una aplicaciÓn de la teorÍa de valores … - oviedo/trabajos/pdf/271...una aplicación de la...
TRANSCRIPT

UNA APLICACIÓN DE LA TEORÍA DE VALORES EXTREMOS AL CÁLCULO DEL VALOR EN RIESGO
Joaquín Aranda Gallego - [email protected] J. Alberto de Luca Martínez - [email protected]
Universidad de Murcia
Reservados todos los derechos. Este documento ha sido extraído del CD Rom “Anales de Economía Aplicada. XIV Reunión ASEPELT-España. Oviedo, 22 y 23 de Junio de 2000”. ISBN: 84-699-2357-9

Una aplicación de la
Teoría de Valores Extremos
al cálculo del Valor en Riesgo
Aranda Gallego, JoaquínDe Luca Martínez, J. Alberto
Dpto. de Métodos Cuantitativos para la EconomíaUniversidad de Murcia
PonenciaAbril 2000
Resumen: El Valor en Riesgo, VaR, constituye en la actualidad la herramienta básica de todo gestorde riesgos financieros así como el referente más reciente de la aplicación masiva de las técnicas estadís-ticas al campo de las Finanzas.
Desde su incorporación al instrumental básico de la práctica financiera, han sido múltiples lascaracterizaciones y propuestas de cómputo que se han venido realizando. Sin embargo, en la mayoríade las ocasiones, entendemos que se ha perdido la perspectiva del verdadero problema: la mayor partede estos planteamientos olvida el hecho de que VaR es un cuantil extremo y así, en lugar de hacer uso delas herramientas que la Estadística ofrece para el estudio de estos sucesos de baja probabilidad, recurrena métodos típicos de inferencia que, si bien son apropiados para determinar los valores centrales de unadistribución, son poco eficaces para recoger el comportamiento en las colas.
En nuestro trabajo, proponemos una aproximación al cálculo del VaR basada en la Teoría de Va-lores Extremos, una rama de la Teoría de la Probabilidad cuyo objetivo es, precisamente, analizar losextremos observados de una distribución y predecir más allá de estos.
Palabras clave: Riesgo de Mercado, VaR, Teoría de Valores Extremos
Área: G2. Métodos de estadística económica
Correos electrónicos: [email protected], [email protected]

1
1 Fundamentos del Valor en RiesgoEl progresivo acortamiento de los márgenes de intermediación del negocio bancario
tradicional, vivido en los últimos 20 años, ha provocado que las entidades financieras
se vuelvan cada vez más hacia los mercados financieros como forma de complementar
sus cuentas de resultados. De esta manera, las entidades de crédito a nivel mundial
comenzaron a verse potencialmente afectadas, no sólo por el tradicional riesgo de que
sus acreditados no devolvieran los créditos, sino también, y de una forma cada vez
mayor, por los riesgos derivados de los cambios de los precios de los activos financie-
ros en los que invertían. Dicho de otra forma, los sistemas bancarios a nivel interna-
cional se exponían de forma importante, no solo al tradicional riesgo de crédito, sino
también al de mercado, entendido éste, según la definición del Banco Internacional de
Pagos de Basilea, BIS (1988), como �El riesgo de pérdidas en las posiciones de dentro
y fuera de balance derivadas de movimientos en los precios de mercado�
Las instituciones supervisoras, conscientes de esta situación, fueron emitiendo
normativas nacionales tendentes a incluir, de una forma u otra, el riesgo de mercado
en los requisitos de capital de las entidades financieras y fue surgiendo la necesidad,
en un entorno financiero cada vez más globalizado, de que se llegara a un consenso a
nivel internacional sobre esta cuestión.
Así, en Abril de 1993, el Comité de Basilea de Supervisión Bancaria emitió una
recomendación donde se recogía un conjunto de sistemas de cómputo de la exposición
al riesgo de mercado de las entidades financieras, conformando lo que se conoce como
modelo estándar. Apenas dos meses después de la quiebra de Barings PCL, en Abril
de 1995, dicho Comité publicó tres documentos adicionales, BIS (1995a, 1995b,
1995c), anticipando sus intenciones de modificar el Acuerdo de Capital de 1988.
Finalmente, en enero de 1996 se emitió la �Enmienda al Acuerdo de Capital pa-
ra incorporar el riesgo de mercado�, BIS (1996), la cual establecía que, a más tardar
el 1 de enero de 1998, se debería incluir el riesgo de mercado en el computo de los
requerimientos de recursos propios de las entidades. Si bien la propia Enmienda reco-
gía una ampliación del modelo estándar, su principal novedad radicó en que permitía
a las entidades la utilización de sus propios modelos internos de determinación del

2
riesgo de mercado para la cuantificación de los requerimientos mínimos de recursos
propios.
No obstante, el acuerdo del BIS estableció que las entidades que se acogieran a
la opción de utilizar sus modelos internos habían de considerar en ellos una serie de
requisitos mínimos tanto de carácter cualitativo (existencia de una unidad indepen-
diente de control de riesgo, emisión de informes diarios...) como cuantitativo. En la
definición de estos últimos tomaban una gran importancia dos conceptos que resultan
complementarios, el Value-at-Risk (VaR), que trata de cuantificar el riesgo que asu-
me una entidad usualmente por su participación en los mercados, y el Stress Testing,
un ejercicio que tiene por objeto evaluar el riesgo en que se incurre en situaciones ex-
cepcionales. Ambas técnicas, no obstante, ya se estaban empezando a implantar en
una parte de la industria financiera, sobre todo a medida que se generalizaba la ope-
rativa con productos derivados.
Como una primera aproximación, siguiendo a Jorion (1997), se puede definir el
VaR como un método de cálculo del riesgo de mercado que utiliza técnicas estadísti-
cas estándar para medir la peor pérdida previsible del valor de una cartera de activos
( )V en un intervalo de tiempo ( )h bajo condiciones normales de mercado a un nivel
de confianza dado ( )u . Esto es, el VaR sería aquel valor tal que
Pr VaR 1t tt hV V I u
siendo tI el conjunto de información disponible en t. Así pues, si el VaR diario de
una cartera al 99% es de 10 millones de euros, se tiene una confianza de que solo el
1% de los días la variación diaria de los precios de mercado hará perder a la entidad
más de 10 millones de euros. Alternativamente, el VaR puede entenderse, como apun-
ta Prisker (1996), como �el volumen de capital que la entidad requeriría para absorber
las pérdidas registradas por su cartera en casi todas las circunstancias�.
La Enmienda concretaba, de una forma un tanto confusa, que cuando el VaR
fuera a servir de base para la determinación del los requerimientos mínimos de capital
de una entidad, se debía computar diariamente, a un nivel del confianza del 99% y
para un periodo de mantenimiento de los activos de 10 días.

