3. conceptos de probabilidad - itamallman.rhon.itam.mx/~lnieto/index_archivos/notasep2.pdf ·...
TRANSCRIPT

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 105
3. Conceptos de probabilidad
La Probabilidad es una medida de la incertidumbre
La incertidumbre que mide es la asociada a la eventual ocurrencia
de sucesos inciertos.
Toda medida requiere de un patrón de referencia que posibilite la
interpretación de los resultados que produce.
En el caso de la Probabilidad se ha adoptado un patrón que se
basa en las propiedades de las frecuencias relativas.
De esta manera, la probabilidad se caracteriza a través de la forma
como opera, es decir a través de sus propiedades.
Sea A un evento incierto, es decir uno cuya ocurrencia no
necesariamente es segura. Entonces, la probabilidad de que A
ocurra se denota como P(A) y esta medida debe cumplir las
siguientes propiedades básicas:
i) 1 P(A) 0 ≤≤ .
ii) 1 P(A) = sólo si A ocurre seguro.
iii) 0 P(A) = sólo si A no ocurre seguro.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 106
Otras propiedades, que involucran dos eventos son las siguientes.
Sean A y B dos eventos inciertos.
iv) Si A ocurre siempre que ocurre B A) (B ⊆ entonces,
P(A) P(B) ≤ .
v) Si sucede que A y B no pueden ocurrir simultáneamente
)A (B φ=∩ entonces, P(B)P(A) B)P(A +=∪ .
Además, es conveniente introducir la siguiente definición: Sean A y
B dos eventos inciertos de forma que 0 P(A) ≠ . Entonces, la
Probabilidad Condicional de B dado A se define como
P(A)B)P(A)A B(P ∩
=
Con esta definición, se puede introducir una más. Sean A y B dos
eventos. Entonces se dice que A y B son independientes si se tiene
que
P(B)P(A)B)P(A ×=∩
y en ese caso, P(B))A B(P = .
Todas estas propiedades han sido adoptadas con el propósito de
reproducir, para las probabilidades, el comportamiento que tienen
las frecuencias relativas. De hecho, en los casos más simples las
probabilidades se calculan directamente como frecuencias
relativas.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 107
Existe, sin embargo, una inmensa variedad de situaciones en
donde las frecuencias no están disponibles en la forma necesaria y
es ahí donde las probabilidades cobran importancia ya que, en
particular, se pueden calcular utilizando otros procedimientos.
Para empezar, no todos los fenómenos inciertos se manifiestan a
través de eventos en donde sólo es relevante si estos ocurren o no.
En muchas aplicaciones, el fenómeno aleatorio bajo estudio puede
producir distintos resultados e interesa el análisis de todos los
resultados posibles.
Aparece entonces, asociado a la observación de un fenómeno
aleatorio, el concepto de variable aleatoria. Como en el caso del
AE, una variable no es más que la codificación numérica de los
posibles resultados que se derivan de la observación de un
fenómeno.
De la misma forma que en el AE, las variables -ahora aleatorias-
pueden clasificarse como cualitativas y cuantitativas, o con mas
detalle en nominales, ordinales, discretas y continuas, de acuerdo
con su naturaleza.
El interés se concentra en la descripción de la incertidumbre
asociada al fenómeno aleatorio bajo estudio, es decir, la
incertidumbre asociada a sus posibles resultados. Por su parte, la
variable aleatoria asigna un valor distinto a cada posible resultado
diferente.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 108
Entonces, el problema equivale a describir la incertidumbre
asociada a la variable aleatoria, es decir a la ocurrencia de sus
distintos valores.
Ahora bien, si la ocurrencia de cada posible valor es incierta, la
incertidumbre correspondiente se puede describir a través de la
probabilidad respectiva.
Como conclusión, la incertidumbre asociada a una variable
aleatoria queda descrita en cuanto se describe el conjunto de
valores que puede producir y la probabilidad asociada con cada
valor.
En este punto es conveniente introducir dos nuevos términos:
1. Al conjunto de los valores que puede producir una variable
aleatoria X se le conoce como el Soporte de la variable y
habitualmente se le denota como X.
2. Al soporte, junto con la relación que asocia a cada valor de la
variable aleatoria su probabilidad de ocurrencia, se le conoce
con el nombre de Función de Probabilidad y habitualmente se
denota como PX, P(X) ó P(X = x).
Con estos conceptos se tiene que la incertidumbre asociada a una
variable aleatoria queda descrita en cuanto se conoce su función de
probabilidad.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 109
Imagine una variable aleatoria X que, al ser observada, produce
uno de los siguientes valores: x1, x2, x3, x4, x5 y x6 .
Como ya se ha indicado, la incertidumbre asociada a X queda
descrita en cuanto se informa de los valores x1 a x6 y de los valores
de probabilidad P(X = x1), … P(X = x6).
Esta información puede reportarse a través de una tabla como
sigue:
X P(X = x) x1 P(X = x1) x2 P(X = x2) x3 P(X = x3) x4 P(X = x4) x5 P(X = x5) x6 P(X = x6) 1.00
Equivalentemente, si se abrevia para a cada valor de X, pi
= P(X = xi) la tabla tiene el siguiente aspecto:
X P(X = x) x1 p1 x2 p2 x3 p3 x4 p4 x5 p5 x6 p6 1.00
Función de Probabilidad de X

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 110
Esta representación establece una similitud evidente entre la
función de probabilidad y la tabla de frecuencias relativas. Es muy
importante percibir ahora las diferencias.
La diferencia más importante entre las frecuencias y las
probabilidades estriba en el hecho de que las primeras describen la
información observada (ya registrada) en un banco de datos,
mientras que las probabilidades describen la manera en como
podría registrarse la información por observarse (futura) de una
variable aleatoria.
X fr / p 0 0.10 1 0.30 2 0.20 3 0.20 4 0.15 5 0.05 1.00
En la tabla que antecede, si los valores de la segunda columna
fuesen frecuencias relativas, estos se podrían interpretar, por
ejemplo, como sigue:
1. Un 15% de los casos en el banco presentó un valor de 4.
2. El valor que se presentó con más frecuencia (la moda) fue el 1
(30%).

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 111
Por otra parte, esta tabla debiese incluir el tamaño del banco (n).
X fr / p 0 0.10 1 0.30 2 0.20 3 0.20 4 0.15 5 0.05 1.00
Si, por el contrario, la tabla se refiriese a una función de
probabilidad, la interpretación seguiría otra línea. Por ejemplo:
1. Con una probabilidad de 0.15 se espera que, al observar la
variable, se presente un valor de 4.
2. El valor que se espera con mayor probabilidad (la moda) es el
1 (0.30).
En este caso la noción de tamaño del banco simplemente no existe.
Las características más notables de este ejemplo se pueden
generalizar para concluir que, así como la tabla de frecuencias es
un resumen eficiente (suficiente y minimal) de la información
contenida en un banco de datos, la función de probabilidad
constituye el resumen correspondiente si el propósito es describir la
incertidumbre asociada a una variable aleatoria.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 112
Por otra parte, una vez que ha sido establecida esta
correspondencia entre tabla de frecuencias y función de
probabilidad, surge de manera natural la idea de transportar
también al terreno de la probabilidad otros resúmenes propios del
Análisis Exploratorio.
El objetivo es el mismo: proveer una descripción, en este caso del
comportamiento de la variable aleatoria. El concepto también
coincide: emplear resúmenes parciales que si bien no capturan
toda la información relevante, destacan algún aspecto que puede
ser de especial interés.
De esta manera es posible referirse a las medidas de localización y
dispersión para variables aleatorias introduciendo algunas
modificaciones en las definiciones correspondientes.
MEDIDAS DE LOCALIZACIÓN
(para variables aleatorias)
Moda. Es el valor más probable de X.
Mediana. Es el valor X(0.5), en el soporte de X, que satisface
simultáneamente las dos siguientes condiciones:
P( X ≤ X(0.5) ) ≥ 0.5
P( X ≥ X(0.5) ) ≥ 0.5 .

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 113
Cuantil (de orden q). Es el valor X(q), en el soporte de X, que
satisface simultáneamente las dos siguientes condiciones:
P( X ≤ X(q) ) ≥ q
P( X ≥ X(q) ) ≥ 1-q .
Mínimo. Es el valor más pequeño, X[-], en el soporte de X.
Máximo. Es el valor más grande, X[+], en el soporte de X.
Media (Valor Esperado ó Esperanza). Es un promedio ponderado
de los valores en el soporte de X donde las probabilidades
respectivas sirven como pesos. Por ejemplo, si la variable X
produce los valores x1, x2, x3, x4, x5 y x6 con probabilidades p1, p2,
p3, p4, p5 y p6 respectivamente, entonces la media de X se calcula
como:
µ = E(X) = ∑=
6
1iiixp
Como puede observarse, todas las medidas de localización
originalmente diseñadas para servir propósitos descriptivos en el
AE tienen una versión equivalente en Probabilidad que se obtiene,
para todo propósito práctico, sustituyendo frecuencias relativas por
probabilidades.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 114
Posiblemente el caso en el que esta identificación resulta menos
clara es la media. Aparentemente se tiene una diferencia relevante
cuando aquí se define como un promedio ponderado mientras que
en AE se definió como un promedio aritmético simple. Esta
diferencia es sólo aparente.
Recuerde que en un banco de datos puede presentarse la
repetición de valores. De hecho, el propósito del cálculo de
frecuencias es precisamente dar cuenta de esas repeticiones.
Por otra parte, en el soporte de una variable solamente se incluyen
los valores distintos de X.
Así pues si se observa que la definición de la media en AE se
refiere al promedio sobre todos los casos en el banco, mientras que
en Probabilidad se consideran los valores en el soporte, es
inmediato comprobar que las dos definiciones coinciden.
Considere el siguiente conjunto de datos que describe los años
transcurridos desde la obtención del título profesional para el grupo.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 115
Compruebe que si calcula la media utilizando, primero, la fórmula
∑=
==n
1iin
1 xXµ
en donde n es el número de casos y después construye la tabla de
frecuencias relativas, sin agrupar, y calcula ahora
E(X) = ∑=
k
1 iiixfr
donde k es el número de valores distintos en el banco (de
renglones en la tabla de frecuencias), obtiene el mismo resultado.
De la misma manera se puede proceder con las medidas de
dispersión.
A ñ o s435539054493
1 5335562

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 116
MEDIDAS DE DISPERSIÓN
(para variables aleatorias)
Rango. Es el valor R que se calcula como la diferencia entre los
valores máximo y el mínimo de la variable:
R = X[+] – X[-].
Rango entre cuartiles. Es el valor REC, que se calcula como la
diferencia entre los cuantiles de orden 0.75 (tercer cuartil) y 0.25
(primer cuartil):
REC = X(0.75) – X(0.25).
Error Medio. Es un promedio ponderado de las diferencias que
guardan, en valor absoluto, los valores en el soporte de X respecto
a una medida de localización. Las probabilidades respectivas sirven
como pesos y por ejemplo, si la variable X produce los valores x1,
x2, x3, x4, x5 y x6 con probabilidades p1, p2, p3, p4, p5 y p6
respectivamente, y X(0.5) es la mediana de X, entonces el EM,
respecto a la mediana, se calcula como:
EM(X) = ∑=
−6
1 i(0.5)ii Xxp
Varianza. Es el valor σ2 que se calcula como un promedio
ponderado de las diferencias que guardan, elevadas al cuadrado,
los valores en el soporte de X respecto a la media de la variable.
Las probabilidades respectivas sirven como pesos y por ejemplo, si

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 117
la variable X produce los valores x1, x2, x3, x4, x5 y x6 con
probabilidades p1, p2, p3, p4, p5 y p6 respectivamente, entonces la
varianza de X se calcula como:
σ2(X) = Var(X) = ∑=
−6
1i
2ii )µx(p .
Desviación estándar. Es el valor σ que se calcula como la raíz
cuadrada de la varianza. De nuevo, por ejemplo, si la variable X
produce los valores x1, x2, x3, x4, x5 y x6 con probabilidades p1, p2,
p3, p4, p5 y p6, entonces la desviación estándar de X resulta:
σ(X) = [Var(X)]1/2 = ∑=
−6
1i
2ii )µx(p .
Tanto las medidas de localización como las medidas de dispersión
que se han presentado para las variables aleatorias parten del
supuesto de que el soporte X de la variable X esta formado por un
número finito de posibles valores.
Estrictamente en la práctica, este supuesto es correcto. Sin
embargo, existen modelos de probabilidad que son muy útiles y
convenientes y que tienen un soporte con un número infinito de
posibles valores.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 118
En tal caso es necesario modificar, en cierto sentido, las
definiciones de algunos de estos resúmenes. Considere el caso en
que el soporte es infinito pero discreto. Es decir, el caso en que X =
{ x1, x2, x3,… } donde los valores constituyen una secuencia de
puntos aislados sin fin.
La primera consecuencia de esta estructura es que en
correspondencia con los valores en X, debe existir una secuencia,
también infinita, de probabilidades { p1, p2, p3,… }. Cada una de
estos valores debe cumplir con las propiedades que caracterizan a
las probabilidades y en conjunto deben satisfacer, la condición:
1p1i
i =∑∞
=.
En términos técnicos, se dice que la sucesión definida por la suma
de las probabilidades debe converger a 1.
Además, todos los resúmenes que involucran promedios
ponderados deben incorporar la modificación correspondiente. Esto
significa que en el caso de variables aleatorias discretas con
soporte infinito se tiene que:
µ = E(X) = ∑∞
= 1 iiixp ,
EM(X) = ∑∞
=−
1 i(0.5)ii Xxp ,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 119
σ2 = ∑∞
=−
1i
2ii )µx(p y
σ = ∑∞
=−
1i
2ii )µx(p .
Naturalmente, ahora cada una de estas medidas define una
sucesión que, al menos en teoría, podría no converger. Por
supuesto, los modelos más comunes y, en particular, los que se
consideran en este texto no presentan esa anomalía.
Un caso ligeramente más sofisticado es el de las variables
aleatorias continuas. Como en AE, se dice que una variable es
continua si puede producir cualquier valor en un intervalo. Es decir,
si el soporte X es un intervalo.
Conceptualmente, la dificultad más importante cuando se
consideran variables continuas radica en el hecho de que si X es un
intervalo, no existe forma de recorrer puntualmente, uno a la vez,
los valores en el soporte para calcular los promedios requeridos.
Suponga, por ejemplo, que tiene una variable continua con soporte
X igual al intervalo [0, 10]. Evidentemente, el mínimo valor en el
soporte es cero pero no es posible establecer cual es el que le
sigue. Cualquier candidato, digamos A, queda descartado
automáticamente si se reconoce que entre cero y el número A
existe una infinidad de valores más.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 120
La solución a este dilema está inspirada en la idea, ya bien
conocida, de agrupar. Suponga que el soporte X se divide en un
número finito, digamos k, de subintervalos o clases. Suponga,
además, que las probabilidades asociadas a todas y cada una de
las clases son Ak
A2
A1 p,....,p,p .
Si ahora se elige, en cada clase un valor de X como representante
y se forma la colección Ak
A2
A1 xxx ,....,, entonces una aproximación
al valor de, por ejemplo, la media está dado por:
E*(X) = ∑=
k
1i
Ai
Ai xp
Es intuitivamente claro que la calidad de esta aproximación será
mejor en la medida en que el número de clases aumente y la
longitud de todos y cada uno de los subintervalos sea cada vez
menor. De esta manera, y desde un punto de vista técnico de
nuevo, se tiene que la Media se puede obtener como resultado de
un proceso límite:
E(X) xp kk
1i
Ai
Ai → ∞→
=∑
Ahora bien, es un resultado bien conocido del cálculo integral que
una suma como la que se ha construido, cuando converge, lo hace
a una integral. En este caso,
∫∑ → ∞→
= Xdx f(x) x xp k
k
1i
Ai
Ai

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 121
en donde f(x) es una función con las siguientes características:
1. f(x) ≥ 0 para toda x en X.
2. 1dx f(x) =∫X
.
A la función f(x) se le conoce como la función de densidad de
probabilidad de X.
La otra propiedad importante de f(x) es la siguiente: Para cualquier
intervalo [a, b] que se encuentre contenido en el soporte de X, la
probabilidad del evento A = {a ≤ X ≤ b} se calcula como:
∫=b
adx f(x)P(A) .
Esta propiedad implica que, en particular, un peculiar resultado
según el cual si x es un valor fijo cualquiera de una variable
aleatoria X continua entonces
P( X = x ) = 0.
Es decir, cualquier modelo de probabilidad para variables
continuas:
1. Asigna a un intervalo una probabilidad que se calcula como el
área bajo la curva definida por la función de densidad.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 122
2. A todo valor aislado de la variable le asigna probabilidad cero.
Es importante observar que las variables aleatorias continuas no
cuentan con función de probabilidad; en su lugar se tiene la función
de densidad de probabilidad.
Comente cuales son las similitudes y diferencias entre la función de
probabilidad (para variables discretas) y la función de densidad
(para variables continuas).
Existe otra función definida para ambos tipos de variables: La
Función de Distribución. Si X es una variable aleatoria y x es un
valor cualquiera, entonces, la función de distribución de X evaluada
en x se define como
FX(x) = P(X ≤ x).
A la Función de Distribución también se le llama función de
probabilidad acumulada y la forma de cálculo es distinta para las
variables discretas y continuas.
Caso discreto:
∑∑ ≤≤===≤= xy yxyX py)P(Xx)P(X(x)F .

