estimación del valor en riesgos a través de wavelets
TRANSCRIPT


,
TECNOLOGICO DE MONTERREY
Hacemos constar que en la Ciudad de México, el día 23 de julio de 2009, el alumno:
Jesús Cuauhtémoc Téllez Gaytán
sustentó el Examen de Grado en defensa de la Tesis titulada:
Estimación del Valor en Riesgo a través de W avelets.
Presentada como requisito final para la obtención del Grado de:
DOCTOR EN CIENCIAS FINANCIERAS
• •. . ., .. . '
Ante la evidencia presentada en el trabajo de tesis y en este examen, el Comité Examinador, presidido por el DR. ARTURO LORENZO V ALDÉS, ha tomado la siguiente resolución:
Dr. Pablo Pér
Dr. Fernando Cruz Aranda Lector
- A P l\o P.,A DO -
Dr. Arturo Lorenzo Valdés Codirector
Dr. José n 10 Núñez Mora Director del Programa Doctoral
Campus Ciudad de México Calle del Puente 222, Col. Ejidos de Huipu!co
14380 Tlalpan, México D.F. México Tel: (52/55) 5483 2020 Fax: (52/55) 5673 2500

, TECNOLOGICO DE MONTERREY
. ·,, .,, .'lo .... .. '/ ,. .... . .·
... ~ .... -.......... ' l ,.... '. •
• ' .. ..,,.,.. ., JI ··. ; '~:1 1T: ~y··,_;···· ' ' "'· .; 1 ·~
'\ª,\.Jt'klle, .' : _-..~, , .. ... ... _. -'11:",1.F, CI.~ •·\l.~
Instituto Tecnológico y de Estudios Superiores
de Monterrey
Campus Ciudad de México
Estimación del Valor en Riesgo a través de W avelets
TESIS QUE PARA RECIBIR EL TÍTULO DE DOCTORADO EN
CIENCIAS FINANCIERAS PRESENTA
Jesús Cuauhtémoc Téllez Gaytán
Director de Tesis:
Dr. Pablo Pérez Akaki
Codirector de Tesis:
Dr. Arturo Lorenzo Valdés
Lector:
Dr. Fernando Cruz Ar anda
México D.F., 23 Julio 2009

Dedicatoria
Dedico la presente tesis a mi amada esposa Rocío y queridos hijos Mauricio y Valeria,
quienes sacrificaron su tiempo y estuvieron conmigo en el recorrido para la obtención del
grado doctoral; y quienes siguen conmigo en la realización de nuevos proyectos.
Con todo mi cariño y amor a mi papá, Ing. Jesús Téllez Gutiérrez, de quien tengo presente
sus enseñanzas y la escalera de la vida; y a mi mamá, Sra. Bertha Gaytán Galicia, quien
me ha sostenido en sus oraciones. Los quiero.
Con cariño a mis hermanos, Lic. Xochiquétzal Téllez Gaytán e Ing. Osear Cuitláhuac Téllez
Gaytán, quienes no dejan de mostrar su amor y afecto como hermanos.

Agradecimientos
Agradezco a Jesucristo mi Señor, por su misericordia en darme años de vida y permitirme
cursar el doctorado, a quien le doy la honra y la gloria por lo que he logrado alcanzar.
Agradezco al Tecnológico de Monterrey-Campus Estado de México, por haberme dado la
oportunidad en cursar el doctorado.
Agradezco al Comité Doctoral por su tiempo dedicado a la revisión de la tesis y atención en
las diferentes etapas de la disertación, en particular al Dr. Pablo Pérez Akaki por su interés
en la dirección de la tesis y motivación para concluir la misma.
Agradezco a Benjamín García y Eduardo Carbajal, por haber confiado en mí e impulsarme
a realizar los estudios de posgrado.
Agradezco a Jorge Morelos por sus consejos y guía en la conducción de mi vida académica.
Agradezco a la familia Alcántar, la familia Wodarczak, Virginia Valencia, Alejandro Valen
zuela, Mónica Pinal y a todos aquellos que influyeron en la realización de mis estudios
doctorales y que forman parte de mi ejercicio profesional.
11

Resumen
Wavelets son funciones que oscilan (wave) y decaen (let) a cierto número de desvane
cimientos, las cuales funjen como filtros para capturar componentes de alta frecuencia con
duración de corto tiempo y componentes de baja frecuencia que ocurren en periodos de
mayor tiempo. Contrario al análisis de Fourier, el análisis por wavelets permite analizar una
serie de tiempo en el espacio tiempo-frecuencia. Su principal flexibilidad es que permiten
estudiar fenómenos temporales, no estacionarios y de variación en el tiempo; fenómenos que
caracterizan y se identifican como hechos estilizados de las series de tiempo financieras.
La presente investigación aplica la teoría <le wavelets para estimar el Valor en Riesgo
del principal índice accionario mexicano, IPC, y de las emisoras que lo conforman. En
particular se utilizan la Transformada Wavelet Discreta (TWD) y su versión no-decimada,
la Transformada Wavelet Discreta de Máximo Traslape (TWDMT); y como filtro la función
wavelet de Daubechies de mínima asimetría de longitud ocho, para descomponer las series
de rendimientos en diferentes niveles de resolución. En cada nivel de resolución se estima la
varianza wavelet y a partir de ella se estima el VaR para cada escala de tiempo. El VaR de
la posición es la agregación de los VaR's en cada escala, metodología que es posible dada la
propiedad de decorrelación que se logra vía la TWD.
Los resultados de la investigación muestran a través del backtesting utilizando la prueba
de proporción de fallas de Kupiec, que el número de niveles de descomposición juega un papel
crucial en la validación de la metodología como adecuada para pronosticar las pérdidas. U na
herramienta útil para definir el número de niveles es la distribución de energía relativa, la
cual muestra la contribución relativa que cada nivel guarda respecto a la energía total de
la serie de tiempo. El VaR vía wavelets se compara con la metodología de Riskmetrics y el
modelo GARCH, los cuales mostraron un número mayor de excesos respecto de wavelets.
Una futura línea de investigación es aplicar la metodología para un portafolio de N
activos y la estimación del VaR en el contexto no paramétrico a través de la estimación de
la función de densidad vía wavelets.
lII

, Indice general
Dedicatoria
Agradecimientos
Resumen
l. Introducción
1.1. Antecedentes
1.2. Planteamiento del Problema
1.3. Hipótesis . . . . . . . . . . .
1.4. Objetivos . . . . . . . . . .
1.5. Justificación y Limitaciones
1.6. Contribución
2. Métodos de Estimación del Riesgo de Mercado
2.1. Modelos Probabilísticos de Rendimientos de Precios
2.2. Valor en Riesgo . . . . . . . . . . .
2.2.1. Estimación Paramétrica ..
2.2.2. Estimación No Paramétrica
2.2.3. Estimación Semiparamétrica .
2.3. Pérdida Esperada en la Cola .
3. Teoría de Wavelets
3.1. Bases Matemáticas y Propiedades
3.1.1. Series y Transformada de Fourier
3.1.2. Funciones base y concentración de energía
3.1.3. Convolución . . . . . . .
3.1.4. Propiedades de Wavelets
3.2. Análisis por Multiresolución ..
IV
I
11
111
1
2
6
9
9
9
10
12
13
26
26
31
32
35
38
40
40
46
49
51
52

3.2.1. Transformada de Fourier de Corto Tiempo (TFCT)
3.2.2. Transformada Wavelet Continua .
3.2.3. Transformada Wavelet Discreta .
3.2.4. Transformada Wavelet Discreta de Máximo Traslape
3.3. Varianza Wavelet . . . . . . . .
3.3.1. Intervalos de Confianza.
4. Metodología
4.1. Preparación de los datos
53
55
57
65 68
71
74
74
4.2. Estadísticos Descriptivos y Descomposición de las Series de Tiempo 75
4.3. La Varianza Wavelet . . . . . . . . 75
4.4. Estimación del Riesgo de Mercado . 75
5. Análisis y Resultados 80
5.1. Análisis Exploratorio de Datos . 80
5.2. Análisis de la Varianza Wavelet 83
5.3. Análisis del Riesgo de Mercado 86
6. Conclusiones 93
A. Descomposición por Multiresolución de Emisoras 96
B. Descomposición de la Varianza de Emisoras en 6 Niveles 101
C. Estimación del Modelo GARCH (1,1) 107
V

, Indice de figuras
2.1. Comparación entre Distribución Normal y de Cauchy . . . . . . . . . . 19
2.2. Comparación entre distribuciones Normal, t-student(5gl) y de Cauchy. . 22
2.3. Distribución Log-Normal conµ= O y a= l 24
2.4. Metodología de estimación aplicando TVE. . . . . . . . . . . . . . . . . 35
3.1. Cajas de Heisenberg en el plano frecuencia-tiempo con funciones-ventana fijas. 54
3.2. Cajas de Heisenberg en el plano frecuencia-tiempo y la función wavelct. 56
3.3. Funciones wavelet continuas. . . . . . . . . . . . . . . . . . . . . . 58
3.4. Representación wavelet de la descomposición por multiresolución. 60
3.5. Wavelet Haar. . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.6. Funciones de Daubechies de mínima fase de longitud 4 y 8. . . . . 64
5.1. (a) Rendimientos del IPyC y (b) Rendimientos al Cuadrado del IPyC. . 82
5.2. Descomposición por Multiresolución del IPyC vía TWDMT. . . . . . . 82
5.3. Evolución de la Varianza Wavelet del IPyC vía TWD: 03/01/2008-31/12/2008 83
5.4. Evolución de la Varianza Wavclet del IPyC vía TWDMT:03/01/2008-
31/12/2008 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.5. Evolución de la Varianza Wavelet del IPyC vía TWD: 05/05/2008-30/04/2009. 85
5.6. Valor en Riesgo en la Cola Inferior y Superior del IPyC al (a) 95% y (b) 99%. 86
5.7. Valor en Riesgo en la Cola Inferior y Superior del IPyC al 95 % para (a) 7 y
(b) 6 niveles de resolución. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.8. Valor en Riesgo vía TWD al (a) 95 % y (b) 99 %. . . . . . . . . . . . . . . . 91
5.9. Valor en Riesgo al 95% a través de (a) Varianza Wavelet, (b) Riskmetrics y
(c) GARCH (1,1) 92
A.l. MRD de Alfa . . 96
A.2. MRD de América Móvil 96
A.3. MRD de Ara 97
A.4. MRD de Bimbo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
VI

A.5. MRD de Cemex . . . . . . . .
A.6. MRD de Comercial Mexicana
A.7. MRD de Elektra ...
A.8. MRD de Femsa . . . .
A.9. MRD de Grupo Carso
A.10.MRD de Geo .....
A.11.MRD de Grupo México.
A.12.MRD de Grupo Modelo
A.13.MRD de lnbursa .
A.14.MRD de Kimberly
A.15.MRD de Banorte
A.16.MRD de Peñoles
A.17.MRD de Soriana
A.18.MRD de Telecom
A.19.MRD de Teléfonos de México
A.20.MRD de Televisa .
A.21.MRD de Wal-Mart ..
B. l. Varianza Wavelet Alfa
B.2. Varianza Wavelet América Móvil
B.3. Varianza Wavelet de Ara . .
B.4. Varianza Wavelet de Bimbo . . .
B.5. Varianza Wavelet de Cemex ...
B.6. Varianza Wavelet de Comercial Mexicana.
B.7. Varianza Wavelet de Elektra .
B.8. Varianza Wavelet de Femsa .
B.9. Varianza Wavelet de GCarso .
B.10. Varianza Wavelet de Geo . . .
B.11.Varianza Wavelet de Banorte
B.12.Varianza Wavelet de Inbursa .
B.13. Varianza Wavelet de GMéxico
B.14.Varianza Wavelet de Modelo .
B.15.Varianza Wavelet de Kimberly .
B.16.Varianza Wavelet de Peñoles .
B.17.Varianza Wavelet de Soriana.
B.18.Varianza Wavelet de Telecom
VII
97
97
97
97
98
98
98
98
98
98
99
99
99
99
99
99
100
101
101
102
102
102
102
103
103
103
103
104
104
104
104
105
105
105
105

B.19.Varianza Wavelet de Televisa
B.20. Varianza Wavelet de Telmex .
B.21. Varianza Wavelet de Wal-Mart
VIII
106
106
106

, Indice de cuadros
5.1. Estadísticos Descriptivos del IPyC y Emisoras. . . . . . . . . . . . . . . . . . 81
5.2. Backtesting Cola Inferior al 95 % del IPyC. . . . . . . . . . . . . . . . . . . . 88
5.3. Backtesting Cola Inferior al 95 % del IPyC y Emisoras (n=250). . . . . . . . 89
5.4. Distribución de Energía del IPyC con filtro Daubechies MA{8): 08/02/2001
- 31/12/2008. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.5. Distribución de Energía del IPyC con filtro Daubechies MA{8): 16/04/2004
- 30/04/2008. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
C.l. Resultados Modelo GARCH {1,1) ......................... 108
IX

Capítulo 1
Introducción
La conjunción de los avances en disciplinas como la estadística, matemáticas y com
putación, ha tenido sus resultados en finanzas en general y en particular en la adminsitración
de riesgos. Por un lado, su aplicación ha sido para validar los hechos estilizados que han
descrito el comportamiento de los precios de activos financieros entre ellos, grandes cambios
en los precios y memoria de largo plazo. Por otro lado, al poder capturar a través de mode
los esos hechos estilizados, se ha logrado una mejora en las metodologías de estimación del
riesgo al que los respectivos activos están expuestos, siendo uno de los más significativos el
riesgo de mercado.
Uno de los enfoques de mayor aceptación por la industria financiera y organismos re
guladores para la estimación del riesgo de mercado, ha sido Valor en Riesgo (VaR) cuya
definición más exacta la hace Jorion (1996). Precisamente, los avances y resultados en las
disciplinas arriba mencionados, han dado pie a una evolución en las metodologías para su estimación las cuales se clasifican en paramétricas, no paramétricas y semi-paramétricas.
Entre las metodologías de estimación de mayor sofisticación, por su propiedad de capturar
fenómenos como volatilidad agrupada y grandes cambios en los precios, han sido los modelos
de volatilidad condicional y la aplicación de la teoría de valores extremos; a partir de los
cuales se han realizado propuestas híbridas como GARCH-TVE desarrollada por McNeil
(2000), GARCH-fraccional y la modelación de las colas de una distribución de Pareto a
través de la función generalizarla de valores extremos propuesta por Khindanova, Rachev y
Schwartz (2000).
Recientemente, una de las aplicaciones matemáticas que ha ganado terreno en finanzas y
economía por su flexibilidad en analizar simultáneamente las series de tiempo en el dominio
de frecuencia y tiempo, ha sido la teoría de wavelets, contrario al análisis de Fourier el cual únicamente analiza la señal en el dominio de las frecuencias. Wavclets son funciones que
oscilan ( wave) y decaen (let) a cierto número de desvanecimientos, las cuales se consideran
1

como filtros idóneos para descomponer una señal en diferentes niveles de resolución, método
conocido como descomposición por multiresolución. El beneficio principal que ha tenido en
diversas disciplinas como la geofísica, medicina y estadística, es su capacidad de analizar
fenómenos no estacionarios, temporales y de variación en el tiempo.
Las primeras aplicaciones de wavelets en finanzas y economía se realizan por Ramsey
y Lampart (1999) quienes analizan las relaciones entre variables macroeconómicas. En es
tudios posteriores, Lee (2004) analiza el comportamiento entre los mercados accionarios de
Estados Unidos y Korea; Fernandez (2005) estima la beta de CAPM para países emergentes
a través de la descomposición por multiresolución de los rendimientos accionarios y en cada
nivel estima la varianza wavelet y el VaR. Norsworthy, et al. (2000) y Xiong, et al. (2005)
estiman la beta del CAPM para emisoras del S&P500 y de la Bolsa de Valores de Shangai,
respectivamente. Aplicaciones más recientes se han realizado en la valuación de opciones.
La presente investigación tiene por objetivo aplicar el análisis por wavelets para estimar
el Valor en Riesgo de emisoras pertenecientes al Índice de Precios y Cotizaciones (IPC) basa
do en la descomposición por multiresolución de la varianza utilizando funciones wavelets. La
metodología de estimación se basa en: 1) Fernández (2005), quien utiliza la Transformada
Wavelet Discreta de Máximo Traslape (TWDMT) para descomponer el Valor en Riesgo de
mercados accionarios emergentes; y, 2) Lai, He, Xie y Chen (2006), quienes estiman el riesgo
de mercado del crudo basado en un enfoque híbrido de wavelets y GARCH (1,1). La inves
tigación compara y muestra las implicaciones de utilizar la transformada wavelet discreta
(TWD) contra su versión modificada (TWDMT) en la estimación del VaR, y la elección del
l)Úmero de niveles de descomposición para validar la metodología propuesta como adecuada
en el pronóstico de las pérdidas.
1.1. Antecedentes
Valor en Riesgo (VaR) es una medida de riesgo que resume la peor pérdida esperada
sobre un horizonte objetivo dado un intervalo de confian:.:::a, e igualmente resume en un solo
número la exposición global a riesgos de mercado y la probabilidad de movimientos adversos
en las variables financieras. 1 La importancia e implicaciones de la función de distribución a
la cual hace referencia VaR, son descritas por Fama de la siguiente forma:
En general, la forma de la distribución es un factor principal en la determinación
del riesgo de una inversión en acciones comunes. Por ejemplo, a pesar de que
dos posibles distribuciones diferentes para los cambios en el precio puedan tener
1 Philippe Jorion, Value at Risk: The New Benchmark far Managing Financia/ Risk, página 47.
2

la misma media y cambio esperado en el precio, la probabilidad de cambios muy
grandes puede ser mayor en una distribución que en la otra. 2
Las primeras propuestas en la modelación de los precios de los activos datan del mode
lo de caminata aleatoria de Bachelier (1900), el cual considera que los cambios sucesivos
en los precios de los activos son aleatorios, estadísticamente independientes, idénticamente
distribuidos y de distribución Gaussiana con media cero. Sin embargo, el propio Bachelier
argumentaba que no existía la evidencia de que los precios siguiesen el modelo de cami
nata aleatoria también identificado como Movimiento Browniano, ya que las distribuciones
empíricas de los cambios en los precios mostraban ser leptokúrtikas o de colas largas. A
Osborne (1959) se le atribuye la caracterización del mercado accionario como un Movimien
to Browniano, ya que él argumenta que los precios de las acciones y el valor del dinero
se pueden representar como un conjunto de decisiones en equilibrio estadístico análogo al
conjunto de coordenadas de moléculas cuya distribución corresponde al de una partícula
en movimiento Browniano. La principal aportación de Osborne (1959) fue trabajar con las
diferencias en los logaritmos de los precios más que los cambios en los precios.
Dada la evidencia empírica en que la distribución de las diferencias logarítmicas de los
precios se representa por una distribución leptokúrtika, surgieron nuevas propuestas para
modelar los precios de los activos financieros dada la presencia de fenómenos como grandes
cambios en los precios, varianza que cambia en el tiempo ya identificados por Bachelier,
que hacen de las distribuciones empíricas alejarse del enfoque Gaussiano. El precursor fue
Mandelbrot (1963) al proponer una distribución estable de Pareto. Posteriormente Fama
(1965) valida la hipótesis de un mercado Paretiano propuesto por Mandclbrot al encontrar
que el parámetro a, < 2 para los rendimientos de emisoras pertenecientes al Dow Janes
Industrial Average. 3
En estudios posteriores, Praetz (1972) encuentra una a < 2 pero propone la distribu
ción de los rendimientos condicionada a la varianza y los modela bajo una distribución-t
argumentando que dicha distribución ajusta en mejor manera que el modelo Paretiano de
Mandelbrot, ya que es común que el mercado accionario presente periodos largos de activi
dad relativa seguido de periodos largos de inactvidad relativa. Officer (1972) y Perry (1983)
encuentran el parámetro a, < 2 en la distribución de los rendimientos de emisoras del New
York Stock Exchange, sin embargo Officer argumenta que la propiedad de estabilidad no se
cumple y Pcrry concluye que la varianza es finita pero <le estilo complejo más que la carac
terización de una varianza infinita. Igualmente Blattberg y Gonedes (1974) encuentran que
2Eugene Fama, The Behavior of Stock-Market Prices, página 41. 3 El parámetro o: se conoce como el parámetro del exponente rararterísl ico de la disl rib11ción estable de
Pareto y determina el grueso de la cola de la distribución. Se caracteriza por tomar valores entre O y 2.
3

la distribución-t de Student ajusta mejor los rendimientos que el modelo Paretiano. Upton
y Shannon (1979) detectan que los rendimientos de activos convergen a un distribución
log-normal en la medida que el horizonte de tiempo se alarga.
En estudios más recientes, Fielitz y Roselle (1983), Kon (1984), Harris (1986), y Hall et
al. (1989) muestran que los rendimientos de los activos se ajustan en mejor forma a través
de mezcla de distribuciones normales. Nelson (1991) propuso la Distribución Generalizada
de Errores junto con el proceso GARCH con el objetivo de incorporar las colas anchas de
los rendimientos, y posteriormente Zangari (1996) aplica dicha distribución junto con el
modelo EGARCH para estimar el Valor en Riesgo. Eberlein y Keller (1995) modelan los
rendimientos de los precios a través de una distribución hiperbólica.
La contribución de las investigaciones previas en administración de riesgos, dada la im
portancia que la forma de la distribución representa para determinar el riesgo de una inver
sión, se aprecia en una evolución de la medición del VaR. El primer enfoque (paramétrico) de
Valor en Riesgo, método varianza-covarianza, tiene sus antecedentes en la teoría de portafo
lios por Harry Markowitz (1952), teoría que establece que el agente económico define como
regla para estructurar sus carteras y seleccionar activos la relación rendimiento esperado
varianza de los rendimientos (E-V); cuyos supuestos se basan en el modelo de caminata
aleatoria el cual asume normalidad e independencia serial en los rendimientos. Este método
de varianza-covarianza hacen del VaR fácil de estimar computacionalmente ya que bajo el
supuesto de normalidad implica que los percentiles son múltiplos conocidos de la desviación
estándar; bajo el supuesto de independencia significa que el tamaño del cambio en el precio
en un día no afectará el cambio en el precio en un día siguiente, lo cual implica que la
desviación estándar de un horizonte de largo plazo se puede calcular como una multipli
cación de las desviaciones estándar de horizonte diario por la raíz cuadrada del número <le
días en el horizonte largo.
Ante la evidencia empírica de que los rendimientos mostraron distribuciones de colas
pesadas, nuevas propuestas surgieron para estimar el Valor en Riesgo con el objetivo de
capturar los grandes cambios en los precios de los activos financieros. Zangari (1996) propu
so una nueva metodología del VaR basada en la mezcla de distribuciones normales, las cuales
permiten capturar la distribución de colas pesadas en los rendimientos. Posteriormente Hull
y White (1998) estiman el VaR a través de una transformación de la distribución de proba
bilidad en una nueva distribución multivariada normal. Estas metodologías suponen que la
desviación estándar no cambia a través del tiempo (homoscedasticidad), fenómeno ya identi
ficado por Bachelier, por lo que Engle (2001) propuso la aplicación del modelo GARCH(l,1).
Engle (2001) estima el VaR al uno por ciento para un portafolio construido con un 50
por ciento del Nasdaq, 30 por ciento del Dow Jones y 20 por ciento con bonos del Tesoro con
4

vencimiento de 10 años. Los estadísticos descriptivos mostraron presencia de colas pesadas
vistas a través del valor de kurtosis, siendo éste mayor que 3 para cada uno de los activos y
el portafolio; la presencia de valores extremos negativos más que positivos se observa en un
valor negativo del sesgo. La presencia de efectos ARCH las detecta a través de las autocor
relaciones de los residuales al cuadrado, las cuales inician en 0.210 y decaen gradualmente
a 0.83 después de 15 rezagos. Sus resultados arrojan que la desviación estándar pronosti
cada para un día es de 0.0146 y dado que los residuales estandarizzados no son cercanos a
una distribución normal, entonces el cuantil al 1 por ciento corresponde a 2.844 contrario a
2.327 desviaciones estándar en una distribución normal. Por lo tanto el valor en Riesgo del
portafolio es de $39,996 comparado con el VaR bajo una distribución normal de $33,977.
Los enfoques paramétricos del VaR arriba expuestos asumen una distribución de pro
babilidad por igual para el total de los rendimientos y para los valores en las colas de la
distribución, teniendo presente que uno de los hechos estilizados que han caracterizado a los
datos financieros son los grandes cambios en los precios o valores extremos, haciendo que las
distribuciones empíricas sean de colas pesadas. Por lo cual una de las principales alternativas
al enfoque paramétrico ha sido la aplicación de la Teoría de Valores Extremos (TVE) que
modela los valores de las colas de una distribución no necesariamente conocida.4 El objetivo
de la Teoría de Valores Extremos es estimar el índice de la cola de la distribución a través
del cual se derivan las fronteras para rendimientos en exceso de muy bajas probabilidades.
Una de las principales investigaciones que aplica la TVE es la realizada por Longin
(2000), quien estima el VaR para los rendimientos diarios del S&P500 en el periodo de
enero-1962 a diciembre-1993. Su metodología se basa en 8 pasos entre los cuales: selecciona
los rendimientos, estima los parámetros de la distribución asintótica de los rendimientos
mínimos, aplica pruebas de bondad de ajuste para validar la hipótesis de la distribución
asintótica y finalmente selecciona el valor de probabilidad extrema de los rendimientos
mínimos para estimar el VaR de la posición.
Un tercer enfoque desarrollado se refiere a la simulación histórica, el cual no hace
supuesto alguno de la distribución de probabilidad de donde provienen los rendimientos,
por lo que su aplicación se basa en la determinación de ventanas de tiempo. El primer paso
es elegir una ventana de observaciones y después, los rendimientos del activo o del portafo
lio dentro de esta ventana se ordenan en forma ascedente. El cuantil q de interés es aquel
rendimiento que represente el q % de las observaciones en el lado izquierdo de la información
4Coronado (2001) afirma que la aplicación de la TVE debe servir como un análisis complementario para la estimación del VaR más que un enfoque de estimación en el sentido estricto, quien cita además rl punto de vista del expresidente de Chase Manhattan corporation, "In my view, value at Tisk is imporlant but it cannot stand alone". Coronado concluye que Valor en Riesgo no es un modelo si no un concepto: Valor en Riesgo mide el nivel de riesgo bajo ciertos supuestos.
5