3
Así, la obtención del VaR se limita a algo que, a priori, parece de gran sencillez:
calcular diariamente el percentil de orden 0,01 de la distribución de incrementos de-
cenales del valor de la cartera. Computado este percentil, tras algunos ajustes, se de-
terminaría el nivel de capital necesario para hacer frente al riesgo de mercado. Sin
embargo, llegados a este punto aparecen tres dificultades básicas a la hora de calcular
el VaR.
En primer lugar tendríamos que determinar el origen del riesgo al que se enfren-
ta la cartera o, desde un punto de vista más operativo, el conjunto de factores de
riesgo que alteran los precios de mercado de los activos. Por ejemplo, en el caso de
instrumentos cuyos precios dependen de los tipos de interés, el BIS propone que se
identifiquen un mínimo de seis factores de riesgo que den cuenta de los movimientos
de la estructura temporal de los tipos de interés; para riesgo de cambio, el BIS pro-
pone que se consideren como factores de riesgo todos los tipos de cambio que pueden
afectan al valor de la cartera...
Definidos los factores de riesgo, el siguiente paso en el proceso de medición de
riesgos consiste en determinar la forma en que aquéllos afectan a los precios y, por
último, encontrar la distribución que siguen los factores de riesgo1. Desgraciadamente,
ninguna de estas tareas es sencilla y ambas pueden ser fuente de errores importantes
en la estimación del riesgo. Precisamente ha sido en estas cuestiones en las que se ha
centrado la investigación en los últimos cinco años dando a un gran número de pro-
puestas alternativas de cálculo del VaR que difieren, básicamente, en las últimas dos
circunstancias: en el uso o no de aproximaciones para el cálculo de las variaciones en
el valor de las carteras y en el tipo de distribución que se asume para los factores de
riesgo.
Atendiendo a la primera, pueden distinguirse, muy someramente, dos grandes
categorías de métodos: los métodos delta y delta-gamma y los métodos de valoración
completa (o full valuation). Los primeros proponen aproximar el cambio en el valor de
la cartera mediante un desarrollo en serie de Taylor de orden uno (los métodos delta)
1 Con mayor precisión, la distribución de las variaciones de los factores de riesgo, pues son éstas laque originan los cambios en los precios. A partir de ahora, entiéndase que al hablar de factores deriesgo como fuente del riesgo de mercado, nos referimos a sus variaciones.

4
o de orden dos (los métodos delta�gamma) en el cambio en los factores de riesgo. Los
segundos, mucho más lentos pero más exactos, sobre todo para posiciones con fuertes
no linealidades como es el caso de los activos con opcionalidad, simulan posibles tra-
yectorias de los factores de riesgo a lo largo del tiempo y proceden a la valoración
exacta de los activos de la cartera en cada escenario.
En un gran número de métodos, y éste es el tercero de los problemas, es necesa-
rio disponer de una distribución para los rendimientos de los factores de riesgo. Ante
este problema, es común asumir una distribución normal para los rendimientos, su-
puesto éste, que si bien facilita enormemente los cálculos y desarrollos, no parece muy
realista a la vista de las principales referencias sobre distribuciones de rendimientos
de activos financieros2. En todas ellas se rechaza la hipótesis de normalidad y, aunque
no se alcanza un consenso sobre la distribución exacta que subyace a los rendimien-
tos, todos coinciden en que la distribución ha de tener colas gruesas.
La detección de colas gruesas no hace más que complicar el problema a que nos
enfrentamos ya que, como indican Jansen y De Vries (1991), �hay una considerable
controversia en relación con la masa exacta de probabilidad que reside en las colas de
la distribución�, cuando precisamente el VaR se define como un cuantil extremo. Esta
misma circunstancia es la que hace no recomendable el uso de los métodos de ajuste
estadístico habituales. Diebold (1998) hace referencia explícitamente a esta cuestión:
�[Los] métodos paramétricos implícitamente se centran en realizar un buen ajuste en
las regiones donde están la mayoría de los datos [...], incluso sofisticados métodos no
paramétricos [...] es bien conocido que realizan un ajuste pobre en las colas�. Pero es
que es más, el escaso número de observaciones extremas hace muy difícil encontrar un
método que, sobre la base exclusivamente de esta información, sea capaz de ofrecer
estimaciones fiables para futuros eventos extremos.
Ambas apreciaciones nos llevan a pensar que la estimación de una función de
densidad completa no parece la mejor forma de aproximarnos al problema de la esti-
mación de extremos, el caso que aquí nos ocupa. En este sentido, las recientes aplica-
2 Puede verse, por citar solo las más significativas, Mandelbrot (1963, 67), Fama (1965), Praetz(1972), Blattberg et al. (1974), Kon (1984), Boothe y Glassman (1987) o Mittnik y Rachev (1993).

5
ciones de la Teoría de Valores Extremos, EVT en adelante, al campo de las Finanzas
parecen ofrecer un punto de vista novedoso y, a priori, bien fundamentado desde un
punto de vista estadístico, con el que realizar la estimación de medidas del riesgo de
mercado. Esto es así porque la EVT se centra en el estudio de los extremos de una
distribución, de los sucesos de baja probabilidad, desarrollando un conjunto de he-
rramientas a partir de las cuales es posible determinar los cuantiles extremos de una
distribución sin necesidad de conocer la distribución completa.
Siendo nuestro objetivo ilustrar la aplicación de la EVT al cálculo del VaR, or-
ganizamos lo que resta del presente trabajo de la siguiente forma: en el epígrafe se-
gundo realizamos una breve reseña de los principales desarrollos teóricos y de estima-
ción de la Teoría de Valores Extremos orientando nuestra reseña hacia el estudio de
información financiera; en el tercero, realizamos una aplicación al cálculo del VaR de
una posición en divisas, haciendo especial hincapié en su comparación con los méto-
dos normales de cálculo del VaR; finalizaremos con unas breves conclusiones.
2 Teoría de Valores ExtremosSi bien los orígenes de esta disciplina podemos encontrarlos en el siglo XVIII, su desa-
rrollo se ha producido básicamente en los últimos 100 años. De hecho, no fue sino
hasta 1958 cuando E. J. Gumbel publicó Estadísticos de extremos, el primer libro
dedicado íntegramente a la EVT. En esta publicación se define el objetivo de la EVT
como �[...] analizar los extremos observados y predecir más allá de éstos�. Este obje-
tivo, aunque ambicioso, es alcanzable, en la medida que, tal como reseña Gumbel
�Los extremos no son constantes sino que son nuevas variables estadísticas que de-
penden de la distribución inicial y del tamaño de la muestra. No obstante, se pueden
alcanzar resultados ciertos que no dependen de la distribución inicial�.
En la breve reseña teórica que realizamos a continuación nos centraremos en los
desarrollos de distribuciones asintóticas del máximo3 de un conjunto de variables
3 Nos centramos, por comodidad, en el caso del máximo, lo cual no supone una pérdida de generali-dad en la medida que, como es conocido, 1 2 1 2min , , , max , , ,n nX X X X X X .

