resumen automático en twitter
TRANSCRIPT

Resumen automático
en TwitterJORGE GÁLVEZ GAJARDO
MAGISTER EN INGENIERÍA INFORMÁTICA

Contenido
Introducción
Problema
Objetivos
Marco Teórico
Resúmenes automáticos de texto
Procesamiento de lenguaje natural
Metodología propuesta
Resultados y discusiones
Conclusiones
Trabajo futuro

Introducción

Introducción
Era de la información y las telecomunicaciones
Crecimiento de Internet y redes sociales
Facebook, Twitter, MySpace, Orkut, Foursquare, Flickr, Fotolog,
Instagram, Tumblr…
Microblog
Temas del momento

Problema

Problema al resumir Microblog
Textos de a lo más 140 caracteres.
Variedad de temas tratados en los mensajes
Frecuencia de actualización
Múltiples intereses de los usuarios comentando
Lenguaje informal
Diferentes finalidades de los mensajes (conversaciones,
comentarios o compartir noticias)
Es posible definir como texto a un mensaje o al conjunto de
mensajes analizados.

Problema
Demostrar si existe la posibilidad de identificar un
mensaje en Twitter que represente a un conjunto mayor
de mensajes asociados a un tema especifico

Objetivos

Objetivos
Seleccionar un conjunto de tweets resumen que sean
representativos de un conjunto mayor de tweets relacionados a un
término en común de manera automática
Construir un corpus compuesto por mensajes de Twitter
Determinar representación de los mensajes
Probar técnicas de selección
Estimar la representatividad de los tweets resúmenes

Marco Teórico


Es un servicio de microblogging
230 millones de usuarios activos
500 millones de tweets son enviados diariamente
Del total de tweets que se comparten:
40% son sin sentido
38% son conversaciones
9% son RT (mensajes repetidos)
5% son promociones
4% son basura (spam)
4% son noticias

Fue usada para organizar protestas
Revolución egipcia de 2011
Revolución tunecina
Protestas electorales en irán de 2009
En Chile, consigue un auge a partir del Terremoto de 2010
Es usada para seguimiento de eventos, charlas, generar entrevistas,
llevar a una segunda pantalla programas de televisión

Resúmenes automáticos de texto

Resúmenes automáticos de texto
Nace en los años 60 en algunas bibliotecas de USA
Restricciones en el volumen de almacenamiento
30 años evolucionando las distintas técnicas hasta el surgimiento de
Internet.
Hoy existe mayor capacidad de almacenamiento
Surge el problema de filtrar la abundante información disponible

Resúmenes automáticos de texto
Dos enfoques para generar un resumen automático:
Extracción: considera las fuentes como un conjunto de frases y
considera criterios de selección para obtener los fragmentos más
importantes
Abstracción: se analiza el texto con mayor profundidad para poder
comprenderlo y generar un resumen a partir de la información
analizada en la fuente

Resúmenes automáticos de texto
Evaluación de forma empírica debido al juicio que puede emitir un
humano.
Evaluación humana no es viable
Puede existir más de un resumen correcto
Se hace necesaria la combinación de diferentes métodos de
evaluación para garantizar una mínima calidad en el resumen.

Resúmenes automáticos de texto
Algunas técnicas de evaluación
Medir el nivel de compresión, entre el resumen generado y la fuente original.
Evaluar el nivel de relación entre la información del resumen generado y de
la fuente original.
Calcular el solapamiento entre el resumen y la fuente original mediante
ROUGE (Recall oriented understudy for Gisting Evaluation)

Procesamiento de lenguaje natural

Procesamiento de lenguaje natural
Procesamiento estadístico
Cada documento está descrito por un conjunto de palabras denominadas
términos índice
Se asigna un peso a cada término en función de su importancia.
No se toma en consideración el orden, la estructura o el significado de las
palabras.
Procesamiento lingüístico
Se aplican distintas técnicas que codifican de forma explicita el
conocimiento lingüístico.
Lo documentos son analizados a partir de distintos niveles lingüísticos.