ó ( 1 - q) % en el lado derecho.
Propuestas más recientes para estimar el VaR bajo el argumento de que logran cap
turar los hechos estilizados o fenoménos de las series de tiempo finacieras han sido: modelos
GARCH-fraccionales, modelación de las colas de una distribución de Pareto a través de la
función generalizada de valores extremos, y de creciente aplicación la teoría de waveletes.
Ésta última ha ganado terreno en el análisis de datos económicos y financieros por ser un
enfoque que permite el análisis de fenómenos temporales, no estacionarios y de variación en
el tiempo; a la vez permite el análisis simultáneo de frecuencia y escala en el tiempo de las
series de tiempo.
Una de las primeras contribuciones en economía y finanzas de la teoría de wavelets la
realizan Ramsey y Lampart (1999) quienes analizan las relaciones entre variables macroe
conómicas. Su metodología consiste en descomponer las series económicas en diferentes
escalas de tiempo y aplicar pruebas de causalidad de Granger para cada nivel de descom
posición. En un estudio similar por Aguiar, Azcvedo y Soares (2007) analizan el impacto del
cambio en las tasas de interés sobre variables macroeconómicas, quienes analizan la cova
rianza usando la transformada wavelet cruzada, la correlación local a través de la coherencia
wavelet, y la sincronización en fase a través de las diferencias en fase. Lee (2004) estudia
la transmisión de precios y volatilidad entre el mercado accionario Koreano y N orteameri
cano, cuyos resultados muestran que los rendimientos accionarios se deben principalmente
a fluctuaciones de muy corto tiempo.
La aplicación de wavelets para estimar el riesgo de mercado es muy reducida, siendo una
de las principales aportaciones en administración de riesgos la investigación de Fernández
(2005) quien descompone el VaR y la beta de CAPM para 7 mercados accionarios emergentes
a través de la Transformada Wavelct Discreta de Máximo Traslape (TWDMT). Norsworthy,
et al. (2000) y Xiong, et al. (2005) estiman la beta del CAPM para emisoras del S&P500
y de la Bolsa de Valores de Shangai, respectivamente. Lai, He, Xie y Chen (2006), estiman
el riesgo de mercado del crudo a través de un enfoque híbrido wavelets-GARCH (1,1). Su
metodología consiste en descomponer la serie de rendimientos del crudo y para cada nivel de
descomposición aplican el modelo de volatilidad condicional GARCH (1,1); posteriormente
agregan el VaR de cada escala para obtener el VaR total del commodity en cuestión.
1.2. Planteamiento del Problema
La problemática en la modelación de los rendimientos de precios de activos ha sido en
encontrar aquella familia de distribuciones que mejor ajuste tenga de los datos financieros
toda vez que la evidencia empírica ha mostrado distribuciones del tipo leptokúrtikas, mani-
6

festando la presencia de fenómenos como colas largas, volatilidad cambiante y agrupada, y
dependencia de largo plazo. Fenómenos que fueron indentificados desde Bachelier al referirse
a grandes cambios en los precios, varianza que cambia; Kendall al referirse a ruleta que no
tiene memoria; Fama al argumentar de la presencia de dependencia y volatilidad agrupada
como rendimientos positivos le siguen a rendimientos positivos, y rendimientos negativos le
siguen a rendimientos negativos. La importancia e implicaciones de lo anterior se refleja en
el riesgo asociado al comportamiento de un mercado financiero, en particular el mercado
accionario, tal como Fama argumenta: "la forma de la distribución es un factor mayor en la
determinación del riesgo en una inversión" .
Sin embargo, dada la evidencia, las propuestas de los diferentes modelos no han sido del
todo satisfactorias. Algunas por violar su propiedad principal como lo es estabilidad, otras
por suponer aún independencia en los rendimientos y en general por ser modelos paramétri
cos propuestos para representar a través de un sola función de distribución los diferentes
horizontes. Esto es, los modelos propuestos no del todo han logrado capturar los fenómenos
que describen el comportamiento del mercado. Lo anterior se ha reflejado en una evolución
de las metodologías para estimar el valor en riesgo, teniendo cada una sus diferentes desven
tajas.
El modelo de varianza-covarianza presenta dos debilidades en la estimación del VaR:
• La presencia de valores extremos en la distribución de los rendimientos más allá de lo
que la distribución normal captura, arroja un Valor en Riesgo mayor de aquel estimado
bajo el enfoque normal.
• Al ser los rendimientos no estacionarios, implica que la varianza y covarianza cambian
a través del tiempo, por lo que el Valor en Riesgo subestimaría al verdadero valor.
Una primera alternativa para resolver la problemática de homoscedasticidad en el modelo
varianza-covarianza, fue la aplicación del modelo GARCH( 1, 1), que a pesar de su flexibili
dad para modelar la variabilidad en la varianza, una de su principales debilidades es suponer
que los residuales estandarizados se distribuyen bajo una normal lo cual no es consistente
con el comportamiento de los rendimientos de los activos financieros. Manganelli y Engle
(2001) argumentan de tres fuentes que hacen del enfoque GARCH débil para estimar el VaR
y en consecuencia la incorrecta especificación en estos modelos: 1) incorrecta especificación
de la ecuación de la varianza, 2) incorrecta especificación de la distribución para construir la
verosimilitud logarítmica, y 3) los residuales estandarizados no son idéntica e independien
temente distribuidos (i.i.d). Adicionalmente, Mikosch y Starica (2000) argumentan que los
modelos GARCH no son capaces de describir libres de errores el comportamiento extremo
7

en encontrar aquella familia de distribuciones que mejor ajusten la información. Sin
embargo las propuestas no han sido del todo satisfactorias y con ello sus implicaciones
en las metodologías propuestas para estimar el riesgo de mercado, las cuales cada una
de ellas han presentado desventajas en su aplicación.
2. La metodología de wavelets se basa en la dilatación y traslación de una función que
permite analizar a detalle las pequeñas características de una serie de tiempo en el
dominio de tiempo-frecuencia y tiempo escala. Por lo que dicha serie de tiempo se
puede descomponer para analizarla a detalle y en diferentes escalas, y nuevamente
reconstruirla sin perder información relevante. Su flexibilidad se observa porque per
mite el análisis de fenómenos temporales, no estacionarios y de variación en el tiempo
-fenómenos que han caracterizado a datos económicos y financieros.
Su eficiencia se aprecia por la aplicabilidad que ha tenido ( en contraste con el análisis
de Fourier) en diversos campos como en la ingeniería en el procesamiento de señales
y compresión de datos (Norsworthy, Li y Gorener (2000)); en estudios geofísicos para
analizar relaciones causales físicas (Grinsted, Moore y Jevrejeva (2004)); en el campo
de la estadística para la estimación de la varianza (Abramovich, Bailey y Sapatinas
(2000), y Serroukh, Walden y Percival (2000)), simulación de procesos estocásticos
(Dijkerman y Mazumdar (1994)) y procesos con memoria de largo plazo y estimación
de densidades (Donoho, Johnstone, Kerkyacharian y Picard (1996)); y en el campo de
economía y finanzas para analizar funciones no estacionarias, realización de pronósti
cos, relaciones causales y análisis de cambios estructurales (Ramsey y Lampart (1999) ).
3. El desarrollo de plataformas tecnológicas ha hecho de la aplicación de wavelcts más
eficiente en cuanto al tiempo de estimación y aproximación en el uso de algoritmos
numéricos para la estimación de parámetros.
La investigación se limita en estimar el riesgo de mercado de activos individuales
pertenecientes al IP&C que han cotizado de forma continua desde el 2001. Los resultados
se limitan a compararse con el enfoque EWMA y el modelo GARCH (1,1).
1.6. Contribución
La investigación contribuirá a la literatura en administración de riesgos en las siguientes
formas:
1. Análisis por multiresolución de los rendimientos del mercado accionario mexicano y
de las emisoras pertenecientes al IPyC.
10

2. Estimación del riesgo de mercado a través de la descomposición por wavelets de la va
rianza, para estimar el Valor en Riesgo de activos individuales en el mercado accionario
mexicano.
3. Contrastación en la descomposición por multiresolución y estimación de la varianza
wavelet a través de la transformada wavelet discreta y transformada wavelet discreta
de máximo traslape.
11

Capítulo 2
Métodos de Estimación del Riesgo de
Mercado
Una de las medidas de riesgo de mercado más importantes y aceptadas en finanzas ha
sido Valor en Riesgo (VaR), la cual resume la peor pérdida esperada en un horizonte de
tiempo específico dado un nivel de confianza. U na definición formal de VaR la proporciona
Venegas-Martínez (2006), en donde el valor en riesgo de X dentro de un nivel de confianza
(1 - a) se expresa como
P0{-VaR{_0
:s; X}= 1- a, (2.1)
donde - V aRf_ 0
satisface
(2.2)
Igualmente VaR puede ser estimado en términos del valor del portafolio ( Jorion ( 1996)),
¡-w 1 - a= }_
00
J(w)dw, (2.3)
del rendimiento del portafolio
1 - a= 1-: J(r)dr, (2.4)
o la distribución normal estandarizada Z
¡-z 1 - a= }_
00
<l>(E)dE. (2.5)
Su estimación asume una distribución de probabilidad de la variable financiera, bajo el
supuesto común de una distribución Gaussiana, y descrita por Fama (1965) de la siguiente
forma
12

En general, la J arma de la distribuc'ión es un factor principal en la determinación
del riesgo de una inversión en acciones comunes. Por ejemplo, a pesar de que
dos posibles distribuciones dij eren tes para los cambios en el precio puedan tener
la misma media y cambio esperado en el precio, la probabilidad de cambios muy
grandes puede ser mayor en una distribución que en la otra. 1
El trabajo realizado por la estadística ha sido amplio en encontrar aquella distribución
apropiada que mejor ajuste los datos empíricos dado que estos han mostrado ser no
estacionarios, básicamente caracterizados por grandes cambios en los precios, volatilidad
cambiante y memoria de largo plazo (Longin (1991), Cont (2001)). Lo anterior ha dado
como resultado una evolución en la forma de estimar el riesgo de mercado en general y en
particular el Valor en Riesgo, y clasificada como estimación paramétrica, semiparamétrica
y no-paramétrica.
Por lo anterior, el presente capítulo inicia con una revisión de las diferentes familias de
distribuciones que se han propuesto para modelar los rendimientos de los precios de activos
financieros cuyo propósito ha sido en lograr capturar los fenómenos como valores extremos,
volatilidad cambiante y dependencia de largo plazo; toda vez que la evidencia empírcia ha
mostrado que la distribución de los rendimientos ha sido del tipo leptokúrtika o de colas
largas (Mandelbrot (1963)). La segunda sección trata sobre las diferentes metodologías de
estimación de Valor en Riesgo, y finalmente la tercera sección aborda la pérdida esperada
en la cola (PEC), medida de riesgo complementaria al VaR y descrita por Artzner (1999)
como una medida coherente de riesgo.
2.1. Modelos Probabilísticos de Rendimientos de Pre-.
CIOS
El supuesto inicial que se estableció en la distribución de los rendimientos de los precios
se remonta al modelo de caminata aleatoria para el mercado de activos y commodities
construido por Bachelier (1900), quien consideró que los cambios en los precios de activos se
generaban bajo una distribución normal. El modelo de Bachelier considera que los cambios
sucesivos en los precios de activos, Z(t+ T)-Z(t), poseen las propiedades de: a) aleatoriedad,
b) independencia estadística, c) distribución idéntica, y d) distribución marginal Gaussiana
con media cero. Por lo cual a este modelo se le ha llamado caminata aleatoria Gaussiana
estacionaria o simplemente movimiento Browniano.
Sin embargo a Osborne (1959) se le atribuye la caracterización del comportamiento del
1 Eugene Fama, The Behavior of Stock-Market Prices, página 41.
13

mercado accionario como un Movimiento Browniano, al argumentar que los precios de las
acciones y el valor del dinero se pueden representar como un conjunto de decisiones en un
estado estable o de equilibrio estadístico análogo al conjunto de coordenadas de un gran
número de moléculas. Su principal aportación en contraste con el modelo de Bachelier,
considera que los cambios en los precios son de la forma
Y= loge[P(t + r )/ Po(t)], (2.6)
donde P(t + r) y P0 (t) son los precios de las acciones en los tiempos aleatorios t + r y t;
y Y posee una función de distribución en equilibrio correspondiente al de una partícula en
movimiento Browniano de la forma
(2.7)
La justificación de Osborne en utilizar los cambios logarítmicos de los precios más que los
cambios de precios conforme al modelo de Bachelier se basa en un punto de vista racional,
ya que en intervalos iguales la variable aleatoria elegida debe ser física o psicológicamente
significativa, lo que implicaría que la diferencia en la sensación subjetiva de ganancia o
pérdida, o cambio de valor, en el precio de una acción de $10 a $11 debe ser igual al cambio
de $100 a $110. Para tales efectos, aplica la ley de Weber-Fechner y con ella construye la
función de distribución en un estado estable, haciendo énfasis en que el valor de la sensación
subjetiva como lo es la posición absoluta en un espacio físico no es medible, pero los cambios
o diferencias en la sensación subjetiva cumplen con el criterio de ser medibles.
La investigación de Osborne (1959) concluye que bajo la hipótesis de la ley de Weber
Fechner, las ganancias son medibles a través de los cambios en el logaritmo de los precios,
por lo que la ganancia esperada de cada cambio es cero; y bajo estas condiciones es a lo
que se llama indiferencia de decisión en primer orden o los cambios en el logaritmo de los
precios se encuentran estadísticamente en equilibrio entre el comprador y vendedor. Una de
las más importantes aplicaciones tanto del modelo de Bachelier como el de Osborne, fue en
la construcción del modelo Black-Scholes para valuar opciones (Black y Scholes (1973)), en
donde el comportamiento del activo subyacente es descrito por el movimiento geométrico
Browniano
14

Sin embargo y dada la evidencia empírica, los cambios en los precios han reflejado una
distribución no-normal del tipo leptokúrtica.2 Mandelbrot (1967) comenta que el propio
Bachelier argumentó que no existía evidencia a favor de un movimiento Browniano justifi
cado por dos razones: 1) la varianza muestra! de los cambios en el precio varía en el tiempo,
observándose esto a través de colas más anchas en el histograma respecto al caso Gaussiano;
y, 2) ni una mezcla razonable de distribuciones Gaussianas es capaz de capturar el tamaño de
los más grandes cambios en el precio, describiendo a este fenómeno corno "contaminadores"
o "outliers" .
Fama (1965) encuentra que la distribución de las diferencias logarítmicas de los precios
de treinta emisoras del Dow Jones Industrial Average presentan cierto grado de leptokur
tosis, ya que las distribuciones empíricas presentan un mayor pico en el centro y colas más
largas que la distribución normal. Brada, Ernst y Tassel (1966) modifican el modelo origi
nal de Bachelier para estudiar la propiedad de independencia considerando las diferencias
de los precios a lo largo de transacciones más que las diferencias de los precios a lo largo
de periodos de tiempo. Para ello utilizan precios de 10 emisoras en un rango de 102 días
trading y sus resultados muestran que las distribuciones de las diferencias en los precios son
excesivamente puntiagudas.
Contrario a los resultados obtenidos por Fama (1965), Brada, Ernst y Tassel (1966)
muestran que dichas distribuciones no son de colas anchas, concluyendo que efectivamente
las distribuciones son no-normales debido al alto pico más que a las colas anchas. El argu
mento para justificar sus resultados se basa en que siendo un mercado casi perfecto donde
existen muchos compradores y vendedores, es de esperarse un precio de equilibrio que per
sista en el largo plazo.
Praetz (1972) estudia el comportamiento del cambio en el logaritmo de precios mensuales
de 17 emisoras pertenecientes a la Bolsa de Valores de Sydney. Su estudio basado en las
pruebas de bondad de ajuste de una x2 y en los momentos muestrales de tercero y cuarto
orden, atroja que ninguna de las series presenta una distribución normal al encontrar que
el valor del parámetro u del exponente de la distribución estable de Pareto varía entre 1.66
y 1.96. Su principal contribución fue la reinterpretación del modelo de Osborne (1959) al
representar la distribución de los cambios logarítmicos de los precios (2. 7) condicionada al
valor de la dispersión a, de la forma
(2.8)
2Mills (1927) ya caracterizaba a la distribución de los precios como leptokúrtica (colas largas). Una definición clara de este fenómeno se encuentra en Eberlein-Keller (1995) al mencionar: "Es evidente que existe considerablemente mayor masa alrededor del origen y en las colas que lo que pueda proporcionar una distribución normal estándar."
15

Una modificación a (2.8) asumiendo que el intervalo de tiempo es unitario T = 1 y que y
tiene una media µ diferente de cero, entonces
1 J(y I o-2) = ~exp (-(y - µ)2 /20-2).
21ra-2 (2.9)
Praetz (1972) argumenta que la modificación al modelo de Osborne (1959) se justifica
en que el mercado accionario comúnmente presenta periodos largos de relativa actividad
seguidos de periodos largos de relativa inactividad. Para ello realiza una analogía con el
movimiento Browniano donde o-2 es proporcional a la temperatura del gas, y la "tempe
ratura" del mercado accionario se puede representar como el grado de actividad o energía
en los mercados. Por lo tanto, el valor de o-2 variará significativamente en la medida que el
grado de actividad en el mercado varíe. 3
Officer (1972) muestra que los rendimientos de precios mensuales de 39 emisoras se ca
racterizan por un proceso que no es generado por una distribución normal al detectar que
las distribuciones empíricas presentan colas anchas ya que el valor obtenido del parámetro
a que describe al exponente característico de una distribución estable es de 1.51. Así mismo
encuentra que el valor de a estimado para 50 emisoras con un total de 217 observaciones
diarias y clasificadas en ocho subperiodos oscila en el rango de 1.61 a 1.67. El resultado ante
rior hace confirmar de una aparente estacionariedad en la distribución de los rendimientos.
Sin embargo, el mismo Officer (1972) encuentra que la propiedad de estabilidad no se
cumple ya que al agregar rendimientos diarios hasta obtener sumas de 20 observaciones, el
parámetro a aumenta en la medida que la agregación de las observaciones aumenta. Por
lo cual concluye que los rendimientos se caracterizan por una distribución de colas pesadas
aunque la propiedad de estabilidad no se cumple del todo cuando se suman observaciones
diarias.
Posteriormente Perry (1983) estudia el comportamiento de 37 emisoras listadas en el
New York Stock Exchange y encuentra que el valor de a del exponente característico de
la distribución estable es inferior a 2. A pesar de que las distribuciones empíricas de los
rendimientos se consideren de colas pesadas, concluye que las respectivas distribuciones no
son de varianza infinita si no de varianza finita que cambia a través del tiempo en un estilo
complejo.
En estudios más recientes, Eberlein y Keller (1995) encuentran que las distribuciones
empíricas de 10 emisoras pertenecientes al índice accionario alemán DAX "presentan una
masa considerable alrededor del origen y en las colas respecto de la distribución normal."
Para validar la hipótesis de normalidad consideran la metodología de las funciones de mo-
3P. Praetz, The Distribution of Share Price Changes, página 50.
16

mentos y la prueba de Kolmogorov-Smirnoff; en la primera reportan que el valor del sesgo y
kurtosis para la emisora BASF es 0.52 y 7.40 respectivamente, y para la emisora Deutsche
Bank es 1.40 y 16.88, respectivamente. En la prueba de Kolmogorov-Smirnoff se obtiene que
los valores de todas las emisoras oscila entre 0.70 y 1.20, inferior al valor de prueba de 1.63.
Cont (2001) analiza y describe las propiedades empíricas de los rendimientos de ac
tivos, llamándole a dichas propiedades como hechos estilizados. Entre los hechos de mayor
discusión dadas sus implicaciones en la validación de la hipótesis de normalidad en los
rendimientos de los precios y en consecuencia sus efectos en la cuantificación del riesgo, han
sido: colas pesadas (presencia de valores extremos), volatilidad cambiante en el tiempo y
dependencia en el corto y largo plazo. La primera de ellas, valores extremos, Bachelier
(1900) la identificó como grandes cambios en el precio. Mandelbrot (1963) argumentó que
los grandes cambios en el precio se deben a que las observaciones son generadas por una
mezcla de distribuciones normales, de las cuales una de ellas tiene un menor peso en la
mezcla pero con una varianza grande por lo cual es considerada como "contaminador".
Referente a la propiedad de volatilidad cambiante, Bachelier (1900) ya la identificaba
como varianza muestral que varía en el tiempo; Roberts (1959) la señaló como "la tendencia
de agrupamiento de observaciones similares", al comparar la simulación de rendimientos de
52 semanas con el comportamiento del Dow Jones Industrial Average, mencionando que
dicho fenómeno de agrupamiento era contrario a la intuición y por lo cual el modelo de
probabilidad generaba esperanzas temporales de predictibilidad. Fama (1965) relacionó este
fenómeno con el supuesto de independencia en el modelo de caminata aleatoria de Bachelier,
al mencionar
Por ejemplo, a noticias buenas le siguen noticias buenas más que noticias malas,
y a noticias malas le siguen noticias malas más que noticias buenas. 4
A lo anterior concluía que la dependencia estaba presente tanto en el proceso que genera
el ruido como en el proceso que está generando la nueva información, teniendo como re
sultado la dependencia en los cambios sucesivos en el precio. Con referencia a la propiedad
de independencia y su relación estrecha con volatilidad cambiante, Roberts (1959) comenta
los resultados obtenidos por Kendall (1953), los cuales reflejan como si los cambios en los
precios fuesen generados por una ruleta en donde cada observación es estadísticamente inde
pendiente de su historia y para los cuales las frecuencias relativas han sido razonablemente
estables a través del tiempo. Por lo tanto, toda vez que una persona acumula evidencia para
estimar las probabilidades de los resultados en la ruleta, esta persona basaría sus predic
ciones únicamente en estas probabilidades sin prestar atención al comportamiento de los
4 Eugene Fama, The Behavior of Stock-Market ?rices, página 37.
17

giros recientes.
Sin embargo, los giros recientes de la ruleta serían relevantes en las predicciones en tan
to contribuyan con estimaciones más precisas en las probabilidades. A lo anterior, Roberts
(1959) argumenta que en términos de apuestas, la ruleta no tiene memoria. Entonces una
distribución de frecuencias de los cambios pasados es una buena base para estimar las proba
bilidades en tanto se cumpla el supuesto de independencia. En contraste, Mandelbrot (1963)
establece que la independencia no es posible ya que esto implicaría que el inversionista no
podría utilizar su conocimiento pasado para incrementar su ganancia esperada.
Dada la evidencia en que los cambios (logarítmicos) de los precios han mostrado ser de
una distribución no-normal y la presencia de fenómenos como valores extremos, volatilidad
cambiante y dependencia, en los datos financieros, el trabajo estadístico en finanzas se ha
oreintado en encontrar aquella familia de distribuciones que mejor ajusten los cambios en
los precios de los activos y permitan capturar los respectivos fenómenos. A pesar de que
estos fenómenos fueron identificados por Bachelier (1900), Kendall (1953),y Roberts (1959),
a Mandelbrot (1963) se le atribuye como el precursor en la modelación de los cambios en el
logaritmo de los precios a través de una distribución no-normal.
La principal contribución de Mandelbrot (1963) radica en haber modificado el modelo
de Bachelier reemplazando la distribución marginal Gaussiana por una distribución estable
de Pareto, con el objetivo de capturar los cambios signi.ficativos en los precios y presentar
un proceso que generalizara al de Bachelier.5 Una distribución estable de Pareto se define
como el logaritmo de la función característica de la forma:
loge<f>x(t) = loge [1: eitxdF(x)] = iót - 1 1 t Iº [1 + if](t/ 1 t l)w(t, a)], (2.10)
donde a determina la probabilidad total en las colas de la distribución y puede tomar valores
entre O y 2, ó es el parámetro de locación y cuando a= 1 dicho parámetro representa el valor
esperado de la distribución; f3 representa el índice de sesgo y puede tomar valores entre -1 y
1, cuando /3=0 entonces la distribución es simétrica; y, 1 representa el parámetro de escala.
En particular, cuando a= 1 la distribución es de Cauchy y cuando a:=2 la distribución es
Normal.
La figura 2.1 muestra la diferencia entre una distribución Normal y de Cauchy. Se ob
serva que la distribución de Cauchy presenta colas más pesadas que la Normal, pero ésta
última tiene un mayor piro en la parte central que la de Cauchy.
Fama (1965) describe las propiedades de una distribución estable de Pareto, quien
5 A Paul Lévy ( 1 !)25) se Ir atribuye el desarrollo de las distriburiones rstablrs también conocidas como
distribuciones a-estable sesgada de Lévy.
18

Dislnbuoon Normal y do Ceuchy
0.4
0.3
0.2
0.1
o.o
-6 -4 -2
Figura 2.1: Comparación entre Distribución Normal y de Cauchy
además valida la hipótesis de Mandelbrot (1963), al encontrar que el parámetro a del
exponente característico fue menor que 2 para las distribuciones en los cambios logarítmi
cos de los precios para 30 emisoras pertenecientes al Dow Jones Industrial Average. Las
propiedades de una distribución estable de Pareto son:
l. Estabilidad. Dicha propiedad se refiere a que la distribución es invariante bajo adición,
esto es, la distribución de la sumas son independientes e idénticamente distribuidas y
de la misma forma que la distribución de las variables aleatorias individuales (suman
dos). Por lo tanto, los parámetros a y (3 permanecen constantes bajo adición;
2. Las distribuciones de Pareto son las únicas distribuciones limitantes posibles para
sumas de variables aleatorias independientes e idénticamente distribuidas.
En su estudio, Fama (1965) aplica las técnicas de doble logaritmo, análisis de rango y de
varianza secuencial, para estimar el parámetro a; y para validar el supuesto de independencia
aplica el modelo de correlación serial, prueba de cambios de signos y la técnica de filtrado
de Alexander. En el caso de la estimación de a, concluye que el parámetro del componente
estadístico es siempre menor que dos por lo cual es apreciable que la hipótesis de Mandelbrot
(1963) ajusta la información en mejor forma que la hipótesis Gaussiana, teniendo dos tipos
de implicaciones:
• Económicas. En un mercado Paretiano con a < 2, el precio de un activo tenderá a
moverse a la alza o a la baja en cantidades muy grandes durante periodos de tiempo
muy cortos; contrario en un mercado Gaussiano, si la suma de grandes cambios en los
precios en un periodo de tiempo largo resulta en un cambio grande, entonces existe
la posibilidad de que cada cambio individual del precio durante dicho periodo de
19

tiempo sea poco significativo comparado con el cambio total. Por lo que esos grandes
o abruptos cambios en los precios representarían un mayor riesgo y con probabilidad
de mayores pérdidas en un mercado Paretiano que en un mercado Gaussiano.
• Estadísticas. Una distribución estable de Pareto con un parámetro a < 2 represen
ta una distribución de varianza que no es finita, por lo que la varianza y desviación
estándar muestra! para un proceso Paretiano con a < 2 mostrará un comportamien
to extremadamente errático aún para muestras grandes, por lo que en tamaños de
muestras cada vez más grandes la variabilidad de la varianza y desviación estándar
muestral nunca se reducirá tal como se esperaría en un proceso Gaussiano. Por lo
tanto, la varianza y desviación estándar muestra! son medidas de variabilidad de poco
sentido en un proceso Paretiano con a < 2. Dado lo anterior, la recomendación es
utilizar rangos interfractiles o la desviación absoluta sobre la media como medidas de
variabilidad, o en su caso usar distribuciones de colas largas con varianza finita para
describir los datos. En un sentido estricto, al inversionista únicamente le interesará la
forma de la distribución para definir la probabilidad de ganancias o pérdidas mayores
a ciertas cantidades.
Referente a las pruebas de independencia, Fama (1965) no encuentra evidencia de depen
dencia en los datos por lo que el supuesto de independencia en el modelo de caminata
aleatoria resulta adecuado para describir la realidad. Las implicaciones se reflejan en que la
independencia en los cambios en los precios es una situación consistente con la existencia de
un mercado eficiente, por lo que en cualquier momento del tiempo los precios actuales re
presentarían buenos estimadores de los valores intrínsecos de los activos. Al respecto, Fama
(1965) argumenta que existen dos factores que posiblemente contribuyan a la independencia
en los datos:
l. La existencia de muchos analistas sofisticados de gráficos que activamente compiten
entre ellos para tomar ventaja de cualquier dependencia en los cambios de precios;
2. La existencia de analistas sofisticados donde la sofisticación implica la habilidad para
predecir los eventos políticos y económicos, y para evaluar los efectos eventuales de
dichos eventos en los precios.
Fama (1965) concluye su investigación con la propuesta de dos líneas de investigación: a)
pruebas adicionales de dependencia, y b) distribuciones de los cambios en los precios, en
donde se exploren procesos más básicos bajo los cuales se estén generando las distribu
ciones empíricas corno es el caso de distribuciones en los cambios de precios en términos del
comportamiento de variables económicas más básicas; o en su caso desarrollar aún más la
20

teoría estadística de las distribuciones estables de Pareto ante la afirmación de que dichas
distribuciones son las que describen los cambios en los precios.
Mandelbrot (1967), como una extensión a su investigación en 1963, encuentra evidencia
de no-normalidad en las variaciones de los logaritmos en los precios del algodón, de ac
ciones de emisoras ferrocarrileras, y variación en las tasas de interés y tipos de cambio. La
estimación del parámetro a la realiza a través del método de máxima verosimilitud con el
objetivo de representar la densidad estable de Pareto a través de dos expresiones, una para
la parte central acampanada o Gaussiana y otra para las colas que capturan los valores ex
tremos a través de una representación hiperbólica. Para tales efectos, determina la cantidad
de outliers suponiendo que las colas de la distribución son simétricas.
En un estudio posterior, Praetz (1972) modifica el modelo de Osborne (1959) para re
presentar la distribución de equilibrio (2. 7) condicionada a la varianza (2.8) y así obtener
una distribución-in escalada ( n grados de libertad) que ajusta en mejor forma los cambios
en los precios respecto a la distribución estable de Pareto propuesto por Mandelbrot (1963).
Praetz (1972) argumenta de tres desventajas del modelo Paretiano:
l. La varianza infinita presente en la distribución estable que hace inaplicable la teoría
estadística convencional;
2. Las funciones de distribuciones que genera la distribución estable de Pareto son des
conocidas salvo en los casos cuando a=l que representa a una distribución de Cauchy
y cuando a=2 que representa a una distribución normal;
3. Los métodos de estimación de los parámetros no han sido satisfactorios.
Así mismo y conforme a los resultados obtenidos, la distribución-in escalada puede repre
sentar una distribución de Cauchy cuando v = l o una distribución normal cuando v = 2,
por lo que Praetz (1972) sugiere la aplicación de la distribución-tn como alternativa para
modelar los cambios en los precios dada su representación conjunta del riesgo e incertidum
bre: riesgo visto en la distribución normal e incertidumbre en la distribución de la varianza.
La función de densidad de una variable aleatoria que se distribuye bajo una t-student se
representa por (v+l)
f (v!l) ( x2)--2 Jv(x) = r (~) J"Íl1r 1 +-; , (2.11)
donde v = n - l es el parámetro que representa los grados de libertad y r(v) es la función
Gamma. Un ejemplo comparativo de la distribución t-student respecto a la Normal y de
Cauchy, se observa en la figura 2.2.
21


