“nettalk en español” - 148.206.53.84148.206.53.84/tesiuami/uami12946.pdf · por otro lado, en...
TRANSCRIPT

Universidad Autónoma Metropolitana I ztapalapa
Ciencias Básicas e IngenieríaLicenciatura en Computación
99321701. Molina Villegas Alejandro201320439. García Arias Néstor Hugo202212079. Nuñez Reyna José Ismael
“NETtalk en español”
Marzo 2006
1

Índice
INTRODUCCIÓN. .................................................................................................................................. 4
CAPITULO I. Redes Neuronales aplicadas a la clasificación de fonemas ................................... 5
1. Redes Neuronales Artificiales ................................................................................................................. 51.1 La máquina de Turing y la fisiología de lo computable. .......................................................... 51.2 Elementos de una Red Neuronal Artificial. ............................................................................. 61.3 Clasificación de las RNA. ........................................................................................................ 71.4 Las redes como reconocedores de patrones. .......................................................................... 10
2. Conexionismo y procesamiento del lenguaje natural ............................................................................ 112.1 Expresiones fonéticas y Caracterización articulatoria. ........................................................... 122.2 Unidades de representación. ................................................................................................... 132.3 El Alfabeto Fonético Internacional (AFI) y el SAMPA. ........................................................ 152.4 Sistemas TTS. ......................................................................................................................... 17
3. NETtalk .................................................................................................................................................. 243.1 Representación y Estructura de la red NETtalk. ..................................................................... 253.2 Metodología. ........................................................................................................................... 273.3 Implementación de la red neuronal de NETTalk en español. ................................................. 293.4 Descripción de la codificación del programa. ......................................................................... 31
CAPITULO II. Árboles de Decisión aplicados a la clasificación de fonemas .................................... 48
1. ¿Qué son los árboles de decisión? ........................................................................................................ 482. Algoritmo básico de aprendizaje de los árboles de decisión. ............................................................... 49
2.1 Entropía. .................................................................................................................................. 493. Reglas de poda. ..................................................................................................................................... 50
3.1 Poda por estimación del error. ............................................................................................... 513.2 Poda por coste-complejidad. .................................................................................................. 513.3 Poda pesimista. ....................................................................................................................... 52
4. Sobreajuste con los datos de entrenamiento. ....................................................................................... 525. Implementación de un árbol de decisión para Nettalk. ......................................................................... 53
5.1 Descripción general del problema. ........................................................................................ 535.2 Descripción del programa. ..................................................................................................... 56
CAPITULO III. Redes Recurrentes ...................................................................................................... 64
1. La red neuronal recurrente de Elman. ................................................................................................... 642. Creación de una red recurrente simple con SNNS. ............................................................................... 65
2.1 Una arquitectura propuesta. ................................................................................................... 662.2 Estructura de la red recurrente. .............................................................................................. 682.3 Inicialización de los pesos con la función JE_Weights. ........................................................ 692.4 Función de aprendizaje. ......................................................................................................... 702.5 Función de actualización de pesos JE_Order. ....................................................................... 702.6 Función de inicialización de pesos. ....................................................................................... 70
3. Archivo de patterns SNNS. ………………………………………………………………………….. 704. Archivo de resultados del entrenamiento del SNNS. ........................................................................... 71
2

CAPITULO IV. Asignación de valores a los parámetros de entonación ........................................... 73
1. Explicación de la implementación de la red neuronal para asignar los parámetros de duración y pitch. ..................................................................................................................................................................... 732. Explicación de la implementación con árboles de decisión para asignar los parámetros de duración y pitch. ........................................................................................................................................................... 74
2.1 Descripción del programa. ..................................................................................................... 75
CAPITULO V. Resultados ...................................................................................................................... 81
1. Resultados de la implementación del perceptron multicapa para clasificación de fonemas. ....... 812. Resultados de la implementación del Perceptrón multicapa para asignación de valores a los
parámetros de entonación. ............................................................................................................ 903. Resultados de la implementación con árboles de decisión para la clasificación de fonemas. ..... 914. Resultados de la implementación con árboles de decisión para la asignación de parámetros de
entonación. .................................................................................................................................. 1045. Resultados de la implementación con redes recurrentes para clasificación de fonemas. ........... 106
CONCLUSIONES. ................................................................................................................................. 111
ANEXOS ................................................................................................................................................. 113
A. Stuttgart-Java NNS ............................................................................................................................. 113B. MBROLA ........................................................................................................................................... 116C. CRUISE .............................................................................................................................................. 121D. El Stuttgart Neural Network Simulator SNNS ................................................................................... 128
REFERENCIAS .................................................................................................................................... 143
3

Introducción:
El presente trabajo describe detalladamente la implementación de diversas versiones de NETtalk aplicado al español. En una primera aproximación el objetivo principal consistió en reproducir el experimeno de Terrence Sejnowski y Charles Rosenberg efectuado en 1986 y descrito en NETtalk: A Parallel Network that Learns to Read Aloud1, para lo cual se utilizó una arquitectura de perceptrón multicapa cuyas entradas representan ventanas que incluyen el contexto de un fonema y cuyas salidas representan una clase fonémica. Dicho perceptrón, con ayuda de otros modulos auxiliares, estan implementados en un proyecto JAVA; de tal manera que siguiendo el procesamiento adecuadamente, es posible comenzar con un texto arbitrario y terminar con la lectura de algún otro texto en el sintetizador MBROLA. La segunda aproximación consiste en la utilización de árboles de desición para la clasificación de fonemas, dichos árboles son entrenados y podados por el programa CRUISE y posteriormente transformados en una clase JAVA que representa el árbol que clasifica de manera óptima cualquier texto previamente procesado para ese fin. Al igual que en el caso anterior, es posible comenzar con un texto arbitrario y terminar con la lectura de algún otro texto. También se utiliza la idea de ventanas. Posteriormente, se utiliza una arquitectura de red neuronal basada en la red de Elman2. Esta arquitectura permite eliminar el contexto de los fonemas a la entrada de la red dado que dicho contexto queda plasmado en la arquitectura misma de la red. En este caso se implementa con la ayuda del software SNNS y es posible, en todo momento, recuperar la red entrenada, así como la configuración de la misma. Es necesario, por cuestión de compatibilidad, procesar los archivos de entrada y salida en un proyecto JAVA para poder reproducir el experimento.Finalmente, se agregan valores a los parámetros de entonación utilizados por el sintetizador MBROLA mediante dos técnicas. La primera es utilizando árboles de decisión y la segunda con perceptrón multicapa.
1 Sejnowski,T. and Rosenberg, C.R. 1986. "NETtalk: A parallel network that learns to read aloud." Johns Hopkins University Technical ReportJHU/EEC~86/01.
2 Elman, J. L. (1991). Distributed representations, simple recurrent networks, and grammatical structure. Machine Learning, 7, 195–225.
4

CAPITULO I. Redes neuronales aplicadas a la clasificación de fonemas
1. Redes Neuronales ArtificialesA finales de los años 80, los sistemas que procesan información “al estilo del cerebro” definieron,
junto con la inteligencia artificial, un nuevo paradigma en la Computación. Pero esta historia se inició en 1943, cuando el neurofisiólogo Warren McCulloch y el matemático Walter Pitts desarrollaron un modelo formal basado en una abstracción que integraba algunas de las propiedades básicas de los sistemas neurológicos biológicos, como el hecho de estar formada por unidades conectadas entre sí (neuronas o nodos). Ellos sugirieron que el cerebro de los seres vivos posee un gran poderío lógico y computacional. Posteriormente, este modelo simple de Redes de Neuronas Artificiales fue enriquecido por varios grupos de investigación al incorporar mecanismos de aprendizaje (por ejemplo la red llamada Perceptrón de Frank Rosenblatt, 1958, la cual era capaz de reconocer patrones sencillos y de generalizar similitudes entre patrones). Sin embargo, el campo de la computación neuronal obtuvo una gran aceptación y reconocimiento con la aparición del trabajo de los mapas autoorganizados de Kohonen (1982) y, sobre todo, con el algoritmo de aprendizaje de Retropropagación del Error (Rumelhart et al, 1986).
1.1 La máquina de Turing y la fisiología de lo computable
La ciencia de la computación se originó en la década de 1930 con la máquina universal de Turing, desarrollada por el matemático inglés Alan Turing. La computación neuronal surgió durante la década siguiente, en 1943, con el trabajo de McCulloch y Pitts sobre un modelo formal de las propiedades básicas (anatómicas y fisiológicas) de la neurona biológica.
Una máquina de Turing M puede visualizarse como un sistema de Control de Estados Finitos (asociado a un conjunto finito de estados Q= {q0,q1,...,qm} ) conectado con una cinta de almacenamiento que puede extenderse en ambas direcciones de manera indefinida. La cinta se divide en casillas que pueden contener un símbolo especial B (significa que el espacio está en blanco), o uno de cualquiera de los símbolos terminales x j,=1,2,...,n, que pertenecen a un alfabeto X, o de los símbolos variables Al ,l=1,2,...,p. El Control de Estados Finitos (CEF) está acoplado a la cinta a través de una cabeza de lectura y escritura, la cual se controla de acuerdo con Reglas de Transición, §:Q x (XU{B}UAl)>Q x (X U {B}U{Al} x {I,N,D}, que representan la forma en que una máquina M lleva a cabo un algoritmo específico. A cada instante, el CEF se encuentra en un estado qi, se lee el símbolo en la casilla donde está colocada la cabeza lectora y, con base en la regla que aplique, el CEF pasa al estado q j, se escribe un símbolo terminal, o variable, en la casilla y la cabeza de lectura/escritura se desplaza (a la Izquierda o a la Derecha) o no se mueve. Por ejemplo, para determinar si una cadena w=aabb pertenece, o no, al lenguaje L={anbn|n≥0}, la máquina M se define como, M =(Q,X,q0,qa,§) , donde:
Q={q0,q1,q2,q3,qa} es un conjunto finito de estados,X = {a,b} es un alfabeto finito de símbolos terminales, q0 es el estado inicial, con el que arranca el
CEF todo proceso, qa es el estado de aceptación (sólo si M está en qa cuando termina de procesar la cadena bajo análisis se concluye que w está en L), y
§={(q0,a,q1,&,D),(q1,a,q1,a,D),(q1,b,q2,#,I),(q2,a,q2,a,I),(q2,#,q2,#,I),(q2,&,q0,&,D),(q1,#,q1,#,D),(q0,#,q3,#,D),(q3,#,q3,#,D),(q3,B,qa,B,N,)}
5

La máquina de Turing es la base de la Teoría de la Computabilidad que permitió el desarrollo de la computadora digital, indicando claramente sus limitaciones: con ella sólo se pueden programar funciones que sean realizables a través de un algoritmo.
Por otro lado, en el desarrollo del modelo de una neurona artificial, McCulloch y Pitts combinaron la neurofisiología con la lógica matemática, tomando en cuenta la propiedad de Todo-o-Nada de la activación de la neurona biológica para modelarla como una unidad binaria operando en una escala de tiempo discreto, t=0,1,2,.... En los animales, las células del sistema nervioso central reciben señales en su cuerpo celular (soma) y arborización dendrítica, a través de sus conexiones con otras neuronas o con receptores asociados a órganos sensoriales. A cada instante, las entradas o salidas están activas o inactivas, lo que se indica con un valor binario de 1 o 0, respectivamente. Cada conexión, o sinapsis, de la salida de una neurona a la entrada de otra tiene asociado un nivel de ponderación (peso). Sea wi el peso de la i-ésima entrada a una neurona dada, ésta se denomina como excitadora si wi>0, o como inhibitoria si wi<0. Cada neurona tiene asociado un valor de umbral 0, de tal manera que cuando la suma ponderada de sus n entradas a un tiempo t es igual o mayor que 0, la neurona “dispara” (asigna un valor de 1 a su salida en el axón) en el tiempo t+1, simulando la generación de un potencial de acción de la neurona biológica. Además, la neurona permanece inactiva (su salida tiene un valor de 0) en t+1 cuando no hay entradas activas, o cuando la suma ponderada de sus entradas en un tiempo t es menor que 0. Esto es, si el valor de la i-ésima entrada es x1(t), entonces, la salida un tiempo después es:
y(t+1)=1 sí y solo sí Σiwixi(t)≥0
Con este modelo simple de neurona artificial se pueden implementar las operaciones lógicas AND, OR y NOT, lo que permite conformar una lógica booleana funcionalmente completa. Esto implica que, conectando de manera apropiada algunos de estos elementos, podemos formar Redes de Neuronas Artificiales (RNA) con un poderío computacional análogo al de los circuitos de control de una computadora digital. Así, en principio, con RNA se pueden realizar computaciones arbitrariamente complejas, y es por esta razón que el trabajo realizado por McCulloch y Pitts3 a menudo es considerado como el descubrimiento de la “Fisiología de lo Computable”.
1.2 Elementos de una Red Neuronal Artificial
Desde un punto de vista matemático, se puede ver una red neuronal como una gráfica dirigida y ponderada donde cada uno de los vértices son neuronas artificiales y las aristas los arcos que unen los nodos son las conexiones sinápticas. Al ser dirigido, los arcos son unidireccionales, es decir, la información se propaga en un único sentido, desde una neurona presináptica (neurona origen) a una neurona postsináptica (neurona destino).
Por otra parte es ponderado, lo que significa que las conexiones tienen asociado un número real (un peso), que indica la importancia de esa conexión con respecto al resto de las conexiones. Si dicho
3 Warren McCulloch and Walter Pitts, A Logical Calculus of Ideas Immanent in Nervous Activity, 1943, Bulletin of Mathematical Biophysics 5:115-133.
6

peso es positivo la conexión se dice que es excitadora, mientras que si es negativa se dice que es inhibidora.
Lo usual es que las neuronas se agrupen en capas de manera que una RNA esta formada por varias capas de neuronas. Aunque todas las capas son conjuntos de neuronas, según la función que desempeñan, suelen recibir un nombre especifico. Las más comunes son las siguientes:
• Capa de entrada: las neuronas de la capa de entrada, reciben los datos que se proporcionan a la RNA para que los procese.
• Capas ocultas: estas capas introducen grados de libertad adicionales en la RNA. El número de ellas puede depender del tipo de red que estemos considerando. Este tipo de capas realiza gran parte del procesamiento.
• Capa de salida: Esta capa proporciona la respuesta de la red neuronal. Normalmente también realiza parte del procesamiento.
1.3 Clasificación de las RNA
Si nos fijamos en la arquitectura podemos tener dos posibilidades distintas:
• Si la arquitectura de la red no presenta ciclos, es decir, no se puede trazar un camino de una neurona a sí misma, la red se llama unidireccional (feedforward).
• Por el contrario, si podemos trazar un camino de una neurona a sí misma la arquitectura presenta ciclos. Este tipo de redes se denominan recurrentes o realimentados (recurrent).
7

• Otro criterio habitual para clasificar las redes neuronales es el tipo de aprendizaje que se utilice. Hay cuatro clases de aprendizaje distintos:
• Aprendizaje supervisado: En este tipo de aprendizaje se le proporciona a la RNA una serie de ejemplos consistentes en unos patrones de entrada, junto con la salida que debería dar la red. El proceso de entrenamiento consiste en el ajuste de los pesos para que la salida de la red sea lo más parecida posible a la salida deseada. Es por ello que en cada iteración se use alguna función que nos dé cuenta del error o el grado de acierto que esta cometiendo la red.
• Aprendizaje no supervisado o autoorganizado: En este tipo de aprendizaje se presenta a la red una serie de ejemplos pero no se presenta la respuesta deseada. Lo que hace la RNA es reconocer regularidades en el conjunto de entradas, es decir, estimar una función densidad de probabilidad p(x) que describe la distribución de patrones x en el espacio de entrada Rn.
• Aprendizaje Híbrido: Es una mezcla de los anteriores. Unas capas de la red tienen un aprendizaje supervisado y otras capas de la red tienen un aprendizaje de tipo no supervisado. Este tipo de entrenamiento es el que tienen redes como las RBF.
• Aprendizaje reforzado (reinforcement learning): Es un aprendizaje con características del supervisado y con características del autoorganizado. No se proporciona una salida deseada, pero si que se le indica a la red en cierta medida el error que comete, aunque es un error global.
Arquitectura del Perceptrón Multicapa PMC
Es basada en otro tipo de red más simple llamada Perceptrón simple solo que en esta él numero de capas ocultas es mayor o igual a uno y es una red unidireccional.
8

Características:• Las capas ocultas usan como regla de propagación la suma ponderada de las entradas
con los pesos y a esta suma se le aplica la función de transferencia tipo sigmoide.• El aprendizaje es de tipo backpropagation.
Redes Autoorganizadas. Redes SOFM
En este tipo de redes el entrenamiento o aprendizaje es diferente al de las redes con entrenamiento supervisado. A la red no se le suministra junto a los patrones de entrenamiento, una salida deseada. Lo que hará la red es encontrar regularidades o clases en los datos de entrada, y modificar sus pesos para ser capaz de reconocer estas regularidades o clases.
Uno de los tipos de redes que pertenece a esta familia y que se ha usado bastante son los mapas autoorganizados, SOM (Self-Organizing Maps). La arquitectura típica de este tipo de mapas es la siguiente:
Características:
• Red unidireccional• Tiene 2 capas La primera consiste en el conjunto de neuronas de entrada La segunda capa en un
arreglo bidimensional de neuronas• El aprendizaje es de tipo no supervisado• Cada neurona utiliza como regla de propagación la distancia de su vector de pesos sinápticos al
patrón de entrada.• Emplea los conceptos de neurona ganadora y vecindad de neuronas
9

• Emplea el algoritmo de aprendizaje de Kohonen
Redes de función de base radial (RBF)
Este tipo de redes se caracteriza por tener un aprendizaje o entrenamiento híbrido. La arquitectura de estas redes se caracteriza por la presencia de tres capas: una de entrada, una única capa oculta y una capa de salida.
Características:
• Similar a la arquitectura de PMC• Las neuronas calculan la distancia euclidiana entre el vector de pesos sinápticos (que recibe el
nombre en este tipo de redes de centro o centroide) y la entrada (de manera casi análoga a como sé hacia con los mapas SOM) y sobre esa distancia se aplica una función de tipo radial con forma gaussiana.
• Para el aprendizaje de la capa oculta, hay varios métodos, siendo uno de los más conocidos el algoritmo denominado k-medias (k-means) que es un algoritmo no supervisado de clustering.
1.4 Las redes como reconocedores de patrones
El objetivo del procesamiento e interpretación de datos sensoriales es lograr una descripción concisa y representativa del universo observado. La información de interés incluye nombres, características detalladas, relaciones, modos de comportamiento, etc. que involucran elementos del universo (objetos, fenómenos, conceptos). Estos elementos se perciben como patrones y los procesos que llevan a su comprensión son llamados procesos preceptúales. El etiquetado (clasificación, asignación de nombres) de esos elementos es lo que se conoce como reconocimiento de patrones. Por lo tanto, el reconocimiento de patrones es una herramienta esencial para la interpretación automática de datos sensoriales.El sistema nervioso humano recibe aproximadamente 109 bits de datos sensoriales por segundo y la mayor de esta información es adquirida y procesada por el sistema visual. Análogamente, la mayoría de los datos a ser procesados automáticamente aparecen en forma de imágenes.El procesamiento de imágenes de escenas complejas es un proceso en múltiples niveles mostrando la participación relativa de los dos tipos de metodologías necesarias:Reconocimiento de patrones basado en atributos.
10

Reconocimiento de patrones basado en la estructura.• Píxel.• Información de Atributos.• Segmentos de Objetos• Objetos Grupos Primitivas de Objetos.• Escena.• Información Relacional.
Modelo de Sistema de Reconocimiento de Patrones
Los procesos preceptúales del ser humano pueden ser modelados como un sistema de tres estados:1 Adquisición de datos sensoriales.2 Extracción de características.3 Toma de decisiones.
Por lo tanto es conveniente dividir el problema del reconocimiento automático de una manera similar. Para el Sensor Su propósito es proporcionar una representación feasible de los elementos del universo a ser clasificados. Es un subsistema crucial ya que determina los límites en el rendimiento de todo el sistema.Idealmente uno deberá entender completamente las propiedades físicas que distinguen a los elementos en las diferentes clases y usar ese conocimiento para diseñar el sensor, de manera que esas propiedades pudieran ser medidas directamente. En la práctica frecuentemente esto es imposible porque no se dispone de ese conocimiento muchas propiedades útiles no se pueden medir directamente (medición no intrusiva), es decir, no es económicamente viable la Extracción de Características. Esta etapa se encarga, a partir del patrón de representación, de extraer la información discriminatoria eliminando la información redundante e irrelevante. Su principal propósito es reducir la dimensionalidad del problema de reconocimiento de patrones. En la etapa de toma de decisiones en el sistema. Su rol es asignar a la categoría apropiada los patrones de clase desconocida a priori.
2. Conexionismo y procesamiento del lenguaje natural
El ser humano se vale de las más diversas maneras para transmitir ideas, lo hace mediante gestos, gritos, actitudes, movimientos; pero su lenguaje más frecuente es la voz, la cual está constituida por sonidos cuyos elementos sonoros básicos son los fonemas. Por otra parte es bien conocida la importancia de la escritura como medio de comunicación, la cual está basada en un conjunto de símbolos gráficos o grafemas. La unidad básica teórica que permite describir cómo el habla transporta significado lingüístico a través del sonido es denominada fonema. Cada fonema puede ser considerado un código que consiste de un conjunto único de gestos articulatorios, los cuales incluyen el tipo y la ubicación de la estimulación de sonido así como la posición o movimiento de los articuladores vocales. El acto concreto de hablar se realiza mediante la producción de sonido articulado, esto es, cada segmento sonoro es el resultado de utilizar simultáneamente los órganos del aparato vocal: lengua, labios, glotis, etc. Cada emisión de un sonido es distinta a otra emisión del mismo. Por ejemplo, la emisión de la secuencia escrita flores no es
11

siempre igual; la /s/ puede aparecer más o menos sonora.; la /o/ admite realizaciones más o menos abiertas, etc. Hay sin embargo, un conjunto de características comunes a todas las variantes de un determinado fonema, que le permite ser reconocido como tal. Reconocemos una /s/ entre todas las variaciones de la /s/; una /o/ entre todas las infinitas pronunciaciones de /o/. Es decir, un fonema está constituido por un conjunto de alófonos que representan la libertad permisible dentro de cada lenguaje para la producción de un fonema. Toda lengua dispone de un conjunto pequeño de fonemas, que actúan como elementos constitutivos de la palabra, es decir, permiten la construcción de las mismas, y con ellas los mensajes del habla.
2.1 Expresiones fonéticas y Caracterización articulatoria
Traducción texto-fonema.
Dependiendo del lenguaje, la relación entre los grafemas y los fonemas es más o menos próxima. En el idioma castellano en general, y en el castellano rioplatense en particular, esta relación es muy cercana, ya que a partir de cualquier sucesión de grafemas se genera una única sucesión de fonemas. Por otra parte, la relación inversa no es cierta en virtud que, frecuentemente, varias sucesiones de grafemas diferentes producen la misma sucesión de fonemas. Si bien, en el castellano rioplatense, la vinculación entre una sucesión de grafemas con la correspondiente sucesión de fonemas es totalmente determinística, esto no significa que a cada grafema le corresponda un sólo fonema. El fonema correspondiente a un determinado grafema sólo puede obtenerse a partir del conocimiento de los grafemas que le anteceden y suceden. En otras palabras, puede decirse que la relación entre los grafemas y los fonemas es una relación funcional pero cuando la misma se aplica a un conjunto de grafemas. Si a cada fonema le correspondiera una letra e inversamente a cada letra le correspondiera un fonema, no habría ningún tipo de dificultad ortográfica en este aspecto o causada por esta relación, sin embargo, a pesar de que como ya se dijo el castellano es una de las lenguas que tiene mayor relación entre fonemas y grafemas, se producen algunas situaciones de disociación con sus correspondientes dificultades ortográficas. Este fenómeno es más notorio en el castellano rioplatense, ya que existen menos fonemas que en otras variantes del mismo idioma. Por ejemplo los sonidos asociados al grafema /c/ antes de /e/ o /i/ no se distinguen del sonido del grafema /s/ y también ocurre que el sonido que surge del par de grafemas /ll/, no se distinguen del que surge del grafema /y/ antes de una vocal. Como ya se indicó más arriba, un aspecto a ser tenido en cuenta, es que cada fonema no es un sonido monolítico e invariante, sino que está influenciado por los fonemas que lo encierran, generándose de esta manera los diferentes alífonos del fonema en cuestión. En el castellano existen grafemas que suelen ser afectados por símbolos, como el acento y la diéresis. El primero de ellos se caracteriza por influir a las vocales, en tanto que el segundo es utilizado para destacar el sonido asociado con la letra /u/ cuando es precedida por la letra /g/ y seguida de otra vocal, donde habitualmente su sonoridad es nula por ejemplo en la palabra lingüista. Por otra parte, ciertas consonantes al combinarse con las consonantes /l/ o /r/ forman grupos consonánticos cuyas característica más relevante es que en el silabeo forman duplas que no es posible separar, y durante la dicción aunque se trate de dos fonemas independientes actúan como un grupo consonántico consolidado. Las vocales también presentan características similares a los grupos anteriores, pero sus agrupaciones poseen distintos nombres dependiendo de la combinación y cantidad existente de las mismas, cuando el conjunto de vocales pertenece a una misma sílaba se trata de diptongos o triptongos, cuando involucra a la(s) vocal(es)
12

final(es) de una palabra y a la(s) vocal(es) inicial(es) de la palabra siguiente es una sinalefa. Cuando el grupo vocálico que puede ser tanto un diptongo como un triptongo, se haya separado constituyendo más de una sílaba, recibe el nombre de hiato.
Proceso de acentuación
Tanto en la lectura de un texto como en el diálogo coloquial, en la pronunciación de las palabras se aprecia claramente la existencia de distintas intensidades sonoras para las diferentes sílabas que las constituyen. Algunas tienen una sonoridad mucho más destacada que el resto, otras poseen sonoridad intermedia y las restantes sonoridad baja. La sílaba con mayor intensidad de una palabra se dice que tiene el acento principal de la misma, éste puede ser tanto escrito como prosódico. Además de este acento, existen otros de menor intensidad conocidos como acentos secundarios. Las sílabas con acento secundario, comparten con el acento prosódico el hecho de no tener una representación escrita. Su diferencia reside en la menor intensidad sonora con la que se pronuncian. En una secuencia de sílabas correspondientes a una palabra, el acento secundario se distribuye según un esquema conocido como el del principio alternativo: a partir de la sílaba con acento principal tanto hacia el final de la palabra como hacia el inicio, las sílabas se clasifican en no tónica y tónica alternativamente. Existe una excepción a esta alternancia que se da en las palabras que poseen 4 o 5 sílabas con acento principal sobre la cuarta sílaba, en donde el acento secundario no recae sobre la sílaba segunda sino sobre la primera. La influencia del tipo de acento que recibe una determinada sílaba se extiende a todos los fonemas de la misma de tal manera que se producen sonidos cuya diferencia es notoriamente perceptible. Los fonemas correspondientes a las sílabas con acento principal poseen mayor intensidad sonora y se extienden durante un periodo más largo que los mismos fonemas cuando pertenecen a sílabas con acento secundario o sin acentuación en absoluto. Finalmente, los fonemas pertenecientes a sílabas sin acento, o sílabas relajadas, tienen una intensidad y una duración menor aún que aquellas con acento secundario. En principio esta diferencia no resulta perceptible a nivel de las expresiones faciales asociadas a los fonemas, pero definitivamente la duración de los mismos es mayor, por lo que es posible que esta diferencia pueda ser notada por una persona que realiza la actividad de lectura de labios. La secuencia de fonemas recibida del paso anterior es modificada de acuerdo a la posición del acento principal y de los acentos secundarios generándose una secuencia de fonemas acentuados, la cual es utilizada para seleccionar de una tabla las expresiones faciales y las duraciones correspondientes.
2.2 Unidades de representación
COMPONENTES DEL LENGUAJE Para una mejor identificación y caracterización de cada uno de estos componentes, se hace referencia a cada uno de ellos por separado, aún cuando dentro del proceso de comunicación sé interrelacionen y complementen.La sintaxis se concentra en el orden de la colocación de las palabras y en las reglas que determinan su relación con otros elementos de la oración.Es la parte de la gramática que describe las estructuras del lenguaje e incluye reglas para combinar palabras en la formación de frases (la frase es la unidad más pequeña a la que se pueden aplicar los conceptos de verdad o falsedad).
13

Es fundamental su uso, para un eficaz enlazamiento y ordenamiento de las palabras en la oración y de un párrafo. Un conjunto de principios que determinan cómo se pueden combinar las palabras de una forma gramatical. La importancia de la sintaxis en la comunicación se basa en que orienta la construcción adecuada de las oraciones, dando como resultado una expresión oral coherente. En términos simplificados, la sintaxis es el orden y la estructura de las palabras y frases dentro de la gramática. Incluye el dominio de las relaciones entre las palabras dentro de las oraciones y de cómo expresar estas relaciones. Cada elemento sintáctico constituye una unidad funcional. Así, que no es suficiente que el niño o la niña conozcan los significados individuales expresados en “delfín”, “niña”, “jugar”, sino también que sepa asociar estos significados a su función dentro de la oración.
Morfología:La morfología se dedica al estudio de las unidades más pequeñas del lenguaje que tienen sentido así como las reglas que determinan la estructura de las palabras y de sus formas variadas. Es aquella parte de la gramática que proporciona reglas para combinar morfemas en palabras. Un morfema es la unidad lingüística más pequeña con significado propio.También se refiere a la estructura de las palabras, las cuales se pueden descomponer en partes más pequeñas denominadas afijos: prefijos y sufijos. Como lo indica su nombre, la morfología se encarga de estudiar la estructura interna de las palabras desde la perspectiva de sus formas.Es válido rescatar que el componente morfológico genera formas “palabras” para el componente sintáctico.
Fonología:El origen de esta función se ubica desde el estadio sensorio motriz, cuando el bebé succiona, deglute, eructa, llora, grita y emite sonidos. Todo este incipiente sistema de sonidos permito ejercitar los órganos que intervienen en la articulación de los fonemas (lengua, labios, paladar, mandíbula, entre otros).La fonología se interesa por el estudio de la organización de los sonidos en un sistema valiéndose de sus caracteres articulatorios y de la distribución o suma de los contextos en que pueden aparecer. Lo que indica que la fonología intenta entender la influencia que los sonidos tienen unos sobre otros, dando sentido a los datos fonéticos y analizando elementos que permitan reconocer el mismo sonido. Para terminar se recuerda que la fonología se distingue de la fonética, porque esta última estudia la sustancia de los sonidos, es decir la pronunciación de los sonidos.
Semántica:La semántica se refiere al significado del lenguaje, y ésta se encarga de la integración del concepto verbal. Analiza el contenido o significado de las palabras. Este aspecto se ve ampliamente influido por las interacciones sociales del niño así como por las características culturales del medio.El estudio de la semántica se centra en el significado de la palabras y de las combinaciones de palabras.De aquí se concluye que la semántica es “lo que tiene significado”, su finalidad es establecer el significado de los signos y su influencia en lo que la gente hace y dice. Es el que se relaciona por tanto con el significado e incluye el conocimiento de las categorías conceptuales del lenguaje, de las palabras y expresiones (léxico).
14

EntonaciónLa entonación son las variaciones del tono o altura tonal de la voz cuando se habla. Estas variaciones se dan en las palabras, en las frases y en las oraciones y son muy significativas en el lenguaje cotidiano, por cuanto abarcan las cuestiones relacionadas que afectan la articulación melódica del texto en forma ascendente o descendente y también el acento.
PragmáticaLa pragmática estudia el funcionamiento del lenguaje en contextos sociales, situacionales y comunicativos, es decir, analiza las reglas que explican o regulan el uso intencional del lenguaje, teniendo en cuenta que se de trata de un sistema social que dispone de normas para su correcta utilización en contextos correctos. Este componente reviste una especial importancia, pues sin él se limitaría la funcionalidad del lenguaje. Una encrucijada entre el lenguaje como sistema y las metas e intenciones de la comunicación humana. Esto porque el desarrollo de las habilidades pragmáticas comienza antes del uso del lenguaje propiamente dicho. La perspectiva pragmática plantea que, además de la adquisición por parte del niño (a) del léxico y de las reglas estructurales del lenguaje, ellos aprenden, a nivel implícito, otro conjunto de reglas referidas al momento apropiado para expresar determinados actos de habla, para permanecer en silencio, para emplear un determinado nivel (culto, popular) y registro de habla (formal, informal, familiar, coloquial). En síntesis, dominar un lenguaje es, entre otras cosas, manejar los componentes semánticos, sintácticos, fonológicos y pragmáticos de su sistema y relacionarlos mutuamente.
2.3 El Alfabeto Fonético Internacional (AFI) y el SAMPALa fonética es la rama de la lingüística que estudia la producción, naturaleza física y percepción de los sonidos de una lengua.Los símbolos fonéticos y sus definiciones articulatorias son las descripciones abreviadas de las actividades de los órganos orales que intervienen en la producción de sonidos, en qué posición se encuentran y cómo esas posiciones varían los distintos caminos que puede seguir el aire cuando sale por la boca, nariz, o garganta, para que se produzcan sonidos diferentes. Los símbolos fonéticos que se usan más frecuentemente son los adoptados por la Asociación Fonética Internacional en el alfabeto fonético internacional (A.F.I.) que se escriben entre corchetes.Por desgracia dichos símbolos no pueden ser escritos directamente desde un teclado estándar, razón por la cual surge SAMPA (Speech Assessment Methods Phonetic Alphabet) como una alternativa a este problema. Desarrollado originalmente a finales de los 80’s para seis lenguas Europeas bajo EEC-ESPIRIT project (1541) SAMPA es, básicamente, un alfabeto fonético reconocible por computadora basado en el alfabeto internacional fonético (IPA) cuyos caracteres se encuentran en el rango 33…127 del código ASCII imprimible de 7 bits.Hoy en día SAMPA ha sido desarrollado para muchos otros idiomas, entre los cuales se encuentra el Español (España) pero existen dificultades en la validación entre diversos lenguajes dado que cada cual cuenta con una tabla propia que no es compatible con otras. Como alternativa a este problema surge X-SAMPA que es una variante de SAMPA desarrollada en 1995 por J. C. Wells4, catedrático de fonética en la Universidad de Londres. Esta variante se diseñó con el objetivo de unificar los distintos alfabetos 4 Wells, John, 2003. Phonetic symbols in word procesing and on the web. In Solé, M.J., Recasens D. and Romero J. (eds.), Proc. 15th Int. Congress of Phonetic Sciences, Barcelona, S.2.8:6
15

