guia de programacion en ruby
TRANSCRIPT

1
Lenguaje de programación orientado a objetos Ruby(Traducción Libre de la 2ª edición del libro “Programming Ruby. The Pragmatic Programmers’ Guide” de Dave Thomas)
Nombres Ruby
Ruby utiliza una convención para ayudar a distinguir el uso de un nombre: los primeros caracteres de un nombre indican cómo se utiliza el nombre. Los nombres de las variables locales, de los métodos y de los parámetros de método deben comenzar con una letra minúscula o con un guión bajo. Las variables globales van precedidas de un signo de dólar ($), y las variables de instancia deben comenzar con una “arroba” (@). Las variables de clase empiezan con dos arrobas (@@). Por último, los nombres genéricos, nombres de módulos, y las constantes debe comenzar con una letra mayúscula. Muestras de diferentes nombres se dan en la Tabla 1.1:
Después de este carácter inicial, un nombre puede tener cualquier combinación de letras, dígitos y carácter de subrayado (con la salvedad de que el carácter que sigue a un signo @ no puede ser un dígito). Sin embargo, por convención, los casos de variables de instancia con varias palabras se escriben con caracteres de subrayado entre las palabras y los nombres de clase con varias palabras están escritos en clase MixedCase (con cada palabra capitalizada).
Arrays y Hashes
Los arrays y hashes de Ruby son colecciones indexadas. Ambas colecciones de objetos almacenados son accesibles mediante una clave. Con las matrices, la clave es un número entero, mientras que los hashes soportan cualquier objeto como una clave. Ambos, matrices y hashes pueden crecer según sea necesario para mantener los nuevos elementos. Es más eficiente acceder a elementos de la matriz, pero los hashes proporcionan una mayor flexibilidad. Cualquier array o hash particular, puede contener obje-tos de diferentes tipos. Se puede tener una matriz que contiene un entero, una cadena, y un número de punto flotante, como veremos en un minuto.
Puede crear e inicializar un nuevo objeto matriz con un array literal --un conjunto de elementos entre corchetes. Dado un objeto matriz, puede acceder a elementos individuales mediante el suministro de un índice entre corchetes, como muestra el siguiente ejemplo. Tenga en cuenta que los índices ruby de array comienzan en cero.
a = [ 1, ‘cat’, 3.14 ] # matriz con tres elementos # acceso al primer elemento a[0] -> 1 # establecer el tercer elemento a[2] = nil # volcado de salida de la matriz a -> [1, “cat”, nil]
Puede haber notado que hemos usado el valor especial nil en este ejemplo. En muchos idiomas, el

2
concepto de cero (o nulo) significa “no hay ningún objeto.” En Ruby, este no es el caso, nada es un objeto como cualquier otro, que pasa a representar nada.
A veces, la creación de matrices de palabras puede ser un dolor de cabeza, con todas las comillas y comas. Afortunadamente, Ruby tiene un acceso directo: %w hace exactamente lo que queremos.
a = [ ‘ant’, ‘bee’, ‘cat’, ‘dog’, ‘elk’ ] a[0] → “ant” a[3] → “dog”# esto hace lo mismo: a = %w{ ant bee cat dog elk } a[0] → “ant” a[3] → “dog”
Los hashes de Ruby son similares a las matrices. Un hash literal utiliza llaves en lugar de corchetes. El literal debe proporcionar dos objetos para cada entrada: uno para la clave, y el otro para el valor.
Por ejemplo, es posible que desee asignar instrumentos musicales para sus secciones de orquesta. Usted puede hacer esto con un hash.
inst_section = { ‘cello’ => ‘string’, ‘clarinet’ => ‘woodwind’, ‘tambor’ => ‘percussion’, ‘oboe’ => ‘woodwind’, ‘trumpet’ => ‘brass’, ‘violin’ => ‘string’ }
Lo que hay a la izquierda de la => es la clave y lo que hay a la derecha es el valor correspondiente. Las claves en un hash en particular deben ser únicas, no se puede tener dos entradas para “tambor”. Las claves y los valores de un hash pueden ser objetos arbitrarios --se pueden tener hash donde los valores son arrays, otros hashes, etc.
Los valores hash son indexados usando la misma notación de corchetes como en las matrices.
inst_section[‘oboe’] → “woodwind” inst_section[‘cello’] → “string” inst_section[‘bassoon’] → nil
Como muestra el ejemplo anterior, un hash por defecto devuelve nil cuando es indexado por una cla-ve que no contiene. Normalmente esto es útil, ya que nil significa falso cuando se utiliza en las expresio-nes condicionales. A veces querrá cambiar este valor predeterminado. Por ejemplo, si está utilizando un hash para contar el número de veces que cada tecla tiene lugar, es conveniente tener el valor por defecto de cero. Esto se hace fácilmente mediante la especificación de un valor por defecto cuando se crea un nuevo hash vacío.
histogram = Hash.new(0) histogram[‘key1’] → 0 histogram[‘key1’] = histogram[‘key1’] + 1 histogram[‘key1’] → 1
Los objetos array y hash tienen un montón de métodos útiles que se verán en las correspondientes secciones de referencia.
Estructuras de control
Ruby tiene todas las estructuras de control habituales, como las sentencias if y los bucles while. Los programadores de Java, C o Perl pueden quedar atrapados por la falta de llaves alrededor de los cuerpos de estas declaraciones. En su lugar, Ruby utiliza la palabra clave end para indicar el final de un cuerpo.

3
if count > 10 puts “Intentalo otra vez” elsif tries == 3 puts “Pierdes” else puts “Escribe un número” end
Del mismo modo, las sentencias while se terminan con end.
while peso < 100 and num_pallets <= 30 pallet = next_pallet() peso += pallet.peso num_pallets += 1 end
La mayoría de las sentencias en Ruby devuelven un valor, lo que significa que se pueden utilizar como condiciones. Por ejemplo, el método jets devuelve la siguiente línea del flujo de entrada estándar o nil cuando se alcanza el final del fichero. Debido a que Ruby trata nil como un valor falso en las condiciones, podría escribir lo siguiente para procesar las líneas de un archivo.
while linea = gets puts linea.downcase end
En este caso, la sentencia de asignación establece la variable linea ya sea a la siguiente línea de texto o a nulo, y a continuación, la sentencia while comprueba el valor de la asignación, que termina el bucle cuando es nil.
Los modificadores de declaración ruby son un atajo útil si el cuerpo de un if o while es una sola expresión. Simplemente escriba la expresión, seguido por if o while y la condición. Por ejemplo, aquí una simple declaración if.
if radiation > 3000 puts “Danger, Will Robinson” end
Aquí otra vez, reescrita mediante un modificador de declaración.
puts “Danger, Will Robinson” if radiation > 3000
Del mismo modo, un bucle while como
square = 2 while square < 1000 square = square*square end
se convierte en el más breve
square = 2square = square*square while square < 1000
Estos modificadores de declaración debe ser familiares a los programadores de Perl.
Expresiones Regulares
Muchos de los tipos ruby empotrados (built-in) serán familiares para todos los programadores. La mayoría de los idiomas tienen cadenas, enteros, reales, matrices, etc. Sin embargo, el soporte para

4
expresiones regulares se construye típicamente sólo en lenguajes de programación como Ruby, Perl y awk. Esto es una pena: las expresiones regulares, aunque crípticas, son una poderosa herramienta para trabajar con texto. Y si están integradas, en lugar de pegadas a través de una interfaz de biblioteca, hay una gran diferencia.
Libros enteros se han escrito sobre las expresiones regulares (por ejemplo, Mastering Regular Expres-sions [Fri02]), por lo que no vamos a tratar de cubrir todo en esta breve sección. En su lugar, vamos a ver algunos ejemplos de expresiones regulares en acción. Se encontrará una cobertura completa de las expresiones regulares más adelante.
Una expresión regular es simplemente una manera de especificar un patrón de caracteres que se ajustaran a una cadena. En Ruby, se suele crear una expresión regular escribiendo un patrón entre los caracteres de barra inclinada (/patrón/). Y en Ruby, como es Ruby, las expresiones regulares son objetos y se pueden manipular como tal.
Por ejemplo, podría escribir un patrón que coincida con una cadena que contiene el texto Perl o Python con la siguiente expresión regular.
/Perl|Python/
Las barras inclinadas delimitan el patrón, que consiste en las dos cosas que son coincidentes separa-dos por una barra vertical (|). El caracter pipe en este caso, significa “o bien la cosa a la derecha o bien la cosa a la izquierda”, ya sea Perl o Python. Se pueden utilizar paréntesis dentro de los patrones, tal como se puede en las expresiones aritméticas, por lo que también se podría haber escrito este patrón
/P(erl|ython)/
También puede especificar la repetición dentro de los patrones. /ab+c/ coincide con una cadena que contiene una a seguida de una o más b, seguida por una c. Cambiar el signo más por un asterisco, y /ab*c/ crea una expresión regular que coincide con una a, cero o más b y una c.
También puede coincidir con un elemento de un grupo de caracteres dentro de un patrón. Algunos ejemplos comunes son las clases caracter como \s, que coincide con un espacio en blanco (espacio, ta-bulador, nueva línea, etc); \d,que coincide con cualquier dígito, y \w, que coincide con cualquier carácter que pueda aparecer en una palabra típica. Un punto (.) coincide con (casi) cualquier carácter. Una tabla de estas clases carácter se mostrará más adelante en su correspondiente sección.
Podemos juntar todo esto para producir algunas expresiones regulares útiles.
/\d\d:\d\d:\d\d/ # un momento tal que 12:34:56 /Perl.*Python/ # Perl, cero o más caracteres y Python /Perl Python/ # Perl, un espacio y Python /Perl *Python/ # Perl, cero o más espacios y Python /Perl +Python/ # Perl, uno o más espacios y Python /Perl\s+Python/ # Perl, espacio en blanco y Python /Ruby (Perl|Python)/ # Ruby, un espacio , y cualquiera de los dos, Perl o Python
Una vez que se haya creado un patrón, es una pena no usarlo. El operador de emparejamiento =~ se pueden utilizar para comparar una cadena con una expresión regular. Si el patrón se encuentra en la cadena, =~ devuelve su posición inicial y en caso contrario devuelve nil. Esto significa que usted puede utilizar expresiones regulares como condición en las declaraciones if y while. Por ejemplo, el siguiente fragmento de código escribe un mensaje si una cadena contiene el texto Perl o Python.
if line =~ /Perl|Python/ puts “Scripting language mentioned: #{line}” end
La parte de una cadena coincidente con una expresión regular puede ser sustituida por otro texto me-diante uno de los métodos de sustitución de Ruby.

5
line.sub (/Perl/, ‘Ruby’) # cambiar el primer ‘Perl’ por ‘Ruby’ line.gsub (/Python/, ‘Ruby’) # cambiar cada ‘Python’ por ‘Ruby’
Puede reemplazar todas las apariciones de Perl y Python con Ruby utilizando
line.gsub (/Perl|Python/, ‘Ruby’)
Vamos a decir mucho más acerca de las expresiones regulares a medida que avanzamos a través del libro.
Bloques e Iteradores
Esta sección describe brevemente uno de los puntos fuertes de Ruby. Vamos a ver como lucen los blo-ques de código: trozos de código que se pueden asociar con las llamadas a métodos casi como si fueran parámetros. Esta es una característica muy poderosa. Uno de nuestros revisores comentó en este punto: “Esto es muy interesante e importante, y si no le estaba prestando atención antes, probablemente debería empezar ahora.” Tendríamos que estar de acuerdo.
Se pueden utilizar los bloques de código para implementar rellanadas (son más simples que las clases anónimas internas de Java), para pasar trozos de código (son más flexibles que los punteros a funciones de C), y para implementar iteradores.
Los bloques de código son trozos de código entre llaves o entre do…end.
{ puts “Hello” } # esto es un bloque do ### club.enroll(person) # y así es en este person.socialize # end ###
¿Por qué hay dos tipos de delimitadores? Es en parte porque a veces uno siente más natural escribir uno que otro. Es en parte también, porque tienen distintas precedencias: las llaves unen con más fuerza que los pares do/end. En este libro, tratamos de seguir lo que se está convirtiendo en un estándar de Ruby y las llaves se usan para bloques de una sola línea y do/end para bloques multilinea.
Una vez que se haya creado un bloque, puede ser asociado con una llamada a un método. Esto se hace poniendo el inicio del bloque al final de la línea fuente que contiene la llamada al método. Por ejem-plo, en el siguiente código, el bloque que contiene puts “Hola” está asociado con la llamada al método greet (saludar).
greet { puts “Hola” }
Si el método tiene parámetros, aparecen antes del bloque.
verbose_greet(“Dave”, “cliente fiel”) { puts “Hola” }
Un método puede invocar un bloque asociado una o más veces con la declaración Ruby yield (pro-ductividad). Usted puede pensar en yield como algo parecido a una llamada a un método que llama al bloque asociado con el método que contiene yield.
El siguiente ejemplo muestra esto en acción. Se define un método que llama a yield dos veces. A con-tinuación, llama a este método, poniendo un bloque en la misma línea después de la llamada (y después de los argumentos para el método).
A algunas personas les gusta pensar en la asociación de un bloque con un método como una especie de paso de parámetros. Esto funciona en un nivel, pero en realidad no es toda la historia. Usted puede ver mejor al bloque y al método como co-rutinas que transfieren el control de ida y vuelta entre ellos.
def call_block puts “Start of method” yield

6
yield puts “End of method” end call_block { puts “In the block” }
produce:
Inicio del método En el bloque En el bloque Final del método
Observe cómo funciona el código en el bloque (puts “In the bolck”) se ejecuta dos veces, una para cada llamada a yield.
Usted puede proporcionar parámetros a la llamada a yield: estos serán pasados al bloque. Dentro del mismo, liste los nombres de los argumentos entre barras verticales (|) para recibir estos parámetros.
Los bloques de código se utilizan en la biblioteca Ruby para implementar iteradores: métodos que de-vuelven elementos sucesivos de algún tipo de colección como una matriz.
animals = %w( ant bee cat dog elk ) # crier ulna lista animals.each {|animal| puts animal } # iterate sobre el contenido
produce:
ant bee cat dog elk
Vamos a ver cómo podemos poner en práctica la clase Array each, iterador que usamos en el ejem-plo anterior. El iterador each hace un bucle través de cada elemento de la matriz, llamando a yield por cada uno de ellos. En pseudo-código, esto puede parecerse a esto:
# dentro de la clase Array... def each for each elemento # <--not valid Ruby yield(elemento) end end
Muchas de las construcciones de bucles que están integradas en lenguajes como C y Java son simple-mente llamadas a métodos en Ruby con métodos que invocan al bloque asociado cero o más veces.
[ ‘cat’, ‘dog’, ‘horse’ ].each {|name| print name, “ “ } 5.times { print “*” } 3.upto(6) {|i| print i } (‘a’..’e’).each {|char| print char } produce: cat dog horse *****3456abcde

7
Aquí le pedimos al objeto 5 llamar a un bloque cinco veces y luego se pide al objeto 3 llamar a un bloque, pasando valores sucesivos hasta llegar a 6. Finalmente, el rango de caracteres desde a hasta e, invoca a un bloque mediante el método each.
Lectura y Escritura
Ruby cuenta con una amplia biblioteca de E/S. Sin embargo, en la mayoría de los ejemplos en este li-bro vamos a seguir unos pocos métodos sencillos. Ya hemos llegado llegado a dos métodos para la salida. puts escribe sus argumentos, añadiendo una nueva línea después de cada uno. print también escribe sus argumentos, pero sin salto de línea. Ambos pueden ser utilizados para escribir en cualquier objeto de E/S, pero por defecto, escriben en la salida estándar.
Otro método de salida que se utiliza mucho es printf, que imprime sus argumentos bajo el control de una cadena de formato (al igual que printf en C o Perl).
printf(“Number: %5.2f,\nString: %s\n”, 1.23, “hola”)
produce:
Number: 1.23, String: hola
En este ejemplo, la cadena de formato “Number: % 5.2f,\nString: %s\n”, le dice a printf que sustituya a un número de punto flotante (permitiendo cinco caracteres en total, con dos decimales) y a una cadena. Aviso de los saltos de línea (\n) incluidos en la cadena, cada uno mueve la salida a la línea siguiente.
Usted tiene muchas maneras de leer la entrada en su programa. Probablemente el más tradicional es el uso de la rutina gets, que devuelve la siguiente línea desde el flujo de entrada estándar de su programa .
line = gets print line
Ruby escapa a su pasado
En los viejos tiempos Ruby tomó prestado mucho del lenguaje Perl. Una de estas características es una cierta “magia” cuando se trata de variables globales, y probablemente en las no globales más ma-gia con $_. Por ejemplo, el método gets tiene un efecto secundario: así como regresa la línea que aca-ba de leer, también la almacena en $_. Si llama a print sin ningún argumento, se imprime el contenido de $_. Si usted escribe un if o un while con sólo una expresión regular como condición, ésta expresión se compara con $_. Como resultado de toda esta magia, se podría escribir el siguiente programa para buscar todas las líneas de un archivo que contengan el texto Ruby.
while gets if /Ruby/ print end end
Sin embargo, este estilo de programación de Ruby está cayendo rápidamente en desuso con los puristas. Como uno de esos puristas pasa a ser Matz, nos vamos a encontrar ahora advertencias de Ruby para muchos de estos usos especiales: esperamos que estas desaparezcan en un futuro.
Esto no significa que usted tienga que escribir programas más detallados. El “vía Ruby” para escribir esto sería el uso de un iterador y el objeto ARGF predefinido, que representa los archivos de entrada del programa.
ARGF.each {|line| print line if line =~ /Ruby/ }

8
Adelante y hacia arriba
Esto es todo. Hemos terminado nuestro veloz recorrido por algunos de los rasgos básicos de Ruby. Hemos echado un vistazo a los objetos, métodos, cadenas, contenedores y expresiones regulares. Hemos visto algunas estructuras de control simple y algunos iteradores ingeniosos. Esperamos que este capítulo le haya dado munición suficiente como para ser capaz de atacar el resto de este libro.
Ahora toca seguir adelante a un nivel superior. A continuación, vamos ver las clases y objetos, que son al mismo tiempo tanto las construcciones de más alto nivel en Ruby como los fundamentos esenciales de la lengua entera.
Clases, Objetos y Variables
De los ejemplos que hemos mostrado hasta ahora, puede que se pregunte acerca de nuestra afirma-ción anterior de que Ruby es un lenguaje orientado a objetos. Bueno, este capítulo es en donde se justifica esta afirmación. Vamos a ver cómo crear clases y objetos en Ruby, y algunas de las formas en que Ruby es más poderoso que la mayoría de los lenguajes orientados a objetos.
Después de meses de trabajo, nuestra muy bien pagada gente de investigación y desarrollo ha deter-minado que necesitamos un jukebox de canciones. Entonces, nos parece una buena idea empezar por la creación de una clase Ruby que represente las cosas que son canciones. Sabemos que una canción de verdad tiene un nombre, un artista y una duración, por lo que querrá asegurarse de que los objetos can-ción en nuestro programa también.
Vamos a empezar por la creación de la clase básica Song, que contiene sólo un único método, initialize (como mencionamos anteriormente, los nombres de clases comienzan con una letra mayúscula, y normal-mente, los nombres de método comienzan con una letra minúscula).
class Song def initialize(name, artist, duration) @name = name @artist = artist @duration = duration end end
initialize es un método especial en los programas Ruby. Cuando usted llama a Song.new para crear un nuevo objeto canción, Ruby reserva algo de memoria para contener un objeto no inicializado y luego llama al método initialize de ese objeto, pasandole todos los parámetros que se le pasan a los nue-vos. Esto le da la oportunidad de escribir código que configura el estado de su objeto.
Para la clase Song, el método initialize toma tres parámetros. Estos parámetros actúan como variables locales dentro del método, por lo que siguen la convención de nombres de variable local que empiezan con una letra minúscula.
Cada objeto representa su propia canción, así que necesitamos cada uno de los objetos canción lle-vando su propio nombre, el artista y su duración. Esto significa que tenemos que almacenar estos valores como variables de instancia dentro del objeto. Las variables de instancia son accesibles a todos los méto-dos en un objeto y cada objeto tiene su propia copia de sus variables de instancia.
Y se puede escribir mucho más concisamente:
print ARGF.grep(/Ruby/)
En general hay un alejamiento de algunos de los Perlismos en la comunidad Ruby. Si ejecuta sus programas con la opción -w para habilitar las advertencias se encontrará en el intérprete de Ruby cap-turas de la mayoría de ellas.

9
En Ruby, una variable de instancia es simplemente un nombre precedido de una “arroba” (@). En nues-tro ejemplo, el parámetro name se asigna a la variable de instancia @name, artist se asigna a @artist, y duration (la duración de la canción en segundos) se asigna a @duration.
Vamos a probar nuestra nueva clase:
song = Song.new(“Bicylops”, “Fleck”, 260) song.inspect → #<Song:0x1c7ca8 @name=”Bicylops”, @duration=260, @artist=”Fleck”>
Bueno, parece que funciona. De manera predeterminada, el mensaje inspect, que puede ser enviado a cualquier objeto, formatea el ID de objeto y las variables de instancia. Parece que lo hemos configurado correctamente.
Nuestra experiencia nos dice que durante el desarrollo vamos a imprimir el contenido de un objeto Song muchas veces, e inspeccionar el formato por defecto deja mucho que desear. Afortunadamente, Ruby tiene un mensaje estándar, to_s, que envía a cualquier objeto que quiere reporducirlo como una cadena. Vamos a intentarlo en nuestra canción.
song = Song.new(“Bicylops”, “Fleck”, 260)song.to_s -> “#<Song:0x1c7ec4>”
Que no es demasiado útil -- y que acaba de informar del ID de objeto. Por lo tanto, vamos a redefinir to_s en nuestra clase. Al hacer esto, también debemos tomar un momento para hablar de cómo estamos mostrando las definiciones de clase en este libro.
En Ruby, las clases no están cerradas: siempre se pueden añadir métodos a una clase existente. Esto se aplica a las clases que escriba, así como a las clases estándar y las clases built-in. Sólo tiene que abrir una definición de clase de una clase existente, y los nuevos contenidos que especifique se agregarán a lo que hay.
Esto es ideal para nuestros propósitos. A medida que avancemos a través de este capítulo, añadiremos características a las clases y mostraremos sólo las definiciones de clase para los nuevos métodos; los viejos todavía estarán ahí. Esto nos ahorra tener que repetir cosas redundantes en cada ejemplo. Obvia-mente, sin embargo, si usted comenzara la creación de este código desde cero, probablemente incluiriía todos los métodos en una definición de clase.
Volvamos a la adición del método to_s a nuestra clase Song. Vamos a utilizar el carácter # en la cadena para interpolar el valor de las tres variables de instancia.
class Song def to_s “Song: #@name--#@artist (#@duration)” endendsong = Song.new(“Bicylops”, “Fleck”, 260)song.to_s -> “Song: Bicylops--Fleck (260)”
Excelente, estamos haciendo progresos. Sin embargo, hemos puesto algo sutil en el mix. Hemos dicho que Ruby soporta to_s para todos los objetos, pero no dijimos cómo. La respuesta tiene que ver con la he-rencia, subclases y cómo Ruby determina qué método ejecutar cuando se envía un mensaje a un objeto. Este es un tema para una nueva sección, por lo que ...
Herencia y Mensajes
La herencia permite crear una clase que es un refinamiento o especialización de otra clase. Por ejem-plo, nuestra máquina de discos tiene el concepto de las canciones, que se encapsulan en la clase Song. Luego, el de marketing viene y nos dice que tenemos que apoyar karaoke. Una canción de karaoke es como cualquier otra (no tiene una pista de voz, pero eso no nos interesa). Sin embargo, también tiene

10
asociado una letra de canción, junto con information de sincronización.Cuando nuestro jukebox toque una canción de karaoke, las letra debe fluir a través de la pantalla en la parte frontal de la máquina de discos, sincronizada con la música.
Una aproximación a este problema consiste en definir una nueva clase, KaraokeSong, que es como Song, pero con una pista con la letra (lyrics).
class KaraokeSong < Song def initialize(name, artist, duration, lyrics) super(name, artist, duration) @lyrics = lyrics endend
El “< Song” en la línea de definición de la clase le dice a Ruby que KaraokeSong es una subclase de Song. (No es de extrañar, esto significa que Song es una superclase de KaraokeSong La gente también habla de relaciones padre-hijo, por lo el padre de KaraokeSong sería Song...) Por el momento, no se preocupe demasiado por el método initialize, vamos a hablar sobre la llamada super más adelante.
Vamos a crear KaraokeSong y comprobar nuestro código de trabajo. (En el sistema final, lyrics se llevará a cabo en un objeto que incluye el texto y la información de sincronización). Para probar nuestra clase, sin embargo, sólo tendremos que utilizar una cadena. Este es otro beneficio de los lenguajes de tipo dinámico --no tiene que definir todo antes de empezar la ejecución de código.
song = KaraokeSong.new(“My Way”, “Sinatra”, 225, “And now, the...”)song.to_s -> “Song: My WaySinatra (225)”
Bueno, se ejecutó. Pero ¿por qué el método to_s muestra la letra?
La respuesta tiene que ver con la forma con la que Ruby determina a qué método se debe llamar cuando se envía un mensaje a un objeto. Durante el análisis inicial del código fuente del programa, cuan-do Ruby se encuentra con la invocación de método song.to_s, en realidad no sabe dónde encontrar el método to_s. En cambio, difiere la decisión hasta que se ejecute el programa. En ese momento, le aparece en la clase Song. Si esa clase implementa un método con el mismo nombre que el mensaje, el método se ejecuta. De lo contrario, Ruby busca un método en la clase principal, y luego en la clase abuelo, y así sucesivamente toda la cadena de los ancestros. Si se queda sin padres sin encontrar el método adecuado, se necesita una acción especial que normalmente resulta en un error (de hecho puede interceptar este error, que le permite engañar a los métodos en tiempo de ejecución. Esto se describe en Object#method_missing).
Volviendo a nuestro ejemplo. Enviamos el mensaje to_s a la canción, un objeto de la clase Karaoke-Son. Ruby ve en KaraokeSong un método llamado to_s pero no lo halla. El intérprete entonces busca en la clase padre Song, y allí se encuentra el método to_s que habiamos definido anteriormente. Es por eso que imprime los detalles de la canción pero no la letra --la clase Song no sabe nada de letras.
Vamos a solucionar este problema mediante la implementación de KaraokeSong#to_s. Hay varias ma-neras de hacer esto y vamos a empezar con una mala. Vamos a copiar el método to_s de Song y a añadirlo en la letra.
class KaraokeSong # ... def to_s “KS: #@name--#@artist (#@duration) [#@lyrics]” endendsong = KaraokeSong.new(“My Way”, “Sinatra”, 225, “And now, the...”)song.to_s → “KS: My Way--Sinatra (225) [And now, the...]”
Para mostrar correctamente el valor de la variable de instancia @lyrics, la subclase accede direc-tamente a las variables de instancia de sus ancestros. ¿Por qué esta es una mala manera de poner en

11
práctica to_s?
La respuesta tiene que ver con el buen estilo de programación (y algo llamado disociación). Al hurgar dentro de la estructura interna de las clases padres y examinado explícitamente sus variables de instan-cia, nos estamos atando fuertemente a su implementación. Digamos que se decidió cambiar Song para almacenar la duración en milisegundos. Inesperadamente, KaraokeSong empieza a presentar valores ridí-culos. La idea de una versión karaoke “My Way”, que tiene una duración de 3.750 minutos es demasiado amdrentadora para considerarla.
¿Cómo evitar este problema haciendo que cada clase maneje sus propios detalles de implementación? Cuando se llame a KaraokeSong#to_s, vamos a tener que llamar al método to_s de sus ancestros para obtener los detalles de la canción. A continuación, añadirlos a la información de la letra y retornar el resultado. El truco aquí es la palabra clave Ruby super. Cuando se invoca sin argumentos, Ruby envía un mensaje a los padres del objeto en curso, pidiendo que se invoque un método del mismo nombre que el método de invocación de super. Pasa a este método los parámetros que se pasan al método invocado originalmente. Ahora podemos implementar nuestra to_s nueva y mejorada.
class KaraokeSong < Song # Formato por nosotros mismos como una cadena por adición # Nuestras letras con el valor #to_s de nuestros padres. def to_s super + “ [#@lyrics]” endendsong = KaraokeSong.new(“My Way”, “Sinatra”, 225, “And now, the...”)song.to_s → “Song: My Way--Sinatra (225) [And now, the...]”
Ruby nos dice explícitamente que KaraokeSong es una subclase de Song, pero sin especificar una clase padre para Song misma. Si no se especifica un padre en la definición de una clase, Ruby suministra una clase Objeto por defecto. Esto significa que todos los objetos tienen Objeto, como un ancestro y los métodos de instancia de la clase Objeto están disponibles para todos los objetos de Ruby. Atrás mencio-namos que to_s está disponible para todos los objetos. Ahora sabemos por qué: to_s es uno de los más de 35 métodos de instancia en la clase Object. La lista completa se verá más adelante.
Hasta aquí hemos estado viendo las clases y sus métodos. Ahora es el momento de pasar a los obje-tos, como las instancias de la clase Song.
Objetos y Atributos
Los objetos Song que hemos creado hasta ahora tienen un estado interno (como el título de la canción y el artista). Este estado es privado para los objetos --otro no objeto puede acceder a las variables de instancia de un objeto. En general, esta es bueno. Esto significa que el objeto es el único responsable de mantener su propia consistencia.
Sin embargo, un objeto que es totalmente secreto es bastante inútil. Se puede crear, pero no se puede hacer nada con el. Normalmente se van a definir los métodos que le permiten acceder y manipular el es-tado de un objeto, permitiendo al mundo exterior interactuar con el objeto. Estas facetas visibles desde el exterior de un objeto se denominan atributos.
Para nuestros objetos Song, la primera cosa que puede necesitar, es la capacidad de encontrar el título y el artista (que es lo que podemos mostrar mientras la canción está sonando) y la duración (por lo que se puede mostrar algún tipo de barra de progreso).
Herencia y Mixins
Algunos lenguajes orientados a objetos (tales como C++) admiten la herencia múltiple, donde una clase puede tener más de un pariente inmediato, heredando la funcionalidad de cada uno. Aunque
poderosa, esta técnica puede ser peligrosa, ya que la jerarquía de herencia puede ser ambigua.

12
class Song def name @name end def artist @artist end def duration @duration endendsong = Song.new(“Bicylops”, “Fleck”, 260)song.artist -> “Fleck”song.name -> “Bicylops”song.duration -> 260
Aquí hemos definido tres métodos de acceso para devolver los valores de las tres variables de instan-cia. El método name(), por ejemplo, devuelve el valor de la variable de instancia @name. Debido a que esto es un idioma común, Ruby proporciona un atajo conveniente: attr_reader crea estos métodos de acceso para usted.
class Song attr_reader :name, :artist, :durationendsong = Song.new(“Bicylops”, “Fleck”, 260)song.artist -> “Fleck”song.name -> “Bicylops”song.duration -> 260
En este ejemplo se ha introducido algo nuevo. La construcción :artist es una expresión que devuel-ve un objeto Symbol correspondiente a artist. Se puede imaginar :artist en el sentido del nombre de la variable artist, y artist llano en el sentido del valor de la variable. En este ejemplo, hemos llamado a los métodos de acceso name, artist y duration. Las variables de instancia correspondientes, @name, @artist y @duration se crearán automáticamente. Estos métodos de acceso son idénticos a los escritos antes a mano.
Atributos de Escritura
A veces es necesario ser capaz de establecer un atributo desde fuera del objeto. Por ejemplo, supon-gamos que la duración que inicialmente se asocia con una canción es una estimación (tal vez se obtuvo a partir de la información de un CD o en los datos de MP3). La primera vez que ponemos el tema, llegamos a saber el tiempo que realmente tiene y queremos guardar este nuevo valor en el objeto Song.
En lenguajes como C++ y Java, se haría esto con las funciones setter (de ajuste).
Otros lenguajes, como Java y C#, admiten la herencia única. Aquí, una clase sólo puede tener un pariente inmediato. Aunque más limpia (y más fácil de implementar), la herencia simple también tiene
inconvenientes ya que los objetos del mundo real suelen heredar los atributos de múltiples fuentes (una pelota es a la vez una cosa que rebota y una cosa esférica, por ejemplo).
Rubí ofrece un compromiso interesante y potente, que le dá la sencillez de la herencia simple y la potencia de la herencia múltiple. La clase Ruby tiene solo un padre directo, así que Ruby es un lenguaje de herencia simple. Sin embargo, las clases Ruby pueden incluir la funcionalidad de cualquier número de mixins (un mixin es como una definición de clase parcial). Esto proporciona la capacidad de un con-trol como de herencia múltiple pero con ninguno de sus inconvenientes. Vamos a ver sobre los mixins
más adelante.

13
class JavaSong { // código Java private Duration _duration; public void setDuration(Duration newDuration) { _duration = newDuration; }}s = new Song(....);s.setDuration(length);
En Ruby, los atributos de un objeto se pueden acceder como si se tratara de cualquier otra variable. Hemos visto esto anteriormente con frases como song.name. Por lo tanto, parece natural que se pueda asignar a estas variables cuando se quiere establecer el valor de un atributo. En Ruby esto se hace me-diante la creación de un método cuyo nombre termina con un signo igual. Estos métodos se pueden utilizar como destino de las asignaciones.
class Song def duration=(new_duration) @duration = new_duration endendsong = Song.new(“Bicylops”, “Fleck”, 260)song.duration -> 260song.duration = 257 # ajuste de atributo con el valor actualizadosong.duration -> 257
La asignación song.duration = 257 invoca al método duration= en el objeto song, pasandole 257 como argumento. De hecho, la definición de un nombre de método que termina en un signo igual hace que el nombre pueda aparecer en el lado izquierdo de una asignación.
Una vez más, Ruby proporciona un acceso directo para la creación de estos sencillos métodos de ajus-te de atributo.
class Song attr_writer :durationendsong = Song.new(“Bicylops”, “Fleck”, 260)song.duration = 257
Atributos virtuales
Estos métodos de acceso a atributos no tienen que ser simples envoltorios alrededor de las variables de instancia de un objeto. Por ejemplo, es posible que desee acceder a la duración en minutos y fraccio-nes de un minuto, en lugar de en segundos tal como lo hemos estado haciendo.
class Song def duration_in_minutes @duration/60.0 # forzar punto flotante end def duration_in_minutes=(new_duration) @duration = (new_duration*60).to_i endendsong = Song.new(“Bicylops”, “Fleck”, 260)song.duration_in_minutes -> 4.33333333333333song.duration_in_minutes = 4.2song.duration -> 252
Aquí hemos utilizado métodos de atributos para crear una variable de instancia virtual. Para el mundo exterior, duration_in_minutes parece ser un atributo como cualquier otro. Internamente, sin embargo, no tiene ninguna variable de instancia correspondiente.

14
Esto es más que una curiosidad. En su libro de referencia en Construcción de Software Orientado a Objetos [Mey97], Bertrand Meyer llama a esto el Principio de Acceso Uniforme. Al ocultar la diferencia entre las variables de instancia y los valores calculados, se blinda al resto del mundo a partir de la imple-mentación de su clase. Usted es libre de cambiar cómo funcionaran las cosas en el futuro sin afectar a los millones de líneas de código que pueda utilizar la clase. Esto es un gran acierto.
Atributos, Variables de Instancia y Métodos
Esta descripción de los atributos puede hacer pensar que no son nada más que métodos, ¿por qué tenemos que inventar un nombre aparte para ellos? En cierto modo, eso es absolutamente correcto. Un atributo es sólo un método. A veces un atributo simplemente devuelve el valor de una variable de instan-cia. A veces un atributo devuelve el resultado de un cálculo. Y a veces los cobardes métodos con signos de igualdad al final de sus nombres se utilizan para actualizar el estado de un objeto. Entonces la pregunta es, ¿dónde terminan los atributos y donde comienzan los métodos regulares? ¿Qué hace que algo sea un atributo y no sólo un método simple y llano? En última instancia, que es una de esas preguntas sin respuesta clara. Aquí hay una cuestión personal.
Al diseñar una clase, usted decide qué estado interno tiene y también decide cómo ese estado va a aparecer al exterior (para los usuarios de la clase). El estado interno se lleva a cabo en las variables de instancia. El estado externo está expuesto a través de métodos que llamamos atributos. Y las demás acciones que su clase puede realizar son métodos comunes y corrientes. Realmente no es una distinción sumamente importante, pero el llamar al estado externo de un objeto como sus atributos, está ayudando a dar a la gente una pista de cómo deben ver la clase que ha escrito.
Variables de Clase y Métodos de Clase
Hasta ahora, todas las clases que hemos creado contienen variables de instancia y métodos de instan-cia: las variables se asocian a una instancia particular de la clase, y los métodos que trabajan con estas variables. A veces las clases necesitan tener sus propios estados. Aquí es donde las variables de clase tienen lugar.
Variables de clase
Una variable de clase es compartida entre todos los objetos de una clase y es accesible también a los métodos de clase que vamos a describir después. Sólo existe una copia de una variable de clase particu-lar en una clase determinada. Los nombres de variables de clase comienzan con dos “arrobas”, tal como @@contador . A diferencia de las variables globales y de instancia, las variables de clase debe ser inicia-lizadas antes de ser utilizadas. A menudo, esta inicialización es una simple asignación en el cuerpo de la definición de clase.
Por ejemplo, si usted quiere, nuestro jukebox puede registrar cuántas veces se ha puesto cada can-ción. Este contador sería probablemente una variable de instancia del objeto Song. Cuando se reproduce una canción el valor en la instancia se incrementa. Pero dice que también quiere saber cuántas canciones se han jugado en total. Podemos hacer esto mediante la búsqueda de todos los objetos Song y la suma de sus contadores, o que podría correr el riesgo de excomunión de la Iglesia del Buen Diseño y hacer uso de una variable global. En su lugar, vamos a utilizar una variable de clase.
class Song @@plays = 0 def initialize(name, artist, duration) @name = name @artist = artist @duration = duration @plays = 0 end def play @plays += 1 # lo mismo que @plays = @plays + 1 @@plays += 1

15
“This song: #@plays plays. Total #@@plays plays.” endend
Para la depuración, hemos arreglado Song#play para retornar una cadena que contiene el número de veces que se ha puesto esa canción junto con el número total para todas las canciones. Esto se puede comprobar fácilmente.s1 = Song.new(“Song1”, “Artist1”, 234) # test songs..s2 = Song.new(“Song2”, “Artist2”, 345)s1.play ! “This song: 1 plays. Total 1 plays.”s2.play ! “This song: 1 plays. Total 2 plays.”s1.play ! “This song: 2 plays. Total 3 plays.”s1.play ! “This song: 3 plays. Total 4 plays.”
Las variables de clase son privadas de una clase y sus instancias. Si desea que sean accesibles al mundo exterior, tendrá que escribir un método de acceso. Este método podría ser un método de instancia o, lo que nos lleva a la siguiente sección, un método de clase.
Métodos de clase
A veces una clase debe proporcionar métodos que funcionen sin estar atados a ningún objeto en parti-cular. Ya nos hemos encontrado con uno de esos métodos. El método new crea un objeto Song new, pero no se asocia con una canción en particular.
song = Song.new(....)
Encontrará métodos de clase dispersos a lo largo de las bibliotecas Ruby. Por ejemplo, los objetos de la clase File representan archivos abiertos en el sistema de archivos subyacente. Sin embargo, la clase File también ofrece varios métodos de clase para la manipulación de los archivos que no están abiertos y por lo tanto no tienen un objeto File. Si se quiere eliminar un archivo, se llama al método de clase File.Delete pasandole el nombre.
File.delete(“doomed.txt”)
Los métodos de clase se distinguen de los métodos de instancia por su propia definición. Los métodos de clase se definen mediante la colocación del nombre de clase y un punto delante del nombre del método.
class Example def instance_method # método de instancia end def Example.class_method # método de clase endend
¿El jukebox cobra por cada canción reproducida? no, por el momento. Esto haría las canciones cortas más rentables que las largas. Es posible que desee evitar que las canciones que se hayan puesto mucho estén disponibles en la lista de canciones. Podríamos definir un método de clase en SongList que com-pruebe si una canción en particular ha superado el límite. Vamos a establecer este límite mediante una constante de clase, que es simplemente una constante (¿recuerda las constantes? Comienzan con una letra mayúscula) que es inicializada en el cuerpo de la clase.
class SongList MAX_TIME = 5*60 # 5 minutos
def SongList.is_too_long(song) return song.duration > MAX_TIME endendsong1 = Song.new(“Bicylops”, “Fleck”, 260)SongList.is_too_long(song1) -> false

16
song2 = Song.new(“The Calling”, “Santana”, 468)SongList.is_too_long(song2) -> true
Singletons y Otros Constructores
A veces se desea reemplazar el modo por defecto en el que Ruby crea objetos. Como ejemplo, eche-mos un vistazo a nuestra máquina de discos. Como vamos a tener muchas máquinas de discos, repartidas por todo el país, queremos hacer el mantenimiento lo más fácil posible. Una parte que se requiere es re-gistrar todo lo que sucede en la máquina jukebox: las canciones reproducidas, el dinero recibido, los flui-dos extraños vertidos en ella y así sucesivamente. Como queremos el ancho de banda de red reservado para la música, vamos a almacenar los archivos de registro a nivel local. Sin embargo, queremos un sólo objeto de registro por jukebox, y queremos que sea un objeto compartido entre los demás objetos para que lo utilicen.
Aquí entra el patrón Singleton, documentado en Design Patterns [GHJV95]. Vamos a organizar las co-sas para que la única manera de crear un registro sea por la llamada a MyLogger.create, y nos vamos a asegurar que se crea un sólo objeto registro.
class MyLogger private_class_method :new @@logger = nil def MyLogger.create @@logger = new unless @@logger @@logger endend Al hacer nuevo método privado MyLogger, evitamos que nadie pueda crear un objeto de registro con el constructor convencional. En su lugar, proporcionamos un método de clase, MyLogger.create. Este método utiliza la variable de clase @@logger, para mantener una referencia a una sola instancia del re-gistro retornando la instancia cada vez que se le llama. Podemos comprobar esto mirando a los identifica-dores de objeto que retorna el método.
MyLogger.create.id -> 936550MyLogger.create.id -> 936550
(La implemetación de singletons que aquí presentamos no es segura para subprocesos. Si están corrien-do varios hilos, sería posible crear varios objetos del registrador. En lugar de añadir nosotros mismos la seguridad de hilo, probablemente usaríamos el mixin Singleton que se suministra con Ruby y que ve-remos más adelante).
Definiciones de Metodo de Clase
Anteriormente hablamos sobre que los métodos de clase se definen colocando el nombre de clase y un punto delante del nombre del método. En realidad esto es una simplificación (un objetivo de trabajo siempre).
De hecho, usted puede definir los métodos de clase de varias formas. Para una comprensión objetiva de esas formas de trabajo tendrá que esperar hasta más adelante, por lo menos hasta el capítulo Cla-ses y Objetos. Por ahora, sólo vamos a mostrar las expresiones que usa la gente, para el caso de que las encuentre en código Ruby.
Lo siguiente define los metodos de clase en la clase Demo:
class Demo def Demo.meth1 # ... end

17
Utilizar métodos de clase como pseudo-constructores también puede hacer la vida más fácil a los usuarios de su clase. Como un ejemplo trivial, vamos a ver una clase Shape que representa un polígono regular. Instancias de Shape son creadas por el constructor dando el número de lados y el perímetro total.
class Shape def initialize(num_sides, perimeter) # ... endend
Sin embargo, un par de años más tarde, esta clase se utiliza en una aplicación diferente, donde los programadores la utilizan para crear formas por su nombre y especificando la longitud de un lado, no el perímetro. Basta con añadir algunos métodos de clase a Shape.
class Shape def Shape.triangle(side_length) Shape.new(3, side_length*3) end def Shape.square(side_length) Shape.new(4, side_length*4) endend
Los métodos de clase tienen muchos usos interesantes y de gran alcance, pero la explorar todos ellos haría que terminasemos nuestro jukebox muy tarde, así que vamos a seguir adelante.
Control de Acceso
En el diseño de una interfaz de clase, es importante tener en cuenta hasta qué punto el acceso a su clase se expone al mundo exterior. Permitiendo demasiado el acceso en su clase, corre el riesgo de au-mentar el acoplamiento en la aplicación. Los usuarios se verán tentados a confiar en los detalles de la implementación de su clase, en lugar de en su interfaz lógica. La buena noticia es que la única manera fácil de cambiar el estado de un objeto en Ruby es llamando a uno de sus métodos. Controlar el acceso a los métodos es controlar el acceso al objeto. Una buena regla general es no exponer los métodos que podrían dejar al objeto en un estado no válido. Ruby le ofrece tres niveles de protección.
•Losmétodos públicos pueden ser llamados por cualquiera --no se aplica control de acceso. Los métodos son públicos por defecto (excepto initialize, que es privado). •Losmétodos protegidos sólo pueden ser invocado por los objetos de la clase que define y sus sub-clases. El acceso se mantiene dentro de la familia.
•Losmétodos privados no pueden ser llamados con un receptor explícito --el explícito es siempre uno mismo. Esto significa que a los métodos privados sólo se les puede llamar en el contexto del objeto actual, no se puede invocar métodos privados de otro objeto.
La diferencia entre “protegido” y “privado” es bastante sutil y es diferente en Ruby que en la mayoría de los lenguajes OO comunes. Si un método está protegido, puede ser llamado por cualquier instancia de
def self.meth2 # ... end class <<self def meth3 # ... end endend

18
la clase que define o sus subclases. Si un método es privado, sólo puede ser llamado dentro del contexto de la llamada al objeto --nunca es posible tener acceso a métodos privados de otro objeto directamente, incluso si el objeto es de la misma clase que el llamador.
Ruby se diferencia de otros lenguajes OO en otra cosa importante. El control de acceso se determina de forma dinámica, cuando el programa se ejecuta, no estáticamente. Usted recibirá una violación de ac-ceso sólo cuando el código intenta ejecutar un método restringido.
Especificación de Control de Acceso
Se puede especificar los niveles de acceso a los métodos dentro de las definiciones de clase o módulo utilizando una o más de las tres funciones public, protected y private. Puede utilizar las funciones de dos maneras diferentes.
Si se utilizan sin argumentos, las tres funciones establecen el control de acceso por defecto de los métodos definidos posteriormente. Esta es, probablemente el comportamiento familiar si usted es un pro-gramador de C++ o Java, donde se utilizan palabras clave como public para lograr el mismo efecto.
class MyClass def method1 # por defecto ‘public’ #... end protected # métodos posteriores serán ‘protected’ def method2 # será ‘protected’ #... end private # métodos posteriores serán ‘private’ def method3 # será ‘private’ #... end public # métodos posteriores serán ‘public’ def method4 # y esto será ‘public’ #... endend
Como alternativa, puede establecer niveles de acceso a los métodos llamados mediante su inclusión como argumentos a las funciones de control de acceso.
class MyClass def method1 end # ... etc public :method1, :method4 protected :method2 private :method3end
Vamos a ver algún ejemplo. Tal vez estemos haciendo un sistema de contabilidad en el que cada débito tiene el correspondiente crédito. Cómo queremos asegurarnos de que nadie pueda romper esta regla, va-mos a hacer privados los métodos que hacen los débitos y los créditos y vamos a definir nuestra interfaz externa en términos de transacciones.
class Accounts def initialize(checking, savings) @checking = checking @savings = savings end private def debit(account, amount)

19
account.balance -= amount end def credit(account, amount) account.balance += amount end public #... def transfer_to_savings(amount) debit(@checking, amount) credit(@savings, amount) end #...end
El acceso protegido se utiliza cuando los objetos necesitan acceder al estado interno de otros objetos de la misma clase. Por ejemplo, puede querer permitir a los objetos individuales Account comparar los saldos, pero puede que desee ocultar los saldos al resto del mundo (tal vez porque los presentemos de una forma diferente).
class Account attr_reader :balance # acceso al método ‘balance’ protected :balance # y que sea protegido def greater_balance_than(other) return @balance > other.balance endend
Debido a que el atributo balance está protegido, sólo está disponible dentro de los objetos Account.
Variables
Ahora que nos hemos tomado la molestia de crear todos estos objetos, vamos a asegurarnos de que no se pierdan. Las variables se utilizan para realizar un seguimiento de los objetos; cada variable tiene una referencia a un objeto.
Vamos a confirmar esto con algo de código.
person = “Tim”person.id -> 936870person.class -> Stringperson -> “Tim”
En la primera línea, Ruby crea un nuevo objeto String con el valor “Tim”. Una referencia a este objeto se coloca en la variable local person. Una revisión rápida muestra que la variable ha seguido de hecho la personalidad de una cadena con un identificador de objeto, una clase y un valor.
Por lo tanto, ¿es una variable de un objeto? En Ruby, la respuesta es “no”. Una variable es simplemen-te una referencia a un objeto. Los objetos flotan en un gran estanque en algún lugar (el montón, la mayoría de las veces) y son señalados por variables.
Vamos a hacer el ejemplo un poco más complicado.
person1 = “Tim”person2 = person1
person1[0] = ‘J’
person1 -> “Jim”person2 -> “Jim”

20
¿Qué ha pasado aquí? Hemos cambiado el primer carácter de person1, pero ambos, person1 y person2 han cambiado de “Tim” a “Jim”.
Todo se reduce al hecho de que las variables contienen referencias a objetos, no los objetos mismos. La asignación de person1 a persona2 no crea nuevos objetos, sino que es simplemente una copia de la referencia al objeto person1 en person2, por lo que tanto person1 como person2 se refieren al mismo ob-jeto. Esto se muestra en la Figura 2:
La asignación de alias a objetos, hace posible múltiples variables que hacen referencia al mismo ob-jeto. Pero, ¿puede causar problemas en el código? Puede, pero no tan a menudo como se podría pensar (los objetos en Java, por ejemplo, funcionan exactamente de la misma manera). En el ejemplo de la Figura 2, se puede evitar el aliasing mediante el método dup a String, que crea un nuevo objeto String con idéntico contenido.
person1 = “Tim”person2 = person1.dupperson1[0] = “J”person1 -> “Jim”person2 -> “Tim”
También puede impedir que alguien cambie un objeto en particular por medio de freezing (congelación --se hablará más sobre los objetos freezing más tarde). Al intentar modificar un objeto congelado Ruby provocará una excepción TypeError.
person1 = “Tim”person2 = person1person1.freeze # evitar modificaciones en el objetoperson2[0] = “J”
produce:
prog.rb:4:in `[]=’: can’t modify frozen string (TypeError)from prog.rb:4
Con esto concluye esta mirada a las clases y objetos en Ruby. Este material es importante; todo lo que se manipula en Ruby es un objeto. Y una de las cosas más comunes que hacemos con los objetos es crear colecciones de ellos. Pero ese es el tema de nuestro próximo capítulo.

21
Contenedores, Bloques e Iteradores
Un jukebox con una canción es poco probable que sea popular (excepto quizás en algun bar tétrico), por lo que muy pronto vamos a tener que empezar a pensar en la producción de un catálogo de canciones disponibles y una lista de canciones a la espera de ser reproducidas. Ambos son contenedores: objetos que contienen referencias a uno o más objetos.
Tanto el catálogo como la lista necesitan un conjunto similar de métodos: agregar una canción, elimi-nar una canción, ver una lista de canciones y así sucesivamente. La lista de reproducción puede realizar tareas adicionales, como la inserción de publicidad de vez en cuando o hacer el seguimiento del tiempo de reproducción acumulado, pero vamos a preocuparnos por estas cuestiones más tarde. Mientras tanto, parece una buena idea esarrollar algún tipo de clase genérica SongList, que pueda especializarse en los catálogos y listas de reproducción.
Contenedores
Antes de empezar la implementación, tendremos que encontrar la manera de almacenar la lista de canciones dentro de un objeto SongList. Tenemos tres opciones obvias. Podemos usar el tipo Array de Ruby, utilizar el tipo hash Ruby, o crear nuestra propia estructura lista. Perezosamente, por ahora vamos a ver los arrays y hashes y elegir uno de estos para nuestra clase.
Arrays
La clase Array contiene una colección de referencias a objetos. Cada referencia a un objeto ocupa una posición en la matriz, identificada por un índice de enteros no negativos.
Usted puede crear matrices mediante el uso de literales o explícitamente por la creación de un objeto Array. Una matriz literal es simplemente una lista de objetos entre corchetes.
a = [ 3.14159, “pie”, 99 ]a.class -> Arraya.length -> 3a[0] -> 3.14159a[1] -> “pie”a[2] -> 99a[3] -> nil
b = Array.newb.class -> Arrayb.length -> 0b[0] = “second”b[1] = “array”b -> [“second”, “array”]
Las matrices son indexados usando el operador [ ]. Como con la mayoría de los operadores de Ruby, esto es en realidad un método (un método de instancia de la clase Array) y por lo tanto puede ser anulado en las subclases. Como muestra el ejemplo, los índices de los arrays comienzan con cero. El índice de una matriz con un número entero no negativo, devuelve el objeto en esa posición o devuelve nil si no hay nada. El índice de una matriz con un entero negativo cuenta desde el final.
a = [ 1, 3, 5, 7, 9 ]a[-1] -> 9a[-2] -> 7a[-99] -> nil
Este esquema de indexación se ilustra con más detalle en la Figura 3 en la página siguiente.

22
También puede indexar arrays con un par de números, [ inicio, cuenta ]. Esto devuelve una nueva matriz que consta de referencias para contar objetos a partir de la posición inicio.
a = [ 1, 3, 5, 7, 9 ]a[1, 3] -> [3, 5, 7]a[3, 1] -> [7]a[-3, 2] -> [5, 7]
Por último puede indexar matrices usando rangos, en los que las posiciones de inicio y final están se-parados por dos o tres puntos. El formato de dos puntos incluye la posición final mientras que en el de tres puntos no está incluido el límite final.
a = [ 1, 3, 5, 7, 9 ]a[1..3] -> [3, 5, 7]a[1...3] -> [3, 5]a[3..3] -> [7]a[-3..-1] -> [5, 7, 9]
El operador [ ] tiene su correspondiente operador [ ]= operador, que permite establecer elementos de la matriz. Si se utiliza con un índice de tipo entero, el elemento en esa posición se sustituye por lo que está en el lado derecho de la asignación. Las lagunas que dan lugar se llena de nada. Cualquier vacío que resulte se rellena con nil.
a = [ 1, 3, 5, 7, 9 ] -> [1, 3, 5, 7, 9]a[1] = ’bat’ -> [1, “bat”, 5, 7, 9]a[3] = ’cat’ -> [1, “bat”, “cat”, 7, 9]a[3] = [ 9, 8 ] -> [1, “bat”, “cat”, [9, 8], 9]a[6] = 99 -> [1, “bat”, “cat”, [9, 8], 9, nil, 99]
Si el índice en [ ] = es de dos números (un comienzo y una longitud) o un rango, entonces los elemen-tos de la matriz original se sustituyen por lo que está en el lado derecho de la asignación. Si la longitud es cero, el lado derecho de la asignación se inserta en la matriz antes de la posición, no se eliminan los elementos. Si el lado derecho es en si una matriz, sus elementos se utilizan en la sustitución. El tamaño de la matriz se ajusta automáticamente si el índice selecciona un número diferente de elementos que se encuentran en el lado derecho de la asignación.
a = [ 1, 3, 5, 7, 9 ] -> [1, 3, 5, 7, 9]a[2, 2] = ’cat’ -> [1, 3, “cat”, 9]a[2, 0] = ’dog’ -> [1, 3, “dog”, “cat”, 9]a[1, 1] = [ 9, 8, 7 ] -> [1, 9, 8, 7, “dog”, “cat”, 9]a[0..3] = [] -> [“dog”, “cat”, 9]a[5..6] = 99, 98 -> [“dog”, “cat”, 9, nil, nil, 99, 98]
Las matrices tienen un gran número de métodos útiles. Usándolas, usted puede tratar las matrices

23
como pilas, conjuntos, colas, o FiFOs. Una lista completa de los métodos de array se verá más adelante en su correspondiente documentación.
Hashes
Los hashes (conocidos a veces como arrays asociativos, mapas o diccionarios) son similares a las matrices en que también se indexan las colecciones de referencias de objetos. Sin embargo, mientras que las matrices se indexan con números enteros, puede indexar un hash con objetos de cualquier tipo: cadenas, expresiones regulares, etc. Cuando se almacena un valor en un hash, en realidad se suministran dos objetos, el índice, normalmente se llamado key, y el valor. Posteriormente se puede recuperar el valor de la indexación de los hash con la clave misma. Los valores de un hash pueden ser objetos de cualquier tipo.
El ejemplo que sigue utiliza literales hash: una lista de pares clave => valor entre llaves.
h = { ‘dog’ => ‘canine’, ‘cat’ => ‘feline’, ‘donkey’ => ‘asinine’ }
h.length -> 3h[‘dog’] -> “canine”h[‘cow’] = ‘bovine’h[12] = ‘dodecine’h[‘cat’] = 99h -> {“cow”=>”bovine”, “cat”=>99, 12=>”dodecine”, “donkey”=>”asinine”, “dog”=>”canine”}
En comparación con los arrays, los hashes tienen una ventaja significativa: pueden usar cualquier ob-jecto como un índice. Sin embargo, también tienen una importante desventaja: sus elementos no están ordenados, por lo que no puede utilizar un hash como una pila o una cola.
Encontrará que los hashes son una de las estructuras más comunes de datos en Ruby. Una lista com-pleta de los métodos implementados por la clase Hash, más adelante en su correspondiente sección de clase.
Implementación del contenedor SongList
Después de una pequeña desviación en los arrays y hashes, ahora estamos listos para implementar la lista de canciones del jukebox. Vamos a inventar una lista de métodos que necesitaremos en nuestra SongList. Empezaremos con lo básico y a medida que avancemos iremos añadiendo más.
append(song) -> list Añadir una canción dada a la lista.
delete_first() -> song Quitar la primera canción de la lista, retornando esa canción.
delete_last() -> song Quitar la última canción de la lista, devolviendo esa canción.
[index] -> song Traer la canción del entero index.
with_title(title) -> song Traer la canción con el título dado.
Esta lista nos da una pista de la implementación. La capacidad de añadir canciones al final, y eliminar-las de la parte delantera y final, sugiere un dequeue, una cola de dos extremos, que sabemos que pode-mos poner en práctica usando un Array. Del mismo modo, la capacidad de devolver una canción de una posición de un entero de la lista soportado por las matrices.
Sin embargo, también hay que ser capaz de recuperar canciones por título, lo que puede sugerir el uso

24
de un hash, con el título como clave y la canción como valor. ¿Podríamos utilizar un hash? Bueno, tal vez, pero esto causaría problemas. En primer lugar, un hash no está ordenado, por lo que probablemente ten-dríamos que usar una matriz auxiliar para realizar un seguimiento de la lista. Un segundo problema más grande, es que el hash no es compatible con múltiples claves con el mismo valor. Esto sería un problema para nuestra lista de reproducción, donde puede estar la misma canción en cola para reproducir varias veces. Así que por ahora, nos quedamos con una matriz de canciones, buscando por títulos cuando sea necesario. Si esto se convierte en un cuello de botella para el rendimiento, siempre podemos añadir más tarde algún tipo de hash basado en búsqueda.
Vamos a empezar la clase con un método initialize básico, que va a crear la matriz que se va a utilizar para contener las canciones y almacena una referencia a ella en la variable de instancia @songs.
class SongList def initialize @songs = Array.new endend
El método SongList#append añade la canción en cuestión al final de la matriz @Songs. También re-torna self, una referencia al objeto en curso SongList. Esta es una convención útil, ya que nos permite encadenar varias llamadas a anexar. Vamos a ver un ejemplo de esto más adelante.
class SongList def append(song) @songs.push(song) self endend
Ahora vamos a añadir los métodos delete_first y delete_last, implementados trivialmente utili-zando Array#shift y Array#pop respectivamente.
class SongList def delete_first @songs.shift end def delete_last @songs.pop endend
Hasta ahora, todo bien. Nuestro método siguiente es [ ], que accede a los elementos por su índice. Este tipo de métodos simples por delegación se producen con frecuencia en el código Ruby.
class SongList def [](index) @songs[index] endend
Ahora tenemos que añadir la funcionalidad que nos facilite buscar una canción por el título. Esto va a implicar la exploración de las canciones de la lista, comprobando el título de cada una. Para ello, primero tenemos que pasar por un par de páginas que nos muestre una de las mejores características de Ruby: los iteradores.
Bloques e iteradores
Nuestro siguiente problema con SongList es la aplicación del método with_title que toma una cadena y busca una canción con ese título. Esto parece sencillo: tenemos una lista de canciones, así que vamos a ir de elemento en elemento hasta encontrar el que queremos.

25
class SongList def with_title(title) for i in [email protected] return @songs[i] if title == @songs[i].name end return nil endend
Esto funciona y se ve cómodamente familiar: un bucle for itera sobre una matriz. ¿Qué podría ser más natural?
Resulta que hay algo más natural. En cierto modo, nuestro bucle for es un tanto demasiado íntimo con la matriz; pregunta por una longitud y a continuación recupera los valores sucesivamente, hasta que encuentra una coincidencia. ¿Por qué no pedir simplemente a la matriz aplicar un test a cada uno de sus elementos? Esto es justamente lo que el método find hace en la matriz.
class SongList def with_title(title) @songs.find {|song| title == song.name } endend
El método find es un iterador: un método que invoca a un bloque de código repetidamente. Los itera-dores y los bloques de código son algunas de las características más interesantes de Ruby, así que vamos a pasar un buen rato viéndolos (y en el proceso, vamos a saber exactamente lo que esa línea de código de nuestro método with_title, hace en realidad).
Implementar Iteradores
Un iterador Ruby es simplemente un método que puede invocar a un bloque de código. A primera vista, un bloque en Ruby se ve como un bloque en C, Java, C# o Perl. Pero en este caso, las apariencias enga-ñan. Un bloque en Ruby es una forma de agrupación de declaraciones o sentencias, pero no en la forma convencional.
En primer lugar, un bloque sólo puede aparecer junto a una llamada a un método. El bloque se escribe a partir de la misma línea que el último parámetro de la llamada a método (o paréntesis de cierre de la lista de parámetros). En segundo lugar, el código en el bloque no se ejecuta en el momento en que se encuentra. En su lugar, Ruby recuerda el contexto en el que aparece el bloque (las variables locales, el objeto actual, etc) y luego entra en el método. Aquí es donde comienza la magia.
Dentro del método, un bloque puede ser invocado casi como si se tratara de un método en sí mismo, con la sentencia yield. Cada vez que se ejecuta yield, se invoca al código en el bloque. Cuando el bloque termina, se recoge una copia de seguridad inmediatamente después de yield. Vamos a empezar con un ejemplo trivial.
def three_times yield yield yieldendthree_times { puts “Hola” }
produce:
HolaHolaHola

26
El bloque (el código entre las llaves) se asocia con la llamada al método three_times. Dentro de este método, se llama tres veces a yield. Cada vez, se invoca el código en el bloque y un saludo alegre se imprime. Lo que hace a estos bloques interesante, sin embargo, es que se les puede pasar parámetros y recibir valores de ellos. Por ejemplo, podríamos escribir una simple función que devuelva los miembros de la serie de Fibonacci hasta un cierto valor (La serie de Fibonacci es una secuencia de números enteros, empezando con dos 1, en la que cada término siguiente es la suma de los dos anteriores. La serie se uti-liza a veces en algoritmos de ordenación y en análisis de fenómenos naturales).
def fib_up_to(max) i1, i2 = 1, 1 # asignación paralela (i1 = 1 y i2 = 1) while i1 <= max yield i1 i1, i2 = i2, i1+i2 endendfib_up_to(1000) {|f| print f, “ “ }
produce:
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
En este ejemplo, la sentencia yield tiene un parámetro. Este valor se pasa al bloque asociado. En la definición del bloque, la lista de argumentos aparece entre barras verticales. En este caso, la variable f recibe el valor pasado a yield, por lo que el bloque imprime los sucesivos miembros de la serie (este ejemplo muestra también la asignación paralela que veremos más adelante). Aunque es común pasarle un sólo valor al bloque, esto no es un requisito porque un bloque puede tener cualquier número de argu-mentos.
Si los parámetros de un bloque son las variables locales existentes, estas variables se utilizan como los parámetros del bloque y sus valores pueden ser modificados por la ejecución del bloque. Lo mismo se aplica a las variables dentro del bloque: si aparecen por primera vez en el bloque, son locales para el bloque. Si en cambio, aparecieron por primera vez fuera del bloque, las variables serán compartidas entre el bloque y el entorno (Aunque en ocasiones es extremadamente útil, esta característica puede dar lugar a un comportamiento inesperado y es objeto de acalorados debates en la comunidad Ruby. Es posible que Ruby 2.0 cambie la forma en que los bloques heredan las variables locales).
En este ejemplo (inventado), vemos que el bloque hereda las variables a y b del ámbito circundante, pero c es local para el bloque (¿el método defined? retorna nil si su argumento no está definido).
a = [1, 2]b = ‘cat’a.each {|b| c = b * a[1] }a -> [1, 2]b -> 2defined?(c) -> nil
Un bloque también puede retornar un valor al método. El valor de la última expresión evaluada en el bloque se pasa al método como el valor de yield. Así es como trabaja el método find utilizado por la clase Array (el método find se define en realidad en el módulo Enumerable, que se mezcla con la clase Array). Su implementación sería algo así como lo siguiente.
class Array def find for i in 0...size valor = self[i] return valor if yield(valor) end return nil endend

27
[1, 3, 5, 7, 9].find {|v| v*v > 30 } -> 7
Esto pasa sucesivos elementos de la matriz al bloque asociado. Si el bloque devuelve true, el método devuelve el elemento correspondiente. Si no coincide con ningún elemento, el método devuelve nil. El ejemplo muestra el beneficio de este enfoque por iteradores. La clase Array es lo que mejor hace, ac-cede a elementos de una matriz, dejando al código de la aplicación concentrarse en sus requerimientos particulares (en este caso, encontrar una entrada que cumpla con algunos criterios matemáticos).
Algunos iteradores son comunes a muchos tipos de colecciones en Ruby. Ya hemos visto find. Otros dos son each y collect. El iterador más simple es probablemente each que lo únco que hace es dar elementos sucesivos de su colección.
[ 1, 3, 5, 7, 9 ].each {|i| puts i }
produce:
13579
El iterador each tiene un lugar especial en Ruby. Más adelante se describe como se usa como la base del lenguaje para los bucles, y aún más adelante veremos cómo definir un método each para agregar mucha más funcionalidad a una clase.
Otro iterador común es collect, que toma cada elemento de una colección y se lo pasa al bloque. Los resultados devueltos por el bloque se utilizan para construir una nueva matriz. Por ejemplo:
[“H”, “A”, “L”].collect {|x| x.succ } -> [“I”, “B”, “M”]
Los iteradores no se limitan a acceder a los datos existentes en los arrays y hashes. Como vimos en el ejemplo de Fibonacci, un iterador puede devolver valores derivados. Esta capacidad, Ruby la utiliza en sus clases de entrada/salida que implementan un interfaz iterador que devuelve sucesivas líneas (o bytes) en un flujo de E/S (el siguiente ejemplo utiliza do..end para definir un bloque. La diferencia entre esta notación y el uso de llaves para definir bloques, es la prioridad: do..end tiene menos prioridad que {...}).
f = File.open(“testfile”)f.each do |line| puts lineendf.close
produce:
This is line oneThis is line twoThis is line threeetc ...
Echemos un vistazo a otro iterador más útil. El (algo oscuramente nombrado) método inject (que se define en el módulo Enumerable) le permite acumular un valor entre los elementos de una colección. Por ejemplo, puede sumar todos los elementos de una matriz, y encontrar su producto, utilizando código como:
[1,3,5,7].inject(0) {|sum, element| sum+element} -> 16[1,3,5,7].inject(1) {|product, element| product*element} -> 105

28
inject funciona así: la primera vez que se llama al bloque asociado, la suma se configura para inyec-tar el parámetro y el elemento se establece en el primer elemento de la colección. La segunda y posterio-res veces que se llama al bloque, la suma se establece en el valor devuelto por el bloque de la llamada anterior. El valor final a inyectar es el valor devuelto por el bloque en la última vez que fue llamado. Hay una cosa final: si se llama a inject sin ningún parámetro, se utiliza el primer elemento de la colección como el valor inicial y comienza la iteración con el segundo valor. Esto significa que podría haber escrito los ejemplos anteriores como:
[1,3,5,7].inject {|sum, element| sum+element} -> 16[1,3,5,7].inject {|product, element| product*element} -> 105
Iteradores Internos y externos
Vale la pena gastar un párrafo comparando el enfoque de Ruby con los iteradores al de otros lenguajes como C++ y Java. En Ruby, el iterador es interno a la colección --es simplemente un método, idéntico a cualquier otro, que pasa a llamar a yield cada vez que genera un nuevo valor. Lo que usa el iterador es sólo un bloque de código asociado a este método.
En otros lenguajes, las colecciones no contienen sus propios iteradores. En su lugar, generan objetos externos de ayuda (por ejemplo, los basados en la interfaz Iterator de Java) que llevan el estado iterador. En esto, como en muchos otros aspectos, Ruby es un lenguaje transparente. Cuando escribes un progra-ma en Ruby, te concentras en hacer el trabajo, no en la construcción de andamios para apoyar al mismo lenguaje.
También vale la pena gastar un párrafo para ver por qué los iteradores internos de Ruby no son siem-pre la mejor solución. Un área donde caen mal es cuando se necesita tratar el iterador como un objeto en sí mismo (por ejemplo, pasar el iterador en un método que lo necesita para acceder a cada uno de los valores devueltos por ese mismo iterador). También es dificil iterar sobre dos colecciones en paralelo con el esquema de iterador interno de Ruby. Afortunadamente, Ruby 1.8 viene con la biblioteca Generator (que se describe más adelante), que implementa iteradores externos para tales ocasiones.
Bloques para Transacciones
Aunque a menudo los bloques son objeto de un iterador, también tienen otros usos. Echémosles un vistazo.
Puede utilizar los bloques para definir un trozo de código que debe ejecutarse en algún tipo de control de transacciones. Por ejemplo, muchas veces se abre un archivo, se hace algo con su contenido, y se quiere asegurar de que el archivo se cierre cuando se haya terminado. Aunque usted puede hacer esto uti-lizando código convencional, hay razones para hacer al archivo responsable de cerrarse. Podemos hacer esto con bloques. Una implementación ingenua (ignorando el manejo de errores) podría ser algo como lo siguiente.
class File def File.open_and_process(*args) f = File.open(*args) yield f f.close() endend
File.open_and_process(“testfile”, “r”) do |file| while line = file.gets puts line endend
produce:
This is line one

29
This is line twoThis is line threeetc ...
open_and_process es un método de clase, se le puede llamar independientemente de cualquier ob-jeto archivo en particular. Queremos que tome los mismos argumentos que el método File.open conven-cional, pero en realidad no importa lo que son esos argumentos. Para ello, se especifican los argumentos como *args, que significa “recoger los parámetros actuales pasados al método en una matriz llamada args”. A continuación, llamamos a File.open, pasándole *args como un parámetro. Esto expande la matriz de nuevo en los parámetros individuales. El resultado neto es que open_and_process pasa de forma trasparente todos los parámetros que recibió a File.open.
Una vez que se ha abierto el archivo, open_and_process hace llamadas a yield pasandole el objeto archivo abierto al bloque. Cuando retorna el bloque, se cierra el archivo. De esta manera, la responsabili-dad de cerrar el archivo abierto ha pasado desde el usuario del objeto archivo a los propios archivos.
La técnica de hacer que los archivos gestionen su propio ciclo de vida es tan útil que la clase File suministrada con Ruby lo soporta directamente. Si File.open tiene un bloque asociado, cuando se invo-que al bloque con un objeto archivo, éste se cerrará cuando el bloque termine. Esto es interesante, ya que significa que File.open tiene dos diferentes comportamientos: cuando se invoca con un bloque, éste se ejecuta y se cierra el archivo. Cuando se invoca sin bloque, devuelve el objeto archivo. Esto se hace posible gracias al método Kernel.block_given?, que devuelve true si el bloque está asociado con el método en curso. Usando este método, se puede implementar algo similar al File.open estándar (de nuevo, haciendo caso omiso de la gestión de errores) como lo siguiente:
class File def File.my_open(*args) result = file = File.new(*args) # Si hay un bloque, pasar el archivo y cerrar el archivo #cuando retorne if block_given? result = yield file file.close end return result endend
Esto tiene un último giro: en los ejemplos anteriores del uso de bloques para el control de los recursos, no hemos abordado el tratamiento de errores. Si quisieramos poner en práctica correctamente estos mé-todos, necesitaríamos asegurarnos de que cerramos los archivos, incluso si el código de procesamiento del archivo a abortado de alguna manera. Esto lo hacemos con el manejo de excepciones, de lo que ha-blaremos más adelante.
Los Bloques pueden ser Cierres
Volvamos a nuestro jukebox. En algún momento vamos a trabajar en el código que se encarga de la interfaz de usuario, con los botones que la gente presiona para seleccionar las canciones y controlar el jukebox. Vamos a tener que asociar acciones con estos botones: pulsar START y comienza la música. Resulta que los bloques de Ruby ofrecen una conveniente manera para hacer esto. Vamos a asumir que los que hicieron el hardware implementaron una extensión de Ruby que nos dá una clase botón básica.
start_button = Button.new(“Start”)pause_button = Button.new(“Pause”)# ...
¿Qué sucede cuando el usuario pulsa uno de los botones? En la clase Button, la gente de hardware ha manipulado las cosas para que se invoque un método de devolución de llamada, button_pressed. La manera obvia de añadir la funcionalidad de estos botones es la creación de subclases de Button y hacer que cada subclase implemente su propio método button_pressed.

30
class StartButton < Button def initialize super(“Start”) # invocar initialize Button end def button_pressed# se inician acciones... endendstart_button = StartButton.new
Esto tiene dos problemas. En primer lugar, esto dará lugar a un gran número de subclases. Si la interfaz Button cambia, podría envolvernos en una gran cantidad de mantenimiento. En segundo lugar, las ac-ciones realizadas cuando se pulsa un botón se expresan en el nivel equivocado, no son una característica del botón, sino una característica de la máquina de discos que utiliza los botones. Podemos arreglar estos dos problemas con los bloques.
songlist = SongList.newclass JukeboxButton < Button def initialize(label, &action) super(label) @action = action end def button_pressed @action.call(self) endendstart_button = JukeboxButton.new(“Start”) { songlist.start }pause_button = JukeboxButton.new(“Pause”) { songlist.pause }
La clave de todo esto es el segundo parámetro a JukeboxButton#initialize. Si el último paráme-tro en una definición de método se precede con un signo & (por ejemplo, &action), Ruby busca un bloque de código cada vez que se llama al método. El bloque de código que se convierte en un objeto de la clase Proc y es asignado al parámetro. A continuación, puede tratar el parámetro como cualquier otra variable. En nuestro ejemplo, se asigna a la variable de instancia @action. Cuando se invoca al método de retorno button_pressed, se utiliza el método Proc#call en ese objeto para invocar el bloque.
Entonces, ¿qué es exactamente lo que tenemos cuando se crea un objeto Proc? Lo interesante es que es algo más que un trozo de código. Asociado a un bloque (y por lo tanto al objeto Proc) es todo el contexto en el que se ha definido al bloque: el valor mismo y los métodos, las variables y constantes a su alcance. Parte de la magia de Ruby es que el bloque aún puede utilizar toda esta información del alcance original, incluso si el entorno en el que se define de otra manera ha desaparecido. En otros lenguajes, esta característica se denomina cierre.
Veamos un ejemplo inventado en el que se utiliza el método lambda, que convierte un bloque a un objeto Proc.
def n_times(thing) return lambda {|n| thing * n }end
p1 = n_times(23)p1.call(3) -> 69p1.call(4) -> 92p2 = n_times(“Hola “)p2.call(3) -> “Hola Hola Hola “
El método n_times devuelve un objeto Proc que hace referencia al parámetro thing. A pesar de que el parámetro está fuera de alcance de momento se llama al bloque, para que el parámetro sea accesible para el bloque.

31
Contenedores por todas partes
Contenedores, bloques e iteradores son conceptos fundamentales en Ruby. Cuanto más se escribe en Ruby, más se ve alejado de las construcciones convencionales de bucles. En su lugar, vamos a escribir clases que admiten la iteración sobre su contenido. Usted encontrará que este código es compacto y fácil de leer y mantener.
Tipos Estándar
Hasta ahora nos hemos divertido con la plicación de piezas de código a nuestro jukebox. Pero hemos sido negligentes. Hemos visto arrays, hashes y procs, pero no hemos cubierto los otros tipos básicos de Ruby: números, cadenas, rangos y expresiones regulares. Ahora vamos a pasar unas cuantas páginas con estos bloques de construcción básicos.
Números
Ruby soporta números enteros y de punto flotante. Los enteros pueden ser de cualquier longitud (hasta un máximo determinado por la cantidad de memoria disponible en su sistema). Enteros en un rango de-terminado (normalmente -230 a 230-1 o -262 a 262-1) se llevan a cabo internamente de forma binaria y son objetos de la clase Fixnum. Enteros fuera de este rango se almacenan en objetos de la clase Bignum (actualmente implementados como un conjunto de longitud variable de enteros cortos). Este proceso es transparente y Ruby gestiona automáticamente la conversión de ida y vuelta.
num = 816.times do puts “#{num.class}: #{num}” num *= numend
produce:
Fixnum: 81Fixnum: 6561Fixnum: 43046721Bignum: 1853020188851841Bignum: 3433683820292512484657849089281Bignum: 11790184577738583171520872861412518665678211592275841109096961
Se pueden escribir números enteros con signo opcional, un indicador de base opcional (0 para octal, 0d para decimal (por defecto), 0x para hexadecimal y 0b para binario) seguido de una cadena de digitos en la base apropiada. Los guiones bajos son ignorados (algunas personas los utilizan en lugar de comas para números grandes).
123456 => 123456 # Fixnum0d123456 => 123456 # Fixnum123_456 => 123456 # Fixnum guión bajo ignorado-543 => -543 # Fixnum número negativo0xaabb => 43707 # Fixnum hexadecimal0377 => 255 # Fixnum octal-0b10_1010 => -42 # Fixnum binario (negativo)123_456_789_123_456_789 => 123456789123456789 # Bignum
Los caracteres de control se pueden generar utilizando ?\Cx y ?\cx (el controlde versión de x es x & 0x9f). Metacaracteres (x | 0x80) se puede generar utilizando ?\Mx. La combinación de meta y control se genera con ?\M\C-x. Se puede obtener el valor entero del caracter barra invertida utilizando la secuencia ?\\.

32
?a => 97 # caracter ASCII?\n => 10 # codigo para nueva línea (0x0a)?\C-a => 1 # control a = ?A & 0x9f = 0x01?\M-a => 225 # meta bit 7?\M-\C-a => 129 # meta y control a?\C-? => 127 # delete character
Un literal numérico con un punto decimal y/o un exponente se convierte en un objeto Float, que co-rresponde al tipo de dato double en la arquitectura nativa. El punto decimal tiene que ir precedido y se-guido por un dígito (si se escribe 1.0e3 como 1.e3, Ruby trata de invocar al método e3 en la clase Fixnum).
Todos los números son objetos y responden a una variedad de mensajes (una lista completa se verá más adelante). Así, a diferencia (por ejemplo) de C++, el valor absolutode un número se encuentra escribiendo num.abs, no abs(num).
Los enteros también soportan varios iteradores útiles. Hemos visto ya uno: 6.times en elcódigo de ejemplo anterior. Otros incluidos son upto y downto, para iterar hacia arriba y hacia abajo entre dos enteros. La clase Numeric también proporciona el método más general step, que es más como un bucle for tradicional.
3.times { print “X “ }1.upto(5) {|i| print i, “ “ }99.downto(95) {|i| print i, “ “ }50.step(80, 5) {|i| print i, “ “ }
produce:
X X X 1 2 3 4 5 99 98 97 96 95 50 55 60 65 70 75 80
Por último, vamos a ofrecer un toque de atención a los usuarios de Perl. Las cadenas que contienen sólo dígitos no se convierten automáticamente a números cuando se utilizan en las expresiones. Esto tiende a engañar con más frecuencia al leer números de un archivo. Por ejemplo, podemos querer hallar la suma de dos números de cada línea de un archivo, como:
3 45 67 8
El siguiente código no funciona:
some_file.each do |line| v1, v2 = line.split # división de línea en espacios print v1 + v2, “ “end
produce:
34 56 78
El problema es que la entrada no se lee como números, sino como cadenas. El operador + concatena cadenas, asi que es eso lo que vemos en la salida. Para solucionar esto, utilice el método Integer para convertir la cadena a un entero.
some_file.each do |line| v1, v2 = line.split print Integer(v1) + Integer(v2), “ “end
produce: 7 11 15

33
Cadenas
Las cadenas en Ruby son simplemente secuencias de bytes de 8 bits. Normalmente tienen caracteres imprimibles, pero no es un requisito, una cadena también puede contener datos binarios. Las cadenas son objetos de la clase String.
Las cadenas se crean utilizando una literales de cadena --secuencias de caracteres entre delimitado-res. Como los datos binarios son difíciles de representar de otra forma en el código fuente del programa, puede colocar varias secuencias de escape en un literal de cadena. Cada una se sustituye por el valor bi-nario correspondiente cuando se compila el programa. El tipo de delimitador de cadena determina el grado de sustitución realizado. Dentro de comillas simples, dos barras invertidas consecutivas se sustituyen por una sola, y una barra invertida seguida de una comilla simple se convierte en una comilla simple.
‘escape using “\\”’ -> escape using “\”‘That\’s right’ -> That’s right
Las cadenas entre comillas dobles soportan un cargamento de secuencias de escape. El más común es probablemente, \n, el carácter de nueva línea. Más adelante se muestra una tabla con la lista com-pleta. Además, puede sustituir el valor de cualquier código Ruby en una cadena mediante la secuencia #{ expr } . Si el código es una variable global, una variable de clase, o una variable de instancia, puede omitir las llaves.
“Seconds/day: #{24*60*60}” -> Seconds/day: 86400“#{‘Ho! ‘*3}Merry Christmas!” -> Ho! Ho! Ho! Merry Christmas!“This is line #$.” -> This is line 3
El código de interpolación puede ser una o más declaraciones, no sólo una expresión:
puts “now is #{ def the(a) ‘the ‘ + a end the(‘time’) } for all good coders...”
produce:
now is the time for all good coders...
Hay tres formas de construir cadenas literales: %q, %Q, y here documents.
%q y %Q al inicio delimita cadenas entre comillas simples y dobles (se puede imaginar %q como comi-lla fina ‘ y %Q como comilla gruesa “).
%q/general singlequoted string/ -> general singlequoted string%Q!general doublequoted string! -> general doublequoted string%Q{Seconds/day: #{24*60*60}} -> Seconds/day: 86400
El carácter que sigue a q ó a Q es el delimitador. Si se trata de un corchete de apertura “[“, llave “{“ pa-réntesis “(“ o signo menor que “<”, la cadena se lee hasta que se encuentra el símbolo correspondiente de cierre. De lo contrario la cadena se lee hasta la próxima ocurrencia del mismo delimitador. El delimitador puede ser cualquier carácter no alfanumérico o no multibyte.
Por último, puede crear una cadena con here document (un documento aquí).
string = <<END_OF_STRING El cuerpo de la cadena son las líneas de entrada hasta que una de ellas termina con el mismo texto que siguió a ‘<<’END_OF_STRING

34
Un here document se compone de líneas hasta, pero no incluyendo, la cadena de terminación que se especifica después de los caracteres <<. Normalmente, este terminador debe comenzar en la primera columna. Sin embargo, si usted pone un signo menos después de <<, puede sangrar el terminador.
print <<-STRING1, <<-STRING2 Concat STRING1 enate STRING2
produce:
Concat enate
Tenga en cuenta que Ruby no quita espacios iniciales de los contenidos de las cadenas en estos casos.
Trabajar con Cadenas
String es probablemente la clase más grande construida en Ruby, con más de 75 metodos estándar. No vamos a tratar todos ellos, la referencia de la biblioteca tiene una lista completa. En su lugar, vamos a ver algunas expresiones comunes de cadenas --las que más suelen aparecer durante el día a día de la programación.
Volvamos a nuestra máquina de discos. A pesar de que está diseñada para conectarse a Internet, tam-bién tiene copias de algunas canciones populares en un disco duro local. De esta manera, si una ardilla muerde nuestra conexión a la red, todavía será capaz de entretener a los clientes.
Por razones históricas (¿hay alguna otra?), la lista de canciones se almacena como filas en un archivo plano. Cada fila contiene el nombre del archivo que contiene la canción, la duración de la canción, el ar-tista y el título, con barras verticales para separar los campos. Un archivo típico puede comenzar
/jazz/j00132.mp3 | 3:45 | Fats Waller | Ain’t Misbehavin’/jazz/j00319.mp3 | 2:58 | Louis Armstrong | Wonderful World/bgrass/bg0732.mp3| 4:09 | Strength in Numbers | Texas Red : : : :
En cuanto a los datos, está claro que vamos a utilizar algunos de los muchos métodos de la clase String, para extraer y limpiar los campos antes de crear objetos Song basados en ellos. Como mínimo, tendremos que
•dividircadalíneaencampos, •convertirlostiemposdefuncionamientodesdemm:ssasegundos,y •eliminarlosespaciosenblancodelosnombresdelosartistas.
Nuestra primera tarea es dividir cada línea en campos, y String#split va hacer el trabajo adecua-damente. En este caso, vamos a pasar a split una expresión regular, /\s*\|\s*/, que divide la línea en fichas donde split encuentra una barra vertical, opcionalmente rodeada de espacios. Y, debido a que la línea a leer del archivo tiene un carácter de nueva línea al final, vamos a utilizar String#chomp para quitarlo justo antes de aplicar la separación.
File.open(“songdata”) do |song_file| songs = SongList.new song_file.each do |line| file, length, name, title = line.chomp.split(/\s*\|\s*/) songs.append(Song.new(title, name, length)) end puts songs[1]end

35
produce:
Song: Wonderful World--Louis Armstrong (2:58)
Desafortunadamente, el que creó el archivo original introdujo los nombres de los artistas en columnas, por lo que algunos contienen espacios adicionales. Estos se ven feos en nuestra alta tecnología, super-twist, pantalla plana, Day-Glo display. Así que mejor quitar estos espacios extra antes de ir más allá. Te-nemos muchas maneras de hacer esto, pero probablemente la más simple sea String#squeeze, que recorta tiradas de caracteres repetidos. Vamos a utilizar la forma squeeze! del método, que altera la cadena.
File.open(“songdata”) do |song_file| songs = SongList.new song_file.each do |line| file, length, name, title = line.chomp.split(/\s*\|\s*/) name.squeeze!(“ “) songs.append(Song.new(title, name, length)) end puts songs[1]end
produce:
Song: Wonderful WorldLouis Armstrong (2:58)
Por último, tenemos el asunto de menor importancia del formato del tiempo: el archivo dice 2:58 y que-remos el número en segundos, 178. Se podría utilizar split de nuevo, que dividiría el campo del tiempo en torno al carácter de dos puntos.
mins, secs = length.split(/:/)
En su lugar, vamos a utilizar un método relacionado. String#scan es similar a split en que rompe una cadena en trozos sobre la base de un patrón. Sin embargo, a diferencia de split, con scan se es-pecifica el patrón que se desea que coincida con los trozos. En este caso, queremos que coincida con uno o más dígitos para ambos componentes, los minutos y los segundos. El patrón para uno o más dígitos es /\d+/.
File.open(“songdata”) do |song_file| songs = SongList.new song_file.each do |line| file, length, name, title = line.chomp.split(/\s*\|\s*/) name.squeeze!(“ “) mins, secs = length.scan(/\d+/) songs.append(Song.new(title, name, mins.to_i*60+secs.to_i)) end puts songs[1]end
produce:
Song: Wonderful WorldLouis Armstrong (178)
Nuestro jukebox debe tener capacidad de búsqueda por palabra clave. Dada una palabra de un título de una canción o el nombre de un artista, aparecerá una lista de todas las pistas que coinciden. Escriba fats, y mostrará canciones de Fats Domino, Fats Navarro, y Fats Waller, por ejemplo. Lo vamos a poner en práctica mediante la creación de una clase de indexación. Esto ilustra un poco más los muchos métodos de la clase String.

36
class WordIndex def initialize @index = {} end def add_to_index(obj, *phrases) phrases.each do |phrase| phrase.scan(/\w[\w’]+/) do |word| # extraer cada palabra word.downcase! @index[word] = [] if @index[word].nil? @index[word].push(obj) end end end def lookup(word) @index[word.downcase] endend
El método String#scan extrae los elementos de una cadena que coincida con una expresión regular. En este caso, el patrón \w[-\w‘’]+ coincide con cualquier carácter que pueda aparecer en una palabra, seguido de uno o más de lo que se especifica entre corchetes (un guión, otro caracter de la palabra, o una comilla simple ). Más adelante hablaremos más acerca de las expresiones regulares. Para hacer nuestras búsquedas case insensitive, podemos asignar tanto las palabras que se extraen como las palabras usadas como claves en la búsqueda de minúsculas. Tenga en cuenta el signo de exclamación al final del primer nombre del método downcase!. Al igual que con el método squeeze! utilizado anteriormente, esto es una indicación de que el método va a modificar al receptor en su lugar, en este caso la conversión de la cadena a minúsculas (Este ejemplo de código contiene un error menor: la canción “Gone, Gone, Gone” tendría la indexación en tres ocasiones. ¿Se podría arreglar?).
Vamos a ampliar nuestra clase SongList indexándole canciones a medida que se agregan y añadirle un método para buscar una canción dándole una palabra.
class SongList def initialize @songs = Array.new @index = WordIndex.new end def append(song) @songs.push(song) @index.add_to_index(song, song.name, song.artist) self end def lookup(word) @index.lookup(word) endend
Por último, vamos a probar todo.
songs = SongList.newsong_file.each do |line| file, length, name, title = line.chomp.split(/\s*\|\s*/) name.squeeze!(“ “) mins, secs = length.scan(/\d+/) songs.append(Song.new(title, name, mins.to_i*60+secs.to_i))endputs songs.lookup(“Fats”)puts songs.lookup(“ain’t”)puts songs.lookup(“RED”)puts songs.lookup(“WoRlD”)

37
produce:
Song: Ain’t Misbehavin’--Fats Waller (225)Song: Ain’t Misbehavin’--Fats Waller (225)Song: Texas Red--Strength in Numbers (249)Song: Wonderful World--Louis Armstrong (178)
En el código anterior, el método de búsqueda (lookup) devuelve una matriz de coincidencias. Cuando se pasa un array puts, simplemente escribe cada elemento, a su vez, separado por un salto de línea.
Podríamos pasar las próximas 50 páginas viendo todos los métodos de la clase String. Sin embargo, vamos a seguir adelante para ver un tipo de datos más simple: el rango.
Rangos
Los rangos se dan en todas partes: de enero a diciembre, 0-9, mal bien hecho, líneas 50 a 67, etc. Si Ruby nos ayuda a modelar la realidad, parece lógico el apoyo de estos rangos. De hecho, Ruby hace algo mejor: realmente utiliza los rangos para la implementación de tres distintas características: las secuen-cias, las condiciones y los intervalos.
Rangos como Secuencias
El primer uso y quizás el más natural de los rangos es el de expresar una secuencia. Las secuencias tienen un punto de inicio, un punto final, y una manera de producir valores sucesivos de la secuencia. En Ruby, estas secuencias se crean utilizando los operadores de rango “..” y “...”. La forma de dos puntos crea un rango inclusivo, y la forma de tres puntos crea un rango que excluye el valor más alto especificado.
1..10‘a’..’z’my_array = [ 1, 2, 3 ]0...my_array.length
En Ruby, a diferencia de algunas versiones anteriores de Perl, los rangos no se representan interna-mente como listas: la secuencia de 1..100000 se mantiene como un objeto Range que contiene referen-cias a dos objetos Fixnum. Si se necesita, se puede convertir un rango a una lista mediante el método to_a.
(1..10).to_a -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10](‘bar’..’bat’).to_a -> [“bar”, “bas”, “bat”]
Los rangos implementan métodos que nos permiten iterar sobre ellos y probar su contenido de varias maneras.
digits = 0..9digits.include?(5) -> truedigits.min -> 0digits.max -> 9digits.reject {|i| i < 5 } -> [5, 6, 7, 8, 9]digits.each {|digit| dial(digit) } -> 0..9
Hasta ahora hemos mostrado rangos de números y cadenas. Sin embargo, como era de esperar de un lenguaje orientado a objetos, Ruby puede crear rangos basados en objetos que se pueden definir. La única restricción es que los objetos deben responder a succ devolviendo el siguiente objeto en la secuen-cia, y que los objetos deben ser comparables usando <=>. A veces llamando al operador spaceship, <=> compara dos valores, devolviendo -1, 0 ó +1 dependiendo de si el primero es menor, igual o mayor que el segundo.
A continuación tenemos una clase simple que representa las filas para los signos #. Es posible que la desee utilizar como una versión basada en texto del control de volumen del jukebox.