Posteriomente, Blattberg y Gonedes (1974) estiman y comparan una distribución
estable simétrica y de Student para modelar la distribución de los rendimientos de 30
emisoras norteamericanas. Ambos modelos fueron generados en el marco de procesos es
tocásticos subordinados, en donde las distribuciones estable simétrica y de Student son pro
cesos subordinados a un proceso estocástico estacionario Gaussiano. Un proceso estocástico
subordinado se define de la siguiente forma: Sean [ X ( s); s 2 O] y [h( s); s 2 O] procesos
estocásticos y se define otro proceso Z(s) = X[h(s); s 2 O], entonces el proceso [.Z(s)] se
dice que es subordinado al proceso [X ( s)] y el proceso [h( s)] es el proceso direccional.
Su investigación concluye que la distribución de Student ajusta de mejor forma los
rendimientos de los precios que la distribución estable, y a pesar de que ambas distribuciones
son de colas anchas, la distribución de Student converge a una normal para muestras de
tamaño grande.7 Los métodos que utilizan para discriminar entre una distribución estable y
de Student son (1) pruebas de convergencia a un distribución normal empleando un tamaño
de suma de 5 observaciones, y (2) el valor de la razón de verosimilutd logarítmica para los
rendimientos diarios. Así mismo detectan dependencia en las series de los rendimientos, ya
que largos rendimientos son superados por largos rendimientos pero de signo no predeci
ble. A pesar del fenómeno de dependencia en los rendimientos, concluyen que el modelo de
Student es de mayor validez descriptiva que el modelo estable simétrico propuesto desde
Mandelbrot (1963).
Upton y Shannon (1979) analizan y comparan la distribución de rendimientos de precios
mensuales, trimestrales, semestrales y anuales; donde primeramente aplican las pruebas de
Kolmogorov-Smirnoff para validar la hipótesis de normalidad y el estadístico del Rango de
Student para discriminar entre una distribución estable de Pareto y normal. Así mismo
aplican el estadístico-g de Fisher para probar sesgo y kurtosis.8 La importancia de su inves
tigación radica en que analizan la distribución del logaritmo en los rendimientos más que la
distribución en el cambio del logaritmo de los precios, por lo que el rendimiento de los ac
tivos en un intervalo de tiempo, R1 , se puede observar como el producto de los rendimientos
k sobre N subintervalos,
(2.13)
7Biattbcrg y Gone<les (l!J74) suponen que los rendimientos son independientes por lo que la distribución de Student no del todo describe adecuadamente los resultados empíricos.
8 La prueba de Kolmogorov-Smirnoff es una prueba de bondad de ajuste en tanto que las pruebas de sesgo y kurtosis son aplicables para tendencias asintóticas.
23

El producto de los rendimientos tendrá una distribución lognormal en tanto que la dis
tribución de k sea estacionaria, independiente y k > O para toda i; y en tanto el proceso
subyacente sea constante, los parámetros de la distribución de k serán estacionarios, en
tonces el Proceso Estocástico Subordinado9
Iím R1 ,...., lognormal. N-+oo
(2.14)
La función de densidad de una variable aleatoria que se distribuye como una lognormal se
representa de la forma:
Jµ,u(x) = ~ exp {-2
12 (log x - µ) 2
}, X<I 27í <7
(2.15)
donde x > O, y µ y u > O son la media y desviación estándar respectivamente, del logaritmo
de la variable aleatoria. La representación gráfica de una distribución lognormal se aprecia
en la figura 2.3, cuyo particular esµ= O y u2 = l.
Dislribuci n Log-Noma
0.8
0.6
0.2
O.O
10
Figura 2.3: Distribución Lag-Normal conµ= O y a= l
El estudio de Upton y Shannon (1979) arroja que la distribución leptokúrtika permanece
para horizontes mensuales, sin embargo en la medida que el horizonte de tiempo se alarga,
la distribución de los activos converge a una distribución lognormal aunque lo anterior no es
señal de que el parámetro a < 2. Aún así, se preferiría la propuesta del Proceso Estocástico
Subordinado respecto del modelo estable Paretiano.
Propuestas alternas al modelo Paretiano de Mandelbrot (1967), distribución de Student
por Practi (1972) y al enfoque de Procesos Estocásticos Subordinados, hacen referencia a la
hipótesis de mezcla de distribuciones propuesta por: Fiel (1983), Kon (1984), Harris (1986),
9Si Y"' N(µ, a 2) entonces exp(Y) "'Log-N(µ, a 2
)
24

Harris (1987), Hall, Brorsen e Irwin (1989) y, a la distribución hiperbólica propuesta por
Eberlein y Keller (1995). Una mezcla de distribuciones es una clase de distribuciones de
colas pesadas donde cada distribución se conoce como componente de la mezcla, la cual se
define como cualquier combinación convexa de los componentes de la forma
k k
I>di(x), ¿Pi=l k > 1, (2.16) i=l i=l
y en el caso continuo
g(x) = fe!(x l 0)h(0)d0 (2.17)
donde cada Íi representa comúnmente a una familia paramétrica con parámetros 0i des
conocidos. Un caso particular es la mezcla de distribuciones normales donde 0 representa la
media y varianza desconocidas.
25

2.2. Valor en Riesgo
La presente sección describe las diferentes metodologías de estimación del Valor en Riesgo
y especificaciones de los modelos propuestos para su estimación, la cual se basa en: Jorion
(2007), Manganelli y Engle (2001), Engle (2001), McNeil (2000), Longin (2000), y Enders
(2004).
2.2.1. Estimación Paramétrica
El método paramétrico considera una función de distribución conocida F( ·) junto con
el parámetro de comportamiento a que caracteriza dicha distribución de probabilidad. El
supuesto común que se ha hecho en cuanto a la distribución de los rendimientos diarios de
los activos financieros ha sido el de una normal, por lo que F(a) corresponde al cuantil
apropiado de la distribución normal estándar. Para efectos de estimación del riesgo, el VaR
es un múltiplo de la desviación estándar del activo en cuestión o de un portafolio de activos
y se representa de la forma
VaR = -Vocav, (2.18)
donde V0 es el valor inicial del activo, e es el parámetro correspondiente al nivel de confianza
establecido y av es la desviación estándar del activo, y el signo negativo identifica que el
valor crítico de la distribución para el nivel de confianza seleccionado es negativo.
Enfoque Varianza-Covarianza
El primer enfoque paramétrico se ha identificado como varianza-covarianza, en particular
cuando se habla del riesgo de un portafolio. Por lo que el VaR del portafolio se reduce a la
estimación de la matriz de varianzas y covarianzas de los factores de mercado que explican el
comportamiento del portafolio. Lo anterior junto con la información referente a las posiciones
que componen el portafolio, permite determinar la desviación estándar del portafolio y en
consecuencia el VaR del mismo.
Si el rendimiento del portafolio del periodo t a l + l se define como
N
RP,t+I = ¿ wiRi,t+I,
i=l
(2.19)
donde N es el número de activos en el portafolio, Ri,t+I es el rendimiento del activo i y
wi es el peso del activo en el portafolio. A diferencia del enfoque media-varianza, en VaR
cada activo se considera como un factor de riesgo del portafolio y wi la exposición lineal al
respectivo factor de riesgo.
26

En el contexto matricial, el rendimiento del portafolio se expresa de la forma
=w'R '
(2.20)
donde w' representa el vector traspuesto de los pesos de los activos y R el vector columna
que contiene cada uno de los rendimientos de los activos.
A partir de lo anterior, es posible expresar el rendimiento esperado del portafolio de la
forma
y la varianza del portafolio como
N
E(Rp) = µp = L wiµi,
i=l
N N N
var(Rp) = O"i = L w/O"/ + L ¿ W¡WjO"ij
i=l i=l j=l,jf,i
N N N
= L w/O"/ + 2 ¿ ¿ W¡WjO"ij,
i=l i=l j<i
la cual puede representarse en notación matricial como
O"N3
y su representación compacta se escribe de la forma
2 ,..., O"p = W L...,W,
y en términos de exposiciones en dólares x se tiene
2w2 ,..., O"p = X L...,X.
(2.21)
(2.22)
(2.23)
(2.24)
(2.25)
La medida de VaR se obtiene a partir de la varianza del portafolio para lo cual se debe
conocer la distribución de probabilidad de los rendimientos del portafolio. En el contexto de
normalidad, todos los activos individuales se consideran de distribución normal, por lo que
el rendimiento del portafolio es normal. Lo anterior es posible ya que al ser el portafolio una
27

combinación lineal de factores de riesgo que se distribuyen conjuntamente como variables
aleatorias normales, entonces éste será normal.
De la forma anterior es posible moverse de la varianza del portafolio a la medida de
VaR traduciendo el nivel de confianza e previamente definido al de una desviación estándar
normal a, tal que la probabilidad de observar la peor pérdida menor que -a es c. Por lo
tanto, el VaR de un portafolio cuyo valor inicial es W se expresa de la forma
VaRp = aapW = aVx'Ex. (2.26)
A partir de varianza del portafolio definida en (2.22), se observa que el VaR del portafolio
depende de las varianzas, covarianzas y número de activos; en donde la magnitud de la
covarianza entre los activos dependerá de la varianza de los mismos. Para tales efectos, el
coefiente de correlación es un estadístico que ayuda a medir la dependencia lineal entre
activos, la cual se expresa de la forma
(2.27)
y su valor cae en el intervalo de -1 a + l. Cuando p = 1, los activos estarán perfectamete
correlacionados y cuando p = O, los activos se encuentran no correlacionados. De lo anterior
se desprenden tres representaciones generales del VaR de un portafolio:
• Cuando existe correlación entre los activos, siendo ésta baja o alta:
(2.28)
• Cuando la correlación es cero:
(2.29)
• Cuando la correlación es igual a la unidad y las ponderaciones w1 y w2 son positivas:
VaRp = JvaR¡ + VaR~ + 2VaR1 xVaR2 = VaR1 + VaR2. (2.30)
De la expresión (2.28), se obtiene que una correlación baja ayuda a diversificar el riesgo del
portafolio. A partir de la expresión ( 2. 29), se obtiene que el riesgo del portafolio es menor
que cualquier de los activos, ya que p = O refleja un comportamiento independiente entre
los activos por lo que el riesgo del portafolio debe ser menor que la suma de los VaR's
28

individuales. Lo anterior hace que el VaR satisfaga el concepto de medida coherente de
riesgo siempre que las distribuciones sean normales y en general distribuciones elípticas.
Finalmente, la expresión (2.30) establece que el VaR de un portafolio es la suma de los
VaR's de los activos siempre que estén perfectamente correlacionados.
Enfoque de Volatilidad Condicionada: Riskmetrics y GARCH
U no de los hechos estilizados mayormente documentado referente a los rendimientos de
precios de los activos financieros es volatilidad agrupada (Engle (2001), Cont (2001)), la cual
se relaciona con el hecho en que eventos de alta volatilidad tienden a agruparse en el tiempo
debido a que diferentes medidas de volatilidad arrojan autocorrelación positiva en varios
días (Cont (2001)). Lo anterior es una descripción de que la volatilidad no es constante y
por lo tanto a depende del tiempo. Ante esta situación, el VaR de un activo o portafolio se
puede expresar de la siguiente forma
VaRt+Ilt = F(o:)at+I, (2.31)
donde ªt+l se define como la desviación estándar condicionada a la información disponible
en t.
Lo anterior ha sido motivación para proponer una parametrización del comportamiento
de los rendimientos de precios tal como Riskmetrics (1996) y la familia de modelos GARCH
inicialmente introducidos por Engle (1982) y Bollerslev (1986). El modelo de Riskmetrics
es un enfoque bajo el cual la varianza se calcula a través del método de medias móviles
ponderadas exponencialmente (EWMA), el cual corresponde a un modelo GARCH integrado
(caso particular de los modelos GARCH) de la forma
(2.32)
donde >. se conoce como el factor de decaimiento y toma valores menores a la unidad.
Usualmente el valor ha sido 0.94 y 0.97 para datos diarios y mensuales, respectivamente.
La modelación de la varianza condicionada a través del modelo GARCH tiene las ventajas
de modelar volatilidad no constante a través del tiempo, mostrar que la volatilidad tiene un
comportamiento a la alza y a la baja, identificar la existencia de memoria en el proceso y
predecir la volatilida futura. El modelo GARCH, una extensión del modelo ARCH propuesto
por Engle (1982), incorpora rezagos en la varianza condicionada y se describe como un
modelo GARCH infinito con una ecuación de la media
Rt =µ+Et, (2.33)
29

donde Et es una variable aleatoria normal, y la ecuación de la varianza se describe de la forma
q p
e7¡ = ªº + L O'¡E¡_¡ + ¿/3j<7¡_j, (2.34) i=l j=l
con las restricciones w > O, a¡~O, i = 1, ... , q y /31~0, j = 1, ... ,p.
El proceso GARCH es de orden p y q, y la ecuación de la varianza condicionada es una
función de tres términos:
• La media w;
• Innovaciones en la volatilidad respecto del periodo previo, medido como el rezago en
el residual al cuadrado de la ecuación de la media: t:z_¡ ( término ARCH); y,
• El pronóstico de la varianza en el último periodo: e7¡_¡ (término GARCH).
El caso particular es el proceso G ARCH ( 1, 1), el cual se refiere a la presencia de primer orden
en el término GARCH y de primer orden en el término ARCH. El modelo GARCH (1,1) se
puede interpetar en finanzas de la siguiente forma: un agente económico puede predecir la
varianza del periodo actual al establecer un promedio ponderado de un promedio de largo
plazo (la constante) , la varianza pronosticada en el último periodo (término GARCH) y con
información referente a la volatilidad observada en el periodo previo (término ARCH).
Por lo tanto, el modelo GARCH (1,1) se especificaría de la forma
Rt =µ+Et, (2.35)
(2.36)
con una varianza no condicionada de la forma
(2.37)
Una extensión al modelo GARCH se refiere a TGARCH (Threshold-GARCH), el cual busca
capturar el comportamiento asimétrico de la volatilidad toda vez que la evidencia empírica
ha mostrado que la volatilidad tiende a incrementar más ante noticias malas que noticias buenas (Black (1976)) , fenómeno identificado como efecto apalancamiento. Para tales efec
tos, el modelo EGARCH busca capturar el mayor riesgo asociado a rendimientos negativos
que positivos. La representación del modelo TGARCH es de la forma
(2.38)
30

donde dt-I es una variable dummy que toma el valor de uno si el rendimiento en el periodo
previo t - 1 se encuentra por debajo de su media, y el valor será cero si se encuentra por
arriba de la media,
d - { 1 ft-1 < o, t-1 -
o ft-120. (2.39)
Cuando ft-1 = Rt-I - µ < O (buenas noticias), la varianza condicionada se representa de la
forma
(2.40)
y cuando ft-1 = Rt-I - µ 2 O (malas noticias), la varianza condicionada se expresará de la
forma
(2.41)
en cuyo caso la varianza será mayor mostrando un mayor riesgo.
2.2.2. Estimación No Paramétrica
El enfoque no paramétrico simplifica sustancialmente la estimación del VaR ya que no
se hace supuesto alguno sobre la distribución de los rendimientos del activo o el portafolio.
El método más común es la Simulación Histórica (SH) el cual se basa en la rotación de
ventanas, en donde se utilizan los rendimientos históricos para estimar el VaR a través del
percentil empírico de la distribución muestral. Su expresión es de la forma
V aRt+Ilt = Percentil { {zt}~=l, alOO}. (2.42)
Lo anterior considera que la distribución de los rendimientos futuros es bien descrita por
la distribución histórica de los rendimientos. La principal ventaja de este método es que
al no suponer alguna distribución de los rendimientos, es posibles capturar distribuciones
no-normales y el fenómenos de colas pesadas; con la desventaja de no poder capturar la
volatilidad condicionada.
El método de SH se resume en los siguientes pasos:
• Elegir una ventana de observaciones la cual osicla comúnmente entre 6 y dos años de
historia;
• Ordenar en forma ascendente los rendimientos del activo o portafolio dentro de la
ventana y el q-cuantil de interés será aquel rendimiento que se encuentre q % de las
observaciones a la izquierda y (1 - q) % observaciones a la derecha;
31

• Cuando el cuantil de interés cae entre dos observaciones, será posible aplicar alguna
regla de interpolación; y,
• Para estimar el VaR un día siguiente, la ventana completa se moverá hacia adelante
en una observación y se repite el procedimiento anterior.
Una variación al método SH es el enfoque híbrido propuesto por Boudoukh, Richardson
y Whitelaw (1998); el cual combina las metodologías de Riksmetrics y SH con el propósito
de capturar la volatilidad condicinada, al aplicar pesos con decaimiento exponencial a los
rendimientos pasados del activo o portafolio. Este enfoque se resume en los siguientes pasos:
• A cada uno de los K rendimientos más recientes Yt, Yt-1, ... , Yt-K+l se le asocia un 1-.>. ( 1-.>. ) \ ( 1-.>. ) \ K -1 t' t peso 1_.>.R, 1_.>.R A, .•. , 1_.>.R /\ , respec 1vamen e;
• Los rendimientos se ordenan en forma ascendente; y,
• El q % del VaR se encuentra sumando los correspondientes pesos hasta que el q % se haya alcanzado iniciando del rendimiento más bajo. El VaR del activo o portafo
lio será entonces el rendimiento correspondiente al último peso utilizado en la suma
previa.
La diferencia entre el enfoque de SH y el híbrido, es que SH asigna el mismo peso a cada
rendimiento, en tanto que el enfoque híbrido asigna diferentes pesos a los rendimientos
dependiendo de que tan rezagada sea la observación.
2.2.3. Estimación Semiparamétrica
El enfoque semi-paramétrico es una combinación de la estimación paramétrica y no
paramétrica cuyas bondades se reflejan en que a través <le la aproximación paramétrica se
puede actualizar la volatilidad a partir de un modelo de volatilidad conocido como G ARCH
(1,1), y la ganancia en combinarla con la aproximación no-pararnétrica es que no se requiere
una distribución de los rendimientos.
Una de las primeras proposiciones de estimación semi-paramétrica del VaR la hacen
Hull y White (1998) y Barone-Adesi, et al (1996), al establecer una Simulación Histórica
Filtrada en donde es posible modelar las colas pesadas y actualizar la varianza. Por lo que
el VaR se estimaría de la forma
VaRt+llt = Percentil{ {t:t}~=1,o:lüü}at+l, (2.43)
donde Et y ªt+l son generados a través <le un modelo <le volatili<la<l conocido.
Una de las aplicaciones estadísticas de mayor aceptación en el enfoque semi-paramétrico
32

ha sido la Teoría de Valores Extremos, la cual se refiere a la modelación de las colas de una
distribución de probabilidad F; donde las observaciones X 1, X2, .. . , Xn se consideran una
secuencia de variables aleatorias idéntica e independientemente distribuidas (iid), las cuales
representan las pérdidas y riesgos con una función de densidad acumulada (FDA) de F.
Los eventos extremos se consideran aquellos valores de X¡ que exceden un umbral u, por lo
que la distribución de los excesos por arriba del umbral u se define como la probabilidad
condicional:
F(y + u) - F(u) Fu(Y) = Pr{X - u:Sy IX> u}= F( ) , 1 - 11,
y> O. (2.44)
Si u es lo suficientemente grande, entonces existe una función positiva /3( u) tal que la
distribución de los excesos se aproxima a través de una Distribución Generalizada de Pareto
(DGP):
(2.45)
1 - e-y/(J(u), V€ = O
donde f3(u) > O, y?_O cuando €?.0, y 0:Sy:S - /3(u)/€ cuando€< O.
Uno de los objetivos en la TVE es estimar el índice de la cola de la distribución a través
del cual se derivan las fronteras para los rendimientos en exceso de muy bajas probabilidades,
en donde la DGP ofrece una buena aproximación de la cola de F para un valor fijo de € y
/3, los cuales dependen a la vez de u. Los resultados de la TVE se deben a Fisher y Tippet
(1928) quienes especificaron la forma de la distribución límite para un máximo normalizado
teniendo tres posibles leyes de probabilidad límite sobre el máximo:
• Distribución tipo Gumbel
P [X < x] = exp { -e(x-µ)/rr} (2.46)
• Distribución tipo Fréchet
P[X < x] = { exp {- (X~JLr~}) x?.µ
Ü, X<µ
(2.47)
33

• Distribución tipo Weibull
¡ exp {- (7)-{}, x'S_µ
P[X < x] =
0, X>µ
(2.48)
donde µ, a, y ~ > O, son los parámetros de localización , escala y de forma, respectiva
mente.10
Las tres distribuciones se representan como miembros de una sola familia de distribu
ciones generalizadas propuestas por Jenkinson (1955) y conocidas como Distribuciones Ge
neralizadas de Valores Extremos (DGVE), cuya función de distribución acumulada es
(2.49)
donde 1 + ~(x - µ)/a> O, -oo < ~ < oo, y a> O.
Cuando ~ > O la distribución es de Fréchet; para~ < O la distribución es de Weibull, y
cuando ~ ---; oo ó -oo, la distribución es del tipo Gumbel. Por lo anterior, la expresión se
conoce como la distribución generalizada de valores extremos.
Una de las principales investigaciones de referencia en la aplicación de la TVE para la
estimación del VaR corresponde a Longin (2000), quien estima el VaR sobre los rendimientos
diarios del S&PSOO en el periodo de enero de 1962 a diciembre de 1993, cuya metodología
se describe en la figura 2.4.
El VaR que se estima en el último paso de la figura 2.4, el cual es un porcentaje del
valor de la posición, se obtiene de la distribución asintótica estimada de los rendimientos
mínimos
{ ( (-VaR _ f3 ) ) l/r}
pexc = 1 - F'z!int ( - V aR) = exp - 1 + T O'.n n , (2.50)
dando como resultado
VaR = -/3n + O'.n [1 - (-In (pexc) )] , T
(2.51)
10 Una de las tareas importantes en TVE es encontrar los estimadores apropiados del parámetro de forma ~, para lo cual existen tres metodologías (Ernbrechts, Klüppelberg y Mikosch (1997)):
1. Estimador de Pickands para ~ E IR.
2. Estimador de Hill para ~ = cx- 1 > O.
3. Estimador de Dekkers-Einmahl-de Haan para~ E IR.
34

Selección de la frecuencia/ de los rendimientos.
Construcción de los rendimientos históricos R, de la posición.
Selección de la longitud del horizonte de tiempo T.
Selección de los rendimientos mínimos z.
Estimación de los parámetros a,., p,., y rde la distribución asintótica de los rendimientos
mínimos.
Prueba de bondad de ajuste de la hipótesis: La distribución asintótica de los rendimientos
mínimos describe correctamente los rendimientos mínimos observados.
Se rechaza la hipótesis No se rechaza la hipótesis
Cálculo del VaR de la posición
Figura 2.4: Metodología de estimación aplicando TVE.
y cuyas especificaciones del modelo son:
• n es el número <le rendimientos básicos <le <lon<le se seleccionan los rendimientos
mínimos;
• D'n, fJn y T, son los parámetros <le la distribución asintótica F de los rendimientos
mínimos: y,
• pexc es la probabilidad de observar un rendimiento mínimo en que no exceda el VaR.
2.3. Pérdida Esperada en la Cola
La sección 2.1 trató sobre los diferentes modelos probabilísticos que se han propuesto
para ajustar los rendimientos de los precios de activos financieros y en consecuencia lograr
capturar aquellos fenómenos conocidos como hechos estilizados. En particular, se ha buscado
aquella distribución de probabilidad que meJor modele los rendimientos para efectos de
35

medir el riesgo de mercado, dada la importancia que tiene la distribución en el riesgo de
las inversiones. La sección 2.2 trató los métodos de estimación del riesgo de mercado en el
marco del Valor en Riesgo, haciendo énfasis en la Teoría de Valores Extremos como uno de
los principales enfoques aplicables en la aproximación semi-paramétrica.
La presente sección describe la medida de riesgo Pérdida Esperada en la Cola (PEC)
que surge como respuesta a las debilidades del contexto VaR, motivada de la presencia de
valores extremos en los rendimientos de los precios de activos y a la propia definición de
VaR. Artzner (1997) fue el precursor en proponer esta medida de riesgo también llamada
VaR Condicional, Pérdida Promedio en Exceso, Más allá del VaR, ó VaR en la Cola; la
cual se define como la pérdida esperada condicionada dada la pérdida por arriba del nivel
de VaR y se expresa como
(2.52)
donde VaR se define conforme a Artzner et al. (1999) de la forma
VaR0 (X) = sup {x I P [X2:x] >a}. (2.53)
Así como el VaR de la posición depende de una distribución F y su nivel de probabilidad
p, PEC se expresa igualmente de la forma (Longin (2001)):
J-VaR ( ) _
00 x.f n x dx
PEC(FR,P) = -E(RIR < -VaR) = - FR(-VaR) , (2.54)
donde f R corresponde a la función de densidad de probabilidad de los rendimientos y FR
la función de distribución acumualda de los rendimientos. De la expresión anterior, PEC
incorpora visto en el denominador, la frecuencia de las pérdidas más allá del VaR y a través
del numerador, captura el tamaño de las pérdidas más allá del VaR al considerar el primer
momento de la distribución de las pérdidas que exceden el VaR.
La relación que pueda guardar VaR y PEC depende sustancialmente de la distribución de
probabilidad. En un contexto normal el VaR y PEC son múltiplos escalares de la desviación
estándar, por lo que ambos proporcionarán la misma información en la cola. Ante este caso,
P EC se calcula de la forma
(2.55)
36

donde q0 representa el percentil 100a superior de la distribución normal estándar.
La relación asintótica entre VaR y P EC cuando la distribución de los rendimientos es
normal está dada por
(2.56)
La expresión anterior supone una cola fina de la distribución normal, por lo que las pérdidas
más allá del VaR están concentradas cerca del VaR. Conforme a la teoría de valores extremos,
el grado de anchura de una distribución se caracteriza a través del parámetro índice de la
cola. El valor del índice de la cola puede ser positivo, cero o negativo, correspondiente a una
distribución de cola ancha, cola fina o limitada.
La siguiente relación entre VaR y PEC se define para una distribución estable de Pareto
VaR PEC~VaR+--,
'P + l (2.57)
donde rp > 1 es el exponente característico de la distribución de Pareto, y se ha considerado
en la relación anterior un parámetro de locación igual a cero, parámetro de escala igual a
uno y parámetro de sesgo igual a cero. En consecuencia, entre más ancha sea la cola de
la distribución lo cual implica un valor del exponente característico menor, más dispersas
serán las pérdidas respecto del VaR.
37