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 123
Caso Continuo:
∫∞−
=≤=x
X f(y)dyx)P(X(x)F .
Volviendo al problema de describir una variable aleatoria, ahora es
posible plantear la descripción en términos más generales que
incluyan tanto a las variables discretas como a las continuas:
Una variable aleatoria está completamente descrita en cuanto se
define su soporte y su función de distribución.
En relación con este tema vale la pena observar que existe una
cantidad incontable de variables aleatorias.
De hecho, cualquier colección de números positivos cuya suma sea
finita puede dar lugar a una función de probabilidad y por tanto a
una variable discreta.
Por su parte cualquier función positiva cuya área bajo la curva sea,
también, finita puede dar lugar a una función de densidad y por
tanto a una variable continua.
Una forma muy conveniente de trabajar con variables aleatorias es
a través de modelos.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 124
Un modelo (paramétrico) para una variable aleatoria es una
ecuación que permite el cálculo de una función de distribución (o de
probabilidad o de densidad) una vez que se fijan los valores de un
conjunto de índices o parámetros.
Alguno de los modelos parámetricos más comunes son los
siguientes:
Variables discretas:
1. Uniforme.
2. Triangular.
3. Bernoulli
4. Binomial.
5. Poisson.
6. Geométrica
7. Binomial Negativa.
Variables Continuas:
1. Uniforme
2. Triangular.
3. Exponencial,
4. Normal,
5. Ji cuadrada
6. t de Student
7. F.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 125
Algunos de estos modelos, o mejor dicho, algunas de estas familias
de modelos ya han sido presentadas. Sin embargo y para tener un
panorama conjunto, aquí se revisan nuevamente.
Modelo Uniforme Discreto.
Soporte:
X = {1, 2, 3, …N}.
Función de Probabilidad:
P(X = x) = 1/N para todo x en X.
Esperanza:
E(X) = (N+1)/2
Varianza:
Var(X) = (N2 –1)/12
Esta familia tiene tantos elementos como valores existen de N
enteros mayores que 1.
0.00
0.03
0.06
0.09
0.12
0.15
0 1 2 3 4 5 6 7 8 9 10 11
Función de Probabilidad Uniforme Discreta (N=10)

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 126
Modelo Triangular Discreto.
Soporte:
X = {1, 2, 3, …N}.
Función de Probabilidad:
P(X = x) = bx para todo x en X.
( b = 2/{(N(N+1)} ).
Esperanza:
E(X) = (2N+1)/3
Varianza:
Var(X) = {(N –1)(N +1)}/18
Esta familia de modelos tiene tantos elementos como valores N
existen enteros y mayores que 1.
Función de Probabilidad Triangular Discreta (N=10)
0
0.03
0.06
0.09
0.12
0.15
0.18
0 1 2 3 4 5 6 7 8 9 10 11
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 127
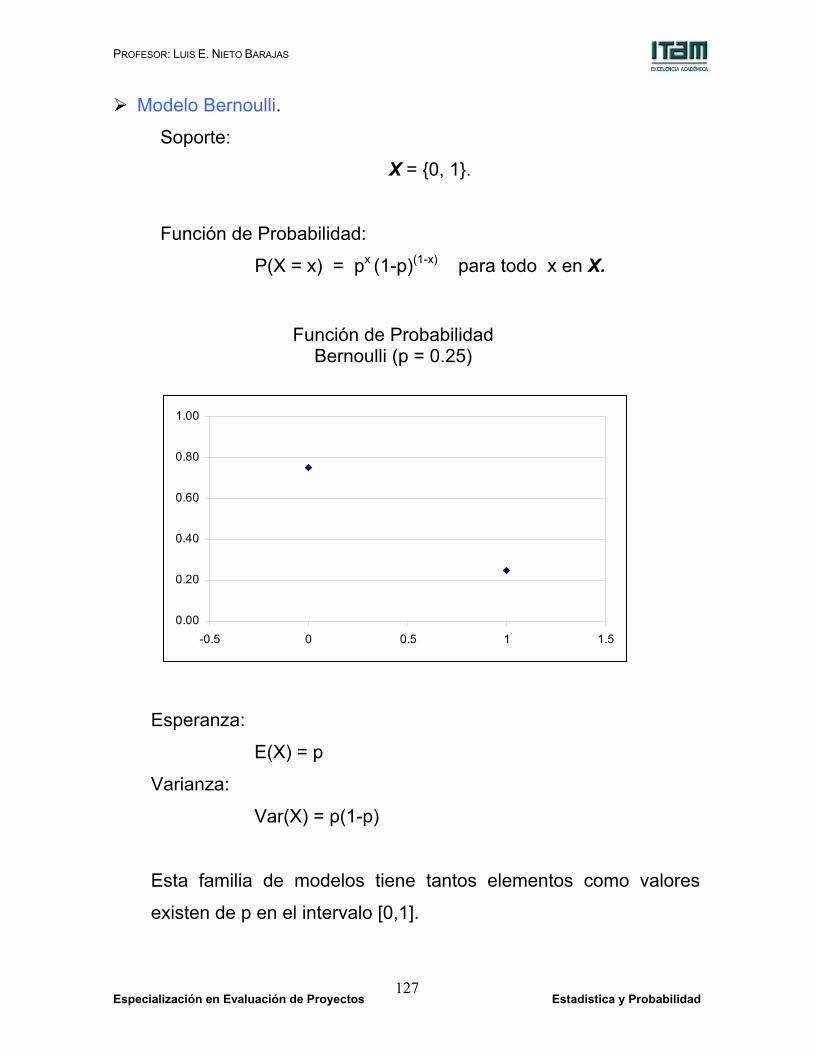
Modelo Bernoulli.
Soporte:
X = {0, 1}.
Función de Probabilidad:
P(X = x) = px (1-p)(1-x) para todo x en X.
Esperanza:
E(X) = p
Varianza:
Var(X) = p(1-p)
Esta familia de modelos tiene tantos elementos como valores
existen de p en el intervalo [0,1].
Función de Probabilidad Bernoulli (p = 0.25)
0.00
0.20
0.40
0.60
0.80
1.00
-0.5 0 0.5 1 1.5
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 128
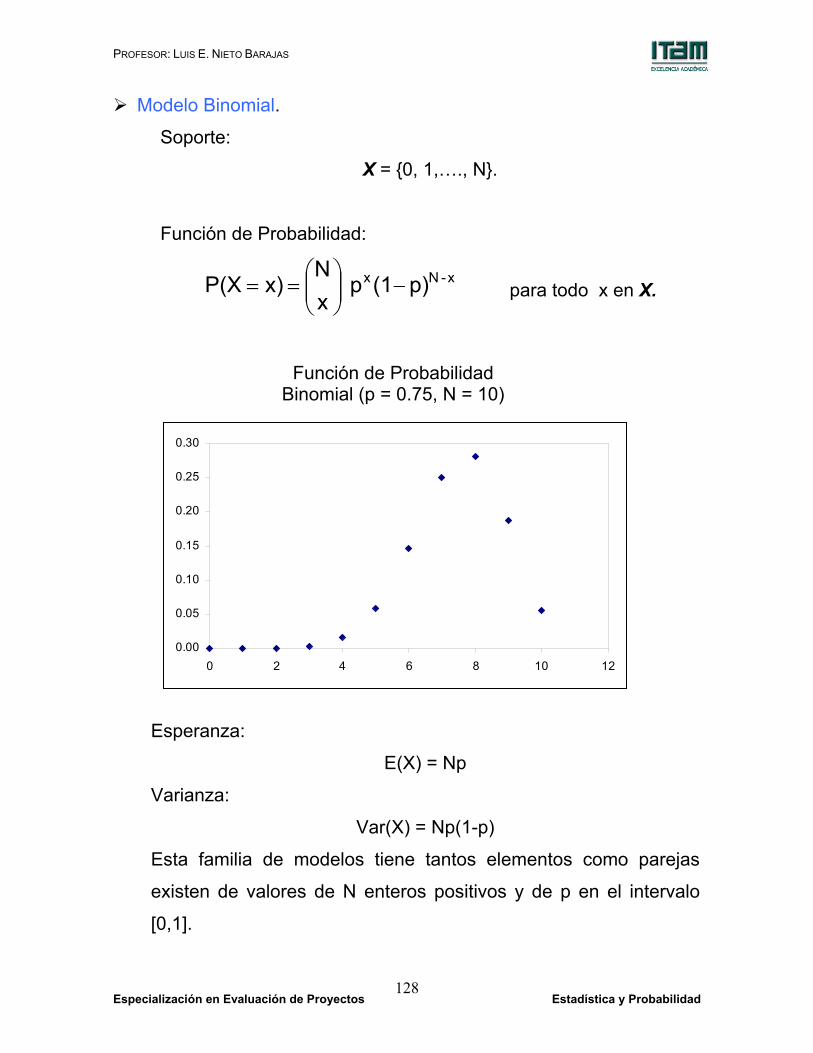
Modelo Binomial.
Soporte:
X = {0, 1,…., N}.
Función de Probabilidad:
x- Nx p)(1p xN
x)P(X −
== para todo x en X.
Esperanza:
E(X) = Np
Varianza:
Var(X) = Np(1-p)
Esta familia de modelos tiene tantos elementos como parejas
existen de valores de N enteros positivos y de p en el intervalo
[0,1].
Función de Probabilidad Binomial (p = 0.75, N = 10)
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 2 4 6 8 10 12
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 129
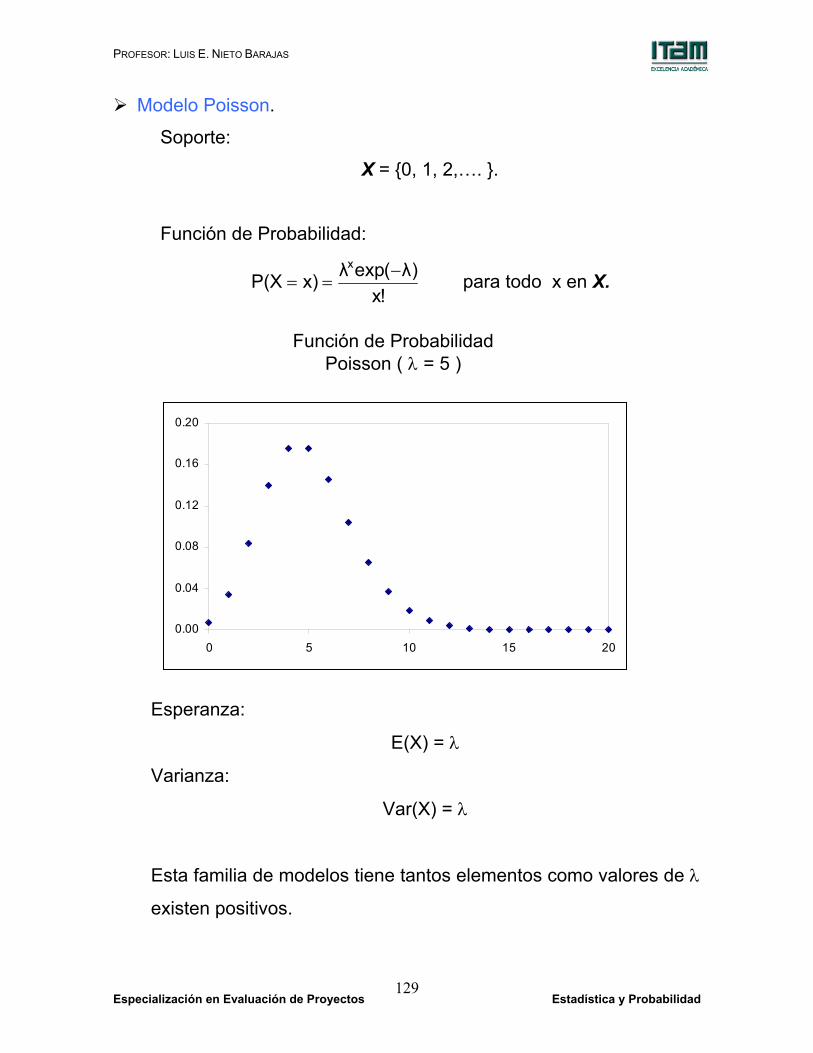
Modelo Poisson.
Soporte:
X = {0, 1, 2,…. }.
Función de Probabilidad:
!x)λ(expλx)P(X
x −== para todo x en X.
Esperanza:
E(X) = λ
Varianza:
Var(X) = λ
Esta familia de modelos tiene tantos elementos como valores de λ
existen positivos.
Función de Probabilidad Poisson ( λ = 5 )
0.00
0.04
0.08
0.12
0.16
0.20
0 5 10 15 20
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 130
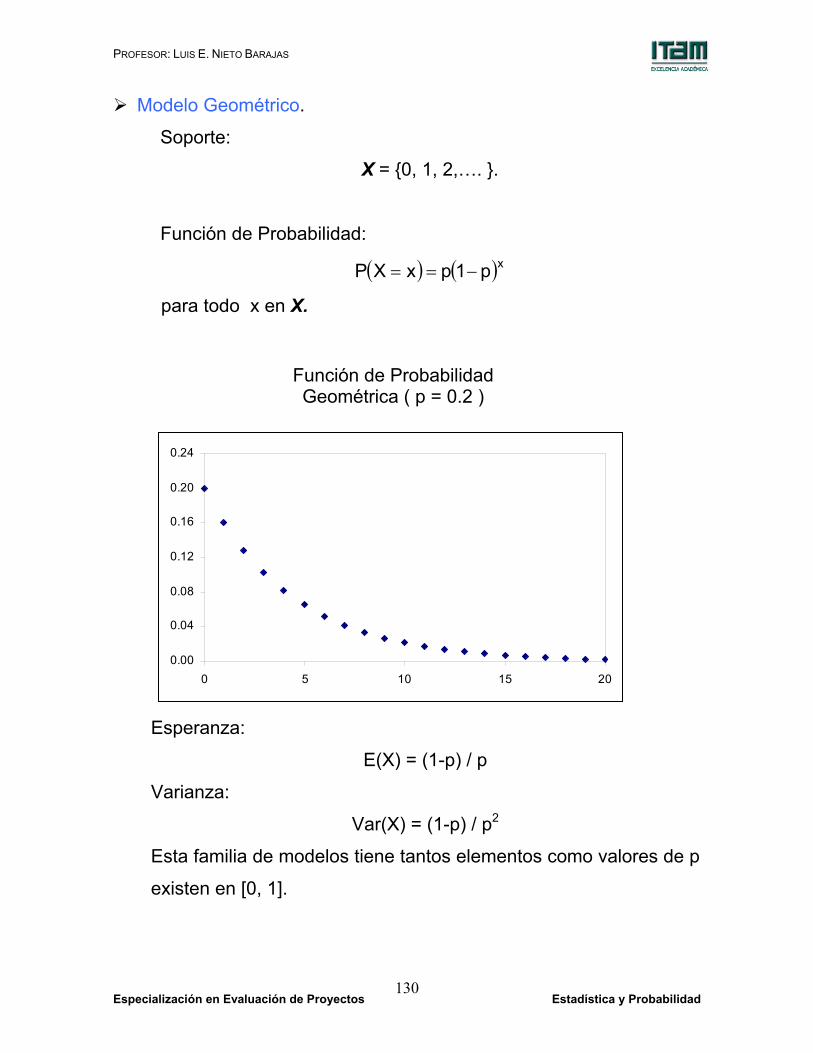
Modelo Geométrico.
Soporte:
X = {0, 1, 2,…. }.
Función de Probabilidad:
( ) ( )xp1pxXP −==
para todo x en X.
Esperanza:
E(X) = (1-p) / p
Varianza:
Var(X) = (1-p) / p2
Esta familia de modelos tiene tantos elementos como valores de p
existen en [0, 1].
Función de Probabilidad Geométrica ( p = 0.2 )
0.00
0.04
0.08
0.12
0.16
0.20
0.24
0 5 10 15 20

