1. preparación de las variables - uned.es · con el contraste de la diferencia de medias de...
TRANSCRIPT

1
Práctica 1
Introducción al contraste de hipótesis y análisis de varianza
La realización de esta práctica permite afianzar los conocimientos y aplicación de los
contrastes de significación de diferentes estadísticos. Se utilizan datos reales procedentes de
un barómetro de opinión del CIS que se analizará mediante el paquete PSPP. En el ejercicio se
indagará sobre las diferencias por sexo y edad respecto a la ubicación en la escala de ideología
política entre derecha e izquierda. Se comenzará por realizar un contraste de proporciones
sobre el nivel de respuesta en función del sexo a la pregunta de autoubicación para continuar
con el contraste de la diferencia de medias de posicionamiento ideológico entre hombres y
mujeres. La cuestión se extenderá a variables con múltiples categorías como la edad con el
uso de técnicas ANOVA.
1. Preparación de las variables
Además de aprender a realizar e interpretar los estadísticos de contraste de hipótesis, la
cuestión que queremos responder con este ejercicio es acerca de la existencia, o no, de
diferencias en posicionamiento político entre hombres y mujeres, así como por edad. ¿Son
más de derechas las mujeres que los hombres, y los mayores que los jóvenes? Vamos a
responder a este tipo de preguntas. Para ello vamos a utilizar el estudio 3005 del CIS
(Noviembre de 2013). Una vez descargado y generado el fichero activo vamos a centrarnos en
la pregunta 27:
Dicha pregunta permite la autoubicación del entrevistado en una escala de 1 a 10 entre las
posiciones políticas de izquierda y de derecha.

2
Vamos a solicitar las frecuencias de dicha variable, podemos hacerlo mediante el recurso de
menús:
O, escribiendo en el fichero de sintaxis, la instrucción, y ejecutándola:
El comando FREQUENCIES, que puede abreviarse –como todos los de PSPP- mediante el uso de
las tres primeras permite la obtención de tablas completas de frecuencias indicando
únicamente el nombre de la variable o variables.
Los resultados obtenidos, nos muestran que algo más del 25% (12,86%+13.55%) de los
entrevistados de la muestra no se han ubicado en dicha escala. La cifra, uno de cada cuatro, es
elevada, sin embargo vamos a comprobar si puede afectar a nuestro interés que es la
comparación entre hombres y mujeres. Vamos a solicitar un cruce de la variable ideología
(p27) respecto de la variable sexo (p29). Como en otras ocasiones podemos utilizar el sistema
de menús: (Analizar-Estadística Descriptiva- Tablas Cruzadas...)
FRE P27.

3
También podemos obtener la tabla de contingencia mediante comandos de sintaxis:
El comando CROSSTABS, en su forma abreviada CROS, viene seguido del nombre de la variable
que se coloca en filas y después de la partícula BY el nombre de la variable de columnas. Con el
subcomando /CELLS indicamos el contenido de las casillas. En este caso utilizamos COUNT que
es la frecuencia absoluta y COL que es el porcentaje vertical. Si quisiéramos el porcentaje
horizontal o de filas indicaríamos ROW.
Los resultados nos orientan que la “no respuesta” a ubicación política hay diferencias
importantes entre hombres y mujeres. Para los hombres es el 23,37% mientras que para las
mujeres alcanza el valor de 29,46%.
Antes de continuar el análisis vamos a generar las distintas variables que necesitaremos para la
práctica. De la P27 vamos a obtener dos variables:
Resp27
Dicha variable será dicotómica y tomará valores 0 y 1 para informarnos de si ha
respondido o no la autoubicación política.
CROS P27 BY P29 /CELLS=COUNT COL.

4
Ideo
Esta variable tomará valores entre 1 y 10 y nos indicará, sólo para aquéllos que han
respondido en P27, su posición en la escala izquierda derecha.
Además utilizaremos la edad de forma agrupada:
Edad4
Esta variable agrupa la edad –ver pregunta 30 y variable P30- en cuatro grupos.
El fichero de instrucciones para la generación de las tres variables que usaremos se reproduce
a continuación. Conviene ejecutarlo de una vez y generar el fichero “sav”. Las explicaciones de
los comandos se detallan posteriormente cuando se utilizan las variables. (Recuerde que los
comando que comienzan con “*” y terminan con “.” son comentarios o notas de texto.
2. Contraste de proporciones
Vamos a estudiar en primer lugar la diferencia en la respuesta en función del sexo. Pedimos la
tabla, bien mediante las opciones de menú, o bien mediante comandos:
*Variable dicotómica sobre respuesta en P27.
COMPUTE Resp27=0.
IF (P27=98 OR P27=99) Resp27=1.
VALUE LABEL Resp27 0 “Responde” 1 No Responde”.
*Variable IDEO posicionamiento de 1-10.
COMPUTE Ideo=P27.
MISSING VALUE Ideo (98,99).
*Variable EDAD4 edad en cuatro grupos.
COMPUTE Edad4=P30.
RECODE Edad4 (18 THRU 29=1) (30 THRU 49=2) (50 THRU 64=3) (65 THRU 97=4).
VALUE LABELS Edad4 1 “18-29” 2 “30-49” 3 “50-64” 4 “65+”.