38
class VU include Comparable attr :volume def initialize(volume) # 0..9 @volume = volume end def inspect ‘#’ * @volume end # soporte para rangos def <=>(other) self.volume <=> other.volume end def succ raise(IndexError, “Volume too big”) if @volume >= 9 VU.new(@volume.succ) endend
Como nuestra clase VU implementa succ y <=>, se puede participar en los rangos.
medium_volume = VU.new(4)..VU.new(7)medium_volume.to_a -> [####, #####, ######, #######]medium_volume.include?(VU.new(3)) -> false
Rangos como Condiciones
Así como la representación de secuencias, los rangos también se pueden utilizar como expresiones condicionales. En este caso, actúan como una especie de conmutador de palanca --que enciende cuan-do la condición en la primera parte del rango se cumple, y se apaga cuando la condición en la segunda parte se cumple. Por ejemplo, el siguiente fragmento de código imprime conjuntos de líneas en la entrada estándar, donde la primera línea de cada conjunto contiene la palabra start y la última línea contiene la palabra end.
while line = gets puts line if line =~ /start/ .. line =~ /end/end
Entre bambalinas, el rango realiza un seguimiento del estado de cada una de las pruebas. Vamos a mostrar algunos ejemplos de esto en la descripción de los bucles más adelante
En versiones antiguas de Ruby, rangos desnudos se pueden utilizar como condiciones en if, while y sentencias similares. Se hubiera podido, por ejemplo, haber escrito el fragmento de código anterior como
while gets print if /start/../end/end
Esto ya no es compatible. Desafortunadamente, no revela ningún error, el test sólo tendrá éxito en cada ocasión.
Rangos como Intevalos
Un uso final de los versátiles rangos es un test de intervalo: ver si algún valor se encuentra dentro del intervalo representado por el rango. Esto se puede hacer utilizando el operador de igualdad de caso ===.
(1..10) === 5 -> true(1..10) === 15 -> false(1..10) === 3.14159 -> true

39
(‘a’..’j’) === ‘c’ -> true(‘a’..’j’) === ‘z’ -> false
Más adelante veremos un ejemplo de una expresión de caso que muestra esta prueba en acción: dado un año, la determinación de un estilo de jazz.
Expresiones Regulares
De vuelta a lo visto anteriormente, cuando se crea una lista de canciones a partir de un archivo, se utiliza una expresión regular para que coincida con el delimitador de campo en el archivo de entrada. He-mos afirmado que la expresión line.split (/\s*\|\s*/) coincide con una barra vertical rodeada de espacio en blanco opcional. Vamos a explorar las expresiones regulares con más detalle para ver por qué esta afirmación es verdadera.
Las expresiones regulares se utilizan para comparar patrones con cadenas. Ruby proporciona soporte interno que hace la comparación y sustitución de patrones conveniente y concisa. En esta sección vamos a trabajar con las principales características de las expresiones regulares. No se van a cubrir algunos detalles aquí, más adelante veremos más.
Las expresiones regulares son objetos de tipo Regexp. Pueden ser creados por una llamada al cons-tructor explicitamente o mediante el uso de las formas literales /patrón/ y %r{patron}.
a = Regexp.new(‘^\s*[az]’) -> /^\s*[az]/b = /^\s*[az]/ -> /^\s*[az]/c = %r{^\s*[az]} -> /^\s*[az]/
Una vez que tiene un objeto de expresión regular, puede compararlo con una cadena con Regexp# match(cadena) o con los operadores de comparación =~ (comparación positiva) y !~ (comparación ne-gativa). Los operadores de comparación se definen para ambos objetos, Strings y Regexp. Al menos un operando del operador de comparación debe ser una expresión regular. (En versiones anteriores de Ruby, ambos operandos pueden ser cadenas, en cuyo caso el segundo operando se convierte en una expresión regular entre bambalinas).
name = “Fats Waller”name =~ /a/ -> 1name =~ /z/ -> nil/a/ =~ name -> 1
Los operadores de comparación retornan la posición de carácter en la que la comparación se produjo. También tienen el efecto secundario de configurar un montón de variables Ruby. $& recibe la parte de la cadena que fue coincidente con el patrón, $` recibe la parte de la cadena que precedió la comparación, y $’ recibe la cadena después de la comparación. Se puede usar esto para escribir un método, show_re-gexp, que muestra donde se coincide con un patrón particular.
def show_regexp(a, re) if a =~ re “#{$`}<<#{$&}>>#{$’}” else “no match” endend
show_regexp(‘very interesting’, /t/) -> very in<<t>>erestingshow_regexp(‘Fats Waller’, /a/) -> F<<a>>ts Wallershow_regexp(‘Fats Waller’, /ll/) -> Fats Wa<<ll>>ershow_regexp(‘Fats Waller’, /z/) -> no match
La comparación también configura el hilo de variables globales $~ y $1 a $9. La variable $~ es un obje-to MatchData (descrito más adelante) que contiene todo lo que usted quiera saber sobre la comparación. $1 y siguientes, mantiene los valores de las partes de la comparación. Hablaremos de esto más tarde. Y

40
para las personas que se encogen cuando ven estos nombres de variables como las de Perl, estad aten-tos. Hay buenas noticias al final del capítulo.
Patrones
Cada expresión regular contiene un patrón, que se utiliza para comparar la expresión regular con una cadena.
Dentro de un patrón, todos los caracteres excepto ., |, (, ), [, ], {, }, +, \, ^, $, * y ?, coinciden con ellos mismos.
show_regexp(‘kangaroo’, /angar/) -> k<<angar>>ooshow_regexp(‘!@%&_=+’, /%&/) -> !@<<%&>>_=+
Si se quiere comparar con uno de estos caracteres especiales, literalmente, se preceden con una barra invertida. Esto explica en parte el modelo que utilizamos para dividir la línea de song, /\s*\|\s*/. El \| significa “compara una barra vertical.” Sin la barra invertida, el | habría significado alternancia (que describiremos más adelante).
show_regexp(‘yes | no’, /\|/) -> yes <<|>> noshow_regexp(‘yes (no)’, /\(no\)/) -> yes <<(no)>>show_regexp(‘are you sure?’, /e\?/) -> are you sur<<e?>>
La barra invertida seguida por un carácter alfanumérico se utiliza para introducir una construcción de comparación especial, que vamos a cubrir más tarde. Además, una expresión regular puede contener sustituciones #{...}.
Anclas
Por defecto, una expresión regular va a tratar de encontrar la primera coincidencia del patrón en una cadena. La comparación de /iss/ con la cadena “Mississippi”, que encuentra la subcadena “iss” comen-zando en la posición uno. Pero, ¿cómo forzar que un patrón se comapre sólo con el principio o el final de una cadena?
Los patrones ^ y $ coinciden con el comienzo y el final de una línea respectivamente. A menudo, son usados para anclar una coincidencia de patrón: por ejemplo, /^option/ coincide con la palabra option sólo si aparece en el comienzo de una línea. La secuencia \A coincide con el comienzo de una cadena, y \z y \Z coinciden con el final de una cadena. (En realidad, \Z coincide con el final de una cadena a menos que la cadena termine con un \n, que este caso coincide justo antes del n\).
show_regexp(“this is\nthe time”, /^the/) -> this is\n<<the>> timeshow_regexp(“this is\nthe time”, /is$/) -> this <<is>>\nthe timeshow_regexp(“this is\nthe time”, /\Athis/) -> <<this>> is\nthe timeshow_regexp(“this is\nthe time”, /\Athe/) -> no match
Del mismo modo, los patrones \b y \B coinciden con el límite de palabra (si no aparece dentro de una especificación de rango) y con el no límite de palabra, respectivamente. Caracteres de palabra son letras, números y guiones bajos.
show_regexp(“this is\nthe time”, /\bis/) -> this <<is>>\nthe timeshow_regexp(“this is\nthe time”, /\Bis/) -> th<<is>> is\nthe time
Clases Carácter
Una clase carácter es un conjunto de caracteres entre corchetes: [caracteres] coincide con cualquier carácter individual entre los corchetes. [aeiou] coincidrá con una vocal, [,.:;!?] coincidirá con un sig-no de puntuación, etc. La importancia de los caracteres especiales de expresiones regulares -- .|()[{+^$*? -- se anula dentro de los corchetes. Sin embargo, la sustitución normal de cadenas se sigue pro-duciendo, por lo que (por ejemplo) \b representa un carácter de retroceso y \n una nueva línea. Además,

41
puede utilizar las abreviaturas mostradas en la Tabla 2 en la siguiente página, para ver que (por ejemplo) \s coincide con cualquier carácter de espacio, no sólo un espacio literal. Las clases de caracteres POSIX en la segunda mitad de la tabla corresponden a los macros ctype(3) con el mismo nombre.
show_regexp(‘Price $12.’, /[aeiou]/) -> Pr<<i>>ce $12.show_regexp(‘Price $12.’, /[\s]/) -> Price<< >>$12.show_regexp(‘Price $12.’, /[[:digit:]]/) -> Price $<<1>>2.show_regexp(‘Price $12.’, /[[:space:]]/) -> Price<< >>$12.show_regexp(‘Price $12.’, /[[:punct:]aeiou]/) -> Pr<<i>>ce $12.
Dentro de los corchetes, la secuencia c1-c2 representa todos los caracteres entre c1 y c2 ambos inclusive.
a = ‘see [Design Patternspage 123]’show_regexp(a, /[AF]/) -> see [<<D>>esign Patternspage 123]show_regexp(a, /[AFaf]/) -> s<<e>>e [Design Patternspage 123]show_regexp(a, /[09]/) -> see [Design Patternspage <<1>>23]show_regexp(a, /[09][09]/) -> see [Design Patternspage <<12>>3]
Si desea incluir los caracteres literales [ y - dentro de una clase carácter, deben aparecer en el inicio. Ponga un ^ inmediatamente después de un corchete abierto para negar una clase carácter: [^a-z] coin-cide con cualquier carácter alfabético que no sea en minúsculas.
a = ‘see [Design Patternspage 123]’show_regexp(a, /[]]/) -> see [Design Patternspage 123<<]>>show_regexp(a, /[]/) -> see [Design Patterns<<>> page 123]show_regexp(a, /[^az]/) -> see<< >>[Design Patternspage 123]show_regexp(a, /[^az\s]/) -> see <<[>>Design Patternspage 123]
Algunas clases carácter se utilizan con tanta frecuencia que Ruby proporciona abreviaturas para ellas. Estas abreviaturas se listan en la Tabla 2 en la página siguiente --y pueden ser utilizadas tanto entre
Tabla 2. Abreviaturas de la clase carácter.

42
corchetes como en el cuerpo de un patrón.
show_regexp(‘It costs $12.’, /\s/) -> It<< >>costs $12.show_regexp(‘It costs $12.’, /\d/) -> It costs $<<1>>2.
Finalmente, un punto (.) que aparezca fuera de los corchetes representa cualquier carácter excepto un salto de línea (aunque en modo multilínea también coincidiría con una nueva línea).
a = ‘It costs $12.’show_regexp(a, /c.s/) -> It <<cos>>ts $12.show_regexp(a, /./) -> <<I>>t costs $12.show_regexp(a, /\./) -> It costs $12<<.>>
Repetición
Cuando especificamos el patrón que divide la línea de lista de canciones, /\s*\|\s*/, dijimos que queríamos que coincidiera con una barra vertical rodeado por una cantidad arbitraria de espacios en blanco. Ahora sabemos que las secuencias con la \s coincide con un único espacio en blanco, por lo que parece probable que los asteriscos de alguna manera signifiquen “una cantidad arbitraria.” De hecho, el asterisco es uno de una serie de modificadores que permiten la coincidencia con múltiples ocurrencias de un patrón.
Si r se encuentra precediendo inmediatamente a la expresión regular dentro de un patrón, entonces
r* coincide con cero o más apariciones de r.r+ coincide con uno o más apariciones de r.r? coincide con cero o una ocurrencia de r.r{m,n} coincide al menos con “m” y como máximo “n” ocurrencias de r.r{m,} coincide al menos con “m” apariciones de r.r{m} coincide exactamente con “m” apariciones de r.
Estas construcciones de repetición tienen alta prioridad, --se ligan sólo a la expresión regular inmedia-tamente anterior en el patrón. /ab+/ coincide con una a seguida de una o más b, y no una secuencia de ab. Hay que tener cuidado con las construcciones con * --el patrón /a*/ coincide con cualquier cadena, cada cadena tiene cero o más aes.
A estos patrones se les llama codiciosos, ya que por defecto van a coincidir con gran parte de la cade-na. Se puede modificar este comportamiento y hacer que coincida con el mínimo, mediante la adición de un sufijo de signo de interrogación.
a = “The moon is made of cheese”show_regexp(a, /\w+/) -> <<The>> moon is made of cheeseshow_regexp(a, /\s.*\s/) -> The<< moon is made of >>cheeseshow_regexp(a, /\s.*?\s/) -> The<< moon >>is made of cheeseshow_regexp(a, /[aeiou]{2,99}/) -> The m<<oo>>n is made of cheeseshow_regexp(a, /mo?o/) -> The <<moo>>n is made of cheese
Alternancia
Sabemos que la barra vertical es especial, porque nuestro patrón de división de línea tuvo que escapar de ella con una barra invertida. Esto se debe a que un barra vertical sin escape (|) coincide con cualquiera de las dos, la expresión regular que lo precede o la expresión regular que se sigue.
a = “red ball blue sky”show_regexp(a, /d|e/) -> r<<e>>d ball blue skyshow_regexp(a, /al|lu/) -> red b<<al>>l blue skyshow_regexp(a, /red ball|angry sky/) -> <<red ball>> blue sky
Hay una trampa para los incautos aquí y es que | tiene muy baja prioridad. En el ejemplo anterior coin-cide con red ball o con angry sky, no con red ball sky o red angry sky. Para que coincida con red ball sky

43
o con red angry sky, hay que anular la precedencia predeterminada, usando agrupamiento.
Agrupamiento
Se pueden utilizar paréntesis para agrupar términos en una expresión regular. Todo lo de dentro del grupo es tratado como una única expresión regular.
show_regexp(‘banana’, /an*/) -> b<<an>>anashow_regexp(‘banana’, /(an)*/) -> <<>>bananashow_regexp(‘banana’, /(an)+/) -> b<<anan>>a
a = ‘red ball blue sky’show_regexp(a, /blue|red/) -> <<red>> ball blue skyshow_regexp(a, /(blue|red) \w+/) -> <<red ball>> blue skyshow_regexp(a, /(red|blue) \w+/) -> <<red ball>> blue skyshow_regexp(a, /red|blue \w+/) -> <<red>> ball blue sky
show_regexp(a, /red (ball|angry) sky/) -> no matcha = ‘the red angry sky’show_regexp(a, /red (ball|angry) sky/) -> the <<red angry sky>>
Los paréntesis también recogen los resultados de la coincidencia de patrones. Ruby cuenta los parén-tesis de apertura, y para cada uno almacena el resultado de la coincidencia parcial entre éste y el parénte-sis de cierre correspondiente. Se puede utilizar esta coincidencia parcial tanto en el resto del patrón como en el programa de Ruby. Dentro de este esquema, la secuencia \1 se refiere a la coincidencia del primer grupo, \2 a la del segundo grupo, y así sucesivamente. Fuera del patrón, las variables especiales $1, $2 y sucesivas tienen el mismo propósito.
“12:50am” =~ /(\d\d):(\d\d)(..)/ -> 0“Hour is #$1, minute #$2” -> “Hour is 12, minute 50”“12:50am” =~ /((\d\d):(\d\d))(..)/ -> 0“Time is #$1” -> “Time is 12:50”“Hour is #$2, minute #$3” -> “Hour is 12, minute 50”“AM/PM is #$4” -> “AM/PM is am”
La posibilidad de utilizar parte de la actual coincidencia más tarde, le permite buscar diversas formas de repetición.
# match duplicated lettershow_regexp(‘He said “Hello”’, /(\w)\1/) -> He said “He<<ll>>o”# match duplicated substringsshow_regexp(‘Mississippi’, /(\w+)\1/) -> M<<ississ>>ippi
También se pueden utilizar de nuevo las referencias para que coincidan con delimitadores.
show_regexp(‘He said “Hello”’, /([“’]).*?\1/) -> He said <<”Hello”>>show_regexp(“He said ‘Hello’”, /([“’]).*?\1/) -> He said <<’Hello’>>
Patrones de sustitución
A veces encontrar un patrón en una cadena es la pera. Si un amigo te reta a encontrar una palabra que contiene las letras a, b, c, d, y e en orden, se podría buscar una lista de palabras con el patrón /a.*b*c.*d.*e/ y encontrar abjectedness, absconded, ambuscade y carbacidometer, entre otras. Esto tiene que ser algo que valga la pena.
Sin embargo, a veces es necesario cambiar las cosas sobre la base de una coincidencia de patrón. Volvamos a nuestra fichero de lista de canciones. Quién lo creó introdujo todos los nombres de los artistas en minúsculas. Al mostrarlos en la pantalla de nuestra máquina de discos, se verían mejor en mayúsculas y minúsculas. ¿Cómo podemos cambiar el primer carácter de cada palabra a mayúsculas?

44
Los métodos String#sub y String#gsub buscan la parte de una cadena que coincide con su primer argumento y la reemplazan por su segundo argumento. String#sub realiza un reemplazo, y String#gsub reemplaza todas las ocurrencias de la comparación. Ambas rutinas devuelven una nueva copia de la cadena con las sustituciones. Las versiones mutadoras String#sub! y String#gsub! mo-difican la cadena original.
a = “the quick brown fox”a.sub(/[aeiou]/, ‘*’) -> “th* quick brown fox”a.gsub(/[aeiou]/, ‘*’) -> “th* q**ck br*wn f*x”a.sub(/\s\S+/, ‘’) -> “the brown fox”a.gsub(/\s\S+/, ‘’) -> “the”
El segundo argumento de las dos funciones puede ser una cadena o un bloque. Si se utiliza un bloque, se pasa la subcadena coincidente y el valor del bloque se sustituye en la cadena original.
a = “the quick brown fox” a.sub(/^./) {|match| match.upcase } -> “The quick brown fox”
a.gsub(/[aeiou]/) {|vowel| vowel.upcase } -> “thE qUIck brOwn fOx”
Por lo tanto, esto parece una respuesta a la conversión de los nombres de nuestros artistas. El patrón que coincide con el primer carácter de una palabra es \b\w --busca un límite de palabra seguido de un carácter de palabra. Combine esto con gsub y ya puede manipular los nombres de los artistas.
def mixed_case(name) name.gsub(/\b\w/) {|first| first.upcase }end
mixed_case(“fats waller”) -> “Fats Waller”mixed_case(“louis armstrong”) -> “Louis Armstrong”mixed_case(“strength in numbers”) -> “Strength In Numbers”
Secuencias de Barra Invertida en la Sustitución
Anteriormente hemos señalado que las secuencias \1, \2, etc, están disponibles para los patrones, posicionando hasta el enésimo grupo encontrado. Las mismas secuencias se encuentran disponibles en el segundo argumento de sub y gsub.
“fred:smith”.sub(/(\w+):(\w+)/, ‘\2, \1’) -> “smith, fred”“nercpyitno”.gsub(/(.)(.)/, ‘\2\1’) -> “encryption”
Las secuencias con barra invertida adicional funcionan en las sustitución de cadenas así: \& (última coincidencia), \+ (último grupo coincidente), \` (cadena anterior a la coincidencia), \’ (cadena siguiente a la coincidencia) y \\ (barra invertida literal).
Se vuelve confuso si se desea incluir una barra invertida en una sustitución. Lo obvio es escribir:
str.gsub(/\\/, ‘\\\\’)
Claramente, este código está tratando de reemplazar cada barra invertida en la cadena con dos. El pro-gramador duplicó las barras invertidas en la sustitución de texto, a sabiendas de que serían convertidas a \\ en el análisis de la sintaxis. Sin embargo, cuando se produce la sustitución, el motor de expresiones regulares realiza otro paso en la cadena, convirtiendo \\ a \, por lo que el efecto neto consiste en reem-plazar cada barra individual con otra barra invertida. Se tiene que escribir gsub(/\\/, ‘\\\\\\\\’)!
str = ‘a\b\c’ -> “a\b\c”str.gsub(/\\/, ‘\\\\\\\\’) -> “a\\b\\c”
Sin embargo, con el hecho de que \& sustituye por la cadena coincidente, también se puede escribir:

45
str = ‘a\b\c’ -> “a\b\c”str.gsub(/\\/, ‘\&\&’) -> “a\\b\\c” Si se utiliza la forma de bloque de gsub, la cadena de sustitución se analiza sólo una vez (durante la fase de sintaxis) y el resultado da lo que pretendía.
str = ‘a\b\c’ -> “a\b\c”str.gsub(/\\/) { ‘\\\\’ } -> “a\\b\\c”
Finalmente, como ejemplo de la asombrosa expresividad de combinar expresiones regulares con blo-ques de código, considere el siguiente fragmento de código del módulo de la biblioteca CGI, escrito por wakou Aoyama. El código tiene una cadena que contiene secuencias de escape HTML y lo convierte en ASCII normal. Este código fue escrito para un público japonés, donde se utiliza el modificador n en las expresiones regulares que anula el procesamiento de caarácter ancho.
def unescapeHTML(string) str = string.dup str.gsub!(/&(.*?);/n) { match = $1.dup case match when /\Aamp\z/ni then ‘&’ when /\Aquot\z/ni then ‘”’ when /\Agt\z/ni then ‘>’ when /\Alt\z/ni then ‘<’ when /\A#(\d+)\z/n then Integer($1).chr when /\A#x([09af]+)\z/ni then $1.hex.chr end } strendputs unescapeHTML(“1<2 && 4>3”)puts unescapeHTML(“"A" = A = A”)
produce:
1<2 && 4>3“A” = A = A
Expresiones Regulares Orientadas a Objetos
Tenemos que admitir que, si bien todas estas variables extrañas son muy fáciles de usar, no son muy orientadas a objetos y son ciertamente crípticas. Y, ¿no decíamos que todo en Ruby es un objeto? ¿Qué ha fallado aquí?
Nada, en realidad. Sólo que cuando Matz diseñó Ruby, produjo un sistema de manejo de expresiones regulares totalmente orientado a objetos y a continuación, envolvió todo para que resultara familiar a los programadores de Perl. Los objetos y las clases siguen ahí, debajo de la superficie. Así que vamos a pasar un rato en la excavación.
Ya hemos encontrado una clase: los literales de expresiones regulares crean instancias de la clase RegExp (documentado más adelante).
re = /cat/re.class -> Regexp
El método Regexp#match hace comparar una expresión regular con una cadena. En caso de éxito, devuelve una instancia de la clase MatchData, (documentado más adelante). Y ese objeto MatchData le da acceso a toda la información disponible sobre la comparación. Todas esas cosas interesantes que se puede obtener a partir de las variables $ se incluyen en un objeto pequeño y práctico.
re = /(\d+):(\d+)/ # match a time hh:mm

46
md = re.match(“Time: 12:34am”)md.class -> MatchDatamd[0] # == $& -> “12:34”md[1] # == $1 -> “12”md[2] # == $2 -> “34”md.pre_match # == $` -> “Time: “md.post_match # == $’ -> “am”
Dado que los datos coincidentes se almacenan en su propio objeto, se pueden mantener los resultados de dos o más coincidencias de patrones disponibles al mismo tiempo, algo que no se puede hacer con las variables $. En el siguiente ejemplo, comparamos el mismo objeto RegExp con dos cadenas. Cada coin-cidencia devuelve un objeto MatchData único, que se verifica mediante el examen de los dos campos de sub-patrón.
re = /(\d+):(\d+)/ # coincide con una hora hh:mmmd1 = re.match(“Time: 12:34am”)md2 = re.match(“Time: 10:30pm”)md1[1, 2] -> [“12”, “34”]md2[1, 2] -> [“10”, “30”]
Entonces, ¿cómo se ajustan las variables $? Bueno, después de cada comparación, Ruby almacena una referencia al resultado (cero o un objeto MatchData) en una variable local de subprocesos (accesible a través de $~). Todas las demás variables de expresiones regulares se derivan entonces de este objeto. Aunque en realidad no podemos pensar en un uso para el siguiente código, este demuestra que todas las demás variables $ relacionadas con MatchData son de hecho esclavas del valor en $~.
re = /(\d+):(\d+)/md1 = re.match(“Time: 12:34am”)md2 = re.match(“Time: 10:30pm”)[ $1, $2 ] # última coincidencia con éxito -> [“10”, “30”]$~ = md1[ $1, $2 ] # anterior coincidencia con éxito -> [“12”, “34”]
Habiendo dicho todo esto, tenemos que hacer una “confesión”. Utilizamos normalmente las variables $ en lugar de preocuparnos por los objetos MatchData. Para el uso diario acaba siendo más conveniente. A veces, simplemente no se puede dejar de ser pragmático.
Más sobre los Métodos
Hasta ahora en este libro, hemos ido definiendo y utilizando métodos sin pensarlo mucho, pero ha lle-gado el momento de entrar en los detalles.
La Definición de un Método
Como hemos visto, un método se define con la palabra clave def.Method debe comenzar con una le-tra minúscula (Usted no recibirá un error inmediato si utiliza una letra mayúscula, pero cuando Ruby vea la llamada al método, primero supondrá que es una constante y no una invocación al método, y como resul-tado puede analizar la llamada incorrectamente). Los métodos que actúan como consultas se nombran a menudo con un ? final, Como instance_of?. Los métodos que son “peligrosos”, o modifican al receptor, son nombrados con un ! final. Por ejemplo, String proporciona chop y chop!. El primero devuelve una cadena modificada y el segundo modifica al receptor en su lugar. Finalmente, los métodos que se pueden asignar, (una característica que hemos visto anteriormente) termina con un signo igual (=). ?, !, = son los únicos caracteres “raros” permitidos como sufijos en el nombre del método.
Ahora que hemos especificado un nombre para nuestro nuevo método, es posible que tengamos que declarar algunos parámetros. Estos son simplemente una lista de nombres de variables locales entre paréntesis. (Los paréntesis son opcionales en torno a los argumentos de un método, la convención es usarlos cuando un método tiene argumentos y se omiten cuando no los tienen).
def my_new_method(arg1, arg2, arg3) # 3 argumentos

47
# Aquí, el código del métodoenddef my_other_new_method # Sin argumentos# Aquí, el código del métodoend
Ruby le permite especificar los valores por defecto para los argumentos de un método --los valores que se utilizarán si el invocador no los pasa de forma explícita. Para ello, se utiliza el operador de asignación.
def cool_dude(arg1=”Miles”, arg2=”Coltrane”, arg3=”Roach”) “#{arg1}, #{arg2}, #{arg3}.”end
cool_dude -> “Miles, Coltrane, Roach.”cool_dude(“Bart”) -> “Bart, Coltrane, Roach.”cool_dude(“Bart”, “Elwood”) -> “Bart, Elwood, Roach.”cool_dude(“Bart”, “Elwood”, “Linus”) -> “Bart, Elwood, Linus.”
El cuerpo de un método contiene expresiones Ruby normales, salvo que no se puede definir una clase no única o un módulo dentro de un método. Si se define un método dentro de otro método, el método in-terno es definido cuando se ejecuta el método externo. El valor de retorno de un método es el valor de la última expresión ejecutada o el resultado de una expresión explícita de retorno.
Listas de Argumentos de longitud Variable
Pero, ¿y si lo que desea es pasar un número variable de argumentos o capturar múltiples argumentos en un solo parámetro? Colocar un asterisco antes del nombre del parámetro después de parámetros “nor-males” hace justamente eso.
def varargs(arg1, *rest) “Got #{arg1} and #{rest.join(‘, ‘)}”end
varargs(“one”) -> “Got one and “varargs(“one”, “two”) -> “Got one and two”varargs “one”, “two”, “three” -> “Got one and two, three”
En este ejemplo, el primer argumento se asigna como de costumbre al primer parámetro del método. Sin embargo, el siguiente parámetro es prefijado con un asterisco, por lo que todos los argumentos res-tantes se agrupan en una nueva matriz, que se asigna a ese parámetro.
Métodos y Bloques
Como ya comentamos en la sección de bloques e iteradores, cuando se invoca un método, puede ser asociado a un bloque. Normalmente, sólo tiene que llamar al bloque desde dentro del método con yield.
def take_block(p1) if block_given? yield(p1) else p1 endend
take_block(“no block”) -> “no block”take_block(“no block”) {|s| s.sub(/no /, ‘’) } -> “block”
Sin embargo, si el último parámetro en una definición de método se precede con un signo &, cualquier bloque asociado se convierte en un objeto Proc, y ese objeto se le asigna al parámetro.

48
class TaxCalculator def initialize(name, &block) @name, @block = name, block end def get_tax(amount) “#@name on #{amount} = #{ @block.call(amount) }” endend
tc = TaxCalculator.new(“Sales tax”) {|amt| amt * 0.075 }
tc.get_tax(100) -> “Sales tax on 100 = 7.5”tc.get_tax(250) -> “Sales tax on 250 = 18.75”
Invocación de un Método
Se llama a un método mediante la especificación de un receptor, el nombre del método y, opcionalmen-te, algunos parámetros y un bloque opcional.
connection.download_MP3(“jitterbug”) {|p| show_progress(p) }
En este ejemplo, el objeto connection es el receptor, download_MP3 es el nombre del método, “jitterbug” es el parámetro, y lo que hay entre las llaves es el bloque asociado.
Para los métodos de clase y de módulo, el receptor será la clase o el nombre del módulo.
File.size(“testfile”) -> 66Math.sin(Math::PI/4) -> 0.707106781186548
Si se omite el receptor, el valor por defecto es self, el objeto actual en curso.
self.class -> Objectself.frozen? -> falsefrozen? -> falseself.id -> 967900id -> 967900
Este mecanismo por defecto es cómo Ruby implementa los métodos privados. Los métodos privados no pueden ser llamados con un receptor, por lo que deben ser métodos disponibles en el objeto en curso.
Además, en el ejemplo anterior hemos llamado a self.class, pero no podíamos llamar al método class sin un receptor. Esto es así porque class es también una palabra clave de Ruby (que introduce las definiciones de clase), por lo que su uso independiente generaría un error de sintaxis.
Los parámetros opcionales siguen al nombre del método. Si no existe ambigüedad, puede omitir los pa-réntesis alrededor de la lista de argumentos cuando se llama a un método (Otra documentación de Ruby a veces llama comandos a estas llamadas de método sin paréntesis). Sin embargo, excepto en los casos más simples, no recomendamos esto --puede haber algunos problemas sutiles (En particular, se deben utilizar paréntesis en una llamada a método que en sí un parámetro a otro método invocado --a menos que sea el último parámetro). Nuestra regla es simple: si tienes dudas, utiliza paréntesis.
a = obj.hash # es lo mismoa = obj.hash() # que esto.obj.some_method “Arg1”, arg2, arg3 # es lo mismoobj.some_method(“Arg1”, arg2, arg3) # que con paréntesis.
Las versiones anteriores de Ruby agravan el problema porque permiten poner espacios entre el nom-bre del método y el paréntesis de apertura. Esto hace difícil analizar: ¿el paréntesis es el inicio de los parámetros o el inicio de una expresión? A partir de Ruby 1.8 se obtiene una advertencia si se pone un espacio entre el nombre del método y un paréntesis de apertura.

49
Métodos que retornan valores
Cada método llamado devuelve un valor (aunque no hay regla dice que haya que utilizar ese valor). El valor de un método es el valor de la última instrucción ejecutada durante la ejecución del método. Ruby tiene una sentencia return, que produce una salida desde el método actualmente en ejecución. El valor de return es el valor de su argumento(s). Se trata de idiomáticas Ruby que omitien el return si no es necesario.
def meth_one “one”endmeth_one -> “one”
def meth_two(arg) case when arg > 0 “positive” when arg < 0 “negative” else “zero” endend
meth_two(23) -> “positive”meth_two(0) -> “zero”
def meth_three 100.times do |num| square = num*num return num, square if square > 1000 endendmeth_three -> [32, 1024]
Como ilustra el último caso, si se le da a return varios parámetros, el método devuelve en una matriz. Se puede utilizar la asignación paralela para recolectar este valor de retorno.
num, square = meth_threenum -> 32square -> 1024
Expansión de Arrays en llamadas a Métodos
Anteriormente, vimos que si se pone un asterisco delante de un parámetro formal de una definición de método, se incluirán en una matriz múltiples argumentos en la llamada al método. Bueno, lo mismo fun-ciona a la inversa.
Cuando se llama a un método, se puede explorar una matriz y cada uno de sus elementos se toma como un parámetro independiente. Para ello, hay que anteponer al argumento matriz (y lo deben seguir todos los argumentos regulares) un asterisco.
def cinco(a, b, c, d, e)“I was passed #{a} #{b} #{c} #{d} #{e}”endcinco(1, 2, 3, 4, 5 ) -> “I was passed 1 2 3 4 5”cinco(1, 2, 3, *[‘a’, ‘b’]) -> “I was passed 1 2 3 a b”cinco(*(10..14).to_a) -> “I was passed 10 11 12 13 14”

50
Haciendo Bloques Más Dinámicos
Ya hemos visto cómo asociar un bloque con una llamada a método.
list_bones(“aardvark”) do |bone| # ...end
Normalmente, esto es perfectamente suficiente, se asocia un bloque de código con un método de la misma manera que cualquier trozo de código después de una instrucción if o while.
A veces, sin embargo, le gustaría ser más flexible. Por ejemplo, para la enseñanza de las matemáticas.
Un estudiante puede pedir una tabla de n-plus o de n-veces. Si el estudiante solicta una tabla de 2 ve-ces, nos da la salida 2, 4, 6, 8, y así sucesivamente. (Este código no verifica sus entradas para los errores.)
print “(t)imes or (p)lus: “times = getsprint “number: “number = Integer(gets)if times =~ /^t/ puts((1..10).collect {|n| n*number }.join(“, “))else puts((1..10).collect {|n| n+number }.join(“, “))end
produce:
(t)imes or (p)lus: tnumber: 22, 4, 6, 8, 10, 12, 14, 16, 18, 20
Esto funciona pero es feo, con el código prácticamente idéntico en cada rama de la instrucción if. Estaría mejor si factorizamos el bloque que realiza el cálculo.
print “(t)imes or (p)lus: “times = getsprint “number: “number = Integer(gets)if times =~ /^t/ calc = lambda {|n| n*number }else calc = lambda {|n| n+number }endputs((1..10).collect(&calc).join(“, “))
produce:
(t)imes or (p)lus: tnumber: 22, 4, 6, 8, 10, 12, 14, 16, 18, 20
Si el último argumento de un método está precedido por un signo &, Ruby asume que es un objeto Proc. Si se quita de la lista de parámetros, convierte el objeto Proc en un bloque y lo asocia con el método.
Recoger Argumentos Hash
Algunos lenguajes cuentan con argumentos de palabras clave, es decir, en lugar de pasar los argumen-tos en un orden y cantidad determinados, se pasa el nombre del argumento con su valor en cualquier or-den. Ruby 1.8 no tiene argumentos de palabras clave (mentirosos nosotros, porque en la versión anterior

51
de este libro dijimos que habría. Tal vez en Ruby 2.0). Mientras tanto, la gente está utilizando hashes como una forma de lograr el mismo efecto. Por ejemplo, se podría considerar la adición de un motor de búsque-da de nombres más potente para nuestra SongList.
class SongList def create_search(name, params) # ... endendlist.create_search(“short jazz songs”, { ‘genre’ => “jazz”, ‘duration_less_than’ => 270 })
El primer parámetro es el nombre a buscar, y el segundo es un hash literal que contiene los parámetros de búsqueda. El uso de un hash nos permite simular palabras clave: Buscar canciones con un género “jazz” y una duración inferior a 4 minutos y medio. Sin embargo, este enfoque es un poco torpe, y lo que hay entre llaves podría ser fácilmente confundido con un bloque asociado con el método. Por lo tanto, Ruby tiene un acceso directo. Usted puede colocar parejas clave => valor en una lista de argumentos, siempre y cuando vayan a continuación de los argumentos normales y precedan a los argumentos de la matriz y del bloque. Todos estos pares serán recogidos en un hash único y pasados como un argumento para el método. No son necesarias las llaves.
list.create_search(‘short jazz songs’, ‘genre’ => ‘jazz’, ‘duration_less_than’ => 270)
Por último, el lenguaje Ruby probablemente haría uso de símbolos en lugar de cadenas, ya que éstos dejan claro que te refieres al nombre de algo.
list.create_search(‘short jazz songs’, :genre => :jazz, :duration_less_than => 270)
Un programa bien escrito de Ruby normalmente contiene muchos métodos, cada uno muy pequeño, por lo que vale la pena familiarizarse con las opciones disponibles en la definición y en el uso de los mé-todos de Ruby.
Expresiones
Hasta ahora hemos sido muy arrogantes con el uso de expresiones en Ruby. Después de todo, a = b + c es una cosa bastante estándar. Puedes escribir un montón de código Ruby sin leer nada de este capítulo.
Pero no sería tan divertido ;-)
Una de las primeras diferencias de Ruby es que todo lo que razonablemente puede devolver un valor es considerado una expresión. ¿Qué significa esto en la práctica?
Algunas cosas obvias incluyen la capacidad de encadenar las declaraciones.
a = b = c = 0 -> 0[ 3, 1, 7, 0 ].sort.reverse -> [7, 3, 1, 0]
Algo quizás menos obvio, las cosas que normalmente son declaraciones en C o Java son expresiones en Ruby. Por ejemplo, las sentencias if y case, ambas retornan el valor de la última expresión ejecutada.song_type = if song.mp3_type == MP3::Jazz if song.written < Date.new(1935, 1, 1) Song::TradJazz

52
else Song::Jazz end else Song::Other end
rating = case votes_cast when 0...10 then Rating::SkipThisOne when 10...50 then Rating::CouldDoBetter else Rating::Rave end
Más adelante hablaremos más sobre if y case.
Operadores
Ruby tiene el conjunto básico de operadores (+, -, *, /, etc), así como algunas sorpresas. Más ade-lante daremos una tabla con la lista completa de los operadores y sus precedencias.
En ruby, muchos operadores se implementan en realidad como llamadas a métodos. Por ejemplo, al escribir a * b + c en realidad estás pidiendo al objeto referenciado por a, ejecutar el método * pasán-dole el parámetro b. A continuación, le pides al objeto que con los resultados de dicho cálculo ejecute el método + pasándole c como parámetro. Esto es equivalente a escribir:
(a.*(b)).+(c)
Ya que todo es un objeto y porque se pueden redefinir los métodos de instancia. Siempre puede rede-finir la aritmética básica si no le gustan las respuestas que está recibiendo.
class Fixnum alias old_plus +
# Redefinir suma en Fixnums. Esto# es una MALA IDEA! def +(other) old_plus(other).succ endend
1 + 2 -> 4a = 3a += 4 -> 8a + a + a -> 26
Más útil es que las clases que escriba puedan participar en las expresiones del operador como si se tra-tara de objetos integrados. Por ejemplo, podemos querer ser capaces de extraer el número de segundos de música a la mitad de una canción. Esto podemos hacerlo usando el operador de indexación [] para especificar la música que se va a extraer.
class Song def [](from_time, to_time) result = Song.new(self.title + “ [extract]”, self.artist, to_time - from_time) result.set_start_time(from_time) result endend

53
Este fragmento de código extiende la clase Song con el método [], que toma dos parámetros (una hora de inicio y una hora de finalización). Devuelve una nueva canción, con la música recortada al intervalo dado. A continuación, podría poner la introducción de una canción con código como:
song[0, 15].play
Misceláneo de Expresiones
Así como es obvio que el operador en una expresión es una llamada a método y las (tal vez) menos obvias expresiones declaración (como if y case), Ruby tiene un par de cosas más que se pueden utilizar en expresiones.
Expansión de Comandos Si escribe una cadena entre apóstrofes (a veces llamados acentos abiertos), o utiliza el prefijo delimi-tador de formato %x, será ejecutada (por defecto) como un comando por el sistema operativo subyacente. El valor de la expresión es la salida estándar de ese comando. Los saltos de línea no se quitan, por lo que es probable que el valor que recupere tenga un retorno final o un carácter de salto de línea.
`date` -> “Thu Aug 26 22:36:31 CDT 2004\n”`ls`.split[34] -> “book.out”%x{echo “Hello there”} -> “Hello there\n”
Puede utilizar la expansión de expresión y todas las secuencias usuales de escape en la cadena comando :
for i in 0..3 status = `dbmanager status id=#{i}` # ...end
El estado de salida del comando está disponible en la variable global $?.
Redefinición de Apóstrofes
En la descripción de la expresión de salida del comando, hemos dicho que una cadena entre apóstrofes “por defecto” se ejecuta como un comando. De hecho, la cadena se pasa al método llamado Kernel. `(Un único apóstrofe). Si lo desea, puede sustituirlo por éste.
alias old_backquote `def `(cmd) result = old_backquote(cmd) if $? != 0 fail “Command #{cmd} failed: #$?” end resultendprint `date`print `data`
produce:
Thu Aug 26 22:36:31 CDT 2004prog.rb:10: command not found: dataprog.rb:5:in ``’: Command data failed: 32512 (RuntimeError)from prog.rb:10

54
Asignación
Casi todos los ejemplos que hemos dado hasta ahora en este libro han contado con la asignación. Tal vez es hora de decir algo al respecto.
Una sentencia de asignación establece la variable o atributo en su lado izquierdo para referirse al valor de la derecha. A continuación, devuelve ese valor como el resultado de la expresión de asignación. Esto significa que puede encadenar asignaciones y que puede realizar asignaciones en lugares inesperados.
a = b = 1 + 2 + 3a -> 6b -> 6a = (b = 1 + 2) + 3a -> 6b -> 3File.open(name = gets.chomp)
Ruby tiene dos formas básicas de asignación. La primera asigna una referencia de objeto a una varia-ble o constante. Esta forma de trabajo está integrada en el lenguaje.
instrumento = “piano”MIDDLE_A = 440
La segunda forma de asignación consiste en tener un atributo de objeto o referencia a elemento en el lado izquierdo.
song.duration = 234instrument[“ano”] = “ccolo”
Estas formas son especiales, porque se implementan mediante llamadas a métodos en los valores de la izquierda, lo que significa que se pueden anular.
Ya hemos visto como definir un atributo de un objeto. Basta con definir el nombre del método seguido de un signo de igual. Este método recibe como parámetro el valor de la derecha de la asignación.
class Song def duration=(new_duration) @duration = new_duration endend
Estos métodos de configuración de atributos no tienen que corresponder con las variables de instancia internas, y no es necesario un lector de atributos para todos los escritores de atributos (o viceversa).
class Amplifier def volume=(new_volume) self.left_channel = self.right_channel = new_volume endend
En versiones antiguas de Ruby, el resultado de la asignación es el valor devuelto por el atributo esta-blecido del método. En Ruby 1.8, el valor de la asignación es siempre el valor del parámetro, el valor de retorno del método se descarta.
class Test def val=(val) @val = val return 99 endend

55
t = Test.newa = t.val = 2a -> 2
En versiones anteriores de Ruby, a se establecería a 99 por la asignación, y en Ruby 1.8 se establece a 2.
Asignación Paralela
Durante su primera semana en un curso de programación, podría tener que escribir código para cam-biar los valores de dos variables.
int a = 1;int b = 2;int temp;temp = a;a = b;b = temp;
Se puede hacer esto más limpiamente en Ruby:
a, b = b, a
Las asignaciones de ruby son realizadas efectivamente en paralelo, por lo que los valores asignados no se ven afectados por la asignación misma. Los valores en el lado derecho se evalúan en el orden en que aparecen antes de hacer la asignación a las variables o atributos a la izquierda. Un ejemplo un tanto artificial ilustra esto. La segunda línea asigna a las variables a, b, y c los valores de las expresiones x, x += 1 y x += 1, respectivamente.
x = 0 -> 0a, b, c = x, (x += 1), (x += 1) -> [0, 1, 2]
Cuando una asignación tiene más de un valor a la izquierda, la expresión de asignación devuelve una matriz de valores a la derecha. Si una asignación contiene más valores a la izquierda que a la derecha, los valores de la izquierda excedentes se establecen a nil. Si una asignación múltiple contiene más valores a la derecha que a la izquierda, los valores a la derecha adicionales se omiten. Si una asignación tiene sólo un valor a la izquierda y varios valores a la derecha, los valores de la derecha se convierten en una matriz que es asignada al valor de la izquierda.
Utilizar descriptores de acceso en una clase
¿Por qué escribimos self.left_channel en uno de los ejemplos anteriores? Bueno, los atributos de escritura tienen un gotcha oculto (un inesperado o poco intuitivo, pero documentado, comportamien-to de un sistema informático --en oposición a un fallo). Normalmente, los métodos internos de una clase pueden invocar otros métodos de su misma clase y superclases en la forma funcional (es decir, con un receptor implícito de si mismo). Sin embargo, esto no funciona con los escritores de atributos. Ruby vela asignación y decide que el nombre de la izquierda debe ser una variable local, no un método de lla-mada a un escritor de atributos.
class BrokenAmplifier attr_accessor :left_channel, :right_channel def volume=(vol) left_channel = self.right_channel = vol end end ba = BrokenAmplifier.new ba.left_channel = ba.right_channel = 99 ba.volume = 5 ba.left_channel -> 99
ba.right_channel -> 5

56
Se pueden contraer y expandir las matrices con el operador de Ruby de asignación paralela. Si el úl-timo valor de la izquierda está precedido por un asterisco, todos los valores a la derecha restantes serán recolectados y asignados a ese valor de la izquierda como una matriz. Del mismo modo, si el último valor a la derecha es una matriz, se puede prefijar con un asterisco y efectivamente se expande en sus valores constituyentes en su lugar. (Esto no es necesario si el valor derecho es lo único que hay en este lado de-recho --la matriz se expande de forma automática.)
a = [1, 2, 3, 4]b, c = a -> b == 1, c == 2b, *c = a -> b == 1, c == [2, 3, 4]b, c = 99, a -> b == 99, c == [1, 2, 3, 4]b, *c = 99, a -> b == 99, c == [[1, 2, 3, 4]]b, c = 99, *a -> b == 99, c == 1b, *c = 99, *a -> b == 99, c == [1, 2, 3, 4]
Asignaciones Anidadas
Las asignaciones en paralelo tienen una característica que vale la pena mencionar. El lado izquierdo de una asignación puede contener una lista de elementos entre paréntesis. Ruby trata estos elementos como si se tratara de una sentencia de asignación anidada. Se extrae el valor de la derecha que corresponde, asignándole los términos entre paréntesis antes de continuar con la asignación de más alto nivel.
b, (c, d), e = 1,2,3,4 -> b == 1, c == 2, d == nil, e == 3b, (c, d), e = [1,2,3,4] -> b == 1, c == 2, d == nil, e == 3b, (c, d), e = 1,[2,3],4 -> b == 1, c == 2, d == 3, e == 4b, (c, d), e = 1,[2,3,4],5 -> b == 1, c == 2, d == 3, e == 5b, (c,*d), e = 1,[2,3,4],5 -> b == 1, c == 2, d == [3, 4], e == 5
Otras Formas de Asignación
Al igual que muchos otros lenguajes, Ruby tiene un atajo sintáctico: a = a + 2 se puede escribir como a += 2.
La segunda forma se convierte internamente a la primera. Esto significa como cabría esperar, que los operadores se han definido como métodos en sus propias clases de trabajo.
class Bowdlerize def initialize(string) @value = string.gsub(/[aeiou]/, ‘*’) end def +(other) Bowdlerize.new(self.to_s + other.to_s) end def to_s @value endend
a = Bowdlerize.new(“damn “) -> d*mna += “shame” -> d*mn sh*m*
Algo que no se encuentra en Ruby son los operadores de autoincremento (++) y (--) de C y Java. Se utilizan en su lugar las formas += y -=.
Nos olvidamos de poner “self.” delante de la asignación a left_channel, por lo que Ruby alma-cena el nuevo valor en una variable local del método volume=; el atributo del objeto nunca se actua-liza. Esto puede dar lugar a un error difícil de localizar.

57
Ejecución Condicional
Ruby tiene diferentes mecanismos para la ejecución condicional de código. Con la mayoría de ellos debe sentirse familiarizado y muchos tienen algunas peculiaridades muy cuidadas. Antes de entrar en ellos, sin embargo, tenemos que pasar un tiempo viendo las expresiones booleanas.
Expresiones Booleanas
Ruby tiene una definición sencilla de la verdad. Cualquier valor que no es nil ni la constante false es verdadero. Usted encontrará que las rutinas de biblioteca utilizan esto constantemente. Por ejemplo, IO#gets que devuelve la siguiente línea de un archivo, retorna nil al final del archivo, lo que le permite escribir bucles como
while line = gets # process lineend
Sin embargo, los programadores de C, C++ y Perl as veces caen en una trampa. El número cero no se interpreta como un valor falso y tampoco es una cadena de longitud cero. Esto puede ser un hábito difícil de romper.
Defined?, And, Or y Not
Ruby soporta todos los operadores lógicos estándar y presenta el nuevo operador defined?.
Tanto and como && se evalúan como true sólo si ambos operandos son verdaderos. Evalúan el se-gundo operando sólo si el primero es cierto (esto se conoce como evaluación de cortocircuito). La única diferencia en las dos formas es la prioridad (and la tiene más baje que &&).
Del mismo modo, tanto or como || evalúan como true si alguno de los operandos es cierto. Evalúan su segundo operando sólo si el primero es falsa. Al igual que con and, la única diferencia entre or y || es su prioridad.
Sólo para hacer la vida más interesante, and y or tienen la misma prioridad, e && tiene prioridad mayor que ||.
not y ! retornan el contrario de su operando (false si el operando es cierto, y true si el operando es falso). Y sí, not y ! sólo se diferencian en la precedencia. Todas estas reglas de precedencia se resumen en una tabla más adelante.
El operador defined? retorna nil si su argumento (que puede ser una expresión arbitraria) no está definido, de lo contrario retorna una descripción de ese argumento. Si el argumento es yield, defined? retorna la cadena “yield” si se asocia un bloque de código con el contexto actual.
defined? 1 -> “expression”defined? dummy -> nildefined? printf -> “method”defined? String -> “constant”defined? $_ -> “global-variable”defined? Math::PI -> “constant”defined? a = 1 -> “assignment”defined? 42.abs -> “method”
Además de los operadores booleanos, los objetos de Ruby soportan comparación con los métodos ==, ===, <=> =~, eql? y equal? (véase el cuadro en la página siguiente). Todos, pero <=> se define en la clase Object y a menudo son anulados por los descendientes a fin de proporcionar una semántica adecuada. Por ejemplo, la clase Array redefine == para que dos objetos matriz sean iguales si tienen el mismo número de elementos y si sus correspondientes elementos son iguales.

58
Operador Significado== Test de valor igual=== Utilizado para comparar los elementos de un each con los objetivos en una claúsula
de una sentencia case<=> Operador de comparación general. Devuelve -1, 0 o +1, dependiendo de si el receptor
es menor, igual o mayor que su argumento.<, <=, >=, > Operadores de comparación para menor que, menor o igual, mayor o
igual y mayor que=~ Expresión regular coincide con el patróneql? True si el receptor y el argumento tienen ambos el mismo tipo y valor igual. 1 == 1.0
devuelve true, pero 1.eql?(1,0) devuelve false.equal? True si el receptor y el argumento tienen el mismo identificador (ID) de objeto.
== y =~ tienen la forma negada != y !~. Cuando Ruby lee el programa, a != b es equivalente a !(a==b) y a !~ b es lo mismo que !(a=~b). Esto significa que si usted escribe una clase que anula == o =~ obtiene el funcionamiento de != y !~ gratis. Pero por otro lado esto también significa que != y !~ no se pueden definir independientemente de == y =~, respectivamente.
Se puede utilizar un rango Ruby como exprersión booleana. Un rango como exp1..exp2 se evaluará como false hasta que exp1 se cumple. El rango se evaluará como true hasta que exp2 se cumple. Una vez que esto sucede, se reestablece el rango, listo para actuar de nuevo. Un poco más adelante mostra-mos algunos ejemplos.
Antes de Ruby 1.8, se podía utilizar una expresión regular cruda como una expresión booleana. Ahora esto está en desuso. Se puede utilizar el operador ~ para comparar $_ frente a un patrón.
El valor de las Expresiones Lógicas
En el texto, que dice cosas como “and da como resultado true si ambos operandos son verdaderos”. Pero en realidad es un poco más sutil que eso. Los operadores and, or, && y || retornan el primero de sus argumentos que determinan la verdad o falsedad de la condición. Suena muy bien. ¿Qué significa?
Tomamos la expresión “val1 and val2”. Si val1 es falso o nulo, entonces sabemos que la expresión no puede ser verdad. En este caso, el valor de val1 determina el valor total de la expresión, por lo que es el valor devuelto. Si val1 tiene otro valor, el valor total de la expresión depende de val2, por lo que se devuelve el valor de este último.
nil and true -> nilfalse and true -> false99 and false -> false99 and nil -> nil99 and “cat” -> “cat”
Tenga en cuenta que a pesar de toda esta magia, el valor de verdad total de la expresión es correcto.
La misma evaluación se lleva a cabo para or (excepto que en una expresión or el valor se conoce antes si val1 es no falso).
false or nil -> nilnil or false -> false99 or false -> 99 Un lenguaje común como Ruby hace uso de esto:
words[key] ||= []words[key] << word
La primera línea es equivalente a words[key] = words[key] || []. Si la entrada para key en el hash words no está definida (nil) el valor de || será el segundo operando, una nueva matriz vacía. Por

59
lo tanto, esta línea de código asignará una matriz a un elemento hash que ya no tiene un valor, dejando intacto lo contrario. A veces se va a ver esto escrito en una línea como:
(words[key] ||= []) << word
Expresiones If y Unless
Una expresión if en Ruby es bastante similar a una sentencia “if” en otros lenguajes.
if song.artist == “Gillespie” then handle = “Dizzy”elsif song.artist == “Parker” then handle = “Bird”else handle = “unknown”end
Si la declaración if se dispone en varias lineas, puede dejar fuera la palabra clave then.
if song.artist == “Gillespie” handle = “Dizzy”elsif song.artist == “Parker” handle = “Bird”else handle = “unknown”end
Sin embargo, si desea presentar su código de mejor manera, puede separar la expresión lógica de las siguientes sentencias con la palabra clave then.
if song.artist == “Gillespie” then handle = “Dizzy”elsif song.artist == “Parker” then handle = “Bird”else handle = “unknown”end
Se puede hacer incluso más conciso utilizando los dos puntos (:) en lugar de then.
if song.artist == “Gillespie”: handle = “Dizzy”elsif song.artist == “Parker”: handle = “Bird”else handle = “unknown”end
Se puede tener cero o más cláusulas elsif y una cláusula else opcional.
Como hemos dicho antes, if es una expresión, no una sentencia, que devuelve un valor. No tiene que usar el valor de una expresión if, pero puede ser útil.
handle = if song.artist == “Gillespie” then “Dizzy” elsif song.artist == “Parker” then “Bird” else “unknown” end
Ruby también tiene una forma de negación de la sentencia if.

60
unless song.duration > 180 cost = 0.25else cost = 0.35end
Finalmente, para los aficionados de C que haya por ahí, Ruby también es compatible con la expresión condicional estilo C:
cost = song.duration > 180 ? 0.35 : 0.25
Una expresión condicional devuelve el valor de las expresión antes o después de los dos puntos, de-pendiendo de si la expresión lógica antes del signo de interrogación se evalúa como verdadera o falsa. En este caso, si la duración del tema es mayor de tres minutos, la expresión devuelve 0,35 y para canciones más cortas, devuelve 0,25. Sea cual sea el resultado, se asigna a cost.
Modificadores If y Unless
Ruby comparte una característica interesante con Perl. Los modificadores de instrucciones le permiten cambiar sentencias condicionales al final de una sentencia normal.
mon, day, year = $1, $2, $3 if date =~ /(\d\d)(\d\d)(\d\d)/puts “a = #{a}” if debugprint total unless total.zero?
Por un modificador if, la expresión anterior sólo se evaluará si la condición es verdadera. unless trabaja a la inversa.
File.foreach(“/etc/fstab”) do |line| next if line =~ /^#/ # Skip comments parse(line) unless line =~ /^$/ # No parsear líneas vacíasend
Como if es en sí una expresión, se puede volver muy oscura con sentencias tales como
if artist == “John Coltrane” artist = “’Trane”end unless use_nicknames == “no”
Este camino conduce a las puertas de la locura.
Expresiones Case
La expresión Ruby case es una poderosa bestia, y para hacerla aún más potente, viene en dos sabores.
La primera forma es bastante cercana a una serie de sentencias if: le permite enumerar una serie de condiciones y ejecutar la instrucción correspondiente a la primera que se cumple. Por ejemplo, los años bisiestos deben ser divisibles por 400 o por 4 y no por 100.
bisiesto = case when year % 400 == 0: true when year % 100 == 0: false else year % 4 == 0 end
La segunda forma de la sentencia case es probablemente más común. Puede especificar un objetivo al principio de la sentencia case, y un cada when en claúsulas con una o más comparaciones.
case input_linewhen “debug”

61
dump_debug_info dump_symbolswhen /p\s+(\w+)/ dump_variable($1)when “quit”, “exit” exitelse print “Illegal command: #{input_line}”end
Al igual que con if, case devuelve el valor de la última expresión ejecutada, y se puede utilizar la palabra clave then, si la expresión está en la misma línea que la condición.
kind = case year when 1850..1889 then “Blues” when 1890..1909 then “Ragtime” when 1910..1929 then “New Orleans Jazz” when 1930..1939 then “Swing” when 1940..1950 then “Bebop” else “Jazz” end
Y al igual que con if, puede utilizar los dos puntos (:) en lugar de then.
kind = case year when 1850..1889: “Blues” when 1890..1909: “Ragtime” when 1910..1929: “New Orleans Jazz” when 1930..1939: “Swing” when 1940..1950: “Bebop” else “Jazz” end
case opera mediante comparación del objetivo (la expresión después de la palabra clave case) con cada una de las expresiones de comparación después de la palabra clave when. Esta prueba se realiza mediante comparación === objetivo. Mientras una clase defina una semántica significativa para === (y todas las clases internas al lenguaje -built-in- lo hacen), los objetos de esa clase se puede utilizar en las expresiones case.
Por ejemplo, las expresiones regulares definen === como una simple comparación de patrón.
case linewhen /title=(.*)/ puts “Title is #$1”when /track=(.*)/ puts “Track is #$1”when /artist=(.*)/ puts “Artist is #$1”end
Las clases de Ruby son instancias de la clase Class, que define === para comprobar si el argumento es una instancia de la clase o una de sus superclases. Así que (abandonando los beneficios del polimor-fismo y tirando a los dioses de la refactorización de las orejas), se puede testear la clase de los objetos.
case shapewhen Square, Rectangle # ...when Circle # ...when Triangle

62
# ...else # ... end
Bucles
No se lo digais a nadie, pero Ruby tiene internamente una construcción de bucles bastante primitiva.
El bucle while ejecuta el cuerpo de la sentencia cero o más veces, siempre y cuando su condición sea verdadera. Por ejemplo, este código común lee hasta que se agota la entrada.
while line = gets # ...end
El bucle until que es todo lo contrario, se ejecuta el cuerpo hasta que la condición sea verdadera.
until play_list.duration > 60 play_list.add(song_list.pop)end
Al igual que con if y unless, se pueden utilizar ambas en los bucles como modificadores de sentencia .
a = 1a *= 2 while a < 100a -= 10 until a < 100a -> 98
En la sección de expresiones booleanas, dijimos que un rango se puede utilizar como una especie de flip-flop, retornando true cuando ocurre algún evento y permanece true hasta que un segundo evento ocurre. Esta funcionalidad se utiliza normalmente en los bucles. En el ejemplo siguiente, se lee un archivo de texto que contiene los diez primeros números ordinales (“primero”, “segundo”, y así sucesivamente), pero solo empieza a imprimir las líneas cuando coincide con “tercero” y termina cuando coincide con “quinto ”.
file = File.open(“ordinal”)while line = file.gets puts(line) if line =~ /third/ .. line =~ /fifth/end
produce:
thirdfourthfifth
Programadores que vienen de Perl pueden escribir el ejemplo anterior de forma ligeramente diferente.
file = File.open(“ordinal”)while file.gets print if ~/third/ .. ~/fifth/end
produce:
thirdfourthfifth
Este sistema utiliza un comportamiento mágico entre bastidores: gets asigna la última línea para la

63
lectura de la variable global $_, el operador ~ hace una comparación de expresión regular contra $_ y print sin argumentos imprime $_. Este tipo de código está pasado de moda en la comunidad Ruby.
Los elementos de un rango utilizados en una expresión booleana pueden ser también expresiones. Es-tos son evaluados cada vez que se evalúa la expresión lógica en general. Por ejemplo, el siguiente código utiliza el hecho de que la variable $. contiene el número de línea de entrada actual, para mostrar números de línea del uno al tres y aquellas que coincidan entre la comparación /eig/ y /nin/.
File.foreach(“ordinal”) do |line| if (($. == 1) || line =~ /eig/) .. (($. == 3) || line =~ /nin/) print line endend
produce:
firstsecondthirdeighthninth
Uno se puede arrugar al usar while y until como modificadores de sentencia. Si la declaración que va a modificar es un bloque de begin/end, el código en el bloque siempre se ejecutará al menos una vez independientemente del valor de la expresión lógica.
print “Hello\n” while falsebegin print “Goodbye\n”end while false
produce:
Goodbye
Iteradores
Si se lee el comienzo de la sección anterior, es posible que se haya desanimado. “Ruby tiene inter-namente una construcción de bucles bastante primitiva”, se dijo. No se desespere, amable lector, ya que tenemos una buena noticia. Ruby no necesita ningún tipo de complejos bucles integrados, porque todas las cosas divertidas se implementan mediante iteradores Ruby.
Por ejemplo, Ruby no tiene un bucle “for”, (por lo menos no del tipo que se encuentran en C, C++ o Java). En cambio, Ruby utiliza métodos definidos en varias clases integradas para proporcionar equiva-lentes, pero menos propensos a errores..
Veamos algunos ejemplos.
3.times do print “Ho! “end
produce:
Ho! Ho! Ho!
Es fácil evitar errores, este ciclo se ejecutará tres veces y punto. Además de con times, con los nú-meros enteros se pueden hacer bucles en intervalos específicos llamando a downto y upto, y para todos los tipos de números se peuede utilizar step. Por ejemplo, un tradicional bucle “for” que recorre de 0 a 9 (algo así como i = 0; i <10; i++) se escribe como sigue:

64
0.upto(9) do |x| print x, “ “end
produce:
0 1 2 3 4 5 6 7 8 9
Un bucle de 0 a 12 cada 3 se puede escribir de la siguiente manera:
0.step(12, 3) {|x| print x, “ “ }
produce:
0 3 6 9 12
Del mismo modo, iterar sobre matrices y otros contenedores se hace fácil con el método each:
[ 1, 1, 2, 3, 5 ].each {|val| print val, “ “ }
produce:
1 1 2 3 5
Y una vez que una clase soporta each, los otros métodos están disponibles en el módulo Enumerable (documentado más adelante). Por ejemplo, la clase File proporciona un método each, que devuelve cada línea de un archivo por turno. Utilizando el método grep en Enumerable, podríamos iterar sólo aquellas líneas que cumplen una determinada condición.
File.open(“ordinal”).grep(/d$/) do |line| puts lineend produce:
secondthird
Por último, está el lazo más básico de todos. Ruby proporciona un iterador integrado llamado loop.
loop do # block ...end
El iterador loop llama al bloque asociado para siempre (o por lo menos hasta interrumpir del bucle, pero antes tendrá que seguir leyendo para saber cómo hacerlo).
For...In
Anteriormente hemos dicho que las únicas primitivas de bucle integradas son while y until. ¿Qué es for, entonces? Bueno, for es casi un terrón de azúcar sintáctico. Cuando se escribe:
for song in songlist song.playend
Ruby lo traduce en algo así como:

65
songlist.each do |song| song.playend
La única diferencia entre el bucle for y la forma each es el alcance de las variables locales que se definen en el cuerpo. Esto se discute ahora un poco más adelante.
Se puede utilizar for para iterar sobre cualquier objeto que responde al método each, como un Array o un Range.
for i in [‘fee’, ‘fi’, ‘fo’, ‘fum’] print i, “ “endfor i in 1..3 print i, “ “endfor i in File.open(“ordinal”).find_all {|line| line =~ /d$/} print i.chomp, “ “end
produce:
fee fi fo fum 1 2 3 second third
Mientras su clase defina un razonable método each, se puede utilizar un bucle for para recorrer sus objetos.
class Periods def each yield “Classical” yield “Jazz” yield “Rock” endend
periods = Periods.new for genre in periods print genre, “ “end
produce:
Classical Jazz Rock
Break, Redo y Next
Las construcciones de control de bucle break, redo y next permiten alterar el flujo normal de un bucle o iterador.
break termina el bucle inmediatamente y el control se reanuda en la siguiente instrucción del bloque. redo repite el bucle desde el principio, pero sin volver a evaluar la condición o ir a buscar el siguiente elemento (en un iterador). next salta al final del bucle a partir de la próxima iteración.
while line = gets next if line =~ /^\s*#/ # saltar comentarios break if line =~ /^END/ # parada al final # sustitución de cosas en acentos abiertos y volver a intentarlo redo if line.gsub!(/`(.*?)`/) { eval($1) } # process line ...end

66
Estas palabras clave también se pueden utilizar con cualquiera de los mecanismos basados en bucle iterador.
i=0loop do i += 1 next if i < 3 print i break if i > 4end
produce:
345
A partir de Ruby 1.8, break y next pueden recibir argumentos. En bucles convencionales, es proba-ble que sólo tienga sentido hacer esto con break (ya que cualquier valor dado a next efectivamente se pierde). Si un bucle convencional no ejecuta un break, este valor es nil.
result = while line = gets break(line) if line =~ /answer/ endprocess_answer(result) if result
Retry
La sentencia redo hace un bucle para repetir la iteración actual. A veces, sin embargo, es necesario darle cuerda al bucle para que vuelva al principio. La sentencia retry es justo el billete. retry reinicia cualquier tipo de bucle iterador.
for i in 1..100 print “Now at #{i}. Restart? “ retry if gets =~ /^y/iend
La ejecución de esta forma es interactiva, puede se puede ver:
Now at 1. Restart? nNow at 2. Restart? yNow at 1. Restart? n . . .
retry volverá a evaluar los argumentos para el iterador antes de reiniciarlo. He aquí un ejemplode un bucle until “hágalo usted mismo”. def do_until(cond) break if cond yield retryendi = 0do_until(i > 10) do print i, “ “ i += 1end
produce:
0 1 2 3 4 5 6 7 8 9 10

67
Ámbito de las Variables, Bucles y Bloques
Los bucles while, until y for se construyen integrados en el lenguaje y no introducen nuevas posi-bilidades; los locales ya existentes se pueden utilizar en el bucle y cualquier otros nuevos locales creados estarán disponibles después.
Los bloques utilizados por iteradores (tales como loop y each) son un poco diferentes. Normalmente, las variables locales creadas en estos bloques no son accesibles fuera del bloque.
[ 1, 2, 3 ].each do |x| y = x + 1end[ x, y ]
produce:
prog.rb:4: undefined local variable or method `x’ for main:Object (NameError)
Sin embargo, si un momento dado en el bloque se ejecuta una variable local que ya existe con el mismo nombre que el de una variable en el bloque, éste utiliza la variable local existente. Su valor por lo tanto, estará disponible después de terminar el bloque. Como muestra el siguiente ejemplo, esto se aplica tanto a las variables normales como a los parámetros del bloque.
x = nily = nil[ 1, 2, 3 ].each do |x| y = x + 1end[ x, y ] -> [3, 4]
Tenga en cuenta que a la variable no tiene por qué habérsele dado un valor en el ámbito externo: el intérprete de Ruby sólo tiene que verla.
if false a = 1end3.times {|i| a = i }
a -> 2
Todo este tema del ámbito de las variables y los bloques es el que genera debate en la comunidad Ruby. El esquema actual tiene problemas definidos (sobre todo cuando las variables son alias inesperada-mente dentro de bloques), pero de momento no se ha logrado llegar a algo que sea mejor y más aceptable para la comunidad en general. Matz ha prometido cambios en Ruby 2.0, pero mientras tanto, tenemos un par de sugerencias para minimizar los problemas con las interferencias de las variables locales y los bloques.
•Mantenerbrevessusmétodosybloques.Conmenosvariables,menoreslaposibilidaddequevayana darse una paliza entre sí. También es más fácil de cara el código para comprobar que no tiene nombres en conflicto.
•Utilizardiferentesesquemasdenomenclaturaparalasvariableslocalesylosparámetrosdebloques.Por ejemplo, es probable que no quiera una variable local llamada “i”, pero podría ser perfectamente acep-table como un parámetro de bloque.
En realidad, este problema no se plantea en la práctica tan a menudo como se pueda pensar.

68
Excepciones, Capturas y Lanzamientos
Hasta ahora hemos estado desarrollando código en Pleasantville, un lugar maravilloso donde nada, nunca, va mal. Cada llamada a librería tiene éxito, los usuarios no introducen datos incorrectos y los re-cursos son abundantes y baratos. Bueno, eso está por cambiar. ¡Bienvenido al mundo real!
En el mundo real, los errores ocurren. Los buenos programas (y programadores) se anticipan y ha-cen arreglos para manejarlos correctamente. Esto no siempre es tan fácil como pueda parecer. A menudo, el código que detecta un error no tiene el contexto para saber qué hacer al respecto. Por ejemplo, intentar abrir un archivo que no existe es aceptable en algunas circunstancias y es un error fatal en otras ocasio-nes. ¿Cómo vá a hacer su módulo de manejo de archivos?
El enfoque tradicional es el uso de códigos de retorno. El método open devuelve un valor específico para decir que falla. Este valor se propaga de nuevo a través de las capas de las llamadas a rutina hasta que alguien quiere asumir la responsabilidad de ello.
El problema con este enfoque es que la gestión de todos estos códigos de error puede ser un dolor de cabeza. Si en una función hay llamadas a open, luego leer, finalmente cerrar, y cada una puede devolver una indicación de error, ¿cómo puede distinguir la función estos códigos de error en el valor que devuelve a su llamador?
En gran medida, las excepciones resuelven este problema. Las excepciones le permiten empaquetar información sobre un error en un objeto. El objeto de excepción después se propaga de vuelta a la pila de llamadas de forma aautomática, hasta que el sistema de ejecución se encuentra el código que explícita-mente declara que sabe manejar ese tipo de excepción.
La Clase Exception
El paquete que contiene la información sobre una excepción es un objeto de la clase Exception o uno de los hijos de la misma. Ruby predefine una jerarquía ordenada de excepciones, que se muestra en la Figura 4 de la página siguiente. Como veremos más adelante, esta jerarquía hace el manejo de excep-ciones mucho más fácil.
Cuando usted necesita poner una excepción, puede utilizar una de las clases Exception integradas, o puede crear una propia. Si usted crea la suya, puede que quiera que sea una subclase de StandardE-rror o una de sus hijos. Si no lo hace su excepción no será capturada por defecto.
Cada Excepction tiene asociada una cadena de mensaje y un trazado de pila. Si define sus propias excepciones, puede añadir información adicional.
Manejo de Excepciones
Nuestra máquina de discos descarga canciones de Internet a través de un socket TCP. El código básico es simple (suponiendo que el nombre del archivo y el socket se han configurado).
op_file = File.open(opfile_name, “w”)while data = socket.read(512) op_file.write(data)end
¿Qué pasa si tenemos un error fatal a mitad de la descarga? Desde luego, no desea almacenar una canción incompleta en la lista de canciones. “I Did It My *click*”.
Vamos a añadir un código de control de excepciones y ver cómo ayuda. El manejo de excepciones que incluya el código que podría lanzar una excepción en un bloque begin/end y usar una o más cláusulas rescue que digan a Ruby los tipos de excepciones que queremos manejar. En este caso particular es-tamos interesados en detectar excepciones SystemCallError (y, por ende, las excepciones que son subclases de SystemCallError), así que sea eso es lo que aparece en la línea de rescue. En el bloque
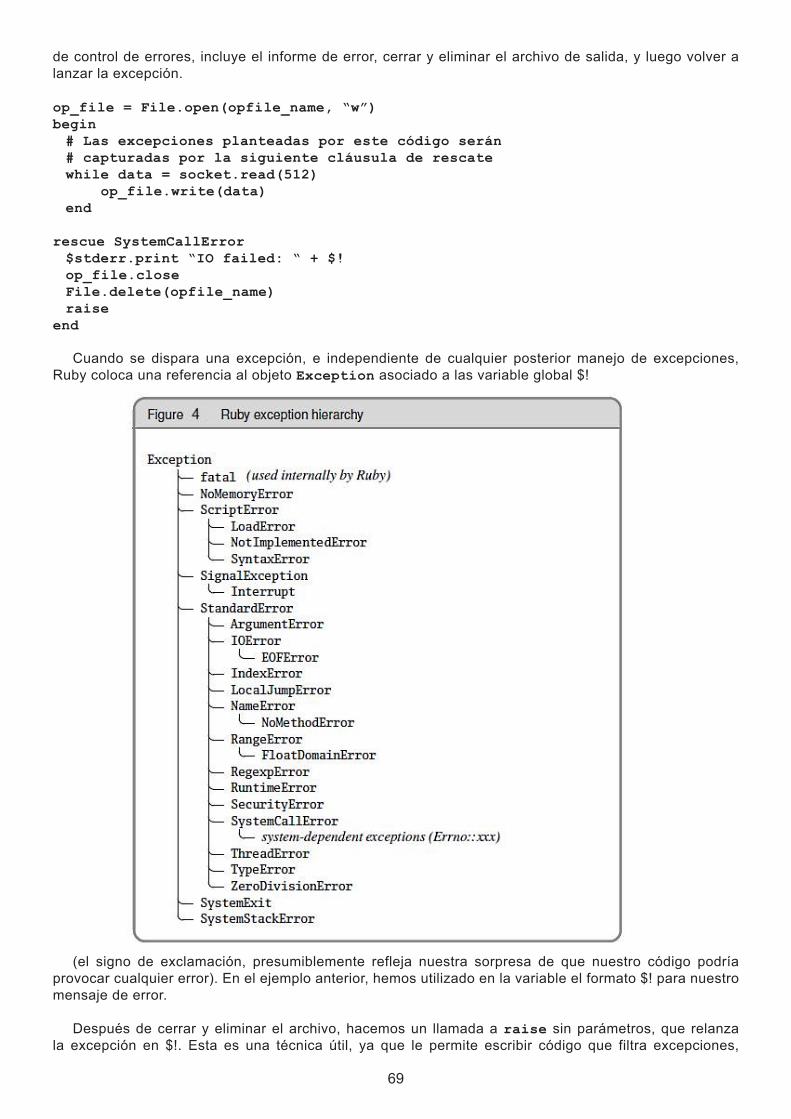
69
de control de errores, incluye el informe de error, cerrar y eliminar el archivo de salida, y luego volver a lanzar la excepción.
op_file = File.open(opfile_name, “w”)begin # Las excepciones planteadas por este código serán # capturadas por la siguiente cláusula de rescate while data = socket.read(512) op_file.write(data) end
rescue SystemCallError $stderr.print “IO failed: “ + $! op_file.close File.delete(opfile_name) raiseend
Cuando se dispara una excepción, e independiente de cualquier posterior manejo de excepciones, Ruby coloca una referencia al objeto Exception asociado a las variable global $!
(el signo de exclamación, presumiblemente refleja nuestra sorpresa de que nuestro código podría provocar cualquier error). En el ejemplo anterior, hemos utilizado en la variable el formato $! para nuestro mensaje de error.
Después de cerrar y eliminar el archivo, hacemos un llamada a raise sin parámetros, que relanza la excepción en $!. Esta es una técnica útil, ya que le permite escribir código que filtra excepciones,

70
transmitiendo aquellas que usted no puede manejar a niveles superiores. Es casi como la aplicación de una jerarquía de herencia para el procesamiento de errores.
Se pueden tener varias cláusulas rescue en un bloque begin, y cada cláusula rescue puede especi-ficar múltiples excepciones a capturar. Al final de cada cláusula rescue se le puede dar a Ruby el nombre de una variable local para recibir la excepción que coincida. Mucha gente encuentra esto más legible que el uso de $! por todas partes.
begin eval stringrescue SyntaxError, NameError => boom print “String doesn’t compile: “ + boomrescue StandardError => bang print “Error running script: “ + bangend
¿Cómo decide Ruby que cláusula rescue ejecutar? Resulta que el proceso es bastante similar a la utilizada por la instrucción case. Para cada cláusula rescue en el bloque begin, Ruby compara la excep-ción formulada contra cada uno de los parámetros por turno. Si la excepción coincide con un parámetro, Ruby ejecuta el cuerpo de rescue y deja de buscar. La comparación se hizo con parámetro===$!. Para la mayoría de las excepciones, esto significa que la comparación tendrá éxito si la excepción nombrada en la cláusula rescue es del mismo tipo que la excepción que se ha lanzado actualmente, o es una su-perclase de esta excepción (Esta comparación se debe a que las excepciones son clases, y las clases, a su vez son tipos de módulo. El método === está definido para los módulos y devuelve true si el operando es de la misma clase que el receptor o uno de sus ancestros. Si escribes una cláusula rescue, sin lista de parámetros, el parámetro por defecto es StandardError.
Si no coincide ninguna cláusula rescue o si se lanza una excepción fuera de un bloque begin/end, Ruby se mueve hacia arriba de la pila y busca un manejador de excepción en el llamador y sino en el que llama al llamador y así sucesivamente.
Aunque los parámetros de la cláusula rescue suelen ser los nombres de las clases Exception, en realidad pueden ser expresiones arbitrarias (incluyendo llamadas a métodos) que retornan una clase Exception .
Errores del sistema
Los errores del sistema se producen cuando una llamada al sistema operativo devuelve un código de error. En los sistemas POSIX, estos errores tienen nombres tales como EAGAIN y EPERM. (Si estás en una máquina Unix, puede escribir man errno para obtener una lista de estos errores.)
Ruby tiene estos errores y envuelve cada uno en un objeto de excepción específico. Cada uno es una subclase de SystemCallError y se define en un módulo llamado Errno. Esto significa que usted encontrará excepciones con nombres de clase como Errno::EAGAIN, Erno::EIO y Errno::EPERM. Si desea obtener el código de error del sistema subyacente, cada objeto de excepción Errno tiene una constante de clase llamada (un tanto confusamente) Errno que contiene el valor.
Errno::EAGAIN::Errno -> 35Errno::EPERM::Errno -> 1Errno::EIO::Errno -> 5Errno::EWOULDBLOCK::Errno -> 35
Tenga en cuenta que EWOULDBLOCK y EAGAIN tienen el mismo número de error. Esta es una ca-racterística del sistema operativo de la computadora utilizada para producir este libro --las dos cons-tantes mapeadas con el mismo número de error. Para hacer frente a esto, Ruby arregla las cosas para que Errno::EAGAIN y Errno::EWOULDBLOCK sean tratadas de manera idéntica en una cláusula res-cue. Ya sea que usted pida un rescate, ya sea que usted rescate. Para ello, se hace la redefinición de SystemCallError#=== de modo que si se comparan dos subclases de SystemCallError, la compa-ración se haga con su número de error y no con su posición en la jerarquía.

71
Poner en Orden
A veces es necesario garantizar que algún tipo de procesamiento se realiza al final de un bloque de código, independientemente de si se disparó alguna excepción. Por ejemplo, usted puede tener un archivo abierto en la entrada del bloque, y necesita asegurarse de que se cerrará al salir del bloque.
La cláusula ensure hace justo esto. ensure va después de la última cláusula rescue y contiene un trozo de código que se ejecuta siempre cuando termina el bloque. No importa si se cierra el bloque con normalidad, si se levanta y rescata una excepción, o si se termina por una excepción no capturada --ensure ejecuta el bloque.
f = File.open(“testfile”)begin # .. processrescue # .. handle errorensure f.close unless f.nil?end
La cláusula else tiene similar, aunque menos útil, construcción. Si está presente, va después de las cláusulas rescue y antes de ensure. El cuerpo de una cláusula else solamente se ejecuta si no hay excepciones disparadas por el cuerpo principal del código.
f = File.open(“testfile”)begin # .. processrescue # .. handle errorelse puts “Congratulations-- no errors!”ensure f.close unless f.nil?end
Correr de nuevo
A veces usted puede ser capaz de corregir la causa de una excepción. En esos casos, puede utilizar la instrucción retry dentro de una cláusula rescue para repetir todo el bloque begin/end. Claramente, aquí existe un enorme margen de bucles infinitos, así que esta característica hay que utilizarla con pre-caución (y con un dedo ligeramente apoyado sobre la tecla de interrupción).
Como ejemplo de código que vuelve a intentar en las excepciones, echar un vistazo al siguiente, adap-tado de la librería net/smtp.rb de Minero Aoki’s:
@esmtp = truebegin # Primero trate un inicio de sesión extendido, di no se consigue porque # el servidor no lo admite, recurrir a un inicio de sesión normal if @esmtp then @command.ehlo(helodom) else @command.helo(helodom) endrescue ProtocolError if @esmtp then @esmtp = false retry else raise

72
endend
Este código intenta primero conectarse a un servidor SMTP con el comando EHLO, que no está sopor-tado universalmente. Si el intento de conexión falla, el código establece la variable @esmtp en false y vuelve a intentar la conexión. Si no lo consigue por segunda vez, se lanza una excepción al llamador.
Lanzando Excepciones
Hasta ahora hemos estado a la defensiva, manejando excepciones lanzadas por otros. Es hora de de-volver la pelota y pasar a la ofensiva.
Puede crear excepciones en su código con el método Kernel.raise (o su sinónimo un tanto crítico, Kernel.fail).
raiseraise “bad mp3 encoding”raise InterfaceException, “Keyboard failure”, caller
La primera forma simplemente relanza la excepción actual (o un RuntimeError si no es la excepción en curso). Esta se utiliza en los controladores de excepcion que necesitan interceptar una excepción antes de transmitirla.
La segunda forma crea una nueva excepción RuntimeError, estableciendo su mensaje a la cadena dada. Esta excepción disparó la pila de llamadas.
La tercera forma utiliza el primer argumento para crear una excepción y establece el mensaje asociado al segundo argumento y el trazado de pila para el tercer argumento. Normalmente, el primer argumento será el nombre de una clase de la jerarquía Exception o una referencia a un objeto instancia de una de estas clases (Técnicamente, este argumento puede ser cualquier objeto que responde al mensaje ex-ception mediante la devolución de un objeto, de tal manaera como object.kind_of?(Exception) es verdadero). El trazado de pila se produce normalmente mediante el método Kernel.caller.
Aquí algunos ejemplos típicos de raise en acción.
raiseraise “Missing name” if name.nil?if i >= names.size raise IndexError, “#{i} >= size (#{names.size})”endraise ArgumentError, “Name too big”, caller
En el último ejemplo, se elimina la rutina actual de la traza de pila, que a menudo es útil en los módu-los de librería. Podemos ir más lejos: el siguiente código elimina dos rutinas de la traza, pasando sólo un subconjunto de llamadas de la pila a la nueva excepción.
raise ArgumentError, “Name too big”, caller[1..1]
Añadiendo Información a las Excepciones
Puede definir sus propias excepciones para que contengan cualquier información que usted necesite pasar desde el lugar del error. Por ejemplo, ciertos tipos de errores de red puede ser transitorios en fun-ción de las circunstancias. Si se produce un error y las circunstancias lo permiten, se puede establecer un indicador (flag) en la excepción, para decirle al controlador que puede valer la pena volver a intentar la operación.
class RetryException < RuntimeError attr :ok_to_retry def initialize(ok_to_retry) @ok_to_retry = ok_to_retry

73
endend
En algún lugar en lo más profundo del código, se produce un error transitorio.
def read_data(socket) data = socket.read(512) if data.nil? raise RetryException.new(true), “error de lectura transitorio” end # .. normal processingend
Más arriba en la pila de llamadas, controlamos la excepción.
begin stuff = read_data(socket) # .. process stuffrescue RetryException => detail retry if detail.ok_to_retry raiseend
Catch y Throw
Mientras que los mecanismos de excepciones raise y rescue son muy buenos para abandonar la ejecución cuando las cosas van mal, a veces también es bueno ser capaz de saltar en una construcción profundamente anidada durante el procesamiento normal. Aquí es donde catch y throw son muy útiles.
catch (:done) do while line = gets throw :done unless fields = line.split(/\t/) songlist.add(Song.new(*fields)) end songlist.playend
catch define un bloque que se etiqueta con el nombre dado (que puede ser un Symbol o un String). El bloque se ejecuta con normalidad hasta que se encuentra un throw.
Cuando Ruby encuentra un throw, tira hacia atrás en la pila de llamadas en busca de un bloque catch con el símbolo correspondiente. Cuando lo encuentra, Ruby despliega la pila a ese punto y termina el bloque. Por lo tanto, en el ejemplo anterior, si la entrada no contiene correctamente el formato de lineas, throw salta al final del correspondiente catch, no sólo termina el bucle while, sino también salta en el repertorio de la lista de canciones. Si a throw se le llama con el segundo parámetro opcional, este valor se retorna como el valor de catch.
El siguiente ejemplo utiliza un throw para terminar la interacción con el usuario si se escribe ! en res-puesta a cualquier aviso (prompt).
def prompt_and_get(prompt) print prompt res = readline.chomp throw :quit_requested if res == “!” resendcatch :quit_requested do name = prompt_and_get(“Name: “) age = prompt_and_get(“Age: “) sex = prompt_and_get(“Sex: “)

74
# ... # process informationend
Como ilustra este ejemplo, throw no tiene que aparecer en el ámbito estático de catch.
Modulos
Los módulos son una forma de agrupar métodos, clases y constantes. Los módulos le darán dos ven-tajas importantes.
1. Los módulos proporcionan un espacio de nombres y evitan conflictos de nombre. 2. Los módulos implementan la facilidad mixim.
Los Espacios de Nombres
Al empezar a escribir programas más y más grandes de Ruby, se encontrará, naturalmente, la produc-ción de trozos de código reutilizables --librerías de rutinas relacionadas que son de aplicación general. Usted querrá separar este código en archivos separados para que los contenidos puedan ser compartidos entre los diferentes programas de Ruby.
A menudo, este código se organiza en clases, así que probablemente se quedará con una clase (o un conjunto de clases relacionadas entre sí) en un archivo.
Sin embargo, hay ocasiones en las que deseará agrupar algunas cosas que, naturalmente, no forman una clase.
Una primera aproximación puede ser la de poner todas estas cosas en un archivo y simplemente car-gar ese archivo en cualquier programa que lo necesite. Esta es la forma en la que el lenguaje C funciona. Sin embargo, este enfoque tiene un problema. Digamos que hay que escribir un conjunto de funciones de trigonometría sin, cos, etc. Se meten todos en un archivo, trig.rb para las generaciones futuras y a disfrutar. Mientras tanto, Sally está trabajando en una simulación del bien y del mal y en los códigos de un conjunto de sus propias rutinas útiles, incluyendo be_good (ser_bueno) y sin (pecado), y las pone en moral.rb. Joe, que quiere escribir un programa para saber cuántos ángeles pueden bailar en la cabeza de un alfiler, carga tanto trig.rb como moral.rb en su programa. Pero ambos definen un método lla-mado sin. Malas noticias.
La respuesta es el mecanismo de módulo. Los módulos de definen un espacio de nombres (namespace ), una caja en la que sus métodos y constantes pueden correr sin tener que preocuparse de ser pisados por otros métodos y constantes. Las funciones trigonométricas pueden ir en un módulo:
module Trig PI = 3.141592654 def Trig.sin(x) # .. end def Trig.cos(x) # .. endend
y los métodos sobre la buena y la mala “moral” pueden ir en otro.
module Moral VERY_BAD = 0 BAD = 1 def Moral.sin(badness) # ... endend

75
Las constantes de módulo se designan como constantes de clase, con una letra mayúscula inicial. Las definiciones de método es similar: los métodos del módulo se definen como métodos de clase.
Si un programs de terceros quiere usar estos módulos, simplemente puede cargar los dos archivos (utilizando la declaración Ruby require, que se discute más adelante) y referenciar a los nombres cuali-ficados.
require ‘trig’require ‘moral’y = Trig.sin(Trig::PI/4)wrongdoing = Moral.sin(Moral::VERY_BAD)
Al igual que con los métodos de clase, llamar a un método de módulo precediendo su nombre con el nombre del módulo y un punto, y se hace referencia a una constante con el nombre de módulo y dos sig-nos de dos puntos.
Mixins
Los módulos tienen otro uso extraordinario. De un golpe prácticamente eliminan la necesidad de heren-cia múltiple proporcionando un servicio llamado mixin.
En los ejemplos de la sección anterior, hemos definido los métodos de módulo, métodos cuyos nom-bres fueron precedidos por el nombre del módulo. Si esto le hizo pensar en los métodos de clase, su si-guiente pensamiento podría ser “¿qué pasa si yo defino los métodos de instancia dentro de un módulo?”
Buena pregunta. Un módulo no puede tener instancias, ya que no es una clase. Sin embargo, puede incluir un módulo dentro de una definición de clase. Cuando esto sucede, todos los métodos de instancia del módulo están de pronto disponibles como métodos de la clase también. Se mezclan (mixed in). De hecho, el mezclado en los módulos efectivamente hace que se comporten como superclases.
module Debug def who_am_i? “#{self.class.name} (\##{self.id}): #{self.to_s}” endendclass Phonograph include Debug # ...endclass EightTrack include Debug # ...endph = Phonograph.new(“West End Blues”)et = EightTrack.new(“Surrealistic Pillow”)
ph.who_am_i? -> “Phonograph (#935520): West End Blues”et.who_am_i? -> “EightTrack (#935500): Surrealistic Pillow”
Al incluir el módulo Debug, tanto Phonograph como EightTrack ganan el acceso al método de ins-tancia who_am_i? .
Vamos a ver un par de puntos acerca de la instrucción include antes de continuar. En primer lugar, no tiene nada que ver con los archivos. Los programadores de C utilizan la directiva de preprocesador llamada #include para insertar el contenido de un archivo en otro durante la compilación. El include de Ruby simplemente hace referencia a un nombre de módulo. Si este módulo se encuentra en un archivo separado, deberá utilizar require (o su primo menos usado, load) para rastrear el archivo antes de uti-lizar include. En segundo lugar, un include de Ruby no sólo tiene que copiar los métodos del módulo de instancia en la clase. Por el contrario, hace una referencia desde la clase al módulo incluido. Si varias clases incluyen el módulo, todos ellas apuntan al mismo. Si cambia la definición de un método dentro de

76
un módulo, incluso cuando el programa se está ejecutando, en todas las clases que incluyan a este mó-dulo se presentan el nuevo comportamiento (Por supuesto, aquí estamos hablando sólo de los métodos. Las variables de instancia son siempre por objeto, por ejemplo).
Los mixins le dan una forma extraordinariamente controlada de añadir funcionalidad a las clases. Sin embargo, su verdadero poder viene cuando el código en el mixin empieza a interactuar con el código de la clase que lo utiliza. Tomemos el mixin estándar de Ruby Comparable como ejemplo. Usted puede utilizar el mixin Comparable para añadir los operadores de comparación (<, <=, ==,>=, y >), así como el método between?, en una clase. Para que esto funcione, Comparable asume que cualquier clase que le utilice define el operador <=>. Por lo tanto, como escritor de clase, se define un método <=>, incluyendo Comparable y se obtienen seis funciones de comparación de forma gratuita. Vamos a probar esto con nuestra clase Song, para hacer las canciones comparables en función de su duración. Todo lo que tene-mos que hacer es incluir el módulo Comparable y poner en práctica el operador de comparación <=>.
class Song include Comparable def initialize(name, artist, duration) @name = name @artist = artist @duration = duration end def <=>(other) self.duration <=> other.duration endend
Podemos comprobar que los resultados son sensibles con una prueba de algunas canciones.
song1 = Song.new(“My Way”, “Sinatra”, 225)song2 = Song.new(“Bicylops”, “Fleck”, 260)
song1 <=> song2 -> 1song1 < song2 -> truesong1 == song1 -> truesong1 > song2 -> false
Iteradores y el Módulo Enumerable
Usted probablemente haya notado que las clases de la colección de Ruby soportan un gran número de operaciones que permiten hacer varias cosas con ella: recorrerla, ordenarla, etc. Usted puede estar pensando: “¡Vaya, seguro que estaría bien si mi clase puede soportar todas estas interesantes caracterís-ticas, también!” (Si usted realmente lo cree, probablemente es tiempo de dejar de ver las repeticiones la televisión de la década de 1960).
Bueno, las clases pueden soportar todas estas interesantes características, gracias a la magia de mixins y el módulo Enumerable. Todo lo que tiene que hacer es escribir un iterador llamando a each, que devuelva los elementos de su colección por turno. Mezclar en Enumerable, y de repente su clase admite cosas como mapa, include? y find_all?. Si los objetos de su colección implementan semántica sig-nificativa ordenando el uso del método <=>, también obtendrá métodos como min, max y short.
Composición de Módulos
Anteriormente vimos el método inject de Enumerable. Enumerable es otro mixin estándar, que im-plementa una serie de métodos en cuanto a la acogida de clase del método each. Debido a esto, podemos usar inject en cualquier clase que incluya el módulo Enumerable y defina el método each. Muchas clases integradas hacen esto.
[ 1, 2, 3, 4, 5 ].inject {|v,n| v+n } -> 15( ‘a’..’m’).inject {|v,n| v+n } -> “abcdefghijklm”

77
También podríamos definir nuestra propia clase que mezcle en Enumerable y por lo tanto se soporte inject.
class VowelFinder include Enumerable def initialize(string) @string = string end def each @string.scan(/[aeiou]/) do |vowel| yield vowel end endend
vf = VowelFinder.new(“the quick brown fox jumped”)
vf.inject {|v,n| v+n } -> “euiooue”
Observe que hemos usado el mismo patrón en la llamada a inject en estos ejemplos --lo estamos utilizando para realizar una sumatoria. Cuando se aplica a los números, devuelve la suma aritmética, cuando se aplica a las cadenas las concatena. También se puede utilizar un módulo para encapsular esta funcionalidad.
module Summable def sum inject {|v,n| v+n } endendclass Arrayinclude Summableendclass Range include Summableendclass VowelFinder include Summableend
[ 1, 2, 3, 4, 5 ].sum -> 15( ‘a’..’m’).sum -> “abcdefghijklm”
vf = VowelFinder.new(“the quick brown fox jumped”)vf.sum -> “euiooue”
Variables de Instancia en Mixins
Gente que viene a Ruby de C++ nos preguntan con frecuencia: “¿Qué sucede con las variables de instancia en un mixin? En C++, tengo que saltar a través de unos aros para controlar cómo se comparten las variables en una jerarquía de herencias múltiples. ¿Cómo maneja esto Ruby? “
Bueno, para empezar, les decimos que no es una buena pregunta. Recuerda cómo trabajan las varia-bles de instancia en Ruby: la primera mención a una variable prefijada con @ crea la variable de instancia en el objeto actual, self.
Para un mixin, esto significa que el módulo se mezcla en su clase cliente (el mixee?) pudiendo crear variables de instancia en el objeto cliente y pudiendo utilizar attr_reader y amigos para definir el acce-so para estas variables de instancia. Por ejemplo, el módulo Observable en el ejemplo siguiente agrega una variable de instancia @observer_list a cualquier clase que se incluya.

