master en diseÑo y tratamiento estadÍstico de encuestas · estadÍstico de encuestas pruebas de...
TRANSCRIPT

Identificación del alumno: Nombre
Apellidos
Fecha de envío
Calificación
Master en DISEÑO Y TRATAMIENTO ESTADÍSTICO DE ENCUESTAS
PRUEBAS DE EVALUACIÓN
Curso Académico 2013/2014
UNIVERSIDAD NACIONAL DE EDUCACIÓN A DISTANCIA
FACULTAD DE CIENCIAS ECONOMICAS Departamento de Economía Aplicada y Estadística

NORMAS PARA EL ENVÍO DE LAS “PRUEBAS DE
EVALUACIÓN A DISTANCIA”,
1. Se enviarán, convenientemente rellenadas, a:
2. Se enviarán antes del 15 de septiembre de 2014. En caso de existir una causa justificada que impida su envío en dicho plazo, se comunicará: al teléfono 91-3989336 o por fax al 91-3986697
3. Es obligatorio consignar los datos del alumno en el lugar que existe al
efecto en la portada. 4. El alumno mantendrá OBLIGATORIAMENTE en su poder una copia
del envío realizado, por si se produjera extravío; en este caso le sería requerida dicha copia.
5. Se recomienda utilizar un medio de envío que permita al aluno aportar
resguardo documental de que lo ha realizado; una buena forma de envío sería por correo certificado o el mail.
6. Las pruebas de evaluación se podrán descargar de la página Web del
curso: http://www.uned.es/diseno-tratamiento-encuestas/tablon.html, y se pueden enviar por e-mail a la siguiente dirección de correo: [email protected]
7. El alumno deberá utilizar el espacio que estime oportuno para
responder las preguntas, no tiene que ceñirse al que se da entre las preguntas.
D. Pedro Cortiñas Vázquez Dpto. de Economía Aplicada y Estadística Facultad de Ciencias Económicas y Empresariales Universidad Nacional de Educación a Distancia Paseo Senda del Rey, nº 11 28040 Madrid

PRUEBAS MODULOS 1 y 2
P 1. Según la American Marketing Asociation, ¿Cuál es la definición de investigación de mercados?
P 2. ¿Cuáles son los problemas más habituales para aplicar el método
científico a la investigación de mercados? P 3. En cuanto a su denominación, ¿qué tipo de datos secundarios
podemos encontrar en nuestra empresa? Cite algunos ejemplos P 4. ¿Qué fases hay que tener en cuenta al solicitar un estudio ad-hoc? P 5. ¿Cuáles son los problemas más comunes que nos podemos
encontrar al realizar una investigación de mercados internacional? P 6. ¿Cuál es la finalidad de la LOPD? P 7. ¿Qué diferencia existe entre un panel de consumidores y uno de
detallistas? P 8. ¿Qué es el geomarketing? P 9. ¿Cuál es el motivo de la utilización de métodos cualitativos en la
investigación exploratoria? P 10. ¿Qué es la validez interna de un experimento? P 11. ¿Qué diferencia existe entre una observación y una encuesta? P 12. ¿Cuáles son los campos de aplicación de la investigación comercial? P 13. ¿Cuál es la función del Marketing? P 14. ¿Qué áreas constituyen las estrategias básicas de gestión del
Marketing?

P 15. ¿Cuáles son las características más importantes que pueden
modificarse para lograr la diferenciación? P 16. ¿Cuáles son las etapas del ciclo de vida de un producto? P 17. indicar las cinco estrategias de precios más comunes P 18. ¿Cuáles son los criterios de segmentación de mercados? P 19. ¿Qué es un sistema de información de Marketing?
P 20. ¿Qué es la Creación de valor a la hora de fidelizar a un cliente? P 21. ¿Cuál es la principal aplicación del concepto de Lifetime Value? P 22. ¿qué entendemos por los Bulletin Boards? P 23. ¿Qué diferencia existe entre un Chat-Group y un Focus Group? P 24. ¿Existen limitaciones a la hora de realizar los Focus Groups online? P 25. ¿Cuáles? P 26. Enumere los pasos para llevar a cabo una investigación de mercados P 27. ¿Cuáles son los tipos de investigación de mercados?
P 28. ¿Cuándo debe llevarse a cabo el proceso de evaluación de la
investigación? P 29. ¿Cuáles son los métodos para evaluar dicho proceso?

P 30. ¿En qué consiste la investigación cuantitativa? ¿A qué preguntas responde?
P 31. ¿Cuáles son los principales inconvenientes de los cuestionarios por Internet?
P 32. ¿Cuáles son los tipos de preguntas empleadas en los cuestionarios?
P 33. Elabore un cuestionario sobre un estudio del consumo de productos congelados. Los objetivos son los siguientes:
o Cuantificación del mercado de consumidores de productos congelados
o Frecuencia de consumo o Lealtad del consumidor hacia los productos congelados
envasados y no envasados o Perfil del consumidor de productos congelados envasados y
no envasados o Categorías de productos congelados consumidos o Tipos de consumo o Factores de influencia, actitudes y ventajas buscadas en la
compra de este tipo de productos o Atributos de marcas de productos congelados o Datos de clasificación
P 34. ¿Qué se entiende por error aleatorio?
P 35. Enumere los tipos de muestreo no probabilístico
P 36. Diferencias entre los tipos de cuestionarios
P 37. ¿En qué consiste la depuración de los datos?
P 38. ¿En qué entornos se puede llevar a cabo la observación?
P 39. ¿Cuáles son las aplicaciones de la observación?

P 40. ¿Qué es la pseudocompra?
P 41. ¿Cuáles son los objetivos de los métodos cualitativos?
P 42. En investigación cualitativa, ¿en qué consiste la captación?
P 43. ¿En qué consiste la reunión de grupo? ¿Cuáles son sus objetivos?
P 44. ¿Qué es una “Reunión Creativa”?
P 45. ¿Qué son las técnicas predictivas?
P 46. ¿Qué diferencia al Panel de la encuesta?
P 47. Ventajas e inconvenientes del Panel
P 48. ¿Cuáles son las características de los estudios Ómnibus?
P 49. ¿Qué son los sistemas de apoyo a la decisión o DSS?
P 50. Enumere las fases de un proyecto de Data Mining
P 51. ¿Qué metodología para el análisis de datos propone SAS?
P 52. ¿Cuáles son los principales criterios para la selección de variables?
P 53. ¿Cuáles son los tipos de análisis cluster?
P 54. ¿En qué consiste la regresión logística?
P 55. Cuando la variable de respuesta es de tipo nominal o binario ¿qué criterios de generación de un árbol se pueden elegir?

P 56. ¿Cuándo son útiles las redes neuronales?
P 57. ¿Qué es un Datawarehouse?
P 58. Enumere algunos sectores en los que se aplica un Datawarehouse?

