portal de voz en voicexml - repositorios universidad...
TRANSCRIPT

PORTAL DE VOZ EN VOICEXML
León Daniel Benarroch Hadida
Rubén Darío Mariña Muñoz Tutor: Edgar León Perez
Caracas, Julio 2001.
Universidad Metropolitana Facultad de Ingeniería Escuela de Ingeniería de Sistemas

`
II
DERECHO DE AUTOR
Cedemos a la Universidad Metropolitana el derecho de reproducir y difundir
el presente trabajo, con las únicas limitaciones que establece la legislación
vigente en materia de derecho de autor.
En la ciudad de Caracas, a los 23 días del mes de julio del año 2000.
___________ __ _______ ______________________
León Daniel Benarroch Hadida Rubén Darío Mariña Muñoz

`
III
APROBACIÓN
Consideramos que el Trabajo Final titulado
PORTAL DE VOZ EN VOICEXML
elaborado por los ciudadanos
LEÓN DANIEL BENARROCH HADIDA
RUBÉN DARÍO MARIÑA MUÑOZ
para optar al título de
INGENIERO DE SISTEMAS
Reúne los requisitos exigidos por la Escuela de Ingeniería de Sistemas de la
Universidad Metropolitana, y tiene méritos suficientes como para ser
sometido a la presentación y evaluación exhaustiva por parte del jurado
examinador que se designe.
En la ciudad de Caracas, a los 23 días del mes de julio del año 2001.
____________ _____
Ing. Edgar León Perez

`
IV
ACTA DE VEREDICTO
Nosotros, los abajo firmantes constituidos como jurado examinador y
reunidos en Caracas, el día ________________________, con el propósito
de evaluar el Trabajo Final titulado
PORTAL DE VOZ EN VOICEXML
presentado por los ciudadanos
LEÓN DANIEL BENARROCH HADIDA
RUBÉN DARÍO MARIÑA MUÑOZ
para optar al título de
INGENIERO DE SISTEMAS
emitimos el siguiente veredicto:
Aprobado__ Notable__ Sobresaliente__
Sobresaliente con Mención Honorífica__
Observaciones:_________________________________________________
_____________________________________________________________
__________________ ___________________ __________________

`
V
AGRADECIMIENTOS
A nuestros padres por habernos dado el apoyo necesario para la realización
de este proyecto.
A Lena por habernos ayudado con la corrección del tomo y darnos apoyo
moral para poder terminar el trabajo.
A todos nuestros amigos, por estar pendientes y preocupados por nosotros.
A Edgar por darnos su apoyo y respaldo durante todo el proyecto.
Al Personal de Netcom C.A, por darnos su apoyo incondicional, además de
habernos permitido trabajar con Uds.
En general, damos gracias a todos aquellos que nos ayudaron, sin
conocernos, a través de Internet.

`
VI
TABLA DE CONTENIDO
LISTA DE TABLAS Y FIGURAS .........................................................................VIII
RESUMEN.................................................................................................................. IX
INTRODUCCIÓN........................................................................................................ 1
CAPÍTULO I. OBJETIVOS, LIMITACIONES Y ALCANCES.......................... 5
I.1. OBJETIVO GENERAL............................................................................... 6
I.2. OBJETIVOS ESPECÍFICOS.................................................................... 6
I.3. LIMITACIONES Y ALCANCES................................................................ 7
CAPÍTULO II. MARCO DE REFERENCIA...................................................... 9
II.1. PORTALES DE VOZ...............................................................................10
II.2. RECONOCIMIENTO DE DISCURSO...................................................13
II.2.1. Identificación - Verificación de la voz ............................................17
II.2.2. Gramáticas ........................................................................................18
II.2.3. Funcionamiento del Motor de Reconocimiento...........................21
II.2.4. Problemática del Reconocimiento de Discurso...........................24
II.2.5. Reconocimiento de Discurso en la Industria de la Telefonía ....26
II.3. PROMPTS (MENSAJES DE AUDIO) ...................................................27
II.3.1. Archivos Pregrabados .....................................................................29
II.3.2. Síntesis de Texto (Text to Speech) ...............................................29
II.4. VOICE EXTENSIBLE MARKUP LENGUAGE .....................................34
II.4.1. Funcionamiento................................................................................36
II.4.2. Arquitectura.......................................................................................39
CAPÍTULO III. DESARROLLO METODOLÓGICO......................................42
III.1. ANÁLISIS...................................................................................................45
III.1.1. Análisis de las herramientas de desarrollo ..................................45
III.1.2. Elaboración del diagrama de casos de uso.................................52
III.1.3. Elaboración de los diagramas de secuencia...............................56
III.2. DISEÑO .....................................................................................................57

`
VII
III.2.1. Módulo I .............................................................................................60
III.2.2. Módulo II ............................................................................................67
III.2.3. Módulo III ...........................................................................................71
III.3. IMPLEMENTACIÓN Y PRUEBAS.........................................................73
III.3.1. Interfaz de voz ..................................................................................73
III.3.2. Interfaz Web......................................................................................75
III.3.3. Pantalla del Back-end......................................................................81
CAPÍTULO IV. CONCLUSIONES ....................................................................83
CAPÍTULO V. RECOMENDACIONES ...........................................................87
GLOSARIO ...............................................................................................................89
REFERENCIAS BIBLIOGR AFICAS ....................................................................97
APÉNDICE A. SECUENCIA TÍPICA DE EVENTOS DE LOS DIAGRAMAS
DE CASOS DE USO .............................................................................................101
APÉNDICE B. DIAGRAMA DE SECUENCIAS................................................110
APÉNDICE C. DIAGRAMA DE CLASES..........................................................115
APENDICE D. ESPECIFICACIÓNES DE LAS HERRAMIENTAS ...............116

`
VIII
LISTA DE TABLAS Y FIGURAS
Tabla 1. Tabla comparativa de las herramientas evaluadas. ..........................51
Figura 1. Evolución histórica de acceso a internet ............................................11
Figura 2. Gramática estática de opciones para enviar un mensaje. ...............19
Figura 3. Reconocimiento de un número de 7 dígitos. .....................................20
Figura 4. Componentes de un motor de reconocimiento de discurso............22
Figura 5. Historia de VoiceXML ............................................................................34
Figura 6. Arquitectura de una plataforma en VoiceXML..................................40
Figura 7. Diagrama de Caso de Uso escenario global .....................................55
Figura 8. Diseño del Sistema.................................................................................58
Figura 9. Arquitectura conceptual de VoiceXML................................................60
Figura 10. Definición de gramática de correo electrónico................................63
Figura 11. Definición de gramática de agenda...................................................65
Figura 12. Proceso para la síntesis de texto de un mensaje electrónico......71
Figura 13. Pantalla de acceso...............................................................................76
Figura 14. Pantalla principal..................................................................................77
Figura 15. Pantalla sección correo.......................................................................78
Figura 16. Pantalla sección contactos .................................................................79
Figura 17. Pantalla sección agenda .....................................................................80
Figura 18. Pantalla del Modulo II ..........................................................................81
Figura 19. Icono de status .....................................................................................82

`
IX
RESUMEN
PORTAL DE VOZ EN VOICEXML
Autores: León Daniel Benarroch Hadida Caracas, Julio 2001. Rubén Darío Mariña Muñoz Tutor: Edgar León Perez
El objetivo de este trabajo fue desarrollar un sistema que utiliza el reconocimiento de lenguaje natural a través de la voz, para proveer servicios de lectura de mensaje de correo, interconexión telefónica y agendas personales. El sistema se dividió en 3 módulos, en el módulo I se encuentra las interfaces del sistema, tanto la de voz como la de web (valor agregado al presente proyecto). En el módulo II, están las rutinas necesarias para la integración con los servidores de correo (entrante y saliente) así como los procedimientos necesarios para la integración del sistema. Finalmente el modulo III se encarga de la transformación de los mensajes entrantes en archivos de audio, a través de la síntesis de texto utilizando la herramienta de Text To Speech (TTS). Para el logro de este objetivo, se realizó una investigación en el área de aplicaciones de voz, identificándose los elementos necesarios para el desarrollo del mismo, determinando así la importancia de un sistema como este para la red de Internet y para ciertos servicios en la telefonía. En el desarrollo de la aplicación se utiliz ó la metodología de análisis y diseño orientado a objeto propuesta por Rumbaugh, complementada con el uso de UML (Unifed Modeling Language) como lenguaje de modelado. La directiva principal del diseño fue lograr un ambiente que presente facilidades de adaptación y crecimiento. Una vez que se llevan a cabo las etapas de análisis y diseño, se inició la implementación de la aplicación, usando los lenguajes y objetos necesarios para cada módulo del sistema. Como resultado se obtuvo un portal de voz el cual cumple a cabalidad los objetivos planteados, y como valor agregado se realizó la interfaz web que complementa al sistema.

`
1
INTRODUCCIÓN
¡ Teclados Temblad !
Párraga, 2001
La comunicación oral es la más natural e inherente al ser humano. El
desarrollo de Internet ha multiplicado la capacidad del hombre para
comunicarse y por lo tanto se ha generado la necesidad de buscar una forma
más sencilla de navegar en la red. Es evidente que la voz será de las
herramientas más poderosas en este ámbito.
Internet, la red de mayor impacto en el mundo, es responsable de ser el
mayor mecanismo de divulgación de información, sin embargo, ha llegado a
un punto donde pareciera que su crecimiento ha disminuido, debido a la
limitación que presenta el hecho de ser, un computador su única forma de
acceso. Buena parte de la industria ha estado buscando alternativas para
que el acceso a esta red, no sea dependiente de una sola forma de entrada,
sino que ofrezca posibilidades mediante dispositivos accesibles para la gran
mayoría de la población en las últimas décadas y no para una minoría.
El dispositivo o producto en el área de las telecomunicaciones de mayor
impacto en el mundo, ha sido el teléfono celular. En el caso de Venezuela,
6,5 millones de usuarios para el año 2001, un 30 % de la población, mientras
que sólo un 33% de estos usuarios tienen acceso a internet (Párraga, 2001).
Hoy en día uno de los grandes retos de la industria informática es mejorar la
eficacia y la naturalidad de la relación entre los dispositivos inalámbricos e
Internet. Actualmente existen tecnologías tales como Wireless Application
Protocol (WAP), Celullar Digital Packet Data (CDPD), Short Message Service

`
2
(SMS) entre otras, que permiten acceder a cierto nivel de información, sin
embargo, ninguna de ellas ha logrado impactar completamente el mercado
mundial debido a las limitaciones que generan en el usuario.
La supervivencia a mediano y largo plazo de las nuevas tecnologías de
intercambios de información inalámbrica, está condicionada por la aceptación
de los cambios en los patrones de conducta de los usuarios que su uso
representa, además de conquistar con éxito la relación Costo / Beneficio. Sin
embargo, la realidad indica que las tecnologías en lugar de competir y/o
morir tienden a adaptarse y encontrar algún nicho en el cual pueden existir
con relativa longevidad, de esta forma se aprecia como en el desarrollo del
intercambio de información inalámbrica se establecen niveles de
participación tecnológica.
De todos los procesos que afectan la comunicación entre el hombre y la
máquina, el nivel de interfaz es el que representa el mayor reto debido a que
en él se combinan los factores tecnológicos y culturales. Las cualidades que
una buena interfaz Hombre-Máquina, reducido al ámbito del tema discutido
(comunicación inalámbrica), deben tener las siguientes características: ser
naturales, no inhabilitantes y efectivas.
Natural se refiere al hecho de que la interfaz debe estar más cercana al
hombre que a la máquina. No inhabilitante, implica que el hombre, de forma
natural usa sus órganos y sentidos cooperativa pero independientemente,
cualquier actividad en la que tengamos que enfocar gran parte de nuestra
atención y recursos, será realizada sólo si es necesario. Y efectiva, una
buena interfaz debe potenciar la comunicación y minimizar las
barreras.(Placer, 2001)

`
3
En este ámbito es necesario introducir el término “Portal de Voz”, el cual
representa la forma de acceso a este nuevo nivel de interfaz hombre-
máquina.
Según Fernandez, Ortega, Serrano (2000, p.p 1-5) el concepto de portal de
voz, da un paso más allá de la pura navegación por voz y pretende relacionar
el mundo de Internet con el mundo de la voz a través de un conjunto de
servicios que amplían, complementan y dan un valor añadido al acceso voc al
a internet propiamente dicho. Los servicios predominantes de los portales de
voz son, la lectura de correo, agendas personales y el acceso a contenidos
específicos.
Las tecnologías involucradas para el desarrollo de un portal de voz son
sumamente complicadas, y el resultado de años de estudio es lo que hoy en
día nos permite “soñar” una realidad sobre todas las aplicaciones que se
pueden realizar de una manera muy sencilla. Es evidente que el desarrollo
de estas tecnologías es aún prematuro, pero es suficiente para generar el
ciclo de desarrollo que involucra tanto el uso del mismo como la continua
investigación para su perfeccionamiento.
En este sentido el objetivo general de este trabajo es desarrollar un sistema
que utilice el reconocimiento de lenguaje natural* a través de la voz, para
proveer servicios de lectura de mensaje de correo, interconexión telefónica y
agendas personales.
El presente informe está estructurado de la siguiente manera:
En el capítulo I, se presentan las referencias teóricas dentro del contexto de
la investigación. Primero, se ubica al lector en el entorno de los portales de
* Término definido en el glosario

`
4
voz, haciendo notar la importancia de los mismos en el mercado mundial.
Después se describen tecnologías necesarias para el desarrollo del mismo.
Por último se explica en detalle el lenguaje sobre el cual se va a realizar el
desarrollo.
En el capítulo II, se presentan en detalle las etapas de la metodología de
análisis, diseño, desarrollo y implementación que guió este trabajo. Primero
se presenta el análisis realizado el cual refleja el producto de la investigación,
el diagrama de casos de uso y los diagramas de secuencia. Seguidamente
se describe el diseño que se siguió durante el desarrollo a través de figuras
demostrativas, de igual forma se soporta con el diagrama de clases. Por
último se ilustra el resultado del trabajo mediante la navegación del mismo.

`
5
CAPÍTULO I. OBJETIVOS, LIMITACIONES Y ALCANCES

`
6
I.1. OBJETIVO GENERAL
Desarrollar un Sistema que utilice el reconocimiento de Lenguaje Natural a
través de la voz, para proveer servicios de lectura de e-mail, interconexión
telefónica y agendas personales.
I.2. OBJETIVOS ESPECÍFICOS
1. Desarrollar una Interfaz de reconocimiento de Lenguaje Natural.
1.1 Identificar de los elementos sociales y culturales que
determinan una buena comunicación eficaz en el ámbito
de los servicios de lectura de email y agenda personal.
1.2 Construir de la interfaz de reconocimiento para el
sistema de consulta de email, para esto se debe definir:
?? Gramáticas: ámbito en el cual el reconocimiento es
realizado, ¿qué se puede reconocer?
?? Diálogos: sucesión lógica de gramáticas, manejos de
errores y casos excepcionales.
?? Diccionarios. Descripción fonética de aquello que puede
ser reconocido, ¿cómo reconocer?
?? Prompts: Interfaz hablada del sistema al usuario
?? Caracteres: personalidad del sistema
1.3 Construcción de la interfaz de reconocimiento para el
sistema de asistente telefónico, para esto se debe
definir:

`
7
?? Gramáticas
?? Diálogos
?? Diccionarios
?? Prompts
?? Caracteres
2. Definición y desarrollo de Interfaces de Datos entre Módulos.
2.1 Identificación de Sistemas Externos a integrar
2.2 Definición de estándares y políticas de existencias e
intercambios de información entre módulos prestadores
de servicio.
3. Definición y desarrollo de procedimientos, sistemas administrativos
y de mantenimiento.
I.3. LIMITACIONES Y ALCANCES
?? El sistema a desarrollar pretende la implantación de una cantidad limitada
de servicios, tales como la lectura de email y asistente telefónico,
demostrando a través de esta implantación la características que deben
poseer en cuanto a la interfaz Hombre-Máquina.
?? Las definiciones que se hagan en cuanto a la gramática condicionan la
capacidad de reconocimiento de los sistema.

`
8
?? La variedad en cuanto a las interfaces técnicas con los proveedores de
contenido hace virtualmente imposible la homogenización de ésta, se
tendrán que seleccionar algunos proveedores de acuerdo a las realidades
del mercado.
?? Por compromisos de la empresa la selección de la tecnología de
reconocimiento no es posible, se usará la que está disponible.
?? En cuanto a la fonética el sistema será capaz de reconocer las palabras
dichas en cierta forma. Como regla general el sistema deberá ser capaz
de reconocer cualquier palabra dicha que esté presente en el contexto y
que un ser humano pueda entender. Es posible que bajo ciertas
condiciones de ruido el reconocimiento sea imposible.
?? El sistema a desarrollar deberá poseer la capacidad de adaptarse para
crecer y permitir la adhesión de otros módulos que puedan ser
desarrollados en el futuro.

`
9
CAPÍTULO II. MARCO DE REFERENCIA

`
10
En este capítulo se plantea una referencia sobre las tecnologías y términos
necesarios para el desarrollo de este trabajo. Primeramente se da un breve
descripción del concepto involucrado en los portales de voz. Seguidamente
se explica el funcionamiento de las tecnologías necesarias para el desarrollo
de una aplicación de voz, describiendo los diferentes elementos y
problemáticas que lo involucran.
II.1. PORTALES DE VOZ
Siendo la voz uno de los principales canales de la comunicación humana, por
su naturalidad y facilidad de expresión* entre los individuos, se hace
necesario que la nueva tecnología, como lo es internet, se adapte a las
necesidades y capacidades del individuo, insertando, para una mayor
facilidad de manejo de la red, el uso de la voz natural.
Con los portales de voz, se traslada el concepto y las posibilidades de
internet a los clientes del servicio telefónico, lo que hasta la fecha estaba
reservado sólo a los usuarios con PC y más recientemente a los dispositivos
móviles con tecnología WAP.
En la Figura 1 se muestra la evolución histórica del acceso a internet. En un
principio existió el lenguaje html para acceder a los contenidos de internet a
través de un browser, viendo que la cantidad de usuarios se encontraba
limitada a aquellos que poseían un computador y que existía un gran
mercado en los usuario de dispositivos móviles se comenzó buscar una
nueva tecnología que permitiera llevar el contenido y los servicios de internet
a estos dispositivos, dicha tecnología es WAP (Wireless Application
Protocol).