6
aleatorias, pues ésta es la base para lograr plantear una versión estimada de la fun-
ción de distribución de las variables originales, válida únicamente en los extremos, a
partir de la cual estimar los cuantiles extremos deseados.
2.1 Distribución asintótica del máximo de un conjunto devariables aleatorias
Partimos de un conjunto 1 2, , , ,nX X X de variables aleatorias no degeneradas, inde-
pendientes e idénticamente distribuidas con función de distribución desconocida, F y
estadísticos de orden :1: 2: n nn nX X X y estamos interesados en estudiar la
distribución del máximo, 1: ,nX que vendrá dada por
1: 1: 1 2( ) Pr Pr max , , , ( )nnn nF x X x X X X x F x
ahora bien, la utilidad práctica de esta expresión es muy limitada en nuestro caso en
la medida que requiere conocer la distribución de las variables aleatorias de partida
que, por hipótesis, es desconocida.
Ante esto, se puede realizar un planteamiento alternativo, inspirado en el Teo-
rema Central del Límite, y que consiste en estudiar la distribución asintótica del má-
ximo de un conjunto de variables aleatorias con el objetivo de que nos sirva de apro-
ximación para analizar la distribución del máximo de un número lo suficientemente
alto de variables aleatorias.
Dicho de otro modo, estamos interesados en estudiar bajo qué condiciones exis-
ten las constantes 0nc y nd tal que se verifica que 1:( )n nnc X d tiende en Ley
a alguna variable aleatoria no degenerada, cuáles son las posibles leyes límite y bajo
qué condiciones dicha convergencia tiene lugar hacia una distribución límite concreta.
El Teorema de Tipos Extremos, uno de los resultados fundamentales de la EVT,
da respuesta a la pregunta anterior en tanto que establece que, si existen las constan-
tes de normalización, únicamente pueden existir tres tipos de leyes que pueden jugar
el papel de variables límite, los llamados tipos extremos.

7
Teorema 1. Teorema de Tipos Extremos4
Sea 1 2, , , nX X X una sucesión de variables aleatorias, independientes e idéntica-
mente distribuidas con función de distribución F y sea :1: 2: n nn nX X X sus
estadísticos de orden. Si existen las constantes de normalización 0nc y nd tal
que se verifica
1:L
n nnc X d G (1)
siendo G una variable aleatoria límite no degenerada, entonces G pertenece a alguno
de los tres tipos de valores extremos siguientes:
1,
2,
3,
1
2
3
0 0( )
exp 0
exp 0( )
0 0
( ) exp exp
Tipo
Tipo
Tipo
xFréchet G xx x
x xWeibull G xx
Gumbel G x x x
siendo 0 el índice de cola de la distribución.
Inversamente, cada uno de los tres tipos puede aparecer como distribución límite en
(1) y de hecho aparece cuando G es la distribución de las variables X.
En definitiva, partiendo del supuesto de que el máximo debidamente normaliza-
do de una sucesión de variables aleatorias tiene una distribución límite no degenera-
da, este teorema garantiza su atracción hacia alguno de los tres tipos extremos (esto
es, su pertenencia al dominio máximo de atracción del tipo que corresponda). Hemos
de indicar que este resultado, como otros que seguirán, no depende crucialmente de la
verificación del supuesto de independencia e igualdad de distribución de las variables
de partida sino que es generalizable, con leves modificaciones, a sucesiones dependien-
tes5.
4 Puede verse la demostración en Resnick (1987).5 Una excelente referencia para consultar esta cuestión es Leadbetter et al. (1983); también puede
consultarse en Galambos (1978).

8
Por último, es de interés reseñar que existe una representación alternativa de los
tipos extremos, debida a Jenkinson y von Mises que resulta de gran utilidad en la
medida que representa los tres tipos en una única familia de funciones de distribución
dependientes de un parámetro que guarda una estrecha relación con .
Definición 2. Tipo generalizado de valores extremos
Definimos el tipo generalizado de valores extremos, Gξ, como
1/exp (1 ) 0( )
exp exp( ) 0
xG x
x
con y tal que 1 0x .
Se puede fácilmente comprobar que esta función, dependiendo de los valores de
, puede dar lugar a los tres tipos extremos. De hecho, si 1 0, se tiene el tipo
Fréchet, cuando 1 0, se obtiene el tipo Weibull y el caso 0, es, trivial-
mente, el Gumbel.
2.2 Colas de la distribución original y dominios de atracción
La principal aportación del Teorema de Tipos Extremos es que facilita una especifica-
ción funcional aproximada con la que estudiar la distribución del máximo de un nú-
mero lo suficientemente alto de rendimientos haciendo innecesario conocer, al menos
en principio, la distribución completa de la variable aleatoria original. Ahora bien,
este resultado sobre la distribución asintótica del máximo aparentemente parece que
tiene poco que ver con nuestro objetivo original: estimar el VaR, un cuantil extremo
de una distribución de rendimientos, no de su máximo.
Sin embargo existe una estrecha relación entre la distribución asintótica del má-
ximo y el comportamiento en la cola de la distribución original. Intuitivamente parece
claro, el máximo es un suceso que, por definición, pertenece a la cola derecha de la
distribución y, por tanto, la distribución asintótica del máximo debería estar estre-
chamente relacionada con la distribución de la variable aleatoria original cuando nos
situamos en su cola. El siguiente Teorema y su Corolario permiten centrar definiti-
vamente esta cuestión.

9
Teorema 3. Aproximación de Poisson6
Sea { }nX una sucesión de variables aleatorias independientes e idénticamente distri-
buidas con función de distribución F. Sea 0 y supongamos que existe una
sucesión (no decreciente) de números reales { }nu tal que se verifica
lim 1 ( )nnn F u (2)
entonces
:lim Pr exp( )n n nnX u (3)
La inversa también es cierta.
Nótese que, a partir de la aproximación de Poisson, particularizando adecuada-
mente el valor de para cada x, podemos llegar fácilmente al Teorema 1.
La aproximación de Poisson no hace más que justificar la intuición anterior so-
bre la relación entre la cola y el máximo, ya que si se cumple la ecuación (2),
1 ( )nF u ha de ser extremadamente pequeño, lo cual implica que estamos en la cola
de la distribución original y, por tanto, en ese caso y solo en ese caso, podemos pasar
a (3). Precisamente esta relación entre la cola y el máximo, unida al Teorema 1 per-
mite caracterizar los dominios de atracción de los tres tipos de valores extremos a
partir del comportamiento en la cola de la distribución original.
Corolario 4. Condición alternativa de convergencia7
La función de distribución F pertenece al dominio máximo de atracción de algún tipo
de valores extremos, G , con constantes de normalización 0nc y nb si y solo si
lim 1 / ln ( )n nnn F x c d G x
entendiendo que cuando ( ) 0G x el límite es infinito.
Así, dicho al contrario, si estimamos el índice de cola de la distribución asintóti-
ca del máximo tendremos absolutamente determinada la parte derecha de la expre-
6 La demostración puede consultarse en Leadbetter et al. (1983).7 Puede verse la demostración, por ejemplo, en Embrechts et al. (1997).