Ejercicio práctico:
Basándonos en el ejemplo del desarrollo lógico y funcional de la aplicación de la investigación de mercados en el área de marketing, que se presentaba como capítulo 5 del primer módulo, se pide la realización de una investigación de mercados para la evaluación de la viabilidad a la hora de introducir un producto concreto en un mercado concreto. Para ello se deberá definir en primer lugar el producto sobre el que vamos a realizar la investigación, en segundo lugar el mercado de referencia y por último se deberá exponer de forma razonada todas las acciones a realizar para la evaluación de la viabilidad de introducir el producto elegido en el mercado seleccionado. La investigación deberá recoger el mayor número posible de condicionantes reales (legislación del entorno, datos sobre el mercado, etc.) hasta donde sea posible. En el caso de que se deba de realizar alguna suposición se indicará que dicha cifra o dato es “inventado” indicándose también el motivo (entendemos que en algunos casos puede ser difícil el acceso a determinada información, así como tampoco se exige que las investigaciones tipo encuestas u observaciones se lleven a cabo en la práctica, aunque se valorará siempre la profundidad del razonamiento realizado al suponer un resultado). Por último se deberán de presentar todos los formularios utilizados en las investigaciones (cuestionarios, guías de entrevistas en profundidad, etc...). PRODUCTO SELECCIONADO:___________________________________ ÁMBITO DEL MERCADO SELECCIONADO:________________________

MODULOS 3,4 Y.5 1. Señale las diferencias básicas entre una investigación estadística de carácter probabilístico y una de carácter no probabilístico. )¿Una muestra probabilística es siempre una muestra estadísticamente representativa? 2. Señale 2 situaciones u operaciones estadísticas de carácter económico o social en las que para llevar a cabo correctamente una estimación, resulte imprescindible realizar una investigación de carácter probabilístico. 3. El director del Departamento de investigación de mercados de un gran banco desea conocer el grado de satisfacción de sus clientes y explicar las causas de que un 1% de su clientela haya anulado sus cuentas durante el último año. Para ello encarga una investigación telefónica ¿Cuál sería su universo de muestreo? ¿Cuál sería su marco estadístico? 4. ¿Qué diferencia hay entre un estimador y una estimación? 5. Describa el muestreo estratificado respondiendo a los siguientes interrogantes ¿En qué consiste? Una vez delimitados los estratos ¿Es necesario seguir el mismo método de selección muestral en cada estrato o puede ser diferente en unos estratos que en otros?. Si se trabaja con este tipo de muestreo ¿para obtener la estimación final es necesario obtener previamente la estimación correspondiente a cada uno de los estratos? Explica el criterio de afijación proporcional de la muestra por estratos. 6. Explica los problemas de marco que suelen presentarse al realizar una encuesta a empresas y las dificultades más habituales que pueden surgir para resolverlas. 7. El 75 % de los entrevistados en una encuesta telefónica realizada en España son amas de casa con más de 45 años de edad; ¿Qué opinas de esta operación estadística? ¿A qué ha podido deberse esta desviación? ¿Crees que está necesariamente sesgada y que sus resultados son totalmente inválidos? 8. Indica en qué situaciones es conveniente aplicar un muestreo con probabilidades desiguales. 9. ¿Cuál es el número máximo de estratos recomendado en un muestreo estratificado? Razona la respuesta. 10. Defina y relacione los términos precisión estadística y nivel de confianza. 11. Defina el concepto de estimador insesgado. Desarrolle este concepto con un sencillo ejemplo. 12. Explique las ventajas e inconvenientes de las encuestas telefónicas, indicando algunos ejemplos en los que estén especialmente recomendadas.

13. Explique cómo se calcula y de qué depende el tamaño de una muestra en un muestreo estratificado; desarrolle la pregunta bajo los supuestos de que se estiman proporciones trabajando con variables binomiales y de que la selección de individuos en cada estrato se realiza por muestreo aleatorio simple. 14. Explique la diferencia entre el error estadístico empleado en la fase de diseño estadístico y el error de muestreo de las estimaciones realizadas. Ejercicio 1 Supongamos que durante el mes de abril del año 2002 un determinado establecimiento ha tenido 100 clientes y que dispone de la información sobre las compras en euros que ha realizado cada uno de ellos; Explica con un caso concreto (inventa los datos) el procedimiento que seguirías para obtener una muestra de tamaño 10: 1) Mediante un muestreo aleatorio simple 2) Mediante un muestreo sistemático con arranque aleatorio. 3) Mediante un muestreo con probabilidades desiguales en el que se da tanta mayor probabilidad de salida a los individuos cuánto mayor sea su volumen de compras (probabilidades proporcionales al tamaño). 4) ¿Qué ventajas principales aporta el muestreo sistemático con arranque aleatorio sobre el muestreo aleatorio simple? 5) ¿Puede presentar algún inconveniente? 6) ¿Crees que lo presenta en este caso concreto? Ejercicio 2 En el ejemplo creado anteriormente, genera una muestra de 20 clientes mediante muestreo estratificado; explica que criterio has seguido para determinar: 1) El número de estratos a considerar 2) Los límites de dichos estratos 3) La afijación de la muestra por estratos Ejercicio 3 Exponer dos ejemplos prácticos lo más detallados posibles en el que se realice una estimación empleando muestreo por conglomerados

