interpolación15
DESCRIPTION
interpolacionTRANSCRIPT

InterpolaciónPara otros usos de este término, véase Interpolación (desambiguación).
En el subcampo matemático del análisis numérico, se denomina interpolación a la obtención de nuevos puntos partiendo del conocimiento de un conjunto discreto de puntos.
En ingeniería y algunas ciencias es frecuente disponer de un cierto número de puntos obtenidos por muestreo o a partir de un experimento y pretender construir una función que los ajuste.
Otro problema estrechamente ligado con el de la interpolación es la aproximación de una función complicada por una más simple. Si tenemos una función cuyo cálculo resulta costoso, podemos partir de un cierto número de sus valores e interpolar dichos datos construyendo una función más simple. En general, por supuesto, no obtendremos los mismos valores evaluando la función obtenida que si evaluamos la función original, si bien dependiendo de las características del problema y del método de interpolación usado la ganancia en eficiencia puede compensar el error cometido.
En todo caso, se trata de, a partir de n parejas de puntos (xk,yk), obtener una función f que verifique
a la que se denomina función interpolante de dichos puntos. A los puntos xk se les llama nodos. Algunas formas de interpolación que se utilizan con frecuencia son la interpolación lineal, la interpolación polinómica (de la cual la anterior es un caso particular), la interpolación por medio de spline o la interpolación polinómica de Hermite.
Interpolación Lineal
La línea azul representa la interpolación lineal entre los puntos rojos.
Uno de los métodos de interpolación más sencillos es el lineal. En general, en la interpolación lineal se utilizan dos puntos, (xa,ya) y (xb,yb), para obtener un tercer punto interpolado (x,y) a partir de la siguiente fórmula:
La interpolación lineal es rápida y sencilla, pero en ciertos casos no muy precisa.
Mínimos cuadrados
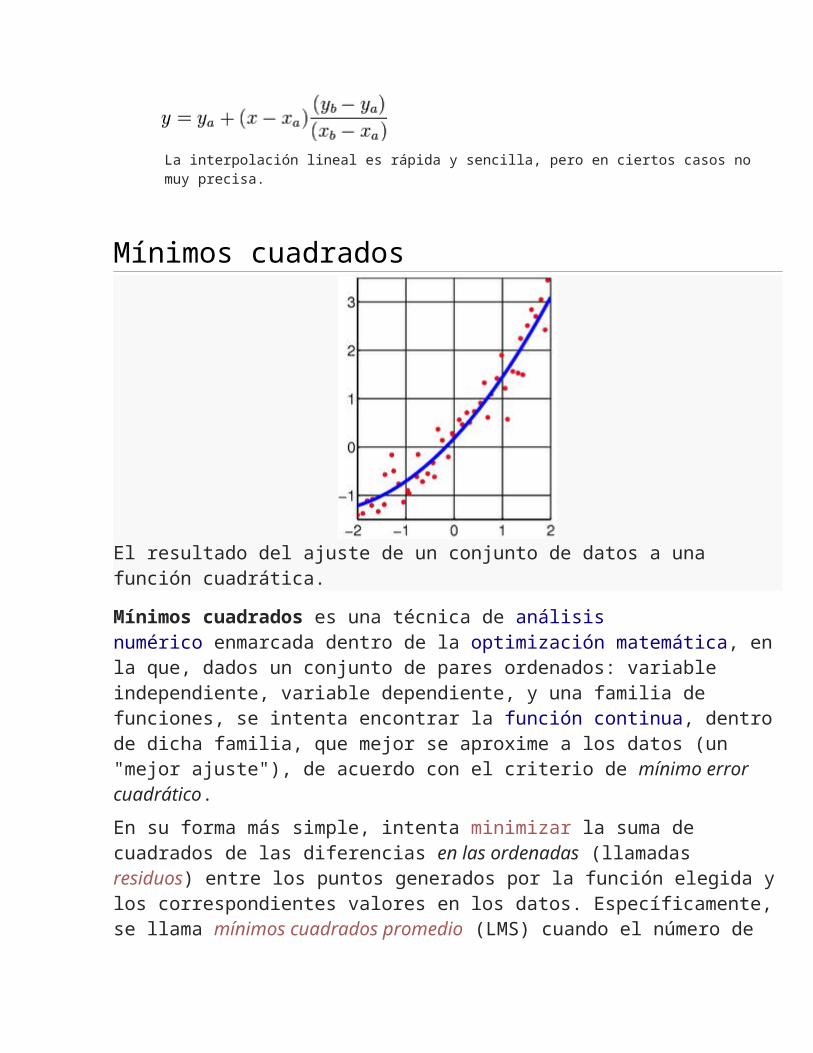
El resultado del ajuste de un conjunto de datos a una función cuadrática.
Mínimos cuadrados es una técnica de análisis numérico enmarcada dentro de la optimización matemática, en la que, dados un conjunto de pares ordenados: variable independiente, variable dependiente, y una familia de funciones, se intenta encontrar la función continua, dentro de dicha familia, que mejor se aproxime a los datos (un "mejor ajuste"), de acuerdo con el criterio de mínimo error cuadrático.
En su forma más simple, intenta minimizar la suma de cuadrados de las diferencias en las ordenadas (llamadas residuos) entre los puntos generados por la función elegida y los correspondientes valores en los datos. Específicamente, se llama mínimos cuadrados promedio (LMS) cuando el número de datos medidos es 1 y se usa el método de descenso por gradiente para minimizar el residuo cuadrado. Se puede demostrar que LMS minimiza el residuo cuadrado esperado, con el mínimo de operaciones (por iteración), pero requiere un gran número de iteraciones para converger.
Desde un punto de vista estadístico, un requisito implícito para que funcione el método de mínimos cuadrados es que los errores de cada medida estén distribuidos de forma aleatoria. El teorema de Gauss-Márkov prueba que los estimadores mínimos cuadráticos carecen de sesgo y que el muestreo de datos no tiene que ajustarse, por ejemplo, a una distribución normal. También es importante que los datos a procesar estén bien escogidos, para que permitan visibilidad en las variables que han de ser resueltas (para dar más peso a un dato en particular, véase mínimos cuadrados ponderados).
La técnica de mínimos cuadrados se usa comúnmente en el ajuste de curvas. Muchos otros problemas de optimización pueden expresarse también en forma de mínimos cuadrados, minimizando la energía o maximizando la entropía.

