procesamiento digital de voz -...
TRANSCRIPT

Procesamiento digital de voz
Seminario de Audio2005
Ernesto LópezMartín Rocamora
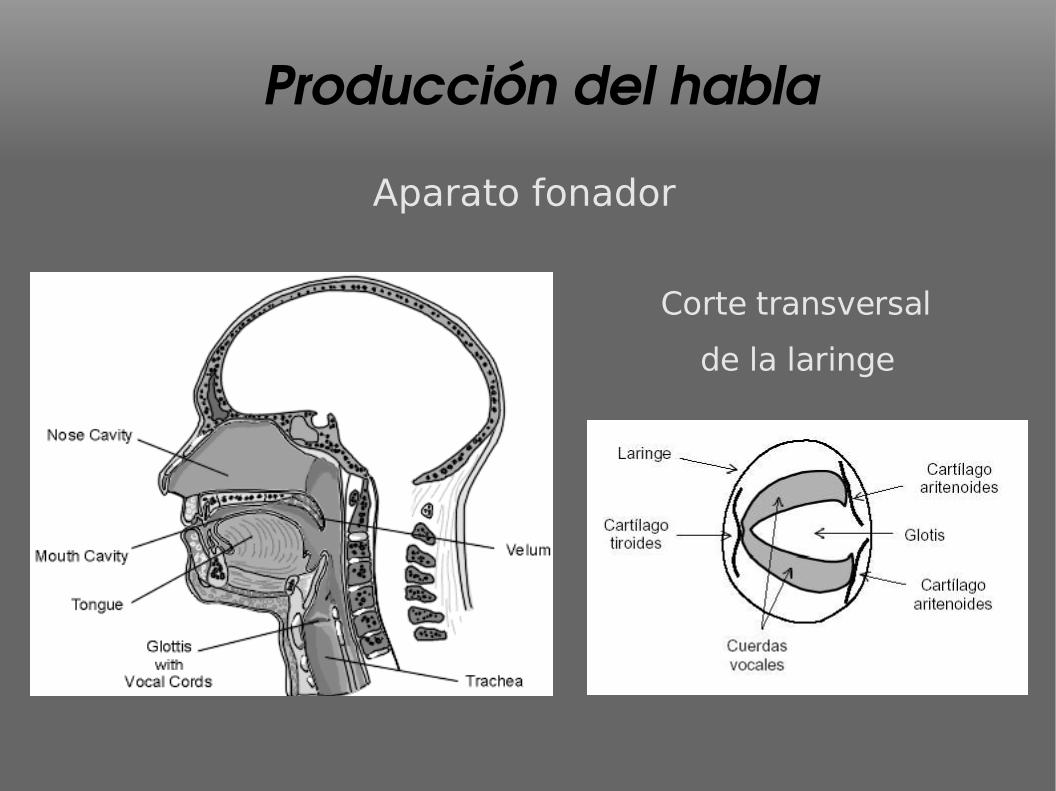
Producción del habla
Aparato fonador
Corte transversal
de la laringe
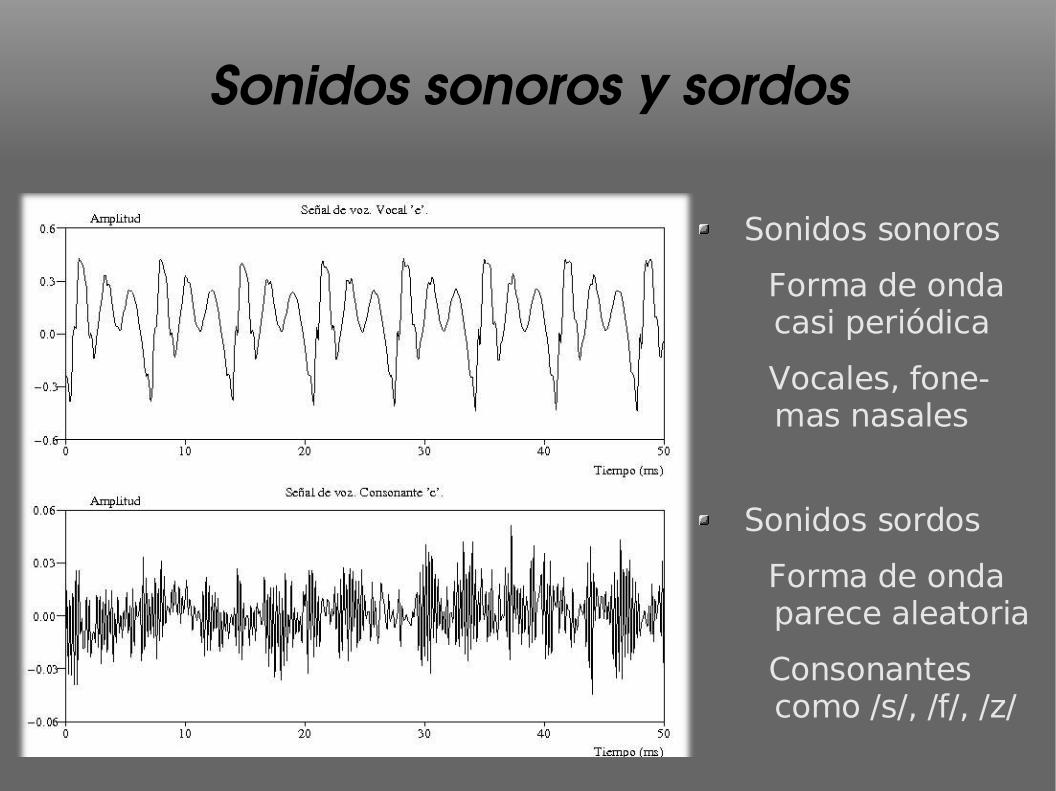
Sonidos sonoros y sordos
Sonidos sonoros
Forma de onda casi periódica
Vocales, fone-mas nasales
Sonidos sordos
Forma de onda parece aleatoria
Consonantes como /s/, /f/, /z/
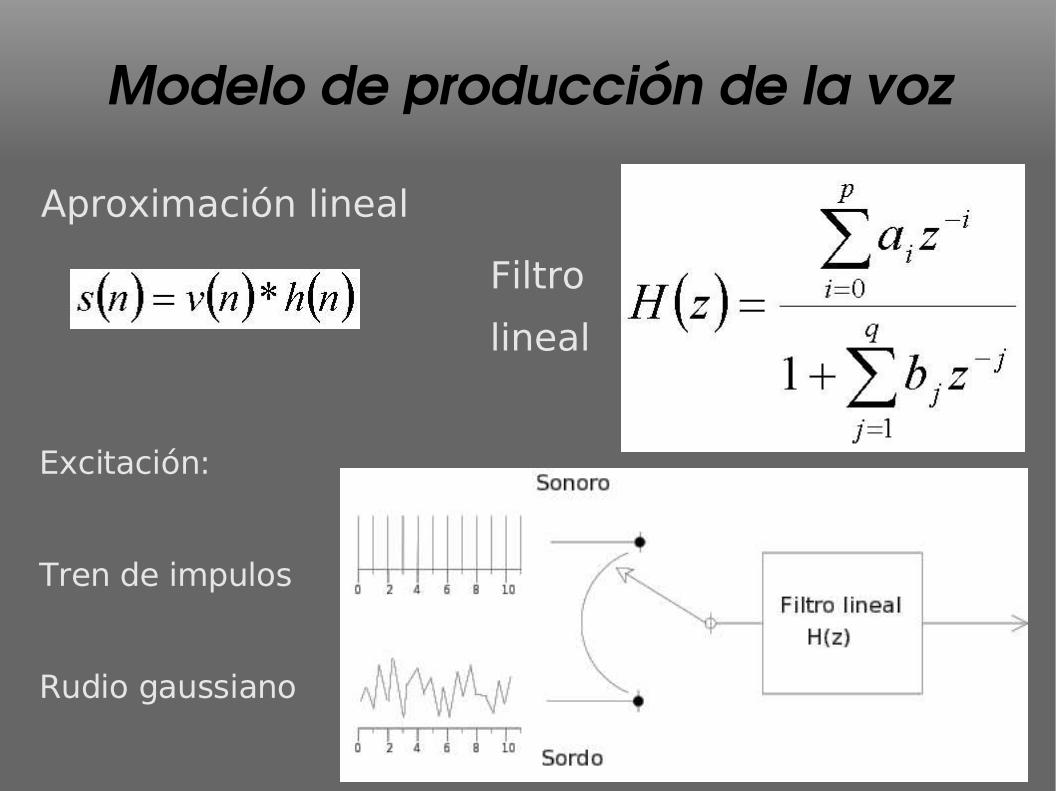
Modelo de producción de la voz
Aproximación lineal
Filtro
lineal
Excitación:
Tren de impulos
Rudio gaussiano