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 131
Modelo Binomial Negativa.
Soporte:
X = {0, 1, 2,…. }.
Función de Probabilidad:
xr p)(1p x
1xrx)P(X −
−+==
para todo x en X.
Esperanza:
E(X) = r (1-p) / p
Varianza:
Var(x) = r (1-p) / p2
Esta familia de modelos tiene tantos elementos como existen
parejas de valores r entero positivo y p en [0, 1].
Función de Probabilidad Binomial Negativa (r = 3, p = 0.3) )
0.00
0.04
0.08
0.12
0 5 10 15 20
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 132
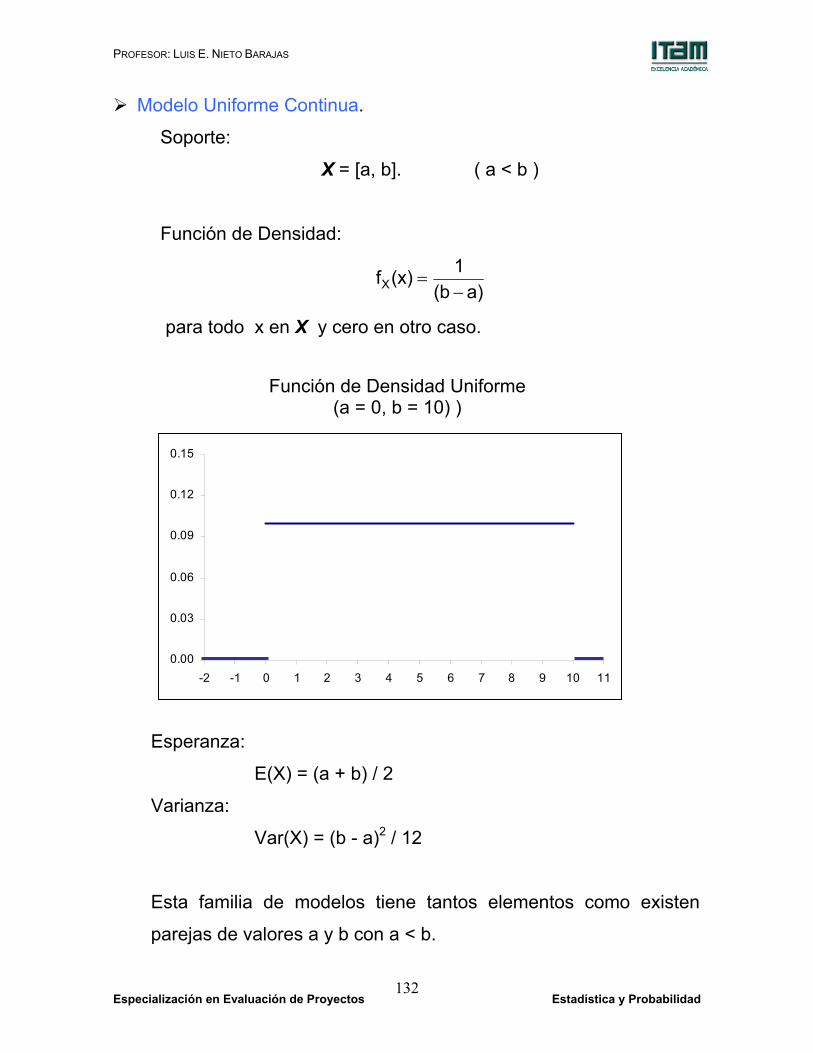
Modelo Uniforme Continua.
Soporte:
X = [a, b]. ( a < b )
Función de Densidad:
a)b(1(x)fX −
=
para todo x en X y cero en otro caso.
Esperanza:
E(X) = (a + b) / 2
Varianza:
Var(X) = (b - a)2 / 12
Esta familia de modelos tiene tantos elementos como existen
parejas de valores a y b con a < b.
Función de Densidad Uniforme (a = 0, b = 10) )
0.00
0.03
0.06
0.09
0.12
0.15
-2 -1 0 1 2 3 4 5 6 7 8 9 10 11
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 133
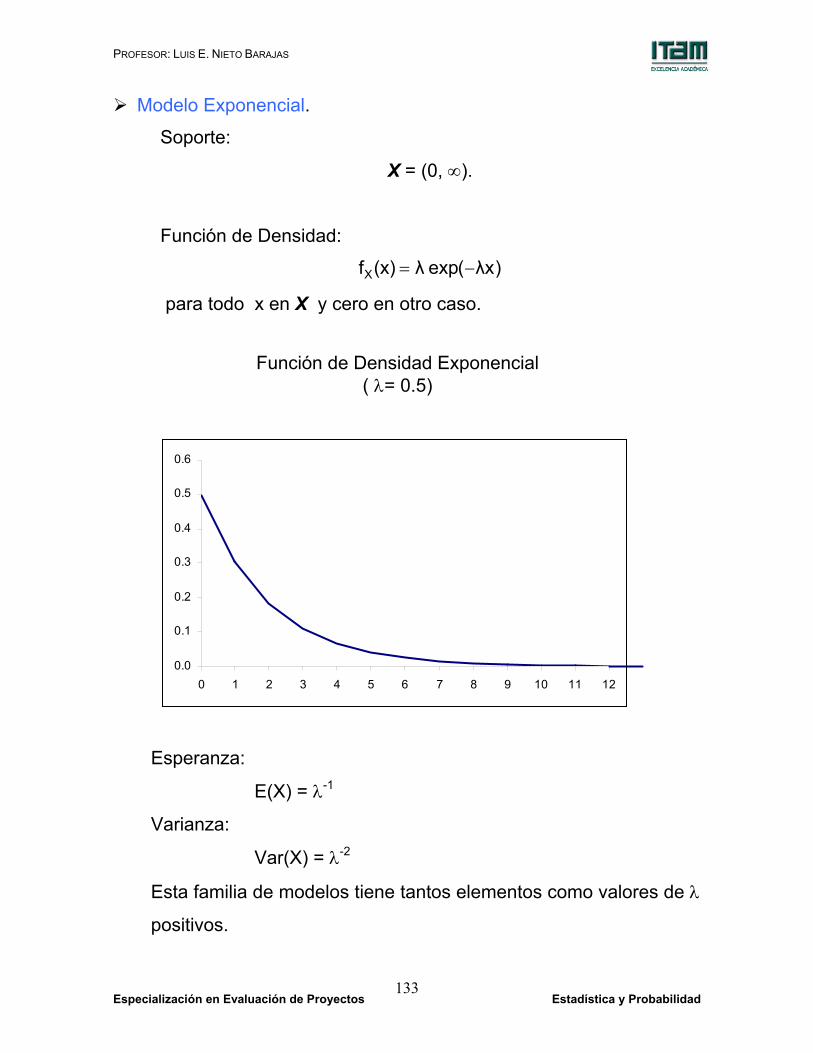
Modelo Exponencial.
Soporte:
X = (0, ∞).
Función de Densidad:
)xλ(exp λ(x)fX −=
para todo x en X y cero en otro caso.
Esperanza:
E(X) = λ-1
Varianza:
Var(X) = λ-2
Esta familia de modelos tiene tantos elementos como valores de λ
positivos.
Función de Densidad Exponencial ( λ= 0.5)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0 1 2 3 4 5 6 7 8 9 10 11 12
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 134
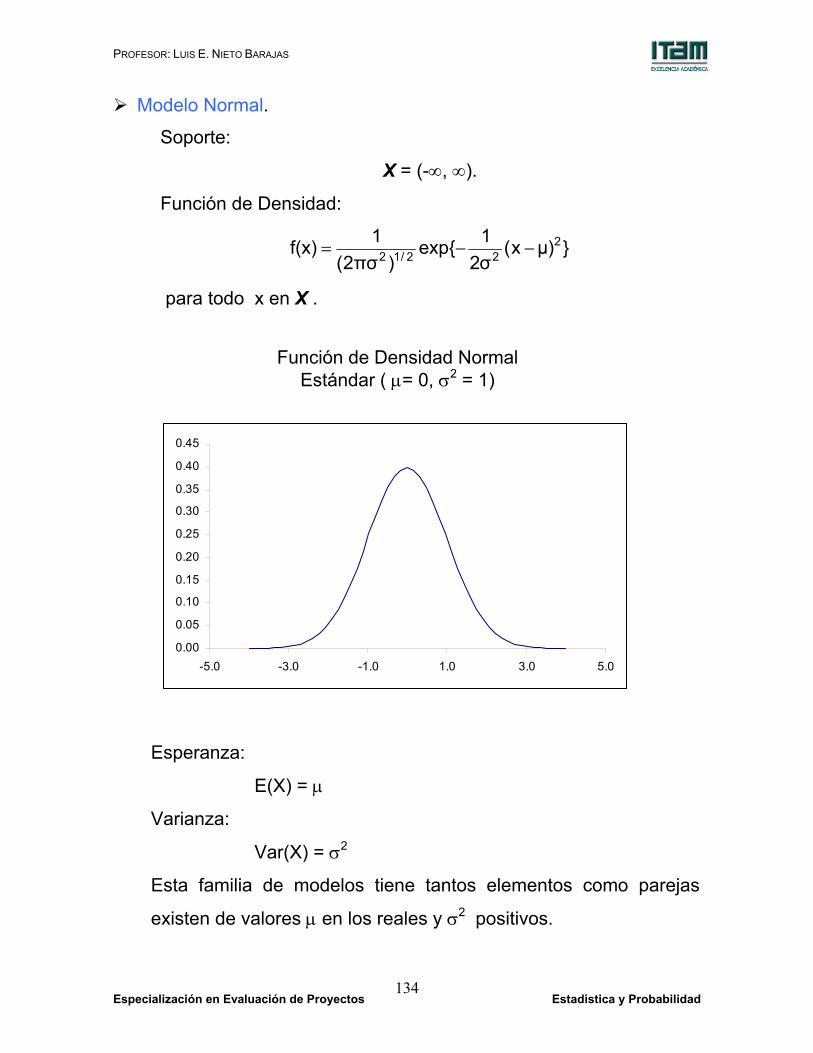
Modelo Normal.
Soporte:
X = (-∞, ∞).
Función de Densidad:
})µx(σ21{exp
)πσ2(1 f(x) 2
22/12 −−=
para todo x en X .
Esperanza:
E(X) = µ
Varianza:
Var(X) = σ2
Esta familia de modelos tiene tantos elementos como parejas
existen de valores µ en los reales y σ2 positivos.
Función de Densidad Normal Estándar ( µ= 0, σ2 = 1)
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
-5.0 -3.0 -1.0 1.0 3.0 5.0

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 135
Modelo Ji cuadrada (χ2).
Soporte:
X = (0, ∞).
Función de Densidad:
( ) )2/xexp(x 2(r/2)1 f(x) 1) 2 / r (2 / r - −
Γ= −
para todo x en X .
Esperanza:
E(X) = r
Varianza:
Var(X) = 2 r
Esta familia de modelos tiene tantos elementos como valores de r
existen enteros positivos. Al parámetro r se le conoce como el
número de grados de libertad o, mas brevemente, grados de
libertad.
El modelo Ji cuadrada está relacionado con el modelo Normal en
virtud de que si Z tiene una distribución Normal estándar, entonces
Z2 sigue una distribución Ji cuadrada con r = 1 (un grado de
libertad).
Por otra parte, si U es Ji cuadrada con r grados de libertad y V es Ji
cuadrada con s grados de libertad y, además U y V son
independientes, entonces la variable W = U + V tiene una
distribución Ji cuadrada con r + s grados de libertad.
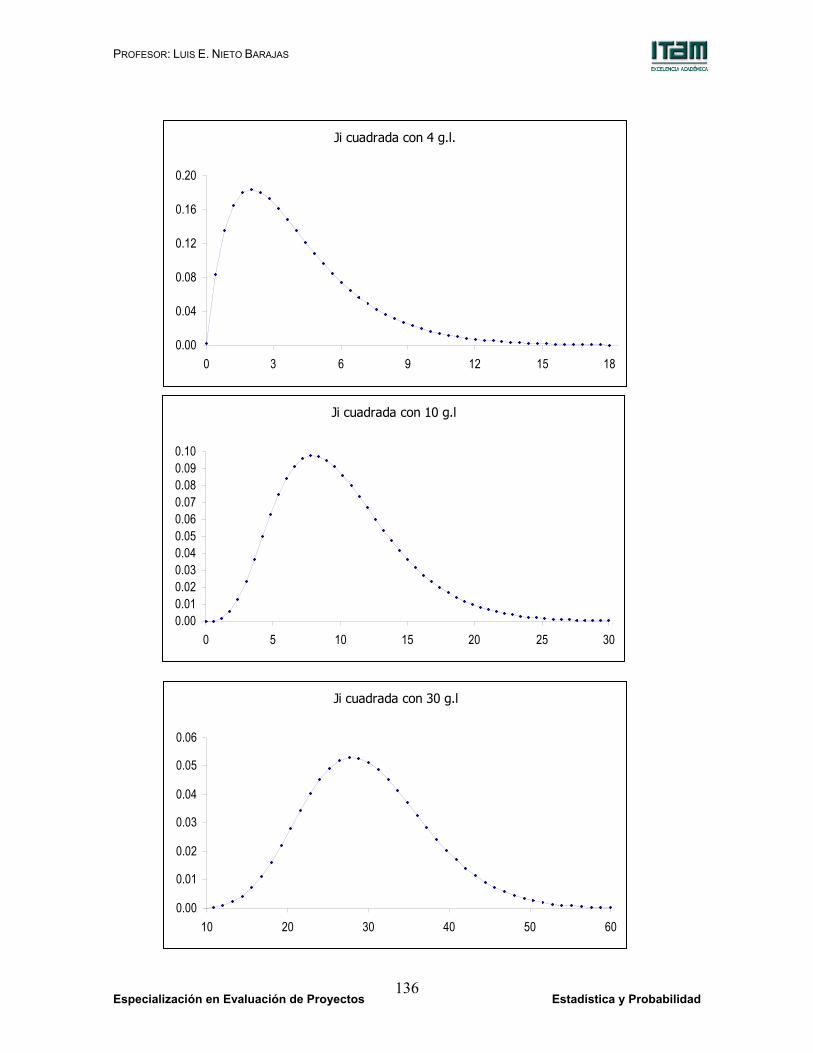
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 136
Ji cuadrada con 4 g.l.
0.00
0.04
0.08
0.12
0.16
0.20
0 3 6 9 12 15 18
Ji cuadrada con 10 g.l
0.000.010.020.030.040.050.060.070.080.090.10
0 5 10 15 20 25 30
Ji cuadrada con 30 g.l
0.00
0.01
0.02
0.03
0.04
0.05
0.06
10 20 30 40 50 60
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 137
Modelo t de Student.
Soporte:
X = (-∞, ∞).
Función de Densidad:
( ) 1)/2(r -21/2- /r)x(1r(r/2)
1)/2][(r f(x) ++πΓ
+Γ=
para todo x en X .
Esperanza:
E(X) = 0 (si r > 1)
Varianza:
Var(X) = r / (r-2) (si r > 2)
Esta familia de modelos tiene tantos elementos como existen
valores de r enteros positivos. A r se le conoce como los grados
de libertad de la distribución.
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
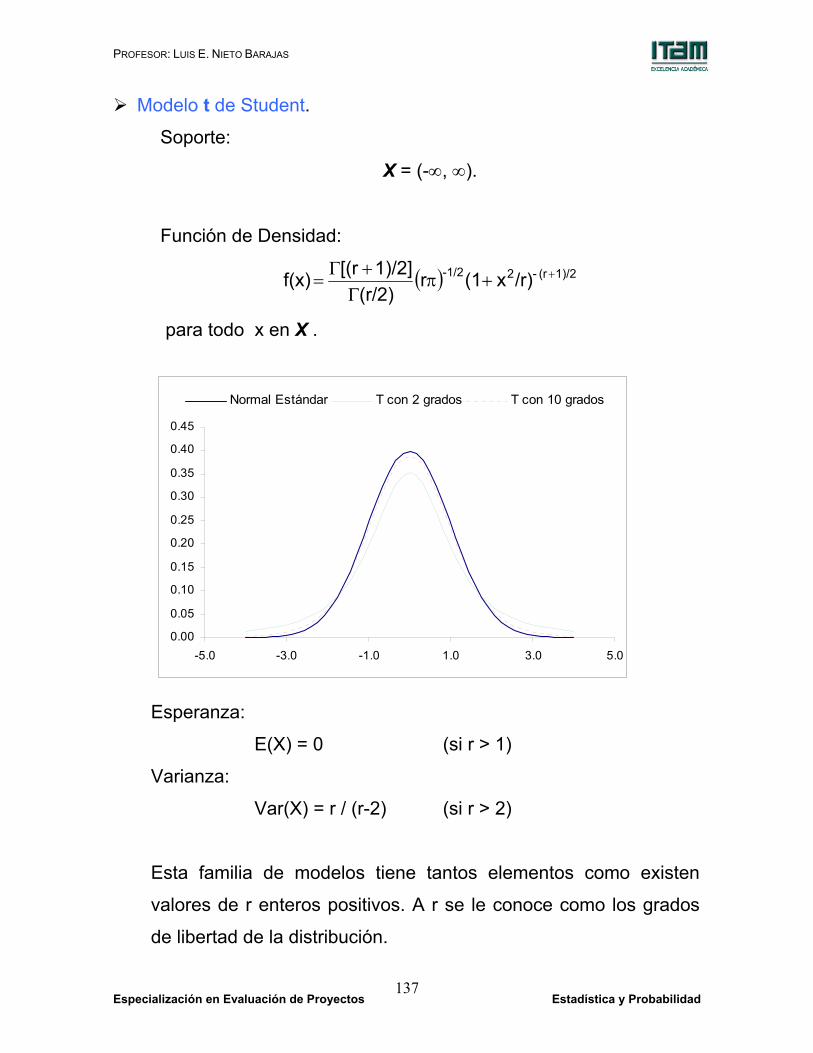
-5.0 -3.0 -1.0 1.0 3.0 5.0
Normal Estándar T con 2 grados T con 10 grados