Formulación formal del problema bidimensional
Sea un conjunto de n puntos en el plano real, y sea una base de m funciones linealmente independiente en un espacio de funciones. Queremos encontrar una
función que sea combinación lineal de las funciones base, de modo que , esto es:
Por tanto, se trata de hallar los m coeficientes que hagan que la función
aproximante dé la mejor aproximación para los puntos dados . El criterio de "mejor aproximación" puede variar, pero en general se basa en aquél que minimice una "acumulación" del error individual (en cada punto) sobre el conjunto total. En primer lugar,
el error (con signo positivo o negativo) de la función en un solo punto, , se define como:
pero se intenta medir y minimizar el error en todo el conjunto de la
aproximación, . En matemáticas, existen diversas formas de definir el error, sobre todo cuando éste se refiere a un conjunto de puntos (y no sólo a uno), a una función, etc. Dicho error (el error "total" sobre el conjunto de puntos considerado) suele definirse con alguna de las siguientes fórmulas:
Error Máximo:
Error Medio:
Error cuadrático medio:
La aproximación por mínimos cuadrados se basa en la minimización del error cuadrático medio o, equivalentemente, en la minimización del radicando de dicho error, el llamado error cuadrático, definido como:
Para alcanzar este objetivo, se utiliza el hecho que la función f debe poder describirse como una combinación lineal de una base de funciones. Los coeficientes de la combinación lineal serán los parámetros que queremos determinar. Por ejemplo, supongamos que f es una función cuadrática, lo que quiere decir que es una combinación

lineal, , de las funciones , y (m=3 en este caso), y que se pretende determinar los valores de los coeficientes: , de modo que minimicen la suma (S) de los cuadrados de los residuos:
Esto explica el nombre de mínimos cuadrados. A las funciones que multiplican a los coeficientes buscados, que en este caso son: , y , se les conoce con el nombre de funciones base de la aproximación, y pueden ser funciones cualesquiera. Para ese caso general se deduce a continuación la fórmula de la mejor aproximación discreta (i.e. para un conjunto finito de puntos), lineal y según el criterio del error cuadrático medio, que es la llamada aproximación lineal por mínimos cuadrados. Es posible generar otro tipo de aproximaciones, si se toman los errores máximo o medio, por ejemplo, pero la dificultad que entraña operar con ellos, debido al valor absoluto de su expresión, hace que sean difíciles de tratar y casi no se usen.
Solución del problema de los mínimos cuadradosLa aproximación mínimo cuadrática consiste en minimizar el error cuadrático mencionado más arriba, y tiene solución general cuando se trata de un problema de aproximación lineal (lineal
en sus coeficientes ) cualesquiera que sean las funciones base: antes mencionadas. Por lineal se entiende que la aproximación buscada se expresa como una combinación lineal de dichas funciones base. Para hallar esta expresión se puede seguir un camino analítico, expuesto abajo, mediante el cálculo multivariable, consistente en optimizar los coeficientes ; o bien, alternativamente, seguir un camino geométrico con el uso de el álgebra lineal, como se explica más abajo, en la llamada deducción geométrica. Para los Modelos estáticos uniecuacionales, el método de mínimos cuadrados no ha sido superado, a pesar de diversos intentos para ello, desde principios del Siglo XIX. Se puede demostrar que, en su género, es el que proporciona la mejor aproximación.
Deducción analítica de la aproximación discreta mínimo cuadrática lineal
Mínimos cuadrados y análisis de regresiónEn el análisis de regresión, se sustituye la relación
por

