matemmaticas aplicadas ii - consellería de cultura, educación e … · 2º bachillerato...
TRANSCRIPT

2º BACHILLERATO HUMANIDADES Y CIENCIAS SOCIALES
MATEMÁTICAS APLICADAS A LAS CIENCIAS SOCIALES II
EDUARDO CASTRO PERALTA

2º Bachillerato Humanidades y Ciencias Sociales 1
I.1.- CONCEPTO DE MATRIZ. LA MATRIZ COMO EXPRESIÓN DE TABLAS Y GRAFOS. TIPOS DE
MATRICES.
Definición de matiz nxp. Elementos de una matriz. Notaciones. Tipos de matrices: rectangulares, cuadradas (triangulares, diagonal, identidad, simétricas…). Matrices fila y columna. Matriz nula. Traspuesta de una matriz. DEFINICIÓN DE MATRIZ nxp. ELEMENTOS DE UNA MATRIZ. NOTACIONES. Se llama matriz de orden (o tipo, o dimensión) nxp a cualquier conjunto de nxp números (normalmente reales) ordenados en n filas y p columnas. Una matriz se representa de cualquiera de las formas siguientes:
( )
==≤≤≤≤
npn2n1
2p2221
1p1211
pj1ni1ij
a............aa
.....................
.....................
a............aa
a............aa
aA
Los elementos de una matriz son los números que aparecen en ella. Los subíndices de cada elemento indican la fila y columna en que está situado. Dos matrices son iguales si son del mismo tipo y los elementos correspondientes en ambas son iguales.
El conjunto de todas las matrices nxp se representa Mnxp.

2º Bachillerato Humanidades y Ciencias Sociales 2
TIPOS DE MATRICES: RECTANGULARES, CUADRADAS (TRIANGULARES, DIAGONAL, IDENTIDAD, SIMÉTRICAS…). M ATRICES FILA Y COLUMNA. MATRIZ NULA. TRASPUESTA DE UNA MATR IZ. Una matriz se llama rectangular si tiene distinto número de filas que de columnas (n ≠ p) y cuadrada si tiene igual número de filas que de columnas (n = p). Para las matrices cuadradas es suficiente decir que son de orden n. En una matriz cuadrada son importantes la diagonal principal que está formada por los elementos con índices iguales (i = j) y la diagonal secundaria que está formada por los elementos cuyos índices cumplen que i + j = n + 1. (Son las dos diagonales del cuadrado que forma la matriz). Una matriz cuadrada se llama triangular superior si todos los elementos que están situados por debajo de la diagonal principal son nulos (aij = 0 si i > j) y triangular inferior si todos los elementos situados por encima de la diagonal principal son nulos (aij = 0 si i < j). Una matriz cuadrada se llama diagonal si todos los elementos situados fuera de la diagonal principal son nulos (aij = 0 si i ≠ j). La matriz identidad o unidad de orden n, In, es la matriz diagonal cuya diagonal principal está formada sólo por unos (aii = 1 i). Una matriz cuadrada se llama simétrica si sus elementos son simétricos respecto a la diagonal principal, es decir, si aij = aji i,j. (Si doblándola por la diagonal principal coincide consigo misma). Se llama matriz fila a la que está formada sólo por una fila, es decir, que es del tipo 1xp. Y matriz columna a la que está formada sólo por una columna, es decir, que es del tipo nx1. La matriz nula de orden nxp es la que está formada sólo por ceros. Dada una matriz A = ( )ija de orden nxp, su matriz traspuesta At = ( )ijb es la
matriz de orden pxn cuyos elementos son bij = aji i,j. Es decir, la que se obtiene poniendo como filas las columnas de la matriz A y como columnas las filas de la matriz A. Evidentemente una matriz cuadrada A es simétrica si y sólo si A = At.

2º Bachillerato Humanidades y Ciencias Sociales 3
I.2.- OPERACIONES CON MATRICES. Suma de matrices de orden nxp. Opuesta de una matriz. Propiedades de la suma de matrices. Producto de un número por una matriz. Propiedades. Definición del producto de matrices. Propiedades del producto de matrices: asociatividad, no conmutatividad, distributividad respecto a la suma. Elemento neutro. SUMA DE MATRICES DE ORDEN nxp. OPUESTA DE UNA MATRI Z. PROPIEDADES DE LA SUMA DE MATRICES. Dadas dos matrices del mismo orden nxp: A = (aij), B = (bij), se define su suma como la matriz del mismo orden nxp que se obtiene sumando entre sí los elementos correspondientes de las dos matrices.
A + B = (aij + bij)
La suma de matrices nxp es interna en el conjunto Mnxp y además tiene las siguientes propiedades (por tenerlas los números reales):
1) Asociativa: (A + B) + C = A + (B + C) 2) Conmutativa: A + B = B + A 3) Existe elemento neutro que es la matriz nula nxp: A + 0 = 0 + A = A 4) Todas las matrices tienen elemento simétrico para la suma. El simétrico de una
matriz A es la misma matriz con todos los signos cambiados y se llama matriz opuesta de la matriz A representándose – A: A + (- A) = (- A) + A = 0
Por cumplir estas propiedades las matrices nxp con la suma forman un grupo conmutativo o abeliano. PRODUCTO DE UN NÚMERO POR UNA MATRIZ. PROPIEDADES. Se define el producto de un número real k (que suele llamarse escalar) por una matriz nxp A = (aij) como la matriz del mismo tipo que se obtiene multiplicando todos los elementos de la matriz A por el número k.
k·A = (k·aij)

2º Bachillerato Humanidades y Ciencias Sociales 4
Esta operación tiene las siguientes propiedades: 1) k·(A + B) = k·A + k·B 2) (k + h)·A = k·A + h·A 3) k·(h·A) = (k·h)·A 4) 1·A = A
DEFINICIÓN DEL PRODUCTO DE MATRICES. PROPIEDADES DE L PRODUCTO DE MATRICES: ASOCIATIVIDAD, NO CONMUTATIVI DAD, DISTRIBUTIVIDAD RESPECTO A LA SUMA. ELEMENTO NEUTRO . Dadas una matriz A = (aij) de orden nxp y otra B = (bij) de orden pxq se define el producto de A por B (en ese orden) como la matriz A·B = (cij) de tipo nxq cuyos elementos se obtienen multiplicando las filas de la matriz A por las columnas de la matriz B, es decir:
∑=
⋅=p
1kkjikij bac
Nótese que para poder multiplicar dos matrices tiene que coincidir el número de columnas de la primera con el de filas de la segunda. Esta operación tiene las propiedades: Asociativa: (A·B)·C = A·(B·C) Distributiva respecto a la suma por ambos lados: A·(B + C) = A·B + A·C (A + B)·C = A·C + B·C Pero no tiene la propiedad conmutativa por las siguientes razones: 1.- a veces es posible hacer un producto pero no el otro. (si A es 2x3 y B 3x4, puede hacerse A·B pero no B·A). 2.- pudiendo hacer los dos los resultados pueden ser de tipos distintos. (si A es 2x3 y B 3x2 el producto A·B será 2x2 y el B·A 3x3). 3.- pudiendo hacer los dos y siendo los resultados del mismo tipo no tienen por qué ser iguales. Si nos restringimos a matrices cuadradas de orden n también es una operación interna y además tiene elemento neutro (la matriz identidad de orden n), por lo que el
conjunto Mnxn de las matrices cuadradas de orden n con la suma y el producto forman un anillo unitario no conmutativo que además tiene divisores de cero (elementos no nulos cuyo producto es la matriz nula). En general no existe inverso para el producto. En el tema siguiente se verá qué condiciones debe cumplir una matriz cuadrada para tener inversa (ser regular) y quien es esa inversa en caso de existir.

2º Bachillerato Humanidades y Ciencias Sociales 5
I.3.- OBTENCIÓN DE MATRICES INVERSAS SENCILLAS POR EL MÉTODO DE GAUSS.
DEFINICIÓN DE MATRIZ INVERSA. Hemos visto que las matrices cuadradas de orden n con la suma y el producto de matrices forman un anillo unitario no conmutativo en el que el elemento neutro para el producto es la matriz unidad o identidad de orden n: In. Nos faltaba estudiar si las matrices cuadradas tienen simétrica para el producto (inversa) y quién es esa inversa en caso de existir. La matriz inversa de una matriz cuadrada A será otra matriz cuadrada A- 1, si existe, que cumpla que:
A·A- 1 = In y A- 1·A = In No todas las matrices cuadradas tienen inversa. No vamos a estudiar qué condiciones debe cumplir una matriz cuadrada para tener inversa. Intentaremos calcularla; si lo conseguimos la tendrá y si no lo conseguimos no la tendrá. Las matrices cuadradas que tienen inversa se llaman regulares y las que no singulares. En caso de existir las matrices inversas cumplen las siguientes propiedades: 1.- La inversa del producto de dos matrices cuadradas e inversibles de orden n es el producto de sus inversas en orden contrario: (A·B)- 1 = B- 1·A- 1. 2.- La inversa de la inversa es la matriz original: (A- 1)- 1 = A. 3.- La inversa de una matriz cuadrada, si existe, es única. OBTENCIÓN DE LA MATRIZ INVERSA APLICANDO LA DEFINIC IÓN. Para calcular la inversa podemos aplicar la definición: la inversa de una matriz cuadrada A, si existe, será otra matriz cuadrada A- 1 (del mismo tipo) que cumpla que A·A- 1 = A- 1·A = In. Entonces, considerando como incógnitas los elementos de la matriz A- 1, se plantea un sistema de ecuaciones. Si hay solución obtenemos la inversa A- 1 y si no hay solución la matriz A no tiene inversa.

2º Bachillerato Humanidades y Ciencias Sociales 6
NOTA IMPORTANTE: La matriz A- 1 tiene que cumplir que A·A- 1 = In y que A- 1 ·A = In. Como sólo planteamos una de las dos igualdades no hay que olvidarse de comprobar que los valores que se obtienen al resolver el sistema también cumplen la otra igualdad ya que, de no cumplirla, la matriz obtenida no sería la inversa de A. (Esto se debe a que el producto de matrices no es conmutativo). OBTENCIÓN DE LA MATRIZ INVERSA POR EL MÉTODO DE GAU SS. El cálculo de la inversa de una matriz cuadrada aplicando la definición puede llevar a sistemas grandes (simplemente si la matriz es de orden 4 el sistema tiene 16 ecuaciones y 16 incógnitas) cuya resolución da bastante trabajo. Hay otro método, conocido como método de Gauss, o de Gauss-Jordan, que permite obtener la matriz inversa de una forma bastante sencilla. El método consiste en lo siguiente: Partimos de la matriz formada por la matriz cuadrada A, cuya inversa queremos calcular, y a su lado ponemos la matriz identidad del mismo orden que A. Esta matriz se llama matriz ampliada y se representa (A/I):

2º Bachillerato Humanidades y Ciencias Sociales 7
A esta matriz se le aplican una serie de transformaciones u operaciones elementales hasta llegar a otra matriz de la forma (I/B):
La matriz B, así obtenida, es la inversa de la matriz A. Las transformaciones u operaciones elementales que se pueden hacer son:
• Intercambiar entre sí dos filas. • Multiplicar (o dividir) una fila por un número distinto de 0. • Sumarle a una fila un múltiplo de otra.
Veamos un ejemplo:

2º Bachillerato Humanidades y Ciencias Sociales 8
Como se ha visto en el ejemplo, para calcular una matriz inversa por el método de Gauss se hace lo siguiente (usando las transformaciones citadas antes):
1.- conseguir que el elemento a11 valga 1. 2.- a partir de ese elemento conseguir que todos los demás de la primera
columna valgan 0. 3.- hacer lo mismo con el elemento a22 y la segunda columna, etc.
Si en alguno de los pasos del cálculo de la matriz inversa de A aparece una fila de ceros o dos filas proporcionales en la parte izquierda de la matriz ampliada, entonces la matriz A no tiene inversa.

2º Bachillerato Humanidades y Ciencias Sociales 9
I.4.- SISTEMAS DE ECUACIONES LINEALES. Definición de: ecuación lineal con p incógnitas, solución de una ecuación lineal, sistema de n ecuaciones lineales con p incógnitas, solución de un sistema de ecuaciones. Forma matricial de un sistema de ecuaciones lineales. Clasificación de los sistemas según el número de soluciones. DEFINICIÓN DE: ECUACIÓN LINEAL CON p INCÓGNITAS, SO LUCIÓN DE UNA ECUACIÓN LINEAL. Una ecuación lineal (de primer grado) con p incógnitas es una expresión de la forma
a1x1 + a2x2 + ..... + apxp = b
donde los ai son números reales que se llaman coeficientes de la ecuación, b es un número real que se llama término independiente y las xi son las incógnitas de la ecuación. Si el término independiente es nulo la ecuación se llama homogénea. Una solución de la ecuación es un conjunto de p números reales s1, s2, ... ,sp, (uno por cada incógnita) que, sustituidos en lugar de las correspondientes incógnitas, cumplen la igualdad que indica la ecuación. DEFINICIÓN DE: SISTEMA DE n ECUACIONES LINEALES CON p INCÓGNITAS, SOLUCIÓN DE UN SISTEMA DE ECUACIONES. Un sistema de n ecuaciones lineales (de primer grado) con p incógnitas es cualquier expresión de la forma
=+++
=+++
=+++
npnp2n21n1
2p2p222121
1p1p212111
bxa..........xaxa
.........................................................
.........................................................
bxa..........xaxa
bxa..........xaxa

2º Bachillerato Humanidades y Ciencias Sociales 10
donde los aij son números reales que se llaman coeficientes del sistema, los bi son también números reales que se llaman términos independientes y las xj son las incógnitas del sistema. Si todos los términos independientes son nulos el sistema se llama homogéneo. Se llama solución del sistema a cualquier conjunto de p números reales s1, s2, ..., sp (uno por cada incógnita) que, sustituidos en lugar de las incógnitas, cumplan todas las ecuaciones del sistema.
Resolver un sistema es averiguar si tiene solución y, en caso afirmativo, hallarlas todas. Ya son conocidos los métodos de reducción, igualación y sustitución para resolver sistemas de ecuaciones lineales. En este curso se verá otro método: el de Gauss. FORMA MATRICIAL DE UN SISTEMA DE ECUACIONES LINEALE S. Dado un sistema de n ecuaciones lineales con p incógnitas se pueden considerar las siguientes matrices:
=
=
=
n
2
1
p
2
1
npn2n1
2p2221
1p1211
b
...
...
b
b
B
x
...
...
...
...
x
x
X
a............aa
.....................
.....................
a............aa
a............aa
A
que se llaman respectivamente matriz del sistema o de los coeficientes (nxp), matriz de las incógnitas (px1) y matriz de los términos independientes (nx1), así como la matriz ampliada (nx(p + 1)):
( )
=
n
2
1
npn2n1
2p2221
1p1211
b
...
...
b
b
a............aa
.....................
.....................
a............aa
a............aa
BA

2º Bachillerato Humanidades y Ciencias Sociales 11
con lo que el sistema puede escribirse en la forma llamada matricial (usando matrices):
A·X = B
=
⋅
n
2
1
p
2
1
npn2n1
2p2221
1p1211
b
...
...
b
b
x
...
...
...
...
x
x
a............aa
.....................
.....................
a............aa
a............aa
Y también, si representamos por Cj las columnas de la matriz del sistema, podemos escribir el sistema en la llamada forma vectorial:
C1x1 + C2x2 + .......... + Cpxp = B
=
++
+
n
2
1
p
np
2p
1p
2
n2
22
12
1
n1
21
11
b
...
...
b
b
x
a
...
...
a
a
..........x
a
...
...
a
a
x
a
...
...
a
a
CLASIFICACIÓN DE LOS SISTEMAS SEGÚN EL NÚMERO DE SOLUCIONES. Como vimos antes, resolver un sistema es averiguar si tiene alguna solución y, en caso afirmativo, hallarlas todas. Un sistema se llama compatible si tiene alguna solución e incompatible si no tiene ninguna. Los sistemas compatibles se dividen en determinados si la solución es única (un único valor para cada incógnita) e indeterminados si tienen varias soluciones (en cuyo caso son infinitas). Evidentemente los sistemas homogéneos son siempre compatibles porque tienen al menos la solución llamada trivial: x1 = x2 = .......... = xp = 0.

2º Bachillerato Humanidades y Ciencias Sociales 12
I.5.-RESOLUCIÓN DE ECUACIONES Y SISTEMAS SENCILLOS DE ECUACIONES MATRICIALES.
Utilización del método de Gauss en la discusión y resolución de un sistema de ecuaciones lineales con 2 ó 3 incógnitas. SISTEMAS EQUIVALENTES. Dos sistemas de ecuaciones, con las mismas incógnitas, se llaman equivalentes si tienen las mismas soluciones. (Pueden tener distinto número de ecuaciones). Muchos métodos de resolución de sistemas, como el de reducción, se basan en aplicar al sistema una serie de transformaciones que permitan convertirlo en otro equivalente pero de resolución más sencilla. Las transformaciones que permiten convertir un sistema en otro equivalente son: 1.- Si se multiplican o se dividen los dos miembros de una ecuación por un mismo
número distinto de 0 se obtiene un sistema equivalente. 2.- Si a una ecuación se le suma una combinación lineal de las demás se obtiene un
sistema equivalente. 3.- Si en un sistema se suprime (o se añade) una ecuación que sea combinación
lineal de todas las del sistema se obtiene un sistema equivalente. Evidentemente, también el cambiar de orden las ecuaciones o sumarle a los dos miembros de una de ellas un mismo número o expresión algebraica llevan a un sistema equivalente al inicial. MÉTODO DE GAUSS. El método de Gauss (o de eliminación, o de triangulación), que se basa en el de reducción, consiste en aplicar al sistema sucesivas transformaciones que permitan convertirlo en otro equivalente pero triangular o escalonado, es decir, que su matriz sea triangular o escalonada (aquella en la que el primer elemento no nulo de cada fila está mas a la derecha que el primer elemento no nulo de la fila anterior), con lo que la solución del sistema es inmediata. (En la práctica se puede trabajar sólo con la matriz ampliada). Las transformaciones que pueden aplicarse son las que permiten transformar un sistema en otro equivalente.

2º Bachillerato Humanidades y Ciencias Sociales 13
Ejemplo:
=−−=−+=−+
6zy3x
73z2yx
6zy2x
El método consiste en lo siguiente: 1º.- Cambiar el orden de las ecuaciones o de las incógnitas para que el
coeficiente de la primera incógnita en la primera ecuación sea 1 o -1.
=−−=−+=−+
6zy3x
6zy2x
73z2yx
2º.- A la segunda y tercera ecuaciones se les suma o resta un múltiplo
conveniente de la primera para que en ellas desaparezca la primera incógnita
−−=+−−−=+−
=−+
13
12
E3E158z7y
E2E85z3y
73z2yx
. Si no se hubiera conseguido coeficiente 1, aplicar el método de reducción entre
primera y segunda ecuaciones y entre primera y tercera. 3º.- Se repite el proceso entre la segunda y tercera ecuaciones con otra incógnita.
−=+−−=+−
=−+
3
2
E34524z21y
E75635z21y
73z2yx
−=−−=+−
=−+
23 EE1111z
56z3521y
73z2yx
Con lo que la solución es z = - 1, y = 1, x = 2 Al aplicar el método de Gauss podemos encontrarnos con tres casos: 1º: Quedan tantas ecuaciones como incógnitas (como en el ejemplo). En este
caso la solución es única (un valor para cada incógnita) y se trata de un sistema compatible (con solución) determinado (la solución es única).
2º: Quedan menos ecuaciones que incógnitas. En este caso sólo se puede obtener
los valores de unas incógnitas en función de los valores que tomen otras y se trata de un sistema compatible (con solución) indeterminado (hay infinitas soluciones).
Ejemplo:
−=−+−=+
=++
33zyx
13y2x
23z2yx

2º Bachillerato Humanidades y Ciencias Sociales 14
3º: Aparece alguna ecuación de la forma 0 = k, lo cual es absurdo y significa que el sistema es incompatible (no tiene solución).
Ejemplo:
=−+−=+−
=++−
42zyx
2z2yx
1zy2x
En caso de que el sistema sea homogéneo (todos los términos independientes valen 0) es siempre compatible ya que tiene, al menos, la solución trivial (todas las incógnitas iguales a 0).
Ejemplos:
=+=−=+
=+=−=++
02y2x
0yx
0yx
02yx
0zy
0zyx
INTERPRETACIÓN GEOMÉTRICA DE LOS SISTEMAS DE ECUAC IONES LINEALES CON DOS Y TRES INCÓGNITAS. Una ecuación lineal con dos incógnitas: ax + by = c puede interpretarse como la ecuación de una recta en el plano, recta formada por los puntos cuyas coordenadas (x, y) cumplen la ecuación. Por lo tanto un sistema de ecuaciones lineales con dos incógnitas puede interpretarse como un conjunto de rectas en el plano y sus soluciones (si las hay), por cumplir todas las ecuaciones, serán las coordenadas de los puntos comunes a todas ellas.
Si se trata de un sistema de dos ecuaciones con dos incógnitas los casos que pueden presentarse son: 1.- sistema incompatible: no hay ninguna solución, luego las rectas no tienen ningún punto común, por lo tanto son paralelas. 2.- sistema compatible determinado: la solución es única, lo que corresponde a que las rectas se corten en un único punto. 3.- sistema compatible indeterminado: hay infinitas soluciones, es decir, hay infinitos puntos comunes, luego las rectas coinciden.

