desarrollo de un sistema automático de medición de la masa
TRANSCRIPT

Desarrollo de un sistema automático de medición de la masa de café en rama a
través de visión de máquina
Paula Jimena Ramos Giraldo
Universidad Nacional de Colombia
Facultad de Ingeniería y Arquitectura
Manizales, Colombia
2017

Desarrollo de un sistema automático de medición de la masa de café en rama a
través de visión de máquina
Paula Jimena Ramos Giraldo
Universidad Nacional de Colombia
Facultad de Ingeniería y Arquitectura
Manizales, Colombia
2017

Desarrollo de un sistema automático de medición de la masa de café en rama a
través de visión de máquina
Paula Jimena Ramos Giraldo
Tesis de doctorado presentada como requisito parcial para optar al título de:
Doctora en Ingeniería Automática
Director:
Ph.D., Flavio Augusto Prieto Ortíz
Codirector (a):
Ph.D., Carlos Eugenio Oliveros Tascón
Línea de Investigación:
Visión de máquina aplicada a la agricultura
Grupo de Investigación:
GAUNAL (UNAL) – Poscosecha (Cenicafé)
Universidad Nacional de Colombia
Facultad de Ingeniería y Arquitectura
Manizales, Colombia
2017


J: Se hace tarde, te siento desmotivada. ¿Cómo vas
con la tesis? ¿Por qué no has vuelto a trabajar en
las noches, como solías hacerlo?
P: No lo sé. No tengo claro el camino que debo
seguir, ya me han rechazado dos veces el artículo y
es desmotivaste. El trabajo y el estudio son
agotadores.
J: Piensa con determinación a dónde quieres
llegar. Y haz lo que sea necesario, nadie la hará por
ti. Cuenta conmigo en lo que pueda ayudarte, tu
sabes que siempre seré tu apoyo.
Luego de una profunda reflexión, madrugué todos
los días, salía a las 4 am de casa, regresaba en la
tarde y continuaba trabajando. Esto! por cerca de
2 años. Si no hubiera contado con el apoyo de mi
esposo, la historia sería diferente.
“¿Cómo alcanzar tus sueños? Con enfoque, pasión
y disciplina”. Cardona & Ramos.


Agradecimientos
Esta tesis doctoral, es el resultado de muchos años de esfuerzo y dedicación. Es el fruto del esfuerzo,
no solo personal, sino también de un grupo de personas e instituciones. Desde lo personal,
profesional y académico, es una enseñanza de vida, un proyecto que demuestra que, si bien el
resultado es importante, el esfuerzo y dedicación generan la victoria en este emprendimiento.
Muchos momentos de angustia y desesperación aparecieron en el camino, pero gracias al soporte de
aquellos más cercanos, fue posible levantar la cabeza, respirar profundo, visualizar la meta y seguir
adelante. Otros momentos de satisfacción fueron posibles, y también tuve la fortuna de celebrarlo
con sus protagonistas.
Un agradecimiento especial al director de este trabajo, el Doctor Flavio Prieto Ortiz, Profesor de la
Universidad Nacional, quien, con su dedicación y disciplina, siempre estuvo presente, como guía,
tutor y coinvestigador. De igual manera, un gran agradecimiento al Doctor Carlos E. Oliveros,
Investigador Principal de la Disciplina de Poscosecha de Cenicafé, quien con su experiencia y
conocimiento acerca del gremio cafetero, enfocó este proyecto a lo práctico y aplicable.
Agradezco a un grupo de personas que de una u otra forma aportaron su granito de arena a este
trabajo: Al Ingeniero Álvaro Guerrero, por su apoyo, disposición para trabajo en campo y aportes en
el sistema de navegación inercial. Al Ingeniero Jonathan Avendaño, por su aporte en el algoritmo
3D. Al Ingeniero Carlos Mario Muñoz, por sus aportes en el aplicativo móvil. Y, a la Doctora Esther
Cecilia Montoya, por sus aportes en el análisis estadístico.
El trabajo en campo es fuerte, requiere de entereza, fuerza y muchas ganas de hacer las cosas, por
esta razón agradezco a la Estación Experimental Naranjal, donde se desarrollaron todos los trabajos
de campo con el apoyo del personal dirigido por el Ingeniero Jhon Félix Trejos, a quien le expreso
mis más sinceros agradecimientos. Gracias a Gustavo García, Ángela Burgos, Deisy Cuartas, Lina
Melchor y a todos los que de una u otra forma colaboraron en la ardua labor de campo. Fue una gran

VIII Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
experiencia conocer de primera mano todas las condiciones agronómicas que condicionaban este
trabajo.
Un agradecimiento especial para mi amiga y compañera de trabajo la Doctora Aida Peñuela, con
quien compartí momentos dulces y amargos de este duro trasegar de los estudios de doctorado.
Dos personas muy importantes en mi vida que siempre se mostraron preocupadas por mi falta de
tiempo, y mi estrés constante. Quienes comprendieron que, entre los estudios, las actividades diarias
y mi hogar, no había mucho tiempo para ellos. A mis padres, por su comprensión, interés y apoyo.
Los agradecimientos para mi esposo son infinitos, él tomó las riendas del hogar, mientras yo estaba
inmersa en mis estudios, fue un tutor de vida, lograba decirme siempre las verdades por más crudas
que fueran y me felicitaba cuando veía un avance en todo este proceso. Gracias a él por su
incondicional apoyo, paciencia, consejos y motivación. Por compartir conmigo cada momento y
nunca dejarme sola.
Paula Jimena Ramos Giraldo.
Manizales, 15 de mayo de 2017.

Resumen IX
Resumen La estimación de producción de café en Colombia es un proceso que se realiza periódicamente para
proyectar la dinámica del negocio del café, tanto a nivel Nacional como Internacional. Actualmente
no se cuenta con herramientas, dispositivos o sistemas que asistan esta labor, es un proceso que se
lleva a cabo de forma manual, siendo costoso y dispendioso. Como un primer acercamiento a una
solución del problema anterior se propone, a través de esta tesis doctoral, desarrollar un sistema para
estimar la producción de café en una rama a partir de imágenes adquiridas con sistemas monoculares
en condiciones de campo. Se desarrollaron algoritmos con alta robustez a los cambios en iluminación
y con un manejo adecuado del ruido en imágenes generadas por sistemas monoculares, como el
presente en algunos dispositivos móviles.
Este trabajo se desarrolló en cuatro etapas: (i) La primera consistió en diseñar una estrategia para
adquirir imágenes en condiciones de campo, se desarrolló un aplicativo móvil para controlar la
adquisición y el almacenamiento de las imágenes y realizar geolocalización de cada una de las ramas
chequeadas en una parcela de café; (ii) En la segunda etapa se diseñó un algoritmo para la
identificación y conteo de frutos de café por estado de desarrollo, en condiciones de campo, usando
información de textura (2D) en las imágenes adquiridas; se tuvieron en cuenta técnicas de
segmentación adecuadas para frutos visibles y medianamente ocluidos, reconocimiento de patrones
para diferenciar los frutos de otras estructuras vegetativas presentes en las ramas, como por ejemplo
hojas, flores, tallo, etc.; (iii) La etapa tres consistió en diseñar un algoritmo 3D para obtener el
modelo geométrico de los frutos de café en la rama, e inferir su estado de desarrollo a partir de la
información geométrica y de color de cada nube de puntos generada: (iv) La última etapa consistió
en probar cada uno de los algoritmos desarrollados en la segunda y tercera etapa y crear modelos de
estimación de producción a nivel de rama, para cada uno de los estados de desarrollo.
Se logró estimar el número de frutos en una rama de café, por medio del conteo automático generado
por el sistema de visión de máquina desarrollado, con un R2 del 0,98 y un error del 17%. Se estimó
también el porcentaje de maduración de la rama con un R2 del 0,94 y un error del 7%. La masa de
la rama fue estimada a partir del conteo automático y se obtuvo un R2 de 0,94 con un error de

X Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
estimación del 22%. Se realizaron estimaciones a nivel de árbol y parcela que muestran que es
posible estimar la masa a cosechar de la parcela por medio del conteo automático a frutos de café en
ramas.
La información obtenida en este trabajo permitirá generar herramientas para que los caficultores
utilicen un método eficiente, no destructivo y de bajo costo que proporcione información útil para
planificar el trabajo agrícola y la obtención de beneficios económicos de la gestión eficiente de los
recursos.
Palabras clave: aplicativo móvil, integración sensores, algoritmo 2D, algoritmo 3D, conteo de
frutos, modelo geométrico, modelos de estimación, café.

Resumen XI
Development of an automatic system for measuring the mass of coffee branch by machine vision
Abstract The process of coffee production estimation in Colombia is carried out periodically, in order to
predict the dynamics of the coffee business nationally and internationally. Currently, there are no
tools, devices, or systems that help in this endeavor. Instead, it is a process conducted manually,
which is both costly and wasteful. In hopes of solving the previously mentioned problem, by way of
this doctoral thesis, a coffee branch production estimation system will be developed, using images
acquired with monocular systems in field conditions. Algorithms highly resistant to changes in
illumination and with adequate handling of image noise generated by monocular systems, such as
those present on some mobile devices, are developed.
This investigation was undertaken in four stages: (i) The first consisted in designing a strategy for
image acquisition in field conditions. A mobile application was created, in order to control image
acquisition and storage, and for geolocation of each of the branches checked on a coffee parcel; (ii)
In the second stage, an algorithm was designed for the identification and counting of coffee fruits
according to ripeness, in field conditions, using texture information (2D) in the acquired images.
Segmentation techniques adequate for visible and moderately occluded fruit, pattern recognition for
differentiation of fruits from other vegetative structures present on branches, such as leaves, flowers,
stems, etc., were taken into account; (iii) The third stage consisted of designing a 3D algorithm for
obtention of a geometric model of coffee fruits on branches, and inferring their ripeness using
information about their geometry, and the color of each point cloud generated: (iv) The last stage
consisted of testing each of the algorithms created in the second and third stages, and creating
production estimation models on the branch level, for each of the stages of ripeness.
It was possible to estimate the number of fruits on a coffee branch, using the automatic count
generated by the machine vision system developed, with an R2 of 0.98 and 17% error. Also, the
ripeness percentage on the branch was estimated, with an R2 of 0.94 and 7% error. The mass of the

XII Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
branch was estimated using the automatic count, and an R2 of 0.94 with 22% estimation error was
obtained. Estimations on the tree and parcel level were performed, which show that it is possible to
estimate the amount to be harvested from the parcel, using the automatic count of coffee fruits on
branches.
The information obtained in this research will allow for the generation of tools, so that coffee
growers can use an efficient, non-destructive, low cost method, that provides useful information for
the planning of agricultural work, and obtention of economic benefits from efficient resource
management.
Keywords: mobile application, sensor integration, 2D algorithm, 3D algorithm, fruit count,
geometric model, estimation models, coffee.

Contenido XIII
Contenido
Pág.
Resumen .......................................................................................................................................... IX
Abstract ........................................................................................................................................... XI
Lista de figuras ............................................................................................................................ XVI
Lista de tablas .............................................................................................................................. XIX
1. Introducción. ............................................................................................................................ 1 1.1 Definición de problema a tratar. ......................................................................................... 2 1.2 Objetivos. ........................................................................................................................... 3
1.2.1 General. .......................................................................................................................... 3 1.2.2 Específicos. .................................................................................................................... 3
1.3 Estado del arte. ................................................................................................................... 3 1.3.1 Generalidades del café. .................................................................................................. 3 1.3.2 Estimación de producción en café y otros cultivos. ....................................................... 5 1.3.3 Evolución de tecnologías de los sistemas de visión de máquina en el agro. .................. 9
1.4 Contribuciones. ................................................................................................................ 13 1.4.1 Contribuciones de la tesis en sistema de adquisición de imágenes en campo. ............. 14 1.4.2 Contribuciones de la tesis en algoritmo de identificación y conteo de frutos a partir de características 2D. .................................................................................................................... 14 1.4.3 Contribuciones de la tesis en algoritmo de identificación y de frutos a partir de características 3D. .................................................................................................................... 15 1.4.4 Contribuciones de la tesis en los modelos de estimación de número de frutos por rama. 15
1.5 Estructura de la tesis ......................................................................................................... 15
2. Aplicativo móvil, integración de sensores y protocolo para la adquisición de las imágenes. ......................................................................................................................................... 16
2.1 Exploración de sistemas de adquisición ........................................................................... 16 2.2 Condiciones para adquisición de imágenes en campo. .................................................... 21
2.2.1 Especificaciones de diseño para adquisición de imágenes. .......................................... 22 2.3 Control de adquisición de imágenes y georreferenciación a partir de un Sistema de Navegación Inercial (SNI). .......................................................................................................... 25
2.3.1 Captura y análisis de movimiento. ............................................................................... 26 2.3.2 Sistema de Navegación Inercial (SNI) propuesto. ....................................................... 26
2.4 Resultados. ....................................................................................................................... 34 2.4.1 Calibración y evaluación del SNI propuesto en modo navegación MN. ..................... 34

XIV Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
2.4.2 Evaluación del SNI propuesto en modo control de adquisición de imágenes MCA. .. 38 2.4.3 Adquisición de vídeos y análisis de imágenes para selección de cuadros de un vídeo. 41
2.5 Conclusiones .................................................................................................................... 44
3. Identificación de frutos de café en rama, a partir de imágenes 2D. .................................. 47 3.1 Algoritmo 2D para detección de frutos. ........................................................................... 47
3.1.1 Adquisición y adecuación de imágenes. ...................................................................... 48 3.1.2 Segmentación de regiones homogéneas. ...................................................................... 50 3.1.3 Detector de contornos candidatos a frutos de café. ...................................................... 52 3.1.4 Ajuste y selector de elipses correspondientes a frutos de café. .................................... 55 3.1.5 Detección, clasificación y conteo de elipses/frutos. ..................................................... 56
3.2 Evaluación del conteo automático. .................................................................................. 59 3.2.1 Porcentaje de visibilidad de frutos en imágenes. ......................................................... 60 3.2.2 Sistema de conteo de frutos en imágenes. .................................................................... 60
3.3 Conclusiones .................................................................................................................... 64
4. Obtención del modelo geométrico de los frutos en la rama. .............................................. 66 4.1 Reconstrucción 3D. .......................................................................................................... 67 4.2 Filtrado y submuestreo ..................................................................................................... 70
4.2.1 Filtrado estadístico de outliers ..................................................................................... 71 4.2.2 Remoción de fondo ...................................................................................................... 71 4.2.3 Submuestreo ................................................................................................................. 72
4.3 Extracción de características y clasificación .................................................................... 73 4.3.1 Verificación del tamaño de los frutos medidos en la nube de puntos .......................... 73 4.3.2 Características 3D ........................................................................................................ 77 4.3.3 Características 2D ........................................................................................................ 78 4.3.4 Clasificador de puntos pertenecientes a frutos. ............................................................ 78
4.4 Segmentador RANSAC para frutos independientes. ....................................................... 81 4.5 Extracción y análisis del modelo geométrico. .................................................................. 83
4.5.1 Análisis de ubicación. .................................................................................................. 85 4.5.2 Análisis de forma. ........................................................................................................ 87
4.6 Detección, conteo y estimación de volumen de los frutos de café. .................................. 91 4.6.1 Detección de frutos y conteo por estado de desarrollo................................................. 91 4.6.2 Estimación de volumen. ............................................................................................... 94
4.7 Conclusiones. ................................................................................................................... 96
5. Estimación de número de frutos, porcentaje de maduración y masa en la rama. ........... 98 5.1 Relaciones número de frutos, producción y porcentaje de maduración. .......................... 99
5.1.1 Relación frutos observados en inicio de cosecha vs. Producción acumulada en toda la cosecha principal (Julio/ 2015). ............................................................................................. 100 5.1.2 Relación frutos observados en pico de cosecha vs. Producción pico de cosecha (septiembre/2015). ................................................................................................................. 102 5.1.3 Dinámica de producción de cada tercio del árbol en la parcela estudiada. ................ 103 5.1.4 Análisis de producción promedio por árbol, producción en los 30 árboles del muestreo y de toda la parcela. ............................................................................................................... 105 5.1.5 Estimación del porcentaje de maduración con la información observada en el pase de septiembre. ............................................................................................................................. 110
5.2 Obtención de modelos lineales para la estimación del número de frutos en rama a partir del conteo automático. ............................................................................................................... 111

Resumen XV
5.3 Evaluación de los modelos lineales para conteo de frutos, medición de porcentaje de maduración y medición del peso de frutos en rama. .................................................................. 113
5.3.1 Evaluación de los modelos lineales para conteo de frutos ......................................... 114 5.3.2 Medición del porcentaje de maduración de una rama. ............................................... 114 5.3.3 Medición del peso de los frutos en una rama de café. ................................................ 115
5.4 Validación de la estimación del conteo de frutos. .......................................................... 116 5.4.1 Validación conteo automático de frutos no cosechables. ........................................... 117 5.4.2 Validación estimación de producción un pase pico de cosecha. ................................ 120 5.4.3 Validación estimación de producción acumulada. ..................................................... 123
6. Conclusiones generales y trabajo futuro. ........................................................................... 127 6.1 Conclusiones. ................................................................................................................. 127 6.2 Trabajo futuro................................................................................................................. 130
7. Anexos ................................................................................................................................... 132
A. Interface del aplicativo móvil para navegación y adquisición de imágenes en plantaciones de café. .................................................................................................................... 132
B. Sistema de anotación semiautomático. ............................................................................... 134 B.1 Tipo de estructuras vegetativas en imágenes de rama. ............................................. 135 B.2 Etiquetado y asignación de clases. .............................................................................. 136 B.3 Transformación Watershed. ....................................................................................... 136 B.4 Creación de información ground-truth. ..................................................................... 137 B.5 Resultados de SASGROT. ........................................................................................... 139 B.6 Conclusiones SASGROT. ............................................................................................ 143
C. Modelado geométrico con supercuádricas. ........................................................................ 145
Bibliografía ................................................................................................................................... 147

Contenido XVI
Lista de figuras Pág.
Figura 1-1: Árbol de café variedad Castillo®. ................................................................................. 4 Figura 1-2: Desarrollo de los frutos de café después de la floración. Fuente: FNC® ...................... 5 Figura 1-3: Primer prototipo del equipo REV Rendement Estimé par le Volume”(Estimador de productividad por volumen). Rabatel y Guizard [43] ...................................................................... 10 Figura 1-4: Vehículos en campo para adquirir información de frutas. ........................................... 11 Figura 2-1: Cámara CMUCAM3, exploración de opciones de cámara. ......................................... 17 Figura 2-2: WebCams para adquisición de imágenes en condiciones de campo. .......................... 17 Figura 2-3: Sistema para adquirir imágenes por medio de una tableta Samsung y soporte. .......... 18 Figura 2-4: Sistema para adquirir imágenes por medio celular y soporte. ..................................... 18 Figura 2-5: Aspectos morfológicos relacionados con los tallos del árbol de café. ......................... 21 Figura 2-6: Movimiento y soporte del dispositivo móvil en la rama de café. ................................ 23 Figura 2-7: Tipo de imágenes adquiridas. ...................................................................................... 25 Figura 2-8: Sistema de Navegación Inercial (SNI) Propuesto. Diagrama del procesamiento de las señales inerciales adquiridas desde el celular. ................................................................................. 28 Figura 2-9: Cálculo de periodos estacionarios. ............................................................................... 31 Figura 2-10: Ajuste y cálculo de velocidad y posición del movimiento......................................... 32 Figura 2-11: Efecto de compensación del DRIFT en el desplazamiento calculado. ...................... 36 Figura 2-12: Histograma del error absoluto. ................................................................................... 36 Figura 2-13: Puntos georreferenciados con el GPS y con el SNI propuesto. ................................. 38 Figura 2-14: Georreferenciación de árboles en una parcela sembrada en café. Foto tomada de Google Maps. ................................................................................................................................... 38 Figura 2-15: Velocidades de desplazamiento del dispositivo móvil sobre la rama de café. ........... 40 Figura 2-16: Detección de periodos de movimiento para tres velocidades. ................................... 41 Figura 2-17: Detección de regiones de interés e índices de emborronamiento. ............................. 43 Figura 2-18: Intervalos de confianza para índice de nitidez a diferentes velocidades de adquisición de imágenes. ..................................................................................................................................... 44 Figura 2-19: Intervalos de confianza para el costo computacional de cada índice/filtro aplicado para calcular nitidez. ........................................................................................................................ 44 Figura 3-1: Sistema de visión de máquina 2D propuesto. .............................................................. 49 Figura 3-2: Conjuntos de imágenes por rama. ................................................................................ 50 Figura 3-3: Segmentación de regiones homogéneas....................................................................... 51 Figura 3-4: Análisis contorno resultado de segmentación de regiones homogéneas. ..................... 53 Figura 3-5: Relación entre tres puntos consecutivos. Líneas y ángulos. Algoritmo 3-1. ............... 54 Figura 3-6: Estimación de puntos para posterior ajuste de elipse. .................................................. 55

Resumen XVII
Figura 3-7: Reglas para determinar si una elipse detectada corresponde a un fruto. ...................... 57 Figura 3-8: Estimación de puntos para posterior ajuste de elipse. .................................................. 57 Figura 3-9: Tipos de imágenes que generan errores en la detección y conteo de frutos................. 63 Figura 3-10: Frutos ocluidos detectados por las elipses ajustadas. ................................................. 64 Figura 4-1: Sistema de visión de máquina 3D propuesto. .............................................................. 68 Figura 4-2: Adquisición en secuencia de vídeos sobre una rama de café. ...................................... 69 Figura 4-3: Pasos para reconstrucción 3D de una rama de café. .................................................... 70 Figura 4-4: Pasos dentro de la fase de filtrado. ............................................................................... 72 Figura 4-5: Resultado del proceso de submuestreo. ....................................................................... 73 Figura 4-6: Ejes ecuatoriales y eje polar de un fruto de café en los tres ejes coordenados. ........... 73 Figura 4-7: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos. ............................................................................................................................. 74 Figura 4-8: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos, para ramas sin problemas de adquisición de imágenes. ..................................... 75 Figura 4-9: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos, para ramas con problemas de adquisición de imágenes. .................................... 75 Figura 4-10: Relación entre tamaño de la nube de puntos (eje x), densidad volumétrica de cada nube de puntos (eje principal y) y error relativo en la dimensión del tamaño por cada fruto medido en la nube de puntos (eje secundario y). .......................................................................................... 76 Figura 4-11: Comparación entre nube de puntos Ground-truth (izq.) y nube clasificada (der.). .... 80 Figura 4-12: Clasificación de un fruto pintón dentro de la nube de puntos. ................................... 81 Figura 4-13: Segmentación RANSAC de la nube de puntos de una rama de café. ........................ 83 Figura 4-14: Reconstrucción gráfica para un cluster segmentado. ................................................. 84 Figura 4-15: Superelipsoides de una rama completa, luego de la estimación de forma y reconstrucción gráfica. ..................................................................................................................... 85 Figura 4-16: Diagrama de dispersión Centroide en x vs. Centroide en y; línea de tendencia. ........ 86 Figura 4-17: Histograma del error absoluto (Ecuación (4.13)) de los datos Centroide.y con relación a la línea de tendencia. Datos mayores a 3 desviaciones estándar son considerados atípicos. ............................................................................................................................................ 86 Figura 4-18: Comparación de la distancia euclidea entre centroides consecutivos de superelipsoides y el radio mínimo entre ellas. ................................................................................. 87 Figura 4-19: Resultado de seleccionar las superelipsoides que son consideradas frutos de café. Rama 1. ............................................................................................................................................ 89 Figura 4-20: Resultado de seleccionar las superelipsoides que son consideradas frutos de café. Rama 1. ............................................................................................................................................ 90 Figura 4-21: Relación entre el número de superelipsoides seleccionadas y el número total real de frutos en las ramas. ........................................................................................................................... 91 Figura 4-22: Relación entre el número de frutos inmaduros detectados y el número de frutos inmaduros en las ramas. ................................................................................................................... 93 Figura 4-23: Histograma para el volumen de los frutos inmaduros en la rama 1. .......................... 95 Figura 4-24: Histograma para el volumen de los frutos inmaduros en la rama 5. .......................... 95 Figura 4-25: Correlación entre la masa real de los frutos en las ramas y la masa detectada con el método del volumen. ........................................................................................................................ 96

XVIII Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 4-26: Correlación entre la masa real de los frutos en las ramas y la masa detectada a partir del conteo de frutos y factores de conversión [103]. ....................................................................... 96 Figura 5-1: Número de frutos conteo manual (CM) vs. Masa acumulada de frutos por zonas productivas del árbol. ..................................................................................................................... 101 Figura 5-2: Número de frutos conteo manual vs. Masa acumulada de frutos por zonas productivas del árbol durante el pase pico de cosecha. Septiembre 2015. ........................................................ 103 Figura 5-3: Intervalos de confianza para producción por zona productiva del árbol y para todo el árbol. .............................................................................................................................................. 104 Figura 5-4: Número de frutos conteo manual vs. Masa acumulada de frutos por zonas productivas del árbol durante el pase pico de cosecha. Septiembre 2015. ........................................................ 105 Figura 5-5: Producción promedio por árbol, acumulada en la muestra seleccionada y total en la parcela. ........................................................................................................................................... 106 Figura 5-6: Relación producción promedio por árbol vs producción total de la parcela. ............. 107 Figura 5-7: Composición de la masa cosechada. .......................................................................... 109 Figura 5-8: Número total de frutos en conteo manual vs. Número total de frutos medidos automáticamente. Verificación de relación lineal. ......................................................................... 112 Figura 5-9: Error relativo (asintótico) para la estimación automática de frutos cosechables y no cosechables. ................................................................................................................................... 113 Figura 5-10: Intervalos de confianza para el conteo manual y conteo automático en los 4 lotes de café seleccionado y en las 4 ramas seleccionadas (promedio del número de frutos en 4 ramas). . 119 Figura 5-11: Comparación entre el conteo manual y el conteo automático. ................................ 120 Figura 5-12: Porcentaje de maduración en cada pase de cosecha en cada lote y porcentaje de maduración estimado con la detección automática. ....................................................................... 122 Figura 5-13: Intervalos de confianza para la masa real (MR) y la masa estimada (ME) en los 4 lotes de café seleccionado y en las 4 ramas seleccionadas. ........................................................... 124 Figura 5-14: Producción total de las cuatro ramas seleccionadas vs. Producción de la parcela en cada pase. ....................................................................................................................................... 126 Figura 5-15: Producción estimada de las 4 ramas vs. Producción de la parcela........................... 126 Figura 7-1: Apariencia de la aplicación desarrollada. .................................................................. 133 Figura 7-2: Diagrama de flujo del sistema semiautomático de anotación para generar información ground-truth. .................................................................................................................................. 137 Figura 7-3: Verificación y mejora de las marcas para creación de la ROI. .................................. 138 Figura 7-4: Tipo de marcas generadas. ......................................................................................... 139 Figura 7-5: Imágenes segmentadas con la transformada watershed. ............................................ 139 Figura 7-6: Imágenes ground-truth. Arriba. Cuatro estructuras, Abajo. 12 estructuras. .............. 139 Figura 7-7: Comparación de zonas generadas, izq. Método propuesto, der. Labelme (Russell et al. 2008). ............................................................................................................................................. 141 Figura 7-8: Ejemplo de Supercuádricas y parámetros de forma. .................................................. 146

Contenido XIX
XIX
Lista de tablas Pág.
Tabla 1-1: Estado del arte en detección de características 3D y 2D sobre estructuras vegetativas. ........... 12 Tabla 2-1: Características de cámara, ventajas y desventajas de cada sistema probado. ........................... 20 Tabla 2-2: Gama media y alta de dispositivos inteligentes marca Samsung. ............................................. 20 Tabla 2-3: Sensores incorporados en el dispositivo móvil ......................................................................... 28 Tabla 2-4: Constantes para el cálculo de máximos locales (K) y valor mínimo de umbral (min(THDis)).30 Tabla 2-5: Puntos utilizados para el ajuste en modo navegación. .............................................................. 34 Tabla 3-1: Estructuras vegetativas pertenecientes a frutos en una rama de café. ....................................... 58 Tabla 3-2: Tasa de verdaderos positivos para cada uno de los clasificadores en cada clase. ..................... 59 Tabla 3-3: Porcentaje de visibilidad para frutos contados en imágenes a ramas de café. .......................... 60 Tabla 3-4: Coeficientes de regresión, intercepto y de determinación para cada uno de estados de desarrollo identificados por el MVS. .......................................................................................................... 61 Tabla 4-1: Parámetros intrínsecos de la cámara. ........................................................................................ 68 Tabla 4-2: Datos de tamaño, volumen y problemas de adquisición de cada nube de puntos analizada. .... 75 Tabla 4-3: F1-Score por clase y tamaño de cada región. ........................................................................... 79 Tabla 4-4: Exactitud para la clasificación de frutos, tallos, hojas y flores en una rama de café 3D. ......... 81 Tabla 4-5: Umbral distancia, radio mínimo y máximo para modelo esfera en ramas de café. .................. 82 Tabla 4-6: Número de superelipsoides totales, eliminadas y seleccionadas, comparadas con el número total de frutos por rama. .............................................................................................................................. 90 Tabla 4-7: Posibles combinaciones y reglas para definir el Estado de Maduración (EM) final del fruto detectado. ..................................................................................................................................................... 92 Tabla 4-8: Conteo de frutos por estado de maduración en cada una de las ramas. .................................... 92 Tabla 4-9: Costo computacional de cada proceso realizado para detectar frutos y realizar el conteo (i5 3,6GHz 8Gb). .............................................................................................................................................. 93 Tabla 5-1: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la Figura 5-1. ................................................................................................................................................ 101 Tabla 5-2: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la Tabla 5-1. .................................................................................................................................................. 103 Tabla 5-3: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la de masa para estimar la producción de la parcela. .................................................................................... 106 Tabla 5-4: Coeficientes de regresión, intercepto y de determinación para las relaciones de número de frutos conteo manual (CM) y la masa en diferentes tercios del árbol. ...................................................... 109

XX Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Tabla 5-5: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la Porcentaje de Maduración calculado con el conteo de frutos (PMCM) y Porcentaje de Maduración calculado con la masa cosechada (PMMC). Figura 5-1 ........................................................................... 110 Tabla 5-6: Coeficientes de regresión, intercepto y de determinación para cada uno de los grupos en la relación frutos contados manualemente vs. Frutos medidos con el algoritmo 2D. ................................... 112 Tabla 5-7: Coeficientes de regresión y de determinación para la evaluación de las relacionas de la Tabla 5-6.............................................................................................................................................................. 114 Tabla 5-8: Coeficientes de regresión, intercepto y de determinación para el porcentaje de maduración y masa, de los frutos detectados automáticamente y lo real en la rama. ...................................................... 116 Tabla 5-9: Coeficientes de regresión y de determinación para la relación conteo manual (CM) versus conteo automático (CA) para cada uno de los lotes seleccionados y para todos los lotes. ....................... 118 Tabla 5-10: Validación del factor 2,217 aplicado para estimar el número total de frutos en las ramas para todos los lotes. ........................................................................................................................................... 118 Tabla 5-11: Coeficiente de regresión y de determinación para la relación Conteo Automático (CA) en las cuatro ramas Septiembre/2016 versus Masa en las cuatro ramas en el mismo pase. ................................ 120 Tabla 5-12: Intercepto, coeficiente de regresión y de determinación para la relación masa en las cuatro ramas Septiembre/2016 versus Masa por árbol (Septiembre 2016). ......................................................... 122 Tabla 5-13: Coeficiente de regresión y de determinación para la relación Conteo Manual (CM) en las cuatro ramas Julio/2016 versus Masa acumulada en las cuatro ramas (Julio-Diciembre 2016). .............. 123 Tabla 5-14: Intercepto, coeficiente de regresión y de determinación para la relación masa en las cuatro ramas Julio/2016 versus Masa acumulada por árbol (Julio-Diciembre 2016). ......................................... 125 Tabla 7-1: Estructuras vegetativas para una rama de café. ...................................................................... 138 Tabla 7-2: Tiempos promedio en segundos (ū) y desviación estándar (σ), requeridos para realizar marcas sobre estructuras, imágenes y vídeo con el SASGROT, LabelMe (Russell et al. 2008) y reducción de tiempo con sistema propuesto. .................................................................................................................. 140 Tabla 7-3: Matriz de confusión, segmentación de ROI. ........................................................................... 140 Tabla 7-4: Comparación entre los sistemas consultados y SASGROT .................................................... 144

1
1. Introducción.
El comercio del café es el segundo de más valor en el mundo, después del petróleo. Pese a su importancia,
con excepción de algunas fincas en Brasil, el café continúa siendo un cultivo con muy bajo empleo de
tecnología en las labores agrícolas, especialmente en la recolección. A nuestro conocimiento, los
productores no disponen de tecnología que permita obtener información de la producción de café de manera
anticipada, para planificarla, con mejor aprovechamiento de los recursos, principalmente la mano de obra.
En Colombia el método que emplea la Federación Nacional de Cafeteros (FNC) para estimar la producción,
es bianual y cada semestre se desprenden, contabilizan y pesan, todos los frutos de los árboles muestreados
en lotes de diferentes regiones del país; este método entrega valores acertados de producción anual, sin
embargo, es un método destructivo, costoso, lento, y tiene un alto requerimiento de mano de obra.
Generalmente, los caficultores pueden hacer cálculos aproximados de su cosecha, a partir de su experiencia
evalúan la intensidad de floración, la fructificación, el estado fitosanitario de la planta y llevan registros de
ciclos de producción anteriores, para determinar si su cosecha actual será buena, regular o mala. Sin
embargo, el cafetal puede sufrir influencias negativas, tanto de factores externos, como de factores de
manejo, que pueden producir la caída de flores y/o frutos, y alterar la intensidad de la cosecha. Finalmente,
los caficultores no tienen conocimiento preciso de la cantidad de café que pueden producir realmente y las
necesidades de infraestructura y mano de obra.
Con el fin de programar adecuadamente las actividades en el campo, hacer uso eficiente de los recursos
humanos, económicos, tecnológicos, reducir el impacto ambiental y generar una trazabilidad de los cultivos,
nace la agricultura de precisión (AP). Tomar decisiones en campo a partir de medidas reales del cultivo,
referenciadas en el espacio y el tiempo, ha llevado al desarrollo de diferentes tecnologías para estimar,
evaluar y entender variaciones de una plantación que afectan su producción. La AP está acompañada de la
medición de múltiples variables en campo que requieren de sistemas computacionales para su
almacenamiento y procesamiento. Se han desarrollado dispositivos dedicados para medición del estado
nutricional [1], índice de área foliar [2] y análisis de suelos [3], que por su alto costo, no están disponibles
para pequeños productores agrícolas. Hoy en día los dispositivos móviles son computadoras con múltiples
sensores, capacidades de control y monitoreo de variables, y pueden ser utilizados en condiciones de campo

2 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
con el empleo de aplicaciones ajustadas a las necesidades de los agricultores, quienes ya tienen este tipo de
tecnología al alcance de la mano.
Dentro de este trabajo se crean y utilizan técnicas 2D y 3D para la identificación de frutos de café en las
ramas, con imágenes adquiridas en condiciones de campo. Adicionalmente, se logró desarrollar un
aplicativo móvil con el cual se adquieren las imágenes y se georreferencia cada rama chequeada. Finalmente,
se obtiene un método para estimar la producción (masa y número de frutos de café), a nivel de rama y de
parcela, a partir de la información parcial obtenida en cada rama chequeada.
1.1 Definición de problema a tratar. El cultivo del café, como otros cultivos de Colombia, requiere de sistemas que apoyen la labor del agricultor,
o del caficultor para el caso específico. La mayoría de las decisiones tomadas en torno a un cultivo se dan
por el ánimo propio, las capacidades, conocimientos y experiencias del agricultor. Actualmente el caficultor
puede conocer la distribución de su cosecha, sin embargo, no existe una metodología aplicada por los
caficultores para calcular la producción de su finca. Tanto para las agremiaciones, gobierno y caficultores
es importante tener una oportuna y confiable estimación de la producción de café, sin embargo, los métodos
actuales pueden resultar lentos y costosos para el gremio y podrían no estar al alcance de los caficultores.
Es por esta razón que se plantea desarrollar un sistema capaz de medir la producción de café en una rama
por medio de técnicas de visión de máquina en condiciones de campo; este tipo de desarrollo, se proyectaría
para realizar estimaciones de producción sin necesidad de realizar muestreos destructivos a lo largo y ancho
del país y, además, permitiría al caficultor conocer la producción de su finca y de esta manera realizar
planeaciones sobre las actividades entorno al negocio del café.
Este trabajo, propone un sistema para obtener información de la producción de las ramas de los árboles, de
manera no destructiva, a partir de la información parcial obtenida con imágenes adquiridas en un solo lado
visible de la rama. Dicho sistema, basado en visión de máquina (2D y/o 3D), permite detectar y registrar el
número de frutos en las ramas de café y su masa, sin muestreos destructivos y bajo condiciones no
controladas de iluminación, contraste de ramas y oclusión de frutos. Las imágenes son adquiridas con la
cámara principal de un dispositivo móvil y, a su vez, procesadas por un algoritmo para detectar y contar
frutos de café por estado de desarrollo. Dicho algoritmo (2D y/o 3D) determina el número de frutos visibles
en un solo lado de la rama y con esta información se estima el número total de frutos en la rama. El sistema
fue evaluado y validado en ramas de café para diferentes condiciones de cultivo y épocas de producción.

Introducción 3
A partir de imágenes adquiridas en ramas de café es posible obtener información de la planta, su producción,
aspectos nutricionales, presencia de plagas o enfermedades. La adquisición de estas imágenes es compleja,
pues el espacio es reducido y no es posible tomar una sola imagen por rama, se requiere tomar imágenes de
manera sucesiva para obtener la información completa de la rama. Adicionalmente, es necesario
georreferenciar las imágenes adquiridas de cada árbol y el GPS del dispositivo móvil no tiene la resolución
necesaria para georreferenciar adecuadamente cada árbol, pues los errores de georreferenciación de este
sistema (2,5m – 5 m) superan la distancia entre plantas, mínima de 0,5 m.
1.2 Objetivos.
1.2.1 General. Desarrollar un sistema automático de medición de la masa de café en rama a partir de información de textura
e información geométrica de imágenes obtenidas en campo con una sola cámara.
1.2.2 Específicos. Diseñar un protocolo de adquisición de imágenes con variaciones de iluminación típicas en campo para
entrenamiento y validación.
Diseñar un algoritmo para la identificación del estado de desarrollo de frutos de café en rama, en
condiciones de campo a partir de imágenes 2D.
Diseñar un algoritmo para la obtención del modelo geométrico de los frutos en la rama, a partir de
imágenes monoculares.
Ajustar la medición de la masa a partir de los frutos identificados en los objetivos anteriores.
1.3 Estado del arte.
1.3.1 Generalidades del café.
Un árbol de café variedad Castillo alcanza alturas de 2,8 m y florece a partir del mes número 12 después
de la siembra en cultivos tecnificados en la zona central cafetera (Figura 1-1a). El tallo mide entre 7 y 8
centímetros de diámetro, cuenta en promedio con 40 ramas productivas y su producción toma entre 30 y 36
semanas, dependiendo de la oferta ambiental en el cultivo [6]. Una rama café (Figura 1-1b) presenta
diferentes estructuras vegetativas, entre ellas hojas, flores, tallo, y frutos en racimos. Por otro lado, el
proceso de maduración de los frutos presenta un cambio de color sobre la superficie que evidencia las

4 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
diferentes etapas de desarrollo, desde el color verde hasta el rojo, pasando por tonalidades amarillas y
naranjas, y finalizando con tonalidades violetas o negras (Figura 1-1).
Se identifican cuatro etapas en la producción de frutos: la primera va desde la floración hasta la semana
número siete, el crecimiento es lento, el color de los frutos es verde y aún no hay formación de la semilla.
La segunda etapa comprendida entre las semanas 8 y 25 después de la floración, se caracteriza por un
crecimiento rápido de los frutos, tanto en tamaño como en peso fresco. A partir de la semana 18 comienza
la formación de la semilla, en el interior del fruto, hasta que completa su desarrollo. En la tercera etapa,
semanas 26 a 32, tiene lugar la maduración, el fruto se encuentra fisiológicamente desarrollado y las semillas
en su interior aptas para ser procesadas. Finalmente, la cuarta etapa se presenta después de la semana 32 y
se caracteriza porque el fruto se sobremadura y se seca, [6] (Figura 1-2).
En general, durante la maduración, los frutos presentan cambios físicos y químicos, que han sido estudiados
para conocer la incidencia de los estados de desarrollo del fruto y la calidad final de la bebida [7, 8, 9 y 10].
En estos estudios se demuestra que características como el color, tamaño, masa, entre otros, logran
diferenciar los frutos por etapa de desarrollo (Figura 1-2). La oferta de frutos en una rama puede ser
variable, debido a que hay floraciones durante todo el año, teniendo picos de cosecha en algunos periodos
y menores producciones durante el resto del año. Solo los frutos maduros y sobremaduros deben ser
cosechados, los frutos inmaduros y semi-maduros (pintones) deben esperar otro momento de recolección.
En países como Brasil pueden existir 6 pases al año, mientras que en países como Colombia son 20 pases
al año, debido a la oferta climática de la zona cafetera.
(a) Estructuras árbol de café v. Castillo® [4]. (b) Estructuras vegetativas de una rama [5].
Figura 1-1: Árbol de café variedad Castillo®.

Introducción 5
Figura 1-2: Desarrollo de los frutos de café después de la floración. Fuente: FNC®
1.3.2 Estimación de producción en café y otros cultivos. A pesar de la fuerte necesidad de estimaciones confiables y oportunas, en el agro, la situación actual dista
de ser satisfactoria [11]. En los cultivos, las predicciones se hacen necesarias con mayor importancia en la
producción, ataque de plagas y enfermedades [11]. Con relación a la producción, las estimaciones son
necesarias para tomar decisiones políticas, con respecto al almacenamiento, distribución, precios,
comercialización, importación y exportación. Encontrar a tiempo las plagas y las enfermedades, permitiría
aplicar medidas preventivas que logren disminuir la pérdida en el rendimiento del cultivo [11].
La productividad de un cultivo, indica la masa por unidad de área que es producida en un rango de tiempo
determinado, es un indicador estimado por medio de históricos de producción y modelos alimentados por
diversos factores como, por ejemplo: la dinámica climática, la deficiencia o exceso de un elemento químico,
las características del suelo, la polinización, plagas, estructuras vegetativas de las plantas, entre otros. Tener
conocimiento de la productividad de un cultivo, es de vital importancia tanto para las empresas
agroindustriales como para el gobierno de cada país, pues con esta información se plantean políticas de
seguridad alimentaria, planes de fertilización, estimaciones de exportación, determinación de expansión de
tierras para aumentar producción, pronóstico de rentabilidades futuras, políticas para disminuir el riesgo
económico de producción por déficit/exceso del producto. Lobell et al. [12] y Agarwal [11].

