modelos de mixturas y m´etodos mcmc de dimensi´on param...
TRANSCRIPT

Modelos de mixturas y metodos MCMC de
dimension parametrica variable.
Marzo, 2004

De que vamos a hablar....
1. Modelos de mixturas.
2. Inferencia Bayesiana para mixturas cuando el numero de componentes es
conocido.
3. Metodos MCMC de dimension parametrica variable para mixturas.
a) Metodos de salto reversible (Richardson y Green, 1997).
b) Metodos MCMC en tiempo continuo (Stephens, 2000).
4. Aplicaciones a colas.

1. Modelos de Mixturas
Un modelo de mixtura es una combinacion convexa,
f (x | k,w,φ) = kPr=1
wrfr (x | φr) ,
de densidades fr (x | φr), donde w =(w1, ..., wr) tal quePkr=1wr = 1.
Siendo modelos parametricos son tan flexibles que pueden aproximar situa-
ciones no parametricas.
A partir de densidades muy sencillas se obtienen densidades con estructura
muy compleja.

Las componentes de la mixtura no tienen que tener un significado fısico.
Las mixturas pueden describir comportamientos complejos de datos en
sistemas complejos: astronomıa, bioinformatica, computacion, ecologıa,
economıa, ingenierıa, bioestadıstica,....
Observar que E [Xr] =kPr=1
wrEfr [Xr]
Se requieren herramientas computacionalmente elevadas para la inferencia:
Metodos MCMC, algoritmo EM,...
Antes de los metodos MCMC, no existıa un procedimiento sencillo para la
estimacion Bayesiana de mixturas.
El enfoque Bayesiano permite descomponer la estructura compleja de una
mixtura en un conjunto de estructuras sencillas mediante el uso de variables
latentes.

Algunos ejemplos:
Ejemplo1: Mixturas de normales (Las habeis visto en clase).
f (x | k,w,φ) =kXr=1
wrfr(x | µr, σ2r),
donde φ=³µ1, σ
21, ..., µk, σ
2k
´y fr(x | µr, σ2r) es la densidad de una normal
de media µr y varianza σ2r.
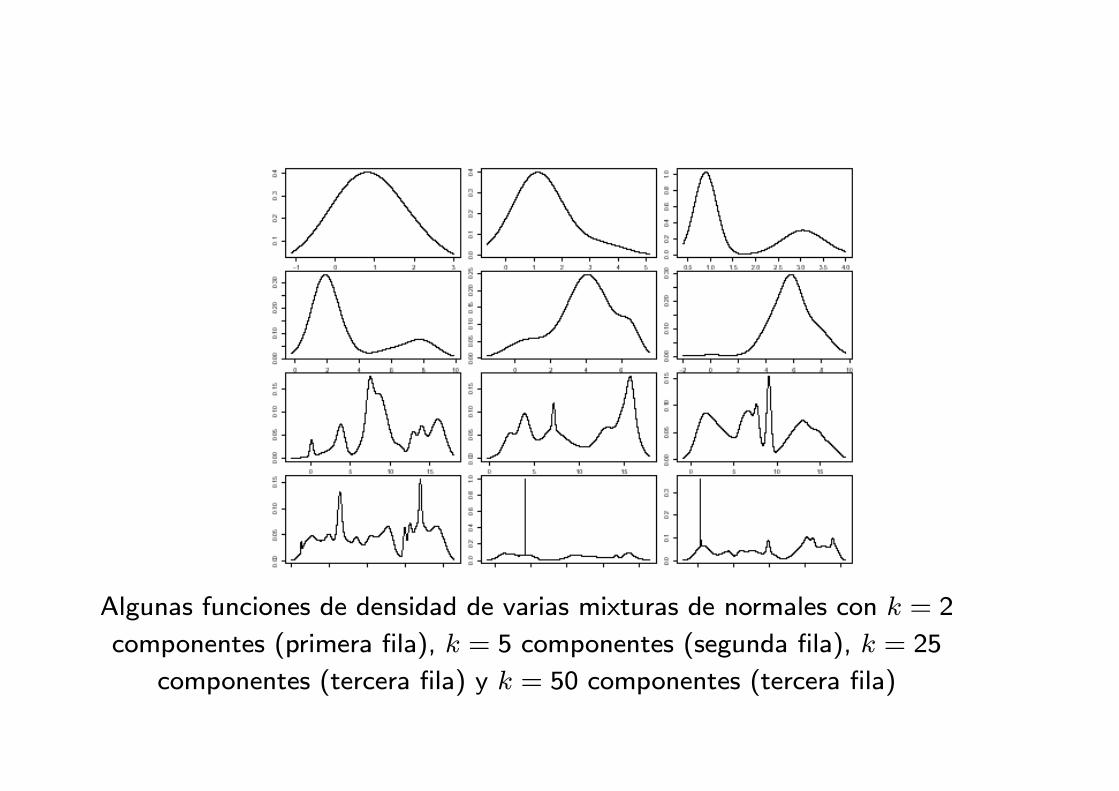
Algunas funciones de densidad de varias mixturas de normales con k = 2
componentes (primera fila), k = 5 componentes (segunda fila), k = 25
componentes (tercera fila) y k = 50 componentes (tercera fila)

Ejemplo 2: Mixturas de exponenciales (Hk).
f (x | k,w,µ) =kXr=1
wrfr(x | µr),
donde w=(w1, ..., wk) y µ = (µ1, ...., µk) y donde
fr(x | µr) = µr exp (−µrx) ,
es la densidad de una exponencial de tasa µr.

0 10 20 300
0.05
0.1
0.15
0.2
0.25
0 20 40 60 80 1000
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
Dos mixturas de exponenciales. Izquierda: k = 3, w = (0.3, 0.35, 0.35) y
µ = (1/2, 1/6, 1/12) . Derecha: k = 5, w = (0.2, 0.2, 0.2, 0.2, 0.2) y
µ = (1/2, 1/6, 1/12, 1/20/1/50) .

Ejemplo 3: Mixturas de distribuciones Erlang (HEr).
f(x | k,w,µ,ν) =kXr=1
wrfr(x | νr, µr),
donde w =(w1, ..., wk), ν= (ν1, ...., νk) y µ = (µ1, ...., µκ) y donde,
fr(x | νr, µr) =(νrµr)
νr
Γ(νr)xνr−1 exp(−νrµrx),
es la densidad de una distribucion Erlang de parametros ν, µ.
Cada distribucion Erlang de la mixtura es una suma de ν exponenciales de
tasa νµ :
νµ νµ νµ...

