revista latinoamericana de ingenieria de...
TRANSCRIPT

REVISTA LATINOAMERICANA DE INGENIERIA DE SOFTWARE JUNIO 2014 VOLUMEN 2 NUMERO 3 ISSN 2314-2642
PUBLICADO POR EL GISI-UNLa
EN COOPERACIÓN POR LOS MIEMBROS DE LA RED DE INGENIERÍA DE SOFTWARE DE LATINOAMÉRICA
ARTÍCULOS TÉCNICOS UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio Citali Nieves-Guerrero, Juan Ucán-Pech, Víctor Menéndez-Domínguez
137-143
Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy
144-148
Composición Musical a Través del Uso de Algoritmos Genéticos Ezequiel Moldaver, Hernán Merlino, Enrique Fernández
149-156

REVISTA LATINAMERICANA
DE INGENIERIA DE SOFTWARE
La Revista Latinoamericana de Ingenieria del Software es una publicación tecnica auspiciada por la Red de Ingeniería de Software de Latinoamérica (RedISLA). Busca: [a] difundir artículos técnicos, empíricos y teóricos, que resulten críticos en la actualización y fortalecimiento de la Ingeniería de Software Latinoamericana como disciplina y profesión; [b] dar a conocer de manera amplia y rápida los desarrollos científico-tecnológicos en la disciplina de la región latinoamericana; y [c] contribuir a la promoción de la cooperación institucional entre universidades y empresas de la Industria del Software. La línea editorial, sin ser excluyente, pone énfasis en sistemas no convencionales, entre los que se prevén: sistemas móviles, sistemas, plataformas virtuales de trabajo colaborativo, sistemas de explotación de información (minería de datos), sistemas basados en conocimiento, entre otros; a través del intercambio de información científico y tecnológica, conocimientos, experiencias y soluciones que contribuyan a mejorar la cadena de valor del desarrollo en la industria del software.
Comité Editorial
RAUL AGUILAR VERA (México) Cuerpo Academico de Ingenieria de Software
Facultad de Matemáticas Universidad Autonoma de Yucatán
PAOLA BRITOS (Argentina)
Grupo de Ingeniería de Explotación de Información Laboratorio de Informática Aplicada Universidad Nacional de Río Negro
RAMON GARCÍA-MARTINEZ (Argentina)
Grupo de Investigación en Sistemas de Información Licenciatura en Sistemas
Departamento de Desarrollo Productivo y Tecnológico Universidad Nacional de Lanús
ALEJANDRO HOSSIAN (Argentina)
Grupo de Investigación de Sistemas Inteligentes en Ingeniería
Facultad Regional del Neuquén Universidad Tecnológica Nacional
BELL MANRIQUE LOSADA (Colombia) Programa de Ingeniería de Sistemas
Facultad de Ingeniería Universidad de Medellín
CLAUDIO MENESES VILLEGAS (Chile)
Departamento de Ingeniería de Sistemas y Computación Facultad de Ingeniería y Ciencias Geológicas
Universidad Católica del Norte
JONÁS MONTILVA C. (Venezuela) Facultad de Ingeniería
Escuela de Ingeniería de Sistemas Universidad de Los Andes
MARÍA FLORENCIA POLLO-CATTANEO (Argentina)
Grupo de Estudio en Metodologías de Ingeniería de Software
Facultad Regional Buenos Aires Universidad Tecnológica Nacional
JOSÉ ANTONIO POW-SANG (Perú) Maestría en Informática
Pontifica Universidad Católica del Perú
DIEGO VALLESPIR (Uruguay) Instituto de Computación
Universidad de la Republica
FABIO ALBERTO VARGAS AGUDELO (Colombia) Dirección de Investigación Tecnológico de Antioquia
CARLOS MARIO ZAPATA JARAMILLO (Colombia)
Departamento de Ciencias de la Computación y de la Decisión
Facultad de Minas Universidad Nacional de Colombia
Contacto
Dirigir correspondencia electrónica a:
Editor de la Revista Latinoamericana de Ïngenieria de Software RAMON GARCIA-MARTINEZ e-mail: [email protected]
e-mail alternativo: [email protected] Página Web de la Revista: http://www.unla.edu.ar/sistemas/redisla/ReLAIS/index.htm
Página Web Institucional: http://www.unla.edu.ar
Dirigir correspondencia postal a:
Editor de la Revista Latinoamericana de Ïngenieria de Software RAMON GARCIA-MARTINEZ Licenciatura en Sistemas. Departamento de Desarrollo Productivo y Tecnológico Universidad Nacional de Lanus Calle 29 de Septiembre No 3901. (1826) Remedios de Escalada, Lanús. Provincia de Buenos Aires. ARGENTINA.
Normas para Autores
Cesión de Derechos de Autor Los autores toman conocimiento y aceptan que al enviar una contribución a la Revista Latinoamericana de Ingenieria del Software, ceden los derechos de autor para su publicación electrónica y difusión via web por la Revista. Los demas derechos quedan en posesión de los Autores.
Políticas de revisión, evaluación y formato del envío de manuscritos La Revista Latinoamericana de Ingenieria del Software recibe artículos inéditos, producto del trabajo de investigación y reflexión de investigadores en Ingenieria de Software. Los artículos deben presentarse redactados en el castellano en el formato editorial de la Revista. El incumplimiento del formato editorial en la presentación de un artículo es motivo de retiro del mismo del proceso de evaluación. Dado que es una publicación electrónica no se imponen limites sobre la cantidad de paginas de las contribuciones enviadas. También se pueden enviar comunicaciones cortas que den cuenta de resultados parciales de investigaciones en progreso. Las contribuciones recibidas están sujetas a la evaluación de pares. Los pares que evaluaran cada contribución son seleccionados por el Comité Editorial. El autor que envíe la contribución al contacto de la Revista será considerado como el autor remitente y es con quien la revista manejará toda la correspondencia relativa al proceso de evaluación y posterior comunicación. Del proceso de evaluación, el articulo enviado puede resultar ser: [a] aceptado, en cuyo caso será publicado en el siguiente numero de la revista, [b] aceptado con recomendaciones, en cuyo caso se enviará al autor remitente la lista de recomendaciones a ser atendidas en la nueva versión del articulo y su plazo de envio; ó [c] rechazado, en cuyo caso será devuelto al autor remitente fundando el motivo del rechazo.
Temática de los artículos La Revista Latinoamericana de Ingeniería del Software busca artículos empíricos y teóricos que resulten críticos en la actualización y fortalecimiento de la Ingeniería de Software Latinoamericana como disciplina y profesión. La línea editorial pone énfasis en sistemas no convencionales, entre los que se prevén: sistemas móviles, sistemas multimediales vinculados a la televisión digital, plataformas virtuales de trabajo colaborativo, sistemas de explotación de información (minería de datos), sistemas basados en conocimiento, entre otros. Se privilegiarán artículos que contribuyan a mejorar la cadena de valor del desarrollo en la industria del software.
Política de Acceso Abierto La Revista Latinoamericana de Ingeniería de Software: Sostiene su compromiso con las políticas de Acceso Abierto a la información científica, al
considerar que tanto las publicaciones científicas como las investigaciones financiadas con fondos públicos deben circular en Internet en forma libre, gratuita y sin restricciones.
Ratifica el modelo de Acceso Abierto en el que los contenidos de las publicaciones científicas se encuentran disponibles a texto completo libre y gratuito en Internet, sin embargos temporales, y cuyos costos de producción editorial no son transferidos a los autores.
No retiene los derechos de reproducción o copia (copyright), por lo que los autores podrán disponer de las versiones finales de publicación, para difundirlas en repositorios institucionales, blogs personales o cualquier otro medio electrónico, con la sola condición de hacer mención a la fuente original de publicación, en este caso Revista Latinoamericana de Ingeniería de Software.
Lista de Comprobación de Preparación de Envíos Como parte del proceso de envío, se les requiere a los autores que indiquen que su envío cumpla con todos los siguientes elementos, y que acepten que envíos que no cumplan con estas indicaciones pueden ser devueltos al autor: 1. La contribución respeta el formato editorial de la Revista Latinoamericana de Ingenieria del
Software (ver plantilla). 2. Actualidad/Tipo de referencias: El 45% de las referencias debe hacerse a trabajos de publicados
en los últimos 5 años, así como a trabajos empíricos, para cualquier tipo de artículo (empírico o teórico).
3. Características artículos empíricos (análisis cuantitativo de datos): Se privilegian artículos empíricos con metodologías experimentales y cuasi experimentales, con pruebas estadísticas robustas y explicitación del cumplimiento de los supuestos de las pruebas estadísticas usadas.
4. Características artículos empíricos (análisis cualitativo de datos): Se privilegian artículos empíricos con estrategias de triangulación teórica-empírica, definición explícita de categorías orientadoras, modelo teórico de análisis, y análisis de datos asistido por computadora.
5. Características artículos de revisión: Para el caso de artículos de revisión, se evaluará que los mismos hayan sido desarrollados bajo el formato de meta análisis, la cantidad de referencias deben superar las 50, y deben explicitarse los criterios de búsqueda, bases consultadas y pertinencia disciplinar del artículo.
6. El artículo (en formato word y pdf) se enviará adjunto a un correo electrónico dirigido al contacto de la Revista en el que deberá constar la siguiente información: dirección postal del autor, dirección de correo electrónico para contacto editorial, número de teléfono y fax, declaración de que el artículo es original, no ha sido previamente publicado ni está siendo evaluado por otra revista o publicación. También se debe informar de la existencia de otras publicaciones similares escritas por el autor y mencionar la versión de la aplicación de los archivos remitidos (versión del editor de texto y del conversor a archivo pdf) para la publicación digital del artículo.
7. Loa Autores aceptan que el no cumplimiento de los puntos anteriores es causal de No Evaluación del articulo enviado.
Compromiso de los Autores de Artículos Aceptados La Revista Latinoamericana de Ingeniería del Software busca ser una revista técnica de calidad, en cuyo desarrollo estén involucrados los investigadores y profesionales latinoamericanos de la disciplina. En este contexto, los Autores de artículos aceptados asumen ante la Revista y la Comunidad Latinoamericana de Ingeniería del Software el compromiso de desempeñarse como pares evaluadores de nuevas contribuciones.

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio. Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
137
UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método
en Caso de Estudio
Citlali G. Nieves-Guerrero, Juan P. Ucán-Pech, Víctor H. Menéndez-Domínguez Facultad de Matemáticas
Universidad Autónoma de Yucatán Mérida, Yucatán, México
[email protected], {juan.ucan, mdoming}@uady.mx
Resumen — La Ingeniería Web propone nuevos métodos para el diseño de aplicaciones que se ejecutan en esta nueva plataforma que es la World Wide Web. Uno de estos métodos es UWE (UML Web Engineering), el cual aprovecha la notación estándar del UML e incorpora elementos que son propios del desarrollo Web. En este artículo se presenta un caso de estudio para el diseño de un Sistema de Recomendación de Objetos de Aprendizaje, donde el modelado básico se realiza mediante el UWE. Se modela una aplicación Web que permite a los usuarios realizar la composición de los Objetos de Aprendizaje que el mismo sistema le recomienda al usuario previo análisis de las características tanto del mismo como de los Objeto de Aprendizaje almacenados en un repositorio especializado llamado AGORA.
Palabras Clave — UWE, UML, Estereotipo, AGORA, Objetos de Aprendizaje.
I. INTRODUCCIÓN El área de Ingeniería Web es relativamente una nueva dirección de la Ingeniería de Software para el desarrollo de Aplicaciones Web [1]. La Ingeniería Web trata varios aspectos, metodologías, herramientas y técnicas que hacen único del desarrollo y construcción de aplicaciones que se ejecutan en la World Wide Web [2]. Este artículo se enfoca en el aspecto de diseño en Ingeniería Web.
Para el desarrollo de modelos conceptuales de aplicaciones Web existen varios métodos de diseño en Ingeniería Web, por ejemplo: OOHDM (Object-Oriented Hypermedia Design Model) [3], WebML (Web Modeling Language) [4], OO-H (Object Oriented approach) [5], UWE (UML Web Engineering) [6], entre otros. UWE fue uno de los primeros proyectos usado especialmente para aplicaciones Web [7].
El propósito de este artículo es presentar la aplicación de la metodología UWE en el diseño de un Sistema de Recomendación de Objetos de Aprendizaje. La aplicación Web sugiere a los usuarios una colección de recursos educativos que pueden resultar útiles para la creación de un Objeto de Aprendizaje compuesto. Los objetos son recuperados de un repositorio especializado denominado AGORA [8].
Este artículo está estructurado de la siguiente forma: se inicia con esta introducción que describe el propósito del documento. Luego se presenta una descripción del método UWE, indicando los elementos que lo constituyen. La tercera sección presenta un caso de estudio que sirve de guía para presentar el desarrollo del modelo para una situación práctica. Finalmente se proporcionan las conclusiones del estudio.
II. INTRODUCCIÓN A UWE Desde hace unos años, la World Wide Web se ha convertido en una plataforma para la ejecución de toda clase de aplicaciones que cumplen un sinfín de funciones. Partiendo de páginas estáticas, la Web ha evolucionado incorporando elementos de seguridad, optimización, concurrencia y demás requerimientos que son necesarios para crear soluciones sólidas.
Sin embargo, el desarrollo de una aplicación Web incluye elementos que no son comunes a una aplicación de escritorio. Esto requiere cambios importantes en la forma de realizar y controlar el proceso de desarrollo. Es decir, pasar de una Ingeniería de Software a una Ingeniería Web.
Una de las primeras metodologías desarrolladas fue la Ingeniería Web basada en UML (UWE [9]).
UWE es una metodología que permite especificar de mejor manera una aplicación Web en su proceso de creación [6] mantiene una notación estándar basada en el uso de UML (Unified Modeling Language [10]) para sus modelos y sus métodos, lo que facilita la transición. La metodología define claramente la construcción de cada uno de los elementos del modelo.
En su implementación se deben contemplar las siguientes etapas y modelos [6]:
Análisis de requisitos. Plasma los requisitos funcionales de la aplicación Web mediante un modelo de casos de uso.
Modelo de contenido. Define, mediante un diagrama de clases, los conceptos a detalle involucrados en la aplicación.
Modelo de navegación. Representa la navegación de los objetos dentro de la aplicación y un conjunto de estructuras como son índices, menús y consultas.
Modelo de presentación. Representa las interfaces de usuario por medio de vistas abstractas.
Modelo de proceso. Representa el aspecto que tienen las actividades que se conectan con cada clase de proceso.
Como se hace notar, UWE provee diferentes modelos que permite describir una aplicación Web desde varios puntos de vista abstractos [11], dichos modelos están relacionados tal como se ilustra en la figura 1.
Cada uno de estos modelos se representa como paquetes UML [10], dichos paquetes son procesos relacionados que pueden ser refinados en iteraciones sucesivas durante el desarrollo del UWE [12].

