introducción al procesamiento de voz
TRANSCRIPT

Introducción al procesamiento
de voz
Sonia H. Contreras Ortiz, PhD
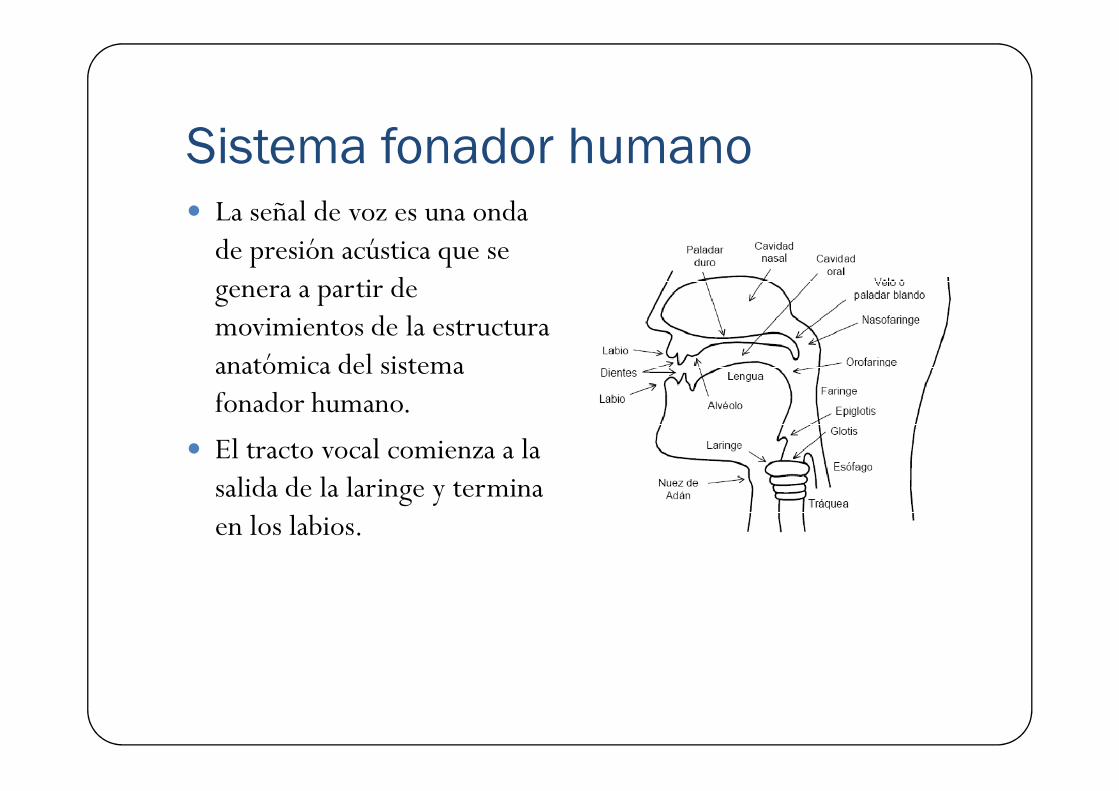
Sistema fonador humano� La señal de voz es una onda de presión acústica que se genera a partir de movimientos de la estructura anatómica del sistema fonador humano.fonador humano.
� El tracto vocal comienza a la salida de la laringe y termina en los labios.

Sistema fonador humano� Parámetros del sistema articulatorio
� Las cuerdas vocales
� El paladar
� La lengua
� Los dientes� Los dientes
� Los labios
� La mandíbula
� Etapas del proceso de producción de la voz� Generación
� Articulación
� Radiación

Clasificación de los fonemas� Vocales
Localización
Anterior Medio Posterior
AberturaMínima i u
Media e o
Máxima a
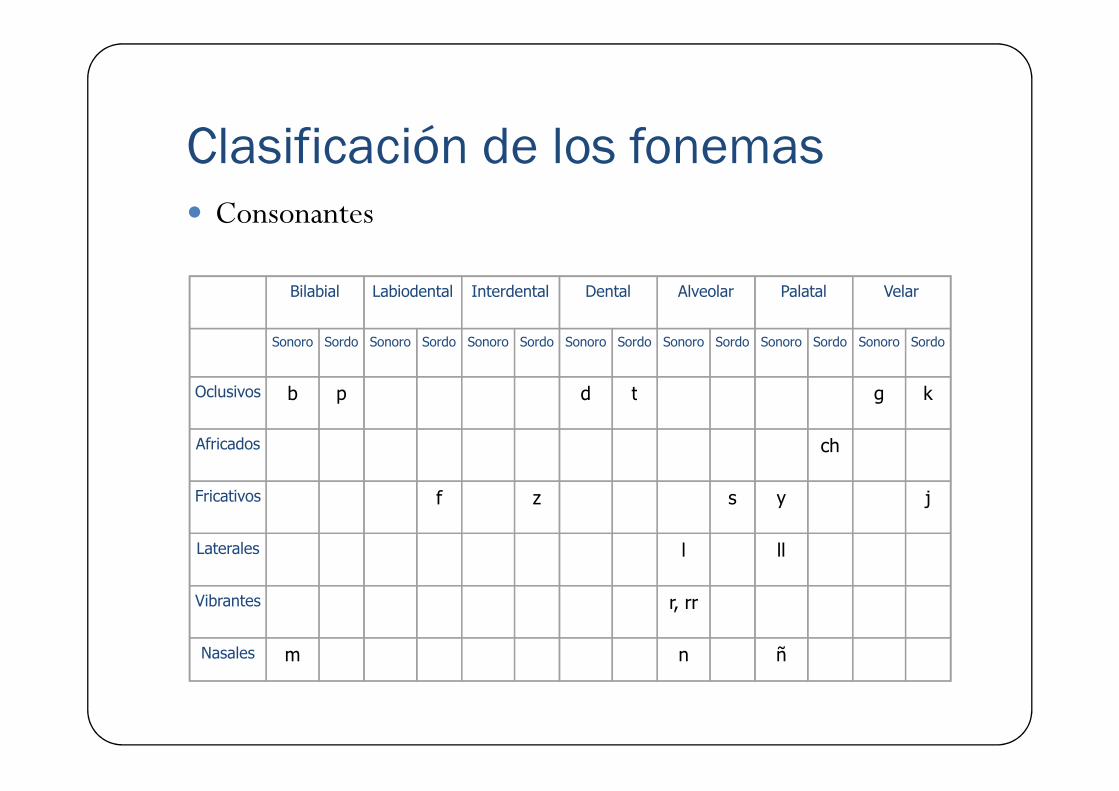
Clasificación de los fonemas� Consonantes
Bilabial Labiodental Interdental Dental Alveolar Palatal Velar
Sonoro Sordo Sonoro Sordo Sonoro Sordo Sonoro Sordo Sonoro Sordo Sonoro Sordo Sonoro Sordo
Oclusivos b p d t g kOclusivos b p d t g k
Africados ch
Fricativos f z s y j
Laterales l ll
Vibrantes r, rr
Nasales m n ñ