0 5 10 15 200
0.05
0.1
0.15
0.2
0.25
0 5 10 15 200
0.05
0.1
0.15
0.2
0 5 10 15 200
0.05
0.1
0.15
0.2
0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Cuatro mixturas de distribuciones Erlang con k = 2 componentes (arriba) y
k = 3 componentes (abajo).

Ejemplo 4: Mezclas de distribuciones Erlang Generalizadas (MGE).
No es exactamente una mixtura porque los parametros de cada compo-
nente no son independientes entre sı.
f(x | L,P,µ) =LXr=1
Prfr(x | µ1, ..., µr),
donde P =(w1, ..., wk) y µ = (µ1, ...., µκ) y donde,
fr (x | µ1, ..., µr) =rXt=1
Ys6=t
õs − µtµsµt
!−1µ2−rt e−µtx
es la densidad de una suma de r exponenciales.

Es decir,
X =
Y1, con prob = P1Y1 + Y2, con prob = P2... ...Y1 + ...+ YL, con prob = PL
donde Yr ∼ exp (µr) yPLr=1Pr = 1.
...µ1 µLµ2 µ3
P1 P2 P3 PL

La familia MGE contiene a las distribuciones HEr por tanto todas las densidades
de antes se pueden obtener con una distribucion MGE.
Sin embargo, la parametrizacion es distinta y hace falta un numero elevado de
componentes en la distribucion Coxiana para obtener densidades multimodales.
La distribucion MGE es muy adecuada cuando se quieren aproximar distribu-
ciones unimodales con colas muy pesadas.
0 50 100 150 200 250 3000
0.005
0.01
0.015
0.02
0.025
0.03
0.035

2. Inferencia Bayesiana para mixturas con k fijo.
Supongamos que tenemos n observaciones x =(x1, ..., xn) i.i.d. de un modelo
de mixtura,
f (x | w,φ) = Σkr=1wrfr (x | φr) , (1)
donde k es fijo. Queremos hacer inferencia Bayesiana sobre (w,φ) .
2.1. ¿Que problemas tiene?
La verosimilitud es,
L (φ,w | x) = nQi=1
kPr=1
wrfr (xi | φr) ,
constituida por kn terminos, lo cual implica un coste computacional muy alto
para un numero no muy grande de n.

2.2. Estructura de variables faltantes o latentes.
Se trata de utilizar la estructura de componentes (faltante) propia de una
mixtura como una herramienta para facilitar la estimacion.
Siempre es posible asociar a cada variable observable Xi distribuida segun una
mixtura de k distribuciones, (1), otra variable Zi tal que,
Xi | Zi = r ∼ f (x | φr) , y P (Zi = r) = wr.
Estas variables auxiliares identifican a que componente de la mixtura pertenece
cada observacion.
Es decir, para cada muestra de datos x =(x1, ..., xn) se supone que existe un
conjunto de datos faltantes (etiquetas) z =(z1, ..., zn), que indican a que com-
ponente pertence cada dato.

Con esta estructura de variables latentes, se simplifica mucho la verosimilitud,
L (w,φ | x, z) =nQi=1
wzifr³xi | φzi
´
=kQr=1
wnrr
" Qi:zi=r
fr (xi | φr)#,
donde nr = #{zi = r} y Σnr = n.
Conocido el valor de un dato, xi, la probabilidad de que proceda de una deter-
minada componente es:
P (zi = r | xi,w,φ) =wrf (xi | φr)Pkr=1wrf (xi | φr)
.

2.3. Inferencia para una mixtura de k (fijo) normales (Repaso).
Con las variables auxiliares z = (z1, ..., zn) se simplifica mucho la verosimilitud:
L³w,µ,σ2 | x, z
´∝ kQr=1
µwr
σr
¶nrexp
− 1
2σ2r
Xi:zi=r
(xi − µr)2 ,
donde nr = #{zi = r}.
Se tiene que:
P³zi = r | xi,w,µ,σ2
´=
wrσrexp{− 1
2σ2r(xi − µr)2}
kPr=1
wrσrexp{− 1
2σ2r(xi − µr)2}

A priori A posteriori
w ∼D (δ1, ..., δk) w | x, z ∼D³δ∗1, ..., δ∗k
´σ2r ∼ GI (α/2, β/2) σ2r| x, z, µr ∼ GI (α∗r/2, β∗r/2)
µr | σ2r ∼ N³mr, σ2r/cr
´µr | x, z, σ2r ∼ N
³m∗r, σ2r/c∗r
´donde
δ∗r = δr + nr, α∗r = α+ nr,
β∗r = β +P
i:zi=r(xi − µr)2 , c∗r = cr + nr,
m∗r = crmr+nrxrcr+nr
.
Por identificabilidad, se asume a priori que µ1 < ... < µk.

2.3.1. Algoritmo Gibbs para una mixtura de normales.
1. Fijar valores iniciales para w(0),µ(0) y σ(0).
2. Actualizar z generando de z(j+1) ∼ z|x,w(j),µ(j),σ2(j).
3. Actualizar w generando de w(j+1) ∼ w|x, z(j+1).
4. Actualizar σ2r generando de σ2(j+1)r ∼ σ2r| x, z(j+1), µ(j)r .
5. Actualizar µr generando de µ(j+1)r ∼ µr|x, z(j+1), σ2(j+1)r .
6. Ordenar µ(j+1) y colocar w(j+1) y σ2(j+1) segun este orden.
7. j = j + 1. Ir a 2.

Una vez obtenida una muestra MCMC de tamano J de la distribucion a pos-
teriori de los parametros³w,µ,σ2
´:½µ
w(j)1 , ..., w
(j)k
¶,µµ(j)1 , ..., µ
(j)k
¶,µσ2(j)1 , ..., σ2(j)
¶¾, para j = 1, ..., J,
podemos estimar, por ejemplo, cada una de las medias mediante:
E [µr | x] =1
J
J+BXj=1+B
µ(j)r , para r = 1, ..., k,
y la densidad predictiva con:
f(x | x) = 1
J
J+BXj=1+B
kXr=1
w(j)r
(2π)1/2 σrexp
−µx− µ(j)r
¶22σ2(j)r
donde B indica el numero de iteraciones de burn in .

Veamos ejemplos con MATLAB....

