos al método que
realiza la consulta, $errorconsulta=$conexion->Consulta($consulta); donde
$errorconsulta es una variable donde se devuelve si la consulta se realizó con éxito o
no.
� Según el valor de la variable $errorconsulta admitiremos la consulta con $conexion-
>Commitar(); o con $conexion->RollBack(); volveremos sobre nuestros pasos
anulando la consulta. Más adelante profundizaremos sobre la utilidad de las
transacciones.
� Una vez terminemos las consultas, cerramos la conexión con el método $conexion-
>Cerrar();.

Modelo Entidad-Relación en MySQL
92
4.3.3 Transacciones e integridad referencial
El servidor de bases de datos MySQL soporta distintos tipos de tablas, tales como ISAM,
MyISAM, InnoDB, y DBD (Berkeley Database). De éstos, InnoDB es el tipo de tabla más
importante (después del tipo predeterminado, MyISAM), y será el que usaremos en nuestra
base de datos.
Las tablas del tipo InnoDB tienen soporte para la definición de claves foráneas, por lo que
se nos permite definir reglas o restricciones que garanticen la integridad referencial de los
registros, además de permitir trabajar con transacciones.
Para asegurarnos que tenemos soporte para el tipo de tablas INNODB podemos ejecutar
la siguiente sentencia en el intérprete de comandos de MySQL:
mysql> SHOW VARIABLES LIKE ‘%innodb%’;
donde nos fijaremos que la variable have_innodb se encuentre con el valor YES.
Transacciones
Las transacciones aportan una fiabilidad superior a las bases de datos. Si disponemos de
una serie de consultas SQL que deben ejecutarse en conjunto, con el uso de transacciones
podemos tener la certeza de que nunca nos quedaremos a medio camino de ejecución. De
hecho, podríamos decir que las transacciones aportan a las aplicaciones de base de datos la
característica de “deshacer” un grupo de consultas.
Los pasos para usar transacciones en MySQL son:
� Iniciar una transacción con el uso de la sentencia BEGIN.
� Actualizar, insertar o eliminar registro en la base de datos.
� Si se quieren los cambios a la base de datos, completar la transacción con el uso de la
sentencia COMMIT. Únicamente cuando se procesa un COMMIT los cambios hechos
por las consultas serán permanentes.
� Si sucede algún problema, podemos hacer uso de la sentencia ROLLBACK para
cancelar los cambios que han sido realizados por las consultas que han sido ejecutadas
hasta el momento.

Modelo Entidad-Relación en MySQL
93
Las transacciones también son útiles en el caso de desconexiones con el servidor, ya que
si por ejemplo estamos haciendo una inserción de muchos datos, hasta que no procesemos un
COMMIT, ninguna de las inserciones tendrá efecto, evitando así inconsistencias en la base de
datos.
Integridad Referencial
Hay dos reglas de integridad muy importantes que son restricciones que se deben cumplir
en todas las bases de datos relacionales y en todos sus estados o instancias (las reglas se deben
cumplir todo el tiempo). Estas reglas son la regla de integridad de entidades y la regla de
integridad referencial.
▪ Regla de integridad de entidades
La primera regla de integridad se aplica a las claves primarias de las relaciones base:
ninguno de los atributos que componen la clave primaria puede ser nulo.
Por definición, una clave primaria es un identificador irreducible que se utiliza para
identificar de modo único las tuplas. Irreducible significa que ningún subconjunto de la clave
primaria sirve para identificar las tuplas de modo único. Si se permite que parte de la clave
primaria sea nula, se está diciendo que no todos sus atributos son necesarios para distinguir
las tuplas, con lo que se contradice la irreducibilidad.
▪ Regla de integridad referencial
La segunda regla de integridad se aplica a las claves foráneas: si en una relación hay
alguna clave foránea, sus valores deben coincidir con valores de la clave primaria a la que
hace referencia, o bien, deben ser completamente nulos.
La regla de integridad referencial se enmarca en términos de estados de la base de datos:
indica lo que es un estado ilegal, pero no dice cómo puede evitarse. La cuestión es ¿qué hacer
si estando en un estado legal, llega una petición para realizar una operación que conduce a un
estado ilegal? Existen dos opciones: rechazar la operación, o bien aceptar la operación y
realizar operaciones adicionales compensatorias (en cascada, valores por defecto, etc) que
conduzcan a un estado legal.

Modelo Entidad-Relación en MySQL
94
Por lo tanto, para cada clave foránea de la base de datos habrá que plantearse tres
cuestiones:
1. Regla de los nulos: ¿Tiene sentido que la clave foránea acepte nulos?
2. Regla de borrado: ¿Qué ocurre si se intenta borrar la tupla referenciada por la clave
ajena?
o Restringir: no se permite borrar la tupla referenciada.
o Propagar: se borra la tupla referenciada y se propaga el borrado a las tuplas que
la referencian mediante la clave ajena.
o Anular: se borra la tupla referenciada y las tuplas que la referenciaban ponen a
nulo la clave ajena (sólo si acepta nulos).
3. Regla de modificación: ¿Qué ocurre si se intenta modificar el valor de la clave
primaria de la tupla referenciada por la clave ajena?
o Restringir: no se permite modificar el valor de la clave primaria de la tupla
referenciada.
o Propagar: se modifica el valor de la clave primaria de la tupla referenciada y se
propaga la modificación a las tuplas que la referencian mediante la clave ajena.
o Anular: se modifica la tupla referenciada y las tuplas que la referenciaban
ponen a nulo la clave ajena (sólo si acepta nulos).
En nuestra aplicación hay claves foráneas que si aceptan valores nulos, ya que hay
parámetros que no son obligatorios evaluar (por ejemplo la causa de fallecimiento). En cuanto
a la regla del borrado y de modificación se ha llevado a cabo la opción de restringir, ya que
controlamos en la aplicación este tipo de inconsistencias.

Implementación Aplicación Web
95
CAPÍTULO 5:
IMPLEMENTACIÓN APLICACIÓN WEB 5.1 Introducción
5.2 Sistema de autenticación
5.3 Nociones básicas
5.4 Zona de administración
5.5 Zona de usuarios

Implementación Aplicación Web
96
5.1 INTRODUCCIÓN
En este capítulo realizaremos una descripción detallada de la interfaz de usuario de
nuestra aplicación Web. Para ello recorreremos las distintas páginas y formularios de la
aplicación describiendo detalladamente cada uno de ellos.
Durante el capítulo se mostrarán capturas de pantalla para facilitar la compresión del uso
de la aplicación.
5.2 SISTEMA DE AUTENTICACIÓN
Una vez iniciada la aplicación aparecerá por pantalla la ventana de entrada al sistema.
Ésta nos permitirá el acceso o no, dependiendo de sí nos encontramos registrados en el
sistema.
Figura 5.1 Sistema de autenticación
La aplicación consta de dos módulos principales:
� Zona de administración.
� Zona de usuario.

Implementación Aplicación Web
97
5.3 NOCIONES BÁSICAS
El programa presenta una serie de comportamientos comunes para casi la totalidad de los
diálogos que interactúan con el usuario. Dichos comportamientos se especifican a
continuación:
► Botones
Botón Nuevo: Nos permite añadir un nuevo registro en la base de datos.
Botón Modificar: Nos permite modificar los datos de un registro en la base de
datos.
Botón Eliminar: Nos permite eliminar el registro que en ese momento está
seleccionado, mostrando una ventana de confirmación previa a la eliminación.
Botón Ficha: En todos los listados cada registro va acompañado de este botón, al
pulsarlo se mostrará los datos del mismo en forma de ficha.
Botones Anterior y Siguiente: Estos botones permiten navegar por los distintos
registros de nuestra base de datos, pudiendo avanzar o retroceder en ellos.
► Diálogo de aviso: Este tipo de diálogo aparecen cuando se produce un error porque
faltan datos o por datos incorrectos.
Figura 5.2 Situación de error

Implementación Aplicación Web
98
Los usuarios con permisos de solo lectura no podrán añadir, modificar ni tampoco
eliminar datos. Si en algún momento pulsa una de estas opciones aparecerá un mensaje
como el siguiente:
Figura 5.3 Situación de error
Este mensaje también aparece cuando se realiza una opción no válida en cualquier
momento, como la de pulsar el botón modificar paciente sin haber ningún paciente
cargado en ese momento.
► La opción salir y ver la ayuda está disponible en cualquier parte de la aplicación.
► Los campos de los formularios que contienen un * son campos obligatorios.
► Todos los listados están ordenados por fecha en orden descendente, menos el de
pacientes que está ordenado por los apellidos en orden alfabético.