SAMPA y extenderlos para lograr cubrir todos los rasgos que ahora cubre el Alfabeto Fonético Internacional (IPA). El resultado ha sido un alfabeto fonético inspirado en el SAMPA que emplea los 7 bits del código ASCII.
A continuación se muestra la notación de SAMPA en Español
La notación SAMPA del Español
Notación SAMPA
Ejemplo Ejemplo en SAMPA
p padre "paDreb vino "binot tomo "tomod donde "dondek casa kasatS mucho "mutSojj hielo "jjelof fácil "faTilB (= /b/) cabra "caBraT cinco "TinkoD (= /dd) nada "naDas sala "salax mujer mu"xerG (= /g/) luego "lweGom mismo "mismon nunca "nunkaJ año aJol lejos "lexosL caballo ka"baLo (o ka"bajjo)r puro "purorr torre "torrej rey / pie rrej / pjew deuda / muy "deuDa / mwia valle "baLee pero "peroi pico "picoo toro "torou duro "duro
16

Un ejemplo de su uso en la oración “La señorita del abanico” se escribe en SAMPA como "la seJorita del aBaniko". Fácilmente podemos verificar el mapeo por palabra
1. la [la] 2. señorita [seJorita] 3. del [del] 4. abanico [aBaniko]
De esta manera hemos obtenido una representación en caracteres ASCII introducidos desde un teclado estándar de una oración arbitraria. Existen hoy en día diversas aplicaciones de SAMPA que resaltan su facilidad de uso. Principalmente estas aplicaciones están orientadas hacia la síntesis de voz. Inmediatamente surge la inquietud de llevar el uso de SAMPA a la realización de sistemas que conviertan texto ordinario en su equivalente fonético para finalmente ser pronunciado por computadora. Dichos sistemas son mejor conocidos como sitemas text-to-speech (TTS) y existe una variedad en la forma de concebirlos; claro ejemplo de estos lo podemos encontrar en el experimento conocido como NET-talk en el cual mediante el uso de técnicas de inteligencia artificial (redes neuronales artificiales) se entrena al sistema para poder leer en voz alta. Otra aplicación interesante la podemos encontrar en el software comercial. Virtual Singer es un módulo adicional para Melody Assistant o Harmony Assistant (misma compañía) cuya función es combinar estos editores de música con texto escrito para generar entonación y duración apropiada a una melodía, es decir, también las maquinas pueden cantar.
2.4 Sistemas TTS
La síntesis de discurso es la producción artificial del discurso humano. Un sistema usado para en este propósito se llama un sintetizador de discurso, y se puede poner en ejecución software. Los sistemas de la síntesis de discurso a menudo se llaman los sistemas text-to-speech (TTS ) en referencia a su capacidad de convertir el texto en discurso. Sin embargo, existen los sistemas que pueden rendir solamente representaciones lingüísticas simbólicas como transcripciones fonéticas a discurso.
Descripción de la tecnología de la síntesis de discurso
Un sistema text-to-speech (o el motor) se compone de dos porciones: un extremo delantero y un extremo posterior. Ampliamente, el extremo delantero toma la entrada en el formulario del texto y hace salir una representación lingüística simbólica. El extremo posterior toma la representación lingüística simbólica como entrada y hace salir la forma de onda sintetizada del discurso. El naturalness de un sintetizador de discurso se refiere generalmente a cuánto suena la salida como el discurso de una persona verdadera.
El extremo delantero tiene dos tareas importantes. Primero toma el texto crudo y convierte cosas como números y las abreviaturas en sus equivalentes escritos-hacia fuera de la palabra. Este proceso a menudo se llama normalización, proceso previo, o tokenization del texto. Entonces asigna transcripciones fonéticas a cada palabra, y divide y marca el texto en varias unidades prosódicas, como frases, las
17

cláusulas, y las oraciones. El proceso de asignar transcripciones fonéticas a las palabras se llama conversión del texto-a-fonema (TTP) o del grafema-a-fonema (GTP). La combinación transcripciones fonéticas e información sobre unidades prosódicas del hace hacia arriba la salida lingüística simbólica de la representación del extremo delantero.
La otra parte, el extremo posterior, toma la representación lingüística simbólica y la convierte en salida sana real. El extremo posterior se refiere a menudo como el sintetizador. El diverso uso de los sintetizadores de las técnicas se describe abajo.
HistoriaMucho antes el proceso de señal electrónica moderno fue inventado, los investigadores del discurso intentaron construir las máquinas para crear discurso humano. Los ejemplos tempranos de cabezas discurso fueron hechos por Gerbert de Aurillac (d. 1003), de Albertus Magnus (1198-1280), y del tocino de Roger (1214-1294).
En 1779, Kratzenstein cristiano de St. Petersburg construyó modelos de la zona vocal humana que podría producir los cinco sonidos largos de la vocal (a, e, i, o y u). Esto fue seguida por la máquina Acustico-Mecánica bellows-operated del discurso por Wolfgang Von Kempelen de Viena, Austria, descrita en sus 1791 que el der de papel de Mechanismus menschlichen el seiner de Beschreibung del der del nebst de Sprache sprechenden Maschine ("mecanismo del discurso humano con la descripción su máquina de discurso", J.B. de Degen, de Wien). Esta máquina agregó los modelos la lengüeta y los labios, permitiéndole producir consonantes así como vocales. En Charles 1837 Wheatstone produjo de máquina discurso basada en el diseño de von Kempelen, y en 1857 M. Faber construyó el Euphonia. El diseño de Wheatstone fue resucitado en 1923 por Paget.
VODER de la imagen fue exhibido en el mundo 1939 de Nueva York favorablemente y produjo discurso sin obstrucción inteligible.
En los años 30, los laboratorios de Bell desarrollaron el VOCODER, un analizador electrónico keyboard-operated y el sintetizador del discurso que fue dicho para ser sin obstrucción inteligible. Homer Dudley refinó este dispositivo en el VODER, que él exhibió en la feria 1939 del mundo de Nueva York.
Los sintetizadores de discurso electrónicos tempranos sonaban muy robóticos y eran a menudo pelado inteligibles. La salida de sistemas contemporáneos de TTS es a veces indistinguible de discurso humano real.
A pesar del éxito de la síntesis de discurso electrónica, la investigación todavía se está conduciendo en los sintetizadores de discurso mecánicos para el uso en robustezas del humanoide. Incluso un sintetizador electrónico perfecto es limitado por la calidad del transductor (generalmente un altavoz) que produce el sonido, así que en una robusteza un sistema mecánico puede poder producir un sonido más natural que un altavoz pequeño.
18

Los primeros sistemas computarizados de la síntesis de discurso fueron creados en los últimos años 50 y el primer sistema text-to-speech completo fue terminado en 1968. Desde entonces, ha habido muchos avances en las tecnologías usadas sintetiza discurso. Ver los ejemplos abajo para los sistemas text-to-speech comerciales y libres avanzados.
Tecnologías del sintetizadorHay dos tecnologías principales usadas para las formas de onda sintéticas del discurso que generan: síntesis concatenative y síntesis del formant
Síntesis de Concatenative
La síntesis de Concatenative se basa en el encadenamiento (o la encadenación junto) de segmentos del discurso registrado. Generalmente, la síntesis concatenative da el discurso sintetizado que suena más natural. Sin embargo, en la variación natural discurso y las técnicas automatizadas para dividir las formas de onda en segmentos da lugar a veces a interferencias audibles en la salida, detrayendo del naturalness. Hay tres subtipos principales de la síntesis concatenative:
• La síntesis de la selección de unidad utiliza las bases de datos grandes del discurso (más de una hora de discurso registrado). Durante la creación de base de datos en, cada elocución registrada se divide en segmentos algo o todo el siguiente: teléfonos individuales, sílabas, morfemas, palabras, frases, y oraciones. La división en segmentos se puede hacer usando un número de técnicas, como arracimar, usando un reconocedor especialmente modificado del discurso, o a mano, con representaciones visuales tales como los la forma de onda y espectrograma. Un índice en unidades en la base de datos del discurso entonces se crea basado de las la segmentación y los parámetros acústicos como la frecuencia fundamental (echada). En el tiempo de pasada, la elocución deseada de la meta es creada determinando la mejor cadena de las unidades del candidato de la base de datos (selección de unidad). Esta técnica da el naturalness más grande debido al hecho de que no aplica técnicas de proceso de la señal numérica al discurso registrado, que a menudo hace el sonido registrado del discurso menos natural. En hecho, la salida de los mejores sistemas de la selección de unidad es a menudo indistinguible de voces humanas verdaderas, especialmente en los contextos para los cuales se ha templado el sistema de TTS. Sin embargo, el naturalness máximo requiere a menudo bases de datos del discurso de la selección de unidad ser muy grandes, en algunos sistemas que se extienden en los gigabytes de datos registrados y que numeran en las docenas de horas del discurso registrado.
• La síntesis de Diphone utiliza una base de datos mínima del discurso que contiene todo el Diphones (transiciones del sonido-a-sonido) que ocurre en una lengua dada. El número de diphones depende del phonotactics de la lengua: El español tiene cerca de 800 diphones, cerca de 2500 alemanes. En síntesis del diphone, solamente un ejemplo de cada diphone se contiene en la base de datos del discurso. En el tiempo de pasada, la meta prosody de una oración se sobrepone en estas unidades mínimas por medio de técnicas de proceso de la señal numérica tales como codificación profética linear, PSOLA o MBROLA. La calidad del discurso que resulta no es generalmente tan buena como ésa de la selección de unidad pero natural-sonando que la salida de
19

los sintetizadores del formant. La síntesis de Diphone de sufre de las interferencias sonic la síntesis concatenative y la naturaleza robótico-que suena de la síntesis del formant, y de la tiene pocas de las ventajas de cualquier acercamiento con excepción de tamaño pequeño. Como tal, su uso en aplicaciones comerciales está declinando, aunque continúa ser utilizado en la investigación porque hay un número de puestas en práctica libremente disponibles.
• la síntesis Dominio-especifica concatena palabras previas de antemano y las frases para crear elocuciones completas. Se utiliza en las aplicaciones como donde la variedad de textos que el sistema hará salir se limita a un dominio particular, avisos del horario del tránsito o los informes del tiempo. Esta tecnología es muy simple poner en ejecución, y ha estado en uso comercial durante mucho tiempo: ésta es la tecnología usada por cosas como los relojes que hablan y las calculadoras. El naturalness de estos sistemas puede potencialmente ser muy alto porque la variedad de tipos de la oración es limitada y empareja de cerca el prosody y entonación de los registros originales. Sin embargo, por de porque estos sistemas son limitados las palabras y las frases en su base de datos, no son de uso general y la lata sintetiza solamente las combinaciones palabras y las frases que se han preprogramado con.
Síntesis del formant
La síntesis del formant no utiliza ninguna muestras de discurso humana en el tiempo de pasada. En lugar, se crea el discurso sintetizado salida usando un modelo acústico. Los parámetros tales como frecuencia fundamental, expresando, y los niveles de ruidos se varían en un cierto plazo de crear una forma de onda del discurso artificial. Este método a veces se llama síntesis Rule-based pero algo discute que de porque muchos sistemas concatenative utilizan los componentes basados en las reglas para algunas partes el sistema, como el extremo delantero, el término no es bastante específico.
Muchos sistemas basados en tecnología de la síntesis del formant generan artificial, robótico-sonando discurso, y la salida nunca sería confundida desde el discurso de un ser humano verdadero. Sin embargo, el naturalness máximo no es siempre la meta de un sistema de la síntesis de discurso, y los sistemas de la síntesis del formant tienen sistemas concatenative del excedente de algunas ventajas.
El discurso sintetizado formant puede ser muy confiablemente inteligible, incluso a una velocidad muy elevada, evitando las interferencias acústicas que pueden plagar a menudo sistemas concatenative. El discurso sintetizado de alta velocidad es utilizado a menudo por deteriorado visualmente para las computadoras rápidamente de navegación usando a un lector de la pantalla. En segundo lugar, los sintetizadores del formant son a menudo programas más pequeños que sistemas concatenative porque no tienen una base de datos de las muestras de discurso. Pueden ser utilizados así en situaciones que computan encajadas donde están a menudo escasas la memoria y la energía del procesador. Durar, porque los sistemas formant-basados tienen control total sobre todos los aspectos del discurso de la salida, una variedad amplia de prosody o la entonación se puede hacer salir, transportando preguntas no apenas y declaraciones, sino una variedad de emociones y tonos de la voz.
20

Otros métodos de la síntesis
• La síntesis de Articulatory es un método de la síntesis sobre todo de interés académico en el momento. Se basa en modelos de cómputo la zona vocal humana y los procesos de la articulación que ocurren allí. Estos modelos no se avanzan actualmente suficientemente o de cómputo eficiente ser utilizado en sistemas comerciales de la síntesis de discurso.
• La síntesis híbrida casa aspectos el formant y síntesis concatenative para disminuir las interferencias acústicas de cuando se concatenan los segmentos del discurso.
• la síntesis HMM-basada es un método de la síntesis basado en un HMM. En este sistema, el espectro de discurso (zona vocal), la frecuencia fundamental (fuente vocal), y la duración (prosody) son modelados simultáneamente por las formas de onda se generan de HMMs ellos mismos del discurso de HMMs. basado en el criterio de la toda probabilidad.
Desafíos anticipados
Desafíos de la normalización del textoEl proceso de normalizar el texto es raramente directo. Los textos son completos de homógrafos, de números y de las abreviaturas que todos en última instancia requieren la extensión en una representación fonética.
Hay muchas palabras en inglés que se pronuncian basada diferentemente en contexto. Algunos ejemplos:
• proyecto: Mi proyecto más último es aprender cómo mejorar proyecto mi voz. • arco: Informaron la muchacha con el arco en su pelo al arco profundamente al saludar a sus
superiores.
La mayoría de los sistemas de TTS no generan las representaciones semánticas de sus textos de entrada, pues los procesos para hacer tan no son confiables, bien entendido, o de cómputo eficaz. Consecuentemente, las varias técnicas heurísticas se utilizan para conjeturar la manera apropiada de quitar ambigüedades de homógrafos, como observar palabras vecinas y usar estadística sobre la frecuencia de la ocurrencia.
Decidir a cómo convertir números es otros sistemas del problema TTS tiene que tratar. Es un desafío de programación bastante simple para convertir un número en palabras, como 1325 que se convierte en "mil trescientos veinticinco". Sin embargo, los números ocurren en muchos diversos contextos en textos, y 1325 se deben leer probablemente como "trece veinticinco" cuando parte de una dirección (St de 1325 cañerías.) y como "un tres dos cinco" si es los cuatro dígitos pasados de un número de Seguridad Social. Un sistema de TTS puede deducir a menudo cómo ampliar un número basado en palabras, números, y la puntuación circundante, y los sistemas proporcionan a veces una manera de especificar el tipo de contexto si es ambiguo.
21

Semejantemente, las abreviaturas tienen gusto del "etc." se rinden fácilmente como" etcétera ", pero a menudo las abreviaturas pueden ser ambiguas. Por ejemplo, la abreviatura "hacia adentro." en el ejemplo siguiente: "llovió ayer 3 hacia adentro. Tomar 1 hacia fuera, después poner 3 hacia adentro." "St." puede también ser ambiguo: "St Del St. Juan." Los sistemas de TTS con los extremos delanteros inteligentes pueden hacer conjeturas educadas sobre cómo ocuparse de abreviaturas ambiguas, mientras que otros hacen la misma cosa en todos los casos, dando por resultado salidas absurdas pero a veces cómicas: "llovió ayer tres hacia adentro." o "tomar uno hacia fuera, entonces ponen tres pulgadas."
Desafíos del Texto-a-fonemaLos sistemas de la síntesis de discurso utilizan dos acercamientos básicos para determinar la pronunciación de una palabra basada en su deletreo, un proceso que a menudo se llame conversión del texto-a-fonema o del grafema-a-fonema, pues el fonema es el término usado por los lingüistas para describir sonidos distintivos en una lengua.
El acercamiento más simple a la conversión del texto a fonema es el acercamiento diccionario-basado. En este acercamiento, un diccionario grande que contiene todas las palabras una lengua y su pronunciación correcta es almacenado por el programa. La determinación de la pronunciación correcta de cada palabra es una cuestión de observar encima de cada palabra en el diccionario y de sustituir el deletreo por la pronunciación especificada en el diccionario.
El otro acercamiento usado para la conversión del texto a fonema es el acercamiento basado en las reglas. En este acercamiento, las reglas para las pronunciaciones de palabras se aplican a las palabras para resolver sus pronunciaciones basadas en sus deletreos. Esto es similar a "sonar fuera" de acercamiento a la lectura que aprende.
Cada acercamiento tiene ventajas y las desventajas. El acercamiento diccionario basado tiene las ventajas de ser rápido y exacto, pero falla totalmente si se da una palabra que no esté en su diccionario, y como el tamaño del diccionario crece, hace tan también los requisitos de la memoria del sistema de la síntesis. Por otra parte, el acercamiento basado en las reglas trabaja en cualquier entrada, pero la complejidad de las reglas crece substancialmente mientras que considera deletreos irregulares o las pronunciaciones. Consecuentemente, casi todos los sistemas de la síntesis de discurso utilizan una combinación de ambos acercamientos.
Algunos idiomas, como español, tienen un sistema muy regular de la escritura, y la predicción de la pronunciación de las palabras basadas en el deletreo trabaja correctamente en casi todos los casos. Los sistemas de la síntesis de discurso para las idiomas como esto utilizan a menudo el acercamiento basado en las reglas como el acercamiento de la base para conversión la extranjera del texto-a-fonema, recurriendo a los diccionarios solamente para esas pocas palabras, como nombres y los préstamos, que pronunciación no es obvia del deletreo. Por otra parte, la síntesis de discurso para las idiomas tiene gusto de los ingleses, que tienen sistemas extremadamente irregulares del deletreo, a menudo confían para sobre todo en los diccionarios y utilizan acercamientos basados en las reglas solamente las palabras inusuales o los nombres que no están en el diccionario.
22

Ejemplos de sistemas actualesSistemas libremente disponibles de TTS:
• El festival es un sistema completo libremente disponible de la selección TTS del encadenamiento y de unidad del diphone.
• Flite (Festival-lite) es una versión alternativa más pequeña, más rápida del festival diseñada para los sistemas encajados y los servidores del alto volumen.
• MBROLA es un sistema libremente disponible del encadenamiento del diphone (extremo posterior).
• Gnuspeech es un paquete extensible, text-to-speech, basado en tiempo real, articulatory, discurso síntesis por reglas.
• FreeTTS escrito enteramente en el Java, basada sobre Flite. • Epos es un sistema regla-conducido de TTS diseñado sobre todo para servir como herramienta de
la investigación. • HTS es un sistema HMM-basado libremente disponible de la síntesis de discurso (extremo
posterior).
Sistemas comercialmente disponibles de TTS:
• Apple PlainTalk.• Speechworks Speechify. • RVoice retórico. • Loquendo TTS. • ScanSoft RealSpeak. • Motor Del Texto-a-Discurso De Sakrament.• Matiz Vocalizar.• Voces Naturales de AT&T.• Versión parcial de programa En línea China Del Mandarín TTS De Microsoft, Versión parcial de
programa Inglesa. • El MONTAJE es un programa articulatory de la síntesis desarrollado en los laboratorios de
Haskins. • Cepstral.
Software barato que hace el buen uso de los motores de TTS:
• CoolSpeech de ByteCool Software inc. • ZebraSpeak TTS plugin para el iShell.
Dispositivos externos:
• Apolo.• PC De la Charla Doble.• SpeakJet.
23

Idiomas del margen de beneficio de la síntesis de discursoUn número de idiomas del margen de beneficio para la interpretación del texto como discurso en un formato obediente de XML, se han establecido, lo más recientemente posible el SSML propuesto por el W3C (aún en estado del bosquejo a la hora de esta escritura). Más viejas idiomas del margen de beneficio de la síntesis de discurso incluyen el SABLE y JSML. Aunque cada uno de éstos fue propuesto como nuevo estándar, todavía no se ha adoptado ningunos de ellos extensamente.
Un subconjunto de la especificación de conexión en cascada de las hojas 2 del estilo incluye las hojas de conexión en cascada aurales del estilo.
Los idiomas del margen de beneficio de la síntesis de discurso deben ser distinguidos de idiomas del margen de beneficio del diálogo tales como VoiceXML, que incluye, además de margen de beneficio text-to-speech, las etiquetas relacionadas con el reconocimiento de discurso, la gerencia del diálogo y marcar del touchtone.
Eslabones externos
• Muestras de los sistemas comerciales de TTS. • El sistema libre de la síntesis de discurso diseñó para vocally haber deteriorado, con eslabones
otros relacionados discurso assistive tecnologías y los recursos para a los PALS.
3. NETtalk
NETtalk es una de las más reconocidas redes neuronales artificiales. Resultado de investigaciones que llevaron a cabo Terrence Sejnowski y Charles Rosenberg en 1986 descritas en NETtalk: A Parallel Network that Learns to Read Aloud[1]. En este artículo presentaron la red NETtalk, cuya finalidad era leer y hablar textos en inglés.
Los autores se percataron de que aprender a leer es un mecanismo complejo que implica muchas partes del cerebro humano. NETtalk no modela específicamente el reconocimiento de las imagenes producidas en la corteza visual. Sino que asume que las letras han sido pre-codificadas, y que estas sucesiones de letras comprenden palabras.Así, las palabras son mostradas a la red neural durante la etapa de entrenamiento. Es la tarea de NETtalk de aprender las asociaciones apropiadas entre la pronunciación correcta con una sucesión dada de letra en el contexto en el que aparecen. En otras palabras NETtalk aprende a clasificar letras alrededor del contexto.
.La intención detrás de NETtalk fue construir un modelo conexionista simplificado que demostrara la capacidad las redes neuronales de aprender tareas al nivel de las habilidades cognitivas humanas. Es una red especialmente fascinante porque al escuchar los ejemplos en audio del progreso en el entrenamiento de la red neural parecen el progreso de un bebé que balbucéa o parece que lo que suena suena es como un niño joven que lee un texto del jardín de niños, comete errores ocaionalmente, pero demuestra claramente que aprendió las reglas de los mayores al hacer la lectura.
24

Para aquellos que no estudian las redes neurales y sus limitaciones rigurosamente, parecería ser inteligencia artificial en el sentido más verdadero de la palabra. Aún cuando no es una mentira total, es un ejemplo de la equivocación en la diferencia de lo que los cerebros humanos hacen cuando leen, y lo qué NETtalk es capaz de aprender. Es capaz de leer y pronunciar texto que no es el mismo que comprender realmente lo que se lee y entenderlo en términos de la representación verdadera de imágenes y conocimiento, y esto es una diferencia clave entre un niño humano que aprende a leer y una red neural experimental tal como NETtalk. Es decir, es capaz de pronunciar a "abuela" no es lo mismo que saber quién o qué es una abuela, y cómo ella se relaciona con su familia más cercana. NETtalk no hace específicamente la representación humana del conocimiento ni recrea sus complejidades. . 3.1 Representación y Estructura de la red NETtalk
NETtalk tiene una estructura de tres capas interconectadas con cerca de 200 sinapsis de entradas:
En la capa de entrada encontramos 7 grupos de 29 unidades cada uno (203 unidades de entrada); De las 29 neuronas que consta cada grupo de la capa entrada(sensorial), 26 codifican una letra del alfabeto inglés y las otras tres restantes la puntuación y los límites entre palabras. Puesto que las unidades de entrada se distribuyen en siete grupos, el patrón de entrada que la red es capaz de reconocer hasta 7 caracteres como máximo. Las unidades de salida o motoras codifican las dimensiones fundamentales del habla: fonemas, acentos y hiatos entre sílabas. La red transformaba los datos de entrada (las letras) en fonemas o sonidos. Dado que los pesos originales se establecieron al azar, los primeros resultados no eran buenos; el entrenamiento consistió en presentar cerca de 200 palabras
La Capa OcultaEn el experimento de NETtalk se probó inicialmente con un subconjunto de 1,000 palabras, las más usuales, viendo resultados con diferente cantidad de unidades ocultas.Al probar con 0 unidades ocultas obtuvieron un mejor desempeño de aproximadamente 82%, pero la tasa de aprendizaje y desempeño mejora constantemente al incrementar él numero de unidades ocultas (hasta
25

el 98% con 120 unidades ocultas) Con estas 120 unidades ocultas la red obtenía resultados aproximados del 80% después de 5,000 palabras presentadas y después de 30,000 obtenía el 98%, con este preentrenamiento con 20,000 palabras de prueba y sin adiestramiento adicional se acertó en el 77% de los casos, después de 5 pasadas con las mismas palabras el rendimiento aumentó al 90% de casos correctos Sejnowski reporto que en experimentos posteriores con una ventana de 11 caracteres se obtenían mejores resultados.
Información del archivo NETtalk.pat del JavaNNS
El archivo nettalk.pat no es el archivo original de patrones sino más bien un selecto grupo de los patrones originales de NETtalk con una distribución estadística de bits de entrada puestos en ‘1’ similar y una cantidad de palabras por carácter de aproximadamente 6.
El archivo de patrones que se usó tanto para el entrenamiento y prueba con retropropagación tomado de SNNS y probado en diferentes maquinas, sistemas operativos y compiladores consisten de 200 patrones de entrada, mientras que en el archivo original de patrones había 1,000 patrones de entrada tomados de un diccionario de 20,000 patrones de entrada.
El archivo de patrones de esta versión de NETtalk además contiene información acerca del número de unidades de entrada, ocultas y de salida:
• 203 unidades de entrada que codifican una ventana móvil de 7 caracteres.• 120 unidades ocultas (que como vimos antes aumentan el rendimiento del modelo).• 26 unidades de salida (que codifican los fonemas respectivos a la ventana de caracteres).
Todas las capas están completamente conectadas con la capa superior:
26

3.2 Metodología
Los alfabetos ingles y español no son tan distintos, pero el alfabeto español contiene caracteres que el ingles no contiene (como la ñ) y no contempla la escritura de las vocales acentuadas, para hacer una implementación del NETtalk en español tendríamos que tomar la idea de un arreglo de bits que contuviera información propia de la gramática española y la forma de representación grafica de los caracteres, así como de los signos de puntuación
El Perceptrón es una red capaz de aprender. En su configuración inicial a los pesos de las conexiones se le da valores arbitrarios, por lo que ante la presencia de estímulos la red genera respuestas arbitrarias, respuestas que no coinciden con las deseadas. Se considera que la red ha conseguido aprender cuando los pesos se han ajustado de tal modo que la respuesta que emite es la deseada. El procedimiento propuesto por Rosenblatt para este entrenamiento era sencillo: se le presenta a la red un patrón cuya señal se transmite hasta la capa de salida, provocando la activación de alguna de sus unidades; si se activan las unidades de respuesta correcta, no se hace ningún ajuste de sus pesos; si la respuesta es incorrecta se procede de la manera siguiente: si la unidad debía estar activada y no lo está, aumentar todos los pesos de sus conexiones; si la unidad debía estar desactivada y está activada, disminuir los pesos de sus conexiones. Se repite este procedimiento con todos los patrones deseados de estímulo-respuesta. Rosenblatt creyó que era posible hacer que los pesos converjan en un conjunto de valores, a partir de los cuales le es posible a la red procesar cada uno de los patrones de entrada para producir los correspondientes patrones de salida.
27

En los párrafos anteriores se han descrito de modo cualitativo y poco preciso la modificación que han de sufrir los pesos cuando la red produce errores; existen varios algoritmos que se pueden utilizar para detallar con exactitud el modo de modificar los pesos de las conexiones, por ejemplo:
• Si la respuesta es 0 debiendo ser 1, wij (t+1) = wij(t) + µ*oi;
• si la respuesta es 1 debiendo ser 0, wij (t+1) = wij(t) – µ*oi
donde: wij: es el peso correspondiente a la conexión de la unidad i con la unidad joi: es la salida de la unidad i µ: es la tasa de aprendizaje que controla la velocidad de adaptación
La capa de salida.
La capa de salida consta de 21 unidades de salida representando diversas características articulatorias y cinco unidades codificando acentuación y limites entre silabas. Cabe mencionar que no se encontró información que describiera exactamente como se codifica la salida de la red NETtalk, no obstante, se encontró que dicha información debe estar contenida en un total de 26 unidades. Algunos ejemplos encontrados se muestran a continuación:
Palabra FonemasAcento/info
silabaCódigo palabras
extranjeras/irregularesFonema->grafema
abattoir @bxt-+-r 1<0<>2<< 2 /+/ -> 'oi'
beaujolais b-o-Zxle-- >2<<>0>1<< 2/Z/ -> 'j' y /e/
-> 'ais'Tortilla tcrti--a >0<>1>>0 2 /i/ -> 'ill'Pizza pi!-x >1<>0 2 /!/ -> 'zz'Fjord Ficrd >01<< 2 /i/ -> 'j'
En la tabla se desglosa el significado de una salida típica de NETtalk, así se puede notar que en la salida se codifica información acerca de las características fonéticas de las palabras pero no se encontró información de la salida en su codificación binaria ni del significado de los grupos de bits.
3.3 Implementación de la red neuronal de NETTalk en español
Codificación de entradas y salidas:
Codificación de entradas:Son las codificaciones de los caracteres en el idioma español a forma de vectores binarios:a: 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b: 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 *: 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 /*corresponde a la ch*/
28

d: 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e: 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f: 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g: 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 &:0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 /*corresponde a rr*/i: 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j: 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k: 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l: 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 m: 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 n: 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ñ:0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 o: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 p: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 @: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 /*corresponde a ll*/r: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 s: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 t: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 u: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 v: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 w: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 x: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 y: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 _ : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Codificación de salidas en forma de fonemas que reconoce el MBrola:
a: 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b: 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d: 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 dZ: 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e: 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f: 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g: 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 i: 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j: 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k: 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l: 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 m:0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 n: 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0ny: 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
29

o: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 p: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 r: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 rr: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 s: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 t: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 tS: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0u: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 w: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 x: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 _: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 N: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
La capa de entradaConsta de un vector de bits como los descritos anteriormente de tamaño 28 por el tamaño de la ventana, es decir, si la ventana es de tamaño 5 él numero neuronas de la capa de entrada será de tamaño 140
La capa ocultaPara poder realizar la experimentación se tomaron variantes de 0, 15, 30, 60, 80 y 120 unidades ocultas, en la sección de experimentación se analizan los resultados obtenidos con estas configuraciones de red
La capa de salidaConsta de 26 bits con la codificación antes descrita, cada vector de bits representa un fonema reconocido por el sintetizar de voz MBrola
3.4 Descripción de la codificación del programa
Implementación de la red neuronal artificialPara la implementación en la red neuronal en un principio utilizamos el simulador de redes
neuronales JavaNNS, como vimos antes este simulador requiere que se diseñe una red con su interfaz grafica, para nuestro caso fue una red que variaba en su numero de unidades de neuronas de entrada, unidades de neuronas ocultas pero que no variaba en su numero de unidades de neuronas de salida, esto nos significo problemas por que necesitábamos crear un archivo para cada variación en el numero de unidades, otra complicación que tuvimos con este simulador fue el crear el archivo de patrones, ya que el numero de ejemplos es muy grande no es practico generar manualmente el archivo de patrones por lo que creamos una clase en java que se especializa en realizar esta tarea, al intentar cargar el patrón en el simulador este generaba muchos errores porque en un principio no sabíamos que necesita un esquema en especifico para la generación del patrón, después de haber investigado cual era la forma en que el simulador pide que sea introducido el patrón, nos dimos a la tarea de modificar la clase anteriormente mencionada, una vez que modificamos la clase que creamos anteriormente, volvimos a intentar cargar el patrón generado por nuestra clase y el simulador volvió a rechazarlo por razones desconocidas y
30

suponemos que tenia un tamaño no permitido por el simulador. Otro problema que nos causo el uso del simulador fue que no encontramos el archivo en donde deposita la matriz de pesos de la red neuronal ya entrenada, por estos problemas decidimos abandonar el uso de este simulador y optamos por buscar en java una clase que realizara las funciones elementales de una red neuronal, encontramos dicha clase en Internet que proveía el código de dicha clase junto con una prueba para la misma, las ventajas del uso de esta clase fueron que recibe como parámetros el numero de unidades ocultas, de entrada y de salida, junto con los parámetros eta(η) y momentum por lo que no fue necesario crear archivos distintos para la prueba de la red, otra ventaja fue que al tener el código de esta clase pudimos modificarlo para agregar otra función relacionada con el conjunto de validación, la clase de prueba de la red nos arroja los errores producidos por cada iteración de la clase de la red neuronal, con estos errores pudimos obtener la graficas de error de la red, además modificando la clase de prueba logramos obtener los vectores de resultados que la red neuronal ya entrenada nos arroja, con estos vectores aplicando la función hardlim obtuvimos los vectores binarios que representan los fonemas que la red neuronal ya entrenada reconoce, y de estos vectores binarios generamos en un archivo del tipo de Mbrola que contenía el fonema y una duración constante para todos ellos, al reproducir este archivo se escucha con si un robot estuviera leyendo el texto.
Al experimentar con la clase de prueba nos dimos cuenta que la red sin unidades de neuronas ocultas fallaba mucho aun cuando él numero de iteraciones fuera elevado, al introducir unidades de neuronas en la capa oculta la eficiencia de red se veía empobrecida por los parámetros de eta(η) y momentum, ya que en un principio el error empezaba a subir y después a comenzaba a bajar muy torpemente, por lo que decidimos introducir valores de eta y momentum muy pequeños cuando él numero de unidades ocultas fuese grande, con esto la eficiencia de la red neuronal incremento considerablemente pero su costo computacional incremento bastante.
En la clase de prueba de red insertamos el método correspondiente para obtener la matriz de confusión la cual nos sirve para obtener la cantidad de fonemas mal clasificados. Lo que hicimos para la implementación fue mandarle el vector generado por la red neuronal y el vector ideal producido por la clase GenadorPattern y el método hace una comparación entre estos e incrementa elemento de la matriz correspondiente.
Para la obtención de las graficas de error una vez que la red había sido entrenada arrojaba los errores por iteración del conjunto de validación y entrenamiento, con estos errores generamos scripts en MATLAB que dibujan la graficas del error de la red neuronal.
Implementación del ProgramaRealizando un análisis del programa:
1. Nos dan algún texto que la red neuronal tiene que reproducir como voz, por tanto necesitamos de algún medio para leer el archivo que nos proporcionen.
2. Tenemos que considerar los fonemas que constan de 2 letras como el caso de rr, ch, ll, etc.3. Tenemos que realizar experimentación con la ventana de caracteres.
31