Clasificación de los fonemas� Sonoros: Las cuerdas vocales vibran y el aire pasa a través del tracto vocal sin impedimentos importantes: vocales, b, d, m...
� Sordos: Las cuerdas vocales no vibran y existen restricciones importantes al paso del aire que proviene de los pulmones: s, t, k, f...
VOZ SORDA Y SONORA /se/
0 0.05 0.1 0.15-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4VOZ SORDA Y SONORA /se/
Tiem po (s)
Am
plit
ud

Segmento sonoro� Es de naturaleza cuasi-periódica.
� Posee una frecuencia fundamental (pitch) que corresponde con la frecuencia de vibración de las cuerdas
-0.2
0
0.2
0.4
0.6
SEGMENTO SONORO
Am
plitu
d
de vibración de las cuerdas vocales. Toma valores entre 50Hz y 500Hz.
1.45 1.455 1.46 1.465 1.47 1.475 1.48 1.485 1.49 1.495 1.5
-0.4
-0.2
Tiempo (seg)
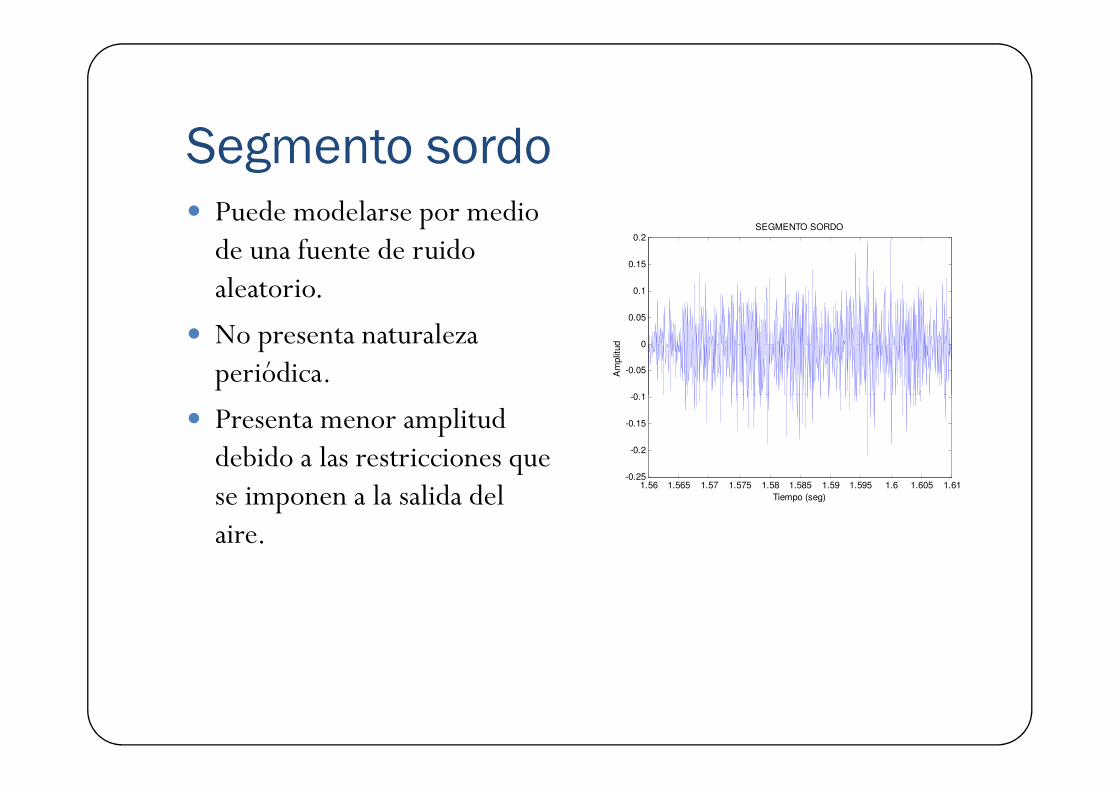
Segmento sordo� Puede modelarse por medio de una fuente de ruido aleatorio.
� No presenta naturaleza periódica.