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio.
Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
138
El análisis de requisitos en UWE se modela con casos de uso. Está conformado por los elementos actor y caso de uso. En este sentido, los actores se utilizan para modelar los usuarios de la aplicación Web.
Figura 1. Modelos de UWE.
El modelo de contenido es el modelo conceptual del
dominio de aplicación tomando en cuenta los requerimientos especificados en los casos de uso [12] y se representa con un diagrama de clases. Basado en el análisis de requisitos y el modelo de contenido se obtiene el modelo de navegación. Éste se representa con clases de navegación que serán explicados en el caso de estudio de este artículo. Basado en el modelo de navegación y en los aspectos de la interfaz usuario (requisitos), se obtiene el modelo de presentación. Dicho modelo describe la estructura de la interacción del usuario con la aplicación Web. El modelo de navegación puede ser extendido mediante clases de procesos. El modelo del proceso representa el aspecto que tienen las acciones de las clases de proceso.
III. APLICACIÓN DEL MÉTODO EN CASO DE ESTUDIO En el ámbito del e-Learning, los Objetos de Aprendizaje [13] están teniendo una importante repercusión como componentes que pueden organizarse y distribuirse para satisfacer un objetivo educativo. Este tipo de recursos facilitan la construcción de experiencias de aprendizaje significativas que pueden almacenarse en repositorios para su posterior incorporación en algún sistema de gestión.
Los Objetos de Aprendizaje proponen un modelo para la composición de estructuras y contenidos con el propósito de fomentar la interoperabilidad y la reutilización entre distintas aplicaciones y contextos de aprendizaje [14-15].
Un Objeto de Aprendizaje está constituido por dos elementos: una colección de recursos y un conjunto de descriptores, denominados metadatos [13]. El recurso puede ser cualquier colección de archivos multimedia, una aplicación o una dirección de Internet. Incluso pueden incluir otros objetos para constituir Objetos de Aprendizaje más complejos, esto es lo que se denomina Composición de Objetos de Aprendizaje. Todos estos elementos son almacenados en una estructura de información que es conforme a un estándar de descripción y distribución, lo que garantiza su reutilización [16].
La gestión de los Objetos de Aprendizaje involucra factores como el objetivo educativo, el estilo de aprendizaje, el grado de interacción, el diseño de la interfaz de usuario, las estructuras de almacenamiento, los descriptores, etc. Además, incluye varios procesos como la catalogación, la búsqueda y recuperación, la generación y composición de objetos, etc. [17]. Generalmente, el profesor realiza estos procesos de forma
empírica y utilizando herramientas independientes, desarrolladas para tareas concretas de otra índole, lo que limita y complica su utilización.
El uso de procesos automáticos para la gestión de los Objetos de Aprendizaje es una temática recurrente en numerosos proyectos de e-Learning [18]; principalmente en lo que respecta a la reutilización de los objetos [29][20].
El proyecto AGORA [8] es un marco arquitectónico que modela los procesos involucrados en la gestión de Objetos de Aprendizaje (véase figura 2). El marco sirve como base para el desarrollo de un entorno integrado que controla y asiste a los usuarios durante el ciclo de vida de los objetos.
Figura 2. Arquitectura de AGORA.
Uno de los objetivos más relevantes del marco es emplear
un enfoque de asistencia y recomendación para la ejecución de los procesos como el etiquetado de Objetos de Aprendizaje.
Para ello, se considera el uso de diversas tecnologías y aspectos informáticos relacionados con la Ingeniería de Software, el Soft-Computing, la Ingeniería del Conocimiento, la Web semántica, la Minería de datos y otras herramientas, con el fin de establecer modelos, técnicas e instrumentos que faciliten el desarrollo, la explotación y evaluación de todos tipo de recursos orientados a la instrucción y el aprendizaje.
Para los propósitos de este estudio se ha utilizado un proyecto de investigación que se orienta a desarrollar una aplicación Web que facilite el proceso de composición de Objetos de Aprendizaje a partir de los recursos que se encuentran almacenados en el repositorio de AGORA. En realidad, la aplicación Web es un Sistema de Recomendación [21] que propone una lista de recursos conforme a las características y necesidades educativas de un usuario, según un perfil predefinido.
Los recursos están almacenados y disponibles para su recuperación desde el repositorio de AGORA. Se caracterizan por sus metadatos, que son una serie de campos que los describen y hacen más fácil su localización, dependiendo del grado de su completitud.
Los usuarios relacionados con la aplicación se pueden clasificar en anónimo, tutor, consultor y alumno. Dependiendo del tipo de usuario que inicie sesión en la aplicación, será el formulario de su perfil y por ende el tipo de acciones que podrá realizar.
El usuario interesado en realizar la creación de un objeto de aprendizaje compuesto deberá iniciar sesión en la aplicación y si es la primera vez, deberá registrarse previamente, llenando un formulario que corresponde a su perfil. Esta información permitirá que la aplicación personalice las recomendaciones a dicho usuario.
Una vez que se inicie sesión, el usuario podrá realizar consultas sobre la temática de su interés y la aplicación proporcionará recomendaciones de acuerdo a su consulta y el

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio. Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
139
perfil registrado según la actividad de usuarios con perfiles similares o recursos similares a los que haya consultado.
Una vez presentada una lista de recursos educativos relevantes provenientes del repositorio, el usuario podrá optar por realizar la composición de los Objetos de Aprendizaje seleccionados.
Esto da inicio al proceso de composición que consiste en la localización física de los objetos en el repositorio y a la identificación de sus metadatos para poder integrarlos en un solo Objeto de Aprendizaje de mayor nivel. Posteriormente, el usuario puede optar por guardar el nuevo objeto compuesto en su computadora o en el mismo repositorio.
A. Especificando los requisitos Una de las primeras actividades en la construcción de aplicaciones Web es la identificación de los requisitos, y en UWE se especifican mediante el modelo de requerimientos, que involucra el modelado de casos de uso con UML.
El diagrama de casos de uso está conformado por los elementos actor y caso de uso. Los actores se utilizan para modelar los usuarios de la aplicación Web que para este caso de estudio son los diferentes tipos de usuarios (anónimo, consultor, tutor, alumno) que pueden interactuar con el mismo. Los casos de uso se utilizan para visualizar las diferentes funcionalidades que la aplicación tiene que proporcionar, como son: crear a un nuevo usuario, identificar al usuario, realizar una búsqueda, realizar la composición de un nuevo objeto y guardar el objeto compuesto
En la figura 3 se ilustra el diagrama de casos de usos para la aplicación web. Es de mencionar que para cada etapa del modelado, UWE provee diferentes estereotipos [22]. La lista de todos los estereotipos que pueden utilizarse en esta etapa se encuentra el Perfil UWE (Profile UWE) del sitio oficial de UWE [23].
Figura 3. Casos de uso.
El caso de uso "RealizarBusqueda" es del estereotipo explorar ( «browsing»). Modela la búsqueda de los objetos de aprendizaje por medio de las características de los objetos y de los usuarios para que el sistema pueda proporcionar una recomendación personalizada.
El caso de uso "RealizarComposicion" es del estereotipo procesar ( «processing»). Según la lista final seleccionada por el usuario, ejecuta el proceso de composición para conformar un nuevo objeto de mayor nivel de instrucción añadiendo cambios a los metadatos si el usuario así lo decide.
El caso de uso "IdentificarUsuario" es del estereotipo explorar ( «browsing»). Ejecuta el proceso de inicio de sesión el cual verifica si el usuario proporcionado existe en el sistema.
El caso de uso "Guardar" es del estereotipo procesar ( «processing»). Ejecuta la conversión del objeto compuesto al estándar IEEE-LOM [24] y almacena el objeto compuesto en la computadora o en el repositorio para su posterior uso.
El caso de uso "CrearUsuario" es el estereotipo procesar ( «processing»). Registra los datos de un nuevo usuario que se agrega al sistema, lo que facilita información de su perfil y mejora la personalización de los resultados.
El nivel de detalle y la formalidad de la especificación de requerimientos dependen de los riesgos del proyecto y de la complejidad de la aplicación Web a construir. A menudo una especificación basada solamente en casos de uso no es suficiente [25].
Siguiendo el principio de usar UML para la especificación hasta donde sea posible, es factible emplear diagramas de actividades en esta fase. Para cada caso de uso descrito para actividades no triviales se puede construir al menos un diagrama de actividad por cada flujo principal de tareas realizadas en orden. Esto con el fin de describir la funcionalidad indicada por el caso de uso correspondiente.
B. Definiendo el contenido El objetivo del modelo de contenido es proporcionar una especificación visual de la información en el dominio relevante para la aplicación Web.
Este es un diagrama UML normal de clases, por ello se debe pensar en las clases que son necesarias para el caso de estudio presentado.
En la figura 4 se presenta el diagrama de clases para el modelo de contenido. En particular, la información de los usuarios es modelada por la clase "PerfilUsuario" donde se almacenan las propiedades que describen a los diferentes tipos de usuarios.
Figura 4. Modelo de Contenido.
En la clase "Inicio" se modela el inicio de la aplicación
web, se almacenan las credenciales y propiedades que sirven para identificar al usuario que quiere iniciar sesión. La clase "Búsqueda" modela la información que el usuario proporciona para realizar una consulta y los métodos que se ejecutan para generar la lista de recomendación, la selección de los objetos y la recuperación de los mismos con sus metadatos. La clase "metadatos" modela las características devueltas por los objetos de aprendizaje que el usuario ha seleccionado y el método de realizar la composición con la selección y los metadatos proporcionados. La clase "guardar" modela las características de almacenamiento del nuevo objeto compuesto.

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio.
Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
140
C. Estructura de Navegación En una aplicación para la Web es útil saber cómo están enlazadas las páginas. Ello significa que se requiere un diagrama de navegación con nodos y enlaces. Este diagrama se modela con base en el análisis de los requisitos y el modelo de contenido.
UWE provee diferentes estereotipos para el modelado de navegación, en la figura 5 se presentan los usados en este caso de estudio y seguidamente se da una descripción de cada uno de ellos.
Figura 5. Estereotipos de estructura de navegación.
Las clases de navegación ( «navigationClass»)
representan nodos navegables de la estructura de hipertexto; los enlaces de navegación ( «navigationLink») muestran vínculos directos entre las clases de navegación; las rutas alternativas de navegación son manejadas por menú ( «menu»). Los accesos se utilizan para llegar a múltiples instancias de una clase de navegación ( «index» o « guidedTour») o para seleccionar los elementos ( «query»). Las clases de procesos ( «processClass») forman los puntos de entrada y salida de los procesos de negocio en este modelado y la vinculación entre sí y a las clases de navegación se modela por enlaces de procesos ( «processLink»).
En la figura 5, las clases de navegación "Inicio y PerfilUsuario" representan nodos navegables de la estructura de hipertexto y se consideran relevantes para la navegación. Los enlaces de navegación "navigationLink" y "processLink" muestran vínculos directos entre las clases de navegación y representan posibles pasos a seguir por el usuario y, por lo tanto, estos vínculos tienen que ser dirigidos.
Figura 5. Clases de navegación
La navegación por diferentes alternativas es representada por las clases «menu» ("SeleccionUsuario, MenuBusqueda y MenuObjetosAprendizaje") que se añaden a cada clase de navegación que tiene más de una asociación saliente.
Las primitivas de acceso «index» como es "ListaObjetosAprendizaje" se utilizan para llegar a múltiples instancias de una clase de navegación o para seleccionar los elementos con los tipos «query» como "IniciarPerfil y BuscarObjetosAprendizaje", este tipo de clase se debe agregar entre dos clases de navegación cada vez que la multiplicidad de la meta final de su asociación de enlace sea mayor que 1. Las entradas y salidas de las clases "RegistrarPerfil, VisualizarMetadatos y GuardarSeleccion" son modeladas por las clases «process».
Es así que desde la página de Inicio un usuario puede, por medio de "SeleccionUsuario", tener una representación personalizada según sea su tipo de usuario con el que accede al sistema. Puede optar por usar "IniciarPerfil" para consultar si existe su clave de usuario proporcionada, o por "registrarPerfil" que inicia el proceso de registro del nuevo usuario. El usuario que ingresa a la aplicación proporciona palabras clave para “BuscarObjetosAprendizaje” que arroja una “ListaObjetosAprendizaje” para la selección por parte del usuario. De los objetos que son seleccionados en un “MenuObjetosAprendizaje”, el usuario puede “VisualizarMetadatos” de los objetos que son candidatos a conformar un nuevo Objeto de Aprendizaje de nivel superior de complejidad para “GuardarSeleccion”.
D. Modelo de presentación El modelo de presentación ofrece una visión abstracta de la interfaz de usuario de una aplicación Web. Se basa en el modelo de navegación y en los aspectos concretos de la interfaz de usuario (IU). Describe la estructura básica de la IU, es decir, ¿qué elementos de interfaz de usuario (por ejemplo , texto, imágenes, enlaces, formularios) se utilizan para presentar los nodos de navegación?. Su ventaja es que es independiente de las técnicas actuales que se utilizan para implementar un sitio Web, lo que permite a las partes interesadas discutir la conveniencia de la presentación antes de que realmente se aplique.
Una clase de presentación está compuesta de elementos de IU como texto ( «text»), enlaces ( «anchor»), botones ( «button»), imágenes ( «image»), formularios ( «form») y colecciones de enlaces ( «anchored collection»). La figura 4 muestra un ejemplo de la clase de presentación para la clase de navegación Inicio.
En la figura 6 se modela la página de presentación "PaginaInicio". Existe una representación de texto para el encabezado y un mensaje de presentación. Modela también un formulario de entrada para que el usuario introduzca clave y contraseña, así como los botones de "iniciarperfil" y "registrarPErfil".
Usualmente la información de varios nodos de aplicación es presentada en una página Web, la cual es modelada por páginas en UWE, por ejemplo, en la figura 6 se tiene una ( «presentationPage»). Las páginas de presentación también pueden contener grupos de presentación ( «presentationGroup»), grupos de presentación iterativos ( «iteratedPresentationGroup»), y presentaciones alternativas ( «presentationAlternative»), por ejemplo ajustar la interfaz al dispositivo utilizado para ejecutar la aplicación. Un grupo de presentación puede contener a si mismo grupos de presentación y clases de presentación.