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 138
El modelo t de Student se aproxima al modelo Normal estándar a
medida que el número de grados de libertad aumenta.
Por otra parte, es interesante tener presente el siguiente resultado.
Si Z es Normal estándar, V es Ji cuadrada con r grados de libertad
y estas dos variables son independientes entonces
rV / Z W =
tiene una distribución t de Student con r grados de libertad.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 139
Modelo F.
Soporte:
X = (0, ∞).
Función de Densidad:
2 / )nm(
2 / 2) m (2 / m
]x)n/m(1[x
nm
(n/2)(m/2)n)/2](m[ f(x) +
−
+
ΓΓ+Γ
=
para todo x en X .
Esperanza:
E(X) = n / (n-2) (si n > 2)
Varianza:
Var(X) = [2n2 (m+n-2)]/ [m(n-2)2 (n-4)], (si n > 4) Esta familia de modelos tiene tantos elementos como parejas
existen de enteros positivos m y n. Al parámetro m se le conoce
como grados de libertad del numerador mientras que a n se le
llama grados de libertad del denominador.
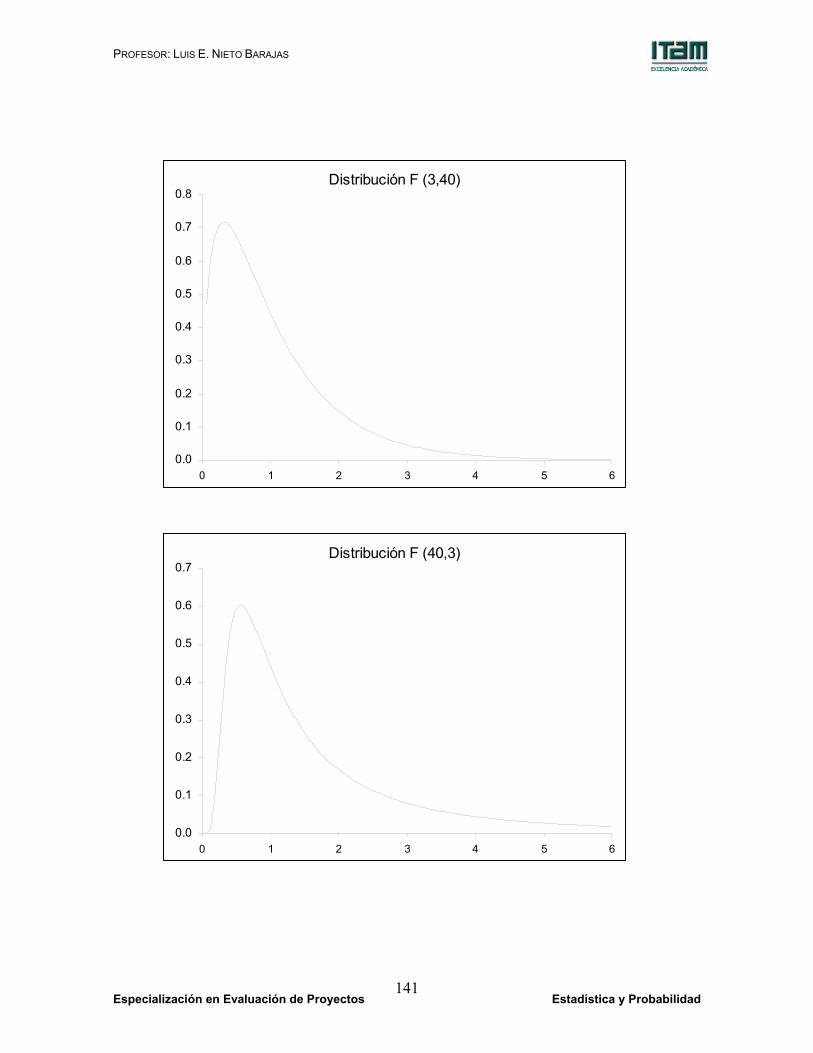
Distribución F (3,3)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 1 2 3 4 5 6

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 140
Distribución F (10,10)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 1 2 3 4 5 6
Distribución F (40,40)
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
0 1 2 3 4 5 6
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 141
Distribución F (3,40)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 1 2 3 4 5 6
Distribución F (40,3)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 1 2 3 4 5 6

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 142
El modelo F está relacionado con el modelo Ji cuadrada y por tanto
con el modelo Normal. Específicamente, si U y V son dos variables
aleatorias independientes y U es Ji cuadrada con m grados de
libertad mientras que V es Ji cuadrada con n grados de libertad,
entonces la variable
n/Vm / U W =
sigue una distribución F con m grados de libertad en el numerador
y n grados de libertad en el denominador.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 143
4. Estimación y Pronóstico
Un problema inherente al uso de modelos es el de la selección del
modelo.
Este problema, cuando se recurre al empleo de familias
paramétricas de modelos, se puede plantear en dos etapas.
El primer paso consiste en la selección de la familia apropiada
(Normal, Poisson, Binomial, etc., etc.). En general, esta fase se
resuelve tomando en cuenta las características generales de la
variable en cuestión. Primero hay que establecer si se trata de una
variable discreta o continua y determinar cual es su soporte.
También se toma en cuenta el tipo concreto de fenómeno que se
intenta describir. Existe experiencia que puede resultar muy valiosa
para determinara la familia apropiada.
La segunda parte del problema, una vez que se ha decidido la
familia, se refiere a la selección del modelo particular, dentro de la
familia. En otras palabras la selección del parámetro.
En términos generales, los parámetros se seleccionan para que el
modelo reproduzca en la manera más fiel posible el
comportamiento observado en los datos.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 144
Existen distintos métodos o técnicas que pueden emplearse para
este fin. Conceptualmente, se distinguen en lo que se refiere a los
aspectos del banco de datos que pretenden reproducir.
El más simple, y muy útil en muchos casos, es el Método de
Momentos que se basa, precisamente, en la noción de momento.
Si se tiene un banco con los datos x1, x2,... xn entonces se define el
momento muestral de orden r como el promedio de los datos, cada
uno de ellos elevado a la potencia r (con r un entero positivo).
∑=
=n
1i
rin
1r )(xm
Es interesante notar que esta noción de momento generaliza la
idea de la media. En particular, para el caso r = 1, m1 coincide
precisamente con la media X. Además, se puede comprobar que la
varianza se puede expresar en función de los dos primeros
momentos:
n1n − S2 = m2 – m1
2
Por su parte, si se tiene una variable aleatoria X, se define el
momento poblacional de orden r como el valor esperado de la
variable elevada a la potencia r (con r un entero positivo). Así,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 145
Mr = ∑=
k
1ii
ri p)(x en el caso discreto,
∫=X
dx f(x) xM rr en el caso continuo.
Como en el caso de un banco de datos, para las variables
aleatorias se tienen las mismas relaciones con la esperanza y la
varianza.
E(X) = M1
Var(X) = M2 - M12
El método utiliza el hecho de que los momentos de una variable
aleatoria con una distribución que pertenece a una familia
paramétrica están, en general, relacionados con los parámetros de
la familia.
Algoritmo: Así, el método de momentos procede en forma
secuencial estableciendo la igualdad de los momentos del modelo
con los momentos de los datos en el banco hasta determinar los
valores de los parámetros.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 146
1. El primer paso consiste en establecer la igualdad de los
momentos de orden 1 es decir, la esperanza del modelo con la
media de los datos. Si esta igualdad determina los parámetros
involucrados el proceso termina.
2. En caso contrario, se establece la igualdad entre los momentos
de orden 2 lo cual equivale a establecer la igualdad entre la
varianza del modelo y la varianza de los datos.
3. Si estas dos ecuaciones determinan por completo el valor de los
parámetros el proceso finaliza; en caso contrario, el proceso
continua estableciendo la igualdad entre los momentos de orden
sucesivamente mayor hasta fijar los parámetros.
Como ejemplo considere el ejemplo de unos datos que se pretende
aproximar con un modelo Poisson. En el caso de este modelo la
esperanza coincide con el valor del parámetro λ.
o Así, la igualdad M1 = m1 se traduce en la ecuación
λ = X
Que determina el valor del parámetro y el proceso de ajuste
termina.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 147
22 S=σ
Otro ejemplo útil es el caso Normal. Para este modelo se tienen dos
parámetros. La primera ecuación M1 = m1 equivale a la igualdad
µ = X
o Que determina el valor del parámetro µ mientras que la segunda
(M2 = m2) equivale a la igualdad de las varianzas y, por tanto, se
traduce en la relación
y, de esta forma, el proceso de ajuste termina.
Aquí, es de la mayor importancia introducir una consideración que
se presenta con frecuencia en la práctica. En diversas
circunstancias el banco de datos recoge la información disponible
sobre el fenómeno de interés pero esta información no es toda la
que el fenómeno puede producir.
De esta manera el banco contiene solamente una fracción de la
información posible. De hecho, en esos casos existe, al menos
potencialmente, la posibilidad de contar con otros bancos de datos
sobre el mismo fenómeno.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 148
En estas circunstancias la aplicación del método de momentos (o
de cualquier otro método de ajuste) produce el valor óptimo de los
parámetros para describir el comportamiento de los datos en el
banco disponible pero es necesario reconocer que un estudio
similar que utilizase otro banco de datos podría arrojar valores
distintos para los parámetros y por tanto, una descripción diferente
del fenómeno bajo estudio.
Este hecho plantea una situación que sólo se puede abordar desde
la perspectiva de la Inferencia Estadística.
Por una parte, el valor que se obtiene en el ajuste del modelo ya no
puede considerarse como el parámetro que describe el
comportamiento del fenómeno sino únicamente una aproximación a
su valor desconocido.
En los términos comunes del lenguaje estadístico se dice que el
valor obtenido constituye una estimación (o valor estimado) del
parámetro y con el fin de distinguir ambos valores si el parámetro
es θ, la estimación (o estimador) se denota con el símbolo θ.
Por otra parte, si el valor del estimador depende del particular
banco de datos que se haya empleado para la estimación, se
plantea el siguiente dilema: ¿Cómo determinar el grado en que el
estimador aproxima el verdadero valor desconocido del parámetro?