-0.1
-0.05
0
0.05
0.1
0.15
0.2SEGMENTO SORDO
Am
plitu
d
� Presenta menor amplitud debido a las restricciones que se imponen a la salida del aire.
1.56 1.565 1.57 1.575 1.58 1.585 1.59 1.595 1.6 1.605 1.61-0.25
-0.2
-0.15
-0.1
Tiempo (seg)
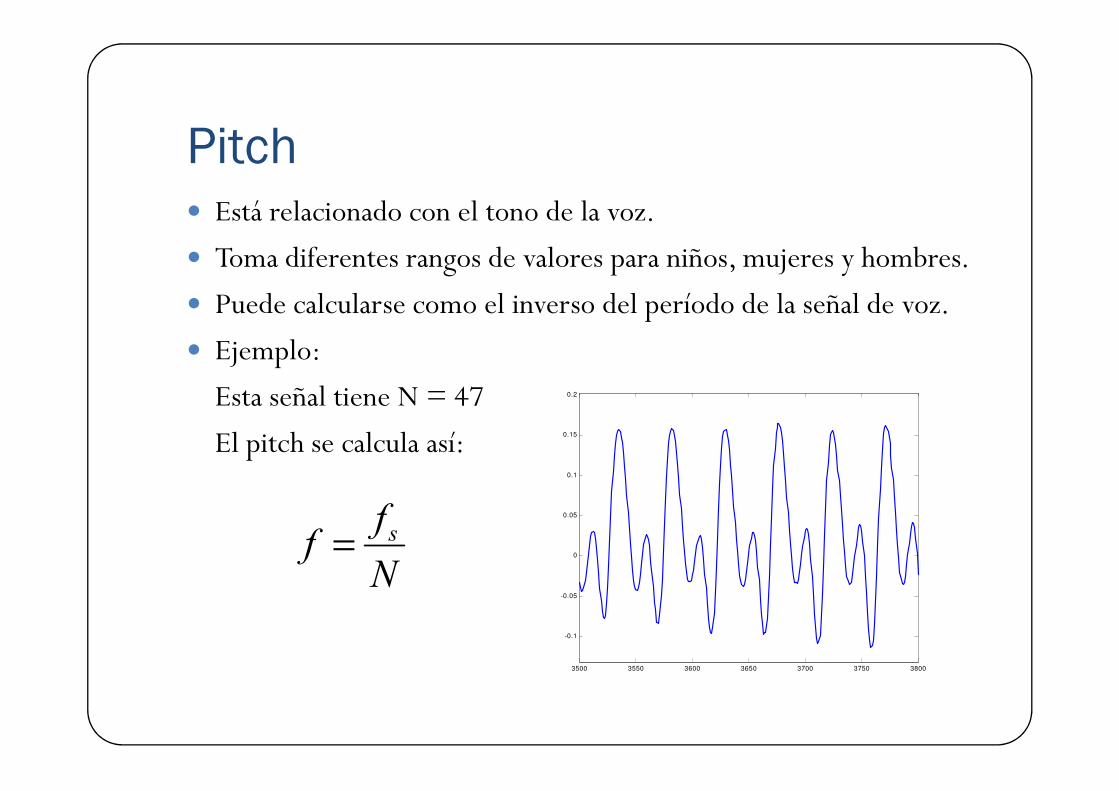
Pitch� Está relacionado con el tono de la voz.
� Toma diferentes rangos de valores para niños, mujeres y hombres.
� Puede calcularse como el inverso del período de la señal de voz.
� Ejemplo:
Esta señal tiene N = 47 0.2Esta señal tiene N = 47
El pitch se calcula así:
3500 3550 3600 3650 3700 3750 3800
-0.1
-0.05
0
0.05
0.1
0.15
0.2
N
ff s=
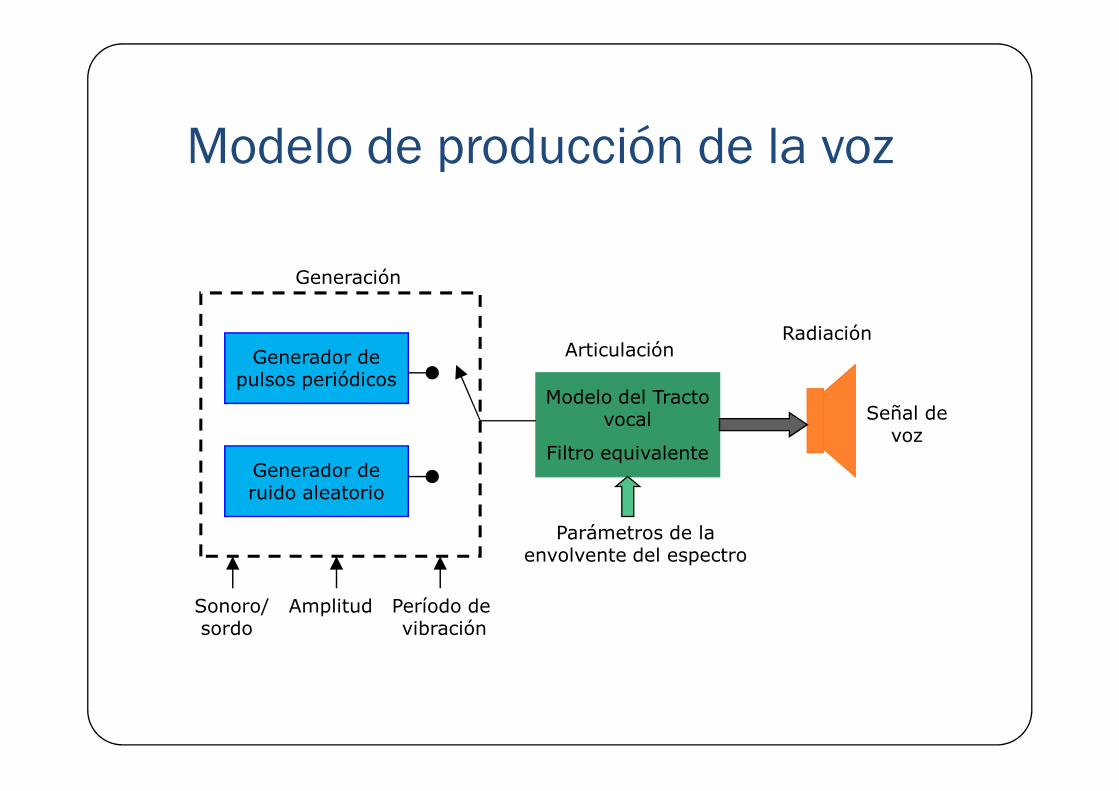
Modelo de producción de la voz
Generador de pulsos periódicos
Modelo del Tracto
Generación
ArticulaciónRadiación
Generador de ruido aleatorio
Modelo del Tracto vocal
Filtro equivalente
Sonoro/ Amplitud Período de sordo vibración
Parámetros de la envolvente del espectro
Señal de voz