6 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Para realizar un manejo adecuado de los cultivos es necesario conocer cómo crecen y cómo y cuándo se
definen las componentes que determinan directa o indirectamente el rendimiento del cultivo. A través de las
buenas prácticas agrícolas del cultivo se busca un adecuado estado de la plantación a lo largo de todo su
ciclo productivo, considerando todos los posibles riesgos a enfrentar por impactos negativos en el
rendimiento y la producción y generando estrategias de acción para minimizar dichos impactos y lograr
productividades altas y buena calidad del producto.
Para medir el potencial de producción Lobell et al. [12] y Agarwal [11] reportan tres estrategias: 1) Modelos
agroclimáticos de simulación; 2) modelos basados en características de la planta, datos espectrales, pruebas
de rendimiento en experimentos de campo y 3) modelos de valoración por parte de los agricultores. El rango
de dichos modelos va de lo simple a lo complejo, los modelos simples a menudo utilizan información de
áreas extensas, basados en estadísticos del clima, históricos de producción y dinámica del sistema suelo-
planta-atmósfera.
Los censos y encuestas, métodos ampliamente utilizados desde los años 50 [13], toman información acerca
de la superficie cultivada, información de producción y de gastos. Son medidas directas sobre una población
seleccionada con un método de muestreo que abarca una muestra representativa de un país o una región,
presentan un límite geográfico y temporal establecido y tienen un alto requerimiento de mano de obra
calificada [14].
Por otro lado, los modelos de simulación incluyen análisis estadísticos, funcionales y mecanicismos sobre
los fenómenos que tienen relación con el rendimiento del cultivo [15]. Se basan en la fenología de la planta,
las características térmicas, la dinámica del agua en el suelo y sustancias esenciales presentes o ausentes en
las plantas. Estos modelos son útiles para la evaluación de un factor único de gestión, como fecha de
siembra, fertilización, poda y recolección [12], sin embargo carecen de veracidad ante escenarios de cambio
climático. Para disminuir la incidencia del clima y la relación con la planta, se plantean mediciones directas
en campo, como las reportadas por Huddleston [13], con las cuales sea posible determinar expresiones
fenológicas reflejadas en las estructuras vegetativas, como área foliar, número de frutos, ramas, tallos,
niveles de clorofila, déficit/exceso de nutrientes, plagas y enfermedades, independiente de los factores
climáticos de la época.
Modelos basados en mediciones directas en campo son reportados por Vogel [16], Cilas y Descroix [17] y
Upreti et al. [18]. En ellos se realiza un conteo de las estructuras vegetativas-productivas de la plantación,
como los frutos, racimos, ramas y tallos. Este tipo de modelos entregan un valor muy cercano a la producción

Introducción 7
real del cultivo. Las ventajas son: 1) Método cuantitativo, 2) desarrollado sobre bases fisiológicas, 3) elimina
problemas de la distribución de la cosecha, siempre y cuando el muestreo sea definido rigurosamente, 4)
incorpora variabilidad climática y manejo del cultivo, 5) incorpora expresiones de las plantas en su relación
suelo – atmosfera. Las principales desventajas son: 1) requerimiento de un muestreo destructivo, 2) alto
requerimiento de mano de obra calificada, 3) deben ser definidos los momentos para realizar el muestreo,
ya que es posible que la expresión de la planta cambie desde la adquisición de la información hasta la
recolección.
Estimación de producción en café.
Para el caso específico de café, Cilas y Descroix [17] y Upreti et al. [18] muestran estimaciones de
producción de café a partir de variables endógenas, como los diferentes componentes de producción en el
árbol: número de tallos/árbol, racimos/rama, frutos/racimo y racimos/árbol. Cilas y Descroix [17] estiman
el número de frutos por árbol (𝐹𝐹�) a partir de la Ecuación (1.1).
𝐹𝐹� = 𝑠𝑠𝑡𝑡 ∙ 𝑏𝑏𝑠𝑠 ∙ 𝑔𝑔𝑏𝑏 ∙ 𝑓𝑓𝑔𝑔. (1.1)
Donde 𝑠𝑠𝑡𝑡 es el número de tallos por árbol, 𝑏𝑏𝑠𝑠 es el número de ramas por tallo, 𝑔𝑔𝑏𝑏 es el número de racimos
por rama y 𝑓𝑓𝑔𝑔 es el número de frutos por racimo. Adicionalmente reportan métodos estratificados para
diferentes áreas, alturas, suelos, relaciones área/suelo y área/altitud con error de estimación inferior al
3,19%.
En la década de los 80's, en Cenicafé se desarrolló un modelo matemático para simular la producción
potencial del cultivo, Montoya et al [19]. Este modelo simula la producción potencial que el café puede
alcanzar con una suficiente y adecuada cantidad de agua y nutrientes y relaciona cinco submodelos: i)
Dinámica de radiación solar; ii) Interceptación de la radiación solar y fotosíntesis; iii) Crecimiento y
mortalidad foliar; iv) Desarrollo fenológico; y v) Acumulación y distribución de la materia seca. El modelo
descrito por Montoya et al [19], fue evaluado en el período comprendido entre 1980 y 1985 en Quindío,
Caldas y Tolima, para tres densidades de siembra: 2.500, 5.000 y 10.000 plantas por hectárea. Los errores
absolutos, entre el valor observado por planta y el valor simulado fluctuaron entre 44,5% y 83,5%, durante
los seis primeros trimestres del cultivo; a partir del séptimo y durante cinco años el error fue dependiente
del Departamento, sin embargo, mostraron una disminución.
Otros autores como Castro-Tanzi et al. [20] también utiliza un método de conteo de frutos con un muestreo
aleatorio y estratificado, a través de modelos empíricos formulados utilizando tanto las variables

8 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
dependientes e independientes en la escala logarítmica. Sobre café variedad Caturra y Catuaí, utilizaron el
número de ramas laterales productivas por árbol y el número de frutos por rama. Ellos encontraron que
contando los frutos presentes en 8 o 9 ramas por árbol es posible determinar el número total de frutos por
árbol, en condiciones de dos tallos por sitio para las variedades mencionadas, con coeficientes de regresión
entre 0,73 y 0,92. Los mismos autores señalan la importancia de realizar estimaciones cerca de la temporada
de cosecha, y conoce lo complejo de este tema, pues el café no está sincronizado fenológicamente y
diferentes eventos de floración pueden ocurrir durante todo el año. Adicionalmente, eventos de nutrición y
presencia de lluvias pueden cambiar la dinámica de la producción.
Estimación de producción en cultivos con visión de máquina.
El uso de imágenes es una de las principales herramientas para automatizar la adquisición de la información
para diferentes modelos de estimación y pueden existir diferentes maneras de adquirirlas: con satélites,
vehículos aéreos, imágenes en campo y sensores remotos dispuestos en las diferentes plataformas.
Tanto las imágenes satelitales, como las imágenes aéreas buscan factores de producción en unidades de
masa por unidad de área [21 y 22], a partir de índices de vegetación [21, 23, 24 y 25]. Este tipo de
mediciones en campo, explican la variabilidad de la producción potencial entre un 78% y 86%. Usar este
tipo de imágenes para estimar la producción de café en Colombia es poco viable, debido a las condiciones
climáticas, la topografía (caficultura de alta pendiente), la alta densidad (5.000 – 10.000 árboles por
hectárea) y las condiciones socioeconómicas de la mayoría de caficultores.
Las imágenes en tierra buscan medir estructuras vegetativas y productivas de las plantas, por medio de
vehículos terrestres instrumentados y dispositivos móviles que asistan la labor de adquisición de imágenes
en tierra. Stajnko et al. [26], Wang et al. [27], Nuske et al. [28] y Aggelopoulou et al. [29] y reportan
modelos de estimación de producción de manzanas y uvas, basados en la medición de las características de
frutos y flores en condiciones de campo, con cámaras de alta resolución dispuestas en vehículos que viajan
a lo largo de los surcos de las plantaciones. Para cada uno de los casos el desempeño fue diferente, Stajnko
et al. [26], obtuvo una eficacia de detección de manzanas del 89%, el error en la estimación de producción
reportada por Aggelopoulou et al. [29], basada en la medición de flores en los árboles de manzanas, fue del
18%. Para Wang et al. [27], el error en la estimación de producción de manzanas estuvo entre –3,2% y
1,2%, para Nuske et al. [28] se generó una sobre estimación del 10% en el cultivo de la uva y correlaciones
entre lo real y lo medido del 60%. En dichos modelos se encontró una relación entre la medición de las
estructuras vegetativas y la producción real, a partir de relaciones matemáticas sencillas basadas en el conteo

Introducción 9
de dichas estructuras y el peso promedio de cada una, y relaciones lineales simples, sin embargo, los
coeficientes de correlación fueron menores del 60%.
En este trabajo se plantea un modelo que, a partir del conteo de los frutos visibles en una sección de la rama
de café, se determine la totalidad de los frutos presentes en la misma y se cuantifique el potencial productivo
de una rama. El modelo planteado es sencillo, responde a una relación lineal simple y muestra que este tipo
de modelos es aplicable al cultivo del café. Puede ser aplicado por cualquier usuario para determinar el
potencial productivo; el costo de este método es bajo comparado con otras tecnologías descritas en este
estado del arte.
1.3.3 Evolución de tecnologías de los sistemas de visión de máquina en el agro. La visión de máquina es un área ampliamente usada en la agricultura, debido a que permite desarrollar
sistemas no destructivos que sirven para estudiar y analizar diferentes tipos de cultivos. Los procesos como
seguimiento de un cultivo, la navegación visual de vehículos auto-tripulados para la siembra automática, el
riego de fertilizantes y pesticidas, la cosecha de cultivos y la separación de frutos, pueden realizarse
aplicando sistemas visión de máquina. Estos sistemas buscan emular las tareas que hace el ser humano, e
incluyen como principal sensor, la visión. Sin embargo, esta no es tarea fácil, debido a las múltiples
condiciones (luminosidad, ruido, oclusión, etc.), en que se puede presentar una escena. Además, los procesos
de visión artificial requieren de un alto costo computacional, lo que hace que sea difícil realizar sistemas en
tiempo real [30].
En el estado del arte se encuentran en general tres formas para detectar, por medio de técnica de imágenes,
las características en la planta, y en algunas ocasiones usan históricos de producción, clima y otra
información del desarrollo de la planta, para definir modelos más ajustados que determinen índices de
productividad. Las tres técnicas son: (i) Imágenes satelitales; (ii) imágenes aéreas; y (iii) imágenes desde
tierra. El tipo de tecnología que se utilice varía según el cultivo en estudio y el estudio mismo a realizarse
sobre la plantación.
Las imágenes en tierra pueden ser adquiridas por vehículos en tierra tripulados y no tripulados, por cámaras
convencionales o dispositivos móviles que pueden ser llevados por un operario en el cultivo. Sin embargo,
la adopción de una u otra tecnología dependerá directamente del bolsillo de los agricultores y de la asistencia
de los proveedores de tecnología.

10 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Algunas tareas que realizan los sistemas de visión de máquina son: detectar el crecimiento de las plantas,
modelar automáticamente la geometría 3D de las mismas, realizar una predicción acertada de las cosechas,
estimar la localización de las frutas a cosechar. En dichos procesos, algoritmos 2D y 3D son diseñados junto
con sistemas mecánicos, en algunas ocasiones, para evitar trabajos invasivos y con un manejo eficiente de
los recursos. Algunos ejemplos de estos trabajos son: la clasificación de suelos para seleccionar las técnicas
de labrado a utilizar en cultivos [31]; el desarrollo de robots agrícolas [32 y 33], la inspección de calidad y
detección de enfermedades en alimentos [34–38]; el reconocimiento del tipo de fruto utilizado y la
determinación del tiempo de envejecimiento en licores [39]; la estimación automática del peso de animales
en granjas [40]; la medición del volumen en productos alimenticios como es el caso de las manzanas
deshidratadas [41] y el monitoreo de los granos de café en la fase de tostado [42].
Se han desarrollado equipos que deben ser llevados manualmente al árbol, como el mostrado por Rabatel y
Guizard [43] en la Figura 1-3 y equipos que son llevados en vehículos o máquinas cosechadoras como se
muestra en los trabajos de Annamalai et al. [44] (Figura 1-4a) y Hayashi et al. [45] (Figura 1-4b) El
objetivo en común de estas investigaciones está en encontrar los frutos cosechables en el árbol y determinar
por medio de diferentes relaciones los porcentajes de productividad de un lote. Es necesario considerar en
las aplicaciones directas de detección en campo, sistemas que toleren condiciones no controladas de la
iluminación, presencia de sombras y oclusiones de los frutos u otras estructuras en las imágenes adquiridas
[46, 47 y 48].
Figura 1-3: Primer prototipo del equipo REV Rendement Estimé par le Volume”(Estimador de productividad por volumen). Rabatel y Guizard [43]

Introducción 11
Figura 1-4: Vehículos en campo para adquirir información de frutas.
La implementación de técnicas basadas en características de forma sobre imágenes de campo genera cierta
independencia a los problemas de oclusión [49 y 50]. Recientemente, técnicas no destructivas usando visión
por computador han sido implementadas para la detección y clasificación de estructuras vegetativas
trabajando con imágenes de campo. Los diferentes trabajos han sido aplicados en gran variedad de cultivos
como: maíz [51–53], tomate [50] y naranjas [54]. Los anteriores trabajos se basan en el uso de características
2D. Por su parte trabajos que utilizan técnicas 3D han sido implementados en cultivos de: duraznos [55],
uvas [56], algodón [57], piñas [58], y hortalizas como col, repollo, coliflor, girasol y remolacha [59].
Finalmente, algunos trabajos utilizan conjuntamente sensores 2D y 3D como es el caso del trabajo
presentado en [60], donde se realizó un sistema para el conteo automático de manzanas. Es clara la tendencia
de investigar y desarrollar sistemas no destructivos que trabajen en campo para la clasificación de estructuras
vegetativas, ya sea con algoritmos 2D y/o 3D.
La Tabla 1-1 resume los resultados de algunos desarrollos y aplicaciones de visión por computador
existentes que operan en campo y en algunos casos bajo condiciones de luminosidad no controladas. En
general, al utilizar únicamente características 2D, se presentan inconvenientes con las condiciones de
luminosidad, oclusión y ruido cuando se trabaja en campo [49, 54, 50]. Mientras que al usar información
3D se genera una tolerancia mayor a los cambios antes mencionados. Sin embargo, en algunos casos es
necesario utilizar la información 2D, debido a que los datos geométricos (3D) no son lo suficientemente
relevantes para la clasificación de las estructuras vegetativas. Por ejemplo, en el caso del café, donde los
frutos en sus diferentes estados de desarrollo pueden tener la misma forma geométrica pero diferentes
tonalidades de color. Algunos de los trabajos listados en la Tabla 1-1, se aplican a cultivos cuyas estructuras
vegetativas (frutos, tallos, hojas) son mayor tamaño a las presentes en los cultivos de café, por ejemplo:
tomates [67], piña [58] y manzanas [60]. Con los anteriores métodos obtuvieron buenos desempeños sobre
los cultivos en los que trabajaron.
(a) Vehículo en campo para estimación de
cosecha de naranjas [44]. (b) Robot cosechador de fresas [45].

12 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Tabla 1-1: Estado del arte en detección de características 3D y 2D sobre estructuras vegetativas.
Referencia Tipo de cultivo Características Número de estructuras
Radio estructuras
(cm) Inconvenientes
Moorinta et al. [58] Piña Scale-invariant feature
transform - SIFT (1) Frutos. 10 Ambigüedad SfM
Patel et al. [49], [54]
Cerezas, uvas, manzana, peras, fresas, naranjas melocotones.
Color y forma (1) Frutos. 3 Luminosidad
Hunt et al [60] Cereal Cromaticidad. Intensidad de infrarrojo, profundidad (1) Cultivo No reporta Costo
computacional
Dey et al. [62] Uvas 2D: color y curvaturas (3) Frutos, hojas y tallos 3
Ruido inducido por la clasificación,
independiente de cada punto.
Verma et al. [50] Tomates Forma (1) Frutos 5 Oclusión
Jay et al. [59] Col, repollo,
coliflor, girasol y remolacha
Altura e índice de vegetación (1) Hojas 20 – 60
Movimiento de las estructuras por el
viento Gongal et al.
[61] Manzanas Color y ubicación espacial de los frutos (1) Frutos 2-3 No reportan
Agricultura de precisión en dispositivos móviles
Los dispositivos móviles se utilizan en la agricultura principalmente para controlar drones [63] o vehículos
en tierra [64], crear formularios para almacenar información [65], estar conectados a una red de sensores
inalámbricos para gestionar, almacenar y enviar a la nube cada una de las mediciones en tiempo real [66].
Sin embargo, el dispositivo móvil por sí mismo puede ser una herramienta para adquirir información y
procesarla, además de controlarla y monitorearla. Por ejemplo en la medición de clorofila por medio de la
cámara integrada y accesorios para mejorar la calidad de las imágenes a adquirir [68], o la medición del
vigor y la porosidad del dosel en la vid [69] para hacer seguimiento del crecimiento de las plantas.
Una de las principales técnicas que está siendo utilizada hoy en día en la agricultura de precisión es la visión
de máquina y con ella diferentes tipos de cámara adaptadas para trabajar en entornos con condiciones no
controladas [50, 54, 60, 70-74]. Dependiendo del tipo de técnica de procesamiento, los requerimientos
computacionales son diferentes y dependerán del tamaño de las imágenes, el número de canales por escena,
procesamiento 3D [73-74] o procesamiento 2D [50, 54, 62, 70-72], y de esta forma los requerimientos de
máquina son diferentes. La mayoría de las aplicaciones de dispositivos móviles que procesan imágenes,
buscan procesos sencillos como binarización y conteo de píxeles [75], de otra forma, las imágenes son
cargadas en un servidor para su posterior proceso [76]. Para este último caso, es necesario utilizar una
adecuada cantidad de imágenes con calidad para subir a la nube, sin duplicar información, ni saturar las

Introducción 13
bases de datos. La calidad de las imágenes tomadas bajo condiciones de campo, es un punto crítico, ya que
las condiciones de luminosidad, nitidez, contraste y oclusión de las estructuras vegetativas, pueden afectar
el desempeño de los algoritmos de visión implementados.
Con sensores de georreferenciación, como el GPS de bajo costo, es posible relacionar un marcador de
posición a la información adquirida con cualquier tipo de dispositivo. Sin embargo, el error de esta
georreferenciación pues estar entre los 2,5 m y 5m, distancia que en muchas ocasiones pueden superar la
distancia de siembra entre los árboles en algunos cultivos, aunque en plantaciones de grandes extensiones
suele ser suficiente para obtener información de su estado [77]. En otras ocasiones la información del GPS
no es suficiente y debe ser corregida por medio de un sistema IMU (Inertial Measurement Unit), donde se
utiliza los ángulos de orientación del movimiento para realizar mapeos 3D [78]. El uso de dispositivos
móviles puede integrar GPS e IMU, con el fin de compensar errores de posición por medio de diferentes
intervalos de integración de información, logrando errores de hasta 14cm [79] en entornos interiores
controlados.
Para las aplicaciones en agricultura, tanto el control de la adquisición, selección de las imágenes, y la
georreferenciación con mayor resolución, puede lograrse con el uso de los sensores integrados en un
dispositivo móvil. Actualmente, la mayoría de aplicaciones móviles con sensores para la agricultura, utilizan
GPS y cámara [80], sin embargo, es posible integrar los sensores inerciales del móvil para controlar la
adquisición de las imágenes y georreferenciar los árboles con menores errores, en ambiente externos de
trabajo y en entornos no controlados.
Lo que busca este proyecto es desarrollar un sistema de adquisición de imágenes, controlado por un
dispositivo móvil y con el cual sea posible determinar el número de frutos de café presentes en las ramas,
bajo condiciones de campo y con las cuales sea posible generar mapas de producción referenciados
espacialmente. Esta información podrá ser utilizada por los caficultores para tomar decisiones de carácter
administrativo en la finca cafetera.
1.4 Contribuciones. Con esta tesis se realizaron contribuciones en cada uno de los objetivos planteados. Se realizaron
publicaciones en revistas con factor de impacto superior a 1, catalogadas por Colciencias como A1.
Adicionalmente, se participó en eventos internacionales con diferentes presentaciones orales y poster.
Durante el desarrollo de este trabajo de tesis se gestionó un proyecto cofinanciado por Colciencias en el que

14 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
es posible aplicar parte de los resultados obtenidos en beneficio directo de los caficultores colombianos y el
gremio cafetero del país.
1.4.1 Contribuciones de la tesis en sistema de adquisición de imágenes en campo.
Se desarrolló un aplicativo móvil para controlar la adquisición de las imágenes y georreferenciarlas a nivel
de centímetro, por medio de un sistema de navegación inercial desarrollado e implementado para trabajar
con los sensores propios del dispositivo móvil. Todo esto con el fin de dotar al agricultor de una herramienta
de bajo costo, móvil, de fácil adquisición que le permita tomar información georreferenciada de su cultivo
con precisiones relativas de ±15cm y que le permita recorrer libremente el terreno.
Ramos P.J, Guerrero A, Muñoz C.M, Prieto F.A, Oliveros C.E. Sensor Fusion of a Mobile Device to Control and Acquire Videos or Images of Coffee Branches and for Georeferencing Trees. Sensors 2017, 17, 786. doi:10.3390/s17040786.
1.4.2 Contribuciones de la tesis en algoritmo de identificación y conteo de frutos a partir de características 2D.
Se desarrolló un algoritmo 2D para identificar y contar frutos, por estados de maduración, en una rama de
café. Se logró estimar el número de frutos totales de cada rama, el porcentaje de maduración de la misma y
la masa de dichos frutos, sin muestreos destructivos. La técnica utilizada detecta frutos ocluidos y frutos no
ocluidos, en imágenes adquiridas en condiciones de campo.
P. J. Ramos, F. A. Prieto, E. C. Montoya, and C. E. Oliveros. “Automatic Fruit Count on Coffee Branches Using Computer Vision.” Computers and Electronics in Agriculture 137 (May 2017): 9–22. doi:10.1016/j.compag.2017.03.010.
P.J. Ramos, F.A. Prieto, and C.E. Oliveros. “Semiautomatic annotation system to generate ground-truth in image sequence of agricultural sceneries”. In: 2016 4th CIGR International Conference of Agricultural Engineering. Aahurs. Denmark. June 2016.
P.J. Ramos, F.A. Prieto, C.E. Oliveros, N. Alexios, F. Albert, J. Blasco. “Medición del porcentaje de madurez en ramas de café mediante dispositivos móviles y visión por computador”. In: VIII Congreso Ibérico de Agroingeniería. Libro de actas pp. 907-915. ISBN 978-84-16024-30-8. Orihuela (Spain), 01-03 June 2015.

Introducción 15
1.4.3 Contribuciones de la tesis en algoritmo de identificación y de frutos a partir de características 3D.
Se desarrolló el modelo geométrico de frutos de café en rama, por medio de análisis 3D con el cual es
posible realizar el conteo de frutos en rama y detectar su volumen. El procesamiento 3D se realizó a
conjuntos de imágenes, secuencias de video, que fueron adquiridas en condiciones de campo sin control de
iluminación, ni contraste, por medio de un dispositivo móvil.
J. Avendaño, P.J. Ramos, and F.A. Prieto. “Classification of vegetal structures present in coffee branches using computer vision”. In 2016 4th CIGR International Conference of Agricultural Engineering. Aahurs. Denmark. June 2016.
J. Avendaño, P.J. Ramos, and F.A. Prieto. “A System for Classifying Vegetative Structures on Coffee Branches based on Videos Recorded in the Field by a Mobile Device”. Expert Systems. Vol. 88 December 2017. Pages 178-192. https://doi.org/10.1016/j.eswa.2017.06.044
1.4.4 Contribuciones de la tesis en los modelos de estimación de número de frutos por rama.
Se construyeron modelos de estimación de producción para ramas y parcelas, por medio del conteo
automático generado por el algoritmo 2D. Se identificó la dinámica de producción en cultivos monolínea y
cultivos multilínea. Se generó información importante acera de la producción zonificada de los árboles de
café, la dinámica de esta producción a lo largo de una cosecha y las relaciones de conteo de frutos con masa
y porcentaje de maduración.
1.5 Estructura de la tesis Esta tesis está dividida en seis capítulos, donde se exponen, una introducción al trabajo de investigación, el
cumplimiento de cada uno de los objetivos, los resultados alcanzados y las conclusiones. Se muestra como
se lograron cada uno de los objetivos planteados, las contribuciones y los resultados más relevantes. Cada
capítulo es auto contenido, sin embargo, al inicio del documento se encuentra en estado del arte que agrupa
información de importancia para cada uno de los capítulos ya mencionados. Algunos anexos son
referenciados para ampliar información en algunos de los resultados adicionales de la tesis.

16
2. Aplicativo móvil, integración de sensores y protocolo para la adquisición de las imágenes.
Durante el desarrollo de este trabajo se exploraron diversos sistemas para adquirir información de ramas de
café en condiciones de campo. El objetivo de es garantizar una adecuada adquisición de las imágenes a las
ramas de café, para posteriormente ser procesadas por los algoritmos 2D y/o 3D. Finalmente, se seleccionó
un dispositivo inteligente como una herramienta útil para el control y monitoreo de variables en la
agricultura. Su capacidad de proceso, instrumentación, conectividad, bajo costo y uso masivo, hacen que
personas del sector rural como agricultores puedan utilizarlos fácilmente, con aplicaciones que se ajusten a
sus necesidades. En este capítulo se presenta el uso de la cámara principal de un celular y la integración de
sensores inerciales y GPS para levantar información en un lote sembrado en café. Se desarrolló una
aplicación en Android con dos modos de operación: (i) Navegación: para georreferenciación de árboles de
café, que pueden estar sembrados cada 0,5 m; y (ii) Adquisición: Control de adquisición de vídeo a partir
del movimiento del móvil sobre la rama, y medición de la calidad de las imágenes a través de índices de
nitidez para seleccionar las más adecuadas para aplicación de futuros procesos. La integración de los
sensores inerciales con el GPS, en el modo navegación logra errores de ±0,15 m. En el modo adquisición el
sistema identifica correctamente el inicio y la finalización del movimiento en el 99% de los casos y
determinan la calidad de las imágenes midiendo su emborronamiento y seleccionando las mejores para
procesarlas con los algoritmos 2D y 3D descritos en los Capítulos 3 y 4. Se cuenta con un aplicativo móvil
para controlar la adquisición de imágenes, medir su calidad, seleccionar automáticamente las imágenes
adecuadas y definir los marcadores de ubicación de cada árbol con precisiones relativas de ±15cm.
2.1 Exploración de sistemas de adquisición Antes de definir el dispositivo móvil como la mejor opción para realizar la adquisición de las imágenes,
fueron exploradas diferentes cámaras de bajo costo que trabajaban tanto en el espectro de luz visible como
en el infrarrojo: (i) CMUCAM3, cámara programable y embebida, con un sistema óptico seleccionado
particularmente para ver frutos de café en modo macro y un sistema de iluminación LED atrás de la cámara
y soporte para disponerla sobre la rama, Figura 2-1; (ii) WebCam Visible e infrarrojo, dos cámaras web

Aplicativo móvil 17
USB2 conectadas a un computador portátil, sin iluminación controlada y con un soporte para llevarlas a
campo y disponerlas sobre la rama de café, Figura 2-2; (iii) Cámara de una tableta Samsung, con un sistema
de iluminación estructurada correspondiente a tres láser en línea, con un soporte que ayudaba tanto a
mantener la tableta frente a la rama como a direccionar la iluminación al mismo punto enfocado por la
cámara, Figura 2-3; y(iv) Cámara del dispositivo móvil Samsung Galaxy S5, con un soporte adecuado para
ser llevado a campo y disponerlo en frente de las ramas de café, no cuenta con iluminación adicional, Figura
2-4.
(a) Instalación de la
CMUCAM3, con lente gran
angular.
(b) Imagen de rama adquirida
a máxima distancia de 80 mm.
(c) Imagen de rama adquirida
a mínima distancia de 10 mm.
Figura 2-1: Cámara CMUCAM3, exploración de opciones de cámara.
(a) Instalación WebCams. (b) Imagen adquirida con la cámara visible.
(c) Imagen adquirida con la cámara infrarroja.
Figura 2-2: WebCams para adquisición de imágenes en condiciones de campo.
(a) Diseño y prototipado rápido del
accesorio para soporte tableta. (b) Soporte tableta y sistema de
luz estructurada.
(c) Soporte tableta, luz estructurada e iluminación
LED.

18 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 2-3: Sistema para adquirir imágenes por medio de una tableta Samsung y soporte.
(a) Diseño y prototipado rápido del accesorio
para soporte de celular. (b) Celular montado en soporte diseñado.
Figura 2-4: Sistema para adquirir imágenes por medio celular y soporte.
El sistema de CMUCAM3, Figura 2-1, muestra un comportamiento adecuado, pues logra adquirir una
longitud de 15 cm a lo largo de la rama, a distancias entre la lente y la rama entre 80 mm y 10 mm. Las
imágenes adquiridas con este sistema fueron procesadas y fue posible obtener un sistema de representación
de color para frutos cosechables y no cosechables. Este sistema de representación se expresa como se
muestra en la Ecuaciones (2.1), (2.2), (2.3) y (2.4), y basa su funcionamiento según el espacio de color LUX
(Logarithmic hUe eXtension), utilizado para detectar piel en vídeo conferencias con diferentes condiciones
de iluminación [81]. El sistema de la cámara embebida CMUCAM3 es configurable y no requiere de un
computador adicional para realizar el chequeo de las imágenes adquiridas.
( ) ( ) ( ) 1111 1,06,03,0 −+++++= RGRL , (2.1)
caso otroEn Si
11
2
11
2 LR
RLMM
LRM
U>
++
−
++
= , (2.2)
caso otroEn Si
11
2
11
2 LR
BLMM
LBM
X>
++
−
++
= , (2.3)
caso otroEn Si
11
2
11
2modificado
LB
GLMM
LGM
GLUX
>
++
−
++
=− , (2.4)

Aplicativo móvil 19
El sistema de WebCams, Figura 2-2, muestra dos cámaras, una de ellas modificada para adquirir
información en el infrarrojo y la otra sin modificaciones, trabajando en el espectro de luz visible. Ambos
lentes de las cámaras fueron configurados para que las imágenes se pudieran adquirir adecuadamente si las
cámaras se encontraban a 80 mm de las ramas. Las cámaras fueron siempre llevadas a campo con un
computador portátil, con el fin de configurarlas y adquirir información. Las imágenes adquiridas fueron
procesadas para detectar contornos y evaluar el efecto de las condiciones de iluminación no controladas,
sobre los procesos 2D realizados. Según las observaciones realizadas con este sistema, las imágenes de
infrarrojo son de gran ayuda para realizar segmentación en condiciones de iluminación baja, como imágenes
dentro del follaje del árbol. La información segmentada puede ser buscada posteriormente en las imágenes
del espectro de luz visible y encontrar las características de color real de cada región de interés. Sin embargo,
esta opción fue descartada por el requerimiento de llevar un computador portátil al campo.
El sistema de la tableta, Figura 2-3, crea un contraste constante y aísla la información que hay detrás de la
rama. El soporte a pesar de ser sencillo (Figura 2-3a), no es fácil de disponer en las ramas en los árboles.
Se probaron dos tipos de iluminación con la tableta: (i) iluminación estructurada, con cuatro láseres en línea
de color rojo; y (ii) iluminación LED detrás de la cámara. La iluminación láser en entornos no controlados
de luz se pierde si hay una alta radiación solar y la iluminación LED, reflejaba en el contraste generado por
el soporte. Adicionalmente, la cámara de esta tableta no tiene características adecuadas para su
funcionamiento en condiciones no controladas de iluminación. Lo positivo de la tableta es que no requiere
un computador para adquirir y almacenar las imágenes. Esta opción fue descartada por la complejidad para
llegar a todas las ramas del árbol.
A partir de los sistemas anteriormente descritos, se implementa la opción del celular con una cámara de alta
resolución y características adecuadas de funcionamiento en condiciones no controladas de iluminación. El
sistema con el Samsung Galaxy S5, Figura 2-4, cuenta con un celular de buenas especificaciones de diseño
y capaz de soportar ambientes húmedos. Para disponer este celular sobre las ramas fue necesario diseñar el
soporte de la Figura 2-4a, pues con este se tiene acceso a ramas de café que se encuentran por encima de
120 cm o por debajo de los 60 cm. Fue seleccionada esta opción por las ventajas frente a simplicidad de
llevar el equipo y disponer sobre cualquier rama, capacidad de proceso y almacenamiento, y cámara de alta
resolución configurable.
La Tabla 2-1 muestra una comparación entre cada una de las tecnologías mencionadas. Finalmente, se
seleccionó el dispositivo móvil Samsung Galaxy S5, pues tiene la cámara configurable de mejor resolución,

20 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
adicionalmente no se requiere un computador adicional para almacenar la información y se conecta
fácilmente a la nube para subir las imágenes y posteriormente procesarlas en un servidor. Adicionalmente,
el dispositivo móvil utilizado cuenta con un conjunto de sensores, con los cuales es posible georreferenciar
las imágenes, crear rutas de los recorridos en las parcelas y controlar la adquisición de las imágenes por
medio de los sensores inerciales presentes en el dispositivo.
Tabla 2-1: Características de cámara, ventajas y desventajas de cada sistema probado.
Nombre sistema Características cámara
y lente. Ventajas y desventajas
CMUCAM3 Cámara de 0,1 Mpx Cámara programable – baja calidad de las imágenes.
WebCams VIS-
IR
Cámara de 1 Mpx sin
lente modificada Bajo costo – requerimiento de computador
Tablet Cámara de 3 Mpx sin
lente modificada Sin requerimiento de computador – baja calidad de las imágenes
Smartphone Cámara de 12 Mpx sin
lente modificada
Sin requerimiento de computador, alta calidad de las imágenes y
especificaciones de diseño para trabajar en ambientes húmedos.
En la Tabla 2-2, se observa una comparación técnica entre los dos dispositivos móviles probados en esta investigación.
Tabla 2-2: Gama media y alta de dispositivos inteligentes marca Samsung.
Característica Smartphone Samsung S5 Tableta Samsung Galaxy Tab2.0
CPU Qualcomm Snapdragon 801, quad-core a 2,5
GHz Dual-core 1 GHz Cortex-A9
RAM 2 GB 1GB
CÁMARA Principal de 16 MP (ISOCELL / 1/2.6") con
Enfoque Selectivo y vídeo UHD (secundaria de 2 MP)
3,15 MP, 2048x1536 pixels
VÍDEO Yes, 1080p@24 30fps Yes, 720p
SENSORES Acelerómetro, giróscopo, sensor de proximidad,
brújula, barómetro Acelerómetro, giróscopo, brújula.

Aplicativo móvil 21
2.2 Condiciones para adquisición de imágenes en campo. El cultivo tecnificado del café, es un cultivo adensado, entre los 5.000 y 10.000 árboles por hectárea, se
encuentra en zonas tropicales y subtropicales de América, Asia y Oceanía. En las zonas tropicales de
América se puede encontrar en regiones montañosas entre los 1.200 y 2.000 msnm, necesitando condiciones
de clima y suelo para producir café de excelente calidad. El árbol de café o cafeto, pertenece a la familia de
las rubiáceas, se caracteriza por tener hojas que salen en pares, sin divisiones ni bordes lisos, flores
hermafroditas y el fruto generalmente tiene dos semillas. Los aspectos morfológicos más sobresalientes
tienen que ver con los dos tipos de tallos, Figura 2-5: (i) Ortotrópicos: El tallo principal crece verticalmente.
(ii) Plagiotrópicos: Las ramas primarias, secundarias y terciarias crecen horizontalmente. El cafeto puede
crecer hasta 2,8 m en cultivos tecnificados, y crece a razón de 24 ramas por año en promedio, aunque esto
dependerá de las condiciones climáticas y de suelo de cada cultivo. La producción del café se encontrará en
las ramas plagiotrópicas, principalmente en el tercio medio del árbol, el cual se moverá en la medida que el
árbol crezca.
Figura 2-5: Aspectos morfológicos relacionados con los tallos del árbol de café.
La producción del café puede ser estimada a partir del conteo de frutos en las ramas productivas, [17, 82,
18]. Actualmente se realizan muestreos destructivos para estimar la producción de árboles y parcelas. Sin
embargo, con procesamiento de imágenes es posible realizar la detección, clasificación y conteo de frutos
en las ramas y, a su vez, obtener modelos de estimación que relacionen los frutos medidos automáticamente
con los frutos reales observados en cada una de las ramas, sin requerirse muestreos destructivos. Con el
objetivo de usar dispositivos móviles, visión de máquina y Tecnología de la Información y Comunicaciones
para medir la producción de un árbol de café, se desarrolló un sistema integral para adquirir imágenes sobre
ramas de café, detectar el movimiento del dispositivo sobre la rama para controlar la adquisición de las
imágenes y detectar los movimientos en el cultivo para georreferenciar cada uno de los árboles muestreados.

22 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Las imágenes a adquirir corresponden a ramas de café orientadas de manera horizontal y presentes entre los
tercios superior e inferior de un árbol, lo que significa que la información a adquirir se encuentra dentro del
follaje de un árbol. Esta condición no facilita la adquisición de imágenes, sin mencionar, la altura de los
árboles que en ocasiones puede superar los 2 m y la condición topográfica del terreno, alta pendiente. No
hay control de iluminación y el fondo presente en las imágenes corresponde a otras ramas del mismo árbol
o de árboles contiguos. Adicionalmente, por las condiciones morfológicas ya mencionadas, no es posible
tomar una imagen de una rama completa, debido a que la distancia entre ramas es corta. La opción para
adquirir información en campo a las ramas, es tomar un conjunto de imágenes que representen la totalidad
de la rama vista desde la parte superior, es decir, solo se tendrán imágenes de un solo lado de la rama. Es
posible realizar esta actividad mediante la cámara de fotografía del dispositivo móvil o hacer un vídeo sobre
la rama. En cualquiera de los dos casos las imágenes deben tener condiciones adecuadas para ser procesadas.
Las imágenes de las ramas de café deben ser homogéneas, la información de la rama debe centrarse en la
imagen orientada horizontalmente, y al menos el 70% de la imagen debe corresponder a la rama chequeada.
Las imágenes pueden tener problemas de iluminación, generados por auto-sombreamiento o exceso de
radiación solar sobre las ramas. Estos problemas no son controlables y debe seleccionarse un momento del
día para evitarlos. Por otro lado, deben evitarse las imágenes desenfocadas y emborronadas. Para adquirir
las imágenes en las mejores condiciones se diseñaron e implementaron las siguientes estrategias: (i) Para
evitar el desenfoque: garantizar la distancia entre la rama y la cámara; y (ii) Para evitar el emborronamiento:
medir la velocidad del desplazamiento y garantizar adquisición a bajas velocidades.
Al momento de adquirir la información en condiciones de campo se dificulta controlar la pantalla táctil del
dispositivo móvil, ya que si objetos como una hoja o una gota de agua, tocan la pantalla las condiciones de
adquisición pueden cambiar: (i) enfocar otro punto de la imagen; (ii) hacer zoom in o zoom out; (iii) parar
la grabación o tomar imágenes indeseadas. Esta condición es aún más crítica si se consideran: (i) las cortas
distancias entre ramas; (ii) la probabilidad de que hojas de ramas vecinas toquen la pantalla; o (iii) cafetales
húmedos consecuencia de épocas lluviosas. Adicionalmente, las horas del día con alto brillo solar
imposibilitan interactuar adecuadamente con la pantalla del dispositivo móvil.
2.2.1 Especificaciones de diseño para adquisición de imágenes. La aplicación desarrollada y los accesorios necesarios, deben considerar cada una de las condiciones de
adquisición de imágenes, para esto se generan las siguientes especificaciones de diseño.

Aplicativo móvil 23
Configuración de la cámara vídeos/imágenes.
Las imágenes fueron adquiridas con la cámara principal de un dispositivo móvil, Samsung Galaxy S5 SM-
G900M. La cámara fue configurada en Full-HD (1920x1080), 30 fps, sin activación de flash. El balance de
blancos e ISO en automático y el valor de exposición en 0. Las demás características son configuradas por
defecto por el equipo. Otro modo de adquisición de imágenes, como el modo ráfaga no fue viable, pues se
perdía previsualización de las imágenes en pantalla, en la medida que avanzaba con el celular sobre la rama.
Soporte para un dispositivo móvil: evitar desenfoque en imágenes.
Las imágenes de una rama de café son adquiridas mientras el dispositivo móvil se desplaza paralelamente
sobre la rama, solo los frutos de un lado de la rama son fotografiados (Figura 2-6a). Con el fin de garantizar
una distancia constante entre la cámara y la rama, se diseñó un soporte que cuenta con un sujetador, una
base para disponer el dispositivo y un conjunto de dos botones para controlar el enfoque y la adquisición,
justo debajo de donde queda soportado el dispositivo móvil (Figura 2-6b). La inclinación de 11,3° grados
garantiza que el usuario pueda ver y controlar el enfoque de la rama antes de comenzar a grabar los vídeos.
Esta inclinación puede cambiar en la medida que se realice el vídeo, pues el usuario ajusta la posición del
celular si la rama cambia de forma o presenta curvas. Si la base del soporte está alineada con el eje
longitudinal de la rama, se garantiza una distancia entre la cámara y la rama que puede estar entre 80 mm y
150 mm, suficiente para que la información de una parte de la rama esté dentro de la imagen adquirida por
el celular.
(a) Movimiento del dispositivo móvil paralelo a la rama.
(b) Dimensiones del soporte del dispositivo móvil.
Figura 2-6: Movimiento y soporte del dispositivo móvil en la rama de café.
Control de enfoque y adquisición de imágenes por botón pulsador.
Debido a que la pantalla no se usa como interfaz, el sujetador descrito en la Sección anterior, está dotado
con dos botones, uno para hacer enfoque a la zona central de la imagen, donde está la rama. El segundo
botón sirve para dar inicio y parada de vídeo o para adquisición de imágenes estáticas, dependiendo de la

24 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
configuración inicial que se seleccione. Las condiciones de luminosidad, contraste de las ramas y oclusión
de los frutos no fueron controladas y, como ya se mencionó, el dispositivo móvil fue accionado sin el uso
del flash. Con el uso del soporte y la interfaz a través de botones en el sujetador, se logra total control de la
adquisición de imágenes sobre la rama.
Medición del movimiento al adquirir vídeos/imágenes y cálculo de emborronamiento por movimiento.
En pruebas preliminares realizadas se determinó que es necesario tener un tiempo de espera desde que se
inicia la grabación del vídeo hasta que se inicia el recorrido del dispositivo sobre la rama, con el fin de
enfocar adecuadamente la rama y esperar el tiempo de respuesta de otros sensores utilizados. Por esta razón
el inicio del vídeo no corresponde con el inicio del movimiento y se requiere un análisis del desplazamiento
generado sobre la rama para segmentar el vídeo solo en los momentos de movimiento. Por otro lado, se debe
considerar que la velocidad de desplazamiento debe ser baja pues la cámara tiene una frecuencia de 30fps y
las condiciones de iluminación no son controladas, dos aspectos que fácilmente pueden favorecer el
emborronamiento. Debido a lo anterior, se realizó una integración de sensores inerciales para detectar el
inicio y la finalización del movimiento. Con esta información se logra segmentar los vídeos solo en los
momentos de desplazamiento, y se determina si el vídeo o las imágenes son adecuadas o deben ser
nuevamente adquiridas. Adicionalmente, se determinó un índice de emborronamiento que indica si hay o
no problemas por movimiento. De igual manera se determinó un índice de emborronamiento con el cual es
posible inferir la velocidad de desplazamiento con la que fue adquirida la información de imágenes, que se
explica en la Sección 2.4. En promedio, los movimientos sobre las ramas productivas de café tienen una
duración de 15s, si se realiza a una velocidad de 3cm.s-1, y un desplazamiento de 50 cm. En la Sección 2.4
se explica cómo se realiza la medición de los tiempos de inicio y final de movimiento, a partir de la detección
de la velocidad angular a bajas velocidades sobre la rama, seleccionar la parte del vídeo a ser procesada.
Tipo de imágenes adquiridas.
La información fue adquirida bajo condiciones de campo no-controladas, los vídeos fueron tomados durante
varios días, a diferentes horas del día, con el fin de garantizar diferentes condiciones de iluminación. La
iluminación fue la presente bajo las condiciones climáticas presentes en cada toma de información y el fondo
de las imágenes estaba conformado por suelo, malezas, hojas secas, y ramas de otros árboles. Un rama puede
medir entre 40 cm y 60 cm, al hacer un vídeo sobre ella con una cámara de 30fps, a una velocidad promedio
de 3cm.s-1 (para evitar emborronamiento), se obtienen cerca de 450 cuadros de los cuales sólo son necesarios
el 20% para aplicar algoritmos de detección 2D/3D [83]. Algunos ejemplos de tipo de imágenes adquiridas
se pueden ver en la Figura 2-7. La Figura 2-7a muestra las imágenes adecuadas para el postproceso y las
Figura 2-7b y 2-7c muestra imágenes emborronadas y con desenfoque, que deben ser evitadas. Las

Aplicativo móvil 25
imágenes mostradas en las Figura 2-7d y 2-7e, presenta problemas por exceso de luz y sombra generados
por la luz solar directamente sobre la rama y la sombra que hace a través del follaje. Este tipo de imágenes
deben ser evitadas, para lo que se requiere usar un parasol o entrar al lote entre las 6:00 a.m. y 8:00 a.m. Los
problemas de emborronamiento y desenfoque son solucionados por medio de medición de velocidad de
desplazamiento e medición de calidad de las imágenes por medio de un índice de nitidez, como se mostrará
en las secciones siguientes.
(a) Imagen correcta, bien
enfocada, centrada y sin efecto de emborronamiento por
movimiento
(b) Imagen emborronada por movimiento
(c) Imagen desenfocada por distancia corta entre la
cámara y la rama
(d) Imagen con sombras generadas por el follaje. (c) Imagen sobreiluminada.
Figura 2-7: Tipo de imágenes adquiridas.
2.3 Control de adquisición de imágenes y georreferenciación a partir de un Sistema de Navegación Inercial (SNI).
Medir movimientos a bajas velocidades es un problema difícil de resolver por medio de sensores inerciales
como el acelerómetro. Para un giróscopo, la medición de pequeños movimientos es posible, siempre y
cuando el movimiento sea rotacional. Para el caso, el movimiento generado sobre una rama es de carácter
lineal y si bien no puede ser medido con exactitud por un acelerómetro debido a la baja velocidad, ni medido
por un giróscopo por su carácter lineal, si puede ser detectado por este último. Adicionalmente,
georreferenciar un árbol dentro de una plantación de alta densidad por medio del GPS del celular tiene
diversas complicaciones, debido a que el único proveedor de localización en zona rural para este trabajo,
son los satélites disponibles desde la parcela de café. En zona rural el proveedor de localización no cuenta
con conexión a internet o red móvil y se pueden generar los siguientes problemas: i) tiempo de respuesta
del GPS: mientras el sensor entrega una coordenada ya se han recorrido varios árboles del lote, se pierde el
recorrido realizado; ii) resolución de puntos georreferenciados: la resolución del GPS de un celular puede
estar entre 2,5 m y 5m, mientras la plantación presenta árboles sembrados cada 0,5 m; iii) precisión del GPS:

26 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
durante la navegación en un lote, la lectura del GPS no es constante ni repetible. Se plantea en este capítulo
como utilizar los sensores inerciales tanto para controlar la adquisición de imágenes como para ajustar una
lectura inicial del GPS para georreferenciar cada uno de los árboles chequeados y obtener precisiones del
orden de centímetros durante el recorrido en una plantación de café.
Fue desarrollado un Sistema de Navegación Inercial (SNI) para la detección y medición de movimiento del
orden de centímetros a bajas velocidades para navegación en plantaciones y control de adquisición de
imágenes, Figura 2-8. En esta Sección se explica cada una de las etapas seguidas para obtener dicha
medición del movimiento. La etapa uno se refiere a la adquisición de las señales inerciales, la etapa dos
consiste en el preprocesamiento de estas señales para obtener periodos de movimiento, y la tercera etapa
consiste en el cálculo de la velocidad y desplazamiento del movimiento generado.
2.3.1 Captura y análisis de movimiento. Con una unidad de medición inercial es posible capturar y analizar el movimiento, mediante la integración
de aceleraciones lineales, la velocidad angular y la orientación de los acelerómetros, giroscopios y
magnetómetros, respectivamente. La información obtenida en cada sensor es integrada de manera que se
obtenga, velocidad, posición y orientación, con los mínimos errores posibles. Si a lo anterior se le adiciona
información de localización inicial GPS, es posible obtener datos de navegación georreferenciados de alta
resolución, ya que mientras el error del GPS, por sí solo, es de 2,5 m – 5 m, el error en los movimientos
capturados con una unidad de medida inercial puede ser del orden de centímetros. En esta sección del trabajo
se presenta Sistema de Navegación Inercial (SNI), para detectar y medir movimientos del orden de
centímetros a bajas velocidades. La información de movimiento es adquirida con los sensores inerciales de
un dispositivo móvil, y con ella se controla la calidad de las imágenes adquiridas con la cámara del mismo
equipo, se seleccionan cuadros de los vídeos y se georreferencia la información en cada árbol. Para lograr
lo anterior fue desarrollado un algoritmo de procesamiento de información inercial.
2.3.2 Sistema de Navegación Inercial (SNI) propuesto. El algoritmo desarrollado tiene dos modos de operación para analizar la información inercial en campo: (i)
Modo Navegación (MN): Con el cual es posible georreferenciar con resoluciones del orden de centímetros
cada uno de los árboles de café a ser chequeados en una plantación; y (ii) Modo Control de Adquisición
(MCA) de imágenes: En este modo de operación se logra detectar el movimiento del dispositivo móvil a
bajas velocidades sobre una rama de café y controlar la adquisición de imágenes. Para el primer modo de
operación el sistema utiliza la información de aceleración lineal, ángulos de orientación y GPS. Para el

Aplicativo móvil 27
segundo modo de operación el sistema utiliza la información de velocidad angular y aceleración lineal. En
cualquiera de los dos modos, la señal de aceleración (MN) y la señal de velocidad angular (MCA), serán
consideradas como señal inercial (is) y se utilizarán para detectar o medir el movimiento, y algunas variables
dependerán del modo de operación.
El algoritmo desarrollado propone una técnica para encontrar los periodos de movimiento a partir de la
detección de máximos locales sobre las señales inerciales definidas anteriormente. Para cualquiera de los
dos modos se utiliza la información de aceleración lineal con el fin de encontrar velocidades y
desplazamientos. Los errores acumulativos son eliminados por dos vías: (i) Eliminación de periodos
estacionarios; y (ii) compensación del DRIFT (desviación de la medida). Se generan correctas detecciones
de movimiento en el 98% de los casos. Adicionalmente, la técnica utiliza los valores de orientación para
orientar el movimiento con respecto al norte magnético en el modo MN, en el modo MCA no es necesario
dicha orientación, ya que solo se requiere detectar si hay o no movimiento. El sistema propuesto se divide
en tres etapas: (i) adquirir y acondicionar las señales de los sensores disponibles en el dispositivo móvil; (ii)
determinar los periodos estacionarios y de movimiento; y (iii) calcular la velocidad y el desplazamiento con
compensación del DRIFT. En la Figura 2-8 se muestra un esquema del sistema propuesto.
Adquisición y acondicionamiento de señales.
El dispositivo móvil utilizado cuenta con un conjunto de sensores de movimiento (Tabla 2-3), que entregan
las señales calibradas y acondicionadas frente a posibles problemas de ruido por temperatura, y efecto de la
gravedad. El sistema es configurado para crear un archivo de texto con la información de los sensores de
aceleración lineal (3 ejes), giroscopio (3 ejes), los tres ángulos de orientación (yaw, pitch y roll), la
información del magnetómetro y los datos de latitud y longitud del GPS. El sistema crea dos archivos
independientes, uno para cada modo, pero con la misma estructura e información. El archivo para el modo
MN, es uno solo para todo el desplazamiento por la parcela y el archivo para el modo MCA es uno para
cada una de las ramas de café escaneadas. El tiempo de muestreo es de 10 ms en ambos modos.
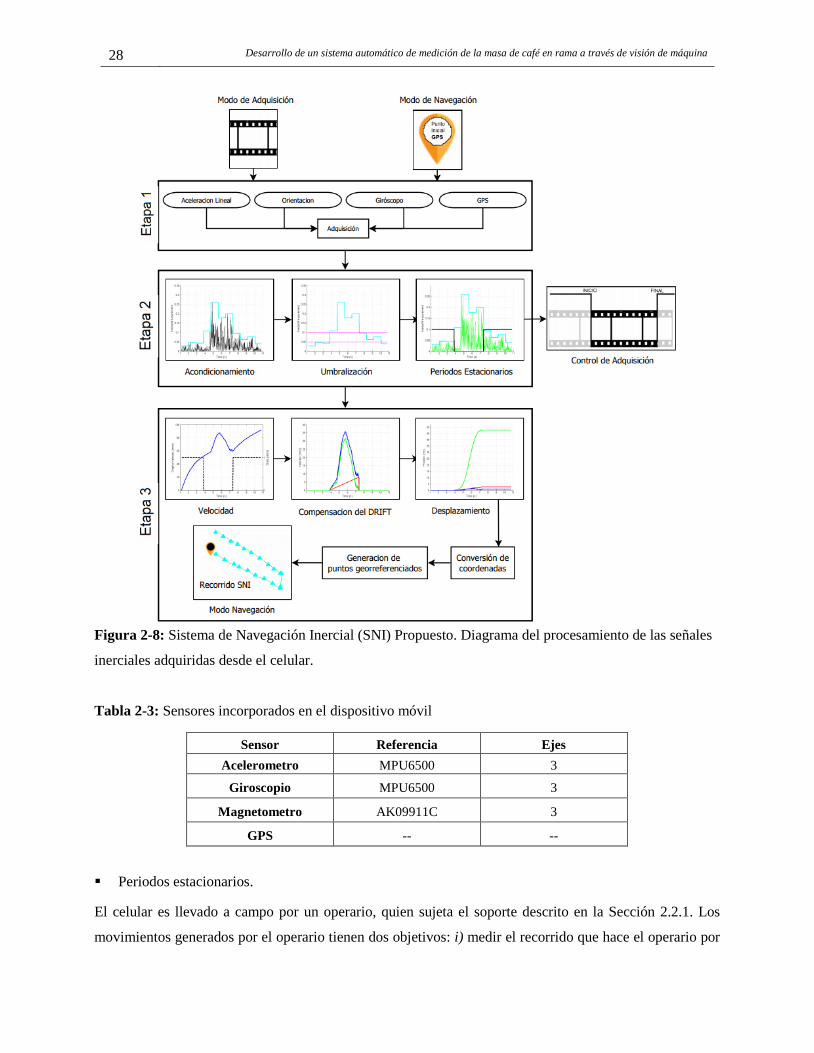
28 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 2-8: Sistema de Navegación Inercial (SNI) Propuesto. Diagrama del procesamiento de las señales
inerciales adquiridas desde el celular.
Tabla 2-3: Sensores incorporados en el dispositivo móvil
Sensor Referencia Ejes Acelerometro MPU6500 3
Giroscopio MPU6500 3
Magnetometro AK09911C 3
GPS -- --
Periodos estacionarios.
El celular es llevado a campo por un operario, quien sujeta el soporte descrito en la Sección 2.2.1. Los
movimientos generados por el operario tienen dos objetivos: i) medir el recorrido que hace el operario por

