introducción a la tarificación de la cartera de autos con sas
TRANSCRIPT

Introducción a la Tarificación de la Cartera de Autos con SAS
Marcos Aguilera KeyserInstituto de Actuarios Españoles
24-26 mayo, 2014
Primera parte: Introducción a los modelos lineales generalizados (GLM)

Índice• Visión global de los modelos GLM• Especificación de los modelos GLM• Relación entre media y varianza• Conceptos básicos: función de link, estructura de error, desviaciones y residuos• Optimización de los modelos GLM: máxima verosimilitud• Modelos para la Frecuencia:
– El problema de la sobre dispersión– El problema del exceso de ceros
• Modelos para el Coste Medio:– Estructuras de error Gamma, Gaussiana Inversa y Log-normal– El problema de los siniestros punta
• Modelos para la Prima Pura:– El modelos Tweedie

VISIÓN GLOBAL DE LOS MODELOS GLM

Visión global de los models GLM

¿Por qué usamos modelos GLM?En seguros:• la variable respuesta es positiva (Frecuencia, Coste Medio)• recorren varios órdenes de magnitud - incurridos entre 50 Euros y 500.000 Euros• Incrementos unitarios en el factor de riesgo (antigüedad del vehículo) conllevan incrementos
geométricos en la variable respuesta

ESPECIFICACIÓN DE LOS MODELOS GLMEl modelo estándar de regresión múltiple

Modelo estándar de regresión lineal (cont.)
De otra forma
dónde
y el predictor lineal

Modelo estándar de regresión lineal (cont.)¿Qué conocemos?• es la variable respuesta, aquello que queremos predecir, la frecuencia, el coste medio o el burning
cost (prima pura)• también es conocida, son los factores de riesgo, la antigüedad del vehículo, el número de puertas,
etc.¿Qué desconocemos?• No conocemos las , queremos estimar su valor para saber si nos ayuda a predecir • No conocemos , que representa el término de error de nuestro modeloPredictor lineal: • El objetivo es predecir el valor medio de condicionado a los valores que tomen , • Es lineal en parámetros (las betas)• es una variable aleatoria que sigue una distribución normal con varianza constante• es el valor esperado, la media y representa al predictor lineal
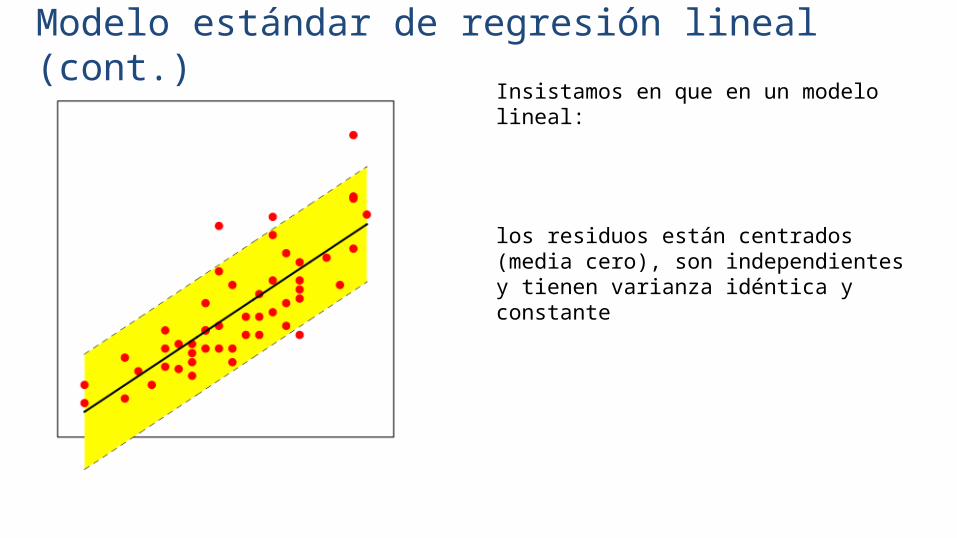
Modelo estándar de regresión lineal (cont.)Insistamos en que en un modelo lineal:
los residuos están centrados (media cero), son independientes y tienen varianza idéntica y constante

Modelo estándar de regresión lineal (cont.)La idea aquí es asumir
produce el mismo modelo que el anterior, basado en un término errorTenemos dos partes aquí:• El incremento lineal del promedio
• La varianza constante de la distribución Normal

ESPECIFICACIÓN DE LOS MODELOS GLMLa “función de link”

Especificación de los modelos GLM: la “función de link”
• La “función de link” es : los modelos GLM relacionan el valor esperado de la variable dependiente con el predictor lineal a través de la “función de link”
• Ejemplo: función de link logarítmica:
que equivale a