5
La tabla que contiene los resultados es la siguiente:
Hombres Mujeres
Responden 76,73% 70,54%
No responden 23,27% 29,46%
Total 100% (1216)
100% (1256)
La cuestión ahora es, las diferencias observadas (alrededor del 6%) entre la respuesta de
hombres y mujeres a la cuestión de autoubicación política ¿son significativas?
Para contestar a esta cuestión, y descartar el efecto del azar, podemos realizar un contraste de
igualdad de proporciones.
Vamos a definir que:
Ho: ph=pm ó de forma equivalente ph-pm = 0
H1: ph≠pm ó de forma equivalente │ph-pm│ 0
Como los tamaños muestrales son grandes vamos a utilizar el estadístico Z.
Según Estadística para la investigación social (pp.284). La distribución muestral de la diferencia
de proporciones es (en este caso utilizamos h para la muestra de hombres y m para las
mujeres):
( ) ( )
Siendo el error típico
( ) √
Si damos valores:
( ) √
( )
CROS Resp27 BY P29 /CELLS=COL.

6
El estadístico nos señala que la diferencia entre ambas proporciones nos informa que hay más
de 3 desviaciones estándar de diferencia. Si observamos en tablas de la curva normal el valor
de probabilidad asociado a dicho Z-3,5095 es p=0,00022446, como se trata de una prueba
bilateral, dicho valor es
por lo tanto el nivel α será igual a 0,00044892.
Con una probabilidad (p<1/1000) podemos rechazar la hipótesis nula que indica que no hay
diferencias en la respuesta de ubicación política entre hombres y mujeres. Las diferencias que
observamos (un 6%) de respuesta resulta muy improbable que se deban al azar. Podemos
afirmar, con gran seguridad, que las mujeres responden de forma distinta la cuestión
ideológica. (Otra cuestión es la intensidad de la diferencia de respuesta. La prueba de hipótesis
nos indica que hay diferencias, ahora bien estas pueden ser grandes o pequeñas).
Este resultado, de diferencia en la tasa de respuesta a cuestiones políticas entre hombres y
mujeres es habitual, y es efecto de varios factores. Por una parte por el mayor grado de
envejecimiento de la población femenina, y el hecho de que las edades más elevadas
aumenten la no respuesta en cuestiones de opinión. Por otra parte, y esta cuestión resulta
relevante, por el hecho que muestran los datos como esta encuesta, de la mayor dificultad que
tienen las mujeres a expresar en público sus opiniones políticas, como residuo de la cultura
patriarcal dominante.
2.1 Contraste de proporciones con programas informáticos
Para realizar un contraste de hipótesis de proporciones los programas de ordenador exigen
variables “dummy”. Las variables dummy son variables dicotómicas que toman el valor 1
cuando se cumple la característica (en este caso no responder) y 0 en los demás casos
(=ausencia de característica).
En el apartado anterior hemos construido, mediante comandos de sintaxis, una variable
dicotómica que llamamos “Resp27” que tomaba dos valores “0” cuando el entrevistado se
posiciona en la escala izquierda-derecha y “1” cuando no sabe o no contesta a la pregunta 27.
Para ello con el comando COMPUTE inicializamos la variable Resp27 con el valor 0. Mediante el
siguiente comando IF, indicamos que en los casos en que en la pregunta 27 (variable P27) se
ha respondido 98 o 99, cambie el valor de Resp27 a “1”. Con el comando VALUE LABEL
asignamos etiquetas de valor a la variable. Podemos observar lo realizado, solicitando las
frecuencias de la variable.
COMPUTE Resp27=0.
IF (P27=98 OR P27=99) Resp27=1.
VALUE LABEL Resp27 0 “Responde” 1 No Responde”.
SET FORMAT=F12.6.
FRE Resp27.

