estadÍstica guÍa bÁsica para economistas y administradores
DESCRIPTION
Universidad Nacional José Faustino Sánchez CarriónAutores: Benigno Walter Moreno Mantilla, Cristián Iván Escurra Estrada, Miguel Ángel Aguilar Luna VictoriaTRANSCRIPT

ESTADÍSTICA GUÍA BÁSICA PARA
ECONOMISTAS Y ADMINISTRADORES

2
U N I V E R S I D A D N A C I O N A L
JOSÉ FAUSTINO SÁNCHEZ CARRIÓN
FACULTAD DE CIENCIAS
INSTITUTO DE INVESTIGACIÓN
TEXTO UNIVERSITARIO
ESTADÍSTICA GUÍA BÁSICA PARA
ECONOMISTAS Y ADMINISTRADORES
AUTORES
Mg. Benigno Walter Moreno Mantilla
Lic. Cristián Iván Escurra Estrada
Lic. Miguel Ángel Aguilar Luna Victoria
HUACHO – PERÚ
2011
1

3
AGRADECIMIENTO
En forma muy especial a cada una de nuestras familias,
quienes reconocen el esfuerzo que le ponemos en cada una
de nuestras hazañas académicas, y hacen de nuestra labor
de investigación el mas insaciable gusto por aportar a la
ciencia. Así como también, a los investigadores y autores
de textos bibliográficos que nos han servido de consulta en
el desarrollo del texto que presentamos.
Los autores
2

4
ÍNDICE DE CONTENIDO
Pág.
PROLOGO
UNIDAD I: Definiciones básicas, comparación y discusión.
Variables 6
UNIDAD II: Cálculo del tamaño muestral. Técnicas y
Métodos para la recolección de datos y diseños
de cuestionarios.
13
UNIDAD III: Tablas de frecuencia, gráficos. Medidas de
tendencia central. Medidas de Dispersión.
Asimetría y Kurtosis.
26
UNIDAD IV: Regresión y correlación lineal simple.
40
EPILOGO 44
GLOSARIO DE TÉRMINOS 45
BIBLIOGRAFÍA 46
APENDICE 47

5
PRÓLOGO
En este texto, presentamos las principales técnicas para cálculos estadísticos, con
aplicaciones en la empresa:
a) Definiciones básicas, comparación y discusión. Variables. Ver Unidad I.
b) Cálculo del tamaño muestral. Técnicas y Métodos para la recolección de
datos y diseños de cuestionarios. Ver Unidad II.
c) Tablas de frecuencia, gráficos. Medidas de tendencia central. Medidas de
Dispersión. Asimetría y Kurtosis. Ver Unidad III.
d) Regresión y correlación lineal simple. Ver Unidad IV.
Los autores
5

6
UNIDAD I: Definiciones básicas, comparación y discusión. Variables.
DEFINICIÓN DE ESTADÍSTICA
La estadística, es la ciencia que trata de la recopilación, organización presentación, análisis
e interpretación de datos generalmente numéricos con el fin de realizar una toma de
decisión más efectiva. Así mismo, se puede considerar como el conjunto de indicadores
numéricos que caracterizan diferentes aspectos de la vida social, incluyendo la producción,
las relaciones políticas, culturales de la vida cotidiana; se refiere alas colecciones
sistemáticas de datos relativos a un fenómeno.
La Estadística aplicada a la Economía da una caracterización cuantitativa y cualitativa del
volumen, composición y dinamismo de las fuerzas productivas y además refleja el
comportamiento de las relaciones de producción, estudia las fuerzas productivas de un
país, las condiciones de producción, etc.
TIPOS DE ESTADÍSTICA
Teniendo en cuenta las funciones, cometidos y el ámbito de la Estadística entendida como
método de aplicación de los principios científicos para la resolución de problemas
socioeducativos y la toma de decisiones, podemos identificar dos grandes tipos, según las
tareas a las que debe enfrentarse, la descriptiva y la inferencial:
Estadística Descriptiva: Es la técnica que se va a encargar de la recopilación,
presentación, tratamiento y análisis de los datos, con el objeto de resumir, describir las
características de un conjunto de datos y por lo general toman forma de tablas y gráficas.
En realidad, transforma un conjunto de números u observaciones en índices que sirven para
describir o caracterizar esos datos dentro de los grupos de sujetos. La podemos considerar
como una parte de la Estadística que se ocupa del estudio de los métodos y técnicas
necesarios para la descripción gráfica y numérica de los conjuntos de datos, ello nos ofrece
una visión global del grupo de sujetos que es objeto de estudio. Estos cálculos tienen
limitaciones en la interpretación de los estadísticos, pues en muchas ocasiones nos

7
debemos centrar en una comparación entre el valor de la muestra y otros que procedan de
muestras similares, por lo que no aporta suficientes argumentos científicos al investigador
en la toma de decisiones sobre los grupos.
Estadística Inferencial: Técnica mediante la cual se sacan acerca de parámetros de una
población basándose en los estadígrafos de una muestra de población. Se dedica a la
generación de los modelos, inferencias y predicciones asociadas a los fenómenos en
cuestión teniendo en cuenta la aleatoriedad de las observaciones, bajo un nivel de
confianza definido por el investigador. Se usa para modelar patrones en los datos y extraer
inferencias acerca de la población bajo estudio
POBLACIÓN: Es el conjunto de todos los posibles elementos que intervienen en un
experimento o en un estudio.
CENSO: Al estudio completo de la población.
TIPOS DE POBLACIÓN:
POBLACIÓN FINITA: Es aquella que indica que es posible alcanzarse o sobrepasarse al
contar. Es aquella que posee o incluye un número limitado de medidas y observaciones.
POBLACIÓN INFINITA: Es infinita si se incluye un gran conjunto de medidas y
observaciones que no pueden alcanzarse en el conteo.
Son poblaciones infinitas porque hipotéticamente no existe límite en cuanto al número de
observaciones que cada uno de ellos puede generar.
MUESTRA: Un conjunto de medidas u observaciones tomadas a partir de una población
dada. Es un subconjunto de la población.
MUESTRA REPRESENTATIVA: Un subconjunto representativo seleccionado de una
población de la cual se obtuvo.
MUESTREO: Al estudio de la muestra representativa.
PARÁMETRO: Son las características medibles en una población completa. Se le asigna
un símbolo representado por una letra griega.

8
ESTADÍSTICO O ESTADÍGRAFO: Es la medida de una característica relativa a una
muestra. La mayoría de los estadísticos muestrales se encuentran por medio de una fórmula
y suelen asignárseles nombres simbólicos que son letras latinas.
DATOS ESTADÍSTICOS: Los datos son agrupaciones de cualquier número de
observaciones relacionadas.
Para que se considere un dato estadístico debe tener 2 características:
a) Que sean comparables entre sí.
b) Que tengan alguna relación.
VARIABLE: Es una característica de los elementos de la población que pueden ser
medibles.
TIPOS DE VARIABLES: Existen varios tipos de Variables, entre ellos tenemos:
Por su Dependencia en la Investigación. Pueden ser:
Variable Dependiente: Aquellas que su valor a medir depende de otras variables.
Variable Independiente: Aquellas cuyo valor a medir no depende de otras variables y
en algunos casos afecta el resultado de otras variables.
Variable Interviniente: Aquellas que en una investigación intervienen indirectamente
en el efecto de otra variable o que cuyo valor se necesita tomar en cuenta para
interpretar o analizar otras variables principales.
Por su Naturaleza. Pueden ser:
Variable Cuantitativa: cuando la variable a medir asume valores netamente
numéricos, estas a su vez se clasifican en:
Variable Cuantitativa Discreta: Es aquella que puede asumir sólo ciertos
valores, mas conocidos como números enteros. Estos deben ser indivisibles y es
ilógico interpretarlos como decimales.

9
Ejemplo: El número de hijos (0, 1, 2, 3, …)
Variable Cuantitativa Continua: Es aquella que teóricamente puede tomar
cualquier valor en una escala de medidas, ya sea entero o fraccionario.se puede
interpretar con cierta lógica en decimales.
Ejemplo: Estatura: (1.90 m.); Ingreso Económico (700.52)
Variables Cualitativas: Cuando no es posible hacer medidas numéricas sino que son
caracteres de los elementos de población y son susceptibles de clasificación.
Ejemplo: Color de autos: rojo, verde, azul.
UNIDAD DE ANÁLISIS: La unidad de análisis corresponde a la entidad mayor o
representativa de lo que va a ser objeto específico de estudio en una medición y se refiere
al qué o quién es objeto de interés en una investigación. Por ejemplo:
Debe estar claramente definida en un protocolo de investigación y el investigador debe
obtener la información a partir de la unidad que haya sido definida como tal, aun cuando,
para acceder a ella, haya debido recorrer pasos intermedios. Las unidades de análisis
pueden corresponder a las siguientes categorías o entidades:
Personas
Grupos humanos
Poblaciones completas
Unidades geográficas determinadas
Eventos o interacciones sociales (enfermedades, accidentes, casos de infecciones
intrahospitalarias, etc)
Entidades intangibles, susceptibles de medir (exámenes, días camas)
El tipo de análisis al que se someterá la información es determinante para elegir la unidad
de análisis.
EXPERIMENTO: Es una actividad planificada, cuyos resultados producen un conjunto
de datos. Es el proceso mediante el cual una observación o medición es registrada. En un
experimento se consideran todas las variables relevantes que intervienen en el fenómeno,
mediante la manipulación de las que presumiblemente son su causa, el control de las
variables extrañas y la aleatorización de las restantes. Estos procedimientos pueden variar

10
mucho según las disciplinas (no es igual en Física que en Psicología, por ejemplo), pero
persiguen el mismo objetivo: excluir explicaciones alternativas (diferentes a la variable
manipulada) en la explicación de los resultados. Este aspecto se conoce como validez
interna del experimento, la cual aumenta cuando el experimento es replicado por otros
investigadores y se obtienen los mismos resultados. Cada repetición del experimento se
llama prueba o ensayo.
Las distintas formas de realizar un experimento (en cuanto a distribución de unidades
experimentales en condiciones o grupos) son conocidas como diseños experimentales.
Ejemplo: ¿Cuál será la preferencia del consumidor ante dos marcas de refresco con
similares características en un ambiente armónico y sin publicidad?
ESCALAS DE MEDICIÓN
Medir significa “asignar números a objetos y eventos de acuerdo a reglas” (Stevens, 1951),
esta definición es adecuada para el área de ciencias naturales, en el campo de las ciencias
sociales medir es “el proceso de vincular conceptos abstractos con indicadores empíricos”
(Carmines y Zeller, 1979, p. 10).
La medición de las variables puede realizarse por medio de cuatro escalas de medición.
Dos de las escalas miden variables categóricas y las otras dos miden variables numéricas
(Therese L. Baker, 1997). Los niveles de medición son las escalas nominal, ordinal, de
intervalo y de razón. Se utilizan para ayudar en la clasificación de las variables, el diseño
de las preguntas para medir variables, e incluso indican el tipo de análisis estadístico
apropiado para el tratamiento de los datos.
Una característica esencial de la medición es la dependencia que tiene de la posibilidad de
variación. La validez y la confiabilidad de la medición de una variable depende de las
decisiones que se tomen para operacionalizarla y lograr una adecuada comprensión del
concepto evitando imprecisiones y ambigüedad, pero en caso contrario, la variable corre el
riesgo inherente de ser invalidada debido a que no produce información confiable. Se
conocen cuatro escalas de medición:
Escala Nominal: Usa nombres para designarlos, pueden usar números pero solo para
designarlos, sus clasificaciones no tiene un orden jerárquico. Por ejemplo, si la unidad de