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 149
En otras palabras: ¿Cómo determinar el grado en que el banco
disponible refleja el resultado que se obtendría si se contase con
toda la información del fenómeno (población)?
Este problema se ha resuelto incorporando un supuesto más en el
proceso. Primero dos definiciones.
Cuando se cuenta con toda la información que el fenómeno bajo
estudio puede producir se dice que se tiene un Censo.
De la misma manera, cuando únicamente se cuenta con una
fracción de la información que el fenómeno bajo estudio puede
producir se dice que se tiene una Muestra.
El supuesto que permite, de nuevo, utilizar las herramientas de la
probabilidad para describir esta nueva fuente de incertidumbre
consiste en considerar a los datos disponibles como si hubiesen
sido seleccionados de entre todos los datos potencialmente
posibles a través de un sorteo (muestreo aletorio).
Conceptualmente esto equivale a suponer, en el caso más simple,
que todos los datos posibles se alojaron en una urna de donde se
extrajeron por sorteo aquellos que finalmente forman el banco.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 150
De esta manera, se establece un principio de representatividad del
banco (que ahora recibe el nombre de muestra aleatoria). La idea
es que se cuenta con datos que se produjeron con un
procedimiento que concede a todos los datos potenciales la misma
oportunidad de aparecer en la muestra.
En nivel más técnico, esta forma de seleccionar la muestra (que se
conoce como muestreo probabilístico) equivale a suponer que cada
dato disponible procede de la observación de una variable aleatoria
que tiene como distribución el modelo establecido.
Como consecuencia el estimador, que se calcula a partir de los
datos disponibles (aleatorios), también se puede considerar a su
vez como una variable aleatoria cuya distribución permite evaluar el
grado en que el estimador se aproxima al verdadero valor del
parámetro.
En particular, es posible calcular medidas de localización y
dispersión a partir del modelo que describe el comportamiento del
estimador para, por ejemplo, determinar su esperanza y su
varianza.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 151
De esta manera, el valor del estimador se puede interpretar como si
fuese el resultado de observar una variable aleatoria y si se tiene
que
θ=θ)E( ˆ
se puede concluir que esa variable aleatoria produce valores
alrededor del verdadero valor de θ. En este caso se dice que el
estimador es insesgado.
Si, por otra parte se calcula la varianza del estimador, )ˆVar(θ , es
posible establecer qué tan similar podría haber resultado la
estimación si se hubiese contado con otro banco de datos del
mismo tipo.
De hecho, y como se verá en el caso de los modelos de regresión,
la varianza permite determinar el efecto que en la calidad de una
estimación tiene un posible incremento en el tamaño del banco (el
tamaño de la muestra).
Todas estas ideas se ilustrarán, en la siguiente sección, con los
modelos estadísticos que se emplean para describir la asociación
lineal entre variables. Es decir, con los modelos de regresión lineal.
Antes de proceder, vale la pena mencionar que la idea que subyace
en la producción de muestras probabilísticas no es un mero artificio
conceptual.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 152
En una variedad de aplicaciones reales, la selección de los datos
que constituyen la muestra se lleva a cabo explícitamente a través
de un sorteo o de un procedimiento que emula un sorteo. De
hecho, existe toda una rama de la disciplina estadística (conocida
como muestreo) que se ocupa de estas técnicas.
PRONÓSTICOS PROBABILÍSTICOS
La idea básica que da origen a la producción de pronósticos
probabilísticos es la identificación de las frecuencias relativas con
las probabilidades.
Como ya se ha indicado, las frecuencias tienen el propósito de
describir lo que ya ocurrió, a partir de la información contenida en
un banco de datos.
Por su parte, las probabilidades pretenden la descripción de lo que
puede ocurrir en el futuro.
Identificar frecuencias con probabilidades, tiene sentido sólo si, en
un nivel más primario, se acepta que lo que va a ocurrir es similar
con lo que ya ha ocurrido.
Esta idea se traduce, cuando no se utilizan modelos, a suponer que
el valor futuro se habrá de producir como si fuese resultado de un
sorteo entre los valores que se han presentado en el pasado.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 153
En ese caso, además, la probabilidad con la que se supone
aparecerá un valor futuro es igual a la frecuencia relativa con la que
se presentó en el banco de datos.
En otras palabras, el valor futuro se considera una observación de
una variable aleatoria.
El soporte de la variable aleatoria está determinado por valores que
aparecieron en el banco (y sólo esos) y su función de probabilidad
por las frecuencias relativas correspondientes.
Este procedimiento tiene ventajas:
1. Es simple,
2. Hace uso del resumen eficiente,
3. No pone en duda la representatividad de la información en el
banco.
Pero también implica desventajas:
1. No contempla la posibilidad de valores que no hayan ocurrido
previamente,
2. No permite el contraste de pronósticos que proceden de bancos
similares pero diferentes.
3. No toma en cuenta el procedimiento de construcción del banco.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 154
En tales circunstancias es conveniente y resulta natural, el empleo
de modelos para la producción de pronósticos probabilísticos.
Si el pronóstico se considera el producto de la observación de una
variable aleatoria, es posible y razonable utilizar un modelo para
describir el comportamiento de esa variable aleatoria.
Si además se considera conveniente utilizar un modelo
relativamente simple y con propiedades que sean interpretables
con facilidad, entonces una posibilidad son las familias
paramétricas de modelos (Binomial, Poisson, Normal, Uniforme y
Exponencial entre otras).
Ahora bien, es importante reconocer que los pronósticos que se
obtienen a partir de modelos prácticamente nunca coinciden con los
que se obtienen en forma directa de las frecuencias relativas. No
tendría por que ocurrir de otro modo, estos pronósticos se fundan
en supuestos diferentes y tienen distintos alcances.
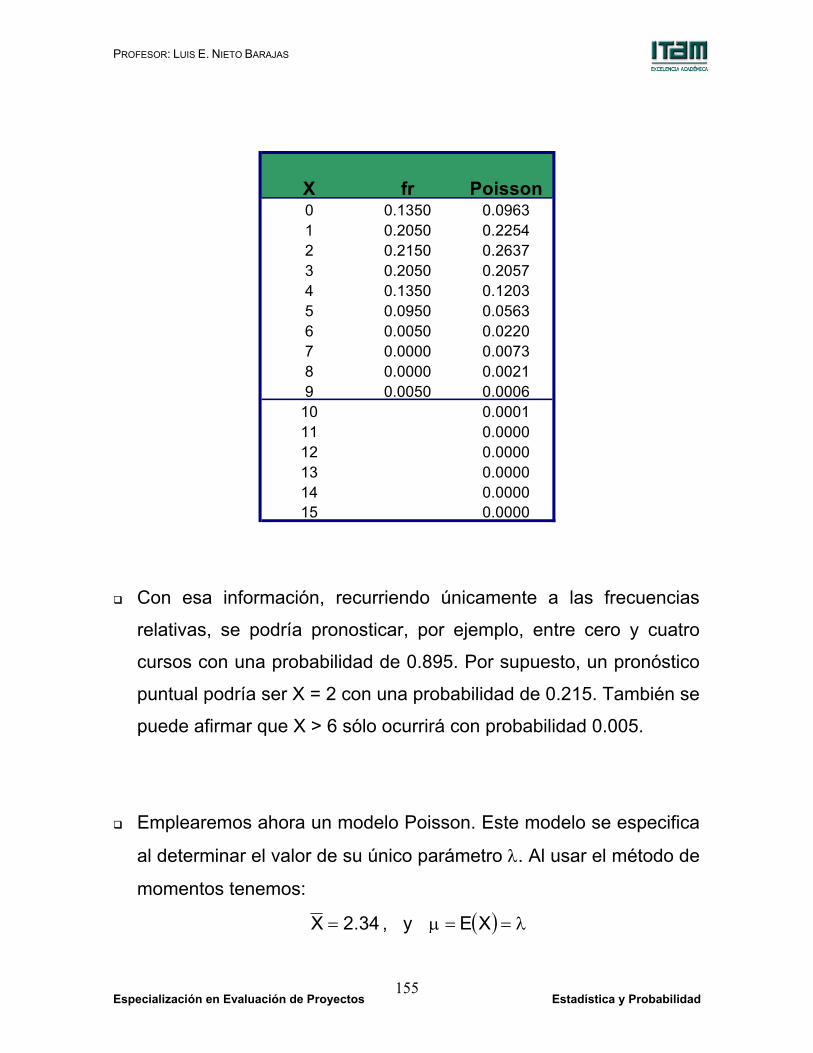
Considere el ejemplo de la variable cursos que se discutió
anteriormente. Ahí, se tenía por una parte las frecuencias
observadas que se muestran en la segunda columna de la
siguiente tabla.
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 155
Con esa información, recurriendo únicamente a las frecuencias
relativas, se podría pronosticar, por ejemplo, entre cero y cuatro
cursos con una probabilidad de 0.895. Por supuesto, un pronóstico
puntual podría ser X = 2 con una probabilidad de 0.215. También se
puede afirmar que X > 6 sólo ocurrirá con probabilidad 0.005.
Emplearemos ahora un modelo Poisson. Este modelo se especifica
al determinar el valor de su único parámetro λ. Al usar el método de
momentos tenemos:
34.2X = , y ( ) λ==µ XE
X fr Poisson0 0.1350 0.09631 0.2050 0.22542 0.2150 0.26373 0.2050 0.20574 0.1350 0.12035 0.0950 0.05636 0.0050 0.02207 0.0000 0.00738 0.0000 0.00219 0.0050 0.0006
10 0.000111 0.000012 0.000013 0.000014 0.000015 0.0000
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 156
Al igualar obtenemos el estimador para λ
34.2ˆ =λ
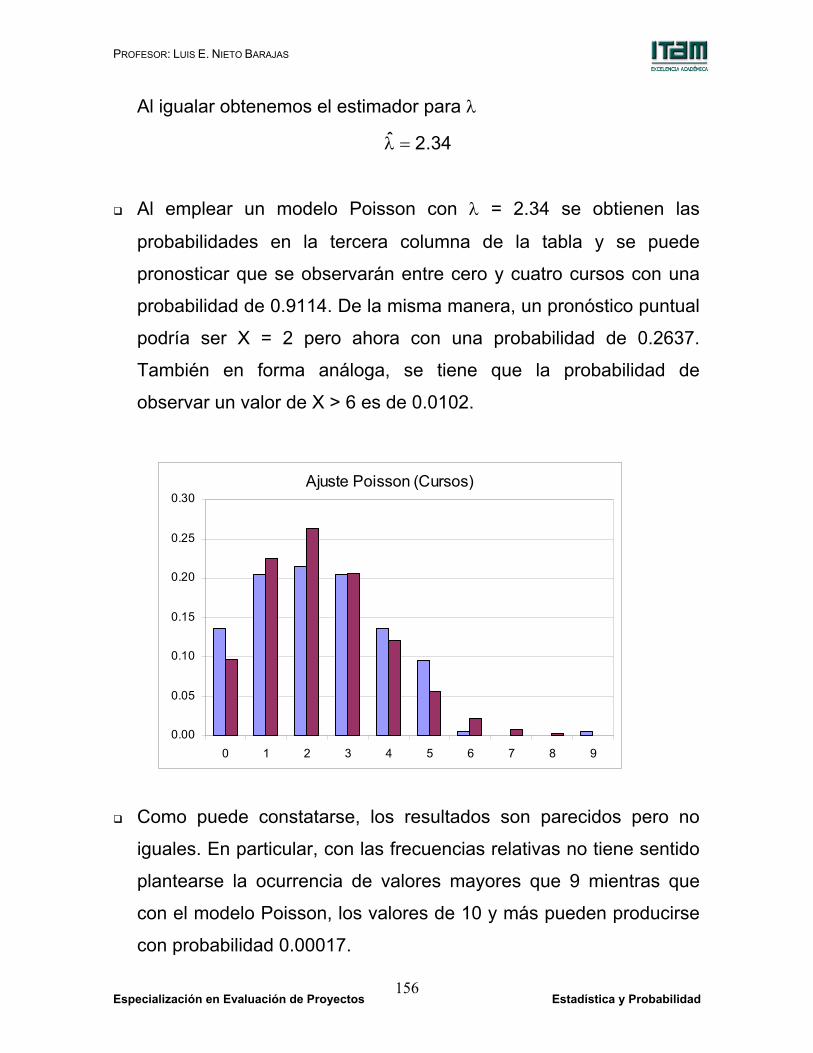
Al emplear un modelo Poisson con λ = 2.34 se obtienen las
probabilidades en la tercera columna de la tabla y se puede
pronosticar que se observarán entre cero y cuatro cursos con una
probabilidad de 0.9114. De la misma manera, un pronóstico puntual
podría ser X = 2 pero ahora con una probabilidad de 0.2637.
También en forma análoga, se tiene que la probabilidad de
observar un valor de X > 6 es de 0.0102.
Como puede constatarse, los resultados son parecidos pero no
iguales. En particular, con las frecuencias relativas no tiene sentido
plantearse la ocurrencia de valores mayores que 9 mientras que
con el modelo Poisson, los valores de 10 y más pueden producirse
con probabilidad 0.00017.
Ajuste Poisson (Cursos)
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 1 2 3 4 5 6 7 8 9

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 157
Es importante notar que, en términos generales, los pronósticos del
modelo Poisson son compatibles con los obtenidos directamente a
partir de las frecuencias. La diferencia cualitativa más notable es
que con el modelo algunos valores que no ocurrieron en el banco
tienen una probabilidad positiva.
Por otra parte, si se adopta un modelo distinto (como el Binomial
Negativo para los datos del ejemplo) también se pueden registrar
cambios en los pronósticos.
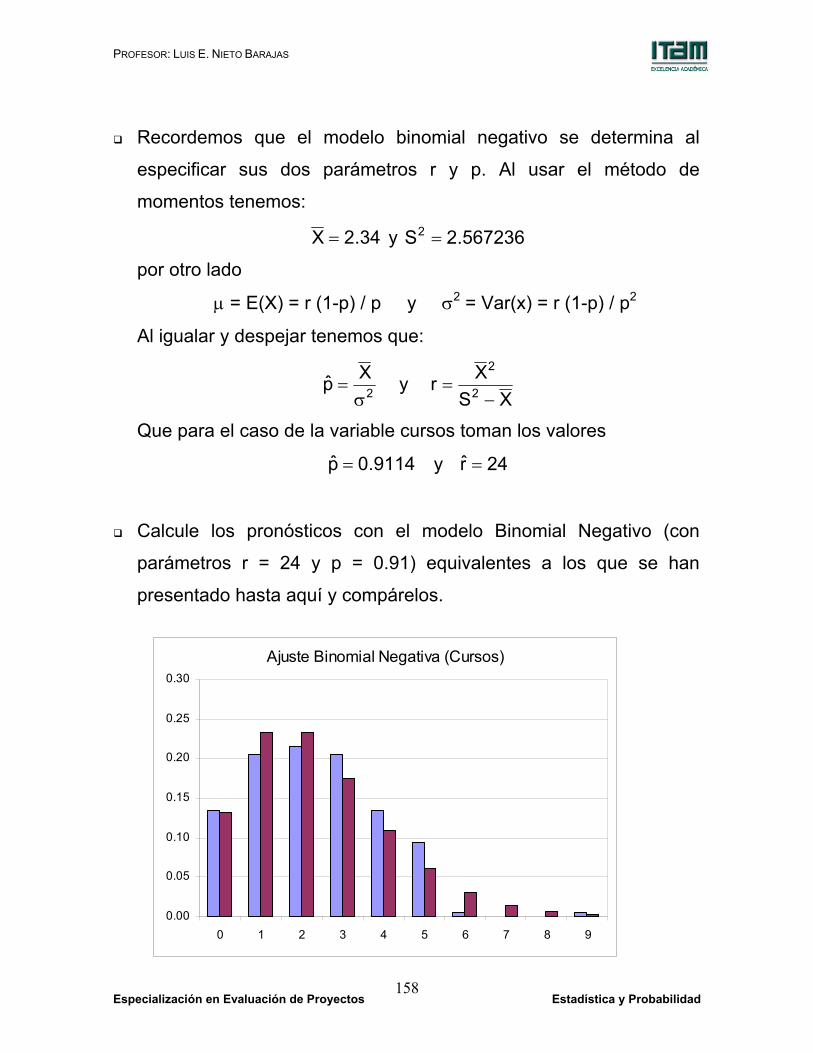
X fr Bin. Neg.0 0.1350 0.13281 0.2050 0.23292 0.2150 0.23343 0.2050 0.17544 0.1350 0.10995 0.0950 0.06066 0.0050 0.03037 0.0000 0.01418 0.0000 0.00629 0.0050 0.002610 0.001011 0.000412 0.000213 0.000114 0.000015 0.0000
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 158
Recordemos que el modelo binomial negativo se determina al
especificar sus dos parámetros r y p. Al usar el método de
momentos tenemos:
34.2X = y 567236.2S2 =
por otro lado
µ = E(X) = r (1-p) / p y σ2 = Var(x) = r (1-p) / p2
Al igualar y despejar tenemos que:
2Xpσ
= y XS
Xr 2
2
−=
Que para el caso de la variable cursos toman los valores
9114.0p = y 24r =
Calcule los pronósticos con el modelo Binomial Negativo (con
parámetros r = 24 y p = 0.91) equivalentes a los que se han
presentado hasta aquí y compárelos.
Ajuste Binomial Negativa (Cursos)
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 1 2 3 4 5 6 7 8 9