78
module Observable def observers @observer_list ||= [] end def add_observer(obj) observers << obj end def notify_observers observers.each {|o| o.update } endend
Sin embargo, este comportamiento nos expone a un riesgo. Una variable de instancia mixin puede entrar en conflicto con las de la clase de acogida o con las de otros mixins. El ejemplo siguiente muestra una clase que utiliza nuestro módulo Obsevable, pero que desgraciadamente también utiliza una variable de instancia llamada @observer_list. En tiempo de ejecución, este programa va a salir mal de algunas formas difíciles de diagnosticar.
class TelescopeScheduler # otras clases pueden registrarse para recibir # notificaciones cuando cambia el horario include Observable def initialize @observer_list = [] # personas con tiempo de telescopio end def add_viewer(viewer) @observer_list << viewer end # ...end
En su mayor parte, los módulos mixin no trata de llevar los datos a su propia instancia --hace uso de métodos de acceso para recuperar los datos del objeto cliente. Pero si usted necesita crear un mixin que tiene que tener su propio estado, asegúrese de que las variables de instancia tienen nombres únicos para distinguirlas de cualquier otro mixin en el sistema (tal vez utilizando el nombre del módulo como parte del nombre de la variable). Alternativamente, el módulo podría utilizar un hash a nivel de módulo, indexado por el identificador (ID) de objeto actual para almacenar datos específicos de la instancia, sin necesidad de utilizar las variables de instancia Ruby.
module Test State = {} def state=(value) State[id] = value end def state State[id] endendclass Client include Testend
c1 = Client.newc2 = Client.newc1.state = ‘cat’c2.state = ‘dog’c1.state -> “cat”c2.state -> “dog”

79
Resolución de Nombres de Método Ambiguos
Una de las otras preguntas la gente hace acerca de los mixins es, ¿cómo se maneja el método de bús-queda? En particular, ¿qué sucede si métodos con el mismo nombre se definen en una clase, en la clase del padre de la clase y en un mixin incluido en la clase?
La respuesta es que Ruby mira primero en la clase inmediata de un objeto, en los mixins incluidos en esa clase y después de las superclases y sus mixins. Si una clase tiene varios módulos mixtos en ella, el último incluido se busca en primer lugar.
Incluyendo Otros Archivos
Debido a que Ruby hace que sea fácil escribir buen código modular, a menudo se encontrará produ-ciendo un pequeño archivo que contiene alguna funcionalidad auto-contenida --una interfaz de x, un algo-ritmo, etc. Lo normal es que organizar estos archivos como librerías de clase o módulo.
Después de haber producido estos archivos, usted deseará incorporarlos a sus nuevos programas. Ruby tiene dos instrucciones que hacen esto. El método load incluye el llamado archivo código fuente Ruby cada vez que se ejecuta el método.
load ‘filename.rb’
El más comúnmente utilizado método require carga cualquier archivo dado una sola vez.
require ‘filename’
Esto no es estrictamente cierto. Ruby mantiene una lista de los archivos cargados por require en el array $”. Sin embargo, esta lista contiene sólo los nombres de los archivos tal como se le da a require. Es posible engañar a Ruby y obtener el mismo archivo cargado dos veces.
require ‘/usr/lib/ruby/1.9/English.rb’require ‘/usr/lib/ruby/1.9/rdoc/../English.rb’
$” → [“/usr/lib/ruby/1.9/English.rb”, “/usr/lib/ruby/1.9/rdoc/../English.rb”]
En este caso, ambas declaraciones require terminan señalando el mismo archivo, pero utilizan di-ferentes caminos para cargarlo. Algunos consideran esto un error y este comportamiento también puede cambiar en versiones posteriores.
Las variables locales en un archivo cargado o requerido no se propagan con el alcance de quien las carga o requiere. Por ejemplo, aquí hay un archivo llamado included.rb.
a = 1def b 2end
Y esto es lo que sucede cuando la incluimos en otro archivo:
a = “cat”b = “dog”require ‘included’
a -> “cat”b -> “dog”b() -> 2
require tiene una funcionalidad adicional: puede cargar las librerías binarias compartidas. Las rutinas aceptan rutas absolutas y relativas. Si se les da una ruta relativa (o sólo un nombre común), van a buscar en todos los directorios en la ruta de carga en curso ($:, se verá más adelante) para el archivo.

80
Los archivos cargados con load o require pueden, por supuesto, incluir otros archivos, que incluyan otros archivos, y así sucesivamente. Lo que no puede ser obvio es que require es una sentencia ejecu-table --que puede estar dentro de una sentencia if, o puede incluir una cadena que acaba de ser cons-truida. La ruta de búsqueda se puede modificar en tiempo de ejecución. Sólo tiene que añadir el directorio que desea para el array $:.
Ya que load incluirá los fuentes de forma incondicional, se puede utilizar para volver a cargar un ar-chivo fuente que puede haber cambiado desde que comenzó el programa. El ejemplo que sigue es (muy) artificial.
5.times do |i| File.open(“temp.rb”,”w”) do |f| f.puts “module Temp” f.puts “ def Temp.var” f.puts “ #{i}” f.puts “ end” f.puts “end” end load “temp.rb” puts Temp.varend
produce:
01234
Para un uso menos artificial de esta funcionalidad, considere una aplicación Web que recarga los com-ponentes mientras está funcionando. Esto le permite actualizarse a sí misma sobre la marcha y no nece-sita ser reiniciada para que la nueva versión del software se integre. Esta es una de las muchas ventajas de usar un lenguaje dinámico como Ruby.
Entrada y Salida Básica
Ruby proporciona lo que a primera vista se ve como dos grupos separados de rutinas de I/O. La prime-ra es la interfaz sencilla --la hemos estado usando casi exclusivamente hasta el momento.
print “Enter your name: “name = gets
Hay todo un conjunto de métodos relacionados con I/O que se implementan en el módulo Kernel --gets, open, print, printf, putc, puts, readline, readlines, y test --que hacen que sea sen-cillo y cómodo escribir sencillos programas en Ruby. Estos métodos suelen hacer I/O a la entrada y la salida estándares, que los hace útiles para la escritura de filtros. Usted los encontrará documentados más adelante.
La segunda forma, que le da mucho más control, es el uso de objetos IO.
¿Qué es un Objeto IO?
Ruby define una clase base única, IO, para manejar la entrada y salida. Esta clase base es una sub-clase de las clases File y BasicSocket para proporcionar un comportamiento más especializado, pero los principios son los mismos. Un objeto IO es un canal bidireccional entre un programa de Ruby y otros recursos externos.
Para aquellos que sólo tienen que saber los detalles de implementación, esto significa que un solo objeto IO a veces puede hacer la gestión de más de un descriptor de fichero del sistema operativo.

81
Por ejemplo, si abre un par de pipes (tubos), un solo objeto IO contiene un pipe de lectura y un pipe de escritura . Un objeto IO puede tener más de lo que parece a simple vista, pero al final, simplemente escriba en él y lea de él.
En este capítulo, nos concentraremos en la clase IO y su subclase más comúnmente utilizada, la clase File. Más detalles sobre el uso de las clases tipo socket para trabajo en red, se verán más adelante.
Abrir y Cerrar Ficheros
Como cabe esperar, se puede crear un objeto fichero nuevo utilizando File.new.
file = File.new(“testfile”, “r”)# ... process the filefile.close
Usted puede crear un objeto archivo que se abre para lectura, escritura, o ambas, de acuerdo con la cadena de modo. (Aquí abrimos testfile para la lectura con una “r”. También podría haber usado “w” para escribir o “rw” para lectura y escritura. La lista completa de modos permitidos aparece más adelante).
Opcionalmente, cuando se crea un archivo también puede especificar los permisos de archivo. Con-sulte la descripción de File.new para más detalles. Después de abrir el archivo, podemos trabajar con el y escribir y/o leer datos según sea necesario. Por último, como ciudadanos responsables del software, cerramos el archivo, lo que garantiza que todos los datos en el búfer se han escrito y que todos los recur-sos relacionados son liberados.
Ruby puede hacer la vida un poco más fácil para usted. El método File.open también abre un archivo . En uso normal se comporta como File.new. Sin embargo, si con la llamada está asociado un bloque, open se comporta de diferente manera. En lugar de devolver un nuevo objeto File, se invoca al bloque, pasandole el archivo recién abierto como un parámetro. Cuando se sale del bloque, el archivo se cierra automáticamente.
File.open(“testfile”, “r”) do |file| # ... process the fileend
Este segundo enfoque tiene un beneficio añadido. En el caso anterior, si al procesar el archivo se lanza una excepción, no puede llevarse a cabo la llamada a file.close. Una vez que la variable de archivo está fuera de ámbito, entonces la recolección de basura eventualmente lo cierre, pero esto no puede su-ceder durante un tiempo. Mientras tanto, los recursos están abiertos.
Esto no sucede con la forma de bloque de File.open. Si se lanza una excepción dentro del bloque, el archivo se cierra antes de que la excepción se propague al llamador. El método abierto se parece a lo siguiente.
class File def File.open(*args) result = f = File.new(*args) if block_given? begin result = yield f ensure f.close end end return result endend

82
Lectura y Escritura de Ficheros
Los mismos métodos que se usan para la I/O “simple” están disponibles para todos los objetos fichero. Por lo tanto, gets lee una línea de la entrada estandar (o de cualquier fichero espcificado en la línea de comandos cuando se invoca el script), y file.gets lee una línea del objeto fichero file.
Por ejemplo, se puede crear un programa llamado copy.rb
while line = gets puts lineend
Si se ejecuta este programa sin argumentos, lee líneas desde la consola y copia de vuelta a la misma. Tenga en cuenta que se repite cada línea, una vez que se pulsa la tecla return (en este ejemplo y el si-guiente, se muestra la entrada de usuario en cursiva).
% ruby copy.rbThese are linesThese are linesthat I am typingthat I am typing^D
También puede pasar uno o más nombres de archivo en la línea de comandos, en cuyo caso gets leerá cada uno por turno.
% ruby copy.rb testfileThis is line oneThis is line twoThis is line threeAnd so on... Finalmente, se puede abrir el archivo y leer de él explícitamente.
File.open(“testfile”) do |file| while line = file.gets puts line endend
produce:
This is line oneThis is line twoThis is line threeAnd so on... Así como con gets, los objetos I/O disfrutan de un conjunto adicional de métodos de acceso, todo con la intención de hacernos la vida más fácil.
Iteradores para Lectura
Igual que se usan bucles comunes para leer datos de un flujo IO, también se pueden usar varios ite-radores Ruby. IO#each_byte invoca un bloque con el siguiente byte de 8 bits de un objeto IO (en este caso, un objeto de tipo File).
File.open(“testfile”) do |file| file.each_byte {|ch| putc ch; print “.” }end

83
produce:
T.h.i.s. .i.s. .l.i.n.e. .o.n.e..T.h.i.s. .i.s. .l.i.n.e. .t.w.o..T.h.i.s. .i.s. .l.i.n.e. .t.h.r.e.e..A.n.d. .s.o. .o.n........
IO#each_line llama al bloque con cada línea del archivo. En el siguiente ejemplo, vamos a hacer visi-bles los saltos de línea originales usando String#dump, para que se pueda ver que no estamos engañando.
File.open(“testfile”) do |file| file.each_line {|line| puts “Got #{line.dump}” }end
produce:
Got “This is line one\n”Got “This is line two\n”Got “This is line three\n”Got “And so on...\n”
Se puede pasar a each_line cualquier secuencia de caracteres, como por ejemplo un separador de línea, y separará la entrada en consecuencia, retornando el fin de línea al final de cada línea de datos. Es por esto que usted ve los caracteres \n en la salida del ejemplo anterior. En el siguiente ejemplo, vamos a utilizar el carácter e como separador de línea.
File.open(“testfile”) do |file| file.each_line(“e”) {|line| puts “Got #{ line.dump }” }end
produce:
Got “This is line”Got “ one”Got “\nThis is line”Got “ two\nThis is line”Got “ thre”Got “e”Got “\nAnd so on...\n”
Si se combina la idea de un iterador con la característica de bloque autoclosing, se obtiene IO.foreach. Este método toma el nombre de una fuente de I/O abriéndola para lectura, llama al iterador una vez por cada línea del archivo y luego cierra automáticamente el archivo.
IO.foreach(“testfile”) {|line| puts line }
produce:
This is line oneThis is line twoThis is line threeAnd so on...
O si lo prefiere, puede recuperar un archivo entero en una cadena o en una matriz de líneas.
# lectura en una cadenastr = IO.read(“testfile”)str.length -> 66str[0, 30] -> “This is line one\nThis is line “

84
# lectura en una matrizarr = IO.readlines(“testfile”)arr.length -> 4arr[0] -> “This is line one\n”
No hay que olvidar que las operaciones de I/O nunca son seguras en un mundo incierto. Se lanazarán excepciones en la mayoría de errores que puedan ocurrir y usted debe estar dispuesto a rescatarlos y tomar las medidas adecuadas.
Escritura en Ficheros
Hasta ahora, hemos estado llamando a puts y print alegremente, pasándoles cualquier objeto anti-guo y confiando en que Ruby va a hacer lo correcto (que por supuesto lo hace). Pero, ¿qué es exactamen-te lo que hace?
La respuesta es bastante simple. Salvo un par de excepciones, todos los objetos que se pasan a puts y print se convierten en una cadena llamando al método to_s de ese objeto. Si por alguna razón, el método to_s no devuelve una cadena válida, se crea una que contiene el nombre de clase del objeto y el ID, algo así como #<ClassName:0x123456>.
Las excepciones son simples, quizás demasiado. El objeto nil que imprime la cadena “nil”, y una matriz pasada a puts se ecriben como si cada uno de sus elementos por turno fueran pasados separada-mente a puts.
¿Qué pasa si usted quiere escribir datos binarios y Ruby no quiere lidiar con ellos? Bueno, por lo gene-ral, simplemente se puede utilizar IO#print y pasarle una cadena que contiene los bytes a escribir. Sin embargo, si realmente quiere, puede llegar a las rutinas de entrada y salida de bajo nivel --eche un vistazo a la documentación de IO#sysread y IO#syswrite.
Y ¿cómo obtener los datos binarios en una cadena en primer lugar? Las tres formas más comunes son usar un literal, empujar byte a byte, o usar Array#pack.
str1 = “\001\002\003” -> “\001\002\003”str2 = “”str2 << 1 << 2 << 3 -> “\001\002\003”[ 1, 2, 3 ].pack(“c*”) -> “\001\002\003”
Pero echo de menos mi C++ iostream
A veces simplemente no hay nada que decir sobre gustos... Sin embargo, tal como se puede añadir un objeto a una matriz con el operador <<, también se puede añadir un objeto a un flujo de salida IO.
endl = “\n”STDOUT << 99 << “ red balloons” << endl
produce:
99 red balloons
Una vez más, el método << utiliza to_s para convertir sus argumentos a cadenas antes de enviarlos a su alegre camino.
A pesar de que empezamos despectivos sobre el pobre operador <<, en realidad hay algunas bue-nas razones para usarlo. Debido a que otras clases (como String y Array) también implementan un operador << con semántica similar, muy a menudo se puede escribir código que añade a algo, utilizando << sin importar si se añade a una matriz, a un archivo o a una cadena. Esta flexibilidad también hace fáciles las pruebas de unidad.

85
Hacer I/O con cadenas
A menudo hay momentos en los que se necesita trabajar con el código que se supone que se está leyendo o escribiendo en uno o más archivos. Pero hay un problema: los datos no se encuentran en los archivos. Quizás están disponibles a través de un servicio SOAP, o se les han pasado como parámetros de línea de comandos. O tal vez se está ejecutando pruebas de unidad y no desea modificar el sistema de archivos real.
Introduzca objetos StringIO. Se comportan igual que otros objetos I/O, pero leen y escriben cade-nas, no archivos. Si se abre un objeto StringIO para lectura, le proporciona una cadena. Luego, todas las operaciones de lectura en el objeto StringIO leen de esta cadena. Del mismo modo, cuando se quie-re escribir en un objeto StringIO, se le pasa una cadena.
require ‘stringio’
ip = StringIO.new(“now is\nthe time\nto learn\nRuby!”)op = StringIO.new(“”, “w”)
ip.each_line do |line| op.puts line.reverseendop.string -> “\nsi won\n\nemit eht\n\nnrael ot\n!ybuR\n”
Hablando con redes
Ruby es fluído en la mayoría de los protocolos de Internet, tanto de bajo como de alto nivel.
Para quienes gustan deslizarse en torno al nivel de red, Ruby viene con un conjunto de clases en la biblioteca socket (documentada más delante). Estas clases le dan acceso a TCP, UDP, SOCKS y sockets de dominio Unix, así como culaquier tipo de socket adicional compatible con su arquitectura. La librería también ofrece clases de ayuda para hacer la escritura a los servidores más fácil. He aquí un sencillo pro-grama que obtiene información sobre el usuario “mysql” en nuestra máquina local utilizando el protocolo finger.
require ‘socket’client = TCPSocket.open(‘127.0.0.1’, ‘finger’)client.send(“mysql\n”, 0) # 0 means standard packetputs client.readlinesclient.close
produce:
Login: mysql Name: MySQL ServerDirectory: /var/empty Shell: /usr/bin/falseNever logged in.No Mail.No Plan.
En un nivel superior, el conjunto lib/net de los módulos de librería proporciona los controladores para un conjunto de protocolos de nivel de aplicación (actualmente FTP, HTTP, POP, SMTP y telnet). Estos están documentados más adelante. Por ejemplo, el programa siguiente lista las imágenes que se mues-tran en la página home del Programador Pragmático.
require ‘net/http’h = Net::HTTP.new(‘www.pragmaticprogrammer.com’, 80)response = h.get(‘/index.html’, nil)if response.message == “OK” puts response.body.scan(/<img src=”(.*?)”/m).uniqend

86
produce:images/title_main.gifimages/dot.gif/images/Bookshelf_1.5_in_green.pngimages/sk_all_small.jpgimages/new.jpg
Aunque atractivamente simple, este ejemplo se podría mejorar de manera significativa. En particular, no hace mucho en la forma del manejo de errores. En realidad, debe informar de los errores “Not Found” (en los famosos 404), y debe manejar redirecciones (que ocurren cuando un servidor web da al cliente una dirección alternativa para la página solicitada). Podemos llevar esto a un nivel aún más alto. Al traer la librería open-uri a un programa, de repente el método Kernel.open reconoce http:// y ftp:// URLs en el nombre del archivo. No sólo eso, sino que también maneja las redirecciones automaticamente.
require ‘open-uri’open(‘http://www.pragmaticprogrammer.com’) do |f| puts f.read.scan(/<img src=”(.*?)”/m).uniqend
produce:images/title_main.gifimages/dot.gif/images/Bookshelf_1.5_in_green.pngimages/sk_all_small.jpgimages/new.jpg
Hilos y Procesos
Ruby le ofrece dos formas básicas para organizar el programa de modo que se puedan ejecutar dife-rentes partes del mismo “al mismo tiempo”. Se pueden dividir las tareas de cooperación dentro del pro-grama utilizando varios hilos, o puede dividir las tareas entre diferentes programas utilizando múltiples procesos. Echemos un vistazo a cada uno de estos.
Multithreading
A menudo, la forma más sencilla de hacer dos cosas a la vez es mediante el uso de hilos Ruby. Estos son totalmente integrados en proceso, implementados con el intérprete de Ruby, lo que los hace totalmen-te portables, no basándose en el sistema operativo. Al mismo tiempo, no se obtienen ciertos beneficios de tener soporte nativo para subprocesos. ¿Qué significa esto?
Se puede experimentar falta de subprocesos (donde un subproceso de prioridad baja no tiene la opor-tunidad de correr). Si logra obtener el punto muerto de sus hilos, todo el conjunto de procesos puede pa-ralizarse y si hay algún hilo que hizo una llamada al sistema operativo que lleva mucho tiempo en comple-tarse, todos los hilos se paran hasta que el intérprete toma el control de nuevo. Por último, si su máquina tiene más de un procesador, los hilos de Ruby no se aprovechan de ello --ya que se ejecutan en un único proceso y en un único hilo nativo, y están obligados a ejecutarse en un procesador a la vez.
Todo esto suena horrible. En la práctica, sin embargo, en muchos casos los beneficios de utilizar los hilos son muy superiores a los posibles problemas que puedan ocurrir. Utilizar los hilos Ruby es una ma-nera eficiente y ligera de conseguir el paralelismo en el código. Sólo tiene que comprender las cuestiones de aplicación subyacentes y hacer el diseño en consecuencia.
Crear Subprocesos Ruby
Crear un nuevo subproceso o hilo es bastante sencillo. El código siguiente es un ejemplo sencillo. Es capaz de descargar un conjunto de páginas Web en paralelo. Para cada dirección URL que se le pide que descargue, el código crea un subproceso independiente que se encarga de la transacción HTTP.

87
require ‘net/http’pages = %w( www.rubycentral.com slashdot.org www.google.com )threads = []for page_to_fetch in pages threads << Thread.new(page_to_fetch) do |url| h = Net::HTTP.new(url, 80) puts “Fetching: #{url}” resp = h.get(‘/’, nil ) puts “Got #{url}: #{resp.message}” endend
threads.each {|thr| thr.join }
produce:
Fetching: www.rubycentral.comFetching: slashdot.orgFetching: www.google.comGot www.google.com: OKGot www.rubycentral.com: OKGot slashdot.org: OK
Echemos un vistazo con más detalle a este código para ver como ocurren algunas sutiles cosas.
Con la llamada Thread.new se crean nuevos hilos. Se le pasa a un bloque que contiene el código que se ejecutará en un nuevo hilo. En nuestro caso, al bloque que utiliza la librería net/http en busca de la primera página de cada uno de los sitios indicados. Nuestra búsqueda muestra claramente que las descargas se llevan a cabo en paralelo.
Cuando creamos el hilo, se pasa la dirección URL requerida como un parámetro, y éste, se pasa al bloque como url. ¿Por qué hacemos esto en lugar de simplemente utilizar el valor de la variable page_to_fetch dentro del bloque?
Un hilo comparte todas las instancias globales y las variables locales que se encuentran en existencia en el momento del comienzo del hilo. Como puede decir cualquiera con un hermano pequeño, el compartir no es siempre una buena cosa. En este caso, los tres hilos comparten la variable page_to_fetch. Se inicia el primer hilo y page_to_fetch se ajusta a “www.rubycentral.com”. Mientras tanto, aún está en marcha el bucle para creación de los hilos. En un segundo momento, page_to_fetch se ajusta a “slashdot.org”. Si el primer hilo aún no ha terminado de usar la variable page_to_fetch, de pronto se comenzará a usar este nuevo valor. Este tipo de errores son difíciles de localizar.
Sin embargo, las variables locales creadas en un bloque de un hilo son realmente locales para ese hilo, --cada hilo tiene su propia copia de estas variables. En nuestro caso, la URL de la variable se establecerá en el momento de crear el hilo y cada hilo tendrá su propia copia de la dirección de página. Puede pasar cualquier número de argumentos en el bloque a través de Thread.new.
Manipulación de Hilos
Se produce otra sutileza en la última línea en nuestro programa de descarga. ¿Por qué llamamos a join en cada uno de los hilos que hemos creado?
Cuando un programa de Ruby termina, todas los hilos han muertos, independientemente de sus es-tados. Sin embargo, usted puede esperar a que termine un hilo en particular llamando para el mismo al método Thread#join. La llamada a subproceso se bloqueará hasta que el subproceso dado haya ter-minado. Llamando a join praa cada uno de los hilos, puede asegurarse de que las tres solicitudes se completan antes de terminar el programa principal. Si no se desea bloquear indefinidamente, se le puede dar a join un tiempo de espera como parámetro, --si el tiempo de espera expira antes de que termine el subproceso, la llamada a join retorna nil. Otra variante de join, el método Thread#value, retorna el valor de la última instrucción ejecutada por el hilo.

88
Además de join, se utilizan algunas otras rutinas para manipular los hilos. El flujo en curso siempre es accesible a través de Thread.current. Puede obtener una lista de todos los hilos con Thread.list, que devuelve una lista con todos los objetos Thread que son ejecutables o que se pueden detener. Para determinar el estado de un hilo en particular, puede utilizar Thread#status y Thread#alive?.
Además, puede ajustar la prioridad de un hilo con Thread#priority=. Los hilos con mayor prioridad se ejecutarán antes que los de menor. Hablaremos más sobre la programación de subprocesos y la deten-ción e inicio de los mismos, en un momento.
Variables de Hilo Un hilo normalmente puede tener acceso a las variables del ámbito cuando se crea el hilo. Las varia-bles locales al bloque que contiene el código del hilo son locales al hilo y no se comparten.
Pero lo que si es necesario es que variables de hilos que puedan ser accedidas por otros hilos --¿in-cluyendo el hilo main? La clase Thread cuenta con un mecanismo especial que permite que las variables de subproceso local se creen y se accedan por su nombre. Sólo tiene que tratar el objeto hilo, como si se tratara de un hash, escribiendo los elementos utilizando []= y leyendo de nuevo con []. En el ejemplo que sigue, cada hilo registra el valor actual de la variable count en una variable de subproceso local con la clave mycount. Para ello, el código utiliza la cadena “mycount” al indexar los objetos hilo.
(En este código existe una condición de carrera, pero sin embargo, no hemos hablado acerca de la sincronización y tendremos que ignorarlo tranquilamente por el momento. Simplemente decir, que se produce una condición de carrera, cuando dos o más piezas de código (o hardware) tratan de acceder a algún recurso compartido y cambian los resultados en función del orden en que lo hacen. En este ejemplo, es posible para un hilo establecer el valor de su variable mycount a count, pero antes de que llegue la oportunidad de incremento para count, el hilo se desincronice y otro subproceso vuelve a utilizar el mismo valor de count. Estas cuestiones se fijan mediante la sincronización del acceso a los recursos compartidos --tal como la variable count).
count = 0threads = []10.times do |i| threads[i] = Thread.new do sleep(rand(0.1)) Thread.current[“mycount”] = count count += 1 endendthreads.each {|t| t.join; print t[“mycount”], “, “ }puts “count = #{count}”
produce:
4, 1, 0, 8, 7, 9, 5, 6, 3, 2, count = 10
El hilo principal espera a que los hilos secundarios terminen y luego imprime el valor de count captu-rado por cada uno. Sólo para hacerlo más interesante, tenemos a cada hilo esperando un tiempo aleatorio antes de registrar el valor.
Hilos y Excepciones
¿Qué sucede si un hilo produce una excepción no controlada? Depende de la configuración de la bandera abort_on_exception y la de la bandera debug del intérprete (que se documentarán más adelante ).
Si abort_on_exception es false y la bandera de depuración no está habilitada (configuración por defecto), una excepción incontrolada simplemente mata a hilo en curso, --todo el resto seguirá ejecután-dose. De hecho, ni siquiera oirá hablar de la excepción hasta que se emita un join en el hilo que la ha lanzado.

89
En el siguiente ejemplo, el hilo 2 explota y no produce ninguna salida. Sin embargo, todavía se puede ver la huella de los demás hilos.
threads = []4.times do |number| threads << Thread.new(number) do |i| raise “Boom!” if i == 2 print “#{i}\n” endendthreads.each {|t| t.join }
produce:
013prog.rb:4: Boom! (RuntimeError)from prog.rb:8:in `join’from prog.rb:8from prog.rb:8:in `each’from prog.rb:8
Podemos rescatar la excepción a la vez que los hilos se unen.
threads = []4.times do |number| threads << Thread.new(number) do |i| raise “Boom!” if i == 2 print “#{i}\n” endendthreads.each do |t| begin t.join rescue RuntimeError => e puts “Failed: #{e.message}” endend
produce:
013Failed: Boom!
Sin embargo, establecer abort_on_exception en true, o usar -d en su momento en la bandera de depuración, hace que una excepción no controlada mate a todos los subprocesos que se ejecutan. Una vez que el subproceso 2 muere, no se produce más salida.
Thread.abort_on_exception = truethreads = []4.times do |number| threads << Thread.new(number) do |i| raise “Boom!” if i == 2 print “#{i}\n” endendthreads.each {|t| t.join }

90
produce:
01prog.rb:5: Boom! (RuntimeError)from prog.rb:4:in `initialize’from prog.rb:4:in `new’from prog.rb:4from prog.rb:3:in `times’from prog.rb:3
Este código también ilustra un gotcha. Dentro del bucle, los hilos utilizan print, en lugar de puts, para escribir el número. ¿Por qué? Porque entre bastidores, puts divide su labor en dos trozos: escribe su argumento y luego escribe una nueva línea. Entre estos dos, un hilo podría conseguir tiempo de pro-grama y la salida se intercalaría. Llamando a print con una sola cadena que ya contiene la nueva línea soluciona el problema.
Controlar el Tiempo de Programa de Hilo
Una aplicación bien diseñada normalmente va a dejar que los hilos hagan lo suyo. La construcción de las dependencias de tiempo en una aplicación multiproceso, está generalmente considerado como de mal gusto. Hace al código mucho más complejo y también impide al planificador de procesos la optimización de la ejecución del programa.
Sin embargo, a veces es necesario controlar los subprocesos de manera explícita. Nuestra máquina de discos va a tener un hilo que muestre un espectáculo de luces, que se tendrá que detener temporalmente cuando la música se detiene. Se puede tener dos hilos en una relación clásica de productor-usador, donde el usador tiene que hacer una pausa si se atrasa el productor. La clase Thread proporciona una serie de métodos para controlar el planificador de hilos. Invocando Thread.stop detiene el subproceso actual e invocacando Thread#run para un hilo particular organiza que este se ejecute. Thread.pass desprograma el subproceso actual, lo que permite que se ejecuten otros, Thread#join y Thread#value suspenden el hilo de llamada hasta que otro hilo determinado concluye.
Podemos demostrar estas características en el siguiente programa, totalmente inútil. Se crean dos procesos hijo, T1 y T2, cada uno de ellos ejecuta una instancia de la clase Chaser. El método chase in-crementa un contador, pero sin dejar que se supere en dos el contador por el otro hilo. Para hacer esto, se plantea un método Thread.pass, que permite al chase en el otro hilo ponerse al día. Para hacerlo más interesante (para una definición menor de interesante), tenemos los hilos inicialmente suspendidos para luego comienzar uno en primer lugar aleatoriamente.
class Chaser attr_reader :count def initialize(name) @name = name @count = 0 end def chase(other) while @count < 5 while @count other.count > 1 Thread.pass end @count += 1 print “#@name: #{count}\n” end endendc1 = Chaser.new(“A”)c2 = Chaser.new(“B”)

91
threads = [ Thread.new { Thread.stop; c1.chase(c2) }, Thread.new { Thread.stop; c2.chase(c1) }]
start_index = rand(2)threads[start_index].runthreads[1 - start_index].runthreads.each {|t| t.join }
produce:
B: 1B: 2A: 1B: 3A: 2B: 4A: 3B: 5A: 4A: 5
Sin embargo, utilizar estas primitivas para lograr el código de sincronización en la vida real no es fácil --las condiciones de carrera siempre estarán a la vuelta de la esquina. Y cuando se trabaja con datos compartidos, las condiciones de carrera te garantizan sesiones de depuración más o menos largas y frustrantes. De hecho, el ejemplo anterior tiene justamente como un error: es posible para el contador ser incrementado en un hilo pero antes de que pueda poner la salida de su cuenta, el segundo hilo obtiene tiempo de programa y pone la suya. La salida resultante estará fuera de secuencia.
Afortunadamente, los hilos tienen una característica adiciona: la idea de exclusión mutua. Utilizando esto, podemos construir un esquema de sincronización seguro.
Exclusión Mutua
El método de más bajo nivel para bloquear la ejecución de otros hilos utiliza una condición global thread-critical. Cuando la condición está establecida a true (utilizando el método Thread.critical=), el planificador no programa para ejecutar ningún hilo existente. Sin embargo, esto no bloquea la creación de nuevos hilos para ejecutar. Ciertas operaciones de hilo (como la de detener o matar un hilo, mandar a dormir al hilo en curso o lanzar una excepción) puede causar la asignación de tiempo a un hilo, aun estan-do en una sección crítica.
Utilizar Thread.critical= directamente es ciertamente posible pero no es muy conveniente. De hecho, le recomendamos encarecidamente que no lo use a menos que tenga cinturón negro en multithrea-ding (y afición por las sesiones de depuración largas). Afortunadamente, Ruby viene con varias alternati-vas. Ahora vamos a ver una de estas, la librería Monitor. También se puede consultar la librería Sync, la librería Mutex_m y la clase Queue implementada en la librería Thread (todas se verán más adelante).
Monitores
Aunque las primitivas para hilos proporcionan sincronización básica, son dificiles de usar. Con los años, varias personas han llegado a alternativas de más alto niuvel. Una que funciona especialmente bien en sistemas orientados a objetos es el concepto de monitor.
Los monitores envuelven objetos que contienen algún tipo de recursos con funciones de sincroniza-ción. Para verlos en acción, vamos a ver un simple contador al que se accede desde dos hilos.
class Counter attr_reader :count def initialize

92
@count = 0 super end def tick @count += 1 endend
c = Counter.new
t1 = Thread.new { 10000.times { c.tick } }t2 = Thread.new { 10000.times { c.tick } }
t1.joint2.join
c.count -> 11319
Sorprendentemente quizás, el recuento no es igual a 20.000. La razón está en una simple línea de código:
@count += 1
Esta línea en realidad es más compleja de lo que parece. En el intérprete de Ruby podría descompo-nerse en
val = fetch_current(@count)add 1 to valstore val back into @count
Ahora imagine que dos hilos ejecutan este código al mismo tiempo. La tabla 3 muestra el número de los hilos (t1 y t2), el código que se está ejecutando, y el valor del contador (que se inicializa a 0). Aunque nuestro básico conjunto de instrucciones load/add/store se ejecuta cinco veces, termina-mos con el contador a 3. Como el hilo 1 interrumpe la ejecución del hilo 2 en medio de una secuencia, cuando se reanuda el hilo 2 almacena un valor antiguo al volver a @count.
La solución es arreglar las cosas para que sólo un hilo pueda ejecutar el método de incremento tick en un momento dado. Esto es fácil utilizando monitores.require ‘monitor’class Counter < Monitor attr_reader :count

93
def initialize @count = 0 super end def tick synchronize do @count += 1 end endend
c = Counter.newt1 = Thread.new { 10000.times { c.tick } }t2 = Thread.new { 10000.times { c.tick } }
t1.join; t2.joinc.count -> 20000
Al hacer nuestro contador un monitor, gana el acceso al método synchronize. Sólo un hilo puede ejecutar código en un bloque de sincronización, para un objeto monitor particular en un momento dado. Así, ya no tenemos dos hilos almacenando en caché los resultados intermedios al mismo tiempo, y nuestra cuenta tiene el valor esperado.
No tenemos que hacer de nuestra clase una subclase de monitor para conseguir estos beneficios. Tam-bién puede combinar en una variante, MonitorMixin.
require ‘monitor’class Counter include MonitorMixin . . .end
El ejemplo anterior pone la sincronización dentro del recurso que se está sincronizado. Esto es apro-piado cuando todos los accesos a todos los objetos de la clase requieren sincronización. Pero si se quiere controlar el acceso a los objetos que requieren sincronización, sólo en algunas circunstancias, o si la sin-cronización se reparte entre un grupo de objetos, entonces puede ser mejor usar un monitor externo.
require ‘monitor’
class Counter attr_reader :count def initialize @count = 0 end def tick @count += 1 endend
c = Counter.newlock = Monitor.new
t1 = Thread.new { 10000.times { lock.synchronize { c.tick } } }t2 = Thread.new { 10000.times { lock.synchronize { c.tick } } }t1.join; t2.join
c.count -> 20000
Se pueden incluso hacer objetos específicos en los monitores:

94
require ‘monitor’
class Counter # como antes ...end
c = Counter.newc.extend(MonitorMixin)
t1 = Thread.new { 10000.times { c.synchronize { c.tick } } }t2 = Thread.new { 10000.times { c.synchronize { c.tick } } }
t1.join; t2.joinc.count -> 20000
En este caso, como la clase Counter no sabe lo que es un monitor en el momento en que se define, tenemos que realizar la sincronización externa (en este caso, envolviendo las llamadas a c.tick). Esto claramente es un poco peligroso: si algún otro código llama a tick, pero no realiza la sincronización re-querida, estamos de vuelta en el mismo lío en el que comenzamos.
Colas
Los monitores nos dan la mitad de lo que necesitamos, porque hay un problema. Digamos que tenemos dos hilos accediendo a una cola compartida. Uno para añadir las entradas, y el otro para leer (tal vez la lista de las canciones la espera de ser puestas en nuestro jukebox: añade las selecciones que hacen los clientes, y vacía los registros que terminaron).
Ya sabemos lo que necesitamos para sincronizar el acceso, por lo que intentamos algo así como
require ‘monitor’playlist = []playlist.extend(MonitorMixin)# Hilo reproductorThread.new do record = nil loop do playlist.synchronize do # < < BUG!!! sleep 0.1 while playlist.empty? record = playlist.shift end play(record) endend# Petición de canción del clienteThread.new do loop do req = get_customer_request playlist.synchronize do playlist << req end endend
Pero este código tiene un problema. En el interior del hilo reproductor, se accede al monitor y luego el bucle espera que se añada algo a la lista de reproducción. Pero debido a que en el propio monitor el hilo de clientes no será capaz de entrar en su bloque sincronizado, nunca agregará nada a la lista de repro-ducción. Estamos atascados. Lo que necesitamos es ser capaces de indicar que la lista tiene algo en ella para proporcionar una sincronización entre los hilos sobre la base de esta condición, manteniéndonos a la vez dentro de la seguridad de un monitor. En términos más generales, tenemos que ser capaces de abandonar temporalmente el uso exclusivo de la región crítica y al mismo tiempo decirle a los clientes que

95
estamos esperando un recurso. Cuando el recurso esté disponible, tenemos que ser capaces de captar y reobtener el bloqueo de la región crítica, todo en un solo paso.
Ahí es donde vienen las variables de condición. Una variable de condición es una forma controlada de comunicar un evento (o una condición) entre dos hilos. Un hilo puede esperar la condición y el otro puede enviarle señales. Por ejemplo, podríamos reescribir nuestra máquina de discos utilizando variables de condición. (A los efectos de este código vamos a escribir métodos de código auxiliar para recibir las soli-citudes de los clientes y para escuchar los discos. También tenemos que añadir una bandera para decirle al reproductor cuando puede cerrar. Normalmente se ejecutaría indefinidamente)
require ‘monitor’SONGS = [ ‘Blue Suede Shoes’, ‘Take Five’, ‘Bye Bye Love’, ‘Rock Around The Clock’, ‘Ruby Tuesday’]START_TIME = Time.nowdef timestamp (Time.now - START_TIME).to_iend
# Esperar un máximo de 2 minutos entre las peticiones de los clientesdef get_customer_requestsleep(120 * rand)song = SONGS.shiftputs “#{timestamp}: Requesting #{song}” if songsongend
# Canciones toman entre dos y tres minutosdef play(song) puts “#{timestamp}: Playing #{song}” sleep(120 + 60*rand)endok_to_shutdown = false
# y aquí está nuestro código originalplaylist = []playlist.extend(MonitorMixin)plays_pending = playlist.new_cond
# Petición de canción del clientecustomer = Thread.new do loop do req = get_customer_request break unless req playlist.synchronize do playlist << req plays_pending.signal end endend
# Hilo reproductorplayer = Thread.new do loop do song = nil playlist.synchronize do

96
break if ok_to_shutdown && playlist.empty? plays_pending.wait_while { playlist.empty? } song = playlist.shift end break unless song play(song) endendcustomer.joinok_to_shutdown = trueplayer.join
produce:
26: Requesting Blue Suede Shoes28: Playing Blue Suede Shoes72: Requesting Take Five188: Requesting Bye Bye Love214: Playing Take Five288: Requesting Rock Around The Clock299: Requesting Ruby Tuesday396: Playing Bye Bye Love563: Playing Rock Around The Clock708: Playing Ruby Tuesday
Ejecución de Múltiples Procesos
A veces es posible que desee dividir una tarea en procesos de uno u otro tamaño --o tal vez se necesita ejecutar un proceso separado que no estaba escrito en Ruby. No hay problema: Ruby tiene una serie de métodos por los cuales se pueden generar y gestionar procesos separados.
Generar Nuevos Procesos
Hay varias maneras de generar un proceso separado, lo más fácil es ejecutar algún comando y esperar a que se complete. Puede que uno se encuentre haciendo esto para ejecutar algún comando por separado o recuperar datos del sistema anfitrión. Ruby lo hace por usted con los métodos system y acento grave (o tilde).
system(“tar xzf test.tgz”) -> trueresult = `date`result -> “Thu Aug 26 22:36:55 CDT 2004\n”
El método Kernel.system ejecuta un comando dado en un subproceso. Si se ha encontrado el co-mando y se ha ejecutado correctamente devuelve true, y false, en caso contrario. En caso de fallo, se encuentra el código de salida del subproceso en la variable global $?.
Un problema con system es que la salida del comando, simplemente va al mismo destino que la salida del programa, que puede no ser lo que se pretende. Para capturar la salida estándar de un subproceso, puede utilizar los caracteres de acento grave, al igual que con `date` en el ejemplo anterior. Recuerde que se puede necesitar utilizar String#chomp para eliminar los caracteres de fin de línea del resultado.
OK, esto está bien para los casos simples, podemos ejecutar algún otro proceso y obtener el estado de retorno. Pero muchas veces tenemos que controlar algo más que eso. Nos gustaría mantener una comunicación con el subproceso, como envíarle datos y la posibilidad de conseguir algunos de vuelta. El método IO.popen hace justamente esto. El método popen ejecuta un comando como un subproceso y se conecta a la entrada estándar de subprocesos y a la salida estándar de un objeto IO Rubí. Escribe en el objeto IO y el subproceso puede leer en la entrada estándar. Cualquiera cosa que el subproceso escribe está disponible en el programa Ruby con la lectura del objeto IO.
Por ejemplo, en nuestros sistemas una de las utilidades más conveniente es pig, un programa que lee

97
palabras de la entrada estándar y las imprime en pig latín (o igpay atinlay). Podemos utilizar esta opción cuando nuestros programas Ruby necesita enviarnos una salida que nuestros cinco-años-de-edad no de-berían ser capaz de entender (Pig Latin es un giro del Inglés para personas que quieren hacerse el tonto, o para los niños que no quieren que sus padres sepan lo que están hablando).
pig = IO.popen(“/usr/local/bin/pig”, “w+”)pig.puts “ice cream after they go to bed”pig.close_writeputs pig.gets
produce:
iceway eamcray afterway eythay ogay otay edbay
Este ejemplo ilustra la aparente simplicidad y la verdadera complejidad del mundo real en la que parti-cipa la conducción de los subprocesos a través de las tuberías (pipes). El código parece ciertamente bas-tante simple: abrir el pipe, escribir una frase, y de vuelta a leer la respuesta. Pero resulta que el programa pig no limpia la salida que escribe. Nuestro primer intento en este ejemplo, que tenía un pig.puts se-guido de un pig.gets, se quedó colgado para siempre. El programa pig procesa nuestra entrada, pero su respuesta no fue escrita en la tubería. Hemos tenido que insertar la línea pig.close_write. Esto envía un fin de archivo a la entrada estándar de pig y la salida buscada se vacía cuando pig termina.
popen tiene una peculiaridad más. Si el comando que se le pasa es un signo menos (-), popen será un fork de un nuevo intérprete de Ruby. Tanto éste como el intérprete original se seguirán ejecutando me-diante el retorno de popen. El proceso original recibirá un nuevo objeto IO y el hijo recibirá nil. Esto sólo funciona en sistemas operativos que soporten la llamada a fork(2) (y por ahora esto excluye a Windows).
pipe = IO.popen(“”,”w+”)if pipe pipe.puts “Get a job!” STDERR.puts “Child dice ‘#{pipe.gets.chomp}’”else STDERR.puts “Papa dice ‘#{gets.chomp}’” puts “OK”end
produce:
Papa dice ‘Get a job!’Child dice ‘OK’
Además del método popen, algunas plataformas soportan los métodos Kernel.fork, Kernel.exec e IO.pipe. La convención de nomenclatura de archivos de muchos métodos IO y Kernel.open también genera subprocesos si se pone a | como el primer carácter del nombre de archivo (véase la introducción a la clase IO para más detalles). Tenga en cuenta que no se puede crear pipes utilizando File.new ya que es sólo para archivos.
Procesos Hijo Independientes
A veces no hace falta ser tan práctico: nos gustaría dar al subproceso sus cometidos y luego ir a nuestro negocio. Algún tiempo después, vamos a comprobar si ha terminado. Por ejemplo, es posible que queramos poner en marcha una clasificación externa de larga ejecución.
exec(“sort testfile > output.txt”) if fork.nil?# The sort is now running in a child process# carry on processing in the main program# ... dum di dum ...# then wait for the sort to finishProcess.wait

98
La llamada a Kernel.fork devuelve un identificador de proceso en el padre y nil en el hijo, por lo que éste llevará a cabo la llamada a Kernel.exec y se ejecutará sort. Algún tiempo después, emitimos una llamada a Process.wait, que espera a que sort termina (y devuelve su identificador de proceso).
Si prefiere ser notificado cuando un subproceso sale (en vez de esperar la vuelta), puede configurar un controlador de señal con Kernel.trap (que se describe más adelante). Aquí hemos configurado una trampa en SIGCLD, que es la señal enviada a la “muerte del proceso hijo.” trap(“CLD”) do pid = Process.wait puts “Child pid #{pid}: terminated”endexec(“sort testfile > output.txt”) if fork.nil?# hacer otras cosas...
produce:
Child pid 25816: terminated
Para más información sobre el uso y control de procesos externos, consulte la documentación de Kernel.open , IO.popen y la sección del módulo Process.
Bloques y Subprocesos
IO.popen trabaja con un bloque más o menos de la misma forma que File.open. Si se le pasa un comando, como date, el bloque pasa un objeto IO como un parámetro.
IO.popen(“date”) {|f| puts “Date is #{f.gets}” }
produce:
Date is Thu Aug 26 22:36:55 CDT 2004
El objeto IO se cerrará automáticamente cuando se sale del bloque de código, tal como con File.open.
Si asocia un bloque con Kernel.fork, el código del bloque se ejecutará en un subproceso Ruby, y el padre continuará después del bloque.
fork do puts “In child, pid = #$$” exit 99endpid = Process.waitputs “Child terminated, pid = #{pid}, status = #{$?.exitstatus}”
produce:
In child, pid = 25823Child terminated, pid = 25823, status = 99
$? es una variable global que contiene información sobre la terminación de un subproceso. Para más información ver la sección sobre Process::Status.
Pruebas de Unidad
Las pruebas de unidad (la descripción en el siguiente recuadro resaltado) es una técnica que ayuda a los desarrolladores a escribir mejor código. Esto ayuda antes de que se escriba realmente el código, ya

99
que pensar acerca de las pruebas nos lleva de forma natural a crear mejores diseños más disociados. Ayuda en la reescritura del código, ya que da información instantánea sobre la forma exacta del mismo. Y ayuda después de haber escrito el código, tanto porque le da la posibilidad de comprobar que el código todavía funciona como porque ayuda a otros a entender cómo usar el código.
Las pruebas de unidad son una cosa buena.
Pero ¿por qué hay un capítulo sobre las pruebas de unidad en medio de un libro sobre Ruby? Porque pruebas de unidad y lenguajes como Ruby parecen ir de la mano. La flexibilidad de Ruby hace fácil escribir pruebas, y a éstas, ser más fácil comprobar el código en el que se está trabajando. Una vez que usted en-tra en su swing, se encontrará escribiendo un poco de código, después una o dos pruebas comprobando que todo está en orden, y a continuación, seguir escribiendo un poco más de código.
Las pruebas de la unidad también son bastante triviales, --se ejecuta un programa que llama a una parte de código de la aplicación, se obtienen algunos resultados, y a continuación, se comprueba que los resultados son los esperados.
Digamos que estamos probando una clase para números romanos. Por ahora, el código es bastante simple: sólo nos permite crear un objeto que representa un número determinado y mostrar el objeto en números romanos. La figura 5 muestra nuestro primer intento de una aplicación.
Podríamos probar este código escribiendo este otro programa:
require ‘roman’r = Roman.new(1)fail “’i’ expected” unless r.to_s == “i”
r = Roman.new(9)fail “’ix’ expected” unless r.to_s == “ix”
Sin embargo, como el número de pruebas en un proyecto va creciendo, este tipo de enfoque ad-hoc puede empezar a complicarse para su gestión. Con los años, han surgido diversos marcos (frameworks) para pruebas unitarias para ayudar a estructurar el proceso de prueba. Ruby cuenta con uno pre-instala-do, Test::Unit de Nathaniel Talbott’s.

100
Framework Test::Unit
El Framework Test::Unit es, básicamente, tres utilidades envueltas en un paquete ordenado.
1. Te da una manera de expresar las pruebas individuales. 2. Proporciona un marco para la estructuración de las pruebas. 3. Te da formas flexibles de invocar las pruebas.
Afirmaciones == Resultados Esperados
En lugar de tener que escribir una serie de sentencias if individuales en las pruebas, Test::Unit ofrece una serie de afirmaciones que logran lo mismo. Aunque existe un número de diferentes estilos de afirmación, todas siguen básicamente el mismo patrón. Cada afirmación le da una forma de especificar el resultado o la salida deseados y una manera de pasar el resultado actual. Si el actual no es igual al esperado, la afirmación muestra un bonito mensaje y registra el hecho como un fallo.
Por ejemplo, podríamos reescribir nuestra prueba anterior de la clase romana en Test::Unit. Por el momento, vamos a ignorar el código de andamiaje con el inicio y el final, y nos bastará con ver el método assert_equal.
require ‘roman’require ‘test/unit’class TestRoman < Test::Unit::TestCase def test_simple assert_equal(“i”, Roman.new(1).to_s) assert_equal(“ix”, Roman.new(9).to_s) endend
produce:Loaded suite - Started.Finished in 0.003655 seconds.
1 tests, 2 assertions, 0 failures, 0 errors
¿Qué son las Pruebas de Unidad?
Las pruebas de unidad se centra en pequeños trozos (unidades) de código, métodos típicamente individuales o líneas dentro de métodos. Esto contrasta con la mayoría de otras formas de prueba, que consideran el sistema como un todo.
¿Por qué centrarse tan estrechamente? Porque al final todo el software se construye en capas: una capa de código se basa en el correcto funcionamiento del código en las capas inferiores. Si este có-digo subyacente resulta contener errores, entonces todas las capas superiores están potencialmente afectadas. Este es un gran problema. Fred puede escribir el código con un bug una semana, y luego puede terminar llamandole, indirectamente, dos meses después. Cuando el código comienza a generar resultados incorrectos, a Fred le llevará un tiempo encontrar el problema en el método. Y cuando Fred se pregunte por qué lo escribió de esa manera, la respuesta será probablemente “no me acuerdo. Eso fue hace meses“.
Si en lugar de esto, Fred hubiera puesto a prueba su código cuando lo escribió, habrían sudecido dos cosas. En primer lugar, habría encontrado el error cuando el código todavía está fresco en su men-te. En segundo lugar, como las pruebas de unidad se hacen con el código que se acababa de escribir, cuando se presenta el bug, sólo hay que mirar un puñado de líneas para encontrarlo, en lugar de
hacer arqueología en el resto de la base del código.

101
La primera afirmación dice que estamos esperando la representación de números romanos de una cadena como “i”, y la segunda que podemos esperar que 9 sea “ix”. Por suerte para nosotros, las expec-tativas se cumplen y el informe de seguimiento dice que se ha pasado la prueba.
Vamos a añadir unas cuantas pruebas más.
require ‘roman’require ‘test/unit’class TestRoman < Test::Unit::TestCase def test_simple assert_equal(“i”, Roman.new(1).to_s) assert_equal(“ii”, Roman.new(2).to_s) assert_equal(“iii”, Roman.new(3).to_s) assert_equal(“iv”, Roman.new(4).to_s) assert_equal(“ix”, Roman.new(9).to_s) endend
produce:
Loaded suite - StartedFFinished in 0.021877 seconds.
1) Failure: <”ii”> expected but was<”i”>.
1 tests, 2 assertions, 1 failures, 0 errorstest_simple(TestRoman) [prog.rb:6]:
¡Uh oh! La segunda afirmación falló. Ver cómo el mensaje de error utiliza el hecho de que las afirma-ciones conocen tanto los valores esperados como los reales: se espera obtener “ii” pero se obtiene “i”. En cuanto a nuestro código, se puede ver un error evidente en to_s. Si el recuento después de dividir por el factor es mayor que cero, entonces debemos tenemos en la salida muchos dígitos romanos. El código existente produce sólo uno. La solución es fácil.
def to_s value = @value roman = “” for code, factor in FACTORS count, value = value.divmod(factor) roman << (code * count) end romanend
Ahora vamos a ejecutar nuestras pruebas otra vez.
Loaded suite - Started.Finished in 0.002161 seconds.
1 tests, 5 assertions, 0 failures, 0 errors
En buen estado. Ahora podemos ir un paso más allá y eliminar algunas duplicidades.
require ‘roman’require ‘test/unit’

102
class TestRoman < Test::Unit::TestCase NUMBERS = [ [ 1, “i” ], [ 2, “ii” ], [ 3, “iii” ], [ 4, “iv”], [ 5, “v” ], [ 9, “ix” ] ] def test_simple NUMBERS.each do |arabic, roman| r = Roman.new(arabic) assert_equal(roman, r.to_s) end endend
produce:
Loaded suite - Started.Finished in 0.004026 seconds.
1 tests, 6 assertions, 0 failures, 0 errors
¿Qué otra cosa se puede probar? Bueno, el constructor comprueba que el número se le pasa se puede representar como un número romano y lanza una excepción si no se puede. Vamos a probar la excepción.
require ‘roman’require ‘test/unit’class TestRoman < Test::Unit::TestCase def test_range assert_raise(RuntimeError) { Roman.new(0) } assert_nothing_raised() { Roman.new(1) } assert_nothing_raised() { Roman.new(499) } assert_raise(RuntimeError) { Roman.new(5000) } endend
produce:
Loaded suite - Started.Finished in 0.002898 seconds.
1 tests, 4 assertions, 0 failures, 0 errors
Podríamos hacer muchas más pruebas en nuestra clase Roman, pero vamos a pasar a cosas más grandes y mejores. Antes de seguir, sin embargo, debemos decir que sólo hemos arañado la superficie del conjunto de afirmaciones disponible dentro de Test::Unit. La figura 6 un poco más adelante da una lista completa. El parámetro final de cada afirmación es un mensaje que se emite antes que cualquier mensaje de error. Esto normalmente no es necesario, ya que los mensajes de Test::Unit son normalmente bas-tante razonables. La única excepción es el test assert_not_nil, donde el mensaje “<nil> esperado no ser nil” no ayuda mucho. En este caso, es posible que desee añadir alguna anotación por su cuenta.
require ‘test/unit’class TestsWhichFail < Test::Unit::TestCase def test_reading assert_not_nil(ARGF.read, “Read next line of input”) endend

103
produce:
Loaded suite - StartedFFinished in 0.033581 seconds.
1) Failure:Read next line of input.<nil> expected to not be nil.
1 tests, 1 assertions, 1 failures, 0 errorstest_reading(TestsWhichFail) [prog.rb:4]:
Pruebas de Estructuración
Antes dijomos hacer caso omiso del andamiaje en torno a nuestras pruebas. Pues ahora es el momento de verlo.
En su unidad de prueba se incluye la utilidad Test::Unit con la siguiente línea:
require ‘test/unit’
Las pruebas de unidad parecen caer naturalmente bien en grupos de alto nivel, llamados test cases. En grupos de bajo nivel, los métodos se prueban en sí mismos. Los casos de prueba generalmente contienen todas las pruebas relacionadas con una utilidad o característica en particular. Nuestra clase de números romanos es bastante simple, por lo que todas las pruebas para ella probablemente entrarán en un solo caso de prueba. En un caso de prueba, es probable que desee organizar sus afirmaciones en una serie de métodos de prueba, en la que cada método contiene las afirmaciones de un tipo de prueba: un método que puede comprobar la conversión regular de números, otro podría poner a prueba el manejo de errores, etc.
Las clases que representan los casos de prueba deben ser subclases de Test::Unit::TestCase. Los métodos que llevan las afirmaciones deben tener nombres que empiezan con test. Esto es importan-te: Test::Unit utiliza el reflejo para encontrar las pruebas a ejecutar y sólo los métodos cuyos nombres empiezan con test son elegibles.
Muy a menudo se encontrará todos los métodos de prueba en un caso de prueba configurados para un escenario particular. Entonces, cada método de prueba sondea algún aspecto de ese escenario. Final-mente, cada método puede ponerse en orden a sí mismo. Por ejemplo, podría ser la prueba de una clase que extrae las listas de reproducción del jukebox de una base de datos.
require ‘test/unit’require ‘playlist_builder’require ‘dbi’class TestPlaylistBuilder < Test::Unit::TestCase def test_empty_playlist db = DBI.connect(‘DBI:mysql:playlists’) pb = PlaylistBuilder.new(db) assert_equal([], pb.playlist()) db.disconnect end def test_artist_playlist db = DBI.connect(‘DBI:mysql:playlists’) pb = PlaylistBuilder.new(db) pb.include_artist(“krauss”) (pb.playlist.size > 0, “Playlist shouldn’t be empty”) pb.playlist.each do |entry| assert_match(/krauss/i, entry.artist) end

104
db.disconnect end def test_title_playlist db = DBI.connect(‘DBI:mysql:playlists’) pb = PlaylistBuilder.new(db) pb.include_title(“midnight”) assert(pb.playlist.size > 0, “Playlist shouldn’t be empty”) pb.playlist.each do |entry| assert_match(/midnight/i, entry.title) end db.disconnect end # ...end
produce:
Loaded suite - Started...Finished in 0.004809 seconds.
3 tests, 23 assertions, 0 failures, 0 errors
Cada prueba se inicia mediante la conexión a la base de datos y la creación de un nuevo constructor de lista de reproducción. Cada prueba termina por desconexión de la base de datos. (La idea de utilizar una base de datos real en las pruebas unitarias es cuestionable, ya que las pruebas de unidad se supone que ejecutan rápido, son independientes del contexto y fácil de configurar, pero ilustra el tema).
Podemos extraer de todo este código común los métodos de montaje y desmontaje. Dentro de una clase TestCase, se ejecutará un método llamado setup (montaje) antes de cada uno de los métodos de prueba. Un método llamado teardown (desmontaje) se llevará a cabo después de que termina cada méto-do de prueba. Hacemos hincapié en que: los métodos de montaje y desmontaje soportan cada prueba, en lugar de ser ejecutado una vez para el caso de prueba.
Nuestra prueba vendría a ser:
require ‘test/unit’require ‘playlist_builder’require ‘dbi’class TestPlaylistBuilder < Test::Unit::TestCase def setup @db = DBI.connect(‘DBI:mysql:playlists’) @pb = PlaylistBuilder.new(@db) end def teardown @db.disconnect end def test_empty_playlist assert_equal([], @pb.playlist()) end def test_artist_playlist @pb.include_artist(“krauss”) assert(@pb.playlist.size > 0, “Playlist no de be estar vacía”) @pb.playlist.each do |entry| assert_match(/krauss/i, entry.artist) end end def test_title_playlist @pb.include_title(“midnight”)

105
assert(@pb.playlist.size > 0, “Playlist no debe estar vacía”) @pb.playlist.each do |entry| assert_match(/midnight/i, entry.title) end end # ...end
produce:
Loaded suite - Started...Finished in 0.00691 seconds.3 tests, 23 assertions, 0 failures, 0 errors
Organización y Ejecución de las Pruebas
Los casos de prueba que hemos demostrado hasta el momento son todos programas ejecutables Test::Unit. Si, por ejemplo, el caso de prueba para la clase Roman estaba en un archivo llamado test_roman.rb, podríamos ejecutar las pruebas desde la línea de comandos con
% ruby test_roman.rbLoaded suite test_romanStarted...Finished in 0.039257 seconds.
2 tests, 9 assertions, 0 failures, 0 errors
Test::Unit es lo suficientemente funcional como para notar que no existe un programa principal, así que recolecta toda las clases de caso de prueba y ejecuta cada una de ellas.
Si queremos, podemos pedir que se ejecute un sólo método de prueba en particular.
% ruby test_roman.rb --name test_rangeLoaded suite test_romanStarted.Finished in 0.006445 seconds.
1 tests, 4 assertions, 0 failures, 0 errors
Dónde Colocar Pruebas
Una vez que se entra en las pruebas de unidad, es muy posible encontrar que se genera casi tanto código de prueba como código de producción. Todas esas pruebas tienen que vivir en alguna parte. El problema es que si se colocan junto a los archivos de producción regular de código fuente, los directorios comienzan a hincharse --efectivamente se terminará con dos archivos por cada archivo fuente producido.
Una solución común es tener un directorio test/ donde colocar todos los archivos fuente de prueba. Este directorio se coloca paralelo al directorio que contiene el código que está en desarrollo. Por ejemplo, para nuestra clase de números romanos, podemos tener:

106
roman | |---- lib/ | | | |---- roman.rb | |---- otros ficheros... | |---- test/ | | | |---- test_roman.rb | |---- otros test... | |---- otras cosas
Esto funciona bien como forma de organización de archivos, pero te deja con un pequeño problema: ¿cómo decir a Ruby dónde encontrar los archivos de librería para probar? Por ejemplo, si nuestro código de prueba TestRoman está en el subdirectorio /test ¿cómo sabe Ruby dónde encontrar el archivo fuen-te roman.rb que estamos tratando de probar?
Una opción que no funciona correctamente es la construcción de la ruta con la declaración require y ejecutar las pruebas desde el subdirectorio /test.
require ‘test/unit’require ‘../lib/roman’class TestRoman < Test::Unit::TestCase # ...end
¿Por qué no funciona? Debido a que el archivo roman.rb puede a su vez necesitar otros archivos fuente en la biblioteca que estamos escribiendo. Que se van a cargar con require (sin el “../lib/”), y como no están en $LOAD_PATH de Ruby, no se encontrarán. Simplemente no se ejecutará nuestra prueba. Un segundo problema, menos inmediato, es que no vamos a ser capaces de usar estas mismas pruebas para nuestras clases una vez instalado en un sistema de destino, ya que luego van a referenciar con require ‘roman’.
Una solución mejor es ejecutar las pruebas desde el directorio que contiene la biblioteca que se está probando. Debido a que el directorio actual se encuentra en la ruta de carga, el código de prueba será capaz de encontrarlo.
% ruby ../test/test_roman.rb
Sin embargo, este enfoque no sirve si se quiere ser capaz de ejecutar las pruebas en algún otro lugar del sistema. Tal vez su proceso de gestión de procesos (scheduled) ejecuta las pruebas para todo el soft-ware de la aplicación, simplemente buscando archivos llamados test_xxx y ejecutandolos. En este caso, se necesita un poco de magia en la ruta de carga. Al principio de su código de prueba (por ejemplo, en test_roman.rb), se añade la siguiente línea:
$:.unshift File.join(File.dirname(__FILE__), “..”, “lib”)require ...
Esta magia funciona porque el código de prueba se encuentra en una ubicación conocida en relación con el código que se está probando. Se inicia con la elaboración del nombre del directorio desde el que se ejecuta el archivo de prueba y luego la construcción de la ruta a los archivos bajo prueba. Este directorio es el antepuesto a la ruta de carga (la variable $:). A partir de entonces, código tal como require ‘ro-man’ buscará la librería que se probó por primera vez.
Conjuntos de Prueba
Después de un tiempo, tendrá una decente colección de casos de prueba para su aplicación. Puede que encuentre que tienden a agruparse: un grupo de casos de prueba para un determinado conjunto de

107
funciones y otro grupo de pruebas parsa un conjunto diferente de funciones. Puede agrupar los casos de prueba en conjuntos de pruebas, lo que le permite ejecutar todos como un grupo.
En Test::Unit esto es fácil de hacer. Todo lo que hay que hacer es crear un archivo de Ruby que requiera test/unit y a continuación, requierir cada uno de los archivos de los casos de prueba que se desean agrupar. De esta manera, se construye una jerarquía de material de prueba y
•Puedeejecutarpruebasindividualesporsunombre.•Puedeejecutartodaslaspruebasenunarchivomediantelaejecucióndedichoarchivo.•Puedeagruparunaseriedearchivosenunconjuntodepruebayejecutarlascomounaunidad.•Puedeagruparconjuntosdepruebaenunconjuntodeprueba.
Esto le da la capacidad de ejecutar las pruebas de unidad controlando el nivel de granularidad, testear sólo un método o toda la aplicación.
En este punto, vale la pena pensar acerca de las convenciones de nombres. Nathaniel Talbott, el autor de Test::Unit, utiliza la convención de que los casos de prueba se encuentran en archivos con el nom-bre tc_xxx y los conjuntos (suites) de pruebas se encuentran en archivos con el nombre ts_xxx.
# file ts_dbaccess.rbrequire ‘test/unit’require ‘tc_connect’require ‘tc_query’require ‘tc_update’require ‘tc_delete’
Ahora, si ejecuta Ruby con el archivo ts_dbaccess.rb, se ejecutarán los casos de prueba de los cuatro archivos que ha requerido.
¿Eso es todo lo que hay? No, usted puede hacer que sea más complicado si lo desea. Puede crear y rellenar manualmente objetos TestSuite, aunque no parece tener mucho sentido en la práctica. Para obtener más información, ri Test::Unit debería ayudar.
Test::Unit viene con una serie de lujo de ejecutables GUI de pruebas. Aunque los auténticos pro-gramadores utilizan la línea de comandos, no se describe aquí sin embargo. Una vez más, consulte la documentación para más detalles.
Cuando Atacan los Problemas
Es triste decirlo, pero es posible escribir programas con errores usando Ruby. Se siente.
¡Pero no se preocupe! Ruby tiene varias características que ayudan a depurar los programas. Pronto nos ocuparemos de estas características, y le mostraremos algunos errores comunes que se pueden co-meter en Ruby y cómo solucionarlos.
El Depurador de Ruby
Ruby cuenta con un depurador que está muy bien integrado en el sistema base. Puede ejecutar el depurador llamando al intérprete con la opción -r debug, junto con cualquier otra opción de Ruby y el nombre de su script.
ruby -r debug [ debug-options ] [ programfile ] [ program-arguments ]
El depurador es compatible con la habitual gama de características que usted esperaría, incluyendo la posibilidad de establecer puntos de interrupción, entrar en y pasar por encima de las llamadas a métodos y mostrar los marcos de pila y variables. También se pueden enumerar los métodos definidos para un ob-jeto o clase en particular y le permite la lista y control de los hilos separados dentro de Ruby. La tabla 4 un poco más adelante enumera todos los comandos disponibles para el depurador.

108
Si la instalación de Ruby tiene activado soporte para readline, puede utilizar las teclas de cursor para moverse adelante y atrás en la historia de comandos y el uso de edición de línea de comandos para modificar la entrada anterior.
Para hacerse una idea de como es el depurador de Ruby, aquí va un ejemplo de sesión (con la entrada del usuario en negrita).
% ruby -r debug t.rbDebug.rbEmacs support available.t.rb:1:def fact(n)(rdb:1) list 1-9[1, 10] in t.rb=> 1 def fact(n) 2 if n <= 0 3 1 4 else 5 n * fact(n1) 6 end
Figura 6. Afirmaciones Test::Unit

109
7 end 8 9 p fact(5)(rdb:1) b 2Set breakpoint 1 at t.rb:2(rdb:1) cbreakpoint 1, fact at t.rb:2t.rb:2: if n <= 0(rdb:1) disp n 1: n = 5(rdb:1) del 1(rdb:1) watch n==1Set watchpoint 2(rdb:1) cwatchpoint 2, fact at t.rb:factt.rb:1:def fact(n)1: n = 1(rdb:1) where--> #1 t.rb:1:in `fact’ #2 t.rb:5:in `fact’ #3 t.rb:5:in `fact’ #4 t.rb:5:in `fact’ #5 t.rb:5:in `fact’ #6 t.rb:9(rdb:1) del 2(rdb:1) c120
Ruby Interactivo
Si quiere jugar con Ruby, le recomendamos Ruby Interactivo --irb, por sus siglas. irb es esencialmente una “shell” Ruby, similar en concepto a una shell del sistema operativo (completa, con control de trabajos). Proporciona un entorno donde se puede “jugar” con el lenguaje en tiempo real. Puede inciar irb en el símbolo del sistema.
irb [ irb-options ] [ ruby_script ] [ program-arguments ]
irb mostrará el valor de cada expresión a medida que se complete. Por ejemplo:
% irbirb(main):001:0> a = 1 +irb(main):002:0* 2 * 3 /irb(main):003:0* 4 % 5=> 2irb(main):004:0> 2+2=> 4irb(main):005:0> def testirb(main):006:1> puts “Hello, world!”irb(main):007:1> end=> nilirb(main):008:0> testHello, world!=> nilirb(main):009:0>
irb también le permite crear subsesiones en las que cada una de las cuales puede tener su propio contexto. Por ejemplo, puede crear una subsesión con el mismo contexto (nivel superior) que la sesión originaria o crear una subsesión en el contexto de una determinada clase o instancia. La sesión de ejem-plo que se muestra en la figura 7 en la página 111 muestra cómo se pueden crear subsesiones y cambiar entre ellas.

110
Para una descripción completa de todos los comandos que soporta irb, se muestra la tabla de refe-rencia más adelante.
Al igual que con el depurador, si su versión de Ruby fue construida con soporte para GNU readline, puede utilizar las teclas de flecha (como con Emacs) o combinaciones de teclas estilo vi para modificar las líneas individuales o volver atrás y volver a ejecutar o modificar una línea anterior --igual que una shell de comandos.
irb es una gran herramienta de aprendizaje: es muy útil si quiere probar una idea de forma rápida y ver si funciona.
Soporte de Editor
El intérprete de Ruby está diseñado para leer un programa de una sola pasada. Esto significa que usted puede canalizar todo un programa por un pipe a la entrada estándar del intérprete y funcionará muy bien.
Podemos tomar ventaja de esta característica para ejecutar código Ruby desde el interior de un editor. En Emacs, por ejemplo, puede seleccionar una región de texto Ruby y utilizar el comando Meta-| para ejecutar Ruby. El intérprete de Ruby usará la región seleccionada como la entrada estándar, y la salida se destinará a un buffer llamado *Shell Command Output*. Esta característica ha llegado a ser muy útil mientras escribíamos este libro, --sólo tenía que seleccionar unas pocas líneas de Ruby en medio de un párrafo y ¡pruébelo!
Se puede hacer algo similar en el editor vi con :%ruby que sustituye el texto del programa con su salida, o :w !ruby, que muestra la salida sin afectar al buffer. Otros editores tienen características simi-lares.
Ya que estamos en el tema, este probablemente sería un buen momento para mencionar que hay un modo de Ruby para Emacs incluido en la distribución de código fuente de Ruby como ruby-mode.el en el subdirectorio /misc. También puede encontrar los módulos de resaltado de sintaxis para vim (una versión mejorada del editor vi), jed, y otros editores en la red. Echar una ojeada a preguntas frecuentes (FAQ) acerca de Ruby (http://rubyhacker.com/clrFAQ.html) para obtener una lista actualizada y referen-cias a otros recursos.
Pero, ¡no funciona!
Con lo que ha leído ya en este libro, usted comienza a escribir su programa propio en Ruby, pero, ¡no funciona!. Aquí hay una lista de errores comunes y otros consejos.
•Enprimerlugar,ejecutarlassecuenciasdecomandosconlasadvertenciasactivadas(laopción-w de línea de comandos).
•Siseolvidadeuna“,” en una lista de argumentos, sobre todo para imprimir, puede producir algunos mensajes de error muy extraños.
•Unerrordeanálisisenlaúltimalíneadelfuenteamenudoindicaquefaltaunapalabraclaveend (a veces un poco antes).
• Un atributosetter que no se está llamando. Dentro de una definición de clase, Ruby analizará setter= como una asignación a una variable local, no como una llamada al método. Utilice la forma self.setter= para indicar la llamada al método.
class Incorrect attr_accessor :one, :two def initialize one = 1 # incorrect sets local variable self.two = 2 endend

111
obj = Incorrect.newobj.one -> nilobj.two -> 2
•Objetosqueparecennoestarbienconfiguradospuedeserporunaescrituraincorrectadelmétodoinitialize.
class Incorrect attr_reader :answer def initialise # < < < spelling error @answer = 42 endend
ultimate = Incorrect.newultimate.answer -> nil
En esta misma sesión irb, vamos a crear una nueva subsesión en el contexto de la clase VolumeKnob.
Podemos usar fg 0 para volver a la sesión principal, mirar todos los trabajos actuales, y ver qué mé-todos de instancia define VolumeKnob.
Hacer un objeto Volume-Knob nuevo y crear una nueva subsesión con este objeto según el contexto.
Volver a la sesión principal, matar las subsesiones y salir.
Figura 7. Ejemplo de sesión irb.

112
•Sucedelomismosiseescribeincorrectamenteelnombredeunavariabledeinstancia.
class Incorrect attr_reader :answer def initialize @anwser = 42 # < < < spelling error endend
ultimate = Incorrect.newultimate.answer -> nil
•Losparámetrosdebloqueestánenelmismoámbitoquelasvariableslocales.Siexisteunavariablelocal con el mismo nombre que un parámetro de bloque cuando éste se ejecuta, la variable será modifi-cada por la llamada al bloque. Esto puede o no puede ser una buena cosa.
c = “carbon”i = “iodine”elements = [ c, i ]elements.each_with_index do |element, i| # do some chemistryend
c -> “carbon”i -> 1
• Tenga cuidado con los problemas de prioridad, especialmente cuando se utiliza {} en lugar de do/end .
def one(arg) if block_given? “block given to ‘one’ returns #{yield}” else arg endenddef two if block_given? “block given to ‘two’ returns #{yield}” endendresult1 = one two { “three”}result2 = one two do “three”endputs “With braces, result = #{result1}”puts “With do/end, result = #{result2}”
produce:
With braces, result = block given to ‘two’ returns threeWith do/end, result = block given to ‘one’ returns three
•Lasalidadeunterminalpuedeestarenunbuffer. Esto significa que puede no ver de inmediato un mensaje. Además, si escribe mensajes a $stdout y $stderr, la salida puede no aparecer en el or-den que se esperaba. Utilice siempre I/O sin buffer (configuración sync=true) para los mensajes de depuración .

113
•Silosnúmerosnosalenbientalvezsoncadenas.EltextoleídodeunarchivoesunString y Ruby no lo convierte automáticamente en un número. Una llamada a Integer hará maravillas (y producirá una excepción si la entrada no es un entero bien formado). Un error común que los programadores de Perl hacen es:
while line = getsnum1, num2 = line.split(/,/) # ...end
Puede volver a escribir esto como:
while line = getsnum1, num2 = line.split(/,/)num1 = Integer(num1)num2 = Integer(num2) # ...end
O puede convertir todas las cadenas utilizando map :
while line = gets num1, num2 = line.split(/,/).map {|val| Integer(val) } # ...end
•aliasingnointencionado.Siestáutilizandounobjetocomolaclavedeunhash,asegúresedequenocambia su valor hash (o los arreglos para llamar Hash#rehash si lo hace).
arr = [1, 2]hash = { arr => “value” }hash[arr] -> “value”arr[0] = 99hash[arr] -> nilhash.rehash -> {[99, 2]=>”value”}hash[arr] -> “value”
•Asegúresedequelaclasedelobjetoqueestáutilizandoesloqueustedpiensaquees.Encasodeduda, utilice puts mi_obj.class.
•Asegúresedequelosnombresdemétodocomienzanconunaletraminúsculaylosnombresdeclasey constante comienzan con una letra mayúscula.
•Si lasllamadasamétodosnoestánhaciendoloqueseespera,asegúresedequehapuestoentreparéntesis los argumentos.
•Asegúresedequeelparéntesisdeaperturadelosparámetrosdemétodoestápegadoalnombredelmismo, sin espacios intermedios.
•Utiliceirb y el depurador.
•UtiliceObject#freeze. Si usted sospecha que alguna porción de código desconocido está fijando una variable a un valor falso, trate de congelar la variable. El culpable será capturado al intentar modificar la variable.
Una mayor técnica hace escribir código Ruby tanto más fácil y divertido. Desarrolle sus aplicaciones de forma incremental. Escriba unas pocas líneas de código y ejecútelo. Utilize Test::Unit y escriba algu-nas pruebas. Escriba unas pocas líneas más de código y ejercítelo. Una de las principales ventajas de un lenguaje de tipos dinámicos es que las cosas no tienen por qué estar completas antes de usarlas.

114
¡Pero es demasiado lento!
Ruby es un lenguaje de alto nivel interpretado, y como tal, no puede llevar un desempeño tan rápido como un lenguaje de bajo nivel como C. En las siguientes secciones, vamos a enumerar algunas cosas básicas que usted puede hacer para mejorar el rendimiento. También eche un vistazo en el índice de bajo rendimiento para otras sugerencias.
Por lo general, los programas de ejecución lenta tienen uno o dos cementerios de rendimiento, lugares donde el tiempo de ejecución va a morir. Búsquelos, mejorelos y de repente su programa entero volverá a la vida. El truco es encontrarlos. El módulo Benchmark y los perfiladores de Ruby pueden ayudar.
Benchmark
Se puede utilizar el módulo Benchmark, que se describe más adelante, para ver el desempeño de secciones de código. Por ejemplo, podemos preguntarnos que es más rápido: un bucle grande utilizando variables locales en el bloque o el uso de variables del ámbito circundante. La figura 8 muestra cómo uti-lizar Benchmark para averiguarlo.
Hay que tener cuidado con el benchmarking, porque muchas veces los programas de Ruby pueden funcionar lentamente debido a la sobrecarga de la recolección de basura. Debido a que esta recolección de basura puede ocurrir que en cualquier momento durante la ejecución del programa, puede encontrar que la comparación da resultados engañosos y muestre que una sección de código se ejecuta lentamente, cuando en realidad la ralentización fue causada porque la recolección de basura se dispara mientras se ejecuta el código. El módulo Benchmark tiene el método bmbm que ejecuta las pruebas dos veces, una como un ensayo y otra para medir el desempeño en un intento de minimizar la distorsión introducida por la recolección de basura. El proceso de evaluación comparativa (benchmarking) en sí tiene relativamentebuenos modales --no ralentiza el programa mucho más.
El Perfilador
Ruby cuenta con un analizador de código (documentado más adelante). El perfilador muestra el nú-mero de veces que se llama en el programa a cada método y el tiempo promedio y acumulativo que Ruby pasa en ellos.

115
Se pueden agregar perfiles al código con la opción -r profile en la línea de comandos o desde dentro del código utilizando require ‘profile’. Por ejemplo:
require ‘profile’count = 0words = File.open(“/usr/share/dict/words”)while word = words.gets word = word.chomp! if word.length == 12 count += 1 endendputs “#{count} twelve-character words”
La primera vez que se corre esto (sin perfiles) contra de un diccionario de casi 235.000 palabras, tar-da varios segundos en completarse. Como parece excesivo, hemos añadido la opción -r profile en la línea de comandos ejecutándolo de nuevo. Eventualmente hemos visto que la salida se parecía a lo siguiente.
20460 twelve-character words % cumulative self self totaltime seconds seconds calls ms/call ms/call name7.76 12.01 12.01 234937 0.05 0.05 String#chomp!7.75 24.00 11.99 234938 0.05 0.05 IO#gets7.71 35.94 11.94 234937 0.05 0.05 String#length7.62 47.74 11.80 234937 0.05 0.05 Fixnum#==0.59 48.66 0.92 20460 0.04 0.04 Fixnum#+0.01 48.68 0.02 1 20.00 20.00 Profiler__.start_profile0.00 48.68 0.00 1 0.00 0.00 File#initialize0.00 48.68 0.00 1 0.00 0.00 Fixnum#to_s0.00 48.68 0.00 1 0.00 0.00 File#open0.00 48.68 0.00 1 0.00 0.00 Kernel.puts0.00 48.68 0.00 2 0.00 0.00 IO#write0.00 48.68 0.00 1 0.00 154800.00 #toplevel
Lo primero a notar es que los tiempos se muestran mucho más lentos que cuando el programa se ejecuta sin el perfilador. Este conlleva una seria sobrecarga, pero asumiendo que se aplica en todos los ámbitos, los números relativos son aún significativos. Este programa en particular pasa claramente mucho tiempo en el bucle, que ejecuta casi 235.000 veces. Probablemente podríamos mejorar el rendimiento si se pueden hacer las cosas en el bucle menos costosas o eliminando el bucle completamente. Una forma de hacer esto último es mediante la lectura de la lista de palabras en una cadena larga y entonces usar un patrón que corresponda para extraer las palabras de doce caracteres.
require ‘profile’words = File.read(“/usr/share/dict/words”)count = words.scan(PATT= /^............\n/).sizeputs “#{count} twelve-character words”
Nuestros números de perfil son ahora mucho mejores (y el programa se ejecuta hasta cinco veces más rápido cuando se vuelve a tomar el perfil).
20460 twelve-character words % cumulative self self totaltime seconds seconds calls ms/call ms/call name96.67 0.29 0.29 1 290.00 290.00 String#scan 6.67 0.31 0.02 1 20.00 20.00 Profiler__.start_profile 0.00 0.31 0.00 1 0.00 0.00 Array#size 0.00 0.31 0.00 1 0.00 0.00 Kernel.puts 0.00 0.31 0.00 2 0.00 0.00 IO#write

116
0.00 0.31 0.00 1 0.00 0.00 Fixnum#to_s 0.00 0.31 0.00 1 0.00 300.00 #toplevel 0.00 0.31 0.00 1 0.00 0.00 File#read
Recuerde revisar después el código sin el perfilador, ya que a veces la ralentización que el perfilador introduce puede enmascarar otros problemas.
Ruby es un lenguaje extraordinariamente transparente y expresivo, pero no exime al programador de la necesidad de aplicar el sentido común: la creación de objetos innecesarios realizando trabajos que no son necesarios y la creación de código hinchado ralentizará sus programas sin importar el lenguaje.
Ruby en su Entorno
Ruby y su Mundo
Es un hecho desafortunado de la vida que nuestras aplicaciones tienen que lidiar con un mundo grande y malo. En este capítulo, veremos cómo Ruby interactúa con su entrono. Los usuarios de Microsoft Win-dows también puedrán ver las especificaciones de su plataforma más adelante.
Argumentos de la Línea de Comandos
“En el principio fue la línea de comandos”(Este es el título de un fabuloso ensayo de Neal Stephenson disponible en línea en http://www.spack.org/index.cgi/InTheBeginningWasTheCommandLine). Indepen-dientemente del sistema en el que Ruby es desplegado, ya sea una super estación de trabajo de gráficos científicos de alta calidad, o, un dispositivo PDA integrado, hay que iniciar el intérprete de Ruby de alguna manera, y ésto, nos da la oportunidad de pasar argumentos de línea de comandos.
Una línea de comandos Ruby consta de tres partes: opciones para el intérprete de Ruby, el nombre de un programa a ejecutar opcionalmente, y, opcionalmente también, un conjunto de argumentos para ese programa.
ruby [ options ] [ --- ] [ programfile ] [ arguments ]
Las opciones de Ruby terminan con la primera palabra en la línea de comandos que no comienza con un guión, o por la bandera especial -- (dos guiones).
Si no hay ningún nombre de archivo en la línea de comandos, o si el nombre del archivo es un guión (-), Ruby lee el código fuente del programa a partir de la entrada estándar.
Los argumentos para el programa van a continuación del nombre del programa. Por ejemplo:
% ruby -w - “Hello World”
permitirá los avisos y leerá un programa de la entrada estándar pasándole la cadena entre comillas “Hola Mundo” como un argumento.
Opciones de la Línea de Comandos
-0[octal]. La bandera 0 (el dígito cero) especifica el carácter separador de registro (\0, si no dígitos siguientes). --00 indica el modo párrafo: los registros están separados por dos caracteres separadores de registro sucesivos. 0777 lee todo el archivo a la vez (ya que es un carácter no válido). Establece $/.
-a Modo auto división cuando se utiliza con -n o -p, equivalente a ejecutar $F = $ _.split en la parte superior de cada iteración del bucle.
-C directorio. Cambiar el directorio de trabajo al directorio dado antes de ejecutar.
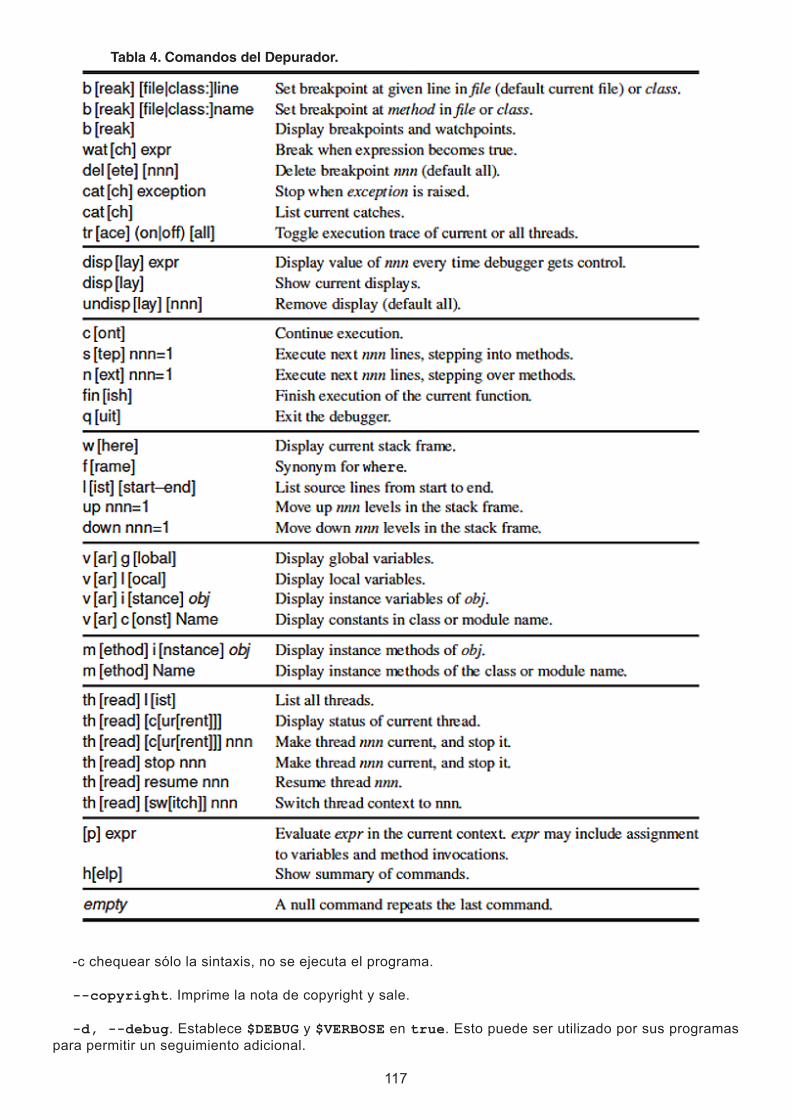
117
-c chequear sólo la sintaxis, no se ejecuta el programa.
--copyright. Imprime la nota de copyright y sale. -d, --debug. Establece $DEBUG y $VERBOSE en true. Esto puede ser utilizado por sus programas para permitir un seguimiento adicional.
Tabla 4. Comandos del Depurador.

118
-e ‘comando’. Ejecuta el comando como una línea de código fuente Ruby. Se permiten varias -e’s, y los comandos son tratados como varias líneas en el mismo programa. Si se omite programfile cuando está presente -e, se detiene la ejecución después de que los -e comandos se han ejecutado. Los programas que se ejecutan con -e tienen acceso al antiguo comportamiento de los rangos y las expresiones regu-lares en condicionales --rangos de números enteros se comparan con el número de la entrada de línea actual y las expresiones regulares contra $_.
-F patrón. Especifica el separador de campos de entrada ($;) que se utiliza como valor predetermi-nado para split() (afecta a la opción -a).
-h, --help. Muestra una pantalla de ayuda.
-I directorios. Especifica los directorios que se anteponen a $LOAD_PATH ($:). Múltiples opcio-nes -I pueden estar presentes y varios directorios pueden aparecer después de cada -I, separados por dos puntos (:) en sistemas tipo Unix y por un punto y coma (;) en DOS/Windows.
-i [extension]. Edita archivos ARGV. Para cada archivo nombrado en ARGV, cualquier cosa que escriba en la salida estándar se guarda en el contenido de ese archivo. Se hará una copia de seguridad del archivo si se suministra la extensión.
% ruby -pi.bak -e “gsub(/Perl/, ‘Ruby’)” *.txt
-K kcodigo. Especifica el conjunto de códigos que se utilizarán. Esta opción es útil sobre todo cuando Ruby se utiliza para el procesamiento del idioma japonés. kcode puede ser uno de: e, E para la EUC; s, S para SJIS; u, U para UTF-8; o bien a, A, n, N para ASCII.
-l Permite procesamiento automático de final de línea. Establece $\ con el valor de $/ y corta cada línea de entrada de forma automática.
-n Asume un bucle while ... en torno a su programa. Por ejemplo, se puede implementar un coman-do grep como
% ruby -n -e “print if /wombat/” *.txt
-p Coloca el código del programa en el bucle while ...; print.
% ruby -p -e “$_.downcase!” *.txt
-r librería. Requiere la biblioteca llamada antes de ejecutar.
-S Busca el archivo de programa en RUBYPATH o donde indique la variable de entorno PATH.
-s Cualquier modificador de línea de comandos encontrado tras el nombre del programa, pero antes cualquier argumento de archivo o de --, se elimina de ARGV y se asigna a una variable global llamada para el cambio. En el siguiente ejemplo, el efecto de esto sería establecer la variable $opt en “electric” .
% ruby -s prog -opt=electric ./mydata
-T[nivel]. Ajusta el nivel de seguridad, que entre otras cosas permite pruebas en modo conteminado (más adelante se verá). Establece $SAFE.
-v, --verbose. Establece $VERBOSE en true, lo que permite el modo detallado. También se impri-me el número de versión. En modo detallado se imprimen las advertencias de compilación. Si no aparece ningún nombre de archivo de programa en la línea de comandos, Ruby sale.
--version. Muestra el número de versión de Ruby y sale.
-w Activa el modo detallado. A diferencia de -v, lee el programa de la entrada estándar si no están presentes archivos de programa en la línea de comandos. Se recomienda ejecutar sus programas Ruby con -w.