Implementación Aplicación Web
99
5.4 ZONA DE ADMINISTRACIÓN
Una vez que se ha accedido al sistema como administrador, se podrá visualizar la pantalla
principal de administración que consta de las siguientes partes:
� Usuarios. En esta zona el administrador podrá dar de alta, editar o dar de baja a los
usuarios de la aplicación.
� Sistema. En esta zona el administrador podrá dar de alta, editar o dar de baja registros
en determinadas tablas de la base de datos.
� Tratamientos: En esta zona el administrador tiene la posibilidad de añadir nuevos
tratamientos a los pacientes registrados, mediante la carga de un archivo XML con un
formato determinado.
5.4.1 Usuarios
En esta pantalla se muestra un listado de todos los usuarios dados de alta en el sistema.
Para añadir un nuevo usuario pulsar el botón Nuevo Usuario, si lo que se desea es visualizar
los datos de un determinado usuario pulsar el botón Ficha Usuario que lo acompaña.
Figura 5.4 Usuarios

Implementación Aplicación Web
100
Nuevo Usuario
Para añadir un nuevo usuario insertar los datos del usuario y pulsar el botón Guardar, si
todo es correcto se mostrará de nuevo el listado de usuarios incluyendo el usuario añadido.
Figura 5.5 Nuevo Usuario
Para salir sin insertar un nuevo usuario, pulsar el botón Listado Usuarios. Las opciones de
Modificar Usuario y Eliminar Usuario son opciones no válidas en esta pantalla.

Implementación Aplicación Web
101
Ficha Usuario
Al pulsar el botón de la ficha del usuario que se desea mostrar, aparecerá una pantalla
como la siguiente pantalla:
Figura 5.6 Ficha Usuario
A continuación podrá realizar una de las siguientes acciones:
� Insertar un nuevo usuario.
� Modificar usuario. Modificar los datos de usuario y pulsar el botón Guardar, a
continuación se mostrará el listado de todos los usuarios.
� Eliminar usuario. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación, aparecerá el listado sin el usuario que se ha eliminado.
� Listado de usuario. Aparecerá el listado de todos los usuarios.
� Anterior y siguiente. Permite navegar pos los distintos usuarios registrados.

Implementación Aplicación Web
102
5.4.2 Sistema
En esta zona se le da flexibilidad al sistema pudiendo crear nuevos registros en
determinadas tablas de la base de datos.
En esta pantalla se muestra un listado con el nombre de las tablas, pulsar el botón que
acompaña a la tabla que se desea que se muestren sus datos, a continuación aparecerá en la
parte derecha el listado de todos los registros de la tabla seleccionada.
Las tablas Análisis y Cuestionarios contienen un campo Activo, para poder activar o
desactivar el registro. Solo los registros activados aparecerán en la interfaz de la zona de
usuario.
Figura 5.7 Sistema
► Nuevo
Para añadir una nueva entrada en la tabla pulsar el botón Nuevo, insertar el valor y
pulsar el botón guardar.
► Modificar
Para modificar una entrada en la tabla pulsar el botón Modificar, que acompaña al
registro que queremos modificar, a continuación modificar los valores y pulsar el
botón guardar.

Implementación Aplicación Web
103
Figura 5.8 Modificar registro
► Eliminar
Para eliminar una entrada en la tabla pulsar el botón Eliminar, que acompaña al
registro que queremos eliminar, a continuación aparecerá un mensaje de confirmación.
5.4.3 Tratamientos
Al pulsar la pestaña Tratamientos aparecerá la siguiente pantalla:
Figura 5.9 Tratamientos de la AMH

Implementación Aplicación Web
104
Para cargar los tratamientos de los pacientes por medio de un archivo Xml, seleccionar
por medio del botón Examinar el archivo deseado, a continuación pulsar el botón Cargar
tratamientos, se mostrará un listado con los tratamientos que contiene dicho archivo.
Figura 5.10 Tratamientos de la AMH
Cada tratamiento que se muestra tiene asociado una o varias dosis, para mostrar las dosis
pulsar el botón que acompaña al tratamiento que se desee, a continuación se mostrará un
listado con las dosis de ese tratamiento.
Figura 5.11 Dosis de un tratamiento

Implementación Aplicación Web
105
Para cargar los datos a la base de datos, pulsar el botón Añadir tratamientos, de esta
forma los tratamientos que se encuentran en el archivo Xml se almacenarán en las tablas de la
base de datos.
5.5 ZONA DE USUARIOS
Una vez que se ha accedido al sistema como usuario, se visualizará la siguiente pantalla:
Figura 5.12 Ventana principal de Usuario

Implementación Aplicación Web
106
Esta dividida en variar partes:
� Menú principal.
- Nuevo paciente.
- Modificar paciente.
- Buscar paciente.
- Estadísticas.
- Anterior.
- Siguiente.
- Ayuda.
- Salir.
� Datos principales del paciente.
� Datos médicos del paciente.
- General.
- Tratamientos.
- Análisis.
- Articulaciones.
- Inhibidores.
- Cuestionarios.
- Informes.

Implementación Aplicación Web
107
5.5.1 Nuevo Paciente
Para añadir un nuevo paciente introducir los datos personales y los datos generales el
paciente a continuación pulsar el botón guardar, de esta forma el paciente quedará registrado.
Figura 5.13 Nuevo paciente

Implementación Aplicación Web
108
5.5.2 Modificar Paciente
La ventana que aparece es similar que la ventana de nuevo paciente, con la única
diferencia que se editan los datos para que puedan ser modificados. Una vez modificado los
datos que se deseen, pulsar el botón Guardar, de esta forma los cambios quedarán registrados.
Figura 5.14 Modificar paciente

Implementación Aplicación Web
109
5.5.3 Buscar Pacientes
La búsqueda de pacientes se realiza por los datos principales del paciente.
Figura 5.15 Buscar paciente
Introducir los datos de búsqueda y pulsar el botón buscar. A continuación aparecerá un
listado de los pacientes que cumple el criterio de búsqueda.

Implementación Aplicación Web
110
Figura 5.16 Listado de pacientes
Para cargar los datos de un paciente pulsar el botón ficha que acompaña al paciente que se
desea mostrar.
5.5.4 Estadísticas
Al pulsar la opción de Estadísticas aparecerá una pantalla con los criterios con los que se
puede realizar la estadística.

Implementación Aplicación Web
111
Figura 5.17 Estadísticas
Introducir los campos por los que se desea realizar la estadística y pulsar el botón aceptar.
A continuación se mostrará un diálogo como el siguiente dependiendo del navegador:
Figura 5.18 Abrir Listado Estadística
Para abrir el listado de los pacientes que cumplen los criterios elegidos seleccionar la
aplicación con la que se desea mostrar, para guardarlo seleccionar “Guardar en disco” y pulsar
el botón aceptar.

Implementación Aplicación Web
112
5.5.5 General
En la pestaña General se encuentra los datos generales del paciente.
Figura 5.19 Datos Generales
� Listado de profilaxis y porta-a-cath: Para añadir una nueva profilaxis o nuevo porta-a-
cath al paciente, pulsar el botón de añadir. Para modificar o eliminar una profilaxis o
un porta-a-cath pulsar los botones correspondientes que acompaña al registro que se
desea eliminar o modificar.
� La información de recuperación, tratamiento recomendado y próxima visita son datos
del último análisis que se le realizó a paciente.
� El campo inhibidor indica si el paciente tiene registrado algún inhibidor, así como
también si lo tuvo previamente.

Implementación Aplicación Web
113
5.5.6 Tratamientos
Cuando se pulsa la pestaña Tratamientos se muestra un listado con todos los tratamientos
del paciente que esta activo en ese momento. Para añadir un nuevo tratamiento pulsar el botón
Nuevo Tratamiento, si lo que se desea es visualizar un determinado tratamiento pulsar el
botón Ficha Tratamiento que lo acompaña.
Figura 5.20 Listado tratamientos

Implementación Aplicación Web
114
Nuevo Tratamiento
Para añadir un nuevo tratamiento insertar los datos del tratamiento y pulsar el botón
Guardar, si todo es correcto se mostrará de nuevo el listado de tratamiento incluyendo el
tratamiento añadido.
Figura 5.21 Nuevo Tratamiento

Implementación Aplicación Web
115
Ficha Tratamiento
Al pulsar el botón de la ficha de un determinado tratamiento, aparecerá la siguiente
pantalla. Aquí se muestra los datos del tratamiento.
Figura 5.22 Ficha Tratamiento
A continuación podrá realizar una de las siguientes acciones:
� Insertar un nuevo tratamiento.
� Añadir Concentrado/Dosis. Al pulsar en esta opción se muestra el listado de las dosis
de ese tratamiento. Para insertar una nueva dosis pulsar el botón Nuevo, para modificar
o eliminar pulsar el botón que acompaña al registro que queremos modificar o eliminar
respectivamente.
� Modificar tratamiento. Modificar los datos del tratamiento y pulsar el botón Guardar, a
continuación se mostrará el listado de los tratamientos con la modificación realizada.
� Eliminar tratamiento. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación, aparecerá el listado sin el tratamiento que se ha eliminado.