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 159
En este punto vale la pena recordar que los modelos Poisson y
Binomial Negativo, al igual que los demás que se han considerado
en este texto, constituyen en realidad familias de modelos y que
existen tantos modelos en cada familia como valores posibles
puedan asignarse a los parámetros respectivos.
Ejercicio de clase: realice un pronóstico probabilístico para las
variables Salario y Antigüedad del banco de datos 1 utilizando un
modelo probabilístico adecuado.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 160
5. Modelos de regresión lineal
Suponga que cuenta con un banco de datos que contiene
información relativa a dos variables X y Y las cuales se presume
guardan una relación aproximadamente lineal. El ejemplo de las
variables Estatura y Peso que ya se ha examinado es pertinente en
este punto.
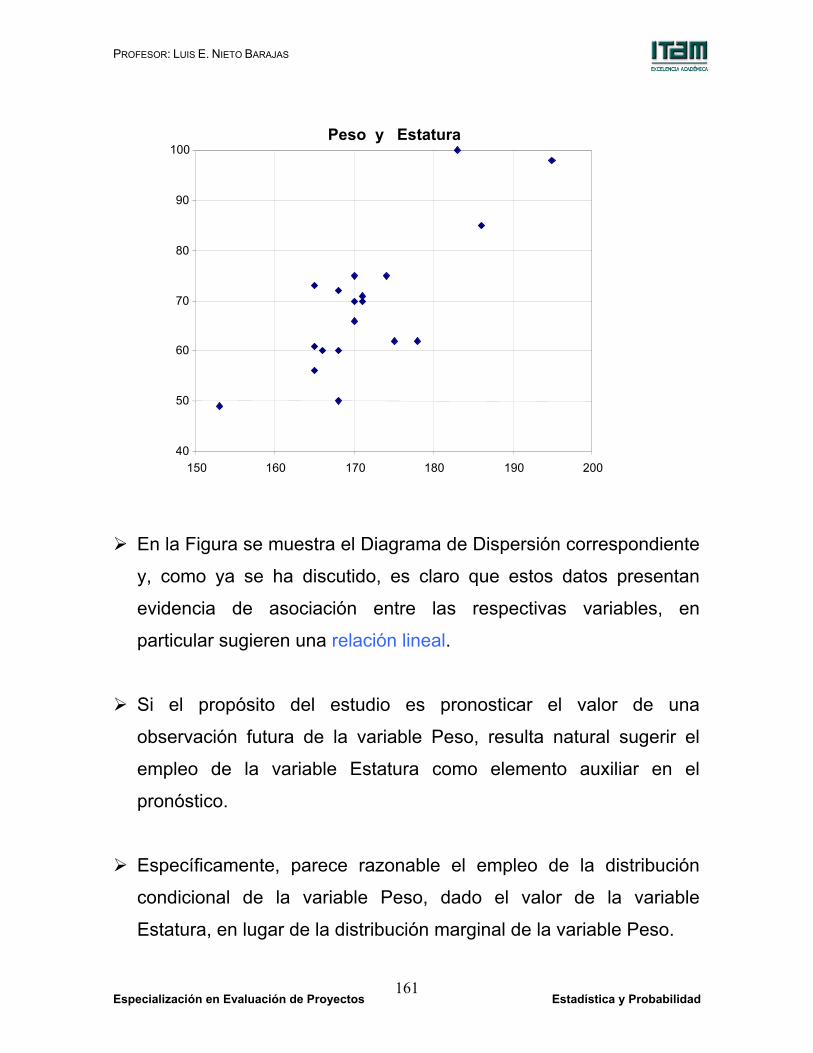
Caso Estatura Peso1 166 602 170 663 174 754 168 605 195 986 186 857 170 708 165 739 153 49
10 168 7211 171 7112 178 6213 165 6114 171 7015 183 10016 170 7517 175 6218 165 5619 168 50
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 161
En la Figura se muestra el Diagrama de Dispersión correspondiente
y, como ya se ha discutido, es claro que estos datos presentan
evidencia de asociación entre las respectivas variables, en
particular sugieren una relación lineal.
Si el propósito del estudio es pronosticar el valor de una
observación futura de la variable Peso, resulta natural sugerir el
empleo de la variable Estatura como elemento auxiliar en el
pronóstico.
Específicamente, parece razonable el empleo de la distribución
condicional de la variable Peso, dado el valor de la variable
Estatura, en lugar de la distribución marginal de la variable Peso.
Peso y Estatura
40
50
60
70
80
90
100
150 160 170 180 190 200

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 162
Más aun, y en virtud de la evidencia gráfica, resulta pertinente
explorar la viabilidad de un modelo que incorpore explícitamente la
relación lineal que se presume guardan estas dos variables.
Precisamente con esa idea, un segundo paso después del análisis
gráfico, consiste en la evaluación cuantitativa de la fuerza con que
se manifiesta esta relación.
En este punto resulta conveniente el cálculo del, ya conocido,
coeficiente de correlación.
YYXX
XYYX, SS
SR =
Para el cálculo de este coeficiente es necesario recordar que:
∑ −−= )yy)(xx(S iiXY ,
∑ −= 2iXX )xx(S y
∑ −= 2iYY )yy(S .
Así, para los datos del ejemplo se tiene que
SXY = 1824.5,
SYY = 3423.2 y
SXX = 1498.4;

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 163
Por tanto,
RX,Y = 0.806 y 2YX,R = 0.649 .
Estos cálculos permiten establecer que existe evidencia de
asociación lineal positiva en los datos. La interpretación concreta,
es la siguiente:
El patrón de asociación lineal con la Estatura explica el 65% de la
variabilidad del Peso.
Recordando la discusión que se presentó cuando se trató el
Análisis Exploratorio de Asociación, si se cuenta con la información
de dos variables cuantitativas para n casos de forma que el banco
incluye los pares (x1, y1), (x2, y2), … (xn, yn) entonces se dice que las
variables tienen una relación lineal si existen dos constantes β0 y β1
tales que la ecuación
yi = β0 + β1 xi
se cumple en forma exacta para todos y cada uno de los casos en
el banco.
Evidentemente, esta no es la situación con los datos de la Estatura
y el Peso. El patrón que se manifiesta es, mas bien, una tendencia.
En otras palabras, una relación lineal aproximada.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 164
En consecuencia, es necesario precisar la noción de tendencia
lineal e incorporarla explícitamente en un modelo estadístico para
pronósticos.
La forma en que la idea de tendencia lineal se incorpora en los
modelos estadísticos para pronósticos, particularmente en los de
regresión es la siguiente.
Para cada valor fijo x de la variable explicativa (en este caso la
Estatura) se considera que el valor correspondiente de la variable
de respuesta Y (el Peso en el ejemplo) se produce de acuerdo a
una ecuación de la forma
y = β0 + β1 x + ε
en donde ε es una variable aleatoria que suma una gran cantidad
de factores que, además de la Estatura, influyen en el Peso.
Este supuesto se conoce con el nombre de supuesto estructural de
separabilidad aditiva. Este es sólo el primero de diversos supuestos
que se suelen incorporar en los modelos de regresión.
En principio se supone que ε tiene una distribución Normal. Este
supuesto, de normalidad, es particularmente razonable si se
considera que ε es un error de medición.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 165
Por su parte el supuesto de media cero considera que los factores
que componen y se integran en ε tienen efectos que pueden ser
tanto negativos como positivos y se compensan en promedio, de
manera que E(ε) = 0.
Particularmente por conveniencia se adopta un supuesto más, de
homoscedasticidad, según el cual los errores asociados a las
distintas observaciones tienen la misma varianza, aunque
desconocida, 2σ .
Finalmente, los modelos estadísticos de regresión incorporan el
supuesto de independencia. Es decir, suponen que los errores o
perturbaciones asociadas a las distintas observaciones (y, en
consecuencia, las observaciones mismas de la variable Y) no están
relacionadas en forma alguna.
En consecuencia, un Modelo de Regresión Lineal Simple supone
que la distribución condicional de la variable Y, dado un valor fijo x
de la variable explicativa X, es de la forma
Y ~ Normal (β0 + β1x, σ2)
y que los datos disponibles en el banco constituyen observaciones
independientes de la variable Y.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 166
Vale la pena insistir en los supuestos clave que involucra un
modelo de este tipo:
1. Separabilidad Aditiva
2. Normalidad
3. Homoscedasticidad
4. Independencia.
La idea práctica más importante en el desarrollo conceptual de este
tipo de modelos es que, si los valores de los parámetros β0, β1 y σ2
fuesen conocidos, entonces el comportamiento de Y dado un valor
fijo de X, por ejemplo x, estaría completamente descrito por un
modelo Normal cuyos parámetros serían totalmente conocidos.
Por ejemplo, si fuese posible establecer que los parámetros toman
los valores β0 = -135, β1 = 1.2 y σ2 = 64, entonces para una Estatura
de X = 170 centímetros, la respectiva distribución condicional del
Peso resultaría una Normal con media
µ = -135 + (1.2)*(170) = 69
y varianza
σ2 = 64.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 167
Así, cualquier pronóstico sobre el Peso dada una Estatura de 170
cms. Se obtendría del modelo correspondiente.
Distribución Normal (69, 64).
En nuestro ejemplo de peso y estatura no se conocen los valores
de los parámetros. Esta es la situación en general y, por tanto, es
necesario seleccionarlos o, con un lenguaje más estadístico,
estimarlos, a partir de los datos en el banco disponible.
De hecho, la estructura que se conoce como modelo de regresión
lineal simple no es un modelo sino una familia paramétrica de
modelos en el sentido que se ha discutido previamente.
0.00
0.01
0.02
0.03
0.04
0.05
40 50 60 70 80 90 100

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 168
Esta familia tiene tres parámetros (β0, β1 y σ2) y contiene tantos
modelos como combinaciones de:
1. ordenada al origen (β0) en los reales,
2. pendiente (β1) también en los reales y
3. varianza (σ2) positiva
existan. Por supuesto, hay una cantidad infinita e incontable de este
tipo de modelos.
Por otra parte, y ya que de parámetros se trata, es interesante
observar que un modelo de esta familia no solamente describe una
distribución condicional para Y sino que, en cuanto se fijan los
valores de los parámetros (β0, β1 y σ2), al cambiar el valor de x se
pueden obtener todas las distribuciones condicionales de Y dada X.
El problema que resta es el de estimación de los parámetros –el
banco típicamente es sólo una muestra- y, en particular, interesa
que el método de estimación ajuste el modelo a los datos tomando
en cuenta que éste será utilizado para producir pronósticos.
Suponga que, con algún procedimiento, se determinan los valores
estimados de los parámetros 210 ˆ y ˆ ,ˆ σββ . Entonces, la estimación
de la esperanza condicional de Y, dado un valor fijo de la variable
Estatura X = x, está dada por

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 169
x ˆ ˆˆ 10x β+β=µ .
Observe que xµ estima el punto en torno al cual se espera que
ocurran los valores de Y cuando X tome el valor x.
En ese sentido, y aún cuando se sabe que todo pronóstico puntual
tiene confiabilidad cero puesto que el modelo Normal es continuo,
es que a ˆ xµ suele considerársele un pronóstico puntual para Y
cuando X = x.
De hecho, usualmente se utiliza la notación ˆy xx µ= , o
simplemente ˆy xµ= , y a la ecuación
x ˆ ˆy 10 β+β=
se le conoce como la recta ajustada.
Ahora bien si, al menos en términos indicativos, el valor de
y xµ= ˆˆ puede interpretarse como un pronóstico, entonces se
puede proponer un criterio para la estimación de los parámetros del
modelo.
La idea es seleccionar los parámetros que produzcan los mejores
pronósticos. En concreto, aquellos que, para cada valor de X en el
banco de datos, produzcan el valor y más cercano al
correspondiente valor observado y.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 170
En otras palabras, los parámetros deben seleccionarse de manera
que la diferencia
y- y e =
sea lo más pequeña posible para todos y cada uno de los casos en
el banco.
Es fácil comprobar, con un argumento gráfico, que no es posible
minimizar todos los errores de predicción {e1,e2,…en}
simultáneamente. Es necesario entonces definir una medida
individual cuya minimización pueda interpretarse como una forma
de minimización global de los errores.
Existen distintas posibilidades pero la más común, que además
resulta simple, es la siguiente:
∑=
=∆n
1i
2ie
o equivalentemente,
∑=
−=∆n
1i
2ii )y(y .
Más explícitamente aún se puede escribir, en términos de los
parámetros:
∑=
β−β−=ββ∆n
1i
2i10i10 )xˆˆ(y)ˆ,ˆ(

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 171
La propuesta es seleccionar los valores de los parámetros que
minimicen el valor de la función ∆.
Este criterio se conoce en la literatura con el nombre de Método de
Mínimos Cuadrados.
Es evidente que ∆ no puede tomar valores negativos y que la única
manera en que puede alcanzar el valor cero es cuando todos y
cada uno de los errores son iguales a cero (cuando el ajuste es
perfecto).
Casualmente es interesante notar que si los errores tienen media
igual a cero entonces, salvo porque el número de datos no aparece
como divisor, ∆ coincide con la varianza de {e1, e2, …en}. Así que el
método de mínimos cuadrados también puede interpretarse como
un método de mínima varianza.
El caso es que la minimización de ∆ puede llevarse a cabo de
distintas formas. Una de ellas consiste en reconocer que es una
función diferenciable de 0β y 1β . De esta forma, se pueden calcular
las derivadas parciales de ∆ respecto a estos dos parámetros;
Establecer la igualdad con cero de las dos expresiones y resolver el
par de ecuaciones.
Las derivadas parciales son las siguientes:

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 172
∑=
β−β−=β∂∆∂ n
1ii10i
0)(-1)xˆˆ(y2ˆ
∑=
β−β−=β∂∆∂ n
1iii10i
1
))(-xxˆˆ(y2ˆ
De donde se obtiene el sistema de ecuaciones lineales:
∑∑==
=β+βn
1ii
n
1ii10 yxˆˆn
∑∑∑===
=β+βn
1iii
n
1i
2i1
n
1ii0 yxxˆxˆ
Cuya solución está dada por los valores:
xˆyˆ10 β−=β
∑
∑
=
=
−=β n
1i
2i
n
1iii
1
)x-(x
)y)(yx-(xˆ
Equivalentemente,
xˆyˆ10 β−=β
XX
XY1 S
Sˆ =β
se conocen como los estimadores de mínimos cuadrados de los
coeficientes de la regresión.
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 173
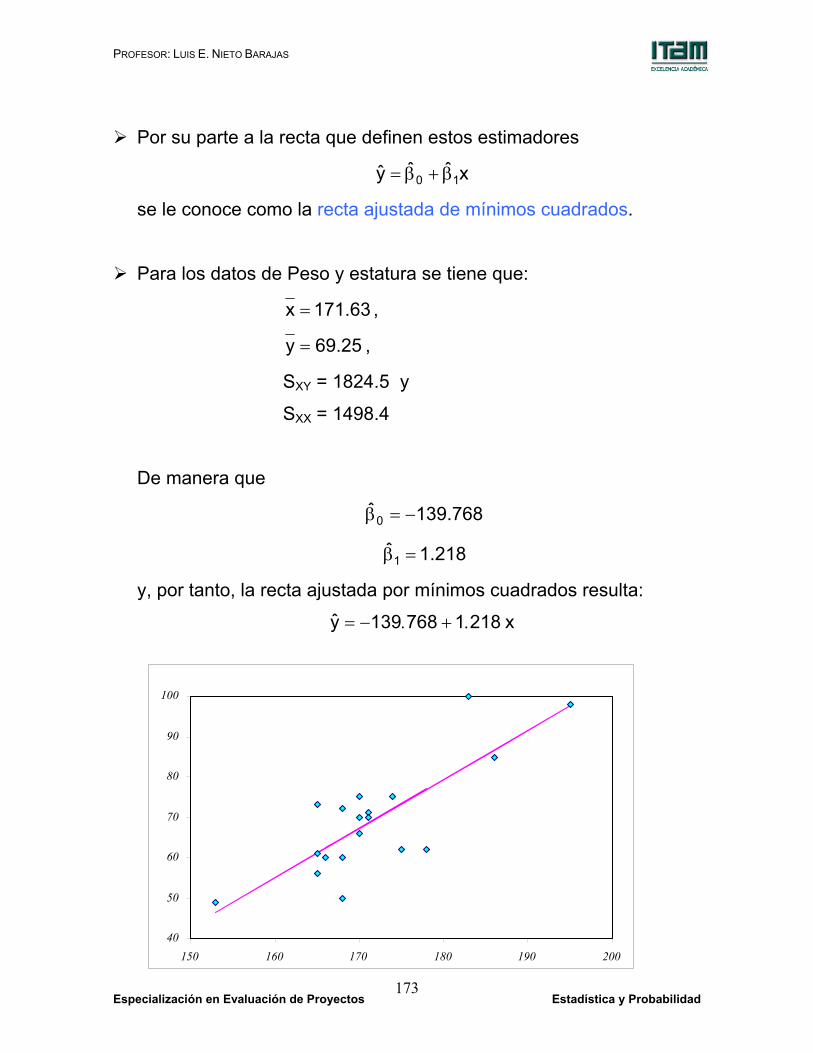
Por su parte a la recta que definen estos estimadores
x ˆ ˆy 10 β+β=
se le conoce como la recta ajustada de mínimos cuadrados.
Para los datos de Peso y estatura se tiene que:
171.63x = ,
69.25y = ,
SXY = 1824.5 y
SXX = 1498.4
De manera que
139.768ˆ0 −=β
1.218ˆ1 =β
y, por tanto, la recta ajustada por mínimos cuadrados resulta:
x 2181 768139y .+.−=
40
50
60
70
80
90
100
150 160 170 180 190 200

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 174
La gráfica exhibe los datos del ejemplo junto con la correspondiente
recta ajustada por mínimos cuadrados.
De acuerdo con la discusión de las ideas que subyacen la
producción de estimadores, es claro que tanto 0β como 1β han sido
calculados a partir de los datos disponibles y que de ellos, las
observaciones de la variable Y son el resultado de registrar
variables aleatorias.
Por tanto los valores estimados de los parámetros también se
pueden considerar como el resultado de observar sendas variables
aleatorias. A partir de los supuestos del modelo es posible probar
que
)S/,N(~ˆxx
211 σββ
y
)(nSx,N~ˆxx
n
1i
2i
200
σββ ∑
=
En particular, entonces, se tiene que
)ˆE 11 β=β(
y
)ˆE 00 β=β( .