Ejercicio 4: Defina los conceptos de homocedasticidad, linealidad y normalidad. Indique los estadísticos que emplearía para comprobar si se cumplen estas propiedades. ¿Qué consecuencias existen en el caso de que no se cumplan estas propiedades? Ejercicio 5. Se conocen los siguientes datos de las siguientes variables:
Compras de Revistas
(unidades)
COMPRAS DE
LIBROS (UNIDADES)
ALTURA EN CMS.
ASISTENCIAS
ANUALES AL
TEATRO
GRADO DE
SATISFACCIÓN
CLIENTE
SEXO
EDAD DEL
ENCUESTADO
17
2
120
8
1
1
19
22
15
130
9
2
0
72 19
15
130
9
2
1
80
39
10
140
9
2
1
42 48
6
110
7
3
0
22
11
17
190
15
1
1
78 42
17
140
10
2
1
79
26
17
120
8
3
0
30 11
20
170
13
3
1
86
28
17
130
9
1
0
41
Grado de Satisfacción: 1=Bajo; 2=Medio; 3=Alto; Sexo: 1=Hombre; 0=Mujer
Se pide:
a) Indicar qué tipo de variable es cada una y en qué escala está formulada b) Calcular media, varianza y desviación típica de cada una de ellas c) Calcular el coeficiente de correlación de Pearson entre ventas de libros y edad d) ¿Qué mandatos se deberían efectuar en el SPSS para lograr la media, mediana, y
desviación típica de las ventas de libros de los clientes varones mayores de 70 años y que asisten al teatro más de 10 veces al año?
e) En el caso de la variable grado de satisfacción del cliente, ¿qué estadístico de los siguientes es el más apropiado?
Media Geométrica Estadístico T Coeficiente de correlación de Pearson Coeficiente de Spearman
f) En el caso de la variable venta de revistas, ¿qué estadístico de los siguientes es el más apropiado?
Coeficiente de contingencia Estadístico T Kruskall-Wallis Spearman
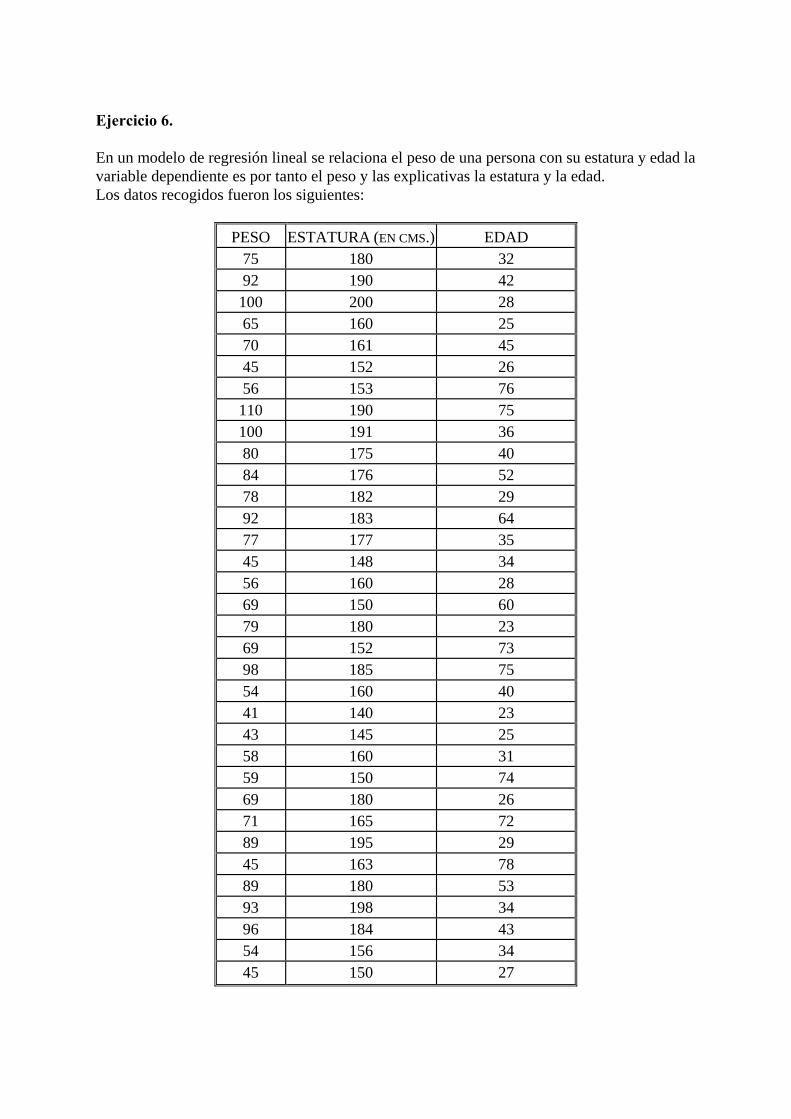
Ejercicio 6. En un modelo de regresión lineal se relaciona el peso de una persona con su estatura y edad la variable dependiente es por tanto el peso y las explicativas la estatura y la edad. Los datos recogidos fueron los siguientes:
PESO ESTATURA (EN CMS.)
EDAD
75
180
32 92
190
42
100
200
28 65
160
25
70
161
45 45
152
26
56
153
76 110
190
75
100
191
36 80
175
40
84
176
52 78
182
29
92
183
64 77
177
35
45
148
34 56
160
28
69
150
60 79
180
23
69
152
73 98
185
75
54
160
40 41
140
23
43
145
25 58
160
31
59
150
74 69
180
26
71
165
72 89
195
29
45
163
78 89
180
53
93
198
34 96
184
43
54
156
34 45
150
27
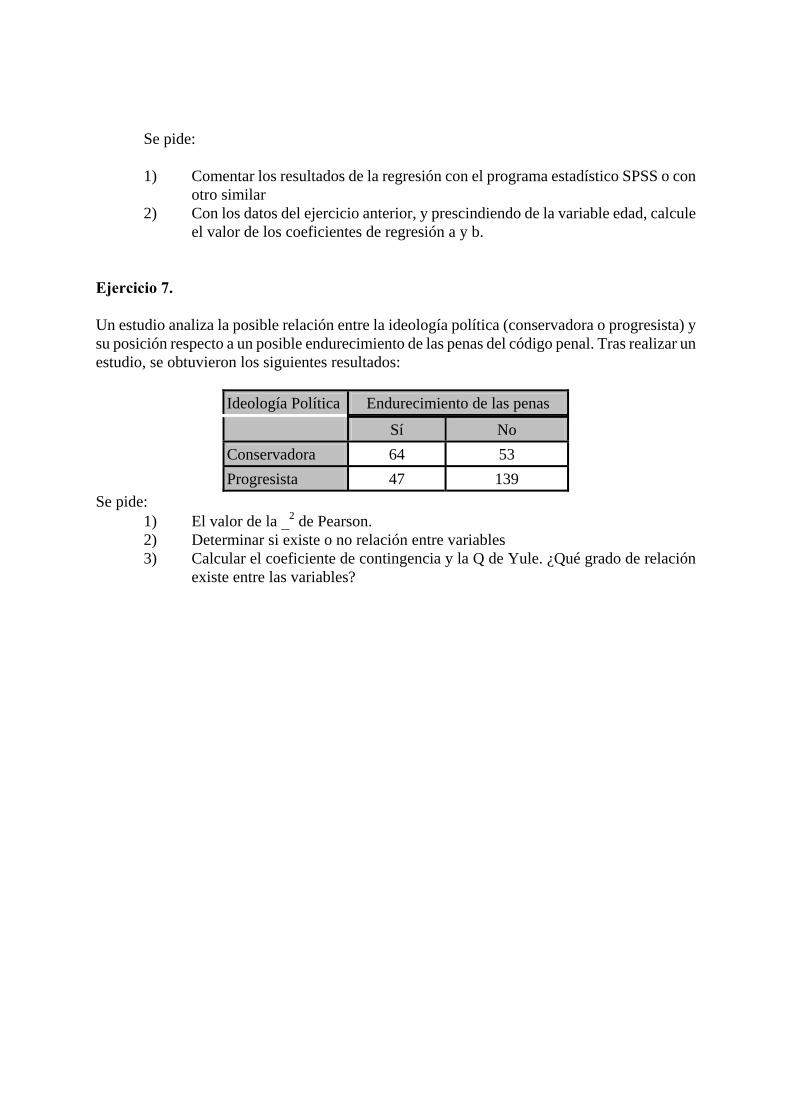
Se pide:
1) Comentar los resultados de la regresión con el programa estadístico SPSS o con
otro similar 2) Con los datos del ejercicio anterior, y prescindiendo de la variable edad, calcule
el valor de los coeficientes de regresión a y b. Ejercicio 7. Un estudio analiza la posible relación entre la ideología política (conservadora o progresista) y su posición respecto a un posible endurecimiento de las penas del código penal. Tras realizar un estudio, se obtuvieron los siguientes resultados:
Ideología Política
Endurecimiento de las penas
Sí
No
Conservadora
64
53
Progresista
47
139
Se pide: 1) El valor de la 2 de Pearson. 2) Determinar si existe o no relación entre variables 3) Calcular el coeficiente de contingencia y la Q de Yule. ¿Qué grado de relación
existe entre las variables?