Aplicativo móvil 29
el lote (MN); y ii) determinar el momento de inicio y finalización del movimiento que hace el operario sobre
la rama (MCA). Se logran identificar dos tipos de movimiento: i) en reposo: el dispositivo es sostenido por
el operario sin hacer ningún movimiento, pero los valores adquiridos desde los sensores son diferentes de
cero; y ii) en movimiento: el operario mueve el dispositivo sobre las ramas o se desplaza entre la plantación,
mientras se adquieren las señales correspondientes. En teoría cuando el sistema está ausente de movimiento
(en reposo), la lectura de la aceleración lineal debería ser cero, sin embargo, esto no se cumple y se obtienen
mediciones de ±10 mg. Adicional a lo anterior, se puede presentar un error de calibración de ±1 mg, lo que
puede generar un error de posición de 166.6 cm.s-1 [84]. En este trabajo, las lecturas de ±10 mg cuando el
dispositivo está sujetado por el operario sin generar movimiento pueden causar un error de 1666.6 cm.s-1.
Por lo anterior es necesario un proceso de calibración para determinar a partir de que valores el operario
mueve realmente el dispositivo y obtener una estrategia para forzar a cero las aceleraciones que se
encuentran por debajo del movimiento real y evitar errores acumulativos en la medición de la posición.
Para determinar los periodos de movimiento y los periodos estacionarios se utiliza la magnitud de la señal
inercial (Magis, Ecuación (2.5)) propia para cada modo (Figura 2-9a). La magnitud de la señal inercial (is)
correspondiente a: (i) la aceleración lineal en el eje X (AccLx) y la aceleración lineal en el eje Y (AccLy) para
el modo MN; y (ii) la velocidad angular en el eje Y (ωy) para el modo MCA (Figura 2-9b). El valor de dicha
magnitud cambia considerablemente con la mínima perturbación (Ecuación (2.5)).
{ }yyxis AccLAccLisistMag ω;;:)( 2 ∴= , (2.5)
En cualquiera de los dos modos, se aplica la estimación de máximos locales sobre la magnitud de la señal
inercial. El cálculo de los máximos locales (LocalMax(Magis), Ecuación (2.6)), consiste en dividir la señal
de magnitud en intervalos fijos de M muestras y calcular el valor máximo de la magnitud en cada intervalo
(j). Todos los valores de la señal magnitud, toman el valor máximo de ese intervalo, obteniéndose la señal
de la Figura 2-9c. El valor M mencionado fue obtenido mediante una evaluación estadística y corresponde
a 85 muestras.
( )( ) ( ) tMMjMagMjjMagLocalMax Mj
jisis ...2,,0max: =∴=+ +
. (2.6)
Para obtener los peridos de movimiento, la señal de máximos locales es calculada, y comparada con un
umbral dinámico (THDis, Ecuación (2.7)), el cual se calcula con la media (μ(Magis)) y la desviación estándar
(σ(Magis)) de cada magnitud y un factor K de ajuste, que dependerá de cada sensor inercial utilizado,
Ecuación (2.7).
( ) ( )isisis MagKMagTHD σµ ⋅+= . (2.7)

30 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Existe un valor mínimo de umbral (min(THD)), el cual corresponde al valor máximo de magnitud de la señal
inercial con el dispositivo en reposo (Figura 2-9d). Este valor de umbral mínimo fue obtenido mediante
una caracterización de la señal inercial cuando el operario tiene el dispositivo en su mano, pero no genera
ningún movimiento. El umbral dinámico pueda cambiar dependiendo de la persona que lo sujeta y debe
medirse para cada operario. En la Tabla 2-4 se observan tanto los valores de K y el umbral mínimo para
cada modo.
Finalmente, se determina un vector de carácter booleano, donde hay ceros en los periodos de movimiento y
unos en los periodos estacionarios (Figura 2-9e). Este vector sirve para forzar a cero las señales de los
sensores cuando el dispositivo está en reposo, y dejar las señales sin modificación cuando un movimiento
es detectado, y esto eliminará errores acumulativos.
Con la información obtenida con los periodos estacionarios y de movimiento se segmentan los vídeos
adquiridas sobre las ramas de café, es decir, el modo MCA finaliza su proceso en esta sección del SNI
propuesto.
Tabla 2-4: Constantes para el cálculo de máximos locales (K) y valor mínimo de umbral (min(THDis)).
Constantes Aceleración lineal X Aceleración lineal Y Velocidad angular Y K 1,8 0,44 1,8
min( isTHD ) 0,15 0,15 0,05
(a) Señal inercial cruda. (b) Magnitud de la señal inercial.
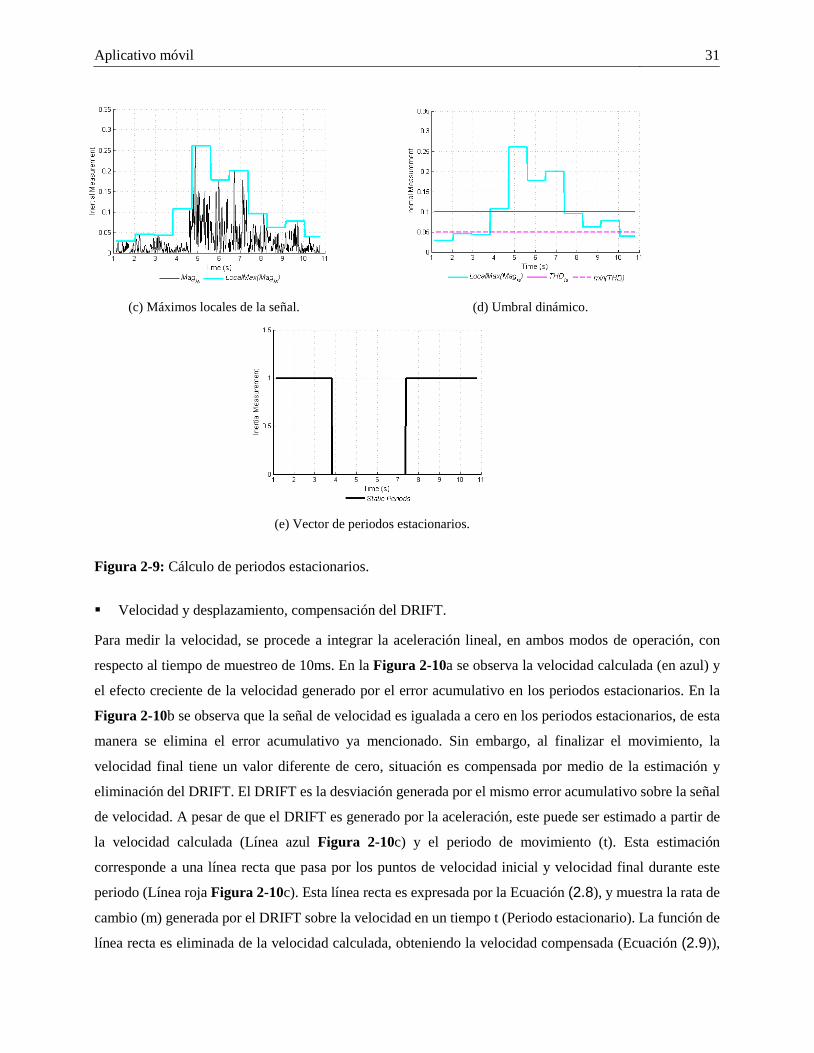
Aplicativo móvil 31
(c) Máximos locales de la señal. (d) Umbral dinámico.
(e) Vector de periodos estacionarios.
Figura 2-9: Cálculo de periodos estacionarios.
Velocidad y desplazamiento, compensación del DRIFT.
Para medir la velocidad, se procede a integrar la aceleración lineal, en ambos modos de operación, con
respecto al tiempo de muestreo de 10ms. En la Figura 2-10a se observa la velocidad calculada (en azul) y
el efecto creciente de la velocidad generado por el error acumulativo en los periodos estacionarios. En la
Figura 2-10b se observa que la señal de velocidad es igualada a cero en los periodos estacionarios, de esta
manera se elimina el error acumulativo ya mencionado. Sin embargo, al finalizar el movimiento, la
velocidad final tiene un valor diferente de cero, situación es compensada por medio de la estimación y
eliminación del DRIFT. El DRIFT es la desviación generada por el mismo error acumulativo sobre la señal
de velocidad. A pesar de que el DRIFT es generado por la aceleración, este puede ser estimado a partir de
la velocidad calculada (Línea azul Figura 2-10c) y el periodo de movimiento (t). Esta estimación
corresponde a una línea recta que pasa por los puntos de velocidad inicial y velocidad final durante este
periodo (Línea roja Figura 2-10c). Esta línea recta es expresada por la Ecuación (2.8), y muestra la rata de
cambio (m) generada por el DRIFT sobre la velocidad en un tiempo t (Periodo estacionario). La función de
línea recta es eliminada de la velocidad calculada, obteniendo la velocidad compensada (Ecuación (2.9)),

32 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Línea verde Figura 2-10c). En dicha señal la velocidad final es cero. En la Figura 2-10c se presenta la
velocidad no compensada, el DRIFT estimado y la velocidad compensada.
tm ⋅=ε̂ , (2.8)
ε̂−= −compensednoncompenseed velvel , (2.9)
(a) Velocidad sin ajustes. (b) Velocidad ajustada por periodos estacionarios.
(c) Compensación del DRIFT. (d) Posición al integrar la velocidad compensada.
Figura 2-10: Ajuste y cálculo de velocidad y posición del movimiento.
En la Figura 2-10d se observa el desplazamiento de 50 cm, resultado de integrar la señal de velocidad
compensada de la Figura 2-10c. Esta señal corresponde a una posición relativa adquirida con el SNI durante
un desplazamiento en modo navegación. Durante el recorrido por la plantación existen varios periodos
estacionarios y varios periodos de movimiento. En cada periodo de movimiento se actualizan las
coordenadas de localización a partir del movimiento generado en los ejes X y Y, y la orientación medida
por el celular (Azimut). Es necesario aclarar que la primera posición georreferenciada viene dada por el GPS,
pero las siguientes coordenadas son generadas por el SNI.

Aplicativo móvil 33
El punto inicial obtenido con el GPS está dado en coordenadas elipsoidales [Latitud(Lat), Longitud(Lon)],
utilizando el sistema de referencia geográfica mundial WGS84. El SNI propuesto entrega la posición en
metros (ejes X y Y), razón por la cual se requiere hacer una conversión de coordenadas para integrar ambas
mediciones en metros. Se realiza la conversión entre coordenadas elipsoidales [Lat, Lon] y coordenadas
planas de Gauss-Krüger [Norte(N), Este(E)] [85], para llevar todo el sistema de georreferenciación a
coordenadas planas de Gauss-Krüger y realizar el levantamiento de los recorridos con la información del
SNI. Posteriormente se realiza la conversión inversa para llevar la información a un sistema
georreferenciados [Lat, Lon] y mostrarlo en un mapa de Google Maps.
Con relación a la orientación del movimiento, tanto el sistema de coordenadas elipsoidales como el sistema
de coordenadas planas de Gauss-Krüger, están orientados con referencia al norte geográfico. El dispositivo
móvil entrega la orientación referenciado al norte magnético. Por lo anterior, se hace una compensación de
declinación magnética (DM), que para la zona donde se realizó el trabajo es de -6.13°.
Luego de calcular el desplazamiento del eje X y el eje Y del celular, y obtener la orientación compensada,
se debe recalcular la nueva coordenada de georreferenciación. La Ecuación (2.10) muestra el cálculo de la
orientación compensada con declinación magnética. La Ecuación (2.11) muestra el desplazamiento relativo
de los ejes X y Y, medidos con el celular y el SNI en coordenadas planas Gauss-Krüger [N,E]. Y la Ecuación
(2.12) es la posición actual, guardando la información anterior del recorrido. Los valores iniciales de N y E
corresponden a la lectura inicial del GPS en coordenadas planas Gauss-Krüger. En la Ecuación (2.10) 𝜃𝜃 es
el ángulo de orientación con corrección de declinación magnética. En la Ecuación (2.11)
𝛥𝛥𝛥𝛥,𝛥𝛥𝛥𝛥,𝛥𝛥𝛥𝛥,𝛥𝛥𝛥𝛥 son los cambios en las coordenadas 𝛥𝛥,𝛥𝛥, y en los desplazamientos 𝛥𝛥,𝛥𝛥, respectivamente.
𝜃𝜃 = 𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴 − 𝐷𝐷𝐷𝐷, (2.10)
𝛥𝛥𝛥𝛥 = 𝛥𝛥𝛥𝛥 ∗ cos(𝜃𝜃) + 𝛥𝛥𝛥𝛥 ∗ 𝑐𝑐𝑐𝑐𝑠𝑠(𝜃𝜃 + 90), 𝛥𝛥𝛥𝛥 = 𝛥𝛥𝛥𝛥 ∗ sin(𝜃𝜃) + 𝛥𝛥𝛥𝛥 ∗ 𝑠𝑠𝐴𝐴𝑠𝑠(𝜃𝜃 + 90),
(2.11)
𝛥𝛥 = 𝛥𝛥 + 𝛥𝛥𝛥𝛥, 𝛥𝛥 = 𝛥𝛥 + 𝛥𝛥𝛥𝛥, (2.12)
La posición medida con el SNI es una posición relativa al punto de inicio del movimiento. El punto inicial
es georreferenciado a través del GPS del celular y puede tener un error de localización entre 2,5 m y 5m. El
SNI desarrollado generar recorridos evitando las complicaciones del GPS mencionadas al inicio de esta
sección con mediciones más precisas de desplazamientos y ajuste en las ubicaciones georreferenciadas.

34 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
2.4 Resultados.
El algoritmo descrito en la Sección 2.3, fue calibrado para el modo de navegación y evaluado para ambos
modos. En el modo de navegación se realiza la medición del desplazamiento sobre un terreno, este modo
requiere un ajuste adicional que involucre la dinámica de la medición a diferentes tamaños de paso. Con la
información inicial del GPS, las mediciones del SNI calibrado y la conversión de coordenadas, se obtienen
puntos georreferenciados ajustados a nivel de centímetros. Se verificó si esta información de
georreferenciación dependía del rango de desplazamientos y/o velocidades dentro de la parcela.
Por otro lado, en el modo de control de adquisición de imágenes, la velocidad de desplazamiento debe ser
baja, para obtener imágenes de calidad adecuada. Esta velocidad no debe ser superior a 5cm.s-1, sin embargo,
bajo estas condiciones no es posible medir desplazamientos, solo se logra identificar los momentos de inicio
y finalización de movimiento, como se mostró en la Sección 2.3.2, con el fin de recortar los vídeos
adquiridos y continuar con un análisis cuadro a cuadro para definir si la información es apta para ser
procesada, o por el contrario presenta problemas de emborronamiento o falta de nitidez.
2.4.1 Calibración y evaluación del SNI propuesto en modo navegación MN.
Calibración del modo navegación.
Con el fin de determinar el funcionamiento del SNI propuesto en la medición de desplazamientos dentro de
una parcela de café, se realizaron diferentes ensayos, donde se varió el tamaño del paso, la forma del
desplazamiento, la distancia total recorrida, la velocidad del recorrido, y la orientación del movimiento,
sobre un arreglo de puntos equidistantes. En la Tabla 2-5, se muestra una distribución de puntos (P),
utilizados para calibrar las mediciones de desplazamientos. La distancia entre cada uno de los puntos, fue
considerada como el tamaño del paso y varió entre 0,5 m y 3,75 m. Sobre los puntos mostrados se generaron
5 tipos de desplazamientos, como se muestra a continuación: (i) Movimiento 1: P00 a P0i; (ii) movimiento 2:
P00 a Pj0; (iii) movimiento 3: P00 a Pj0, Pj0 a Pj1, Pj1 a P01; (iv) movimiento 4: Pj1 a P01, P01 a P00, P00 a Pj0, y
(v) movimiento 5: P00 a Pj0, Pj0 a Pj1, Pj1 a P01, P01 a P02, P02 a Pj2. Las coordenadas del GPS para el punto de
inicio P00 fue de 1043915,9141 N 831420,7374 E en coordenadas planas Gauss-Krüger.
Tabla 2-5: Puntos utilizados para el ajuste en modo navegación.
𝑃𝑃00 𝑃𝑃01 𝑃𝑃02 … 𝑃𝑃0𝑖𝑖
𝑃𝑃10 𝑃𝑃11 𝑃𝑃12 … 𝑃𝑃1𝑖𝑖
𝑃𝑃20 𝑃𝑃21 𝑃𝑃22 … 𝑃𝑃2𝑖𝑖

Aplicativo móvil 35
⋮ ⋮ ⋮ ⋱ ⋮
𝑃𝑃𝑗𝑗0 𝑃𝑃𝑗𝑗1 𝑃𝑃𝑗𝑗2 … 𝑃𝑃𝑗𝑗𝑖𝑖
Cada punto P fue marcado en el terreno, a diferentes distancias en metros (0,5 m, 0,75 m, 1 m, 1,5 m, 2,25
m, 3 m, 3,75 m). Por cada movimiento fueron generadas 8 señales con el dispositivo móvil y procesadas
como se mencionó en la Sección 2.3.
Como se muestra en la Figura 2-11a, el recorrido generado por el SNI muestra pequeños retrocesos en la
finalización de cada paso, esto se debe a que en muchas ocasiones la compensación del DRIFT genera
velocidades finales negativas como se muestra en la Figura 2-11b. En ningún momento hubo movimientos
de retroceso. Esta situación pudo ser generada porque la velocidad promedio de los movimientos fue de 44
cm.s-1 (entre 45 cm.s-1 y 42 cm.s-1). Para velocidades más altas no se generan compensaciones negativas del
DRIFT. Por esta razón se realizó un ajuste o calibración al vector posición que muestra el recorrido, pues
normalmente el recorrido por la parcela se realiza a estas velocidades, debido a la complejidad de moverse
en un terreno adensado.
Para calcular el factor de calibración de la medición del desplazamiento, se realizó un análisis de regresión
lineal entre los valores de desplazamiento calculados por el algoritmo y los valores reales en cinco señales
por cada movimiento, para determinar el factor de ajuste de la medición en el rango de tamaño de paso
mencionado. El análisis estimó el coeficiente de regresión en un valor de 1,4735, un coeficiente de
determinación (R2) de 0,98, y un intercepto igual a cero según prueba t al 1%. El valor del coeficiente de
regresión de 1,4735 sirve como factor de calibración para los valores calculados por el algoritmo.
(a) Desplazamiento negativo marcado en los
recuadros en dos secciones del vector posición.
(b) Velocidad compensada negativa por efecto de la velocidad final y compensación del DRIFT.
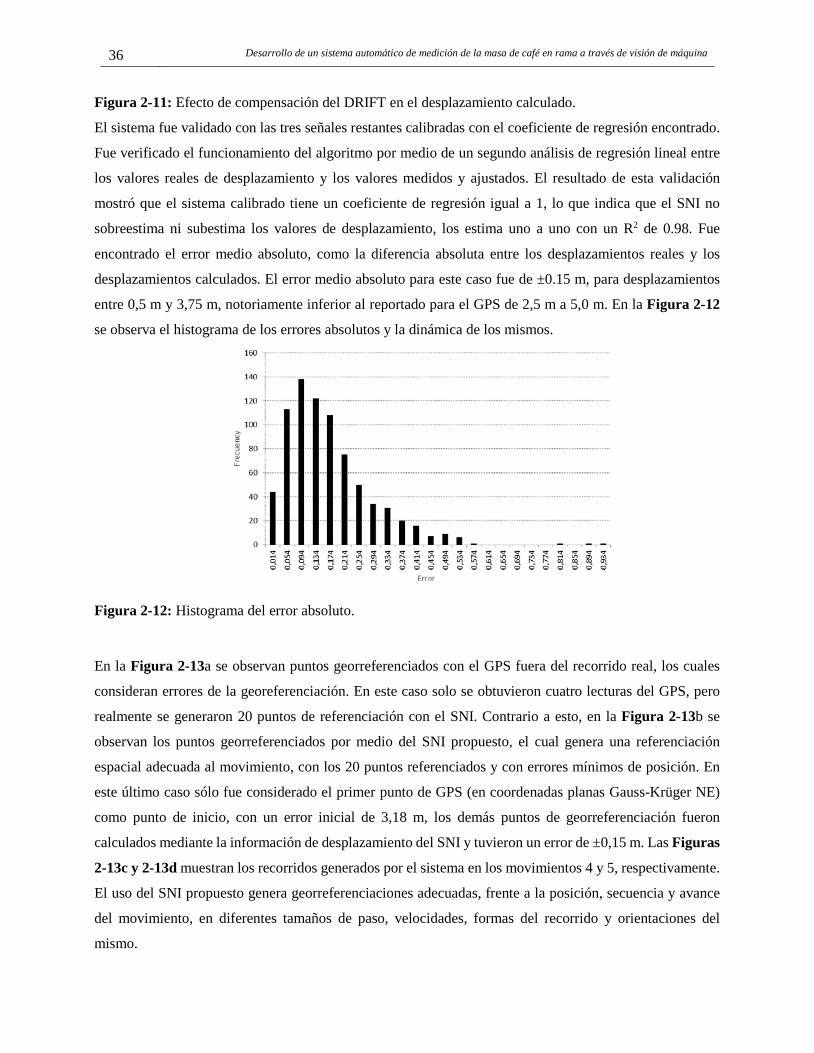
36 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 2-11: Efecto de compensación del DRIFT en el desplazamiento calculado.
El sistema fue validado con las tres señales restantes calibradas con el coeficiente de regresión encontrado.
Fue verificado el funcionamiento del algoritmo por medio de un segundo análisis de regresión lineal entre
los valores reales de desplazamiento y los valores medidos y ajustados. El resultado de esta validación
mostró que el sistema calibrado tiene un coeficiente de regresión igual a 1, lo que indica que el SNI no
sobreestima ni subestima los valores de desplazamiento, los estima uno a uno con un R2 de 0.98. Fue
encontrado el error medio absoluto, como la diferencia absoluta entre los desplazamientos reales y los
desplazamientos calculados. El error medio absoluto para este caso fue de ±0.15 m, para desplazamientos
entre 0,5 m y 3,75 m, notoriamente inferior al reportado para el GPS de 2,5 m a 5,0 m. En la Figura 2-12
se observa el histograma de los errores absolutos y la dinámica de los mismos.
Figura 2-12: Histograma del error absoluto.
En la Figura 2-13a se observan puntos georreferenciados con el GPS fuera del recorrido real, los cuales
consideran errores de la georeferenciación. En este caso solo se obtuvieron cuatro lecturas del GPS, pero
realmente se generaron 20 puntos de referenciación con el SNI. Contrario a esto, en la Figura 2-13b se
observan los puntos georreferenciados por medio del SNI propuesto, el cual genera una referenciación
espacial adecuada al movimiento, con los 20 puntos referenciados y con errores mínimos de posición. En
este último caso sólo fue considerado el primer punto de GPS (en coordenadas planas Gauss-Krüger NE)
como punto de inicio, con un error inicial de 3,18 m, los demás puntos de georreferenciación fueron
calculados mediante la información de desplazamiento del SNI y tuvieron un error de ±0,15 m. Las Figuras
2-13c y 2-13d muestran los recorridos generados por el sistema en los movimientos 4 y 5, respectivamente.
El uso del SNI propuesto genera georreferenciaciones adecuadas, frente a la posición, secuencia y avance
del movimiento, en diferentes tamaños de paso, velocidades, formas del recorrido y orientaciones del
mismo.

Aplicativo móvil 37
Evaluación del modo navegación.
La evaluación del SNI en modo navegación fue realizada en una parcela sembrada en café con una distancia
de siembra de 1,5 m × 1 m. En la Figura 2-13 se muestran los resultados obtenidos sobre la parcela sembrada
en café, con pasos de 1 y 1,5 m, múltiplo de la distancia de siembra y un punto de GPS inicial de
1043868,786 N 831230,1454 E, con un error inicial de ±1,8 m. En la Figura 2-14 se ven dos trayectorias
de movimiento: (i) una por los costados de la parcela; (ii) y otra en forma de “U” dentro de la parcela. En
total se generaron 80 puntos georreferenciados con el SNI, mientras que con el GPS tradicional solo se
obtuvieron 4 puntos. La evaluación para este caso mostró que el sistema no sobreestima ni subestima los
desplazamientos, y es capaz de estimar uno a uno la posición de los árboles a chequear dentro de la parcela.
Las velocidades de desplazamiento estuvieron dentro del rango mencionado en la Sección 2.4.1, entre 45
cm.s-1 y 42 cm.s-1, y el error medio absoluto del recorrido generado por el SNI fue de ±0,26 m entre pasos.
Los recorridos mostrados en la Figura 2-14 tienen un error total de ±(1,8 ± 0,26) m. Sin embargo, el SNI
garantiza que no haya pérdidas en la información del recorrido sobre la parcela, como si las puede haber
solo usando el GPS del celular.
(a) Datos de GPS para el movimiento 3 y recorrido
generado por SIN. (b) Datos georreferenciados con el SNI propuesto para el movimiento 3 con punto de partida leído del GPS.

38 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(c) Datos georreferenciados con el SNI propuesto para el
movimiento 4. (d) Datos georreferenciados con el SNI propuesto para
el movimiento 5.
Figura 2-13: Puntos georreferenciados con el GPS y con el SNI propuesto.
Figura 2-14: Georreferenciación de árboles en una parcela sembrada en café. Foto tomada de Google Maps.
2.4.2 Evaluación del SNI propuesto en modo control de adquisición de imágenes MCA.
Al entrar en la opción para adquisición de vídeo/imágenes, se identifica la rama a digitalizar y se crea una
carpeta con el nombre de la rama. En esta carpeta se almacena el vídeo/imágenes y el archivo de texto de
las señales inerciales del SNI propuesto. Una vez la cámara está activada se ubica adecuadamente la rama,
se enfoca la imagen y se comienza a grabar el vídeo. El desplazamiento del dispositivo móvil sobre la rama
solo puede comenzar cuando la imagen en pantalla se encuentre enfocada adecuadamente. El sistema detecta
el comienzo y fin del desplazamiento, y con esta información se segmentan los vídeos. Con esta
segmentación se adquiere información válida para el procesamiento de imágenes.
La velocidad de desplazamiento debe ser tal que las imágenes no sufran emborronamiento o problemas de
ruido por movimiento. Por esta razón, se determinaron tres velocidades (baja, media y alta), para adquirir
imágenes y determinar, a partir de qué velocidad, las imágenes o cuadros de los vídeos comienzan a verse
emborronadas. Este ejercicio se hizo sobre ramas de longitud de 50cm y la velocidad se determinó
manualmente considerando los tiempos de desplazamiento entre el inicio y el final de la rama. Las tres
velocidades a que se hace referencia son: (i) Baja: menor a 5 cm.s-1; (ii) media: entre 5cm.s-1 y 10cm.s-1; y
(iii) alta: mayor a 10cm.s-1. En las Figuras 2-15a, 2-15c y 2-15e, se muestran las señales de velocidades
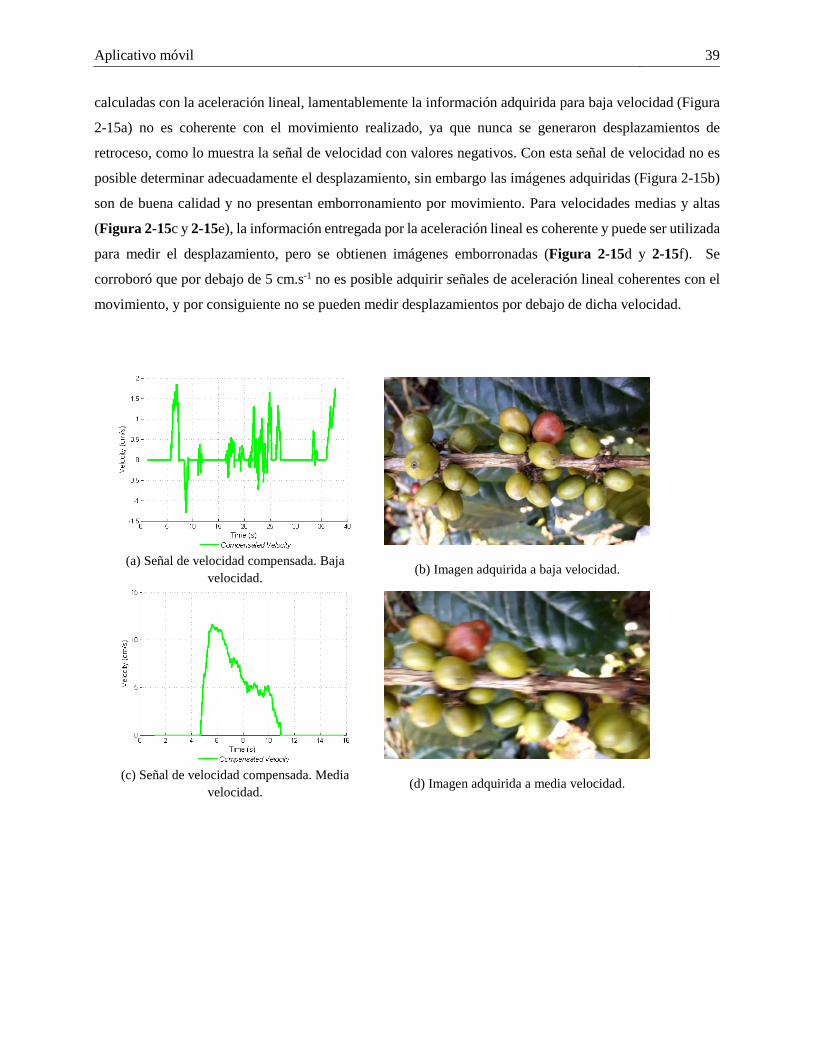
Aplicativo móvil 39
calculadas con la aceleración lineal, lamentablemente la información adquirida para baja velocidad (Figura
2-15a) no es coherente con el movimiento realizado, ya que nunca se generaron desplazamientos de
retroceso, como lo muestra la señal de velocidad con valores negativos. Con esta señal de velocidad no es
posible determinar adecuadamente el desplazamiento, sin embargo las imágenes adquiridas (Figura 2-15b)
son de buena calidad y no presentan emborronamiento por movimiento. Para velocidades medias y altas
(Figura 2-15c y 2-15e), la información entregada por la aceleración lineal es coherente y puede ser utilizada
para medir el desplazamiento, pero se obtienen imágenes emborronadas (Figura 2-15d y 2-15f). Se
corroboró que por debajo de 5 cm.s-1 no es posible adquirir señales de aceleración lineal coherentes con el
movimiento, y por consiguiente no se pueden medir desplazamientos por debajo de dicha velocidad.
(a) Señal de velocidad compensada. Baja
velocidad. (b) Imagen adquirida a baja velocidad.
(c) Señal de velocidad compensada. Media
velocidad. (d) Imagen adquirida a media velocidad.
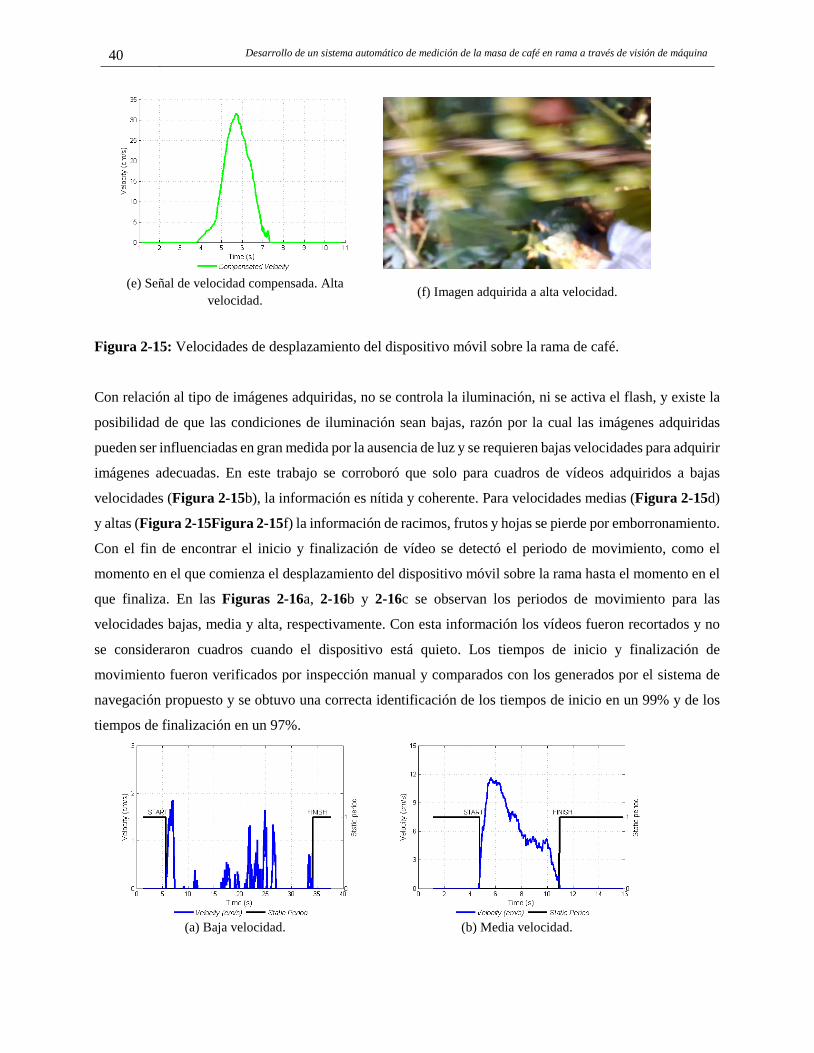
40 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(e) Señal de velocidad compensada. Alta
velocidad. (f) Imagen adquirida a alta velocidad.
Figura 2-15: Velocidades de desplazamiento del dispositivo móvil sobre la rama de café.
Con relación al tipo de imágenes adquiridas, no se controla la iluminación, ni se activa el flash, y existe la
posibilidad de que las condiciones de iluminación sean bajas, razón por la cual las imágenes adquiridas
pueden ser influenciadas en gran medida por la ausencia de luz y se requieren bajas velocidades para adquirir
imágenes adecuadas. En este trabajo se corroboró que solo para cuadros de vídeos adquiridos a bajas
velocidades (Figura 2-15b), la información es nítida y coherente. Para velocidades medias (Figura 2-15d)
y altas (Figura 2-15Figura 2-15f) la información de racimos, frutos y hojas se pierde por emborronamiento.
Con el fin de encontrar el inicio y finalización de vídeo se detectó el periodo de movimiento, como el
momento en el que comienza el desplazamiento del dispositivo móvil sobre la rama hasta el momento en el
que finaliza. En las Figuras 2-16a, 2-16b y 2-16c se observan los periodos de movimiento para las
velocidades bajas, media y alta, respectivamente. Con esta información los vídeos fueron recortados y no
se consideraron cuadros cuando el dispositivo está quieto. Los tiempos de inicio y finalización de
movimiento fueron verificados por inspección manual y comparados con los generados por el sistema de
navegación propuesto y se obtuvo una correcta identificación de los tiempos de inicio en un 99% y de los
tiempos de finalización en un 97%.
(a) Baja velocidad. (b) Media velocidad.
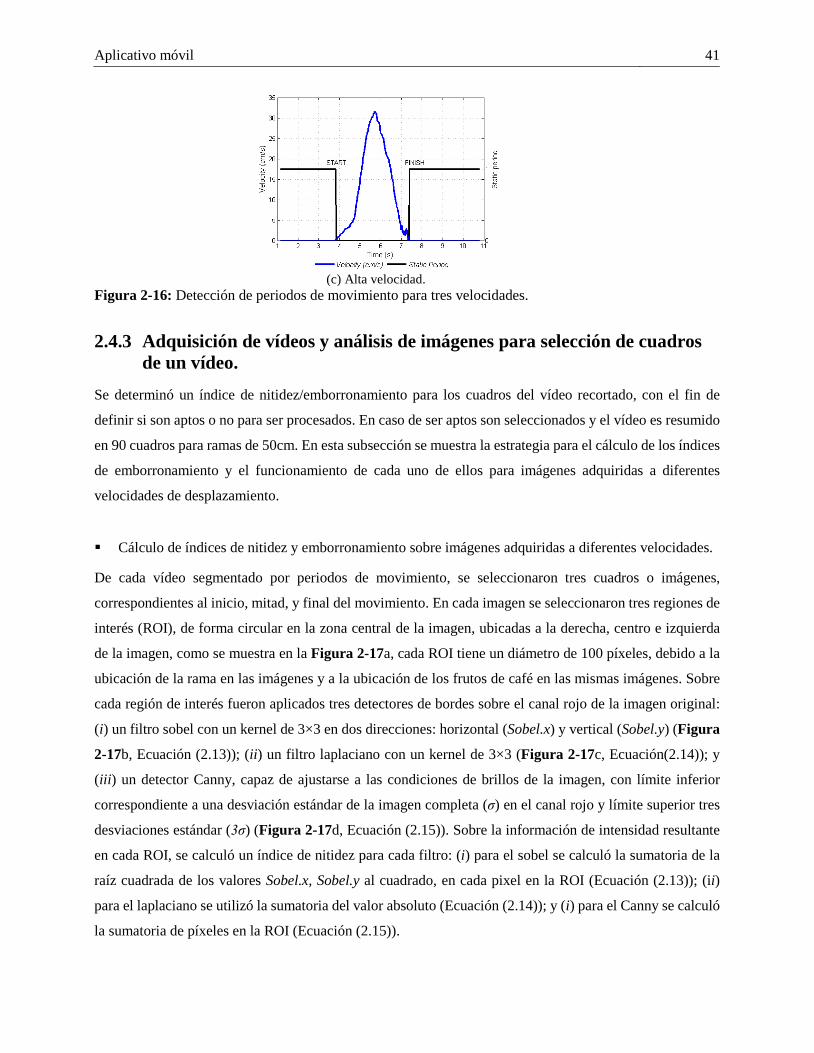
Aplicativo móvil 41
(c) Alta velocidad.
Figura 2-16: Detección de periodos de movimiento para tres velocidades.
2.4.3 Adquisición de vídeos y análisis de imágenes para selección de cuadros de un vídeo.
Se determinó un índice de nitidez/emborronamiento para los cuadros del vídeo recortado, con el fin de
definir si son aptos o no para ser procesados. En caso de ser aptos son seleccionados y el vídeo es resumido
en 90 cuadros para ramas de 50cm. En esta subsección se muestra la estrategia para el cálculo de los índices
de emborronamiento y el funcionamiento de cada uno de ellos para imágenes adquiridas a diferentes
velocidades de desplazamiento.
Cálculo de índices de nitidez y emborronamiento sobre imágenes adquiridas a diferentes velocidades.
De cada vídeo segmentado por periodos de movimiento, se seleccionaron tres cuadros o imágenes,
correspondientes al inicio, mitad, y final del movimiento. En cada imagen se seleccionaron tres regiones de
interés (ROI), de forma circular en la zona central de la imagen, ubicadas a la derecha, centro e izquierda
de la imagen, como se muestra en la Figura 2-17a, cada ROI tiene un diámetro de 100 píxeles, debido a la
ubicación de la rama en las imágenes y a la ubicación de los frutos de café en las mismas imágenes. Sobre
cada región de interés fueron aplicados tres detectores de bordes sobre el canal rojo de la imagen original:
(i) un filtro sobel con un kernel de 3×3 en dos direcciones: horizontal (Sobel.x) y vertical (Sobel.y) (Figura
2-17b, Ecuación (2.13)); (ii) un filtro laplaciano con un kernel de 3×3 (Figura 2-17c, Ecuación(2.14)); y
(iii) un detector Canny, capaz de ajustarse a las condiciones de brillos de la imagen, con límite inferior
correspondiente a una desviación estándar de la imagen completa (σ) en el canal rojo y límite superior tres
desviaciones estándar (3σ) (Figura 2-17d, Ecuación (2.15)). Sobre la información de intensidad resultante
en cada ROI, se calculó un índice de nitidez para cada filtro: (i) para el sobel se calculó la sumatoria de la
raíz cuadrada de los valores Sobel.x, Sobel.y al cuadrado, en cada pixel en la ROI (Ecuación (2.13)); (ii)
para el laplaciano se utilizó la sumatoria del valor absoluto (Ecuación (2.14)); y (i) para el Canny se calculó
la sumatoria de píxeles en la ROI (Ecuación (2.15)).

42 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
𝐼𝐼𝐼𝐼𝐼𝐼𝑠𝑠𝑠𝑠𝑏𝑏𝑠𝑠𝑠𝑠 = ∑�𝑆𝑆𝑐𝑐𝑏𝑏𝑆𝑆𝑆𝑆. 𝐼𝐼2 + 𝑆𝑆𝑐𝑐𝑏𝑏𝑆𝑆𝑆𝑆. 𝑦𝑦2, (2.13)
𝐼𝐼𝐼𝐼𝐼𝐼𝑠𝑠𝑙𝑙𝑙𝑙𝑠𝑠𝑙𝑙𝑙𝑙𝑖𝑖𝑙𝑙𝑙𝑙 = ∑𝑎𝑎𝑏𝑏𝑠𝑠(𝐿𝐿𝑎𝑎𝐿𝐿𝑆𝑆𝑎𝑎𝑐𝑐𝐴𝐴𝑎𝑎𝑠𝑠), (2.14)
𝐼𝐼𝐼𝐼𝐼𝐼𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑐𝑐 = ∑𝑐𝑐𝑎𝑎𝑠𝑠𝑠𝑠𝑦𝑦|𝜎𝜎3𝜎𝜎, (2.15)
Se obtuvieron en total 10 vídeos, 30 imágenes y 270 índices para cada una de las 3 velocidades. Se
determinaron intervalos de confianza al 95% de nivel de confianza, para cada índice, región de interés y
velocidad de desplazamiento del celular.
En la Figura 2-18 se muestran dichos intervalos de confianza para para cada índice, en las tres velocidades,
los tres detectores de bordes, y las tres regiones de interés. En el eje de las X se observan identificadores de
velocity.index.ROI, este identificador muestra: i) velocity con tres valores Low, Med y High; ii) index con
tres opciones Sobel, Laplacian y Canny; iii) ROI tres regiones de interés ROI1, ROI2 y ROI3. La Figura
2-18 muestra que no hay una diferenciación estadística entre índices de borrosidad en las tres ROI, y que
los tres índices de borrosidad son diferentes estadísticamente para una misma velocidad. Además, un mismo
índice de borrosidad es diferente estadísticamente en las tres velocidades. Por esta razón es posible inferir
que los índices de borrosidad están relacionados con la velocidad de adquisición de una imagen. Y que con
el índice de borrosidad de una sola ROI es suficiente para determinar el de las otras dos ROI. Cualquiera de
los tres filtros puede ser utilizado para determinar la nitidez de las imágenes, pues cada uno muestra
diferenciación estadística a diferentes velocidades. Un segundo aspecto para encontrar el filtro a seleccionar
es el costo computacional de la implementación en el dispositivo móvil.
(a) Imagen en canal rojo con tres ROI. (b) Filtro sobel sobre las tres ROI.

Aplicativo móvil 43
Figura 2-17: Detección de regiones de interés e índices de emborronamiento.
En la Figura 2-19 se muestran los intervalos de confianza para el costo computacional del cálculo de cada
índice para las ROI en las tres imágenes seleccionadas por cada vídeo, este costo computacional se
determinó sobre el dispositivo móvil. Se concluye que no hay diferencia estadística en el costo
computacional entre un índice y otro.
Bajo los dos criterios de selección para el índice de borrosidad (diferencia estadística para cada velocidad y
mínimo requerimiento computacional), cualquiera de los índices funciona de manera adecuada. Analizando
los resultados obtenidos con los intervalos de confianza de la Figura 2-19, solo serán aceptados los cuadros
de los vídeos que presenten en una de las ROI un factor de nitidez superior a 1.100.000 para el filtro e índice
sobel, o superior a 54.000 para el filtro e índice laplaciano, o superior a 290.000 para el filtro e índice Canny.
Si el valor es inferior a estos valores, se considera que es una imagen sin la nitidez necesaria para ser
procesado pues pudo ser adquirido a velocidades superiores a 5cm.s-1, lo que genera emborronamiento en
los cuadros del vídeo.
(c) Filtro laplaciano sobre las tres ROI. (d) Detector Canny sobre las tres ROI.

44 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 2-18: Intervalos de confianza para índice de nitidez a diferentes velocidades de adquisición de imágenes.
Figura 2-19: Intervalos de confianza para el costo computacional de cada índice/filtro aplicado para calcular nitidez.
La descripción de la interfaz se muestra en el Anexo A. Allí se puede visualizar la apariencia de la app y las principales funciones configuradas desde el dispositivo móvil.
2.5 Conclusiones Se realizó de manera precisa la identificación del movimiento de un dispositivo móvil, a medida que captura
vídeo y se desplaza sobre las ramas del árbol de café. Esta característica tecnológica hace que los vídeos
resultantes de un muestreo, sean de menor tamaño y se requiera menor espacio en los servidores o el mismo
dispositivo. Adicionalmente, el tipo de emborronamiento de la imagen puede ser un indicio de la velocidad

Aplicativo móvil 45
con la que fue adquirido el vídeo, ya que esta no puede ser medida cuando el desplazamiento es realizado a
velocidades inferiores a 5 cm.s-1. Se logran seleccionar imágenes con índice de nitidez adecuado, sin
embargo, en muchas ocasiones si un cuadro se ha desenfocado es necesario repetir el vídeo. La curvatura
de la rama no ayuda a llevar un movimiento rectilíneo y se requiere moverse sobre ella con la misma
curvatura que proyecta. Es importante tener siempre visible la pantalla del celular con el fin de verificar
manualmente que el vídeo es correctamente adquirido, de esta manera el índice de nitidez si descartaría
algunos cuadros del vídeo que no sean adecuados.
El sistema de navegación inercial desarrollado utiliza los sensores dispuestos en el dispositivo móvil y logra
ubicaciones relativas del orden de los -+0,15 m, con menor error que un GPS. El GPS entrega el valor inicial
del recorrido y puede tener un error entre 2,5 m y 5 m. Este error inicial afecta directamente el error absoluto
del recorrido que puede estar entre ± (2,5 ± 0,15) m y ± (5 ± 0,15) m. Sin embargo, y pese al error absoluto
del sistema, el SNI garantiza que no haya pérdidas en la información del recorrido sobre una parcela, como
si las puede haber solo usando el GPS del celular. Esto es una gran ventaja para la herramienta desarrollada,
ya que, para los cultivos adensados como el café, obtener información entre árboles sembrados a pocos
centímetros es de vital importancia, pues cada árbol puede ser georreferenciado con ubicaciones correctas
en las parcelas y con la información espacialmente referenciada, es posible a futuro, generar estrategias
logísticas de labores de campo, de manera selectiva sobre cada parcela. Con el fin de solucionar el problema
de la precisión del GPS, en futuros trabajos se podría generar el punto de inicio por medio de la interfaz de
GoogleMaps, creando un marcador de ubicación sobre las parcelas a chequear.
La compensación del DRIFT en muchas ocasiones puede generar velocidades finales negativas sin existir
movimiento de retroceso. Esto llevó a generar un factor de ajuste en el modo navegación y se convirtió en
una gran ventaja del sistema desarrollado, ya que en otros desarrollos la compensación del DRIFT requiere
tiempos de integración fijos, en este caso se puede realizar en ventanas de tiempo dinámicas y ajustes de
calibración posteriores, logrando correctas detecciones en el 98% de los casos.
Los resultados obtenidos con este objetivo, integran el control de la adquisición de imágenes en movimiento,
su ubicación en el espacio y la calidad de la información. Con lo anterior y un adecuado uso de la tecnología
se podría en un futuro a mediano plazo, tener al alcance del caficultor una herramienta económica, precisa
y versátil para adquirir información de las ramas de café. Adicionalmente, esta tecnología podría ser aplicada
no solo a cultivos de café sino también a otros cultivos como manzanas, naranjas, etc.