10
sión anterior y, por tanto, podremos utilizarla, bajo ciertas condiciones, para realizar
una aproximación8 a la cola de la distribución de la variable aleatoria original, que era
el objetivo buscado.
2.3 Variaciones regulares y tipos extremos
Ante una muestra de datos financieros concreta y asumiendo que las premisas del
Teorema de Tipos Extremos se cumplen, surge ahora una nueva pregunta ¿qué tipo
extremo es el relevante para esa muestra? Analizando esta cuestión desde un punto
de vista estrictamente teórico, existe un amplio conjunto de condiciones necesarias
y/o suficientes que ha de cumplir la variable aleatoria original para pertenecer a cada
uno de los dominios de atracción9.
En cualquier caso, al aplicar la Teoría de Valores Extremos al análisis de rendi-
mientos financieros el problema de la elección del tipo extremo se simplifica bastante
al ser posible analizar las condiciones de pertenencia a los dominios de atracción a la
luz de las regularidades estadísticas de las variables financieras. Concretamente, como
se ha comentado anteriormente, la principal constante de los últimos 30 años en la
modelización de rendimientos es que las distribuciones no son normales y que presen-
tan colas gruesas.
Si bien es cierto que a nivel estadístico no existe una definición unívoca sobre lo
que se entiende por una distribución de cola gruesa no lo es menos que si nos centra-
mos en la literatura financiera reciente el consenso es prácticamente generalizado10,
por no decir total: una distribución tiene colas gruesas si 1 ( )F x varía regularmen-
te11 en infinito con índice 0a , condición ésta que nos permite seleccionar el dominio
8 Es muy importante destacar que la aproximación sólo es válida cuando estamos muy a la derechade la distribución original, esto es cuando ( ) 1F x .
9 Una referencia muy útil para consultar la amplia gama de condiciones de convergencia para cadatipo de valores extremos es Embrechts et al. (1997).
10 Vease, por ejemplo, Jansen y De Vries (1991), Hols y De Vries (1991), Longin (1996), Lux (1996),Bassi et al. (1997), Dannielson y De Vries (1997a), Dannielson y De Vries (1997b), Embrechts et al.(1997), Kearns y Pagan (1997), Resnick (1997), Dannielson et al. (1998), Diebold et al. (1998),Resnick y Starica (1998), Dewachter y Gielens (1999), McNeil (1999).
11 Puede consultarse este concepto y algunas de sus propiedades en Feller (1971).

11
máximo de atracción del tipo Fréchet en virtud del siguiente Teorema debido a Gne-
denko (1943):
Teorema 5 Condición necesaria y suficiente de pertenencia al dominio máximode atracción del tipo Fréchet
Una función de distribución F pertenece al dominio máximo de atracción del tipo
Fréchet si y solo si se verifica que
sup ; ( ) 1Fx x F x01 ( )lim01 ( )t
F tx xxF t
en este caso, las constantes de normalización de la convergencia vendrán dadas por11 11nc F n 0nd
Dicho de otro modo, una función de distribución pertenece al dominio máximo de
atracción del tipo Fréchet si, no teniendo punto final a la derecha, varía regularmente
con índice 0 .
2.4 Técnicas de estimación
Existen, al menos desde un punto de vista histórico, dos métodos para enfrentarnos al
problema de la estimación del índice de cola de un tipo extremo: la estimación para-
métrica, planteada inicialmente por Gumbel (1958), y que actualmente se encuentra
en desuso a nivel financiero, y la estimación que se puede denominar de Dominio Má-
ximo de Atracción, MDA, que parte de los artículos de Pickands (1975) y Hill (1975)
y que actualmente es, prácticamente, la única que se utiliza en nuestro campo.
Las técnicas de estimación MDA parten del supuesto de que se dispone de un
conjunto de variables aleatorias, 1 2, , , nX X X , no degeneradas, independientes e
idénticamente distribuidas según una función de distribución, F, desconocida que per-
tenece al dominio máximo de atracción de algún tipo extremo y con estadísticos de
orden :1: 2: n nn nX X X .
Mediante la aplicación de alguna de las propiedades asintóticas derivadas de la
pertenencia a los dominios máximos de atracción, estas técnicas consiguen obtener una
versión paramétrica o semiparamétrica de la distribución original, válida para los ma-

12
yores valores de la variable, a partir de la cual realizar la estimación del índice de cola.
En función de la propiedad utilizada aparecen los diferentes estimadores del índice de
cola, por orden cronológico, Pickands (1975), Hill (1975), De Haan y Resnick (1980),
Smith (1987), Decker et al. (1989), Leabetter (1991) y Kratz y Resnick (1995).
En cualquiera de los casos, merece la pena destacar que el verdadero nexo de
unión entre estas técnicas se encuentra, desde nuestro punto de vista, en el hecho de
que solamente se cumplen sus supuestos cuando x o, dicho de otra forma,
cuando se quiere conocer el comportamiento de la variable para valores de la variable
suficientemente altos. Es por ello que, como decíamos, sólo utilizan una parte de la
información de la muestra original, en particular, las mayores observaciones, para
realizar la estimación.
La idea intuitiva que subyace a estos métodos de estimación es utilizar única-
mente la información que pertenece (presumiblemente) a la cola de la distribución,
puesto que se desea realizar inferencia sobre el máximo (la cola) de ésta, eliminando
así la información central de la muestra que, a nuestros efectos, es irrelevante. Es por
ello que este tipo de métodos estadísticos también se conocen bajo el acrónimo de
�Let the tails speaks for themselves�
También es importante destacar que, en lo que sigue, utilizaremos indistinta-
mente las dos notaciones introducidas con anterioridad para el índice de cola, esto es,
su notación habitual, , y la notación inversa , teniendo en cuenta que en el caso
Fréchet, 1 .
El estimador de Hill
En este trabajo utilizaremos el estimador propuesto por Bruce M. Hill en 1975 en su
artículo �A simple general approach to inference about the tail of a distribution� que,
sin duda alguna, es el estimador del índice de cola más importante y extendido en el
campo de las Finanzas. Su expresión viene dada por
1
: ::1
1 ln lnm
Hm n m ni n
i
X Xm
(4)
siendo m el número de estadísticos de orden que entran a formar parte de la estima-
ción.