Especificación de los modelos GLM: la “función de link”Si nuestra función de link es logarítmica:
• El incremento del promedio ya no es lineal
• La varianza constante de la distribución Normal
• Un modelo multiplicativo debido a link = log• Un modelo que sigue siendo homoscedástico
pero no lineal en su relación con

Especificación de los modelos GLM: la “función de link”

ESPECIFICACIÓN DE LOS MODELOS GLMLa “familia exponencial”

Especificación de los modelos GLM: “familia exponencial”Hemos dicho que sigue una distribución de la familia exponencial. La familia exponencial de distribuciones depende de dos parámetros y se define como:
donde• , y son funciones especificadas de ante mano• es un parámetro relacionado con la media• es un parámetro de escala relacionado con la varianza

Especificación de los modelos GLM: “familia exponencial”Desde un punto de vista práctico, es útil conocer que la familia exponencial tiene dos propiedades:1. La distribución queda completamente especificada en términos de media y varianza2. La varianza de es función de su mediaEsta segunda propiedad de queda más clara si expresamos la varianza así:)=donde • se le llama función de varianza, es una función especificada previamente• el parámetro de dispersión que simplemente escala la varianza• y el es una constante que asigna un peso, o credibilidad, a la observación iLa familia exponencial engloba múltiples distribuciones: Normal, Gamma, Binomial, Poisson, Negative Binomial, Gaussiana Inversa, entre otras

Especificación de los modelos GLM: “familia exponencial”Si sigue una distribución de Poisson entonces
• El incremento lineal del promedio
• La varianza constante de la distribución Poisson es igual a la media
• Tenemos un modelo aditivo, lineal pero heterocedastico

…en resumen…link logarítmica y función error Poisson…Si sigue una distribución de Poisson entonces
• El incremento no lineal del promedio
• La varianza constante de la distribución Poisson es igual a la media
• Tenemos un modelo multiplicativo, no lineal y heteroscedastico

…en resumen…tres funciones de error

ESPECIFICACIÓN DE LOS MODELOS GLMEl término “offset”

Especificación de los modelos GLM: el término “offset”
• El término “offset” es interesante, es como una pero sin el parámetro delante• Permite introducir efectos que conocemos• En los modelos lineales estándar también existen dichos efectos, pero no es necesario explicitarlos,
sencillamente podemos pasarlos al otro lado de la ecuación y restarlos de • Ejemplo: en los modelos de frecuencia la exposición de la póliza es el típico término offset

Especificación de los modelos GLM: el término “offset”…un ejemplo clásico, la Exposición de la póliza como término “offset”:

RELACIÓN ENTRE MEDIA Y VARIANZA EN LOS MODELOS GLM

Relación entre media y varianza• En el modelo lineal estándar la varianza es constante
• Independientemente del valor que tome el valor esperado de
• No hay relación entre ambos componentes• Sin embargo sabemos que los siniestros pequeños tienen menos varianza que los grandes. Luego el
supuesto clásico no es práctico• Por suerte tenemos otras alternativas como elegir una función de error de Poisson, Gamma,
Gaussiana Inversa, Log normal, etc.

Relación entre media y varianzaRecordemos que definimos la varianza como:)=
Donde las distintas funciones de varianza son: Normal Poisson Gamma Inverse Gaussian Negative Binomial

Relación entre media y varianza• Normal: no existe relación entre media y
varianza• Poisson: tiene una relación una relación lineal,
el valor esperado de una variable aleatoria que sigua una Poisson es igual a la varianza de dicho valor
• Gamma: la relación entre media y varianza es cuadrática. La varianza de es el cuadrado de la media de
• Gaussiana Inversa: la relación entre media y varianza es cúbica. La varianza de es el cubo de la media de
𝔼 (𝑌|𝑋=𝑥 )
𝑉𝑎𝑟
(𝑌|𝑋
=𝑥
)

MODELOS PARA LA FRECUENCIADistribuciones Poisson, Binomial Negativa, ZIP, ZINB y Hurdle

MODELOS PARA LA FRECUENCIAEl problema de sobre dispersión

Definición de la función de error Poisson

Repaso del modelos de PoissonEl modelo de Poisson es el más habitualmente utilizado como punto de partida en los modelos de Frecuencia es el siguiente:
El incremento no lineal del promedio
La varianza constante de la distribución Poisson es igual a la media
Tenemos un modelo multiplicativo, no lineal y heteroscedastico