119
-W nivel. Ajusta el nivel de las alertas emitidas. Con un nivel o dos (o sin especificar nivel), equi-valente a -w -- se dan advertencias adicionales. Si el nivel es 1, se ejecuta en el nivel estándar (por defecto). Con -W0 no se se dá absolutamente ninguna advertencia (¡ incluyendo las emitidas utilizando Kernel.warn !).
-X directorio. Cambia el directorio de trabajo al directorio dado antes de ejecutar. Igual que -C directorio.
-x [directorio] Se despoja del texto antes de la línea #!ruby y cambia el directorio de trabajo a un directorio dado si se le da.
-y, --yydebug. Habilita la depuración yacc en el analizador (fooooorma demasiada información).
ARGV
Los argumentos de línea de comandos tras el nombre del programa están disponibles para el programa Ruby en la matriz global ARGV. Por ejemplo, supongamos que test.rb contiene el siguiente programa:
ARGV.each {|arg| p arg }
Invocándole en la línea de comandos:
% ruby -w test.rb “Hello World” a1 1.6180
Genera la salida siguiente:
“Hello World”“a1”“1.6180”
Hay aquí un gotcha para los programadores de C --ARGV[0] es el primer argumento del programa, no el nombre del programa. El nombre del programa en curso está disponible en la variable global $0. Tenga en cuenta que todos los valores de ARGV son cadenas.
Si el programa intenta leer de la entrada estándar (o utiliza el archivo especial ARGF, que se describe más adelante), los argumentos del programa en ARGV se tomarán comonombres de archiv, y Ruby leerá-de estos archivos. Si el programa tiene una mezcla de argumentos y nombres de archivo, asegúrese de vaciar los argumentos que no son nombres de archivo del arrray ARGV antes de la lectura.
Terminación de Programa
El método Kernel#exit termina su programa devolviendo un valor de estado para el sistema ope-rativo. Sin embargo, a diferencia de otros lenguajes, la salida no termina el programa inmediatamente. Kernel#exit primero lanza una excepción SystemExit, que se puede capturar y a continuación, rea-liza una serie de acciones de limpieza incluyendo la ejecución de cualquiera de los métodos at_exit y finalizadores de objetos registrados. Se puede ver la referencia de Kernel#exit más adelante.
Variables de Entorno
Se puede acceder a las variables de entorno del sistema con la variable predefinida ENV. Responde a los mismos métodos que Hash (ENV en realidad no es un hash, pero si es necesario, se puede convertir en un hash utilizando ENV#to_hash).
ENV[‘SHELL’] -> “/bin/sh”ENV[‘HOME’] -> “/Users/dave”ENV[‘USER’] -> “dave”ENV.keys.size -> 34ENV.keys[0, 7] -> [“MANPATH”, “TERM_PROGRAM”, “TERM”, “SHELL”, “SAVEHIST”, “HISTSIZE”, “MAKEFLAGS”]

120
Ruby lee los valores de algunas variables de entorno cuando se inicia por primera vez. Estas variables modifican el comportamiento del intérprete como se muestra en la tabla 5.
Nombre de Variable DescripciónDLN_LIBRARY_PATH Ruta de búsqueda para los módulos de carga dinámica.HOME Indicadores al directorio home del usuario. Se utiliza para la expansión de ~ en nombres de archivos y directorios.LOGDIR Puntero de reserva para el directorio home del usuario en caso de que $HOME no esté definida. Utilizado sólo por Dir.chdir.OPENSSL_CONF Especifica la ubicación del archivo de configuración de OpenSSL.RUBYLIB Ruta de búsqueda adicional para los programas Ruby ($SAFE debe ser 0).RUBYLIB_PREFIX (Sólo Windows) Mutila la ruta de búsqueda RUBYLIB por la adición de este prefijo a cada componente.RUBYOPT Opciones adicionales de línea de comandos para Ruby, examinadas después de analizar las de línea de comandos real ($SAFE debe ser 0).RUBYPATH Con la opción -S, la ruta de búsqueda para los programas Ruby (por defecto PATH).RUBYSHELL Shell a utilizar al lanzar un proceso en Windows. Si no se establece, también se comprobará SHELL o COMSPEC.RUBY_TCL_DLL Ignorar el nombre por defecto para la DLL o librería compartida TCL.RUBY_TK_DLL Ignorar el nombre por defecto para la DLL o librería compartida Tk. Tanto ésta como RUBY_TCL_DLL se deben establecer si se van a utilizar.
Escribir Variables de Entorno
Un programa Ruby puede escribir en el objeto ENV. En la mayoría de los sistemas esto cambia los va-lores de las variables de entorno correspondientes. Sin embargo, este cambio es local al proceso que lo hace y para cualquier proceso hijo generado posteriormente. Esta herencia de las variables de entorno se ilustra en el código que sigue. Un subproceso cambia una variable de entorno, y se inicia otro proceso que hereda este cambio. Sin embargo, el cambio no es visible para el padre de origen. (Esto sólo sirve para demostrar que los padres nunca saben realmente lo que están haciendo sus hijos.)
puts “In parent, term = #{ENV[‘TERM’]}”fork do puts “Start of child 1, term = #{ENV[‘TERM’]}” ENV[‘TERM’] = “ansi” fork do puts “Start of child 2, term = #{ENV[‘TERM’]}” end Process.wait puts “End of child 1, term = #{ENV[‘TERM’]}”endProcess.waitputs “Back in parent, term = #{ENV[‘TERM’]}”
produce:
In parent, term = xtermcolorStart of child 1, term = xtermcolorStart of child 2, term = ansiEnd of child 1, term = ansiBack in parent, term = xtermcolor
Dónde Encuentra Ruby Sus Módulos
Se utiliza require o load para llevar un módulo de librería a su programa Ruby. Algunos de estos módulos se suministran con Ruby, otros pueden estar instalados fuera de Ruby Application Archive y otros puede haberlos escrito usted mismo. ¿Cómo los encuentra Ruby?
Tabla 5. Variables de entorno utilizadas por Ruby.

121
Cuando Ruby se construye para su máquina particular, permite predefinir un conjunto de directorios estándar para mantener las cosas de librería. Entonces estos directorios dependen de la máquina en cuestión. Usted puede determinar desde la línea de comandos con algo como
% ruby -e ‘puts $:’ En una máquina Linux típica, es probable encontrar algo como lo siguiente. Notar que a partir de Ruby 1.8, el orden de estos directorios se ha cambiado --los directorios de arquitectura específica ahora siguen a sus homólogos independientemente de la máquina.
/usr/local/lib/ruby/site_ruby/1.8/usr/local/lib/ruby/site_ruby/1.8/i686-linux/usr/local/lib/ruby/site_ruby/usr/local/lib/ruby/1.8/usr/local/lib/ruby/1.8/i686-linux
Los directorios site_ruby estándestinados a contener módulos y extensiones que haya añadido. Los directorios dependientes de la arquitectura (i686-linux en este caso) tienen ejecutables y otras cosas específicas para esta máquina en particular. Todos estos directorios se incluyen automáticamente en la búsqueda de Ruby para los módulos.
A veces esto no es suficiente. Tal vez usted vuelva a trabajar en un gran proyecto escrito en Ruby, y usted y sus colegas han construido una considerable biblioteca de código Ruby. Entonces quiere que todos los del equipo tengan acceso a todo este código. Usted tiene un par de opciones para lograr esto. Si su programa se ejecuta en un nivel seguro establecido en cero (más adelante se verá esto), se puede entonces establecer la variable de entorno RUBYLIB a una lista de uno o más directorios donde buscar (El separador entre las entradas depende de la plataforma. Para Windows, es el punto y coma. Para Unix, son dos puntos, : ). Si su programa no es setuid, puede utilizar el parámetro de línea de comandos -I para hacer lo mismo.
La variable de Ruby $: es una serie de lugares para buscar los archivos cargados. Como hemos visto, esta variable se inicializa en la lista de directorios estándar, además de cualquier otra adicional que se es-pecifica utilizando RUBYLIB e -I. Siempre se pueden añadir directorios adicionales para esta serie dentro de su programa en ejecución.
Para hacer las cosas más interesantes, una nueva forma de organización de librerías llegó justo a tiem-po para este libro. Un poco más adelante se describe RubyGems, un sistema de paquetes con capacidad de gestión a través de la red.
Construir el Entorno
Cuando Ruby es compilado para una arquitectura particular, todos los ajustes pertinentes utilizados para su construcción (incluyendo la arquitectura de la máquina en la que se compiló, las opciones del compilador, el directorio de código fuente, etc) se escriben en el módulo Config dentro del archivo de librería rbconfig.rb. Después de la instalación, cualquier programa Ruby puede usar este módulo para obtener detalles sobre cómo se compiló Ruby.
require ‘rbconfig.rb’include ConfigCONFIG[“host”] -> “powerpcappledarwin7.5.0”CONFIG[“libdir”] -> “/Users/dave/ruby1.8/lib”
Las librerías de extensión utilizan este archivo de configuración con el fin de compilar y enlazar correc-tamente en cualquier arquitectura dada. Véase más adelante el capítulo “Extensión de Ruby” y la referen-cia para mkmf para más detalles.

122
Ruby Shell Interactivo
Unas páginas atrás se introdujo irb, un módulo de Ruby que le permite entrar en los programas Ruby de forma interactiva y ver los resultados inmediatamente. En este capítulo se entra en más detalles sobre el uso y la personalización de irb.
De Línea de Comandos
irb se ejecuta desde la línea de comandos.
irb [ irb-options ] [ ruby_script ] [ program arguments ]
Las opciones de línea de comandos para irb se enumeran en la tabla 6. Por lo general, se encontrará con irb sin opciones, pero si quieres ejecutar un script y ver la descripción con puntos y comas de que se ejecuta, puede proporcionar el nombre del script Ruby y las opciones para ese script.
Opción Descripción
--back-trace-limit n Mostrar la información de backtrace con las últimas n entradas. El valor predeterminado es 16.-d Establecer $DEBUG en true (lo mismo que ruby -d).-f Suprime la lectura de ~/.irbrc.-I path Especifica el directorio $LOAD_PATH.--inf-ruby-mode Establecer irb para ejecutarse en inf-ruby-mode bajo Emacs. Cambia el prompt y suprime --readline.--inspect Utiliza Object#inspect para el formato de salida. (por defecto, menos en el modo matemático). --irb_debug n Ajuste el nivel de depuración interna en n (sólo es útil para desarrollo irb).-m Modo matemático (soporte para fracciones y matrices)--noinspect No utilizar inspect para la salida.--noprompt No mostrar un prompt.--noreadline No utilizar el módulo de extensión Readline.--prompt prompt-mode Cambiar el prompt. Los modos prompt predefinidos son null, default, classic, simple, xmp, e inf-ruby.--promp-tmode Lo mismo que --prompt.-r load-module Lo mismo que ruby -r.--readline Utilizar el módulo de extensión readline.--simple-prompt Utilizar prompt simple.--tracer Mostrar la traza para la ejecuciónd e comandos.-v,--version Imprimir la versión de irb.
Una vez iniciado, irb muestra un mensaje y espera la entrada. En los ejemplos que siguen vamos a utilizar el prompt irb por defecto, que muestra el símbolo actual, el nivel de anidamiento y el número de línea.
En el símbolo del sistema puede escribir código Ruby. irb incluye un analizador de Ruby, por lo que sabe cuando los estados están incompletos. Cuando esto ocurre, el indicador termina con un asterisco. Puede abandonar irb escribiendo exit o quit o introduciendo un carácter de fin de archivo (a menos que esté establecido el modo IGNORE_EOF).
% irbirb(main):001:0> 1 + 2=> 3irb(main):002:0> 3 +irb(main):003:0* 4=> 7irb(main):004:0> quit%

123
Durante una sesión irb, el trabajo que hace se acumula en el espacio de trabajo irb. Las variables que se definen, los métodos y las clases que se crean son recordados y pueden recordarse posteriormente .
irb(main):001:0> def fib_up_to(n)irb(main):002:1> f1, f2 = 1, 1irb(main):003:1> while f1 <= nirb(main):004:2> puts f1irb(main):005:2> f1, f2 = f2, f1+f2irb(main):006:2> endirb(main):007:1> end=> nilirb(main):008:0> fib_up_to(4)1123=> nil
Observe el valor de retorno nil. Es el resultado de definir el método y luego ejecutarlo. La salida del método son números de Fibonacci, pero luego vuelve a nil.
Un gran uso de irb es experimentar con el código que ya ha escrito. Quizás usted desea localizar un error o tal vez sólo quier jugar. Si carga el programa en irb, a continuación puede crear instancias de las clases que defina e invocar sus métodos. Por ejemplo, el código del archivo /fib_up_to.rb contiene la definición de método siguiente:
def fib_up_to(max) i1, i2 = 1, 1 while i1 <= max yield i1 i1, i2 = i2, i1+i2 endend
Podemos cargarlo en irb y jugar con el método.
% irbirb(main):001:0> load ‘code/fib_up_to.rb’=> trueirb(main):002:0> result = []=> []irb(main):003:0> fib_up_to(20) {|val| result << val}=> nilirb(main):004:0> result=> [1, 1, 2, 3, 5, 8, 13]
En este ejemplo, se utiliza load en lugar de require para incluir el archivo en nuestra sesión. Hace-mos esto como una cuestión de práctica: load nos permite cargar el mismo archivo varias veces, así que si encuentra un error y edita el archivo, se podría volver a cargar en la sesión irb.
Autocompletado
Si la instalación de Ruby tiene soporte para readline, se puede utilizar la característica de autocom-pletado. Una vez cargado (y vamos s ver como se carga en breve), el autocompletado cambia el significa-do de la tecla TAB cuando se escriben expresiones en el prompt irb. Cuando se pulsa TAB hasta cierto punto de una palabra, irb va a buscar las terminaciones posibles que tengan sentido en ese momento. Si sólo hay una, el IRB la va a rellenar de forma automática. Si hay más de una opción válida, irb inicial-mente no hace nada. Sin embargo, si usted presiona TAB, se mostrará la lista de terminaciones válidas en ese momento.

124
Por ejemplo, es posible que en medio de una sesión irb, acabe de asignar un objeto string a la varia-ble a.
irb(main):002:0> a = “cat”=> “cat”
Ahora quieren probar el método de String#reverse en ese objeto. Empieza por escribir a.re y lue-go pulsa TAB dos veces.
irb(main):003:0> a.reTABTABa.reject a.replace a.respond_to? a.reverse a.reverse! irb lista de todos los métodos admitidos por el objeto cuyos nombres empiezan por “re”. Vemos lo que queríamos, reverse, e introducimos el siguiente carácter de su nombre, v, seguido de la tecla TAB.
irb(main):003:0> a.revTABirb(main):003:0> a.reverse=> “tac”irb(main):004:0>
irb responde a la tecla TAB ampliando el nombre tan lejos como pueda ir, en este caso completando la palabra reverse. Si teclea TAB dos veces en este punto, se nos muestran las opciones actuales, re-verse y reverse!. Sin embargo, como el que queremos es reverse, presionamos ENTER y se ejecuta la línea de código.
La implementación del tabulador no se limita sólo a los nombres integrados. Si definimos una clase en irb, la implementación del tabulador funciona cuando tratamos de acogernos a alguno de sus métodos.
irb(main):004:0> class Testirb(main):005:1> def my_methodirb(main):006:2> endirb(main):007:1> end=> nilirb(main):008:0> t = Test.new=> #<Test:0x35b724>irb(main):009:0> t.myTABirb(main):009:0> t.my_method
La implementación del tabulador se implementa como una librería de extensión, irb/completion. Se puede cargar al invocar irb desde la línea de comandos.
% irb -r irb/completion
También puede cargar la libería completion cuando irb se está ejecutando.
irb(main):001:0> require ‘irb/completion’=> true
Si utiliza la implementación del tabulador todo el tiempo, es probable que sea más conveniente poner el comando require en su archivo .irbrc.
require ‘irb/completion’
Subsesiones
irb soporta múltiples sesiones concurrentes. Una de ellos es siempre la actual, las otros permanecen latentes hasta que se activan. Entrando el comando irb dentro de irb se crea un subsesión. Introducien-do el comando jobs se enumeran todas las sesiones e introduciendo fg, se activa una sesión inactiva en particular.

125
Este ejemplo también ilustra la opción -r de línea de comandos, que carga el archivo dado antes de comenzar irb.
% irb -r code/fib_up_to.rbirb(main):001:0> result = []=> []irb(main):002:0> fib_up_to(10) {|val| result << val }=> nilirb(main):003:0> result=> [1, 1, 2, 3, 5, 8]irb(main):004:0> # Crear una sesión irb anidadairb(main):005:0* irbirb#1(main):001:0> result = %w{ cat dog horse }=> [“cat”, “dog”, “horse”]irb#1(main):002:0> result.map {|val| val.upcase }=> [“CAT”, “DOG”, “HORSE”]irb#1(main):003:0> jobs=> #0->irb on main (#<Thread:0x331740>: stop)#1->irb#1 on main (#<Thread:0x341694>: running)irb#1(main):004:0> fg 0irb(main):006:0> result=> [1, 1, 2, 3, 5, 8]irb(main):007:0> fg 1irb#1(main):005:0> result=> [“cat”, “dog”, “horse”]
Si se especifica un objeto cuando se crea un subsesión, ese objeto se convierte en el valor de sí mismo (self) en ese enlace. Esta es una forma cómoda de experimentar con los objetos. En el siguiente ejemplo, creamos un subsesión con la cadena “wombat” como el objeto por defecto. Los métodos sin receptor se-rán ejecutado por este objeto.
% irbirb(main):001:0> self=> mainirb(main):002:0> irb “wombat”irb#1(wombat):001:0> self=> “wombat”irb#1(wombat):002:0> upcase=> “WOMBAT”irb#1(wombat):003:0> size=> 6irb#1(wombat):004:0> gsub(/[aeiou]/, ‘*’)=> “w*mb*t”irb#1(wombat):005:0> irb_exitirb(main):003:0> self=> mainirb(main):004:0> upcaseNameError: undefined local variable or method `upcase’ for main:Object
Configuración
irb es muy configurable. Puede configurar las opciones de configuración con el comando options, dentro de un archivo de inicialización y mientras estamos dentro del mismo irb.
Archivo de Inicialización
irb utiliza un archivo de inicialización en el que puede definir las opciones de uso común o ejecutar cualquier declaración Ruby necesaria. Cuando se ejecuta irb, intentará cargar un archivo de inicializa-ción de los siguientes por este orden: ~/.irbrc, .irbrc, irb.rc, _irbrc y $irbrc.

126
En el archivo de inicialización puede ejecutar cualquier código Ruby arbitrario. También puede estable-cer valores de configuración. La lista de variables de configuración las veremos ahora un poco más ade-lante --los valores que se pueden utilizar en un archivo de inicialización son los símbolos (comienzan con dos puntos). Se pueden utilizar estos símbolos para establecer los valores en la tabla hash IRB.conf. Por ejemplo, para que el valor por defecto del prompt para todas las sesiones de irb sea SIMPLE, se puede tener lo siguiente en el fichero de inicialización:
IRB.conf[:PROMPT_MODE] = :SIMPLE
Como una interesante peculiaridad sobre la configuración de irb, se puede establecer IRB.conf[:IRB_RC] a un objeto Proc. Este proc se invoca cada vez que el contexto cambia e irb recibirá la configuración de ese contexto como un parámetro. Usted puede utilizar esta función para cambiar la configuración de forma dinámica en función del contexto. Por ejemplo, el archivo .irbrc siguiente esta-blece el prompt de modo que sólo el prompt main muestra el nivel irb, pero le pide la continuación y el resultado todavía se alinea.
IRB.conf[:IRB_RC] = proc do |conf| leader = “ “ * conf.irb_name.length conf.prompt_i = “#{conf.irb_name} --> “ conf.prompt_s = leader + ‘ \-” ‘ conf.prompt_c = leader + ‘ \-+ ‘ conf.return_format = leader + “ ==> %s\n\n” puts “Welcome!”end
Una sesión irb con este archivo .irbrc tiene el siguiente aspecto:
% irbWelcome!irb --> 1 + 2 ==> 3
irb --> 2 + \-+ 6 ==> 8
Extendiendo irb
Como lo que escribe para irb se interpreta como código Ruby, se puede efectivamente extender irb mediante la definición de nuevos métodos de nivel superior. Por ejemplo, puede ser capaz de buscar la documentación de una clase o método mientras está en irb. Si añade lo siguiente a su archivo .irbrc, añadirá un método llamado ri que invoca el comando externo ri en sus argumentos:
def ri(*names) system(%{ri #{names.map {|name| name.to_s}.join(“ “)}})end
La próxima vez que inicie irb, será capaz de utilizar este método para obtener la documentación.
irb(main):001:0> ri Proc--------------------------------------------------------- Class: Proc
Proc objects are blocks of code that have been bound to a set of local variables. Once bound, the code may be called in different contexts and still access those variables.and so on...
irb(main):002:0> ri :strftime------------------------------------------------------- Time#strftime
time.strftime( string ) => string---------------------------------------------------------------------

127
Formats time according to the directives in the given format string. Any text not listed as a directive will be passed through to the output string.
Format meaning:%a - The abbreviated weekday name (``Sun’’)%A - The full weekday name (``Sunday’’)%b - The abbreviated month name (``Jan’’)%B - The full month name (``January’’)%c - The preferred local date and time representation%d - Day of the month (01..31)
and so on...
irb(main):003:0> ri “String.each”------------------------------------------------------String#each str.each(separator=$/) |substr| block => str str.each_line(separator=$/) |substr| block => str-------------------------------------------------------------------- Splits str using the supplied parameter as the record separator ($/
by default), passing each substring in turn to the supplied block. If a zero-length record separator is supplied, the string is split on \n characters, except that multiple successive newlines are appended together.
print “Example one\n” “hello\nworld”.each |s| p s and so on...
Configuración Interactiva
La mayoría de los valores de configuración están disponibles mientras se está corriendo irb. La lis-ta que comienza en esta página muestra estos valores como conf.xxx. Por ejemplo, para cambiar el prompt de vuelta a DEFAULT, se puede hacer lo siguiente:
irb(main):001:0> 1 +irb(main):002:0* 2=> 3irb(main):003:0> conf.prompt_mode = :SIMPLE=> :SIMPLE>> 1 +?> 2=> 3
Opciones de Configuración irb
En las descripciones que siguen, una etiqueta de la siguiente forma :XXX representa una clave utiliza-da en el hash IRB.conf en un archivo de inicialización, y conf.xxx, representa un valor que se puede establecer de forma interactiva. El valor entre corchetes al final de la descripción es la opción por defecto.
:AUTO_INDENT / conf.auto_indent_mode Si es true, irb sangra las estructuras anidadas como se escriben. [false]
:BACK_TRACE_LIMIT / conf.back_trace_limit Muestra las n líneas iniciales y n finales de la traza de ejecución. [16]
:CONTEXT_MODE Qué binding utilizar para las nuevas áreas de trabajo: 0 -> proc en el nivel superior, 1 -> binding en un archivo cargado anónimo, 2 -> binding por hilo en un archivo cargado, 3 -> binding en una función de nivel superior. [3]. (Un binding es una “ligadura” o referencia a otro símbolo más largo y complicado, y que se usa frecuentemente).

128
:DEBUG_LEVEL / conf.debug_level Ajusta a n el nivel de depuración interna. Es útil si se está depuración irb lexer. [0]
:IGNORE_EOF / conf.ignore_eof Especifica el comportamiento de un fin de archivo recibido en la entrada. Si es true, se tendrá en cuenta, si es false, irb se cerrará. [false]
:IGNORE_SIGINT / conf.ignore_sigint Si es false, ^C (Ctrl+C) hará salir de irb. Si es true, ^C durante la entrada cancela la entrada y retorna al nivel superior. Durante la ejecución, ^C abortará la operación actual. [true]
:INSPECT_MODE / conf.inspect_mode Especifica como se mostrarán los valores: true utiliza inspect, false utiliza to_s y nil utiliza inspect en modo no matemático y to_s en modo matemático. [nil]
:IRB_RC Se peude establecer en un objeto proc llamado cuando se inicia una sesión (o subsesión) irb. [nil]
conf.last_value El último valor de salida de irb. [...]
:LOAD_MODULES / conf.load_modules Una lista de módulos cargados a través de la opción -r de línea de comandos. [[]]
:MATH_MODE / conf.math_mode Si true, irb se ejecuta cargado on la librería math. [false]
conf.prompt_c El prompt para una declaración que continúa (por ejemplo, inmediatamente después de un “if”). [depends ]
conf.prompt_i El prompt estándar de nivel superior. [depends ]
:PROMPT_MODE / conf.prompt_mode Estilo de prompt a mostrar. [DEFAULT]
conf.prompt_s El prompt para una cadena que continúa. [depends ]
:PROMPT Consultar configuración del prompt.
:RC/ conf.rc Si false no se carga un archivo de inicialización. [true]
conf.return_format Formato a utilizar para mostrar los resultados de las expresiones introducidas de forma interactiva. [depends ]
:SINGLE_IRB Si true, todas las sesiones irb anidadas comparten el mismo binding, de lo contrario será creado un nuevo binding de acuerdo con el valor de: CONTEXT_MODE. [nil]
conf.thread Una referencia de sólo lectura para el objeto Thread que se está ejecutando. [current thread]
:USE_LOADER/ conf.use_loader Especifica si es el propio método irb para leer archivos con load/require. [false]

129
:USE_READLINE / conf.use_readline irb utilizará la biblioteca readline si está disponible a menos que esta opción esté establecida en false, en cuyo caso no se utilizará nunca readline, o nil, en el que readline no se utilizará en modo inf-ruby. [depends]
:USE_TRACER / conf.use_tracer Si true, traza la ejecución de las sentencias. [false]
:VERBOSE / conf.verbose En teoría activa el traceo adicional cuando es true. En la práctica casi no hay resultados adicionales. [true]
Comandos
En el prompt de irb se puede introducir cualquier expresión válida de Ruby y ver los resultados. Tam-bién puede utilizar cualquiera de los siguientes comandos para controlar la sesión irb.
exit, quit, irb_exit, irb_quit Sale de la sesión o subsesión irb. Si se ha usado cb para cambiar bindings (ver más abajo), sale de este modo binding.
conf, context, irb_context Muestra la configuración actual. La configuración se modifica mediante la invocación de los métodos conf. La lista de la sección anterior muestra los ajustes conf disponibles. Por ejemplo, para establecer el valor predeterminado del prompt para algo subordinado, se puede utilizar:
irb(main):001:0> conf.prompt_i = “Yes, Master? “=> “Yes, Master? “Yes, Master? 1 + 2
cb, irb_change_binding ( obj ) Crea y entra en un nuevo enlace (binding) que tiene su propio espacio para las variables locales. Si se da obj, será utilizado como self en el nuevo enlace.
irb ( obj ) Inicia una subsesión irb. Si se dá obj, será utilizado como self.
jobs, irb_jobs Lista las subsesiones irb.
fg n, irb_fg n Cambia a la subsesión irb especificada. n puede ser cualquiera de: un número de subsesión irb, un ID de hilo, un objeto irb o el objeto que era el valor de self cuando se puso en marcha una subsesión.
kill n, irb_kill n Mata a una subsesión irb. n puede ser cualquiera de los valores descritos para irb_fg.
Configurando el Prompt
Hay una gran flexibilidad para la configuración de los símbolos del sistema que utiliza irb. La configu-ración de prompts se almacena en el hash prompt IRB.conf[:PROMPT].
Por ejemplo, para establecer un nuevo modo de prompt llamado “MY_PROMPT”, podría entrar lo siguien-te (ya sea directamente en el prompt irb o en el archivo .irbrc) :
IRB.conf[:PROMPT][:MY_PROMPT] = { # name of prompt mode :PROMPT_I => ‘-->’, # normal prompt :PROMPT_S => ‘--”’, # prompt for continuing strings :PROMPT_C => ‘--+’, # prompt for continuing statement :RETURN => “ ==>%s\n” # format to return value

130
} Una vez que se haya definido un prompt, hay que decirle a irb que lo utilice. Desde la línea de coman-dos, puede utilizar la opción --prompt. (Observe que el nombre del modo prompt se convierte automáti-camente en mayúscula y los guiones normales a guiones bajos).
% irb --prompt my-prompt
Si se desea utilizar este prompt en todas las sesiones irb futuras, se puede establecer como un valor de configuración en el archivo .irbrc.
IRB.conf[:PROMPT_MODE] = :MY_PROMPT
Los símbolos PROMPT_I, PROMPT_S y PROMPT_C especifican el formato de cada una de las cadenas de prompt. En un formato cadena, se expanden algunas secuencias “%”.
Bandera Descripción
%N Comando actual.%m to_s al objeto main (self).%M inspect al objeto main (self).%l Tipo de delimitador. En las cadenas que se continúan a través de un salto de línea, l% mostrará el tipo de delimitador utilizado para iniciar la cadena, para que se sepa cómo ponerle fin. El delimitador será uno de “, ‘, /, ] o ’.%ni Nivel de sangría. El número opcional n se utiliza como una especificación de amplitud de printf, como printf(“nd%”).%nn Número de línea actual (n como con el nivel de sangría).%% Un signo de procentaje literal.
Por ejemplo, el modo por defecto del sistema se define de la siguiente manera.
IRB.conf[:PROMPT_MODE][:DEFAULT] = {:PROMPT_I => “%N(%m):%03n:%i> “,:PROMPT_S => “%N(%m):%03n:%i%l “,:PROMPT_C => “%N(%m):%03n:%i* “,:RETURN => “%s\n”}
Restricciones
Debido a la como trabaja irb, tiene cierta incompatibilidad con el intérprete estándar de Ruby. El pro-blema radica en la determinación de las variables locales.
Normalmente, Ruby busca una sentencia de asignación para determinar si algo es una variable --si un nombre no ha sido asignado, Ruby asume que el nombre es una llamada a método.
eval “var = 0”var
produce:
prog.rb:2: undefined local variable or method `var’for main:Object (NameError)
En este caso la asignación está ahí, pero dentro de una cadena, por lo que Ruby no lo tiene en cuenta.
irb por su parte, ejecuta sentencias a medida que se introducen.
irb(main):001:0> eval “var = 0”0

131
irb(main):002:0> var0
En irb, la asignación se ejecutó antes de encontrar la segunda línea , por lo que var está correcta-mente identificada como una variable local.
Si se necesita que concuerde más estrechamente con el comportamiento del intérprete Ruby, se pue-den colocar estas declaraciones dentro de un par begin/end.
irb(main):001:0> beginirb(main):002:1* eval “var = 0”irb(main):003:1> varirb(main):004:1> endNameError: undefined local variable or method `var’(irb):3:in `irb_binding’
rtags y xmp
En el caso de que irb no fuera ya lo suficientemente complejo, vamos a añadir unos cuantas repliegues más. Junto con el programa principal, el conjunto irb incluye algunos extras. En las siguientes secciones vamos a ver dos: rtags y xmp.
rtags
rtags es un comando que se utiliza para crear un fichero de etiquetas (TAGS) para su uso con los editores Emacs o vi.
rtags [ -vi ] [ files ]...
Por defecto, rtags hace un archivo TAGS adecuado para Emacs (ver etags.el). La opción -vi hace un fichero TAGS para su uso con vi.
rtags necesita ser instalado de la misma forma que irb (es decir, es necesario instalar irb en la ruta de librería y hacer un enlace desde irb/rtags.rb a bin/rtags).
xmp
xmp irb es una “impresora de ejemplo”, --es decir, una bonita impresora que muestra el valor de cada expresión tal como se ejecuta (al igual que el script que escribimos para dar formato a los ejemplos de este libro). También hay otro xmp independiente en los archivos.
xmp se puede utilizar de la siguiente manera:
require ‘irb/xmp’xmp <<ENDartist = “Doc Severinsen”artist.upcaseEND produce:
artist = “Doc Severinsen”==> “Doc Severinsen”artist.upcase==> “DOC SEVERINSEN”
O xmp se puede utilizar como una instancia de objeto. Usa de esta manera, el objeto mantiene el con-texto entre las invocaciones.

132
require ‘irb/xmp’x = XMP.newx.puts ‘artist = “Louis Prima”’x.puts ‘artist.upcase’
produce:
artist = “Louis Prima”==> “Louis Prima”artist.upcase==> “LOUIS PRIMA”
De forma explícita, puede proporcionar un binding con una u otra forma. De lo contrario, xmp utiliza el entorno del llamador.
xmp code_string, abindingXMP.new(abinding)
Tenga en cuenta que xmp no funciona con múltiples subprocesos.
La Documentación de Ruby A partir de la versión 1.8, Ruby viene con RDoc, una herramienta que extracta y formatea documen-tación que está integrada en los archivos de código fuente de Ruby. Esta herramienta se utiliza para documentar las clases y módulos integrados de Ruby. Un número creciente de bibliotecas y extensiones también están documentados de esta manera.
RDoc tiene dos trabajos. En primer lugar, el análisis de los archivos fuente en Ruby y C en busca de información para documentar (RDoc también pueden documentar los programas de Fortran 77). En segun-do lugar, toma esta información y la convierte en algo legible. Fuera de la caja, RDoc produce dos tipos de salida: HTML y ri. La figura 9.1 en la página siguiente muestra algunos resultados de RDoc en formato HTML en una ventana del navegador. Este es el resultado de alimentar RDoc con un archivo de código fuente Ruby sin documentación adicional --RDoc hace un fidedigno trabajo para producir algo significativo. Si nuestro código fuente contiene comentarios, RDoc los puede utilizar para condimentar los textos que elabore. Por lo general, un comentario antes de un elemento se utiliza para documentar ese elemento, como se muestra en la figura 9.2 más adelante.
RDoc también puede ser utilizado para producir documentación que pueda ser leída por la utilidad de línea de comandos ri. Por ejemplo, si pedimos a RDoc documentar el código de la figura 9.2, podemos acceder a la documentación utilizando ri, como se muestra en la figura 9.3 en la página 135. Las nuevas distribuciones de Ruby tienen las clases y módulos integrados (y algunas bibliotecas) documentados esta manera.
Añadiendo RDoc al código Ruby RDoc analiza los archivos fuente Ruby para extraer los principales elementos (clases, módulos, méto-dos, atributos,etc). Se puede elegir asociar documentación adicional, simplemente añadiendo un bloque de comentario antes del elemento en el archivo.
Los bloques de comentario se pueden escribir de manera bastante natural, ya sea usando # en las lí-neas sucesivas de la observación o mediante la inclusión de comentarios en un bloque =begin...=end. Si se utiliza esta última forma, la línea =begin debe estar marcada con una etiqueta rdoc para distinguir el bloque de otros estilos de documentación.
=begin rdocCalculate the minimal-cost path though the graphusing Debrinkski’s algorithm, with optimizedinverse pruning of isolated leaf nodes.=end
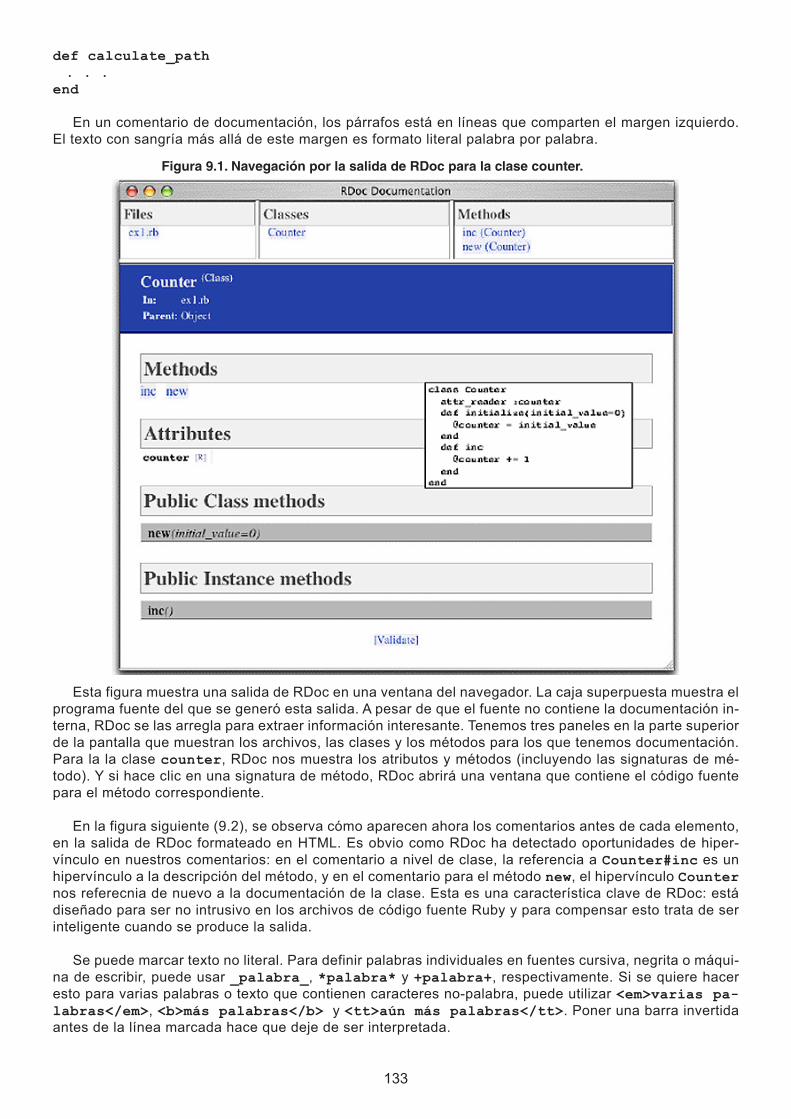
133
def calculate_path . . .end
En un comentario de documentación, los párrafos está en líneas que comparten el margen izquierdo. El texto con sangría más allá de este margen es formato literal palabra por palabra.
Esta figura muestra una salida de RDoc en una ventana del navegador. La caja superpuesta muestra el programa fuente del que se generó esta salida. A pesar de que el fuente no contiene la documentación in-terna, RDoc se las arregla para extraer información interesante. Tenemos tres paneles en la parte superior de la pantalla que muestran los archivos, las clases y los métodos para los que tenemos documentación. Para la la clase counter, RDoc nos muestra los atributos y métodos (incluyendo las signaturas de mé-todo). Y si hace clic en una signatura de método, RDoc abrirá una ventana que contiene el código fuente para el método correspondiente. En la figura siguiente (9.2), se observa cómo aparecen ahora los comentarios antes de cada elemento, en la salida de RDoc formateado en HTML. Es obvio como RDoc ha detectado oportunidades de hiper-vínculo en nuestros comentarios: en el comentario a nivel de clase, la referencia a Counter#inc es un hipervínculo a la descripción del método, y en el comentario para el método new, el hipervínculo Counter nos referecnia de nuevo a la documentación de la clase. Esta es una característica clave de RDoc: está diseñado para ser no intrusivo en los archivos de código fuente Ruby y para compensar esto trata de ser inteligente cuando se produce la salida.
Se puede marcar texto no literal. Para definir palabras individuales en fuentes cursiva, negrita o máqui-na de escribir, puede usar _palabra_, *palabra* y +palabra+, respectivamente. Si se quiere hacer esto para varias palabras o texto que contienen caracteres no-palabra, puede utilizar <em>varias pa-labras</em>, <b>más palabras</b> y <tt>aún más palabras</tt>. Poner una barra invertida antes de la línea marcada hace que deje de ser interpretada.
Figura 9.1. Navegación por la salida de RDoc para la clase counter.
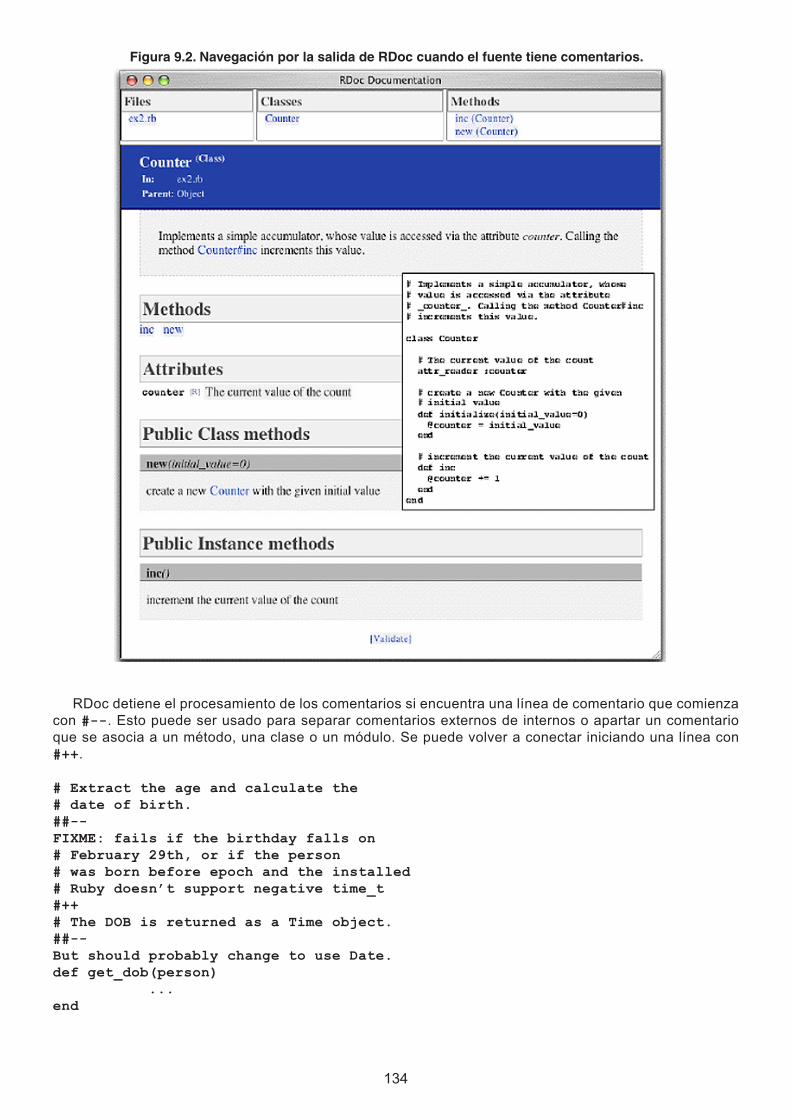
134
RDoc detiene el procesamiento de los comentarios si encuentra una línea de comentario que comienza con #--. Esto puede ser usado para separar comentarios externos de internos o apartar un comentario que se asocia a un método, una clase o un módulo. Se puede volver a conectar iniciando una línea con #++.
# Extract the age and calculate the# date of birth.##--FIXME: fails if the birthday falls on# February 29th, or if the person# was born before epoch and the installed# Ruby doesn’t support negative time_t#++# The DOB is returned as a Time object.##--But should probably change to use Date.def get_dob(person) ...end
Figura 9.2. Navegación por la salida de RDoc cuando el fuente tiene comentarios.

135
Hipervínculos
Los nombres de clases, de archivos de código fuente y cualquier nombre de método que contienga un guión bajo, o vaya precedido por una almohadilla, son hipervínculados automáticamente desde el texto del comentario a su descripción.
Los hipervínculos a la red que son reconocidos comienzan con http:, mailto:, ftp: y www: . Una URL HTTP que hace referencia a un archivo de imagen externo se convierte en una línea con la etiqueta <IMG...> . Hipervínculos a partir de link: se supone que se refieren a archivos locales, cuyas rutas son relativas al directorio --op donde se almacenan los archivos de salida.
Los hipervínculos también pueden ser de la forma label[url], en cuyo caso la etiqueta se utiliza en el texto que se muestra y la url se utiliza como el destino. Si la etiqueta contiene varias palabras, hay que encerrarla entre llaves: {dos palabras}[url].
Listas
Las listas se escriben como párrafos sangrados con:
•un* o un - (para listas), •undígitoseguidodeunpuntoparalistasnumeradasy •unaletramayúsculaominúsculaseguidadeunpuntoparalistasalfa.
Por ejemplo, se podría producir algo así como el texto anterior con:
# Lists are typed as indented paragraphs with:# * a ‘*’ or ‘-’(for bullet lists)# * a digit followed by a period for# numbered lists# * an upper or lower case letter followed# by a period for alpha lists.
Observe cómo las siguientes líneas de un elemento de la lista son sangradas al texto de la primera línea del elemento.

136
Las listas de marcado (a veces llamadas listas de descripción) se escriben utilizando corchetes para la etiqueta.
# [cat] small domestic animal# [+cat+] command to copy standard input# to standard output
Las listas de etiqueta también pueden ser producidas poniendo un doble dos puntos después de la etiqueta. Esto establece el resultado en forma tabular, por lo que las descripciones van alineadas.
# cat:: small domestic animal# +cat+:: command to copy standard input# to standard output
En ambos tipos de listas de etiqueta, si el cuerpo del texto comienza en la misma línea de la etiqueta, el comienzo de ese texto determina el bloque de sangrado para el resto del cuerpo. El texto también puede comenzar en la línea siguiente en la etiqueta, con una sangría desde el inicio de la etiqueta. Esto a menu-do es preferible si la etiqueta es larga. Ambas son válidas para las entradas de las listas de etiqueta:
# <tt>--output</tt> <i>name [, name]</i>::# specify the name of one or more output files. If multiple# files are present, the first is used as the index.## <tt>--quiet:</tt>:: do not output the names, sizes, byte counts,# index areas, or bit ratios of units as# they are processed.
Títulos
Los títulos se registran en las líneas que comienzan con signos de igualdad. A más signos de igual, mayor nivel de título.
# = Level One Heading# == Level Two Heading# and so on...
Se introducen reglas (líneas horizontales) utilizando tres o más guiones.
# and so it goes...# -----# The next section...
Modificadores de Documentación
las listas de parámetros de método se extractan y se muestran con la descripción del método. Si un método llama a yield, entonces también se mostrarán los parámetros pasados a yield. Por ejemplo, considere el siguiente código:
def fred ... yield line, address
Vá a ser documentado como:
fred() {|line, address| ... }
Se puede cambiar esto usando un comentario que contenga :yields: ... en la misma línea que la definición del método.def fred # :yields: index, position ...

137
yield line, address
que se documenta como:
fred() {|index, position| ... }
:yields: es un ejemplo de un modificador de documentación. Estos aparecen inmediatamente des-pués del comienzo del elemento de documento que se está modificando.
Otros modificadores include:
:nodoc: [all] No incluir este elemento en la documentación. Las clases y módulos, los métodos, los alias, constantes y atributos dentro de la clase o módulo afectado directamente, también se excluyen de la documentación. Por defecto sin embargo, serán documentado los módulos y las clases dentro de esa clase o módulo. Esta opción se desactiva, añadiendo el modificador all. Por ejemplo, en el siguiente código, sólo será docu-mentada la clase SM::Imput.
module SM #:nodoc: class Input endendmodule Markup #:nodoc: all class Output endend
:doc: Obliga a la documentación de un método o atributo aunque por otra parte no fuera a ser documentado. Útil si por ejemplo, desea incluir la documentación de un método privado en particular.
:notnew: (Sólo se aplica al método de instancia initialize). Normalmente RDoc asume que la documentación y los parámetros para #initialize son en realidad para el método new de la clase correspondiente y por tanto falsea un método new para la clase. El modificador :notnew: detiene esto. Recuerde que #initialize está protegido, por lo que no se ve la documentación a menos que utilice la opción -a de línea de comandos.
Otras Directivas
Los bloques de comentarios pueden contener otras directivas.
:call-seq: lines. . . El texto hasta la siguiente línea de comentario en blanco se utiliza como la secuencia de llamada cuan-do se genera la documentación (primordial el análisis de la lista de parámetros del método). Una línea se considera en blanco, incluso si comienza con un #. Para esta directiva única, los dos puntos del principio son opcionales.
:include: filename Incluir el contenido del archivo llamado en ese momento. El archivo se buscará en los directorios lista-dos por la opción del --include o en el directorio actual por defecto. El contenido del archivo se despla-zará para tener la misma sangría como : al inicio de la directiva :include: .
:title: text Establece el título del documento. Equivalente al parámetro --títle de la línea de comandos. (El parámetro de línea de comandos reemplaza cualquier directiva :title: del fuente)
:main: name Equivalente al parámetro --main de línea de comandos, establece la página inicial que aparecerá en ese documento.

138
:stopdoc: / :startdoc: Detiene y comienza la adición de nuevos elementos de la documentación para el contenedor actual. Por ejemplo, si una clase tiene una serie de constantes que no se quieren documentar, poner un:stopdoc: antes de la primera y un :startdoc: después de la última. Si no se especifica un :startdoc: para el final del contenedor, desactiva la documentación de toda la clase o módulo.
:enddoc: No documenaro nada más en el nivel léxico actual.
La figura 9.4 en la página siguiente muestra un ejemplo más completo de un archivo fuente documen-tada mediante RDoc.
Añadiendo RDoc a las Extensiones de C
RDoc también entiende muchas de las convenciones utilizadas al escribir extensiones en C para Ruby.
La mayoría de las extensiones de C tienen una función Init_Classname. RDoc la toma como la defini-ción de clase --cualquier de comentario C antes del método Init_ se puede utilizar como documentación de la clase.
La función Init_ normalmente se utiliza para asociar funciones C con nombres de métodos Ruby. Por ejemplo, una extensión Cipher puede definir un método Ruby salt=, implementado por la función C salt_set mediante una llamada como
rb_define_method(cCipher, “salt=”, salt_set, 1);
RDoc analiza esta llamada añadiendo el método salt= a la documentación de la clase. A continuación RDoc busca la fuente de C para la función C salt_set. Si esta función está precedida por un bloque de comentario, RDoc lo utiliza para la documentación del método.
Este esquema básico trabaja sin ningún esfuerzo por su parte más allá de escribir los comentarios de las funciones en la documentación normal. Sin embargo, RDoc no puede discernir la secuencia de llamada para el correspondiente método de Ruby. En este ejemplo, la salida de RDoc mostrará un solo argumento con el (un poco sin sentido) nombre de “arg1.” Se puede cambiar esto usando la directiva call-seq en el comentario de la función. Las siguientes líneas utilizan call-set (hasta una línea en blanco) para do-cumentar la secuencia de llamada del método.
/* * call-seq: * cipher.salt = number * cipher.salt = “string” * * Sets the salt of this cipher to either a binary +number+ or * bits in +string+. */static VALUEsalt_set(cipher, salt)...
Si un método devuelve un valor significativo, debe ser documentado en el call-seq siguiendo a los ca-racteres ->.
/* * call-seq: * cipher.keylen -> Fixnum or nil */ A pesar de la heurística RDoc funciona bien para encontrar los comentarios de clase y de método para extensiones simples, pero no siempre funciona para implementaciones más complejas. En estos casos, puede utilizar las directivas Document-class: y Document-method: para indicar que un comentario C

139
se refiere a una clase o método, respectivamente. Estos modificadores toman el nombre de la clase o del método Ruby que está siendo documentado.
/* * Document-method: reset * * Clear the current buffer and prepare to add new * cipher text. Any accumulated output cipher text * is also cleared. */
Finalmente, en el método Init_ se puede asociar un método Ruby con una función de un fichero fuente C diferente. RDoc no encontrará esta función sin su ayuda: hay que agregar una referencia al archivo que contiene la definición de la función mediante un comentario especial a la llamada rb_defi-ne_method. En el siguiente ejemplo se le indica a RDoc que busque en el archivo md5.c la función (y el comentario relacionado) correspondiente al método md5.
rb_define_method(cCipher, “md5”, gen_md5, -1); /* in md5.c */
La figura 9.4 en la página siguiente muestra un archivo de código fuente en C documentado mediante RDoc. Tenga en cuenta que los cuerpos de varios métodos internos se han omitido para ahorrar espacio.
Ejecutando RDoc
Se puede ejecutar RDoc desde la línea de comandos:
% rdoc [options] [filenames...]
Escriba rdoc --help para un resumen de las opciones hasta a la fecha.
Los archivos se analizan y se recolecta la información que contienen antes de producir cualquier salida. Esto permite resolver las referencias cruzadas entre todos los archivos. Si un nombre es un directorio es traspasado. Si no se especifican nombres, se procesan todos los archivos Ruby en el directorio actual (y subdirectorios).
Un uso típico puede ser la de generar la documentación para un paquete de código fuente Ruby (como el mismo RDoc).
% rdoc
Este comando genera documentación HTML para todos los los archivos fuente en Ruby y C bajo el directorio actual. Estos se almacenan en un árbol de la documentación a partir del subdirectorio doc/.
RDoc utiliza las extensiones de archivo para determinar cómo procesar cada archivo. Ficheros que terminen en .rb y .rbw se supone que son fuentes de Ruby. Archivos con la extensión .c se analizan como archivos de C. Todos los demás archivos se supone que contienen sólo el marcado (con o sin los iniciales marcadores de comentario #). Si se pasan los nombres de directorio a RDoc, se escanean de forma recursiva únicamente para los archivos fuente de Ruby y C. Para incluir archivos que no son fuente como los README en el proceso de documentación, sus nombres deben estar explícitamente en la línea de comandos.
Cuando se escribe una biblioteca Ruby, a menudo tiene algunos archivos de código fuente que imple-mentan la interfaz pública. La mayoría son internos y no son de interés para los lectores de su documenta-ción. En estos casos, se construye un archivo .document en cada uno de los directorios de su proyecto. Si RDoc entra en un directorio que contiene un archivo .document, procesará en ese directorio sólo los archivos cuyo nombre se corresponda con una de las líneas de ese archivo. Cada línea del archivo puede ser un nombre de archivo, un nombre de directorio o un comodín (un sistema de archivos con el patrón “glob” ). Por ejemplo, para incluir todos los archivos Ruby cuyos nombres comienzan con main, junto con el archivo constants.rb, se puede utilizar un archivo .document que contiene:

140

141
main*.rbconstants.rb
Algunos estándares de proyecto piden la documentación en un archivo README de nivel superior. Pue-de que le resulte conveniente escribir este archivo en formato RDoc y luego usar la directiva :include: para incorporar este documento en el de la clase principal.
Crear Documentación para ri
RDoc también se utiliza para crear la documentación que luego se muestra con ri.
Cuando se ejecuta ri, por defecto busca la documentación en tres lugares (Se puede reemplazar la ubicación del directorio con la opción --op de RDoc y, posteriormente, utilizando la opción --doc-dir con ri):
1. el directorio de documentación del sistema, que contiene la documentación distribuida con Ruby, creada por el proceso de instalación de Ruby,
2. el directorio del sitio, que contiene la documentación de todo el sitio agregado localmente, y
3. el directorio de documentación del usuario, almacenada en el directorio home del propio usuario.
Usted puede encontrar estos tres directorios en los siguientes lugares.
• $datadir/ri/<ver>/system/... • $datadir/ri/<ver>/site/... • ~/.rdoc/....
La variable $datadir es el directorio de datos configurado para la instalación Ruby. Se puede encon-trar el datadir local utilizando
ruby -r rbconfig -e ‘p Config::CONFIG[“datadir”]’
Para añadir documentación a ri, es necesario indicar a RDoc que directorio de salida utilizar. Para su propio uso, lo más fácil es usar la opción --ri.
% rdoc --ri file1.rb file2.rb
Si se desea instalar la documentación en todo el sitio, hay que utilizar la opción --ri-site.
% rdoc --ri-site file1.rb file2.rb La opción --ri-system se utiliza normalmente sólo para instalar la documentación para las clases y liberías Ruby estándar integradas. Puede volver a generar la documentación de la distribución desde la distribución del código fuente Ruby (no de las librerías mismas instaladas).
Mostrando el Uso del Programa
La mayoría de los programas de línea de comandos tienen algún tipo de funcionalidad para describir su uso correcto; si se les dan parámetros no válidos reportan un corto mensaje de error seguido de un re-sumen con sus opciones reales. Y, si usted está utilizando RDoc, es probable que haya descrito en un co-mentario RDoc al inicio del programa principal cómo el programa que se debe utilizar. En lugar de duplicar toda esta información en algún lugar con puts, puede utilizar RDoc::usage para extraerla directamente desde el comando y escribirla hacia el usuario.

142
Se puede pasar a RDoc::usage de una serie de parámetros tipo cadena que utiliza para extraer del bloque de comentario sólo aquellas secciones nombradas por los parámetros (donde una sección comien-za con un título igual al parámetro, ignorando mayúsculas y minúsculas). Sin parámetros, RDoc::usage muestra todo el comentario. Además, cierra el programa después de mostrar el mensaje de uso. Si el primer parámetro en la llamada es un número entero, se utiliza como código de salida del programa (de otra forma RDoc::usage sale con un código de error cero). Si no se desea salir del programa después de mostrar el mensaje, hay que llamar a RDoc::usage_no_exit.
En la figura 9.5 se vé un programa trivial que muestra la fecha y la hora. Utiliza RDoc::usage para mostrar el bloque de comentarios completo si el usuario solicita ayuda y muestra sólo la sección de uso si el usuario pasa una opción no válida. La figura 9.6 muestra la salida generada en respuesta la opción --help.
RDoc::usage rinde homenaje a la variable de entorno RI, que pueden ser utilizada para establecer el ancho de la pantalla y el estilo de salida. El resultado de la figura 9.6 en la página 144, se ha generado con la opción de configuración RI en “-f ansi”. Aunque no es demasiado evidente si estás viendo esta figura en el libro en blanco y negro, los encabezados de sección, el código fuente y el enfatizado de fuente, se muestran en diferentes colores, usando secuencias de escape ANSI.

143
Chad Fowler es una figura destacada en lacomunidad Ruby. Está en el consejo de Ruby Central,Inc. Es uno de los organizadores de RubyConf. Yes uno de los escritores de RubyGems. Todo estolo hace especialmente calificado para escribir este capítulo.
Gestión de Paquetes con RubyGems
RubyGems es un marco estandarizado para el empaquetado y la instalación de bibliotecas y aplicacio-nes, que hace fácil encontrar, instalar, actualizar y desinstalar paquetes Ruby. Proporciona a los usuarios y desarrolladores cuatro principales utilidades.
1. Un formato de paquete estandarizado, 2. Un repositorio central para el hospedaje de los paquetes en este formato, 3. Instalación y gestión de múltiples y simultáneas versiones de librerías instaladas, 4. Herramientas de usuario final para efectuar consultas, instalar, desinstalar y otras formas de manipulación de estos paquetes.
Antes de que llegara RubyGems, la instalación de una nueva biblioteca involucraba la búsqueda en la web, la descarga del paquete y tratar de instalarlo, sólo para descubrir que no se cumplían sus dependen-cias. En cambio ahora, si la biblioteca que desea utilizar está empaquetada en RubyGems, puede decirle simplemente que instale el paquete (y todas sus dependencias) y todo se hace automáticamente para usted.
En el mundo de RubyGems, los desarrolladores combinan sus aplicaciones y bibliotecas en archivos individuales llamados gemas. Estos archivos se ajustan a un formato estandarizado, y el sistema Rub-yGems proporciona una herramienta de línea de comandos, con el apropiado nombre de gem, para la manipulación de los archivos gema.
La mejor manera de comprobar si RubyGems se instaló con éxito es utilizando el comando más impor-tante que hay que aprender:% gem helpRubyGems is a sophisticated package manager for Ruby. This isa basic help message containing pointers to more information.Usage: gem -h/--help gem -v/--version gem command [arguments...] [options...]Examples: gem install rake gem list --local gem build package.gemspec gem help installFurther help: gem help commands list all ‘gem’ commands gem help examples show some examples of usage gem help <COMMAND> show help on COMMAND (e.g. ‘gem help install’)Further information: http://rubygems.rubyforge.org
Como la ayuda RubyGems es bastante amplia, no vamos a entrar en detalles sobre cada uno de los comandos y opciones disponibles.
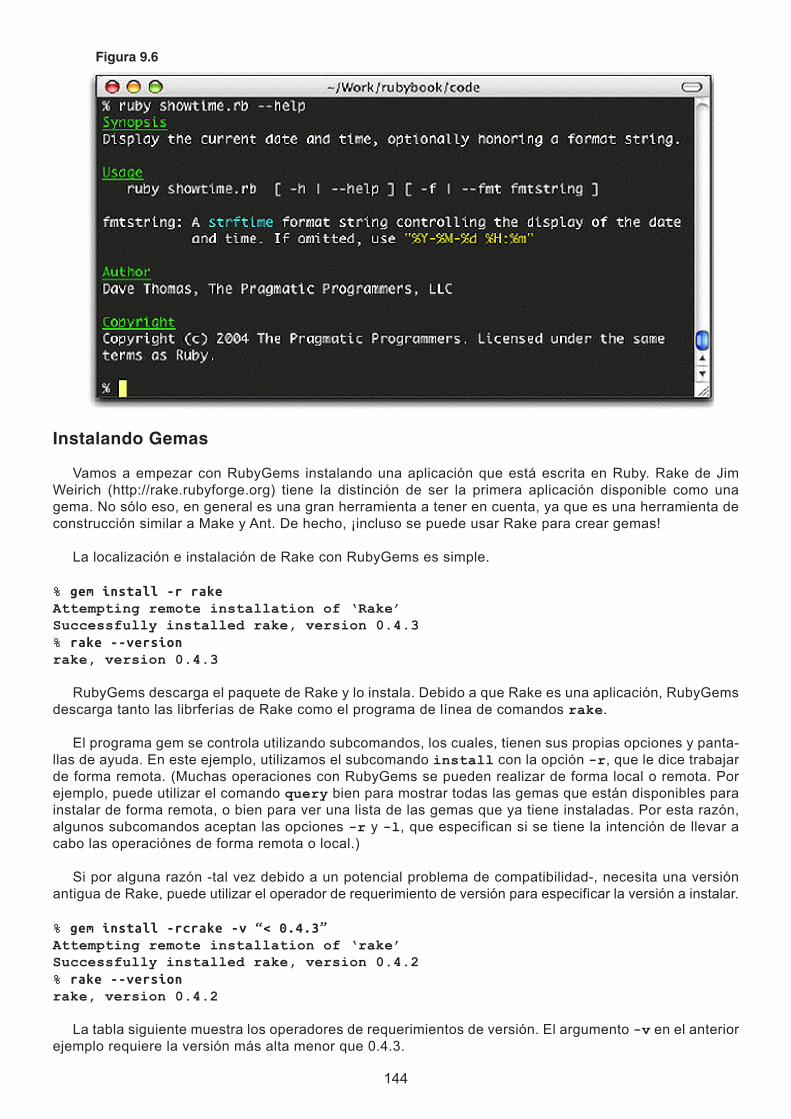
144
Instalando Gemas
Vamos a empezar con RubyGems instalando una aplicación que está escrita en Ruby. Rake de Jim Weirich (http://rake.rubyforge.org) tiene la distinción de ser la primera aplicación disponible como una gema. No sólo eso, en general es una gran herramienta a tener en cuenta, ya que es una herramienta de construcción similar a Make y Ant. De hecho, ¡incluso se puede usar Rake para crear gemas!
La localización e instalación de Rake con RubyGems es simple.
% gem install -r rakeAttempting remote installation of ‘Rake’Successfully installed rake, version 0.4.3% rake --versionrake, version 0.4.3
RubyGems descarga el paquete de Rake y lo instala. Debido a que Rake es una aplicación, RubyGems descarga tanto las librferías de Rake como el programa de línea de comandos rake.
El programa gem se controla utilizando subcomandos, los cuales, tienen sus propias opciones y panta-llas de ayuda. En este ejemplo, utilizamos el subcomando install con la opción -r, que le dice trabajar de forma remota. (Muchas operaciones con RubyGems se pueden realizar de forma local o remota. Por ejemplo, puede utilizar el comando query bien para mostrar todas las gemas que están disponibles para instalar de forma remota, o bien para ver una lista de las gemas que ya tiene instaladas. Por esta razón, algunos subcomandos aceptan las opciones -r y -l, que especifican si se tiene la intención de llevar a cabo las operaciónes de forma remota o local.)
Si por alguna razón -tal vez debido a un potencial problema de compatibilidad-, necesita una versión antigua de Rake, puede utilizar el operador de requerimiento de versión para especificar la versión a instalar.
% gem install -rcrake -v “< 0.4.3”Attempting remote installation of ‘rake’Successfully installed rake, version 0.4.2% rake --versionrake, version 0.4.2
La tabla siguiente muestra los operadores de requerimientos de versión. El argumento -v en el anterior ejemplo requiere la versión más alta menor que 0.4.3.
Figura 9.6

145
= Coincide con la versión exacta. Lanzamientos mayor y menor y nivel de parche deben ser idénticos.!= Cualquier versión que no sea la especificada.> Cualquier versión mayor (incluso en el nivel de parche) que la especificada.< Cualquier versión menor que la especificada.>= Cualquier versión mayor o igual que la especificada.<= Cualquier versión menor o igual que la especificada.~> Operador de versión “Boxed”. La versión debe ser mayor o igual a la especificada después de aumentar en uno su número de versión minor. Esto es para evitar incompatibilidades API entre versiones de lanzamientos menores.
Tanto el método require_gem como el atributo add_dependency en Gem::Specification aceptan un argumento que especifica una versión de la dependencia. La versiones RubyGems de las dependencias son de la forma operator major.minor.patch_level.
Hay una sutileza a la hora de instalar con RubyGems diferentes versiones de la misma aplicación. A pesar de que RubyGems mantiene versiones diferentes de los archivos de biblioteca de la aplicación, no lo hace con la versión del comando real que se utiliza para ejecutar la aplicación. Como resultado de ello, cada instalación de una aplicación sobrescribe de hecho la anterior.
Durante la instalación, también se puede añadir la opción -t para el comando install, que hace que RubyGems ejecute (si se ha creado) la suite de prueba de la gema. Si las pruebas fallan, el instalador le preguntará si mantiene o descarta la gema. Esta es una buena manera de tener cierta confianza en que la gema que se acaba de descargar trabaja en el sistema de la forma para la que el autor la ha escrito.
% gem install SomePoorlyTestedProgram -tAttempting local installation of ‘SomePoorlyTestedProgram1.0.1’Successfully installed SomePoorlyTestedProgram, version 1.0.123 tests, 22 assertions, 0 failures, 1 errors...keep Gem? [Y/n] nSuccessfully uninstalled SomePoorlyTestedProgram version 1.0.1
Si hubiéramos elegido la opción predeterminada y hubiéramos instalado la gema, podríamos haberla inspeccionado para tratar de determinar la causa de que la prueba falle.
Instalación y Uso de las Librerías Gema
Utilizar RubyGems para instalar una aplicación completa es una buena manera de tener los pies mo-jados para empezar su camino de aprendizaje con el comando gem. Sin embargo, en la mayoría de los casos, se va a utilizar RubyGems para instalar las bibliotecas Ruby para utilizar en sus propios programas. RubyGems le permite instalar y gestionar múltiples versiones de la misma biblioteca, pero también tendrá que hacer algunas cosas nuevas específicas de RubyGems en caso de requerir algunas librerías en su código.
Tal vez alguien le ha pedido crear un programa que ayude a mantener y publicar un diario. Usted piensa que estaría bien publicar el diario en formato HTML, pero está preocupado de que la otra persona no pue-da entender todos los pros y contras del código HTML. Por esta razón, usted ha opta por utilizar uno de los muchos excelentes paquetes de plantillas disponibles para Ruby. Después de algunas investigaciones, usted se decide por BlueCloth de Michael Granger, basándose en su reputación de ser muy sencillo de utilizar.
Primero tiene que encontrar e instalar la gema BlueCloth.
% gem query -rn Blue*** REMOTE GEMS *** BlueCloth (0.0.4, 0.0.3, 0.0.2) BlueCloth is a Ruby implementation of Markdown, a text-to-HTML conversion tool for web writers. Markdown allows you to write using an easy-to-read, easy-to-write plain text format, then convert it to structurally valid XHTML (or HTML).
Operador Descripción

146
Esta invocación del comando query utiliza la opción -n para buscar en el repositorio central de gemas, cualquier gema cuyo nombre coincida con la expresión regular /Bluel/. Los resultados muestran las tres versiones disponibles de BlueCloth que existen (0.0.4, 0.0.3 y 0.0.2). Cuando se quiere instalar la más reciente, no hay que indicar una versión explícita en el mandato de instalación, por defecto se descarga la última.
Generación de Documentación de la API
Siendo que esta es su primera vez con BlueCloth, no está muy seguro de cómo usarlo. Necesita un poco de documentación de la API para comenzar. Afortunadamente, añadiendo la opción --rdoc al co-mando de instalación, RubyGems generará la documentación RDoc de la gema que está instalando.
% gem install -r BlueCloth --rdocAttempting remote installation of ‘BlueCloth’Successfully installed BlueCloth, version 0.0.4Installing RDoc documentation for BlueCloth-0.0.4...WARNING: Generating RDoc on .gem that may not have RDoc. bluecloth.rb: cc..............................Generating HTML...
Después de haber generado toda esta documentación HTML útil, ¿cómo la consulta? Hay al menos dos opciones. La manera difícil (aunque en realidad no lo es tanto) es abrir el directorio documentación de RubyGems y consultar la documentación de forma directa. Como con la mayoría de las cosas en Rub-yGems, la documentación de cada gema se almacena en un central, protegido y específico lugar. Esto varía según el sistema y según por dónde explícitamente se ha optado por instalar las gemas. La manera más confiable de encontrar los documentos es pedir al comando gem donde se encuentra el directorio RubyGems principal. Por ejemplo:
% gem environment gemdir/usr/local/lib/ruby/gems/1.8
RubyGems almacena la documentación generada en el subdirectorio /doc de este directorio. En este caso /usr/local/lib/ruby/gems/1.8/doc/. Puede abrir el archivo de index.html y ver la documen-tación. Si se utiliza este path a menudo, puede crear un acceso directo.
La segunda (y fácil) manera de ver la documentación RDoc es utilizar la utilidad incluída en RubyGems, gem_server. Simplemente escriba:
% gem_server[2004-07-18 11:28:51] INFO WEBrick 1.3.1[2004-07-18 11:28:51] INFO ruby 1.8.2 (2004-06-29) [i386mswin32][2004-07-18 11:28:51] INFO WEBrick::HTTPServer#start: port=8808
gem_server inicia un servidor Web que se ejecutan en cualquier ordenador en que se lance. De manera predeterminada, se iniciará en el puerto 8808 y servirá las gemas y su documentación desde el directorio de instalación RubyGems por defecto. Tanto el puerto como el directorio de gemas son reempla-zables a través de opciones de línea de comandos, utilizando -p y -d respectivamente.
Una vez que haya iniciado el programa gem_server, si se está ejecutando en el equipo local, puede acceder a la documentación de sus gemas instaladas escribiendo en la barra de direcciones del navega-dor web http://localhost:8808. Ahí encontrará una lista de las gemas instaladas, con sus descrip-ciones y enlaces a la documentación RDoc.
¡Vamos al Código!
Ahora que tenemos BlueCloth instalado y sabemos cómo utilizarlo, estamos listos para escribir código. Después de haber utilizado RubyGems para descargar la librería, ahora también podemos usarlo para car-gar los componentes de la biblioteca en nuestra aplicación. Antes de RubyGems, diríamos algo así como

147
require ‘bluecloth’
Con RubyGems sin embargo, podemos sacar provecho de su empaquetado y compatibilidad de versio-nes. Para ello, utilizamos require_gem en lugar de require.
require ‘rubygems’require_gem ‘BlueCloth’, “>= 0.0.4”doc = BlueCloth::new <<MARKUP This is some sample [text][1]. Just learning to use [BlueCloth][1]. Just a simple test. [1]: http://ruby-lang.orgMARKUPputs doc.to_html
produce: <p>This is some sample <a href=”http://ruby-lang.org”>text</a>. Justlearning to use <a href=”http://ruby-lang.org”>BlueCloth</a>.Just a simple test.</p>
Las dos primeras líneas es el código específico de RubyGems. La primera línea carga las bibliotecas del núcleo RubyGems que vamos a necesitar para trabajar con las gemas instaladas.
require ‘rubygems’
La segunda línea es donde está la mayor parte de la magia.
require_gem ‘BlueCloth’, “>= 0.0.4”
Esta línea añade la gema BlueCloth a la variable Ruby $LOAD_PATH y utiliza require para cargar todas las bibliotecas que el creador de la gema especifica que se cargen automáticamente.
Cada joya es considerada como un conjunto de recursos. Puede contener un archivo de biblioteca o cien. En una biblioteca antigua, no RubyGems, todos estos archivos se copiaban en algún lugar compar-tido en el árbol de la biblioteca Ruby, un lugar que estaba en la ruta de carga predefinida de Ruby.
RubyGems no funciona de esta manera. Por el contrario, mantiene a cada versión de cada gema en su propio árbol de directorios autónomo. Las gemas no se añaden a los directorios de la biblioteca estándar de Ruby. Como resultado, RubyGems tiene que hacer algunas filigranas para que se pueda llegar a estos archivos. Esto se logra mediante la adición del árbol de directorios de la gema a la ruta de carga de Ruby. Desde el interior de un programa en ejecución, el efecto es el mismo: sólo funciona require. Desde el exterior sin embargo, RubyGems le da mucho más control sobre lo que está cargado en sus programas Ruby.
En el caso de BlueCloth, el código de plantillas se distribuye como un archivo, bluecloth.rb. Este es el archivo que carga require_gem, que además tiene un segundo argumento opcional, que especifica un requerimiento de versión. En este ejemplo, se ha especificado que la versión 0.0.4 o superior de Blue-Cloth debe estar instalada para utilizar este código. Si hubiera requerido la versión 0.0.5 o superior, este programa hubiera fallado, porque la versión que acaba de instalar es demasiado baja para cumplir con los requisitos del programa.
require ‘rubygems’require_gem ‘BlueCloth’, ‘>= 0.0.5’
produce:
/usr/local/lib/ruby/site_ruby/rubygems.rb:30: in `require_gem’: (LoadError)RubyGem version error: BlueCloth(0.0.4 not >= 0.0.5)from prog.rb:2

148
Como hemos dicho anteriormente, el argumento de requerimiento de versión es opcional y este ejem-plo es obviamente artificial. Sin embargo, es fácil imaginar cómo esta función puede ser útil cuando di-ferentes proyectos comienzan a depender de múltiples y potencialmente incompatibles versiones de la misma biblioteca.
Dependencias en RubyGems
Los lectores astutos se habrán dado cuenta de que el código que hemos creado hasta ahora depende de que el paquete RubyGems esté instalado. A largo plazo es una apuesta bastante segura (nos ima-ginamos) que RubyGems hará su camino en la distribución principal de Ruby. Por ahora, sin embargo, RubyGems no es parte de la distribución estándar de Ruby, por lo que si distribuimos código con require “rubygems” en él, ese código fallará.
Se pueden utilizar al menos dos técnicas para lograr solucionar este problema. En primer lugar, se puede ajustar el código RubyGems específico en un bloque y utilizar el manejo de excepciones Ruby para rescatar el LoadError resultante durante el require.
begin require ‘rubygems’ require_gem ‘BlueCloth’, “>= 0.0.4”rescue LoadError require ‘bluecloth’end
Este código intenta en primer lugar el require de la biblioteca RubyGems. Si esto falla, se invoca la línea del rescue y el programa intentará cargar BlueCloth con un require convencional. Esto último producirá un error si BlueCloth no está instalada, que es el mismo comportamiento que los usuarios verán si no utilizan RubyGems.
Por otra parte, RubyGems puede generar e instalar un archivo de código auxiliar durante la instalación de la gema. Este archivo se inserta en la ubicación de la biblioteca estándar de Ruby y llevará el nom-bre del paquete con los contenidos de la gema (de modo que el archivo auxiliar de BlueCloth se llamará bluecloth.rb). Los usuarios que utilicen esta biblioteca pueden simplemente poner
require ‘bluecloth’
Esto es exactamente lo que se habría puesto en los días pre RubyGems. La diferencia ahora es que en lugar de cargar BlueCloth directamente, en su lugar va a cargar el fichero auxiliar que a su vez llama a require_gem para cargar el paquete correcto. Un archivo de código auxiliar para BlueCloth sería algo como esto:
require ‘rubygems’$”.delete(‘bluecloth.rb’)require_gem ‘BlueCloth’
El archivo auxiliar mantiene todo el código RubyGems específico en un solo lugar, por lo que las bibliotecas dependientes no necesitan incluir ningún código RubyGems en su fuente. La llamada
El código entre bastidores
¿Qué es lo que sucede detrás del escenario cuando se llama al método mágico require_gem?
En primer lugar, la biblioteca de gemas modifica su $LOAD_PATH, incluyendo cualquier directorio que se haya añadido a la require_paths de la especificación de gema. En segundo lugar, se llama al método require para cualquiera de los archivos especificados en el atributo autorequires de la especificación de gema (se describe más adelante). Es así como la modificación de la conducta de $LOAD_PATH permite a RubyGems gestionar múltiples versiones instaladas de la misma biblioteca.

149
require_gem carga todo los archivos de biblioteca que mantenedor de la gema ha especificado que cargen automáticamente.
A partir de RubyGems 0.7.0, la instalación de los archivos auxiliares está activada por defecto. Durante la instalación, se puede desactivar con la opción - no-install-stub. La mayor desventaja de la utili-zación de estos archivos auxiliares es que se pierde la capacidad de RubyGems para gestionar múltiples versiones instaladas de la misma biblioteca. Si necesita una versión específica de una biblioteca, es mejor utilizar el método LoadError descrito anteriormente.
Crear su Propia Gema Por ahora, hemos visto lo fácil que RubyGems hace las cosas para los usuarios de una aplicación o una biblioteca. Probablemente esté listo para hacer una gema por su cuenta. Si va a crear código para compar-tir con la comunidad de código abierto, RubyGems es una forma ideal de cara a los usuarios finales para descubrir, instalar y desinstalar el código. También constituye una forma eficaz de gestionar los proyectos internos de empresa o incluso proyectos personales, ya que hace las actualizaciones y restauraciones tan simples. En última instancia, la disponibilidad de más gemas hace más fuerte la comunidad Ruby. Estas gemas tienen que venir de algún lugar y ahora vamos a mostrar cómo pueden comenzar a venir de usted.
Digamos que ha conseguido por fin terminar la aplicación que alguien le solicitó, el diario en línea, “MiRegistro”, y que ha decidido liberarlo bajo una licencia de código abierto. Naturalmente, usted desea liberar MiRegistro como una gema (a la gente le encanta que le den joyas).
Diseño del Paquete
La primera tarea en la creación de una gema es la organización del código en una estructura de direc-torios que tenga sentido. Las mismas reglas que se utilizan en la creación de un archivo tar o zip típicos, se aplican en la organización de paquetes. Algunos convenios generales a continuación.
•ColoquetodoslosarchivosdecódigofuenteRubyenunsubdirectoriollamado/lib. Más tarde, le mostraremos cómo asegurarse de que este directorio se añade a $LOAD_PATH cuando los usuarios car-gan la gema.
•Siesapropiadoparasuproyecto,incluyaunarchivoenlib/yourproject.rb que realice los ne-cesarios comandos require para cargar la mayor parte de la funcionalidad del proyecto. Antes que la característica RubyGems autorequire, esto hace las cosas más fáciles para que otros puedan usar una biblioteca. Incluso para RubyGems, hace más fácil que otros puedan explorar su código si se les da un punto de partida obvio.
•IncluyasiempreunarchivoREADME que contenga un resumen del proyecto, información de contacto del autor e indicaciones para empezar. Utilice el formato RDoc para que se pueda agregar a la documen-tación que se genera durante la instalación de la gema. Recuerde que debe incluir los derechos de autor y de licencia en el archivo README, ya que muchos usuarios comerciales no van a usar un paquete a menos que los términos de la licencia sean claras.
•Laspruebasdebenirenundirectoriollamadotest/. Muchos desarrolladores utilizan una librería de pruebas de unidad como una guía de uso. Es bueno ponerla en algún lugar predecible, lo que facilita a los demás el poderla encontrar.
•Cualquierscriptejecutablesdebenirenunsubdirectoriodenominadobin/.
•ElcódigofuenteparalasextensionesdeRubydebeirenext/.
•Siustedtieneunagrancantidaddedocumentaciónparaincluirensugema,esbuenomantenerlaensupropio subdirectorio llamado docs/. Si el archivo README está en el nivel superior del paquete, asegúrese de referenciar a los lectores a este lugar.
Esta estructura de directorios se ilustra en la figura 10 un poco más adelante.

150
La especificación de Gema
Ahora que tiene los archivos establecidos como deseaba, es el momento de llegar al corazón de la creación de la gema: la especificación de gema, o gemspec. Un gemspec es una colección de metadatos en Ruby o YAML que proporciona información clave sobre su gema. El gemspec se utiliza como entrada para el proceso de construcción de la gema. Puede utilizar diferentes mecanismos para crear una gema, pero todos son conceptualmente lo mismo. A continuación la primera y básica gema MiRegistro:
require ‘rubygems’SPEC = Gem::Specification.new do |s| s.name = “MiRegistro” s.version = “1.0.0” s.author = “Jo Programmer” s.email = “[email protected]” s.homepage = “http://www.joshost.com/MiRegistro” s.platform = Gem::Platform::RUBY s.summary = “An online Diary for families” candidates = Dir.glob(“{bin,docs,lib,tests}/**/*”) s.files = candidates.delete_if do |item| item.include?(“CVS”) || item.include?(“rdoc”) end s.require_path = “lib” s.autorequire = “miregistro” s.test_file = “tests/ts_miregistro.rb” s.has_rdoc = true s.extra_rdoc_files = [“README”] s.add_dependency(“BlueCloth”, “>= 0.0.4”)end
Vamos a recorrer rápidamente este ejemplo. Los metadatos de una gema se llevan a cabo en un objeto de clase Gem::Specification. El gemspec puede expresarse en YAML o código Ruby. Aquí vamos a mostrar la versión Ruby, ya que generalmente es más fácil de construir y más flexible de utilizar. Los cinco primeros atributos en la especificación dan información básica como el nombre de la gema, la versión, el nombre del autor, correo electrónico y página principal.
En este ejemplo, el siguiente atributo es la plataforma sobre la que esta gema se puede ejecutar. En este caso, la gema es una biblioteca pura de Ruby con ningún sistema operativo específico en los reque-rimientos, por lo que hemos establecido la plataforma en RUBY. Si esta gema hubiera sido escrita sólo para Windows, por ejemplo, la plataforma debería estar listada como Win32. Por ahora, este campo sólo es informativo, pero en el futuro será utilizado por el sistema de gemas para la selección inteligente de la extension de gemas precompiladas nativas.
El sumario de la gema es la descripción breve que aparece cuando se ejecuta gem query (como en nuestro ejemplo anterior con BlueCloth).
El atributo files es un conjunto de rutas de acceso a los archivos que se incluirán cuando se cons-truye la gema. En este ejemplo, hemos utilizado Dir.glob para generar la lista y filtrar los ficheros CVS y RDoc.
Magia en Tiempo de Ejecución
Los siguientes dos atributos, require_path y autorequire, le permiten especificar los directorios que se agregarán a $LOAD_PATH cuando require_gem carga la gema, así como cualquier otro archivo que se cargará automáticamente usando require. En este ejemplo, lib se refiere a una ruta relativa al directorio MiRegistro, y autorequire hará que se requiera lib/miregistro.rb cuando se llama a require_gem “MiRegistro”. Para cada uno de estos dos atributos, RubyGems ofrece sus correspon-dientes versiones, require_paths y autorequire, que toman matrices, lo que permite tener muchos archivos cargados automáticamente a partir de diferentes directorios, cuando la gema se carga mediante require_gem.

151
Agregar Pruebas y Documentación
El atributo test_file contiene el nombre de ruta relativa a un único archivo Ruby incluido en la gema y que debe ser cargado como un Test::Unit (se puede usar la forma plural, test_files, para hacer referencia a una serie de archivos que contiengan las pruebas). Para más detalles sobre cómo crear un conjunto de pruebas, consulte el capítulo sobre las pruebas unitarias.
Para terminar con este ejemplo, tenemos dos atributos que controlan la producción de documentación local de la gema. El atributo has_rdoc especifica que se han añadido comentarios RDoc al código. Es posible ejecutar RDoc sin absolutamente ningún comentario, proporcionando una vista navegable de sus interfaces, pero obviamente esto es mucho menos valioso que el funcionamiento de RDoc con el código bien comentado. has_rdoc es una forma de decirle al mundo: “Si. Vale la pena generar la documentación de esta gema“.
RDoc tiene la ventaja de ser muy legible por lo que es una excelente opción para un archivo README incluido en un paquete. Por defecto, el comando rdoc sólo se ejecutará en los archivos de código fuente. El atributo extra_rdoc_file toma una serie de rutas de acceso a los archivos no fuente de la gema que se quisieran incluir en la generación de documentación la RDoc.
Añadir Dependencias
Para que su gema funcione correctamente, los usuarios van a necesitar tener instalado BlueCloth.
Hemos visto anteriormente cómo establecer una dependencia de versión en tiempo de carga para una librería. Ahora tenemos que inicar a nuestro gemspec esta dependencia, para lo que el instalador se ase-gure de que esté presente durante la instalación de MiRegistro. Lo hacemos con la adición de una única llamada al método de nuestro objeto Gem::Specification.
s.add_dependency(“BlueCloth”, “>= 0.0.4”)
Los argumentos al método add_dependency son idénticos a los de require_gem que hemos expli-cado antes.
Después de la generación de esta gema, el intentar instalarla en un sistema limpio sería algo como:
% gem install pkg/MiRegistro-1.0.0.gemAttempting local installation of ‘pkg/MiRegistro-1.0.0.gem’/usr/local/lib/ruby/site_ruby/1.8/rubygems.rb:50:in `require_gem’: (LoadError)Could not find RubyGem BlueCloth (>= 0.0.4)
Debido a que se está realizando una instalación local desde un archivo, RubyGems no intentar resolver la dependencia. Por el contrario, falla estrepitosamente y le dice que necesita BlueCloth para completar la instalación. A continuación, se puede instalar BlueCloth como lo hacíamos antes, y las cosas irán bien la próxima vez que se intente instalar la gema MiRegistro.
Si había subido MiRegistro al repositorio central de RubyGems y luego trata de instalarla como gema en un sistema limpio, se le pedirá que instale automáticamente BlueClot como parte de la instalación de MiRegistro.
% gem install -r MiRegistroAttempting remote installation of ‘MiRegistro’Install required dependency BlueCloth? [Yn] ySuccessfully installed MiRegistro, version 1.0.0
Ahora tienes ambas instaladas, BlueCloth y MiRegistro y tu amigo puede empezar alegremente la pu-blicación de su diario. Si se hubiera optado por no instalar BlueCloth, la instalación habría fallado como lo hizo durante el intento de instalación local.
A medida que se añadan más funciones a MiRegistro, puede que nos encontremos que necesitemos

152
gemas externas adicionales para apoyar esas características. Al método add_dependency se le puede llamar varias veces en una sola gemspec, soportando cualesquiera dependencias que se necesiten.
Extensión de Ruby Gems
Hasta ahora, todos los ejemplos que hemos visto han sido código Ruby puro. Sin embargo, muchas librerías Ruby se crean como extensiones nativas. Hay dos formas de empaquetar y distribuir este tipo de librerías como una gema. Se puede distribuir la gema en formato fuente y que el instalador compile el código en tiempo de instalación. Alternativamente, se pueden precompilar estas extensiones y distribuir una gema por separado para cada plataforma a la que se desee dar soporte.
Para gemas fuente, RubyGems provee un atributo de Gem::Specification adicional denominado extensions . Este atributo es una matriz de rutas de acceso a los archivos Ruby que van a generar Make-files. La forma más habitual para crear uno de estos programas es usar la librería Ruby mkmf (se verán detalles más adelante). Estos archivos son llamados convencionalmente extconf.rb, aunque cualquier nombre valdría.
Su mamá tiene una base de datos computarizada de recetas que es muy querida para ella, ya que ha estado almacenamiento sus recetas durante años, y le gustaría que le diera la posibilidad de publicar estas recetas en la web para sus amigos y familiares. Usted descubre que el programa de recetas, MenuBuilder, tiene una API nativa bastante agradable y decide escribir una extensión de Ruby para envolverlo. Ya que la extensión puede ser útil para otras personas que pueden estar usando MiRegistro, usted decide empa-quetarla como una gema por separado y agregarla como una dependencia adicional para MiRegistro .
Aquí está la gemspec:
require ‘rubygems’spec = Gem::Specification.new do |s| s.name = “MenuBuilder” s.version = “1.0.0” s.author = “Jo Programmer” s.email = “[email protected]” s.homepage = “http://www.joshost.com/projects/MenuBuilder” s.platform = Gem::Platform::RUBY s.summary = “A Ruby wrapper for the MenuBuilder recipe database.” s.files = [“ext/main.c”, “ext/extconf.rb”] s.require_path = “.” s.autorequire = “MenuBuilder” s.extensions = [“ext/extconf.rb”]endif $0 == __FILE__ Gem::manage_gems Gem::Builder.new(spec).buildend
Tenga en cuenta que usted tiene que incluir los archivos de código fuente en la lista de las especifica-ciones de archivos, para que estén incluidos en el paquete de la gema para su distribución.
Cuando se instala una gema fuente, RubyGems ejecuta cada uno de sus programas de extensión y luego ejecuta el Makefile resultante.
% gem install MenuBuilder-1.0.0.gemAttempting local installation of ‘MenuBuilder-1.0.0.gem’ruby extconf.rb inst MenuBuilder-1.0.0.gemcreating Makefile

153
makegcc -fPIC- g -O2 -I. -I/usr/local/lib/ruby/1.8/i686linux \ -I/usr/local/lib/ruby/1.8/i686linux -I. -c main.cgcc -shared -L”/usr/local/lib” -o MenuBuilder.so main.o \ -ldl -lcrypt -lm -lcmake installinstall -c -p -m 0755 MenuBuilder.so \ /usr/local/lib/ruby/gems/1.8/gems/MenuBuilder-1.0.0/.Successfully installed MenuBuilder, version 1.0.0
RubyGems no tiene la capacidad de detectar las dependencias del sistema de librerías que las gemas fuente puedan conllevar. Si una gema fuente depende de una librería que no está instalada, la instalación de la gema va a fracasar y se mostrará cualquier salida de error del comando make.
La distribución de las gemas fuente, requiere obviamente, que el usuario de la gema tenga un conjunto de las herramientas del trabajo de desarrollo. Como mínimo, se va a necesitar algún tipo de programa make y un compilador. Especialmente para los usuarios de Windows, estas herramientas pueden no estar presentes. Se puede superar esta limitación mediante la distribución de las gemas ya precompiladas.
La creación de gemas precompiladas es simple: añadir a la lista files de la especificación de gema los archivos compilados de objetos compartidos (archivos DLL en Windows) , y asegurarse de que estos archivos se encuentran en uno de los atributos require_path de la gema. Al igual que con las gemas puras de Ruby, el comando require_gem modificará la variable Ruby $LOAD_PATH y el objeto comparti-do será accesible a través de require.
Dado que estas gemas son específicas de la plataforma, también puede utilizar el atributo platform (esto lo vimos en el primer ejemplo gemspec) para especificar la plataforma de destino de la gema. La clase Gem::Specification define constantes para Windows, Linux Intel, Macintosh, y Ruby puro. Para las plataformas que noestán en esta lista, se puede utilizar el valor de la variable RUBY_PLATFORM. Este atributo es solamente informativo por ahora, pero es un buen hábito a adquirir. Las futuras versiones de RubyGems utilizaran el atributo platform para seleccionar de forma inteligente las gemas pre-compila-das para la plataforma en la que se está ejecutando el instalador.
La Construcción del Archivo Gema
El archivo de especificación de MiRegistro que acabamos de crear es ejecutable como un programa Ruby. La invocación creará un archivo gema, MiRegistro-0.5.0.gem.
% ruby miregistro.gemspecAttempting to build gem spec ‘miregistro.gemspec’Successfully built RubyGemName: MiRegistroVersion: 0.5.0File: MiRegistro-0.5.0.gem
Alternativamente, puede usar el comando gem build para generar el archivo de la gema.
% gem build miregistro.gemspecAttempting to build gem spec ‘miregistro.gemspec’Successfully built RubyGemName: MiRegistroVersion: 0.5.0File: MiRegistro-0.5.0.gem
Ahora que tenemos un archivo gema, podemos distribuirlo como cualquier otro paquete. Se puede poner en un servidor FTP o un sitio Web para descargar o enviar por correo electrónico a los amigos. Una vez que tus amigos tienen este archivo en su ordenador local (descargado desde el servidor FTP si es necesario), se puede instalar la gema (suponiendo que hayan instalado también RubyGems) mediante la llamada:

154
% gem install MiRegistro-0.5.0.gemAttempting local installation of ‘MiRegistro-0.5.0.gem’Successfully installed MiRegistro, version 0.5.0
Si desea liberar su gema a la comunidad Ruby, la forma más fácil es usar RubyForge (http://rubyforge.org). RubyForge es un sitio Web de gestión de proyectos open-source. También alberga el repositorio central de gemas. Los lanzamientos de gemas a través de la funcionalidad de RubyForge son automática-mente recogidos y añadidos al repositorio central varias veces al día. La ventaja para los posibles usuarios de su software es que éste estará disponible para consulta e instalación remota con RubyGems, haciendo todo aún más fácil.
Construcción con Rake
Por último, pero ciertamente no menos importante, podemos utilizar Rake para construir gemas. Rake utiliza un archivo de comandos llamado Rakefile para controlar la construcción. Este define (¡en la sintaxis de Ruby!) un conjunto de reglas y tareas. Para obtener más información sobre el uso de Rake, ver http://rake.rubyforge.org. Tiene una completa documentación y siempre está actualizada. Aquí, nos centraremos sólo en Rake lo suficiente para construir una gema. De la documentación de Rake:
Las tareas son la unidad principal de trabajo en un Rakefile. Las tareas tienen un nombre (por lo ge-neral como un símbolo o una cadena), una lista de prerequisitos (más símbolos o cadenas) y una lista de acciones (dada como un bloque).
Normalmente, puede utilizar Rake con el método integrado task para definir sus propias tareas por nombre en el Rakefile. Para casos especiales, tiene sentido proporcionar el código de ayuda para automa-tizar algunas tareas repetitivas que puede haber para hacer de otra manera. La creación de gemas es uno de estos casos especiales. Rake viene con una TaskLib especial, llamado GemPackageTask, que ayuda a integrar la creación de gemas con el resto de su funcionalidad de construcción automatizada y el proceso de liberación.
Para utilizar GemPackageTask en el Rakefile, hay que crear el gemspec exactamente como lo hici-mos anteriormente, pero esta vez colocándolo en el Rakefile. Esta especificación de gema ahora es para GemPackageTask .
require ‘rubygems’Gem::manage_gemsrequire ‘rake/gempackagetask’spec = Gem::Specification.new do |s| s.name = “MiRegistro” s.version = “0.5.0” s.author = “Jo Programmer” s.email = “[email protected]” s.homepage = “http://www.joshost.com/MiRegistro” s.platform = Gem::Platform::RUBY s.summary = “An online Diary for families” s.files = FileList[“{bin,tests,lib,docs}/**/*”].exclude(“rdoc”).to_a s.require_path = “lib” s.autorequire = “miregistro” s.test_file = “tests/ts_miregistro.rb” s.has_rdoc = true s.extra_rdoc_files = [“README”] s.add_dependency(“BlueCloth”, “>= 0.0.4”) s.add_dependency(“MenuBuilder”, “>= 1.0.0”)endRake::GemPackageTask.new(spec) do |pkg| pkg.need_tar = trueend
Tenga en cuenta que tendrá que requerir el paquete rubygems en su Rakefile. También note que hemos utilizado la clase de Rake FileList en lugar de Dir.glob para construir la lista de archivos.