Propiedades de la señal de vozEstacionariedad:
Señal fuertemente no estacionaria, pero se puede as-muir que para pequeños bloques de muestras la señal es localmente estacionaria
Largo del bloque de análisis:
Corto - puede no ser suficiente para el algoritmo
Largo - estimaciones son promedios a largo plazo
En general bloques de 20 a 30 ms son adecuados para la mayoría de las aplicaciones (160 a 240 muestras @ 8kHz).
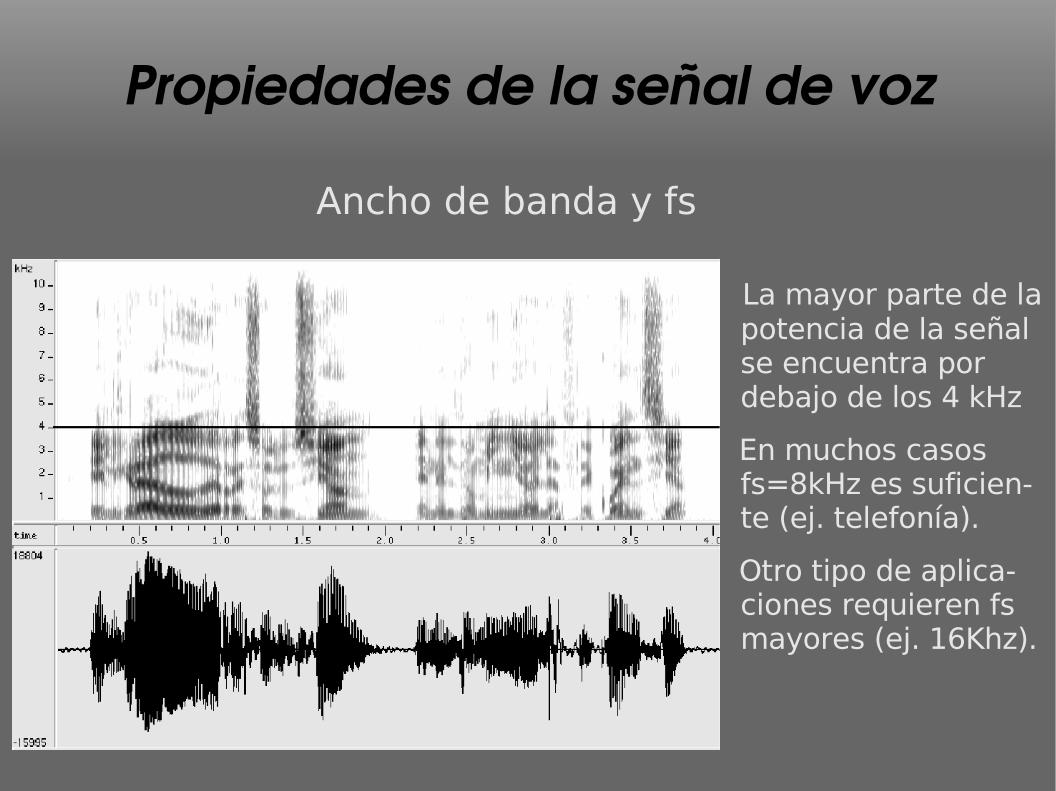
Propiedades de la señal de voz
Ancho de banda y fs
La mayor parte de la potencia de la señal se encuentra por debajo de los 4 kHz
En muchos casos fs=8kHz es suficien-te (ej. telefonía).
Otro tipo de aplica-ciones requieren fs mayores (ej. 16Khz).