4. Realizar limpieza del texto de caracteres extraños, incluyendo la conversión de las vocales acentuadas por vocales simples.
5. Contar el número de fonemas en cada uno de los conjuntos para saber cual es su distribución y no tener, por ejemplo más caracteres de un tipo en el conjunto de prueba y menos en el de entrenamiento porque esto nos traería problemas ya que el carácter tiene menos probabilidades de ser reconocido por la red.
Tomando en cuenta estas consideraciones realizamos clases en Java que modelan el comportamiento del programa que necesitamos.
Para leer los caracteres creamos una clase LectorCaracteres con los métodos verCaracterSiguiente, que muestra el carácter frente al último apuntado y consumirCaracterSiguiente, que avanza el apuntador al carácter de enfrente. Esta clase resuelve los problemas de leer caracteres del archivo y el de considerar fonemas con 2 letras ya que podemos estar situados en un carácter y ver cual es el siguiente carácter y tomar la decisión de que manejo se le va dar a dichas combinaciones de caracteres.
Para poder facilitar la conversión de caracteres a fonemas y desechar caracteres extraños, incluyendo los caracteres acentuados y aquellos caracteres que sean combinación de dos de ellos incluyendo la “h”, creamos la clase LimpiaTexto que se encarga de tomar un archivo con el texto y hacerle las modificaciones adecuadas antes descritas y guardarlo en otro archivo, es aquí donde se ve la utilidad de la clase anterior ya que podemos estar apuntando hacia un carácter en especifico y preguntar por cual es el carácter siguiente, si es alguno de los casos especiales lo podemos contraer en un solo carácter de nuestra codificación. Un problema en la implementación de esta clase es que para no hacer tan grande el filtro de caracteres raros y conocidos utilizamos un método de la clase Character, este método llamado isLetter retorna verdadero si el carácter es una letra y falso si no lo es, el problema radica en que como el método solo contempla caracteres del alfabeto ingles caracteres del alfabeto español como la ‘ñ’ no los reconoce como un carácter permitido, esto se soluciona agregándolos a una lista de caracteres admitidos.
Como mencionamos anteriormente requerimos de una clase que lea caracteres de un archivo y requerimos también guardar información en algún otro archivo para lograr esto creamos la clase EscritorPattern, que esencialmente toma un archivo que se le pasa como parámetro, en el caso de que el archivo no exista intentara crearlo y si no es posible crearlo envía un mensaje de error. Si el archivo a sido creado o era existente escribe en él. La clase consta de un método sobrecargado que una vez que se ha inicializado la clase con un archivo puede escribir cadenas de caracteres (Strings) o bien solo un carácter dependiendo de las necesidades de escritura.
Como mencionamos antes el crear manualmente los patrones tanto para el simulador de redes neuronales como para la clase de redes neuronales no es practico por lo que es necesario crear una clase que automatice esta parte del proceso, para nuestro programa creamos una clase llamada GeneradorPattern que se encarga de generar un patrón que corresponda con las necesidades de la clase que estamos usando. Esta clase se encarga de leer de un archivo de texto con ventanas de caracteres, cada carácter de cada una de las ventanas y realizar 3 funciones:
32

1. Genera un vector que contiene la codificación binaria en forma de dato double del carácter actual.2. Concatenar en un solo vector la codificación binaria en forma de dato double de toda la ventana
de caracteres para obtener una matriz de tipo double que contiene la codificación de todas las ventanas del archivo.
3. Generar un archivo de texto con la codificación binaria en forma de ceros y unos de la matriz generada anteriormente.
También se encarga de leer de otro archivo que contiene los fonemas correspondientes al fonema central de cada ventana y realizar las mismas funciones anteriormente descritas con la excepción de que no realiza la concatenación, en vez de esto busca fonemas que estén conformados de 2 letras y los compactan en un solo vector.
Globalmente la clase tiene varios atributos entre ellos son 2 matrices de tipo double donde se almacena la información de la codificación de las entradas y salidas de la red, estas matrices son indispensables ya que son necesitadas por la clase de red. Algunas operaciones no mencionados anteriormente pero que debieran ser claras son los métodos de lectura de las matrices, las instrucciones de creación del archivo de texto con la codificación de entradas y salidas de la red neuronal y algún medio de creación de las ventanas y obtención del fonema central, esto lo logramos creando otra clase llamada CreaArchivosVentanas que esencialmente toma el archivo que ya no contiene caracteres extraños y lo fragmenta en ventadas de un tamaño definido por el usuario generando tres archivos que contienen las ventanas, los fonemas y las ventanas con el carácter central.
La forma en que logramos la fragmentación de las ventanas fue teniendo un arreglo de caracteres en blanco donde hacíamos un recorrido de estos a la izquierda para dejar el carácter mas a la derecha vació y en este insertamos el carácter del apuntador actual del archivo, en un primer paso recorremos carácter por carácter hasta que el carácter central esta ocupado, después de esto con tres instancias de la clase EscritorPattern apuntando hacia tres archivos diferentes generamos cada uno de los archivos de texto necesarios con la información correspondiente en cada uno de ellos, esto lo logramos recorriendo el carácter de la ventana y de la nueva ventana generada creamos un objeto de tipo de String y este es el que escribimos en el archivo de texto de ventanas y ventanas con carácter, el caso del archivo de texto con fonemas lo que tenemos son caracteres, estos caracteres los pasamos por un filtro que nos regresa los fonemas asociados a los caracteres y esto es lo que escribimos en el archivo de texto, por último en el caso de los caracteres hacemos el paso el paso inverso a la compactación de fonemas de 2 letras, aquí identificamos los caracteres codificados y los regresamos a su representación original.
Como última parte de la implementación requerimos de algún medio para realizar estadísticas acerca de la cantidad de fonemas en los conjuntos de prueba, validación y entrenamiento, para esto creamos una clase llamada CuentaCaracteres que esencialmente tiene entre otros atributos un arreglo de números enteros, uno por cada fonema y un arreglo de caracteres, también uno por cada fonema. La función principal de esta clase es leer caracteres de un archivo de texto e incrementar el contador respectivo al
33

fonema que este leyendo y almacenar en el arreglo de caracteres el fonema correspondiente y por último guardar estos arreglos en otro archivo de texto.
Descripción por clases:
Clase LectorCaracteres:1. Atributos:archivo: PushBackReader, sirve para leer caracteres del archivo y en caso de ser necesario retorna al archivo el carácter leído en su posición original.2. Métodos:
a) Constructor LectorCaracterespublic LectorCaracteres(String nomArchivo)
{try{
// Crea un objeto con el nombre del archivoFile arch=new File(nomArchivo);
// Crea un lector de archivosFileReader fr=new FileReader(arch);
// Crea un PushbackReaderarchivo=new PushbackReader(fr);
}catch(FileNotFoundException e){
// Esto se llama en caso de errorSystem.out.println("Lo siento, el archivo "+nomArchivo+" no
existe...");System.exit(0);
}
}Se necesita el nombre del archivo que va a ser leído para poder crear una instancia de tipo File que es necesaria para poder crear una instancia de FileReader que es necesaria para crear la instancia de PushBackReader que es el tipo de dato que necesitamos para poder tener apuntadores al carácter actual y al siguiente gracias a los métodos de esta read y unread de esta clase. Si se produce alguna excepción el sistema sale por completo de ejecución.
b) VerCaracterSiguietepublic char verCaracterSiguiente()
{try{
int c;// Lee el caracter siguientec = archivo.read();//El -1 ocurre si es fin de archivo
34

if(c == -1){
c = 0;}// Lo "regresa" al archivo archivo.unread(c);// Regresa el valorreturn (char) c;
}catch(IOException e){
// En caso de error regresa 0return '\0';
}}
El método read retorna el ASCII del carácter leído, mientras no ocurra que lee –1 (que significa fin de archivo) seguirá leyendo caracteres del archivo, el método unread regresa el carácter leído al archivo en su posición original, por último se hace un cast a char para retornar el carácter que fue leído. Si ocurre alguna excepción se retorna el carácter fin de archivo.
c) consumirCaracterSiguientepublic char consumirCaracterSiguiente()
{try{
int c;// Lee el caracter siguientec = archivo.read();// El -1 ocurre si es fin de archivoif(c == -1){
c = 0;}return (char)c;
}catch(IOException e){
// En caso de errorreturn '\0';
}}
A diferencia del método anterior este no regresa el carácter leído al archivo, por lo que avanza en el archivo posicionándose en el siguiente carácter.
Clase EscritorPattern
1. Atributosarchivo: FileWriter, tiene un método para poder escribir en un archivo.
35

2. Métodosa) Constructor EscritorPatternpublic EscritorPattern(String nomArchivo)
{try{
// Crea un objeto con el nombre del archivoFile arch=new File(nomArchivo);//crea el archivoarch.createNewFile();//crea el objeto escritor del archivoarchivo=new FileWriter(arch);
}catch(IOException e){
// Esto se llama en caso de errorSystem.out.println("Lo siento, el archivo "+nomArchivo+" no se
puede crear...");System.exit(0);
}}
Recibe el nombre del archivo en donde se desea escribir, ya que un principio el archivo no existe se crea una instancia de archivo y después con uno de sus métodos se ordena la creación del archivo, después este se pasa como parámetro del FileWriter. Si ocurre una excepción, como por ejemplo si no se pudiera crear el archivo, el sistema envía un mensaje del error y aborta la misión.
b) EscribeCadenaEs un método sobrecargado que puede recibir 2 tipos de parámetros distintos (String y char) pero esencialmente realiza la misma función.public FileWriter escribeCadena(String cadena){
try{//System.out.print(cadena);archivo.write(cadena);
}catch(IOException e){System.out.println(e.getMessage());
}return archivo;
}Si no ocurre una excepción se escribe en el archivo el parámetro que le fue pasado. Regresa un FileWriter para que la clase que lo invoca cierre el archivo al terminar de utilizarlo
Clase LimpiaTexto
1. Atributosm_lc: LectorCaracteres, para leer los caracteres que contiene el archivo.m_ec:EscritorPattern, para crear un archivo nuevo sin caracteres especiales y con una codificación diferente para las letras compuestas de 2 caracteres.
36

2. Métodosa) Constructor LimpiaTextopublic LimpiaTexto(String nomArchivoEntrada, String nomArchivoSalida){
m_lc=new LectorCaracteres(nomArchivoEntrada);m_ec=new EscritorPattern(nomArchivoSalida);
}Solo crea las instancias de EscritorPattern y LectorCaracteres con los parámetros que recibe
b) LeeArchivopublic FileWriter leeArchivo(){
char carSiguiente,carActual;carActual=m_lc.consumirCaracterSiguiente();while(m_lc.verCaracterSiguiente()!='\0'){
if(Character.isLetter(carActual) || carActual == ' ' || carActual == 'ñ'){
if(carActual == 'l' || carActual == 'c' || carActual == 'r' || carActual == 'q' || carActual == 'h'){
switch(carActual){case 'c':
if(m_lc.verCaracterSiguiente()=='h'){m_ec.escribeCadena("*");
carActual=m_lc.consumirCaracterSiguiente();carActual=m_lc.consumirCaracterSiguiente();
}else if(m_lc.verCaracterSiguiente()=='e'||m_lc.verCaracterSiguiente()=='i'){
m_ec.escribeCadena("s");carActual=m_lc.consumirCaracterSiguiente();
}else{m_ec.escribeCadena("k");
carActual=m_lc.consumirCaracterSiguiente();}break;
case 'r':if(m_lc.verCaracterSiguiente()=='r'){
m_ec.escribeCadena("&");carActual=m_lc.consumirCaracterSiguiente();
carActual=m_lc.consumirCaracterSiguiente();}else{
m_ec.escribeCadena("r");carActual=m_lc.consumirCaracterSiguiente();
}break;
case 'q':if(m_lc.verCaracterSiguiente()=='u'){
m_ec.escribeCadena("k");carActual=m_lc.consumirCaracterSiguiente();
carActual=m_lc.consumirCaracterSiguiente();}else{
m_ec.escribeCadena("k");carActual=m_lc.consumirCaracterSiguiente();
}
37

break;case 'l':
if(m_lc.verCaracterSiguiente()=='l'){m_ec.escribeCadena("@");
carActual=m_lc.consumirCaracterSiguiente();carActual=m_lc.consumirCaracterSiguiente();
}else{carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("l");}break;
case 'h':carActual=m_lc.consumirCaracterSiguiente();
break;}
}else {m_ec.escribeCadena(carActual);
carActual=m_lc.consumirCaracterSiguiente();}
}else{carActual=m_lc.consumirCaracterSiguiente();
}}m_ec.escribeCadena(carActual);return m_ec.escribeCadena("");
}Se posiciona en el primer carácter del archivo y mientras no sea el fin de archivo le hace un primer filtro para que solo haya letras, con esto se eliminan caracteres especiales y después aplica un segundo filtro para las letras con 2 caracteres o que su representación fonética sea distinta a su representación original (por ejemplo la c suena como s o como k dependiendo del carácter siguiente pero como fonema no se escribe nunca la c).
Clase CreaArchivosVentanas
1. Atributosm_salidaVentana: String, contiene el nombre del archivo donde se va escribir el texto con solo las ventanas generadas.m_salidaCaracteres: String, contiene el nombre del archivo donde se va a escribir el texto con los caracteres centrales de cada ventana.m_salidaFonemas: String, contiene el nombre del archivo donde se va a escribir el texto con los fonemas centrales de cada ventana.m_ventana: char[], es un arreglo de tamaño definido por el usuario, facilita la fragmentación en ventanas. m_tamanoVentana: int, contiene el tamaño de la ventana que define el usuariom_lc: LectorCaracteres, el usuario pasa el nombre del archivo con el texto limpio, esta variable es la que lo leem_cuentaVentanas: int, es el número de ventanas que contiene el archivo de ventanas
38

2. Métodosa) Constructor CreaArchivosVentanaspublic CreaArchivosVentanas(String nomArchivoOrigen, String origen, String ventanas, String caracteres, String fonemas, int tamVentana){
LimpiaTexto lt=new LimpiaTexto(nomArchivoOrigen,origen);try{
lt.leeArchivo().close();}catch(IOException e){
System.out.println(e.getMessage());}m_salidaVentana=ventanas;m_salidaCaracteres=caracteres;m_salidaFonemas=fonemas;m_lc=new LectorCaracteres(origen);m_tamanoVentana=tamVentana;m_ventana=new char[m_tamanoVentana];for(int i=0;i<m_tamanoVentana;i++){
m_ventana[i]=' ';}m_cuentaVentanas=0;
}Llama a LimpiaTexto, inicializa variables, crea las instancias de LectorCaracteres y EscritorPattern e inicializa el arreglo de caracteres con caracteres blancos.
b) recorreVentanapublic void recorreVentana(char[] ventana, char elem){
int i;for(i=0;i<m_tamanoVentana-1;i++){
m_ventana[i]=m_ventana[i+1];}m_ventana[i]=elem;
}Recorre los caracteres a la izquierda, el carácter de la última posición es sustituido por el de una posición anterior y el del principio queda repetido en la posición 1 del arreglo, por tanto en la posición 0 se agrega el carácter que se desea insertar.
c) dameFonemapublic String dameFonema(char elem){
switch(elem){case '*':
return "tS";case '&':
return "rr";case '@':
return "i";case 'ñ':
return "ny";default:
return elem+"";}
39

}Regresa el fonema con codificación de Mbrola dependiendo de cual carácter especial encuentre en el archivo limpio.
d) dameCaracterpublic String dameCaracter(char elem){
switch(elem){case '*':
return "ch";case '&':
return "rr";case '@':
return "ll";default:
return elem+"";}
}Retorna el carácter que corresponde al carácter especial.
e) creaArchivospublic void creaArchivos(){
int i=1;String cadenaTmp;/* * cada ep contiene una dirección que es el nombre del archivo * en donde van a escribir */EscritorPattern ep1=new EscritorPattern(m_salidaVentana);EscritorPattern ep2=new EscritorPattern(m_salidaCaracteres);EscritorPattern ep3=new EscritorPattern(m_salidaFonemas);/* * Escribe los primeros caracteres en la ventana dejando en medio al * primer elemento del archivo */
while(i<=(int)(m_tamanoVentana/2)+1 && m_lc.verCaracterSiguiente()!='\0'){recorreVentana(m_ventana,m_lc.consumirCaracterSiguiente());i++;
}System.out.println(m_ventana[(int)(m_tamanoVentana/2)]);cadenaTmp=new String(m_ventana,0,m_tamanoVentana);/* * escribe la primer ventana */ep1.escribeCadena(cadenaTmp+"\n");/* * escribe la ventana con el carácter de en medio */ep2.escribeCadena(cadenaTmp);ep2.escribeCadena('=');
ep2.escribeCadena(dameCaracter(m_ventana[(int)(m_tamanoVentana/2)])+"\n");/*
40

* escribe la ventana con el fonema de MBrola *///ep3.escribeCadena(cadenaTmp);//ep3.escribeCadena('=');
ep3.escribeCadena(dameFonema(m_ventana[(int)(m_tamanoVentana/2)])+"\n");//escribe la primer ventanam_cuentaVentanas++;while(m_lc.verCaracterSiguiente()!='\0'){
recorreVentana(m_ventana,m_lc.consumirCaracterSiguiente());cadenaTmp=new String(m_ventana,0,m_tamanoVentana);/* * escribe la primer ventana */ep1.escribeCadena(cadenaTmp+"\n");/* * escribe la ventana con el carácter de en medio */ep2.escribeCadena(cadenaTmp);ep2.escribeCadena('=');
ep2.escribeCadena(dameCaracter(m_ventana[(int)(m_tamanoVentana/2)])+"\n");/* * escribe la ventana con el fonema de MBrola *///ep3.escribeCadena(cadenaTmp);//ep3.escribeCadena('=');
ep3.escribeCadena(dameFonema(m_ventana[(int)(m_tamanoVentana/2)])+"\n");//escribe otra ventanam_cuentaVentanas++;
}i=1;while(i<=(int)(m_tamanoVentana/2) ||
m_lc.verCaracterSiguiente()!='\0'){recorreVentana(m_ventana,' ');cadenaTmp=new String(m_ventana,0,m_tamanoVentana);/* * escribe la primer ventana */ep1.escribeCadena(cadenaTmp+"\n");/* * escribe la ventana con el carácter de en medio */ep2.escribeCadena(cadenaTmp);ep2.escribeCadena('=');
ep2.escribeCadena(dameCaracter(m_ventana[((int)(m_tamanoVentana/2))])+"\n");/* * escribe la ventana con el fonema de MBrola */
ep3.escribeCadena(dameFonema(m_ventana[((int)(m_tamanoVentana/2))])+"\n");//escribe las ultimas ventanasm_cuentaVentanas++;i++;
}try{
41

ep1.escribeCadena("").close();ep2.escribeCadena("").close();ep3.escribeCadena("").close();
}catch(IOException e){e.getMessage();
}}Inicializa los EscritorPattern, introduce caracteres en la ventana de caracteres hasta que se
alcanza la mitad de la ventana, escribe en los archivos lo que corresponde en cada uno, después inserta carácter por carácter hasta que encuentra el fin de archivo escribiendo en cada archivo como en el caso anterior y por ultimo recorre la venta hasta que quedan espacios en blanco después del carácter central escribiendo en los archivos un a entrada por cada carácter en blanco insertado. En esta clase se lleva la cuenta de cuantos registros se escriben en los archivos.
f) dameNumeroVentanaspublic int leeNumeroVentanas() {
return m_cuentaVentanas;}
Retorna el número de ventanas que se escribieron en el archivo de ventanas.
Clase GeneradorPattern
1. Atributosm_lcVentanas: LectorCaracteres, lee el contenido del archivo de ventanasm_lcFonemas: LectorCaracteres, lee el contenido del archivo de ventanasm_epVentanas: EscritorPattern, escribe la codificación binaria de las ventanas en un archivo de textom_epFonemas: EscritorPattern, escribe la codificación binaria de los fonemas en un archivo de textom_salidas[][]: double, contiene la codificación en forma de 0’s y 1’s de las ventanas en una matriz de double que es la forma en que la clase Network la necesita para realizar la retropropagaciónm_entradas[][]: double, contiene la codificación en forma de 0’s y 1’s de los fonemas en una matriz de double que es la forma en que la clase Network la necesita para realizar la retropropagaciónm_linea: int, contiene la cantidad de saltos de líneas en el archivo de ventanas
2. Métodosa) Constructor GeneradorPattern
public GeneradorPattern(String origen, String origenLimpio, String nomArchVentanas, String nomArchCaracteres, String nomArchFonemas, int tamVentanas, String nomSalida, String nomEntrada){
CreaArchivosVentanas cav = new CreaArchivosVentanas(origen,origenLimpio,nomArchVentanas,nomArchCaracteres,nomArchFonemas,tamVentanas);
cav.creaArchivos();m_lcVentanas=new LectorCaracteres(nomArchVentanas);m_lcFonemas=new LectorCaracteres(nomArchFonemas);m_epVentanas=new EscritorPattern(nomSalida);m_epFonemas=new EscritorPattern(nomEntrada);m_salidas=new double[cav.leeNumeroVentanas()][26];
42

m_entradas=new double[cav.leeNumeroVentanas()][140];}
Crea las instancias de los LectorCatacteres y EscritorPattern e inicializa las matricesb) creaArchivopublic void creaArchivo(){
int i=0;do{
double x[]=new double[0];while(m_lcVentanas.verCaracterSiguiente()!= '\n'){
x=concatena(x,creaPatternEntrada());}m_entradas[i]=x;//escribir el renglón de salidas y dar enterm_lcVentanas.consumirCaracterSiguiente();m_epVentanas.escribeCadena("\n");i++;
}while(m_lcVentanas.verCaracterSiguiente() != '\0' && i<=4096);i=0;do{
//m_lcFonemas.consumirCaracterSiguiente();m_salidas[i]=creaPatternSalida();//escribir el renglón de salidas en un archivo distinto de
entradasi++;
}while(m_lcFonemas.verCaracterSiguiente() != '\0' && i<=4096);try{
m_epVentanas.escribeCadena("").close();m_epFonemas.escribeCadena("").close();
}catch(IOException e){e.getMessage();
}System.out.println("Saltos de linea: "+m_linea);
}Primero obtiene la codificación de los elementos de la ventana y los concatena en un solo vector y este lo inserta en su posición correspondiente de la matriz de ventanas, esto lo hace para todas las ventanas del archivo, después obtiene la codificación de los fonemas y la inserta directamente en la matriz de fonemas.
c) creaPatternEntradapublic double[] creaPatternEntrada(){
char carSiguiente = m_lcVentanas.verCaracterSiguiente();double x[]=new double[28];if(carSiguiente==' '||Character.isLetter(carSiguiente) ||
carSiguiente == '*' || carSiguiente == '&' || carSiguiente == '@' || carSiguiente == 'ñ'){
x=dameEntrada();}m_lcVentanas.consumirCaracterSiguiente();return x;
}
43

Crea el patrón de entrada para todos los caracteres, avanza al siguiente carácter y retorna su codificación binaria.
c) dameEntradaHace la conversión de carácter a binario de los caracteres de la ventana, regresa el vector con esta codificación y escribe en el archivo de texto la misma codificación que la del vector.
d) creaPatternSalidaHace casi lo mismo que dameSalida pero con la codificación para los fonemas y a diferencia de dameSalida, el mismo avanza al siguiente carácter.
e) concaténapublic double[] concatena(double[] x, double[] y){
double z[]=new double[x.length+y.length];for(int k=0;k<x.length;k++){
z[k]=x[k];}for(int p=(x.length),s=0;p<(x.length+y.length);p++,s++){
z[p]=y[s];}return z;
}Toma 2 vectores y en un nuevo vector coloca todo el primer vector y al término de este coloca el otro vector. Retorna un tercer vector de tipo double.
f) dameSalidas y dameEntradasPermite que otras clases puedan leer el contenido de las matrices de fonemas y ventanas.
Clase CuentaCaracteres
1. Atributosm_lc: LectorCaracteres, lee el archivo del que se requiere la estadísticam_ep: EscritorPattern, escribe en un archivo el fonema y la cantidad de veces que aparecem_numeroCaracteres[]: int, numero de ocurrencias del carácter im_letras[]: char, arreglo de caracteres que contiene todos los fonemas posibles
2. Métodosa) Constructor CuentaCaracterespublic CuentaCaracteres(String nomArch,String archEstadistica){
m_lc=new LectorCaracteres(nomArch);m_ep=new EscritorPattern(archEstadistica);m_numeroCaracteres=new int[29];for(int i=0;i<29;i++){
m_numeroCaracteres[i]=0;}m_letras=new char[29];
44

}Crea las instancias de LectorCaracteres y EscritorPattern e inicializa el vector de ocurrencias y de letras
b) Estadísticapublic void Estadistica(){
while(m_lc.verCaracterSiguiente() != '\0'){dameEntrada();m_lc.consumirCaracterSiguiente();
}for(int i=0;i<29;i++){
System.out.println(m_letras[i]+": "+m_numeroCaracteres[i]);m_ep.escribeCadena(m_letras[i]+":
"+m_numeroCaracteres[i]+"\n");}try{
m_ep.escribeCadena("").close();}catch(IOException e){
e.getMessage();}
}Revisa todo el archivo y crea el archivo con la estadística de todos los fonemas.
c)dameEntradaHace un switch por cada fonema e incrementa su contador correspondiente en el arreglo de enteros y asigna la letra correspondiente en el arreglo de letras.
Clase Network1. AtributosglobalError: double, Error total del aprendizaje.inputCount:int, numero de neuronas de entradahiddenCount: int, numero de neuronas ocultasoutputCount: int, numero de neuronas de salidaneuronCount: int, numero total de neuronas en la red.weightCount:int, numero total de pesos en la redlearnRate: double, parámetro de aprendizajefire[]:double, las salidas de varios niveles matrix[]: double, los pesos de la matriz con los thresholdserror[]: double, los errors del calculo anterioraccMatrixDelta[]: double, matriz de deltas por entrenamientothresholds[]: double, usado como una memoria de la red junto con la matriz de pesosmatrixDelta[]: double, los cambios que deberían ser aplicados a los pesosaccThresholdDelta[]: double, la acumulación de los thresholds de deltasthresholdDelta[]: double, los thresholds de los deltasmomentum: double, el momentum del aprendizajeerrorDelta[]:double, los cambios en los errores
45

errorDeltaVal[]: double, los cambios en los errors del conjunto de validación
2. Métodosa) Constructor Network
Inicializa todas las variables de estado.b) getErrorpublic double getError(int len) { double err = Math.sqrt(globalError / (len * outputCount)); globalError = 0; // clear the accumulator return err; }
Regresa la raíz cuadrada del error de un conjunto completo de entrenamientoc) thresholdpublic double threshold(double sum) { return 1.0 / (1 + Math.exp(-1.0 * sum)); }
Definición de la función de activaciónd)computeOutputsComputa la salida para dar la entrada a la red e) calcErrorValCalcula el error producido por el conjunto de validaciónf)learnModifica la matriz de pesos y threshould basado en la última llamada a calcErrorg)resetReinicia la matriz de pesos y threshouldh) calcErrorCalcula el error del conjunto de entrenamiento
Clase TestNeuralNetwork
1. Atributosm_confusion[][]:int, matriz de confusiónm_indefinido=0: int, contador de fonemas desconocidos
2. Métodosa) Constructor TestNeuralNetworkInicializa la matriz de confusión
b) decodificaFonemaBusca la posición del 1 en el arreglo, en el caso de que haya mas de un 1 o no haya ninguno se tiene un estado alterno de fonema indefinido, este método también escribe en el archivo de Mbrola el fonema y una duración fija, en caso de un fonema indefinido solo se muestra en consola un error de mala clasificación
46

c) generaMatrizConfucionRecibe 2 vectores, 1 el vector generado por la red y el otro es el vector con la codificación correcta del fonema actual. El método obtiene la posición del uno del fonema actual correcto y la posición del uno del fonema generado por la red, después valida que ambas sean codificaciones validas, en el caso de que no lo sean se incrementa en uno la variable de estado m_indefinido, en caso contrario se incrementa el índice correspondiente a m_confucion tomando en cuenta que en variables auxiliares hemos guardado el índice donde se encuentra el uno en la codificación del fonema correcto (nombre de variable: correcto) y del fonema generado por la red (nombre de variable: fonema), entonces hacemos m_confucion[correcto][fonema]++ (los fonemas correctos corresponden a las filas y los generados por la red a las columnas).
d) dameMatrizConfucionImprime en consola la matriz de confusión y la variable de estado m_indefinido
47

CAPITULO II. Árboles de Decisión
1. ¿Que son los árboles de decisión?
Los árboles de decisión constituyen probablemente el modelo de clasificación más popular y utilizado. El conocimiento obtenido durante el proceso de aprendizaje inductivo se representa mediante un árbol en el cual cada nodo interno contiene una pregunta acerca de un atributo particular (con un nodo hijo para cada posible respuesta) y en el que cada hoja se refiere a una decisión (etiquetada con una de las clases del problema).
Un árbol de decisión puede utilizarse para clasificar un ejemplo concreto comenzando en su raíz y siguiendo el camino determinado por las respuestas a las preguntas de los nodos internos hasta que se llega a una hoja del árbol. Su funcionamiento es análogo al de una aguja de ferrocarril: cada caso es dirigido hacia una u otra rama de acuerdo con los valores de sus atributos al igual que los trenes cambian de vía según su destino (las hojas del árbol) en función de la posición de las agujas de la red de ferrocarriles (los nodos internos). Los árboles de clasificación son útiles siempre que los ejemplos a partir de los que se desea aprender se puedan representar mediante un conjunto prefijado de atributos y valores, ya sean estos discretos o continuos. Sin embargo, no resultan demasiado adecuados cuando la estructura de los ejemplos es variable. Tampoco están especialmente indicados para tratar con información incompleta (cuando aparecen valores desconocidos en algunos atributos de los casos de entrenamiento) y pueden resultar problemáticos cuando existen dependencias funcionales en los datos del conjunto de entrenamiento (cuando unos atributos son función de otros).
En principio, se busca la obtención de un árbol de decisión que sea compacto. Un árbol de decisión pequeño nos permite comprender mejor el modelo de clasificación obtenido y, además, es probable que el clasificador más simple sea el correcto, pero no se garantiza que estos modelos sean más eficientes que los modelos que aparentemente son más complejos.
Por desgracia, no podemos construir todos los posibles árboles de decisión derivados de un conjunto de casos de entrenamiento para quedarnos con el más pequeño. Dicho problema es NP completo. La construcción de un árbol de decisión a partir del conjunto de datos de entrada se suele realizar de forma descendente mediante algoritmos greedy de eficiencia de orden O(nlogn), siendo n el número de ejemplos incluidos en el conjunto de entrenamiento.
Los árboles de decisión se construyen recursivamente siguiendo una estrategia descendente, desde conceptos generales hasta ejemplos particulares. Esa es la razón por la cual el acrónimo TDIDT, que proviene de “Top-Down Induction on Decisión Trees", se emplea para hacer referencia a la familia de algoritmos de construcción de árboles de decisión.
Una vez que se han reunido los datos que se utilizaran como base del conjunto de entrenamiento, se descartan a priori aquellos atributos que sean irrelevantes utilizando algún método de selección de características y, finalmente, se construye el árbol de decisión recursivamente
48