47
3. Identificación de frutos de café en rama, a partir de imágenes 2D.
Para obtener valores de producción, el conteo de frutos en árboles y ramas, puede ser el método más
confiable, de realizarse en el momento adecuado, al inicio del ciclo de cosecha. Esta medición
entrega la cantidad de frutos producidos por árbol y se podría interpolar para un lote. En este capítulo
se expone un método no destructivo para contar el número de frutos en una rama de café, usando
información de imágenes digitales de un solo lado de la rama y frutos por estado de desarrollo. En
total, fueron utilizadas 1018 ramas de café con diferentes porcentajes de maduración, número de
frutos, momentos de producción, variedades y edades del cafeto, a las cuales se les adquirieron
imágenes en condiciones de campo. Para crear los algoritmos de identificación, fue necesario realizar
un sistema de anotación semiautomática (Anexo B), con el cual fue posible caracterizar la
información de cada estructura vegetativa presente en las imágenes a procesar. El sistema de
anotación también fue utilizado en el Capítulo 4, con el fin de crear información ground-truth de los
cuadros seleccionados de un vídeo y realizar el entrenamiento del algoritmo 3D. Se construyó un
sistema de visión de máquina (MVS) capaz de contar e identificar frutos cosechables y frutos no
cosechables en un conjunto de imágenes correspondientes a una rama de café. Este MVS está
conformado por un sistema de adquisición de imágenes, basado en dispositivos móviles, como se
mencionó en el capítulo anterior, y un algoritmo de procesamiento de imágenes para clasificar y
detectar cada fruto de las imágenes adquiridas en condiciones no controladas de iluminación.
3.1 Algoritmo 2D para detección de frutos.
El sistema 2D propuesto, se ilustra en la Figura 3-1. Se realizaron dos tipos de conteo, uno manual
y otro automático. El conteo manual fue realizado por personal calificado y el conteo automático fue
realizado como se ilustra en las etapas de la Figura 3-1, comenzando por la adquisición y adecuación
de las imágenes, y siguiendo diferentes pasos hasta obtener el número de frutos por rama. Los valores

48 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
del conteo manual y del conteo automático fueron relacionados para obtener modelos lineales de
estimación, los cuales fueron evaluados y finalmente se realizó una validación del sistema propuesto
en ramas de cuatro parcelas experimentales.
El sistema de visión de máquina (MVS) se desarrolló en seis etapas (Figura 3-1): i) Adquisición de
imágenes, donde se define el hardware utilizado y las condiciones de adquisición de las imágenes;
ii) Preproceso de imágenes adquiridas, donde se realiza un escalamiento de las imágenes para
homogenizarlas y lograr el procesamiento adecuado independiente del tamaño de las imágenes; iii)
Segmentador de regiones homogéneas, este paso consiste en determinar aquellas zonas que pueden
tener la misma información de textura; iv) Detector de candidatos a arcos circulares o semicirculares,
consiste en analizar cada uno de los contornos generados en el paso anterior, y determinar si
pertenecen o no, a un arco circular o semicircular que se ajuste a la forma de un fruto de café; v)
Ajuste y selector de elipses, este paso consiste en ajustar a una elipse los puntos encontrados en el
paso anterior y evaluar si es posible que estas elipses pertenezcan a frutos de café; y vi) Detección,
clasificación y conteo de frutos, este último paso consiste en ubicar la elipse ajustada en la imagen
clasificada por estructuras vegetativas, detectar solo un fruto por elipse y contar los frutos detectados
por estado de desarrollo. En esta sección se explicarán las diferentes etapas requeridas para realizar
el conteo automático, en el subcapítulo 3.2, se mostrará la evaluación de la técnica de procesamiento
de imágenes utilizada.
3.1.1 Adquisición y adecuación de imágenes. Las imágenes adquiridas presentan información parcial de la rama, ya que cada imagen corresponde
a conjuntos de 3 a 4 racimos, y en las imágenes sólo se registra la información de la parte posterior
de la rama. En total por cada rama se adquirieron entre 3 y 5 imágenes, con el fin de registrar todos
los racimos. Se utilizó información de 135 ramas adquiridas en los meses de diciembre de 2013,
enero a abril de 2014, julio a noviembre de 2015 y julio de 2016, para desarrollar y evaluar el
algoritmo 2D.
Las imágenes fueron transformadas, para que independiente de la resolución de la imagen de entrada,
siempre se obtenga un tamaño de imagen estándar con diagonal DRimg. En la Ecuación (3.1), 𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔

Aplicativo móvil 49
y 𝑊𝑊𝑖𝑖𝑖𝑖𝑔𝑔 corresponden al alto y el ancho de la imagen original, respectivamente. 𝐻𝐻𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 y 𝑊𝑊𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔
son el alto y el ancho de la imagen con tamaño estándar.
𝐻𝐻𝐴𝐴𝑓𝑓 = � 0.5 → 𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 = 10800.25 → 𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 = 2448 .
𝑊𝑊𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 = 𝑊𝑊𝑖𝑖𝑖𝑖𝑔𝑔 ∙ 𝐻𝐻𝐴𝐴𝑓𝑓 .
𝐻𝐻𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 = 𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 ∙ 𝐻𝐻𝐴𝐴𝑓𝑓 .
𝐷𝐷𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔 = �𝑊𝑊𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔2 + 𝐻𝐻𝐻𝐻𝑖𝑖𝑖𝑖𝑔𝑔2 .
(3.1)
Figura 3-1: Sistema de visión de máquina 2D propuesto.
Se pueden identificar dos tipos en la base de datos (Figuras 3-2a y 3-2b). La Figura 3-2a
corresponde a imágenes de ramas que tuvieron como fondo tierra, arvenses y hojas secas, con tamaño
de 3264×2448 píxeles. La Figura 3-2b corresponde a imágenes que tuvieron como fondo otras ramas
de café y su tamaño fue de 1920×1080 píxeles.

50 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(a) Fondo conformado por suelo, arvenses y hojas secas.
(b) Fondo conformado por otras ramas.
Figura 3-2: Conjuntos de imágenes por rama.
3.1.2 Segmentación de regiones homogéneas. La segmentación de las regiones homogéneas consiste en un detector de bordes Canny de carácter
dinámico, sobre la imagen original, donde los límites superior e inferior para la umbralización por
histéresis, dependen directamente de las condiciones de luminosidad de la imagen, de la media y la
desviación estándar de cada imagen en escala de grises. El valor máximo de umbral (σmax)
corresponde a tres desviaciones estándar de los valores en escala de grises de la imagen y σmin
corresponde a una desviación estándar (Ecuación (3.2)). En la Ecuación (3.2) N corresponde al
número total de píxeles, xi corresponde a un valor de intensidad de grises y μ al promedio de
intensidad de grises para esa imagen.
𝜎𝜎𝑖𝑖𝑙𝑙𝑚𝑚 = 3� 1𝑁𝑁−1
∑ (𝐼𝐼𝑖𝑖 − 𝜇𝜇)2𝑁𝑁−1𝑖𝑖=0 .
𝜎𝜎𝑖𝑖𝑖𝑖𝑙𝑙 = 13𝜎𝜎𝑖𝑖𝑙𝑙𝑚𝑚.
(3.2)
La segmentación de información homogénea se realiza con diferentes operaciones morfológicas, a
partir de la detección de bordes, ver Figura 3-3. Primero, se calcula la transformada distancia (DT),
que de acuerdo con Borgefors et al. [86], es una operación que convierte una imagen binaria en una
imagen en escala de grises, donde todos los píxeles tienen un valor correspondiente a la distancia de
su píxel más cercano. Para el caso de una imagen con bordes de frutos de café en rama, los puntos

Aplicativo móvil 51
más brillantes corresponden al centro de zonas homogéneas, ya sean frutos, tallos, hojas o fondo. A
partir de esta imagen DT, y un proceso de reconstrucción morfológica por dilatación [87], se
encuentran los máximos locales, los cuales se convertirán en las semillas para aplicar una
trasformación watershed a la imagen original. La reconstrucción morfológica por dilatación [88], de
una imagen máscara f desde una imagen marcador g, ambas con el mismo dominio y g ≤ f, se define
como la dilatación geodésica de g, respecto a f, hasta la idempotencia y se denota como 𝐻𝐻𝑓𝑓(𝑔𝑔)
(Ecuación (3.3)). En la Ecuación (3.3) 𝛿𝛿𝑓𝑓(𝑙𝑙)(𝑔𝑔) corresponde a la dilatación geodésica de tamaño n,
de la imagen marcador g, en la imagen máscara f. El valor n es tal que 𝛿𝛿𝑓𝑓(𝑙𝑙)(𝑔𝑔) = 𝛿𝛿𝑓𝑓
(𝑙𝑙+1)(𝑔𝑔), es
decir, la operación no varía.
𝐻𝐻𝑓𝑓𝛿𝛿(𝑔𝑔) = 𝛿𝛿𝑓𝑓(𝑙𝑙)(𝑔𝑔). (3.3)
Cuando se cumple la condición de idempotencia se detiene el proceso de reconstrucción
morfológica, el resultado de este paso se puede observar en la Figura 3-3 “Dilated local máxima”.
Posteriormente se umbralizan los valores obtenidos, y el resultado de dicha umbralización sirve para
crear las semillas utilizadas en la transformada watershed, último paso de esta sección del algoritmo.
De esta manera se realiza una segmentación automática de regiones homogéneas en la imagen en
escala de grises, y sirve como se muestra más adelante, como una primera segmentación para
identificar frutos de café.
Figura 3-3: Segmentación de regiones homogéneas.

52 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
3.1.3 Detector de contornos candidatos a frutos de café. Una vez segmentadas las regiones homogéneas, el siguiente paso consiste en analizar los contornos
resultantes y evaluar cuales pertenecen a un fruto de café, como se ilustra en la Figura 3-4.
Inicialmente se determina la dinámica de los puntos que conforman un contorno de un fruto de café
completo y sin oclusiones. En la Figura 3-4a se muestra una aproximación polinomial de un
contorno de un fruto de café, allí los segmentos de línea 𝑆𝑆𝑖𝑖 unen cada uno de los puntos resultantes
de la aproximación polinomial. Al mismo tiempo dichos segmentos forman entre si ángulos 𝛼𝛼𝑖𝑖,𝑖𝑖−1,
estos ángulos pueden estar entre 14° y 45°. El número de puntos que forman el contorno completo
de un fruto puede estar entre 14 y 16, y los segmentos de línea pueden ser mayores a 7.5 píxeles o,
en términos de tamaño estándar de la imagen, mayor a DRimg/130 (px). El valor 130 se define por
caracterización de los segmentos de línea que conforman frutos completos, en las imágenes
adquiridas.
(a) Aproximación polinomial de un contorno de un fruto de café solo y sin oclusiones.
(b) Contorno original. (c) Aproximación polinomial del contorno.

Aplicativo móvil 53
(d) Contorno filtrado por medio de las reglas
del Algoritmo-1. (e) Candidatos a arco por medio de las reglas
del Algoritmo-2.
Figura 3-4: Análisis contorno resultado de segmentación de regiones homogéneas.
Los contornos encontrados en la segmentación de regiones homogéneas (Figura 3-4b), son
secuencias de puntos y son representados mediante una aproximación polinomial con el menor
número de vértices, como se muestra en la Figura 3-4c. Para esto se utilizó el algoritmo de Douglas-
Peucker [89] con épsilon (ε) igual a 2. Los puntos pertenecientes a un mismo contorno son
analizados, se eliminan los puntos que generan cambios bruscos (Figura 3-4d) y por cada arco
encontrado se crea un nuevo vector de secuencia de puntos (Figura 3-4e).
Cada aproximación polinomial de un contorno (Figura 3-4c), está conformada por segmentos de
línea, generados por la unión de puntos en sentido antihorario. Un mismo contorno puede contener
diferentes candidatos a arco, llamados vectores de secuencias de candidatos a arco circulares (CAC).
En el Algoritmo 3-1, se muestran las reglas para determinar si puntos contiguos: pertenecen a un
mismo arco, deben ser eliminados de la secuencia, o hacen parte de un arco diferente. Un ejemplo
que ilustra el Algoritmo 3-1, se muestra en la Figura 3-5, donde tres puntos contiguos Aj, Bj y Cj,
que pertenecen al contorno, forman dos segmentos de línea LineAB y LineBC. Un tercer segmento es
creado LineCA como indicador de la intensidad de apertura del ángulo 𝜃𝜃𝑗𝑗. Los valores de entrada del
Algoritmo 3-1 son la secuencia de puntos de cada contorno (C(i)), la secuencia de candidatos a arco
circulares (CAC), los vértices A, B, C, la longitud de los segmentos de línea AB, BC y CA y las
pendientes de dichas líneas. El Algoritmo calcula 𝐼𝐼𝐴𝐴𝑓𝑓𝑓𝑓𝑖𝑖𝐽𝐽 y 𝛼𝛼𝑗𝑗, que corresponden al ángulo diferencia
entre segmentos y el ángulo generado por las pendientes (𝐴𝐴𝐵𝐵𝐵𝐵 y 𝐴𝐴𝐴𝐴𝐵𝐵), respectivamente. Según el
Algoritmo 3-1, son aceptados como candidatos a arco solo aquellos puntos contiguos cuyos
segmentos de línea sean superiores a DRimage/130 (px) (paso 8 Algoritmo 3-1). Si la diferencia entre
ángulos es negativa pero su valor absoluto es mayor de 45°, significa que ha cambiado la tendencia
del contorno y ha aparecido un nuevo arco, en cuyo caso se crea una nueva secuencia (paso 11 del

54 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Algoritmo 3-1). Por el contrario, si la diferencia es positiva y el ángulo entre segmentos es menor a
0° o mayor a 45°, este segmento de línea corresponde a un arco y el punto permanece en la secuencia
(paso 8 del Algoritmo 3-1). Los puntos que cumplan con las reglas mencionadas tienen una alta
probabilidad de ser frutos de café en la imagen, debido a la caracterización inicial realizada sobre
los frutos independientes. Para el ejemplo observado en la Figura 3-4c, los segmentos 𝑆𝑆17, 𝑆𝑆18, 𝑆𝑆20,
𝑆𝑆21, 𝑆𝑆29, 𝑆𝑆30, 𝑆𝑆32, 𝑆𝑆33, 𝑆𝑆34, 𝑆𝑆35, y 𝑆𝑆44, son eliminados de la aproximación polinomial por no cumplir
con las condiciones mostradas en el Algoritmo 1, y como resultado se obtiene el contorno de la
Figura 3-4d. En la Figura 3-4e, se muestran en colores diferentes cuatro secuencias de candidatos
a arco encontradas en el contorno original de la Figura 3-4b.
Figura 3-5: Relación entre tres puntos consecutivos. Líneas y ángulos. Algoritmo 3-1.
Algoritmo 3-1: Reglas para determinar si los puntos son candidatos a arco.
Input: C(i)= secuencia del contorno; CAC = secuencia de candidatos a arco circulares; vértices A, B, C; 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐴𝐴𝐵𝐵, 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐵𝐵𝐵𝐵 ,𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐵𝐵𝐴𝐴, longitud de segmentos de línea; 𝐴𝐴𝐵𝐵𝐵𝐵 ,𝐴𝐴𝐴𝐴𝐵𝐵, pendientes de 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐴𝐴𝐵𝐵, 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐵𝐵𝐵𝐵. Output: CAC(n)[k], n = número de vértices del CAC que pertenecen al k-ésimo arco, k = número de arcos en el contorno. 1: 𝛼𝛼𝑗𝑗 = 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠 � 𝑖𝑖𝐵𝐵𝐵𝐵−𝑖𝑖𝐴𝐴𝐵𝐵
1+(𝑖𝑖𝐵𝐵𝐵𝐵∙𝑖𝑖𝐴𝐴𝐵𝐵)�. 2: 𝐼𝐼𝐴𝐴𝑓𝑓𝑓𝑓𝑖𝑖𝐽𝐽 = 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠(𝐴𝐴𝐵𝐵𝐵𝐵)− 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠(𝐴𝐴𝐴𝐴𝐵𝐵). 3: A=C(0); B=C(1); C=C(2). 4: k=0; n=0. 5: For Each_Contour do 6: 𝛼𝛼𝑗𝑗 = 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠 � 𝑖𝑖𝐵𝐵𝐵𝐵−𝑖𝑖𝐴𝐴𝐵𝐵
1+(𝑖𝑖𝐵𝐵𝐵𝐵∙𝑖𝑖𝐴𝐴𝐵𝐵)�. 7: 𝐼𝐼𝐴𝐴𝑓𝑓𝑓𝑓𝑖𝑖𝐽𝐽 = 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠(𝐴𝐴𝐵𝐵𝐵𝐵) − 𝑎𝑎𝐴𝐴𝑎𝑎𝑠𝑠(𝐴𝐴𝐴𝐴𝐵𝐵).
8: If �𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐴𝐴𝐵𝐵; 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐵𝐵𝐵𝐵; 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐵𝐵𝐴𝐴 > 𝐷𝐷𝐷𝐷𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖
130� || �45° < 𝛼𝛼𝑗𝑗 < 0°�then
9: CAC(n:2)[k]=A,B. k=k; n=n+1; 10: El punto es un candidato a arco dentro del CAC actual. 11: ElseIf �𝐼𝐼𝐴𝐴𝑓𝑓𝑓𝑓𝑖𝑖𝐽𝐽 < 0� ∧ ���𝛼𝛼𝑗𝑗�� > 45� then 12: k=k+1; n=0; 13: El punto pertenece a un nuevo CAC.

Aplicativo móvil 55
14: End If 15: A=B; B=C; C= siguiente punto en el contorno. 16: End For
3.1.4 Ajuste y selector de elipses correspondientes a frutos de café. Gran parte de la información analizada mostró vectores de secuencias de candidatos a arco circulares
(CAC) con solo 5 puntos, generalmente se trataba de frutos ocluidos, esto debido a la naturaleza
aglomerada de los frutos de café en las ramas. Con la información parcial de cada arco, se ajustó una
elipse, utilizando el algoritmo de Fitzgibbon [90]. Este algoritmo requiere al menos 6 puntos para
realizar el ajuste, pero en caso de tener al menos 7, las elipses ajustadas son similares a la elipse de
un fruto de café. Por lo anterior fue necesario estimar puntos adicionales para los CAC que contarán
solo con 5 o 6 puntos. Si el CAC tenía 5 puntos se estimaron dos puntos, uno al inicio de la secuencia
y otro al final. Si el CAC tenía 6 puntos, solo se estimaba un punto adicional, al inicio de la secuencia,
con esto se logra que la elipse resultante sea un poco más cerrada y evita que se hagan ajustes a
elipses más grandes, que no corresponde a frutos.
La longitud del segmento de línea en los segmentos a crear con los puntos estimados, corresponde a
la longitud promedio de los segmentos que hacen parte de CAC, al igual que el ángulo entre
segmentos (Ecuación (3.4) y (3.5)). Por ejemplo, para la Figura 3-6, los puntos a estimar son los p0
y p6. Tanto l10 como l65 tiene la misma longitud (𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝑠𝑠𝑠𝑠𝑡𝑡𝑖𝑖𝑖𝑖𝑙𝑙𝑡𝑡𝑠𝑠𝑒𝑒 y corresponde a la longitud promedio
de los segmentos de línea (Ecuación (3.4)). Los ángulos 𝛼𝛼10 y 𝛼𝛼54 son iguales y corresponde al
𝛼𝛼𝑠𝑠𝑠𝑠𝑡𝑡𝑖𝑖𝑖𝑖𝑙𝑙𝑡𝑡𝑠𝑠𝑒𝑒 de la Ecuación (3.5).
𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝑠𝑠𝑠𝑠𝑡𝑡𝑖𝑖𝑖𝑖𝑙𝑙𝑡𝑡𝑠𝑠𝑒𝑒 = 𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝑙𝑙𝑎𝑎𝑠𝑠𝑎𝑎𝑙𝑙𝑔𝑔𝑠𝑠(𝐿𝐿1𝐿𝐿2���������⃗ ,𝐿𝐿2𝐿𝐿3���������⃗ ,𝐿𝐿3𝐿𝐿4���������⃗ ,𝐿𝐿4𝐿𝐿5���������⃗ ).
(3.4)
𝛼𝛼𝑠𝑠𝑠𝑠𝑡𝑡𝑖𝑖𝑖𝑖𝑙𝑙𝑡𝑡𝑠𝑠𝑒𝑒 = 𝛼𝛼𝑙𝑙𝑎𝑎𝑠𝑠𝑎𝑎𝑙𝑙𝑔𝑔𝑠𝑠(𝛼𝛼21,𝛼𝛼32,𝛼𝛼43).
(3.5)
Figura 3-6: Estimación de puntos para posterior ajuste de elipse.

56 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Las elipses resultantes fueron evaluadas bajo criterios de tamaño, ubicación y forma, para determinar
si pertenecen a frutos de café. Además de contar con la información de DRimage, fue necesario calcular
la longitud acumulada de las líneas de segmentos (LineAB) conforme al final del vector CAC
(Ecuación (3.6)) y el índice de forma de la elipse ajustada (Ecuación (3.7)).
𝐿𝐿𝑆𝑆𝑠𝑠𝑔𝑔𝑔𝑔𝐴𝐴𝐴𝐴𝐵𝐵𝐴𝐴𝐵𝐵 = �𝐿𝐿𝐴𝐴𝑠𝑠𝑆𝑆𝐴𝐴𝐵𝐵
𝑘𝑘
𝑗𝑗
.
(3.6)
𝐴𝐴𝐼𝐼𝐼𝐼𝑠𝑠ℎ𝑙𝑙𝑙𝑙𝑠𝑠 = 𝐴𝐴𝑚𝑚𝑖𝑖𝑠𝑠𝑖𝑖𝑖𝑖𝑚𝑚𝑚𝑚𝑚𝑚
𝐴𝐴𝑚𝑚𝑖𝑖𝑠𝑠𝑖𝑖𝑖𝑖𝑚𝑚𝑚𝑚𝑚𝑚.
(3.7)
Previamente se realizó un caracterización en las imágenes adquiridas y se definieron las reglas
dispuestas en la Figura 3-7, con las cuales se define si una elipse es aceptada como fruto: i) cada
elipse genera una región de interés (ROI) y esta ROI debe cumplir con un tamaño en función del
valor DRimg, tanto el ancho como el alto de la ROI generada por la elipse pueden estar entre el 10%
y 2% de esta diagonal DRimg. ii) El índice de forma, que relaciona el eje mayor con el eje menor debe
ser superior a 0.5. iii) El centroide de la elipse debe estar ubicado entre el 24% de HRimage, y el 78%
de HRimg. iv) La Longcum puede estar entre el 29% y 9% de la DRimg.
3.1.5 Detección, clasificación y conteo de elipses/frutos. Si la elipse cumple con los criterios mostrados en la Figura 3-7, se utiliza como máscara sobre la
región homogénea generada en el subcapítulo 3.1.2, Figura 3-8a. Sobre la información enmascarada
se calcula un vector de 42 características de color, correspondientes a la media y la desviación
estándar de cada componente de color de los espacios RGB, HSV, YCrCb, XYZ, CIELab, LUX y
LUV. Por medio de un análisis discriminante lineal de Fisher, se redujo la dimensión de este vector
característico a 12 características, y posteriormente se implementaron tres clasificadores: i) un
clasificador Bayesiano; ii) un clasificador K-vecinos más cercanos (KNN, k = 11); y iii) un
clasificador de máquina de vectores de soporte (SVM – Kernel Gaussiano). Los estados de
maduración clasificados, o clases correspondieron a: i) frutos inmaduros; ii) frutos semimaduros-1;
iii) frutos semimaduros-2; iv) frutos maduros y sobremaduros. En la Tabla 3-1, se presentan las
clases mencionadas.

Aplicativo móvil 57
Figura 3-7: Reglas para determinar si una elipse detectada corresponde a un fruto.
(a) Máscara sobre imagen original y elipses
ajustadas (b) Máscara sobre imagen clasificada y elipses
ajustadas
(c) Conteo de elipses ajustadas. (d) Sub imágenes generadas con técnica de enmascaramiento por fruto.
Figura 3-8: Estimación de puntos para posterior ajuste de elipse.

58 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Tabla 3-1: Estructuras vegetativas pertenecientes a frutos en una rama de café.
Clase Apariencia Clase Apariencia Frutos inmaduros (no-
cosechables)
Frutos semimaduros2 (cosechables)
Frutos semimaduros1 (cosechables)
Frutos maduros y sobremaduros (cosechables)
Con el fin de seleccionar uno de los tres clasificadores, se usaron 300 frutos de café, 75 frutos por
clase, y posteriormente los clasificadores fueron evaluados. Para dicha evaluación se utilizó los
criterios de la matriz de confusión, tasa de verdaderos positivos (TPR, Ecuación (3.8), donde TP
corresponde a verdaderos positivos y FN a falsos negativos) y tasa de aciertos general (OSR overall
success rate, Ecuación (3.9)). El valor OSR, correspondió a la sumatoria de las instancias
correctamente clasificadas en relación con el número total de instancias clasificadas. La tasa de
verdaderos positivos fue la relación entre los verdaderos positivos y la sumatoria de los falsos
negativos y los verdaderos positivos.
𝑇𝑇𝐻𝐻𝑃𝑃 = 𝑇𝑇𝑇𝑇𝑇𝑇𝑇𝑇+𝐹𝐹𝑁𝑁
.
(3.8)
𝑂𝑂𝑆𝑆𝐻𝐻 = 𝑇𝑇𝑇𝑇4𝑐𝑐𝑐𝑐𝑖𝑖𝑐𝑐𝑖𝑖𝑐𝑐𝐹𝐹𝑁𝑁𝑡𝑡𝑚𝑚𝑡𝑡𝑖𝑖𝑐𝑐+𝑇𝑇𝑇𝑇𝑡𝑡𝑚𝑚𝑡𝑡𝑖𝑖𝑐𝑐
.
(3.9)
La tasa de aciertos general (OSR) fue de 88,02% para el SVM, para el KNN fue de 83,09% y para
el Bayesiano fue de 83,57% (Tabla 3-2). El clasificador seleccionado fue el clasificador SVM por
generar los mejores resultados a nivel general y particular por clases. El clasificador implementado
asigna el valor de clase al píxel central de una matriz de 5x5.

Aplicativo móvil 59
Tabla 3-2: Tasa de verdaderos positivos para cada uno de los clasificadores en cada clase.
Clase Bayes KNN SVM
TPR TPR TPR
Inmaduros 86,49% 89,48% 86,49%
Semimaduros-1 100,00% 100,00% 100,00%
Semimaduros-2 89,65% 79,52% 88,9%
Maduros 72,41% 79,1% 82,76%
OSR 83,57% 83,09% 88,02%
El clasificador analiza la zona segmentada como región homogénea y las elipses encontradas se
ajustan a esta zona segmentada (Figura 3-8b). De esta manera, se crean subimágenes de frutos
clasificados (Figura 3-8d), y a cada una de estas subimágenes se les asigna el valor de la clase que
más se repita dentro de los píxeles de la subimagen. El MVS realiza un conteo de frutos por clase, y
un conteo de frutos total (Figura 3-8c), por imagen y por rama. Adicionalmente, cuando una elipse
es detectada, no solo se incrementan los contadores, sino que también, se marca un área alrededor
de su centroide para evitar que elipses repetidas incrementen el conteo (Figura 3-8c). El tiempo de
proceso para analizar cada rama fue en promedio de 1 minuto, en este tiempo el sistema entrega
directamente el número de frutos y su estado de desarrollo por rama.
3.2 Evaluación del conteo automático. Luego de diseñar e implementar el MVS propuesto, se evaluó su desempeño. Primero se determinó
la proporción de frutos visibles en las imágenes adquiridas, por medio de la comparación entre el
conteo manual de frutos realizado a las imágenes y el número total de frutos presentes en la rama.
Con esta relación, se determinó el porcentaje de visibilidad de los frutos en una sola vista de la rama.
Adicionalmente, fue comparado el conteo manual sobre las imágenes y el conteo automático
realizado por el MVS propuesto, para cada estado de desarrollo (1) Maduros y sobremaduros, 2)
semimaduros, 3) inmaduros, y 4) todos los estados), con la información presente en 72 ramas de
café. El criterio de aceptación del funcionamiento del MVS fue: i) coeficientes de regresión lineal
diferentes de cero, de acuerdo con el estadístico de prueba t al 1%; y ii) coeficientes de determinación
mayores 0,70. También se calculó el promedio de las diferencias relativas y absolutas entre el

60 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
número de frutos detectados por el MVS y los frutos observados en las imágenes procesadas, y su
intervalo.
3.2.1 Porcentaje de visibilidad de frutos en imágenes. En la Tabla 3-3 se presenta el promedio del porcentaje de visibilidad, con su respectivo intervalo,
para todos los estados de desarrollo. De acuerdo con el estadístico de prueba t al 5%, los frutos
maduros y sobremaduros presentan el mayor porcentaje de visibilidad con relación a los frutos
inmaduros, y los frutos semimaduros tienen el mismo porcentaje de visibilidad de los inmaduros.
Esta observación es muy importante para determinar si la eficacia de detección del MVS propuesto
depende del sistema propiamente o si depende de aspectos externos a él, cómo se mostrará más
adelante. Considerando que el conteo de los frutos detectados sin ajustes es del 46%, 30% menos
que la visibilidad generada en el conteo manual de los frutos en las imágenes. El ajuste estadístico
que se realiza al modelo de conteo, mejora esta diferencia.
Tabla 3-3: Porcentaje de visibilidad para frutos contados en imágenes a ramas de café.
Límites superior e inferior y promedio de la variable
“Visibilidad”
Cosechables No-cosechables
Todos los estados
Maduro sobre maduro Semi-maduro Inmaduro
Promedio 85,18% 76,81% 79,15% 80,99%
Superior 87,83% 85,36% 81,39% 82,64%
Inferior 82,54% 68,25% 76,91% 79,33%
3.2.2 Sistema de conteo de frutos en imágenes. El número de frutos contados manualmente sobre las imágenes, fue comparado con el número de
frutos detectados por el MVS, para cada estado de desarrollo y para todos los estados. Para medir el
correcto funcionamiento del algoritmo de conteo se compararon, mediante regresión lineal, los
valores medidos con los observados en las imágenes. Es de esperar, que, para cero frutos presentes
en la rama, el sistema no detecte frutos, y que exista una alta correlación entre los valores medidos

Aplicativo móvil 61
y los observados. Por lo anterior se define como criterio de aceptación del algoritmo, que los
interceptos de las regresiones lineales puedan ser igualados a cero estadísticamente y que los
coeficientes de determinación sean superiores a 0,70.
La Tabla 3-4 muestra los coeficientes de regresión, determinación e intercepto de las regresiones
para los estados: 1) Maduros y sobremaduros, 2) semimaduros, 3) inmaduros y 4) todos los estados.
En la sección de Intercepto Diferente de Cero (IDC) de la Tabla 3-4, se observa que el conteo de
frutos semimaduros no cumple con estos criterios mencionados, ya que el R2 es de 0,356. Para los
otros estados el algoritmo funciona adecuadamente, según estos criterios. Este comportamiento se
debe a la dinámica del estado de desarrollo “semimaduro”, ya que el promedio de frutos visibles en
las imágenes no supera 5 frutos por rama y el porcentaje de visibilidad debido a la oclusión, es el
menor encontrado, con un valor de 76,81%. Debido a este resultado los frutos semimaduros se unen
a los frutos maduros y sobremaduros, conformando un grupo llamado “Frutos cosechables” y se
observa en la sección IDC de la Tabla 3-4, que esta relación si cumple con los criterios mencionados.
Tabla 3-4: Coeficientes de regresión, intercepto y de determinación para cada uno de estados de desarrollo identificados por el MVS.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de Regresión R2
Coeficiente de Regresión R2
Estado Estimación EE Estimación EE Estimación EE
Maduro - Sobremaduro 0,702 1,370 1,310* 0,071 0,827 1,343* 0,030 0,965
Semimaduro** 2831* 0,501 0,502* 0,080 0,356 -- -- --
Cosechable 3,142 1,936 1,166* 0,80 0,745 1,286* 0,033 0,953
Inmaduro 2,629 2,735 1,674* 0,114 0,749 1,775* 0,046 0,953
Todos los estado -3,187 4,084 1,625* 0,088 0,825 1,560* 0,028 0,976
* diferente de cero según prueba t al 1%; ** no cumple con los criterios.
En las relaciones encontradas que cumplen con los criterios, el 𝛽𝛽0 fue igualado a cero y fueron
nuevamente estimados los coeficientes 𝛽𝛽1 y los coeficientes de determinación. En la sección de
Intercepto Igualado a Cero (IIC) de la Tabla 3-4 se presenta el valor de estos coeficientes. En
general, el conteo generado automáticamente explica el conteo manual de frutos visibles en las
imágenes y que, en ausencia de frutos, el sistema no detecta frutos.

62 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Se observó que el promedio de las diferencias entre la variable observada y la medida, estuvo entre
5.53 frutos y 19.87 frutos, con un error porcentual entre el 18% y el 40%. Analizando las imágenes
que generaron este error, se identificaron 4 problemas sobre las imágenes procesadas: i) un contraste
no adecuado entre la rama y el fondo, ya sea por desenfoque (Figura 3-9a), exceso o deficiencia de
luz sobre la rama (Figura 3-9b); ii) frutos pequeños en ramas y distancia entre racimos amplia
(Figura 3-9c); iii) rama ubicada fuera de la zona central de la imagen (Figura 3-9d); y pocos frutos
en las imágenes. Zonas curvas de ramas y hojas pueden ser confundidas con candidatos a arcos de
frutos. En general, en las imágenes que no presentan estos tipos de problemas, se obtiene un error
menor al 6%.
Los resultados mostrados en la Figura 3-9 indican que el sistema puede ser afectado por algunas
condiciones de campo. Debe tenerse especial cuidado durante la adquisición de las imágenes, evitar
los rayos directos del sol sobre las ramas de café y las sombras que genera el follaje del árbol. Para
el caso de días nublados y con condiciones de baja luminosidad, el sistema funciona adecuadamente,
sin embargo, se debe verificar la nitidez de las imágenes adquiridas. Para días lluviosos, debe
considerarse que la aplicación cámara del dispositivo móvil puede tener algunos inconvenientes,
debido a que la interfaz de esta se realiza por medio de la pantalla. Si llegase a caer una gota de lluvia
sobre la pantalla, estando en la aplicación cámara abierta puede modificarse el zoom, o el balance
de blancos o tomar una imagen sin haberlo deseado. El método puede ser aplicado para imágenes
adquiridas durante el día, teniendo en cuenta los factores antes mencionados
(a) Imágenes desenfocadas por movimiento de la cámara y por distancia entre lente y objeto.

Aplicativo móvil 63
(b) Imágenes sobreiluminadas y con autosombreamiento del árbol.
(c) Imágenes con frutos pequeños y distancias entre racimos amplias. Pocos frutos por imagen.
(d) Imágenes con rama fuera del centro.
Figura 3-9: Tipos de imágenes que generan errores en la detección y conteo de frutos.
Una de las principales ventajas del sistema desarrollado, fue la detección de frutos ocluidos. En la
Figura 3-10 se presentan ejemplos de detección de estos frutos. En la Figura 3-10a, se muestra la
sección original analizada y la elipse ajustada sobre dicha sección. En la Figura 3-10b se presenta
el resultado de sobreponer la elipse ajustada en la zona segmentada como región homogénea y en la
Figura 3-10c se ilustra la sección enmascarada, como resultado de unir la elipse con la zona
homogénea sobre la información clasificada. Se observa como la elipse logra estimar la sección
oculta del fruto, pero solo usa la información visible para determinar a qué clase pertenece.
La técnica de enmascaramiento desarrollada, utiliza tanto la región homogénea resultante del
subcapítulo 3.1.2 y las elipses ajustadas del subcapítulo 3.1.4, esta es una ventaja frente a otros tipos
de segmentaciones watershed que solo utilizan semillas de crecimiento dispuestas puntualmente. En

64 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
este caso las marcas simples de pocos píxeles, no son suficientes para generar una segmentación de
frutos individuales. Para esto, se requiere una marca de mayor área, pues las imágenes utilizadas
presentan gran variabilidad en la intensidad de color y escala de grises sobre un mismo fruto.
(a) Sección original y elipse
ajustada (b) Tecnica de enmascaramiento (c) Elipse ajustada y clasificada
Figura 3-10: Frutos ocluidos detectados por las elipses ajustadas.
3.3 Conclusiones En este trabajo el problema de oclusión de frutos de café fue superado mediante una técnica de
enmascaramiento, la cual garantizó que regiones que muestren arcos o secciones de arco sean
segmentadas por medio de la elipse de mejor ajuste. Esta es una de las ventajas mostradas por el
MVS, ya que los frutos de café en gran proporción se encuentran ocluidos, por la naturaleza de
racimos en rama.
Fue posible estimar el número total de frutos en una rama de manera no destructiva, usando imágenes
y algoritmos de procesamiento. Los frutos son contados, independiente de su estado de desarrollo,
contraste entre la rama, el fondo, y diferentes condiciones de iluminación.
Los problemas mostrados en las imágenes adquiridas generan errores de conteo superiores al 6% y
pueden ser disminuidos por medio de una adecuada adquisición de imágenes. Los frutos deben estar
centrados en las imágenes, enfocados apropiadamente, evitando rayos solares directos o a través del
follaje y evitar el movimiento de la cámara.
El sistema propuesto no requiere cámaras de alta resolución, ni sofisticados sistemas de iluminación,
ni vehículos que se muevan por la plantación. El sistema es llevado por una persona, que fácilmente
puede entrar en un cultivo denso, y con el sistema sujetador y el dispositivo móvil puede adquirir

Aplicativo móvil 65
imágenes en cualquier estrato del árbol, a diferentes alturas y bajo diferentes condiciones de
iluminación, sin el uso de fuentes externas de iluminación.
Este desarrollo se ubica dentro del estado del arte, como un modelo de medición directa, que es capaz
de contar el número total de frutos en una rama a partir del conteo automático de frutos en una sola
vista de la rama. Comparado con modelos similares que realizan conteo de frutos en imágenes [26 y
28], el propuesto presenta un mayor coeficiente de determinación, superior al 0,953 con respecto a
0,60 y una diferencia absoluta promedio de 14 frutos por rama.
El trabajo futuro está en mejorar el algoritmo de detección de frutos con el fin de disminuir el valor
de las diferencias absolutas. Encontrar la manera de disminuir el riesgo de los problemas generados
por la curvatura de la rama, desenfoques en los extremos de las imágenes, y desenfoque por
movimiento. A su vez se espera aplicar este método para estimar la producción a nivel de árbol y
parcela, y generar una herramienta para que el caficultor pueda estimar la producción de su finca en
cualquier momento del año.

66
4. Obtención del modelo geométrico de los frutos en la rama.
Se obtuvo el modelo geométrico de cada uno de los frutos presentes en una rama de café, a través de
un análisis 3D a la secuencia de imágenes de un video, realizado a la rama con el dispositivo móvil
descrito en el Capítulo 2. Se utilizaron las técnicas de Estructura desde Movimiento (Structure From
Motion (SfM)) y Multi visión estéreo basada en parches (Patch-based Multi-view Stereo (PMVS))
para generar las nubes de puntos densa y reducida. Posteriormente se realizó un filtrado de outliers,
remoción de fondo y submuestreo por cada rama. Se extrajeron características 2D y 3D de las nubes
de puntos, basadas en los espacios de color RGB, Lab, Luv, YCbCr y HSV curvaturas, índices de
forma y curvosidad. Se implementó un clasificador de estructuras vegetativas, frutos, tallo, flor y
hoja. Se entrenó una Máquina de vectores de soporte (Support Vector Machines, SVM) y se obtuvo
una precisión del 0,82 y una especificidad (recall) de 0,79. Posteriormente, cada nube de puntos
clasificada como frutos fue segmentada por medio del método RANSAC (Random sample
consensus), y el modelo de esfera con valores de umbral de distancia, radio mínimo y radio máximo
calculado de manera adaptativa para cada nube de puntos. Como resultado se obtuvo una
segmentación uno a uno de los frutos presentes en la rama. Cada fruto tiene una nube de puntos
propia, sobre la cual se estiman tres factores de escala y dos factores de forma, por medio del
concepto de supercuádricas. Con este último análisis es posible determinar qué tan esférico es el
fruto segmentado, encontrar su centroide y ubicarlo en una nueva nube de puntos, para un último
análisis estadístico que determine si su ubicación pertenece a un fruto de café o es un posible error.
Las nubes de puntos esféricas y correctamente ubicadas corresponden a frutos, sobre estos se calcula
el volumen y se determina la masa de cada nube de puntos por medio de la densidad volumétrica de
cada estado de desarrollo, previamente clasificado.
El sistema propuesto está compuesto por 8 fases: reconstrucción 3D, filtrado, sub-muestreo,
extracción de características y clasificación de frutos, segmentación ransac para encontrar esferas
(frutos) independientes, extracción del modelo geométrico de cada esfera segmentada, análisis del

Modelo geométrico 67
modelo geométrico, y por último detección, conteo y estimación del volumen de cada esfera
detectada como fruto de café. Dicho sistema se ilustra en la Figura 4-1. En total se adquirieron 12
vídeos de ramas de café, los cuadros que entregaron mejor información por cada rama fueron
seleccionados, aproximadamente 90. El sistema detecta en total el 56% de los frutos en las ramas y
estima el volumen de cada una de las superelipsoides, sin embargo, este volumen no puede ser
llevado a masa, pues no existe un factor de escalamiento que logre estandarizar todas las nubes de
puntos.
El conteo automático de frutos, muestra un potencial para estimar el número de frutos reales en la
rama, a partir del conteo realizado con la información 3D. Ya que aspectos como la oclusión parcial
de los frutos, presencia de ramas en el fondo de la rama analizada, cambios extremos de iluminación
sobre la rama y los cambios en la distancia entre cámara y rama, nos son impedimento para contar
correctamente los frutos en las ramas.
A diferencia de otros trabajos, la detección de frutos de café es compleja, pues esta estructura
vegetativa, junto con el tallo, hojas y flores, tiene un radio que puede oscilar entre 1 cm y 3 cm. En
este capítulo se muestra la implementación de un sistema de clasificación de 6 estructuras
vegetativas: tallo, hojas, flores y frutos en tres diferentes estados de maduración: verde, pintón y
maduro. Se propone el uso de características 3D para mitigar el efecto negativo que tienen los
cambios de iluminación, mostrados en el subcapítulo 2.2. El sistema propuesto logra tener
independencia de las condiciones de luminosidad y oclusión, permitiendo obtener eficacias de
clasificación cercanas al 82 %.
4.1 Reconstrucción 3D.
El primer paso en el proceso de reconstrucción 3D consiste en encontrar los parámetros intrínsecos
de la cámara utilizada. Para esto, se usó el algoritmo de calibración de cámara desarrollado en [91],
donde se requieren al menos dos imágenes con patrón planar, con diferentes orientaciones. Para esta
ocasión se utilizó un patrón planar de un cuadro de ajedrez con un ancho y alto de 1,7cm por cada
cuadro. La Tabla 4-1 ilustra los parámetros intrínsecos encontrados después de la fase de
calibración.

68 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 4-1: Sistema de visión de máquina 3D propuesto.
Tabla 4-1: Parámetros intrínsecos de la cámara.
Distancia focal Centro de la cámara Coeficientes de distorsión
fx fy Cx Cy k1 k2 k3 k4 k5 698,1 698,1 319,5 179,5 711,2 87,8 0 0 -3,58
La Figura 4-2, ilustra el proceso usado para la implementación de SfM. La cámara del dispositivo
móvil captura vídeos en alta resolución a lo largo de cada rama. La longitud por rama oscila entre
los 40 y 60 centímetros y la duración promedio de los vídeos es de 15 segundos. En cada vídeo se
selecciona uno de cada cinco cuadros. El número de imágenes utilizadas para la reconstrucción de
cada rama es de 90, en promedio. La reconstrucción 3D de cada rama se realizó implementando los
algoritmos de Bundler SfM y PMVS.

Modelo geométrico 69
Figura 4-2: Adquisición en secuencia de vídeos sobre una rama de café.
A continuación se explica brevemente dichos algoritmos, los cuales fueron propuestos por Snavely
y Furukawa y se encuentran descritos en detalle en [92-94]. Bundler SfM es un sistema de visión de
máquina que implementa SfM para la reconstrucción 3D de escenas provenientes de colecciones
desordenadas de imágenes, por ejemplo, fotos de Internet. En primer lugar Bundler SfM extrae
puntos característicos de un conjunto de imágenes, usando Scale-Invariant Feature Transform (SIFT)
[95], luego empareja estos puntos usando la técnica de Approximate Nearest Neighbor (ANN). Con
los parámetros intrínsecos de la cámara, obtenidos mediante un proceso de calibración, y los puntos
emparejados entre imágenes se encuentra el movimiento de la cámara, parámetros extrínsecos, por
medio de la matriz fundamental [96]. El algoritmo de Bundler SfM selecciona dos de las vistas con
mayor número de puntos característicos emparejados, los puntos en estas vistas son proyectados
mediante un proceso de triangulación formando la estructura base. Los puntos de las vistas restantes
son agregados a la estructura base. Finalmente, una reconstrucción 3D de la escena es obtenida
usando un ajuste de Bundler, el cual modifica los parámetros intrínsecos de la cámara, distancia focal
y distorsión, con el objetivo de minimizar el error en la re-proyección. Bundler SfM produce nubes
de puntos dispersas. Para obtener las nubes de puntos densas, se usa PMVS, el cual es un algoritmo
para estéreo, que toma un conjunto de imágenes y los parámetros extrínsecos de cámara para
reconstruir una estructura 3D de un objeto o una escena visible en las imágenes. Este algoritmo
reconstruye únicamente estructuras rígidas. PMVS genera un conjunto de puntos orientados en lugar
de un modelo poligonal, donde tanto las coordenadas 3D como la superficie normal se calculan por
cada punto orientado. En la Figura 4-3 se ilustran algunos resultados obtenidos en cada fase de la

70 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
reconstrucción 3D de una de las ramas utilizadas. En las Figuras 4-3a y 4-4b se ilustran los puntos
clave (keypoints) encontrados en dos cuadros consecutivos de la secuencia de imagen de un vídeo.
En la Figura 4-3c se muestra el emparejamiento de dichos puntos. Y en las Figuras 4-3d y 4-4e se
ilustran la nube de puntos dispersa generada con el algoritmo de Bundler SfM y la nube de puntos
densa generada con PMVS, respectivamente.
(a) Keypoints encontrados por SIFT en la
primera imagen. (b) Keypoints encontrados por SIFT en la
segunda imagen.
(c) Emparejamiento de los keypoints usando Aproximate Nearest Neighbor (ANN).
(d) Nube de puntos dispersa. (e) Nube de puntos densa.
Figura 4-3: Pasos para reconstrucción 3D de una rama de café.
4.2 Filtrado y submuestreo El objetivo de esta fase es eliminar datos que no pertenezcan a la rama, pero se encuentren en la nube
de puntos como valores atípicos y eliminar el fondo de la escena. El primer paso es, realizar un

Modelo geométrico 71
filtrado de outliers que elimina valores atípicos de la nube de puntos, luego mediante el uso de un
filtro pasa-banda se remueve el fondo. La implementación de ambos filtros se realizó utilizando la
librería Point Cloud Library (PCL) [97].
4.2.1 Filtrado estadístico de outliers Cuando se realiza la reconstrucción 3D usando SfM y PMVS se generan puntos atípicos, los cuales
son errores a la hora de triangular los puntos de las imágenes. Para eliminar estos datos se realiza un
análisis estadístico en el vecindario de cada punto, y se eliminan aquellos puntos cuya distancia sea
mayor a la desviación estándar de la distancia media en el vecindario. La Figura 4-4a muestra la
nube de puntos a filtrar, resultado del proceso de reconstrucción 3D de la sección anterior. En la
Figura 4-4b se puede observar el resultado de la fase de filtrado de outliers. La mayor cantidad de
los valores atípicos se presenta en el fondo de la escena. Cada nube de puntos densa tiene un
promedio de 300.000 puntos. El vecindario sobre el cual se procesó cada punto, con el objetivo de
determinar si corresponde a un outlier o no, corresponde al 0,1 % del tamaño total de la nube de
puntos.
4.2.2 Remoción de fondo Para remover el fondo de la escena se utilizó un filtro pasa-banda, donde se eliminan los puntos que
estén dentro o fuera de un rango específico, en la dimensión (dirección) deseada. El filtro
implementado trabajó sobre el eje z, debido a que el fondo se encontraba en esta dirección. Para
remover un punto p, se evalúa sí la componente en z del punto p, se encuentra dentro del rango Zmin
y Zmax definidos a prior. Es decir, sí Zmin < pz < Zmax. En la Figura 4-4c se ilustra el resultado de la
remoción de fondo, dejando únicamente las estructuras de la rama a analizar.
(a) Nube de puntos de entrada. (b) Fitrado de outliers.