Representación espectral
Sonidos sonoros
Armónicos igual-mente espaciados modulados por la transferenica del aparato fonador
Sonidos sordos
Secuencia aleatoria
Al reducir la varian-za de la señal no se obtiene sólo la transferencia del aparato fonador
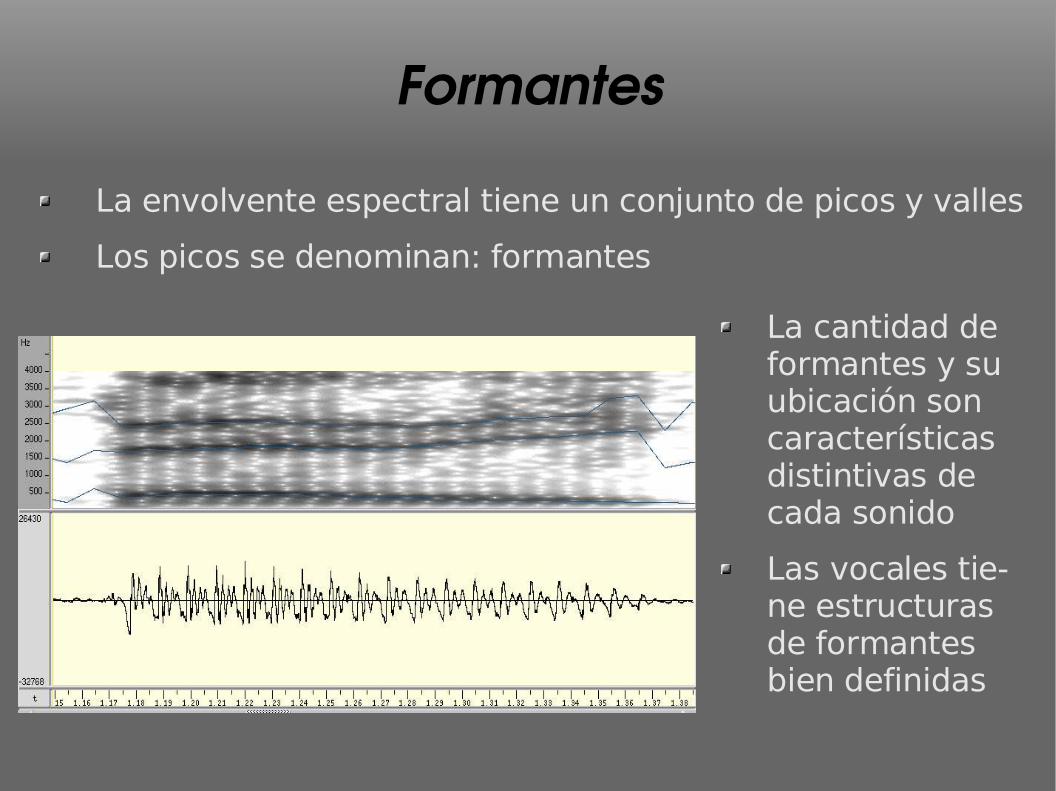
Formantes
La envolvente espectral tiene un conjunto de picos y valles
Los picos se denominan: formantes
La cantidad de formantes y su ubicación son características distintivas de cada sonido
Las vocales tie-ne estructuras de formantes bien definidas
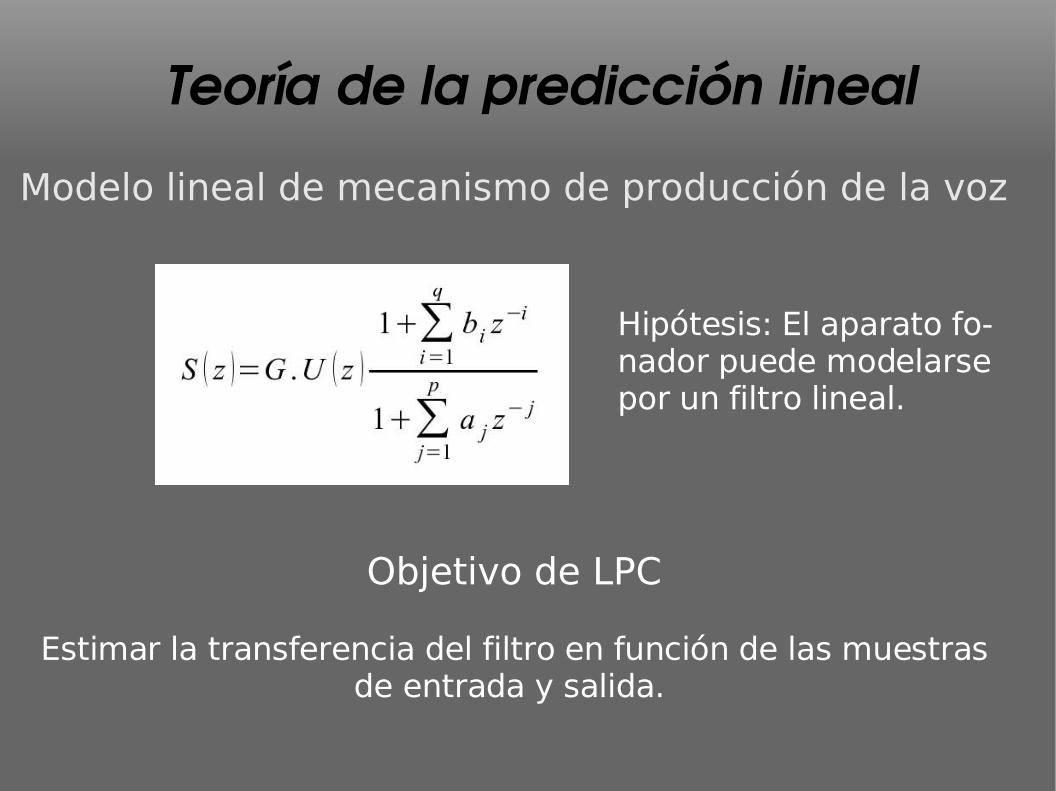
Teoría de la predicción linealModelo lineal de mecanismo de producción de la voz
Hipótesis: El aparato fo-nador puede modelarse por un filtro lineal.
Objetivo de LPC
Estimar la transferencia del filtro en función de las muestras de entrada y salida.