Ejercicio 8 Una empresa se plantea realizar un cambio en la presentación de un producto. Diseña tres presentaciones distintas variando el tamaño del envase, el color, etc. Tras hacerlo se observa si el cliente compra o no el producto. Los datos obtenidos fueron los siguientes:
Presentación
Compra 1
0
1
0 1
0
1
0 1
0
1
0 1
0
1
0 1
0
1
0 1
0
1
1 1
1
2
1 2
1
2
1 2
1
2
1 2
1
2
1 2
0
2
0 2
0
2
0 2
0
2
0 3
0
3
0 3
0
3
0 3
1
3
1 3
1

3 1 3
1
3
1 3
1
3
1 3
1
Donde: Presentación 1= Presentación 1
2= Presentación 2 3= Presentación 3
Compra 1= Si
0= No Obtenemos la siguiente SALIDA DEL SPSS
Resumen del procesamiento de los casos
Casos
Válidos
Perdidos
Total
N
Porcentaje
N
Porcentaje
N
Porcentaje
Tipo de presentación * Compra del producto
39
100,0%
0
,0%
39
100,0%

Tabla de contingencia Tipo de presentación * Compra del producto
Compra del producto
Total
No
Si
Tipo de presentación
Presentación 1
Recuento
11
2
13
Frecuencia esperada
7,0
6,0
13,0
% de Tipo de presentación
84,6%
15,4%
100,0%
% de Compra del producto
52,4%
11,1%
33,3%
% del total
28,2%
5,1%
33,3%
Residuos corregidos
2,7
-2,7
Presentación 2
Recuento
6
7
13
Frecuencia esperada
7,0
6,0
13,0
% de Tipo de presentación
46,2%
53,8%
100,0%
% de Compra del producto
28,6%
38,9%
33,3%
% del total
15,4%
17,9%
33,3%
Residuos corregidos
-,7
,7
Presentación 3
Recuento
4
9
13
Frecuencia esperada
7,0
6,0
13,0
% de Tipo de presentación
30,8%
69,2%%
100,0%
% de Compra del producto
19,0%
50,0%
33,3%
% del total
10,3%
23
33,3%
Residuos corregidos
-2,0
2,0
Total
Recuento
21
18
39
Frecuencia esperada
21,0
18,0
39,0
% de Tipo de presentación
53,8%
46,2%
100,0%
% de Compra del producto
100,0%
100,0%
100,0%
% del total
53,8%
46,2%
100,0%
Pruebas de chi-cuadrado
Valor
gl
Sig. asint. (bilateral) Chi-cuadrado de Pearson
8,048a
2
,018
Razón de verosimilitud 8,679 2 ,013 Asociación lineal por lineal 7,389 1 ,007 N de casos válidos 39 a. 0 casillas (,0%) tienen una frecuencia esperada inferior a 5. La frecuencia mínima esperada es 6,00.

Medidas direccionales
Valor
Error típ. asint.a
T aproximadab
Sig. aproximada
Ordinal por ordinal
d de Somer
Simétrica
,411
,127
3,227
,001
Tipo de presentación dependiente
,481
,149
3,227
,001
Compra de producto dependiente
,359
,111
3,227
,001
a. No asumiendo la hipótesis nula. b. Empleando el error típico asintótico basado en la hipótesis nula.
Medidas simétricas
Valor
Error típ. asint.a
T aproximadab
Sig. aproximada
Nominal por nominal
Coeficiente de contingencia
,414
,018
Ordinal por ordinal
Tau-b de Kendall ,416 ,129 3,227 ,001
Tau-c de Kendall ,479 ,148 3,227 ,001 Gamma ,655 ,166 3,227 ,001 N de casos válidos
39
a. No asumiendo la hipótesis nula. b. Empleando el error típico asintótico basado en la hipótesis nula. Responder a la siguientes preguntas sobre esta salida:
a) ¿Existe relación entre las variables? Para averiguarlo en qué estadístico se fijaría. b) ¿Se puede inferir que el cambio de presentaciones hace variar la percepción del
producto? c) ¿Qué son los residuos estandarizados y qué nos muestran en este caso? ¿Qué
significado tiene el signo que acompaña el residuo?

Ejercicio 9 En relación con la regresión logística, se pide
1) Señalar varios ejemplos de utilización de la regresión logística. 2) ¿Qué utilidad considera que tiene la regresión logística en el campo de la
economía y la sociología? 3) Indicar semejanzas y diferencias entre la regresión logística y la regresión lineal 4) Enunciar un ejemplo de aplicación del modelo de regresión logística. Para ello
tan sólo deberá indicar la variable explicada (dependiente) y las posibles variables explicativas. Señale, asimismo, cuáles de ellas deberían categorizarse.
5) Indique las diferencias que la regresión logística tiene con los denominados “modelos probit”.
Ejercicio 10 En relación con el Análisis de la varianza, se pide contestar a las siguientes preguntas:
1) ¿Qué es y para qué sirve el análisis de la varianza? 2) ¿Qué diferencias tiene con el análisis de la covarianza? 3) ¿En qué consiste el modelo lineal general multivariante? Ponga algún ejemplo del
uso del mismo. 4) Una marca de cavas quiere saber la influencia que la ubicación del local donde se
vende su producto y la música que se pone en él tienen en las ventas del producto.. Tras recoger la siguiente muestra se plantea conocer la influencia realizando un análisis de la varianza.
Compra (número) Música
Zona
12
2
2
21
2
1 25
2
2
27
2
2 28
1
2
26
2
2 36
2
1
35
1
2 34
1
2
38
1
2 39
1
1
41
1
1 42
1
1

Compra (número)
Música
Zona
43
1
1
45
1
1 46
1
1
58
1
1 59
1
1
69
1
2 14
2
1
12
2
1 51
1
1
52
1
1 53
1
1
56
1
2 75
1
1
74
1
1 78
2
1
89
1
1 85
1
1
15
2
2 45
1
1
56
2
1 52
1
1
53
1
1 20
1
2
21
1
2 25
1
2
55
2
2 54
1
1
donde: Música 1 = Música clásica
2 = Música rock Zona 1 = Zona de renta alta
2 = Zona de renta medio-alta Obtenemos la siguiente Salida del SPSS

Resumen del procesamiento de los casosa
Casos
Incluidos
Excluidos
Total
N Porcentaj
e
N
Porcentaje
N
Porcentaje
40
100,0%
0
,0%
40
100,0%
a. Artículos comprados por nivel de renta, tipo de música
ANOVAa,b
Método único
Suma de
cuadrados
gl
Media
cuadrática
F
Sig
Artículos comprados
Efectos principales
(Combinadas)
3681,106
2
1840,553
6,09
5
,005
nivel de renta
1617,668
1
1617,668
5,35
7
,026
tipo de música
1630,370
1
1630,370
5,39
9
,026
Interacciones de orden 2
Nivel de renta* tipo de música
215,785
1
215,785
,715
,404
Modelo
516,046
3
1720,015
5,69
5
,003
Residual
10871,854
36
301,996
Total
16031,900
39
411,074
a. Artículos comprados por nivel de renta, tipo de música b. Todos los efectos introducidos simultáneamente Se pide
1) Interpretar la salida de SPSS indicando todo lo que a su juicio se puede extraer de ella
2) ¿Introduciría alguna covariable en este análisis? ¿Cuál? Razone la respuesta.