72 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(c) Remoción de Fondo.
Figura 4-4: Pasos dentro de la fase de filtrado.
Al finalizar la etapa de filtrado se logró eliminar los valores atípicos de la reconstrucción y el fondo
de la escena. Adicionalmente, por cada nube de puntos se obtuvo una reducción del 50 % del tamaño
original lo cual optimizó el costo computacional en los procesos posteriores, debido a que se usan
menos datos, los cuales contienen la información más relevante de la escena.
4.2.3 Submuestreo Las nubes de puntos filtradas, fueron submuestreadas, con el objetivo de reducir el tiempo de
cómputo en los procesos de extracción de características 2D y 3D. El método implementado para
este objetivo fue el filtrado por voxelización. Se agrupan los puntos de la estructura en vóxeles, luego
se encuentran los centroides en cada vóxel, los cuales son la nueva información de la nube de puntos
submuestreada. El tamaño de los vóxeles (x, y, z) se selecciona de manera automática y depende del
volumen de la nube de puntos, 20% del volumen total de la nube de puntos. Al final del proceso se
genera una nueva nube de puntos en las cual se tiene un número menor de puntos, pero se mantienen
las características geométricas de las ramas. En la Figura 4-5, se puede observar la nube de puntos
de entrada Figura 4-5a y el resultado de submuestrear una rama de café (Figura 4-5b). La reducción
del número puntos en cada rama fue de aproximadamente el 50 % del tamaño original.
(a) Nube de puntos filtrada y sin fondo.
(b) Nube de puntos submuestreada.

Modelo geométrico 73
Figura 4-5: Resultado del proceso de submuestreo.
4.3 Extracción de características y clasificación Luego de obtener la nube de puntos sub-muestreada, se procedió a reconstruir una nube de puntos
anotada manualmente (Ground-truth), donde cada punto corresponde a una de las seis clases: tallo,
hoja, flor, fruto inmaduro, fruto semi-maduro y fruto maduro. Para generar la nube de puntos ground-
truth, por cada punto pi de la nube de puntos sub-muestreada Q, se identificaron las imágenes 2D de
las cuales provino el punto. Fue asignado el valor de la mediana para cada punto pi de la nube de
puntos sub-muestreada, esto con el fin de no generar nuevos datos de color y mantener valores
conocidos de color para aplicar la clasificación.
4.3.1 Verificación del tamaño de los frutos medidos en la nube de puntos Para verificar el tamaño de los frutos adquiridos en la nube de puntos, inicialmente se tomaron las
medidas a tres ejes en los frutos reales observados, por medio de un calibrador pie de rey de
resolución de 0,1mm. Las tres medidas corresponden al eje polar (ep/2), y los dos ejes ecuatoriales
(ee1/2 y ee2/2) como se muestra en la Figura 4-6.
Figura 4-6: Ejes ecuatoriales y eje polar de un fruto de café en los tres ejes coordenados.
Se realizó un proceso de calibración entre la medida real observada en tres frutos de cada uno de las
10 ramas utilizadas, y las medidas obtenidas en esos mismos frutos en las 10 nubes de puntos
correspondientes. La medida real se encuentra en milímetros, mientras que la medida obtenida sobre
la nube de puntos es un valor con unidades de distancia que debe ser configurado para el caso
específico de estructuras en ramas de café. En total se obtuvieron 50 medidas sobre las nubes de
puntos, de las 90 medidas realizadas realmente sobre los frutos. Esto debido a que no todos los frutos
lograban ser medidos desde la nube de puntos en sus tres ejes, ya fuera por la perspectiva y

74 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
orientación de cada fruto o por la presencia de algunos outliers que no permitían realizar la medida
de un punto a otro.
Se realizó un diagrama de dispersión xy, para visualizar la dinámica de la relación entre lo medido
en la nube de puntos y lo real medido, Figura 4-7. En dicha gráfica se observa como los datos tiene
un R2 de 0,12, lo que muestra que no hay relación entre lo medido realmente y lo medido en la nube
de puntos. Sin embargo, fueron identificados dos conjuntos de ramas: (i) aquellas que no tuvieron
problemas de adquisición de las imágenes; y (ii) aquellas donde se presentaron problemas de
desenfoque o cambio de la distancia entre los frutos y la cámara. En la Figura 4-8 y la Figura 4-9
se observa el comportamiento entre lo real y lo medido para cada tipo de ramas. Efectivamente, para
aquellas imágenes que presentan problemas en la adquisición (Figura 4-9), el R2 es cercano a 0,17,
y para las demás el R2 es superior a 0,65, lo que muestra el efecto de la adquisición sobre la calidad
de la nube de puntos. Por lo anterior, se realizó un análisis al conjunto de las 10 ramas adquiridas,
con el cual fue posible obtener factores para adaptar las condiciones de cada nube de puntos y de
esta manera analizarlas independiente de los problemas de adquisición.
En la Tabla 4-2 se observa el número de puntos de cada nube de puntos, las dimensiones en los tres
ejes coordenados, adquiridas manualmente con la ayuda de la librería PCL (Alto, largo y espesor),
el volumen total de cada nube de puntos y la densidad volumétrica de cada nube. Las nubes de puntos
que presentaron problemas en la adquisición de las imágenes son marcadas en la columna “Problema
adquisición” y corresponde a las de menor volumen y mayor densidad volumétrica.
Figura 4-7: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos.
y = 1.6581x + 11.564R² = 0.1229
02468
101214161820
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
Dim
ensio
n m
eida
real
(mm
)
Dimensión medida en nube de puntos
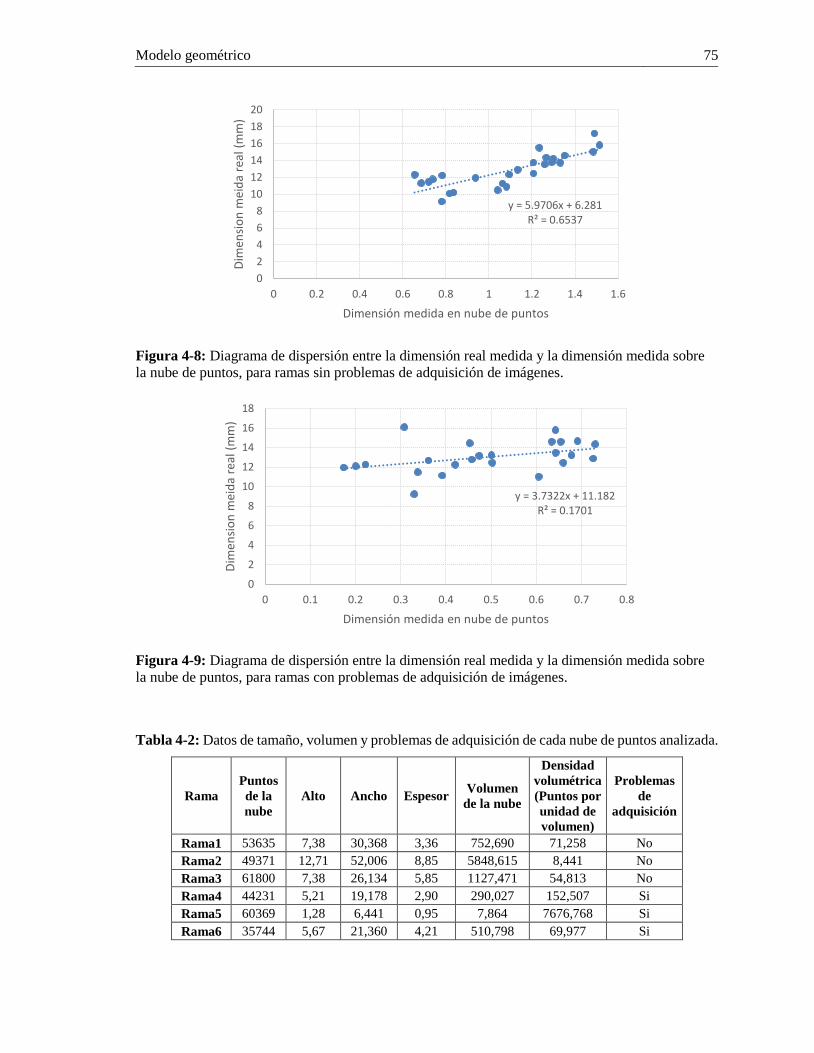
Modelo geométrico 75
Figura 4-8: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos, para ramas sin problemas de adquisición de imágenes.
Figura 4-9: Diagrama de dispersión entre la dimensión real medida y la dimensión medida sobre la nube de puntos, para ramas con problemas de adquisición de imágenes.
Tabla 4-2: Datos de tamaño, volumen y problemas de adquisición de cada nube de puntos analizada.
Rama Puntos de la nube
Alto Ancho Espesor Volumen de la nube
Densidad volumétrica (Puntos por unidad de volumen)
Problemas de
adquisición
Rama1 53635 7,38 30,368 3,36 752,690 71,258 No Rama2 49371 12,71 52,006 8,85 5848,615 8,441 No Rama3 61800 7,38 26,134 5,85 1127,471 54,813 No Rama4 44231 5,21 19,178 2,90 290,027 152,507 Si Rama5 60369 1,28 6,441 0,95 7,864 7676,768 Si Rama6 35744 5,67 21,360 4,21 510,798 69,977 Si
y = 5.9706x + 6.281R² = 0.6537
02468
101214161820
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
Dim
ensio
n m
eida
real
(mm
)
Dimensión medida en nube de puntos
y = 3.7322x + 11.182R² = 0.1701
0
2
4
6
8
10
12
14
16
18
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8
Dim
ensio
n m
eida
real
(mm
)
Dimensión medida en nube de puntos

76 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Rama7 40478 10,56 44,131 10,48 4881,960 8,291 No Rama8 20484 10,20 30,116 16,16 4965,941 4,125 No Rama9 83454 2,27 11,902 1,17 31,675 2634,655 Si
Rama10 49298 9,10 33,148 8,18 2464,776 20,001 No
Los análisis realizados sobre cada nube de puntos, deben estar relacionados, de manera adaptativa,
al tamaño de cada nube y a su densidad volumétrica. Como se observa en la Tabla 4-2 las nubes de
puntos con densidad volumétrica por encima de los 69 puntos por unidad de volumen, presentan
problemas en la adquisición, y como se mostró en la Figura 4-9 no hay relación entre lo real medido
en la rama y lo medido en la nube de puntos. En la Figura 4-10 se observa que a menor tamaño de
nube, mayor su densidad volumétrica y mayor el error de medición de tamaño. De esta forma, el
análisis debe ser adaptativo para posteriores procesos de medición de tamaño y volumen.
Figura 4-10: Relación entre tamaño de la nube de puntos (eje x), densidad volumétrica de cada nube de puntos (eje principal y) y error relativo en la dimensión del tamaño por cada fruto medido en la nube de puntos (eje secundario y).
En caso de que la longitud de la nube de puntos sea inferior a 0,22, independiente de su densidad
volumétrica, esta nube de puntos debe ser procesada de manera diferente, al igual que si la nube de
puntos, además de tener la longitud ya mencionada, tiene una densidad volumétrica superior a 69
puntos por unidad de volumen. En otros casos las nubes de puntos también se procesan de manera
independiente. Las nubes de puntos utilizadas en este trabajo que tuvieron problemas de adquisición
no son descartadas. Ellas se utilizan debido a que en campo es muy probable que este tipo de

Modelo geométrico 77
problemas se presenten y el sistema debe estar preparado para analizar información en un rango
amplio. Como se verá más adelante en algunas ocasiones no es necesario separar el análisis entre un
tipo de nube y otra, ya que esto dependerá de las características a analizar.
4.3.2 Características 3D Las características 3D que se extrajeron para caracterizar las estructuras se basan en las curvaturas
presentes en sub-regiones de cada nube de puntos sub-muestreada. En total 6 características de
curvaturas fueron halladas: cuatro curvaturas: máxima, mínima, gaussiana, y media; el índice de
forma y la curvosidad. Estas características fueron extraídas usando las normales, calculadas sobre
regiones de cada nube de puntos. Cada región fue encontrada usando la búsqueda del vecino más
cercano en una estructura de datos particionada con kd-Trees (tridimensional k = 3) [98].
Para calcular la normal se realizó una descomposición en valores singulares en cada región
encontrada. El vector propio que corresponde al valor propio más pequeño se aproxima a la normal
N de la superficie S sobre el punto p, mientras que las curvaturas máxima k1 y mínima k2, de la
superficie S, se calculan a partir de los valores propios como se muestra en las ecuaciones (4.1) y
(4.2).
𝑘𝑘1 =𝜆𝜆0
𝜆𝜆0 + 𝜆𝜆1 + 𝜆𝜆2. (4.1)
𝑘𝑘2 =𝜆𝜆2
𝜆𝜆0 + 𝜆𝜆1 + 𝜆𝜆2.
(4.2)
Donde 𝜆𝜆0 < 𝜆𝜆1 < 𝜆𝜆2.
Por otra parte las características 3D fueron calculadas siguiendo las ecuaciones (4.3), (4.4), (4.5) y
(4.6), para calcular curvatura gaussiana (K), curvatura media (H), índice de forma (SI) y curvosidad
(R), respectivamente.
𝐾𝐾 = 𝑘𝑘1𝑘𝑘2. (4.3)
𝐻𝐻 =12
(𝑘𝑘1 + 𝑘𝑘2). (4.4)
𝑆𝑆𝐼𝐼 =12−
1𝜋𝜋𝐴𝐴𝑎𝑎𝑠𝑠−1 �
𝑘𝑘1(𝐿𝐿) + 𝑘𝑘2(𝐿𝐿)𝑘𝑘1(𝐿𝐿) − 𝑘𝑘2(𝐿𝐿)�.
(4.5)
𝐻𝐻 =12�𝑘𝑘1
2(𝐿𝐿) + 𝑘𝑘22(𝐿𝐿)
2.
(4.6)

78 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Nótese que en este caso no se requiere análisis independiente por tipo de nube de puntos, ya que las
características 3D utilizadas, son adimensionales, es decir las curvaturas máxima y mínima, de donde
se derivan los cálculos de curvatura gaussiana, curvatura media, índice de forma y curvosidad, se
refieren a los cambios en la curvatura de una superficie. Esto último, hace de cierta manera que el
sistema sea tolerable a los cambios de tamaño, siempre y cuando la densidad volumétrica de la nube
de puntos compense. Sin embargo, como se verá más adelante la zona para encontrar las curvaturas
si dependen del tamaño de la rama en la nube de puntos y se realiza esta zonificación de manera
adaptativa.
4.3.3 Características 2D Las características 2D se extraen en el momento que se realiza el sub-muestreo de la nube de puntos.
A cada conjunto de puntos dentro de un vóxel se le calcula la mediana de los diferentes espacios de
color, RGB, Lab, Luv, YCbCr y HSV. Luego, a cada centroide se le asocia este conjunto de
características de color, que es utilizado para el entrenamiento y validación del sistema propuesto,
junto con las características 3D. En total 11 características de color fueron utilizadas.
En las imágenes capturadas se presentan diferentes intensidades de color para un mismo punto
debido a que se adquirieron bajo condiciones no controladas de luminosidad. Por esta razón, se
trabajó con la mediana en lugar de la media o la desviación estándar para no generar datos nuevos
en las características asociadas a cada punto.
4.3.4 Clasificador de puntos pertenecientes a frutos. Para la clasificación de frutos de café y otras estructuras vegetativas, se usó una SVM, empleando la
librería LIBSVM [99]. La SVM fue entrenada con las 17 características, 11 correspondientes a
espacios de color: R, G, L, a, b, u, v, Cb, Cr, H y S; 4 de curvatura: máxima, mínima, gaussiana,
media, el índice de forma y la curvosidad. Se utilizó un kernel Gaussiano. Para el entrenamiento del
sistema se utilizaron 8 de las 12 ramas, las restantes fueron utilizadas para evaluar el desempeño del
método propuesto. En total seis clases fueron clasificadas: tallo, hoja, flor, fruto verde, fruto pintón
y fruto rojo. La salida del clasificador es una nube de puntos, donde cada punto es asignado a una de
las seis clases.

Modelo geométrico 79
Para evaluar el desempeño del sistema propuesto, se utilizó la matriz de confusión, y las métricas de
exactitud total (Ecuación (4.7)), precisión (Ecuación (4.8)), recall (Ecuación (4.9)) o especificidad y
F1-Score (Ecuación (4.10)). La exactitud relaciona los datos correctamente clasificados y el total de
datos evaluados. La precisión mide la relación que existe entre la cantidad de datos correctamente
clasificados en una clase y el número de datos clasificados como esa clase. Recall (especificidad)
mide la relación que existe entre los datos correctamente clasificados y el número real de datos
pertenecientes a esa clase. Finalmente, con el objetivo de no sesgar la evaluación del sistema se
implementó el índice F1-Score que entrega una ponderación entre la precisión y recall.
𝛥𝛥𝐼𝐼𝑎𝑎𝑐𝑐𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐴𝐼𝐼 =∑ 𝑐𝑐𝐴𝐴𝑖𝑖𝑖𝑖𝑙𝑙𝑗𝑗
∑ ∑ 𝑐𝑐𝐴𝐴𝑖𝑖𝑗𝑗𝑙𝑙𝑗𝑗
𝑙𝑙𝑖𝑖
. (4.7)
𝑃𝑃𝑃𝑃𝑆𝑆𝑐𝑐𝐴𝐴𝑠𝑠𝐴𝐴𝑐𝑐𝑠𝑠 =𝑐𝑐𝐴𝐴𝑖𝑖𝑖𝑖
∑ 𝑐𝑐𝐴𝐴𝑗𝑗𝑖𝑖𝑙𝑙𝑗𝑗
. (4.8)
𝐻𝐻𝑆𝑆𝑐𝑐𝑎𝑎𝑆𝑆𝑆𝑆 =𝑐𝑐𝐴𝐴𝑖𝑖𝑖𝑖
∑ 𝑐𝑐𝐴𝐴𝑖𝑖𝑗𝑗𝑙𝑙𝑗𝑗
. (4.9)
𝐹𝐹1 − 𝑆𝑆𝑐𝑐𝑐𝑐𝑃𝑃𝑆𝑆 = 2𝑃𝑃𝑃𝑃𝑆𝑆𝑐𝑐𝐴𝐴𝑠𝑠𝐴𝐴𝑐𝑐𝑠𝑠 𝐻𝐻𝑆𝑆𝑐𝑐𝑎𝑎𝑆𝑆𝑆𝑆𝑃𝑃𝑃𝑃𝑆𝑆𝑐𝑐𝐴𝐴𝑠𝑠𝐴𝐴𝑐𝑐𝑠𝑠 + 𝐻𝐻𝑆𝑆𝑐𝑐𝑎𝑎𝑆𝑆𝑆𝑆
. (4.10)
Donde, cm es la matriz de confusión construida con los resultados de la clasificación y los datos
ground-truth, y n es el número de clases. En la Sección 4.3, se explicó el proceso para la extracción
de características. Para el caso de las características 3D se determinó el tamaño de las regiones sobre
las cuales se extraen, conforme al tamaño de cada una de las nubes de puntos de ramas de café. La
Tabla 4-3 muestra el índice F1-Score por clase obtenido por el sistema al variar el tamaño de la
región entre el 1,7% y 17% del ancho de la nube de puntos.
Tabla 4-3: F1-Score por clase y tamaño de cada región.
Clase Tamaño de la región (Porcentual al tamaño de la nube)
1,7% 3,3% 5% 6,5% 8,2% 10% 13,2% 17%
Tallo 0,09 0,78 0,79 0,81 0,8 0,78 0,77 0,76
Hoja 0,00 0,66 0,69 0,71 0,67 0,67 0,6 0,56
Flor 0,36 0,63 0,73 0,74 0,74 0,72 0,64 0,59
Fruto verde 0,83 0,88 0,90 0,92 0,91 0,9 0,89 0,87
Fruto pintón 0,52 0,45 0,43 0,47 0,44 0,45 0,58 0,43
Fruto maduro 0,57 0,85 0,84 0,85 0,85 0,89 0,87 0,87

80 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
En la Figura 4-11 se muestra como fueron clasificadas tres nubes de puntos de ramas de café y su
comparación con las nubes de puntos Ground-truth. Se logran observar algunos errores en la
clasificación de hojas y de frutos pintones, principalmente.
(a) Rama 1.
(b) Rama 2.
(c) Rama 3.
Figura 4-11: Comparación entre nube de puntos Ground-truth (izq.) y nube clasificada (der.).
Para la clase fruto, el mejor desempeño se obtuvo en un rango de 5% al 10% del tamaño de la nube
de puntos. Sin embargo se observaron algunos problemas con los frutos pintones, en primer lugar,
debido a los pocos datos obtenidos de este estado de desarrollo y por otro lado, el hecho de ser un
estado de maduración intermedio, hace que algunos puntos sean clasificados como maduros, otros
como inmaduros y otros como pintones, dentro del mismo fruto, Figura 4-12. Se sugiere como
trabajo futuro realizar una mejora para la clasificación de este estado de desarrollo, por medio de un
análisis unificado de los puntos de la misma zona.

Modelo geométrico 81
(a) Imagen original con presencia de fruto
pintón.
(b) Sección clasificada de la nube de puntos,
para fruto pintón.
Figura 4-12: Clasificación de un fruto pintón dentro de la nube de puntos.
Al unir las clases de frutos en una única clase se obtiene la exactitud mostrada en la Tabla 4-4. La
exactitud de clasificación para la clase frutos fue del 97% y corresponde a la nube de puntos con la
que se continúa en este trabajo, en relación a la estimación de la producción por rama de café. Sin
embargo, se debe ser cuidadoso con este resultado, pues otras estructuras también están siendo
clasificadas como frutos de café y se deben evitar falsos positivos al momento de identificar
individualmente cada fruto de café, como se mostrará más adelante.
Tabla 4-4: Exactitud para la clasificación de frutos, tallos, hojas y flores en una rama de café 3D.
Estimación
Frutos Tallo Hoja Flor
Rea
l
Frutos 0,97 0,01 0,01 0,0
Tallo 0,26 0,72 0,01 0,01
Hoja 0,31 0,03 0,65 0,0
Flor 0,25 0,11 0,0 0,64
4.4 Segmentador RANSAC para frutos independientes.
RANSAC corresponde a la abreviatura de "RANdom SAmple Consensus" y es un método iterativo
que se utiliza para estimar cuales puntos de la nube de puntos se ajustan a un modelo matemático
[100]. El algoritmo de RANSAC asume que todos los datos que estamos viendo están compuestos
de tanto inliers como outliers. Y selecciona aquellos inliers que explican el modelo dentro de una
zona específica de la nube de puntos, los demás puntos son considerados outliers hasta que
iterativamente puede ir analizando toda la nube de puntos y al final determinar cuáles puntos no
lograron ajustarse al modelo matemático específico.
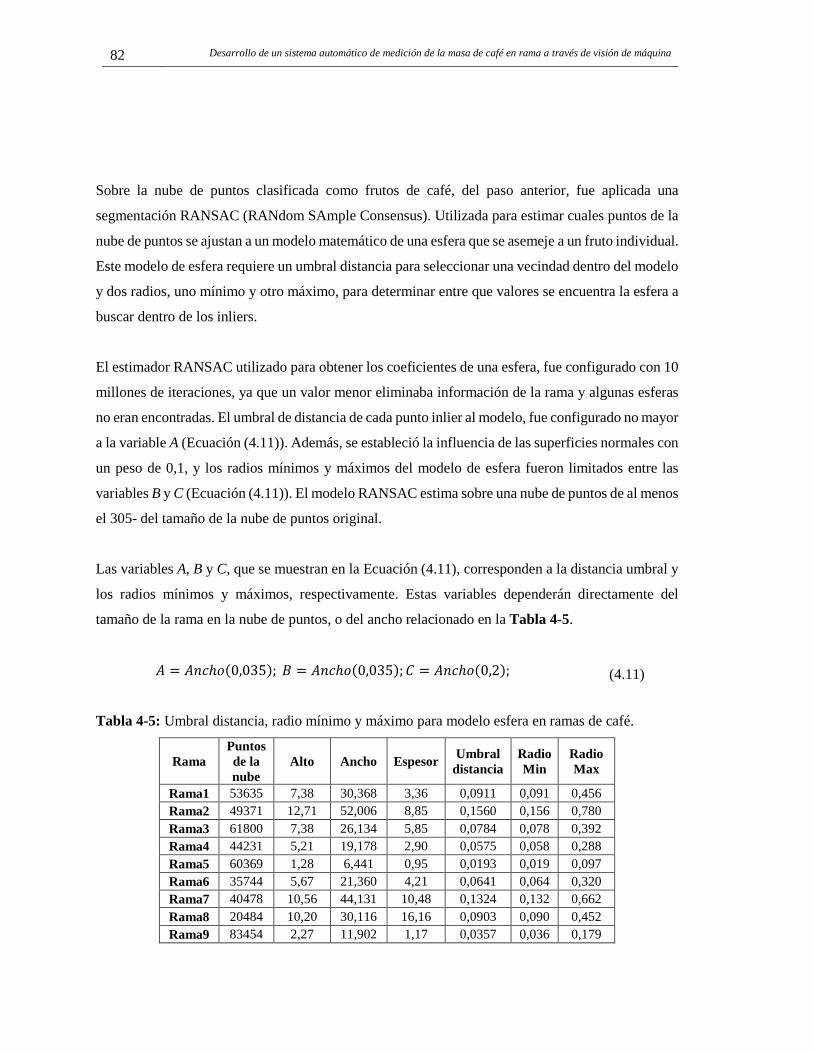
82 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Sobre la nube de puntos clasificada como frutos de café, del paso anterior, fue aplicada una
segmentación RANSAC (RANdom SAmple Consensus). Utilizada para estimar cuales puntos de la
nube de puntos se ajustan a un modelo matemático de una esfera que se asemeje a un fruto individual.
Este modelo de esfera requiere un umbral distancia para seleccionar una vecindad dentro del modelo
y dos radios, uno mínimo y otro máximo, para determinar entre que valores se encuentra la esfera a
buscar dentro de los inliers.
El estimador RANSAC utilizado para obtener los coeficientes de una esfera, fue configurado con 10
millones de iteraciones, ya que un valor menor eliminaba información de la rama y algunas esferas
no eran encontradas. El umbral de distancia de cada punto inlier al modelo, fue configurado no mayor
a la variable A (Ecuación (4.11)). Además, se estableció la influencia de las superficies normales con
un peso de 0,1, y los radios mínimos y máximos del modelo de esfera fueron limitados entre las
variables B y C (Ecuación (4.11)). El modelo RANSAC estima sobre una nube de puntos de al menos
el 305- del tamaño de la nube de puntos original.
Las variables A, B y C, que se muestran en la Ecuación (4.11), corresponden a la distancia umbral y
los radios mínimos y máximos, respectivamente. Estas variables dependerán directamente del
tamaño de la rama en la nube de puntos, o del ancho relacionado en la Tabla 4-5.
𝐴𝐴 = 𝐴𝐴𝑠𝑠𝑐𝑐ℎ𝑐𝑐(0,035); 𝐵𝐵 = 𝐴𝐴𝑠𝑠𝑐𝑐ℎ𝑐𝑐(0,035);𝑔𝑔 = 𝐴𝐴𝑠𝑠𝑐𝑐ℎ𝑐𝑐(0,2); (4.11)
Tabla 4-5: Umbral distancia, radio mínimo y máximo para modelo esfera en ramas de café.
Rama Puntos de la nube
Alto Ancho Espesor Umbral distancia
Radio Min
Radio Max
Rama1 53635 7,38 30,368 3,36 0,0911 0,091 0,456 Rama2 49371 12,71 52,006 8,85 0,1560 0,156 0,780 Rama3 61800 7,38 26,134 5,85 0,0784 0,078 0,392 Rama4 44231 5,21 19,178 2,90 0,0575 0,058 0,288 Rama5 60369 1,28 6,441 0,95 0,0193 0,019 0,097 Rama6 35744 5,67 21,360 4,21 0,0641 0,064 0,320 Rama7 40478 10,56 44,131 10,48 0,1324 0,132 0,662 Rama8 20484 10,20 30,116 16,16 0,0903 0,090 0,452 Rama9 83454 2,27 11,902 1,17 0,0357 0,036 0,179

Modelo geométrico 83
Rama10 49298 9,10 33,148 8,18 0,0994 0,099 0,497
El resultado de aplicar la segmentación RANSAC a las nubes de puntos clasificadas como frutos, es
un conjunto de clusters, cuya forma se asemeja a una esfera (Figura 4-13). Es posible, que por cada
fruto de café aparezca más de un cluster, esto es generado por la aproximación de conjuntos de
puntos de la misma zona en varias esferas, el segmentador identifica clusters diferentes, pero
realmente, estas pertenecen al mismo fruto. Este problema se soluciona más adelante donde es
analizada cada cluster.
(a) Nube de puntos clasificada en 6 estructuras vegetativas. Solo los frutos son usados en la
segmentación RANSAC.
(b) Nube de puntos de frutos segmentada. Cada color corresponde a cluster.
Figura 4-13: Segmentación RANSAC de la nube de puntos de una rama de café.
4.5 Extracción y análisis del modelo geométrico.
Una vez se tienen todos los clusters de una rama completa, estos son analizados por medio de un
modelo de ajuste de superelipsoides. Para esto se utiliza una librería desarrollada por Toyota, dentro
del programa de investigación Code Sprint de PCL, llamada Superquadrics [101]. El modelo de
superelipsoide, entrega los 5 factores mencionados al inicio de este capítulo, correspondientes a los
exponentes ε1 y ε2, con los cuales se logra encontrar la redondez relativa y la cuadratura en ambas
direcciones, horizontal y vertical. Y los parámetros a1, a2 y a3 corresponden a factores de

84 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
escalamiento de cada forma generada. Ver Ecuación (7.1). Adicional a encontrar los parámetros ya
mencionados, el ajuste a superelipsoide, encuentra el centroide de cada cluster y lo ubica de manera
general sobre la rama completa.
Cada forma estimada es graficada en 3D, Figura 4-14, por medio del uso de los ocho factores, cinco
propios de la forma del superelipsoide y 3 correspondientes al centroide del cluster. Cada cluster es
graficado, en la Figura 4-15 se muestra una rama completa reconstruida gráficamente. En esta figura
es posible observar formas con puntas que posiblemente no correspondan a frutos de café, o dos o
más superelipsoides ubicadas con un mismo centroide. Adicionalmente se observan superelipsoides
flotantes fuera del tallo de la rama. Es posible que no todas las superelipsoides modeladas
correspondan a frutos de café. Por lo anterior, fue necesario identificar cuales superelipsoides no
eran frutos, a través de un análisis a los diferentes parámetros, forma y ubicación de cada
superelipsoide modelada.
(a) Cluster segmentado. (b) Reconstrucción gráfica cluster (a)
Figura 4-14: Reconstrucción gráfica para un cluster segmentado.
(a) Nube de puntos de frutos segmentada.

Modelo geométrico 85
(b) Reconstrucción gráfica de las superlipsoides estimadas por cada cluster segmentado en (a).
Figura 4-15: Superelipsoides de una rama completa, luego de la estimación de forma y reconstrucción gráfica.
4.5.1 Análisis de ubicación. Una vez extraídos todos los centroides de las superelipsiodes modeladas, se ubican los centroides
del plano xy, como se muestra en la Figura 4-16. La mayoría de los centroides se encuentran cerca
de una línea de tendencia, que muestra la disposición de los mismos sobre el tallo de la rama. Esta
línea de tendencia, se considera describe la ubicación del tallo de la rama y se puede expresar como
se muestra en la (Ecuación (4.12)). Se calcula el error absoluto de los centroides ubicados en el eje
y (Ecuación (4.13)), con relación a la línea de tendencia y aquellos centroides que se encuentren
fuera de la línea en más de 3,5 desviaciones, son considerados datos atípicos y por consiguiente no
son frutos de café, Figura 4-17. Estos centroides pueden hacer parte de otras estructuras vegetativas
que fueron erróneamente clasificadas, o frutos de café que no fueron filtrados en la fase
correspondiente. Para el caso mostrado en las Figuras 4-16 y 4-17, son 4 los centroides atípicos que
son eliminados, de la relación xy. El mismo análisis no puede ser realizado en los otros dos ejes, ya
que ellos pueden tener diferentes líneas de tendencia dependiendo de la geometría del tallo de la
rama, de esta forma, se realiza el mismo análisis muchas superelipsoides pueden ser eliminadas,
siendo realmente frutos.
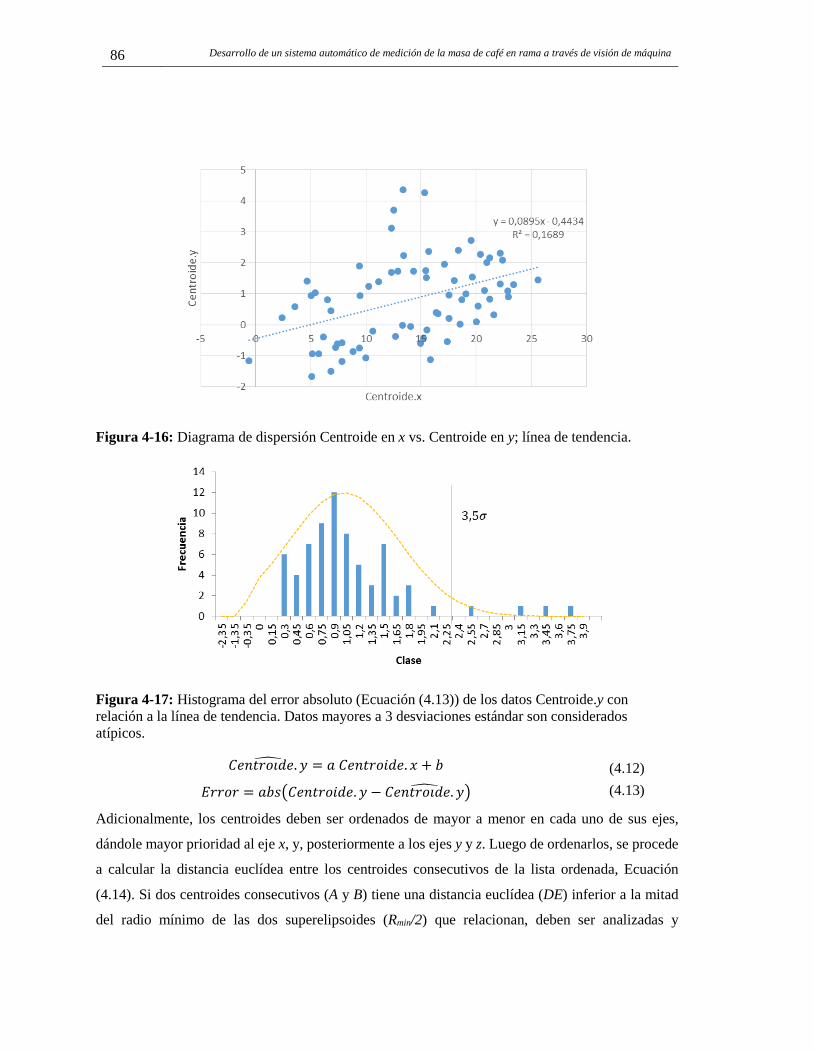
86 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 4-16: Diagrama de dispersión Centroide en x vs. Centroide en y; línea de tendencia.
Figura 4-17: Histograma del error absoluto (Ecuación (4.13)) de los datos Centroide.y con relación a la línea de tendencia. Datos mayores a 3 desviaciones estándar son considerados atípicos.
𝑔𝑔𝑆𝑆𝑠𝑠𝐴𝐴𝑃𝑃𝑐𝑐𝐶𝐶𝐼𝐼𝑆𝑆.𝑦𝑦� = 𝑎𝑎 𝑔𝑔𝑆𝑆𝑠𝑠𝐴𝐴𝑃𝑃𝑐𝑐𝐴𝐴𝐼𝐼𝑆𝑆. 𝐼𝐼 + 𝑏𝑏 (4.12) 𝛥𝛥𝑃𝑃𝑃𝑃𝑐𝑐𝑃𝑃 = 𝑎𝑎𝑏𝑏𝑠𝑠�𝑔𝑔𝑆𝑆𝑠𝑠𝐴𝐴𝑃𝑃𝑐𝑐𝐴𝐴𝐼𝐼𝑆𝑆.𝑦𝑦 − 𝑔𝑔𝑆𝑆𝑠𝑠𝐴𝐴𝑃𝑃𝑐𝑐𝐶𝐶𝐼𝐼𝑆𝑆.𝑦𝑦� � (4.13)
Adicionalmente, los centroides deben ser ordenados de mayor a menor en cada uno de sus ejes,
dándole mayor prioridad al eje x, y, posteriormente a los ejes y y z. Luego de ordenarlos, se procede
a calcular la distancia euclídea entre los centroides consecutivos de la lista ordenada, Ecuación
(4.14). Si dos centroides consecutivos (A y B) tiene una distancia euclídea (DE) inferior a la mitad
del radio mínimo de las dos superelipsoides (Rmin/2) que relacionan, deben ser analizadas y

Modelo geométrico 87
descartada una de las dos, Figura 4-18. Para esto se requiere realizar el análisis de forma,
mencionado en la siguiente sección.
𝐷𝐷𝐴𝐴𝑠𝑠𝐴𝐴𝛥𝛥𝐴𝐴𝑐𝑐𝑆𝑆𝐴𝐴𝐼𝐼𝑆𝑆𝑎𝑎 = �(𝑔𝑔. 𝐼𝐼𝑖𝑖 − 𝑔𝑔. 𝐼𝐼𝑖𝑖−1)2 + (𝑔𝑔.𝑦𝑦𝑖𝑖 − 𝑔𝑔.𝑦𝑦𝑖𝑖−1)2 + (𝑔𝑔. 𝐴𝐴𝑖𝑖 − 𝑔𝑔. 𝐴𝐴𝑖𝑖−1)2 (4.14)
4.5.2 Análisis de forma. Para realizar el análisis de forma se requiere conocer la relación de los parámetros ε1 y ε2, a1, a2 y
a3. En este caso se realizó un análisis de forma de cada uno de los frutos encontrados y que realmente
fueran frutos dentro de 2 ramas de café, en total se analizaron 162 superelipsoides de las cuales solo
109 eran frutos de café. Las condiciones de forma encontradas en este análisis se muestran en las
ecuaciones (4.15) y (4.16), y deben ser cumplidas para que una superelipsoide sea considerada frutos
de café. En la Ecuación (4.15), se limita el factor de forma tanto vertical como horizontal para que
este entre 0,25 y 1,5. Según la Ecuación (4.16) la diferencia entre ambos factores debe ser inferior a
0,51, considerando la forma esférica que debe tener una superelipsoide perteneciente a un fruto de
café.
Figura 4-18: Comparación de la distancia euclidea entre centroides consecutivos de superelipsoides y el radio mínimo entre ellas.
0,25 < (𝜀𝜀1 ∧ 𝜀𝜀2) < 1,5 (4.15) 𝑎𝑎𝑏𝑏𝑠𝑠(𝜀𝜀1 − 𝜀𝜀2) < 0,51 (4.16)

88 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Para detectar formas atípicas de las superelipsoides encontradas, se definió la condición mostrada en
las ecuaciones (4.17) y (4.18), donde a partir de los valores de tendencia de los parámetros a1, a2 y
a3, se encuentran superelipsoides de radios fuera de las 2,5 desviaciones estándar para cada
parámetro en cada eje.
𝑎𝑎𝑖𝑖 > 𝜇𝜇(𝐴𝐴𝑖𝑖) − 2,5𝜎𝜎(𝐴𝐴𝑖𝑖) (4.17) 𝑎𝑎𝑖𝑖 < 𝜇𝜇(𝐴𝐴𝑖𝑖) + 2,5𝜎𝜎(𝐴𝐴𝑖𝑖) (4.18)
Donde ai corresponde a uno de los tres parámetros y Ai corresponde al vector que contiene todos los
datos ai de una misma nube de puntos. De esta manera se calculan la media y la desviación estándar
de cada parámetro y cada dato es comparado con la tendencia general de su mismo conjunto.
Se procedió a utilizar media y desviación estándar, pues como se mostró en el subcapítulo 4.3.1, el
tamaño no es una variable que pueda estandarizarse. Sin embargo, en sí misma la rama clasificada
tiene en su mayoría información de frutos de café y por esta razón es posible determinar valores de
tendencia sobre los mismos datos calculados. Esto le da al sistema adaptabilidad para la detección
de superelipsoides que son frutos de café. Para ilustrar lo mencionado se muestra en las Figuras 4-
19 y 4-20, el comportamiento del análisis de ubicación y de forma en dos nubes de puntos de
diferente tamaño, densidad volumétrica y condiciones de adquisición, la rama 1 se observa en la
Figura 4-19 y la rama 5 se observa en la Figura 4-20. En los literales (a) de ambas imágenes se
observa la nube de puntos clasificada, en los literales (b) se observan todas las superelipsoides
modeladas y en el literal (c) se observan todas las superelipsoides definidas como frutos después del
análisis de ubicación y de forma. El número de superelipsoides encontradas en rama 1 y rama 5,
fueron de 70 y 92, luego del análisis permanecieron 46 y 64, respectivamente.
(a) Nube de puntos clasificada por frutos.
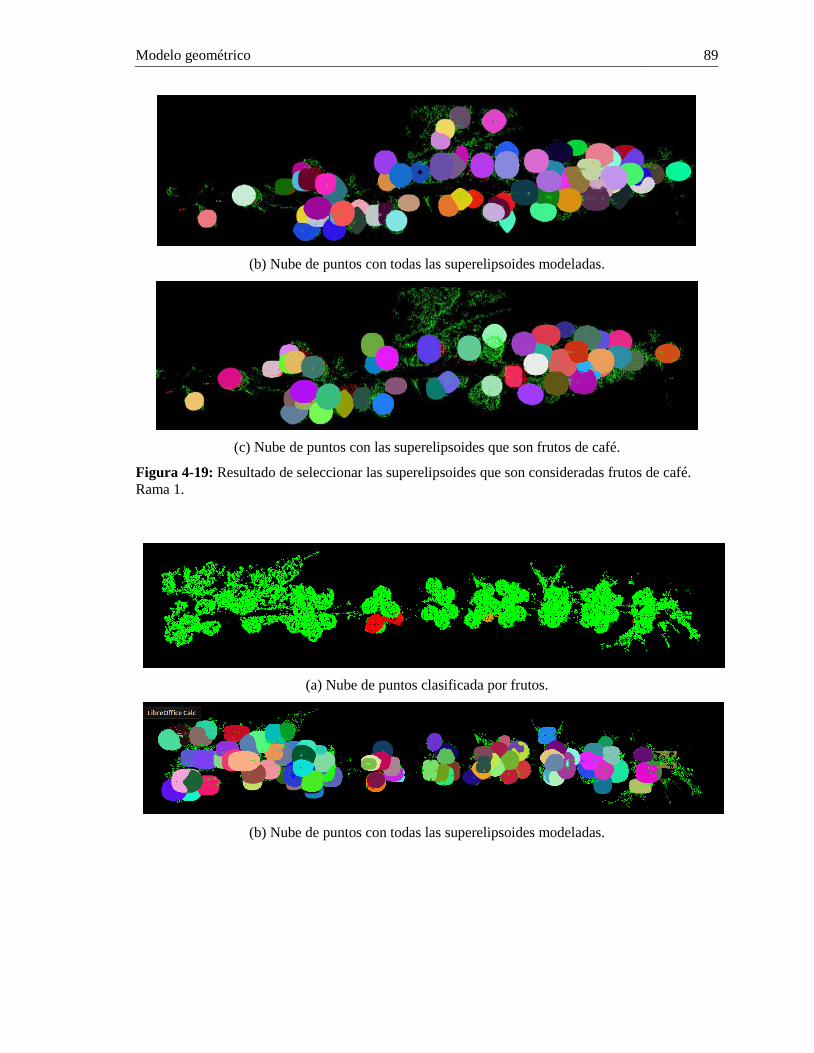
Modelo geométrico 89
(b) Nube de puntos con todas las superelipsoides modeladas.
(c) Nube de puntos con las superelipsoides que son frutos de café.
Figura 4-19: Resultado de seleccionar las superelipsoides que son consideradas frutos de café. Rama 1.
(a) Nube de puntos clasificada por frutos.
(b) Nube de puntos con todas las superelipsoides modeladas.