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 175
De manera que tanto 0β como 1β son estimadores insesgados de
los respectivos parámetros desconocidos. Por otra parte, es
interesante observar como la varianza de cada uno depende tanto
de la varianza en el modelo σ2 como de los datos de la variable X.
Concretamente, en el caso de 1β , la varianza de este estimador
decrece a medida que la varianza de los datos de la variable X
aumenta.
En lo que se refiere a 0β , el resultado es menos obvio pero es
posible comprobar que su varianza decrece a medida que la media
de los datos de la variable X se aproxima a cero.
En cualquier caso, se tienen los estimadores de los parámetros
(coeficientes) del modelo de regresión y, por tanto la recta ajustada.
Sin embargo aún no se ha determinado por completo la distribución
condicional de Y dado un valor fijo de X. Falta por estimar la
varianza σ2.
Para estimar el parámetro σ2 también se pueden utilizar distintos
argumentos. La forma más simple y común se basa en el cálculo de
las diferencias
iii y- y e = i = 1, 2, …, n
entre las observaciones y los valores obtenidos de la recta de
mínimos cuadrados.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 176
Los valores {e1, e2, …en} que se conocen como errores residuales,
tienen media cero y en cierto sentido aproximan el comportamiento
de las variables aleatorias {ε1, ε2, …εn}. En particular, su varianza
estima la varianza de ε.
Puesto, que como ya se indicó la media aritmética de e1, e2, …en es
cero, la correspondiente varianza resulta simplemente
∑
∑
∑
=
=
=
−=
=
)−=
n
1i
2iin
1
n
1i
2in
1
2n
1iin
12
)y(y
e
e(eS
De esta manera, el estimador de la varianza σ2 está dado por la
suma de cuadrados de los residuales dividida por el tamaño del
banco. Es decir,
∑=
−=σn
1i
2iin
12 )y(yˆ
Como variable aleatoria, se tiene que 2σ presenta el siguiente
comportamiento: 2
2)(n22 ~/ˆn −χσσ .
Es decir, 22 /ˆn σσ tiene una distribución Ji cuadrada con n-2
grados de libertad.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 177
La variable W tiene una distribución Ji cuadrada, con r grados de
libertad, si es continua, tiene como soporte el intervalo (0, ∞) y su
función de densidad está dada por:
w/2)exp(w21
(r/2)1 f(w) 1r/2
r/2
−
Γ= −
Dos resultados interesantes son los siguientes:
1. Si Z es Normal estándar, entonces Z2 es Ji cuadrada con 1
grado de libertad.
2. Si W1 es Ji cuadrada con r1 g. l., W2 es Ji cuadrada con r2 g. l. y
son independientes entonces, W = W1+W2 resulta Ji cuadrada
con r1+r2 g. l.
El modelo Ji cuadrada tiene un solo parámetro, que puede tomar
cualquier valor positivo y que se conoce con el nombre de grados
de libertad. Si W es una variable aleatoria Ji cuadrada con r grados
de libertad entonces,
E(W) = r
Var(W) = 2r
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 178
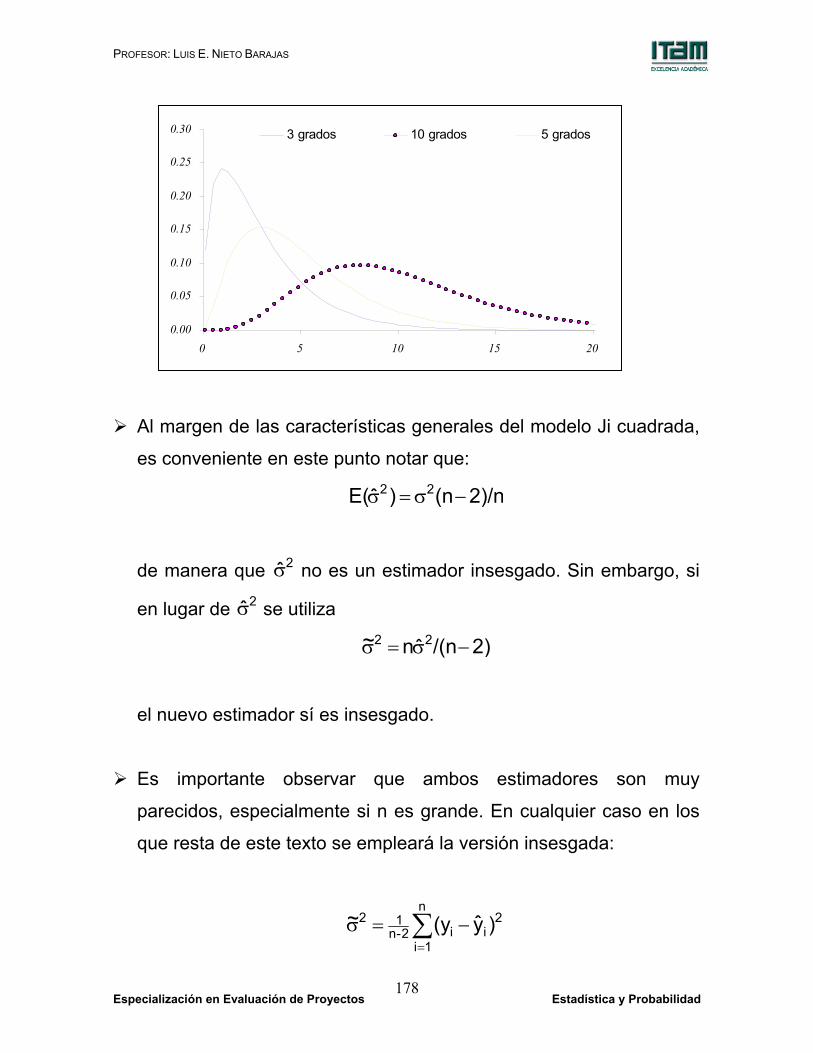
Al margen de las características generales del modelo Ji cuadrada,
es conveniente en este punto notar que:
2)/n(n)ˆE( 22 −σ=σ
de manera que 2σ no es un estimador insesgado. Sin embargo, si
en lugar de 2σ se utiliza
2)/(nˆn~ 22 −σ=σ
el nuevo estimador sí es insesgado.
Es importante observar que ambos estimadores son muy
parecidos, especialmente si n es grande. En cualquier caso en los
que resta de este texto se empleará la versión insesgada:
∑=
−=σn
1i
2ii2-n
12 )y(y~
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 5 10 15 20
3 grados 10 grados 5 grados

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 179
Este estimador tiene las propiedades básicas:
1. 22)(n
22 ~/~2)-(n −χσσ
2. 22)~E( σ=σ
3. 2)-(n/2)~Var( 42 σ=σ
Volviendo a los datos del ejemplo, se tiene que
1201.7)y(yn
1i
2ii =−∑
=
y n-2 = 17.
Por lo tanto,
70.687~2 =σ y 8.408~ =σ
Con estos resultados se puede intentar la determinación de la
distribución condicional de Y dado un valor fijo cualquiera de X. Una
primera aproximación sería, para un valor fijo x,
)~ x,ˆ ˆN(~Y 210 σβ+β
Sin embargo y precisamente porque los valores de los parámetros
constituyen sólo una estimación y no necesariamente coinciden con
los verdaderos valores desconocidos, es necesario incorporar esa
incertidumbre en el modelo.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 180
En la literatura estadística ha sido establecido el procedimiento por
medio del cual la incertidumbre adicional se toma en cuenta.
En primer lugar, el modelo Normal se sustituye por un modelo t (de
Student) que es muy parecido pero con colas más pesadas.
Una variable W tiene una distribución t de Student con r grados de
libertad si es continua con soporte (-∞, ∞) y su función de densidad
está dada por:
( ) 1)/2(r-21/2- /2)w(1r(r/2)
1)/2][(r f(w) ++πΓ
+Γ=
El modelo t de Student se aproxima al modelo Normal estándar a
medida que el número de grados de libertad aumenta.
Por otra parte, es interesante tener presente el siguiente resultado.
Si Z es Normal estándar, V es Ji cuadrada con r grados de libertad
y estas dos variables son independientes entonces
V/rZ W =
tiene una distribución t de Student con r grados de libertad.
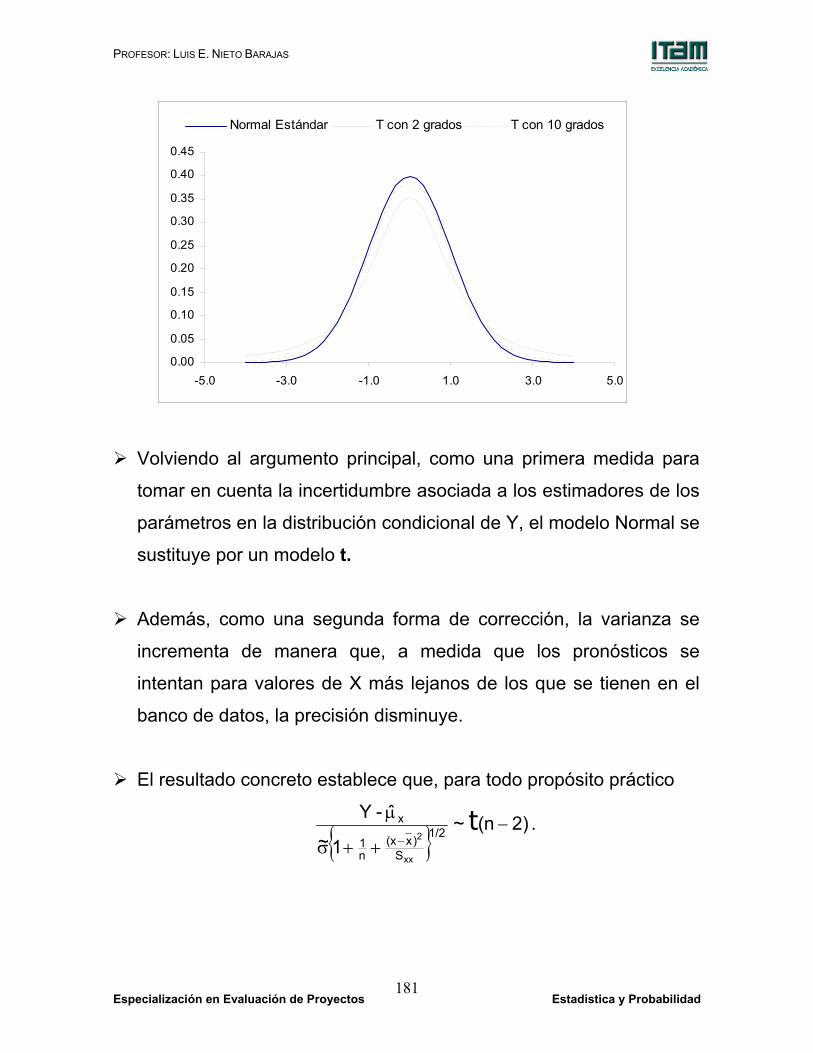
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 181
Volviendo al argumento principal, como una primera medida para
tomar en cuenta la incertidumbre asociada a los estimadores de los
parámetros en la distribución condicional de Y, el modelo Normal se
sustituye por un modelo t.
Además, como una segunda forma de corrección, la varianza se
incrementa de manera que, a medida que los pronósticos se
intentan para valores de X más lejanos de los que se tienen en el
banco de datos, la precisión disminuye.
El resultado concreto establece que, para todo propósito práctico
{ } 2)n(~1~
ˆ-Y1/2
S)x(x
n1
x
xx
2−
++σ
µ−
t .
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
-5.0 -3.0 -1.0 1.0 3.0 5.0
Normal Estándar T con 2 grados T con 10 grados

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 182
Es decir, el valor de la variable Y, debidamente estandarizada,
utilizando la desviación estándar estimada y un factor de
corrección, no sigue ya una distribución Normal sino una
distribución t de Student con n-2 grados de libertad.
Se puede comprobar que toda distribución t de Student es
simétrica, unimodal (con moda en cero) y su densidad tiene forma
de campana como la Normal (con una varianza mayor como se ha
indicado).
En estas condiciones, si se denota por t(r, p) el cuantil de orden p de
una t con r grados de libertad, entonces un pronóstico para el valor
de Y cuando X = x, con confiabilidad de (1-α)×100% está dado por
{ }1/2
S)x(x
n1
/2)-1 2,-(nx xx
21~tˆ −
α ++σ±µ .
Consideremos el caso del ejemplo. Ahí se tiene que
n = 19, 171.63 x = , SXX = 1498.4,
139.768ˆ0 −=β , 1.218ˆ
1 =β y 8.408~ =σ
Si ahora, de tablas, se observa que el cuantil de orden 0.975 de
una distribución t con 17 grados de libertad resulta t(17, 0.975) = 2.11
entonces, un pronóstico con 95% de confiabilidad para el valor de Y
cuando X = x está dado por el intervalo
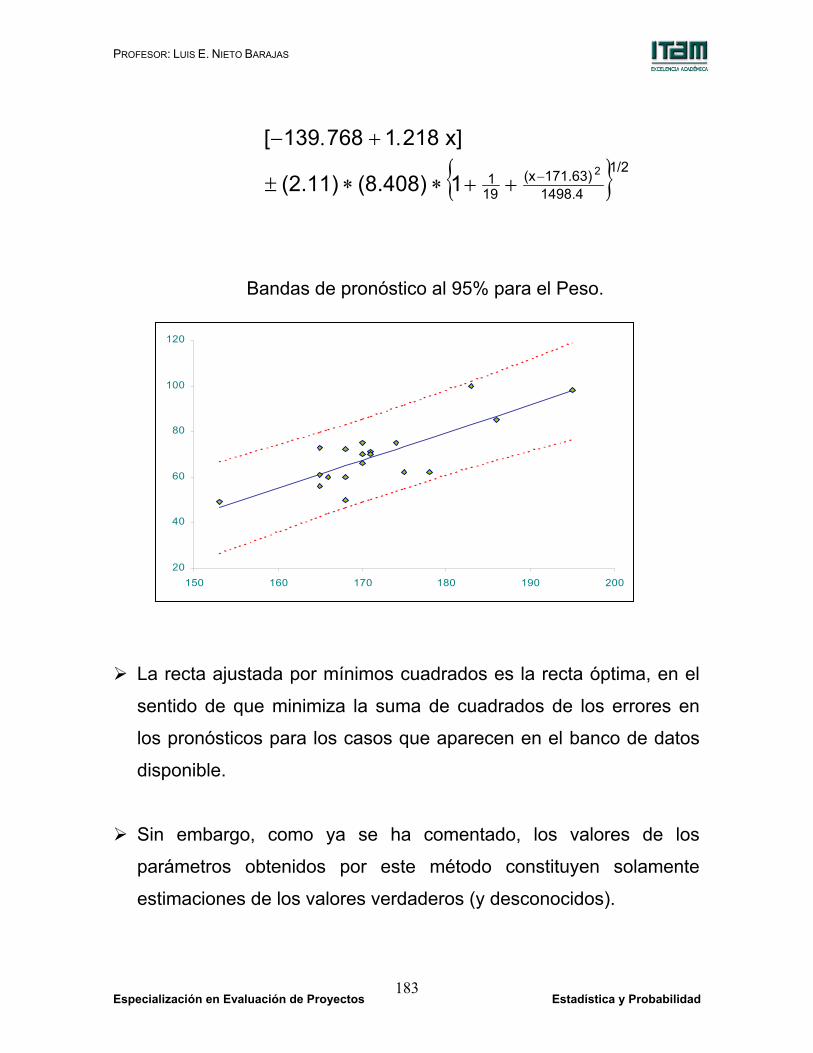
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 183
{ }1/2
1498.4171.63)(x
191 2
1(8.408)(2.11)
x]2181768139[ −++∗∗±
.+ .−
Bandas de pronóstico al 95% para el Peso.
La recta ajustada por mínimos cuadrados es la recta óptima, en el
sentido de que minimiza la suma de cuadrados de los errores en
los pronósticos para los casos que aparecen en el banco de datos
disponible.
Sin embargo, como ya se ha comentado, los valores de los
parámetros obtenidos por este método constituyen solamente
estimaciones de los valores verdaderos (y desconocidos).
20
40
60
80
100
120
150 160 170 180 190 200

