revista latinoamericana de ingenieria de...
TRANSCRIPT

REVISTA LATINOAMERICANA DE INGENIERIA DE SOFTWARE DICIEMBRE 2014 VOLUMEN 2 NUMERO 6 ISSN 2314-2642
PUBLICADO POR EL GISI-UNLa
EN COOPERACIÓN POR LOS MIEMBROS DE LA RED DE INGENIERÍA DE SOFTWARE DE LATINOAMÉRICA
ARTÍCULOS TÉCNICOS
Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Pablo Cigliuti
333-364
Herramienta de Realidad Aumentada para Facilitar la Enseñanza en Contextos Educativos Mediante el Uso de las TICs Jorge Ierache, Santiago Igarza, Nahuel A. Mangiarua, Martín E. Becerra, Sebastián A. Bevacqua, Nicolás N. Verdicchio, Fernando M. Ortiz, Diego R. Sanz, Nicolás D. Duarte, Matías Sena
365-368
Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Hernán Amatriain, Eduardo Diez, Rodolfo Bertone, Enrique Fernández
369-400
COMUNICACIONES SOBRE INVESTIGACIONES EN PROGRESO
Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un Enfoque de Tecnologías Inteligentes Alejandro Hossian, Lilian Cejas, Roberto Carabajal, César Echeverría, Maxiliano Alvial, Verónica Olivera
401-404

REVISTA LATINAMERICANA
DE INGENIERIA DE SOFTWARE
La Revista Latinoamericana de Ingenieria del Software es una publicación tecnica auspiciada por la Red de Ingeniería de Software de Latinoamérica (RedISLA). Busca: [a] difundir artículos técnicos, empíricos y teóricos, que resulten críticos en la actualización y fortalecimiento de la Ingeniería de Software Latinoamericana como disciplina y profesión; [b] dar a conocer de manera amplia y rápida los desarrollos científico-tecnológicos en la disciplina de la región latinoamericana; y [c] contribuir a la promoción de la cooperación institucional entre universidades y empresas de la Industria del Software. La línea editorial, sin ser excluyente, pone énfasis en sistemas no convencionales, entre los que se prevén: sistemas móviles, sistemas, plataformas virtuales de trabajo colaborativo, sistemas de explotación de información (minería de datos), sistemas basados en conocimiento, entre otros; a través del intercambio de información científico y tecnológica, conocimientos, experiencias y soluciones que contribuyan a mejorar la cadena de valor del desarrollo en la industria del software.
Comité Editorial
RAUL AGUILAR VERA (México) Cuerpo Academico de Ingenieria de Software
Facultad de Matemáticas Universidad Autonoma de Yucatán
PAOLA BRITOS (Argentina)
Grupo de Ingeniería de Explotación de Información Laboratorio de Informática Aplicada Universidad Nacional de Río Negro
RAMON GARCÍA-MARTINEZ (Argentina)
Grupo de Investigación en Sistemas de Información Licenciatura en Sistemas
Departamento de Desarrollo Productivo y Tecnológico Universidad Nacional de Lanús
ALEJANDRO HOSSIAN (Argentina)
Grupo de Investigación de Sistemas Inteligentes en Ingeniería
Facultad Regional del Neuquén Universidad Tecnológica Nacional
BELL MANRIQUE LOSADA (Colombia) Programa de Ingeniería de Sistemas
Facultad de Ingeniería Universidad de Medellín
CLAUDIO MENESES VILLEGAS (Chile)
Departamento de Ingeniería de Sistemas y Computación Facultad de Ingeniería y Ciencias Geológicas
Universidad Católica del Norte
JONÁS MONTILVA C. (Venezuela) Facultad de Ingeniería
Escuela de Ingeniería de Sistemas Universidad de Los Andes
MARÍA FLORENCIA POLLO-CATTANEO (Argentina)
Grupo de Estudio en Metodologías de Ingeniería de Software
Facultad Regional Buenos Aires Universidad Tecnológica Nacional
JOSÉ ANTONIO POW-SANG (Perú) Maestría en Informática
Pontifica Universidad Católica del Perú
DIEGO VALLESPIR (Uruguay) Instituto de Computación
Universidad de la Republica
FABIO ALBERTO VARGAS AGUDELO (Colombia) Dirección de Investigación Tecnológico de Antioquia
CARLOS MARIO ZAPATA JARAMILLO (Colombia)
Departamento de Ciencias de la Computación y de la Decisión
Facultad de Minas Universidad Nacional de Colombia
Contacto
Dirigir correspondencia electrónica a:
Editor de la Revista Latinoamericana de Ïngenieria de Software RAMON GARCIA-MARTINEZ e-mail: [email protected]
e-mail alternativo: [email protected] Página Web de la Revista: http://www.unla.edu.ar/sistemas/redisla/ReLAIS/index.htm
Página Web Institucional: http://www.unla.edu.ar
Dirigir correspondencia postal a:
Editor de la Revista Latinoamericana de Ïngenieria de Software RAMON GARCIA-MARTINEZ Licenciatura en Sistemas. Departamento de Desarrollo Productivo y Tecnológico Universidad Nacional de Lanus Calle 29 de Septiembre No 3901. (1826) Remedios de Escalada, Lanús. Provincia de Buenos Aires. ARGENTINA.
Normas para Autores
Cesión de Derechos de Autor Los autores toman conocimiento y aceptan que al enviar una contribución a la Revista Latinoamericana de Ingenieria del Software, ceden los derechos de autor para su publicación electrónica y difusión via web por la Revista. Los demas derechos quedan en posesión de los Autores.
Políticas de revisión, evaluación y formato del envío de manuscritos La Revista Latinoamericana de Ingenieria del Software recibe artículos inéditos, producto del trabajo de investigación y reflexión de investigadores en Ingenieria de Software. Los artículos deben presentarse redactados en el castellano en el formato editorial de la Revista. El incumplimiento del formato editorial en la presentación de un artículo es motivo de retiro del mismo del proceso de evaluación. Dado que es una publicación electrónica no se imponen limites sobre la cantidad de paginas de las contribuciones enviadas. También se pueden enviar comunicaciones cortas que den cuenta de resultados parciales de investigaciones en progreso. Las contribuciones recibidas están sujetas a la evaluación de pares. Los pares que evaluaran cada contribución son seleccionados por el Comité Editorial. El autor que envíe la contribución al contacto de la Revista será considerado como el autor remitente y es con quien la revista manejará toda la correspondencia relativa al proceso de evaluación y posterior comunicación. Del proceso de evaluación, el articulo enviado puede resultar ser: [a] aceptado, en cuyo caso será publicado en el siguiente numero de la revista, [b] aceptado con recomendaciones, en cuyo caso se enviará al autor remitente la lista de recomendaciones a ser atendidas en la nueva versión del articulo y su plazo de envio; ó [c] rechazado, en cuyo caso será devuelto al autor remitente fundando el motivo del rechazo.
Temática de los artículos La Revista Latinoamericana de Ingeniería del Software busca artículos empíricos y teóricos que resulten críticos en la actualización y fortalecimiento de la Ingeniería de Software Latinoamericana como disciplina y profesión. La línea editorial pone énfasis en sistemas no convencionales, entre los que se prevén: sistemas móviles, sistemas multimediales vinculados a la televisión digital, plataformas virtuales de trabajo colaborativo, sistemas de explotación de información (minería de datos), sistemas basados en conocimiento, entre otros. Se privilegiarán artículos que contribuyan a mejorar la cadena de valor del desarrollo en la industria del software.
Política de Acceso Abierto La Revista Latinoamericana de Ingeniería de Software: Sostiene su compromiso con las políticas de Acceso Abierto a la información científica, al
considerar que tanto las publicaciones científicas como las investigaciones financiadas con fondos públicos deben circular en Internet en forma libre, gratuita y sin restricciones.
Ratifica el modelo de Acceso Abierto en el que los contenidos de las publicaciones científicas se encuentran disponibles a texto completo libre y gratuito en Internet, sin embargos temporales, y cuyos costos de producción editorial no son transferidos a los autores.
No retiene los derechos de reproducción o copia (copyright), por lo que los autores podrán disponer de las versiones finales de publicación, para difundirlas en repositorios institucionales, blogs personales o cualquier otro medio electrónico, con la sola condición de hacer mención a la fuente original de publicación, en este caso Revista Latinoamericana de Ingeniería de Software.
Lista de Comprobación de Preparación de Envíos Como parte del proceso de envío, se les requiere a los autores que indiquen que su envío cumpla con todos los siguientes elementos, y que acepten que envíos que no cumplan con estas indicaciones pueden ser devueltos al autor: 1. La contribución respeta el formato editorial de la Revista Latinoamericana de Ingenieria del
Software (ver plantilla). 2. Actualidad/Tipo de referencias: El 45% de las referencias debe hacerse a trabajos de publicados
en los últimos 5 años, así como a trabajos empíricos, para cualquier tipo de artículo (empírico o teórico).
3. Características artículos empíricos (análisis cuantitativo de datos): Se privilegian artículos empíricos con metodologías experimentales y cuasi experimentales, con pruebas estadísticas robustas y explicitación del cumplimiento de los supuestos de las pruebas estadísticas usadas.
4. Características artículos empíricos (análisis cualitativo de datos): Se privilegian artículos empíricos con estrategias de triangulación teórica-empírica, definición explícita de categorías orientadoras, modelo teórico de análisis, y análisis de datos asistido por computadora.
5. Características artículos de revisión: Para el caso de artículos de revisión, se evaluará que los mismos hayan sido desarrollados bajo el formato de meta análisis, la cantidad de referencias deben superar las 50, y deben explicitarse los criterios de búsqueda, bases consultadas y pertinencia disciplinar del artículo.
6. El artículo (en formato word y pdf) se enviará adjunto a un correo electrónico dirigido al contacto de la Revista en el que deberá constar la siguiente información: dirección postal del autor, dirección de correo electrónico para contacto editorial, número de teléfono y fax, declaración de que el artículo es original, no ha sido previamente publicado ni está siendo evaluado por otra revista o publicación. También se debe informar de la existencia de otras publicaciones similares escritas por el autor y mencionar la versión de la aplicación de los archivos remitidos (versión del editor de texto y del conversor a archivo pdf) para la publicación digital del artículo.
7. Loa Autores aceptan que el no cumplimiento de los puntos anteriores es causal de No Evaluación del articulo enviado.
Compromiso de los Autores de Artículos Aceptados La Revista Latinoamericana de Ingeniería del Software busca ser una revista técnica de calidad, en cuyo desarrollo estén involucrados los investigadores y profesionales latinoamericanos de la disciplina. En este contexto, los Autores de artículos aceptados asumen ante la Revista y la Comunidad Latinoamericana de Ingeniería del Software el compromiso de desempeñarse como pares evaluadores de nuevas contribuciones.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
333
Proceso de Identificación de Comportamiento de Comunidades Educativas Basado
en Resultados Académicos
Pablo Cigliuti1, 2, 3 Maestría en Tecnología Informática Aplicada en Educación. Universidad Nacional de La Plata. Argentina
2. Grupo de Investigación en Sistemas de Información. Universidad Nacional de Lanús. Remedios de Escalada, Argentina 3. Departamento de Ingeniería en Sistemas de Información. Universidad Tecnológica Nacional (FRBA). Argentina
Resumen—Los procesos de explotación de información se incorporan al ámbito educativo para ayudar a entender y mejorar tanto la enseñanza de los docentes como el aprendizaje de los alumnos. Entre estas cuestiones se destaca el análisis del comportamiento de comunidades educativas de forma tal de proveer al docente herramientas que ayuden a mejorar la enseñanza/aprendizaje. En este contexto, el presente trabajo tiene como objetivo proponer, estudiar y validar un proceso de explotación de información que permita identificar el comportamiento de comunidades educativas basado en resultados académicos.
Palabras Clave—Procesos de explotación de información, educación, análisis del comportamiento, comunidades educativas.
I. INTRODUCCIÓN En esta sección se presenta el contexto general de este
trabajo (sección A), luego se expone la síntesis del trabajo realizado (sección B), y se aborda la estructura del trabajo (sección C).
A. Contexto General del Trabajo En esta sección se presentan las generalidades propias de la
educación a distancia (sección A1), luego se aborda el contexto general de la explotación de información (sección A2), y finalmente se exponen las generalidades propias de la explotación de información educativa (sección A3).
A1. Educación a Distancia [1] sostienen que tradicionalmente, nunca se había
concebido una fórmula de enseñanza que no contemplara lo presencial, es decir, la coincidencia física en espacio y tiempo del maestro y el alumno. Así, a lo largo de la historia, los procesos educativos se basaban en la idea de que el contacto educador-educado era la actividad básica que posibilitaba una formación esencialmente oral, ayudada por un soporte escrito que podía presentar ciertas limitaciones.
A partir de la invención de la imprenta, la relación educativa, tradicionalmente considerada un asunto exclusivo entre maestro y alumno, incorporó un tercer elemento: los libros. La creación de los grandes sistemas escolares públicos, significó la generalización y la expansión de unas formas de enseñanza y aprendizaje basadas, lógicamente, en la acción de un maestro o maestros sobre un grupo de alumnos más o menos numeroso, en un espacio y en un tiempo concreto (la clase) y con el soporte de libros de texto. En tanto, la enseñanza universitaria no fue ajena a esta evolución.
A finales del siglo XIX, a causa de la disminución progresiva del precio del papel y la creación de los grandes servicios públicos de correos, aparecen las primeras fórmulas alternativas de enseñanza no presencial, concebidas entonces como enseñanza por correspondencia [2]. Todas ellas se basan en la concepción de que aquello que el maestro enseña oralmente (la lección magistral) puede ser sustituido por aquello que puede ser explicado sobre un soporte de papel impreso, pues al fin y al cabo, según esta visión prototípica y tradicional de la enseñanza a distancia, se trata de transmitir contenidos desde la mente del profesor hasta la del estudiante.
A medida que la tecnología fue evolucionando, fueron cambiando las modalidades de la educación a distancia utilizando diferentes soportes para lograr el objetivo: radiodifusión, televisión, videos, informática y telemática fueron algunas de ellas, hasta llegar a la actualidad con internet. Pues ahora la educación a distancia utiliza mayormente plataformas virtuales especialmente preparadas para la ocasión.
La educación a distancia y presencial tienen diferencias tangibles. En la educación a distancia el alumno y el profesor se encuentran separados físicamente y carecen de una interacción cara a cara. La educación a distancia es un sistema de enseñanza mediado por tecnología, donde el profesor y al alumno no comparten un espacio físico en común para llevar a cabo este proceso. Como principales características podemos mencionar [3]: (a) la separación alumno-profesor, (b) la utilización sistemáticas de medios y recursos tecnológicos, (c) el aprendizaje individual, (d) el apoyo de una organización de carácter tutorial y (e) la comunicación bidireccional.
En la educación a distancia la interacción alumno-profesor, en general, se hace por intermedio de recursos tecnológicos [4], donde la posibilidad de comunicarse con lenguaje gestual, corporal y oral, está dificultada. Estos recursos tecnológicos son diversos y han ido cambiando a lo largo del tiempo: correo postal, cassette y teléfono son alguno de los ejemplos. Con la aparición de la computadora personal, y mucho más adelante de internet, la tecnología utilizada como soporte para la educación a distancia ha ido evolucionando rápidamente. Actualmente los cursos de educación dictados a distancia se apoyan, en su mayoría, en Entornos Virtuales de Enseñanza y Aprendizaje (EVEAs). Estas plataformas, además de contener información de los participantes, cuentan también con herramientas que dan soporte a la comunicación entre alumnos (foros, mensajes, chats, repositorios de materiales de lectura, entre otros). Estos instrumentos generan gran cantidad de información [5].

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
334
Para [6] el aprendizaje es definido como un cambio estable en la conducta. Antes de aprender, un alumno no es capaz de lograr un objetivo y, luego del aprendizaje, será capaz de alcanzarlo. En este contexto, la evaluación es la herramienta que utilizan los docentes que les permite observar los avances en el desarrollo de las habilidades de conducta, los objetivos del programa y detectar los errores frecuentes evaluando la eficacia del programa de la materia propuesto. Sin embargo, las evaluaciones por sí mismas no permiten al docente diagnosticar las dificultades de aprendizaje de los alumnos y sus causas.
A2. Explotación de Información En [7] se define el término explotación de información
como el proceso de descubrir nuevas correlaciones, patrones y tendencias utilizando grandes cantidades de datos almacenados en repositorios, utilizando tecnologías de reconocimiento de patrones así como herramientas matemáticas y de estadística.
La Explotación de Información es una subdisciplina de los Sistemas de Información [8] que provee herramientas de análisis y síntesis para extraer conocimiento no trivial el cual se encuentra (implícito) en los datos disponibles en diferentes fuentes de información [9].
Un Proceso de Explotación de Información, puede ser definido como un conjunto de tareas relacionadas lógicamente [10] que son ejecutadas para lograr, desde un conjunto de información con un grado de valor para la organización, otro conjunto de información con un grado mayor de valor que el primero [11];[12].
En [13] se proponen los siguientes procesos de explotación de información: descubrimiento de reglas de comportamiento, descubrimiento de grupos, descubrimiento de atributos significativos, descubrimiento de reglas de pertenencia a grupos y ponderación de reglas de comportamiento o de pertenencia. El proceso de descubrimiento de reglas de comportamiento aplica cuando se requiere identificar cuáles son las condiciones para obtener determinado resultado en el dominio del problema. El proceso de descubrimiento de grupos aplica cuando se requiere identificar una partición en la masa de información disponible sobre el dominio de problema. El proceso de ponderación de interdependencia de atributos aplica cuando se requiere identificar cuáles son los factores con mayor incidencia (o frecuencia de ocurrencia) sobre un determinado resultado del problema. El proceso de descubrimiento de reglas de pertenencia a grupos aplica cuando se requiere identificar cuáles son las condiciones de pertenencia a cada una de las clases en una partición desconocida “a priori”, pero presente en la masa de información disponible sobre el dominio de problema. El proceso de ponderación de reglas de comportamiento o de la pertenencia a grupos aplica cuando se requiere identificar cuáles son las condiciones con mayor incidencia (o frecuencia de ocurrencia) sobre la obtención de un determinado resultado en el dominio del problema, sean éstas las que en mayor medida inciden sobre un comportamiento o las que mejor definen la pertenencia a un grupo.
Cada proceso de explotación de información tiene asociado una familia de técnicas de minería de datos [14] que son útiles para descubrir los patrones de conocimiento que están siendo buscados. Varias de estas técnicas vienen del campo del Aprendizaje Automático [14].
Una vez que el problema de explotación de información es identificado, el Ingeniero de Explotación de Información selecciona la secuencia de procesos de explotación de
información a ser ejecutados para resolver el problema de descubrimiento de patrones de conocimiento.
A3. Explotación de Información Educativa La Explotación de Información Educativa (EIE) consiste en
aplicar técnicas de minería de datos a los datos generados a partir de los procesos de enseñanza y aprendizaje. El objetivo es poder analizar este tipo de datos con el propósito de ayudar a resolver problemas de investigación educativa [15]. La EIE está relacionada con el desarrollo de métodos para explorar tipos únicos de datos en entornos educativos, utilizando estos métodos para comprender mejor a los estudiantes y los entornos en los que aprenden [16]. Por un lado el crecimiento tanto en software educativo como en bases de datos con información de los estudiantes, han creado un gran repositorio de datos, reflejando la forma en que los estudiantes aprenden [17]. Por otro lado, el uso de internet en la educación ha creado un nuevo contexto conocido como e-learning o educación basada en la web, en la cual se genera gran cantidad de información sobre la interacción enseñanza-aprendizaje [18]. La EIE busca usar estos repositorios de datos para comprender mejor a los estudiantes y profesores, y desarrollar aproximaciones computacionales que combinen datos y teoría para mejorar la forma en que se realiza la práctica.
La EIE se ha convertido en un área de investigación en los últimos años para los investigadores de todo el mundo abarcando temáticas como [19]: • Educación Presencial: en este ámbito se transmiten
conocimientos y habilidades basadas en el contacto cara a cara y también se estudia psicológicamente cómo el humano aprende (se han aplicado técnicas psicométricas y estadísticas a datos obtenidos desde los EVEAs, relacionados con el comportamiento y rendimiento de los estudiantes).
• Educación a Distancia y EVEAs: la educación a distancia soportada por EVEAs además de brindar aprendizaje en línea provee herramientas de comunicación, colaboración y administración (se han aplicado técnicas de minería web a los datos que estos sistemas guardan en archivos logs y base de datos sobre las actividades realizadas por los estudiantes).
• Tutoría Inteligente: consiste en sistemas que adaptan el aprendizaje a las necesidades de cada estudiante en particular (la explotación de información ha sido aplicada a los datos generados por estos sistemas, como los archivos de logs, modelos de usuarios, etc.).
Avalando el uso de explotación de información en el campo de la educación se han desarrollado experiencias tanto a [a] nivel internacional como a [b] nivel nacional:
[a] Desde una visión de marco teórico, en [20]; [21] se revisa la historia y las tendencias en el campo de la Explotación de Información Educativa. Se formulan reflexiones sobre el perfil metodológico de la investigación en EIE; y se discuten los cambios y tendencias llevadas por la comunidad. En particular, se discute el mayor énfasis en la predicción y el surgimiento de trabajo utilizando los modelos existentes para hacer descubrimiento de conocimiento en el ámbito educativo. Por otra parte, en [22] analizan la aplicación de explotación de información en los sistemas de enseñanza tradicionales. Se realiza una comparación de la explotación de información aplicadas a sistemas de e-learning con los de e-commerce. En un trabajo posterior [19] formulan una revisión bibliográfica sobre estudios relevantes realizados en EIE. Allí se describen los diferentes grupos de usuarios, tipos de entornos educativos y los datos que estos entornos generan. También se enumeran aplicaciones típicas de la explotación de

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
335
información en el ámbito educativo mencionando las técnicas de minería de datos utilizadas. En [23] se describe un proceso para explotación de información de datos de e-learning, así como la forma de aplicar las técnicas de minería de datos a la obtención de reglas de comportamiento en el espacio virtual provisto por la plataforma Moodle.
Desde una visión de aplicativa, en [24] se clasifican a los estudiantes prediciendo su calificación final basándose en características extraídas de los logs de acceso al EVEA. Se diseñan una serie de patrones de clasificación y se comparan entre sí. En [25] se evalúan aplicaciones de e-learning a través de los datos generados por los estudiantes, proponiendo un acercamiento para detectar potenciales síntomas de baja performance en cursos de e-learning utilizando el proceso de descubrimiento de reglas. En [26] se presenta un caso de estudio en el cual, se utilizan procesos de explotación de información para predecir el abandono de estudiantes de una carrera de ingeniería luego del primer semestre de sus estudios, o antes de entrar a la carrera, e identifica los factores de éxito para esta carrera.
[b] En [27][28] se utilizan procesos de explotación de información para ayudar a los docentes a diagnosticar las dificultades de aprendizaje de los alumnos (y sus causas) relacionadas a sus errores en programación con base en un proceso de descubrimiento del conocimiento de tres pasos. En [28] se presenta una solución al problema de la selección del estilo de enseñanza utilizando el proceso de explotación de información de descubrimiento de grupos, para encontrar los patrones de estudiantes con características comunes partiendo de los datos de estilos de aprendizaje y personales, todos ellos relevados sobre cada individuo. Estos patrones de conocimiento descubiertos son utilizados para determinar el protocolo pedagógico, conforme a los descriptos por la Teoría Uno [29], que mejor aplica a cada estudiante. En [30][31] se aborda el estudio del abandono de los estudios universitarios en el nivel de pregrado buscando posibles causas de deserción, utilizando los procesos de explotación de información: descubrimiento de reglas y descubrimiento de atributos significativos para caracterizar el abandono e identificar las variables con mayor incidencia en la deserción, a partir de la información disponible en el Sistema SIU-Guarani [32]. En [33] se define una metodología basada en procesos de explotación de información: descubrimiento de reglas y descubrimiento de atributos significativos, que permiten al docente: (1) identificar los errores de aprendizaje de los alumnos en instancias evaluativas y (2) diagramar los conceptos enseñados en pos de minimizar, en tanto sea posible, dichos errores.
B. Síntesis del Trabajo Realizado Durante el desarrollo de este trabajo se abordará la
investigación de temas tales como los patrones de comportamiento de comunidades educativas, los procesos de explotación de información, la creación de procesos de explotación de información aplicables a la identificación de comportamientos sociales y la propuesta de procesos de identificación de patrones de comportamientos de poblaciones educativas utilizando explotación de información.
De este modo, y a partir de lo expresado, se espera arribar a la definición de procesos de explotación de información que permitan estudiar el comportamiento de los estudiantes a lo largo de un curso o una carrera. Y así, identificar y resolver distintos problemas asociados a la apropiación de los conceptos y al favorable desarrollo de la materia, brindando una
herramienta que favorezca la comprensión del curso y la posibilidad de implementar medidas que permitan detectar alumnos con dificultades en el curso e intervenir de manera temprana, pudiendo corregir factores que impacten en el resultado de la cursada.
C. Estructura del Trabajo En la sección “Estado de la Cuestión” se presenta una
introducción general a la explotación de información, luego se abordan los diferentes procesos de explotación de información, se presentan los antecedentes de la explotación de información en el ámbito educativo, y se exponen diferentes casos de estudio.
En la sección “Problema” se abordan los problemas comunes relacionados con el rendimiento de los estudiantes tanto en la educación presencial como a distancia, luego se proponen las líneas de investigación con el objetivo de ayudar a resolver los problemas mencionados los diferentes procesos de explotación de información.
En la sección “Solución” se presentan los marcos de la solución propuesta y luego se plantea la solución a los problemas desarrollados en la sección anterior.
En la sección “Validación” se describen tres casos; el primero de ellos de Procesos de Identificación de Comportamiento de Recursantes Utilizando EVEAs, el segundo consiste en Identificación Conceptos Críticos de una Cursada, y por último Identificación de Contenidos Débilmente Apropiados por Estudiantes.
En la sección “Conclusiones” se exponen los aportes realizados por este trabajo y se presentan las futuras líneas de investigación.
II. ESTADO DE LA CUESTIÓN En esta sección se presenta una introducción general a la
explotación de información (sección A), luego se abordan los diferentes procesos de explotación de información (sección B), se presentan los antecedentes de la explotación de información en el ámbito educativo (sección C), y se exponen diferentes casos de estudio (sección D).
A. Introducción General a la Explotación de Información Se denomina inteligencia de negocio al conjunto de
estrategias y herramientas [34] enfocadas a la administración y creación de conocimiento mediante el análisis de datos existentes en una organización [35]. Involucra el uso de los datos de una organización para facilitarle a las personas que realizan la toma de decisiones estratégicas del negocio, la comprensión del funcionamiento actual y la anticipación de acciones para dar una dirección bien informada a la organización [36].
La explotación de información se ha definido como la búsqueda de patrones interesantes y de regularidades importantes en grandes masas de información [37]. Al hablar de explotación de información basada en sistemas inteligentes [38] se refiere específicamente a la aplicación de métodos de sistemas inteligentes, para descubrir y enumerar patrones presentes en la información. Los métodos basados en sistemas inteligentes [39], permiten obtener resultados de análisis de la masa de información que los métodos convencionales [40] no logran tales como: los algoritmos TDIDT (Top Down Induction Decision Trees), los mapas auto organizados (SOM) y las redes bayesianas. Se ha señalado la necesidad de disponer de procesos [41] que permitan obtener conocimiento [42] a

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
336
partir de las grandes masas de información disponible [43], su caracterización [44] y tecnologías involucradas [45].
B. Procesos de Explotación de Información Un proceso de explotación de información [10], puede
definirse como un conjunto de tareas relacionadas lógicamente, que se ejecutan para lograr a partir de un conjunto de información con un grado de valor para la organización, otro conjunto de información con un grado de valor mayor que el inicial [11].
Cada proceso de explotación de información define un conjunto de información de entrada, un conjunto de transformaciones y un conjunto de información de salida. Un proceso de explotación de información puede ser parte de un proceso mayor que lo abarque o bien puede incluir otros procesos de explotación de información que deban ser incluidos en él, admitiendo una visión desde varios niveles de granularidad [12].
Identificado el problema de inteligencia de negocio y las técnicas de explotación de información, un proceso de explotación de información describe cuáles son las tareas que hay que desarrollar para que aplicando las técnicas de explotación a la información que se tenga vinculada al negocio se obtenga una solución al problema de inteligencia de negocio [46].
En este contexto [47] proponen la siguiente caracterización de los problemas de explotación de información asociados a los problemas de inteligencia de negocios:
[a] Descubrimiento de Reglas de Comportamiento: el proceso de descubrimiento de reglas de comportamiento (Fig. 1) aplica cuando se requiere identificar cuáles son las condiciones para obtener determinado resultado en el dominio del problema. Para el descubrimiento de reglas de comportamiento definidos a partir de atributos clases en un dominio de problema que representa la masa de información disponible, se propone la utilización de algoritmos de inducción TDIDT [28] para descubrir las reglas de comportamiento de cada atributo clase.
Fig. 1. Proceso de Descubrimiento de Reglas de Comportamiento.
Los pasos a seguir para este proceso consisten en: a) Identificar todas las fuentes de información (bases de datos, archivos planos, entre otras), e integrarlas entre sí formando una sola fuente de información a la que se llamará datos integrados. b) Seleccionar un atributo clase con base en los datos integrados. c) Aplicar el algoritmo de inducción TDIDT al atributo clase. A partir de esto se obtiene un conjunto de reglas que definen el comportamiento de dicha clase. [b] Descubrimiento de Grupos: se aplica cuando se
requiere identificar una partición en la masa de información disponible sobre el dominio de problema. Para el descubrimiento de grupos, a partir de masas de información del dominio de problema sobre las que no se dispone ningún criterio de agrupamiento “a priori”, se propone la utilización de Mapas Auto Organizados de Kohonen. El uso de esta tecnología busca descubrir si existen grupos que permitan una
partición representativa del dominio de problema que la masa de información disponible representa. Este proceso y sus subproductos pueden ser visualizados gráficamente en la Figura 2 y consiste en:
a) Identificar todas las fuentes de información (bases de datos, archivos planos, entre otras), e integrarlas entre sí formando una sola fuente de información a la que se llamará datos integrados. b) Aplicar mapas auto-organizados con base en los datos integrados. Como resultado de la aplicación de SOM se obtiene una partición del conjunto de registros en distintos grupos a los que se llamará grupos identificados. c) Generar el archivo correspondiente para cada grupo identificado.
Fig. 2. Proceso de Descubrimiento de Grupos
[c] Ponderación de Interdependencia de Atributos: este
proceso (Fig. 3) se aplica cuando se requieren identificar cuáles son los factores con mayor incidencia sobre un determinado resultado o problema. Los pasos de este proceso son los siguientes:
a) Identificar todas las fuentes de información (bases de datos, archivos planos, entre otras), e integrarlas entre sí formando una sola fuente de información a la que se llamará datos integrados. b) Seleccionar el atributo clase con base en los datos integrados. c) Aplicar Redes Bayesianas al archivo con el atributo clase identificado. A partir de esto se obtiene el árbol de aprendizaje. d) Aplicar el aprendizaje predictivo al árbol de aprendizaje obtenido en c). Así, se obtiene el árbol de ponderación de interdependencias que tiene como raíz al atributo clase y como hojas a los otros atributos con la frecuencia (incidencia) sobre el atributo clase.
.
Fig. 3. Proceso de Ponderación de Interdependencia de Atributos.
[d] Descubrimiento de Reglas de Pertenencia a Grupos:
este proceso (Fig. 4) aplica cuando se requiere identificar cuáles son las condiciones de pertenencia a cada una de las clases en una partición desconocida “a priori”, pero presente en la masa de información disponible sobre el dominio de problema. Para el descubrimiento de reglas de pertenencia a

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
337
grupos se propone la utilización de mapas auto-organizados para el hallazgo de los mismos y; una vez identificados los grupos, la utilización de algoritmos de inducción para establecer las reglas de pertenencia a cada uno [48]. Los pasos para realizar este proceso son:
a) Identificar todas las fuentes de información (bases de datos, archivos planos, entre otras), e integrarlas entre sí formando una sola fuente de información a la que se llamará datos integrados. b) Aplicar mapas auto-organizados con base en los datos integrados. A partir de esto se obtiene una partición del conjunto de registro en distintos grupos. A estos grupos se los llama grupos identificados. c) Generar los archivos asociados a cada grupo identificado. A este conjunto de archivos se lo llama grupos ordenados. El atributo “grupo” de cada grupo ordenado se identifica como el atributo clase de dicho grupo, constituyéndose este en un archivo con atributo clase identificado (GR). d) Aplicar el algoritmo de inducción TDIDT al atributo clase de cada grupo GR. De esta manera, se obtiene un conjunto de reglas que definen el comportamiento de cada grupo.
Fig. 4. Proceso de Descubrimiento de Reglas Pertenecientes a Grupos.
[e] Ponderación de Reglas de Comportamiento o de
Pertenencia a Grupos: el proceso de ponderación de reglas de comportamiento (Fig. 5.) se aplica cuando se requiere identificar cuáles son las condiciones con mayor incidencia (o frecuencia de ocurrencia) sobre la obtención de un determinado resultado en el dominio del problema, sean estas las que en mayor medida inciden sobre un comportamiento o las que mejor definen la pertenencia a un grupo. Para la ponderación de reglas de comportamiento o de pertenencia a grupos se propone la utilización de redes bayesianas [48]. Esto puede hacerse a partir de dos procedimientos dependiendo de las características del problema a resolver: cuando no hay clases/grupos identificados; o cuando hay clases/grupos identificados. El procedimiento a aplicar cuando hay clases/grupos identificados consiste en la utilización de algoritmos de inducción TDIDT [28] para descubrir las reglas de comportamiento de cada atributo clase y posteriormente se utiliza redes bayesianas para descubrir cuál de los atributos establecidos como antecedentes de las reglas tiene mayor incidencia sobre el atributo establecido como consecuente. Los pasos para aplicar este proceso son los siguientes:
a) Identificar todas las fuentes de información (bases de datos, archivos planos, entre otras), e integrarlas entre sí formando una sola fuente de información a la que se
llamará datos integrados. Con base en los datos integrados se puede aplicar dos procedimientos posibles: 1) cuando hay clases/grupos identificados, y 2) cuando no hay clases/grupos identificados. 1) Clases o grupos identificados:
1.a) Aplicar el algoritmo de inducción TDIDT al atributo clase, de manera de obtener un conjunto de reglas que definen el comportamiento de dicha clase. 1.b) Construir un archivo con los atributos antecedentes y consecuentes identificados por la aplicación del algoritmo TDIDT.
Fig. 5. Proceso de Ponderación de Reglas de Comportamiento o de
Pertenencia a Grupos.
2) Clases o grupos no identificados: 2.a) Aplicar la técnica de mapas auto organizados. Como resultado de la aplicación de SOM se obtiene una partición del conjunto de registros en distintos grupos a los que se llamará grupos identificados. 2.b) Generar para cada grupo identificado el archivo correspondiente. A este conjunto de archivos se lo llama grupos ordenados. El atributo “grupo” de cada grupo ordenado se identifica como el atributo clase de dicho grupo, constituyéndose este en un archivo con atributo clase identificado (GR). b) Aplicar el aprendizaje estructural a los archivos generados en 1.b) o 2.b) según corresponda, para de esta forma obtener el árbol de aprendizajes. c) Aplicar el aprendizaje predictivo al árbol de aprendizajes. De este modo, se obtiene el árbol de ponderación de interdependencias que tiene como raíz al atributo clase (en este caso el atributo consecuente) y como nodos hojas a los atributos antecedentes con la frecuencia (incidencia) sobre el atributo consecuente.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
338
C. Explotación de Información en el Ámbito Educativo Con el objetivo de proveer un ambiente de aprendizaje más
efectivo se pueden utilizar procesos de explotación de información sobre la información generada por los EVEAs. El proceso de explotación de información aplicado a la educación involucra diferentes grupos de usuarios o participantes. Los diferentes grupos analizan la información relacionada con la educación desde diferentes ángulos de acuerdo a la misión, visión y objetivos de cada uno en cuanto a la utilización de los procesos de explotación de información [49]. En la Tabla I se clasifican posibles grupos a los cuales se les puede aplicar explotación de información [50].
La explotación de información ha sido aplicada al comercio electrónico en forma exitosa [51] y ha comenzado a utilizarse en la educación a distancia con resultados prometedores. [49] sostiene que, si bien los métodos utilizados en el comercio electrónico y en la educación mediada por EVEAs son similares, existen algunas diferencias importantes a resaltar:
[a] Dominio: el propósito del comercio electrónico es guiar a los clientes en las compras, mientras el propósito del aprendizaje mediados por EVEAs es guiar a los estudiantes en el aprendizaje [52].
[b] Datos: en el comercio electrónico la utilización de los datos por lo general es simplemente acceder al log de acceso, pero en el aprendizaje a través de entornos virtuales hay más volumen de información sobre las interacciones del estudiante [53].
[c] Objetivo: el objetivo de la explotación de información en el comercio electrónico es el de incrementar las ganancias, una ganancia tangible y medible en términos de dinero, número de clientes, fidelidad del cliente, y demás. Mientras que el objetivo de la explotación de información aplicada a la educación tiene como objetivo, entre otras cosas, mejorar el aprendizaje. Por supuesto que, en materia de educación, es mucho más subjetivo y difícil de medir.
[d] Técnicas: los EVEAs tienen características especiales que requieren de diferentes tratamientos. Como consecuencia de esto, algunos procesos de explotación de información hay que adaptarlos a necesidades particulares del proceso de aprendizaje [54][53]. Así, algunos pueden ser adaptados mientras que otros no.
TABLA I. GRUPOS DE APLICACIÓN DE PROCESOS DE EXPLOTACIÓN DE INFORMACIÓN
Usuario / Rol Objetivo en la utilización de procesos de explotación
Estudiantes Personalización del aprendizaje; para recomendar actividades, recursos y tareas de aprendizaje que puedan mejorar su aprendizaje; para sugerir experiencias interesantes de aprendizaje; para recomendar cursos; discusiones relevantes; libros, etc.
Profesores / Educadores
Para recibir retroalimentación objetiva sobre el instructor; para analizar el aprendizaje y comportamiento de los estudiantes; para detectar que estudiantes requieren soporte; para agrupar estudiantes en distintos grupos; para encontrar los errores cometidos con más frecuencia, etc
Desarrolladores de cursos / Investigadores de la educación
Para evaluar y mantener los cursos; para mejorar el aprendizaje de los estudiantes; para evaluar la estructura de los contenidos del curso y su efectividad en el proceso de aprendizaje; para construir automáticamente modelos de estudiantes y de tutores; para comparar técnicas de minería de datos con el objetivo de recomendar la más adecuada para cada tarea, etc.
Organizaciones / Universidades /
Para mejorar el proceso de decisiones en la escuela superior; para lograr objetivos específicos; para
Empresas de cursos recomendar ciertos cursos que pueden ser mejores para cierta clase de estudiantes; para encontrar el costo más efectivo para retener alumnos y graduarlos, etc.
Administradores / Directores de colegios / Administradores de redes / Administradores de Sistemas
Para desarrollar la mejor forma de organizar los recursos institucionales (humanos y materiales) y su oferta educativa; para utilizar los recursos disponibles de forma más efectiva; para evaluar a los profesores y los planes de estudio, para configurar parámetros para mejorar la eficiencia de los sitios y adaptarlos a los usuarios, etc
La aplicación de la extracción de conocimiento en sistemas
educativos con el objetivo de mejorar el aprendizaje puede ser vista como una técnica de evaluación formativa. Una técnica de evaluación formativa es la evaluación de un programa de educación mientras está en desarrollo [55], y tiene el propósito de una mejora continua.
En la Figura 6 se puede observar a los profesores y responsables académicos que están encargados de diseñar, planificar, construir, y mantener los sistemas educativos. Los estudiantes utilizan e interactúan con estos sistemas. A partir de la información disponible en los cursos, y la interacción y uso de la misma por parte de los alumnos, se utilizan diferentes procesos de explotación de información para descubrir conocimiento el cual puede ayudar no solo a los educadores, sino también a los estudiantes [56].
[22] sostienen que la minería de datos aplicada a la educación se puedo aplicar en el ámbito de [a] la clase presencial y en [b] educación a distancia.
Fig. 6. El Ciclo de la Aplicación de la Minería de Datos en los Sistemas
Educativos [a] Las clases en modalidad presencial son las más
utilizadas actualmente en el sistema educativo y están basadas en un contacto cara a cara entre alumnos y docentes. Hay varios subtipos de educación presencial: privada, pública, primaria, secundaria, terciaria, universitaria, etc. Este tipo de educación ha sido muy criticada porque fomenta el aprendizaje pasivo, pasa por alto las diferencias individuales y necesidades de los diferentes estudiantes, y no presta atención a la resolución de problemas, pensamiento crítico u otras habilidades de pensamiento de orden superior [57]. En la clase presencial los docentes intentan mejorar sus clases a través de la visualización del rendimiento de los estudiantes por medio de la observación y los registros escritos, como exámenes y ejercicios prácticos. También utilizan información de asistencia, información sobre el curso, objetivos de la materia, etc. Una institución educativa posee diversas y variadas fuentes de información [58]: bases de datos tradicionales (con información de los estudiantes, de los docentes, de las clases, y de la planificación de estas), información en línea (páginas web y cuenta de twitter de las institución, contenido de la materia), base de datos multimedia, etc. La explotación de información puede ayudar a cualquier actor del proceso de aprendizaje (profesores, estudiantes, responsables académicos, entre otros). Las instituciones se

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
339
interesan por saber qué estudiante se podría anotar a qué curso, y qué estudiante necesita ayuda para poder graduarse. Al administrador le podrían interesar predecir los cantidad de estudiantes que se van a anotar a un curso. El alumno podría querer saber cuál es el mejor curso para anotarse de acuerdo a su perfil e incluso predecir su rendimiento. Los docentes podrían querer saber cuáles son las experiencias que más contribuyen a resultados generales de aprendizaje, por qué una clase supera a otra, grupos de estudiantes similares, etc.
[b] La educación a distancia consiste en proveer acceso a programas de educación para estudiantes que están separados por tiempo y espacio del docente. Existen varias formas de implementar la educación a distancia, pero hoy en día una de las más difundidas es mediante Entornos Virtuales de Educación y Aprendizajes (EVEAs). En su mayoría estos entornos pueden por lo general grabar los accesos de los estudiantes, los cuales proveen por donde fue navegando estudiante. Si bien los logs pueden registrar las actividades de los estudiantes, también poseen varias limitaciones, como por ejemplo: se conoce desde qué máquina se conecta el usuario pero no se sabe qué usuario lo hizo, se registran los clics que realiza cada uno pero no hay información sobre la actividad a la que estaban relacionados, además tampoco capturan información del contexto. Por este motivo varios autores plantean otras soluciones. Así, [59] propone otra forma de almacenar las actividades de los estudiantes. La misma incluye el camino de aprendizaje, los cursos preferidos, el tiempo de aprendizaje, y demás. Por otro lado [54] utiliza más canales de comunicación para modelar el comportamiento de navegación de los usuarios: logs de acceso, estructura de los sitios web visitados y sus contenidos. En cambio, [60] combina los datos con otros métodos de investigación, tales como charlas informales con los estudiantes, encuestas, o devolución escrita sobre el sitio web.
En el ámbito de educación a distancia, la explotación de información puede ser utilizada, por ejemplo, para saber cómo los estudiantes hacen uso del curso, cómo una estrategia pedagógica impacta en los diferentes estudiantes, en qué orden los estudiantes estudian las diferentes unidades de las materias, cuánto tiempo el estudiante permanece en una página.
La explotación de información en el ámbito educativo se clasifica en diferentes grupos según el objetivo que ésta persiga. En [50] se propone la siguiente clasificación:
[a] Análisis y visualización de datos: se resalta la información útil y se da soporte a la toma de decisiones mediante técnicas gráficas que ayudan a las personas a analizar y entender los datos. En ambientes educativos, por ejemplo, podría ser de gran ayuda a los docentes para analizar las actividades realizadas en un curso y la información utilizada para tener una vista general del aprendizaje del estudiante.
[b] Proveer conocimiento para dar soporte a los instructores: se genera retroalimentación de las actividades que realizan los estudiantes para que esto ayude a los profesores en la toma de decisiones (sobre mejorar el aprendizaje de los estudiantes y organizar el material de enseñanza de manera más eficiente, entre otras cosas) y en la realización de acciones proactivas y/o correctivas.
[c] Recomendaciones para estudiantes: se hacen recomendaciones a los estudiantes, en forma personalizada, sobre sus actividades, enlaces a visitar, el próximo problema a realizar, etc. También se pueden adaptar contenidos a cada estudiante en particular.
[d] Predecir el rendimiento de los estudiantes: se estima el valor desconocido de las variables que describen al alumno.
En educación a distancia por lo general estos valores se utilizan para predecir el desempeño, conocimiento, y notas de los estudiantes.
[e] Modelado del estudiante: se desarrollan modelos cognitivos para los estudiantes, incluyendo el modelado de sus habilidades y conocimiento declarativo. Se utiliza la explotación de información para examinar de forma automática características del estudiante y su comportamiento de aprendizaje con el objetivo de poder generar modelos de estudiantes en forma automática [61].
[f] Detectar comportamientos no deseados de los estudiantes: se descubren aquellos estudiantes que tienen algún tipo de problema o comportamiento inusual tales como: acciones erróneas, baja motivación, abandono, etc.
[g] Agrupamiento de estudiantes: se crean grupos de estudiantes de acuerdo características particulares, funciones personalizadas, etc. Cada uno de estos grupos puede ser utilizado luego por los docentes para construir un sistema de aprendizaje personalizado, para promover aprendizaje efectivo al grupo, para adaptar contenidos, etc.
[h] Análisis de redes sociales: se busca el estudio de las relaciones entre individuos, en lugar de atributos o propiedades individuales. Una red social es un grupo de personas que están conectados por relaciones sociales, ya sean de amistad, de cooperación o de intercambio de información [62].
[i] Desarrollo de mapas conceptuales: se ayuda a los profesores a la construcción automática de mapas conceptuales. Un mapa conceptual es un gráfico que muestra relaciones entre conceptos y expresa una estructura jerárquica del conocimiento [63].
[j] Construcción de cursos: se ayuda a los instructores y desarrolladores de cursos a distancia a llevar adelante el proceso de construcción y desarrollo del curso y de los contendidos de aprendizaje de forma automática. Por otro lado, también intenta promover la reutilización / intercambio de recursos de aprendizaje existentes entre los diferentes usuarios y sistemas.
[k] Planificación y organización: se mejora el proceso tradicional de educación a través de la planificación de cursos, ayudando con la organización de los estudiantes, planificando la asignación de recursos, colaborando en la admisión y desarrollando planes de estudio, entre otras cosas.
A diferencia de Romero y Ventura, [21] proponen clasificar la explotación de información en el ámbito educativo de la siguiente forma:
[a] Mejoramiento de los modelos de estudiantes: un modelo de estudiante representa información sobre las características o estado del estudiante, tales como el conocimiento actual del mismo, motivación, y actitudes. Modelar las diferencias individuales de los estudiante sobre estas características permite responder a estas diferencias en forma individual, mejorando notablemente el aprendizaje del estudiante [64].
[b] Estudio del apoyo pedagógico: se busca conocer qué tipo de apoyo pedagógico es más efectivo, ya sea en general, o para diferentes grupos de estudiantes, o en distintas situaciones.
[c] Evidencias empíricas: se buscan evidencias en base a las experiencias para refinar y ampliar las teorías de la educación y los fenómenos educativos ya conocidos, a través de la obtención de un conocimiento más profundo de los factores claves que impactan en la educación, siempre teniendo en vista el mejoramiento de los sistemas de aprendizaje.
Así, luego del análisis de ambas clasificaciones en el presente trabajo se tomará una posición más cercana a los

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
340
grupos definidos por [50] y se hará foco en la identificación del comportamiento de las comunidades educativas a través de la explotación de información aplicada a la educación, pudiendo ayudar a actividades como:
[a] Evaluación del rendimiento del estudiante. [b] Mejoramiento del proceso de aprendizaje. Modificación sobre el diseño de los cursos.
Para las diferentes aplicaciones mencionadas anteriormente, los distintos autores proponen la utilización de diversas técnicas de minería de datos, así [65] utiliza las siguientes técnicas:
[a] Estadísticas y Visualización: si bien las estadística es a menudo la herramienta utilizada como punto de partida para el análisis de los datos generados por los sistemas de educación a distancia, no es considerada una técnica de minería de datos [66]. Algunos ejemplos de estadísticas pueden ser indicadores tan simples como el número total de ingresos al EVEA, la cantidad de visitas por páginas, o la distribución a través del tiempo de cómo se fueron conectando los estudiantes a los entornos de aprendizaje. La visualización es una técnica que facilita el análisis de grandes volúmenes de información a través de gráficos (gráficos de línea, de dispersión, gráficos en tres dimensiones, etc.). Muchas veces, con esta técnica se representan los resultados de encuestas de admisión a las universidades, resultados de exámenes de los alumnos, etc [67].
[b] Web Mining: la Minería Web [51] es la aplicación de técnicas de minería de datos para extraer conocimiento a partir de los datos de la web. Hay dos tipos de minería web aplicadas a la educación [54]: • Minería Web Off Line: se utiliza para descubrir patrones u
otra información útil para ayudar a los educadores para validar los modelos de aprendizaje y reestructurar los EVEAs.
• Minería Web On Line: los patrones automáticamente descubiertos son introducidos en un sistema de software inteligente el cual podría ayudar a los estudiantes a llevar adelante sus tareas.
Se utilizan diferentes técnicas de datos para la minería web en sistemas educativos, pero casi todas ellas se pueden agrupar en: • Agrupación, clasificación y detección de outliers: se trata de
un proceso de agrupamiento físico o abstracto de objetos en clases de objetos similares.
• Reglas de asociación y patrones secuenciales: se trata de uno de los métodos de minería más estudiados en donde las normas se asocian con uno o más atributos de un conjunto de datos con otro atributo, produciendo una declaración sobre los valores de los atributos.
• Minería de texto: los métodos de minería de texto pueden ser vistos como una extensión de la minería de datos en datos de texto. Se trata de un área interdisciplinaria que involucra aprendizaje automático y minería de datos, estadísticas, información recuperación y procesamiento de lenguaje natural [68]. La minería de textos puede trabajar con conjuntos de datos no estructurados o semi-estructurados (documentos, archivos HTML, correos electrónicos, etc.)
[21] clasifican las diferentes técnicas de minería de datos para la explotación de información aplicada a la educación en cinco grupos:
[a] Predicción: se utilizan técnicas de minería de datos como clasificación, regresión, y estimación de densidad.
[b] Agrupamiento: se utilizan técnicas de clustering las cuales consisten en algoritmos de agrupamiento.
[c] Minería de relación: se utilizan reglas de asociación, correlación, y patrones secuenciales.
[d] Destilación de los datos para el juicio humano. [e] Descubrimiento con Modelos.
Las técnicas [a], [b], y [c] son las más conocidas y utilizadas por la mayoría de los investigadores. La técnica [d], puede ser comparada con las estadísticas y la técnica de visualización propuesta por [65]. La técnica [e] es, quizás, en el ámbito de la explotación de información la menos común. En esta técnica se desarrolla el modelo de algún evento o hecho específico a través de algún tipo de proceso el cual puede ser validado de alguna forma (por lo general con predicción o ingeniería del conocimiento). Este modelo es luego utilizado como componente para otros análisis, como predicción o minería de relación. El descubrimiento con modelos soporta análisis sofisticados pudiendo responder a preguntas como: qué sub categoría del material de aprendizaje beneficiará mejor al estudiante [69], cómo los diferentes tipos de comportamiento de los estudiantes impacta en la forma de aprender de los estudiantes [70], y cómo las variaciones en el diseño de un tutor inteligente impacta en el comportamiento de los estudiantes a través del tiempo [71].
Las técnicas de minería de relación ha sido una de las técnicas más destacadas en lo concerniente a minería de datos aplicada a la educación. En la encuesta que realiza Romero y Ventura entre 1995 y 2005, de un total de 60 trabajos reportados, en el 43% estaba involucrada la minería de relación, mientras que un 28% utilizaba métodos de predicción. En la Figura 7 se puede observar la distribución de los diferentes métodos utilizados en los trabajos mencionados.
Fig. 7. Publicaciones por Tipo de Técnica de Minería de Datos
Utilizadas [22]
Las técnicas mencionadas anteriormente son propias de la minería de datos. En este trabajo se propone utilizar los procesos de explotación de información definidos por [72]. En la Tabla 2 se realiza el mapeo de las diferentes técnicas con los procesos de explotación de información.
D. Casos de Estudio En esta sección se presenta los distintos casos de estudio de
ámbito internacional (sección D1), y de ámbito nacional (sección D2).
D1. Ámbito Internacional A nivel internacional, los procesos de explotación de
información aplicados a temáticas relacionadas con la