90 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(c) Nube de puntos con las superelipsoides que son frutos de café.
Figura 4-20: Resultado de seleccionar las superelipsoides que son consideradas frutos de café. Rama 1.
Cada nube de puntos fue analizada y los resultados de esta selección se muestran en la Tabla 4-6,
donde se observa el número total de superelipsoides encontradas y el número de superelipsoides
seleccionadas como frutos de café. Sobre este sistema 3D se observa la capacidad para estimar la
cantidad de frutos totales en la rama y la masa de los frutos contenidos en las mismas, por medio de
análisis volumétrico de las superelipsoides seleccionadas. Si bien con el número de datos que se
tienen no es posible inferir parámetros de estimación entre el número de superelipsoides
seleccionadas y el número total de frutos en la rama, se observa un potencial (Figura 4-21) de que
esta técnica 3D logre un conteo aproximado de los frutos en la rama, solucionando problemas, como
el contraste y tolerancia a los cambios bruscos de iluminación, mostrados en el algoritmo 2D.
Tabla 4-6: Número de superelipsoides totales, eliminadas y seleccionadas, comparadas con el
número total de frutos por rama.
Rama Número de
superelipsoides totales
Número de superelipsoides
eliminadas
Número de superelipsoides seleccionadas
Número total real de frutos
1 71 -25 46 66 2 60 -12 48 154 3 90 -20 70 177 4 50 -9 41 74 5 93 -30 63 88 6 49 -10 39 72 7 71 -12 59 111 8 64 -21 43 58 9 55 -8 47 82 10 72 -16 56 66

Modelo geométrico 91
Figura 4-21: Relación entre el número de superelipsoides seleccionadas y el número total real de frutos en las ramas.
4.6 Detección, conteo y estimación de volumen de los frutos de café.
Luego de tener identificada una superelipsoide para cada cluster de puntos perteneciente a un fruto
de café, se realizó el conteo de frutos por estado de desarrollo y la estimación de su volumen, en
cada rama analizada.
4.6.1 Detección de frutos y conteo por estado de desarrollo. Cada superelipsoide seleccionada como fruto de café, está relacionada con un cluster segmentado
con el método RANSAC, dicho cluster está conformado por puntos clasificados por estado de
desarrollo. De esta forma, cada cluster tiene un conjunto de puntos que puede variar, en número y
estados de desarrollo (inmaduro, pintón y maduro), es decir, puede tener un número variable de
puntos clasificados como maduros, pintones o inmaduros, no un único estado.
Se realizó el conteo de puntos totales de cada cluster segmentado, correspondiente a la superelipsoide
seleccionada. Se determinaron cuantos puntos fueron clasificados como inmaduros, pintones y
maduros y se seleccionó el estado de desarrollo final para dicho cluster, como el estado de desarrollo
que más se repita. Sin embargo, si el número de puntos en el estado que más se repite no supera el
60 % del total de los puntos, se debe realizar un análisis adicional: (i) Si el estado que más se repite

92 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
es maduro (menor del 60%) y el estado que continua en número de puntos es pintón, el fruto es
considerado maduro. Este conjunto de reglas se muestra en la Tabla 4-7.
Tabla 4-7: Posibles combinaciones y reglas para definir el Estado de Maduración (EM) final del
fruto detectado.
EM que más se repite > 60%
EM que más se repite < 60%
Segundo EM que más se repite
Estado final del fruto detectado
Maduro -- -- Maduro Pintón -- -- Pintón
Inmaduro -- -- Inmaduro -- Maduro Pintón Maduro -- Maduro Inmaduro Pintón -- Pintón Maduro Maduro -- Pintón Inmaduro Pintón -- Inmaduro Maduro Pintón -- Inmaduro Pintón Inmaduro
Se generaron cuatro contadores de frutos por rama, uno para cada estado de maduración y otro para
conteo total de frutos. En la Tabla 4-8, se muestran los frutos detectados por el sistema 3D,
comparados con el número real de frutos en cada una de las ramas. El sistema 3D, sin ajustes
estadísticos es capaz de detectar el 54% de los frutos en toda la rama, considerando frutos ocluidos,
comparado con el 46% de detección del algoritmo 2D sin ajustes.
Al igual que en el subcapítulo anterior, no es posible inferir parámetros de estimación entre el número
de frutos detectados y el número total de frutos en la rama, a pesar de observarse un potencial de
aproximación al conteo. Se tiene un R2 para inmaduros, pintones y maduros de 0,45, 0,2 y 0,1,
respectivamente. El bajo número de frutos pintones y maduros sesga el desempeño de la detección
y muestra los valores ya mencionados del coeficiente de determinación. En la Figura 4-22 se
muestra la correlación entre los frutos inmaduros detectados y reales en la rama, lo que indica que
hay un potencial en la detección. Para esto se requiere un mayor número de ramas y frutos, lo cual
no se realizó en este trabajo por el alto costo computacional de procesar cada rama de café. Como se
muestra en la Tabla 4-9, el procesamiento para cada rama puede tomar cerca de 40 minutos, sin
incluir el proceso de entrenamiento. Se requieren afinar algunos procesos para disminuir el
requerimiento computacional.
Tabla 4-8: Conteo de frutos por estado de maduración en cada una de las ramas.

Modelo geométrico 93
Real Automático Rama Inmaduro Pintón Maduro Total Inmaduro Pintón Maduro Total
1 54 6 6 66 38 2 6 46 2 146 7 1 154 46 0 2 48 3 177 0 0 177 70 0 0 70 4 67 2 5 74 40 0 1 41 5 85 2 1 88 61 0 2 63 6 66 5 1 72 33 0 6 39 7 97 8 6 111 48 8 3 59 8 53 3 2 58 37 3 3 43 9 76 4 2 82 42 3 2 47
10 62 2 2 66 53 2 1 56
Figura 4-22: Relación entre el número de frutos inmaduros detectados y el número de frutos inmaduros en las ramas.
Tabla 4-9: Costo computacional de cada proceso realizado para detectar frutos y realizar el conteo
(i5 3,6GHz 8Gb).
Proceso Tiempo de ejecución Reconstrucción 3D ~15 min Filtrado Outliers ~1,4 min
Filtrado Pasa-banda ~1 min Submuestreo ~1,5 min
Extracción de características ~36 seg Entrenamiento ~ 48,5 horas Clasificación ~20 min
Segmentador RANSAC ~6 min Extracción y análisis ~ 1 min
Total clasificación por rama ~37 min

94 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
4.6.2 Estimación de volumen. Como se mostró en el subcapítulo 4.3.1, el tamaño y densidad volumétrica de cada nube de puntos
es diferente y no es posible inferir o escalar el tamaño real de los frutos en las ramas a partir de la
información en las nubes de puntos. Debido a esto fue necesario estimar el volumen a partir de
volúmenes experimentales, diferentes para cada estado de maduración y las ecuaciones mostradas
en [102]: (i) 1308,41 mm3 para frutos inmaduros bien desarrollados, con 210 días después de la
floración; (ii) 1607,47 mm3 para frutos pintones, con 224 días después de la floración; y (iii) 1804,65
mm3 para frutos maduros, con 231 días después de la floración. Esta estimación se realiza de manera
independiente y adaptativa para cada rama de café y busca calcular el volumen de cada fruto
individualmente, para posteriormente calcular la masa, considerando que la densidad volumétrica de
un fruto de café es de 1,07 g/cm3.
Es importante aclarar, que la información de las ramas de café utilizadas, fue adquirida en una época
en la que la mayoría de los frutos inmaduros, estaban bien desarrollados y en un tiempo no mayor a
60 días podrían ser frutos maduros.
Cada superelipsoide, además de los parámetros de forma y escalamiento, tiene calculado el volumen,
como se mostró en la Ecuación (7.2). Se identificó cual era el estado de maduración más
predominante en cada una de las ramas de café. Sobre dicho estado de maduración se calculó la
media y desviación estándar sobre la variable volumen. El valor medio de volumen (�̅�𝑣) más una
desviación estándar (𝜎𝜎𝑎𝑎) (Ecuación (4.19), Figuras 4-23 y 4-24), será considerado para escalar el
valor de volumen con el valor experimental de frutos inmaduros de 1308,41 mm3, como se muestra
en la Ecuación (4.19), donde 𝑣𝑣𝑐𝑐𝑆𝑆𝐴𝐴𝐴𝐴𝑆𝑆𝑠𝑠𝑓𝑓𝑎𝑎𝑓𝑓𝑡𝑡𝑠𝑠−𝑖𝑖 es el volumen escalado de 𝑣𝑣𝑐𝑐𝑆𝑆𝐴𝐴𝐴𝐴𝑆𝑆𝑠𝑠𝑠𝑠𝑓𝑓𝑙𝑙𝑠𝑠𝑎𝑎𝑠𝑠𝑠𝑠𝑖𝑖𝑙𝑙𝑠𝑠−𝑖𝑖, que
es el volumen de la superelipsoide.
𝑣𝑣𝑐𝑐𝑆𝑆𝐴𝐴𝐴𝐴𝑆𝑆𝑠𝑠𝑓𝑓𝑎𝑎𝑓𝑓𝑡𝑡𝑠𝑠−𝑖𝑖 =(1308,41𝐴𝐴𝐴𝐴3)𝑣𝑣𝑐𝑐𝑆𝑆𝐴𝐴𝐴𝐴𝑆𝑆𝑠𝑠𝑠𝑠𝑓𝑓𝑙𝑙𝑠𝑠𝑎𝑎𝑠𝑠𝑠𝑠𝑖𝑖𝑙𝑙𝑠𝑠−𝑖𝑖
�̅�𝑣 + 𝜎𝜎𝑎𝑎 (4.19)

Modelo geométrico 95
Figura 4-23: Histograma para el volumen de los frutos inmaduros en la rama 1.
Figura 4-24: Histograma para el volumen de los frutos inmaduros en la rama 5.
Luego de calcular el volumen por fruto, se realizó el cálculo de la masa por fruto, Ecuación (4.20).
Como se observa en la Figura 4-25, la masa calculada con el volumen no explica la masa real de los
frutos de café, esto puede ser debido a los problemas de escalamiento ya mencionados. Sin embargo,
y de la misma manera como se realiza con el algoritmo 2D, la masa puede ser estimada a través del
conteo de los frutos y un factor de conversión para cada esta de desarrollo [103], Figura 4-26.
𝐴𝐴𝑎𝑎𝑠𝑠𝑎𝑎𝑓𝑓𝑎𝑎𝑓𝑓𝑡𝑡𝑠𝑠−𝑖𝑖(𝑔𝑔𝑃𝑃) =(1,07𝑔𝑔𝑃𝑃/𝑐𝑐𝐴𝐴3)𝑣𝑣𝑐𝑐𝑆𝑆𝐴𝐴𝐴𝐴𝑆𝑆𝑠𝑠𝑓𝑓𝑎𝑎𝑓𝑓𝑡𝑡𝑠𝑠−𝑖𝑖(𝐴𝐴𝐴𝐴3)
1000 (4.20)

96 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 4-25: Correlación entre la masa real de los frutos en las ramas y la masa detectada con el método del volumen.
Figura 4-26: Correlación entre la masa real de los frutos en las ramas y la masa detectada a partir del conteo de frutos y factores de conversión [103].
4.7 Conclusiones. Fue propuesto y desarrollado un sistema 3D para detectar, contar y estimar la masa de los frutos de
café en una rama de café. Por medio de la estimación del modelo geométrico de los frutos de café
en las ramas. Los resultados encontrados, muestran que hay un potencial para continuar trabajando
bajo esta línea.

Modelo geométrico 97
Se lograron correctas reconstrucciones 3D, independiente de las condiciones no controladas de
iluminación. Sin embargo, no fue posible escalar el tamaño de los frutos desde la nube de puntos. El
proceso de adquisición de imágenes se realizó lo mejor posible, pero la forma curva de las ramas y
la posición de los frutos en ella no permitieron garantizar una distancia fija entre la cámara y la rama.
Se sugiere realizar corrección de las imágenes al momento de adquirirlas.
El conteo automático de frutos, muestra un potencial para estimar el número de frutos reales en la
rama, a partir del conteo realizado con la información 3D. Ya que aspectos como la oclusión parcial
de los frutos, presencia de ramas en el fondo de la rama analizada, cambios extremos de iluminación
sobre la rama y cambios en la distancia entre cámara y rama, no son impedimento para contar
correctamente los frutos en las ramas.
Fue posible obtener el modelo geométrico de los frutos de café, a partir de imágenes de múltiples
vistas de la parte superior de la rama, extraídas como los mejores cuadros de los vídeos adquiridos.
Cada uno de las fases del algoritmo 3D, garantizan que se realiza un adecuado tratamiento de la
información y se obtiene el número de frutos independiente de las condiciones adversas de los datos.
El sistema propuesto no requiere cámaras de alta resolución, ni sofisticados sistemas de iluminación,
ni vehículos que se muevan por la plantación. El sistema es llevado por una persona, que fácilmente
puede entrar en un cultivo denso, y con el sistema sujetador y el dispositivo móvil puede adquirir
imágenes en cualquier estrato del árbol, a diferentes alturas y bajo diferentes condiciones de
iluminación, sin el uso de fuentes externas de iluminación. Este sistema 3D obtiene información de
frutos por medio de imágenes monoculares adquiridas en condiciones no controladas de campo y
bajo mínimas condiciones de operación.
El trabajo futuro está en mejorar el algoritmo de medición de volumen y lograr inferir la masa, a
través de esta medición adecuada del volumen. Adicionalmente, buscar que los algoritmos
desarrollados sean lo más livianos, óptimos y rápidos, para disminuir el costo computacional de los
mismos, y generar una tecnología que se encuentre al alcance del agricultor común.

98
5. Estimación de número de frutos, porcentaje de maduración y masa en la rama.
Para estimar la producción en las ramas, árboles y parcelas, primero es necesario entender la
dinámica de esta producción frente al número de frutos contados en las ramas. A pesar de los
desarrollos previamente realizados por otros autores [17, 18, 19 y 20], es importante validar las
técnicas automáticas de conteo y estimación de peso, determinar si con los materiales biológicos
actuales, las distribuciones de siembra, las variedades de café sembradas y los sistemas de
producción, es posible determinar la producción por rama, árbol y/o parcela.
Con los desarrollos mostrados en esta tesis, es posible estimar la producción en ramas de café. En
este capítulo se muestra los análisis realizados a sistemas de producción de café, a nivel de parcela,
con unidad mínima de observación la rama y métodos de muestreo aleatorio para seleccionar los
árboles o ramas a chequear de las parcelas. Frente a los resultados mostrados en los capítulos 3 y 4,
se selecciona el algoritmo de conteo de frutos 2D, pues con este es posible procesar ramas de café
con menor costo computacional, cercano a 1 minuto por rama, mientras que para el algoritmo 3D se
requieren 37 minutos por rama, lo que por ahora, no hace posible el análisis de grandes bases de
datos.
Luego de tener la información del número de frutos generada por el algoritmo 2D, se construyeron
modelos lineales de estimación entre los frutos detectados automáticamente y los observados en la
rama de café. Estos modelos fueron calculados para frutos en dos categorías: cosechables y no
cosechables. Los modelos calculados relacionan uno a uno los frutos contados automáticamente con
los observados realmente, con R2 superior a 0,93, con un error del 17%. La información generada
por el algoritmo 2D, no solo es utilizada para estimar el número de frutos en rama, sino también para
estimar el porcentaje de maduración y masa de los frutos en ella, con errores de estimación de 7% y
22%, respectivamente. Los resultados del algoritmo 2D fueron validados en 4 lotes de café variedad
Castillo®, con diferentes edades y densidades de plantación, y se encontró que no sobreestima, ni

Resultados 99
subestima el conteo de frutos y que muestra una correlación superior a 0,90 en momentos tempranos
de la cosecha, cuando todos los frutos del árbol son no cosechables. Para momentos de cosecha se
encontró que el sistema estima adecuadamente el porcentaje de maduración con un 11% de error. La
masa no es correctamente estimada en ninguno de los dos momentos antes y durante la cosecha,
debido a la variabilidad de cada uno de los árboles y lotes seleccionados. La información obtenida
en este trabajo permitirá generar herramientas para que los caficultores utilicen un método eficiente,
no destructivo y de bajo costo que proporcione información útil para planificar el trabajo agrícola y
la obtención de beneficios económicos de la gestión eficiente de los recursos.
5.1 Relaciones número de frutos, producción y porcentaje de maduración.
Con el fin de conocer la dinámica de producción de un conjunto de árboles dentro de una parcela y
encontrar la relación que hay entre el número de frutos presentes en estos árboles y la producción
por árbol, se realizaron las actividades mencionadas a continuación. En esta parte del documento se
relacionan frutos contados manualmente sobre un conjunto de ramas marcadas por árbol, con la
producción total de cada árbol, la producción en el tercio medio y la producción en el tercio inferior.
Esta información es utilizada para encontrar una estrategia en el uso de la tecnología desarrollada en
esta tesis doctoral.
Fue seleccionada una parcela sembrada en café variedad Castillo® (monolínea CU2021) de tercera
cosecha, a una distancia de siembra de 2 m × 1 m y dos tallos por sitio1. La parcela cumplía con las
siguientes condiciones: (i) ramas productivas, ramas primarias (sin bifurcaciones) en los árboles; (ii)
árboles de porte bajo; y (iii) distancia entre sitios de 2 m × 1 m, que facilitó el acceso a cada uno de
los árboles. La parcela en total contó con 650 árboles, de estos se eligieron 30 sitios aleatoriamente,
de cada sitio se identificaron cada uno de los tallos (1, 2) y las siguientes zonas de cada tallo: (i)
tercio medio del árbol, contado a partir de la rama número 12 desde el dosel hasta la rama número
40; y (ii) tercio inferior desde la rama 41 hasta la última rama productiva de la parte baja del árbol.
Fueron marcados cada uno de los árboles seleccionados, y a su vez todas las ramas del tercio medio.
Se registró el número total de ramas del tercio medio para cada tallo, el número de frutos en cada
estado de desarrollo, para cada una de las ramas marcadas, durante la primera semana de julio de
1 Sitio: corresponde al lugar donde se siembra un árbol de café. Este sitio puede contener árboles de uno, dos o tres tallos.

100 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
2015. Se realizó un seguimiento de producción a la parcela seleccionada, cada 15 días durante los
cuatro meses correspondientes a la cosecha principal del año 2015, en total se realizaron 8 pases de
cosecha. Se registró en cada pase la masa de café cosechado en los 650 árboles en total, la masa de
café cosechado en el tercio medio y en el tercio inferior de cada uno de los tallos de los árboles
seleccionados. El café cosechado en cada pase de recolección se trasladó al Beneficiadero de
Cenicafé, donde se caracterizó la masa de café cosechado para cada zona de los árboles. Se determinó
el porcentaje de café en cada estado de desarrollo (inmaduro, verde-pintón, pintón, maduro y
sobremaduro. Adicionalmente, un segundo conteo de frutos se realizó sobre todas las ramas
marcadas, antes del pase principal de cosecha.
5.1.1 Relación frutos observados en inicio de cosecha vs. Producción acumulada en toda la cosecha principal (Julio/ 2015).
Con la información obtenida durante el segundo semestre del año 2015: masa acumulada por zona
productiva durante los 8 pases y el número de frutos contados manualmente al inicio de la cosecha
(Julio/2015), se construyeron las gráficas presentadas en la Figura 5-1. En la Figura 5-1a, b y c, se
observan las relaciones entre el número total de frutos observados o contados en las ramas marcadas
en el mes de julio y la masa acumulada de todo el árbol, tercio medio del árbol y tercio inferior del
árbol, respectivamente. La Figura 5-1b es la que muestra mayor agrupación de los datos, seguida de
la Figura 5-1a y c no muestra ningún tipo de agrupamiento. Lo anterior indica que la información
observada en los árboles en su zona productiva está directamente relacionada con la producción de
esa zona específicamente. Esta situación se refleja en el análisis de regresión lineal realizado entre
Número de frutos contados manualmente (CM) y Masa acumulada (Tabla 5-1), donde el coeficiente
de determinación es de 0,24 para la masa acumulada en el tercio inferior del árbol, pero para el tercio
medio es de 0,86. Si en la regresión se iguala el intercepto a 0, el coeficiente de determinación para
esta última relación es de 0,968, lo que indica que la variable Número de frutos contados
manualmente en el tercio medio en Julio explica el masa acumulada del tercio medio durante todo
el semestre, con errores de 19%. Para el caso de la masa acumulada por árbol, el número de frutos
contados en el tercio medio explica la producción total del árbol en un 0,92, con un error del 32,7%.
Para el caso del tercio inferior el conteo de frutos del tercio medio no explica la producción de este
tercio del tallo del árbol. Los errores antes mencionados podrían cambiar en la medida que se

Resultados 101
modifique la muestra de ramas por árbol y/o árboles por parcela, es decir, este error puede verse
modificado por el error muestral.
(a) Número de frutos con conteo manual (CM) en tercio medio vs. Masa acumulada del árbol.
(b) Número de frutos con conteo manual (CM) en tercio medio vs. Masa acumulada de frutos
en el tercio medio del árbol.
(c) Número de frutos cn conteo manual (CM) en tercio medio vs. Masa acumulada de frutos en
el tercio inferior del árbol.
Figura 5-1: Número de frutos conteo manual (CM) vs. Masa acumulada de frutos por zonas productivas del árbol.
Tabla 5-1: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones
de la Figura 5-1.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de Regresión R2
Coeficiente de Regresión R2
Relación Estimación EE Estimación EE Estimación EE
CM vs Masa acumulada árbol 1005,989 442 2,072* 0,293 0,639 2,662* 0,147 0,917

102 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
CM vs Masa acumulada tercio
medio 194,204 143,152 1,254* 0,095 0,861 1,368* 0,045 0,968
CM vs Masa acumulada tercio
inferior 812 413 0,8181* 0,274 0,24 1,294* 0,135 0,758
* diferente de cero según prueba t al 1%;
Con la información anterior se afirma que es posible estimar la producción total de un árbol de café
si se obtiene la información del número de frutos en la totalidad de las ramas productivas del tercio
medio.
5.1.2 Relación frutos observados en pico de cosecha vs. Producción pico de cosecha (septiembre/2015).
Se realizó un segundo conteo en las ramas marcadas en el mes de septiembre, antes de realizarse el
pase pico de producción de la parcela. En este caso, se contaron los frutos cosechables y no
cosechables de las ramas y se relacionaron con la producción de dicho pase. Se tiene las relaciones
de Número de frutos cosechables observados en septiembre vs. Masa de frutos cosechados en
septiembre. Los coeficientes de determinación fueron mayores que para el caso anterior (acumulado
de la producción). Sin embargo, la relación entre el número de frutos cosechables observado en el
tercio medio no explica la producción del tercio inferior, en ese pase, (Figura 5-2 y Tabla 5-2), al
igual que el caso de la masa acumulada en el tercio inferior. Las demás relaciones si explican el
comportamiento de la producción de todo el árbol y la producción del tercio medio. El error de
estimación en este caso fue de 15,8% para la estimación de la producción del tercio medio y de 35%
para todo el árbol.

Resultados 103
(a) Número de frutos con conteo manual en tercio medio vs. Masa de frutos en el árbol en
septiembre.
(b) Número de frutos con conteo manual en tercio medio vs. Masa de frutos en el tercio
medio del árbol en septiembre.
(c) Número de frutos con conteo manual en tercio medio vs. Masa de frutos en el tercio inferior
del árbol en septiembre.
Figura 5-2: Número de frutos conteo manual vs. Masa acumulada de frutos por zonas productivas del árbol durante el pase pico de cosecha. Septiembre 2015.
Tabla 5-2: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la Tabla 5-1.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de Regresión R2
Coeficiente de Regresión R2
Relación Estimación EE Estimación EE Estimación EE
CM vs Masa acumulada árbol 140,356 109 2,346* 0,218 0,805 2,579* 0,124* 0,936
CM vs Masa acumulada tercio
medio -3,027 38,043 1,549* 0,076 0,936 1,544* 0,042* 0,978
CM vs Masa acumulada tercio
inferior 143 92 0,797* 0,185* 0,398 1,034* 0,106* 0,763
* diferente de cero según prueba t al 1%;
5.1.3 Dinámica de producción de cada tercio del árbol en la parcela estudiada.
En vista que el número de frutos del tercio medio no explican la producción del tercio inferior,
durante el pase pico de producción, se realizó un análisis de la dinámica de producción de cada tercio
del árbol y del árbol en general, a lo largo del semestre productivo del 2015.

104 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
La producción de tercio inferior es igual estadísticamente al tercio medio (Figura 5-3), pero su
dinámica es diferente y se encuentra desplazada en el tiempo (Figura 5-4a y b). Cada uno de los
tercios del árbol es responsable del 50% de la producción total del árbol, a pesar de que el ciclo
productivo del tercio inferior es más lento por razones de autosombreamiento y menores
temperaturas en ésta zona del árbol. Este aspecto es necesario para tenerlo en cuenta al momento de
estimar la producción de un árbol, sin embargo, la dinámica mostrada en este ejercicio puede ser
diferente en cultivo multilínea, diferentes edades y ubicaciones de los árboles.
Figura 5-3: Intervalos de confianza para producción por zona productiva del árbol y para todo el
árbol.
(a) Producción promedio por árbol en cada
pase de cosecha. (b) Diferencia promedio de producción por
árbol entre el tercio medio y el tercio inferior.
Total árbol Tercio medio Tercio medioMedia 3961.17 1857.93 1897.15LimSup 4670.75 2221.11 2345.48LimInf 3251.58 1494.74 1448.82
0.00500.00
1000.001500.002000.002500.003000.003500.004000.004500.005000.00
Producción promedio total

Resultados 105
Figura 5-4: Número de frutos conteo manual vs. Masa acumulada de frutos por zonas productivas del árbol durante el pase pico de cosecha. Septiembre 2015.
El número total de frutos contados al inicio del periodo productivo (Julio/2015) sobre el tercio medio
del árbol, muestra una relación directa con la producción total del árbol en un 92%, y una relación
directa con la producción del tercio medio en un 97%. Con errores de 32,7% y 19%, respectivamente.
El número de frutos cosechables contados en el pase pico de recolección sobre el tercio medio del
árbol, muestra una relación directa con la producción del árbol en ese pase de recolección en un 94%,
y una relación directa con la producción del tercio medio en ese pase en un 98%, con errores de 35%
y 15,8%, respectivamente. Adicionalmente, fue posible determinar el porcentaje de maduración de
un pase por medio de la relación entre el número de frutos contados al inicio del ciclo productivo y
los frutos cosechables en un pase. Esta información comparada con el porcentaje de producción de
cada árbol para dicho pase de cosecha, obtuvo una relación del 98%, lo que indica que a través de la
variable conteo de frutos cosechables y no cosechables es posible inferir el porcentaje de
maduración.
5.1.4 Análisis de producción promedio por árbol, producción en los 30 árboles del muestreo y de toda la parcela.
Se realizó un análisis del promedio producido por árbol, la producción acumulada en la muestra de
30 árboles seleccionados en la parcela y en la producción total de la parcela, durante todos los pases
de cosecha del segundo semestre de 2015. Se determinaron los coeficientes de determinación y
errores generados por la muestra seleccionada o el tipo de variable relacionada. En la Figura 5-5 y
en la Tabla 5-3, se observa el comportamiento de la producción de la muestra (promedio por árbol
y acumulada) con relación a la producción total de la parcela. Se observa en la Figura 5-5 que la
tendencia de los datos es igual para las tres relaciones: (i) Producción promedio por árbol de los 30
árboles seleccionados, Figura 5-5a; (ii) Producción acumulada en los 30 árboles seleccionados en
la parcela, Figura 5-5b; y (iii) Producción total en la parcela para cada pase de cosecha, Figura 5-5.
Para la relación entre la masa promedio por árbol (de la muestra) con la producción total de la
parcela, se obtuvo un coeficiente de determinación de 0,96 y un error del 16,87%, Figura 5-6. Para
la relación entre la masa promedio del tercio medio por árbol y la producción total de la parcela, se
observó un coeficiente de determinación de 0,98 y un error del 17,64%. Esto indica que el promedio
de producción por árbol, ya sea el total o el del tercio medio, explican la producción total de la

106 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
parcela, sin embargo existe un error de carácter muestral del 17% aproximadamente, que podría ser
ajustado si este caso se repitiera en más lotes, sin embargo para este caso, se considera el error solo
de carácter informativo.
(a) Producción promedio por árbol de los 30 árboles
seleccionados. (b) Producción acumulada en los 30 árboles seleccionados
en la parcela.
(c) Producción total en la parcela para cada pase de cosecha.
Figura 5-5: Producción promedio por árbol, acumulada en la muestra seleccionada y total en la parcela.
Tabla 5-3: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la de masa para estimar la producción de la parcela.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
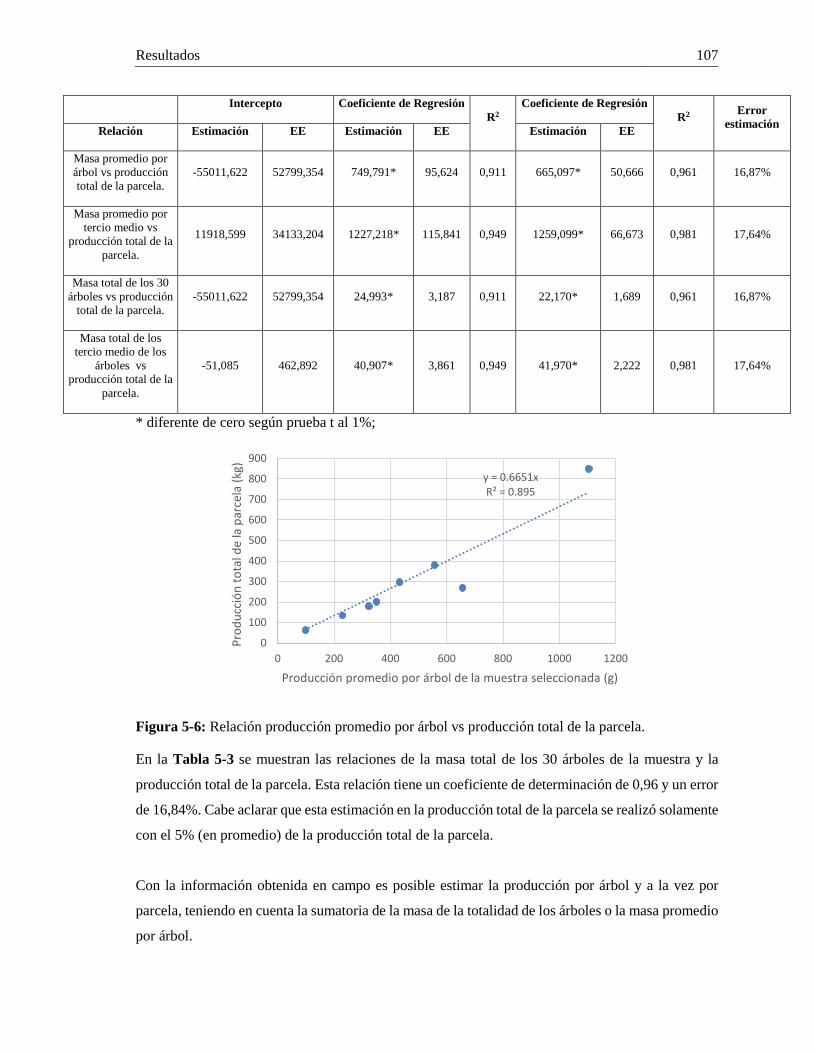
Resultados 107
Intercepto Coeficiente de Regresión R2
Coeficiente de Regresión R2 Error
estimación Relación Estimación EE Estimación EE Estimación EE
Masa promedio por árbol vs producción total de la parcela.
-55011,622 52799,354 749,791* 95,624 0,911 665,097* 50,666 0,961 16,87%
Masa promedio por tercio medio vs
producción total de la parcela.
11918,599 34133,204 1227,218* 115,841 0,949 1259,099* 66,673 0,981 17,64%
Masa total de los 30 árboles vs producción
total de la parcela. -55011,622 52799,354 24,993* 3,187 0,911 22,170* 1,689 0,961 16,87%
Masa total de los tercio medio de los
árboles vs producción total de la
parcela.
-51,085 462,892 40,907* 3,861 0,949 41,970* 2,222 0,981 17,64%
* diferente de cero según prueba t al 1%;
Figura 5-6: Relación producción promedio por árbol vs producción total de la parcela.
En la Tabla 5-3 se muestran las relaciones de la masa total de los 30 árboles de la muestra y la
producción total de la parcela. Esta relación tiene un coeficiente de determinación de 0,96 y un error
de 16,84%. Cabe aclarar que esta estimación en la producción total de la parcela se realizó solamente
con el 5% (en promedio) de la producción total de la parcela.
Con la información obtenida en campo es posible estimar la producción por árbol y a la vez por
parcela, teniendo en cuenta la sumatoria de la masa de la totalidad de los árboles o la masa promedio
por árbol.
y = 0.6651xR² = 0.895
0
100
200
300
400
500
600
700
800
900
0 200 400 600 800 1000 1200
Prod
ucci
ón to
tal d
e la
par
cela
(kg)
Producción promedio por árbol de la muestra seleccionada (g)

108 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Luego de realizar el conteo en campo y cosechar los frutos del tercio medio e inferior de los árboles
muestreados, se realizó una caracterización de la masa de café recolectada por cada tercio de los
árboles muestreados y para toda la parcela cosechada. Del todo el café cosechado en el tercio medio,
se conformó una masa combinada de 1 kg, al igual que para el café cosechado en el tercio inferior y
para el café cosechado en toda la parcela. La muestra combinada de 1 kg fue caracterizada en
diferentes estados de maduración: verdes, verde-pintón, pintones, maduros, sobremaduro y secos.
Se determinó el porcentaje de cada estado de maduración que conformaron la muestra de 1kg y se
muestra para cada uno de los pases que información se obtuvo. En la Figura 5-7 se observa la
composición de la masa cosechada en el tercio medio Figura 5-7a, en el tercio inferior Figura 5-7b
y en toda la parcela Figura 5-7c. Este análisis muestra que no todo el café cosechado es pintón,
maduro o sobremaduro, que idealmente corresponde a frutos cosechables. En la muestra
caracterizada del café cosecha en la parcela, existe un promedio de 14% de frutos no cosechables,
mientras que en la muestra caracterizada del tercio medio hay un promedio del 8% de frutos no
cosechables. Cabe aclarar que la recolección de la parcela completa se realizó con recolectores
tradicionales de la Estación Experimental Naranjal de Cenicafé, sin ninguna recomendación
adicional, es decir, ellos realizaron su labor de manera normal frente a las condiciones dadas por el
cafetal. Y la recolección de los árboles muestreados, fue una actividad realizada por personal experto
de la estación para este tipo de experimentos. Es importante considerar este comportamiento en las
datos para conocer posibles causas de error en las relaciones de la Tabla 5-3.
(a) Composición de la masa cosechada en el tercio medio. (b) Composición de la masa cosechada en el tercio
inferior.
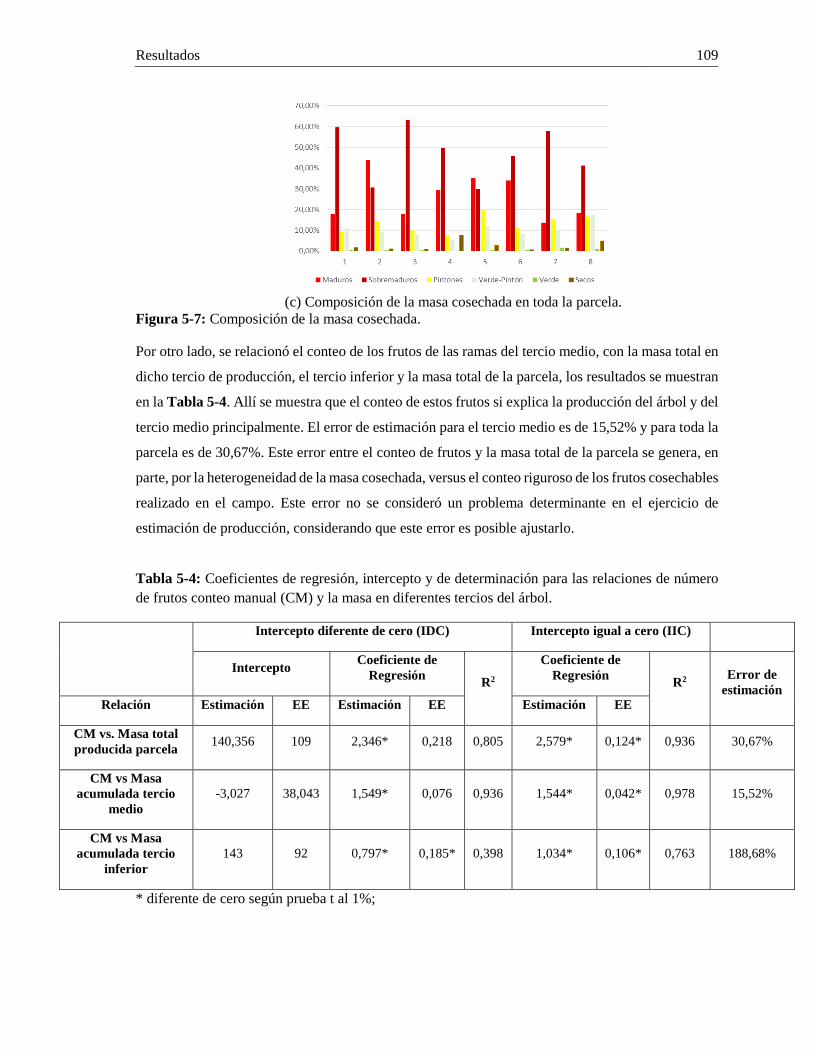
Resultados 109
(c) Composición de la masa cosechada en toda la parcela.
Figura 5-7: Composición de la masa cosechada.
Por otro lado, se relacionó el conteo de los frutos de las ramas del tercio medio, con la masa total en
dicho tercio de producción, el tercio inferior y la masa total de la parcela, los resultados se muestran
en la Tabla 5-4. Allí se muestra que el conteo de estos frutos si explica la producción del árbol y del
tercio medio principalmente. El error de estimación para el tercio medio es de 15,52% y para toda la
parcela es de 30,67%. Este error entre el conteo de frutos y la masa total de la parcela se genera, en
parte, por la heterogeneidad de la masa cosechada, versus el conteo riguroso de los frutos cosechables
realizado en el campo. Este error no se consideró un problema determinante en el ejercicio de
estimación de producción, considerando que este error es posible ajustarlo.
Tabla 5-4: Coeficientes de regresión, intercepto y de determinación para las relaciones de número de frutos conteo manual (CM) y la masa en diferentes tercios del árbol.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de Regresión R2
Coeficiente de Regresión R2 Error de
estimación Relación Estimación EE Estimación EE Estimación EE
CM vs. Masa total producida parcela 140,356 109 2,346* 0,218 0,805 2,579* 0,124* 0,936 30,67%
CM vs Masa acumulada tercio
medio -3,027 38,043 1,549* 0,076 0,936 1,544* 0,042* 0,978 15,52%
CM vs Masa acumulada tercio
inferior 143 92 0,797* 0,185* 0,398 1,034* 0,106* 0,763 188,68%
* diferente de cero según prueba t al 1%;

110 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
5.1.5 Estimación del porcentaje de maduración con la información observada en el pase de septiembre.
Adicionalmente, se calculó el porcentaje de maduración del pase de cosecha de septiembre, como la
relación del número de frutos cosechables observados en septiembre, sobre la totalidad de frutos
observados en julio. Este porcentaje fue relacionado con el porcentaje real entregado por la relación
de masa de la producción de septiembre sobre el peso acumulado durante todo el semestre, árbol por
árbol seleccionado. En la Tabla 5-5 se muestra el comportamiento de la variable porcentaje de
maduración. El conteo de frutos explica el porcentaje de maduración presente durante el pase de
cosecha de septiembre con coeficientes de determinación desde 0,88 hasta 0,98 y errores de
estimación desde 7,8% hasta 4,2%.
Tabla 5-5: Coeficientes de regresión, intercepto y de determinación para cada una de las relaciones de la Porcentaje de Maduración calculado con el conteo de frutos (PMCM) y Porcentaje de Maduración calculado con la masa cosechada (PMMC). Figura 5-1
Relación Coeficiente de regresión
R Square Intervalo del Confianza al 95%
Error de estimación Estimación EE
PMCM vs PMMC de la
parcela 0,939* 0,038 0,954 1,014 / 0,865 5,3%
PMCM vs PMMC del
tercio medio 1,096* 0,031 0,976 1,157 / 1,035 4,2%
PMCM vs PMMC del
tercio inferior 0,798* 0,055 0,878 0,905 / 0,690 7,8%
Analizando el intervalo de confianza generado por cada relación, se concluye que la relación de
PMCM vs PMMC del tercio medio es diferente estadísticamente a las otras dos relaciones y que no
sobreestima ni subestima el porcentaje de maduración real de dicha zona del árbol. Para las otras dos
relaciones el conteo de frutos manual sobreestima el porcentaje de maduración del árbol y/o del
tercio inferior.
Con los resultados mostrados en esta sección, se comprueba que el muestreo es un factor
determinante en los procesos de estimación de producción, sin embargo, los objetivos de esta tesis

Resultados 111
doctoral, están enmarcados en una correcta medición de la producción en la rama de café, buscando
a futuro estimar producciones a mayor nivel de escalamiento en el cultivo, árbol y parcela.
5.2 Obtención de modelos lineales para la estimación del número de frutos en rama a partir del conteo automático.
En este subcapítulo se mostrará el comportamiento del algoritmo 2D para la estimación de número
de frutos en la rama y como con esta información y un diseño muestreal particular fue posible lograr
un acercamiento a la estimación de la producción de una parcela con información parcial de los
árboles muestreados.
Con la información adquirida en 90 ramas de café y un total de 409 imágenes, se obtuvo: i) El número
de frutos observados (fo), como el número total de frutos presentes en la rama, contados de manera
manual; y ii) El número de frutos contados con el algoritmo 2D (fa). Para cada rama, los frutos fueron
separados en dos grupos: a) Cosechables: frutos maduros, sobremaduros y pintones; y b) No-
cosechables: frutos inmaduros. El porcentaje de maduración promedio por rama, para las ramas
utilizadas, tuvo un intervalo entre 22,27% y 30,9% con un coeficiente de confianza del 95%, y el
intervalo para el número de frutos por rama estuvo entre 20 y 100, para el mismo coeficiente de
confianza.
La relación entre la variable medida (fa) y la observada (fo) fue lineal positiva (Figura 5-8), con
coeficiente de regresión diferente de cero, e intercepto igual a cero, según prueba t al 1%, para un
coeficiente de determinación mayor de 0,8. Igualmente se estableció dicha relación para cada uno
de los estados de desarrollo, se determinaron los parámetros 𝛽𝛽0 y 𝛽𝛽1 de la Ecuación (5.1), la
significancia estadística de cada parámetro y el error estándar para cada una de las dos agrupaciones
de frutos (Cosechables y no-cosechables). Las expresiones fueron evaluadas con los siguientes
criterios: i) coeficientes de regresión significativamente diferentes de cero con base en la prueba t al
1%; y ii) coeficientes de determinación mayores 0,70. Con aquellas expresiones que cumplieron con
estos criterios se realizó una evaluación con la información obtenida en 45 ramas y posteriormente
una validación en 940 ramas, tomadas en cuatro lotes de café variedad Castillo® de edades
diferentes.

112 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 5-8: Número total de frutos en conteo manual vs. Número total de frutos medidos automáticamente. Verificación de relación lineal.
𝑓𝑓𝑠𝑠 = 𝛽𝛽0 + 𝛽𝛽1𝑓𝑓𝑙𝑙. (5.1)
En la Tabla 5-6 (Columna IDC) se ilustra la estimación del intercepto y los coeficientes de regresión
para cada uno de los grupos, con la información tomada de las 90 ramas. En los casos en los cuales
el intercepto fue igual a cero, según prueba t al 1%, se obtuvo la estimación del coeficiente de
regresión, pasando por el origen (Columna IIC de la Tabla 5-6).
Tabla 5-6: Coeficientes de regresión, intercepto y de determinación para cada uno de los grupos en la relación frutos contados manualemente vs. Frutos medidos con el algoritmo 2D.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de
regresión R2
Coeficiente de regresión
R2
Error de estimación
(absoluto / relativo) Estados Estimación EE Estimación EE Estimación EE
No cosechables -1,585 3,628 2,255* 0,105 0,836 2,217* 0,057 0,942 11,32/18,41%
Cosechables 0,169 1,187 1,529* 0,057 0,887 1,536* 0,032 0,961 4,6/17,31%
* diferente de cero según prueba t al 1%
Los modelos de regresión tienen un coeficiente de determinación entre 0,942 y 0,961 para los dos
grupos. Las estimaciones cumplen con los criterios mencionados, lo que indica que existe una
y = 1.9508xR² = 0.8008
020406080
100120140160180200
0 10 20 30 40 50 60 70 80
f o-F
ruto
s obs
erva
dos
fa- Frutos medidos automáticamente
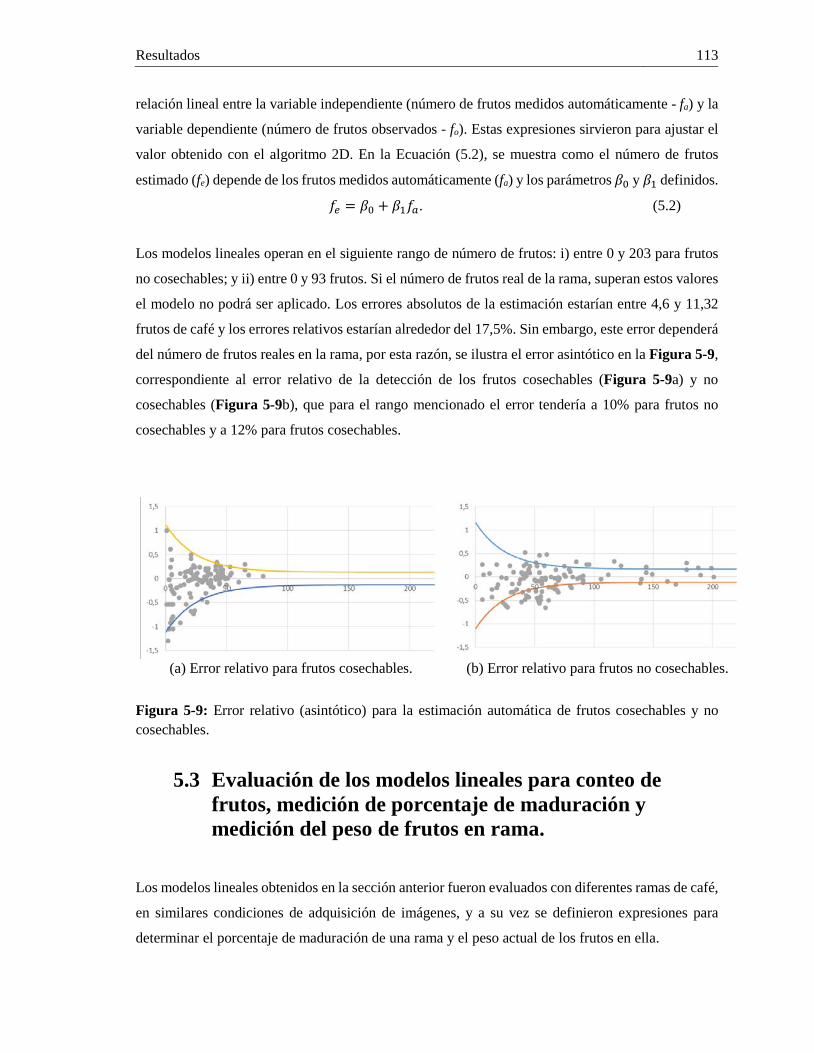
Resultados 113
relación lineal entre la variable independiente (número de frutos medidos automáticamente - fa) y la
variable dependiente (número de frutos observados - fo). Estas expresiones sirvieron para ajustar el
valor obtenido con el algoritmo 2D. En la Ecuación (5.2), se muestra como el número de frutos
estimado (fe) depende de los frutos medidos automáticamente (fa) y los parámetros 𝛽𝛽0 y 𝛽𝛽1 definidos.
𝑓𝑓𝑠𝑠 = 𝛽𝛽0 + 𝛽𝛽1𝑓𝑓𝑙𝑙. (5.2)
Los modelos lineales operan en el siguiente rango de número de frutos: i) entre 0 y 203 para frutos
no cosechables; y ii) entre 0 y 93 frutos. Si el número de frutos real de la rama, superan estos valores
el modelo no podrá ser aplicado. Los errores absolutos de la estimación estarían entre 4,6 y 11,32
frutos de café y los errores relativos estarían alrededor del 17,5%. Sin embargo, este error dependerá
del número de frutos reales en la rama, por esta razón, se ilustra el error asintótico en la Figura 5-9,
correspondiente al error relativo de la detección de los frutos cosechables (Figura 5-9a) y no
cosechables (Figura 5-9b), que para el rango mencionado el error tendería a 10% para frutos no
cosechables y a 12% para frutos cosechables.
(a) Error relativo para frutos cosechables. (b) Error relativo para frutos no cosechables.
Figura 5-9: Error relativo (asintótico) para la estimación automática de frutos cosechables y no cosechables.
5.3 Evaluación de los modelos lineales para conteo de frutos, medición de porcentaje de maduración y medición del peso de frutos en rama.
Los modelos lineales obtenidos en la sección anterior fueron evaluados con diferentes ramas de café,
en similares condiciones de adquisición de imágenes, y a su vez se definieron expresiones para
determinar el porcentaje de maduración de una rama y el peso actual de los frutos en ella.