`
11
Figura 1. Evolución histórica de acceso a internet
Fuente: Igea, Ortega, Serrano Aranda (2000, p.p 1-5)
WAP es una tecnología diseñada para proveer a los usuarios de terminales
móviles un rápido y eficiente acceso a internet. WAP es un protocolo
optimizado, no sólo para ser usado en canales de banda de radio sino para
ser usado para la segunda generación de sistemas digitales inalámbricos,
pero con capacidades limitadas y dependientes del funcionamiento del
sistema del terminal móvil. WAP integra servicios telefónicos con micro-
navegadores. (Wap Forum ,2000).
Hoy en día esta tecnología no ha logrado introducirse completamente en el
mercado, como consecuencia de esto está surgiendo la tecnología de
acceso por voz a los contenidos de internet, de modo tal, que al igual que
WML es el lenguaje estándar para WAP, se quiere que VoiceXML sea el
lenguaje estándar para las aplicaciones de voz.

`
12
Los servicios de los portales de voz pueden ser de gran interés para las
operadoras telefónicas, en concreto, pueden suponer una “reinvención de la
telefonía” para otros aspectos y potencialidades de los teléfonos aún sin
explorar. Además, permitirían fomentar y servir de germen a otras
actividades y negocios relacionados con la publicidad y el comercio
electrónico, todo a través del teléfono.
Los servicios de portales de voz tienen como objetivos:
?? Universalizar el uso de Internet.
?? Incrementar de tráfico telefónico.
?? Incrementar el número de usuarios de acceso vocal a Internet por
teléfono.
?? Generar nuevos negocios asociados: e-commerce, juegos
interactivos, facturación, publicidad, etc.
Usualmente, un portal de voz puede contener las siguientes funcionalidades:
?? Envío y recepción de mensajes de correo.
?? Agendas: personal y de negocios.
?? Servicios de contenidos: Noticias nacionales e internacionales,
horóscopo, entretenimiento, finanzas, localización geográfica de
lugares, servicios de directorios.
?? Navegación por Internet.
?? Directorios de teléfonos.
Para la navegar en un portal de voz se de utilizar reconocimiento de lenguaje
natural*, esto significa que un cliente habla con la máquina de forma continua
como lo haría con otra persona, y la máquina será capaz de reconocer y

`
13
entender lo que dice. Esta característica permite eliminar la rigidez
tradicional en los diálogos hombre-máquina, abriendo un abanico
prácticamente ilimitado de aplicaciones, los cuales hasta la fecha no se
podían ofrecer con un sistema automatizado.
Los portales de voz usualmente tienen una página Web donde se configura y
establece ciertos parámetros que por voz, son muy incómodos de realizar,
tales como las opciones del sistema, agregar un nuevo contacto, entre otros.
II.2. RECONOCIMIENTO DE DISCURSO
Según Kemble (2001) el proceso de reconocimiento de discurso es realizado
por un componente de software que se conoce como motor de
reconocimiento de discurso. La función primaria del motor de reconocimiento
de discurso es procesar una entrada hablada y traducirla en el texto que una
aplicación puede entender. Entonces las aplicaciones de reconocimiento de
discurso se pueden dividir en dos:
?? Las que interpretan el resultado del reconocimiento como un
comando. En este caso, la aplicación es una aplicación de
comando y control. Un ejemplo es cuando el usuario dice "Estado
de Cuenta", y la aplicación devuelve el estado de cuenta del
usuario.
?? Las que manejan el texto recibido simplemente como un texto,
entonces es considerada una aplicación de dictado. En una
aplicación de dictado, si el usuario dijera "estado de cuenta" la
aplicación no devolvería resultado, simplemente devolvería el
texto "estado de cuenta".

`
14
Según Kemble (2001) y Collin (1999, Art 2) el reconocimiento de discurso
tiene los siguientes términos o características que definen y permiten
entender el funcionamiento del mismo:
?? Expresión
Cuando el usuario dice algo, se conoce como una expresión. Una expresión
es cualquier corriente de discurso entre dos períodos de silencio*. Las
expresiones son enviadas al motor de discurso para ser procesadas.
El silencio, en el reconocimiento de discurso es casi tan importante como lo
que es hablado, porque el silencio establece el principio y el final de una
expresión.
El motor de reconocimiento de discurso descubre la entrada de audio debido
a una carencia de silencio y marca el principio de la expresión. Así mismo
cuando el motor descubre una cierta cantidad de silencio, el final de la
expresión es señalada.
Una expresión puede ser una sola palabra, o puede contener múltiples
palabras (oraciones o frases*). Por ejemplo, "balance", "balance de mi cuenta
corriente" o "me gustaría saber el balance de mi cuenta corriente, por favor"
son algunos ejemplos de expresiones posibles que un usuario podría decir a
una aplicación bancaria escrita en VoiceXML para solicitar el balance de su
cuenta. Las gramáticas* activas establecen las palabras y frases válidas en
un punto particular del diálogo.
?? Pronunciación
Un motor de reconocimiento de discurso usa todos los tipos de datos
generados, como los modelos estadísticos y algoritmos, para poder convertir

`
15
la entrada hablada en el texto. Uno de ellos es la pronunciación. La
pronunciación de una palabra representa lo que el motor de discurso piensa
sobre cómo debería sonar dicha palabra.
Las palabras pueden tener pronunciaciones múltiples asociadas con ellas.
Un desarrollador de aplicaciones en VoiceXML, requiere proporcionar
pronunciaciones múltiples para ciertas palabras y frases, para obtener así,
variaciones en cuanto a las maneras que los usuarios pueden expresar.
?? Dependencia contra Independencia del Usuario
La dependencia del usuario describe el grado en el cual un sistema de
reconocimiento de discurso requiere el conocimiento de las características de
voz individuales de un usuario para procesar satisfactoriamente el
reconocimiento. El motor de reconocimiento de discurso tiene la capacidad
de "aprender" sobre cómo un usuario en particular, dice palabras y frases;
este sistema puede ser entrenado para cualquier tipo de voz.
Los sistemas de reconocimiento de discurso, que requieren que un usuario
entrene el sistema con su voz, son conocidos como sistemas dependientes
del usuario. Los sistemas de dictado en los suites de productividad*, son casi
todos dependientes del usuario, ya que ellos funcionan sobre vocabularios*
muy amplios, por lo tanto, trabajan mejor cuando el usuario dedica un tiempo
entrenando al sistema con su propia voz.
Los sistemas de reconocimiento de discurso que no requieren que el usuario
entrene el sistema, son conocidos como sistemas independientes del
usuario. El reconocimiento de discurso en el mundo VoiceXML, debe ser
independiente del usuario, ya que una aplicación de voz debe tener la
capacidad de poder entender a cualquier usuario, independientemente de
sus características individuales.

`
16
?? Exactitud*
El funcionamiento de un sistema de reconocimiento de discurso es medible,
quizás la medida más usada es la exactitud. Es típicamente una medida
cuantitativa y puede ser calculada de varios modos, sin embargo, lo más
importante de la exactitud es si el resultado final deseado ocurrió. Esta
medida es útil en la validez del diseño de aplicación. Por ejemplo, si el
usuario dijo "sí", el motor devolvió "sí", la acción ha sido ejecutada, es claro
que el resultado final deseado ha sido alcanzado. Pero ¿ qué pasa si el
motor devuelve un texto que exactamente no empareja la expresión?. Por
ejemplo, si el usuario dijo "nope", cuando quiso decir “no” y el motor devolvió
"No", ¿Esto debería ser considerado un diálogo acertado? La respuesta a
esta pregunta es sí porque el resultado final deseado ha sido alcanzado.
Otra medida de exactitud de reconocimiento es si el motor reconoció la
expresión exactamente como se dijo. Esta medida de exactitud de
reconocimiento es expresada como un porcentaje, y representa el número de
expresiones aprobadas correctamente según el número total de expresiones
habladas. Esto valida el diseño de gramática. Usando el ejemplo anterior, si
el motor devolviera "nope" cuando el usuario dijo "No", esto sería
considerado como un error de reconocimiento..
La exactitud de reconocimiento es una medida importante para todos las
aplicaciones de reconocimiento de discurso. Esto esta vinculado al diseño de
la gramática y al ambiente acústico* del usuario, explicado posteriormente.
?? Lenguaje Natural
Según Hernández (2000) “el lenguaje se considera, como un conjunto de
oraciones, que usualmente es infinito y se forma con combinaciones de

`
17
palabras del diccionario. Es necesario que esas combinaciones sean
correctas (con respecto a la sintaxis) y tengan sentido (con respecto a la
semántica). Un lenguaje es la función que expresa pensamientos y
comunicaciones entre la gente. Esta función es llevada a cabo por medio de
señales vocales (voz) y/o por signos escritos.”
Existen dos tipos de lenguajes, los lenguajes naturales (ingles, español, etc.)
y los lenguajes formales (matemático, lógico, etc.).
El lenguaje natural es el medio que utilizamos de manera cotidiana para
establecer nuestra comunicación con las demás personas. En el ámbito de
reconocimiento de discurso, el lenguaje esta dado por la definición de las
gramáticas.
Se dice que el reconocimiento es de lenguaje natural, ya que se que se
asemeja al lenguaje natural, pero en realidad el sistema tiene predefinido las
múltiples opciones para entender un comando, esto quiere decir que el
sistema sólo va a entender lo que esta predefinido en el contexto.
II.2.1. Identificación - Verificación de la voz
Identificación es la “acción y efecto de identificar o identificarse”. Identificar
es “hacer que dos o mas cosas que en realidad son distintas aparezcan y se
consideren como una misma” (Salvat, 1976, pp.1754).
Según Collin (1999), en la verificación de un individuo, se compara la
expresión de una persona cooperante con plantillas pregrabadas de una

`
18
forma dependiente del texto dentro de un entorno donde hay un gran número
de posibles candidatos. Una de las principales dificultades al construir un
sistema identificador, es la selección de rasgos* para la discriminación entre
ellos.
La verificación de la voz es utilizada para garantizar cierto nivel de seguridad
en el sistema en las secciones que lo requieran. Esta no puede ser utilizada
individualmente, debe estar ligada a otros aspectos, tales como una clave
secreta, que garanticen, además de la verificación de voz, que el usuario que
está llamando tiene el permiso para acceder al sistema.
II.2.2. Gramáticas
La gramática es el conjunto de reglas que limita el número de combinaciones
permitidas de las palabras del vocabulario. En general, la existencia de una
gramática, en un reconocedor, ayuda a mejorar la tasa de reconocimiento,
eliminar ambigüedades y puede contribuir a la disminución de la necesidad
de cálculo al limitar el número de palabras en una determinada fase del
reconocimiento. En sistemas de palabras aisladas, en los que no existe una
gramática en el sentido estricto del término, se puede entender por tal el
número de palabras a reconocer. (Kunins 2001)
Una gramática usa una sintaxis particular, con ciertas reglas, se definen las
palabras y las frases que deben ser reconocidas por el motor. Una gramática
puede ser tan simple como una lista de palabras, o puede ser
suficientemente flexible, para permitir tanta variabilidad en lo que puede ser
dicho, pareciéndose a lenguaje natural.

`
19
Las gramáticas definen el dominio, o el contexto, en el cual el motor de
reconocimiento trabaja. El motor compara la expresión corriente contra las
palabras y frases en las gramáticas activas. Si el usuario dice algo que no se
encuentra en la gramática, el motor de discurso no será capaz de descifrarlo
correctamente.
Existen dos tipos de gramáticas, la estática y la dinámica. La primera es la
que tiene predefinida toda la gramática y se crea en el momento de diseño; y
la dinámica se diferencia únicamente porque se crea la gramática en tiempo
real, es decir, se genera según los datos que se le proporcionen en el
momento.
?? Gramática Estática
Es creada en el diseño del sistema, y responsable de lo que éste es capaz
de entender.
Un ejemplo específico, es el de un usuario que desea mandar un correo
electrónico, existen distintos modos de expresar este comando, como se
explica en la Figura 2.
Figura 2. Gramática estática de opciones para enviar un mensaje.
Fuente: Elaboración propia

`
20
Se puede definir una sola gramática para la aplicación, de lo contrario se
pueden tener gramáticas múltiples. La posibilidad de la gramática múltiple
es, que la aplicación las activará sólo cuando esto sea necesario. Desde
luego, existen las compensaciones entre la velocidad de reconocimiento
(tiempo de respuesta) y la exactitud, contra el tamaño y complejidad de la
gramática. Por lo tanto, éstas no pueden ser muy extensas, ya que mientras
mayor sea la cantidad de formas de expresar un comando, mayor es la
probabilidad que el sistema se equivoque. Esto reside directamente en el
diseño de la gramática, un ejemplo claro de este problema es el
reconocimiento de un número telefónico. Dicho número, normalmente, está
compuesto por 7 dígitos.
Figura 3. Reconocimiento de un número de 7 dígitos.
Fuente. Elaboración propia
En la Figura 3 sólo se observan tres opciones de expresar el número
telefónico, y se puede notar que, tanto la primera opción como la segunda
tienen una probabilidad mayor de ser utilizada por el usuario que la última
opción, por lo que a la hora de diseñar esta gramática, se debería excluir la
opción 3, ya que la probabilidad de que alguien diga esa opción es mínima,
debido a que no es la forma natural o común de decir un número telefónico.
Con este ejemplo se observa el estudio preliminar que se requiere para
determinar qué es lo que el usuario probablemente vaya a decir y cuáles son

`
21
las principales formas en que lo puede decir. Este paso incide mucho en la
calidad de la interfaz, ya que si el usuario intenta expresar algo y la
aplicación no lo entiende, éste se puede sentir frustrado y probablemente no
vuelva a utilizar el servicio. (Nuance Speech Recognition System Version 7.0
(2000, Cap 1 pp 1)
?? Gramáticas Dinámicas
Una de las ventajas claves de las aplicaciones de reconocimiento de
discurso surgidas por internet, es la capacidad de crear rápidamente
servicios poderosos e integrados que permiten utilizar los datos y sistemas
existentes.
Según Kunins (2001) es un hecho que las gramáticas deben "compilar" al ser
cargadas por cualquier plataforma de reconocimiento de discurso, y que las
gramáticas muy grandes pueden tomar varios segundos para compilar. Esto
no es absolutamente exclusivo de VoiceXML. La diferencia clave es que
VoiceXML hace sumamente fácil para los desarrolladores incorporar
elegantemente gramáticas dinámicas a sus aplicaciones. Los
desarrolladores, que construyen aplicaciones de reconocimiento de discurso
sobre cualquier plataforma, incluyendo VoiceXML, deben planear las
características de la aplicación y diseñar cuándo usar las gramáticas
estáticas* o las dinámicas*.
II.2.3. Funcionamiento del Motor de Reconocimiento
Según Kemble (2001) la tarea del motor de reconocimiento de discurso
implica la traducción de la entrada de audio en un texto.

`
22
Como muestra la Figura 4 , los componentes principales son:
?? Entrada de audio.
?? Gramática.
?? Modelo Acústico.
?? Texto reconocido.
Según la Figura 4, primeramente está la entrada de audio, representada por
el usuario. Esta entrada no sólo contiene los datos del discurso, sino
también el ruido de fondo. Este puede interferir con el proceso de
reconocimiento, por lo tanto, el motor de discurso debe manejarse y
posiblemente adaptarse al ambiente donde el audio es obtenido.
Figura 4. Componentes de un motor de reconocimiento de discurso.
Fuente: Kimberlee A.Kemble (2001)

`
23
Como expresa su definición, el trabajo del motor de reconocimiento de
discurso, es convertir la entrada hablada en texto. Para lograr esto, se
emplean todos los tipos de datos, estadísticas y algoritmos que se
encuentren a su alcance. Su primer trabajo es tratar la señal entrante de
audio y convertirla a un formato más conveniente para el análisis remoto.
Una vez que los datos del discurso están en un formato apropiado, el motor
busca la mejor equivalencia para esa entrada. Esto lo realiza por medio de
las palabras y frases* que conoce (las gramáticas activas). El conocimiento
del ambiente en el que esta trabajando (para VoiceXML, esto es el ambiente
de telefonía), lo proporciona el modelo acústico (ver Figura 4). Una vez que
se identifica la equivalencia más probable de lo que se dijo, el motor retorna
lo que se reconoció en forma de texto.
Algunas técnicas que se utilizan para el diseño de reconocedores de
discurso son:
?? Técnicas topológicas: Dynamic Time Warping (DTW), basados en
el cálculo y comparación de distancias.
?? Técnicas probabilísticas: Modelos ocultos de Markov (HMM), que
son modelos generativos de las palabras del vocabulario.
?? Redes neuronales.
En los cuatro casos está presente una fase de "entrenamiento" (cálculo de
los patrones de referencia, cálculo de los parámetros de los modelos de
Markov, entrenamiento de las redes neuronales o creación de estructuras de
datos para los sistemas expertos), y otra fase de "reconocimiento"
propiamente dicho. Igualmente en los cuatro casos el primer proceso
necesario es la "parametrización" o transformación de la forma de onda de la
señal entrante, en un conjunto de parámetros o características adecuadas
para cada reconocedor.