2º Bachillerato Humanidades y Ciencias Sociales 15
La resolución gráfica del sistema consistiría en dibujar las rectas correspondientes a las ecuaciones y buscar en el dibujo los puntos comunes, cuyas coordenadas serán las soluciones del sistema.
Si se trata de un sistema de tres ecuaciones con dos incógnitas los casos que pueden presentarse son: 1.- sistema compatible determinado: la solución es única luego las tres rectas se cortan en un único punto. 2.- sistema compatible indeterminado: hay infinitas soluciones, luego hay infinitos puntos comunes, es decir, las tres rectas coinciden. 3.- sistema incompatible: no hay solución, luego no hay ningún punto común a las tres rectas. En este caso habría que estudiar los tres subsistemas que forman las ecuaciones tomadas de dos en dos para ver cual de las siguientes situaciones es la que corresponde al sistema: Las tres rectas se cortan de dos en dos. Dos rectas son paralelas y la otra las corta.
Las tres rectas son paralelas. Dos rectas coinciden y la otra es paralela a ellas.
Las ecuaciones lineales con tres incógnitas: ax + by + cz = d, pueden interpretarse como las ecuaciones de planos en el espacio por lo que la interpretación geométrica de un sistema de ecuaciones lineales con tres incógnitas se haría estudiando las posiciones e intersecciones de los planos correspondientes a las ecuaciones del sistema.

2º Bachillerato Humanidades y Ciencias Sociales 16
I.6.- RESOLUCIÓN DE PROBLEMAS CON ENUNCIADOS RELATIVOS A LAS CIENCIAS SOCIALES Y A LA
ECONOMÍA QUE PUEDEN RESOLVERSE MEDIANTE SISTEMAS DE ECUACIONES LINEALES DE DOS O TRES INCÓGNITAS E INTERPRETACIÓN DE LAS
SOLUCIONES EN LOS TÉRMINOS DEL ENUNCIADO.
Este tema trata únicamente de resolución práctica de problemas por lo que no es preciso ningún desarrollo teórico.

2º Bachillerato Humanidades y Ciencias Sociales 17
I.7.- INTRODUCCIÓN A LA PROGRAMACIÓN LINEAL BIDIMENSIONAL.
Igualdades y desigualdades. Propiedades de las desigualdades. Inecuaciones lineales con una y dos incógnitas. Sistemas de inecuaciones lineales con dos incógnitas. Resolución gráfica. IGUALDADES Y DESIGUALDADES. PROPIEDADES DE LAS DESIGUALDADES. Del mismo modo que para expresar que dos cantidades o expresiones algebraicas son iguales se usa el signo de igualdad “ = “, para expresar que son distintas puede emplearse simplemente el signo “ ≠ “, pero se proporciona mas información si se indica cual de ellas es mayor. Para eso tenemos las desigualdades o signos de desigualdad: Mayor que: a > b c positivo / a = b + c Menor que: a < b c positivo / a + c = b Mayor o igual que: a ≥ b c positivo o cero / a = b + c Menor o igual que: a ≤ b c positivo o cero / a + c = b Las desigualdades cumplen las siguientes propiedades:
1.- cacb
ba>⇒
>>
Si un número (o expresión) es mayor que otro y éste que un tercero, el primero es mayor que el tercero. 2.- a > b a + c > b + c Si a los dos miembros de una desigualdad se les suma un mismo número o expresión se obtiene otra desigualdad del mismo sentido.
3.- bcac0c
ba>⇒
>>
Si se multiplican o dividen los dos miembros de una desigualdad por un mismo número positivo se obtiene otra desigualdad del mismo sentido.

2º Bachillerato Humanidades y Ciencias Sociales 18
4.- bcac0c
ba<⇒
<>
Si se multiplican o dividen los dos miembros de una desigualdad por un mismo número negativo se obtiene una desigualdad de sentido contrario.
5.- dbcadc
ba+>+⇒
>>
Si se suman miembro a miembro dos desigualdades del mismo sentido se obtiene otra desigualdad del mismo sentido. (si fueran de sentidos contrarios podría dar cualquier resultado. Y si se restan también).
6.- b
1
a
1
0ab
ba<⇒
>>
Si los dos miembros de una desigualdad tienen el mismo signo y se invierten se obtiene una desigualdad de sentido contrario. INECUACIONES LINEALES CON UNA Y DOS INCÓGNITAS. Así como una ecuación es una igualdad que sólo se cumple para determinados valores de las incógnitas que aparecen en ella, una inecuación es una desigualdad que sólo se cumple para algunos valores de las incógnitas que aparecen en ella. Ejemplo: 3(x + 2) > 5 + 5x Hay inecuaciones de primer y segundo grado, etc.; de una o varias incógnitas; sistemas de inecuaciones; etc. Para resolverlas se utilizan las propiedades de las desigualdades y normalmente tienen infinitas soluciones que pueden representarse mediante una semirrecta para las de una variable (incógnita) y una región del plano o del espacio para las de dos y tres variables. INECUACIONES LINEALES CON UNA INCÓGNITA: Son las que, una vez simplificadas todo lo posible, tienen la forma:
ax + b > 0
Para resolverla hacemos:
<−<
>−>⇒−>
0asia
bx
0asia
bx
bax
Por tanto, en el primer caso las soluciones son todos los números reales del
intervalo
∞− ,a
b, y en el segundo los del intervalo
−∞−a
b, .

2º Bachillerato Humanidades y Ciencias Sociales 19
Gráficamente la solución es una de las semirrectas en que el punto abx −= divide a la
recta (ese punto estará incluido en la solución si el signo de la desigualdad incluye el igual).
INECUACIONES LINEALES CON DOS INCÓGNITAS: Son las que, una vez simplificadas todo lo posible, tienen la forma
ax + by + c > 0 y que, despejando la y, pueden escribirse en la forma
y > mx + p. Si sustituimos el signo de desigualdad por el de igualdad obtenemos la ecuación y = mx + p cuya representación gráfica es una recta en el plano formada por los puntos cuyas coordenadas (x,y) cumplen la ecuación. Esa recta divide al plano en dos semiplanos. En los puntos de uno de ellos el valor de la ordenada es mayor que el calculado mediante la expresión mx + p, luego son los que cumplen la inecuación y > mx + p. Para los puntos del otro semiplano la ordenada es menor que el valor mx + p, luego son los que cumplen la inecuación y < mx + p.
Si en la inecuación aparecen los signos ”≤” o “≥” las coordenadas de los puntos de la recta que determina el semiplano también serán solución de la inecuación.

2º Bachillerato Humanidades y Ciencias Sociales 20
SISTEMAS DE INECUACIONES LINEALES CON DOS INCÓGNITA S. RESOLUCIÓN GRÁFICA. Un sistema de inecuaciones lineales con dos incógnitas es un conjunto de inecuaciones lineales con dos incógnitas cuyas posibles soluciones comunes se trata de averiguar. La solución del sistema es la región formada por los puntos del plano que verifican a la vez todas las inecuaciones. Las coordenadas de cualquier punto que verifique todas las inecuaciones son una solución del sistema. Resolver un sistema de inecuaciones es hallar sus soluciones o decidir que ningún punto la cumple. Para resolverlo se representan los semiplanos que son solución de cada una de las inecuaciones y la parte común a todos ellos es la solución del sistema.
Ejemplos: Resolver los sistemas:
≥≥
≤−≤+
≥≥
≥+≥+
0y
0x
3yx
5yx
0y
0x
213y7x
126y2x

2º Bachillerato Humanidades y Ciencias Sociales 21
I.8.- FORMULACIÓN Y RESOLUCIÓN DE PROBLEMAS DE PROGRAMACIÓN LINEAL.
Formulación de problemas sencillos de programación lineal (en dos variables). Definiciones: función objetivo, conjunto de restricciones, región factible, soluciones óptimas. Resolución por métodos gráficos y analíticos. FORMULACIÓN DE PROBLEMAS SENCILLOS DE PROGRAMACIÓN LINEAL (EN DOS VARIABLES). DEFINICIONES: FUNCIÓN OB JETIVO, CONJUNTO DE RESTRICCIONES, REGIÓN FACTIBLE, SOLUCIO NES ÓPTIMAS. En muchas situaciones de la vida real (industria, economía, etc.) se plantea la necesidad de elegir entre varias posibilidades la más ventajosa: obtener el mayor beneficio posible, conseguir que los costes de producción sean mínimos, establecer la mejor ruta de transporte desde los puntos de producción a los de venta, etc. Este tipo de problemas de optimización es el que estudia la programación lineal; en concreto el problema tipo de programación lineal es el siguiente: Encontrar los valores de dos variables x e y (normalmente no negativos) que hagan máxima o mínima una función lineal de ellos z = ax + by teniendo en cuenta que los valores posibles de las variables están limitados por una serie de condiciones o restricciones que se expresan mediante desigualdades. La función que se pretende maximizar (o minimizar) se llama función objetivo. Las condiciones que deben cumplir las variables forman el conjunto de restricciones. Cada conjunto de valores de las variables que cumplan el conjunto de restricciones constituye una solución factible y el conjunto de todas ellas (su representación gráfica en el plano) forma la región factible. Las soluciones óptimas son aquellas, de entre las factibles, que hagan máxima o mínima (según interese) a la función objetivo. EJEMPLO 1: Una empresa dedicada a la reparación de componentes electrónicos recibe el encargo de reparar ordenadores y consolas de videojuegos. Los aparatos han de pasar por dos talleres de reparación. El primero puede emplear 300 horas de trabajo y necesita emplear 6 horas para cada ordenador y 5 para cada consola. El segundo dispone de 200 horas y necesita 2 horas para reparar cada ordenador y 5 para cada consola. Las ganancias netas que obtiene la empresa son de 10.000 pta por ordenador y 10.000 por consola. La empresa desea obtener una ganancia máxima. ¿Cuáles son las unidades que deben repararse de cada artículo para maximizar las ganancias de la empresa?.

2º Bachillerato Humanidades y Ciencias Sociales 22
Representando los datos en una tabla tenemos:
TALLERES HORAS POR ORDENADOR
HORAS POR CONSOLA
HORAS TOTALES
PRIMERO 6 5 300 SEGUNDO 2 5 200
La función objetivo es la que da el beneficio B = 10.000x + 10.000y Las restricciones por las condiciones de los talleres son: 6x + 5y ≤ 300 2x + 5y ≤ 200 Y también serán, evidentemente: x ≥ 0 y ≥ 0 EJEMPLO 2: Las 20 chicas y los 10 chicos de un grupo de 2º de Bachillerato organizan un viaje para el cual necesitan dinero. Deciden pedir trabajo por las tardes en una compañía encuestadora que contrata a dos tipos de equipos de jóvenes: Tipo A. Parejas: una chica y un chico. Tipo B. Equipos de cuatro, formados por tres chicas y un chico. Se paga a 30 € la tarde del equipo tipo A y 50 € la tarde al tipo B. ¿Cómo les conviene distribuirse para conseguir la mayor cantidad posible de dinero?. Representando los datos en una tabla tenemos:
EQUIPOS Nº DE EQUIPOS CHICAS QUE INTERVIENEN
CHICOS QUE INTERVIENEN
TIPO A x x x TIPO B y 3y y TOTAL x + 3y x + y
La función objetivo es la que da el beneficio (en decenas de euros): B = 3x + 5y Las restricciones por los tipos de equipos serán: x + 3y ≤ 20 x+ y ≤ 10 Y también serán, evidentemente: x ≥ 0 y ≥ 0 RESOLUCIÓN POR MÉTODOS GRÁFICOS (de las rectas de nivel). Si representamos gráficamente y resolvemos las inecuaciones que forman el conjunto de restricciones obtenemos una región del plano, la región factible, que incluye o representa a todas las soluciones factibles ya que sus puntos son aquellos cuyas coordenadas satisfacen todo el conjunto de restricciones. En la figura tenemos la región factible correspondiente al ejemplo 2 teniendo en cuenta que las soluciones (número de

2º Bachillerato Humanidades y Ciencias Sociales 23
equipos de cada tipo) han de ser números enteros por lo que sólo hay esos 54 puntos factibles (1ª figura). Ahora nos falta determinar cual de entre todas las soluciones factibles (infinitas a no ser, como en este ejemplo, que tengan que tomar valores enteros) es la solución óptima, que en este caso será la que haga máxima la función beneficio B = 3x + 5y (se ha escrito en decenas de euros para que la representación gráfica resulte mas sencilla). Vamos a ver como se resuelve este problema gráficamente. La recta 3x + 5y = 0 (en el caso general ax + by = 0) de beneficio 0 pasa por el origen de coordenadas. Si trazamos paralelas a ella (que son las que se llaman rectas de nivel) hacia la derecha (hacia arriba) serán rectas de ecuaciones ax + by = k siendo el beneficio k positivo y cada vez mayor (2ª figura). La intersección de cada una de esas rectas con la región factible da los puntos del plano (y las correspondientes coordenadas los valores de la variable) que proporcionan el valor k a la función objetivo (3ª figura). Por tanto el punto (o puntos) de la región factible que coincidan con la recta de esa familia mas alejada hacia la derecha (arriba) dará los valores de la variable que hacen máxima la función objetivo, y el que coincida con la recta mas alejada hacia la izquierda (abajo) proporcionará los valores que hacen mínima la función objetivo. Normalmente esos puntos serán vértices del polígono que forma la región factible, con lo que la solución óptima será única a no ser que alguna de las rectas obtenidas a partir de las restricciones y que limitan por su parte mas alejada la región factible sea paralela a la familia de rectas ax + by = k en cuyo caso habrá infinitas soluciones óptimas. En la práctica se representa la recta ax + by = 0 y se va desplazando paralelamente a sí misma hasta encontrar el vértice (solución única) o lado (infinitas soluciones) mas alejado en la dirección que interese, según se trate de maximizar o minimizar la función objetivo (4ª figura).
En este ejemplo la solución será el punto de corte de las rectas x + 3y = 20, x + y = 10, por lo que habrá 5 equipos de cada tipo, con un beneficio de 400 euros.

2º Bachillerato Humanidades y Ciencias Sociales 24
RESOLUCIÓN DEL EJEMPLO 1:

2º Bachillerato Humanidades y Ciencias Sociales 25
RESOLUCIÓN ANALÍTICA .
Como consecuencia de lo visto está claro que la solución óptima está en alguno de los vértices del polígono o región factible (a no ser que lo sean todos los puntos de uno de sus lados) por lo que para resolver el problema se puede calcular el valor que toma la función objetivo en cada vértice y ver entonces cual es el que proporciona la solución óptima. Este método se conoce como resolución algebraica o analítica. Este método es que se ha utilizado en el apartado d) del Ejemplo 1 en la página anterior.

2º Bachillerato Humanidades y Ciencias Sociales 26
PROBLEMAS CLÁSICOS: Entre los muchos problemas que se resuelven utilizando la programación lineal hay algunos muy clásicos como son el de la producción, el de la dieta y el del transporte. A continuación se presenta un ejemplo de cada uno de ellos.

2º Bachillerato Humanidades y Ciencias Sociales 27

2º Bachillerato Humanidades y Ciencias Sociales 28

2º Bachillerato Humanidades y Ciencias Sociales 29
II.1.- LÍMITES Concepto intuitivo de límite de una función en un punto. Límites laterales. Cálculo de límites sencillos. Determinación de asíntotas de funciones racionales e interpretación de las tendencias asintóticas en el tratamiento de la información. CONCEPTO INTUITIVO DE LÍMITE DE UNA FUNCIÓN EN UN P UNTO. LÍMITES LATERALES.
εLf(x)δax/0δ0εLf(x)limax
<−⇒<−>∃>∀⇔=→
Nótese que la idea de límite no depende en absoluto de lo que ocurra en el punto a, sólo interesa lo que ocurre al aproximarnos a a.

2º Bachillerato Humanidades y Ciencias Sociales 30
Evidentemente el límite, si existe, es único. Además, si el límite es un número L distinto de cero, existe un entorno del punto a en el que los valores que toma la función tienen el mismo signo que L.

2º Bachillerato Humanidades y Ciencias Sociales 31
LÍMITES INFINITOS: A veces ocurre que al acercarnos a un valor x0 de la variable los valores de la función no se acercan a un valor finito L sino que se hacen cada vez mayores (en valor absoluto); en ese caso diremos que el límite de la función es + ∞ (o - ∞) cuando x tiende a x0. Y hablaremos de asíntotas verticales.
LÍMITES EN EL INFINITO: Otras veces lo que nos interesa es saber qué ocurre con la función a medida que la variable independiente toma valores cada vez mayores, sean positivos o negativos (tiende a infinito). Tenemos entonces lo que se conoce como límites en el infinito. Y hablaremos de asíntotas horizontales.

2º Bachillerato Humanidades y Ciencias Sociales 32
También puede suceder que cuando x tiende a ± ∞ entonces f(x) tienda a ± ∞. En ese caso se trata de límites infinitos en el infinito.
PROPIEDADES DE LOS LÍMITES: 1.- El límite, si existe, es único. 2.- El límite existe si y sólo si existen y coinciden los límites laterales. 3.- Si 0Lf(x)lim
0xx≠=
→, existe un entorno de x0 en el que los valores de la
función tienen el mismo signo que L. 4. - lim (f ± g)(x) = lim f(x) ± lim g(x). 5. - lim (fg)(x) = lim f(x) · lim g(x).
6.- ( )g(x)lim
f(x)limx
g
flim =
, si lim g(x) ≠ 0
7.- ( ) [ ] g(x)limg f(x)lim(x)flim = , si lim f(x) ≥0. 8. - lim (a · f)(x) = a · [lim f(x)].
CÁLCULO DE LÍMITES SENCILLOS.

2º Bachillerato Humanidades y Ciencias Sociales 33
Pero hay que tener cuidado porque pueden aparecer algunos casos
indeterminados en los que no se puede saber de esta forma el valor del límite. Esos casos indeterminados son:
∞ - ∞, 0 · ∞, 0 / 0, ∞ / ∞, 00, ∞0, 1∞ Vamos a ver cómo pueden resolverse algunas de esas indeterminaciones. Algunos libros añaden una indeterminación mas: L/0 siendo L ≠ 0. Para otros no es indeterminación, es un límite con valor ∞. (Ver el apartado relativo a límites infinitos).
Esta indeterminación aparece frecuentemente al calcular límites de la forma
Q(x)
P(x)lim
ax →→→→ siendo P(x) y Q(x) dos polinomios. En este caso, ya que el número a anula a
los dos polinomios, ambos son divisibles por x – a. Se dividen ambos por x – a (varias veces si es necesario) y así desaparece la indeterminación.

2º Bachillerato Humanidades y Ciencias Sociales 34
También puede aparecer esta indeterminación con funciones irracionales (con la variable dentro de una raíz cuadrada). En ese caso se resuelve multiplicando y dividiendo por la expresión conjugada (cambiando el signo del medio) de la que contiene la raíz.