2. Algoritmo básico de aprendizaje de los árboles de decisión
La mayoría de los algoritmos para inferir árboles de decisión son variaciones de un algoritmo básico que emplea una búsqueda descendente (top-down) y egoísta (greedy) en el espacio de posibles árboles de decisión. La presentación de estos algoritmos se centra en ID35.
El algoritmo básico ID3, construye el árbol de decisión de manera descendente, comenzando por preguntarse: ¿Qué atributo debería ser colocado en la raíz del árbol? Para responder esta pregunta, cada atributo es evaluado usando un test estadístico para determinar que tan bien clasifica el solo los ejemplos de entrenamiento. El mejor atributo es seleccionado y colocado en la raíz del árbol.
Una rama y su nodo correspondiente es entonces creada para cada valor posible del atributo en cuestión. Los ejemplos de entrenamiento son repartidos en los nodos descendentes de acuerdo al valor que tengan para el atributo de la raíz. El proceso entonces se repite con los ejemplos ya distribuidos, para seleccionar un atributo que sería colocado en cada uno de los nodos generados. Generalmente, el algoritmo se detiene si los ejemplos de entrenamiento comparten el mismo valor para el atributo que está siendo probado. Este algoritmo lleva a cabo una búsqueda egoísta de un árbol de decisión aceptable, sin reconsiderar nunca las elecciones pasadas (backtracking). La forma en que determinamos que árbol es aceptable y cual no lo es, es la siguiente:
i) El árbol de decisión requiere de menos atributos para llegar a una conclusión, es decir, que el árbol hace menos preguntas para llegar a un nodo hoja.
ii) El árbol nunca llega a un evento imposible, es decir, el árbol jamás llega a un estado desconocido.
Del árbol generado en base a este algoritmo podemos obtener reglas fácilmente ya que cada nodo interno representa una pregunta y cada hoja representa una respuesta o conclusión a la pregunta, estas regla tienen la forma “si [atributo del nodo interno] entonces [clase de la hoja]”, cabe mencionar que no solo con una pregunta se puede encontrar una respuesta por lo que en general (en árboles muy complejos) se tienen muchos “si… entonces” anidados.
2.1 Entropía
Como mencionamos anteriormente el árbol de decisión utiliza un método estadístico para determinar cual es el mejor atributo y de esta forma lograr un árbol compacto (de menos niveles), este método es llamado “Entropía” y funciona de la siguiente forma:
1. Para cada atributo Ak, k=1 hasta numero de atributos se obtiene su entropía en base al calculo de:
5 Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997.
49

))(log)()(()( ,2,1,1 jkijkiNijk
Mjk acpacpapAH k ∑∑ == −=
Donde:)( kAH : Entropía del atributo kA
)( , jkap : Probabilidad de que el atributo k tenga el valor j
)( , jki acp : Probabilidad de que la categoría tenga valor ci cuando el atributo k tiene valor j
Mk: Numero total de valores del atributo Ak
N: Numero total de categorías
2. Se determina cual atributo tiene menor entropía y ese es que se pone a la raíz3. Ya que se tiene un atributo a la raíz se vuelve a calcular la entropía de los atributos restantes sin
considerar los valores del atributo de la raíz, es decir que para la nueva iteración se tendrán N-1 categorías (por que descontamos a la raíz).
En este algoritmo hay que tener cuidado con los datos inconsistentes (que tengan los mismos valores en los atributos pero que pertenezcan a categorías distintas), para poder tratarlos quizás sea necesario agregar un atributo mas que haga diferencia entre las categorías. El algoritmo permite tratar con datos continuos y también se puede optimizar por medio de podas al árbol.
3. Reglas de poda
Los algoritmos TDIDT usualmente presuponen que no existe ruido en los datos de entrada e intentan obtener una descripción perfecta de tales datos. A veces, esto resulta contraproducente en problemas reales, donde se requiere un tratamiento adecuado de la incertidumbre y de la información con ruido presentes en los datos de entrenamiento.
Por desgracia, el método recursivo de construcción de árboles de decisión continúa dividiendo el conjunto de casos de entrenamiento hasta que encuentra un nodo puro o no puede encontrar ninguna forma de seguir ramificando el árbol actual.
La presencia de ruido suele ocasionar la generación de árboles de decisión muy complejos que sobreajustan los datos del conjunto de entrenamiento. Este sobreaprendizaje limita considerablemente la aplicabilidad del modelo de clasificación aprendido. Para evitarlo, las técnicas de poda han demostrado ser bastante útiles. Aquellas ramas del árbol con menor capacidad de predicción se suelen podar una vez que el árbol de decisión ha sido construido por completo.
Un árbol de decisión se puede simplificar eliminando un subárbol completo a favor de una única hoja. También se puede sustituir un subárbol por una de sus ramas (la rama del subárbol más usada).
50

La poda se suele aplicar después de construir el árbol completo (post-poda), ya que la correcta estimación a priori del beneficio obtenido al simplificar un árbol durante su construcción (pre-poda) es muy difícil.
La poda ha de realizarse en función de algún estimador honesto (no sesgado) del error de clasificación del árbol de decisión.
A continuación se comentan algunos de los métodos de poda de árboles de decisión más comunes: la poda por estimación del error, la poda por coste-complejidad y la poda pesimista.
3.1 Poda por estimación del error
Un nodo se poda si el error de resustitución del nodo considerado como hoja es menor que el error de resustitución del subárbol cuya raíz es el nodo.
Este método requiere reservar un conjunto de casos para evaluar cuando es necesaria la poda, por lo cual no se podrían utilizar todos los casos disponibles para construir el árbol de decisión.
Cuando no se dispone de muchos datos, no obstante, aun se puede emplear la poda por estimación del error recurriendo a algún tipo de validación cruzada con el fin de obtener mejores resultados.
3.2 Poda por coste-complejidad
Esta técnica de poda, utilizada en CART, intenta llegar a un compromiso entre la precisión y el tamaño del árbol.
La complejidad del árbol viene dada por el numero de nodos terminales (hojas) que posee. Si T es el árbol de decisión usado para clasificar N casos de entrenamiento y se clasifican mal M ejemplos, la medida de coste-complejidad de T para un parámetro de complejidad α es:
Donde: l (T) es el numero de hojas del árbol T y R (T) = M/N es un estimador del error de T. Es decir, Rα
(T) es una combinación lineal del coste del árbol y de su complejidad.
El árbol podado será el subárbol de mínimo error, aquel que minimice la medida de coste-complejidad Rα(T). Hay que resaltar que conforme el parámetro de complejidad α crece, el tamaño del árbol que minimiza Rα(T) decrece.
La poda por coste-complejidad se puede realizar utilizando un conjunto de prueba independiente del conjunto de entrenamiento o bien validación cruzada.
51

3.3 Poda pesimista
La poda pesimista utiliza solo el conjunto de casos de entrenamiento con los que se construye el árbol, con lo que nos ahorramos tener que reservar casos para realizar la simplificación del árbol.
Cuando una hoja del árbol cubre N casos de entrenamiento, de los cuales E casos son clasificados incorrectamente, su error de resustitución es E/N. El estimador del error de resustitución asociado a un subárbol será, como es lógico, la suma de los errores estimados para cada una de sus ramas.
La probabilidad real del error cometido no se puede determinar con exactitud pero si se puede establecer un intervalo dado un grado de confianza CF, a partir del cual se estima la probabilidad del error UCF (E,N) usando una distribución binomial.
Se poda un subárbol si el intervalo de confianza del error de resustitución (generalmente de amplitud dos veces el error estándar) incluye el error de resustitución del nodo si se trata como una hoja. De esta forma se eliminan los subárboles que no mejoran significativamente la precisión del clasificador. El método es tan cuestionable como cualquier heurística pero suele producir resultados aceptables.
4. Sobreajuste con los datos de entrenamiento
El algoritmo básico de ID3 crece cada rama del árbol en profundidad hasta que logra clasificar perfectamente los ejemplos de entrenamiento. Esta estrategia es razonable, pero puede introducir dificultades si los datos de entrenamiento presentan ruido, o cuando el conjunto de entrenamiento es demasiado pequeño, como para ofrecer un muestreo significativo del concepto objetivo. En estos casos, ID3 puede producir árboles que se sobreajustan a los datos de entrenamiento
Es común observar que a medida que el tamaño del árbol crece, en termino del numero de nodos usado, su precisión sobre el conjunto de entrenamiento mejora monotonicamente, pero, sobre el conjunto de prueba primero crece y luego decae. Esta situación se da por ejemplo cuando los datos están mal clasificados
Existe la posibilidad de sobreajuste, aún cuando el conjunto de entrenamiento esté libre de ruido, por ejemplo, si el conjunto de entrenamiento tiene pocos elementos. En conjuntos de entrenamiento pequeños es fácil encontrar regularidades accidentales en donde un atributo puede particionar muy bien los ejemplos dados, aunque no esté relacionado con el concepto objetivo.
Puesto que el sobreajuste puede reducir la precisión de un árbol inducido por ID3 entre un 10 a 25 %, diferentes enfoques han sido propuestos para evitar este fenómeno. Los enfoques pueden agruparse en dos clases:
52

• Enfoques que detienen el crecimiento del árbol anticipadamente, antes de que alcance un punto donde clasifique perfectamente los ejemplos de entrenamiento.
• Enfoques en donde se deja crecer el árbol para después podarlo.
Aunque el primer enfoque parezca más directo, la poda posterior del árbol ha demostrado tener más éxito en la práctica. Esto se debe a la dificultad de estimar en que momento debe detenerse el crecimiento del árbol. Independientemente del enfoque usado, una pregunta interesante es: ¿Cual es el tamaño correcto de un árbol? Algunos enfoques para responder a esta pregunta incluyen:
• Usar un conjunto de ejemplos, diferentes de los usados en el entrenamiento, para evaluar la utilidad de eliminar nodos del árbol.
• Usar los ejemplos disponibles para el entrenamiento, pero aplicando una prueba para estimar cuando agregar o eliminar un nodo, podría producir una mejora al clasificar nuevos ejemplares, por ejemplo, usar el test χ2 para evaluar si al expandir un nodo, el cambio mejoraría la clasificación sobre los ejemplos de entrenamiento, o sobre toda la distribución.
• Usar explícitamente una medida de complejidad para codificar los ejemplos de entrenamiento y el árbol de decisión, deteniendo el crecimiento cuando el tamaño codificado sea minimizado. Por ejemplo, el principio de descripción mínima (MDL).
5. Implementación de un árbol de decisión para Nettalk
5.1 Descripción general del problema
De igual forma que con las redes neuronales buscamos un clasificador que nos ayude a resolver el problema de clasificar fonemas, en el caso de las redes neuronales los datos recibían un preprocesamiento para después realizar sobre los mismo una codificación, es decir, convertir de los caracteres que escribimos a fonemas y de estos fonemas pasar a vectores binarios con una codificación especifica por cada fonema en base a los fonemas validos para le sintetizador de voz Mbrola.
Para el caso de Árboles de Decisión no es necesario convertir a los fonemas en vectores binarios, por lo que al menos ese procesamiento se elimina, con lo que por consiguiente significa un ahorro en tiempo de procesamiento. Ahora trataremos de explicar como se lleva acabo la solución de este problema.
Es evidente ver que necesitaremos de algún medio para poder leer de archivo y guardar información en archivos por lo que las clases descritas en el capitulo 1 LectorCaracteres y EscritorPattern nos pueden servir para tal propósito, además necesitamos de un medio para quitar del archivo tanto de entrenamiento como de pruebas los caracteres que no nos interesen, esto se puede realizar con la clase LimpiaTexto que ya teníamos.
53

Ahora trataremos la forma de crear el archivo que entrenara al árbol. Primero debemos observar que un archivo de este tipo necesita de la definición de atributos y clases, entonces el primer paso será definir los valores de los atributos en el contexto de NETTalk, cuantos atributos hay y la forma de clasificar a los atributosSe podría definir como valor de un atributo al tipo de fonema que se esta utilizando, por ejemplo, si el fonema en cuestión es consonante o vocal, definiríamos a un atributo con valor consonante o como vocal según sea el caso. Para definir el número de atributos que vamos a contemplar es necesario experimentar con el tamaño de ventana, dependiendo de cual de un mejor rendimiento se utilizara ese tamaño para generar el archivo de entrenamiento.
Hasta este punto hemos tratado dos cosas: una la generación del archivo de entrenamiento, y la partición en ventanas del archivo de texto. El programa que realiza esta operación ya fue elaborado en el capitulo 1 por lo que lo vamos a utilizar para el mismo propósito en este capitulo.
La forma de clasificación de fonemas es por demás obvia, ya que si lo que necesitamos es encontrar los fonemas por tanto debemos clasificar de tal forma que obtengamos fonemas que el sintetizador de voz reconozca. Por lo tanto el proceso de generación de un archivo de entrenamiento suponiendo una ventana de tamaño 7 seria:
Don quijote de la mancha Texto
don kijote de la man*a Texto con los fonemas que reconoce el sintetizador
don don k don kidon kijon kijo Texto partido en ventanasn kijot kijotekijote ijote djote deote de te de le de la de la de la me la ma la manla man*
54

a man*a man*a man*a an*a n*a
Archivo de entrenamiento
var[0]var[1]var[2]var[3]var[4]var[5]var[6]fonemaE E E d o n E do E d o n E k oE d o n E k i nd o n E k i j _o n E k i j o kn E k i j o t iE k i j o t e jk i j o t e E oi j o t e E d tj o t e E d e eo t e E d e E _t e E d e E l de E d e E l a eE d e E l a E _d e E l a E m le E l a E m a aE l a E m a n _l a E m a n * ma E m a n * a aE m a n * a E nm a n * a E E tSa n * a E E E a
Cabe mencionar que todos los atributos deben algún valor por lo que al tener silencios se debe tener algún valor y además este valor no debe ser alguno conocido por el sintetizador para evitar conflictos con el. En este ejemplo utilizamos como valores de los atributos el fonema que corresponde.
Una vez que tenemos este archivo de entrenamiento debemos tener alguna forma de crear el árbol, en un principio utilizamos una clase en JAVA que genera el árbol para pode hacer experimentación y encontrar un árbol bastante bueno, la clase no poda el árbol pero la suposición es que si encontramos un buen árbol que aún no se ha podado al podarlo debería ser mas eficiente.
55

La clase de JAVA genera otra clase que contiene el árbol ya entrenado, por lo que hacer pruebas con esta clase es muy sencillo y solo debemos ingresar los datos según los requiera, para lograr esto creamos una clase en JAVA con la que realizamos pruebas con el árbol ya entrenado. Las pruebas consistirán en cambiar el tamaño de la ventana y cambiar los valores de los atributos.
5.2 Descripción del programa
Clase: LectorCaracteresDescripción: Descrita en el capitulo 1
Clase: Escritor PatternDescripción: Descrita en el capitulo 1
Clase: LimpiaTextoDescripción: Descrita en el capitulo 1
Clase: CreaArchivosVentanasDescripción: Descrita en el capitulo 1
Clase: GeneradorPattern
Descripción: Esta clase se modifico de la clase descrita en el capitulo 1 para que genere un archivo de entrenamiento de la forma que requiere la clase que genera el árbol de decisión.
Atributos:m_lcVentanas: LectorCaracteres, contiene la referencia a el archivo que contiene la partición en ventanas.m_lcFonemas: LectorCaracteres, contiene la referencia al archivo que contiene los fonemas centrales de cada ventanam_epVentanas: EscritorPattern, contiene la referencia al archivo donde se va a almacenar el archivo de entrenamiento num_ventanas: entero, contiene el numero de ventanas generadas por la clase CreaArchivosVentanastam_ventana: entero, contiene el tamaño de la ventana definida por el usuario
Métodos:a) GeneradorPatternpublic GeneradorPattern(String origen, String origenLimpio, String nomArchVentanas, String nomArchCaracteres, String nomArchFonemas, int tamVentanas, String nomSalida){
CreaArchivosVentanas cav=new CreaArchivosVentanas(origen,origenLimpio,nomArchVentanas,nomArchCaracteres,nomArchFonemas,tamVentanas);
cav.creaArchivos();num_ventanas=cav.leeNumeroVentanas();tam_ventana=tamVentanas;
56

m_lcVentanas=new LectorCaracteres(nomArchVentanas);m_lcFonemas=new LectorCaracteres(nomArchFonemas);m_epVentanas=new EscritorPattern(nomSalida);
}
Este método realiza la inicialización de las variables de estado de la clase
b) creaArchivoEste método se encarga de escribir la cabecera del archivo de entrenamiento que requiere la clase que genera el árbol, además de darle a cada entrada de la ventana su valor correspondiente como atributo y escribir el fonema correspondiente al fonema central. El archivo que genera como salida tiene la forma siguiente:
var[0]var[1]var[2]var[3]var[4]var[5]var[6]fonema//***********************************************E E E d o n E do E d o n E k oE d o n E k i nd o n E k i j _o n E k i j o kn E k i j o t iE k i j o t e jk i j o t e E oi j o t e E d tj o t e E d e e
c) creaPatternEntradaEste método se encarga de darle un valor a cada registro de la ventana, es decir, toma el carácter actual de la ventana y los codifica como consonante o vocal (por ejemplo)Ejemplo:d creaPatternEntrada co creaPatternEntrada vn creaPatternEntrada c
Clase: GeneradorPruebas
Descripción: Esta clase sirve para generar un archivo similar al de entrenamiento con la diferencia de que no tiene cabecera ni tiene una clase asociada, sirve como entrada para la clase del árbol y permitirá facilitar la experimentación
Atributos:m_lcVentanas: LectorCaracteres, contiene la referencia a el archivo que contiene la partición en ventanas.
57

m_lcFonemas: LectorCaracteres, contiene la referencia al archivo que contiene los fonemas centrales de cada ventanam_epVentanas: EscritorPattern, contiene la referencia al archivo donde se va a almacenar el archivo de entrenamiento num_ventanas: entero, contiene el numero de ventanas generadas por la clase CreaArchivosVentanastam_ventana: entero, contiene el tamaño de la ventana definida por el usuario
Métodos:a) GeneradorPruebaspublic GeneradorPruebas(String origen, String origenLimpio, String nomArchVentanas, String nomArchCaracteres, String nomArchFonemas, int tamVentanas, String nomSalida){
CreaArchivosVentanas cav=new CreaArchivosVentanas(origen,origenLimpio,nomArchVentanas,nomArchCaracteres,nomArchFonemas,tamVentanas);
cav.creaArchivos();num_ventanas=cav.leeNumeroVentanas();tam_ventana=tamVentanas;m_lcVentanas=new LectorCaracteres(nomArchVentanas);m_lcFonemas=new LectorCaracteres(nomArchFonemas);m_epVentanas=new EscritorPattern(nomSalida);
}
Constructor de la clase que permite inicializar las variables de estado
b) creaArchivoEste método permite crear un archivo similar al de entrenamiento pero sin la cabecera ni clase asociada, el archivo de salida tiene la siguiente forma:
E E E d o n Eo E d o n E kE d o n E k id o n E k i jo n E k i j on E k i j o tE k i j o t ek i j o t e Ei j o t e E dj o t e E d e
La clase del árbol requiere otra forma de obtener los datos, la clase los necesita en forma de matriz de caracteres, por lo que además de crear el archivo genera una matriz de este tipo para satisfacer las necesidades de la clase del árbol.
c) creaPatternEntrada
58

Realiza la misma función que el método creaPatternEntrada de la clase GeneradorPattern
d) leeNumeroVentanasPermite leer el numero de ventanas generadas por la clase CreaArchivosVentanas
e) leeTamanoVentanaPermite leer el tamaño de ventana que el usuario a definido
Clase: ID3Descripción: Esta clase genera un árbol de decisión sin podar empleando el criterio de entropía para determinar que nodo es el mejor
Atributos:numAttributes: entero, numero de atributos incluyendo el atributo de salidaattributeNames: String[], los nombres de todos los atributos en un arreglo de dimensión numAttributes domains: Vector[], cada elemento de este vector contiene valores para el correspondiente atributoClase para representar un dato que consiste de numAttributes valoresclass DataPoint {
//los valores de todos los atributos están es este arreglo, el i-esimo elemento
// es el índice en el vector de domains que representa el valor //simbólico del //atributopublic int []attributes;public DataPoint(int numattributes) {
attributes = new int[numattributes];}
};
Esta clase representa un nodo en la descomposición del árbolclass TreeNode {
public double entropy; //La entropía de un dato si el nodo es una hoja
public Vector data; //Conjunto de datos si el nodo es hojapublic int decompositionAttribute;// Si el nodo no es hoja, este atributo se usa para dividir el conjunto de datospublic int decompositionValue; //Si el nodo no es hoja es el valor usado para dividir el conjunto de datospublic TreeNode []children; //Si no es un nodo hoja se utiliza para referenciar a los nodos hijospublic TreeNode parent; //El padre de este nodo, el raíz tiene
parent=nullpublic TreeNode() { //Construcctor
data = new Vector();}
};
TreeNode root = new TreeNode(); //Es la raíz del árbol
59

private EscritorPattern m_ep; //Contiene una referencia a el lugar donde se creara la clase de Árbol y su nombre
Methods:a) ID3public ID3(String archivoEntrada){
m_ep=new EscritorPattern(archivoEntrada);}Constructor de la clase que recibe el lugar y nombre de la clase de Árbol
b) getSymbolValuepublic int getSymbolValue(int attribute, String symbol) {
int index = domains[attribute].indexOf(symbol);if (index < 0) {
domains[attribute].addElement(symbol);return domains[attribute].size() -1;
}return index;
}Regresa un entero que es el valor simbólico del atributo, si el símbolo no existe en el vector de domain, es adicionado al índice del atributo
c) getAllValuespublic int []getAllValues(Vector data, int attribute) {
Vector values = new Vector();int num = data.size();for (int i=0; i< num; i++) {
DataPoint point = (DataPoint)data.elementAt(i);String symbol =
(String)domains[attribute].elementAt(point.attributes[attribute] );int index = values.indexOf(symbol);if (index < 0) {
values.addElement(symbol);}
}
int []array = new int[values.size()];for (int i=0; i< array.length; i++) {
String symbol = (String)values.elementAt(i);array[i] = domains[attribute].indexOf(symbol);
}values = null;return array;
}Regresa todos los valores del atributo especificado del conjunto de datos
d) getSubset
60

public Vector getSubset(Vector data, int attribute, int value) {Vector subset = new Vector();
int num = data.size();for (int i=0; i< num; i++) {
DataPoint point = (DataPoint)data.elementAt(i);if (point.attributes[attribute] == value)
subset.addElement(point);}return subset;
}Regresa un subconjunto de datos del atributo especificado
e) getComplement
public Vector getComplement(Vector data, Vector oldset) {Vector subset = new Vector();
int num = data.size();for (int i=0; i< num; i++) {
DataPoint point = (DataPoint)data.elementAt(i);int index = oldset.indexOf(point);if (index < 0) subset.addElement(point);
}return subset;
}Regresa un subconjunto de datos que es el complemento del segundo argumento
f) calculateEntropy
public double calculateEntropy(Vector data) {
int numdata = data.size();if (numdata == 0) return 0;
int attribute = numAttributes-1;//System.out.println(attribute + " attribute ");int numvalues = domains[attribute].size();double sum = 0;for (int i=0; i< numvalues; i++) {
int count=0;for (int j=0; j< numdata; j++) {
DataPoint point = (DataPoint)data.elementAt(j);if (point.attributes[attribute] == i) count++;//System.out.println( i + "\t" + j + ": " +
point.attributes[attribute] );}double probability = 1.*count/numdata;if (count > 0) sum += -probability*Math.log(probability);
61

}return sum;
}
Calcula la entropía del conjunto de datos. La entropía es calculada usando los valores del atributo de salida que es el último elemento del arreglo de atributos.
g) alreadyUsedToDescompose
public boolean alreadyUsedToDecompose(TreeNode node, int attribute, int value) {if (node.children != null) {
if (node.decompositionAttribute == attribute && node.decompositionValue == value)
return true;}if (node.parent == null) return false;return alreadyUsedToDecompose(node.parent, attribute, value);
}
Esta función revisa si el atributo y su valor son usados para descomponer el conjunto de datos en cualquiera de los nodos padres
h) decomposeNode
Recibe un nodo y lo descompone de acuerdo al algoritmo de ID3. Recursivamente divide a todos los nodos hijos hast que no es posible dividir otra vez
i) readData
Este método sirve para leer los datos del archivo. La primera línea debe contener los nombres de los atributos y el número de atributos se infiere de aquí. Cada línea subsiguiente contiene el valor del atributo. Si una línea inicia con “//” es ignorada.
j) printTree
Imprime el árbol de decisión en forma de reglas. La forma de las reglas es:Atributo de salida = "valor simbolico"oAtributo de salida = {“Valor1", "Valor2",.. }
La segunda forma es imprimir si el nodo no puede ser descompuesto de ninguna forma dentro de un conjunto homogéneoAdemás crea una parte de la clase Árbol que corresponde a las reglas del árbol de decisión.
k) createDecisionTree
62

Esta función crea el árbol de decisión e imprime las reglas en consola, además crea los renglones correspondientes al package de la clase, los import, el nombre de la clase, el nombre del método, las variables locales y el valor de retorno.
Clase: ÁrbolDescripción: Esta clase representa al árbol de decisión ya entrenado
Atributos:No requiere
Métodos:a) tipoFonema
Este método recibe un vector de cadenas y lo que hace es que dependiendo del valor de cada entrada del arreglo va haciendo preguntas hasta llegar a recomendar un fonema en específico
Clase: TestID3Descripción: Esta clase permite hacer pruebas con la clase de ID3 para poder determinar cual árbol es mejor
Atributos:No requiere
Métodos:a) main
Este método hace una instancia de la clase GeneradorPattern para que realice el archivo de entrenamiento que será utilizado por la clase ID3, también instancia objetos de las clases ID3, Árbol, GeneradorPruebas y EscritorPattern. La instancia de ID3 genera la clase de Árbol, la clase de GeneradorPruebas hace uso de la clase de Árbol y con la clase de Árbol es como se pueden hacer pruebas del árbol que genero la clase ID3, por último la clase EscritorPattern genera un archivo de tipo Mbrola para poder escuchar que es lo que el árbol de decisión clasifica.
63

CAPITULO III. Redes recurrentes 1. La red neuronal recurrente de Elman
La red de Elman[2] típicamente posee dos capas, cada una compuesta de una red tipo Backpropagation, con la adición de una conexión de realimentación desde la salida de la capa oculta hacia la entrada de la misma capa oculta, esta realimentación permite a la red de Elman aprender a reconocer y generar patrones temporales o variantes con el tiempo.
La red de Elman generalmente posee neuronas con función transferencia sigmoidal en su capa oculta y neuronas con función de transferencia tipo lineal en la capa de salida, en esta caso purelin, la ventaja de la configuración de esta red de dos capas con este tipo de funciones de trasferencia, es que según lo demostrado por Funahashi, puede aproximar cualquier función con la precisión deseada mientras que esta posea un numero finito de discontinuidades, para lo cual la precisión de la aproximación depende de la selección del número adecuado de neuronas en la capa oculta.
Para la red de Elman la capa oculta es la capa recurrente y el retardo en la conexión de realimentación almacena los valores de la iteración previa, los cuales serán usados en la siguiente iteración; dos redes de Elman con los mismos parámetros y entradas idénticas en las mismas iteraciones podrían producir salidas diferentes debido a que pueden presentar diferentes estados de realimentación.
Debido a la estructura similar de la red de Elman con una red tipo Backpropagation, esta red puede entrenarse con cualquier algoritmo de propagación inversa como los explicados en las secciones anteriores a este capitulo, entre los cuales se destacan los algoritmos basados en técnicas de optimización como el del gradiente conjugado.
El entrenamiento de la red puede resumirse en los siguientes pasos:
Presentar a la red, los patrones de entrenamiento y calcular la salida de la red con los pesos iniciales, comparar la salida de la red con los patrones objetivo y generar la secuencia de error.
64

Propagar inversamente el error para encontrar el gradiente del error para cada conjunto de pesos y ganancias,
Actualizar todos los pesos y ganancias con el gradiente encontrado con base en el algoritmo de propagación inversa.
La red de Elman no es tan confiable como otros tipos de redes porque el gradiente se calcula con base en una aproximación del error, para solucionar un problema con este tipo de red se necesitan más neuronas en la capa oculta que si se solucionara el mismo problema con otro tipo de red.
2. Creación de una red recurrente simple con SNNS
En esta sección describiremos detalladamente la implementación de una red recurrente simple – con dos entradas y una salida – que nos ayudará posteriormente a comprender mejor la estructura propuesta para resolver nuestro problema principal: Realizar un mapeo de texto a fonemas utilizando una red neuronal, pero evitando utilizar “ventanas” que aumenten la complejidad de la estructura de la red. Es decir, nuestro objetivo final es verificar si es factible utilizar una red cuya estructura permita el mapeo uno a uno de los caracteres en un texto, de tal modo que a la salida de la red obtengamos la codificación fonética del texto.
La primera observación a considerar es que, dada su flexibilidad, SNNS permite realizar casi cualquier arquitectura de red imaginable, de este modo y para fines demostrativos nuestra primera tarea es crear una red de Elman para resolver un problema relativamente sencillo que nos permitirá generalizar la idea hasta extenderla en el desarrollo de una arquitectura de red recurrente que resuelva nuestro problema del mapeo de texto a fonemas.
El flip flop RS
Un biestable, también llamado báscula (flip-flop en inglés), es un multivibrador capaz de permanecer en un estado determinado o en el contrario durante un tiempo indefinido. Esta característica es ampliamente utilizada en electrónica digital para memorizar información.
El slip flor RS tiene dos entradas (y una más para el reloj), que determinan el estado de salida dependiendo en las entradas y en ocasiones en el estado anterior.
flip flop RS
65

Como se puede observar en la tabla, cuando las entradas al slip flor RS son puestas ambas a cero, el estado que resultará en la salida permanece sin cambio del estado anterior.
Esto es representa perfectamente el tipo de comportamiento que estamos pretendiendo simular, es decir, podemos crear una red recurrente cuyas entradas corresponden solamente a los valores de R y de S en un flip flop de este tipo y con ayuda de una capa de retardo, haremos que la red “recuerde” su estado anterior al mismo tiempo que permite que la entrada de los valores determine la salida. Así, extendiendo esta idea al caso del mapeo texto a fonemas. Lograremos una estructura que incluya el contexto de los caracteres en la arquitectura misma de la red. Aparentemente, si la idea funciona para simular un flip flop tipo RS, debería funcionar también para el mapeo.
2.1 Una arquitectura propuesta
A continuación se discute la arquitectura propuesta para resolver el problema del flip flor RS y se explica como se extenderá la idea al mapeo. La figura muestra un diagrama de la red recurrente simple propuesta.
Se puede ver que la red solo tiene dos entradas ( R y S ) pero, en la salida Q esperamos que cuando los valores de entrada sean ambos cero. Q( t ) sea Q ( t-1 ), o lo que es lo mismo, para la entrada de la época t+1 esperamos que el valor de salida Q( t+1 ) sea igual al valor anterior, o sea Q ( t ). Esa es precisamente la funcionalidad que esperamos obtener de la capa de retardo, que sin necesidad de ampliar la entrada de
.
.
.
.
.
.
Archivode entradasa la red
Archivodesalidasde la red
R
S
Q
66
Retardo

la red, se tenga una idea del contexto en el que se encuentra la entrada, en este caso, cuál fue el valor anterior en la salida.
Para el caso del mapeo de texto a fonemas la idea es muy similar. Por ejemplo, supongamos que el texto de entrada es el siguiente:acuerdo acentoevidentemente lo que deseamos como resultado del mapeo es lo siguiente*:
[a][k][u][e][r][d][o][_][a][s][e][n][t][o]Sin embargo, como se vio anteriormente para lograr que la primera ‘c’ sea codificada correctamente con un fonema ‘k’ o ‘s’ es necesario indicar a la red el contexto del carácter. En el caso del perceptrón multicapa se pueden lograr buenos resultados agregando lo que en capítulos anteriores denominamos ventanas pero con este paradigma se tienen algunas desventajas, por ejemplo: el tiempo de procesamiento es lento y el uso de una gran cantidad de recursos empleados resultó inevitable. Aún con esto, el punto más importante a observar es la complejidad de la estructura de la red. Como recordaremos a la entrada del perceptrón utilizado anteriormente debía incluir una entrada por cada bit de codificación de un carácter, y en el caso de ventanas de cinco caracteres, (27 bits de codificación por carácter) * (5 caracteres) = 135 entradas a la red. Esto, a primera vista, no resulta trivial para cualquier persona que este dispuesta a entender la arquitectura.
Lo que se propone, es crear una red que a la entrada contenga solamente el número de bits necesarios para codificar un carácter. Esto es, queremos utilizar una red recurrente que en la capa de entrada reciba una letra (codificada en binario) y cuya salida sea un fonema que es la trascripción del carácter de entrada, considerando, por supuesto, el contexto del carácter en las capas ocultas de la red.Gráficamente:
a [a]c [k]u [u]e [e]r [r]d [d]o [o] [_]a [a]c [s]e [e]n [n]t [t]o [o]
* La codificación fonémica esta dada directamente en simbología MBROLA
67
tiempo
Red recurrente

2.2 Estructura de la red recurrente.
La topología de Elman utilizada resultó simple:
La primera capa está conformada por 28 unidades, cada una de las cuales recibe a su entrada el valor correspondiente del bit de la posición en el carácter previamente codificado. Dicho valor se recibe directamente del archivo de pattern creado creado para este propósito. Más adelante se describe el módulo.
La segunda capa corresponde a una capa oculta con 60 unidades. Cada unidad de esta capa recibe dos conexiones entrantes, una de la capa de entrada y una de su unidad correspondiente en su capa de contexto, tiene una conexión de salida a la capa de salida.
La tercera capa es la correspondiente a la capa de salida. Como en la capa oculta, Cada unidad de esta capa recibe dos conexiones entrantes, una de la capa oculta y una de su unidad correspondiente en su capa de contexto. La salida de esta red se puede captar en un archivo de resultados que posteriormente será procesado para verificar el mapeo en un archivo que sea reconocible por el sintetizador MBROLA, los módulos que realizan estas tareas se describen posteriormente.
Las capas de contexto descritas anteriormente son capas ocultas especiales que mantienen los estados anteriores a la redistribución de pesos de alguna capa, es decir, mantienen el contexto de la capa a la cual están conectadas. En este caso, la capa oculta cuenta con su capa de contexto que mantiene los pesos del tiempo t-1 en el tiempo t. Cada unidad de la capa de contexto tiene una correspondencia 1 a 1 con la capa a la cual está conectada, recibe una conexión de dicha capa, tiene una conexión cíclica hacia sí misma y envía una conexión de regreso a la unidad que le fue asignada.
En SNNS esta configuración no resulta tan flexible como otras, dado que este tipo de redes es considerada especial en el sentido de que contiene ciclos y es por esto que mediante la herramienta BIGNET descrita anteriormente se puede crear una red Elman pero existen muy pocos parámetros en su creación.
En resumen, la configuración topológica de la red de Elman empleada se describe en la tabla:
68