11
análisis es un grupo de personas, para clasificarlas se puede establecer la categoría sexo
con dos niveles, masculino (M) y femenino (F), los respondientes solo tienen que señalar
su género, no se requiere de un orden real.
Así, si se asignan números a estos niveles solo sirven para identificación y puede ser
indistinto: 1=M, 2=F o bien, se pueden invertir los números sin que afecte la medición:
1=F y 2=M.
Escala Ordinal: son aquellas variables cuyas características de medición pueden ser
ordenadas jerárquicamente Las formas mas comunes de variables ordinales son ítems
(reactivos) actitudinales estableciendo una serie de niveles que expresan una actitud de
acuerdo o desacuerdo con respecto a algún referente. Por ejemplo, ante el ítem: La
economía mexicana debe dolarizarse, el respondiente puede marcar su respuesta de
acuerdo a las siguientes alternativas:
___ Totalmente de acuerdo
___ De acuerdo
___ Indiferente
___ En desacuerdo
___ Totalmente en desacuerdo
las anteriores alternativas de respuesta pueden codificarse con números que van del uno al
cinco que sugieren un orden preestablecido pero no implican una distancia entre un
número y otro. Las escalas de actitudes son ordinales pero son tratadas como variables
continuas (Therese L. Baker, 1997).
Escalas de Intervalo: registra de manera numérica la distancia entre dos puntos, el cero no
indica ausencia de variable y es arbitrario. El ejemplo mas representativo de este tipo de
medición es un termómetro, cuando registra cero grados centígrados de temperatura indica
el nivel de congelación del agua y cuando registra 100 grados centígrados indica el nivel
de ebullición, el punto cero es arbitrario no real, lo que significa que en este punto no hay
ausencia de temperatura.

12
Una persona que en un examen de matemáticas que obtiene una puntuación de cero no
significa que carezca de conocimientos, el punto cero es arbitrario por que sigue existiendo
la característica medida. Otros ejemplos son fecha de calendario, horas, etc.
Escala de Razón: Es una escala mas fuerte. Determina la distancia exacta entre los
intervalos de una categoría, el cero es absoluto e implica ausencia y la diferencia de dos
variables es de magnitud conocida. Es decir, en el punto cero no existe la característica o
atributo que se mide. Las variables de ingreso, edad, número de hijos, etc. son ejemplos de
este tipo de escala. El nivel de medición de razón se aplica tanto a variables continuas
como discretas.

13
UNIDAD II: Cálculo del tamaño muestral. Técnicas y Métodos para la recolección
de datos y diseños de cuestionarios.
Población
Es el conjunto de elementos de referencia sobre el que se realizan las observaciones. Es
decir el conjunto de sujetos o individuos con determinadas características demográficas, de
la que se obtiene la muestra para cualquier estudio a la que se quiere inferir los resultados
de dicho estudio. Las poblaciones pueden ser finitas, si existe un número fijo de estos
valores; e infinitas si la poblaión consiste en una sucesión interminable de valores.
Muestra
También llamada muestra aleatoria o simplemente muestra) es un subconjunto de casos o
individuos de una población estadística. Se obtienen con la intención de inferir propiedades
de la totalidad de la población, para lo cual deben ser representativas de la misma. Para
cumplir esta característica la inclusión de sujetos en la muestra debe seguir una técnica de
muestreo. En tales casos, puede obtenerse una información similar a la de un estudio
exhaustivo con mayor rapidez y menor costo. El muestreo puede ser más exacto que el
estudio de toda la población porque el manejo de un menor número de datos provoca
también menos errores en su manipulación.
Ventajas de la elección de una muestra
El estudio de muestras es preferible a los censos por las siguientes razones:
1. La población es muy grande (en ocasiones, infinita, como ocurre en determinados
experimentos aleatorios) y, por tanto, imposible de analizar en su totalidad.
2. Las características de la población varían si el estudio se prolonga demasiado tiempo.
3. Reducción de costos: al estudiar una pequeña parte de la población, los gastos de
recogida y tratamiento de los datos serán menores que si los obtenemos del total de la
población.
4. Rapidez: al reducir el tiempo de recogida y tratamiento de los datos, se consigue mayor
rapidez.
5. Viabilidad: la elección de una muestra permite la realización de estudios que serían
imposible hacerlo sobre el total de la población.

14
6. La población es suficientemente homogénea respecto a la característica medida, con lo
cual resultaría inútil malgastar recursos en un análisis exhaustivo (por ejemplo, muestras
sanguíneas).
7. El proceso de estudio es destructivo o es necesario consumir un artículo para extraer la
muestra (ejemplos: vida media de una bombilla, carga soportada por una cuerda,
precisión de un proyectil, etc.).
Espacio Muestral
Es el conjunto de todas las posibles muestras que se pueden extraer de una población
mediante una determinada técnica de muestreo.
Concepto e importancia del muestreo
Es la actividad por la cual se toman ciertas muestras de una población de elementos de los
cuales vamos a tomar ciertos criterios de decisión, el muestreo es importante porque a
través de él podemos hacer análisis de situaciones de una empresa o de algún campo de
la sociedad.
Terminología básica para el muestreo
Los nuevos términos, los cuales son frecuentemente usados en inferencia estadística son:
Estadístico:
Un estadístico es una medida usada para describir alguna característica de una muestra, tal
como una media aritmética, una mediana o una desviación estándar de una muestra.
Parámetro:
Una parámetro es una medida usada para describir alguna característica de una población,
tal como una media aritmética, una mediana o una desviación estándar de una población.
Cuando los dos nuevos términos de arriba son usados, por ejemplo, el proceso de
estimación en inferencia estadística puede ser descrito como le proceso de estimar un
parámetro a partir del estadístico correspondiente, tal como usar una media muestral ( un
estadístico para estimar la media de la población (un parámetro).
Distribución en el muestreo:
Cuando el tamaño de la muestra (n) es más pequeño que el tamaño de la población (N), dos
o más muestras pueden ser extraídas de la misma población. Un cierto estadístico puede

15
ser calculado para cada una de las muestras posibles extraídas de la población.
Una distribución del estadístico obtenida de las muestras es llamada la distribución en el
muestreo del estadístico.
Por ejemplo, si la muestra es de tamaño 2 y la población de tamaño 3 (elementos A, B, C),
es posible extraer 3 muestras (AB, BC y AC) de la población. Podemos calcular la media
para cada muestra. Por lo tanto, tenemos 3 medias muéstrales para las 3 muestras. Las 3
medias muéstrales forman una distribución. La distribución de las medias es llamada la
distribución de las medias muéstrales, o la distribución en el muestreo de la media. De la
misma manera, la distribución de las proporciones (o porcentajes) obtenida de todas las
muestras posibles del mismo tamaño, extraídas de una población, es llamada la
distribución en el muestreo de la proporción.
Error Estándar:
La desviación estándar de una distribución, en el muestreo de un estadístico, es
frecuentemente llamada el error estándar del estadístico. Por ejemplo, la desviación
estándar de las medias de todas la muestras posibles del mismo tamaño, extraídas de una
población, es llamada el error estándar de la media. De la misma manera, la desviación
estándar de las proporciones de todas las muestras posibles del mismo tamaño, extraídas de
una población, es llamada el error estándar de la proporción. La diferencia entre los
términos "desviación estándar" y "error de estándar" es que la primera se refiere a los
valores originales, mientras que la última está relacionada con valores calculados. Un
estadístico es un valor calculado, obtenido con los elementos incluidos en una muestra.
Error muestral o error de muestreo:
La diferencia entre el resultado obtenido de una muestra (un estadístico) y el resultado el
cual deberíamos haber obtenido de la población (el parámetro correspondiente) se llama el
error muestral o error de muestreo. Un error de muestreo usualmente ocurre cuando no se
lleva a cabo la encuesta completa de la población, sino que se toma una muestra para
estimar las características de la población. El error muestral es medido por el error
estadístico, en términos de probabilidad, bajo la curva normal. El resultado de la media
indica la precisión de la estimación de la población basada en el estudio de la muestra.
Mientras más pequeño el error muestras, mayor es la precisión de la estimación. Deberá
hacerse notar que los errores cometidos en una encuesta por muestreo, tales como
respuestas inconsistentes, incompletas o no determinadas, no son considerados como

16
errores muéstrales. Los errores no muéstrales pueden también ocurrir en una encuesta
completa de la población.
Métodos de selección de muestras.
Una muestra debe ser representativa si va a ser usada para estimar las características de la
población. Los métodos para seleccionar una muestra representativa son numerosos,
dependiendo del tiempo, dinero y habilidad disponibles para tomar una muestra y
la naturaleza de los elementos individuales de la población. Por lo tanto, se requiere un
gran volumen para incluir todos los tipos de métodos de muestreo.
Los métodos de selección de muestras pueden ser clasificados de acuerdo a:
1. El número de muestras tomadas de una población dada para un estudio y
2. La manera usada en seleccionar los elementos incluidos en la muestra. Los métodos de
muestreo basados en los dos tipos de clasificaciones son expuestos en seguida.
Métodos de muestreo clasificados de acuerdo con el número de muestras tomadas de una
población.
Bajo esta clasificación, hay tres tipos comunes de métodos de muestreo. Estos son,
muestreo simple, doble y múltiple.
Muestreo simple
Este tipo de muestreo toma solamente una muestra de una población dada para el propósito
de inferencia estadística. Puesto que solamente una muestra es tomada, el tamaño de
muestra debe ser lo suficientemente grande para extraer una conclusión. Una muestra
grande muchas veces cuesta demasiado dinero y tiempo.
Muestreo doble
Bajo este tipo de muestreo, cuando el resultado dele estudio de la primera muestra no es
decisivo, una segunda muestra es extraída de la misma población. Las dos muestras son
combinadas para analizar los resultados. Este método permite a una persona principiar con
una muestra relativamente pequeña para ahorrar costos y tiempo. Si la primera muestra
arroja una resultado definitivo, la segunda muestra puede no necesitarse.
Por ejemplo, al probar la calidad de un lote de productos manufacturados, si la primera
muestra arroja una calidad muy alta, el lote es aceptado; si arroja una calidad muy pobre, el
lote es rechazado. Solamente si la primera muestra arroja una calidad intermedia, será
requerirá la segunda muestra. Un plan típico de muestreo doble puede ser obtenido de la