2º Bachillerato Humanidades y Ciencias Sociales 35

2º Bachillerato Humanidades y Ciencias Sociales 36
DETERMINACIÓN DE ASÍNTOTAS DE FUNCIONES RACIONALES E INTERPRETACIÓN DE LAS TENDENCIAS ASINTÓTICAS EN EL TRATAMIENTO DE LA INFORMACIÓN. Se verá al estudiar la representación gráfica de funciones en el tema II.5.

2º Bachillerato Humanidades y Ciencias Sociales 37
II.2.- CONTINUIDAD. Idea intuitiva de continuidad en un punto. Continuidad en un intervalo. Interpretación de los distintos tipos de discontinuidad. Estudio de la continuidad de funciones definidas a trozos. IDEA INTUITIVA DE CONTINUIDAD EN UN PUNTO. CONTINUI DAD EN UN INTERVALO.
Intuitivamente una función es continua si su gráfica puede dibujarse sin levantar el lápiz del papel. Los puntos en que haya que levantar el lápiz se llaman puntos de discontinuidad.
En las figuras vemos los casos que pueden presentarse al pasar por un punto x0. En la primera figura la función no es continua porque desde los dos lados no vamos hacia el mismo punto, es decir, no existe f(x)lim
0xx →. En la segunda figura sí van hacia el
mismo sitio, pero falta (no existe) el punto de unión entre los dos trozos o ramas, que sería f(x0). En la tercera existe ese punto de unión f(x0) pero no está colocado en el sitio adecuado: )f(xf(x)lim 0
xx 0
≠→
. Y por último, en la cuarta figura todo está bien y la
función es continua. A la vista de esto podemos dar la definición formal de función continua en un punto como aquella función que cumple las tres condiciones siguientes:
)f(xf(x)lim3.
)f(x2.
f(x)lim1.
0xx
0
xx
0
0
=−∃−
∃−
→
→
(Existen otras formas equivalentes de dar la definición).

2º Bachillerato Humanidades y Ciencias Sociales 38
CONTINUIDAD LATERAL: Cuando una función no es continua en un punto podemos preguntarnos si lo es lateralmente; es decir, si desde algún lado llegamos a f(x0). En concreto: Una función f es continua por la izquierda en un punto x0 si y sólo si )x(f)x(flim 0
xx 0
=−→
.
Una función f es continua por la derecha en un punto x0 si y sólo si )x(f)x(flim 0xx 0
=+→
.
De la misma manera que el límite de una función en un punto existe si y sólo si existen los dos límites laterales y éstos coinciden, una función es continua en un punto si y sólo si la función es continua por la izquierda y por la derecha en ese punto. CONTINUIDAD EN UN INTERVALO: El concepto de continuidad no tiene excesivo interés y aplicación práctica mientras no se extienda a un intervalo para poder tener propiedades en un “trozo” más amplio que un entorno, a veces muy pequeño, alrededor de un punto. Una función es continua en un intervalo si lo es en todos sus puntos. En caso de que el intervalo sea cerrado, [a, b], es necesario que la función también sea continua lateralmente en los extremos.
En total esta función es continua en (-∞, -2] (-2, 1] (1, ∞).

2º Bachillerato Humanidades y Ciencias Sociales 39
INTERPRETACIÓN DE LOS DIFERENTES TIPOS DE DISCONTIN UIDAD.
Cuando una función no es continua en un punto a decimos que tiene o que presenta
una discontinuidad en ese punto. Si nos fijamos en la definición de función continua en un punto vemos que las discontinuidades pueden darse por los siguientes motivos:
a) existe f(x)limax →
pero o bien no coincide con f(a) o bien no existe f(a). Este tipo
de discontinuidad se llama evitable porque se resolvería redefiniendo la función en ese punto (o definiéndola si no existía) por f(a) = f(x)lim
ax →.
b) no existe f(x)lim
ax →. Este tipo de discontinuidad se llama inevitable porque no
tiene solución fácil como el tipo anterior, pero podemos distinguir tres casos:
b1: existen los dos límites laterales y son finitos pero no coinciden (puede existir o no f(a)). En este caso se habla de discontinuidad de salto (finito). b2: alguno de los límites laterales (o los dos) es infinito. En este caso se habla de discontinuidad (de salto) infinita .

2º Bachillerato Humanidades y Ciencias Sociales 40
b3: alguno de los límites laterales (o los dos) no existe. En este caso se habla de discontinuidad esencial.
esta función no tiene límites laterales en el 0 porque oscila infinitas veces entre 1 y –1 cada vez mas cerca del 0.
PROPIEDADES DE LAS FUNCIONES CONTINUAS:
CONTINUIDAD DE LAS FUNCIONES ELEMENTALES: A partir de las propiedades anteriores se obtiene de manera inmediata la continuidad en sus respectivos dominios de las siguientes funciones:

2º Bachillerato Humanidades y Ciencias Sociales 41

2º Bachillerato Humanidades y Ciencias Sociales 42
ESTUDIO DE LA CONTINUIDAD DE FUNCIONES DEFINIDAS A TROZOS.
TEOREMAS RELATIVOS A LA CONTINUIDAD: 1.- TEOREMA DE CONSERVACIÓN DEL SIGNO: Si una función f es continua en un punto a, y f(a) ≠ 0, entonces existe un entorno de a en el que la función tiene el mismo signo que f(a).

2º Bachillerato Humanidades y Ciencias Sociales 43
2.- TEOREMA DE BOLZANO: Si una función f es continua en un intervalo cerrado [a, b] y toma valores de signos contrarios en los extremos del intervalo existe al menos un punto c en el interior del intervalo tal que en él la función vale 0.
f continua en [a, b], f(a)·f(b) < 0 c (a, b) / f(c) = 0. Interpretación geométrica: Geométricamente este teorema significa que una función continua no puede pasar de un lado a otro del eje X sin cortarlo (lo que, evidentemente, corresponde a la idea intuitiva de continuidad).
Observaciones: 1.- el teorema afirma que existe un punto c en (a, b) tal que f(c) = 0, pero no afirma que ese punto sea único. Puede haber varios como en la segunda figura. Y tampoco dice como calcularlo. 2.- el teorema establece una condición suficiente pero no necesaria, para que una función se anule en un punto. Una función puede ser continua en [a, b], no cambiar de signo y sin embargo anularse en algún punto c de (a, b). Por ejemplo f(x) = x2 en [-1, 1]. 3.- la hipótesis de continuidad es fundamental. Si la función no es continua la conclusión puede no ser cierta. Por ejemplo:

2º Bachillerato Humanidades y Ciencias Sociales 44
Consecuencias: Además de su utilidad para determinar ceros de funciones y soluciones de ecuaciones (que sólo veremos por encima en algún ejercicio), una de las consecuencias mas importantes del teorema de Bolzano es el llamado teorema de los valores intermedios que afirma que una función continua no puede pasar de un valor a otro sin tomar todos los valores intermedios; mas concretamente: Si una función f es continua en el intervalo [a, b] toma todos los valores comprendidos entre f(a) y f(b); es decir, para cualquier valor d comprendido entre f(a) y f(b) existe al menos un c en (a, b) tal que f(c) = d. Para comprobarlo basta aplicar el teorema de Bolzano a la función g(x) = f(x) –d
3.- TEOREMA DE WEIERSTRASS: Si una función f es continua en un intervalo cerrado [a, b] existen en ese intervalo dos puntos en los que la función alcanza, respectivamente, sus valores máximo y mínimo. Es evidente que si la gráfica comienza en (a,f(a)) y termina en (b,f(b)), sin levantar el lápiz del papel por ser f continua, no puede dispararse al infinito luego ha de tener un punto de máxima altura y otro de mínima altura. Interpretación geométrica: Geométricamente este teorema significa que dada una función continua en un intervalo cerrado [a, b], su gráfica queda comprendida entre las rectas y = M e y = N, siendo M y N los valores máximo y mínimo que alcanza la función en el intervalo.
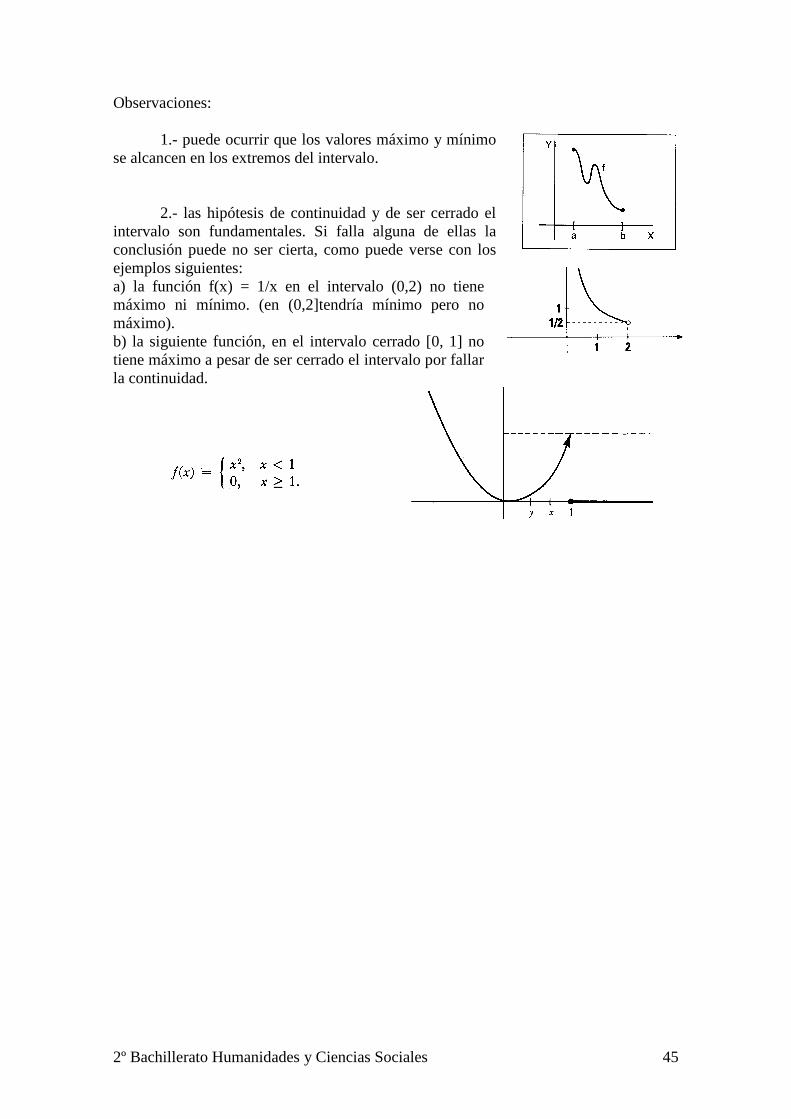
2º Bachillerato Humanidades y Ciencias Sociales 45
Observaciones: 1.- puede ocurrir que los valores máximo y mínimo se alcancen en los extremos del intervalo. 2.- las hipótesis de continuidad y de ser cerrado el intervalo son fundamentales. Si falla alguna de ellas la conclusión puede no ser cierta, como puede verse con los ejemplos siguientes: a) la función f(x) = 1/x en el intervalo (0,2) no tiene máximo ni mínimo. (en (0,2]tendría mínimo pero no máximo). b) la siguiente función, en el intervalo cerrado [0, 1] no tiene máximo a pesar de ser cerrado el intervalo por fallar la continuidad.

2º Bachillerato Humanidades y Ciencias Sociales 46
II.3.- LA DERIVADA. Tasa de variación media. Concepto de derivada de una función en un punto. Interpretación geométrica. Recta tangente a una función en un punto Definición de función derivada. Derivadas sucesivas. TASA DE VARIACIÓN MEDIA. El cálculo de derivadas o cálculo diferencial surge en el siglo XVII al tratar de resolver una serie de problemas que aparecían en las Matemáticas y en la Física, como son (entre otros):
- la definición de velocidad - la determinación de la recta tangente a una curva en un punto dado. - El cálculo de los valores máximos y mínimos que alcanza una función.
En estos y otros problemas similares de lo que se trata, en el fondo, es de estudiar, de medir y cuantificar, la variación de un determinado fenómeno, la rapidez con que se produce un cambio. La tasa de variación media (o cociente incremental) nos da una primera idea de la rapidez con que varía un fenómeno en un intervalo determinado. Se define como el cociente:
∆x
∆y
∆x
f(x)∆x)f(x
h
)f(xh)f(x
xx
)f(xf(x)
ab
f(a)f(b) 00
0
0 =−+=−+
=−−
=−−
es decir, nos dice cuanto variaría la función por cada unidad de variación de la variable independiente dentro del intervalo considerado suponiendo que esa variación fuese uniforme en todo el intervalo. La tasa de variación media coincide, evidentemente con el valor de la pendiente de la recta que une los puntos de coordenadas (x0, f(x0)) y (x0 + h, f(x0 + h)).

2º Bachillerato Humanidades y Ciencias Sociales 47
CONCEPTO DE DERIVADA DE UNA FUNCIÓN EN UN PUNTO. El valor obtenido al calcular la T.V.M. de una función en un intervalo determinado no quiere decir que en todo el intervalo se haya mantenido ese porcentaje de variación; de hecho, no suele ser así. Además, lo que interesa normalmente es saber lo que ocurre en un punto determinado: la velocidad en un instante dado, la trayectoria que seguirá un disco al ser lanzado, el punto en que un proyectil alcanza su máxima altura, etc. Por tanto, el problema es estudiar la variación instantánea de la función en un punto determinado x0. Para ello lo que haremos será estudiar su variación en intervalos [x0, x] (o [x, x0]) cada vez mas pequeños haciendo que x se aproxime a x0. En el momento en que x coincida con x0 la T.V.M. se convertirá en la tasa de variación instantánea que es lo que realmente nos interesa. Pero el problema es que en el cociente que define la T.V.M. al llegar a coincidir x con x0 el denominador valdría 0. Por ello se define la tasa de variación instantánea como
0
0
xx
00
0h xx
)f(xf(x)lim
h
)f(xh)f(xlim
0 −−
=−+
→→
Este mismo límite surge también en otras situaciones y problemas (veremos uno de ellos en la pregunta siguiente), por lo que resulta de gran importancia en las Matemáticas y recibe un nombre especial: Se llama derivada de la función f en el punto x0, representándose de cualquiera
de las formas )(xxd
fd)(xfD)(x´f 000 == , al límite siguiente (si existe):
0
0
xx
00
0h0 xx
)f(xf(x)lim
h
)f(xh)f(xlim)(x´f
0 −−
=−+
=→→
INTERPRETACIÓN GEOMÉTRICA. RECTA TANGENTE A UNA FUN CIÓN EN UN PUNTO.
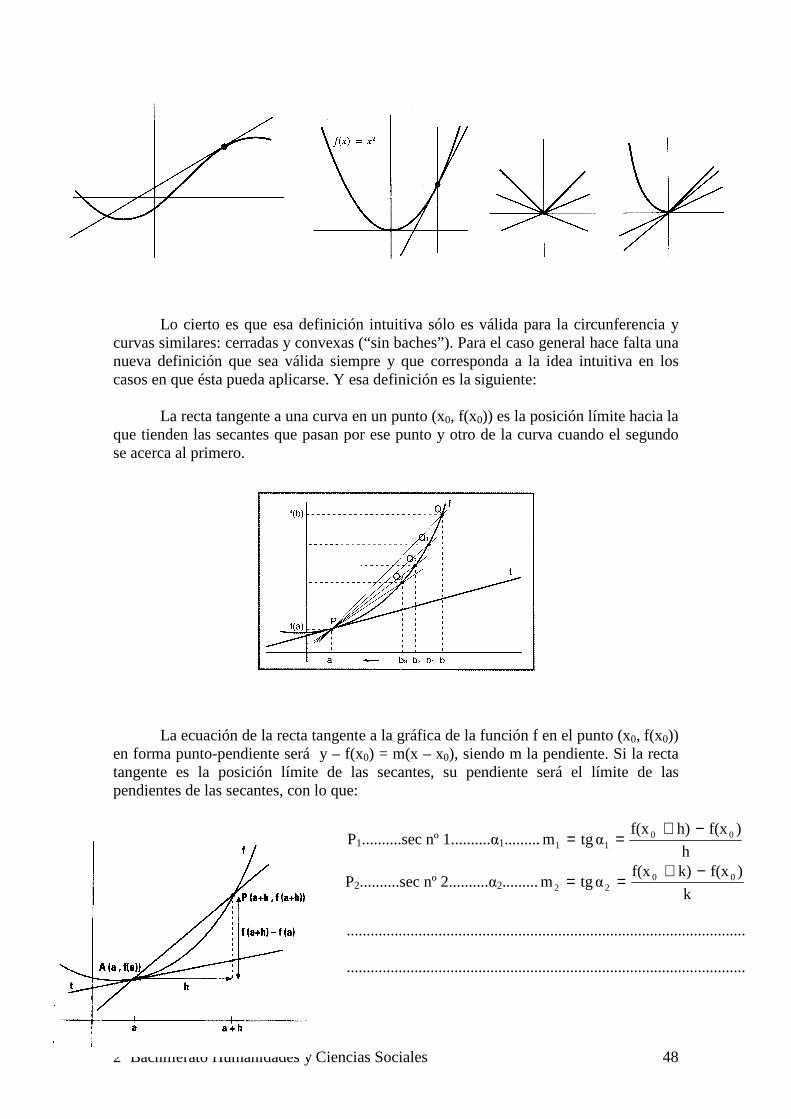
Con la definición intuitiva de que la recta tangente a una curva en un punto es la recta que toca a la curva sólo en ese punto la recta de la primera figura no sería tangente, mientras que en las otras figuras habría varias tangentes (alguna bastante extraña) en un mismo punto.
2º Bachillerato Humanidades y Ciencias Sociales 48
Lo cierto es que esa definición intuitiva sólo es válida para la circunferencia y curvas similares: cerradas y convexas (“sin baches”). Para el caso general hace falta una nueva definición que sea válida siempre y que corresponda a la idea intuitiva en los casos en que ésta pueda aplicarse. Y esa definición es la siguiente: La recta tangente a una curva en un punto (x0, f(x0)) es la posición límite hacia la que tienden las secantes que pasan por ese punto y otro de la curva cuando el segundo se acerca al primero.
La ecuación de la recta tangente a la gráfica de la función f en el punto (x0, f(x0)) en forma punto-pendiente será y – f(x0) = m(x – x0), siendo m la pendiente. Si la recta tangente es la posición límite de las secantes, su pendiente será el límite de las pendientes de las secantes, con lo que:
P1..........sec nº 1..........α1.........h
)f(xh)f(xαtgm 00
11
−+==
P2..........sec nº 2..........α2.........k
)f(xk)f(xαtgm 00
22
−+==
....................................................................................................
....................................................................................................

2º Bachillerato Humanidades y Ciencias Sociales 49
cuando el segundo punto llegue a coincidir con P tendremos la recta tangente, cuya pendiente será:
P...........tangente...............α........... )(x´fh
)f(xh)f(xlimαtgm 0
00
0h=
−+==
→
Por tanto, la derivada de una función en un punto puede interpretarse geométricamente como la pendiente de la recta tangente a la gráfica de la función en el punto (x0, f(x0)).
Así que la ecuación de la recta tangente (si la función es derivable en el punto x0) será:
y – f(x0) = f ‘ (x0)·(x – x0) Se puede demostrar que para que una función sea derivable en un punto ha de ser continua en ese punto; es decir, no puede ser derivable sin ser continua. Pero puede ser continua y no ser derivable. La idea es que una función continua es derivable en todos sus puntos excepto en aquellos en que su gráfica cambie bruscamente de dirección. DEFINICIÓN DE FUNCIÓN DERIVADA. DERIVADAS SUCESIVAS .