Teoría de la predicción linealModelo lineal en el dominio del tiempo
El valor de la muestra de salida actual está determinado por la diferencia de la suma de la muestra actual y las q muestras
pasadas de entrada con la suma de p muestras pasadas de la salida.
Problema: No conocemos la señal excitación u(n).

Modelo todopolos
Se consideran nulos los coeficientes del numerador
Dominio z Dominio del tiempo
Aún hay que conocer la muestra actual de la entrada u(n).
Se deriva una estimación estadística de los coeficientes a partir de el conocimiento de la estadística de u(n).

Modelo de la excitaciónLa autocorrelación y por lo tanto la DEP de un impulso y de ruido gaussiano son idénticas. Los sonidos sonoros y sordos pueden considerarse estadísticamente equivalen-tes.
Puede derivarse un único modelo para los dos tipos de sonidos.
Aproximaciones
La excitación para sonidos sordos es estrictamente ruido gaussiano.
Se considera un tren de impulsos estadísticamente
equivalente a un único impulso.

Cálculo de los coeficientesAproximación de s(n)
Error de estimación
Cálculo de los coeficientes (Mínimos Cuadrados)
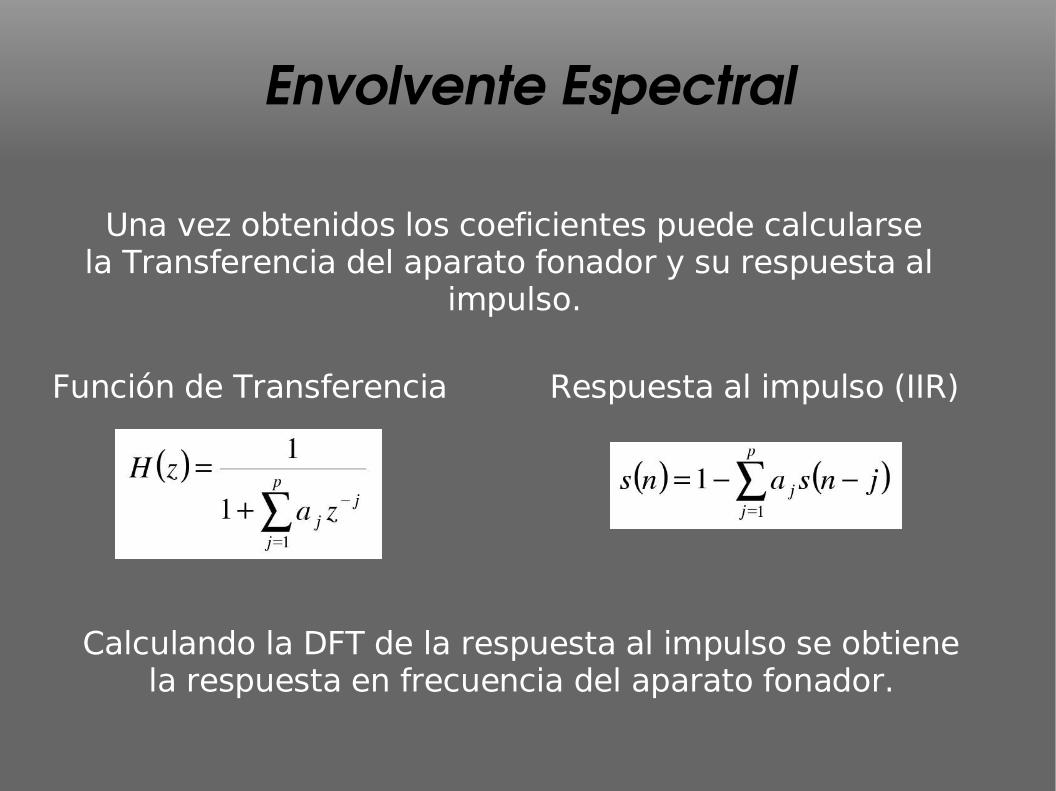
Envolvente Espectral
Función de Transferencia Respuesta al impulso (IIR)
Una vez obtenidos los coeficientes puede calcularsela Transferencia del aparato fonador y su respuesta al
impulso.
Calculando la DFT de la respuesta al impulso se obtienela respuesta en frecuencia del aparato fonador.
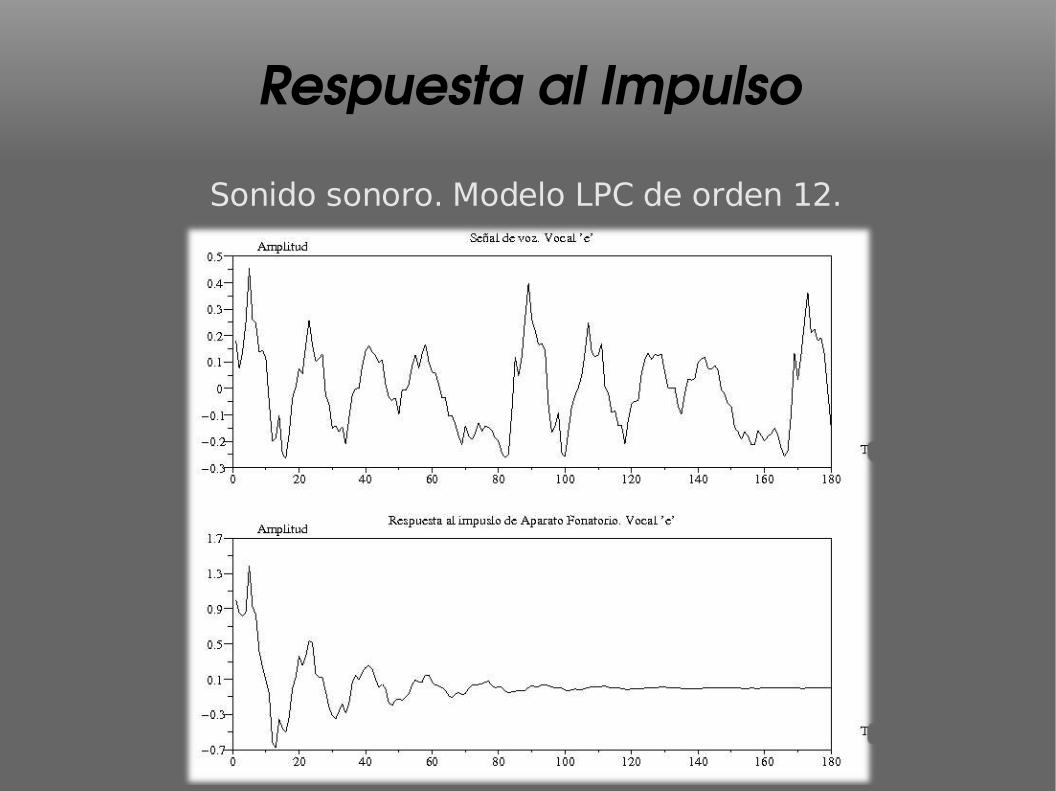
Respuesta al Impulso
Sonido sonoro. Modelo LPC de orden 12.
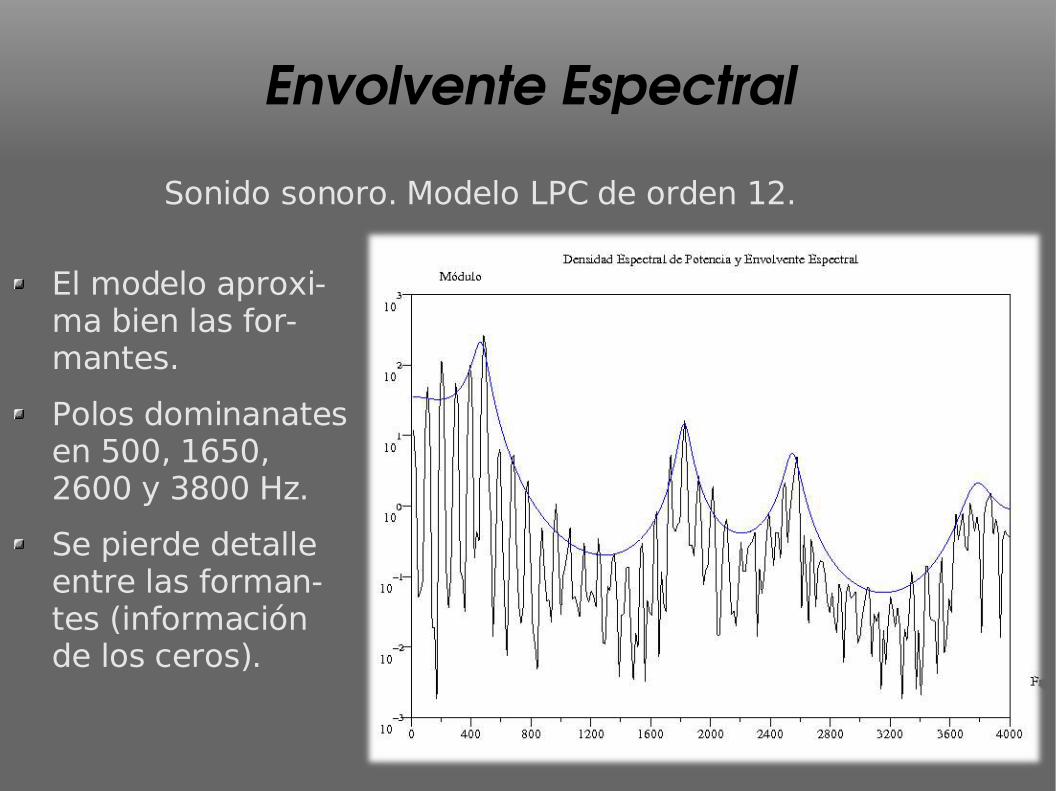
Envolvente EspectralSonido sonoro. Modelo LPC de orden 12.
El modelo aproxi-ma bien las for-mantes.
Polos dominanates en 500, 1650, 2600 y 3800 Hz.
Se pierde detalle entre las forman-tes (información de los ceros).