13
El estimador de Hill es, bajo ciertas condiciones sobre n y m, débilmente consis-
tencia, Mason (1982), fuertemente consistente, Deheuvels et al. (1988), y, tal como
puede verse en Hall (1982), Goldie y Smith (1987) o De Haan y Resnick (1996)
2: 0,
H Lm nm N
Es crucial destacar que no se utilizan todas las observaciones disponibles en la
muestra para estimar el índice de cola sino únicamente las m superiores surgiendo,
así, el principal problema de estos métodos de estimación: la elección de m. Si lo ana-
lizamos desde un punto de vista ligado a la inferencia, podemos hacer la siguiente
reflexión informal, para un tamaño de muestra fijo:
• por una parte nos interesa elegir un m lo suficientemente alto como para que, al
incrementarse el número de datos con el que realizamos la estimación, se consiga
que la distribución y varianza del estimador se acerquen lo más posible a sus
versiones asintóticas.
• pero, por otra parte, también interesa elegir un m suficientemente bajo, ya que
un m demasiado alto implica salirnos del conjunto de observaciones que, presu-
miblemente, cumplen las condiciones de la estimación.
Existe, por tanto, un claro trade-off entre varianza y sesgo. Conforme se consi-
gue disminuir la varianza de la estimación se aumenta su sesgo y viceversa: el objeti-
vo fundamental de cualquier técnica de selección de m ha de ser establecer un equili-
brio adecuado entre ambas fuerzas.
Desafortunadamente no existe ningún procedimiento óptimo de elección de m, si
bien una de las herramienta más extendida son los llamados gráficos de Hill (o del
estimador de que se trate) que representan los valores del índice de cola estimado
como función del número de estadísticos de orden que entran a formar parte de la
estimación, esto es
:, , 1 ,m nm m n m
La idea intuitiva que subyace a la utilización del gráfico es que conforme se in-
crementa m, la varianza del estimador va disminuyendo y el sesgo aumentando y, por

14
tanto, es de prever que exista en el gráfico una zona intermedia para la cual se obser-
ve un relativo equilibrio entre ambas fuerzas y el estimador permanezca estable.
2.5 Cálculo del VaR
Una vez que se dispone de una estimación del índice de cola de la distribución de los
factores de riesgo, el último paso para calcular el VaR es construir la versión estima-
da de la cola de dicha distribución.
Se puede demostrar fácilmente12, a partir de los planteamientos anteriores, que
ésta vendrá dada por
:
:
( ) 1
Hm n
m n
m xF x
n x
y, por tanto, la expresión del cuantil de orden p, 1p , será
:1/
: (1 )Hm n
p m nn
x x pm
siendo muy importante destacar, aún a riesgo de ser reiterativos, que esta expresión
solo es válida para calcular cuantiles extremos de la distribución original y, en ningún
caso, se puede tomar como una expresión general de los cuantiles de dicha distribu-
ción.
En definitiva, si nuestras variables son los rendimientos de los factores de riesgo
de una determinada cartera, la expresión anterior permite, disponiendo de una esti-
mación del índice de cola, calcular los cuantiles extremos de dicha distribución y, por
tanto, utilizando cualquier modelo que relacione los rendimientos de los factores de
riesgo con el valor de la cartera, calcular el VaR.
12 Vease, por ejemplo, Embrechts et al. (1997).

