estadistica aplicada1.pdf · medidas de posición 1 unidad nº 1: medidas de posición...
TRANSCRIPT

Universidad Nacional de La Rioja Sede Universitaria Chepes
Departamento de Ciencias Aplicadas
ESTADISTICA
APLICADA

_________________________________________________________________________________________
Medidas de Posición 1
UNIDAD Nº 1: Medidas de posición
Introducción:
Esta unidad trata sobre la presentación de datos. En particular, se mostrará
cómo grandes series de datos numéricos pueden organizarse y presentarse de manera
más eficaz en forma de tablas y diagramas con el fin de intensificar el análisis e
interpretación de datos, aspectos clave del proceso de toma de decisiones. Para
motivar nuestro análisis sobre la presentación tabular y de diagrama de los datos
numéricos, las observaciones en nuestra serie de datos son de dos tipos, de orden de
tiempo o independientes. Las observaciones de orden de tiempo pueden controlarse
sobre una gráfica digipunto, mientras que las observaciones independientes pueden
presentarse en forma tabular como una distribución de frecuencia o en forma gráfica
como un histograma, polígono u ojiva.
1.1 Frecuencias:
Con el fin de introducir las ideas relevantes, daremos un ejemplo para
desarrollar los contenidos de la presente unidad.
Tomando como base la encuesta realiza por la Dirección de Recursos
Agropecuarios sobre la existencia de ganado caprino en la provincia de La Rioja, a 40
establecimientos de cría de ganado se muestran los resultados en la tabla 1.1.
Es necesario tener en cuenta que cuando se recolecta una serie de datos como
ésta generalmente se hace en forma sin procesar, es decir, las observaciones
numéricas no se disponen en ningún orden o secuencia particular. Como se observa en
la tabla 1.1, al crecer el número de observaciones, se hace más difícil centrarse en las
principales características de un conjunto de datos y se necesitan métodos para
posibilitar organizar las observaciones de tal manera que entendamos mejor la
información que transmite la serie de datos.
Tabla 1.1 Datos sin procesar en existencia de ganad o caprino
678 1204 224 306 1221 322 789 871 569 691

_________________________________________________________________________________________
Medidas de Posición 2
324 987 568 889 743 269 305 290 210 327
630 262 508 224 1199 233 406 224 832 768
1350 1503 1145 960 1478 408 1170 1287 1371 1470
Usando los datos sin procesar de la existencia de ganado caprino de la
provincia, la Dirección de recursos desea construir las tablas y diagramas apropiados
que amplíen el informe que está preparando para el gobierno de la provincia. Al crecer
el número de observaciones se hace necesario condensar aún más los datos en tablas
de resumen apropiadas. Así pues, tal vez se desea acomodar los datos en
agrupamientos de clase (por ejemplo, categorías, cantidad o años) de acuerdo con
divisiones establecidas convenientemente del alcance de la observaciones. Tal
acomodo de los datos en forma tabular se denomina una Distribución de frecuencia.
Una distribución de frecuencia es una tabla de resumen en la que los
datos se disponen en agrupamientos o categorías convenientemente
establecidas de clases ordenadas numéricamente.
Cuando las observaciones se agrupan o condensan en tablas de distribución de
frecuencia, el proceso de análisis e interpretación de los datos se hace mucho más
manejable y significativo. En esta forma resumida las características más importantes
de los datos se aproximan muy fácilmente, compensando así el hecho, que cuando los
datos se agrupan de ese modo, la información inicial referente a las observaciones
individuales que antes se disponía se pierde a través del proceso de agrupamiento o
condensación.
Al construir la tabla de frecuencia de distribución, debe ponerse atención a:
A). Seleccionar el número apropiado de agrupamientos de clase para la tabla.
B). Obtener un intervalo o ancho de clase de cada agrupamiento de clase.
C). Establecer los límites de cada agrupamiento de clase para evitar los traslapes.
A) Selección del número de clases
El número de agrupamientos de clase por utilizar depende principalmente del
número de observaciones en los datos. Esto es, un número mayor de observaciones
requiere un número mayor de grupos de clase. En general, sin embargo, la distribución