Introducción• La sobre dispersión ocurre cuando la varianza empírica es mayor que la varianza teórica para una
distribución en particular. • Es decir, la variabilidad es mayor que la predicha por la función de error del modelo GLM• Cuando tratamos de ajustar un modelo a datos de conteo (0,1,2,…,n) es muy frecuente encontrar
sobre dispersión en los datos. Consecuencias• Cuando la verdadera distribución no es Poisson:
– Los estimadores de máxima verosimilitud siguen siendo consistentes– Pero sus errores estándar son incorrectos
• De hecho la sobre dispersión conlleva:– A infra estimar los errores estándar – A sobre estimar los estadísticos Chi-cuadrados
• En consecuencia sobre estimamos la significación de los parámetros estimados en la regresión

Causas de la sobre dispersión1. Heterogeneidad entre las observaciones debido a un modelo incorrectamente especificado2. Valores atípicos en los datos3. Correlación positiva entre las observaciones como consecuencia de la existencia de clusters

Con mas detalle: heterogeneidad entre las observaciones• El modelo de Poisson asume que la variable respuesta sigue una distribución de Poisson
condicionada a los valores de las variables explicativas• Si alguna variable explicativa importante está ausente del modelo entonces la heterogeneidad entre
las observaciones no explicada por el modelo puede causar mayor variabilidad en la variable respuesta que la predicha por el modelo de Poisson
• Al no existir un término de error en el modelo de Poisson, no hay forma de acomodar la variabilidad extra causada por la omisión de una variable explicativa importante
• En consecuencia, asumir una distribución de Poisson para una variable de conteo es muy simplista ya que la mayoría de los modelos no están correctamente especificados

MODELOS PARA LA FRECUENCIA
Primera solución al problema de sobre dispersión: un factor de dispersión multiplicativo

Factor de dispersión multiplicativo• Un primer camino para solventar el problema de sobre dispersión es hacer uso de un factor de
dispersión cuando definimos la relación entre media y varianza– En la varianza original bajo Poisson: )– La nueva varianza con dispersión: )
• Donde el factor de sobre dispersión multiplicativo es un estadístico Chi-cuadrado dividido por sus grados de libertad
• La matriz de covarianzas está ahora pre multiplicada por , • y la desviación escalada y la función de máxima verosimilitud están ahora dividas por • Como la función de mv. es utilizada para calcular los intervalos de confianza entonces • los errores estándar de cada coeficiente son ajustados de ésta forma
• Éste método produce una inferencia adecuada siempre que la sobre dispersión sea moderada

Factor de dispersión multiplicativo (cont.)• La introducción de un factor de dispersión multiplicativo no genera una nueva distribución de
probabilidad, es sencillamente un término corrector a la hora de testar las estimación de los parámetros bajo el modelo de Poisson
• Los modelos se ajustan de la forma habitual en Poisson• Los parámetros estimados no se ven afectados por el factor de dispersión multiplicativo• Sin embargo, sí se ven afectados los errores estándares de los coeficientes de regresión de forma
que sufren una corrección• Si existe sobre dispersión, los errores estándar se incrementan para albergar el exceso de
variabilidad

Factor de dispersión multiplicativo (cont.)Dos formas de ajustar la matriz de covarianzas en el PROC GENMOD:1. Puedes calcular el factor multiplicativo de sobre dispersión usando las desviaciones (SCALE =
deviance)2. Puedes calcular el factor multiplicativo de sobre dispersión usando el estadístico de la Chi-
cuadrado de Pearson (SCALE = Pearson)La mayoría de las veces estarán muy cerca uno del otro
Nota: recordar que cuando exista evidencia de sobre dispersión hay que investigar primero la existencia de otras razones, especialmente la existencia de valores ausentes o la incorrecta especificación del modelo (si faltan importantes interacciones por ejemplo, asumiendo linealidad de las variables continuas cuando la falta de ella es evidente, etc.)Corrigiendo éstos problemas quizás no haga falta usar el factor de dispersión multiplicativo

MODELOS PARA LA FRECUENCIA
Segunda solución al problema de sobre dispersión: función de error Binomial Negativa

Definición de la función de error Binomial Negativa

Usando una función de error Binomial Negativa• Otra forma de sortear la sobre dispersión es usando una distribución más flexible que la Poisson• La distribución Binomial Negativa permite a la varianza exceder la media• Al contrario que la rígida Poisson, ésta distribución sí es capaz de albergar la heterogeneidad no
recogida por el modelo y tener en cuenta así la sobre dispersión existente
• La relación media-varianza cuando usamos la BN, necesita de la estimación de un parámetro adicional de dispersión que debe bien ser estimado y fijado a un valor
• Gracias a éste parámetro la varianza puede exceder a la media y permite a la BN tener en cuenta la existencia de sobre dispersión