114 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
5.3.1 Evaluación de los modelos lineales para conteo de frutos Para evaluar los modelos estimados, fueron utilizadas 45 ramas de café, sobre las cuales se obtuvo
el valor de frutos detectados automáticamente en cada uno de los grupos y el número de frutos total
observados. Fueron aplicados los coeficientes de la columna IIC de la Tabla 5-6, para los grupos
Cosechables y No-cosechables.
En la Tabla 5-7 se muestran los coeficientes de determinación, regresión e intercepto, y las
diferencias relativas mínimas, máximas y el promedio de las variables estimadas con las observadas.
Se determinó que los modelos no sobreestiman, ni subestiman y que muestran una estimación uno a
uno de las variables estimadas con las observadas, con un coeficiente de determinación mayor de
0,935. Las diferencias absolutas se encuentran entre 8,5 y 17 frutos, lo que, relacionado con el
promedio de frutos observado, muestra un error porcentual entre el 17,1% y 16,24%, muy similar al
error encontrado en la validación de la técnica de la Tabla 5-6
Tabla 5-7: Coeficientes de regresión y de determinación para la evaluación de las relacionas de la Tabla 5-6.
Intercepto igual de cero (IIC) Diferencias absolutas
Coeficiente de regresión R2
Promedio de frutos observados
Error de estimación
Estados Estimación EE
No cosechables 1,005* 0,034 0,954 64,487 17/17,1%
Cosechables 0,984* 0,045 0,935 25,382 8,5/16,24%
* diferente de cero según prueba t al 1%
5.3.2 Medición del porcentaje de maduración de una rama. Adicionalmente, se encontró la relación entre el porcentaje de maduración observado (MPo) y el
porcentaje de maduración detectado automáticamente (MPa), sin pasar por procesos de estimación,
es decir, directamente lo medido es usado para determinar el porcentaje de maduración de la rama.
Para esto fueron utilizadas las 90 ramas mencionadas en el subcapítulo 5.2.

Resultados 115
Se considera que el porcentaje de maduración es la relación entre el número de frutos cosechables
con el número de frutos en todos los estados. En la Ecuación (5.3) se presenta la relación que describe
(MPo) y (MPa), donde fa corresponde a los frutos medidos automáticamente y fo son los frutos
observados. El subíndice harvest corresponde a frutos cosechables y all-stages corresponde a frutos
cosechables y no cosechables. Se compararon ambos valores y se determinó la diferencia absoluta
entre uno y otro.
𝐷𝐷𝑃𝑃𝑠𝑠 = 100 ∙𝑓𝑓𝑚𝑚ℎ𝑖𝑖𝑚𝑚𝑎𝑎𝑖𝑖𝑐𝑐𝑡𝑡
𝑓𝑓𝑚𝑚𝑖𝑖𝑐𝑐𝑐𝑐−𝑐𝑐𝑡𝑡𝑖𝑖𝑖𝑖𝑖𝑖𝑐𝑐.
(5.3)
𝐷𝐷𝑃𝑃𝑙𝑙 = 100 ∙𝑓𝑓𝑖𝑖ℎ𝑖𝑖𝑚𝑚𝑎𝑎𝑖𝑖𝑐𝑐𝑡𝑡
𝑓𝑓𝑖𝑖𝑖𝑖𝑐𝑐𝑐𝑐−𝑐𝑐𝑡𝑡𝑖𝑖𝑖𝑖𝑖𝑖𝑐𝑐. (5.4)
Se encontró que dicha relación tiene un coeficiente de determinación de 0,776. Los coeficientes de
regresión e intercepto de esta relación, se observan en la Tabla 5-8 (Fila Porcentaje de Maduración),
y se determina que la medición de porcentaje de maduración subestima los valores de porcentaje de
maduración observados sobre la rama, según prueba t al 5%. Sin embargo, la expresión puede pasar
por el origen y en este caso tendría un coeficiente de determinación de 0,938, evidenciando la
relación entre las variables de interés, con un error del 7%. Para un rango de información entre 0%
de maduración y 81,25%.
5.3.3 Medición del peso de los frutos en una rama de café.
Para la medición del peso de frutos en la rama, fue necesario realizar muestreos destructivos a 72
ramas de café. Con la información obtenida en estas ramas se realizó un análisis de regresión lineal
entre el peso real de los frutos en una rama y número de frutos medidos automáticamente, sin pasar
por estimaciones, al igual que la subsección anterior.
Las estimaciones mostraron un coeficiente de determinación de 0,94, un coeficiente de regresión de
1,281, pasando por el origen (Tabla 5-8– Fila Peso). Con el conteo de frutos automáticamente se
puede llegar a determinar la masa del café en la rama, sin embargo, el modelo tiende a sobre estimar
el peso real, según prueba t al 5%. Esta variable depende directamente del estado de desarrollo y
cambia en mayor proporción para los frutos no cosechables, por lo tanto, se debe tener prudencia en
la aplicación de esta expresión o tener varios escenarios de maduración, o diferentes momentos de
chequeo de las ramas. El error en este caso es del 22%, similar al encontrado en la relación conteo
manual vs producción en las ramas chequeadas de los subcapítulos 5.1.1 y 5.1.2, del 19% para

116 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
cosechas futuras y 15,8% para pases principales. Esto indica que parte del error generado en la
estimación de la masa se genera principalmente por la naturaleza de la variable masa y su
variabilidad.
Tabla 5-8: Coeficientes de regresión, intercepto y de determinación para el porcentaje de maduración y masa, de los frutos detectados automáticamente y lo real en la rama.
Intercepto diferente de cero (IDC) Intercepto igual a cero (IIC)
Intercepto Coeficiente de regresión R2
Coeficiente de regresión R2 Error de
estimación Estimación EE Estimación EE Estimación EE
Porcentaje de maduración 0,578 2,580 0,763* 0,061 0,792 0,776* 0,031 0,938 7,0%
Peso 6,183 1,165 1,155* 0,032 0,861 1,281* 0,021 0,940 21,8%
* diferente de cero según prueba t al 1%
Las variables de peso y porcentaje de maduración, son muy importantes para la programación de
labores en la finca, ya que, con ellas en conjunto, es posible inferir el número de recolectores a
necesitar para cosechar el café de los árboles.
5.4 Validación de la estimación del conteo de frutos.
Una vez el sistema de detección y estimación de frutos fue evaluado, se prosiguió a validarlo y
obtener su funcionamiento para estimar el peso de los frutos en las ramas de café. Adicionalmente,
se buscó un método sencillo de aplicación para que lograse ser replicado por el caficultor al obtener
información con el dispositivo móvil.
Se realizó una validación sobre cuatro parcelas experimentales sembradas en variedad Castillo®
(multilínea – 35 progenies2), con 2, 3, 4, y 5 años. Las parcelas presentaron distribuciones de 4444,
2 Progenie significa generación o familia.

Resultados 117
6667 y 10000 árboles por hectárea, sembradas a un tallo por sitio. Cada parcela en promedio tenía
650 árboles, de los cuales fueron seleccionados aleatoriamente 60 árboles y a su vez en cada árbol
se seleccionaron cuatro ramas del tercio medio (productivo). Nótese, que en este caso se aumentó el
número de árboles, debido a la variabilidad genética en las parcelas y se disminuyó el número de
ramas a ser muestreadas por tallo, con el fin de hacer la labor de adquisición de imágenes, de manera
ágil y rápida. Esta nueva estrategia fue utilizada, pensando en el usuario final de la tecnología y
validar los desarrollos dentro de un escenario práctico de aplicación. Además, se buscó determinar
si era posible estimar el peso completo del árbol o el de la parcela, por medio de esta información
parcial, tanto al inicio del ciclo productivo, como en uno de los pases principales del segundo
semestre del año 2016.
Al inicio del ciclo productivo de segunda cosecha de 2016, en las ramas seleccionadas, se realizó un
conteo manual de los frutos y se dispuso el dispositivo móvil para adquirir las imágenes, como se
mostró en el subcapítulo 2.2.1 (Figura 2-6), evitando que sobre las imágenes adquiridas aparecieran
los problemas mencionados. En total fueron analizadas 1880 ramas de café y un total de 7430
imágenes. 940 ramas durante el mes de julio de 2016, momento en el cual todos los frutos de café
presentes en las ramas eran inmaduros y por consiguiente pertenecen al grupo de no-cosechables. Y,
940 ramas en el mes de septiembre del mismo año, donde aparecen tanto frutos cosechables como
no-cosechables.
Se registró la producción del conjunto de las cuatro ramas, la producción de cada árbol y de cada
parcela, en cada pase de recolección, durante todo el segundo semestre del 2016. El número de pases
fue variable para cada parcela, entre 4 y 6 pases en el semestre, dependiendo directamente de las
decisiones administrativas de la Estación Experimental. Las condiciones de adquisición fueron
variables para cada parcela, debido a la morfología del árbol, la topografía del terreno, la densidad
de la plantación. En general parcelas adensadas presentan problemas de autosombreamiento, al igual
que las parcelas más jóvenes, donde la producción se encuentra en la parte más baja del árbol. Para
parcelas de más edad, la producción está por encima de 1,5 metros y se requieren sillas/escaleras o
agobiar el árbol, para adquirir las imágenes en el tercio medio del este.
5.4.1 Validación conteo automático de frutos no cosechables. Se prosiguió a verificar el factor estimación del número de frutos contados manualmente a partir del
número de frutos contado automáticamente. Para la época de Julio de 2016 (inicio de cosecha) todos
los frutos presentes en el árbol pertenecen al grupo de no-cosechables. Los factores de estimación

118 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
encontrados por lote se muestran en la Tabla 5-9. El factor a aplicar en cada lote puede ser diferente
y está relacionado a un factor cualitativo de cada parcela. Los lotes 1 y 3 presentaron en general baja
productividad, el factor a aplicar en estos lotes es de 1,86 y para los lotes 2 y 4 con mayor
productividad, el factor de ajuste es de 2,46.
Tabla 5-9: Coeficientes de regresión y de determinación para la relación conteo manual (CM) versus
conteo automático (CA) para cada uno de los lotes seleccionados y para todos los lotes.
Lote Relación Coeficiente de regresión
R2 Estimación EE
1 CM vs CA 1,854* 0,038 0,980 2 CM vs CA 2,491* 0,063 0,973 3 CM vs CA 1,860* 0,045 0,978 4 CM vs CA 2,423* 0,110 0,922
Todos los lotes CM vs CA 2,214* 0,041 0,939
El coeficiente de regresión encontrado para todos los lotes, es igual al estimado para el conteo de
frutos por cada rama de 2,217, mostrado en la construcción del modelo (Sección 5.2). Y logra estimar
uno a uno los frutos en los árboles, el coeficiente R2 es igual a 0,94 (Tabla 5-10), lo que indica que
el número de frutos medidos por la herramienta explica el número de frutos observados.
Tabla 5-10: Validación del factor 2,217 aplicado para estimar el número total de frutos en las ramas
para todos los lotes.
Lote Relación Coeficiente de regresión
R2 Estimación EE
Todos los lotes CM vs CA 0,999* 0,018 0,94
Así entonces, el algoritmo fue aplicado a cada una de las ramas adquiridas durante el mes de
Julio/2016 y se determinó el número de frutos medidos automáticamente de acuerdo con la Ecuación
(5.2), para el grupo de frutos no-cosechables, con 𝛽𝛽1 = 2.217 y 𝛽𝛽0 = 0, para ramas que cumplieran
con el rango de frutos. Fueron comparados los valores de frutos observados y frutos medidos con el
algoritmo 2D y el modelo lineal estimado, de lo que se obtuvo un coeficiente de regresión estimado
de 0,999, igual a 1 según prueba t al 5%. Lo anterior indica que el modelo no sobre estima, ni
subestima y relaciona uno a uno los frutos estimados con los observados. El coeficiente de

Resultados 119
determinación fue 0,94, lo que demuestra que los valores estimados por el algoritmo 2D y el modelo
lineal estimado, explican los valores reales observados en la rama. Por otro lado, el error de
estimación estuvo alrededor del 18%, nótese que el error es similar al generado en la evaluación de
los modelos (subcapítulo 5.3).
Fue comparado el conteo automático con el conteo manual, utilizando análisis de intervalos de
confianza, Figura 5-10. Con esta información se evidencia que el número de frutos contado
automáticamente es estadísticamente igual al número de frutos contado manualmente, para
cualquiera de los cuatro lotes seleccionados. En la Figura 5-11 se muestra un comparativo entre el
conteo manual y el automático, también se muestra la diferencia entre conteo y cómo la tendencia
por lote se mantiene.
Con lo anterior se demuestra que el algoritmo 2D propuesto es una herramienta adecuada, que puede
ser utilizada para determinar el potencial productivo de las ramas de café, antes de la cosecha, donde
todos los frutos se encuentran es un estado de desarrollo inmaduros (no cosechables), independiente
de la edad y distribución de los árboles.
Figura 5-10: Intervalos de confianza para el conteo manual y conteo automático en los 4 lotes de café seleccionado y en las 4 ramas seleccionadas (promedio del número de frutos en 4 ramas).

120 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 5-11: Comparación entre el conteo manual y el conteo automático.
5.4.2 Validación estimación de producción un pase pico de cosecha. Antes de los pases más productivos, a finales del mes de septiembre de 2016, fueron adquiridas,
nuevamente, imágenes a las 940 ramas. En esta entrada a las parcelas solo se adquirió información
de imágenes con el fin de detectar frutos cosechables, no cosechables y su relación con porcentaje
de maduración y producción en ramas, árboles y parcelas. No se adquirió información de conteo
manual.
Tabla 5-11: Coeficiente de regresión y de determinación para la relación Conteo Automático (CA)
en las cuatro ramas Septiembre/2016 versus Masa en las cuatro ramas en el mismo pase.
Lote Relación Coeficiente de
regresión R2 Error de estimación Estimación EE
1 CA vs Masa cuatro ramas (Sept.) 1,856* 0,06297 0,9425 89% 2 CA vs Masa cuatro ramas (Sept.) 1,053* 0,070 0,803 71,3% 3 CA vs Masa cuatro ramas (Sept.) 1,068* 0,034 0,946 27,7% 4 CA vs Masa cuatro ramas (Sept.) 0,871* 0,040 0,894 35,5%
Todos los lotes CA vs Masa cuatro ramas (Sept.) 1,090* 0,032 0,833 52,8% Para lotes de primera cosecha (lote 1), el conteo de frutos subestima la producción de las cuatro
ramas. Para lotes de segunda y tercera cosecha (lotes 2 y 3), el sistema no sobre estima ni subestima.
Para lotes de cuarta cosecha el sistema puede sobre estimar el peso de los frutos. En el caso particular

Resultados 121
del lote 1, los frutos de estas ramas presentaron mayor granulometría y por el contrario en el lote 4
los frutos eran más pequeños y se tenía presencia de enfermedades como roya y mancha de hierro.
En caso de utilizar como factor de estimación el coeficiente de regresión encontrado para todos los
lotes, el error de estimación es del 52,8%. Este error de estimación es alto y hace inviable la
estimación de masa por este método, justo antes de realizarse la cosecha. Cabe aclara que en este
caso no se aplicó un factor de ajuste para estimar la masa, solo se relacionó el conteo automático con
la masa de las cuatro ramas. Este error de estimación es susceptible a mejorar si se garantizan
condiciones de las ramas a chequear, como ausencia de frutos secos, y menor variabilidad entre
árboles de la parcela.
Se concluye que la medición y estimación a partir de las imágenes no sobre estima, ni subestima la
masa de los frutos cosechables, siempre y cuando las ramas sean sanas y el desarrollo de los frutos
sea coherente con la variedad Castillo®, variedad con la cual se hicieron la mayoría de los ensayos.
Las condiciones de las ramas influirán en el desempeño de la medición de masa.
El sistema logra estimar el porcentaje de maduración de la parcela a partir de la medición en el
porcentaje de maduración de las ramas en el pase principal de cosecha con un error del 11%. Sin
embargo, el funcionamiento de la estimación del porcentaje de maduración depende también del tipo
de lote en el que se aplique el método, como se muestra en la Figura 5-12. En la Figura 5-12, la
línea punteada corresponde al día que se realizó la adquisición de las imágenes, el punto naranja
corresponde al porcentaje de maduración detectado automáticamente y las barras corresponde al
porcentaje de café cosechado en cada pase con relación al total del lote.
(a) Lote 1 (b) Lote 2

122 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(a) Lote 3 (b) Lote 4
Figura 5-12: Porcentaje de maduración en cada pase de cosecha en cada lote y porcentaje de maduración estimado con la detección automática.
Al año un tallo de café puede producir entre 12 y 14 pares de ramas primarias. El número total de
ramas en un ciclo productivo para la zona donde se hicieron los ensayos es de 50 ramas por árbol,
aunque árboles jóvenes pueden tener solamente 10 ramas productivas, mientras árboles más viejos
pueden tener 60 ramas productivas en promedio.
Se analizó la relación de la masa de las cuatro ramas durante el pase de septiembre versus la masa
producida por el árbol en el mismo pase. Los resultados muestran una alta variabilidad y coherencia
frente a la producción esperada del árbol según su edad, Tabla 5-12. Para el lote 1 el coeficiente de
regresión de esta relación fue el menor de los cuatro lotes, lo que indica que la masa medida en las
cuatro ramas se acerca al valor total del árbol, esto tiene sentido en la medida que este lote era de
primera cosecha y máximo se presentaron árboles con 10 ramas de café productivas. El caso
contrario ocurre con los árboles de tercera y cuarta cosecha, los cuales en su tercio inferior tiene
ramas productivas, que como vimos en un análisis de la sección 5.1, pueden significar hasta el 50%
de la producción total del árbol. Esto nos muestra que debe ser seleccionado un número de ramas
proporcional a la edad de la plantación con el fin de detectar de manera adecuada los pesos de los
árboles, a partir del peso estimado de las ramas.
Tabla 5-12: Intercepto, coeficiente de regresión y de determinación para la relación masa en las
cuatro ramas Septiembre/2016 versus Masa por árbol (Septiembre 2016).
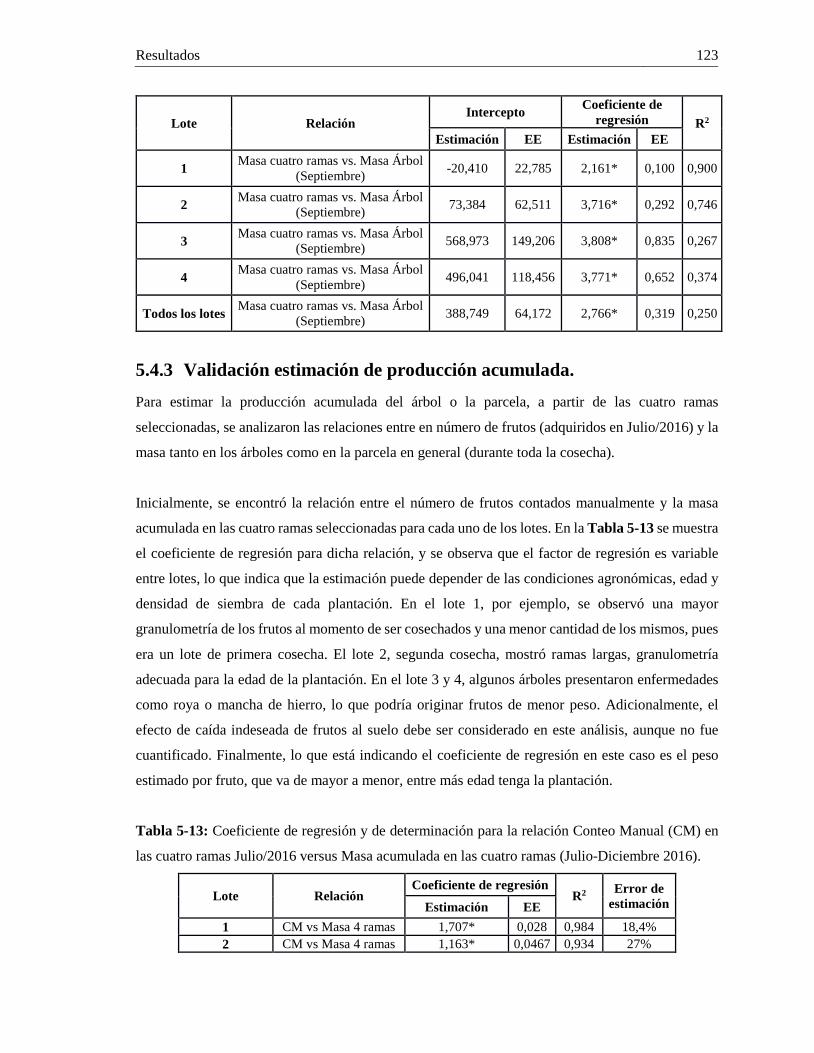
Resultados 123
Lote Relación Intercepto Coeficiente de
regresión R2 Estimación EE Estimación EE
1 Masa cuatro ramas vs. Masa Árbol (Septiembre) -20,410 22,785 2,161* 0,100 0,900
2 Masa cuatro ramas vs. Masa Árbol (Septiembre) 73,384 62,511 3,716* 0,292 0,746
3 Masa cuatro ramas vs. Masa Árbol (Septiembre) 568,973 149,206 3,808* 0,835 0,267
4 Masa cuatro ramas vs. Masa Árbol (Septiembre) 496,041 118,456 3,771* 0,652 0,374
Todos los lotes Masa cuatro ramas vs. Masa Árbol (Septiembre) 388,749 64,172 2,766* 0,319 0,250
5.4.3 Validación estimación de producción acumulada. Para estimar la producción acumulada del árbol o la parcela, a partir de las cuatro ramas
seleccionadas, se analizaron las relaciones entre en número de frutos (adquiridos en Julio/2016) y la
masa tanto en los árboles como en la parcela en general (durante toda la cosecha).
Inicialmente, se encontró la relación entre el número de frutos contados manualmente y la masa
acumulada en las cuatro ramas seleccionadas para cada uno de los lotes. En la Tabla 5-13 se muestra
el coeficiente de regresión para dicha relación, y se observa que el factor de regresión es variable
entre lotes, lo que indica que la estimación puede depender de las condiciones agronómicas, edad y
densidad de siembra de cada plantación. En el lote 1, por ejemplo, se observó una mayor
granulometría de los frutos al momento de ser cosechados y una menor cantidad de los mismos, pues
era un lote de primera cosecha. El lote 2, segunda cosecha, mostró ramas largas, granulometría
adecuada para la edad de la plantación. En el lote 3 y 4, algunos árboles presentaron enfermedades
como roya o mancha de hierro, lo que podría originar frutos de menor peso. Adicionalmente, el
efecto de caída indeseada de frutos al suelo debe ser considerado en este análisis, aunque no fue
cuantificado. Finalmente, lo que está indicando el coeficiente de regresión en este caso es el peso
estimado por fruto, que va de mayor a menor, entre más edad tenga la plantación.
Tabla 5-13: Coeficiente de regresión y de determinación para la relación Conteo Manual (CM) en
las cuatro ramas Julio/2016 versus Masa acumulada en las cuatro ramas (Julio-Diciembre 2016).
Lote Relación Coeficiente de regresión
R2 Error de estimación Estimación EE
1 CM vs Masa 4 ramas 1,707* 0,028 0,984 18,4% 2 CM vs Masa 4 ramas 1,163* 0,0467 0,934 27%

124 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
3 CM vs Masa 4 ramas 1,047* 0,035 0,957 23,9% 4 CM vs Masa 4 ramas 0,793* 0,039 0,909 22,2%
Todos los lotes CM vs Masa 4 ramas 1,079* 0,028 0,886 22,7%
La masa en las cuatro ramas seleccionadas puede ser estimada a partir del conteo de frutos en ellas,
y utilizar en general un factor de estimación de 1,079. El error de estimación de masa en este caso
será de 22,7%, igual al encontrado en la Sección 5.3.3. Si se desea hacer la estimación a partir de los
frutos contados automáticamente, será necesario aplicar inicialmente el factor de estimación para
hallar el número total de frutos en las ramas y luego este resultado deberá ser ajustado con el factor
1,079 para encontrar la masa de las cuatro ramas seleccionadas. En la Figura 5-13, se muestra como
los intervalos de confianza para la estimación de masa son estadísticamente iguales para los lotes 2
y 3, más cercanos al factor de ajuste seleccionado, lo que indica que el sistema de estimación de
masa por conjunto de cuatro ramas funciona para este tipo de lotes, pero no es un comportamiento
que se repita debido a las implicaciones agronómicas de cada una de las plantaciones. La estimación
de masa para los lotes 1 y 4 es estadísticamente diferente por los aspectos mencionados, propios de
cada lote.
Figura 5-13: Intervalos de confianza para la masa real (MR) y la masa estimada (ME) en los 4 lotes de café seleccionado y en las 4 ramas seleccionadas.
Un segundo análisis fue realizado entre la masa de las cuatro ramas seleccionadas y la masa total del
árbol. Este análisis mostró que la relación entre la producción de las cuatro ramas seleccionadas en
el tercio medio, en comparación con la producción del árbol estuvo aproximadamente entre el 25%

Resultados 125
y el 30%. Sin embargo, no es posible explicar la producción acumulada del árbol a partir de la
producción acumulada de las cuatro ramas seleccionadas, debido a la variabilidad entre árboles. Esto
se muestra con los bajos coeficientes de determinación, indicados en la Tabla 5-14, donde el único
lote que tiene una relación adecuada (0,83) es el lote 1, en los demás lotes la producción de las cuatro
ramas no explica la producción de los árboles. Este fenómeno se debe a la variabilidad en la
producción que tiene cada uno de los árboles y la expresión de ellos en cada condición de lote.
Tabla 5-14: Intercepto, coeficiente de regresión y de determinación para la relación masa en las
cuatro ramas Julio/2016 versus Masa acumulada por árbol (Julio-Diciembre 2016).
Lote Relación Intercepto Coeficiente de
regresión R2 Estimación EE Estimación EE
1 Masa acumulada ramas vs Masa acumulada árbol -167,593 69,895 2,634* 0,156 0,830
2 Masa acumulada ramas vs Masa acumulada árbol 1201,984 363,763 2,772* 0,570 0,355
3 Masa acumulada ramas vs Masa acumulada árbol 1157,746 598,973 5,521* 1,542 0,252
4 Masa acumulada ramas vs Masa acumulada árbol -51,085 462,892 6,513* 1,039 0,495
Todos los lotes
Masa acumulada ramas vs Masa acumulada árbol 724,111 257,790 3,422* 0,527 0,185
Se observó que es posible inferir la producción acumulada de la parcela a partir de la producción
acumulada en las cuatro ramas. Sin embargo, estos datos son preliminares y se requiere una
evaluación de mayor número de lotes para determinar los errores de estimación. La Figura 5-14
muestra esta relación para cada uno de los lotes de café. El lote 1 y el lote 3 presentan mayor
dispersión de los datos, pues estos lotes tuvieron dos particularidades de baja productividad,
generada por ser un lote muy joven y un lote enfermo, respectivamente. En la Figura 5-15 se
muestran las relaciones entre la producción estimada en las cuatro ramas y la producción total de la
parcela, tanto para un pase (septiembre), como para la producción acumulada.

126 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
(a) Lote 1 (b) Lote 2
(a) Lote 3 (b) Lote 4
Figura 5-14: Producción total de las cuatro ramas seleccionadas vs. Producción de la parcela en cada pase.
(a) Producción estimada de las cuatro ramas
(septiembre) vs. Producción de la parcela (septiembre).
(b) Producción estimada de las cuatro ramas (julio) vs. Producción de la parcela
(acumulada).
Figura 5-15: Producción estimada de las 4 ramas vs. Producción de la parcela.

127
6. Conclusiones generales y trabajo futuro.
6.1 Conclusiones. Se presenta una alternativa tecnológica para la estimación de frutos presentes en ramas de café,
basada en algoritmos 2D y 3D, tanto para determinar la producción de rama y de parcela en un
cultivo de café.
Se desarrolló un aplicativo móvil que integra sensores inerciales y cámara, para adquirir
imágenes/vídeo, seleccionarlas por calidad de imagen, y para georreferenciar la información
adquirida en un cultivo de café.
El dispositivo móvil es llevado al campo por un sujetador manual que controla las funciones del
aplicativo móvil y a su vez puede ser utilizado en cultivos de diferentes edades, con árboles de café
con alturas que varían entre los 80 cm y 2,8 m, en cualquier condición topográfica y densidad de
plantación.
La interfaz móvil ha sido diseñada, considerando las características de iluminación natural típicas de
las zonas cafeteras y las condiciones de adquisición de imágenes en las ramas de café.
Ambos algoritmos permitieron detectar frutos ocluidos, siendo el algoritmo 3D capaz de detectar el
56% de los frutos de la rama, mientras el algoritmo 2D permite ver el 46%, sin ningún ajuste al
conteo de frutos. Luego de ajustar el algoritmo 2D, se obtuvo un modelo de estimación que logra
encontrar el 100% de la información con error del 6% y coeficiente de determinación superiores al
0,92.
Las condiciones de sobre iluminación y autosombreamiento son más críticas para el algoritmo 2D
que para el 3D. Con relación al desenfoque y emborronamiento, se debe evitar tomar las imágenes a

128 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
velocidades superiores a los 5cm.s-1, hacerlo de manera lenta y considerando que al tener menos luz
sobre las ramas puede existir problemas de desenfoque fácilmente. Este tipo de problemas afectan
el desempeño del algoritmo 2D, presentando errores de detección entre el 18% y 40%. En el
algoritmo 3D, este problema no permite escalar los tamaños de los frutos en diferentes nubes de
puntos y a su vez, se convierte en un problema para el cálculo del volumen individual de cada fruto,
impidiendo inferir la masa de un fruto a través de su volumen.
Se diseñó un algoritmo para la identificación de frutos de café por estado de desarrollo, basado en
un clasificador SVM (Máquina de vectores de soporte), con una eficacia de 88,02%. El desempeño
de este clasificador, en conjunto con la identificación de elipses de manera automática logra
determinar el número de frutos en una rama con un error del 6%, sobre imágenes de ramas de café
adquiridas en condiciones de campo.
Los frutos semimaduros 1 y 2 (pintones), que tienen epicarpio con coloraciones características de
frutos maduros y de inmaduros, lograron ser identificados correctamente por medio de la detección
de modelo geométrico y el análisis general de la nube de puntos de cada cluster detectado en la rama.
La labor manual del conteo de frutos en ramas, puede variar entre 40 segundos y 2,5 minutos,
dependiendo de la carga de cada rama, con un error de conteo entre el 5% y el 20%. El costo
computacional del análisis 3D es aproximadamente de 37 minutos por rama y en el algoritmo 2D de
1 minuto por rama, sin considerar el tiempo de adquisición de imágenes que puede variar entre 40
segundos y 1 minuto. Se optó por construir los modelos de estimación con la información procesada
2D, debido al costo computacional y que no se tenía suficiente información 3D para el análisis
estadístico.
En los datos de dinámica de cultivo obtenidos para una parcela monolínea, donde la variabilidad
genética era mínima, se obtuvo lo siguiente: La relación entre el número de frutos contados
manualmente en un pase de cosecha con la masa producida por dichos frutos, en ese mismo pase,
tiene un R2 de 0,98, y un error del 15,8%. Si se desea conocer la masa de todo el árbol a partir del
número de frutos contados en el tercio medio durante un mismo pase de cosecha, se tiene un R2 de
0,94 y un error de 35%. La relación de número de frutos al inicio de cosecha con la masa producida
por dichos frutos durante toda la cosecha tiene un R2 de 0,97 y un error del 19%. Y la masa

Conclusiones y trabajo futuro 129
acumulada en todo el árbol durante toda la cosecha, puede ser estimada con el conteo manual de
frutos en el tercio medio, con un R2 de 0,92 y un error de 32,7%. En todos casos, la relación con el
conteo manual explica la variable masa, sin embargo, el error puede ser considerado alto y requiere
de un ajuste.
En parcelas multilínea, donde la variabilidad genética aumenta, se obtuvo información de conteo
automático y se construyeron modelos lineales de estimación entre los frutos detectados
automáticamente y los observados en la rama de café. Los modelos calculados relacionan uno a uno
los frutos contados automáticamente con los observados realmente, con R2 superior a 0,93 y un error
de estimación del 17%. La información generada por el algoritmo 2D, no solo es utilizada para
estimar el número de frutos en rama, sino también para estimar el porcentaje de maduración con un
R2 del 0,94 y un error del 7%. La masa de los frutos en ella puede ser estimada con un R2 de 0,94 y
un error del 22%. Este último valor no está muy lejos del mostrado en el párrafo anterior del 19%.
Se puede concluir que el error generado en la estimación de la variable masa se debe, en gran
proporción, a la variabilidad de la masa en una rama de café y las condiciones propias de cada rama.
Para validar la estimación de masa y el conteo automático de frutos, se analizó la información
obtenida en cuatro lotes de café variedad Castillo®, con diferentes edades y densidades de
plantación. Se encontró que el conteo automático de frutos, no sobreestima, ni subestima el conteo
real de frutos y que muestra una correlación superior a 0,90 en momentos tempranos de la cosecha,
con errores del 18%, cuando todos los frutos del árbol son no cosechables. Para momentos de cosecha
se encontró que el sistema estima adecuadamente el porcentaje de maduración, con un R2 de 0,89 y
un 11% de error. Se encontró que la masa para este caso no es correctamente estimada en ninguno
de los dos momentos antes y durante la cosecha, debido a la variabilidad de cada uno de los árboles
y lotes seleccionados.
La dinámica de la producción en un lote de café es compleja y depende en gran medida del tipo de
café sembrado, el sistema de producción, la densidad de siembra y entro otros factores agronómicos.
Es posible entonces estimar la masa de café en ciertas zonas de los árboles con errores inferiores al
19%, siempre y cuando la variabilidad genética sea mínima. En la medida que el número de
progenies aumenta el error de estimación de masa tiende a aumentar. El algoritmo 2D logra
estimaciones correctas tanto del conteo de frutos como del porcentaje de maduración y fue posible
determinar la producción de la parcela a partir del conteo en algunas ramas, sin embargo es necesario
validar en más lotes para inferir estadísticamente los resultados.

130 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
El sistema propuesto no requiere cámaras de alta resolución, ni sofisticados sistemas de iluminación,
ni vehículos que se muevan por la plantación. El sistema es llevado por una persona, que fácilmente
puede entrar en un cultivo denso, y con el sistema sujetador y el dispositivo móvil puede adquirir
imágenes en cualquier estrato del árbol, a diferentes alturas y bajo diferentes condiciones de
iluminación, sin el uso de fuentes externas de iluminación.
La información obtenida en este trabajo permitirá generar herramientas para que los caficultores
utilicen un método eficiente, no destructivo y de bajo costo que proporcione información útil para
planificar el trabajo agrícola y la obtención de beneficios económicos de la gestión eficiente de los
recursos.
6.2 Trabajo futuro Como trabajo futuro, frente al aplicativo móvil, se requiere adelantar la configuración del cliente
servidor y programar la apk (aplicación empaquetada de plataforma Android) para enviar la
información al servidor, donde deberá ser procesada por los algoritmos aquí desarrollados.
Adicionalmente, en futuros trabajos se podría generar el punto de inicio por medio de la interfaz de
GoogleMaps, creando un marcador de ubicación sobre las parcelas a chequear, con el fin de eliminar
el error generado por el GPS del Smartphone (dispositivo inteligente).
También se debe mejorar el algoritmo de detección de frutos, con el fin de disminuir el valor del
error. Encontrar la manera de disminuir el riesgo de los problemas generados por la curvatura de la
rama, desenfoques en los extremos de las imágenes, y desenfoque por movimiento. A su vez se
espera aplicar este método para estimar la producción a nivel de árbol y parcela, y generar una
herramienta para que el caficultor pueda estimar la producción de su finca en cualquier momento del
año.
Con relación al algoritmo 3D, se sugiere mejorar la medición de volumen y lograr inferir la masa, a
través de una adquisición adecuada de la información. Adicionalmente, buscar que los algoritmos
desarrollados sean lo más livianos, óptimos y rápidos, para disminuir el costo computacional de los
mismos, y generar una tecnología que se encuentre al alcance del agricultor común.

Conclusiones y trabajo futuro 131
Se requiere validar métodos de muestreo para disminuir el error de estimación de masa, o determinar
una estrategia para utilizar el conteo de frutos y porcentaje de maduración en la programación de
labores agrícolas. Es necesario realizar más ensayos de validación para verificar el uso de la
herramienta tecnológica desarrollada.

132
7. Anexos
A. Interface del aplicativo móvil para navegación y adquisición de imágenes en plantaciones de café.
Los desarrollos descritos en la sección 2 fueron implementados en un dispositivo móvil. La apariencia de la
aplicación se muestra en la Figura 7-1. En la Figura 7-1a se muestra el pantallazo inicial, donde es posible
seleccionar el modo de operación. En caso de seleccionar modo Navegación, el menú no cambia de aspecto
y el sistema almacena la información inercial para ser procesada. En caso de seleccionar el modo de
Adquisición se despliega el menú de la Figura 7-1b, allí se puede crear un nuevo vídeo, tomar imágenes
estáticas, cargar vídeos anteriores, o ver reportes de anteriores adquisiciones. Si se opta por crear vídeo o
tomar imágenes, el sistema muestra el pantallazo de la Figura 7-1c, en la cual se nombra la carpeta con el
identificador de cada rama, y posteriormente se muestra el pantallazo de la Figura 7-1d, allí se previsualiza
la cámara del dispositivo móvil, donde se puede controlar, desde el sujetador manual del teléfono, el enfoque
e inicio de vídeo o toma de imágenes.
Para el análisis 2D se requiere un número reducido de imágenes, entre 3 y 6 imágenes dependiendo de la
longitud de la rama. Por esta razón, en caso de buscar un proceso 2D la adquisición de las imágenes debe
ser por medio de Fotos (Figura 7-1b). Para el análisis 3D se requiere 1 cuadro cada 5 cuadros con el fin de
tener suficiente información para la reconstrucción de la nube de puntos, en este caso se requiere adquisición
de vídeo y un posterior proceso como se mencionó anteriormente.

Anexos 133
La aplicación generada en Android Studio hace uso de OpenCV para el tratamiento de imágenes y realizar
los cálculos de filtrado, dispone de dos formas de adquisición (imágenes y vídeo), además usa los sensores
inerciales y GPS del dispositivo para georreferenciar cada imagen adquirida. La aplicación es compilada
para dispositivos Android versión 4.4 en adelante y utiliza librerías como SupportDesign, Retrofit y
AndroidAnnotations para su correcto desarrollo.
(b) Menú del modo MCA.
(c) Registro de la rama a adquirir.
(a) Pantallazo inicial de la app desarrollada. (d) Zona de enfoque de la cámara sobre la rama.
Figura 7-1: Apariencia de la aplicación desarrollada.

134 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
B. Sistema de anotación semiautomático. Con el fin de desarrollar algoritmos para analizar secuencias de vídeo y detectar estructuras vegetativas
propias de las imágenes de entornos agrícolas, se desarrolló un sistema de anotación semiautomática, con
el que es posible definir la clase de cada estructura vegetativa presente en una imagen de rama. El sistema
de anotación desarrollado presenta procesos automáticos, semiautomáticos y manuales (Figura 7-2). Las
tareas manuales están enfocadas en supervisar el funcionamiento de las tareas automáticas y se presentan
en varias partes del método. Adicionalmente, con el fin de trabajar con secuencias de vídeo, las marcas
generadas en un cuadro de vídeo pueden trasladarse al siguiente con el fin de disminuir los tiempos de
anotación. El sistema propuesto no requiere delimitar las regiones de interés de una manera definida,
simplemente a través de marcas sencillas se genera automáticamente la región a analizar, por medio de la
aplicación de watershed sobre la imagen original. El sistema pregunta por cada región generada, a la cual
se le debe asignar una etiqueta y continúa iterativamente hasta terminar de analizar la secuencia de imágenes
de un vídeo.
El sistema de anotación desarrollado, es llamado “semiautomatic annotation system to generate ground-
truth in image sequence of agricultural sceneries” o SASGROT por sus siglas en ingles. SASGROT fue
probado principalmente con secuencias de vídeo realizadas a ramas de café. Los resultados de este fueron
comparados con el sistema de anotación on-line LabelMe [104] y se reportan disminuciones de tiempo con
el método propuesto.
Con SASGROT se obtiene un framework que genera información ground-truth de forma semi-automática,
útil para caracterizar, detectar y hacer seguimiento de objetos etiquetados en una secuencia de imágenes.
Para lograr este objetivo sobre imágenes adquiridas en entorno no controlado, se desarrolló un programa en
código C, con la librería OpenCV (superior v 2.4), bajo una distribución de Linux/Ubuntu superior a la
versión 12.0. La interfaz del programa se realiza mediante eventos del mouse y entrada de caracteres por
consola, sin entorno gráfico. SASGROT obtiene imágenes ground-truth, siguiendo el diagrama de la
(Figura 7-2), donde se puede observar como el sistema de anotación está conformado por procesos
manuales, semiautomáticos y automáticos. A continuación, se describe cada uno de los pasos a realizar.
• Paso 1: Adquirir vídeos en condiciones de campo. Como se mencionó en el Capítulo 2.

Anexos 135
• Paso 2: Seleccionar los mejores cuadros de vídeos, uno de cada 5. Seleccionar imágenes enfocadas,
sin emborronamiento generado por el movimiento de la cámara y con la información adecuada para
etiquetar, como se mencionó en el Capítulo 2.
• Paso 3: Generar una lista ordenada de los cuadros a procesar. Crear un archivo director.
• Paso 4: Correr el programa desarrollado para etiquetar estructuras vegetativas. En consola
preguntará el número de rama a procesar, debe escribirse el número que corresponda. Cada vez que
el programa muestre una imagen correspondiente a un cuadro, se verá en consola el nombre del
archivo y su ubicación.
• Paso 5: Marcar de forma sencilla cada uno de los objetos a etiquetar. El sistema ejecuta el algoritmo
watershed, donde cada una de las marcas anteriores, corresponde a una semilla.
• Paso 6: Verificar si las zonas generadas corresponden a los objetos a etiquetar. En caso de ser
necesario se debe ajustar la marca correspondiente y nuevamente ir al paso 5. Si las zonas son
correctas se continúa con el paso 7.
• Paso 7: Asignar un número entre 1 y 12, para estructuras vegetativas de frutos, tallo, hojas y fondo,
como se explicará más adelante. Se deben etiquetar cada una de las ROI generadas con las marcas
y mostradas en ventanas emergentes por el sistema.
• Paso 8: Generar un archivo de texto con el número de la rama, el nombre de la imagen, el número
de la zona analizada, la clase seleccionada y a su vez 42 características de textura propias de cada
zona (reducción a 12 características), el mismo archivo es utilizado para ingresar información de
otros cuadros. Una vez el sistema termine de procesar una imagen, abrirá la próxima en la lista.
• Paso 9: Guardar las imágenes de ground-truth y la imagen de marcas.
• Paso 10: Cargar cuadro siguiente. El sistema genera la opción de cargar las marcas anteriores y
realizar corrimiento de estas a través del movimiento del mouse sobre la imagen. Este proceso podrá
realizarse cuantas veces sea necesario, con el fin de ubicar las marcas correctamente. Es posible
adicionar marcas o borrar parte de estas, con el fin de generar segmentaciones correctas. Se vuelve
al paso 6 hasta terminar.
B.1 Tipo de estructuras vegetativas en imágenes de rama.
Las estructuras vegetativas a clasificar en una rama de café, corresponden de manera general a frutos, tallos,
hojas y fondo. Particularmente pueden aparecer frutos en diferentes estados de desarrollo, debido a las
múltiples floraciones de esta planta durante todo el año. Se tienen entonces 12 estructuras vegetativas a
etiquetar, como se lista en la Tabla 7-1.

136 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
B.2 Etiquetado y asignación de clases.
Una vez comienza el proceso de etiquetado el sistema genera la opción de crear marcas, borrar marcas y
desplazarlas. Estas funciones se realizan con los eventos del mouse: clic izquierdo para crear marcas, y clic
del medio para borrarlas, hasta que las marcas sean verificadas y correspondan a las ROI deseada, Figura
7-3. En caso de realizar un llamado a la marcación anterior, a través de clic izquierdo y movimiento del
mouse se genera un corrimiento de todo el conjunto de marcas sobre la imagen actual, y posteriormente es
posible crear nuevas marcas o borrar marcas existentes. Algunas marcas se muestran en la Figura 7-4.
La intervención manual requerida para la marcación es completa para la primera imagen cargada por el
programa. Para las siguientes imágenes la intervención manual es menor, pues se limita a ajustes de las
marcas anteriores.
B.3 Transformación Watershed.
Luego de tener ubicadas todas las marcas para los objetos de la imagen a analizar, inicia el proceso
automático para la segmentación. Se detectan los bordes para cada marca que servirán de semilla para aplicar
la transformada watershed. Una imagen en escala de grises es calculada a partir de la original y con las
semillas generadas se utiliza la herramienta morfológica, transformada de watershed, para segmentación de
estructuras complejas. La técnica de watershed es una herramienta que logra dividir estructuras similares.
En la Figura 7-5 se observan algunas imágenes segmentadas.
Para cada región generada, se calcula el contorno y se genera la secuencia de los píxeles que conforman
dicha ROI. Con la información de contorno se calcula el área, perímetro y centroide. Con la información de
píxeles de la región se calcula la media y la desviación estándar, para las componentes de siete espacios de
color: RGB, HSV, YCrCb, XYZ, CIELab, LUX y LUV, con el fin de obtener información suficiente para
desarrollo de algoritmos que toleren las condiciones no controladas de las imágenes adquiridas. En el
archivo de texto generado, cada zona corresponde a una fila y allí se almacena el valor de todas las
características mencionadas, junto con el número de la clase que ha sido ingresado por consola.

Anexos 137
B.4 Creación de información ground-truth.
Cada segmento identificado es pintado con un color y se crean dos imágenes ground-truth, una donde solo
se identifican las cuatro estructuras principales, frutos, tallo, hojas y fondo. La segunda donde se identifican
las 12 estructuras mencionadas en la Tabla 7-1. Las imágenes generadas se pueden ver en la Figura 7-6.
Figura 7-2: Diagrama de flujo del sistema semiautomático de anotación para generar información ground-truth.

138 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Tabla 7-1: Estructuras vegetativas para una rama de café.
Número Clase
Tipo de Clase
Etiqueta Aspecto Número
Clase
Tipo de Clase
Etiqueta Aspecto
1 Fruto/Inmaduro1
7
Fruto/Maduro2
2 Fruto/Inmaduro2
8
Fruto/Sobremaduro
3 Fruto/Inmaduro3
9
Tallo
4 Fruto/Semimaduro1
10
Flor
5 Fruto/Semimaduro2
11
Hoja
6
Fruto/Maduro1
12
Fondo
Píxeles que no pertenezcan a las clases de 1-11.
Figura 7-3: Verificación y mejora de las marcas para creación de la ROI.

Anexos 139
Figura 7-4: Tipo de marcas generadas.
Figura 7-5: Imágenes segmentadas con la transformada watershed.
Figura 7-6: Imágenes ground-truth. Arriba. Cuatro estructuras, Abajo. 12 estructuras.
B.5 Resultados de SASGROT.
Según el tipo de imágenes a procesar, el número de estructuras vegetativas puede variar entre 30 y 60 por
imagen, y entre 2.300 y 5.400 por vídeo. Generalmente, el 60% de las estructuras corresponden a frutos, el
20% a tallo, el 10% a hojas y 10% a fondo. La marca generada a cada estructura vegetativa se realiza a nivel
de píxel y consume un tiempo promedio por estructura de 3,8s. El mayor requerimiento de tiempo se genera
en la anotación de fondo y hojas, pues son estructuras más grandes. En la Tabla 7-2 se observa el tiempo
requerido para crear marcas en cada una de las estructuras, el tiempo promedio de creación de marcas por
imagen y por vídeo.