Envolvente EspectralSonido sordo. Modelo LPC de orden 12.
El modelo funciona también para so-nidos sordos.
Los sonidos sordos tienen formantes mas débiles.

Filtrado Inverso
S(z) = H(z).U(z) → U(z) = H-1(z).S(z)
Modelo razonable de la excitación como tren de pulsos.
La excitación provee informa-ción sobre la condición sonoro/sordo.

Limitantes
No se modelan los ceros de la tranferencia.
El modelo falla para voces muy agudas.
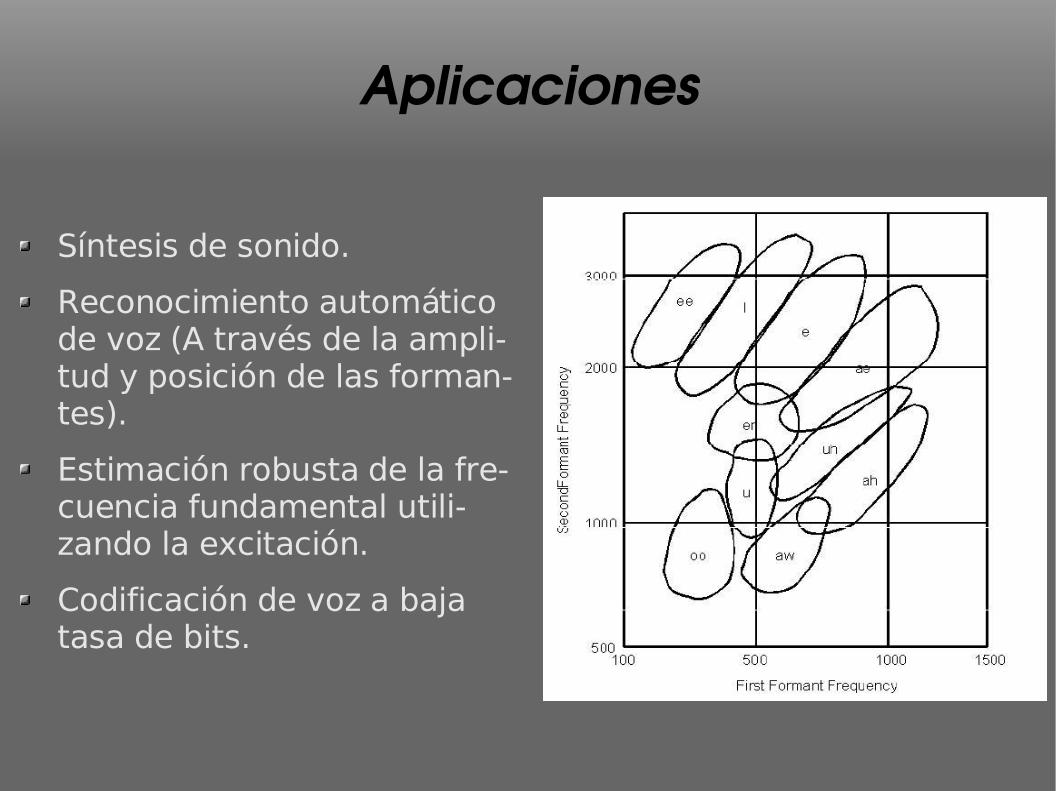
Aplicaciones
Síntesis de sonido.
Reconocimiento automático de voz (A través de la ampli-tud y posición de las forman-tes).
Estimación robusta de la fre-cuencia fundamental utili-zando la excitación.
Codificación de voz a baja tasa de bits.