7
En este caso además del comando FREQUENCIES hemos indicado también la secuencia SET
FORMAT. Este comando nos permite ajustar el número de decimales para los resultados. Por
defecto el PSPP presenta los resultados con 2 decimales, cuando trabajamos con contrastes,
conviene tener más decimales. En este caso con F12.6 le indicamos que los 12 dígitos que
tiene el valor de salida, 6 serán decimales.
Como podemos observar en los resultados de la tabla de frecuencias la categoría que “No
responden” es el 26, 41%. Al ser una variable “dummy” tiene la ventaja de que la media se
corresponde con la proporción. Observe que la media es 0,2641. Esta propiedad nos va a
permitir el uso de los test de contraste de medias para aplicarlos a proporciones.
Para el contraste de hipótesis utilizamos el comando T-Test de PSPP.
Desde las opciones de menú
(Analizar- Comparar Medias- Prueba T para Muestras Independientes):

8
Vamos a contrastar las medias de respuesta (Resp27) para los hombres y mujeres (P29).
Definimos como variable de contraste “Resp27” y como variable de agrupación P29 que es el
sexo del entrevistado. Al definir el grupo se nos abre otra ventana para indicar los valores que
queremos contrastar. En este caso sólo hay dos valores 1=Hombres y 2=Mujeres.
Si escribimos la sintaxis:
El comando T-TEST tiene dos subcomandos obligatorios:
VARIABLE para indicar la variable de contraste y
GROUP para indicar la variable que forma los grupos de contraste con indicación de los valores
a contrastar.
Podemos añadir el subcomando CRITERIA que indica dentro del paréntesis el nivel de
confianza “Confindence Interval” CIN=(0.95) que es el 95% (ó el 5% de significación) Este es el
valor por defecto si no incluimos el subcomando. Si quisiéramos realizar contrastes para un
nivel de significación del 1% entonces deberíamos indicar CIN=(0.99).
Los resultados nos aparecen en las dos tablas siguientes:
Sexo de la persona entrevistada N Media Desviación Estándar Err.Est.Media
Resp27 Hombre 1216 .232730 .422746 .012123
Mujer 1256 .294586 .456038 .012868
Prueba de Levene para la igualdad de varianzas
Prueba T para la Igualdad de Medias
F Sign. t df Sign. (2-
colas)
Diferencia
Media
Err.Est. de la
Diferencia
Intervalo de
confianza 95% de la
Diferencia
Inferior Superior
Resp27 Se asume igualdad de
varianzas
49.185494 .000000 -3.494524 2470.000000 .000483 -.061856 .017679 -.096523 -.027188
Igualdad de varianzas no
asumida
-3.498806 2465.364103 .000476 -.061856 .017679 -.096523 -.027188
T-TEST /VARIABLE=resp27 GROUP=p29 (1,2) CRITERIA=CIN(0.95).

9
En la primera de las tablas obtenemos unos estadísticos descriptivos. Así podemos observar
que la proporción no respuesta de los hombres es 0,2327 y la de las mujeres 0,2945, que son
los porcentajes que habíamos deducido a partir del cruce de la P27 por sexo. Para cada grupo,
tanto de hombres como de mujeres, nos indica también la varianza1, así como el error típico,
que sería de utilidad para la construcción de los intervalos de confianza.
Por ejemplo, para hombres, la no respuesta, dado un nivel de confianza del 95%, será:
[ ]
Para las mujeres:
[ ]
Como podemos observar, para un nivel de confianza del 95% podemos señalar que hay
diferencia en la respuesta entre hombres y mujeres a la pregunta de autoubicación política.
Los intervalos son excluyentes, no tienen ningún punto en común.
Intervalos de confianza del 95% para la proporción de no respuesta a la pregunta de
autoubicación ideológica por sexo.
Fuente: Estudio CIS 3005. Noviembre 2013.
Vamos a analizar ahora la tabla del contraste de medias. La tabla de resultados que nos ofrece
el programa son en realidad dos tablas diferentes:
1 Téngase presente que por regla general los programas de ordenador se refieren a varianza muestral.
Es decir se refieren a la cuasivarianza.
0%
5%
10%
15%
20%
25%
30%
35%
Hombres Mujeres