17
Military Standard Sampling Procedures and Tables for Inspection by Attributes, publicada
por el Departamento de Defensa y también usado por muchas industrias privadas. Al
probar la calidad de un lote consistente de 3,000 unidades manufacturadas, cuando el
número de defectos encontrados en la primera muestra de 80 unidades es de 5 o menos, el
lote es considerado bueno y es aceptado; si el número de defectos es 9 o más, el lote es
considerado pobre y es rechazado; si el número está entre 5 y 9, no puede llegarse a una
decisión y una segunda muestra de 80 unidades es extraída del lote. Si el número de
defectos en las dos muestras combinadas (incluyendo 80 + 80 = 160 unidades) es 12 o
menos, el lote es aceptado si el número combinado es 13 o más, el lote es rechazado.
Muestreo múltiple
El procedimiento bajo este método es similar al expuesto en el muestreo doble, excepto
que el número de muestras sucesivas requerido para llegar a una decisión es más de dos
muestras.
Métodos de muestreo clasificados de acuerdo con las maneras usadas en seleccionar los
elementos de una muestra.
Los elementos de una muestra pueden ser seleccionados de dos maneras diferentes:
a. Basados en el juicio de una persona.
b. Selección aleatoria (al azar)
Muestreo de juicio
Una muestra es llamada muestra de juicio cuando sus elementos son seleccionados
mediante juicio personal. La persona que selecciona los elementos de la muestra,
usualmente es un experto en la medida dada. Una muestra de juicio es llamada una muestra
probabilística, puesto que este método está basado en los puntos de vista subjetivos de una
persona y la teoría de la probabilidad no puede ser empleada para medir el error de
muestreo, Las principales ventajas de una muestra de juicio son la facilidad de obtenerla y
que el costo usualmente es bajo.
Muestreo Aleatorio
Una muestra se dice que es extraída al azar cuando la manera de selección es tal, que cada
elemento de la población tiene igual oportunidad de ser seleccionado. Una muestra
aleatoria es también llamada una muestra probabilística son generalmente preferidas por
los estadísticos porque la selección de las muestras es objetiva y el error muestral puede ser
medido en términos de probabilidad bajo la curva normal. Los tipos comunes de muestreo

18
aleatorio son el muestreo aleatorio simple, muestreo sistemático, muestreo estratificado y
muestreo de conglomerados.
A. Muestreo aleatorio simple
Una muestra aleatoria simple es seleccionada de tal manera que cada muestra posible del
mismo tamaño tiene igual probabilidad de ser seleccionada de la población. Para obtener
una muestra aleatoria simple, cada elemento en la población tenga la misma probabilidad
de ser seleccionado, el plan de muestreo puede no conducir a una muestra aleatoria simple.
Por conveniencia, este método pude ser reemplazado por una tabla de números aleatorios.
Cuando una población es infinita, es obvio que la tarea de numerar cada elemento de la
población es infinita, es obvio que la tarea de numerar cada elemento de la población es
imposible. Por lo tanto, ciertas modificaciones del muestreo aleatorio simple son
necesarias. Los tipos más comunes de muestreo aleatorio modificado son sistemático,
estratificado y de conglomerados.
B. Muestreo sistemático.
Una muestra sistemática es obtenida cuando los elementos son seleccionados en una
manera ordenada. La manera de la selección depende del número de elementos incluidos
en la población y el tamaño de la muestra. El número de elementos en la población es,
primero, dividido por el número deseado en la muestra. El cociente indicará si cada
décimo, cada onceavo, o cada centésimo elemento en la población va a ser seleccionado.
El primer elemento de la muestra es seleccionado al azar. Por lo tanto, una muestra
sistemática puede dar la misma precisión de estimación acerca de la población, que una
muestra aleatoria simple cuando los elementos en la población están ordenados al azar.
C. Muestreo Estratificado
Para obtener una muestra aleatoria estratificada, primero se divide la población en grupos,
llamados estratos, que son más homogéneos que la población como un todo. Los elementos
de la muestra son entonces seleccionados al azar o por un método sistemático de cada
estrato. Las estimaciones de la población, basadas en la muestra estratificada, usualmente
tienen mayor precisión (o menor error muestral) que si la población entera muestreada
mediante muestreo aleatorio simple. El número de elementos seleccionado de cada estrato
puede ser proporcional o desproporcional al tamaño del estrato en relación con la
población.

19
D. Muestreo de conglomerados.
Para obtener una muestra de conglomerados, primero dividir la población en grupos que
son convenientes para el muestreo. En seguida, seleccionar una porción de los grupos al
azar o por un método sistemático. Finalmente, tomar todos los elementos o parte de ellos al
azar o por un método sistemático de los grupos seleccionados para obtener una muestra.
Bajo este método, aunque no todos los grupos son muestreados, cada grupo tiene una igual
probabilidad de ser seleccionado. Por lo tanto la muestra es aleatoria.
Una muestra de conglomerados, usualmente produce un mayor error muestral (por lo tanto,
da menor precisión de las estimaciones acerca de la población) que una muestra aleatoria
simple del mismo tamaño. Los elementos individuales dentro de cada "conglomerado"
tienden usualmente a ser iguales. Por ejemplo la gente rica puede vivir en el mismo barrio,
mientras que la gente pobre puede vivir en otra área. No todas las áreas son muestreadas en
un muestreo de áreas. La variación entre los elementos obtenidos de las áreas
seleccionadas es, por lo tanto, frecuentemente mayor que la obtenida si la población entera
es muestreada mediante muestreo aleatorio simple. Esta debilidad puede reducida cuando
se incrementa el tamaño de la muestra de área.
El incremento del tamaño de la muestra puede fácilmente ser hecho en muestra muestra de
área. Los entrevistadores no tienen que caminar demasiado lejos en una pequeña área para
entrevistar más familias. Por lo tanto, una muestra grande de área puede ser obtenida
dentro de un corto período de tiempo y a bajo costo.
Por otra parte, una muestra de conglomerados puede producir la misma precisión en la
estimación que una muestra aleatoria simple, si la variación de los elementos individuales
dentro de cada conglomerado es tan grande como la de la población.
DISEÑO DE CUESTIONARIOS
Supuestos.
El uso de cuestionarios en investigación supone que:
1. El investigador debe partir de objetivos de estudio perfectamente definidos.
2. Cada pregunta es de utilidad para el objetivo planteado por el trabajo.
3. El investigador debe estructurar las preguntas teniendo en mente siempre los
objetivos del trabajo.
4. El que contesta está dispuesto y es capaz de proporcionar respuestas fidedignas.

20
Confiabilidad.
Una pregunta es confiable si significa lo mismo para todos los que la van a responder.
Se puede confiar en una escala cuando produce constantemente los mismos resultados al
aplicarla a sujetos similares. La confiabilidad implica consistencia.
El investigador debe asegurarse que el tipo de persona a quien se le van a hacer las
preguntas tenga la información necesaria para poder responder.
El asegurar la respuesta de los que se les aplique el cuestionario redundará en resultados
confiables.
Para la confiabilidad de los resultados hay que determinar por qué no todos respondieron el
cuestionario. Es necesario investigar con los no respondientes para conocer las razones.
Un cuestionario largo es demasiado cansado y las preguntas finales se responden sin
entusiasmo, lo cual le resta confiabilidad.
Validez.
Una pregunta es válida si estimula información exacta y relevante. La selección y
la redacción influyen en la validez de la pregunta.
Algunas preguntas que son válidas para un grupo de personas, pueden no serlo para otro
grupo.
Entre menos tenga que reflexionar el sujeto, más válida será la respuesta.
La validez implica congruencia en la manera de plantear las preguntas.
La validez puede ser
De contenido
De criterio
De constructo
Para decir que un instrumento tiene validez de contenido el diseñador del cuestionario debe
asegurarse que la medición representa el concepto medido. Por ejemplo, si el instrumento
es para medir actitudes de las personas, debe medir eso y no sus emociones.
En cuanto a la validez de criterio, el diseñador del cuestionario la puede establecer
comparando la medición del instrumento con un criterio externo. Entre más se relacionen
los resultados de la investigación con el criterio, mayor será la validez del instrumento.
La validez del constructo indica cómo una medición se relaciona con otras de acuerdo con
la teoría o hipótesis que concierne a los conceptos que se están midiendo. De ahí que sea

21
importante que el investigador tome en cuenta dichos conceptos para correlacionarlos
posteriormente.
Cuatro preguntas clave.
1. ¿De cuánto tiempo disponen quienes responderán para contestar el cuestionario?
2. ¿Cuánto tiempo tiene el investigador para editarlo, presentarlo, aplicarlo,
codificarlo, procesarlo y analizarlo?
3. ¿Qué tan dispuestos están para responder quienes van a contestar?
4. ¿Cuánto costará su aplicación?
Antes de diseñar el cuestionario.
Es necesario determinar si el cuestionario tendrá preguntas abiertas o cerradas. Para el
análisis de las preguntas es mejor que éstas sean cerradas. Para cerrarlas, primero se deben
hacer las preguntas abiertas con una muestra de la población. Con estas respuestas, se
pueden diseñar las preguntas cerradas.
Es necesario estar seguros de que los encuestados respondan. Por eso es importante
conocer las opiniones de los posibles sujetos acerca del tema a investigar, antes de
diseñarlo.
El contacto inicial es fundamental para lograr que los encuestados respondan.
Hay que preparar una explicación para los encuestados sobre la importancia de su
participación y lo que se hará con los resultados de la investigación. En esta explicación se
les debe asegurar el anonimato de su participación y ofrecerles una copia del resumen del
trabajo cuando éste esté terminado (habrá que cumplir esta promesa).
No es conveniente mencionar que se está llevando a cabo este trabajo para cubrir un
requisito de graduación (tesis), sino la importancia real del estudio. Todo cuestionario debe
hacerse con ese propósito en mente.
El investigador tiene que pensar en cómo va a presentar los resultados antes de elaborar el
cuestionario. Hay que involucrar a alguien que sea responsable de capturar la información
de los cuestionarios así como a una persona que haga el procesamiento de los datos en
la computadora. Ellos pueden ayudar a determinar la mejor presentación de cada una de las
preguntas. Eso no lo va a hacer un asesor de tesis; es indispensable la ayuda profesional de
un experto en cómputo y en estadística.

22
Diseño del cuestionario.
El título del trabajo debe estar al inicio del cuestionario.
Hay que incluir instrucciones breves, pero incluirlas. Es conveniente usar una tipografía
diferente a la de las preguntas.
Al inicio deben colocarse preguntas interesantes, no amenazantes.
Los puntos importantes deben ir cercanos al inicio del cuestionario, después de las
preguntas interesantes.
Hay que numerar las preguntas.
Es importante agrupar las preguntas en secciones lógicas.
Debe haber una categoría para cada posible respuesta, pues si se omite una opción, se
forzará al que responde a contestar de una manera que no refleje su respuesta. Por eso en
ocasiones se necesita abrir una opción de "otros" con un renglón amplio para dejar esa
parte de la pregunta abierta. También, a veces, es necesario incluir una opción de "no sé",
pues si no existe ésta, el sujeto puede seleccionar cualquier respuesta simplemente para no
dejarla en blanco.
Consejos sobre la presentación.
La apariencia física de un cuestionario es la imagen del investigador con el encuestado. Su
misma forma motiva o impide su lectura. En cuestionarios largos, hay que identificar cada
página con alguna marca por si se separan las hojas. Lo mejor es no hacer cuestionarios
largos. Si hay preguntas por ambos lados de la página, al final de la primera hoja se debe
poner "vuelta". La hoja no debe verse sobrecargada. Los espacios vacíos son agradables.
Hay que dejar suficiente espacio entre cada una de las preguntas.
Consejos sobre el lenguaje.
Una redacción pobre influye en el resultado y también en la calidad de la respuesta
obtenida.
El sujeto no debe tener que adivinar lo que se quiso preguntar. La pregunta debe estar
escrita en lenguaje claro.
La palabra cuestionario asusta o intimida al que va a responder. Encuesta es mejor.
Las preguntas deben estar redactadas para no ofender al sujeto.