Implementación Aplicación Web
116
� Listado de tratamientos. Aparecerá el listado de todos los tratamientos del paciente que
esta activo en ese momento.
� Anterior y Siguiente. Permite navegar por los distintos tratamientos registrados del
paciente actual.
5.5.7 Análisis
Cuando se pulsa la pestaña Análisis se muestra un listado con todos los análisis del
paciente que esta activo en ese momento. Para añadir un nuevo análisis pulsar el botón Nuevo
Análisis, si lo que se desea es visualizar un determinado análisis pulsar el botón Ficha
Análisis que lo acompaña.
Figura 5.23 Listado análisis

Implementación Aplicación Web
117
Nuevo Análisis
Para añadir un nuevo análisis insertar los datos del análisis y pulsar el botón Guardar, si
todo es correcto se mostrará de nuevo el listado de análisis incluyendo el análisis añadido.
Figura 5.24 Nuevo Análisis

Implementación Aplicación Web
118
Ficha Análisis
Al pulsar el botón de la ficha de un determinado análisis, aparecerá la siguiente pantalla:
Figura 5.25 Ficha Análisis
A continuación podrá realizar una de las siguientes acciones:
� Insertar un nuevo análisis.
� Modificar análisis. Modificar los datos del análisis y pulsar el botón Guardar, a
continuación se mostrará el listado de los análisis con la modificación realizada.
� Eliminar análisis. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación aparecerá el listado sin el análisis que se ha eliminado.
� Listado de análisis. Aparecerá el listado de todos los análisis del paciente que esta
activo en ese momento.
� Anterior y Siguiente. Permite navegar por los distintos análisis registrados del paciente
actual.

Implementación Aplicación Web
119
5.5.8 Articulaciones
En la pestaña Articulaciones, se muestra un listado con todas las revisiones realizas al
paciente que esta activo en ese momento. Para añadir una nueva revisión pulsar el botón
Nueva Articulación, si lo que se desea es visualizar una determinada revisión pulsar el botón
Ficha Articulación que lo acompaña.
Figura 5.26 Listado Articulaciones

Implementación Aplicación Web
120
Nueva Articulación
Para añadir una revisión de articulación insertar los datos de la revisión y pulsar el botón
Guardar, si todo es correcto se mostrará de nuevo el listado de las revisiones incluyendo la
añadida
Figura 5.27 Nueva Revisión de Articulación

Implementación Aplicación Web
121
Ficha Articulación
Al pulsar el botón de la ficha de una determinada revisión de articulación, aparecerá la
siguiente pantalla:
Figura 5.28 Ficha Revisión Articulación
A continuación podrá realizar una de las siguientes acciones:
� Insertar una nueva revisión de articulación.
� Modificar articulación. Modificar los datos de la revisión de la articulación y pulsar el
botón Guardar, a continuación se mostrará el listado de las revisiones con la
modificación realizada.
� Eliminar articulación. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación aparecerá el listado sin la revisión de la articulación que se ha
eliminado.
� Listado de articulaciones. Aparecerá el listado de todas las revisiones de articulaciones
del paciente que esta activo en ese momento.

Implementación Aplicación Web
122
� Anterior y Siguiente. Permite navegar por las distintas revisiones de articulaciones
registrados del paciente actual.
5.5.9 Inhibidores
En la pestaña Inhibidores, se muestra un listado con todos los inhibidores del paciente
que esta activo en ese momento. Para añadir un nuevo inhibidor pulsar el botón Nuevo
Inhibidor, si lo que se desea es visualizar un determinado inhibidor pulsar el botón Ficha
Inhibidor que lo acompaña.
Figura 5.29 Listado Inhibidores

Implementación Aplicación Web
123
Nuevo Inhibidor
Para añadir un inhibidor insertar los datos del inhibidor y pulsar el botón Guardar, si todo
es correcto se mostrará de nuevo el listado de los inhibidores incluyendo el añadido.
Figura 5.30 Nuevo Inhibidor

Implementación Aplicación Web
124
Ficha Inhibidor
Al pulsar el botón de la ficha de un determinado inhibidor, aparecerá la siguiente
pantalla:
Figura 5.31 Ficha Inhibidor
A continuación podrá realizar una de las siguientes acciones:
� Insertar un nuevo inhibidor.
� Modificar inhibidor. Modificar los datos del inhibidor y pulsar el botón Guardar, a
continuación se mostrará el listado de los inhibidores con la modificación realizada.
� Eliminar inhibidor. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación, aparecerá el listado sin el inhibidor que se ha eliminado.
� Listado de inhibidores. Aparecerá el listado de todos los inhibidores del paciente que
esta activo en ese momento.
� Anterior y Siguiente. Permite navegar por los distintos inhibidores registrados del
paciente actual.

Implementación Aplicación Web
125
� Inmunotolerancias. Muestra un listado con las inmunotolerancias asociadas al
inhibidor.
� Seguimiento inhibidor. Al seleccionar esta opción se muestra un listado con
información del seguimiento del inhibidor. Para insertar un nuevo registro pulsar el
botón Nuevo, para modificar o eliminar pulsar el botón que acompaña al registro que
queremos modificar o eliminar respectivamente.
5.5.10 Inmunotolerancias
En la pestaña Inmunotolerancias, se muestra un listado con todas las inmunotolerancias,
asociadas a un determinado inhibidor. Para añadir una nueva inmunotolerancia pulsar el botón
Nueva IT, si lo que se desea es visualizar una determinada inmunotolerancia pulsar el botón
Ficha IT que lo acompaña. Para volver al inhibidor pulsar el botón Inhibidor.
Figura 5.32 Listado Inmunotolerancias

Implementación Aplicación Web
126
Nueva Inmunotolerancia
Para añadir una inmunotolerancia insertar los datos de la inmunotolerancia y pulsar el
botón Guardar, si todo es correcto se mostrará de nuevo el listado de las inmunotolerancias
incluyendo la añadida.
Figura 5.33 Nueva Inmunotolerancia

Implementación Aplicación Web
127
Ficha Inmunotolerancia
Al pulsar el botón de la ficha de una determinada inmunotolerancia, aparecerá la
siguiente pantalla:
Figura 5.34 Ficha Inmuntolerancia
A continuación podrá realizar una de las siguientes acciones:
� Insertar una nueva inmunotolerancia.
� Modificar inmunotolerancia. Modificar los datos de la inmunotolerancia y pulsar el
botón Guardar, a continuación se mostrará el listado de las inmunotolerancias con la
modificación realizada.
� Eliminar inmunotolerancia. Aparecerá una ventana de confirmación de la eliminación.
Si se acepta la eliminación, aparecerá el listado sin la inmunotolerancia que se ha
eliminado.
� Listado de inmunotolerancias. Aparecerá el listado de todos las inmunotolerancias del
inhibidor seleccionado previamente.

Implementación Aplicación Web
128
� Anterior y Siguiente. Permite navegar por los distintas inmunotolerancias del inhibidor
seleccionado.
� Inhibidor. Vuelve a la ficha del inhibidor.
5.5.11 Cuestionarios
Listado con todos los cuestionarios del paciente que esta activo en ese momento. Para
añadir un nuevo cuestionario pulsar el botón Nuevo Cuestionario, si lo que se desea es
visualizar un determinado cuestionario pulsar el botón Ficha Cuestionario que lo acompaña.
Figura 5.35 Listado Cuestionarios

Implementación Aplicación Web
129
Nuevo Cuestionario
Para añadir un nuevo cuestionario insertar los datos del cuestionario y pulsar el botón
Guardar, si todo es correcto se mostrará de nuevo el listado de los cuestionarios incluyendo el
añadido.
Figura 5.36 Nuevo Cuestionario

Implementación Aplicación Web
130
Ficha Cuestionario
Al pulsar el botón de la ficha de un determinado cuestionario aparecerá la siguiente
pantalla:
Figura 5.37 Ficha Cuestionario
A continuación podrá realizar una de las siguientes acciones:
� Insertar un nuevo cuestionario.
� Modificar cuestionario. Modificar los datos del cuestionario y pulsar el botón Guardar,
a continuación se mostrará el listado de los cuestionarios con la modificación
realizada.
� Eliminar cuestionario. Aparecerá una ventana de confirmación de la eliminación. Si se
acepta la eliminación, aparecerá el listado sin el cuestionario que se ha eliminado.
� Listado de cuestionarios. Aparecerá el listado de todos los cuestionarios del paciente
que esta activo en ese momento.