_________________________________________________________________________________________
Medidas de Posición 3
de frecuencia debe tener al menos cinco agrupamientos de clase, pero no más de 15.
Si no hay suficientes agrupamientos de clase o si hay demasiados, se obtendrá poca
información. Como ejemplo, una distribución de frecuencia que sólo tiene un
agrupamiento de clase que abarca todo el alcance de las existencias de ganado
caprino de la siguiente manera:
Cantidad de cabezas Nº de establecimientos
200 – 1600 40
Total 40
Sin embargo, de esta tabla de resumen no se obtiene información adicional que
no se conociera ya al examinar los datos sin procesar. Una tabla con demasiada
concentración de datos no es significativa. Lo mismo sería cierto en el otro extremo, si
una tabla tuviera demasiados agrupamientos de clase, habría una subconcentración de
datos, y se sabría muy poco.
B) Obtención de los intervalos de clase
Al desarrollar la tabla de distribución de frecuencia es deseable que el ancho de
cada agrupamiento de clase sea igual. Para determinar el ancho de cada clase, el
alcance de los datos se divide entre el número de agrupamientos de clase deseado:
Rango
Ancho de intervalo: (1.1)
Número de agrupamientos deseados
Puesto que sólo hay 40 observaciones en nuestros datos de ganado caprino, se
decide que siete agrupamientos de clase serán suficientes. El alcance se calcula
tomando el dato más chico y el más grande como 200 - 1503 = 1303 cabezas de
ganado y usando la ecuación (1.1), el ancho del intervalo de clase se aproxima
mediante

_________________________________________________________________________________________
Medidas de Posición 4
Ancho de intervalo = 1303 / 7 = 186 cabezas de ganado
Por conveniencia y facilidad de lectura, el intervalo seleccionado o ancho de cada
agrupamiento de clase se redondea a 200 cabezas de ganado caprino.
C) Establecimiento de los límites de las clases
Para construir la tabla de distribución de frecuencia, es necesario establecer
claramente límites de clase definidos para cada agrupamiento de clase de manera que,
las observaciones, se registren apropiadamente. Debe evitarse el traslape de clases.
Puesto que el ancho de cada intervalo de clase para los datos del ganado se estableció
en 200 cabezas, los límites de los diversos agrupamientos de clase deben establecerse
de manera que incluyan todo el alcance de observaciones. Siempre que sea posible,
estos límites deben elegirse para que faciliten la lectura e interpretación de los datos.
De esta forma, el primer intervalo de clase se establece desde 200 hasta abajo de 400,
el segundo de 400 a abajo de 600, etc. Los datos sin procesar (tabla 1.1) se registran
entonces en cada clase según se muestra:
N° cabezas Registros Frecuencia
200 pero menor que 400 ///// ///// /// 13
400 pero menor que 600 ///// 5
600 pero menor que 800 ///// / 6
800 pero menor que 1000 ///// 5
1000 pero menor que 1200 /// 3
1200 pero menor que 1400 ///// 5
1400 pero menor que 1600 /// 3
Total 40
Estableciendo los límites de cada clase de esta manera, las 40 observaciones se
han registrado en siete clases, cada una con un ancho de intervalo de 200 cabezas de
ganado sin traslape. De esta "hoja de trabajo" la distribución de frecuencia absoluta se
presenta en la tabla 1.2 en la página siguiente.

_________________________________________________________________________________________
Medidas de Posición 5
La principal ventaja de usar una de estas tablas de resumen es que las
principales características de los datos se hacen evidentes inmediatamente para el
lector. Por ejemplo, de la tabla 1.2 vemos que el alcance aproximado de los 40
establecimientos va de 200 a 1600 cabezas de ganado, en la provincia de La Rioja, en
la mayoría de los establecimientos, tendiendo a agruparse entre 200 y 400 cabezas de
ganado caprino.
Tabla 1 .2 Distribución de frecuencia absoluta con intervalos, de número de cabezas de
ganado en 40 establecimientos de La Rioja.
N° cabezas Frecuencia
200 pero menor que 400 13
400 pero menor que 600 5
600 pero menor que 800 6
800 pero menor que 1000 5
1000 pero menor que 1200 3
1200 pero menor que 1400 5
1400 pero menor que 1600 3
Total 40
Fuente: Los datos fueron tomados de la tabla 1.1
Tipos de Distribución de frecuencia:
� Distribución de frecuencia absoluta.
� Distribución de frecuencia relativa.
� Distribución de frecuencia absoluta acumulada.
� Distribución de frecuencia relativa acumulada.
1.1.1 Frecuencia Absoluta:
Se puede definir como la cantidad de veces que se repite un valor de la variable ( n1
).