2º Bachillerato Humanidades y Ciencias Sociales 50

2º Bachillerato Humanidades y Ciencias Sociales 51
II.4.- CÁLCULO DE DERIVADAS. Reglas de derivación. Derivadas de funciones elementales. REGLAS DE DERIVACIÓN. DERIVADAS DE FUNCIONES ELEMEN TALES.
Obtener la expresión de la función derivada de una función dada implica calcular el límite que define a esa función derivada en un punto genérico usando la expresión que define a la función original; es decir, calcular
h
f(x)h)f(xlim(x)´f´y
0h
−+==→
Pero calcular ese límite cada vez que deseemos obtener la derivada de una función resulta bastante engorroso y, por ello, se obtienen (aunque no las demostraremos) unas expresiones o fórmulas generales que permiten obtener fácilmente la derivada de cualquier función. Esas fórmulas o reglas de derivación son las siguientes: 1.- DERIVADA DE UNA FUNCIÓN CONSTANTE: Una función constante es siempre derivable y su derivada vale siempre 0.
f(x) = k f´ (x) = 0 2.- DERIVADA DE LA FUNCIÓN IDENTIDAD: La función identidad es siempre derivable y su derivada vale siempre 1.
f(x) = x f´ (x) = 1 3.- DERIVADA DE LA FUNCIÓN POTENCIAL DE EXPONENTE NATURAL: La función potencial de exponente natural es siempre derivable y su derivada vale
f(x) = xn f´ (x) = n xn – 1 4.- DERIVADA DE UNA SUMA DE FUNCIONES: Si dos funciones f y g son derivables la función suma f + g también es derivable y su derivada es la suma de las derivadas.
(f + g)´ (x) = f´ (x) + g´ (x)

2º Bachillerato Humanidades y Ciencias Sociales 52
5.- DERIVADA DE UN PRODUCTO DE FUNCIONES: Si dos funciones f y g son derivables la función producto f g también es derivable y su derivada vale
(f g)´ (x) = f´ (x) · g(x) + f(x) · g´ (x) Como caso particular tenemos que si una función f es derivable el producto de un número k por la función f también es derivable y su derivada vale
(k · f)´ (x) = k · f´ (x)
En el caso de tres funciones sería: (f g h)´ (x) = f´ (x)·g(x)·h(x) + f(x)·g´ (x)·h(x) + f(x)·g(x)·h´ (x)
y así sucesivamente. 6.- DERIVADA DE UN COCIENTE DE FUNCIONES: Si dos funciones f y g son derivables, en los puntos en que la segunda sea distinta de cero la función cociente también es derivable y su derivada vale
[ ]2g(x)
(x)g´f(x)g(x)(x)f´(x)
g
f ⋅−⋅=′
Como caso particular tenemos que si una función g es derivable la función g
1 es
derivable en todos los puntos en que g sea distinta de cero y su derivada vale
[ ]2g(x)
(x)g´(x)
g
1 −=′
7.- DERIVADA DE LA FUNCIÓN POTENCIAL DE EXPONENTE ENTERO NEGATIVO: La función potencial de exponente entero negativo es siempre derivable y su derivada vale
f(x) = x – n f´ (x) = - n · x - n – 1 8.- DERIVADA DE UNA COMPOSICIÓN DE FUNCIONES. REGLA DE LA CADENA: Dadas dos funciones f y g, si la función f es derivable en un punto x y la función g es derivable en el punto f(x), la función compuesta gΒf es derivable en el punto x y su derivada vale
(gf)´ (x) = g´ [f(x)] · f´ (x)

2º Bachillerato Humanidades y Ciencias Sociales 53
9.- DERIVADA DE LA FUNCIÓN RECÍPROCA O INVERSA: Si una función f es inyectiva y derivable, con derivada distinta de cero, la función recíproca o inversa f - 1 también es derivable y su derivada vale
( ) [ ](x)ff
1(x)f
11
−−
′=′
10.- DERIVADA DE LA FUNCIÓN LOGARÍTMICA: La función logarítmica f(x) = ln (x), que sólo está definida para los números positivos, es siempre derivable y su derivada vale
f(x) = ln x f´ (x) = x
1
11.- DERIVADA DE LA FUNCIÓN POTENCIAL DE EXPONENTE REAL: La función potencial de exponente real f(x) = x a es siempre derivable y su derivada vale
f(x) = x a f´ (x) = a · x a – 1 Como caso particular tenemos la derivada de la raíz n-ésima (que se deduciría escribiéndola como potencia de exponente fraccionario y derivando):
n 1n
n
xn
1(x)fxf(x)
−=′⇒=
Y para la raíz cuadrada: x2
1)x´(fx)x(f =′⇒=
12.- DERIVADA DE LA FUNCIÓN LOGARÍTMICA DE BASE a: La función logarítmica de base un número real a (positivo y distinto de 1), que está definida sólo para números positivos, es siempre derivable y su derivada vale
elogx
1
alnx
1(x)fxlogf(x) aa ⋅=
⋅=′⇒=
13.- DERIVADA DE LA FUNCIÓN EXPONENCIAL DE BASE a: La función exponencial de base un número real a (positivo y distinto de 1) es siempre derivable y su derivada vale
elog
aalna(x)faf(x)
a
xxx =⋅=′⇒=

2º Bachillerato Humanidades y Ciencias Sociales 54
Como caso particular podemos considerar la función exponencial de base el número e, que suele llamarse simplemente función exponencial, cuya derivada es
f(x) = ex f´ (x) = ex Ésta es la única función que coincide con su derivada. 14.- DERIVADAS DE LAS FUNCIONES TRIGONOMÉTRICAS:
a) La función seno es siempre derivable y su derivada vale f(x) = sen x f´ (x) = cos x
b) La función coseno es siempre derivable y su derivada vale
f(x) = cos x f´ (x) = - sen x
c) La función tangente es derivable siempre que exista y su derivada vale
f(x) = tg x xtg1xsecxcos
1(x)f 22
2+===′
15.- DERIVADAS DE LAS FUNCIONES TRIGONOMÉTRICAS INVERSAS:
a) La función arco seno, definida en [-1,1], es derivable en (-1,1) y su derivada vale
f(x) = arc sen x 2x1
1(x)f
−=′
b) La función arco coseno, definida en [-1,1], es derivable en (-1,1) y su derivada
vale
f(x) = arc cos x 2x1
1(x)f
−
−=′
c) La función arco tangente es siempre derivable y su derivada vale
f(x) = arc tg x 2x1
1(x)f
+=′

2º Bachillerato Humanidades y Ciencias Sociales 55
16.- DERIVACIÓN LOGARÍTMICA: Es un método que permite calcular fácilmente muchas derivadas y que consiste en tomar logaritmos neperianos en los dos miembros de la función y derivar a continuación.
Ejemplo: y = x sen x xsenx
1xlncosxy
y
1 ⋅+⋅=′
Ln (y) = ln (x sen x) yxsenx
1xlnxcosy ⋅
⋅+⋅=′
Ln (y) = sen x Α ln x xsenxxsenx
1xlnxcosy ⋅
⋅+⋅=′
17.- DERIVACIÓN IMPLÍCITA: Es un método que se emplea cuando resulta difícil escribir la función a derivar en la forma y = f(x). Ejemplo: 2x·y2 + 3y = 5 2y2 + 2y·y´·2x + 3y´ = 0
34
2 2
+−=′xy
yy

2º Bachillerato Humanidades y Ciencias Sociales 56
II.5.- APLICACIONES DE LAS DERIVADAS Aplicaciones al estudio de la variación de funciones habituales (crecimiento y decrecimiento, extremos relativos, concavidad y convexidad, puntos de inflexión). Estudio y representación gráfica de una función polinómica o racional sencilla a partir de sus propiedades. Aplicaciones a la resolución de problemas de optimización relacionados con las ciencias sociales y la economía. CRECIMIENTO Y DECRECIMIENTO (MONOTONÍA). Intuitivamente decimos que una función crece o decrece si al recorrer su gráfica de izquierda a derecha vamos subiendo o bajando. La definición formalmente correcta y matemáticamente manejable es la siguiente: f crece en el intervalo (a, b) x1,x2 (a, b), x1 < x2 f(x1) ≤f(x2). f decrece en el intervalo (a, b) x1,x2 (a, b), x1 < x2 f(x1) ≥f(x2). f crece estrictamente en el intervalo (a, b) x1,x2 (a, b), x1 < x2 f(x1) <f(x2). f decrece estrictamente en el intervalo (a, b) x1,x2 (a, b), x1 < x2 f(x1) >f(x2).

2º Bachillerato Humanidades y Ciencias Sociales 57
Estudiar el crecimiento y decrecimiento (la monotonía) de una función aplicando la definición es bastante latoso y delicado pero las derivadas nos facilitan el trabajo, aplicando el siguiente teorema (que no demostramos): TEOREMA: Si una función f es derivable en un intervalo abierto (a, b), y en todos los puntos de ese intervalo su derivada es positiva, la función crece estrictamente en ese intervalo. negativa, la función decrece estrictamente en ese intervalo. igual a cero, la función es constante en ese intervalo. La idea gráfica es que donde la función crece (decrece) la tangente forma un ángulo agudo (obtuso) con el eje X lo que corresponde a que la pendiente (que coincide con la derivada) sea positiva (negativa).
El resultado inverso de este teorema es falso porque: 1.- una función puede ser creciente (decreciente) sin ser siempre derivable. Por ejemplo,
la función
>≤
=0xsix
0xsixf(x)
2 es siempre creciente pero no es derivable en x0 = 0.
2.- una función puede ser creciente (decreciente) y derivable sin que su derivada sea siempre positiva (negativa). Por ejemplo, la función f(x) = x3 es siempre creciente y derivable pero f ´(0) = 0.
Lo máximo que puede afirmarse en ese sentido es lo siguiente:

2º Bachillerato Humanidades y Ciencias Sociales 58
TEOREMA: Si la función f es creciente (decreciente) y derivable en el intervalo abierto (a, b) es f ´(x) ≥ 0 (≤ 0) x (a, b). Teniendo en cuenta estos resultados y que las funciones que manejamos son derivables excepto a lo sumo en un número finito de puntos y que además en ellas la función derivada es continua siempre que exista, para estudiar los intervalos de crecimiento y decrecimiento de una función se hace lo siguiente: Hallar los puntos en los que la derivada puede cambiar de signo que son aquellos en los que no existe derivada o la derivada vale cero. Esos puntos dividen al dominio de la función en intervalos en cada uno de los cuales la derivada mantiene signo constante con lo que la función será siempre creciente o siempre decreciente (en cada intervalo). Para saber lo que ocurre realmente en cada intervalo basta con estudiar el signo de la derivada en un punto cualquiera del intervalo. EXTREMOS RELATIVOS (MÁXIMOS Y MÍNIMOS). Intuitivamente los máximos y mínimos de una función son los puntos más altos y más bajos que van apareciendo en su gráfica. Formalmente los definimos así: La función f tiene un máximo en x0 si y sólo si
(x0 – h, x0 + h) / x (x0 – h, x0 + h), x ≠ x0 f(x) < f(x0). La función f tiene un mínimo en x0 si y sólo si
(x0 – h, x0 + h) / x (x0 – h, x0 + h), x ≠ x0 f(x) > f(x0).
También aquí, como en el caso de la monotonía, el estudio de los extremos aplicando directamente la definición es complicado pero de nuevo las derivadas facilitan el trabajo. Se puede demostrar (y parece lógico tanto al ver la gráfica como después de lo visto al estudiar la monotonía) que si una función es derivable en un punto en el que tenga un extremo la derivada en ese punto ha de valer 0 (con lo que la tangente a la gráfica será horizontal).

2º Bachillerato Humanidades y Ciencias Sociales 59
También aquí el resultado inverso es falso porque: 1.- el hecho de que la derivada valga 0 no implica la existencia de extremo. Por ejemplo la función f(x) = x3 tiene derivada nula en x0 = 0 y sin embargo crece en ese punto. 2.- incluso puede haber extremos en puntos en que la función no sea derivable. Por ejemplo, la función f(x) = |x| tiene un mínimo en x0 = 0 pero no es derivable en ese punto.
Por tanto lo único que puede afirmarse es que los extremos están entre los puntos en los que no hay derivada o la derivada vale 0. Para saber si esos puntos son realmente extremos hay dos métodos: 1.-si en ellos la función cambia de crecer a decrecer, o viceversa, habrá un extremo (máximo en el primer caso, mínimo en el segundo). 2.- (sólo vale para puntos en que la derivada es 0). Se siguen calculando derivadas hasta encontrar una que en ese punto sea distinta de 0. Si es de índice par y positiva hay mínimo; si es de índice par y negativa hay máximo; y si es de índice impar no hay extremo (hay un punto de inflexión).
2º Bachillerato Humanidades y Ciencias Sociales 60
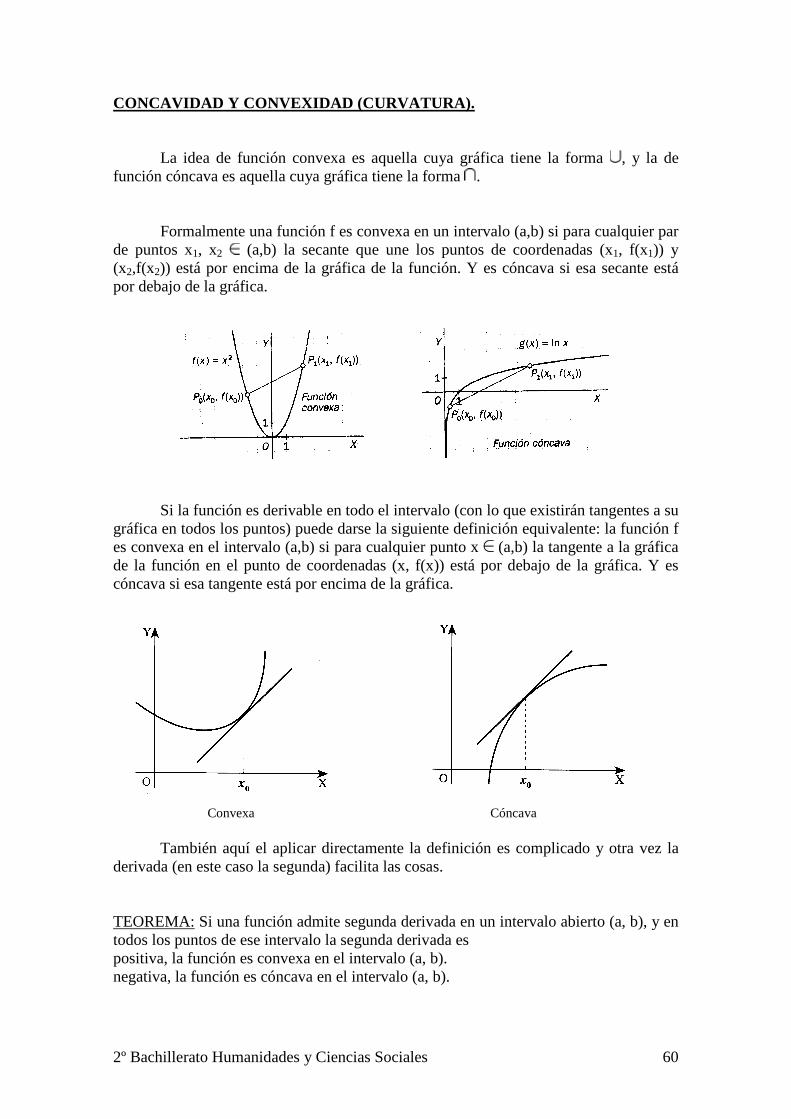
CONCAVIDAD Y CONVEXIDAD (CURVATURA). La idea de función convexa es aquella cuya gráfica tiene la forma , y la de función cóncava es aquella cuya gráfica tiene la forma . Formalmente una función f es convexa en un intervalo (a,b) si para cualquier par de puntos x1, x2 (a,b) la secante que une los puntos de coordenadas (x1, f(x1)) y (x2,f(x2)) está por encima de la gráfica de la función. Y es cóncava si esa secante está por debajo de la gráfica.
Si la función es derivable en todo el intervalo (con lo que existirán tangentes a su gráfica en todos los puntos) puede darse la siguiente definición equivalente: la función f es convexa en el intervalo (a,b) si para cualquier punto x (a,b) la tangente a la gráfica de la función en el punto de coordenadas (x, f(x)) está por debajo de la gráfica. Y es cóncava si esa tangente está por encima de la gráfica.
Convexa Cóncava También aquí el aplicar directamente la definición es complicado y otra vez la derivada (en este caso la segunda) facilita las cosas. TEOREMA: Si una función admite segunda derivada en un intervalo abierto (a, b), y en todos los puntos de ese intervalo la segunda derivada es positiva, la función es convexa en el intervalo (a, b). negativa, la función es cóncava en el intervalo (a, b).

2º Bachillerato Humanidades y Ciencias Sociales 61
El resultado inverso de este teorema es falso porque: 1.- una función puede ser convexa (o cóncava) sin que tenga siempre segunda derivada. 2.- una función puede ser convexa (o cóncava) y tener segunda derivada sin que la segunda derivada sea siempre positiva (negativa). Por ejemplo la función f(x) = x4 es siempre convexa y tiene segunda derivada pero f ´´(0) = 0. Por tanto se puede estudiar la concavidad y convexidad del mismo modo que la monotonía pero con la segunda derivada: Hallar los puntos en los que la segunda derivada puede cambiar de signo que son aquellos en los que no existe o vale 0. Esos puntos dividen al dominio de la función en intervalos en cada uno de los cuales la segunda derivada mantiene signo constante con lo que la función será siempre cóncava o siempre convexa (en cada intervalo). Para saber lo que ocurre realmente en cada intervalo basta estudiar el signo de la segunda derivada en un punto cualquiera del intervalo. PUNTOS DE INFLEXIÓN. Así como los puntos que separan los tramos crecientes de los decrecientes son los extremos, se llaman puntos de inflexión a aquellos en que la función pasa de ser cóncava a convexa, o viceversa. Evidentemente, si en un punto de inflexión hay recta tangente, ésta ha de atravesar la gráfica de la función. Los puntos de inflexión son los únicos puntos “raros” en cuanto a la tangente, en los que la tangente no corresponde a la idea intuitiva.
El estudio de los puntos de inflexión es totalmente análogo al de los extremos, pero con la segunda derivada. Se puede demostrar que si una función admite segunda derivada en un punto en el que tenga un punto de inflexión, en ese punto la segunda derivada ha de valer 0.

2º Bachillerato Humanidades y Ciencias Sociales 62
Pero el resultado inverso es falso porque: 1.- el hecho de que la segunda derivada valga 0 no implica la existencia de punto de inflexión. Por ejemplo, la función f(x) = x4 tiene segunda derivada nula en el 0 pero ese punto no es de inflexión. 2.- puede haber puntos de inflexión en sitios en los que no exista segunda derivada. Por tanto lo único que puede afirmarse es que los puntos de inflexión están entre aquellos en los que no hay segunda derivada o la segunda derivada vale 0. Para saber si esos puntos son realmente de inflexión hay dos métodos: 1.- si en ellos la función pasa de ser cóncava a convexa o viceversa habrá punto de inflexión. 2.- (sólo vale para los puntos en los que la segunda derivada vale 0). Se siguen calculando derivadas hasta encontrar una que en ese punto sea distinta de 0. Si esa derivada es de índice impar hay punto de inflexión. Si es de índice par no. ASÍNTOTAS. Intuitivamente las asíntotas de una curva son rectas a las que la curva se va acercando cada vez más a medida que nos alejamos del origen, pero sin llegar a juntarse.
Según su posición en el plano pueden ser: Verticales: son rectas x = a, tales que ∞±=
→f(x)lim
ax.
Horizontales: son rectas y = b, tales que bf(x)limx
=∞±→
.
Oblicuas: son rectas y = mx + b, tales que [ ]mxf(x)limb,x
f(x)limm
xx−==
∞±→∞±→.