`
24
Cuando el motor de reconocimiento procesa una expresión, devuelve un
resultado. El resultado puede ser uno de estos estados: aceptación o
rechazo. Una expresión aceptada es cuando el motor devuelve un texto
aprobado, mientras que el rechazo es lo contrario.
Algunos motores devuelven una probabilidad de confianza sobre el texto
reconocido, es decir, la probabilidad que el texto devuelto sea el correcto.
II.2.4. Problemática del Reconocimiento de Discurso
Según Poza (1990) existen varias problemáticas presentadas en el
reconocimiento de discurso, asociados a:
?? El Locutor.
Es quizás el aspecto que introduce mayor variabilidad en la forma de onda
entrante, y por tanto requiere que el sistema de reconocimiento sea
altamente robusto. Una persona no pronuncia siempre de la misma forma,
debido a distintas situaciones físicas y psicológicas Existe además gran
variedad entre distintos locutores (hombres, mujeres, niños), diferencias
según la edad o región (es la llamada variabilidad interlocutor). Es mucho
más sencillo que un sistema funcione para un determinado locutor donde
éste lo haya entrenado previamente (se dice que el sistema es dependiente
del locutor), a que un sistema funcione para cualquier locutor (sistema
independiente del locutor).

`
25
?? La forma de hablar.
El humano pronuncia las palabras de una forma continua, y debido a la
inercia de los órganos articulatorios, que no pueden moverse
instantáneamente, se producen efectos coarticulatorios. Ello, unido a las
variaciones introducidas por la prosodia*, hace que una palabra al principio
de una frase sea diferente que cuando se dice en medio de la misma, o que
también, sea diferente dependiendo de qué es lo que le precede o le sigue.
Un reconocedor es relativamente sencillo si sólo tiene que reconocer una
palabra dicha de forma aislada (reconocedor de palabras aisladas) y es más
complejo si debe reconocer las palabras de una frase, pero introduciendo
una pausa entre cada dos de ellas (habla conectada). El sistema más
complicado es aquel que debe funcionar reconociendo habla continua, que
es la forma natural de hablar.
?? El Vocabulario.
Se conoce por tal al número de palabras diferentes que debe reconocer el
sistema. Mientras mayor es el número de palabras, más complejo es el
reconocedor. Esto ocurre por dos motivos, el primero porque al aumentar el
número de palabras es más fácil que aparezcan palabras parecidas entre sí;
y el segundo porque al aumentar el número de palabras que comparar,
aumenta directamente el tiempo de tratamiento. Una solución posible a este
problema sería el utilizar unidades lingüísticas inferiores a la palabra
(alófonos*, sílabas*, etc.) que en principio tienen un número limitado, e
inferior al de posibles palabras. Sin embargo, la dificultad de reconocer estas
unidades es aún mayor debido a que su duración es muy corta, la frontera
entre dos unidades sucesivas es muy difícil de establecer y los efectos
coarticulatorios son mucho más fuertes que entre palabras.

`
26
?? El Entorno físico.
No es lo mismo un sistema que funciona en un ambiente poco ruidoso, como
puede ser el despacho de un pediatra, o el que tiene que funcionar dentro de
un carro o en una fábrica.
II.2.5. Reconocimiento de Discurso en la Industria de la Telefonía
Según Kemble (2001) el reconocimiento de discurso sobre el teléfono
introduce algunos desafíos únicos. Ante todo la amplitud de banda de la
corriente de audio. Los viejos sistemas de telefonía plana (POTS), utilizan
8kHz como rata de cambio, esta amplitud de banda es mucho más baja que
una computadora de escritorio, la cual usa 22kHz. Como la calidad de la
corriente de audio es mucho más baja en el ambiente de telefonía, hace el
reconocimiento más difícil.
El ambiente de telefonía puede ser bastante ruidoso ya que los usuarios
pueden llamar de sus casas, oficinas, autos, el aeropuerto, etc, a demás los
equipos para realizar la llamada son muy variables.
Otra consideración es si realmente soporta el barge-in* (W3C (2000)) El
barge-in (también conocido como cut-thru) se refiere a la capacidad de un
usuario para interrumpir un prompt* cuando se esta reproduciendo, es decir,
cuando se dice algo o se presiona una tecla del teléfono. Esto es a menudo
un rasgo de utilidad importante para usuarios expertos que buscan "un
camino rápido" en aplicaciones donde los prompts no son indispensables.
Cuando el usuario realiza un barge-in, es esencial que el prompt sea
terminado inmediatamente (o, al menos, que sea percibido inmediatamente

`
27
por el usuario). Si hay alguna tardanza sensible (mayor de 300 milisegundos)
entre el momento que el usuario dice algo y el prompts es finalizado,
entonces, el usuario puede pensar que el sistema no escuchó, y muy
probablemente lo repetirá, lo que confundiría al sistema y al usuario, esto es
el mismo efecto que el tartamudeo.
Existe otro fenómeno relacionado con el barge-in, llamado "el Discurso
Lombard". El discurso Lombard se refiere a la tendencia de la gente para
hablar más fuerte en ambientes ruidosos, es una alternativa para ser oída
sobre el ruido. Los usuarios que utilizan el barge-in tienden a hablar más
fuerte de lo que necesitan hablar, lo cual puede ser un problema a la hora
reconocer el discurso. La oratoria más fuerte no ayuda al proceso de
reconocimiento de discurso, al contrario, esto deforma la voz y dificulta el
proceso de reconocimiento.
Todos estos son problemas que afectan únicamente cuando se está tratando
de reconocer un discurso en un ambiente telefónico, por eso el motor de
reconocimiento está preparado para ver qué tipo de recurso está utilizando el
usuario y para tratar de resolver los problemas antes mencionados.
II.3. PROMPTS (MENSAJES DE AUDIO)
Usualmente una interfaz se refiere a algo visual, pero en el caso de las
aplicaciones de voz, se refiere a algo que sólo interactúa con el sentido
auditivo, por lo que ésta debe ser muy buena para poder tener éxito.
Para que una aplicación de voz sea agradable al usuario, debe tener un
conjunto de sonidos que, inconscientemente, hagan entender al usuario lo

`
28
que el sistema trata de decir (Santiago Aldekoa (2000)), por ejemplo, en un
sistema que presente un menú de secciones, se podría crear un sonido que
indique cuando se entra a una sección nueva. Por otro lado la entonación
que use el sistema debe ser la apropiada para el contexto en que se esta
desenvolviendo, para no recibir un rechazo inmediato por parte del usuario.
Esto se puede ver reflejado en el siguiente ejemplo: cuando un usuario
quiera decir un comando y la probabilidad de entendimiento es nula el
sistema le pedirá al usuario de una manera sumisa y con un tono de voz más
suave que repita el comando. De esta forma podemos crear una interfaz
agradable para que el usuario no rechace al sistema aunque éste no haya
entendido las peticiones del mismo.
Jeff Kunins citado por Hoffman, (2000) escribió: “El reto realmente no es de
desarrollo, sino de diseño. Es muy fácil escribir una interfaz terrible y difícil
de usar”. En el desarrollo de esta tecnología, se va ver muchas aplicaciones
que van fracasar sólo por el hecho de no tener un buen diseño de los
prompts aunque la idea como aplicación sea buena. Cualquier persona va a
poder hacer aplicaciones VoiceXML pero lo difícil está en el diseño y no en la
complejidad del código.
Existen dos tipos de prompts, el generado por un sintetizador de texto o Text
To Speech* y el de audio pregrabado. Existen ventajas y desventajas para
cada uno, pero esencialmente su uso es para casos distintos. Este difiere en
cuanto a la necesidad de la creación del discurso en tiempo real, esto quiere
decir, que para poder decir el nombre de un usuario del sistema, es
prácticamente imposible, crear los archivos pregrabados de todos los
nombres de los usuarios del sistema y hacerlo continuamente mientras se
vayan creando. Por lo tanto, es necesario que un sintetizador los genere sin
la necesidad del factor humano.

`
29
II.3.1. Archivos Pregrabados
Los archivos pregrabados son más naturales, ya que no son generados por
una máquina, simplemente son grabados por una voz humana. La ventaja de
estos archivos, es que, se puede difundir cualquier tipo de emoción, que una
máquina por ahora, no puede expresar. Sin embargo, su principal defecto
radica en el tiempo y el costo que involucran.
Usualmente los archivos pregrabados son los que hoy en día están
presentes en la aplicaciones de voz, ya que como nos dan la posibilidad de
elegir la voz humana, permiten que la interfaz del sistema sea mucho más
agradable y atractiva. Esta situación seguirá así hasta que los sintetizadores
de texto puedan equipararse, en naturalidad y entendimiento a lo que es la
voz humana.
II.3.2. Síntesis de Texto (Text to Speech)
Según Dilts M (1984) la tecnología de síntesis de texto o Text To Speech
(TTS), puede definirse como un sistema que transforma cualquier texto
escrito siguiendo las convenciones ortográficas de una determinada lengua
en su equivalente hablado. Los sistemas de conversión de texto a voz son
necesarios cuando el ordenador debe generar una serie infinita de mensajes
imposible de prever.
Ciertas aplicaciones de la síntesis de voz, requieren precisamente la
posibilidad de generar en tiempo real un número infinito de mensajes
impredecibles. Unos ejemplos de estas aplicaciones serían:

`
30
?? Máquinas lectoras para ciegos: Consiste en un sofisticado conversor de
texto a voz asociado a un sistema de reconocimiento óptico que permiten
leer en voz alta cualquier documento impreso.
?? Ayudas para los disminuidos físicos: Las personas que se encuentran
incapacitadas para hablar y usan algún tipo de ayuda que les permite
intercambiar información con sus semejantes deben ser capaces de
producir cualquier mensaje que deseen, y no sólo aquellos que han sido
almacenados previamente en su sintetizador. Hoy en día están
investigándose diversos métodos de control de la prótesis - por ejemplo
mediante movimiento oculares - diseñados especialmente para aquellos
minusválidos a los que les es imposible utilizar un teclado convencional.
?? Terminales parlantes: En ciertos casos es necesario poder obtener de la
máquina cualquier mensaje oral, aunque éste sea completamente nuevo,
especialmente cuando se accede por teléfono a la información. Esta es la
situación que se da cuando se consultan telefónicamente descripciones
de productos, listas de precios, entre otros.
Cada aplicación requiere de una técnica de síntesis específica, pero la
selección de ésta depende básicamente de tres factores: la naturalidad, la
inteligibilidad y la flexibilidad que se necesite. Al mencionar la flexibilidad se
refiere a la capacidad que debe tener el sistema para generar diversos
mensajes a partir de un conjunto finito de elementos. Los sistemas de
conversión de texto a voz existentes en la actualidad ofrecen un grado muy
elevado de flexibilidad, pero en cambio no han llegado aún a alcanzar la
cualidad propia del habla natural. (Crespo, Sardina, Serrano, Larumbe
,1991).

`
31
El lenguaje puede estructurarse en varios niveles que permiten concebir
diversas técnicas de síntesis del habla, según la unidad empleada en el
proceso de almacenamiento y producción de los mensajes hablados (Dilts,
1984):
?? Frases: El almacenamiento de frases completas mediante cualquiera de
los procedimientos existentes para la codificación de la onda sonora
permite obtener voz de una cualidad y una naturalidad prácticamente
insuperables, pero se diferencia muy poco de las grabaciones analógicas.
Es una técnica que presenta una falta total de flexibilidad, puesto que
implica almacenar cada una de las frases que deben producirse.
?? Palabras: El almacenamiento de palabras permite una mayor flexibilidad y
economía, pero presenta dos problemas graves: por un lado, es imposible
reproducir las variaciones contextuales de los sonidos en función de su
entorno fonét ico; por otro, se hace difícil mantener las variaciones de
entonación según la frase y la posición de la palabra en la frase.
?? Morfemas*: Como unidad de síntesis, los morfemas presentan problemas
análogos a las palabras pero aún más acusados. El habla así producida
es muy poco natural debido a las dificultades de concatenación de los
elementos constituyentes.
?? Fonemas* o alófonos : Desde el punto de vista lingüista, ésta parece ser la
unidad más natural para la producción de habla y también es la más
económica desde la perspectiva del ingeniero. El fonema se considera la
mínima unidad abstracta en la que puede dividirse un enunciado, aunque
se reconozca la existencia de elementos menores como los rasgos
distintivos. Cualquier lengua natural puede describirse mediante unos 30-

`
32
40 fonemas, cuya combinación en unidades de nivel más alto - morfemas,
palabras y frases - permite la creación de cualquier enunciado en esta
lengua.
En la teoría lingüística se han dado y se dan aún polémicas sobre la
existencia misma del fonema, sobre su adecuación como nivel de análisis o
incluso sobre su validez psicológica, pero es innegable que el fonema
constituye una buena manera de reducir la información, que debe emplearse
en un sistema de conversión de texto a voz que deba combinar una memoria
pequeña con una gran flexibilidad. Mediante el conjunto de fonemas propio
de una lengua y las reglas para su combinación debería ser posible generar
cualquier enunciado en dicha lengua.
Los sistemas de conversión de texto se puede estructurar de la siguiente
forma:
?? Procesamiento previo del texto escrito.
Un texto escrito que deba ser utilizado como entrada de un convertidor de
texto a voz requiere un procesamiento previo. Las operaciones necesarias
son similares a las que lleva a cabo un hablante humano cuando lee en voz
alta un texto, y comprenden el tratamiento de las siglas, de los números y de
las abreviaciones, que debe aparecer en su forma completa.
?? Conversión de letras a fonemas.
Una vez que se haya hecho el procesamiento de texto se procede a la
conversión de letras a fonemas o a alófonos, según el tipo de sistema que se
trate. Para llevar a cabo esta operación, el linguista escribe primero una

`
33
gramática que tendrá la forma de un conjunto de reglas que relacionan las
letras y los sonidos de una lengua dada. A continuación, algunos sistemas
introducen un estadio intermedio en el que se analiza la estructura interna de
la palabra; en tal caso suele existir un diccionario de morfemas a los que se
asocia su pronunciación, ortografía y reglas de combinación con otros
elementos morfológicos en forma de diccionario de excepciones, tratándose
las palabras polimorfémicas, como una cadena de morfemas. En tales
sistemas, el procesamiento morfológico es previo a la conversión de letra a
sonido, que sólo se lleva a cabo cuando ya se ha realizado el análisis
morfológico.
?? Reglas alofónicas.
Las reglas alofónicas son los mecanismos por los que se definen las
características fonéticas precisas de los fonemas. De su aplicación resulta un
reajuste de las representaciones fonológicas generadas por la aplicación de
las reglas de conversión de letras a sonidos. La necesidad de estas reglas
responde a que, en el habla natural, cada sonido está influido por los sonidos
adyacentes y parece lógico pensar que un conversor de texto a voz, que
aspire a generar habla natural, debe operar de forma parecida.
?? Conversión de parámetros a sonidos.
Una vez que se ha generado una cadena con los valores de los parámetros
asociados a cada alófono, ésta debe convertirse en una señal analógica;
este proceso lo lleva a cabo habitualmente un sintetizador, enviándose el
resultado a un amplificador y un altavoz, con lo cual se obtiene la versión
sonora de la cadena de caracteres.

`
34
II.4. VOICE EXTENSIBLE MARKUP LENGUAGE
En marzo de 1999 se produjo un foro planificado por la organización que
representa al VoiceXML (http://www.voicexml.org). Posteriormente en marzo
del 2000 se produjo la liberación de la especificación de VoiceXML. Ambas
acciones tuvieron como resultado una oleada de actividad en la industria de
telefonía y el reconocimiento de discurso, la cual se orientó hacia el análisis
de los conceptos, productos y servicios del VoiceXML.
En la Figura 5 podemos ver cómo y quienes participaron en el desarrollo del
lenguaje desde 1998.
}
Figura 5. Historia de VoiceXML
Fuente: Ken Rehor (2001, pp 6)
Según Karam (2001) el proceso del Foro para desarrollar el lenguaje de
VoiceXML fue iniciado por AT&T, Lucent, y Motorola a mediados de 1998. El
resultado de esta unión fue la creación de un grupo de discusión sobre

`
35
browsers de voz realizaba por W3G en noviembre de 1998, en donde fue
tomada la decisión de crear el Foro de VoiceXML para acelerar la definición
de un lenguaje estándar para aplicaciones de reconocimiento de discurso.
Tres acontecimientos claves ocurrieron durante este período, el anuncio del
Foro en marzo 1999, la adición de IBM como uno de los fundadores, y la
creación de una especificación preliminar VoiceXML 0.9 en agosto 1999, los
cuales generaron el ímpetu en la industria de telefonía y de reconocimiento
de discurso.
El foro de VoiceXML aceptó comentarios públicos y de socios sobre la
especificación del VoiceXML 0.9, logrando para finales de 1999 y comienzos
del 2000 producir la liberación final de la especificación del VoiceXML 1.0, el
7 de marzo 2000. La liberación del VoiceXML 1.0 provocó otra vez el ímpetu
en el mercado.
En mayo del 2000, el Foro de VoiceXML decidió reorganizarse ampliando su
gama de actividades, abriendo nuevas oportunidades para la participación en
el foro y adoptando las normas de la industria IEEE y la organización de
Tecnología (ISTO).
En septiembre 2000, el Foro VoiceXML lanzo, una nueva estructura de
socios y comenzó nuevos comités para el mercadeo, conformidad y
educación del mismo. En esta estructura de socios se crearon tres niveles:
?? Patrocinador: Cuatro empresas fundadoras, y las que financiaron
el capital inicial para el Foro.
?? Promotor: un nivel de socios con pago anual.
?? Partidario: un nivel de socios libre (gratis).