_________________________________________________________________________________________
Medidas de Posición 6
En el ejemplo dado en la tabla 1.2, las frecuencias son absolutas con intervalos.
También se pueden sacar frecuencias absolutas de números sin intervalos, por
ejemplo, si se toman las edades de los ingresantes a la Universidad de Buenos Aires
en la carrera de Ingeniería Agropecuaria, el caso se ejemplifica en la tabla 1.3
siguiente:
Tabla 1.3 Distribución de edades de los ingresantes
17 18 18 19 20 17 20 20 21 19
18 17 18 19 23 23 18 20 19 22
17 21 20 19 17 21 19 21 18 22
18 20 21 22 19 18 19 20 22 19
18 18 18 23 19 22 23 17 20 20
En este ejemplo no sería necesario determinar la Selección del número de
clases, la Obtención de los intervalos de clase y el Establecimiento de los límites de las
clases debido a que no existe una gran diferencia entre el dato más chico al más
grande, por lo que se puede plantear una distribución de frecuencia por edad, la cual
estaría representado por la tabla 1.4 siguiente:
Tabla 1.4 Distribución de frecuencia absoluta
Edades Frecuencia
17 6
18 11
19 10
20 9
21 5
22 5
23 4
Total 50

_________________________________________________________________________________________
Medidas de Posición 7
1.1.2 Frecuencia Relativa:
Se define como la proporción que en el total de observaciones representa cada valor
de la variable ( hi = n1 / n ).
También se puede decir que la distribución de frecuencia es una tabla de
resumen en la que los datos originales se condensan o agrupan para facilitar el análisis
de datos. Sin embargo, para ampliar el análisis, casi siempre es deseable formar la
distribución de frecuencia relativa o la distribución de porcentaje, dependiendo de si
preferimos proporciones o porcentajes. Estas dos distribuciones equivalentes se
muestran en las tablas 1.5 y 1.6, respectivamente.
Tabla 1.5 Distribución de frecuencia relativa de número de cabezas de ganado caprino
en los 40 establecimientos.
N° cabezas de Proporción
ganado de establecimientos
200 – 400 0.325
400 – 600 0.125
600 – 800 0.150
800 – 1000 0.125
1000 – 1200 0.075
1200 – 1400 0.125
1400 – 1600 0.075
Total 1
Fuente: Los datos fueron tomados de la tabla 1.2 de página 4.

_________________________________________________________________________________________
Medidas de Posición 8
Tabla 1.6 Distribución de porcentaje de número de cabezas de ganado caprino.
N° cabezas de Porcentaje
ganado de establecimientos
200 – 400 32,50
400 – 600 12.50
600 – 800 15.00
800 – 1000 12.50
1000 – 1200 7.50
1200 – 1400 12.50
1400 – 1600 7.50
Total 1
La distribución de frecuencia relativa descrita en la tabla 1.5 se forma
dividiendo las frecuencias de cada clase de distribución de frecuencia (tabla 1.2) entre
el número total de observaciones. Entonces puede formarse una distribución de
porcentaje (tabla 1.6) multiplicando cada frecuencia relativa o proporción entre 100.0.
Por lo tanto, de la tabla 1.5 resulta claro que la proporción de ganado caprino en
distintos establecimientos de la provincia que tienen entre 600 y 800 cabezas es .150,
mientras que en la tabla 1.6 se ve que 15% de los establecimientos tiene esa cantidad
de cabezas del total.
Generalmente es más significativo trabajar con una base de 1 para proporciones
o de 100.0 para porcentajes que usar las frecuencias mismas. De hecho, el uso de la
distribución de frecuencia relativa o de la distribución de porcentaje se vuelve esencial
siempre que una serie de datos se compara con otras series de dato, especialmente si
difiere el número de observaciones en cada serie de datos.
Como ejemplo, supongamos que un psicólogo industrial deseaba comparar
ausentismo diario entre los empleados de oficina de dos tiendas departamentales. Si,
en un día dado, seis empleados de 50 de la tienda A se ausentan y tres empleados de
10 de la tienda B se ausentan, ¿qué conclusiones podemos sacar? Es inapropiado
decir que ocurrió más ausentismo en la tienda A. Aunque hemos observado que en la
tienda A hubo el doble de ausencias que en la tienda B, también había cinco veces