10
Por una parte el programa realiza un contraste sobre la igualdad de varianzas para las
categorías analizadas. Al final de la práctica en un anexo se explica con mayor detalle el test de
Levene. Dicho test nos permite señalar si las varianzas, en este caso de hombres y de mujeres,
son iguales o no. En función de dicho resultado leeremos la segunda tabla. La segunda tabla
tiene dos líneas de resultados, una para el caso en el que consideremos que hay igualdad de
varianzas, y una segunda, si consideramos que las varianzas no son iguales.
La tabla de descriptivos nos indicaba la desviación típica Shombres=0,422746 y Smujeres=0,456038.
Las varianzas respectivas serán: 0,17871418 y
0,20797066.
En este caso, el test de Levene nos indica que las varianzas no son iguales, por ello leeremos la
segunda línea. Observemos que el p-valor (Sign.) del estadístico F es2 p<0,000001. Por ello
decimos que resulta muy improbable que hayan sido distintas por azar.
No obstante, podemos ver que la diferencia, entre considerar igualdad de varianzas o no,
resulta en nuestro caso indiferente. Los estadísticos tienen valores casi idénticos. En la práctica
en análisis de encuestas en sociología los tamaños muestrales son lo suficientemente grandes
para ser insensibles a la cuestión de la homogeneidad de varianzas.
El programa como estadístico de contraste utiliza la distribución “t de Student”. El valor
obtenido es t=-3,499, un valor casi idéntico al valor Z=-3,510 que habíamos calculado
anteriormente mediante la distribución normal. Además del valor “t” nos señala los grados de
libertad. En el caso de igualdad de varianzas son n-2. En el supuesto de no igualdad de
varianzas la expresión resulta distinta. En el anexo se detalla la formulación del error tipico de
la diferencia de medias en ambos casos. Además del valor del estadístico y de sus grados de
libertad el programa nos señala el “p-valor” o grado de significación del valor obtenido. En este
caso p<0,000476.
2 Aunque en la tabla aparece .000000 de manera estricta no podemos decir que es cero, sino que es
insignificante p<1/1.000.000.

11
Realmente este número es el centro de nuestro análisis. Este valor lo podemos interpretar
como la probabilidad de equivocarnos si rechazamos la hipótesis nula, de que esta sea cierta.
Es decir, si rechazamos que haya igualdad de no respuesta entre hombres y mujeres, la
probabilidad que asumimos de equivocarnos es 4,76 diezmilésimas. Francamente es un valor
despreciable. La encuesta dice claramente que hombres y mujeres responden distinto, y ello lo
podemos afirmar al menos con un nivel de confianza mayor del 99,999%.
Otra información que produce la tabla es la diferencia de las medias, en este caso la diferencia
entre proporción de hombres y de mujeres 6,18%, favorable a las mujeres. También el error
típico del estadístico de la diferencia. Recordemos que el error típico de la diferencia de
medias es (Estadística para la Investigación Social, pp. 264):
( ) √
√
Conocido el error típico, el programa nos ofrece el intervalo de la diferencia entre hombres y
mujeres, en este caso para un Nivel de Confianza (CIN=0,95) del 95%. (Z=1,96)
Así:
( ) ( )
-0,61856±1,96x0,0176791=[-0,09650704 : -0,02720496]
Dicho intervalo señala que la diferencia oscilará entre el 9,6% y el 2,7%, siendo siempre mayor
la no respuesta entre hombres y mujeres. Como el intervalo no contiene el “0” podemos decir
que no hay igualdad en la tasa de no respuesta entre hombres y mujeres.
Como puede apreciarse el programa, ofrece de forma conjunta un contraste de hipótesis así
como el intervalo de confianza para la diferencia de medias.
3. Contraste de medias
Para estudiar el posicionamiento entre izquierda y derecha utilizaremos la variable Ideo que
habíamos generado con dos siguientes comandos. Por una parte hacemos una copia de la
variable original P27 mediante el comando COMPUTE y declaramos valores perdidos a los
códigos 98 y 99 mediante el comando MISSING VALUE.
COMPUTE Ideo=P27.
MISSING VALUE Ideo (98,99).

12
Vamos a examinar la variable de posicionamiento ideológico respecto al sexo de dos formas.
Por una parte haremos una tabla de porcentajes verticales, tomando la variable sexo como
variable independiente. –Mediante menus: Analizar-Estadística Descriptiva-Tablas Cruzadas...-.
Y, por otra parte, las medias de la variable para los grupos de hombres y mujeres. (Analizar-
Comparar Medias-Medias...).
Escrito mediante comandos:
Para las medias utilizamos el comando MEANS TABLES que tiene una sintaxis muy parecida a
CROSSTABS. -Variable dependiente BY variable independiente-. El contenido de las celdas o
casillas lo indicamos con el subcomando CELLS. En este caso, solicitamos la media (MEAN), la
desviación estándar (STDDEV), la varianza (VAR) y el número de casos (COUNT).
Las tablas obtenidas:
Ideo
Sexo de la persona entrevistada
Total Hombre Mujer
1,00 5,681% 4,176% 4,948%
2,00 5,788% 6,659% 6,212%
3,00 17,899% 18,397% 18,142%
4,00 17,685% 15,576% 16,658%
5,00 29,796% 30,474% 30,126%
6,00 8,789% 9,594% 9,181%
7,00 7,610% 7,336% 7,477%
8,00 4,180% 5,530% 4,838%
9,00 1,822% 1,467% 1,649%
10,00 0,750% 0,790% 0,770%
Total 100,000% 100,000% 100,000%
.
Sexo de la persona entrevistada Media
Desviación Estándar Varianza N
Ideo Hombre 4,5402 1,83368 3,362 933
Mujer 4,6163 1,82621 3,335 886
Total 4,5772 1,82994 3,349 1819
Además de los datos vamos a representar los porcentajes en un gráfico
Distribución de la población en el espectro ideológico de Izquierda-Derecha por sexo.
(1=Izquierda, 10=Derecha).
CROSS Ideo BY P29 /CELLS=COL.
MEANS TABLES Ideo BY P29 /CELLS=MEAN STDDEV VAR COUNT.