Modelo de producción de la voz� El tracto vocal cambia su forma lentamente durante la pronunciación de los fonemas.
� Por tanto la voz se puede modelar como un filtro lentamente variante en el tiempo (no estacionario).
� Puede suponerse que las características de la señal permanecen Puede suponerse que las características de la señal permanecen constantes en intervalos de 10 a 50 ms.
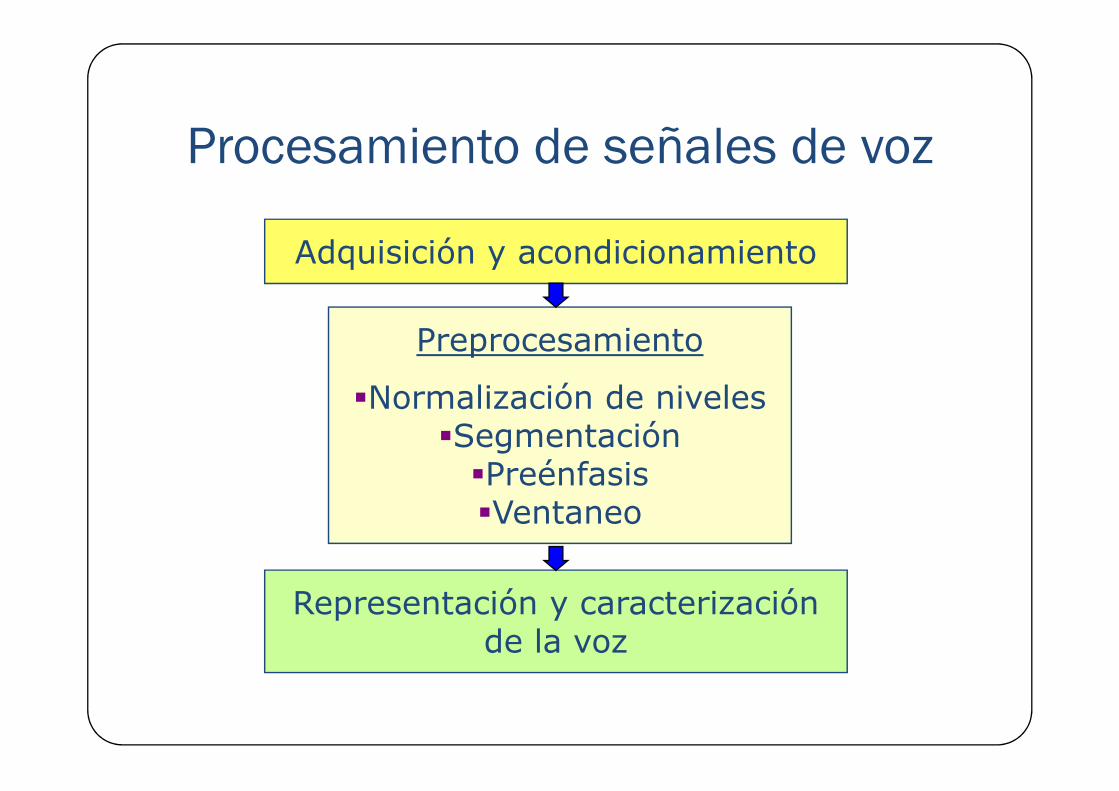
Procesamiento de señales de voz
Adquisición y acondicionamiento
Preprocesamiento
�Normalización de niveles�Normalización de niveles�Segmentación
�Preénfasis�Ventaneo
Representación y caracterización de la voz

Adquisición y acondicionamiento� La adquisición de la señal se realiza por medio de un transductor: micrófono.� Clase
� Impedancia
� Direccionalidad
0.2
0.4
0.6
0.8
1
30
210
6090
120
150
330
180 0
5
10
15
20
25
30
210
6090
120
150
330
180 0
5
10
15
20
30
210
6090
120
150
330
180 0
� Direccionalidad
� Filtrado pasa bajo y conversión A/D.� La frecuencia de muestreo debe satisfacer el criterio de Nyquist(8kHz ... 44kHz)
� El rango dinámico de la voz está entre los 50 y 60dB. Pueden emplearse 8 bits para la codificación.
240270
300 240270
300 240270
300