2.4. Inferencia para una mixtura de k (fijo) distribuciones Erlang.
Como antes, consideramos una estructura equivalente de variables latentes.Para
la mixtura de Erlangs, la probabilidad de que la observacion i pertenezca a la
componente r es,
P (Zi = r | x,w,µ,ν) ∝ wr(νrµr)
νr
Γ(νr)xνr−1i exp(−νrµrxi).
Distribuciones semiconjudadas para:
A priori A posteriori
w ∼D (δ1, ..., δk) w | x, z ∼ D(δ1 + n1, ..., δk + nk)
µr | k ∼ G(α, β) µr | x, z ∼ G(α+ nrνr, β + Srνr),
donde nr = #{zi = r} y Sr =P
i:zi=rxi.

Para los parametros enteros suponemos a priori que νr ∼ Geo (1/ϑ), para
r = 1, ..., k, entonces:
f(νr | x, z,w,µ) ∝ νnrνrr
Γ(νr)nrexp {−νr (− log(1− ϑ) + Srµr − nr logµr − logPr)} ,
(2)
donde Pr =Q
i:Zi=rxi.
Generar valores de (2) puede ser muy costoso, pero podemos hacer uso del
algoritmo Metropolis - Hastings utilizando como distribucion propuesta una
Binomial Negativa,
fBN(ν) =³m+ ν − 2
ν − 1´pm(1− p)ν−1, ν = 1, 2, ... (3)
con valores de m y p interesantes.

2.4.1. Algoritmo MCMC (Gibbs + MH) para una mixtura de Erlangs.
1. Fijar valores iniciales para w(0),µ(0),ν(0).
2. Actualizar z generando de z(j+1) ∼ z|x,w(j),µ(j),ν(j).
3. Actualizar w generando de w(j+1) ∼ w|x, z(j+1).
4. Para r = 1, ..., k,
a. Actualizar µr generando de µ(j+1)r ∼ µr|x, z(j+1).
b. Actualizar νr utilizando un paso Metropolis Hastings.
5. Ordenar µ(j+1) y colocar w(j+1) y ν(j+1) segun este orden.
6. j = j + 1. Ir a 2.
En 4b. se generan candidatos de la Binomial Negativa (3) que se aceptan conla correspondiente probabilidad α = mın{1, Aν}.

2.5. Inferencia para una distribucion MGE con L fijo.
Tenemos una muestra {x1, ..., xn} de observaciones de una distribucion MGEcon L (conocido) fases.
Simplificamos la verosimilitud introduciendo variables latentes:
zi = Estado en el que sale xi.
yir = Tiempo que permanece xi en el estado r.
yi1 yi2 =⇒(
zi = 2xi = yi1 + yi2
)
Entonces,
f³zi, yi1, ..., yizi | L,P,µ
´= Pzi
ziQr=1
µr exp (−µryir)

Familia semiconjugada para los parametros:
A priori A posteriori
P ∼D (δ1, ..., δk) P | x, z ∼ D(δ1 + n1, ..., δk + nk)
µr ∼ Exp(β) µr | x, z ∼ G(α+ nrνr, β + Srνr),
Dados P y L, las distribuciones a posteriori condicionales de las variables la-tentes se pueden generar utilizando el Metodo del Rechazo.
1. Fijar valores iniciales.
2. Actualizar las variables latentes.
(2.1. Generar valores de z | x,P,µ.2.2. Generar valores de y | x, z,P,µ
3. Actualizar los parametros especıficos.
(3.1. Generar valores de z | x,P,µ3.2. Generar valores de y | x, z,P,µ
4. j = j + 1. Ir a 2.

3. Metodos MCMC cuando k es desconocido.
Distribucion a priori para el numero de componentes de la mixtura con soportefinito:
k ∼ UD [1, 10] , k ∼ Po (2) truncada, ...etc
Queremos construir una cadena de Markov que se mueva por la distribucion aposteriori del espacio de parametros:
kmaxSk=1
{(w1, ..., wk), (φ1, ...,φk)}cuya distribucion estacionaria coincida con la distribucion a posteriori de losparametros f (k,w,φ | x) .
En la literatura se han propuesto dos procedimientos:
1. Metodos de salto reversible (Richardson y Green, 1997).
2. Metodos MCMC en tiempo continuo (Stephens, 2000).

3.1. Metodos de Salto Reversible para mixturas.
Es una extension de los metodos Metropolis Hastings.
Recordatorio: en los MH se proponen un movimientos candidato de θj a θj+1
,
generado de una distribucion propuesta, q³θ, θ
´. El movimiento se acepta con
probabilidad,
α =f³θ | x
´p³θ,θ
´f (θ | x) p
³θ, θ
´ .
En los metodos de salto reversible la idea es la misma pero la implementacion
es mas difıcil porque el espacio parametrico es mas complejo. El conjunto de
parametros es: θ =(k,w,φ) , que incluye tambien al tamano de la mixtura, k.

3.1.1. Pasos generales del salto reversible.
1. Comenzar con unos valores θ(0) =³k(0),w(0),φ(0)
´.
Suponiendo que la cadena esta en el estado θ = (k,w,φ).
2. Iteracion MCMC de un algoritmo con k fijo.
3 Proponer un movimiento de θ a θ(j)con probabilidad p
³θ, θ
´.
3.a. Proponer un candidato k. (Suele tomarse k =± 1 con prob = 0.5)
3.b. Proponer un candidato z, w, φ. (p.e. con movtos. de combinacion/separacion).
4. Actualizar θ = θ con probabilidad mın{1, A}, donde A = f(θ|x)p(θ,θ)f(θ|x)p(θ,θ) donde,
f(θ|x)f(θ|x) =
f¡k¢f¡w|k¢f¡z|k,w¢f³φ|k´f³x|z,k,w,φ´
f(k)f(w|k)f(z|k,w)f(φ|k)f(x|z,k,w,φ)

En cuanto a los valores de p³θ,θ
´...
Si dim(θ) > dim(θ) : Se genera un vector u ∼ g(u) tal que dim (θ,u) =
dim³θ´con una transformacion (θ,u)
h→ θ biyectiva. En este caso:
p³θ,θ
´p³θ, θ
´ = p(k, k)
p(k, k)q(u)
¯¯ ∂h
∂ (θ,u)
¯¯
Si dim(θ) < dim(θ) : Se definen determinısticamente los valores can-
didatos con la funcion inversa θh−1→
³θ,u
´. En este caso :
p³θ,θ
´p³θ, θ
´ = p(k, k)q(u)
p(k, k)
¯¯∂h−1∂θ
¯¯

3.1.2. Salto reversible para mixturas de normales con k desconocido.
La idea es introducir un ”paso 8”en el algoritmo de la pagina 19 para actualizarel valor de k que consiste en lo siguiente:
8. 1. Generar un valor candidato k =
k + 1 si k = 1k − 1 si k = kmaxk ± 1 con p = 0.5 si 1 < k < kmax
8.2. Proponer valores candidatos para z, w, µ, σ segun sea k :
8.2.a. Si k = k − 1 (combinacion de dos componentes r1, r2 adyacentes al azar).w = wr1 +wr2
wµ = wr1µr1 +wr2µr2
w³µ2 + σ2
´= wr1
³µ2r1 + σ
2r1
´+wr2
³µ2r2 + σ
2r2
´Ademas, si zi = r1 o r2 entonces zi=r.