2º Bachillerato Humanidades y Ciencias Sociales 63
Al estudiar las asíntotas de una función deben tenerse en cuenta los puntos siguientes: - Las horizontales pueden considerarse un caso particular de las oblicuas para m = 0. - Al estudiar las horizontales y oblicuas hay que distinguir si son por la derecha (x → +
∞) o por la izquierda (x → - ∞) porque pueden ser distintas. - Como máximo hay una (sea horizontal u oblicua) hacia la derecha y otra hacia la
izquierda (es consecuencia de que el límite, si existe, es único) pero puede haber varias verticales (por ejemplo, en la función y = tg x).
- Las funciones polinómicas no tienen asíntotas de ningún tipo. - En las funciones racionales las asíntotas verticales corresponden a los valores de la
variable en que se anula el denominador. Y las horizontales (u oblicuas) son las mismas por la derecha que por la izquierda.
- Una curva puede cortar a una asíntota.
ESTUDIO Y REPRESENTACIÓN GRÁFICA DE UNA FUNCIÓN POLINÓMICA O RACIONAL SENCILLA A PARTIR DE SUS PROP IEDADES. Representar una función sólo a partir de una tabla de valores no es práctico más que para funciones muy sencillas, en otras pueden cometerse errores graves. En general una tabla de valores puede ser una ayuda, pero es necesario obtener más datos. Los que suelen calcularse son: 1.- DOMINIO DE DEFINICIÓN O CAMPO DE EXISTENCIA: Es el subconjunto de
para el que está definida la función. Para las funciones más habituales es: Polinómicas: Racionales: excepto los números que anulan al denominador. Irracionales: si el índice es impar . Si el índice es par ha de ser el radicando mayor o igual que 0. Logarítmicas: la expresión de la que se calcula el logaritmo ha de ser mayor que 0. Exponenciales: . Seno: Coseno: .

2º Bachillerato Humanidades y Ciencias Sociales 64
2.- PUNTOS DE CORTE CON LOS EJES: Se calculan resolviendo el sistema que forma la función con la ecuación de cada eje. Con el eje X puede haber varios, con el eje Y como máximo uno. 3.- SIMETRÍAS: De todas las posibles simetrías que puede haber sólo se estudian dos: Respecto al eje Y (la función se llama par): intuitivamente significa que si doblamos la gráfica de la función por el eje Y coincide una parte sobre la otra. La función f es simétrica respecto al eje Y f(- x) = f(x) x Respecto al origen (la función se llama impar): intuitivamente significa que si doblamos la gráfica de la función primero por un eje y luego por el otro (en cualquier orden) coincide una parte sobre la otra. La función f es simétrica respecto al origen f(- x) = - f(x) x.
Función par Función impar 4.- CRECIMIENTO Y DECRECIMIENTO. MÁXIMOS Y MÍNIMOS. 5.- CONCAVIDAD Y CONVEXIDAD. PUNTOS DE INFLEXIÓN. 6.- ASÍNTOTAS. 7.- En caso necesario pueden obtenerse otros datos, como periodicidad, regiones, puntos de corte con las asíntotas, forma de aproximarse a las asíntotas, tablas de valores, ramas parabólicas, etc.

2º Bachillerato Humanidades y Ciencias Sociales 65
APLICACIONES A LA RESOLUCIÓN DEPROBLEMAS DE OPTIMIZ ACIÓN RELACIONADOS CON LAS CIENCIAS SOCIALES Y LA ECONOMÍ A. Con frecuencia aparecen problemas físicos, económicos, geométricos, biológicos,..., en los que se trata de optimizar una función: hacer máximo un volumen, un beneficio, hacer mínimos unos costes, un área,... El procedimiento a seguir en estos casos es el siguiente: 1.- determinar la función de la que se quiere conseguir el máximo o el mínimo. 2.- mediante los datos del problema expresar esa función utilizando una sola variable. Para ello, si la función depende de varias variables hay que buscar relaciones entre ellas hasta conseguir que la función dependa de una sola. 3.- hallar el máximo o el mínimo de esa función (según exija el problema). 4.- discutir los resultados, es decir, interpretarlos en el contexto del problema analizando si se adaptan o no a las condiciones del problema. Vamos a ver varios ejemplos resueltos:

2º Bachillerato Humanidades y Ciencias Sociales 66

2º Bachillerato Humanidades y Ciencias Sociales 67

2º Bachillerato Humanidades y Ciencias Sociales 68
III.1.- SUCESOS ALEATORIOS. Experimento aleatorio. Espacio muestral. Sucesos. Operaciones con sucesos. Álgebra de sucesos. EXPERIMENTO ALEATORIO. La palabra Estadística aparece en Europa en el siglo XVII para indicar el conjunto de métodos de recolección de datos y documentación útiles en la administración de estado: censos de población, producción de bienes, … El objeto de la Estadística no se limita a la descripción de las muestras que vimos en cursos anteriores al estudiar la Estadística Descriptiva, con sus tablas de frecuencias, representaciones gráficas y medidas características (de centralización y de dispersión).
Ese estudio de las muestras es el punto de partida para el estudio de las poblaciones, de las que las muestras son subconjuntos parciales. Con la Estadística Inferencial se trata de inferir (deducir) las propiedades y comportamiento de la población a partir de los observados en la muestra. Para ello se construyen unos modelos (abstracciones o idealizaciones) como veremos en temas posteriores, que sirven de puente para pasar de lo observado y por tanto conocido (la muestra) a lo desconocido (la población). Y para construirlos es preciso utilizar el Cálculo de Probabilidades al que se dedican este tema y el siguiente.
Actualmente la Estadística podría definirse como la ciencia que recoge, analiza y ordena los datos de un subconjunto procedente de un total y que, a partir del cálculo de probabilidades, se encarga de hacer predicciones sobre el conjunto total.
DEFINICIÓN: Un experimento aleatorio, a diferencia del determinístico, es el que puede presentar varios resultados y es impredecible. Mas exactamente es el que cumple las tres condiciones siguientes: 1.- se puede repetir las veces que se quiera en las mismas condiciones. 2.- puede presentar varios resultados distintos. 3.- es imposible predecir el resultado de cada prueba particular. Además en los experimentos aleatorios se cumple una propiedad muy importante, conocida como Ley de los Grandes Números: al efectuarlo muchas veces se observa que la frecuencia relativa de cada resultado se va estabilizando alrededor de un número determinado.

2º Bachillerato Humanidades y Ciencias Sociales 69
ESPACIO MUESTRAL. SUCESOS. DEFINICIÓN: En un experimento aleatorio se llama suceso elemental a cada uno de los distintos resultados individuales que pueden aparecer directamente al realizar el experimento. Por ejemplo al tirar un dado hay 6 sucesos elementales y al sacar una carta de una baraja hay 40. DEFINICIÓN: El Espacio muestral, Universo o Conjunto Fundamental de Probabilidades asociado a un determinado experimento aleatorio, que se representa Ω, es el conjunto formado por todos los sucesos elementales de ese experimento. Por ejemplo, al tirar un dado será Ω = 1, 2, 3, 4, 5, 6.

2º Bachillerato Humanidades y Ciencias Sociales 70
DEFINICIÓN: Un suceso es cualquier resultado que pueda darse al realizar el experimento aleatorio. Se representan por letras mayúsculas y son los subconjuntos del Espacio muestral. Por ejemplo, al tirar un dado algunos sucesos son: A = salir par = 2, 4, 6 B = salir múltiplo de 3 = 3, 6 C = salir menor que 5 = 1, 2, 3, 4 D = salir 2 = 2 E = 2, 4, 5 . . . . Puede demostrarse que si en un determinado experimento aleatorio hay n sucesos elementales, hay 2n sucesos. El conjunto de todos ellos se representa P(Ω). DEFINICIÓN: Se llama suceso seguro al que siempre ocurre al realizar el experimento. Por ejemplo al tirar un dado “salir un número del 1 al 6”. Considerado como subconjunto del Espacio muestral es el propio Ω. DEFINICIÓN: Se llama suceso imposible al que nunca puede ocurrir al realizar el experimento. Por ejemplo, al tirar el dado “salir el as de copas”. Se representa Ø, y considerado como subconjunto del Espacio muestral es evidentemente el conjunto vacío. DEFINICIÓN: Dos sucesos A y B son compatibles si pueden ocurrir a la vez, e incompatibles en caso contrario; es decir, si nunca pueden ocurrir a la vez. Por ejemplo, al tirar un dado los sucesos A = salir par, B = salir múltiplo de 3, son compatibles. Pero los sucesos A = salir par, C = salir múltiplo de 5, son incompatibles. OPERACIONES CON SUCESOS. ÁLGEBRA DE SUCESOS. Dado que los sucesos son conjuntos, subconjuntos del Espacio muestral, podemos definir entre ellos las mismas operaciones que entre conjuntos, y esas operaciones tendrán también las mismas propiedades. UNIÓN: El suceso unión de dos sucesos A y B, que se representa AB, es el que consiste en que ocurra el suceso A, o el B, o los dos.

2º Bachillerato Humanidades y Ciencias Sociales 71
Por ejemplo, al tirar un dado, si son A = “salir par” y B = “salir múltiplo de 3”, será A B = 2, 3, 4, 6. En caso de que los sucesos A y B sean incompatibles suele escribirse A + B en lugar de A B. INTERSECCIÓN: El suceso intersección de dos sucesos A y B, que se representa A B, es el que consiste en que ocurran el suceso A y el B. Por ejemplo, al tirar el dado, si son A = “salir par” y B = “salir múltiplo de 3”, será A B = 6. La intersección suele representarse A·B, o AB, en lugar de A B. Obsérvese que evidentemente dos sucesos son incompatibles si y sólo si su intersección es Ø. DIFERENCIA: El suceso diferencia entre el suceso A y el suceso B, que se representa A – B, es el que consiste en que ocurra A pero no B. Por ejemplo, al tirar el dado, si son A = “salir par” y B = “salir múltiplo de 3”, será A – B = 2, 4. Y también será B – A = 3. CONTRARIO O COMPLEMENTARIO: El suceso contrario o complementario de un suceso A, que se representa A (o también CA), es el que consiste en que no ocurra el suceso A.
Por ejemplo, el suceso contrario o complementario de “ganar un partido de fútbol” es “perderlo o empatarlo”. Evidentemente es A = Ω – A y se cumplen las siguientes propiedades: 1.- A A = Ø 2.- A A = Ω
3.- A = A
Aparte de las propiedades de cada una de estas operaciones, hay dos propiedades que las relacionan entre sí, llamadas LEYES de DE MORGAN: 1ª: El complementario de la unión es la intersección de los complementarios.
BABA ∩=∪ 2ª: El complementario de la intersección es la unión de los complementarios.
BABA ∪=∩

2º Bachillerato Humanidades y Ciencias Sociales 72
III.2.- PROBABILIDAD. Frecuencias absolutas y relativas. Idea de probabilidad. Cálculo de la probabilidad mediante frecuencias o por aplicación de la ley de Laplace. Propiedades de la probabilidad. Probabilidad condicionada: Experiencias compuestas. Probabilidad condicionada. Sucesos independientes. Regla del producto. Teorema de la probabilidad total. Teorema de Bayes. Antes de desarrollar el tema vamos a exponer un breve resumen de la Combinatoria, estudiada el curso pasado, por ser necesaria para la resolución de ejercicios.

2º Bachillerato Humanidades y Ciencias Sociales 73
FRECUENCIAS ABSOLUTAS Y RELATIVAS. Al realizar N veces un experimento aleatorio se llama frecuencia absoluta de un suceso A al número de veces nA que ocurre el suceso A en esas N pruebas. Y se llama frecuencia relativa del suceso A al cociente entre la frecuencia absoluta y el número N de pruebas.
frecuencia absoluta de A: f(A) = nA frecuencia relativa de A: fr(A) = N
nA
Las frecuencias cumplen las siguientes propiedades:
Frecuencia absoluta 1.- La frecuencia absoluta de cualquier suceso está comprendida entre 0 y N
A 0 ≤ nA ≤ N 2.- La frecuencia absoluta del suceso seguro es N.
nΩ = N 3.- La frecuencia absoluta del suceso imposible es 0.
nØ = 0 4.-La suma de las frecuencias absolutas de un suceso y su contrario es N
nA + A
n = N
5.- La frecuencia absoluta del suceso unión de dos sucesos incompatibles es la suma de sus frecuencias.
Si A y B son incompatibles
BABA nnn +=∪
Frecuencia relativa 1.- La frecuencia relativa de cualquier suceso está comprendida entre 0 y 1
A 0 ≤ fr(A) ≤ 1 2.- La frecuencia relativa del suceso seguro es 1.
fr(Ω) = 1 3.- La frecuencia relativa del suceso imposible es 0.
fr(Ø) = 0 4.- La suma de las frecuencias relativas de un suceso y su contrario es 1.
fr(A) + fr( A ) = 1
5.- La frecuencia relativa del suceso unión de dos sucesos incompatibles es la suma de sus frecuencias.
Si A y B son incompatibles fr(A B) = fr(A) + fr(B)
6.- La frecuencia absoluta del suceso unión de dos sucesos cualesquiera es la suma de sus frecuencias menos la frecuencia de su intersección.
A, B BABABA nnnn ∩∪ −+=
6.- La frecuencia relativa del suceso unión de dos sucesos cualesquiera es la suma de sus frecuencias menos la frecuencia de su intersección.
A,B fr(A B)= fr(A) + fr(B) – fr(A B)

2º Bachillerato Humanidades y Ciencias Sociales 74
IDEA DE PROBABILIDAD. La idea de la probabilidad de un suceso es intentar medir de alguna manera la mayor o menor facilidad de que ocurra ese suceso al realizar el correspondiente experimento aleatorio. Como hemos dicho al definir experimento aleatorio, experimentalmente se comprueba que al aumentar el número de pruebas la frecuencia relativa de cada suceso se va estabilizando en torno a un número determinado (cuantas mas veces tiremos una moneda no trucada más se acercará la proporción de caras al 50%). Por tanto parece lógico, y así se hizo inicialmente, definir la probabilidad de un suceso como el número hacia el que tiende su frecuencia relativa cuando el número de pruebas tiende a infinito. Pero esta definición tiene el inconveniente de que en muchos casos, por diversas razones, la experimentación tiene que ser reducida y, en el mejor de los casos, no se puede repetir un experimento infinitas veces. Además de los problemas que surgirían al operar con ese límite. PROBABILIDAD, DEFINICIÓN AXIOMÁTICA : La idea que acabamos de exponer es buena, pero para resolver esos problemas que plantea es preciso dar una definición axiomática que los solucione y que coincida con los valores que proporciona la frecuencia relativa en aquellos casos en que el número de pruebas pueda ser grande. La definición, que se basa en las propiedades de la frecuencia relativa, es la siguiente: La probabilidad es una aplicación definida en el conjunto P(Ω) de todos los sucesos de un experimento aleatorio con valores reales, p: P(Ω) → , que cumpla las siguientes condiciones: 1.- La probabilidad de cualquier suceso está comprendida entre 0 y 1. A, 0 ≤ P(A) ≤ 1 2.- La probabilidad del suceso seguro es 1. P(Ω) = 1 3.- La probabilidad del suceso unión de dos sucesos incompatibles es la suma de sus probabilidades. Si A y B son incompatibles P(AB) = P(A) + P(B) PROPIEDADES DE LA PROBABILIDAD: A partir de la definición pueden deducirse las siguientes propiedades de la probabilidad: 1.- La probabilidad del suceso imposible es 0. P(Ø) = 0 2.- La suma de las probabilidades de un suceso y su contrario es 1. P(A) + P(A ) = 1 3.- La probabilidad del suceso unión de dos sucesos cualesquiera es la suma de sus probabilidades menos la probabilidad de su intersección. A, B P(A B) = P(A) + P(B) – P(A∩B) Tanto la tercera condición de la definición como la tercera propiedad pueden extenderse fácilmente a más de dos sucesos.

2º Bachillerato Humanidades y Ciencias Sociales 75
CÁLCULO DE LA PROBABILIDAD MEDIANTE FRECUENCIAS O P OR APLICACIÓN DE LA LEY DE LAPLACE. El problema que se plantea al definir la probabilidad de un modo axiomático es cómo asignar sus probabilidades a todos los sucesos de un determinado experimento aleatorio de modo que se cumplan las condiciones de la definición y que los valores asignados concuerden con los que proporciona la experimentación para la frecuencia relativa. El problema puede simplificarse ya que cualquier suceso es una unión de sucesos elementales y estos son independientes entre sí, por lo que la suma de sus probabilidades dará la del suceso estudiado. Por tanto es suficiente conocer o asignar probabilidades a los sucesos elementales para conocer la de cualquier suceso. Los métodos mas empleados para asignar probabilidades a los distintos sucesos de un experimento aleatorio son: 1.- Mediante frecuencias o por Estimación estadística (Ley de los Grandes Números). En los casos en que es posible repetir el experimento un número grande de veces se toma como probabilidad de cada suceso el número hacia el que tiende su frecuencia relativa. 2.- Regla de Laplace. En muchos experimentos todos los sucesos elementales son equiprobables (no hay ninguna razón para que alguno de ellos pueda ocurrir con mayor o menor facilidad que los demás). En esos casos, si hay n sucesos elementales la probabilidad de cada uno
de ellos será n
1, con lo que la de un suceso formado por k elementales será
n
k. Esto se
conoce como Regla de Laplace y suele enunciarse diciendo que en el caso de que todos los sucesos elementales sean equiprobables la probabilidad de cualquier suceso A viene dada por el cociente entre el número de casos (sucesos elementales) en que ocurre el suceso A y el número total de casos (sucesos elementales) posibles.
posiblescasosdenº
favorablescasosdenºP(A) =
EXPERIENCIAS COMPUESTAS. Una experiencia o experimento compuesto consiste en la realización simultánea o (preferentemente) sucesiva de varios experimentos aleatorios, con lo que habrá que estudiar el conjunto de todos los resultados.

2º Bachillerato Humanidades y Ciencias Sociales 76
Ejemplos: tirar tres dados, tirar un dado y una moneda, sacar dos cartas de una baraja,... El espacio muestral de un experimento compuesto es el producto cartesiano de los espacios correspondientes a los experimentos simples que lo componen. Ejemplo: al tirar un dado y una moneda sería:
Ω = (1,c), (1,+), (2,c), (2,+), (3,c), (3,+), (4,c), (4,+), (5,c), (5,+), (6,c), (6,+) Evidentemente, para estudiar la probabilidad de un suceso de la segunda, tercera, etc. prueba tendremos que tener en cuenta cual fue el resultado de la primera (si se devuelve o no la primera carta extraída antes de extraer la segunda), el cual puede condicionar (hacer variar) o no la probabilidad de que pueda producirse o no ese suceso en la segunda,... prueba. PROBABILIDAD CONDICIONADA.
Como hemos dicho, al realizar sucesivamente dos (o más) experimentos el resultado del primero puede influir en el del segundo. En este caso hablamos de probabilidad condicionada. Más concretamente:
Dados dos sucesos A y B, siendo P(A) > 0 (es decir, A ≠ Ø), se define la
probabilidad del suceso B condicionado al suceso A como la probabilidad de que ocurra el suceso B sabiendo que previamente ha ocurrido el A. Se representa P(B/A).
Vamos a ver en un ejemplo lo que ocurre con las frecuencias porque, lo mismo
que en el caso general, esto nos dará la idea para la definición formal de la probabilidad condicionada:
Supongamos que un grupo de 200 personas está formado por 120 hombres y 80 mujeres. Entre los hombres hay 70 fumadores y entre las mujeres 10.
Fum. No Fum. H 70 50 120 M 10 70 80 80 120 200
Se pueden comprobar fácilmente los siguientes valores para las frecuencias:
200
120(H)f
200
70H)(Ff
120
70(F/H)f rrr ==∩=
con lo que tenemos la siguiente igualdad: (H)f
H)(Ff(F/H)f
r
rr
∩=

2º Bachillerato Humanidades y Ciencias Sociales 77
Y lo mismo ocurriría en cualquier otro ejemplo. En base a ello se define la probabilidad condicionada, de modo axiomático, por
P(A)
A)(BP(B/A)P
∩=
Puede comprobarse fácilmente que esta definición cumple las tres condiciones para ser una probabilidad; es decir: 1.- B 0 ≤ P(B/A) ≤ 1 2.- P(Ω/A) = 1 3.- B, C incompatibles P((BC)/A) = P(B/A) + P(C/A) SUCESOS INDEPENDIENTES. REGLA DEL PRODUCTO. Dos sucesos A y B son independientes si el hecho de que ocurra o no uno de ellos no modifica en absoluto la probabilidad de que ocurra el otro; es decir, si P(A/B) = P(A) y P(B/A) = P(B) En caso contrario los sucesos son dependientes. De la definición de probabilidad condicionada se deduce que: en el caso general es P(AB) = P(A)·P(B/A) y para sucesos independientes P(AB) = P(A)·P(B) Si fuesen tres sucesos sería: en el caso general P(AB C) = P(A)·P(B/A)·P(C/(A B)) y si son independientes P(AB C) = P(A)·P(B)·P(C) Esa expresión (la general, porque el caso de sucesos independientes es un caso particular de ella) se conoce como regla del producto y puede enunciarse más formalmente del modo siguiente: Dados n sucesos A1, A2, ..., An – 1, An, tales que P(A1 ... An – 1) > 0, se cumple:
P(A1 ... An) = P(A1)·P(A2/A1)·P(A3/A1 A2)· … ·P(An/A1 A2 … An – 1).