Capítulo 3
Teoría de Wavelets
Wavelets son funciones de estructura especial descritas por funciones base que se re
presentan a través de aproximaciones sucesivas de series, similares a las series de Fourier
las cuales se representan por funciones seno y coseno. Las funciones wavelets ( ondas cor
tas) tienen la propiedad de concentrar su energía en el tiempo para brindar un análisis de
los fenómenos de temporalidad, no estacionariedad y variación en el tiempo, tal como lo
describen Burrus, Gopinath y Guo (1998). La estructura especial de waveletes radica en
que conservan su característica oscilatoria y la habilidad para permitir simultáneamente
el análisis de tiempo y frecuencia, por lo que será posible procesar los datos en diferentes
escalas y resoluciones; a diferencia del análisis de Fourier donde la señal (serie de tiempo)
procesada indica la cantidad de frecuencias y de energía que en cada frecuencia existe en
la señal original pero no brinda información en dón<le una frecuencia en particular aparece
en el dominio del tiempo. Al respecto, Graps (1995) comenta que el análisis por wavelets
es como mirar el bosque ( ventana grande) para detectar las grandes particularidades y a la
vez mirar los árboles (pequeñas ventanas) para detectar las pequeñas particularidades.
El campo de aplicación de wavelets tiene sus antecedentes en ingeniería para el proce
samiento de señales y compresión <le <latos; en el procesamiento <le señales ayudan a opti
mizar el proceso de codificación, compresión y transmisión de una señal, y a la separación de
la verdadera señal de observaciones viciadas por el ruido, y en la compresión de datos para
transformar grandes conjuntos de datos en pequeños conjuntos de datos y posteriormente
estos se puedan recuperar con un mínimo de pérdida de información. Una segunda aplicación
ha sido para el estudio de series de tiempo geofísicos, donde por ejemplo Grinsted, Moore
y Jevrejeva (2004), utilizan la transformada wavelet cruzada para analizar las relaciones
causales físicas entre la atmósfera ártica en estado de invierno y la severidad del invierno re
flejada en las condiciones del hielo, y para validar la significancia estadística de las dos series
estiman el coeficiente de coherencia wavelet de las dos series el cual es análogo al coeficiente
38

de correlación tradicional, con la diferencia que la coherencia wavelet brinda un análisis de
correlación localizable en el espacio y frecuencia de tiempo. Una tercer aplicación ha sido en
el análisis estadístico de series de tiempo con énfasis en el dominio tiempo-escala como lo
es para la estimación de la varianza y la estimación del exponente de escala para procesos
estocásticos fraccionales (1/ !), en general para la simulación de procesos con memoria de
largo plazo.
La aplicación de la teoría de wavelets en economía y finanzas tiene sus antecedentes
tiempo atrás de que Mandelbrot propusiera el enfoque Paretiano, aunque su uso formal no
data más de diez años. Roberts (1959) argumentó de su aplicación en el análisis financiero
al mencionar:
Un nombre común y conveniente para el análisis del patrón del mercado ac
cionario es el "análisis técnico". En parte estos enfoques son meramente empíri
cos; en parte se basan en analogía con procesos físicos, tales como mareas y
ondas.
Así mismo, se tiene registrado que Paul Lévy utilizó la función base de Haar para analizar
el movimiento browniano, en particular la expansión conocida corno "construcción del des
plazamiento del punto medio" . 1
El presente capítulo comprende de las siguientes tres secciones. La primera sección trata
sobre las bases matemáticas y propiedades de wavelets haciendo énfasis en las series y
transformada de Fourier, y el tratamiento de convolución. La segunda sección trata sobre el
análisis por multiresolución, cuya antesala es la Transformada de Fourier de Corto Tiempo
(STFT, por sus siglas en inglés), en donde se describe la Transformada Wavelet Continua
y Transformada Wavelet Discreta. Finalmente la tercera sección, trata sobre la varianza
wavelet y sus propiedades.
1Jaffard, S., Meyer, Y., and Ryan, R. Wavelets. Tools far Science and Technology, página 21. Una realización del movimiento browniano,
d dtX(t,w) = ¿g;(w)Z;(t),
iEJ
puede representarse a través de la expansión
1 00 .
X(t,w) = go(w)t + 2¿r112gn(w)~n(t), n=l
donde 9n(w) son variables aleatorias Gaussianas, independientes e idénticamente distribuidas con media cero y varianza uno.
39

3.1. Bases Matemáticas y Propiedades
Las funciones wavelets poseen dos propiedades que hacen conceptual y matemáticamente
su construcción, admisibilidad y regularidad. 2 La propiedad de admisibilidad hace referencia
al término de wave, la cual consiste en que la transformada de Fourier de una función decaiga
en la frecuencia cero; esto es, el valor promedio de una wavelet en el dominio del tiempo
debe ser cero por lo que la función es oscilatoria y en consencuencia representa una onda
( wave). La condición de regularidad hace referencia al término let o decaimiento rápido, e
implica que la función wavelet debe poseer suavización y concentración en el dominio de
tiempo y frecuencia, por lo que la función wavelet tendrá N momentos de desvanecimiento
u órdenes de aproximación. Por lo tanto, una wavelet hace referencia a una función que
oscila y que decae a cierto número de desvanecimientos o aproximaciones.
La construcción de wavelets se basa en la dilatación (W(x) - W(2x)) y translación
(W (2x) - W (2x - 1)) de una función; si la dilatación y translación se hace en forma
infinita, se tendría la familia de funciones base Wjk(x) = W(2Jx - k) en L2 [0, 1] que junto
con una función de escala </>(x) representaría la construcción de una wavelet, donde j ~ O
y O ::; k ::; 2J. Además, el producto interno de J </>( x) W ( x )dx es cero, teniendo como
resultado la propiedad de ortogonalidad mútua entre las dilataciones y translaciones de W.
Lo anterior hace la importancia de wavelets para analizar series de tiempo en diferentes
escalas y frecuencias a través del tiempo, esto es, la descomposición de la serie para analizar
a detalle sus características y su reconstrucción (síntesis) para obtener la serie original.
3.1. l. Series y Transformada de Fourier
U na de las principales bases en wavelets es el análisis de frecuencias desarrolladas por
Fourier, el cual establece que una señal periódica J ( x) con periodo fundamental L puede
expresarse como la suma de términos seno y coseno de la forma
a0 ~ [ (21rr.r) . (21rrx)] J(x) = 2 + ;=: arcos L + brsm L , -OO <X< +oo (3.1)
2Valens, A really friendly guide to wavelets, pp. 6-7.
40

donde ao, ar, y br son números reales, y 2rr / L es la frecuencia fundamental o angular
comúnmente representada por w;3 los coeficientes ar y br se definen de la forma
2 rxo+L (2rrrx) ar= LÍxo J(x)cos L dx,
b, = f,f+\{x)sin c:x}u El caso particular identificado por Fourier es L = 2rr.
La importancia de las series de Fourier recae en que
r = 1,2, ...
r = 1,2, .. .
... representan la respuesta de un sistema a un insumo periódico, y esta respuesta
comúnmente depende directamente del contenido de la frecuencia del insumo.4
(3.2)
(3.3)
Contrario a las series de Taylor, las series de Fourier pueden describir funciones que no son
del todo continuas y/ o diferenciables; y para que una función pueda representarse a través
de una expansión de series de Fourier, la misma debe satisfacer las siguientes condiciones
conocidas como condiciones de Dirichlet:
l. la función debe ser periódica;
2. la función debe ser de valor único (a cada punto en el dominio le corresponde un
único valor en el rango) y continua, excepto posiblemente en un número finito de
discontinuidades finitas;
3. la función debe poseer un número finito de máximos y mínimos en un periodo; y,
4. la integral de I J(x) 1 sobre un periodo debe converger.
Adicionalmente, cualquier función razonable ( aquella que satisface las condiciones de
Dirichlet) se puede representar como la suma de partes impares y pares de la forma,
1 1 J(x) = 2[J(x) + J(-x)] + 2[J(x) - J(-x)], (3.4)
donde J(x) = -J(-x) representa la parte impar y J(x) = J(-x) la parte par. Por lo que las
series de Fourier se justifica que sean series de suma de términos senos y cosenos, donde la
función seno representa la parte impar y la función coseno la parte par. En consencuencia,
3w = 21r / L = 21r f , donde f es la frecuencia de la señal y mide el número de ciclos por unidad de tiempo,
i.e. , una corriente eléctrica de 60 Hz indica que la onda seno pasa 60 veces por el mismo punto en un
segundo. 4 Riley, Hobson y Bence, Mathematical methods for physics and engineering, página 327.
41

cualquier función (razonable) podrá representarse como la suma <le términos de senos y
cosenos.5
Una de las propiedades que deben satisfacer los términos de las series de Fourier, es que
la integral sobre un periodo del producto de cualquiera de los dos términos sean ortogonales,
esto es,
¡xo+L . (2~rx) (2~px) sm -- cos -- dx = O, ~ L L
para toda r y p, (3.5)
t+L cm) (2KpX) { L parar= p = O,
cos -- cos -- dx = lL parar= p > O, xo L L 2
o para r/-p,
(3.6)
t+L . (2m). (2Kpx) { o parar= p = O,
sm -- sm -- dx= lL parar= p > O, xo L L 2
o para r-=l-p,
(3.7)
donde r y p son enteros mayores que o igual que cero.
Los coeficientes ar y br en (3.2) y (3.3) se pueden estimar de la siguiente forma, teniendo
el caso particular para a0 :
1. Sea una función periódica f ( x) con periodo L = 2~, f ( x + 2~) = f ( x) la cual se puede
representar en forma de series de Fourier
00
J(x) = ~o + í:)ar cos rx + br sin rx ), (3.8) r=l
2. La función J(x) se multiplica por cosp.r para obtener
00
J(x) cos px = ~o cos px +¿)arcos rx cos px + br sin rx cos px ), (3.9) r=l
3. Se integra sobre un periodo completo de -~ a ~ y se ordenan los términos de la
5Una función razonable no puede representarse únicamente por funciones seno, ya que éstas no pueden representar a una función par; así mismo, r.ualquier función razonable no podrá representarse únicamente por funciones coseno, ya que éstas no pueden representar a una función impar.
42

sumatoria e integrales,
r r 00 r }_'Tí J(x)cospxdx = ~o }_'Tí cospxdx+ ;ar }_'Tí cosrxcospxdx
00 r + ¿)r j _ sin r x cos pxdx
r=l -'Tí
4. Considerando el caso r = p =Ose tiene:
Por lo tanto
{ f(x)dx = ~o { dx+ ta, { dx
=ªºrdx 2 }_'Tí
= ~o [x['/í
= ao1r.
1¡'/í a0 = - J(x)dx. 7r -'Tí
(3.10)
(3.11)
Las series de Fourier son una representación particular de funciones las cuales están
definidas en un intervalo finito y en un solo periodo, por lo que el caso general es considerado
a través de la Transformada de Fourier que puede representar una función en términos de la
superposición de términos sinusoidales sobre un intervalo infinito y sin alguna periodicidad
en particular. La función principal de la Transformada de Fourier es medir el contenido de
frecuencia de una señal, información que no es fácil de detectar en el dominio de tiempo de
la señal original, y comúnmente las señales presentan más de un componente de frecuencia.
Para determinar la transformada de Fourier de una función, primeramente es necesario
representar una serie de Fourier en forma simplificada utilizando la expansión exponencial
43

compleja y la ecuación de Euler,6
~ ( 27rirx) J(x) = L.,¡ Cr exp -L- , r=-oo
(3.12)
donde los coeficientes de la serie compleja de Fourier se definen corno
1 ¡xo+L ( 27rirx) Cr = L xo J(x) exp --L- dx. (3.13)
Si la serie compleja de Fourier representa funciones que varían en el tiempo, entonces
00
J(t) = L Creiwrt, (3.14) r=-oo
y los coeficientes de la serie se expresan corno
1 ¡T/2 Cr = - J(t)e-iwrtdt T -T/2
(3.15)
donde Wr = 27rr /T y debe satisfacerse que J~00
1 J ( t) 1 dt sea finita.
Sustituyendo (3.15) en (3.14) se tiene
00
[ 1 {T/2 . l . J(t) = r~oo T j -T/2 J(t)e-,wrtdt eiwrt, (3.16)
6La expansión de Maclaurin de la función exponencial es
x 0 x1 x 2 x3 xn ex = -01 + -11 + -21 + -3, + · · · + 1 ' . . . . n.
cuando nos referimos a números complejos
donde z == i0, se tiene que . 02 i03 04 i05
e'9 == 1 + i0 - - - - + - + - - · · · 2! 3! 4! 5!
Reagrupando términos,
ei9 == 1 - 02 + 04 - ... + i (0 - 03 + 05 - ... ) 2! 4! 3! 5! '
encontramos la ecuación de Euler: e;o == cos 0 + i sin 0.
44

y en la medida que T tienda a infinito, el cambio en la frecuencia se va desvaneciendo y el
espectro de las frecuencias Wr se convierte en una variable continua. 7 Entonces,
f(t) = ,t ~: [1:: f(t)e-"''dt] e'"''
,t L [ 1:: f(t )e-'"'' dt] e'"'' liw
00 1 = L 21rh(wr)eiwrt l:::,.w,
r=-oo
(3.17)
y cuando T --+ oo, l:::,.w --+ O entonces Wr se convierte en una variable continua, por lo tanto
f(w) = lím fr(wr) = f 00 J(t)e-iwtdt, T---+oo -oo
es la Transformada de Fourier de f ( t), donde
es la Integral de Fourier.
J(t) = ~ roo J(w)eiwt(U,), 27!" }_00
(3.18)
(3.19)
Como conclusión, la Transformada de Fourier es el proceso de transformar la función
f ( t) en el dominio del tiempo en la misma función J( w) pero en el dominio de frecuencia y
se expresa como F{!(t)}; y al proceso inverso de regresar a J(t) a partir de J(w) se conoce
como la Transformada Inversa de Fourier, ;:--1 {J(w )}.8 Un aspecto importante al observar
detenidamente la transformada de Fourier (3.18), es que la integración de J(t) se realiza en
todo el intervalo de tiempo sin importar en dónde el componente de la frecuencia w aparece
en el tiempo (t1 , t2 , ... ), ya que el efecto de la frecuencia será el mismo en la integración.
La transformada de Fourier indica la existencia o no del componente de frecuencia w in
dependiente del momento en el tiempo que pueda aparecer, por lo cual su aplicación toma
sentido en señales (series de tiempo) que son estacionarias. En resumen, la Transformada
7
27í 27í ~w = Wr+I - Wr = T(r + l - r) = r·
Por lo que ów = .!. 211 T
8La importancia de transformar una fuución, es la posibilidad de obtener mayor información de la misma respecto de aquella disponible en la señal original.
45

de Fourier proporciona los componentes de frecuencia ( componentes espectrales) existentes
en una señal. 9
3.1.2. Funciones base y concentración de energía
El segundo antecedente radicó en expresar una función x(t) a través de funciones base
con cambio de escala, esto es, migración de análisis de frecuencia a análisis de escala, a
lo cual Graps (1995) define y explica una función base y cambio de escala de la siguiente
forma:
• Funciones base: Un vector de dos dimensiones (x, y) es el resultado de la combinación
de los vectores (1, O) y (O, 1) llamados vectores base, ya que al multiplicar x por (1, O)
resulta en el vector (x, O), y y por el vector (O, 1) resulta en el vector (O, y). Por lo
tanto la suma de ambos vectores, (x, O) y (O, y), resulta en el vector (.1:, y). Donde la
propiedad valúable en los vectores base es que son perpendiculares u ortogonales uno
al otro. En términos de una función J(x), ésta puede representarse a través de las
funciones base senos y cosenos debiéndose cumplir que sean ortogonales a través de
una combinación apropiada entre ellas por lo que el producto interno de las respectivas
funciones sea cero.
• Cambio de escala: Una función base cambia en escala "cortando en pedazos" dicha
función en diferentes tamaños de escala. Ejemplo de ello, sea una señal en el dominio
de O a 1, la cual puede dividirse en funciones de dos etapas con rango de O a ½ y de ½ a
l. Posteriormente se vuelve a dividir la señal original en funciones de cuatro etapas de
O a¼, ¼ a½, ½ a¾ y de ¾ a l. Por lo tanto cada conjunto de representaciones codifica
la señal original en una escala o resolución particular.
Con referencia a las funciones base, éstas son una extensión del espacio vectorial Euclideano a
espacios lineales normados, i.e., de una colección de vectores geométricos nos movemos a una
colección de funciones en donde ahora ese espacio se representa por funciones arbitrarias más
que vectores base. 10 Primeramente, un vector se define como un segmento de recta dirigido
que corresponde a un desplazamiento de un punto A hacia otro punto B, y se denota por -medio de AB. La representación de vectores se realiza a través de coordenadas, i.e., sea el -vector a = O A = [3, 2], el cual especifica que es un par ordenado donde las coordenadas
9EI principio de incertidumbre (de Heisenberg) establece que no es posible conocer exactamente qué frecuencia existe en qué instante del tiempo, si no únicamente conocer las bandas de frecuencia en intervalos de tiempo.
1ºLas definiciones y conceptos de vectores y funciones base en este apartado se basan en Poole, Álgebra Lineal: Una Introducción Moderna y en Goswarni y Chan, Fundamentals of Wavelets, respectivamente.
46

individuales se conocen como los componentes del vector; de modo que en el plano [x, y], X= 3 y y= 2.
A partir de un vector u con coordenadas (componentes) [u1, u2] le puede seguir otro
vector v con coordenadas [v1, v2], por lo que el resultado de seguir ambos vectores cor-
responde a la suma de los mismos, i.e., u+ v = [u1 + v1, u2 + v2]. Por lo tanto, la suma t
de dos vectores u y v en R2, corresponde al vector en posición estándar a lo largo de la
diagonal del paralelograma determinado por ambos vectores. Una de las operaciones básicas
en vectores es la multiplicación por escalares, la cual dado un vector u y un número real a,
el múltiplo escalar au es el vector que se origina en la multiplicación de cada componente ..
del vector u por a.
Cuando en el espacio se tiene un punto representado por tripletas ordenadas de números
reales como U=[l,2,3], entonces se tiene el vector u en R3. En general al conjunto de n
tupletas ordenadas de números reales y su representación vectorial u en Rn será de la forma
donde u¡ es el i-ésimo componente del vector u y la longitud o norma del vector en JRn es
el escalar no negativo II u II definido por
11 u 11= ~=Ju¡ +u~+··· +u;. (3.20)
Además, cuando el producto interno de dos vectores (u, v) = O, entonces se dice que son
ortogonales, y cuando un conjunto de vectores {u1, u2 , ... , un} que en parejas son ortogo
nales y todas con longitud de 1, entonces se dice que son ortonormales.
Si el vector u se encuentra asociado con vectores unitarios ortogonales { a1, a2, ... , ¾} entonces se habrá definirlo un espacio vectorial Euclideano. 11 Los vectores unitarios
ortogonales, { a1 }f=1, se conocen como los vectores base que forman un conjunto ortogonal
11 La definición más precisa de un espacio Euclideano es a<111el espacio (]Ue es métrico y de dimensión finita, donde un espacio métrico se define como al conjunto de puntos tal que a cada par de puntos existe un número real no-negativo llamado distancia que es simétrico y que satisface la desigualdad del triángulo. La desigualdad del triángulo establece que para todos los vectores u y v en IR"
llu+vll S llnll+llvll
47
' J.
'f' - ~ · ····-·

tal que
\/k, l E Z,
donde ók I es la delta de Kronecker definida como: 12
'
ó _ { 1, k = l k,l - o, k=/l.
Los componentes { Uj n=l del vector u se obtienen a través del producto interno
y el vector u es una combinación lineal de sus componentes
N
u=¿v1a1. k=l
En vez de trabajar con vectores base { aj }f=1, se trabaja con funciones arbitrarias.
(3.21)
(3.22)
(3.23)
(3.24)
El tercer antecedente se basa en las investigaciones de Littlewood, Paley y Stein quienes
proponen que la concentración de energía de una función f ( x) puede representarse de la
forma: 1 r2rr 210 1 J(x) 1
2 dx, (3.25)
el cual está relacionado con el teorema de Parseval referente a la ley de la conservación. El
Teorema de Parseval establece que la suma del módulo al cuadrado de los coeficientes de la
serie compleja de Fourier es igual al valor promedio sobre un periodo de I J(x) 12
, esto es
1 rxo+L oo
L J,, 1 f(x) l2dx = ¿ 1 Cr 1
2
xo r=-oc (3.26)
12La delta de Kronecker es una función que coincide con la función delta o distribución de Dirac, que en señales se identifica como el impulso unitario o(t). La delta de Dirac se define como
o(t) = o, t # o
¡,:,: 6(.X)d.X = 1, para cualquier número real E> O,
donde esta segunda condición establece que la función delta tiene área unitaria.
48

Si una función periódica que depende del tiempo f ( t + 21T) = f ( t) se puede representar como
una serie de Fourier 00
ªº ~ J(t) = 2 + L..)arcoswt + brsinwt], r=I
donde w = 21Tr /T, y dado que ( ar cos wt) representa una onda, entonces la energía de la
onda coseno es proporcional a
fT/2 (arcos wt)2dt = a; {T/
2 cos2wtdt
Í-T/2 Í-T/2
a2 ¡T/2 = ; (1 + cos 2wt)dt
-T/2
_ a; ([ ]T/2 1 [ . ]T/2 ) - 2 t -T/2 + 2w sm 2wt -T/2
2 = 1Tar.
Así mismo, la energía de la onda seno
{T/2
(br sinwt)2dt = b; {T/2
sin2 wtdt Í-T/2 Í-T/2
= b; {T/2
(1 - cos2 wt)dt Í-T/2
b2 ¡T/2 = ...!. (1 - cos 2wt)dt 2 -T/2
_ b; (¡ ]T/2 1 [ . ]T/2 ) - 2 t -T/2 - 2w sm 2wt -T/2
- b2 - 1T r·
De acuerdo al Teorema de Parseval se tiene que
{T/2 l oo
}_ 1 J(t) l2dt = 7T 2a~ + 1T ¿(a;+ b;),
-T/2 r=I
(3.27)
(3.28)
(3.29)
el total de energía de una onda es la suma de las energías de todos los componentes de
Fourier.
3. 1.3. Convolución
Convolución es la integral que expresa la cantidad de traslape de una función g(t) en
la medida que se traslada sobre otra función J(t), por lo que ambas funciones se estarán
49

mezclando.13 La convolución sobre un rango finito [O, t] se representa como
f(t) * g(t) = 1t f(T)g(t - T)dT, (3.30)
donde el símbolo J * g denota la convolución de f y g (la cual también se denota como f ®g).
La convolución suele tomarse sobre un rango infinito de la forma
f(t) * g(t) = 1: j(T)g(t - T)dT = 1: g(T)j(t - T)dT,
y el área debajo de la convolución es el producto de las áreas debajo de los factores,
1: U* g)dx = 1: [1: f(u)g(x - u)du] dx
= 1: f(u) [1: g(x - u)dx] du
= [1: J(u)du] [1: g(x)dx].
Si a la expresión (3.32) le aplicamos la transformada de Fourier, se tiene
h(k) = ~ ('° e-ikx [ ('° J(u)g(x - u)du] v21r}_oo J_oo
= ~ 100
f(u)du [ roo g(x - u)e-ikxdx] dx, v 21r -oo } -DO
se realiza cambio de variable, x = z + u, se tiene
h(k) = - 1- roo J(u)du [ roo g(z)e-ik(z+u)dz] J'h }_oo }_oo
= -- J(u)e-ikudu g(z)e-ikzdz . 1 1-00
. 1-00
.
./2-rr -oo -oo
Por lo tanto,
h(k) = ~ X ,/2; f(k) X ,/2;g(k) = ..¡¡; f (k)g(k), v21r
(3.31)
(3.32)
(3.33)
la cual denota la transformada de Fourier de la convolución f * g, y se conoce como el
Teorema de la Convolución que es igual al producto de las transformadas de Fourier por
separado de .f y g multiplicado por -/27r. 13 Las definiciones de convolución y conceptos asociados en esta sección se basan en:
Weisstein, E. CRC Concise Encyclopedia of Mathematics. USA, Chapman and Hall, 1999. Percival, D., and, Walden, A. Wavelet Methods far Time Series Analysis, Cambridge University Press, 2006.
50

La convolución en términos de series, suponiendo que { at} y {bt} son dos secuencias
infinitas de variables valuadas en los reales o complejos, se define corno la secuencia infinita
cuyo t-ésirno elemento.
3.1.4. Propiedades de Wavelets
Los tres antecedentes y el concepto de convolución son aplicables para establecer dos
propiedades o condiciones (suficientes) que wavelets deben satisfacer, admisibilidad y regu
laridad, tal que cualquier función valuada en los reales sea considerada corno wavelet. 14
La condición de admisibilidad sostiene que una función wavelet 1/;( ·) es admisible si su
transformada de Fourier
(3.34)
es tal que -¡00
1 \Jl(w) 1
2
C1/J= ---dw, o w
(3.35)
y se debe cumplir O < C'lj; < oo. Para que la condición de admisibilidad se cumpla, es
necesario que 1-: 1/J(t)dt = o,
y que la integral del cuadrado de 1/;(t) sea 1,
¡: vi(l)dt = 1.
(3.36)
(3.37)
Por lo tanto, la función 1/;(t) debe ser una onda tal que se satisfaga (3.36). La importancia
de la condición de admisibilidad recae en que permite reconstuir una función J(·) a partir
de su transformada wavelet (continua) .15
La segunda propiedad de una función wavelet es que la misma debe satisfacer la condición
de regularidad, la cual hace que la función se desvanezca a cierto número de aproximaciones.
14 Eu sí, se refiere a uua funcióu base couocida como wavelet madre, la cual sirve como prototipo para construir otras funciones.
15 EJ concepto de transformada wavelet continua se decribe a detalle en la sección 3.2.2.
51

3.2. Análisis por Multiresolución
La característica principal de la Transformada de Fourier es representar una función
compleja por medio de la suma ponderada de funciones simples que a la vez, éstas funciones
simples se obtienen a partir de una función más simple conocida como prototipo o función
base. Su principal ventaja es que es una representación de soporte compacto perfecto en el
dominio de la frecuencia, esto es, que es capaz de representar perfectamente el contenido
espectral de una señal pero no tiene alguna indicación de su localización en el tiempo. 16
Dada la última situación, la Transformada de Fourier no es capaz de representar señales
cuyo contenido espectral cambia a través del tiempo ( señales no estacionarias).
La modificación que sufrió entonces la Transformada de Fourier con el propósito de poder
representar señales no estacionarias fue desarrollada por Gabor al establecer la Transforma
da de Fourier de Corto Tiempo (TFCT). La TFCT trabaja segmentando la señal a través
de una función ventana localizable en el tiempo y posteriormente analiza cada segmento de
la señal. Sin embargo, la ventana que utiliza la TFCT es la misma para analizar toda la
señal, lo cual hace inadecuado su uso para analizar señales con componentes de frecuencia
muy altos pero con periodo de tiempo muy cortos y con componentes de frecuencia muy
bajos pero con periodo de tiempo muy largos.17
La problemática de la TFCT en no poder analizar conjuntamente componentes de alta
frecuencia con funciones ventana angostas y componentes de baja frecuencia con funciones
ventana amplias, permitió el desarrollo de las funciones base conocidas como wavelets. Estas
funciones base o funciones ventana tienen la característica de ser pequeñas (let) y oscilato
rias (wave), por lo que se caracterizan en tener soporte compacto en tiempo y frecuencia.
Posteriormente se desarrollaría la transición del análisis continuo de una señal al análisis
discreto, y dentro del contexto del análisis discreto ( transformada wavelet discreta) se desa
rrolló el análisis por multiresolución (AMR). La idea principal del AMR es descomponer una
señal discreta en bandas de frecuencia diádicas a través de una serie de filtros que permiten
el paso de frecuencias bajas (low-pass) y frecuencias altas (high-pass) con el propósito de
calcular la Transformada Wavelet Discreta de la señal. 18
16Un conjunto Ses compacto si, de cualquier secuencia de elementos X 1 , X2, ... de S, es posible extraer siempre una subsecuencia la cual tiende a algún elemento límite de X en S; los conjuntos compactos son por lo tanto cerrados y limitados (CRC Concise Encyclopedia of Mathematics, 1999).
17Este fenómeno fue analizado por J. Morlet a finales de los 70s. 18Los conceptos desarrollados en esta sección se basan en:
Goswami, J.C., and Chan, A. Fundamentals of Wavelets, Wiley and Sons, 1999. Addison, P. The Illustrated Wavelet Transform Handbook, Bristol, 2002.
52