15
3 Una aplicación de la EVT al cálculo del VaREn este epígrafe vamos a aplicar los desarrollos anteriores a un caso de cálculo del
VaR de una posición simple en divisas (straight FX) de dólares estadounidenses,
USD, frente a yenes japoneses, JPY.
La elección de este tipo de posición no es arbitraria sino que responde al hecho
de buscar un activo con el que fuera posible calcular el VaR fácilmente para así cen-
trar nuestra atención en los efectos y consecuencias de la estimación de valores ex-
tremos más que en la propia problemática usual del cálculo del Valor en Riesgo. Así,
se ha buscado un activo para el cual el factor de riesgo, según indica el Banco Inter-
nacional de Pagos, es el propio rendimiento del activo y que se relaciona linealmente
con la variación de valor de la cartera.
Por tanto, el VaR vendría dado, simplemente, por el producto del valor al con-
tado de la cartera de USD, valorado en JPY, y el cuantil que corresponda de la dis-
tribución de rendimientos del tipo de cambio JPY/USD.
La muestra original consiste en los promedios bid�ask de los tipos de cambio
interbancarios diarios JPY/USD tomados todos los miércoles desde el 3 de enero de
1990 hasta el 29 de diciembre de 1999, en total 522 observaciones. Si llamamos tx al
tipo de cambio del día t, el factor de riesgo vendría dado por la tasa de variación se-
manal, en porcentaje, del tipo de cambio, esto es, 7100( / 1)t t tf x x .
En el Apéndice presentamos la representación gráfica de ambas series así como
sus principales estadísticos descriptivos; únicamente destacar el valor del coeficiente
de curtosis del factor de riesgo que claramente supera el registro de la distribución
normal.
Evidentemente, con la información disponible, podemos calcular tanto el VaR
de una posición larga al contado en USD como el de una posición corta, que corres-
ponderían, respectivamente a los cuantiles de orden 0,01 y 0,99 de la distribución del
factor de riesgo.
16
3.1 Estimación de los índices de cola
Puesto que nos interesa calcular el VaR de las dos posiciones vamos a realizar el aná-
lisis de las colas de la distribución de rendimientos por separado, evitando así el
apriorístico supuesto, por lo demás habitual, de que son simétricas. Para ello, dividi-
mos la muestra original del factor de riesgo en dos submuestras: la de valores positi-
vos, 253 observaciones, y la de valores negativos, 268 observaciones.
Como hemos visto con anterioridad, el principal problema de la estimación del
índice de cola radica en determinar dónde comienza exactamente la cola de la distri-
bución y, por tanto, seleccionar, cara a realizar la estimación, únicamente aquellas
observaciones de la muestra original que pertenecen a la cola de la distribución. Ante
la inexistencia de un procedimiento bien fundamentado de selección del m óptimo que
reseñábamos con anterioridad, hemos optado por realizar la selección basándonos en
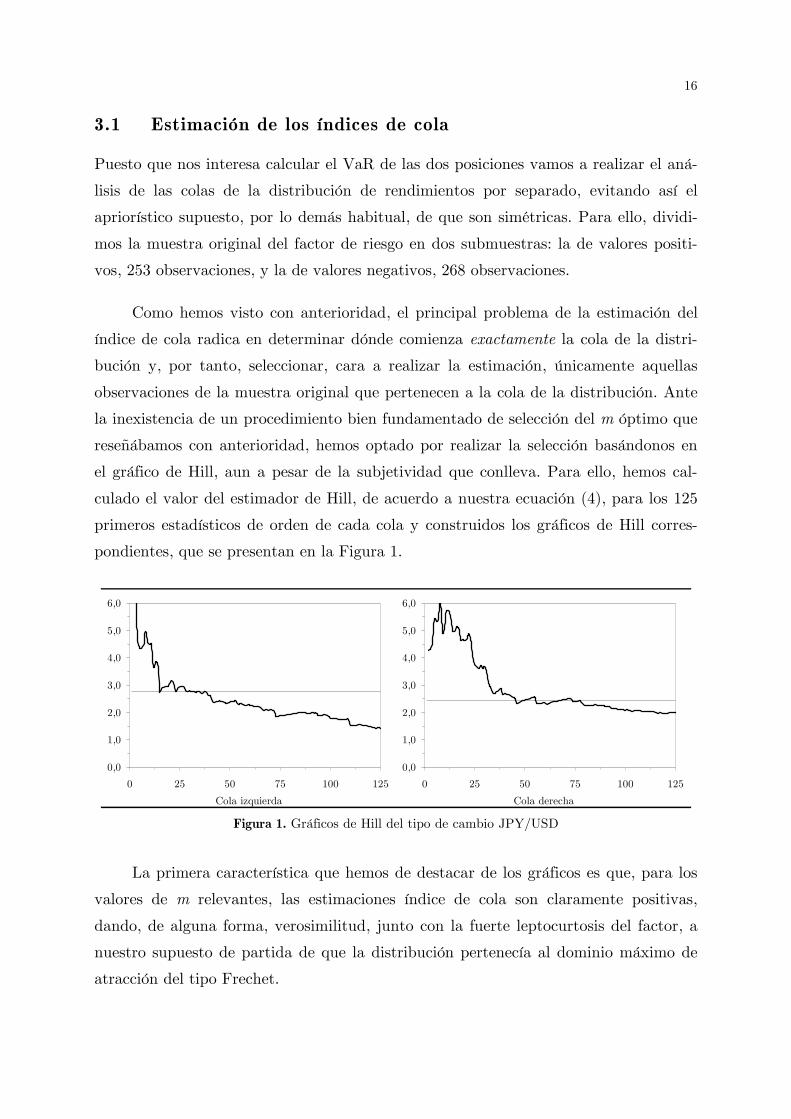
el gráfico de Hill, aun a pesar de la subjetividad que conlleva. Para ello, hemos cal-
culado el valor del estimador de Hill, de acuerdo a nuestra ecuación (4), para los 125
primeros estadísticos de orden de cada cola y construidos los gráficos de Hill corres-
pondientes, que se presentan en la Figura 1.
Cola izquierda Cola derecha
0,0
1,0
2,0
3,0
4,0
5,0
6,0
0 25 50 75 100 125
0,0
1,0
2,0
3,0
4,0
5,0
6,0
0 25 50 75 100 125
Figura 1. Gráficos de Hill del tipo de cambio JPY/USD
La primera característica que hemos de destacar de los gráficos es que, para los
valores de m relevantes, las estimaciones índice de cola son claramente positivas,
dando, de alguna forma, verosimilitud, junto con la fuerte leptocurtosis del factor, a
nuestro supuesto de partida de que la distribución pertenecía al dominio máximo de
atracción del tipo Frechet.

17
Por otra parte, centrándonos ya en el propio gráfico, entendemos que en ambos
casos se sigue razonablemente el comportamiento usual que reseñábamos en el epí-
grafe anterior para esta herramienta. Así, en la zona en la que m es bajo, los valores
estimados del parámetro experimentan fuertes oscilaciones, debido a que los valores
estimados por el estimador de Hill, como consecuencia del escaso número de estadísti-
cos de orden que entran a formar parte de su cálculo, es muy sensible a una entrada
adicional y, por tanto, varía fuertemente ante la entrada de nueva información. Con-
forme se van incorporando más observaciones en su cálculo, los valores estimados se
van estabilizando alcanzando una cierta estabilidad en las zonas indicadas que, pre-
sumiblemente, son aquéllas en las cuales se produce el deseado equilibrio entre sesgo y
varianza. Finalmente, al ir entrando progresivamente estadísticos de orden que cla-
ramente no pertenecen a la cola de la distribución, los valores estimados se van ses-
gando registrando una tendencia descendente.
Pasando ya al estudio detallado de las zonas estables del gráfico de Hill de la
cola izquierda, hemos decidido seleccionar la primera zona relativamente estable que
aparece en el gráfico y que se encontraría entre 29m y 38m donde el valor es-
timado se mueve en torno a 2,7612. El principal motivo que nos lleva esta elección es
elegir un valor de m (un conjunto de valores, estrictamente hablando) que, cumplien-
do el requisito de estabilidad del gráfico, sea lo más bajo posible para �asegurar� que
los valores observados que entran a formar parte de la estimación pertenezcan a la
cola de la distribución. Se podría objetar a esta elección que aparecen otras zonas es-
tables a partir de 40m pero entendemos que éstas se encuentran incluidas dentro
de la zona en la que presumiblemente el sesgo comienza a incrementarse (aunque nó-
tese que se va produciendo a saltos, lo que podría deberse a otro tipo de consideracio-
nes fuera del ámbito de este análisis).
Al analizar la zona estable de la cola derecha, observamos que es necesario se-
leccionar valores algo altos de m para encontrar una zona donde el estimador se man-
tenga relativamente estable en un intervalo de valores de m de una amplitud relevan-
te. La primera zona estable aparece, desde nuestro punto de vista, desde 46m has-
ta 76m en torno a un valor estimado de 2,4227. En este caso, sí se observa con
mayor claridad cómo al finalizar la zona de estabilidad los valores estimados van ses-
gándose de forma lenta pero progresiva.