SegmentaciónPermite separar los eventos de interés (la voz) de otras partes de la señal. Establece los puntos de inicio y fin de palabra y en algunas aplicaciones identifica sonoridad.
0
0.5SEÑAL DE VOZ
SonoroSilencio
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45-0.5
0
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9-0.5
0
0.5
0.95 1 1.05 1.1 1.15 1.2 1.25 1.3 1.35-0.5
0
0.5
t (s)
Sonoro Sordo
Sordo Silencio
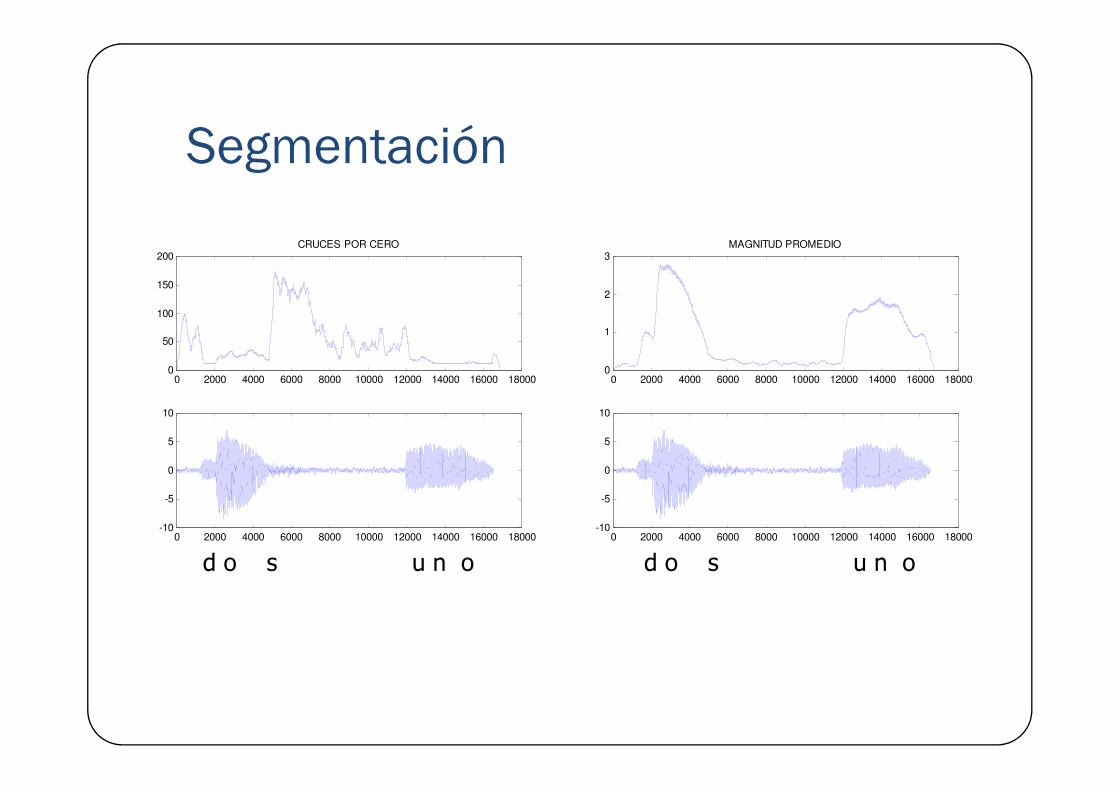
Segmentación
0 2000 4000 6000 8000 10000 12000 14000 16000 180000
50
100
150
200CRUCES POR CERO
0 2000 4000 6000 8000 10000 12000 14000 16000 180000
1
2
3MAGNITUD PROMEDIO
0 2000 4000 6000 8000 10000 12000 14000 16000 18000-10
-5
0
5
10
d o s u n o0 2000 4000 6000 8000 10000 12000 14000 16000 18000
-10
-5
0
5
10
d o s u n o
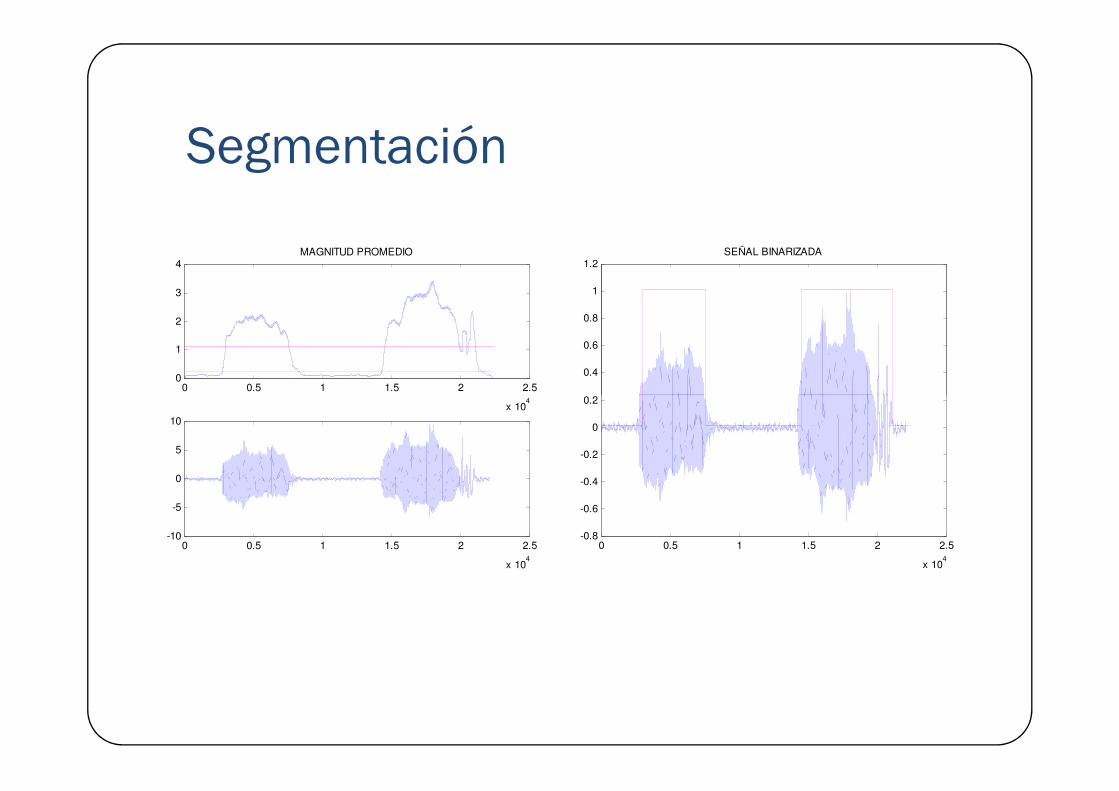
Segmentación
0 0.5 1 1.5 2 2.50
1
2
3
4MAGNITUD PROMEDIO
0.2
0.4
0.6
0.8
1
1.2SEÑAL BINARIZADA
x 104
0 0.5 1 1.5 2 2.5
x 104
-10
-5
0
5
10
0 0.5 1 1.5 2 2.5
x 104
-0.8
-0.6
-0.4
-0.2
0
0.2

Preénfasis� Consiste en pasar la señal por un filtro pasa alto de primer orden con el fin de enfatizar las altas frecuencias y hacer la señal menos susceptible a los efectos de la precisión finita en el procesamiento digital.
( ) 11
−⋅−= zzH α
� 0.9<α<1
( ) 11
−⋅−= zzH α

Ventaneo� La voz se analiza en marcos de datos de 10 a 50ms. En intervalos cortos el sistema puede considerarse lineal e invariante en el tiempo (estacionario).
� El marco de datos se multiplica por una ventana (Hamming o Hanning) para reducir la distorsión espectral ocasionada por Hanning) para reducir la distorsión espectral ocasionada por el hecho de segmentar la señal.