8.2.b. Si k = k + 1 (separacion en dos de una componente r al azar).
Se generan:
u1 ∼ Beta(2, 2), u2 ∼ Beta(2, 2), u3 ∼ Beta(1, 1),
y se fijan:
wr1 = wru1, wr2 = wr (1− u1)
µr1 = µr − u2σrÃwr1wr2
!1/2, µr2 = µr + u2σr
Ãwr1wr2
!1/2
σr1 = u3³1− u22
´σrwr
wr1, σr1 = u3
³1− u22
´σrwr
wr2
Ademas, si zi = r entonces zi =
r1 con prob ∝ wr1fr1³xi | µr1, σ2r1
´r2 con prob ∝ wr2fr2
³xi | µr2, σ2r2
´Importante: Estos movimientos tienen que preservar la reversibilidad.

8.3. Calcular la probabilidad de aceptar mın{1, A} (pg. 29). Tiene una expresioncomplicada pero evaluable. En una combinacion:
A =f¡k¢f¡w|k¢f¡z|k,w¢f¡µ|k,σ2¢f¡σ2|k¢f¡x|z,k,w,µ,σ2¢
f(k)f(w|k)f(z|k,w)f(µ|k,σ2)f(σ2|k)f(x|z,k,w,µ,σ2)p(θ,θ)
p(θ,θ)
A =f(k+1)f(k)
wδ−1r1 wδ−1r2
wδ−1r
wnr1r1 w
nr2r2
wnr1+nr2r
(k+1)f³µr1
|k,σr1´f³µr2
|k,σr1´
f(µr|k,σ2)f(σ2|k) ××razon de verosimilitudes
× dk+1bk (
QP (zi)) g (u1) g (u2) g (u3)
×wr
¯µr1 − µr2
¯σ2r1σ
2r2
u2³1− u22
´(1− u3)σ2r
donde
dk =1
2
1
k − 1(dkmax =1
kmax − 1) y bk =
1
2
1
k(bkmın =
1
kmın),
y donde g son las densidades beta de u1, u2 y u3. El ultimo termino es eldeterminante del jacobiano de la transformacion
(wr, µr, σr, u1, u2, u3)→³wr1, wr2, µr1, µr2, σ
2r1σ
2r2
´

Con una muestra MCMC de tamano J de la distribucion a posteriori de los
parametros³k,w,µ,σ2
´:
½k(j),
µw(j)1 , ..., w
(j)
k(j)
¶,µµ(j)1 , ..., µ
(j)
k(j)
¶,µσ2(j)1 , ..., σ
2(j)
k(j)
¶¾,
para j = 1, ..., J, podemos estimar la densidad predictiva con:
f(x | x) = 1
J
J+BXj=1+B
k(j)Xr=1
w(j)r
(2π)1/2 σrexp
−µx− µ(j)r
¶22σ2(j)r
donde B indica el numero de iteraciones de burn in. (Notar la diferencia con
la predictiva con k fijo en pg. 19)

Ejemplo1: Datos de la actividad enzimatica en la sangre.
Cada funcion de densidad es una mixtura de normales de parametros (k(j),w(j),µ(j), σ(j)).
La media de todas ellas sera la estimacion de la densidad predictiva.
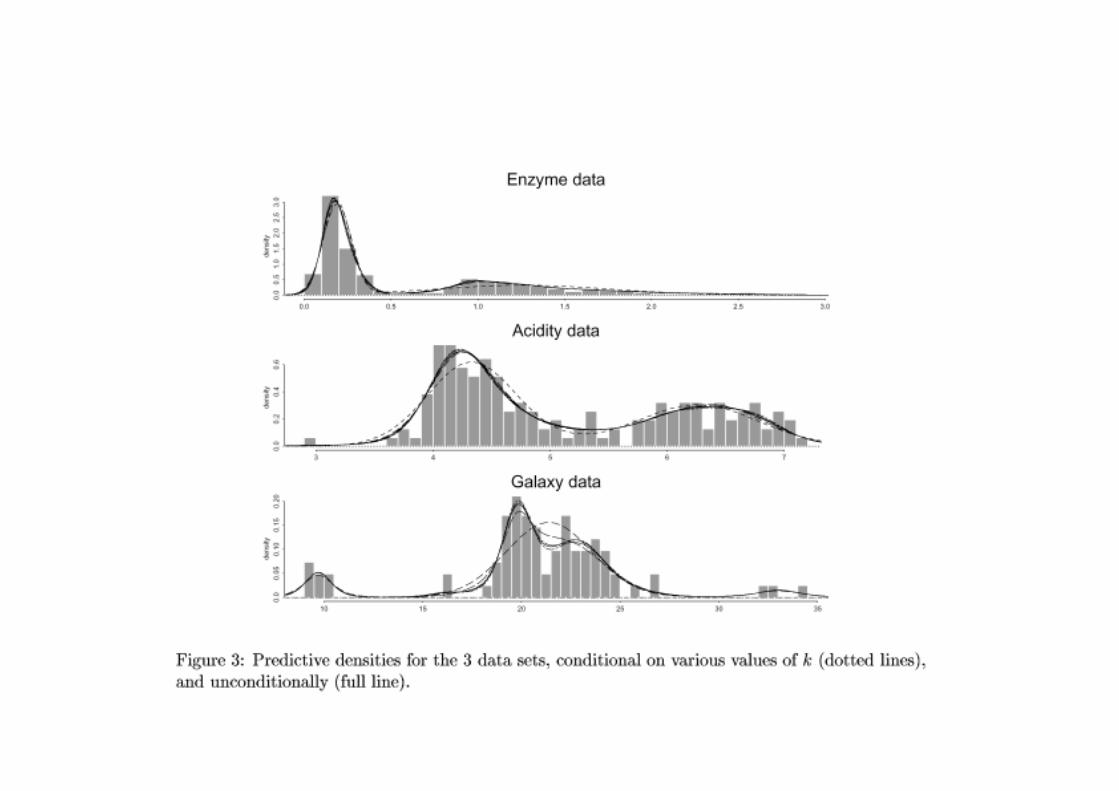