Implementación Aplicación Web
131
� Anterior y Siguiente. Permite navegar por los distintos cuestionarios registrados del
paciente actual.
5.5.12 Informes
Se pueden realizar tres tipos de informes:
► Informe de actividades.
► Informe de viaje.
► Informe de minusvalía.
Figura 5.38 Informes

Implementación Aplicación Web
132
Pulsar en la ficha que acompaña al informe que se desea realizar, a continuación se
mostrará un diálogo como el siguiente dependiendo del navegador:
Figura 5.39 Abrir Informe Para abrir el informe seleccionar la aplicación con la que se desea mostrar, para guardarlo
seleccionar “Guardar en disco” y pulsar el botón aceptar.

Conclusiones
133
CAPÍTULO 6:
CONCLUSIONES 6.1 Resultados y conclusiones
6.2 Trabajos futuros

Conclusiones
134
En este proyecto final de carrera se planteó como objetivo diseñar e implementar una
aplicación Web que automatizará los procesos de almacenamiento, organización y gestión de
la información sobre la evaluación de pacientes con hemofilia en el área sanitaria.
En el inicio de nuestro proyecto marcamos unas fases o etapas de trabajo que gobernaban
el desarrollo del mismo. Ahora es el momento de ver si esos objetivos se han alcanzado:
� Creación de un registro actualizado de los pacientes con hemofilia en el área sanitaria
de Málaga (pero igualmente utilizable en otras zonas geográficas).
� Diseño de una evaluación sistemática de resultados clínicos de estos pacientes que
permita el seguimiento homogeno de los mismos y la comparación de sus evoluciones,
facilitando la optimización de tratamientos, estudios de efectos adversos y
complicaciones, etc.
� Aplicar un cuestionario estadarizado de estudio de calidad de vida a dichos pacientes
para conocer su situación y plantear un abordaje de sus espectativas de forma global.
� Crear un soporte en formato electrónico de esta información, de fácil manejo para los
profesionales, que permita una intervención estadistica avanzada de los mismos.
6.1 RESULTADOS Y CONCLUSIONES
A fin de validar el grado de cumplimiento de estos objetivos por parte de la aplicación
propuesta, vamos a describir la funcionalidad general de la aplicación.
La aplicación ha supuesto la realización de los siguientes pasos:
- Se ha realizado un estudio previo, acerca de cómo organizar la estructura de la
aplicación mediante diagramas UML. Se han utilizado diagramas de casos de usos, en
principio para determinar cada una de las acciones que puede realizar un actor dentro
de la aplicación, con los diagramas de secuencia se consigue esquematizar cada uno de
los pasos que debe dar un actor para conseguir realizar una tarea y por último los
diagramas de estado muestran los diferentes estados que atraviesa un objeto.

Conclusiones
135
- Se ha creado una base de datos, bajo MySQL, para almacenar y consultar toda la
información necesaria para la evaluación de pacientes con hemofilia, también se a
hecho un estudio de cómo interrelacionar los datos dentro del sistema gestor de base
de datos para organizarlo en tablas.
- Se ha creado un interfaz gráfico en HTML para la aplicación acorde a los requisitos
iniciales.
- Se ha proporcionado acceso al sistema de gestión de bases de datos mediante el
lenguaje de programación PHP.
En cuánto a las ventajas de la aplicación podemos destacar:
- Es una aplicación Web, accesible desde cualquier punto simplemente por disponer de
una conexión a Internet y un explorador Web. Este diseño hace la aplicación
independiente de la plataforma de acceso del usuario, quien podría tener instalado el
sistema operativo de su elección y tan solo necesitará su explorador Web. En todo
caso, dada la cobertura del mercado por los productos MS™, se ha elegido iExplorer
como software de referencia para optimizar el acceso y los diseños.
- La aplicación es fácil de usar e intuitiva, proveyendo interfaces construidas sobre
formularios Web. El acceso a la base de datos se hace de forma fiable, oculta al
usuario, eficiente y protegida para la sincronización de acceso simultáneos
(transacciones).
- Desde el punto de vista tecnológico, se hace uso de herramientas de libre distribución
(Open Source) muy extendidas como es el caso de MySQL y PHP.
Algunas de las ventajas de usar PHP son:
� Dispone de una amplia gama de librerías, y agregarle extensiones es muy
fácil. Esto le permite al PHP ser utilizado en muchas áreas diferentes, tales
como encriptado, gráficos, XML, PDF y otras.

Conclusiones
136
� Dispone de muchas interfaces alternativas para cada tipo de Servidor Web.
PHP actualmente se puede ejecutar bajo Apache, IIS, AOLServer, Roxen y
THTTPD.
� Puede interactuar con muchos motores de bases de datos tales como
MySQL, MS SQL, Oracle, Informix, PostgreSQL, y otros muchos.
Siempre podrás disponer de ODBC para situaciones que lo requieran.
� El paradigma de orientación a objetos de PHP mejora con cada nueva
versión.
- La aplicación permite su portabilidad. Puede ser montada en distintos sistemas
operativos (Windows, Linux y Mac OS) y en distintos servidores Web (apache,
cherokee…).
- Se ha realizado un diseño modular que facilita la extensión de la funcionalidad
mediante la incorporación de nuevas herramientas con relativa facilidad. Un ejemplo
es el módulo de importación de tratamientos de la AMH. Para la incorporación de esta
herramienta se ha insertado una nueva pestaña en la zona de administración y se ha
creado un archivo php (cargarXml.php) donde se lleva a cabo las operaciones
necesarias para su funcionamiento.
- Se dispone de un procedimiento sencillo de instalación.
- Extensibilidad. Las tablas sujetas a mayores cambios potenciales –debido a la
aparición de nuevas técnicas, nuevos análisis clínicos, etc.- se han preparado para que
su mantenimiento sea sencillo. De esta forma las tablas pueden incorporar nuevos
parámetros de los pacientes, como diagnósticos, causas de investigación, defectos
genéticos, etc. así como también los parámetros de los análisis y de los cuestionarios.
Estos cambios en las tablas se reflejan automáticamente en los formularios de la
aplicación, para el ingreso de datos, su consulta y la emisión de informes.
- Visibilidad de la aplicación en cualquier idioma. Al darse de alta cada usuario elegirá
el idioma deseado, de esta forma cuando se valide en el sistema la aplicación
aparecerá en ese idioma. Los idiomas se encuentran en la tabla Etiquetas, para añadir
un nuevo idioma solo habrá que insertar un nuevo registro en dicha tabla.

Conclusiones
137
- Importación de tratamientos. Se pueden importar datos del diario de tratamientos de la
AMH (Asociación Malagueña de Hemofilia), para pacientes registrados en ambas
plataformas, mediante el módulo de carga de tratamientos.
6.2 TRABAJOS FUTUROS
La versatilidad de las herramientas que hemos usado en la elaboración de nuestro
proyecto permite una gran flexibilidad en cuanto a expansiones futuras en la aplicación.
Mejoras que se podrían realizar:
� Informes. Actualmente los informes están realizados de una manera fija, es decir la
estructura y el texto están predeterminados. Una mejora sería la opción de que los
usuarios pudieran definir el contenido de los informes mediante un archivo XML, de
esta forma no se necesitaría conocimientos de programación para cambiar su
contenido, solo bastaría con modificar el formato de dicho archivo. También se
podrían realizar mediante formularios, dado una interfaz con la que seleccionar los
campos que se mostrarán en el informe.
� Cuestionarios. En la aplicación se almacenan los resultados que se obtienen de
analizar las respuestas de los cuestionarios, dicho análisis se realiza de forma manual.
La mejora consiste en que la aplicación evaluara ella misma las respuestas, obteniendo
así los resultados de forma automática.
� Conexión con AMH. Actualmente usamos una transferencia asíncrona entre ambas
plataformas, de manera que realizamos el trasvase de información de manera
descentralizada. Almacenamos los datos encriptados desde AMH en un fichero XML
en el ordenador cliente para después subirlo a HemoGest y actualizar la base de datos.
La mejora consistiría en tener un Servicio Web en la AMH, de manera que desde
Hemogest pudiera llamarse para actualizar su información con estos nuevos datos.
� Exportación de datos. La base de datos puede portarse simplemente creando un script
de carga .sql realizando el volcado con la herramienta que proporciona MySQL
(mysqldump). Junto a este método podría mejorarse la portabilidad de los datos
proporcionándolos en otros formatos, como XML, Excel, etc.