155
FileList es más inteligente que Dir.glob para este propósito, ya que ignora automáticamente los ar-chivos comúnmente no usados (como el directorio CVS que la herramienta CVS de control de versiones deja por ahí).
Internamente, GemPackageTask genera un objetivo Rake con el identificador
package_directory/gemname-gemversion.gem
En nuestro caso, este identificador es pkg/MiRegistro-0.5.0.gem. Se puede invocar esta tarea desde el mismo directorio en el que se haya puesto el Rakefile.
% rake pkg/MiRegistro-0.5.0.gem(in /home/chad/download/gembook/code/MiRegistro)Successfully built RubyGemName: MiRegistroVersion: 0.5.0File: MiRegistro-0.5.0.gem
Ahora que tenemos una tarea, se puede utilizar como cualquier otra tarea Rake, añadirle dependencias o agregarla a la lista de dependencias de otra tarea, como el despliegue o la liberación del paquete.
Mantenimiento de la Gema (y un Último Vistazo a MiRegistro)
Ya se ha lanzado MiRegistro y ahora hay nuevos usuarios cada semana. Hemos tenido mucho cuidado de empaquetar la gema de forma limpia y hemos utilizado rake para construirla.
Su gema está “en tierra salvaje” con su información de contacto y sabe que es sólo cuestión de tiempo el empezar a recibir peticiones de nuevas funcionalidades (¡y cartas de admirador!) de sus usuarios. Sin embargo, su primera solicitud llega a través de una llamada telefónica de nada menos que del viejo y que-rido amigo que le pidió la aplicación. Acaba de llegar de unas vacaciones en Florida y le pregunta cómo puede incluir las fotos de vacaciones en su diario. No crees que una explicación de comandos FTP sería una buena idea y como es un amigo de la infancia te pasas la noche en la codificación de un módulo de álbum de fotos para MiRegistro.
Puesto que se ha añadido una nueva funcionalidad a la aplicación (en lugar de sólo la fijación de un error), decide aumentar el número de versión a MiRegistro de 1.0.0 a 1.1.0. También agrega una serie de pruebas para la nueva funcionalidad y un documento sobre cómo configurar la funcionalidad de subir fotos.
La figura 10 en la página siguiente muestra la estructura completa de directorios del paquete MiRegis-tro-1.1.0 (MomLog). La especificación de gema final (extraído del Rakefile) luce así:
spec = Gem::Specification.new do |s| s.name = “MiRegistro” s.version = “1.1.0” s.author = “Jo Programmer” s.email = “[email protected]” s.homepage = “http://www.joshost.com/MiRegistro” s.platform = Gem::Platform::RUBY s.summary = “An online diary, recipe publisher, “ + “and photo album for families.” s.files = FileList[“{bin,tests,lib,docs}/**/*”].exclude(“rdoc”).to_a s.require_path = “lib” s.autorequire = “miregistro” s.test_file = “tests/ts_miregistro.rb” s.has_rdoc = true s.extra_rdoc_files = [“README”, “docs/DatabaseConfiguration.rdoc”, “docs/Installing.rdoc”, “docs/PhotoAlbumSetup.rdoc”] s.add_dependency(“BlueCloth”, “>= 0.0.4”) s.add_dependency(“MenuBuilder”, “>= 1.0.0”)end

156
Ejecuta Rake sobre su Rakefile y ya tiene la gema MiRegistro actualizada. Ya está listo para lanzar la nueva versión. Inicie sesión en su cuenta de RubyForge y cargue su gema en la sección “Files” de su proyecto. Mientras espera a que el proceso automatizado de RubyGems libere la gema en el repositorio central de gemas, puede escribir un anuncio publicando el lanzamiento de su proyecto en RubyForge.
Dentro de aproximadamente una hora, su amigo puede conectarse al servidor para instalar la nueva versión:
% gem query -rn MiRegistro
*** REMOTE GEMS ***
MiRegistro (1.1.0, 1.0.0) An online diary, recipe publisher, and photo album for families.
¡Genial! La consulta indica que hay dos versiones de MiRegistro disponibles. Escribiendo el comando de instalación sin especificar un argumento de versión, se instala por defecto la versión más reciente.
% gem install -r MiRegistroAttempting remote installation of ‘MiRegistro’Successfully installed MiRegistro, version 1.1.0
No ha cambiado ninguna de las dependencias de MiRegistro, por lo que la instalación existente de BlueCloth y MenuBuilder cumple con los requisitos para MiRegistro 1.1.0.

157
Ruby y la Web
Ruby no es ajeno a Internet. No sólo puede escribir su propio servidor SMTP, demonio FTP o servidor Web en Ruby, sino que también puede utilizar Ruby para las tareas más habituales, como programación CGI o como un reemplazo para PHP.
Hay muchas opciones disponibles en la utilización de Ruby para implementar aplicaciones Web, y un solo capítulo, no puede contenerlo todo. En su lugar, vamos a tratar algunos puntos y a poner de relieve las bibliotecas y los recursos que pueden ayudar.
Vamos a empezar con algunas cosas sencillas: la ejecución de programas Ruby como Common Gateway Interface (CGI).
Escritura de Scripts CGI
Se puede utilizar Ruby para escribir scripts CGI con bastante facilidad. Para tener un script Ruby que genere código HTML de salida, todo lo que necesita es algo así como
#!/usr/bin/rubyprint “Content-type: text/html\r\n\r\n”print “<html><body>Hello World! It’s #{Time.now}</body></html>\r\n”
Coloque este script en un directorio CGI marcándolo como ejecutable y podrá accederle a través del navegador (si su servidor web no añade automáticamente las cabeceras, tendrá que añadir la cabecera de respuesta usted mismo).
#!/usr/bin/rubyprint “HTTP/1.0 200 OK\r\n”print “Content-type: text/html\r\n\r\n”print “<html><body>Hello World! It’s #{Time.now}</body></html>\r\n”
Sin embargo, esto está a un nivel bastante bajo. Tendría que escribir su propia solicitud de análisis, gestión de sesión, manipulación de cookies, mecanismo de escape y así sucesivamente. Afortunadamen-te, hay opciones disponibles para hacer esto más fácil.
Utilizando cgi.rb
La clase CGI proporciona soporte para la escritura de scripts CGI. Con ella, se pueden manipular los formularios, cookies y entorno, mantener sesiones de estado, etc. Es una clase bastante grande, pero aquí vamos a echar un rápido vistazo a sus capacidades.
“Escapado”
Cuando se trata de URLs y de código HTML hay que tener cuidado de “escapar” algunos caracteres. Por ejemplo, un carácter de barra (/) tiene un significado especial en una URL, por lo que debe ser esca-pado si no es parte de la ruta. Es decir, cualquier / en la parte de la URL se convertiría en la cadena %2F y debe ser traducida de vuelta a una / para ser usada. El espacio y el símbolo & son también caracteres especiales. Para controlar esto, CGI proporciona las rutinas CGI.escape y CGI.unescape.
require ‘cgi’puts CGI.escape(“Nicholas Payton/Trumpet & Flugel Horn”)
produce:
Nicholas+Payton%2FTrumpet+%26+Flugel+Horn
Más frecuentemente, es posible que desee escapar los caracteres especiales HTML.
require ‘cgi’

158
puts CGI.escapeHTML(“a < 100 && b > 200”)
produce:
a < 100 && b > 200
Para obtener algo realmente de lujo, puede decidir escapar sólo algunos elementos HTML dentro de una cadena.
require ‘cgi’puts CGI.escapeElement(‘<hr><a href=”/mp3”>Click Here</a><br>’,’A’)
produce:
<hr><a href="/mp3">Click Here</a><br>
Aquí sólo el elemento A fué escapado, los otros elementos se quedan. Cada uno de estos métodos tiene una versión “un-” para restaurar la cadena original.
require ‘cgi’puts CGI.unescapeHTML(“a < 100 && b > 200”)
produce:
a < 100 && b > 200
Parámetros de Consulta
Las peticiones HTTP desde el navegador a su aplicación pueden contener parámetros, ya sean pasa-dos como parte de la URL o pasados como datos incrustados en el cuerpo de la solicitud.
El procesamiento de estos parámetros se complica por el hecho de que un valor con un nombre de-terminado puede ser devuelto varias veces en la misma petición. Por ejemplo, supongamos que estamos escribiendo una encuesta para averiguar por qué a la gente le gusta Ruby. El código HTML de nuestro formulario se vería así:
<html> <head><title>Test Form</title></head> <body> I like Ruby because: <form target=”cgi-bin/survey.rb”> <input type=”checkbox” name=”reason” value=”flexible” /> It’s flexible<br /> <input type=”checkbox” name=”reason” value=”transparent” /> It’s transparent<br /> <input type=”checkbox” name=”reason” value=”perlish” /> It’s like Perl<br /> <input type=”checkbox” name=”reason” value=”fun” /> It’s fun <p> Your name: <input type=”text” name=”name”> </p> <input type=”submit”/> </form> </body></html>
Cuando alguien rellena este formulario, puede tener varias razones por las que le gusta Ruby (como se muestra en la figura 11 en la página siguiente). En este caso, el dato del formulario que corresponde al nombre reason tiene tres valores, correspondientes a las tres casillas marcadas.
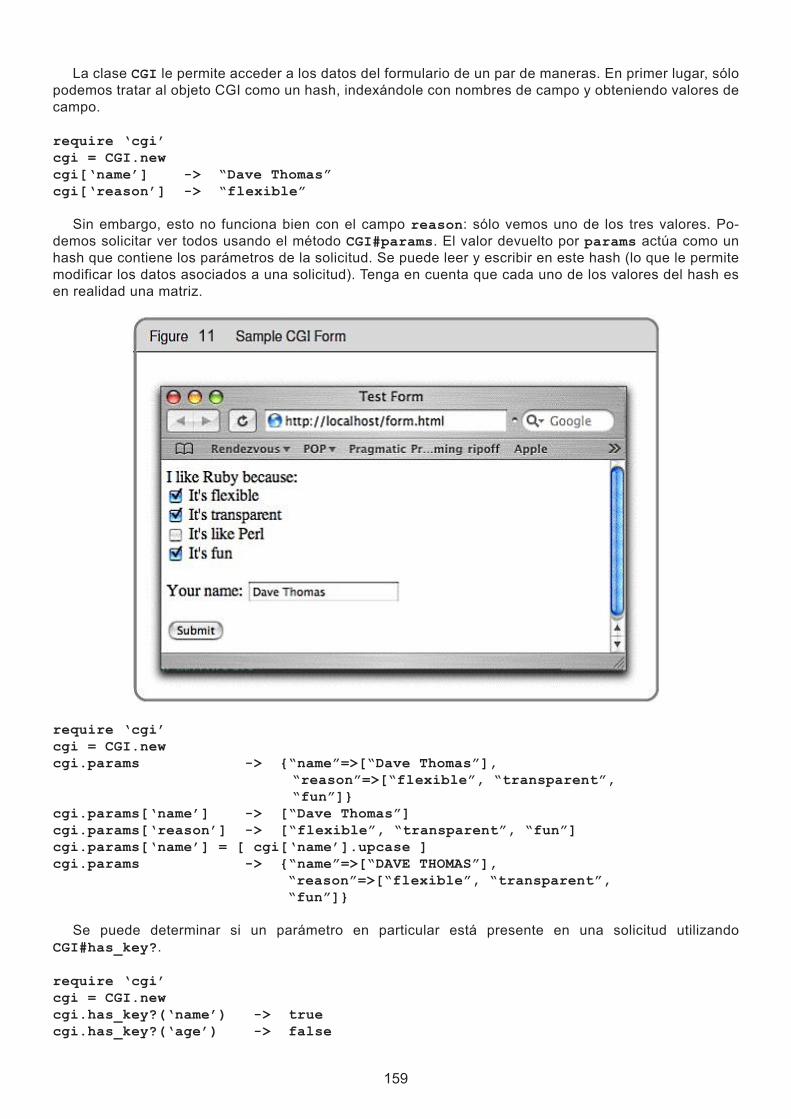
159
La clase CGI le permite acceder a los datos del formulario de un par de maneras. En primer lugar, sólo podemos tratar al objeto CGI como un hash, indexándole con nombres de campo y obteniendo valores de campo.
require ‘cgi’cgi = CGI.newcgi[‘name’] -> “Dave Thomas”cgi[‘reason’] -> “flexible”
Sin embargo, esto no funciona bien con el campo reason: sólo vemos uno de los tres valores. Po-demos solicitar ver todos usando el método CGI#params. El valor devuelto por params actúa como un hash que contiene los parámetros de la solicitud. Se puede leer y escribir en este hash (lo que le permite modificar los datos asociados a una solicitud). Tenga en cuenta que cada uno de los valores del hash es en realidad una matriz.
require ‘cgi’cgi = CGI.newcgi.params -> {“name”=>[“Dave Thomas”], “reason”=>[“flexible”, “transparent”, “fun”]}cgi.params[‘name’] -> [“Dave Thomas”]cgi.params[‘reason’] -> [“flexible”, “transparent”, “fun”]cgi.params[‘name’] = [ cgi[‘name’].upcase ]cgi.params -> {“name”=>[“DAVE THOMAS”], “reason”=>[“flexible”, “transparent”, “fun”]}
Se puede determinar si un parámetro en particular está presente en una solicitud utilizando CGI#has_key ? .
require ‘cgi’cgi = CGI.newcgi.has_key?(‘name’) -> truecgi.has_key?(‘age’) -> false

160
Generación de HTML
CGI contiene un gran número de métodos que pueden utilizarse para crear HTML --un método por cada elemento. Para activar estos métodos, se debe crear un objeto CGI llamando CGI.new, pasándolo al nivel requerido de HTML. En estos ejemplos, vamos a utilizar HTML3.
Para hacer más fácil la anidación de elementos, estos métodos toman su contenido como bloques de código. Éstos deben devolver un String, que se utiliza como contenido del elemento. Para este ejemplo, hemos añadido algunas nuevas líneas gratuitas para hacer que la salida se ajuste a la página.
require ‘cgi’cgi = CGI.new(“html3”) # add HTML generation methodscgi.out { cgi.html { cgi.head { “\n”+cgi.title{“This Is a Test”} } + cgi.body { “\n”+ cgi.form {“\n”+ cgi.hr + cgi.h1 { “A Form: “ } + “\n”+ cgi.textarea(“get_text”) +”\n”+ cgi.br + cgi.submit } } }}
produce:
Content-Type: text/htmlContent-Length: 302
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 3.2 Final//EN”><HTML><HEAD><TITLE>This Is a Test</TITLE></HEAD><BODY><FORM METHOD=”post” ENCTYPE=”application/x-www-form-urlencoded”><HR><H1>A Form: </H1><TEXTAREA NAME=”get_text” ROWS=”10” COLS=”70”></TEXTAREA><BR><INPUT TYPE=”submit”></FORM></BODY></HTML>
Este código producirá un formulario HTML titulado “This Is a Test,” seguido por una línea horizontal y un encabezado de primer nivel, un área de entrada de texto, y finalmente un botón de envío. Cuando se de el envío, tendremos un parámetro CGI llamado get_text que contiene el texto introducido por el usuario.
Aunque es interesante, este método de generación de HTML es bastante laborioso y, probablemente, no se utilice mucho en la práctica. La mayoría de la gente no parece que escriba el código HTML direc-tamente, más bien utiliza un sistema de plantillas, o utiliza un framework de aplicacion, tal como Iowa. Desafortunadamente, no tenemos espacio para hablar de Iowa --puede echar un vistazo a la documenta-ción en línea en http://enigo.com/projects/iowa, o mirar en el capítulo 6 de The Ruby Developer’s Guide [FJN02] --aunque ahora vamos a ver el sistema de plantillas.
Sistema de plantillas
Los sistemas de plantillas le permiten separar lo que es la presentación de lo que es la lógica de su aplicación. Parece que casi todo el mundo que escribe una aplicación web con Ruby, en algún momento también escribe un sistema de plantillas: en el wiki RubyGarden hay unas cuantas. Por ahora, vamos a ver en tres: las plantillas RDoc, Amrita y erb/eruby.

161
Plantillas RDoc
El sistema de documentación RDoc (descrito anteriormente) incluye un sistema muy sencillo de planti-llas, que utiliza para generar su salida en XML y HTML. Como RDoc se distribuye como parte de la norma Ruby, el sistema de plantillas está disponible donde quiera que Ruby versión 1.8.2 o posterior esté ins-talado. Sin embargo, el sistema de plantillas no usa formatos HTML o XML convencionales (ya que está destinado a ser utilizado para generar la salida en diferentes formatos), por lo que los archivos formatea-dos con plantillas RDoc pueden no ser fáciles de editar con las herramientas convencionales de edición de HTML.
require ‘rdoc/template’HTML = %{Hello, %name%.<p>The reasons you gave were:<ul>START:reasons <li>%reason_name% (%rank%)END:reasons</ul>}data = { ‘name’ => ‘Dave Thomas’, ‘reasons’ => [ { ‘reason_name’ => ‘flexible’, ‘rank’ => ‘87’ }, { ‘reason_name’ => ‘transparent’, ‘rank’ => ‘76’ }, { ‘reason_name’ => ‘fun’, ‘rank’ => ‘94’ }, ]}
t = TemplatePage.new(HTML)t.write_html_on(STDOUT, data)
produce:
Hello, Dave Thomas.<p>The reasons you gave were:<ul> <li>flexible (87) <li>transparent (76) <li>fun (94)</ul>
Se le pasa una cadena al construcrtor que contiene la plantilla que se va a utilizar. A continuación, se le pasa al método write_html_on un hash que contiene los nombres y los valores. Si la plantilla contiene la secuencia %xxxx%, se consulta el hash y se sustituye el valor correspondiente al nombre xxx Si la plan-tilla contiene START:yyy, el valor hash que corresponde a yyy se supone que es un array de hashes. Las líneas de la plantilla entre START:yyy y END:yyy se repiten para cada elemento del array. Las plantillas también soportan condicionaless: las líneas entre IF:zzz y ENDIF:zzz se incluyen en la salida sólo si el hash tiene una clave zzz.
Amrita
Amrita (http://amrita.sourceforge.jp/index.html) es una librería que genera documentos HTML a partir de una plantilla que sí es HTML válido. Esto hace que Amrita sea fácil de usar con los actuales editores de HTML. También hace que las plantillas de Amrita se muestren correctamente como páginas HTML in-dependientes.
Amrita utiliza las etiquetas id de los elementos HTML para determinar los valores a sustituir. Si el valor correspondiente a un nombre dado es nil o false, el elemento HTML no se incluirá en el resultado.

162
Si el valor es una matriz, repite el elemento HTML correspondiente.
require ‘amrita/template’include AmritaHTML = %{<p id=”greeting” /><p>The reasons you gave were:</p><ul> <li id=”reasons”><span id=”reason_name”></span>, <span id=”rank”></span></ul>}data = { :greeting => ‘Hello, Dave Thomas’, :reasons => [ { :reason_name => ‘flexible’, :rank => ‘87’ }, { :reason_name => ‘transparent’, :rank => ‘76’ }, { :reason_name => ‘fun’, :rank => ‘94’ }, ]}t = TemplateText.new(HTML)t.prettyprint = truet.expand(STDOUT, data)
produce:
<p>Hello, Dave Thomas</p><p>The reasons you gave were:</p><ul> <li>flexible, 87 </li> <li>transparent, 76 </li> <li>fun, 94 </li></ul>
erb y eruby
Hasta ahora hemos visto el uso de Ruby para crear salida HTML, pero se puede cambiar la cuestión de adentro a afuera. Podemos integrar Ruby en un documento HTML.
Una serie de paquetes permiten integrar las declaraciones Ruby en algún otro tipo de documento, es-pecialmente en páginas HTML. Generalmente, esto se conoce como “eRuby.” Específicamente, existen varias implementaciones diferentes de eRuby, incluyendo eruby y erb. eruby, escrito por Shugo Maeda, está disponible para su descarga desde el Archivo de Aplicaciones Ruby. erb, su primo, está escrito en Ruby puro y se incluye con la distribución estándar. Aquí veremos erb.
La integración de Ruby en HTML es un concepto muy poderoso. Básicamente, nos da el equivalente de una herramienta como ASP, JSP o PHP, pero con toda la potencia de Ruby.
Usando erb
erb normalmente se utiliza como filtro. El texto en el archivo de entrada pasa a través tal cuál, sin tocar, sólo con las siguientes excepciones:
<% ruby code %> Ejecuta el código Ruby entre los delimitadores.<%= ruby expression %> Evalua la expresión de Ruby y reemplaza la secuencia con el valor de la expresión.<%# ruby code %> El código Ruby entre los delimitadores se tiene en cuenta (para pruebas).% line of ruby code Una línea que comienza con el signo porcentaje se supone que contiene sólo código Ruby.
Expresión Descripción

163
erb se invoca:
erb [ opciones ] [ documento ]
Si se omite documento, erb lee desde la entrada estándar. Las opciones de línea de comandos son las siguientes:
-d Establecer $DEBUG a true.-Kkcode Especifica un sistema de codificación alternativo.-n Muestra el resultado de un script Ruby (con números de línea).-r librería Carga la librería dada.-P No procesar con erb las líneas que comienzan con un %.-S nivel Ajusta el nivel de seguridad.-T modo Establece el modo de ajuste.-v Activa el modo detallado.-x Muestra el resultado de el script Ruby.
Veamos algunos ejemplos sencillos. Vamos a correr el ejecutable erb en la siguiente entrada:
% a = 99<%= a %> botellas de cerveza...
La línea que comienza con el signo de porcentaje, simplemente ejecuta la sentencia Ruby dada. La siguiente línea contiene la secuencia <% a %>, que sustituye el valor de a.
erb f1.erb
produce:
99 botellas de cerveza...
erb trabaja reescribiendo su entrada como un script Ruby para a continuación ejecutar el script. Se puede ver el Ruby que genera utilizando las opciones -n o -x.
erb -x f1.erb
produce:
_erbout = ‘’; a = 99_erbout.concat(( a ).to_s); _erbout.concat “ botellas de cerveza...\n”_erbout
Note como erb crea una cadena, _erbout, que contiene tanto las cadenass estáticas de la plantilla como los resultados de la ejecución de las expresiones (en este caso el valor de a).
Por supuesto, puede incrustar Ruby dentro de un tipo de documento más complejo, tal como HTML. La figura 12 muestra un par de bucles en un documento HTML.
Opción Descripción

164
Instalación de eruby en Apache
Si desea utilizar erb como el generador de páginas de un sitio web que recibe una cantidad razonable de tráfico, es probable que prefiera utilizar eruby, que tiene un mejor rendimiento. Entonces, puede confi-gurar el servidor Web Apache para analizar automáticamente documentos integrados de Ruby con eruby, de la misma manera como se hace con PHP. Se pueden crear archivos de Ruby integrados con un sufijo .rhtml y configurar el servidor Web para correr el ejecutable eruby en estos documentos obteniendo así el resultado HTML deseado.
Para utilizar eruby con el servidor Web Apache, es necesario realizar los siguientes pasos:
1. Copiar el binario eruby en el directorio cgi-bin. 2. Añadir las siguientes dos líneas a httpd.conf.
AddType application/x-httpd-eruby .rhtml Action application/x-httpd-eruby /cgi-bin/eruby
3. Si se quiere, también se puede añadir o reemplazar la directiva DirectoryIndex de tal manera que incluya index.rhtml. Esto le permite utilizar Ruby para crear listados de directorios para los directorios

165
que no contengan un index.html.
DirectoryIndex index.html index.shtml index.rhtml
DirectoryIndex acepta rutas y también nombres de archivo, así que se puede utilizar una ruta URL ab-soluta donde dejar un script por defecto:
DirectoryIndex index.html /cgi-bin/index.rb
Cookies
Las cookies son una forma de hacer que las aplicaciones Web almacenen su estado en la máquina del usuario. Mal vistas por algunos, las cookies son todavía una conveniente (si no fiable) manera de recordar la información de sesión.
La clase Ruby CGI controla la carga y almacenamiento de cookies. Se puede acceder a las cookies aso-ciadas con la solicitud en curso utilizando el método de CGI#cookies. Se pueden configurar de nuevo las cookies en el navegador estableciendo el parámetro cookies de CGI#out referenciando a una única cookie o un conjunto de cookies.
#!/usr/bin/rubyCOOKIE_NAME = ‘chocolate chip’require ‘cgi’cgi = CGI.newvalues = cgi.cookies[COOKIE_NAME]if values.empty? msg = “It looks as if you haven’t visited recently”else msg = “You last visited #{values[0]}”endcookie = CGI::Cookie.new(COOKIE_NAME, Time.now.to_s)cookie.expires = Time.now + 30*24*3600 # 30 dayscgi.out(“cookie” => cookie ) { msg }
Sesiones
Las cookies por sí mismas aún necesitan un poco de trabajo para ser útiles. Realmente queremos de la sesión la información que persiste entre las peticiones de un navegador web en particular. Las sesiones se manejan con la clase CGI::Session, que utiliza las cookies pero proporciona una abstracción de alto nivel.
Al igual que con las cookies, las sesiones emulan un comportamiento tipo hash, asociándo valores con claves. A diferencia de las cookies, las sesiones almacenan la mayoría de sus datos en el servidor, utili-zando la cookie del navegador residente simplemente como una forma de identificación única de los datos del lado del servidor. Las sesiones también tienen opciónes respecto a las técnicas de almacenamiento de estos datos: el alamcenamiento se puede dar en archivos normales, en un PStore (Persistent Object Storage), en la memoria o incluso en un almacenaje personalizado.
Después de su utilización, se deben cerrar las sesiones ya que asegura que se guarden los datos. Cuando se haya terminado definitivamente con una sesión, se deben borrar.
require ‘cgi’require ‘cgi/session’cgi = CGI.new(“html3”)sess = CGI::Session.new(cgi, “session_key” => “rubyweb”, “prefix” => “web-session.” )

166
if sess[‘lastaccess’] msg = “You were last here #{sess[‘lastaccess’]}.”else msg = “Looks like you haven’t been here for a while”end
count = (sess[“accesscount”] || 0).to_icount += 1msg << “<p>Number of visits: #{count}”sess[“accesscount”] = countsess[“lastaccess”] = Time.now.to_ssess.closecgi.out { cgi.html { cgi.body { msg } }}
El código anterior utiliza el mecanismo de almacenamiento predeterminado para las sesiones: los datos persistentes se almacenan en archivos en el directorio temporal por defecto (ver Dir.tmpdir). Los nom-bres de archivo emepezarán con web-session. y terminará con una versión hash del número de sesión. Ver ri CGI::Session para más información.
Mejorar el Rendimiento
Se puede utilizar Ruby para escribir programas CGI para la Web, pero, al igual que la mayoría de los programas de CGI, la configuración por defecto tiene que empezar una nueva copia de Ruby con cada ac-ceso de página cgi-bin. Eso es costoso en términos de la utilización de la máquina y puede ser muy lento para los internautas. El servidor Web Apache resuelve este problema soportando módulos cargables.
Típicamente, estos módulos son cargados dinámicamente y se convierten en una parte de los procesos que ejecuta el servidor Web --que no tiene la necesidad de generar otro intérprete una y otra vez para dar servicio a las solicitudes, ya que el servidor Web es el intérprete.
Y así llegamos a mod_ruby (disponible en los archivos), un módulo de Apache que acopla un intérprete Ruby completo en el servidor Apache mismo. El archivo readme incluido con mod_ruby proporciona de-talles sobre cómo compilarlo e instalarlo.
Una vez instalado y configurado, puede ejecutar scripts Ruby más o menos como se hace sin mod_ruby, sólo que ahora mucho más rápido. También puede aprovechar las características adicionales que ofrece mod_ruby (como la integración en el manejo de las solicitudes de Apache).
Sin embargo, hay que prestar atención a algunas cosas. Debido a que el intérprete permanece en la memoria entre solicitudes, puede terminar la tramitación de las solicitudes de varias aplicaciones. Es po-sible que las bibliotecas de estas aplicaciones entren en conflicto (sobre todo si las diferentes bibliotecas contienen clases con el mismo nombre). Tampoco se puede asumir que el mismo intérprete se encargará de manejar la serie de solicitudes de una sesión de navegador --Apache asignará los procesos controla-dores utilizando sus algoritmos internos.
Algunas de estas cuestiones se resuelven mediante el protocolo FastCGI. Este es un hack interesante, a disposición de todos los programas estilo CGI, no sólo Ruby. Utiliza un programa proxy muy pequeño que generalmente se ejecuta como módulo de Apache. Cuando se reciben las solicitudes, este proxy las reenvía a un proceso concreto de larga ejecución que actúa como un script CGI normal. Los resultados se mandan de vuelta al proxy, y a continuación de vuelta al navegador. FastCGI tiene las mismas venta-jas que correr mod_ruby, ya que el intérprete siempre está ejecutandose en segundo plano. También le da más control sobre cómo se asignan las solicitudes a los intérpretes. Encontrará más información en http://www.fastcgi.com.

167
Servidores Web Alternativos
Hasta ahora, hemos estado ejecutando scripts de Ruby bajo el control del servidor Web Apache. Sin embargo, a partir de la versión 1.8 Ruby viene con WEBrick, una flexible herramienta escrita en Ruby para dar servicio HTTP. Básicamente, se trata de un plug-in extensible --basado en framework, que le permite escribir servidores para manejar solicitudes y respuestas HTTP. A continuación un servidor HTTP básico que sirve documentos e índices de directorio:
#!/usr/bin/rubyrequire ‘webrick’include WEBricks = HTTPServer.new( :Port => 2000, :DocumentRoot => File.join(Dir.pwd, “/html”))trap(“INT”) { s.shutdown }s.start
El constructor HTTPServer crea un nuevo servidor web en el puerto 2000. El código establece el directorio raíz de documentos en el subdirectorio /html del directorio actual. A continuación, utiliza Kernel.trap para organizar el cierre ordenado de las interrupciones antes de iniciar la ejecución del servidor. Si se apunta el navegador a http://localhost:2000, se debería ver una lista del subdirec-torio html.
WEBrick puede hacer mucho más que servir contenido estático. Se puede utilizar como un contenedor de servlets de Java. El siguiente código monta un servlet simple en /hello. Se invoca al método do_GET cunado llegan las solicitudes. Se utiliza el objeto respuesta para mostrar la información de agente de usua-rio y los parámetros de solicitud.
#!/usr/bin/rubyrequire ‘webrick’include WEBricks = HTTPServer.new( :Port => 2000 )class HelloServlet < HTTPServlet::AbstractServlet def do_GET(req, res) res[‘Conten-tType’] = “text/html” res.body = %{ <html><body> Hello. You’re calling from a #{req[‘User-Agent’]} <p> I see parameters: #{req.query.keys.join(‘, ‘)} </body></html> } endends.mount(“/hello”, HelloServlet)trap(“INT”){ s.shutdown }s.start
SOAP y Servicios Web
SOAP -jabón, en inglés-, se puso en su tiempo para Simple Object Access Protocol. Cuando la gente ya no pudo soportar la ironía, el acrónimo cayó y ahora SOAP es sólo un nombre.
Ruby viene ahora con una implementación de SOAP. Esto le permite escribir servidores y clientes uti-lizando servicios Web. Por su naturaleza, estas aplicaciones pueden funcionar tanto a nivel local como remota a través de una red. Las aplicaciones SOAP ignoran el lenguaje de implementación de sus pares en la red, por lo que utilizar SOAP es una forma conveniente de interconectar aplicaciones Ruby con otras escritas en lenguajes como Java, Visual Basic o C++.

168
SOAP básicamente es un mecanismo que utiliza XML para enviar datos entre dos nodos de una red. Se suele utilizar para implementar las llamadas a procedimiento remoto, RPC, entre procesos de distri-buidos. Un servidor SOAP publica una o más interfaces. Estas interfaces se definen en términos de tipos de datos y los métodos que utilizan estos tipos. A continucación, el cliente SOAP, crea un proxy local que mediante SOAP se conecta a las interfaces en el servidor. En el proxy se pasa una llamada a un método a la interfaz correspondiente en el servidor, y los valores de retorno generados por el método en el servidor, se devuelven al cliente a través del proxy.
Vamos a empezar con un servicio SOAP trivial. Vamos a escribir un objeto que hace los cálculos de los intereses. Inicialmente, se ofrece un método único, compound, que determina el interés compuesto dando uno principal, una tasa de interés, el número de veces que el interés se ve combinado por año y el número de años. Con fines de gestión, también vamos a llevar un registro de cuántas veces fue llamado este método y hacer disponible este contador a través de un descriptor de acceso. Tenga en cuenta que esta clase es sólo código Ruby regular --no sabe que se está ejecutando en un entorno SOAP.
class InterestCalculator attr_reader :call_count def initialize @call_count = 0 end def compound(principal, rate, freq, years) @call_count += 1 principal*(1.0 + rate/freq)**(freq*years) endend
Ahora vamos a hacer un objeto de esta clase que esté disponible a través de un servidor SOAP. Esto permitirá a las aplicaciones cliente llamar a los métodos del objeto a través de la red. Aquí estamos usando un servidor independiente, lo cual es conveniente cuando se hacen pruebas y se puede utilizar la línea de comandos. También se pueden ejecutar los servidores SOAP Ruby como scripts CGI o bajo mod_ruby.
require ‘soap/rpc/standaloneServer’require ‘interestcalc’NS = ‘http://pragprog.com/InterestCalc’class Server2 < SOAP::RPC::StandaloneServer def on_init calc = InterestCalculator.new add_method(calc, ‘compound’, ‘principal’, ‘rate’, ‘freq’, ‘years’) add_method(calc, ‘call_count’) endendsvr = Server2.new(‘Calc’, NS, ‘0.0.0.0’, 12321)trap(‘INT’) { svr.shutdown }svr.start
Este código define una clase que implementa un servidor SOAP independiente. Cuando se inicializa, la clase crea un objeto InterestCalculator (una instancia de la clase que acabamos de escribir). A continuación, utiliza add_method para añadir los dos métodos utilizados por esta clase, compound y call_count. Finalmente, el código crea y ejecuta una instancia de esta clase servidor. Los parámetros para el constructor son el nombre de la aplicación, el espacio de nombres por defecto, la dirección de la interfaz a utilizar y el puerto.
Entonces necesitamos escribir algún código de cliente para acceder a este servidor. El cliente crea un proxy local para el servicio InterestCalculator en el servidor, agrega los métodos que desea utilizar y luego los llama.
require ‘soap/rpc/driver’proxy = SOAP::RPC::Driver.new(“http://localhost:12321”, “http://pragprog.com/InterestCalc”)proxy.add_method(‘compound’, ‘principal’, ‘rate’, ‘freq’, ‘years’)

169
proxy.add_method(‘call_count’)puts “Call count: #{proxy.call_count}”puts “5 years, compound annually: #{proxy.compound(100, 0.06, 1, 5)}”puts “5 years, compound monthly: #{proxy.compound(100, 0.06, 12, 5)}”puts “Call count: #{proxy.call_count}”
Para probar esto, podemos ejecutar el servidor en una ventana de consola (la salida que se muestra aquí ha sido reformateada ligeramente para adaptarse a esta página).
% ruby server.rbI, [2004-07-26T10:55:51.629451 #12327] INFO -- Calc: Start of Calc.I, [2004-07-26T10:55:51.633755 #12327] INFO -- Calc: WEBrick 1.3.1I, [2004-07-26T10:55:51.635146 #12327] INFO -- Calc: ruby 1.8.2 (2004-07-26) [powerpcdarwin]I, [2004-07-26T10:55:51.639347 #12327] INFO -- Calc: WEBrick::HTTPServer#start: pid=12327 port=12321
A continuación, se ejecuta el cliente en otra ventana.
% ruby client.rbCall count: 05 years, compound annually: 133.822557765 years, compound monthly: 134.885015254931Call count: 2
¡En buen estado! Funciona con éxito, llamamos a todos nuestros amigos y lo ejecutamos de nuevo.
% ruby client.rbCall count: 25 years, compound annually: 133.822557765 years, compound monthly: 134.885015254931Call count: 4
Observar cómo la segunda vez que se ejecuta el cliente, el número de las llamadas se inicia ahora en dos. El servidor crea un solo objeto InterestCalculator para atender las solicitudes de entrada que se vuelve a utilizar para cada solicitud.
SOAP y Google
Es evidente que el beneficio real de SOAP es la forma en que le permite interoperar con otros servicios en la Web. Como ejemplo, vamos a escribir algo de código Ruby para enviar consultas a la API web de Google.
Antes de enviar las consultas a Google, se necesita una clave de desarrollador. Este servicio está dis-ponible desde Google, vaya a http://www.google.com/apis y siga las instrucciones en el paso 2, crear una cuenta de Google. Después de entrar su dirección de correo electrónico y proporcionar una contraseña, Google le enviará una clave de desarrollador. En los siguientes ejemplos, vamos a suponer que usted ha almacenado esta clave en el archivo .google_key en su directorio principal.
Vamos a empezar en el nivel más básico. En cuanto a la documentación de la API de Google, el método doGoogleSearch descubrimos que tiene diez (!) parámetros.
key La clave de desarrollador.q La cadena de consulta.start El índice del primer resultado requerido.maxResults El número máximo de resultados a devolver por la consulta.filter Si está activado, comprime los resultados para que páginas similares y páginas en el mismo dominio sólo se muestren una vez.

170
restrict se restringe la búsqueda a un subconjunto del índice de Google Web.safeSearch Si está activado, elimina los posibles contenidos para adultos de los resultados.lr Restringe la búsqueda a los documentos en un determinado conjunto de lenguas.ie Ignorado (codificación de entrada)oe Ignorado (codificación de salida)
Podemos utilizar la llamada add_method para construir un proxy SOAP para el método doGoogleSearch . El siguiente ejemplo hace exactamente eso, imprime la primera entrada devuelta buscando en Google el término pragmatic.
require ‘soap/rpc/driver’require ‘cgi’endpoint = ‘http://api.google.com/search/beta2’namespace = ‘urn:GoogleSearch’soap = SOAP::RPC::Driver.new(endpoint, namespace)soap.add_method(‘doGoogleSearch’, ‘key’, ‘q’, ‘start’, ‘maxResults’, ‘filter’, ‘restrict’, ‘safeSearch’, ‘lr’, ‘ie’, ‘oe’)query = ‘pragmatic’key = File.read(File.join(ENV[‘HOME’], “.google_key”)).chompresult = soap.doGoogleSearch(key, query, 0, 1, false, nil, false, nil, nil, nil)printf “Estimated number of results is %d.\n”, result.estimatedTotalResultsCountprintf “Your query took %6f seconds.\n”, result.searchTimefirst = result.resultElements[0]puts first.titleputs first.URLputs CGI.unescapeHTML(first.snippet)
Al ejecutarlo, se verá algo como lo siguiente (nótese cómo Google ha puesto el término de consulta de relieve).
Estimated number of results is 550000.Your query took 0.123762 seconds.The <b>Pragmatic</b> Programmers, LLChttp://www.pragmaticprogrammer.com/Home of Andrew Hunt and David Thomas’s best-selling book ‘The<b>Pragmatic</b> Programmer’<br> and The ‘<b>Pragmatic</b> Starter Kit(tm)’ series. <b>...</b> The <b>Pragmatic</b> Bookshelf TM. <b>...</b>
Sin embargo, SOAP permite el descubrimiento dinámico de la interfaz de objetos en el servidor. Esto se hace utilizando WSDL (Web Services Description Language). Un archivo WSDL es un documento XML que describe los tipos, métodos y mecanismos de acceso para una interfaz de servicios Web. Los clientes SOAP pueden leer los archivos WSDL para crear las interfaces de un servidor de forma automática.
La página web http://code.creativecommons.org/svnroot/stats/GoogleSearch.wsdl contiene el WSDL que describe la interfaz de Google. Podemos alterar nuestra aplicación de búsqueda para leer este WSDL, que elimina la necesidad de agregar el método doGoogleSearch explícitamente.
require ‘soap/wsdlDriver’require ‘cgi’WSDL_URL = “http://api.google.com/GoogleSearch.wsdl”soap = SOAP::WSDLDriverFactory.new(WSDL_URL).createDriverquery = ‘pragmatic’key = File.read(File.join(ENV[‘HOME’], “.google_key”)).chompresult = soap.doGoogleSearch(key, query, 0, 1, false, nil, false, nil, nil, nil)printf “Estimated number of results is %d.\n”, result.estimatedTotalResultsCount

171
printf “Your query took %6f seconds.\n”, result.searchTimefirst = result.resultElements[0]puts first.titleputs first.URLputs CGI.unescapeHTML(first.snippet)
Por último, podemos ir un paso más allá utilizando la librería Google de Ian Macdonald (disponible en el Ruby Application Archive, en http://raa.ruby-lang.org/project/ruby-google/), que encapsula la API de ser-vicios Web detrás de una interfaz agradable (bueno, si no por otra razón, por lo menos porque elimina la necesidad de todos los parámetros adicionales). La biblioteca también cuenta con métodos para construir rangos de fechas y otras restricciones para una consulta en Google y proporciona interfaces a la caché de Google y a la facilidad de corrección ortográfica. El siguiente código es nuestra búsqueda de “pragmatic” utilizando la biblioteca de Ian.
require ‘google’require ‘cgi’key = File.read(File.join(ENV[‘HOME’], “.google_key”)).chompgoogle = Google::Search.new(key)result = google.search(‘pragmatic’)printf “Estimated number of results is %d.\n”, result.estimatedTotalResultsCountprintf “Your query took %6f seconds.\n”, result.searchTimefirst = result.resultElements[0]puts first.titleputs first.urlputs CGI.unescapeHTML(first.snippet)
Más Información La programación web con Ruby es un gran tema. Para profundizar más, es posible que desee echar un vistazo al capítulo 9 de The Ruby Way [Ful01], donde encontrará muchos ejemplos de red y de programa-ción Web. En el capítulo 6 de The Ruby Developer’s Guide [FJN02], encontrará algunos buenos ejemplos de la estructuración de las aplicaciones CGI, junto con algunos ejemplos de código Iowa.
Si SOAP puede ser complejo, es posible que desee ver el uso de XML-RPC, que se describe breve-mente más adelante.
Hay un número de otros marcos de desarrollo Ruby para Web que están disponibles en la red. Esta es un área dinámica: nuevos contendientes aparecen constantemente y es difícil para un libro impreso el ser definitivo. Sin embargo, dos frameworks que están atrayendo el espíritu de la comunidad Ruby son
•Rails(http://www.rubyonrails.org), y •CGIKit(http://www.spice-of-life.net/cgikit/index_en.html).
Ruby Tk El archivo de aplicaciones Ruby contiene varias extensiones que proveen a Ruby de una interfaz grá-fica de usuario (GUI), incluyendo las extensiones para Fox, GTK y otras.
La extensión Tk se incluye en la distribución y funciona tanto en sistemas Unix como Windows. Para utilizarla, es necesario tener instalado Tk en su sistema. Tk es un gran sistema y se han escrito libros enteros sobre él, así que no vamos a perder el tiempo y los recursos ahondando demasiado en Tk, pero si vamos a concentrarnos en la forma de acceder a las funciones Tk desde Ruby. Usted necesitará uno de estos libros de referencia con el fin de utilizar Ruby con Tk eficazmente. El binding que utilizamos es el más cercano al binding de Perl, por lo que es probable que desee obtener una copia de Learning Perl/Tk [Wal99] o Perl/Tk Pocket Reference [Lid98].
Tk trabaja según una composición de modelo, es decir, empieza por la creación de un contenedor (como un TkFrame o un TkRoot) y luego crea los widgets (otro nombre para los componentes de la

172
interfaz gráfica de usuario) que lo pueblan, como botones o etiquetas. Cuando se está listo para iniciar la interfaz gráfica de usuario, se llama a Tk.mainloop. El motor de Tk toma entonces el control del progra-ma, que muestra los widgets y llama al código en respuesta a los eventos de la interfaz gráfica de usuario.
Simple aplicación Tk
Una simple aplicación Tk en Ruby puede ser algo como esto:
require ‘tk’root = TkRoot.new { title “Ex1” }TkLabel.new(root) do text ‘Hello, World!’ pack { padx 15 ; pady 15; side ‘left’ }endTk.mainloop
Veamos el código un poco más de cerca. Después de cargar el módulo de extensión Tk, se crea un marco de nivel raíz (root-level) con TkRoot.new. A continuación hacemos un widget TkLabel como proceso hijo del marco raíz, estableciendo varias opciones para la etiqueta. Por último, se empaqueta el marco raíz y se entra en el bucle principal de eventos GUI.
Es un buen hábito especificar la raiz de forma explícita, aunque se puede dejar de lado (junto con las opciones adicionales) y madurar esto en tres líneas:
require ‘tk’TkLabel.new { text ‘Hello, World!’; pack }Tk.mainloop
¡Esto es todo lo que hay que hacer! Armado con uno de los libros de Perl/Tk de los quehacemos re-ferencia al comienzo de este capítulo, se pueden producir todas las sofisticadas interfaces gráficas de usuario que usted necesite. Pero, de nuevo, si desea quedarse para algunos detalles más, aquí vienen.
Widgets
La creación de widgets es fácil. Se toma el nombre del widget como figura en la documentación de Tk y se añade Tk al principio de tal nombre. Por ejemplo, los widgets Label, Button y Entry, se convierten en las clases TkLabel, TkButton y TkEntry. Se crea una instancia de un widget utilizando new, al igual que se haría con cualquier otro objeto. Si no se especifica un padre para un determinado widget, se usará por defecto el marco de nivel raíz. Por lo general, se especifica el padre del widget junto con muchas otras opciones --el color, tamaño, etc. También tenemos que ser capaces de obtener información desde nues-tros widgets durante la ejecución de nuestro programa, mediante la creación de callbacks (rutinas que se invocan cuando ocurren ciertos eventos) y de intercambiar datos.
Opciones de Configuración para los Widgets
Si nos fijamos en un manual de referencia de Tk (el que está escrito para Perl/Tk, por ejemplo), nos daremos cuenta que las opciones para los widgets normalmente se especifican con un guión --como las opciones de línea de comandos. En Perl/Tk, las opciones se le pasan a un widget en un Hash. Se puede hacer en Ruby así, pero también puede pasar las opciones utilizando un bloque de código. El nombre de la opción se utiliza como el nombre de un método dentro del bloque y los argumentos de opción apare-cen como argumentos para la llamada al método. Los widgets toman un padre como primer argumento, seguido de un hash de opciones opcional o el bloque de código de opciones. Por lo tanto, las dos formas siguientes son equivalentes.
TkLabel.new(parent_widget) do text ‘Hello, World!’ pack(‘padx’ => 5, ‘pady’ => 5, ‘side’ => ‘left’)

173
end
# or
TkLabel.new(parent_widget, ‘text’ => ‘Hello, World!’).pack(...)
Una pequeña precaución cuando se utiliza la forma del bloque de código: el ámbito de las variables no es como se piensa que es. El bloque es evaluado realmente en el contexto del objeto widget, no en el del llamador. Esto significa que las variables de instancia del llamador no estarán disponible en el bloque, pero si las variables locales del ámbito que lo contiene y las globales (no es que utilize variables globales, por supuesto). Vamos a mostrar como se pasan las opciones utilizando ambos métodos, en los ejemplos que siguen.
Las distancias (como las opciones padx y pady en estos ejemplos) se supone que son en píxeles, pero puede ser especificado en las diferentes unidades con los sufijos c (cm), i (pulgadas), m (milímetros), o p (puntos). “12p”, por ejemplo, es doce puntos.
Obtención de Datos del Widget
Podemos obtener información de vuelta de los widgets mediante retornos de llamada (callbacks) y por variables binding (vinculantes).
Los retornos de llamada son muy fáciles de configurar. La opción command (que se muestra en la lla-mada a TkButton en el ejemplo que sigue) toma un objeto Proc, que será llamado cuando se dispare el retorno de llamada. Aquí pasamos el proc como un bloque asociado con la llamada al método, pero también podríamos haber utilizado Kernel.lambda para generar un objeto Proc explícito.
require ‘tk’TkButton.new do text “EXIT” command { exit } pack(‘side’=>’left’, ‘padx’=>10, ‘pady’=>10)endTk.mainloop
También se puede enlazar una variable Ruby para un valor widget Tk usando un proxy TkVariable. Esto arregla las cosas de manera que cada vez que cambia el valor del widget, la variable Ruby se actua-liza automáticamente, y cuando cambia la variable, el widget reflejar el nuevo valor.
Se muestra esto en el siguiente ejemplo. Observe cómo está configurado TkCheckButton, la docu-mentación dice que la opción variable toma una var referencia como argumento. Para ello, creamos una variable Tk de referencia con TkVariable.new. El acceso a mycheck.value devolverá la cadena “0” ó “1” dependiendo de si la casilla está marcada. Usted puede utilizar el mismo mecanismo para todo lo que es compatible con una referencia var, como botones radiales y campos de texto.
require ‘tk’packing = { ‘padx’=>5, ‘pady’=>5, ‘side’ => ‘left’ }checked = TkVariable.newdef checked.status value == “1” ? “Yes” : “No”endstatus = TkLabel.new do text checked.status pack(packing)endTkCheckButton.new do variable checked pack(packing)endTkButton.new do

174
text “Show status” command { status.text(checked.status) } pack(packing)endTk.mainloop
Configuración/Obtención de Opciones Dinámicamente
Además de establecer las opciones de un widget cuando se crea, puede volver a configurar un widget mientras se está ejecutando. Cada widget soporta el método configure, que toma un hash o un bloque de código de la misma manera como new. Podemos modificar el primer ejemplo para cambiar el texto de la etiqueta en respuesta a un clic de botón.
require ‘tk’root = TkRoot.new { title “Ex3” }top = TkFrame.new(root) { relief ‘raised’; border 5 }lbl = TkLabel.new(top) do justify ‘center’ text ‘Hello, World!’ pack(‘padx’=>5, ‘pady’=>5, ‘side’ => ‘top’)endTkButton.new(top) do text “Ok” command { exit } pack(‘side’=>’left’, ‘padx’=>10, ‘pady’=>10)endTkButton.new(top) do text “Cancel” command { lbl.configure(‘text’=>”Goodbye, Cruel World!”) } pack(‘side’=>’right’, ‘padx’=>10, ‘pady’=>10)endtop.pack(‘fill’=>’both’, ‘side’ =>’top’)Tk.mainloop
Ahora, cuando se hace clic en el botón Cancelar, el texto de la etiqueta cambia inmediatamente de “¡Hola, Mundo!” a “¡Adiós, mundo cruel!”
También puede consultar los valores de opción particulares para los widgets con cget.
require ‘tk’b = TkButton.new do text “OK” justify “left” border 5endb.cget(‘text’) -> “OK”b.cget(‘justify’) -> “left”b.cget(‘border’) -> 5
Aplicación de Ejemplo
He aquí un ejemplo un poco más largo que muestra una aplicación real --un generador de pig latin. Escriba la frase tal como las reglas de Ruby, y el botón Pig It lo traducirá al instante al latín de cerdo.
require ‘tk’class PigBox def pig(word) leading_cap = word =~ /^[A-Z]/ word.downcase! res = case word
175
when /^[aeiouy]/ word+”way” when /^([^aeiouy]+)(.*)/ $2+$1+”ay” else word end leading_cap ? res.capitalize : res end def show_pig @text.value = @text.value.split.collect{|w| pig(w)}.join(“ “) end def initialize ph = { ‘padx’ => 10, ‘pady’ => 10 } # common options root = TkRoot.new { title “Pig” } top = TkFrame.new(root) { background “white” } TkLabel.new(top) {text ‘Enter Text:’ ; pack(ph) } @text = TkVariable.new TkEntry.new(top, ‘textvariable’ => @text).pack(ph) pig_b = TkButton.new(top) { text ‘Pig It’; pack ph} pig_b.command { show_pig } exit_b = TkButton.new(top) {text ‘Exit’; pack ph} exit_b.command { exit } top.pack(‘fill’=>’both’, ‘side’ =>’top’) endendPigBox.newTk.mainloop
Enlazar Eventos Los widgets están expuestos al mundo real. En ellos se hace clic, se mueve el ratón sobre ellos, los usuarios escriben en ellos, todas estas cosas y muchas más, generan eventos que podemos captar. Se puede crear un binding desde un evento en un widget en particular a un bloque de código, usando el mé-todo de widget bind.
Por ejemplo, supongamos que hemos creado un widget de botón que muestra una imagen. Nos gusta-ría que la imagen cambie cuando el ratón del usuario pasa por encima del botón.
require ‘tk’image1 = TkPhotoImage.new { file “img1.gif” }image2 = TkPhotoImage.new { file “img2.gif” }b = TkButton.new(@root) do image image1 command { exit } packendb.bind(“Enter”) { b.configure(‘image’=>image2) }b.bind(“Leave”) { b.configure(‘image’=>image1) }Tk.mainloop
En primer lugar, se crean dos objetos de imagen GIF a partir de archivos en el disco utilizando TkPhotoImage . Después, se crea un botón (muy atractivo, llamado “b”), que muestra la imagen image1. A continuación, se enlaza el evento Enter para que cambie dinámicamente la imagen mostrada a image2 cuando el ratón está sobre el botón, y el evento Leave para volver a image1 cuando el ratón abandona el botón.
Este ejemplo muestra los eventos simples Enter y Leave. Sin embargo, el nombre de evento dado como un argumento a bind puede estar compuesto de varias sub-cadenas, separadas por guiones, en

176
disposición modificador-modificador-tipo-detalle. Los modificadores son mencionados en la referencia de Tk e incluyen Button1, Control, Alt, Shift, etc. Tipo es el nombre del evento (tomado de las con-venciones de nombres X11) e incluye eventos como ButtonPress, KeyPress y Expose. Detalle puede ser un número del 1 al 5 para los botones o un símbolo clave para la entrada de teclado. Por ejemplo, un binding que tendrá lugar a la liberación del botón 1 del ratón mientras se presiona la tecla control puede especificarse como
Control-Button1-ButtonRelease oControl-ButtonRelease-1
El evento en sí puede contener ciertos campos, como la hora del evento y las posiciones x e y. bind pueden pasar estos elementos al retorno de llamada, utilizando los códigos de campos de evento. Estos se utilizan como las especificaciones printf. Por ejemplo, para obtener las coordenadas x e y en un movimiento del ratón, se especifica la llamada a bind con tres parámetros. El segundo parámetro es el Proc para el retorno de llamada, y el tercer parámetro es la cadena de campo de evento.
canvas.bind(“Motion”, lambda {|x, y| do_motion (x, y)}, “%x %y”)
Canvas
Tk proporciona un widget Canvas con el que se puede dibujar y generar una salida PostScript. La figura 13 en la página 178 muestra un pequeño código simple (adaptado de la distribución) que dibuja líneas rectas. Clikcando y manteniendo pulsado el botón 1 se iniciará una línea, que será “bandeada en goma” según se mueva el ratón. Cuando suelte el botón 1, la línea se dibujará en esa posición.
Unos pocos clics del ratón y tienes una obra maestra instantánea.
Como se suele decir, “No se encontró el artista, así que tuvimos que colgar el cuadro. . . . “
Gestión de la Geometría
En el código de ejemplo de este capítulo, verá referencias al método widget pack. Es una llamada muy importante --olvídese de ella y usted nunca verá el widget. pack es un comando que le dice al gestor de la geometría como colocar el widget de acuerdo a las limitaciones que se especifican. Los gestores de geometría reconocen tres comandos:
Comando Especificación de Colocación
pack Flexible, basada en restricciones de colocaciónplace Posición Absolutagrid Posición Tabular (Fila/Columna)
Como pack es el comando más utilizado, es el que usamos en nuestros ejemplos.

177
Desplazamiento
A menos que se planee hacer dibujos muy pequeños, el ejemplo anterior puede que no sea útil. TkCanvas , TkListbox y TkText pueden ser configurados para usar barras de desplazamiento, y que se pueda trabajar en un subconjunto más pequeño de una “gran imagen”.
La comunicación entre una barra de desplazamiento y un widget es bidireccional. El movimiento de la barra de desplazamiento hace que cambier la vista del widget, pero cuando es ésta la que cambia por algún otro medio, la barra de desplazamiento tiene que cambiar también para reflejar la nueva posición.
Aunque que no hemos hecho mucho con listas, el ejemplo de desplazamiento siguiente utiliza el des-plazamiento para una lista de texto. En el fragmento de código, vamos a empezar por la creación de un simple TkListbox y un TkScrollbar asociados. El callback o retorno de llamada de la barra de des-plazamiento (configurado con command) llama al método widget de lista yview, que hace que cambie el valor de la parte visible de la lista, en la dirección y.
Después de configurar el retorno de llamada, hacemos la relación inversa: cuando la lista tenga la ne-cesidad de desplazarse, vamos a configurar el rango adecuado para scrollbar con TkScrollbar#set. Vamos a utilizar este mismo fragmento en un programa totalmente funcional en la siguiente sección:
list_w = TkListbox.new(frame) do selectmode ‘single’ pack ‘side’ => ‘left’endlist_w.bind(“ButtonRelease-1”) do busy do filename = list_w.get(*list_w.curselection) tmp_img = TkPhotoImage.new { file filename } scale = tmp_img.height / 100 scale = 1 if scale < 1 image_w.copy(tmp_img, ‘subsample’ => [scale, scale]) image_w.pack endendscroll_bar = TkScrollbar.new(frame) do command {|*args| list_w.yview *args } pack ‘side’ => ‘left’, ‘fill’ => ‘y’endlist_w.yscrollcommand {|first,last| scroll_bar.set(first,last) }
Sólo Una Cosa Más
Podríamos seguir hablando de Tk para otros cientos de páginas, pero ese sería otro libro. El siguien-te programa es nuestro último ejemplo Tk --un visor simple de imagenes GIF. Se puede seleccionar un nombre de archivo GIF a partir de la lista de desplazamiento y se mostrará una versión en miniatura de la imagen. Vamos a señalar sólo alguna cosa más.
¿Alguna vez ha utilizado una aplicación que crea un “cursor ocupado” y luego se olvida de restablecerlo a la normalidad? Hay un buen truco en Ruby para evitar que esto suceda. ¿Recuerda cómo File.new utiliza un bloque para asegurarse de que el archivo se cierra después de utilizarlo? Podemos hacer algo similar con el método busy, como se muestra en el siguiente ejemplo.
Este programa también muestra algunas manipulaciones simples con TkListbox --añadir elementos a la lista, crear un retorno de llamada en un botón del ratón (probablemente se requiera a la liberación del botón, no a la pulsación, ya que el widget es seleccionado en la pulsación del botón), y la recuperación de la selección en curso.
Hasta ahora, hemos usado TkPhotoImage para mostrar las imágenes directamente, pero también se puede hacer zoom, submuestreo y también mostrar porciones de las imágenes. Aquí se utiliza la función de sub-muestreo para escalar la imagen para su visualización.

178
require ‘tk’class GifViewer def initialize(filelist) setup_viewer(filelist) end def run Tk.mainloop end

179
def setup_viewer(filelist) @root = TkRoot.new {title ‘Scroll List’} frame = TkFrame.new(@root) image_w = TkPhotoImage.new TkLabel.new(frame) do image image_w pack ‘side’=>’right’ end list_w = TkListbox.new(frame) do selectmode ‘single’ pack ‘side’ => ‘left’ end list_w.bind(“ButtonRelease-1”) do busy do filename = list_w.get(*list_w.curselection) tmp_img = TkPhotoImage.new { file filename } scale = tmp_img.height / 100 scale = 1 if scale < 1 image_w.copy(tmp_img, ‘subsample’ => [scale, scale]) image_w.pack end end filelist.each do |name| list_w.insert(‘end’, name) # Insert each file name into the list end scroll_bar = TkScrollbar.new(frame) do command {|*args| list_w.yview *args } pack ‘side’ => ‘left’, ‘fill’ => ‘y’ end list_w.yscrollcommand {|first,last| scroll_bar.set(first,last) } frame.pack end # Run a block with a ‘wait’ cursor def busy @root.cursor “watch” # Set a watch cursor yield ensure @root.cursor “” # Back to original endendviewer = GifViewer.new(Dir[“screenshots/gifs/*.gif”])viewer.run
Trasladar desde Documentación Perl/Tk
Eso es todo, usted cuenta con usted mismo ahora. En su mayor parte, se puede trasladar fácilmente la documentación entregada para Perl/Tk a Ruby. Hay algunas excepciones, algunos métodos no se aplican y algunas funcionalidades extra indocumentadas. Hasta que un libro de Ruby/Tk salga, lo mejor es pre-guntar en el grupo de noticias o leer el código fuente.
Pero en general, es bastante fácil ver lo que está pasando. Recuerde que las opciones se pueden dar como un hash o en el estilo bloque de código. Y recuerde el entorno del bloque de código se encuentra dentro del TkWidget que se utiliza, no en la instancia de clase.
Creación de Objetos
En la asignación de Perl/Tk, los padres son responsables de crear sus widgets hijos. En Ruby, el padre se pasa como el primer parámetro al constructor de widget.

180
Perl/Tk: $widget = $parent->Widget( [ option => value ] )Ruby: widget = TkWidget.new(parent, option-hash) widget = TkWidget.new(parent) { code block } Puede que no se necesite salvar el valor devuelto del widget recién creado, pero está ahí si se hace. No hay que olvidar empaquetar (pack) el widget (o utilizar una de las otras llamadas de geometría), o no se mostrará.
Opciones
Perl/Tk: -background => colorRuby: ‘background’ => color { background color }
Recuerde que el ámbito de un bloque de código es diferente.
Referencias a Variables
Use TkVariable para vincular una variable Ruby al valor de un widget. A continuación, se puede utilizar el accesor value en TkVariable (TkVariable#value y TkVariable#value=) para afectar directamente al contenido del widget.
Ruby y Microsoft Windows Ruby se ejecuta en numerosos entornos diferentes. Algunos de estos están basados en Unix y otros en las diferentes versiones de Microsoft Windows. Ruby llegó de personas que estaban centradas en Unix, pero con los años se han desarrollado también un montón de características útiles en el mundo de Win-dows. En este capítulo, vamos a ver estas características y compartir algunos secretos para utilizar Ruby eficazmente en Windows.
Obteniendo Ruby para Windows
Dos versiones de Ruby están disponibles para el entorno Windows.
La primera es una versión de Ruby que funciona de forma nativa --es decir, es sólo otra aplicación de Windows. La forma más fácil para esta distribución es utilizar el programa de instalación de un solo clic, que carga una distribución binaria hecho y listo en su compartimento. Siga los enlaces desde http://rubyinstaller.rubyforge.org/ para obtener la última versión.
Si se siente más aventurero, o si necesita compilarlo con las bibliotecas que no se suministran con la distribución binaria, entonces se puede construir desde el código fuente de Ruby. Usted necesitará el compilador VC++ de Microsoft y sus herramientas asociadas para hacerlo. Descargar el código fuente de Ruby de http://www.ruby-lang.org, o usar CVS para comprobar la última versión en desarrollo. A continuación, lea el archivo win32\README.win32 para obtener instrucciones.
Una segunda alternativa utiliza una capa de emulación llamada Cygwin. Esto proporciona un ambiente a modo Unix en la parte superior de Windows. La versión Cygwin de Ruby es la más cercana al Ruby que se ejecuta en las plataformas Unix, pero su funcionamiento conlleva que también tenga que instalar Cygwin. Si usted quiere seguir esta vía, puede descargar la versión Cygwin de Ruby de http://ftp.ruby-lang.org/pub/ruby/binaries/cygwin/. También necesitará Cygwin en sí mismo. El enlace de descarga tiene un puntero a la biblioteca de enlace dinámico (DLL) requerida, o se puede ir a http://www.cygwin.com y descargar el paquete completo (pero atención: necesita asegurarse de que la versión que obtenga es compatible con la de Ruby que se ha descargado).
¿Qué versión de elegir? Cuando se produjo la primera edición de este libro, la versión de Cygwin para Ruby era la distribución a elegir. Esa situación ha cambiado: la construcción nativa se ha vuelto más y más funcional con el tiempo, hasta el punto que ésta es ahora nuestra construcción preferida de Ruby.

181
Ejecutando Ruby en Windows
Hay dos archivos ejecutables en la distribución Windows de Ruby.
ruby.exe está destinado a ser utilizado en un sistema de comandos (un shell de DOS), como en la versión Unix. Para las aplicaciones que leen y escriben en la entrada y salida estándar, esto está muy bien. Pero esto también significa que cada vez que se ejecuta ruby.exe obtendrá un shell de DOS, in-cluso si usted no lo quiere --Windows creará una nueva consola de comandos y la mostrará mientras que Ruby se esté ejecutando. Este no puede ser el comportamiento adecuado si, por ejemplo, se hace doble clic en un script Ruby que usa una interfaz gráfica (como Tk), o si está ejecutando un script Ruby como tarea de fondo o si lo está ejecutando desde el interior de otro programa.
En estos casos, usted querrá usar rubyw.exe. Es lo mismo que ruby.exe excepto que no proporcio-na entrada estándar, salida estándar o error estándar y no lanzar un shell de DOS cuando se ejecuta.
El programa de instalación (por defecto) establece las asociaciones de archivos para que los archi-vos con la extensión .rb utilicen automáticamente rubyw.exe. Al hacer esto, puede hacer doble clic en scripts Ruby y que simplemente correran sin desplegar un shell de DOS.
Win32API
Si su plan es hacer programación Ruby que necesite acceder a algunas de las funciones de la API de Windows 32 directamente, o que tienga que utilizar los puntos de entrada de algunos otros archivos DLL, tenemos buenas noticias para usted --la biblioteca Win32API.
Como ejemplo, aquí tenemos un código que es parte de una aplicación de Windows utilizada por nues-tro sistema para libro de cumplimientos, que descarga e imprime las facturas y los recibos. Una aplicación web genera un archivo PDF que el script Ruby ejecuta en las descargas de Windows a un archivo local. El script utiliza el comando shell print bajo Windows para imprimir este archivo.
arg = “ids=#{resp.intl_orders.join(“,”)}”fname = “/temp/invoices.pdf”site = Net::HTTP.new(HOST, PORT)site.use_ssl = truehttp_resp, = site.get2(“/fulfill/receipt.cgi?” + arg, ‘Authorization’ => ‘Basic ‘ + [“name:passwd”].pack(‘m’).strip )File.open(fname, “wb”) {|f| f.puts(http_resp.body) }shell = Win32API.new(“shell32”,”ShellExecute”, [‘L’,’P’,’P’,’P’,’P’,’L’], ‘L’ )shell.Call(0, “print”, fname, 0,0, SW_SHOWNORMAL)
Se crea un objeto Win32API que representa una llamada a un punto de entrada DLL en particular, especificando el nombre de la función, el nombre del DLL que contiene la función, y el armado de la fun-ción (tipos de argumentos y tipo de retorno). En el ejemplo anterior, la variable shell envuelve la función ShellExecute de Windows en el DLL shell22. La función toma seis parámetros (un número, cuatro punteros de cadena y un número) y retorna un número. (Este tipo de parámetros se describen en la página más adelante) El objeto resultante se puede utilizar para realizar la llamada a imprimir para el archivo que hemos descargado.
Muchos de los argumentos a las funciones DLL son de alguna forma estructuras binarias. Win32API maneja esto mediante el uso de objetos cadena Ruby para pasar los datos binarios de ida y vuelta. Us-ted tendrá que empacar y desempacar estas cadenas cuando sea necesario (más adelante veremos un ejemplo ).
Automatización de Windows
Si deslizarse alrededor de la API de bajo nivel de Windows no le interesa, la automatización de Win-dows puede --se puede utilizar Ruby como un cliente de automatización de Windows, gracias a una

182
extensión de Ruby llamada WIN32OLE, escrita por Masaki Suketa. Win32OLE es parte de la distribución estándar de Ruby.
La Automatización de Windows permite a un controlador de automatización (un cliente) el mandar ór-denes y hacer consultas a un servidor de automatización, como Microsoft Excel, Word, PowerPoint, etc.
Podemos ejecutar un método para un servidor de automatización para llamar a un método del mismo nombre desde un objeto WIN32OLE. Por ejemplo, puede crear un nuevo cliente WIN32OLE que lanza una copia limpia de Internet Explorer y mandarle visitar la página de inicio.
ie = WIN32OLE.new(‘InternetExplorer.Application’)ie.visible = trueie.gohome
También podría hacer que navegue a una página determinada.
ie = WIN32OLE.new(‘InternetExplorer.Application’)ie.visible = trueie.navigate(“http://www.pragmaticprogrammer.com”)
Los métodos que son desconocidos para WIN32OLE (como visible, gohome, o navigate) se pasan al método WIN32OLE#invoke, el cual envía los comandos apropiados al servidor.
Obtener y Configurar Propiedades
Podemos establecer y obtener propiedades del servidor usando la notación hash normal de Ruby. Por ejemplo, para establecer la propiedad Rotation en un gráfico de Excel, se puede escribir
excel = WIN32OLE.new(“excel.application”)excelchart = excel.Charts.Add()...excelchart[‘Rotation’] = 45puts excelchart[‘Rotation’]
Los parámetros de un objeto OLE se configuran automáticamente como atributos del objeto WIN32OLE. Esto significa que se puede establecer un parámetro mediante la asignación de un atributo de objeto.
excelchart.rotation = 45r = excelchart.rotation
El siguiente ejemplo es una versión modificada del archivo de ejemplo excel2.rb (que se encuentra en el directorio ext/win32/samples). Se inicia Excel, se crea un gráfico y luego se gira en la pantalla. ¡Ten cuidado, Pixar!
require ‘win32ole’
# -4100 is the value for the Excel constant xl3DColumn.ChartTypeVal = -4100;excel = WIN32OLE.new(“excel.application”)
# Create and rotate the chartexcel[‘Visible’] = TRUEexcel.Workbooks.Add()excel.Range(“a1”)[‘Value’] = 3excel.Range(“a2”)[‘Value’] = 2excel.Range(“a3”)[‘Value’] = 1excel.Range(“a1:a3”).Select()excelchart = excel.Charts.Add()excelchart[‘Type’] = ChartTypeVal30.step(180, 5) do |rot|

183
excelchart.rotation = rot sleep(0.1)endexcel.ActiveWorkbook.Close(0)excel.Quit()
Argumentos con Nombre
Otros lenguajes de cliente de automatización, tal como Visual Basic tienen el concepto de argumentos con nombre. Supongamos que tienes una rutina de Visual Basic con la forma
Song(artist, title, length): rem Visual Basic
En lugar de llamar con los tres argumentos en el orden especificado, se puede utilizar argumentos con nombre.
Song title := ‘Get It On’: rem Visual Basic
Esto es equivalente a la llamada Song(nil, ’Get It On’, nil).
En Ruby, puede utilizar esta característica pasando un hash con los argumentos con nombre.
Song.new(‘title’ => ‘Get It On’)
for each
Donde Visual Basic tiene una sentencia “for each” para iterar sobre una colección de elementos en un servidor, un objeto WIN32OLE tiene un método each (que toma un bloque) para lograr la misma cosa.
require ‘win32ole’excel = WIN32OLE.new(“excel.application”)excel.Workbooks.Addexcel.Range(“a1”).Value = 10excel.Range(“a2”).Value = 20excel.Range(“a3”).Value = “=a1+a2”excel.Range(“a1:a3”).each do |cell| p cell.Valueend
Eventos
Su cliente de automatización escrito en Ruby puede registrarse a sí mismo para recibir eventos de otros programas. Esto se hace usando la clase WIN32OLE_EVENT. En este ejemplo (basado en el código de la distribución Win32OLE 0.1.1) se muestra el uso de un receptor de eventos que registra las direc-ciones URL por las que un usuario navega cuando utiliza Internet Explorer.
require ‘win32ole’$urls = []def navigate(url) $urls << urlenddef stop_msg_loop puts “IE has exited...” throw :doneenddef default_handler(event, *args) case event when “BeforeNavigate” puts “Now Navigating to #{args[0]}...”

184
endendie = WIN32OLE.new(‘InternetExplorer.Application’)ie.visible = TRUEie.gohomeev = WIN32OLE_EVENT.new(ie, ‘DWebBrowserEvents’)ev.on_event {|*args| default_handler(*args)}ev.on_event(“NavigateComplete”) {|url| navigate(url)}ev.on_event(“Quit”) {|*args| stop_msg_loop}catch(:done) do loop do WIN32OLE_EVENT.message_loop endendputs “You Navigated to the following URLs: “$urls.each_with_index do |url, i| puts “(#{i+1}) #{url}”end
Optimización
Como con la mayoría (si no todos) los lenguajes de alto nivel, puede ser muy fácil agitar hacia fuera código que es insoportablemente lento, pero que se puede fijar fácilmente con un poco de imaginación.
Con WIN32OLE, es necesario tener cuidado con las búsquedas dinámicas innecesarias. Siempre que sea posible, es mejor asignar un objeto WIN32OLE a una variable y luego referenciar elementos desde ella, en lugar de crear una larga cadena de expresiones “.” .
Por ejemplo, en lugar de escribir
workbook.Worksheets(1).Range(“A1”).value = 1workbook.Worksheets(1).Range(“A2”).value = 2workbook.Worksheets(1).Range(“A3”).value = 4workbook.Worksheets(1).Range(“A4”).value = 8
podemos eliminar las subexpresiones comunes de ahorro salvando la primera parte de la expresión a una variable temporal y luego hacer las llamadas a partir de esa variable.
worksheet = workbook.Worksheets(1)worksheet.Range(“A1”).value = 1worksheet.Range(“A2”).value = 2worksheet.Range(“A3”).value = 4worksheet.Range(“A4”).value = 8
También se puede crear archivos de resguardo Ruby para una biblioteca de tipos particulares de Win-dows. Estos archivos envuelven el objeto OLE en una clase de Ruby con un método por punto de entrada. Internamente, el archivo utiliza el número del punto de entrada, no el nombre, lo que acelera el acceso.
Se genera la clase contenedora con el script olegen.rb en el directorio ext\ win32ole\samples, dándole el nombre de la biblioteca de tiposa reflejar.
C:\> ruby olegen.rb ‘NetMeeting 1.1 Type Library’ >netmeeting.rb
Los métodos y los eventos externos de la biblioteca de tipos se escriben para el archivo dado como los métodos de Ruby. A continuación, puede incluirse en sus programas y llamar a los métodos directamente. Vamos a tratar algunos tiempos.
require ‘netmeeting’require ‘benchmark’include Benchmark

185
bmbm(10) do |test| test.report(“Dynamic”) do nm = WIN32OLE.new(‘NetMeeting.App.1’) 10000.times { nm.Version } end test.report(“Via proxy”) do nm = NetMeeting_App_1.new 10000.times { nm.Version } endend
produce:
Rehearsal --------------------------------------- Dynamic 0.600000 0.200000 0.800000 ( 1.623000)Via proxy 0.361000 0.140000 0.501000 ( 0.961000)-------------------------------total: 1.301000sec
user system total realDynamic 0.471000 0.110000 0.581000 ( 1.522000)Via proxy 0.470000 0.130000 0.600000 ( 0.952000)
La versión del proxy es más del 40 por ciento más rápida que el código que hace la búsqueda dinámica.
Más Ayuda
Si usted necesita la interfaz de Ruby para Windows NT, 2000 o XP, es posible que desee echar un vis-tazo al proyecto Win32Utils de Daniel Berger (http://rubyforge.org/projects/win32utils/). Allí encontrará módulos para la conexión al portapapeles de Windows, registro de eventos, planificador de procesos, etc.
Asimismo, la biblioteca DL (que se describe brevemente más adelante) permite a los programas Ruby invocar a los métodos de carga dinámica de objetos compartidos. En Windows, esto significa que el código de Ruby puede cargar y ejecutar los puntos de entrada en un archivo DLL de Windows. Por ejemplo, el siguiente código, tomado a partir del código fuente de la librería DL en la distribución estándar de Ruby, determina a qué botón el usuario ha hecho clic, cuando aparece un cuadro de mensaje en una máquina Windows.
require ‘dl’User32 = DL.dlopen(“user32”)MB_OKCANCEL = 1message_box = User32[‘MessageBoxA’, ‘ILSSI’]r, rs = message_box.call(0, ‘OK?’, ‘Please Confirm’, MB_OKCANCEL)case rwhen 1 print(“OK!\n”)when 2 print(“Cancel!\n”)end
Este código abre el archivo DLL User32. A continuación, crea un objeto Ruby, message_box, que envuelve el punto de entrada MessageBoxA. El segundo parámetro , “ILSSI”, declara que el método devuelve un Integer, y toma un Long, dos Strings y un Integer como parámetros.
El objeto contenedor se utiliza entonces para llamar al punto de entrada del cuadro de mensaje en el DLL. Los valores de retorno son el resultado (en este caso, el identificador del botón pulsado por el usua-rio) y una matriz de parámetros que son pasados (que ignoramos).

186
Extendiendo Ruby
Es fácil extender Ruby con nuevas características escribiéndolas en código Ruby. Pero de vez en cuando necesita intefaces para conectarse con las cosas a bajo nivel. Una vez que se comienza a añadir código de bajo nivel escrito en C, las posibilidades son infinitas. Dicho esto, la materia de este capítulo es bastante avanzada y probablemente, se debiera omitir en una primera lectura rápida del libro.
La extensión de Ruby con C es muy fácil. Por ejemplo, supongamos que estamos construyendo una lista a medida de Internet del jukebox para el “Sunset Diner and Grill”. Se quieren poner archivos de audio MP3 desde un disco duro o CD de audio en el jukebox y queremos ser capaces de controlar el hardware de la máquina de discos desde un programa de Ruby. El proveedor de hardware nos dio un archivo de cabecera C y una biblioteca binaria para utilizar, nuestro trabajo es construir un objeto Ruby que haga las adecuadas llamadas a funciones C.
Mucha de la información de este capítulo se ha tomado del archivo README.EXT que se incluye en la distribución. Si usted está pensando en escribir una extensión para Ruby, es posible que desee buscar referencias en ese archivo para obtener más detalles, así como los últimos cambios.
Su Primera Extensión
Sólo para introducir la escritura de extensiones, vamos a escribir una. Esta extensión es simplemente una prueba del proceso --no hace nada que no se pudiera hacer en Ruby puro. También vamos a presen-tar algunas cosas sin demasiada explicación --todos los detalles enmarañados se darán más adelante.
La extensión que escribamos tendrá la misma funcionalidad que la siguiente clase de Ruby.
class MyTest def initialize @arr = Array.new end def add(obj) @arr.push(obj) endend
Es decir, vamos a escribir una extensión en C que es compatible con esta clase Ruby. El código equi-valente en C debería ser algún tanto familiar.
#include “ruby.h”static int id_push;static VALUE t_init(VALUE self){ VALUE arr; arr = rb_ary_new(); rb_iv_set(self, “@arr”, arr); return self;}static VALUE t_add(VALUE self, VALUE obj){ VALUE arr; arr = rb_iv_get(self, “@arr”); rb_funcall(arr, id_push, 1, obj); return arr;}VALUE cTest;void Init_my_test() { cTest = rb_define_class(“MyTest”, rb_cObject); rb_define_method(cTest, “initialize”, t_init, 0); rb_define_method(cTest, “add”, t_add, 1); id_push = rb_intern(“push”);

187
}
Vamos a ir en detalle a través de este ejemplo, ya que ilustra muchos de los conceptos importantes en este capítulo. En primer lugar, tenemos que incluir el fichero de cabecera ruby.h para obtener las defini-ciones Ruby necesarias.
Ahora observe la última función, Init_my_test. Cada extensión define una función global C llamada Init_name. Esta función es llamada cuando el intérprete carga por primera vez el nombre de extensión (o en el arranque para las extensiones enlazados estáticamente). Se utiliza para inicializar la extensión y para infiltrarse en el entorno Ruby (cómo Ruby sabe exactamente que una extensión es llamada por el nombre lo vamos a cubrir más adelante) En este caso, se define una nueva clase denominada MyTest, que es una subclase de Object (representado por el símbolo externo rb_cObject; ver ruby.h para otros).
A continuación se estableció add e initialize como dos métodos de instancia para la clase MyTest. Las llamadas a rb_define_method establecen un enlace entre el nombre del método Ruby y la función C que lo incorpora. Si el código Ruby llama al método add en uno de nuestros objetos, el intérprete a su vez, llama a la función C t_add con un argumento.
Del mismo modo, cuando new es llamado para esta clase, Ruby va a construir un objeto básico y luego llamar a initialize, que aquí hemos definido para llamar a la función C t_init sin argumentos (Ruby).
Ahora regresa y mira a la definición de t_init. A pesar de que se dijo que no toma argumentos, ¡tiene aqui un parámetro! Además de culaquier argumento Ruby, a cada método se le pasa un argumento inicial VALUE que contiene el receptor para este método (el equivalente de self en código Ruby).
La primera cosa que haremos en t_init es crear una matriz Ruby y establecer la variable de instancia @arr referenciandola. Así como se esperaría si estuviera escribiendo código fuente en Ruby, al hacer re-ferencia a una variable de instancia que no existe, se crea. A continuación, retorna un puntero a si misma.
ADVERTENCIA: Todas las funciones C que se pueden llamar desde Ruby deben devolver un valor, incluso si es sólo Qnil. De lo contrario, el resultado probable será un volcado de memoria (o GPF) .
Por último, la función t_add obtiene la variable de instancia @arr del objeto actual y llama a Array#push para empujar el valor pasado en la matriz. Al acceder a variables de instancia de este modo, el prefijo @ es obligatorio --de lo contrario la variable se crea pero no se puede referenciar desde Ruby.
A pesar de la sintaxis extra, torpe, que impone C, está siendo escrito en Ruby --puede manipular ob-jetos mediante todas las llamadas a método que ha llegado a conocer y amar, con la ventaja adicional de ser capaz de crear código ajustado y rápido cuando sea necesario.
Construyendo Nuestra Extensión
Vamos a tener mucho más que decir sobre la construcción de extensiones después. Por ahora, sin embargo, todo lo que tenemos que hacer es seguir estos pasos.
1. Cree un archivo denominado extconf.rb en el mismo directorio que nuestro archivo de código fuente en C my_text.c. El archivo extconf.rb debe contener las siguientes dos líneas: require ‘mkmf’create_makefile(“my_test”)
2. Ejecutar extconf.rb. Esto generará un Makefile.
% ruby extconf.rbcreating Makefile
3. Utilice make para construir la extensión. Esto es lo que sucede en un sistema OS X.
% make

188
gcc -fno-common -g -O2 -pipe -fno-common -I. -I/usr/lib/ruby/1.9/powerpc-darwin7.4.0 -I/usr/lib/ruby/1.9/powerpcdarwin7.4.0 -I. -c my_test.ccc -dynamic -bundle -undefined suppress -flat_namespace -L’/usr/lib’ -o my_test.bundle my_test.o -ldl -lobjc
El resultado de todo esto es la extensión, todo muy bien envuelto en un objeto compartido (un fichero .so, .dll ó [en OS X] .bundle).
Ejecutando Nuestra Extensión
Podemos utilizar nuestra extensión de Ruby con un simple require de forma dinámica en tiempo de ejecución (en la mayoría de las plataformas). Podemos terminar con esto con una prueba para verificar que todo está funcionando como se espera.
require ‘my_test’require ‘test/unit’class TestTest < Test::Unit::TestCase def test_test t = MyTest.new assert_equal(Object, MyTest.superclass) assert_equal(MyTest, t.class) t.add(1) t.add(2) assert_equal([1,2], t.instance_eval(“@arr”)) endend
produce:
Finished in 0.002589 seconds.1 tests, 3 assertions, 0 failures, 0 errors
Una vez que estamos contentos con nuestras obras de ampliación, se puede instalar a nivel global mediante la ejecución de make install.
Objetos Ruby en C
Cuando escribimos nuestra primera extensión, hicimos trampa, porque en realidad no se hace nada con los objetos Ruby --no se hacen los cálculos basados en cifras Ruby, por ejemplo. Antes de poder ha-cer esto, tenemos que encontrar la manera de representar y acceder a los datos tipo Ruby dentro de C.
Todo en Ruby es un objeto, y todas las variables son referencias a objectos. Cuando vemos los objetos Ruby desde dentro de código en C, la situación es más o menos lo mismo. La mayoría de los objetos Ruby se representan como punteros C a una zona de memoria que contiene los datos del objeto y otros detalles de implementación. En el código C, todas estas referencias son a través de variables de tipo VALUE, por lo que se pase en cuanto a objetos Ruby, se hará por envío de valores.
Esto tiene una excepción. Por motivos de rendimiento, Ruby implementa Fixnums, Symbols, true, false y nil como los llamados valores inmediatos. Estos aún están almacenados en variables de tipo VALUE, pero no son punteros. En cambio, su valor se almacena directamente en la variable.
Así, a veces los valores son punteros y a veces son valores inmediatos. ¿Cómo funciona el intérprete para manejar esta magia? Se basa en el hecho de que todos los punteros apuntan a zonas de memoria alineadas en límites 4 ó 8 bytes. Esto significa que podemos garantizar que los 2 bits menos significativos en un puntero siempre serán cero. Cuando se quiere almacenar un valor inmediato, se las arregla para tener al menos uno de estos bits establecido, permitiendo al resto del código del intérprete distinguir los valores inmediatos de los punteros. Aunque esto suena complicado, es realmente fácil su uso en la prác-tica, en gran parte debido a que el intérprete viene con una serie de macros y métodos que simplifican el trabajo con el sistema de tipos.

189
Esta es la forma en que Ruby implementa código orientado a objetos en C: Un objeto Ruby es una es-tructura asignada en la memoria que contiene una tabla de variables de instancia y la información sobre la clase. La clase en sí es otro objeto (una estructura asignada en la memoria) que contiene una tabla de los métodos definidos para esa clase. Ruby está construido sobre esta base.
Trabajar con Objetos Inmediatos
Como hemos dicho anteriormente, los valores inmediatos no son punteros: Fixnum, Symbol, true, false y nil son almacenados directamente en VALUE.
Los valores Fixnum se almacenan como números de 31 bits (ó de 63 bits en las arquitecturas más am-plias de CPU) que se forman al desplazar el número original un bit a la izquierda y luego establecer el LSB o bit menos significativo (bit 0), a 1. Cuando VALUE se utiliza como un puntero a una estructura específica Ruby, siempre está garantizado el tener el LSB en cero. Los valores inmediatos también tienen el LSB en cero. Por lo tanto, un simple testeo del bit puede indicar si se tiene un Fixnum. Este test está envuelto en una macro, FIXNUM_P. Otros test similares permiten comprobar si hay otros valores inmediatos.
FIXNUM_P(value) -> nonzero if value is a FixnumSYMBOL_P(value) -> nonzero if value is a SymbolNIL_P(value) -> nonzero if value is nilRTEST(value) -> nonzero if value is neither nil nor false
Varias macros útiles de conversión para números, así como otros tipos de datos estándar se muestran en la tabla 5 en la página siguiente.
Los otros valores inmediatos (true, false y nil) se representan en C como las constantes Qtrue, Qfalse y Qnil, respectivamente. Se pueden testear las variables VALUE frente a estas constantes direc-tamente o utilizar las macros de conversión (que llevan a cabo el casting adecuado).
Trabajando con Cadenas
En C, estamos acostumbrados a trabajar con cadenas de terminación nula. Las cadenas Ruby, sin embargo, son más generales y también se pueden incluir valores null incrustados. La manera más segura para trabajar con cadenas Ruby, por lo tanto, es hacer lo que el intérprete hace y utilizando un punte-ro y una longitud. De hecho, los objetos cadena de Ruby son en realidad referencias a una estructura RString , y esta estructura RString contiene una longitud y un campo de puntero. Puede acceder a la estructura a través de la macro RSTRING.
VALUE str;RSTRING(str)->len -> length of the Ruby stringRSTRING(str)->ptr -> pointer to string storage
Sin embargo, la vida es algo más complicada que esto. En lugar de utilizar directamente el objeto VA-LUE cuando se necesita un valor de cadena, es probable que se quiera llamar al método StringValue, pasándole el valor original. Esto retorna un objeto que se puede utilizar en RSTRING o lanzar una excep-ción si no se puede derivar una cadena a partir del original. Todo esto es parte de la iniciativa duck typing de Ruby 1.8, que se describe con más detalle más adelante. El método StringValue comprueba si su operando es un String. Si no, trata de invocar to_str en el objeto y lanza una excepción TypeError si no se puede.
Por lo tanto, si quiere escribir algo de código que itera sobre todos los caracteres en un objeto String, se puede escribir:
static VALUE iterate_over(VALUE original_str) { int i; char *p VALUE str = StringValue(original_str); p = RSTRING(str)->ptr; // puede ser null for (i = 0; i < RSTRING(str)->len; i++, p++) {

190
// process *p } return str;}
Si no se desea utilizar la longitud y basta con acceder al puntero de cadena subyacente, puede utilizar el método de conveniencia StringValuePtr, que resuelve la referencia a cadena y retorna el puntero C al contenido.
Si va a utilizar una cadena para acceder o para el control de algún recurso externo, es probable que desee conectar al mecanismo de corrupción de Ruby. En este caso vamos a usar el método SafeStringValue , que funciona como StringValue pero produce una excepción si el argumento está corrupto y el nivel de seguridad es mayor que cero.
Trabajando con Otros Objetos
Cuando los VALUE no son inmediatos, son punteros a una de las estructuras objeto definidas en Ruby --no se puede tener un VALUE que apunta a un área de memoria arbitraria. Las estructuras para las clases básicas integradas se definen en ruby.h y se nombran de la forma RClasenombre: RArray, RBignum, RClass, RData, RFile, RFloat, RHash, RObject, RRegexp, RString y RStruct.
Se puede chekear para ver qué tipo de estructura se utiliza para un determinado VALUE de varias ma-neras. El macro TYPE(obj) devuelve una constante que representa el tipo C de un objeto dado: T_OBJECT, T_STRING, etc. Las constantes para las clases integradas se definen en ruby.h. Tenga en cuenta que el tipo al que aquí nos referimos es un detalle de implementación --no es lo mismo que la clase de un objeto.