13
Fuente: Estudio CIS 3005. Noviembre 2013.
La distribución de porcentajes no sugiere que existan diferencias entre hombres y mujeres.
Hay una ligera concentración de hombres respecto a mujeres en posiciones de izquierda. Por
ello la media de hombres es más baja 4,54 frente a las mujeres 4,61 –recordemos que 1 es el
polo de izquierda y 10 el de derecha-. La cuestión ahora es, podemos afirmar sin género de
dudas que no hay diferencias de ubicación política por ser hombre o por ser mujer. Para ello
ejecutamos un contraste de medias, bien mediante menús, o mediante comandos, utilizamos
el T-TEST.
Los resultados:
Estadísticos de grupo
Sexo de la persona entrevistada N Media Desviación típ. Error típ. de la media
ideo Hombre 933 4,540193 1,833681 ,060032
Mujer 886 4,616253 1,826214 ,061353
Prueba de muestras independientes
Prueba de Levene para la igualdad de
varianzas Prueba T para la igualdad de medias
F Sig. t gl Sig.
(bilateral) Diferencia de medias
Error típ. de la
diferencia
95% Intervalo de confianza para la
diferencia
Inferior Superior
ideo Se han asumido varianzas iguales
,000845 ,976809 -,886002 1817 ,375734 -,076060 ,085837 -,244410 ,092290
No se han asumido varianzas iguales
-,886095 1812,884987 ,375684 -,076060 ,085837 -,244410 ,092290
0%
5%
10%
15%
20%
25%
30%
35%
1 2 3 4 5 6 7 8 9 10
Hombres
Mujeres
T-TEST /VARIABLE=Ideo GROUP=p29 (1,2).

14
Los resultados muestran que no tenemos evidencia suficiente para afirmar que existen
diferencias entre hombres y mujeres en cuanto a ubicación ideológica. Los datos nos dicen que
podemos considerar que hay igualdad de varianzas. 97,6% sería la probabilidad de
equivocarnos al afirmar que las varianzas son distintas. Asumiendo la homogeneidad de
varianzas, vemos que el p-valor resulta alto (0,375734) para rechazar la hipótesis nula de
igualdad de medias. Las pequeñas diferencias observadas en este caso bien pueden deberse al
azar. Así nos lo confirma también el intervalo de confianza de la diferencia de medias. Las 76
milésimas de diferencia (-0,076) entre la media de hombres y de mujeres, oscilan entre 244
milésimas (-0,244410) o 92 en sentido contrario (+0,092290). Como puede apreciarse dentro
del intervalo también está el 0, es decir el punto de igualdad de medias.
Por ello podemos concluir que no se aprecia ninguna diferencia de ubicación política entre
hombres y mujeres. Tampoco habría motivos teóricos suficientes para soportar que por ser
hombres o mujeres somos políticamente diferentes. Lo que también han puesto en evidencia
los datos es que hay una diferencia relativa en la respuesta a la pregunta de ubicación política.
Convendría investigar de forma más detallada si esta tasa es un efecto de la menor
expresividad pública de las mujeres, y en qué contextos culturales resulta esto todavía cierto.
4. Análisis de Varianza
Discutida la relación entre género y ubicación política, vamos a preguntarnos por el papel que
ejerce la edad en dicha relación. Influye la edad en el posicionamiento político. Para responder
a esta pregunta vamos a dividir la muestra en cuatro grupos de edad: De 18 a 29 años, de 30 a
49 años, de 50 a 64 años y mayores de 65 años. Esta variable la habíamos generado
anteriormente y denominado Edad4 mediante la siguiente secuencia de comandos:
Mediante COMPUTE generamos la variable Edad4 como copia de P30. Con RECODE
recodificamos los valores originales de edad en cuatro grupos. (En este caso hemos
comprobado que no hay ningún valor 99 que hubiera significado No Respuesta). Con VALUE
LABEL etiquetamos los cuatro valores de la nueva variable Edad4.
COMPUTE Edad4=P30.
RECODE Edad4 (18 THRU 29=1) (30 THRU 49=2) (50 THRU 64=3) (65 THRU 97=4).
VALUE LABELS Edad4 1 “18-29” 2 “30-49” 3 “50-64” 4 “65+”.