`
36
Estos niveles han permitido que el desarrollo en el foro sea más participativo
y han logrado conseguir recursos para la continuación del mismo.
II.4.1. Funcionamiento
VoiceXML según Rehor (2001) es un lenguaje para la creación de interfaces
de voz, en particular para el teléfono convencional (fijo o móvil). Este
lenguaje utiliza el reconocimiento de discurso y la detección de tonos multi-
frecuencia* (DTMF*) como entrada, y pregrabado de audio y sintetizador de
texto (TTS) como salida. Este lenguaje trae el paradigma de desarrollo de
web al teléfono (Richardson (2001)). Con el objetivo de que los
desarrolladores de aplicaciones, vendedores de plataforma, pueden
beneficiarse de la transportabilidad y reutilización de código.
Con VoiceXML, el desarrollo de aplicaciones de reconocimiento de discurso
es enormemente simplificado, ya que usa una infraestructura familiar a la de
web (HTML). En vez de la utilización de un computador personal con un
browser de web, cualquier teléfono puede tener acceso a páginas hechas en
VoiceXML vía "un intérprete" VoiceXML, también conocido como "un browser
de voz"; controlado sobre un servidor de telefonía. Mientras que HTML es
comúnmente usado para la creación de usos gráficos de Web, VoiceXML es
para interfaces de voz.
Según Rehor (2001) hay dos tendencias del pensamiento en cuanto al uso
del lenguaje VoiceXML:
?? Como un modo de permitir la voz en una página Web

`
37
?? Como una solución de una arquitectura abierta para la
construcción de la próxima generación de servicios de telefonía
mediante el reconocimiento natural de la voz.
El uso primordial de este lenguaje se concentrará pára la creación de los
portales de voz, los cuales han recibido una considerable atención (León
(2000)). Este, sin embargo, no es el único uso que se va a dar a VoiceXML,
se verá en aplicaciones de voz para intranets, centros de información,
servicios de notificación, entre otros.
Separando las aplicaciones lógicas (que corren en un servidor Web) de los
diálogos de voz (corriendo sobre un servidor de telefonía), se crea un nuevo
modelo de negocio para las aplicaciones telefónicas, conocido como Voice
Service Provider o Proveedor de Servicios de Voz. Usualmente estos
proveedores son las compañías que poseen los portales de voz, ya que
tienen la capacidad de adquirir los equipos necesarios para la infraestructura
requerida. Esto permite a cualquier programador construir servicios
telefónicos y ofrecerlos a través de estos proveedores sin tener la necesidad
de comprar equipo alguno.
VoiceXML en un principio fue diseñado para construir servicios telefónicos,
pero hoy en día, después de ver la capacidad de este lenguaje, se puede
pensar en su utilización, por ejemplo, para controlar electrodomésticos
mediante la voz.
El crecimiento rápido de Internet fue debido en gran parte a su arqui tectura
abierta e interfaces comunes de alto nivel al diferir de las plataformas
disponibles (Internet Explorer, Netscape, etc). De igual forma que un
programador de HTML no tiene que saber como los bits generan la página
web en un computador personal, VoiceXML protege a los programadores de

`
38
muchas de las complejidades de una plataforma de telefonía, abstrayendo lo
que es el diseño de la aplicación y su interfaz, del funcionamiento complejo
que involucra el resto del proceso.
En el contexto de VoiceXML es necesario conocer el significado de los
siguientes términos para poder entender el funcionamiento del mismo W3C
(2000). Dichos términos son:
?? Diálogos y Subdiálogos
Existen 2 tipos de diálogos: Forms* y Menús*. Los Forms definen una
interacción con el us uario la cual obtiene valores para un conjunto de
estados (Field). Cada estado puede especificar una gramática que define el
reconocimiento permitido. Un menú se presenta cuando el usuario tiene que
escoger entre varias opciones para ser trasladado a otro dialogo basado en
esa decisión.
Los Subdiálogos son como la llamada a una función, la cual provee el
mecanismo para invocar una nueva interacción y regresar al lugar de partida.
Los datos locales, las gramáticas y la información del estado son guardadas
y están disponibles cuando se regrese al lugar de partida que llamó al
subdiálogo.
?? Eventos
Los eventos son lanzados por la plataforma por el acontecimiento de un
conjunto de circunstancias, así como cuando el usuario no responde o no
habla o simplemente pide ayuda. El interpretador también puede lanzar un
evento si encuentra un error semántico en el documento VoiceXML. Los

`
39
eventos son capturados por el elemento <catch> y son lanzados por el
elemento <throw>. También existen elementos que capturan un evento en
particular como por ejemplo, <noinput>, que sucede cuando el usuario no
dice nada.
?? Aplicación
Según definición del VoiceXML 1.0 (W3C 2000) una aplicación es un
conjunto de documentos que comparten el mismo documento raíz. Siempre
que el usuario interactúa con un documento en la aplicación, el documento
raíz es cargado. El documento raíz permanece cargado mientras que exista
una transición entre un documento y otro, y se descarga cuando el
documento destino no pertenece a la misma aplicación. Cuando el
documento raíz es cargado se mantienen activas las variables y son
conocidas como variables de la aplicación. Las gramáticas también pueden
mantenerse activas en toda la aplicación.
II.4.2. Arquitectura
Una aplicación VoiceXML requiere de varios componentes, los cuales se
pueden apreciar en la Figura 6:
?? Servidor de Aplicación: Es típicamente un servidor Web, que controla la
lógica de la aplicación, y puede tener sus bases de datos o interfaces
para una base de datos externa o un servidor de transacciones.
?? Servidor de Telefonía VoiceXML: Es una plataforma que controla el
interpretador de VoiceXML que actúa como cliente del servidor de

`
40
aplicación. El intérprete entiende diálogos VoiceXML y controla los
recursos de telefonía y reconocimiento de discurso. Estos recursos
incluyen ASR, TTS, reproductores de audio y funciones de grabación, así
como la interfaz de red telefónica.
?? Red estilo Internet: Es una red basada en paquetes TCP/IP que conecta
al servidor de aplicación con el servidor de telefonía vía HTTP.
?? Red Telefónica: Es típicamente una Public Switched Telephone Network
(PSTN), pero podría ser una red privada telefónica (por ejemplo. PBX o
central telefónica), o una red de paquete VoIP (Voz sobre IP).
?? Usuario: Cualquier teléfono que puede unirse a la red telefónica.
Figura 6. Arquitectura de una plataforma en VoiceXML
Fuente: Rehor (2001)

`
41
Como se ve en la Figura 6, el usuario marca el número de teléfono del
sistema y se comunica a través de la PSTN o PBX con el servidor de
VoiceXML, éste interpreta las páginas VXML que el servidor de aplicaciones
le provee, y con las herramientas que posee, le muestra al usuario el
contenido de la página.
El servidor de VoiceXML posee herramientas tales como el Sintetizador de
Texto, capacidad de reproducción de audio, servicios de telefonía etc, que
permiten realizar satisfactoriamente la comunicación entre el usuario y el
sistema.

`
42
CAPÍTULO III. DESARROLLO METODOLÓGICO

`
43
Este capítulo comprende la fase de desarrollo del Portal de Voz.
Primeramente se describe la metodología utilizada y seguidamente se
presentan los procesos de análisis, diseño, desarrollo, y implementación, que
llevan al logro de los objetivos planteados.
La metodología de análisis y diseño con orientación a objetos, propuesta por
Rumbaugh (1991), representa la mejor opción para el diseño y desarrollo de
sistemas complejos y muy flexibles con respectos a los cambios.
Se selecciona esta metodología porque resulta sencillo realizar el modelado
debido a la similitud que presentan los modelos con la vida real, así como
también permite realizar fácilmente cambios y modificaciones al modelo
inicial sin afectar a otros elementos del sistema. Otra característica
importante es que la reutilización del código es sencilla. Por ello, se
selecciona el lenguaje unificado de modelado de objeto UML (Unifed
Modeling Languaje) para el modelaje de la aplicación.
UML, desarrollado por Booch, Jacobson y Rumbaugh de Rational Software
Corporation (2000), está basado en las metodologías de OMT (Object
Modeling Technique), Booch y OOSE (Object-Oriented Software
Engineering), convirtiéndose en el heredero natural de éstas. UML es, desde
fines de 1997, el lenguaje de modelado orientado a objetos estándares, de
acuerdo con el Object Management Group.
Cabe destacar que el proyecto fue realizado en la empresa Netcom C.A, la
cual nos ofreció durante todo el proyecto, su com pleta colaboración y apoyo
para la realización del presente trabajo.

`
44
Para llevar a cabo ésta de investigación se siguieron las siguientes etapas
metodológicas, adaptadas a las necesidades del presente trabajo:
?? Análisis. En esta etapa se seleccionan y analizan los lenguaje de
programación a emplear, así como los demás elementos
necesarios para el desarrollo de la aplicación. Además, se
elaboran los diagramas de casos de uso y secuencias.
?? Diseño y Desarrollo. Esta etapa incluye la elaboración del
diagrama de clases y el diseño del sistema completo. También se
hacen modificaciones al diseño a medida que se va
implementando la aplicación
?? Implementación y pruebas. Una vez realizado el desarrollo se
muestra el resultado final de este trabajo, mostrando la navegación
del mismo. Al mismo tiempo, se realizan pruebas con el fin de
detectar posibles fallas.
Se utiliza la herramienta de modelado Rational Rose C++ 4.0, obtenido de
Rational Software Corporation (2000), con el fin de elaborar los diagramas de
la notación UML.
A continuación se exponen cada una de las etapas de la metodología, con
las cuales se desarrolló la aplicación para llegar al producto final deseado.

`
45
III.1. ANÁLISIS
En esta sección, se analizan las diferentes interfases que contiene el
sistema, así como también se detallan cada una de las investigaciones que
se llevaron a cabo para determinar el lenguaje y las herramientas más
apropiadas para el desarrollo del Portal de Voz.
Es necesario para lograr el correcto desarrollo de cualquier proyecto que
involucre tecnología de información, se analicen con detenimiento las
herramientas, tanto de Hardware como de Software, con las cuales fue
posible cumplir con los objetivos previamente definidos del proyecto.
III.1.1. Análisis de las herramientas de desarrollo
La selección de las herramientas se basó en consultas realizadas por medio
de Internet, tomando en cuenta las herramientas que la compañía ya poseía.
La plataforma requerida para la implementación de un portal de voz,
explicada posteriormente en el diseño del sistema, exige la existencia de
varias computadoras conectadas en una red LAN*, en donde deben
interactuar de una manera eficiente. Debido a que la interacción de las
distintas partes del sistema se lleva a cabo a través de la base de datos, ésta
debe ofrecer un alto desempeño para el acceso simultáneo. Por otro lado, la
interfaz web también requiere de una base de datos capaz de soportar el
acceso simultaneo de muchos usuarios.

`
46
Por ello, se eligió la base de datos MYSQL, la cual, además de ser gratuita,
ofrece una gran estabilidad y desempeño para sistemas con este tipo de
exigencias (www.mysql.com).
Se utilizó el enlace ODBC* (Data Sources Open Database Connectivity) o
conectividad abierta de bases de datos de MYSQL, que permite usar la base
de datos por medio de un DSN* (Data Source Name). De esta forma se dejó
abierta la posibilidad de cambiar, cuando se desee, la base de datos
manteniendo el mismo nombre de DSN pero variando el motor de ésta (por
ejemplo ORACLE). Existen ciertas limitaciones para este cambio, ya que
algunas bases de datos no soportan funciones que si son utilizadas por
otras, sin embargo en el ámbito en que se utilizó la base de datos en este
sistema, no debería existir problema alguno debido al uso del lenguaje
estándar SQL.
Por otro lado, se vió en la necesidad de utilizar un objeto que permitiese
realizar la interacción con los servidores POP* y SMTP*, este objeto realiza
todas las funciones necesarias para la interpretación de los mensajes
entrantes, y el envío de mensajes. El objeto elegido fue el Power TCP Mail
Tool (http://www.dart.com), obtenido por la compañía donde se está
realizando el proyecto. De esta forma se evitó la programación de funciones
no especificadas dentro del los objetivos del proyecto y que requerirían de
tiempo no disponible para su realización.
Se utilizó el servidor POP, debido a que éste es el servidor de correo que
todos los ISP* (Internet Service Provider) poseen, en el diseño del portal se
dejó abierta la posibilidad para que en un futuro se pueda agregar la
interacción con los servidores IMAP, los cuales presentan una mejor

`
47
estabilidad y desempeño para la mensajería electrónica. El objeto elegido
puede realizar las operaciones de mensajería con el servidor IMAP.
Para la programación de esta parte se eligió Microsoft Visual Basic 6.0, ya
que permite crear aplicaciones complejas de una manera sencilla, orientada
a objetos y relativamente rápida.
Para la interfaz de web, la cual conforma un valor agregado al proyecto, se
pensó en utilizar el lenguaje ASP* (Active Server Pages), debido al previo
conocimiento que se tenía de éste.
Este lenguaje permite combinar elementos estándares de HTML como
tablas, textos y títulos, con elementos de lenguaje script, como bases de
datos, información fecha/tiempo, entre otros; las cuales producen una página
Web que se genera dinámicamente cada vez que dicha página es requerida
en el browser. El browser solicita la página de ASP, la que es luego
procesada por el IIS* (Internet Information Server). El servidor ejecuta el
Vbscript, convirtiéndolo en las etiquetas y textos estándares de HTML, que
pueden ser vistas desde un browser. Para la selección del editor de dicho
lenguaje se utilizó Macromedia Dream Weaver UltraDev 4.0.
Así mismo, se requirió de un objeto que permitiera realizar el envió de
archivos desde el cliente al servidor, por lo que utilizamos el objeto
AspSmartUpload (http://www.aspsmart.com), obtenido por la compañía
donde se está realizando el proyecto.
Para el desarrollo de la interfaz de voz, fue necesario indagar en detalle
sobre el tema del reconocimiento de discurso , lenguaje natural,
sintetizadores de texto y sobre la evolución que han tenido las aplicaciones

`
48
de voz últimamente, con el objeto de estar en capacidad de elegir
adecuadamente el lenguaje que se utilizó para el desarrollo de la interfaz.
De esta forma, se seleccionó el lenguaje VoiceXML para el desarrollo de la
interfaz de voz. Como se explicó en el marco de referencia, este lenguaje
promete ser el estándar para las aplicaciones de voz, abriendo un abanico de
posibilidades para el rápido crecimiento e implantación de esta tecnología.
Además de ofrecer una fácil integración y adhesión de módulos.
De los proveedores tecnológicos que existen en el mercado, todos se basan
en el estándar de VoiceXML de W3C, pero cada uno plantea de forma
distinta el uso de esta tecnología, esto implica que no se puede utilizar
cualquier herramienta de desarrollo de VoiceXML y hacerlo correr en
cualquier servidor de otro proveedor, lo cual obliga a elegir un sólo proveedor
que ofrezca lo mejor en todos los aspectos. Para cumplir con esta premisa
fundamental fue necesario investigar, analizar y evaluar hasta donde fuese
posible, las herramientas y aplicaciones, que permitan el reconocimiento de
discurso, interpretador de VoiceXML y sintetizadores de texto (TTS)
existentes en el mercado en la actualidad.
Plataformas de VoiceXML
Para la preselección de las herramientas se tomó en cuenta los siguientes
criterios:
?? Estabilidad. Se refiere a la estabilidad de la compañía como
desarrollador de herramientas para la implantación de la nueva
plataforma VoiceXML.

`
49
?? Soporte. Implica la capacidad de respuesta ante los problemas que
surgen durante el desarrollo de la aplicación, este soporte debe ser de
fácil acceso, y posibilitar al usuario la interacción tanto con los técnicos de
la compañía, como con todos los usuarios que están desarrollando
aplicaciones con su herramienta.
?? Capacidad. La herramienta y el software deben tener una capacidad
suficiente para la implementación del sistema cumpliendo cabalmente con
los objetivos del proyecto.
?? Disponibilidad. Debe permitir un fácil acceso a las herramientas, así
como a las actualizaciones de los mismos. Por otro lado, tiene que existir
la posibilidad realizar el desarrollo y pruebas con una hardware accesible.
?? Eficiencia. Debe tener herramientas que demuestren ser eficientes a la
hora de la implantación. Esto se refiere, principalmente, al reconocimiento
de discurso.
?? Calidad. La compañía debe tener reconocimiento de la calidad de sus
herramientas, reflejada en los actuales clientes que presente.
?? Independencia entre los módulos. El sistema requerido consta de
varios módulos: el reconocimiento de discurso, el interpretador de
VoiceXML y el sintetizador de texto (TTS) . Por lo tanto es necesario que
el módulo de TTS sea independiente de los otros módulos, debido a que
existe una gran diferencia entre las calidades de los distintos proveedores
de TTS en el idioma español.