Ejercicio 11 1) Responde brevemente a la siguiente pregunta ¿Qué es y para qué sirve el análisis de
componentes principales? 2) Un investigador desea saber los factores que influyen en la capacidad de una persona. En
un grupo de posibles candidatos a un puesto de trabajo estudia las siguientes variables: renta familiar, número de cursos realizados, viajes al extranjero (para mejorar el nivel de idiomas), nota media durante el colegio, nota media durante la universidad, coeficiente de inteligencia. Tras recoger los datos realiza un análisis de componentes principales, intentando distinguir las variables relacionadas.
Renta
familiar anual
Nota media
colegio
Número de
cursos realizados
Viajes al
extranjero
Coeficiente
de inteligencia
Nota media universidad
10.00 5.00 5 6.00 110.00 6.00
2.50
8.00
1
1.00
160.00
9.00
3.00
9.00
2
.00
180.00
9.00
9.00
5.50
7
8.00
110.00
5.50
4.00
8.00
3
4.00
180.00
8.00
9.00
6.00
7
8.00
110.00
6.00
36.00
8.00
10
9.00
180.00
7.00
10.00
5.00
5
6.00
120.00
6.00
2.60
7.00
2
1.00
180.00
8.00
9.00
6.00
6
7.00
110.00
7.00
15.00
5.00
7
8.00
115.00
5.00
20.00
9.00
5
8.00
180.00
9.00
20.00
9.00
5
8.00
170.00
8.50
3.00
5.00
1
.00
110.00
5.50
2.50
5.00
1
1.00
105.00
5.00
3.00
8.00
1
.00
170.00
8.00
8.00
6.00
7
6.00
110.00
7.00
9.00
6.00
7
8.00
110.00
6.00
1.50
7.00
1
.00
115.00
6.00
2.00
9.00
1
.00
190.00
9.00
1.70
8.50
1
.00
180.00
9.00

2.00 9.00 2 1.00 190.00 9.00
10.00
5.00
7
8.00
110.00
5.00
10.00
5.00
7
8.00
115.00
5.00
8.00
6.00
8
7.00
110.00
6.00
2.00
9.00
1
.00
190.00
9.00
2.50
9.00
1
.00
195.00
9.50
10.00
5.00
7
8.00
110.00
5.00
10.00
5.00
7
8.00
115.00
5.00
20.00
9.00
5
8.00
170.00
8.50
3.00
5.00
1
.00
110.00
5.50
2.50
5.00
1
1.00
105.00
5.00
10.00
5.00
5
6.00
110.00
6.00
2.50
8.00
1
1.00
160.00
9.00
3.00
9.00
2
.00
180.00
9.00
10.00
5.00
5
6.00
120.00
6.00
2.60
7.00
2
1.00
180.00
8.00
9.00
6.00
6
7.00
110.00
7.00
36.00
8.00
10
9.00
180.00
7.00
10.00
5.00
5
6.00
120.00
6
Introducidos los datos en el SPSS obtiene la siguiente Salida:
Comunalidades
Inicial Extracción
Cursos realizados
1,000
,942 coeficiente de inteligencia
1,000
,940
nota media colegio
1,000
,960 nota media universidad
1,000
,932
renta familiar (en millones)
1,000
,889 viajes al extranjero
1,000
,931

Método de extracción: Análisis de Componentes principales.
Varianza total explicada (1)
Autovalores iniciales
Suma de las saturaciones al cuadrado de la extracción
Suma de las saturaciones al cuadrado de la rotación
Total
% de la varianz
a
%
acumulado
Total
% de la varianz
a
%
acumulado
Total
% de la varianz
a
%
acumulado
1
3,599 59,980
59,980
3,599
59,980
59,980
2,958
49,301
49,301
2 1,996 33,270 93,250 1,996 33,270 93,250 2,637 43,949 93,2503 ,221 3,677 96,927 4
8,622E-02
1,437
98,364
5
5,530E-02
,922
99,286
6
4,283E-02
,714
100,000
(1) Componente Método de extracción: Análisis de Componentes principales.
Matriz de componentesa
Componente
1
2
cursos realizados
-,806
-,541 coeficiente de inteligencia
,805
,540
nota media colegio
,805
,558 nota media universidad
,870
,420
renta familiar (en millones)
-,484
,809 viajes al extranjero
-,814
,519
Método de extracción: Análisis de Componentes principales
a. 2 componentes extraídos.

Matriz de componentes rotadosa
Componente
1
2
cursos realizados
-,283
,929 coeficiente de inteligencia
,965
-9,05E-02
nota media colegio
,977
-7,67E-02 nota media universidad
,939
-,225
renta familiar (en millones)
,137
,933 viajes al extranjero
-,303
,916
Método de extracción: Análisis de Componentes principales Método de rotación: Normalización Varimax con Kaiser. a. La rotación ha convergido en 3 iteraciones
Matriz de transformación de las componentes
Componente
1
2
1
,775
-,6322 ,632 ,775 Método de extracción: Análisis de Componentes principales Método de rotación: Normalización Varimax con Kaiser.
Se pide:
1) Interpretar la salida indicando todo lo que a su juicio puede extraerse de ella. 2) ¿Podría identificar los componentes principales extraídos? 3) ¿Son lógicos los resultados a su juicio?
Ejercicio 12 En relación con los test paramétricos y no paramétricos, conteste a las siguientes preguntas: 1) ¿Cuándo y para qué se utilizan los test no paramétricos?. Indique cuándo se debe utilizar
un test paramétrico y cuándo uno no paramétrico. 2) Determine y razone qué test no paramétrico se debe utilizar en cada uno de estos casos y
determine su valor.

A) Un investigador desea conocer la posible mejora en el nivel de satisfacción por un producto de un grupo de clientes que presentan tras una campaña publicitaria:
Nivel de satisfacción
Nivel de satisfacción posterior a la campaña
Previo
2
1
1
12
4 2
3
1
1 = Negativo. 2 = Positivo
B) Un investigador desea estudiar el efecto que una determinada noticia de crítica hacia un determinado producto ha tenido en él. Para ello se recoge en una escala el nivel de satisfacción del mismo en un grupo de clientes antes y después de la noticia. La satisfacción ha sido valorada en una escala de 1 a 10 donde 1 significa completa insatisfacción y el 10 alto grado de satisfacción. Los resultados se muestran a continuación:
Nota: Para resolverlo deberá hallar T y posteriormente hallar el valor de z tal como se indica en el material del curso (aunque el número de datos sea insuficiente para asegurar su aproximación a una distribución normal).
Cliente
Nivel satisfacción
anterior
Nivel satisfacción
posterior 1
10
3
2
9
3 3
8
4
4
4
1 5
4
5
6
4
6 7
8
5
8
7
2 9
10
2
10
10
1