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio. Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
141
Figura 6. Página de presentación: Inicio
En la figura 7 se modela la página de presentación "paginaBusqueda" donde se representa como texto un encabezado y el nombre del usuario. Existe un formulario donde se puede introducir las palabras clave de búsqueda así como seleccionar los algoritmos que se pueden aplicar. Esta página de presentación contiene un grupo de presentación para modelar las listas de objetos candidatos a la composición y los botones de buscar y ver metadatos.
Figura 7. Página de presentación: Búsqueda.
E. Modelo de proceso La estructura de navegación puede ser extendida mediante clases de procesos que representan la entrada y la salida de procesos de negocio. El modelo del proceso representa el aspecto que tienen las acciones de las clases de proceso. En este modelo se tienen dos tipos de modelos:
Modelo de estructura del proceso, que describe las relaciones entre las diferentes clases de proceso, y
Modelo de flujo del proceso, que específica las actividades conectadas con cada « processClass».
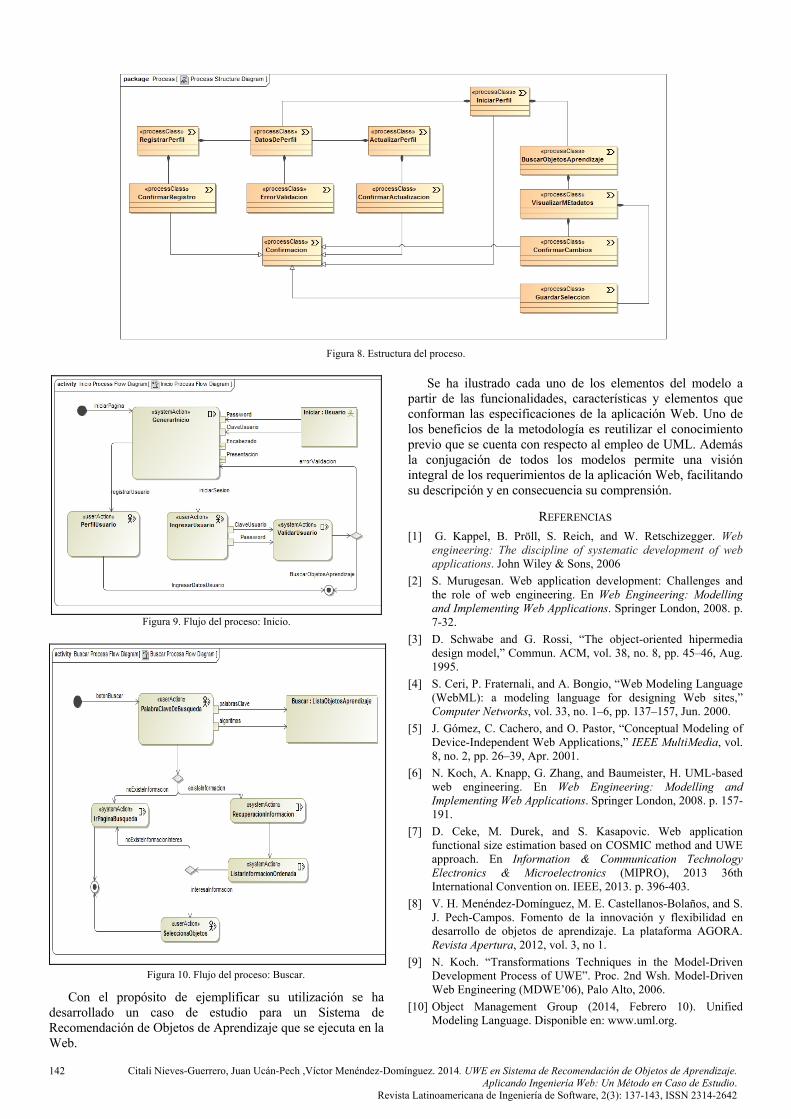
A continuación se describen cada uno de ellos: Modelo de estructura del proceso. Es representado por un diagrama de clases donde se describen las relaciones entre las diferentes clases de proceso. La figura 8 presenta la aplicación del modelo para el caso de estudio analizado.
Modelo del flujo del proceso. Siguiendo el principio de la utilización de UML se han refinado los requisitos con los diagramas de actividad UML. Los diagramas de actividades incluyen actividades, actores responsables de estas actividades (opcional) y elementos de flujo de control. Ellos pueden ser enriquecidos con flujos de objetos que muestran objetos relevantes para la entrada o salida de esas actividades.
Estos diagramas representan el flujo del proceso, describiendo el comportamiento de una clase de proceso. En la figura 9 se ilustra el diagrama de actividad para el proceso "Inicio". El diagrama muestra que al generar la página de inicio el usuario puede optar por dos opciones:
proporcionar su clave de usuario y contraseña si es un usuario registrado,
activar el botón para registrarse como nuevo usuario. En el caso de la primera opción, el sistema debe validar al
usuario proporcionando el acceso a la búsqueda de objetos a aquellos usuarios que sean confirmados como válidos o mostrando un mensaje de error para el caso contrario. En la segunda opción, se debe activar el proceso de registro para capturar el perfil del nuevo usuario.
En la figura 10 se ilustra el diagrama de actividad para el proceso "Buscar". El diagrama muestra que se activa con el botón buscar y el usuario proporciona las palabras clave para iniciar la búsqueda. La aplicación regresa una lista de objetos de aprendizaje candidatos a ser seleccionados por el usuario. Si existe la información se recupera la misma desde el repositorio, en caso contrario se regresa a la página de búsqueda. Si la información listada es de interés para el usuario, este selecciona la misma, en caso contrario cambia sus parámetros de búsqueda.
Adicionalmente a estos modelos es requerido conformar la documentación requerida para la descripción de los modelos, así como los diccionarios de datos necesarios para clarificar el conocimiento representado.
IV. CONCLUSIONES El desarrollo de aplicaciones requiere de metodologías
acordes a las características de la plataforma donde estas sean ejecutadas. La Ingeniería Web propone nuevas metodologías orientadas al desarrollo y modelación de los procesos asociados a aplicaciones que se ejecuten en la World Wide Web.
En este trabajo se ha presentado UWE, una metodología basada en UML que tiene como finalidad especificar de una manera clara y conocida, una aplicación Web.
Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje. Aplicando Ingeniería Web: Un Método en Caso de Estudio.
Revista Latinoamericana de Ingeniería de Software, 2(3): 137-143, ISSN 2314-2642
142
Figura 8. Estructura del proceso.
Figura 9. Flujo del proceso: Inicio.
Figura 10. Flujo del proceso: Buscar.
Con el propósito de ejemplificar su utilización se ha desarrollado un caso de estudio para un Sistema de Recomendación de Objetos de Aprendizaje que se ejecuta en la Web.
Se ha ilustrado cada uno de los elementos del modelo a partir de las funcionalidades, características y elementos que conforman las especificaciones de la aplicación Web. Uno de los beneficios de la metodología es reutilizar el conocimiento previo que se cuenta con respecto al empleo de UML. Además la conjugación de todos los modelos permite una visión integral de los requerimientos de la aplicación Web, facilitando su descripción y en consecuencia su comprensión.
REFERENCIAS [1] G. Kappel, B. Pröll, S. Reich, and W. Retschizegger. Web
engineering: The discipline of systematic development of web applications. John Wiley & Sons, 2006
[2] S. Murugesan. Web application development: Challenges and the role of web engineering. En Web Engineering: Modelling and Implementing Web Applications. Springer London, 2008. p. 7-32.
[3] D. Schwabe and G. Rossi, “The object-oriented hipermedia design model,” Commun. ACM, vol. 38, no. 8, pp. 45–46, Aug. 1995.
[4] S. Ceri, P. Fraternali, and A. Bongio, “Web Modeling Language (WebML): a modeling language for designing Web sites,” Computer Networks, vol. 33, no. 1–6, pp. 137–157, Jun. 2000.
[5] J. Gómez, C. Cachero, and O. Pastor, “Conceptual Modeling of Device-Independent Web Applications,” IEEE MultiMedia, vol. 8, no. 2, pp. 26–39, Apr. 2001.
[6] N. Koch, A. Knapp, G. Zhang, and Baumeister, H. UML-based web engineering. En Web Engineering: Modelling and Implementing Web Applications. Springer London, 2008. p. 157-191.
[7] D. Ceke, M. Durek, and S. Kasapovic. Web application functional size estimation based on COSMIC method and UWE approach. En Information & Communication Technology Electronics & Microelectronics (MIPRO), 2013 36th International Convention on. IEEE, 2013. p. 396-403.
[8] V. H. Menéndez-Domínguez, M. E. Castellanos-Bolaños, and S. J. Pech-Campos. Fomento de la innovación y flexibilidad en desarrollo de objetos de aprendizaje. La plataforma AGORA. Revista Apertura, 2012, vol. 3, no 1.
[9] N. Koch. “Transformations Techniques in the Model-Driven Development Process of UWE”. Proc. 2nd Wsh. Model-Driven Web Engineering (MDWE’06), Palo Alto, 2006.
[10] Object Management Group (2014, Febrero 10). Unified Modeling Language. Disponible en: www.uml.org.

Citali Nieves-Guerrero, Juan Ucán-Pech ,Víctor Menéndez-Domínguez. 2014. UWE en Sistema de Recomendación de Objetos de Aprendizaje Aplicando Ingeniería Web: Un Método en Caso de Estudio. Revista Latinoamericana de Ingeniería de Software, 2( 3): 137-143, ISSN 2314-2642
143
[11] M. Busch and M. A. G. de Dios. ActionUWE: Transformation of UWE to ActionGUI Models. Transformation, 2012, vol. 3, p. 2.
[12] N. Koch, A. Kraus, and R. Hennicker. The authoring process of the uml-based web engineering approach. En First International Workshop on Web-Oriented Software Technology. 2001.
[13] D. Wiley. Connecting learning objects to instructional design theory: A definition, a metaphor, and a taxonomy. In D. A. Wiley (Ed.), The instructional use of learning objects. 2003.
[14] R. McGreal. Learning objects: A practical definition. International Journal of Instructional Technology and Distance Learning (IJITDL), 2004, vol. 9, no 1.
[15] M.-a. Sicilia, E.Garcia-Barriocanal, , S. Sanchez-Alonso, and J. Soto. A semantic lifecycle approach to learning object repositories. En Telecommunications, 2005. advanced industrial conference on telecommunications/service assurance with partial and intermittent resources conference/e-learning on telecommunications workshop. aict/sapir/elete 2005. proceedings. IEEE, 2005. p. 466-471.
[16] Ip. Albert, I. Morrison, and M. Currie. What is a learning object, technically. World Conference on the WWW and Internet Proceedings, Orlando, EE.UU., 23-27 Octubre. En WebNet. 2001. p. 580-586.
[17] O. Catteau, P. Vidal, and J. Broisin. A generic representation allowing for expression of learning object and metadata lifecycle. En Advanced Learning Technologies, 2006. Sixth International Conference on. IEEE, Kerkrade, Holanda, 5-7 Julio 2006: IEEE Computer Society. pp. 30-32.
[18] O. Motelet, N. Baloian, and J. A. Pino. Learning object metadata and automatic processes: Issues and perspectives. In K. Harman, y A. Koohang (Eds.), Learning objects: Standards, metadata, repositories, and lcms (pp. 185-220). Santa Rosa: Informing Science Press. 2006.
[19] R. G. Farrell, S. D. Liburd, and J. C. Thomas Dynamic assembly of learning objects. In Proceedings of the 13th international World Wide Web conference on Alternate track papers & posters, New York, EE.UU., 2004 (pp. 162-169): ACM. doi:http://doi.acm.org/10.1145/1013367.1013394.
[20] R.Fraser, and P.Mohan. (2014, Mayo 11). Using web services for dynamically re-purposing reusable online learning resources. Paper presented at the Proceedings of the IEEE International Conference on Advanced Learning Technologies.
[21] F. Ricci, L. Rokach, and B. Shapira, Recommender Systems Handbook. Boston, MA: Springer US, 2011, pp. 1–35
[22] M. Busch, M. Ochoa, and R. Schwienbacher. Modeling, Enforcing and Testing Secure Navigation Paths for Web Applications. 2013.
[23] LMU. Web Engineering Group (2014, Enero 5). UWE Website. Disponible en: http://uwe.pst.ifi.lmu.de/.
[24] IEEE-LTSC (2002). 1484.12.1-2002 ieee standard for learning object metadata. Disponible en: http://ltsc.ieee.org/wg12/.
[25] P. Vilain, D. Schwabe, and, C. de Souza. A diagrammatic tool for representing user interaction in UML. In A. Evans, S. Kent, and B. Selic, eds., Proceedings Third International Conference on Unified Modeling Language (UML’00), pp. 133–147.
Citlali Guadalupe Nieves Guerrero es Licenciada en Ciencias de la Computación por la Universidad Autónoma de Yucatán y cuenta con una Especialización en Competencias Docentes por la Universidad Pedagógica Nacional (ambas de México). Actualmente se encuentra cursando la Maestría en Ciencias de la Computación de la Universidad Autónoma de Yucatán, México. Es
docente en el Colegio de Educación Profesional Técnica del Estado de Yucatán, Plantel Tizimín, México. Su trabajo de investigación se centra en temas relacionados con Objetos de Aprendizaje,
Composición y Sistemas de Recomendación para la Educación a distancia.
Juan Pablo Ucán Pech es Maestro en Sistemas Computacionales con especialidad en Ingeniería de Software por el Instituto Tecnológico de Mérida, México. Licenciado en Ciencias de la Computación por la Facultad de Matemáticas de la Universidad Autónoma de Yucatán, México. Actualmente se encuentra cursando el Doctorado en Sistemas Computacionales de la Universidad del Sur,
México. Es Profesor Titular en la Facultad de Matemáticas de la Universidad Autónoma de Yucatán, México. Su trabajo de investigación se centra en temas relacionados con la Ingeniería de Software, Ingeniería Web e Informática Educativa.
Víctor Hugo Menéndez Domínguez es Doctor en Tecnologías Informáticas Avanzadas por la Universidad de Castilla-La Mancha, España, tiene un Máster en Tecnologías Informáticas por la misma institución. Además, cuenta con una Especialización en Docencia y una Licenciatura en Ciencias de la Computación por parte de Universidad Autónoma de Yucatán, México. Es
Profesor Titular en la Facultad de Matemáticas de la Universidad Autónoma de Yucatán, México. Su trabajo de investigación se centra en temas relacionados con la Educación a distancia, la representación del conocimiento el aprendizaje, así como la gestión de Objetos de Aprendizaje.

Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy. 2014. Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública.
Revista Latinoamericana de Ingeniería de Software, 2(3): 144-148, ISSN 2314-2642
144
Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes
de la Administración Pública
Marcia V. Sappa Figueroa, Pedro L. Alfonzo, Sonia I. Mariño, Maria V. Godoy Departamento de Informática. Facultad de Ciencias Exactas y Naturales y Agrimensura. 9 de Julio Nº 1449. 3400. Corrientes.
Argentina. Universidad Nacional del Nordeste. 1, [email protected], [email protected], [email protected]
Resumen—En este trabajo se aborda una de las medidas de calidad de la Ingeniería del Software: la Accesibilidad Web y su validación en el dominio de dos instituciones del sector de finanzas públicas de alcance nacional. Esta medida se convirtió en varios países del mundo en una preocupación porque atañe directamente a la posibilidad de acceso de los ciudadanos a la información, comunicación y servicios (públicos y privados) ofrecidos a través de la web. Por lo expuesto, es necesario que los sitios de la administración pública, en este caso particular, los bancarios carezcan de problemas de acceso a los contenidos, lo que se logra siguiendo los estándares propuestos por el Consorcio W3C. Se describe la metodología orientada a la evaluación del cumplimiento de las pautas WCAG 2.0, propuestas por el mencionado Consorcio. La indagación demuestra la necesidad de fomentar la aplicación de las mencionadas pautas en el proceso de desarrollo de sitios bancarios.
Palabras Clave— Accesibilidad Web, Ingeniería del Software, medición en sitios web bancarios.
I. INTRODUCCIÓN La Ingeniería del Software (IS) es una disciplina de la
Informática cuya meta es el desarrollo costeable de sistemas informáticos [1]. Comprende los aspectos de la producción de software desde las etapas iniciales de la especificación del sistema hasta su mantenimiento, incluyendo su implementación [1-2].
A la hora de realizar un desarrollo de software se deben contemplar numerosos factores, especialmente los relacionados con la calidad, tanto los funcionales como los no funcionales. Por lo tanto, se puede definir la calidad del software como “la concordancia con los requerimientos funcionales y de rendimiento explícitamente establecidos, con los estándares de desarrollo explícitamente documentados y con las características implícitas que se espera de todo software desarrollado profesionalmente” [1].
La calidad de un producto software es un concepto de vasto recorrido y amplío alcance. Son numerosos los factores [1] y criterios de calidad [3] que pueden tenerse en cuenta, y que de hecho se tienen presente en forma de requerimientos, desde las primeras fases del proceso de desarrollo, con el fin de contribuir a lograr la máxima calidad del mismo. No obstante, se carece de consenso a la hora de definir estos factores y criterios. Además, un producto software puede cumplir los requerimientos funcionales marcados por sus destinatarios, pero si este sistema es difícil de utilizar, puede convertirse en un auténtico fracaso. De las medidas de calidad del software, un atributo que en los últimos tiempos ha cobrado relevancia es la Accesibilidad Web, siendo considerado como un requerimiento no funcional [4].
A nivel mundial, la Accesibilidad Web se ha convertido en una preocupación porque atañe directamente a la posibilidad de acceso de los ciudadanos a la información, comunicación y servicios (públicos y privados) ofrecidos a través de la web. Entre las principales acciones se menciona la abordada por el W3C, la Organización Internacional para la Estandarización (ISO) [5], la Fundación Sidar [6], el Centro de Investigación y Desarrollo de Adaptaciones Tiflotécnicas (CIDAT) [7], promovido por ONCE, entre otros, para determinar cómo lograr que las tecnologías y las Tecnologías de la Información y Comunicación (TIC) estén al servicio de los seres humanos para mejorar su calidad de vida [8-10].
Como antecedente se menciona el Consorcio W3C (Consorcio World Wide web), reflejada en su Iniciativa para la Accesibilidad a la web (WAI o web Accessibility Initiative) [11], siendo su objetivo definir las pautas que faciliten el acceso de las personas con discapacidad, a los contenidos WEB. W3C es un organismo que establece estándares web y pautas, siendo su lema: “Guiar la web hacia su máximo potencial a través del desarrollo de protocolos y pautas que aseguren el crecimiento futuro de la web” [12].
El W3C ha desarrollado recomendaciones, denominadas Directrices de Accesibilidad al Contenido web o web Content Accessibility Guidelines (WCAG), versión 1.0 (WCAG 1.0) [13] y versión 2.0 (WCAG 2.0) [14], son consideradas como normas de facto y citadas como referencia obligada en la mayoría de las legislaciones sobre Tecnologías de la Información y Comunicación (TIC) de todo el mundo. Estas directrices explican cómo hacer accesibles los contenidos de la web a personas con discapacidad. Están pensadas para todos los desarrolladores de contenidos de la web (creadores de páginas y diseñadores de sitios) y para sus metodólogos [4].
En el año 2012, se aprobó como un estándar internacional ISO, las denominadas Pautas de Accesibilidad al Contenido web (WCAG) 2.0. La aplicación de estas, logran un contenido accesible a una gama más amplia de personas con discapacidad, incluyendo ceguera y baja visión, sordera y pérdida de la audición, problemas de aprendizaje, limitaciones cognitivas, limitaciones de movimiento, entre otros (ISO / IEC 40500:2012) [15].
La Industria del Software y el Sector de Servicios Informáticos han cobrado gran connotación en los últimos tiempos, dado el crecimiento de las TIC en diversos aspectos del mercado y la sociedad. Los sitios generados para apoyar a las empresas que ofrecen servicios a través de la web, en particular el sistema financiero, adquieren importancia al incrementarse la cantidad de personas que operan con los bancos en línea en los últimos años, lo que muestra un

Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy. 2014. Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública. Revista Latinoamericana de Ingeniería de Software, 2(3): 144-148, ISSN 2314-2642
145
crecimiento constante de este sector. Además, permiten al sector financiero beneficiarse al suministrar información sobre los servicios ofrecidos y facilitando que las personas, con alguna discapacidad o no puedan disponer de éstos sin restricciones de espacio-temporales. En este contexto, es imprescindible que los sitios bancarios no evidencien problemas de acceso a los contenidos, lo que se logra siguiendo las pautas y estándares propuestos por la W3C.
En este sentido, numerosas acciones se han centrado en promover la sanción y aplicación de legislación referente a la Accesibilidad Web. En Argentina está logrando una mayor difusión tras su promulgación en el mes de noviembre del año 2010, según la Ley 26.653.
Este trabajo forma parte de una investigación centrada en el estudio de la accesibilidad. Como antecedentes previos en la temática se mencionan [16-21].
En particular, se abordó la evaluación de dos sitios bancarios que operan en la República Argentina, con el objetivo de determinar el nivel de accesibilidad de los mismos y con miras a promover la responsabilidad social en las empresas. Por otra parte, los resultados expuestos en el presente trabajo permitan ampliar la categoría “métodos y aplicaciones prácticas” propuesta en [22].
II. METODOLOGÍA Se abordó un estudio experimental basado en las pautas
WCAG 2.0 [14], aplicadas a la evaluación de las instituciones seleccionadas. Se siguió una metodología compuesta por las siguientes etapas:
Etapa 1. Investigación bibliográfica documental. Revisión de proyectos que tratan el estudio y análisis de la Accesibilidad Web.
Profundización del marco teórico del tema. Etapa 2. Selección de herramientas para la evaluación
automática y manual. Se seleccionaron y aplicaron como validadores TAW [23] y EXAMINATOR [24], dado que automatizan la valoración de las pautas WCAG 2.0.
Se utilizó Web Developer, complemento del navegador Mozilla Firefox, para la evaluación manual, aplicándose en los puntos recomendados por los validadores automáticos.
Etapa 3. Selección de dos sitios bancarios públicos. Por razones de privacidad no se especifican sus nombres y direcciones electrónicas.
Etapa 4. Evaluación y análisis de los resultados. Etapa 5. Elaboración de conclusiones.
III. RESULTADOS En esta sección se describen los resultados derivados de la
evaluación de la accesibilidad con los validadores automáticos TAW y EXAMINATOR, atendiendo a los principios de la WCAG 2.0. Se evaluó la página principal de cada seleccionado de acuerdo a las WCAG 2.0 [14], la cual se organiza en torno a cuatro principios teóricos que buscan garantizar el acceso a los contenidos. Estos se agrupan en pautas, que contienen los criterios a verificar.
Principio perceptible: son aquellas condiciones que buscan que la información y los componentes de la interfaz del usuario sean presentados, de modo que pueda percibirlo de la manera más inteligible u óptima:
Alternativas textuales, alternativas para convertir texto a otros formatos dependiendo la capacidad de la persona que los necesite.
Medios tempodependiente, para proporcionar acceso a los multimedios y sincronizados, como son sólo audio, sólo vídeo, audio y vídeo, audio y/o video combinado con interacción.
Adaptable, contenido que pueda presentarse de diferentes formas sin perder información o estructura.
Distinguible, se busca facilitar a los usuarios ver y oír el contenido, incluyendo la separación entre el primer plano y el fondo.
Principio operable: garantiza que los componentes de usuario y la interfaz de navegación deben ser fáciles:
Accesible por teclado, proporcionar acceso a toda la funcionalidad mediante el teclado.
Tiempo suficiente, proporcionar el tiempo suficiente para leer y usar el contenido.
Convulsiones, evitar en el diseño del contenido la provocación de ataques, espasmos o convulsiones.
Navegable, proporcionar medios para ayudar a navegar, encontrar contenido y determinar dónde se encuentran.
Principio comprensible: indica que la información y el manejo de la interfaz de usuario deben ser claros. Se enfoca en características como:
Legibilidad, hacer que los contenidos textuales resulten claros y comprensibles.
Predecible, hacer que las páginas web aparezcan y operen de manera previsible.
Entrada de datos asistida, para ayudar a evitar y corregir los errores.
Principio robusto: establece que el contenido debe ser lo suficientemente consistente y fiable para permitir su uso con una amplia variedad de agentes de usuario, ayudas técnicas y estar preparado para las tecnologías posteriores:
Compatible, para maximizar la semejanza con las aplicaciones de usuario actuales y futuras, incluyendo las ayudas técnicas.
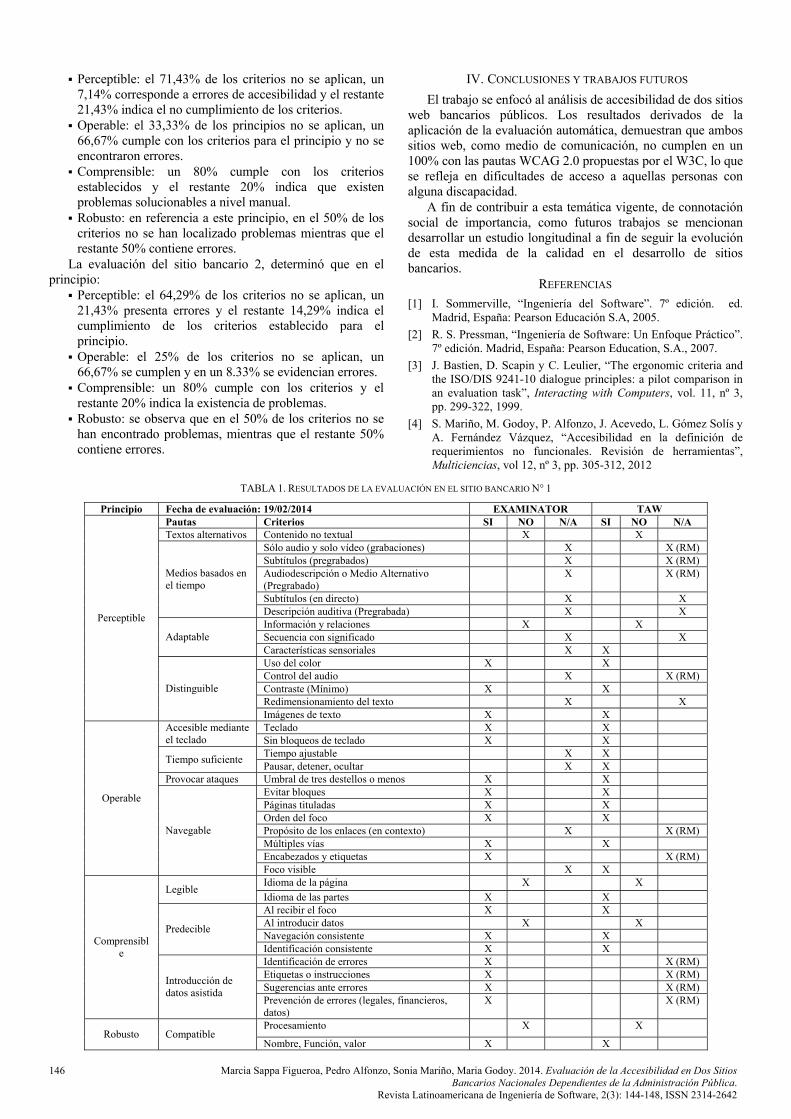
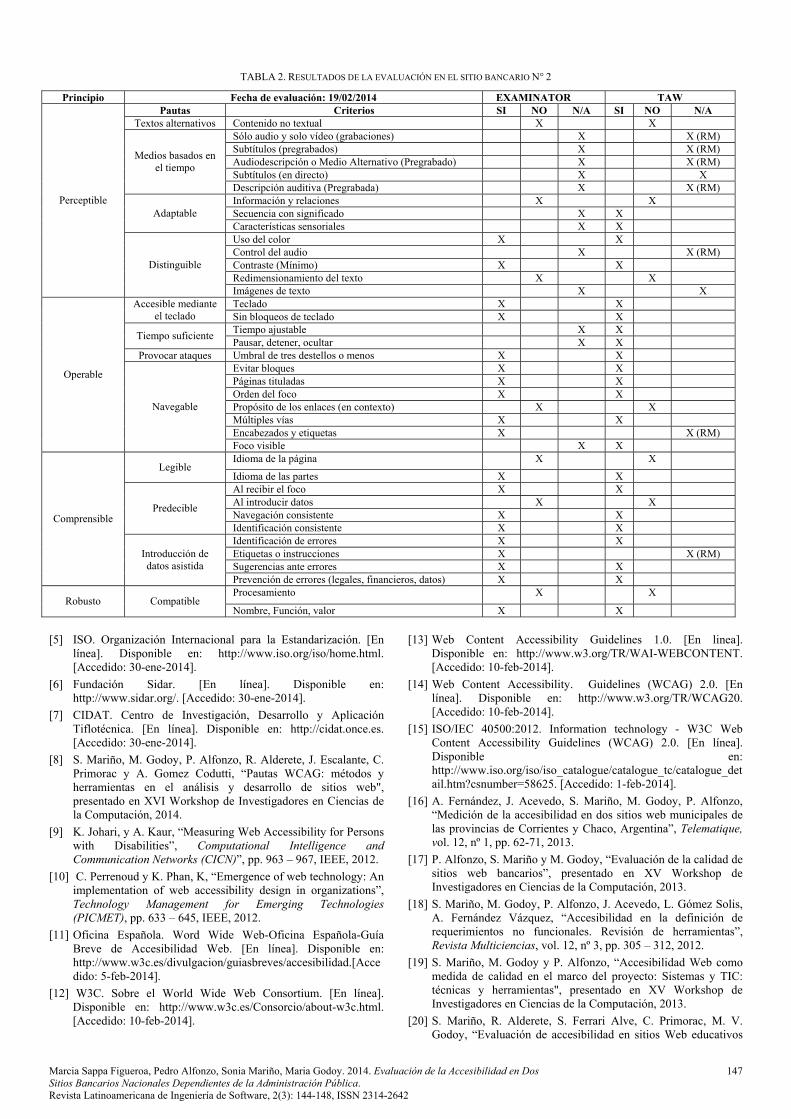
En las Tablas 1 y 2 se presentan los resultados obtenidos de la evaluación de accesibilidad de acuerdo a los principios de la WCAG 2.0 nivel AA, aplicado a cada página principal analizada. Para cada punto de verificación, las referencias indican si se cumplió (SI), no se cumplió (NO), no se aplicó (N/A) respectivamente.
La sigla RM indica que se comprobó con herramientas de revisión manual como Web Developer. Cabe aclarar que no se realizaron cambios atendiendo que se carece de acceso al desarrollo web del banco.
Los resultados demuestran como principales problemas detectados: escasa declaración del idioma, uso indiscriminado de elementos Flash, ausencia de etiquetas alternativas para identificar los elementos no textuales y el uso de tablas para maquetar. Lo expuesto implicaría el incumplimiento de los aspectos técnicos propuestos por la W3C.
La falta de accesibilidad generalizada podría considerarse que aquellos criterios correctamente utilizados podrían deberse más a razones coyunturales que a un dominio de la temática. Aspecto que se comprobaría aplicando una encuesta a los desarrolladores web.
Considerando que ambos validadores automáticos seleccionados en el presente trabajo presentan básicamente los mismos resultados, a continuación se sintetizan los resultados obtenidos de la aplicación del validador TAW y presentados en la Tablas 1 y 2.
La valoración del sitio bancario 1, comprobó que en el principio:
Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy. 2014. Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública.
Revista Latinoamericana de Ingeniería de Software, 2(3): 144-148, ISSN 2314-2642
146
Perceptible: el 71,43% de los criterios no se aplican, un 7,14% corresponde a errores de accesibilidad y el restante 21,43% indica el no cumplimiento de los criterios.
Operable: el 33,33% de los principios no se aplican, un 66,67% cumple con los criterios para el principio y no se encontraron errores.
Comprensible: un 80% cumple con los criterios establecidos y el restante 20% indica que existen problemas solucionables a nivel manual.
Robusto: en referencia a este principio, en el 50% de los criterios no se han localizado problemas mientras que el restante 50% contiene errores.
La evaluación del sitio bancario 2, determinó que en el principio:
Perceptible: el 64,29% de los criterios no se aplican, un 21,43% presenta errores y el restante 14,29% indica el cumplimiento de los criterios establecido para el principio.
Operable: el 25% de los criterios no se aplican, un 66,67% se cumplen y en un 8.33% se evidencian errores.
Comprensible: un 80% cumple con los criterios y el restante 20% indica la existencia de problemas.
Robusto: se observa que en el 50% de los criterios no se han encontrado problemas, mientras que el restante 50% contiene errores.
IV. CONCLUSIONES Y TRABAJOS FUTUROS El trabajo se enfocó al análisis de accesibilidad de dos sitios
web bancarios públicos. Los resultados derivados de la aplicación de la evaluación automática, demuestran que ambos sitios web, como medio de comunicación, no cumplen en un 100% con las pautas WCAG 2.0 propuestas por el W3C, lo que se refleja en dificultades de acceso a aquellas personas con alguna discapacidad.
A fin de contribuir a esta temática vigente, de connotación social de importancia, como futuros trabajos se mencionan desarrollar un estudio longitudinal a fin de seguir la evolución de esta medida de la calidad en el desarrollo de sitios bancarios.
REFERENCIAS [1] I. Sommerville, “Ingeniería del Software”. 7º edición. ed.
Madrid, España: Pearson Educación S.A, 2005. [2] R. S. Pressman, “Ingeniería de Software: Un Enfoque Práctico”.
7º edición. Madrid, España: Pearson Education, S.A., 2007. [3] J. Bastien, D. Scapin y C. Leulier, “The ergonomic criteria and
the ISO/DIS 9241-10 dialogue principles: a pilot comparison in an evaluation task”, Interacting with Computers, vol. 11, nº 3, pp. 299-322, 1999.
[4] S. Mariño, M. Godoy, P. Alfonzo, J. Acevedo, L. Gómez Solís y A. Fernández Vázquez, “Accesibilidad en la definición de requerimientos no funcionales. Revisión de herramientas”, Multiciencias, vol 12, nº 3, pp. 305-312, 2012
TABLA 1. RESULTADOS DE LA EVALUACIÓN EN EL SITIO BANCARIO N° 1
Principio Fecha de evaluación: 19/02/2014 EXAMINATOR TAW Pautas Criterios SI NO N/A SI NO N/A Textos alternativos Contenido no textual X X
Sólo audio y solo vídeo (grabaciones) X X (RM) Subtítulos (pregrabados) X X (RM) Audiodescripción o Medio Alternativo (Pregrabado)
X X (RM)
Subtítulos (en directo) X X
Medios basados en el tiempo
Descripción auditiva (Pregrabada) X X Información y relaciones X X Secuencia con significado X X Adaptable Características sensoriales X X Uso del color X X Control del audio X X (RM) Contraste (Mínimo) X X Redimensionamiento del texto X X
Perceptible
Distinguible
Imágenes de texto X X Teclado X X Accesible mediante
el teclado Sin bloqueos de teclado X X Tiempo ajustable X X Tiempo suficiente Pausar, detener, ocultar X X
Provocar ataques Umbral de tres destellos o menos X X Evitar bloques X X Páginas tituladas X X Orden del foco X X Propósito de los enlaces (en contexto) X X (RM) Múltiples vías X X Encabezados y etiquetas X X (RM)
Operable
Navegable
Foco visible X X Idioma de la página X X
Legible Idioma de las partes X X Al recibir el foco X X Al introducir datos X X Navegación consistente X X Predecible
Identificación consistente X X Identificación de errores X X (RM) Etiquetas o instrucciones X X (RM) Sugerencias ante errores X X (RM)
Comprensible
Introducción de datos asistida
Prevención de errores (legales, financieros, datos)
X X (RM)
Procesamiento X X Robusto Compatible
Nombre, Función, valor X X
Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy. 2014. Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública. Revista Latinoamericana de Ingeniería de Software, 2(3): 144-148, ISSN 2314-2642
147
TABLA 2. RESULTADOS DE LA EVALUACIÓN EN EL SITIO BANCARIO N° 2
Principio Fecha de evaluación: 19/02/2014 EXAMINATOR TAW Pautas Criterios SI NO N/A SI NO N/A
Textos alternativos Contenido no textual X X Sólo audio y solo vídeo (grabaciones) X X (RM) Subtítulos (pregrabados) X X (RM) Audiodescripción o Medio Alternativo (Pregrabado) X X (RM) Subtítulos (en directo) X X
Medios basados en el tiempo
Descripción auditiva (Pregrabada) X X (RM) Información y relaciones X X Secuencia con significado X X Adaptable Características sensoriales X X Uso del color X X Control del audio X X (RM) Contraste (Mínimo) X X Redimensionamiento del texto X X
Perceptible
Distinguible
Imágenes de texto X X Teclado X X Accesible mediante
el teclado Sin bloqueos de teclado X X Tiempo ajustable X X Tiempo suficiente Pausar, detener, ocultar X X
Provocar ataques Umbral de tres destellos o menos X X Evitar bloques X X Páginas tituladas X X Orden del foco X X Propósito de los enlaces (en contexto) X X Múltiples vías X X Encabezados y etiquetas X X (RM)
Operable
Navegable
Foco visible X X Idioma de la página X X
Legible Idioma de las partes X X Al recibir el foco X X Al introducir datos X X Navegación consistente X X Predecible
Identificación consistente X X Identificación de errores X X Etiquetas o instrucciones X X (RM) Sugerencias ante errores X X
Comprensible
Introducción de datos asistida
Prevención de errores (legales, financieros, datos) X X Procesamiento X X
Robusto Compatible Nombre, Función, valor X X
[5] ISO. Organización Internacional para la Estandarización. [En
línea]. Disponible en: http://www.iso.org/iso/home.html. [Accedido: 30-ene-2014].
[6] Fundación Sidar. [En línea]. Disponible en: http://www.sidar.org/. [Accedido: 30-ene-2014].
[7] CIDAT. Centro de Investigación, Desarrollo y Aplicación Tiflotécnica. [En línea]. Disponible en: http://cidat.once.es. [Accedido: 30-ene-2014].
[8] S. Mariño, M. Godoy, P. Alfonzo, R. Alderete, J. Escalante, C. Primorac y A. Gomez Codutti, “Pautas WCAG: métodos y herramientas en el análisis y desarrollo de sitios web", presentado en XVI Workshop de Investigadores en Ciencias de la Computación, 2014.
[9] K. Johari, y A. Kaur, “Measuring Web Accessibility for Persons with Disabilities”, Computational Intelligence and Communication Networks (CICN)”, pp. 963 – 967, IEEE, 2012.
[10] C. Perrenoud y K. Phan, K, “Emergence of web technology: An implementation of web accessibility design in organizations”, Technology Management for Emerging Technologies (PICMET), pp. 633 – 645, IEEE, 2012.
[11] Oficina Española. Word Wide Web-Oficina Española-Guía Breve de Accesibilidad Web. [En línea]. Disponible en: http://www.w3c.es/divulgacion/guiasbreves/accesibilidad.[Accedido: 5-feb-2014].
[12] W3C. Sobre el World Wide Web Consortium. [En línea]. Disponible en: http://www.w3c.es/Consorcio/about-w3c.html. [Accedido: 10-feb-2014].
[13] Web Content Accessibility Guidelines 1.0. [En linea]. Disponible en: http://www.w3.org/TR/WAI-WEBCONTENT. [Accedido: 10-feb-2014].
[14] Web Content Accessibility. Guidelines (WCAG) 2.0. [En línea]. Disponible en: http://www.w3.org/TR/WCAG20. [Accedido: 10-feb-2014].
[15] ISO/IEC 40500:2012. Information technology - W3C Web Content Accessibility Guidelines (WCAG) 2.0. [En línea]. Disponible en: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=58625. [Accedido: 1-feb-2014].
[16] A. Fernández, J. Acevedo, S. Mariño, M. Godoy, P. Alfonzo, “Medición de la accesibilidad en dos sitios web municipales de las provincias de Corrientes y Chaco, Argentina”, Telematique, vol. 12, nº 1, pp. 62-71, 2013.
[17] P. Alfonzo, S. Mariño y M. Godoy, “Evaluación de la calidad de sitios web bancarios”, presentado en XV Workshop de Investigadores en Ciencias de la Computación, 2013.
[18] S. Mariño, M. Godoy, P. Alfonzo, J. Acevedo, L. Gómez Solis, A. Fernández Vázquez, “Accesibilidad en la definición de requerimientos no funcionales. Revisión de herramientas”, Revista Multiciencias, vol. 12, nº 3, pp. 305 – 312, 2012.
[19] S. Mariño, M. Godoy y P. Alfonzo, “Accesibilidad Web como medida de calidad en el marco del proyecto: Sistemas y TIC: técnicas y herramientas", presentado en XV Workshop de Investigadores en Ciencias de la Computación, 2013.
[20] S. Mariño, R. Alderete, S. Ferrari Alve, C. Primorac, M. V. Godoy, “Evaluación de accesibilidad en sitios Web educativos