3.1.3. Salto reversible para mixturas de Erlangs con k desconocido.
1. Valores Iniciales.
2. MCMC con k fijo. (Algoritmo HEr.)
3. Una combinación (o separación) de componentes.
4. Una muerte (o nacimiento) de una componente vacía.
5. Ir a 2.
k = 4 k = 3
k = 3 k = 2

Combinacion/separacion:
Se genera un candidato k = k ± 1 con Pr = 0.5.Combinacion: Se escogen al azar dos componentes adyacentes para fusionarse en una.
Separacion: Se escoge al azar una componentes para separarse en dos.
Se modifican los parametros para preservar los momentos de orden 0 y 1 de X.
Se acepta o se rechaza el movimiento.
Nacimiento/muerte de componentes vacıas:
Se genera un candidato k = k ± 1 con Pr = 0.5.Nacimiento: Se generan parametros de la priori para crear una nueva componente vacıa.
Muerte: Se escoge al azar una componente vacıa para desaparecer.
Se modifican los pesos para que sumen uno.
Se acepta o se rechaza el movimiento.

3.1.4. Salto reversible para la distribucion MGE con L desconocido.
1. Valores Iniciales.
2. MCMC con L fijo. (Algoritmo MGE.)
3. Una combinación (o separación) de componentes.
5. Ir a 2.
L = 4 L = 3
4. Una muerte (o nacimiento) de una componente vacía.
L = 2L = 3

Ejemplos:
1. 100 datos generados de una distribucion exponencial de media 1.0.
2. 100 observaciones generadas de una mixtura de distribuciones Erlang con,
w =(0.3, 0.35, 0.35) ,µ =(1/2, 1/6, 1/12) y ν =(10, 15, 25) .
3. 100 observaciones generadas de una distribucion Coxiana con parametros
P =(0.1, 0.9) y µ =(5, 30) .
4. 100 datos iguales a 1.0 procedentes de una distribucion degenerada.
5. 100 datos de una distribucion Weibull, Weib (1.5, 1.5) .
6. 1092 datos de la duracion (en dıas) de la estancia de enfermos en un
hospital geriatrico.

0 2 4 6 8 100
0.5
1
Caso 1: Exponencial0 5 10 15 20
0
0.1
0.2
0.3
0.4
Caso 2: Mixtura HEr
0 0.5 1 1.50
1
2
3
4
Caso 3: Mixtura MGE0 1 2 3
0
10
20
30
Caso 4: Degenerada
0 1 2 3 40
0.5
1
1.5
Caso 5: Weibull
Funciones de densidad predictivas suponiendo los dos modelos de mixtura,
HEr (− −) y MGE (· · · ) ,
0 50 100 1500
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
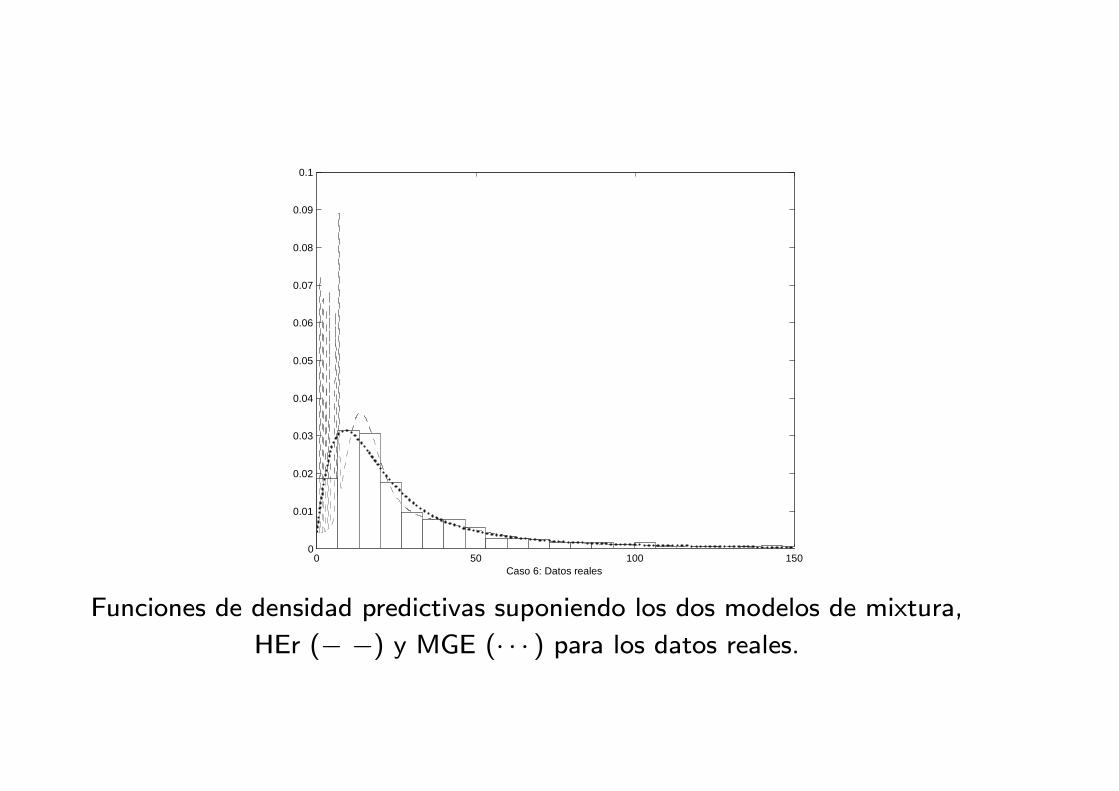
Caso 6: Datos reales
Funciones de densidad predictivas suponiendo los dos modelos de mixtura,
HEr (− −) y MGE (· · · ) para los datos reales.

3.2. Metodos MCMC en tiempo continuo para mixturas.
Los metodos en tiempo continuo (CTMCMC) son una alternativa a los de
salto reversible (RJMCMC).
La idea se basa en construir un proceso de Markov (en tiempo continuo)
cuya distribucion estacionaria coincida con la posteriori de los parametros.
El numero de componentes de la mixtura varıa en tiempo continuo.
Estos procedimientos fueron introducidos por Stephens (2000) consideran-
do procesos de nacimiento y muerte (BDMCMC).
• Se sustituyen los movimientos de tipo Metropolis Hastings del saltoreversible (RJ) por un proceso de nacimiento y muerte (BD) cuyo es-
pacio de estados es el espacio parametrico incluida la dimension de la
mixtura.