Anexos
138
ANEXOS

Anexos
139
ANEXO I
INSTALACIÓN DE LA APLICACIÓN
� Introducción
A continuación indicaremos los pasos necesarios para inicializar nuestro proyecto en
cualquier servidor que deseemos instalarlo: prerrequisitos, inicialización de la base de datos e
instalación de la aplicación Web.
� Prerrequisitos
La aplicación puede ser montada en distintos sistemas operativos (Windows, Linux y
Mac). Para ello necesitamos instalar las siguientes aplicaciones:
- Instalación de Servidor Web con soporte para PHP (Apache 2.0.48, www.apache.org).
- Instalación de PHP (versión 4 o superior, www.php.net).
- Instalación de la librería DOMXML.
- Instalación de un Servidor de Base de Datos (MySQL, www.mysql.com).
El acceso a la base de datos se ha realizado con una clase que se puede cambiar para
acceder a otras BD visibles desde PHP (Oracle, Informix, PostgreSQL…)
� Inicialización de la Base de Datos
Para inicializar la base de datos, usaremos el archivo de texto llamado BaseDatos.sql que
contiene las instrucciones necesarias para crear la base de datos y las tablas. Ejecutaremos la
siguiente sentencia en nuestro intérprete de comandos:
mysql –u <usuario> –p < BaseDatos.sql

Anexos
140
Una vez ejecutada dicha sentencia nos pedirá la contraseña de root en MySQL, tras unos
segundos quedará instalada la base de datos en el sistema.
Hay que realizar una carga mínima en la base de datos en la tabla Etiquetas. Esta tabla
contiene la información de los idiomas, por lo tanto para poder visualizar la aplicación hay
que añadir un registro, esto se lleva a cabo cargando el archivo de texto llamado Idiomas.sql.
El lenguaje cargado será el español.
mysql –u <usuario> –p < Idiomas.sql
Para añadir un nuevo idioma solo habrá que traducir las etiquetas contenidas en el archivo
Idiomas.sql y lanzar de nuevo la sentencia anterior.
Es necesario añadir a la base de datos un usuario administrador para poder acceder por
primera vez al sistema, para ello cargamos el archivo de texto llamado Usuarios.sql.
mysql –u <usuario> –p < Usuarios.sql
El login y la password por defecto para este usuario es admin. Una vez iniciada la
aplicación cambiar los datos de este usuario.
� Instalación de la Aplicación Web
Los datos de conexión de la base de datos se encuentran en un archivo llamado
hemogest.config,
Para instalar nuestra aplicación Web solo habría que descomprimir la carpeta
HemoGest.tar en el directorio de nuestro servidor Web donde colgaremos la aplicación, de
esta forma obtendremos una carpeta hemogest donde se encuentran todas las páginas php, las
hojas de estilos y las imágenes de la aplicación.

Anexos
141
Para iniciar nuestra aplicación Web, abrimos nuestro navegador y accedemos a ella:
http://<Nombre del servidor>\hemogest
Una vez iniciada la aplicación aparecerá por pantalla la ventana de entrada al sistema.
Introducir el login y la password (admin) insertado anteriormente en la base de datos.

Anexos
142
ANEXO II
TERMINOLOGÍA BÁSICA DE LA HEMOFILIA
� Hemofilia: Alteración genética de la coagulación de la sangre que provoca la ausencia
o disminución de algunos de los factores de coagulación. Es una anomalía hereditaria
ligada al sexo, al cromosoma “X”. La transmite el sexo femenino y la padece el sexo
masculino, salvo en raras excepciones que también la puede padecer la mujer.
Existen diferentes tipos de hemofilia en función de la cual sea el factor de coagulación
deficitario: - HEMOFILIA A: Ausencia o disminución del factor VIII; aproximadamente el
85 por ciento de los hemofílicos padece el tipo A.
- HEMOFILIA B: Ausencia o disminución del factor IX. También llamada
enfermedad del christmas.
- VON WILLBRAND: Ausencia del factor Von Willeband pero cursa como un
déficit del factor VII y disminución del funcionamientos las plaquetas.
En hemofilia, dependiendo de la cantidad de factor que sintetiza cada persona,
existen tres grados de severidad:
- Severa: menos del 1%.
- Moderada: entre un 1 y un 5% .
- Leve: entre un 5 y 25%.
� DDAVP: Medicamento para la hemofilia A leve.
� Inhibidor: Anticuerpo (proteínas) que neutraliza la actividad de un factor de
coagulación.
� Port-a-cath: Accesos venosos artificiales que facilita la administración del
tratamiento en los pacientes más jóvenes.

Anexos
143
� Profilaxis: Infusión regular del factor de coagulante dos o tres veces por semana. Se
aplica de esta manera para prevenir sangrados en las coyunturas (articulaciones). Se
cree que la profilaxis prevendrá el daño de las coyunturas o de su empeoramiento.
� Inmunotolerancia: Eliminación del inhibidor, normalización de la vida media del
factor VIII y ausencia de respuesta anamnésica.
� Tratamiento antirretrovial: Se aplican a los adultos y a los niños infectados por el
VIH.
� Elisa, PCR-VHC: Métodos de escrutinio para la hepatitis C capaces de detectar el
99.9% de las donaciones contaminadas con el virus de la hepatitis C.
� Ribavirina: Medicamento para tratar las hepatitis C.
� Genotipo VHC: El genotipo se refiere a la formación genética de un organismo o
virus. Hay por lo menos 6 genotipos del VHC identificados claramente.
� ALT: Alanina aminotransferasa. Esta es una enzima que las células hepáticas
descargan en el torrente sanguíneo cuando el hígado se lesiona. Un nivel de ALT
superior a lo normal puede indicar daño hepático. Los niveles de ALT se incluyen en
los estudios rutinarios que se le hacen a los pacientes con hepatitis B crónica.
� GGT: Gamma-glutamil transferasa. Es otra enzima producida en las vías biliares que
puede aparecer elevada en las personas con enfermedades de las vías biliares. La
hepatitis y el consumo excesivo de alcohol también aumentan la GGT.
� HBsAg: Antígeno de superficie de la hepatitis B. El “antígeno de superficie” forma
parte del virus de la hepatitis B que se encuentra en la sangre de una persona infectada.
Si el resultado es positivo, significa que el virus de la hepatitis B está presente.
� Anti-HBs: Anticuerpo de superficie de la hepatitis B. El “anticuerpo de superficie” se
forma en respuesta al virus de la hepatitis B. El organismo puede producir este
anticuerpo si usted es vacunado, o si se ha recuperado de una infección de hepatitis B.

Anexos
144
Si el resultado es positivo, su sistema inmunológico ha desarrollado con éxito un
anticuerpo protector contra el virus de la hepatitis B, que le brindará protección a largo
plazo contra infecciones futuras del mismo. Las personas que obtienen un resultado
positivo en el anticuerpo de superficie no están infectadas y no le pueden contagiar el
virus a los demás.
� Anti-HC: Anticuerpo de superficie de la hepatitis C.
� HCV-PCR: Prueba cuantitativa que mide la cantidad de virus circulando en la
corriente sanguínea de la persona.
� AntiHAV: Anticuerpo de superficie de la hepatitis A.
� NºCD4: Nº de células de este tipo. El VIH causa en la mayoría de las personas una
lenta disminución en estas células.
� Carga viral: Valor dentro del pronóstico muy importante en cuanto se refiere a la
progresión de la infección por el VIH, así como para valorar la respuesta al
tratamiento antiretroviral y a su eficacia.