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
341
educación llevan unos cuantos años. La cantidad de trabajos publicados sobre explotación de información aplicada a la educación ha incrementado notablemente año a año. En la Figura 8 se puede apreciar la cantidad de publicaciones que ha realizado el grupo de investigación Working Group in EDM (Educational Data Mining) a lo largo de los años [50].
Si bien se trata de las publicaciones de un solo grupo de investigación, esto puede tomarse como una muestra para apreciar la tendencia de crecimiento en cantidad de publicaciones.
TABLA II. MAPEO DE PROCESOS DE EXPLOTACIÓN DE INFORMACIÓN CON TÉCNICAS DE MINERÍA DE DATOS.
Proceso de explotación de
información
Técnicas de minería de datos /
Algorítmos
Descubrimientos de Grupos • Agrupación
• Estimación de densidad
• Detección de Outliers
Descubrimiento de Reglas de
Comportamiento
• Clasificación
• Minería de Texto
• Árboles de decisión
Ponderación de Interdependencia de
Atributos
• Reglas de Asociación
Si bien se trata de las publicaciones de un solo grupo de
investigación, esto puede tomarse como una muestra para apreciar la tendencia de crecimiento en cantidad de publicaciones.
En [20] se propone monitorear y predecir la transferencia de estudiantes entre colegios a través de procesos de explotación de información. El modelo realizado ayuda a predecir la transferencia de cada estudiante inscripto y tiene como objetivo proveer el perfil de los estudiantes transferidos y predecir qué estudiantes anotados en el colegio solicitarán una transferencia para, de esta forma, poder personalizar y planificar sus iteraciones e intervenciones con estos estudiantes, quienes probablemente necesiten de asistencia para realizar estos trámites. Se utilizaron datos de tres universidades diferentes sumando un total de treinta y dos mil estudiantes. Los datos utilizados incluyen algunas de las siguientes características: demográficas, ayuda financiera, estado de la transferencia, cantidad de transferencias, total de unidades ganadas y calificaciones por tipo de curso.
Para preparar los datos se proponen cuatro pasos basados en la metodología CRISP-DM:
[a] Investigar la posibilidad de aplicar procesos de explotación de información directamente desde el Data Warehouse. Esto evita posibles errores en nombre de campos, cambios inesperados en los tipos de datos, esfuerzo extra en llenar diferentes repositorios de datos.
[b] Seleccionar una sólida herramienta de consulta para poder dar forma a los archivos sobre los cuales se trabajarán.
[c] Visualización y validación de información. Esto significa examinar la distribución de esta información a través de histogramas, gráficos y otros tipos de herramientas. Este paso da a los investigadores una primera impresión del contenido de los datos y cómo aprovecharlos en el análisis.
[d] Explotar los datos. Se utilizaron redes neuronales, y algoritmos de inducción C5.0 y CR&T para comparar ambos modelos y complementar los resultados.
Fig. 8. Cantidad de Papers publicados hasta el 2009 agrupados por año
[50]
Una vez obtenidos los resultados se concluye: [a] La utilización de explotación de información para la
investigación en los colegios secundarios en un gran desafío. [b] A través de la utilización de algoritmos como la
máquina de aprendizaje y la inteligencia artificial para discernir reglas, asociaciones y la probabilidad de eventos, la explotación de información tiene un profundo significado de aplicación.
[c] A través del uso de explotación de información se pudo convertir una base de datos poco manejable y caótica en una base para planificar el programa y para resolver cuestiones operativas.
[d] La potencialidad de la explotación de información radica en el hecho que simultáneamente mejora las salidas y reduce costos. La doctrina del 1% [20] dice que un cambio del 1% significa una unidad de ganancia y una unidad de ahorro.
[e] La posibilidad de intervenir en aquellos estudiantes que van a abandonar o a cambiarse de colegio genera un valor agregado que va más allá de los costos y ahorro que se puedan generar.
[f] La explotación de información ayuda a predecir la probabilidad de personas interesadas en inscribirse a un colegio. Esto permite a los colegios anticiparse y enviarle al potencial estudiante material para que se asesore antes del ingreso.
[23] proponen aplicar explotación de información sobre datos generados por un EVEA implementado sobre Moodle.
Moodle guarda en forma detallada todas las acciones que realizan los estudiantes [Rice, 2006]. En base a esas acciones guardadas en tablas de la base de datos del EVEAs se propone aplicar los siguientes procesos:
La aplicación de los procesos de información en EVEAs es un proceso iterativo [73]. Se define un proceso de cuatro pasos que consiste en:
[a] Recolectar datos del EVEA, [b] Procesar los datos, [c] Aplicar procesos de explotación de información, e [d] Interpretar y evaluar los resultados e implementarlos
en el EVEA (Fig. 9) La aplicación de la explotación de información en la
educación no dista mucho de su aplicación en otras áreas, aunque hay algunas características importantes que le son propias [74]:
[a] Datos: en otros sistemas basados en web los datos utilizados para analizar, por lo general son sacados de un log

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
342
de acceso, pero en los sistemas EVEAs hay mucha más información disponible sobre la interacción de los estudiantes. Los EVEAs pueden registrar cualquier actividad que el estudiante realice (leer, escribir, realizar exámenes, realizar diferentes tareas, e incluso comunicarse con sus compañeros). Normalmente este tipo de sistemas proveen una base de datos que almacena toda la información del sistema con la información personal de los usuarios y los datos de interacción de los usuarios.
Fig. 9. Minería de Datos sobre Moodle [23]
[b] Objetivo: el objetivo de la explotación de información
en cada área es diferente y puede ser más o menos objetiva. Por ejemplo, en comercio electrónico el objetivo es incrementar la rentabilidad, lo cual es tangible y puede ser medido en término de cantidades de dinero, números de clientes, y fidelidad de los clientes. Sin embargo, los objetivos de la explotación de información son los de mejorar el proceso de aprendizaje y guiar a los estudiantes en ese proceso. Este objetivo es más subjetivo y más delicado de medir.
[c] Técnicas: los EVEAs tienen características especiales que requieren un tratamiento diferente de los problemas de minería. Algunas técnicas tradicionales pueden ser aplicadas directamente, pero otras no, y tienen que ser adaptadas a un problema de educación específico.
Esta actividad se ha realizado sobre una base de 438 alumnos donde los profesores utilizan actividades del EVEA como tareas, mensajes, foros y encuestas. A continuación se mencionan los pasos utilizados para la preparación de datos:
[a] Se creó una tabla de sumarización donde se puede almacenar la información al nivel requerido para el análisis, en este caso a nivel alumno. Esta tabla tendrá la suma por fila del total de cada actividad que ha realizado cada estudiante.
[b] Se pasaron los datos continuos a discretos para poder mejorar la interpretación y comprensión.
[c] Se transformaron los datos al formato necesario para poder aplicar las técnicas de minería de datos
Una vez preparados los datos y aplicadas diferentes técnicas de explotación de información se concluye que:
[a] Se puede observar cómo diferentes técnicas de explotación de información pueden ser utilizadas para mejorar el curso y el aprendizaje de los estudiantes.
[b] Estas técnicas pueden ser aplicadas por separado en un mismo sistema o todas juntas en un sistema híbrido.
[c] Si bien se describieron las técnicas más comunes utilizadas en la explotación de información aplicada a la educación, existen otras técnicas también aplicables.
[d] En el futuro será muy útil tener herramientas de explotación de información enfocadas en la educación. Actualmente, éstas son diseñadas pensando en potencia y flexibilidad, más que en simplicidad. Las mismas son demasiado complejas de utilizar para los educadores, entonces, deben tener una interfaz de usuario más amigable. También es necesario que las herramientas de explotación de información sean integradas en los EVEAs y que éstas sean una
herramienta más que el docente pueda utilizar para obtener resultados del curso y de los alumnos.
[24] se propone utilizar la explotación de información para predecir la performance de los estudiantes, buscando responder las siguientes preguntas:
[a] ¿Se pueden detectar diferentes clases de estudiantes? Es decir, existen grupos de estudiantes que utilizan los recursos del EVEA en forma similares. ¿Se pueden identificar esas clases en cada estudiante? Contestando estas preguntas se podrá lograr que los estudiantes utilicen mejor los recursos, basado en el uso de los recursos por los otros estudiantes de la misma clase.
[b] ¿Se pueden clasificar los problemas que han resuelto los alumnos? En caso de poder, se podrá ver cómo diferentes tipos de problemas impactan en el logro de cada alumno y permitirá ayudar a los profesores a realizar los ejercicios de tarea de forma más efectiva y eficiente.
Este trabajo se realiza sobre el EVEA de la Universidad del Estado de Michigan (MSU) [75]. Se utilizan los datos de un curso introductorio de física, compuesto por 12 tareas con un total de 184 problemas por resolver, donde se matricularon 261 alumnos y terminaron 221. El EVEA almacena diferentes características de las actividades que realiza el alumno de las cuales se utilizarán las siguientes:
[a] Número total de respuestas correctas [b] Resolución del problema en la primera oportunidad en
contraposición a la resolución del problema en un número alto de oportunidades.
[c] Total de intentos para realizar el problema en forma correcta.
[d] El tiempo total desde que se empezó a resolver el problema, hasta que se lo resolvió correctamente.
[e] El tiempo que se tardó en abordar por primera vez el ejercicio, más allá de que se haya resuelto o no.
[f] Resolución del problema tras la participación en el mecanismo de comunicación en contraposición a la resolución del problema en forma aislada.
Para este problema se utiliza el proceso de descubrimiento de reglas de comportamiento y se concluye que:
La optimización exitosa de la clasificación de estudiantes demostró los méritos de utilizar los datos del EVEA para predecir las notas finales de los estudiantes basadas en sus características extraídas de las tareas.
La explotación de información puede ser aplicada en forma exitosa por los docentes para incrementar el aprendizaje de los estudiantes.
[25] sostienen que la tecnología ha ayudado a la adopción de la educación a distancia mediante EVEAs. A través de estas plataformas podemos obtener, entre otros beneficios, mayor interacción con el alumno, enriquecer la experiencia de aprendizaje, flexibilidad de acceso, etc. Sin embargo el diseño y la evaluación de la educación a distancia mediada por sistemas EVEAs aún es una tarea compleja que requiere tiempo y experiencia que muchos docentes todavía no poseen, y quienes por lo general necesitan ayuda de expertos para poder diseñar sus cursos. Por lo tanto, se propone evaluar los sistemas EVEA´s en base al análisis de los datos que los mismos registran en su log. Uno de los desafíos para un instructor que evalúa los EVEAs es la falta de evidencia de los estudiantes, ya que los mismos tienen solo acceso a las interacciones con el material de estudio y no se puede observar su comportamiento o recibir feedback de ellos en el momento. Dado que el comportamiento de los estudiantes está oculto dentro de sus interacciones, los instructores deberían

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
343
analizarlos para evaluar performance de los estudiantes y evaluar el software de e-learning. Lo que es más, los sistemas EVEAs generan gran cantidad de datos en sus logs. Se considera que la explotación de información es lo más adecuado para realizar esta tarea, ya que es una tecnología que combina métodos de análisis de datos tradicionales con algoritmos complejos para procesar grandes volúmenes de datos con el objetivo de descubrir información útil [76]. El objetivo de este trabajo es encontrar patrones o síntomas que puedan indicar la baja performance de los estudiantes, para esto se analizan los logs generados por los EVEAs. Entonces, por ejemplo, se podrían detectar a aquellos estudiantes que en un ejercicio superan la cantidad de errores que se comenten en promedio.
Es difícil para los instructores detectar este tipo de síntomas sin la ayuda de la explotación de información. Al mismo tiempo, es beneficioso para el profesor poder ser advertido de ciertos problemas que están teniendo los estudiantes con un conjunto de ejercicios en particular y, por lo tanto, poder tomar una acción a tiempo. ¿Cómo ocurren estos síntomas? ¿Qué factores los disparan? Este trabajo propone responder a todas esas preguntas proveyendo un método para detectar síntomas de baja performance de los estudiantes en un curso.
Naturalmente, cada síntoma observado en los datos, significa una variación de performance en el curso. Es útil identificar aquellos patrones que puedan causar caídas en el rendimiento, como así también identificar cuáles son los más importantes. Para esto se propone un método que ayuda a filtrar y armar un ranking de los síntomas detectados basado en Descubrimiento de Reglas de Comportamiento.
[25] trabaja sobre datos por la Escuela de Ciencias de la Información de la Universidad de Pittsburgh (Pittsburgh, EEUU) los cuales fueron recolectados durante el año 2007 del EVEAs de la materia Introducción a la Programación en C, generando un registro de análisis de 55 alumnos, con un total de 52734 interacciones. Las actividades desarrolladas para esta materia en el sistema EVEA se basan en cuestionarios. Cuando un estudiante responde una pregunta del cuestionario se genera un nuevo registro en la tabla de log del sistema. Para el análisis se realizan cinco pasos:
[a] Se selecciona el algoritmo a utilizar. Se eligen árboles de decisión, en especial el algoritmo C4.5 dado los buenos resultados que ha arrojado en trabajos previos [25].
[b] Se definen los atributos del archivo de log a ser analizado, y cuál de ellos se utilizará como clase.
[c] Se aplica el algoritmo para poder obtener los resultados e interpretarlos.
[d] Se analizan los resultados y se deja la rama del árbol donde están todos los casos en los cuales los alumnos fallaron al responder la encuesta.
[e] Se filtran las reglas con el objetivo de solo quedarse con aquellas reglas relevantes. Para esto se calcula la banda inferior como el 10% de los casos utilizados en las reglas.
Luego de aplicados los pasos mencionados se concluye que:
Se detectaron tres reglas que indican la caída de rendimiento para varios estudiantes.
[a] Esta información puede ser relevante para el instructor o diseñador del curso ya que puede realizar mejoras generando nuevas actividades o modificando las existentes o, incluso, modificando la estructura del curso.
[b] Los árboles de decisión muestran cierta debilidad, sus resultados están fuertemente relacionados con la distribución
de los datos y la proporción de las clases. En consecuencia, para futuros trabajos aplicarán reglas de asociación.
[c] Por último, se resalta la importancia de probar y verificar, con otros tipos de datos, el análisis propuesto. En este contexto, en futuros trabajos se procurará utilizar datos de otros EVEAs con el objetivo de mejorar el método de detección.
[77] propone la utilización de la explotación de información para predecir el abandono de estudiantes. El monitoreo y apoyo a los estudiantes de primer año es un tema que se considera sumamente importante en varias instituciones de educación. En algunas facultades la inscripción de los estudiantes recién graduados del bachillerato puede ser menor a lo deseado y, cuando se combina con un alto ratio de abandono, ponen de manifiesto la necesidad de dar forma a enfoques efectivos para predecir el abandono de los estudiantes, así como la identificación de los factores que afectan a todo ello. Entonces, se propone utilizar la explotación de información para predecir el abandono de los estudiantes. En el departamento de ingeniería eléctrica de la Universidad de Tecnología de Eindhoven el porcentaje de abandono de los nuevos estudiantes es de un 40% [77]. Aparte de que el departamento intenta disminuir este porcentaje, existe otra razón para identificar el éxito o fracaso de un estudiante en la etapa temprana (antes del primer semestre): la carrera de Ingeniería Eléctrica de la universidad vecina acepta alumnos provenientes de otra universidad antes del mes de enero. Por otro lado, existe siempre un grupo de estudiantes que el departamento lo considera un grupo de riesgo como, por ejemplo, estudiantes que necesitan atención extra o algún cuidado especial que los ayude a aprobar la materia. Detectar estos grupos en una etapa temprana le permite al departamento de ingeniería eléctrica enfocar sus recursos hacia los estudiantes que más lo necesitan y de esta forma poder evitar el abandono de la materia.
D2. Ámbito Nacional La aplicación de procesos de explotación de información
aplicados a la educación, a nivel nacional, es algo reciente. Se han realizado algunas experiencias en temas tales como: identificación de errores de apropiación [78], detección de problemas de aprendizaje [79], e identificación de comportamiento en comunidades educativas [80].
En [27] se propone la utilización de herramientas de explotación de información como ayuda a los docentes para diagnosticar las dificultades de aprendizaje de los alumnos (y sus causas) relacionadas con la programación, para el cual se utilizan herramientas de bases de datos de sistemas inteligentes: inducción de reglas por algoritmos TDIDT y redes bayesianas, con base en un descubrimiento del conocimiento de tres pasos:
Construir una base de datos sobre una caracterización estándar de cada estudiante y conceptos mal aprendidos de programación. Esta caracterización se focaliza en aspectos de: metodología de desarrollo del programa escrito por el estudiante, funcionalidad del programa desarrollado por el estudiante y calidad del diseño del programa creado por el estudiante.
Proceder al descubrimiento de reglas (mediante algoritmos TDIDT) las cuales establecen una relación entre conceptos no comprendidos de programación y sus posibles causas. Las reglas obtenidas son aplicadas para revisar la estructura propuesta para el curso y la hipótesis de los profesores. Los resultados experimentales indican que aplicando este paso, el

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
344
profesor puede descubrir posibles causas de los conceptos mal aprendidos por los estudiantes.
Descubrir el peso que cada una tiene sobre cada concepto mal aprendido (mediante redes bayesianas). Esto permite establecer el rango de importancia de las causas de conceptos no comprendidos para proponer estrategias de enseñanzas remediales.
[78] proponen la utilización de procesos de explotación de información para la identificación de errores de apropiación de conceptos. El proyecto busca la obtención de una metodología que le permita al docente:
[a] Identificar los errores de aprendizaje de los alumnos en instancias educativas y;
[b] Diagramar los conceptos enseñados en pos de minimizar, en tanto sea posible, dichos errores.
Para esto, se utilizan los procesos de explotación de información [13][72]: descubrimiento de reglas de comportamiento y ponderación de interdependencia de atributos. Se tuvieron en cuenta dos casos de estudio, uno con la asignatura Análisis de Sistemas correspondiente a la carrera de Ingeniería en Sistemas de Información de la Universidad Tecnológica Nacional Facultad Regional Buenos Aires (UTN-FRBA) y otro con la asignatura Sistemas y Organizaciones de la misma casa de altos estudios. Para ambos se utilizó el siguiente proceso de cinco pasos para identificar errores de apropiación de conceptos:
Paso 1: conceptualización del dominio [a] Seleccionar los conceptos enseñados que se consideran
importantes para la determinación del aprendizaje del individuo.
[b] Construir un glosario de términos [c] Construir el mapa de dependencia o precedencia
conceptual Paso 2: identificación de Subdominio de Análisis [a] Identificar el submapa candidato para el análisis [b] Refinar los conceptos del submapa candidato en
subconceptos. [c] Identificar los atributos de evaluación vinculados al
submapa candidato. Paso 3: preparación de datos [a] Identificar los valores de los atributos de evaluación,
vinculados a los subconceptos del submapa candidato en las instancias de evaluación individual.
[b] Construir la Base de Datos usando como campos los atributos de evaluación y, como instancias, los valores de estos atributos para cada sujeto de la población en estudio.
Paso 4: Explotación de Información [a] Aplicar el Descubrimiento de Reglas de
Comportamiento [13], tomando como clase el atributo que se encuentra en la raíz del subárbol asociado al submapa candidato.
[b] Aplicar el proceso Ponderación de Interdependencia de Atributos [13], tomando a los atributos hoja de las reglas obtenidas en el Subpaso 4.1 y atributo clase.
Paso 5: interpretar los resultados [a] Interpretar los resultados generados a partir de los
procesos de explotación de información del Paso 4. Luego de realizada las pruebas de concepto con las
materias mencionadas anteriormente se concluye que [78]: [a] La apropiación de conceptos por parte del alumno no
es un proceso unidireccional. Si bien requiere un esfuerzo del alumno, es fundamental la participación del docente no solo en
la transmisión pura del conocimiento sino en el proceso que esa transmisión implica.
[b] Para el docente es de gran ayuda contar con una metodología o proceso que le permita determinar qué errores en la apropiación de conceptos de los alumnos provienen de la implementación del proceso de transmisión mencionado. Entonces, se plantea una metodología que le permita a un docente revisar, en caso de ser necesario, el proceso utilizado en el dictado de sus clases para intentar minimizar los errores de apropiación de conceptos detectados en los alumnos.
[c] El proceso propuesto constituye una nueva herramienta de diagnóstico en el área; y si bien los resultados obtenidos en este estadio del proyecto son prometedores, no son concluyentes.
[80] sostienen que los procesos de explotación de información pueden ser utilizados también, para identificar el comportamiento de comunidades educativas, en este caso, las centradas en entornos virtuales de enseñanza.
Para cumplir con los objetivos de este estudio se llevan a cabo los siguientes pasos:
[a] Realizar una Investigación documental, estudio y síntesis de los marcos teóricos de:
1. Educación mediada por EVEAs, 2. Explotación de información y 3. Comportamientos de poblacionales con
comunicación mediada por tecnología. [b] Identificar las variables utilizadas para el modelado de
comportamientos poblacionales con comunicación mediada por EVEAs.
[c] Crear y validar los procesos de explotación de información que identifiquen comportamientos de poblaciones con comunicación mediadas por EVEA.
[d] Realizar una prueba de concepto de los procesos de explotación creados utilizando datos reales de poblaciones con comunicación mediadas por EVEA. A través de los pasos mencionados el proyecto busca:
[a] La comprensión de comportamientos de comunidades mediada por tecnología con énfasis en comunidades educativas; y
[b] La formulación de una propuesta de identificación de patrones de comportamientos poblacionales en comunidades educativas mediadas por EVEAs utilizando procesos de explotación de información.
[81] proponen utilizar la explotación de información para la mejora de la asignatura de grado de Inteligencia Artificial de la Universidad Tecnológica Nacional. Dicha materia es aprobada por el 65% de los alumnos que la cursan. Si bien actualmente la mayoría de los alumnos aprueba el parcial, desde el 2011 se observa una tendencia negativa que proyectada al año 2013 bajaría a menos del 50%. Entonces, se estudian alternativas en el desarrollo de la clase con el objetivo de aumentar el porcentaje de aprobación.
Los temas que forman parte de la asignatura son los siguientes: • Teoría (TEORIA), donde se incluyen preguntas teóricas de
todos los conceptos de la asignatura. • Modelos de Arquitecturas de Sistemas Inteligentes (ARQ)
que incluye preguntas teóricas sobre conceptos y tipos de sistemas inteligentes (Redes Neuronales, Sistemas Expertos y Algoritmos Genéticos).
• Métodos de Búsqueda (BUSQ), Emparrillado (EMP), Análisis de Protocolos (AP), Deducción Natural (DEDNAT) y Traducción Lógica (TRAD), que engloban ejercicios prácticos para cada tema.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
345
Se propone como solución la aplicación de un proceso de explotación de información aplicándolo sobre la información proveniente de exámenes parciales ya evaluados de la asignatura en cuestión, para así estudiar los temas relevantes para la evaluación de los exámenes parciales. El proceso de explotación utilizado es el de Descubrimiento de Reglas de Comportamiento [72] a través de los siguientes pasos: • Se prepara la base de datos con un total de 229 registros
(cada uno representado por un parcial realizado por un alumno) los cuales están formados por 25 atributos y una clase.
• Se aplica el algoritmo de inducción C4.5 de la familia TDIDT [82] y como resultado se obtienen 11 reglas.
• Se interpretan los resultados Realizados estos pasos se concluye que:
• La solución propuesta un ejemplo de herramienta de diagnóstico en el área satisfactorio.
• Se pudo observar en detalle el grado de importancia de los resultados finales permitiendo al docente mejorar el dictado de la asignatura haciendo hincapié en aquellos temas críticos para su aprobación.
• Estos resultados con concluyentes y prometedores para ser analizados en un futuro y evaluar su incidencia en la fase de aprobación de los alumnos.
III. PROBLEMA En esta sección se abordan los problemas comunes
relacionados con el rendimiento de los estudiantes tanto en la educación presencial como a distancia (sección A), luego se proponen las líneas de investigación con el objetivo de ayudar a resolver los problemas mencionados los diferentes procesos de explotación de información (sección B).
A. Generalidades del Problema La institución u organización es la que enseña
(organización que ayuda la llama [83] y organización de apoyo lo denomina [84]), no el profesor. En la enseñanza presencial es el docente el que habitualmente diseña, produce, distribuye, desarrolla y evalúa el proceso de enseñanza-aprendizaje, por lo que el aprendizaje del alumno suele estar en función de que le haya correspondido un buen o un mal docente. En la enseñanza a distancia, sin embargo, el docente nunca es uno, son multitud los agentes que intervienen en el proceso de enseñar y aprender, hasta tal punto que solemos reconocer a la institución como la portadora de la responsabilidad de enseñar. Por tanto, es la institución, más que el profesor, la que diseña, produce, distribuye, desarrolla o tutela el proceso de aprendizaje de los estudiantes. Pero este aprendizaje ha de permitir al estudiante ser protagonista en cuanto al tiempo, espacio y ritmo de aprender, es decir, el proceso de enseñanza diseñado por la institución propicia el aprendizaje flexible del estudiante. Y esa flexibilidad es facilitada a través de la comunicación o diálogo didáctico mediado entre institución y estudiante. Son, en efecto, los medios los que permiten la flexibilidad antes referida [3].
Al tratar el caso de un nuevo paradigma de enseñanza basado en los entornos de aprendizaje virtual, existe la tendencia a centrarse en las posibilidades positivas. Sin embargo, hay otra cara de esta visión. [85] en su investigación, tienen que enfrentarse a problemas causados por las diferencias horarias y de cultura que son inherentes a la interacción entre países. Algunos de los problemas que han encontrado eran predecibles, como el hecho de que algunos profesores se sintieran amenazados por la tecnología y el hecho de que los
estudiantes quisieran tener contacto real unos con otros. Otras dificultades resultaron más inesperadas Se produjeron problemas de intransigencia de la propia tecnología y modelos de conducta inesperados, como una exagerada comunicación por correo electrónico.
[3] sostiene que uno de los problemas que más acusan los alumnos de esta modalidad de enseñanza es el de la soledad y alejamiento del profesor y de los compañeros de estudio. La necesidad de relacionarse con los otros se convierte a veces en determinante para el logro de resultados de aprendizaje. Entonces, el reto de la educación a distancia consiste en mantener un sistema comunicacional no presencial ya que se prescinde de la habitual presencia cara a cara entre profesores y alumnos. Si se logra una buena comunicación el alumno no se sentirá tan solo y contará con la orientación y motivación del profesor y de sus propios compañeros.
Uno de los principales escollos con los que topa el desarrollo de nuevos sistemas de enseñanza a distancia basados en internet es la ausencia de un marco teórico adecuado. En efecto, por una parte, las instituciones dedicadas tradicionalmente a la enseñanza a distancia encuentran dificultades para cambiar, rápidamente, sus métodos y procedimientos por causa de resistencias en parte internas de la propia institución y en parte en la mentalidad de sus usuarios, sean éstos docentes o estudiantes. Por otra parte, las instituciones que nacen asentadas sobre una base tecnológica innovadora tienen el riesgo de comprometerse excesivamente con una determinada tecnología, hasta el punto de verse en dificultades en el momento en que dicha tecnología pase a ser obsoleta [1].
Lo que distingue la enseñanza a distancia del resto es el carácter diferido en el tiempo de buena parte de las ayudas pedagógicas, contenidas ya en los materiales didácticos [84]. Quienes participan en la elaboración de dichos materiales acostumbran a preocuparse no sólo del contenido sino también, de la disposición de las actividades que deben ayudar al estudiante a relacionar los con sus conocimientos previos. Así, a diferencia de otros procesos de enseñanza en que toda interacción se da en una coincidencia espacio-temporal, aquí se parte del convencimiento que esa coincidencia o no es posible o bien debe reducirse al mínimo imprescindible. Las nuevas tecnologías ayudan decididamente a que los materiales didácticos sean más ricos en las posibilidades de diferir las ayudas pedagógicas y, por supuesto, de diversificarlas de forma individualizada [86].
La función docente, en este contexto, debe considerarse como la organización de las ayudas pedagógicas y la gestión de los ajustes derivados de la individualización del proceso [87]. Por consiguiente, la gestión del aprendizaje debe ser considerada el resultado de un proceso en el que participan tanto el docente como el estudiante.
El desarrollo tradicional de los cursos de e-learning es una actividad laboriosa [88] en el que el promotor (por lo general el profesor del curso) tiene que elegir los contenidos que se mostrarán, decidir sobre la estructura de los contenidos, y determinar los elementos de contenido más adecuadas para cada tipo de usuario potencial del curso. Debido a la complejidad de estas decisiones, un diseño de una sola vez es poco factible, incluso cuando se hace con cuidado. En su lugar, será necesario en la mayoría de los casos para evaluar y posiblemente modificar los contenidos del curso , la estructura y la navegación basada en la información de uso de los estudiantes, de preferencia , incluso siguiendo un enfoque continuo de evaluación empírica [89] . Para facilitar esto, se

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
346
necesitan métodos y herramientas de análisis de datos para observar el comportamiento de los estudiantes y para ayudar a los maestros en la detección de posibles errores, deficiencias y posibles mejoras. Análisis de datos tradicional en e-learning es hipótesis o suposición conducido [90] en el sentido de que el usuario comienza a partir de una pregunta y explora los datos para confirmar la intuición. Mientras que esto puede ser útil cuando un número moderado de factores y datos están involucrados, puede ser muy difícil para el usuario encontrar patrones más complejos que se relacionan diferentes aspectos de los datos. Una alternativa al análisis de datos tradicional es utilizar la minería de datos como un enfoque inductivo para descubrir automáticamente información oculta presente en los datos. La minería de datos, en contraste, es el descubrimiento impulsado en el sentido de que la hipótesis se extrae automáticamente de los datos y por lo tanto es impulsado por los datos en lugar de basados en la investigación o inducido por el hombre [66]. La minería de datos se construye modelos analíticos que descubren patrones y tendencias interesantes de la información de uso de los estudiantes que pueden ser utilizados por el profesor para mejorar el aprendizaje y por supuesto el mantenimiento del estudiante.
La utilización de EVEAs ha crecido exponencialmente en los últimos años, estimulado por el hecho de que ni los estudiantes ni los profesores están obligados a una ubicación específica y que esta forma de educación basada en la computadora es prácticamente independiente de cualquier plataforma de hardware específicos [91]. Las herramientas de colaboración y comunicación se están utilizado cada vez más en contextos educativos así, como resultado, los Entornos de Aprendizaje y Enseñanza Virtuales se instalan cada vez más por las universidades, colegios comunitarios, escuelas, empresas e incluso también son utilizados por instructores individuales con el fin de agregar tecnología web para sus cursos y para complementar los cursos tradicionales cara a cara [92]. Estos sistemas pueden ofrecer una gran variedad de canales y espacios de trabajo para facilitar el intercambio de información y la comunicación entre los participantes en un curso, para permitir que los educadores de distribuir información a los estudiantes, producir material de contenido, preparar las tareas y exámenes, participar en debates, gestionar las clases a distancia y permitir la colaboración aprendizaje con foros, chats, áreas de almacenamiento de archivos, servicios de noticias, etc. Estos entornos de aprendizaje acumulan una gran cantidad de información que es muy valiosa para el análisis del comportamiento de los estudiantes y podrían crear una mina de oro de datos educativos [93]. Se puede grabar cualquier actividad en la que los estudiantes están involucrados, tales como leer, escribir, realizar exámenes, la realización de diversas tareas, e incluso comunicarse con los compañeros [94].Por lo general, estas plataformas no proporcionan a los educadores las herramientas específicas que les permitan realizar un seguimiento a fondo, la posibilidad de evaluar todas las actividades realizadas por sus alumnos, ni tampoco cuentan con un mecanismo para evaluar la estructura, el contenido del curso, y su eficacia en el proceso de aprendizaje. Aunque algunas plataformas ofrecen herramientas como reportes de gestión, cuando existe un gran número de estudiantes, la tarea de extraer información útil se vuelve difícil [56]. Entonces, un área muy prometedora para el logro de este objetivo, es el uso de minería de datos [95].
El EVEA registra todas las instancias de comunicación interpersonales. Tales registros podrían utilizarse como base
para modelar el comportamiento de los alumnos de educación a distancia.
En la educación presencial los docentes intentan mejorar sus clases a través de la visualización del rendimiento de los estudiantes por medio de la observación. Dicho método puede ser muchas veces subjetivo e incompleto. También existen registros escritos, como exámenes y ejercicios prácticos en los cuales los docentes se pueden apoyar para mejorar sus clases. También utilizan información de asistencia, información sobre el curso, objetivos de la materia, etc. Una institución educativa posee diversas fuentes de información y variadas [58]: bases de datos tradicionales (con información de los estudiantes y de los docentes, de las clases, y la programación de las mismas).
B. Pregunta de Investigación La explotación de información permite identificar
conocimiento oculto en los datos registrados. El proceso de aprendizaje está compuesto por una serie de hitos que permiten al docente identificar puntos críticos para favorecer la comprensión de los temas expuestos. En [80] se plantea la línea de investigación cuyos objetivos son: [a] La comprensión de comportamientos de comunidades mediadas por tecnología con énfasis en comunidades educativas. [b] La formulación de una propuesta de identificación de patrones de comportamientos poblacionales en comunidades educativas mediadas por EVEAs utilizando procesos de explotación de información.
En este contexto, se plantea la siguiente pregunta de investigación:
¿Se puede desarrollar un proceso de explotación de información que ayude a la comprensión del comportamiento de comunidades educativas a partir de los resultados académicos?
IV. SOLUCIÓN En la presente sección se abordan los marcos de la solución
propuesta (sección A), y luego se presenta la solución a los problemas planteados en la sección anterior (sección B).
A. Marco de la Solución Un Proceso de Explotación de Información se define como
un grupo de tareas relacionadas lógicamente [10] que, a partir de un conjunto de información con un cierto grado de valor para la organización, se ejecuta para lograr otro, con un grado de valor mayor que el inicial. Adicionalmente, existe una variedad de técnicas de minería de datos, en su mayoría provenientes del campo del aprendizaje automático [14], susceptibles de utilizar en cada uno de estos procesos.
[13] propone los siguientes procesos de explotación de información: descubrimiento de reglas de comportamiento, descubrimiento de grupos, descubrimiento de atributos significativos, descubrimiento de reglas de pertenencia a grupos y ponderación de reglas de comportamiento o de pertenencia. El proceso de descubrimiento de reglas de comportamiento aplica cuando se requiere identificar cuáles son las condiciones para obtener determinado resultado en el dominio del problema. El proceso de descubrimiento de grupos aplica cuando se requiere identificar una partición en la masa de información disponible sobre el dominio de problema. El proceso de ponderación de interdependencia de atributos aplica cuando se requiere identificar cuáles son los factores con mayor incidencia (o frecuencia de ocurrencia) sobre un determinado resultado del problema. El proceso de