2º Bachillerato Humanidades y Ciencias Sociales 78
TEOREMA DE LAPROBABILIDAD TOTAL.
El estudio de la probabilidad condicionada puede llevarnos a plantear algunas preguntas que, aparentemente, no son de fácil solución. Vamos a empezar con un ejemplo:
Un carpintero tiene tornillos en dos cajas, una azul y otra roja. En la caja azul
hay cuatro tornillos de 15mm y cinco de 20mm, y en la roja hay seis de 15mm y dos de 20mm. El carpintero echa la mano a cualquier caja sin mirar pero como la azul está más cerca coge tornillos de ella dos de cada tres veces. Se pide:
¿cuál es la probabilidad de que coja un tornillo de 20mm?
Para responder a esta pregunta tenemos que darnos cuenta de que hay dos pasos: elegir la caja y coger el tornillo, por lo que:
p(20mm) = p[(azul y 20mm) o (roja y 20mm)] = p(azul y 20mm) + p(roja y 20mm) =
p(azul)·p(20mm / azul) + p(roja)·p(20mm / roja) = 108
49
8
2
3
1
9
5
3
2 =⋅+⋅
Este es un ejemplo del teorema de la probabilidad total que vamos a enunciar a
continuación de modo formal. Si la primera parte (o el primer experimento) puede descomponerse en n sucesos
incompatibles A1, A2, …, An (lo que se llama una partición o un sistema completo de sucesos del espacio muestral Ω) cualquier suceso B de la segunda parte (o del segundo experimento) sólo puede darse asociado a alguno o varios de los de la primera parte (no necesariamente con todos: en la figura no tiene nada que ver con A5), por lo que será
Y como los Ai son incompatibles será:
Realmente acabamos de demostrar el teorema de la probabilidad total que vamos
a enunciar ahora: Si A1, A2, … , An forman una partición del espacio muestral Ω, para cualquier
suceso B se cumple: ( )∑=
⋅=
n
1i ii A
BpAp)B(p

2º Bachillerato Humanidades y Ciencias Sociales 79
Veamos algunos ejemplos:

2º Bachillerato Humanidades y Ciencias Sociales 80
TEOREMA DE BAYES.
El teorema o Regla de Bayes estudia lo que suele llamarse probabilidades a posteriori y nos permite responder a un tipo de preguntas aparentemente sin respuesta. Volvamos al carpintero y preguntémonos:
Tiene en la mano un tornillo de 20mm, ¿cuál es la probabilidad de que lo haya
cogido en la caja azul? Parece que no tenemos datos para contestar, pero si nos fijamos se trata
simplemente de un caso de probabilidad condicionada: p(azul / 20mm), por lo que, según vimos, será:
( ))mm20(p
)mm20yazul(pmm20
azulp =
Como sabemos p(azul y 20mm) = p(azul) · p(20mm / azul) = 9
5
3
2 ⋅
Y también, según calculamos al ver el teorema de la probabilidad total p(20mm)
= 108
49 por lo que el resultado será
49
40.
Podemos, entonces, teniendo en cuenta la definición de probabilidad
condicionada y el teorema de la probabilidad total, enunciar el teorema de Bayes: Si A1, A2, … , An forman una partición del espacio muestral Ω, para cualquier
suceso B se cumple: ( )
( )∑=
⋅
⋅
=
n
1i ii
ii
i
ABpAp
ABpAp
BAp
Veamos también algunos ejemplos:

2º Bachillerato Humanidades y Ciencias Sociales 81

2º Bachillerato Humanidades y Ciencias Sociales 82
VARIABLE ALEATORIA DISCRETA. FUNCIONES ASOCIADAS.
Definición y ejemplos de variables aleatorias discretas. Función de probabilidad. Función de distribución. Parámetros de una distribución: esperanza matemática, desviación típica. DEFINICIÓN Y EJEMPLOS DE VARIABLES ALEATORIAS DISCR ETAS. Como ya vimos al empezar la tercera parte del programa (Estadística y Probabilidad) el estudio de las muestras que se hace en la Estadística Descriptiva (estudiada en cursos pasados) es el punto de partida para el estudio de las poblaciones. Para dar ese paso se construyen unos modelos matemáticos llamados Distribuciones de probabilidad, que requieren una serie de abstracciones o idealizaciones en las que es necesario utilizar el Cálculo de probabilidades porque, por ejemplo, hay que pasar de las frecuencias observadas en la muestra a las frecuencias esperadas en la población (y la probabilidad viene a ser la frecuencia relativa esperada). Al estudiar las muestras llamábamos Variable Estadística a la característica de la muestra que nos interesaba estudiar y dentro de ellas distinguíamos las Cualitativas que no pueden expresarse numéricamente (sexo, preferencias políticas,...) y las Cuantitativas que sí se expresan numéricamente y a su vez se dividen en discretas si sólo pueden tomar un número finito de valores (número de hijos) y continuas si pueden tomar cualquier valor real dentro de un intervalo determinado (altura, peso). Al pasar de la muestra a la población cambiamos ese nombre por el de Variable Aleatoria pero además, para conseguir un mejor manejo matemático, convertimos las cualitativas en cuantitativas discretas asociando un número a cada posible valor de la variable ( mujer → 1, hombre → 0). De forma más concreta: DEFINICIÓN: Una Variable Aleatoria es una aplicación definida en el espacio muestral asociado a un determinado experimento aleatorio con valores reales (luego asocia a cada suceso elemental un número).

2º Bachillerato Humanidades y Ciencias Sociales 83
Un modelo de distribución de probabilidad es la representación idealizada de un experimento aleatorio y se construye indicando los posibles valores de la variable aleatoria asociada al experimento y sus probabilidades respectivas. En este tema veremos el caso de las variables discretas y más adelante el de las continuas. DEFINICIÓN: Una Variable aleatoria X es discreta cuando sólo puede tomar un número finito de valores. Ejemplos: nº de hijos, puntos en un dado, nº de caras al lanzar tres monedas, ... FUNCIÓN DE PROBABILIDAD. FUNCIÓN DE DISTRIBUCIÓN. DEFINICIÓN: Se llama función de masa de probabilidad (o simplemente función de probabilidad) de una variable aleatoria discreta X a la función que asocia a cada posible valor de la variable la probabilidad de que la variable tome ese valor.
Se escribe f(xi) = pi = P(X = xi)
Esta función cumple que xi P(X = xi) ≥ 0, y que 1)xP(Xn
1ii ==∑
=.
La función de probabilidad es la idealización o modelo matemático de las tablas de frecuencias relativas y, al igual que ellas, se representa gráficamente mediante un diagrama de barras. Por ejemplo, si en el experimento aleatorio consistente en lanzar cuatro monedas consideramos la variable aleatoria X = número de caras obtenidas, su función de probabilidad y la representación gráfica correspondiente son: xi 0 1 2 3 4 P(X = xi) 16
1
16
4
16
6
16
4
16
1

2º Bachillerato Humanidades y Ciencias Sociales 84
DEFINICIÓN: La función de distribución es la que asocia a cada número real la probabilidad de que la variable aleatoria tome valores menores o iguales que ese número. Se escribe ∑
≤==≤=
txi
i
)xP(Xt)P(XF(t)
Esta función corresponde a las frecuencias acumuladas y tiene las siguientes propiedades: 1.- t 0 ≤ F(t) ≤ 1 2.- es constante entre cada dos valores consecutivos de la variable. 3.- es no decreciente: x2 > x1 F(x2) ≥ F(x1) 4.- F(- ∞) = 0, F(+ ∞) = 1 Su representación gráfica tiene forma escalonada, correspondiendo los saltos a los valores que realmente toma la variable. Por ejemplo, al lanzar las cuatro monedas y contar el número de caras obtenidas la función de distribución y su representación gráfica serían:
PARÁMETROS DE UNA VARIABLE ALEATORIA DISCRETA: ESPE RANZA MATEMÁTICA Y DESVIACIÓN TÍPICA. Recordemos que al estudiar una variable estadística sobre una muestra se definían unas medidas características (de centralización y de dispersión), de las que las más importantes eran:

2º Bachillerato Humanidades y Ciencias Sociales 85
Media: ∑∑∑ === iiiiii xfx
N
n
N
nxx
Desviación típica:
( ) ( ) ( ) 2i
2i
i
2
ii2
ii
2
i xN
nxfxx
N
nxx
N
nxxs −=−=−=
−= ∑
∑∑∑
De modo análogo para una variable aleatoria discreta definida sobre una población se definen sus parámetros o medidas características: Esperanza matemática (media): ∑== ii pxE(X)µ
Desviación típica: ( ) ( ) [ ]222i
2ii
2i E(X)XEµpxpµxσ −=−=−= ∑∑
La esperanza indica el valor medio que cabría esperar al realizar el experimento aleatorio un gran número de veces. Su nombre proviene de la teoría de juegos: la esperanza de un juego es lo que debería ganar o perder un jugador por término medio en cada partida cuando el número de partidas es grande. Sirve para medir la justicia del juego: según sea >, = ó < que 0 el juego será ventajoso, equitativo o perjudicial para el jugador.

2º Bachillerato Humanidades y Ciencias Sociales 86
DISTRIBUCIÓN BINOMIAL. Descripción de la distribución binomial. Aplicaciones. Fórmulas de la esperanza y de la desviación típica. DESCRIPCIÓN DE LA DISTRIBUCIÓN BINOMIAL. APLICACION ES. FÓRMULAS DE LA ESPERANZA Y DE LA DESVIACIÓN TÍPICA. La distribución binomial es un modelo de distribución de probabilidad correspondiente a un tipo de variables aleatorias discretas al que se adaptan multitud de situaciones: sexo, lanzamiento de una moneda, etc. (en general todas las que presenten sólo dos resultados del tipo acierto y fallo). Se llama experimento de Bernouilli al que sólo puede presentar dos resultados mutuamente excluyentes (contrarios) llamados éxito (cuya probabilidad representaremos por p) y fracaso (cuya probabilidad evidentemente será 1 – p y la representaremos por q). La variable aleatoria binomial es la que estudia el número de éxitos obtenidos al realizar n pruebas sucesivas e independientes de un experimento de Bernouilli; es decir, cumpliéndose las siguientes condiciones: 1.- en cada prueba (realización del experimento) sólo son posibles dos resultados contrarios A y Ā. 2.- el resultado de cada prueba es independiente de los resultados obtenidos en las pruebas anteriores. 3.- la probabilidad del suceso A no varía de una prueba a otra, permanece siempre constante. La variable aleatoria binomial puede tomar los valores de 0 a n, y la distribución de probabilidad correspondiente se llama distribución binomial, denotándose B(n,p): distribución binomial de n pruebas con probabilidad de éxito p en cada prueba. Las correspondientes funciones de probabilidad y distribución son:
∑=
−
−−−
⋅⋅
=≤=
⋅⋅
=⋅⋅===
t
0k
knk
knkknk,n
knk
qpk
nt)P(XF(t)
qpk
nPRqpk)P(Xf(k)
Y puede demostrarse que su esperanza y desviación típica son
µ =n·p σ = qpn ⋅⋅

2º Bachillerato Humanidades y Ciencias Sociales 87
APÉNDICE.

2º Bachillerato Humanidades y Ciencias Sociales 88

2º Bachillerato Humanidades y Ciencias Sociales 89
VARIABLE ALEATORIA CONTINUA. FUNCIONES ASOCIADAS.
Definición y ejemplos de variables aleatorias continuas. Función de densidad. Función de distribución. Parámetros de una distribución: esperanza matemática, desviación típica. DEFINICIÓN Y EJEMPLOS DE VARIABLES ALEATORIAS CONTI NUAS. Una variable aleatoria es continua si puede tomar cualquier valor en un intervalo determinado [a, b] de números reales. Ejemplos: altura de una persona, duración de una bombilla, temperatura de un cuerpo,... FUNCIÓN DE DENSIDAD. Para las variables aleatorias continuas no se puede definir la función de probabilidad, que en este caso se llama función de densidad, del mismo modo que para las discretas (indicando los posibles valores de la variable y sus probabilidades correspondientes), porque las continuas pueden tomar infinitos valores (todos los del intervalo). Por tanto seguiremos otro procedimiento para llegar a ella. Empecemos viendo un ejemplo:
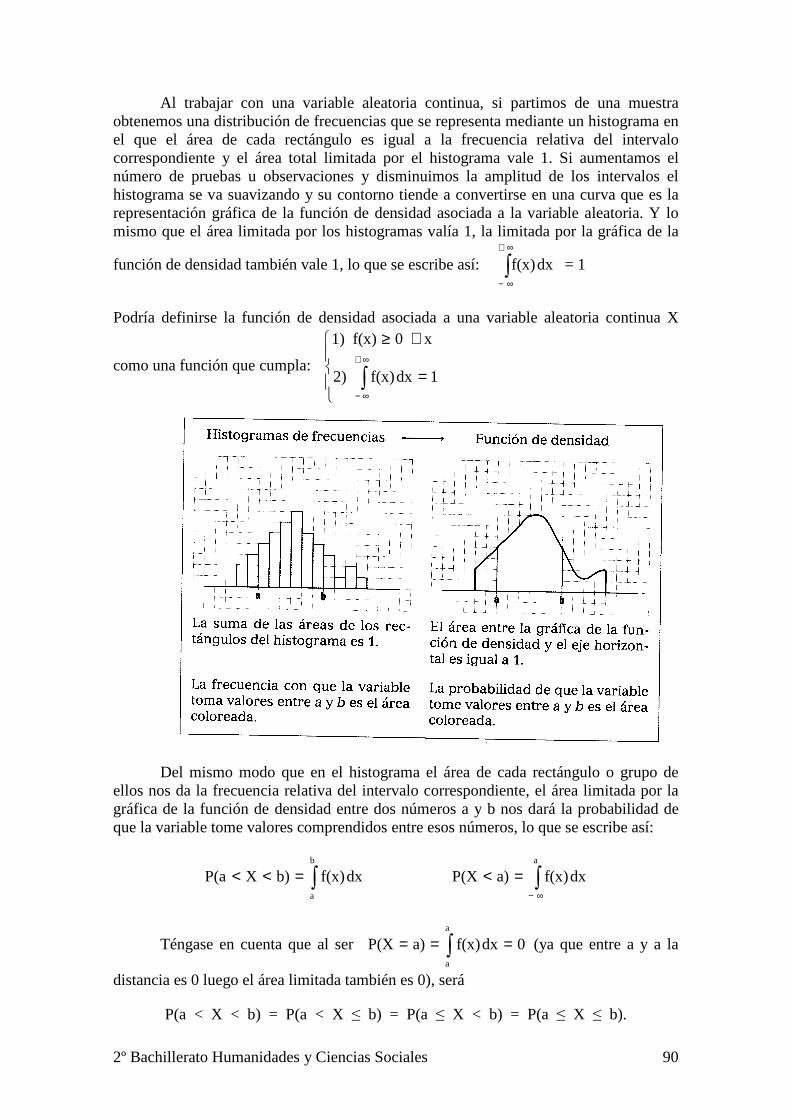
2º Bachillerato Humanidades y Ciencias Sociales 90
Al trabajar con una variable aleatoria continua, si partimos de una muestra obtenemos una distribución de frecuencias que se representa mediante un histograma en el que el área de cada rectángulo es igual a la frecuencia relativa del intervalo correspondiente y el área total limitada por el histograma vale 1. Si aumentamos el número de pruebas u observaciones y disminuimos la amplitud de los intervalos el histograma se va suavizando y su contorno tiende a convertirse en una curva que es la representación gráfica de la función de densidad asociada a la variable aleatoria. Y lo mismo que el área limitada por los histogramas valía 1, la limitada por la gráfica de la
función de densidad también vale 1, lo que se escribe así: ∫∞+
∞−
dxf(x) = 1
Podría definirse la función de densidad asociada a una variable aleatoria continua X
como una función que cumpla:
=
∀≥
∫∞+
∞−
1dxf(x)2)
x0f(x)1)
Del mismo modo que en el histograma el área de cada rectángulo o grupo de ellos nos da la frecuencia relativa del intervalo correspondiente, el área limitada por la gráfica de la función de densidad entre dos números a y b nos dará la probabilidad de que la variable tome valores comprendidos entre esos números, lo que se escribe así:
∫∫∞−
=<=<<ab
a
dxf(x)a)P(Xdxf(x)b)XP(a
Téngase en cuenta que al ser 0dxf(x)a)P(Xa
a
=== ∫ (ya que entre a y a la
distancia es 0 luego el área limitada también es 0), será
P(a < X < b) = P(a < X ≤ b) = P(a ≤ X < b) = P(a ≤ X ≤ b).

2º Bachillerato Humanidades y Ciencias Sociales 91
Ejemplo:
FUNCIÓN DE DISTRIBUCIÓN.
Para una variable aleatoria continua la función de distribución se define de modo análogo al caso de una variable aleatoria discreta como la función que asocia a cada número real la probabilidad de que la variable tome valores menores o iguales que ese número. (lo que se calcularía midiendo el área que limita la función de densidad hasta llegar a ese número).
∫∞−
=≤=t
dxf(x)t)P(XF(t)
Si la variable sólo toma valores en un intervalo [a, b] la función de distribución
será:
>
≤≤
<
= ∫
bxsi1
bxasidtf(t)
axsi0
F(x)x
a
La función de distribución cumple prácticamente las mismas propiedades que en el caso discreto: 1.- 0 ≤ F(x) ≤ 1 x 2.- es no decreciente: x2 > x1 F(x2) ≥ F(x1) 3.- F(- ∞) = 0, F(+ ∞) = 1

2º Bachillerato Humanidades y Ciencias Sociales 92
Ejemplo:
PARÁMETROS DE UNA VARIABLE ALEATORIA CONTINUA. Al trabajar con variables continuas el cálculo de la media µ y de la desviación típica σ requiere el uso el cálculo integral que no hemos visto, por lo que no podemos calcularlas. Pero tienen el mismo significado que en el caso de variables discretas: La media es la medida central que puede tomarse como “centro de gravedad” de la distribución de los datos. La desviación típica mide el grado de dispersión (separación o agrupamiento) de los datos respecto a la media.

2º Bachillerato Humanidades y Ciencias Sociales 93
DISTRIBUCIÓN NORMAL. Descripción. Función de densidad. Parámetros de la distribución normal: media y varianza. Cálculo de probabilidades de distribuciones con el uso de las tablas. DESCRIPCIÓN. FUNCIÓN DE DENSIDAD. PARÁMETROS DE LA DISTRIBUCIÓN NORMAL: MEDIA Y VARIANZA.
Hasta tal punto es corriente que una variable continua siga la distribución normal que durante mucho tiempo se pensó que todas las distribuciones continuas se aproximarían a la normal si dispusiésemos de un número suficientemente grande de observaciones bien hechas. Una variable aleatoria continua sigue una distribución normal de media µ y desviación típica σ si su función de densidad es:
2
2
1
2
1)(
−−
⋅⋅
= σµ
πσ
x
exf
La gráfica correspondiente se llama campana de Gauss o curva normal. Tiene su máximo en x0 = µ y dos puntos de inflexión a distancia σ de µ. El eje OX es asíntota horizontal y la recta x = µ es su eje de simetría. Es mas ancha y achatada (lo que corresponde a que la distribución sea mas dispersa) cuanto mayor sea σ.