Deconvolución Cepstral
Objetivo: Estimar la función de transferencia del aparato fonador.
Ventaja: No se realiza ninguna de las hipótesis necesa-rias en LPC.
Procedimiento: Transformación no lineal para transfor-mar la convolución en suma de secuencias.

Cepstrum
Separación de la excitación y transferencia
Modelo lineal: convolución de excita-ción y respuesta del aparato fonador
Espectro: producto del espectro de la excitación y transferencia.
Densidad Espectral de Potencia
Cepstrum: suma del cepstrum de la excitación y la transferencia
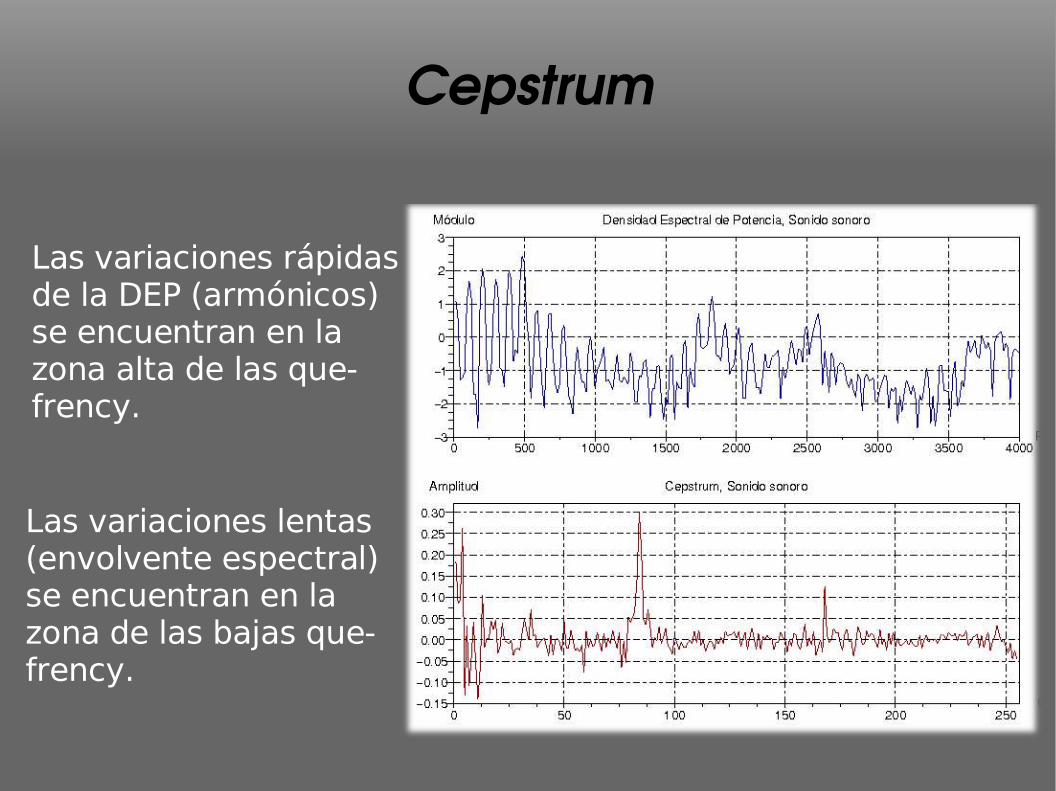
Cepstrum
Las variaciones rápidas de la DEP (armónicos) se encuentran en la zona alta de las que-frency.
Las variaciones lentas (envolvente espectral) se encuentran en la zona de las bajas que-frency.