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
347
descubrimiento de reglas de pertenencia a grupos aplica cuando se requiere identificar cuáles son las condiciones de pertenencia a cada una de las clases en una partición desconocida “a priori”, pero presente en la masa de información disponible sobre el dominio de problema. El proceso de ponderación de reglas de comportamiento o de la pertenencia a grupos aplica cuando se requiere identificar cuáles son las condiciones con mayor incidencia (o frecuencia de ocurrencia) sobre la obtención de un determinado resultado en el dominio del problema, sean estas las que en mayor medida inciden sobre un comportamiento o las que mejor definen la pertenencia a un grupo.
En particular, las metodologías de explotación de información destacan la importancia de la comprensión del negocio y la vinculación entre el problema de negocio con el patrón o regularidad a descubrir en la información a partir del proceso de explotación de información a utilizar. Sin embargo, es un problema abierto determinar de manera sistemática cual es el proceso de explotación de información que se debe aplicar para resolver el problema de negocio.
B. Solución Propuesta Como respuesta al problema planteado [96] se propone un
procedimiento que permite derivar del proceso de explotación de información a partir del modelado del dominio de negocio (Tabla 4.1).
Los formalismos de ingeniería de conocimiento que se utilizan para modelar el dominio de negocio y de explotación de información son las redes semánticas [97] y las tablas concepto - atributo - valor [98].
Con base en los formalismos señalados, se proponen doce formalismos para el modelado del dominio: • Tabla concepto - atributo - valor del dominio (CAVD): se
utiliza para la representación sistemática de los conceptos del dominio, con detalles de los atributos y valores.
• Tabla concepto - relación del dominio (CRD): se utiliza para modelar las relaciones entre los conceptos del dominio.
• Red semántica del modelo de negocio (RSMN): modela el dominio del negocio.
• Tabla concepto - atributo - valor del problema de explotación de información (CAVPEI): es una representación sistemática de los conceptos del problema de explotación de información, con detalles de los atributos y valores.
• Tabla concepto - relación del problema de explotación de información (CRPEI): busca modelar las relaciones entre los conceptos del problema de explotación de información.
• Tabla de entradas/salidas del problema de explotación de información (E/S - PEI): es un listado de entradas/salidas del problema de explotación de información.
• Red semántica del problema de explotación de información (RSPEI): representación sistemática del problema de explotación de información.
• Red semántica del problema de explotación de información con datos de entrada y salida identificados (RSPEI - DE/S): modela el problema de explotación de información con los datos identificados de entrada y salida.
• Tabla concepto - atributo - valor Integrada (CAVI): representación sistemática integrada de los conceptos del dominio y del problema de explotación de información, con detalles de los atributos y valores.
• Tabla concepto - relación Integrada (CRI): modela de manera integrada las relaciones entre los conceptos del dominio y del problema de explotación de información.
• Red semántica integrada modelo negocio - explotación de información (RSI - MN - EI): representación sistemática integrada del modelo de negocio y del problema de explotación de información.
• Red semántica integrada modelo negocio - explotación de información con datos de entrada y salida identificados (RSI - MN - EI - DE/S): representación sistemática integrada del modelo de negocio y del problema de explotación de información con los datos identificados de entrada y salida.
TABLA III. PROCEDIMIENTO DE DERIVACIÓN DEL PROCESO DE EXPLOTACIÓN DE INFORMACIÓN A PARTIR DEL MODELADO DEL
DOMINIO DEL NEGOCIO.
Procedimiento de derivación
Paso 1: Identificación de conceptos del dominio.
Paso 2: Identificación de relaciones entre conceptos.
Paso 3: Conceptualización del dominio.
Paso 4: Identificación de conceptos y relaciones del problema de explotación de información.
Paso 5: Conceptualización del problema de explotación de información.
Paso 6: Identificación de los datos de entradas y resultados del problema de explotación de información.
Paso 7: Integración de las novaciones que introduce el problema de explotación de información al dominio.
Paso 8: Integración de los conceptos del dominio y del problema de explotación de información.
Paso 9: Identificación Integrada de los datos de entrada y objetivo.
Paso 10: Derivación del proceso de explotación de información.
El procedimiento propuesto por [96] conceptualiza el
dominio a partir de la identificación de los conceptos del dominio y las relaciones entre estos conceptos (pasos 1 a 3). En los pasos siguientes (4 a 6) se conceptualiza el problema de explotación de información con base en la identificación de conceptos y relaciones del problema de explotación de información y la identificación de los datos de entradas y resultados del problema de explotación de información. En la representación lograda hasta el momento se producen novaciones que introduce el problema de explotación de información al dominio, los mismos se incorporan a la representación del dominio. En este punto se pueden integrar los conceptos del dominio y del problema de explotación de información; e identificar de manera integral los datos de entrada y objetivo (pasos 7 a 9). A partir de este punto, y con base en los sub pasos del paso 10 que se presentan en la Tabla IV, se deriva el proceso de explotación de información. Ante la falta de herramientas por parte de los educadores para evaluar a los alumnos, las estructuras, el contenido del curso y su eficacia en el proceso de aprendizaje, este trabajo propone como solución un recurso. El mismo permite estudiar el comportamiento de los estudiantes a lo largo de un curso o una carrera, identificando y resolviendo los distintos problemas asociados al aprendizaje y al favorable desarrollo de la materia. De esta manera, los docentes tendrán a su disposición una herramienta que favorece la comprensión del curso y la
Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
348
posibilidad de implementar medidas que les permitan detectar alumnos con dificultades para, así, intervenir de manera temprana con la posibilidad de corregir factores que impacten en el resultado de la cursada.
TABLA IV. DETALLE DE LOS SUBPASOS DE DERIVACIÓN DEL PROCESO DE EXPLOTACIÓN DE INFORMACIÓN
SI En la Red semántica integrada modelo negocio - explotación de información con datos de entrada y salida identificados (RSI - MN - EI - DE/S) se puede identificar un resultado intermedio.
ENTONCES Ir a Subpaso 10.5.
Subpaso 10.1:
SINO Ir a Subpaso 10.2. SI El objetivo de la red semántica integrada
modelo negocio - explotación de información con datos de entrada y salida identificados (RSI - MN - EI - DE/S) es un único nodo cuya arista se identifica con las palabras: pertenece, integra, es, es miembro de, u otras palabras de similar significado.
ENTONCES Aplicar proceso descubrimiento de grupos.
Subpaso 10.2:
SINO Ir a Subpaso 10.3. SI En la red semántica del problema de
explotación de información con datos de entrada y salida identificados (RSPEI - DE/S) se busca detectar los valores que más se destacan o que aparecen con mayor frecuencia del conjunto de datos de salida
ENTONCES Aplicar proceso ponderación de interdependencia de atributos.
Subpaso 10.3:
SINO Ir a Subpaso 10.4. SI En la red semántica del problema de
explotación de información con datos de entrada y salida identificados (RSPEI - DE/S) se busca identificar, a partir del conjunto de datos de salida, el valor de un atributo determinado
ENTONCES Aplicar proceso descubrimiento de reglas de comportamiento.
Subpaso 10.4:
SINO Representación errónea. SI La Red semántica integrada modelo negocio -
explotación de información con datos de entrada y salida identificados (RSI - MN - EI - DE/S) tiene un concepto resultado intermedio, para el cual el arco que llega se rotula con las palabras: “pertenece”, “integra”, “es”, “es miembro de” u otras palabras de similar significado
ENTONCES Ir a Subpaso 10.6.
Subpaso 10.5:
SINO Representación errónea. SI El resultado intermedio de la red semántica
integrada modelo negocio - explotación de información con datos de entrada y salida identificados (RSI - MN - EI - DE/S), cuya relación se define con las palabras pertenece, integra, es, es miembro de, u otras palabras de similar significado, es un nodo existente en la red semántica del modelo de negocio (RSMN).
ENTONCES Aplicar proceso ponderación de reglas de pertenencia a grupos (grupos definidos).
Subpaso 10.6:
SINO Ir a Subpaso 10.7. SI En la Red semántica del problema de
explotación de información con datos de entrada y salida identificados (RSPEI - DE/S) se busca detectar aquellos valores de los atributos pertenecientes al concepto identificado como resultado intermedio, que más se destacan o que aparecen con mayor frecuencia en el conjunto de datos de salida.
ENTONCES Aplicar proceso ponderación de reglas de pertenencia a grupos (grupos no definidos).
Subpaso 10.7:
SINO Ir a Subpaso 10.8.
Subpaso 10.8:
SI En la red semántica del problema de explotación de información con datos de entrada y salida identificados (RSPEI - DE/S)
se busca definir el identificador del resultado intermedio, de acuerdo con los atributos de salida
ENTONCES Aplicar proceso descubrimiento de reglas de pertenencia a grupos.
SINO Representación errónea. El proceso propuesto hace uso de los procesos de explotación de información y del de derivación del problema de explotación de información definido mencionados anteriormente.
TABLA V. PROCESO PROPUESTO PARA EL ESTUDIO DEL COMPORTAMIENTO DE COMUNIDADES EDUCATIVAS
Paso 1: Conceptualización del Dominio
Subpaso1.1:Identificación de los elementos relevantes del dominio
Subpaso 1.2:Identificación de las relaciones entre elementos del dominio
Subpaso 1.3:Representación conceptual del dominio.
Paso 2: Conceptualización del Problema de Explotación de Información
Subpaso 2.1:Identificación del problema de negocio y su traducción al problema de explotación de información
Subpaso 2.2:Identificación de los conceptos pertenecientes al problema de explotación de información
Subpaso 2.3:Identificación de las relaciones entre elementos del problema de explotación de información
Subpaso 2.4:Identificación de dependencias entre los elementos conceptuales del problema
Subpaso 2.5:Representación del problema de explotación de información
Paso 3: Identificación del Proceso de Explotación de Información Derivación del proceso de explotación de información
Paso 4: Preparación de los Datos
Subpaso 4.1:Selección de los campos asociados al problema de explotación de información
Subpaso 4.2:Conversión de los datos
Subpaso 4.3:Generación de la base de datos
Paso 5: Implementación
Subpaso 5.1:Implementación
Subpaso 5.2:Interpretación de los resultados
A continuación se presenta el proceso propuesto compuesto
por los siguientes 5 pasos: El primer paso se orienta a la comprensión y
conceptualización del negocio a analizar (reconociendo los distintos elementos que conforman al estudio del curso a analizar), identificando aquellos conceptos dependientes.
El segundo paso se orienta a la identificación del problema de negocio, entendiendo como problema de negocio a aquel objetivo que se quiere resolver, para el cual se requiere obtener información relevante que soporte la toma de decisión, su traducción a lenguaje técnico (problema de explotación de información), la identificación de los elementos que lo componen y la conceptualización del mismo.
El tercer paso consiste en identificar el proceso de explotación a utilizar, que es el que define las técnicas de minería de datos a implementar para dar solución al problema de negocio.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
349
El cuarto paso consiste en generar la base de datos y los datos acorde al proceso de explotación de información identificado y de los algoritmos de minería de datos a utilizar, convirtiendo los datos en base a las necesidades de los mismos.
El último paso es el que consiste en implementar e interpretar los resultados obtenidos, aportando información relevante para la olución del problema de negocio previamente identificado.
V. VALIDACIÓN En esta sección se describen tres casos de validación. El
primero de Identificación de Comportamiento de Recursantes Utilizando EVEAs (sección A), el segundo consiste en la Identificación del Conceptos Críticos de una Cursada (sección B), y por último de Identificación de Contenidos Débilmente Apropiados por Estudiantes (sección C).
A. Proceso de Identificación de Comportamiento de Estudiantes Recursantes Utilizando EVEAs En esta sección se describe el caso de estudio (sección A1),
luego se aplica el proceso (sección A2), y por último se describe la conclusión (sección A3).
A1. Descripción del Caso Desde el año 2007, [99] la Secretaría de Gestión
Académica de la Facultad Regional Buenos Aires (UTN-FRBA) lidera un proyecto para la creación de aulas virtuales como apoyatura a la presencialidad, desarrollado en el marco del PROMEI (Programa de Mejoramiento para la Enseñanza de la Ingeniería) [100]. En el mismo se involucran distintas asignaturas homogéneas del plan de las Carreras de Ingeniería con la utilización de entornos virtuales, integrándolos paulatinamente al proceso de aprendizaje de los alumnos.
Un antecedente desarrollado en paralelo a este proyecto es la experiencia del curso de ingreso, en donde se pusieron en juego usos educativos de las TIC que se desarrollaron en el Entorno Virtual de Enseñanza y Aprendizaje (EVEA) que proveyó la Universidad para cada Facultad Regional.
A inicios del año 2008, profundizando esta línea de acción y atendiendo a la Ordenanza de la Universidad Tecnológica Nacional N° 1129 “Cursado Intensivo” [101], la Secretaría de Gestión Académica de la F.R.B.A. presentó una nueva propuesta denominada “Mejoramiento de la calidad educativa favoreciendo la retención estudiantil mediante el uso de las nuevas tecnologías” cuyo objetivo General fue el de profundizar las acciones de Educación a Distancia en la Carrera de Grado en el Marco de la Ordenanza antes mencionada. Dentro de los objetivos específicos de dicha presentación se encontraban: • Implementar el régimen de cursado intensivo para la
aprobación de asignaturas de la carrera de grado en el ámbito de la Facultad Regional Buenos Aires.
• Integrar significativamente las nuevas tecnologías a la formación aprovechando las potencialidades que ofrecen.
• Capacitar a docentes/tutores en el uso de las herramientas de gestión del campus virtual de la Facultad.
• Preparar material didáctico apto para la intervención pedagógica en entornos virtuales.
Bajo estas circunstancias la Secretaría de Gestión Académica junto con la Cátedra de Matemática Discreta, asignatura del primer Nivel de la Carrera Ingeniería en Sistemas de Información, se abocaron a la generación del proyecto del “Cursado Intensivo de Matemática Discreta” [99].
La asignatura involucrada en esta investigación se dicta en forma cuatrimestral para la Carrera Ingeniería en Sistemas de Información que dicta la Facultad Regional Buenos Aires. Se pensó, en el momento de la implementación en cursos que se desarrollen con la modalidad a distancia, pero que tienen previsto instancias presenciales, dichas instancias tienen la siguiente característica:
[a] No obligatoria: clases de consulta [b] Obligatoria: encuentro para la toma de parciales y
recuperatorios. Con la puesta en marcha de este Proyecto, la Facultad
apunta a resolver, entre otros, problemas relacionados con la deserción y ofrecerle a los alumnos que tienen que recursar dicha asignatura, la posibilidad de cursarla bajo otra modalidad.
En la actualidad, para poder cursar de forma intensiva (Escuela de Verano presencial) una asignatura que la Facultad ofrece, los alumnos deben cumplir con las siguientes condiciones:
a) Posean la condición de alumno regular al momento de la inscripción.
b) Hayan sido cursantes de las asignaturas en cuestión en el Ciclo Lectivo que se realiza la inscripción a la Escuela de Verano en la UTN-FRBA y se hayan presentado, al menos, a dos instancias de evaluación.
c) No hayan sido dados de baja por inasistencias (estén incluidos en el Acta de Trabajos Prácticos - TPA).
d) Además, podrán inscribirse quienes no cumpliendo con los puntos b y c, hayan rendido por cuarta vez mal el final correspondiente (lo que los obligaría según Reglamento de Estudios a recursar la asignatura).
Las condiciones antes enunciadas han sido estipuladas fundamentalmente por temas presupuestarios, esto lleva aparejado que un número importante de alumnos no puedan cursarla, aunque sea su deseo hacerlo.
El hecho de poder hacer la cursada en forma semi-presencial o a distancia lleva implícito, al entender de la Institución, varios elementos favorables a tener en cuenta:
a) La cursada podrá comenzar antes y así dedicarle más tiempo que el actual curso. Esto es así dado que no será necesario el trabajo de demasiados docentes, teniendo en cuenta que en el período de verano se encuentran de vacaciones.
b) Como ya se indicó, la institución ha establecido normas que restringen la inscripción, con el objeto de minimizar la cantidad de cursos a raíz de dos problemas centrales:
1- No es fácil conseguir los docentes que dicten este curso en época estival por una remuneración, además, que es menor a la establecida para una cursada estándar. Todo ello a raíz de cuestiones presupuestarias.
2- El recurso "aulas" es limitado dado que conviven en el mismo momento tres actividades académicas diferentes: los cursos de ingreso a las diferentes carreras, los exámenes finales y la Escuela de Verano. Con esta nueva propuesta, este tipo de restricciones no serían necesarias, dado que optimizaríamos tanto el recurso docente como el de espacio físico y, por ende, más alumnos podrían aprovechar esta oportunidad. Los alumnos podrían organizar su horario de estudio de mejor forma, ya que en la actualidad para este tipo de cursos hay un solo horario de cursada.
c) Teniendo en cuenta que los alumnos ya cursaron la asignatura en cuestión, cabe suponer que hay temas en los que solo necesitan repasar y otros a los que les debe dedicar más tiempo.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
350
d) Es un alto número de alumnos el que año tras año preguntan sobre la posibilidad de cursar estas asignaturas (la que conforman la escuela de verano) en la modalidad a distancia.
Por lo antes expuesto, el curso intensivo estaría dirigido a todos los alumnos que quieran cursar mediante esta modalidad y hayan sido cursantes, en este caso particular de la asignatura Matemática Discreta, en el Ciclo Lectivo que se realiza la inscripción en la UTN-FRBA o hayan rendido por cuarta vez mal el final correspondiente.
Entre los objetivos de propuesta podemos enumerar: [a] Objetivo general: [b] Implementar estrategias de innovación pedagógica
basada en entornos virtuales. Ofrecer una nueva modalidad de cursada, atendiendo en
una primera instancia a alumnos de los dos primeros niveles de estudio apuntando al área de matemática.
Objetivos específicos: [a] Desarrollar entornos virtuales de aprendizaje para el
dictado de asignaturas del Ciclo General de Conocimientos Básicos, como ser, Matemática Discreta.
[b] Capacitar a los docente para trabajar bajo esta modalidad
[c] Capacitar a los tutores para acompañar el proceso de aprendizaje de los alumnos.
[d] Generar materiales multimediales que acompañen el proceso en el entorno virtual.
[e] Crear herramientas de gestión acordes a este proceso de enseñanza-aprendizaje.
[f] Desarrollar en los alumnos capacidades inherentes al compromiso que deben asumir con su propia formación.
La materia se encuentra dividida en unidades temáticas en las cuales el alumno deberá ir presentando trabajos prácticos para cada una de ellas. Un alumno aprueba la cursada a distancia si cumple con la entrega del 75% de los trabajos prácticos. La materia en esta modalidad fue cursada desde el año 2010 al 2012 por un total de 363 alumnos.
La materia está implementada en un EVEA bajo la plataforma Moodle la cual cuenta con módulos donde el alumno podrá realizar diferentes actividades:
1- Bajar el material de lectura: el alumno podrá bajar el material de lectura correspondiente a las diferentes unidades de la materia.
2- Subir trabajos prácticos: el alumno podrá subir los trabajos prácticos para cada una de las unidades (actividades). Los trabajos prácticos podrán ser subidos más de una vez si el docente lo requiere.
3- Leer foros: el alumno podrá acceder a leer los foros visualizando los diferentes temas de discusión. Una vez adentro de algún foro podrá entrar a leer algún tema de discusión específico del foro. Existen tres tipos de foros:
3.1. Aquellos relacionados con las diferentes unidades de las materias.
3.2. El foro de novedades, donde el docente publicará las novedades referentes a la materia.
3.3. Foro de alumnos, donde los alumnos podrán publicar cualquier tipo de consulta dirigida hacia los docentes o hacia el resto de los alumnos.
4- Crear nuevos temas de discusión en los foros. El alumno podrá crear nuevos temas de discusión en el foro 3.1 y el foro 3.3.
5- Agregar comentarios temas de discusión ya creados: el alumno podrá agregar algún comentario sobre algún tema de discusión de algún foro. Lo podrá realizar sobre los foros del tipo 3.1 y 3.3”
Las variables relacionadas con cada una de las actividades descriptas anteriormente se ven reflejadas en la Tabla VI.
Cada uno de los campos previamente mencionados, tienen como valor posible los caracteres “SI” y “NO”, con excepción del campo “Id_curso” e “Id_alumno”, los cuáles son de tipo numérico.
El problema de negocio presentado consiste en estudiar a los alumnos con respecto a su participación en el curso con el objetivo de disminuir la cantidad de alumnos que desaprueban la cursada de la materia.
B1.Aplicación del Proceso Paso 1: Conceptualización del dominio (figuras y tablas
corridas) La conceptualización del dominio del negocio se compone
de 3 subpasos: • Subpaso 1.1. Identificación los elementos relevantes del
dominio Para la idenificación de los elementos relevantes del dominio de negocio, se hace uso de las técnicas propuestas en [96]. Los formalismos resultantes de ejecutar dichas técnicas en el caso de estudio propuesto son la tabla término-categoría-definición del dominio (Tabla VII) y la tabla concepto-atributo-relación-valor del dominio (Tabla VIII).
• Subpaso 1.2. Identificación de las relaciones entre elementos del dominio
TABLA VI. LISTADO DE CAMPOS REGISTRADOS
Campo Descripción Id_curso Es el número que identifica un único curso.
id_alumno Es el número que identifica a un único alumno. ingreso_curso Cantidad de ingresos al EVEA. bajo_material Indica si el alumno bajó material de lectura de alguna
de las unidades de la materia. actividad_tp Indica si el alumno subió actividades de tp.
subio_tp Indica si subió más de un tp para alguna actividad. vio_foro_unida
d Indica si el alumno entro a alguno de los foros correspondientes a las unidades de la materia.
vio_discusion_unidad
Indica si el alumno entró a ver alguna discusión particular de algún foro correspondiente a las
unidades. comento_discu
sión_unidad Indica si el alumno realizó algún comentario en los foros correspondientes a las unidades de la materia.
creo_discusion_unidad
Indica si el alumno creo algún tema de discusión en un foro correspondiente a una unidad
vio_foro_alumno
Indica si el alumno entro a ver el foro de alumno.
vio_discusion_alumno
Indica si el alumno entró a ver alguna discusión particular del foro de alumnos.
comento_discusión_alumno
Indica si el alumno comentó alguna discusión del foro de alumnos.
creo_discusion_alumno
Indica si el alumno creo algún tema de discusión en el foro de alumnos.
vio_foro_novedades
Indica si el alumno entro a ver el foro de novedades.
vio_discusion_novedades
Indica si el alumno entró a ver alguna discusión particular del foro de novedades.
aprueba_cursada
Indica si el alumno aprobó la cursada.
TABLA VII. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL DOMINO APLICADA AL CASO DE ESTUDIO.
Término Categoría Definición actividad_tp Atributo Indica si el alumno subió
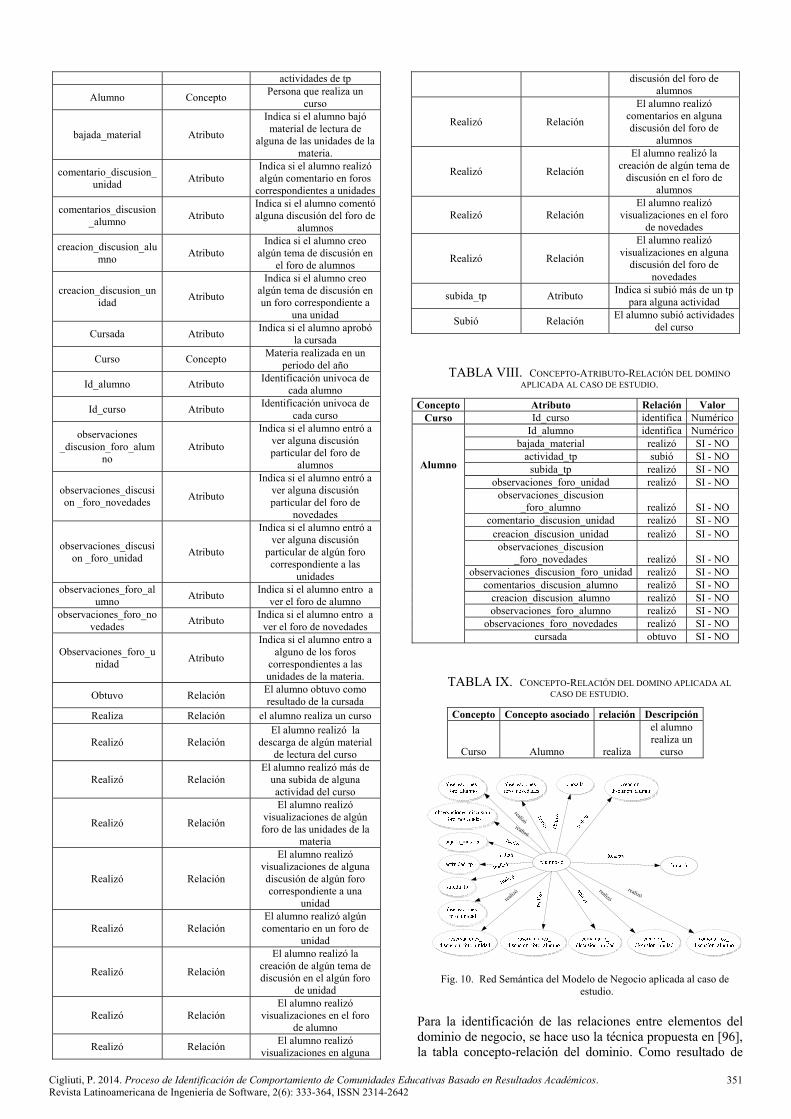
Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
351
actividades de tp
Alumno Concepto Persona que realiza un curso
bajada_material Atributo
Indica si el alumno bajó material de lectura de
alguna de las unidades de la materia.
comentario_discusion_unidad Atributo
Indica si el alumno realizó algún comentario en foros
correspondientes a unidades
comentarios_discusion_alumno Atributo
Indica si el alumno comentó alguna discusión del foro de
alumnos
creacion_discusion_alumno Atributo
Indica si el alumno creo algún tema de discusión en
el foro de alumnos
creacion_discusion_unidad Atributo
Indica si el alumno creo algún tema de discusión en un foro correspondiente a
una unidad
Cursada Atributo Indica si el alumno aprobó la cursada
Curso Concepto Materia realizada en un periodo del año
Id_alumno Atributo Identificación univoca de cada alumno
Id_curso Atributo Identificación univoca de cada curso
observaciones _discusion_foro_alum
no Atributo
Indica si el alumno entró a ver alguna discusión particular del foro de
alumnos
observaciones_discusion _foro_novedades Atributo
Indica si el alumno entró a ver alguna discusión particular del foro de
novedades
observaciones_discusion _foro_unidad Atributo
Indica si el alumno entró a ver alguna discusión
particular de algún foro correspondiente a las
unidades observaciones_foro_al
umno Atributo Indica si el alumno entro a ver el foro de alumno
observaciones_foro_novedades Atributo Indica si el alumno entro a
ver el foro de novedades
Observaciones_foro_unidad Atributo
Indica si el alumno entro a alguno de los foros
correspondientes a las unidades de la materia.
Obtuvo Relación El alumno obtuvo como resultado de la cursada
Realiza Relación el alumno realiza un curso
Realizó Relación El alumno realizó la
descarga de algún material de lectura del curso
Realizó Relación El alumno realizó más de
una subida de alguna actividad del curso
Realizó Relación
El alumno realizó visualizaciones de algún foro de las unidades de la
materia
Realizó Relación
El alumno realizó visualizaciones de alguna discusión de algún foro correspondiente a una
unidad
Realizó Relación El alumno realizó algún comentario en un foro de
unidad
Realizó Relación
El alumno realizó la creación de algún tema de discusión en el algún foro
de unidad
Realizó Relación El alumno realizó
visualizaciones en el foro de alumno
Realizó Relación El alumno realizó visualizaciones en alguna
discusión del foro de alumnos
Realizó Relación
El alumno realizó comentarios en alguna discusión del foro de
alumnos
Realizó Relación
El alumno realizó la creación de algún tema de
discusión en el foro de alumnos
Realizó Relación El alumno realizó
visualizaciones en el foro de novedades
Realizó Relación
El alumno realizó visualizaciones en alguna
discusión del foro de novedades
subida_tp Atributo Indica si subió más de un tp para alguna actividad
Subió Relación El alumno subió actividades del curso
TABLA VIII. CONCEPTO-ATRIBUTO-RELACIÓN DEL DOMINO APLICADA AL CASO DE ESTUDIO.
Concepto Atributo Relación Valor Curso Id_curso identifica Numérico
Id_alumno identifica Numéricobajada_material realizó SI - NO
actividad_tp subió SI - NO subida_tp realizó SI - NO
observaciones_foro_unidad realizó SI - NO observaciones_discusion
_foro_alumno realizó SI - NO comentario_discusion_unidad realizó SI - NO
creacion_discusion_unidad realizó SI - NO observaciones_discusion
_foro_novedades realizó SI - NO observaciones_discusion_foro_unidad realizó SI - NO
comentarios_discusion_alumno realizó SI - NO creacion_discusion_alumno realizó SI - NO observaciones_foro_alumno realizó SI - NO
observaciones_foro_novedades realizó SI - NO
Alumno cursada obtuvo SI - NO
TABLA IX. CONCEPTO-RELACIÓN DEL DOMINO APLICADA AL CASO DE ESTUDIO.
Concepto Concepto asociado relación Descripción
Curso Alumno realiza
el alumno realiza un
curso
realizó
realizó
realizó
realizó
realizó
Fig. 10. Red Semántica del Modelo de Negocio aplicada al caso de
estudio.
Para la identificación de las relaciones entre elementos del dominio de negocio, se hace uso la técnica propuesta en [96], la tabla concepto-relación del dominio. Como resultado de

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
352
aplicar la técnica tabla concepto-relación del dominio al caso de estudio propuesto se obtiene la Tabla IX.
• Subpaso 1.3. Representación conceptual del dominio Para la conceptualización del dominio del negocio, se hace uso de la técnica red semántica del modelo de negocio propuesto en [96]. El resultado de aplicar dicha técnica al caso de estudio propuesto, se presenta en la Figura 10.
Paso 2: Conceptualización del problema de explotación de información
La conceptualización del problema de explotación de información está compuesta por 5 subpasos: • Subpaso 2.1. Identificación del problema de negocio y su
traducción al problema de explotación de información. A partir del problema de negocio definido en la descripción
del caso de estudio (sección 5.1), se obtiene como problema de explotación de información:
“Identificar aquellas características relevantes del alumno que definen la aprobación o no del curso”. • Subpaso 2.2. Identificación de los conceptos pertenecientes al
problema de explotación de información A partir del problema de explotación de información se procede a seleccionar y determinar cuáles elementos están relacionados con el mismo. Para ello se implementa las técnicas tabla Término-Categoría-Definición del Problema de Explotación de Información y Tabla Concepto-Atributo-Relación-Valor Extendida del Problema de Explotación de Información, propuestas en [96]. El resultado de aplicar cada una de ellas al caso de estudio propuesto, se presenta en las Tablas X y XI respectivamente.
• Subpaso 2.3. Identificación de las relaciones entre elementos del problema de explotación de información Para la identificación de las relaciones entre elementos del problema de explotación de información, se implementa la técnica propuesta en [96]: la tabla concepto-relación del problema de explotación de información. El resultado de aplicar dicha tabla al caso de estudio propuesto se presenta en la Tabla XII.
• Subpaso 2.4. Identificación de dependencias entre los elementos conceptuales del problema El objetivo de este paso es identificar aquellos elementos que presenten dependencias cognitivas con otros elementos los cuales brinden información redundante o afecten la comprensión del conocimiento oculto en los datos. Para ello se propone la tabla de dependencias cuyo objetivo es identificar las dependencias existentes entre los datos, y eliminar aquellas que se consideren perjudiciales para el desarrollo del proceso. La tabla de dependencias está compuesta por tres columnas: en la primera se registra el elemento que no posea dependencia, en la segunda el elemento dependiente del elemento anteriormente registrado, y en la tercera columna se registra la necesidad o no de eliminar el elemento dependiente. En la Tabla XIII se presentan los elementos identificados en el caso de estudio propuesto.
• Subpaso 2.5. Representación del problema de explotación de información Para la conceptualización del problema de explotación de información, se hace uso de la técnica red semántica del problema de explotación propuesta en [96]. El resultado de aplicar dicha técnica al caso de estudio propuesto, se presenta en la Figura 11.
Paso 3: Identificación del proceso de explotación de información
A partir de las conceptualizaciones del dominio del negocio y del problema de explotación previamente presentadas, se establece el proceso de explotación de información a implementar, a través de aplicar el algoritmo de derivación del proceso de explotación de información propuesto en [96]. El proceso de explotación de información obtenido es: el proceso de Ponderación de Interdependencia de atributos.
Paso 4: Preparación de los datos La preparación de los datos para la ejecución del proceso
de explotación de información previamente detectado, consta de 3 subpasos: • Subpaso 4.1: Selección de los campos asociados al problema
de explotación de información A partir de conceptualizar los distintos elementos involucrados se seleccionan aquellos campos asociados al problema de explotación de información previamente establecido, obteniéndose el listado de datos que conformarán la base de datos a implementar. En el caso de estudio propuesto, los campos a utilizar son: • bajo_material • actividad_tp • subio_tp • vio_foro_unidad • vio_discusion_unidad
TABLA X. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE ESTUDIO.
Termino Categoría Descripción Alumno Concepto Persona que realiza un curso
bajada_material Atributo Indica si el alumno bajó material de lectura de alguna de las unidades de
la materia. Caracteristicas
relevantes Concepto Las características relevantes definen la aprobación de la cursada
comentario_discusion_unidad Atributo
Indica si el alumno realizó algún comentario en los foros
correspondientes a las unidades de la materia
comentarios_discusion_alumno Atributo Indica si el alumno comentó alguna
discusión del foro de alumnos creacion_discusion_
alumno Atributo Indica si el alumno creo algún tema de discusión en el foro de alumnos
creacion_discusion_unidad Atributo
Indica si el alumno creo algún tema de discusión en un foro
correspondiente a una unidad Cursada Atributo Indica si el alumno aprobó la cursada
Id_alumno Atributo Identificación univoca de cada alumno
Id_caracteristicas_relevantes Atributo Identificación univoca de las
características observaciones
_discusion_foro_alumno
Atributo Indica si el alumno entró a ver
alguna discusión particular del foro de alumnos
observaciones_discusion
_foro_novedades Atributo
Indica si el alumno entró a ver alguna discusión particular del foro
de novedades
observaciones_discusion _foro_unidad Atributo
Indica si el alumno entró a ver alguna discusión particular de algún foro correspondiente a las unidades
observaciones_foro_alumno Atributo Indica si el alumno entro a ver el
foro de alumno observaciones_foro_
novedades Atributo Indica si el alumno entro a ver el foro de novedades
Observaciones_foro_unidad Atributo
Indica si el alumno entro a alguno de los foros correspondientes a las
unidades de la materia.
Según Relación Las características relevantes del
alumno se definen según el resultado de la cursada
Subconjunto Relación bajada del material es un elemento
del conjunto de características relevantes

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
353
Subconjunto Relación Observar discusiones del foro de
alumnos es un elemento del conjunto de características relevantes
Subconjunto Relación Observar discusiones en el foro de unidad es un elemento del conjunto
de características relevantes
Subconjunto Relación Observar discusiones del foro de
unidades es un elemento del conjunto de características relevantes
Subconjunto Relación Observar el foro alumno es un
elemento del conjunto de características relevantes
Subconjunto Relación Observar el foro novedades es un
elemento del conjunto de características relevantes
Subconjunto Relación Observar el foro de las unidades es
un elemento del conjunto de características relevantes
Subconjunto Relación Comentario en foro de unidad es un
elemento del conjunto de características relevantes
Subconjunto Relación Comentarios sobre discusiones del
foro de alumnos es elemento conjunto de características relevantes
Subconjunto Relación Crear un tema de discusión en foro
de alumnos es elemento del conjunto de características relevantes
Subconjunto Relación Crear un tema de discusión en foro
de unidad es un elemento del conjunto de características relevantes
Subconjunto Relación Subir más de un tp es un elemento
del conjunto de características relevantes
subida_tp Atributo Indica si subió más de un tp para alguna actividad
TABLA XI. CONCEPTO-ATRIBUTO-RELACIÓN-VALOR EXTENDIDA DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE
ESTUDIO.
Concepto Atributo Relación Entrada/ Salida Valor Identifica
dor identifica Salida Numéric
o bajada_m
aterial subconjunto Elemento
Conjunto Salida SI - NO actividad
_tp subconjunto Elemento
Conjunto Salida SI - NO
subida_tp subconjunto Elemento
Conjunto Salida SI - NO observaciones_foro_unidad subconjunto
Elemento Conjunto Salida SI - NO
observaciones_disc
usion _foro_alu
mno subconjunto Elemento
Conjunto Salida SI - NO comentario_discusion_unid
ad subconjunto Elemento
Conjunto Salida SI - NO creacion_discusion_unidad subconjunto
Elemento Conjunto Salida SI - NO
observaciones_disc
usion _foro_novedades subconjunto
Elemento Conjunto Salida SI - NO
observaciones_discusion_foro_unidad subconjunto
Elemento Conjunto Salida SI - NO
comentarios_discusion_alu
mno subconjunto Elemento
Conjunto Salida SI - NO
Características relevantes
creacion_ subconjunto Elemento
SI - NO
discusion_alumno
Conjunto Salida
observaciones_foro_alumn
o subconjunto
Elemento Conjunto Salida
SI - NO observaciones_foro_noveda
des subconjunto Elemento
Conjunto Salida SI - NO Id_alumn
o identifica No relevante Numéric
o Alumno
cursada según Entrada SI - NO
TABLA XII. CONCEPTO-RELACIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE ESTUDIO.
Concepto
Concepto
asociadoRelac
ión Descripción Características relevantes Alumno
definen
Las características relevantes definen la cursada del alumno
TABLA XIII. DEPENDENCIAS APLICADAS AL CASO DE ESTUDIO.
Elemento Elemento
dependiente Eliminar
actividad_tp subida_tp NO
s s
s
s
s
Fig. 11. Red Semántica del Problema de Explotación de Información
aplicada al caso de estudio.
• comento_discusión_unidad • creo_discusion_unidad • vio_foro_alumno • vio_discusion_alumno • comento_discusión_alumno • creo_discusion_alumno • vio_foro_novedades • vio_discusion_novedades • aprueba_cursada
• Subpaso 4.2: Conversión de los datos
A partir de los algoritmos de minería de datos seleccionados, en base al proceso de explotación de información determinado, puede ser necesario convertir el tipo de dato de alguno de los campos seleccionados. Para el caso de estudio propuesto, no fue necesario convertir ningún dato.
• Subpaso 4.3: Generación de la base de datos Una vez identificados y convertidos los datos, es necesario realizar un proceso que integre todos los campos seleccionados en una única y misma fuente de datos. El resultado de aplicar el subpaso actual es la generación de la base de datos en la cual se implementará el proceso de explotación de información.
Paso 5: Implementación

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
354
El paso implementación está conformado por 2 subpasos: • Subpaso 5.1: Implementación
Este subpaso tiene como objetivo implementar el proceso de explotación de información identificado (mediante la ejecución de los algoritmos de minería de datos), en la base de datos generada en el paso anterior.
• Subpaso 5.2: Interpretación de los resultados A partir de los resultados obtenidos en el subpaso anterior, se realiza una interpretación de los mismos cuyo objetivo es identificar información relevante, descartando aquella que no sea fiable, y presentar la información obtenida. La información obtenida del caso de estudio presentado es: Los atributos de mayor incidencia para la desaprobación del curso son: • comento_discusion_unidad = NO, con un 91% de
incidencia. • vio_discusion_novedades = NO, con un 86% de incidencia. • comento_discusion_alumno = NO, con un 81% de
incidencia. • actividad_tp = NO, con un 73% de incidencia. Adicionalmente, los atributos de mayor incidencia para la aprobación del curso son: • actividad_tp = SI, con un 100% de incidencia. • vio_discusion_unidad = SI, con un 100% de incidencia. • vio_foro_unidad = SI, con un 100% de incidencia. Es decir, que los atributos que tienen mayor influencia para determinar que un alumno no apruebe la cursada son: si no comenta en algún foro de alguna unidad, si no observa las discusiones en los foros de novedades, si no comenta en las discusiones en los foros de alumnos y si no realiza las actividades. Mientras que para determinar que un alumno aprueba la cursada, son: que realice las actividades, que vea las discusiones y los foros de las unidades.
A3. Conclusión del Caso de Validación En este caso de estudio se ha presentado un proceso basado
en explotación de información orientado a encontrar patrones sobre el comportamiento de estudiantes que cursan asignaturas universitarias mediadas por EVEA.
Se ha ilustrado el uso del proceso propuesto con una prueba de concepto en el dominio de alumnos que recursan en la modalidad virtual una materia del área de ciencias básicas cuya primera cursada fue presencial. Este caso difiere de los descriptos en [28][24] en que a diferencia de los alumnos considerados en aquellos casos, en el que se presenta aquí los alumnos tuvieron un primer acercamiento presencial a los contenidos.
La población estudiada estuvo integrada por 363 estudiantes, que al término del curso virtual aprobaron el curso 31,95%, lo desaprobaron el 41,32%, y lo abandonaron el 26,72%.
Los resultados obtenidos son intuitivamente válidos y no presentan indicios que contraríen las creencias del equipo docente sobre las condiciones de aprobación del curso en esta modalidad. Sin embargo, con relación a las condiciones de desaprobación y considerando que la población estudiada era pequeña, el hecho que los atributos de mayor incidencia para la desaprobación presenten porcentajes sensiblemente por debajo del 100% se considera un indicador que permite postular que la replicación del proceso sobre una población por lo menos mayor en un orden de magnitud, puede hacer emerger atributos específicos que permitan refinar en distintos grupos las causales de desaprobación.
El proceso propuesto constituye una nueva herramienta de diagnóstico en el área; y si bien los resultados obtenidos en este estadio son consistentes, solo sirven para ilustrar la aplicación de la solución propuesta.
B. Identificación de Conceptos Críticos de una Cursada En esta sección se describe el caso de estudio (sección B1),
luego se aplica el proceso (sección B2), y por último se describe la conclusión (sección B3).
B1. Descripción del Caso La carrera Ingeniería en Sistemas de Información de la de
la Universidad Tecnológica Nacional Facultad Regional Buenos Aires (UTN-FRBA) tiene un programa académico el cual divide la cursada de materias a lo largo de cinco años. Análisis de Sistemas [102] es una de las materias de segundo año y troncales de la carrera la cual se focaliza en la enseñanza de la herramienta: diagrama de Flujo de Datos (DFD). El aprendizaje de esta herramienta para el alumno resulta dificultosa generando una cantidad de desaprobados en los exámenes parciales, incluso generando a veces, que el alumno termine recursando la materia. Por tal motivo se desea describir la calificación final de los alumnos, en base a los resultados obtenidos en cada una de las áreas de evaluación. Cuando se evalúa al alumno, para aprobar DFD el alumno debe tener bien el Diagrama de Contexto, la Tabla de Eventos y el DFD propiamente dicho. Se registra un identificador por alumno, además de los atributos de evaluación vinculados que se identifican son (si el alumno es capaz de): definir alcance sistema, identificar entidades, identificar entradas, identificar salidas, identificar funciones, identificar activación, identificar respuestas, graficar procesos, asignar activación, asignar entradas, asignar salidas, definir demoras e identificar comunicación entre procesos. Los atributos pueden tomar los valores: bien (B), Regular (R) y Mal (M). Cada uno de los atributos de evaluación mencionados anteriormente corresponde a alguna de las herramientas que conforman el DFD. Por último se registra un campo que define el resultado de la cursada del alumno, cuyos valores son Aprobó (A) o Desaprobó (D) la cursada. La base de datos cuenta con 101 casos para su estudio.
B1. Aplicación del Proceso Paso 1: Conceptualización del dominio La conceptualización del dominio del negocio se compone
de 3 subpasos: • Subpaso 1.1. Identificación los elementos relevantes del
dominio. Los formalismos resultantes de ejecutar el paso actual son las tablas término-categoría-definición del dominio y concepto-atributo-relación-valor del dominio (tabla XIV y XV respectivamente).
• Subpaso 1.2. Identificación de las relaciones entre elementos del dominio. La ejecución de la técnica tabla concepto-relación del dominio en el caso de estudio propuesto no identifica relaciones, dado que solo existe un único concepto.
• Subpaso 1.3. Representación conceptual del dominio El resultado de aplicar dicha técnica al caso de estudio, se presenta en la Figura 12.
Paso 2: Conceptualización del problema de explotación de información
La conceptualización del problema de explotación de información está compuesta por 5 subpasos:
Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
355
• Subpaso 2.1. Identificación del problema de negocio y su traducción al problema de explotación de información A partir del problema de negocio definido en la sección 5.1, se define el siguiente Problema de Explotación de Información: “Identificar las reglas que describan el resultado del alumno en base a las condiciones de evaluación.”
• Subpaso 2.2. Identificación de los conceptos pertenecientes al problema de explotación de información A partir del problema de explotación de información se procede a seleccionar y determinar cuáles elementos están relacionados con el mismo, implementando las tablas Término-Categoría-Definición del Problema de Explotación de Información y Tabla Concepto-Atributo-Relación-Valor Extendida del Problema de Explotación de Información (tablas XVI y XVII respectivamente).
TABLA XIV. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL DOMINO APLICADA AL CASO DE ESTUDIO
Término Categoría Definición
Alumno Concepto Estudiante de la materia Análisis de Sistemas
Asigna las entradas y salidas
a cada proceso Atributo
Posibilidad del alumno de Asignar las entradas y salidas de cada proceso en el
DFD Define las demoras Atributo Posibilidad del alumno de definir las
demoras
es capaz de Relación El alumno es capaz de identificar el alcance del sistema
es capaz de Relación El alumno es capaz de Identifica entidades externas
es capaz de Relación El alumno es capaz de Identifica entradas y salidas
es capaz de Relación El alumno es capaz de Puede identificar funciones?
es capaz de Relación El alumno es capaz de Identifica la forma de activación
es capaz de Relación El alumno es capaz de Identifica las respuestas
es capaz de Relación El alumno es capaz de Grafica los procesos de nivel 1 según TE
es capaz de Relación El alumno es capaz de Asigna las entradas y salidas a cada proceso
es capaz de Relación El alumno es capaz de Marca la activación de los procesos
es capaz de Relación El alumno es capaz de Identifica la comunicación entre procesos
es capaz de Relación El alumno es capaz de Define las demoras Grafica los
procesos de nivel 1 según TE
Atributo Posibilidad del alumno de graficar los procesos de nivel 1 según la TE
Identifica Relación El alumno se identifica con un código único
Identifica el alcance del
sistema Atributo Posibilidad del alumno de identificar el
alcance del sistema
Identifica entidades externas
Atributo Posibilidad del alumno de identificar las entidades externas que interactúan con el
sistema Identifica
entradas y salidas Atributo Posibilidad del alumno de identificar las entradas y salidas del sistema
Identifica la comunicación entre procesos
Atributo Posibilidad del alumno de identificar la comunicación entre los procesos
Identifica la forma de
activación Atributo Posibilidad del alumno de identificar la
forma en la cual se activa el sistema
Identifica las respuestas Atributo
Posibilidad del alumno de identificar las respuestas que el sistema provee a las
entidades externas
Identificador Atributo Código Único que permite identificar a un alumno
Marca la activación de los
procesos Atributo Posibilidad del alumno de identificar la
activación de los procesos
Obtuvo Relación El alumno obtuvo un resultado Puede identificar
funciones? Atributo Posibilidad del alumno de identificar las funcionalidades del sistema
Resultado Atributo Calificación que obtuvo el alumno
• Subpaso 2.3. Identificación de las relaciones entre elementos del problema de explotación de información Para la identificación de las relaciones entre elementos del problema de explotación de información, se implementa la técnica tabla concepto-relación del problema de explotación de información (Tabla XVIII).
• Subpaso 2.4. Identificación de dependencias entre los elementos conceptuales del problema
TABLA XV. CONCEPTO-ATRIBUTO-RELACIÓN-VALOR DEL DOMINO APLICADA AL CASO DE ESTUDIO
Concepto Atributo Relación Valor identificador identifica Numérico
Identifica el alcance del sistema es capaz de B - R - M
Identifica entidades externas es capaz de B - R - M
Identifica entradas y salidas es capaz de B - R - M Puede identificar
funciones? es capaz de B - R - M Identifica la forma de
activación es capaz de B - R - M Identifica las respuestas es capaz de B - R - M Grafica los procesos de
nivel 1 según TE es capaz de B - R - M Asigna las entradas y salidas a cada proceso es capaz de B - R - M
Marca la activación de los procesos es capaz de B - R - M
Identifica la comunicación entre procesos es capaz de B - R - M
Define las demoras es capaz de B - R - M
Alumno
Resultado Obtuvo D - A
TABLA XVI. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE ESTUDIO
Termino Categoría Descripción
Alumno Concepto Estudiante de la materia Análisis de Sistemas
Asigna las entradas y salidas a cada
proceso Atributo
Posibilidad del alumno de Asignar las entradas y salidas de cada
proceso en el DFD
Define las demoras Atributo Posibilidad del alumno de definir las demoras
Grafica los procesos de nivel 1
según TE Atributo Posibilidad del alumno de graficar
los procesos de nivel 1 según la TE
Identifica Relación El alumno se identifica con un código único
Identifica Relación Una regla se identifica a partir de un código único
Identifica el alcance del sistema Atributo Posibilidad del alumno de identificar
el alcance del sistema
Identifica entidades externas Atributo
Posibilidad del alumno de identificar las entidades externas que interactúan con el sistema
Identifica entradas y salidas Atributo Posibilidad del alumno de identificar
las entradas y salidas del sistema Identifica la
comunicación entre procesos
Atributo Posibilidad del alumno de identificar la comunicación entre los procesos
Identifica la forma de activación Atributo
Posibilidad del alumno de identificar la forma en la cual se activa el
sistema
Identifica las respuestas Atributo
Posibilidad del alumno de identificar las respuestas que el sistema provee
a las entidades externas

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
356
Identificador Atributo Código Único que permite identificar a un alumno
Identificador Atributo Código Único que permite identificar a una regla
Marca la activación de los procesos Atributo Posibilidad del alumno de identificar
la activación de los procesos Puede identificar
funciones? Atributo Posibilidad del alumno de identificar las funcionalidades del sistema
Regla Concepto
Descripción del resultado obtenido por el alumno en base a los
elementos de evaluación Resultado Atributo Calificación que obtuvo el alumno
Según Relación
Las reglas que definen al alumno se definen según los elementos de
evaluación
Subconjunto Relación Identifica el alcance del sistema es un elemento del conjunto a evaluar
Subconjunto Relación Identifica entidades externas es un
elemento del conjunto a evaluar
Subconjunto Relación Identifica entradas y salidas es un elemento del conjunto a evaluar
Subconjunto Relación Puede identificar funciones? es un elemento del conjunto a evaluar
Subconjunto Relación Identifica la forma de activación es un elemento del conjunto a evaluar
Subconjunto Relación Identifica las respuestas es un
elemento del conjunto a evaluar
Subconjunto Relación
Grafica los procesos de nivel 1 según TE es un elemento del
conjunto a evaluar
Subconjunto Relación
Asigna las entradas y salidas a cada proceso es un elemento del conjunto
a evaluar
Subconjunto Relación
Marca la activación de los procesos es un elemento del conjunto a
evaluar
Subconjunto Relación
Identifica la comunicación entre procesos es un elemento del
conjunto a evaluar
Subconjunto Relación Define las demoras es un elemento
del conjunto a evaluar
TABLA XVII. CONCEPTO-ATRIBUTO-RELACIÓN-VALOR EXTENDIDA DEL PROCESO DE EXPLOTACIÓN DE INFORMACIÓN
APLICADA AL CASO DE ESTUDIO
Concepto Atributo Relación Entrada/Salida Valor Identificador identifica Salida NuméricoIdentifica el alcance del
sistema subconjunto Elemento
Conjunto Salida B - R - MIdentifica entidades externas subconjunto
Elemento Conjunto Salida B - R - M
Identifica entradas y
salidas subconjunto Elemento
Conjunto Salida B - R - MPuede
identificar funciones? subconjunto
Elemento Conjunto Salida B - R - M
Identifica la forma de
activación subconjunto Elemento
Conjunto Salida B - R - MIdentifica las
respuestas subconjunto Elemento
Conjunto Salida B - R - MGrafica los procesos de
nivel 1 según TE subconjunto
Elemento Conjunto Salida B - R - M
Asigna las entradas y
salidas a cada proceso subconjunto
Elemento Conjunto Salida B - R - M
Regla
Marca la activación de los procesos subconjunto
Elemento Conjunto Salida B - R - M
Identifica la comunicación entre procesos subconjunto
Elemento Conjunto Salida B - R - M
Define las demoras subconjunto
Elemento Conjunto Salida B - R - M
Id_alumno identifica No relevante NuméricoAlumno Resultado según Entrada D - A
El objetivo de este paso es identificar aquellos elementos que presenten dependencias cognitivas con otros elementos los cuales brinden información redundante o afecten la comprensión del conocimiento oculto en los datos. En el caso
TABLA XVIII. CONCEPTO-RELACIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE ESTUDIO
Concepto Concepto asociado Relación Descripción
Regla Alumno define La regla define el resultado que
obtuvo el alumno
Fig. 12. Representación Conceptual del Domino.
de estudio propuesto, no se identifican datos dependientes que afecten los resultados del análisis.
• Subpaso 2.5. Representación del problema de explotación de información Para la conceptualización del problema de explotación de información, se hace uso de la técnica red semántica del problema de explotación, cuyo resultado se presenta en la Figura 13.
Paso 3: Identificación del proceso de explotación de información
A partir de las conceptualizaciones del dominio del negocio y del problema de explotación previamente presentadas, se establece el proceso de explotación de información a implementar, a través de aplicar el algoritmo de derivación del proceso de explotación de información propuesto en [96]. El proceso de explotación de información obtenido es: el Proceso de Descubrimiento de Reglas de Comportamiento.
Paso 4: Preparación de los datos La preparación de los datos para la ejecución del proceso
de explotación de información previamente detectado, consta de 3 subpasos: • Subpaso 4.1: Selección de los campos asociados al problema
de explotación de información Se presenta el listado de datos a utilizar para la ejecución del proceso de explotación de información previamente definido.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
357
Para el caso de estudio propuesto, solo se excluirá el identificador del alumno, dada su irrelevancia en el problema a analizar.
• Subpaso 4.2: Conversión de los datos A partir de los algoritmos de minería de datos seleccionados, en base al proceso de explotación de información determinado, puede ser necesario convertir el tipo de dato de alguno de los campos seleccionados. Para el caso de estudio propuesto, no fue necesario convertir ningún dato.
Fig. 13. Red Semántica del Problema de Explotación de Información aplicada al caso de estudio.
• Subpaso 4.3: Generación de la base de datos
Una vez identificados y convertidos los datos, es necesario realizar un proceso que integre todos los campos seleccionados en una única y misma fuente de datos. El resultado de aplicar el subpaso actual es la generación de la base de datos sobre la cual se implementará el proceso de explotación de información.
Paso 5: Implementación El paso implementación está conformado por 2 subpasos:
• Subpaso 5.1: Implementación Este subpaso tiene como objetivo implementar el proceso de explotación de información identificado (mediante la ejecución de los algoritmos de minería de datos), en la base de datos generada en el paso anterior.
• Subpaso 5.2: Interpretación de los resultados A partir de los resultados obtenidos en el subpaso anterior, se descartan aquellos patrones irrelevantes, informando aquellas piezas de conocimientos útiles para dar soporte a la toma de decisiones.
En el caso de estudio propuesto, se identificaron dos reglas que definen al comportamiento de los alumnos:
[a] Los alumnos que aprueban, se caracterizan por realizar bien la asignación de las entradas y salidas de cada proceso e identificar las respuestas de cada proceso de manera bien (regla soportada por el 62.5% de los alumnos aprobados);
[b] Los alumnos que aprueban, se caracterizan por realizar bien la asignación de las entradas y salidas de cada proceso e identificar las respuestas de cada proceso de manera regular (regla soportada por el 30% de los alumnos aprobados); y
[c] Los alumnos que desaprueban, se caracterizan por realizar regular o mal la asignación de las entradas y salidas de cada proceso (regla soportada por el 100% de los alumnos desaprobados). Se identifica que la comprensión de la asignación de las entradas y salidas junto con la identificación de las respuestas de cada proceso son claves para la aprobación del tema, siendo apoyado por más de un 90% de los casos.
Asimismo, se resalta que no realizar de forma correcta (Bien) la asignación de las entradas y salidas de cada proceso, garantiza la desaprobación del alumno.
B3. Conclusión del Caso de Validación El proceso propuesto, permite identificar los conceptos
fundamentales para la aprobación de la cursada, permitiendo generar acciones para fortalecer a los alumnos en dicho tema, garantizando un mayor grado de aprobados.
C. Identificación de Conceptos Débilmente Apropiados por Estudiantes En esta sección se describe el caso de estudio (sección C1),
luego se aplica el proceso (sección C2), y por último se describe la conclusión (sección C3).
C1. Descripción del Caso La carrera Ingeniería en Sistemas de Información de la de
la Universidad Tecnológica Nacional Facultad Regional Buenos Aires (UTN - FRBA) tiene un programa académico el cual divide la cursada de materias a lo largo de cinco años. Sistemas y Organizaciones es una de las materias de primer año y troncales de la carrera [102]. Dicha materia es el primer acercamiento del alumno con los conceptos de sistemas de información y circuitos administrativos siendo de gran importancia la comprensión de estos temas por parte del alumno y la aprobación de la materia. Por tal motivo se desea poder entender el desempeño de los alumnos en esta materia en base a los exámenes finales.
Para el desarrollo del actual trabajo se han utilizado 449 exámenes finales correspondientes al período comprendido entre octubre 2012 y febrero 2013. Los temas evaluados en dichos exámenes se corresponden con los siguientes temas:
Metodología de Sistemas de Información (Teoría de Metodología): el alumno debe poder describir el objetivo, las principales actividades, las técnicas y herramientas de cada una de las etapas de la Metodología de Sistemas de Información.
Teoría General (V/F Teoría): abarca preguntas teóricas de todos los conceptos de la asignatura.
Circuitos Administrativos (Teoría de Circuitos): comprende teoría sobre los circuitos básicos de una organización genérica junto con las normas de control interno.
Cursograma (Práctica de Cursograma): consiste en señalar los errores de un ejercicio resuelto mediante esta técnica gráfica.
Las condiciones de aprobación del examen son tener al menos la mitad de cada ejercicio respondido correctamente. Las preguntas no respondidas al igual que las respondidas erróneamente, no suman ni restan en la nota final. Además se debe considerar que los finales pueden ser de dos tipos de acuerdo a los temas evaluados: Cursograma (347 finales) o Circuitos Administrativo (102 finales). En la siguiente tabla se pueden los tipos de ejercicios y las cantidades según tipo de final [103].
Las variables relacionadas con el caso de estudio propuesto, se presentan en la Tabla XIX.
C2. Aplicación del Proceso Paso 1: Conceptualización del dominio La conceptualización del dominio del negocio se compone
de 3 subpasos: • Subpaso 1.1. Identificación los elementos relevantes del
dominio Para la identificación de los elementos relevantes del dominio de negocio, se hace uso de las técnicas propuestas en [96].