El parámetro de dispersión k• Se estima por máxima verosimilitud• No se permite que varié entre observaciones• Cuando k = 0 el modelo corresponde a un modelo de Poisson• Cuando k > 0 la sobre dispersión es evidente y los errores estándar se incrementarán en
consecuencia. Los valores estimados de los parámetros permanecen sin apenas cambio en relación al modelo de Poisson pero los mayores errores estándar son capaces de aumentar para reflejar la sobre dispersión no capturada por el modelo de Poisson

MODELOS PARA LA FRECUENCIA
El problema de exceso de ceros: modelos con inflación de ceros y “hurdle”

Introducción• El problema de exceso de ceros se produce cuando los datos observados muestran una proporción
de valores ceros mayor de la que puede ser explicada por un modelo estándar para datos de conteo como el Poisson o Binomial Negativo
• Existen dos vías para resolver el problema:– El modelo de inflación o exceso de ceros o “zero inflated model” en inglés– El modelo “hurdle” o modelo de “dos partes”
• Ambos modelos el “hurdle” y el “zero inflated” tienen su versión para la Poisson y para la Binomial. En consecuencia, tenemos a nuestra disposición un total de 4 modelos más con los que abordar la modelización de la Frecuencia
• Los modelos ZIP y ZINB suelen también utilizarse para solventar el problema de sobre dispersión además del problema de exceso de ceros

¿Qué significa “exceso de ceros” exactamente?• El modelo de Poisson no es capaz de ajustar
correctamente éstos datos. Es el exceso de ceros lo que impide el correcto ajuste
• Sin embargo, el modelo con inflación de ceros (ZIP) es capaz de ajustarse correctamente a los datos
• La misma capacidad tendría un modelo “hurdle”
0 1 2 3 4 5 60
10
20
30
40
50
60
70
80
90
100
Número de siniestrosZIP Poisson

Causas del exceso de cerosExisten dos posibles causas en que generan exceso de ceros:• Existen dos o más poblaciones distintas en nuestros datos
– Ejemplo: si nuestra cartera de autos posee una elevada proporción de persona de edad avanzada que, aunque aseguran su vehículo no lo conducen. En consecuencia no es posible que tengan un accidente con su automóvil
– En éste caso la aproximación al problema la haríamos desde un modelo con exceso de ceros• Existen incentivos que alteran el comportamiento del asegurado:
– Ejemplo: se trata del fenómeno de “huger for bonus”, que significa que el asegurado no reporta a la compañía todos sus siniestros (evidentemente los de cuantía pequeña) para conservar su bonus el próximo año. En definitiva, para evitar ser penalizado con un incremento de prima mayor que coste del siniestro
– En éste caso la aproximación al problema la haríamos desde un modelo “hurdle”

Modelos con inflación de ceros: intuiciónSiguiendo con nuestro ejemplo:
– imaginemos que el 30% de nuestra cartera está formado por personas mayores que no conducen (pese a estar asegurados)
– Imaginemos por un momento que podemos distinguirlos (sabemos quién conduce y quién no). Obviamente en la realidad no disponemos de ésta información y de ahí el problema de exceso de ceros
• En consecuencia podemos observar que nuestra distribución con inflación de ceros tiene la forma que vemos a la izquierda:
– Un 30% de nuestros conductores no conducen y, por tanto, no pueden tener un accidente
– El 70% restante conduce y, en consecuencia, podrá o no tener un accidente
0 1 2 3 4 5 60
10
20
30
40
50
60
70
80
90
100
conducen no conducen

Modelos con inflación de ceros: intuición (cont.)Para abordar la modelización del problema de exceso de ceros desde la perspectiva de los modelos con inflación de ceros construimos dos modelos:• Un modelo GLM con función de error Binomial
y link logit (o probit) que determina la probabilidad de que el cliente conduzca o no conduzca
• Un modelo de Poisson o de Binomial negativa para recoger el hecho de que si el cliente conduce éste puede tener 0, 1, 2, …,n siniestros
• Gracias a construir dos modelos podemos modelizar correctamente el exceso de ceros
0 10
20
40
60
80
100
no conducen conducen
0 1 2 3 4 5 60
102030405060708090
100
conducen

Modelos “hurdle”: intuiciónLos modelos “hurdle” o en dos partes son interesantes porque nos permiten modelizar el comportamiento del cliente como un proceso de decisión en dos partes:• En la primera parte el cliente decide si declara
sus siniestros de baja cuantía a la compañía o no lo hace
• En la segunda parte, si el cliente ha decidido declarar sus siniestros de baja cuantía a la compañía entonces declarará 1, 2, 3,…,n siniestros
Los modelos “hurdle” (valla, como las de los corredores de 110 metros vallas) reflejan que para declarar algún siniestro positivo debes haber saltado la “valla” de haber decidido previamente declarar tus siniestros
0 1 2 3 4 5 60
10
20
30
40
50
60
70
80
90
100
declaran no declaran