siendo el término de perturbación ε una variable aleatoria con media cero. Obśervese que estamos asumiendo que los valores x son exactos, y que todos los errores están en los valores y. De nuevo, distinguimos entre regresión lineal, en cuyo caso la función f es lineal para los parámetros a ser determinados (ej., f(x) = ax2 + bx + c), y regresión no lineal. Como antes, la regresión lineal es mucho más sencilla que la no lineal. (Es tentador pensar que la razón del nombre regresión lineal es que la gráfica de la función f(x) = ax + b es una línea. Ajustar una curva f(x) = ax2 + bx + c, estimando a, b y cpor mínimos cuadrados es un ejemplo de regresión lineal porque el vector de estimadores mínimos cuadráticos de a, b y c es una transformación lineal del vector cuyos componentes son f(xi) + εi).
Los parámetros (a, b y c en el ejemplo anterior) se estiman con frecuencia mediante mínimos cuadrados: se toman aquellos valores que minimicen la suma S. El teorema de Gauss-Márkov establece que los estimadores mínimos cuadráticos son óptimos en el sentido de que son los estimadores lineales insesgados de menor varianza, y por tanto de menor error cuadrático medio, si tomamos f(x) = ax + b estando a y b por determinar y con los términos de perturbación ε independientes y distribuidos idénticamente (véase el artículo si desea una explicación más detallada y con condiciones menos restrictivas sobre los términos de perturbación).
La estimación de mínimos cuadrados para modelos lineales es notoria por su falta de robustez frente a valores atípicos (outliers). Si la distribución de los atípicos es asimétrica, los estimadores pueden estar sesgados. En presencia de cualquier valor atípico, los estimadores mínimos cuadráticos son ineficientes y pueden serlo en extremo. Si aparecen valores atípicos en los datos, son más apropiados los métodos de regresión robusta.
Métodos Numéricos para Regresiones No Lineales por mínimos cuadradosEn estadística, la regresión no lineal es un problema de inferencia para un modelo tipo:
El objetivo de la regresión no lineal se puede clarificar al considerar el caso de la regresión polinomial, la cual es mejor no tratar como un caso de regresión no lineal. Cuando la función toma la forma:
la función es no lineal en función de pero lineal en función de los parámetros desconocidos , , y . Este es el sentido del término "lineal" en el contexto de la regresión estadística. Los procedimientos computacionales para la regresión polinomial son procedimientos de regresión lineal (múltiple), en este caso con dos variables predictoras y . Sin embargo, en ocasiones se sugiere que la regresión no lineal es necesaria para ajustar polinomios. Las consecuencias prácticas de esta mala interpretación conducen a que un procedimiento de optimización no lineal sea usado cuando en realidad hay una solución disponible en términos de regresión lineal. Paquetes (software) estadísticos

consideran, por lo general, más alternativas de regresión lineal que de regresión no lineal en sus procedimientos.
Ejemplo de regresión no lineal
Regresión Exponencial
En determinados experimentos, en su mayoría biológicos, la dependencia entre las variables X e Y es de forma exponencial, en cuyo caso interesa ajustar a la nube de puntos una función del tipo:
Mediante una transformación lineal, tomando logaritmos neperianos, se convierte el problema en una cuestión de regresión lineal. Es decir, tomando logaritmos neperianos:
Ejemplo.- Por regresión exponencial calcule Y cuando X=5, siX= 1 1.2 1.5 2 3 3.7 4 4.5Y= 3 3.4 5 2 4.1 5 7 6.5
x y ln(y) x2 x ln(y) (ln y)2
1 3 1,0986 1 1,0986 1,2069
1,2 3,4 1,2237 1,44 1,4684 1,4974
1,5 5 1,6094 2,25 2,4141 2,5901
2 2 0,6931 4 1,3862 0,4803
3 4,1 1,4109 9 4,2327 1,9906