_________________________________________________________________________________________
Medidas de Posición 9
más empleados que en la tienda B. Por lo tanto, en estos tipos de comparaciones,
debemos formular nuestras conclusiones a partir de los cocientes relativos de
ausentismo, no de los conteos reales. Así pues, puede establecerse que el cociente de
ausentismo es dos veces y media mayor en la tienda B (30.0%) que en la tienda A
(12.0%).
Ahora suponga, al desarrollar su informe para el Gobierno de la provincia de La
Rioja, el analista investigador deseaba comparar las cantidades de cabezas de ganado
caprino, con las de 40 establecimientos de la provincia de Córdoba. La tabla 1.7
muestra información sobre las cantidades de cabezas de ganado caprino en la
provincia por cada uno de los 40 establecimientos encuestados de Córdoba.
Para comparar las cantidades de los 40 establecimientos de La Rioja con los de
los establecimientos de Córdoba, se desarrolla una distribución de porcentaje para este
último grupo. Esta nueva tabla se comparará entonces con la tabla 1.6.
Tabla 1.7 Datos sin procesar referentes a cantidades de cabezas de ganado caprino de
la provincia de Córdoba.
650 400 701 853 534 786 990 1507 1567 1152
694 520 855 577 707 782 1264 711 522 958
987 424 700 683 823 639 577 756 799 1260
759 690 852 1084 999 319 948 842 1300 520
La tabla 1.8 describe tanto la distribución de frecuencia como la distribución de
porcentaje de las colegiaturas cobradas a residentes fuera de la provincia por las 45
escuelas de Córdoba. Esta tabla se ha construido en lugar de las dos tablas separadas
para ahorrar espacio. Observe que los agrupamientos de clase seleccionados en la
tabla 1.8 concuerdan, donde es posible, con aquellos seleccionados en la tabla 1.2
para las escuelas de Buenos Aires. Los límites de las clases deberían concordar o ser
múltiplos entre sí con el fin de facilitar las comparaciones.

_________________________________________________________________________________________
Medidas de Posición 10
Tabla 1.8 Distribución de frecuencia y distribución de porcentaje de las colegiaturas
para residentes fuera de la provincia en 45 escuelas de Córdoba.
Cantidades Número de Porcentaje de
de cabezas establecimientos cabezas
200 – 400 1 2.5
400 – 600 8 20
600 – 800 14 35
800 – 1000 10 25
1000 – 1200 2 5
1200 – 1400 3 7.5
1400 – 1600 2 5
Total 40 100
Fuente: Los datos fueron tomados de la tabla 1.8.
Usando las distribuciones de porcentaje de las tablas 1.6 y 1.8, ahora resulta
significativo comparar la cantidad de las dos provincias en términos de las cabezas de
ganado que poseen los 40 establecimientos. De las dos tablas resulta evidente que las
cantidades generalmente son menores en La Rioja que en Córdoba. Por ejemplo, en
La Rioja las cantidades por lo general se agrupan entre 200 y 400 cabezas de caprinos
(es decir, 32.50 de los establecimientos), mientras que en Córdoba las cantidades por
lo general se agrupan entre 600 y 800 cabezas de caprinos (es decir, 35% de los
establecimientos).
Distribución de frecuencia absoluta acumulada y re lativa acumulada
Otros métodos útiles de representación de datos que facilitan el análisis y la
interpretación son las tablas de distribución de frecuencia acumulativa. Esta puede
desarrollarse a partir de la tabla de distribución de frecuencia absoluta, de la tabla de
distribución de frecuencia relativa.
Tomando como fuente la tabla 1.2 y 1.5 se pueden obtener las siguiente tabla
de frecuencias:

_________________________________________________________________________________________
Medidas de Posición 11
Tabla 1.9 Frecuencias Absoluta , Relativa y porcentual acumuladas
Colegiatura (en $00) Abs. Acumulada Rel. Acumulada % Acumulad
200 pero menor que 400 13 0.325 32.50
400 pero menor que 600 18 0.450 45.00
600 pero menor que 800 24 0.600 60.00
800 pero menor que 1000 29 0.725 72.50
1000 pero menor que 1200 32 0.800 80.00
1200 pero menor que 1400 37 0.925 92.50
1400 pero menor que 1600 40 100 100
La forma en que se calcula la frecuencia absoluta acumulada esta dado por la
fórmula Fj = n1 + n2 + ...+ nj , es decir, que la frecuencia absoluta acumulada se obtiene
de la suma de cada una de las frecuencias absolutas; mientras que la frecuencia
relativa acumulada esta dado por la fórmula Frj = n1 + n2 + ... + nj, , es decir, la suma de
cada una de las frecuencias relativas.
1.1.3 Cuadros y Gráficos
A menudo se dice que "una imagen vale más que mil palabras". De hecho, los
estadísticos han empleado las técnicas gráficas para describir de manera más vívida
series de datos. En particular, los histogramas, diagrama de barras, los polígonos y el
diagrama de ojiva se usan para describir los datos numéricos que han sido agrupados
en distribuciones de frecuencia, de frecuencia relativa o de porcentaje.
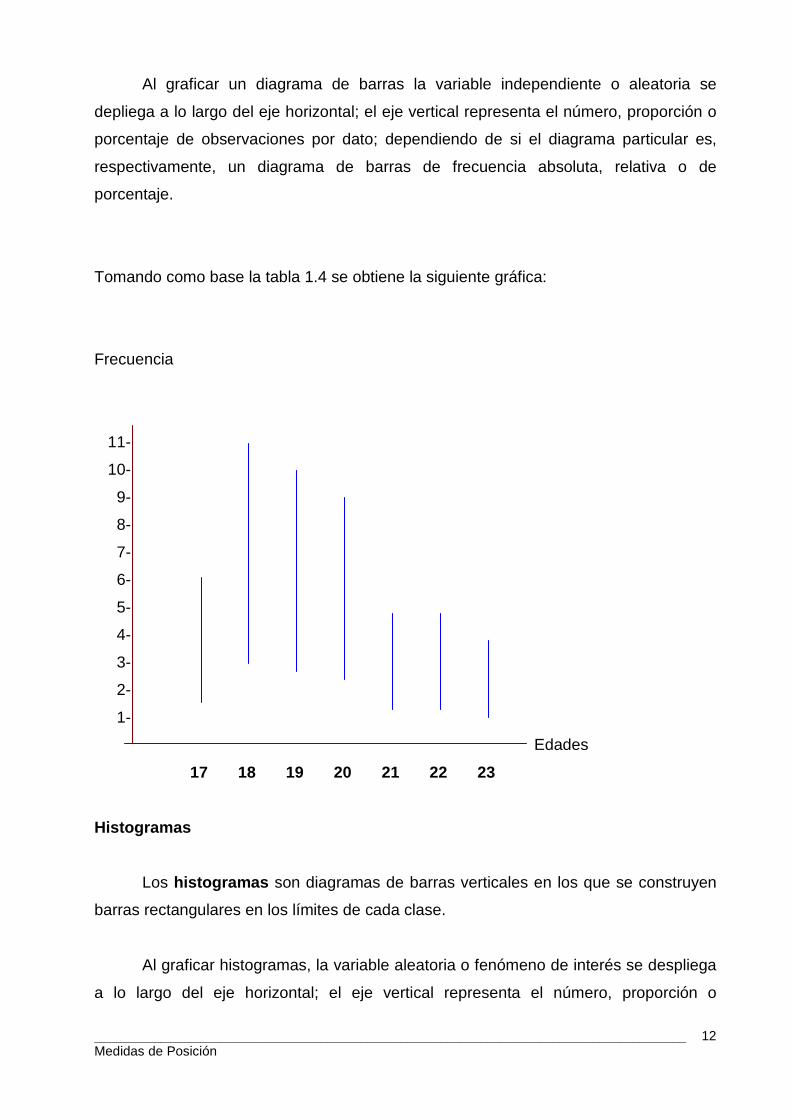
Diagrama de Barras
Son una serie de líneas o palos verticales u horizontales que se desplazan hasta
los límites de cada dato cuantitativo.
_________________________________________________________________________________________
Medidas de Posición 12
Al graficar un diagrama de barras la variable independiente o aleatoria se
depliega a lo largo del eje horizontal; el eje vertical representa el número, proporción o
porcentaje de observaciones por dato; dependiendo de si el diagrama particular es,
respectivamente, un diagrama de barras de frecuencia absoluta, relativa o de
porcentaje.
Tomando como base la tabla 1.4 se obtiene la siguiente gráfica:
Frecuencia
11-
10-
9-
8-
7-
6-
5-
4-
3-
2-
1-
Edades
17 18 19 20 21 22 23
Histogramas
Los histogramas son diagramas de barras verticales en los que se construyen
barras rectangulares en los límites de cada clase.
Al graficar histogramas, la variable aleatoria o fenómeno de interés se despliega
a lo largo del eje horizontal; el eje vertical representa el número, proporción o

_________________________________________________________________________________________
Medidas de Posición 13
porcentaje de observaciones por intervalo de clase; dependiendo de si el histograma
particular es, respectivamente, un histograma de frecuencia absoluta, un histograma de
frecuencia relativa o un histograma de porcentaje. Tomando como base la tabla 1.4 la
gráfica se muestra a continuación:
Histograma
0
2
4
6
8
10
12
17 18 19 20 21 22 23
Edades
frecuencia
Teniendo en cuanta la tabla 1.2 la gráfica es la siguiente:
Histograma
0
2
4
6
8
10
12
14
200 –
400
400 –
600
600 –
800
800 –
1000
1000 –
1200
1200 –
1400
1400 –
1600
Cabezas
Fre
cuen
cia
Polígonos
Al igual que con los histogramas, al graficar polígonos el fenómeno de interés se
despliega a lo largo del eje horizontal y el eje vertical representa el número, proporción
o porcentaje de observaciones por intervalo de clase.