`
50
Los sistemas de reconocimiento de discurso e interpretadores de VoiceXML
que han cumplido con los requerimiento son:
?? IBM WebSphere Voice Server Disponible en: http://www-4.ibm.com/software/speech/enterprise/ep_1.html
Inicialmente estaba en su propio lenguaje pero posteriormente fue cambiado
al estándar de VoiceXML. Permite crear rápidamente aplicaciones de Voz
para proveer soluciones a E-business, este año ganó en la exposición de
CTExpo Best Of Show (Computer Telephony 2001) realizado en el mes de
marzo de 2001. Las especificaciones se muestran en el apéndice D.
?? Mya Voice Platforms, Voice Developer Gateway de AT&T
Disponible en: http://www.motorola.com/MIMS/ISG/voice/syssoft/vdg.htm
Ofrece una solución final para el desarrollo de herramientas de Voz, que
incluye todo lo necesario en un sólo paquete incluyendo el hardware y
software. Ganó como “Most Innovative Telephony Application” en “The 20th
Annual AVIOS Conference” realizado en Abril de 2001 (Mya Voice Platforms
Press Release 2001). Las especificaciones se muestran en el Apéndice D.
?? Nuance Voice Web Server Y Nuance 7.0
Disponible en: http://www.nuance.com/products/voicewebserver.html
Nuance 7.0 es un sistema para el reconocimiento de discurso, el cual provee
una gran precisión, escalabilidad y confiabilidad para aplicaciones de voz vía
telefónica. Actualmente tiene clientes tales como: American Airlines,
BeVocal, British Airways, Cisco Systems, Sears, Sprint PCS, TellMe
Networks, entre otros.
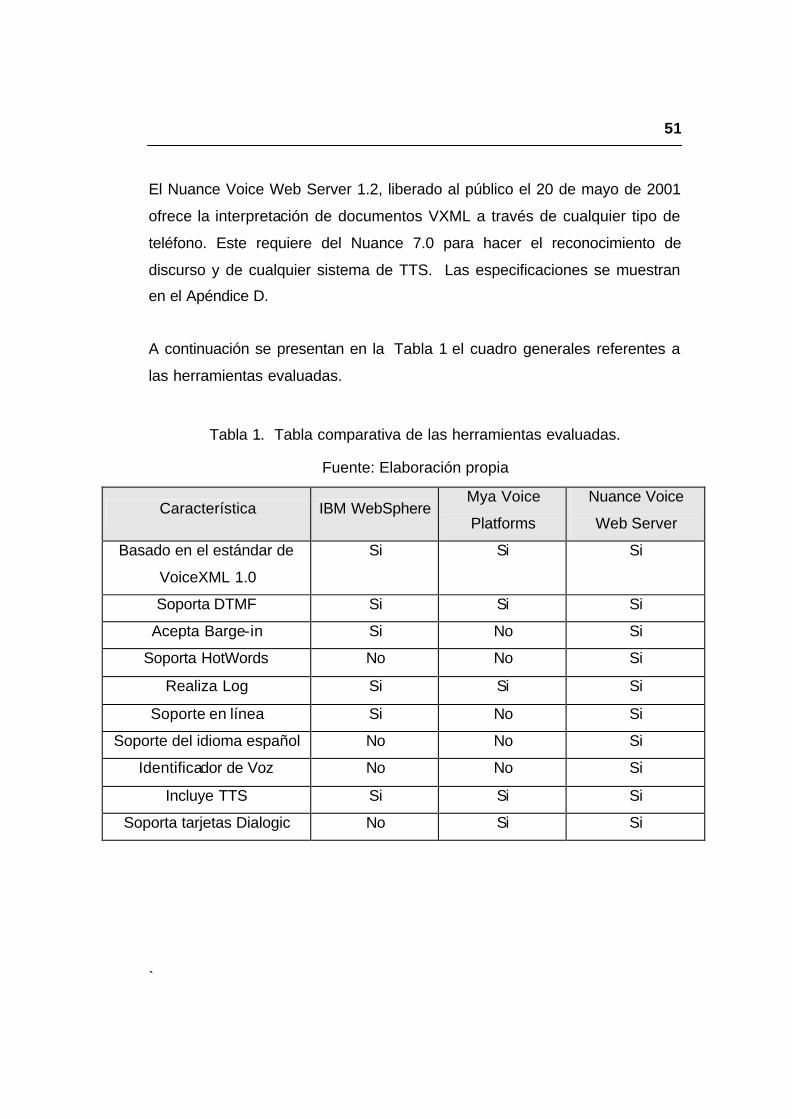
`
51
El Nuance Voice Web Server 1.2, liberado al público el 20 de mayo de 2001
ofrece la interpretación de documentos VXML a través de cualquier tipo de
teléfono. Este requiere del Nuance 7.0 para hacer el reconocimiento de
discurso y de cualquier sistema de TTS. Las especificaciones se muestran
en el Apéndice D.
A continuación se presentan en la Tabla 1 el cuadro generales referentes a
las herramientas evaluadas.
Tabla 1. Tabla comparativa de las herramientas evaluadas.
Fuente: Elaboración propia
Característica IBM WebSphere Mya Voice
Platforms
Nuance Voice
Web Server
Basado en el estándar de
VoiceXML 1.0
Si Si Si
Soporta DTMF Si Si Si
Acepta Barge-in Si No Si
Soporta HotWords No No Si
Realiza Log Si Si Si
Soporte en línea Si No Si
Soporte del idioma español No No Si
Identificador de Voz No No Si
Incluye TTS Si Si Si
Soporta tarjetas Dialogic No Si Si

`
52
Resultado del Análisis:
De acuerdo al análisis realizado y a la información recolectada, se decidió
trabajar utilizando un conjunto de herramientas y aplicaciones que, según
sus características, se adaptan mejor en el momento de cumplir las
necesidades del sistema.
Como producto elegido para el desarrollo del sistema, dado sus
características presentadas, se eligió el sistema de NUANCE. Este
proveedor tecnológico ofrece las siguientes herramientas para el desarrollo
en lenguaje VoiceXML:
?? V-Builder 1.2. Herramienta para programar en el lenguaje
VoiceXML.
?? Voice Web Server 1.2. Servidor de VoiceXML
?? Vocalizer. Text To Speech en español e ingles
III.1.2. Elaboración del diagrama de casos de uso
Uno de los diagramas que ofrece UML es el diagrama de los Casos de Uso,
a través del cual se modela la interacción entre actores (usuarios o entes
externos) y el sistema que se quiere construir.
Previo a la elaboración del diagrama de casos de uso, se identifican los
actores y se especifica el escenario en que está enmarcado dicho diagrama.
Se identificó un actor del sistema, que en este caso es el usuario y el
escenario, que es global, es decir abarca la totalidad de la aplicación.

`
53
Las acciones o casos de uso se describen a continuación, especificando los
actores involucrados, los casos de uso relacionados y finalmente una breve
descripción:
?? Gestionar Correo Electrónico.
o Actores involucrados: Usuario (Inicia el caso de uso).
o Casos de Uso relacionados: Interconexión Telefónica,
Gestionar Contactos.
o Descripción: El usuario compone, responde, re-envía y/o lee
sus mensajes. Si el usuario requiere llamar al remitente del
mensaje se desencadena el caso de uso Interconexión
Telefónica. Si el usuario requiere agregar en su lista de
contactos al remitente, se desencadenara el caso de uso
Gestionar Contacto. Cuando el usuario requiera Re-enviar o
componer un mensaje se desencadenara automáticamente el
caso de uso Gestionar Contactos (Consultar Contacto). Si el
usuario requiere Agregar un Contacto, se desencadenara el
caso de uso Gestionar Contacto.
?? Gestionar Agenda
o Actores involucrados: Usuario (Inicia el caso de uso)
o Casos de Uso relacionados: Gestionar Contactos,
Interconexión Telefónica

`
54
o Descripción: El usuario anota, consulta o borra una cita o un
recordatorio. Si el usuario requiere llamar cuando se encuentra
consultando una cita o recordatorio se desencadena el caso
de uso Interconexión Telefónica. Si el usuario requiere Agregar
un Contacto, se desencadenara el caso de uso Gestionar
Contacto. Cuando el usuario requiere anotar una cita o
recordatorio se desencadenara automáticamente el caso de
uso Gestionar Contactos (Consultar Contacto).
?? Gestionar contactos
o Actores involucrados: Usuario (Inicia el caso de uso)
o Casos de Uso relacionados: Interconexión Telefónica,
Gestionar Mail.
o Descripción: El usuario consulta, modifica, agrega y elimina un
contacto. Si el usuario requiere componer un mensaje cuando
se encuentra consultando un contacto se desencadena el
caso de uso Gestionar Mail. Si el usuario requiere Llamar
cuando se encuentra consultando un contacto se desencadena
el caso de uso Interconexión Telefónica.
?? Interconexión Telefónica
o Actores involucrados: Usuario (Inicia el Caso de uso)
o Casos de Uso relacionados: Gestionar Contactos

`
55
o Descripción: El usuario llama a unos de sus contactos de la
libreta de direcciones. Cuando el usuario Llama se
desencadenara automáticamente el caso de uso Gestionar
Contactos (Consultar Contacto)
En la Figura 7 se muestra el diagrama de casos de usos para el escenario
global.
Figura 7. Diagrama de Caso de Uso escenario global
Fuente: Elaboración propia
En el Apéndice A se incluyen los casos de uso detallados y tablas de
secuencia de eventos típicos para cada caso de uso.
Gestionar Agenda
Interconección Telefonica
Gestionar Mensaje
Gestionar ContactosUsuario

`
56
III.1.3. Elaboración de los diagramas de secuencia
Una vez elaborado el diagrama de casos de uso, se procede a elaborar los
diagramas de secuencia para aquellos casos que lo requieran. Los
diagramas de secuencia son diagramas de interacción que se incluyen en la
notación del lenguaje de modelado UML.
Un diagrama de interacción involucra actores, usuarios del sistema u otros
sistemas externos y componentes (objetos) para un escenario particular del
dominio o del problema que se quiere modelar. Los diagramas de
interacción modelan la comunicación entre los distintos componentes y
actores del sistema, a través de la representación del envío de mensajes
entre los mismos.
Los diagramas de secuencia enfatizan el paso de mensajes entre los
componentes (u objetos) del sistema y desde los actores a los componentes
de los mismos dentro de un escenario particular de los casos de usos, en
función del tiempo. La elaboración de los diagramas de secuencia constituye
un paso esencial para la derivación de los métodos públicos de los objetos.
Los diagramas de secuencia elaborados se anexan en el Apéndice B.

`
57
III.2. DISEÑO
Un buen diseño es directamente proporcional a una buena calidad y
eficiencia del sistema, por lo que se buscó un diseño capaz de adaptarse
fácilmente a cambios tecnológicos y/o implementaciones futuras. Para
lograr esto fue necesario estudiar los diferentes temas involucrados para el
desarrollo de la aplicación.
Se decidió dividir el diseño del sistema en módulos, para facilitar el desarrollo
en grupo del mismo.
En la Figura 8 se puede ver el diseño detallado del sistema, éste muestra
tanto los módulos como los componentes involucrados en el mismo.
Como esta especificado, se dividió el sistema en Front-end* y Back-end*,
esta división se refiere a los módulos que interactúan con el usuario y los
módulos que sirven al Front-end y actúan independientemente del usuario.
En el Front-end se encuentra el módulo I, este módulo es el que contiene las
interfaces del sistema, tanto la de Web como la de voz. Se encarga
básicamente de la interacción con el usuario independientemente de la
interfaz usada. La forma de comunicación con los módulos restantes del
sistema se realiza a través de la base de datos.
En el Back-end se encuentran el resto de los módulos, y los elementos
externos al sistemas, tales como los servidores POP3* y SMTP* y la central
telefónica, denominada PSTN (central telefónica).

`
58
Figura 8. Diseño del Sistema
yr

`
59
Se definieron estándares tanto para la interfaz de voz como para la de Web.
Con relación a esto, la definición del lenguaje VoiceXML 1.0, contiene una
serie de etiquetas (tags) o comandos para la realización de una aplicación de
voz, debido a lo prematuro del lenguaje, existe un comando llamado <object>
que permite agregar objetos hechos en Java para realizar funciones que no
fueron tomadas en cuenta en el diseño del lenguaje. Un ejemplo de esto es
la conexión a la base de datos, para realizar esto se utilizó un objeto
proveído por la plataforma de NUANCE, este objeto realiza las operaciones
necesarias para conectar a través del ODBC la aplicación a la base de datos.
El uso de estos objetos debe tratar de reducirse al mínimo ya que hacen la
aplicación dependiente de la plataforma o interpretador que se utilicé. Cabe
destacar que ciertas funciones, como la mencionada anteriormente, serian
imposibles de realizar sin estos objetos, pero la idea es tratar de utilizarlos lo
menos posible.
De igual manera, se agregaron comentarios en la programación de todos los
programas del sistema, permitiendo que cualquier persona fuera del equipo
de trabajo pueda comprender la lógica de la programación, permitiendo así la
continua actualización y entonación del mismo.

`
60
III.2.1. Módulo I
El Módulo I se encarga de manejar el Front-end del sistema. Este módulo
posee dos tipos de interfase, véase la Figura 9. La primera y la principal, es
la interfaz de voz, donde se realiza el reconocimiento del lenguaje natural
como interpretación de los comandos del usuario. La segunda interfaz,
complemento de la primera, es la de la Web, que tiene como objetivo
permitirle al usuario la personalización en el sistema, y adicionalmente, usar
el sistema y todos sus servicios a través de Internet. Esta interfaz no estuvo
contemplada en los objetivos del trabajo.
La razón de la creación de esta interfaz es debido al incremento en las
alternativas de acceso al sistema, en el cual, independientemente de su
ubicación, el usuario pueda accesar a los diferentes servicios sin barreras ni
limitaciones, siendo así, si el usuario se encuentra en su oficina, podrá
accesar por Internet; pero si se encuentra en su carro, la vía más cómoda de
acceso es por el teléfono celular. Con el fin de adaptar el sistema al usuario y
no que el usuario se adapte al sistema.
Figura 9. Arquitectura conceptual de VoiceXML
Fuente: Tellme Studio (2000)

`
61
En lo que se refiere a la interfaz de voz, existen dos tipos de perfiles de
usuarios, el primero es para los usuarios con amplios conocimientos de
Internet, el cual suele ser más rápido, directo y natural, en donde, con pocas
palabras y sin ningún tipo de navegación puede lograr su objetivo.
El segundo tipo es para los usuarios con pocos conocimientos de Internet,
aquí se ofrecen más ayudas, haciendo preguntas más concretas y objetivas
para que así, de manera sencilla y sin dificultades logre su objetivo.
Un ejemplo de estos dos tipos es el siguiente: Si el usuario desea enviar un
correo electrónico, podrá hacerlo de estas dos formas:.
Ejemplo 1
Usuario: Quiero enviarle un correo a Juan González.
Sistema: Diga el mensaje que le desea enviar
Usuario: Mensaje, enviar
Sistema: Su mensaje ha sido enviado
Ejemplo 2
Sistema: Que desea hacer, lee las opciones: Correo, Agenda...
Usuario: Correo
Sistema: Que desea hacer, lee las opciones: Redactar, Leer Mensajes
Usuario: Redactar
Sistema: A quien le desea enviar el Mensaje
Usuario: Juan Gonzáles
Sistema: Diga el mensaje que le desea enviar

`
62
Usuario: Mensaje
Sistema: Desea enviarlo, escucharlo o grabarlo de nuevo
Usuario: Enviarlo
Sistema: Su mensaje ha sido enviado
Este módulo se divide en dos secciones, Correo Electrónico y Agenda
Personal, los cuales ofrecen en los dos tipos de interfaces, sin embargo, en
éste documento sólo se va mencionar el diseño de la interfaz de voz.
Al entrar al sistema, el usuario debe proporcionar su número de teléfono
celular. El primer paso del sistema es identificar la voz del usuario, si la
identificación es correcta no es necesario que el usuario proporcione la clave
y se le dará la bienvenida al sistema; pero si la identificación no es correcta,
se le pedirá la clave al usuario. Al entrar al sistema el usuario se encontrará
en el Menú Principal donde se ofrecen todas las secciones que contiene el
portal, para que así el usuario seleccione la opción que deseen utilizar,
detallando así cada sección.
Servicio de Correo Electrónico
Al entrar a esta sección se activa o levanta la gramática mostrada en la
Figura 10 para así crear el contexto que permita el entendimiento de los
comandos de cada sub-sección. Esta sección se divide en tres sub-
secciones, las cuales son: Envío Correo, Lectura Correo y Vaciar Buzón.
Primeramente el sistema menciona el status de los mensajes del usuario,
comenzando por los correos urgentes, seguidos por los nuevos y los
guardados. Luego, el sistema espera por el reconocimiento del siguiente
comando, es decir, espera que el usuario diga lo que desea realizar.

`
63
Figura 10. Definición de gramática de correo electrónico
Fuente: Elaboración propia

`
64
La gramática, contiene los casos para que el usuario pueda o no decir el
destinatario cuando desee escribir un mensaje, esto quiere decir que, si el
usuario dice que quiere escribir un mensajes, y no menciona a quién, el
sistema le pregunta antes de grabar el mensaje, a quién desea enviarlo, para
finalmente grabarlo en la base de datos.
Cabe destacar que esta gramática es dinámica, debido a que se genera la
lista de contactos del usuario en el momento en que se activa.
Una limitación en este ámbito es que el usuario no puede enviar un correo a
una persona que no esté en su lista de contactos, ya que la inserción de
nuevos contactos, implicaría, por las limitaciones del sistema, que el usuario
deletreara el nombre y la dirección de correo, por lo que se pensó en la
interfaz web para su realización.
En el momento que el usuario se encuentre en la sub-sección Leer
Mensajes, se cargan todos sus mensajes previamente manipulados por el
módulo III, explicado posteriormente, ordenados según el status (urgente,
nuevo o leído) y su fecha.
Mientras el sistema empieza a leer los mensajes, el usuario puede navegar
por medio de comandos sencillos, tales como: siguiente, anterior, último
mensaje, primer mensaje, además podrá borrar, leer en español o leer en
inglés.
Por otra parte, el usuario podrá responder o re-enviar el mensaje, o
simplemente llamar al remitente si éste se encuentra en la lista de contactos.
Por último, el usuario puede borrar todos los mensajes que tiene en el buzón,
acción que es confirmada para luego proceder a borrar todos los mensajes.

`
65
Servicio de Agendas Personales
Esta sección se divide en cuatro sub-secciones, las cuales son: Agregar
Llamada, Agregar Cita, Listar Agenda y Borrar Agenda. Para este momento
se levanta la siguiente gramática (ver Figura 11) que crea el contexto para el
entendimiento de los comandos de cada sub- sección.
Figura 11. Definición de gramática de agenda
Fuente: Elaboración propia

`
66
Como se muestra en la Figura 11 el sistema puede entender sólo la palabra
“agregar” en vez de “agregar cita” o “agregar llamada”. Para este caso se
genera otro estado de reconocimiento, cuya función es definir que tipo de
llamada desea agregar el usuario.
La diferencia entre Agregar Cita y Agregar Llamada es que la cita graba un
mensaje de audio realizado por el usuario, mientras que agregar llamada
utiliza un mensaje estándar del sistema.
Cuando el usuario desea agregar una cita o una llamada, el sistema le pide
la fecha y la hora de la misma, luego le solicita el lugar donde desea recibir la
llamada, éste lugar puede ser su casa, su celular u otro número. Por último,
si es una cita, el sistema le pide que grabe el mensaje, para que, cuando se
llame al usuario, dicho mensaje de audio sea reproducido.
En la opción de Listar Agenda, el sistema pide la fecha en que se desea listar
y empieza a nombrar las citas. La forma de navegación entre las citas es
muy similar a la navegación entre los mensajes, puede ir a la primera, la
ultima, la siguiente y la llamada anterior, además puede borrar las llamadas
del día o borrar toda la agenda, lo cual elimina de la base de datos todas
citas correspondientes al usuario.