18
Ante la necesidad de elegir un valor concreto de m para proceder a la estima-
ción del índice de cola, hemos decidido seleccionar aquel m que hace que valor esti-
mado del índice de cola sea el que más se acerca a su valor medio en la zona. En
cualquier caso, esta elección concreta tiene escasa relevancia en los resultados finales
ya que, por la propia construcción del estimador, tanto los valores del índice de cola
estimado como los del último estadístico de orden utilizado son, dentro de cada zona,
muy similares. La estimación final del índice de cola y los estadísticos relevantes de
cada cola los resumimos en la Tabla 1.
Valoresestimados
Colaizquierda
Cola derecha
n 253 268
�m 35 66
� :m nx -2,3524 1,4245
:�m n 2,7603 2,4210
Tabla 1. Estimaciones del índice de cola JPY/USD
3.2 Cálculo del VaR
Una vez que disponemos de ambas estimaciones del índice de cola, por aplicación di-
recta de las fórmulas expuestas en 2.5 podemos calcular los cuantiles extremos de la
distribución del factor de riesgo. Así, en la tabla siguiente recogemos el cuantil del 1%
de la distribución de los incrementos porcentuales del factor, válido para calcular el
VaR de una posición larga en USD y el del 99%, útil para calcular el de la posición
corta.
Cola izquierdaPosición Larga
Cola derechaPosición Corta
Estimaciones bajo EVT
-6,0932% 5,3506%
Estimaciones bajo normalidad
-3,5723% 3,5723%
Tabla 2. Cuantiles del factor de riesgo JPY/USD
Para calcular el VaR bastaría con cambiar de signo el producto del valor de la
cartera de USD, expresado en JPY, por los cuantiles anteriores. Si el valor de la car-
tera lo fijamos en 100 JPY, el Valor en Riesgo de la cartera de USD sería de 6,0932
JPY para la posición larga y de 5,3506 JPY para la corta. Merece la pena destacar
que el cuantil izquierdo registra un valor algo superior al derecho, dando lugar a pen-

19
sar que el mantenimiento de una posición larga en USD es más arriesgado, si habla-
mos de riesgo en términos estrictos de VaR, que el mantener la posición corta.
Pero donde realmente se pone de manifiesto la relevancia del análisis es al com-
parar los resultados obtenidos por Teoría de Valores Extremos con los que se des-
prenderían utilizando el supuesto usual de normalidad. En nuestro caso, para la mis-
ma cartera de USD con valor contado 100 JPY, el VaR descendería hasta 3,5723
JPY: prácticamente la mitad. Así, una entidad que realizara el cálculo del VaR utili-
zando el supuesto de normalidad, de forma consciente o inconsciente mediante la uti-
lización de un procedimiento de caja negra, estaría infravalorando en casi un 50% el
riesgo que soporta al mantener la posición en divisas. O, dicho de otra forma, el nivel
de confianza al que está calculando su VaR está muy lejos del 99% exigido por el
BIS.
Una forma alternativa de apreciar este hecho vendía dada por la Figura 2 en la
que representamos, con los niveles de confianza en el eje de abcisas, los valores esti-
mados para el VaR según la estimación de Teoría de Valores Extremos (línea gruesa)
y la basada en la Normal (línea fina) para ambas posiciones.
Posición larga Posición corta
0,0
5,0
10,0
15,0
20,0
0,95 0,96 0,97 0,98 0,99 1
0,0
5,0
10,0
15,0
20,0
0,95 0,96 0,97 0,98 0,99 1
Figura 2. VaR EVT vs VaR Normal
Como era de esperar, conforme se incrementa el nivel de confianza con que se
realiza la estimación, mayor es el error en que se incurre, evidenciando la importancia
que tienen los sucesos extremos y poco probables en el cálculo de una medida de lo
poco probable como es el VaR.

20
4 ConclusiónPartiendo de la idea de que estimar el VaR es, en última instancia, estimar un cuantil
extremo de una distribución, en este trabajo hemos intentado poner de manifiesto la
necesidad de implementar métodos de cálculo de este cuantil que estén específicamen-
te diseñados para la estimación de sucesos extremos.
Así, frente a los métodos de inferencia paramétrica y no paramétrica tradicio-
nales de los que se viene haciendo uso asiduamente para estas cuestiones, aparecen
otros, los basados en la Teoría de Valores Extremos, que ofrecen un instrumental al-
ternativo, específicamente diseñado para trabajar con sucesos extremos.
Para ilustrar esta afirmación hemos realizado una aplicación de cálculo del VaR
para una posición USD/JPY llegando a un resultado claro: la estimación del VaR
utilizando el supuesto usual de normalidad infravalora el riesgo de la posición en casi
un 50%, con las consecuencias que esto implica.
Si bien es cierto que, en la medida que el tipo de cambio permanezca estable o
evolucione de forma favorable para la entidad, la situación no tiene por qué tener
mayores consecuencias (de hecho, los beneficios serán muy satisfactorios13), no lo es
menos que un movimiento adverso y extremo (que bien puede ser puramente coyun-
tural) puede hacer que se materialicen, de forma súbita e inesperada, quebrantos muy
importantes en la cartera FX. En cualquier caso, aunque la probabilidad de este suce-
so es muy pequeña, no es menos cierto en este terreno merece la pena ser prudentes.
Bibliografía
BANK FOR INTERNATIONAL SETTLEMENTS (1988): International convergence of capital measurementsand capital standard, Basle Committee on banking supervision, Basilea.
BANK FOR INTERNATIONAL SETTLEMENTS (1995a): An internal model-based approach to market riskcapital requirements, Basle Committee on banking supervision, Basilea.
13 Las operaciones de Nick Leeson, el operador jefe de Barings PCL en Singapur, y que a la postreharían quebrar el Banco el 23 de febrero de 1995, habían generado una quinta parte de los benefi-cios de Barings en 1994.