Capa de entrada Capa oculta Capa de salida
Numero de unidades 28 60 26Conexiones
entrantes28 desde archivo de patterns 1740 1586
Conexiones salientes 1680 1620
52. 26 hacia archivo de
resultados y 26 hacia la capa de
contexto
Capa de contexto no Sí Sí
Unidades en la capa de contexto
0 60 26
El diagrama de la topología se muestra a continuación:
2.3 Inicialización de lo pesos con la función JE_Weights
La función de inicialización de los pesos con la función JE_Weights requiere los siguientes cinco parámetros:
1. α, β: los valores del intervalo en el cual los pesos de las conexiones forward serán inicializados. Los valores seleccionados fueron [-1.0, 1.0].
2. λ: el peso de las conexiones de las unidades de contexto a ellas mismas. El valor de esté parámetro fue 0.0.
.
.
.
.
.
....
.
.
.
.
.
.
.
.
.
Archivode entradasa la red
Archivodesalidasde la red
.
.
.
69

3. γ: el peso de las conexiones de las unidades de contexto a otras unidades. El valor seleccionado fue 1.0 .
4. ψ: el valor de la activación de las unidades de contexto. Se seleccionó el valor de 0.0.
2.4 Función de aprendizaje
En SNNS, cuando se crea una red de Elman las entradas de las unidades de contexto tienen dos componentes, la primera es un vector con el patrón entrante a la capa y la segunda es un vector de estado de la capa a la que hace referencia. Dicho vector se actualiza con cada paso de la función de aprendizaje. En este sentido, el algoritmo de backpropagation puede ser fácilmente modificado para entrenar este tipo de red de la siguiente manera:
1. Inicialización de las unidades de contexto2. Ejecución de secuencia de entrenamiento.
La función JE_BP fue creada especialmente para este tipo de arquitecturas y sus parámetros son los siguientes:
Eta: es el ya conocido parámetro de aprendizaje. Dado que en la implementación el entrenamiento se efectuó en diversos ciclos, en ocasiones se eligió algún valor alto como 0.70 y en ocasiones un valor pequeño como 0.05, dependiendo del comportamiento del error registrado.
Momentum: es también el ya conocido parámetro de backpropagation con momentum. En esta implementación se eligió el valor de 0.0.
Backstep: Determina los estados previos a recordar. En este caso con 3 estados fue suficiente para obtener una buena clasificación.
2.5 Función de actualización de pesos JE_Order
JNNS cuenta con su propia función para actualizar los pesos. Es decir, el orden que se tiene que seguir para determinar el peso de las conexiones antes de realizar otro paso en el ciclo. JE_Order, es una función, de hecho la única que soporta JNNS para arquitecturas de redes parcialmente recurrentes.
2.6 Función de inicialización de pesos
La inicialización se realizo de manera aleatoria pero acotando la inicialización mediante los parámetros correspondientes a la sección INIT de la ventana de control. Los valores iniciales son 1 y -1 y la función Randomize_Weights asegura la selección de entre una distribución uniforme de valores entre el intervalo.
3. Archivo de patterns JNNS
70

Como se mencionó anteriormente, nos vimos en la necesidad de implementar algunos módulos en Java que nos auxiliaran en la implementación y prueba de la red recurrente creada en JNNS. El primero de estos módulos fue el GeneradorPattern.
La clase GeneradorPattern tiene como objetivo principal generar el archivo de patrones de entrada que es compatible con JNNS, debido a que sin este archivo resulta imposible el entrenamiento de la red. Los parámetros que recibe esta clase, son: Tamaño de la ventana, nombre del archivo *.pat a crear y otros parámetros que en este momento no resultan de interés. Al ejecutar el módulo obtendremos la fuente de los datos para entrenar la red que esperábamos.
El formato del archivo cuenta esencialmente de dos partes, a saber, la cabecera y propiamente los datos. En la sección de la cabecera se especifica el número de unidades de entrada y de salida, por lo que en principio, la sección de datos puede ser un gran renglón consecutivo con cada valor separado por espacio. Los saltos de línea simplemente son ignorados por JNNS pero por cuestiones de estética y control, decidimos incorporar un salto con cada final de secuencia entrada-salida.
A continuación se muestra el ejemplo del archivo generado por el módulo descrito anteriormente, la sección en negritas del primer renglón de datos corresponde a la codificación en binario del carácter que se pretende mapear al fonema codificado en los siguiente 26 bits. En el segundo renglón de la sección de datos se muestra en negritas la codificación de salida deseada de los primeros 28 bits de la misma línea.
SNNS pattern definition file V3.2generated at Fri Apr 22 20:18:25 1994
No. of patterns : 4096No. of input units : 28No. of output units : 26
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 …0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Se puede notar que en la cabecera del archivo se describe el número de patrones contenidos en el mismo, así como el número de unidades entrada y salida. Esta información es suficiente para realizar el entrenamiento, dado que a SNNS no le interesa la arquitectura interna de la red que se pretende entrenar.
71

4. Archivo de resultados del entrenamiento
SNNS a diferencia de JNNS brinda la posibilidad de generar un archivo que describa el resultado de mostrar un conjunto de patrones a la red pero sin realizar entrenamiento alguno, es decir, para efectos de pruebas. Evidentemente dicho archivo de resultados tiene un formato bien definido y que tiene que ser procesado para los fines que se pretendan. En este caso, el archivo de resultados fue procesado mediante diversos módulos que como resultado generan un archivo que el sintetizador MBROLA puede interpretar. Las clases generadas para tales propósitos fueron: LectorSNN, TestFiletoData y TestNeuralNetwork. La funcionalidad de cada una de ellas se describe a continuación.
LectorSNN: Se encarga de limpiar el archivo de resultados, en el sentido de eliminar todo aquello que no corresponda a datos puros, esto es, elimina comentarios y encabezado.
TestFiletoData: Retoma el archivo limpio de cabecera y comentarios generado por LectorSNN y agrega cada uno de los datos resultantes en un arreglo de doubles que puede ser procesado por el siguiente módulo.
TestNeuralNetwork: Genera el archivo *.pho que para ser interpretado por el sintetizador MBROLA a partir de un arreglo de doubles.Una vez descritos los módulos, se muestra a continuación un ejemplo del archivo que resulta del entrenamiento en SNNS.
72

SNNS result file V1.4-3Dgenerated at Tue Mar 21 13:00:17 2006
No. of patterns : 4096No. of input units : 28No. of output units : 26startpattern : 1endpattern : 4096#1.10.00025 0.00001 0.00009 0.00006 0.00015 0 0 0.00004 0.00006 0.000240.00146 0.00001 0 0.00067 0.00013 0.99755 0.00004 0.00195 0.00051 0.000480.00061 0 0.00006 0.00029 0.00012 0.00006 #2.10.00049 0.00005 0.00022 0.00007 0.00023 0.00002 0.00001 0 0.00017 00.00025 0.00007 0.00042 0.00017 0.00012 0 0.99897 0.00003 0.00019 0.000050.00045 0 0.00007 0.0003 0.00009 0.00007…#4096.10.00028 0.00009 0.00032 0.00009 0.00034 0 0.00034 0 0.00001 0.000010.99869 0.00022 0.00039 0.00009 0.00013 0.00003 0.00026 0.00027 0.00043 0.000020.00004 0.00015 0.00009 0.0004 0.00024 0.00009
73

CAPITULO IV. Asignación de valores a los parámetros de entonación
Durante el habla la persona no sólo articula sonidos que configuran una expresión sin que simultáneamente controla otras características vocales como el volumen, tempo, ritmo. Dichas características constituyen la estructura prosódica del habla. Se utilizarán parámetros acústicos (duración, pitch) para el análisis de la señal, a los que se aplicará un conjunto de reglas para determinar la localización de las etiquetas. La prosodia es muy relevante en la comunicación, realizando funciones como la estructuración del discurso, expresión de la actitud del hablante, etc. El propósito del proyecto es el desarrollo de un sistema de etiqueta automático de eventos prosódicos como límites prosódicos y acentos con técnicas jerárquicas y basadas en el conocimiento. Definición:
• Duración incluye la medida global del discurso, la duración y distribución de las pausas, y la longitud de las sílabas. La variación de duración sólo se puede realizar de forma cuantificada (resolución de un período de pitch).
• Pitch es la percepción de la frecuencia fundamental, que corresponde a nivel fisiológico, con la frecuencia de vibración de las cuerdas vocales. La codificación de pitch comporta una modificación en la duración del segmento, que se tiene que compensar.
La noción de acentuación está a otro nivel abstracto. Un acento es la manifestación de la intensidad, pitch y/o duración de una sílaba. Los acentos pueden expresar énfasis, o ser de tipo léxico cuya posición es siempre la misma para una palabra dada.
En la realización de esta parte del proyecto utilizamos dos técnicas de inteligencia artificial las cuales son los árboles de decisión y las redes neuronales siendo una red de retropropagación.
1. Explicación de la implementación de la red neuronal para asignar los parámetros de duración y pitch
En la utilización de la red neuronal intentamos en una primera instancia modificar la red que nosotros habíamos creado con anterioridad para la clasificación de los fonemas con una duración fija para todos estos fonemas, utilizando también el archivo obtenido del programa txt2pho como parámetro de entrenamiento estable, pero nos encontramos con dificultades ya que aunque en un principio teníamos una clasificación agradable de los fonemas al introducir las modificaciones pertinentes para obtener duración y pitch la red dejo de clasificar los fonemas correctamente e incluso asigno la misma duración y pitch para todos estos entiéndase la misma no como la que nosotros asignábamos por default si no como una que la red neuronal asignaba después de haber sido entrenada, encontrando siempre el mismo fonema, duración y pitch.
Por lo tanto decidimos utilizar un software libre llamado SNNS para Windows conocido como Stuttgart aunque existen varias versiones decidimos utilizar la versión para Windows y realizado en C por la comodidad y funcionamiento que nos proporciono aunque tuvimos que descargar de Internet el Xwin32.exe para el funcionamiento de las ventanas del SNNS.
74

Y lo que realizamos fue de la siguiente forma, introducimos el archivo obtenido del txt2pho a una clase de java que nombramos como GeneradorPatternDyP la cual hace una procesamiento de este archivo de tal forma que pega las ventanas y pega la duración y pitch obtenidos del archivo obtenido del txt2pho, con una correspondencia 1 a 1 entre estos dos archivos y nos genera un archivo (dyppat) el cual tiene el formado requerido para introducirlo como archivo de entrenamiento o patrón para la red SNNS tan solo insertándole manualmente una cabecera requerida por este. Teniendo esto entrenamos a nuestra red la cual es del tipo:
Función de aprendizaje: retropropagación estándar. Función de actualización: orden topológico. Función de inicialización: pesos aleatorios. Función de remapeo: ninguna.
Una vez entrenada la red neuronal tomamos los resultados y regresamos una vez mas a java a hacer una codificación de lo obtenido para darle un formato MBrola.Árboles de decisión:
En la utilización del árbol de decisión le hicimos las modificaciones convenientes de las cuales haremos mención mas adelante, al programa realizado anteriormente para solo la clasificación de los caracteres, llamado ArbolesDecision teniendo como resultado el DuracionPitch. Todo esto lo realizamos sobre la plataforma java (Eclipse). Y tomando ayuda del programa txt2pho para obtener un archivo de texto en formato MBrola para dárselo al árbol como un parámetro confiable de entrenamiento y asigne una mejor clasificación de los fonemas con su duración y pitch.
2. Explicación de la implementación con árboles de decisión para asignar los parámetros de duración y pitch
Modificaciones al programa ArbolesDesicion para llegar a DuracionPitch:
La primera diferencia notable se encuentra en que aunque los dos tienen una clase jamada Arbol.java estas dos son totalmente distintas ya que obviamente se forman árboles distintos ya que en uno se incluye duración y pitch lo cual hace que el árbol se forma diferente.
La clase CreaArchivosVentanas.java es totalmente idéntica en los dos experimentos. Lo mismo sucede con la clase EscritorPattern.java, GeneradorPattern.java, GeneradorPruebas.java, LectorCaracteres.java, ID3.java, de los dos experimentos, por esta razón no indagaremos mas en ellas ya que se fue mas explicito anteriormente.
En la clase LimpiaTexto.java en el método leeArchivo en el switch se le agregaron los casos especiales en los que encuentre un fonema acentuado lo codifique como el mismo fonema solamente que poniéndolo como mayúscula para identificarlo y darle un trato especial.
75

2.1 Descripción del programa
public FileWriter leeArchivo(){char carSiguiente,carActual;carActual=m_lc.consumirCaracterSiguiente();while(m_lc.verCaracterSiguiente()!='\0'){ if(Character.isLetter(carActual) || carActual == ' ' || carActual ==
'ñ'){if(carActual== 'á'||carActual== 'é'||carActual== 'í'||carActual==
'ó'||carActual== 'ú'||carActual == 'v' || carActual == 'y' || carActual == 'l' || carActual == 'c' || carActual == 'r' || carActual == 'q' || carActual == 'h'){
switch(carActual){case 'c': if(m_lc.verCaracterSiguiente()=='h'){
m_ec.escribeCadena("*"); carActual=m_lc.consumirCaracterSiguiente();
carActual=m_lc.consumirCaracterSiguiente();}else
if(m_lc.verCaracterSiguiente()=='e'||m_lc.verCaracterSiguiente()=='i'){m_ec.escribeCadena("s");
carActual=m_lc.consumirCaracterSiguiente();}else{
m_ec.escribeCadena("k");carActual=m_lc.consumirCaracterSiguiente();
}break;
case 'r':if(m_lc.verCaracterSiguiente()=='r'){
m_ec.escribeCadena("&");carActual=m_lc.consumirCaracterSiguiente();carActual=m_lc.consumirCaracterSiguiente();
}else{m_ec.escribeCadena("r");
carActual=m_lc.consumirCaracterSiguiente();}break;
case 'q':if(m_lc.verCaracterSiguiente()=='u'){
m_ec.escribeCadena("k");carActual=m_lc.consumirCaracterSiguiente();carActual=m_lc.consumirCaracterSiguiente();
}else{m_ec.escribeCadena("k");
carActual=m_lc.consumirCaracterSiguiente();}break;
case 'l':if(m_lc.verCaracterSiguiente()=='l'){
m_ec.escribeCadena("L");carActual=m_lc.consumirCaracterSiguiente();carActual=m_lc.consumirCaracterSiguiente();
}else{
76

carActual=m_lc.consumirCaracterSiguiente();m_ec.escribeCadena("l");
}break;
case 'h'://System.out.println("h");
carActual=m_lc.consumirCaracterSiguiente();break;
case 'y':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("i");break;
case 'v':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("b");break;
case 'á':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("A");System.out.println("encontre un acento en a");break;
case 'é':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("E");System.out.println("encontre un acento en e");break;
case 'í':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("I");System.out.println("encontre un acento en i");break;
case 'ó':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("O");System.out.println("encontre un acento en o");break;
case 'ú':carActual=m_lc.consumirCaracterSiguiente();
m_ec.escribeCadena("U");System.out.println("encontre un acento en u");break;}
}else {m_ec.escribeCadena(carActual);carActual=m_lc.consumirCaracterSiguiente();
}}else{
carActual=m_lc.consumirCaracterSiguiente();}
}m_ec.escribeCadena(carActual);return m_ec.escribeCadena("");
}
77

TestID3.java en esta clase las modificaciones son mínimas ya que solo requiere de especificaciones para que tomo la clase correcta para realizar el test de el árbol.public class TestID3 {
public TestID3(){}public String dameDuracionPitch(String fonema){
String duracionypitch;duracionypitch=fonema.replace('$','\t');duracionypitch=duracionypitch.replace('#',' ');System.out.println(duracionypitch);return duracionypitch;
}/** * @param args */public static void main(String[] args) {
// TODO Auto-generated method stubchar tipos[][];int i,j;/** * En el caso de tipo de fonemas funciona bien con una ventna de tamaño
5, al igual que en el caso de * clasificación con vocales y consonantes, pero en el caso de
clasificación con fonemas * la ventana optima es de tamaño 7 */GeneradorPattern gp=new
GeneradorPattern("texto750.txt","quijotelimpio.txt","ventanas.txt","caracteres.txt","fonemas.txt",3,"pattern.txt");
gp.creaArchivo();VentanaRuso vr=new VentanaRuso("ventanas.txt", "750.txt","try.txt");vr.leeArchivo();TestID3 id3=new TestID3();
ID3 id=new ID3("c:/Eclipse/workspace/DuracionPitch/src/mx/uam/proyecto2/duracionypitch/Arbol.java");
try{id.readData("try.txt");
}catch(Exception e){e.printStackTrace();
}id.createDecisionTree();GeneradorPruebas gpp=new
GeneradorPruebas("pruebas.txt","pruebaslimpias.txt","ventanaspruebas.txt","caracterespruebas.txt","fonemaspruebas.txt",3,"patternpruebas.txt");
tipos=gpp.creaArchivo();Arbol tree=new Arbol();String parametroArbol[]=new String[gpp.leeTamanoVentana()];EscritorPattern ep=new EscritorPattern("lectura.pho");
78

ep.escribeCadena("_\t30\n");for(i=0;i<gpp.leeNumeroVentanas();i++){
for(j=0;j<gpp.leeTamanoVentana();j++){parametroArbol[j]=tipos[i][j]+"";
}String fonema[]=tree.tipoFonema(parametroArbol);/*for(int k=0;k< fonema.length;k++){
System.out.print(fonema[k]+" ");}System.out.println();*/ep.escribeCadena(id3.dameDuracionPitch(fonema[0])+"\n");
}ep.escribeCadena("_\t30\n");try{
ep.escribeCadena("").close();}catch(IOException e){
e.printStackTrace();}
}
}
VentanaRuso.java esta clase es única para este experimento en la cual su función principal es unir el archivo de ventanas.txt y 750.txt teniendo una codificación de ventana duración (pitch) pero nos es necesario quitar los espacios ya que para el procesamiento del GeneradorPattern pero debemos dejar marca de que ahí debe haber un espacio y que tipo de espacio porque en la codificación MBrola el tabulador que separa la duración del pitch y entre pitch y pitch lo cual lo codificaremos como ($) y el espacio normal que separa a los dos valores de cada uno de los valores de pitch y denotamos como(#) esta clase genera el archivo try.txt
public class VentanaRuso {
private LectorCaracteres m_lc;private LectorCaracteres m_lc2;private EscritorPattern m_ec;public VentanaRuso(String nomArchivoEntrada, String nomArchivoEntrad2, String
nomArchivoSalida){m_lc=new LectorCaracteres(nomArchivoEntrada);m_lc2=new LectorCaracteres(nomArchivoEntrad2);m_ec=new EscritorPattern(nomArchivoSalida);
}
public void leeArchivo(){char carActual;int i=0,j;for(j=0;j<3;j++){
m_ec.escribeCadena("var["+j+"]\t");}m_ec.escribeCadena("fonema\n");m_ec.escribeCadena("//****************************************\n");
79

while(i<4096){while(m_lc.verCaracterSiguiente() != '\n' ){
carActual=m_lc.verCaracterSiguiente();if(carActual!=' '){
m_ec.escribeCadena(m_lc.verCaracterSiguiente()+"\t");System.out.print(m_lc.verCaracterSiguiente()+"\t");
}else{m_ec.escribeCadena("C\t");System.out.print("C\t");
}m_lc.consumirCaracterSiguiente();
}m_lc.consumirCaracterSiguiente();while(m_lc2.verCaracterSiguiente() != '\n' &&
m_lc2.verCaracterSiguiente() !='\0'){carActual=m_lc2.verCaracterSiguiente();if(carActual=='\t' || carActual==' '){
if(carActual=='\t'){m_ec.escribeCadena("$");System.out.print("$");
}else{m_ec.escribeCadena("#");System.out.print("#");
}}else{m_ec.escribeCadena(m_lc2.verCaracterSiguiente());System.out.print(m_lc2.verCaracterSiguiente());}m_lc2.consumirCaracterSiguiente();
}m_lc2.consumirCaracterSiguiente();m_ec.escribeCadena("\n");System.out.print("\n");i++;
}try{
m_ec.escribeCadena("").close();}catch(IOException e){
e.printStackTrace();}
}
public static void main(String args[]){VentanaRuso vr=new VentanaRuso("ventanas.txt","750.txt","try.txt");vr.leeArchivo();
}}
80

CAPUTULO V. Resultados
1. Resultados de la implementación del Perceptrón multicapa para clasificación de fonemasEstadísticaPara ningún fonema del conjunto de entrenamiento debe haber 0 ocurrencias, para los demás conjuntos existe la posibilidad de que esto no se cumpla. Ya que de otra forma no podría clasificar los fonemas que no aparecen y habría errores en los otros dos conjuntos.
fonemas
conjuntoa b * d e f g & i j k l m n ñ o p @ r s t u v w x y z " "
entrenamiento 319 57 7 95 310 15 29 3 138 14 107 105 70 153 10 203 49 24 151 172 92 81 22 7 9 26 12 530 1
validación 149 16 3 62 127 10 12 2 59 3 49 47 29 65 2 102 15 12 61 102 36 28 11 0 0 15 9 231 0
prueba 92 10 6 43 103 4 9 0 52 4 29 42 23 57 1 75 11 7 41 54 27 15 6 0 0 9 2 169 0
Conjunto de entrenamiento:
Estadística: Conjunto de Entrenamiento
0
100
200
300
400
500
600
a b ch d e f g rr i j k l m n ñ o p ll r s t u v w x y z _Letras
Oc
urr
ec
ia d
e l
as
Le
tra
s
Conjunto de validación:
Estadística: Conjunto de Validación
0
50
100
150
200
250
a b ch d e f g rr i j k l m n ñ o p ll r s t u v w x y z _
Letras
Ocu
rrec
ia d
e la
s L
etra
s
Conjunto de prueba:
81

Estadística: Conjunto de Prueba
020406080
100120140160180
a b ch d e f g rr i j k l m n ñ o p ll r s t u v w x y z _Letras
Ocu
rren
cia
de
las
Let
ras
Nota: el carácter ‘_’ significa que el programa no conoce la letra
Experimentación:Notas:La línea roja corresponde a los errores en el conjunto de entrenamiento, y la azul a los de validaciónTamaño de ventana: 3, Unidades ocultas: 0, Numero de iteraciones: 200
Prueba 1: eta: 0.3 Prueba 2: eta: 0.1 Prueba 3: eta: 0.005
Tamaño de ventana: 3, Unidades ocultas: 15, Numero de iteraciones: 150
Prueba 4: eta: 0.4 Prueba 5: eta: 0.15 Prueba 6: eta: 0.05
Tamaño de ventana: 3, Unidades ocultas: 30, Numero de iteraciones: 120
82
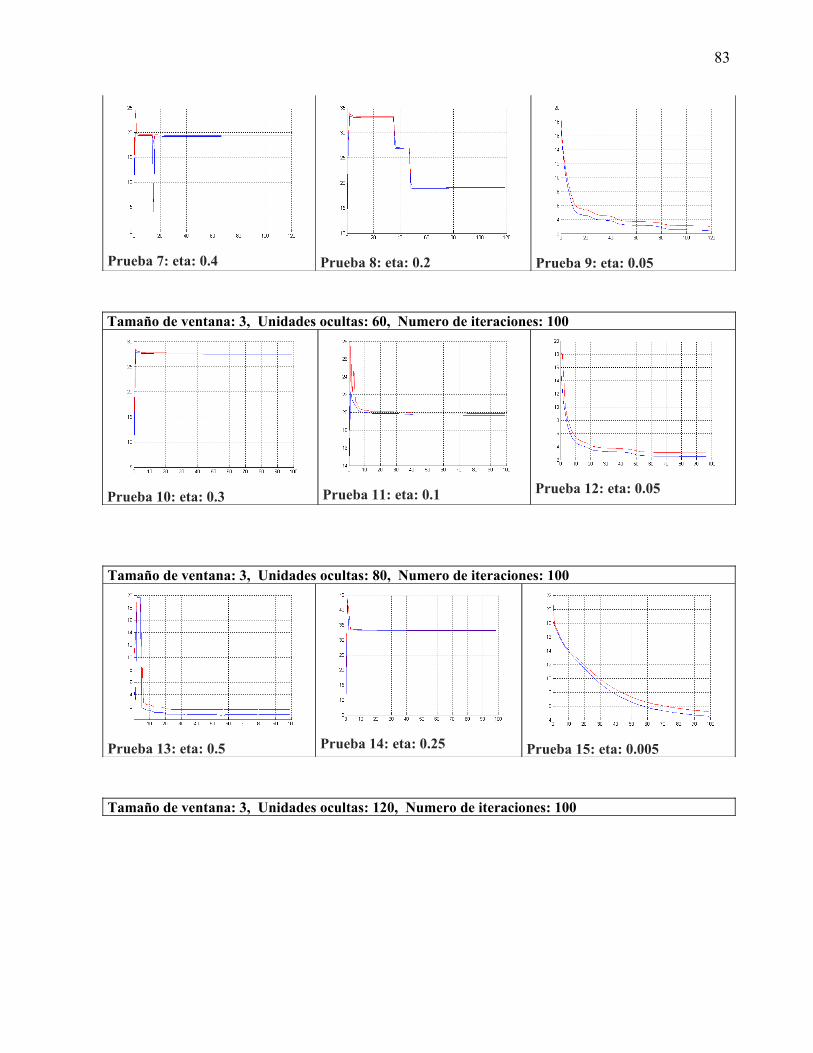
Prueba 7: eta: 0.4 Prueba 8: eta: 0.2 Prueba 9: eta: 0.05
Tamaño de ventana: 3, Unidades ocultas: 60, Numero de iteraciones: 100
Prueba 10: eta: 0.3 Prueba 11: eta: 0.1 Prueba 12: eta: 0.05
Tamaño de ventana: 3, Unidades ocultas: 80, Numero de iteraciones: 100
Prueba 13: eta: 0.5 Prueba 14: eta: 0.25 Prueba 15: eta: 0.005
Tamaño de ventana: 3, Unidades ocultas: 120, Numero de iteraciones: 100
83
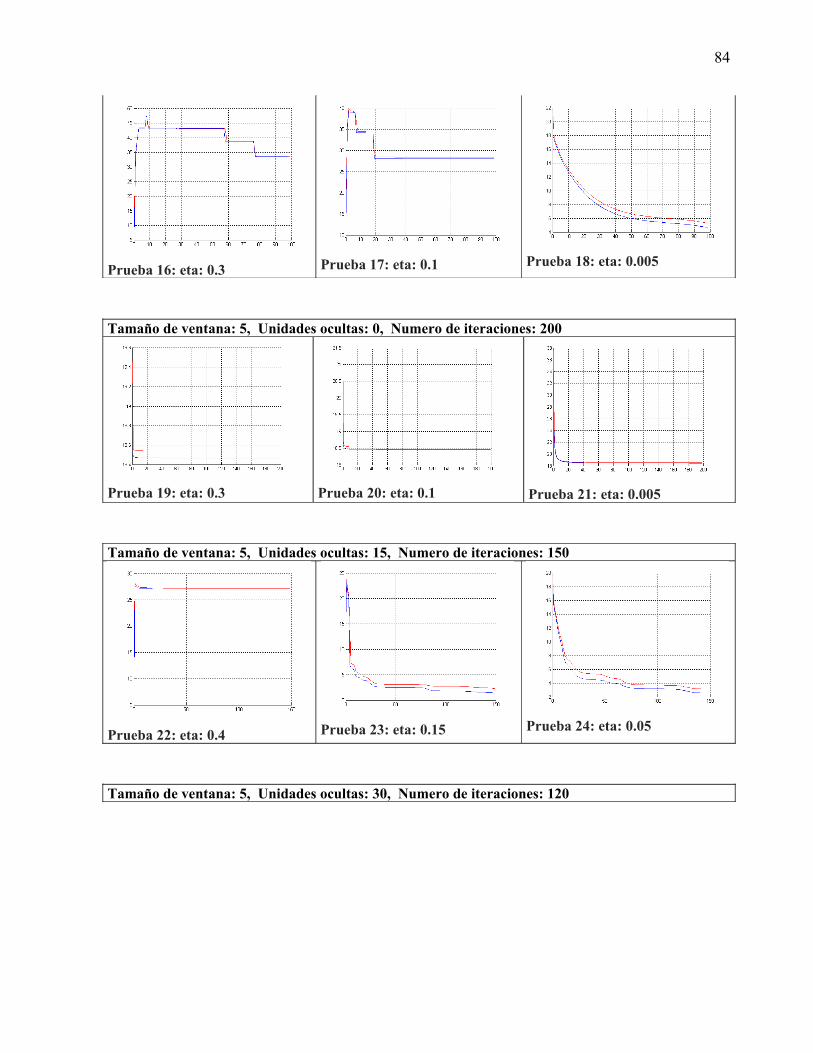
Prueba 16: eta: 0.3 Prueba 17: eta: 0.1 Prueba 18: eta: 0.005
Tamaño de ventana: 5, Unidades ocultas: 0, Numero de iteraciones: 200
Prueba 19: eta: 0.3 Prueba 20: eta: 0.1 Prueba 21: eta: 0.005
Tamaño de ventana: 5, Unidades ocultas: 15, Numero de iteraciones: 150
Prueba 22: eta: 0.4 Prueba 23: eta: 0.15 Prueba 24: eta: 0.05
Tamaño de ventana: 5, Unidades ocultas: 30, Numero de iteraciones: 120
84
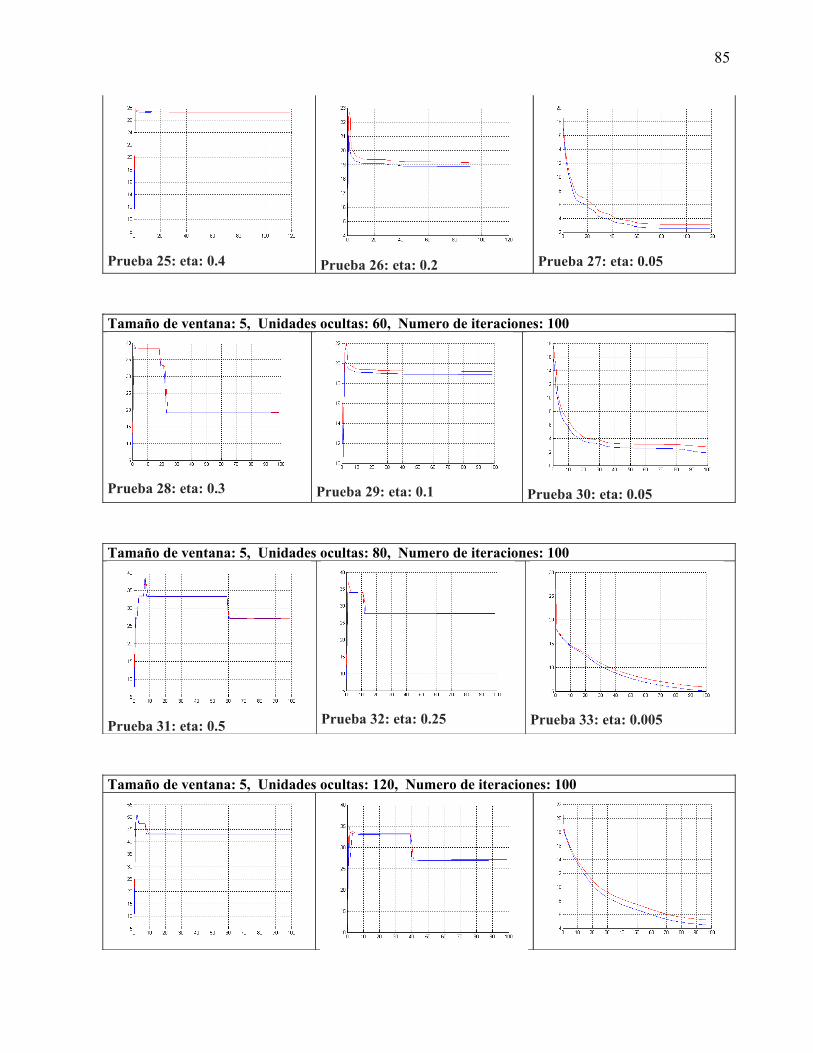
Prueba 25: eta: 0.4 Prueba 26: eta: 0.2 Prueba 27: eta: 0.05
Tamaño de ventana: 5, Unidades ocultas: 60, Numero de iteraciones: 100
Prueba 28: eta: 0.3 Prueba 29: eta: 0.1 Prueba 30: eta: 0.05
Tamaño de ventana: 5, Unidades ocultas: 80, Numero de iteraciones: 100
Prueba 31: eta: 0.5 Prueba 32: eta: 0.25 Prueba 33: eta: 0.005
Tamaño de ventana: 5, Unidades ocultas: 120, Numero de iteraciones: 100
85
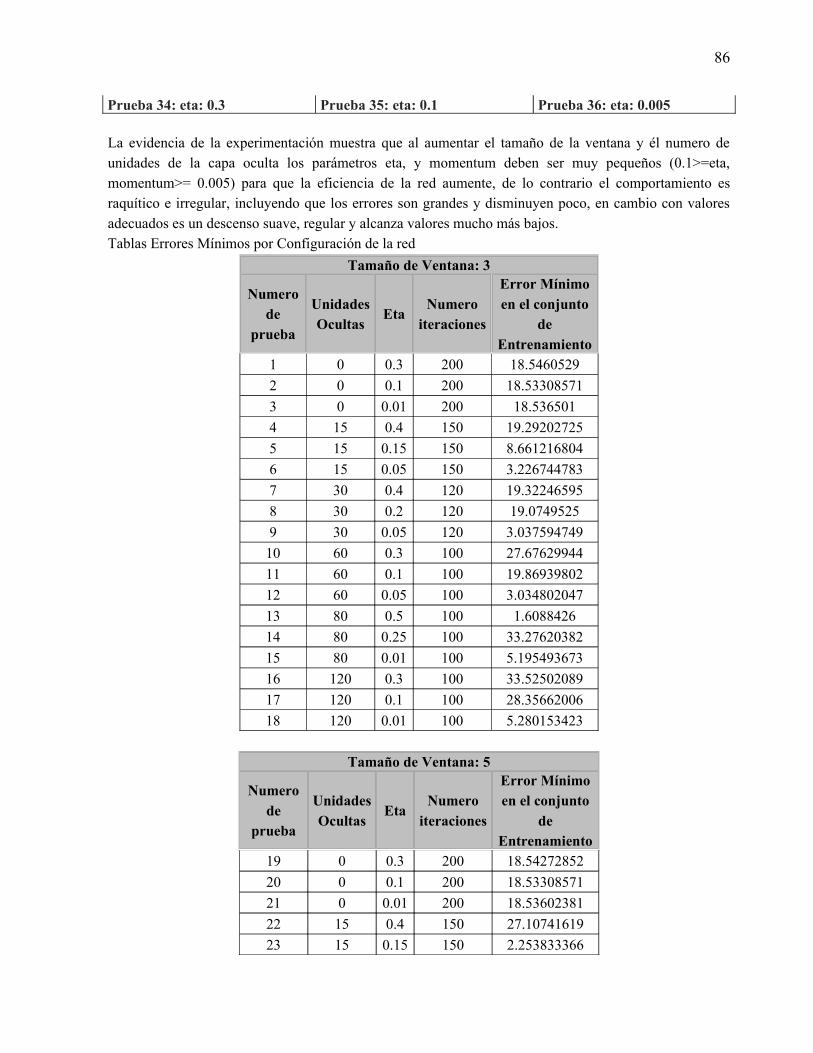
Prueba 34: eta: 0.3 Prueba 35: eta: 0.1 Prueba 36: eta: 0.005
La evidencia de la experimentación muestra que al aumentar el tamaño de la ventana y él numero de unidades de la capa oculta los parámetros eta, y momentum deben ser muy pequeños (0.1>=eta, momentum>= 0.005) para que la eficiencia de la red aumente, de lo contrario el comportamiento es raquítico e irregular, incluyendo que los errores son grandes y disminuyen poco, en cambio con valores adecuados es un descenso suave, regular y alcanza valores mucho más bajos. Tablas Errores Mínimos por Configuración de la red
Tamaño de Ventana: 3
Numero de
prueba
Unidades Ocultas
EtaNumero
iteraciones
Error Mínimo en el conjunto
de Entrenamiento
1 0 0.3 200 18.54605292 0 0.1 200 18.533085713 0 0.01 200 18.5365014 15 0.4 150 19.292027255 15 0.15 150 8.6612168046 15 0.05 150 3.2267447837 30 0.4 120 19.322465958 30 0.2 120 19.07495259 30 0.05 120 3.037594749
10 60 0.3 100 27.6762994411 60 0.1 100 19.8693980212 60 0.05 100 3.03480204713 80 0.5 100 1.608842614 80 0.25 100 33.2762038215 80 0.01 100 5.19549367316 120 0.3 100 33.5250208917 120 0.1 100 28.3566200618 120 0.01 100 5.280153423
Tamaño de Ventana: 5
Numero de
prueba
Unidades Ocultas
EtaNumero
iteraciones
Error Mínimo en el conjunto
de Entrenamiento
19 0 0.3 200 18.5427285220 0 0.1 200 18.5330857121 0 0.01 200 18.5360238122 15 0.4 150 27.1074161923 15 0.15 150 2.253833366
86