_________________________________________________________________________________________
Medidas de Posición 14
El polígono de porcentaje se forma permitiendo que el punto medio de cada
clase represente los datos de esa clase y luego conectando la sucesión de puntos
medios con sus respectivos porcentajes de clase.
Debido a que los puntos medios consecutivos son conectados por una serie de
líneas rectas, el polígono algunas veces está dentado en apariencia. Sin embargo, al
tratar con una serie de datos muy grande, si tuviéramos que crear los límites de las
clases en su distribución de frecuencia más juntos (incrementando así el número de
clases en esa distribución), las líneas dentadas del polígono se "suavizarían". Tomando
en cuanta la tabla 1.6 ganado caprino de La Rioja en porcentaje se obtiene la siguiente
gráfica:
Polígono
0
5
10
15
20
25
30
35
200-400 400-600 600-800 800-
1000
1000-
1200
1200-
1400
1400-
1600
Cabezas
Porcentaje
Polígono de porcentaje acumulativo
Para construir un polígono de porcentaje acumulativo (también conocido
como ojiva), observamos que el fenómeno de interés, la cantidad de cabezas de
ganado caprino nuevamente se grafica en el eje horizontal, mientras que los
porcentajes acumulativos se grafican en el eje vertical. En cada límite inferior,
graficamos el valor de porcentaje (acumulativo) correspondiente del listado de la
distribución de porcentaje acumulativo. Entonces conectamos estos puntos con una
serie de segmentos de líneas rectas.

_________________________________________________________________________________________
Medidas de Posición 15
La figura a continuación ilustra el polígono de porcentaje acumulativo de las cabezas
de ganado caprino de la Provincia de La Rioja. La principal ventaja de la ojiva sobre
otros diagramas es la facilidad con que podemos interpolar entre los puntos graficados.
Tomando los datos de la tabla 1.9 se desprende la siguiente gráfica:
Ojiva
0
20
40
60
80
100
120
200-
400
400-
600
600-
800
800-
1000
1000-
1200
1200-
1400
1400-
1600
Cabezas
Po
rce
nta
je
Mediciones de la tendencia central
La mayor parte de las series de datos muestran una clara tendencia a agruparse
alrededor de un cierto punto central. Así pues, dada cualquier serie de datos particular,
por lo general es posible seleccionar algún valor o promedio típico para describir toda la
serie de datos. Este valor descriptivo típico es una medición de tendencia central o de
ubicación.
Cuatro tipos de promedios a menudo usados como mediciones de tendencia central
son la media aritmética, la mediana, la moda y el eje medio.
1.2 La media aritmética
La media aritmética (también llamada la media) es el promedio o medición de
tendencia central de uso más común. Se calcula sumando todas las observaciones, de

_________________________________________________________________________________________
Medidas de Posición 16
una serie de datos y luego dividiendo el total entre el número de elementos
involucrados.
Por lo tanto, para una muestra que contiene una serie de n observaciones X1, X2, ...,
Xn, la media aritmética (dada por el símbolo X, denominado "X barra") puede escribirse
como :
_ X1 + X2 + ... + Xn
X =
n
Para simplificar la notación y por comodidad se usa convencionalmente el término
n
∑∑∑∑ Xi
i=1
( que significa la sumatoria de todos los valores Xi ) siempre que deseemos sumar una
serie de observaciones. Esto es
n
∑ Xi = X1 + X2 + ...+ Xn
i=1
Usando esta notación de sumatoria, la media aritmética de la muestra puede
expresarse de manera más simple como:
n
_ ∑∑∑∑ Xi
X = i=1
n
donde _
X = media aritmética de la muestra
n = tamaño de la muestra
Xi = iésima observación de la variable aleatoria X
n
∑ Xi = sumatoria de todos los valores X de la muestra