140 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Tabla 7-2: Tiempos promedio en segundos (ū) y desviación estándar (σ), requeridos para realizar marcas sobre estructuras, imágenes y vídeo con el SASGROT, LabelMe (Russell et al. 2008) y reducción de tiempo con sistema propuesto.
Estructuras Por imagen Por vídeo
Frutos Tallo Hojas Fondo
SASGROT 2,43 (ū) 0,65 (σ)
2,03 (ū) 0,63 (σ)
2,86 (ū) 0,61(σ)
8,01 (ū) 0,99 (σ)
146,87 (ū) 14,6 (σ)
807,78 (ū)
LabelMe 17,62 (ū)
3,7 (σ) 19,97 (ū) 3,43 (σ)
27,45 (ū) 1,91 (σ)
90,82 (ū) 3,4(σ)
1301,64 (ū) 199,1 (σ) 14318,01 (ū)
Reducción con SASGROT [%]
86,20 89,84 89,60 91,18 88,72 94,36
La calidad del etiquetado fue medida mediante matriz de confusión, determinando cuantos píxeles de la
zona pertenecían realmente a esa región, y cuantos que pertenecían a la región no habían sido agrupados.
Para cada una de las regiones segmentadas se determinó por inspección manual los falsos positivos, falsos
negativos y los verdaderos positivos. Para esta medición no tenemos verdaderos negativos, pues los píxeles
siempre harán parte de alguna región. Los resultados se reportan en la Tabla 7-3, y muestran una eficacia
de segmentación del 98%.
Otros autores han desarrollado herramientas de anotación, sin embargo, pocos han reportado
cuantitativamente el desempeño de sus herramientas. La comparación de imágenes Ground-truth contra la
realidad propia de imagen, es compleja de medir. Por esta razón y para ubicar el SASGROT en el estado
del arte de la técnica, primero se seleccionó una herramienta disponible para hacer mediciones similares a
las ya mencionadas y obtener una comparación cuantitativa de la herramienta. Por último, se realizó una
descripción con características afines a los sistemas de anotación encontrados en el estado del arte y se
realizó una comparación cualitativa con el SASGROT.
Tabla 7-3: Matriz de confusión, segmentación de ROI.
Matriz de confusión Segmentado
Positivo Negativo Verdad actual 98% 1,49% Falso actual 1.17% --
La herramienta seleccionada para realizar una comparación fue LabelMe (Russell et al. 2008), cuya
anotación se realiza a nivel de polígono. Con las mismas imágenes usadas por el SASGROT, se generaron

Anexos 141
anotaciones con el LabelMe y se determinó el tiempo de requerido para etiquetar y la calidad de dichas
anotaciones. En la Tabla 7-2, también se observan los tiempos de marcación por estructura vegetativa,
imagen y vídeo, además se observa el porcentaje de reducción de tiempo si comparamos el LabelMe con el
SASGROT. Se obtiene una reducción de hasta el 91% en marcación de estructuras, 88,7% para marcar
imágenes completas y 94% para marcar vídeos completos.
La calidad del etiquetado con la técnica de poligonos es inferior a la obtenida con el SASGROT, debido a
que la delimitación de las ROI con el sistema LabelMe (Russell et al. 2008) es poco precisa, mientras que
con el SASGROT, las ROI quedan correctamente delimitadas, Figura 7-7. A partir de un análisis de matriz
de confusión se obtuvo una eficacia de correcta segmentación para el LabelMe de 85%, que, sin ser
despreciable, es inferior a la mostrada por el SASGROT. Para el caso de las evaluaciones con el LabelMe,
la herramienta siempre subsegmenta, es decir, las regiones siempre fueron más pequeñas a la realidad, sin
embargo, esto dependerá completamente del tipo de marca que se genere.
Con relación a la comparación cualitativa, en la Tabla 7-4, se muestran las principales características de los
sistemas consultados. Características como, tracking manual, funcionamiento bajo condiciones de cámara
en movimiento, verificación de ROI y manejo de imágenes en entornos agrícolas, hacen diferenciador el
sistema propuesto, al igual que el manejo simple de creación de anotaciones sobre cada ROI.
Figura 7-7: Comparación de zonas generadas, izq. Método propuesto, der. Labelme (Russell et al. 2008).
D’Orazio et al. [105] y Kim et al. [106] cuentan con módulos independientes para detección automática de
objetos y así realizar la anotación. D’Orazio et al. [105] reporta que con el uso de su sistema hay una
reducción de tiempo en un 40% comparado con un etiquetado manual de los vídeos. Mientras que Kim et
al. [106], reporta que con el uso de su sistema hay una reducción del 60% comparado con un etiquetado
manual. Para el caso del LabelMeVideo [104], la intervención manual consiste en entregar información del
movimiento de los siguientes cuadros, para disponer las marcas ya creadas en el cuadro anteriores y no
reportan tiempos de ejecución.

142 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Cuevas et al. [107] plantean cinco métodos para determinar el tiempo de etiquetado de su sistema, el primero
es una etiquetado netamente manual, el segundo es comenzar en un punto de un contorno creado en una
imagen anterior, el tercero es un detector de movimiento y contorno activo, el cuarto es un detector de
movimiento y selección de ROI, y el quinto es seleccionar un punto de un contorno activo de una imagen
previa. El tiempo efectivamente dependerá del tipo de información a etiquetar, sin embargo, para etiquetar
a una persona en una imagen podría requerir entre 70s y 200s, independiente del método a utilizar. La
disminución del tiempo entre el etiquetado manual y el semiautomático que se propone en Cuevas et al.
[107] es del 65%.
Actualmente el SASGROT cuenta con un sistema de marcación sencillo. Los píxeles marcados se convierten
en semillas para una transformada de watershed, con la cual se realiza un crecimiento de regiones y se
genera una región de interés. La ROI se convierte a su vez en un objeto segmentado y será seguido con la
marca inicial o modificada en los cuadros siguientes. Debido a las condiciones de las imágenes y al tipo de
adquisición que se realiza en el SASGROT, el fondo no puede eliminarse y debe ser caracterizado, a
diferencia de la estrategia propuesta por algunos autores [105, 107, 108], donde el fondo es constante y
puede ser extraído y los objetos detectados por movimiento y forma.
Por otro lado, algunas estructuras vegetativas que tienen características similares de textura no logran ser
identificadas con detectores automáticos de objetos convencionales, como los utilizados por Kim et al.
[106]. Adicionalmente, hacer seguimiento a objetos como en Comaschi et al. [109] y Tebaldi [110], es
complicado pues las condiciones de luz son cambiantes entre los mismos cuadros y en algunas ocasiones
las imágenes logran desenfocarse.
Generalmente los sistemas de anotación están siendo usados en la caracterización de entornos urbanos [106,
111, 112 y 113], otros autores se han interesado en desarrollar estos sistemas para ambientes biológicos
[108 y 114] y, a nuestro conocimiento, ninguno ha sido reportado con un uso preferencial para imágenes de
entornos agrícolas.
Algo en común que tiene los sistemas de anotación consultados es el bajo número (< 10) de etiquetas
generadas en una misma imagen. Para el caso, el sistema desarrollado tiene la capacidad de etiquetar las

Anexos 143
estructuras que sean necesarias, sin tener un límite por cuadro. Todos los sistemas consultados funcionan
bajo condiciones no controladas de iluminación y generan un archivo de texto o XML, con el fin de llevar
una estadística de las etiquetas creada en cada imagen de una base de datos.
B.6 Conclusiones SASGROT.
Fue propuesto e implementado un nuevo sistema para generar imágenes ground-truth en escenarios
agrícolas. El SASGROT, como fue llamado el sistema de anotación, integra procesos manuales,
semiautomáticos y automáticos con el fin de obtener información ground-truth de buena calidad para
secuencias de imágenes adquiridas bajo condiciones de iluminación, velocidad y distancia objeto-cámara
no controladas y variables.
SASGROT requiere marcas a nivel de píxel, que no delimiten la región de interés, solo que marquen algunos
píxeles de la misma región. La marcación podrá ser modificada, y/o trasladada a cuadros siguientes y
siempre se podrá realizar una verificación manual de la calidad de las ROI generadas.
Para el SASGROT la disminución del etiquetado semiautomático frente al manual, es del orden del 90%,
comparado con otros sistemas que con la misma comparación han alcanzado disminuciones desde 40%
hasta el 65%. El sistema propuesto funciona adecuadamente para un gran número de etiquetas en una
imagen, sin poseer un límite para esto.
Los resultados obtenidos con SASGROT podrán ser aplicados a otro tipo de productos agrícolas, para esto
deben definirse claramente las clases a identificar, las condiciones de las imágenes a adquirir y el sistema
de adquisición de imágenes a utilizar.
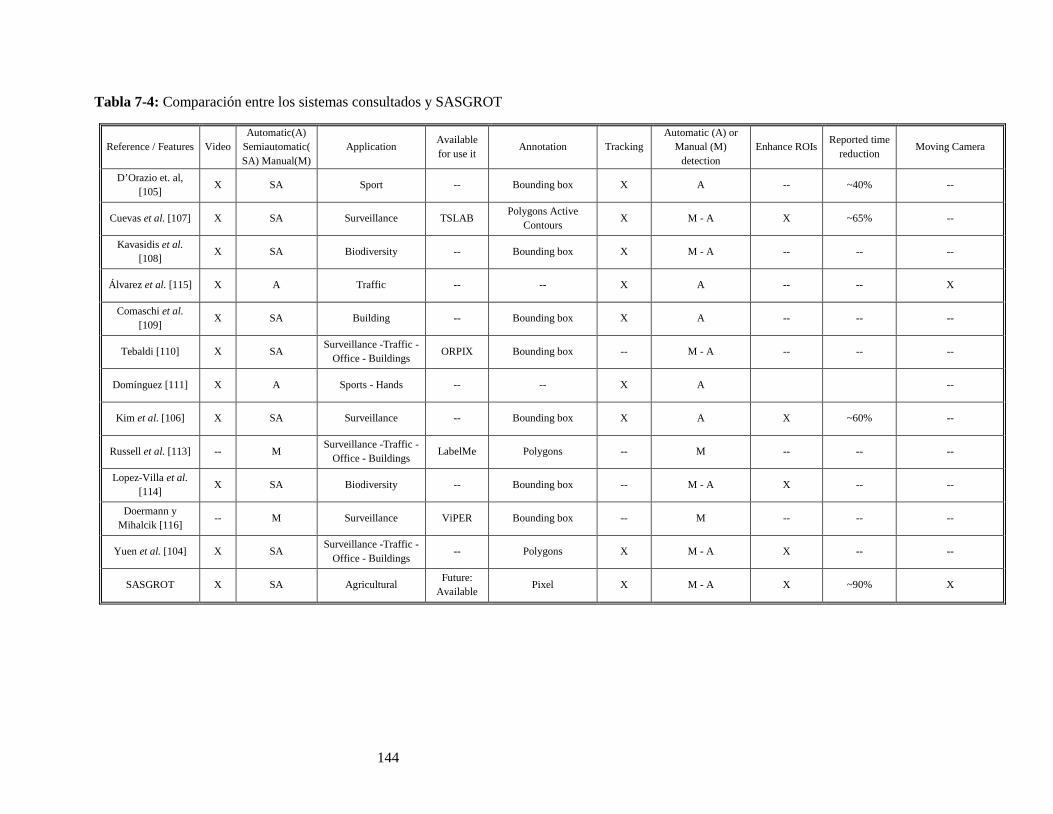
144
Tabla 7-4: Comparación entre los sistemas consultados y SASGROT
Reference / Features Video Automatic(A)
Semiautomatic(SA) Manual(M)
Application Available for use it
Annotation Tracking Automatic (A) or
Manual (M) detection
Enhance ROIs Reported time
reduction Moving Camera
D’Orazio et. al, [105] X SA Sport -- Bounding box X A -- ~40% --
Cuevas et al. [107] X SA Surveillance TSLAB Polygons Active Contours X M - A X ~65% --
Kavasidis et al. [108] X SA Biodiversity -- Bounding box X M - A -- -- --
Álvarez et al. [115] X A Traffic -- -- X A -- -- X
Comaschi et al. [109] X SA Building -- Bounding box X A -- -- --
Tebaldi [110] X SA Surveillance -Traffic - Office - Buildings ORPIX Bounding box -- M - A -- -- --
Domínguez [111] X A Sports - Hands -- -- X A --
Kim et al. [106] X SA Surveillance -- Bounding box X A X ~60% --
Russell et al. [113] -- M Surveillance -Traffic - Office - Buildings LabelMe Polygons -- M -- -- --
Lopez-Villa et al. [114] X SA Biodiversity -- Bounding box -- M - A X -- --
Doermann y Mihalcik [116] -- M Surveillance ViPER Bounding box -- M -- -- --
Yuen et al. [104] X SA Surveillance -Traffic - Office - Buildings
-- Polygons X M - A X -- --
SASGROT X SA Agricultural Future: Available Pixel X M - A X ~90% X

145
C. Modelado geométrico con supercuádricas. Por medio del análisis 3D es posible obtener información volumétrica de cada una de las estructuras
identificadas. Para el caso café, los frutos se caracterizan por una densidad volumétrica de 1,07 g/cm3 [117],
con la cual es posible determinar su masa si se conoce el volumen de cada fruto [10]. Algunos autores se
han interesado en estudiar el comportamiento volumétrico de los frutos de café con el fin de obtener
información sobre su comportamiento mecánico [118, 119], ellos mismos validan que el modelo geométrico
de los frutos aproxima el volumen de los mismos con un error entre el 1,2% y 8,1% sobre el real medido y
determinan que un fruto de café es una forma compleja, formada por la revolución de tres diferentes
parábolas sobre cada uno de los ejes coordenados.
Por otra parte, la evolución de los gráficos por computador y la expresión de estructuras 3D, han generado
una potente herramienta para crear formas paramétricas de superficie, conocidas en inglés como
superquadrics o en español supercuádricas. Estas formas hacen parte de una familia de objetos paramétricos
tridimensionales, utilizados para el modelado geométrico. Los modelos dependen de un número pequeño
de parámetros y se pueden obtener, con estos, una gran variedad de formas. Las supercuádricas se dividen
en cuatro formas paramétricas, superelipsoides, superhiperboloides de una pieza, superboloides de dos
piezas y supertoroides. Cada una de estas formas se deriva de una expresión matemática [120]. Para el
interés de este trabajo, se requieren utilizar las superellipsoides, pues con ellas es posible describir el modelo
geométrico de un fruto de café y se expresa con la Ecuación (7.1).
𝑃𝑃(𝜂𝜂,𝜔𝜔) = �𝑎𝑎1 𝑐𝑐𝑐𝑐𝑠𝑠(𝜂𝜂)𝜀𝜀1𝑐𝑐𝑐𝑐𝑠𝑠(𝜔𝜔)𝜀𝜀2
𝑎𝑎2 𝑐𝑐𝑐𝑐𝑠𝑠(𝜂𝜂)𝜀𝜀1𝑠𝑠𝐴𝐴𝑠𝑠(𝜔𝜔)𝜀𝜀2
𝑎𝑎3 𝑠𝑠𝐴𝐴𝑠𝑠(𝜂𝜂)𝜀𝜀1�−
𝜋𝜋2≤ 𝜂𝜂 ≤
𝜋𝜋2
−𝜋𝜋 ≤ 𝜔𝜔 ≤ 𝜋𝜋 .
(7.1)
Las superficies supercuádricas tienen una elevada flexibilidad gracias a los exponentes ε1 y ε2, con los
cuales se logra controlar la redondez relativa y la cuadratura en ambas direcciones, horizontal y vertical. Y
los parámetros a1, a2 y a3 corresponden a factores de escalamiento de cada forma generada. Por ejemplo
ε1 controla el componente vertical y aumenta el valor de izquierda a derecha, mientras que ε2 controla la
componente horizontal y aumenta de arriba hacia abajo, Figura 7-8.

146 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Figura 7-8: Ejemplo de Supercuádricas y parámetros de forma.
En este trabajo se determina entre que valores de ε1 y ε2 se encuentran los frutos de café, la ubicación de
ellos en la nube de puntos general de toda la rama y el volumen de cada fruto a partir de las Ecuaciones
(7.2) y (7.3), [121].
𝑉𝑉 = 2 𝑎𝑎1 𝑎𝑎2 𝑎𝑎3 𝜀𝜀1 𝜀𝜀2 𝐵𝐵 �𝜀𝜀12
+ 1, 𝜀𝜀1�𝐵𝐵 �𝜀𝜀22
,𝜀𝜀22� . (7.2)
𝐵𝐵(𝐼𝐼,𝑦𝑦) = 2� 𝑠𝑠𝐴𝐴𝑠𝑠(𝜑𝜑)2𝑚𝑚−1𝑐𝑐𝑐𝑐𝑠𝑠(𝜑𝜑)2𝑐𝑐−1𝜋𝜋/2
0𝐼𝐼𝜑𝜑. (7.3)
Algunos trabajos han reportado el uso de supercuádricas para detectar la pose de un pimiento, con el fin de
realizar cosecha robotizada, [122] y [123]. Los resultados muestran es el uso de supercuádricas tiene
potencial para análisis de productos agrícolas, sin embargo, en ninguno de los trabajos encontrados, se ha
trabajado bajo condiciones de campo, con estructuras pequeñas como las de los frutos de café y con
agrupación en racimos.

147
Bibliografía 1. S, Sumriddetchkajorn. “How Optics and Photonics Is Simply Applied in Agriculture?” Proceedings
of SPIE - The International Society for Optical Engineering 8883:888311–888311 – 7, 2013. doi:10.1117/12.2021854.
2. R. Confalonieri, M. Foi, R. Casa, S. Aquaro, E. Tona, M. Peterle, A. Boldini, “Development of an App for Estimating Leaf Area Index Using a Smartphone. Trueness and Precision Determination and Comparison with Other Indirect Methods.” Computers and Electronics in Agriculture 96 (August 2013): 67–74. doi:10.1016/j.compag.2013.04.019.
3. R.A. Viscarra Rossel, and R. Webster. “Discrimination of Australian Soil Horizons and Classes from Their Visible–near Infrared Spectra.” European Journal of Soil Science 62, no. 4 (August 1, 2011): 637–47. doi:10.1111/j.1365-2389.2011.01356.x.
4. J.A. Cardona. “Diseño de una máquina portátil para la cosecha asistida de café”. Universidad Tecnológica de Pereira. Trabajo de grado. Facultad de Ingeniería Mecánica, 2006.
5. Köhler's Medizinal-Pflanzen in naturgetreuen Abbildungen mit kurz erläuterndem Texte : Atlas zur Pharmacopoea germanica, austriaca, belgica, danica, helvetica, hungarica, rossica, suecica, Neerlandica, British pharmacopoeia, zum Codex medicamentarius, sowie zur Pharmacopoeia of the United States of America 1887.
6. M.R. Salazar G., B. Chaves C., N.M. Riaño H., J. Arcila P., and A. Jaramillo R. “Crecimiento del fruto de café Coffea arabica var. Colombia”. In: Revista Cenicafé 45 (1994), p. 41-50.
7. S. Marín L., J. Arcila P., E.C. Montoya R., and C. Oliveros T. “Cambios físicos y químicos durante la maduración del fruto de café (Coffea arabica L. var. Colombia)”. In: Revista Cenicafé 54 (2003), Nr. 3, p. 208-225.
8. P.J. Ramos G., J.R. Sanz U., and C. Oliveros T. “Identificación y clasificación de frutos de café en tiempo real, a través de la medición de color”. In: Revista Cenicafé 61 (2010), Nr. 4, p. 315-326
9. J.R. Sanz U., P.J. Ramos G., and C. Oliveros T. “Algorithm to Identify Maturation Stages of Coffee Fruits”. In: Society , IEEE C. (Ed.): IAENG Special Edition of the World Congress on Engineering and Computer Science Vol. I, IEEE, 2008, p. 167-174.
10. I.D. Aristizábal T., J.J. Carvajal H.,and C. Oliveros T. “Physical and mechanical properties correlation of coffee fruit (Coffea arabica) during its ripening.” In: Dyna 79 (2012), Nr. 172, p. 148-155.
11. R. Agarwal. “Forecasting techniques in crops”. Indian Agricultural Statistics Research Institute; Library Avenue, New Delhi – 110012. (2005).
12. D.B. Lobell, K.G. Cassman, and C. Field, C. “Crop Yield Gaps: Their Importace, Magnitudes, and Causes.” In: Annual Review of Environment and Resources. Vol 34. (2009). p. 179–204. DOI: 10.1146/annurev.environ.041008.093740
13. H.F. Huddleston. “Sampling techniques for measuring and forecasting crop yields”. United States. Dept. of Agriculture. Economics, Statistics, and Cooperatives Service. (1978). 193 p.

148 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
14. J. Cotter, C. Davies, J. Nealon, and R. Roberts. “Chapter 11. Area Cuadro Design for Agricultural Surveys”, Agricultural Survey Methods, Edited by Benedetti, R., Bee, M., Espa, G., Piersimoni, F., John Wiley & Sons, Ltd. (2010)
15. B. Basso, D. Cammarano, and E. Carfagna. Review of Crop Yield Forecasting Methods and Early Warning Systems. Lecture Notes of Global Strategy in Scientific Advisory Committtee meeting. FAO Headquarters. (2013). 56 p.
16. F.A. Vogel, F.A. “Crop forecasting methodology current and future procedures in the U.S”. In: Proceedings of the 45th session of the International Statistical Institute, held at Amsterdam: 12.1-1 to 13.1-15. (1985).
17. Ch. Cilas, and F. Descroix. “Yield Estimation and Harvest Period”. WINTGENS, J.N. Coffee: Growing, Processing, Sustainable Production. Weinheim, Alemania, Ed. Wiley-VCH. (2004). p 595- 603.
18. G. Upreti, H.C. Bittenbender, and J-L. Ingamells. “Rapid estimation of coffee yield”. In Proc. ASIC 14 Collq., San Francisco, CA. (1991). p. 585-593.
19. E.C. Montoya-Restrepo, J. Arcila-Pulgarín, A. Jaramillo, N.M. Riaño, F. Quiroga. Modelo para simular la producción potencial de café en Colombia. Boletín Técnico No. 33 del Centro Nacional de Investigaciones de Café – Cenicafé. Federación Nacional de Cafeteros de Colombia, 2009. ISSN 0120-047X
20. S. Castro-Tanzi, M. Flores, N. Warner, T.V. Dietsch, J. Banks, N. Ureña-Retana, and M. Chandler. “Evaluation of a non-destructive sampling 681 method and a statistical model for predicting fruit load on individual coffee (coff ea arabica) trees”. Scientia Horticulturae 167, 117–126. (2014).
21. S.S. Panda, D.P. Ames, and S. Panigrahi. “Application of Vegetation Indices for Agricultural Crop Yield Prediction Using Neural Network Techniques”. Remote Sensing, Nr 2, p. 673–696. (2010). DOI:10.3390/rs2030673.
22. F. Rembold, C. Atzberger, I. Savin, and O. Rojas. “Using Low Resolution Satellite Imagery for Yield Prediction and Yield Anomaly Detection”. Remote Sensing, Nr 5, p. 1704–1733. (2013). DOI:10.3390/rs5041704.
23. A.K. Prasad, L. Chai, R.P. Singh, and M. Kafatos. “Crop yield estimation model for Iowa using remote sensing and surface parameters”. International Journal of Applied Earth Observation and Geoinformation. Vol 8, Issue 1, p. 26 – 33. (2006). ISSN 0303–2434. DOI: 10.1016/j.jag.2005.06.002.
24. G. Pan, G.J. Sun, and F.M. Li. “Using QuickBird imagery and a production effciency model to improve crop yield estimation in the semi-arid hilly Loess Plateau, China”. In: Environmental Modelling & Software. Vol 24, Issue 4, p. 510 – 516. (2009). ISSN 1364–8152. DOI: 10.1016/j.envsoft.2008.09.014.
25. D.K. Bolton, and M.A. Friedl, “Forecasting crop yield using remotely sensed vegetation indices and crop phenology metrics”. In: Agricultural and Forest Meteorology, Vol. 173, Pages 74-84, (2013). ISSN 0168-1923. DOI:10.1016/j.agrformet.2013.01.007.
26. D. Stajnko, J. Rakun, and M. Blanke. “Modelling Apple Fruit Yield Using Image Analysis for Fruit Colour”. In: European Journal of Horticultural Science. Vol. 74, Nr. 6, p. 260-267. (2009).
27. Q. Wang, S. Nuske, M. Bergerman, and S. Singh. “Automated Crop Yield Estimation for Apple Orchards”. 13th Internation Symposium on Experimental Robotics. (2012).
28. Nuske, S.T., Achar, S., Bates, T., Narasimhan, S.G. and Singh, S. (2011). Yield Estimation in Vineyards by Visual Grape Detection. En: Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems.

Bibliografía 149
29. A.D. Aggelopoulou, D. Bochtis, S. Fountas, K.C. Swain, T.A. Gemots, and G.D. Nanos. “Yield prediction in apple orchards based on image processing”. Precision Agriculture. Vol. 12, Issue 3, pp 448-456. (2011). DOI:10.1007/s11119-010-9187-0
30. B. Ji, W. Zhu, B. Liu, C. Ma, and X. Li, “Review of recent machine-vision technologies in agriculture,” in Knowledge Acquisition and Modeling, 2009. KAM ’09. Second International Symposium on, vol. 3, pp. 330–334, Nov 2009.
31. F. R. Ajdadi, Y. A. Gilandeh, K. Mollazade, and R. P. Hasanzadeh, “Application of machine vision for classification of soil aggregate size,” Soil and Tillage Research, vol. 162, pp. 8 – 17, 2016.
32. L. Jiang, A. Koch, S. A. Scherer, and A. Zell, “Multi-class fruit classification using rgb-d data for indoor robots,” in 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 587–592, Dec 2013.
33. A. Gollakota and M. B. Srinivas. A multipurpose agricultural robot. In 2011 Annual IEEE India Conference, pp. 1–4, Dec 2011.
34. M. K. Dutta, A. Singh, and S. Ghosal, “A computer vision based technique for identification of acrylamide in potato chips,” Computers and Electronics in Agriculture, vol. 119, pp. 40 – 50, 2015.
35. Øystein Sture, E. R. Øye, A. Skavhaug, and J. R. Mathiassen, “A 3d machine vision system for quality grading of atlantic salmon,” Computers and Electronics in Agriculture, vol. 123, pp. 142 – 148, 2016.
36. B. Zhang, W. Huang, L. Gong, J. Li, C. Zhao, C. Liu, and D. Huang, “Computer vision detection of defective apples using automatic lightness correction and weighted {RVM} classifier,” Journal of Food Engineering, vol. 146, pp. 143 – 151, 2015.
37. C. Nansen, K. Singh, A. Mian, B. J. Allison, and C. W. Simmons, “Using hyperspectral imaging to characterize consistency of coffee brands and their respective roasting classes,” Journal of Food Engineering, vol. 190, pp. 34 – 39, 2016.
38. E. M. de Oliveira, D. S. Leme, B. H. G. Barbosa, M. P. Rodarte, and R. G. F. A. Pereira, “A computer vision system for coffee beans classification based on computational intelligence techniques,” Journal of Food Engineering, vol. 171, pp. 22 – 27, 2016.
39. B. Rodrigues, A. Soares, R. Costa, J. V. Baalen, R. Salvini, F. Silva, M. Caliari, K. Cardoso, T. Ribeiro, A. Delbem, F. Federson, C. Coelho, G. Laureano, and T. Lima, “A feasibility cachaca type recognition using computer vision and pattern recognition,” Computers and Electronics in Agriculture, vol. 123, pp. 410 – 414, 2016.
40. A. K. Mortensen, P. Lisouski, and P. Ahrendt, “Weight prediction of broiler chickens using 3d computer vision,” Computers and Electronics in Agriculture, vol. 123, pp. 319 – 326, 2016.
41. D. J. Sampson, Y. K. Chang, H. V. Rupasinghe, and Q. U. Zaman, “A dual-view computer-vision system for volume and image texture analysis in multiple apple slices drying,” Journal of Food Engineering, vol. 127, pp. 49 – 57, 2014.
42. L. Virgen-Navarro, E. J. Herrera-López, R. I. Corona-González, E. Arriola-Guevara, and G. M. Guatemala-Morales, “Neuro-fuzzy model based on digital images for the monitoring of coffee bean color during roasting in a spouted bed,” Expert Systems with Applications, vol. 54, pp. 162 – 169, 2016.
43. G. Rabatel , and C. Guizard. “Grape berry calibration by computer vision using elliptical model fitting”. In: Papers presented at the 6th European Conference on Precision Agriculture, p. 581-587, 2007.
44. P. Annamalai, W.S. Lee, and T.F. Burks. “Color Vision System for Estimating Citrus Yield in Real-time”. In: ASAE/CSAE Annual International Meeting, 2004.
45. S. Hayashi, T. Ota, J. Kubota, K. Ganno, and N. Kondo. “Robotic Harvesting Technology for Fruit Vegetables in Protected Horticultural Production”. In: Information and Technology for Sustainable Fruit and Vegetable Production, 12 - 16 September 2005, Montpellier France.

150 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
46. B. Zhang, W. Huang, J. Li, C. Zhao, S. Fan, J. Wu, and C. Liu, “Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review,” Food Research International, vol. 62, pp. 326 – 343, 2014.
47. A. Djuricic, M. Weinmann, and B. Jutzi, “Potentials of small, lightweight and low cost multi-echo laser scanners for detecting grape berries,” ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. XL-5, pp. 211–216, 2014.
48. L. Luo, Y. Tang, X. Zou, M. Ye, W. Feng, and G. Li, “Vision-based extraction of spatial information in grape clusters for harvesting robots,” Biosystems Engineering, vol. 151, pp. 90 – 104, 2016.
49. H. N. Patel, R.k.jain, and M.v.joshi, “Automatic segmentation and yield measurement of fruit using shape analysis,” International Journal of Computer Applications, vol. 45, pp. 19–24, May 2012.
50. U. Verma, F. Rossant, I. Bloch, J. Orensanz, and D. Boisgontier, “Shape-based segmentation of tomatoes for agriculture monitoring,” in International Conference on Pattern Recognition Applications and Methods (ICPRAM), pp. 402–411, March 2014.
51. J. Guerrero, M. Guijarro, M. Montalvo, J. Romeo, L. Emmi, A. Ribeiro, and G. Pajares, “Automatic expert system based on images for accuracy crop row detection in maize fields,” Expert Systems with Applications, vol. 40, no. 2, pp. 656 – 664, 2013.
52. J. Romeo, G. Pajares, M. Montalvo, J. Guerrero, M. Guijarro, and J. de la Cruz, “A new expert system for greenness identification in agricultural images,” Expert Systems with Applications, vol. 40, no. 6, pp. 2275 – 2286, 2013.
53. F. Kurtulmus and Ismail Kavdir, “Detecting corn tassels using computer vision and support vector machines,” Expert Systems with Applications, vol. 41, no. 16, pp. 7390 – 7397, 2014.
54. H. N. Patel, D. R.K.Jain, and D. M.V.Joshi, “Fruit detection using improved multiple features based algorithm,” International Journal of Computer Applications, vol. 13, pp. 1–5, January 2011.
55. M. Nielsen, D. C. Slaughter, and C. Gliever, “Vision-based 3d peach tree reconstruction for automated blossom thinning,” IEEE Transactions on Industrial Informatics, vol. 8, pp. 188–196, Feb 2012.
56. D. Dey, L. Mummert, and R. Sukthankar, “Classification of plant structures from uncalibrated image sequences,” in Applications of Computer Vision (WACV), 2012 IEEE Workshop on, pp. 329–336, Jan 2012.
57. R. N. Lati, S. Filin, and H. Eizenberg, “Estimating plant growth parameters using an energy minimization-based stereovision model,” Computers and Electronics in Agriculture, vol. 98, pp. 260– 271, 2013.
58. J. Moonrinta, S. Chaivivatrakul, M. N. Dailey, and M. Ekpanyapong, “Fruit detection, tracking, and 3d reconstruction for crop mapping and yield estimation.,” in ICARCV, pp. 1181–1186, IEEE, 2010.
59. S. Jay, G. Rabatel, X. Hadoux, D. Moura, and N. Gorretta, “In-field crop row phenotyping from 3d modeling performed using structure from motion,” Computers and Electronics in Agriculture, vol. 110, pp. 70 – 77, 2015.
60. E. R. Hunt, C. S. T. Daughtry, S. B. Mirsky, and W. D. Hively. “Remote Sensing With Simulated Unmanned Aircraft Imagery for Precision Agriculture Applications.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 7, no. 11 (November 2014): 4566–71. doi:10.1109/JSTARS.2014.2317876.
61. A. Gongal, A. Silwal, S. Amatya, M. Karkee, Q. Zhang, and K. Lewis, “Apple crop-load estimation with over-the-row machine vision system,” Computers and Electronics in Agriculture, vol. 120, pp. 26 – 35, 2016.

Bibliografía 151
62. D. Dey, L. Mummert, and R. Sukthankar. “Classification of Plant Structures from Uncalibrated Image Sequences.” In 2012 IEEE Workshop on the Applications of Computer Vision (WACV), 329–36, 2012. doi:10.1109/WACV.2012.6163017.
63. H.S. Abdullahi, F. Mahieddine, and R. E. Sheriff. “Technology Impact on Agricultural Productivity: A Review of Precision Agriculture Using Unmanned Aerial Vehicles.” In Wireless and Satellite Systems, edited by Prashant Pillai, Yim Fun Hu, Ifiok Otung, and Giovanni Giambene, 388–400. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering. Springer International Publishing, 2015. http://link.springer.com/chapter/10.1007/978-3-319-25479-1_29.
64. B. Liu, and A. Bulent Koc. “SafeDriving: A Mobile Application for Tractor Rollover Detection and Emergency Reporting.” Computers and Electronics in Agriculture 98 (October 2013): 117–20. doi:10.1016/j.compag.2013.08.002.
65. Y. Murakami, “iFarm: Development of Web-Based System of Cultivation and Cost Management for Agriculture.” In 2014 Eighth International Conference on Complex, Intelligent and Software Intensive Systems, 624–27, 2014. doi:10.1109/CISIS.2014.89.
66. J. Lee, K. Hye-Jin, P. Gyung-Leen, K. Ho-Young, and M.K. Cheol. “Intelligent Ubiquitous Sensor Network for Agricultural and Livestock Farms.” In Algorithms and Architectures for Parallel Processing, edited by Yang Xiang, Alfredo Cuzzocrea, Michael Hobbs, and Wanlei Zhou, 196–204. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2011. http://link.springer.com/chapter/10.1007/978-3-642-24669-2_19.
67. N. El-Bendary, E. E. Hariri, A. E. Hassanien, and A. Badr, “Using machine learning techniques for evaluating tomato ripeness,” Expert Systems with Applications, vol. 42, no. 4, pp. 1892 – 1905, 2015.
68. Intaravanne, Yuttana, and Sarun Sumriddetchkajorn. “BaiKhao (rice Leaf) App: A Mobile Device-Based Application in Analyzing the Color Level of the Rice Leaf for Nitrogen Estimation,” Optoelectronic Imaging and Multimedia Technology II. 8558:85580F – 85580F – 7, 2012. doi:10.1117/12.2001120.
69. R. De Bei, S. Fuentes, M. Gilliham, S. Tyerman, E. Edwards, N. Bianchini, J. Smith, and C. Collins. “VitiCanopy: A Free Computer App to Estimate Canopy Vigor and Porosity for Grapevine.” Sensors 16, no. 4 (April 23, 2016): 585. doi:10.3390/s16040585.
70. J.M. Guerrero, M. Guijarro, M. Montalvo, J. Romeo, L. Emmi, A. Ribeiro, and G. Pajares. “Automatic Expert System Based on Images for Accuracy Crop Row Detection in Maize Fields.” Expert Systems with Applications 40, no. 2 (February 1, 2013): 656–64. doi:10.1016/j.eswa.2012.07.073.
71. J. Romeo, G. Pajares, M. Montalvo, J. M. Guerrero, M. Guijarro, and J. M. de la Cruz. “A New Expert System for Greenness Identification in Agricultural Images.” Expert Systems with Applications 40, no. 6 (May 2013): 2275–86. doi:10.1016/j.eswa.2012.10.033.
72. F. Kurtulmuş, and İ. Kavdir. “Detecting Corn Tassels Using Computer Vision and Support Vector Machines.” Expert Systems with Applications 41, no. 16 (November 15, 2014): 7390–97. doi:10.1016/j.eswa.2014.06.013.
73. M. Nielsen, D. C. Slaughter, and C. Gliever. “Vision-Based 3D Peach Tree Reconstruction for Automated Blossom Thinning.” IEEE Transactions on Industrial Informatics 8, no. 1 (February 2012): 188–96. doi:10.1109/TII.2011.2166780.
74. R.N. Lati, S. Filin, and H. Eizenberg. “Estimating Plant Growth Parameters Using an Energy Minimization-Based Stereovision Model.” Computers and Electronics in Agriculture 98 (October 2013): 260–71. doi:10.1016/j.compag.2013.07.012.
75. L. Gómez-Robledo, N. López-Ruiz, M. Melgosa, A.J. Palma, L.F. Capitán-Vallvey, and M. Sánchez-Marañón. “Using the Mobile Phone as Munsell Soil-Colour Sensor: An Experiment under Controlled

152 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
Illumination Conditions.” Computers and Electronics in Agriculture 99 (November 2013): 200–208. doi:10.1016/j.compag.2013.10.002.
76. N. Canagarajah, A. Jhunjhunwala, J. Umadikar, and S. Prashant. “A New Personalized Agriculture Advisory System - Conference Papers - VDE Publishing House,” 6. Guildford, UK, 2013.
77. R.L.J. Kalinka, C. Branco, O.T Júnior, L.O. Neris, L.F.C. Chavier, and R. Minghim. “A Toolbox for Aerial Image Acquisition and Its Application to Precision Agriculture,” n.d.
78. F. Rovira-Más, “Global 3D Terrain Maps for Agricultural Applications.” Advances in Theory and Applications of Stereo Vision, January 8, 2011, 227–42. doi:10.5772/13003.
79. P. Dabove, G. Ghinamo, and A. M. Lingua. “Inertial Sensors for Smartphones Navigation.” SpringerPlus 4, no. 1 (December 30, 2015): 834. doi:10.1186/s40064-015-1572-8.
80. S. Pongnumkul, P. Chaovalit, and N. Surasvadi. “Applications of Smartphone-Based Sensors in Agriculture: A Systematic Review of Research.” Journal of Sensors 2015 (July 30, 2015): e195308. doi:10.1155/2015/195308.
81. M. Lievin and F. Luthon. “Nonlinear color space and spatiotemporal MRF for hierarchical segmentation of face features in video”. Trans. Img. Proc. 13, 1 (January 2004), 63-71. DOI=10.1109/TIP.2003.818013 http://dx.doi.org/10.1109/TIP.2003.818013.
82. J. Arcila, F. Farfán, A. Moreno, L.F. Salazar, and E. Hincapié, E. Cenicafé Ed. Sistemas de Producción de café en Colombia. Federación Nacional de Cafeteros de Colombia. 2007.
83. J. Avendaño, P.J. Ramos, and F. Prieto. “Classification of vegetal structures present in coffee branches using computer vision”. In 2016 4th CIGR International Conference of Agricultural Engineering.
84. J. B. S. Prowald, “Calibración de acelerómetros para la medida de microaceleraciones en aplicaciones espaciales” (Tesis Doctoral). Universidad Politecnica de Madrid, Madrid. Retrieved from http://oa.upm.es/368/1/JULIAN_SANTIAGO_PROWALD.pdf (2000, February)
85. B. Hofmann-Wellenhof, G. Kienast, and H. Lichtenegger. GPS in der Praxis (Third Edition). New York. 1994.
86. G. Borgefors, “Distance transformations in digital images”. Computer Vision, Graphics, and Image Processing 34, 344 – 371. 1986.
87. L. Vincent, “Morphological grayscale reconstruction in image analysis: applications and efficient algorithms”. IEEE Transactions on Image Processing 2, 176 – 201. 1995.
88. F.G. Ortiz Zamora. “Procesamiento morfológico de imágenes en color: aplicación a la reconstrucción geodésica”. Tesis doctoral. Universidad de Alicante. Departamento de Física, Ingeniería de Sistemas y Teoría de la Señal. 2002.
89. D. H. Douglas, and T.K. Peucker. “Algorithms for the reduction of the number of points requires to represent a digitized line or its caricature”. Classics in Cartography: Reflections on Influencial Articles from Cartographica, 15 – 28. 2011.
90. A. Fitzgibbon, M. Pilu, and R.B. Fisher. “Direct least square fitting of ellipses”. IEEE Transactions on pattern analysis and machine intelligence 21, 476 – 480. 1999.
91. Z. Zhang, “A flexible new technique for camera calibration,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, pp. 1330–1334, Nov. 2000.
92. N. Snavely, S. M. Seitz, and R. Szeliski, “Photo tourism: Exploring photo collections in 3d,” ACM Trans. Graph., vol. 25, pp. 835–846, July 2006.
93. N. Snavely, S. M. Seitz, and R. Szeliski, “Modeling the world from internet photo collections,” Int.J. Comput. Vision, vol. 80, pp. 189–210, Nov. 2008.
94. Y. Furukawa and J. Ponce, “Accurate, dense, and robust multi-view stereopsis,” in Computer Vision and Pattern Recognition, 2007. CVPR ’07. IEEE Conference on, pp. 1–8, June 2007.

Bibliografía 153
95. D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Int. J. Comput. Vision, vol. 60, pp. 91–110, Nov. 2004.
96. R. I. Hartley and A. Zisserman, Multiple View Geometry in Computer Vision. Cambridge University Press, ISBN: 0521540518, second ed., 2004.
97. PCL, “Point cloud library (pcl).” online. Retrieved April 26, 2016, from: http://pointclouds.org/downloads/.
98. J.L. Bentley. 1975. “Multidimensional binary search trees used for associative searching”. Commun. ACM 18, 9 (September 1975), 509-517. DOI=http://dx.doi.org/10.1145/361002.361007.
99. C.-C. Chang and C.-J. Lin, “LIBSVM: A library for support vector machines,” ACM Transactions on Intelligent Systems and Technology, vol. 2, pp. 27:1–27:27, 2011. Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
100. M.A. Fischler and R.C. Bolles. 1981. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 24, 6 (June 1981), 381-395. DOI=http://dx.doi.org/10.1145/358669.358692.
101. A.E. Ichim. PCL Toyota Code Sprint 2.0 – Superquadrics. Open Perception Inc. PCL and Toyota. Technical Report. 2013. Consulta On-line (http://lgg.epfl.ch/~ichim/projects/Alex_Ichim_TOCS2_superquadrics_report) (Vistado Marzo 2017).
102. J. J. Carvajal H., C. E. Oliveros T., and Iván Darío Aristizábal Torres. “Evaluación de propiedades físicas y mecánicas del fruto de café (Coffea arabica L. var. Colombia) durante su desarrollo y maduración.” DYNA 79, no. 173 (May 1, 2012): 116–24.
103. J. Montilla-Pérez, J. Arcila-Pulgarín, M. Aristizábal-Loaiza, E.C. Montoya-Restrepo, G.I. Puerta-Quintero, C.E. Oliveros-Tascón, G. Cadena –Gómez. “Propiedades físicas y factores de conversión del café en el proceso de beneficio”. Avances Técnicos Cenicafé. Número 370. Abril 2008.
104. J. Yuen, B. Russell, C. Liu, and A. Torralba. “LabelMe Video: Building a Video Database with Human Annotations.” In 2009 IEEE 12th International Conference on Computer Vision, 1451–58, 2009. doi:10.1109/ICCV.2009.5459289.
105. T. D’Orazio, M. Leo, N. Mosca, P. Spagnolo, and P. L. Mazzeo. “A Semi-Automatic System for Ground-truth Generation of Soccer Video Sequences.” In Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, 2009. AVSS ’09, 559–64, 2009. doi:10.1109/AVSS.2009.69.
106. J. Kim, G. Ryu-Hyeok, P. Jin-Tak, K. Hakil, and K. Yoo-Sung. “A Semi-Automatic Video Annotation Tool to Generate Ground-truth for Intelligent Video Surveillance Systems.” In Proceedings of International Conference on Advances in Mobile Computing & Multimedia, 509:509–509:513. MoMM ’13. New York, NY, USA: ACM, 2013. doi:10.1145/2536853.2536936.
107. C. Cuevas, E.M. Yáñez, and N. García. “Tool for Semiautomatic Labeling of Moving Objects in Video Sequences: TSLAB.” Sensors (Basel, Switzerland) 15, no. 7 (2015): 15159–78. doi:10.3390/s150715159.
108. I. Kavasidis, S. Palazzo, R. Di Salvo, D. Giordano, and C. Spampinato. “A Semi-Automatic Tool for Detection and Tracking Ground-truth Generation in Videos.” In Proceedings of the 1st International Workshop on Visual Interfaces for Ground-truth Collection in Computer Vision Applications, 6:1–6:5. VIGTA ’12. New York, NY, USA: ACM, 2012. doi:10.1145/2304496.2304502.
109. F. Comaschi, S. Stuijk, T. Basten, and H. Corporaal. “A Tool for Fast Ground-truth Generation for Object Detection and Tracking from Video.” In 2014 IEEE International Conference on Image Processing (ICIP), 368–72, 2014. doi:10.1109/ICIP.2014.7025073.
110. M. Tebaldi. “Designing a Labeling Application for Image Object Detection,” 2010. http://tesi.cab.unipd.it/26022/.

154 Desarrollo de un sistema automático de medición de la masa de café en rama a través de visión de máquina
111. G. F. Domínguez. “Semi-Automatic Generation of Accurate Ground-truth Data in Video Sequences.” In 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI, 310–15, 2014. doi:10.1109/ICACCI.2014.6968309.
112. J.M. Mossi, A. Albiol, A. Albiol, and J. Oliver. “Ground-truth Annotation of Traffic Video Data.” Multimedia Tools and Applications 70, no. 1 (2013): 461–74. doi:10.1007/s11042-013-1396-x.
113. B.C. Russell, A. Torralba, K.P. Murphy, and W.T. Freeman. “LabelMe: A Database and Web-Based Tool for Image Annotation.” Int. J. Comput. Vision 77, no. 1–3 (May 2008): 157–73. doi:10.1007/s11263-007-0090-8.
114. J. S. Lopez-Villa, H. D. Insuasti-Ceballos, S. Molina-Giraldo, A. Alvarez-Meza, and G. Castellanos-Dominguez. “A Novel Tool for Ground-truth Data Generation for Video-Based Object Classification,” 1–6. IEEE, 2015. doi:10.1109/STSIVA.2015.7330395.
115. J. M. Álvarez, F. Diego, A. M. López, J. Serrat, and D. Ponsa. “Automatic Ground-Truthing Using Video Registration for on-Board Detection Algorithms.” In 2009 16th IEEE International Conference on Image Processing (ICIP), 4389–92, 2009. doi:10.1109/ICIP.2009.5413620.
116. D. Doermann, and D. Mihalcik. “Tools and Techniques for Video Performance Evaluation.” In 15th International Conference on Pattern Recognition, 2000. Proceedings, 4:167–70 vol.4, 2000. doi:10.1109/ICPR.2000.902888.
117. H.J. Ciro, C.E. Oliveros-Tascon, and F. Álvarez. “Estudio dinámico bajo oscilación forzada del sistema fruto-pedúnculo (SFP) del café variedad Colombia”. Rev. Facul. Nacional Agronomía Medellin 51 (1), 63–90. 1998.
118. H.A. Tinoco, D.A. Ocampo, F.M. Peña, and J.R. Sanz-Uribe. “Finite element modal analysis of the fruit-peduncle of Coffea arabica L. var. Colombia estimating its geometrical and mechanical properties”. Computers and Electronics in Agriculture, Volume 108, October 2014, Pages 17-27, ISSN 0168-1699, http://doi.org/10.1016/j.compag.2014.06.011.
119. H. A. Tinoco. Modeling Elastic and Geometric Properties of coffea arabica L. var. Colombia Fruits by an Experimental-numerical Approach, International Journal of Fruit Science, 2017. DOI: 10.1080/15538362.2016.1270249 disponible en: http://journal-dl.co
120. A.H. Barr, “Superquadrics and Angle-Preserving Transformations”. IEEE Computer Graphics and Applications, 1, 11-22. 1981.
121. A. Jaklič, A. Leonardis, and F. Solina. “Superquadrics and Their Geometric Properties.” In Segmentation and Recovery of Superquadrics, 13–39. Dordrecht: Springer Netherlands, 2000. http://dx.doi.org/10.1007/978-94-015-9456-1_2.
122. C. Lehnert, A. English, C. McCool, A. W. Tow and T. Perez, "Autonomous Sweet Pepper Harvesting for Protected Cropping Systems," in IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 872-879, April 2017. doi: 10.1109/LRA.2017.2655622
123. C. Lehnert, I. Sa, C. McCool, B. Upcroft and T. Perez, "Sweet pepper pose detection and grasping for automated crop harvesting," 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, 2016, pp. 2428-2434. doi: 10.1109/ICRA.2016.7487394.