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
358
Los formalismos resultantes de ejecutar dichas técnicas en el caso de estudio propuesto son la tabla término-categoría-definición del dominio (Tabla XX) y la tabla concepto-atributo-relación-valor del dominio (Tabla XXI).
TABLA XIX. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADO AL CASO DE ESTUDIO.
Campo Descripción Valores
MET_1 1° Pregunta Teórica de Metodología 0, 0.5 y 1
MET_2 2° Pregunta Teórica de Metodología 0, 0.5 y 1
ToF_1 1° Afirmación Verdadero o Falso 0, 0.5 y 1
ToF_2 2° Afirmación Verdadero o Falso 0, 0.5 y 1
ToF_3 3° Afirmación Verdadero o Falso 0, 0.5 y 1
ToF_4 4° Afirmación Verdadero o Falso 0, 0.5 y 1
Tipo Es el tipo de final tomado Circuito - Cursograma
-1: En caso de que no aplique CIR_1
1° Ejercicio para completar Teoría de
Circuitos 0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CIR_2
2° Ejercicio para completar Teoría de
Circuitos 0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CIR_3
3° Ejercicio para completar Teoría de
Circuitos 0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CIR_4
4° Ejercicio para completar Teoría de
Circuitos 0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CUR_1 1° Ejercicio cursograma
0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CUR_2 2° Ejercicio cursograma
0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CUR_3 3° Ejercicio cursograma
0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CUR_4 4° Ejercicio cursograma
0, 0.5 o 1: En caso de que aplique
-1: En caso de que no aplique CUR_5 5° Ejercicio cursograma
0, 0.5 o 1: En caso de que aplique
A: Aprobado Resultado Indica si el alumno
aprobó o no el final D: Desaprobado
• Subpaso 1.2. Identificación de las relaciones entre elementos
del dominio Para la identificación de las relaciones entre elementos del dominio de negocio, se hace uso la técnica propuesta en [96], la tabla concepto-relación del dominio. Como resultado de aplicar la técnica tabla concepto-relación del dominio al caso de estudio propuesto se obtiene la Tabla XXII.
• Subpaso 1.3. Representación conceptual del dominio Para la conceptualización del dominio del negocio, se hace uso de la técnica red semántica del modelo de negocio propuesto en [96]. El resultado de aplicar dicha técnica al caso de estudio propuesto, se presenta en la figura 14.
Paso 2: Conceptualización del problema de explotación de información
La conceptualización del problema de explotación de información está compuesta por 5 subpasos:
• Subpaso 2.1. Identificación del problema de negocio y su traducción al problema de explotación de información
TABLA XX. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL DOMINIO APLICADA AL CASO DE ESTUDIO.
Término Categoría Definición Alumno Concepto Persona que realiza la cursada de SyO
CIR_1 Atributo 1° Ejercicio para completar Teoría de Circuitos
CIR_2 Atributo 2° Ejercicio para completar Teoría de Circuitos
CIR_3 Atributo 3° Ejercicio para completar Teoría de Circuitos
CIR_4 Atributo 4° Ejercicio para completar Teoría de Circuitos
contiene Relación El examen contiene una primer pregunta teórica de metodología
contiene Relación El examen contiene una segunda pregunta teórica de metodología
contiene Relación El examen contiene una primer pregunta de afirmación
contiene Relación El examen contiene una segunda pregunta de afirmación
contiene Relación El examen contiene una tercera pregunta de afirmación
contiene Relación El examen contiene una cuarta pregunta de afirmación
CUR_1 Atributo 1° Ejercicio cursograma
CUR_2 Atributo 2° Ejercicio cursograma
CUR_3 Atributo 3° Ejercicio cursograma
CUR_4 Atributo 4° Ejercicio cursograma
CUR_5 Atributo 5° Ejercicio cursograma
es Relación El examen es de un tipo posible
Examen Concepto Evaluación final de la cursada
id_alumno Atributo Identificador único del alumno
id_examen Atributo Identificador único del examen
identifica Relación el id_alumno identifica a un alumno
identifica Relación el id_examen identifica a un examen
MET_1 Atributo 1° Pregunta Teórica de Metodología
MET_2 Atributo 2° Pregunta Teórica de Metodología
Nota Atributo Indica si el alumno aprobó o no el final
obtiene Relación El alumno obtiene una calificación por el examen realizado
puede contener Relación El examen puede contener un primer ejercicio de teoría de circuitos
puede contener Relación El examen puede contener un segundo ejercicio de teoría de circuitos
puede contener Relación El examen puede contener un tercero ejercicio de teoría de circuitos
puede contener Relación El examen puede contener un cuarto ejercicio de teoría de circuitos
puede contener Relación El examen puede contener un primer ejercicio de cursograma
puede contener Relación El examen puede contener un segundo ejercicio de cursograma
puede contener Relación El examen puede contener un tercero ejercicio de cursograma
puede contener Relación El examen puede contener un cuarto ejercicio de cursograma
puede contener Relación El examen puede contener un quinto ejercicio de cursograma
Rinde Relación El alumno rinde el examen final
Tipo Atributo Es el tipo de final tomado
ToF_1 Atributo 1° Afirmación Verdadero o Falso
ToF_2 Atributo 2° Afirmación Verdadero o Falso
ToF_3 Atributo 3° Afirmación Verdadero o Falso
ToF_4 Atributo 4° Afirmación Verdadero o Falso

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
359
TABLA XXI. CONCEPTO-ATRIBUTO-RELACIÓN-VALOR DEL DOMINO APLICADA AL CASO DE ESTUDIO
Concepto Atributo Relación Valor
Alumno Id_Alumno identifica Numérico
Nota obtiene A - D
Examen Id_examen identifica Numérico
MET_1 contiene 0, 0.5 y 1
MET_2 contiene 0, 0.5 y 1
ToF_1 contiene 0, 0.5 y 1
ToF_2 contiene 0, 0.5 y 1
ToF_3 contiene 0, 0.5 y 1
ToF_4 contiene 0, 0.5 y 1
Tipo es Circuito - Cursograma
CIR_1 puede contener 0, 0.5,1 y -1
CIR_2 puede contener 0, 0.5,1 y -1
CIR_3 puede contener 0, 0.5,1 y -1
CIR_4 puede contener 0, 0.5,1 y -1
CUR_1 puede contener 0, 0.5,1 y -1
CUR_2 puede contener 0, 0.5,1 y -1
CUR_3 puede contener 0, 0.5,1 y -1
CUR_4 puede contener 0, 0.5,1 y -1
CUR_5 puede contener 0, 0.5,1 y -1
TABLA XXII. CONCEPTO-RELACIÓN DEL DOMINIO APLICADA AL CASO DE ESTUDIO
Concepto Concepto asociado relación Descripción
Alumno Examen rinde el alumno rinde un examen
Fig. 14. Red semántica del Modelo de Negocio aplicada al caso de estudio A partir del problema de negocio definido en la descripción
del caso de estudio (sección 5.1), se obtiene como problema de explotación de información: “comprender cuales son los elementos (preguntas) relevantes para la aprobación o no del examen”. • Subpaso 2.2. Identificación de los conceptos pertenecientes al
problema de explotación de información A partir del problema de explotación de información se procede a seleccionar y determinar cuáles elementos están relacionados con el mismo. Para ello se implementa las
técnicas tabla Término-Categoría-Definición del Problema de Explotación de Información y Tabla Concepto-Atributo-Relación-Valor Extendida del Problema de Explotación de Información, propuestas en [96]. El resultado de aplicar cada una de ellas al caso de estudio propuesto, se presenta en las tablas XXIII y XXIV respectivamente.
• Subpaso 2.3. Identificación de las relaciones entre elementos del problema de explotación de información Para la identificación de las relaciones entre elementos del problema de explotación de información, se implementa la técnica propuesta en [96]: la tabla concepto-relación del problema de explotación de información. El resultado de aplicar dicha tabla al caso de estudio propuesto se presenta en la tabla XXV.
• Subpaso 2.4. Identificación de dependencias entre los elementos conceptuales del problema El objetivo de este paso es identificar aquellos elementos que presenten dependencias cognitivas con otros elementos los cuales brinden información redundante o afecten la comprensión del conocimiento oculto en los datos. Para ello se propone la tabla de dependencias cuyo objetivo es identificar las dependencias existentes entre los datos, y eliminar aquellas que se consideren perjudiciales para el desarrollo del proceso. La tabla de dependencias está compuesta por tres columnas: en la primera se registra el elemento que no posea dependencia, en la segunda el elemento dependiente del elemento anteriormente registrado, y en la tercera columna se registra la acción a realizar. En la tabla XXVI se presentan los elementos identificados en el caso de estudio propuesto.
• Subpaso 2.5. Representación del problema de explotación de información Para la conceptualización del problema de explotación de información, se hace uso de la técnica red semántica del problema de explotación propuesta en [96]. El resultado de aplicar dicha técnica al caso de estudio propuesto, se presenta en la figura 15.
Paso 3: Identificación del proceso de explotación de información
A partir de las conceptualizaciones del dominio del negocio y del problema de explotación previamente presentadas, se establece el proceso de explotación de información a implementar, a través de aplicar el algoritmo de derivación del proceso de explotación de información propuesto en [96]. El proceso de explotación de información obtenido es: el Proceso de Ponderación de Reglas de Pertenencia a Grupos (Grupos definidos).
Paso 4: Preparación de los datos La preparación de los datos para la ejecución del proceso
de explotación de información previamente detectado, consta de 3 subpasos: • Subpaso 4.1: Selección de los campos asociados al problema
de explotación de información A partir de conceptualizar los distintos elementos involucrados se seleccionan aquellos campos asociados al problema de explotación de información previamente establecido, obteniéndose el listado de datos que conformarán la base de datos a implementar. En el caso de estudio propuesto, los campos a utilizar son todos los datos identificados en la tabla XIX.
• Subpaso 4.2: Conversión de los datos A partir de los algoritmos de minería de datos seleccionados, en base al proceso de explotación de

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
360
TABLA XXIII. TÉRMINO-CATEGORÍA-DEFINICIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN APLICADA AL CASO DE
ESTUDIO
Termino Categoría Descripción
Examen Concepto Evaluación final de la cursada SyO
CIR_1 Atributo 1° Ejercicio para completar Teoría de Circuitos
CIR_2 Atributo 2° Ejercicio para completar Teoría de Circuitos
CIR_3 Atributo 3° Ejercicio para completar Teoría de Circuitos
CIR_4 Atributo 4° Ejercicio para completar Teoría de Circuitos
CUR_1 Atributo 1° Ejercicio cursograma
CUR_2 Atributo 2° Ejercicio cursograma
CUR_3 Atributo 3° Ejercicio cursograma
CUR_4 Atributo 4° Ejercicio cursograma
CUR_5 Atributo 5° Ejercicio cursograma
elementos relevantes Concepto Conjunto de elementos del examen que
definen la calificación Es Atributo el examen es de un tipo
Id_Examen Atributo Identificador único del examen Identifica Relación el id_examen identifica al examen MET_1 Atributo 1° Pregunta Teórica de Metodología
MET_2 Atributo 2° Pregunta Teórica de Metodología
Nota Atributo Indica la calificación del examen
Pertenecen Relación Los elementos relevantes pertenecen al
examen final
Según Relación la nota del examen se caracteriza según
los resultados en elementos identificados
Subconjunto Relación
los elementos (preguntas) del examen son el subconjunto de elementos
relevantes Tipo Atributo Es el tipo de final tomado
ToF_1 Atributo 1° Afirmación Verdadero o Falso ToF_2 Atributo 2° Afirmación Verdadero o Falso
ToF_3 Atributo 3° Afirmación Verdadero o Falso
ToF_4 Atributo 4° Afirmación Verdadero o Falso
TABLA XXIV. CONCEPTO-ATRIBUTO-RELACIÓN-VALOR EXTENDIDA DEL PROBLEMA DE EXPLOTACIÓN DE INFORMACIÓN
APLICADA AL CASO DE ESTUDO.
oncepto Atributo Relación Entrada/Salida Valor
MET_1 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
MET_2 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
ToF_1 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
ToF_2 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
ToF_3 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
ToF_4 subconjunto Elemento
Conjunto Salida 0, 0.5 y 1
Tipo subconjunto Elemento
Conjunto Salida Circuito -
Cursograma
CIR_1 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CIR_2 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CIR_3 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CIR_4 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CUR_1 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
caracteristicas relevantes
CUR_2 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CUR_3 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CUR_4 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1
CUR_5 subconjunto Elemento
Conjunto Salida 0, 0.5,1 y -1 Id_Examen identifica No relevante Numérico Examen
Nota según Entrada A - D
TABLA XXV. CONCEPTO-RELACIÓN DEL PROBLEMA DE EXPLOTACIÓN DE INFORAMCIÓN APLICADA AL CASO DE ESTUDIO.
Concepto Concepto asociado Relación Descripción
elementos relevantes Examen pertenecen
Los elementos relevantes pertenecen al examen final
TABLA XXVI. DEPENDENCIAS APLICADAS AL CASO DE ESTUDIO
Elemento Elemento dependiente Acción Tipo CIR_1 Tipo CIR_2 Tipo CIR_3 Tipo CIR_4 Tipo CUR_1 Tipo CUR_2 Tipo CUR_3 Tipo CUR_4 Tipo CUR_5
Incorporar al elemento Tipo como variable del problema
de explotación de información
s
s ss
s s s s
segú
n
s
s egú
n
Fig. 15. Semántica del Problema de Explotación de Información aplicada
al caso de estudio
información determinado, puede ser necesario convertir el tipo de dato de alguno de los campos seleccionados. Para el caso de estudio propuesto, no fue necesario convertir ningún dato.
• Subpaso 4.3: Generación de la base de datos Una vez identificados y convertidos los datos, es necesario realizar un proceso que integre todos los campos seleccionados en una única y misma fuente de datos. El resultado de aplicar el subpaso actual es la generación de la base de datos en la cual se implementará el proceso de explotación de información.
Paso 5: Implementación El paso implementación está conformado por 2 subpasos:
• Subpaso 5.1: Implementación Este subpaso tiene como objetivo implementar el proceso de explotación de información identificado (mediante la ejecución de los algoritmos de minería de datos), en la base de datos generada en el paso anterior.
• Subpaso 5.2: Interpretación de los resultados A partir de los resultados obtenidos en el subpaso anterior, se realiza una interpretación de los mismos cuyo objetivo es

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
361
identificar información relevante, descartando aquella que no sea fiable, y presentar la información obtenida. La información obtenida del caso de estudio presentado es: Se identifican distintos elementos ponderantes a partir de las dependencias conceptuales identificadas en el paso 2.4, es decir, que según el tipo de examen se identificó la relevancia de distintas preguntas. Para el examen de cursograma, los elementos relevantes para la aprobación o no del mismo son las Preguntas Teóricas de Metodología, con una ponderación aproximadamente del 95%. Mientras que para el examen de Circuito, los ejercicios para completar de la Teoría de Circuitos presentan una ponderación del 81%.
A parir de los resultados obtenidos, puede afirmarse que los conceptos a reforzar para mejorar la calidad de los resultados de los estudiantes son:
[a] La teoría sobre la Metodología de Sistemas de Información, y
[b] La teoría sobre Circuitos Administrativos.
C3. Conclusión del Caso de Validación La Explotación de Información Educativa tiene un
desarrollo de más de una década y emerge como una contribución a la sistematización del entendimiento de: comportamientos estudiantiles, fallas en los procesos de enseñanza, contenidos mal apropiados, entre otros patrones de conocimiento identificables mediante los procesos y las técnicas que propone la Ingeniería de Explotación de Información. Si bien las primeras aplicaciones se centraron en la información provista por los espacios virtuales de enseñanza aprendizaje y los sistemas de gestión de calificaciones y perfiles de estudiantes; hace más de un lustro que se vienen desarrollando experiencias sobre aplicaciones a la evaluación de procesos de enseñanza-aprendizaje presenciales [Britos et al., 2008a; 2008b; Saavedra-Martinez et al., 2012].
En este trabajo, se ha propuesto un proceso que permite identificar contenidos débilmente apropiados por los estudiantes. En el caso de estudio estos son:
[a] la teoría sobre la Metodología de Sistemas de Información, y
[b] la teoría sobre Circuitos Administrativos. Esta identificación, permite generar acciones para fortalecer los aprendizajes en dichos temas.
VI. CONCLUSIÓN En esta sección se exponen los aportes realizados por este
trabajo (sección A), y se presentan las futuras líneas de investigación (sección B).
A. Aportaciones del trabajo. La Explotación de Información Educativa tiene un
desarrollo de más de una década y emerge como una contribución a la sistematización del entendimiento de: comportamientos estudiantiles, fallas en los procesos de enseñanza, contenidos mal apropiados, entre otros patrones de conocimiento identificables mediante los procesos y las técnicas que propone la Ingeniería de Explotación de Información. Si bien los primeros resultados se centraron en la información provista por los espacios virtuales de enseñanza aprendizaje y los sistemas de gestión de calificaciones y perfiles de estudiantes; hace más de un lustro que se vienen desarrollado experiencias sobre aplicaciones a la evaluación de procesos de enseñanza-aprendizaje presenciales [28][48][79].
En este trabajo se ha presentado un proceso basado en explotación de información que permite estudiar el comportamiento de los estudiantes durante el desarrollo de un curso o una carrera, logrando identificar y resolver distintos problemas asociados a la apropiación de los conceptos y al favorable desarrollo de la materia, brindando una herramienta que favorezca la comprensión del curso y la posibilidad de implementar medidas que permitan detectar alumnos con dificultades, e intervenir de manera temprana pudiendo corregir factores que impacten en el resultado de la cursada.
Este proceso se ha validado con tres casos de estudio: [a] procesos de identificación de comportamiento de estudiantes recursantes utilizando EVEAs, [b] identificación de conceptos críticos de una cursada, [c] identificación de contenidos débilmente apropiados por estudiantes.
En [a] se ilustra el uso del proceso propuesto con una prueba de concepto en el dominio de alumnos que recursan en la modalidad virtual una materia del área de ciencias básicas cuya primera cursada fue presencial. Los resultados obtenidos son intuitivamente válidos y no presentan indicios que contraríen las creencias del equipo docente sobre las condiciones de aprobación del curso en esta modalidad. Sin embargo, con relación a las condiciones de desaprobación y considerando que la población estudiada era pequeña, el hecho que los atributos de mayor incidencia para la desaprobación presenten porcentajes sensiblemente por debajo del 100% se considera un indicador que permite postular que la replicación del proceso sobre una población por lo menos sea mayor en un orden de magnitud, permitiendo emerger atributos específicos sobre los distintos grupos de causales de desaprobación. En cambio en [b] y [c] se identificaron reglas que definen fuertemente el comportamiento de los estudiantes.
De lo anterior se desprende que el proceso propuesto constituye una nueva herramienta de diagnóstico en el área; y si bien en [a] los resultados obtenidos son consistentes pero sólo sirven para ilustrar la aplicación de la solución propuesta en [b] y [c] se refleja el comportamiento del alumno permitiendo identificar los conceptos fundamentales para la aprobación de la cursada, posibilitando la generación de acciones para fortalecer a los alumnos en dicho tema, garantizando un mayor grado de aprobados.
B. Futuras Líneas de Investigación En este trabajo se propuso obtener procesos de
comportamiento de comunidades educativas basadas en Entornos Virtuales de Enseñanza y Aprendizaje, dada la característica de los mismos que poseen toda la información de interacción alumno –profesor almacenada en un único repositorio de datos. De esta forma, se obtiene la información para el análisis del comportamiento al alcance, siendo de fácil acceso y procesamiento.
Los resultados obtenidos del proceso de adquisición de patrones en búsqueda de comportamiento a partir de la información disponible en EVEAs, el reducido tamaño de las muestras utilizadas para la búsqueda de patrones si bien arrojo resultados promisorios, no son concluyentes y se planea continuar en esta línea de trabajo con poblaciones mayores.
De las otras validaciones ha surgido que los docentes usan explotación de información desde distintas visiones. Unos para revisar sus prácticas docentes, es decir, qué temas el docente cree que está enseñando bien, pero no es necesariamente así. En tanto, otros la utilizan para revisar e identificar aquellos conceptos críticos, es decir, qué conceptos tienen una complejidad tal que más allá de ser bien transmitidos por los

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
362
docentes, no son correctamente apropiados por los alumnos. En este contexto, surgen como futuras líneas de trabajo: proponer extensiones al proceso propuesto que contribuyan a la gestión de la información disponible necesaria para evaluar cada una de estas dos visiones.
ACKNOWLEDGMENT The preferred spelling of the word “acknowledgment” in
America is without an “e” after the “g”. Avoid the stilted expression, “One of us (R. B. G.) thanks . . .” Instead, try “R. B. G. thanks”. Put applicable sponsor acknowledgments here; DO NOT place them on the first page of your paper or as a footnote.
REFERENCES [1] Tiffin, J., & Rajasingham, L. (1997). En busca de la clase
virtual: la educación en la sociedad de la información. (Vol. 43). Editorial Paidós.
[2] Moore, M. G. y Kearsley, G. (1996), Distance Education. A Systems View, Belmont, CA, Wadsworth Publishing Company.
[3] L. G. Aretio, L. G. “Hacia una definición de educación a distancia.” Boletín informativo de la Asociación Iberoamericana de Educación Superior a Distancia. Abril, 1987. Año 4, N° 18, 4pp.
[4] Quesada Catillo, Rocío. (2006). Evaluación del aprendizaje en la educación a distancia “en línea”. RED Revista de Educación a Distancia
[5] Charum, V, (2007). Modelo de Evaluación de Plataformas Tecnológicas. Tesis de Magíster en Telecomunicaciones. Escuela de Posgrado, Instituto Tecnológico de Buenos Aires.
[6] Spotts, T y Bowman, M. (1995). Faculty Use of Instructional Technologies in Higher Education, en Educational Technology, 35(2): 56-64.
[7] Larose, D. T. (2005). Discovering Knowledge in Data, an introduction to Data Mining. John Wiley & Sons
[8] Negash, S. Gray, P. (2008). Business Intelligence. In Handbook on Decision Support Systems 2, eds. F. Burstein y C. Holsapple (Heidelberg, Springer), Pp. 175-193.
[9] Schiefer, J., Jeng, J., Kapoor, S. Chowdhary, P. (2004). Process Information Factory: A Data Management Approach for Enhancing Business Process Intelligence. Proceedings IEEE International Conference on E-Commerce Technology. Pp. 162- 169.
[10] Curtis, B., Kellner, M., Over, J. (1992). Process Modelling. Communications of the ACM, 35(9): 75-90.
[11] Ferreira, J., Takai, O., Pu, C. (2005). Integration of Business Processes with Autonomous Information Systems: A Case Study in Government Services. Proceedings Seventh IEEE International Conference on Ecommerce Technology. Pp. 471-474.
[12] Kanungo, S. (2005). Using Process Theory to Analyze Direct and Indirect Value-Drivers of information Systems. Proceedings of the 38th Annual Hawaii International Conference on System Sciences. Pp. 231-240.
[13] Britos, P. (2008). Procesos de Explotación de Información Basados en Sistemas Inteligentes. Tesis de Doctorado en Ciencias Informáticas. Facultad de Informática. Universidad Nacional de La Plata.
[14] García - Martínez, R., Britos, P., Rodríguez, D. (2013). Information Mining Processes Based on Intelligent Systems. Lecture Notes on Artificial Intelligence, 7906: 402 - 410. ISBN 978 - 3 - 642 - 38576 - 6
[15] Barnes, T., Desmarais, M., Romero, C., Ventura, S. (2009). Educational Data Mining 2009: 2nd International Conference on Educational Data Mining, Proceedings. Cordoba, Spain.
[16] Baker, R (2010). Data Mining for Education. To appear in McGaw, B., Peterson, P., Baker, E. (Eds.) International Encyclopedia of Education (3rd edition). Oxford, UK: Elsevier.
[17] Koedinger, K., Cunningham, K., Skogsholm A., Leber, B. (2008). An open repository and analysis tools for fine-grained, longitudinal learner data. In 1st International Conference on Educational Data Mining, Montreal, 157-166.
[18] Castro, F., Vellido, A., Nebot, A. Mugica, F. (2007). Applying Data Mining Techniques to e-Learning Problems. In: Jain, L.C., Tedman, R. and Tedman, D. (eds.) Evolution of Teaching and Learning Paradigms in Intelligent Environment. Studies in Computational Intelligence, 62, Springer-Verlag, 183-221
[19] Romero, C., Ventura, S. (2010). Educational data mining: a review of the state of the art. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 40(6), 601-618.
[20] Luan, J. (2002). Data mining and its applications in higher education. New directions for institutional research, 2002(113), 17-36.
[21] Baker, R. S., Yacef, K. (2009). The state of educational data mining in 2009: A review and future visions. JEDM-Journal of Educational Data Mining, 1(1), 3-17.
[22] Romero, C., Ventura, S. (2007). Educational data mining: A survey from 1995 to 2005. Expert systems with applications, 33(1), 135-146.
[23] Romero, C., Ventura, S., García, E. (2008). Data mining in course management systems: Moodle case study and tutorial. Computers & Education, 51(1), 368-384.
[24] Minaei-Bidgoli, B., Kashy, D. A., Kortmeyer, G., Punch, W. F. (2003). Predicting student performance: an application of data mining methods with an educational web-based system. In Frontiers in Education, 2003. FIE 2003 33rd Annual (Vol. 1, pp. T2A-13). IEEE.
[25] Bravo, J., Ortigosa, A. (2009). Detecting Symptoms of Low Performance Using Production Rules. International Working Group on Educational Data Mining.
[26] Dekker, G. W., Pechenizkiy, M., & Vleeshouwers, J. M. (2009). Predicting Students Drop Out: A Case Study. International Working Group on Educational Data Mining.
[27] Jiménez Rey, E. M., Rodríguez, D., Britos, P. V., García Martínez, R. (2008). Identificación de problemas de aprendizaje de programación con explotación de información. In XIV Congreso Argentino de Ciencias de la Computación.
[28] Britos, P., Jiménez Rey, E., García-Martínez, E. (2008a). Work in Progress: Programming Misunderstandings Discovering Process Based On Intelligent Data Mining Tools.Proceedings 38th ASEE/IEEE Frontiers in Education Conference. Session F4H: Assessing and Understanding student Learning. ISBN 978-1-4244-1970-8.
[29] Perkings, D. (1995), La escuela inteligente. Gedisa. [30] Kuna, H., García Martínez, R., Villatoro, F. (2009).
Identificación de Causales de Abandono de Estudios Universitarios. Uso de Procesos de Explotación de Información. Revista Iberoamericana de Tecnología en Educación y Educación en Tecnología 5: 39-44.
[31] Kuna, H., García Martínez, R. Villatoro, F. (2010). Pattern Discovery in University Students Desertion Based on Data Mining. Advances and Applications in Statistical Sciences Journal, 2(2): 275-286. ISSN 0974-6811.
[32] SIU-Guarani. (2014). ¿Qué es SIU Guaraní y para qué sirve? http://www.perio.unlp.edu.ar/ node/1014. Último acceso septiembre 2014.
[33] Saavedra Martínez, P., Pollo Cattaneo, M. F., Pytel, P., Rodríguez, D., García Martínez, R. (2012). Detección de problemas de aprendizaje basado en explotación de información.

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos. Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
363
[34] Reinschmidt, J., Allison F. (2000). Business Intelligence Certification Guide. IBM International Technical Support Organization. SG24-5747-00.
[35] Negash, S. Gray, P. (2008). Business Intelligence. In Handbook on Decision Support Systems 2, eds. F. Burstein y C. Holsapple (Heidelberg, Springer), Pp. 175-193.
[36] Lönnqvist, A., Pirttimäki, V. (2006). The Measurement of Business Intelligence. Information Systems Management, 23(1): 32-40.
[37] Grigori, D., Casati, F., Castellanos, M., Dayal, u., Sayal, M., Shan, M. (2004). Business Process Intelligence. Computers in Industry 53(3): 321-343
[38] Michalski, R. Bratko, I. Kubat, M. (1998). Machine Learning and Data Mining, Methods and Applications (Editores) John Wiley & Sons.
[39] Kononenko, I., Cestnik, B. (1986). Lymphography Data Set. UCI Machine Learning Repository. http://archive.ics.uci.edu/ml/datasets/Lymphography. Último acceso 29 de Abril del 2008.
[40] Michalski, R. (1983). A Theory and Methodology of Inductive Learning. Artificial Intelligence, 20: 111-161
[41] Chen, M., Han, J., Yu, P. (1996). Data Mining: An Overview from a Database Perspective. IEEE Transactions on Knowledge and Data Engineering, 8(6): 866-883.
[42] Chung, W., Chen, H., Nunamaker, J. (2005). A Visual Framework for Knowledge Discovery on the Web: An Empirical Study of Business Intelligence Exploration. Journal of Management Information Systems, 21(4): 57-84.
[43] Chau, M., Shiu, B., Chan, I., Chen, H. (2007). Redips: Backlink Search and Analysis on the Web for Business Intelligence Analysis. Journal of the American Society for Information Science and Technology, 58(3): 351-365.
[44] Golfarelli, M., Rizzi, S., Cella, L. (2004). Beyond data warehousing: what's next in business intelligence?. Proceedings 7th ACM international workshop on Data warehousing and OLAP. Pág. 1-6.
[45] Koubarakis, M., Plexousakis, D. (2000). A Formal Model for Business Process Modeling and Design. Lecture Notes in Computer Science, 1789: 142-156.
[46] Musen, M., Neumann, B., Studer, R. (2003). Guest Editors' Introduction: IFIP Conference on Intelligent Information Processing. IEEE Intelligent Systems 18(2): 16-17.
[47] García Martínez, R., Britos, P. (2004) Ingeniería de Sistemas Expertos. Editorial Nueva Librería. ISBN 987 - 1104 - 15 - 4
[48] Britos, P., Grosser, H., Rodríguez, D., García-Martínez, R. (2008b). Detecting Unusual Changes of Users Consumption. In Artificial Intelligence in Theory and Practice II, ed. M. Bramer, (Boston: Springer), en prensa.
[49] Hanna, M. (2004). Data mining in the e-learning domain. In Campus-Wide Information Systems, Volume 21, Number 1, 29-34
[50] Romero, C., Ventura, S. (2010). Educational data mining: a review of the state of the art. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 40(6), 601-618.
[51] Srivastava, J., Cooley, R., Deshpande, M., Tan, P. (2000). Web usage mining: Discovery and applications of usage patterns from web data. SIGKDD Explorations, 1(2), 12–23.
[52] Romero, C., Ventura, S., Bra, P. D. (2004). Knowledge discovery with genetic programming for providing feedback to courseware author. User Modeling and User-Adapted Interaction: The Journal of Personalization Research, 14(5), 425–464.
[53] Pahl, C., Donnellan, C. (2003). Data mining technology for the evaluation of web-based teaching and learning systems. In Proceedings of the congress e-learning, Montreal, Canada. Paulsen, M. (2003). Online education and learning
[54] Li, J., Zaïane, O. (2004). Combining usage, content, and structure data to improve web site recommendation. In International conference on ecommerce and web technologies (pp. 305–315).
[55] Arruabarrena, R., Pérez, T. A., López-Cuadrado, J., Vadillo, J. G. J. (2002). On evaluating adaptive systems for education. In Adaptive hypermedia (pp. 363–367).
[56] Zorrilla, M. E., Menasalvas, E., Marin, D., Mora, E., Segovia, J. (2005). Web usage mining project for improving web-based learning sites. In Web mining workshop, Cataluna.
[57] Johnson, S., Arago, S., Shaik, N., Palma-Rivas, N. (2000). Comparative analysis of learner satisfaction and learning outcomes in online and face-to-face learning environments. Journal of Interactive Learning Research, 11(1), 29–49.
[58] Ma, Y., Liu, B., Wong, C., Yu, P., Lee, S. (2000). Targeting the right students using data mining. In KDD ’00: Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 457–464).
[59] Yu, P., Own, C., Lin, L. (2001). On learning behavior analysis of web based interactive environment. In Proceedings of ICCEE, Oslo/Bergen, Norway
[60] Ingram, A. (1999). Using web server logs in evaluating instructional web sites. Journal of Educational Technology Systems, 28(2), 137–157.
[61] Frias-Martinez, E., Chen, S. Y., Liu, X. (2006). Survey of data mining approaches to user modeling for adaptive hypermedia. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 36(6), 734-749.
[62] Freeman, L. (2006). The Development of Social Network Analysis. Empirical Press.
[63] Novak, J.D., Cañas, A.J. (2006). The theory underlying concept maps and how to construct and use them. Technical Report IHMC CmapTools 2006-01.
[64] Corbertt, A.T. (2001). Cognitive Computer Tutors: Solving the Two-Sigma Problem. In Proceedings of the International Conference on User Modeling, 137-147.
[65] Romero, C., Ventura, S. (2007). Educational data mining: A survey from 1995 to 2005. Expert systems with applications, 33(1), 135-146
[66] Tsantis, L., Castellani, J., (2001). Enhancing learning environments through solution-based knowledge discovery tools. Journal of Special Education Technology, 16 (4), 1-35.
[67] Shen, R., Yang, F., & Han, P. (2002). Data analysis center based on elearning platform. In Proceedings of the 5th international workshop on the internet challenge: Technology and applications (pp. 19–28).
[68] Grobelnik, M., Mladenic, D., Jermol, M. (2002). Exploiting text mining in publishing and education. In Proceedings of the ICML-2002 workshop on data mining lessons learned (pp. 34–39).
[69] Beck, J.E., Mostow, J. (2008). How who should practice: Using learning decomposition to evaluate the efficacy of different types of practice for different types of students. In Proceedings of the 9th International Conference on Intelligent Tutoring Systems, 353-362.
[70] Cocea, M., Hershkovitz, A. and Baker, R.S.J.D. (2009). The Impact of Off-task and Gaming Behaviors on Learning: Immediate or Aggregate? In Proceedings of the 14th International Conference on Artificial Intelligence in Education, 507-514.
[71] Jeong, H. and Biswas, G. (2008). Mining Student Behavior Models in Learning-by-Teaching Environments. In Proceedings of the 1st International Conference on Educational Data Mining, 127-136.
[72] Britos, P., García-Martínez, R. (2009). Propuesta de Procesos de Explotación de Información. Proceedings XV Congreso

Cigliuti, P. 2014. Proceso de Identificación de Comportamiento de Comunidades Educativas Basado en Resultados Académicos Revista Latinoamericana de Ingeniería de Software, 2(6): 333-364, ISSN 2314-2642
364
Argentino de Ciencias de la Computación. Workshop de Base de Datos y Minería de Datos. Págs. 1041-1050. ISBN 978-897-24068-4-1.
[73] Romero, C., Porras, A.R., Ventura, S., Hervás, C., Zafra, A. (2006). Using sequential pattern mining for links recommendation in adaptive hipermedia educational systems. In International Conference Current Developments in Technology-Assisted Education. Sevilla, Spain (pp.1016-1020).
[74] Romero, C., Ventura, S. (2006). Data mining in e-learning, Southampton, UK: Wit Press.
[75] MSU (2014). Computer Science and Engineering – Michigan State University. http://www.cse.msu.edu. Último acceso octubre 2014.
[76] Tan, P., Steinbach, M., Kumar, V. (2006). Introduction to Data Mining. Pearson-Addison Wesley Publishers, Boston, USA.
[77] Dekker, G. W., Pechenizkiy, M., & Vleeshouwers, J. M. (2009). Predicting Students Drop Out: A Case Study. International Working Group on Educational Data Mining.
[78] Saavedra-Martínez, P., Pollo-Cattaneo, F., Rodríguez, D., Britos, P., & García-Martínez, R. (2012b). Proceso de identificación de errores de apropiación de conceptos basado en explotación de información. In VII Congreso de Tecnología en Educación y Educación en Tecnología.
[79] Saavedra Martínez, P., Pollo Cattaneo, M. F., Pytel, P., Rodríguez, D., García Martínez, R. (2012a). Detección de problemas de aprendizaje basado en explotación de información.
[80] Cigliuti, P., Pollo Cattaneo, M. F., García Martínez, R. (2012). Procesos de identificación de comportamiento de comunidades educativas centradas en EVEAs. In XIV Workshop de Investigadores en Ciencias de la Computación.
[81] Deroche, A., Pytel, P., Pollo Cattaneo, M. F. (2013). Propuesta de mejora en asignatura de grado mediante Explotación de Información. In VIII Congreso de Tecnología en Educación y Educación en Tecnología.
[82] Quinlan J. (1990). Learning Logic Definitions from Relations. Machine Learning, 5:239-266.
[83] Delling, R.M. (1987). Towards a theory of distance education. ICDE Boulletin, 13, pp. 21-25.
[84] Holmberg, B. (1989), Theory and Practice of Distance Education.
[85] Sherman, B. Y Judkins, P. (1992), Glimpses of Heaven, Visions of Hell. Londres, Hodder & Stoughton.
[86] Pedró, F. (1997), Didactic design, production and distribution of study materials in open higher education. A case-study on the transition from printed materials to digital media. Paper submitted to the ICDE Conference, Pennsylvania State University
[87] Alsina, C. (1997). Tutoring versus academic counselling in open and distance learning. A case-study on the redefinition of tutoring in a virtual campus. Paper submitted to the ICDE Conference, Pennsylvania State University.
[88] Herin, D. Sala, M. Pompidor, P. (2002). Evaluating and Revising Courses from Web Resources Educational. In Int. Conf. on Intelligent Tutoring Systems, Spain (pp. 208–218).
[89] Ortigosa, A., Carro, R.M. (2003). The Continuous Empirical Evaluation Approach: Evaluating Adaptive Web-based Courses. In Int. Conf. User Modeling, Canada (pp. 163-167).
[90] Gaudioso, E., Talavera, L. Data mining to support tutoring in virtual learning communities: experiences and challenges. Data mining in e-learning. Eds. Romero, C, Ventura, S., Southampton, UK: Wit Press. (pp. 207-226).
[91] Brusilovsky, P., Peylo, C., (2003). Adaptive and intelligent web-based educational systems. International Journal of Artificial Intelligence in Education, 13, 156-169.
[92] Cole, J. (2005). Using Moodle. O’Reilly.
[93] Mostow, J., Beck., J. (2006). Some useful tactics to modify, map and mine data from intelligent tutors. In Journal Natural Language Engineering, 12 ,2, 195-208.
[94] Mostow, J., Beck, J., Cen, H., Cuneo, A., Gouvea, E., Heiner, C., (2005). An educational data mining tool to browse tutor-student interactions: Time will tell! In Proceedings of the Workshop on Educational Data Mining, Pittsburgh, USA (pp. 15–22).
[95] Zaïane, O., Luo, J. (2001). Web usage mining for a better web-based learning environment. In Proceedings of conference on advanced technology for education, Banff, Alberta (pp. 60–64).
[96] Martins, S. (2014). Derivación del Proceso de Explotación de Información Desde el Modelado del Negocio. Revista Latinoamericana de Ingeniería de Software, 2(1): 53-76, ISSN 2314-2642
[97] Sowa, J. (1992). Semantic Networks. En Encyclopedia of Artificial intelligence (Editor S. Shapiro, 2da edicion). Wiley & Sons. ISBN 978 – 0471503071.
[98] García Martínez, R., Britos, P. (2004) Ingeniería de Sistemas Expertos. Editorial Nueva Librería. ISBN 987 - 1104 - 15 - 4
[99] Cuzzani, Karina. (2014). Proceso de Evaluación Constante: “Una herramienta indispensable en el momento de re-definir Proyectos de Educación Semi-Presencial”, Tesis de Maestría de Educación a Distancia. Universidad de Morón. Facultad de Filosofía, Ciencias de la Educación y Humanidades. Versión preliminar facilitado por la autora.
[100] PROMEI. (2014). Programa de Mejoramiento para la Enseñanza de la Ingeniería. http://portales.educacion.gov.ar/spu/ calidad-universitaria/proyectos-de-mejoramiento/promei-i-y-ii/. Último acceso octubre 2014.
[101] Ord1129. (2014). Ordenanza de la Universidad Tecnológica Nacional N° 1129 “Cursado Intensivo”. Secretaría Académica UTN-FRBA http://academica.frba.utn.edu.ar/ordenanzas/1129_ cursado_intensivo.pdf. Último acceso octubre 2014.
[102] DISI. (2014). Departamento de Ingeniería en Sistemas de Información. Universidad Tecnológica Nacional – Facultad Regional Buenos Aires. http://sistemas.frba.utn.edu.ar Último acceso octubre 2014.
[103] Raus, N. A., Lujan, F. N., Deroche, A., Vegega, C., Pytel, P., & Pollo-Cattaneo, M. F. (2013) Aplicación del Proceso de Ponderación de Reglas de Pertenencia a Grupos en Evaluaciones Finales en Carreras de Grado. Memorias del 1er Congreso Nacional de Ingeniería Informática / Sistemas de Información. ISSN 2347-0372.
Pablo Cigliuti. Es Ingeniero en Sistemas de Información por la Universidad Tecnológica Nacional (Facultad Regional Buenos Aires), y Candidato a Magister en Tecnología Informática Aplicada a la Educación por la Facultad de Informática de la Universidad Nacional de La Plata. Es Profesor Adjunto en el Departamento de Ingeniería de Sistemas de Información de la
Facultad Regional Buenos Aires de la Universidad Tecnológica Nacional. Es Investigador Tesista de Maestría en el Grupo de Investigación en Sistemas de Información del Departamento de Desarrollo Productivo y Tecnológico de la Universidad Nacional de Lanús. Su área de investigación es Explotación de Información aplicada a Educación.

Ierache, J., Igarza, S., Mangiarua, N., Becerra, M., Bevacqua, S., Verdicchio, N., Ortiz, F., Sanz, D., Duarte, N., Sena, M.. 2014. Herramienta de Realidad Aumentada para facilitar la enseñanza en contextos educativos mediante el uso de las TICs. Revista Latinoamericana de Ingeniería de Software, 2(6): 365-368, ISSN 2314-2642
365
Herramienta de Realidad Aumentada para Facilitar la Enseñanza en Contextos Educativos
Mediante el Uso de las TICs
Jorge Ierache, Santiago Igarza, Nahuel A. Mangiarua, Martín E. Becerra, Sebastián A. Bevacqua, Nicolás N. Verdicchio, Fernando M. Ortiz, Diego R. Sanz, Nicolás D. Duarte, Matías Sena
Departamento de Ingeniería e Investigaciones Tecnológicas Universidad Nacional de La Matanza
San Justo, Buenos Aires [email protected], [email protected]
Resumen—La Realidad Aumentada agrega elementos virtuales al entorno Real, proporcionándonos información de interés para el usuario aprovechando la infraestructura de las TICs. De esta manera, el entorno real es enriquecido con información mejorando así las experiencias en diferentes áreas, tales como entretenimiento, salud, Industria y principalmente los entornos educativos. En este artículo se presenta un framework que facilite a los educadores la enseñanza de los contenidos y aumente la participación de los alumnos, usando un juego de mesa. De esta manera, el alumnado interactúa directamente con los contenidos virtuales con el fin de afianzar sus conocimientos en diferentes áreas.
Palabras clave— Realidad Aumentada, dispositivos móviles aplicados en RA, aplicación de RA en la educación, Framework de RA.
I. INTRODUCCIÓN En la actualidad, los avances tecnológicos han permitido
que la experiencia de Realidad Aumentada sea posible tanto en computadoras personales como en Smartphones. Estos últimos son los que ofrecen mayor usabilidad de las aplicaciones creadas con esta tecnología al ser dispositivos potentes, portables y versátiles debido a los servicios y sensores que brindan.
Bajo el término de realidad aumentada [1] (en inglés Augmented Reality o AR) se agrupan aquellas tecnologías que permiten la superposición, en tiempo real, de imágenes o marcadores1 o información generados virtualmente, sobre imágenes del mundo real. De esta manera, se crea un entorno en el que la información y los objetos virtuales se fusionan con los objetos reales, ofreciendo una experiencia tal para el usuario, que puede llegar a pensar que forma parte de su realidad cotidiana. La Realidad Aumentada es una tecnología que ayuda a enriquecer nuestra percepción de la realidad con una nueva lente gracias a la cual la información del mundo real se complementa con la del digital.
La Realidad Aumentada (RA) [2] agrega información sintética a un ambiente real. La diferencia principal entre esta y la Realidad Virtual (RV) es que la última implica inmersión del participante en un mundo totalmente virtual; en cambio RA implica mantenerse en el mundo real con agregados virtuales.
1 Marcador, es una imagen impresa que proporciona una referencia espacial, permitiendo al dispositivo imprimir la información virtual en el entorno real captado relativo al mismo.
Para Ronald Azuma [3, 4], un sistema de RA es aquél que cumple con tres condiciones de base: (a) Combina la realidad y lo virtual. Al mundo real se le agregan objetos sintéticos que pueden ser visuales como texto u objetos 3D (wireframe o fotorealistas), auditivos, sensibles al tacto y/o al olfato, (b) Es interactivo en tiempo real. El usuario ve una escena real con objetos sintéticos agregados, que le que ayudarán a interactuar con su contexto, (c) Las imágenes son registradas en espacios 3D. La información virtual tiene que estar vinculada espacialmente al mundo real de manera coherente. Se necesita saber en todo momento la posición del usuario respecto al mundo real y de esta manera puede lograrse el registro de la mezcla entre información real y sintética. En síntesis un sistema de RA tiene tres requerimientos según Ronald Azuma: combina la realidad con información sintética, los objetos virtuales están registrados en el mundo real, es interactivo en tiempo real.
En base a lo anterior descripto, el presente trabajo se basa en la generación de una herramienta en el contexto de Realidad Aumentada para contribuir al aprendizaje de contenidos educativos, con la aplicación de los ultimas avances en las TIC’s de manera de crear una experiencia donde los alumnos interactúen con dichos contenidos. La propuesta del Grupo de Realidad Aumentada es proporcionar a los Educadores, un framework para dispositivos móviles que permita enriquecer la experiencia de un juego de mesa enfocado a un contexto educativo en el que se formulan preguntas previamente desarrolladas en los contenidos. Por ejemplo, preguntas de interés general, historia argentina, salud, biología, etc.
II. ESTADO DEL ARTE
A. Realidad Aumentada en ámbitos educativos En el estado del arte enfocado a los ámbitos educativos,
podemos encontrar diferentes proyectos que enriquecen los métodos de enseñanza.
En [5] se describe una herramienta RA llamada AuthorAR. Esta herramienta de autor está orientada a la creación de actividades educativas de RA, con la inclusión de plantillas específicas para el escenario de educación especial, con foco en el entrenamiento de competencias comunicacionales. Las dos plantillas que desarrollaron hasta el momento de su publicación son: una para actividades de exploración y otra para actividades de estructuración de frases.

Ierache, J., Igarza, S., Mangiarua, N., Becerra, M., Bevacqua, S., Verdicchio, N., Ortiz, F., Sanz, D., Duarte, N., Sena, M.. 2014. Herramienta de Realidad Aumentada para facilitar la enseñanza en contextos educativos mediante el uso de las TICs
Revista Latinoamericana de Ingeniería de Software, 2(6): 365-368, ISSN 2314-2642
366
Por un lado se desarrollaron herramientas para facilitarles a personas con diferentes dificultades, la enseñanza de contenidos educativos. Un ejemplo es PictogramRoom [6], es un proyecto que involucra una habitación de Realidad Aumentada para enseñar a comprender los pictogramas que permiten la comunicación a personas con trastornos del espectro del autismo. En otro orden Eyering [7], plantea un anillo de Realidad Aumentada equipado con una pequeña cámara, un procesador, conectividad Bluetooth y retroalimentación auditiva, a través de un dispositivo portátil, que podría ayudar a las personas con dificultades visuales a identificar objetos y leer texto. E-labora [8], incorpora la Realidad Aumentada y la tecnología 3G en actividades de entrenamiento y formación profesional. Este proyecto pretende mejorar la integración de las personas con discapacidad intelectual en el lugar de trabajo. En materia de juegos se han obtenido diversos resultados aplicando RA, como por ejemplo Virtuoso [9], un Juego educativo multiusuario que corre en el interior de un museo de Historia y Arte. El objetivo es ubicar cronológicamente, de izquierda a derecha, las palabras claves en las ranuras de la línea de tiempo, representada en la pared mediante marcadores. Usando la tecnología RA, cada ítem es representado virtualmente en la línea de tiempo y proporciona información de base acerca del mismo, con su nombre y una descripción sintética.
III. HERRAMIENTA DE REALIDAD AUMENTADA La herramienta propuesta consiste en un framework que
permite articular con el plano de un juego que contiene casilleros y se encuentra desplegado en un tablero físico, los contenidos de Realidad Aumentada previamente configurados, seleccionados y almacenados en función de la temática. La aplicación ejecuta videos sobre el casillero de la superficie del tablero, proporcionando la sensación de que el video se posiciona y ejecuta realmente en el casillero físico, generando de esta forma una aumentación de la realidad. Cada video ofrece tres opciones de las cuales el jugador elegirá una mediante un toque en la pantalla de su dispositivo.
El proceso consiste en que cada alumno participante del juego toca el dado virtual para que su ficha virtual avance a través de los casilleros del tablero físico. En cada casillero aparecerá un video aleatorio correspondiente a la temática seleccionada, sobre el que el sistema le hará una pregunta, para que este pueda seguir avanzando. En caso que conteste incorrectamente, perderá el turno y seguirá otro alumno. En caso de acertar, el alumno sigue jugando. El alumno al llegar a la meta no solamente alcanza el objetivo de completar el recorrido del juego, sino que se obtiene una puntuación del mismo y detalles de sus aciertos y errores, sobre los cuales se puede recurrir para luego fijar los contenidos que el alumno no pudo superar en el juego.
A. Framework El desarrollo se realizó en Android y se empleó las
herramientas Unity3D [10] y Vuforia [11]. A continuación se explicara el funcionamiento del
framework. En la Fig. 1 se puede observar, los componentes del framework.
La aplicación está compuesta por el controlador del juego que administra el funcionamiento general, delegando tareas a los componentes restantes durante la ejecución del mismo. Otro componente es Contenidos Target, se encarga de seleccionar el contenido para cargar los videos y las opciones sobre los marcadores para el jugador de turno. En cuanto a la
representación de los elementos virtuales sobre el tablero, el componente Elementos Juego se encarga de administrar el Tablero, Dado, Ficha del Jugador 1 y Ficha de Jugador 2. Cada una se encarga de representar cada elemento virtual respectivamente. Por último, el componente Controlador Respuesta se encarga de determinar el resultado según la opción que elijan los jugadores.
Fig. 1. Componentes del Framework
En la Fig. 2, se puede observar un diagrama de clases
conceptuales que aporta una visión más detallada de las relaciones más relevantes entre entidades que conforman los componentes de la aplicación.
Fig. 2. Diagrama de clases
A continuación, se muestra una secuencia que explica la
secuencia normal del framework. El escenario consiste en que el usuario toca el dado virtual de la aplicación para que el controlador del juego indique a la ficha su movimiento al casillero correspondiente y que le indique al gestor de contenido, proceda la carga del video con las opciones correspondientes.
Fig. 3. Secuencia normal
IV. CASO DE ESTUDIO, APLICACIÓN JUEGA PULSAR PLAY
A. Framework de aplicación Para utilizar el framework, los usuarios deben contar con
un Smartphone que cuente con sistema operativo Android y la aplicación presentada previamente instalada. Para jugar los usuarios deben enfocar el tablero con su dispositivo para que los elementos virtuales puedan ser visualizados a través del visor del dispositivo. Al iniciar el turno, el alumno que participa, toca el dado virtual para determinar cuántos

Ierache, J., Igarza, S., Mangiarua, N., Becerra, M., Bevacqua, S., Verdicchio, N., Ortiz, F., Sanz, D., Duarte, N., Sena, M.. 2014. Herramienta de Realidad Aumentada para facilitar la enseñanza en contextos educativos mediante el uso de las TICs. Revista Latinoamericana de Ingeniería de Software, 2(6): 365-368, ISSN 2314-2642
367
casilleros avanzar. Luego, la ficha asociada al alumno jugador de turno se desplazará hasta la posición que fue determinada por el número aleatorio obtenido al tirar el dado, aumentando la realidad sobre el tablero físico de juego. A continuación, un video se ejecutará para realizar una pregunta al alumno en el marco del juego. Al finalizar la reproducción de video, se mostrarán las opciones en la que se debe elegir una como respuesta. Como resultado se puede esperar que el jugador continúe con su turno, si contesto correctamente. Caso contrario, pierde el turno para cedérselo al otro alumno participante. La partida finaliza cuando algún participante llega a la meta. El usuario aumenta la realidad del tablero físico de juego a través de su dispositivo móvil el que corre la aplicación Juega PulsAR Play [12] seleccionando marcadores temáticos correspondiente a las categorías de las preguntas, que contiene los videos de contenidos con los que interactúa el usuario en un ambiente de Realidad Aumentada, se muestra una imagen en la Fig. 4.
Fig. 4. Dispositivo móvil-usuario eligiendo una opción
Se describen a continuación marcadores utilizados en
presentaciones iniciales del sistema desarrolladas durante las exposiciones: “Segunda Muestra Municipal de Ciencia y Tecnología - Plaza Ciencia 2013” y “ExpoProyecto UNLaM 2013” que tomaron lugar en el partido de La Matanza.
Se generaron contenidos y preguntas asociados a los marcadores, referido a diferentes temáticas, como: Actualidad Fig. 5a, Historia Fig. 5b, Música Fig. 5c, Cine Fig. 5d, Deporte Fig. 5e. Con estos contenidos se realizaron pruebas con el público visitante aplicando el framework desarrollado para la plataforma Android.
Fig. 5a. Actualidad Fig. 5b. Historia
B. Tablero físico Para utilizar el framework, en este caso se diseñó un tablero
físico con el correspondiente plano del juego, como el que se observa en Fig. 6, en el que las fichas virtuales de los jugadores avanzan por un camino junto a los casilleros que representan las categorías temáticas identificadas en función de los marcadores, que presentan las preguntas, a partir de los videos en su dispositivo móvil. Cada casillero pertenece a una de las categorías.
Cada categoría tiene asociada videos de contenidos temáticos sobre los que realizan preguntas al alumno que debe seleccionar una opción luego de la reproducción de video.
Fig. 5c. Música Fig. 5d. Películas Fig. 5e. Deportes
Fig. 6. Tablero físico
Las Fig. 5a hasta 5e funcionan como marcadores que
indican una referencia espacial para el contenido virtual (videos y opciones para responder), los marcadores permiten que se adapte exitosamente el mundo real del tablero físico y actúan como identificadores de contenidos temáticos para el alumno que se encuentra participando del juego.
C. Elementos virtuales La aplicación de RA, a través del empleo del Smartphone o
Tablet, que es enfocada y posicionada en el tablero físico, presenta los elementos virtuales que aumenta la realidad, en este orden para su utilización la aplicación presenta: un dado virtual (Fig. 7a), las fichas virtuales para cada jugador (Fig. 7b), videos, respuestas posibles sobre las que el alumno tiene que elegir una opción (Fig. 8).
Fig. 7a Dado Virtual
Fig. 7b Fichas de jugadores
Fig. 8. Video con opciones para responder
D. Modalidad de funcionamiento Para utilizar el framework, los usuarios deben contar con
un Smartphone que cuente con sistema operativo Android con la aplicación previamente instalada. Para utilizarlo los usuarios deben enfocar el tablero con su dispositivo para que los elementos virtuales puedan ser visualizados a través del visor del dispositivo. Para iniciar el turno, el jugador correspondiente, toca el dado virtual para determinar cuántos casilleros avanzar. Luego, La ficha asociada al jugador de turno se desplazará hasta la posición que fue determinada por