3,7 5 1,6094 13,69 5,9547 2,5901
4 7 1,9459 16 7,7836 3,7865
4,5 6,5 1,8718 20,25 8,4231 3,5056
Σ: 20,9
Σ: 36Σ: 11,4628
Σ: 67,63 Σ: 32,7614 Σ: 17,6455
Numero de datos = n = 8
=
x promedio = 2.6125
=
ln(y) promedio = 1.4328Usando la forma lineal de la Regresión Exponencial:
b = =
recordemos que
entonces ln(a) =ln(y) - bx
La ecuación final que modela el sistema es
Si x=5 entonces y= 7.0175
Regresión Logarítmica
La curva logarítmica es también una recta, pero en lugar de estar referida a las variables originales e , está referida a y a
Ejemplo.- Por regresión logarítmica calcule Y cuando X=5, six= 1 1.2 1.5 2 3 3.7 4 4.5y= 3 3.4 5 2 4.1 5 7 6.5
x y ln x ln2 x y*ln x y2
1 3 0 0 0 9

1.2 3.4 0.1823 0.0332 0.6198 11.56
1.5 5 0.4054 0.1643 2.027 25
2 2 0.6931 0.4803 1.3862 4
3 4.1 1.0986 1.2069 4.5042 16.81
3.7 5 1.3083 1.7116 6.5415 25
4 7 1.3862 1.9215 9.7034 49
4.5 6.5 1.5040 2.2620 9.776 42.25
Σ: 20.9
Σ: 36 Σ: 6.5779 Σ: 7.7798 Σ: 34.5581 Σ: 182.62
a = = =
a= 2.09051
b = = 4.5 - (2.09051)(0.8222) = 2.78117
La ecuación final que modela el sistema es
y =6.1456
Regresión polinomial
Algunas veces cuando la relación entre las variables dependientes e independientes es no lineal, es útil incluir términos polinomiales para ayudar a explicar la variación de nuestra variable dependiente.
Las regresiones polinomiales se pueden ajustar la variable independiente con varios términos
Que, derivando respecto a cada uno de los coeficientes nos da el planteamiento un sistema de ecuaciones de la siguiente forma (donde m es el número de pares de datos):

Ejemplo.- Por regresión polinomial calcule Y cuando X=5, siX= 1 1.2 1.5 2 3 3.7 4 4.5Y= 3 3.4 5 2 4.1 5 7 6.5
x y xy x2 y2 x2y x3 x4
1 3 3 1 9 3 1 1
1.2 3.4 4.08 1.44 11.56 4.896 1.728 2.0736
1.5 5 7.5 2.25 25 11.25 3.375 5.0625
2 2 4 4 4 8 8 16
3 4.1 12.3 9 16.81 36.9 27 81
3.7 5 18.5 13.69 25 68.45 50.653 187.4161
4 7 28 16 49 112 64 256
4.5 6.5 29.25 20.25 42.25 131.625 91.125 410.0625
Σ 20.9
Σ 36
Σ 106.63
Σ 67.63
Σ 182.62
Σ 376.121
Σ 246.881
Σ 958.6147
Usando una Matriz para calcular valores de los coeficientes
Usando el método de Eliminación de Gauss-Jordan
La ecuación final que modela el sistema es

Finalmente si x = 5, entonces
y=4.57543-1.52445*5+0.46209*5^2 = 8.5054
Extrapolación (matemática)En matemáticas, extrapolación es el proceso de estimar más allá del intervalo de observación original, el valor de la variable en base a su relación con otra variable. Es similar a la interpolación, la cual produce estimados entre las observaciones conocidas, a diferencia de esta la extrapolación es sujeta a una mayor incertidumbre y a un mayor riesgo de producir resultados insignificantes. Extrapolación también puede significar extensión de un método, asumiendo que se pueden aplicar métodos similares.
Ilustración de ejemplo del problema de extrapolación, consistente en asignar un valor significactivo a la caja azul, en
, dados los datos como puntos rojos.
Métodos de extrapolaciónUna opción muy sonada en la cual se aplica el método de extrapolación se fundamenta en el conocimiento a priori del proceso que ha creado los puntos para los datos existentes. Algunos expertos han propuesto el uso de fuerzas casuales en la evaluación de los métodos de extraplación.1 Preguntas cruciales son por ejemplo si los datos se pueden suponer continuos, llanos, posiblemente periódicos, etc.
Extrapolación Lineal
Extrapolación significa crear una línea tangente al final de los datos conocidos y extendiéndola más allá de ese límite. La Extrapolación lineal proveerá buenos resultados sólo cuando se use para extender la gráfica de una función lineal aproximadamente o no muy lejana de los datos conocidos.