3.2.1. Transformada de Fourier de Corto Tiempo (TFCT)
La transformada de Fourier tiene la principal característica en permitir el análisis de una
señal (serie de tiempo) en forma global, ello porque los términos coswt y sinwt son funciones
que representan funciones globales, por lo que se argumenta en que la transformada de
Fourier no es de soporte compacto en el tiempo. Esto es, la transformada de la función
original se integra en la línea de los reales (-oo, oo)
](w) = 1: f(t)e-iwtdt. (3.38)
Sin embargo, lo anterior no permitiría el análisis del contenido de la frecuencia de la señal
en forma local, ya que en diversas situaciones se requiere analizar una porción en particular
del espectro, y posteriormente conocer aquella porción de la señal en el dominio del tiempo
responsable de la característica del espectro. Dicha transición de análisis global a local, es
posible a través de la Transformada de Fourier de Corto Tiempo (TFCT), la cual trabaja
removiendo aquella porción de la señal deseada y posteriormente se aplica la transformada
de Fourier a dicha porción. Para ello, se requiere de una función conocida como ventana a
través de la cual es posible remover la porción deseada de la señal. Por lo anterior, la TFCT
es también conocida como transf armada de Fourier ventaneada.
Una función ventana es una función valuada en los reales, <j)(t) E L2 (IR), cuya finalidad
es remover alguna porción de la señal original, esto es, la convolución de la señal original
con la función ventana, J(t)<j)(t - b) =: fb(t). El resultado es la información contenida de
f ( t) en la vecindad de t = b, donde el valor de la convolución será cero fuera del intervalo
deseado,
( )-{ j(l), l E [b-T,b+T)
Íb t - ' O, de otro forma.
(3.39)
donde el parámetro b representa la magnitud con la cual se puede desplazar la función
ventana sobre el eje del tiempo.
La función ventana en </J(l), igualmente llamada ventana del tiempo, se describe por los
parámetros de centro y anchura, donde el parámetro centro se define por
t* := 11 : 1121: ti </J(t) l2dt, (3.40)
y un radio de raíz cuadrada media /j.<t> como
1 [100 ] 1/2 f;i<J;, := m -X (t - t*)21 </>(t) l2dt (3.41)
53

Así como una ventana del tiempo, existe una ventana de frecuencia, ~(w), con centro w*
1 ¡00 A 2 w* := -A - wl </>(w) 1 (Ú,.J,
11 </> 11 2 - 00
(3.42)
y un radio de raíz cuadrada media !).J definida por
1 [ roo l 1/2 Í),.J := m 1_00
(t - t*)21 <t>(t) 1
2dt (3.43)
Por lo tanto la función <f>(t) es conocida como ventana de tiempo-frecuencia. La importancia
de una ventana de tiempo y ventana frecuencia, radica en el Principio de Incertidumbre de
Heisenberg, el cual establece que no es posible conocer simultáneamente y con exactitud, el
momento y posición de una partícula en movimiento. Por lo tanto, lo mejor que se puede
conocer son los intervalos de tiempo en donde existen ciertas bandas de frecuencia.
La figura 3.1 representa las cajas de Heisenberg para una función ( señal) f ( t) de la cual
se desea obtener sus contenidos de frecuencia en una vencidad t = b, entonces ventaneando
dicha función a través de una función ventana </>(t), el producto será una función ventaneada
fb(t) = f(t)</>(t - b). El siguiente paso es aplicar la transformada de Fourier cuyo resultado
será la Transformada de Fourier de Corto Tiempo (TFCT).
ú)
.,; --------- cr,----m-Bt "-
t
Figura 3.1: Cajas de Heisenberg en el plano frecuencia-tiempo con funciones-ventana fijas.
Lo anterior permite representar la TFCT de una función f ( t) respecto de una función
ventana <f>(t), evaluada en (b, w) en el plano tiempo-frecuencia, de la forma
T FCT¡ = 1: J(t)</>(I, - b)e-iwtdt, (3.44)
donde la función sinusoidal e-iwt fluctúa dentro de la función ventana </>(t).
54

La versión discreta de la TFCT se define como la suma de series
donde
y
N-1
T FCTf :=:::: h L J(tk)<P(tk - bn)e-iwntk,
k=O
21rn Wn = Nh,
k =O, ... ,N -1
-N N n = -2-,· · · '2·
En el caso particular h = 1,19 se tiene
N-1
TFCTf ~ L J(k)cp(k - n)e-i(2TCkn)/N_
k=O
3.2.2. Transformada Wavelet Continua
(3.45)
(3.46)
(3.47)
(3.48)
La transformada wavelet así como la transformada de Fourier, en particular la Transfor
mada de Fourier de Corto Tiempo, es un método para convertir la señal (función) original en
alguna otra forma con el objetivo de analizarla de una manera más manejable, a diferencia
de la transformada de Fouricr que la transformada wavelet permite el análisis en el dominio
frecuencia-tiempo. Ello se aprecia en que la TFCT trabaja con una función ventana cons
tante para analizar toda la señal. A través de la transformada wavelet se permite corregir el
fenómeno de estacionariedad, ya que será posible incrementar el radio de la función ventana
en el tiempo cuando las frecuencias reduzcan, y disminuir el respectivo radio en el tiempo
cuando las frecuencias aumenten.
Retomando la importancia de la función ventana descrita en la sección anterior, la trans
formada wavelet no es más que la convolución de la función wavelet con la señal original,
donde la función wavelet depende de dos parámetros: 1) traslación (localización), el cual
representa el movimiento de la función wavelet sobre el eje del tiempo; y, 2) dilatación, el
19Donde h se conoce como el periodo de muestreo, y representa la distancia entre los puntos adyacentes de la muestra. El valor de h no debe exceder 1r/O. tal que la función f(t) pueda ser reconstruida. Lo anterior hace referencia al Teorema del Muestreo, el cual establece que si una señal f(t) está delimitada por un ancho de banda 20., entonces la señal se puede reconstruir exactamente a partir de los valores de la muestra en los puntos equidistantes. Cuando h = 1r/O., entonces la frecuencia del muestreo J.= 1/h = n/7r, y se conoce como la tasa de Nyquist. Una función o señal J(t) puede reconstruirse con la fórmula
J(t) = ¿f(kh)sin [O.(t - kh)]' kEZ kEZ 1r(t - kh)
55

cual permite la expansión y contracción <le la función wavelet, y a través del cual se pueden
capturar las frecuencias (altas o bajas) de la señal original. Lo anterior hace la transformada
wavelet flexible en permitir el análisis en el dominio tiempo-frecuencia de señales (series de
tiempo) en el contexto de no-estacionariedad.
La figura 3.2 ilustra las cajas de Heisenberg cuando se aplica la transformada wavelet
y se busca analizar una señal, en donde las cajas muestran la expansión y contracción <le
la función según las frecuencias que se busquen capturar y su ocurrencia en el tiempo. El gráfico inferior muestra la serie de tiempo y la flexibilidad de la función wavelet en cuanto
a su habilidad para trasladarse sobre el eje del tiempo y dilatarse o contraerse según las
frecuencias que esté capturando. El gráfico superior muestra las cajas de Heisenberg en el
plano frecuencia-tiempo, en donde se observa las diferentes amplitudes de las cajas según
las frecuencias que la función wavelet captura a través del tiempo: para frecuencias bajas
w1, las cajas se expanden para poderlas capturar con mejor resolución en el tiempo, lo cual
refleja la dilatación de la función wavclct; y, para frecuencias altas w2, las cajas se contraen
para poderlas capturar con mejor resolución cuando este tipo de frecuencias ocurren en
periodos de tiempo muy cortos, lo cual refleja la contraccción de la función wavelet .
. t 11 12
lfl a.b (1)
x(t) t
b¡ b2
Figura 3.2: Cajas de Heisenberg en el plano frecuencia-tiempo y la función wavelet.
La transformada wavclet trabaja en dirección opuesta respecto a la TFCT, la cual
primeramente descompone la señal original en bandas de frecuencia y después la analiza
56
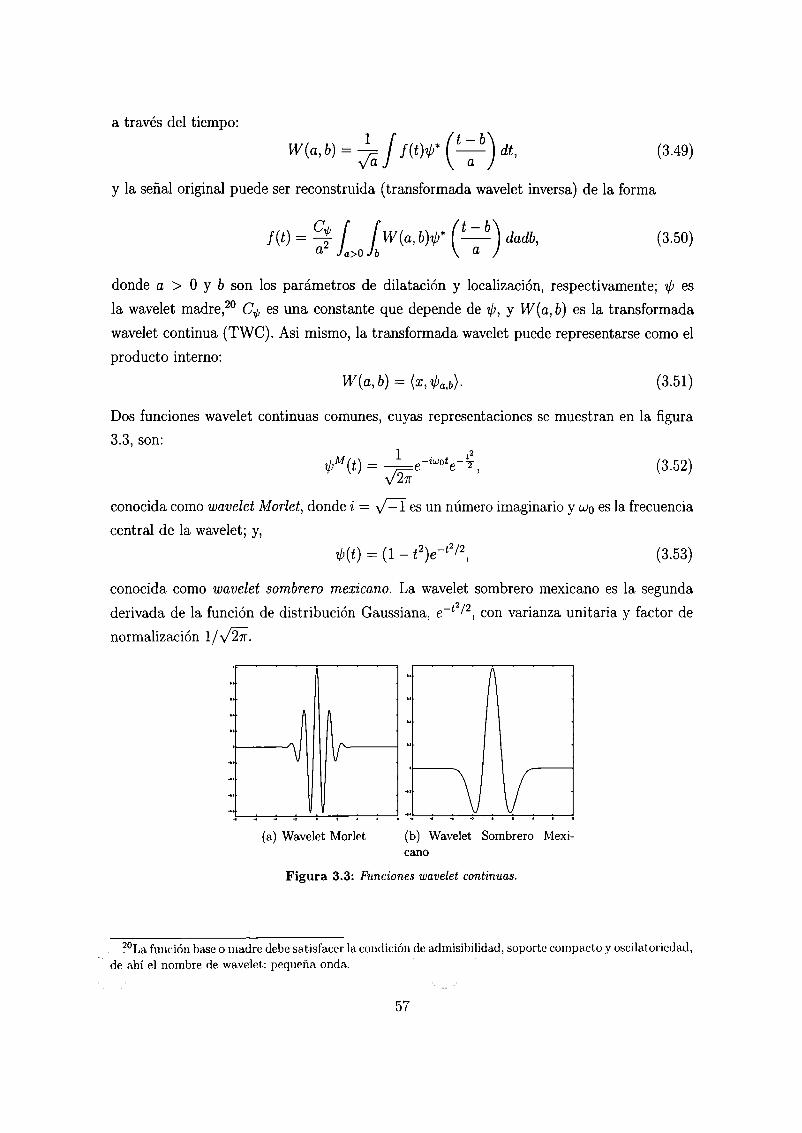
a través del tiempo:
1 J (t-b) W(a, b) = va J(t)'l/;* -a- dt, (3.49)
y la señal original puede ser reconstruida ( transformada wavelet inversa) de la forma
J(t) = ºt 1 ¡w(a, b)'l/;* (t -b) dadb, a a>O b a
(3.50)
donde a > O y b son los parámetros de dilatación y localización, respectivamente; '1/; es
la wavelet madre,2° C"" es una constante que depende de '1/;, y W(a, b) es la transformada
wavelet continua (TWC). Asimismo, la transformada wavelet puede representarse como el
producto interno:
W(a, b) = (x, 'l/Ja,b)- (3.51)
Dos funciones wavelet continuas comunes, cuyas representaciones se muestran en la figura
3.3, son: 1 t2
'l/JM (t) = J21re-iwote- 2 , (3.52)
conocida como wavelet Morlet, donde i = FI es un número imaginario y w0 es la frecuencia
central de la wavelet; y,
(3.53)
conocida como wavelet sombrero mexicano. La wavelet sombrero mexicano es la segunda
derivada de la función de distribución Gaussiana, e-t212 , con varianza unitaria y factor de
normalización 1/ J27r.
:-~,\ V'
(a) Wavelet Morlet (b) Wavelet Sombrero Mexicano
Figura 3.3: Funciones wavelet continuas.
2ºLa función base o madre debe satisfacer la condición de admisibilidad, soporte compacto y oscilatoriedad, de ahí el nombre de wavelet: pequeña onda.
57

3.2.3. Transformada Wavelet Discreta
La transformada wavelet continua es una función que depende de dos parámetros con
tinuos, lo cual da como resultado información redundante, esto es, un número variante de
coeficientes con un número reducido de escalas. Dicho problema es resuelto discretizando los
parámetros a y b a través del análisis por multiresolución desarrollado por Mallat (1989),
en el cual se aplican iterativamente filtros de alto- y bajo-paso, y susbsecuentemente se
muestrean en forma de cascada. El anterior proceso resulta en la transformada wavelet dis
creta (TWD). 21
La TWD es la transformada ortonormal en el nivel J de un vector X, 22
W=WX, (3.54)
donde W es un vector columna de longitud N el cual contiene los coeficientes de la trans
formada: los primeros elementos N - N /21 representan los coeficientes wavclet y los últimos
elementos N /21 representan los coeficientes de escala; y, W es una matriz ortonormal N x N
valuada en los reales, esto es, una matriz que satisface wrw = l. La forma de construir una matriz W es a través de un filtro (de alto-paso) wavelet
h1,0, · · ·, h1,L1-l, (3.55)
para L1 ~ N, y
L 1 -1- 21 { l [ = Q L h1,nhl,n+21 = ' _ l=o O, l - 1, 2, ... , (L1 - 2)/2.
(3.56)
Lo cual satisface la propiedad de integración a cero
L-l
¿h1=0 (3.57) l=O
y energía unitaria
L-1
¿h¡ = 1, (3.58) 1=0
21 La presente subsección se basa en Percival y Mofjeld ( 1997). 22 X es una secuencia de N observaciones X 0 , X 1 , ... , XN-l provenientes de una serie de tiempo valuada
en los reales y que representa un vector de observaciones de longitud diádica (N = 21), donde X 1 es la
observación en el tiempo tD.t (ates el intervalo de tiempo entre cada observación adyacente).
58

donde h1,n es el filtro asociado a la escala l::l.t = .X11::l.t el cual se aproxima a un filtro de
alto-paso con una banda de paso definido en el intervalo de frecuencias [1/(41::l.t), 1/(2Lit)].
La transformación wavelet para escalas mayores Ajb.t se obtiene aplicando la transfor
mada discreta de Fourier al filtro wavelet rellanada por N - L1 ceros,
N-l
H = "h e-i2nnk/N 1,k - L 1,n , k =O, ... ,N - l. (3.59) n=O
Si ahora se denota a g1,n como un filtro de escalamiento también conocido como filtro espejo
de la cuadratura, definido por
n = O, ... , L1 - l, (3.60)
en donde debe satisfacerse la relación inversa respecto al filto wavelet
h¡ = (-l) 19L-l-l· (3.61)
Si G1,k representa la transformada discreta de Fourier del filtro de escalamiento, entonces
los filtros wavelet de órdenes mayores serán
N-l
h = _!__ ~ H · ei21rnk/N J,n - N L J,k ,
k=O
(3.62)
donde j-2
Hj,k = H1,2i- 1k mód N IT G1,21k mód N, (3.63) l=O
cuyos elementos hí,Li, hj,1,j+I, ... , hj,N-I serán O si Lí = (2í - l)(L1 - 1) + 1 < N; donde el
filtro hj,n se aproxima a un filtro de paso de banda con una banda de pase en el intervalo de
frecuencias [1/(2í+1f::l.t), 1/(2íf::l.t)]. El filtro de escalamiento para el orden J se define como
donde
N-I
= _!_ ~ G ei21rnk/N .91,n - N L 1,k ,
k=O
J-I
G1,k = IT G1.21k mód N,
l=O
59
(3.64)
(3.65)

y el filtro gJ,n se aproxima a un filtro de bajo-paso con banda de pase en el intervalo de
frecuencias [O, 1/(2J+1~t)].23 De esta forma, el proceso de filtración de las observaciones Xt
de una serie de tiempo a través de funciones de alto-paso (wavelet) se puede representar
como
Xt - H(w) __.. UJ,t,
donde J
H(w) = I1 Hi(w), (3.66) j=l
es la función transferencia de h1, y UJ,t es la convolución de Xt con h1•
En general, al proceso de filtración de una señal a través de filtros de alto- y bajo-paso
se le conoce como descomposición por multiresolución. En particular, cuando la filtración
es vía la transformada wavelet discreta, se le conoce como representación wavelet de la des
composición por multiresolución. Dicha representación fue desarrollada por Mallat (1989),
al proponer un algoritmo piramidal tanto para descomponer una señal en diferentes escalas
como en la reconstrucción de la misma. La figura 3.4 ilustra el proceso de descomposición
en un nivel de un vector X utilizando la función wavelet h1 y función de escalamiento g1,
donde el símbolo l 2 significa que de cada 2 muestras que producen los filtros, una es la
que se mantiene, por lo que la longitud en cada nuevo vector Wi de coeficientes wavelet
tendrá una longitud de N /2i. El mecanismo de descomposición es el siguiente:
H(w)-12-Wi
/ X
~ G(w) -- 12 --- Vi
Figura 3.4: RepresentaC'ión wavelet de la descomposición por multiresolución.
• La serie original X pasa a través <le un filtro de pase-alto H(w) y <le un filtro de
pase-bajo G(w), donde cada filtro está definido por un intervalo de frecuencias;
23 La transformada de Fourier H(w) y G(w) e.le los filtros h1 y g¡, respectivamente, también se co11oce11 como las funciones de transferencia en el dominio de la frecuencia; y, H(w) y Q(w), representan el cuadrado e.le las funciones ganancia e.le las funciones de transferencia, respectivamente.
60

• Del resultado de la primera filtración, se obtienen N /2 coeficientes de la función
wavelet contenidos en el vector W y N /2 coeficientes de la función de escalamien
to contenidos en el vector V:
L-l
WI,t = L h1X2t+1-l mód N
1=0
donde t = O, 1, ... , N /2 - l.
y L-l
VI,t = L 91X2t+l-l mód N
l=O
(3.67)
• Posteriormente y a partir de los coeficientes de escalamiento obtenidos en V en la
primeración iteración, se vuelve a aplicar la filtración, de la cual se obtendrán nuevos
coeficientes de la función wavelet y función de escalamiento:
L-l
W2,t = L h¡v1,2t+l-l mód N
l=O
donde t = O, 1, ... , N /4 - l.
y L-l
V2,t = L 9lVI,2t+l-l mód N
l=O
(3.68)
• Por lo tanto, en las dos primeras iteraciones se obtendrán los siguientes vectores de
coeficientes wavelet y uno de coeficientes de escalamiento
(3.69)
Si el algoritmo sigue, entonces el vector de coeficientes wavelet se representa por:
(3.70)
donde cada vector de coeficientes wavelet W 1 es de una longitud N /21 asociado a los
cambios en la escala de longitud ).,1 = 21- 1, y el vector de coeficientes de escalamiento
V.J de longitud N /2J.
• Retomando W = WX, la matriz W contiene en sus primeros N - N /21 renglones,
los coeficientes del filtro wavelet h1,n bajo una versión circular desplazada, esto es, en
orden reverso de la forma
(3.71)
Si T representa una matriz de N x N la cual desplaza circularmente a h1 en una
unidad, se tiene
(3.72)
61

De esta forma, la matriz wr se conforma de N /2i columnas asociadas a la escala Tj~t,
donde las primeras N/2 columnas corresponden al desplazamiento circular T 2k-
1h1
para k = 1, ... , N/2. Así mismo, las últimas columnas N/21 contienen las versiones
desplazadas del filtro de escalamiento 9J,n de orden J, esto es, T 2Jk- 1g1 para k
1, ... ,N/21 .
Un ejemplo de la versión circularmente desplazada en la primera escala >.1 de la matriz W
para una longitud del filtro L = 4 siendo N > 4, se muestra en la ecuación (3.73)
h1,1 h1,o o o o o ... o o o o o h1,3 h1,2
h1,3 h1,2 h1,1 o o o ... o o o o o o o o o h1,3 h1,2 h1,1 h1,o ··· o o o o o o o
W1 = (3.73) ..
o o o o o o ... 0 ht,3 h1,2 h1,1 o o o o o o o o o ... o o o h1,3 h1,2 h1,1 h1,o
donde W1 es una matriz de N /2 x N cuyos renglones h 1 son circularmente desplazados por
una cantidad 2m - 1 donde m = 1, ... , N /2. Las matrices restantes W2, ... , W1 se definen
en forma similar que en (3.73), siendo ahora los renglones desplazados por 2im - 1 para
m = 1, ... , N /2i, y la matriz V 1 es de una dimensión idéntica a W 1 pero que ahora contiene
versiones circularmente desplazadas de la función de escalamiento g1 en vez de h1 , por una
cantidad 21 m - 1 para m = 1, ... , N/21 .
Finalmente, ejemplos comunes de filtros wavelct discretos se refieren a las funciones de
Haar (1910) y de Daubechies (1988). El primero hace referencia a un filtro de longitud L = 2
y definido por filtros de escalamiento por
1 9o = 91 = J2'
equivalente a filtros de alto-paso
1 ho=-
v'2 y
(3.74)
(3.75)
La figura 3.5 muestra la representación de la función wavelet (alto-paso) y de escalamiento
de Haar (1910), cuya característica principal es ser el único filtro ortonormal de soporte
compacto simétrico. Sin embargo, es poco usual en aplicaciones reales ya que es una apro
ximación pobre a un filtro ideal de pase de banda.
El segundo ejemplo de filtro discreto, wavelet de Daubechies (1988), hace referencia a
una función de soporte compacto con un número máximo de momentos de decaimiento, y
aunque no existe una forma explícita de representar a este tipo de filtros se pueden definir
62

Función escala phi Función wavelet psi
0.8 0.5
0.6
o 0.4
-0.5 0.2
o.__ ________ ___, -1L------=====:::I
o 0.2 o.4 o.6 o.a o 0.2 0.4 0.6 0.8
Figura 3.5: Wavelet Haar.
a través del cuadrado de la función ganancia del filtro de escalamiento:
L/2-
1 (L/2 - 1 + l)
(J(J) = 2cosL(1rf) ~ l sin2/(1rf), (3.76)
donde la longitud L del filtro es un número par entero y el primero término de la suma se
define como
(ª) a! f(a + 1) b - b!(a - b)! - f(b + l)f(a - b + l)"
(3.77)
Así mismo, el cuadrado de la función ganancia del filtro wavelet se expresa de la forma
(3.78)
cuya función de transferencia expresada en notación polar es
H(J) =I H(J) 1 eiO(f) = [1t(J)]l/2eiO(f), (3.79)
por lo que la tarea será encontrar el número de mices de I H (J) 1 a través de un proceso
llamado factorización espectral. 24 Conforme al proceso de factorización espectral, es posible
clasificar a los filtros de Daubechies en dos tipos: filtros de mínima fase D(L), aquellos cuyas
raíces de I H(J) 1 caen dentro del círculo unitario; y, los filtros de mínima asimetría LA(L),
aquellos cuya fase es lineal en la medida posible.
La figura 3.6 muestra la comparación entre un filtro D( 4) y D(8), donde 4 y 8 representan
24 La factorización espectral es un método para recuperar la función de transferencia a través del cual se construyen filtros de mínima fase. Entre los diferentes métodos de factorización espectral se encuentra el de Kolmogoroff el cual trabaja únicamente en el dominio de frecuencia, y su alternativa ha sido el método de Wilson-I3urg el cual trabaja en el dominio del tiempo basado en el método de Newton (Fome!, Sava, Rirkctt y Claerbout (2003)).
63

la longitud del filtro equivalente a 2 y 4 momentos de desvanecimiento, respectivamente.
El caso particular cuando la longitud del filtro es 2, equivalente a 1 momento de desvane
cimiento, se tiene la función de Haar (Daubechies ( 1988)).
Función Wavelel psi Función Wavelel psi
1.5 1.5
0.5 0.5
o o -0.5
-0.5
-1 -1
o 0.5 1.5 2 2.5 3 o 2 3 4 5 6 7
(a) D(4) (b) LA(8)
Figura 3.6: Funciones de Daubechies de mínima f a.~e de longit,ud 4 y 8.
Daubcchies (1988) mostró, que cuando los parámetros a dilatación y b traslación de una
función wavelet se representan de la forma 2J y k2J, respectivamente, es posible construir
funciones base ortonormales de wavelets con soporte compacto. Por consiguiente, la integral
en (3.49) se vuelve
(3.80)
la cual se aproxima de la forma
(3.81) n
donde el periodo de muestreo h = l. Por lo tanto, dados a y b discretizados, y una función
J(t) en L2(JR) la cual puede representarse a través de la secuencia de funciones wavelet
(madre) y de escalamiento (padre), 1/; y </;, respectivamente, se tiene
(3.82)
·;2 . ·;2 (t -2J k) </J1,k(t) = r 1 q;(2-1t - k) = 2-1 </;
21 . (3.83)
64