Modelos “hurdle”: intuición (cont.)Para abordar la modelización del problema de exceso de ceros desde la perspectiva de los modelos “hurdle” construimos dos modelos:• Un modelo GLM con función de error Binomial
y link logit (o probit) que determina la probabilidad de “saltar la valla”, es decir de que el cliente decida o no declarar sus siniestros de cuantía baja
• Un modelo de Poisson o de Binomial negativa truncado en el valor cero para recoger el hecho de que si el cliente conduce éste puede tener 1, 2, …,n siniestros
• Gracias a construir dos modelos podemos modelizar correctamente el exceso de ceros
0 10
20
40
60
80
100
no declaran declaran
0 1 2 3 4 5 60
102030405060708090
100
declaran

Modelos con inflación de ceros• Se trata de modelos que son útiles cuando sospechamos que podrían existir dos sub poblaciones en
nuestra población• El modelo básico tiene la siguiente forma
donde• = la probabilidad de pertenecer a un grupo de población (no usan el coche) u otro (lo usan)• y se basan en algún modelo, bien en un Poisson, bien en un Binomial Negativo

Modelos con inflación de ceros (cont.)ZIP modelo de Poisson con inflación de ceros con link = log usualmente:
Notar que si tenemos un modelo de Poisson con link=logFinalmente la pertenencia a una clase u otra es una variable dicotómica que podemos modelizar con una regresión logística

Modelos con inflación de ceros con el PROC GENMOD• Sin modelo para la probabilidad de pertenencia a una u otra población:proc genmod data=credrpt;
model mdr = age income avgexp / link=log dist=zip type3;zeromodel / link=logit;
run;• Con modelo para la probabilidad de pertenencia a una u otra población :proc genmod data=credrpt;
model mdr = age income avgexp / link=log dist=zip type3;zeromodel age income avgexp / link=logit;
run;• En el “zeromodel” pueden aparecer las mismas variables, sólo algunas u otras completamente
distintas a las que aparecen en la sentencia “model”• La distribuciones utilizada también puede ser “zinb”

Modelos con inflación de ceros con el PROC FMM• Sin modelo para la probabilidad de pertenencia a una u otra población:proc fmm data=credrpt;
model mdr = age income avgexp / dist=poisson;model mdr = / dist=constant;probmodel;
run;• Con modelo para la probabilidad de pertenencia a una u otra población :proc fmm data=credrpt;
model mdr = age income avgexp / dist=poisson;model mdr = / dist=constant;probmodel age income ownrent;
run;

Distribuciones Poisson y Binomial Negativa en proc FMM*Poisson;proc fmm data=credrpt;
model mdr = age income avgexp / dist=poisson;run;
*Negative Binomial;proc fmm data=credrpt;
model mdr = age income avgexp / dist=negbin;run;

Modelos “hurdle”• Su función de densidad es la siguiente:
donde• = la probabilidad de pertenecer a un grupo de población (no usan el coche) u otro (lo usan)• y se basan en algún modelo, bien en un Poisson, bien en un Binomial Negativo

Modelos “hurdle” (cont.)ZIP modelo de Poisson con inflación de ceros con link = log usualmente:
Notar que si tenemos un modelo de Poisson con link=logFinalmente la pertenencia a una clase u otra es una variable dicotómica que podemos modelizar con una regresión logística

Modelos “hurdle” con el PROC FMM• Los modelos “hurdle” no pueden ser estimados con el PROC GENMOD a día de hoy. Así que podemos usar el PROC FMM• Sin modelo para la probabilidad de pertenencia a una u otra población:proc fmm data=credrpt;
model mdr = age income avgexp / dist=tpoisson lin=log offset=ln_exp;model mdr = / dist=constant;probmodel age income ownrent;
run;• Con modelo para la probabilidad de pertenencia a una u otra poblaciónproc fmm data=credrpt;
model mdr = age income avgexp / dist=tpoisson link=log offset=ln_exp;model mdr = / dist=constant;probmodel age income ownrent;
run;• En el “probmodel” pueden aparecer las mismas variables, sólo algunas u otras completamente distintas a las que aparecen
en la sentencia “model”• La distribuciones utilizada también puede ser “tnegbin”• La segunda sentendia “model” va siempre sin variables explicativas