Marcia Sappa Figueroa, Pedro Alfonzo, Sonia Mariño, Maria Godoy. 2014. Evaluación de la Accesibilidad en Dos Sitios Bancarios Nacionales Dependientes de la Administración Pública.
Revista Latinoamericana de Ingeniería de Software, 2(3): 144-148, ISSN 2314-2642
148
basados en CMS”, Revista Digital Sociedad de la Información, enero-2013. [En línea]. Disponible en: http://www.sociedadelainformacion.com/39/evaluacion.pdf. [Accedido: 1-feb-2014]
[21] S. Mariño, P. Alfonzo, I. Giménez y M. Godoy, "La Accesibilidad Web como aspecto de calidad en el desarrollo de software. Experiencia de un taller como espacio de actualización de conocimientos", presentado en 1er Congreso Nacional de Ingeniería Informática/Sistemas de Información (CoNaIISI), 2013.
[22] G. Barchini y M. Sosa, “La informática como disciplina científica. Ensayo de mapeo disciplinar”, Revista de Informática Educativa y Medios Audiovisuales, año 1, vol. 1, nº 2, pp. 1-11, 2004.
[23] TAW. Validador de accesibilidad. [En línea]. Disponible en: http://www.tawdis.net. [Accedido: 19-feb-2014].
[24] EXAMINATOR. Validador de accesibilidad. [En línea]. Disponible en: http://examinator.ws/. [Accedido: 19-feb-2014].
Marcia Sappa. Alumna avanzada de la Carrera Licenciatura en Sistemas de Información. Facultad de Ciencias Exactas y Naturales y Agrimensura – Universidad Nacional del Nordeste. Pedro Alfonzo. Docente-Investigador. Experto en Estadística y Computación (Facultad de Ciencias Exactas y Naturales y Agrimensura –Universidad Nacional del Nordeste). Especialista en Ingeniería de Software (Universidad Nacional de la Plata). Magíster en Ingeniería de Software (Universidad Nacional de La Plata).
Sonia Mariño. Docente–Investigadora, Profesora Titular, Dedicación Exclusiva, del Departamento de Informática de la Facultad de Ciencias Exactas de la Universidad Nacional del Nordeste (UNNE). Licenciada en Sistemas. Es Magíster en Informática y Computación. (UNNE - Universidad de Cantabria - España), Magíster en Epistemología
y Metodología de la Investigación Científica (Facultad de Humanidades - UNNE). Cursa el Doctorado en “Ciencias Cognitivas”, Facultad de Humanidades (UNNE).
María V. Godoy. Docente–Investigadora, Profesora Titular, Dedicación Exclusiva, del Departamento de Informática de la Facultad de Ciencias Exactas de la Universidad Nacional del Nordeste (UNNE). Experta en Estadística y Computación, y Licenciada en Sistemas. Es Magíster en Informática y Computación. (UNNE - Universidad de Cantabria - España). Cursa el
Doctorado en “Ciencias Cognitivas”, Facultad de Humanidades (UNNE).