191
Si desea asegurarse de que un puntero value apunta a una estructura particular, puede utilizar la ma-cro Check_Type, que provocará una excepción TypeError si value no es del tipo esperado (una de las constantes T_STRING, T_FLOAT, etc).
Check_Type(VALUE value, int type)
Una vez más, tenga en cuenta que estamos hablando de “tipo” como la estructura C que representa un particular tipo integrado. La clase de un objeto es una bestia completamente diferente. Los objetos clase para las clases integradas se almacenan en las variables C globales llamadas rb_cNombreclase (por ejemplo rb_cObject). Los módulos se denominan rb_mNombremodulo.
No es conveniente modificar directamente los datos en estas estructuras C --se puede mirar, pero no tocar. En cambio, normalmente vamos a usar las funciones de C suministradas para manipular los datos Ruby (hablaremos más sobre esto en un momento).
No obstante, en aras de la eficiencia puede ser necesario profundizar en estas estructuras para la ob-tención de datos. Para desreferenciar los miembros de estas estructuras C, se tiene que emitir el VALUE genérico para el tipo apropiado de estructura. ruby.h contiene una serie de macros que realizan el re-parto adecuado para usted, lo que le permite desreferenciar los miembros de la estructura de forma fácil. Estas macros se llaman RNOMBRECLASE, como RSTRING o RARRAY. Ya hemos visto el uso de RSTRING cuando se trabaja con cadenas. Se puede hacer lo mismo con las matrices.
Acceso a Cadenas Anterior a la Versión 1.8
Antes de Ruby 1.8, si se suponía que VALUE contienía una cadena, era posible acceder a los cam-pos RSTRING directamente, y eso era todo. En 1.8, sin embargo, la introducción gradual de duck typing (escritura pato), junto con varias optimizaciones, significa que este enfoque probablemente no funcio-nará de la manera que se desea. En particular, el campo ptr de un objeto STRING puede ser null para cadenas de longitud cero. Si se utiliza el método 1.8 StringValue, maneja este caso reseteando punteros nulos que referencian una única, compartida y vacía cadena.
Así que, ¿cómo se escribe una extensión que funciona tanto con Ruby 1.6 como con 1.8? Cuidado-samente y con macros. Tal vez algo como esto
#if !defined(StringValue)# define StringValue(x) (x)#endif#if !defined(StringValuePtr)# define StringValuePtr(x) ((STR2CSTR(x)))#end
Este código define las macros 1.8 StringValue y StringValuePtr en términos de sus homólo-gos 1.6. Si escribe entonces código en función de estas macros, se debe compilar y ejecutar en los dos intérpretes, el antiguo y el nuevo.
Si desea que el código tenga el comportamiento duck-typing 1.8, incluso cuando se ejecute en 1.6, es posible que quiera definir StringValue de forma ligeramente diferente. La diferencia entre esta y la anterior implementación se describe un poco más adelante.
#if !defined(StringValue)# define StringValue(x) do { \ if (TYPE(x) != T_STRING) x = rb_str_to_str(x); \ } while (0)#end

192
VALUE arr;RARRAY(arr)->len -> length of the Ruby arrayRARRAY(arr)->capa -> capacity of the Ruby arrayRARRAY(arr)->ptr -> pointer to array storage
Hay accesores similares para los hashes (RHASH), archivos (RFILE), etc. Habiendo dicho todo esto, es necesario tener cuidado sobre la construcción de una excesiva dependencia en el chequeo de tipos en el código de extensión. Vamos a hablar más sobre las extensiones y el sistema de tipos Ruby un poco más adelante.
Variables Globales
La mayoría de las veces, las extensiones implementan clases y el código Ruby utiliza estas clases. Los datos que se comparten entre el código Ruby y el código C serán pulcramente envueltos dentro de los objetos de la clase. Así es como debe ser.
A veces, sin embargo, puede que tenga que implementar una variable global accesible tanto por la extensión C como por el código Ruby.
La forma más sencilla de hacer esto es tener la variable como un VALUE (es decir, un objeto Ruby) y entonces, ligar la dirección de esta variable C con el nombre de una variable Ruby. En este caso, el pre-fijo $ es opcional, pero ayuda a aclarar que es una variable global. Y recordar: hacer global una variable basada en la pila Ruby no va a trabajar (por mucho tiempo).
static VALUE hardware_list;static VALUE Init_SysInfo() { rb_define_class(....); hardware_list = rb_ary_new(); rb_define_variable(“$hardware”, &hardware_list); ... rb_ary_push(hardware_list, rb_str_new2(“DVD”)); rb_ary_push(hardware_list, rb_str_new2(“CDPlayer1”)); rb_ary_push(hardware_list, rb_str_new2(“CDPlayer2”));}
Del lado de Ruby se puede acceder a la variable C hardware_list como $hardware.
$hardware -> [“DVD”, “CDPlayer1”, “CDPlayer2”]
A veces, sin embargo, la vida es más complicada. Tal vez usted desea definir una variable global cuyo valor debe ser calculado cuando se accede a ella. Esto se hace mediante la definición de las variables de enganche y virtuales. Una variable de enganche es una variable real que se inicia por una función nombra-da cuando se accede a la correspondiente variable Ruby. Las variables virtuales son similares, pero nunca se almacenan: su valor proviene puramente de la evaluación de la función de enlace. Vea la sección API que comienza un poco más adelante para más detalles.
Si se crea un objeto Ruby desde C y se almacena en una variable C global sin exportarlo a Ruby, se debe por lo menos pasar el recolector de basura sobre él, no sea que se recoja inadvertidamente.
static VALUE obj;// ...obj = rb_ary_new();rb_global_variable(obj);
La Extensión Jukebox
Hemos cubierto lo suficiente sobre los fundamentos como para volver ahora a nuestro ejemplo de juke-box --la interfaz de código C con Ruby y el intercambio de datos y comportamiento entre los dos mundos.

193
Envolver Estructuras C
Tenemos la biblioteca del proveedor que controla las unidades de CD de audio del jukebox, y estamos listos para conectarlo a Ruby. El archivo de cabecera del proveedor se parece a esto.
typedef struct _cdjb { int statusf; int request; void *data; char pending; int unit_id; void *stats;} CDJukebox;// Allocate a new CDJukebox structureCDJukebox *new_jukebox(void);// Assign the Jukebox to a playervoid assign_jukebox(CDJukebox *jb, int unit_id);// Deallocate when done (and take offline)void free_jukebox(CDJukebox *jb);// Seek to a disc, track and notify progressvoid jukebox_seek(CDJukebox *jb, int disc, int track, void (*done)(CDJukebox *jb, int percent));// ... others...// Report a statisticdouble get_avg_seek_time(CDJukebox *jb);
Este vendedor tiene que organizarse. Aunque es posible que no lo admita, el código está escrito con un sabor orientado a objetos. No sabemos lo que significan todos estos campos dentro de la estructura CDJukeBox, pero OK --lo podemos tratar como un montón opaco de bits. El Vendedor del código sabe qué hacer con él, nosotros sólo tenemos que trasladarlo.
Cada vez que se tenga una estructura sólo en C que se quiera manejar como un objeto Ruby, se debe envolver en una clase especial e internos de Ruby llamada DATA (tipo T_DATA). Dos macros hacen este envoltorio y una macro recupera la estructura de vuelta.
La API: Envolviendo Tipos de Datos C
VALUE Data_Wrap_Struct( VALUE class, void (*mark)(), void (*free)(), void *ptr )
Envuelve el tipo dado de datos C ptr, registros de las dos rutinas de recolección de basura (ver abajo), y devuelve un puntero VALUE a un verdadero objeto Ruby. El tipo C del objeto resultante es T_DATA, y su clase de Ruby es la class.
VALUE Data_Make_Struct( VALUE class, c-type, void (*mark)(), void (*free)(), c-type * )
Asignación y configuración a cero de una estructura del tipo indica-do y después procede como Data_Wrap_Struct. c-type es el nombre del tipo de datos C que está envolviendo, no una variable de ese tipo.
Data_Get_Struct( VALUE obj,c-type,c-type * )Devuelve el puntero original. Esta macro es un contenedor de tipo seguro para toda la macro DATA_PTR(obj), que evalúa el puntero.
El objeto creado por Data_Wrap_Struct es un objeto normal de Ruby, excepto que tiene un adicional tipo de datos C al que no se puede acceder desde Ruby. Como se puede ver en la figura 14 en la pági-na siguiente, este tipo de datos C es independiente de las variables de instancia que contiene el objeto. Pero puesto que es algo separada, ¿cómo deshacerse de él cuando el recolector de basura reclama este

194
objeto? ¿Qué pasa si hay que liberar algunos recursos (cerrar algún archivo, limpiar algún mecanismo de bloqueo o IPC, etc)?
Ruby utiliza un esquema de marca y barrido de recolección de basura. Durante la fase de marca, Ruby busca punteros a zonas de memoria y marca estas áreas como “en uso” (porque algo está apuntando a ellas). Si esas mismas áreas contienen más punteros, la memoria de estos punteros de referencia también son marcados, y así sucesivamente. Al final de la fase de marca, toda la memoria a la que se hace refe-rencia se ha marcado, y las áreas huérfanas no tienen marca. En este punto se inicia la fase de barrido, la liberación de memoria que no está marcada.
Para participar en el proceso Ruby de marcar y barrer de la recolección de basura, es necesario de-finir una rutina para liberar su estructura y, posiblemente, una rutina para marcar las referencias de su estructura a otras estructuras. Ambas rutinas reciben un puntero void, una referencia a esa estructura. La rutina de marca será llamada por el recolector de basura durante su fase de “marca”. Si su estructura referencia otros objetos Ruby, entonces su función de marca tiene que identificar estos objetos utilizando rb_gc_mark(valor). Si la estructura no hace referencia a otros objetos Ruby, simplemente puede pasar 0 como un puntero a función.
Cuando el objeto tiene que ser eliminado, el recolector de basura llamará a la rutina libre para liberarlo. Si usted tiene asignada alguna memoria para usted mismo (por ejemplo, mediante el uso de Data_Make_Struct), tendrá que pasar una función libre --incluso si es justo la rutina free de la biblioteca estándar de C. Para asignaciones de estructuras complejas, es posible que su función libre tenga la necesidad de recorrer toda la estructura para liberar toda la memoria asignada.
Echemos un vistazo a nuestra interfaz del reproductor de CD. La biblioteca del vendedor pasa la información entre sus diversas funciones en una estructura CDJukebox. Esta estructura representa el estado de la máquina de discos y por lo tanto es una buena candidata para envolverla dentro de nuestra clase Ruby. Creamos nuevas instancias de esta estructura mediante la llamada al método de biblioteca CDPlayerNew . A continuación, querríamos envolver la estructura creada dentro de un nuevo objeto Ruby CDPlayer. Un fragmento de código para hacer esto puede tener el siguiente aspecto. (Vamos a hablar del parámetro mágico klass en un minuto.)
CDJukebox *jukebox;VALUE obj;// Vendor library creates the Jukeboxjukebox = new_jukebox();// then we wrap it inside a Ruby CDPlayer objectobj = Data_Wrap_Struct(klass, 0, cd_free, jukebox);
Una vez que se ejecuta este código, obj tendría una referencia a un objeto Ruby CDPlayer recién asignado, envolviendo a una nueva estructura C CDJukebox. Por supuesto, para obtener que este código compile, tendríamos que trabajar un poco más. Tendríamos que definir la clase CDPlayer y almacenar una referencia a él en la variable cCDPlayer. También tendríamos que definir la función para liberar nuestro objeto, cdplayer_free. Esto es fácil: simplemente se llama al método de biblioteca que provee el vendedor.
static void cd_free(void *p) { free_jukebox(p);}
Sin embargo, los fragmentos de código no hacen un programa. Tenemos que empaquetar todas estas cosas de una manera que se integren en el intérprete. Y para hacer esto, tenemos que ver algunas de las convenciones que utiliza el intérprete.
Creación de Objetos
Ruby 1.8 ha racionalizado la creación y la inicialización de objetos. A pesar de que las formas antiguas todavía funcionan, la nueva forma, utilizando las funciones de asignación, es mucho más ordenada (y es menos probable que se deje de utilizar en el futuro).

195
La idea básica es simple. Digamos que usted está creando un objeto de la clase CDPlayer en su pro-grama Ruby:
cd = CDPlayer.new
Entre bastidores, el intérprete llama al método de clase new para CDPlayer. Como CDPlayer no tiene definido un método new, Ruby busca en su clase padre, la clase Class.
La implementación de new en la clase Class es bastante simple: se asigna memoria para el nuevo objeto y luego se llama al método de objeto initialize para inicializar esta memoria.
Por lo tanto, si nuestra extensión CDPlayer va a ser una buena habitante de Ruby, debe trabajar en este marco. Esto significa que tendremos que implementar una función de asignación y un método initialize .
Funciones de Asignación
La función de asignación es la responsable de la creación de la memoria que va a utilizar el objeto. Si el objeto que estamos implementando no utiliza ningún otro dato que las variables de instancia Ruby, entonces no es necesario escribir una función de asignación --el asignador Ruby por defecto funciona bien. Pero si su clase envuelve una estructura C, tendrá que asignar espacio para esta estructura con la función de asignación. Ésta, se pasa a la clase del objeto que viene a ser asignado. En nuestro caso, con toda probabilidad un cCDPlayer, pero vamos a utilizar el parámetro como dado, ya que esto significa que vamos a trabajar correctamente si se subclasifica.
static VALUE cd_alloc(VALUE klass) { CDJukebox *jukebox; VALUE obj; // Vendor library creates the Jukebox jukebox = new_jukebox(); // then we wrap it inside a Ruby CDPlayer object obj = Data_Wrap_Struct(klass, 0, cd_free, jukebox); return obj;}
A continuación, deberá registrar su función de asignación de código de inicialización de clase.
void Init_CDPlayer() { cCDPlayer = rb_define_class(“CDPlayer”, rb_cObject); rb_define_alloc_func(cCDPlayer, cd_alloc); // ...}

196
La mayoría de los objetos, probablemente también tengan la necesidad de definir un inicializador. La función de asignación crea un objeto vacío, sin inicializar, y tendremos que rellenarlo con los valores es-pecíficos. En el caso del reproductor de CD, se llama al constructor con el número de unidad del player para ser asociado a este objeto.
static VALUE cd_initialize(VALUE self, VALUE unit) { int unit_id; CDJukebox *jb; Data_Get_Struct(self, CDJukebox, jb); unit_id = NUM2INT(unit); assign_jukebox(jb, unit_id); return self;}
Una de las razones para este protocolo de varios pasos de creación de objeto, es que permite al in-térprete manejar situaciones donde los objetos tienen que ser creados por el “procedimiento de puerta trasera.” Un ejemplo es cuando los objetos vienen a deserializarse de su forma de cálculo de referencias. En este caso, el intérprete tiene que crear un objeto vacío (llamando al asignador), pero no puede llamar a la inicialización (ya que no tiene conocimiento de los parámetros para su uso). Otra situación común es cuando los objetos están duplicados o clonados. Aquí se esconde otro tema. Debido a que los usuarios pueden optar por omitir el constructor, es ne-cesario asegurarse de que el código de asignación deja el objeto retornado en un estado válido. No con-tendrá toda la información que hubiera tenido si se hubiera establecido mediante #initialize, pero al menos tiene que ser utilizable.

197
Clonacion de Objetos
Todos los objetos Ruby pueden ser copiados usando uno de los dos métodos, dup y clone. Los dos métodos son similares: ambos producen una nueva instancia de la clase receptora llamando a la función de asignación. Luego se copian las variables de instancia del original. clone va un poco más allá y co-pia la clase singleton original (si la tiene) y las banderas (como la bandera que indica que un objeto está congelado). Se puede pensar en dup como una copia de los contenidos y en clone como una copia del objeto completo.
Sin embargo, el intérprete de Ruby no sabe cómo manejar la copia del estado interno de los objetos que se escriben como extensiones C. Por ejemplo, si su objeto envuelve una estructura C que contiene un descriptor de fichero abierto, depende de la semántica de su implementación si el descriptor simplemente se deben copiar en el nuevo objeto, o si se debe abrir un nuevo descriptor de fichero.
Para manejar esto, el intérprete delega en su código la responsabilidad de copiar el estado interno de los objetos que se implementan. Después de copiar las variables de instancia del objeto, el intérprete invo-ca el método initialize_copy del nuevo objeto, pasandole una referencia al objeto original. Depende de usted el implementar la semántica significativa en este método.
Para nuestra clase CDPlayer vamos a adoptar un enfoque bastante simple con la cuestión de la clo-nación: simplemente se va a copiar la estructura CDJukebox del objeto original.
Asignación de Objetos Anterior a la Versión 1.8
Antes de Ruby 1.8, si se quería asignar espacio adicional en un objeto, o bien había que poner el código en el método initialize, o bien había que definir un nuevo método para su clase. Guy De-coux recomienda el siguiente enfoque híbrido para maximizar la compatibilidad entre las extensiones 1.6 y 1.8.
static VALUE cd_alloc(VALUE klass) { // igual que antes}static VALUE cd_new(int argc, VALUE *argv, VALUE klass) { VALUE obj = rb_funcall2(klass, rb_intern(“allocate”), 0, 0); rb_obj_call_init(obj, argc, argv); return obj;}
void init_CDPlayer() { // ...#if HAVE_RB_DEFINE_ALLOC_FUNC // 1.8 allocation rb_define_alloc_func(cCDPlayer, cd_alloc);#else // define manual allocation function for 1.6 rb_define_singleton_method(cCDPlayer, “allocate”, cd_alloc, 0);#endif rb_define_singleton_method(cCDPlayer, “new”, cd_new, 1); // ...}
Si está escribiendo código que debe ejecutarse en las versiones antiguas y recientes de Ruby, ten-drá que adoptar un enfoque similar a este. Sin embargo, es probable que también necesite manejar la clonación y la duplicación, y demás tendrá que considerar qué sucede cuando su objeto calcula las referencias.

198
Hay un pedacito de código extraño en este ejemplo. Para probar que el objeto original es de hecho algo que se puede clonar desde el nuevo, el código comprueba que el original
1. tiene un tipo T_DATA (lo que significa que es un objeto no esencial), y
2. tiene una función libre con la misma dirección que nuestra función libre.
Esta es una forma relativa de alto rendimiento para verificar que el objeto original es compatible con el nuestro (siempre y cuando no se compartan las funciones libres entre clases). Una alternativa, que es más lenta, sería utilizar rb_obj_is_kind_of y hacer una prueba directa de la clase.
static VALUE cd_init_copy(VALUE copy, VALUE orig) { CDJukebox *orig_jb; CDJukebox *copy_jb; if (copy == orig) return copy; // we can initialize the copy from other CDPlayers // or their subclasses only if (TYPE(orig) != T_DATA || RDATA(orig)->dfree != (RUBY_DATA_FUNC)cd_free) { rb_raise(rb_eTypeError, “wrong argument type”); } // copy all the fields from the original // object’s CDJukebox structure to the new object Data_Get_Struct(orig, CDJukebox, orig_jb); Data_Get_Struct(copy, CDJukebox, copy_jb); MEMCPY(copy_jb, orig_jb, CDJukebox, 1); return copy;}
Nuestro método de copia no tiene que asignar una estructura envuelta para recibir los objetos origina-les de la estructura CDJukebox: el método cd_alloc ya se ha ocupado de eso.
Tenga en cuenta que en este caso es correcto hacer la comprobación de tipos basados en las clases: necesitamos que el objeto original tenga una estructura CDJukebox envuelta, y los únicos objetos que tienen una de estas se derivan de la clase CDPlayer.
Poniéndolo Todo Junto
OK, finalmente estamos listos para escribir todo el código de nuestra clase CDPlayer.
// Helper function to free a vendor CDJukeboxstatic void cd_free(void *p) { free_jukebox(p);}// Allocate a new CDPlayer object, wrapping// the vendor’s CDJukebox structurestatic VALUE cd_alloc(VALUE klass) { CDJukebox *jukebox; VALUE obj; // Vendor library creates the Jukebox jukebox = new_jukebox(); // then we wrap it inside a Ruby CDPlayer object obj = Data_Wrap_Struct(klass, 0, cd_free, jukebox); return obj;}// Assign the newly created CDPLayer to a// particular unitstatic VALUE cd_initialize(VALUE self, VALUE unit) {

199
int unit_id; CDJukebox *jb; Data_Get_Struct(self, CDJukebox, jb); unit_id = NUM2INT(unit); assign_jukebox(jb, unit_id); return self;}// Copy across state (used by clone and dup). For jukeboxes, we// actually create a new vendor object and set its unit number from// the oldstatic VALUE cd_init_copy(VALUE copy, VALUE orig) { CDJukebox *orig_jb; CDJukebox *copy_jb; if (copy == orig) return copy; // we can initialize the copy from other CDPlayers or their // subclasses only if (TYPE(orig) != T_DATA || RDATA(orig)->dfree != (RUBY_DATA_FUNC)cd_free) { rb_raise(rb_eTypeError, “wrong argument type”); } // copy all the fields from the original object’s CDJukebox // structure to the new object Data_Get_Struct(orig, CDJukebox, orig_jb); Data_Get_Struct(copy, CDJukebox, copy_jb); MEMCPY(copy_jb, orig_jb, CDJukebox, 1); return copy;}// The progress callback yields to the caller the percent completestatic void progress(CDJukebox *rec, int percent) { if (rb_block_given_p()) { if (percent > 100) percent = 100; if (percent < 0) percent = 0; rb_yield(INT2FIX(percent)); }}// Seek to a given part of the track, invoking the progress callback// as we gostatic VALUEcd_seek(VALUE self, VALUE disc, VALUE track) { CDJukebox *jb; Data_Get_Struct(self, CDJukebox, jb); jukebox_seek(jb, NUM2INT(disc), NUM2INT(track), progress); return Qnil;}// Return the average seek time for this unitstatic VALUEcd_seek_time(VALUE self){ double tm; CDJukebox *jb; Data_Get_Struct(self, CDJukebox, jb); tm = get_avg_seek_time(jb); return rb_float_new(tm);}// Return this player’s unit numberstatic VALUE

200
cd_unit(VALUE self) { CDJukebox *jb; Data_Get_Struct(self, CDJukebox, jb); return INT2NUM(jb->unit_id);;}void Init_CDPlayer() { cCDPlayer = rb_define_class(“CDPlayer”, rb_cObject); rb_define_alloc_func(cCDPlayer, cd_alloc); rb_define_method(cCDPlayer, “initialize”, cd_initialize, 1); rb_define_method(cCDPlayer, “initialize_copy”, cd_init_copy, 1); rb_define_method(cCDPlayer, “seek”, cd_seek, 2); rb_define_method(cCDPlayer, “seek_time”, cd_seek_time, 0); rb_define_method(cCDPlayer, “unit”, cd_unit, 0);}
Ahora podemos controlar nuestra máquina de discos desde Ruby de una forma agradable y orientada a objetos.
require ‘CDPlayer’p = CDPlayer.new(13)puts “Unit is #{p.unit}”p.seek(3, 16) {|x| puts “#{x}% done” }puts “Avg. time was #{p.seek_time} seconds”p1 = p.dupputs “Cloned unit = #{p1.unit}”
produce:
Unit is 1326% done79% done100% doneAvg. time was 1.2 secondsCloned unit = 13
Este ejemplo demuestra la mayor parte de lo que hemos hablado hasta ahora, con una muy buena característica adicional. La biblioteca del vendedor proporciona una rutina de retorno de llamada --un pun-tero a función a la que se llama de vez en cuando mientras que el hardware está trabajando en el camino hacia el siguiente disco. Hemos establecido hasta aquí la ejecución de un bloque de código que se pasa como argumento a seek. En la función progress, comprobamos para ver si hay un iterador en el contex-to actual y, si existe, se ejecuta con el porcentaje en curso como un argumento.
Asignación de Memoria
A veces puede ser necesario asignar memoria a una extensión que no será utilizada para el almace-namiento de objetos - tal vez usted tiene un mapa de bits gigante para un filtro Bloom, una imagen o un montón de pequeñas estructuras que Ruby no utiliza directamente. Para trabajar correctamente con el recolector de basura, se deben utilizar las rutinas de asignación de memoria siguientes. Estas rutinas hacen un poco más de trabajo que el estándar malloc. Por ejemplo, si ALLOC_N determina que no puede asignar la cantidad deseada de memoria, se invoca el recolector de ba-sura para tratar de recuperar algo de espacio. Se genera un NoMemError si no se puede o si la cantidad de memoria solicitada no es válida.
API: Asignación de Memoria
type * ALLOC_N( c-type, n ) Asigna n objetos c-tipo, donde c-tipo es el nombre literal del tipo C, no una variable de ese tipo.
type * ALLOC( c-type )

201
Asigna un y convierte el resultado a un puntero de ese tipo.
REALLOC_N( var, c-type, n ) Reasigna n c-tipos y asigna el resultado a var, un puntero a una variable de tipo c-tipo.
type * ALLOCA_N( c-type, n ) Asigna memoria para n objetos c-tipo en la pila --esta memoria se libera automáticamente cuan-do la función que invoca ALLOCA_N retorna.
Sistema de Tipos Ruby
En Ruby, se depende menos del tipo (o clase) de un objeto y más de sus capacidades. Esto se llama duck typing. Se describen con más detalle más adelante. Se encontrarán muchos ejemplos de esto si se examina el código fuente del propio intérprete. Por ejemplo, el siguiente código implementa el método Kernel.exec.
VALUErb_f_exec(argc, argv) int argc; VALUE *argv;{ VALUE prog = 0; VALUE tmp; if (argc == 0) { rb_raise(rb_eArgError, “wrong number of arguments”); } tmp = rb_check_array_type(argv[0]); if (!NIL_P(tmp)) { if (RARRAY(tmp)->len != 2) { rb_raise(rb_eArgError, “wrong first argument”); } prog = RARRAY(tmp)->ptr[0]; SafeStringValue(prog); argv[0] = RARRAY(tmp)->ptr[1]; } if (argc == 1 && prog == 0) { VALUE cmd = argv[0]; SafeStringValue(cmd); rb_proc_exec(RSTRING(cmd)->ptr); } else { proc_exec_n(argc, argv, prog); } rb_sys_fail(RSTRING(argv[0])->ptr); return Qnil; /* dummy */}
El primer parámetro de este método puede ser una cadena, o una matriz que contiene dos cadenas. Sin embargo, el código no hace explícitamente comprobación del tipo del argumento. En su lugar, primero llama a rb_check_array_type, pasándolo en el argumento. ¿Qué es lo que hace este método? Vamos a ver.
VALUErb_check_array_type(ary) VALUE ary;{ return rb_check_convert_type(ary, T_ARRAY, “Array”, “to_ary”);}
La trama se complica. Vamos a rastrear rb_check_convert_type.

202
VALUErb_check_convert_type(val, type, tname, method) VALUE val; int type; const char *tname, *method;{ VALUE v; /* always convert T_DATA */ if (TYPE(val) == type && type != T_DATA) return val; v = convert_type(val, tname, method, Qfalse); if (NIL_P(v)) return Qnil; if (TYPE(v) != type) { rb_raise(rb_eTypeError, “%s#%s should return %s”, rb_obj_classname(val), method, tname); } return v;}
Ahora estamos llegando a alguna parte. Si el objeto es del tipo correcto (T_ARRAY en nuestro ejemplo), se retorna el objeto original. De lo contrario..., no nos demos por vencidos todavía. En su lugar, llama-mos a nuestro objeto original y le pedimos que si se puede representar como una matriz (que llama a su método to_ary). Si se puede, nos alegramos y continuamos. El código está diciendo “yo no necesito un Array, sólo necesito algo que se pueda representar como una matriz”. Esto significa que Kernel.exec lo aceptará como un parámetro matriz cualquiera que implementa un método to_ary. Se discuten estos protocolos de conversión con más detalle (pero desde la perspectiva de Ruby) más adelante.
¿Qué significa todo esto para usted como escritor de extensión? Hay dos mensajes. En primer lugar, tratar de evitar la comprobación de los tipos para parámetros que se le pasan. En su lugar, ver si hay un método rb_check_xxx_type que cnvierte el parámetro en el tipo que se necesita. Si no, buscar si exis-te una función conversora (como rb_Array, rb_Float o rb_Integer) que vaya a hacer el truco para usted. En segundo lugar, si se está escribiendo una extensión que implementa algo que puede ser utilizao significativamente como una cadena o una matriz Ruby, considerar la implementación de los métodos to_str o to_ary, permitiendo así la implementación de los objetos por su extensión para ser utilizado en contextos de cadena o matriz.
La Creación de una Extensión
Después de haber escrito el código fuente de una extensión, tenemos que compilarlo para que Ruby pueda utilizarlo. Podemos hacer esto como un objeto compartido que se carga dinámicamente en tiempo de ejecución, o se vinculando estáticamente la extensión en el intérprete principal mismo de Ruby. El pro-cedimiento básico es el mismo.
1. Crear el archivo o archivos fuente de código C en un directorio determinado. 2. Opcionalmente, crear un archivo Ruby de soporte en un subdirectorio lib. 3. Crear extconf.rb. 4. Ejecutar extconf.rb para crear un Makefile para los archivos C en este directorio. 5. Ejecutar make. 6. Ejecutar make install.
La Creación de un Makefile con extconf.rb
La figura 15 muestra el flujo de trabajo en la construcción de una extensión. La clave de todo el proceso es el programa extconf.rb que usted, como desarrollador, tiene que crear. En el fichero extconf.rb , se escribe un sencillo programa que determina qué características estarán disponibles en el sistema de usuario y donde se encuentran estas características. La ejecución de extconf.rb cons-truye un Makefile personalizado, adaptado tanto para la aplicación como para el sistema en el que está siendo compilado. Cuando se ejecuta el comando make contra este Makefile, se construye e instala (opcional) la extensión.
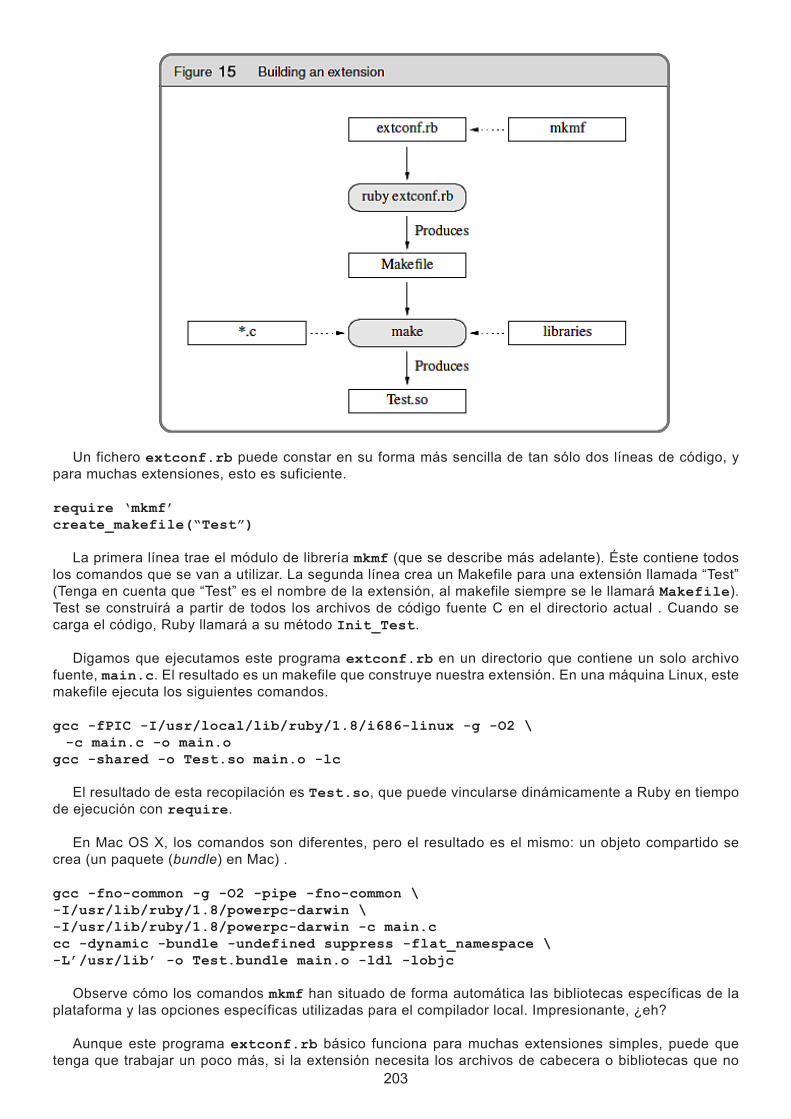
203
Un fichero extconf.rb puede constar en su forma más sencilla de tan sólo dos líneas de código, y para muchas extensiones, esto es suficiente.
require ‘mkmf’create_makefile(“Test”)
La primera línea trae el módulo de librería mkmf (que se describe más adelante). Éste contiene todos los comandos que se van a utilizar. La segunda línea crea un Makefile para una extensión llamada “Test” (Tenga en cuenta que “Test” es el nombre de la extensión, al makefile siempre se le llamará Makefile). Test se construirá a partir de todos los archivos de código fuente C en el directorio actual . Cuando se carga el código, Ruby llamará a su método Init_Test.
Digamos que ejecutamos este programa extconf.rb en un directorio que contiene un solo archivo fuente, main.c. El resultado es un makefile que construye nuestra extensión. En una máquina Linux, este makefile ejecuta los siguientes comandos.
gcc -fPIC -I/usr/local/lib/ruby/1.8/i686-linux -g -O2 \ -c main.c -o main.ogcc -shared -o Test.so main.o -lc
El resultado de esta recopilación es Test.so, que puede vincularse dinámicamente a Ruby en tiempo de ejecución con require.
En Mac OS X, los comandos son diferentes, pero el resultado es el mismo: un objeto compartido se crea (un paquete (bundle) en Mac) .
gcc -fno-common -g -O2 -pipe -fno-common \-I/usr/lib/ruby/1.8/powerpc-darwin \-I/usr/lib/ruby/1.8/powerpc-darwin -c main.ccc -dynamic -bundle -undefined suppress -flat_namespace \-L’/usr/lib’ -o Test.bundle main.o -ldl -lobjc
Observe cómo los comandos mkmf han situado de forma automática las bibliotecas específicas de la plataforma y las opciones específicas utilizadas para el compilador local. Impresionante, ¿eh?
Aunque este programa extconf.rb básico funciona para muchas extensiones simples, puede que tenga que trabajar un poco más, si la extensión necesita los archivos de cabecera o bibliotecas que no

204
están incluidas en el entorno de compilación por defecto, o si la compilación de código condicional está basada en la presencia de bibliotecas o funciones.
Un requisito común es especificar los directorios no estándar donde se puedan encontrar otros fi-cheros y librerías que se incluyan. Se trata de un proceso en dos pasos. En primer lugar, su fichero extconf.rb debe contener uno o más comandos dir_config. Esto especifica una etiqueta para un conjunto de directorios. A continuación, cuando se ejecuta extconf.rb, decirle en mkmf donde se en-cuentran los directorios físicos correspondientes del sistema en curso.
Si extconf.rb contiene la línea dir_config(nombre), entonces dará la ubicación de los directorios correspondientes con las opciones de línea de comandos
--with-name-include=directory Añadir el directorio/include para el comando de compilación.
--with-name-lib=directory Añadir el directorio/lib al comando de enlazado.
Si (como es común) los directorios de inclusión y de librerías son los subdirectorios llamados include y lib de algún otro directorio, puede tomar un atajo.
--with-name-dir=directory Añadir el directorio/lib y el directorio/include a los comandos de enlazado y de compilación, respec-tivamente.
Así como especificar todas estas opciones “--with” a la hora de ejecutar extconf.rb, también se puede utilizar --with con las opciones que se especificaron cuando Ruby se construyó para su máquina. Esto significa que usted puede descubrir y utilizar la ubicación de las bibliotecas que se utilizan por Ruby mismo.
Para concretar, digamos que se necesitan utilizar las bibliotecas CDJukebox del proveedor y los fiche-ros para el reproductor de CD que estamos desarrollando. El fichero extconf.rb puede contener:
require ‘mkmf’dir_config(‘cdjukebox’)# ... más cosascreate_makefile(“CDPlayer”)
Y entonces, se ejecuta extconf.rb de forma así como
Dividir el espacio de nombres
Los escritores de extensión están siendo cada día mejores ciudadanos. En lugar de instalar su di-rectorio de trabajo en uno de los directorios de las librerías de Ruby, están usando subdirectorios para agrupar sus archivos juntos. Esto es fácil con extconf.rb. Si el parámetro para la llamada crea-te_makefile contiene delante barras diagonales, mkmf asume que todo lo que hay antes de la última barra es un nombre de directorio y que el resto es el nombre de extensión. La extensión se instalará en el directorio dado (en relación con el árbol de directorios Ruby). En el siguiente ejemplo, la exrtensión sigue siendo denominada Test.
require ‘mkmf’create_makefile(“wibble/Test”)
Sin embargo, en caso de requerirse esta clase en un programa Ruby, hay que escribir
require ‘wibble/Test’

205
% ruby extconf.rb --with-cdjukebox-dir=/usr/local/cdjb
El Makefile generado podría asumir que /usr/local/cdjb/lib contiene las bibliotecas y /usr/local/cdjb/include los archivos de inclusión.
El comando dir_config se añade a la lista de lugares para la búsqueda de bibliotecas y archivos a incluir. Lo que no hace, en cambio, es vincular las bibliotecas a su aplicación. Para ello, tendrá que utilizar uno o más comandos have_library o find_library.
have_library busca un punto de entrada en la biblioteca dada. Si no encuentra el punto de entrada, se añade la biblioteca a la lista de las bibliotecas a utilizar cuando se enlaza la extensión. find_library es similar, pero le permite especificar una lista de directorios de búsqueda para la biblioteca. Estos son los contenidos del fichero extconf.rb que utilizamos para enlazar nuestro reproductor de CD:
require ‘mkmf’dir_config(“cdjukebox”)have_library(“cdjukebox”, “new_jukebox”)create_makefile(“CDPlayer”)
Una biblioteca particular, puede estar en diferentes lugares en función del sistema del host. El sistema X Window, por ejemplo, es notorio que habita en diferentes directorios en diferentes sistemas. El comando find_library buscará en la lista de directorios suministrada, para encontrar el correcto (es diferente de have_library, que sólo utiliza la información de configuración para la búsqueda). Por ejemplo, para crear un Makefile que utiliza X Windows y una biblioteca JPEG, extconf.rb puede contener
require ‘mkmf’if have_library(“jpeg”,”jpeg_mem_init”) and find_library(“X11”, “XOpenDisplay”, “/usr/X11/lib”, # list of directories “/usr/X11R6/lib”, # to check “/usr/openwin/lib”) # for librarythen create_makefile(“XThing”)else puts “No X/JPEG support available”end
Hemos añadido algunas funcionalidades adicionales a este programa. Todos los comandos mkmf re-tornan false si fallan. Esto significa que puede escribir un extconf.rb que genera un Makefile sólo si todo lo que necesita está presente. La distribución Ruby hace esto para tratar de compilar sólo las ex-tensiones que son compatibles con su sistema.
También puede querer que su código de extensión pueda configurar las características que utiliza en función del entorno de destino. Por ejemplo, nuestro reproductor de máquina de discos puede ser capaz de utilizar un decodificador MP3 de alto rendimiento, si el usuario final tiene uno instalado. Se puede com-probar mediante la búsqueda de su archivo de cabecera.
require ‘mkmf’dir_config(‘cdjukebox’)have_library(‘cdjb’, ‘CDPlayerNew’)have_header(‘hp_mp3.h’)create_makefile(“CDJukeBox”)
También puede comprobar para ver si el entorno de destino tiene una función particular en cualquiera de las bibliotecas que va a utilizar. Por ejemplo, la llamada setpriority sería útil, pero no siempre es tá disponible. Se puede comprobar con
require ‘mkmf’

206
dir_config(‘cdjukebox’)have_func(‘setpriority’)create_makefile(“CDJukeBox”)
Ambos, have_header y have_func definen constantes de preprocesador si encuentran sus objeti-vos. Los nombres están formados por la conversión del nombre de destino en mayúsculas y anteponiendo HAVE_. El código C puede tomar ventaja de esta construcción tal como
#if defined(HAVE_HP_MP3_H)# include <hp_mp3.h>#endif#if defined(HAVE_SETPRIORITY) err = setpriority(PRIOR_PROCESS, 0, 10)#endif
Si usted tiene requisitos especiales que no se pueden cumplir con todos estos comandos mkmf, su pro-grama puede añadir directamente las variables globales $CFLAGS y $LFLAGS, que se pasan al compilador y enlazador, respectivamente.
A veces creamos un fichero extconf.rb y simplemente parece no funcionar. Se le da el nombre de una biblioteca, y jura que no se dispone de la biblioteca como que jamás ha existido en todo el planeta. Se ajusta y se hacen cambios, pero mkmf todavía no puede encontrar la biblioteca que se necesita. Sería bueno si se pudiera saber exactamente lo que está haciendo entre bambalinas. Bueno, se puede. Cada vez que se ejecuta el script extconf.rb, mkmf genera un archivo de registro que contiene los detalles de lo que hizo. Si nos fijamos en el fichero mkmf.log, podremos ver los pasos que el programa ha utilizado para tratar de encontrar las bibliotecas que se han solicitado. A veces, intentar estos pasos de forma ma-nual ayuda a localizar el problema.
La Instalación de Destino
El Makefile producido por el fichero extconf.rb incluirá una “instalación” de destino. Esto copiará la biblioteca compartida objeto en el lugar correcto en su sistema de archivos de usuario (o usuarios) local. El destino está ligado a la ubicación de la instalación del intérprete Ruby que se utiliza en primer lugar para ejecutar extconf.rb. Si se tienen varios interpretes Ruby instalados en el sistema, la extensión se instala en el árbol de directorios del que ejecutó extconf.rb.
Además de instalar la biblioteca compartida, extconf.rb comprobará la presencia de un subdirectorio /lib. Si encuentra uno, se encargará de todos los archivos Ruby que haya que instalar junto con su ob-jeto compartido. Esto es útil si desea dividir el trabajo de escritura de la extensión en código de bajo nivel C y en código de alto nivel Ruby.
Enlazamiento Estático
Finalmente, si su sistema no admite la vinculación dinámica, o si usted tiene un módulo de extensión que desea tener enlazado estáticamente a Ruby, hay que editar el archivo ext/Setup de la distribución y añadir su directorio a la lista de extensiones. En el directorio de su extensión, cree un fichero llamado MANIFEST que contenga una lista de todos los archivos de su extensión (fuentes, extconf.rb, lib/, etc). A continuación, reconstruya Ruby. Las extensiones que figuren en el fichero Setup serán enlazadas estáticamente al archivo ejecutable de Ruby. Si se desea desactivar cualquier enlace dinámico, y enlazar todas las extensiones de forma estática, hay editar ext/Setup para que contenga la siguiente opción:
option nodynamic
Un Atajo
Si está ampliando una biblioteca ya existente escrita en C o C++, es posible que desee investigar SWIG (http://www.swig.org). SWIG es un generador de interfaz: toma una definición de biblioteca (por lo general a partir de un archivo de cabecera) y genera automáticamente el código de unión necesario para acceder a la biblioteca de otro lenguaje. SWIG soporta Ruby, lo que significa que pueden generar los ar-

207
chivos de código fuente en C que envuelven las librerías externas en las clases Ruby.
Inrtegración de un intérprete de Ruby
Además de extender Ruby añadiéndole código C, también se le puede dar la vuelta al problema e in-crustar Ruby dentro de una aplicación. Hay tiene dos maneras de hacer esto. La primera es dejar que el intérprete tome el control llamando a ruby_run. Este es el método más sencillo, pero tiene un inconve-niente importante --el intérprete nunca regresa de una llamada a ruby_run. He aquí un ejemplo:
#include “ruby.h”int main(void) { /* ... las cosas propias de la aplicación ... */ ruby_init(); ruby_init_loadpath(); ruby_script(“embedded”); rb_load_file(“start.rb”); ruby_run(); exit(0);}
Para inicializar el intérprete de Ruby, es necesario llamar a ruby_init (). Sin embargo, en algunas plataformas, puede ser necesario tomar medidas especiales antes de esto.
#if defined(NT) NtInitialize(&argc, &argv);#endif#if defined(__MACOS__) && defined(__MWERKS__) argc = ccommand(&argv);#endif
Ver main.c en la distribución Ruby para caulquier otra definición especial o configuración necesaria para su plataforma.
Es necesario incluir los archivos Ruby de inclusión y poner los de librería accesibles para compilar el código incrustado. En mi ordenador (Mac OS X) tengo el intérprete Ruby 1.8 instalado en un directorio privado, por lo que mi Makefile tiene el siguiente aspecto.
WHERE=/Users/dave/ruby1.8/lib/ruby/1.8/powerpc-darwin/CFLAGS=-I$(WHERE) -gLDFLAGS=-L$(WHERE) -lruby -ldl -lobjcembed: embed.o $(CC) -o embed embed.o $(LDFLAGS)
La segunda forma de embeber Ruby permite al código Ruby y al código C participar en más de un diálogo: el código C llama a algún código Ruby, y el código Ruby responde. Para ello, se incializa el intér-prete como de costumbre. Entonces, en lugar de entrar en el bucle principal del intérprete, se llama a los métodos específicos en el código Ruby. Cuando estos métodos retornan, el código C toma el control de nuevo.
Sin embargo, hay una pega. Si el código Ruby genera una excepción y no es atrapada, el programa C terminará. Para superar esto, se tiene que hacer lo que el intérprete hace y proteger todas las llamadas que podrían lanzar una excepción. Esto puede causar problemas. La llamada al método rb_protect envuelve la llamada a otra función C. Esta segunda función debe invocar al método Ruby. Sin embargo, el método envuelto por rb_protect está definido para tomar un sólo único parámetro. Para pasar más implica algún feo lance en C.
Veamos un ejemplo. He aquí una simple clase Ruby que implementa un método para devolver la suma de los números desde uno al max.

208
class Summer def sum(max) raise “Invalid maximum #{max}” if max < 0 (max*max + max)/2 endend
Vamos a escribir un programa en C que llama a una instancia de esta clase varias veces. Para crear el ejemplo, vamos a obtener el objeto de la clase (mediante la búsqueda de una constante de alto nivel cuyo nombre es el nombre de nuestra clase). A continuación, le pedimos a Ruby crear una instancia de esa clase --rb_class_new_instance es en realidad una llamada a Class.new. (Los dos 0 parámetros iniciales son el recuento de argumentos y un puntero ficticio a los argumentos mismos). Una vez que ten-gamos este objeto, se puede invocar su método sum con rb_funcall.
#include “ruby.h”static int id_sum;int Values[] = { 5, 10, 15, -1, 20, 0 };static VALUE wrap_sum(VALUE args) { VALUE *values = (VALUE *)args; VALUE summer = values[0]; VALUE max = values[1]; return rb_funcall(summer, id_sum, 1, max);}static VALUE protected_sum(VALUE summer, VALUE max) { int error; VALUE args[2]; VALUE result; args[0] = summer; args[1] = max; result = rb_protect(wrap_sum, (VALUE)args, &error); return error ? Qnil : result;}int main(void) { int value; int *next = Values; ruby_init(); ruby_init_loadpath(); ruby_script(“embedded”); rb_require(“sum.rb”); // get an instance of Summer VALUE summer = rb_class_new_instance(0, 0, rb_const_get(rb_cObject, rb_intern(“Summer”))); id_sum = rb_intern(“sum”); while (value = *next++) { VALUE result = protected_sum(summer, INT2NUM(value)); if (NIL_P(result)) printf(“Sum to %d doesn’t compute!\n”, value); else printf(“Sum to %d is %d\n”, value, NUM2INT(result)); } ruby_finalize(); exit(0);}
Una última cosa: el intérprete de Ruby no fue escrito originalmente con la incrustación en mente. Pro-bablemente, el mayor problema es que se mantiene el estado de las variables globales, por lo que no es un subproceso seguro (thread-safe). Se puede integrar Ruby --un solo intérprete por proceso.
Un buen recurso para embeber Ruby en C++ se encuentra en http://metaeditor.sourceforge.net/embed/. Esta página también contiene enlaces a otros ejemplos de incrustación Ruby.

209
API Ruby Empotrado
void ruby_init( ) Crea e inicializa el intérprete. Esta función debe ser llamada antes de cualquier otra relacionada a Ruby.
void ruby_init_loadpath( ) Inicializa la variable $: (la ruta de carga), es necesario si el código carga cualquier módulo de librería.
void ruby_options( int argc, char **argv ) Da las opciones de línea de comandos del intérprete de Ruby.
void ruby_script( char *name ) Establece el nombre del script Ruby (y $0) a nombre.
void rb_load_file( char *file ) Carga el archivo dado en el intérprete.
void ruby_run( ) Ejecuta el intérprete.
void ruby_finalize( ) Cierra el intérprete.
Para otro ejemplo de incorporación de un intérprete Ruby dentro de otro programa, véase también eruby, que hemos descrito en páginas anteriores.
Puenteando Ruby y Otros Lenguajes
Hasta ahora, hemos hablado de la extensión de Ruby añadiendo rutinas escritas en C. Sin embargo, puede escribir extensiones en casi cualquier lenguaje, siempre y cuando se puedan unir los dos lenguajes con C. Casi todo es posible, incluidos los matrimonios difíciles de Ruby y C++, Ruby y Java, etc.
Pero se puede ser capaz de lograr lo mismo sin recurrir a código C. Por ejemplo, se puede puentear a otros lenguajes usando middleware tales como SOAP o COM. Ver la sección sobre SOAP y la sección sobre inicio de automatización de Windows en páginas anteriores para más detalles.
API Ruby C
Por último, pero no menos importante, aquí están algunas de las funciones de nivel C que pueden serle de utilidad al escribir una extensión.
Algunas funciones requieren un ID: se puede obtener un ID para una cadena mediante rb_intern y reconstruir el nombre de un ID mediante rb_id2name.
Como la mayoría de estas funciones C tienen equivalentes Ruby que ya se han descrito en detalle en este libro, las descripciones que hagamos aquí, serán breves.
La siguiente lista no es completa. Muchas más funciones están disponibles --ya que resultaría demasia-do documentar todas. Si se necesita un método que no se encuentra aquí, mire en ruby.h o intern.h para posibles candidatos. Además, en o cerca de la parte inferior de cada fichero fuente hay un conjunto de definiciones de métodos que describen la unión de los métodos Ruby a las funciones C. Usted pue-de ser capaz de llamar a la función C directamente o buscando una función contenedora que llama a la función que usted necesita. La siguiente lista, basada en la de README.EXT, muestra los archivos fuente principales del intérprete.

210
Core del Lenguaje Ruby class.c, error.c, eval.c, gc.c, object.c, parse.y, variable.c
Funciones de Utilidad dln.c, regex.c, st.c, util.c
Intérprete Ruby dmyext.c, inits.c, keywords main.c, ruby.c, version.c
Librería Base array.c, bignum.c, compar.c, dir.c, enum.c, file.c, hash.c, io.c, marshal.c, math.c, numeric.c, pack.c, prec.c, process.c, random.c, range.c, re.c, signal.c, sprintf.c, string.c, struct.c, time.c
API: Definición de Clases
VALUE rb_define_class( char *name, VALUE superclass ) Define una nueva clase en el nivel superior con el nombre y la superclase dados (para la clase Object, utilice rb_cObject).
VALUE rb_define_module( char *name ) Define un nuevo módulo en el nivel superior con el nombre dado.
VALUE rb_define_class_under( VALUE under, char *name, VALUE superclass ) Define una clase anidada dentro de la clase o módulo under.
VALUE rb_define_module_under( VALUE under, char *name ) Define un módulo anidada en la clase o módulo under.
void rb_include_module( VALUE parent, VALUE module ) Incluye el módulo dado en la clase o padre del módulo.
void rb_extend_object( VALUE obj, VALUE module ) Extender obj con el modulo.
VALUE rb_require( const char *name ) Equivalente a require nombre. Retorna Qtrue o Qfalse.
API: Definición de Estructuras
VALUE rb_struct_define( char *name, char *attribute..., NULL ) Define una nueva estructura con los atributos dados.
VALUE rb_struct_new( VALUE sClass, VALUE args..., NULL ) Crea una instancia de sClass con los valores de atributo dados.
VALUE rb_struct_aref( VALUE struct, VALUE idx ) Devuelve el elemento nombrado o indexado por idx.
VALUE rb_struct_aset( VALUE struct, VALUE idx, VALUE val ) Establece el atributo nombrado o indexado desde idx a val.
...
Tambien están ==> API: Defining Methods, API: Defining Variables and Constants, API: Calling Methods, API: Exceptions, API: Iterators, API: Accessing Variables, API: Object Status y API: Commonly Used Methods. Se pueden ver en el original en inglés de Programming Ruby (2nd edition): The Pragma-tic Programmers’ Guide.

211
Ruby Cristalizado
El Lenguaje Ruby
Este capítulo es una mirada de arriba a abajo del lenguaje Ruby. La mayor parte de lo que aparece aquí es la sintaxis y la semántica del lenguaje en sí mismo --que en su mayoría se ignoran las clases y los módulos integrados (que se tratan en profundidad en la sección siguiente). Ruby a veces implementa caraacterísticas en sus librerías que en la mayoría de los lengiuajes son parte de la sintaxis básica. Hemos incluido aquí estos métodos y hemos tratado de marcar ésto con “Librería” en el margen.
El contenido de este capítulo puede parecer familiar --por una buena razón. Hemos cubierto casi todo esto como tutorial en los capítulos anteriores. Considere la posibilidad de ver este capítulo como una re-ferencia independiente para el núcleo del lenguaje Ruby.
Diseño de los Fuentes
Los programas Ruby están escritos en ASCII de 7 bits, Kanji (utilizando EUC o SJIS) o UTF-8. Si se usa un conjunto de códigos que no sean ASCII de 7 bits, la opción KCODE debe ser un valor apropiado, como dijimos anteriormente.
Ruby es un lenguaje orientado a línea. Las expresiones y las declaraciones Ruby se terminan al final de una línea a menos que el analizador pueda determinar que la declaración está incompleta --por ejemplo, si el último símbolo de una línea es un operador o una coma. Se puede utilizar un punto y coma para separar las expresiones múltiples en una línea. También se puede poner una barra invertida al final de una línea para continuar en la siguiente. Los comentarios comienzan con # y corren hasta el final de la línea física. Los comentarios son ignorados durante el análisis sintáctico.
a = 1b = 2; c = 3d = 4 + 5 + 6 + 7 # no necesita ‘\’e = 8 + 9 \ + 10 # necesita‘\’
Las líneas físicas entre una línea que comienza con =begin y otra línea que comienza con =end son ignoradas por Ruby y pueden usarse para comentar secciones de código o para incrustar documentación.
Ruby lee la entrada del programa de una sola pasada, por lo que se pueden canalizar los programas al intérprete Ruby a través de un pipe a la entrada estandar.
echo ‘puts “Hello”’ | ruby
Si Ruby llega a través de una línea en cualquier parte del código fuente que contiene sólo “__END__”, sin espacios en blanco iniciales o finales, esa línea se trata como el final del programa --las líneas subsi-guientes no serán tratadas como código del programa. Sin embargo, estas últimas se pueden leer en el programa que se está ejecutando utilizando el objeto IO global DATA, descrito más adelante.
Bloques BEGIN / END
Cada archivo de código fuente en Ruby puede declarar bloques de código que se ejecutan como un archivo que se carga (los bloques BEGIN) y también después que el programa ha terminado de ejecutar (los bloques END).BEGIN { begin code}END { end code}

212
Un programa puede incluir varios bloques BEGIN y END. Los bloques BEGIN se ejecutan en el orden en que se encuentran. Los bloques END se ejecutan en orden inverso.
Delimitadores Generales de Entrada
Así como el mecanismo normal de entrecomillado, las formas alternativas de cadenas literales, matri-ces, expresiones regulares y comandos de la shell se especifican mediante una sintaxis de delimitación-generalizada. Todos estos literales comienzan con un carácter de porcentaje, seguido de un carácter único que identifica el tipo de literal. Estos carácteres se resumen en:
%q Cadena entre comillas simples.%Q, % Cadena entre comillas dobles.%w, %W Matriz de cadenas.%r Patrón de expresión regular.%x Comandos de shell.
Los literales se describen en las secciones correspondientes en este mismo capítulo.
Siguiendo al carácter de tipo hay un delimitador, que puede ser cualquier carácter no alfabético o no multibyte. Si el delimitador es uno de los carácteres (, [, { o <, el literal se compone de los caracteres-hasta el delimitador de cierre correspondiente, teniendo en cuenta los pares de delimitadores anidados. Para todos los demás delimitadores, el literal comprende los caracteres hasta la siguiente aparición de carácter delimitador.
%q/this is a string/%q-string-%q(a (nested) string)
Las cadenas delimitadas pueden continuar en varias líneas; los finales de línea y todos los espacios al principio de las líneas de continuación se incluyen en la cadena.
meth = %q{def fred(a) a.each {|i| puts i } end}
Los tipos Básicos
Los tipos básicos de Ruby son números, cadenas, arrays, hashes, rangos, símbolos y expresiones regulares.
Números Enteros y de Punto Flotante
Los enteros Ruby son objetos de la clase Fixnum o Bignum. Los objetos Fixnum contienen enteros que caben dentro de la palabra nativa de la máquina menos 1 bit. Sin embargo, si un Fixnum supera este rango, se convierte automáticamente en un objeto Bignum, cuyo rango está limitado sólo por la memo-ria disponible. Si una operación con un Bignum tiene un resultado con un valor final que se ajusta a un Fixnum , este resultado será devuelto como un Fixnum.
Los enteros se escriben con un signo opcional, un indicador de base opcional (0 para octal, 0d para decimal, 0x para hexadecimal o 0b para binario), seguidos de una cadena de dígitos en la base corres-pondiente. El caracter guión bajo es ignorado en ñla cadena de dígitos.
123456 => 123456 # Fixnum0d123456 => 123456 # Fixnum123_456 => 123456 # Fixnum - underscore ignored-543 => -543 # Fixnum - negative number0xaabb => 43707 # Fixnum - hexadecimal0377 => 255 # Fixnum - octal-0b10_1010 => -42 # Fixnum - binary (negated)

213
123_456_789_123_456_789 => 123456789123456789 # Bignum
Se puede obtener el valor entero correspondiente a un caracter ASCII precediendo éste por un signo de cierre de interogación. Se pueden generar caracteres de control utilizando ?\C-x y ?\cx (la versión control de x es x&0x9f). Se pueden generar meta caracteres (x | 0x80) utilizando ?\M-x. La combi-nación de meta y control se genera utilizando ?\M-\C-x. Se puede obtener el valor entero de la barra invertida con la secuencia ?\\.
?a => 97 # ASCII character?\n => 10 # code for a newline (0x0a)?\C-a => 1 # control a = ?A & 0x9f = 0x01?\M-a => 225 # meta sets bit 7?\M-\C-a => 129 # meta and control a?\C-? => 127 # delete character
Un literal numérico con un punto decimal y/o un exponente se convierte en un objeto Float, que co-rresponde al tipo de dato double de la arquitectura nativa. Se debe seguir el punto decimal con un dígito, ya que 1.e3 trata de invocar el método e3 de la clase Fixnum. A partir de Ruby 1.8 también se debe colocar al menos un dígito antes del punto decimal.
12.34 -> 12.34-0.1234e2 -> -12.341234e-2 -> 12.34
Cadenas
Ruby proporciona una serie de mecanismos para la creación de cadenas literales. Cada uno genera objetos de tipo String. Estos mecanismos varían en términos de cómo una cadena está delimitada y que cantidad de sustitución se realiza en el contenido literal.
Literales de cadena entre comillas simples (‘cosas’ y %q/cosas/) se sometan a la sustitución mínima. La secuencia \\ se convierte en una sola barra invertida y la forma \’ en una comilla simple. Todas las otras barras invertidas aparecen en la cadena literalmente.
‘hello’ -> hello‘a backslash \’\\\’’ -> a backslash ‘\’%q/simple string/ -> simple string%q(nesting (really) works) -> nesting (really) works%q no_blanks_here ; -> no_blanks_here
Cadenas entre comillas dobles (“cosas”, %Q/cosas / y %/cosas/) se someten a sustituciones adiciona-les, que se muestran en la Tabla 6 en la página siguiente.
a = 123“\123mile” -> Smile“Say \”Hello\”” -> Say “Hello”%Q!”I said ‘nuts’,” I said! -> “I said ‘nuts’,” I said%Q{Try #{a + 1}, not #{a - 1}} -> Try 124, not 122%<Try #{a + 1}, not #{a - 1}> -> Try 124, not 122“Try #{a + 1}, not #{a - 1}” -> Try 124, not 122%{ #{ a = 1; b = 2; a + b } } -> 3
Las cadenas pueden continuar a través de varias líneas de entrada, en cuyo caso contienen caracteres de nueva línea. También es posible utilizar documentos para expresar literales de cadena larga. Siempre que Ruby analiza la secuencia <<identificador o <<cadena entrecomillada, se reemplaza con una cade-na literal construida de las sucesivas líneas lógicas de entrada. Interrumpe la construcción de la cadena cuando se encuentra una línea que comienza con el identificador o cadena entrecomillada. Usted puede poner un signo menos inmediatamente después de los <<caracteres, en cuyo caso el terminador puede

214
ser sangrado o indentado desde el margen izquierdo. Si para especificar el terminador se utiliza una cadena entre comillas, sus reglas de entrecomillado se aplican al documento, de lo contrario, se aplican comillas dobles.
print <<HEREDouble quoted \here document.It is #{Time.now}HEREprint <<’-THERE’ This is single quoted. The above used #{Time.now} THERE
produce:
Double quoted here document.It is Thu Aug 26 22:37:12 CDT 2004 This is single quoted. The above used #{Time.now}
Cadenas en la entrada adyacentes a comillas simples y dobles se concatenan para formar un único objeto String.
‘Con’ “cat” ‘en’ “ate” -> “Concatenate” Las cadenas se almacenan como secuencias de bytes de 8 bits (para su uso en Japón, la biblioteca jcode soporta un conjunto de operaciones de cadenas escritas con codificación EUC, SJIS o UTF-8. La cadena subyacente, sin embargo, sigue siendo accedida como una serie de bytes., y cada byte puede contener cualquiera de los 256 valores de 8 bits, incluyendo nulos y saltos de línea. Las secuencias de sustitución en la Tabla 6 permiten insertar de forma vonveniente y portable caracteres no imprimibles
Cada vez que se utiliza una cadena literal en una asignación o como un parámetro, se crea un nuevo objeto String.
3.times do print ‘hello’.object_id, “ “end
produce:937140 937110 937080
La documentación para las diferentes clases, entre ellas String, comienza páginas adelante.
Rangos
Fuera del contexto de una expresión condicional, expr..expr y expr...expr construyen objetos Range.

215
La forma de dos puntos es un rango inclusivo y el que tiene tres puntos es un rango que excluye su último elemento. Véase la descripción de la clase Range más adelante para más detalles. Vea también la des-cripción de las expresiones condicionales para otros usos de los rangos.
Matrices
Los literales de la clase Array se crean mediante la colocación de una serie de objetos separados por comas referenciados entre corchetes. Una coma al final se ignora.
arr = [ fred, 10, 3.14, “This is a string”, barney(“pebbles”), ]
Se pueden construir matrices de cadenas usando la notación w% y %W. La forma en minúscula se ob-tiene con los elementos sucesivos de la matriz separados por espacios. No se realiza sustitución en las cadenas individuales. La forma en mayúscula también convierte las palabras en una matriz, pero realiza sustituciones normales de cadenas entre comilladas en cada palabra. Se puede poner un espacio ente palabras con una barra invertida. Esta es una forma de entrada delimitada generalizada.
arr = %w( fred wilma barney betty great\ gazoo )arr -> [“fred”, “wilma”, “barney”, “betty”, “great gazoo”]arr = %w( Hey!\tIt is now -#{Time.now}- )arr -> [“Hey!\\tIt”, “is”, “now”, “-#{Time.now}-”]arr = %W( Hey!\tIt is now -#{Time.now}- )arr -> [“Hey!\tIt”, “is”, “now”, “-Thu Aug 26 22:37:13 CDT 2004-”]
Hashes
Un literal hash se crea mediante la colocación de una lista de pares clave/valor entre llaves, con una coma o la secuencia => entre la clave y el valor. Una coma final se ignora.
colors = { “red” => 0xf00, “green” => 0x0f0, “blue” => 0x00f }
Las claves y/o valores de un hash particular no necesitan ser del mismo tipo.
Requisitos para una Clave Hash
Las claves hash deben responder al mensajes hash retornando un código hash, y este código hash para una clave determinada no debe cambiar. Las claves utilizadas en los hashes también deben ser com-parables utilizando eql?. Si eql? retorna true para dos claves, entonces estas claves también deben tener el mismo código hash. Esto significa que ciertas clases (como Array y Hash) no pueden ser conve-nientemente utilizadas como claves, debido a que sus valores pueden cambiar en función de su contenido.
Si se mantiene una referencia externa a un objeto que se utiliza como una clave, y la utilización de esta referencia altera al objeto, cambiando así su código hash, la búsqueda hash a partir de esa clave puede no funcionar.
Dado que las cadenas son las claves más utilizadas, y los contenidos de las cadenas a menudo cam-bian, Ruby trata las claves cadena de forma especial. Si utiliza un objeto String como clave hash, el hash duplicará la cadena internamente y utilizará la copia como clave. La copia será congelada. Cualquier cambio realizado en la cadena original no afectará al hash. Si usted escribe sus propias clases y utiliza instancias de ellas como claves hash, necesita asegurarse de que (a) los valores hash de los objetos clave no cambian una vez que los objetos han sido creados o (b) recuerda llamar al método Hash#rehash para reindexar el hash cada vez que una clave hash es cambiada.

216
Símbolos
Un símbolo en Ruby es un identificador que corresponde a una cadena de caracteres, a menudo un nombre. Se construye el símbolo para un nombre precediéndole por dos puntos, y se puede construir el símbolo para una cadena arbitraria precediendo la cadena literal por dos puntos. Se producen las sustitu-ciones en las cadenas entre comillas dobles. Un nombre o cadena en particular siempre va a generar el mismo símbolo, independientemente de cómo se usa ese nombre en el programa.
:Object:my_variable:”Ruby rules”a = “cat”:’catsup’ -> :catsup:”#{a}sup” -> :catsup:’#{a}sup’ -> :”\#{a}sup”
Otros lenguajes llaman a este proceso internado y a los símbolos átomos.
Expresiones Regulares
Las expresiones regulares literales son objetos de tipo RegExp. Se crean de forma explícita median-te una llamada al constructor Regexp.new o implícitamente mediante el uso de las formas literales, /patrón/ y %r{patrón}. La construcción %r es una forma de entrada delimitada generalizada.
/pattern//pattern/options%r{pattern}%r{pattern}optionsRegexp.new( ‘pattern’ [ , options ] )
Opciones de las Expresiones Regulares
Una expresión regular puede incluir una o más opciones que modifican la forma en que el patrón coinci-de con cadenas. Si se utilizan literales para crear el objeto RegExp, entonces las opciones son uno o más caracteres colocados inmediatamente después del terminador. Si se utiliza Regexp.new, las opciones son constantes que se utilizan como segundo parámetro del constructor.
i Case Insensitive. La comparación de patrón ignora si las letras del patrón y la cadena son mayús-culas o minúsculas. Poner $= para hacer comparaciones case insensitive está ya en obsoleto.
o Sustituir una vez. Cualquier sustitución #... en una particular expresión regular literal se llevará a cabo sólo una vez, la primera vez que se evalúa. De otra manera, se llevarán a cabo las sustituciones cada vez que el literal genera un objeto RegExp.
m Modo multilínea. Normalmente, “.” Coincide con cualquier carácter excepto con el de nueva línea. Con la opción /m, “.” coincide con cualquier carácter.
x Modo extendido. Expresiones regulares complejas pueden ser de dificil lectura. La opción x le per-mite insertar espacios, nuevas líneas y comentarios en el patrón para que sea más legible.
Otro conjunto de opciones permiten configurar la codificación de idioma de la expresión regular. Si no se especifica ninguna de estas opciones, se utiliza la codificación por defecto del intérprete (definido me-diante -K o $KCODE).
n: no encoding (ASCII) e: EUC s: SJIS u: UTF-8

217
Patrones de Expresión Regular
caracteres regulares Todos los caracteres excepto ., |, (, ), [, \, ^, {, +, $, *, y ? coinciden con ellos mismos . Para coincidir con uno de estos caracteres, hay precederles con una barra invertida. ^ Coincide con el comienzo de una línea.
$ Coincide con el final de una línea.
\A Coincide con el comienzo de una cadena.
\z Coincide con el final de una cadena.
\Z Coincide con el final de la cadena a menos que la cadena termina con un \n, en cuyo caso coincide justo antes del \n.
\b, \B Coincide con los limites de palabra y no palabra respectivamente.
\G La posición donde una búsqueda repetitiva anterior se completó (pero sólo en algunas situaciones). Consulte la información adicional justo ahora más adelante.
[caracteres] Una expresión con corchetes coincide con cualquiera de los caracteres de la lista entre los corchetes. Los caracteres ., |, (, ), [, \, ^, {, +, $, *, y ? que tienen un significado especial en otros casos en los patrones, pierden su significado especial entre corchetes . Las secuencias \nnn \xnn, \cx, \C-x, \M-x y \M-\C-x tienen el significado que se muestra en la tabla 6 tres páginas atrás. Las secuencias \d, \D, \s, \S, \w, y \W son abreviaturas de grupos de caracteres, como se muestra en la Tabla 2 en la sección clases caracter. La secuencia [:clase:] coincide con una clase de caracteres POSIX y también se muestra en la Tabla 2 (Tenga en cuenta que los corchetes de apertura y cierre son parte de la clase, por lo que el patrón /[_[:dígito:]]/ coincidiría con un dígito o un guión bajo). La secuencia de c1-c2 representa todos los caracteres entre c1 y c2, inclusives. Caracteres literales ] o - deben aparecer inmediatamente después del corchete de apertura. Un carácter de intercalación (^) inmediatamente después del corchete de apertura niega el sentido de la coincidencia --el patrón coincide con cualquier carácter que no está en la clase caracter.
\d, \s, \w Abreviaturas para las clases caracter que coinciden con dígitos, espacios en blanco y caracteres de palabra, respectivamente. Estas abreviaturas se resumen en la Tabla 2.
\D, \S, \W Las formas de negación de \d, \s, y \w, coincidiendo con los caracteres que no son dígitos, espacios en blanco o caracteres de palabra.
. (punto) Apareciendo fuera de los corchetes, coincide con cualquier carácter excepto una nueva línea. (Con la opción /m, coincidiría también con salto de línea).
re* Coincide con cero o más apariciones de re.
re+ Coincide con una o más apariciones de re.
re{m,n} Coincide al menos con “m” y como máximo “n” apariciones de re.
re{m,} Coincide al menos con “m” apariciones de re.
re{m} Coincide exactamente con “m” apariciones de re.
re? Coincide con cero o una ocurrencia de re. Los modificadores *, + y {m, n} son codiciosos por defecto. Se añade un signo de interrogación para que sean mínimos.

218
re1|re2 Coincide con re1 o re2. La barra | tiene baja prioridad.
(...) Los paréntesis se utilizan para agrupar expresiones regulares. Por ejemplo, el patrón /abc+/ coincide con una cadena que contiene una a, ab y una o más c. /(abc)+/ coincide con una o más secuencias de abc. Los paréntesis también se utilizan para recoger los resultados de las coincidencias de patrón. Para cada paréntesis de apertura , Ruby almacena el resultado de la coincidencia parcial entre éste y el paréntesis de cierre correspondiente como grupos sucesivos. Dentro del mismo patrón, \1 se refiere a la coincidencia del primer grupo, \2 del segundo grupo y así sucesivamente. Fuera del patrón, las variables especiales $1, $2 y sucesivos, tienen el mismo propósito.
El ancla \G trabaja con los métodos de comparación repetitiva String#gsub, String#gsub!, String #index y String#scan. En ua comparación repetitiva, representa la posición en la cadena donde se ha dado la última coincidencia cuando termina la iteración. \G apunta inicialmente al comienzo de la cadena (o al caracter referenciado por el segundo parámetro de String#index).
“a01b23c45 d56”.scan(/[a-z]\d+/) -> [“a01”, “b23”, “c45”, “d56”]“a01b23c45 d56”.scan(/\G[a-z]\d+/) -> [“a01”, “b23”, “c45”]“a01b23c45 d56”.scan(/\A[a-z]\d+/) -> [“a01”]
Sustituciones
#{...} Realiza una sustitución de expresión, como con cadenas. Por defecto, se lleva a cabo la sustitución cada vez que se evalua una expresión regular literal. Con la opción /o se realiza sólo la primera vez.
\0, \1, \2, ... \9, \&, \`, \’, \+ Sustituye el valor comparado con la enésima subexpresión agrupada. O por toda la coincidencia, o por la pre- o postcoincidencia, o por el grupo más alto.
Extensiones de expresiones regulares
Al igual que en Perl y Python, las expresiones regulares en Ruby ofrecen algunas extensiones sobre las expresiones regulares Unix. Todas las extensiones se introducen entre los caractereses (? y ). Los paréntesis que encierran estas extensiones son grupos, pero no generan de vuelta referencias: no esta-blecen los valores de \1 y $1, etc. (?# comentario) Inserta un comentario en el patrón. El contenido se ignora durante la comparación de patrones.
(?:re) Convierte re en un grupo sin generar de vuelta referencias. Esto a menudo es útil cuando es necesario agrupar un conjunto de construcciones, pero no se quiere que el grupo establecezca el valor de $1 o lo que sea. En el ejemplo que sigue, los patrones coinciden con una fecha, ya sea con dos puntos o ya sea con espacios entre el mes, el día y el año. La primera forma almacena el carácter separador en $2 y $4, pero el segundo patrón no almacena el separador en una variable externa.
date = “12/25/01”date =~ %r{(\d+)(/|:)(\d+)(/|:)(\d+)}[$1,$2,$3,$4,$5] -> [“12”, “/”, “25”, “/”, “01”]date =~ %r{(\d+)(?:/|:)(\d+)(?:/|:)(\d+)}[$1,$2,$3] -> [“12”, “25”, “01”]
(?=re) Compara re en esa posición, pero no lo usa (también encantadoramente conocido como zero-width positive lookahead). Esto le permite buacar hacia adelante en el contexto de una comparación sin afectar a $&. En este ejemplo, el método scan coincide palabras seguidas de una coma, pero las comas no se incluyen en el resultado.

219
str = “red, white, and blue”str.scan(/[a-z]+(?=,)/) -> [“red”, “white”]
(?!re) Compara si re no coincide en esa posición. No consume la comparación (zero-width positive lookahead). Por ejemplo, /hot(?!dog)(\w+)/ coincide con cualquier palabra que contenga las letras hot y no continúen con dog, retornando el final de la palabra en $1.
(?>re) Anida una expresión regular independiente dentro de la primera expresión regular. Esta expresión se ancla en la posición de coincidencia actual. Si usa caracteres, estos no estarán ya disponibles para la expresión regular de primer nivel. Esta construcción por lo tanto, inhibe la marcha atrás y puede producir una mejora de rendimiento. Por ejemplo, el patrón /a.*b.*a/ toma un tiempo exponencial cuando se compara con una cadena que contiene una a seguida de una serie de b, pero sin a final. Sin embargo, esto se puede evitar mediante el uso de la expresión regular anidada /a(?>.*b).*a/. De esta forma, la expresión anidada consume toda la cadena de entrada hasta el último carácter b posible. Cuando el chequeo para una a final no ocurre entonces , no hay necesidad de dar marcha atrás, y la coincidencia de patrón falla de inmediato.
require ‘benchmark’include Benchmarkstr = “a” + (“b” * 5000)bm(8) do |test| test.report(“Normal:”) { str =~ /a.*b.*a/ } test.report(“Nested:”) { str =~ /a(?>.*b).*a/ }end
produce:
user system total realNormal: 1.090000 0.000000 1.090000 ( 1.245818)Nested: 0.000000 0.000000 0.000000 ( 0.001033)
(?imx) Se convierte en la correspondiente opcoón. Si se utiliza dentro de un grupo, el efecto se limita a ese grupo.
(?-imx) Desactiva la opción i, m o x.
(?imx:re) Activa la opción i, m o x para re.
(?-imx:re) Desactiva la opción i, m o x para re.
Nombres
Los nombres Ruby se utilizan para referirse a constantes, variables, métodos, clases y módulos. El primer carácter de un nombre ayuda a Ruby a distinguir su propósito. Algunos nombres, que figuran en la Tabla 7 en la página siguiente, son palabras reservadas y no se deben utilizar como nombres de método, variable, clase o módulo.
Los nombres para los métodos se describen en la sección correspondiente un poco más adelante.
En las siguientes descripciones, letras minúsculas son los carácteres desde la a hasta la z, así como el guión bajo (_). Letras mayúsculas son los carácteres desde la A hasta la Z y dígitos significa desde el 0 hasta el 9. Un nombre es una letra mayúscula, minúscula o un guión bajo, seguido por carácteres de nombre: cualquier combinación de letras mayúsculas, minúsculas, guiones bajos y dígitos.
Un nombre de variable local se compone de una letra minúscula seguida de caracteres de nombre. Lo normal es utilizar guiones bajos en lugar de camelCase (mayúsculas y minúsculas mezcladas) para escribir nombres con varias palabras, pero no es obligatorio.
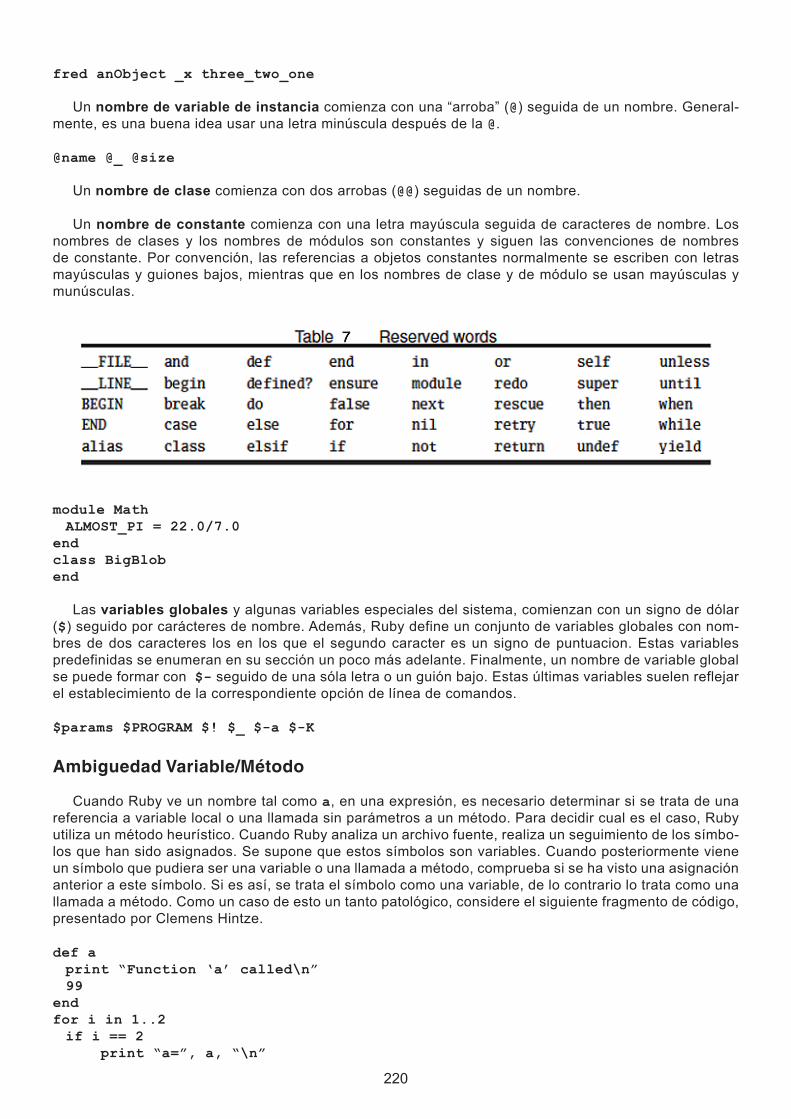
220
fred anObject _x three_two_one
Un nombre de variable de instancia comienza con una “arroba” (@) seguida de un nombre. General-mente, es una buena idea usar una letra minúscula después de la @.
@name @_ @size
Un nombre de clase comienza con dos arrobas (@@) seguidas de un nombre.
Un nombre de constante comienza con una letra mayúscula seguida de caracteres de nombre. Los nombres de clases y los nombres de módulos son constantes y siguen las convenciones de nombres de constante. Por convención, las referencias a objetos constantes normalmente se escriben con letras mayúsculas y guiones bajos, mientras que en los nombres de clase y de módulo se usan mayúsculas y munúsculas.
module Math ALMOST_PI = 22.0/7.0endclass BigBlobend
Las variables globales y algunas variables especiales del sistema, comienzan con un signo de dólar ($) seguido por carácteres de nombre. Además, Ruby define un conjunto de variables globales con nom-bres de dos caracteres los en los que el segundo caracter es un signo de puntuacion. Estas variables predefinidas se enumeran en su sección un poco más adelante. Finalmente, un nombre de variable global se puede formar con $- seguido de una sóla letra o un guión bajo. Estas últimas variables suelen reflejar el establecimiento de la correspondiente opción de línea de comandos.
$params $PROGRAM $! $_ $-a $-K
Ambiguedad Variable/Método
Cuando Ruby ve un nombre tal como a, en una expresión, es necesario determinar si se trata de una referencia a variable local o una llamada sin parámetros a un método. Para decidir cual es el caso, Ruby utiliza un método heurístico. Cuando Ruby analiza un archivo fuente, realiza un seguimiento de los símbo-los que han sido asignados. Se supone que estos símbolos son variables. Cuando posteriormente viene un símbolo que pudiera ser una variable o una llamada a método, comprueba si se ha visto una asignación anterior a este símbolo. Si es así, se trata el símbolo como una variable, de lo contrario lo trata como una llamada a método. Como un caso de esto un tanto patológico, considere el siguiente fragmento de código, presentado por Clemens Hintze.
def a print “Function ‘a’ called\n” 99endfor i in 1..2 if i == 2 print “a=”, a, “\n”

221
else a = 1 print “a=”, a, “\n” endend
produce:
a=1Function ‘a’ calleda=99
Durante el análisis, Ruby ve el uso de a en la primera sentencia print y, como aún no había visto ninguna asignación para a, supone que se trata de una llamada a método. En el momento en que llega a la segunda sentencia print, sin embargo, ha visto una asignaciónn, por lo que la trata como una variable. Tenga en cuenta que la asignación no tiene que ser ejecutada --Ruby sólo tiene que haberla visto. Este programa no generará un error:
a = 1 if false; a
Variables y Constantes
Las variables y las constantes Ruby contienen referencias a objetos. Las variables en si mismas no tie-nen un tipo intrínseco. En su lugar, el tipo de una variable se define únicamente por los mensajes a los que responde el objeto referenciado por la variable (cuando decimos que una variable es no tipada, queremos decir que cualquier variable dada puede tener en diferentes momentos, referencias a objetos de diferentes tipos).
Una constante Ruby es también una referencia a un objeto. Las constantes se crean cuando se asig-nan por primera vez (normalmente en una definición de clase o módulo). Ruby, a diferencia de lenguajes menos flexible, permite modificar el valor de una constante, aunque genera un mensaje de advertencia.
MY_CONST = 1MY_CONST = 2 # generates a warning
produce:
prog.rb:2: warning: already initialized constant MY_CONST
Tenga en cuenta que pese a que las constantes no se deben cambiar, se puede alterar el estado interno de los objetos a los que hacen referencia.
MY_CONST = “Tim”MY_CONST[0] = “J” # alter string referenced by constantMY_CONST -> “Jim”
Potencialemnte se pueden asignar alias a objetos, dando al mismo objeto diferentes nombres.
Ambito de constantes y Variables
Las constantes definidas dentro de una clase o módulo pueden ser accedidas sin adornos en cual-quier lugar dentro de la clase o módulo. Fuera de la clase o módulo, se pueden acceder con el operador de ámbito :: prefijado por una expresión que retorna el objeto clase o módulo apropiado. Las constantes definidas fuera de cualquier clase o módulo se puede acceder sin adornos, o utilizando el operador de ámbito :: sin prefijo. No se pueden definir constantes en los métodos. Las constantes pueden ser añadi-dos desde el exterior a las clases y módulos existentes, utilizando el nombre de la clase o el módulo y el operador de ámbito antes del nombre de constante.

222
OUTER_CONST = 99class Const def get_const CONST end CONST = OUTER_CONST + 1endConst.new.get_const -> 100Const::CONST -> 100::OUTER_CONST -> 99Const::NEW_CONST = 123
Las variables globales están disponibles a través del programa. Toda referencia a un nombre global en particular devuelve el mismo objeto. La referencia a una variable global no inicializada devuelve nil.
Las variables de clase están disponibles a través de una clase o cuerpo de módulo. Las variables de clase deben inicializarse antes de ser utlizadas. Una variable de clase es compartida por todas las instan-cias de una clase y está disponible dentro de la propia clase.
class Song @@count = 0 def initialize @@count += 1 end def Song.get_count @@count endend
Las variables de clase pertenecen a la clase o módulo más interior en la que están. Las variables de clase utilizadas en el nivel superior se definen en Object y se comportan como variables globales. Las variables de clase definida dentro de los métodos singleton pertenecen al nivel superior (aunque este uso está obsoleto y genera una advertencia). En Ruby 1.9, las variables de clase serán de carácter privado a la clase que la define.
class Holder @@var = 99 def Holder.var=(val) @@var = val end def var @@var endend@@var = “top level variable”a = Holder.new
a.var -> 99
Holder.var = 123a.var -> 123
# This references the top-levelobjectdef a.get_var @@varenda.get_var -> “top level variable”
Las variables de clase son compartidas para los hijos de la clase en que se definieron por primera vez.

223
class Top @@A = 1 def dump puts values end def values “#{self.class.name}: A = #@@A” endendclass MiddleOne < Top @@B = 2 def values super + “, B = #@@B” endendclass MiddleTwo < Top @@B = 3 def values super + “, B = #@@B” endendclass BottomOne < MiddleOne; endclass BottomTwo < MiddleTwo; endTop.new.dumpMiddleOne.new.dumpMiddleTwo.new.dumpBottomOne.new.dumpBottomTwo.new.dump
produce:
Top: A = 1MiddleOne: A = 1, B = 2MiddleTwo: A = 1, B = 3BottomOne: A = 1, B = 2BottomTwo: A = 1, B = 3
Las variables de instancia están disponibles dentro de los métodos de instancia a través del cuerpo de la clase. La referencia a una variable de instancia sin inicializar retorna nil. Cada instancia de una clase tiene un conjunto único de variables de instancia. Las variables de instancia no están disponibles para los métodos de clase (aunque las clases en si mismas puedan tener variables de instancia --se verá más adelante).
Las variables locales son únicas en sus ámbitos que son determinados estáticamente, aunque su existencia se haya establecido de forma dinámica.
Una variable local se crea dinámicamente la primera vez que se le asigna un valor durante la ejecución del programa. Sin embargo, el alcance de una variable local es estáticamente determinado para el bloque más inmediato en el que está englobada, ya sea definición de método, definición de clase, definición de módulo o un programa de nivel superior. Referenciar una variable local para el mismo ámbito pero que aún no se ha creado aún, genera una excepción NameError. Las variables locales con el mismo nombre son variables diferentes si aparecen en ámbitos disjuntos.
Los parámetros de método se consideran variables locales a ese método.
A los parámetros de bloque se les asignan valores cuando se invoca al bloque.
a = [ 1, 2, 3 ]a.each {|i| puts i } # i local to blocka.each {|$i| puts $i } # assigns to global $i

224
a.each {|@i| puts @i } # assigns to instance variable @ia.each {|I| puts I } # generates warning assigning to constanta.each {|b.meth| } # invokes meth= in object bsum = 0var = nila.each {|var| sum += var } # uses sum and var from enclosing scope
Si una variable local (incluido un parámetro de bloque) es asignada primero en un bloque, es local al bloque. Si una variable del mismo nombre ya está establecida en el momento en el bloque se ejecuta, el bloque hereda esa variable.
Un bloque toma el conjunto de variables locales que existen en el momento en que se crea. Esto forma parte de su ligadura. Tenga en cuenta que aunque la unión de las variables se fija en este punto, el bloque tiene acceso a los valores en curso de estas variables cuando se ejecuta. La unión preserva estas varia-bles, aunque el ámbito englobado original se destruye.
Los cuerpos while, until y los bucles for son parte del ámbito que los contiene; los locales ya exis-tentes se pueden utilizar en el bucle y cualquier otro nuevo local creado estará disponible después fuera de los cuerpos.
Variables Predefinidas
Las variables a continuación están predefinidas en el intérprete de Ruby. En las siguientes descripcio-nes, la notación [r/o] indica que las variables son de sólo lectura. Se produce un error si un programa intenta modificar una variable de sólo lectura. Después de todo, probablemente no se desee cambiar el sentido de true a mitad de un programa (excepto, quizás, si se es un político). Las entradas marcadas [hilo] son subprocesos locales.
Muchas variables globales son palabrejas como $_, $!, $&, etc. Esto es por razones “históricas”, ya que la mayoría de estos nombres de variables vienen de Perl. Si usted encuentra difícil memorizar toda esta puntuacion, es posible que desee echar un vistazo al archivo de biblioteca llamado English, documenta-do máss adelante, que da a las variables de uso global más comunes nombres más descriptivos.
En las tablas de variables y constantes que siguen, se muestra el nombre de la variable, el tipo del objeto referenciado y una descripción.
Información de excepción
$! Excepción El objeto de excepción pasó a raise. [hilo]
$@ Array El trazado de pila generado por la última excepción. Ver Kernel#caller más adelante para más detalles. [hilo]
Variables de Coincidencia de Patrones
Estas variables (excepto $=) se ponen a cero después de una comparación de patrón sin éxito.
$& String La cadena coincidente (siguiendo a una comparación de patrón con éxito). Esta variable es local en el ámbito actual. [r/o, hilo]
$+ String El contenido del grupo numerado más alto coincidente tras un comparación de patrón con éxito. Así, en “cat” =~/(c|a)(t|z)/, $+ se establece a “t”. Esta variable es local en el ámbito actual. [r/o, hilo]
$` String La cadena previa a una comparación de patrón con éxito. Esta variable es local en el ámbito actual. [r/o, hilo]
$’ String La cadena siguiente a una comparación de patrón con éxito. Esta variable es local en el ámbito actual. [r/o, hilo]

225
$= Object Obsoleto. Si se establece en cualquier valor, aparte de nil o false, todas las comparaciones de patrón serán case insensitive, en las comparaciones con cadenas y los valores hash de cadena se ignorarán mayúsculas y minúsculas.
$1 to $9 String El contenido de los sucesivos grupos coincidentes en una comparación de patrón con éxito. En “cat” =~/(c|a)(t|z)/, $1 se ajustará a “a” y $2 a “t”. Esta variable es local en el ámbito actual. [r/o, hilo]
$~ Datos coincidentes Un objeto que encapsula los resultados de una comparación de patrón con éxito . Las variables $&, $`, $’, y $1 a $9 se derivan de $~. La asignación de $~ cambia los valores de estas variables derivadas. Esta variable es local en el ámbito actual. [hilo]
Variables de Entrada/Salida
$/ String El separador de registros de entrada (salto de línea por defecto). Este es el valor que las rutinas como Kernel#gets utilizan para determinar los límites de registro. Si se establece a nil, gets va a leer todo el archivo.
$-0 String Sinónimo de $/.
$, String El separador de cadena de salida entre los parámetros a los métodos tales como Kernel#print y Array#join. Por defecto a nil que no añade el texto.
$. Fixnum El número de la última línea a leer del archivo de entrada actual.
$; String El separador de patrón predeterminado utilizado por String#split. Se puede configurar desde la línea de comandos utilizando la opción -F.
$< Object Un objeto que permite el acceso a la concatenación de los contenidos de todos los archivos dados como argumentos de línea de comandos o $stdin (en el caso de que no haya argumentos). $< soporta los métodos similares a un objeto File: binmode, close, closed?, each, each_byte, each_line, eof, eof?, file, filename , fileno, getc, gets, lineno, lineno=, path, pos, pos=, read , readchar, readline, readlines, rewind, seek, skip, tell, to_a, to_i, to_io, to_s, junto con los métodos de Enumerable. El método de fichero retorna un objeto File para el archivo que se está leyendo. [r/o]
$> IO El destino de salida para Kernel#print y Kernel#printf. El valor predeterminado es $stdout.
$_ String La última línea leída por Kernel#gets o Kernel#readline. Muchas de las funciones relacionadas con cadenas en el módulo kernel operan en $_ por defecto. La variable es local en el ámbito actual. [hilo]
$defout IO Sinónimo de $>. Obsoleto: utilizar $stdout.
$deferr IO Sinónimo de STDERR. Obsoleto: utilizar $stderr.
$-F String Sinónimo de $;.
$stderr IO La salida de error estándar en curso.
$stdin IO La entrada estándar en curso.
$stdout IO La salida estándar actual. La asignación a $stdout está obsoleta: utilizar $stdout.reopen en su lugar.

226
Variables de entorno de ejecución
$0 String El nombre del programa de nivel superior Ruby que se está ejecutando. Normalmente , este será el nombre del archivo del programa. En algunos sistemas operativos, la asignación a esta variable va a cambiar el nombre del proceso reportado (por ejemplo ) por el comando ps(1).
$* Array Una matriz de cadenas que contiene las opciones de línea de comandos de la invocación del programa. Las opciones utilizadas por el intérprete Ruby se han eliminado . [r/o]
$” Array Una matriz que contiene los nombres de los módulos cargados por require. [r/o]
$$ Fixnum El número de proceso del programa que se ejecuta. [r/o]
$? Process::Status El estado de salida del último subproceso al terminar. [r/o, hilo]
$: Array Una matriz de cadenas, donde cada cadena especifica un directorio para buscar scripts de Ruby y extensiones binarias utilizados por los métodos load y require. El valor inicial es el valor de los argumentos pasados a través de la opción -I de línea de comandos, seguido de una definición de localización de instalación de la biblioteca estándar, seguido por el directorio actual (“.”). Esta variable se puede establecer dentro de un programa para modificar la ruta de búsqueda por defecto. Por lo general, los programas utilizan $: << dir para añadir dir a la ruta. [r/o]
$-a Object True si se especifica la opción -a en la línea de comandos. [r/o]
$-d Object Sinónimo de $DEBUG.
$DEBUG Object Establecido a true si se especifica la opción -d de línea de comandos.
__FILE__ String El nombre del fichero fuente actual. [r/o]
$F Array La matriz que recibe la línea de entrada dividida si se utiliza la opción -a de línea de comandos.
$FILENAME String El nombre del fichero de entrada actual. Equivalente a $<.filename. [r/o]
$-i String Si el modo edición está activado (tal vez usando la opción -i de línea de comandos), $-i tiene la extensión utilizada al crear el archivo de copia de seguridad. Si establece un valor en $-i, activa el modo de edición. $-I Array Sinónimo de $:. [r/o]
$-K String Establece el sistema de codificación multibyte para las cadenas y expresiones regulares . Equivalente a la opción -K de línea de comandos.
$-l Object Establece a true si la opción -l (que permite el procesamiento de fin de línea) está presente en la línea de comandos.
__LINE__ String El número de línea actual en el fichero fuente. [r/o]
$LOAD_PATH Array Sinónimo de $:. [r/o]
$-p Object Establece a true si la opción -p (que pone un bucle while gets ... end implícito en torno a su programa) está presente en la línea de comandos. [r/o]
$SAFE Fixnum El nivel de seguridad actual. El valor de esta variable nunca puede ser reducido por asignación. [hilo]

227
$VERBOSE Object Se establece en true si la opciónes -v, --version, -W o -w se especifican en la línea de comandos. Se establece en false si no hay opción o se da -W1. Se establece a nil si se ha especificado -W0. El establecer esta opción en true hace que el intérprete y algunas rutinas de biblioteca para proporcionen información adicional. Ajuste a nil suprime todas las advertencias (incluyendo la salida de Kernel.warn). $-v Object Sinónimo de $VERBOSE.
$-w Object Sinónimo de $VERBOSE.
Objetos Estándar
ARGF Object Sinónimo de $<.
ARGV Array Sinónimo de $*.
ENV Object Un objeto hash que contiene las variables de entorno del programa. Una instancia de la clase Object, ENV implementa el conjunto completo de métodos Hash. Se utiliza para consultar y establecer el valor de una variable de entorno, como en ENV[“PATH”] y ENV[“term”]=“ansi”.
false FalseClass Instancia singleton de la clase FalseClass. [r/o]
nil NilClass Instancia singleton de la clase NilClass. El valor de las instancias y las variables globales no inicializadas. [r/o]
self Object El receptor (objeto) del método actual. [r/o]
true TrueClass Instancia singleton del la clase TrueClass. [r/o]
Constantes Globales
Las siguientes constantes están definidas por el intérprete Ruby.
DATA IO Si el el programa principal contiene la directiva __END__, la constante DATA se iniciará de manera que la lectura de la misma retornará la líneas siguientes de __END__ del archivo de fuente.
FALSE FalseClass Sinónimo de false.
NIL NilClass Sinónimo de nil.
RUBY_PLATFORM String El identificador de la plataforma de ejecución del programa. Esta cadena está en la misma forma que el identificador de la plataforma utilizada por la utilidad de configuración de GNU (no es una coincidencia).
RUBY_RELEASE_DATE String La fecha de la liberación actual.
RUBY_VERSION String El número de versión del intérprete.
STDERR IO El flujo de error estándar actual del programa. El valor inicial para $stderr.
STDIN IO El flujo de entrada estándar actual del programa. El valor inicial para $stdin.
STDOUT IO El flujo de salida estándar actual del programa. El valor inicial para $stdout.