Ventaneo
0 200 400 600
-0.5
0
0.5
a0 200 400 600
0
0.2
0.4
0.6
0.8
1
ba b
0 200 400 600
-0.5
0
0.5
c
a) Corresponde a un marco de la señal original
b) Forma de la ventana de Hamming
c) Señal enventanada

Representación de la voz� Busca reducir el volumen de información necesario para analizar, almacenar o transmitir la señal de voz.
� Con las características que se extraen de la voz, puede obtenerse información sobre la persona que habla, contenido de lo que se dice y cómo lo dice. de lo que se dice y cómo lo dice.
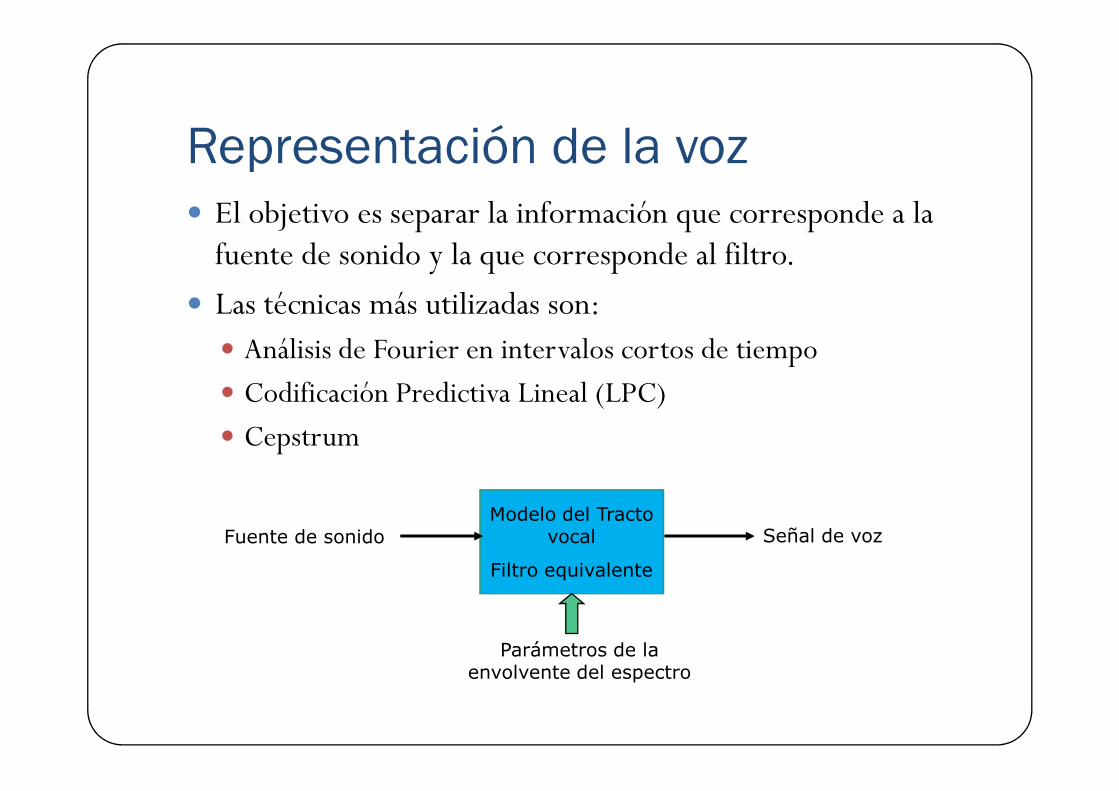
Representación de la voz� El objetivo es separar la información que corresponde a la fuente de sonido y la que corresponde al filtro.
� Las técnicas más utilizadas son:� Análisis de Fourier en intervalos cortos de tiempo
� Codificación Predictiva Lineal (LPC)� Codificación Predictiva Lineal (LPC)
� Cepstrum
Modelo del Tracto vocal
Filtro equivalente
Fuente de sonido
Parámetros de la envolvente del espectro
Señal de voz

Análisis de Fourier en intervalos
cortos de tiempo� Se considera que en intervalos cortos de tiempo, la señal de voz es estacionaria; es decir que su comportamiento (periodicidad o aleatoriedad) se mantiene aproximadamente constante.
� La señal se descompone en segmentos cortos llamados � La señal se descompone en segmentos cortos llamados marcos (de 5 a 100ms) y se analiza cada uno independientemente.
� Se calcula el espectro de la señal en cada marco.

Análisis de Fourier en intervalos
cortos de tiempo� El marco puede definirse como el producto de la señal de voz por una función ventana que es diferente de cero sólo en una pequeña región.
� Se calcula la DFT en cada marco (los marcos pueden traslaparse).traslaparse).
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000-1
0
1
Señ
al
Ilustración del enventanado
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000-1
0
1
Ven
tana
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000-1
0
1
Pro
duct
o

Espectrograma� Es una herramienta que permite visualizar el contenido de frecuencias de una señal con respecto al tiempo.
� Muestra gráficamente la intensidad de la transformada de Fourier evaluada en cada marco.
� Permite observar los formantes, el pitch e identificar � Permite observar los formantes, el pitch e identificar segmentos sonoros y sordos.

Espectrograma
0 1 2 3 4 5 6 7 8-1
-0.5
0
0.5
1Señal de voz y su Espectrograma
x 104
1 2 3 4 5 6 70
2000
4000
Time
Fre
quen
cy (
Hz)
Formantes