Ierache, J., Igarza, S., Mangiarua, N., Becerra, M., Bevacqua, S., Verdicchio, N., Ortiz, F., Sanz, D., Duarte, N., Sena, M.. 2014. Herramienta de Realidad Aumentada para facilitar la enseñanza en contextos educativos mediante el uso de las TICs
Revista Latinoamericana de Ingeniería de Software, 2(6): 365-368, ISSN 2314-2642
368
el número aleatorio obtenido. A continuación, un video se ejecutará para realizar una pregunta al jugador. Al finalizar la reproducción de video, se mostrarán las opciones en la que se debe elegir una como respuesta. Como resultado se puede esperar que el jugador continúe con su turno, si contesto correctamente. Caso contrario, pierde el turno para cederle el turno a su contrincante. La partida finaliza cuando un jugador llega a la meta.
Nuestro grupo de investigación realizó pruebas de este
framework en la Expo Proyecto UNLaM 2013 a través de la aplicación Juega PulsAR Play, donde alumnos de escuelas secundarias y estudiantes universitarios de diversas carreras fueron invitados a participar de partidas de prueba. Durante los 3 días de la exposición se observaron resultados satisfactorios donde los alumnos demostraban gran interés por la mecánica del juego que recompensa el conocimiento y aprendizaje. Se observó también un alto nivel de incorporación de los contenidos expuestos en la instancia de prueba por parte de estudiantes que participaron de la prueba en más de una ocasión.
V. CONCLUSIONES Y FUTURAS LÍNEAS DE TRABAJO La explotación del Framework en función del programa de
estudios con el que cuentan los educadores para llevar a cabo la transmisión de conocimientos en un contexto educativo, requiere que se definan las categorías que se quieran abordar para segmentar las preguntas y respuestas posibles para que la aplicación funcione. Además se debe diseñar el tablero físico y los marcadores de acuerdo a las temáticas propuestas, ya que las categorías se usan como marcadores representativos de las mismas. Es posible también generar la imagen del tablero y los marcadores proyectándolos sobre el pizarrón o pared a fin de ahorrar costos y tiempos con la construcción física de los mismos. La colaboración de contenidos educativos para explotar en el Framework de RA, se puede realizar a través de un catálogo de contenidos de RA [13] el que actualmente se encuentra en desarrollo, permitiendo que se puedan publicar y compartir contenidos, marcadores, cuestionarios y resultados.
Debido a los resultados obtenidos en las experiencias previamente citadas, este tipo de tecnologías y en especial la herramienta presentada, contribuye a enriquecer los métodos de enseñanza. Nuestro framework hace uso de una nueva tecnología emergente como lo es la Realidad Aumentada que utiliza las TICs para añadir al entorno real de las personas, nuevas alternativas que enriquezcan los métodos de enseñanza de contenidos educativos. La línea de investigación a seguir es desarrollar nuevos incrementos del GestorTargetContenido para permitirle al usuario generar el contenido, marcadores y las preguntas para que el framework funcione a través del mismo facilitando la colaboración de contenidos de RA a través del catálogo de RA que se encuentra en desarrollo.
AGRADECIMIENTOS Este trabajo es financiado en el marco del proyecto
PROINCE C-168 del DIIT, nuestro agradecimiento a la Ing. Zaloa Urrutikoetxea quien dio origen a la conformación del grupo de RA de la UNLaM.
REFERENCIAS [1] Fundación Telefónica, “Realidad aumentada: una nueva lente
para ver el mundo”, 1st ed., pp. 291-325, Jan. 2011.
[2] C. Manresa Yee, M. J. Abásolo, R. Más Sansó, M. Vénere, “Realidad virtual y realidad aumentada. Interfaces avanzadas”, 1st ed., pp. 16-18, Universidad Nacional de La Plata, La Plata, Buenos Aires, Argentina, 2011.
[3] R. T. Azuma, “A survey of augmented reality”, in Presence: Teleoperators and Virtual Environments, vol. 6, no. 4, pp. 355-385, Aug. 1997.
[4] R. T. Azuma, Y. Baillot, R. Behringer, S. K. Feiner, S.J. Julier, B. MacIntyre, “Recent advances in augmented reality” in IEEE Computer Graphics and Applications, pp. 34-47, Nov-Dec, 2001.
[5] L. Moralejo, C. Sanz, P. Pesado, S. Baldassarri, “Avances en el diseño de una herramienta de autor para la creación de actividades educativas basadas en realidad aumentada” in XIX Congreso Argentino de Ciencias de la Computación - CACIC 2013, 1st ed., pp. 516-525, Jan. 2013.
[6] Pictogram room, http://www.pictogramas.org/proom/init.do? method=initTab, (Vigente: Noviembre 2014).
[7] Eyering, http://www.digitalavmagazine.com/2012/08/13/el-mit-crea-un-dispositivo-de-realidad-aumentada-para-ciegos-activado -por-voz/, (Vigente: Noviembre 2014).
[8] T. de Andrés, M. Satur Torre, “Augmented Reality for e-labora: aplicaciones móviles para trabajadores con discapacidad intelectual”,http://www.qualcomm.com/media/documents/files/wireless-reach-case-study-spain-augmented-reality-spanish-.pdf, (Vigente: Noviembre 2014).
[9] Á. Belcastro, “Realidad Aumentada. UNLP: Virtuoso”, http://www.ing.unp.edu.ar/asignaturas/ias/realaum.pdf, (Vigente: Noviembre 2014)
[10] Unity3D, www.unity3d.com, (Vigente: Noviembre 2014). [11] Vuforia, https://www.vuforia.com/, (Vigente: Noviembre 2014). [12] Juega PulsAR Play, https://play.google.com/store/apps/details?
id=com.unlam.realidadaumentada.juegapulsarplay, (Vigente: Noviembre 2014).
[13] J. Ierache, N. Mangiarua, S. A. Bevacqua, M. Becerra, N. Verdicchio, M. Sena, N. Duarte, D. Sanz, F. Ortiz, S. Igarza, “Sistema de catálogo para la asistencia a la creación, publicación, gestión y explotación de contenidos multimedia y aplicaciones de realidad aumentada” in XX Congreso Argentino de Ciencias de la Computación, 1st ed., art. 6627, Oct. 2014.
Jorge Ierache es Doctor en Ciencias Informáticas por la Facultad de Informática de la Universidad Nacional de la Plata, profesor adjunto de la Universidad Nacional de La Matanza y Director del Grupo de Realidad Aumentada Aplicada. Santiago Igarza es Ingeniero en Informática, Director de Carrera de Ingeniería Informática de la Universidad Nacional de La Matanza, Codirector del Grupo de Realidad Aumentada Aplicada y egresado de la misma. Nahuel Adiel Mangiarua es Ingeniero en Informática, ayudante de primera, miembro del Grupo de Realidad Aumentada Aplicada de la Universidad Nacional de La Matanza y egresado de la misma. Martín Ezequiel Becerra, Sebastián Ariel Bevacqua, Nicolás Nazareno Verdicchio, Fernando Martín Ortiz, Diego Rubén Sanz, Nicolás Daniel Duarte y Matías Sena son estudiantes de la carrera de Ingeniería en Informática y becarios del Grupo de Realidad
Aumentada Aplicada de la Universidad Nacional de La Matanza.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
369
Establecimiento del Modelo de Agregación más Apropiado para Ingeniería del Software
Hernán Guillermo Amatriain1, Eduardo Diez1, Rodolfo Bertone2, Enrique Fernandez1,3 1. Grupo de Investigación en Sistemas de Información. Departamento de Desarrollo Productivo y Tecnológico. Universidad
Nacional de Lanús. Argentina. 2. Instituto de Investigaciones en Informática LIDI. Facultad de Informática. Universidad Nacional de La Plata. Argentina. 3. Cátedra de Sistemas de Programación no Convencional de Robots. Facultad de Ingeniería. Universidad de Buenos Aires.
Argentina [email protected]
Resumen—Antecedentes: la síntesis cuantitativa consiste en integrar los resultados de un conjunto de experimentos, previamente identificados, en una medida resumen. Al realizar este tipo de síntesis, se busca hallar un resultado que sea resumen representativo de los resultados de los estudios individuales, y por tanto que signifique una mejora sobre las estimaciones individuales. Este tipo de procedimientos recibe el nombre de Agregación o Meta-Análisis. Existen dos estrategias a la hora de agregar un conjunto de experimentos, la primera parte del supuesto de que las diferencias en los resultados de un experimento a otro obedecen a un error aleatorio propio de la experimentación y de que existe un único resultado o tamaño de efecto que es compartido por toda la población, la segunda estrategia parte del supuesto de que no existe un único tamaño de efecto representativo de toda la población, sino que dependiendo del origen o momento en que se realicen los experimentos los resultados van a modificarse debido a la influencia de variables no controladas, a pesar de esto puede obtenerse un promedio de los distintos resultados para una conclusión general. A la primera de las estrategias se la denominada modelo de efecto fijo y a la segunda se la denominada modelo de efectos aleatorios. Los autores que han comenzado a trabajar en Meta-Análisis, no muestran una línea de trabajo unificada. Este hecho hace que sea necesaria la unificación de criterios para la realización de este tipo de trabajos. Objetivo: establecer un conjunto de recomendaciones o guías que permitan, a los investigadores en Ingeniería del Software, determinar bajo qué condiciones es conveniente desarrollar un Meta-Análisis mediante modelo de efecto fijo y cuando es conveniente utilizar el modelo de efectos aleatorios. Métodos: la estrategia sería la de obtener los resultados de experimentos de características similares mediante el método de Monte Carlo. Todos ellos contarían con un número de sujetos bajo, ya que esa es la característica principal en el campo de la Ingeniería de Software y que genera la necesidad de tener que agregar el resultado de varios experimentos. Luego se agrega el resultado de estos experimentos con el método de Diferencia de Medias Ponderadas aplicada primero con el modelo de efecto fijo, y posteriormente con el modelo de efectos aleatorios. Con las combinaciones realizadas, se analiza y compara la fiabilidad y potencia estadística de ambos modelos de efectos. Resultados: el modelo de efecto fijo se comporta mejor que el modelo de efectos aleatorios, presentando potencia con más de 80 sujetos/experimentos cuando el modelo de efecto aleatorio no posee potencia en ninguno de los casos analizados, y fiabilidad para todos los casos en que la varianza es baja o media. Cuando los efectos poblacionales son altos o muy altos, el modelo de efecto fijo tiende a perder fiabilidad sobre todo cuando se incrementa la cantidad de experimentos y la cantidad de sujetos experimentales. Conclusiones: la baja potencia del modelo de efectos aleatorios dentro del contexto de simulación desarrollado, provoca en la práctica que el resultado final del meta-análisis hecho con este tipo de modelo tienda a dar diferencias no
significativas en todo momento, no permitiendo de esta forma poder afirmar que un tratamiento es mejor que otro cuando en realidad lo es.
Palabras Claves—meta-análisis, agregación estadística, modelo efecto fijo, modelo efectos aleatorios, síntesis cuntitativa, diferencia de medias ponderadas
I. INTRODUCCIÓN A. Meta-Análisis como herramienta para la construcción de
conocimiento A.1. Necesidad del Meta-Análisis
Hoy día es difícil poder pensar que una disciplina que se considere una ciencia no posea un procedimiento Empírico propio para validar la calidad de los conocimientos que se aplican en la misma. En este sentido es difícil pensar que en el mediano plazo la Ingeniería de Software pueda resolver los problemas de escases de sujetos experimentales para el desarrollo de los experimentos con un alto nivel de evidencia.
La cantidad de estudios experimentales en Ingeniería de Software se ha incrementado significativamente en los últimos años en cuanto a cantidad de experimentos [107]. Uno de los principales problemas a los cuales se enfrentan los investigadores en Ingeniería de Software a la hora de generar evidencias empíricas, es la imposibilidad de desarrollar un experimento de gran envergadura (que contenga gran cantidad de sujetos experimentales). Por en ejemplo, en el trabajo de revisión de [13], donde se identifican 21 experimentos, el promedio de sujetos experimentales por experimento ascienda a 6. Si bien las conclusiones de estos trabajos aportan cocimientos interesantes, difícilmente estos trabajos de forma aislada puedan generar las evidencias necesarias para mejorar la calidad de los conocimientos que se aplican en la industria del software, debido a la baja representatividad de las muestras. Esto produce que las nuevas innovaciones en la industria del software se apliquen porque se asumen que serán útiles debido al respeto o fama de las personas que las formulan [67].
Ahora bien, si se deja de ver a los experimentos de manera aislada y los mismos se analiza en forma conjunta mediante su agregación, como se hizo, por ejemplo, en los trabajos de [31, 13], pasamos de tener conocimientos abalados por cuatro o seis sujetos experimentales, a tener evidencias abaladas por más de 100 sujetos, lo cual mejora en gran medida la calidad de la conclusión. No solo porque a la vista de quien analiza los resultados las conclusiones se apoyan en mayor nivel de evidencia, sino también por los métodos estadísticos se

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
370
comportan más eficientemente (poseen menor error de tipo I y II) cuando las muestras son mayores. A.2. Antecedentes
Según [6] la síntesis de resultados consiste en integrar los resultados de un conjunto de experimentos, previamente identificados, en una medida resumen. Al realizar este tipo de síntesis, se busca hallar un resultado que sea resumen representativo de los resultados de los estudios individuales, y por tanto que signifique una mejora sobre las estimaciones individuales. Idealmente, se debe partir de los estudios individuales -con sus virtudes y defectos- y obtener un resultado que sea más fiable que los resultados individuales de los que partíamos. Este tipo de procedimientos recibe el nombre de Agregación, Síntesis de resultados experimentales o Meta-Análisis. Este último término fue definido por [43] y significa análisis después del análisis en alusión a que los elementos con lo que trabajan los Meta-Análisis son los experimentos desarrollados y analizados por sus autores primarios.
En la síntesis de resultados existen dos estrategias bien diferenciadas a la hora de agregar un conjunto de experimentos. La primera de ellas parte del supuesto de que las diferencias en los resultados de un experimento a otro obedecen a un error aleatorio propio de la experimentación y de que existe un único resultado o tamaño de efecto que es compartido por toda la población. La segunda estrategia parte del supuesto de que no existe un único tamaño de efecto representativo de toda la población, sino que dependiendo del origen o momento en que se realicen los experimentos los resultados van a modificarse debido a la influencia de variables no controladas, a pesar de esto puede obtenerse un promedio de los distintos resultados para una conclusión general. A la primera de las estrategias se la denominada modelo de efecto fijo y a la segunda se la denominada modelo de efectos aleatorios [6].
Dentro de este contexto, los autores que han comenzado a trabajar concretamente en Meta-Análisis, no muestran una línea de trabajo unificada, por ejemplo en el Meta-análisis desarrollado por [31], donde se agregan 15 experimentos vinculado a la programación de a pares, se aplican ambos modelos de agregación, en cambio en [13] donde se agregan experimentos vinculados a técnicas de inspección de código en tres grupos de 5, 7 y 9 experimentos respectivamente se aplica únicamente el modelo de efecto fijo. Este hecho hace que sea necesaria la unificación de criterios para la realización de este tipo de trabajos. A.3. Ejemplos
Tómese como ejemplo el intento de determinar de manera experimental que paradigma de programación es más adecuado para resolver un tipo de problema específico o que lenguaje de desarrollo presenta una curva de aprendizaje más abrupta, se verá que no es sencillo encontrar sujetos experimentales de similares características, es decir, que se presenten homogéneos ante el experimento.
En el primer ejemplo, podría tratarse de determinar si la programación estructurada es más adecuada para el desarrollo de una aplicación de manejo de inventario utilizando un motor de base de datos relacional, o la programación orientada a objetos es una opción más acertada. Para ello, hay que determinar un conjunto de características que deberán ser tenidas en cuenta. Por ejemplo, ¿cuáles van a ser las variables a medirse para determinar que paradigma es más adecuado?, ¿el tiempo de desarrollo?, ¿el tamaño del sistema (que a su vez
presenta el inconveniente de decidir cómo se mide el tamaño)?, ¿la performance a la hora de utilizarse? Por otro lado, habría que determinar que lenguaje de programación utilizar para cada paradigma o si se usarán más de un lenguaje por paradigma (lo que dificulta aún más encontrar sujetos experimentales). Estas características hacen que a la hora de realizar el mismo experimento, distintos investigadores en distintos puntos geográficos puedan tomar decisiones distintas, haciendo más dificultosa la agregación. Pero volviendo al tema de discusión, un investigador debería hallar programadores para cada desarrollo. Si pudiera encontrar 10 programadores, tendría que utilizar 5 para el tratamiento de control (programación estructurada) y los otros 5 para el tratamiento experimental (programación orientada a objetos). La cantidad de 10 programadores no es un número sencillo, menos si se requieren desarrolladores ya formados. En ese caso, el investigador se encontrará que no todos los sujetos son egresados de la misma facultad, que no todos tienen la misma edad, y por tanto no todos tienen la misma experiencia, además que la experiencia la habrán obtenido en lugares distintos, cada uno con sus metodologías de trabajo distintas (no solo se encontrará con desarrolladores egresados de distintas facultades, sino que tendrá que los sujetos vienen de distintas experiencias laborales).
Para el segundo ejemplo, si se quiere determinar si es más simple aprender java o VB.NET, habrá que encontrar desarrolladores con conocimientos en programación orientada a objetos, pero que no conozcan estos lenguajes. Otra vez, los sujetos experimentales serán pocos (hay que buscar programadores) y vendrán de distintos centros universitarios. Para un experimento de este tipo, pueden buscarse estudiantes, en cuyo caso, podría suponerse que es más sencillo llegar a un número más adecuado. Sin embargo, si todos los estudiantes vienen de la misma facultad, entonces probablemente manejen los mismos lenguajes, por lo que habría que buscar estudiantes de distintas carreras, lo que hace que los sujetos sean forzosamente heterogéneos.
Por otro lado, si los sujetos experimentales tienen horarios laborales distintos, quizás el experimento deba desarrollarse en distintos horarios, teniendo que desarrollar el experimento con algunos sujetos antes de su horario laboral, y con otros después de su horario laboral, haciendo del cansancio un factor no controlable que influirá en la investigación experimental. En este caso, parecería adecuado utilizar el modelo de efectos aleatorios, pero no hay consenso teórico ni evidencia práctica que lo asevere. A.4. Aplicabilidad de los Modelos al actual contexto de la
Ingeniería de Software Si se tiene en cuenta la gran diversidad cultural de la
personas que trabajan a nivel mundial en la Ingeniería de Software, la evolución de las carreras universitarias en cuanto a la formación de los profesionales del área o la influencia de la experiencia laboral, se puede suponer que lo más apropiado para esta disciplina sería utilizar un modelo de efectos aleatorios, ya que la variedad de factores no controlados de los experimentos es alta y su influencia en los resultados puede asumirse que también lo es.
Ahora bien, que pasa con las advertencia de [6], en Ingeniería de Software no solo los Meta-Análisis poseen pocos experimentos, sino que también los experimentos poseen pocos sujetos (cosa que no sucede en Medicina donde los autores analizan el comportamiento de los métodos), por ello no se puede afirmar a priori que el modelo de efectos aleatorios sea el apropiado para esta rama de la ciencia, por lo tanto ambas

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
371
estrategias serán tenidas en cuenta dentro de la presente investigación.
Según [6], el desarrollo de un Meta-Análisis debe partir de la agregación de los experimentos mediante un modelo de efecto fijo, ya que a priori no se sabe si los resultados de los experimentos muestran incompatibilidades o no. Luego se debe verificar la existencia o no de incompatibilidades entre los experimentos agregados mediando un análisis de heterogeneidad. En caso de no observarse evidencia de heterogeneidad, el proceso de da por concluido, en caso contrario se podrá agregar los experimentos mediante un modelo de efectos aleatorios.
Sin embargo hay estudios que demuestran que los métodos para análisis de heterogeneidad no tienen potencia con pocos experimentos [6]. De acuerdo a [50], cuando se combinan estadísticamente el resultado de varios experimentos a través de los métodos de Meta-Análisis y se estudia la heterogeneidad, si la agregación se realizó con un número bajo de experimentos, entonces el análisis de heterogeneidad no tiene potencia, por lo que no es determinante.
B. Objetivo de la Investigación Por lo expuesto hasta aquí, no se puede asegurar cual de los
dos modelos de efecto de Meta-Análisis se adapta mejor al actual contexto experimental de la Ingeniería de Software.
No hay un argumento teórico que permita determinar dentro del actual contexto de la Ingeniería de Software cual sería el modelo adecuado a emplear en la estrategia de Meta-Análisis, ni evidencia empírica al respecto.
Por otro lado, y debido a la diferencia de opiniones entre los investigadores sobre el modelo a utilizar, se vislumbra la necesidad de zanjar esta cuestión.
Por tanto, el objetivo del presente trabajo de investigación reside en establecer un conjunto de recomendaciones o guías que permitan, a los investigadores en Ingeniería del Software, determinar bajo qué condiciones es conveniente desarrollar un Meta-Análisis mediante modelo de efecto fijo y cuando es conveniente utilizar el modelo de efectos aleatorios, en las actuales condiciones experimentales de la Ingeniería del Software.
II. ESTADO DE LA CUESTIÓN A. Meta-Análisis A.1. Experimentos y Agregación de Experimentos
Puede observarse en los últimos 20 años el incremento de la cantidad de experimentos realizados dentro del ámbito de la Ingeniería del Software (IS) [107]. Entre los años 1993 y 2003 solo se publicaron 93 experimentos [32] en journals y conferencias de primer nivel, como es por ejemplo IEEE Transactions on Software Engineering. Sin embargo, la cantidad de experimentos desarrollados dentro del campo de la Ingeniería de Software fue mucho mayor, duplicando o incluso triplicando la cifra antes mencionada [26]. Estos experimentos abarcan diversas áreas, tales como el desempeño de las técnicas de testing, la educción de requerimientos, o la performance de los lenguajes de programación, por citar algunos. Si bien los experimentos aportan conocimientos interesantes en cada caso, en general son pequeños (rara vez utilizan más de 20 sujetos experimentales [24]), por ello para que la información que aportan sea valiosa los resultados deben agregarse para poder obtener conclusiones avaladas con la mayor evidencia empírica posible.
La agregación de experimentos consiste en combinar los resultados de varios experimentos, que analizan el
comportamiento de un par de tratamientos específico, en un contexto determinado, para obtener un único resultado final. El nuevo resultado será más general y fiable que los resultados individuales, porque el mismo estará sustentado por un mayor nivel de evidencia empírica [15].
Las distintas estrategias de combinación de resultados experimentales se conocen con el nombre genérico de métodos de síntesis [12] o métodos de agregación [16], como típicamente acostumbran a denominarse en Ingeniería del Software.
Para que los resultados de un proceso de agregación sean fiables, se incluyen dentro de una Revisión Sistemática (RS). Una RS es un procedimiento que aplica estrategias científicas para aumentar la fiabilidad del proceso de recopilación, valoración crítica y agregación de los estudios experimentales relevantes sobre un tema [46]. Para combinar los resultados de los estudios individuales, las RS utilizan el Meta-Análisis como estrategia de agregación.
El Meta-Análisis es un nombre colectivo que hace referencia a un conjunto de métodos estadísticos que intentan hallar un resultado numérico que sea resumen representativo de los resultados de los estudios individuales, y por tanto que signifique una mejora sobre las estimaciones individuales.
Es importante destacar que para poder aplicar Meta-Análisis se deben verificar ciertas restricciones, tales como un número mínimo de experimentos, adecuadamente recopilados y homogéneos [46]. De esta forma se podrá garantizar que la conclusión alcanzada es realmente sólida y fiable.
Si bien la agregación de experimentos no es un tema nuevo para ciencias como la Psicología, la educación o la Medicina, recién a mediados de los 90’ comienza a ser propuesta como una alternativa para generar conocimiento en Ingeniería de Software [4]. Desde entonteces varios autores abordaron el tema. Se puede citar al procedimiento de RS desarrollado por [73], el cual surge de una adaptación de los procesos de RS desarrollados en medicina, donde se contemplan diversos niveles de calidad de experimento acorde al actual contexto de la Ingeniería de Software. En dicho procedimiento, de la misma manera de lo que se hace en medicina, se recomienda el uso del método estadístico Diferencia Medias Ponderadas (DMP) [55] para la agregación de los resultados.
En [31] se ha trabajado en la aplicación de las RS, donde se identifican 11 estudios experimentales vinculados al desempe-ño de los programadores cuando trabajan de a pares y se combinan sus resultados mediante un método de Meta-Análisis estándar (aplicando el método de Diferencias Medias Ponderadas como se sugiere en [73]).
Ahora bien, no todos los trabajos vinculados a la Agregación hechos en el ámbito de la Ingeniería de Software han sido exitosos. En [3, 105, 59, 116, 69, 65], si bien los autores pudieron desarrollar el procedimiento de búsqueda y selección de experimentos, la combinación de los mismos mediante Meta-Análisis resultó impracticable. Los principales motivos que limitaron la aplicación del Meta-análisis, en el actual contexto de la Ingeniería del Software, se vinculan con los siguientes problemas: • La escasez de experimentos, replicaciones y homogeneidad
entre los mismos. [24, 84]. • La carencia de estándares para reportes de experimentos. Por
ejemplo, [9] no publican varianzas y [11] ni siquiera reporta las medias de los resultados experimentales.
• La falta de estandarización de las variables respuesta. Los trabajos de [1, 117] utilizan diferentes variables respuesta

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
372
para analizar un mismo aspecto, lo cual hace que estos experimentos no puedan ser agregados.
La Ingeniería de Software no es la única ciencia que padece el problema de escasez de experimentos y que posee altos costos para el desarrollo de los mismos. Un ejemplo es la ecología, donde los costos y el tiempo necesario para evaluar el crecimiento de algunas especies son elevados [118]. Tampoco la Ingeniería de Software es la única ciencia que tiene problemas vinculados a la calidad de los estudios desarrollados (en general solo se trabaja con ensayos de laboratorio), los cuales limitan la calidad o fiabilidad de las conclusiones obtenidas, ya que este problema surge en ciencias mucho más comprometidas con la experimentación como lo es la medicina [48, 104]. A.2. Modelos de Meta-Análisis
Según [6] la síntesis de resultados consiste en integrar los resultados de un conjunto de experimentos previamente identificados, en una medida resumen. Al realizar este tipo de síntesis, se busca hallar un valor que sea representativo de los resultados de los estudios individuales, y por tanto que signifique una mejora sobre las estimaciones individuales. Se parte de los estudios individuales -con sus virtudes y defectos- y se obtiene un resultado que es más fiable que los resultados individuales de los que se parte. Este tipo de procedimientos recibe el nombre de Agregación, Síntesis de resultados experimentales o Meta-Análisis. Este último término fue definido por [43] y significa análisis después del análisis en alusión a que los elementos con lo que trabajan los Meta-Análisis son los experimentos desarrollados y analizados por sus autores primarios.
Existen dos estrategias para la agregación de experimentos: modelo de efecto fijo y modelo de efectos aleatorios. La primera de ellas parte del supuesto que las diferencias en los resultados de un experimento a otro obedecen a un error aleatorio propio de la experimentación y que existe un único resultado o tamaño de efecto que es compartido por toda la población. La segunda estrategia parte del supuesto que no existe un único tamaño de efecto representativo de toda la población, sino que dependiendo del origen o momento en que se realicen los experimentos los resultados van a modificarse debido a la influencia de variables no controladas, a pesar de esto puede obtenerse un promedio de los distintos resultados para una conclusión general. A la primera de las estrategias se la denominada modelo de efecto fijo y a la segunda se la denominada modelo de efectos aleatorios [6].
Las Figura 1 y 2 ilustran lo dicho anteriormente, mostrando en la Figura 1 un único tamaño de efecto y un conjunto de resultados que se diferencias del mismo únicamente por un error propio de la experimentación, y en la Figura 2 varios tamaños de efecto, donde los experimentos también poseen error experimental y un promedio general de los tamaños de efecto [103].
Figura 1: Supuestos del modelo de efecto fijo
Figura 2: Supuestos del modelo de efectos Aleatorios
En las siguientes subsecciones se explica con más detalle en qué consiste cada una de las estrategias, sus diferencias a la hora de evaluar la ponderación de un experimento dentro de la conclusión y su aplicabilidad en Ingeniería de Software. A.3. Modelo de efecto fijo
Para el modelo de efecto fijo existe un único tamaño de efecto al cual pertenecen todos los experimentos que van a ser agregados. Por ende, cualquier diferencia en los resultados obedece únicamente a un error experimental aleatorio propio de la experimentación [6]. Por ello, dentro de este enfoque la ponderación de los experimentos se realiza únicamente en base a la inversa de su varianza, asumiendo que cuanto menor sea la varianza más preciso es el experimento. Dado que la varianza es inversamente proporcional al tamaño del experimento (cantidad de sujetos que posee) tendremos que los experimentos de mayor tamaño tendrán una mayor representatividad en la conclusión que los pequeños. Un experimento con 1.000 sujetos experimentales tendrá una ponderación 10 veces mayor que la que tiene una de 100 sujetos experimentales [6]. Esto produce que la conclusión general se vuelque hacia el resultado particular de un estudio cuando este es mucho más grande que los demás. A.4. Modelo de efectos aleatorios
A diferencia del modelo de efecto fijo, para el modelo de efectos aleatorios existe más de un tamaño de efecto, por ende existen dos tipos de errores, el error propio de cada uno de los experimentos producto de la experimentación (como sucede con el modelo de efectos fijo) y el error producido por la combinación de estudios provenientes de distintos tamaños de efecto [6]. Este se traduce en la estimación de dos tipos de varianzas, la varianza interna de los estudios y la varianza entre estudios. De esta forma los experimentos reciben una “doble ponderación”, la cual tiende a mitigar la influencia de los experimentos grandes en la conclusión general haciendo más representativos a los experimentos con menos sujetos, ya que a diferencia del modelo de efecto fijo cada experimento puede estar aportando un tamaño de efecto diferente.
La inclusión de la varianza entre experimentos trae aparejado un nuevo problema, el error asociado a su estimación, el cual se incremente cuando el Meta-Análisis posee pocos experimentos. Por ello, autores como [6], no recomiendan su uso cuando el Meta-Análisis posea pocos experimentos (en la práctica menos de 10). A.5. La estadística y el error experimental
Dado que para los investigadores resulta imposible censar o evaluar a todos los individuos de una población, los conocimientos científicos se infieren a través de experimentos realizados sobre muestras que se consideran representativas de

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
373
dicha población [41]. Sir Ronald Fisher [38] demostró que los métodos estadísticos son útiles para tratar estos problemas y que los mismos se enfrentan a tres dificultadas principales: • Error de experimentación, también conocido como ruido, que
es causado por factores distorsiónales y, en ciertos casos por problema al realizar la medición.
• Confusión entre correlación y causalidad, que se produce cuando se confunde la influencia entre variables, provocando así que se piense que dos variables son dependientes entre sí, cuando en realidad dependen de una tercera que no se toma en cuenta.
• Complejidad de combinaciones entre varias variables y una tercera, sucede cuando dos o más variables afectan a una tercera de distinta manera, dependiendo de los valores que toma cada una. Entonces no existe una fórmula lineal y directa que prediga los resultados.
Estos problemas pueden ser solucionados con la estadística de la siguiente manera: • El error de experimentación puede ser reducido por un
diseño y análisis apropiado de los experimentos. Al utilizar un análisis estadístico que provea de formas para medir la precisión de la cantidad bajo estudio y juzgar cuando hay fuerte evidencia empírica para atribuir a ciertas razones las diferencias observadas.
• La confusión de correlación y causalidad puede ser solucionado utilizando los principios del diseño experimental y “aleatorización”, para generar datos de mayor calidad e inferir las relaciones causales verdaderas.
Bajo estos supuestos, los métodos estadísticos están sometido a dos tipos de errores [17]: α, o error de tipo I, y β, o error de tipo II. Dichos errores se producen por la incertidumbre asociada a estimar parámetros (básicamente medias y desvíos típicos) de una población a partir de una muestra de la misma. Tal y como indica la Tabla I, α es el error asociado a aceptar la hipótesis alternativa (H1) cuando en la población se verifica la hipótesis nula (H0), y β es la probabilidad asociada al evento justamente inverso.
TABLA I. TIPOS DE ERROR DE UN TEST ESTADÍSTICO
H0 verificada en a población
H1 verificada en la población
H0 respuesta del experimento
Decisión correcta (1-α)
β (Tipo II error)
H1 aceptada respuesta del experimento
α (Tipo I error)
Decisión correcta (1-β)
Según la teoría estadística, un test de hipótesis, se basa en 4
factores [34]: α, β, el tamaño del efecto (d) (el cociente entre la diferencia entre las medias y la varianza para el caso del DMP o el cociente de las medias para RR) y el número de sujetos experimentales (n) o, dicho con mayor precisión, el tamaño de la muestra. La relación entre estos factores se muestra en la Fórmula 1 (donde z representa la distribución normal tipificada):
αβ −− −= 11 2zdnz
Fórmula 1: relación entre los factores de un test estadístico
Como se ve, los 4 factores implicados en la fórmula 1 forman un sistema cerrado, haciendo que una disminución o incremento en cualquiera de los factores provoque incrementos o disminuciones en los demás factores, donde solo d depende de las condiciones del experimento y no puede ser controlado o
manipulado por el investigador. De los demás factores podemos decir que para un investigador, el error más importante es α. La razón es sencilla: toda la comunidad informática intenta desarrollar nuevos métodos y técnicas que hagan más eficiente el desarrollo del software. Pero necesitamos demostrar que dichos métodos y técnicas son efectivamente mejores. El punto aquí es que si nuestra conclusión es falsa podemos movilizar a la comunidad del software a un cambio innecesario que solo genere gastos. Por este motivo, si el test arroja que H1 es cierto (o sea, acontece la segunda fila de la tabla II que es lo que realmente queremos) esto debe estar acompañado de un error de α lo menor posible (donde generalmente α = 0.05), lo cual hace que el resultado sea fiable. Por ello, al complemento del error α se lo llama fiabilidad y se estima como 1 - α. De los 2 factores restantes, según la teoría estadística la variable de ajuste debería ser el tamaño de la muestra, pero la realidad indica que en Ingeniería de Software (como también sucede en otras ramas de la ciencia) rara vez se cuente con el presupuesto necesario para realizar un experimento que implique gran cantidad de sujetos, por ello, el error de tipo II se verá incrementado o lo que es igual el test perderá potencia estadística, siendo la potencia estadística la capacidad que el test posea para determinar que H1 es verdadera [34]. La relación que existe entre los distintos parámetros, descripta anteriormente, puede apreciarse en la Figura 3:
Figura 3: Relación entre factores que afectan la potencia estadística de un test
A.6. Técnicas de Agregación de Experimentos Existen varias técnicas de agregación cuantitativas,
podemos mencionar dentro de las más conocidas [54]: • Diferencia de medias ponderadas (DMP) • Response Ratio (RR) paramétricos • Response Ratio (RR) no paramétricos • Vote Counting (conteo de votos)
A.6.1. Diferencia de Medias Ponderadas: La técnica de diferencia de medias ponderadas [55] es la
técnica de estimación de tamaño de efecto, o mejora de un tratamiento respecto de otro, más conocida y difundida para el análisis de variables continuas. Esta técnica es conceptualmente sencilla: el estimador de efecto individual (para cada experimento) se estima como el cociente de las diferencias entre las medias y el desvío estándar y el efecto global se calcula como una media ponderada de los estimadores de efecto de los estudios individuales.
La estimación del efecto individual consiste en estimar, para un estudio particular, si el tratamiento Experimental es mejor o no que el tratamiento de control. Estos se hace dividiendo la diferencia de medias de ambos grupos por la varianza conjunta [55]. La estimación del efecto global se realiza como la suma ponderada de los efectos individuales [6, 55]. Donde cada estudio es ponderado en función de su tamaño y la inversa de la varianza, de esta forma los estudios que
Tamaño de efecto
Fiabilidad 1-α
Tamaño de la muestra
Potencia 1-β
Afecta (+)
Afecta (+)
Afecta (-)

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
374
incluyan mayor cantidad de sujetos experimentales y posean una menor varianza recibirán una mayor ponderación, por considerar que sus resultados son más fiables, que los estudios más pequeños. A.6.2. Response Ratio paramétrico:
Para estimar el Response Ratio (RR) de un estudio particular, como se mencionó anteriormente, se debe dividir la media del tratamiento experimental por la media del tratamiento de control [54]. Si bien, realizar en forma directa el cociente de ambas medias permite obtener un índice de mejora para un estudio en particular, para que la combinación de un conjunto de estudios sea más precisa se le incorporó el logaritmo natural [54, 82]. Esto permite linealizar los resultados (mientras que el RR es afectado más por los cambios en el denominador que en el numerador, el Ln (RR), gracias a las propiedades de los logaritmos, afecta de modo parejo al numerador y al denominador y así normalizar su distribución, convirtiéndolo en un método apropiado para estimaciones de conjuntos de experimentos pequeños.
Una vez estimado el tamaño de efecto, podrá estimarse el intervalo de confianza. Para estimar el error típico, esta versión del Response Ratio no requiere conocer las varianzas, como lo hace la versión original. En su lugar hace una estimación en base a la cantidad de sujetos y el response ratio. Una vez estimados el intervalo de confianza, se debe aplicar el anti-logaritmo a los resultados para obtener nuevamente el índice de relación. Es importante destacar que esta situación traer aparejado que el nuevo intervalo de confianza no sea simétrico.
La estimación del efecto global se realiza mediante la suma ponderada de los efectos individuales [63]. Donde, a semejanza de lo que sucede con las diferencias medias ponderadas, cada estudio es ponderado en función de su tamaño y la inversa de la varianza. A.6.3. Response Ratio no paramétrico:
La estimación del Response Ratio no paramétrico consiste en dividir la media del tratamiento Experimental por la media del tratamiento de Control [54] como en el caso anterior. Para estimar el error típico (necesario para establecer el intervalo de confianza), esta versión del Response Ratio no requiere conocer las varianzas, como lo hace la versión original. En su lugar hace una estimación en base a la cantidad de sujetos y el response ratio [118] A.6.4. Conteo de Votos:
El Vote Counting es un método que requiere muy poca información para poder ser aplicado, básicamente conocer si existe o no diferencia entre las medias de los tratamientos y la cantidad de sujetos experimentales utilizados en el estudio experimental. Si bien existen varias versiones de esta técnica, en este apartado se describirá la versión desarrollada por [55]. Esta versión permite estimar el tamaño de efecto partiendo del signo de las diferencias de las medias y la cantidad de sujetos experimentales, los cuales se combinan mediante la aplicación de la función de verosimilitud. Esta función que permite establecer, en base al signo de la diferencia de medias y la cantidad de sujetos, cual es el valor de efecto que tiene mayor probabilidad de ocurrencia [55]. Una vez establecido el efecto de mayor probabilidad se podrá determinar el intervalo de confianza para el mismo, el cual es más amplio que el estimado mediante DMP [55]
A.6.5. Técnica de agregación elegida para el desarrollo de la investigación:
Cada técnica antes mencionada tiene sus ventajas y desventajas. Sin embargo, fueron desarrolladas para contextos
experimentales maduros, que no es el caso de la Ingeniería de Software. Como se comprobó en [37], en contextos experimentales pocos maduros la técnica DMP ha demostrado mejor potencia y fiabilidad general que los otros métodos. Por ello, se escoge esta técnica para analizarla bajo los dos supuestos de efecto de Meta-Análisis: modelo de efecto fijo y modelo de efectos aleatorios. A.7. Diferencia de Medias Ponderadas aplicada bajo el
supuesto de modelo de efecto fijo El método Diferencias Medias Ponderadas (DMP) [43],
como se mencionó anteriormente, es la técnica de estimación de tamaño de efecto (effect size), o mejora de un tratamiento respecto de otro, más conocida y difundida para el tratamiento de variables continuas. El estimador de efecto individual se estima como el cociente de las diferencias entre las medias y el desvío estándar y el efecto global se calcula como una media ponderada (donde cada estudio es ponderado en base a la inversa de su varianza) de los estimadores de efecto de los estudios individuales. Este método fue desarrollado originalmente por [43] y optimizado por [55], quienes incorporaron a la función de estimación de efecto individual una variable de corrección que permite mejorar la precisión del método cuando los estudios experimentales poseen pocos sujetos. Es un método de tipo paramétrico el cual requiere para ser aplicado normalidad en la distribución y homoesticidad (igualdad de las varianzas). Estos aspectos pueden estimarse por el investigador primario o pueden asumirse en función de las características del fenómeno que se está tratando.
Como los resultados que arroja este método (tamaño de efecto) son poco comprensibles, para facilitar la comprensión de los resultados obtenidos, se ha tabulado un conjunto de valores de corte a partir de los cuales los resultados pueden considerarse: Nulos (no existe diferencia entre los tratamientos analizados), Bajos (si bien uno de los tratamientos es mejor que el otro, la diferencia en el desempeño no es muy importante), Medios (uno de los tratamientos es mejor que el otro, y la diferencia a favor es considerables) o Altos (uno de los tratamientos es mucho mejor que el otro). En la Tabla II, se describe el análisis de resultados realizado por [111], donde se puede observar cual es el nivel de solapamiento o coincidencia entre los resultados en función del tamaño de efecto obtenido.
TABLA II. INTERPRETACIÓN DEL TAMAÑO DE EFECTO
Nivel de diferencia
Tamaño de efecto (d)
Porcentaje de no solapamiento de los tratamientos
2.0 81.1% 1.9 79.4% 1.8 77.4% 1.7 75.4% 1.6 73.1% 1.5 70.7% 1.4 68.1% 1.3 65.3% 1.2 62.2% 1.1 58.9% 1.0 55.4% 0.9 51.6%
Alto 0.8 47.4% 0.7 43.0% 0.6 38.2%
Medio 0.5 33.0% 0.4 27.4% 0.3 21.3%
Bajo 0.2 14.7% 0.1 7.7%
Nulo 0.0 0%

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
375
En las siguientes subsecciones se describen las funciones de estimación del método y las ventajas y desventajas asociadas a su posible uso en Ingeniería de Software A.7.1. Descripción del método
La aplicación del método consta de dos pasos, primeramente se debe estimar el tamaño de efecto de cada uno de los experimentos, y una vez estimado el mismo, podrá estimarse el tamaño de efecto global. A continuación vamos a presentar las función de estimación del tamaño de efecto para un experimento (o efecto individual) desarrollada por [43] (ver Fórmula 2).
P
CE
SYYg −
=
g representa el tamaño de efecto Y‘s representa a las medias del grupo experimental (E) y de control (C) Sp representa el desvió estándar conjunto
Fórmula 2: Tamaño de efecto individual
La Fórmula 2 tiende a sobre estimar los efectos de los estudios pequeños (que cuentan con pocos sujetos experimentales), y, como se mencionó anteriormente, fue optimizada por [55], quién incorporó un ponderador que ayuda a reducir el error de los experimentos más pequeños (ver Fórmula 3). Esta nueva versión del método es la más conocida en Ingeniería de Software ([73, 31]).
P
CE
SYYJd −
= 94
31−
−=N
J
d representa el tamaño de efecto J representa el factor de corrección Y‘s representa a las medias del grupo experimental (E) y de control (C) Sp representa el desvió estándar conjunto N representa el total de sujetos experimentales incluidos en el experimento
Fórmula 3: Tamaño de efecto individual con factor de corrección
Luego de estimar el tamaño de efecto, se estima el error típico, y en base a este se establece el intervalo de confianza asociado al efecto para el nivel de fiabilidad deseado, generalmente del 95%, lo que equivale a un error de tipo I del 5% (α = 0,05). Ver Fórmula 4.
)(2
2
CE nndñv++
=
CE
CE
nnnnñ
*+
=
vZdvZd 2/2/ αα λ +≤≤− v representa el error típico d representa el tamaño de efecto n‘s representa la cantidad de sujetos experimentales del grupo
experimental (E) y de control (C) Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) Fórmula 4: Error típico e intervalo de confianza
Una vez estimados los tamaños de efectos de los estudios individuales se debe estimar el tamaño de efecto global (ver Fórmula 5).
∑∑=
)(/1)(/
* 2
2
ddd
di
ii
σσ
v = (1/∑ )(/1 2 diσ )
d* representa el tamaño de efecto global ∑ )(/ 2 dd ii σ es la sumatoria de los efectos individuales ∑ )(/1 2 diσ es la sumatoria de la inversa varianza v representa el error típico
Fórmula 5: Tamaño de efecto grupal
Para ello se realiza una suma ponderada de los tamaños de efecto de cada uno de los estudios, donde cada estudio es ponderado en función de la inversa de la varianza [6, 55], de esta forma los estudios con mayor precisión (que en general son los que incluyen mayor cantidad de sujetos experimentales) recibirán una mayor ponderación por considerar que sus resultados son más fiables, o tienen menor posibilidad de incurrir en un error experimental.
Una vez estimado el tamaño de efecto global, se debe estimar el intervalo de confianza asociado al mismo, para ello se utiliza la Fórmula 6.
vZdvZd 2/2/ ** αα λ +≤≤− d* representa el tamaño de efecto global Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) v representa el error típico
Fórmula 6: Intervalo de confianza grupal
A.7.2. Ventajas y desventajas del método En esta sección se presentan una serie de ventajas que se
espera obtener si un conjunto de experimentos es agregado mediante DMP, y luego un conjunto de desventajas o inconvenientes para su aplicación:
Ventajas • Existe gran cantidad de reportes que describan su uso en otras
ramas de la ciencia, principalmente medicina y educación [16]
• Existe gran variedad de software que soporta su aplicación (por ejemplo [80, 85] entre otros)
• La función corregida por [55] minimiza el error de estimación cuando los estudios son pequeños lo cual es importante en el actual contexto de la Ingeniería de Software.
• Es el método recomendado por [73] • Se conoce procesos de agregación que han podido aplicar
esta técnica en estudios hechos en Ingeniería de Software [83, 31]
Desventajas • Requiere la publicación de todos los parámetros estadísticos
(medias, varianzas y cantidad de sujetos experimentales) • Se debe verificar o suponer homosticidad y normalidad [55] • Hay revisiones sistemáticas en Ingeniería de Software que no
llegaron a combinar los resultados porque la calidad de los estudios identificados no cumplían con el mínimo de requisitos necesarios para aplicar este método, por ejemplo [27].
A.8. Diferencia de Medias Ponderadas aplicada bajo el supuesto de modelo de efectos aleatorios
La aplicación del método consta de dos pasos, primeramente se debe estimar el tamaño de efecto de cada uno de los experimentos, y una vez estimado el mismo, podrá estimarse el tamaño de efecto global [55]. Dado que la forma de estimar el tamaño de efecto para cada uno de los experimentos es la misma que la que se describió para el método DMP en la sección 2.4, en esta sección solo vamos a describir como se estima el tamaño de efecto global.
Este es un método de tipo paramétrico el cual requiere para ser aplicado normalidad en la distribución y homoesticidad (igualdad de las varianzas). Estos aspectos pueden estimarse por el investigador primario o pueden asumirse en función de las características del fenómeno que se está tratando.
La forma de interpretar los resultados es la misma que se utiliza con el modelo de efecto fijo, a modo de recordatorio.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
376
En la Tabla III, se presenta un resumen de la Tabla II, donde se indican los valores de corte asociados a cada nivel de tamaño de efecto.
TABLA III. INTERPRETACIÓN DEL TAMAÑO DE EFECTO
Tamaño de efecto Nivel de diferencia 0 Nulo
0.2 Bajo 0.5 Medio 0.8 Alto 1.2 Muy Alto
A.8.1. Descripción del método Para estimar el tamaño de efecto de un grupo de
experimentos, la función de estimación incluye, a demás de la varianza propia de cada experimento, la estimación de la varianza entre experimentos. Esto se debe a que el cálculo final es básicamente un promedio de tamaños de efectos el cual, como todo promedio, tiene una varianza asociada [6, 55]. Ver Fórmula 7.
∑∑=Δ
i
iid2
2
/1/γγ
Δ representa el tamaño de efecto global ∑ iid 2/γ representa la sumatoria de los efectos individuales
∑ i2/1 γ representa la sumatoria de la inversa de las varianzas entre-
estudios e intra-estudios Fórmula 7: Tamaño de efecto global para el modelo de efectos aleatorios
Una vez estimado el tamaño de efecto global, se debe estimar el intervalo de confianza asociado al mismo, para ello se utiliza la Fórmula 8.
vZvZ 2/2/ αα +Δ≤Δ≤−Δ
∑=
iv 2/1
1γ
Δ representa el tamaño de efecto global Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) v representa el error típico
Fórmula 8: Error típico global e intervalo de confianza para el modelo de efectos aleatorios
A.8.2. Ventajas y desventajas del método En esta sección se presentan una serie de ventajas que se
espera obtener si un conjunto de experimentos es agregado mediante el modelo de efectos aleatorios, y luego un conjunto de desventajas o inconvenientes para su aplicación:
Ventajas • Permite combinar estudios a pesar de que existen indicios de
heterogeneidad entre los mismos • Existe gran variedad de software que soporta su aplicación
(por ejemplo [80, 85] entre otros) • La función corregida de [55] minimiza el error de estimación
cuando los estudios son pequeños lo cual es importante en el actual contexto de la Ingeniería de Software
• Fue aplicada en el procesos de agregación desarrollado por [31]
Desventajas • Requiere la publicación de todos los parámetros estadísticos
(medias, varianzas y cantidad de sujetos experimentales) • Se debe verificar o suponer homosticidad y normalidad [55] • Hay autores que afirman que el nivel de error que introduce
la varianza entre experimentos, cuando el proceso de
agregación contiene menos de 10 experimentos, es muy alto y no debe aplicarse en esos casos [6].
A.9. Heterogeneidad estadística Es altamente probable que un conjunto de experimentos
que analizan el desempeño de un par de tratamientos arrojen resultados diferentes, esto se debe fundamentalmente a la selección y asignación de sujetos experimentales de manera aleatoria. Pero también es esperable que estas diferencias no sean demasiado notorias, ya que si esto sucediera sería esperable que exista algún factor no controlado que está condicionando el resultado del estudio. En cuyo caso se dirá que los experimentos son heterogéneos.
Existen básicamente tres tipo de heterogeneidad: la “heterogeneidad estadística” (diferencias en los efectos reportados), “heterogeneidad metodológica” (diferencias en el diseño de los estudios) y “heterogeneidad de sujetos” (diferencias entre los estudios referidas a características clave de los participantes, nivel de experiencia profesional, formación académica, motivación, entre otros). La heterogeneidad puede deberse a diferencias entre los participantes, la variables respuesta, las métricas y un gran número de otros factores que pueden afectar al experimento y los participantes.
La heterogeneidad estadística puede observarse claramente mediante un diagrama de árboles, gráfico con el que habitualmente se presentan los resultados del meta-análisis. En estos gráficos se representan los tamaños de efectos de los estudios individuales, así como el tamaño de efecto global, juntamente con sus respectivos intervalos de confianza [108]. En la Figura 4, se presenta un ejemplo.
Figura 4: Ejemplo Diagrama de árboles, con experimentos homogéneos
Cuando los estudios de un Meta-Análisis son homogéneos, los intervalos de confianza de los mismos se solapan entre sí. Por el contrario, si el resultado de algún estudio no se solapa con ninguno de los intervalos de confianza de los otros experimentos, es bastante probable que este estudio no es homogéneo (o sea heterogéneo).
Si se analiza el ejemplo de la Figura 4, se puede decir que no existen indicios de heterogeneidad o, lo que es lo mismo, que existe homogeneidad entre los experimentos, ya que los intervalos de confianza de los tres experimentos se solapan entre sí. Por el contrario, si analizamos el ejemplo de la Figura 5, podemos decir que existen indicios de heterogeneidad, ya que el intervalo de confianza del estudio 2 no se solapa con los intervalos de confianza de los otros experimentos. Nótese que si bien estos gráficos son muy fáciles de construir e interpretar, los resultados que aportan son muy dependientes del meta-analista y por ello son cuestionados por algunos autores. Para ser más concretos en esta afirmación, en el ejemplo planteado, en la Figura 5, el estudio 2 no tiene solapamiento con los otros dos experimentos, pero es habitual que exista un leve solapamiento entre los intervalos de confianza de los experimentos, en estos casos dependiendo de quién evalúe los