C) Un investigador desea conocer en qué medida el clima puede influir en el número de compras de un determinado producto. Con el fin de averiguarlo, selecciona muestras en tres regiones diferentes del país. El estudio se ha realizado en tres intervalos diferentes de edades: de 50 a 60 años, de 60 a 70 años y de 70 a 80 años. Se presentan a continuación el número de compras que se dieron en cada región climática:
Edad
Región I
Región II
Región III
50-60 años
7
8
9 60-70 años
3
5
4
70-80 años
2
3
4 Región I: Clima frío, Región II: Clima templado, Región III: Clima cálido
Ejercicio 13. Determinar el coeficiente de correlación de Spearman de dos variables medidas en una escala ordinal que va desde 0 hasta 10, y que presenta los siguientes resultados:
Individuo 1
2
3
4
5
6
7
8
9
10
x 9
7
5
3
5
8
9
5
9
8
y 8
6
4
6
7
6
4
1
2
3
Ejercicio 14 En relación con el análisis de conglomerados o cluster, ¿cuál es su utilidad?. Ponga un ejemplo qué se le ocurra sobre su posible utilización y responda a las siguientes preguntas: a) ¿Qué es y cómo se define la “distancia euclidea al cuadrado?”? b) ¿Qué es un “análisis cluster jerárquico”? c) ¿En qué consiste el método de “vinculación inter-grupos”? Ejercicio 15 En relación al análisis de correspondencias, ¿cuándo y para qué se usa?. ¿Qué muestra la “contribución de la dimensión a la inercia en el punto”?. ¿Qué relación tiene esta técnica con las tablas de contingencia?

Ejercicio 16 En cuanto al escalamiento multidimensional, indique cuándo se utiliza y responda a las siguientes preguntas: d) ¿Cuál es la forma más habitual de introducir los datos en el escalamiento multidimensional? e) ¿Qué es la condicionalidad por matriz? f) ¿De qué dependen fundamentalmente los modelos de escalamiento? g) ¿Qué le indicaría un “coeficiente de Stress” igual a 0? h) ¿Qué es el gráfico de ajuste lineal? Ejercicio 17 ¿Para qué se utiliza principalmente el análisis conjunto?. Indique un ejemplo de su uso y responda a las siguientes preguntas: a) ¿Qué pasos se deben seguir en la realización de un análisis conjunto? b) En la lectura de los resultados qué es el “subfile summary” c) ¿Qué nos está indicando el concepto que el SPSS denomina “Averaged Importance”? d) ¿Qué indica el coeficiente de utilidad (“utility”)?

MODULOS 6 Y 7 Capítulo 1: Análisis de series temporales univariantes.
1. Explique que entiende por proceso estocástico y por serie temporal. ¿hay alguna
relación entre ambos?
2. Explique con un ejemplo la etapa de identificación (Enfoque Box-Jenkins ) del proceso generador de una serie estacional.
3. En que consiste la etapa de diagnosis y reformulación de un modelo ARMA.
4. Con la serie temporal “PIB de Francia”, serie trimestral que se alarga desde I/1969 hasta II/2005, se procede a estimar el siguiente modelo:
tt aPIBFranLogB =∇− )()1( 1φ
Los resultados de la estimación se presentan a continuación:
Dependent Variable: DLPIBFRAN Method: Least Squares Sample(adjusted): 1978:3 2005:2 Included observations: 108 after adjusting endpoints Convergence achieved after 2 iterations
Variable Coefficient Std. Error t-Statistic Prob. AR(1) 0.638831 0.072372 8.826992 0.0000
R-squared -0.284072 Mean dependent var 0.005037 Adjusted R-squared -0.284072 S.D. dependent var 0.004583 S.E. of regression 0.005193 Akaike info criterion -7.673672 Sum squared resid 0.002886 Schwarz criterion -7.648837 Log likelihood 415.3783 Durbin-Watson stat 2.596864 Inverted AR Roots .64
El residuo, así como la ACF y PACF residual se presentan en el gráfico y la tabla siguiente:

ACF PACF Q-Stat Prob 1 -0.469 -0.469 24.398 2 0.149 -0.090 26.894 0.000 3 0.077 0.143 27.560 0.000 4 -0.214 -0.140 32.778 0.000 5 0.143 -0.046 35.141 0.000 6 -0.069 -0.008 35.697 0.000 7 0.003 0.005 35.698 0.000 8 -0.069 -0.144 36.257 0.000 9 0.173 0.146 39.863 0.000
10 -0.128 0.029 41.865 0.000 11 0.190 0.168 46.306 0.000 12 -0.174 -0.113 50.073 0.000 13 0.009 -0.078 50.082 0.000 14 0.084 0.027 50.983 0.000 15 -0.147 -0.014 53.745 0.000 16 0.124 -0.021 55.725 0.000 17 -0.130 -0.077 57.945 0.000 18 0.012 -0.091 57.964 0.000
¿Es adecuado el modelo para la serie “PIB de Francia”? Realice la etapa de diagnosis.
104968880726456484032241680
70 72 74 76 78 80 82 84 86 88 90 92 94 96
4
2
0
-2
-4
acf
87654321
10.5
0-0.5
-1
pacf
87654321
10.5
0-0.5
-1
residuos pibfrancia
Q ( 8 ) = 36.3 Q ( 8 ) = 36.3
W__
(s^
_W
) = 0.18 % (0.05 %)
s^W = 0.49 %

5. En los gráficos siguientes se presenta la serie temporal “pasajeros de RENFE”. Esta serie es mensual y se alarga desde Ene-1964 hasta Sep-2005.
Comente cada gráfico y finalmente proponga un proceso generador de los datos.
480456432408384360336312288264240216192168144120967248240
1964 1966 1968 1970 1972 1974 1976 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004
4
2
0
-2
-4
acf
362412
10.5
0-0.5
-1
pacf
362412
10.5
0-0.5
-1
pasa_renfe
Q ( 39 ) = 9500.9
W__
(s^_W
) = 715.33 % (0.64 %) s^W
= 14.34 %
480456432408384360336312288264240216192168144120967248240
1964 1966 1968 1970 1972 1974 1976 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004
6
0
-6
acf
362412
10.5
0-0.5
-1
pacf
362412
10.5
0-0.5
-1
pasa_renfeÑ
Q ( 39 ) = 301.8
W__
(s^_W
) = 0.11 % (0.26 %) s^W
= 5.85 %
480456432408384360336312288264240216192168144120967248240
1964 1966 1968 1970 1972 1974 1976 1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004
5
0
-5
acf
362412
10.5
0-0.5
-1
pacf
362412
10.5
0-0.5
-1
pasa_renfeÑÑ12
Q ( 39 ) = 549.0
W__
(s^_W
) = -0.05 % (0.39 %) s^W
= 8.72 %