Procesamiento estadístico
Consta de dos etapas:
Preprocesado: se prepara el documento, como eliminar elementos que no
serán objetos de análisis, normalización o lematización.
Parametrización: consiste en asignar un peso a cada uno de los términos
Preprocesado Parametrización

Preprocesado
Se eliminan palabras sin significado como artículos, pronombres,
preposiciones, etc.
Se pueden reducir palabras a su raíz.
Normalizar textos.
N gramas
Es una sub secuencia de n elementos de una secuencia dada
Es posible adaptarlo a silabas, letras o palabras.
N es el número de unidades que se tiene en cuenta
Los valores de n, pueden variar entre 2 y 7

Parametrización
Booleano: asigna el peso de 1 si la palabra está en el documento y
0 en caso contrario
Frecuencia de término: asigna el número de veces que el termino
se encuentra en el documento
TF-IDF: asigna un peso a la palabra en el documento en
proporciona al numero de ocurrencias de la palabra en el
documento y en proporción inversa al numero de documentos de
la colección.

Metodología

Metodología
Corpus: Extracción de un
conjunto de mensajes asociados a un término.
Representación: Procesamiento de los
mensajes mediante dos técnicas propuestas
Selección: Determinar el
conjunto de mensajes que mejor representa un
conjunto mayor.

Corpus

Corpus
Se recolectó durante 10 días información referente a 5 temas
Para cada tema se almacenaron 500 tweets diariamente.
NOMBRE DEL TEMA TÉRMINOS ASOCIADOS
Allamand Allamand
Bachelet Bachelet
Longueira Longueira
Enriquez-Ominami “Enriquez Ominami”, MarcoPorChile
Claude Claude

Propuestas de representación

Propuestas de representación
𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
N-Gramas más Hacker News

Propuesta de representación
𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Preprocesado •Eliminar Stop Words
Parametrización• 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Existen dos formas para definir un documento:
Un único documento que tome en cuenta todos los tweets
TF se calcula fácilmente, sin embargo hace perder la componente IDF ya que sólo se dispone de un único documento
Cada tweet como un documento
TF tendrá poco peso debido a que cada tweet contiene pocas palabras y casi nunca se repite
𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
TF se calcula utilizando todos los tweets como un gran documento
IDF se calcula tomando en cuenta que cada tweet es un documento distinto.

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Cada palabra del tweet tiene un peso
El pesos del tweet será la sumatoria de las palabras que contenga
Se obtiene el tweet con mayor peso y se selecciona como el tweet
resumen del tema.

Propuesta de representación N-Grama
más Hacker News

Representación N-Grama más
Hacker News
Representación N-Grama más Hacker News
Preprocesado •N-Grama
Parametrización• Frecuencia
•Hacker News

Representación N-Grama más
Hacker News
Se agrupan las secuencias de palabras de cada tweet
A través del algoritmo hacker news se obtiene el grama con mayor
puntaje
Se selecciona el tweet resumen utilizando 𝑡𝑓𝑠𝑒𝑡𝑥 𝑖𝑑𝑓𝑡𝑤𝑒𝑒𝑡 sobre el
conjunto de tweets que contienen el grama.