15
En primer lugar examinamos la relación de la variable edad (como independiente) con
Ideología como dependiente. Observemos que la variable Edad4 es una variable nominal en
cuatro grupos, que podríamos haber etiquetado como Jóvenes, Maduros, Seniors y Mayores,
por ejemplo. La variable Ideo es una variable de intervalo. Para examinar la relación entre
ambas variables solicitamos la tabla de porcentajes verticales y la tabla con las medias.
Edad4
Total 18-29 30-49 50-64 65+
ideo 1,00 6,7% 4,3% 6,7% 2,5% 4,9%
2,00 7,6% 6,3% 7,6% 3,1% 6,2%
3,00 19,1% 18,2% 19,4% 15,6% 18,1%
4,00 16,2% 18,1% 16,6% 14,2% 16,7%
5,00 33,4% 31,4% 24,9% 30,9% 30,1%
6,00 9,2% 8,7% 10,9% 8,1% 9,2%
7,00 4,8% 7,0% 6,7% 11,7% 7,5%
8,00 1,3% 4,8% 5,5% 7,2% 4,8%
9,00 ,6% ,7% 1,2% 5,0% 1,6%
10,00 1,0% ,4% ,5% 1,7% ,8% Total 100,0% 100,0% 100,0% 100,0% 100,0%
ideo
Edad4 Media Desv. típ. Varianza N
18-29 4,2580 1,69768 2,882 314
30-49 4,5105 1,71828 2,952 713
50-64 4,4273 1,88559 3,555 433
65+ 5,1699 1,96096 3,845 359
Total 4,5772 1,82994 3,349 1819
Nótese que en el total sólo hay 1819 casos, téngase en cuenta que al igual que sucedía en el
análisis por sexo, la variable Ideo sólo se refiere al grupo que han respondido a la pregunta 27.
Distribución de la población en el espectro ideológico de Izquierda-Derecha por grupos de edad. (1=Izquierda, 10=Derecha).
CROSS Ideo BY Edad4 /CELLS=COL.
MEANS TABLES Ideo BY Edad4 /CELLS=MEAN STDDEV VAR COUNT.

16
Fuente: Estudio CIS 3005. Noviembre 2013.
El gráfico sugiere que los mayores de 65 años se posicionan más a la derecha. Los más jóvenes
(18-29) por el contrario no se posicionan en valores de la escala cercanos al polo de derecha
sino más cerca de la izquierda. Los maduros entre 50 y 64 años se polarizan más entre
izquierda y derecha, evitando relativamente su posicionamiento en el centro.
Los datos de la tabla de medias evidencian que éstas varían con la edad, subiendo en la escala.
En nuestra escala esto quiere decir que hay algún desplazamiento entre la izquierda y la
derecha según aumenta la edad.
La cuestión ahora es ¿estas apreciaciones son significativas? Para ello vamos a realizar un
contraste de medias. Sin embargo la variable de agrupación, que ahora denominamos factor,
tiene más de dos categorías. Por ello vamos a utilizar el Análisis de Varianza (ANOVA) para
realizar un contraste múltiple de hipótesis. La hipótesis nula será que las medias son iguales
entre los cuatro grupos de edad. Lo que quiere decir que no hay diferencias en ubicación
política por edad, y que las diferencias que hemos observado son de carácter aleatorio.
( ) ( ) ( ) ( )
( ) ( ) ( ) ( )
El ANOVA podemos realizarlo mediante menús:
Analizar-Comparar Medias-ANOVA de un factor...
0%
5%
10%
15%
20%
25%
30%
35%
40%
1 2 3 4 5 6 7 8 9 10
18-29
30-49
50-64
65+
17
Indicamos la variable dependiente (Ideo) y el factor (Edad4).
Desde el editor de comandos la sintaxis resulta sencilla:
El comando se denomina ONEWAY y especifica las variables mediante el subcomando
VARIABLES, con el formato Variable Dependiente BY Factor.
La tabla de resultados que ofrece sigue el modelo clásico de descomposición de suma de
cuadrados y de presentación del estadístico F:
ANOVA
ideo
Suma de cuadrados gl Media cuadrática F Sig.
Inter-grupos 171,028 3 57,009 17,488 ,000
Intra-grupos 5916,870 1815 3,260
Total 6087,898 1818
El resultado también es claro, no hay evidencia para soportar la idea de que las medias de
ideología son iguales por edad. El nivel de significación es p<1/1000. Dicho de otra forma este
es el riesgo que asumimos cuando decimos que no hay igualdad en las medias de ubicación
política y por tanto debemos suponer que hay diferencias. La aportación en términos de
varianza que hacen los grupos de edad es 17 veces superior a la que hacen los propios sujetos.
Los grupos son diferentes. Sin embargo el trabajo del sociólogo no termina aquí, debería
señalarse si esto es así para todos los grupos del factor.
Una inspección gráfica de los intervalos de las medias por cada categoría del factor nos puede
ayudar a especificar la relación que existe entre edad e ideología.
El propio comando de ANOVA nos permite obtener los intervalos de confianza, pulsando en la
casilla de Descriptivos:
ONEWAY /VARIABLES= Ideo BY Edad4.