Capítulo 2: Análisis de Intervención
1. Explique para qué se utiliza el análisis de intervención en una serie temporal que sigue un proceso ARIMA.
2. Defina qué es una variable impulso, qué es una variable escalón y qué es una variable rampa.
3. ¿Qué es la función de transferencia de una variable de intervención? Proponga
un ejemplo de función de transferencia polinómica para el caso de una variable escalón e interprete los coeficientes de la función.
4. Para los casos que se presentan a continuación, indique qué tipo de variable de intervención incorporaría en un modelo ARIMA para incorporar los siguientes sucesos deterministas:
a. En una serie temporal que mide el número de desempleados en España, un
cambio legal que modifica la definición de desempleado a partir de una fecha determinada.
b. En una serie temporal que mide la tasa de inflación en una economía, la decisión del Banco Central Europeo de incrementar la oferta monetaria en los países de la eurozona de forma gradual.
c. En una serie temporal que mide el Índice de Producción Industrial de España,
una huelga general que paraliza la actividad del país durante un día.
d. En una serie temporal que mide el número de vehículos que circulan por una
carretera nacional, un suceso consistente en un accidente que obliga a cortar parcialmente y en determinadas horas la carretera durante una semana.
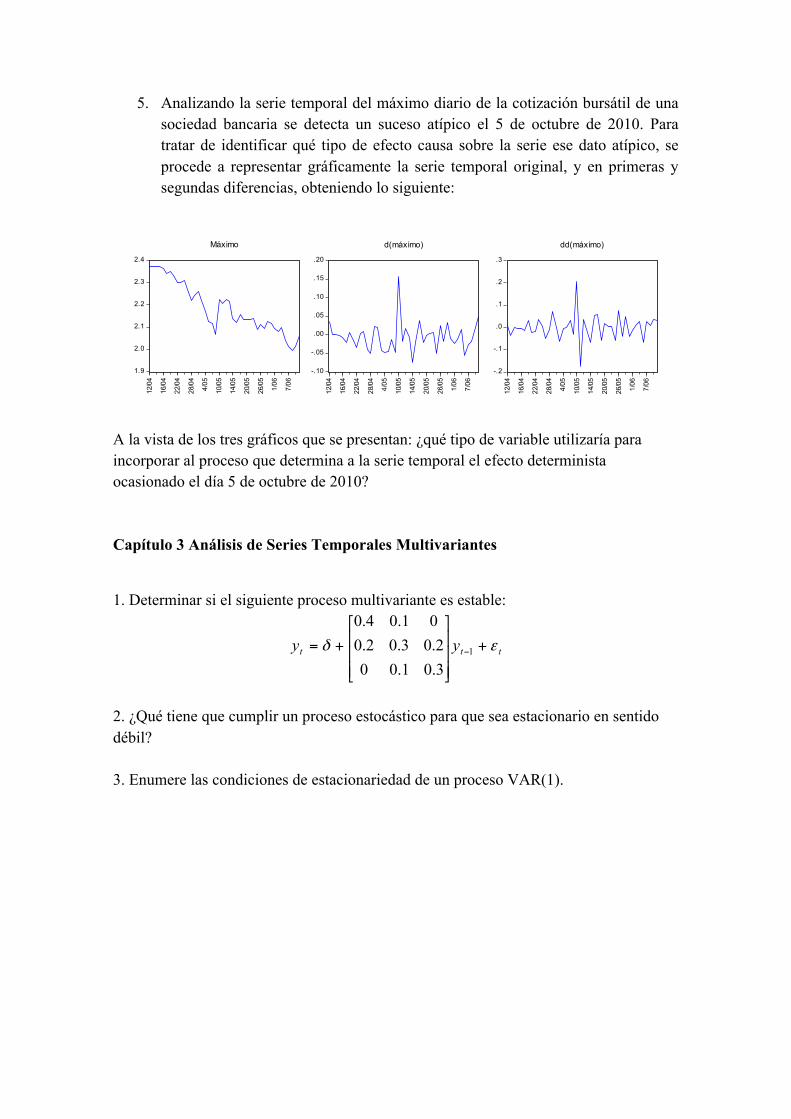
5. Analizando la serie temporal del máximo diario de la cotización bursátil de una sociedad bancaria se detecta un suceso atípico el 5 de octubre de 2010. Para tratar de identificar qué tipo de efecto causa sobre la serie ese dato atípico, se procede a representar gráficamente la serie temporal original, y en primeras y segundas diferencias, obteniendo lo siguiente:
A la vista de los tres gráficos que se presentan: ¿qué tipo de variable utilizaría para incorporar al proceso que determina a la serie temporal el efecto determinista ocasionado el día 5 de octubre de 2010? Capítulo 3 Análisis de Series Temporales Multivariantes 1. Determinar si el siguiente proceso multivariante es estable:
ttt yy εδ +
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
+= −1
3.01.002.03.02.001.04.0
2. ¿Qué tiene que cumplir un proceso estocástico para que sea estacionario en sentido débil? 3. Enumere las condiciones de estacionariedad de un proceso VAR(1).
1.9
2.0
2.1
2.2
2.3
2.4
12/04
16/04
22/04
28/04
4/05
10/05
14/05
20/05
26/05
1/06
7/06
Máximo
-.10
-.05
.00
.05
.10
.15
.20
12/04
16/04
22/04
28/04
4/05
10/05
14/05
20/05
26/05
1/06
7/06
d(máximo)
-.2
-.1
.0
.1
.2
.3
12/04
16/04
22/04
28/04
4/05
10/05
14/05
20/05
26/05
1/06
7/06
dd(máximo)