23
Hay que utilizar lenguaje común y corriente. No especializado.
No deben usarse palabras vagas ni palabras ambiguas o que tengan varios significados.
Las preguntas no deben estar en negativo.
No se debe abreviar.
Hay que ser sutil para cambiar de una sección a otra.
La formulación correcta de una pregunta es una tarea muy difícil, mucho más de lo que
una persona que nunca ha diseñado un cuestionario puede imaginarse. Hay que hacerlo con
cuidado.
Consejos generales.
El contestar un cuestionario es una imposición para quien lo contesta. Hay que estar
conscientes de ello.
El uso de un cuestionario es únicamente para hacer preguntas que no se pueden obtener de
ninguna otra manera.
Lo que recuerda el sujeto no se debe considerar como un hecho. Puede ser muy diferente el
hecho a lo que recuerda la persona que está respondiendo.
Todas las preguntas en el cuestionario tienen que ser analizadas. Por eso hay que
seleccionar únicamente reactivos indispensables para obtener los objetivos del trabajo.
Es indispensable pilotear el cuestionario.
Se debe establecer el procedimiento de análisis y evaluación de los resultados antes de
llevar a cabo la encuesta. Así se sabrá cómo analizar las respuestas.
Vale la pena consultar a expertos en estadística y en procesamiento de datos antes de
aplicar un cuestionario.
Las posibles respuestas tienen que estar cerca de las preguntas. Esto evita confusiones.
El decidir utilizar un cuestionario obedece a los indicadores que el autor determine en sus
fundamentos teóricos. Analizar los indicadores puede ayudar al investigador a determinar
que el cuestionario no es el instrumento adecuado para el estudio que desea realizar.
En general a la gente en México no le gusta responder a cuestionarios.

24
Análisis de preguntas abiertas.
Para analizar las preguntas abiertas se anotará en una hoja (#1) la respuesta a la primera
pregunta abierta del primer cuestionario. Si la respuesta a la primera pregunta del segundo
cuestionario es similar, se anotará en la misma hoja (#1). Si es diferente se anotará en otra
hoja (#2). Si la respuesta a la primer pregunta del tercer cuestionario es semejante a la del
primer cuestionario se anotará en esa hoja (#1); si es similar a la del segundo cuestionario
se anotará en esa hoja (#2) y si es diferente a ambas respuestas se anotará en una tercera
hoja (#3) y así sucesivamente hasta terminar con la primera pregunta de todos los
cuestionarios. Una vez terminado el análisis de la primera pregunta de todos los
cuestionarios, se seleccionará la mejor redactada o bien se hará un resumen de todas las
respuestas en cada una de las tarjetas y se anotará el número de respuestas a cada tarjeta.
Posteriormente se hará lo mismo con cada una de las preguntas abiertas que se hayan
hecho en el cuestionario.
Análisis de los resultados.
Es necesario una revisión detallada de lo que se introduce a la computadora para asegurar
que la información que entre a ella sea la que está plasmada en el cuestionario. Hay que
revisar la información capturada con cada cuestionario. No se debe esperar hasta el final,
pues pudiera suceder que es necesario hacer todo de nuevo.
Algunos consejos para entrevistas.
Si la entrevista es en una oficina, es necesario asegurarse que el entrevistado estará
disponible y que tiene el tiempo para responder a las preguntas.
El entrevistador tiene que ser muy objetivo en sus presentaciones para que en todas se
utilice el mismo tono de voz, pronunciación de los reactivos, modismos, el lenguaje del
cuerpo y vestimenta. Todo esto influye en las respuestas y se trata de que todos los
entrevistados entiendan lo mismo y estén motivados de la misma manera.
El entrevistar en la casa del sujeto a veces resulta práctico para el entrevistado. Quizá a
través de una llamada por teléfono, se pueda hacer una cita con él.
Hay tres factores importantes en una entrevista:

25
1. La calidad del entrevistador. Hay que aprender a establecer un contacto positivo desde
el primer momento. Hay cosas impredecibles que afectarán sin que el entrevistador
pueda remediarlas: la edad, el sexo, su manera de vestir y su personalidad. Ni modo. Por
eso hay que cuidar todo lo demás.
2. La introducción que hace el entrevistador al entrevistado. Le tiene que indicar el
objetivo del estudio y debe convencerlo de que vale la pena responder a sus preguntas.
3. La manera como está estructurada la entrevista. Hay que iniciar con preguntas
interesantes para "enganchar" al entrevistado.

26
UNIDAD III: Tablas de frecuencia, gráficos. Medidas de Tendencia Central. Medidas
de Posición. Medidas de Dispersión. Asimetría y Kurtosis.
Una distribución de frecuencias o tabla de frecuencias es una ordenación en forma de tabla
de los datos estadísticos, asignando a cada dato su frecuencia correspondiente.
Tipos de frecuencia
Frecuencia absoluta
La frecuencia absoluta es el número de veces que aparece un determinado valor en un
estudio estadístico.
Se representa por fi.
La suma de las frecuencias absolutas es igual al número total de datos, que se representa
por N.
Para indicar resumidamente estas sumas se utiliza la letra griega Σ (sigma mayúscula) que
se lee suma o sumatoria.
Frecuencia relativa
La frecuencia relativa es el cociente entre la frecuencia absoluta de un determinado valor y
el número total de datos.
Se puede expresar en tantos por ciento y se representa por ni.
La suma de las frecuencias relativas es igual a 1.
Frecuencia acumulada

27
La frecuencia acumulada es la suma de las frecuencias absolutas de todos los valores
inferiores o iguales al valor considerado.
Se representa por Fi.
Frecuencia relativa acumulada
La frecuencia relativa acumulada es el cociente entre la frecuencia acumulada de un
determinado valor y el número total de datos. Se puede expresar en tantos por ciento.
Ejemplo para variables cuantitativas discretas.
Si se conoce el número de hijos de 31 trabajadores de una empresa:
0, 7, 4, 4, 6, 4, 4, 4, 1, 1, 2, 2, 2, 3, 3, 3, 5, 3, 4, 4, 4, 2, 2, 2, 3, 3, 3, 5, 5, 6, 6.
En la primera columna de la tabla colocamos la variable ordenada de menor a mayor, en la
segunda hacemos el recuento y en la tercera anotamos la frecuencia absoluta.
xi Recuento fi Fi ni Ni ni% Ni%
0 I 1 1 0.032 0.032 3.2 3.2
1 II 2 3 0.065 0.097 6.5 9.7
2
6 9 0.194 0.290 19.4 29.0
3
7 16 0.226 0.516 22.6 51.6
4
8 24 0.258 0.774 25.8 77.4
5 III 3 27 0.097 0.871 9.7 87.1
6 III 3 30 0.097 0.968 9.7 96.8
7 I 1 31 0.032 1 3.2 100.0
Total 31 - 1 - 100.0 -

28
Distribución de frecuencias agrupadas
La distribución de frecuencias agrupadas o tabla con datos agrupados se emplea si las
variables toman un número grande de valores o la variable es continua.
Se agrupan los valores en intervalos que tengan la misma amplitud denominados clases. A
cada clase se le asigna su frecuencia correspondiente.
Límites de la clase
Cada clase está delimitada por el límite inferior de la clase y el límite superior de la clase.
Amplitud de la clase
La amplitud de la clase es la diferencia entre el límite superior e inferior de la clase.
Marca de clase
La marca de clase es el punto medio de cada intervalo y es el valor que representa a todo el
intervalo para el cálculo de algunos parámetros.
Construcción de una tabla de datos agrupados.
1º se localizan los valores menor y mayor de la distribución.
R = número máximo – número menor
2º Encontrar el número de clases o intervalos de clases (K). El número de clases debe ser
tal que se evite el detalle innecesario, pero que no conduzca a la perdida de más
información de la que puede ser convenientemente ignorada. Para este cálculo se utiliza la
formula de Sturges:
K = 1 + 3.322log(n)
2º Determinar la amplitud o constante.
C = R /K
Ejemplo para variables cuantitativas continuas
La tienda CABRERA’S Y ASOCIADOS estaba interesada en efectuar un análisis de sus
cuentas por comprar. Uno de los factores que más interesaba a la administración de la
tienda era el de los saldos de las cuentas de crédito. Se escogió al azar una muestra
aleatoria de 30 cuentas y se anotó el saldo de cada cuenta (en unidades monetarias) como
sigue:

29
77.97 13.02 17.97 89.19 12.18 8.15 34.40 43.13 79.61 90.99 43.66 29.75 7.42 93.91 20.64
21.10 17.64 81.59 60.94 43.97 32.67 43.66 51.69 53.40 68.13 11.10 12.98 38.74 70.15
25.68
donde: X1 = valor mínimo = 7.42
Xn= valor máximo = 93.91
1. Efectuar el arreglo ordenado de la población o muestra:
R = valor mayor – valor menor = 93.91 – 7.42 = 86.49
2. Encontrar el número de filas o clases que tendrá la tabla
K=1+3.322(log N)
Nota: en el ejemplo en estudio N=30 por cuanto que son 30 clientes en la muestra:
K = 1 + 3.322 (log 30)
= 1 + 3.322 (1.477) el log fue obtenido según calculadora
= 1+ 4.9069
= 5.9069 ~6 aproximado al siguiente entero
3. Determinar la amplitud de la clase: "C"
Nota: obsérvese que se va a trabajar con una cifra significativa más cómoda, o sea como
los datos están dados en centésimos, se calculo C hasta el milésimo para evitar que algún
dato coincida con el límite de clases

30
Clases Xi fi Fi< Fi> ni Ni ni% Ni%
7.420 – 21.835 14.628 10 10 30 0.33 0.33 33.0 33.0
21.835 – 36.250 29.043 4 14 20 0.13 0.46 13.0 46.0
36.250 – 50.665 43.458 5 19 16 0.17 0.63 17.0 63.0
50.665 – 65.080 57.873 3 22 11 0.10 0.73 10.0 73.0
65.080 – 79.495 72.288 3 25 8 0.10 0.83 10.0 83.0
79.495 – 93.910 86.703 5 30 5 0.17 1.00 17.0 100.0
Total - 30 - - 1.00
100.0 -
Simbología utilizada:
Xi = Punto medio o marca de clases.
fi = frecuencia absoluta simple.
Fi> = frecuencia absoluta acumulada mayor que.
Fi< = frecuencia absoluta acumulada menor que.
ni = frecuencia relativa simple.
Ni = frecuencia relativa acumulada.
ni% = frecuencia relativa simple porcentual.
Ni% = frecuencia relativa acumulada porcentual.
Tipos de curvas de frecuencia

31
MEDIDAS DE TENDENCIA CENTRAL
Son indicadores estadísticos quemuestran hacia que valor (o valores) se agrupan los datos.
Entre las principales medidas tenemos:
La media aritmética
La moda
La mediana
Media Aritmética
Es aquella medida que se obtiene al dividir la suma de todos los valores de una variable
por la frecuencia total. En palabras más simples, corresponde a la suma de un conjunto de
datos dividida por el número total de dichos datos. Y se calcula con el fin de representar al
conjunto de datos.
Para datos desagrupados:
X = ∑ Xi / n
Para datos agrupados:
X = ∑( Xi*fi) / n
Mediana
Para reconocer la mediana, es necesario tener ordenados los valores sea de mayor a menor
o lo contrario. Usted divide el total de casos (N) entre dos, y el valor resultante
corresponde al número del caso que representa la mediana de la distribución.
Es el valor central de un conjunto de valores ordenados en forma creciente o decreciente.
Dicho en otras palabras, la Mediana corresponde al valor que deja igual número de valores
antes y después de él en un conjunto de datos agrupados.
Para datos desagrupados
Según el número de valores que se tengan se pueden presentar dos casos:
- Si el número de valores es impar, la Mediana corresponderá al valor central de
dicho conjunto de datos.
- Si el número de valores es par, la Mediana corresponderá al promedio de los dos
valores centrales (los valores centrales se suman y se dividen por 2).
Para datos agrupados