Entonces la función f ( t) se representará de la forma
J(t) = L SJ,k</>J,k(t) + L d1,k<P1,k(t) + L d1-1, k'l/J1-1,k(t) k k k
+ · · · + L d1,k'l/JI,k(t), k
(3.84)
donde los coeficientes .SJ,k y d1,k, . .. , d1,k son los coeficientes de la transformada wavelet con
tenidos en W, los cuales miden la contribución de la función wavelet en la señal original. Los
coeficientes SJ,k son los coeficientes de suavización los cuales representan el comportamiento
suave implícito en la señal a escalas gruesas ( no refinadas) 21 ; d1,k son los coeficientes de
detalle también conocidos corno cristales los cuales representan las desviaciones del com
portamiento suave, donde d1,k describe las desviaciones en la escala gruesa y d1 _ 1,k, ... , d1,k
son las desviaciones a escalas finas.
En conclusión, la función f ( t) podrá representarse en términos de su serie de detalles
en diferentes resoluciones
Dj(t) = L dj,k'l/JJ,k(t) para j=l,2, ... ,J.
y variaciones suaves
dando corno resultado
k
S1(t) = L SJ,k<PJ,k(t), k
y lo anterior es descrito igualmente corno análisis por multiresolución.
3.2.4. Transformada Wavelet Discreta de Máximo Traslape
(3.85)
(3.86)
(3.87)
La transformada wavelet discreta de máximo traslape (TWDMT) es una versión mo
dificada no-diezmada de la transformada wavelet discreta la cual trabaja sobre cualquier
tamaño de muestra N sin limitarse a una longitud diádica de observaciones como lo es
la TWD. Lo anterior hace que la TWDMT no sea sensible al punto inicial de la serie
de tiempo y ello se logra eliminando el método del submuestreo al aplicar doblemente el
algoritmo piramidal de la TWD tomando aquellos resultados descartados del filtro TWD
vía filtración circularmente desplazada.
Los nuevos vectores columna, W 1, W 2 , W.1, contendrán los coeficientes wavclct resultado
65

de la TWDMT asociados a cambios en cada escala Aj= 21- 1, y V J contendrá los coeficientes
de escalamiento de la TWDMT asociados a los cambios en la escala AJ = 2J y mayores:
(3.88)
Similar al ejemplo de la TWD en la ecuación (3.73), la matriz W se construye con J + 1
matrices cada una de dimensión N x N de la forma
(3.89)
en particular para la matriz W1 con una longitud L = 4 y N > 4 se tiene
h1,o o o o o o ... o o o o h1,3 h1,2 h1,1
h1,1 h1,o O o o o ... o o o o o h1,3 h1,2
h1,2 h1,1 h1,o o o o ... o o o o o o h1,3
h1,3 h1,2 h1,1 h1,o o o ... o o o o o o o o h1,3 h1,2 h1,1 h1,o o ... o o o o o o o
W1 = o o h1,3 h1,2 h1,1 h1,o ··· O o o o o o o (3.90)
... o o o o o o ··· O h1,3 h1,2 h1,1 h1,o o o o o o o o o ... o o h1,3 h1,2 h1,1 h1,o O o o o o o o ... o o o h1,3 h1,2 h1,1 h1,o
donde W1 es una matriz de dimensión NxN. Los vectores wavelet h 1 y de escalamiento
g1 son los filtros y funciones de escalamiento rcescalados y circularmente desplazados por la
cantidad m - 1 para m = 1, ... , N, de la forma h.1 = h1/2112, j = 1, ... , J, y gJ = gJ/2Jf2
,
respectivamente, donde:
(3.91)
es un vector columna que contiene los elementos del filtro wavelet h1,n, y
gJ = [9J,O, 9J,N-l, 9J,N-2, · · ·, 9J,2, 9J,lir, (3.92)
es un vector columna que contiene los elementos del filtro de escalamiento 9J,n-
Por lo tanto, así como en (3.87) es posible llevar a cabo el análisis por multiresolución
de J(t), J
J(t) = ¿Í\ +81, (3.93) j=l
66

donde Di son las series de detalles y 81 son las variaciones suaves. En un sentido estricto,
Di es una representación matricial dada por
(3.94)
la cual contiene los coeficientes de detalle de máximo traslape de orden j. Por igual, la
representación matricial de Si es
- -T k-* S1 = V 1 T g1 , k =O, ... , N - 1; (3.95)
la cual contiene las variaciones suaves de máximo traslape de orden J, donde
(3.96)
y
(3.97)
En resumen, (3.94) se obtiene filtrando X a través de hi para obtener W y nueva-- -
mente W se filtra circularmente utilizando h;; donde el mismo resultado es posible obtener
utilizando un solo filtro cuya transformada de Fourier discreta (TFD) se define por
(3.98)
y (3.95) se obtiene de la misma forma aplicando el filtro
(3.99)
El resultado anterior se define como la propiedad de fase-cero, la cual permite alinear los
eventos a detalle y de suavización con aquellos ocurridos en la serie de tiempo original.
Finalmente, las diferencias entre la TWD y la TWDMT se enumeran a continuación:
l. La TWDMT de orden J-ésimo se define adecuadamente para una muestra de tamaño
N, mientras que la TWD se restringe a una muestra de tamaño diádica 21 .
2. Los coeficientes de detalle y suavización vía TWDMT se asocian a filtros de fase-cero,
lo cual significa que es posible alinear eventos de la serie de tiempo original con las
características del análisis por multiresolución.
3. La TWD~lT es invariante en desfasamiento, lo cual significa que desfasando circular-
67

mente la serie de tiempo en cualquier monto, se desafasará circularmente en el mismo
monto la TWDMT.
4. La TWDMT desarrolla un análisis de la varianza con estimadores asintóticamente
más eficientes que la TWD.
3.3. Varianza Wavelet
El desarrollo de la presente subsección se basa en Serroukh, Walden y Percival (2000),
y algunas demostraciones se remiten a Percival y Walden (2000). La varianza wavelet se
sustenta en la propiedad de conservación de energía de wavelets, en donde la ortonormalidad
de la matriz W, esto es, W = WX se pueda reconstruir X= wrw, implica que la TWD
sea una transformada que preserva la energía tal que 11 W 11 2=11 X IJ 2. Lo cual se demuestra
de la siguiente forma
(3.100)
Lo anterior hace que la energía en X pueda descomponerse de escala en escala de la forma
J
11 x 112
= 11 w 112
= ¿ 11 wj 112 + 11 vj 11
2, (3.101)
j=l
donde JI Wj JJ 2 representa la contribución a la energía de X debido a los cambios en la
escala Aj y JI Vj JJ 2 representa la contribución debido a las variaciones en las escalas A.J+I y
mayores.
En consecuencia, la varianza del proceso puede descomponerse de escala en escala
N-I
-2 1 ~ -)2 1 1 ¡ 2 2 <7x = N L..,.(X1 - X = NI W 1 - X t=O
J 1~ 2 1 2 2
= N L..,.11 Wj 11 + N JJ V J JI - X ,
(3.102)
j=l
donde aJ es la varianza muestra! de X y X= (1/N) ¿X1 es la media muestra!. De esta
forma, se puede definir la varianza wavelet independiente del tiempo como la varianza de
los coeficientes wavelet en la escala Aj
(3.103)
68

y mostrar que la varianza wavelet es la descomposición de escala en escala de la varianza
deXt 00
Var{Xt} = ¿11}(.Xj), j=l
y el estimador insesgado de la varianza wavelet se representa como
Ni-1 ~2 (, ) _ 1 ~ 2 llx l\j = 2.X .f¡. L.,¡ wj,t:
J J l=L'. J
donde Ní = N/2í, Ñí = Ní - L: y L: = f(L- 2)(1- 2-íl-25
(3.104)
(3.105)
Adicionalmente y dado que W es una matriz ortonormal, la varianza wavelet vía la TWD
se puede representar de la forma
(3.106)
donde 11 Dí 112
/ N se interpreta como la varianza muestra! de los N elementos en Dí y
(1/N)II S1 112 - X2 es la varianza muestra! de los N elementos contenidos en S1 .
Así mismo, y con base a las propiedades de la descomposición de energía y descom
posición aditiva de la TWD, es posible obtener la varianza wavelet vía TWDMT, cuya
representación es J
11 x 112= I: 11 wj 11
2 + 11 vJ 112
. (3.107) j=l
Sin embargo, dado que W es no-ortogonal, la igualdad entre 11 Wí 112 y 11 i\ 11
2 no se cumple,
teniendo la pérdida de la propiedad de fase-cero. Este problema fue resuelto por Daubechies
al filtrar los datos a través de funciones de mínima asimetría (LA), los cuales brindan
aproximaciones a filtros de fase-cero siempre que 11 Wí 112 y 11 V J 11
2 sean apropiadamente
desfasados circularmente.
Por lo anterior, la varianza wavelet vía TWDMT en cada escala Aj se define como
donde Li-1
wj.t = L hj,1Xi-1,
1=0
25Donde íl representa el mínimo de dos cantidades.
69
(3.108)
l E Z, (3.109)

es la señal filtrada a través de los filtros wavelet hi,l de longitud l = O, ... , LJ para niveles
j = 1, ... , J. En si, Wj,t representa un proceso estocástico filtrado utilizando la TWDMT.
El resultado anterior es posible bajo el supuesto de que la varianza wavelet en cada escala
>..i es invariante en el tiempo. Por lo anterior, si la varianza wavelet existe y es finita, su
representación cuando es dependiente del tiempo es de la forma
(3.110)
A partir de la varianza wavelet invariante al tiempo, son posibles tres resultados según el
tipo de estacionariedad de la serie de tiempo:
l. Varianza wavelet para un proceso estacionario Xt, cuyos coeficientes wavelet Wj,t son
también estacionarios;
2. Varianza wavelet para un proceso no-estacionario Xt que en diferencias de orden-d
es estacionario, entonces también los coeficientes wavelet Wj,t para t = O, ... , N - l
serán estacionarios;
3. Varianza wavelet para procesos estacionarios cuyo proceso en diferencias es esta
cionario localmente, y sera posible estimar la varianza wavelet para tiempos específicos.
De tal forma y análogamente a la descomposición de la varianza en (3.104), la varianza de
un proceso estocástico estacionario es de la forma
1/2 J
var(Xt) = r Sx(w)dw = L Vk(>..j) + var(Vi,t), 1-1/2 j=l
(3.111)
donde
1-
1/2 1-1/2 = Swi(w)dw = Hi(w)Sx(w)dw.
-1/2 -1/2
(3.112)
Lo anterior es posible ya que al ser Xi un proceso estacionario, en consecuencia su descom
posición Wj,t para j = 1, ... , J es un proceso estacionario con media O, autocovarianza .swj.k
para k E Z, y función de densidad espectral
(3.113)
donde
(3.114)
70

y L3-l
Hj(w) = L hj,le-i21rwz, (3.115) 1=0
es la función de transferencia del filtro wavelet. Adicionalmente, si la media µx del proceso
es desconocida, entonces el valor esperado del proceso W j,t es
L3-l L3-l
E(Wj,t) = L hj,1E(Xt-1) = µX L hj,I = o, (3.116) 1=0 1=0
donde se ha aplicado la propiedad Lt~~1 hj,I = O. De esta forma es posible obtener una
estimación insesgada de la varianza wavelet 11}(.Xj) de la varianza del proceso Wj,t·
(3.117)
donde Mj(N) = N - Lj - 1 y Wj,t = W1,1 si el módulo de N no es necesario.
3.3.1. Intervalos de Confianza
El intervalo de confianza para la varianza wavelet vía TWDMT bajo una aproximación
Normal y un porcentaje plOO %, se define como
[ (2A·) 1/2 (2A·) 1
/
2
] vi(.xj) - <I>-1(1 - p) M; , vi(.xj) + <I>-1(1 - p) 1vl (3.118)
donde un estimador insesgado aproximado de Aj para un tamaño grande de Mj está dado
por
Aj=! r112
[s;P)(w)] 2
dw (3.119) 2 J -1/2
y 2 N-l
5(P) = ~ '""' MI- e-i21rwt J - M- L J,t '
1 t=L3-1
(3.120)
para un tamaño grande de N, O <I w I< 1/2 y con igualdad en distribución de una chi
cuadrada se tiene
(3.121)
71

Por lo anterior, y aplicando el teorema de Parceval
1/2 M-j-1 ¡ [~ ]2 ~ (~(P))2 Sj(P)(w) dw = L.,¡ sj,r ,
-1/2 ( ) >-=- Mj-1
(3.122)
donde s;~) se define corno el estimador sesgado de la estructura de la autocovarianza de
W i,t de la forma
(3.123)
y s;~) = O cuando 1-XI > Mi, se obtiene el estimador de Ai
(3.124) >-=1
Sin embargo, la desventaja del anterior método para estimar los intervalos podría generar
un límite inferior negativo, cuando se esperaría un valor no negativo de vl(>.i). Este pro
blema se resuelve con la aproximación conforme a Percival y Walden (2000), al establecer
que la distribución de la suma de cuadrados de variables aleatorias normal correlacionadas
con media cero y de varianza común, puede aproximarse a través de una distribución chi
cuadrada con r¡ grados de libertad y de esta forma poder capturar la correlación entre las
variables aleatorias. Dicha aproximación se da la forma
(3.125)
donde r¡ se define como los grados de libertad equivalentes (EDOF, por sus siglas en inglés).
Por lo anterior, el intervalo de confianza aproximado 100(1- 2p) % para la varianza wavelet
se define por
(3.126)
donde Q..,(p) es el plO0 % de la distribución chi-cuadrada y los grados de libertad equivalentes
se pueden estimar de las siguientes tres formas:
(3.127)
72

_ 2(¿~,!1¡-l)/2lcj(wk)r
1/2 = "[(Mj-1)/2) C-2( ) ' L..,k=I J Wk
(3.128)
donde Cj es una función conocida que satisface Sj(w) = aCj(w) y wk = k/Mi. Finalmente,
(3.129)
Conforme a los resultados por Percival, sugiere aplicar i¡1 cuando el tamaño de muestra Mj
es grande (Mi = 128), r,2 para una muestra pequeña pero cuando se conoce la forma de
Si ( ·), y r¡3 como caso alternativo de T/2.
73

Capítulo 4
Metodología
La presente sección describe el tratamiento de las variables financieras utilizadas en la
investigación, descripción de los pruebas estadísticas realizadas a nivel espectral (global) y a
detalle, y la metodología de estimación del riesgo de mercado aplicando wavelets en el marco
de Valor en Riesgo así como la descripción del backtesting. El análisis por multiresolución y
estimación de la varianza wavelet se realizaron utilizando el software S-Plus versión 8.0. La
cstimacion del modelo benchmark GARCH se realizó a través de Eviews versión 6.0.
4.1. Preparación de los datos
1. Los datos corresponden a precios diarios del Índice de Precios y Cotizaciones (IPC) y
emisoras pertenecientes al IPC.
2. El primer estudio comprende del 7 de febrero de 2001 al 31 de diciembre de 2009, el cual
implica dos subperiodos: el primero para estimar el VaR y el segundo un horizonte de
250 días para el backtesting. Las series de tiempo en cuestión no presentan el mismo
número de observaciones, ya que aun en días hábiles o de trading, las emisoras no
cotizaron en todos esos días. Aquellos días de trading en que no cotizó la emisora
fueron eliminados; en términos de precio reflejó el mismo valor del día anterior y en
términos de rendimiento un valor de cero.
3. El seguno estudio comprende el periodo del 15 de abril del 2004 al 30 de abril del 2009,
igualmente con dos subperiodos como el inciso anterior. Este segundo estudio para
estimar el VaR se justifica en actualizar las estimaciones utilizando datos históricos
con base a una referencia de carácter oficial como lo es el Anexo-G de la Circular
CONSAR 15-22 del 28 de octubre de 2008, la cual estipula 1,000 observaciones de
historia al día en que se estime el VaR.
74

4. Los precios históricos se obtuvieron de Reuters y corresponden a valores de cierre sin
ajuste por pago de dividendos.
5. Los precios diarios se transformaron a rendimientos diarios de la forma
4.2.
Pt Rett = --¡:;- ,
•t-1 ( 4.1)
donde Pt representa el precio actual de la emisora y Pt-I el precio en un día anterior
de la respectiva emisora.
Estadísticos Descriptivos y Descomposición de las
Series de Tiempo
l. Se calculan cuatro momentos de los rendimientos de los precios a nivel global: media,
varianza, sesgo y kurtosis.
2. Se realiza la descomposición por multiresolución utilizando la TWD y TWDMT a
través de las funciones de Haar y mínima asimetría de Daubechies 1(8).
4.3. La Varianza Wavelet
l. A partir de las series de rendimientos descompuestas en escalas de tiempo del IPC y de
las emisoras, se estima la varianza wavelet insesgada a través de la TWDMT y sesgada
a través de la TWD, utilizando igualmente como wavelet la función de Daubechies
1(8).
2. La varianza wavelet estimada en cada escala se compara y presentan los resultados en
el apéndice B.
4.4. Estimación del Riesgo de Mercado
1. La estimación cfal riesgo de mercado se realiza en el marco de Valor en Riesgo VaR,
lfD11{-VaR{_0
::;: X} = 1 - a. (4.2)
75

2. A partir de la varianza wavelet estimada en cada escala de tiempo para cada serie de
rendimientos descompuesta, se estima el VaR en la respectiva escala de la forma
(4.3)
donde Vo es el valor inicial del portafolio, Z0 = <1>- 1(1-o:) es la probabilidad acumulada
inversa de una distribución normal estándar, y vri es la desviación estándar en cada
escala )..í·
3. El VaR total (aditivo) se calcula de la forma
J
VaR= ~VaR>.i L.., Q' (4.4)
j=l
donde la aditividad del VaR es posible debido a la propiedad de decorrelación del
análisis por wavelets. 1
4. El backtesting se realiza sobre una ventana de 250 días de la siguiente forma:
• Primeramente, el horizonte de tiempo se divide en dos subperiodos: el primer
periodo sirve como el punto de partida para estimar el VaR donde el número de
observaciones difiere para cada serie de rendimientos de precios de las emisoras
debido a que no todas cotizaron los mismos días de negociación, y el segundo
periodo comprende 250 días de negociación definido como el periodo de backtest
mg;
• La contabilización de los 250 días de backtesting se hace a partir de la fecha final
hacia atrás, por lo que la estimación de V aRt=O no coincide en la misma fecha
para todas las emisoras en cuestión debido a lo descrito en el punto anterior;
• El V aRt=O funje como el pronóstico de la pérdida esperada en t = l, V aRt=I
corresponde al pronóstico de la pérdida esperada en t = 2, y así sucesivamente
hasta V aRi=24g es el pronóstico de la pérdida esperada en t = 250;
• Lo anterior implica estimar 250 veces el VaR;
• Finalmente el VaRt-I se compara con la pérdida/ganancia (Ret) realizada en t,
y aquellas fechas donde Rett fue mayor a VaRt-I, entonces se considera como un
exceso o falla. Las pruebas estadísticas se aplican sobre las fallas obtenidas en el
periodo de backtesting.
1 La demostración de la decorrelación de los coeficientes wavelrt se remite a: Pe ter F. Craigmile y Donald B. Percival, J EEE Transactions on lnformation Theory, 2005.
76

5. El método de backtesting aplicado corresponde a la prueba de Proporción de Fallas
(PdF) de Kupiec (1995) junto con el apoyo de intervalos de confianza. El método
en cuestión parte del supuesto en que los excesos o fallas se distribuyen como una
binomial de la forma
(4.5)
donde x representa el número de excesos o fallas, p es la probabilidad de una falla
dado un nivel de confianza y n es el número de pruebas.
• Prueba de Proporción de Fallas (PdF) de Kupiec. Esta prueba estadística mide
la consistencia del nivel de significancia propuesta en el VaR con la proporción
de excesos o fallas del modelo, esto es, examina el número de veces en que el VaR
se viola en un periodo de tiempo. Por lo que la hipótesis nula por evaluar consiste
en comparar el nivel de significancia o: previamente establecido con el número
de violaciones en el periodo de tiempo definido de backtesting. Si el número de
fallas (violaciones) difiere considerablemente del ax 100 %, entonces la precisión
del modelo de riesgo se cuestionaría. Partiendo de que el número de fallas x
sigue una distribución binomial ( 4.5) y dada una muestra de n observaciones, la
prueba de Kupiec (1995) estima la probabilidad de la falla a través del método
de máxima verosimilitud, por lo que al tomar logaritmos de ( 4.5) se tiene
Ln(P) = Ln(:) + xLn(p) + (n - x)Ln(l - p). (4.6)
Al maximizar la anterior expresión se obtiene la condición de primer orden
8Ln(P) 1 1 o(p) = x- - (n - .r)- = O,
p 1-p (4.7)
de la cual se obtiene la probabilidad estimada p = x/n de las fallas en el VaR
y es comparada con la probabilidad teórica p aplicando la prueba de razón de
verosimilitud
(4.8)
donde el numerador corresponde al valor de la función de verosimilitud bajo
la hipótesis nula p y el denominador a la función de verosimilitud valuada en
el estimador no restringido de máxima verosimilitud x/n, y la distribución de la
proporción de fallas se distribuye corno una x-cuadrada con un grado de libertad.
El valor obtenido de la razón PdF se compara con el valor crítico de la x-cuadrada
77

al nivel de significancia a previamente establecido y con un grado de libertad. Si
el valor de la razón PdF es menor al valor crítico, entonces se argumenta que el
modelo de riesgo propuesto es adecuado para pronosticar las pérdidas.
• Intervalos de Confianza (Aproximación Normal). El motivo de construir un in
tervalo de confianza es para identificar si en el intervalo estimado contiene o no
contiene al parámetro de referencia, en este caso, que el intervalo contenga la
proporción de fallas equivalente a p = a bajo la hipótesis nula. La aproximación
normal para un intervalo de confianza binomial se representa de la forma
~ vp(l - p) P = ±zi-o/2 n , (4.9)
donde p representa la proporción de interés o también el estimador de máxima
verosimilitud no restringido de p, esto es, p = x/n; n es el tamaño de la muestra,
en este caso 250; a es el nivel de confianza deseado, y z1_ 012 es el valor z para
el nivel de confianza deseado, cuyos casos particulares de 95 % y 99 %, el valor z
corresponde a 1.9599 y 2.5758, respectivamente.
• Intervalo de Confianza de Clopper-Pearson (Distribución beta). Este intervalo
de confianza propuesto por Clopper y Pearson (1934) representa una alternativa
cuando np > 5 ó n(l - p) > 5, en donde se utiliza la distribución beta para
calcular la función de distribución acumulada de una binomial. El intervalo de
confianza se construye con los siguientes límites inferior y superior
(1-o: ) pis = 1 - B-1 -
2-, x + 1, n - x , (4.10)
( 1- a ) PLI = 1 - B- 1 1 - -
2-, x, n - x + 1 , (4.11)
donde Pis y PLI representan los límites superior e inferior del intervalo de con
fianza, respectivamente, y B-1 se refiere a la función beta-inversa.
6. La metodología del VaR propuesto a través de wavelets se compara con Riskmetrics
y el modelo de volatilidad condicionada GARCH (1,1):
• Riskmetrics. La modelación de la varianza se basa en el enfoque de Promedio
Móvil Ponderado Exponencialmente (PMPE), 2 en donde el pronóstico de la va
rianza en t + 1 es un promedio ponderado de la varianza actual con un ponderador
2 EWMA: Exponrntially Wcighted Moving Average, por sus siglas en inglés.
78

.X y el rendimiento actual al cuadrado con un ponderador (1 - .X):
o-?+i = .Xo-¡ + (1 - .X)r;, (4.12)
donde .X se conoce corno el factor de decaimiento y es menor que uno.
• GARCH(l,1). Modelo de volatilidad condicionada el cual relaja el supuesto de
volatilidad constante e introduce cambios en la volatilidad donde la varianza
del proceso se considera heteroscedástica. El modelo GARCH representa una
ecuación de la media del proceso y una ecuación de la varianza de la forma:
Rt =µ+Et, (4.13)
donde se asume que Et es una variable aleatoria normal con varianza condicional
ht de la forma q p
ht = ªº + í: O'.if.;_i + I: /3iht-i, ( 4.14) i=l i=l
con las condiciones p~O, q > O, o:0 > O, o:i > O, y /3i > O. El caso particular
GARCH(l,1) se especifica de la forma:
Rt =µ+Et, (4.15)
( 4.16)
La varianza no-condicionada del proceso se estima de la forma:
( 4.17)
Para ambos casos, el VaR se estará estimando de la forma
(4.18)
donde T corresponde al número de días en el horizonte de tiempo.
79

Capítulo 5
Análisis y Resultados
5.1. Análisis Exploratorio de Datos
El cuadro 5.1 muestra los estadísticos descriptivos de los rendimientos del IPyC y de los
precios de las emisoras, para lo cual se han considerado los cuatro momentos de referencia
y la prueba de normalidad parámetrica Jarque-Bera. Se observa en el cuadro que una pro
porción sustancial de emisoras arrojan un sesgo negativo, lo cual indica que en la ventana
histórica de cada emisora se han presentado más rendimientos negativos que positivos. Res
pecto al estadístico de kurtosis, todas las emisoras y el IPyC muestran un valor mayor que
tres indicando que la distribución de probabilidad es del tipo leptokúrtica, esto es, mayor
masa en las colas y en la parte central.
La prueba de Jarque-Bera indica que no se puede aceptar la hipótesis nula en que la
distribución de los rendimientos es normal. Junto con el valor de kurtosis se establece que la
distribución de los rendimientos es leptokúrtica como anteriormente mencionado, aunque los
valores del estadístico no difieren sustancialmente. Algunas excepciones se presentan como
los casos de Ara, Inbursa, Kimber y Peñoles.
Como ejemplo particular, la figura 5.1 muestra la serie histórica de los rendimientos del
IPyC y los rendimientos al cuadrado como proxy de la volatilidad histórica. En el gráfico de
la izquierda se aprecia el hecho identificado como agrupamiento de la volatilidad; en tanto
que en el gráfico de la derecha se observan picos muy altos asociados a los grandes cambios
que han mostrado históricamente los precios del IPC.
La descomposición de los rendimientos del IPyC vía TWDMT y utilizando como filtro la
función de Daubechies, se muestra en la figura 5.2. 1 El análisis por multiresolución se realiza
en seis niveles de resolución, donde cada nivel también llamado detalle o cristal, representa
1 El Apéndice A muestra la descomposición por multiresolución de todas emisoras.
80

Cuadro 5.1: Estadísticos Descriptivos del JPyC y Emisoras.
Emisora Muestra Media Desv. Sesgo Kurtosis Jarque-Est. Bera
IPyC 1739 0.000871 0.012363 -0.203935 5.410978 433.2409 ALFA 1715 0.001062 0.021807 -0.294617 6.599651 950.7307 AMXL 1714 0.001331 0.020323 0.000369 5.062584 303.8245 ARA 1663 0.000838 0.020154 -0.580092 10.20867 3694.002
BIMBO 1667 0.000976 0.018672 0.329450 6.735326 999.2836 CEMEX 1724 0.000666 0.017149 0.183418 4.535515 179.0357
COMERCI 1627 0.000811 0.020821 0.207456 5.478538 428.1248 ELEKTRA 1680 0.001111 0.022609 -0.141410 6.888541 1064.052
FEMSA 1718 0.000859 0.016953 -0.091636 5.286534 376.6589 GFBANORTE 1703 0.001450 0.020650 0.184959 5.965567 633.7593
GCARSO 1695 0.000943 0.018557 -0.045831 5.480572 435.1657 GEO 1667 0.001601 0.022853 0.110515 5.860899 571.8918
GFINBURSA 1659 0.000505 0.020366 -1.109346 19.13588 18338.12 GMEXICO 1684 0.001138 0.025799 -0.054791 4.854985 242.2838 GMODELO 1703 0.000419 0.015814 0.114336 5.205402 348.8375
KIMBER 1670 0.000381 0.015164 -0.380854 7.771283 1624.446 PEÑOLES 1600 0.002157 0.029126 -0.190690 7.638209 1443.895 SORIANA 1680 0.000707 0.018399 -0.018222 4.724815 208.3419 TELECOM 1709 0.000766 0.018801 -0.031407 4.137461 92.41153 TELEVISA 1715 0.000427 0.019759 -0.301650 6.781925 1048.074 TELMEX 1682 0.000588 0.014960 0.035394 3.878371 54.42302 WALMEX 1721 0.000705 0.017941 0.094738 5.444831 431.1895
la escala asociada a los componentes de frecuencia de la señal original. La primera serie
identificada como sum representa la serie de tiempo original de los rendimientos del IPyC.
La siguiente serie D 1 representa la serie de los componentes de frecuencias en la escala de
tiempo 21- 1 = 2° = 1 días, esto es, las frecuencias más altas de los rendimientos del IPyC
se presentan en escala de tiempo de un día.
El detalle D2 equivalente a una escala de 2 días, representa frecuencias más bajas res-
pecto de un día y que se presentan en una escala de tiempo de dos días. Así sucesivamente
hasta llegar al detalle D6, en donde las frecuencias más bajas de los rendimientos se están
presentando en intervalos de tiempo de 32 días. El último gráfico identificado corno S6,
equivale al ciclo de la serie original y captura las fluctuaciones por arriba de 32 días; a este
nivel también se le conoce como el componente de suavización.
81

.Oo,-------------~
.o
-.o
250 500 750 1000 ]250 1500 250 500 750 1000 1250 1500
(a) (b)
Figura 5.1: (a) Rendimientos del IPyC y {b} Rendimientos al Cuadrado del IPyC.
sum
D1
D2 '""'1,.,¡..,.,. ....... ~.,,.' . ., ,... • ",.¡,. .. ,. D3
D4
D5
D6
S6
O 500 1000 1500
Figura 5.2: Descomposición por Multiresolución del IPyC vía TWDMT.
82