Anexos
145
ANEXO III
DESARROLLO CON UML
� Casos de Uso
Un diagrama de casos de uso es un grafo constituido por actores, casos de uso y las
relaciones que se establecen entre ellos. Cada diagrama constituye un escenario, donde se
describen los distintos requisitos funcionales del sistema.
Los elementos que constituyen un diagrama de casos de uso son los siguientes:
� Actores: Un actor es algo o alguien que se encuentra fuera del sistema y que interactúa
con él. En general, los actores son los usuarios del sistema u otros sistemas externos.
Un único actor puede representar a varios usuarios distintos, y un usuario puede actuar
como diferente actores.
Actor
� Casos de uso: Los casos de uso especifican el comportamiento del sistema de
información o de una parte de él, según una manera específica de dar respuesta a los
usuarios. Un caso de uso representa un requisito funcional del sistema, describiendo el
conjunto de secuencias de acciones, incluyendo variantes, que ejecuta el sistema para
producir un resultado observable de interés para un actor.
Caso de uso

Anexos
146
� Escenarios: Los escenarios son cada uno de los diferentes caminos que pueden darse
en un caso de uso, dependiendo de las condiciones que se den en su realización. A
cada uno de estos caminos se les llama diagramas de secuencia, los cuales veremos
más adelante. Normalmente un caso de uso tiene varios tipos de caminos o flujo de
eventos, siendo uno de ellos el flujo principal, compuesto por una serie de acciones
que realiza el actor que interviene en ese caso de uso junto a la correspondiente
respuesta del sistema. El resto de flujos se corresponden a ejecuciones erróneas o
excepcionales, en las que se incumplen los requisitos el sistema y donde el actor
obtiene una respuesta errónea.
� Paquetes: Los paquetes se emplean en los diagramas de casos de uso para la
organización de éstos. Se determina una partición del sistema y a cada una de estas
divisiones se le asocia un paquete en el que se incluyen los casos de usos
correspondientes.
� Relaciones: Las relaciones pueden tener lugar entre actores y casos de uso entre los
mismos casos de uso. La relación entre un actor y un caso de uso es una relación de
comunicación, e indica que un actor interviene en ese caso de uso. Normalmente, el
actor aporta información para la realización de un caso de uso o recibe información
como resultado de la realización del mismo, por tanto, esta relación puede ser tanto
unidireccional como bidireccional, predominando esta última. En cambio la relación
entre casos de uso suele ser unidireccional.
A continuación pasamos a detallar las diferentes relaciones existentes:
- Actor-Actor: La relación que pueden mantener dos actores es la relación de
generalización. En esta relación el actor hijo hereda el comportamiento de un
actor padre, además de poder definir los atributos propios que lo diferencian de
los demás.
Paquete

Anexos
147
- Actor-Caso de uso: La relación que puede tener un actor con un caso de uso
es una relación de comunicación.
- Casos de uso-Caso de uso: Mediante estas relaciones mejoramos el modelado
e interacción de comportamientos. A su vez distinguiremos tres tipos:
1. Generalización / Especificación: Un caso de uso hijo hereda el
comportamiento y el significado de otro caso de uso padre. El caso
de uso hijo puede añadir información el comportamiento o bien
redefinirlo.
2. Inclusión: La inclusión se presenta cuando existe un comportamiento
común entre varios casos de uso. Si un caso de uso A incorpora
explícitamente el comportamiento de otro caso de uso B, este
comportamiento común se recoge en un tercer caso de uso C, que se
relaciona con A y B mediante una relación de inclusión.
Padre Hijo
Padre Actor
Caso de uso
Padre Hijo

Anexos
148
3. Extensión: Representa un comportamiento opcional de un caso de
uso. Por lo tanto un caso de uso A que este relacionado con otro B
puede escoger o no el comportamiento del caso de uso B dentro del
escenario. La elección de escoger dicho comportamiento viene
determinada por una serie de factores, los cuales influyen
directamente en la extensión. Este tipo de relación es denominado
<<extend>>. En estas relaciones la flecha parte del caso de uso con el
comportamiento adicional hacia aquel que recoge el comportamiento
básico.
Básico Opcional
<<extend>>
C
B A
<<include>> <<include>>

Anexos
149
� DIAGRAMAS DE CLASES
El objetivo principal de los diagramas de clases es la representación de los aspectos
estáticos del sistema, utilizando para ello diversos mecanismos de abstracción como son la
clasificación, generalización y agregación. Los diagramas de clases identifican las clases,
relaciones, atributos y operaciones que se utilizarán en el sistema de información. Debido a su
carácter estático es mucho más fácil de entender que los modelos dinámicos. El diagrama de
clases está compuesto por varios tipos de componentes que se describirán a continuación.
� Clases: Las clases agrupan o abstraen objetos con atributos, relaciones y operaciones
comunes y con la misma semántica y comportamiento. Una clase se representa como
una caja dividida en tres zonas por líneas horizontales. En la zona superior se
identifica el nombre e la clase. La zona central contiene una lista de atributos y la zona
inferior incluye una lista con las operaciones que proporciona la clase.
� Objetos: Un objeto de una clase es la instancia de esa clase.
� Atributos: Propiedad de una clase compartida por todos sus objetos. Los atributos son
de dos tipos: base o derivados. Los atributos base son atributos básicos (int, String,
etc.) y los atributos derivados se calculan a partir de los atributos base. Los atributos
de una clase representan los datos asociados a los objetos instanciados por esa clase,
cada atributo tiene un nombre único de su clase y el conjunto de valores de los
atributos determina el estado de un objeto. El formato que siguen los atributos es el
siguiente:
{visibilidad} atributo: tipo = valor-inicial
� Operaciones: Representan el comportamiento de los objetos de una clase y lo
caracterizan. Las operaciones pueden modificar los datos de un objeto. El formato que
siguen las operaciones es el siguiente:

Anexos
150
{visibilidad} operación (lista-de-argumentos): tipo-devuelto
La visibilidad tanto de los atributos como de las operaciones se descompone en tres
tipos:
+ público
- privado
# protegido
� Relaciones: Las relaciones son las conexiones que pueden tener los distintos
elementos.
Existen varios tipos de relaciones:
- Asociación: La asociación es una relación estructural que especifica que los
objetos de un elemento están conectados con los objetos de otro. Cada enlace
es una instancia de una asociación. Las asociaciones se plantean
bidireccionales, pero el nombre establece el sentido en que se recorre. Éstas
pueden ser unarias, binarias, ternarias, n-arias. Una clase también puede tener
asociaciones reflexivas. Cada relación tiene una multiplicidad que
especifica cuántas instancias de una clase están asociadas a una instancia de la
otra clase. La asociación se representa gráficamente como una línea continua
entre las clases asociadas, junto a la línea puede tener un nombre que define la
semántica o naturaleza de la asociación.
Multiplicidad:
Cero a 1. 0..1
Muchos. 0..n ó 0..*
Uno o más. 1..n ó 1..*
Número exacto. 7
Combinaciones. 0..1, 3..4, 6..*

Anexos
151
- Agregación: La agregación es un caso particular de la asociación, parte de la
relación jerárquica entre un objeto que representa la totalidad de ese objeto y
las partes que lo componen. Su representa gráficamente mediante un rombo
hueco en la clase cuya instancia es una agregación de las instancias de la otra.
- Dependencia: La relación de dependencia representa que una clase requiere de
otra para proporcionar alguno de sus servicios. Su representación gráfica
consiste en una flecha con línea discontinua apuntando a la clase cliente.
- Generalización o herencia: Es el mecanismo que permite a una clase de
objetos reutilizar atributos y métodos de otra clase, incorporándolos a los que
ya tiene. Es una relación Padre-Hijo, donde la clase hijo hereda la estructura y
el comportamiento de la clase padre pudiendo redefinirlos para sus instancias.

Anexos
152
- Paquete: Los paquetes se usan para dividir el modelo de clases del sistema de
información agrupando clases u otros paquetes. Las dependencias entre los
paquetes se definen a partir de las relaciones establecidas entre los distintos
elementos que se agrupan en éstos. Las dependencias se representan con
flechas discontinuas entre los paquetes dependientes. La representación gráfica
de un paquete es un icono con forma de carpeta.

Anexos
153
ANEXO IV
TABLAS DE LA BASE DE DATOS
� Pacientes. Datos personales de los pacientes.
IdPaciente Identificador del paciente.
NUHSA Número Único de Historia de Salud de Andalucía.
SeguridadS Número de la seguridad social.
NumeroH Número del historial.
CodigoF Código familia.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya dado de alta al paciente.
DNI Documento nacional de identidad.
Nombre Nombre del paciente.
Apellido1 Primer apellido del paciente.
Apellido2 Segundo apellido del paciente.
Sexo Sexo del paciente
EstadoC Estado civil.
FechaN Fecha de nacimiento.
Direccion Dirección del paciente.
CP Código postal.
Email Dirección de correo.
TelefonoF Número de teléfono fijo.
TelefonoM Número de teléfono móvil.
TelefonoT Número de teléfono del trabajo.
NombreP Nombre de un pariente.
TelefonoP Teléfono del pariente.
FechaF Fecha de fallecimiento.