32
Me = Li + ( C (n/2 - Fi – 1) / (Fi - Fi – 1) )
Donde:
n = muestra
F(i – 1) = frecuencia acumulada “menor que” anterior a la clase seleccioanada.
Fi = frecuencia acumulada seleccionada (inmediatamente superior a n/2)
Moda
Es la medida que indica cual dato tiene la mayor frecuencia en un conjunto de datos; o
sea, cual se repite más.
Para datos desagrupados: la moda es el dato que se repite con mayor frecuencia. Se tiene 4
tipos:
- Unimodal (una moda)
- Bimodal (dos modas)
- Trimodal (tres modas)
- Multimodal (mas de tres modas)
Para datos agrupados
Mo = Li + C (fi – 1 / (fi – 1 + fi + 1 ) )
Medidas de Posición
Cuartiles
Los cuartiles son medidas estadísticas de posición que tienen la propiedad de dividir la
serie estadística en cuatro grupos de números iguales de términos.
Se emplean generalmente en la determinación de estratos o grupos correspondientes a
fenómenos socio-económicos, monetarios o teóricos. Los tres cuartiles suelen designarse
con los símbolos:
Q1 = primer cuartil
Q2 = segundo cuartil
Q3 = tercer cuartil

33
En lo que se refiere a los cuartiles, el número de orden del primer cuartil es igual al número
de términos de la distribución más uno, sobre cuatro. Para el segundo cuartil el número de
orden se calculará sumando uno al total de términos y dividiéndolo entre dos.
Así mismo el número de orden del tercer cuartil ser igual a tres cuartos del número de
términos de la distribución más uno.
Para datos Desagrupados
a) Si se adopta el símbolo No Q para denotar el número de orden, donde: No es el
número de términos y Q el cuartil a calcular, entonces en el ejemplo cuyos
términos son: 3, 4, 5, 7, 8, 10, 11, que es número de términos impar, el número de
orden se calcula así:
NoQ1 = (N + 1) / 4 = (7+1)/4 = 2, el cual indica que el valor jdel segundo término (4)
es el valor de Q1, luego Q1 =4
NoQ2 = (N + 1) / 2 = (7+1)/2 = 4, el cual indica que el valor del cuarto término (7) es
el valor de Q2 , y Q2=7
NoQ3 = 3(N + 1) / 4 = 3(7+1)/4 = 6, que indica que el valor del sexto término (10) es
el valor de Q3 , y Q3 = 10
b) Cuando el número de términos es par como la distribución constituida por: 3, 4, 5,
7, 9, 10, 11, 14
NoQ1 = (No + 1) / 4 = (8+1)/4 = 2.25, luego Q1 =4.25
NoQ2 = (No + 1) / 2 = (8+1)/2 = 4.5, luego Q2 =8
NoQ3 = 3(No + 1) / 4 = 3(8+1)/4 = 6.75, luego Q3 =10.75
Para datos Agrupados
Qi = Li + [C ( i(N + 1) / 4 - Fi – 1) / (Fi - Fi – 1) ]
Donde: i=1, 2, 3
n = muestra
F(i – 1) = frecuencia acumulada “menor que” anterior a la clase seleccioanada.
Fi = frecuencia acumulada seleccionada inmediatamente superior a (i(N+1)/4)

34
Deciles
Los deciles son medidas estadísticas de posición que tienen la propiedad de dividir la
serie estadística en diez grupos de números iguales de términos. D1, D2,…..D9.
Para el cálculo de estas nueve medidas de posición es necesario arreglar los términos
en forma creciente o decreciente. Así, en el caso de un ordenamiento simple, el
siguiente paso es determinar el "número de orden" de los deciles, el cual indicará el
lugar que ocupen en la distribución.
Para datos desagrupados
NoDi = i (No + 1) / 10 donde i=1, 2, 3, 4, 5, 6, 7, 8, 9
Para datos Agrupados
Di = Li + [C ( i(N + 1) 10 - Fi – 1) / (Fi - Fi – 1) ]
Donde: i=1, 2, 3
n = muestra
F(i – 1) = frecuencia acumulada “menor que” anterior a la clase seleccioanada.
Fi =frecuencia acumulada seleccionada inmediatamente superior a (i(N+1)/10)
Percentiles
Los Percentiles son medidas estadísticas de posición que tienen la propiedad de dividir
la serie estadística en cien grupos de números iguales de términos. P1, P2,…..P99.
Para el cálculo de estas noventainueve medidas de posición es necesario arreglar los
términos en forma creciente o decreciente. Así, en el caso de un ordenamiento simple,
el siguiente paso es determinar el "número de orden" de los percentiles, el cual indicará
el lugar que ocupen en la distribución.
Para datos desagrupados
NoPi = i (No + 1) / 100 donde i=1, 2, 3, 4, 5,……99
Para datos Agrupados
Pi = Li + [C ( i(N + 1) 100 - Fi – 1) / (Fi - Fi – 1) ]
Donde: i=1, 2, 3, ….99
n = muestra
F(i – 1) = frecuencia acumulada “menor que” anterior a la clase seleccioanada.
Fi =frecuencia acumulada seleccionada inmediatamente superior a (i(N+1)/100).

35
Medidas de Asimetría
1) Las basadas en el grado de alejamiento que tiene los términos con respecto a diversas
medidas centrales a medida que la distribución se hace asimétrica.
2) Las basadas en el sistema de momentos (A3 ).
En lo que se refiere a las primeras, estas medidas nos indican no sólo el grado de asimetría
de la curva sino también la dirección de la misma. Si su valor es negativo, la asimetría es
hacia la izquierda y si es positiva la asimetría será hacia la derecha. De (1) usaremos el
coeficiente Pearson, como se recordará en una distribución simétrica la media, moda y
mediana, se encuentran en el mismo punto. Si la distribución es asimétrica, el valor de cada
uno de ellos se localizan en diferentes puntos de la distribución.
Puesto que en una distribución asimétrica el valor de la moda permanece en lo alto de la
curva y el de la media se mueve hacia los extremos de la distribución, usando el coeficente
Pearson tendremos que:
Asimetría = (X−Mo) / σ
Cuando no se conoce la moda o es difícil localizarla, pero se conoce la mediana, el
coeficiente de Pearson será:
Asimetría = 3(X−Md) / σ
Luego la asimetría o dirección de la curva de la distribución es a la derecha (si asimetría <
0), indicando que la mayor parte de los datos están a la derecha del promedio. Y hacia la
izquierda si la asimetría es > 0.
Medidas de Kurtosis
Esta medida determina el grado de concentración que presentan los valores en la región
central de la distribución. Por medio del Coficiente de Curtosis, podemos identificar si

36
existe una gran concentración de valores (Leptocúrtica), una concentración normal
(Mesocúrtica) ó una baja concentración (Platicúrtica).
Donde (g2) representa el coeficiente de Curtosis, (Xi) cada uno de los valores, ( ) la
media de la muestra y (ni) la frecuencia de cada valor. Los resultados de esta fórmula se
interpretan:
(g2 = 0) la distribución es Mesocúrtica: Al igual que en la asimetría es bastante
difícil encontrar un coeficiente de Curtosis de cero (0), por lo que se suelen aceptar
los valores cercanos (± 0.5 aprox.).
(g2 > 0) la distribución es Leptocúrtica
(g2 < 0) la distribución es Platicúrtica
Medidas de dispersión
Rango o recorrido
El rango es la diferencia entre el mayor y el menor de los datos de una distribución
estadística.
R = N° máx. - N° mín.

37
Desviación Media
La desviación respecto a la media es la diferencia entre cada valor de la variable
estadística y la media aritmética.
Di = x – x
La desviación media es la media aritmética de los valores absolutos de las desviaciones
respecto a la media. La desviación media se representa por
Para datos desagrupados:
Para datos agrupados seria:
Varianza
La varianza es la media aritmética del cuadrado de las desviaciones respecto a la
media de una distribución estadística. La varianza se representa por .

38
Para datos desagrupados:
Una forma mas simple
Para datos agrupados:
Una forma mas simple
Desviación Estándar:
Es la raíz cuadrada de la varianza. Es decir, la raíz cuadrada de la media de los cuadrados
de las puntuaciones de desviación. Y mide la distancia promedio entre los datos.
σ = Ѵ σ2
Coeficiente de Variación de Pearson:
Las medidas de tendencia central tienen como objetivo el sintetizar los datos en un valor
representativo, las medidas de dispersión nos dicen hasta que punto estas medidas de
tendencia central son representativas como síntesis de la información. Las medidas de

39
dispersión cuantifican la separación, la dispersión, la variabilidad de los valores de la
distribución respecto al valor central. Distinguimos entre medidas de dispersión absolutas,
que no son comparables entre diferentes muestras y las relativas que nos permitirán
comparar varias muestras.
El problema de las medidas de dispersión absolutas es que normalmente son un indicador
que nos da problemas a la hora de comparar. Comparar muestras de variables que entre sí
no tienen cantidades en las mismas unidades, de ahí que en ocasiones se recurra a medidas
de dispersión relativas.
Un problema que se plantea, tanto la varianza como la desviación estándar, especialmente
a efectos de comparaciones entre distribuciones, es el de la dependencia respecto a las
unidades de medida de la variable. Cuando se quiere comparar el grado de dispersión de
dos distribuciones que no vienen dadas en las mismas unidades o que las medias no son
iguales se utiliza el llamado "Coeficiente de Variación de Pearson", del que se demuestra
que nos da un número independiente de las unidades de medidas empleadas, por lo que
entre dos distribuciones dadas diremos que posee menor dispersión aquella cuyo
coeficiente de variación sea menor., y que se define como la relación por cociente entre la
desviación estándar y la media aritmética; o en otras palabras es la desviación estándar
expresada como porcentaje de la media aritmética.
Definición del Coeficiente de Variación
Donde: C.V. representa el número de veces que la desviación típica contiene a la media
aritmética y por lo tanto cuanto mayor es CV mayor es la dispersión y menor la
representatividad de la media.
Propiedades del Coeficiente de Variación:
Si a todos los valores de la variable se le suma una misma constante el coeficiente
de variación queda alterado.