5.2. Análisis de la Varianza Wavelet
Así como es posible la descomposición por multiresolución (DMR) de los rendimientos de
la variable financiera en diferentes escalas utilizando alguna transformada y función wavelet
en particular, es posible descomponer la varianza del proceso en diferentes escalas )..j para
j = 1, ... , J donde j representa el nivel de descomposición. Por lo que a través de la DMR
es posible identificar la microestructura de la variabilidad del proceso. La descomposición
de la varianza se le conoce como varianza wavelet y ello se logra debido a la propiedad de
conservación de energía que satisface el análisis por wavelets.
La figura 5.3 muestra el ejemplo particular de la evolución de la varianza wavelet
estimada a través de la TWD en siete escalas para el periodo de backtesting correspondiente
a 250 días de negociación del 3 de enero al 31 de diciembre de 2008, donde Dj representa la
evolución de la varianza en el detalle o cristal respecto al nivel j, por ejemplo: Dl representa
la varianza wavelet en la escala )..1 = 21- 1 = 1 días. En consecuencia D2 representa la
evolución de la varianza wavelet en la escala de dos días y así sucesivamente. La figura 5.4
igualmente muestra la evolución de la varianza wavelet pero descompuesta a través de la
TWDMT. 2
, ..... ~
OIOllC
0041Hl
H 110 no HI ne
"""[7ill '""' I\ """ - I \) '"º" ~
!C :10 ;,o acc 210
·'""Q . HHl"
. ffttl
·'"" ..w,¡JJ,W,l¡J,J,i,illJ
·ºº"ª '~ . OOIIII ~ IU lit lff nt
Figura 5.3: Evolución de la Varianza Wavelet del /PyC vía TWD: 03/0J/2008-31/12/2008
En ambos casos, varianza wavelet vía TWD y TWDMT, los valores estimados en cada
escala son cercanos entre sí y la suma cercana a la varianza de la señal original. Sin embargo,
la diferencia del comportamiento radica en el proceso de filtración ya que la TWD genera
los coeficientes wavelet y de escalamiento a través de un algoritmo piramidal, en <lon<le los
2Véase Apéndice B referente a la evolución de la varianza wavelet de cada una de las emisoras.
83

PCDl PCD2
.000090 .00005
.000085 .00005
.000010
·ºººº" .000015
·ºººº" .000070
.000065 ·ºººº" so 100 lSO 200 "' 50 100 150 200 250
PCD3 PCD4
.00003 .000010
.00003
.000009
.00002
.00002 .000009
.00002
.000008
.00002
.00002 .000008 so 100 lSO 200 "º 50 100 150 200 250
PCDS PCD6
.000005 1.9011·0
.000005 1.858·0
.000005
l.8011·0
.00000-t
1.1511-0 .00000-t
.00000-t 1.708-0 so 100 1'0 200 2SO 50 100 ¡50 200 250
Figura 5.4: Evolución de la Varianza Wavelet del /PyC vía TWDMT:03/01/2008-31/12/2008
coeficientes wavelet se interpretan como la diferencia entre dos promedios ponderados, el
cual hace que en cada nivel se elimine un décimo de los coeficientes (diezmar).
Conforme a Percival y Walden (2000), los intervalos sobre los cuales se construyen los
coeficientes wavelets se fijan rígidamente a priori, lo cual no permite su alineación con las
características de la serie de tiempo original. Por lo que un cambio en el punto inicial en
la serie de tiempo arrojará resultados diferentes debido a la yuxtaposición de la serie de
tiempo con los intervalos promediados predefinidos por la TWD.3
La figura 5.5 muestra la evolución de la varianza wavelet en diferentes escalas, estimada
a través de la DWT para el mismo horizonte de tiempo del backtesting pero en el periodo del
5 de mayo del 2008 al 30 de abril del 2009, donde ahora se ha utilizado un vector de datos x
de tamaño diádico divisble entre 26 .4 Los gráficos muestran un patrón de comportamiento
similar al de la figura 5.3, recordando que la diferencia en el proceso de descomposición
3Percival y Walden, Wavelet Methods for Time Series Analysis, p. 179. 4El número de observaciones utilizadas fueron 1,024, número cercano a las observaciones históricas que
se requieren para estimar el VaR según CONSAR.
84