Si los dos puntos cercanos al punto que serán extrapolados son y , la extrapolación lineal nos da la función:
(la cual es idéntica a Interpolación_lineal si ). Es posbile incluir más de dos puntos y promediar la inclinación del interpolante lineal, haciendo técnicas de regresión, en los puntos de los datos que serán incluidos. Esto es similar a la predicción lineal.
Extrapolación polinómica
Una extrapolación polinómica se puede calcular a partir de todos los datos conocidos o tan sólo de los datos extremos. La curva resultante puede ser extendida a posterior más allá de los datos conocidos. La extrapolación polinómica se calcula usualmente mediante interpolación Lagrange o utilizando el método de Newton de diferencias finitas (creando series de Newton a partir de los datos). El polinomio así calculado se puede usar para extrapolar los datos.
La extrapolación mediante polinomios de alto grado debe ser usada con cautela. Por ejemplo, en el conjunto de datos y el problema de la figura anterior, cualquiera que esté polinomios de grado mayor que uno puede producir valores inutilizables, un error estimado del valor extrapolador crecerá con el grado de la extrapolación polinómica. Este hecho está relacionado con el llamado fenómeno de Runge.
Extrapolación cónica
Puede computarse una sección cónica utilizando los puntos cercanos al final de los datos conocidos. Si la sección cónica calculada es una elipse o un círculo, creará un bucle y se unirá nuevemante en sí misma. Una curva parabólica o hiperbólica no se unirá nuevamente en sí, pero puede curvearse respecto al eje X. Este tipo de extrapolación puede se puede hacer con una plantilla de secciones cónicas (en papel) o mediante computadora.
Extrapolación de Curva Francesa
La Extrapolación de curva Francesa es un método adecuado para cualquier distribución que tenga una tendencia a convertirse en exponencial, pero con factores de aceleración o desaceleración.2 Este método se ha utilizado exitosamente para proveer proyecciones de pronósticos en el crecimiento de VIH/SIDA en el Reino Unido desde 1987 y variantes de la enfermedad Creutzfeldt-Jakob en el Reino Unido desde hace varios años [1]. Otro estudio ha mostrado que la extrapolación puede producir la misma calidad de resultados que otras estrategias de pronóstico.3
Calidad de la extrapolaciónTípicamente, la calidad de un método de extrapolación en particular está limitado por las suposiciones acerca de la función producida por el método. Si el método asume que los datos son llanos, entonces una función no llana se encontrará pobremente extrapolada.
En términos de series de tiempo complejas, algunos expertos han descubierto que la extrapolación es más precisa cuando se realiza a través de la descomposición de las fuerzas causales.4
Aún con los supuestos apropiados acerca de la función, la extrapolación puede divergir fuertemente desde la función. El ejemplo clásico son representaciones del sin(x) en series de potencias truncadas y funciones trigonométricas relacionadas. Por ejemplo tomando sólo datos cercanos dex = 0, podemos estimar que la función se comporta como sin(x) ~ x. En la cercanía de x = 0, este es un estimado excelente. Lejos de x = 0 sin embargo la extrapolación se mueve arbitrariamente lejos del eje x mientras sin(x) permanece en el intervalo [−1,1]. Ej., el error aumenta sin un límite.

Tomando más términos con potencia de las series del sin(x) alrededor x' = 0 producirán un mejor acuerdo sobre un intervalo largo cercano a x = 0, pero producirán extrapolaciones que eventualmente divergen lejos del eje x aun más rápido que la aproximación lineal.
Esta divergencia es una propiedad específica de los métodos de extrapolación y sólo es eludida cuando las formas funcionales asumidas por el método de extrapolación (inadvertida o intencialmente debido a información adicional) representan de forma precisa la naturaleza de la función extrapolada. Para problemas particulares, esta información adicional puede estar disponible, pero generalmente es imposible satisfacer todos los comportamientos de la función con un conjunto pequeño de información trabajable de comportamiento potencial.
Extrapolación en el plano complejoEn el análisis complejo, un problema de extrapolación se puede convertir en un problema
de Interpolación por el cambio de variable . Esta transformación intercambia la parte del Plano Complejo dentro de un círculo unitario con la parte del plano complejo fuera del círculo unitario. En particular, la compactificación del punto al infinito se mapea al origen y vice versa. Se debe tener cuidado con esta transformación sin embargo, desde que la función original puede tener "características", por ejemplo polos y otras singularidades, al infinito que no eran evidentes desde los datos de la muestra.
Otro problema de la extrapolación que está íntimamente relacionado con el problema de la continuación analítica, donde (típicamente) una representación de series de potencias de una función es expandida a uno de sus puntos de convergencia para producir una series de potencias con un mayor radio de convergencia. En efecto, un conjunto de datos de una pequeña región se usa para extrapolar una función a una región mayor.
Nuevamente la continuación analítica, puede frustar las características de las funciones que no fueron evidentes en los datos de inicio.
Así mismo, uno puede utilizar transformación secuencial como la aproximación Padé y la transformación secuencial del tipo Levin como métodos de extrapolación que conllevan a la adición de series de potencias que son divergentes fuera del radio de convergencia original. En este caso uno obtiene a veces el aproximado racional
Interpolación polinómica de LagrangeEn análisis numérico, el polinomio de Lagrange, llamado así en honor a Joseph-Louis de Lagrange, es
una forma de presentar el polinomio queinterpola un conjunto de puntos dado. Lagrange publicó este
resultado en 1795, pero lo descubrió Edward Waring en 1779 y fue redescubierto más tarde por Leonhard
Euler en 1783.1 Dado que existe un único polinomio interpolador para un determinado conjunto de puntos,
resulta algo engañoso llamar a este polinomio el polinomio interpolador de Lagrange. Un nombre más
apropiado es interpolación polinómica en la forma de Lagrange.