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
377
resultados podrá plantearse que existe o no heterogeneidad. Por eso este tipo de análisis es criticado.
Figura 5: Ejemplo Diagrama de árboles, con experimentos heterogéneos
Los tests estadísticos de heterogeneidad se utilizan para valorar si la variabilidad en los resultados de los estudios (la magnitud de los efectos) es mayor que aquella que se esperaría hubiera ocurrido por azar [57]. La prueba más conocidas para valorarla la heterogeneidad estadística es el método Q propuesto por [25] el cual se basa en el test desarrollado por [14]. Este método en general es recomendado por cuestiones de validez y sencillez computacional [16] (Fórmula 9).
k representa número de experimentos wi representa el peso del estudio i (se corresponde con la inversa de la
varianza del mismo) Ei representa el tamaño de efecto del experimento E representa el tamaño de efecto global
Fórmula 9: Estimador Q para análisis de heterogeneidad
Q posee una distribución Chi2 con K – 1 grados de libertad (k, tal y como se indica en la Fórmula 9 representa el número de experimento combinados en el meta-análisis)
Una vez calculado Q, si su valor obtenido es inferior a k-1, se considera que los experimentos son homogéneos. Si el resultado es superior a K-1 es posible que exista heterogeneidad experimental, y la posibilidad de tal existencia se determina utilizando la distribución Chi2 antes citada. El nivel de significación habitual es α = 0.05, aunque algunos autores [103] recomiendan utilizar α = 0.1 para aumentar la potencia del test.
A pesar de sus ventajas, esta prueba analítica presenta baja potencia estadística cuando se la aplica a un número de estudios experimentales pequeño (como suele suceder en Ingeniería de Software, donde rara vez se pueda superar los 10 experimento). Por eso se considera, como dice [73], que, a pesar de los problemas de interpretación que presenta la técnica Funel Plot [21], hoy día consiste en la alternativa más conveniente para el análisis de la heterogeneidad en Ingeniería de Software.
Si llegara a detectarse que existe heterogeneidad entre los experimentos, existen básicamente dos caminos a seguir, el primero de ellos es intentar combinar los resultados mediante un método de modelo de efectos aleatorios, y el segundo es intentar determinar cuál es el método que genera la heterogeneidad (básicamente mediante la observación del diagrama de árboles) y quitarlo del grupo, para luego re-agregar los experimentos.
B. Análisis de Heterogeneidad en contextos experimentales poco maduros. Limitaciones del estimador Q Está bien documentada en la literatura la baja potencia de Q
cuando el número de experimentos incluidos en el Meta-
Análisis es bajo [6]. No obstante, no es este el problema más importante para la Ingeniería de Software. Desde la perspectiva de la Ingeniería de Software, el mayor problema reside en la incapacidad de Q para determinar la heterogeneidad de los experimentos realizados con pocos sujetos experimentales [50]. Esto se debe a que los experimentos pequeños, en general, están asociados a una alta varianza, por su mayor nivel de incertidumbre, lo cual incremente el tamaño del intervalo de confianza (IC). Este hecho hace que para los métodos gráficos los resultados se vean solapados y en lo que respecta al método Q es un fuerte atenuador debido a que cada experimento es ponderado por la inversa de su varianza (Wi = 1/vi). Dificultando de esta forma la posibilidad de detectar diferencia significativa en el test de Q (para α = 0.05 o α = 0.1).
Para ver esto con más claridad vamos a recurrir a un análisis gráfico, donde los ICs amplios, asociados a los experimentos pequeños, funcionan como una máscara que encubre las diferencias entre los resultados. Esto puede verse claramente en el siguiente ejemplo: supongamos un hipotético caso en el cual se cuenta con 4 experimentos que son agregados mediante el método Diferencia de Medias Ponderadas (DMP) [55] y entre los cuales existe heterogeneidad, dos de ellos dan como resultado un efecto medio (d = 0.5) y los otros dos dan como resultado un efecto muy alto (d = 1). Si estos experimentos son construidos con cien sujetos experimentales se obtiene el resultado que se indica en la Figura 6. Donde el solapamiento de los ICs de los experimentos es nulo y el p asociado al Q (12.626) es 0.00552, por tanto existe claramente heterogeneidad entre los resultados.
Figura 6: Diagrama de árbol que resultan de agregar los experimentos: E1, E2 con: media 1 = 100, media 2 = 90, desvío std 1 = 10, desvío std 2 = 9, y E3, E4
con: media 1 = 100, media 2 = 95, desvío std 1 = 10, desvío std 2 = 9, incluyendo 100 sujetos experimentales por brazo por cada experimento.
Ahora bien, si en lugar de cien sujetos los experimentos hubieran sido realizados con veinticinco sujetos, los resultados serían los que se indican en la Figura 7.
Figura 7: Diagrama de árbol que resultan de agregar los experimentos: E1, E2 con: media 1 = 100, media 2 = 90, desvío std 1 = 10, desvío std 2 = 9, y E3, E4
con: media 1 = 100, media 2 = 95, desvío std 1 = 10, desvío std 2 = 9, incluyendo 25 sujetos experimentales por brazo por cada experimento.
Puede observarse claramente que los ICs son mucho mayores que los del caso anterior, y el solapamiento entre los
( )∑∑
∑∑
=
=
=
=
−=⎟⎠
⎞⎜⎝
⎛
−=k
iiik
ii
k
iiik
iiiT EEw
w
EwEwQ
1
2
1
2
1
1
2

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
378
mismos es más que evidente. El p asociado al Q (3.087) es 0.378372, lo que indica la no existencia de heterogeneidad. Nótese que la heterogeneidad entre experimentos no ha desaparecido al reducir el número de sujetos (E1 y E2 poseen un efecto de 0.5 y E3 y E4 un efecto de 1). Lo que ha ocurrido es que Q ha perdido su capacidad de detectar dicha heterogeneidad debido al bajo número (relativamente hablando) de sujetos experimentales involucrados.
Es importante destacar que este problema, en general, no puede ser solucionado con la incorporación de más experimentos como podría pensarse. Por ejemplo, supongamos que en lugar de 4 experimentos se contara con 40 (20 de efecto 0.5 y 20 de efecto 1). El resultado del meta-análisis sería el indicado en la Figura 8, donde el solapamiento de ICs se mantiene y el valor Q (30.872) es inferior a la cantidad de experimentos menos 1 (39). Por tanto, Q no arroja evidencia alguna de heterogeneidad.
Figura 8: Diagrama de árbol que resultan de agregar los experimentos: E1 a E20 con : media 1 = 100, media 2 = 90, desvío std 1 = 10, desvío std 2 = 9, y
E21 a E40 con: media 1 = 100, media 2 = 95, desvío std 1 = 10, desvío std 2 = 9, incluyendo 25 sujetos experimentales por brazo por cada experimento.
Diversos investigadores, tales como [78, 64, 110] han estudiado la potencia del estimador Q. Sin embargo, dichos estudios parten de posiciones muy alejadas a la realidad de la experimentación actual en IS, sobre todo a lo referente al elevado número de sujetos experimentales. Existen, no obstante, dos estudios que se aproximan bastante a la Ingeniería de Software, [72, 50].
En [72] se analiza la potencia de Q mediante una simulación de Monte Carlo variando los siguientes parámetros: cantidad de experimentos, cantidad de sujetos experimentales por experimento y diferencias en el tamaño de efecto. Configurando los mismos de la siguiente forma: la cantidad de experimentos a incluir en los meta-análisis toma los siguientes valores: 5, 10 y 30 experimentos, la cantidad de sujetos por experimentos toma los siguientes valores: 10, 30 y 300 sujetos, la diferencia entre el tamaño de efecto del tratamiento experimental y de control se establece mediante la siguiente relación de uno respecto del otro: 20%, 40% y 60% (por ejemplo, para un tamaño de efecto del tratamiento experimental de 1, el efecto del tratamiento de control se fija en 1.2 o 0.8 en el primer caso, 1.4 o 0.6 en el segundo caso y 1.6 o 0.4 en el tercer caso). Como resultado de este proceso los autores concluyen que el método Q tiene alta potencia (cercana al 100%) cuando los estudios tienen 300 sujetos, independientemente de la cantidad de experimentos que se agreguen o la diferencia de efecto, pero también consideran inaceptable la potencia mostrada cuando los experimentos contienen 10 o 30 sujetos.
Por su parte [50], también analizan la potencia de Q mediante una simulación de Monte Carlo, pero, a diferencia del trabajo anterior, no aplicando directamente la función de Q, sino utilizando la función de potencia estadística de Q. Los parámetros que varían en este trabajo son: la cantidad de experimentos a incluir en los meta-análisis fijado en: 5, 10 y 20
experimentos, y la varianza entre estudios fijada (la cual define la diferencia de efecto entre los mismos) en: 5, 10 y 20. Como resultado de esta simulación los autores concluyen que el método Q posee baja potencia, pero si el peso del estudio heterogéneo es alto, la capacidad del método puede verse beneficiada.
C. Meta-Análisis en Ingeniería de Software Empírica C.1. Reseña de la utilización del Meta-Análisis en Ingeniería
de Software Empírica La aplicación del Meta-Análisis en Ingeniería de Software
es bastante tardía, en consonancia con la también tardía utilización de la experimentación como herramienta metodológica de investigación. El primero en señalar su posible uso en Ingeniería de Software fue [83], que empleó DMP para combinar 5 experimentos que exploraban distintas técnicas de prueba de software. Pero, el Meta-Análisis tardó bastantes años en calar en la comunidad de Ingeniería de Software, en buena parte debido a la deprimente presentación que Miller realizó pues concluyó que el Meta-Análisis (sólo aplicó DMP pero generalizó erróneamente el resultado de su estudio, sin considerar que existen otras técnicas de meta-análisis) no era aplicable porque no se cumplían las condiciones formales que exige. En consecuencia, la síntesis estadística de resultados experimentales quedaba descartada para la Ingeniería de Software Empírica. Las consecuencias de esta conclusión fueron demoledoras, y durante muchos años en los artículos de síntesis [24, 69, 65] hubo una total ausencia de aplicación de Meta-Análisis. En su lugar se realizaban combinaciones de los resultados experimentales mediante técnicas, que podríamos denominar, narrativas por su total ausencia de formalidad.
En 2004, Kitchenham publica su bien conocido reporte acerca de revisión sistemática de experimentos [73]. En la actualidad, se estima que se han publicado unas 100 revisiones sistemáticas en Ingeniería de Software [20]. Sería esperable, por lo tanto, que el número de meta-análisis hubiera aumentado en concordancia (nótese que revisión sistemática y Meta-Análisis son conceptos relacionados, pero distintos. Una revisión sistemática es una revisión sistemática comprende todo el proceso de revisión, mientras que el Meta-Análisis se circunscribe al proceso de síntesis [73]). Sin embargo, la realidad muestra que, a pesar del gran número de revisiones sistemáticas realizadas, sólo se ha aplicado meta-análisis en el 2% de casos. Pero aún, de las citadas 100 revisiones sólo se aplicó alguna técnica de síntesis (estadística o no) en unos cinco casos como máximo [20], tratándose el 95% de los casos restantes de lo que recientemente se ha dado en denominar mapping studies, para diferenciarlos de las revisiones sistemáticas puras donde la agregación de resultados es una parte consustancial.
Si bien el trabajo de [84] fue pionero en cuanto a la aplicación de un Meta-Análisis en Ingeniería del Software, solo combino los resultados de cuatro experimentos, por cuanto la aplicación real de los conocimientos generados fue escaza. Más recientemente, en el trabajo de [31], se identifican 20 experimentos sobre programación de a pares, los cuales son agregados en tres grupos, el primero de 11 experimentos, el segundo de 11 experimentos y el tercero de 10 experimentos, donde el experimento más pequeño contiene 4 sujetos por tratamiento, el mayor 35 sujetos por tratamiento, mientras que el promedio asciende a 13 sujetos por tratamiento.
Así como se menciona el trabajo de [31], hay una gran cantidad de autores que, si bien pudieron desarrollas las tareas

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
379
de búsqueda y selección de estudios experimentales, no pudieron agregar los resultados para generar una conclusión basada en un mayor nivel de evidencia utilizando el método DMP. Por ejemplo: en [27] se analizaron un conjunto de experimentos vinculados a las técnicas de educción de requisitos y, debido a que la gran mayoría de los reportes no publicaba las varianzas, se generan un conjunto de recomendaciones respecto del uso de las mismas mediante un conteo de votos (el tratamiento que tenía mayor cantidad de estudios que indicaban que era mejor era proclamado como el más adecuado), en [86] se analizó la reutilización del software en la modificación y/o creación de nuevos productos, como había problemas de compatibilidad en las variables respuesta analizadas en cada estudios y falencias en los reportes, se recurrió a un conteo de votos como estrategia para generar las conclusiones. C.2. Meta-Análisis realizados en Ingeniería de Software
Empírica Hasta el presente se han realizado 2 Meta-Análisis en IS,
los cuales ya han sido mencionados, pero a continuación se los describe con mayor detalle: • [31], en este trabajo se identifican 20 experimentos sobre
programación de a pares, los cuales son agregados en tres grupos, el primero de 11 experimentos, el segundo de 11 experimentos y el tercero de 10 experimentos, donde el experimento más pequeño contiene 4 sujetos por tratamiento, el mayor 35 sujetos por tratamiento, mientras que el promedio asciende a 13 sujetos por tratamiento. Los resultados son agregados mediante DMP en sus dos versiones modelo de efecto fijo y aleatorio.
• [13], en este trabajo se identifican 21 experimentos sobre técnicas de inspección, los cuales son agregados en tres grupos, el primero conteniendo 7 experimentos, el segundo 9 y el tercero 5, dichos experimentos poseen tamaños variados, conteniendo el menor 3 sujetos experimentales por tratamiento, el mayor 45 sujetos por tratamiento, mientras que el promedio asciende a 6 sujetos por tratamiento. Los resultados son agregados mediante una variante del método DMP para modelo de efecto fijo.
III. DESCRIPCIÓN DEL PROBLEMA A. La agregación estadística de experimentos en Ingeniería
de Software como solución a un contexto experimental poco maduro La Ingeniería en Software, de acuerdo a la norma 610.12 de
la IEEE, debe aplicar conocimiento científico para el desarrollo, operación y mantenimiento de los sistemas software. Esto implica poder determinar dentro de una serie de métodos, técnicas y herramientas cual se debe utilizar en cada actividad de acuerdo a las condiciones del proyecto [67]. Para ello, es necesario contar con un marco que permita a los ingenieros de software poder conocer como es el comportamiento de los métodos y herramientas mediante un enfoque científico y por lo tanto objetivo. El marco experimental a fin a todas las ingenierías, permite brindar información objetiva sobre que conviene aplicar en cada etapa de un proyecto software según las circunstancias. Entonces, como afirma [92], de esta forma se “permita ganar más entendimiento de cómo hacer un software bueno y cómo hacerlo mejor”.
Varios autores [24, 84, 15, 32] han señalado que la Ingeniería de Software presenta un contexto experimental poco maduro, donde existe escasez de experimentos, y la cantidad de
sujetos experimentales es también pobre [24]. En este contexto, la mejor opción que se presenta es la de combinar el resultado de diversos experimentos por medio de un proceso de agregación como propone [15].
En el capítulo anterior se exploraron las técnicas de agregación más utilizadas y mejor documentadas. Hay estudios [37] que establecieron que la Diferencia de Medias Ponderadas (DMP) se adapta mejor al contexto poco madura que presenta en la actualidad la Ingeniería de Software. No obstante ello, queda otra cuestión que zanjar: esta técnica de agregación estadística puede ser utilizada en dos modelos de Meta-Análisis bien diferentes entre sí: (a) el modelo de efecto fijo supone la existencia de un único resultado poblacional, el cual se irá estabilizando a medida que se incorporen experimentos al meta-análisis, y (b) el modelo de efecto aleatorio supone que existe un conjunto de variables no controladas que influyen en los resultados de los experimentos provocando que los resultados cambien a medida que se incorporan experimentos de distintas vertientes, ambos analizados.
Entonces se presenta el dilema de cuál es el modelo de efecto de Meta-Análisis que mejor se adapta a las necesidades de la experimentación en el campo de la Ingeniería de Software.
B. Los modelos de efecto de Meta-Análisis en el actual contexto experimental de la Ingeniería de Software El Meta-Análisis es hoy día una práctica conocida dentro
de la Ingeniería de Software Empírica. Desde que fue propuesto por [5] hubo varios trabajos abordados desde esta óptica [3, 105, 59, 116, 69, 65, 73, 31], sin embargo no existe un criterio unificado de qué modelo de Meta-Análisis se debe aplicar hoy día en Ingeniería de Software.
Si se remite a la teoría estadística, esto debería hacerse en base al análisis de la heterogeneidad entre los experimentos, lo cual no es factible realizar en la práctica en el actual contexto de la Ingeniería de Software debido a que las muestras de los experimentos son pequeñas y los Meta-Análisis agregan pocos experimentos. En este contexto, como se indica en [50, 72], la heterogeneidad no es medible ya que los test no tienen potencia. Esto hace que autores como Tore Dyba aplique en sus trabajos [31] ambos métodos de Meta-Análisis, o que [13] se pase por alto el tema y se agreguen los experimentos solo con el modelo de efecto fijo.
Fuera del contexto de la Ingeniería de Software, a nivel general [103] proponen utilizar el modelo de efectos aleatorio en todos los casos, ya que por las limitaciones de las técnicas de heterogeneidad no es factible determinar si existe o no la misma, y según el modelo teórico que ellos abalan, si un grupo de experimentos sin heterogeneidad se agrega mediante el modelo de efectos aleatorios, el resultado será similar al del modelo de efecto fijo.
Por otra parte, se define en [6] que para el Meta-Análisis donde el conjunto de experimentos es menor a 10 el error de la varianza entre experimentos es demasiado alto y la única alternativa es el modelo de efecto fijo. Es decir, no hay desde la teoría consenso respecto sobre qué modelo utilizar, como así tampoco, evidencia práctica sobre cuál de las posturas es la correcta dentro del ámbito de la Ingeniería de Software.
C. Elección del modelo de efecto de Meta-Análisis: alcance y límites del problema Cuando se intenta determinar de manera experimental si
una metodología o técnica nueva presenta una mejor performance que una ya existente, se plantea un test de hipótesis para establecer que tratamiento es superior. En el

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
380
actual contexto de la Ingeniería de Software Empírica, poder realizar una prueba de hipótesis con el número adecuado de sujetos experimentales [24] es sumamente difícil, por las características intrínsecas de la misma experimentación. Por ello se planteó [4] como solución la utilización del Meta-Análisis. Sin embargo, existen dos modelos bien definidos y debe determinarse cuál es el más adecuado. Esto constituiría una herramienta para que el investigador pudiera determinar de manera aproximada a la realidad (errores de Tipo I y II bajos [17], establecidos en 0,05 y 0,2) si un tratamiento experimental es superior al tratamiento de control, y cuál es la medida de esta mejoría (tamaño de efecto).
Para determinar la utilidad e importancia del desarrollo de una herramienta de este tipo debería plantearse la siguiente pregunta: ¿cuál es el riesgo de no poder o saber escoger entre un modelo u otro? El riesgo principal consiste en terminar eligiendo un modelo de Meta-Análisis no adecuado, y que haga que el resultado obtenido de la agregación no tenga suficiente potencia o carezca de la fiabilidad adecuada. O incluso, que no se sepa que potencia y fiabilidad tiene el método de agregación seleccionado con el modelo de Meta-Análisis utilizado.
No tener la fiabilidad deseada, implica caer en un error de Tipo I, y la falta de potencia lleva a caer en un error de Tipo II. En el primer caso, se estará afirmando que el tratamiento experimental supera al de control, cuando en realidad no lo hace, llegando a un resultado equivocado. En el segundo caso, se tiene un tratamiento experimental que supera al de control (que es lo que se quiere determinar) pero la experimentación no permite aseverarlo. Por último, si no se conoce la fiabilidad o potencia del modelo usado, entonces se puede cometer un error (de Tipo I y/o de Tipo II), y no se conocería esta circunstancia, en cuyo caso, las consecuencias serían las de tener un resultado con un grado de certeza desconocida (incertidumbre del resultado obtenido).
El problema que se presenta entonces, es determinar qué modelo de efecto de Meta-Análisis es más adecuado para aplicar la técnica de Diferencia de Medias Ponderadas para agregar estadísticamente los resultados de investigaciones experimentales en el campo de la Ingeniería e Software. Como se mencionara anteriormente, y al no existir un consenso sobre qué modelo de Meta-Análisis utilizar, se deberá recurrir a la experiencia práctica, para lo que deberán probarse ambos modelos y analizar su comportamiento. Sin embargo, por tratarse de un contexto experimental poco maduro, no es posible contar con los experimentos necesarios para realizar el estudio, por lo que se recurrirá a realizar un proceso de simulación que permita validar el modelo adecuado a utilizar en el actual contexto de la Ingeniería de Software Empírica.
Lo que se propone, entonces, es determinar cuál es el modelo de Meta-Análisis más adecuado para utilizar en una agregación de experimentos por el método de Diferencia de Medias Ponderadas. Para ello, se van a realizar agregaciones con experimentos de igual tamaño y con experimentos de tamaños distintos (que es un contexto más representativo de la realidad experimental en la Ingeniería de Software Empírica). Esto lleva a considerar la existencia de dos escenarios bien definidos: (a) la agregación de experimentos realizados con distinta cantidad de sujetos (experimentos de distinto tamaño), y (b) la agregación de experimentos realizados con la misma cantidad de sujetos (experimentos de igual tamaño).
D. Resumen de investigación Al realizar una agregación de experimentos, hay un número
de parámetros que influyen directamente en las características
de los mismos, por lo que impactan en los resultados obtenidos. Por ello, debe tenerse en cuenta que determinar cuál es el modelo de Meta-Análisis que mejor se adapta al actual contexto de la Ingeniería de Software Empírica o se limita a señalar uno solo de los modelos en forma determinante, sino que se deberá determinar qué modelo es más adecuado de acuerdo a las características que presenta la agregación (dependiendo, es decir, de los conjuntos de valores que tomen los diversos parámetros).
También se mencionó que hay dos escenarios bien definidos en la agregación de experimentos: la combinación de experimentos de igual tamaño (todos con la misma cantidad de sujetos experimentales) y la combinación de experimentos de distinto tamaño. Éste último escenario es más representativo de la realidad experimental de la Ingeniería de Software Empírica, pero no puede elegirse a priori sin determinar la fiabilidad y potencia que presenta cada modelo, o si alguno tiene un error (sea de Tipo I o de Tipo II) no aceptable (Error Tipo I mayor a 0,05 y/o Error Tipo II mayor a 0,2 [17]).
Finalmente, se pueden formular los siguientes objetivos y preguntas de investigación:
Objetivo 1: determinar cuál es el modelo de efecto que mejor se adapta al Meta-Análisis en Ingeniería de Software Empírica cuando los experimentos a agregar tienen el mismo tamaño.
Pregunta de investigación: ¿Es posible establecer un conjunto de recomendaciones para escoger el modelo de Meta-Análisis más adecuado en la agregación de experimentos en Ingeniería de Software de igual tamaño con la utilización del método de Diferencia de Medias Ponderadas?
Objetivo 2: determinar cuál es el modelo de efecto que mejor se adapta al Meta-Análisis en Ingeniería de Software Empírica cuando los experimentos a agregar tienen el distinto tamaño.
Pregunta investigación: ¿Es posible establecer un conjunto de recomendaciones para escoger el modelo de Meta-Análisis más adecuado en la agregación de experimentos en Ingeniería de Software de distinto tamaño con la utilización del método de Diferencia de Medias Ponderadas?
IV. MATERIALES Y MÉTODOS A. Propuesta de simulación como medio para establecer el
modelo de efectos de Meta-Análisis a aplicar en Ingeniería de Software El modelo de efecto en el cual aplicar el método de
Diferencia de Medias Ponderadas [37] no está determinado aún, y hay posturas encontradas al respecto [13, 103].
La estrategia para decidir si se debe utilizar un modelo de efecto fijo o un modelo de efecto aleatorio, se basa en determinar si hay heterogeneidad o no entre los experimentos, sin embargo hay estudios que demuestran que los métodos para análisis de heterogeneidad no tienen potencia con pocos experimentos [6, 50, 72]. Por ello, es imposible determinar metodológicamente cual sería el modelo a utilizar, surgiendo la necesidad de obtener una solución de forma empírica.
Para resolver el problema pragmáticamente, bastaría con agregar los resultados de diferentes experimentos en cada uno de los escenarios propuestos, y luego analizar cuál se adecúa más a las características que presenta la Ingeniería de Software Empírica.
La estrategia sería la de obtener los resultados de experimentos de características similares. Todos ellos contarían con un número de sujetos bajo, ya que esa es la característica principal en este campo [24] y que genera la necesidad de tener

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
381
que agregar el resultado de varios experimentos. Luego se agregaría el resultado de estos experimentos con el método de Diferencia de Medias Ponderadas [55] aplicada primero con el modelo de efecto fijo, y posteriormente con el modelo de efectos aleatorios. Con las combinaciones así realizadas, se debería analizar y comparar la fiabilidad y potencia estadística de ambos modelos de efectos. De esta manera, se podrá determinar el modelo de efectos que mejor se adapta al propósito señalado.
Por simulación de Monte Carlo se obtendrá la cantidad de estudios experimentales necesarios para poder llegar a una conclusión apoyada por una evidencia empírica adecuada (potencia y fiabilidad estadística de 80% y 95% respectivamente [17]).
B. Simulación por el Método de Monte Carlo Como herramienta de investigación, la simulación de
Monte Carlo es un procedimiento sólidamente establecido que proporciona soluciones aproximadas a una gran variedad de problemas.
El método de Monte Carlo (o simulación de Monte Carlo, como también se denomina) [81] es un tipo de algoritmo probabilístico que permite encontrar soluciones a problemas que no poseen una formulación explícita pero pueden plantearse en términos de experimentos aleatorios. Un ejemplo bien conocido es el cálculo de π mediante la Buffon’s Leedle [7].
Un uso bastante corriente de las simulaciones de Monte Carlo es comprobar el comportamiento de estimadores estadísticos (en este caso, los distintos modelos de meta-análisis) en situaciones no asintóticas [101], como la ausencia de normalidad o pequeñas muestras, que es el caso que aborda esta investigación. De hecho, la simulación de Monte Carlo ha sido utilizada en todos las investigaciones similares a la presente [51, 77, 39, 110, 78, 64] realizadas hasta la fecha.
Para una técnica de meta-análisis, la simulación de Monte Carlo se realizaría del modo siguiente: Paso 1. Se definen los parámetros de la(s) población(es) sobre
las que se desea probar la con exactitud del estimador. Entre estos parámetros se encuentra el tipo de distribución de probabilidad (por regla general se escoge la distribución normal), así como el tamaño de efecto poblacional δ. Otros parámetros poblacionales (medias y varianzas) pueden definirse si la simulación así lo exige.
Paso 2. Se extraen muestras de dicha(s) población(es), utilizando para ello una tabla o generador de números aleatorios. El número de muestras extraídas depende de los parámetros de la simulación.
Paso 3. Se calculan los valores del estimador estadístico correspondiente (por ejemplo: tamaño de efecto global d* calculado mediante el modelo de efectos fijos, intervalos de confianza de d*). Nótese que estos valores son calculados utilizando las fórmulas asintóticas (basadas en la Ley de Grandes Números) del estimador bajo estudio.
Paso 4. Se comparan los valores del estimador con los valores poblacionales. Por ejemplo, para obtener la exactitud del estimador, habría que comprobar si el intervalo de confianza de d* contiene el tamaño de efecto poblacional δ. En caso afirmativo, se incrementaría el valor de una variable (número de aciertos). Para la potencia empírica se procedería de modo análogo.
Paso 5. Se repiten los pasos 2-4 un número de veces que asegure la convergencia al resultado, ya que la precisión de una simulación de Monte Carlo es directamente proporcional al número de veces que se ejecuta [7].
C. Simulador La herramienta esencial para la realización del proceso de
simulación, es un software de simulación. Se procederá, entonces, al diseño y desarrollo de un simulador para los propósitos de la presente investigación.
Para diseñar y desarrollar el simulador habrá que tener en cuenta las herramientas de desarrollo disponibles y el hardware disponible. En este caso, se utiliza VB.NET su generador de números aleatorios. Como el generador de VB.NET genera números aleatorios de distribución uniforme, el conjunto de números generados debe convertirse a otro conjunto de números de distribución normal, fijando la media y desvío estándar deseado y utilizando una función de conversión (fórmula 10)
cX *σμ +=
)2cos(*)(*2 21 rrInc π−=
Fórmula 10: Función de conversión de valores de distribución uniforme a valores de distribución normal.
Donde: μ es la media σ es el desvío estándar
1r y 2r son números aleatorios uniformemente distribuidos Estos puntos, así como el diseño y desarrollo del simulador
escapan a los propósitos de esta investigación, y su complejidad se corresponde con un desarrollo de grado de nivel medio, por lo que los detalles del mismo se obvian en la Investigación.
V. EXPERIMENTACIÓN A. Introducción
El objetivo que se persigue con la experimentación es determinar a través de simulaciones cuales son las condiciones bajo las cuales es conveniente agregar experimentos bajo el modelo de efecto fijo y cuando es mejor utilizar el modelo de efectos aleatorios, basándose siempre en el método de agregación Diferencia de Medias Ponderadas [37].
Utilizando los modelos de efecto fijo y efectos aleatorios, y con la ayuda de un simulador que se desarrollará con la finalidad de realizar las experimentaciones (sección V.D) éstas se llevaron a cabo, y a partir del análisis de los resultados, se ha podido desarrollar una serie de recomendaciones para el investigador a la hora de utilizar el Meta-Análisis como herramienta de estudio.
B. Diseño experimental Se realizan simulaciones bajo distintas condiciones para
determinar qué modelo se comporta con mejor fiabilidad y potencia estadística en cada circunstancia. Las condiciones consideradas son cada una de las combinaciones posibles de los valores que toman las distintas variables independientes (sección V.C.1) del experimento.
Las simulaciones consisten en recrear las condiciones experimentales que pueden darse en una investigación de

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
382
Ingeniería de Software Empírica. A través de un tratamiento de control, busca determinarse si un tratamiento experimental tiene mejor performance. Para ello debe establecerse el parámetro a medir en cada experimento y hacer una comparación de las medias obtenidas entre los tratamiento de control y experimental.
Se realiza la simulación de varios experimentos, los cuales se agregan con la técnica Diferencia de Medias Ponderadas, bajo dos supuestos:
1) Existe un único tamaño de efecto poblacional, y las diferencias observadas son propias del error asociado directamente a la experimentación. En este caso se utilizará el modelo de Meta-Análisis de efecto fijo.
2) No existe un único tamaño de efecto poblacional, y las diferencias se deben a circunstancias ajenas a los errores experimentales. En este caso se utilizará el modelo de Meta-Análisis de efectos aleatorios.
En cada corrida, se generan números aleatorios que representan las medias poblacionales de un tratamiento y otro (tratamiento de control y experimental). Para ello, se realiza la simulación suponiendo que el tratamiento experimental es mejor que el tratamiento de control en una medida igual al tamaño de efecto teórico a analizar.
Posteriormente se calculan los tamaños de efecto según el caso que se trate (modelo de efecto fijo o aleatorio), y luego se observa la fiabilidad y potencia estadística que se obtiene al aplicar cada modelo, para poder saber en qué condiciones es aconsejable utilizar uno u otro modelo.
C. Variables de estudio C.1. Variables independientes
Se considera el siguiente conjunto de variables independientes:
• Cantidad de sujetos por experimentos. • Cantidad de experimentos a agregar/combinar. • Media poblacional del tratamiento de control. • Desvío estándar teórico. • Tamaño de efecto poblacional teórico. A continuación se detallará cada una de estas variables
junto a los valores que les fueron asignados durante las simulaciones. C.1.1. Cantidad de sujetos experimentales
La cantidad de sujetos experimentales es que la cantidad de sujetos que intervienen en cada experimento.
Para conocer los valores límites de esta variable, se ha tenido en cuenta que ese número, es muy bajo [24]. Como se señala en [36] el concepto de pequeña muestra es bastante impreciso. Hoyle proporciona la cifra general de 150 sujetos como representativa de las pequeñas muestras [58], si bien existen estudios que rebajan esta cifra a 50 [47, 94]. En meta-análisis las cifras manejadas son incluso menores, en el orden de los 10-20 sujetos por estudio [52].
Debido a que existe una falta de acuerdo, se ha decidido tomar una postura intermedia, y estudiar experimentos que posean unos 40 sujetos totales (20 para el grupo del tratamiento de control y 20 para el grupo del tratamiento experimental). Con valores mayores de 20 por grupo, se estaría muy cerca ya de los 30 sujetos que habitualmente se consideran suficientes para asumir normalidad [41]. Por otro lado, y como se indica en [36] la mayoría de estudios en IS están por debajo de los valores anteriores, a modo de ejemplo [107] reporta que la mediana de la distribución del número de sujetos por experimentos es de 30, estando la media muy por debajo de
este valor. Así mismo, los Meta-Análisis realizados hasta el momento en IS muestran los siguientes valores: en [31] el promedio de sujetos por experimento asciende a 13 sujetos por brazo y en [13] el promedio asciende a solo 6 sujetos por grupo.
Por tanto, la decisión tomada con respecto al tamaño de experimentos (cantidad de sujetos experimentales) es de tomar como cota mínima 4 y cota máxima 20. Asimismo, se hará referencia a estas cantidades como baja o pocos (4-9), media (10-12) y alta o muchos (13-20). C.1.2. Cantidad de experimentos a combinar
El contexto experimental de la Ingeniería de Software no aporta hoy día muchos experimentos potencialmente combinables en un proceso de agregación, debido a diversos motivos, a saber: escasez de experimentos, replicaciones y homogeneidad entre los mismos [24, 84], carencia de estándares para reportes de experimentos. Por ejemplo, [9] no publican varianzas y [11] ni siquiera reporta las medias de los resultados experimentales, y la falta de estandarización de las variables respuesta, por ejemplo, los trabajos de [1, 117] utilizan diferentes variables respuesta para analizar un mismo aspecto, lo cual hace que estos experimentos no puedan ser agregados. Esta limitación hace que la cantidad de experimentos que simulemos para agregar no sea elevada. Algunos autores coinciden en señalar [6] que si el Meta-Análisis posee menos de 10 experimentos los riesgos de caer en un error son altos, al punto que no se recomienda utilizar el modelo de efectos aleatorios si la cantidad de experimentos es inferior a 10. Los Meta-Análisis realizados hasta el momento en IS muestran los siguientes valores: en [31] se realizaron dos agregaciones de 11 experimentos y una de 10 y en [13] se realizaron 3 agregación con 5, 7 y 9 experimentos. Por ello, la cantidad de experimentos a agregar en cada meta-análisis oscilará entre 2 y 10, incrementándose de dos en dos. Se hará referencia a estos valores como bajo o pocos (2 y 4), medio (6) y alto o muchos (8 y 10).
Sin embargo, puede suceder que haya que combinar experimentos de distintos tamaños por no poder disponer del ideal recién expresado. En este caso, estaríamos combinando el resultado de experimentos con distinta cantidad de sujetos experimentales. Con este punto planteado, se consideró que era necesario realizar simulaciones que agreguen experimentos que difieran en cantidad de sujetos marcadamente, por lo que se descartó combinar experimentos con una cantidad de sujetos media, y se tomaron como tamaño de experimentos los valores 4, 14 y 20. Para este caso, se tomarán las combinaciones de sujetos y experimentos que se muestran en la Tabla IV.
De esta manera, se realizarán cuatro tipos de simulaciones: • Simulaciones con modelo de efecto fijo e igual tamaños de
experimentos a agregar (todos con la técnica DMP) • Simulaciones con modelo de efecto aleatorio e igual tamaños
de experimentos a agregar (todos con la técnica DMP) • Simulaciones con modelo de efecto fijo y distintos tamaños
de experimentos a agregar (todos con la técnica DMP) • Simulaciones con modelo de efecto aleatorio y distintos
tamaños de experimentos a agregar (todos con la técnica DMP)
C.1.3. Media poblacional del tratamiento de control Es la media estadística del valor medido en cada
experimento aplicado al tratamiento de control. La media
poblacional del tratamiento de control (cμ ) es fijada en 100 a
efectos de cálculo. Este valor es tomado de manera arbitraria,

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
383
sin necesidad de seguir ningún lineamiento. Por ello, se elige este número (100), ya que se considera que facilitará los cálculos, la lectura de resultados y el posterior análisis comparativo.
TABLA IV. COMBINACIÓN DE SUJETOS Y EXPERIMENTOS A AGREGAR
Sujetos por experimentos Experimentos a agregar 4-4-14 3 4-4-20 3 4-14-14 3 4-14-20 3 4-20-20 3
14-14-20 3 14-20-20 3
4-4-4-4-14-14 6 4-4-4-4-20-20 6
4-4-14-14-14-14 6 4-4-14-14-20-20 6 4-4-20-20-20-20 6
14-14-14-14-20-20 6 14-14-20-20-20-20 6
4-4-4-4-4-4-14-14-14 9 4-4-4-4-4-4-20-20-20 9
4-4-4-14-14-14-14-14-14 9 4-4-4-14-14-14-20-20-20 9 4-4-4-20-20-20-20-20-20 9
14-14-14-14-14-14-20-20-20 9 14-14-14-20-20-20-20-20-20 9
C.1.4. Desvío estándar teórico Es la desviación estándar estadística de la media
poblacional. Se supone igual para ambos tratamientos. Posteriormente, se calculará el desvío estándar real que es el que se observa en los experimentos simulados.
De acuerdo al actual contexto experimental de la Ingeniería de Software, los valores que pueden alcanzar el desvío estándar en distintos experimentos [39] son del 10% (desvío estándar bajo), del 40% (desvío estándar medio) y del 70% (desvío estándar alto) de la media poblacional. C.1.5. Tamaño de efecto poblacional teórico
El tamaño de efecto indica la mejoría de un tratamiento experimental sobre uno de control. El efecto teórico, se refiere a la suposición que se realiza sobre la medida en que el tratamiento experimental supera al de control.
Los tamaño de efecto poblacional (d) a analizar, de acuerdo al actual contexto experimental de la Ingeniería de Software [17, 71], son: bajo (0,2), medio (0,5), alto (0,8) y muy alto (1,2). C.2. Variables dependientes e intermedias
Se utiliza el término de variables intermedias, a aquellas que no son independientes, ni son las variables de interés directo en el estudio, pero son necesarias para calcular las variables dependientes. Se han tenido en cuenta el siguiente conjunto de variables: • Los tamaños de efecto poblacional medido o real, desvío
estándar medido e intervalo de confianza (intermedias) • La media poblacional del tratamiento experimental
(intermedia) • Potencia y fiabilidad deseadas (errores de tipo I y II,
variables dependientes).
C.2.1. Tamaño de efecto poblacional medido o real, desvío estándar e intervalo de confianza
El tamaño de efecto indica la mejoría de un tratamiento experimental sobre uno de control, y se calcula de acuerdo al método de agregación que se esté utilizando. En este caso, se usará la fórmula de la Diferencia de Medias Ponderadas, la cual varía teniendo en cuenta que se trate del modelo de efecto fijo o el modelo de efecto aleatorio. El desvío estándar medido es la desviación estándar estadística de la media poblacional, observado en la simulación de los experimentos
Para el modelo de efecto fijo, estas variables se calculan con ecuaciones vistas en el capítulo dos y que aquí se repiten:
P
CE
SYYJd −
= 94
31−
−=N
J
d representa el tamaño de efecto J representa el factor de corrección Y‘s representa a las medias del grupo experimental (E) y de control (C) Sp representa el desvió estándar conjunto N representa el total de sujetos experimentales incluidos en el experimento
Fórmula 11: tamaño de efecto individual por el método de Diferencia de Medias Ponderadas para el modelo de efecto fijo
)(2
2
CE nndñv++
= CE
CE
nnnnñ
*+
=
vZdvZd 2/2/ αα λ +≤≤− v representa el error típico d representa el tamaño de efecto n‘s representa la cantidad de sujetos experimentales del grupo
experimental (E) y de control (C) Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) Fórmula 12: error típico e intervalo de confianza por el método de Diferencia
de Medias Ponderadas para el modelo de efecto fijo
∑∑=
)(/1)(/
* 2
2
ddd
di
ii
σσ
v = (1/∑ )(/1 2 diσ ) d* representa el tamaño de efecto global ∑ )(/ 2 dd ii σ es la sumatoria de los efectos individuales ∑ )(/1 2 diσ es la sumatoria de la inversa varianza v representa el error típico
Fórmula 13: tamaño de efecto grupal y desvío estándar por el método de Diferencia de Medias Ponderadas para el modelo de efecto fijo
vZdvZd 2/2/ ** αα λ +≤≤− d* representa el tamaño de efecto global Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) v representa el error típico
Fórmula 14: intervalo de confianza grupal por el método de Diferencia de Medias Ponderadas para el modelo de efecto fijo
Y para el modelo de efectos aleatorios:
∑∑=Δ
i
iid2
2
/1/γγ
Δ representa el tamaño de efecto global ∑ iid 2/γ representa la sumatoria de los efectos individuales ∑ i
2/1 γ representa la sumatoria de la inversa de las varianzas entre-estudios e intra-estudios
Fórmula 15: tamaño de efecto global por el método de Diferencia de Medias Ponderadas para el modelo de efectos aleatorios

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
384
vZvZ 2/2/ αα +Δ≤Δ≤−Δ
∑=
iv 2/1
1γ
Δ representa el tamaño de efecto global Z representa la cantidad de desvíos estándar que separan, al nivel de
significancia dado, la media del límite. En general es 1,96 (α = 0,05) v representa el error típico
Fórmula 16: desvío estándar grupal e intervalo de confianza por el método de Diferencia de Medias Ponderadas para el modelo de efectos aleatorios
C.2.2. Media poblacional del tratamiento experimental El valor de la media poblacional del tratamiento
experimental deberá estimarse, y esto se hará de la siguiente forma σδμ *100+=E .
C.2.3. Potencia y fiabilidad deseadas (errores de tipo I y II) El error α, o error de tipo I, y β, o error de tipo II, fueron
tratados en el capítulo dos. Aquí se explica cómo se calculan en la simulación y los valores que se tomarán como cota mínima aceptable. También se repite la tabla que muestra estos errores (Tabla V).
TABLA V. TIPOS DE ERROR DE UN TEST ESTADÍSTICO
H0 verificada en a población
H1 verificada en la población
H0 respuesta del experimento
Decisión correcta (1-α)
β (Tipo II error)
H1 aceptada respuesta del experimento
α (Tipo I error)
Decisión correcta (1-β)
Los resultados vinculados a la fiabilidad indican el
porcentaje de veces que el intervalo de confianza estimado contuvo el valor del tamaño de efecto poblacional, mientras que los resultados vinculados a la potencia estadística indican el porcentaje de veces que dicho intervalo de confianza no contuvo el valor 0 (cero). En cada corrida de la simulación, entonces, la forma de proceder será calcular la media del tratamiento experimental, los tamaños de efecto poblacionales, error estándar e intervalos de confianza. Luego, si el tamaño de efecto poblacional calculado queda dentro del intervalo de confianza, entonces esa corrida suma a la cantidad de veces que el intervalo de confianza contuvo al efecto (aciertos). Al final de las simulaciones, se calcula el porcentaje de aciertos, y ese es el valor de la fiabilidad. De la misma manera, se calcula la cantidad de veces que el intervalo de confianza no contuvo el valor 0, y el porcentaje calculado al final del proceso de simulación, indicará la potencia del método.
Con el objeto de determinar en qué condiciones los métodos de agregación son fiables y tienen buena potencia estadística, se fijarán los valores deseados en 95% (error de tipo I = 0,05) y 80% (error de tipo II = 0,2) respectivamente, ya que estos valores son los habitualmente recomendados [17]. C.3. Cantidad de simulaciones
La Ley de los Grandes Números [36] permite establece una cota de error a los resultados de una simulación. Esta cota depende del problema particular a resolver, pero en general su magnitud es proporcional a √(1/n), siendo n la cantidad de muestreos realizados [81]. En otras palabras, a medida que el número de muestreos se incrementa, la precisión de la simulación aumenta en consecuencia. Con 300 muestreos se alcanza una precisión razonable [87]. En el caso de esta investigación, en cada simulación se realizarán 1000 muestreos, los cuales aseguran la validez de los resultados
obtenidos. Para cada simulación todas las combinaciones de parámetros posibles, según los valores fijados, de esta manera, se tendrán las siguientes combinaciones para igual tamaño de experimento: • Cantidad de sujetos experimentales: 4, 8, 10, 14 y 20. • Cantidad de experimentos a agregar: 2, 4, 6, 8 y 10. • Cantidad de efectos poblacionales distintos: 0.2, 0.4, 0.8 y
1.2. • Cantidad de desvíos estándares a considerar: 10%, 40% y
70%. • Modelos de efecto de Meta-Análisis: modelo de efecto fijo y
modelo de efecto aleatorio. Por tanto, se tienen 600 (5x5x4x3x2) combinaciones
posibles. Como se dijo que se realizarían 1000 simulaciones por cada combinación de parámetros posibles, se tendrá un total de 600.000 simulaciones.
Por otro lado, las simulaciones a realizar con distinto tamaño de experimentos será: • Combinación de experimentos y sujetos: 21 • Cantidad de efectos poblacionales distintos: 0.2, 0.4, 0.8 y
1.2. • Cantidad de desvíos estándares a considerar: 10%, 40% y
70%. • Modelos de efecto de Meta-Análisis: modelo de efecto fijo y
modelo de efecto aleatorio. Por tanto, se tienen 504 (21x4x3x2) combinaciones
posibles. Como se dijo que se realizarían 1000 simulaciones por cada combinación de parámetros posibles, se tendrá un total de 504.000 simulaciones
Finalmente, tendremos un total de 504.000 + 600.000 = 1.104.000 simulaciones.
D. Resultados experimentales Se desarrolla y prueba el simulador, y se procede a la
realización de las simulaciones que arrojaron los resultados que se muestran a continuación. Para el simulador se utiliza VB.NET y su generador de números aleatorios. El desarrollo del simulador corresponde a un nivel de grado medio, por lo que su detalle se obvia en la presente Investigación. D.1. Convención adoptada para lectura de las tablas que
muestran los resultados de los experimentos de igual tamaño
Para analizar los resultados de las simulaciones y poder visualizarlos de manera rápida y clara, se adopta para la lectura de las tablas el marcado que se explica a continuación: • Modelo de efecto fijo y tamaño 0,2: cuadro marcado en las
tablas con una línea continua. • Modelo de efecto fijo y tamaño 0,5: cuadro marcado en las
tablas con una línea de puntos. • Modelo de efecto fijo y tamaño 0,8: cuadro marcado en las
tablas con una doble línea continua. • Modelo de efecto fijo y tamaño 1,2: cuadro marcado en las
tablas con una línea en zigzag. • Modelo de efectos aleatorios y tamaño 0,2: cuadro marcado
en las tablas con una línea de segmentos. • Modelo de efectos aleatorios y tamaño 0,5: cuadro marcado
en las tablas con una línea de segmentos y puntos. • Modelo de efectos aleatorios y tamaño 0,8: cuadro marcado
en las tablas con una triple línea continua. • Modelo de efectos aleatorios y tamaño 1,2: cuadro marcado
en las tablas con una línea doble en zigzag.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
385
D.2. Cuadro comparativo de simulaciones para análisis de fiabilidad con desvío estándar de 10% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla VI, donde se muestran los resultados de la fiabilidad para experimentos de igual tamaño y desvío estándar del 10%
Se hace el análisis para cada modelo y para cada tamaño de efecto (la zona en gris indica los casos en que se alcanzó la fiabilidad del 95%): • Modelo de efecto fijo y tamaño 0,2: para este caso se observa
que sin importarla cantidad de sujetos ni la cantidad de experimentos, la fiabilidad propuesta se alcanza siempre, solo se observa una excepción para la agregación 28 sujetos distribuidos en dos experimentos (14 sujetos por experimentos).
• Modelo de efecto fijo y tamaño 0,5: en el cuadro señalado se alcanza la fiabilidad siempre y cuando la cantidad de sujetos y experimentos no sea alta. También no se alcanza la cota mínima para muchos sujetos y pocos experimentos (sí para un número medio de experimentos).
• Modelo de efecto fijo y tamaño 0,8: la tendencia observada en el caso anterior se acentúa, de tal forma que si antes no se alcanzaba la fiabilidad para muchos sujetos y pocos experimentos, ahora tampoco se alcanza para niveles medios de ambos. Ya podemos decir que se observa que a medida que se incrementa el tamaño de efecto, se pierde fiabilidad cuando el número de sujetos y experimentos crece.
• Modelo de efecto fijo y tamaño 1,2: siguiendo la tendencia observada hasta este caso, se ha perdido casi por completo la fiabilidad deseada, alcanzándose solamente cuando se agregan 2 experimentos con 4 u 8 sujetos cada uno (total de 8 y 16 sujetos experimentales respectivamente).
• Modelo de efectos aleatorios y tamaño 0,2: salvo para los casos de muchos sujetos experimentales, si la cantidad de experimentos a agregar son dos (2), entonces no se alcanza la fiabilidad, en todos los demás casos se está por encima del 95% esperado.
• Modelo de efectos aleatorios y tamaño 0,5: como en el caso del modelo de efecto fijo, ya se está en condiciones de asegurar que la tendencia para el modelo de efectos aleatorios es que a medida que el tamaño de efecto crece, la fiabilidad cae por debajo de la cota mínima a medida que la cantidad de experimentos decrece y la cantidad de sujetos crece. Así, para muchos sujetos y pocos experimentos no se llega al límite de fiabilidad del 95% (tenemos un caso de excepción para 2 sujetos y 20 experimentos).
• Modelo de efectos aleatorios y tamaño 0,8: se incrementa la tendencia, es decir, que mientras más grande es la cantidad de experimentos, debe ser más pequeña la cantidad de sujetos para alcanzar la fiabilidad de 95%. Tenemos el caso excepcional de 20 sujetos y 2 experimentos que sí alcanza la fiabilidad deseada.
• Modelo de efectos aleatorios y tamaño 1,2: la tendencia se incrementa al punto en que solamente se alcanza la fiabilidad para 10 experimentos o un nivel medio/alto de experimentos y pocos sujetos. También se presenta el caso excepcional de 20 sujetos y 2 experimentos que sí alcanza la fiabilidad deseada.
• Modelo de efecto fijo: para cada caso de tamaño de efecto, la fiabilidad crece al decrecer la cantidad de experimentos (de derecha a izquierda en cada cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
TABLA VI. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 10% (VALORES EXPRESADOS EN PORCENTAJES)
Fiabilidad Desvío 10%
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 99,0 99,4 100 99,0 99,0 92,3 96,6 99,2 99,8 100 8 99,6 99,4 99,9 99,9 99,8 83,7 97,6 99,2 99,8 100
10 97,6 99,9 99,6 99,8 99,3 85,8 97,0 98,7 99,9 100 14 86,8 95,0 99,8 100 99,8 89,5 93,8 98,6 99,3 100
0,2
20 95,8 100 100 99,8 100 98,1 98,7 100 100 100
4 98,3 99,3 99,9 98,9 96,5 87,6 95,2 98,0 99,8 100 8 99,6 99,4 98,5 98,2 97,4 76,6 91,9 97,5 98,9 99,9
10 96,4 100 96,9 97,9 89,6 78,7 88,6 95,3 98,6 99,7 14 85,1 92,8 96,4 97,8 93,6 90,3 86,0 92,3 93,8 97,6
0,5
20 92,5 99,6 97,4 93,0 90,1 98,7 80,0 90,6 96,2 99,5
4 97,2 97,9 97,1 94,0 89,2 80,9 91,8 96,9 98,8 99,8 8 99,0 96,3 90,8 85,5 83,4 71,6 85,1 91,4 95,7 98,2
10 94,5 96,2 87,3 83,6 74,1 76,1 78,4 86,4 95,9 98,1 14 78,8 85,7 84,6 79,6 71,2 88,5 82,5 91,8 88,2 97,9
0,8
20 85,5 90,8 81,1 69,4 62,0 97,9 80,6 87,1 96,1 97,5
4 95,9 91,8 86,4 78,4 70,5 74,7 90,2 95,0 96,9 99,0 8 96,3 85,0 73,8 67,7 64,1 71,7 83,7 90,6 89,5 95,3
10 91,1 84,4 71,3 61,9 53,5 78,2 76,4 82,1 94,4 95,2 14 76,3 70,1 62,7 59,1 50,6 82,1 84,6 94,9 90,9 97,9
1,2
20 73,6 67,1 58,3 50,4 44,5 99,6 84,9 94,4 93,0 97,5