_________________________________________________________________________________________
Medidas de Posición 17
i=1
Para la muestra de nuestro ejemplo tomamos las encuestas de la cantidad de ganado
caprino de 6 establecimientos de la provincia de La Rioja:
X1 = 678
X2 = 1199
X3 = 408
X4 = 233
X5 = 224
X6 = 960
La media aritmética para esta muestra se calcula como
n
_ ∑∑∑∑ Xi
X = i=1 = 678 + 1199 + 408 + 233 + 224 + 960 = 617 cabezas de ganado
n 6
Aquí observamos que la media se calcula como 617cabezas de ganado caprino,
cuando ningún establecimiento en particular de la muestra tenía realmente esa
cantidad. Además, para esta serie de datos tres observaciones son menores que la
media y tres son mayores. La media actúa como punto de equilibrio de tal forma que
las observaciones menores compensan aquellas que son mayores.
Observe que el cálculo de la media se basa en todas las observaciones (X1, X2,
..., Xn) de la serie de datos. Ninguna otra medición de tendencia central comúnmente
usada posee esta característica. Puesto que su cálculo se basa en cada observación,
la media aritmética se ve afectada en gran medida por cualquier valor extremo. En
estos casos, la media aritmética presenta una representación distorsionada de lo que
los datos están transmitiendo; así pues, la media no sería el mejor promedio a usarse
para describir o resumir esta serie de datos.
La media de la población está dad por el símbolo µx , la letra minúscula griega
mu subíndice x, es decir:

_________________________________________________________________________________________
Medidas de Posición 18
N
Σ X1
i=1
µ =
N
donde:
N: tamaño de población
X: iésimo valor de la variable aleatoria x
N
Σ X: sumatoria de todos los valores X de la población
i=1
1.3 Mediana
La mediana es el valor medio de una secuencia ordenada de datos. Si no hay empates,
la mitad de las observaciones serán menores y la otra mitad serán mayores, la
mediana no se ve afectada, por ninguna observación extrema de una serie de datos.
Por tanto, siempre que esté presente una observación extrema es apropiado usar la
mediana en vez de la media para describir una serie de datos.
Para calcular la mediana de una serie de datos recolectados en su forma sin procesar,
primero debemos poner los datos en una clasificación ordenada. Después usar la
fórmula del punto de posicionamiento
n + 1
2
para encontrar el lugar de la clasificación ordenada que corresponde al valor de la
mediana. Se sigue una de las dos reglas:

_________________________________________________________________________________________
Medidas de Posición 19
• Regla 1: Si el tamaño de la muestra es un número impar, la mediana se
representa mediante el valor numérico correspondiente al punto de
posicionamiento, la observación ordenada es {n + 1)/2.
• Regla 2: Si el tamaño de la muestra es un número par, entonces el punto de
posicionamiento cae entre las dos observaciones medias de la clasificación
ordenada. La mediana es el promedio de los valores numéricos correspondientes a
estas dos observaciones medias,
Muestra de tamaño uniforme: Para la muestra de nuestro ejemplo de las cantidades de
ganado caprino en 6 establecimientos, los datos sin procesar fueron
678 1199 408 233 224 960
La clasificación ordenada se vuelve:
224 233 408 678 960 1199
1 2 3 4 5 6
Mediana = 543
Para estos datos, el punto de posicionamiento es (n + 1)/2= ( 6 + 1)/2 = 3.5. Por
consiguiente, la mediana se obtiene promediando la tercera y cuarta observación
ordenada:
408 + 678 / 2 = 543 cabezas de ganado
Como puede verse en la clasificación ordenada, la mediana no se ve por
observaciones extremas. Sin importar si la cantidad mayor es 1278 cabezas, 1578 o
1145cabezas, la mediana sigue siendo 543 cabezas.
Muestra de tamaño no uniforme: Si la muestra hubiera tenido un número impar, la
mediana estaría representada simplemente por el Valor numérico dado a la
observación (n + 1)/2 de la clasificación ordenada. Por tanto, clasificación ordenada de
n = 5 encuestas de establecimientos, la mediana es valor de la tercera observación
ordenada, [es decir, (5 + 1)/2]= 3= 590

_________________________________________________________________________________________
Medidas de Posición 20
500 570 559900 600 690
Mediana
Empates en los datos: Al calcular la mediana, ignoramos el hecho de que pueden
haber valores empatados en los datos. Suponga, por ejemplo, que la siguiente serie de
datos representa la superficie plantada con olivares en distintas zonas de la provincia
de La Rioja en hectáreas:
465 789 456 465 246 833 345
La clasificación ordenada se vuelve
246 345 456 446655 465 789 833
1 2 3 4 5 6 7
Mediana
Para esta muestra de tamaño impar, el punto de posicionamiento de la mediana
es la (n + 1)/2 = 4a observación ordenada. Así, la mediana es 465 hectáreas plantadas
con olivares, el valor medio de la secuencia ordenada, aun cuando la tercera
observación sea también 456 hectáreas.
Para resumir, el cálculo del valor de la mediana se ve afectado por el número de
observaciones, no por la magnitud de cualquier extremo, cualquier observación
seleccionada aleatoriamente tiene la misma probabilidad de exceder la mediana como
de ser excedida por ésta.