228
SCRIPT_LINES__ Hash Si se define una constante SCRIPT_LINES__ y hace referencia a un Hash, Ruby va a almacenar una entrada que contenga el contenido de cada archivo que analiza, con el nombre del archivo como clave y una matriz de cadenas como el valor. Vea Kernel.require más adelante para un ejemplo.
TOPLEVEL_BINDING Binding Un objeto Binding que representa la unión en el nivel superior de Ruby --el nivel en el que los programas son ejecutados inicialmente.
TRUE TrueClass Sinónimo de true.
La constante __FILE__ y la variable $0 se utilizan a menudo en conjunto para ejecutar código sólo si aparece en el archivo ejecutado directamente por el usuario. Por ejemplo, los escritores de librería suelen utilizar esto para incluir pruebas en las bibliotecas que se ejecutarán si la fuente de la biblioteca se ejecuta directamente, pero no si la fuente es necesaria en otro programa.
# library code# ...if __FILE__ == $0 # tests...end
Expresiones
Cualquiera de los siguientes pueden ser términos simples en una expresión:
• Literal. Lliterales de ruby son números, cadenas, arrays, hashes, rangos, símbolos y expresiones regulares.
• El comando Shell. Un comando shell es una cadena encerrada entre apóstrofes o en un delimitador de cadena general que comienza con %x. El valor de la cadena es la salida estándar de ejecución del co-mando representado por la cadena del shell estándar del sistema operativo anfitrión. La ejecución también establece la variable $? con el estado de salida del comando.
filter = “*.c”files = `ls #{filter}`files = %x{ls #{filter}}
• Generador de símbolos. Un objeto Symbol se crea anteponiendole un nombre de operador, cadena, variable, constante, clase o módulo y dos puntos. El objeto símbolo es único para cada diferente nombre, pero no hará referncia a una particular instancia del nombre, sino que el símbolo (por ejemplo) :fred será el mismo independientemente del contexto. Un símbolo es similar al concepto de los átomos en otros lenguajes de alto nivel.
• Referencia a Variable o Constante. Se hace referencia a una variable citando su nombre. Depen-diendo de su ámbito, se hace referencia a una constante, ya sea citando su nombre o por la cualificación del nombre, utilizando el nombre de la clase o módulo que contiene la constante con el operador de ámbito (::).
barney # variable referenceAPP_NAMR # constant referenceMath::PI # qualified constant reference
• Invocación a Método. Hay varias formas para invocar métodos. Se describirán un poco más adelante en su correspondiente sección.

229
Expresiones Operador
Las expresiones pueden combinarse mediante operadores. La tabla 8 muestran los operadores Ruby por orden de precedencia. Los operadores marcados en la columna Método se implementan como métodos y se pueden obviar.
Más sobre la Asignación
El operador de asignación asigna uno o más rvalues (la r significa “right” (derecha), ya que rvalues tienden a aparecer en la parte derecha de la asignación) a uno o más lvalues (valores “left”). Qué significa la asignación depende de cada individual lvalue.
Si un valor a la izquierda es un nombre de variable o constante, dicha variable o constante recibe una referencia al correspondiente valor a la derecha.
a = /regexp/b, c, d = 1, “cat”, [ 3, 4, 5 ]
Si el valor a la izquierda es un atributo de objeto, se llamará al método de configuración de atributo correspondiente en el receptor, pasándole como parámetro el valor a la derecha.

230
obj = A.newobj.value = “hello” # equivalent to obj.value=(“hello”) Si el valor de la izquierda es una referencia a una matriz de elementos, Ruby llama al operador de asig-nación de elementos ([]=) en el receptor, pasándole como parámetros los elementos indexados que apa-rezcan entre los corchetes seguidos del valor de la derecha. Esto se ilustra en la siguiente tabla:
Referencia a Elementos Llamada al Método Actual
obj[] = “one” obj.[]=(“one”) obj[1] = “two” obj.[]=(1, “two”) obj[“a”, /^cat/] = “three” obj.[]=(“a”, /^cat/, “three”)
El valor de una expresión de asignación es el valor a la derecha. Esto es cierto incluso si la asignación es un método de atributo que devuelve algo diferente.
Asignación Paralela
Una expresión de asignación puede tener uno o más valores a la izquierda y uno o más valores a la derecha. En esta sección se explica cómo maneja Ruby la asignación con diferentes combinaciones de argumentos.
•Sielvalorderechoseprecedeconunasteriscoyse implementato_ary, es reemplazado por los elementos de la matriz, con cada elemento formando su propio valor derecho.
•Silaasignacióncontienevariosvaloresalaizquierdayunsolovaloraladerecha,esteseconvierteen un un Array y esta matriz se expande en un conjunto de valores a la derecha, tal como se explica en las páginas 55 y 56.
•Valoressucesivosaladerechaseasignanavaloresalaizquierda.Estaasignaciónefectivamentesucede en paralelo, de modo que (por ejemplo) a,b = b,a intercambia los valores de a y b.
•Sihaymásvaloresalaizquierdaquevaloresaladerecha,elexcesoseráasignadoanil.
•Sihaymásvaloresaladerechaquealaizquierda,elexcesoseráignorado.
•Estasreglassemodificanligeramente,sielúltimovaloralaizquierdaestáprecedidoporunasterisco.Este valor siempre recibirá una matriz durante la asignación. La matriz consistirá de cualquier valor a la derecha que normalmente habría sido asignado a este valor izquierdo, seguido por el exceso de valores a la derecha (si hay).
•Sielvaloralaizquierdacontieneunalistaentreparéntesis,lalistaestratadacomounasentenciadeasignación anidada, y se hace la asignación del valor a la derecha correspondiente como se describe en estas reglas.
Expresiones Bloque
begin bodyend
Las expresiones se pueden agrupar en un bloque begin - end. El valor de la expresión de bloque es el valor de la última expresión ejecutada.
Las expresiones bloque también juegan un papel importante en el manejo de excepciones, que se dis-cutirá un poco más adelante.

231
Expresiones Booleanas
Ruby predefine los valores globales false y nil. Ambos son tratados como si fueran falso en un contexto booleano. Todos los demás valores son tratados como true. La constante true está disponible para cuando se necesita un valor “verdadero” explícito.
And, Or, Not, y Defined?
Los operadores and y && evaluan su primer operando. Si es falso, la expresión devuelve el valor del primer operando, de lo contrario, la expresión devuelve el valor del segundo operando.
expr1 and expr2expr1 && expr2
Los operadores or y || evaluan su primer operando. Si es verdadero, la expresión devuelve el valor de su primer operando, de lo contrario, la expresión devuelve el valor del segundo operando.
expr1 or expr2expr1 || expr2
Los operadores not y ! evaluan su operando. Si es verdadero, la expresión devuelve false. Si es fal-so, la expresión devuelve true. Por razones históricas, una cadena, expresion regular o rango no puede aparecer como el único argumento para not o !.
La formas de palabra de estos operadores (AND, OR y NOT) tienen una menor prioridad que las formas símbolo correspondiente (&&, || y !). Véase la Tabla 8 dos páginas atrás para más detalles.
El operador defined? devuelve nil si su argumento, que puede ser una expresión arbitraria, no está definido. De lo contrario, devuelve una descripción de ese argumento.
Operadores de Comparación
La sintaxis de Ruby define los operadores de comparación ==, ===, <=>, <, <=, >, >= y =~. Todos estos operadores se implementan como métodos. Por convención, el lenguaje también utiliza los métodos es-tándar eql? y equal?. Aunque los operadores tienen un significado intuitivo, le corresponde a las clases que los implementan el producir una semántica de comparación significativa. La referencia de biblioteca más adelante describe la semántica de comparación de las clases integradas. El módulo Comparable proporciona soporte para la implementación de los operadores ==, <, <=, >, >= y el método between? en términos de <=>. El operador === se utiliza en expresiones case, que se describen un poco más adelante.
Los operadores == y =~ tienen las formas negadas != y !~. Ruby los convierte durante el análisis sin-táctico: a != b es mapeado a !(a == b), y a !~ b es mapeado a !(a =~ b). No hay métodos para != y !~.
Rangos en las Expresiones Booleanas
if expr1 .. expr2while expr1 ... expr2
Un rango utilizado en una expresión lógica actúa como un flip-flop. Tiene dos estados, establecido y no establecido y está no establecido inicialmente. En cada llamada, el rango ejecuta una transición en la máqui-na de estados como se muestra en la Figura 16 en la página siguiente. La expresión rango retorna true si la máquina de estados está en estado establecido al final de la llamada, y en caso contrario, retorna false.
La forma de dos puntos de un rango se comporta de forma ligeramente diferente que la forma de tres puntos. La forma de dos puntos hace primero la transición de no establecido a establecido, evalúa de inmediato la condición final y hace la transición en consecuencia. Esto significa que si expr1 y expr2 se evalúan ambas como true en la misma llamada, la forma de dos puntos termina la llamada en el estado no establecido. No obstante, todavía devuelve true para esta llamada.

232
La forma de tres puntos no hace la evaluación de la condición final de inmediato al entrar en el estado establecido.
La diferencia se ilustra con el siguiente código:
a = (11..20).collect {|i| (i%4 == 0)..(i%3 == 0) ? i : nil}a -> [nil, 12, nil, nil, nil, 16, 17, 18, nil, 20]
a = (11..20).collect {|i| (i%4 == 0)...(i%3 == 0) ? i : nil}a -> [nil, 12, 13, 14, 15, 16, 17, 18, nil, 20]
Expresiones Regulares en Expresiones Booleanas
En las versiones de Ruby anteriores de la 1.8, una expresión regular simple en la expresión booleana se comparaba con el valor en curso de la variable $_. Este comportamiento ahora sólo se admite si la condición aparece en el parámetro de línea de comandos -e. En código regular, el uso de $_ y operandos implícitos está siendo eliminado poco a poco, por lo que es mejor usar una comparación explícita con una una variable. Si es necesaria una comparación con $_, utilice
if ~/re/ ... o if $_ =~ /re/ ...
Expresiones if y unless
if boolean-expression [ then | : ] body[ elsif boolean-expression [ then | : ] body , ... ][ else body ]end
unless boolean-expression [ then | : ] body[ else body ]end
La palabra clave then (o el signo :) separa el cuerpo de la condición. No es necesario si el cuerpo comienza en una nueva línea. El valor de una expresión if o unless es el valor de la última expresión evaluada en la ejecución del cuerpo.
Modificadores if y unless
expression if boolean-expressionexpression unless boolean-expression

233
Evalúa la expresión booleana sólo si la expresión es verdadera (para if) o falsa (para unless).
Operador Ternario
boolean-expression ? expr1 : expr2
retorna expr1 si la expresión booleana es verdadera y expr2 de lo contrario.
Expresión case
Ruby tiene dos formas de declaración case. La primera permite una serie de condiciones a evaluar, ejecutando de código correspondiente a la primera condición si esta es verdadera.
casewhen condition [, condition ]... [ then | : ] bodywhen condition [, condition ]... [ then | : ] body ...[ else body ]end
La segunda forma de una expresión case toma una expresión de destino después de la palabra clave case. Se busca una coincidencia, comenzando en la primera comparación (arriba a la izquierda), realizando :
comparison === destino.
case destinowhen comparison [, comparison ]... [ then | : ] bodywhen comparison [, comparison ]... [ then | : ] body ...[ else body ]end
La comparación puede ser una referencia a matriz precedida por un asterisco, en cuyo caso se ex-pande en los elementos de dicha matriz antes de que se realicen las pruebas en cada uno. Cuando la comparación devuelve true, se detiene la búsqueda y se realiza el cuerpo asociado con la comparación (no es necesario un break). case devuelve entonces el valor de la última expresión ejecutada. Si no hay coincidencia con la comparación: si una cláusula else está presente, se ejecuta su cuerpo, de lo contra-rio, silenciosamente case retorna nil.
La palabra clave then (o el signo :) separa las comparaciones cuando (when comparison)de los cuerpos y no es necesario si el cuerpo comienza en una nueva línea.
Bucles
while boolean-expression [ do | : ] bodyend
Ejecuta el cuerpo, cero o más veces, siempre y cuando la expresión booleana es verdadera.
until boolean-expression [ do | : ] bodyend

234
Ejecuta el cuerpo, cero o más veces, siempre y cuando la expresión booleana es falsa.
En ambas formas, el do o dos puntos separan la expresión booleana del cuerpo y se pueden omitir cuando el cuerpo empieza en una línea nueva.
for name [, name ]... in expression [ do | : ] bodyend
El bucle for se ejecuta como si fuera el siguiente bucle each, excepto que las variables locales de-finidas en el cuerpo del bucle estarán disponible fuera del mismo, mientras que no lo estarán para las definidas dentro de un bloque iterador.
expression.each do | name [, name ]... | bodyend
loop, que itera su bloque asociado, no es una construcción del lenguaje --es un método en el módulo Kernel.
loop do print “Input: “ break unless line = gets process(line)end
Modificadores while y until
expression while boolean-expressionexpression until boolean-expression
Si la expresión es otra cosa que un bloque begin/end, se ejecuta la expresión cero o más veces mientras que la expresión booleana es verdadera (para while) o falsa (para until).
Si la expresión es un bloque begin/end, el bloque se ejecutará siempre al menos una vez.
break, redo, next y retry
break, redo, next, y retry alteran el flujo normal a través de un while, until, for o un iterador que controla el bucle.
break termina el bucle inmediatamente englobado --reanuda el control en la siguiente declaración del bloque. redo repite el bucle desde el principio, pero sin volver a evaluar la condición o ir al siguiente elemento (en un iterador). La palabra clave next salta al final del bucle, comienza efectivamente en la siguiente iteración. retry reinicia el bucle, reevaluando la condición. Opcionalmente, break y next pueden tener uno o más argumentos. Si se utiliza dentro de un bloque, el o los argumentos dados se retornan como el valor de producción. Si se usa dentro de un bloque while, until o for, el valor dado a se retorna el valor dado al break como el valor de la declaración, y el valor dado al next se ignora silenciosamente. Si no se llama nunca al break, o si se le llama sin ningún valor, el bucle retorna nil.
match = while line = gets next if line =~ /^#/ break line if line =~ /ruby/ endmatch = for line in ARGF.readlines next if line =~ /^#/ break line if line =~ /ruby/ end

235
Definición de Método
def defname [ ( [ arg [ =val ], ... ] [ , *vararg ] [ , &blockarg ] ) ] bodyend
defname es tanto el nombre del método como opcionalmente, el contexto en el que es válido.
Un nombre-método es otro operador redefinible (véase la tabla 8) o un nombre. Si nombre-método es un nombre, debe comenzar con una letra minúscula (o guión bajo), seguido opcionalmente por letras mayúsculas y minúsculas, guiones bajos y dígitos. Opcionalmente un nombre-método puede terminar con un signo de interrogación (?), signo de exclamación (!), o signo igual (=). El signo de interrogación y de exclamación son simplemente parte del nombre. El signo de igualdad es también parte del nombre, pero, además, señala que este método puede ser utilizado como un valor a la izquierda que tiene un correspon-diente valor asignado a la derecha.
Una definición de método utilizando un nombre sin adornos dentro de una definición de clase o módulo crea un método de instancia, que sólo puede ser invocado mediante el envío de este nombre a un receptor que es una instancia de la clase que lo define (o una de las subclases de esa clase).
Fuera de una definición de clase o módulo, una definición con un nombre de método sin adornos, se añade como un método privado a la clase Object, y por lo tanto puede ser llamado en cualquier contexto sin un receptor explícito.
Una definición que utiliza un nombre de método de la forma constante.nombremetodo o la más general (expr).nombremetodo crea un método asociado con el objeto que es el valor de la constante o de la ex-presión. A este método sólo se le podrá llamar suministrandole como receptor el objeto referenciado por la expresión. Este es el estilo de definición creada por objeto o método singleton.
class MyClass def MyClass.method # definición endendMyClass.method # llamadaobj = Object.newdef obj.method # definiciónendobj.method # llamadadef (1.class).fred # el receptor puede ser una expresiónendFixnum.fred # llamada
Las definiciones de métodos no pueden contener definiciones de clase o módulo. Pueden contener definiciones de instancia anidada o de métodos singleton. Se define un método interno cuando se ejecuta el método que lo contiene. El método interno no actúa como un cierre en el contexto del método anidado --es autónomo.def toggle def toggle “subsequent times” end “first time”end
toggle -> “first time”toggle -> “subsequent times”toggle -> “subsequent times”
El cuerpo de un método actúa como si se tratara de un bloque de begin/end, ya que puede contener declaraciones de manejo de excepción (rescue, else y ensure).

236
Argumentos de Método
Una definición de método puede tener cero o más argumentos regulares, un argumento matriz opcional y un argumento bloque opcional. Los argumentos están separados por comas y se puede encerrar entre paréntesis una lista de argumentos.
Un argumento regular es un nombre de variable local opcionalmente seguido por un signo igual y una expresión que da un valor por defecto. La expresión se evalúa en el momento que se llama al método. Las expresiones se evalúan de izquierda a derecha y una expresión puede hacer referencia a un parámetro que le precede en la lista de argumentos.
def options(a=99, b=a+1) [ a, b ]endoptions -> [99, 100]options 1 -> [1, 2]options 2, 4 -> [2, 4]
El argumento matriz opcional debe seguir a cualquier argumento regular y no pueden haber uno pre-determinado. Cuando se invoca al método, Ruby establece el argumento matriz para que referencie a un nuevo objeto de la clase Array. Si la llamada al método especifica algún parámetro de más en la cuenta de argumentos regulares, todos estos parámetros adicionales se recogen en esta matriz recién creada.
def varargs(a, *b) [ a, b ]endvarargs 1 -> [1, []]varargs 1, 2 -> [1, [2]]varargs 1, 2, 3 -> [1, [2, 3]]
Si un argumento matriz sigue a los argumentos con valores por defecto, los primeros parámetros que se pasen se utilizarán para reemplazar a los valores por defecto. El resto será utilizado para rellenar la matriz.
def mixed(a, b=99, *c) [ a, b, c]endmixed 1 -> [1, 99, []]mixed 1, 2 -> [1, 2, []]mixed 1, 2, 3 -> [1, 2, [3]]mixed 1, 2, 3, 4 -> [1, 2, [3, 4]]
El argumento bloque opcional debe ser el última en la lista. Cada vez que se llama a un método, Ruby busca un bloque asociado. Si hay un bloque, se convierte en un objeto de la clase Proc y se asigna al argumento bloque. Si no hay ningún bloque, el argumento se establece a nil.
def example(&block) puts block.inspectendexampleexample { “a block” }
produce:
nil#<Proc:0x001c9940@:-6>

237
Invocación de un Método
[ receiver. ] name [ parameters ] [ block ][ receiver:: ] name [ parameters ] [ block ]
parameters <-- ( [ param, ... ] [ , hashlist ] [ *array ] [ &a_proc ] )
block <-- { blockbody } do blockbody end
Se asignan parámetros iniciales a los argumentos reales del método. Lo siguiente a estos parámetros puede ser una lista de pares clave => valor. Estos pares se recogen en un único objeto Hash nuevo y se pasan como un parámetro único.
Y siguiendo a estos parámetros puede haber un parámetro único precedido de un asterisco. Si este parámetro es una matriz, Ruby lo reemplaza con cero o más parámetros correspondientes a los elementos de la matriz.
def regular(a, b, *c) # ...endregular 1, 2, 3, 4regular(1, 2, 3, 4)regular(1, *[2, 3, 4])
Un bloque puede estar asociado con una llamada al método utilizando ya sea un bloque literal (que debe comenzar en la misma línea fuente que la última línea de la llamada al método), o ya sea un pa-rámetro que contiene una referencia a un objeto Proc o Method prefijado con un signo &. Indepen-dientemente de la presencia de un argumento bloque, Ruby se encarga del valor de la función global Kernel.block_given? para reflejar la disponibilidad de un bloque asociado con la llamada.
a_proc = lambda { 99 }an_array = [ 98, 97, 96 ]def block yieldendblock { }block do endblock(&a_proc)def all(a, b, c, *d, &e) puts “a = #{a.inspect}” puts “b = #{b.inspect}” puts “c = #{c.inspect}” puts “d = #{d.inspect}” puts “block = #{yield(e).inspect}”endall(‘test’, 1 => ‘cat’, 2 => ‘dog’, *an_array, &a_proc)
produce:
a = “test”b = {1=>”cat”, 2=>”dog”}c = 98d = [97, 96]block = 99
Se llama a un método pasando su nombre a un receptor. Si no se especifica un recptor, se asume self. El receptor comprueba la definición del método en su propia clase y luego sus clases anteceso-ras de forma secuencial. Los métodos de instancia de módulos incluidos actúan como si estuvieran en

238
superclases anónimas de la clase que los incluye. Si no se encuentra el método, Ruby invoca al método method_missing en el receptor. El comportamiento predeterminado que se define en Kernel.method_missing es para informar de un error y terminar el programa.
Cuando se especifica un receptor explícitamente en una invocación a método, puede ser separado del nombre del método utilizando un punto “.” o un signo dos puntos doble “::”. La única diferencia entre estas dos formas se produce si el nombre del método comienza con una letra mayúscula. En este caso, Ruby asume que esta llamada a método receptor::Loquesea es realmente un intento de acceder a una constante llamada Loquesea en el receptor a menos que la invocación al método lleve una lista de parámetros entre paréntesis.
Foo.Bar() # llamada a métodoFoo.Bar # llamada a métodoFoo::Bar() # llamada a métodoFoo::Bar # acceso a constante
El valor de retorno de un método es el valor de la última expresión ejecutada.
return [ expr, ... ]
Una expresión return sale inmediatamente de un método. Si se llama sin parámetros, el valor de return es nil. Si se llama con un parámetro es el valor de este parámetro y si se llama con más de un parámetro es una matriz que contiene todos los parámetros.
super
super [ ( [ param, ... ] [ *array ] ) ] [ block ]
Dentro del cuerpo de un método, una llamada a super actúa igual que una llamada a ese método ori-ginal, excepto que la búsqueda de un cuerpo de método se inicia en la superclase del objeto que contiene el método original. Si no se pasan parámetros a super (y no hay paréntesis), se pasarán los parámetros del método original, de lo contrario, se pasarán los parámetros de super.
Métodos de Operador
expr1 operatoroperator expr1expr1 operator expr2
Si el operador en una expresión de operador corresponde a un método redefinible (véase la tabla 8), Ruby ejecutará la expresión de operador como si se hubiera escrito
(expr1).operator(expr2)
Asignación de Atributos
receptor.nombreattr = rvalue
Cuando la forma receptor.nombreattr aparece como un valor a la izquierda, Ruby invoca a un método llamado nombreattr= en el receptor, pasandole el valor a la derecha como un único parámetro. El valor devuelto por esta asignación es siempre el valor derecho --se descarta el valor de retorno del método nom-breatrr=. Si desea acceder el valor de retorno (en el improbable caso de que éste no sea el valor derecho), envíe un mensaje explícito al método.
class Demo attr_reader :attr def attr=(val) @attr = val “return value”

239
endend
d = Demo.new
# En todos estos casos, @attr es establecido a 99d.attr = 99 -> 99d.attr=(99) -> 99d.send(:attr=, 99) -> “return value”d.attr -> 99
Operador de Referencia a Elemento
receptor[ expr [, expr ]... ]receptor[ expr [, expr ]... ] = rvalue
Cuando se utiliza como un valor a la derecha, el elemento de referencia invoca el método [] en el re-ceptor, pasando como parámetros las expresiones entre paréntesis.
Cuando se utiliza como un valor a la izquierda, el elemento de referencia invoca al método []= en el recep-tor, pasando como parámetros las expresiones entre paréntesis, seguido por el valor asignado a la derecha.
Alias
alias new_name old_name
Crea un nombre nuevo que se refiere a un método, operador, variable global o referencia a expresión regular ($&, $`, $’ y $+) ya existentes. Las variables locales, variables de instancia, variables de clase, y las constantes no pueden ser un alias. Los parámetros para alias pueden ser nombres o símbolos.
class Fixnum alias plus +end1.plus(3) -> 4alias $prematch $`“string” =~ /i/ -> 3$prematch -> “str”
alias :cmd :`cmd “date” -> “Thu Aug 26 22:37:16 CDT 2004\n”
Cuando se crea un alias de un método, el nombre nuevo se refiere a una copia del cuerpo del método original. Si se redefine el método posteriormente, el alias aún invoca a la implementación original.
def meth “original method”endalias original methdef meth “new and improved”endmeth -> “new and improved”original -> “original method”
Definición de Clase
class [ scope:: ] classname [ < superexpr ] bodyend

240
class << obj bodyend
Una definición de clase crea o extiende un objeto de la clase Class mediante la ejecución del código en el cuerpo. En la primera forma, se crea o extiende una clase llamada class. El Objeto Class resultante se asigna a una constante llamada nombreclase (ver más abajo las normas de ambito). Este nombre debe comenzar con una letra mayúscula. En la segunda forma, una clase anónima (singleton) se asocia con el objeto específico.
Si está presente, superexpr debería ser una expresión que se evalúa como un objeto Class que será la superclase de la clase que se define. Si se omite, es de la clase Object por defecto.
Dentro del cuerpo, la mayoría de las expresiones Ruby se ejecutan como la definición que se lee. Sin embargo:
•Lasdefinicionesdemétodoregistraránlosmétodosenunatablaenlaclasedelobjeto.
•Lasdefinicionesdeclaseymóduloanidadasseguardaránenconstantesdentrodelaclase,peronosonconstantes globales. Estas clases y módulos anidados se pueden acceder desde fuera de la clase que las define utilizando “::” para calificar sus nombres.
module NameSpace class Example CONST = 123 endendobj = NameSpace::Example.newa = NameSpace::Example::CONST
•ElmétodoModule#include añade los módulos nombrados como superclases anónimas de la clase que se define.
En una definición de clase, el nombreclase puede ser precedido por los nombres de las clases o módu-los existentes utilizando el operador de ámbito (::). Esta sintaxis inserta la nueva definición en el espacio de nombres del módulo o módulos, clase o clases prefijados, pero no interpreta la definición en el ámbito de estas clases externas. Un nombreclase con un operador inicial de ámbito coloca a la clase o módulo en el ámbito de nivel superior.
En el ejemplo siguiente, la clase C se inserta en el espacio de nombres del módulo A, pero no se in-terpreta en el contexto de A. Como resultado de ello, la referencia a CONST se resuelve a la constante de nivel superior de ese nombre. También hay que calificar completamente el nombre del método singleton, ya que C por sí sola no es una constante conocida en el contexto de A::C.
CONST = “outer”module A CONST = “inner” # This is A::CONSTendmodule A class B def B.get_const CONST end endend
A::B.get_const -> “inner”
class A::C

241
def (A::C).get_const CONST endend
A::C.get_const -> “outer”
Vale la pena destacar que una definición de clase es el código ejecutable. Muchas de las directrices utilizadas en la definición de clase (como attr e include) son en realidad simples métodos privados de instancia de la clase Module (documentada más adelante).
El capítulo sobre Clases y Objetos que comienza un poco más adelante, describe con más detalle cómo los objetos Class interactuan con el resto del entorno.
Creación de Objetos de Clases
obj = classexpr.new [ ( [ args, ... ] ) ]
La clase de Class define el método de instancia Class#new, que crea un objeto de la clase del recep-tor (classexpr en el ejemplo de sintaxis). Esto se hace llamando al método classexpr.allocate. Se puede obviar este método, pero su implementación debe devolver un objeto de la clase correcta. A conti-nuación se invoca a initialize en el objeto recién creado pasándole a new los argumentos originales.
Si una definición de clase anula el método de clase new sin llamar a super, no se pueden crear los objetos de esa clase y las llamadas a new silenciosamente retornaran nil.
Al igual que cualquier otro método, initialize debe llamar a super si se quiere garantizar que las clases padres han sido correctamente inicializadas. Esto no es necesario cuando el padre es Object, ya que la clase Object no hace inicialización de una específica instancia.
Declaraciones de Atributos de Clase
Las declaraciones de atributos de clase no forman parte de la sintaxis de Ruby: son simplemente mé-todos definidos en la clase Module que crea métodos accesores de forma automática.
class name attr attribute [ , writable ] attr_reader attribute [, attribute ]... attr_writer attribute [, attribute ]... attr_accessor attribute [, attribute ]...end
Definiciones de Módulo
module name bodyend
Un módulo es básicamente una clase que no puede ser instanciada. Al igual que una clase, su cuerpo se ejecuta durante la definición y el objeto Module resultante se almacena en una constante. Un módulo puede contener métodos de clase y de instancia y puede definir constantes y variables de clase. Al igual que con las clases, los métodos de módulo se invoca utilizando el objeto Module como un receptor y las constantes son accesibles usando el operador “::” de resolución de ámbito. El nombre de una definición de módulo opcionalmente puede ser precedido por los nombres de la clase o clases y/o módulo o módulos que lo engloban.
CONST = “outer”module Mod CONST = 1

242
def Mod.method1 # module method CONST + 1 endendmodule Mod::Inner def (Mod::Inner).method2 CONST + “ scope” endendMod::CONST -> 1Mod.method1 -> 2Mod::Inner::method2 -> “outer scope”
Mixins --Incluyendo los Módulos
class|module name include exprend
Un módulo puede ser incluido en la definición de otro módulo o clase utilizando el método include. El módulo o clase que contiene el include gana el acceso a las constantes, variables de clase y los méto-dos de instancia del módulo que incluye.
Si un módulo se incluye dentro de una definición de clase, las constantes del módulo, las variables de clase y los métodos de instancia son efectivamente ligados en un anónima (e inaccesible) superclase de esa clase. Los objetos de la clase responderán a los mensajes enviados a los métodos de instancia del módulo. Las llamadas a métodos no definidos en la clase se pasan al módulo (o módulos) mezclado en la clase, antes de ser enviados a cualquier clase padre. Un módulo puede optar por definir un método initialize , que llamará a la creación de un objeto de una clase mezclada con el módulo si: (a) la clase no define su método initialize propio, o (b) el método initialize de la clase invoca a super.
Un módulo puede ser incluido también en el nivel superior, en cuyo caso las constantes, las variables de clase y los métodos de instancia del módulo estarán disponibles en el nivel superior.
Funciones de Módulo
A pesar de que include es útil para proporcionar la funcionalidad de mixin, también es una forma de llevar las constantes, variables de clase y los métodos de instancia de un módulo, a otro espacio de nombres. Sin embargo, la funcionalidad definida en un método de instancia no estará disponible como un método de módulo.
module Math def sin(x) # endend# La única forma de acceder a Math.sin es...include Mathsin(1)
El método Module#module_function resuelve este problema tomando uno o más métodos de ins-tancia del módulo y copiando sus definiciones en los correspondientes métodos de módulo.
module Math def sin(x) # end module_function :sinendMath.sin(1)

243
include Mathsin(1)
El método de instancia y el método de módulo son dos métodos diferentes: la definición del método ha sido copiada por module_function, no es un alias.
Control de Acceso
Ruby define tres niveles de protección para las constantes y métodos de clase y de módulo:
• Público. Accesibles a cualquiera.
• Protegido. Sólo pueden ser invocados por los objetos de la clase que define y sus subclases.
• Privado. Sólo se pueden llamar en forma funcional (es decir, con un self implícito como receptor). Los métodos privados por lo tanto, sólo se pueden llamar en la clase que define y por los descendientes directos dentro del mismo objeto. Véase la descripción que comienza en la página 17 para ver ejemplos.
private [ symbol, ... ]protected [ symbol, ... ]public [ symbol, ... ]
Cada función se puede utilizar de dos maneras diferentes.
1. Si se utiliza sin argumentos, las tres funciones establecen el control de acceso por defecto de los métodos definidos posteriormente.
2. Con argumentos, las funciones establecen el control de acceso de los métodos y constantes nombrados .
El control de acceso se aplica cuando se invoca un método.
Bloques, Cierres y Objetos Proc
Un bloque de código es un conjunto de declaraciones y expresiones Ruby entre llaves o entre un par do/end. El bloque puede comenzar con una lista de argumentos entre barras verticales. Un bloque de código sólo puede aparecer inmediatamente después de una invocación de método. El inicio del bloque (la llave o el do) debe estar en la misma línea lógica que el final de la invocación.
invocation do | a1, a2, ... |end
invocation { | a1, a2, ... |}
Las llaves tienen prioridad alta y el do tiene baja prioridad. Si la invocación del método tiene paráme-tros que no se están entre paréntesis, la forma de bloque entre llaves se unirá al último parámetro, no a la invocación total. La forma do se unirá a toda la invocación.
Dentro del cuerpo del método invocado, se puede llamar al bloque de código con la palabra clave yield. Los parámetros pasados a yield se asignarán a los argumentos en el bloque. Se generará una advertencia si yield pasa varios parámetros a un bloque que tiene sólo uno. El valor de retorno de yield es el valor de la última expresión evaluada en el bloque o el valor pasado a la sentencia next ejecutada en el bloque.
Un bloque es un cierre; recuerda el contexto en el que se define y utiliza ese contexto cada vez que se le llama. El contexto incluye el valor de self, las constantes, las variables de clase, las variables locales y de cualquier bloque capturado.

244
class Holder CONST = 100 def call_block a = 101 @a = 102 @@a = 103 yield endendclass Creator CONST = 0 def create_block a = 1 @a = 2 @@a = 3 proc do puts “a = #{a}” puts “@a = #@a” puts “@@a = #@@a” puts yield end endendblock = Creator.new.create_block { “original” }Holder.new.call_block(&block)
produce:
a = 1@a = 2@@a = 3original
Objetos Proc, break y next
Los bloques de Ruby son trozos de código asociados a un método que operan en el contexto del lla-mador. Los bloques no son objetos pero pueden ser convertidos en objetos de la clase Proc. Hay tres maneras de convertir un bloque en un objeto Proc.
1. Pasando el bloque a un método cuyo último parámetro se precede con un signo &. Ese parámetro recibe el bloque como un objeto Proc.
def meth1(p1, p2, &block) puts block.inspectendmeth1(1,2) { “a block” }meth1(3,4)
produce:
#<Proc:0x001c9940@-:4>nil
2. Llamando Proc.new, asociándole de nuevo con un bloque
block = Proc.new { “a block” }block -> #<Proc:0x001c9ae4@-:1>
3. Al llamar al método Kernel.lambda (o el equivalente Kernel.proc) por la asociación de un

245
bloque con la llamada.
block = lambda { “a block” }block -> #<Proc:0x001c9b0c@-:1>
Los dos primeros estilos de objeto Proc son idénticos en su uso. Vamos a llamar a estos objetos procs crudos. El tercer estilo, generado por lambda, añade algunas funciones adicionales al objeto Proc, como veremos en un minuto. Llamaremos a estos objetos lambdas.
Dentro de cada tipo de bloque, la ejecución de next causa la salida del bloque. El valor del bloque es el valor (o valores) pasados a next o nil si no se pasan valores.
def meth res = yield “The block returns #{res}”end
meth { next 99 } -> “The block returns 99”
pr = Proc.new { next 99 }pr.call -> 99
pr = lambda { next 99 }pr.call -> 99
Dentro de un proc crudo, el break termina el método que invocó el bloque. El valor de retorno del mé-todo son los parámetros pasados a break.
Bloques y Retorno
Un retorno desde el interior de un bloque que aún está en en un ámbito actúa como un retorno de ese ám-bito. El retorno de un bloque cuyo contexto original ya no es válido lanza una excepción (LocalJumpError o ThreadError dependiendo del contexto). El siguiente ejemplo ilustra el primer caso.
def meth1 (1..10).each do |val| return val # returns from method endendmeth1 -> 1
Este ejemplo muestra un retorno fallido porque el contexto de su bloque ya no existe.
def meth2(&b) bendres = meth2 { return }res.call
produce:
prog.rb:5: unexpected return (LocalJumpError)from prog.rb:5:in `call’from prog.rb:6
Y aquí hay un retorno fallido porque el bloque se crea en un hilo y la llamada en otro.
def meth3 yieldend

246
t = Thread.new do meth3 { return }endt.join
produce:
prog.rb:6: return can’t jump across threads (ThreadError)from prog.rb:9:in `join’from prog.rb:9
La situación de los objetos Proc es un poco más complicada. Si utiliza Proc.new para crear un proc de un bloque, este proc actúa como un bloque y se aplican las reglas anteriores.
def meth4 p = Proc.new { return 99 } p.call puts “Never get here”end
meth4 -> 99
Si el objeto Proc es creado usando Kernel.proc o Kernel.lambda, se comporta más como un cuerpo de método independiente: un return simplemente retorna desde el bloque a la llamada del blo-que.
def meth5 p = lambda { return 99 } res = p.call “The block returned #{res}”end
meth5 -> “The block returned 99”
Debido a esto, si se utiliza Module#define_method, es probable que se le quiera pasar un proc crea-do con lambda, no con Proc.new, ya que el retorno funcionará como se espera en el primero y generará un LocalJumpError en el segundo.
Excepciones
Las excepciones Ruby son objetos de la clase Exception y sus descendientes (la lista completa de las excepciones integradas se dá más adelante).
Levantamiento de Excepciones
El método Kernel.raise lanza una excepción.
raiseraise stringraise thing [ , string [ stack trace ] ]
La primera forma resube la excepción en $! o una nueva RuntimeError si $! es nil.
La segunda forma crea una nueva excepción RuntimeError, estableciendo su mensaje en la cadena dada.
La tercera forma crea un objeto excepción invocando al metodo exception en su primer argumento. A continuación, establece el mensaje de esta excepción y hace la traza de sus argumentos segundo y tercero.

247
La clase Exception y los objetos de esta clase contienen un método de fábrica denominado exception , por lo que el mismo nombre de clase o instancia se puede utilizar como primer parámetro para levantar una excepción.
Cuando se lanza una excepción, Ruby coloca una referencia al objeto excepcion en la variable global $!.
Manejo de Excepciones
Las excepciones se pueden manejar:
•enelámbitodeunbloquebegin/end,
begin code... code...[ rescue [ parm, ... ] [ => var ] [ then ] error handling code... , ... ][ else no exception code... ][ ensure always executed code... ]end
•dentrodelcuerpodeunmétodo
def method and args code... code...[ rescue [ parm, ... ] [ => var ] [ then ] error handling code... , ... ][ else no exception code... ][ ensure always executed code... ]end
•ydespuésdelaejecucióndeunasentenciaúnica.
statement [ rescue statement, ... ]
Un bloque o método puede tener varias cláusulas de rescate, y cada cláusula de rescate puede es-pecificar cero o más parámetros de excepción. Una cláusula de rescate sin parámetros se trata como si fuera un parámetro de StandardError. Esto significa que algunas excepciones de menor nivel no serán capturadas por una clase rescue sin parámetros. Si se quiere rescatar todas las excepciones hay que utilizar
rescue Exception => e
Cuando se lanza una excepción, Ruby escanea la pila de llamadas hasta que encuentra un bloque begin/end, un cuerpo de método o la declaración con un modificador de rescate. Para cada cláusula de rescate en ese bloque, Ruby compara la excepción levantada contra cada uno de los parámetros de la cláusula de rescate. Cada parámetro se pone a prueba utilizando parámetro===$!. Si la excepción planteada coincide con un parámetro de rescue, Ruby ejecuta el cuerpo del rescue y deja de buscar. Si una cláusula de rescate encontrada termina con => y un nombre de variable, la variable se establece en $!.
Aunque los parámetros de la cláusula de rescate suelen ser los nombres de las clases Exception, en realidad pueden ser expresiones arbitrarias (incluyendo llamadas a métodos) que retornan una clase apropiada.

248
Si no se encuentra cláusula de rescate coincidente con la excepción levantada, Ruby se mueve hacia arriba de la pila buscando un bloque begin/end de nivel superior que coincida. Si una excepción se propa-ga al nivel superior del hilo principal sin ser rescatada, el programa termina con un mensaje.
Si está presente una cláusula else, se ejecuta su cuerpo si no se plantearon excepciones en el código. Las excepciones lanzadas durante la ejecución de la cláusula else no son capturadas por cláusulas de rescate en el mismo bloque del else.
Si está presente una cláusula ensure, se ejecuta siempre su cuerpo cuando se abandona el bloque (incluso si hay una excepción no capturada en proceso de propagarse).
Dentro de una cláusula rescue, raise sin parámetros relanza la excepción en $!.
Modificadores de Rescate de Declaración
Una declaración puede tener un modificador rescue opcional seguido de otra sentencia (y por exten-sión un nuevo modificador rescue y así sucesivamente). El modificador rescue no tiene parámetro de excepción y rescata StandardError y sus subprocesos hijos.
Si se lanza una excepción a la izquierda de un modificador rescue, se abandona la declaración de la izquierda y el valor de la línea total es el valor de la declaración de la derecha.
values = [ “1”, “2.3”, /pattern/ ]
result = values.map {|v| Integer(v) rescue Float(v) rescue String(v) }
result -> [1, 2.3, “(?-mix:pattern)”]
Intentando de nuevo un bloque
La declaración retry se puede utilizar dentro de una cláusula rescue para reiniciar el bloque begin/end englobado desde el principio.
Agarrar y Tirar
El método Kernel.catch ejecuta su bloque asociado.
catch ( symbol | string ) do block...end
El método Kernel.throw interrumpe el proceso normal de una sentencia.
throw( symbol | string [ , obj ] )
Cuando se ejecuta throw, Ruby busca en la pila de llamadas el primer bloque catch con un símbolo o cadena coincidente. Si se encuentra, la búsqueda se detiene y se reanuda la ejecución más allá del final del bloque de la capturado. Si al throw se le pasó un segundo parámetro, se devuelve ese valor como el valor del catch. Ruby hacer honor a las cláusulas ensure de cualquier bloque de expresiones que atra-viesa en la búsqueda de un correspondiente catch.
Si no hay ningún bloque catch que coincide con el throw, Ruby lanza una excepción NameError en la ubicación del throw.
Duck Typing Usted habrá notado que en Ruby no se declaran los tipos de variables o de métodos --todo es simple-mente un tipo de objeto.

249
Ahora, parece que la gente reacciona a esto de dos maneras. A algunos les gusta este tipo de flexi-bilidad y se sienten cómodos escribiendo código con variables y métodos de tipados dinámicamente. Si eres uno de estos, es posible que desees pasar a la sección llamada “Clases no son Tipos” en la página siguiente. Algunos sin embargo, se ponen nerviosos cuando piensan en todos los objetos que flotan alre-dedor sin restricciones. Si usted ha llegado a Ruby a partir de un lenguaje como C# o Java, en los que es-tamos acostumbrados a dar a todas los métodos y variables un tipo, puede sentir que Ruby es demasiado descuidado para utilizarlo en la escritura “real” de aplicaciones.
No lo es.
Nos gustaría pasar un par de párrafos tratando de convencerle de que la falta de tipos estáticos no es un problema cuando se trata de escribir aplicaciones confiables. No estamos tratando de criticar a otros lenguajes aquí. En su lugar, sólo dar un contraste de enfoques.
La realidad es que los sistemas de tipo estático en la mayoría de los principales lenguajes, no ayudan mucho en términos de seguridad del programa. Si el sistema de tipos Java fuera fiable, por ejemplo, no sería necesario implementar ClassCastException. La excepción es necesaria, sin embargo, porque en Java hay incertidumbre de tipo en tiempo de ejecución (como lo hay en C++, C# y otros). El tipado estáti-cos puede ser bueno para la optimización de código, y puede ayudar a los IDEs a hacer cosas inteligentes con herramientas de información, pero no hemos visto mucha evidencia de que promueva un código más seguro.
Por otro lado, una vez que se utiliza Ruby por un tiempo, se cae en cuenta de que el tipado dinámico de las variables en realidad agrega productividad de muchas maneras. También se sorprende uno al descu-brir que sus temores sobre el caos de tipos eran infundados. Grandes y de larga duración, los programas Ruby ejecutan aplicaciones importantes y simplemente no arrojan ningún tipo de error relacionado. ¿Por qué es esto?
En parte, es una cuestión de sentido común. Si se ha codificado en Java (Java pre 1.5), todos los con-tenedores efectivamente no eran tipados: todo en un contenedor era sólo un Object, y se conviertía al tipo necesario en la extracción de un elemento. Y sin embargo, no se mostraba un ClassCastException al ejecutar estos programas. La estructura del código simplemente no lo permite: se ponen en objetos Per-son y más tarde se toman o se llevan a cabo los objetos Person. Simplemente no se escriben programas que trabajan de otra manera.
Bueno, es igual en Ruby. Si se utiliza una variable para algún propósito, hay muchas posibilidades de que se estará usando para la misma finalidad cuando se acceda de nuevo tres líneas más adelante. El tipo de caos que podría producirse simplemente no ocurre.
Además de eso, mucha de la gente que codifica en Ruby tiende a adoptar un cierto estilo de codifica-ción. Escriben un montón de métodos en corto y los prueban sobre la marcha. Métodos en corto significa que el alcance de la mayoría de las variables es limitado: simplemente no hay mucho tiempo para que las cosas vayan mal con su tipo. Y las pruebas capturan los errores tontos cuando suceden: errores ortográ-ficos y demás simplemente no tienen la oportunidad de propagarse a través del código.
El resultado es que la “seguridad” en “la seguridad de tipos” es a menudo ilusoria y que la codificación en un lenguaje más dinámico como Ruby es segura y productiva. Por lo tanto, si nos hemos puesto ner-viosos por la falta de tipos estáticos en Ruby, le sugerimos que trate de poner estas preocupaciones en un segundo plano por un tiempo para darle una oportunidad a Ruby. Creemos que usted se sorprenderá de cuán raramente aparecen errores debido a problemas de tipo, y en lo productivo que será una vez que comience a explotar el poder del tipado dinámico.
Clases no son Tipos
La cuestión de los tipos es en realidad algo más profunda que un debate entre los defensores del tipado fuerte y la gente hippie-freak del tipado dinámico. El verdadero problema es la cuestión de que es un tipo en primer lugar?
Si usted ha estado programando en lenguajes con tipos convencionales, lo que le ha sido enseñado es que el tipo de un objeto es su clase --todos los objetos son instancias de alguna clase y la clase es el tipo

250
de objeto. La clase define las operaciones (métodos) que el objeto soporta, junto con el estado (variables de instancia) en la que los métodos funcionan. Vamos a ver algo de código Java.
Customer c;c = database.findCustomer(“dave”); /* Java */
En este fragmento se declara la variable c para ser de tipo Customer, y se establece como referencia el objeto customer para Dave que hemos creado a partir de un registro de base de datos. Por lo que el tipo de objeto en c es Customer, ¿verdad?
Tal vez. Sin embargo, incluso en Java, el tema es un poco más profundo. Java soporta el concepto de interfaces, que son una especie de clase base abstracta mutilada. Una clase Java puede ser declarada como la implementación de múltiples interfaces. Al utilizar esta característica, es posible que se hayan definido las clases de la siguiente manera:
public interface Customer { long getID(); Calendar getDateOfLastContact(); // ...}public class Person implements Customer { public long getID() { ... } public Calendar getDateOfLastContact() { ... } // ...}
Así que incluso en Java, la clase no siempre es el tipo --a veces el tipo es un subconjunto de la clase, y en ocasiones objetos implementan varios tipos.
En Ruby, la clase no es (bueno, casi nunca) el tipo. En cambio, el tipo de un objeto se define más por lo que ese objeto puede hacer. En Ruby, llamamos a esto duck typing. Si un objeto camina como un pato y habla como un pato, entonces, el intérprete se siente feliz de tratarlo como si fuera un pato.
Veamos un ejemplo. Tal vez hemos escrito un método para escribir el nombre de nuestros clientes al final de un archivo abierto.
class Customer def initialize(first_name, last_name) @first_name = first_name @last_name = last_name end def append_name_to_file(file) file << @first_name << “ “ << @last_name endend
Para ser buenos programadores, vamos a escribir una prueba unitaria para esto. Hay que ser prevenido --es complicado (pero vamos a mejorar en breve).
require ‘test/unit’require ‘addcust’class TestAddCustomer < Test::Unit::TestCase def test_add c = Customer.new(“Ima”, “Customer”) f = File.open(“tmpfile”, “w”) do |f| c.append_name_to_file(f) end f = File.open(“tmpfile”) do |f| assert_equal(“Ima Customer”, f.gets)

251
end ensure File.delete(“tmpfile”) if File.exist?(“tmpfile”) endend
produce:
Finished in 0.003473 seconds.1 tests, 1 assertions, 0 failures, 0 errors
Tenemos que hacer todo este trabajo para crear un archivo para escritura, volverlo a abrir y leer el con-tenido para verificar que se ha escrito la cadena correcta. También tenemos que eliminar el archivo cuando se haya terminado (pero sólo si existe).
En su lugar, sin embargo, podemos confiar en el tipado pato. Todo lo que necesitamos es algo que camina como un archivo y habla como un archivo que puede pasar al método bajo prueba. Y todo esto significa que en esta circunstancia necesitamos un objeto que responde al método << añadiendo algo. ¿Tenemos algo que hace esto? ¿Qué tal un humilde String?
require ‘test/unit’require ‘addcust’class TestAddCustomer < Test::Unit::TestCase def test_add c = Customer.new(“Ima”, “Customer”) f = “” c.append_name_to_file(f) assert_equal(“Ima Customer”, f) endend
produce:
Finished in 0.001951 seconds.1 tests, 1 assertions, 0 failures, 0 errors
El método bajo prueba piensa que está escribiendo en un archivo, pero en su lugar simplemente está añadiendo a una cadena. Al final, podemos entonces sólo prober que el contenido es correcto.
No tenemos que usar una cadena --para el objeto que estamos probando aquí, una matriz va a funcio-nar igual de bien.
require ‘test/unit’require ‘addcust’class TestAddCustomer < Test::Unit::TestCase def test_add c = Customer.new(“Ima”, “Customer”) f = [] c.append_name_to_file(f) assert_equal([“Ima”, “ “, “Customer”], f) endend
produce:
Finished in 0.001111 seconds.1 tests, 1 assertions, 0 failures, 0 errors
De hecho, esta forma puede ser más conveniente si queremos comprobar que las cosas individuales se insertan correctamente.

252
Por tanto, el tipado pato es conveniente para las pruebas, pero, ¿qué pasa en el cuerpo de las propias aplicaciones? Bueno, resulta que lo mismo que hizo fácil las pruebas del ejemplo anterior también hace fácil la escritura de código de aplicación flexible.
De hecho, Dave tuvo una experiencia interesante donde el tipado pato le sacó (y a un cliente) de un agujero. Había escrito una gran aplicación Ruby basada en Web que (entre otras cosas) mantiene una tabla de base de datos completa de los detalles de los participantes en una competición. El sistema pro-porciona valores separados por comas (CSV) con la capacidad de poderlos descargar, lo que permite a los administradores importar esta información en sus hojas de cálculo de forma local.
Justo antes de la competición, el teléfono empieza a sonar. La descarga, que había estado trabajando muy bien hasta ese momento, estaba tomando tanto tiempo que las solicitudes agotaban el tiempo de espera. La presión fue intensa, ya que los administradores tenían que usar esa información para hacer planificaciones y enviar correos.
Un poco de experimentación demostró que el problema estaba en la rutina que tomaba los resultados de la consulta de la base de datos y generaba la descarga CSV. El código se veía algo así como
def csv_from_row(op, row) res = “” until row.empty? entry = row.shift.to_s if /[,”]/ =~ entry entry = entry.gsub(/”/, ‘””’) res << ‘”’ << entry << ‘”’ else res << entry end res << “,” unless row.empty? end op << res << CRLFendresult = “”query.each_row {|row| csv_from_row(result, row)}http.write result
Cuando este código corre con conjuntos de datos de tamaño moderado, desempeña bien. Pero a un tamaño de entrada determinado, se desacelera de repente y se viene abajo. ¿El culpable? La recolección de basura. El enfoque estaba generando miles de cadenas intermedias y la construcción de una gran ca-dena de resultado, una línea a la vez. Como esta gran cadena crece, se necesita más espacio y se invoca la recolección de basura, que requiere el escaneo y eliminación de todas las cadenas itermedias.
La respuesta era simple y sorprendentemente efectiva. En lugar de construir la cadena de resultado a medida que avanzaba, el código se cambió para almacenar cada fila CSV como un elemento de una ma-triz. Esto significaba que las líneas intermedias seguian siendo todavía referenciadas y por lo tanto ya no eran basura. También significaba que ya no se contruía una gran cadena cada vez mayor que obligaba a la recolección de basura. Gracias al tipado pato, el cambio fue trivial.
def csv_from_row(op, row) # como antesendresult = []query.each_row {|row| csv_from_row(result, row)}http.write result.join
Lo único que cambia es que pasamos una matriz en el método csv_from_row. Debido a que (implí-citamente) utilizamos tipado pato, el método en sí no fué modificado: continua añadiendo los datos que genera a su parámetro, sin importarle el tipo de parámetro que es. Después que el método devuelve el resultado, se unen todas las líneas individuales en una gran cadena. Este cambio trajo una reducción del tiempo de ejecución desde más de 3 minutos a unos pocos segundos.

253
Codificando Como un Pato
Si desea escribir sus programas con la filosofía tipado pato, sólo se necesita recordar una cosa: un tipo de objeto está determinado por lo que puede hacer, no por su clase. (De hecho, Ruby 1.8 ahora desaprue-ba el método Objeto#type a favor de Objeto#class por esta razón: el método devuelve la clase del receptor, por lo que la palabra type es engañosa).
¿Qué significa esto en la práctica? En un nivel, simplemente significa que a menudo hay poco valor para probar la clase de un objeto.
Por ejemplo, es posible que vaya a escribir una rutina para añadir información de una canción en una cadena. Si usted viene de C# o Java, puede estar tentado a escribir:
def append_song(result, song) # test para probar que se dan los parámetros correctos unless result.kind_of?(String) fail TypeError.new(“String expected”) end unless song.kind_of?(Song) fail TypeError.new(“Song expected”) end
result << song.title << “ (“ << song.artist << “)”end
result = “”append_song(result, song) -> “I Got Rhythm (Gene Kelly)”
Adoptanto el tipado pato de Ruby se escribe código mucho más simple.
def append_song(result, song) result << song.title << “ (“ << song.artist << “)”end
result = “”append_song(result, song) -> “I Got Rhythm (Gene Kelly)”
No es necesario comprobar el tipo de los argumentos. Si soportan << (en el caso de result) o title y artist (en el caso de song), todo va a funcionar. Si no, el método dará una excepción de todos modos (como lo habría hecho si hubiera revisado los tipos). Pero sin la comprobación de tipos, su método de repente es mucho más flexible: se puede pasar una matriz, una cadena, un archivo o cualquier otro objeto usando << y vá a funcionar.
Ahora, a veces usted puede querer utilizar más este estilo de programación de laissez-faire. Puede ha-ber buenas razones para comprobar que un parámetro puede hacer lo que se necesita. ¿Será expulsado fuera del club de tipado pato si comprueba el parámetro con una clase? No (El club tipado pato no com-prueba para ver si usted es miembro...). Sin embargo, es posible que prefiera considerar la comprobación sobre la base de las capacidades del objeto, en lugar de su clase.
def append_song(result, song) # test para probar que se dan los parámetros correctos unless result.respond_to?(:<<) fail TypeError.new(“’result’ needs `<<’ capability”) end unless song.respond_to?(:artist) && song.respond_to?(:title) fail TypeError.new(“’song’ needs ‘artist’ and ‘title’”) end
result << song.title << “ (“ << song.artist << “)”end

254
result = “”append_song(result, song) -> “I Got Rhythm (Gene Kelly)”
Sin embargo, antes de ir por este camino, asegúrese de que está obteniendo un beneficio real --ya que hay que escribir y mantener una gran cantidad de código extra.
Sobre Protocolos y Coerciones Estándares
Aunque técnicamente no es parte del lenguaje, el intérprete y la biblioteca estándar utilizan varios pro-tocolos para manejar los asuntos en los que se ocupan otros lenguajes para el uso de tipos.
Algunos objetos tienen más de una representación natural. Por ejemplo, usted puede querer escribir una clase para representar los números romanos (I, II, III, IV, V, etc). Esta clase no es necesariamente una subclase de Integer, debido a que sus objetos son representaciones de números, no números en sí mismos. Al mismo tiempo, ellos tienen una calidad similar a entero. Sería bueno poder utilizar los objetos de nuestra clase número Romano donde Ruby espera ver un entero.
Para ello, Ruby tiene el concepto de protocolos de conversión --un objeto puede optar por convertirse en un objeto de otra clase. Ruby tiene tres formas estándar de hacer esto.
Ya hemos encontrado la primera. Métodos tales como to_s y to_i convierten su receptor en cadenas y enteros. Estos métodos de conversión no son muy estrictos: si un objeto tiene algún tipo de represen-tación decente como una cadena, por ejemplo, es probable que tenga un método to_s. Nuestra clase romana, probablemente implementaría to_s con el fin de devolver la representación de cadena de un número (VII, por ejemplo).
La segunda forma de la función de conversión utiliza métodos con nombres como to_str y to_int. Estas son las funciones estrictas de conversión: sólo se pueden poner en práctica si el objeto, de forma natural, se puede utilizar en todos los lugares donde una cadena o un entero podrían ser utilizados. Por ejemplo, nuestros objetos de números romanos tienen una clara representación de número entero y por lo tanto deben implementar to_int. Cuando se trata de la cadeneidad, sin embargo, la cosa es más dificil.
Números romanos claramente tienen una representación de cadena, pero ¿son cadenas? ¿debemos utilizar una cadena siempre que podamos utilizar una cadena en sí misma? No, probablemente no. Lógi-camente, son una representación de un número. Se pueden representar como cadenas pero no son co-nectables a las cadenas. Por esta razón, un número romano no ejecutará to_str --en realidad no es una cadena. Para volver al principio: Los números romanos se pueden convertir en cadenas utilizando to_s, pero no son inherentemente cadenas, por lo que no implementan to_str.
Para ver cómo funciona esto en la práctica, echemos un vistazo a la apertura de un archivo. El primer parámetro de File.new puede ser un desciptor de fichero existente (representado por un número entero) o un nombre de archivo para abrirlo. Sin embargo, Ruby no se limita a mirar el primer parámetro y com-probar si su tipo es Fixnum o String. Por el contrario, da al objeto pasado la oportunidad de presentarse como un número o una cadena. Escribirlo en Ruby, puede parecer algo así como
class File def File.new(file, *args) if file.respond_to?(:to_int) IO.new(file.to_int, *args) else name = file.to_str # llamada al sistema operativo para abrir el archivo ‘name’ end endend
Así que vamos a ver qué pasa si queremos pasar a File.new un entero descriptor de archivo alma-cenado como un número romano. Debido a que nuestra clase implementa to_int, el primer test res-pond_to? tendrá éxito. Vamos a pasar una representación de entero de nuestro número a IO.open y será devuelto el descriptor de fichero, todo ello envuelto en un nuevo objeto IO.

255
La librería estándar tiene incorporadas un pequeño número de funciones de conversión estricta:
to_ary → Array Se usa cuando el intérprete necesita convertir un objeto en una matriz para el paso de parámetros o la asignación múltiple.
class OneTwo def to_ary [ 1, 2 ] endendot = OneTwo.newa, b = otputs “a = #{a}, b = #{b}”printf(“%d -- %d\n”, *ot)
produce:
a = 1, b = 21 -- 2
to_hash → Hash Se utiliza cuando el intérprete espera ver un Hash. (El único uso conocido es el segundo parámetro de Hash#replace).
to_int → Integer Se utiliza cuando el intérprete espera ver un valor entero (tal como un descriptor de fichero o un pará-metro para Kernel.Integer).
to_io → IO Se utiliza cuando el intérprete está esperando objetos IO (tales como parámetros para IO#reopen o IO.select).
to_proc → Proc Se utiliza para convertir un objeto precedido de un signo & en una llamada a método.
class OneTwo def to_proc proc { “one-two” } endenddef silly yieldendot = OneTwo.newsilly(&ot) -> “one-two”
to_str → String Se utiliza en casi cualquier lugar cuando el intérprete busca un valor String.
class OneTwo def to_str “one-two” endendot = OneTwo.newputs(“count: “ + ot)File.open(ot) rescue puts $!.message

256
produce:
count: one-twoNo such file or directory - one-two
Nótese, sin embargo, que el uso de to_str no es universal - algunos métodos que quieren argumen-tos de cadena no llaman a to_str.
File.join(“/user”, ot) -> “/user/#<OneTwo:0x1c974c>”
to_sym → Symbol Expresan el receptor como un símbolo. No utilizado por el intérprete para las conversiones y probable-mente no sea útil en el código de usuario.
Un último punto: las clases como Integer y Fixnum implementan el método to_int y la clase String implementa to_str. De esa manera se pueden llamar a las funciones de conversión estricta polimórficamente:
# No importa si obj es un Fixnum o un número Romano, # la conversión todavía tiene éxitonum = obj.to_int
Coerción Numérica
Un par de páginas atras se dijo que el intérprete realiza tres tipos de conversión. Cubrimos la conver-sión flexible y la estricta. La tercera es la coerción numérica.
He aquí el problema. Cuando se escribe “1 + 2”, Ruby sabe llamar al + en el objeto 1 (un Fixnum), pasándole el Fixnum 2 como parámetro. Sin embargo, cuando se escribe “1+2.3”, el método + recibe ahora un parámetro Float. ¿Cómo puede saber qué hacer (en particular, como comprueba las clases de sus parámetros si va en contra del espíritu de tipado pato)?
La respuesta está en el protocolo de coerción de Ruby, basado en el método coerce. El funcionamien-to básico de coerce es simple. Necesitan dos números (uno como su receptor, el otro como un paráme-tro). Devuelve una matriz de dos elementos que contiene representaciones de estos dos números (pero con el parámetro primero, seguido por el receptor). El método coerce garantiza que estos dos objetos tienen la misma clase y por tanto, que se pueden sumar (o multiplicar, o comparar o lo que sea).
1.coerce(2) -> [2, 1]1.coerce(2.3) -> [2.3, 1.0](4.5).coerce(2.3) -> [2.3, 4.5](4.5).coerce(2) -> [2.0, 4.5]
El truco es que el receptor llama al método coerce de su parámetro para generar esta matriz. Esta técnica, llamada double dispatch, permite a un método cambiar el comportamiento basado no sólo en su clase, sino también en la clase de su parámetro. En este caso, estamos dejando que el parámetro decida exactamente qué clases de objetos se suman (o multiplican, dividen, etc.)
Digamos que estamos escribiendo una nueva clase con la intención de tomar parte en la aritmética. Para participar en la coerción, es necesario implementar el método coerce. Éste toma algún otro tipo de número como parámetro y devuelve una matriz que contiene dos objetos de la misma clase cuyos valores son equivalentes.
Para nuestra clase número Romano es bastante fácil. Internamente, cada objeto número Romano tiene su valor real como un Fixnum en una variable de instancia @value. El método coerce comprueba si la clase de su parámetro es también un Integer. Si es así, retorna su parámetro y su valor interno. Si no es así, convierte primero a ambos en coma flotante.
class Roman def initialize(value)

257
@value = value end
def coerce(other) if Integer === other [ other, @value ] else [ Float(other), Float(@value) ] end end# .. otras cosas de Romanend
iv = Roman.new(4)xi = Roman.new(11)
3 * iv -> 121.1 * xi -> 12.1
Por supuesto, la clase Roman tal como se implementa no sabe que hacer sumas de si misma: no se podría haber escrito “xi + 3” en el ejemplo anterior, ya que Roman no tiene un método “mas”. Y así es probablemente como debe ser. Pero ahora vamos a implementar la suma para números romanos.
class Roman MAX_ROMAN = 4999 attr_reader :value protected :value def initialize(value) if value <= 0 || value > MAX_ROMAN fail “Los valores romanos deben ser > 0 y <= #{MAX_ROMAN}” end @value = value end def coerce(other) if Integer === other [ other, @value ] else [ Float(other), Float(@value) ] end end def +(other) if Roman === other other = other.value end if Fixnum === other && (other + @value) < MAX_ROMAN Roman.new(@value + other) else x, y = other.coerce(@value) x + y end end FACTORS = [[“m”, 1000], [“cm”, 900], [“d”, 500], [“cd”, 400], [“c”, 100], [“xc”, 90], [“l”, 50], [“xl”, 40], [“x”, 10], [“ix”, 9], [“v”, 5], [“iv”, 4], [“i”, 1]] def to_s value = @value roman = “” for code, factor in FACTORS count, value = value.divmod(factor)

258
roman << (code * count) end roman endend
iv = Roman.new(4)xi = Roman.new(11)
iv + 3 -> viiiv + 3 + 4 -> xiiv + 3.14159 -> 7.14159xi + 4900 -> mmmmcmxixi + 4990 -> 5001
Por último, tenga cuidado con coerce --siempre tratar de coercionar a un tipo más general, o se puede terminar generando bucles de coerción, donde A intenta coercionar a B, y B trata de coercionar de vuelta a A.
Walk the Walk, Talk the Talk (Recorrer el Camino, Predicar con el Ejemplo) Duck typing puede generar controversia. De vez en cuando se un hilo arde en las listas de correo o algún blog con alguien favor o en contra del concepto. Muchos colaboradores en estas discusiones tienen algunas posiciones bastante extremas.
En última instancia, sin embargo, duck typing no es un conjunto de reglas, sólo es un estilo de progra-mación. Diseñe sus programas para equilibrar la paranoia y la flexibilidad. Si usted siente la necesidad de restringir los tipos de los objetos que los usuarios de un método pasan, pregúntese por qué. Trate de determinar qué podría salir mal si usted esperaba una cadena y en su lugar obtiene una matriz. A veces, la diferencia es de vital importancia. A menudo, sin embargo, no lo es. Trate de errar en el lado más permisi-vo por un tiempo y observe si suceden cosas malas. Si no, tal vez duck typing no sea sólo para las aves.
Clases y Objetos Las clases y los objetos son, obviamente, el centro de Ruby, pero a primera vista puede parecer un poco confuso. Parece que hay un montón de conceptos: clases, objetos, objetos de clase, métodos de instancia, métodos de clase, clases singleton y clases virtuales. En realidad, sin embargo, Ruby tiene sólo una sola estructura de clase y objeto subyacente, de la que hablaremos en este capítulo. De hecho, el modelo básico es muy simple, podemos describirlo en un solo párrafo.
Un objeto en Ruby tiene tres componentes: un conjunto de banderas, algunas variables de instancia y una clase asociada. Una clase en Ruby es un objeto de la clase Class, que contiene todas las cosas de un objeto además de una lista de métodos y una referencia a una superclase (que a su vez es otra clase). Todas las llamadas a métodos en Ruby nombran a un receptor (que por propio defecto es self, el objeto en curso). Ruby encuentra el método a invocar buscando en la lista de métodos de la clase del receptor. Si no encuentra el método allí, mira en todos los módulos incluidos, luego en su superclase, los módulos de la superclase, luego en la superclase de la superclase y así sucesivamente. Si el método no se pue-de encontrar en la clase del receptor o de cualquiera de sus ascendientes, entonces invoca el método method_missing en el receptor original.
Y eso es todo, la explicación completa. Siguiente capítulo.
“Pero espere”, grita usted: “Gasté un buen dinero en este capítulo. ¿Qué pasa con todas esas otras cosas --las clases virtuales, los métodos de clase, etc. ¿Cómo funcionan?” Buena pregunta.
Cómo Interactúan las Clases y los Objetos
Todas las interacciones clase/objeto se explican utilizando el modelo simple dado anteriormente: ob-jetos referencian clases, y las clases referencian cero o más superclases. Sin embargo, conseguir los detalles de implementación puede ser un poco complicado.

259
Hemos encontrado que la forma más sencilla de visualizar todo esto es dibujando las estructuras reales que implementa Ruby. Por lo tanto, en las páginas siguientes vamos a ver todas las posibles combinacio-nes de clases y objetos. Tenga en cuenta que estos no son diagramas de clases en sentido UML, estamos mostrando las estructuras en memoria y los punteros entre ellas.
Su Objeto Básico, de uso diario
Vamos a empezar viendo un objeto creado a partir de una clase simple. La figura 17 muestra un objeto referenciado por una variable, lucille, la clase del objeto, Guitar y la superclase de la clase, Object. Observe como la referencia a la clase del objeto, klass, apunta a la clase de objeto y cómo el puntero super hace referencia a la clase padre. Si invocamos el método lucille.play(), Ruby va al receptor, Lucille, y sigue la referencia klass al objeto de clase Guitar. Busca en la tabla el método, encuentra play y lo invoca.
Si en su lugar se llama a lucille.display(), Ruby comienza de la misma manera, pero no puede encontrar display en la tabla de métodos de la clase de Guitar. A continuación sigue la referencia super a la superclase de Guitar, Object, donde encuentra el método y lo ejecuta.
Metaclases
Los lectores astutos (sí, pensamos que son todos ustedes) se habran dado cuenta de que los miembros klass de objetos class no apuntan a nada significativo en la figura 17. Ahora tenemos toda la informa-ción que necesitamos para resolver a lo que debe hacer referencia.
Cuando usted dice lucille.play(), Ruby sigue puntero klass para encontrar un objeto de cla-se en el que buscar métodos. Entonces, ¿qué sucede cuando se invoca un método de clase, como Guitar.strings(...)? Aquí, el receptor es el objeto mismo de la clase, Guitar. Por lo tanto, para que haya consistencia, es necesario atenerse a los métodos de otra clase, referenciada por el puntero klass de Guitar. Esta nueva clase contendrá todos los métodos de clase de Guitar. Aunque la terminología es un poco dudosa, vamos a llamar a esto una metaclase (vea el recuadro en la página siguiente). Vamos a denotar la metaclase de Guitar como Guitar’. Pero esto no es toda la historia. Debido a que Gui-tar es una subclase de Object, su metaclase Guitar’será una subclase de la metaclase de Object,
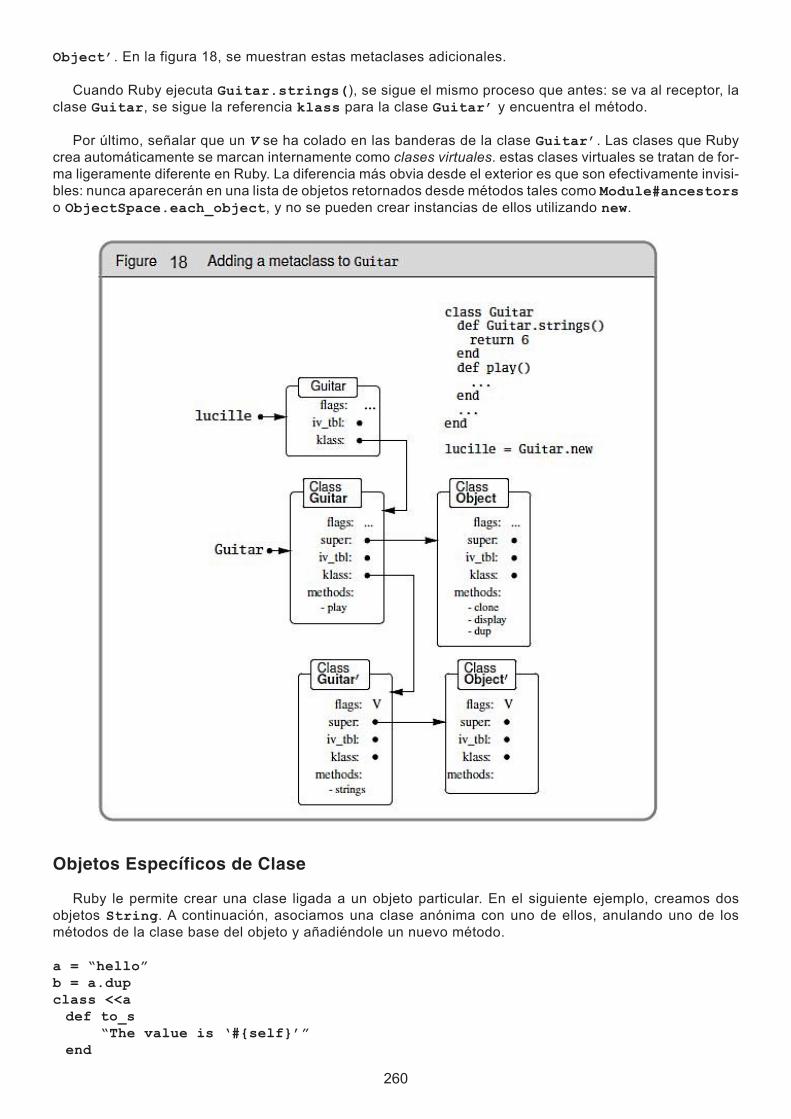
260
Object’. En la figura 18, se muestran estas metaclases adicionales.
Cuando Ruby ejecuta Guitar.strings(), se sigue el mismo proceso que antes: se va al receptor, la clase Guitar, se sigue la referencia klass para la clase Guitar’ y encuentra el método.
Por último, señalar que un V se ha colado en las banderas de la clase Guitar’. Las clases que Ruby crea automáticamente se marcan internamente como clases virtuales. estas clases virtuales se tratan de for-ma ligeramente diferente en Ruby. La diferencia más obvia desde el exterior es que son efectivamente invisi-bles: nunca aparecerán en una lista de objetos retornados desde métodos tales como Module#ancestors o ObjectSpace.each_object, y no se pueden crear instancias de ellos utilizando new.
Objetos Específicos de Clase
Ruby le permite crear una clase ligada a un objeto particular. En el siguiente ejemplo, creamos dos objetos String. A continuación, asociamos una clase anónima con uno de ellos, anulando uno de los métodos de la clase base del objeto y añadiéndole un nuevo método.
a = “hello”b = a.dupclass <<a def to_s “The value is ‘#{self}’” end

261
def two_times self + self endend
a.to_s -> “The value is ‘hello’”a.two_times -> “hellohello”b.to_s -> “hello”
En este ejemplo se utiliza la notación class <<obj, que básicamente dice “aconstruir una nueva clase sólo para el objeto obj”. También se podría haber escrito como
a = “hello”b = a.dupdef a.to_s “The value is ‘#{self}’”enddef a.two_times self + selfend
a.to_s -> “The value is ‘hello’”a.two_times -> “hellohello”b.to_s -> “hello” El efecto es el mismo en ambos casos: una clase se añade al objeto a. Esto nos da un fuerte indicio sobre la implementación Ruby: se crea una clase virtual y se inserta como clase directa de a. La clase original de a, String, se hace superclase esta clase virtual. La imagen del antes y el después se muestra en la figura 19 en la página siguiente: Hay que recordar que las clases en Ruby nunca se cierran. Siempre se puede abrir una clase y añadir nuevos métodos a la misma. Lo mismo se aplica a las clases virtuales. Si la referencia de un objeto klass ya apunta a una clase virtual, no se creará una nueva. Esto significa que la primera de las dos definiciones de método en el ejemplo anterior crea una clase virtual, pero el segundo simplemente añadir un método a la misma.
El método Object#extend añade los métodos en su parámetro a su receptor, por lo que si es nece-sario, también crea una clase virtual. obj.extend(Mod) es básicamente equivalente a:
Metaclases y Clases Singleton
Durante la revisión de este libro, el uso del término metaclase generó una gran discusión, ya que las metaclases Ruby son diferentes a las de lenguajes como Smalltalk. Pasado un tiempo, Matz intervino con lo siguiente:
Se le puede llamar metaclase, pero, a diferencia de Smalltalk, no es una clase de una clase, es una clase singleton de una clase.
•Todos losobjetosenRubytienensuspropiosatributos(métodos,constantes,etc)queenotrosidiomas están en manos de las clases. Es como que cada objeto tiene su propia clase.
•Paramanejaratributosporobjeto,Rubyproporcionaalgo similar a una clase para cada objeto que se llama a veces clase singleton.
•Enlaimplementaciónactual,lasclasessonobjetosdelaclasesingletonespecialmenteseñaladaentre los objetos y su clase. Estas pueden ser clases “virtuales” si lo decide el implementador del len-guaje.
•LasclasesSingletonsecomportanparalasclasescomometaclasesdeSmalltalk.
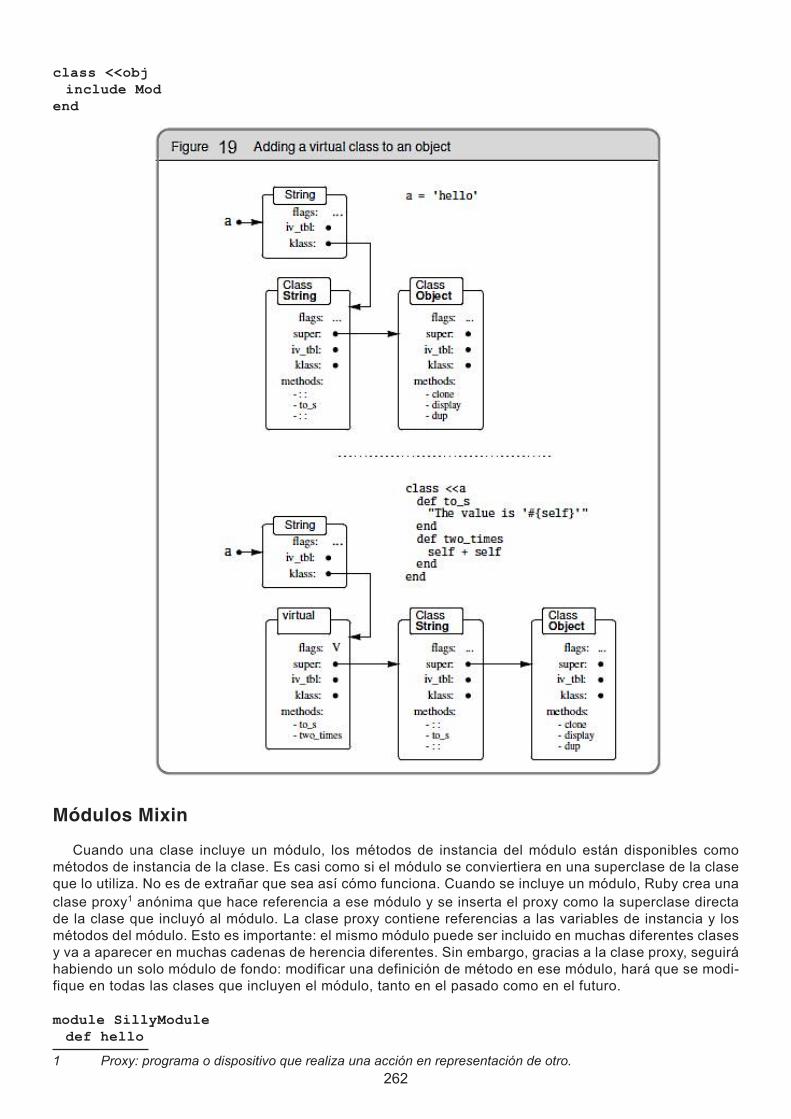
262
class <<obj include Modend
Módulos Mixin
Cuando una clase incluye un módulo, los métodos de instancia del módulo están disponibles como métodos de instancia de la clase. Es casi como si el módulo se conviertiera en una superclase de la clase que lo utiliza. No es de extrañar que sea así cómo funciona. Cuando se incluye un módulo, Ruby crea una clase proxy1 anónima que hace referencia a ese módulo y se inserta el proxy como la superclase directa de la clase que incluyó al módulo. La clase proxy contiene referencias a las variables de instancia y los métodos del módulo. Esto es importante: el mismo módulo puede ser incluido en muchas diferentes clases y va a aparecer en muchas cadenas de herencia diferentes. Sin embargo, gracias a la clase proxy, seguirá habiendo un solo módulo de fondo: modificar una definición de método en ese módulo, hará que se modi-fique en todas las clases que incluyen el módulo, tanto en el pasado como en el futuro.
module SillyModule def hello
1 Proxy: programa o dispositivo que realiza una acción en representación de otro.

263
“Hello.” endend
class SillyClass include SillyModuleend
s = SillyClass.news.hello -> “Hello.”
module SillyModule def hello “Hi, there!” endend
s.hello -> “Hi, there!”
La relación entre las clases y los módulos mixin que incluyen se muestra en la figura 20 en la página siguiente. Si se incluyen varios módulos se añaden a la cadena en orden.
Si un módulo en si mismo incluye otros módulos, se va a añadir una cadena de clases proxy a cualquier clase que incluya este módulo. Un proxy para cada módulo que está directa o indirectamente incluido.
Extender Objetos
Así como se puede definir una clase anónima para un objeto mediante class <<obj, se puede mez-clar un módulo en un objeto utilizando object#extend. Por ejemplo:
module Humor def tickle “hee, hee!” endend
a = “Grouchy”a.extend Humora.tickle -> “hee, hee!”
Hay un truco interesante con extend. Si lo usa en una definición de clase, los métodos del módulo se convierten en los métodos de clase. Esto se debe a que llamar a extend es equivalente a self.extend, por lo que los métodos se añaden a self, que en una definición de clase es la clase misma.
He aquí un ejemplo de cómo agregar métodos de un módulo a nivel de clase.
module Humor def tickle “hee, hee!” endendclass Grouchy include Humor extend Humorend
Grouchy.tickle -> “hee, hee!”a = Grouchy.newa.tickle -> “hee, hee!”
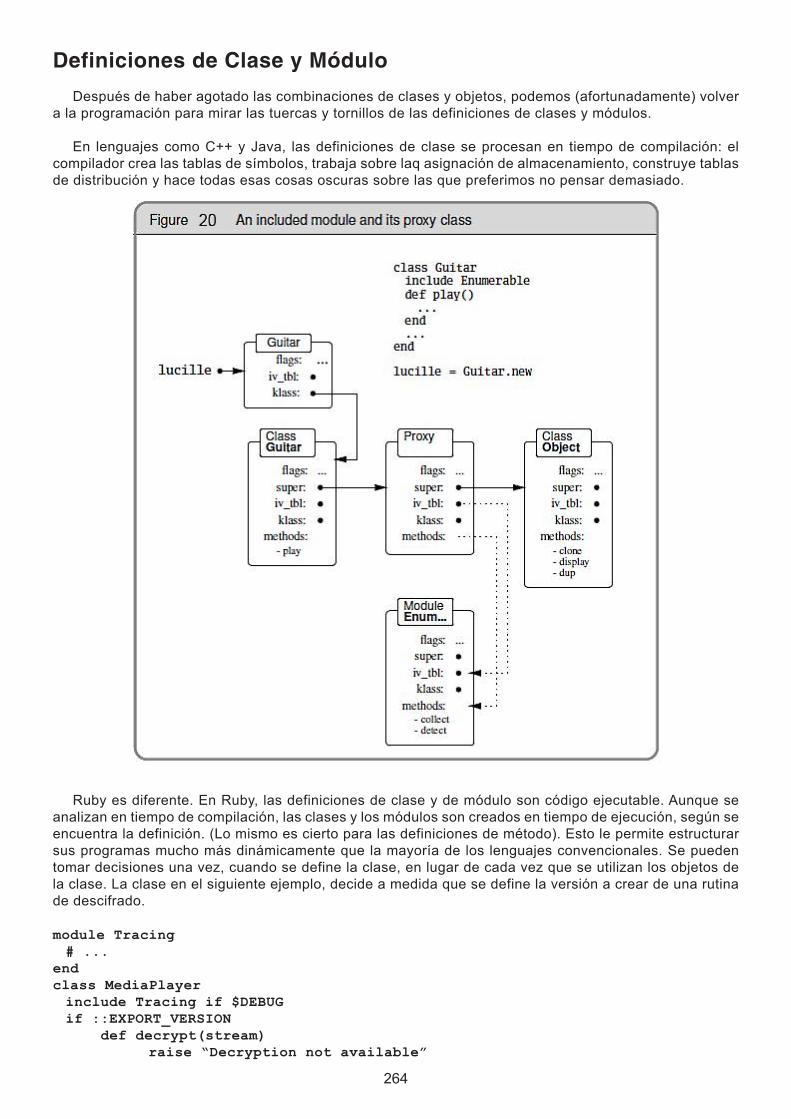
264
Definiciones de Clase y Módulo
Después de haber agotado las combinaciones de clases y objetos, podemos (afortunadamente) volver a la programación para mirar las tuercas y tornillos de las definiciones de clases y módulos.
En lenguajes como C++ y Java, las definiciones de clase se procesan en tiempo de compilación: el compilador crea las tablas de símbolos, trabaja sobre laq asignación de almacenamiento, construye tablas de distribución y hace todas esas cosas oscuras sobre las que preferimos no pensar demasiado.
Ruby es diferente. En Ruby, las definiciones de clase y de módulo son código ejecutable. Aunque se analizan en tiempo de compilación, las clases y los módulos son creados en tiempo de ejecución, según se encuentra la definición. (Lo mismo es cierto para las definiciones de método). Esto le permite estructurar sus programas mucho más dinámicamente que la mayoría de los lenguajes convencionales. Se pueden tomar decisiones una vez, cuando se define la clase, en lugar de cada vez que se utilizan los objetos de la clase. La clase en el siguiente ejemplo, decide a medida que se define la versión a crear de una rutina de descifrado.
module Tracing # ...endclass MediaPlayer include Tracing if $DEBUG if ::EXPORT_VERSION def decrypt(stream) raise “Decryption not available”

265
end else def decrypt(stream) # ... end endend
Si las definiciones de clase son código ejecutable, esto implica que se ejecutan en el contexto de un objeto: self debe hacer referencia a algo. Vamos a ver lo que es.
class Test puts “Class of self = #{self.class}” puts “Name of self = #{self.name}”end
produce:
Class of self = ClassName of self = Test
Esto significa que una definición de clase se ejecuta con esa clase como el objeto actual. Volviendo a la sección sobre metaclases unas páginas atrás, podemos ver que esto significa que los métodos en la me-taclase y sus superclases estarán disponibles durante la ejecución de la definición del método. Podemos comprobar esto.
class Test def Test.say_hello puts “Hello from #{name}” end say_helloend
produce:
Hello from Test
En este ejemplo se define un método de clase, Test.say_hello, y luego es llamado en el cuerpo de la definición de clase. Dentro de say_hello, llamamos a name, un método de instancia de la clase Module . Debido a que Module es un ancestro de Class, sus métodos de instancia se pueden llamar sin un receptor explícito dentro de una definición de clase.
Variables de Instancia de Clase
Si se ejecuta una definición de clase en el contexto de algún objeto, esto implica que una clase puede tener variables de instancia.
class Test @cls_var = 123 def Test.inc @cls_var += 1 endend
Test.inc -> 124Test.inc -> 125
Si las clases tienen sus propias variables de instancia, ¿podemos utilizar attr_reader y amigos para acceder a ellos? Podemos, pero tenemos que ejecutar estos métodos en el lugar correcto. Para las va-riables de instancia normales, los accesores de atributo se definen a nivel de clase. Para las variables de

266
instancia de clase, tenemos que definir los métodos de acceso en la metaclase.
class Test @cls_var = 123 class <<self attr_reader :cls_var endend
Test.cls_var -> 123
Esto nos lleva a un punto interesante. Muchas de las directivas que se utilizan para definir una clase o módulo, cosas como alias_method, attr y public, son simplemente métodos en la clase Module. Esto crea algunas posibilidades intrigantes --se puede ampliar la funcionalidad de las definiciones de clase y módulo escribiendo código Ruby. Echemos un vistazo a un par de ejemplos.
Vamos a ver un ejemplo de adición de una línea de documentación básica a los módulos y las clases. Esto nos permite asociar una cadena a módulos y clases que escribimos y que es accesible cuando el programa está en funcionamiento. Vamos a elegir una sintaxis sencilla.
class Example doc “This is a sample documentation string” # .. rest of classend
Tenemos que hacer doc disponible para cualquier módulo o clase, por lo que necesitamos hacerlo un método de instancia de la clase Module.
class Module @@docs = {} # invocado en las definiciones de clase def doc(str) @@docs[self.name] = self.name + “:\n” + str.gsub(/^\s+/, ‘’) end # invocado para obtener la documentación def Module::doc(aClass) # Si nos pasa una clase o módulo, se convierte en cadena # (‘<=’ Para las clases de comprobación de la misma clase o subtipo) aClass = aClass.name if aClass.class <= Module @@docs[aClass] || “No documentation for #{aClass}” endend
class Example doc “This is a sample documentation string” # .. rest of classendmodule Another doc <<-edoc And this is a documentation string in a module edoc # rest of moduleend
puts Module::doc(Example)puts Module::doc(“Another”)
produce:

267
Example:This is a sample documentation stringAnother:And this is a documentation stringin a module
El segundo ejemplo es una mejora de rendimiento basada en el módulo date de Tadayoshi Funaba (que se verá más adelante). Digamos que tenemos una clase que representa una cierta cuantificación subyacen-te (en este caso, una fecha). La clase puede tener muchos atributos que presentan la misma fecha subya-cente de diversas maneras: como un número de día Juliano, como una cadena, como un triple [año, mes, día] , etc. Cada valor representa la misma fecha y su derivación puede implicar un cálculo bastante complejo. Quisiéramos por tanto, tener el cálculo de cada atributo de una sola vez, la primera que es accedido. La forma manual sería añadir una prueba para cada accesor.
class ExampleDate def initialize(day_number) @day_number = day_number end def as_day_number @day_number end def as_string unless @string # complex calculation @string = result end @string end def as_YMD unless @ymd # another calculation @ymd = [ y, m, d ] end @ymd end # ...end
Esta es una técnica torpe --Vamos a ver si podemos llegar a algo más sexy. Lo que estamos buscando es una directiva que indique que el cuerpo de un método en particular debe ser invocado sólo una vez. El valor devuelto por la primera llamada debe ser almacenado en caché. A par-tir de entonces, la llamada a ese mismo método debe devolver el valor almacenado en caché sin volver a evaluar el cuerpo del método de nuevo. Esto es similar al modificador de Eiffel once para las rutinas. Nos gustaría ser capaces de escribir algo como:
class ExampleDate def as_day_number @day_number end def as_string # complex calculation end def as_YMD # another calculation [ y, m, d ] end once :as_string, :as_YMDend

268
Podemos utilizar once como una directiva escribiéndola como un método de clase de ExampleDate, pero, ¿como tiene que verse internamente? El truco está en reescribir los métodos cuyos nombres se pa-san. Para cada método, se crea un alias para el código original, y luego se crea un nuevo método con el mismo nombre. Aquí está el código de Tadayoshi Funaba, ligeramente reordenado.
def once(*ids) # :nodoc: for id in ids module_eval <<-”end;” alias_method :__#{id.to_i}__, :#{id.to_s} private :__#{id.to_i}__ def #{id.to_s}(*args, &block) (@__#{id.to_i}__ ||= [__#{id.to_i}__(*args, &block)])[0] end end; endend
Este código utiliza module_eval para ejecutar un bloque de código en el contexto del módulo llamador (o, en este caso, la clase llamadora). El método original se renombra con __nnn__, donde la parte nnn es la representación de número entero del símbolo ID del nombre del método. El código utiliza el mismo nombre para la variable de instancia de caché. Entonces se define un método con el nombre original. Si la variable de instancia de caché tiene un valor, se devuelve ese valor, de lo contrario se llama al método original y se devuelve su valor de retorno en caché.
Si se entiende este código se estará bien encaminado a cierto dominio de Ruby.
Sin embargo, podemos ir más lejos. Observando el módulo date se verá el método once escrito lige-ramente diferente.
class Date class << self def once(*ids) # ... end end # ...end
Lo interesante aquí es la definición de la clase interna << self. Se define una clase basada en el objeto self, y self pasa a ser el objeto de la clase Date. ¿El resultado? Todos los métodos dentro de la definición de la clase interna son automáticamente métodos de clase de Date.
La característica once es aplicable en general --debería funcionar para cualquier clase. Si se toma once y se convierte en un método privado de instancia de la clase Module, estará disponible para en cualquier clase Ruby. (Y por supuesto se puede hacer esto, ya que la clase Module es abierta y usted es libre de añadir métodos en ella.)
Los Nombres de Clase son Constantes
Hemos dicho que cuando se llama a un método de clase, todo lo que estamos haciendo es enviar un mensaje al objeto Class en sí. Cuando usted dice algo como String.new(“Gumby”), está enviando el mensaje new al objeto que es la clase String. Pero, ¿cómo hace Ruby para saber como hacer esto? Des-pués de todo, el receptor de un mensaje debe ser una referencia de objeto, lo que implica que debe haber una constante llamada String en alguna parte que contiene una referencia al objeto String2. Y de hecho, esoesexactamenteloquesucede.Todaslasclasesintegradas,juntoconlasclasesqueusteddefina,tienenuna correspondiente constante global con el mismo nombre que la clase. Esto es directo y sutil. La sutileza viene del hecho de que las dos cosas son nombradas (por ejemplo) String en el sistema. Hay una cons-tante que referencia la clase String (un objeto de la clase Class), y está el objeto (la clase) en sí mismo.2 Será una constante, no una variable, ya que String comienza con una letra mayúscula.