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
386
Podría resumirse cada tendencia de la siguiente manera: • Modelo de efectos aleatorios: para cada caso de tamaño de
efecto, la fiabilidad crece al aumentar la cantidad de experimentos (de izquierda a derecha en cada cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
D.3. Cuadro comparativo de simulaciones para análisis de fiabilidad con desvío estándar de 40% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla VII, donde se muestran los resultados de la fiabilidad para experimentos de igual tamaño y desvío estándar del 40%.
Analizando la Tabla VII, se observa que el comportamiento de ambos modelos es similar al caso en que se tiene un desvío estándar del 10%.
El comportamiento descrito para desvío del 10%, es también válido para desvío del 40%: • Modelo de efecto fijo: para cada caso de tamaño de efecto
(cada cuadro marcado), la fiabilidad crece al decrecer la cantidad de experimentos (de derecha a izquierda en cada cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
• Modelo de efectos aleatorios: para cada caso de tamaño de efecto (cada cuadro marcado), la fiabilidad crece al aumentar la cantidad de experimentos (de izquierda a derecha en cada
cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
D.4. Cuadro comparativo de simulaciones para análisis de fiabilidad con desvío estándar de 70% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla VIII, donde se muestran los resultados de la fiabilidad para experimentos de igual tamaño y desvío estándar del 70%.
Analizando la Tabla VIII, se observa que el comportamiento de ambos modelos es similar al caso en que se tiene un desvío estándar del 10% y 40%. Se puede concluir, que para análisis de fiabilidad de agregación de experimentos de igual tamaño, los modelos de efecto fijo y efectos aleatorios (al aplicar el método de Diferencia de Medias ponderadas, que es el método de Meta-Análisis que se está analizando) se comportan de igual manera para cualquier valor de la desviación estándar.
El análisis (que aquí se repite) es aplicable a cualquier tamaño de desvío estándar: • Modelo de efecto fijo: para cada caso de tamaño de, la
fiabilidad crece al decrecer la cantidad de experimentos (de derecha a izquierda en cada cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
TABLA VII. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 40% (VALORES EXPRESADOS EN PORCENTAJES)
Fiabilidad Desvío 40%
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 98,4 99,5 99,6 99,4 99,5 90,4 96,6 99,3 100 100 8 99,8 99,6 99,8 99,8 99,6 85,3 97,6 98,9 99,9 100
10 98,2 100 99,6 99,8 99,3 87,3 97,0 99,0 99,9 100 14 87,5 95,1 99,8 100 99,8 88,0 94,4 97,3 99,0 99,8
0,2
20 95,2 100 100 100 100 97,9 98,7 99,8 100 100
4 97,6 99,0 99,9 98,6 96,2 84,8 94,7 99,1 99,7 100 8 99,5 99,5 98,6 97,4 96,1 76,1 91,5 96,6 98,3 99,9
10 96,9 100 97,5 97,7 89,7 78,2 88,5 95,6 98,2 100 14 83,6 94,3 96,9 96,4 93,2 90,0 85,5 93,5 94,8 98,4
0,5
20 93,4 99,6 98,6 91,2 91,5 97,5 79,7 89,1 95,3 99,6
4 96,8 97,6 95,8 93,6 87,4 81,8 92,5 96,2 98,8 99,7 8 98,9 95,9 91,2 87,8 85,3 72,6 85,5 94,1 96,4 98,9
10 95,4 97,1 86,1 83,7 71,7 74,7 75,3 86,6 95,0 98,4 14 80,7 86,5 80,3 80,1 70,7 87,3 81,8 92,2 88,9 95,7
0,8
20 84,2 88,0 83,3 70,1 65,2 97,7 80,4 87,1 96,0 96,1
4 96,7 92,5 85,6 77,4 69,3 78,6 91,5 94,7 96,8 98,9 8 95,2 86,1 74,2 66,4 61,7 71,0 84,9 89,7 91,2 96,1
10 90,3 83,1 69,5 62,0 55,0 80,0 78,9 81,2 95,5 95,6 14 78,7 70,4 62,4 53,5 48,1 87,3 84,0 94,7 92,9 97,9
1,2
20 77,9 67,5 58,4 49,5 43,8 99,1 87,9 95,3 92,9 97,9

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
387
TABLA VIII. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 70% (VALORES EXPRESADOS EN PORCENTAJES)
Fiabilidad Desvío 70%
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 98,5 98,6 100 99,2 99,2 92,7 95,8 99,2 100 100 8 99,5 99,7 100 100 99,6 83,7 98,2 99,3 99,7 100
10 98,1 100 99,7 99,8 99,2 87,6 97,6 99,1 100 99,7 14 85,9 95,4 99,7 100 99,9 87,1 94,4 97,9 98,6 100
0,2
20 95,9 100 100 100 100 97,0 98,6 99,9 100 100
4 98,1 99,5 100 99,2 97,2 85,5 95,0 99,0 99,8 100 8 99,5 99,3 98,8 96,8 96,9 77,6 91,7 96,8 98,9 99,8
10 96,1 100 97,7 97,5 91,5 79,2 90,2 95,6 98,9 99,9 14 84,5 93,3 96,9 97,9 92,3 89,4 85,7 94,7 93,8 98,2
0,5
20 92,4 99,2 98,0 93,1 89,7 96,8 81,9 88,7 95,9 99,5
4 96,3 97,9 96,8 93,5 91,9 81,8 90,8 97,1 98,9 99,8 8 99,2 95,8 92,4 88,0 81,2 73,2 84,9 92,1 94,2 98,9
10 96,0 97,1 87,1 84,8 72,0 75,1 77,3 87,6 95,6 97,8 14 84,6 85,7 81,1 79,2 72,5 88,5 81,1 91,9 89,2 96,3
0,8
20 87,1 88,4 80,3 72,0 65,3 98,0 79,6 88,8 95,0 96,8
4 96,8 92,9 86,6 79,7 67,0 76,8 88,4 93,6 96,7 98,8 8 97,1 86,2 72,8 68,5 62,8 73,6 83,2 90,4 90,0 95,4
10 90,8 81,6 71,5 65,6 56,8 78,3 79,6 82,9 94,2 95,5 14 76,9 71,6 61,4 58,4 48,2 84,8 86,1 94,6 91,1 98,4
1,2
20 76,2 69,9 60,0 49,3 43,8 99,0 88,8 95,9 93,0 98,0
• Modelo de efectos aleatorios: para cada caso de tamaño de
efecto, la fiabilidad crece al aumentar la cantidad de experimentos (de izquierda a derecha en cada cuadro) y al decrecer la cantidad de sujetos (de abajo hacia arriba en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la fiabilidad es mayor cuando el tamaño de efecto es menor, por lo que la fiabilidad crece al decrecer el tamaño de efecto.
D.5. Cuadro comparativo de simulaciones para análisis de potencia con desvío estándar de 10% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla IX, donde se muestran los resultados de la potencia para experimentos de igual tamaño y desvío estándar del 10%
Se hace el análisis para cada modelo y para cada tamaño de efecto (la zona en gris indica los casos en que se alcanzo la potencia del 80%): • Modelo de efecto fijo y tamaño 0,2 (cuadro marcado en la
tabla con una línea continua): en este caso, no se observa potencia en ninguna circunstancia.
• Modelo de efecto fijo y tamaño 0,5 (cuadro marcado en la tabla con una línea de puntos): la potencia se presenta para muchos sujetos y muchos experimentos. También hay casos de muchos sujetos y un nivel medio/alto de experimentos. Para un nivel medio de sujetos no se alcanza la potencia del 80%.
• Modelo de efecto fijo y tamaño 0,8 (cuadro marcado en la tabla con una doble línea continua): ya se puede observar la tendencia, a medida que la cantidad de experimentos aumenta (desplazamiento en la tabla de izquierda a derecha) y la
cantidad de sujetos también (desplazamiento en la tabla de arriba hacia abajo), la potencia también lo hace.
• Modelo de efecto fijo y tamaño 1,2 (cuadro marcado en la tabla con una línea en zigzag): con la tendencia descripta (aumento de la potencia con el incremento de la cantidad de sujetos y experimentos) se llega a este caso en que solo no se alcanza la potencia del 80% para pocos experimentos y pocos sujetos.
• Para el modelo de efectos aleatorios no se observa potencia en ningún caso
En este caso, puede resumirse la tendencia como sigue: • Modelo de efecto fijo: para cada caso de tamaño de efecto
(cada cuadro marcado), la potencia crece al crecer la cantidad de experimentos (desplazamiento de izquierda a derecha en cada cuadro) y al crecer la cantidad de sujetos (de arriba hacia abajo en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la potencia es mayor cuando el tamaño de efecto es mayor, por lo que la potencia crece al crecer el tamaño de efecto. Al ver este análisis y compararlo con el análisis de fiabilidad, la tendencia es inversa.
• Modelo de efectos aleatorios: no alcanza la potencia en ningún caso.
D.6. Cuadro comparativo de simulaciones para análisis de potencia con desvío estándar de 40% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla X., donde se muestran los resultados de la potencia para experimentos de igual tamaño y desvío estándar del 40%.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
388
TABLA IX. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO ESTÁNDAR DEL 10% (VALORES EXPRESADOS EN PORCENTAJES)
Potencia Desvío 10%
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 1,5 2,1 2,4 2,3 2,3 0 0,2 0 0 0 8 2,6 4,4 4,3 4,9 6,7 0 0 0 0 0
10 8,7 0,9 9,0 8,3 17,2 0 0 0 0 0 14 20,3 12,8 11,1 8,4 16,2 0 0 0 0 0
0,2
20 6,0 2,8 6,0 17,2 15,1 0 0 0 0 0
4 5,4 11,6 16,1 19,7 27,5 0 0,1 0 0 0 8 14,5 30,3 43,9 59,5 74,7 0 0,9 0,1 0 0
10 25,5 34,5 59,0 76,8 77,9 0 0,2 0 0,1 0 14 39,3 53,4 73,5 95,5 96,3 0 0,5 0,3 0 0
0,5
20 36,9 81,9 95,6 98,8 99,8 0 0,3 0,2 0,2 0
4 12,5 31,4 47,4 63,8 71,0 0,5 0,5 0,1 0 0 8 39,2 68,4 87,9 95,9 98,7 0,1 1,6 0,2 0,1 0,1
10 51,6 86,4 93,4 98,5 99,8 0,2 1,4 0,7 0 0 14 62,6 91,1 98,4 99,8 99,9 0,8 1,5 0,1 0,3 0,1
0,8
20 76,4 99,6 100 99,8 99,8 0 1,4 0,2 0,3 0,2
4 33,0 64,5 88,1 94,2 97,0 2,7 0,7 0,6 0,1 0 8 78,1 98,0 99,1 99,8 99,8 1,1 0,4 0,5 0,4 0,2
10 86,9 98,9 99,9 100 99,9 1,9 0,8 2,6 0,7 0,3 14 90,3 99,9 99,7 100 100 6,2 0,9 0 0,6 0,2
1,2
20 96,7 100 100 100 100 0,3 0,6 1,3 0,3 0
TABLA X. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO ESTÁNDAR DEL 40% (VALORES EXPRESADOS EN PORCENTAJES)
Potencia Desvío 40%
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 1,8 3,1 2,1 2,1 3,6 0 0 0 0 0 8 1,9 4,7 3,7 4,6 7,4 0 0 0,1 0 0
10 7,0 1,1 9,1 7,2 16,7 0 0 0 0 0 14 16,4 13,0 12,2 6,6 18,9 0 0 0 0 0
0,2
20 5,9 3,8 5,9 19,8 16,7 0 0 0 0 0
4 6,1 11,5 14,9 21,7 26,8 0,3 0,4 0 0 0 8 12,6 27,5 42,6 59,6 74,6 0 0,6 0 0,1 0
10 24,3 37,8 61,2 73,3 77,4 0 0,1 0,2 0 0 14 38,1 55,3 75,1 93,2 96,2 0,1 0,1 0,4 0,1 0
0,5
20 39,0 83,6 97,8 98,6 99,6 0 0,4 0,2 0 0
4 14,0 30,2 43,4 62,5 71,1 0,8 0,6 0,2 0 0 8 39,9 69,6 88,1 96,2 99,1 0,2 1,8 0,2 0,4 0
10 52,1 87,7 94,9 98,4 99,3 0,2 0,5 0,8 0 0 14 64,0 91,5 98,9 100 99,9 0,7 1,0 0,2 0,6 0
0,8
20 75,5 98,5 99,9 100 99,9 0 0,7 0,4 0,3 0,1
4 29,6 68,8 87,2 94,6 96,4 2,2 0,9 1,1 0,1 0 8 79,4 96,9 99,6 99,7 99,9 1,6 0,6 0,2 0,7 0,5
10 85,8 99,2 99,7 100 100 2,3 1,1 2,6 0,1 0,3 14 90,5 99,4 99,9 100 100 3,8 0,9 0,4 0,4 0,3
1,2
20 97,0 100 99,9 100 100 0,2 0,2 1,7 0 0,1

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
389
TABLA XI. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO ESTÁNDAR DEL 70% (VALORES EXPRESADOS EN PORCENTAJES)
Potencia Desvío 70% Cantidad de experimentos (Mod. Efecto Fijo) Cantidad de experimentos (Mod. Efectos Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 2,6 3,2 2,5 2,2 2,3 0 0,2 0 0 0 8 2,7 4,6 3,7 4,1 6,2 0 0 0 0 0 10 7,3 0,9 8,8 8,4 17,3 0 0,1 0 0 0 14 19,4 14,5 13,1 8,0 16,2 0 0 0 0 0
0,2
20 7,6 3,4 7,2 18,3 14,5 0 0 0 0 0
4 6,2 9,5 15,6 19,6 25,0 0,2 0,3 0 0 0 8 14,1 26,8 44,0 60,9 73,3 0 0,3 0 0,2 0 10 27,0 38,2 61,8 74,7 79,5 0 0,7 0,2 0 0 14 38,0 54,9 73,0 95,1 96,1 0 0,3 0 0,1 0
0,5
20 39,2 80,9 96,4 98,7 99,2 0 0,6 0,1 0,2 0
4 12,4 29,7 45,4 59,1 73,8 0,9 0,3 0,4 0 0 8 37,8 69,5 90,2 96,8 98,2 0 1,9 0 0,3 0 10 52,3 87,6 95,6 98,8 99,4 0,1 0,7 0,8 0 0 14 64,4 92,4 98,7 99,5 100 1,0 1,0 0,2 0,2 0
0,8
20 77,3 99,0 99,9 100 99,9 0 0,6 0,4 0,1 0
4 32,2 67,2 88,4 96,2 96,4 2,3 1,0 1,4 0,1 0,1 8 80,1 97,7 99,2 99,9 99,9 0,6 0,7 0,2 0,5 0,4 10 86,5 99,8 99,8 100 99,9 1,2 1,3 3,8 0,2 0,1 14 91,1 99,4 99,9 100 100 4,6 1,0 0,2 0,5 0
1,2
20 96,4 99,8 100 100 100 0,4 0,4 1,5 0 0
Analizando la Tabla X, se observa que el comportamiento
de ambos modelos es similar al caso en que se tiene un desvío estándar del 10%. El comportamiento descrito para desvío del 10%, es también válido para desvío del 40%: • Modelo de efecto fijo: para cada caso de tamaño de efecto
(cada cuadro marcado), la potencia crece al crecer la cantidad de experimentos (desplazamiento de izquierda a derecha en cada cuadro) y al crecer la cantidad de sujetos (de arriba hacia abajo en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la potencia es mayor cuando el tamaño de efecto es mayor, por lo que la potencia crece al crecer el tamaño de efecto.
• Modelo de efectos aleatorios: no alcanza la potencia en ningún caso.
D.7. Cuadro comparativo de simulaciones para análisis de potencia con desvío estándar de 70% e igual tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XI, donde se muestran los resultados de la potencia para experimentos de igual tamaño y desvío estándar del 70%
Al analizar la Tabla XI, se puede observar que los resultados son los mismos que los que se presentan para desvíos bajo y medio. Se observa la misma tendencia y resultados similares en todos los casos. Se puede concluir, que para análisis de potencia de agregación de experimentos de igual tamaño, los modelos de efecto fijo y efectos aleatorios (al aplicar el método de Diferencia de Medias ponderadas, que es el método de Meta-Análisis que se está analizando) se comportan de igual manera para cualquier valor de la desviación estándar. El análisis (que aquí se repite) es aplicable a cualquier tamaño de desvío estándar: • Modelo de efecto fijo: para cada caso de tamaño de efecto
(cada cuadro marcado), la potencia crece al crecer la cantidad
de experimentos (desplazamiento de izquierda a derecha en cada cuadro) y al crecer la cantidad de sujetos (de arriba hacia abajo en cada cuadro). Además, para cada cuadro se ve que la cantidad de casos en que se alcanza la potencia es mayor cuando el tamaño de efecto es mayor, por lo que la potencia crece al crecer el tamaño de efecto.
• Modelo de efectos aleatorios: no alcanza la potencia en ningún caso.
D.8. Convención adoptada para lectura de las tablas que muestran los resultados de los experimentos de distinto tamaño
Para analizar los resultados de las simulaciones y poder visualizarlos de manera rápida y clara, se adopta para la lectura de las tablas el marcado que se explica a continuación: • Modelo de efecto fijo y 3 experimentos: cuadro marcado en
la tabla con una línea continua. • Modelo de efecto fijo y 6 experimentos: cuadro marcado con
una línea de puntos. • Modelo de efecto fijo y 9 experimentos: cuadro marcado en
la tabla con una doble línea continua. • Modelo de efectos aleatorios y 3 experimentos: cuadro
marcado en la tabla con una línea de segmentos. • Modelo de efectos aleatorios y 6 experimentos: cuadro
marcado en la tabla con una línea de segmentos y puntos. • Modelo de efectos aleatorios y 9 experimentos: cuadro
marcado en la tabla con una triple línea continua. D.9. Cuadro comparativo de simulaciones para análisis de
fiabilidad con desvío estándar de 10% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XII, donde se muestran los resultados de la fiabilidad para experimentos de distinto tamaño y desvío estándar del 10%.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
390
TABLA XII. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 10% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 94,3 93,3 91,2 83,8 96,2 87,7 78,0 72,6 4-4-20 3 98,4 98,6 97,9 89,4 99,6 93,4 78,3 68,5
4-14-14 3 91,3 88,2 81,5 70,4 96,4 90,7 85,2 82,0 4-14-20 3 92,1 90,2 80,6 70,3 99,8 98,0 86,7 83,2 4-20-20 3 96,6 93,3 84,5 73,9 97,3 93,0 81,9 76,3 14-14-20 3 91,4 87,1 80,2 71,5 98,9 86,2 83,3 84,0 14-20-20 3 94,1 90,2 82,3 67,8 96,6 88,5 84,8 89,6
4-4-4-4-14-14 6 97,5 93,0 85,3 70,3 100 98,6 96,0 93,1 4-4-4-4-20-20 6 97,1 92,8 82,1 65,5 100 99,9 96,3 92,7
4-4-14-14-14-14 6 96,2 92,5 82,5 65,3 99,1 92,4 86,8 86,2 4-4-14-14-20-20 6 94,1 90,2 76,6 59,6 100 98,0 87,7 86,9 4-4-20-20-20-20 6 100 98,3 81,8 60,7 100 99,0 94,6 92,4
14-14-14-14-20-20 6 97,1 91,2 74,1 57,1 100 98,0 94,4 96,2 14-14-20-20-20-20 6 99,1 91,7 78,0 57,5 100 93,9 89,1 92,8
4-4-4-4-4-4-14-14-14 9 96,6 90,9 79,4 65,1 100 99,5 98,2 96,0 4-4-4-4-4-4-20-20-20 9 100 97,5 83,2 61,6 100 100 100 97,4
4-4-4-14-14-14-14-14-14 9 99,9 91,8 72,7 53,6 100 99,2 97,1 97,0 4-4-4-14-14-14-20-20-20 9 98,5 91,5 73,5 55,7 100 99,7 96,1 91,8 4-4-4-20-20-20-20-20-20 9 100 95,3 74,2 51,3 100 99,3 97,1 95,6
14-14-14-14-14-14-20-20-20 9 99,8 88,6 72,6 47,9 100 99,9 96,8 97,9 14-14-14-20-20-20-20-20-20 9 99,8 91,4 68,4 53,9 100 98,2 93,7 94,1
Se hace el análisis para cada modelo y para cada cantidad de experimentos (la zona en gris indica los casos en que se alcanzó la fiabilidad del 95%): • Modelo de efecto fijo y 3 experimentos (cuadro marcado en
la tabla con una línea continua): en este cuadro se observa que se alcanza la fiabilidad para tamaño de efecto pequeño y combinaciones de sujetos por experimentos de 4-4-20 y 4-20-20. Para efecto medio y alto hay fiabilidad para 4-4-20. Eso significa que la fiabilidad se alcanza cuando la diferencia de tamaño entre experimentos a agregar es máxima.
• Modelo de efecto fijo y 6 experimentos (cuadro marcado en la tabla con una línea de puntos): en este caso, puede observarse que se alcanza la fiabilidad propuesta para tamaño de efecto pequeño (menos el caso en que se combinan 4-4-14-14-20-20 sujetos por experimento).
• Modelo de efecto fijo y 9 experimentos (cuadro marcado en la tabla con una doble línea continua): se alcanza fiabilidad en todos los casos de tamaño de efecto pequeño y para tamaño de efecto medio solo para los casos en que la diferencia de tamaño de experimentos a agregar es máxima (4-4-4-4-4-4-20-20-20 y 4-4-4-20-20-20-20).
• Modelo de efectos aleatorios y 3 experimentos (cuadro marcado en la tabla con una línea de segmentos): los casos en que se presenta fiabilidad es para tamaño de efecto pequeño.
• Modelo de efectos aleatorios y 6 experimentos (cuadro marcado en la tabla con una línea de segmentos y puntos): hay fiabilidad para tamaño de efecto pequeño y tamaño de efecto medio salvo en dos casos (4-4-14-14-14-14 y 14-14-20-20-20-20). También hay dos casos de fiabilidad para tamaño de efecto grande (4-4-4-4-14-14 y 4-4-4-4-20-20).
• Modelo de efectos aleatorios y 9 experimentos (cuadro marcado en la tabla con una triple línea continua): se alcanza la fiabilidad en casi todos los casos. Las excepciones son 3 (sobre 25): 14-14-14-20-20-20-20-20-20 para tamaño de efecto grande y muy grande y 4-4-4-14-14-14-20-20-20 para tamaño de efecto muy grande.
Se puede resumir la tendencia observada para desvío del 10% como sigue: • Modelo de efecto fijo: a medida que se incrementa la
cantidad de experimentos y el tamaño de efecto es pequeño, se incrementa la fiabilidad. También se observa que mejora la potencia cuando la diferencia de tamaño de experimentos a agregar es máxima (los casos de combinar experimentos de 4 y 20 sujetos).
• Modelo de efectos aleatorios: la fiabilidad se incrementa al subir la cantidad de experimentos y (el desplazamiento sobre la tabla es de cuadro a cuadro de arriba hacia abajo) y crecer el tamaño de efecto (el desplazamiento en la tabla en cada cuadro es de izquierda a derecha).
D.10. Cuadro comparativo de simulaciones para análisis de fiabilidad con desvío estándar de 40% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XIII, donde se muestran los resultados de la fiabilidad para experimentos de distinto tamaño y desvío estándar del 40%. Analizando la Tabla XIII, se observa que el comportamiento de ambos modelos es similar al caso en que se tiene un desvío estándar del 10%. El comportamiento descrito para desvío del 10%, es también válido para desvío del 40%: • Modelo de efecto fijo: a medida que se incrementa la
cantidad de experimentos y el tamaño de efecto es pequeño, se incrementa la fiabilidad. También se observa que mejora la potencia cuando la diferencia de tamaño de experimentos a agregar es máxima (los casos de combinar experimentos de 4 y 20 sujetos).
• Modelo de efectos aleatorios: la fiabilidad se incrementa al subir la cantidad de experimentos y (el desplazamiento sobre la tabla es de cuadro a cuadro de arriba hacia abajo) y crecer el tamaño de efecto (el desplazamiento en la tabla en cada cuadro es de izquierda a derecha).

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
391
TABLA XIII. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 40% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 93,4 92,5 91,8 82,9 96,3 89,6 80,2 73,6 4-4-20 3 98,4 98,0 96,6 90,1 99,2 91,8 76,0 70,3
4-14-14 3 92,9 87,4 80,3 70,0 96,6 91,3 84,6 84,1 4-14-20 3 92,6 90,9 81,8 72,0 99,3 97,5 87,0 82,9 4-20-20 3 96,5 92,0 87,4 73,7 98,0 92,0 82,9 79,6 14-14-20 3 89,6 87,5 81,9 69,6 98,9 86,5 83,1 84,3 14-20-20 3 94,1 90,1 83,1 67,3 97,1 88,6 82,9 90,1
4-4-4-4-14-14 6 97,8 92,8 86,5 69,2 99,9 99,8 96,2 92,6 4-4-4-4-20-20 6 97,7 92,5 80,5 66,6 100 99,8 96,1 91,0
4-4-14-14-14-14 6 96,1 91,5 81,3 66,8 99,3 93,6 85,2 84,7 4-4-14-14-20-20 6 95,1 91,2 75,5 63,2 100 98,6 88,9 86,0 4-4-20-20-20-20 6 100 98,6 83,7 59,8 100 98,2 94,1 92,8
14-14-14-14-20-20 6 95,7 90,1 74,1 57,9 100 97,6 94,9 96,8 14-14-20-20-20-20 6 99,5 92,9 76,6 57,3 100 94,7 88,3 92,2
4-4-4-4-4-4-14-14-14 9 96,6 92,2 79,5 61,9 100 99,1 98,5 96,5 4-4-4-4-4-4-20-20-20 9 100 97,5 82,1 62,6 100 100 100 97,1
4-4-4-14-14-14-14-14-14 9 99,9 91,1 75,2 54,8 100 99,3 97,1 97,7 4-4-4-14-14-14-20-20-20 9 98,8 91,6 70,6 54,0 100 100 96,9 93,5 4-4-4-20-20-20-20-20-20 9 100 94,4 73,6 53,7 100 99,8 97,1 94,5
14-14-14-14-14-14-20-20-20 9 100 89,2 66,5 46,5 100 99,9 97,7 97,2 14-14-14-20-20-20-20-20-20 9 100 90,6 69,7 49,7 100 98,1 93,5 94,3
D.11. Cuadro comparativo de simulaciones para análisis de
fiabilidad con desvío estándar de 70% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XIV, donde se muestran los resultados de la fiabilidad para experimentos de distinto tamaño y desvío estándar del 70%. Analizando la Tabla XIV, se observa que el comportamiento de ambos modelos es similar al caso en que se tiene un desvío estándar del 10%. Se puede concluir, que para análisis de fiabilidad de agregación de experimentos de igual tamaño, los modelos de efecto fijo y efectos aleatorios (al aplicar el método de Diferencia de Medias ponderadas, que es el método de Meta-Análisis que se está analizando) se comportan de igual manera para cualquier valor de la desviación estándar. El análisis (que aquí se repite) es aplicable a cualquier tamaño de desvío estándar: • Modelo de efecto fijo: a medida que se incrementa la
cantidad de experimentos y el tamaño de efecto es pequeño, se incrementa la fiabilidad. También se observa que mejora la potencia cuando la diferencia de tamaño de experimentos a agregar es máxima (los casos de combinar experimentos, donde los mismos tienen 4 o 20 sujetos, como ser 4-4-20 o 4-20-20).
• Modelo de efectos aleatorios: la fiabilidad se incrementa al subir la cantidad de experimentos y (el desplazamiento sobre la tabla es de cuadro a cuadro de arriba hacia abajo) y crecer el tamaño de efecto (el desplazamiento en la tabla en cada cuadro es de izquierda a derecha).
D.12. Cuadro comparativo de simulaciones para análisis de potencia con desvío estándar de 10% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XV, donde se muestran los resultados de la potencia para
experimentos de distinto tamaño y desvío estándar del 10%. Se hace el análisis para cada modelo y para cada cantidad de experimentos (la zona en gris indica los casos en que se alcanzo la potencia del 80%): • Modelo de efecto fijo y 3 experimentos (cuadro marcado en
la tabla con una línea continua): en este caso, se alcanza la potencia propuesta del 80% cuando el tamaño de efecto es muy grande, o para tamaño de efecto grande si la cantidad total de sujetos es elevada (que es para los casos en que se combinan 14 y 20 sujetos por experimento)
• Modelo de efecto fijo y 6 experimentos (cuadro marcado en la tabla con una línea de puntos): hay potencia cuando el tamaño de efecto es grande y muy grande (para el caso de tamaño de efecto de 0,8, no se alcanza la potencia cuando la cantidad de sujetos totales es baja, es decir, 4-4-14). También hay potencia para tamaño de efecto medio si la cantidad de sujetos totales es alta.
• Modelo de efecto fijo y 9 experimentos (cuadro marcado en la tabla con una doble línea continua): en este caso se alcanza la potencia del 80% para tamaño de efecto grande y muy grande. Para tamaño de efecto medio, se alcanza la potencia mínima deseada para una cantidad de sujetos totales media/alta.
• Para el modelo de efectos aleatorios no se observa potencia en ningún caso.
Analizando la tendencia observada a lo largo de los cuadros de la Tabla XV, puede resumirse el comportamiento de cada modelo para desvío estándar del 10% como sigue: • Modelo de efecto fijo: la potencia se incrementa al subir la
cantidad de experimentos (desplazamiento en la tabla de arriba hacia debajo de cuadro a cuadro) y al crecer el tamaño de efecto (desplazamiento dentro de cada cuadro de izquierda a derecha).
• Para el modelo de efectos aleatorios no se observa potencia en ningún caso

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
392
TABLA XIV. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE FIABILIDAD CON DESVÍO ESTÁNDAR DEL 70% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 94,0 92,4 90,6 85,0 96,1 89,5 77,3 73,1 4-4-20 3 99,2 98,6 96,8 89,0 99,3 92,8 78,5 69,8
4-14-14 3 90,5 84,5 82,7 72,5 95,7 91,9 81,0 83,3 4-14-20 3 92,7 88,9 80,6 70,6 99,7 96,8 87,8 84,1 4-20-20 3 96,8 91,5 87,7 74,7 99,3 92,6 82,2 75,4 14-14-20 3 90,3 86,5 81,1 71,2 98,6 89,2 82,5 82,7 14-20-20 3 93,7 90,9 84,3 69,9 97,4 87,2 84,7 90,0
4-4-4-4-14-14 6 97,7 93,3 84,2 68,5 100 99,4 96,8 94,4 4-4-4-4-20-20 6 97,1 93,5 81,0 63,3 100 99,9 96,2 91,5
4-4-14-14-14-14 6 96,8 91,1 79,3 63,1 99,0 92,1 84,3 82,9 4-4-14-14-20-20 6 95,9 90,7 78,6 61,3 100 98,4 86,2 86,9 4-4-20-20-20-20 6 100 98,6 82,0 60,6 100 98,8 94,5 92,3
14-14-14-14-20-20 6 96,2 88,3 76,5 55,1 100 97,7 93,2 96,5 14-14-20-20-20-20 6 99,1 92,0 78,2 55,3 99,9 94,3 88,8 91,7
4-4-4-4-4-4-14-14-14 9 95,9 90,6 79,0 62,2 99,9 99,4 98,2 96,0 4-4-4-4-4-4-20-20-20 9 100 97,8 83,2 61,9 100 100 100 97,0
4-4-4-14-14-14-14-14-14 9 100 92,8 73,6 52,8 100 99,3 97,2 97,9 4-4-4-14-14-14-20-20-20 9 98,0 93,2 75,7 54,4 100 99,6 97,4 92,4 4-4-4-20-20-20-20-20-20 9 100 94,7 74,9 50,7 100 99,6 96,7 94,7
14-14-14-14-14-14-20-20-20 9 99,9 88,5 69,8 43,7 100 99,9 98,0 98,1 14-14-14-20-20-20-20-20-20 9 99,8 91,7 71,0 47,2 100 99,1 94,5 94,7
TABLA XV. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO ESTÁNDAR DEL 10% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 7,3 25,1 49,1 84,4 0 0,2 0,9 2,7 4-4-20 3 4,3 26,4 67,6 96,0 0 0,1 0,9 2,5
4-14-14 3 10,9 33,4 58,6 90,9 0 0,1 0 0,9 4-14-20 3 8,5 29,3 70,5 94,0 0 0 0 0,4 4-20-20 3 9,0 38,4 79,1 98,6 0 0,5 0,8 0,4 14-14-20 3 17,2 45,4 81,0 98,9 0 0,1 0,7 0,8 14-20-20 3 13,8 54,4 87,4 98,8 0 1,5 1,4 0,4
4-4-4-4-14-14 6 7,8 35,3 78,6 98,7 0 0 0 0,2 4-4-4-4-20-20 6 6,7 46,1 88,5 99,1 0 0 0,1 0,7
4-4-14-14-14-14 6 10,6 61,4 92,2 99,7 0 0,3 0,6 0,5 4-4-14-14-20-20 6 17,1 64,8 93,8 99,9 0 0 0,9 0,5 4-4-20-20-20-20 6 3,4 82,8 99,3 100 0 0,1 0,3 0,5
14-14-14-14-20-20 6 16,7 78,1 99,3 100 0 0 0,1 0,1 14-14-20-20-20-20 6 10,9 87,5 99,6 100 0 0 0,4 0,3
4-4-4-4-4-4-14-14-14 9 7,3 55,7 91,5 99,7 0 0 0 0,8 4-4-4-4-4-4-20-20-20 9 7,4 78,0 99,4 100 0 0 0 0,2
4-4-4-14-14-14-14-14-14 9 10,4 73,5 98,4 99,9 0 0 0,1 0,2 4-4-4-14-14-14-20-20-20 9 18,4 88,3 99,9 100 0 0 0,1 0,8 4-4-4-20-20-20-20-20-20 9 7,4 96,3 100 100 0 0 0,1 0,2
14-14-14-14-14-14-20-20-20 9 16,5 93,6 100 100 0 0 0,1 0,1 14-14-14-20-20-20-20-20-20 9 27,5 98,6 100 100 0 0 0,2 0,2

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
393
TABLA XVI. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO
ESTÁNDAR DEL 40% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 8,8 25,1 51,7 83,2 0 0 0,9 2,8 4-4-20 3 5,1 27,3 67,4 96,2 0 0,1 0,7 1,7
4-14-14 3 9,8 33,3 58,8 91,2 0 0 0,1 0,5 4-14-20 3 7,4 28,9 71,0 95,4 0 0 0 0,4 4-20-20 3 6,9 44,0 82,4 97,2 0 0,7 0,8 0,6 14-14-20 3 17,1 44,9 82,7 98,5 0 0 1,2 1,0 14-20-20 3 10,9 52,4 87,4 99,5 0,1 0,6 1,8 0,1
4-4-4-4-14-14 6 7,9 39,0 78,8 98,5 0 0 0,2 0,6 4-4-4-4-20-20 6 6,3 46,7 87,4 99,7 0 0 0 0,6
4-4-14-14-14-14 6 11,1 57,6 92,3 99,7 0,1 0 0,6 0,5 4-4-14-14-20-20 6 17,0 66,8 93,6 99,8 0 0 0,1 1,4 4-4-20-20-20-20 6 3,5 83,4 99,4 100 0 0 0,2 1,1
14-14-14-14-20-20 6 16,7 76,6 99,2 99,9 0 0,1 0 0 14-14-20-20-20-20 6 13,7 87,8 99,4 100 0 0 0,4 0,4
4-4-4-4-4-4-14-14-14 9 9,6 57,3 92,0 99,6 0 0 0 0,4 4-4-4-4-4-4-20-20-20 9 4,2 77,6 98,8 99,9 0 0 0 0,2
4-4-4-14-14-14-14-14-14 9 9,3 73,8 99,5 100 0 0 0,1 0,1 4-4-4-14-14-14-20-20-20 9 19,6 87,8 99,8 100 0 0 0,1 1,0 4-4-4-20-20-20-20-20-20 9 6,8 95,6 99,8 100 0 0 0 0,3
14-14-14-14-14-14-20-20-20 9 16,0 94,3 99,9 100 0 0 0,1 0,3 14-14-14-20-20-20-20-20-20 9 26,2 98,4 99,9 100 0 0 0,4 0,4
D.13. Cuadro comparativo de simulaciones para análisis de
potencia con desvío estándar de 40% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XVI, donde se muestran los resultados de la potencia para experimentos de distinto tamaño y desvío estándar del 40%
Analizando la Tabla XVI, se observa que el comportamiento de ambos modelos es similar al caso en que se tiene un desvío estándar del 10%. El comportamiento descrito para desvío del 10%, es también válido para desvío del 40%: • Modelo de efecto fijo: la potencia se incrementa al subir la
cantidad de experimentos (desplazamiento en la tabla de arriba hacia debajo de cuadro a cuadro) y al crecer el tamaño de efecto (desplazamiento dentro de cada cuadro de izquierda a derecha).
• Para el modelo de efectos aleatorios no se observa potencia en ningún caso
D.14. Cuadro comparativo de simulaciones para análisis de potencia con desvío estándar de 70% y distinto tamaño de experimentos
Los resultados de las simulaciones hechas para los modelos de efecto fijo y efecto aleatorio se sintetizan en la Tabla XVII, donde se muestran los resultados de la potencia para experimentos de distinto tamaño y desvío estándar del 70%
Al analizar la Tabla XVII, se puede observar que los resultados son los mismos que los que se presentan para desvíos bajo y medio. Se observa la misma tendencia y resultados similares en todos los casos.
Se puede concluir, que para análisis de potencia de agregación de experimentos de igual tamaño, los modelos de efecto fijo y efectos aleatorios (al aplicar el método de
Diferencia de Medias ponderadas, que es el método de Meta-Análisis que se está analizando) se comportan de igual manera para cualquier valor de la desviación estándar.
El análisis (que aquí se repite) es aplicable a cualquier tamaño de desvío estándar:
• Modelo de efecto fijo: la potencia se incrementa al subir la cantidad de experimentos (desplazamiento en la tabla de arriba hacia debajo de cuadro a cuadro) y al crecer el tamaño de efecto (desplazamiento dentro de cada cuadro de izquierda a derecha).
• Para el modelo de efectos aleatorios no se observa potencia en ningún caso E. Resumen de los resultados obtenidos y recomendaciones
A continuación se mostrará un resumen del análisis de los resultados obtenidos en la experimentación para luego elaborar un conjunto de recomendaciones sobre el modelo de Meta-Análisis a utilizar para agregar experimentos en Ingeniería de Software Empírica, según sean las características dadas. E.1. Resumen de los resultados obtenidos en la
experimentación Los resultados obtenidos en la sección V.D, deben
agruparse bajo un criterio que haga simple su análisis visual (donde se utiliza las convenciones adoptadas y explicadas en las secciones D.1 y D.8), para lo cual se diseñaron las tablas que siguen a continuación, donde se resumen los resultados de la comparación de ambos métodos para agrupar experimentos de igual tamaño (Tabla XVIII) y experimentos de distinto tamaños (Tabla XIX).
La alta fiabilidad se indica con (+) y la baja con espacio en blanco. En tanto que la alta potencia se indica con (//) y la baja potencia con espacio en blanco.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
394
TABLA XVII. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO ESTÁNDAR DEL 70% (VALORES EXPRESADOS EN PORCENTAJES)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 8,7 22,6 51,0 85,2 0,1 0 0,8 2,4 4-4-20 3 5,0 28,6 67,5 96,6 0 0 0,2 1,0
4-14-14 3 12,7 35,3 61,4 92,4 0 0 0 0,6 4-14-20 3 7,9 30,4 70,0 94,1 0 0 0 0,1 4-20-20 3 5,4 41,8 83,4 97,5 0 0,4 0,9 0,9 14-14-20 3 15,3 44,9 82,3 99,4 0 0 0,8 1,5 14-20-20 3 11,9 52,0 88,9 99,1 0 0,9 1,7 0,2
4-4-4-4-14-14 6 8,1 34,7 78,2 98,3 0 0 0 0,1 4-4-4-4-20-20 6 7,0 46,6 87,8 99,6 0 0 0 0,6
4-4-14-14-14-14 6 11,4 54,9 89,8 99,5 0 0,2 0,9 0,6 4-4-14-14-20-20 6 18,5 64,0 94,0 100 0 0 0,3 1,0 4-4-20-20-20-20 6 3,5 82,2 99,2 99,6 0 0 0,2 0,6
14-14-14-14-20-20 6 18,4 76,2 99,2 100 0 0 0 0,1 14-14-20-20-20-20 6 13,7 86,9 99,8 100 0 0 0,3 0,2
4-4-4-4-4-4-14-14-14 9 9,1 55,6 91,4 99,5 0 0 0,1 0,6 4-4-4-4-4-4-20-20-20 9 3,8 78,4 99,1 99,9 0 0 0 0,3
4-4-4-14-14-14-14-14-14 9 9,6 74,9 99,5 99,9 0 0 0,1 0,2 4-4-4-14-14-14-20-20-20 9 19,2 90,4 99,6 100 0 0 0,1 0,8 4-4-4-20-20-20-20-20-20 9 8,0 96,3 99,7 100 0 0 0,5 0,4
14-14-14-14-14-14-20-20-20 9 15,2 93,7 100 100 0 0 0 0 14-14-14-20-20-20-20-20-20 9 25,8 98,4 100 100 0 0 0,5 0,2
TABLA XVIII. CUADRO COMPARATIVO DE AMBOS MODELOS PARA EXPERIMENTOS DE IGUAL TAMAÑO. COMPARACIÓN DE FIABILIDAD (+) Y POTENCIA ESTADÍSTICA (//)
Fiabilidad y Potencia
Cantidad de experimentos (Modelo de Efecto Fijo) Cantidad de experimentos (Modelo de Efectos
Aleatorios) Efecto Sujetos 2 4 6 8 10 2 4 6 8 10
4 + + + + + + + + + 8 + + + + + + + + +
10 + + + + + + + + + 14 + + + + + + +
0,2
20 + + + + + + + + + +
4 + + + + + + + + 8 + + + + + + + +
10 + + + + + + + 14 + + // + // +
0,5
20 + // + // // // + + +
4 + + + + + + 8 + + // // // + +
10 + + // // // // + + 14 // // // // +
0,8
20 // // // // + + +
4 + // // // + + 8 + // // // // +
10 // // // // + + 14 // // // // +
1,2
20 // // // // + + +

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
395
TABLA XIX. CUADRO COMPARATIVO DE AMBOS MODELOS PARA EXPERIMENTOS DE DISTINTO TAMAÑO. COMPARACIÓN DE FIABILIDAD (+) Y POTENCIA ESTADÍSTICA (//)
Modelo de efecto fijo Modelo de efectos aleatorios
Sujetos Experi-mentos
Efecto 0,2
Efecto 0,5
Efecto 0,8
Efecto 1,2 Efecto
0,2 Efecto
0,5 Efecto
0,8 Efecto
1,2 4-4-14 3 // + 4-4-20 3 + + + // +
4-14-14 3 // + 4-14-20 3 // + + 4-20-20 3 + // + 14-14-20 3 // + 14-20-20 3 // +
4-4-4-4-14-14 6 + // + + + 4-4-4-4-20-20 6 + // // + + +
4-4-14-14-14-14 6 + // // + 4-4-14-14-20-20 6 // // + + 4-4-20-20-20-20 6 + // // // + +
14-14-14-14-20-20 6 + // // + + 14-14-20-20-20-20 6 + // // // +
4-4-4-4-4-4-14-14-14 9 + // // + + + + 4-4-4-4-4-4-20-20-20 9 + + // // + + + +
4-4-4-14-14-14-14-14-14 9 + // // + + + + 4-4-4-14-14-14-20-20-20 9 + // // // + + + 4-4-4-20-20-20-20-20-20 9 + + // // // + + + +
14-14-14-14-14-14-20-20-20 9 + // // // + + + + 14-14-14-20-20-20-20-20-20 9 + // // // + +
En todos los casos, cuando se hace referencia a baja o alta
potencia y a baja o alta fiabilidad, es en referencia a los valores establecidos como límites aceptables en la sección C.2. Esto es un valor del 95% o superior para la fiabilidad y del 80% o mayor para la potencia estadística.
De esta manera, pueden agruparse los resultados similares en solamente dos tablas, donde no se indica la potencia y fiabilidad alcanzada, sino simplemente si se llegó (o superó) la cota superior propuesta como objetivo (sección C.2). E.2. Recomendaciones para elegir un modelo de Meta-Análisis
en la agregación de experimentos en Ingeniería de Software Empírica
Habiendo agrupado los resultados de las simulaciones obtenidas durante la experimentación, se formulan las recomendaciones a los investigadores en el campo de la Ingeniería de Software Empírica, sobre la elección del modelo de Meta-Análisis que es conveniente escoger para agregar experimentos con el método de Diferencia de Medias Ponderadas, de acuerdo a las características del estudio a desarrollar. E.2.1. Recomendaciones para elegir un modelo de Meta-
Análisis en la agregación de experimentos de igual tamaño
La primera recomendación para utilizar Meta-Análisis como método de investigación en ingeniería de Software Empírica, es para casos en que se trabaja con un tamaño de efecto medio. En este caso, se aconseja utilizar el método de Diferencia de Medias ponderadas bajo el modelo de efecto fijo utilizando entre 14 y 20 sujetos y realizando de 4 a 10 experimentos. Bajo estas circunstancias, puede esperarse que los resultados obtenidos tengan fiabilidad y potencia estadística aceptables.
Para cualquier otro caso, la potencia y fiabilidad no pueden asegurarse simultáneamente. Sin embargo, para casos de tamaño de efecto pequeño a mediano, se recomienda utilizar el modelo de efecto fijo, que presenta fiabilidad y si bien no presenta la potencia deseada, si tiene mayor potencia que el modelo de efectos aleatorios.
Solamente se recomienda (con reservas) utilizar el modelo de efectos aleatorios para tamaños de efecto grande y muy grande, y para el caso en que se agreguen de 8 a 10 experimentos o 6 experimentos con 20 sujetos. Sin embargo, debe aclararse que en estos casos, el modelo no tiene potencia estadística (no solo no alcanza la cota deseada, sino que el valor es realmente bajo).
En todo caso, para las dos últimas recomendaciones, debe tenerse en cuenta dos cosas, primero que la segunda recomendación es para usar un modelo que no alcanza la potencia deseada, pero que de todas formas presenta ciertos valores de potencia que dependiendo de las circunstancias de la experimentación pueden llegar a ser aceptables, en tanto que el tercer método no tiene potencia alguna. En segundo lugar, debe recordarse que una aplicación estadística que no presenta potencia indica una alta probabilidad de cometer un error de Tipo II sin poder detectarse, es decir, el error que proviene de aceptar la hipótesis nula cuando en realidad se verifica la hipótesis alternativa. Esto quiere decir que no se puede asegurar que el tratamiento experimental supera al de control cuando en realidad sí lo hace. En todo caso, nunca se hará una recomendación que incremente el error de Tipo I, ya que éste implica que se acepta erróneamente el tratamiento experimental como superior al de control.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
396
E.2.2. Recomendaciones para elegir un modelo de Meta-Análisis en la agregación de experimentos de distinto tamaño
En este caso, puede observarse que no coincide para ningún modelo fiabilidad y potencia, por lo que la primera recomendación es la de no agregar experimentos de distinto tamaño.
Si de todas formas, deben agregarse experimentos de distinto tamaño, se recomienda utilizar el modelo de efecto fijo para tamaño de efecto pequeño y más de 6 experimentos.
En este caso, también puede utilizarse el modelo de efectos aleatorios si la cantidad de experimentos es superior a 6 y cualquier tamaño de efecto o cualquier cantidad de experimentos para tamaño de efecto pequeño. De todas maneras, se recuerda que siempre que se escoja el modelo de efectos aleatorios para agregar experimentos, éste no presenta nunca potencia estadística.
Finalmente, se recomienda utilizar siempre el modelo de efecto fijo para los casos que presenta fiabilidad, ya que siempre tiene mayor potencia que el modelo de efectos aleatorios, aunque esta elección se deja en manos del investigador. E.2.3. Resumen de recomendaciones para elegir un modelo de
Meta-Análisis en la agregación de experimentos En la Tabla XX se resumen las recomendaciones antes
detalladas, que busca ser una herramienta de apoyo al investigador que se dedica al campo de la Ingeniería de Software Empírica.
VI. CONCLUSIONES A. Análisis de los resultados obtenidos e interpretación
A.1. Análisis comparativo de simulaciones para análisis de fiabilidad e igual tamaño de experimentos
Según se vio en el capítulo V (Experimentación), el modelo de efecto aleatorio presenta fiabilidad para tamaño de efecto pequeño y mediano, en tanto, para tamaños de efecto alto y muy alto, la fiabilidad disminuye al incrementarse la cantidad de sujetos y experimentos.
Por otro lado, el modelo de efectos aleatorios presenta fiabilidad para un número grande de experimentos. La
fiabilidad con este modelo crece al disminuir la cantidad de sujetos por experimentos y el tamaño de efecto.
Ambos modelos presentan mayor fiabilidad para los casos de tamaño de efecto pequeño (con la cantidad de sujetos y experimentos con que se realizó el proceso de simulación), pero en general, para tamaños de efecto pequeño y medio, es mayor la fiabilidad del modelo de efecto fijo. A.2. Análisis comparativo de simulaciones para análisis de
potencia e igual tamaño de experimentos La potencia para el modelo de efecto fijo se presenta
cuando la cantidad de sujetos por experimentos y la cantidad de experimentos a agregar es alta. En general, el modelo de de efecto fijo presenta potencia para 80 sujetos totales (en la combinación de todos los experimentos a agregar) y tamaño de efecto medio, 40 sujetos totales para tamaño de efecto grande y 20 sujetos para tamaño de efecto muy grande. No hay potencia para tamaño de efecto pequeño.
El modelo de efectos aleatorios no alcanza la potencia deseada (80 %) en ningún caso. A.3. Análisis comparativo de simulaciones para análisis de
fiabilidad y distinto tamaño de experimentos El modelo de efecto fijo presenta fiabilidad para 6 y 9
experimentos (independientemente de la cantidad de sujetos que se combinen en cada experimento) y tamaño de efecto pequeño.
El modelo de efectos aleatorios tiene fiabilidad para tamaño de efecto pequeño y 3 experimentos, tamaño de efecto pequeño y medio y 6 experimentos y siempre que se combinen 9 experimentos.
En este caso, el modelo de efectos aleatorios presenta más fiabilidad que el modelo de efecto fijo. A.4. Análisis comparativo de simulaciones para análisis de
potencia y distinto tamaño de experimentos En este caso, el modelo de efecto fijo tiene potencia para
tamaño de efecto muy alto y 3 experimentos, tamaño de efecto alto y muy alto y 6 experimentos y para tamaño de efecto medio a muy alto y 9 experimentos.
Para el modelo de efectos aleatorios no se observa potencia en ningún caso (por debajo del 80 % en todos los casos).
TABLA XX. CUADRO DE SIMULACIONES PARA AMBOS MODELOS DE EFECTO DE META-ANÁLISIS, PARA COMPARACIÓN DE POTENCIA CON DESVÍO
ESTÁNDAR DEL 40% (VALORES EXPRESADOS EN PORCENTAJES)
Características de la experimentación Recomendación Tamaños de los experimentos a
agregar
Tamaño de efecto
Desvío estándar
Sujetos experimentales
Cantidad de experimentos
Modelo recomendado
Nota a la recomendación
Medio Indiferente >14 >4 FIJO Potencia y fiabilidad deseada
Bajo y medio Indiferente Indiferente Indiferente FIJO Fiabilidad deseada y
potencia baja Grande y
muy grande Indiferente Indiferente >8 NINGUNO (ALEATORIO)
Fiabilidad deseada y potencia NULA
Experimentos igual tamaño
Grande y muy grande Indiferente 20 6 NINGUNO
(ALEATORIO) Fiabilidad deseada y
potencia NULA
Pequeño Indiferente Indiferente >6 FIJO Fiabilidad deseada y potencia baja
Indiferente Indiferente Indiferente >6 NINGUNO (ALEATORIO)
Fiabilidad deseada y potencia NULA
Experimentos de distinto tamaño
Pequeño Indiferente Indiferente Indiferente NINGUNO (ALEATORIO)
Fiabilidad deseada y potencia NULA