2º Bachillerato Humanidades y Ciencias Sociales 94
Como para cualquier otra función de densidad el área limitada por la curva normal vale 1, pero en este caso se cumple además que: El área comprendida entre µ – σ y µ + σ vale 0,6826 µ - 2σ y µ + 2σ vale 0,9544 µ - 3σ y µ + 3σ vale 0,9977 Se utiliza la notación N(µ, σ) para referirse a una variable aleatoria continua que sigue una distribución normal con media µ y desviación típica σ. CÁLCULO DE PROBABILIDADES DE DISTRIBUCIONES NORMALE S CON EL USO DE LAS TABLAS. Como ya se vio en el tema anterior para cualquier variable continua la probabilidad de que la variable tome un valor comprendido entre dos números a y b vendrá dada por el área limitada por la función de densidad entre a y b. Dada la dificultad de calcular el valor del área en el caso de una distribución normal existen tablas que proporcionan dicho valor. Esas tablas se refieren sólo a la distribución N(0, 1) llamada normalizada o tipificada. Para otras distribuciones normales se hace el
cambio de variable σ
µ−= xz que se llama tipificación de la variable y que transforma
la variable X de distribución N(µ, σ) en una variable Z de distribución N(0, 1) para la que sí disponemos de tablas. De esta forma se tiene que
−≤=≤
σ
µxZP)xP(X 0
0
que figura en las tablas.
Para terminar vamos a ver como se calculan las probabilidades correspondientes a todos los casos que pueden plantearse al estudiar una distribución N(0, 1), ya que en las tablas lo que aparece es el valor de P(Z ≤ k) siendo k ≥ 0.

2º Bachillerato Humanidades y Ciencias Sociales 95

2º Bachillerato Humanidades y Ciencias Sociales 96
III.3.- APROXIMACIÓN DE LA BINOMIAL A LA NORMAL. CORRECCIÓN DE YATES PARA LA
CONTINUIDAD.
APROXIMACIÓN DE LA BINOMIAL A LA NORMAL.
En una distribución binomial B(n, p) las funciones de probabilidad y de distribución son:
∑=
−− ⋅
=≤=⋅
===
k
0r
rnrknk qpr
nk)P(XF(k)qp
k
nk)P(Xf(k)
con lo que, si n es grande, el cálculo, especialmente de la función de distribución es muy engorroso. Por ejemplo, en una distribución B(200, 0´3) sería
∑=
−⋅
=≤=
70
0r
r200r 0´70´3r
20070)P(XF(70)
lo que obliga a calcular 71 números bastante grandes, que además no vienen en las tablas. Sin embargo, al aumentar n la representación gráfica de la función de probabilidad se va pareciendo cada vez mas a una campana de Gauss, lo que sugiere que pueda haber alguna relación entre las distribuciones binomial y normal.
El matemático francés De Moivre demostró que los valores correspondientes a una distribución binomial B(n, p) pueden aproximarse por los de una normal N(µ, σ)
siendo µ = n·p, σ = qpn ⋅⋅ ; es decir, con las mismas media y desviación típica que la
binomial.

2º Bachillerato Humanidades y Ciencias Sociales 97
Esta aproximación puede hacerse siempre y cuando n·p y n·q sean mayores que 3; y si pasan de 5 la aproximación ya es muy buena. En general la aproximación es mejor cuanto mayor sea n y más próximo esté p a 0,5. CORRECCIÓN DE YATES PARA LA CONTINUIDAD Al efectuar esta aproximación surge el problema de que mientras la distribución binomial es discreta con lo que las probabilidades a calcular son puntuales, la normal es continua y sus probabilidades se calculan midiendo áreas con lo que en ella las probabilidades puntuales son nulas:
0dxf(x)a)P(Xa
a
=== ∫ .
Para resolver este problema se utiliza la corrección de Yates que consiste en considerar los valores de la variable aleatoria discreta como marcas de clase de intervalos de amplitud 1, es decir, [a – 0´5, a + 0´5). Entonces será:
P(X = a) = P(a – 0´5 ≤ X < a + 0´5)
P(X < a) = P(X < a – 0´5) P(X > a) = P(X ≥ a + 0´5)
P(X ≤ a) = P(X < a + 0´5) P(X ≥ a) = P(X ≥ a – 0´5) EJEMPLO: En el experimento aleatorio consistente en lanzar 12 monedas consideramos la variable aleatoria X = número de caras obtenidas. Vamos a calcular la probabilidad de que aparezcan entre 5 y 8 caras (ambos inclusive) utilizando directamente la distribución binomial y su aproximación mediante la normal para ver que la aproximación es realmente buena.
Binomial: B(12, 0´5). Sería p(5 ≤ X ≤ 8) = ∑=
−
8
5k
k12k 5050k
12 = 0´7332
Normal: µ = n·p = 6, σ = qpn ⋅⋅ = 1´73, N(6, 1´73)
Al pasar de discreta a continua tenemos que aplicar la corrección de Yates por lo que calcularemos P(4´5 ≤ X < 8,5). Y para poder usar las tablas tenemos que tipificar la
variable: 451731
65858870
731
65454 =−=⇒=−=−=⇒= zxzx
Con lo que será: P(4´5 ≤ X < 8´5) = P(- 0´87 ≤ Z < 1´45) = P(Z < 1´45) – P(Z < - 0´87) = P(Z < 1´45) – P(Z > 0´87) = P(Z < 1´45) – [1 – P(Z ≤ 0´87)] = 0´7343

2º Bachillerato Humanidades y Ciencias Sociales 98
III.4.- CONCEPTO DE POBLACIÓN Y MUESTRA. TÉCNICAS DE MUESTREO. PARÁMETROS
POBLACIONALES Y ESTADÍSTICOS MUESTRALES. CONCEPTO DE POBLACIÓN Y MUESTRA. TÉCNICAS DE MUESTR EO. En Estadística se llama Población al conjunto de personas, objetos,..., sobre el que interesa estudiar una característica o variable determinada. Normalmente, por razones económicas, de tiempo, ..., ese estudio no se realiza sobre toda la población si no sobre una parte o subconjunto de ella llamada Muestra.. Esa muestra debe estar bien escogida y ser del tamaño adecuado para que los resultados obtenidos a partir de ella puedan extenderse con garantía a toda la población. Ahora veremos las posibles formas de escogerla y en un tema posterior veremos qué tamaño debe tener.
Los métodos de muestreo (extracción de muestras) más importantes son: 1.- MUESTREO ALEATORIO SIMPLE: se numeran todos los elementos de la población y después se realiza un sorteo para escoger los que van a formar parte de la muestra. 2.- MUESTREO ALEATORIO SISTEMÁTICO: se obtiene por sorteo el primer elemento de la muestra y a partir de él, por “saltos” de igual longitud se obtienen los demás. (p. ej. de 10 en 10 si queremos que la muestra sea la décima parte de la población). La amplitud del salto se llama coeficiente de elevación y se obtiene dividiendo el tamaño N de la población entre el tamaño n de la muestra.

2º Bachillerato Humanidades y Ciencias Sociales 99
3.- MUESTREO ESTRATIFICADO: se emplea cuando se supone que el comportamiento de cada elemento de la población puede variar según su pertenencia a uno u otro “estrato” de esa población: sexo, edad,... . En este caso el número de elementos de cada estrato en la muestra debe ser proporcional al número de elementos de ese estrato en la población. 4.- MUESTREO POR CONGLOMERADOS: se emplea cuando la población está dividida en conjuntos (conglomerados) similares entre sí. En este caso lo que se seleccionan son conglomerados y, si hace falta, dentro de ellos se escogen elementos. Por ejemplo: escoger un grupo (el A, el B,...) para hacer un estudio sobre los alumnos de un curso determinado, en control de calidad se cogen envases de una docena de huevos o una caja de 12 litros de leche,... Todos estos muestreos se llaman probabilísticos y normalmente son sin reemplazamiento, o sea que cada individuo solo puede aparecer una vez, pero también pueden ser con reemplazamiento en algunos casos. También hay muestreos no probabilísticos en los que se escoge la muestra según otros criterios: elementos que nos parecen representativos de la población, ... . Normalmente los resultados obtenidos a partir de muestreos no probabilísticos no son muy fiables. PARÁMETROS POBLACIONALES (media µ, proporción p, varianza σ2) Y ESTADÍSTICOS MUESTRALES (media muestral X , proporción muestral p
cuasivarianza muestral 2S ).

2º Bachillerato Humanidades y Ciencias Sociales 100
Los parámetros poblacionales (suelen representarse por θ o λ) son los valores reales correspondientes a la población formada por N individuos que se quiere estudiar. Normalmente son desconocidos porque como dijimos antes no se estudia la población completa y se aproximan mediante los valores obtenidos en una muestra de tamaño n
que se llaman estadísticos muestrales (suelen representarse por θ o A). Los más utilizados son los siguientes: MEDIA MUESTRAL X : Como aproximación de la media real µ correspondiente a la
población se utiliza la media de la muestra escogida n
nxx ii∑= .
PROPORCIÓN MUESTRAL p : Como aproximación de la proporción de individuos p
que en la población cumplen una característica determinada se utiliza la proporción
muestral n
np i= que no es mas que la proporción o frecuencia relativa en la muestra.
CUASIVARIANZA MUESTRAL 2S : Como aproximación de la varianza real σ2 de la
población se utiliza la cuasivarianza muestral 221n
2 s1n
nss
−== − .
(se utiliza la cuasivarianza y no la varianza de la muestra porque, como veemos más adelante, aproxima mejor el valor real).

2º Bachillerato Humanidades y Ciencias Sociales 101
III.5.- TEOREMA CENTRAL DEL LÍMITE. DISTRIBUCIONES DE PROBABILIDAD DE LAS MEDIAS
Y DE LAS PROPORCIONES MUESTRALES. INTRODUCCIÓN. Al escoger una muestra los estadísticos correspondientes: media, varianza, proporción,..., sirven como aproximación al parámetro poblacional correspondiente. Pero seguramente con otra muestra los resultados obtenidos serían distintos. La situación que tenemos es la siguiente:
1.- Si la población está formada por N individuos podemos extraer de ella
=
n
NCn
N
muestras distintas sin reemplazamiento formadas por n elementos. Si fuesen con
reemplazamiento el número sería
−+=
n
1nNCRn
N .
2.- Para cada una de ellas podríamos calcular el valor correspondiente al estadístico considerado: media, proporción, ... Podemos entonces considerar la variable aleatoria que asigna a cada muestra el valor correspondiente del estadístico considerado. Esta nueva variable tiene su propia distribución de probabilidad que se llama distribución muestral de ese estadístico. Según cual sea el estadístico hablaremos de distribución muestral de las medias, de la varianza, de las proporciones, etc. DISTRIBUCIÓN DE PROBABILIDAD DE LAS MEDIAS MUESTRAL ES. Se puede comprobar que si la población objeto del estudio sigue una distribución normal N(µ,σ), la media muestral también se distribuye normalmente con la misma
media µ y desviación típica n
σ .

2º Bachillerato Humanidades y Ciencias Sociales 102
TEOREMA CENTRAL DEL LÍMITE. En el caso de que la población original no siga una distribución normal podemos aplicar uno de los resultados más importantes y “curiosos” de la Estadística que se llama Teorema Central del Límite y dice que: Si en una población con media µ y desviación típica σ tomamos muestras aleatorias de tamaño n, la distribución de probabilidad de la media muestral X tiende a
una normal de media µ y desviación típica n
σ cuando n tiende a infinito.
Dicho en forma más abreviada: para n grande (llega con que sea n > 30), X se
distribuye aproximadamente como una
σµ
n,N .
DISTRIBUCIÓN DE PROBABILIDAD DE LAS PROPORCIONES
MUESTRALES .
A veces lo que pretendemos estimar es una proporción o porcentaje. Esto ocurre cuando la variable que estudiamos sólo puede tomar dos valores complementarios entre sí: éxito o fracaso (hombres o mujeres, aficionados al fútbol o no,…).
Se puede demostrar que las proporciones muestrales siguen una distribución
normal de media p (la proporción poblacional) y desviación típica nqp ⋅ . Esto se
cumple mejor cuanto mayor sea n y cuanto mas próximo esté p a 0,5; si n·p y n·q son mayores que 5 la aproximación a que la proporción muestral siga una distribución normal es buena.
DISTRIBUCIÓN DE PROBABILIDAD DE LA DIFERENCIA DE ME DIAS MUESTRALES.
Cuando queremos comparar los resultados correspondientes a dos poblaciones diferentes (duran más las bombillas de la marca A o de la marca B, tiene menor porcentaje de grasa corporal la gente que hace ejercicio regularmente que la que no lo hace,…) lo que hacemos es ver si la diferencia entre la media de una muestra extraída de una población y la de una muestra extraída de la otra población es significativa o no.

2º Bachillerato Humanidades y Ciencias Sociales 103
En este caso se puede demostrar que si las dos poblaciones siguen distribuciones normales N(µ1, σ1) y N(µ2, σ2) respectivamente, y tomamos muestras de tamaños n1 y n2 respectivamente de las que calculamos sus respectivas medias muestrales X 1 y X 2, se cumple que la variable aleatoria que asigna a cada par de muestras (una de cada población) la diferencia de sus medias muestrales X 1 - X 2 sigue una distribución normal de media la diferencia de medias poblacionales µ1 – µ2, y desviación típica
2
22
1
21
XX nn21
σ+σ=σ −
Y, por el Teorema Central del Límite, esto se cumple aunque las poblaciones no
sean normales si los tamaños muestrales son suficientemente grandes (mayores que 30).

2º Bachillerato Humanidades y Ciencias Sociales 104
III.6.- INTERVALO DE CONFIANZA PARA LA PROPORCIÓN Y PARA LA MEDIA DE UNA DISTRIBUCIÓN NORMAL DE DESVIACIÓN TÍPICA CONOCIDA. ESTIMACIÓN PUNTUAL. Como hemos dicho una estimación es una aproximación del valor real de una magnitud. Por ejemplo, la media obtenida en una muestra nos sirve como estimación del valor (desconocido) de la media correspondiente a la población. La estimación puede hacerse de dos maneras:
1. PUNTUAL cuando un único número, obtenido de una muestra, se toma como estimación del valor real correspondiente a la población.
2. POR INTERVALOS cuando se estima que el valor real pertenece a un intervalo, dándose además la probabilidad de que realmente pertenezca a ese intervalo.
Un estimador θ (o A) se llama centrado o insesgado si su media (la media de los valores del estimador obtenidos a partir de las distintas muestras posibles) coincide
con el valor real del parámetro θ (o λ) estimado: E(θ ) = θ. En caso contrario se llama
sesgado, siendo su sesgo la diferencia E(θ ) – θ, es decir, lo que por término medio se desvía el estimador del valor teórico.

2º Bachillerato Humanidades y Ciencias Sociales 105
Se puede demostrar que la media muestral es siempre un estimador no sesgado de la media poblacional. Es decir, la distribución muestral de medias, que como vimos sigue una distribución normal, tiene una media (la media de las medias de las muestras) que coincide con la media de la población. La proporción muestral también es un estimador no sesgado de la proporción poblacional. Sin embargo la varianza muestral s2 es un estimador sesgado de la varianza poblacional σ2 y ese sesgo es mayor cuanto mas pequeño sea n Por ello para la varianza poblacional se utiliza como estimador (no sesgado) la llamada cuasivarianza muestral:
221n
2 s1n
nss
−== − .
EJEMPLO:

2º Bachillerato Humanidades y Ciencias Sociales 106

2º Bachillerato Humanidades y Ciencias Sociales 107
Se puede demostrar que en el caso de poblaciones infinitas y también en el de poblaciones finitas si las muestras se toman con reemplazamiento (lo que no ocurre en el ejemplo que acabamos de ver) la forma mas sencilla de construir, a partir de la varianza muestral, un estimador insesgado de la varianza poblacional es por medio de la cuasivarianza muestral:
Un estimador es mas eficiente cuanto mas concentrados o próximos estén los valores obtenidos de las distintas muestras al valor real del parámetro poblacional correspondiente

2º Bachillerato Humanidades y Ciencias Sociales 108
ESTIMACIÓN POR INTERVALOS DE CONFIANZA. La estimación puntual se utiliza poco porque no hay datos que nos indiquen el grado de aproximación al parámetro estimado y, por tanto, la fiabilidad de la estimación. Es más útil la estimación por intervalos que consiste en determinar un intervalo en el cual esperamos que esté el parámetro poblacional buscado con una probabilidad fijada de antemano. Evidentemente cuanto mas amplio sea el intervalo utilizado más probable será que incluya al parámetro con lo que será mayor el grado de confianza que tendremos en que efectivamente lo contenga. Es decir, si deseamos tener más seguridad en que el parámetro estimado esté en el intervalo habrá que usar un intervalo más amplio para reducir el riesgo. Llamamos intervalo de confianza al intervalo que, con una cierta probabilidad, contenga al parámetro que se está estimando. Llamamos nivel de confianza Nc a la probabilidad de que el intervalo de confianza contenga al verdadero valor del parámetro. Llamamos nivel de significación al número α = 1 – Nc.

2º Bachillerato Humanidades y Ciencias Sociales 109
La idea de la estimación por intervalos es la siguiente: como hemos dicho, aunque la población no siga una distribución normal si el tamaño de la muestra es grande (n > 30) cualquier estadístico no sesgado A que se tome como estimador de un parámetro λ sigue una distribución normal de media el propio λ. Por tanto, si conociéramos λ podríamos tomar un intervalo I centrado en λ tal que P(A I) = Nc = 1 – α para un α prefijado; con lo que el 100·Nc por ciento de los valores de A obtenidos en las distintas muestras estarán en ese intervalo. Luego, inversamente, para el 100·Nc por ciento de los valores de A que tomemos el valor real del parámetro estará en el intervalo de igual amplitud que I centrado en A. Ejemplo: Si sabemos que el 90% de las capitales de provincia españolas están a una distancia de Madrid menor de 600 Km., inversamente, si tomamos al azar una capital cualquiera en el 90% de los casos Madrid estará a menos de 600 km. Por tanto, un intervalo de radio 600 Km. de centro en esa ciudad es, en este caso, el intervalo de confianza al 90%. DETERMINACIÓN DEL INTERVALO DE CONFIANZA Supongamos que queremos hacer una estimación por intervalos de confianza con nivel de confianza Nc = 1 – α (p. Ej. 0,9 ó 90%) del parámetro λ; es decir, que la probabilidad de que el valor real de λ esté en ese intervalo sea del 100·Nc por ciento (90%). λ es un parámetro cualquiera (después veremos los casos concretos de la media poblacional µ, de la proporción poblacional p y de la diferencia de medias µ1 – µ2). Tomamos un estimador no sesgado A de ese parámetro λ (la media muestral x ,
la proporción muestral p o la diferencia de medias muestrales X 1 - X 2). Ese estimador tomará un valor determinado Ai en cada muestra. Sabemos que si el tamaño muestral n es grande, sea como sea la distribución de la población, el estimador A sigue una distribución normal de media el valor real de λ y
con la desviación típica σA que le corresponda según lo que estemos estimando (n
σ

2º Bachillerato Humanidades y Ciencias Sociales 110
para la media muestral, nqp ⋅ para la proporción muestral,
2
22
1
21
nn
σ+σ para la
diferencia de medias). Si, supuesto conocido λ, buscamos un intervalo que contenga al 100·Nc por ciento (p. ej. 90%) de los valores Ai, inversamente para el 100·Nc por ciento de los valores Ai obtenidos de las distintas muestras su intervalo contendrá al valor real de λ como vimos en el ejemplo de las capitales de provincia. De ahí el nombre de intervalo de confianza al 100·Nc por ciento (90% siguiendo con el ejemplo). Para calcular los límites a y b de ese intervalo tendremos que tipificar la variable
A normal N(λ, σA) obteniendo A
AZ
σλ−= que es normal N(0, 1).
Dado que fuera del intervalo queda el 100·α por ciento (10% en el ejemplo), en
cada cola quedará 2α , y por eso los valores correspondientes de la variable Z se
representan ± 2
zα . El valor 2
zα se llama valor crítico de nivel de confianza 1 – α.
Puesto que la distribución de Z está tabulada podemos hallar ese intervalo
− αα
22z,z tal que α−=
≤≤− αα
1zZzP22
:
)95,0(2
2
21zZP)90,0(1zZzP
222
α−=α+α−=
≤⇒α−=
≤≤− ααα
entonces la tabla nos da el valor de 2
zα (1,65 en el ejemplo), que coincidirá con A
b
σλ−
con lo que serán b = λ + 2
zα σA (b = λ + 1,65·σA)
a = λ - 2
zα ·σA (a = λ – 1,65·σA)
En consecuencia, en el intervalo
σ⋅+λσ⋅−λ αα A
2A
2z,z estarán el 100·Nc
por ciento de los valores de A por lo que, inversamente, dado un valor de A obtenido de