Espectrograma� Hay dos clases de espectrogramas:
� De banda ancha: emplean ventanas pequeñas (< 10ms) y tienen buena resolución en el tiempo, con lo cual pueden observarse mejor los cambios en la señal.
� De banda angosta: emplean ventanas grandes (> 20ms) y tienen De banda angosta: emplean ventanas grandes (> 20ms) y tienen buena resolución en frecuencia. Permiten observar los armónicos más claramente.
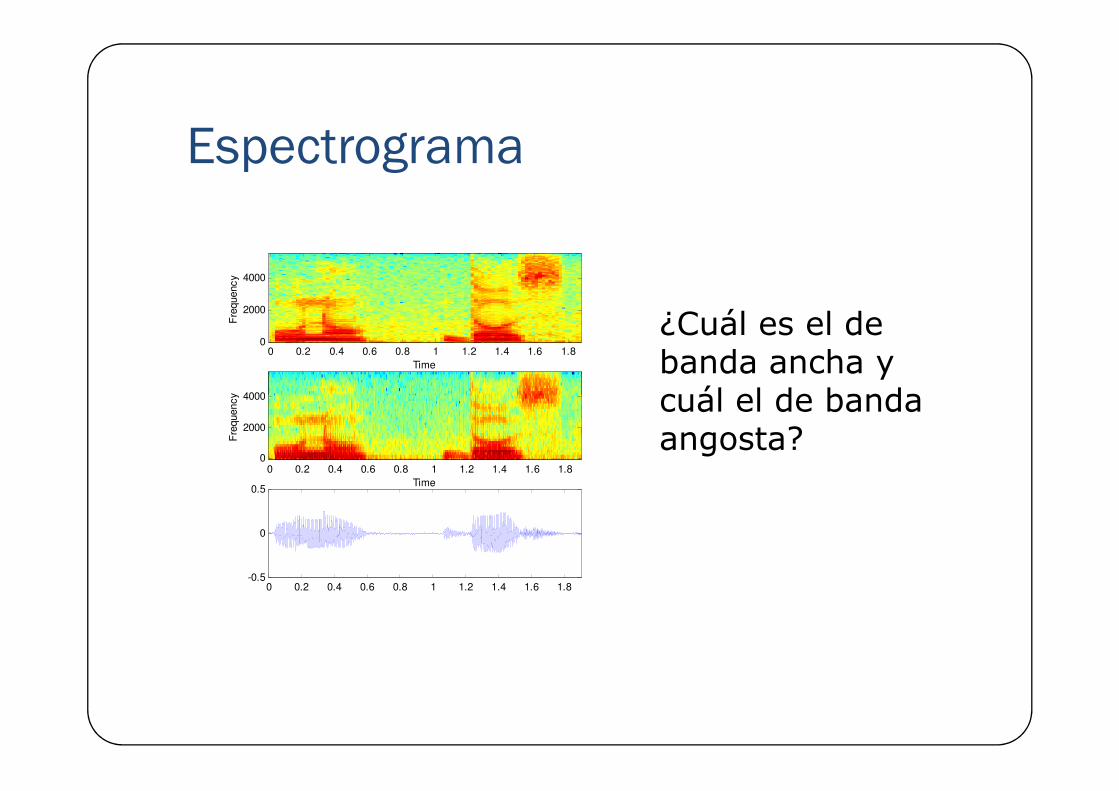
Espectrograma
Time
Fre
quen
cy
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.80
2000
4000
Fre
quen
cy 4000
¿Cuál es el de banda ancha y cuál el de banda
Time
Fre
quen
cy
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.80
2000
4000
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8-0.5
0
0.5
cuál el de banda angosta?
Análisis de Fourier en intervalos
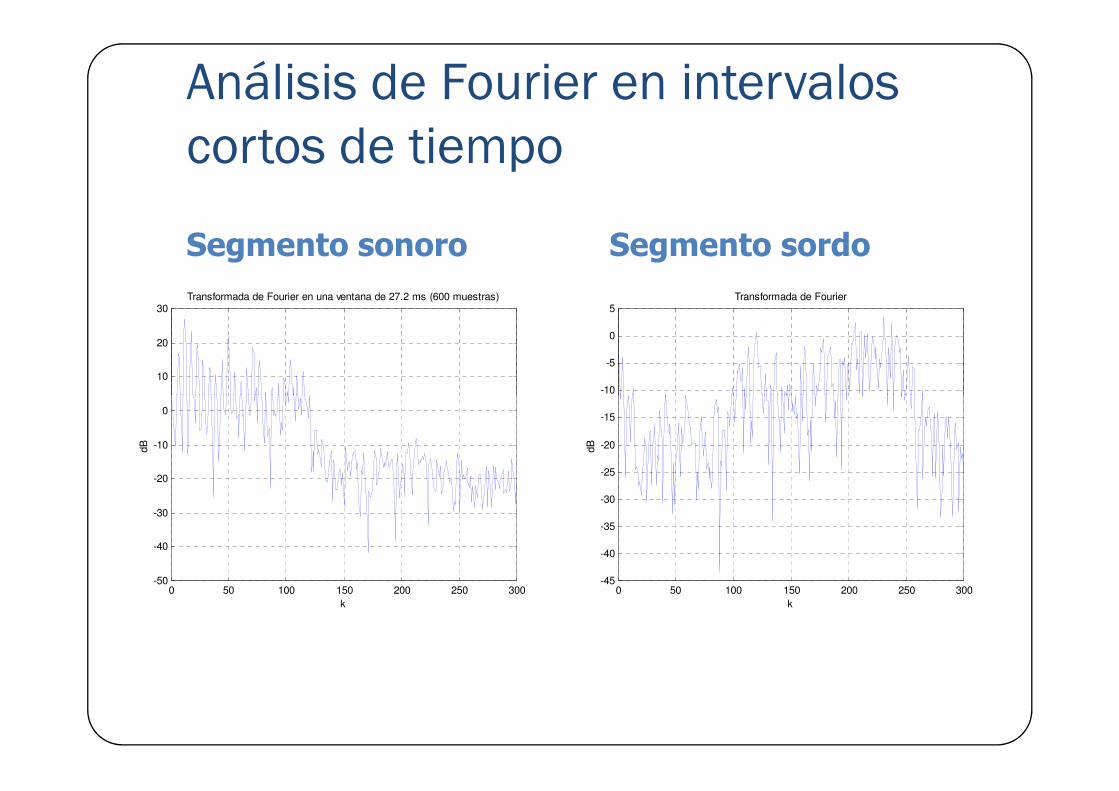
cortos de tiempo
Segmento sonoro Segmento sordo
10
20
30Transformada de Fourier en una ventana de 27.2 ms (600 muestras)
-10
-5
0
5Transformada de Fourier
0 50 100 150 200 250 300-50
-40
-30
-20
-10
0
k
dB
0 50 100 150 200 250 300-45
-40
-35
-30
-25
-20
-15
kdB