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 184
Es natural preguntarse entonces, cuales otros valores podrían ser
estimaciones aceptables de esos parámetros desconocidos o si un
valor específico es compatible con la estimación que se ha
obtenido.
La clave para resolver estas interrogantes se encuentra en el
modelo de probabilidad que describe el comportamiento de los
estimadores como variables aleatorias.
Como ya se ha indicado, bajo los supuestos del modelo de
regresión lineal simple se tiene que
)S/,N(~ˆxx
211 σββ
y
))/(nSx,N(~ˆxx
n
1i
2i
200 ∑
=σββ
Considere, como ejemplo, el caso de ˆ1β . A partir del modelo
correspondiente se sigue que el error en la estimación tiene la
siguiente distribución
)S/,N(0~-ˆxx
211 σββ .
En consecuencia, si la varianza 2σ fuese conocida sería posible
calcular intervalos para el error en el pronóstico y, por tanto,
intervalos para otros valores estimados igualmente aceptables, con
grado de confiabilidad determinado.

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 185
Ahora bien, 2σ no es conocida pero se puede estimar con ~2σ y
entonces, se podría afirmar que aproximadamente,
)S/~,N(0~-ˆxx
211 σββ .
La corrección precisa, como en el caso de los pronósticos, recurre
al empleo de la distribución t de Student. El resultado es el
siguiente:
2)n(~~)-ˆS 11XX −
σββ( t
Por lo tanto, si t(n-2, p) es el cuantil de orden p de la distribución t de
Student con n-2 grados de libertad, entonces
α=≤σ
ββ(≤− α−−α−− -1)t ~
)-ˆS tP( 2) / 2,1(n
11XX2) / 2,1(n
De tal manera que cualquier valor 1β que cumpla con la condición
2) / 2,1(n11XX
2) / 2,1(n t ~)-ˆS
t α−−α−− ≤σ
ββ(≤−
es un valor tan compatible como ˆ1β con el banco de datos
disponible.
En otros términos, se puede decir que un estimación por intervalo
para el verdadero valor de 1β , con una confiabilidad de

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 186
(1-α)×100%, está dada por
XX2) / 2,1(n1 S
~ tˆ
2
α−−σ
±β .
De hecho, en un sentido contrario, se puede decir que todo valor
del parámetro que no cumpla la condición
2) / 2,1(n11XX
2) / 2,1(n t ~)-ˆS
t α−−α−− ≤σ
ββ(≤−
no es compatible con el banco de datos disponible (con un nivel
de confiabilidad de (1-α)×100%).
Si por ejemplo, hubiese razones –contextuales, teóricas o de algún
otro tipo- para plantear que 1β puede tomar el valor (conocido)
1∗β entonces, con un nivel de confiabilidad (1-α)×100%, se puede
afirmar que la hipótesis 11∗β=β se rechaza, a partir de la evidencia
en el banco de datos, si no se cumple la condición
2) / 2,1(n
*11XX
2) / 2,1(n t ~)-ˆS
t α−−α−− ≤σ
ββ(≤−

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 187
Es decir, la hipótesis 11∗β=β se rechaza –con un nivel de
confiabilidad (1-α)×100%-, si
2) / 2,1(n11XX t ~ -ˆ S
α−−
∗
>σ
ββ
Un caso de interés particular es 0. 1 =β∗ Es decir, el contraste de la
hipótesis 0.H 1 =β : La hipótesis se rechaza, con un nivel de
confiabilidad (1-α)×100%, si
2) / 2,1(n1XX t ~
ˆ Sα−−>
σ
β
La importancia del contraste de 0H 1 =β : (contra la alternativa
0H 1A ≠β : ) es de importancia porque si el banco de datos es
compatible con H, entonces existe evidencia para declarar que, al
menos linealmente, la variable X no influye en los pronósticos de Y.
En el caso del ejemplo, se tiene que 1.218ˆ1 =β ,
70.687~2 =σ ( 8.408~ =σ ) y SXX = 1498.4. Además, de tablas se
observa que t(17, 0.975) = 2.11. Por tanto, el intervalo con 95% de
confiabilidad para 1β está dado por
1498.468770 2.111.218 .
±

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 188
es decir, [0.7597, 1.6763]. En otras palabras, cualquier valor entre
0.7597 y 1.6763 es un valor de 1β compatible con los datos
(siempre con 95% de confiabilidad).
Con el mismo nivel de confiabilidad, 95%, se puede afirmar que los
valores fuera de este intervalo no son compatibles con la evidencia
que proporciona el banco de datos. En particular, puesto que el
cero está fuera del intervalo, se rechaza la hipótesis 0.H 1 =β : Este
hecho puede también comprobarse si se verifica que
5.6078 σ~
β S 1XX=
mientras que t(17, 0.975) = 2.11. Por tanto,
2) / 2,1(n1XX t ~
ˆ Sα−−>
σ
β
y se obtiene el resultado.
El caso de 0β es similar. Como ya se ha indicado, bajo los
supuestos del modelo,
))/(nSx,N(~ˆxx
n
1i
2i
200 ∑
=σββ
En consecuencia,

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 189
))/(nSx,N(0~- ˆxx
n
1i
2i
200 ∑
=σββ
Nuevamente si 2σ fuese conocida, ese modelo podría emplearse
para describir el grado de aproximación de 0β como estimador de
0β . Como ya se comentó, la varianza es desconocida pero puede
estimarse con 2~σ y como una primera aproximación puede
afirmarse que
))/(nSx~,N(0~- ˆxx
n
1i
2i
200 ∑
=σββ
La versión precisa de esta afirmación, utilizando la t de Student, es
la siguiente:
2)n(~~)-ˆ
xnS 00
2i
xx −σ
ββ(
∑t
De donde se tiene que una estimación por intervalo para el
verdadero valor de 0β , con una confiabilidad de (1-α)×100%, está
dada por
XX
2i
2) / 2,1(n0 nS)x(~
tˆ ∑2
α−−σ
±β .

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 190
Asimismo, el contraste de ∗β=β : 00 H (contra la alternativa
∗β≠β : 00AH ) puede llevarse a cabo, con una confiabilidad (1-
α)×100%, comprobando si ∗β0 pertenece al intervalo descrito. La
hipótesis se rechaza si el valor en la hipótesis se encuentra fuera
del intervalo y, en caso contrario, se puede afirmar que la evidencia
en el banco no permite rechazarla.
Equivalentemente, también es posible llevar a cabo el contraste de ∗β=β: 00H , con un nivel de confiabilidad (1-α)×100%, si se rechaza
cuando
2) / 2,1(n00
2i
xx t ~)-ˆ
xnS
α−−
∗
>σ
ββ(
∑
Recurriendo, una vez más, a los datos del ejemplo se tiene
139.768ˆ0 −=β , 70.687~2 =σ ( 8.408~ =σ ), 171.63X = y SXX =
1498.4. Por otra parte y como ya se indicó, de tablas se observa
que el cuantil relevante es t(17, 0.975) = 2.11. Por tanto, el intervalo
con 95% de confiabilidad para 0β está dado por
4.440 8.4082.11139.768- ××±
es decir, [-218.534, -61.002].

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 191
o Respecto al parámetro σ2 se puede proceder de forma similar. El
estimador insesgado de la varianza está dado
∑=
−=σn
1i
2ii2-n
12 )y(y~
Por otra parte, como se indicó, 2
2)(n22 ~/~ 2)-(n −χσσ .
Ahora, si se tiene que
p) P( 2p) 2,(n
22)(n =≤ −− χχ ,
es decir, si 2p) (r,χ es el cuantil de orden p de una Ji cuadrada con r
grados de libertad entonces
α=≥σσ α−χ -1) /~ 2)-(n P( 2) 2,(n
22 .
De donde se sigue que
α=σ≤σ α−χ -1)/~ 2)-(n P( 2) 2,(n
22
de forma que una estimación por intervalo, con una confiabilidad de
(1-α)×100% para σ2 está dada por el intervalo
)/~ 2)-(n , ( 2) 2,(n
2α−χσ0 .
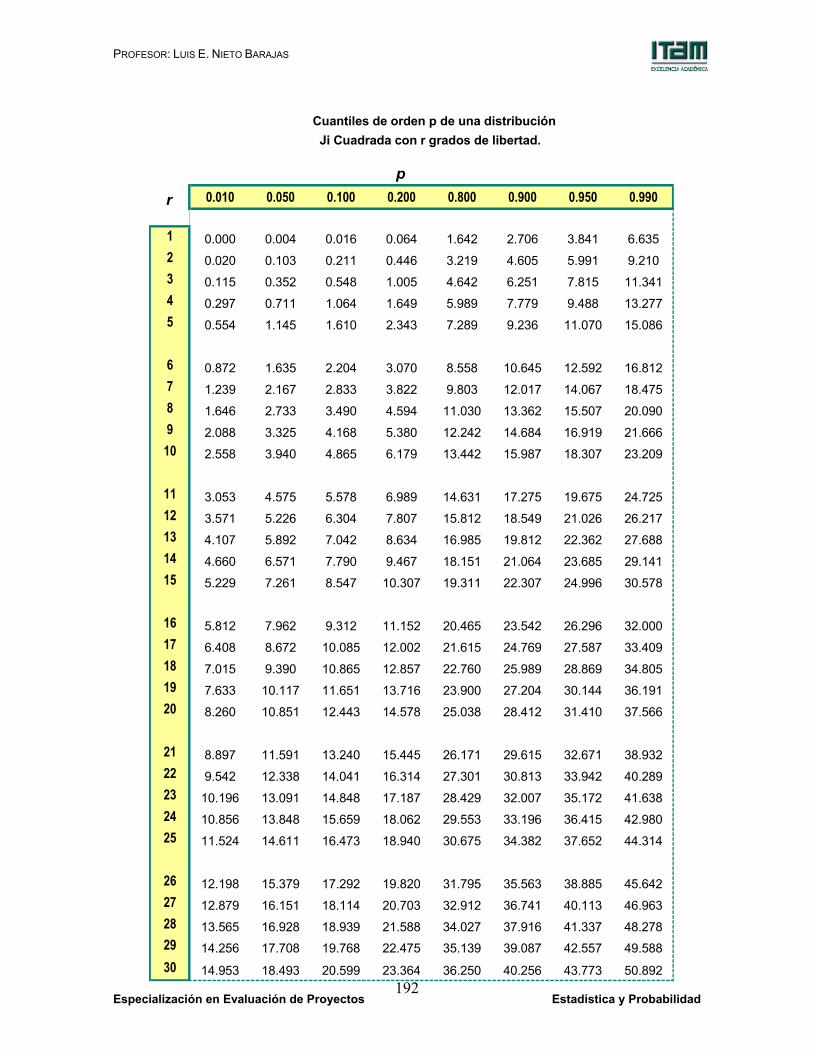
PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 192
Cuantiles de orden p de una distribución Ji Cuadrada con r grados de libertad.
pr 0.010 0.050 0.100 0.200 0.800 0.900 0.950 0.990
1 0.000 0.004 0.016 0.064 1.642 2.706 3.841 6.6352 0.020 0.103 0.211 0.446 3.219 4.605 5.991 9.2103 0.115 0.352 0.548 1.005 4.642 6.251 7.815 11.3414 0.297 0.711 1.064 1.649 5.989 7.779 9.488 13.2775 0.554 1.145 1.610 2.343 7.289 9.236 11.070 15.086
6 0.872 1.635 2.204 3.070 8.558 10.645 12.592 16.8127 1.239 2.167 2.833 3.822 9.803 12.017 14.067 18.4758 1.646 2.733 3.490 4.594 11.030 13.362 15.507 20.0909 2.088 3.325 4.168 5.380 12.242 14.684 16.919 21.66610 2.558 3.940 4.865 6.179 13.442 15.987 18.307 23.209
11 3.053 4.575 5.578 6.989 14.631 17.275 19.675 24.72512 3.571 5.226 6.304 7.807 15.812 18.549 21.026 26.21713 4.107 5.892 7.042 8.634 16.985 19.812 22.362 27.68814 4.660 6.571 7.790 9.467 18.151 21.064 23.685 29.14115 5.229 7.261 8.547 10.307 19.311 22.307 24.996 30.578
16 5.812 7.962 9.312 11.152 20.465 23.542 26.296 32.00017 6.408 8.672 10.085 12.002 21.615 24.769 27.587 33.40918 7.015 9.390 10.865 12.857 22.760 25.989 28.869 34.80519 7.633 10.117 11.651 13.716 23.900 27.204 30.144 36.19120 8.260 10.851 12.443 14.578 25.038 28.412 31.410 37.566
21 8.897 11.591 13.240 15.445 26.171 29.615 32.671 38.93222 9.542 12.338 14.041 16.314 27.301 30.813 33.942 40.28923 10.196 13.091 14.848 17.187 28.429 32.007 35.172 41.63824 10.856 13.848 15.659 18.062 29.553 33.196 36.415 42.98025 11.524 14.611 16.473 18.940 30.675 34.382 37.652 44.314
26 12.198 15.379 17.292 19.820 31.795 35.563 38.885 45.64227 12.879 16.151 18.114 20.703 32.912 36.741 40.113 46.96328 13.565 16.928 18.939 21.588 34.027 37.916 41.337 48.27829 14.256 17.708 19.768 22.475 35.139 39.087 42.557 49.58830 14.953 18.493 20.599 23.364 36.250 40.256 43.773 50.892

PROFESOR: LUIS E. NIETO BARAJAS
Especialización en Evaluación de Proyectos Estadística y Probabilidad 193
Volviendo al ejemplo, de las tablas se puede observar que
8.67220.05) (17, =χ
mientras que
70.687~2 =σ
de manera que, con 95% de confiabilidad, el intervalo para σ2
resulta 8.672) / 70.68717 0, ( × . Es decir, 138.57) 0, ( .
En otras palabras, se puede afirmar que con un 95% de
confiabilidad la varianza desconocida 2σ no es mayor que 138.57.
Equivalentemente, la desviación estándar σ no es mayor que
11.772.