18
O añadiendo el subcomando ESTATISTICS, la especificación de DESCRIPTIVES nos ofrece un
resumen de los estadísticos para cada grupo del factor.
Descriptivos
ideo
N Media
Desviación
típica Error típico
Intervalo de confianza para la
media al 95%
Mínimo Máximo Límite inferior Límite superior
18-29 314 4,2580 1,69768 ,09581 4,0695 4,4465 1,00 10,00
30-49 713 4,5105 1,71828 ,06435 4,3842 4,6369 1,00 10,00
50-64 433 4,4273 1,88559 ,09062 4,2491 4,6054 1,00 10,00
65+ 359 5,1699 1,96096 ,10350 4,9664 5,3735 1,00 10,00
Total 1819 4,5772 1,82994 ,04291 4,4931 4,6614 1,00 10,00
La tabla nos ofrece además de la media el error típico, recuérdese que es
√ , por ejemplo
en el primer grupo de edad:
√ y con el valor de los errores típicos los
intervalos de confianza para las medias, por defecto para Niveles de Confianza del 95% (Z=1,96). El gráfico siguiente nos permite observar con mayor detalle. Intervalos de confianza del 95% para la media de autoubicación ideológica por grupos de
edad.
ONEWAY /VARIABLES= Ideo BY Edad4 /STATISTICS= DESCRIPTIVES.

19
Fuente: Estudio CIS 3005. Noviembre 2013.
El grupo de mayores de 65 años presenta una media claramente distinta a los otros grupos de edad. Mientras que los grupos de 18 a 65 años no se diferencian de forma significativa en su posicionamiento en la escala de ideología política, los intervalos de confianza de sus medias se solapan, la media de los mayores queda claramente alejada del resto. Los mayores de 65 años son por regla general más conservadores que la población general.
3
3,5
4
4,5
5
5,5
18-29 30-40 40-65 65+