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
149
Composición Musical a Través del Uso de Algoritmos Genéticos
Ezequiel Moldaver1, Hernán Merlino1,2, Enrique Fernández1,2 1. Cátedra de Sistemas de Programación no Convencional de Robots. Facultad de Ingeniería. Universidad de Buenos Aires 2. Laboratorio de Investigación y Desarrollo en Arquitecturas Complejas (LIDAC). Grupo de Investigación en Sistemas de
Información (GISI). Universidad Nacional de Lanús. Argentina [email protected]
Resumen—Este trabajo se enfocará en el uso de los algoritmos genéticos (AAGG) con el fin de mezclar armonías y melodías de forma que se genere una composición musical de buen sonido para el oído, lo que significa que el contexto de cada nota respaldará la sonoridad de la misma provocando que no se genere un efecto disonante de forma permanente, que se genere una disonancia momentánea es permisible ya que es parte de la misma música generar tensión a través de pequeños intervalos poco agradables al oído.
Palabras Clave—algoritmos genéticos, música, redes neuronales, composición.
I. INTRODUCCIÓN La composición musical es el arte que tiene como objetivo
la creación de obras musicales, es una actividad humana que sirve para la expresión, comunicación y entendimiento entre personas. Se podría dividir en 2 partes básicas: la melodía y la armonía. La primera, según la Real Academia Española (RAE)[1] es “La parte de la música que trata del tiempo con relación al canto, y de la elección y número de sones con que han de formarse en cada género de composición los períodos musicales, ya sobre un tono dado, ya modulando para que el canto agrade al oído”, siendo la segunda “la unión de tres o más sonidos simultáneos, entendiendo que el canto o melodía producido por una sola voz es homónimo, con dos voces se producen intervalos armónicos y, a partir de 3 voces o sonidos simultáneos hablamos de armonía”.
Si bien los AAGG [2-3] no fueron diseñados para imitar comportamiento humano sino para resolver problemas u optimizar soluciones, se puede pensar en la composición de la música como el problema de encontrar una canción que suene bien al tomar en consideración el conjunto de todas las composiciones posibles como el espacio de soluciones, este espacio no está estructurado, es decir, que las buenas soluciones pueden estar junto a las malas; al cambiar algunas notas clave en una pieza, ésta puede llegar a ser menos interesante, aunque parezcan parecidas. La idea principal es mezclar de forma aleatoria distintos temas musicales de forma iterativa, en cada iteración se seleccionarán las mejores canciones para ser la base de la iteración siguiente. Además, en base a una variable probabilística se realizará un cambio aleatorio sobre uno de los compases de alguno de los temas, que también será elegido al azar. Luego de varias repeticiones se obtendrán como resultado distintas piezas musicales que serán totalmente distintas a las primeras, generando de esta forma, nueva música.
Con el fin priorizar la estructura de temas agradables o buscados por el usuario se utilizarán o un sistema de premios y castigos o redes neuronales (RRNN) [4-5] que serán entrenadas
para permitir un procesamiento automático de composición basado en sus gustos e inclinaciones musicales. Las mismas serán entrenadas con este fin para interpretar de todas las canciones candidatas en cada iteración y seleccionar aquellas que, de acuerdo a la estructura generada por el entrenamiento, sean las que el usuario hubiese elegido.
II. OBJETIVOS El proyecto tiene diversos objetivos que se encuentran
orientados a las distintas aristas que tiene la composición musical. Cuando un músico o compositor musical se encuentra sin inspiración permanente puede utilizar cómo método de ayuda para superar esta situación el compositor musical a través de AAGG. El primer objetivo de todos los que se van a plantear es que las canciones generadas por la herramienta sean agradables al oído, es decir, las partes disonantes deben ser armónicas y deben ser una minoría en proporción a las que no. No tendría sentido que una persona componga un tema que sea desagradable al escucharlo, si bien hay distintos géneros musicales y existen personas que no les gustan unos y si otros, dentro de cada género existen ciertos comportamientos intrínsecos a él que hacen que éstos tengan una estructura más o menos definida y, dentro de esta, serán agradables al oído de las personas a las que les gusta ese tipo de música. El segundo objetivo es netamente legislativo, para proteger la propiedad intelectual de los compositores. Las canciones generadas por el algoritmo de composición musical no deben ser plagio de las partituras que les dieron origen. Se fijará un criterio el cuál debe cumplirse estrictamente para no ser victimarios del delito de plagio, respetando de esta manera a toda la comunidad artística de la cuál se forma parte. Se debe ser muy cuidadoso a la hora de producir un nuevo contenido artístico ya que este puede incurrir en el delito de violación a la ley 11.723 de Propiedad Intelectual de la República Argentina, por estos motivos se fija este objetivo completamente orientado al proteccionismo y al respeto. Como tercer parte este programa debe respetar los gustos musicales del usuario, se buscará que la respuesta del sistema sea una clara consecuencia de la entrada que se le de al mismo, suponiendo de esta forma que el usuario quiera usar como base generadora de su composición las partituras iniciales, manteniendo ciertas características de los mismos, viéndose afectadas en parte, lo suficiente como para generar una canción que cumpla con el segundo objetivo pero a la vez se cumpla con el que se esta definiendo en este punto. Por último, el software debe generar una partitura con ciertos criterios definibles por el compositor, todas las transformaciones que sufran las partituras de entrada al sistema deben estar reguladas a gusto y capricho del usuario, pudiendo definir distintos tipos de restricciones o reglas a través de las

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
150
cuáles se premien o se castiguen ciertas mezclas o características musicales que se puedan ir dando a lo largo del proceso iterativo de composición, cumpliendo así con las metas que esté buscando el usuario en función de poder manejar algunas de las variables que se encuentran libradas al azar dentro de la ejecución del programa.
III. PROBLEMA A RESOLVER Un músico muchas veces cae en mesetas de inspiración que
limitan su producción musical, la mayoría de las veces esto sucede luego de haber tenido una etapa muy fructífera en cuanto a composición. Además, un compositor sufre de momentos efímeros de iluminación que muchas veces terminan decantando en pequeñas piezas musicales que quedan condenadas, en general, al olvido.
Por ello, se necesitaría implementar una solución que permita obtener un material en crudo para ser escuchado, estudiado, analizado y, finalmente, modificado a criterio del músico con el fin de servirle a éste de ayuda para los momentos de poca inspiración. Este material debe poder obtenerse de manera flexible tanto de las pequeñas piezas que se componen como de canciones completas ya que no siempre se cuentan con las primeras.
Dado que en la música oriental existen 12 notas musicales y distintos tipos de combinación entre ellas es difícil para un algoritmo saber cuando una pieza suena bien o no, además existen estudios llamados de armonía que se encargan de este tipo de cuestión. Si bien existen las disonancias, sonidos tensos o poco agradables al oído, éstas enriquecen la composición quitándole la monotonía de seguir algún tipo de escala conocida para ese tipo de estructura de canción. Además, las mismas pueden ser una introducción a un cambio de tonalidad haciendo de “pase” o puente entre una y otra. Por último, queda señalar, que siempre la música queda reducida al criterio del compositor, lo que busca, siente y quiere expresar, no existen reglas que descarten la disonancia, pero por oro lado a nadie le gustaría una canción que en cada una de sus partes haya tensión o sea totalmente disonante.
Por una cuestión de respeto tanto a la comunidad artística como al público y de idoneidad, una canción no debe ser un plagio de otra. No existe un criterio uniforme que determine cuando una pieza musical ha copiado a otra, esto genera varias preguntas:
1. Con que tenga alguna mínima parte igual ya implica que un artista a copiado a otro?
2. Qué significa una mínima parte? Cuánto es? 3. Cómo se determina esto en los géneros más populares
dónde las canciones son más parecidas ente ellas? 4. Qué y cuánto tienen que tener de distinto para
diferenciarse? Se podrían escribir muchos interrogantes similares que nos
den cuenta que este es un problema complejo y difícil de solucionar. Tanto es así que en los juicios sobre plagio no se aplica otro criterio que no sea el de os peritos musicales, no hay un método o regla exacta que nos permita descubrir o determinar si se ha incurrido en una violación a la propiedad intelectual.
Cada artista tiene su estilo bien marcado, esta esta característica no puede ser simplificada a algunas pocas formas y recursos musicales, es mucho más complejo que eso. Se sabe que la búsqueda de una identidad musical le lleva varios años de trabajo y esfuerzo a cualquier compositor o músico de cualquier género. Además, una vez que se encuentra el mismo,
no se deben estancar en la simplicidad de haber llegado a su (primera) meta, el camino recién empieza, ahora quedará la profundización del concepto, las variaciones para no caer en la monotonía, la evolución de lo que se ha encontrado, etc. es un trabajo arduo y continuo que no tiene un fin determinado.
Más allá del género o estilo musical que se este buscando respetar, generar o lograr, el compositor puede estar interesado en que no estén presentes ciertas características musicales en función de sus objetivos. Que el usuario pueda tratar de evitar una conjunción de notas disonantes, exceso de silencio en los compases, muchas idas y vueltas en cuanto a los tiempos musicales a lo largo de la canción y la cantidad de notas máximas y mínimas por compás es fundamental para poder llegar a las metas que un músico se propone cuando busca algún tipo de inspiración a partir de la cuál desarrollar sus habilidades. Este problema también se puede plantear de la forma inversa, es decir, que en vez de que se evite que se formen ciertas particularidades en las partituras generadas, se desee fomentarlas.
IV. SOLUCIONES A LOS PROBLEMAS PLANTEADOS Con el fin de solucionar el primer problema planteado,
poder generar temas musicales agradables al oído, se ha pensado en que la mejor solución para no caer en la rigidez y la monotonía es usar el criterio del usuario. Esto no significa que el mismo tendrá la ardua tarea de identificar en cada paso de cada iteración si las canciones que se están generando son o no agradables al oído, por el contrario, esto implicará que el compositor defina cuáles son las primeras soluciones al problema de composición para el algoritmo genético y, de esta manera, ya estará dando por sentado las bases de las posibles combinaciones entre partituras que se den en las distintas instancias de la evolución en el proceso de composición automática. Si bien no se puede planear o imaginar todas las combinaciones posibles que pueden tener las piezas musicales entre ellas, se puede hacer un análisis general sobre el problema a través del los tonos de las canciones. Hay tonos que pueden combinarse con otros sin ser disonantes, otros que generan una disonancia de tensión que puede enriquecer mucho el tema y otros que finalmente no podrían mezclarse porque no podría cumplir con la regla de generar canciones agradables al oído. La cantidad de temas, su longitud, sus variaciones, sus tonos, todas sus características y sus proporciones quedarían en manos del usuario en función de establecer y sentar las bases para la composición.
En función de no caer una violación a la propiedad intelectual el algoritmo genético no sólo irá mezclando los distintos compases de las diferentes canciones, sino que también, aplicará una mutación o modificación de los compases de manera estadística que producirá una gran variación de las canciones de las cuales partimos. De esta forma y, a partir de las iteraciones evolutivas que se establezcan, se irá modificando paso a paso cada una de las piezas musicales que se encuentran como parte del proceso de composición automática. Dado que estas variaciones no son determinísticas en cuanto a cuándo se producen, sino que por el contrario es un proceso estocástico, otra vez se verá involucrado el usuario para definir una probabilidad de ocurrencia de este fenómeno.
En función de poder respetar los gustos o preferencias musicales de un usuario se definirá la implementación de un sistema de premios y castigos para poder fomentar y desalentar ciertas características o propiedades de acuerdo a lo que el usuario esté buscando. Si se desea componer un tema de rock

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
151
se alentará que estén presentes todas las particularidades que posee el género, en cambio, si se busca formar una pieza musical de jazz, se pedirá que las combinaciones que se premien sean otras totalmente distintas. Por este motivo, se intentará generar una cantidad de reglas genéricas que abarquen un gran espectro de posibilidades y, que de acuerdo a su combinación y especificación le permitan al compositor poder expresarse con mínimas limitaciones para poder llegar a su objetivo. Si bien el sistema de restricciones definido por las reglas que exprese el usuario no es determinístico en función de lo buscado, si lo será en función de las canciones que mejor se adapten a éstas.
El compositor puede estar buscando que su composición se encuentre sesgada por ciertos rasgos que no son comunes a un género o estilo musical, para ello sería ideal poder contar con una herramienta que con tan solo recibir partituras que posean estos rasgos extraiga su idea principal, musicalmente hablando, con el fin de plasmarla en la composición final. Como un ejemplo de ello se podría decir que se está queriendo llegar a componer una canción que sea un HIT, esto no es propio de ninguna rama de la música. Para poder lograr la solución a este problema se puede entrenar una red neuronal que procese el tipo de canción que el usuario especifique y obtenga un modelo con tal de respetar el criterio definido musicalmente. Como contraste a esto, también se solicitará al compositor que indique las partituras que están alejadas de los objetivos o no cumplan con la idea musical que se desea encontrar.
V. TRABAJOS REALIZADOS EN ESTE CAMPO Se han desarrollado varios estudios en base al estudio del
arte computacional [6-11], en particular para este caso aplicaciones de desarrollo de la soluciones RRNN y AAGG para la composición musical [12-34] pero todos de diferentes enfoques, análisis y conclusiones; incluso hasta se han grabado discos y se ha promocionado este tipo de arte tecnológico. Los enfoques más importantes son: Gibson and Byrne [35] hicieron un trabajo basado en la armonización de melodías usando solamente las notas tónicas subdominantes (la cuarta nota de una escala musical, Ej. en la escala de Do la subdominante es el Fa) y dominantes (la quinta nota de una escala musical, Ej. en la escala de Do la dominante es el Sol) de los acordes pertenecientes de las melodías estudiadas.
Jacob [36] presentó su trabajo de composición en el cuál los AAGG son usados para identificar y diferenciar melodías aceptables para el oído humano, las mismas son tomadas de la salida que produce un proceso de generación de música estocástico. A partir de esa elección comienza el proceso de mejora y refinamiento propio del AG. McIntyre [37] realizó estudios de armonización de 4 partes usando una armonía barroca.
Uno de los proyectos más conocidos es GenJam (Biles) [37-41] un AG que genera solos de jazz en base a una sucesión de acordes. Establece escalas para la improvisación de acuerdo al acorde utilizado en el momento. Dada la progresión de los mismos se analiza y se establecen las notas en base a las escalas musicales. Mientras la aplicación da una muestra en tiempo real de como quedaría el solo, el usuario aprueba o rechaza la misma dando de esta manera un entrenamiento a una red neuronal que luego tomará las decisiones por el usuario de forma automática.
Se ha hecho un trabajo similar (George Papadopoulos and Geraint Wiggins) [42] para establecer una melodía dada la
progresión de acordes que se recibe, en este caso se establece una función de aptitud y no una red neuronal para elegir a los individuos más aptos. Esta investigación se focalizó en intentar reproducir el comportamiento humano de la composición por lo que se utilizan una función de aptitud basada en conocimiento psicológico musical.
Este trabajo se diferenciará de los dos últimos mencionados ya que se enfocará en la composición musical desde todos los puntos de vista y maneras de trabajar, no sólo se podrán componer nuevas melodías sino que también nuevas progresiones de acordes. También se trabajará con distintos tipos de métodos en la determinación de los individuos más aptos, lo que llevará a un entendimiento con el usuario para adaptar los AAGG a su gusto. Finalmente se evaluará a la partitura generada determinando si ésta es realmente una nueva pieza musical de forma genuina y auténtica o es un plagio de alguna de las partituras originales.
Una característica a destacar es que en la forma en la que trabajaremos podremos utilizar como fuentes de composición melodías o progresiones de acordes que pertenezcan a cualquier ritmo musical lo que aporta una riqueza en el producto final que no se posee en los trabajos hasta ahora mencionados.
VI. DESARROLLO DE LA SOLUCIÓN El objetivo de este trabajo es romper totalmente con los
esquemas de investigación y desarrollo que se han utilizado en el área, intentando componer, tal como lo hace una persona, nuevas piezas musicales. Para ello se trabajará con una cantidad inicial de partituras de temas ya existentes o recién compuestos que en los que se quiera investigar, sobre ellos se considerará a cada compás como un cromosoma del individuo interviniente y entre ellos se realizará la cruza. Luego de varias iteraciones cada uno de los temas originales se verán totalmente modificados en estructura, tiempos, ritmos, sonoridades, etc. generando de esta manera canciones nuevas. De la morfología, estructura y sonoridad de éstas puede nacer la inspiración que busca el compositor, o, directamente una nueva composición musical de manera automática. Además, los AAGG, al depender del azar pueden producir muchas soluciones diferentes, lo que es necesario en los ambientes creativos.
Como función de aptitud (para elegir las mejores canciones de cada iteración) se utilizarán tres posibilidades distintas: Un archivo de configuración en el cuál se especificarán ciertos parámetros asociados a las combinaciones musicales buscadas penando las que no se produzcan en ese sentido.
El usuario podrá entrenar una red neuronal que permita discernir que melodías son las buscadas y seguirán en pie dando origen a la población siguiente y que melodías pasarán al olvido.
Se usado un software open source para utilizar su modelado, abstracción, gráfica, etc. para la escritura de las partituras musicales a procesar. En el mismo también se diseñan, escriben y guardan los archivos de datos correspondiente a la entrada de la aplicación a desarrollar. El archivo de salida será de igual formato que los que ingresan, para ser reproducidos, nuevamente se apelará al editor de partituras en cuestión. Por estar desarrollado en el lenguaje de programación Java, ser un software OpenSource, su simpleza en cuanto a la usabilidad, su capacidad de abrir y guardar en los formatos más conocidos de partituras, se eligió el TuxGuitar como editor de partituras.