_________________________________________________________________________________________
Medidas de Posición 21
1.4 La moda
Algunas veces, al resumir o describir una serie de datos, la moda se usa como
una medición de tendencia central. La moda es el valor de una serie de datos que
aparece con más frecuencia. Se obtiene fácilmente de una clasificación ordenada. A
diferencia de la media aritmética, la moda no se ve afectada por la ocurrencia de
cualesquier valores extremos. Sin embargo, la moda no se usa para propósitos más
que descriptivos porque es más variable de muestra a muestra que otras mediciones
de tendencia central. .
Usando la clasificación ordenada de las cantidades de ganado caprino en 6
establecimientos, los datos sin procesar fueron :
678 1199 408 233 224 960
vemos que no hay moda. Ninguna de las colegiaturas fue la “más típica”.
Observe que hay una diferencia entre ninguna moda y una moda de 0, como se
ilustra en la siguiente clasificación ordenada de temperaturas de mediodía (°C) en Rio
Gallegos durante la primera semana de diciembre
-4° -2° -1° -1° 0° 0° 0° 0°
Moda = 0.
Además, una serie de datos puede tener más de una moda, como se ilustra en
la siguiente clasificación ordenada de temperaturas de mediodía (°C) en Necochea
durante la primera semana de enero:
21° 28° 28° 35° 31° 31° 29°
En Necochea vemos que hubo dos modas, 28° y 31°. Estos datos se describen como
bimodales.
1.5 Cuartiles, deciles y percentiles

_________________________________________________________________________________________
Medidas de Posición 22
Además de las mediciones de tendencia central, existen también algunas
mediciones útiles de ubicación “no central” que se emplean particularmente al resumir o
describir las propiedades de grandes series de datos numéricos. La medición de este
tipo más ampliamente usadas son los cuartiles.
Mientras que la mediana es un valor que divide la clasificación ordenada a la
mitad (50 % de las observaciones son menores y 50% de las observaciones son
mayores), los cuartiles son mediciones descriptivas que dividen los datos ordenados en
cuatro cuartos.
El primer cuartil, Q 1, es un valor tal que 25.0% de las observaciones son menores y
75.0% de las observaciones son mayores.
El segundo cuartil, Q 2, es la mediana , 50.0% de las observaciones son menores y
50.0% de las observaciones son mayores.
El tercer cuartil, Q 3, es un valor tal que 75.0% de las observaciones son menores y
25.0% son mayores.
Para aproximar los cuartiles, se usan las siguientes fórmulas de punto de
posicionamiento:
Q1 = valor correspondiente a n + 1 observación clasificada
4
Q2 = mediana, el valor correspondiente a 2 ( n + 1 ) = n + 1 observación clasificada
4 2
Q3 = valor correspondiente a 3 ( n + 1 ) observación clasificada
4
Las siguientes reglas se usan para obtener los valores de cuartiles:
1) Si el punto de posicionamiento resultante es un entero, se elige la observación
numérica particular correspondiente a ese punto de posicionamiento para el cuartil.
2) Si el punto de posicionamiento resultante está a la mitad del camino entre dos
enteros, se selecciona el promedio de sus valores correspondientes,

_________________________________________________________________________________________
Medidas de Posición 23
3) Si el punto de posicionamiento resultante no es ni un entero ni un valor a la mitad del
camino; entre dos enteros, se usa una regla simple para aproximar el cuartil particular
que consiste en redondear al punto de posicionamiento entero más cercano y
seleccionar el valor numérico de la observación correspondiente.
También se pueden obtener las mediciones llamadas deciles y percentiles ,
donde las primeras dividen a conjunto de datos en diez partes iguales y las segundas
dividen al conjunto de datos en cien partes iguales.
En resumen los cuantiles pueden ser:
� Cuartiles : dividido en 4 partes
� Deciles: dividido en 10 partes
� Percentiles: dividido en 100 partes