En esta imagen se muestran, para cuatro puntos ((−9, 5), (−4, 2),(−1, −2), (7, 9)), la interpolation polinómica
(cúbica) L(x), que es la suma de la bases polinómicasescaladas y0l0(x), y1l1(x), y2l2(x) yy3l3(x). La interpolación
polinómica pasa exactamente por los cuatro puntos (llamados puntos de control) y cada base polinómicaescalada pasa
por su respectivo punto de control y se anula cuandox corresponde a los otros puntos de control.
Definición
Dado un conjunto de k + 1 puntos
donde todos los xj se asumen distintos, el polinomio interpolador en la forma de Lagrange es
la combinación lineal
de bases polinómicas de Lagrange
Demostración
La función que estamos buscando es una función polinómica L(x) de grado k con el problema
de interpolación puede tener tan solo una solución, pues la diferencia entre dos tales
soluciones, sería otro polinomio de grado k a lo sumo, con k+1 ceros.
Por lo tanto, L(x) es el único polinomio interpolador
Concepto
La resolución de un problema de interpolación lleva a un problema de álgebra lineal en el cual
se debe resolver un sistema de ecuaciones. Usando unabase monómica estándar para nuestro
polinomio interpolador, llegamos a la matriz de Vandermonde. Eligiendo una base distinta, la
base de Lagrange, llegamos a la forma más simple de matriz identidad = δi,j, que puede
resolverse inmediatamente.
UsoEjemplo
La función tangente y su interpolador.
Se desea interpolar en los puntos
Con cinco puntos, el polinomio interpolador tendrá, como máximo, grado cuatro (es decir, la
máxima potencia será cuatro), al igual que cada componente de la base polinómica.
La base polinómica es:

Así, el polimomio interpolador se obtiene simplemente como la
combinación lineal entre los y los valores de las abscisas:
Desventajas de su uso
Si se aumenta el número de puntos a interpolar (o nodos) con la intención de mejorar la aproximación a
una función, también lo hace el grado del polinomio interpolador así obtenido, por norma general. De este
modo, aumenta la dificultad en el cálculo, haciéndolo poco operativo manualmente a partir del grado 4,
dado que no existen métodos directos de resolución de ecuaciones de grado 4, salvo que se puedan tratar
como ecuaciones bicuadradas, situación extremadamente rara.
La tecnología actual permite manejar polinomios de grados superiores sin grandes problemas, a costa de
un elevado consumo de tiempo de computación. Pero, a medida que crece el grado, mayores son las
oscilaciones entre puntos consecutivos o nodos. Se podría decir que a partir del grado 6 las oscilaciones
son tal que el método deja de ser válido, aunque no para todos los casos.
Sin embargo, pocos estudios requieren la interpolación de tan sólo 6 puntos. Se suelen contar por decenas
e incluso centenas. En estos casos, el grado de este polimonio sería tan alto que resultaría inoperable. Por
lo tanto, en estos casos, se recurre a otra técnica de interpolación, como por ejemplo a laInterpolación
polinómica de Hermite o a los splines cúbicos
Otra gran desventaja, respecto a otros métodos de interpolación, es la necesidad de recalcular todo el
polinomio si se varía el número de nodos.
Otras aplicaciones
Aunque el polinomio interpolador de Lagrange se emplea mayormente para interpolar funciones e
implementar esto fácilmente en una computadora, también tiene otras aplicaciones en el campo del álgebra