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
152
Se tomará el siguiente criterio de plagio: si las piezas resultantes contienen hasta 8 compases idénticos, sin importar el orden, a alguna de las melodías que les dieron origen, se considerará que no a compuesto música, que se está plagiando; en caso contrario diremos que el resultado es genuinamente original.
Se podrán mezclar cualquier instrumento excepto la batería ya que no sigue las mismas reglas de escritura musical de una partitura que cualquiera de los otros instrumentos que existen. El formato para escuchar las canciones resultantes será mediante el protocolo de comunicación MIDI.
Se desarrolló un sistema que en base a una entrada de partituras musicales genera, de acuerdo a la función de aptitud elegida, una partitura sin violar la ley de propiedad intelectual con respecto a las originales, que es la que mejor se adapta según lo seleccionado por la función de aptitud.
El primer caso es un sistema de penalizaciones que se aplica cuando se dan ciertas condiciones. Todas las canciones empiezan con un puntaje determinado y se le van restando las penalizaciones, el individuo más apto será el que tenga mayor cantidad de puntos. Vale aclarar que para hacer el camino inverso al de la penalización, es decir, la premiación de alguna condición o característica musical presente, se puede penalizar con un valor menor a cero, por lo que la misma se transformaría en una adición de puntos en lugar de una quita. Esta funcionalidad inversa puede ser aplicada a cualquier tipo restricción.
Las 3 condiciones que hoy se contemplan son las siguientes: 1. Restricción de notas: penaliza que en un mismo compás se
encuentren dos notas especificadas (expresadas en notación americana, DO-RE-MI-FA-SOL-LA-SI es equivalente a C-D-E-F-G-A-B), se evalúan para todos los compases de la partitura. Se definene la penalidad y las dos notas involucradas.
2. Restricción de tiempos: penaliza que en una misma partitura se encuentren los dos tiempos especificados (Ejemplo 2/4, 4/4, etc). Se establece la penalidad y ambos tiempos.
3. Restricción de cantidad de notas: penaliza la cantidad de notas, ya sea mínima o máxima, que se encuentran en un compás a lo largo de toda la partitura. Se indica la penalidad y la cantidad de notas. El segundo tipo de función de aptitud se establece a través
de una red neuronal, puede ser una que ya hallamos entrenado o se puede entrenar una nueva red. La misma es del tipo Backpropagation y tiene 4 capas, una de entrada, dos ocultas y una de salida. La primer capa tiene la cantidad de neuronas igual a la menor cantidad de compaces de las canciones con las cuáles se entrenó, la segunda y la tercer capa son configurables, la última sólo tiene una neurona que indica de 0 a 1 la preferencia de ese tema para continuar en la siguiente iteración del algoritmo genético.
Para que la red pueda ser entrenada hay que pasar la dirección a una carpeta que contenga las partituras que representen los objetivos buscados y otra a una carpeta que contenga las canciones que poseen propiedades que no nos interesan de un tema. Luego de ser entrenada la red se guarda en disco para que pueda ser utilizada más adelante.
A. Armado de la Red Neuronal Para serializar los datos hay que tener en cuenta que en una
partitura todos los datos que se pueden leer se pueden asociar y
combinar sin ninguna limitación, desde las notas propiamente dichas (es “infinito” cuán aguda o grave es una nota, la única limitación aquí es el instrumento, cuántas teclas tiene el piano, cuántos trastes la guitarra, el largo del violín o el chelo, etc), la cantidad de notas (en un compás o que suenan en simultáneo), sus tiempos asociados (redonda, blanca, negra, semi corchea, etc) hasta la cantidad de compaces. Dadas las características de estas variables se diseñó una manera de serializar los datos que tenga en cuenta todos estos aspectos.
Se tuvieron que plantear ciertas limitaciones para establecer el universo en el cuál la aplicación se va a manejar. Las mismas son: Se determinó que habrá una relación unívoca entre neuronas de entrada y compaces de las canciones, al ser un número variable entre todas ellas se fijó que se evaluarán solamente los compaces de la canción que tenga menor cantidad de ellos, todos los compaces que superen ese número no serán evaluados. Ejemplo: Si tenemos 3 canciones: A, B y C que tienen respectivamente 50, 60 y 100 compaces solamente se tomarán en cuenta los primeros 50 generando una red neuronal con ese número de neuronas en la primer capa.
Se fijó la nota más grave y la nota más aguda de acuerdo a un instrumento de referencia, en este caso, la guitarra. Por lo que por su conformación la nota más grave es un Mi mayor tocando la sexta cuerda (la más gruesa) sin presionar ningún traste, lo que comúnmente se llama “al aire”. De la misma forma, por una limitación física del instrumento, se establece la nota más aguda que se puede producir, que en este caso, se logra tocando la 1er cuerda (la más fina) en el último traste, comúnmente, el número 29.
Por una cuestión de simplicidad a la hora de abordar el problema se decidió ignorar en la serialización los efectos que una nota o un conjunto de notas pueda llegar a tener.
Dado que una partitura puede tener escrita todos los instrumentos y no es compatible mezclarlos deliberadamente se toma en cuenta solamente el primer track de la canción, es decir, que todos los tracks más allá del elegido para ser evaluado serán ignorados.
A partir de estas bases se estableció un número correspondiente a cada nota, para la más grave un 1, para la siguiente un 2 y así sucesivamente hasta alcanzar el número máximo alcanzable por el instrumento. En la práctica se observó que la red funcionaba mucho mejor con datos normalizados por lo que finalmente la nota serializada es: N° nota / N° nota máxima. En cada compás se suman todas las serializaciones de las notas generando la entrada de datos para la red. Cuando la nota sea un silencio se tomará el valor cero para el mismo.
Usando esta configuración y forma de manejar los datos se tienen en cuenta la cantidad de notas que se encuentran en un compás y sus valores intrínsecos. También se valora, de acuerdo a la escala normal utilizada, las octavas de preferencia de las notas; no es lo mismo un Mi grave que uno agudo, esto se produce al tener una distinta representación numérica como dato de entrada serializado para el uso de la red neuronal. Los valores mas agudos tendrán un valor más cercano a uno dado que se producen a medida que se avanza sobre el traste de la guitarra y los sonidos más graves serán representados por números cercanos al 0. De forma menos ortodoxa también es tenido en cuenta el tiempo de cada nota y el del compás en la modelización en cuestión, esto sucede porque musicalmente cuando se define un tiempo para un compás o serie de

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
153
compaces se limita el tamaño del tiempo de las notas, si el tiempo de un compás es definido en 4/4 entran o 4 negras o 2 blancas o 1 redonda y si se lo define en 3/3 se pueden escribir o 3 negras o 1 blanca y una negra pero no una redonda; entonces al sumar cada nota del compás habrá distintos valores medios por compás de acuerdo a este tipo de característica.
La elección de la función de transferencia fue un paso importante para este proyecto, de acuerdo con las variantes que había disponibles se eligieron las que podían resolver mejor este problema y, empíricamente se hicieron distintas pruebas para determinar la mejor opción de todas. Las posibilidades más importantes eran: Lineal y = b * x: Es la función de transferencia más simple que existe, se transfiere a la siguiente capa el valor de entrada aplicándole solamente una transformación lineal. Este tipo de función se utiliza generalmente para transferir una entrada de datos a dos capas paralelas de procesamiento, este uso se muestra en el siguiente diagrama (figura 1):
Fig. 1. Diagrama de conexión del Linear Layer.
Biased y = x + biasn (biasn es el bias de la enésima neurona): Esta tipo de transferencia es una extensión de la lineal porque aplica una transformación lineal pero a la vez difiere en dos aspectos:
1. Al usar biases la transformación se va modificando durante la fase de entrenamiento.
2. No tiene un multiplicador como parte de la función.
Sigmoid y= 1/ (1+e− x) : Aplica una transferencia no lineal con un rango de datos que va desde cero a uno, es un buena función para ser utilizada en las capas ocultas de una red neuronal.
TanH y= (ex− e− x)/ (ex+e− x) : Es similar a la Sigmoid, sólo que se aplica la tangente hiperbólica y por lo tanto la salida quedará limitada en un rango comprendido entre menos uno y uno.
SoftMaxy= ex /∑
j= 1
c
ex
: Como la Sigmoid tiene una salida que cubre el rango entre cero y uno, pero la gran diferencia es que la suma de todas las neuronas de la misma capa suman 1. Gracias a esta característica la salida de esta función de transferencia puede ser interpretada como probabilística. Su uso más frecuente es en redes neuronales supervisadas para la clasificación entre C elementos.
Logarítmica
y= log(1+x)si x≥ 1y= log(1− x )si x<1 : En este caso el
resultado de la función va de cero a infinito. Esta relación nos permite evitar la saturación de procesar muchos elementos entre cero y uno, dónde la Sigmoid y la TanH tienen una curva de respuesta de muy poca pendiente.
Seno y= sin (x) : Este tipo de transferencia suele utilizarse para problemas que poseen cierta periodicidad en su estructura. El rango de salida es de menos a uno.
La función de transferencia que se utilizó para resolver el aprendizaje sobre la composición musical buscada fue la Sigmoid.
La estructura interna de la red depende de la cantidad de información que debe aprender, por lo que para hacerla más flexible se pueden configurar el número de neuronas de las 2 capas ocultas de la misma. Empíricamente se comprobó que para “memorizar” los 40 primeros compaces de entre 25 y 30 canciones se necesitan 10 neuronas en cada una de las capas.
La conformación de la cantidad de neuronas por capa de la red siempre sigue el siguiente patrón: 1. Capa de entrada de datos: La mínima cantidad de compaces
que posean de los temas de aprendizaje. 2. Primer capa oculta. 3. Segunda capa oculta. 4. Capa de salida de datos: La última capa se resume a la
probabilidad de que ese tema sea el buscado. Si el número es cercano a uno estamos en presencia de patrones musicales de agrado para el usuario, para el caso contrario el límite es el cero. La morfología de la red neuronal depende del
entrenamiento que se le dé a la misma (dado que en ese momento se establecerá la cantidad de neuronas de entrada, es decir, la cantidad de compaces que se tomarán en cuenta para la evaluación), la configuración que se especifique para las capas ocultas y, finalmente, la capa de salida de datos que revelará la probabilidad de que ese tema contenga la idea musical que se está buscando. Esta flexibilidad que se posee permite al usuario afrontar problemas de menor y mayor embergadura en cuanto se refiere a la composición musical buscada solamente cambiando el archivo de configuración que recibe la aplicación. Si se desea trabajar con estilos de música cuyos temas en general son de duración extendida sólo se debe agregar más neuronas en las capas ocultas ya que para la capa de entrada se identifica automáticamente la cantidad de neuronas necesarias para llevar a cabo su procesamiento; en cambio, si se desea trabajar con un universo de temas musicales cuya característica es tener una corta duración sólo se debe disminuir el número de neuronas de las capas ocultas.
VII. VALIDACIÓN DE LA SOLUCIÓN Se han diseñado 2 casos totalmente distintos para probar la
solución desarrollada. La idea básica es probar las distintas aristas a nivel de composición que brinda la herramienta, validando tanto el método de penalizaciones como el de aprendizaje vía redes neuronales.
En todos los casos se evaluará la existencia o no de violaciones a la ley de propiedad intelectual, ya que el propio sistema en la salida indica si se ha caído en el plagio.
Se cuenta con una amplia base de datos de partituras de canciones que se deben adaptar a lo que se está buscando. Dado que siempre se mezcla la primera pista de partituras se debe proceder a editar la misma y colocar la pista con la que se desea trabajar como track principal. Una vez hecho esto se puede hacer un pulido más fino eliminando algunos silencios y/o corrigiendo algunos compaces en función de las tonalidades de las demás partituras o en base a lo que se está buscando.
Cabe aclarar que para utilizar el software y tener respuestas satisfactorias, se deben tener muy en cuenta las soluciones iniciales que se le brindan al algoritmo genético, ya que a partir de ellas se delimita el universo de las posibles soluciones, estableciendo de esta forma un espectro de resultados posibles.