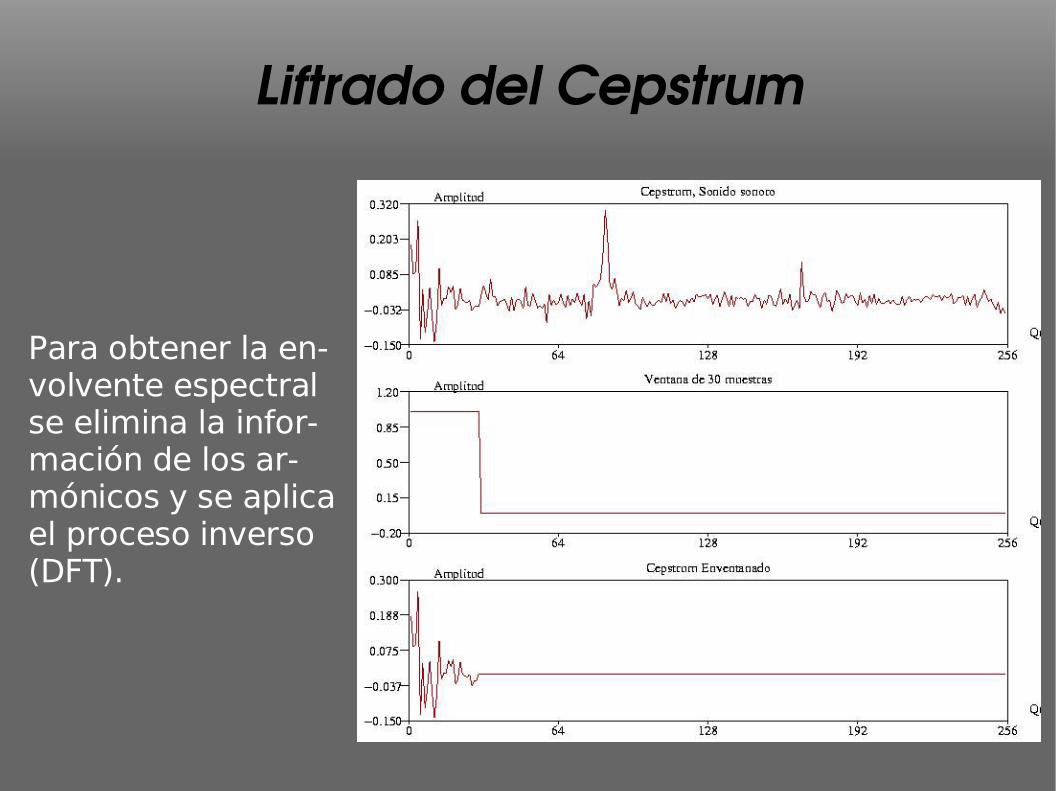
Liftrado del Cepstrum
Para obtener la en-volvente espectral se elimina la infor-mación de los ar-mónicos y se aplica el proceso inverso (DFT).
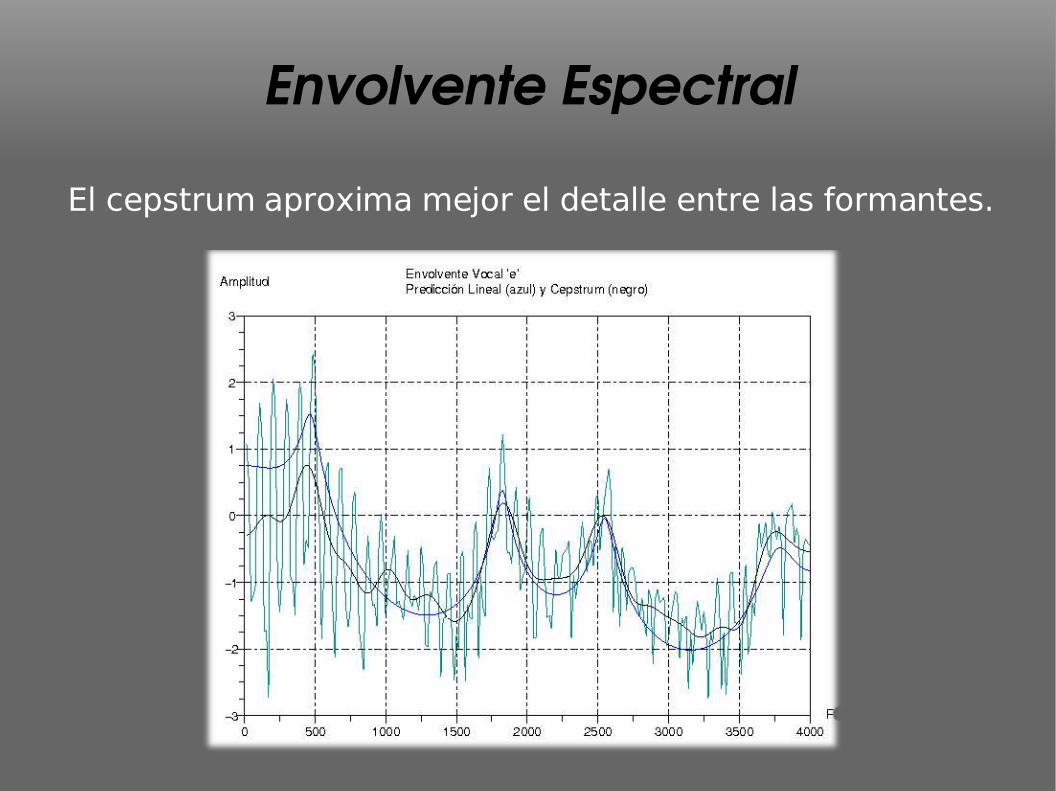
Envolvente Espectral
El cepstrum aproxima mejor el detalle entre las formantes.

Limitantes
Para voces de frecuencia fun-damental alta, la envolvente es-pectral aparece “muestreada” en pocos puntos.
No es posible se-parar la excita-ción de la envol-vente espectral.

Aplicaciones
Reconocimiento automático de voz.
Estimación de la frecuencia fundamental a partir de la de-tección de picos en el cepstrum.

Referencias
Speech Analysis – E. Chilton
La voz humana – F. Miyara
Processing Singing Voice for Music Retrieval – E. Pollastri
Discrete-time signal processing – A.V. Oppenhiem
R.W. Schafer