exacta, lo que ha hecho más célebre a este polinomio, por ejemplo en el campo de los proyectores
ortogonales:
Sea un espacio vectorial complejo de dimensión finita E en el que definimos un producto escalar (no
necesariamente el usual). Sea F un operador normal, tal que gracias al teorema de la descomposición
espectral es igual a . Donde son los proyectores ortogonales y los autovectores de F
asociados a cada proyector. Entonces:
Siendo I la matriz identidad.
Demostración:
Haciendo uso de la descomponsición espectral y aplicando las propiedades de los proyectores:
Interpolación polinómica de NewtonEs un método de interpolación polinómica. Aunque sólo existe un único polinomio que interpola una serie de puntos, existen diferentes formas de calcularlo. Este método es útil para situaciones que requieran un número bajo de puntos para interpolar, ya que a medida que crece el número de puntos, también lo hace el grado del polinomio.
Existen ciertas ventajas en el uso de este polinomio respecto al polinomio interpolador de Lagrange. Por ejemplo, si fuese necesario añadir algún nuevo punto o nodo a la función, tan sólo habría que calcular este último punto, dada la relación de recurrencia existente y demostrada anteriormente.
Definición analíticaDados n+1 escalares distintos y n+1 escalares (iguales ó distintos) se define el polinomio interpolador en la forma:
Siendo las coordenadas del polinomio y la expresión anterior del polinomio interpolador la conocida como diferencias divididas.
Teniendo en cuenta que existe una función p tal que y haciendo sucesivamente:

Se llega a:
Con los siguientes polinomios:
Las satisfacen la relación de recurrencia:
Y finalmente se obtiene el vector en , con lo que se puede escribir el polinomio interpolador de Newton en función de la nueva base , de la forma que sigue:
3 MÉTODO DE DIFERENCIAS DIVIDIDAS (Polinomio Interpolante de Newton)
La forma general del polinomio interpolante de Newton para n+1 datos (x0, ƒ(x0)), (x1, ƒ(x1)), ..., (xn, ƒ(xn)) es:
Los coeficientes ai se obtienen calculando un conjunto de cantidades denominadas diferencias divididas.
La notación para las diferencias divididas de una función ƒ(x) están dadas por:

Las diferencias divididas de orden superior se forman de acuerdo con la siguiente regla recursiva:
Retomando el polinomio interpolante de Newton:Pn(x) = a0 + a1(x – x0) + a2(x – x0)(x – x1) + ... +an(x – x0)(x – x1)…(x – xn-1)
Observe que Pn(x0) = a0. Como Pn(x) interpola los valores de ƒ en xi, i=0,1,2,...,nentonces P(xi) = ƒ(xi), en particular Pn(x0) = ƒ(x0) = a0. Si se usa la notación de diferencia dividida a0= ƒ[x0].
Ahora, Pn(x1)= a0 + a1(x1 – x0), como Pn(x1)= ƒ(x1) y a0= ƒ(x0), entonces reemplazando se tiene
ƒ(x1)=ƒ(x0) + a1(x11–x0), donde
Si se usa la notación de diferencia dividida a1= ƒ[x0, x1].De manera similar cuando se evalúa Pn(x) en x = x2 se obtiene a2 = ƒ[x0, x1, x2] (ver ejercicio 15, de este capítulo).En general ai = ƒ[x0 ,x1 ,x2, ..., xi], y el polinomio interpolante de Newton se escribe como:
(2)
En la figura 3.2 se muestra la forma recursiva para calcular los coeficientes del polinomio interpolante de Newton para 4 pares de valores (x, ƒ(x))
Los elementos de la diagonal (superior) en la figura 3.2 son los coeficientes del polinomio interpolante de Newton para el caso de un polinomio de grado 3.
Ejemplo.
Halle el polinomio que interpola los datos:

X 1 2 3 5
f(x) 4 3.5 4 5.6
Solución:El polinomio interpolante de Newton es de grado 3 ya que se tienen 4 puntos, usando la fórmula (2) el polinomio que resulta es:
En este caso x0=1, x1=2, x2=3
Para determinar el valor de los coeficientes, se construye la tabla de diferencias divididas
xi f(xi)
1 4
-0.5
2 3.5 0.5
0.5 -0.1
3 4 0.1
0.8
5 5.6
Luego P3(x)=4 – 0.5(x - 1) + 0.5(x - 1)(x - 2) – 0.1(x - 1)(x - 2)(x - 3)
Observe que P3(1) = 4, P3(2) = 3.5, P3(3) = 4, P3(5) = 5.6
Este ejercicio se resolvió con el método de Lagrange en la sección anterior y el cálculo para encontrarlo fue mucho mayor.