40
UNIDAD III: REGRESIONES Y CORRELACIONES
La regresión como una técnica estadística, una de ellas la regresión lineal simple y la
regresión multifactorial, analiza la relación de dos o mas variables continuas, cuando
analiza las dos variables a esta se le conoce como variable bivariante que puede
corresponder a variables cualitativas, la regresión nos permite el cambio en una de las
variables llamadas respuesta y que corresponde a otra conocida como variable explicativa,
la regresión es una técnica utilizada para inferir datos a partir de otros y hallar una
respuesta de lo que puede suceder.
Siendo así la regresión una técnica estadística, por lo tanto para interpretar situaciones
reales, pero a veces se manipula de mala manera por lo que es necesario realizar una
selección adecuada de las variables que van a construir las formulas matemática, que
representen a la regresión, por eso hay que tomar en cuenta variables que tiene relación, de
lo contraria se estaría matematizando un galimatías.
Se pueden encontrar varios tipos de regresión, por ejemplo:
1. Regresión lineal simple
2. Regresión múltiple ( varias variables)
3. Regresión logística
La regresión lineal técnica que usa variables aleatorias, continuas se diferencia del otro
método analítica que es la correlación, porque esta última no distingue entre las variables
respuesta y la variable explicativa por que las trata en forma simétrica.
La matematización nos da ecuaciones para manipular los datos, como por ejemplo medir el
gasto de acuerdo al ingreso económico promedio anual de una familia, aquí podemos
inferir o predecir que el gasto variará de acuerdo al nivel de ingreso de cada familia, en
este ejercicio el gasto es la respuesta y el ingreso económico la variable explicativa.
En la regresión tenemos ecuaciones que nos representan las diferentes clases de regresión:
Regresión Lineal: y = A + Bx
Regresión Logarítmica: y = A + BLn(x)
Regresión Exponencial: y = Ac(bx)
Regresión Cuadrática: y = A + Bx +Cx2
Para obtener un modelo de regresión es suficiente establecer la regresión para eso se hace
uso del coeficiente de correlación: R.

41
R = Coeficiente de correlación, este método mide el grado de relación existente entre dos
variables, el valor de R varía de -1 a 1, pero en la práctica se traba con un valor absoluto de
R.
El valor del coeficiente de relación se interpreta de modo que a media que R se aproxima a
1, es más grande la relación entre los datos, por lo tanto R (coeficiente de correlación)
mide la aproximación entre las variables.
El coeficiente de correlación se puede clasificar de la siguiente manera:
CORRELACIÒN VALOR O RANGO
1) Perfecta R = 1
2) Excelente R = 0.9 < = R < 1
3) Buena R = 0.8 < = R < 0.9
4) Regular R = 0.5 < = R < 0.8
5) Mala R < 0.5
DISTRIBUCIÒN BIVARIANTE
La distribución bivariante es cuando se estudia en una población dos variables, que forman
pares correspondientes a cada individuo, como por Ejm:
Las notas de 10 alumnos en biología y lenguaje
BIOLOGIA 2 4 5 5 6 6 7 7 8 9
LENGUAJE 2 2 5 5 5 7 5 8 7 10
Los pares de valores son: ( 2, 2) (4,2) (5,5)…….(8,7) (9,10) forman una distribución
bivariante.
La correlación, método por el cual se relacionan dos variables se pude graficar con un
diagrama de dispersión de puntos, a la cual muchos autores le llaman nubes de puntos,
encuadrado dentro de un gráfico de coordenadas X Y en la cual se pude trazar una recta y
cuyos puntos mas cercanos de una recta hablaran de una correlación mas fuerte, ha esta
recta se le denomina recta de regresión, que puede ser positiva o negativa, la primera
contundencia a aumentar y la segunda en descenso o decreciente.

42
También se puede describir un diagrama de dispersión en coordenadas cartesianas valores
como en la distribución bivariante, en donde la nube de puntos representa los pares de
valores.
GRAFICOS DE DISPERSIÓN DE UNA RECTA DE REGRESIÒN
Por último se pueden graficar las líneas de tendencia, herramienta muy útil para el
mercadeo porque es utilizada para evaluar la resistencia que proyectan los precios. Cuando
una línea de tendencia central se rompe ya sea con tendencia al alza o en la baja es porque
ocurre un cambio en los precios, por lo tanto las líneas de tendencia pueden ser alcista
cuando se unen los puntos sucesivos y bajista cuando se unen los puntos máximos.
También existen gráficos que representan la dispersión de datos dentro de las coordenadas
cartesianas, ósea las nubes de puntos y que pueden darse según la relación que representa,
que puede ser lineal, exponencial y sin relación, esta última cuando los puntos están
dispersos en todo el cuadro sin agruparse lo cual sugiere que no hay relación.

43
Los gráficos siguientes nos muestran esta relación:
Matemáticamente las ecuaciones serían:
Ajuste Lineal: Y = Bx + A
Ajuste Logarítmico: Y =BLnX + A
Ajuste Exponencial: Y = AC BX
En el modelo de regresión lineal simple se utiliza la técnica de estimación de los mínimos
cuadrados, este modelo tiene solo una variable de predicción y se supone una ecuación de
regresión lineal.
Es evidente que no todos dibujaríamos exactamente la misma recta para una nube de
puntos, aunque la correlación fuera bastante fuerte.
De todas las rectas posibles los matemáticos han elegido como la mejor aproximación la
llamada de los mínimos cuadráticos, Su cálculo es también algo mecánico que podemos
hacer con calculadora o un ordenador. En el siguiente apartado encontrarás un ejercicio
para estudiar sus propiedades.
La recta de regresión sirve para hacer estimaciones, teniendo en cuenta que:
Los valores obtenidos son aproximaciones en términos de probabilidad: es probable
que el valor correspondiente a x0 sea y0.
La fiabilidad es mayor cuanto más fuerte sea la correlación.
La fiabilidad aumenta al aumentar el número de datos.
La estimación es más fiable para los valores de x próximos a la media.

44
EPILOGO
Mientras elaborábamos este texto, se nos vino a la mente muchas técnicas, ecuaciones
diagramas y conteos que servirán a muchos estudiantes e investigadores de la rama
empresarial para solucionar los problemas económicos y administrativos, utilizando estas
herramientas presentadas de una manera bastante didáctica y sencilla de entender y aplicar,
Otras técnicas que bien existen, pero cuyo desarrollo es un poco complicado para quienes
no tienen mucha familiaridad con las matemáticas se ha reemplazado por otras mas
sencillas de aplicar en este campo.
Finalmente si este texto contribuyó un ápice en dar a algún investigador una visión mas
amplia de la aplicación de la estadística en la rama empresarial, nos damos por satisfechos.

45
GLOSARIO DE TÉRMINOS
SÍMBOLO SIGNIFICA SE DICE
x media aritmética x barra
σ Error estándar poblacional Sigma
σx Error estándar de la media Sigma subíndice x
Dx Desviación media D subíndice x

46
Bibliografía
1 ANDERSON S. Williams. Estadística para administración y economía. Internacional
Thomson editores. Volumen I y II Séptima Edición 2005.
2 DEVORE, Jay. PROBABILIDAD Y ESTADÍSTICA PARA INGENIERÍA Y
CIENCIAS. 4º Edición. Internacional Thomson Publishing 2002.
3 LIND MASON MARCHAL. Estadistica para administradores y economia. Mc. Draw
Hill tercera edición 2001.
4 BERESON, Mark./ LEVINE, Dadid. Estadística básica en administración: conceptos y
aplicaciones. Sexta edición. Editorial Prentice Hall México 2000.
4 CORDOVA Zamora Manuel. Estadística Descriptiva e Inferencial. Cuarta Edición.
Editorial Moshera RL. Lima Perú 2000.
5 STEVENSON William. ESTADÍSTICA PARA ADMINISTRACIÓN Y ECONOMÍA.
ED HARLA – MÉXICO 2000.
6 GUERRERO G. VIERE M. Estadística para estudiantes de economía y otras ciencias
sociales. Primera Edición fondo de cultura económica. México 1989.
7 HOEL Paúl G. Estadística básica para negocios y economía. Tercera edición. Editorial
continental. México 1999.
8 Levin, Richard I.: “Estadística para Administradores”. Sexta Edición. Prentice – Hall
Hispanoamericana S.A. México 1996.

47
APENDICE
EJERCICICOS DE ESTADÍSTICA BÁSICA
Ejemplo1:
Suponga que un investigador desea determinar cómo varía el peso de un grupo de
estudiantes de primer semestre de una universidad. Selecciona una muestra de 50
estudiantes y registra sus pesos en kilogramos. Los datos obtenidos fueron los
siguientes:
65 63 65 63 69 67 53 58 60 61
64 65 64 72 68 66 55 57 60 62
64 65 64 71 68 66 56 59 61 62
63 65 63 70 67 66 57 59 61 62
64 64 63 69 67 66 58 60 61 62
Para determinar el número de veces que aparece cada dato (frecuencia absoluta), se
utiliza el diagrama de tallo y hojas. Se traza una línea y a la izquierda se escriben las
cifras anteriores a las unidades que tengan los datos, a la derecha de la línea se
escriben la cifra de las unidades para cada uno de los datos. Este diagrama facilita
determinar la cantidad de veces que se repite un dato y los valores de los datos con el
fin de escribirlos de manera ordenada en la tabla.
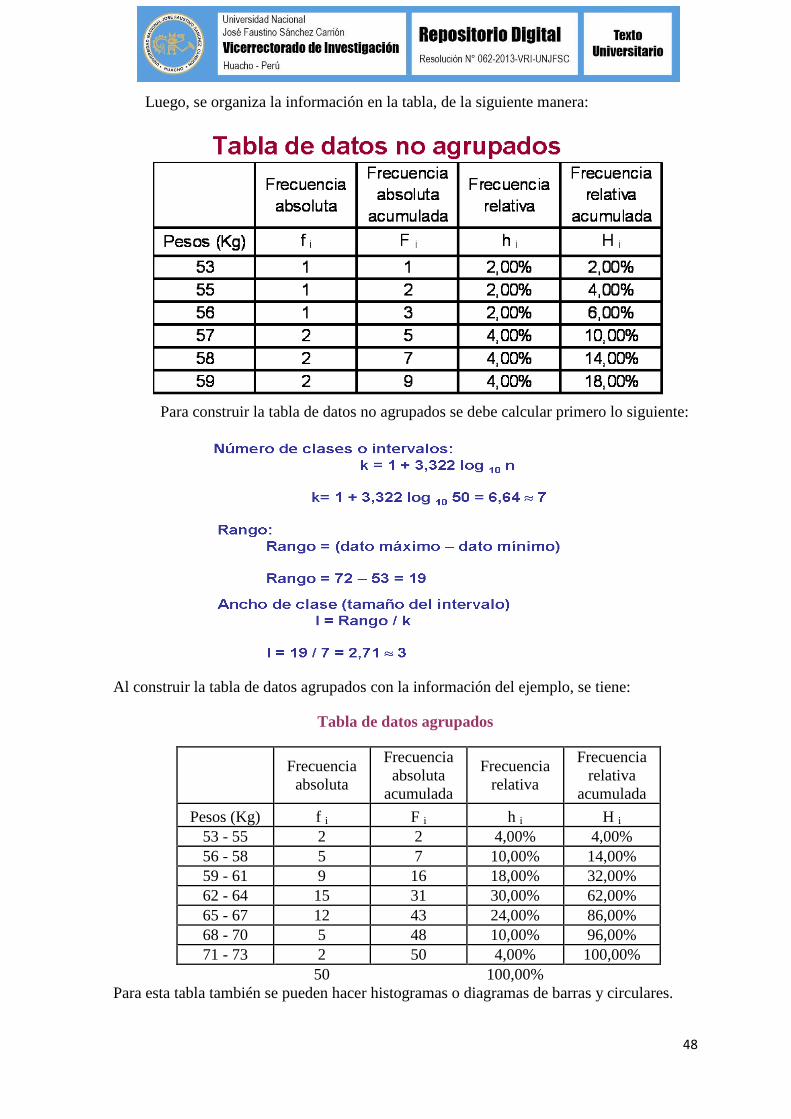
48
Luego, se organiza la información en la tabla, de la siguiente manera:
Para construir la tabla de datos no agrupados se debe calcular primero lo siguiente:
Al construir la tabla de datos agrupados con la información del ejemplo, se tiene:
Tabla de datos agrupados
Frecuencia
absoluta
Frecuencia
absoluta
acumulada
Frecuencia
relativa
Frecuencia
relativa
acumulada
Pesos (Kg) f i F i h i H i
53 - 55 2 2 4,00% 4,00%
56 - 58 5 7 10,00% 14,00%
59 - 61 9 16 18,00% 32,00%
62 - 64 15 31 30,00% 62,00%
65 - 67 12 43 24,00% 86,00%
68 - 70 5 48 10,00% 96,00%
71 - 73 2 50 4,00% 100,00%
50 100,00%
Para esta tabla también se pueden hacer histogramas o diagramas de barras y circulares.