Análisis de Fourier en intervalos
cortos de tiempo� El espectro de una señal de voz está dado por:
� Una envolvente: en donde se observan las resonancias y antiresonancias del tracto vocal.
� Una estructura fina: refleja la periodicidad de la fuente sonora.
80
0 1000 2000 3000 4000 5000-100
-80
-60
-40
-20
0
20
40
60
80
Frecuencia (Hz)
dB

LPC� Una señal puede modelarse expresando el valor de la señal x[n] en el instante n como una combinación lineal de muestras en instantes anteriores:
[ ] [ ]∑ −=p
k knxanx~
� De esta forma, el proceso de producción de la voz se modela como un filtro IIR.
[ ] [ ]∑=
−=k
k knxanx1

LPC� Los parámetros ak pueden calcularse a partir de la minimización del error de la señal original y la aproximación dada por la ecuación anterior.
� Hay dos métodos principales para estimar los coeficientes de predicción lineal:predicción lineal:� El método de autocorrelación.
� El método de covarianza.

LPC� Los coeficientes de predicción permiten modelar el tracto vocal como un filtro de solo polos, con lo cual se puede estimar la envolvente del espectro.
( )( )
( )==
zXzH
1
� La señal error puede emplearse para aproximar la fuente de sonido.
( )( )
( )∑
=
−−
==p
k
k
k zazE
zXzH
1
1
1
[ ] [ ] [ ] [ ] [ ]∑=
−−=−=p
k
k knxanxnxnxne1
~
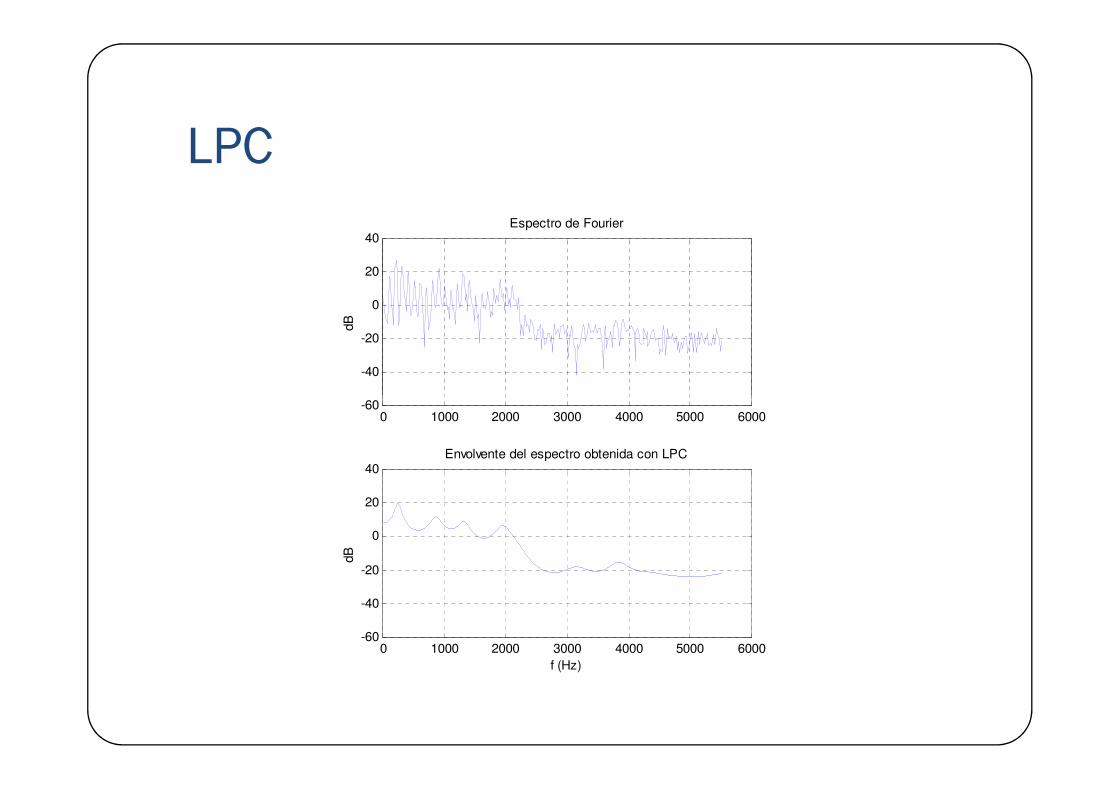
LPC
-40
-20
0
20
40Espectro de Fourier
dB
0 1000 2000 3000 4000 5000 6000-60
0 1000 2000 3000 4000 5000 6000-60
-40
-20
0
20
40Envolvente del espectro obtenida con LPC
f (Hz)
dB

Cepstrum� Una transformación homomórfica convierte una convolución en una suma:
� El cepstrum es una transformación homomórfica que
[ ] [ ] [ ]nhnenx *= [ ] [ ] [ ]nhnenx ˆˆˆ +=
� El cepstrum es una transformación homomórfica que permite separar la información sobre la fuente de sonido de la del filtro del tracto vocal.

Cepstrum� El cepstrum real se define:
El término cepstrum resulta de invertir la primera sílaba de
[ ] ( )∫−
=
π
π
ωω ωπ
deeXnc jjln
2
1
� El término cepstrum resulta de invertir la primera sílaba de la palabra spectrum. Se definió así porque se obtiene al calcular la transformada inversa del logaritmo del espectro de la señal.
� La información del tracto vocal aparece en los primeros coeficientes cepstrales y la información de la fuente en los coeficientes más altos.

Cepstrum
-40
-20
0
20
40Espectro de Fourier
dB
-0.5
0
0.5
1Segmento sonoro
0 50 100 150 200 250 300-60
-40
0 50 100 150 200 250 300-60
-40
-20
0
20
40Envolvente del espectro por el método de Cepstrum
k
dB
0 100 200 300 400 500-1
0 100 200 300 400 500-1
-0.5
0
0.5
1Cepstrum real
Muestra