21
BANK FOR INTERNATIONAL SETTLEMENTS (1995b): Planned supplement to the Capital Accord toincorporate market risks, Basle Committee on banking supervision, Basilea.
BANK FOR INTERNATIONAL SETTLEMENTS (1995c): Proposal to issue a supplement to the Basle CapitalAccord to cover market risks, Basle Committee on banking supervision, Basilea.
BANK FOR INTERNATIONAL SETTLEMENTS (1996): Amendment to the Capital Accord to incorporatemarket risks, Basle Committee on banking supervision, Basilea.
BASSI, F., P. EMBRECHTS Y M. KAFETZAKI (1997): A survival kit on quantile estimation, Swiss FederalInstitute of Technology, Zurich (Preprint), pp. 19.
BLATTBERG, R. C. Y N. J. GONEDES (1974): �A comparison of the stable and student distributions asstatistical models for stock prices�, Journal of business, 47, pp. 244-280.
BOOTHE, P. Y D. GLASSMAN (1987): �The statistical distribution of exchange rates�, Journal ofinternational economics, 22, pp. 297-319.
DANIELSSON, J. Y C. G. DE VRIES (1997): Beyond the sample: extreme quantile and probabilityestimation, Tinbergen Institute Technical Report, 39.
DANIELSSON, J. Y C. G. DE VRIES (1997a): Value-at-risk and extreme returns, Financial MarketGroup Working Paper 273, London School of Economics, 33 pp.
DANNIELSON, J. Y C. G. DE VRIES (1997b): Extreme returns, tail estimation, and value-at-risk,Tinbergen Institute Discussion Paper, 29 pp., Rotterdam.
DE HAAN, L. Y S. I. RESNICK (1980): �A simple asymptotic estimate for the index of a stabledistribution�, Journal of the Royal Statistical Society, B (42), pp. 83-87.
DEKKERS, A. L. M., J. H. J. EINMAHL Y L. DE HAAN (1989): �A moment estimator for the index of anextreme-value distribution�, Annals of statistics (47), pp. 1833-1855.
DEWACHTER, H. Y G. GIELENS (1999): �Setting futures margins: the extremes approach�, Appliedfinancial economics (9), pp. 173-181.
DIEBOLD, F. X., T. SCHUERMANN Y J. D. STROUGHAIR (1998): Pitfalls and opportunities in the use ofextreme value theory in risk management, Wharton Financial Institutions Center WP 98-10, 20pp., Pennsylvania.
EMBRECHTS, P., C. KLÜPPELBERG Y T. MIKOSCH (1997): Modelling extremal events, Springer-Verlag,1ª ed., Berlin.
FAMA, E. F. (1965): �The behaviour of stock-market prices�, Journal of business, 34, pp. 34-105.
FELLER, W. (1971): An introduction to probability theory and its applications, vol. II., John Wiley &Sons, 2ª ed., New York.
GALAMBOS, J. (1987): Asymptotic theory of extreme order statistics, Krieger, 2ª ed., Florida.
GNEDENKO, B. V. (1943): �Sur la distribution limite du terme maximum d'une série aléatoire�, Annalsof mathematics, 44, pp. 423-453.
GUMBEL, E.J. (1958): Statistics of extremes, Columbia University Press, 1ª ed., Nueva York
HILL, B. M. (1975): �A simple general approach to inference about the tail of a distribution�, Annalsof statistics, 3 (5), pp. 1163-1174.
HOLS, M. C. A. B. Y C. G. DE VRIES (1991): �The limiting distribution of extremal exchange ratereturns�, Journal of applied econometrics, 6, pp. 287-302.
JANSEN, D. W. Y C. G. DE VRIES (1991): �On the frecuency of large stock returns, putting booms andbusts into perspective�, Review of economics and statistics, LXXIII, pp. 18-24.
JORION, P. (1997): Value at risk, McGraw Hill, 1ª ed.
KEARNS, P. Y A. PAGAN (1997): �Estimating the density tail index for financial time series�, Review ofeconomics and statistics, LXXIX (2), pp. 171-175.

22
KON, S. J. (1984): �Models of stock returns � A comparison�, Journal of finance, XXXIX (1), pp. 147-165.
KRATZ, M. F. Y S. I. RESNICK (1995): The qq-estimator and heavy tails, Cornell University, School ofOperational Research and Industrial Engineering Technical Report 1122, 25 pp..
LEADBETTER, M. R. (1991): �On the basis for 'peaks over threshold' modeling�, Statistical probabilityletters (12), pp. 357-362.
LEADBETTER, M. R., G. LINDRENG Y H. ROOTZÉN (1983): Extremes and related properties of randomsequences and processes, Springer Series in Statistics, Springer-Verlag, 1ª ed., New York.
LONGIN, F. M. (1996): �The asymptotic distribution of extreme stock market returns�, Journal ofbusiness, 69 (3), pp. 383-408.
LUX, T. (1996): �The stable Paretina hypothesis and the frequency of large returns: an examination ofmajor German stock�, Applied financial economics (6), pp. 463-475.
MANDELBROT, B. (1963): �The variation of certain speculative prices�, Journal of business, 36, pp.394-419.
MANDELBROT, B. (1967): �The variation of some others speculative prices�, Journal of business, 40,pp. 393-413.
MCNEILL, A. J. (1999): Extreme value theory for risk managers, Swiss Federal Institute of Technology,Zurich Preprint, 22 pp..
MITTNIK, S. Y S. T. RACHEV (1993): �Modeling asset returns with alternative stable distributions�,Econometric reviews, 12 (3), pp. 261-330.
PICKANDS, J. III (1975): �Statistical inference using extreme order statistics�, Annals of statistics (3),pp. 119-131.
PRAETZ, P. D. (1972): �The distribution of share price changes�, Journal of business, pp. 49-55.
PRITSKER, M. (1996): Evaluating Value at Risk methodologies: Accurancy versus computational time,Wharton Financial Institutions Center WP 96-48, 77 pp., Pennsylvania.
RESNICK, S. I. (1987): Extreme values, regular variation and point processes, Springer-Verlag, NuevaYork.
RESNICK, S. I. (1997): �Heavy tail modelling and teletraffic data�, Annals of statistics, 25, pp. 1805-1869.
RESNICK, S. I. Y STARICA, C. (1997): �Smoothing the Hill estimator�, Advances in applied probability(29), pp. 271-293.
SMITH, R. L. (1987): �Estimating tails of probability distributions�, Annals of statistics, pp. 1174-1207.

23
Apéndice
Recogemos a continuación un breve resumen de los principales estadísticos descripti-
vos de las series utilizadas.
Tipo de cambio JPY/USD
Núm. datos 522 Cuantiles muestralesMedia 118,7244 Orden Valor Orden ValorVarianza 259,3943 0,005 83,27 0,995 158,60 Asimetría 0,1632 0,010 83,72 0,990 157,86 Curtosis -0,4070 0,025 87,24 0,975 151,80 Mínimo 80,6000 0,050 96,99 0,950 145,91 Mediana 0,0296 0,100 99,85 0,900 138,37 Máximo 159,6600 0,250 106,17 0,750 129,90
Factor de riesgo JPY/USD
Núm. datos 521 Cuantiles muestralesMedia -0,0557 Orden Valor Orden ValorVarianza 2,4322 0,005 -5,4630 0,995 3,6978Asimetría -0,5679 0,010 -4,5456 0,990 3,4063Curtosis 2,9139 0,025 -3,5885 0,975 2,8624Mínimo -8,1614 0,050 -2,6470 0,950 2,2869Mediana 0,0296 0,100 -1,8898 0,900 1,5888Máximo 6,8487 0,250 -0,8786 0,750 0,9197
Representación gráfica
Factor de riesgoTipo de cambio
80,0
90,0
100,0
110,0
120,0
130,0
140,0
150,0
160,0
90 91 92 93 94 95 96 97 98 99
-10,0
-8,0
-6,0
-4,0
-2,0
0,0
2,0
4,0
6,0
8,0
10,0
90 91 92 93 94 95 96 97 98 99