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
397
B. Conclusiones y recomendaciones
B.1. Conclusiones La presente investigación ha mostrado la baja potencia del
modelo de efectos aleatorios dentro del contexto de simulación desarrollado, esto provoca en la práctica que el resultado final del meta-análisis hecho con este tipo de modelo tienda a dar diferencias no significativas en todo momento, no permitiendo de esta forma poder detectar la comisión de un error de tipo II (afirmar que un tratamiento es mejor que otro cuando en realidad los es).
Por otro lado, la fiabilidad del modelo de efectos aleatorios, es superior a la del modelo de efecto fijo cuando el efecto es alto o muy alto, cuando se combinan un número elevado de sujetos por experimentos y la cantidad de experimentos agregados es igualmente elevada. Esto surge en principio como consecuencia directa de los amplios tamaños de los intervalos de confianza que el método DMP arroja bajo el supuesto que indica utilizar el modelo de efectos aleatorios.
Se puede observar que el modelo de efecto fijo se comporta mejor que el modelo de efectos aleatorios, presentando potencia con más de 80 sujetos/experimentos (para tamaño de efecto medio que es cuando además tiene fiabilidad) cuando el modelo de efecto aleatorio no posee potencia en ninguno de los casos analizados, y presenta fiabilidad (el modelo de efecto fijo) para todos los casos en que la varianza es baja o media. Cuando los efectos poblacionales son altos o muy altos, el modelo de efecto fijo tiende a perder fiabilidad sobre todo cuando se incrementa la cantidad de experimentos y la cantidad de sujetos experimentales. Este hecho se produce por una reducción en el tamaño del intervalo de confianza y por una subestimación del tamaño de efecto por diferencias en los valores del desvío estándar, pero se compensa, en parte, con el aumento de la potencia estadística, lo cual permite a los investigadores asegurar que uno de los tratamientos es mejor que el otro a pesar de que el tamaño de efecto indicado no sea exacto, algo que no sucede con el modelo de efectos aleatorios (debido a la falta de potencia que presenta). B.2. Recomendaciones
De los análisis anteriores surge en primera instancia, que nunca se aconseja utilizar el modelo de efectos aleatorios, ya que carece de potencia en todos los casos (posibilidad de cometer un error de tipo II sin ser detectado).
Sin embargo, el modelo de efecto fijo no presenta fiabilidad y potencia en todos los casos, y se recomienda utilizar éste modelo bajo las siguientes circunstancias: i) Combinar siempre experimentos de igual tamaño (ya que
para los casos en que se combinan experimentos de distinto tamaño, el modelo presenta fiabilidad cuando pierde la potencia y viceversa)
ii) Para que los resultados de la agregación tenga potencia (>= 80%) y fiabilidad (>= 95%), deben combinarse al menos un total de 80 sujetos para casos de tamaño de efecto medio. En estas circunstancias, el desvío estándar es indiferente. Para cualquier otro caso, el método DMP para ambos
modelos no presenta fiabilidad y potencia simultáneamente, por lo que no existe recomendación alguna para estos casos. B.3. Futuros trabajos
Según lo estableciera [36], el DMP es la técnica de agregación de experimentos que mejor fiabilidad y potencia presenta en general. En el presente trabajo, además se estableció qué modelo de Meta-Análisis utilizar.
Sin embargo, en [36] se compararon cuatro técnicas de agregación de experimentos, y para los casos en que el DMP pierde fiabilidad, el Response Ratio (RR) la ganaba. De hecho, para casos de muchos sujetos y muchos experimentos, se recomienda utilizar el RR.
En la investigación presente se estudiaron ambos modelos de Meta-Análisis con la técnica DMP, pero no se realizaron simulaciones para analizar ésta otra técnica (RR).
Debido a que ya fue analizado el RR para el modelo de efecto fijo e igual tamaño de experimentos, se plantea como futuras líneas de trabajo: i) Analizar el RR para el modelo de efecto fijo y distintos
tamaños de experimentos. ii) Analizar el RR para el modelo de efectos aleatorios para
distintos tamaños de experimentos. iii) Analizar el RR para el modelo de efectos aleatorios para
igual tamaño de experimentos.
REFERENCIAS [1] Agarwal, R., Tanniru, M., 1990, Knowledge Acquisition Using
Structured Interviewing: An Empirical Investigation, Journal of Management Information System, M.E. Sharpe, Vol. 7 N. 1.
[2] Bailey, J. y Basili, V. 1981: A Meta-Model for Software Development Resource Expenditures, IEEE Press, pp. 107-116
[3] Banker y Keremer, 1989, Scale economies in new software development. IEEE Transactions on Software Engineering. (15): 10, pp. 1199-1205.
[4] Basili, V., Green, S., Laitenberger, O., Lanubile, F., Shull, F., Sörumgård, S. y Zelkowitz, M. 1996: The empirical investigation of perspective-based reading, International Journal on Empirical Software Engineering, Vol. 1, No. 2, pp. 133–164.
[5] Basili, V. y Weiss, D. 1981: Evaluation of a Software Requirements Document by Analysis of Change Data, IEEE Press, pp. 314-323
[6] Borenstein, M., Hedges, L. y Rothstein, H. 2007: Meta-Analysis Fixed Effect vs. random effect, www.Meta-Analysis.com
[7] Brassard, G. y Bratley, P. 1988: Algorithmics: Theory and Practice, Prentice-Hall
[8] Burton, A., Shadbolt, N., Hedgecock, A. y Rugg, G. 1988: A Formal Evaluation of Knowledge Elicitation Techniques for Expert Systems: Domain 1. Proceedings of Expert Systems '87 on Research and Development in Expert Systems IV, pp. 136-145.
[9] Burton, A., Shadbolt, N., Rugg, G. y Hedgecock, A. 1990: The Efficacy of Knowledge Elicitation Techniques: A Comparison Across Domains and Level of Expertise. Knowledge Acquisition, pp. 167-178.
[10] Cabrero García, L. y Richart Martínez, M. 1996: El debate investigación cualitativa frente a investigación cuantitativa Enfermería clínica, pp. 212-217.
[11] Crandall Klein, B. y Asociados, 1989: A Comparative Study Of Think-Aloud And Critical Decision Knowledge Elicitation Method. SIGAR Newsletter, April 1989, Number 108, Knowledge Acquisition Special Issue, pp. 144-146.
[12] Chalmers, I., Hedges, L. y Cooper, H. 2002: A brief history of research synthesis, Eval Health Prof March, pp. 2–37.
[13] Ciolkowski, M. 2009: What do we know about perspective-based reading? An approach for quantitative aggregation in software engineering, 3rd International Symposium on Empirical Software Engineering and Measurement, pp. 133-144.
[14] Cochran, W. 1954: The combination of estimates from different experiments, Biometrics, pp. 101–129.
[15] Cochrane, 2008: Curso Avanzado de Revisiones Sistemáticas, www.cochrane.es/?q=es/node/198
[16] Cochrane collaboration, 2011: Open learning material, http://www.cochranenet. org/openlearning/html/mod0.htm, disponible al 26 de agosto de 2012.
[17] Cohen, J. 1988: Statistical Power Analysis for the Behavioral Sciences (2nd ed.), ISBN 0-8058-0283-5.

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
398
[18] Cooper, H. y Hedges, L. 1994: The Handbook of Research Synthesis, Russell Sage Foundation: New Cork, NY.
[19] Corbridge, C., Rugg, G., Major, P., Shadbolt N. y Burton, A. 1994: Laddering: Technical and Tool in Knowledge Acquisition, Department of Psychology, University of Nottingham.
[20] Cruzes, D. y Dybå, T. 2010: Synthesizing evidence in software engineering research, Proceedings of ACM-IEEE International Symposium on Empirical Software Engineering and Measurement.
[21] Daren S. Starnes, Dan Yates, David Moore, 2010. The Practice of Statistics. Editorial Freeman, ISBN 978-142924-559-3
[22] Davies, P. 1999: What is evidence-based education?, British Journal of Educational Studies, pp. 108-121.
[23] Davis, D. y Holt, C. 1992: Experimental Economics, Princeton University Press
[24] Davis, A., Dieste, O., Hickey, A. Juristo, N. y Moreno, A. 2006: Effectiveness of Requirements Elicitation Techniques: Empirical Results Derived from a Systematic Review, 14th IEEE International Requirements Engineering Conference (RE'06), pp. 179-188
[25] DerSimonian, R. y Laird, N. 1986: Meta-Analysis in clinical trials, Control Clin Trials, pp. 177-88.
[26] Dieste, O. y Griman, A. 2007: Developing Search Strategies for Detecting Relevant Experiments for Systematic Reviews, IEEE Press
[27] Dieste, O., y Juristo, N. 2009: Systematic Review and Aggregation of Empirical Studies on Elicitation Techniques, IEEE Transactions on Software Engineering, TSE-2009-03-0052, http://main.grise.upm.es/reme/publicaciones_download.aspx?type=REV&id=64
[28] Dieste, O., Fernández, E., García, R., y Juristo, N, 2010: “Hidden Evidence Behind Useless Replications”, 1st RESER
[29] Dieste, O., Fernández, E., García, R. y Juristo, N. 2011. “Comparative analysis of meta-analysis methods: when to use which?” 6th EASE Durham (UK)
[30] Dixon-Woods, M., Agarwal, S., Jones, D., Young, B. y Sutton, A. 2005: Synthesising qualitative and quantitative evidence: a review of possible methods, Journal of Health Services Research and Policy, 10, 1, 45-53B (9)
[31] Dyba, T., Aricholm, E., Sjoberg, D., Hannay, J. y Shull, F. 2007: Are two heads better than one? On the effectiveness of pair programming. IEEE Software, pp. 12-15.
[32] Dyba, T., Kampenes, V. y Sjoberg, D. 2006: A systematic review of statistical power in software engineering experiments, Information and Software Technology, vol. 48, pp. 745-755
[33] El Emam, K. y Laitenberger, O. 2001: Evaluating Capture-Recapture Models with Two Inspectors, IEEE Transaction on Software Engineering, pp. 851-864.
[34] Everitt, B. 2003: The Cambridge Dictionary of Statistics, CUP, ISBN: 0-521-81099-x
[35] Fenton, N. y Pfleeger, S. 1997: Software metrics. A rigurous and practical approachFuente, PWS Publishing Company
[36] Fernández, E. 2013: Proceso de agregación para estudios experimentales en Ingeniería de Software, Tesis Doctoral, Facultad de Informática, UNLP.
[37] Fernández, E., Pollo, F., Amatriain, H., Dieste, O., Pesado, P. y García-Martínez, R. 2009: Aplicabilidad de los Métodos de Síntesis Cuantitativa de Experimentos en Ingeniería de Software. Proceedings XV Congreso Argentino de Ciencias de la Computación. Workshop de Ingeniería de Software, pp. 752-761. ISBN 978-897-24068-4-1.
[38] Fisher, R. A. (1915). Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika, pp. 507-521.
[39] Friedrich, J., Adhikari, N. y Beyene, J. 2008: The ratio of means method as an alternative to mean differences for analyzing continuous outcome variables in meta-analysis: A simulation study, BMC Medical Research Methodology
[40] Gambara, H., Botella, J. y Gempp, R. 2002: Empty time and full time. A meta-analysis of age-related changes perceiving time, © 2002 by Fundación Infancia y Aprendizaje, ISSN: 0210-9395
[41] García, R. 2004: Inferencia Estadística y Diseño de Experimentos, eudeba, Buenos Aires Argentina
[42] Gavaghan, D., Moore, A. y McQay, H. 2000: An evaluation of homogeneity tests in meta-analysis in pain using simulations of patient data, Pain, vol. 85, pp. 415-424.
[43] Glass, G. 1976: Primary, secondary, and meta-analysis of research, Educational Researcher, pp. 3-8
[44] Glass, G. 2000: Meta-analysis at 25, http://glass.ed.asu.edu/ gene/papers/meta25.html
[45] Good, P. y Hardin, J. 2006: Common Errors in Statistics (and How to Avoid Them), second edition, wiley & Sons, ISBN-13: 978-0-471-79431-8.
[46] Goodman, C. 1996: Literature Searching and Evidence Interpretation for Assessing Health Care Practices, SBU, Stockholm.
[47] Graham, J. y Schafer, J. 1999: On the Performance of Multiple Imputation for Multivariate Data With Small Sample Size, v-29, Sage PublicationsCarpetas
[48] Guerra Romero, L., 1996: La medicina basada en evidencia: un intento de acercar la ciencia al arte de la práctica médica, Plan Nacional sobre el Sida. Ministerio de Sanidad y consumo, Madrid, España, Med Clin (Barc) 1996, 107, pp. 377-382
[49] Gurevitch, J. y Hedges, L. 2001: Meta-analysis: Combining results of independent experiments, Design and Analysis of Ecological Experiments (eds S.M. Scheiner and J. Gurevitch), Oxford University Press, Oxford, pp. 347–369.
[50] Hardy, R.J. y Thompson, S.G, 1998: Detecting and describing heterogeneity in meta-analysis.
[51] Hedges, L 1982: Fitting categorical model to effect size from a series of experiments, journal educational statistics, pp. 119-137.
[52] Hedges, L. 1993: Statistical Considerations, Russell Sage Foundation, First edition
[53] Hedges, L., Gurevitch, J. y Curtis, P. 1999: The Meta-Analysis of Response Ratio in Experimental Ecology, The Ecological Society of America
[54] Hedges, L., Gurevitch, J. y Curtis, P. 1999: Meta Analysis http://www.bio.mq.edu.au/pgrad/SIBS/Meta_analysis.PPT
[55] Hedges, L. y Olkin, I. 1985: Statistical methods for meta-analysis. Academic Press
[56] Higgins, J. y Green, S. 2011: Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0, The Cochrane Collaboration
[57] Higgins, J y Thompson, S. 2002: Quantifying heterogeneity in a meta-analysis, Statistics in Medicine, vol. 21, pp. 1539-1558
[58] Hoyle, R. 1999: Preface, v-vii, Sage Publications [59] Hu, Q., 1997, Evaluating Alternative Software Production
Function. IEEE Transactions on Software Engineering. (23): 6, pp. 379-387.
[60] Hunt, M. 1997: How Science takes stock: the story of meta-analysis, Russell Sage Foundation: New York
[61] Hunter, J. y Schmidt, F. 2004: Methods of meta-analysis: correcting error and bias in research findings, Sage Publications
[62] Ioannidis, J., Patsopoulos, N. y Evangelou, E. 2007: Uncertainty in heterogeneity estimates in metaanalyses, BMJ, 335: 914 doi: 10.1136/bmj.39343.408449.80
[63] Johnson, D. W. y Curtis, P. S. 2001: Effects of forest management on soil C and N storage: meta-analysis, Forest Ecology and Management, pp. 227-238
[64] Jones, M., O'Gorman, T., Lemke, J. y Woolson, R. 1989: A Monte Carlo Investigation of Homogeneity Tests of the Odds Ratio under Various Sample Size Configurations, Biometrics, Vol. 45, No. 1
[65] Jørgensen, M. 2004: A Review of Studies on Expert Estimation of Software Development Effort, Journal of Systems and Software, (70): 1-2, pp. 37-60.
[66] Judd, C., Smith, E. y Kidder, L. 1991: Research Methods in Social Relations, Hartcourt Brace Jovanovich College Publishers, Orlando, Florida

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
399
[67] Juristo, N. y Moreno, A. 2001: Basics of Software Engineering Experimentation. Boston: Kluwer Academic Publisher.
[68] Juristo, N. y Moreno, A. 2002: Reliable Knowledge for Software Development, IEEE Software, pp. 98-99.
[69] Juristo, N, Moreno, A. y Vegas, S. 2004: Towards building a solid empirical body of knowledge in testing techniques, Acm Sigsoft Software Engineering Notes (Sigsoft), pp. 1-4
[70] Juristo N. y Vegas, S. 2011: The Role of Non-Exact Replications in Software Engineering Experiments, Journal: Empirical Software Engineering
[71] Kampenes, V., Dyba, T., Hannay, J. y Sjøberg, D. 2007: A systematic review of effect size in software engineering experiments, Information and Software Technology 49, pp. 1073–1086
[72] Kim, W., 2000: A Meta-Analysis of Fear Appeals: Implications for Effective Public Health Campaigns
[73] Kitchenham, B. 2004: Procedures for performing systematic reviews. Keele University, TR/SE-0401. Keele University Technical Report.
[74] Knuth, D. E. 1997: The Art of Computer Programming, Addison-Wesley, vol 2, 1997
[75] Laitenberger, O., Atkinson, C., Schlich, M. y El Emam, K. 2000: An experimental comparison of reading techniques for defect detection in UML design documents, J.Syst.Software, 53, 2, pp. 183-204
[76] Laitenberger, O. y Rombach, D. 2003: (Quasi-)Experimental Studies in Industrial Settings, World Scientific
[77] Lajeunesse, M. y Forbes, M. 2003: Variable reporting and quantitative reviews: a comparison of three meta-analytical techniques. Ecology Letters, 6, pp. 448-454.
[78] Liang, K. y Self, S. 1985: Tests for Homogeneity of Odds Ratio When the Data are Sparse, Biometrika, Vol. 72, No. 2
[79] Lipsitz, S., Dear, K., Laird, N. y Molenberghs, G. 1998: Tests for homogeneity of the risk difference when data are sparse, Biometrics, vol. 54, pp. 148-160.
[80] Meta-Analysis, 2011: disponible en http://www.meta-analysis.com/
[81] Metropolis, N. y Ulam, S. 1949: The Monte Carlo Method, Journal of the American Statistical Association, 44(247), pp. 335-341.
[82] Miguez, E. y Bollero, G. 2005: Review of Corn Yield Response under winter cover cropping systems using Meta-Analytic Methods, Crop Science Society of America
[83] Miller, J. 1999, Can Results from Software Engineering Experiments be Safely Combined?, IEEE METRICS, pp. 152-158
[84] Miller, J. 2000: Meta-analytical Procedures to Software Engineering Experiments, Journal of Systems and Software, 54, 1, pp. 29-39
[85] Mix, 2011: disponible en http://www.mix-for-meta-analysis. info/
[86] Mohagheghi, P. y Conradi, R. 2004: Vote-Counting for Combining Quantitative Evidence from Empirical Studies - An Example. Proceedings of the International Symposium on Empirical Software Engineering (ISESE'04).
[87] Morales Vallejo, P. 2011: Tamaño necesario de la muestra ¿Cuántos sujetos necesitamos?, www.upcomillas.es/personal/ peter/investigacion/TamañoMuestra.pdf
[88] Myers, D. y Lamm, H. 1975: The polarizing effect of group discussion, American Scientist, 63, pp. 297-303Navarro, Giribet y Aguinaga, 1999: Psiquiatría basada en la evidencia: Ventajas y limitaciones, Psiquiatría Biológica, 6, pp. 77-85.
[89] Noortgate, W. y Onghena, P. 2003: Estimating the mean effect size un meta-analysis: Bias, precision, and mean squared error of different weighting methods. Behavioral research methods, instruments and computers, 35, pp. 504-511
[90] Pearson, K. 1904: Report on certain enteric fever inoculation statistics, BMJ 3, pp. 1243-1246.
[91] Petrosino, A., Boruch, R., Soydan, H., Duggan, L. y Sánchez-Meca, J. 2001: Meeting the challenges of Evidence-Based
Policy: The Campbell Collaboration, Annals of the American Academy of Political & Social Science, 578, pp. 14-34.
[92] Pfleeger, S. 1999: Albert Einstein and Empirical Software Engineering, Computer, pp. 32-37.
[93] Reichart, C. y Cook, T. 1986: Hacia una superación del enfrentamiento entre los métodos cualitativos y cuantitativos, En: Cook TD, Reichart ChR (ed). Métodos cualitativos y cuantitativos en investigación evaluativa. Madrid: Morata.
[94] Richy, F., Ethgen, O., Bruyere, O., Deceulaer, F. y Reginster, J. 2004: From Sample Size to Effect-Size: Small Study Effect Investigation (SSEi), The Internet Journal of Epidemiology, 1, 2
[95] Rogers, D. 2006: Fifty years of Monte Carlo simulations for medical physics, Physics in Medicine and Biology, 51, pp. R287-R301
[96] Sabaliauskaite, G., Kusumoto, S. & Inoue, K. 2004: Assessing defect detection performance of interacting teams in object-oriented design inspection, Information and Software Technology 46 (2004), pp. 875–886, Available online at: www.sciencedirect.com
[97] Sabaliauskaite, G., Matsukawa, F., Kusumoto, S. & Inoue, K. 2002: An experimental comparison of checklist-based reading and perspective-based reading for UML design document inspection, Empirical Software Engineering, pp. 148-157
[98] Sackett, D. y Wennberg, J. 1997: Choosing the best research design for each question, BMJ, 315:1636
[99] Sanchez-Meca, J. y Botella, J. 2010: Revisiones Sistemáticas y Meta-Análisis: Herramientas Para La práctica Profesional, Papeles del Psicólogo, Vol. 31, Núm. 1, pp. 7-17
[100] Sánchez-Meca, J. y Marín-Martínez, F. 1998: Testing continuous moderators in meta-analysis: A comparison of procedures, British Journal of Mathematical and Statistical Psychology, 51:311–26.
[101] Sawilowsky, S. y Fahoome, G. 2002: Statistics Through Monte Carlo Simulation with Fortran, ed: JMASM.
[102] Schweickert, R., Burton, A., Taylor, N., Corlett, E., Shadbolt, N., Rugg, G. y Hedgecock, A. 1987: Comparing Knowledge Elicitation Techniques: A Case Study, Artificial Intelligence Review (1), pp. 245-253.
[103] Schmidt, F. y Hunter, J. 2003: Handbook of Psychology, Research Methods in Psychology, Chapter 21, “Meta-Análisis”, Schinka, J., Velicer, W., Weiner, I. Editors, Volume 2.
[104] Shekelle, P., Maglione, M., Morton, S., 2003, Judging What to Do About Ephedra, http://rand.org/publications/randreview/ issues/spring2003/evidence.htm
[105] Shull, F., Carver, J., Travassos, G. H., Maldonado, J. C., Conradi, R., and Basili, V. R., 2003: Replicated Studies: Building a Body of Knowledge about Software Reading Techniques. Lecture Notes on Empirical Software Engineering. World Scientific. Chapter 2, pp. 39-84.
[106] Sidhu, D. y Leung, T. 1989: Formal Methods for Protocol Testing: A Detail Study, IEEE Transaction on Software Engineering, 15(4) pp. 413-426.
[107] Sjoberg, D. 2005: A survey of controlled Experiments in Software Engineering, IEEE Transactions on Software Engineering, Vol 31 Nro. 9.
[108] Song, F., Sheldon, T., Sutton, A., Abrams, K. y Jones, D. 2001: Methods for Exploring Heterogeneity in Meta-Analysis, Evaluation and The Health professions, vol. 24 no. 2, pp. 126-151.
[109] Strain, D. y Lee, J. 1984: Variance Component Testing in the Longitudinal Mixed Effects Model, Biometrics, vol. 50, pp. 1171-1177.
[110] Takkouche, B., Cadarso-Suarez, C. y Spiegelman, D. 1999: Evaluation of old and new tests of heterogeneity in epidemiologic meta-analysis, Am. J. Epidemiol, PubMed ChemPort,150, pp. 206–215,
[111] Thalheimer, W. y Cook, S. 2002: How to calculate effect sizes from published research: A simplified methodology, A Work-Learning Research Publication.
[112] Tichy, W. 1971: Should computer scientists experiment more?, IEEE Computer, vol. 31, pp. 32-40

Amatriain, H., Diez, E., Bertone, R., Fernandez, E. 2014. Establecimiento del Modelo de Agregación más Adecuado para Ingeniería del Software Revista Latinoamericana de Ingeniería de Software, 2(6): 369-400, ISSN 2314-2642
400
[113] Tichy, W. 1998: Should Computer Scientists Experiment More?, IEEE Computer, vol. 31, pp. 32-40
[114] Vander Wiel y Votta, 1993: Assessing Software Design Using Capture-Recapture Methods, IEEE Transaction on Software Engineering, 19(11), pp. 1045-1054.
[115] Weinberg, G. 1971: The Psychology of Computer Programming, Van Nostrand Reinhold, New York
[116] Wohlin, C., Runeson, P., Hˆst, M., Ohlsson, M. C., Regnell, B. y WesslÈn, A. 2000: Experimentation in Software engineering: An Introduction, International Series in Software Engineering, id: 29, Record: 5370, Volume: 6
[117] Woody, J., Will, R., Blanton, J., 1996, Enhancing Knowledge Elicitation using the Cognitive Interview, Expert system with application, Vol. 10 N. 1
[118]Worn, B, Barbier, E., Beaumont, N., Duffy, J., Folke, C., Halpern, B., Jackson, J., Lotze, H., Micheli, F., Palumbi, S., Sala, E., Selkoe, K., Stachowics, J. y Watson, R. 2007: Supporting Online Material: Impacts of biodiversity loss on ocean ecosystem services.
Hernán Amatriain. Es Profesor Adjunto del Área de Ingeniería de Software en la Licenciatura en Sistemas de la Universidad Nacional de Lanús (UNLa). Es Investigador del Grupo de Investigación en Sistemas de Información (GISI) y dirige el Laboratorio de Investigación y Desarrollo en Ingeniería del Software del GISI del
Departamento de Desarrollo Productivo y Tecnológico de la UNLa. Es Ingeniero en Sistemas de Información por la Universidad Tecnológica Nacional y Magister en Ingeniería de Software por la Facultad de Informática de la Universidad Nacional de La Plata.
Eduardo Diez. Es Profesor Asociado del Área de Ingeniería de Software en la Licenciatura en Sistemas de la Universidad Nacional de Lanús (UNLa). Es Investigador del Grupo de Investigación en Sistemas de Información (GISI) y dirige el Laboratorio de Investigación y Desarrollo en Aseguramiento de Calidad de Software del GISI
del Departamento de Desarrollo Productivo y Tecnológico de la UNLa. Es Analista de Sistemas y Licenciado en Sistemas por la Universidad de Belgrano. Es Especialista en Ingeniería de Sistemas Expertos y Magister en Ingeniería de Software por el Instituto Tecnológico de Buenos Aires y por la Facultad de Informática de la Universidad Politécnica de Madrid.
Rodolfo Bertone. Es Profesor Titular del área de Bases de Datos. Es Investigador del Instituto de Investigación en Informática (III-LIDI) de la Facultad de Informática de la Universidad Nacional de La Plata (UNLP). Es Licenciado en Informática y Magister en Ingenieria de Software por la Universidad Nacional de La Plata. Es
Docente Investigador Categoría II en el Programa de Incentivos del Ministerio de Educación.
Enrique Fernández. Es Investigador Adscripto al Grupo de Investigación en Sistemas de Información de la Licenciatura en Sistemas de la Universidad Nacional de Lanús. Es Docente de la Cátedra de Sistemas de Programación no Convencional de Robots de la Facultad de
Ingeniería de la Universidad de Buenos Aires. Es Doctor en Ciencias Informáticas por la Universidad Nacional de La Plata.

Hossian, A., Cejas, L., Carabajal, R., Echeverría, C., Alvial, M., Olivera, V. 2014. Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un Enfoque de Tecnologías Inteligentes. Revista Latinoamericana de Ingeniería de Software, 2(6): 401-404, ISSN 2314-2642
401
Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un
Enfoque de Tecnologías Inteligentes
Alejandro Hossian, Lilian Cejas, Roberto Carabajal, César Echeverría, Maxiliano Alvial, Verónica Olivera Proyecto de Investigación UTI3536 de la Facultad Regional Neuquén. Universidad Tecnológica Nacional. Argentina.
Resumen— La propuesta del presente proyecto es el desarrollo de distintas arquitecturas de software ejecutándose en diversas plataformas de hardware que permitan definir los comportamientos de robots autónomos y manipuladores en base a un enfoque cognitivo. Se pretende que el robot posea un comportamiento deseado en función a las prestaciones requeridas al mismo. Este comportamiento deseado podrá evaluarse a través de distintos indicadores que reflejarán la aptitud del agente robótico para llevar a cabo las tareas y conductas que le son requeridas, en particular cuando interactúa en entornos dinámicos y cambiantes. Con el objeto de lograr este propósito de relacionar adecuadamente arquitecturas software y plataformas de hardware con distintos ambientes y comportamientos deseados en función de las prestaciones requeridas, se explorará el uso de diferentes recursos tecnológicos para el diseño de la estructura cognitiva del robot. Entre los soluciones tecnológicas a emplear en el diseño del cerebro del robot se encuentran Redes Neuronales Artificiales, Lógica Difusa, Sistemas Expertos, Aprendizaje Automático, algoritmos genéticos. Asimismo, el proyecto explorará el diseño de arquitecturas cognitivas híbridas que combinen e integren adecuadamante las tecnologías previamente enunciadas, procurando brindar recomendaciones para la construcción de un módulo inteligente de robot que optimice su comportamiento global en términos de las prestaciones requeridas, para determinadas plataformas de hardware y para distintas configuraciones de entornos de navegación robótica tanto estáticos como dinámicos.
Palabras claves—Robótica, Software, Hardware, Tecnologías Inteligentes, Entornos de navegación.
I. JUSTIFICACIÓN DE LA PROPUESTA La globalización de los mercados productivos ha generado
un ambiente altamente competitivo, dando como resultado la modificación y en algunos casos el desarrollo de nuevas tecnologías. Para mantener esquemas de producción rentables, las grandes compañías se han visto en la necesidad de optimizar sus procesos de manufactura. Esto ha creado la demanda de recursos humanos altamente capacitados y enfocados a la mejora continua de los procesos industriales en general.
En este contexto se plantea la necesidad de abordar nuevas perspectivas desde las Tecnologías Inteligentes a los efectos de responder a este nuevo paradigma de los mercados competitivos.
II. ESTADO ACTUAL DEL CONOCIMIENTO SOBRE EL TEMA El entorno real para los robots autónomos es dinámico e
impredecible. Esto causa que, para la mayor parte de los dominios, tener una teoría del dominio (modelo) perfecta de cómo afectan las acciones del robot el entorno es un ideal.
Se conocen dos perspectivas mayoritarias entre los diferentes tipos de arquitecturas para el control de robots autónomos a lo largo de los últimos años. Por un lado se encuentran las arquitecturas reactivas, como la observada en la figura 1, que proponen la consecución de metas complejas por parte del robot basándose únicamente en un conjunto de reacciones simples. Estas reacciones simples reciben distintos nombres: módulos, agentes, agencias, controladores o comportamientos.
Fig. 1. Arquitectura reactiva. Por otro lado se encuentran las arquitecturas más clásicas
dentro del campo de los sistemas inteligentes, que postulan la necesidad de técnicas de razonamiento a más largo plazo sobre un modelo del mundo [2]. Este tipo de arquitectura, con un módulo de alto nivel que toma las decisiones a largo plazo, obliga a que el robot tenga una representación interna del mundo donde realiza las acciones. El proceso de razonamiento a alto nivel trabaja sobre resultados intermedios de dicha representación, siendo ésta la única manera posible de solucionar problemas complejos.
Fig. 2. Arquitectura basada en Conocimiento. En cualquiera de los dos casos existe una tercera
perspectiva que trabaja con el problema de la integración de múltiples robots para lograr la realización de metas complejas. El aspecto cooperativo, dado un sistema multiagente de
ENTRADA SENSORES
SALIDA ACTUADORES
SALIDA DE ACTUADORES
ENTRADA DE SENSORES
Modelado del ambiente
Planificación de acciones
Ejecución de las acciones
Interpretación de la información de los sensores

Hossian, A., Cejas, L., Carabajal, R., Echeverría, C., Alvial, M., Olivera, V. 2014. Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un Enfoque de Tecnologías Inteligentes.
Revista Latinoamericana de Ingeniería de Software, 2(6): 401-404, ISSN 2314-2642
402
robots, aparece en los dos tipos de arquitectura como un tercer nivel encargado de los aspectos de comunicación [5].
Siguiendo esta línea, el proyecto enfoca la integración de tecnologías de aprendizaje automático, redes neuronales, lógica difusa, algoritmos genéticos, computación evolutiva y sistemas inteligentes autónomos en el campo de la robótica cognitiva [1] [4]. Las metas del uso de dichas tecnologías varían desde el aprendizaje de modelos del entorno para realizar planificación reactiva, hasta la adquisición automática de heurísticas que controlen planificadores. Asimismo, se prevé la comparación de técnicas híbridas con técnicas evolutivas basadas en algoritmos genéticos y funciones de aptitud a efectos de comparar su efectividad en el diseño de la estructura cognitiva del robot.
III. OBJETIVO DEL PROYECTO El principal objetivo de este proyecto es diseñar y ensayar
diferentes arquitecturas de software donde coexistan módulos que permitan definir aspectos de comportamiento de robots autónomos y manipuladores, buscando maximizar aquellos parámetros que delimiten un desempeño deseado del robot en términos de sus prestaciones e interacción con el medio ambiente.
IV. METODOLOGÍA DEL DESARROLLO A efectos de estudiar la relación entre la arquitectura
neuronal del robot y su comportamiento en distintos ambientes y en el desempeño de diferentes objetivos de navegación, se procederá a utilizar el paquete de software MATLAB, versión 12.0, (con utilización del Toolbox de Neural Networks, Genetic Algorithms y Fuzzy Logic) tanto para la construcción del entorno como del agente robótico propiamente dicho, tal como se observa en la figura 3.
Fig. 3. Entorno de Navegación.
Fig. 4. Diseño del robot.
El esquema presentado en la figura 3, indica un entorno cuyos obstáculos se reducen a recuadros negros dentro de la grilla, cuyo ordenamiento corresponden a un eje cartesiano, a
fin de posicionar al robot, donde los espacios en blanco representan lugares habilitados para el desplazamiento del robot. Más abajo, en la figura 4, puede observarse un robot tipo, dotado de cuatro sensores de obstáculos, esto es SA, SB, SC, SD, dos sensores de posición, PX y PY y dos motores o actuadores, los que le permiten desplazarse, MA y MB [3].
Los resultados de las simulaciones serán implementados en sistemas microcontrolados. Se prevén dos tipos de hardware. Uno será orientado a propósitos generales dedicado al manejo de motores y control básico. Este sistema incluirá manipulación de señales analógicas preveniente de los sensores e interfase de salida de potencia. Además se incluirá un transceptor en 2.4 Ghz para el enlace con un sistema de alto nivel que permitirá realizar el data logging para las tareas de depuración y verificación de la simulación.
La segunda estructura de hardware, se construirá basada en DSC Digital Signal Controllers. Estos dispositivos combinan la potencia de cálculo de los DSP junto con las interfases analógicas y digitales necesarias en implementaciones robóticas. Los algoritmos de mayor exigencia de procesamiento en tiempo real serán implementados en este tipo de hardware. También incorporará un transceptor de 2.4 Ghz para las tareas de data logging mediante una computadora personal.
Se estudiará la mutua dependencia entre arquitectura de la red neuronal y complejidad de las trayectorias. Se tratará de encontrar pautas para el diseño de la red neuronal. Se le incorporarán al agente robótico módulos de memoria y de detección de condiciones de lazo cerrado. La evaluación de performance del agente se basará en la evitación de colisiones tanto para obstáculos fijos como móviles y en el cumplimiento de determinados objetivos básicos de comportamiento, como por ejemplo trasladar un objeto desde un punto a otro del entorno de navegación.
A continuación, se procederá a evaluar el comportamiento del robot cuando se lo programa empleando técnicas del aprendizaje automático, basadas fundamentalmente en al algoritmo ID3 de Quinlan [9], al que se lo adaptará para una versión en código MATLAB. Para evaluar el grado de efectividad del programa diseñado se lo comparará con los resultados arrojados por la herramienta de software Ctree. El aprendizaje automático permitirá extraer del árbol generado por el mismo las reglas de aprendizaje que describen el comportamiento del robot bajo este paradigma. De este modo, al ingresar un patrón de entrada, se obtendrá el valor de salida asignado al mismo conforme a este modelo. Es decir, dada una situación del robot en el ambiente, el paradigma basado en aprendizaje automático indicará la acción a seguir.
A efectos de comparar la performance de los paradigmas redes neuronales y aprendizaje automático tomados individualmente, se procederá a realizar distintos experimentos con posiciones de partida aleatorias. Se elaborará una función de aptitud que tenga en cuenta el número de colisiones y el número de situaciones de lazo cerrado con relación al número de experimentos realizados a efectos de analizar la efectividad de cada técnica cuando se la emplea por separado. Se busca conocer cuál de los dos métodos de programación permitió alcanzar la meta un mayor número de veces en el menor tiempo de simulación posible.
Con posterioridad, se procederá a hibridar la composición de la estructura cognitiva del robot conforme a un modelo jerárquico de capas, asignando conductas modeladas mediante redes neuronales (paradigma reactivo) a las capas de comportamiento más básicas y conductas de tipo más

Hossian, A., Cejas, L., Carabajal, R., Echeverría, C., Alvial, M., Olivera, V. 2014. Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un Enfoque de Tecnologías Inteligentes. Revista Latinoamericana de Ingeniería de Software, 2(6): 401-404, ISSN 2314-2642
403
abstracto (paradigma del aprendizaje automático) a las capas superiores. Se estudiará que conductas es propicio asignar a cada capa, como así también sus características de diseño e interacción con las otras capas. Se realizarán experimentos con esta técnica de programación y se procederá a evaluar la efectividad de los diferentes paradigmas utilizados en términos de parámetros indicativos de: precisión, eficiencia, robustez y complejidad.
Una vez efectuada la comparación de las ventajas y desventajas de las distintas técnicas (redes neuronales, aprendizaje automático e híbrida) se procederá a agregar más capas a la estructura cognitiva del robot conteniendo estrategias de conducta superiores orientadas al cumplimiento de objetivos y sub-objetivos de comportamiento.
V. CONTRIBUCION AL AVANCE DEL CONOCIMIENTO CIENTÍFICO Y/O TECNOLÓGICO
La robótica es un área científica y tecnológica que en su definición más amplia abarca sistemas físicos, en general articulados, que son reactivos a condiciones no estructuradas. La robótica ha evolucionado de ser un área liderada por profesores de las facultades de mecánica en los cincuentas, pasando por la electrónica-eléctrica en los ochentas, a una disciplina con méritos propios, considerada independiente de las ciencias aplicadas.
La manufactura es una actividad tecnológica que realiza la transformación de materias primas, por medio de labor física o automatizada, en productos terminados para su venta, especialmente considerando procesos de producción a gran escala. La investigación en esta área es de naturaleza compleja que requiere para su buena ejecución de diversas disciplinas asociadas tanto a la tecnología de los productos y de los sistemas de producción, como a las áreas administrativas de distribución y comercialización.
La manufactura moderna tiene diferentes áreas de desarrollo que estudian y enfrentan problemas a diferentes niveles del proceso de producción, esto es, desde el nivel más bajo consistente en la elaboración de componentes simples, pasando por sistemas ensamblados compuestos, sistemas complejos de producción y distribución, hasta las estrategias operativas de todo un sector corporativo. En todos estos niveles se innova con el establecimiento de estrategias de diseño basadas en el modelado, simulación y control, para ayudar a la toma de decisiones. Particularmente, a partir de los noventas se ha dado una mayor importancia a la investigación de fenómenos encaminados a la mejora de los medios de producción por medio de la organización racional de tareas y de los medios de suministro, esto es, calidad total, manufactura esbelta, sistemas integrados de manufactura por computadora, sistemas flexibles de manufactura, etc.
El presente proyecto de investigación se fija como objetivo la obtención de estrategias de diseño ideales para las arquitecturas hardware-software de agentes robóticos tanto móviles como industriales, en función de las conductas y rendimiento deseados para el robot. Por lo tanto, su contribución a la generación de conocimiento científico y tecnológico está directamente relacionada con el desarrollo de proyectos para la construcción de robots desde un punto de vista innovativo.
VI. CONTRIBUCION AL DESARROLLO SOCIO-ECONÓMICO Para una sociedad, la robótica es sinónimo de progreso y
desarrollo tecnológico. Los países y las empresas que cuentan con una fuerte presencia de robots no solamente consiguen
una extraordinaria competitividad y productividad, sino que también trasmiten una imagen de modernidad. En los países desarrollados, las inversiones en tecnologías robóticas han crecido de forma significativa y muy por encima de otros sectores. No obstante, el conocimiento sobre robótica de la mayoría de la sociedad sigue siendo muy limitado.
La robótica tiene como intención final complementar o sustituir las funciones de los humanos, alcanzando, en algunos casos, aplicaciones masivas. En el contexto industrial, donde los robots se utilizan con notable éxito desde hace varias décadas, los beneficios empresariales y sociales del presente proyecto se pueden resumir en cuatro aspectos: Productividad: aumento de la producción y reducción de los costos, sobre todo laborales, de materiales, energéticos y de mantenimiento. Flexibilidad: permite la fabricación de una familia de productos sin la necesidad de que se modifique la cadena de producción y por consiguiente, sin paradas ni pérdidas de tiempo. Calidad: debido al alto nivel de repetitividad de las tareas realizadas por los robots, las mismas aseguran una calidad uniforme del producto final. Seguridad: dado que los procesos de fabricación se llevan a cabo con un mínimo número de personas, se disminuye la posibilidad de accidentes laborales y se reemplaza a operarios en la ejecución de tareas tediosas o peligrosas.
VII. CONDICIONES INSTITUCIONALES PARA EL DESARROLLO DEL PROYECTO DE INVESTIGACIÓN
Este proyecto articula líneas de investigación en el área de Robótica del Laboratorio de Electrónica de la Facultad Regional del Neuquén en articulación con el Departamento de Ciencias Básicas de la misma casa de altos estudios, a cargo del Director propuesto. Las líneas de investigación del área cuentan con financiamiento de la Secretaría de Ciencia y Técnica de la misma Universidad.
VI. REFERENCIAS [1] García Martínez, R. Sistemas Autónomos. Aprendizaje
Automático. 170 páginas. Editorial Nueva Librería. ISBN 950-9088-84-6. 1997.
[2] García Martínez, R., Servente, M. y Pasquini, D. 2003. Sistemas Inteligentes. 347 páginas. Editorial Nueva Librería. ISBN 987-1104-05-7.
[3] Adrian. E. Scillato, Daniel. L. Colón y Juan. E. Balbuena. Técnicas de Navegación Híbrida para Navegación de Robots Móviles. Ed. Rama de Estudiantes del IEEE. Tesis de grado para obtener el grado de Ingeniero Electrónico. Universidad Nacional del Comahue. (2005)
[4] Sierra, E. Hossian, A. Britos, P. García Martínez, R. Fuzzy control for improving energy management in indoor building environments Proceedings del Congreso de Robótica Electrónica y Mecánica Automotriz, CERMA 2007. IEEE. Morelos (Cuernavaca), México.
[5] Sierra, E. Hossian, A. Britos, P. García Martínez, R. A multi-agent intelligent tutoring systems for learning computer programming. Proceedings del Congreso de Robótica Electrónica y Mecánica Automotriz, CERMA 2007. IEEE. Morelos (Cuernavaca), México.

Hossian, A., Cejas, L., Carabajal, R., Echeverría, C., Alvial, M., Olivera, V. 2014. Investigación en Progreso: Desarrollo de Modelos y Algoritmos del Campo de la Robótica Basado en un Enfoque de Tecnologías Inteligentes.
Revista Latinoamericana de Ingeniería de Software, 2(6): 401-404, ISSN 2314-2642
404
Alejandro Armando Hossian. Es responsable de formar recursos humanos en el área de investigación y desarrollo dirigiendo tesis de doctorado y maestría vinculadas a sus áreas de especialización. Es Profesor Titular Regular de la Facultad Regional Neuquén, Universidad Tecnológica Nacional (UTN - FRN). Es Docente Investigador, Director del grupo de investigación
de robótica cognitiva y Director de Posgrado de la misma casa de altos estudios. Es Docente Investigador Categoría III del Ministerio de Educación y Par Evaluador de la Comisión Nacional de Evaluación y Acreditación Universitaria (CONEAU), Republica Argentina. Acredita estudios universitarios de Ingeniero Civil por la Universidad Católica Argentina, es Especialista en Ingeniería de Sistemas de Expertos por el Instituto Técnico Buenos Aires (ITBA), es Máster en Ingeniería de Software por la Universidad Politécnica de Madrid (UPM), es Magister en Ingeniería de Software por el Instituto Técnico Buenos Aires (ITBA) y es Doctor en Ciencias Informáticas por la Facultad de Informática de la Universidad Nacional de La Plata (UNLP).
Lilian. Cejas. Posee titulo de grado universitario de Ingeniera Química, una Especialización en Docencia Universitaria y Maestría en Docencia Universitaria. Se ha capacitado en distintos cursos afines a su desempeño profesional enfocado principalmente al área educacional superior universitario. Se ha desempeñado desde hace más
de veinticinco años en la Universidad Tecnológica Nacional, Argentina. Es docente-investigadora en la modalidad presencial y desde unos diez años en la modalidad virtual, como docente, investigadora. Es Directora de Departamento de Ciencias Básica y Directora de Carrera de la Licenciatura en Tecnología Educativa, modalidad a distancia. Participa como docente invitada en la modalidad virtual de la Universidad Autónoma del estado de Hidalgo, México. Ha participado en numerosos congresos y reuniones científicas nacionales e internacionales, tanto con presentación de trabajos de investigación como organizadora, como así también es miembro de comisiones científicas y tecnológicas.
Roberto Carabajal. Egresado como Ingeniero Electricista orientación Automática, se ha especializado en software para la administración y control en la industria, con amplia experiencia en redes, servidores y bases de datos. Ha trabajado como proveedor de servicios en el área del mantenimiento electrónico para informática. Fue profesor en la carrera corta Técnico Superior en
Programación de la Facultad Regional del Neuquén, y actualmente se desempeña como profesor en ingeniería química y electrónica de la misma facultad. Está categorizado con Categoría “5”: Programa de Incentivos a docentes e investigadores de Universidades Nacionales y con Categoría “E”: Carrera de docente investigador de UTN. Ha participado en diversas publicaciones científicas y en el grupo de investigación Desarrollo de Métodos y modelos no convencionales para la programación de comportamientos en robots. Es codirector de la obra de diseño y puesta en marcha de la planta Planta Piloto-Unidad de Destilación de Dos Componentes de la F.R.N.
Carlos César Echeverría. Ingeniero Electrónico por la Universidad Nacional de La Plata. Docente de la Universidad Tecnológica Nacional Facultad Regional de Neuquén en las cátedras de Teoría de Circuitos 2, Electrónica Aplicada 1 y Medidas Electrónicas 1. Categorizado con Categoría “5” del
Programa de Incentivos a docentes e investigadores de Universidades Nacionales y con Categoría “E” de la Carrera de docente investigador de UTN. Profesor en Disciplinas Industriales (PDI) - Profesor en Docencia Superior (PDS). Diplomatura Superior en Enseñanza de las Ciencias. Especialización en “Tecnología de antenas para uso Satelital”. Ha participado en diversas publicaciones científicas y en el grupo de investigación Desarrollo de Métodos y modelos no convencionales para la programación de comportamientos en robots.
Ha desarrollado varios proyectos sobre la implementación de tecnología en las aulas de enseñanza de Ingeniería y ciencias duras como la Física y la Matemática.
Lorena Verónica Olivera. Trabaja en el grupo de Investigación de Robótica de la Facultad Regional del Neuquén de la Universidad Tecnológica Nacional (UTN-FRN). Docente Investigador por la Universidad Tecnológica Nacional. Ha participado en la elaboración de artículos sobre automatización y Robótica Cognitiva. Es
Ayudante de la Cátedra de "Tecnología de redes neuronales" en UTN - FRN. Es Estudiante avanzado de Ingeniería Electrónica en la misma casa de altos Estudios.
Emanuel Maximiliano Alveal. Becario de investigación que desarrolla sus actividades en el marco del Grupo de Investigación en Robótica de Manipuladores de la Universidad Tecnológica Nacional – Facultad Regional del Neuquén. Estudiante avanzado de la Carrera de Ingeniería Electrónica de la misma casa de altos estudios.