24 15 0.05 150 3.12929739725 30 0.4 120 27.2717378526 30 0.2 120 19.1117966627 30 0.05 120 3.09918475228 60 0.3 100 19.3241638829 60 0.1 100 19.1663349730 60 0.05 100 2.78790259731 80 0.5 100 27.12242932 80 0.25 100 27.9138609733 80 0.01 100 5.91416552134 120 0.3 100 43.141991535 120 0.1 100 27.127001336 120 0.01 100 5.174884158
Matriz de Confusión:Una vez que listamos todos los errores vemos que hay 1 configuración que tiene un error mínimo y una con un error máximo en las pruebas, sobre estas configuraciones vamos a aplicar la matriz de confusión para observar los resultados que nos reportaMejor red:
Tamaño de Ventana: 3Numero de
pruebaUnidades Ocultas Eta Numero iteraciones
Error Mínimo en el conjunto de Entrenamiento
13 80 0.5 100 1.6088426Peor red:
Tamaño de Ventana: 3
Numero de prueba
Unidades Ocultas
EtaNumero
iteraciones
Error Mínimo en el conjunto de
Entrenamiento16 120 0.3 100 33.52502089
Matriz de confusión para la mejor red:92 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 43 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 103 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 29 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 42 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
87

0 0 0 0 0 0 0 0 0 0 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 57 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 75 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 54 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 169 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 número de fonemas desconocidos: 17
88

Matriz de confusión para la peor red:13 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 36 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 116 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 número de fonemas desconocidos: 636
Lo que representan las matrices anteriores es:Las columnas representan a los fonemas que deberían ser obtenidos por la red, los renglones representan los fonemas que identifico la red y el contador de numero de fonema desconocidos representa él numero de fonemas que la red no conoce, recordar que cada fonema es representado por un vector binario, el caso de esta variable cuenta él numero de vectores con solo ceros o con mas de un uno.La forma de interpretar esta matriz es que cuando los datos del diagonal son distintos de cero significa que el fonema han sido clasificado de forma correcta, además lo ideal sería que en los triángulos superiores e inferiores se tuvieran solo ceros lo que significaría que la red no se confunde al clasificar un fonema, y que el contador de fonemas desconocidos fuese cero.Como se puede observar en la red con menor error en el conjunto de entrenamiento los fonemas son clasificados en el tipo de fonema que le corresponde, es decir, que la red se confunde en pocas ocasiones
89
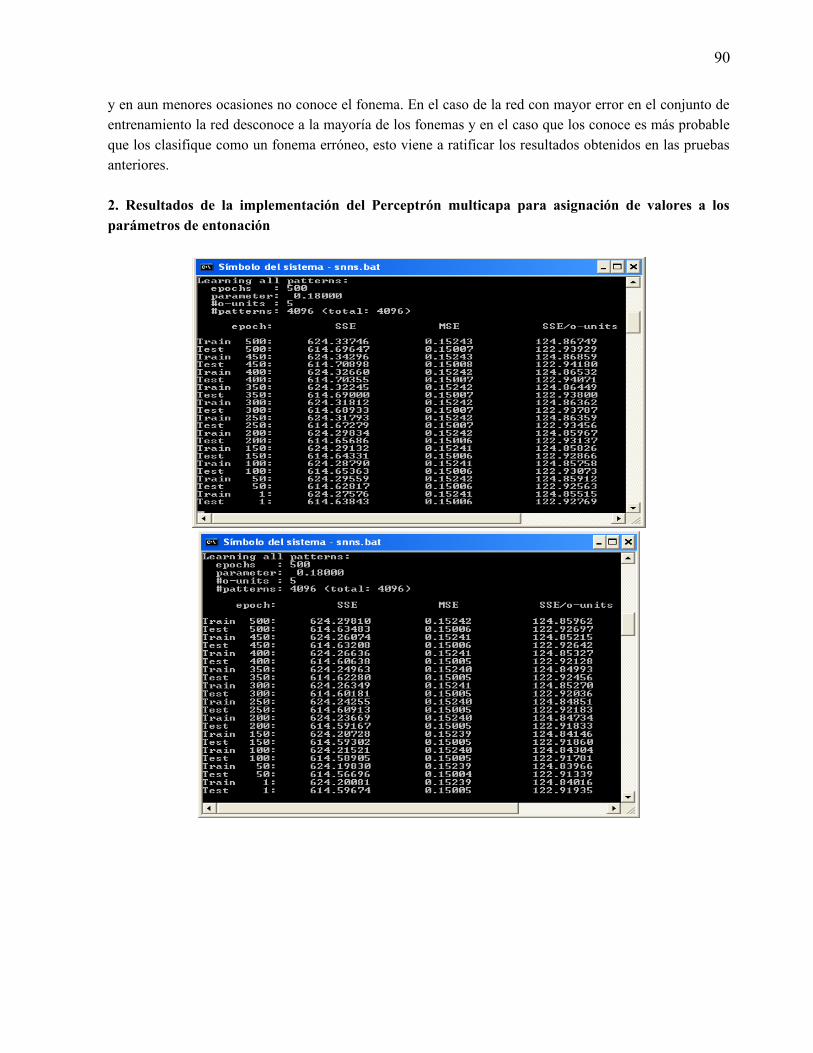
y en aun menores ocasiones no conoce el fonema. En el caso de la red con mayor error en el conjunto de entrenamiento la red desconoce a la mayoría de los fonemas y en el caso que los conoce es más probable que los clasifique como un fonema erróneo, esto viene a ratificar los resultados obtenidos en las pruebas anteriores.
2. Resultados de la implementación del Perceptrón multicapa para asignación de valores a los parámetros de entonación
90

Como podemos ver en los resultados que interpretamos del error SSE tanto para el entrenamiento como para el test nos lleva a un estancamiento en los datos ya que el error deja de disminuir y se mantienen en un rango demasiado alto como para seguir con la experimentación, ya que necesitaríamos valores de error menores a 5.00 lo cual difícilmente tendremos en vista del progreso mostrado.Aunque intentamos modificando todo tipo de parámetro para intentar mejores resultados esto fue lo mejor que pudimos obtener, inclusive intentamos cambiar el patrón de entrada con el cual toma tanto las entradas y salidas y lo que obtuvimos fue una rotunda decepción. Por lo tanto decidimos no mostrarles mas pantallas ya que solo agrandaríamos el proyecto sin lograr ver un avance considerable.
Intentamos también experimentar con el Joone pero también tuvimos el mismo tipo de problemática, pudimos concluir con estos datos que no es una manera optima de realizar el experimento.
3. Resultados De la implementación con árboles de decisión para la clasificación de fonemasDescripción:
Para es té apartado vamos a describir 3 experimentos con 3 variantes cada uno. Los experimentos realizados fueron:
1. Codificación de los elementos de la ventana en forma de vocal, consonante y silencio2. Codificación de los elementos de la ventana en forma del tipo de fonema (africativo, fricativo,
semivocal, etc.) y silencio
91

3. Codificación de los elementos de la ventana en forma de fonemas y silencio. Los fonemas codificados corresponden a los fonemas que reconoce el sintetizador de voz Mbrola
Las variantes por experimento son:
1. Pruebas con un tamaño de ventana 32. Pruebas con un tamaño de ventana 53. Pruebas con un tamaño de ventana 7
Para cada prueba creamos un archivo de patrones con el que generamos un árbol de decisión a través de la clase ID3, una vez con el árbol ya creado se crea un archivo que contiene los caracteres en la misma codificación pero del conjunto de prueba, estos caracteres son pasados a la clase Árbol y esta clase genera un archivo del tipo Mbrola
Una vez con los archivos creados los ejecutamos con el sintetizador y empíricamente obtenemos resultados que apuntan a que la codificación con fonemas es la mejor forma de codificar los elementos de la ventana
Estadística:
fonemas
conjuntoa b * d e f g & i j k l m n ñ o p @ r s t u V w x y z " "
entrenamiento
775 460 68 0 182 459 21 41 0 197 15 0 238 96 226 6 321 59 0 211 248 121 158 29 0 1 44 16 774
prueba 170 92 10 0 43 103 4 9 0 52 4 0 56 23 57 1 75 11 0 41 44 27 31 6 0 0 9 2 169
Conjunto de Prueba:
Estadìstica: Conjunto de Prueba
050
100150200
a b * d e f g & i j k l m n ñ o p @ r s t u v w x y z "
Letras
Ocu
rren
cia
de
las
letr
as
Conjunto de entrenamiento:
92
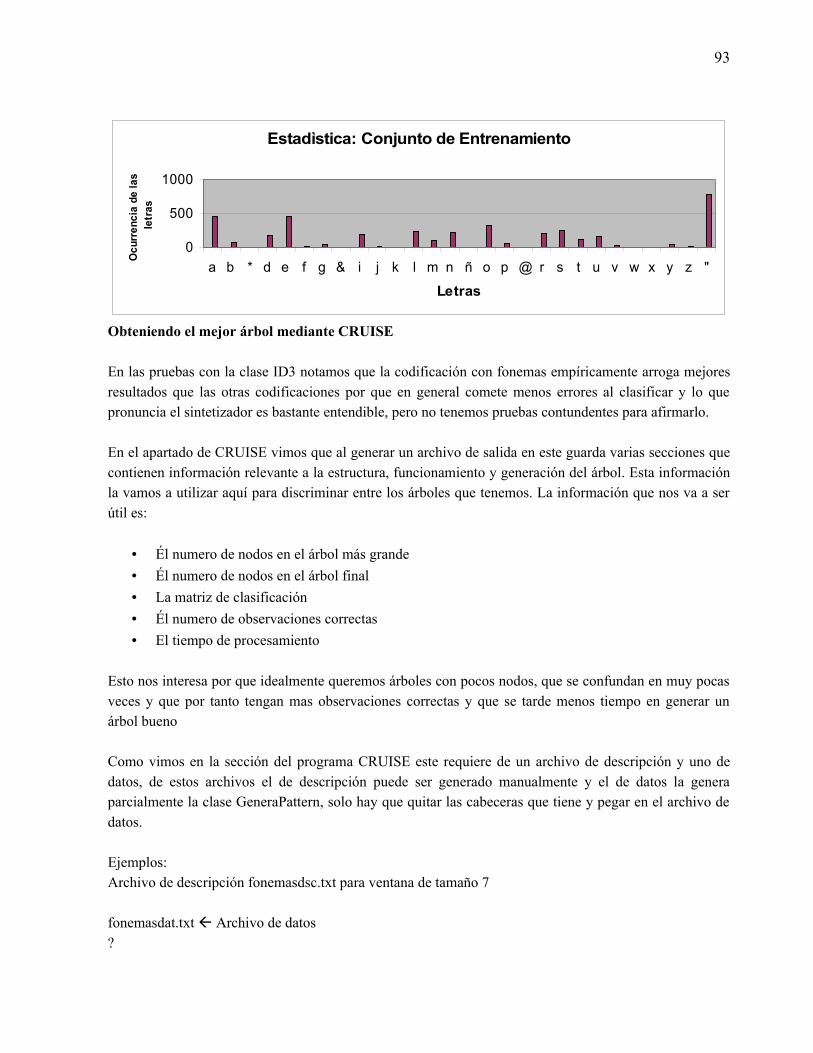
Estadìstica: Conjunto de Entrenamiento
0
500
1000
a b * d e f g & i j k l m n ñ o p @ r s t u v w x y z "
Letras
Ocu
rren
cia
de la
s le
tras
Obteniendo el mejor árbol mediante CRUISE
En las pruebas con la clase ID3 notamos que la codificación con fonemas empíricamente arroga mejores resultados que las otras codificaciones por que en general comete menos errores al clasificar y lo que pronuncia el sintetizador es bastante entendible, pero no tenemos pruebas contundentes para afirmarlo.
En el apartado de CRUISE vimos que al generar un archivo de salida en este guarda varias secciones que contienen información relevante a la estructura, funcionamiento y generación del árbol. Esta información la vamos a utilizar aquí para discriminar entre los árboles que tenemos. La información que nos va a ser útil es:
• Él numero de nodos en el árbol más grande• Él numero de nodos en el árbol final• La matriz de clasificación• Él numero de observaciones correctas• El tiempo de procesamiento
Esto nos interesa por que idealmente queremos árboles con pocos nodos, que se confundan en muy pocas veces y que por tanto tengan mas observaciones correctas y que se tarde menos tiempo en generar un árbol bueno
Como vimos en la sección del programa CRUISE este requiere de un archivo de descripción y uno de datos, de estos archivos el de descripción puede ser generado manualmente y el de datos la genera parcialmente la clase GeneraPattern, solo hay que quitar las cabeceras que tiene y pegar en el archivo de datos.
Ejemplos:Archivo de descripción fonemasdsc.txt para ventana de tamaño 7
fonemasdat.txt Archivo de datos?
93

column,varname,vartype1,var[0],c2,var[1],c3,var[2],c4,var[3],c5,var[4],c6,var[5],c7,var[6],c8,fonema,d
En la primer columna se lista el orden de las columnas del archivo de datos, en la segunda el nombre de las columnas y en la tercera el tipo de dato que este caso es de tipo carácter y la ultima variable corresponde a la clase.
Archivo de datos:
Archivo generado por la clase GeneradorPattern
var[0] var[1] var[2] var[3] var[4] var[5] var[6] fonema//**************************************************E E E p r i m pE E p r i m e rE p r i m e r ip r i m e r a mr i m e r a E ei m e r a E p rm e r a E p a ae r a E p a r _
Archivo fonemasdat.txt
E E E p r i m pE E p r i m e rE p r i m e r ip r i m e r a mr i m e r a E ei m e r a E p rm e r a E p a ae r a E p a r _
Como vemos efectivamente solo hay que quitar la cabecera del archivo generado por la clase GeneradorPattern y además observamos que las columnas están descritas por el archivo de descripción.
94

Una vez que tenemos todos los archivo de descripción y datos para cada experimento (en total 9 de descripción y 9 de datos), corremos el programa CRUISE para que nos genere el árbol correspondiente y podado
Resultados:
Experimento 1:
Codificación de elementos de la ventana por consonante, vocal y silencio con tamaño de ventana 3
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 37 Number of nodes in final tree = 21
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.189 774 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 a 460 0.112 0 244 0 0 194 0 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b 97 0.024 0 0 0 0 0 0 0 0 0 25 0 0 0 16 0 0 0 0 43 0 13 0 0 0 0 d 182 0.044 0 0 0 0 0 0 0 0 0 102 0 0 0 2 0 0 0 0 56 0 22 0 0 0 0 e 459 0.112 0 173 0 0 276 0 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f 21 0.005 0 0 0 0 0 0 0 0 0 13 0 0 0 1 0 0 0 0 5 0 2 0 0 0 0 g 41 0.010 0 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 14 0 18 0 0 0 0 i 276 0.067 0 90 0 0 34 0 0 117 0 9 0 0 0 0 0 0 0 0 26 0 0 0 0 0 0 j 15 0.004 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 11 0 2 0 0 0 0 k 147 0.036 0 0 0 0 0 0 0 0 0 108 0 0 0 2 0 0 0 0 27 0 10 0 0 0 0 l 168 0.041 0 0 0 0 0 0 0 0 0 76 0 0 0 17 0 0 0 0 58 0 17 0 0 0 0 m 96 0.023 0 0 0 0 0 0 0 0 0 39 0 0 0 14 0 0 0 0 32 0 11 0 0 0 0 ny 6 0.001 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 n 226 0.055 0 0 0 0 0 0 0 0 0 22 0 0 0 75 0 0 0 0 126 0 3 0 0 0 0 o 321 0.078 0 159 0 0 159 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 p 59 0.014 0 0 0 0 0 0 0 0 0 46 0 0 0 0 0 0 0 0 1 0 12 0 0 0 0 r 203 0.050 0 0 0 0 0 0 0 0 0 18 0 0 0 36 0 0 0 0 95 0 54 0 0 0 0 rr 4 0.001 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 s 294 0.072 0 0 0 0 0 0 0 0 0 61 0 0 0 34 0 0 0 0 190 0 9 0 0 0 0 tS 12 0.003 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 0 3 0 0 0 0 t 121 0.030 0 0 0 0 0 0 0 0 0 30 0 0 0 4 0 0 0 0 18 0 69 0 0 0 0 u 96 0.023 0 43 0 0 27 0 0 26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 x 1 0.000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 z 16 0.004 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ü 1 0.000 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Total obs = 4096, # correct = 1853 Elapsed system time in seconds: 21.3
Experimento 2:
95

Codificación de elementos de la ventana por consonante, vocal y silencio con tamaño de ventana 5
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 104 Number of nodes in final tree = 62
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 556 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 172 46 a 460 0.040 0 62 0 0 88 0 0 22 0 0 0 0 0 0 172 0 0 0 0 0 0 116 0 0 0 b 97 0.040 0 0 6 0 0 7 0 0 3 3 0 0 3 16 0 9 0 19 0 10 13 0 8 0 0 d 182 0.040 0 0 1 64 0 8 0 0 3 0 0 0 7 2 0 26 0 18 6 23 22 0 2 0 0 e 459 0.040 0 13 0 0 255 0 0 1 0 0 0 0 0 0 87 0 0 0 0 0 0 103 0 0 0 f 21 0.040 0 0 0 0 0 6 0 0 1 0 0 0 1 1 0 6 0 0 0 2 2 0 2 0 0 g 41 0.040 0 0 2 0 0 1 3 0 0 0 0 0 1 0 0 6 0 2 1 6 18 0 1 0 0 i 276 0.040 0 14 0 0 22 0 0 132 0 0 0 0 0 0 30 0 0 0 0 0 0 78 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 2 0 0 0 2 0 0 0 0 2 0 7 2 0 0 0 0 k 147 0.040 0 0 5 40 0 16 0 0 5 6 0 0 4 2 0 42 0 6 0 9 10 0 2 0 0 l 168 0.040 0 0 7 36 0 16 2 0 1 0 0 0 1 40 0 16 10 6 12 11 7 0 3 0 0 m 96 0.040 0 0 2 4 0 12 1 0 3 0 0 0 7 14 0 18 0 6 0 14 11 0 4 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 3 0 0 0 0 0 n 226 0.040 0 0 2 13 0 3 3 0 0 0 0 0 6 122 0 4 0 17 36 12 3 0 5 0 0 o 321 0.040 0 16 0 0 49 0 0 3 0 0 0 0 0 0 194 0 0 0 0 0 0 59 0 0 0 p 59 0.040 0 0 1 0 0 12 0 0 2 0 0 0 0 0 0 31 0 0 0 1 12 0 0 0 0 r 203 0.040 0 0 0 6 0 8 4 0 0 0 0 0 9 41 0 4 34 35 20 17 20 0 5 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 0 0 0 0 0 s 294 0.040 0 0 0 29 0 10 2 0 4 4 0 0 7 54 0 18 0 16 97 25 9 0 19 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 6 3 0 0 0 0 t 121 0.040 0 0 2 0 0 7 2 0 0 0 0 0 0 4 0 21 0 6 0 9 69 0 1 0 0 u 96 0.040 0 4 0 0 22 0 0 4 0 0 0 0 0 0 9 0 0 0 0 0 0 57 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 1 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Total obs = 4096, # correct = 1724 Elapsed system time in seconds: 121.
Experimento 3:
Codificación de elementos de la ventana por consonante, vocal y silencio con tamaño de ventana 7
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 127 Number of nodes in final tree = 84
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 616 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 147 11
96

a 460 0.040 0 99 0 0 88 0 0 22 0 0 0 0 0 0 172 0 0 0 0 0 0 79 0 0 0 b 97 0.040 0 0 9 0 0 4 1 0 9 0 1 0 9 16 0 16 0 18 0 4 9 0 1 0 0 d 182 0.040 0 0 3 52 0 0 0 0 4 12 13 0 27 2 0 22 0 11 6 10 19 0 1 0 0 e 459 0.040 0 36 0 0 255 0 0 1 0 0 0 0 0 0 87 0 0 0 0 0 0 80 0 0 0 f 21 0.040 0 0 0 0 0 4 0 0 1 0 1 0 2 1 0 11 0 1 0 0 0 0 0 0 0 g 41 0.040 0 0 0 0 0 1 5 0 2 0 0 0 4 0 0 7 0 3 1 0 17 0 1 0 0 i 276 0.040 0 37 0 0 22 0 0 132 0 0 0 0 0 0 30 0 0 0 0 0 0 55 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 2 0 0 0 3 0 0 0 0 6 0 2 2 0 0 0 0 k 147 0.040 0 0 7 26 0 2 0 0 10 14 15 0 9 2 0 45 0 5 0 5 7 0 0 0 0 l 168 0.040 0 0 0 29 0 0 0 0 8 7 26 0 9 40 0 9 10 10 12 1 7 0 0 0 0 m 96 0.040 0 0 0 3 0 1 1 0 3 1 7 6 15 8 0 25 0 7 0 5 11 0 3 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 2 0 0 0 0 0 0 0 n 226 0.040 0 0 0 8 0 0 2 0 2 5 3 8 15 114 0 7 0 18 36 3 3 0 2 0 0 o 321 0.040 0 32 0 0 49 0 0 3 0 0 0 0 0 0 194 0 0 0 0 0 0 43 0 0 0 p 59 0.040 0 0 0 0 0 0 0 0 2 0 3 0 0 0 0 41 0 1 0 0 12 0 0 0 0 r 203 0.040 0 0 0 0 0 3 1 0 0 6 1 0 21 41 0 12 34 35 20 8 20 0 1 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.040 0 0 5 18 0 11 0 0 4 11 7 12 19 42 0 25 0 27 97 4 4 0 8 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 2 3 0 0 0 0 t 121 0.040 0 0 3 0 0 3 2 0 2 0 4 0 8 4 0 24 0 7 0 0 64 0 0 0 0 u 96 0.040 0 11 0 0 22 0 0 4 0 0 0 0 0 0 9 0 0 0 0 0 0 50 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 15 1 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 Total obs = 4096, # correct = 1841 Elapsed system time in seconds: 236.
Experimento 4:
Codificación de elementos de la ventana por tipo de fonema y silencio con tamaño de ventana 3
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 120 Number of nodes in final tree = 43
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.189 774 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 a 460 0.112 0 191 0 0 204 0 0 19 0 0 0 0 0 0 43 0 0 0 0 0 0 3 0 0 0 b 97 0.024 0 0 16 43 0 0 0 0 0 25 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 d 182 0.044 0 0 1 57 0 0 0 0 0 102 0 0 0 0 0 0 0 0 0 0 22 0 0 0 0 e 459 0.112 0 56 0 0 344 0 0 10 0 0 0 0 0 0 49 0 0 0 0 0 0 0 0 0 0 f 21 0.005 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 0 0 0 0 0 0 g 41 0.010 0 0 0 14 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 18 0 0 0 0 i 276 0.067 0 56 0 0 46 0 0 110 0 0 9 0 0 0 21 0 26 0 0 0 0 8 0 0 0 j 15 0.004 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.036 0 0 0 29 0 0 0 0 0 108 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 l 168 0.041 0 0 0 0 0 0 0 0 0 0 82 0 0 0 0 0 86 0 0 0 0 0 0 0 0 m 96 0.023 0 0 0 0 0 0 0 0 0 0 0 50 0 46 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.001 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0
97

n 226 0.055 0 0 0 0 0 0 0 0 0 0 0 25 0 201 0 0 0 0 0 0 0 0 0 0 0 o 321 0.078 0 96 0 0 142 0 0 3 0 0 0 0 0 0 78 0 0 0 0 0 0 2 0 0 0 p 59 0.014 0 0 0 1 0 0 0 0 0 46 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 r 203 0.050 0 0 0 0 0 0 0 0 0 0 20 0 0 0 0 0 183 0 0 0 0 0 0 0 0 rr 4 0.001 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 s 294 0.072 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 294 0 0 0 0 0 0 tS 12 0.003 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.030 0 0 4 18 0 0 0 0 0 30 0 0 0 0 0 0 0 0 0 0 69 0 0 0 0 u 96 0.023 0 13 0 0 42 0 0 19 0 0 0 0 0 0 9 0 0 0 0 0 0 13 0 0 0 x 1 0.000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 z 16 0.004 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ü 1 0.000 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Total obs = 4096, # correct = 2597 Elapsed system time in seconds: 62.4 Experimento 5:
Codificación de elementos de la ventana por tipo de fonema y silencio con tamaño de ventana 5
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 199 Number of nodes in final tree = 129
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 694 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 74 6 a 460 0.040 0 51 0 0 81 0 0 49 0 0 0 0 0 0 217 0 0 0 0 0 0 62 0 0 0 b 97 0.040 0 0 60 10 0 0 7 0 0 3 0 0 0 0 0 10 0 0 0 0 7 0 0 0 0 d 182 0.040 0 0 27 110 0 0 3 0 0 10 0 0 0 0 0 15 0 0 0 0 17 0 0 0 0 e 459 0.040 0 5 0 0 256 0 0 14 0 0 0 0 0 0 98 0 0 0 0 0 0 86 0 0 0 f 21 0.040 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g 41 0.040 0 0 7 6 0 0 17 0 0 0 0 0 0 0 0 6 0 0 0 0 5 0 0 0 0 i 276 0.040 0 19 0 0 22 0 0 155 0 0 0 0 0 0 34 0 0 0 0 0 0 46 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.040 0 0 28 51 0 0 3 0 0 39 0 0 0 0 0 19 0 0 0 0 7 0 0 0 0 l 168 0.040 0 0 0 0 0 0 0 0 0 0 122 0 0 0 0 0 36 10 0 0 0 0 0 0 0 m 96 0.040 0 0 0 0 0 0 0 0 0 0 0 57 24 15 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 n 226 0.040 0 0 0 0 0 0 0 0 0 0 0 29 16 181 0 0 0 0 0 0 0 0 0 0 0 o 321 0.040 0 3 0 0 34 0 0 20 0 0 0 0 0 0 245 0 0 0 0 0 0 19 0 0 0 p 59 0.040 0 0 4 3 0 0 1 0 0 5 0 0 0 0 0 36 0 0 0 0 10 0 0 0 0 r 203 0.040 0 0 0 0 0 0 0 0 0 0 24 0 0 0 0 0 126 53 0 0 0 0 0 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.040 0 0 0 0 0 69 0 0 0 0 0 0 0 0 0 0 0 0 151 0 0 0 74 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.040 0 0 12 6 0 0 10 0 0 12 0 0 0 0 0 16 0 0 0 0 65 0 0 0 0 u 96 0.040 0 1 0 0 14 0 0 10 0 0 0 0 0 0 11 0 0 0 0 0 0 60 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 Total obs = 4096, # correct = 2501 Elapsed system time in seconds: 730.
98

Experimento 6:
Codificación de elementos de la ventana por tipo de fonema y silencio con tamaño de ventana 7
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 199 Number of nodes in final tree = 132
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 693 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 75 6 a 460 0.040 0 70 0 0 92 0 0 43 0 0 0 0 0 0 198 0 0 0 0 0 0 57 0 0 0 b 97 0.040 0 0 51 8 0 0 11 0 0 4 0 0 0 0 0 18 0 0 0 0 5 0 0 0 0 d 182 0.040 0 0 23 89 0 0 13 0 0 23 0 0 0 0 0 18 0 0 0 0 16 0 0 0 0 e 459 0.040 0 9 0 0 273 0 0 14 0 0 0 0 0 0 94 0 0 0 0 0 0 69 0 0 0 f 21 0.040 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g 41 0.040 0 0 5 2 0 0 24 0 0 2 0 0 0 0 0 6 0 0 0 0 2 0 0 0 0 i 276 0.040 0 26 0 0 23 0 0 151 0 0 0 0 0 0 27 0 0 0 0 0 0 49 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.040 0 0 18 28 0 0 12 0 0 62 0 0 0 0 0 20 0 0 0 0 7 0 0 0 0 l 168 0.040 0 0 0 0 0 0 0 0 0 0 127 0 0 0 0 0 36 5 0 0 0 0 0 0 0 m 96 0.040 0 0 0 0 0 0 0 0 0 0 0 51 24 21 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 n 226 0.040 0 0 0 0 0 0 0 0 0 0 0 23 16 187 0 0 0 0 0 0 0 0 0 0 0 o 321 0.040 0 23 0 0 35 0 0 20 0 0 0 0 0 0 225 0 0 0 0 0 0 18 0 0 0 p 59 0.040 0 0 1 2 0 0 1 0 0 7 0 0 0 0 0 38 0 0 0 0 10 0 0 0 0 r 203 0.040 0 0 0 0 0 0 0 0 0 0 30 0 0 0 0 0 135 38 0 0 0 0 0 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.040 0 0 0 0 0 36 0 0 0 0 0 0 0 0 0 0 0 0 244 0 0 0 14 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.040 0 0 10 3 0 0 14 0 0 13 0 0 0 0 0 18 0 0 0 0 63 0 0 0 0 u 96 0.040 0 4 0 0 16 0 0 8 0 0 0 0 0 0 8 0 0 0 0 0 0 60 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 Total obs = 4096, # correct = 2619 Elapsed system time in seconds: 0.146E+04
Experimento 7:
Codificación de elementos de la ventana por fonema y silencio con tamaño de ventana 3
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 33 Number of nodes in final tree = 25
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü
99