49
Ejemplo2:
Si los datos están agrupados ya sea en tablas de frecuencias simples o en intervalos de
clase, debemos utilizar un criterio diferente para calcular los distintos estadígrafos.
Analicemos el siguiente ejemplo:
Consideremos la siguiente distribución de frecuencias que corresponden a los puntajes de
50 alumnos en una prueba.
Intervalos M.C.
(x) fi f·x Fa
[60 – 65) 62,5 5 312.5 5
[65 – 70) 67,5 5 337.5 10
[70 – 75) 72,5 8 580 18
[75 – 80) 77,5 12 930 30 Intervalo mediano
[80 – 85) 82,5 16 1320 46 Intervalo modal
[85 – 90) 87,5 4 350 50
TOTALES 50 3830
La Media Aritmética:
f
xfx
· 6.76
50
3830x ptos. 77 ptos.
Para calcular La Mediana necesitamos la siguiente fórmula:
i
a
f
AFn
LMe
·2
en el ejemplo, la cantidad de datos es 50, luego 50 : 2 = 25, y la Fa 25 se encuentra en el
intervalo [75 – 80) ya que el 25 esta aquí, en cambio en la anterior (18) no esta. Luego el
intervalo mediano es [75 – 80)
Entonces: L = 75 (límite inferior)
fi = 8
A = 5 (80 – 75 = 5)
Fa = 18 (frecuencia acumulada del intervalo anterior)
Donde: L es el límite inferior del intervalo mediano.
Fa es la frecuencia acumulada hasta antes del
intervalo mediano.
fi es la frecuencia absoluta del intervalo
mediano.
A es la Amplitud del intervalo.

50
375.79375.4758
5·775
8
5·182
50
75
Me 79 ptos.
y finalmente, para calcular la Moda en datos agrupados, utilizamos la siguiente fórmula,
teniendo presente que la clase modal es la que tiene mayor frecuencia, y esta es la
Frecuencia Modal.
Add
dLMo ·
21
1
L = 80 (intervalo modal [80 – 85), ya que la frecuencia es 16, que es la mayor)
d1= 16 – 12 = 4 (diferencia con la frecuencia anterior)
d2= 16 – 4 = 12 (diferencia con la frecuencia siguiente)
A = 5
Luego, 25,8116
20 80 5 ·
124
480
Mo puntos. 81 puntos.
Se estima que el valor más repetido de los puntajes de esta prueba fue el 81.
L: Límite real inferior de la clase modal.
d1: es la diferencia entre la frecuencia modal y la frecuencia
anterior.
d2: es la diferencia entre la frecuencia modal y la frecuencia
siguiente.
A: amplitud del intervalo
51
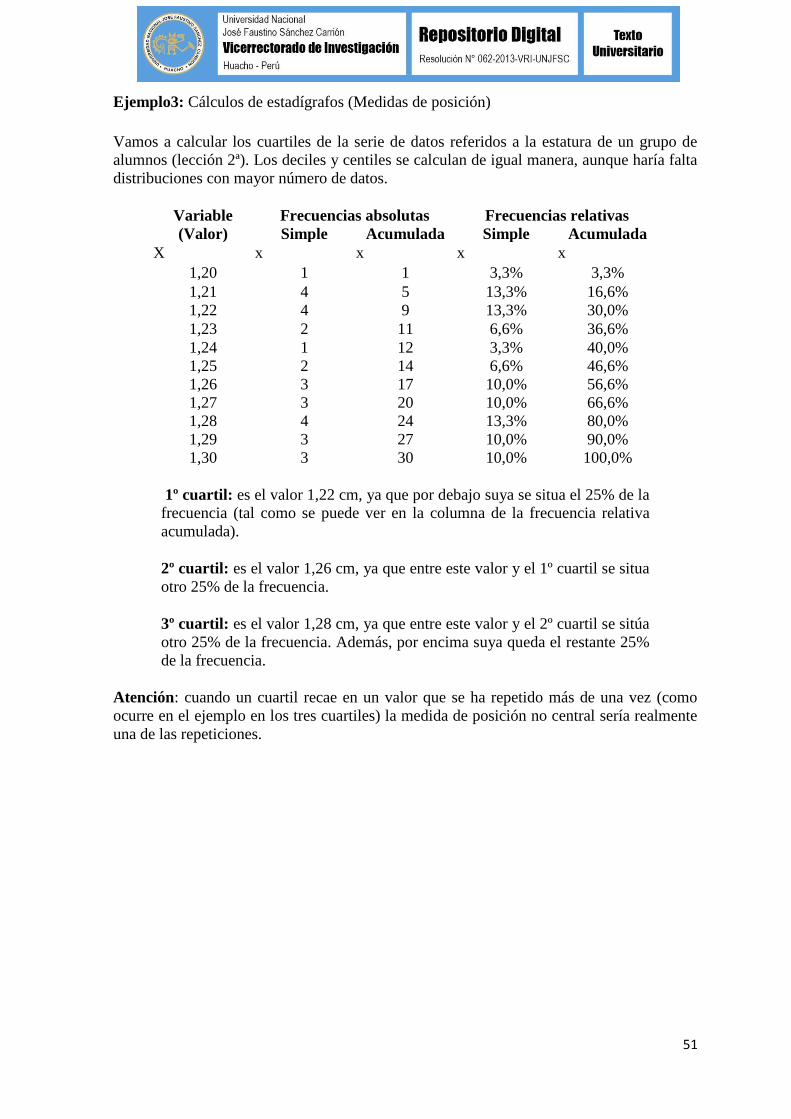
Ejemplo3: Cálculos de estadígrafos (Medidas de posición)
Vamos a calcular los cuartiles de la serie de datos referidos a la estatura de un grupo de
alumnos (lección 2ª). Los deciles y centiles se calculan de igual manera, aunque haría falta
distribuciones con mayor número de datos.
Variable Frecuencias absolutas Frecuencias relativas
(Valor) Simple Acumulada Simple Acumulada
X x x x x
1,20 1 1 3,3% 3,3%
1,21 4 5 13,3% 16,6%
1,22 4 9 13,3% 30,0%
1,23 2 11 6,6% 36,6%
1,24 1 12 3,3% 40,0%
1,25 2 14 6,6% 46,6%
1,26 3 17 10,0% 56,6%
1,27 3 20 10,0% 66,6%
1,28 4 24 13,3% 80,0%
1,29 3 27 10,0% 90,0%
1,30 3 30 10,0% 100,0%
1º cuartil: es el valor 1,22 cm, ya que por debajo suya se situa el 25% de la
frecuencia (tal como se puede ver en la columna de la frecuencia relativa
acumulada).
2º cuartil: es el valor 1,26 cm, ya que entre este valor y el 1º cuartil se situa
otro 25% de la frecuencia.
3º cuartil: es el valor 1,28 cm, ya que entre este valor y el 2º cuartil se sitúa
otro 25% de la frecuencia. Además, por encima suya queda el restante 25%
de la frecuencia.
Atención: cuando un cuartil recae en un valor que se ha repetido más de una vez (como
ocurre en el ejemplo en los tres cuartiles) la medida de posición no central sería realmente
una de las repeticiones.

52
Ejemplo 4: Coeficiente de Asimetría de Fisher
g
x x n
ns
m
s
i
i
i
1
3
3
3
3
Sí la distribución es simétrica en el denominador tendremos el mismo número de desviaciones positivas como negativas y por tanto g1 = 0.
Si g1>0 la distribución es asimétrica positiva o asimétrica a derechas. Si g1<0
la distribución es asimétrica negativa o asimétrica a izquierdas.
Elemplo :
xi ni xi-x (xi-x)3 ni(xi-x)
3
0 2 -2.52 -16.003 -32.006
l 4 -1.52 -3.512 -14.047
2 21 -0.52 -0.141 -2.953
3 15 0.48 0.11 1.658
4 6 1.48 3.242 19.451
5 1 2.48 15.253 15.253
6 1 3.48 42.144 42.144
29.5
g
x x n
ns
i
i
i
1
3
3
0.42 >0 luego asimétrica positiva.
Ejemplo 5: Coeficiente de Asimetría de Pearson
Es mucho más fácil de calcular que el anterior pero sólo es aplicable a aquellas distribuciones que tienen una sola moda y cuya distribución tiene forma de campana. Se define:
Ax M
ss
o
Si la distribución es simétrica x=Me y por tanto As=0. Si As>0 la distribución es asimétrica positiva. Si As<0 la distribución es asimétrica negativa. Ejemplo : As = (2.52-2)/1.12=0.46 COEFICIENTE DE APUNTAMIENTO DE FISHER. Se define como:
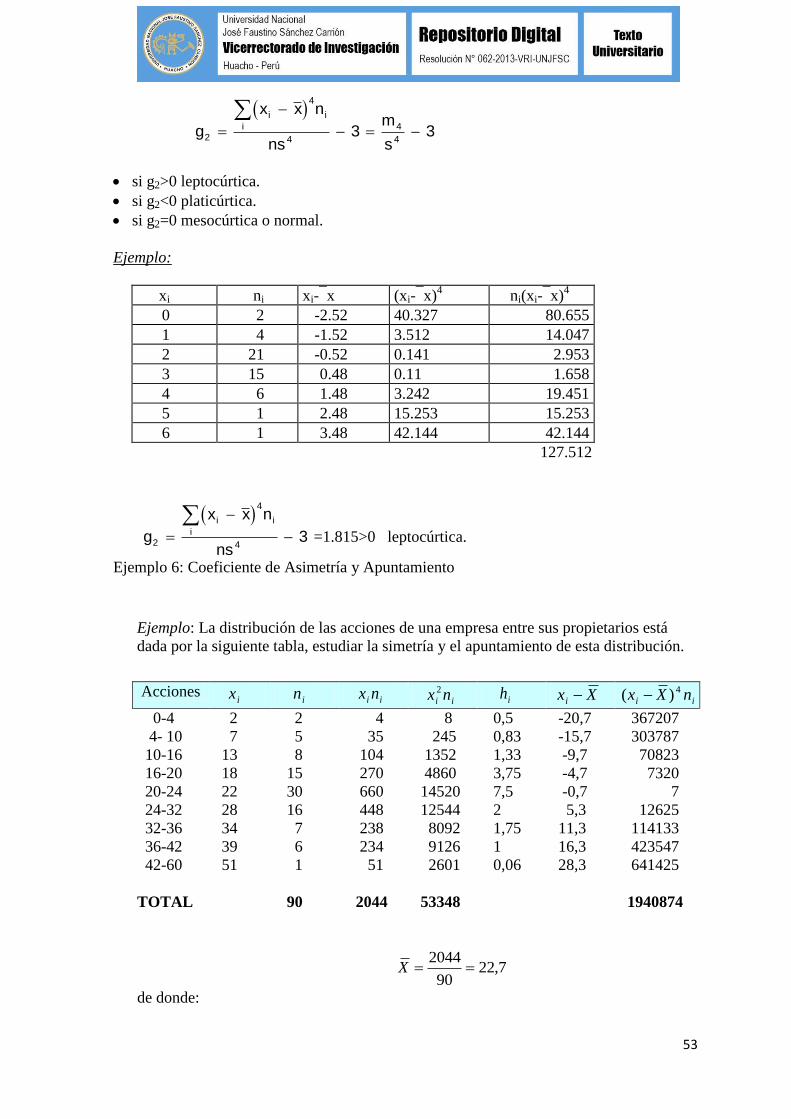
53
g
x x n
ns
m
s
i
i
i
2
4
4
4
43 3
si g2>0 leptocúrtica.
si g2<0 platicúrtica.
si g2=0 mesocúrtica o normal.
Ejemplo:
xi ni xi-x (xi-x)4 ni(xi-x)
4
0 2 -2.52 40.327 80.655
1 4 -1.52 3.512 14.047
2 21 -0.52 0.141 2.953
3 15 0.48 0.11 1.658
4 6 1.48 3.242 19.451
5 1 2.48 15.253 15.253
6 1 3.48 42.144 42.144
127.512
g
x x n
ns
i
i
i
2
4
43
=1.815>0 leptocúrtica.
Ejemplo 6: Coeficiente de Asimetría y Apuntamiento
Ejemplo: La distribución de las acciones de una empresa entre sus propietarios está
dada por la siguiente tabla, estudiar la simetría y el apuntamiento de esta distribución.
Acciones ix in ii nx ii nx 2 ih Xxi ii nXx 4)(
0-4 2 2 4 8 0,5 -20,7 367207
4- 10 7 5 35 245 0,83 -15,7 303787
10-16 13 8 104 1352 1,33 -9,7 70823
16-20 18 15 270 4860 3,75 -4,7 7320
20-24 22 30 660 14520 7,5 -0,7 7
24-32 28 16 448 12544 2 5,3 12625
32-36 34 7 238 8092 1,75 11,3 114133
36-42 39 6 234 9126 1 16,3 423547
42-60 51 1 51 2601 0,06 28,3 641425
TOTAL 90 2044 53348 1940874
7,2290
2044X
de donde:

54
77,896,76
96,7679,51575,59290
2044
90
53348
4,214·75,32
220
2
2
S
S
M o
Como se trata de una distribución en forma de campana, con una sola moda,
calcularíamos el coeficiente de asimetría de Pearson:
15,077,8
14,217,22
As
Se trata, pues de una distribución que presenta una asimetría por la derecha.
Para averiguar el tipo de apuntamiento vamos a calcular el coeficiente de
aplastamiento de Fisher:
3·
1 1
4
4
N
nXx
SAp
n
i
ii
= 6,0390
1940874·
77,8
14
Se trata de un una distribución de tipo leptocúrtico, esto quiere decir que una
gran cantidad de datos se agrupan alrededor de la media.
Ejemplo 7: Regresión lineal
A partir de las siguientes observaciones para 5 años de las variables X e Y, ajústese el
modelo de regresión de Y en función de X más idóneo.
Donde,
Y: producción nacional de un subsector industrial, en millones de toneladas.
X: tiempo
Año X Y
1995 1 1,25
1996 2 5
1997 3 11,25
1998 4 20
1999 5 30,5

55
1.- Ajuste de una función lineal: Y* = a + b X
X Y X2
XY Y2
Y* e=Y-Y
* e
2
1 1,25 1 1,25 1,56 -1,1 2,35 5,5225
2 5 4 10 25 6,25 -1,25 1,5625
3 11,25 9 33,75 126,56 13,6 -2,35 5,5225
4 20 16 80 400 20,95 -0,95 0,9025
5 30,5 25 152,5 930,25 28,3 2,2 4,84
15 68 55 277,5 1483,3 68 0 18,35
1/5 3 13,6 11 55,5 296,67 13,6 0 3,67
7,352
14,7
311
13,6)(3-55,5
XX1/5
Y X-XY1/5
S
S b
2222
X
XY
8,45- 37,35 -13,6 X b-Ya
Y* = -8,45 + 7,35 X
Bondad del Ajuste:
Coeficiente de determinación: R2 = 2
XYr = 0,9671 111,715
3,67 -1
S
S-1
S
S
2
Y
2
2
Y
2
Y e*
111,715 13,6 - 296,675 YY1/5 S 2222
Y
3,67N
eECM S
2
1
2
e
Ejemplo 8: Diagrama de caja y bigotes
Para la siguiente muestra de 36 datos (ordenados de menor a mayor), construir el diagrama
de caja y bigotes:
128-129-134-137-147-147-148-149-150-150-156-156-157-158-158-159-160-162
167-169-177-177-179-185-186-190-198-203-209-210-220-230-250-255-270-290
Calculados los valores correspondientes:
Media = 179,17 Mediana = 164,50 Desviación típica = 40,324 Rango = 162
Máximo = 128

56
Mínimo = 128 Cuartil 1º = 150 Cuartil 2º = 201,75 Rango intercuartilico = 51,75
Repasemos el cálculo de los valores que vamos a usar en la construcción del
diagrama:
- La caja queda delimitada por 75,201150 31 QyQ . La mediana es 50,164eM
- El rango intercuartilico es 75,5113 QQQ . Así pues 625,775,1 Q
- El bigote de la izquierda llega hasta
128)375,72128()5,1( 1min yMaxQQyXMax
- El bigote de la derecha llega
375,279)375,279290()5,1( 3max yMinQQyXMin
128 150 164,5 201,75 279,35 Outlier
(290)
*
Xmin Q1 Me Q3 Xmax
En este diagrama se puede observar entre otras cosas:
- El valor 290 es un outlier y habría que estudiarlo por separado.
- El bigote de la izquierda es mas corto que el de la derecha. Esto se interpreta diciendo
que la cuarta parte de los niveles mas bajos de la variable en estudio están más
concentrados que la cuarta parte de los niveles mas altos.
- La parte izquierda de la caja (niveles entre 150 y 164,5) es menor que la parte derecha
niveles entre (164,5 y 201,75). Diremos que los niveles de la variable en estudio
comprendidos entre el 25% y el 50% están más concentrados que los comprendidos
entre el 50% y el 75%.
- La distribución tiene una asimetría positiva o a la derecha.

57
Ejemplo 9: Regresión no lineal
Ajuste de una función parabólica: Y* = a + b X + c X
2
X Y X2
X3 X
4 XY X
2Y Y
* e=Y-
Y*
e2
1 1,25 1 1 1 1,25 1,25 1,18 0,07 0,0049
2 5 4 8 16 10 20 5,11 -0,11 0,0121
3 11,25 9 27 81 33,75 101,5 11,32 -0,07 0,0049
4 20 16 64 256 80 320 19,81 0,19 0,0361
5 30,5 25 125 625 152,5 762,5 30,58 -0,08 0,0064
15 68 55 225 979 277,5 1205 68 0 0,0644
1/5 3 13,6 11 55,5 13,6 0 0,0128
Aplicando el método de los mínimos cuadrados se obtiene el siguiente sistema de
ecuaciones:
979c225b55a1205
225c55b15a277,5
55c15b5a 68
X cXb XaYX
X cXb XaXY
Xc X b Na Y
4322
32
2
Resolviendo este sistema se obtiene: a= -0,47 b= 0,51 c= 1,14
Y* = -0,47 + 0,51 X + 1,14 X
2
Bondad del Ajuste:
Coeficiente de determinación: R2 = 0,9998
111,715
0,01288 -1
S
S-1
S
S
2
Y
2
2
Y
2
Y e*
0,01288N
eECM S
2
2
2
e

58
Ejemplo 10: Regresión no lineal
Ajuste de una función potencial: Y* = a X
b
En primer lugar linealizamos: lnY* = lna + b lnX V
* = A + b U
X Y U=lnX V=lnY U2
UV Y* e=Y-Y
* e
2
1 1,25 0 0,2231 0 0 1,2557 -0,0057 0,0000
2 5 0,6931 1,6094 0,4803 1,1156 4,9888 0,0112 0,0001
3 11,25 1,0986 2,4203 1,2069 2,6590 11,18 0,0697 0,0049
4 20 1,3863 2,9957 1,9215 4,1530 19,82 0,1799 0,0324
5 30,5 1,6094 3,4177 2,5901 5,5006 30,901 -0,4012 0,1610
15 68 4,7875 10,666 6,1988 13,428 68,146 -0,1461 0,1984
1/5 3 13,6 0,9575 2,1332 1,2397 2,6856 13,629 -0,0292 0,0397
e0
1,99020,95751,2397
2,13320,9575-2,6856
UU1/5
V U-UV1/5
S
S b
2222
U
UV
0,2277 0,95751,9902 -2,1332 U b-VA
Deshacemos el cambio efectuado: a= antilnA = antiln 0,2277 = 1,2557
Por lo que el ajuste efectuado es: Y* = 1,2557 X
1,9902
Bondad del Ajuste:
0,0397N
eECM
2
3
Nótese que al haber transformado la variable dependiente ya no se minimiza 2e sino
2*lnY-(lnY ) , de ahí que 0e .

59
Ejemplo 11: Regresión no lineal
Ajuste de una función exponencial: Y* = a b
X
En primer lugar linealizamos: lnY* = lna + X lnb V
* = A + B X
X Y V=lnY X2
XV Y* e=Y-Y
* e
2
1 1,25 0,2231 1 0,2231 1,7794 -0,529 0,2798
2 5 1,6094 4 3,2188 3,86 1,138 1,2950
3 11,25 2,4203 9 7,2609 8,37 2,88 8,2944
4 20 2,9957 16 11,983 18,18 1,82 3,3124
5 30,5 3,4177 25 17,088 39,45 -8,95 80,102
15 68 10,666 55 39,774 71,64 -3,641 95,803
1/5 3 13,6 2,1332 11 7,9548 14,328 -0,728 19,16
e0
0,7776311
32,1332-7,9548
XX1/5
V X-XV1/5
S
S B
2222
X
XV
0,1996- 30,7776 -2,1332 X b-VA
Deshacemos los cambios efectuados: a= antilnA = antiln-0,1996 = 0,819
b= antilnB =antiln 0,7776 = 2,176
Por lo que el ajuste efectuado es: Y* = 0,819 . 2,176
X
Bondad del Ajuste:
19,16N
eECM
2
4
La comparación de la bondad de modelos de regresión mediante el coeficiente de
determinación sólo es correcta cuando la variable dependiente no ha sido sometida a
transformaciones no lineales (por ejemplo, una transformación logarítmica). En este
ejercicio, mediante R2 sólo podemos comparar la regresión lineal y la parabólica. Por eso,
para comparar los cuatro ajustes efectuados utilizamos el Error Cuadrático Medio. El
mejor ajuste resulta ser el parabólico puesto que presenta el menor valor para el ECM.