`
67
III.2.2. Módulo II
Este módulo se encarga de realizar la sincronización del sistema con el
servidor POP3. La razón por la que se pensó en hacer un duplicado del
servidor POP3, es que los procesos que se deben realizar después de bajar
los mensajes del servidor, tomarían demasiado tiempo y consumo de
recursos para realizarlo en tiempo real, por lo que los mensajes son bajados,
procesados y almacenados para que estén disponibles en el momento en
que el usuario entre al sistema.
Por otro lado, el módulo II se encarga de enviar los mensajes al servidor
SMTP, estos mensajes pueden o no tener archivos adjuntos. La razón por la
cual se necesita realizar dicha utilidad, es que el envío de los mensajes
pueden requerir mucho ancho de banda, lo cual se vería reflejado en el
tiempo de respuesta para recibir la confirmación del envío del mensaje, por lo
que es preferible guardarlo en la base de datos, para luego ser enviados por
este módulo.
Así mismo, el módulo convierte los archivos de sonidos que fueron grabados
por la interfaz de voz, a un formato estándar, ya que éste maneja los
archivos de sonido en un formato que optimiza el rendimiento, pero que no
es compatible con los reproductores tradicionales de Windows, por lo que es
necesario realizar una conversión de formatos para que en la interfaz de
web se puedan mostrar.
El programa de sincronización con los servidores POP3, SMTP y conversión
de archivos de audio, lleva un registro de los errores que ocurren en archivos
de texto identificados por el tipo de proceso y la fecha en que ocurrieron.

`
68
Dentro de ese archivo se guarda la hora en que ocurrió y una breve
descripción del error.
Proceso de recepción de mensajes
El sistema revisa periódicamente, según el timer* establecido, todas las
cuentas que existen en la base de datos en el servidor POP3, esta consulta
se realiza según el proveedor de cada cuenta.
Durante la revisión, una vez establecida la conexión con el POP3, se
procede a obtener los encabezado o header de los mensajes disponible. El
encabezado de un mensaje contiene el identificador único del mensaje (UID),
la fecha, el asunto, el mandatario y el status del mensaje en el servidor. El
objetivo de bajarse el encabezado se debe a que éste presenta la forma más
eficiente y rápida de saber qué mensajes existen en el buzón de correo, sin
tener la necesidad de bajarse el mensaje completo. De esta forma, con el
UID del mensaje se revisa si el mensaje ya fue bajado del servidor o, de lo
contrario, si es necesario bajarlo. Si el UID no se encuentra en la base de
datos, el módulo procede a bajarse el mensaje completo, sino chequea si
éste esta marcado como borrado, de ser así, se borra del servidor POP3 y
seguidamente se borra de la base de datos, sólo si éste no es requerido por
una respuesta o re-envió de un mensaje (no está bloqueado).
Una vez que se chequearon los UID de todos los mensajes, se procede a
guardar en la base de datos los mensajes bajados del servidor POP3. Para
realizar esto, es necesario identificar las distintas partes del mensaje, entre
las cuales están: el status del mensaje, la fecha del mensaje, el tamaño del
mensaje, los archivos adjuntos, apartando de éstos los que sean del tipo de

`
69
sonido (WAV* o WMA*); y por último el mensaje que va a ser sintetizado por
el módulo de Síntesis de Texto.
Proceso de envío de mensajes
Al igual que en el proceso de recepción de mensaje, éste realiza revisiones
periódicas según el timer establecido, a la base de datos del sistema para
revisar si existen mensajes para ser enviados.
Tanto la interfaz de voz, como la de Web insertan en la base de datos los
mensajes que deben ser enviados, identificando el tipo de mensaje según
sea: una respuesta, la cual lleva el indicador del mensaje al que se
responde; un re-envío, que lleva el indicador del mensaje que se quiere re-
enviar; un mensajes nuevo, el cual puede o no tener archivos adjuntos y un
mensaje enviado por la interfaz de voz, que contiene un archivo adjunto de
voz para procesar. Según sea el caso, el sistema realiza los pasos
necesarios para mandar el mensaje utilizando el objeto Power TCP Mail
Tool.
Una vez que consiga un mensaje para ser enviado, establece la conexión
con el servidor SMTP de la cuenta, y según el tipo de mensaje, procede a
realizar los pasos necesarios para el envío de éste. En el caso de un
mensaje de la interfaz de voz, el sistema realiza los siguientes pasos:
?? Convierte el archivo de voz adjunto del formato de la interfaz de
voz (Linear Encoding*) al formato estándar de Microsoft Windows
(RIFF*).
?? Convierte del formato WAV el cual tiene una frecuencia de 8 khz
Mono en el formato comprimido WMA a 32 kbps Mono. La razón

`
70
por la que se comprimen los archivos de audio, es debido a que de
esta forma se ahorra ancho de banda al enviar el mensaje por
internet.
?? Adjunta el archivo al mensaje, le agrega el asunto del sistema, el
mandatario y el destinatario. Finalmente envía el mensaje.
?? Borra los archivos de sonido que se crearon.
Una vez que el mensaje es enviado, éste se borra de la base de datos. Si el
mensaje fue una respuesta o un re-envió, se desbloquea el mensaje
correspondiente.
Proceso de conversión de archivos de audio
Este proceso es necesario para la sección de agenda en la pagina WEB.
Cuando el usuario agrega una cita en la interfaz de voz, este proceso debe
convertir el mens aje grabado del formato que utiliza la interfaz de voz (linear
encoding) al formato (RIFF), y seguidamente comprime el archivo al igual
que el proceso para enviar mensaje, de esta forma se ahorra espacio en
disco duro en el servidor web.
De igual forma que los otros procesos, éste posee un timer, encargado de
establecer el tiempo que debe esperar el sistema para chequear si hay
archivos nuevos y de ser así, convertirlos.

`
71
III.2.3. Módulo III
Este módulo se encarga de procesar y sintetizar los mensajes que
previamente han sido bajados y almacenados en la base de datos por el
módulo II.
Como se ve en la Figura 12, el primer paso de este módulo es identificar las
partes del mensaje, para así procesar sólo la información necesaria, que
consisten en: el remitente, la fecha, el asunto, el contenido y finalmente, el
tipo de los archivos adjuntos.
Figura 12. Proceso para la síntesis de texto de un mensaje electrónico
Fuente: Elaboración propia
Cada una de estas partes se procesa para capturar las palabras que tienen
que ser editadas, con el objeto de quitar o cambiar aquellas que no cumplan
con el sentido de la oración. El motivo de este proceso es generar un archivo
de audio que represente adecuadamente el mensaje enviado.

`
72
Un ejemplo, puede ser cuando se consigue en el texto la palabra “yahoo”. La
pronunciación de esta palabra no es correcta si se leyera textualmente, por lo
que es necesario cambiarla por la palabra “yajuu”, para cuando el
sintetizador de texto la procese, se va a generar el sonido adecuado de la
misma.
Por esta razón se vió en la necesidad de crear un diccionario que contenga
este conjunto de palabras que deben ser editadas. Es evidente que éste
diccionario debe ser actualizado constantemente, para poder garantizar que
la lectura de los mensajes sea “natural”.
Por otra parte también se tienen que identificar los tipos de archivo que se
encuentran adjuntos al mensaje, para esto existe otro diccionario que
contiene todos los tipos de archivos adjuntos con su respectiva etiqueta para
poder identificarlos.
Una vez que se ha obtenido todo el texto filtrado por los diccionarios, se
procede a sintetizarlo según el idioma indicado, para esta síntesis se utilizó
un software elegido por la compañía, el cual toma el texto enviado y devuelve
el archivo de audio a la ubicación indicada. Esta ubicación está dada según
el identificador del mensaje en la base de datos.

`
73
III.3. IMPLEMENTACIÓN Y PRUEBAS
Debido a la naturaleza del sistema, y al hecho de que su principal interfaz es
de voz, no se puede demostrar visualmente el resultado del proyecto, pero
sin embargo, sí se puede mostrar la navegación del mismo, y así poder
observar el producto final. Para tener una visión más clara del sistema se
anexan las pantallas de la interfaz de web (no contemplado en los objetivos
de trabajo), lo que ayuda a soportar visualmente la interfaz de voz.
III.3.1. Interfaz de voz
Existen varias limitaciones cuando se intenta mostrar una interacción vía voz
entre un usuario y una máquina, sin embargo, se tratará de explicar lo más
cercano posible a la realidad. Una de estas limitaciones son las voces y
sonidos. En el ejemplo que se muestra a continuación se van a asumir dos
voces distintas, la de un hombre, que se identifica cuando la palabra
“sistema” se encuentra en color azul y la voz de una mujer en color rojo. La
finalidad de este cambio de voz, es que el usuario se de cuenta cuando
existe un cambio de sección. Existen otros métodos que se utilizan para este
tipo de eventos, tales como la reproducción de un sonido en particular al
entrar a las secciones del portal, de manera que el usuario se de cuenta del
cambio.
El siguiente ejemplo muestra como un usuario envía un correo electrónico
y agrega una cita a su agenda desde cualquier teléfono convencional. En
este caso se tomará en cuenta la falta de experiencia del usuario, el cual no

`
74
interrumpe al sistema y navega por el portal de voz de una forma metódica,
es decir, éste responde a las peticiones del sistema.
Sistema: Bienvenido al Portal de Voz, Por favor dime tu número celular. Usuario: cero catorce tres, cuarenta, cinco siete siete ocho. Sistema: ok, ahora dime tu clave de acceso. Usuario: doce, tres cuatro Sistema : Buenas tardes, Rubén Mariña, te ofrecemos Horóscopo, Agenda,
Correo y Finanzas ¿Qué sección quieres visitar? Usuario: Correo Sistema: Recuerda que en cualquier momento puedes volver al menú
principal diciendo principal. Sistema: Bienvenido a correo, tienes 12 mensajes nuevos, uno es urgente
de un total de 18 mensajes. Entre las operaciones que puedes realizar están, leer tus mensajes, escribir un mensaje nuevo o vaciar tu buzón. ¿Qué te gustaría hacer?.
Usuario: Enviarle un mensaje a León. Sistema: Di el mensaje que quieres enviar después del tono. Usuario: León recuérdate que hay que enviar el correo. Sistema: Te gustaría escuchar tu mensaje, grabarlo de nuevo o enviarlo?. Usuario: Enviarlo. Sistema: Tu mensaje ha sido enviado. ¿Qué deseas hacer? Usuario: Agenda. Sistema: Bienvenido a agenda aquí podrás registrar tus citas más
importantes y llamadas recordatorias, entre las operaciones que puedes realizar están, agregar cita, agregar llamada, borrar cita, borrar llamada y listar agenda. ¿Qué te gustaría hacer? Si necesitas ayuda, di ayuda.
Usuario: Agregar cita. Sistema: Por favor dime la fecha y la hora en la que quieres que te llame. Usuario: el 11 de julio a las 9:00 de la mañana. Sistema: Ok, dónde quieres que te llame a tu casa, celular, oficina o a otro
Número?. Usuario: A mi Casa. Sistema: Bien, quieres una llamada recordatoria el 11 de julio del 2001 a las
9 en punto am, a tu casa. Es correcto?. Usuario: si. Sistema: Di el mensaje que quieres enviar después del tono. Usuario: Recordar llamar al tutor. Sistema: Te gustaría escuchar tu mensaje, grabarlo de nuevo, o enviarlo?. Usuario: enviarlo.

`
75
Sistema: Muy bien, ya agregué la llamada a tu agenda. ¿Qué te gustaría hacer?, si necesitas ayuda, di ayuda.
Usuario: Menú principal. Sistema: En qué te puede ayudar?. Usuario: Adiós. Sistema: Estás seguro que quieres salir?. Usuario: Si Sistema: Hasta luego.
III.3.2. Interfaz Web
Esta es una herramienta cuyo objetivo principal es complementar la interfaz
de voz. A continuación se mostrarán y explicarán algunas pantallas del
portal web que es llamado V-mail, con el fin soportar visualmente el sistema.
Pantalla de Acceso
Esta pantalla es de libre acceso y muestra información general sobre lo que
concierne al sistema. Por otra parte, para tener acceso al sistema se debe
tener una cuenta registrada, ésta se crea dándole click al botón de Crear
Cuenta. Cada usuario debe introducir la información necesaria, para que este
proceso sea exitoso. Existen ciertos datos que el usuario debe asegurarse de
introducir correctamente, debido a la importancia que tienen para el
funcionamiento adecuado de otros procesos. Estos datos son los siguientes:
la cuenta POP3 y su contraseña, para la recepción y envió de mensajes
electrónicos. El número celular, debido a las llamadas del sistema, y por
último la fecha de nacimiento, por el horóscopo. El usuario para entrar al
sistema debe introducir su número celular, su contraseña y presionar el
botón “Login”, como se muestra en la Figura 13.

`
76
Figura 13. Pantalla de acceso
Fuente: Elaboración propia
Pantalla Principal
Una vez que el usuario ingresa a la pantalla principal tiene acceso a todos
los servicios que V-mail ofrece. Esta pantalla muestra el status del usuario,
sus correos urgentes, nuevos y guardados, véase
Figura 14. Además le avisa al usuario si tiene un cumpleaños de alguno de
sus contactos o una cita pendiente. Por otra parte, el usuario puede
configurar sus datos personales, o simplemente cambiar su contraseña.

`
77
Con la opción configurar cuenta de correo el usuario tiene la posibilidad de
revisar varias cuentas de correo de diferentes proveedores de servicios de
Internet. Sólo es necesario accesar a la pantalla de cuenta de correo y
editar los datos que en ésta se encuentran.
Para facilitarle el acceso a los diferentes servicios de V-mail, en la parte
superior de la pantalla se encuentran todos los botones de las secciones que
la interfaz de voz ofrece, con la excepción de horóscopo que no se encuentra
en la interfaz web.
Figura 14. Pantalla principal
Fuente: Elaboración propia

`
78
Pantalla de la Sección de Correo
En esta pantalla se muestra una lista de todos los correos del usuario. Donde
se despliega el encabezado del mensaje, es decir, el remitente, asunto,
tamaño, fecha, status del mensaje y si tiene archivos adjuntos. Una
característica especial de este servicio es que si el usuario posee un
mensaje de voz, el sistema lo detecta y muestra una imagen indicando que
ese mensaje en particular posee un archivo de audio. Si el usuario le hace
click a esta imagen se reproducirá dicho archivo.
El usuario puede tener acceso a los diferentes mensajes haciendo click en el
remitente del mensaje, y podrá borrarlo o bloquearlo marcando la casilla
correspondiente y oprimiendo el botón borrar. Véase la Figura 15.
Figura 15. Pantalla sección correo
Fuente: Elaboración propia

`
79
Pantalla de la Sección de Contactos
En esta pantalla se muestra la lista de los contactos del usuario, que se
encuentran almacenados en la base de datos, se muestra su nombre,
apellido, teléfonos y dirección de correo electrónico. La consulta y/o edición
de dichos contactos se puede observar haciendo click en el nombre del
contacto. También se muestra una lista de letras, con la finalidad de que el
usuario, haciendo click en una de ellas, pueda observar sólo los contactos
cuyo apellido comienza por dicha letra. Ver Figura 16.
Por otra parte si algunos de los contactos del usuario aparecen de color gris,
significa que ese contacto no será levantado en la gramática dinámica a la
hora de reconocimiento, es decir, el usuario no puede enviar a este contacto
ningún correo a través del portal de voz. Esto ocurre debido a que el contacto
se encuentra escrito de una manera errónea, con algún carácter que no es
válido, como signos de puntuación, espacios, entre otros.
Figura 16. Pantalla sección contactos
Fuente: Elaboración propia

`
80
Pantalla de la sección Agenda
En esta pantalla se muestra el calendario, mensual y diario del usuario. Se
visualiza en negritas los días en que el usuario posee una cita o llamada
(véase Figura 17). En la parte superior izquierda de la pantalla aparecen los
cumpleaños de los contactos en el mes que se encuentra seleccionado.
Una característica especial de este servicio es que si el usuario posee una
cita que se agregó desde el portal de voz, el sistema muestra una imagen
indicando que ésta cita en particular, posee un archivo de audio. Si el usuario
le hace click a esta imagen se reproducirá dicho archivo.
Figura 17. Pantalla sección agenda
Fuente: Elaboración propia

`
81
III.3.3. Pantalla del Back-end
En la Figura 18 se muestra la pantalla de los procesos del módulo II. En la
parte superior se encuentra el status de los mensajes recibidos, y en la
inferior, de los mensajes enviados. En los botones, aparece el tiempo
restante para el chequeo o envío de los mensajes, así mismo el usuario
puede presionar el botón para no tener que esperar que se cumpla el tiempo
establecido.
Figura 18. Pantalla del Modulo II
Fuente: Elaboración propia

`
82
Como se ve en el recuadro de envío de mensajes, el usuario puede pausar el
proceso mientras lo desea, esta opción esta disponible en el menú File.
En el menú de configuración se establecen los tiempos de los timer de todos
los procesos.
Figura 19. Icono de status
Fuente: Elaboración propia
Debido a que el programa que realiza las funciones del módulo II debe estar
las 24 horas del día funcionando, para así garantizar la sincronización con
los servidores, se vió en la necesidad que, mientras éste se encuentre activo,
muestre un icono del status del mismo en la sección de iconos que se
encuentren junto a la hora del sistema (véase Figura 19), realizando así una
interfaz más agradable para el usuario.