20
ANEXO. Comentarios sobre la cuestión de la homogeneidad de varianzas y test de Levene.
En la construcción de los test de hipótesis para la diferencia de medias los estadísticos
diferencian dos situaciones: que los grupos de comparación tengan la misma varianza o
varianzas distintas. ¿Por qué?
Porque los errores típicos dependen de la varianza poblacional, y como por regla general
desconocemos la varianza de la población, debemos estimar ésta a través de las varianzas de
la muestra. Y dicha estimación resulta distinta según el grado de homogeneidad de la varianza
poblacional. De forma sencilla hay homogeneidad de la varianza cuando esta no cambia con
los distintos niveles de la variable, y heterogeneidad en el caso en que exista asociación entre
la media y la varianza. En cada caso vamos a utilizar una forma distinta para estimar el error
típico.
Supongamos por ejemplo que estamos analizando el gasto en alimentación de una población.
Si dicha población la dividimos en dos grupos por la inicial del apellido A-L y de la M-Z que
vamos a comparar, no encontraremos diferencias en la varianza del gasto y probablemente
también el gasto medio de ambos grupos será el mismo. Sin embargo si dividimos dicha
población en grupos por su estatus socieconómico, observaremos diferencias en la media de
gasto pero también asociados a la misma en la varianza. Los grupos de menor estatus tienen
comportamientos más homogéneos mientras que los grupos de estatus más elevado son muy
diversos entre sí en referencia a sus prácticas de consumo. Mayor gasto supone mayor
diversidad, menor gasto supone menor diversidad.
El efecto que puede tener la heterogeneidad de la varianza es relevante si se está trabajando
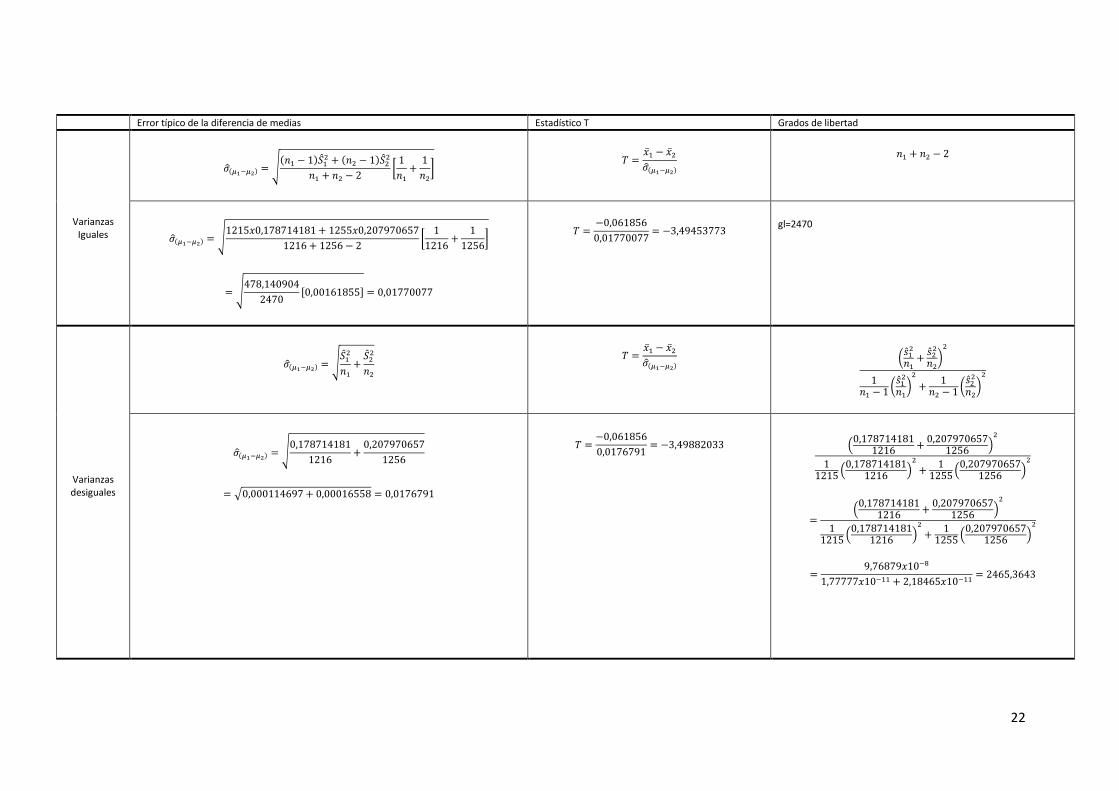
con muestras pequeñas. En el cuadro adjunto se detallan las formulaciones del error típico
para los casos de igualdad y de diferencia de varianzas entre grupos. Se han utilizado los datos
referentes a la variable Resp27.
Como puede apreciarse la formulación se diferencia en la medida en que se combinan
las varianzas de los grupos. Cuando son iguales se calcula la varianza combinada. En el
caso en el que se suponen varianzas desiguales, la varianza se supone una
combinación lineal de dos fuentes independientes, por ello se complejiza
algebraicamente la cuestión de los grados de libertad que se estima mediante la
fórmula de Welch.
Hombres Mujeres
0,232730 0,294586
0,178714181 0,207970657
n 1216 1256

21
22
Error típico de la diferencia de medias Estadístico T Grados de libertad
Varianzas Iguales
( ) √( )
( )
[
]
( )
( ) √
[
]
√
[ ]
gl=2470
Varianzas desiguales
( ) √
( )
(
)
(
)
(
)
( ) √
√
(
)
(
)
(
)
(
)
(
)
(
)

23
Para la elección de uno o de otro estadístico se utiliza el test de Levene. El test de Levene es
similar al test F de Fisher. El test F, contrasta la varianza de las medias dentro y entre los
grupos para observar la relación entre ambas. El test de Levene sigue también la distribución F
de Fisher. Puede calcularse su valor de forma análoga al análisis de varianza3. Su interpretación
es idéntica al análisis de varianza. En este caso la hipótesis nula es, no la igualdad de medias,
sino la igualdad de varianzas. Además del valor del estadístico, aparece su p-valor asociado.
Como regla general admitiremos la hipótesis nula –hay homogeneidad de varianza- cuando
p<0,05.
3 Se pueden utilizar las fórmulas de la suma de cuadrados, sustituyendo los valores x de la variable por
las diferencias absolutas del valor a la media. Se utiliza en vez de xi el valor | |. De la misma
forma las medias se convierten en las medias de las desviaciones absolutas ∑
.