Algoritmo Hacker News
Es un algoritmo pensado en resaltar las tendencias del momento
Donde:
P son los puntos del artículo.
T el tiempo desde que apareció (en horas).
G la gravedad (1,8 por defecto).
Puntaje = 𝑃−1
(𝑇+2)𝐺
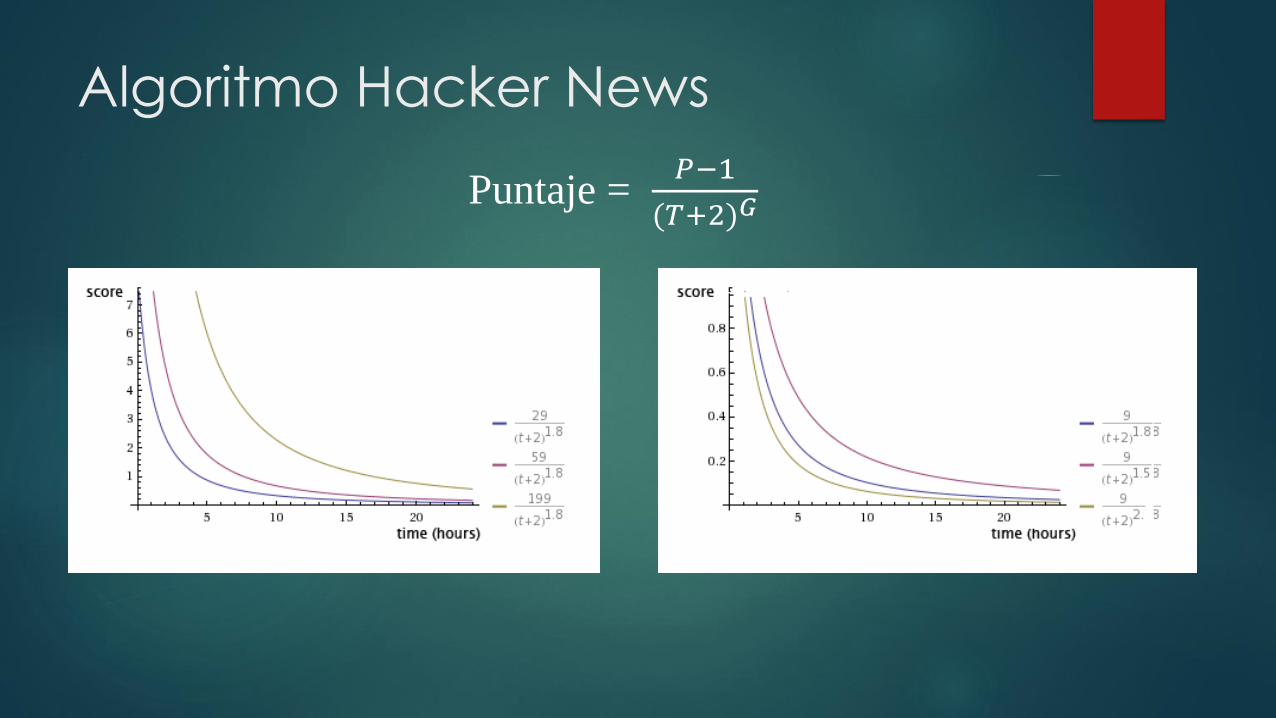
Algoritmo Hacker News
Puntaje = 𝑃−1
(𝑇+2)𝐺

Resultados

Resultados
Se presentan resultados utilizando la técnica 𝑡𝑓𝑠𝑒𝑡𝑥 𝑖𝑑𝑓𝑡𝑤𝑒𝑒𝑡 y luego
se valida que los tweets elegidos representen a un conjunto mayor
del corpus analizado.
Se presentan resultados utilizando la técnica n-grama más hacker
news ordenando los gramas importantes en relación al puntaje
otorgado por el algoritmo hacker news. Luego del conjunto de
tweets que contienen el grama, se obtiene el tweet más importante
utilizando 𝑡𝑓𝑠𝑒𝑡𝑥 𝑖𝑑𝑓𝑡𝑤𝑒𝑒𝑡

Resultados de propuesta de
representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Peso Cantidad de tweetsrepresentativos
Tweet
0.220 1636 Longueira o allamand?
0.096 489 RT @MisterEKY: En encuentro PROA V Región para acompañar a
nuestro tremendo candidato RN Andrés @allamand.@AllamandPdte #firmecontigo
0.088 163 Andrés Allamand siendo senador promovió los cultivos
transgénicos y Michelle Bachelet envió al Congreso...http://t.co/zDcrKuWVAs
0.074 155 RT @Fr_parisi: Allamand habla del Impuesto específico a los
combustibles (nosotros hace mucho) pero se atreverá cobrarle alas mineras?
0.057 115 Jovino Novoa dice en el Que Pasa que el responsable de la caidade Golborne se llama ANDRES ALLAMAND!!!.
0.056 86 El pc apoya a la candidata sin programa,"derrotar a la derecha"
pero entre allamand, longeira y bachelet no hay muchadiferencia.