`
83
CAPÍTULO IV. CONCLUSIONES

`
84
Ya que el presente trabajo de investigación está enmarcado en el área de
sistemas de voz, la cual se encuentra en pleno auge y desarrollo, es evidente
que la investigación realizada aporta diversos beneficios a la comunidad y al
área de la investigación como tal.
Se ha comprobado que la elaboración de un diseño bien estructurado y
genérico, ha permitido la creación de una plataforma base escalable para los
servicios de un portal de voz, permitiendo así su expansión y desarrollo
continuo.
A continuación se listan las conclusiones más importantes de éste trabajo:
?? Utilizar una metodología de análisis y diseño orientado a objetos, facilita
la concepción de un modelo escalable de fácil adaptación e integración a
nuevos modelos.
?? Haber desarrollado la aplicación de voz en el lenguaje VoiceXML ubica al
presente trabajo en la vanguardia tecnológica de aplicaciones de voz, en
el cual se están desarrollando aplicaciones de este tipo para su
introducción y aprobación en el mercado mundial.
?? El lenguaje VoiceXML no se encuentra listo para su uso en una aplicación
como producto de una empresa. Esto es debido a que todavía se
encuentra en etapa de desarrollo e investigación para lograr conformar el
lenguaje esperado. Para finales de este año está planeado la liberación
de la definición o versión 2.0 de éste lenguaje, el cual promete mayor
estabilidad.

`
85
?? Los Portales de Voz en el lenguaje VoiceXML van a conformar un papel
importante en las aplicaciones de voz, debido a que van a ofrecer un
sistema abierto para cualquier persona o grupo que desee desarrollar su
aplicación de voz para ser accesada mediante la misma.
?? Durante las pruebas se notó que la tecnología involucrada en el
reconocimiento de voz es suficientemente buena para ser usada, pero
todavía le falta cierto nivel de madurez para lograr tener el nivel de
reconocimiento esperado.
?? Para la realización de este proyecto se trato de usar en lo menos posible
los sintetizadores de texto, debido a que estos no ofrecen la naturalidad
suficientes para ser mostrados. Por lo que se utilizó los archivos
pregrabados, lo cual por un lado crea una interfaz agradable, pero por el
otro crea una dependencia sobre el locutor que creo los archivos. Para
las secciones que requieren de una continua actualización fue necesario
utilizar el sintetizadores de texto
?? El diseño de las gramáticas es un factor que involucra a la calidad y
eficiencia del sistema. Por ello debe hacerse un buen uso de los distintos
tipos de gramáticas disponibles para garantizar el buen entendimiento del
sistema. Esto es debido a que existen compensaciones entre la velocidad
de reconocimiento (tiempo de respuesta y la exactitud, contra el tamaño y
complejidad de la gramática. Por lo tanto, estas gramáticas no pueden ser
muy extensas, ya que mientras mayor sea la cantidad de formas de
expresar un comando, mayor es la probabilidad que el sistema se
equivoque.

`
86
?? Según los estudios realizados para la elaboración del proyecto, se podría
decir que una vez finalizado el sistema e incorporado al mercado mundial,
el número de usuarios con acceso a internet, aumentaría gracias a que el
dispositivo necesario para el acceso a éste, es de manejo común, es
decir, que con sólo tener un teléfono, ya sea fijo o móvil, se garantiza la
entrada al sistema.
?? El sistema desarrollado presenta sólo un eslabón de la cadena de
desarrollo del producto de una empresa. Esto quiere decir, que este
proyecto es un prototipo que requiere depuraciones, pruebas y estudios
de factibilidad, así como, complementarlo con otras áreas de aplicación
para llegar a convertirse en un producto comercializable.
Por último, uno de los aprendizajes más importantes obtenidos con el
desarrollo de este proyecto, es la importancia de integrar varias áreas
diferentes de la ingeniería, para así obtener soluciones más completas y con
mayor alcance.

`
87
CAPÍTULO V. RECOMENDACIONES

`
88
Luego de obtener la aplicación como el resultado de este trabajo, sugieren
las siguientes recomendaciones que pueden ser tomadas en cuenta para su
uso, administración y enriquecimiento.
- Los recordatorios de la sección de agenda se realizan por medio de una
llamada. Se recomienda agregar opciones de envió de mensajes de texto
(SMS), los cuales son más económicos para el usuario.
- Agregar un administrador vía http, que permita manejar todas las
opciones y/o funciones del módulo II de forma remota, para así permitir
un manejo y monitoreo del mismo sin encontrarse físicamente en la
empresa.
- Hacer un constante monitoreo sobre las gramáticas utilizadas, para así,
poder agregar y/o quitar las frases que los usuarios normalmente usan.
- Agregar la opción bloqueo de correo para la sección de correo, ya que
ésta ofrece una medida preventiva para los usuarios de recibir mensajes
indeseados.
- Investigar sobre las nuevas versiones del lenguaje VoiceXML y las
tecnologías involucradas en el reconocimiento de voz, para que de esta
forma se pueda mejorar y depurar el sistema desarrollado.

`
89
GLOSARIO
Active Server Pages (ASP)
Disponible en: http://www.microsoft.com/windows2000/en/server/iis/
Es un ambiente de encriptac ión del lado del servidor que puede ser utilizado
para crear paginas Web dinámicas o para construir aplicaciones Web. Las
paginas ASP son archivos que contienen etiquetas HTML, texto y comandos
encriptados. Con ASP, el usuario podrá añadir a sus paginas un contenido
interactivo o simplemente construir aplicaciones web que utilizan paginas
HTLM como interfaz para sus consumidores.
Alófonos
Ver fonema.
Ambiente Acústico.
Se refiere al ambiente generado por el dispositivo usado por el usuario, este
puede ser un celular, un teléfono fijo, entre otras.
Barge-in
Es la capacidad de un usuario para interrumpir un prompt cuando se esta
reproduciendo, es decir, cuando se dice algo o se presiona una tecla del
teléfono.
DSN (Data Source Name)
Disponible en: http: //www.microsoft.com/windows2000/en/server/iis/
Es el nombre lógico utilizado por Conectividad de Base de Datos Abierta
(ODBC) para referirse al controlador y otra informaciones requeridas para
accesar data. Este nombre es utilizado por el IIS para conexiones ODBC a
un manejador de base de datos, como SQL Server o MySQL.

`
90
DTMF (Dual Tone Multi Frequency)
Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci213922,00.html
Es una señal generada cuando se presiona una tecla en los teléfonos de una
central telefónica. Esta señal esta compuesta por dos tonos con frecuencias
especificas para que la voz de un ser humano no pueda generarla por si
sola. Se genera una frecuencia alta y una baja, por ejemplo para el numero
1, la frecuencia baja es de 697 Hz y la alta de 1209 Hz.
Expresión
Disponible en: Salvat, 1976, pp.1351. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Del latino expressio, -sionis. Palabra, locución o signos exteriores con que se
expresa una cosa.
Exactitud
Disponible en: Salvat, 1976, pp.1343. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Puntualidad y fidelidad en la ejecución de una cosa.
Fonema
Disponible en: Salvat, 1976, pp.1433. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976
Del gr phónema, sonido de voz. Cada uno de los sonidos diferenciables de
una lengua.
Forms
Se definen como una interacción con el usuario la cual obtiene valores para
un conjunto de estados (Field).

`
91
Frases
Disponible en: Salvat, 1976, pp.1463. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Conjunto de palabras que basta para formar sentido, y especialmente
cuando no llega a constituir una oración cabal.
Frecuencia
Disponible en: http://docs.us.dell.com/docs/ACC/0396P/Sp/glossary.htm
La frecuencia es la medida de cuán a menudo ocurre un evento periódico, tal
como una señal a través de un ciclo completo. Generalmente, la frecuencia
se mide en Hertz (Hz), donde 1 Hz es igual a 1 ocurrencia (ciclo) por
segundo. En los Estados Unidos, la electricidad doméstica es corriente
alterna con una frecuencia de 60 Hz. También se puede medir la frecuencia
en kilohertz (kHz o 1.000 Hz), megahertz (MHz, o 1.000 kHz), gigahertz
(GHz, o 1.000 MHz), o terahertz (THz o 1.000 GHz). Comparar con longitud
de onda.
Front-end, Back-end
Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci212161,00.html
Front-end y Back-end son términos usados para caracterizar las interfaces
de programas y servicios. En una aplicación Front-end el usuario interactúa
directamente con ésta, mientras que una aplicación Back-end sirve o soporta
indirectamente al de Front-end
Gramática
Es el conjunto de reglas que limita el número de combinaciones permitidas
de las palabras del vocabulario.

`
92
Gramáticas estática
Es creada en el diseño del sistema, y responsable de lo que éste es capaz
de entender.
Gramática dinámica
Se diferencia de la gramática estática únicamente porque se crea en tiempo
real, es decir, se genera según los datos que se le proporcionen en el
momento.
Internet service provider (ISP) Disponible en: http://www.microsoft.com/windows2000/en/server/iis/
Proveedor Público de conexiones remotas a Internet. Es una compañía o
institución educativa que permite a usuarios de lugares remotos tener acceso
a Internet por medio de conexiones telefónicas o líneas arrendadas.
Internet Information Server (IIS) Disponible en: http://www.microsoft.com/windows2000/en/server/iis/
Es una marca de servidores Web de Microsoft, que utiliza HTTP (Hypertext
Transfer Protocol) para la entrega de documentos World Wide Web. Este
incorpora varias funciones de seguridad, permite programas CGI y también
provee servicios Gopher y FTP.
LAN (Local Area Network )
Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci212495,00.html
Una LAN o red de área local es un grupo de computadoras y dispositivos
asociados que comparten una línea de comunicación y típicamente
comparten los recursos de un procesador o servidor en una pequeña área
geográfica (por ejemplo, una oficina).

`
93
Lenguaje Natural
Es el medio que utilizamos de manera cotidiana para establecer nuestra
comunicación con las demás personas. En el ámbito de reconocimiento de
discurso, el lenguaje esta dado por la definición de las gramáticas.
Linear Encoding Disponible en: http://extranet.nuance.com/support/get_knowledge.html?id=930071842
Dentro de cada sample (flujo del sonido dividido en pequeñas unidades) el
sonido es convertido en información digital, esto quiere decir que la energía
acústica es convertida en números. La codificación linear es una técnica que
usa 16 dígitos binarios o bits que contienen los números que definen el
sonido en el sample.
Menú
Un menú se presenta cuando el usuario tiene que escoger entre varias
opciones para ser trasladado a otro dialogo basado en esa decisión.
Morfemas.
Disponible en: Salvat, 1976, pp.2289. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Elemento lingüístico cuya misión es relacionar los semantemas en la oración
(preposiciones, conjunciones, etc.) e delimitar su función y significado (afijos,
desinencias, alternancias, etc.)
ODBC (Open Database Connectivity)
Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci214133,00.html
Es un API (Aplication Programming Interface) para el acceso a base de
datos. Ofrece un medio de conexión para base de datos que tengan el
modulo o driver para este API. ODBC esta basado en el lenguaje estándar

`
94
SQL para las consultas. El api convierte las consultas hechas por el usuario
en el formato individual de cada base de datos.
POP3 (Post Office Protocol 3) Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci212805,00.html
Es la versión más reciente de un protocolo estándar para recibir el correo
electrónico. Es un protocolo cliente / servidor en el cual el correo electrónico
es recibido y llevado a cabo por su servidor de Internet.
Prompt
Es la interfaz de voz por parte de sistema hacia el usuario.
Prosodia
Disponible en: Salvat, 1976, pp.2742. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Estudio normativo tradicional de la pronunciación y acentuación del idioma.
Rasgo
Disponible en: Salvat, 1976, pp.2805. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Peculiaridad, propiedad o nota distintiva.
RIFF (Resource Interchange File Format)
Disponible en: http://frederic.marand.free.fr/faqriff.htm
Es una estructura de archivo en el cual muchos tipos de formatos de archivos
se pueden basar. Microsoft Multimedia Products utiliza esta estructura en los
archivos de formato WAV y ASF, todos los reproductores de sonido de
Microsoft están basados en la estructura RIFF.

`
95
Sílabas
Disponible en: Salvat, 1976, pp.3035. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
El grupo fonético básico, compuesto de varios sonidos de diversa
perceptibilidad que se agrupan en torno a uno de perceptibilidad máxima
(cumbre o cima silábica, centro silábico o punto vocálico, que puede ser
vocal o una sonante.
Silencio
Disponible en: Salvat, 1976, pp.3034. En Enciclopedia Salvat Diccionario. Salvat Editores,
S.A. Barcelona 1976.
Del latino silentium. Abstención de hablar
SMTP (Simple Mail Transfer Protocol)
Disponible en: http://whatis.techtarget.com/definition/0,289893,sid9_gci214219,00.html
es un protocolo de TCP/IP usado para enviar y la recibir correo electrónico.
Sin embargo, puesto que se limita en su capacidad de hacer cola de
mensajes en el extremo de recepción, se utiliza generalmente sólo para
enviar mensajes.
Suites de productividad.
Se refiere a los paquetes de software como Microsoft Office.
Text To Speech (Sintesis de Texto)
Se definirse como un sistema que transforma cualquier texto escrito,
siguiendo las convenciones ortográficas de una determinada lengua, en su
equivalente hablado.

`
96
Timer
Es una rutina interna que provoca que el sistema envié una señal, cada vez
que se cumpla el tiempo determinado en el mismo.
Vocabulario
Se conoce por tal al número de palabras diferentes que debe reconocer el
sistema
WAV Disponible en: http://docs.us.dell.com/docs/ACC/0396P/Sp/glossary.htm
WAV es el formato de archivo para audio de forma de onda. El formato de
archivo Microsoft* de sonido .WAV (WAVE-onda) se deriva del formato RIFF
(Resource Interchange File Format - formato de archivos para intercambio de
recursos) usado por Microsoft Windows. Los archivos .WAV pueden grabarse
a una frecuencia de 11 kHz, 22 kHz, y 44 kHz, y con formatos mono y
estéreo de 8 ó 16 bits.
WMA (Windows Media Audio)
Disponible en:
http://support.microsoft.com/support/mediaplayer/wmp7help/htm/glossary.asp#w
Un formato de archivo que comprime los archivos de sonido a un tamaño
mucho menor que el requerido para la calidad de CD. Un minuto de música,
comprimido en WMA requiere cerca de 1 megabyte de disco, mientras que
en el formato WAV requeriría de 10 megabytes de disco.

`
97
REFERENCIAS BIBLIOGRAFICAS
Libros y artículos
?? ALLEN, J. (1973). Reading Machines for the Blind: The Technical
Problems and the Methods Adopted for Their Solution, IEEE
Transactions on Audio and Electroacoustics. (pp 259-264).
?? Cooper, F.S.- Gaitenby, J.H.- Mattingly, I.G. - Umeda, N. (1969).
Reading Aids for the Blind: A Special case of Machine-to-Man
Communication, IEEE Transactions on Audio and Electroacoustics.(pp
266-270).
?? Lee, F.F. (1969). Reading Machine: From Text to Speech, IEEE
Transactions on Audio and Electroacoustics.(pp 275-282).
?? Dilts, M. (1984). Text to Speech in G. Bristow (Ed) Electronic Speech
Synthesis. Techniques, Technology and Applications.London.
Granada (pp. 94-113).
?? Llisterri, J.- West M. (1983). Analysis of stop-vowel transitions in
Catalan in 11th International Congress on Acoustics, (vol 4: pp 279-
283).
?? M.J.Poza J.F.Mateos y J.A.Siles (1990). Audiotext with Speech
Recognition and Text to Speech Conversion for the Spanish
Telephone Network. Proceedings de Worldwide Voice Systems,
London [1990].
?? Sonia Fernandez Igea, Raœl Ortega, David Serrano Aranda (2000, p.p
1-5). Portales de Voz: Internet en el teléfonos . Disponible en :
http://www.tid.es/presencia/ publicaciones/comsid/esp/19/ART_2.PDF
[2000, 19 de diciembre].
?? Ken Rehor (2001). VoiceXML VoiceXML Standards Standards
Activitie. Disponible en: http://www.voicexml.org/ugm-karam.pdf [2001,
6 de abril]

`
98
?? Rumbaught, J., Blaha, M., Premerlani, W. y Hedí, F. (1991). Object-
Oriented Modeling and Design. Estados Unidos, Prentice Hall.
?? Nuance Speech Recognition System Version 7.0 [2000, Cap 1 pp 1].
Nuance Grammar Developer's Guide. [2000, Diciembre]
?? Tellme Studio (2000) VoiceXML in the Enterprise: Facts and Fiction
Disponible en: http://studio.tellme.com/whitepapers/VoiceXML_Facts_
and_Fiction.pdf. [2000]
?? Párraga Marianna (2001). 6.5 millones de venezolanos tienen teléfono
celular . El Nacional, cuerpo F- 1. [2001, 27 de junio]
?? Placer (2001). La voz se perfila como la interfaz del futuro. El
Nacional, cuerpo F-10 [2001, 29 de junio]
Términos definidos
?? Salvat, 1976, pp.1754. En Enciclopedia Salvat Diccionario. Salvat
Editores, S.A. Barcelona 1976
Documentos Electrónicos
?? Allan Hoffman (2000). Speaking the Language of VoiceXML.
Disponible en: http://tech.monster.com/articles/voicexml/index [2000, 7
de junio].
?? Jeff Kunins (2001). Answer to your Quetions about VoiceXML.
Disponible en: http://www.voicexmlreview.org/voicexml/Review/
columns/Jan2001_speak_listen2.html [2001, 1 de enero].
?? Gerald M.Karam (2001). Open Dialog: Activities of the VoiceXML
Forum and W3C. Disponible en: http://www.voicexml.org/voicexml/
Review/features/Jan2001_open_dialog.html [2000, 1 de enero]