• El tamano de la mixtura, k, varıa de modo que “nacen” y “mueren”sus componentes en tiempo continuo.
• No se aceptan ni rechazan candidatos para k. Los estados mas proba-bles son aquellos en los que se permanece mas tiempo.
• Los nacimientos se producen con tasa constante.
• La tasa de muerte de cada componente es baja si explica poco sobrelos datos y viceversa.
• El proceso BD se combina con metodos MCMC en los que el valor dek permanece fijo.
Stephens (2000) describe un metodo BDMCMC para mixturas de normales
con k desconocida.
Vamos a construir algoritmos BDMCMC para mixturas de Erlang y para la
distribucion MGE.

3.2.1. Metodo BDMCMC para una mixtura de Erlangs con k desconocido.
1. Valores Iniciales.
2. Proceso BD durante un tiempo t0.
3. MCMC con k fijo. (Algoritmo HEr.).
4. Ir a 2.
Valor Inicial (k = 3)
t = t0
t = 0
Nacimiento (k = 4)
Muerte (k = 3)
Muerte (k = 2)
Nacimiento (k = 3)

Veamos el paso 2 con mas detalle:
El proceso BD se simula durante un tiempo fijo, p.e., t0 = 1.
La tasa de nacimiento, γ, es constante, (p.e. γ = 2). Cuando nace una com-
ponente, se genera un nuevo peso wr ∼ Be (1, k) y el resto de parametros φ
de la priori.
La tasa de muerte, δ, varıa a lo largo del proceso y es igual a δ =Pkr=1 δr,
donde,
δr0 = γp(k−1)kp(k)
nQi=1
Pk
r=1r 6=r0
wr1−wr0
Er(xi|νr,µr)Pkr=1wrEr(xi|νr,µr)
, para r0 = 1, ..., k.
Cuando muere una componente, los pesos restantes se reescalan para que
sumen 1.

El paso 2 tiene la estructura siguiente:
2. Proceso BD simulado durante t0.
a. Comenzar en³w(t),µ(t),ν(t)
´.
b. Calcular las tasa de muerte para r = 1, ..., k(j).
c. Simular un tiempo Exp (δ + γ) hasta el proximo nacimiento o muerte.
d. Generar si se trata de nacimiento (prob = γγ+δ) o muerte (prob =
δγ+δ).
e. Modificar w, µ y ν para reflejar el nacimiento o muerte.
f. Si el tiempo de ejecucion es menor que t0 ir a (b).

3.2.2. Metodo BDMCMC para una distribucion MGE con L desconocido.
1. Valores Iniciales.
2. Proceso BD durante un tiempo t0.
3. MCMC con L fijo. (Algoritmo MGE.).
4. Ir a 2.
Valor Inicial (L = 4)
t = t0
t = 0
Nacimiento (L = 5)
Muerte (L = 4)
Muerte (L = 3)
Muerte (L = 2)