Similitud entre cadenas de texto
Es posible calcular la similitud entre dos cadenas como la similitud
de dos vectores en un espacio que posee un producto interior en el
que se evalúa el valor del coseno del ángulo correspondido entre
ellos.

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
0
0,05
0,1
0,15
0,2
0,25Pe
so
Tweets50002644

Discusiones a resultados obtenidos
con propuesta de representación
𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Tema Cantidad de tweets Porcentaje del total
Allamand 2.644 52.9%
Bachelet 2.490 49,8%
Claude 4.082 81,6%
Enriquez-Ominami 1.974 39,5%
Longueira 2.567 51,3%

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Tweet Cantidad de tweets representativos
Tema
Marcel Claude ! :) 3681 Claude
Longueira o allamand? 1636 Allamand
#longueira 885 Longueira
@estadonacional Todos a
votar por el SI y el NO deBachelet
802 Bachelet
@marcoporchile tu no 784 Enriquez-Ominami

Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Al obtener 6 tweets es posible representar al 50% del corpus en los temas Allamand, Bachelet y Longueira por lo que se evita leer la mitad del corpus
Al existir temas muy homogéneos, como Claude, es posible representar a un porcentaje mayor de tweets
Al existir temas muy heterogéneos, como Henriquez-Ominami, no entrega buenos resultados la representatividad.
Debe limitarse la cantidad de palabras del tweet resumen elegido.

Resultados de propuesta de
representación N-Grama más
Hacker News

Representación N-Grama más
Hacker NewsPuntaje HN Delta Tiempo
(horas)Repeticiones del
grama
Grama
0.343 25.5 139 especifico-a
0.216 18.5 52 allamand-presento
0.154 93 565 andres-allamand
0.049 92.2 177 a-los
0.044 76.5 116 los-combustibles
0.043 17 10 el-impuesto
0.013 39 12 en-arica

Discusiones a resultados obtenidos
con propuesta de representación
N-Grama más Hacker News

Representación N-Gramas y
Hacker News
ALLAMAND
BI-Grama Número de veces encontrados en el conjunto de tweets
especifico-a 139
allamand-presento 52
andres-allamand 565
a-los 177
los-combustibles 116
el-impuesto 10
en-arica 12

Representación N-Gramas y
Hacker News
LONGUEIRA
Bi-Grama Número de veces encontrados en el conjunto de tweets
enacional-ningunea 12
efren_osorio-enacional 11
de-estudiantes 13
a-longueira 230
longueira-como 14
a-los 111
no-a 64

Representación N-Gramas y
Hacker News
Al utilizar bi-gramas sería interesante hacer pruebas removiendo
stop words
Al comparar gramas, no se toma en cuenta los tweets que dicen lo
mismo pero escrito de otra forma
Al trabajar con tweets es importante ponderar el peso con un
algoritmo como hacker news. Se ve reflejado en que el algoritmo
detecta los temas mas comentados de las ultimas horas.

Conclusiones

Conclusiones
Se requiere de distintas técnicas de manejo de corpus en bases de
datos no estructuradas.
Al encontrar comentario escritos formal y coloquialmente es
necesario generar un análisis lingüístico para obtener mejores
resultados.
Al ser Twitter una plataforma que entrega información en tiempo
real, es importante trabajar con un algoritmo que pondere el
tiempo.
Al ser un tema de investigación muy reciente, se requiere de
métricas estándares para medir la efectividad de los distintos
algoritmos propuestos

Trabajo futuro

Trabajo futuro
Construir un benchmark que permita comparar resultados
obtenidos con distinto preprocesado y parametrización en las dos
técnicas propuestas.

Trabajo futuro
Representación 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕
Preprocesado•Eliminar Stop Words
•Utilizar raíz
•Utilizar n-gramas
Parametrización• 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕•Hacker news
•Frecuencia

Trabajo futuro
Representación N-Grama más Hacker News
Preprocesado• Eliminar Stop Words
• Utilizar raíz
• Utilizar n-gramas
Parametrización• 𝐹𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎
•Hacker News
• 𝒕𝒇𝒔𝒆𝒕 𝒙 𝒊𝒅𝒇𝒕𝒘𝒆𝒆𝒕

Gracias..!