Anexos
154
CausaF
Clave foránea a la tabla Causas_ Fallecimiento. Este campo almacenará
el identificador de la causa de fallecimiento o “0” en caso de que este
parámetro no sea evaluado.
� General. Información general de los pacientes.
IdPaciente Identificador del paciente.
FechaA Fecha de alta.
Causa
Clave foránea a la tabla Causas_ Investigación. Este campo almacenará
el identificador de la causa de investigación.
Diagnóstico
Clave foránea a la tabla Diagnosticos. Este campo almacenará el
identificador del diagnóstico.
Defecto
Clave foránea a la tabla Defectos. Este campo almacenará el identificador
del defecto genético.
Herencia
Valor “1” si la hemofilia ha sido adquirida por herencia o “0” en caso
contrario.
HijoB Valor “1” si es hijo biológico o “1” en caso contrario.
ADiagnostico Año del diagnóstico.
Inhibidor Valor “1” si el paciente tiene inhibidor o “0” en caso contrario.
InhibidorP
Valor “1” si el paciente ha tenido inhibidor previamente o “0” en caso
contrario.
Especificacion Defecto específico.
VHA
Valor “1” si el paciente tiene el virus de la hepatitis A o “0” en caso
contrario.
VacunaA
Valor “1” si el paciente esta vacunado del virus de la hepatitis A o “0” en
caso contrario.
DDAVP
Valor “1” si al paciente se le ha realizado la prueba de DDAVP o “0” en
caso contrario.
PDDAVP Valores de la prueba DDAVP.
Tasa
Valor “1” si tiene tasa al factor o “0” en caso contrario.
VHB
Valor “1” si el paciente tiene el virus de la hepatitis B o “0” en caso
contrario.

Anexos
155
VacunaB
Valor “1” si el paciente tiene la vacuna para el virus de la hepatitis B o
“0” en caso contrario.
PortadorB
Valor “1” si el paciente es portador del virus de la hepatitis B o “0” en
caso contrario.
VHC
Valor “1” si el paciente tiene el virus de la hepatitis C o “0” en caso
contrario.
GenotipoC
Clave foránea a la tabla Genotipovhc. Este campo almacenará el
identificador del genotipoC o el valor “0” en caso de que no se evalúe
este término.
PortadorC
Valor “1” si el paciente es portador del virus de la hepatitis C o “0” en
caso contrario.
VHI
Valor “1” si el paciente tiene el virus de inmunodeficiencia humana o “0”
en caso contrario.
TratamientoI
Valor “1” si tiene carga viral o “0” en caso contrario.
Comentarios Campo donde se almacenará comentarios del doctor.
FechaP Fecha próxima visita.
Rayox Valor “1” si la próxima visita es para rayos X o “0” en caso contrario.
Rehabilitador
Valor “1” si la próxima visita es para el rehabilitador o “0” en caso
contrario.
Concentrado Clave foránea a la tabla Concentrados. Este campo almacenará el
identificador del concentrado alternativo o el valor “0” si no se ha
seleccionado ningún concentrado alternativo.
FvWRCo Factor von Willebrand cofactor ristocetina.
FvWAg Factor von Willebrand antigénico.
TasaFvWRCo Tasa factor von Willebrand cofactor ristocetina.
TasaFvWAg Tasa Factor von Willebrand antigénico.

Anexos
156
� Porta. Información de los porta-a-cath.
IdPorta Identificador del Porta-a-cath.
IdPaciente Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Implantado Fecha de implantación del Porta-a-cath
Extraido Fecha de extracción del Porta-a-cath
CausaExtraccion Clave foránea a la tabla Causa_Extraccion. Este campo almacenará el
identificador de la causa de extracción del porta-a-cath o el valor “0” si
no se ha seleccionado ninguna causa de extracción.
� Profilaxis. Información de las profilaxis.
IdProfilaxis Identificador de la profilaxis.
IdPaciente Identificador del paciente.
Empieza Fecha de inicio de la profilaxis.
Termina Fecha de fin de la profilaxis.
Tipo Clave foránea a la tabla Tipo_Profilaxis. Este campo almacenará el
identificador del tipo de profilaxis.
� Tratamientos. Información de los tratamientos.
IdTratamiento Identificador del Tratamiento.
IdPaciente
Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Fecha Fecha del tratamiento.
Doctor
Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya dado de alta al tratamiento.
Px Valor “1” si el tratamiento es a profilaxis o “0” en caso contrario.
Dm Valor “1” si el tratamiento es a demanda o “0” en caso contrario.
Q
Valor “1” si en la visita se ha valorado una cirugía o “0” en caso
contrario

Anexos
157
VArticulacion
Valor “1” si en la visita se ha valorado una articulación o “0 en caso
contrario.
Articulacion
Clave foránea a la tabla Articulaciones. Este campo almacenará el
identificador de la articulación valorada o el valor “0” si no se ha
valorado ninguna articulación.
IDArti
Valor “1” si la articulación valorada es la izquierda, “2” si es la derecha o
“0” si no se ha evaluado una articulación.
VSangrado
Valor “1” si en la visita se ha valorado un sangrado o “0 en caso
contrario.
Sangrado
Clave foránea a la tabla Sangrados. Este campo almacenará el
identificador del sangrado valorado o el valor “0” si no se ha valorado un
sangrado.
IDSangrado
Valor “1” si el sangrado valorado se encuentra en la articulación
izquierda, “2” si es en la derecha o “0” si no se ha valorado un sangrado.
Cirugia Clave foránea a la tabla Cirugias. Este campo almacenará el identificador
de la cirugía valorada o el valor “0” si no se ha valorado una cirugía.
Recogida Valor “1” si se ha recogido factor o “0” en caso contrario.
It Valor “1” si en la visita se ha valorado una inmunotolerancia o “0” en
caso contrario.
Operacion Valor “1” si el tratamiento ha sido recomendado por el médico o “2” si el
tratamiento ha sido importado de diario de tratamientos de la AMH.
� Historial_Tratamiento. Información del seguimiento de cada tratamiento.
IdHistorial Identificación del historial.
IdTratamiento Identificación del tratamiento.
FechaT Fecha del tratamiento.
Concentrado Clave foránea a la tabla Concentrados. Este campo almacenará el
identificador del concentrado.
Dosis Dosis del tratamiento.

Anexos
158
� Análisis. Información de los análisis de cada paciente.
IdAnalisis Identificador del análisis.
IdPaciente Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya realizado el análisis.
FechaA Fecha del análisis.
Peso Peso del paciente.
DosisP Dosis del tratamiento de recuperación
ConcentradoR Clave foránea a la tabla Concentrados. Este campo almacenará el
identificador del concentrado de recuperación o el valor “0” si no se ha
seleccionado ningún concentrado de recuperación.
HorasR Horas recomendadas de la recuperación.
FAntes FVIII/IX:C antes de la recuperación.
FDespues FVIII/IX:C después de la recuperación.
Trombosis Contendrá el valor “1” si el paciente tiene una trombosis y “0” en caso
contrario.
Localizacion Clave foránea a la tabla Localizaciones. Este campo almacenará el
identificador de la localización de la trombosis o el valor “0” si no se ha
seleccionado ninguna localización.
Otras Clave foránea a la tabla Otras_Reacciones. Este campo almacenará el
identificador de otras reacciones adversas o el valor “0” si no se ha
seleccionado ninguna reacción adversa.
TTratamiento Contendrá el valor “1” si el tipo de tratamiento es a demanda, “2” si es a
profilaxis.
DosisT Dosis del tratamiento.
Concentrado Clave foránea a la tabla Concentrados. Este campo almacenará el
identificador del concentrado del tratamiento recomendado.
Intervalo Clave foránea a la tabla Intervalos. Este campo almacenará el
identificador del intervalo del tratamiento recomendado.
Comentarios Campo donde se almacenará comentarios del doctor.