`
99
?? Kenneth G. Rehor (2001). What is VoiceXML. Disponible en:
http://www.voicexmlreview.org/Jan2001/features/Jan2001_what_is_voi
cexml.htm [2001, 1 de enero].
?? Robert Richardson (2001). VoiceXML Named "Paradigm of the Year".
Disponible en: http://www.voicexml.org/paradigm.html [2001, 10 de
junio]
?? W3C (2000). Voice eXtensible Markup Language (VoiceXML™)
version 1.0. Disponible en: http://www.w3.org/TR/2000/NOTE-
voicexml-20000505 [2000, 5 de mayo].
?? Kimberlee A.Kemble (2001). Introduction to Speech Recognition.
Disponible en: http://www.voicexmlreview.org/Mar2001/features/
recognition.html [2001, 1 de marzo].
?? Transtecnia (2001). La red mundial saca la voz; V-commerce.
Disponible en: http://www.transtecnia.cl/nueva/tecnologia/articulos/
vcommerce.asp [2001]
?? Teresa León (2000). Traducción Internet escucha la voz humana.
Disponible en : http://noticias.eluniversal.com/2000/05/22/21282AA.s
html [2000, 22 de mayo]
?? Nick Collin (1999, Art 1). Voice Verification. Disponible en:
http://www.ncollin.demon.co.uk/voiceverification.htm [1999, Octubre]
?? Nick Collin (1999, Art 2). Automated Speech Recognition. Disponible
en: http://www.ncollin.demon.co.uk/speechrecognition.html
?? Santiago Aldekoa (2000). La Programación Neurolinguistica (PNL).
Disponible en: http://www.santiagoaldekoa.com/Pnl.html [2000]
?? M. A. Rodríguez Crespo, J. G. Escalada Sardina, L. Monzón Serrano,
A. Macarrón Larumbe (1991). Teoría y aplicaciones de la Conversión
Texto Voz .Disponible en: http://www.tid.es/presencia/publicaciones/
comsid/esp/articulos/vol24/textovoz/voz.html [1991, diciembre]

`
100
?? Sonal Bansal y Gaurav Pal (2001). What is SMS?. Disponible en:
http://www.javaworld.com/javaworld/jw-03-2001/jw-0330-sms.html
[2001, marzo]
?? Wap Forum (2000). What is WAP and WAP Forum?. Disponible en:
http://www.wapforum.org/faqs/index.htm [2000]
?? RCPTI Online (2000). WHAT IS CDPD?. Disponible en:
http://www.wsurcpi.org/tech/cdpd.html [2000]
?? Cutberto Uriel Paredes Hernández (2000). Procesamiento
Computacional del Lenguaje Natural. [en línea]. Disponible en:
http://www.monografias.com/trabajos5/proco/proco.shtml [2000, 30 de
septiembre].
?? Rational Software. Disponible en http://www.rational.com. [2000, 1 de
enero]
?? Computer Telephony (2001). Award-Winning Product Uses VoiceXML
And IBM ViaVoice Technology To Provide Easy Phone Access To
Information Around The Clock. Disponible en: http://www-
4.ibm.com/software/speech/ news/pr-CTExpo.html [2001,marzo]
?? Mya Voice Platforms Press Release (2001). The 20th Annual AVIOS
Conference Announces Best of Show Award Winners. Disponible en:
http://www.motorola.com/MIMS/ISG/voice/press/PR042401.htm

`
101
APÉNDICE A. SECUENCIA TÍPICA DE EVENTOS DE LOS DIAGRAMAS DE CASOS DE USO
Caso de uso Gestionar Mensaje
Fuente: Elaboración propia
Caso de uso Gestionar Agenda
Fuente: Elaboración propia
Agregar Cita/Llamada
Consultar Cita/Llamada
Eliminar Cita/Llamada
Usuario
Responder Mensaje
Re-enviar Mensaje
ConsultarContactos
Componer Mensaje
Leer Mensaje
Usuario
Llamar

`
102
Caso de uso Gestionar Contactos
Fuente: Elaboración propia
Caso de Uso Interconexión telefónica
Fuente: Elaboración propia
LlamarUsuario ConsultarContacto
Llamar
Componer Mensaje
Eliminar Contacto
Consultar ContactoUsuario

`
103
Caso de Uso: Leer Mail Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Responder Mail, Reenviar Mail, Llamar, Agregar Contacto, Eliminar Mail Descripción: El usuario Lee sus mensajes urgentes, nuevos y guardados.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para leer los mensajes.
2.- Empieza a leer los mensajes urgentes, nuevos y guardados.
3.- El usuario dice el comando para responder mensaje
4.- Ir a caso de uso responder mensaje.
5.- El usuario dice el comando para reenviar el mensaje
6.- Ir a caso de uso re-enviar mensaje
7.- El usuario dice el comando de llamar al remitente.
8.- Ir a caso de uso llamar 9.- El usuario dice el comando de agregar remitente a su lista de contactos.
10.- Ir a caso de uso Agregar Contacto
9.- El usuario dice comando para borrar un Mail.
10.- Ir a caso de uso Eliminar Mail 11.- Cuando se acaben los mensajes
finalizar caso de uso.

`
104
Caso de Uso: Componer Mail Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Consultar Contactos, Agregar Contactos Descripción: El usuario desea enviar un mensaje de mensaje a un individuo de su lista de contactos.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.-El usuario dice el comando para componer un mensaje.
2.-Si la lista de contactos está vacía Finaliza el caso de uso 3.-Preguntar el nombre de el
contacto 4.- El usuario dice el nombre del contacto.
5.-Ir a el caso de Uso consultar contacto
6.- Preguntar el contenido del mensaje
7.-El usuario dice el mensaje que desea enviar.
8.- Preguntar si desea confirmar el mensaje o si desea enviarlo.
9.-El usuario responde si desea escucharlo o enviarlo de una vez.
10.-El sistema confirma los datos obtenidos y envía el mensaje.
Finaliza el caso de uso.

`
105
Caso de Uso: Responder Mail Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Ninguno. Descripción: El usuario desea Responder un mensaje que esta leyendo.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para responder un mensaje.
2.- Preguntar el contenido del
mensaje 3.-El usuario dice el mensaje que desea enviar.
4.- Preguntar si desea confirmar el mensaje o si desea enviarlo.
5.-El usuario responde si desea escucharlo o enviarlo de una vez.
6.-El sistema confirma los datos obtenidos y envía el mensaje.
Finaliza el caso de uso. Caso de Uso: Reenviar Mail Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Consultar Contactos, Agregar Contactos Descripción: El usuario desea Reenviar un mensaje que esta leyendo.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.-El usuario dice el comando para reenviar un mensaje.
2.-Si la lista de contactos está vacía Finaliza casa de uso 3.-Preguntar el nombre de el contacto
o grupo 4.- El usuario dice el nombre del contacto o grupo.
5.- Ir a Consultar Contactos 6.-El sistema confirma los datos
obtenidos y envía el mensaje. Finaliza el caso de uso.

`
106
Caso de Uso: Eliminar Mail Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Ninguno. Descripción: El usuario desea borrar un mensaje que esta leyendo.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para borrar un mensaje.
2.- Confirma que el usuario desea borar el mensaje
Fin del Caso de Uso Caso de Uso: Consultar Contacto Actores Involucrados: Usuario Casos de Uso Relacionados: Modificar Contacto, Llamar, Componer Mail, Eliminar Contacto. Descripción: El usuario desea consultar un contacto de su libreta de direcciones.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para consultar un contacto.
2.- El sistema pide el nombre del contacto que se desea consultar.
3.-El usuario dice el nombre 4.- El sistema confirma el nombre 5.- El sistema empieza leer todos los
datos del contacto 6.- El usuario dice el comando componer un mensaje
7.- Ir a caso de uso componer mensaje
8.- El usuario dice el comando llamar 9.- Ir a caso de uso Llamar 12.- El usuario dice el comando Eliminar Contacto
13.- Ir a caso de uso Eliminar Contacto
Fin de Caso de Uso Nota: Cuando un caso de uso consulta un contacto es invisible para el usuario.

`
107
Caso de Uso: Llamar. Actores Involucrados: Usuario (Inicia el Caso de Uso) Casos de Uso Relacionados: Consultar Contacto, Agregar Contactos. Descripción: El Usuario desea llamar a la casa/celular/trabajo de un contacto de su libreta de direcciones.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para Llamar a un contacto.
2.- Si la lista de contactos esta vacía ir finaliza Caso de Uso.
3.- Preguntar el nombre del contacto. 4.- El usuario responde el nombre y el apellido del contacto.
5.-Ir a el caso de Uso Consultar Contacto
6.- Si el contacto tiene mas de un teléfono registrado (casa/celular/oficina), preguntar al usuario a cual desea llamar.
7.-El usuario responde el sitio donde desea hacer la llamada
8.- Hacer la conexión de la llamada. Finaliza el Caso de Uso.

`
108
Caso de Uso: Consultar Cita/Llamada Actores Involucrados: Usuario (Inicia Caso de Uso) Casos de Uso Relacionados: Llamar, Componer Mail. Descripción: El usuario desea consultar una cita o Llamada de su itinerario.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando para consultar su itinerario.
2.- Si el comando del usuario no incluye la fecha se dará el itinerario del día actual.
3.- Si el usuario da la fecha se leerá el itinerario de dicha fecha.
4.- El usuario dice el comando llamar 5.- Ir a caso de uso Llamar 8.- El usuario dice el comando Eliminar Cita/Llamada
9.- El sistema elimina la cita o llamada
Fin de Caso de Uso

`
109
Caso de Uso: Agregar Cita/Llamada Actores Involucrados: Usuario(Inicia el Caso de uso) Casos de Uso Relacionados: Ninguno. Descripción: El usuario desea agregar una cita o llamada en su itinerario.
Secuencia típica de eventos
Acción del actor Respuesta del Sistema 1.- El usuario dice el comando agregar una Cita/Llamada.
2.- El sistema pide la fecha en la que quiere agregar.
3.-El usuario dice la fecha. 4.- El sistema la confirma 5.- El sistema pide si desea Agregar
una Cita o una Llamada. 6.-El usuario dice lo que desea Agregar.
7.- El sistema pide la Cita o la Llamada.
8.-El usuario dice la Cita o el Llamada.
9.-El sistema confirma Fin del caso de Uso

`
110
APÉNDICE B. DIAGRAMA DE SECUENCIAS
Diagrama de Secuencia Componer Mail
Fuente: Elaboración propia
Usuario Interfaz Módulo I Módulo II Base de Datos SMTP Server(externo)
Chequa si hay mensajes para enviar
Mensajes para ser enviados
Envía los mensajes
Petición para enviar un mensajes
Petición para enviar un mensaje
Pregunta remitente, asunto y contenido
Pregunta remitente,asunto y contenido
Responde remintente, asunto y contenido
Remintente, asuntoy contenido
Guarda Mensaje para ser enviado

`
111
Diagrama de Secuencia Leer Mail
Fuente: Elaboración propia
Módulo IIIMódulo IInterfazUsuario Base de datos Pop Server (externo)
TTSMódulo II
Envía mensaje nuevos para la convesión en formato de audio
Envía mensaje en formato de texto
Envía mensaje en formato de audio
Graba mensaje (en formato de texto y audio en la base de datos)
Petición de lectura de mensajes
Petición de lectura de mensaje
Petición de mensaje urgentes, nuevos y guardados en formato de audio
Mensaje urgentes, nuevos y guardados en formato de audio
Lectura de los mensajes
Lectura de mensajes
Petición para responder mensajes
Petición para responder mensaje
Pregunta el contenido del mensaje
Pregunta el contenido del mensaje
Responde contenido del mensaje
Contenido del menaje
Guarda el mensaje para luego ser enviado
Petición para re-enviar el mensaje
Petición para re-enviar el mensaje
Pregunta a que contactos destinos
Pregunta los contactos destinos
Responde los contactos de destino
Contactos de destino
Guarda el mail para luego ser enviado
Petición para borrar el mensaje
borrar mensaje
Marca el mensaje como borrado
Chequea los mensajes nuevos cada minuto y los marca como leídos
Envía los mensajes nuevos

`
112
Diagrama de Secuencia Consultar Agenda
Fuente: Elaboración propia
Usuario Interfaz Módulo I Base de Datos
Petición para consultarcita / llamada
Petición para consultarcita / llamada
Obtiene las citas / llamadas
Devuelve las citas y las llamadas,
en orden de horaDevuelve las citas
y las llamadas,en orden de hora
Petición para borrar unacita / llamada
Borrar una cita / llamada
Pregunta que cita / llamada va a borrar
Pregutna que cita / llamada
va a borrar
Responde lo datos de la cita / llamada que desea
Datos de la cita / llamada
Borra cita / llamada

`
113
Diagrama de Secuencia Agregar Agenda
Fuente: Elaboración propia
Usuario Interfaz Módulo I Base de Datos
Petición para agregar una cita / llamada
Petición para agregar unacita / llamada
Pregunta la fecha para lacita / llamada
Pregunta la fecha para lacita / llamada
Responde la fecha de la cita / llamada
Fecha de la cita / llamada
Pregunta la cita o el llamada
Pregunta la cita o la llamada
Responde la cita o la llamada
Responde la cita o la llamada
Guarda la cita o la llamada

`
114
Usuario Interfaz Módulo I Base de Datos PBX
Petición para llamar a un contacto en específico
Petición para llamar a un contacto
Obtinen el teléfono del contacto
Llamada
Responde el contacto y el tipo de teléfono (casa,oficina, celular)
Contacto y tipo de teléfono (casa, oficina, celular)
Teléfono del contacto
Petición para hacer la llamada al número telefónico (parámetro)
Petición para hacer la llamada al número telefonico (parámetro)
Llamada
Diagrama de Secuencia Llamar
Fuente: Elaboración propia

`
115
APÉNDICE C. DIAGRAMA DE CLASES
Diagrama de Clases
Fuente: Elaboración propia

`
116
APENDICE D. ESPECIFICACIÓNES DE LAS HERRAMIENTAS
Especificaciones del IBM WebSphere Voice Server : Disponible en: http://www-4.ibm.com/software/speech/enterprise/ep_1.html
?? Esta basado en el estándar de Voice eXtensible Markup Language
versión 1.0, W3C (W3C (2000)).
?? Reconoce discursos o tonos DTMF (teclas de teléfonos) como
entrada.
?? Sintetiza texto o archivos pregrabados ( 8 kHz. .au audio format), el
módulo de TTS esta completamente ligado a los demás módulos.
?? Acepta “Barge-in”, los usuario pueden interrumpir los prompts.
?? Basado en gramática de reconocimiento de discurso, incluye
soporte para gramática dinámica.
?? Soporte para “mixed initiative dialogs”, los usuarios de la aplicación
pueden incluir múltiples expresiones en una sola interacción.
?? Realiza Log (anotación de las actividades que se producen en el
sistema) y mecanismos de alarma.
?? Permite múltiples conexiones simultaneas.
?? Solo permite el idioma Ingles.
Los requerimiento de hardware son los siguiente:
?? Intel® Pentium ® 550 MHz processor.
?? Unidad de CD-ROM.
?? 256 MB RAM (mínimo).
?? 250 MB de espacio de disco duro (mínimo).
Los requerimientos para la parte de telefonía son los siguientes:
?? Cisco H.323 V2.0 compliant VoIP gateway (models 1750-2600).

`
117
?? Ethernet 10/100 network que soporte VoIP.
?? Conexión de teléfono PSTN/GSM.
?? Líneas Analógicas.
?? ISDN PRI T1/E1.
?? No soporta por ahora tarjetas Dialogic.
?? Soporta tarjeta de sonido Sound Blaster.
Especificaciones del Mya Voice Platforms, Voice Developer Gateway
de AT&T :
Disponible en: http://www.motorola.com/MIMS/ISG/voice/syssoft/vdg.htm
?? Browser de Voz Mya de Motorola.
?? Esta basado en el estándar de Voice eXtensible Markup Language
versión 1.0, W3C (W3C (2000)).
?? Software de Sintetizador de texto (TTS).
?? Reconocimiento de discurso de NUANCE (ASR software).
?? Log de llamadas (anotación de las actividades que se producen en
el sistema).
?? Solo permite el idioma Ingles.
Los requerimiento de hardware es el siguiente:
?? Compaq Poliant server con Windows NT. Incluye la computadora.
Los requerimientos para la parte de telefonía:
?? Soporta tarjetas de telefonía Dialogic.
?? Soporta hasta 4 puertos análogos.
?? Soporta T1 ISDN PRI.
?? Soporta E1 ISDN PRI.
?? Soporta tarjeta de sonido Sound Blaster.

`
118
Especificaciones del Nuance Voice Web Server Y Nuance 7.0
Disponible en: http://www.nuance.com/products/voicewebserver.html
?? Esta basado en el estándar de Voice eXtensible Markup Language
versión 1.0, W3C (W3C (2000)).
?? Capacidad de HotWord o Comandos Universales.
?? Suporte en línea de todos sus productos en forma de foros de
discusión abiertos.
?? Soporta SpeechObject, que son aplicaciones en javascrip que
realizan ciertas tareas especificas.
?? Identificador de Voz.
?? Completamente documentado.
?? Soporta 20 idiomas (incluye al español).
?? Sintetiza texto (TTS) llamado Nuance Vocalizer, el cual viene como
un sistema separado.
Los requerimiento de hardware es el siguiente:
?? Dual Intel® Pentium ® 500 MHz processor.
?? 512 MB RAM.
?? Disco duro de 9.1 GB UltraWide SCSI.
?? 100 BaseT Ethernet Lan.
?? Windows NT 4.0 SP5.
Los requerimientos para la parte de telefonía:
?? Soporta tarjetas de telefonía Dialogic.
?? Soporta tarjeta de sonido Sound Blaster.