Actual class #obs Prior --------------------- _ 774 0.189 774 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 a 460 0.112 0 460 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b 97 0.024 0 0 97 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d 182 0.044 0 0 0 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e 459 0.112 0 0 0 0 459 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f 21 0.005 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g 41 0.010 0 0 0 0 0 0 41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 i 276 0.067 0 0 0 0 0 0 0 276 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j 15 0.004 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.036 0 0 0 0 0 0 0 0 0 147 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l 168 0.041 0 0 0 0 0 0 0 0 0 0 168 0 0 0 0 0 0 0 0 0 0 0 0 0 0 m 96 0.023 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.001 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 n 226 0.055 0 0 0 0 0 0 0 0 0 0 0 0 0 226 0 0 0 0 0 0 0 0 0 0 0 o 321 0.078 0 0 0 0 0 0 0 0 0 0 0 0 0 0 321 0 0 0 0 0 0 0 0 0 0 p 59 0.014 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 0 0 0 0 0 0 0 0 0 r 203 0.050 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 203 0 0 0 0 0 0 0 0 rr 4 0.001 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.072 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 294 0 0 0 0 0 0 tS 12 0.003 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.030 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 0 0 0 0 u 96 0.023 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 x 1 0.000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.004 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ü 1 0.000 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Total obs = 4096, # correct = 4079 Elapsed system time in seconds: 57.7
Experimento 8:
Codificación de elementos de la ventana por fonema y silencio con tamaño de ventana 5
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 34 Number of nodes in final tree = 28
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 700 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 74 0 a 460 0.040 0 460 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b 97 0.040 0 0 97 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d 182 0.040 0 0 0 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e 459 0.040 0 0 0 0 459 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f 21 0.040 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g 41 0.040 0 0 0 0 0 0 41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 i 276 0.040 0 0 0 0 0 0 0 276 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.040 0 0 0 0 0 0 0 0 0 147 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l 168 0.040 0 0 0 0 0 0 0 0 0 0 168 0 0 0 0 0 0 0 0 0 0 0 0 0 0 m 96 0.040 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 n 226 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 226 0 0 0 0 0 0 0 0 0 0 0
100

o 321 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 321 0 0 0 0 0 0 0 0 0 0 p 59 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 0 0 0 0 0 0 0 0 0 r 203 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 203 0 0 0 0 0 0 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 294 0 0 0 0 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 0 0 0 0 u 96 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 Total obs = 4096, # correct = 4022 Elapsed system time in seconds: 0.161E+04
Experimento 9:
Codificación de elementos de la ventana por fonema y silencio con tamaño de ventana 7
Resultados arrojados por CRUISE
Number of nodes in maximum tree = 36 Number of nodes in final tree = 28
Classification Matrix : Predicted class _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Actual class #obs Prior --------------------- _ 774 0.040 700 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 74 0 a 460 0.040 0 460 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b 97 0.040 0 0 97 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d 182 0.040 0 0 0 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e 459 0.040 0 0 0 0 459 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 f 21 0.040 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 g 41 0.040 0 0 0 0 0 0 41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 i 276 0.040 0 0 0 0 0 0 0 276 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 j 15 0.040 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k 147 0.040 0 0 0 0 0 0 0 0 0 147 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l 168 0.040 0 0 0 0 0 0 0 0 0 0 168 0 0 0 0 0 0 0 0 0 0 0 0 0 0 m 96 0.040 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 0 0 0 0 0 0 0 0 0 0 ny 6 0.040 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 n 226 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 226 0 0 0 0 0 0 0 0 0 0 0 o 321 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 321 0 0 0 0 0 0 0 0 0 0 p 59 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 0 0 0 0 0 0 0 0 0 r 203 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 203 0 0 0 0 0 0 0 0 rr 4 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 s 294 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 294 0 0 0 0 0 0 tS 12 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 t 121 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 0 0 0 0 u 96 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 x 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 z 16 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 ü 1 0.040 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 Total obs = 4096, # correct = 4022 Elapsed system time in seconds: 0.342E+04
101

Tabla de resultados
Numerode
prueba
Numerode Nodos
en elárbol mas grande
Numerode Nodos enel árbol final
Numero deObservaciones
correctas
Tiempo deProcesamiento
en seg.
Porcentaje de errorEn el conjunto de
entrenamiento
1 37 21 1853 21.3 54.760742192 104 62 1724 121 57.910156253 127 84 1841 236 55.053710944 120 43 2597 62.4 36.596679695 199 129 2501 730 38.940429696 199 132 2619 1460 36.059570317 33 25 4079 57.7 0.4150360628 34 28 4022 1610 1.8066406259 26 28 4022 3420 1.806640625
Con los datos mostrados en esta tabla podemos concluir que la codificación con fonemas con un tamaño de ventana 3 es el mejor árbol que podemos generar por lo que para hacer pruebas subsecuentes vamos a utilizar esta configuración.
Estructura del Mejor Árbol generado por CRUISE
Node 1 : var[1] = & Node 5: Terminal Node, predicted class = rr Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 Node 1 : var[1] = x Node 6: Terminal Node, predicted class = x Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 Node 1 : var[1] = p Node 7: Terminal Node, predicted class = p Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = g Node 8: Terminal Node, predicted class = g Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = ñ Node 9: Terminal Node, predicted class = ny Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = d Node 10: Terminal Node, predicted class = d Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = m Node 11: Terminal Node, predicted class = m Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = l Node 12: Terminal Node, predicted class = l Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü
102

Class size : 0 0 0 0 0 0 0 0 0 0 168 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = b Node 13: Terminal Node, predicted class = b Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 97 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = s Node 14: Terminal Node, predicted class = s Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 294 0 0 0 0 0 0 Node 1 : var[1] = r Node 15: Terminal Node, predicted class = r Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 203 0 0 0 0 0 0 0 0 Node 1 : var[1] = u Node 16: Terminal Node, predicted class = u Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 96 0 0 0 Node 1 : var[1] = e Node 17: Terminal Node, predicted class = e Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 459 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = * Node 18: Terminal Node, predicted class = tS Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 Node 1 : var[1] = @ i Node 19: Terminal Node, predicted class = i Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 276 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = E a Node 20 : var[1] = a Node 499: Terminal Node, predicted class = a Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 460 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 20 : var[1] = & * @ E b d e f g i j k l m n o p r s t u x ñ Node 500: Terminal Node, predicted class = _ Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 774 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 1 Node 1 : var[1] = k Node 21: Terminal Node, predicted class = k Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 147 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = o Node 22: Terminal Node, predicted class = o Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 321 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = n Node 23: Terminal Node, predicted class = n Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 226 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = f Node 24: Terminal Node, predicted class = f Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = j Node 25: Terminal Node, predicted class = j Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Node 1 : var[1] = t Node 26: Terminal Node, predicted class = t Class label : _ a b d e f g i j k l m ny n o p r rr s tS t u x z ü Class size : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 0 0 0 0
103

var[1]
rr x p g ny d m l b s r u
& x p g ñd m l b s r u
Primeras ramas del mejor árbol de desición obtenido mediante CRUISE
En este caso las etiquetas sobre las ramas no parecen indicar información liguistica, ya que al examinar los niveles del árbol las etiquetas de las ramas que se van generando siempre guardan el mismo orden bajo las mismas condiciones y no guardan algún tipo de relación entre ellas.
Más aún pareciera no guardar información acerca del contexto de la ventana por que siempre se pregunta por el fonema del centro de la ventana, cosa que no ocurre en los otros experimentos por que en este caso cuando se encuentra con un fonema a o E se vuelve a preguntar por el fonema del centro de la ventana y en los otros experimentos en general se pregunta por otro vecino del fonema del centro.
4. Resultados de la implementación con árboles de decisión para la asignación de parámetros de entonación Como el cruise tiene un buffer de sus patrones de 10 nos vimos forzados a que nuestras salidas tuvieran una longitud de cadena menor a este valor lo cual fue un reto ya que nuestras salidas pueden llegar a tener longitudes de 3 a 15 sin contar con los caracteres que representan al tabulador y el espacio sencillo, por lo cual tuvimos que encontrar las clases existente que pueden aparecer o darse en combinación por lo que obtuvimos las siguientes clases:0 p$1001 r$502 i$803 m$704 e$108$$30#1305 a$906 _$07 p$100$$0#1008 a$108$$30#1309 t$8510 e$90$$$90#10011 d$6512 e$9013 l$8014 i$80$$0#100
104

15 n$8016 g$13017 i$6018 o$108$$30#13019 s$11020 o$9021 d$6022 g$5023 d$60$$0#10024 k$100$$0#10025 j$6026 m$70$$0#10027 tS$13528 u$96$$30#13029 o$90$$$90#10030 k$10031 t$85$$0#10032 T$10033 i$96$$30#13034 e$90$$0#10035 f$100$$0#10036 a$90$$$90#10037 u$8038 l$80$$0#10039 jj$9040 n$80$$0#10041 b$6042 a$90$$0#10043 a$10844 _#$50$$0#100$30#13045 b$60$$0#10046 L$10547 u$6048 rr$80$$0#10049 g$50$$0#10050 rr$8051 u$96$$0#100$30#13052 o$108$$0#100$30#13053 a$108$$0#100$30#13054 s$110$$0#10055 n$80$$$90#10056 s$110$$$90#10057 ny$10058 e$108$$0#100$30#13059 f$10060 i$80$$$90#10061 o$90$$0#10062 L$105$$0#10063 T$100$$0#10064 x$13065 ny$100$66 _67 u$60$$0#10068 u$80$$0#10069 _#$070 i$96$$0#100$30#13071 g$8072 l$80$$99#80
105

Lo cual intentamos sustituir por él numero de la clase(número mas a la izquierda) pero fue en vano ya que una vez que pasamos esto al cruise como parámetro de entrenamiento simplemente no pudo generar el árbol ya que imprimía un error y no se tenían resultados ni pequeñamente satisfactorios.
Por lo que decidimos quedarnos con el experimento realizado en java DuracionPitch con la clase de ID3.java la cual no tiene ningún problema con los valores que se le dan como patrón de aprendizaje y genera sin problema alguno la clase Arbol.java la cual contiene el árbol de decisión que clasifica de una forma muy satisfactoria tanto al fonema como su duración y pitch.
5. Resultados de la implementación con redes recurrentes para clasificación de fonemas
A continuación se describe el porcentaje de clasificación asertiva obtenido de los experimentos descritos anteriormente, relacionados con redes neuronales artificiales recurrentes. Dicho porcentaje se obtiene mediante la comparación entre los vectores de salida utilizados en la etapa de entrenamiento de la red y los vectores de salida obtenidos durante la etapa de pruebas.
Previo a esto, debe entenderse la manera en la cual, finalmente se obtuvieron vectores binarios – que representan una clase fonética - a partir de las salidas de la implementación de la red en SNNS. Así pues, debemos recordar que el archivo de resultados (descrito en secciones previas de este reporte) incluye los valores correspondientes a cada unidad de salida en la red en formato de número real.
En el disco anexo a este reporte se incluye dicho archivo de salidas procesado por un módulo Java que se encarga de obtener los datos puros, es decir, sin encabezados ni comentarios de línea. El nombre del archivo es “resultados_snns_procesados.txt” y abajo se muestran parte del contenido como ejemplo del formato del mismo:
0.00025 0.00001 0.00009 0.00006 0.00015 0 0 0.00004 . . .
0.00049 0.00005 0.00021 0.00007 0.00024 0.00002 0.00002 . . .
0.00017 0.00004 0.00015 0.00002 0.00001 0.00001 0.00018 0.99925 . . .
. . .
0.00002 0.00004 0.00011 0 0.9994 0 0.00003 0 0.00002 0 0.00011 . . .
Muestra del archivo “resultados_snns_procesados.txt”
El paso siguiente en la obtención de vectores binarios comparables con los utilizados en la etapa de entrenamiento es responsabilidad del módulo Java “FileToMatrix” que se describe a continuación:
public class FileToMatrix {
private File arch;int rengs,colums;
public FileToMatrix(String namefile, int rows, int cols){
106

arch =new File(namefile);rengs=rows; colums=cols;
}public int[][] getmatrix(int type) throws FileNotFoundException{
if(type==1){ //escanea enteros
}else{ // escanea doubles
double[][] doubleArray = new double[rengs][colums];int[][] arrayReturn =new int[rengs][colums];Scanner sc = new Scanner(arch);
for(int i=0; i<rengs; i++){
for(int j=0; j<colums; j++){doubleArray[i][j]= sc.nextDouble();
}}sc.close();
for(int i=0; i<rengs; i++){
arrayReturn[i]=doubleArrToIntArr(doubleArray[i],indexOfMax(doubleArray[i]))
}return arrayReturn;
}}
}Versión simplificada del módulo “FileToMatrix.java”
Se puede inferir rápidamente que la utilidad de este módulo consiste en transformar los datos de salida de números reales a enteros. La idea es tomar cada renglón del archivo –salida real de la red - y verificar la posición del valor máximo de dicho renglón; en cuyo caso se asignará el valor ‘1’. En caso contrario se asigna el valor de ‘0’.
Cabe mencionar que una vez que entendimos el mecanismo mediante el cual obtenemos una matriz de binarios comparables con la matriz de vectores que codifica las salidas deseadas, es imposible que exista un vector – en su codificación binaria - de salida de la red que solo contenga 0’s. Dicho de otra manera, dado que se busca el valor máximo en cada renglón del archivo procesado y a ese valor se le asigna el valor ‘1’, no existirán vectores binarios que no contengan ningún valor ‘1’. La importancia de este hecho se ve reflejada en la estadística - posteriormente desarrollada – donde finalmente se obtuvieron 90 entradas que no contenían un carácter que pudiera ser clasificado con algún fonema valido y que terminaron por asignarse al vector cero pero que al momento de presentarlo como entrada a la red, debía ser sujeto de clasificación, no importando cual fuera esta.
A continuación se muestra la tabla de frecuencias obtenidas de la clasificación realizada por la red:
107

774
1096
12
121
294
4
203
59
321
6
226
96167147
55
232
4121
459
15
182
68
460
0100200300400500600700800
a b d dZ e f g i j k l m n ny o p r rr s t tS u w x
Tabla de frecuencias obtenida de la prueba de clasificación realizada por la red recurrente
651
910
9612
121
294
14
203
59
321
6
226
96167147
15
230
4125
459
18
182
68
460
0
100200
300
400500
600
700
a b d dZ e f g i j k l m n ny o p r rr s t tS u w x
Tabla de frecuencias obtenidas de la codificación del texto de entrenamiento
Una rápida inspección nos lleva a concluir que la distribución obtenida a partir de la codificación del texto de entrenamiento y la distribución obtenida a partir de la prueba de la red entrenada, son muy semejantes.
De las 25 categorías fonéticas posibles del texto de entrenamiento original, solamente 6 de ellas fueron mal interpretadas en al menos una ocasión, esto es, el 76% de las categorías fonéticas fueron preservadas íntegramente después del entrenamiento.
La tasa de error en la clasificación total es de 2.19 %
Mirando más a fondo estos resultados podemos ver en la tabla siguiente un detalle del estudio de las categorías fonéticas que fueron mal clasificadas y encontraremos datos importantes:
Categoría dZ i j rr x _Número de apariciones mal clasificadas 3 2 40 10 90 123Porcentaje de apariciones mal clasificadas 16.6 % 0.8 % 26.6 % 71. 42 % 98.8 % 18.8 %
108

Desde estos resultados podemos concluir algunas cuestiones importantes, por ejemplo. El problema en la mala clasificación de la categoría ‘rr’ la podemos atribuir a la cantidad escasa de ejemplos que fueron mostrados durante la etapa de entrenamiento, no obstante, existen otras categorías que tampoco aparecieron frecuentemente en el entrenamiento (algunas, menos veces que ‘rr’) pero que sin embargo, perduraron correctamente en la etapa de pruebas. Una buena hipótesis sería que la mala clasificación de la rr se puede atribuir a que la regla que la determina en el español actual, es casi patológica; es decir que existen casos particulares de uso en la lengua más que una regla generalizada de su uso. Queda fuera de los límites del presente estudio determinarlo.
Igualmente complicado resulta el caso de la categoría ‘x’, dado que en su mayoría la clasificación correcta del uso recae en otras clases. Tal es el caso de la ‘s’ y de la ‘dZ’. Dicho de otra forma, la clase a la que hace referencia ‘x’ está definida en su totalidad por el contexto antes y después de la aparición del carácter. Así, desafortunadamente el entrenamiento provoca que el contexto pueda no ser incluido por que este queda almacenado en los estados anteriores de la red y resulta imposible verificar los estados posteriores que entrarán en ella.
El entrenamiento se realizó en 5 etapas. La diferencia entre cada una de las etapas fue que en cada una de ellas el parámetro de aprendizaje se ajusto dé acuerdo con el comportamiento de la red. El criterio fue disminuir el número de épocas en cada etapa, así como el valor del parámetro eta dado que el valor del error fue disminuyendo y no queríamos que el entrenamiento logrado se arruinara. Así, se muestra en la tabla el resumen de los resultados obtenidos en cada etapa.
Etapa Épocas Eta SSE MSE SSE/u-salidaTiempo de
procesamiento estimado1 200 0.7 98.375 0.024017334 3.78365385 30 min.2 200 0.1 34.518 0.00842724609 1.32761538 35 min.3 100 0.25 7.530 0.00183837891 0.289615385 25 min.4 50 0.07 3.464 0.000845703125 0.133230769 20 min.5 50 0.025 1.687 0.000411865234 0.0648846154 20 min.
La decisión de realizar el entrenamiento en varias etapas se tomo a partir de una etapa previa de experimentación que por motivos de espacio no se mencionará en este documento pero cabe mencionar que concluimos que el entrenamiento en una sola etapa de la red recurrente podría no generar los resultados deseados, esto es, si el valor del parámetro de aprendizaje es grande, se converge con velocidad pero resulta muy difícil determinar el número de épocas necesarias de entrenamiento dado que en algún momento, el error bajaba lo suficiente pero volvía a subir o simplemente la red se sobre-entrenaba. Por otro lado, si el valor de eta era pequeño, la convergencia resultaba muy lenta y era necesario ajustar el número de épocas a un valor muy grande, lo que repercutió en un tiempo de procesamiento no adecuado.
Interpretación de resultados
Los resultados obtenidos relacionados con esta fase del experimento se pueden interpretar de la siguiente manera: La utilización de una red recurrente tipo Elman para el problema de mapeo de texto a fonema sin incluir el contexto en la entrada de la red es posible. Sin embargo, el entrenamiento de este tipo de red resulta más complicado que en el caso de un perceptrón multicapa. Por otro lado, a pesar de que se utilizó un software especializado en la simulación de redes neuronales, la complejidad del entrenamiento y
109

retropropagación en este tipo de redes dificultan el procesamiento en tiempo de entrenamiento, resultando en un aumento considerable en el tiempo total de entrenamiento.
La clasificación de los caracteres en fonemas, sin embargo, se puede considerar exitosa, el resultado final del archivo generado por la red es tan bueno en legibilidad como el producido por el perceptrón al momento de ser escuchado en el sintetizador MBROLA.
Otra cuestión importante a considerar es que la implementación del perceptrón multicapa fue desarrollada en Java y que por esta razón resulta aventurado generar conclusiones sin tener un punto más equilibrado de comparación. Para este efecto, se implementó la misma estructura del PMC en SNNS y se utilizaron valores de los parámetros de acuerdo con los mejores resultados obtenidos en la implementación. Los resultados de dicha implementación fueron totalmente congruentes con los obtenidos en la implementación del PMC en Java con la diferencia del tiempo de procesamiento. La implementación en SNNS resulto ser más eficiente durante la etapa de entrenamiento aproximadamente por el doble de velocidad. Los resultados respecto a la clasificación fueron muy similares y por tanto, lo antes dicho con respecto a la comparación del PMC y la red tipo Elman sigue siendo válido.
110

Conclusiones
En este proyecto tuvimos dificultades para poder desarrollar las diferentes etapas del proceso ya que la definición de las arquitecturas de las redes y de los árboles no fue fácil de determinar, por ejemplo: Para poder obtener la red neuronal del tipo perceptrón tuvimos dificultades al encontrar una arquitectura adecuada para el desarrollo del proyecto, pero conforme la experimentación avanzaba la arquitectura y los valores de los parámetros de aprendizaje y momentum se fue haciendo clara ya que al incrementar el número neuronas de la capa oculta, disminuir el tamaño de la ventana y reducir el valor de los parámetros de aprendizaje y momentum los valores de error que arrojaba la red neuronal fueron disminuyendo, esto debido a que en el idioma español las sílabas que se pueden encontrar difícilmente tienen un tamaño mayor a 3 por lo que una arquitectura con 80 unidades ocultas y un contexto de 3 caracteres fue suficiente para que la red neuronal arrojara valores considerablemente aceptables.Para este mismo experimento intentamos obtener una red neuronal que determinara los valores de duración y pitch para cada fonema, pero este red neuronal propuesta no arrojó resultados considerablemente buenos ya que la red neuronal se tardaba mucho tiempo en disminuir el error y aún así este no era un error que siquiera se pudiera considerar bueno, inclusive cambiando cualquiera de los parámetros e iteraciones, pensando que el problema era la arquitectura propuesta cambiamos en varias ocasiones tanto la arquitectura como la herramienta para crear la red neuronal y aún así el error de la red era extremadamente muy alto. Sin embargo, al intentar obtener la duración y pitch con los árboles de decisión se encontraban los parámetros correctos según el patrón con el que fue entrenado el árbol. Este experimento tiene un inconveniente muy notorio, el árbol solo reconoce los valores según el patrón con el que fue entrenado y a cada uno se le asigna una clase esto nos implica rigidez al seleccionar los parámetros cuando lo ideal sería que se seleccione un valor por cada parámetro. La dificultad esencial en este experimento fue que el programa CRUISE nunca pudo arrojar un árbol de decisión que clasificara más de un fonema con su correspondiente duración y pitch por lo que tuvimos que obtenerlo de una clase que no poda el árbol de decisión. Esto evidentemente implica un desperdicio de tiempo en la búsqueda del fonema a través del árbol de decisión, más sin embargo, este método fue mejor en tiempo invertido para resolver el experimento y tiempo de procesamiento y en resultados que la red neuronal.Haciendo referencia a los árboles de decisión para los fines de este experimento y con los datos arrojados por la red neuronal y la experimentación con los árboles de decisión encontramos que esta técnica fue más eficiente que las redes neuronales aún con las limitaciones que el mismo algoritmo tiene. Para el experimento de clasificación de fonemas encontramos que de igual forma que con las redes neuronales el tamaño de la ventana de 3 es optimo para segmentar el texto para procesarlo y con la codificación de cada elemento de la ventana por el fonema que le corresponde según los fonemas que el Mbrola reconoce el árbol de decisión arroja resultados demasiado buenos.La última fase del experimento fue la implementación de la red neuronal de NETTalk con redes neuronales recurrentes tipo Elman, los resultados obtenidos en esta fase arrojan que el mapeo de texto a fonema es posible sin incorporar el contexto pero su principal inconveniente es la dificultad de entrenar la red neuronal, a pesar de la utilización de software especializado para el entrenamiento. Sin embargo la red neuronal recurrente clasificó satisfactoriamente.Por último, cabe mencionar que la unificación de todos los módulos auxiliares empleados para generar un software que realice el proceso por completo es motivo de otro proyecto por la dificultad que requiere
111

resolver las incompatibilidades entre los formatos de archivos de la variedad de herramientas utilizadas, sin embargo, los resultados de este proyecto se pueden considerar satisfactorios en el sentido de que se lograron los objetivos principales y le implementación de todas las fases de experimentación fueron completadas.
112

ANEXOS:
ANEXO AStuttgart-Java NNSIntroducciónJava Neural Network Simulator (JavaNNS) es un simulador para redes neuronales desarrollado en Wilhelm-Schickard-Institute for Computer Science (WSI) en Tübingen, Alemania. Esta basado en el kernel 4.2 de Stuttgart Neural Network Simulator (SNNS), con una nueva interfaz gráfica escrita en Java. Como consecuencia, las capacidades de JavaNNS son en su mayor parte iguales a las capacidades del SNNS, mientras que la interfaz de usuario ha sido diseñada nuevamente y puede llegar a ser más fácil e intuitivo su uso. Algunas complejas aunque no muy a menudo utilizadas características del SNNS (por ejemplo. el despliegue tridimensional de redes neuronales) ha sido dejadas o aplazadas para una versión posterior, mientras que cosas nuevas, como el log panel, ha sido introducidas. InstalaciónPara utilizar JavaNNS, se tiene que tener instalado el Java Runtime Environment (o el JDK, que lo contenga). JavaNNS se ha probado para trabajar con Java 1.3 y quizás el 1.2.2 trabaje también, aunque se han informado ciertos problemas con la administración de archivos en ciertos ambientes. JavaNNS para plataformas Windows se distribuye como el archivo de JavaNNS-Win.zip. El archivo contiene:
1. JavaNNS.jar - el archivo Java que ejecuta JavaNNS.2. examples – carpeta con ejemplos de redes, patrones etc.3. manual – carpeta que contiene el manual.
Y solo tiene que ser descomprimido y al ejecutar JavaNNS.jar por primera vez aparecerá un dialogo que lo guiará a través de una sencilla configuración del JRE. Listo ahora se puede empezar a utilizar JavaNNS escribiendo java –jar JavaNNS.jaren el prompt del sistema o haciendo doble click con el mouse en el icono del archivo directamente desde el ambiente gráfico.
Un paseo rápido por JavaNNSJavaNNS es un simulador de redes neuronales artificiales inspirado en las redes neuronales biológicas. Este Permite utilizar redes predefinidas o crear y editar redes propias, analizarlas y entrenarlas.
Iniciando JavaNNSPara iniciar el paseo, inicie el JavaNNS como se describe en el punto anterior referente a la instalación. Después de iniciado el programa, la pantalla principal es desplegada y dado que el simulador fue abierto sin parámetros de entrada dicha pantalla aparece vacía como se muestra en la figura.
113

Pantalla principal
Cargando archivosUtilice el menú File/Open para abrir un archivo de ejemplo: Navegando por la carpeta examples seleccione el archivo nettalk.net. Aparecerá un cuadro de dialogo preguntando si también desea abrir el archivo de configuración, seleccione la opción sí. Se desplegaran dos ventanas, una de las cuales contiene una versión de la red de la red de NETtalk y otra que contiene en forma abreviada la distribución de las unidades de todas las capas para que se puedan apreciar con mayor facilidad. Ver figura.
Red de ejemplo NETtalk
Opcionalmente puede configurar la información correspondiente a la red que este interesado en desplegar en los diagramas, esto se puede hacer desde el menú view/display settings. Por ejemplo, en la figura se muestra el diagrama de configuración de la red NETtalk mencionado anteriormente pero a través del tab units & links del dialogo display settings se ha agregado la opción show links.
114

Vista de las conexiones de las unidades de la red NETtalkEntrenando la redEl entrenamiento de la red es relativamente sencillo una vez que se tienen editados los archivos de pattern (patrones), para cargarlos a nuestro ejemplo seleccionamos nuevamente el menú file/open y abrimos el archivo nettalk.pat, depuse desde el menú tools/control panel desde el tab learning presionamos el botón learn current. Observaremos como los pesos de las unidades comienzan a cambiar.
Analizando la redPara analizar el rendimiento de la red JavaNNS cuenta con diversas herramientas donde se pueden tener registrados (importar o imprimir incluso) aquellos eventos importantes en el entrenamiento de la red, así como también los índices de error y comportamiento de esta. Como ejemplo de esto podemos abrir desde el menú view/error graph y view/log una grafica del error obtenido durante los ciclos de entrenamiento y una especie de consola de sistema donde se registra el valor exacto de dicho error. También se pueden analizar otros parámetros de la red desde el menú tools/analyzer, en la figura 4 se muestran las ventanas correspondientes al entrenamiento de la red NETtalk del ejemplo, se puede observar que estos diálogos son muy fáciles de utilizar y por tanto, se puede obtener fácilmente la gráfica de algún aspecto de nuestro interés.
115
Herramientas de análisis de JavaNNS
ANEXO B.
MBROLAMbrola de por sí, no es capaz de convertir a sonidos un texto plano, necesita un fichero de fonemas. pho para que la generación de las frases sea aceptable. Encontré un programa escrito el Perl con las tablas de fonemas adaptadas al castellano llamado tts-Spanish, el cual, después de algunos cambios, se adaptó perfectamente al proyecto.
Características del sistema auditivo humanoEscucha de 25 Hz a 20000 HzHabla: Hombres: 70 a 200 Hz
Mujeres: 150 a 400 HzNiños: 200 a 600 Hz
Sonidos del castellanoAdaptado de Alistair Conkie (proyecto Mbrola)Vocales: a e i o u á é í ó ú (iguales a las sin acentuación) Diptongos: ai ay au ei ey eu oi oySemiconsonantalización:
ia ie io iu ua ue ui uo ía íe ío íu úa úe úi úo
Sonidos de Consonantesb d f g x h j k l m n ñ p r s t ch ks ll rr w y v z (en algunos países)
116

Emofilt es un programa para simular despertar emocional con la síntesis de discurso basada en libre para no comercial utiliza el motor de la síntesis de MBROLA. Es entre UN NO sistema text-to-speech completo, sino actos como transformador el phonemisation y el componente de la discurso-generacion. Usted necesita tan tener Mbrola instalado para utilizar el emofilt Convertido originalmente en la universidad técnica de Berlín en 1998 fue restablecido recientemente como proyecto de la abrir fuente de la fragua de la fuente y reescrito totalmente en el lenguaje de programación de Java.Los módulos language-dependent de Emofilt son controlados por los XML archivos externos y es tan multilingüe como MBROLA que apoye actualmente 35 idiomas. Conocida como uno de los desafíos más grandes de la síntesis text-to-Speech por el porvenir. Portugués brasileño, bretón, inglés británico, holandés, francés, alemán, rumano, español, y sueco ya disponible como sintetizadores de discurso multilingües del software completo (es decir, la pieza de DSP de un sistema de TTS. Muchos otras idiomas están en la preparación.
La puntería del proyecto de MBROLA, iniciada por el laboratorio de TCTS del laculté Polytechnique de Mons (Bélgica), es obtener un sistema de los sintetizadores de discurso para tantos idiomas como sea posible, y las proporciona libremente para los usos no comerciales. La última meta es alzar la investigación académica sobre síntesis de discurso, y particularmente sobre la generación prosody, conocida como uno de los desafíos más grandes tomados por los sintetizadores de Text-To-Speech por el porvenir.
MBROLA, un sintetizador de discurso basado en el encadenamiento de diphones. Toma una lista de fonemas como entrada, junto con la información prosódica (duración de fonemas y de una descripción por trozos linear de la echada), y produce muestras de discurso en 16 pedacitos (lineares), en la frecuencia de muestreo de la base de datos del diphone usada (es por lo tanto NO una text-To-Speech (TTS) synthesizer, puesto que no acepta el texto crudo como entrada). Este sintetizador se proporciona para libre, para los usos no comerciales, no militares solamente.
Las bases de datos de Diphone se adaptaron al formato de Mbrola son necesarias funcionar el sintetizador. Las voces francesas han sido hechas disponibles por los autores de MBROLA, y el proyecto sí mismo de MBROLA se ha organizado para incitar a otros laboratorios o compañías de investigación para compartir sus bases de datos del diphone. Los términos de esta política que comparte pueden ser resumidos como sigue:
Después de un cierto acuerdo oficial entre el autor de MBROLA y del dueño de una base de datos del diphone, la base de datos es procesada por el autor y adaptada al formato de Mbrola, para libre. La base de datos del diphone de Mbrola que resulta se hace disponible para el uso no comercial, no militar como parte del proyecto de MBROLA. Sigue habiendo las derechos comerciales en la base de datos de Mbrola con el abastecedor de base de datos para el uso exclusivo con el software de Mbrola.
El sintetizador de MBROLA TTS recientemente se ha puesto a disposición los usuarios del Internet en el contexto del proyecto de MBROLA .
117