INTERPOLACIÓN POLINOMIAL DE LAS DIFERENCIAS FINITAS DE NEWTON
GENERALIZACIÓN
El análisis anterior se puede generalizar en el ajuste de un polinomio de n-ésimo orden a los n+1puntos. El polinomio de n-ésimo orden es:
(11)
Como se hizo anteriormente con las interpolaciones lineales y cuadráticas, se usan los puntos en la evaluación de los coeficientes b0, b1, ... , bn.
Se requieren n + 1 puntos para obtener un polinomio de n-ésimo orden: X0, X1, ... , Xn.
Usando estos datos, con las ecuaciones siguientes se evalúan los coeficientes:
b0 = f (X0)b1 = f [X1, X0]b2 = f [X2, X1, X0] (12)...bn = f [X n, Xn-1, ..., X1, X0]
En donde las evaluaciones de la función entre corchetes son diferencias divididas finitas.
Por ejemplo, la primera diferencia dividida finita se representa generalmente como:
(13)
La segunda diferencia dividida finita, que representa la diferencia de dos primeras diferencias divididas finitas, se expresa generalmente como:
(14)
De manera similar, la n-ésima diferencia dividida finita es:
(15)

Estas diferencias se usan para evaluar los coeficientes de la ecuación (12), los cuales se sustituyen en la ecuación (11), para obtener el polinomio de interpolación:
f n (X) = f(X0) + (X-X0) f[X1, X0] + (X-X0)(X-X1) f[X2, X1, X0] +...+ (X-X0)(X-X1)...(X-Xn-1) f[Xn, Xn-1,...,X1, X0]
(16)
Al cual se le llama Polinomio de Interpolación con Diferencias Divididas de Newton.
Se debe notar que no es necesario que los datos usados en la ecuación (16) estén igualmente espaciados o que los valores de la abscisa necesariamente se encuentren en orden ascendente, como se ilustra en el ejemplo 3.3
Todas las diferencias pueden arreglarse en una tabla de diferencias divididas, en donde cada diferencia se indica entre los elementos que la producen:
i Xi f(Xi) Primera Segunda Tercera
0 X0 f(X0) f(X1, X0) f(X2, X1, X0) f(X3, X2, X1, X0)
1 X1 f(X1) f(X2, X1) f(X3, X2, X1)
2 X2 f(X2) f(X3,X2)
3 X3 f(X3)
EJEMPLO 3.3
Usando la siguiente tabla de datos, calcúlese ln 2 con un polinomio de interpolación de Newton con diferencias divididas de tercer orden:
X f(X)
1 0.000 0000
4 1.386 2944
6 1.791 7595
5 1.609 4379
SOLUCIÓN:
El polinomio de tercer orden con n = 3, es.

Las primeras diferencias divididas del problema son:
Las segundas diferencias divididas son:
La tercera diferencia dividia es:
Los resultados para f(X1, X0), f(X2, X1, X0) y f(X3, X2, X1, X0) representan los coeficientes b1, b2y b3 Junto con b0 = f (X0) = 0.0, la ecuación da:
f 3 (X) = 0 + 0.46209813 (X-1) - 0.0518731 (X-1)(X-4) + 0.0078655415 (X-1)(X-4)(X-6)
Arreglando la tabla de diferencias
X f [X] f 1 [ ] f 2 [ ] f 3 [ ]
1.0 0.00000000 0.46209813 - 0.051873116 0.0078655415
4.0 1.3862944 0.20273255 - 0.020410950
6.0 1.7917595 0.18232160
5.0 1.6094379

Con la ecuación anterior se puede evaluar para X = 2
f 3 (2) = 0.62876869
lo que representa un error relativo porcentual del e% = 9.3%.
Nótese que la estructura de la ecuación (16) es similar a la expresión de la serie de Taylor en el sentido de que los t�rminos agregados secuencialmente consideran el comportamiento de orden superior de la función representada. Estos términos son diferencias divididas finitas, y por lo tanto, representan aproximaciones a las derivadas de orden superior. En consecuencia, como sucede con la serie de Taylor, si la función representativa es un polinomio de n-ésimo orden, el polinomio interpolante de n-ésimo orden bajado en n + 1 llevará� a resultados exactos.
El error por truncamiento de la serie de Taylor es:
(17)
en donde es un punto cualquiera dentro del intervalo (Xi, Xi+1). Una relación análoga del error en un polinomio interpolante de n-ésimo orden está dado por:
(18)
En donde es un punto cualquiera dentro del intervalo que contiene las incógnitas y los datos. Para uso de esta fórmula la función en cuestión debe ser conocida y diferenciable. Y usualmente, este no es el caso.
Afortunadamente existe una fórmula alternativa que no requiere conocimiento previo de la función. En vez de ello, se usa una diferencia dividida finita que aproxima la (n+1)-ésima derivada:
Rn = f [X, Xn, Xn-1, ... , X1, X0](X-X0)(X-X1)..(X-Xn) (19)
en donde f(X, Xn, Xn-1, ... , X0) es la (n+1)-ésima diferencia dividida.
Ya que la ecuación (19) contiene la inc�gnita f(X), ésta no se puede resolver y obtener el error. Sin embargo, si se dispone de un dato adicional f(Xn+1), la ecuación (19) da una aproximación del error como:

(20)