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
154
A. A través de penalizaciones Usando el sistema de penalizaciones como función de
aptitud se hicieron 50 pruebas distribuidas en 10 casos distintos con 5 repeticiones por caso. La definición de los 10 casos se dieron en base a los siguientes parámetros: Probabilidad de mutaciones. Cantidad de evoluciones. Factor de cruza. Partituras iniciales. Restricciones de cantidad de notas (tanto máximas como mínimas).
Restricciones de tiempos. Restricciones de mezcla de notas especificas por compás.
Los distintos parámetros se eligieron en función de las características musicales de las partituras con las que se trabajó. Pues no tiene sentido alguno establecer restricciones de tiempos que no existan en las partituras o penalizar cierta conjunción de notas dentro de un compás cuando dicha combinación notas tampoco podría producirse.
Lo primero que se puede destacar de las validaciones realizadas es que es raro que las soluciones de composición musical automática se repitan con frecuencia, sólo ocurrió el 4% de los casos, en otras palabras, de las 50 canciones generadas únicamente hay 4 que son iguales, lo que representa una repetición en 2 casos.
Lo segundo para destacares que más allá de las restricciones que se pongan en cuanto a la cantidad de notas máximas de un compás un factor importante en este aspecto es la probabilidad de mutaciones con respecto a la cantidad de evoluciones, ya que esta mezcla 2 compases al azar y genera que se sumen la cantidad de notas que poseen ambos. Entonces, al haber una gran cantidad de iteraciones sobre el mismo espacio de canciones genera que inevitablemente se den estas condiciones a pesar de su penalización. Esto se debe a que la penalización pierde su poder restrictivo en el sentido mas estricto porque todas las canciones habrán tenido muchas notas en un mismo compás.
Otro factor que merece ser mencionado es que si se superan las 200 evoluciones la probabilidad de plagio se reduce muchísimo y se coloca en el 2% mientras que por debajo de este nivel es críticamente alto, llegando al 40% de plagio sobre las partituras originales. Esto se debe a que al haber más iteraciones sobre el algoritmo genético se generan más cruzas entre canciones y más mutaciones, por lo que se van mezclando hasta perder su morfología original.
El último tema a discutir es la sonoridad generada en las soluciones que se obtienen. En este sentido se observar que la misma depende básicamente de la compatibilidad musical entre las partituras originales es un arma de doble filo, porque en un margen mínimo se obtienen resultados interesantes si la disonancia de los tonos a mezclar es mínima, pero si cada tema tiene un tono distinto no quedará nada que se pueda rescatar musicalmente como tal, si podría ser el disparador para el compositor, pero difícilmente salga algo agradable al oído humano. Existen otros factores que afectan en menor medida pero le dan forma al resultado final, ellos son todas las condiciones y características de configuración.
Empíricamente se pudo comprobar que los resultados producidos no pueden llegar a ser en su totalidad una nueva canción, pero si pueden tomarse distintas fracciones de la partitura, realizar conjunciones, variaciones sobre la misma, etc. como disparadores para ayudar al compositor en la ardua
tarea de generar música cuando cae en una meseta de inspiración propia.
B. A través del aprendizaje de gustos musicales Para generar partituras a través del uso de RRNN se
hicieron 10 pruebas. Se tomaron 5 voluntarios, dos de ellos con conocimientos musicales en cuanto a composición, partituras, armonía, etc. y se les propuso hacer 2 pruebas a cada uno. Hay que tener en cuenta que este tipo de pruebas es muy costosa en cuestión de tiempo ya que hay que entrenar una red neuronal para que aprenda los criterios de cada voluntario, luego hay que definir los parámetros del algoritmo y finalmente esperar que se produzcan los resultados; en total, el proceso completo lleva aproximadamente 5 horas ya que el entrenamiento y ejecución de los conocimientos es una tarea muy costosa en cuanto al procesamiento.
Si bien los resultados producidos no son muchos, no se han visto casos de plagio con respecto a las partituras originales. Esto puede deberse ya a que diferencia del caso anterior la función de aptitud es general, es decir, se toma a la canción como un todo para evaluar los gustos de la persona que la entrenó y no restricciones estrictas sobre las distintas características de cada uno de los compaces, lo cuál genera más flexibilidad ante los cambios que pueda llegar a producir el algoritmo sobre las piezas musicales.
En cuanto a los resultados producidos se puede observar que al igual que en el caso anterior no se podría tomar la pieza musical resultante como producto terminado ya que hay algunas partes de la partitura que no son agradables al oído, pero la mayoría de la partitura corresponde con una composición musical agradable y armónica al oído humano. Sin embargo, los voluntarios aprobaron las canciones que “compusieron” justificando que respetaba en un amplio margen sus gustos y la forma de la cuál habían entrenado la red. Cabe destacar que las soluciones iniciales brindadas al algoritmo genético debían compartir algunas características de las canciones con las que se entrenaron la red ya que el espectro musical es extremadamente amplio y no tiene sentido, por ejemplo, entrenar una red con temas característicos de pop y aplicarla a temas de heavy metal. Esta restricción es en base a cada usuario y se aplica su razonabilidad a la hora de utilizar la herramienta en cuestión. Si, en cambio, se permite cierto tipo de diversidad musical ya que esto enriquecerá el producto final, pero debe ser aplicado con valores razonables.
VIII. CONCLUSIONES A la primera conclusión que se puede llegar a partir de las
pruebas que sean realizado es que el sistema sirve, como mínimo, de manera de disparador de composición para el músico que se encuentra en una depresión productiva, que no se encuentra inspirado. Al utilizar esta herramienta y jugar con ella puede utilizar los compaces más jugosos de acuerdo a su búsqueda como primer paso de una canción. Quedará a su criterio completar los baches de poca sonoridad que se pueden generar o seguir ejecutando la herramienta y realizar una conjunción de todos los resultados producidos y así llegar a una composición completamente automática en varios pasos.
Un resultado importante que nos arrojan los análisis realizados es que es difícil que se caiga en una violación a la ley 11.723 de Propiedad Intelectual de la República Argentina, lo cuál es un gran logro ya que sin esto el fin de la herramienta se vería reducido ampliamente. No tiene sentido usar una ayuda para componer que plagie las partituras de entrada del sistema, generaría mucho más trabajo para el músico ya que

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
155
debería ocuparse de cambiar la canción generada lo suficiente como para no incurrir en este delito.
Un aspecto novedoso de esta herramienta es que permite convertir a cualquier persona en un compositor musical ya que no es necesario que se tenga conocimientos de música, solamente entender básicamente cómo funciona un algoritmo genético, que ya de por si es una idea básica que al estar basada en la Teoría de la Evolución la mayoría de las personas conocen. Con indicarle a una red neuronal cuáles son las canciones que a uno le gustan, las que no le gustan y seleccionar una cantidad de canciones para que sean la entrada del programa alcanza para que la implementación de los algoritmos haga el resto y produzca un resultado acorde. De esta manera la herramienta permite universalizar el proceso de composición y ponerlo al alcance de la mano de cualquier persona. Cabe destacar que la música que se genere de este modo respetará lo más posible los resultados musicales buscados por el usuario, dependiendo de lo posible que eso sea de acuerdo al estímulo de entrada que se le brinde. Por lo que esta herramienta no sólo permite convertir a cualquier persona en compositor sino que también reflejará la idea musical del mismo.
Una arista fundamental que posee el sistema de composición es, que más allá de los criterios que el usuario intente tratar de imponer tanto con una red neuronal como con penalizaciones, los resultados siempre estarán sujetos a las partituras de entrada que se le hayan brindado. No tiene sentido tratar de imponer un castigo a la cantidad de notas mínimas o máximas cuando en las canciones que se barajan se violan ambas restricciones, esto provocará que todas las partituras sean penalizadas de igual forma, por lo que no habrá diferencias entre ellas a la hora de seleccionar las más aptas para la siguiente evolución. El mismo punto de vista puede ser aplicado para las redes neuronales, ya que la red intentará memorizar ciertas estructuras, escalas, notas, etc. y si la entrada al programa no tiene nada que ver con el entrenamiento el comportamiento será completamente azaroso. La buena elección de criterios y canciones de entrenamiento con respecto a la música con la cuál se va a trabajar será fundamental para acercarse más y más a las ideas musicales a las que se desea llegar.
AGRADECIMIENTOS Quiero agradecer a al Mg. Ing. Hernán Merlino y al Dr.
Enrique Fernández que sin ellos no hubiera podido desarrollar este trabajo. También me gustaría agradecer a mi familia por el apoyo y a la Facultad de Ingeniería de la Universidad de Buenos Aires que fue mi segundo hogar y me dio todas las herramientas que hoy tengo profesionalmente.
REFERENCIAS [1] URL: http://lema.rae.es/drae/?val=melod%C3%ADa Página
válida al 20/09/2011. [2] Mitchell, M. (1996) An Introduction to Genetic Algorithms.
Cambridge, MA: MIT Press/Bradford Books. [3] Ross, P. M. and D. Corne (1995). Applications of Genetic
Algorithms. AISB Quarterly 89, 23-30. [4] Braun H., Weisbrod J. Evolving Feedforward Neural Networks.
Proc. of the 1993 International Conference on Artificial Neural Nets and Genetic Algorithms
[5] Griffith N. and Todd P. M, editors. Musical Networks. MIT Press, 1997.
[6] URL: http://www.jardindegente.com.ar/index.php?nota=prensa _365_1. Página válida al 20/09/2011.
[7] Spector, L., and Alpern A. 1994. Criticism, Culture, and the Automatic Generation of Artworks. In Proceedings of the Twelfth National Conference on Artificial Intelligence, AAAI-94, pp. 3-8. Menlo Park, CA and Cambridge, MA: AAAI Press/The MIT Press.
[8] Todd, P. M. & Werner, G. M. (1999). Frankensteinian Methods for Evolutionary Music Composition. In Griffith and Todd, P. M. (Eds.) Musical networks: Parallel perception and performance, 313-339.
[9] Todd, P.M. (1988) A sequential network design for musical applications. In D. Touretzky, G. Hinton, & T. Sejnowski (Eds.), Proceedings of the 1988 Connectionist Models Summer School (pp. 76-84). San Mateo, CA: Morgan Kaufmann.
[10] Todd, P.M. (1989) A connectionist approach to algorithmic composition. Computer Music Journal, 13(4), 27-43.
[11] Todd S. & Latham, W. (1992) Evolutionary Art and Computers. New York: Academic Press.
[12] Wiggins G., Papadopoulos G., Phon-Amnuaisuk S., and Tuson A.. Evolutionary Methods for Musical Composition. International Journal of Computing Anticipatory Systems (inpress), 1999.
[13] Bharucha, J.J. & Todd, P.M. (1989) Modeling the perception of tonal structure with neural nets. Computer Music Journal, 13(4), 44-53. Also in P.M. Todd & D.G. Loy (Eds.), Music and Connectionism (pp. 128-137). Cambridge, MA: MIT Press.
[14] Burton A. and Vladimirova T.. A Genetic Algorithm Utilising Neural Network Fitness Evaluation for Musical Composition. In International Conference on Genetic Algorithms and Artificial Neural Networks, 1997a.
[15] Burton A. R. & Vladimirova T. (1999). Generation of Musical Sequences with Genetic Techniques. Computer Music Journal, 23 (4), 59-73.
[16] Burton, A. and Vladimirova, T. (1997). Applications of Genetic Techniques to Musical Composition.
[17] Feulner J., Hörnel D.. MELONET: Neural Networks that Learn Harmony Based Melodic Variations. Proc. of the 1994 International Computer Music Conference, ICMA Århus 1994
[18] Feulner J., Neural Networks that Learn and Reproduce Various Styles of Harmonization. Proc. of the 1993 International Computer Music Conference, ICMA Tokyo 1993
[19] Giomi F. and Ligabue M. Computational Generation and Study of Jazz.
[20] Griffith N. and Todd P.M. (Eds.) (1998). Musical networks: Parallel distributed perception and performance. Cambridge, MA: MIT Press/Bradford Books.
[21] Hörnel, D., & Ragg, T. (1996) Learning musical structure and style by recognition, prediction and evolution. In Proceedings of the 1996 International Computer Music Conference (pp. 59-62). San Francisco: International Computer Music Association.
[22] Horner, A. & Goldberg, D. E. (1991). Genetic algorithms and Computer Assisted Music Composition. ICMC’91 Proceedings, San Francisco: International Computer Music Association, 479-482.
[23] Horner, A. and Goldberg, D. (1991). Genetic algorithms and computer-assisted composition. In Proceedings of the Fourth International Conference on Genetic Algorithms.
[24] Horner, A., & Ayers, L. (1995) Harmonization of musical progressions with genetic algorithms. In Proceedings of the 1995 International Computer Music Conference (pp. 483-484). San Francisco: International Computer Music Association.
[25] Horner, A., Assad, A., & Packard, N. (1994) Artificial music: The evolution of musical strata. Leonardo Music Journal, 3, 81.
[26] Horowitz, D. (1994). Generating rhythms with genetic algorithms. In Proceedings of the International Computer Music Conference.
[27] Koza, J. (1993) Genetic Programming. Cambridge, MA: MIT Press/Bradford Books.

Ezequiel Moldaver, Hernán Merlino, Enrique Fernández. 2014. Composición Musical a Través del Uso de Algoritmos Genéticos Revista Latinoamericana de Ingeniería de Software, 2(3): 149-156, ISSN 2314-2642
156
[28] Moore, J.H. (1994) GAMusic: Genetic algorithm to evolve musical melodies.
[29] Moroni A., Manzoulli J., Von Zuben F., Gudwin R., Vox Populi: Evolutionary computation for music evolution. In P.J. Bentley, D. W. Corne, Creative evolutionary Systems, Morgan Kaufmann, 2002, pp. 205-221.
[30] Putnam, J.B. (1994) Genetic Programming of Music. Unpublished manuscript. Socorro, NM: New Mexico Institute of Mining and Technology.
[31] Ralley D. (1995). Genetic algorithms as a tool for melodic development. In Proceedings of the 1995
[32] Ralley D. Genetic algorithms as a tool for melodic development. In Proceedings of the International Computer Music Conference, 1995.
[33] Thywissen, K. (1996) GeNotator: An environment for investigating the application of genetic algorithms in computer assisted composition. In Proceedings of the 1996 International Computer Music Conference. San Francisco: International Computer Music Association.
[34] Towsey, M., Brown, A., Wright, S., & Diederich, J. (2000). Interactive Music Composition using Genetic Algorithms. Paper presented at the 7thConf. of the International Society for the Study of European Ideas (ISSEI), 14-18 August, 2000, University of Bergen, Norway.
[35] Gibson, P. and Byrne, J. (1991). Neurogen, musical composition using genetic algorithms and cooperating neural networks. In Proceedings of the 2nd International Conference in Artificial Neural Networks.
[36] Jacob, B. (1995). Composing with genetic algorithms. In Proceedings of the International Computer Music Conference.
[37] Biles, J.A. (1994). Genjam: A genetic algorithm for generating jazz solos. In Proceedings of the International Computer Music Conference.
[38] Biles J.A, Autonomous GenJam: Eliminating the Fitness Bottleneck by Eliminating Fitness, Workshop on Non-routine Design with Evolutionary Systems, Genetic and Evolutionary Computation Conference, 2001.
[39] Biles, J., Anderson, P., and Loggi, L. (1996). Neural network fitness functions for a musical IGA. Technical report, Rochester Institute of Technology.
[40] Biles, J.A. (1995a) The Al Biles Virtual Quintet: GenJam. Compact disc recording DRK-CD-144. Rochester, NY: Dynamic Recording Studios.
[41] Biles, J.A. (1995b) GenJam Populi: Training an IGA via audience-mediated performance. In Proceedings of the 1995 International Computer Music Conference (pp. 347-348). San Francisco: International Computer Music Association.
Ezequiel Moldaver. Es Ingeniero en Informática por la Facultad de Ingeniería de la Universidad de Buenos Aires. Es docente de física I en la misma facultad y actualmente trabaja como desarrollador de software. Hernán Merlino. Es Magister en Ingeniería de Software por la Universidad Politécnica de Madrid. Es Profesor Titular Regular de la Licenciatura en Sistemas y Director del Laboratorio de Investigación y Desarrollo en Arquitecturas Complejas de la Universidad Nacional de Lanús. Es Profesor Adjunto Regular de la Cátedra de Sistemas de Programación no Convencional de
Robots de la Facultad de Ingeniería de la Universidad de Buenos Aires. Es Docente Investigador del Programa de Incentivos de la Secretaria de Políticas Universitarias del Ministerio de Educación. Su áreas de investigación son: patrones de diseño y de desarrollo de software; sistemas inteligentes y sus aplicaciones.
Enrique Fernández. Es Doctor en Ciencias Informáticas por la Universidad Nacional de La Plata. Es Investigador Adscripto al Grupo de Investigación en Sistemas de Información de la Licenciatura en Sistemas de la Universidad Nacional de Lanús. Es Docente de la Cátedra de Sistemas de Programación no Convencional de
Robots de la Facultad de Ingeniería de la Universidad de Buenos Aires..