3.3. Comentarios y comparaciones de RJMCMC y CTMCMC.
Los algoritmos de tipo BDMCMC son sencillos de implementar. No hay
que calcular jacobianos de transformaciones.
Aunque la simplicidad de la programacion de los BDMCMC es mas bien por
el tipo de movimiento (nacimiento/muerte) y no por el diseno en tiempo
continuo del algoritmo.
• Se podrıan construir algoritmos CTMCMC con movimientos de com-binacion/separacion.
• Se podrıan construir algoritmos RJMCMC solo con movimientos de
nacimiento/separacion.
Los BDMCMC son un poco mas costosos computacionalmente.
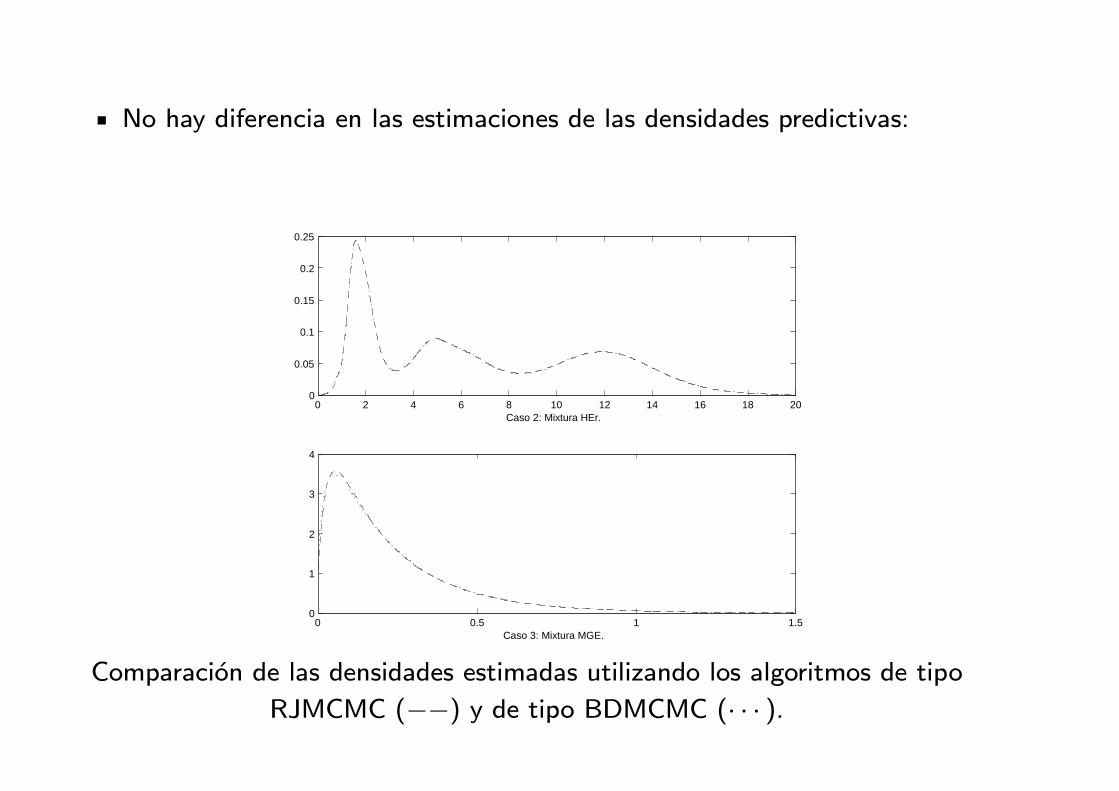
No hay diferencia en las estimaciones de las densidades predictivas:
0 2 4 6 8 10 12 14 16 18 200
0.05
0.1
0.15
0.2
0.25
Caso 2: Mixtura HEr.
0 0.5 1 1.50
1
2
3
4
Caso 3: Mixtura MGE.
Comparacion de las densidades estimadas utilizando los algoritmos de tipo
RJMCMC (−−) y de tipo BDMCMC (· · · ).
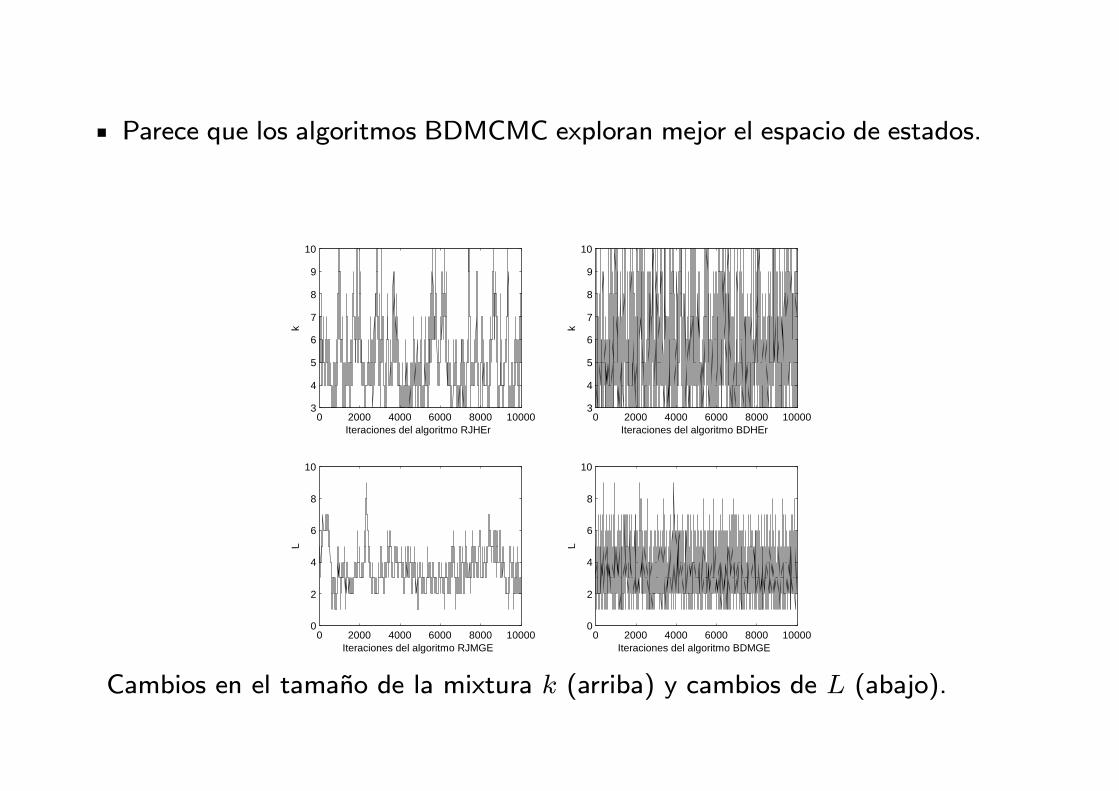
Parece que los algoritmos BDMCMC exploran mejor el espacio de estados.
0 2000 4000 6000 8000 100003
4
5
6
7
8
9
10
Iteraciones del algoritmo RJHEr
k
0 2000 4000 6000 8000 100003
4
5
6
7
8
9
10
Iteraciones del algoritmo BDHEr
k
0 2000 4000 6000 8000 100000
2
4
6
8
10
L
Iteraciones del algoritmo RJMGE0 2000 4000 6000 8000 10000
0
2
4
6
8
10
Iteraciones del algoritmo BDMGE
L
Cambios en el tamano de la mixtura k (arriba) y cambios de L (abajo).

Las probabilidades a posteriori del numero de componentes en la mixtura
son parecidas:
P (k | x) 1 2 3 4 5 6 7 8 9 10Alg. RJHEr .000 .005 .194 .260 .217 .145 .088 .052 .026 .009Alg. BDHEr .000 .002 .167 .194 .171 .146 .120 .095 .078 .022
P (L | x) 1 2 3 4 5 6 7 8 9 10Alg. RJMGE .008 .218 .379 .260 .096 .031 .005 .001 .000 .000Alg. BDMGE .039 .288 .335 .204 .088 .031 .009 .002 .000 .000
En resumen:
• Los algoritmos BDMCMC utilizados son mas sencillos de implementary pueden visitar estados improbables.
• Los algoritmos RJMCMC utilizados son menos costosos computacional-mente en cuanto a velocidad y a memoria requerida.

4. Aplicaciones a colas.
Un modelo de colas se caracteriza con la notacion de Kendall:
A/S/c/K
donde A y S el la conducta de llegadas y servicios, resp., c es el numero de
servidores y K es la capacidad del sistema.
Ejemplos: M/M/1, GI/M/c,M/HEr/c/c,...etc
Una medida de la ocupacion del sistema es la intensidad de trafico,
ρ =tasa media de llegadas
tasa media de servicio=E [S]
E [A].

Hay toda una Teorıa de Colas destinada al estudio probabilıstico de estos
modelos.
Su objetivo es, dados los parametros de llegadas y de servicio,:
1. Predecir las cantidades de interes: Numero de clientes en el sistema,
tiempo de espera....
2. Introducir estas cantidades en disenos y optimizacion de costes.
Sin embargo, en la TC se asume que los parametros y el modelo de colas
es conocido.
Existe poco trabajo destinado a la inferencia en colas.

4.1. ¿Como abordar la inferencia?
Experimento tradicional: Observar (por separado) na tiempos entre llegadas,
t = {t1, ..., tna}, y ns tiempos de servicio, s = {s1, ..., sns}.
Independencia a priori entre llegadas y servicios → Independencia a posteriori
entre llegadas y servicios.
IDEA: Aproximar las distribuciones desconocidas mediante los modelos de mix-
tura HEr o MGE (definidas en (0,∞)), p.e.:M/G/1 'M/HEr/1
y utilizar los metodos de inferencia para mixturas con k desconocido que hemos
utilizado antes.