4. La Tabla siguiente muestra la estimación de un modelo que relaciona la tasa de variación diaria de los índices bursátiles de Madrid (IBEX-35), Fráncfort (DAX) y París (CAC-40).
VARIABLES DEPENDIENTES
VARIABLES EXPLICATIVAS ( )tIBEX 35ln −∇ ( )tDAXln∇ ( )tCAC40ln∇
( ) 135ln −−∇ tIBEX ⎟⎠⎞⎜
⎝⎛ 0746.02534.0
⎟⎠⎞⎜
⎝⎛ 0729.01583.0
( ) 235ln −−∇ tIBEX ⎟⎠⎞⎜
⎝⎛
−0305.00704.0
⎟⎠⎞⎜
⎝⎛
−0287.00572.0
⎟⎠⎞⎜
⎝⎛
−0298.00697.0
( ) 535ln −−∇ tIBEX ⎟⎠⎞⎜
⎝⎛
−0289.00735.0
⎟⎠⎞⎜
⎝⎛
−0299.00646.0
( ) 1ln −∇ tDAX ⎟⎠⎞⎜
⎝⎛ 0842.04234.0
⎟⎠⎞⎜
⎝⎛ 0794.03118.0
⎟⎠⎞⎜
⎝⎛ 0824.04328.0
( ) 4ln −∇ tDAX ⎟⎠⎞⎜
⎝⎛ 0319.00732.0
( ) 140ln −∇ tCAC ⎟⎠⎞⎜
⎝⎛
−1081.06404.0
⎟⎠⎞⎜
⎝⎛
−0760.03142.0
⎟⎠⎞⎜
⎝⎛
−1062.05630.0
( ) 340ln −∇ tCAC ⎟⎠⎞⎜
⎝⎛
−0312.00888.0
⎟⎠⎞⎜
⎝⎛
−0294.00680.0
⎟⎠⎞⎜
⎝⎛
−0305.00950.0
a) ¿Qué proceso sigue la serie temporal multivariante? b) Interprete los coeficientes estimados para la tasa de variación del índice bursátil
de Fráncfort, ( )tDAXln∇ .
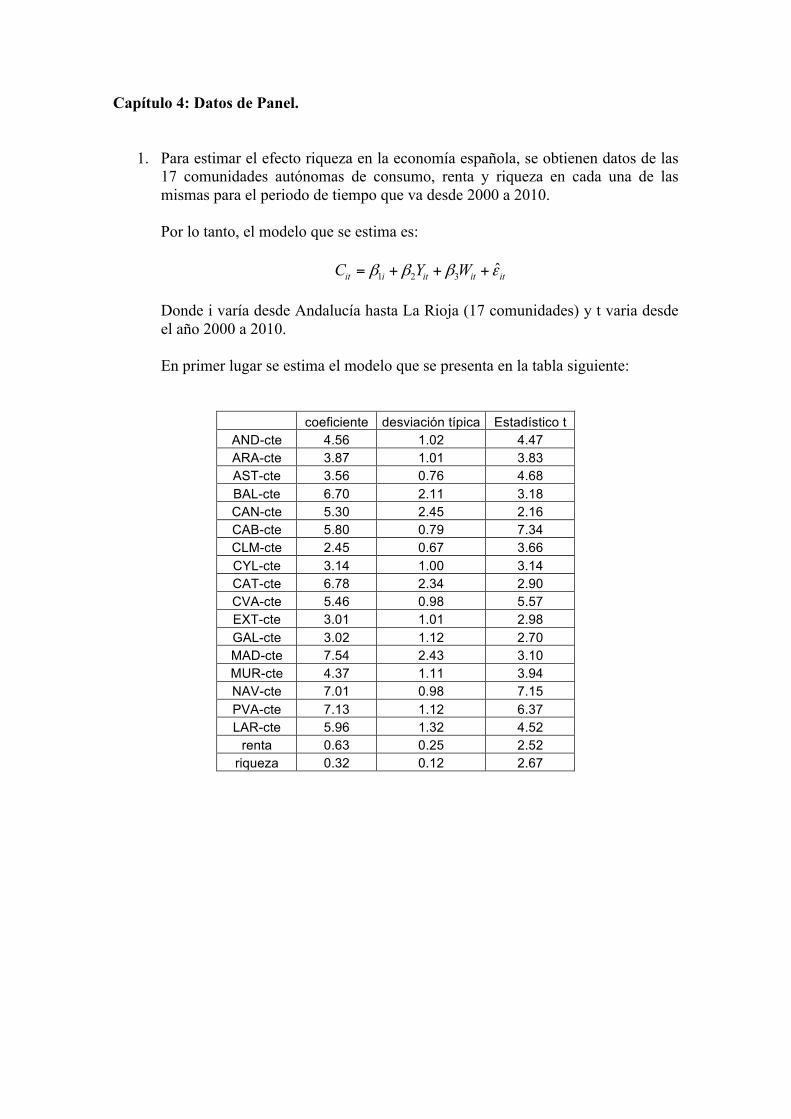
Capítulo 4: Datos de Panel.
1. Para estimar el efecto riqueza en la economía española, se obtienen datos de las 17 comunidades autónomas de consumo, renta y riqueza en cada una de las mismas para el periodo de tiempo que va desde 2000 a 2010. Por lo tanto, el modelo que se estima es:
1 2 3 ˆit i it it itC Y Wβ β β ε= + + + Donde i varía desde Andalucía hasta La Rioja (17 comunidades) y t varia desde el año 2000 a 2010.
En primer lugar se estima el modelo que se presenta en la tabla siguiente:
coeficiente desviación típica Estadístico t AND-cte 4.56 1.02 4.47 ARA-cte 3.87 1.01 3.83 AST-cte 3.56 0.76 4.68 BAL-cte 6.70 2.11 3.18 CAN-cte 5.30 2.45 2.16 CAB-cte 5.80 0.79 7.34 CLM-cte 2.45 0.67 3.66 CYL-cte 3.14 1.00 3.14 CAT-cte 6.78 2.34 2.90 CVA-cte 5.46 0.98 5.57 EXT-cte 3.01 1.01 2.98 GAL-cte 3.02 1.12 2.70 MAD-cte 7.54 2.43 3.10 MUR-cte 4.37 1.11 3.94 NAV-cte 7.01 0.98 7.15 PVA-cte 7.13 1.12 6.37 LAR-cte 5.96 1.32 4.52
renta 0.63 0.25 2.52 riqueza 0.32 0.12 2.67

Posteriormente se estima el modelo que aparece en la tabla siguiente:
coeficiente desviación típica Estadístico t AND-cte -0.31 ARA-cte -1.35 AST-cte -1.22 BAL-cte 1.70 CAN-cte 0.04 CAB-cte 0.55 CLM-cte -2.66 CYL-cte -1.92 CAT-cte 1.75 CVA-cte 0.23 EXT-cte -2.89 GAL-cte -1.64 MAD-cte 2.28 MUR-cte -0.64 NAV-cte 1.19 PVA-cte 3.01 LAR-cte -0.16
constante 5.12 1.3 3.94 renta 0.63 0.25 2.52
riqueza 0.32 0.12 2.67
Se pide: a) Diga que métodos se han utilizado para estimar el modelo en ambas tablas. b) Interprete los coeficientes de dichas tablas.
2. En un modelo dinámico con datos de panel explique las ventajas e inconvenientes de estimar dicho modelo transformando las series (diferenciándolas).

MODULO 8
En la última parte del Máster dedicada a la minería de datos se propone trabajar con 3 bases de datos incluidas en la carpeta DATA del programa WEKA, cuyo directorio de instalación es habitualmente: c:\archivos de programa\weka 3-‐7\data). Estas son las cinco cuestiones planteadas como ejercicio de evaluación:
Para resolver las tres primeras preguntas planteadas se trabaja con diferentes clasificadores y se utiliza el fichero vote.arff. Las otras dos cuestiones que se proponen están relacionadas con la reglas de asociación y se utilizan dos ficheros más.
Para el fichero vote.arff se pide que se ejecuten con el programa WEKA los siguientes clasificadores: redes neuronales, regresión logística, el clasificador j48, redes bayesianas y los multiclasificadores bagging y stacking.
1. Elabore una tabla de resultados con los diferentes clasificadores y comente los resultados.
2. Construya (con Weka) el árbol de clasificación que se obtiene al aplicar el algoritmo j48 y explique lo que se deduce del gráfico.
3. Realice una selección de variables con los procedimientos incluidos en WEKA y, una vez se haya seleccionado un conjunto significativo de variables, aplique los mismos procedimientos de clasificación que en el apartado primero y comente los resultados en relación a los resultados obtenidos cuando se utilizan todas las variables.
4. Usando la base de datos Weather Nominal: Ejecutar el algoritmo apriori. Examinando el resultado razonar qué reglas se han obtenido y cómo podríamos aplicar el conocimiento adquirido a una situación real.
5. La base de datos Supermarket es un conjunto de tickets de venta de un supermercado, cada instancia representa un ticket de venta en el que se indica de qué secciones se han comprado productos, así como si el importe final de la compra es elevado o bajo. Carga esta base de datos en Weka, y ejecuta esta vez el algoritmo FPGrowth. ¿Qué reglas se obtienen? ¿Podrías dar alguna explicación examinando los datos de por qué en todas las reglas aparece “bread and cake”?