Anexos
159
� Datos_Análisis. Valores correspondiente a cada parámetro evaluado en el análisis.
IdAnalisis Clave foránea a la tabla Análisis.
IdEtiqueta Clave foránea a la tabla Etiquetas_Analisis. Junto con el IdAnalisis
forman la clave primaria de esta tabla.
Valor Valor de una etiqueta (IdEtiqueta) para un análisis determinado
(IdAnalisis).
� Etiquetas_Analisis. Etiquetas de los parámetros del análisis.
IdEtiqueta Identificador de la etiqueta del análisis.
Etiqueta Nombre de la etiqueta.
Tipo Valor “0” si la etiqueta es de tipo cadena, “1” si es de tipo +/- o “2” si es
de tipo numérico.
Activo Valor “1” si la etiqueta está activa o “0” en caso contrario.
� Revisiones_Articulaciones. Información de las revisiones de las articulaciones
IdRevision Identificador de la revisión.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya realizado la revisión.
IdPaciente Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Fecha Fecha de la revisión.
Articulación Clave foránea a la tabla Articulaciones. Este campo almacenará el
identificador de la articulación valorada.
DI Valor “1” si la articulación valorada es la izquierda o “2” si es la derecha.
Posición Valor “1” si la posición de la articulación valorada es -, “2” si es + o “0”
no se ha seleccionado ninguna posición.
Valor Valoración de la articulación.
Comentarios Campo para comentarios.

Anexos
160
� Inhibidores. Información de los inhibidores.
IdInhibidor Identificador del inhibidor.
IdPaciente Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Fecha Fecha del inhibidor.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya dado de alta al inhibidor.
Concentrado Clave foránea a la tabla Concentrados. Este campo almacenará el
identificador del concentrado.
DemPro Contendrá el valor “2” si el tipo de tratamiento es a demanda y el valor
“1” si es a profilaxis.
TituloD Título al diagnóstico.
UnidadD Clave foránea a la tabla Unidades_Titulos. Este campo almacenará el
identificador de la unidad del título.
PicoM Pico máximo.
UnidadM Clave foránea a la tabla Unidades_Titulos. Este campo almacenará el
identificador de la unidad del pico máximo.
FechaP Fecha pico máximo.
Activo Valor “1” si el inhibidor está activo o “0” en caso contrario.
� Historial_Inhibidor. Información del historial de cada inhibidor.
IdHistorial Identificador del historial.
IdInhibidor Clave foránea a la tabla Inhibidores. Este campo almacenará el
identificador del inhibidor.
FechaT Fecha del título.
Titulo Título.
Unidad Clave foránea a la tabla Unidades_titulos. Este campo almacenará el
identificador de la unidad del título.

Anexos
161
� Inmunotolerancias. Información de las inmunotolerancias de cada inhibidor.
IdInmuno Identificador de la Inmunotolerancia.
IdInhibidor Clave foránea a la tabla Inhibidores. Este campo almacenará el
identificador del inhibidor.
FechaF Fecha del inhibidor.
FechaIT Fecha de la inmunotolerancia.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya dado de alta a la inmunotolerancia.
Protocolo Clave foránea a la tabla Protocolos. Este campo almacenará el
identificador del protocolo.
Éxito Valor “1” si la inmunotolerancia ha tenido éxito, “2” si no ha tendido
éxito o “3” si está pendiente.
UnidadIT Clave foránea a la tabla Unidades_Titulos. Este campo almacenará el
identificador de la unidad del TituloIT.
Comentarios Comentarios sobre la inmunotolerancia.
� Cuestionarios. Información de los cuestionarios de calidad de vida.
IdCuestionario Identificador del cuestionario.
IdPaciente Clave foránea a la tabla Pacientes. Este campo almacenará el
identificador del paciente.
Fecha Fecha del cuestionario.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya realizado el cuestionario.
Total Resultado final del cuestionario.

Anexos
162
� Datos_Cuestionarios. Información de los ítems de los cuestionarios.
IdCuestionario Clave foránea a la tabla Cuestionario.
IdEtiqueta Clave foránea a la tabla Etiquetas_Cuestionarios. Junto con el
IdCuestionario forman la clave primaria de esta tabla.
Valor Valor del item (IdEtiqueta) para un cuestionario determinado
(IdCuestionario).
� Etiquetas_Cuestionarios. Ítems de los cuestionarios.
IdEtiqueta Identificador del ítem.
Etiqueta Nombre del ítem.
Activo Valor “1” si el ítem está activo o “0” en caso contrario.
� Articulaciones.
Id Identificador de la articulación.
Descripcion Descripción de la articulación.
� Causas_Fallecimiento.
Id Identificador de la causa de fallecimiento.
Descripción Descripción de la causa de fallecimiento.
� Causas_Investigación.
Id Identificador de la causa de investigación.
Descripción Descripción de la causa de investigación.
� Causas_Extraccion.
Id Identificador de la causa de extracción.
Descripción Descripción de la causa de extracción.

Anexos
163
� Cirugías.
Id Identificador de la cirugía.
Descripción Descripción de la cirugía.
� Concentrados.
Id Identificador del concentrado.
Descripcion Descripción del concentrado.
� Defectos
Id Identificador del defecto genético.
Descripcion Descripción de defecto genético.
� Diagnosticos.
Id Identificador del diagnóstico.
Descripcion Descripción del diagnóstico.
� Genotipovhc.
Id Identificador del valor genotipoVHC.
Descripcion Descripción del valor genotipoVHC.
� Intervalos.
Id Identificador del intervalo.
Descripcion Descripción del intervalo.

Anexos
164
� Localizaciones.
Id Identificador de la localización.
Descripcion Descripción de la localización.
� Otras_Reacciones.
Id Identificador de la reacción.
Descripcion Descripción de la reacción.
� Protocolos.
Id Identificador del protocolo.
Descripción Descripción del protocolo.
� Sangrados.
Id Identificador del sangrado.
Descripcion Descripción del sangrado.
� Tipo_Profilaxis.
Id Identificador del tipo de profilaxis.
Descripcion Descripción del tipo de profilaxis.
� Unidades_Títulos.
Id Identificador de la unidad.
Descripcion Descripción de la unidad.

Anexos
165
� Usuarios. Información de los usuarios del sistema.
IdUsu Identificador del usuario.
Nombre Nombre del usuario.
Apellido1 Primer apellido del usuario.
Apellido2 Segundo apellido del usuario.
Institución Institución a la que pertenece el usuario.
Login Nombre del usuario para acceder al sistema.
Password Palabra clave de acceso.
Email Correo electrónico del usuario.
Permisos Carácter que determina la clase de privilegios del usuario,
1=administrador de la aplicación Web, 2=usuario de lectura y escritura,
3=usuario de lectura.
Pais País del usuario.
Departamento Departamento al que pertenece el usuario.
Telefono Teléfono del usuario.
Idioma Clave foránea a la tabla Etiquetas. Este campo almacenará el
identificador del idioma elegido por el usuario. Cada vez que entre este
usuario al sistema, la aplicación aparecerá del idioma indicado en este
campo.
Doctor Clave foránea a la tabla Usuarios. Este campo almacenará el identificador
del usuario que haya dado de alta al usuario.

Bibliografía
166
BIBLIOGRAFÍA
� Setrag Khoshafian y A. Brad Baker (1996) Multimedia and Imaging Databases. Morgan
Kaufman Publishers.
� Toby Teorey (1994) Database Modeling and Desing: The Fundamental Principles. Morgan
Kaufman Publishers.
� R.G.G. Cattell (1995) The Object Database Standard: ODMG-93, Release 1.2. Morgan
Kaufman Publishers
� Gupta Amarnath (1997), Visual Information Retrieval Technology: A Virage perspective.
Rev.4, Virage Image Engine API Specification (http://www.virage.com)
� Guptha Amarnath and Ramesh Jain, (1997), Visual Information Retrieval, Communications
of the ACM, vol.40.n5
� Chang, S.K. and Hsu A. (1992), Image Information Systems: Where do we go from here?,
IEEE Trans Knowl Data Eng, 5-4., 644-658
� Phil Gross, Macromedia Director 7. Manuales y Guias de usuario, Ed.Anaya
� Ray Kristov y Amy Satran, Diseño Interactivo. Ed.Anaya
� www.apache.org. Documentación Apache.
� www.php.net. Documentación sobre programación en PHP.
� www.mysql.com. Documentación sobre MySQL.
� Turecek PL, Váradi K, Schwarz HP. Thrombin generation assay (TGA): test for
monitoring the pharmacological properties of inhibitor treatment in hemophilia.
Haematologica 2004;89 (supple):33-40.
� Guidelines on the selection and use of therapeutic products to treat haemophilia and other
hereditary bleeding disorders. Haemophilia 2003; 9(1):1-23.
� Remor E y The Hemophilia-QoL Group. Desarrollo en España de un nuevo cuestionario de
calidad de vida específico para adultos con hemofilia: el Hemofjilia-QoL. Haematologica
2004;89 (supple):21-5