entre la TWD y la TWDMT radica en la aplicación del algoritmo piramidal: la TWD utiliza
en cada nivel de filtración la mitad de los coeficientes wavelet estimados y los remanentes
son nuevamente filtrados a través de la función de escalamiento g para obtener nuevos
coeficientes wavelet y de escalamiento. Por el contrario, a través de la TWDT la filtración se
realiza directamente sobre los coeficientes de escalamiento sin el submuestreo de coeficientes.
Por lo tanto, la TWDMT hace que en cada vector de observaciones N existan coeficientes
wavelet redundantes y que la matriz W sea no-ortonormal y en consecuencia no se cumpla
11 cii 112
=11 wi 112
-
PCDl lPCD2
.0001 0001
.0001 0000
.0001 0000
.0001 0000
.0001 .0000
.0000 . 0000
.0000 0000
·ºººº .000 0 so )00 150 200 "º so 100 150 200 ,so
lPCD3 lPCD4
. 0000 .00002
.00001
0000 .0000¡
.00001
0000 .00001
.0000 .00001
,00000
.0000 ·ººººº so 100 150 200 ,so so 100 lSO ,oo ,so
JPCDS lPCD6
.00000 .000004
~~~M~\~~ .00000.f.Q
~~ 1 /1~ .00000&
.ooooon .00000·
.00000)
·ººººº' .000002
1~VVNV .000002
.ooooos .00000!!
.00000 .00000¡
so :.oo ~!iO ,oo m so 100 lSO ,oo ,so
Figura 5.5: Evolución de la Varianza Wavelet del JPyC vía TWD: 05/05/2008-30/04/2009.
Dado lo anterior y conforme a Percival y Walden (2000), el análisis de la varianza a
través de la TWDMT se limita a utilizar los coeficientes y no los detalles o cristales. Cabe
recordar, que el algoritmo piramidal de la TWDMT inicia con la filtración de la señal original
a través de funciones wavelet y de escalamiento reescalados y la filtración de la misma
pero circularmente desplazada. Por lo que la TWDMT induce a la correlación entre los
coeficientes int.ra-es,ala y entre-escalas, fenómeno que al menos entre-escala no es inducido
por la TWD y es explotado para estimar el riesgo de mercado.
85
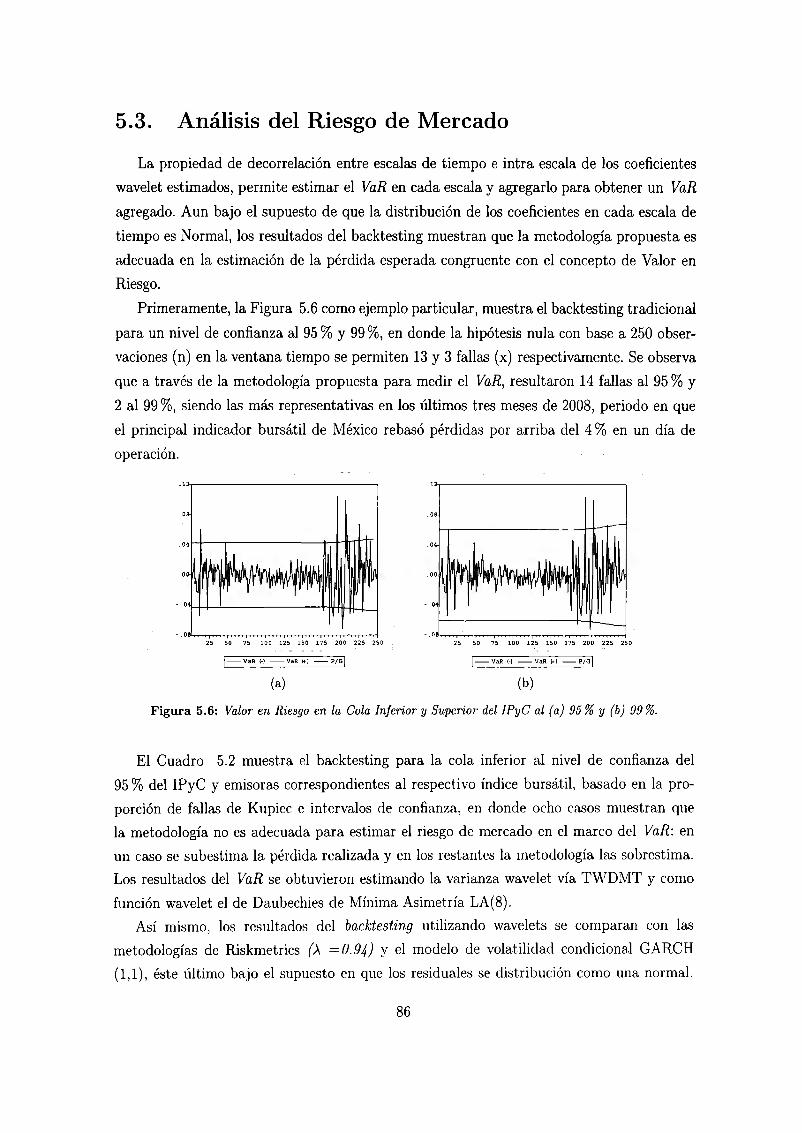
5.3. Análisis del Riesgo de Mercado
La propiedad de decorrelación entre escalas de tiempo e intra escala de los coeficientes
wavelet estimados, permite estimar el VaR en cada escala y agregarlo para obtener un VaR
agregado. Aun bajo el supuesto de que la distribución de los coeficientes en cada escala de
tiempo es Normal, los resultados del backtesting muestran que la metodología propuesta es
adecuada en la estimación de la pérdida esperada congruente con el concepto de Valor en
Riesgo.
Primeramente, la Figura 5.6 como ejemplo particular, muestra el backtesting tradicional
para un nivel de confianza al 95 % y 99 %, en donde la hipótesis nula con base a 250 obser
vaciones (n) en la ventana tiempo se permiten 13 y 3 fallas (x) respectivamente. Se observa
que a través de la metodología propuesta para medir el VaR, resultaron 14 fallas al 95 % y
2 al 99 %, siendo las más representativas en los últimos tres meses de 2008, periodo en que
el principal indicador bursátil de México rebasó pérdidas por arriba del 4 % en un día de
operación .
. lJ....------------~ .lJ,------------~
.O .o
.,.l--l-~-----4-.J--lr-rt1Tl .O
25 50 75 100 125 150 175 200 225 250 25 so 75 100 125 150 175 200 225 250
1-VaR (-) -VaR e) -P/GI 1-VaR (-) -VaR e) -P/GI
(a) (b)
Figura 5.6: Valor en Riesgo en la Cola Inferior y Superior del !PyC al {a} 95 % y {b} 99 %.
El Cuadro 5.2 muestra el backtesting para la cola inferior al nivel de confianza del
95 % del IPyC y emisoras correspondientes al respectivo índice bursátil, basado en la pro
porción de fallas de Kupiec e intervalos de confianza, en donde ocho casos muestran que
la metodología no es adecuada para estimar el riesgo de mercado en el marco del VaR: en
un caso se subestima la pérdida realizada y en los restantes la metodología las sobrestima.
Los resultados del VaR se obtuvieron estimando la varianza wavelet vía TWDMT y como
función wavelet el de Daubechies ele Mínima Asimetría LA(8).
Así mismo, los resultados del backtesting utilizando wavelets se comparan con las
metodologías de Riskmetrics (>.. =0.94) y el modelo de volatilidad condicional GARCH
(1,1), éste último bajo el supuesto en que los residuales se distribución como una normal.
86

Cuadro 5.2: Backtesting Cola Inferior al 95 % del /PyC.
Emisora Muestra Fallas Proporción Prueba Prueba PdF Kupiec Intervalos de Confianza de Fallas Binomial Valor crítico = 3.8414 Aproximación Normal Clopper-Pearson
X p* RV Valor-p Inferior Superior Inferior Superior Hipótesis Nula 13 0.05 Ho : p=0.05 IPyC 1739 14 0.056 0.0995 0.1827 0.6691 0.0275 0.0845 0.0309 0.0922 ALFA 1715 10 0.040 0.0963 0.5634 0.4529 0.0157 0.0643 0.0193 0.0723 AMXL 1714 6 0.024 0.0183 4.3687 0.0366 0.0050 0.0430 0.0089 0.0515 ARA 1663 7 0.028 0.0336 3.0089 0.0828 0.0076 0.0484 0.0113 0.0568
BIMBO 1667 4 0.016 0.0033 8.1852 0.0042 0.0004 0.0316 0.0044 0.0405 CEMEX 1724 19 0.076 0.0202 3.0905 0.0787 0.0432 0.1088 0.0464 0.1161
COMERCI 1627 9 0.036 0.0760 1.1383 0.2860 0.0129 0.0591 0.0166 0.0672 ELEKTRA 1680 1 0.004 0.0000 18.4966 0.0000 -0.0038 0.0118 0.0001 0.0221
00 FEMSA 1718 9 0 .036 0.0760 1.1383 0 .2860 0.0129 0.0591 0.0166 0 .0672 -..J
GFBANORTE 1703 13 0 .052 0.1117 0.0208 0.8853 0 .0245 0.0795 0.0280 0.0873 GCARSO 1695 12 0 .048 0.1160 0.0213 0.8839 0.0215 0.0745 0.0250 0.0823
GEO 1667 14 0.056 0.0995 0.1827 0.6691 0.0275 0.0845 0.0309 0.0922 GFINBURSA 1659 1 0.004 0.0000 18.4966 0.0000 -0.0038 0.0118 0.0001 0.0221
GMEXICO 1684 6 0.024 0.0183 4.3687 0.0366 0.0050 0.0430 0.0089 0.0515 GMODELO 1703 7 0.028 0.0336 3.0089 0.0828 0.0076 0.0484 0.0113 0.0568
KIMBER 1670 6 0.024 0.0183 4.3687 0.0366 0.0050 0.0430 0.0089 0.0515 PEÑOLES 1600 7 0.028 0.0336 3.0089 0.0828 0.0076 0.0484 0.0113 0.0568 SORIANA 1680 6 0.024 0.0183 4.3687 0.0366 0.0050 0.0430 0.0089 0.0515 TELECOM 1709 8 0.032 0 .0537 1.9441 0.1632 0.0102 0 .0538 0.0139 0.0621 TELEVISA 1715 3 0 .012 0.0010 10.8123 0.0010 -0.0015 0.0255 0.0025 0.0347 TELMEX 1682 10 0.040 0.0963 0.5634 0.4529 0.0157 0.0643 0.0193 0.0723 WALMEX 1721 8 0.032 0.0537 1.9441 0.1632 0.0102 0.0538 0.0139 0.0621

En el caso particular del IPyC, la representación del modelo GARCH (1,1) fue de la forma: 5
Rt = 0.001521 + Et,
(J¡ = 0.0000119 + 0.130713(~-1 + 0.794318CJ¡_1,
donde E = Rt-I - µ. Por lo que la varianza pronosticada en t (primer día de backtest) se
determinó de la forma:
(J¡ = 0.0000119 + 0.130713(0.00561712-0.00087060)2 + 0.794318(0.00015283)2
= 0.00013624.
El Cuadro 5.3 muestra los resultados del backtesting para un nivel de confianza del 95 %
con base a las tres metodologías arriba mencionadas, en el cual es apreciable que en los casos
de Cemex y Grupo México, las fallas o excepciones superan sustancialmente las permitidas
conforme al nivel de confianza inicialmente planteado. En un solo caso (Cemex) las tres
metodologías subestiman las pérdidas en el marco de VaR. Cabe mencionar que el 27 % de
los casos a través de Riskmetrics y GARCH (1,1), el estimador de máxíma verosimilitud
no restringido se ubica en el rango de 0.04 < H0 =0.05¡0.06, y un 32 % es igual a 0.06. En
tanto que la metodología por Wavelets tan solo un 18 % de los casos se ubica en el respectivo
rango; en los demás casos dicha metodología está sobrestimando las pérdidas con excepción
de Cemex.
Los resultados del backtesting en la estimación del VaR utilizando wavelets se vuelven
cruciales debido al número de niveles de descomposición que se emplean en la estimación,
ya que a menor número de detalles en la descomposición se esperaría un mayor número <le
fallas. Una herramienta para determinar el número adecuado de niveles de descomposición
se basaría en la Distribución de la Energía o Energía Wavelet Relativa, la cual estima el
porcentaje que cada detalle contribuye a la energía total de la señal original y cuya aplicación
se describe más adelante.
Conforme a la propiedad de distribución <le energía, la TWD y TWDMT, arrojan va
lores similares de la varianza en cada nivel de descomposición, sin embargo el camino más
apropiado para estimar el VaR agregado es a través de la TWD. Por lo que su estimación se
realiza nuevamente bajo la TWD y el mismo filtro wavelet (Symmlet 8) con 7 y 6 escalas.
La figura 5.7 compara el backtesting tradicional al 95 % de nivel de confianza para (a) 7
y (b) 6 escalas, en el cual los resultados muestran que el VaR agregado con 7 y 6 escalas
presentan 12 y 14 fallas, respectivamente.
5El Apéndice C muestra los resultados econométricos del modelo GARCII ( L l) para cada emisora.
88

Cuadro 5.3: Backtesting Cola Inferior al 95 % del IPyC y Emisoras {n=250}.
Emisora Muestra Riskmetrics GARCH (1,1) Wavelets (,\=0.94) (Symmlet,6)
Fallas Kupiec Fallas Kupiec Fallas Kupiec Hipótesis Nula 13
IPyC 1739 20 4.0395 17 1.5403 14 0.1823 ALFA 1715 15 0.4961 15 0.4961 10 0.5633 AMXL 1714 15 0.4961 15 0.4961 6 4.3687 ARA 1663 15 0.4961 14 0.1827 7 3.0089
BIMBO 1667 12 0.0213 14 0.1827 4 8.1852 CEMEX 1724 23 7.5204 31 20.7920 19 3.0905
COMERCI 1627 18 2.2555 13 0.0208 9 1.1382 ELEKTRA 1680 11 0.1971 14 0.1827 1 18.4966
FEMSA 1718 15 0.4961 17 1.5403 9 1.1382 GFBANORTE 1703 13 0.0208 13 0.0208 12 0.0213
GCARSO 1695 16 0.9514 22 6.2590 14 0.1827 GEO 1667 18 2.2555 21 5.0972 13 0.0208
GFINBURSA 1659 11 0.1971 10 0.5633 1 18.4966 GMEXICO 1684 26 11.8655 23 7.5204 6 4.3687 GMODELO 1703 17 11.8655 23 7.5204 7 3.0089
KIMBER 1670 15 0.4961 14 0.1827 6 4.3687 PEÑOLES 1600 16 0.9514 17 1.5403 7 3.0089 SORIANA 1680 14 0.1827 18 2.2555 6 4.3687 TELECOM 1709 16 0.9514 19 3.0905 8 1.9441 TELEVISA 1715 15 0.4961 15 0.4961 3 10.8123 TELMEX 1682 14 0.1827 18 2.2555 10 0.5633 WALMEX 1721 15 0.4961 16 0.9514 8 1.9441
89

.1-----------~ .ll,------------~
.o .o
.o
2S SO 7S 100 125 150 17S 200 225 250 25 50 75 100 125 150 175 200 225 250
1-VaR (-) -VaR •> -P/GI 1-VaR 1-1 -VaR •1 -P/GI
(a) (b)
Figura 5.7: Valor en Riesgo en la Cola Inferior y Superior del IPyC al 95 % para (a) 7 y (b) 6 niveles de resolución.
En términos de la prueba de PdF de Kupiec, la probabilidad en que el estimador no
restringido sea igual a la hipótesis nula p=0. 05 y una razón de verosimilitud LR=0. 0213, en
tanto que el p-value de 14 fallas fue igual a 0.67 para un valor de LR=0.1826. Lo anterior
muestra que el número de escalas por considerarse en la agregación de los VaRs por escala
conlleve a la probabilidad en que el número de fallas aumente, por lo que el número de
escalas es determinante en la aceptación o rechazo de la metodología propuesta.
La determinación del número de niveles de multiresolución puede resolverse con la ayuda
de la Energía Wavelet Relativa, la cual especifica la distribución de la energía por escala de
la serie de tiempo descompuesta por multiresolución. El cuadro 5.4 muestra la distribución
de energía en siete escalas y una escala extra, en el cual se observa que hasta la escala d5 ya
sobrepasó el 90 % de la distribución de energía. Cabe mencionar que el periodo utilizado para
descomponer la serie de rendimientos del IPyC comprendió 1,739 observaciones, tamaño de
una señal que no corresponde a un vector de longitud diádica, por lo que la TWD genera
un detalle o cristal extra.
Cuadro 5.4: Distribución de Energía del IPyC con filtro Daubechies MA (8): 08/02/2001 - 31/12/2008.
Cristal d 1 d2 d3 d4 d5 d6 Energía(%) 45.91 26.418 13.853 6.095 3.863 0.928
d7 1.399
s7 extra 1.277 0.307
La segunda parte del estudio comprende estimar el VaR en un periodo más actualizado
y con información histórica cercana a las 1,000 observaciones, con el objetivo de obtener
un vector de longitud diádica para estimar la varianza wavclct a través de la TWD y a
la vez cifra cercana a los criterios de referencia para estimar el VaR establecidos en la
CONSAR. De esta forma, el VaR estimado para el IPyC al 2 de mayo del 2008, comprende
1,024 observaciones y horizonte de tiempo para el backtesting del 5 de mayo del 2008 al
90

30 de abril del 2009. Los resultados muestran que en 6 escalas de descomposición de los
rendimientos del IPyC, se obtuvieron 9 fallas a un nivel de confianza del 95 % y 2 fallas
respecto de un nivel de confianza del 99 %, lo cual se observa en la figura 5.8 .
. l.,-------------, .1-----------~
.o .o
- .o
25 50 75 100 125 150 175 200 225 250 25 so 75 100 125 150 175 200 225 250
1-VaR 1-1 -VaR f,) -P/GI 1-VaR 1-1 -VaR el -P/GI
(a) (b)
Figura 5.8: Valor en Riesgo vía TWD al (a) 95 % y (b} 99 %.
Asi mismo, la figura 5.9 muestra en forma comparativa el backtesting vía la varianza
wavelet contra Riskmetrics y GARCH (1,1). Se observa que la metodología de varianza
wavelet no condicionada presenta menos fallas respecto al modelo de varianza condicionada
de Riskmetrics. La PdF de Kupiec para el primer caso corresponde a un valor de LR=l.1382
con valor de probabilidad del estimador no restringido de p=O. 2860 y para el segundo caso
un LR=2.2555 y valor del estimador no restringido de p=0.1331. En ambos casos el valor
del estadístico de razón de verosimilitud es menor al valor crítico de 3.8414, por lo que se
pueden considerar modelos adecuados en el pronóstico de las pérdidas bajo el marco de
VaR.
El número de escalas propuesto originalmente en esta segunda parte se justifica en que
la escala .\6 = 26- 1 = 32 cubre hasta un horizonte de 32 días y conforme a la distribución de
la energía wavelet. El cuadro 5.5 muestra que el cristal d6 ha logrado cubrir hasta un 98 % de la energía de la señal original. Asi mismo, el detalle d7 tiene una contribución inferior
a la unidad porcentual y el detalle s7 concentra el 1.3 % de la distribución de energía para
frecuencias en escalas mayores a 64 días. Al formar un vector X de longitud diádica y muy
cercana a las 1,000 observaciones, ya no es necesario el detalle extra como ocurrió en la
TWD para rendimientos del IPyC de una longitud arbitraria.
Cuadro 5.5: Distribución de Energía del /PyC con filtro Daubechies MA (8): 16/04/2004 - 30/04/2008.
Cristal dl d2 d3 d4 Energía( % ) 45. 709 27.068 12.616 6.431
d5 3.102
d6 d7 1.463 0.310
s7 1.300
Nuevamente el VaR se estima para 5 niveles de descomposición los cuales logran capturar
91

.!>.-------------~ .!.>.--------------
.o .o
--•·1-------l--+'WJUI
25 50 75 100 125 150 175 200 225 250 25 so 75 100 125 150 175 200 225 250
1-VaR 1-1 -VaR ~I -P/GI 1-VaR 1-1 -VaR ~I -P/GI
(a) (b)
.!>.-------------~
.o
25 so 75 100 125 150 175 200 225 250
1-VaR 1-1 -VaR ~I -P/GI
(e)
Figura 5.9: Valor en Riesgo al 95 % a través de (a) Varianza Wavelet, (b) Riskmetrir,;s y (e) GARCH (1,1)
las frecuencias hasta un horizonte de 16 días. Los resultados muestran que ahora el número
de fallas se incrementa a 13, número de fallas equivalente a la hipótesis nula, con valor del
estadístico de razón de verosimilitud de LR=0. 0208 y valor de probabilidad del estimador
de MV no restringido de 0.8853.
92

Capítulo 6
Conclusiones
En esta investigación se aplicó la teoría de wavelets para estimar el riesgo de mercado
en el marco de Valor en Riesgo. La aplicación se realizó sobre el principal índice accionario
mexicano y las emisoras que lo conforman. En particular, se utilizaron la transformada
wavelet discreta y su versión no-decimada conocida como transformada wavelet discreta de
máximo traslape.
Una de las principales motivaciones en la aplicación de wavelets para el análisis de
fenómenos económico-financieros se basa en Graps (1995), al argumentar que una señal se
puede mirar a través de ventanas grandes para percatarnos de sus característics generales;
y si la miramos a través de ventanas pequeñas, nos percataremos de sus detalles. El análisis
permitirá entonces mirar al bosque y los árboles.
El Valor en Riesgo es una de las medidas de riesgo de mercado más utilizadas, la cual
indica la pérdida máxima esperada en un ax 100 mejor de los casos. El valor en riesgo cor
responde al a-ésimo cuantil de la distribución de pérdidas y ganancias del activo financiero.
A pesar de su gran uso y medida estándar del riesgo de mercado, VaR no es una medida
coherente de riesgo bajo ciertas condiciones. El enfoque alternativo ha sido la medida de
riesgo Pérdida Esperada en la Cola.
Los resultados obtenidos en la investigación muestran que a través de la descomposición
por multiresolución es posible capturar las frecuencias altas y bajas en diferentes duraciones
de tiempo, en donde la escala de tiempo tiene una relación inversa con las frecuencias de los
rendimientos de los precios de las emisoras. Los diferentes niveles de resolución conocidos
en la teoría de wavelets como detalles o cristales, mostraron que las frecuencias más altas
de los rendimientos se presentan en una escala de tiempo de un día y las más bajas fueron
posibles capturarlas en una escala de tiempo de 32 días. La distribución de energía relativa
es una herramienta funcional para identificar el peso que cada nivel de descomposición tiene
respecto de la señal original.
93

El VaR estimado vía TWD y TWDMT arroja resultados similares. Sin embargo, la
TWDMT no es aplicable en la metodología de agregación de VaR's de cada escala, ya que
la misma induce correlación entre los coeficientes de cada escala. Lo apropiado para tales
efectos fue la TWD, aun y que la reconstrucción de la varianza por ambas transformadas
arroja un valor cercano a la varianza de la serie de tiempo original. Lo anterior debido al
algoritmo piramidal que en particular se utiliza en la TWD, el cual permite la decorrelación
de los coeficientes tanto a nivel entre-escala como intra-escala.
En particular se utilizó como filtro la función wavelet de Daubechies de mínima asimetría
y longitud ocho, ya que este tipo de función la literatura y estudios empíricos, han mostrado
que la correlación de los coeficientes entre escalas disminuye. Además, de que este tipo de
función es una mejor aproximación a filtros de pase de banda ideales respecto de otros filtros
comúnmente utilizados en finanzas como las funciones de Haar al permitir lo menos posible
fugas de información.
Los resultados del backtesting utilizando la TWD para descomponer los rendimientos de
cada serie de precios, muestran ser "cruciales" en el sentido de que el número de niveles de
resolución influye sustancialmente en el número de fallas en el horizonte de tiempo definido
para la aplicación de la prueba. Lo anterior hace que la metodología se mueva de "adecuada"
a "no adecuada", teniendo el resultado de subestimación de las pérdidas.
El enfoque de wavelets para estimar el VaR se contrastó con el modelo EWMA
de Riskmetrics y el modelo GARCH (1,1). Bajo estos últimos dos enfoques, los resultados
arrojan un mayor número de fallas que el enfoque de wavelets, aunque los resultados bajo
GARCH (1,1) pueden cambiar si la estimación se ejecuta bajo el supuesto de que los resi
duales no se distribuyen como una normal y la aplicación de algún otro modelo de la familia
GARCH como el modelo TGARCH o M-GARCH.
La estimación del VaR se puede clasificar en el método semi-paramétrico, en donde se ha
considerado que los coeficientes obtenidos en cada nivel de resolución se distribuyen como
una normal. Así mismo, el tipo de varianza obtenida vía wavelets se ha considerado como no
condicionada al no permitir innovaciones de la misma de un periodo previo. Por lo anterior,
se proponen las siguientes alternativas para continuar la investigación:
• Estimación del VaR aplicando Relative Wavelet Energy (RWE) bajo la transformada
wavelet discreta de máximo traslape. Lo anterior implica estimar un factor de es
calamiento en cuyo caso estudios previos emplean valores arbitrarios (Karandikar et
a.l.(2009)).
• Estimación del tipo no-paramétrica de los parámetros de la densidad de la distribución
de probabilidad de los rendimientos de los precios vía wavclcts
94

• La aplicación del enfoque híbrido ARMA-GARCH (Lai, He, y Chen (2006)), aunque
sus resultados son igualmente cruciales con base al número de niveles de resolución
utilizados. Igualmente, el número de observaciones históricas debe ser significativo
para estimar el modelo GARCH sobre los coeficientes obtenidos en cada nivel de
resolución, ya que en cada nivel de resolución el número de coeficientes es menor en
tanto la escala de tiempo es mayor.
95

Apéndice A
Descomposición por Multiresolución
de Emisoras
DI ..... ,, 11111 1 • IIO" 1 lit ~ ll ., .. ,.
D2 D2
D3 D3
O< O<
D5 D5
D6 D6
S6 S6
500 1000 1500 500 1000 1500
Figura A.1: MRD de Alfa Figura A.2: MRD de América Móvil
01 ... ~~ , ... ,. ... 8 lt. 1 1 1 1111 V 1 •111 01 .. I~ tt+.. 1 ~ a J, • t a • ' 1 f t 1 • P J 14~
D2 D2
D3 D3
O< O<
D5 D5
D6 D6
S6 S6
500 1000 1500 500 1000 1500
Figura A.3: MRD de Ara Figura A.4: MRD de Bimba
96

o, 01 • • • •ttr,111~ 1 tlu• t-• •fal•,.l 111 ,1 .. , 01 t.,, ' 1 1 , .. 1 " 1 141 1 al • ,. ,+ .... J ,., • .11
D2 D2
DJ DJ
"' "' DS DS
[)6 D6
S6 S6
500 1000 1500 500 1000 1500
Figura A.5: MRD de Cemex Figura A.6: MRD de Comercial Mexicana
,.~1,1,, ,,111,tr1u1ru.,._.,,..,..,~i.A
DI .. .. , ,,,~ 111 -·· 11 ... • • 1 .... 01 ..... ,,,n_• 1 ... ll : 1• t ~t11.fl
D2 D2
DJ DJ
"' "' D5 DS
[)6 [)6
S6 S6
500 1000 1500 500 1000 1500
Figura A.7: MRD de Elektm Figura A.8: MRD de Femsa
o, .1, ~~ • 11 Mttit1t , 11 .. • ' ' l .... 1 .. , ....... ..... DI
D2 D2
DJ DJ
"' "' DS DS
[)6 [)6
S6 S6
500 1000 1500 500 1000 1500
Figura A.9: MRD de Grnpo Carso Figura A.10: MRD de Ceo
DI •••11111 ~111• 1 111 ,, 1 r ,. 1 r 11• t ~ l ll ,,1 01 ,,,1u1 ... _1llllf4 M•• 1 1 11 • PI •• t l~I •l9M D2 D2
DJ D3
"' DS DS
[)6 [)6
S6 S6
500 1000 1500 500 1000 1500
Figura A.11: MRD de r:rnpo México Figura A.12: MRD de Grnpo J\Jodelo
97

lt#r ,~:111 1 .. , 1 •• t 1uml1 • , .., ,.. ,- 1 • 1 .......
D1
D2
D3
DS
D6
56
500 1000 1500
Figura A.13: MRD de Inbursa
DI
14 1r11J1 "''', • ,1 • D2
DJ
D4
DS
D6
56
500 1000 1500
Figura A.15: MRD de Banorte
D2 lbl ... l - .. 11., U. l 1 1al11 ... tll1 PI 11
D3
D4
DS
D6
56
500 1000 1500
Figura A.17: MRD de Soriana
D2 ·~' 1 a• 11 • 11 ..... ¡p ..
DJ
D4
DS
D6
56
500 1000 1500
Figura A.19: AfRD de Tl'léfono8 de !11é.Tico
,... M'1' t,o'I~ /,,t 4 ~"' •
D1 ,. ~ 1 t 11 1 tf J 11 l 1h 1 1 ... 1 •1
D2
DJ
D4
DS
D6
56
500 1000 1500
Figura A.14: MRD de Kimberly
D1 ~~J fl ~ ~ 1 N ,~, ¡u • 1111 11 • 11 ,, 1111 u•I , .., D2
DJ
D4
DS
D6
56
500 1000 1500
Figura A.16: MRD de Peñoles
01 :t ~._, ... , '" • I
D2
111 1 r ·~···· ..... 1,,1 ••
D3
D4
DS
D6
56
500 1000 1500
Figura A.18: MRD de Telecom
DI , 1 .. 11
D2
DJ
"' DS
D6
500 1000 1500
Figura A.20: MRD de Televisa
98

un ~O*"*'b .... "fl.MI Jllt, 1wtt..-,:"l',.,¡p t,lila
o, '~"'"' tlll~JI 1 ''" ,..... 1 1tN• E ••• , J l~NN
D2
º' °' D5
D6
S6
500 1000 1500
Figura A.21: MRD de Wal-Mart
99

Apéndice B
Descomposición de la Varianza de
Emisoras en 6 Niveles
F7 ,o ,,. ,,. m m ,o ,oo "' ,oo m ..______,.._,o ~,., --r,.,~,,.---,,;, Lbd,
ALf'.lD! Allktl' Jt.lULII,
i[~ ·~[SJ ~:~·~bd - - - -HOOJ .000001 .000001 .MOOOI
so ltO :so HO ,so U 100 ISO lDD no so 100 ,se •to .u H ,01 110 '" ªº
Figura B.1: Varianza Wavelet Alfa Figura B.2: Varianza Wavelet América Móvil
100

.....
.... , ..... IIIIIODJ IJIIIODt
_,_ ... " . OIOHI
.0-,1
-·- j
..... .. ... IJUODI
Figura B.3: Varianza Wavelet de Ara Figura B.4: Varianza Wavelet de Bimbo
_, -·c:a :0002 . 0001
.0001
0001
llfl SI IOf 110 200 2U
"" -- --o -... ., . '"
·'" 10 IN 110 ltll lH
--~o --·o '"Q'
- - -·"°" .0001 - ---· - ---· --~ - ·-º
oeO~ 10 IN aO 100 l10 .OOOO M :U IH 200 UO .OOH 1°0 100 110 11D 310
---62] -"'~ -.-- .IOHl2 .too ... .ooo,u -~ .C.OOIU
.NDOCM.
INOC4 .IWIIII
--- .000011 10 100 no 100 110 'º 10, ISO ªº ,u
Figura B.5: Varianza Wavelet de Cemex Figura B.6: Varianza Wavelet de Comercial Mexicana
101
Figura B.7: Varianza Wavelet de Elektra Figura B.8: Varianza Wavelet de Femsa
""Q ·-·o .-'O ·'ª'D - - - --2 ,0001
.0002 .OOII
0001 .l{IDI
oon ,OMI __ ¡ .0000
- - - -ID 100 IID 2DO no so 100 Llll ªº ªº 10 100 110 ªº ª' 10 100 110 lOO ac
OCUIOD(
-~~ -~ ·-~ _,, -~· H 100 110 ne 210
Figura B.9: Varianza Wavelet de GCarso
. 010g)
·"'"[] .COOOI
00001
00001 ,o 100 no 2~0 a,
Figura B.10: Varianza Wavelet de Geo
102

IOlffDl •01ffD2 •10101 •1u1D2 -o .MIi
.... , ·-· ·-· ·-· M 1• IM MI 211
IOl'TIDJ IOlffDt •1UIDJ ::l'ltJIDt
Figura B.11: Varianza Wavelet de Banorte Figura B.12: Varianza Wavelet de Inbursa
-·~ ·""D ·-"E;] .CIOOJ .-I .OIOIU ... , KO:J OOOJ __ ¡¡
wouo on> .0001 - --·ºªº .0001 .00012 - . ,. """ "' - . , .. ,. "' '""' . . .... ,.
.NOO,rn .-mts;J .OOIOII .HUI
.MIOU
.HIOI --011
HIOJ .MOOll
.000011
IOHJ· .10001;
OIIOI SO 1~0 11~ 200 al .ODQOII 10 ICIO IH lt-fl ao
·-"~ ·--~ -·~[;!J ·'""'[;d .ooo~ ___ .OOOOGol .ooo.m
.00011 __ 101 .o;,;oo,i .o.o;e1
GOOI OO ,ooou .OOl!IO'I .110112
.OMOll<I
HUI .00100, .UUOJ .OHOOol
IOOOI .000006 .OOOIH . 1111161
'"" '"'~ ·""" . . .... ., 10 JIO 1,0 211 11 1 U 1,0 \U 100 aO 10 )U ;1~ UO HO 10 100 ISO ~00 1~~
Figura B.13: Varianza Wavelet de GMéxico Figura B.14: Varianza Wavelet de Modelo
103

·-g --· --.o .. ,
--· .MOi
--· --· so 1,a 1n :ioe no
--"w ·-w --·Q .OHM .-DI .1001 __ ,
.MOk --·1 .0001
IOOOl .-H ,MOi
.00001
__ , 00011 __ 01
- - = . - - - - - - - - - - - - - ---·0 --. __ .. , --'"
.otGU2 50 IOI 110 JU ~H
Figura B.15: Varianza Wavelet de Kimberly Figura B.16: Varianza Wavelet de Peñoles
-~·o .a.ooec,
OODIDI
._ºººº" . -··, ·ººº'°' ,o ;oo :so 20& 2u
__ ... o .ooo,c,
.IMIIOO
.MOU5
-·" -OH
so 1n no 210 ,;,
Figura B.17: Varianza Wavelet de Soriana
"-·0 "'~
----·" "º~
-· . . ...... . Figura B.18: Varianza Wavelet de Telecom
104

·-"'t;J .-oo,
-"' -DOtl001
""" . to0002
" 1ot 1se 1to ue
Figura B.19: Varianza Wavelet de Televisa
·-·rs;J .NHI
•• OOHH
00011
OGDOII
. OOUl4
onou ,. llMI ¡to uo u.o
º""'6ZJ ... "~
··"º'º~
IL IN :n JU lM
Figura B.21: Varianza Wavelet de Wal-Mart
,.,.. .. ,
,.,.. .. ,
Figura B.20: Varianza Wavelet de Telmex
105

Apéndice C
Estimación del Modelo GARCH (1,1)
106

Cuadro C.1: Resultados Modelo GARCH {1,1).
Emisora Ecuación Ecuación de la Varianza AIC Schwartz Media Constante ARCH GARCH
IPyC 0.001521 0.0000119 0.130713 0.794318 -6.056001 -6.043439 (5.653285) (6.003545) (7.971036) (32.98045)
ALFA 0.001161 4.03E-06 0.038397 0.951813 -4.984434 -4.971729 (2.499752) (4.628465) (7.98051) (200.957)
AMXL 0.001989 2.52E-05 0.074574 0.861124 -5.032896 -5.020185 (4.355953) (4.590909) (6.509121) (39.21984)
ARA 0.001497 2.13E-05 0.098065 0.856606 -5.028463 -5.015435 (3.134407) (5.194844) (8.20459) (51.67446)
BIMBO 0.001047 2.65E-05 0.109867 0.817135 -5.213806 -5.200804 (2.565291) (5.984273) (7.275223) (36.3291)
CEMEX 0.001143 1.48E-05 0.062486 0.887903 -5.336703 -5.324053 (2.980602) (3.857807) (5.286258) (40.66154)
COMERCI 0.001113 2.70E-05 0.124561 0.817211 -5.003206 -4.989944 (2.302668) (5.120697) (8.122154) (38.91313)
ELEKTRA 0.001825 2.88E-05 0.179274 0.778495 -4.910497 -4.897577 (3.948148) (7.24745) (12.07525) (50.23795)
FEMSA 0.001167 4.36E-06 0.07097 0.916271 -5.429739 -5.417052 (3.207766) (3.159069) (8.043524) (84.642179
GFBANORTE 0.002001 3.58E-05 0.10491 0.813483 -4.991283 -4.978505 (4.339093) (5.264108) (7.996564) (34.81662)
GCARSO 0.001267 2.18E-05 0.133271 0.811097 -5.217813 -5.204986 (3.188313) (6.322051) (9.837445) (44.08776)
GEO 0.002429 4.09E-05 0.156036 0.772971 -4.824319 -4.811317 (4.83229) (6.637878) (10.80673) (40.75986)
GFINBURSA 0.000572 3.45E-05 0.111649 0.816747 -4.987502 -4.974449 (1.251984) (5.188117) (7.351579) (31.5294)
GMEXICO 0.002091 l.68E-05 0.075 0.902222 -4.566949 -4.554053 (3.817174) (4.537883) (6.959393) (69.28219)
GMODELO 0.000552 2.30E-06 0.045812 0.946194 -5.570946 -5.558168 (1.690244) (3.742365) (7.185639) (132.5803)
KIMBER 0.000499 l.18E-05 0.074932 0.875525 -5.623191 -5.610207 (1.483905) (5.988984) (8.806049) (63.95121)
PEÑOLES 0.001594 2.35E-05 0.063056 0.911438 -4.321679 -4.308234 (2.515648) (5.180397) (9.529724) (97.28021)
SORIANA 0.001168 3.57E-05 0.129798 0.768576 -5.221662 -5.208742 (2. 761393) (5.760255) (7.366943) (26.79027)
TELECOM 0.001028 l.38E-05 0.065112 0.89639 -5.156903 -5.144162 (2.331285) (3.120555) (5.33086) (42.97311)
TELEVISA 0.001158 4.32E-06 0.0494 0.937636 -5.186652 -5.173948
(2.860205) (3.262662) (7.447001) (104.5091)
TELMEX 0.000723 4.15E-06 0.045158 0.936933 -5.628583 -5.615675
(2.1311079) (2.425497) (5.256569) (65.91169)
WALMEX 0.000907 6.04E-06 0.067074 0.91535 -5.318087 -5.305418
(2.332996) (4.249008) (8.15721) (95.33118)
107

Bibliografía
[1] Abrarnovich, F., Bailey, F., and Sapatinas, T., 2000; "Wavelet Analysis and Its Sta
tistical Applications", The Statistician, 49 ( 1), 1-29.
[2] Aguiar-Conraria, L., Soares, M., and Azevedo, N., 2007; "Using Wavelets to Decorn
pose Tirne-Frequency Econornic Relations", NIPE Working Papers, Universidade do
Minho, 17.
[3] Artzner, P., et al., 1999; "Coherent Risk Measures of Risk", Mathematical Finance,
9, 203-228.
[4] Artzner, P., et al., 2001; "Thinking Coherently", RISK, 10(11), 68-71.
[5] Bachelier, L., 1900; Theory of Speculation, Translation of Louis Bachelier's thesis, in
The Randorn Character of Stock Market Prices by P. Cootner, MIT, 18-91.
[6] Barnea, A., and Downes, D., 1973; "A Reexarnination of the Ernpirical Distribution
of Stock Price Changes", Finance, 68, 348-350.
[7] I3arndorff-Nielsen, O. E., 1977; "Exponentially Decreasing Distributions for the Log
arithrn of Particle Size", Proceedings of the Royal Society of London. Series A, Math- -
ematical and Physical Sciences, 353, 401-419.
[8] Barone-Adesi, G., and Giannopoulos, K., 1996; "A Simplified Approach to the Con
ditional Estirnation of Value at Risk", Futures and Options World, October, 68-72.
[9] Blattberg, R., and Gonedes, N., 1974; "A Cornparison of the Stable and Student
Distributions as Statistical Models for Stock Prices", The Joumal of Business, 47(2),
244-280.
(10] Bollerslev, T., 1986; "Generalized Autoregressive Conditional Heteroskedasticity",
Journal of Econometrics, 31(3), 307-327.
108

[11] Boudoukh, J., Richardson, M., and Whitelaw, R., 1998; "The Best of Both Worlds",
RISK, 11, 64-67.
[12] Brada, J., Ernst, H., and Tassel, J., 1966; "The Distribution of Stock Price Differences:
Gaussian after ali", Operations Research, 14(2), 334-340.
[13] Burrus, C. S., Gopinath, R. A., and Guo, H., 1998; Introduction to Wavelets and
Wavelet Transforms, A Primer, Prentice Hall, New Jersey, USA.
[14] Clopper, C., and Pearson, S., 1934; "The Use of Confidence or Fiducial Limits Illus
trated in the Case of the Binomial", Biometrika, 26(4), 404-413.
[15] Cont, R., 2001; "Empirical Properties of Asset Returns: Stylized Facts and Statistical
Issues", Quantitative Finance, Institute of Physics Publishing, 1, 223-236.
[16] Coronado, M., 2001; "Extreme Value Theory for Risk Managers: Pitfalls and Oppor
tunities in the use of EVT in Measuring VaR", Proceedings of the V Spanish and 111
Italian-Spanish Conference on Actuaria[ and Financia[ Mathematics, Madrid, Spain.
[17] Craigmile, P. F., and Percival, D. B., 2005; "Asymptotic Decorrelation of Between
Scale Wavelet Coefficients", IEEE Transactions on Information Theory, 51(3), 1039-
1048.
[18] Daubechies, l., 1988; "Orthonormal Bases of Compactly Supported Wavelets", Com
munications on Pure and Applied Mathematics, 41, 909-996.
[19] Dijkerman, R., and Mazumdar, R., 1994; "Wavelet Representation of Stochastic Pro
cesses and Multiresolution Stochastic Models", IEEE Proceedings Transactions on
Signal Processing, 42, 1640-1652.
[20] Donoho, D., Johnstone, l., Kerkyacharian, G., and Picard, D., 1996; "Density Esti
mation by Wavelet Thresholding", The Annals of Statistics, 24(2), 508-539.
[21] Eberlein, E., and Keller, U., 1995; "Hyperbolic Distributions in Finance", Bernoulli,
1(3), 281-299.
[22] Embrechts, P., Klüppelberg, C., and Mikosch, T., 1997; Modelling Extrema[ Events
for lnsurance and Finance, Springer, New York, USA.
[23] Enders, W., 2004; Applied Econometric Time Series, John Wiley and Sons, 2nd. Edi
tion, New Jersey, USA:
109

[24] Engle, R.F., 1982; "Autoregressive Conditional Heteroskedasticity with Estimates of
the Variance of United Kingdom lnflation", Econometrica, 50(4), 345-359.
[25] Engle, R.F., 2001; "GARCH 101: The Use of ARCH and GARCH Models in Applied
Econometrics", Journal of Economic Perspectives, 15, 157-168.
[26] Fama, E., and Roll, R., 1963; "Parameter Estimates for Symmetric Stable Distribu
tions", Joumal of the American Statistical Association, 66(334), 331-338.
[27] Fama, E., 1965; "The Behavior of Stock-Market Prices", The Joumal of Business,
38(1 ), 34-105.
[28] Fernandez, V., 2005; "The International CAPM anda Wavelet-Based Decomposition
of Value at Risk", Studies in Nonlinear Dynamics and Econometrics, 9, 1-35.
[29] Fielitz, B., and Rozelle, J., 1983; "Stable Distributions and the Mixtures of Distri
butions Hypotheses for Common Stock Returns", Joumal of the American Statistical
Association, 78(381), 28-36.
[30] Fisher, R.A., and Tippett, L.H.C., 1928; "Limiting Forms of the Frequency Distribu
tion of the Largest or Smallest Member of a Sample", Mathematical Proceedings of
the Cambridge Philosophical Society, 24, 180-190.
[31] Fomel, S., Sava, P., Rickett, J., and Claerbout, J., 2003; "The Wilson-Burg Method
of Spectral Factorization with Application to Helical Filtering", 51, 409-420.
[32] Graps, A., 1995; "An lntroduction to Wavelets", IEEE Proceedings Computational
Science and Engineering, 2, 50-61.
[33] Grinsted, A., Moore, J., and Jevrejeva, S., 2004; "Application of the Cross Wavelet
Transform and Wavelet Coherence to Geophysical Time Series", 11, 561-566.
[34] Haar, A., 1910; "Zur Theorie der Orthogonalen Funktionensysteme", Mathematische
Annalen, 69, 331-371.
[35] Hall, J., Brorsen, W., and Irwin, S., 1989; "The Distribution of Future Prices: A Test
of the Stable Paretian and Mixture of Normals Hypotheses", 24(1), 105-116.
[36] Harris, L., 1986; "Cross-Security Tests of the Mixture of Distributions Hypothesis",
The Journal of Financia[ and Quantitative Analysis, 21(1), 39-46.
[37] Harris, L., 1987; "Transaction Data Tests of the Mixture of Distributions Hypothesis",
The Journal of Financia[ and Quantitative Analysis, 22(2), 127-141.
110

[38] Hull, J., and White, A., 1998; "Value at Risk when Daily Changes in Market Variables
are not Normally Distributed", The Journal of Derivatives, 5(3), 9-19.
[39] Hull, J., and White, A., 1998; "Incorporating Volatility Updating into the Historical
Simulation Method of VaR", The Journal of Risk, 1, 5-19.
[40] Jacques, G., Frymiare, J., Kounios, J., Clark, C., and Polikar, R., 2004; "Multires
olution Analysis for Early Diagnosis of Alzheimer's Disease", IEEE Proceeding 26th
Annual International Conference of the IEEE EMES, 251-254.
[41] Jenkinson, A.F., 1955; "The Frequency Distribution of the Annual Maximum (or
Minimum) Values of Meteorological Elements", Quarterly Journal of the Royal Mete
orological Society, 81(348), 158-171.
[42] Jorion, P., 1996; "Risk: Measuring the Risk in the Value at Risk", Financia[ Analysis
Journal, 52, 47-56.
[43] Jorion, P., 2007; Value at Risk, The New Benchmark far Managing Financia[ Risk,
McGraw-Hill, 3rd. Edition, New York, USA.
[44] Khindanova, l., Rachev, S., and Schwartz, E., 2000; "Stable Modelling of Value at
Risk", Economics Working Paper Series, University of California at Santa Barbara, 4.
[45] Kon, S., 1984; "Models of Stock Returns - A Comparison", The Journal of Finance,
39(1), 147-165.
[46] Kupiec, P., 1995; "Techniques for Verifying the Accuracy of Risk Management Mod
els", The Journal of Derivatives, 3, 73-84.
[47] Lee, H. S., 2004; "International Transmission of Stock Market Movements: A Wavelet
Analysis", Applied Economics Letters, 11(3), 197-201.
[48] Longin, F., 1991; "Long-term Memory in Stock Market Prices", Econometrica, 59,
1279-1313.
[49] Longin, F., 2001; "Beyond the VaR", The Journal of Derivatives, 8, 36-48.
[50] Longin, F., 2000; "From Value at Risk to Stress Testing: The Extreme Value Ap
proach", The Journal of Banking and Finance, 24, 1097-1130.
[51] McNeil, A.J., and Frey, J., 2000; "Estimation of Tail-Related Risk Measures for Het
eroscedastic Financia} Time Series: An Extreme Value Approach", Journal of Empir
ical Finance, 7, 271-300.
111

[52] Mallat, S., 1989; "A Theory for Multiresolution Signal Decomposition: The Wavelet
Representation", IEEE Transactions on Patterns Analysis and Machine Intelligence,
11(7), 674-693.
[53] Mandelbrot, B., 1963; "The Variation of Sorne Speculative Prices", The Journal of
Business, 36(4), 394-419.
[54] Mandelbrot, B., 1967; "The Variation of Sorne Other Speculative Prices", The Journal
of Business, 40(4), 393-419.
[55] Manganelli, S., and Engle, R., 2001; "Value at llisk Models in Finance", Working
Paper, European Central Bank, 75.
[56] Mikosch, T., and Starica, C., 2000; "Limit Theory for the Sample Autocorrelations
and Extremes of a GARCH (1,1) Process", The Annals of Statistics, 28(5), 1427-1451.
[57] Nason, G., and Sachs, R., 1999; "Wavelets in Time-Series Analysis", Philosophi
cal Transactions: Mathematical, Physical and Engineering Sciences, 357(1760), 2511-
2526.
[58] Norsworthy, J., Li, D., and Gorener, R., 2000; "Wavelet-Based Analysis of Time Series:
An Export from Engineering to Finance", IEEE Proceedings Engineering Management
Society, 126-132.
[59] Officer, R., 1972; "The Distribution of Stock Returns", Joumal of the American Sta
tistical Association, 67(340), 807-812.
[60] Osborne, M., 1959; "Brownian Motion in the Stock Market", Operations Research,
7(2), 145-173.
[61] Percival, D., and Mofjeld, H., 1997; "Analysis of Subtidal Coastal Sea Level Fluc
tuations Using Wavelets", Joumal of the American Statistical Association, 92(439),
868-880.
[62] Percival, D., and Walden, A., 2000; Wavelet Methods for Time Series Analysis, Cam
bridge University Press, London, England.
[63] Perry, P., 1983; "More Evidence on the Nature of the Distribution of Security Re
turns", Journal of Financia[ and Quantitative Analysis, 18(2), 211-221.
[64] Praetz, P., 1972; "The Distribution of Share Price Changes", The Joumal of Business,
45(1), 49-55.
112

[65] Ramsey, J., and Lampart, C., 1999; "The Decomposition of Economic Relationships by
Time Scale using Wavelets: Expenditure and Income", Studies in Nonlinear Dynamics
e3 Econometrics, 3, 23-42.
[66] Ramsey, J., 1999; "The Contribution of Wavelets to the Analysis of Economic and
Financia! Data", Philosophical Transactions: M athematical, Physical and Engineering
Sciences, 357(1760), 2593-2606.
[67] Roberts, H., 1959; "Stock-Market Patterns and Financia! Analysis: Methodological
Suggestions", The Journal of Finance, 14(1), 1-10.
[68] Serroukh, A., Walden, A., and Percival, D. B., 2000; "Statistical Properties and Uses
of the Wavelet Variance Estimator for the Scale Analysis of Time Series", Journal of
the American Statistical Association, 95(449), 184-196.
[69] Strang, G., 1989; "Wavelets and Dilation Equations: A Brief Introduction", SIAM
Review, 31(4), 614-627.
[70] Upton, D., and Shannon, D., 1979; "The Stable Paretian Distribution, Subordinated
Stochastic Processes, and Asymptotic Lognormality: An Empirical Investigation", The
Journal of Finance, 34( 4), 1031-1039.
[71] Valens, C., 1999; "A Really Friendly Guide to Wavelets", Unpublished.
[72] Venegas-Martínez, F., 2006; Riesgos Financieros y Económicos, Thomson, Ciudad de
México, México.
[73] Xiong, X., Zhang, X., Zhang, W., and Li, C., 2005; "Wavelet-based Beta Estimation of
China Stock Market", IEEE Proceedings Fourth International Conference on Machine
Learning and Cybernetics, 6, 3501-3505.
[74] Zangari, P., 1996; "An Improved Methodology for Measuring VaR", Riskmetrics Mon
itor, 7-25.
113

ESTE TRABAJO SE TERMINO DE IMPRIMIR Y EMPASTAR EN CVT GROUP
AV. INSTITUTO POLITECNICO NACIONAL 1905 COL.LINDAVISTA MEXICO D.F.
51195939 55865003