2º Bachillerato Humanidades y Ciencias Sociales 111
una muestra tenemos una probabilidad del 100·Nc por ciento de que el valor real del
parámetro λ esté en el intervalo
σ⋅+σ⋅− αα A
2A
2zA,zA
INTERVALO DE CONFIANZA PARA LA MEDIA DE UNA DISTRIB UCIÓN NORMAL CON VARIANZA CONOCIDA . Sabemos que la media muestral X es un estimador insesgado de la media poblacional y que sigue una distribución normal con la misma media µ que la población
y desviación típica n
σ siendo σ la desviación típica poblacional.
Por tanto, según lo visto anteriormente, si tomamos una muestra con media x el intervalo de confianza para µ con nivel de confianza 1 – α será
σ⋅+σ⋅− ααn
zx,n
zx22
En caso de que la varianza poblacional no fuese conocida se aproximaría por la cuasivarianza muestral, o sea que tomaríamos como aproximación de la desviación
típica poblacional nn s1n
ns ⋅
−=
INTERVALO DE CONFIANZA PARA LA PROPORCIÓN DE UNA DISTRIBUCIÓN BINOMIAL (MUESTRA DE TAMAÑO GRANDE) Ahora vamos a calcular el intervalo de confianza para la proporción p de individuos de una población que cumplen una característica determinada. Como vimos antes, si la muestra es grande (n > 30) la proporción muestral p
sigue una distribución normal
⋅n
qp,pN .Por tanto, si calculamos el valor de la
proporción correspondiente a una muestra M de tamaño n: p)M(p = , se tiene que el intervalo de confianza para la proporción al nivel de confianza 1 – α es

2º Bachillerato Humanidades y Ciencias Sociales 112
⋅⋅+⋅⋅− αα n
qpzp,
n
qpzp
22
Normalmente p es desconocido, pero al ser n grande (> 30) se aproxima por p , con lo que, en la práctica, el intervalo de confianza para la proporción es
⋅⋅+⋅⋅− αα n
qpzp,
n
qpzp
22
INTERVALO DE CONFIANZA PARA LA DIFERENCIA DE MEDIAS .
En este caso sabemos que si las poblaciones de partida son normales, o si los
tamaños muestrales pasan de 30, la difencia de medias muestrales X 1 - X 2 es normal
σ+σµ−µ2
22
1
21
21 nn,N
Con lo que el intervalo de confianza correspondiente será:
σ+σ⋅+−σ+σ⋅−− αα2
22
1
21
221
2
22
1
21
221
nnzxx,
nnzxx
ERROR DE ESTIMACIÓN. DETERMINACIÓN DEL TAMAÑO DE LA MUESTRA. Al principio del tema hablamos de las muestras y dijimos que deben estar bien escogidas para que los resultados obtenidos a partir de ellas puedan extenderse con suficientes garantías a toda la población, y vimos diferentes métodos de muestreo. Pero no hablamos del tamaño que deben tener las muestras. Lógicamente cabe esperar que la fiabilidad de las estimaciones sea mayor cuanto mas grande sea la muestra, pero normalmente hay limitaciones económicas, operativas, temporales, etc. que hacen desaconsejable trabajar con muestras muy grandes. Para determinar el tamaño que debe tener una muestra debemos tener en cuenta dos aspectos:

2º Bachillerato Humanidades y Ciencias Sociales 113
1.- El nivel de confianza 1 – α con que queremos admitir que el verdadero valor del
parámetro λ está en el intervalo de confianza
σ⋅+σ⋅− αα A
2A
2zA,zA .
Es decir, que tengamos una probabilidad del 90%, 95%, 99%,... de que el verdadero valor del parámetro λ esté en el intervalo. Ya vimos antes que para aumentar la confianza debemos, en principio, aumentar el tamaño del intervalo.
2.- El error máximo que estamos dispuestos a admitir en la estimación, que es el radio del intervalo de confianza (si decimos que una persona tiene 25 años con un margen de 5, es decir entre 20 y 30, como máximo nos equivocaremos en 5 años).
A2
zE σ⋅= α
Estos dos aspectos parecen incompatibles porque si fijamos un error máximo (radio y, por tanto, tamaño del intervalo) determinado no podremos mejorar la confianza variando el tamaño del intervalo. Pero hay un tercer aspecto que nos permite compatibilizarlos; es decir, mejorar la confianza sin variar el tamaño, y ese aspecto es el tamaño muestral n porque como ya vimos el radio del intervalo es
2zα σA siendo σA la desviación típica del estimador
empleado y esa desviación típica depende del tamaño muestral n: es n
σ para la
media muestral (en otros estimadores sería similar) luego aumentando n disminuye σA y por tanto el tamaño del intervalo o, inversamente, fijado el tamaño, al aumentar n disminuye σA y por tanto podemos aumentar
2zα manteniendo el mismo tamaño (ya
que el radio es A2
zE σ⋅= α ) lo que hace aumentar la confianza. Concretamente:
Una vez fijados esos dos valores α y E de la igualdad A
2zE σ⋅= α podemos
deducir el valor de n:
En el caso de la media, como n
zE2
σ⋅= α , será 2
22
2
E
zn
σ⋅=
α
(NOTA: en la figura escriben zc en lugar de
2zα ).

2º Bachillerato Humanidades y Ciencias Sociales 114

2º Bachillerato Humanidades y Ciencias Sociales 115
III.7.- CONTRASTE DE HIPÓTESIS PARA LA PROPORCIÓN Y PARA LA MEDIA O DIFERENCIA DE
MEDIAS DE DISTRIBUCIONES NORMALES CON DESVIACIÓN TÍPICA CONOCIDA.
INTRODUCCIÓN.
Supongamos que tenemos una moneda aparentemente perfecta y queremos saber si está trucada (con lo que saldrán más caras que cruces o viceversa) o no. Para averiguarlo podemos suponer inicialmente que es correcta, tirarla diez veces y observar lo que ocurre. Si salen “muchas” o “muy pocas” caras concluiremos que está trucada y si sale un número “normal” de caras supondremos que sí es correcta como habíamos supuesto.
Ya sabemos que al tirar diez veces una moneda, por muy perfecta que sea, no
podemos esperar exactamente cinco caras y cinco cruces. Esto nos obliga a decidir cuantas son “muchas” o “muy pocas” caras o, equivalentemente, cual es un número “normal” de caras. Por ejemplo, si salen 0, 1, 9 ó 10 caras admitiremos que está trucada y en otro caso que es correcta.
Evidentemente una moneda podemos tirarla 50, 100, 1000 ó más veces, pero en
otros casos, por ejemplo pruebas de nuevos medicamentos, el número de pruebas u observaciones tiene que ser forzosamente muy limitado.
Muchas veces nos encontramos ante situaciones parecidas a ésta: se formulan
teorías o hipótesis sobre una población y para decidir si son ciertas o falsas tenemos que basarnos en la información obtenida a partir de una muestra:
1.- Las mujeres conducen mejor que los hombres. 2.- Cierta empresa láctea afirma que cada litro de leche semidesnatada contiene
15’5gr de grasa. 3.- Los turistas extranjeros que visitan las Rías Bajas gastan más dinero que los
españoles. 4.- La estatura media de los hombres españoles mayores de 18 años es de
172cm.
CONTRASTE DE HIPÓTESIS. El contraste de hipótesis es una técnica de inferencia estadística que sirve para
aceptar o rechazar una afirmación o hipótesis sobre una población en base a la información obtenida a partir de una muestra.

2º Bachillerato Humanidades y Ciencias Sociales 116
La hipótesis que se quiere contrastar (decidir si la admitimos como cierta o no) y
que supondremos cierta mientras los datos no nos demuestren lo contrario se llama Hipótesis Nula y se representa H0. La afirmación complementaria (recordar lo que son sucesos complementarios) se llama Hipótesis Alternativa y se representa H1.
Como ejemplo podemos pensar en un juicio. La hipótesis nula es que el acusado
es inocente. Si durante el juicio se aportan pruebas que, en opinión del juez sean suficientes, se rechazará la hipótesis nula y se aceptará la hipótesis alternativa: el acusado es culpable. En otro caso se mantendrá la hipótesis nula: es inocente.
Evidentemente al tomar una decisión según los resultados obtenidos en una
muestra podemos equivocarnos: es muy difícil pero posible que al tirar 10 veces una moneda correcta salgan 9 ó 10 caras, en cuyo caso pensaríamos que está trucada. (O si declaramos culpable a un inocente)
En este caso cometeríamos lo que se llama un error de tipo I: rechazar la hipótesis nula siendo cierta.
Al revés, también podría ocurrir que en una moneda trucada saliesen 7 caras con
lo que pensaríamos que es correcta. (O si declaramos inocente a un culpable). En este caso cometeríamos un error de tipo II: no rechazar (aceptar) la hipótesis
nula siendo falsa.
En la práctica nunca va a ser posible saber si hemos cometido algún error porque
para eso necesitaríamos saber previamente si la hipótesis nula es cierta o no. Lo único que podremos hacer es intentar minimizar la probabilidad de cometerlos.
Normalmente no se pueden minimizar simultáneamente los riesgos de cometer
ambos errores (que por otro lado son incompatibles entre sí: no pueden cometerse a la vez). Se representan respectivamente por α y β las probabilidades de cometer un error de tipo I y de tipo II.
Lógicamente partimos de lo que creemos cierto (hipótesis nula H0) por lo que
tratamos de minimizar el error de tipo I: rechazarla siendo cierta (condenar a un inocente). A su probabilidad α se le llama nivel de significación del test (o contraste).
Aunque no nos ocuparemos de ella, se llama potencia del contraste a 1 – β. Por
tanto un contraste será más potente cuanto menor sea β; es decir, cuanto menor sea la probabilidad de cometer un error de tipo II.

2º Bachillerato Humanidades y Ciencias Sociales 117
PASOS PARA LA CONSTRUCCIÓN DE UN CONTRASTE DE HIPÓTESIS. 1º: Enunciar claramente las hipótesis nula (H0) y alternativa (H1). Normalmente se toma como hipótesis nula la que creemos que es cierta.
También, dado que vamos a intentar minimizar el error de tipo I (rechazarla siendo cierta) podemos escoger la hipótesis nula de modo que el error de tipo I sea el más grave (condenar a un inocente).
Aquí sólo usaremos como hipótesis nula y alternativa un valor o un intervalo de valores posibles para un parámetro poblacional: media, proporción o diferencia de medias.
2º: Fijar el valor máximo que admitiremos para el error de tipo I: el nivel de
significación α 3º: Escoger el estadístico muestral que usaremos como estimador para el
parámetro poblacional a estudiar. 4º: Determinar las zonas o regiones de aceptación y rechazo. Es decir, en
base al nivel de significación escogido, qué valores del estimador consideramos admisibles para aceptar como cierta la hipótesis nula, y qué valores no consideramos admisibles y nos llevarán a rechazarla (0, 1, 9 ó 10 caras en el ejemplo inicial).
5º: Tomar una muestra de la población y calcular en ella el valor del
estadístico usado como estimador. 6º: Decidir si aceptamos o rechazamos la hipótesis nula en función de que el
valor obtenido en la muestra esté en la zona de aceptación o de rechazo (también llamada zona crítica).
DETERMINACIÓN DE LAS REGIONES DE ACEPTACIÓN (R A) Y RECHAZO (RC).
Partimos de una población que sigue una distribución normal N(µ,σ) siendo la desviación típica σ conocida. Distinguiremos dos posibilidades según la hipótesis nula sea que el parámetro poblacional λ toma un valor determinado λ0 (en cuyo caso hablaremos de contraste bilateral o de dos colas), o que λ toma un valor mayor o igual (o menor o igual) que λ0 (en cuyo caso hablaremos de contraste unilateral o de una cola).
Tomamos un estimador no sesgado A de ese parámetro λ. Ese estimador tomará un valor determinado Ai en cada muestra.

2º Bachillerato Humanidades y Ciencias Sociales 118
El estimador A sigue una distribución normal de media el valor real de λ y con la desviación típica σA que le corresponda según lo que estemos estimando. Esto ocurriría también aunque el parámetro a estimar no siguiese una distribución normal siempre que el tamaño muestral fuese mayor que 30 (Teorema Central del Límite). CONTRASTE BILATERAL: Como ya vimos, al ser la hipótesis nula λ = λ0, lo lógico es rechazarla si el valor Ai obtenido en la muestra para el estimador A está lejos de λ0 (tanto por exceso como por defecto) y aceptarla si está próximo.
Para determinar si ese valor Ai está lejos o cerca de λ0 usamos el nivel de significación α (p. ej. 10%); es decir, el riesgo que admitimos de cometer un error de tipo I (rechazar la hipótesis nula siendo cierta). O sea que la región crítica RC es la que cumple que:
p(Ai RC) = α p(Ai RC) = p(Ai RA) = 1 – α Al ser la hipótesis alternativa λ ≠ λ0 rechazaremos los valores alejados de λ0
tanto por exceso como por defecto, por lo que la región crítica tendrá dos partes simétricas respecto a λ0, por lo que será de la forma:
RC = (- ∞, λ0 – k) ( λ0 + k, + ∞)
Y la de aceptación será
RA = (λ0 – k, λ0 + k) Para un cierto k que tenemos que determinar. Para hallarlo partiremos de
p (λ0 – k ≤ A ≤ λ0 + k) = 1 – α
Luego se trata de hallar el intervalo de confianza al nivel de confianza Nc = 1 – α lo que ya vimos en el tema anterior.

2º Bachillerato Humanidades y Ciencias Sociales 119
Por lo que repetiremos el proceso efectuado para su cálculo:
Para calcular los límites λ0 – k y λ0 + k de ese intervalo (al hablar del intervalo de confianza les llamábamos a y b) tendremos que tipificar la variable A normal N(λ,
σA) obteniendo A
0AZ
σλ−= que es normal N(0, 1).
Dado que fuera del intervalo queda el 100·α por ciento (10% en el ejemplo), en
cada cola quedará 2α , y por eso los valores correspondientes de la variable Z se
representan ± 2
zα . El valor 2
zα se llama valor crítico de nivel de confianza 1 – α.
Puesto que la distribución de Z está tabulada podemos hallar ese intervalo
− αα
22z,z
tal que α−=
≤≤− αα
1zZzP22
:
)95,0(2
2
21zZP)90,0(1zZzP
222
α−=α+α−=
≤⇒α−=
≤≤− ααα
entonces la tabla nos da el valor de
2zα (1,64 en el ejemplo), con lo que serán
b = λ0 + k = λ0 + 2
zα σA (λ0 + k = λ0 + 1,64·σA)
a = λ0 – k = λ0 - 2
zα ·σA (λ0 – k = λ0 – 1,64·σA)
En consecuencia, el intervalo
RA =
σ⋅+λσ⋅−λ αα A
20A
20 z,z
será la región de aceptación y la región crítica o de rechazo será
RC = (- ∞, λ0 –
2zα ·σA) ( λ0 +
2zα ·σA, + ∞)
O sea que si el valor para el estimador en la muestra está en la región de
aceptación admitiremos como cierta la hipótesis nula y si está en la región crítica la rechazaremos y admitiremos como cierta la hipótesis alternativa.

2º Bachillerato Humanidades y Ciencias Sociales 120
CONTRASTE UNILATERAL DERECHO (el izquierdo se haría igual): En este caso la hipótesis nula es del tipo λ ≤ λ0, con lo que la alternativa es λ > λ0. (El caso λ ≥ λ0 sería exactamente igual).
Por tanto, la región de rechazo será simplemente
RC = (λ0 + k, + ∞)
Con lo que toda la región de rechazo queda en la parte o cola derecha de la distribución, así que al tipificar la variable tendremos que buscar el valor zα tal que
p (Z ≤ zα) = 1 – α (0’90)
como antes la tabla nos da el valor de zα (ahora sería 1,28 en lugar de 1,64 porque toda la región crítica está a la derecha y no repartida a los dos lados), así que:
λ0 + k = λ0 + zασA (λ0 + k = λ + 1,28σA)
Por tanto la región de aceptación será
RA = (-∞,λ0 + zασA] Y la de rechazo
RC = (λ0 + zασA, + ∞)
CONTRASTE DE HIPÓTESIS PARA LA MEDIA.
En este caso el estadístico usado para estimar la media poblacional µ es la media muestral X , y sabemos que si la media poblacional es normal N(µ,σ), la media muestral
es
σµ
n,N , siendo n el tamaño muestral.
Por tanto en un contraste bilateral en el que la hipótesis nula H0 es µ = µ0, la
región de aceptación será
RA =
σ⋅+µσ⋅−µ ααn
z,n
z2
02
0
Y en un contraste unilateral derecho en el que la hipótesis nula H0 es µ ≤ µ0, la
región de aceptación será:
RA =
σ⋅+µ∞− αn
z, 0

2º Bachillerato Humanidades y Ciencias Sociales 121
CONTRASTE DE HIPÓTESIS PARA LA PROPORCIÓN. En este caso el estadístico usado para estimar la proporción poblacional p es la
proporción muestral p , y sabemos que la proporción muestral se distribuye
normalmente
⋅n
qp,pN .
Por tanto en un contraste bilateral en el que la hipótesis nula H0 es p = p0, la
región de aceptación será
⋅⋅+⋅⋅− αα n
qpzp,
n
qpzp 00
20
00
20
Y en un contraste unilateral derecho en el que la hipótesis nula es p ≤ p0, la
región de aceptación será
⋅⋅+∞− α n
qpzp, 00
0
CONTRASTE DE HIPÓTESIS PARA LA DIFERENCIA DE MEDIAS . Para comparar dos poblaciones haremos un contraste sobre la igualdad de sus
medias o, equivalentemente, que la diferencia entre sus medias es 0:
H0: µ1 = µ2 H0: µ1 – µ2 = 0 Con lo que la región de aceptación será
RA =
σ+σ⋅+−σ+σ⋅−− αα2
22
1
21
221
2
22
1
21
221
nnzxx,
nnzxx
Y de modo análogo para el contraste unilateral derecho en que la hipótesis nula
sería H0: µ1 µ2 H0: µ1 - µ2 0
La región de aceptación será
RA =
σ+σ⋅+−∞− α2
22
1
21
221
nnzxx,

2º Bachillerato Humanidades y Ciencias Sociales 122
ÍNDICE ÁLGEBRA I.1.- Concepto de matriz. ..................................................................................................1 I.2.- Operaciones con matrices. ........................................................................................3 I.3.- Matrices inversas sencillas por el método de Gauss.................................................5 I.4.- Sistemas de ecuaciones lineales................................................................................9 I.5.- Resolución de ecuaciones y sistemas......................................................................12 I.6.- Resolución de problemas mediante sistemas de ecuaciones...................................16 I.7.- Iniciación a la Programación Lineal bidimensional................................................17 I.8.- Formulación y resolución de problemas de Programación Lineal..........................21 ANÁLISIS II.1.- Límites...................................................................................................................29 II.2.- Continuidad ...........................................................................................................37 II.3.- La derivada ............................................................................................................46 II.4.- Cálculo de derivadas..............................................................................................51 II.5.- Aplicaciones de las derivadas................................................................................55 ESTADÍSTICA Y PROBABILIDAD III.1.- Sucesos aleatorios ................................................................................................67 III.2.- Probabilidad .........................................................................................................71 Variable aleatoria discreta ..............................................................................................81 Distribución binomial .....................................................................................................85 Variable aleatoria continua.............................................................................................88 Distribución normal........................................................................................................92 III.3.- Aproximación de la binomial a la normal............................................................95 III.4.- Concepto de población y muestra ........................................................................97 III.5.- Teorema Central del Límite ...............................................................................100 III.6.- Intervalos de confianza.......................................................................................103 III.7.- Contrastes de hipótesis. ......................................................................................114