Por ejemplo, supongamos que tenemos un sistema M/G/1 cuyo proceso de
llegadas es Poisson de tasa λ (que suponemos conocida).
Aproximamos la distribucion general de servicio con una mixtura de Erlangs.
Supongamos que a partir de los datos de servicio t = {t1, ..., tna} y ten-emos una muestra MCMC de la distribucion a posteriori de sus parametros:
{k(j),w(j),µ(j),ν(j)}Jj=1. Podemos estimar el tiempo medio de servicio,
E [S | t] ≈ k(j)Pr=1
w(j)r
µ(j)r
y podemos estimar la intensidad de trafico,
E [ρ | t, s] ≈ λE [S | t]y la probabilidad de que haya equilibrio en el sistema,
P (ρ < 1 | t, s) ≈ 1
J#nρ(j) < 1
o, donde ρ = λ
Pk(j)r=1w
(j)r /µ
(j)r . (4)

Si ρ < 1, entonces el sistema es estable y existen las distribuciones estacionar-ias de las cantidades de interes, como el numero de clientes en el sistema,N . Por eso, la estimacion de la probabilidad (4) es muy importante, si es losuficientemente alta se asume equilibrio.
Si la probabilidad de equilibrio es alta, podemos estimar la distribucion delnumero de clientes en el sistema, N,
P (N = n | t, s, ρ < 1) ≈ 1
R
Xj:ρ(j)<1
P³N = n | λ,w(j),µ(j),ν(j)
´,
donde R es el numero de veces que se verifica la condicion de equilibrio.
Importante: Tenemos que conocer la distribucion de N dados los parametros,para eso utilizamos los resultados de la Teorıa de Colas.
Analogamente, se puede estimar la funcion de distribucion del tiempo de esperaen cola, W :
FW (x | t, s, ρ < 1) ≈ 1
R
Xj:ρ(j)<1
FW³x | λ,w(j),µ(j),ν(j)
´

4.2. Ejemplos.
5 sistemas de colas simulados cuyos tiempos de servicio son los 5 conjuntos
de datos simulados de antes.
Se asume la tasa de llegadas λ conocida y tal que ρ = 0.6 en los 5 sistemas.
P (ρ < 1 | datos) M/M/1 M/HEr/1 M/MGE/1 M/D/1 M/Weib/1Alg. RJHEr 0.9980 0.9995 0.9881 0.9964 0.9973Alg. RJMGE 0.9990 0.9994 0.9971 0.9891 0.9962
E [ρ | ρ < 1] M/M/1 M/HEr/1 M/MGE/1 M/D/1 M/Weib/1Alg. RJHEr 0.6279 0.6062 0.6010 0.6033 0.5877Alg. RJMGE 0.6177 0.6093 0.5963 0.5813 0.5762
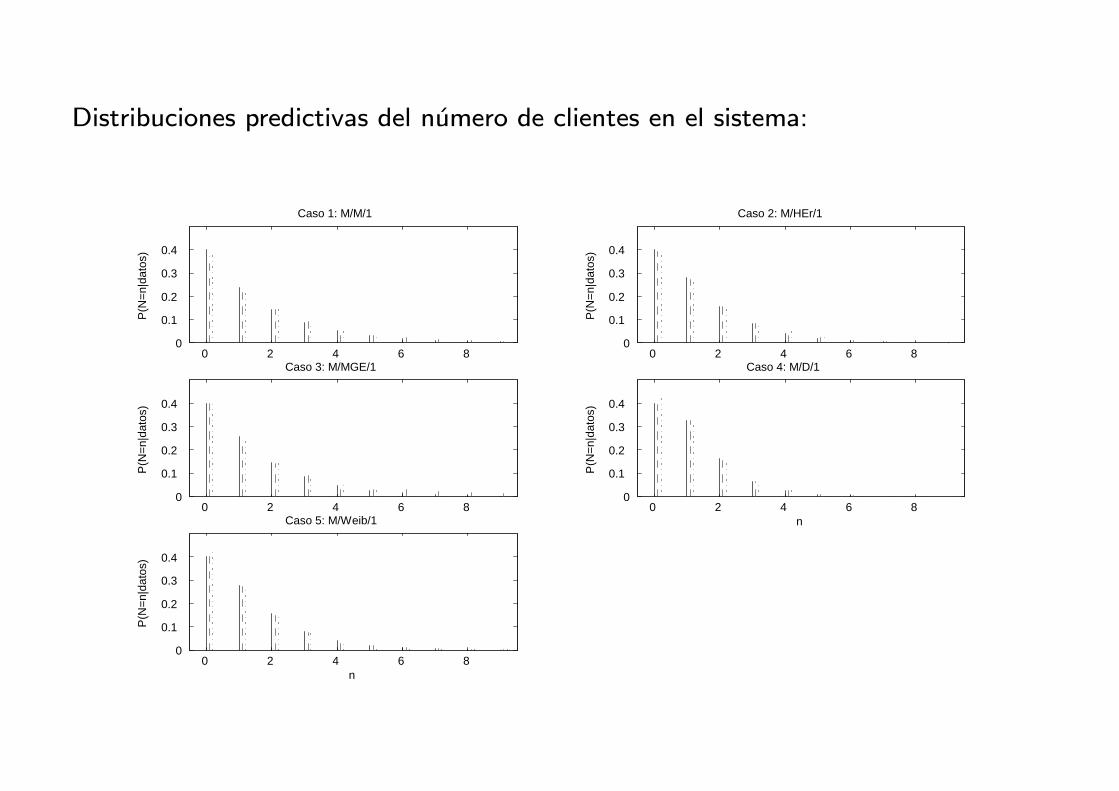
Distribuciones predictivas del numero de clientes en el sistema:
0 2 4 6 80
0.1
0.2
0.3
0.4
Caso 1: M/M/1
P(N
=n|
dato
s)
0 2 4 6 80
0.1
0.2
0.3
0.4
Caso 2: M/HEr/1
P(N
=n|
dato
s)
0 2 4 6 80
0.1
0.2
0.3
0.4
Caso 3: M/MGE/1
P(N
=n|
dato
s)
0 2 4 6 80
0.1
0.2
0.3
0.4
Caso 4: M/D/1
n
P(N
=n|
dato
s)
0 2 4 6 80
0.1
0.2
0.3
0.4
Caso 5: M/Weib/1
n
P(N
=n|
dato
s)

Tiempo
Distribuciones predictivas del tiempo de espera en cola:
0 5 10 15 200
0.5
1Caso 1: M/M/1
FW
(x|d
atos
)
0 20 40 60 80 1000
0.5
1Caso 2: M/HEr/1
FW
(x|d
atos
)
0 1 2 3 4 50
0.5
1Caso 3: M/MGE/1
FW
(x|d
atos
)
0 5 10 15 200
0.5
1Caso 4: M/D/1
xF
W(x
|dat
os)
0 5 10 15 200
0.5
1Caso 5: M/Weib/1
x
FW
(x||d
atos
)