IMPORTANTE: Debe ser acentuado que, para probar la calidad segmentaría de este sintetizador encadenamiento-basado independientemente de efectos suprasegmental, hemos provisto de ella la información prosódica directamente estilizada de la pronunciación natural del texto.
Por ejemplo, "bonjour.raw" fue obtenido del fichero de entrada siguiente:
_ 51 25 114b 62en 127 48 170j 110 53 116ou 211r 150 50 91_ 91
Cada línea contiene un nombre del fonema, una duración (en ms), y una serie (posiblemente ninguna) de puntos del patrón de la echada compuso de dos números cada uno del número entero: la posición del punto del patrón de la echada dentro del fonema (en % es de su duración total), y el valor de la echada (en el hertzio) en esta posición. Por lo tanto, la primera línea de bonjour.pho:
_ 51 25 114
Dice el sintetizador producir un silencio del ms 51, y poner un punto del patrón de la echada de 114 hertzios en el 25% de 51 puntos del patrón del ms echada defina una curva por trozos linear de la echada. Festival ofrece un sistema texto a voz completo con varias APIs, así como un entorno de desarrollo e investigación de técnicas de síntesis de voz. Está escrito en C++ con un intérprete de órdenes basado en Scheme para el control general. Además de la investigación en la síntesis de voz, festival es útil como un programa de síntesis de voz autónomo. Es capaz de producir voz claramente comprensible a partir de texto. Recite es un programa para la síntesis de voz. La calidad del sonido que produce no es terriblemente buena, pero debería ser adecuada para informar verbalmente de mensajes de error ocasionales. Dado algún texto en inglés, recite lo convertirá en una serie de fonemas, entonces se convierten los fonemas en una secuencia de parámetros vocales, y entonces la síntesis del sonido vocalmente le haría decir la frase. Recite puede desarrollar un subconjunto de estas operaciones, de forma que se puede usar para convertir texto en fonemas, o producir una pronunciación basada en los parámetros vocales calculados por otro programa. Proporciona un capa independiente de dispositivos para la síntesis de voz. Soporta varios sintetizadores de voz por «software» y «hardware» como base y proporciona una capa genérica para la síntesis de voz y reproducir datos PCM a las aplicaciones a través de aquellos programas base distintos. Varios conceptos de alto nivel como encolar vs. Interrumpir la voz y configuraciones de usuario de aplicaciones específicas se implementan en un dispositivo de forma independiente, por eso de liberar al programador de la aplicación de tener que reinventar la rueda de nuevo. Todas las soluciones libres para «software» basadas en la síntesis de voz disponibles actualmente parecen compartir una deficiencia común: La mayoría están principalmente limitadas al inglés, proporcionando solo un soporte muy marginal para otras lenguas, o en lo mayoría de los casos ninguno. Entre todos los sintetizadores de voz de software libre para Linux, solo el festival de CMU soporta más de
118

una lengua natural. el Festival de CMU puede sintetizar inglés, español y galés. No se soporta el alemán. No se soporta el francés. No se soporta el ruso. Cuándo la internacionalización y localización son las tendencias en el software y los servicios «web», ¿es razonable pedir a la gente ciega interesada en Linux que aprendan inglés solo para entender lo que dice su ordenador y llevar toda su correspondencia en una lengua extranjera?
Desafortunadamente, la síntesis de voz no es realmente el proyecto doméstico favorito de Jane Hacker. Crear un «software» sintetizador de voz inteligible conlleva tareas que consumen tiempo. La síntesis de voz concatenativa requiere la cuidadosa creación de una base de datos de fonemas que contengan todas las posibles combinaciones de sonidos de la lengua objetivo. Las reglas que determinan las transformación de la representación en texto a fonemas individuales también se necesitan desarrollar con sumo cuidado, normalmente requiere la división del flujo de caracteres en grupos lógicos como oraciones, frases y palabras. Tal análisis léxico requiere un léxico específico de la lengua raramente publicable bajo una licencia libre.Una de las mayores promesas en los sistemas de síntesis de voz es Mbrola, con bases de datos de fonemas para más de diez lenguas. Desafortunadamente, la licencia elegida para el proyecto es muy restrictiva. Mbrola solo se puede distribuir como binario preconstruido. Además, las bases de datos de fonemas son solo para uso no militar ni comercial. Nosotros contactamos con los desarrolladores del proyecto, pero no eran capaces de cambiar la licencia de su trabajo debido al conjunto de limitaciones que pusieron varios contribuyentes. Desafortunadamente, dado el modelo de licencia restrictiva de Mbrola, no se puede usar como base para un trabajo mayor en esa dirección, al menos no en el contexto del Sistema Operativo Debian.Sin un «software» sintetizador de voz ampliamente plurilingüe, Linux no puede ser aceptado por proveedores de tecnología de asistencia y gente con discapacidades visuales. ¿Qué podemos hacer para mejorar esto?Básicamente hay dos métodos posibles:Organizar un grupo de gente deseoso de ayudar en este asunto, e intentar activamente mejorar la situación. Esto puede ser un poco complicado, ya que se necesita un montón de conocimiento específico sobre síntesis de voz, lo que no es que sea fácil si se hace de forma autodidacta. Sin embargo, esto no debería descorazonarle. Si piensa que puede motivar un grupo de gente lo suficientemente grande para alcanzar algunas mejoras, valdría la pena hacerlo.Obtener fondos y contratar a algún instituto que ya tenga el conocimiento de como crear las bases de datos de fonemas necesarios, léxico y reglas de transformación. Este método tiene la ventaja de que tiene mayores probabilidades de generar resultados de calidad, y también debería alcanzar algunas mejoras mucho antes que el primer método. Por supuesto, la licencia bajo la que se publicaría todo el trabajo resultante se debería acordar por adelantado, y debería pasar los requerimientos de las DFSG. La solución ideal sería por supuesto convencer a alguna universidad para sufragar tal proyecto con sus propios fondos, y contribuir con los resultados a la comunidad del Software Libre.Extensiones de revisión de pantalla de Emacs.Un sistema de salida por voz que permitirá a cualquiera que no pueda ver trabajar directamente en un sistema UNIX. Una vez inicie Emacs con Emacspeak cargado, obtendrá respuesta hablada para todo lo que haga. Su rendimiento variará dependiendo de como de bien sepa usar Emacs. No hay nada que no pueda hacer en Emacs. Este paquete incluye servidores de voz escritos en tcl para soportar los
119

sintetizadores de voz DECtalk Express y DECtalk MultiVoice. Para otros sintetizadores, busque paquetes separados de servidores de voz como Emacspeak-ss o Un cliente de Emacs y una biblioteca de Elisp para el Proporciona una compleja interfaz para Emacs, enfocado especialmente (pero no limitado) a los usuarios ciegos o con daños visuales. Permite al usuario trabajar con Emacs sin mirar la pantalla, usando la salida de voz producida por los sintetizadores de voz soportados por el expendedor de voz.Lectores de consola (modo-texto)Un demonio que proporciona acceso a la consola de Linux para una persona ciega usando un «software» para mostradores de braille.Maneja el terminal braille y proporciona funcionalidad para la revisión de la pantalla completa.Los siguientes modelos de mostrado se soportan actualmente (en la versión 3.4.1-2): Alva (ABT3xx/Delphi). BrailleLite (18/40) BrailleNote (18/32). EcoBraille displaysEuroBraille displays. HandyTech (Bookworm/Braillino/Braille Wave/Braille Star 40/80). LogText 32. MDV braille displays. Papenmeier. Tieman Voyager 44/70 (USB), CombiBraille, MiniBraille and MultiBraille. TSI (PowerBraille/Navigator). Vario (Emul. 1 (40/80)/Emul. 2). Videobraille. VisioBraille. BRLTTY también proporciona una infraestructura basada en cliente / servidor para aplicaciones que deseen utilizar un dispositivo de mostrado en Braille. El proceso demonio escucha conexiones TCP/IP entrantes en un cierto puerto. Una biblioteca de objetos compartidos para clientes. En el paquete se proporciona una biblioteca estática, archivos de encabezado y documentación.Esta funcionalidad la usa por ejemplo Gnopernicus para proporcionar soporte a tipos de mostradores que aún no soporta Gnopernicus directamente.
El programa lector de pantalla en segundo plano lee la pantalla y le pasa la información a un paquete de «software» Texto-a-Voz (Como festival o un sintetizador de voz por «hardware».El paquete del núcleo contiene un núcleo Linux parcheado con speakup, un lector de pantalla para la consola de Linux. La propiedad especial de speakup es que se ejecuta en espacio de núcleo, lo que proporciona un acceso a un nivel del sistema un poco más bajo que lo que pueden proporcionar otros lectores de pantalla.Speakup puede, por ejemplo, leerle mensajes críticos del núcleo en el punto donde el núcleo ya está colapsado, y no hay programa de espacio de usuario que pueda hacer nada útil ya.
ANEXO C.
120

CRUISE
Introducción a CRUISE
CRUISE es un programa para árboles de decisión estructurados. CRUISE consiste algunos algoritmos para la construcción de árboles de decisión. Algunas de sus características principales son:
• Análisis discriminativo de recursividad lineal• Selección imparcial de variables vía calibración “bootstrap”• Cambio de árbol podado por validación cruzada o por muestras de prueba• Simplificación del árbol usando modelo de nodo bivariable
El algoritmo básico de CRUISE es descrito en Kim and Loh (2001) y Kim and Loh (2003)6.
Instalación y ejecución
CRUISE es un programa compatible con plataformas PC, SUN y LINUX, este programa puede ser descargado en un zip del a pagina:
http://www.stat.wisc.edu/˜loh/
Al descomprimirse se producen los archivos:
1. cruise. PDF: Manual de usuario2. cruise.exe: El archivo ejecutable para Win95/98/NT/2000/XP3. heartdat.txt, heartdsc.txt: Archivos usados como ejemplos para las entradas del programa
El programa puede ser invocado desde la línea de comandos o con un doble click sobre el icono del ejecutable.
Archivos de entrada
Se necesitan tres archivos de texto:
1) Archivo de datos: Contiene los datos de aprendizaje o entrenamiento, cada registro consiste de observaciones y una clase de predicción. Las entradas por cada registro deben ser separadas por coma o por espacio, cada registro pude ocupar una o más líneas en el archivo, pero cada uno debe empezar en una nueva línea. Los valores de los registros pueden ser numéricos, caracteres o cadenas de caracteres de longitud no mayor a 15 caracteres (si la longitud es mayor se corta en 15 caracteres).
6 http://stat.bus.utk.edu/techrpts/2001/2001-3.pdf
121

2) Archivo de descripción: Es usado para proveer al programa de información acerca del nombre del archivo de datos, los nombres de las columnas y la localización en las columnas de los datos y los tipos de datos en el análisis.
Por ejemplo:heartdat.txt El nombre del archivo de datos?column, varname, varitype Se describe el numero de la columna, 1 age n
el nombre del dato y el tipo de 2 sex c variable3 chestpain c4 bloodpres n5 cholestor n6 bloodsuga c7 restcardi c8 heartrate n
Como vemos efectivamente la primera línea da el nombre del archivo de datos, la segunda línea da el código que denota un valor perdido en el dato. El código del valor perdido puede ser mayor a 15 caracteres de longitud. Un código de valor perdido puede aparecer en la segunda línea incluso si este no es un valor perdido en el dato. La tercera línea contiene tres cadenas de caracteres para indicar las cabeceras de las columnas de las subsecuentes líneas. La posición, nombre y rol de cada variable que viene después debe en el orden dado por la línea anterior, los roles permitidos son:
c Esta es una variable categórican Esta es una variable numéricax Esta indica que la variable es excluidad Esta es una clase o variable dependiente. Solo puede haber una variable de este tipo
3) Archivo de pruebas: Este archivo sirve para guardar la información generada por el programa
Ejecutando CRUISE
Como se menciono antes se puede hacer la invocación al programa desde la línea de comandos o dando doble click al icono de ejecutable, al realiza una de estas dos acciones se debe mostrar la siguiente pantalla:
122

CRUISE basa en hace preguntas sobre el modo de creación del árbol y por cada pregunta despliega un rango permitido y un recomendación, para este caso el rango es de [0:2] y la recomendación es uno. Entonces seleccionamos 1 y damos enter, se debe mostrar la siguiente pantalla
En esta pantalla debemos ingresar el nombre del archivo en donde se va a volcar la salida del programa, es decir, el archivo en donde se va a escribir el árbol y su análisis.
123

Si el archivo no existe previamente el programa debe pedir el nombre del archivo de descripción, damos el archivo de descripción y debe aparecer la siguiente pantalla:
Se pude observar que si el archivo no es un archivo valido o no existe el programa marca un error y pide nuevamente el nombre del archivo, una vez que el archivo es valido el programa despliega la información relevante al archivo de descripción y pide las opciones de generación del árbol, damos las opciones por default presionando 1 y dando enter:
124
En este momento el sistema ha creado el archivo y ha generado el árbol de decisión con sus análisis, para finalizar el programa damos enter y la pantalla se cierra
El programa también puede generar archivos complementarios donde se cree solamente el árbol e incluso código en LATEX para visualizarlo, esto se logra de la siguiente manera:
1. Iniciar CRUISE2 Seleccionar el modo interactivo3. Ingresar el archivo donde se guardará la salida del programa4. Ingresar el archivo de descripción5. Se selecciona el modo de opciones avanzadas (opción 2)
125

6. Se selecciona el modo de “for univariate split” (opción 1)7. Se selecciona el modo de “for univariable selection via 2D method” (opción 2)8. Se selecciona el modo de “for split selection via discriminant analysis” (opción 1)9. Se selecciona el modo de “for equal priors” (opción 1)10. Se selecciona la primer modalidad
11. Se selecciona el modo de “for pruning via cross-validation” (opción 1)12. Se seleccionan las opciones por default en las siguientes tres preguntas13. El programa pregunta si se desea crear un archivo con las predicciones de las clases, se le da la opción de 214. Después en las siguientes preguntas se le da la opción por default hasta que pregunta el nombre del archivo LATEX
126

15. Ingrese el nombre del archivo16. En la siguiente pregunta presione 2 y después ingrese el nombre del archivo que contendrá el árbol podado por el programa17. Presione enter una vez que el programa lo pida para terminar con su ejecución
Ahora si se observa en el directorio en donde se encuentra el programa de CRUISE se han generado los dos archivos, uno que contiene le código en LATEX y otro que contiene el árbol podado
Archivo con el árbol podado:
Node1:thal Node2:vessels class=1 Node5:exercise class=1 class=2 Node3:vessels Node6:chestpain class=1 class=2 class=2
Archivo de salida
127

El primer elemento del archivo de salida es la información recolectada del archivo de descripción, donde se incluyen el nombre del archivo de descripción, el de datos y la información contenida en el archivo de descripción.
La segunda parte contiene información relevante al archivo de datos, entre otra información contiene le numero de registro, y cuantas variables hay de cada tipo.
La tercera sección corresponde a las repuesta de las preguntas que le dimos al programa sobre que archivo queríamos que nos generara y la forma de generación del árbol.
La cuarta sección contiene el método de poda
La sección 5 es una tabla que muestra la secuencia de poda y la tabla siguiente es la estimación de la validación cruzada y los errores estándar.
La sección 6 es un resumen de los nodos del árbol.
La sección 7 muestra la estructura del árbol.
La sección 8 muestra el detalle de la estructura del árbol
La sección 9 lista el número total de nodos y el número total de nodos terminales
La sección 10 muestra los resultados de clasificación para el conjunto de entrenamiento, muestra el parámetro de error con el error estándar.
La sección 11 muestra el error de la validación cruzada y el error estándar de la validación cruzada
La sección 12 muestra el tiempo que el programa se llevo en realizar el análisis
ANEXO D.
El Stuttgart Neural Network Simulator SNNS
SNNS (Stuttgart Neural Network Simulator), es un simulador para redes Neuronales desarrollado por el Instituto para Sistemas de Alto Rendimiento Paralelo y Distribuido de la Universidad de Stuttgart desde 1989. El objetivo del proyecto es crear un eficiente y flexible ambiente de simulación para investigación y aplicación de redes neuronales.
128

Instalación de SNNS
El proceso de instalación que se describirá a continuación consta de tres partes, este proceso de instalación será descrito para las plataforma de Linux y Windows. En la primera parte se describirá como poder obtener el simulador SNNS (Linux y Windows), luego en la segunda parte, se explicará como configurar la instalación del simulador (Linux) y por último, se explicará como instalar el SNNS (Linux y Windows).
Como obtener SNNS
El simulador SNNS puede ser obtenido por un ftp anónimo del host, aquí se encuentran los archivos tanto para Linux como para Windows:
ftp.informatik.uni-tuebingen.de (134.2.12.18)
en el subdirectorio
/pub/SNNS (Linux y Windows)
como el archivo
SNNSv4.2.tar.gz (Linux)
SNNSv4.1-win32-full.zip (Windows)
X-Server (Windows)
En Linux, después de descargar el archivo exitosamente, se debe mover el archivo dentro del directorio donde se instalará el SNNS, luego se debe descomprimir el archivo de la siguiente manera:
Unzip -dc SNNSv4.2.tar.gz | tar -xvf -
Configurando la Instalación del SNNS
En Linux, lo primero que se debe hacer es crear un directorio donde residirá el simulador SNNS, al cual llamaremos <SNNSDIR>. Por esto, lo primero que se debe hacer es crear el directorio SNNSDIR. Luego se deben teclear los siguientes comandos:
configure
->instala en <SNNSDIR>//[tools|xgui]/bin/<HOST>
confugure –enable-global
129

->instala en /usr/local/bin
configure –enable-global –prefix /home/tudirectorio
->instala en /home/tudirectorio/bin
Instalando el SNNS
En Linux, después de configurara la instalación, lo que hay que hacer es usualmente la del kernel y las herramientas de interfaz gráfica. Esto se puede hacer fácilmente con el siguiente comando:
make install
dándole el directorio base donde se corrió el comando “configure”. Para compilar solamente se debe usar el siguiente comando:
make compile
después de instalar SNNS se debe limpiar la fuente de los directorios (se borran todos los objetos y librerías), con el comando:
make clean
por último si se quiere desinstalar el SNNS se debe usar el comando:
make uninstall
En Windows, después de descargar ambos archivos (SNNS para Windows y X-Server), lo que se debe hacer primero es la instalación del X-Server, ya que el SNNS está diseñado para trabajar en una plataforma distinta a la de Windows, la cuál es X-Windows de Linux, por esto es necesario que se disponga de un algún programa que simule tal plataforma para que el SNNS y así este pueda ser ejecutado, esto lo permite el X-Server.
Una vez instalado correctamente el X-Server, lo único que se tiene que hacer es descomprimir el archivo SNNSv4.1-win32-full.zip en el disco duro, para esto se puede ocupar cualquier software que realice las funciones de descompresión de archivos con formato*.zip, algunos de estos son WinZip, WinRar, etc.
Guía rápida de usuario de SNNS
En Linux, para comenzar utilizar el simulador SNNS basta tan solo con escribir el comando SNNS.
En Windows, el primer paso para iniciar el programa es ejecutar el emulador de X-Windows, el cuál es el X-Server en nuestro caso.
130

Para iniciar el SNNS se debe ejecutar el archivo snns.bat del directorio raíz donde se descomprimió el archivo SNNSv4.1-win32-full.zip.
En ambos casos una vez iniciado el SNNS aparecerá la pantalla de presentación la que se ilustra en la figura.
Pantalla Inicial del SNNS.
Después de iniciada la presentación esta se puede cerrar presionando el botón izquierdo del mouse. Al hacer esto, habilitará el menú principal. El menú principal del SNNS es el que se muestra en la figura.
Pantalla Principal del SNNS.
Esta pantalla provee las funciones que son realizadas por el simulador. No es necesario ejecutar todas las opciones para realizar una determinada tarea. Los botones más importantes que componen el Menú Principal son descritos más adelante en ésta guía de usuario.
131
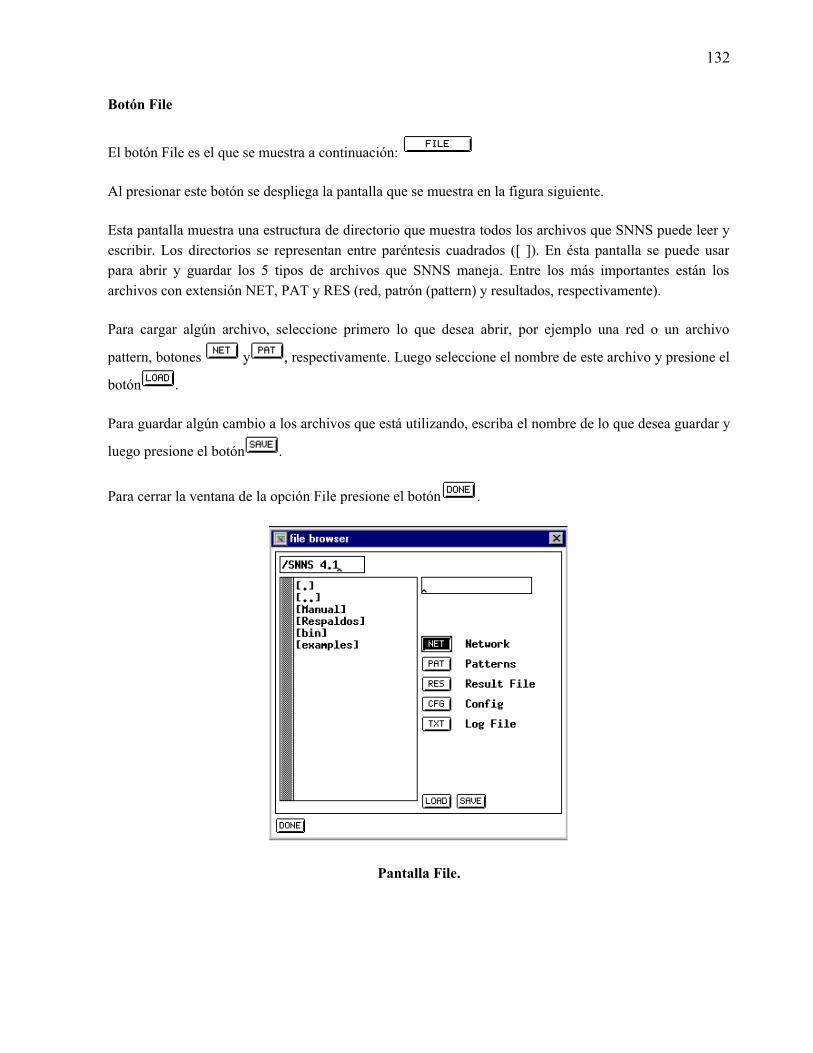
Botón File
El botón File es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura siguiente.
Esta pantalla muestra una estructura de directorio que muestra todos los archivos que SNNS puede leer y escribir. Los directorios se representan entre paréntesis cuadrados ([ ]). En ésta pantalla se puede usar para abrir y guardar los 5 tipos de archivos que SNNS maneja. Entre los más importantes están los archivos con extensión NET, PAT y RES (red, patrón (pattern) y resultados, respectivamente).
Para cargar algún archivo, seleccione primero lo que desea abrir, por ejemplo una red o un archivo
pattern, botones y , respectivamente. Luego seleccione el nombre de este archivo y presione el
botón .
Para guardar algún cambio a los archivos que está utilizando, escriba el nombre de lo que desea guardar y
luego presione el botón .
Para cerrar la ventana de la opción File presione el botón .
Pantalla File.
132

Para guardar los resultados de una red entrenada, ocupe el botón . Este archivo contiene las activaciones de todas las neuronas de salida. Estas activaciones son obtenidas al realizar un paso de una
propagación hacia delante. Después de presionar el botón la siguiente pantalla se desplegará:
Formato de los archivos de Resultados
En esta pantalla puede incluir los patrones (patterns) tanto de entrada como de salida, así como también crear un nuevo archivo o agregar los resultados a un archivo existente.
Para guardar los resultados en el archivo presione el botón .
Botón Control
El botón Control es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura.
Pantalla Control.
Esta pantalla consiste de dos partes. La parte superior controla los parámetros definiendo el proceso de entrenamiento, las tres filas inferiores pueden ser llenadas para definir los parámetros de aprendizaje, el rango sobre el cual los pesos serán aleatoriamente distribuidos cuando la red sea inicializada. Los valores
133

por defecto de los parámetros de aprendizaje son (0.2, 0 , 0 , 0 , 0) mientras que los pesos están configurados por defecto entre 1 y –1 (1.0 , -1.0 , 0 , 0 , 0).
La tabla muestra todas las opciones de entrada con los tipos y rangos de valores. Los 5 parámetros de aprendizaje dependen de la función de entrenamiento seleccionada.
Nombre Tipo Rango de valorSteps (pasos actuales)
Count (cuenta para pasos)
Cycles
Pattern (numero actual de pattern)
Valid
Learn (5 parámetros)
Update (5 parámetros)
Init (5 parámetros)
Texto
Etiqueta
Texto
Etiqueta
Texto
Texto
Texto
Texto
Mayor o igual a 0
Mayor o igual a 0
Mayor o igual a 0
Mayor o igual a 0
Mayor o igual a 0
Real
Real
Real
Campos de entrada del Panel de Control.
Las funciones de algunos de los botones de la figura son:
: Inicializa la red con valores de acuerdo a la función y los parámetros dados en la última línea del panel.
: El contador es re-iniciado y las neuronas son asignadas a su activación inicial.
: La red es entrenada con todos los parámetros para el número de ciclos de entrenamiento especificados en el campo Cycles.
: El usuario puede probar el comportamiento de la red con todos los patrones (patterns) cargados. Los valores de activación de las neuronas de entrada y salida son copiados hacia la red.
: Si este botón está presionado, una secuencia aleatoria de patrones (patterns) es creada automáticamente.
134

Botón Info
El botón Info es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura .
Pantalla Info.
Esta pantalla despliega todos los datos de dos neuronas y el peso asociado a la unión de ellas. La neurona donde comienza la unión es llamada Fuente (Source), la otra Destino (Target).
Este panel es también muy importante para la edición, desde algunas operaciones referentes al despliegue de unidades Target o uniones Source-Target. Una neurona por defecto puede también ser creada aquí, cuyos valores (activación, función de activación, función de salida, etc.) son copiados hacia todas las neuronas seleccionadas de la red.
En la Pantalla Display, se puede seleccionar las neuronas de las distintas capas de la red haciendo click con el botón del centro del mouse. Esto hará una copia automática de todas las uniones de las neuronas pertenecientes a esa capa a la Pantalla Info. Para ver los valores muévase con los botones de desplazamiento.
Botón Display
El botón Display es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura. Esta pantalla muestra en forma gráfica la topología de la red neuronal, las activaciones de las neuronas y los pesos de las uniones.
Las neuronas son desplegadas como cajas, donde el tamaño de la caja es proporcional al valor del atributo desplegado. Cada neurona puede ser desplegada con dos de varios atributos. Uno sobre la neurona y otro
135

bajo ésta. Los atributos para ser desplegados pueden ser seleccionados en la pantalla de configuración (ver más abajo).
Las uniones son mostradas como líneas, con una representación del peso en forma opcional.
Pantalla Display.
Las opciones de ésta ventana son las siguientes:
: Cierra la ventana Display.
: Con este botón puede configurar la forma de visualización de la red. La siguiente pantalla se desplegará:
136
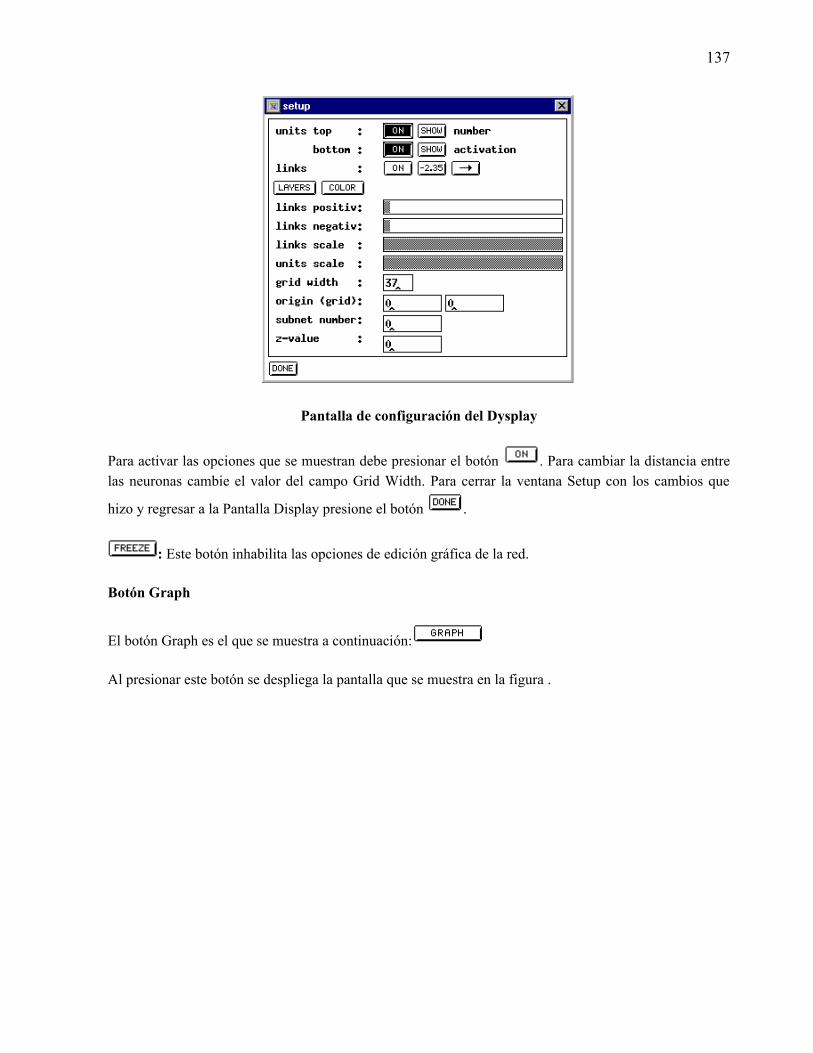
Pantalla de configuración del Dysplay
Para activar las opciones que se muestran debe presionar el botón . Para cambiar la distancia entre las neuronas cambie el valor del campo Grid Width. Para cerrar la ventana Setup con los cambios que
hizo y regresar a la Pantalla Display presione el botón .
: Este botón inhabilita las opciones de edición gráfica de la red.
Botón Graph
El botón Graph es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura .
137

Pantalla Graph.
Es una herramienta para visualizar la evolución del error de una red. La curva de error de la red es dibujada hasta que la red es inicializada o hasta que una nueva red es cargada, en cuyo caso el contador de
ciclo es reiniciado a cero. Esta ventana, sin embargo, no es limpiada hasta que el botón sea presionado. Esto permite la posibilidad de comparar varias curvas de error en una sola pantalla. El número máximo de curvas que pueden ser desplegadas simultáneamente son 25.
Cuando la curva sobrepasa la ventana de visualización, automáticamente ésta se re-escala con respecto al eje x.
Para cerrar la Pantalla Graph presione el botón .
Botón Bignet
El botón Bignet es el que se muestra a continuación:
Al presionar este botón se despliega un submenú y al seleccionar Feed Forward aparece la pantalla que se muestra en la figura.
138

Pantalla Bignet para Redes BackPropagation.
La opción Bignet divide la red en varios planos. La capa de entrada, la de salida y cada capa oculta es llamada un plano en la notación de Bignet. Un plano es un arreglo bidimensional de neuronas.
Bignet crea una red en dos pasos:
*Editar la red:
Esta genera estructuras de datos internas en Bignet las cuales describen la red pero no generan la red. Esto permite la fácil modificación de los parámetros de la red antes de crear la red.
*Generar la red en SNNS:
Este genera la red desde las estructuras internas de Bignet.
Los botones en Bignet hacen lo siguiente:
139

: Datos de entrada son ingresados al final del plano o de la lista enlazada.
: Datos de entrada son insertados en la lista del plano en el frente del plano actual.
: El elemento actual es reemplazado por el dato de entrada.
: El elemento actual es eliminado.
: Los datos del plano actual son escritos por el editor de planos.
: Los datos de las uniones actuales son escritas por el editor de uniones.
: El tipo (entrada, oculta, salida) de las neuronas de un plano es determinado.
: La posición de un plano es descrita en forma relativa (izquierda, derecha, abajo) con respecto al plano anterior.
: Una red BackPropagation totalmente conectada es generada.
: Si existen n planos entonces cada neurona en el plano i con 1 <= i < n está conectada con cada neurona en todos los planos j con i < j <= n.
: La red descrita por los dos editores es generada por SNNS. El nombre por defecto de la red es SNNS_NET.net.
: Todos los datos internos de los editores son borrados.
: Sale de Bignet y vuelve al menú principal.
Botón Weights
El botón Weights es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura.
140

Pantalla Weights.
La pantalla weigths es una ventana especializada separada para desplegar los pesos de una red. Esta puede ser usada para analizar la distribución de los pesos o para observar la evolución de los pesos durante el aprendizaje.
Los botones de Zoom, y , sirven para acercar o alejar la visualización de los pesos en la pantalla.
Al hacer click con el botón izquierdo del Mouse y dejar éste presionado sobre un cuadrado de color, que representa el peso entre dos neuronas, se despliega una caja de texto que indica la unión entre dos neuronas y el peso asociado a esa unión.
Botón Help
El botón Help es el que se muestra a continuación:
Al presionar este botón se despliega la pantalla que se muestra en la figura. Esta pantalla muestra la ayuda que el Software posee.
141

Pantalla de Ayuda del SNNS.
Para cerrar esta ventana presione con el mouse el botón .
Botón Quit
El botón Quit es el que se muestra a continuación:
Al presionar este botón se sale del SNNS.
142

Referencias:
[1] Sejnowski,T. and Rosenberg, C.R. 1986. "NETtalk: A parallel network that learns to read aloud." Johns Hopkins University Technical ReportJHU/EEC~86/01.
[2] Elman, J. L. (1991). Distributed representations, simple recurrent networks, and grammatical structure. Machine Learning, 7, 195–225.
[3] Warren McCulloch and Walter Pitts, A Logical Calculus of Ideas Immanent in Nervous Activity, 1943, Bulletin of Mathematical Biophysics 5:115-133.
[4] Wells, John, 2003. Phonetic symbols in word procesing and on the web. In Solé, M.J., Recasens D. and Romero J. (eds.), Proc. 15th Int. Congress of Phonetic Sciences, Barcelona, S.2.8:6
[5] Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997.
En Internet:
• El sitio oficial de CRUISE Classification Tree (version 2.8):
http://www.cs.wisc.edu/~loh/cruise.html
• El API de Java para la implementación del algoritmo ID3:
http://www.kddresearch.org/Groups/Machine-Learning/MLJJavaDocs/index.html
• Un interesante estudio del documento "Automatic labelling of prosodic events":
http://www.infor.uva.es/~descuder/proyectos/ipo/docproy1.html
• El sitio oficial de Stuttgsrt Neural Netwok Simulator:
http://www-ra.informatik.uni-tuebingen.de/SNNS/
• La guia completa de usuario de Stuttgart Neural Netwok Simulator:
http://www-ra.informatik.uni-tuebingen.de/SNNS/UserManual/UserManual.html
143

• El sitio oficial del Java Object Oriented Neural Engine:
http://www.jooneworld.com/
• El sitio oficial del MBROLA Project:
http://tcts.fpms.ac.be/synthesis/mbrola.html
• El sitio official del Speech Assessment Methods Phonetic Alphabet Project:
http://www.phon.ucl.ac.uk/home/sampa/home.htm
• Una descripción del experimento original de NETtalk y sus resultados:
http://www.ics.uci.edu/~mlearn/databases/undocumented/connectionist-bench/nettalk/
144