269
El hecho de que los nombres de clase son constantes significa que se puede tratar a las clases como a cualquier otro objeto Ruby: pueden copiarse, pasarse a métodos y utilizarse en expresiones.
def factory(klass, *args) klass.new(*args)end
factory(String, “Hello”) -> “Hello”factory(Dir, “.”) -> #<Dir:0x1c90e4>
flag = true(flag ? Array : Hash)[1, 2, 3, 4] -> [1, 2, 3, 4]flag = false(flag ? Array : Hash)[1, 2, 3, 4] -> {1=>2, 3=>4}
Esto tiene otra faceta: si una clase que no tiene nombre se asigna a una constante, Ruby le da a la clase el nombre de la constante.
var = Class.newvar.name -> “”
Wibble = varvar.name -> “Wibble”
Entrono de Ejecución de Nivel Superior
Muchas veces en este libro hemos afirmado que todo en Ruby es un objeto. Sin embargo, hemos utili-zado una y otra vez lo que parece contradecir esto --el entorno de ejecución de alto nivel de Ruby.
puts “Hola, Mundo”
No hay un objeto a la vista. Bien podríamos haberlo escrito en alguna variante de Fortran o BASIC. Sin embargo, si se cava más profundo, se encontrararán objetos y clases que acechan incluso en el más simple código.
Sabemos que el literal “Hola, Mundo” genera un String de Ruby, por lo que es un objeto. También sabemos que la llamada al método pelado puts al e es efectivamente la misma que self.puts. Pero, ¿qué es self?
self.class --> Object En el nivel superior, estamos ejecutando el código en el contexto de un objeto predeterminado. Cuan-do definimos los métodos, en realidad estamos creando métodos de instancia (privados) para la clase Object . Esto es bastante sutil, ya que como están en la clase Object, estos métodos están disponibles en todas partes. Y ya que estamos en el contexto de Object, podemos utilizar todos los métodos de Object (incluidos los mixtos de Kernel) en forma de función. Esto explica por qué podemos llamar a los métodos de Kernel, como puts en el nivel superior (y de hecho a lo largo de todo Ruby): estos métodos son parte de cada objeto.
Las variables de instancia de alto nivel también pertenecen a este objeto de nivel superior.
Herencia y Visibilidad
La última arruga en la herencia de clases es bastante oscura.
Dentro de una definición de clase, se puede cambiar la visibilidad de un método en una clase antece-sora. Por ejemplo, usted puede hacer algo como
class Base def aMethod

270
puts “Got here” end private :aMethodendclass Derived1 < Base public :aMethodendclass Derived2 < Baseend
En este ejemplo, se debe ser capaz de invocar aMethod en instancias de la clase Derived1, pero no a través de las instancias de Base o Derived2.
Entonces, ¿cómo logra Ruby esta hazaña de tener un método con dos visibilidades diferentes? En pocas palabras: se engaña.
Si una subclase cambia la visibilidad de un método en una clase padre, Ruby inserta efectivamente un método proxy oculto en la subclase que invoca el método original utilizando super. A continuación, esta-blece la visibilidad de ese proxy para lo que se ha pedido. Esto significa que el código
class Derived1 < Base public :aMethodend
es efectivamente lo mismo que
class Derived1 < Base def aMethod(*args) super end public :aMethodend
La llamada a super puede acceder a métodos de los padres, independientemente de su visibilidad, por lo que la reescritura permite a la subclase reemplazar las reglas de visibilidad de su clase padre. Dá miedo, ¿eh?
Congelación de Objetos
A veces usted ha trabajado duro para hacer de su objeto exactamente correcto y, que le aspen si usted permite que nadie lo vaya a cambiar. Tal vez tiene que pasar algún tipo de objeto opaco entre dos de sus clases a través de algunos objeto de terceros y desea asegurarse de que llega sin modificaciones. Tal vez desee utilizar un objeto como una clave hash y necesitee asegurarse de que nadie lo modifique mientras se está utilizando. Tal vez algo está haciendo corrupto uno de sus objetos y le gustaría que Ruby provoque una excepción tan pronto como se produzca el cambio.
Ruby proporciona un mecanismo muy simple para ayudar en esto. Cualquier objeto puede ser con-gelado por la invocación de Object#freeze. Un objeto congelado no puede ser modificado: no puede cambiar sus variables de instancia (directa o indirectamente), no se le puede asociar métodos singleton, y, si se trata de una clase o módulo, no se les puede añadir, eliminar o modificar sus métodos. Una vez congelado, un objeto se mantiene congelado: no hay ningún Object#deshielo. Usted puede probar si un objeto está congelado mediante Object#frozen?.
¿Qué sucede cuando se copia un objeto congelado? Eso depende del método que se utilice. Si se llama al método de un objeto clone, el estado del objeto entero (incluyendo si está congelado) se copia en el nuevo objeto. Por otro lado, dup normalmente sólo copia el contenido del objeto --la nueva copia no heredará el estado congelado.
str1 = “hello”str1.freeze -> “hello”

271
str1.frozen? -> truestr2 = str1.clonestr2.frozen? -> truestr3 = str1.dupstr3.frozen? -> false
Aunque al principio la congelación de objetos puede parecer una buena idea, es posible que prefiera esperar a hacerlo hasta que llegue una necesidad real. La congelación es una de esas ideas que se ven esenciales en el papel pero que no se utilizan mucho en la práctica.
Bloqueo de Seguridad de Ruby
Walter WebCoder tiene una gran idea para un sitio de portal: la Página Web de la Aritmética. Rodeado de todo tipo de fríos enlaces matemáticos y anuncios de banner que lo hará rico, es un sencillo formulario web que contiene un campo de texto y un botón. Los usuarios escriben una expresión aritmética en el campo, hacen clic en el botón, y se muestra la respuesta. Todas las calculadoras del mundo se vuelven obsoletos de la noche a la mañana, Walter hace caja y se retira para dedicar la vida a su colección de números de matrículas de coches.
La aplicación de la calculadora es fácil, piensa Walter. Accede a los contenidos del campo del formulario utilizando la biblioteca CGI de Ruby y utiliza el método eval para evaluar la cadena como una expresión .
require ‘cgi’cgi = CGI.new(“html4”)# Recuperar el valor del campo del formulario “expression”expr = cgi[“expression”].to_sbegin result = eval(expr)rescue Exception => detail# manejar expresiones malasend# mostrar el resultado de vuelta al usuario...
Aproximadamente siete segundos después de que Walter pone la aplicación en línea, una niña de doce años de edad, desde Waxahachie, con problemas glandulares y sin vida real, tipea system(“rm *”) en el formulario y, al igual que los archivos de su ordenador, los sueños de Walter se vienen abajo.
Walter aprendió una importante lección: Toda la información externa es peligrosa. No deje cerca a las interfaces que pueden modificar su sistema. En este caso, el contenido del campo de formulario fué el de datos externos y la llamada a eval fue la violación de la seguridad.
Afortunadamente, Ruby proporciona soporte para la reducción de este riesgo. Toda la información del mundo exterior puede ser marcada como contaminada. Cuando se ejecuta en un modo seguro, los méto-dos potencialmente peligrosos lanzarán un SecurityError si pasa un objeto contaminado.
Los Niveles de Seguridad
La variable $SAFE determina el nivel Ruby de paranoia. La Tabla 25.1, dos páginas adelante, propor-ciona más detalles de las comprobaciones realizadas en cada nivel de seguridad. El valor por defecto de $SAFE es cero en la mayoría de las circunstancias. Sin embargo, si un script Ruby se ejecuta en modo setuid o setgid3, o si se ejecuta bajo mod_ruby, se establece su nivel de seguri-dad automáticamente en 1. El nivel de seguridad también se pueden ajustar mediante el uso de la opción -T de línea de comandos y mediante la asignación de $SAFE dentro del programa. No es posible reducir el valor de $SAFE por asignación.
3 Un script de Unix puede ser marcado para ejecutarse con el ID de usuario o grupo al que pertenece. Esto permite a otro usuario ejecutar con script los privilegios que no tiene y poder acceder a los recursos que de otro modo tendría prohibidos. Estos scripts se llaman setuid o setgid.

272
El valor en curso de $SAFE se hereda cuando se crean hilos nuevos. Sin embargo, dentro de cada hilo, se puede cambiar el valor de $SAFE sin afectar al valor en otros hilos. Esta característica se puede utilizar para implementar “cajas” seguras. Áreas en las que el código externo se puede ejecutar sin peligro para el resto de la aplicación o sistema. Para ello, se envuelve el código que se va a cargar desde un archivo, en su propio módulo anónimo. Esto protegerá el espacio de nombres del programa de cualquier alteración involuntaria.
f=open(filename,”w”)f.print ... # escribir en un fichero el programa no fiablef.closeThread.start do $SAFE = 4 load(filename, true)end
Con un nivel $SAFE de 4, sólo se pueden cargar archivos envueltos. Véase la descripción de Kernel.load más adelante para más detalles.
El nivel de seguridad en vigor cuando se crea un objeto Proc se almacena con ese objeto. Un Proc no se puede pasar a un método si está contaminado y el nivel de seguridad actual es mayor que el que estaba en vigor cuando se creó el bloque.
Objetos Contaminados
Cualquier objeto Ruby obtenido de una fuente externa (por ejemplo, una cadena leída desde un archi-vo o una variable de entorno) es automáticamente marcado como contaminado. Si el programa utiliza un objeto contaminado para obtener un nuevo objeto, ese nuevo objeto también estará contaminado, como se muestra en el código de abajo. Cualquier objeto con datos externos de algún momento de su pasado va a estar contaminado. Este proceso de contaminado se lleva a cabo independientemente del nivel de seguridad en curso. Puede ver si un objeto está contaminado utilizando Object#tainted?.
Se puede forzar la contaminación de un objeto invocando al método taint. Si el nivel de seguridad es inferior a 3, se puede descontaminar un objeto mediante la invocación de untaint. Esto no es como para hacerlo a la ligera (también se pueden utilizar algunos trucos tortuosos para hacer esto sin usar untaint, pero vamos a dejar que su lado más oscuro los encuentre).
Está claro que Walter ha ejecutado el script CGI en el nivel seguro 1. Esto hizo que se lanzara una
$SAFE Limitaciones
0 No se comprueba el suminstro externo de datos (contaminados). Modo por defecto. ≥1 No se permite el uso de datos contaminados para operaciones potencialmente peligrosas. ≥2 Se prohíbe la carga de archivos de programa desde ubicaciones globales para escritura. ≥3 Todos los objetos de nueva creación se consideran contaminados. ≥4 Ruby particiona eficazmente la ejecución del programa en dos. Objetos no contaminados no pueden ser modificados.
# internal data# =============
x1 = “a string”x1.tainted? -> false
x2 = x1[2, 4]x2.tainted? -> false
x1 =~ /([a-z])/ -> 0$1.tainted? -> false
# external data# =============
y1 = ENV[“HOME”]y1.tainted? -> true
y2 = y1[2, 4]y2.tainted? -> true
y1 =~ /([a-z])/ -> 2$1.tainted? -> true

273
excepción cuando el programa trató de pasar datos del formulario a eval. Una vez que sucede esto, Wal-ter tiene una serie de opciones. Podría haber optado por aplicar un programa de análisis de expresiones adecuadas, evitando los riesgos inherentes al uso de eval. Por lo menos, ¡la pereza!, probablemente tendría que haber realizado alguna comprobación simple de seguridad en los datos del formulario para descontaminarlos y que pasen sólo los inocuos.
require ‘cgi’;$SAFE = 1cgi = CGI.new(“html4”)expr = cgi[“expression”].to_sif expr =~ %r{\A[-+*/\d\seE.()]*\z} expr.untaint result = eval(expr) # display result back to user...else # display error message...end
Personalmente, creemos que Walter sigue corriendo riesgos indebidos. Probablemente preferiríamos ver un verdadero analizador, pero la implementación de uno aquí, no tendría nada que enseñarnos acerca de los objetos contaminados, así que vamos a pasar a otros temas.
Reflexión, Espacio de Objeto y Ruby Distribuído
Una de las muchas ventajas de los lenguajes dinámicos como Ruby es la capacidad de introspección --el examinar los aspectos del programa desde el propio programa. Java, por ejemplo, llama a esta carac-terística reflection, pero las capacidades de Ruby van más allá de Java.
La palabra reflexión evoca la imagen de mirarse en el espejo --tal vez la investigación de la propaga-ción implacable de la calva en la parte superior de la cabeza. Es una analogía muy apropiada: se utiliza la reflexión para examinar las partes de nuestros programas que normalmente no son visibles desde donde estamos.
En este estado de ánimo profundamente introspectivo, mientras que estamos contemplando nuestro ombligo y quemando incienso (teniendo cuidado de no intercambiar las dos tareas), ¿qué podemos apren-der de nuestro programa? Pues, podríamos descubrir:
•Quéobjetoscontiene, •Lajerarquíadeclases, •losatributosymétodosdelosobjetosy •informaciónsobrelosmétodos.
Armados con esta información, podemos mirar a los objetos particulares y decidir cuáles de sus méto-dos llamar en tiempo de ejecución --incluso si no existía la clase del objeto cuando se escribió por primera vez el código. También podemos empezar a hacer cosas inteligentes, tal vez modificar el programa según se está ejecutando.
¿Causa temor? No tiene por qué. De hecho, con estas capacidades de reflexión vamos a hacer algunas cosas muy útiles. Más adelante en este capítulo vamos a ver Ruby distribuido y el cálculo de referencias, dos tecnologías basadas en la reflexión que nos permite enviar objetos en todo el mundo y a través del tiempo.
Mirando Objetos
¿Alguna vez ha anhelado la posibilidad de recorrer todos los objetos que viven en su programa? ¡Pode-mos! Ruby le permite realizar este truco con ObjectSpace.each_object. Podemos usarlo para hacer todo tipo de truquitos.

274
Página 383 del original en inglés.

275
Por ejemplo, para iterar sobre todos los objetos de tipo Numeric, se podría escribir lo siguiente.
a = 102.7b = 95.1ObjectSpace.each_object(Numeric) {|x| p x }
produce:
95.1102.72.718281828459053.141592653589792.22044604925031e-161.79769313486232e+3082.2250738585072e-308
Hey, ¿de dónde salen todos esos números extra? No los definimos en nuestro programa. Más adelante, veremos que la clase Float define las constantes para el float máximio y mínimo, así como Epsilon, la más pequeña diferencia distinguible entre dos floats. El módulo Math define constantes para e y π. Puesto que estamos examinando todos los objetos que viven en el sistema, estos a su vez aparecen también.
Vamos a probar el mismo ejemplo con números diferentes.
a = 102b = 95ObjectSpace.each_object(Numeric) {|x| p x }
produce:
2.718281828459053.141592653589792.22044604925031e-161.79769313486232e+3082.2250738585072e-308
Ninguno de los objetos Fixnum que hemos creado apareció. Esto es porque ObjectSpace no sabe acerca de los objetos con valores inmediatos: Fixnum, Symbol, true, false y nil.
Mirando Dentro de los Objetos
Una vez que haya encontrado un objeto interesante, puede tener la tentación de averiguar lo que puede hacer. A diferencia de los lenguajes estáticos, donde el tipo de una variable determina su clase y, por lo tanto, los métodos que soporta, Ruby soporta objetos liberados. Usted realmente no puede decir exacta-mente lo que un objeto puede hacer hasta que mira debajo de su capota (o bajo su capó, para los objetos creados al este del Atlántico). Hablamos de esto en el capítulo de Duck Typing, anteriormente.
Por ejemplo, podemos obtener una lista de todos los métodos a los que un objeto va a responder.
r = 1..10 # Crear un objeto Rangelist = r.methodslist.length -> 68list[0..3] -> [“collect”, “to_a”, “instance_eval”, “all?”]
O bien, podemos comprobar si un objeto admite un método en particular.
r.respond_to?(“frozen?”) -> truer.respond_to?(:has_key?) -> false“me”.respond_to?(“==”) -> true

276
Podemos determinar la clase de nuestro objeto y su identificador de objeto único (ID) y poner a prueba su relación con otras clases.
num = 1num.id -> 3num.class -> Fixnumnum.kind_of? Fixnum -> truenum.kind_of? Numeric -> truenum.instance_of? Fixnum -> truenum.instance_of? Numeric -> false
Mirando Clases
Saber acerca de los objetos es una parte de la reflexión, pero para obtener el cuadro completo, usted también necesita ser capaz de mirar a las clases --los métodos y constantes que contienen.
En cuanto a la jerarquía de clases es fácil. Puede obtener la clase padre de cualquier clase en particu-lar con Class#superclass. Para clases y módulos, Module#ancestors lista tanto superclases como módulos mixed-in.
klass = Fixnumbegin print klass klass = klass.superclass print “ < “ if klassend while klassputsp Fixnum.ancestors
produce:
Fixnum < Integer < Numeric < Object[Fixnum, Integer, Precision, Numeric, Comparable, Object, Kernel]
Si se quiere construir una jerarquía de clases completa, basta con ejecutar este código para cada clase en el sistema. Podemos utilizar ObjectSpace para iterar sobre todos los objetos Class.
ObjectSpace.each_object(Class) do |klass| # ...end
Mirando Dentro de las Clases
Podemos buscar un poco más en los métodos y las constantes de un objeto en particular. En lugar de sólo comprobar si el objeto responde a un mensaje dado, podemos preguntarle a los métodos por el nivel de acceso e inquirir sólo por los métodos singleton. También podemos echar un vistazo a las constantes, locales y variables de instancia del objeto.
class Demo @@var = 99 CONST = 1.23
private def private_method endprotected def protected_method endpublic def public_method

277
@inst = 1 i = 1 j = 2 local_variablesend
def Demo.class_method endend
Demo.private_instance_methods(false) -> [“private_method”]Demo.protected_instance_methods(false) -> [“protected_method”]Demo.public_instance_methods(false) -> [“public_method”]Demo.singleton_methods(false) -> [“class_method”]Demo.class_variables -> [“@@var”]Demo.constants Demo.superclass.constants -> [“CONST”]
demo = Demo.newdemo.instance_variables -> []# Obtener ‘public_method’ para retornar sus variables locales # y establecer una variable de instanciademo.public_method -> [“i”, “j”]demo.instance_variables -> [“@inst”]
Module.constants devuelve todas las constantes disponibles a través de un módulo, incluyendo las constantes de las superclases del módulo. No estamos interesados en estas justo en este momento, así que las restamos de nuestra lista.
Usted puede preguntarse acerca de los parámetros false del código anterior. A partir de Ruby 1.8, estos métodos de reflexión, por defecto recorre las clases padres y las clases padres de éstas y así sucesivamente hasta recorrer toda la cadena de los antepasados. Pasando false se detiene este tipo de fisgoneo.
Dada una lista de nombres de métodos, ahora puede verse tentados a tratar de llamalos. Afortunada-mente, esto es fácil con Ruby.
Llamar a Métodos de Forma Dinámica
Los programadores de C y Java a menudo se encuentran escribiendo una especie de mesa de despa-cho: funciones que se invocan sobre la base de un comando. Piense en el típico lenguaje C donde se tiene que traducir una cadena a un puntero a función.
typedef struct { char *name; void (*fptr)();} Tuple;Tuple list[]= { { “play”, fptr_play }, { “stop”, fptr_stop }, { “record”, fptr_record }, { 0, 0 },};...void dispatch(char *cmd) { int i = 0; for (; list[i].name; i++) { if (strncmp(list[i].name,cmd,strlen(cmd)) == 0) { list[i].fptr(); return; }

278
} /* not found */}
En Ruby, usted puede hacer todo esto en una sola línea. Ponga todas las funciones de comando en una clase, cree una instancia de esa clase (llamamandola commands), y haga que el objeto ejecute un método llamado con el mismo nombre que la cadena de comando.
commands.send(command_string)
Ah, y por cierto, hace mucho más que la versión C --ya que es de forma dinámica. La versión Ruby encuentra nuevos métodos añadidos en tiempo de ejecución con la misma facilidad.
No se tienen que escribir las clases especiales de comando para send: funciona en cualquier objeto.
“John Coltrane”.send(:length) -> 13“Miles Davis”.send(“sub”, /iles/, ‘.’) -> “M. Davis”
Otra forma de invocar métodos de forma dinámica es utilizando objetos Method. Un objeto Method es como un objeto Proc: representa un trozo de código y un contexto en el que se ejecuta. En este caso, el código es el cuerpo del método y el contexto es el objeto que creó el método. Una vez que tenemos nuestro objeto Method, se puede ejecutar en algún momento más adelante mediante el envío del mensaje call.
trane = “John Coltrane”.method(:length)miles = “Miles Davis”.method(“sub”)
trane.call -> 13miles.call(/iles/, ‘.’) -> “M. Davis”
Puede pasar el objeto Method como lo haría con cualquier otro objeto y cuando se invoca Method#call, se ejecuta el método como si se hubiera invocado en el objeto original. Es como tener un puntero a función de estilo C, pero de forma totalmente orientada a objetos.
También puede utilizar los objetos Method con iteradores.
def double(a) 2*aend
mObj = method(:double)
[ 1, 3, 5, 7 ].collect(&mObj) -> [2, 6, 10, 14]
Los objetos Method están destinados a un objeto en particular. Se puede crear métodos no consolida-dos (de la clase UnboundMethod) y, posteriormente, unirse a uno o más objetos. La unión (binding) crea un nuevo objeto Method. Al igual que con los alias, los métodos no ligados son referencias a la definición del método en el momento de su creación.unbound_length = String.instance_method(:length)class String def length 99 endendstr = “cat”str.length -> 99bound_length = unbound_length.bind(str)bound_length.call -> 3
Como las cosas buenas vienen de tres en tres, esta es otra manera de llamar a los métodos de forma dinámica. El método eval (y sus variantes, tales como class_eval, module_eval y instance_eval)

279
analizará y ejecutará una cadena arbitraria de código fuente legítimo Ruby.
trane = %q{“John Coltrane”.length}miles = %q{“Miles Davis”.sub(/iles/, ‘.’)}
eval trane -> 13eval miles -> “M. Davis”
Cuando se utiliza eval, puede ser útil de manera explícita el contexto en el que la expresión debe ser eva-luada, en lugar de utilizar el contexto actual. Se puede obtener un contexto llamando a Kernel#binding en el punto deseado.
def get_a_binding val = 123 bindingend
val = “cat”
the_binding = get_a_bindingeval(“val”, the_binding) -> 123eval(“val”) -> “cat”
La primera eval evalúa val en el contexto de la unión, como era cuando el método get_a_binding se estaba ejecutando. En esta unión, la variable val tiene un valor de 123. El segundo eval evalúa val en el nivel superior de unión, donde se tiene el valor “cat”.
Consideraciones sobre el rendimiento
Como hemos visto en esta sección, Ruby nos ofrece varias formas de invocar un método arbitrario de algún objeto: Object#send, Method#call y las diferentes versiones de eval.
Es posible que se prefiera utilizar cualquiera de estas técnicas en función de las necesidades, pero hay que teneren cuenta que eval es significativamente más lento que los otros (o, para los lectores optimis-tas, send y call son significativamente más rápidos que eval).
require ‘benchmark’include Benchmarktest = “Stormy Weather”m = test.method(:length)n = 100000bm(12) {|x| x.report(“call”) { n.times { m.call } } x.report(“send”) { n.times { test.send(:length) } } x.report(“eval”) { n.times { eval “test.length” } }}
produce:
user system total realcall 0.250000 0.000000 0.250000 (0.340967)send 0.210000 0.000000 0.210000 (0.254237)eval 1.410000 0.000000 1.410000 (1.656809)
Sistema de Ganchos
Un gancho es una técnica que le permite atrapar algún evento Ruby, tal como la creación de objetos. La técnica de gancho más simple en Ruby es interceptar las llamadas a métodos en las clases del siste-ma. Tal vez se quiere registrar todos los comandos del sistema operativo que ejecuta el programa. Basta con cambiar el nombre del método Kernel.system y sustituirlo por uno a elegir que registre tanto los

280
comandos como las llamadas al método Kernel original.
module Kernel alias_method :old_system, :system def system(*args) result = old_system(*args) puts “system(#{args.join(‘, ‘)}) returned #{result}” result endendsystem(“date”)system(“kangaroo”, “-hop 10”, “skippy”)
produce:
Thu Aug 26 22:37:22 CDT 2004system(date) returned truesystem(kangaroo, -hop 10, skippy) returned false
Un gancho potente es la captura de los objetos que se crean. Si se puede estar presente en cada objeto que nace, se puede hacer todo tipo de cosas interesantes: se pueden envolver, añadirles y eliminarles mé-todos, añadirles a contenedores que implementan persistencia, lo que sea. Vamos a mostrar un ejemplo sencillo: vamos a añadir una marca de tiempo a cada objeto que se crea. Primero, añadiremos un atributo timestamp a cada objeto del sistema. Podemos hacer esto hackeando la mismísima clase Object.
class Object attr_accessor :timestampend
Después tenemos que enganchar la creación de objetos para agregarles esta marca de tiempo. Una manera de hacer esto es mediante nuestro truco de cambiar el nombre de método en Class#new, el método al que se llama para reservar espacio para un nuevo objeto. La técnica no es perfecta, algunos objetos integrados, tales como cadenas literales, se construyen sin llamar a new --pero va a funcionar bien para los objetos que escribamos.
class Class alias_method :old_new, :new def new(*args) result = old_new(*args) result.timestamp = Time.now result endend
Por último, podemos realizar una prueba. Vamos a crear un par de objetos con unos pocos milisegun-dos de diferencia y a comprobar sus marcas de tiempo.
class Testend
obj1 = Test.newsleep(0.002)obj2 = Test.new
obj1.timestamp.to_f -< 1093577843.1312obj2.timestamp.to_f -> 1093577843.14144
Todo esto cambiar el nombre de método está muy bien y realmente funciona, pero hay que tener en cuenta que puede causar problemas. Si una subclase hace lo mismo, y cambia el nombre de los métodos utilizando los mismos nombres, se terminará con un bucle infinito. Se puede evitar esto con alias de los

281
métodos a un nombre de símbolo único o mediante el uso de una nomenclatura coherente.
Hay otras formas más refinadas de obtener el corazón de un programa en ejecución. Ruby ofrece va-rios métodos de retorno de llamada que permiten atrapar ciertos eventos de una manera controlada.
Retornos de Llamada en Tiempo de Ejecución (Runtime Callbacks)
Usted puede ser notificado cada vez que ocurre uno de los siguientes eventos:
Por defecto, estos métodos no hacen nada. Si se define un método de retorno en una clase, va a ser invocado de forma automática. La secuencia real de llamada se ilustra en las descripciones de librería para cada método de retorno de llamada.
Hacer un seguimiento del método de creación y la utilización de clases y módulos permite crear una imagen exacta del estado dinámico del programa. Esto puede ser importante. Por ejemplo, puede haber se escrito código que envuelva todos los métodos de una clase, tal vez para añadir soporte transaccional o para implementar alguna forma de delegación. Esto sólo sería la mitad del trabajo: la naturaleza dinámica de Ruby hace que los usuarios de esta clase pudieran añadirle nuevos métodos en cualquier momento. Utilizando estas devoluciones de llamada, se puede escribir código que envuelva estos nuevos métodos a medida que se crean.
Seguimiento de la Ejecución del Programa Mientras nos estamos divirtiendo con este tema sobre la reflexión de los objetos y las clases en nues-tros programas, no nos olvidemos de las humildes declaraciones que hacen que nuestro código en reali-dad funcione eficazmente. Resulta que Ruby nos permite también mirar en detalle estas declaraciones.
En primer lugar, se puede ver al intérprete como ejecuta el código. set_trace_func ejecuta un Proc con todo tipo de jugosa información de depuración siempre que se ejecuta una línea fuente nueva, lla-madas a métodos, objetos creados, etc. Se encontrará una descripción completa más adelante pero aquí vamos a ver una muestra.
class Test def test a = 1 b = 2 endendset_trace_func proc {|event, file, line, id, binding, classname|printf “%8s %s:%-2d %10s %8s\n”, event, file, line, id, classname}t = Test.newt.test
produce:
line prog.rb:11 falsec-call prog.rb:11 new Classc-call prog.rb:11 initialize Object
Adición de un método de instancia Module#method_addedEliminación de un método de instancia Module#method_removedMétodo de instancia no definido Module#method_undefinedAdición de un método singleton Kernel.singleton_method_addedEliminación de un método singleton Kernel.singleton_method_removedMétodo singleton no definido Kernel.singleton_method_undefinededSe crea una subclase Class#inheritedSe crea un método mixin Module#extend_object
Evento Método de Retorno de llamada

282
c-return prog.rb:11 initialize Objectc-return prog.rb:11 new Classline prog.rb:12 falsecall prog.rb:2 test Testline prog.rb:3 test Testline prog.rb:4 test Testreturn prog.rb:4 test Test
El método trace_var le permite agregar un gancho a una variable global. Cada vez que se haga una asignación a nivel global, se invoca el objeto Proc.
¿Cómo Llegamos Hasta Aquí?
Una buena pregunta, y uno se la hace con frecuencia. Lapsos mentales a un lado, en Ruby al menos se puede saber exactamente “cómo se llegó allí” con el método caller, que devuelve un array de objetos String que representa la pila de llamadas en curso.
def cat_a puts caller.join(“\n”)enddef cat_b cat_aenddef cat_c cat_bendcat_c
produce:
prog.rb:5:in `cat_b’prog.rb:8:in `cat_c’prog.rb:10
Una vez que haya averiguado cómo llegó allí, el dónde ir ahora depende de usted.
Código Fuente
Ruby ejecuta programas desde antiguos ficheros planos. Se pueden ver estos archivos para examinar el código fuente que compone el programa con una de una serie de técnicas.
La variable especial __FILE__ contiene el nombre del archivo fuente actual. Esto lleva a un muy corto (si hacer trampa) Quine --un programa que produce su propio código fuente como salida única.
print File.read(__FILE__)
El método Kernel.caller devuelve la pila de llamadas --la lista de la pila existente en el momento en que se llamó al método. Cada entrada de esta lista comienza con un nombre de archivo, dos puntos y un número de línea en ese archivo. Se puede analizar esta información para buscar en el código fuente. En el siguiente ejemplo, tenemos un programa principal, main.rb, que llama a un método en un archivo separado, sub.rb. Este método invoca a su vez un bloque, donde se recorre la pila de llamadas y escribe las líneas fuente en cuestión. Nótese el uso de un hash del contenido del archivo, indexado por el nombre de archivo.
Aquí está el código que hace el volcado de la pila de llamadas, incluyendo información de la fuente.
def dump_call_stack file_contents = {} puts “File Line Source Line” puts “-------------------------------------------------------+------+--------------------”

283
caller.each do |position| next unless position =~ /\A(.*?):(\d+)/ file = $1 line = Integer($2) file_contents[file] ||= File.readlines(file) printf(“%-25s:%3d - %s”, file, line, file_contents[file][line-1].lstrip) endend
El (trivial) archivo sub.rb contiene un solo método.
def sub_method(v1, v2) main_method(v1*3, v2*6)end
Y aquí está el programa principal, que invoca el volcado de pila después de haber sido llamado por el submétodo.
require ‘sub’require ‘stack_dumper’def main_method(arg1, arg2) dump_call_stackendsub_method(123, “cat”)
produce:
File Line Source Line----------------------------------+------+--------------------code/caller/main.rb : 5 - dump_call_stack./code/caller/sub.rb : 2 - main_method(v1*3, v2*6)code/caller/main.rb : 8 - sub_method(123, “cat”)
La constante SCRIPT_LINES__ está estrechamente relacionada con esta técnica. Si un programa inicializa una constante llamada SCRIPT_LINES__ con un hash, este hash recibe el código fuente de to-dos los archivos cargados posteriormente en el intérprete añ utilizar require o load. Vea más adelante Kernel.require para un ejemplo.
Ruby Formateado (marshaling) y Distribuído
Java ofrece la posibilidad de serializar objetos, lo que permite guardarlos en algún lugar y reconstruirlos cuando sea necesario. Se puede utilizar esta función, por ejemplo, para salvar un árbol de objetos que repre-sentan una parte del estado de la aplicación --un documento, un dibujo en CAD, una pieza de música, etc.
Ruby llama a este tipo de serialización marshaling (hay que pensar en una estación de clasificación de ferrocarril, donde los automóviles se montan secuencialmente en un tren completo, que luego es enviado a alguna parte). Salvar un objeto y todos o algunos de sus componentes se realiza mediante el método Marshal.dump. Por lo general, se vuelca un árbol de objetos completo a partir de un objeto dado. Más tarde, se puede reconstituir el objeto utilizando Marshal.load.
He aquí un breve ejemplo. Contamos con una clase Chord que contiene una colección de notas musi-cales. Nos gustaría salvar fuera un acorde particularmente fabuloso para poderlo enviar por correo elec-trónico a un par de cientos de nuestros amigos más cercanos. Así pueden cargarlo en su copia de Ruby y disfrutarlo también. Vamos a empezar con las clases Note y Chord.
Note = Struct.new(:value)class Note def to_s value.to_s

284
endendclass Chord def initialize(arr) @arr = arr end def play @arr.join(‘-’) endend
Ahora vamos a crear nuestra obra maestra y a utilizar Marshal.dump para salvarla a una versión se-rializada en el disco.
c = Chord.new( [ Note.new(“G”), Note.new(“Bb”), Note.new(“Db”), Note.new(“E”) ] )File.open(“posterity”, “w+”) do |f| Marshal.dump(c, f)end
Finalmente, para que nuestros nietos lo lean y se transporten por la grandiosidad de nuestra creación.
File.open(“posterity”) do |f| chord = Marshal.load(f)endchord.play -> “G-Bb-Db-E”
Estrategia de Serialización Personalizada
No todos los objetos pueden ser objeto de volcado: bindings, objetos de procedimiento, instancias de la clase IO y objetos singleton no se pueden salvar fuera del entorno de ejecución Ruby (se produce un TypeError si se intenta). Incluso si su objeto no contiene uno de estos objetos problemáticos, es posible que desee tomar el control de la serialización de objetos por sí mismo.
Marshal ofrece los ganchos que se necesitan. En los objetos que requieran serialización personali-zada, simplemente hay aplicar dos métodos de instancia: marshal_dump, que escribe el objeto a una cadena y marshal_load, que lee una cadena que se habrá creado previamente y la utiliza para iniciali-zar un objeto recién asignado. (En versiones anteriores de Ruby tendrá que utilizar los métodos llamados _dump y _Load, pero las nuevas versiones desempeñan mejor con el nuevo esquema de asignación de Ruby 1.8). El método de instancia Marshal_dump debe devolver un objeto que representa el estado de volcado. Cuando el objeto es reconstituido posteriormente utilizando Marshal.load que llama a este objeto, lo utilizará para establecer el estado de su receptor --que se llevará a cabo en el contexto de una asignación pero no inicializa el objeto de la clase que se está cargando.
Por ejemplo, aquí hay una clase de ejemplo que define su propia serialización. Por las razones que sean, en Special no se quiere salvar uno de sus miembros de datos interno, @volatile. El autor ha decidido serializar las otras dos variables de instancia en una matriz.
class Special def initialize(valuable, volatile, precious) @valuable = valuable @volatile = volatile @precious = precious end def marshal_dump [ @valuable, @precious ] end def marshal_load(variables)

285
@valuable = variables[0] @precious = variables[1] @volatile = “unknown” end def to_s “#@valuable #@volatile #@precious” endendobj = Special.new(“Hello”, “there”, “World”)puts “Before: obj = #{obj}”data = Marshal.dump(obj)obj = Marshal.load(data)puts “After: obj = #{obj}”
produce:
Before: obj = Hello there WorldAfter: obj = Hello unknown World
Para más detalles, consulte la sección de referencia Marshal más adelante.
YAML para el Formateado
El módulo Marshal está integrado en el intérprete y utiliza un formato binario para almacenar los ob-jetos externos. Aunque rápido, este formato binario tiene una gran desventaja: si el intérprete cambia de manera significativa, el formato marshal binario también puede cambiar, y los antiguos archivos volcados ya no se podrán cargar.
Una alternativa es utilizar un formato externo menos exigente, preferentemente uno de texto en lugar de archivos binarios. Una opción suministrada como librería estándar de Ruby 1.8 es YAML (http://www.yaml.org. YAML es sinónimo de YAML no es el lenguaje de marcado --YAML Ain’t Markup Language--, pero esto no parece importante.
Podemos adaptar nuestro ejemplo marshal anterior para utilizar YAML. En lugar de aplicar métodos específicos de carga y volcado para controlar el proceso marshal, simplemente definimos el método to_yaml_properties, que devuelve una lista de variables de instancia para ser salvadas.
require ‘yaml’class Special def initialize(valuable, volatile, precious) @valuable = valuable @volatile = volatile @precious = precious end def to_yaml_properties %w{ @precious @valuable } end def to_s “#@valuable #@volatile #@precious” endendobj = Special.new(“Hello”, “there”, “World”)puts “Before: obj = #{obj}”data = YAML.dump(obj)obj = YAML.load(data)puts “After: obj = #{obj}”
produce:
Before: obj = Hello there World

286
After: obj = Hello World
Podemos echar un vistazo a lo que crea YAML como forma serializada del objeto --es bastante simple.
obj = Special.new(“Hello”, “there”, “World”)puts YAML.dump(obj)
produce:
--- !ruby/object:Specialprecious: Worldvaluable: Hello
Ruby Distribuído
Ya que puede serializar un objeto o un conjunto de objetos en una forma adecuada para almacenarlos fuera de proceso, podemos utilizar esta capacidad para la transmisión de objetos de un proceso a otro. Unimos esto con la poderosa capacidad de las redes y, voilà: Se tiene un sistema de objetos distribuidos. Para ahorrarle la molestia de tener que escribir el código, le sugerimos que utilice la librería de Ruby dis-tribuido (Distributed Ruby library -drb-) de Masatoshi Seki, que ya está disponible como librería estándar de Ruby.
Utilizando drb, un proceso Ruby puede actuar como un servidor, como un cliente o como ambos. Un servidor drb actúa como fuente de objetos, mientras que un cliente es un usuario de esos objetos. Para el cliente, los objetos aparecen como locales, pero en realidad el código está siendo ejecutado de forma remota.
Un servidor inicia un servicio mediante la asociación de un objeto con un puerto determinado. Entonces se crean hilos internamente para manejar las peticiones entrantes en ese puerto, a fin de recordar la unión al hilo drb antes de salir del programa.
require ‘drb’class TestServer def add(*args) args.inject {|n,v| n + v} endendserver = TestServer.newDRb.start_service(‘druby://localhost:9000’, server)DRb.thread.join # No salir todavía!
Un cliente drb sencillo, simplemente crea un objeto drb local y la asocia con el objeto en el servidor remoto. El objeto local es un proxy.
require ‘drb’DRb.start_service()obj = DRbObject.new(nil, ‘druby://localhost:9000’)# Ahora utilizamos objputs “Sum is: #{obj.add(1, 2, 3)}”
El cliente se conecta al servidor y llama al método add, que utiliza la magia de inyectar a la suma sus argumentos. Se devuelve el resultado, que imprime el cliente.
Sum is: 6
El argumento inicial nil a DRbObject indica que se desea adjuntar un nuevo objeto distribuido. Tam-bién se puede utilizar un objeto existente.
Ho Hum, dice usted. Esto suena como RMI de Java, o CORBA, o lo que sea. Sí, se trata de un me-canismo de objetos distribuidos funcional--pero está escrito en tan sólo unos pocos cientos de líneas de

287
código Ruby. Nada de C, nada lujoso, simple y viejo código plano Ruby. Por supuesto, no tiene servicio de nombres u operador de servicios, ni nada parecido a lo que vemos en CORBA, pero es sencillo y razona-blemente rápido. En un sistema Powerbook de 1GHz, este código de ejemplo ejecuta alrededor de unas 500 llamadas de mensajes remotos por segundo.
Y, si le gusta el aspecto de JavaSpaces de Sun, la base de la arquitectura JINI, le interesará saber que el drb se distribuye con un breve módulo que realiza el mismo tipo de cosas. JavaSpaces se basa en una tecnología llamada Linda. Para probar que su autor japonés tiene sentido del humor, la versión de Ruby de Linda se conoce como Rinda.
Si le gusta la mensajería remota gruesa, tonta e interoperable, también podría buscar en las bibliotecas de SOAP distribuidas con Ruby (SOAP hace mucho tiempo abandonó la parte simple de sus siglas. La implementación Ruby de SOAP es una maravillosa pieza de trabajo).
¿Tiempo de Compilación? ¿Tiempo de Ejecución? ¡En Cualquier Momento!
Lo importante que hay recordar acerca de Ruby es que no hay una gran diferencia entre “tiempo de compilación” y “tiempo de ejecución.” Es todo lo mismo. Puede agregar código a un proceso en ejecución. Puede volver a definir los métodos sobre la marcha, cambiar su ámbito de public a private, etc. Usted puede incluso alterar los tipos básicos, como Class y Object.
Una vez que uno se acostumbra a esta flexibilidad, es difícil volver a un lenguaje estático como C++ o incluso a un lenguaje medio estático como Java.
Pero, ¿por qué querría uno hacer eso?
Referencia de Librería Ruby
Clases y Módulos Integrados
Este capítulo documenta las clases y módulos integrados en el estándar del lenguaje Ruby. Están dis-ponibles para todos los programas de Ruby automáticamente sin necesidad de require. Esta sección no contiene las diversas variables y constantes predefinidas, las cuales se enumeraron anteriormente.
Más adelante se muestran las invocaciones de ejemplo para cada método.
new String.new( some_string ) → new_string
Esta descripción muestra un método de clase que se invoca como String.new. El parámetro en cur-siva indica que se pasa una sola cadena, y la flecha indica que se devuelve otra cadena desde el método. Como este valor de retorno tiene un nombre diferente que el del parámetro, representa un objeto diferente.
En la ilustración de los métodos de instancia, se muestra un ejemplo de llamada con un nombre de objeto ficticio en cursiva, como el receptor.
each str.each( sep=$/ ) {| record | block } → str
El parámetro de String#each ha demostrado tener un valor por defecto. Si se llama a each sin pa-rámetros, se utilizará el valor de $/ . Este método es un iterador, por lo que la llamada es seguida por un bloque. String#each devuelve su receptor, por lo que el nombre del mismo (str en este caso) aparece de nuevo después de la flecha.
Algunos métodos tienen parámetros opcionales. Se muestran estos parámetros entre paréntesis angu-lares, < xxx >. (Además, se usa la notación < xxx > * para indicar cero o más ocurrencias de xxx, y se usa < xxx > + para indicar una o más ocurrencias de xxx).

288
index self.index( str < , offset > ) → pos o nil Por último, para métodos que se pueden llamar de varias formas diferentes, se lista cada forma en una línea separada.
Clase
Array < Object
Las matrices son colecciones ordenadas de cualquier objeto indexadas con enteros. L ndexación de un array empieza en 0, como en C o Java. Un índice negativo se asume que es relativo al final de la matriz, es decir, un índice de -1 indica el último elemento de la matriz, -2 es el siguiente al último elemento de la matriz y así sucesivamente.
Se mezcla enEnumerable:all?, any?, collect, detect, each_with_index, entries, find, find_all, grep, include?, inject, map, max, member? , min, partition, reject, select, sort, sort_by, to_a, zip
Métodos de Clase
[ ] Array[ < obj >* ]→ una_matriz
Devuelve una matriz nueva llenada con los objetos dados. Equivalente a la forma del operador Array. [](...)
Array.[]( 1, ‘a’, /^A/ ) -> [1, “a”, /^A/]Array[ 1, ‘a’, /^A/ ] -> [1, “a”, /^A/][ 1, ‘a’, /^A/ ] -> [1, “a”, /^A/]
new Array.new→ una_matrizArray.new ( size=0, obj=nil )→ una_matriz
Array.new( array )→ una_matrizArray.new( size ) {| i | block } → una_matriz
Devuelve una matriz nueva. En la primera forma, la nueva matriz está vacía. En el segunda, se crea con copias tamaño size de obj (es decir, las referencias de tamaño al mismo obj). En la tercera forma se crea una copia de la matriz pasada como parámetro (la matriz se genera llamando a to_ary en el pará-metro). En la última forma, se crea una matriz del tamaño dado. Cada elemento de este vector se calcula pasando el índice del elemento al bloque dado y almacenando el valor de retorno.
Array.new -> []Array.new(2) -> [nil, nil]Array.new(5, “A”) -> [“A”, “A”, “A”, “A”, “A”]
# sólo se creauna instancia del objeto por defectoa = Array.new(2, Hash.new)a[0][‘cat’] = ‘feline’a -> [{“cat”=>”feline”}, {“cat”=>”feline”}]a[1][‘cat’] = ‘Felix’a -> [{“cat”=>”Felix”}, {“cat”=>”Felix”}]
a = Array.new(2) { Hash.new } # varias instanciasa[0][‘cat’] = ‘feline’

289
a -> [{“cat”=>”feline”}, {}]
squares = Array.new(5) {|i| i*i}squares -> [0, 1, 4, 9, 16]
copy = Array.new(squares) # inicializado por copiasquares[5] = 25squares -> [0, 1, 4, 9, 16, 25]copy -> [0, 1, 4, 9, 16]
Métodos de Instancia
& arr & otra_matriz → una_matriz
Intersección de conjuntos --Devuelve una nueva matriz que contiene elementos comunes a las dos matrices, sin duplicados. Las reglas para la comparación de los elementos son los mismas que para las claves hash. Si se necesita un comportamiento similar a los conjuntos, ver la librería de la clase Set.
[ 1, 1, 3, 5 ] & [ 1, 2, 3 ] -> [1, 3]
* arr * int → una_matriz arr * str → una_cadena
Repetición --Con un argumento responde a to_str, equivalente a arr.join (str). De otra manera, devuelve una nueva matriz construida mediante la concatenación de int copias a arr.
[ 1, 2, 3 ] * 3 -> [1, 2, 3, 1, 2, 3, 1, 2, 3][ 1, 2, 3 ] * “--” -> “1--2--3”
+ arr + otra_matriz → una_matriz
Concatenación --Devuelve una nueva matriz construida mediante la concatenación de las dos matrices para producir una tercera matriz.
[ 1, 2, 3 ] + [ 4, 5 ] -> [1, 2, 3, 4, 5]
– arr - otra_matriz → una_matriz
Diferencia --Devuelve una nueva matriz que es una copia de la matriz original, eliminando todos los ele-mentos que también aparecen en otra_matriz. Si se necesita un comportamiento similar a los conjuntos, ver la librería de la clase Set.
[ 1, 1, 2, 2, 3, 3, 4, 5 ] - [1, 2, 4 ] -> [3, 3, 5]
<< arr << obj → arr
Adición --Empuja el objeto dado al final de la matriz. Esta expresión devuelve la propia matriz, por lo varias adiciones pueden ser encadenadas juntos. Véase también Array#push.
[ 1, 2 ] << “c” << “d” << [ 3, 4 ] -> [1, 2, “c”, “d”, [3, 4]]
<=> arr <=> otra_matriz → −1, 0, +1
Comparación --Devuelve un entero -1, 0 o +1 si la matriz es menor, igual o mayor que otra_matriz. Cada objeto en cada matriz es comparado (utilizando <=>). Si algún valor no es igual, entonces esta des-igualdad es el valor de retorno. Si todos los valores encontrados son iguales, entonces el retorno se basa en una comparación de las longitudes de matriz. De este modo, dos matrices son “iguales”, de acuerdo a Array#<=> si y sólo si tienen la misma longitud y el valor de cada elemento es igual al valor del corres-pondiente elemento de la otra matriz.

290
[ “a”, “a”, “c” ] <=> [ “a”, “b”, “c” ] -> -1[ 1, 2, 3, 4, 5, 6 ] <=> [ 1, 2 ] -> 1
== arr == obj → true o false
Igualdad --Dos matrices son iguales si contienen el mismo número de elementos y si cada elemento es igual a (de acuerdo a Object#==) el correspondiente elemento de la otra matriz. Si obj no es una matriz, trata de convertirlo utilizando to_ary y retorna obj==arr.
[ “a”, “c” ] == [ “a”, “c”, 7 ] -> false[ “a”, “c”, 7 ] == [ “a”, “c”, 7 ] -> true[ “a”, “c”, 7 ] == [ “a”, “d”, “f” ] -> false
[ ] arr[int] → obj o nil arr[start, length] → una_matriz o nil arr[range] → una_matriz o nil
Referencia a Elemento --Devuelve el elemento situado int en el índice int, devuelve una submatriz co-menzando en el índice start y continuando hasta length elementos, o devuelve una submatriz especificado por range. Los índices negativos cuentan hacia atrás desde el final de la matriz (-1 es el último elemento). Devuelve nil si el índice del primer elemento seleccionado es mayor que el tamaño de la matriz. Si el ín-dice de inicio es igual al tamaño de la matriz y se dá un parámetro length o range, se devuelve una matriz vacía. Equivalente a Array#slice.
a = [ “a”, “b”, “c”, “d”, “e” ]a[2] + a[0] + a[1] -> “cab”a[6] -> nila[1, 2] -> [“b”, “c”]a[1..3] -> [“b”, “c”, “d”]a[4..7] -> [“e”]a[6..10] -> nila[-3, 3] -> [“c”, “d”, “e”]
# casos especialesa[5] -> nila[5, 1] -> []a[5..10] -> []
[ ]= arr[int] = obj → obj arr[start, length] = obj → obj
arr[range] = obj → obj
Asignación de elementos --Establece el elemento en el índice int, sustituye a una submatriz comen-zando en el índice start y continuando hasta length elementos, o reemplaza a una submatriz especificada por range. Si int es mayor que la capacidad actual de la matriz, la matriz crece de forma automática. Un int negativo cuenta hacia atrás desde el final de la matriz. Inserta los elementos, si la longitud es igual a cero. Si obj es nil, borra elementos de arr. Si obj es una matriz, la forma con índice único insertará esta matriz en arr y las formas con una longitud o con un rango reemplazará los elementos dados en arr con el contenido de la matriz. Se lanza un IndexError si los índices negativos van más allá del principio de la matriz. Véase también Array#push y Array#unshift.
a = Array.new -> []a[4] = “4”; a -> [nil, nil, nil, nil, “4”]a[0] = [ 1, 2, 3 ]; a -> [[1, 2, 3], nil, nil, nil, “4”]a[0, 3] = [ ‘a’, ‘b’, ‘c’ ]; a -> [“a”, “b”, “c”, nil, “4”]a[1..2] = [ 1, 2 ]; a -> [“a”, 1, 2, nil, “4”]a[0, 2] = “?”; a -> [“?”, 2, nil, “4”]a[0..2] = “A”; a -> [“A”, “4”]

291
a[-1] = “Z”; a -> [“A”, “Z”]a[1..-1] = nil; a -> [“A”]
| arr | otra_matriz → una_matriz
Unión --Devuelve una matriz nueva de la unión de una matriz con otra_matriz, eliminando duplicados. Las reglas para la comparación de los elementos son las mismas que para las claves hash. Si se necesita un comportamiento similar a los conjuntos, ver la librería de la clase Set.
[ “a”, “b”, “c” ] | [ “c”, “d”, “a” ] -> [“a”, “b”, “c”, “d”]
assoc arr.assoc( obj ) → una_matriz o nil
Busca en una matriz cuyos elementos son también matrices, comparando obj con el primer elemento de cada matriz contenida utiliznado obj.==. Devuelve la primera matriz contenida que coincida (es decir, la primera matriz associada) o nil si no hay coincidencia. Véase también Array#rassoc.
s1 = [ “colors”, “red”, “blue”, “green” ]s2 = [ “letters”, “a”, “b”, “c” ]s3 = “foo”a = [ s1, s2, s3 ]a.assoc(“letters”) -> [“letters”, “a”, “b”, “c”]a.assoc(“foo”) -> nil
at arr.at( int ) → obj o nil
Devuelve el elemento en el índice int. Un índice negativo cuenta desde el final de arr. Devuelve nil si el índice está fuera de rango. Véase también Array#[]. (Array#at es ligeramente más rápido que el Array#[], ya que no acepta rangos, etc.)
a = [ “a”, “b”, “c”, “d”, “e” ]a.at(0) -> “a”a.at(-1) -> “e”
clear arr.clear → arr
Elimina todos los elementos de arr.
a = [ “a”, “b”, “c”, “d”, “e” ]a.clear -> []
collect! arr.collect! {| obj | block } → arr
Invoca block una vez para cada elemento de arr, sustituyendo el elemento con el valor devuelto por el bloque. Véase también Enumerable#collect.
a = [ “a”, “b”, “c”, “d” ]a.collect! {|x| x + “!” } -> [“a!”, “b!”, “c!”, “d!”]a -> [“a!”, “b!”, “c!”, “d!”]
compact arr.compact → una_matriz
Devuelve una copia de arr con todos los elementos nil eliminados.
[ “a”, nil, “b”, nil, “c”, nil ].compact -> [“a”, “b”, “c”]
compact! arr.compact! → arr o nil
Elimina los elementos nil de arr. Retorna nil si no se hicieron cambios.

292
[ “a”, nil, “b”, nil, “c” ].compact! -> [“a”, “b”, “c”][ “a”, “b”, “c” ].compact! -> nil
concat arr.concat( otra_matriz ) → arr
Añade los elementos de otra_matriz en arr.
[ “a”, “b” ].concat( [“c”, “d”] ) -> [“a”, “b”, “c”, “d”]
delete arr.delete( obj ) → obj o nilarr.delete( obj ) { block } → obj o nil
Elimina elementos de arr que son iguales a obj. Si no se encuentra el elemento, devuelve nil. Si se dá el bloque de código opcional, devuelve el resultado del bloque si no se encuentra el elemento.
a = [ “a”, “b”, “b”, “b”, “c” ]a.delete(“b”) -> “b”a -> [“a”, “c”]a.delete(“z”) -> nila.delete(“z”) { “not found” } -> “not found”
delete_at arr.delete_at( index ) → obj o nil
Elimina el elemento en el índice especificado, devolviendo ese elemento, o nil si el índice está fuera de rango. Véase también Array#slice!.
a = %w( ant bat cat dog )a.delete_at(2) -> “cat”a -> [“ant”, “bat”, “dog”]a.delete_at(99) -> nil
delete_if arr.delete_if {| item | block } → arr
Elimina todos los elementos de arr para los cuáles block evalúa true.
a = [ “a”, “b”, “c” ]a.delete_if {|x| x >= “b” } -> [“a”]
each arr.each {| item | block } → arr
Llamadas a block una vez por cada elemento de arr, pasando ese elemento como un parámetro.
a = [ “a”, “b”, “c” ]a.each {|x| print x, “ -- “}
produce:
a -- b -- c
each_index arr.each_index {| index | block } → arr
Lo mismo que Array#each uno, pero pasa el índice del elemento en lugar del propio elemento.
a = [ “a”, “b”, “c” ]a.each_index {|x| print x, “ -- ”}
produce:

293
1 -- 2 -- 3
empty? arr.empty? → true o false
Devuelve true si la matriz arr no contiene elementos.
[].empty? -> true[ 1, 2, 3 ].empty? -> false
eql? arr.eql?( otro ) → true o false
Devuelve true si arr y otro son el mismo objeto o si otro es un objeto de la clase Array con la misma longitud y contenido que arr. Los elementos de cada matriz se comparan utilizando Object#eql?.Véase también Array#<=>.
[ “a”, “b”, “c” ].eql?([“a”, “b”, “c”]) -> true[ “a”, “b”, “c” ].eql?([“a”, “b”]) -> false[ “a”, “b”, “c” ].eql?([“b”, “c”, “d”]) -> false
fetch arr.fetch( index ) → obj arr.fetch( index, default ) → obj arr.fetch( index ) {| i | block } → obj
Intenta devolver el elemento en la posición index. Si el índice está fuera de la matriz, la primera forma produce una excepción IndexError, la segunda forma devuelve default, y la tercera forma devuelve el valor de la invocación del bloque, al que se le pasa el índice. Los valores negativos del índice cuentan desde el final de la matriz.
a = [ 11, 22, 33, 44 ]a.fetch(1) -> 22a.fetch(-1) -> 44a.fetch(-1, ‘cat’) -> 44a.fetch(4, ‘cat’) -> “cat”a.fetch(4) {|i| i*i } -> 16
fill arr.fill( obj ) → arr arr.fill( obj, start < , length > ) → arr arr.fill( obj, range ) → arr arr.fill {| i | block } → arr arr.fill( start < , length > ) {| i | block } → arr arr.fill( range ) {| i | block } → arr
Las tres primeras formas establecen los elementos seleccionados de arr (que puede ser toda la matriz) para obj. Un start nil es equivalente a cero. Una longitud nil es equivalente a arr.length. Las tres úl-timas formas llenan la matriz con el valor del bloque, al que se le pasa el índice absoluto de cada elemento por cubrir.a = [ “a”, “b”, “c”, “d” ]a.fill(“x”) -> [“x”, “x”, “x”, “x”]a.fill(“z”, 2, 2) -> [“x”, “x”, “z”, “z”]a.fill(“y”, 0..1) -> [“y”, “y”, “z”, “z”]a.fill {|i| i*i} -> [0, 1, 4, 9]a.fill(-3) {|i| i+100} -> [0, 101, 102, 103]
first arr.first → obj o nil arr.first( count ) → una_matriz
Devuelve el primer elemento o los primeros elementos del recuento de arr. Si la matriz está vacía, la

294
primera forma retorna nil y la segunda devuelve una matriz vacía.
a = [ “q”, “r”, “s”, “t” ]a.first -> “q”a.first(1) -> [“q”]a.first(3) -> [“q”, “r”, “s”]
flatten arr.flatten → una_matriz
Devuelve una nueva matriz que es un aplanamiento de una dimensión de esta matriz (recursivamente). Es decir, para cada elemento que es una matriz, extrae sus elementos en la nueva matriz.
s = [ 1, 2, 3 ] -> [1, 2, 3]t = [ 4, 5, 6, [7, 8] ] -> [4, 5, 6, [7, 8]]a = [ s, t, 9, 10 ] -> [[1, 2, 3], [4, 5, 6, [7, 8]], 9, 10]a.flatten -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
flatten! arr.flatten! → arr o nil
Igual que el Array#flatten, pero modifica el receptor en su lugar. Retorna nil si no se realizaron modificaciones (es decir, arr no contiene submatrices).
a = [ 1, 2, [3, [4, 5] ] ]a.flatten! -> [1, 2, 3, 4, 5]a.flatten! -> nila -> [1, 2, 3, 4, 5]
include? arr.include?( obj ) → true o false
Devuelve true si el objeto dado está presente en arr (es decir, si cualquier objeto == obj), false en caso contrario.
a = [ “a”, “b”, “c” ]a.include?(“b”) -> truea.include?(“z”) -> false
indexes arr.indexes( i1, i2, ... iN ) → una_matriz
Obsoleto, utilizar Array#values_at.
indices arr.indices( i1, i2, ... iN ) → una_matriz
Obsoleto, utilizar Array#values_at
insert arr.insert( index, < obj >+ ) → arr
Si el índice no es negativo, se inserta el valor dado antes del elemento con el índice dado. Si el índice es -1, añade los valores a arr. De lo contrario inserta los valores después del elemento con el índice dado.
a = %w{ a b c d }a.insert(2, 99) -> [“a”, “b”, 99, “c”, “d”]a.insert(-2, 1, 2, 3) -> [“a”, “b”, 99, “c”, 1, 2, 3, “d”]a.insert(-1, “e”) -> [“a”, “b”, 99, “c”, 1, 2, 3, “d”, “e”]
join arr.join( separator=$, ) → str
Devuelve una cadena creada mediante la concatenación de cada elemento de la matriz separando cada uno por el separador.

295
[ “a”, “b”, “c” ].join -> “abc”[ “a”, “b”, “c” ].join(“-”) -> “a-b-c”
last arr.last → obj o nil arr.last( count ) → una_matriz Devuelve el último elemento o elementos últimos del recuento de arr. Si la matriz está vacía, la primera forma devuelve nil, la segunda una matriz vacía.
[ “w”, “x”, “y”, “z” ].last -> “z”[ “w”, “x”, “y”, “z” ].last(1) -> [“z”][ “w”, “x”, “y”, “z” ].last(3) -> [“x”, “y”, “z”]
length arr.length → int
Devuelve el número de elementos de arr. Véase también Array#nitems.
[ 1, nil, 3, nil, 5 ].length -> 5
map! arr.map! {| obj | block } → arr
Sinónimo de Array#collect!.
nitems arr.nitems → int
Devuelve el número de elementos no nil de arr. Vease también Array#length.
[ 1, nil, 3, nil, 5 ].nitems -> 3
pack arr.pack ( template ) → binary_string
Empaqueta los contenidos de arr en una secuencia binaria de acuerdo a las directivas en template (ver la Tabla 9 en la página siguiente). Las directivas A, a y Z puede ser seguido por un recuento, que da el ancho del campo resultante. El resto de directivas también pueden tomar un conteo, indicando el número de elementos a convertir de la matriz. Si el contador es un asterisco (*), se convertirán todos los elemen-tos restantes de la matriz. Cualquiera de las directivas “sSiIlL” pueden ser seguida por un guión bajo (_) para utilizar el tamaño nativo de la plataforma subyacente para el tipo especificado. De otra manera, utilizará una plataforma independiente del tamaño. Los espacios son ignorados en la cadena de plantilla. Los comentarios comenzando con # al siguiente salto de línea o al final de la cadena también se ignoran. Véase también String#unpack.
a = [ “a”, “b”, “c” ]n = [ 65, 66, 67 ]a.pack(“A3A3A3”) -> “a̺̺b̺̺c ”a.pack(“a3a3a3”) -> “a\000\000b\000\000c\000\000”n.pack(“ccc”) -> “ABC”
pop arr.pop → obj o nil
Elimina el último elemento de arr y lo devuelve, o retorna nil si la matriz está vacía.
a = [ “a”, “m”, “z” ]a.pop -> “z”a -> [“a”, “m”]

296
push arr.push( < obj >* ) → arr
Añade el argumento o argumentos dados a arr.
a = [ “a”, “b”, “c” ]a.push(“d”, “e”, “f”) -> [“a”, “b”, “c”, “d”, “e”, “f”]
rassoc arr.rassoc( key ) → una_matriz o nil
Busca en la matriz elementos que son también matrices. Compara key con el segundo elemento de cada matriz contenida con ==. Devuelve la primera matriz contenida que coincide. Véase también Array#assoc.
1 Los octetos de un entero BER-comprimido representan un entero sin signo en base de 128, con el dígito más significativo en primer lugar y con tan pocos dígitos como sea posible. Se establece el octavo bit (el bit alto) en cada byte, excepto el último (Self-DescribingBinary Data Representation, MacLeod)

297
a = [ [ 1, “one”], [2, “two”], [3, “three”], [“ii”, “two”] ]a.rassoc(“two”) -> [2, “two”]a.rassoc(“four”) -> nil
reject! arr.reject! { block } item → arr o nil
Equivalente a Array#delete_if, pero retorna nil si no se hicieron cambios. Ver también Enumerable#reject.
replace arr.replace( otra_matriz ) → arr
Reemplaza el contenido de arr con los contenidos de otra_matriz, truncando o ampliando si es necesario.
a = [ “a”, “b”, “c”, “d”, “e” ]a.replace([ “x”, “y”, “z” ]) -> [“x”, “y”, “z”]a -> [“x”, “y”, “z”]
reverse arr.reverse → una_matriz
Devuelve una nueva matriz con los elementos de arr en orden inverso.
[ “a”, “b”, “c” ].reverse -> [“c”, “b”, “a”][ 1 ].reverse -> [1]
reverse! arr.reverse! → arr
Invierte arr.
a = [ “a”, “b”, “c” ]a.reverse! -> [“c”, “b”, “a”]a -> [“c”, “b”, “a”][ 1 ].reverse! -> [1]
reverse_each arr.reverse_each {| item | block } → arr
Lo mismo que Array#each, pero atraviesa arr en orden inverso.
a = [ “a”, “b”, “c” ]a.reverse_each {|x| print x, “ “ }
produce:
c b a
rindex arr.rindex( obj ) → int o nil
Devuelve el índice del último objeto en arr, tal que objeto == obj. Devuelve nil si no hay coincidencia.
a = [ “a”, “b”, “b”, “b”, “c” ]a.rindex(“b”) -> 3a.rindex(“z”) -> nil
shift arr.shift → obj o nil
Devuelve el primer elemento de arr y lo elimina (desplazando una posición atrás todos los demás ele-mentos). Devuelve nil si la matriz está vacía.
args = [ “-m”, “-q”, “filename” ]args.shift -> “m”args -> [“q”, “filename”]

298
size arr.size → int
Sinónimo de Array#length.
slice arr.slice( int ) → obj arr.slice( start, length ) → una_matriz arr.slice( range ) → una_matriz
Sinónimo de Array#[ ].
a = [ “a”, “b”, “c”, “d”, “e” ]a.slice(2) + a.slice(0) + a.slice(1) -> “cab”a.slice(6) -> nila.slice(1, 2) -> [“b”, “c”]a.slice(1..3) -> [“b”, “c”, “d”]a.slice(4..7) -> [“e”]a.slice(6..10) -> nila.slice(-3, 3) -> [“c”, “d”, “e”]# casos especialesa.slice(5) -> nila.slice(5, 1) -> []a.slice(5..10) -> []
slice! arr.slice!( int ) → obj o nil arr.slice!( start, length ) → una_matriz o nil arr.slice!( range ) → una_matriz o nil
Elimina el elemento o elementos dados con un índice (de manera opcional con una longitud) o con un rango. Devuelve el objeto eliminado, submatriz o nil si el índice está fuera de rango. Equivalente a
def slice!(*args) result = self[*args] self[*args] = nil resultend
a = [ “a”, “b”, “c” ]a.slice!(1) -> “b”a -> [“a”, “c”]a.slice!(-1) -> “c”a -> [“a”]a.slice!(100) -> nila -> [“a”]
sort arr.sort → una_matriz arr.sort {| a,b | block } → una_matriz
Devuelve una matriz nueva creada por la ordenación de arr. Las comparaciones de la ordenación se llevarán a cabo utilizando el operador <=> operador o utilizando un bloque de código opcional. El bloque implementa una comparación entre a y b, devolviendo -1, 0 o +1. Véase también Enumerable#sort_by.
a = [ “d”, “a”, “e”, “c”, “b” ]a.sort -> [“a”, “b”, “c”, “d”, “e”]a.sort {|x,y| y <=> x } -> [“e”, “d”, “c”, “b”, “a”]
sort! arr.sort!→ arr arr.sort! {| a,b | block } → arr

299
Ordena arr, que queda congelada mientras una ordenación está en curso.
a = [ “d”, “a”, “e”, “c”, “b” ]a.sort! -> [“a”, “b”, “c”, “d”, “e”]a -> [“a”, “b”, “c”, “d”, “e”]
to_a arr.to_a → arr array_subclass.to_a → array
Si arr es una matriz, devuelve arr. Si arr es una subclase de Array, invoca to_ary, y usa el resultado para crear un nuevo objeto matriz.
to_ary arr.to_ary → arr
Devuelve arr.
to_s arr.to_s → str
Devuelve arr.join.
[ “a”, “e”, “i”, “o” ].to_s -> “aeio”
transpose arr.transpose → una_matriz
Asume que arr es una matriz de matrices y transpone las filas y columnas.
a = [[1,2], [3,4], [5,6]]a.transpose -> [[1, 3, 5], [2, 4, 6]]
uniq arr.uniq → una_matriz
Devuelve una nueva matriz mediante la eliminación de los valores duplicados en arr, donde los dupli-cados se detectan por comparación utilizando eql?.
a = [ “a”, “a”, “b”, “b”, “c” ]a.uniq -> [“a”, “b”, “c”]
uniq! arr.uniq! → una_matriz o nil
Igual que el Array#uniq, pero modifica el receptor en su lugar. Devuelve nil si no se realizan cam-bios (es decir, si no se encuentran duplicados).
a = [ “a”, “a”, “b”, “b”, “c” ]a.uniq! -> [“a”, “b”, “c”]b = [ “a”, “b”, “c” ]b.uniq! -> nil
unshift arr.unshift( < obj >+ ) → arr
Antepone el objeto u objetos a arr.
a = [ “b”, “c”, “d” ]a.unshift(“a”) -> [“a”, “b”, “c”, “d”]a.unshift(1, 2) -> [1, 2, “a”, “b”, “c”, “d”]

300
values_at arr.values_at( < selector >* ) → una_matriz
Devuelve una matriz que contiene los elementos de arr correspondientes al selector o selectores da-dos. Los selectores pueden ser índices enteros o rangos.
a = %w{ a b c d e f }a.values_at(1, 3, 5) -> [“b”, “d”, “f”]a.values_at(1, 3, 5, 7) -> [“b”, “d”, “f”, nil]a.values_at(-1, -3, -5, -7) -> [“f”, “d”, “b”, nil]a.values_at(1..3, 2...5) -> [“b”, “c”, “d”, “c”, “d”, “e”]
Clase
Bignum < Integer
Los objetos Bignum contienen enteros fuera del rango de Fixnum. Los objetos Bignum se crean auto-máticamente cuando de otro modo, los cálculos de enteros darían un desbordamiento de Fixnum. Cuando un cálculo en relación a objetos Bignum devuelve un resultado que se ajusta a un Fixnum, el resultado se convierte automáticamente.
A los efectos de las operaciones bit a bit y para [], un Bignum se trata como si fuera una cadena de bits de longitud infinita con la representación de complemento a 2.
Los valores Fixnum son inmediatos, mientras que los objetos Bignum no --las asignaciones y paso de parámetros trabajan con referencias a objetos, no con los objetos mismos.
(...)
Clase
Binding < Objeto
Los Objetos de la clase Binding encapsulan el contexto de ejecución en algún lugar en particular en el código y conservan este contexto para su futuro uso. Las variables, los métodos, el valor de self y posiblemente un bloque iterador se pueden acceder en este contexto ya que están todos retenidos. Los objetos Binding pueden ser creados usando Kernel#binding y están a disposición de la devolución de llamada de kernel#set_trace_func.
Estos objetos de enlace se pueden pasar como el segundo argumento del método Kernel#eval, es-tableciendo un entorno para la evaluación.
class Demo def initialize(n) @secret = n end def get_binding return binding() endend
k1 = Demo.new(99)b1 = k1.get_bindingk2 = Demo.new(-3)b2 = k2.get_binding
eval(“@secret”, b1) -> 99eval(“@secret”, b2) -> 3eval(“@secret”) -> nil
Los Objetos binding no tienen métodos específicos de clase.
(...)

301
[En el original en inglés, continúa con las demás clases: Bignum, Binding, Class, Compa-rable, etc, por orden alfabético. Consultar el mismo, ya que como se vé, viene de forma esque-mática y con ejemplos por lo que es de fácil comprensión. Para terminar se verán algunos otros temas interesantes (aunque no en su totalidad) y nos remitimos a la versión original en inglés o a la tercera edición en inglés, en la que ya se expone la versión 1.9 de Ruby. Comentar que está previsto que para el 2012 salga la versión 2.0.]
Módulo
Comparable
Basado en: <=> El mixin Comparable es utilizado por las clases cuyos objetos pueden ser ordenados. La clase debe definir el operador <=>, que compara el receptor con otro objeto, devolviendo -1, 0 o +1 dependiendo de si el receptor es menor, igual o mayor que el otro objeto. Comparable utiliza <=> para implementar los operadores de comparación convencionales (<, <=, ==, >= y >) y también utiliza el método between?.
class CompareOnSize include Comparable attr :str def <=>(other) str.length <=> other.str.length end def initialize(str) @str = str endend
s1 = CompareOnSize.new(“Z”)s2 = CompareOnSize.new([1,2])s3 = CompareOnSize.new(“XXX”)
s1 < s2 -> trues2.between?(s1, s3) -> trues3.between?(s1, s2) -> false[ s3, s2, s1 ].sort -> [“Z”, [1, 2], “XXX”]
Método de Instancia
between? obj.between?( min, max ) → true o false
Devuelve false si obj <=> min es menor que cero o si obj <=> max es mayor que cero, true si lo contrario.
3.between?(1, 5) -> true6.between?(1, 5) -> false‘cat’.between?(‘ant’, ‘dog’) -> true‘gnu’.between?(‘ant’, ‘dog’) -> false
(...)
Módulo
Enumerable
Basado en: each, <=>
El mixin Enumerable ofrece clases de colección con varios métodos de recorrido y búsqueda y con la capacidad de ordenar. La clase debe proporcionar un método each, que da los miembros sucesivos de una colección. Si se utiliza Enumerable#max, #min, #sort, o #sort_by, los objetos de la colección

302
también deben implementar el operador <=>, ya que estos métodos están basados en una determinada ordenación entre los miembros de la colección.
Métodos de instancia
all? enum.all? < {| obj | block } > → true o false
Pasa cada elemento de la colección al bloque dado. El método devuelve true si el bloque nunca re-torna false o nil. Si no se da el bloque, Ruby añade un bloque implícito {|obj| obj} (donde all? devolverá true sólo si ninguno de los miembros de la colección es false o nil).
%w{ ant bear cat}.all? {|word| word.length >= 3} -> true%w{ ant bear cat}.all? {|word| word.length >= 4} -> false[ nil, true, 99 ].all? -> false
any? enum.any? < {| obj | block } > → true o false
Pasa cada elemento de la colección para el bloque dado. El método devuelve true si el bloque siem-pre retorna un valor que no sea false o nil. Si no se da el bloque, Ruby añade un bloque implícito {|obj| obj} (donde any? devolverá true si al menos uno de los miembros de la colección no es false o nil).
%w{ ant bear cat}.any? {|word| word.length >= 3} -> true%w{ ant bear cat}.any? {|word| word.length >= 4} -> true[ nil, true, 99 ].any? -> true
collect enum.collect {| obj | block } → array
Devuelve una nueva matriz que contiene los resultados de la ejecución del bloque una vez por cada elemento en enum.
(1..4).collect {|i| i*i } -> [1, 4, 9, 16](1..4).collect { “cat” } -> [“cat”, “cat”, “cat”, “cat”]
detect enum.detect( ifnone = nil ) {| obj | block } → obj o nil
Pasa cada entrada de enum al bloque. Retorna la primera para la que el bloque es no falso. Devuelve nil si no coincide con objeto, a menos que se de el ifnone proc, en cuyo caso se llama y se retorna su resultado.
(1..10).detect {|i| i % 5 == 0 and i % 7 == 0 } -> nil(1..100).detect {|i| i % 5 == 0 and i % 7 == 0 } -> 35sorry = lambda { “not found” }(1..10).detect(sorry) {|i| i > 50} -> “not found”
each_with_index enum.each_with_index {| obj, i | block } → enum
Llama al bloque con dos argumentos, el elemento y su índice, para cada elemento de enum.
hash = Hash.new%w(cat dog wombat).each_with_index do |item, index| hash[item] = indexendhash -> {“cat”=>0, “wombat”=>2, “dog”=>1}
entries enum.entries → array
Sinónimo de Enumerable#to_a.
find enum.find( ifnone = nil ) {| obj | block } → obj o nil Sinónimo de Enumerable#detect.

303
find_all enum.find_all {| obj | block } → array
Devuelve una matriz que contiene todos los elementos de enum para los que el bloque es no falso (ver también Enumerable#reject).
(1..10).find_all {|i| i % 3 == 0 } -> [3, 6, 9]
grep enum.grep( pattern ) → array enum.grep( pattern ) {| obj | block } → array
Devuelve una matriz de todos los elementos de enum para los que patrón === elemento. Si se suministra el bloque opcional, se le pasa cada elemento coincidente y el resultado del bloque se almacena en la matriz de salida.
(1..100).grep 38..44 -> [38, 39, 40, 41, 42, 43, 44]c = IO.constantsc.grep(/SEEK/) -> [“SEEK_CUR”, “SEEK_SET”, “SEEK_END”]res = c.grep(/SEEK/) {|v| IO.const_get(v) }res -> [1, 0, 2]
include? enum.include?( obj ) → true o false
Devuelve true si algún miembro de enum es igual a obj. Se prueba la igualdad usando ==.
IO.constants.include? “SEEK_SET” -> trueIO.constants.include? “SEEK_NO_FURTHER” -> false
inject enum.inject(initial) {|memo, obj | block } → obj enum.inject {|memo, obj | block } → obj
Combina los elementos de enum mediante la aplicación del bloque a un valor acumulador (memo) y a cada elemento por separado. En cada paso, memo se establece en el valor devuelto por el bloque. La pri-mera forma permite proporcionar un valor inicial para memo. La segunda forma utiliza el primer elemento de la colección como el valor inicial (y se salta ese elemento, mientras itera).
# Suma algunos números(5..10).inject {|sum, n| sum + n } -> 45# Multiplica algunos números(5..10).inject(1) {|product, n| product * n } -> 151200
# buscar la palabra más largalongest = %w{ cat sheep bear }.inject do |memo, word| memo.length > word.length ? memo : wordendlongest -> “sheep”
# buscar la longitud de la palabra más largalongest = %w{ cat sheep bear }.inject(0) do |memo, word| memo >= word.length ? memo : word.lengthendlongest -> 5
map enum.map {| obj | block } → array
Sinónimo de Enumerable#collect.
max enum.max → obj enum.max {| a,b | block } → obj

304
Devuelve el objeto en enum con el valor máximo. La primera supone que todos los objetos implementan <=>, y la segunda utiliza el bloque para devolver a <=> b.
a = %w(albatross dog horse)a.max -> “horse”a.max {|a,b| a.length <=> b.length } -> “albatross”
member? enum.member?( obj ) → true o false
Sinónimo de Enumerable#include?.
min enum.min → obj enum.min {| a,b | block } → obj
Devuelve el objeto de enum con el valor mínimo. La primera forma supone que todos los objetos imple-mentan Comparable, y la segunda utiliza el bloque para devolver a <=> b.
a = %w(albatross dog horse)a.min -> “albatross”a.min {|a,b| a.length <=> b.length } -> “dog”
partition enum.partition {| obj | block }→[ true_array, false_array ]
Devuelve dos matrices, la primera contiene los elementos de enum para los que el bloque se evalúa como verdadero, la segunda contiene el resto.
(1..6).partition {|i| (i&1).zero?} -> [[2, 4, 6], [1, 3, 5]]
reject enum.reject {| obj | block } → array
Devuelve una matriz que contiene los elementos de enum para los que el bloque es falso (véase tam-bién Enumerable#find_all).
(1..10).reject {|i| i % 3 == 0 } -> [1, 2, 4, 5, 7, 8, 10]
select enum.select {| obj | block } → array
Sinónimo de Enumerable#find_all.
sort enum.sort → array enum.sort {| a, b | block } → array
Devuelve una matriz que contiene los elementos de enum ordenados, ya sea de acuerdo a su propio método <=> o mediante el uso de los resultados del bloque suministrado. El bloque debe devolver -1, 0 o +1 en función de la comparación entre a y b. A partir de Ruby 1.8, el método Enumerable#sort_by implementa una Transformada Schwartzian integrada, útil cuando el cálculo o la comparación de clave son costosos.
%w(rhea kea flea).sort -> [“flea”, “kea”, “rhea”](1..10).sort {|a,b| b <=> a} -> [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
sort_by enum.sort_by {| obj | block } → array
Ordena enum, utilizando claves generadas por asignación a los valores de enum, mediante el bloque dado y utilizando el resultado del bloque para la comparación de elementos.
sorted = %w{ apple pear fig }.sort_by {|word| word.length}

305
sorted -> [“fig”, “pear”, “apple”]
Internamente, sort_by genera una matriz de tuplas que contiene la colección original de elementos y el valor asignado. Esto hace de sort_by bastante costoso cuando los conjuntos de claves son simples.
require ‘benchmark’include Benchmarka = (1..100000).map {rand(100000)}bm(10) do |b| b.report(“Sort”) { a.sort } b.report(“Sort by”) { a.sort_by {|a| a} }end produce:
user system total realSort 0.070000 0.010000 0.080000 ( 0.085860)Sort by 1.580000 0.010000 1.590000 ( 1.811626)
Sin embargo, hay que tener en cuenta el caso de cuando la comparación de claves es una operación no trivial. El código siguiente ordena algunos archivos por tiempo de modificación utilizando el método básico sort.
files = Dir[“*”]
sorted = files.sort {|a,b| File.new(a).mtime <=> File.new(b).mtime}
sorted -> [“mon”, “tues”, “wed”, “thurs”]
Esta ordenación es ineficiente: genera dos nuevos objetos File en cada comparación. Una técnica algo mejor es utilizar el método Kernel#test para generar los tiempos de modificación directamente.
files = Dir[“*”]
sorted = files.sort do |a,b| test(?M, a) <=> test(?M, b)end
sorted -> [“mon”, “tues”, “wed”, “thurs”]
Esto todavía genera muchos objetos Time innecesarios. Una técnica más eficiente es almacenar en caché las claves de ordenación (tiempos de modificación en este caso) antes de la ordenación. Los usua-rios de Perl a menudo llaman a este método una transformación Schwartzian, llamado así por Randal Schwartz. Construimos una matriz temporal, donde cada elemento es una matriz que contiene la clave de ordenación, junto con el nombre de archivo. Ordenamos esta matriz y luego se extrae el nombre del archivo a partir del resultado.
sorted = Dir[“*”].collect {|f| [test(?M, f), f]}.sort.collect {|f| f[1] }
sorted -> [“mon”, “tues”, “wed”, “thurs”]
Esto es exactamente lo que sort_by hace internamente.
sorted = Dir[“*”].sort_by {|f| test(?M, f)}
sorted -> [“mon”, “tues”, “wed”, “thurs”]
sort_by también puede ser útil para ordenaciones multinivel. Un truco, que se basa en el hecho de que las matrices se comparan elemento por elemento, es hacer que el bloque de devuelva una matriz con

306
cada una de las claves de comparación. Por ejemplo, para ordenar una lista de palabras primero por su longitud y luego por orden alfabético, se podría escribir:
words = %w{ puma cat bass ant aardvark gnu fish }sorted = words.sort_by {|w| [w.length, w] }sorted -> [“ant”, “cat”, “gnu”, “bass”, “fish”, “puma”, “aardvark”]
to_a enum.to_a → array
Devuelve una matriz que contiene los elementos de enum.
(1..7).to_a -> [1, 2, 3, 4, 5, 6, 7]{ ‘a’=>1, ‘b’=>2, ‘c’=>3 }.to_a -> [[“a”, 1], [“b”, 2], [“c”, 3]]
zip enum.zip( < arg >+ ) → array
enum.zip( < arg >+ ) {| arr | block } → nil
Convierte los argumentos a matrices y luego fusiona los elementos de enum con los correspondientes elementos de cada argumento. El resultado es una matriz que contiene el mismo número de elementos que enum. Cada elemento es una matriz de n elementos, donde n es uno o más del recuento de los argu-mentos. Si el tamaño de los argumentos es menor que el número de elementos en enum, se suministran valores nil. Si se da un bloque, se invoca para cada matriz de salida, de otra manera se devuelve una matriz de matrices.
a = [ 4, 5, 6 ]b = [ 7, 8, 9 ]
(1..3).zip(a, b) -> [[1, 4, 7], [2, 5, 8], [3, 6, 9]]“cat\ndog”.zip([1]) -> [[“cat\n”, 1], [“dog”, nil]](1..3).zip -> [[1], [2], [3]]
Módulo
Errno
Los objetos excepción de Ruby son subclases de Exception. Sin embargo, los sistemas operativos suelen reportar errores usando simples enteros. El módulo Errno se crea de forma dinámica para asignar estos errores del sistema operativo a las clases Ruby, con cada número de error generando su propia subclase de SystemCallError. Como la subclase se crea en el módulo Errno, su nombre comenzará con Errno::.
Exception StandardError SystemCallError Errno::xxx
Los nombres de las clases Errno:: dependerán del entorno en el que se ejecute Ruby. En una plataforma típica de Unix o Windows, se encuentra que tiene clases Errno como Errno::EACCES, Errno::EAGAIN, Errno::EINTR, etc.
El número entero de error del sistema operativo correspondiente a un particular error está disponible en la constante de clase Errno::error::Errno.
Errno::EACCES::Errno -> 13Errno::EAGAIN::Errno -> 35Errno::EINTR::Errno -> 4
La lista completa de errores del sistema operativo en su plataforma está disponible como las constantes

307
de Errno. Cualquier definición de usuario de excepción en este módulo (incluyendo las subclases de las excepciones existentes) también deben definir una constante Errno.
Errno.constants -> E2BIG, EACCES, EADDRINUSE, EADDRNOTAVAIL, EAFNOSUPPORT, EAGAIN, EALREADY, ...
A partir de Ruby 1.8, las excepciones son comparadas en las cláusulas rescue usando Module#===. El método === se anula para SystemCallError de la clase a fin de comparar en función del valor Errno. Así, si dos clases Errno distintas tienen el mismo valor Errno subyacente, serán tratadas como la misma excepción por una cláusula rescue.
Clase
Exception < Object
Los descendientes de la clase Exception se utilizan para la comunicación entre los métodos raise y las declaraciones rescue en los bloques begin/end. Los objetos Exception contienen información acerca de la excepción --el tipo (nombre de la clase de la excepción), una cadena descriptiva opcional e informa-ción de rastreo opcional.
La librería estándar define las excepciones que se muestran en la Figura 21 en la página siguiente. Véase también la descripción de Errno en la página anterior.
Métodos de Clase
exception Exception.exception( < message > ) → exc
Crea y devuelve un nuevo objeto excepción, opcionalmente se puede establecer un mensaje en mesagge.
new Exception.new( < message > ) → exc
Crea y devuelve un nuevo objeto excepción, opcionalmente se puede establecer un mensaje en mesagge.
Métodos de Instancia
backtrace exc.backtrace → array
Devuelve cualquier traza asociada a la excepción. La traza es una matriz de cadenas, cada una conte-niendo ya sea filename:linea: en ‘metodo’ o filename:linea.
def a raise “boom”enddef b a()endbegin b()rescue => detail print detail.backtrace.join(“\n”)end
produce:
prog.rb:2:in `a’prog.rb:6:in `b’prog.rb:10
exception exc.exception( < message > ) → exc o exception

308
Sin argumento, devuelve el receptor. De lo contrario, crea un nuevo objeto excepción de la misma clase que el receptor pero con un mensaje diferente.
message exc.message → msg
Devuelve el mensaje asociado a esa excepción.
set_backtrace exc.set_backtrace( array ) → array
Establece la información de backtrace asociada con exc. El argumento debe ser un array de objetos String con el formato descrito en Exception#backtrace.
status exc.status → status
(SystemExit solamente) Devuelve el estado de salida asociado a esa excepción SystemExit. Normalmente , esta situación se configura con Kernel#exit.
begin exit(99)rescue SystemExit => e puts “Exit status is: #{e.status}”end
produce:

309
Exit status is: 99
success? exc.success? → true o false
(SystemExit solamente) Devuelve true si el estado de salida es nil o cero.
begin exit(99)rescue SystemExit => e print “This program “ if e.success? print “did” else print “did not” end puts “ succeed”end
produce:
This program did not succeed
to_s exc.to_s → msg
Devuleve el mensaje asociado con esa excepción (o el nombre de la excepción si no tiene mensaje establecido).
begin raise “The message”rescue Exception => e puts e.to_send
produce:
The message
to_str exc.to_str → msg
Devuleve el mensaje asociado con esa excepción (o el nombre de la excepción si no tiene mensaje establecido). Implementar to_str da a las excepciones funcionamiento de cadena.
Clase
File < IO
Un File es una abstracción de cualquier objeto fichero accesible en el programa y está estrechamente relacionada con la clase IO. File incluye los métodos del módulo FileTest como métodos de clase, lo que permite escribir (por ejemplo) File.exist?(“foo”). Los bits de permiso son un conjunto de bits, específico de la plataforma, que indican los permisos de un archivo. En sistemas basados en Unix, los permisos son vistos como un conjunto de tres octetos, para el propietario, para el grupo y para el resto del mundo. Para cada una de estas entidades, los permisos se pueden configurar para leer, escribir o ejecutar el archivo.

310
Los bits de permiso en 0644 (en octal), podrían interpretarse como lectura / escritura para el propietario y de sólo lectura para el grupo y otros. Los bits superiores también pueden ser utilizados para indicar el tipo de archivo (normal, directorio, pipe, socket, etc) y varias otras características especiales. Si los per-misos son para un directorio, el significado del bit de ejecución cambia y cuando se establece, se puede buscar en el directorio.
Cada archivo tiene tres tiempos asociados. El atime es el momento del último acceso. El ctime es el momento en que el estado del archivo (no necesariamente el contenido del archivo) se modificó por última vez. Por último, el mtime es el momento en que los datos del archivo se modificaron por última vez. En Ruby, todos estos tiempos se devuelven como objetos Time.
En los sistemas operativos no POSIX, sólo hay la posibilidad de hacer un archivo de sólo lectura, o de lectura / escritura. En este caso, los bits de permisos restantes serán sintetizados para parecerse a los valores típicos. Por ejemplo, en Windows los bits de permisos por defecto son 0644, lo que significa que son de lectura / escritura para el propietario y de sólo lectura para todos los demás. El único cambio que se puede hacer es pasar el archivo a sólo lectura, que se presenta como 0444.
Véase también Pathname.
Módulo
FileTest
FileTest implementa las operaciones de prueba de archivo similares a las que se utilizan en File::Stat. Los métodos de FileTest están duplicados en la clase File. Aquí sólo vamos a listar los nombres de los métodos. FileTest parece un módulo un poco rudimentario.
Los métodos de FileTest son:
blockdev?, chardev?, directory?, executable?, executable_real?, exist?, exists?, file?, grpowned?, owned?, pipe?, readable?, readable_real?, setgid?, setuid?, size, size?, socket?, sticky?, symlink?, world_readable?, world_writable?, wri-table?, writable_real? y zero?
Clase
IO < Objeto
Subclases: File
La clase IO es la base para todas las entradas y salidas en Ruby. Un flujo de E/S puede ser dúplex (es decir, bidireccional) y por lo tanto puede usar más de un flujo del sistema operativo nativo.
La única subclase estándar de IO es File. Las dos clases están estrechamente relacionadas.
La clase IO utiliza la abstracción Unix de descriptores de fichero (fd), enteros pequeños que represen-tan los archivos abiertos. Convencionalmente, la entrada estándar tiene un fd de 0, la salida estándar un fd de 1 y el error estándar un fd de 2.
Ruby convierte si es posible los nombres de las rutas entre las diferentes convenciones de los sistemas operativos. Por ejemplo, en un sistema Windows el nombre de archivo /gumby/ruby/test.rb se abrirá como \gumby\ruby\test.rb. Cuando se especifica un nombre de archivo al estilo Windows en una cadena Ruby entre comillas dobles, hay que acordarse de escapar las barras invertidas.
“c:\\gumby\\ruby\\test.rb”
Se puede utilizar File::SEPARATOR para obtener el carácter separador de la plataforma específica.
Los puertos de E/S pueden ser abierto en cualquiera de varios modos diferentes, que se muestran en esta sección como una cadena de modo. Esta cadena de modo debe ser uno de los valores listados en la tabla siguiente:

311
Módulo
Marshal
La biblioteca de serialización (marshaling library) convierte colecciones de objetos Ruby en un flujo de bytes, lo que les permite ser almacenados fuera del script que está activo. Estos datos posteriormente pueden ser leídos y reconstituir los objetos originales. Véase también la biblioteca YAML.
Los datos serializados tienen un número de versión mayor y menor almacenados junto con la infor-mación del objeto. En uso normal, el serializado puede cargar datos únicamente escritos con el mismo número de versión mayor y un número de versión menor igual o inferior. Si la bandera Ruby “verbose” está activa (normalmente con -d, -v, -w o --verbose), los números mayores y menores deben coincidir exactamente. La versión de serialización es independiente de los números de versión de Ruby. Puede extraer la versión por la lectura de los dos primeros bytes de los datos serializados.
str = Marshal.dump(“thing”)RUBY_VERSION -> “1.8.2”str[0] -> 4str[1] -> 8
Algunos objetos no pueden ser objeto de volcado: si los objetos a ser objeto de volcado incluyen enla-ces, objetos de procedimiento o método, instancias de la clase IO, objetos singleton, o si se trata de volcar clases o módulos anónimos, se lanzará un TypeError.
Si su clase tiene necesidades especiales de serialización (por ejemplo, si se desea serializar en un formato específico), o si contiene objetos que de otro modo no son serializables, puede implementar su propia estrategia de serialización. Antes de Ruby 1.8, se definen los métodos _dump y _load.
Ruby 1.8 incluye una interfaz más flexible para la serialización personalizada con los métodos de instancia marshal_dump y marshal_load: Si un objeto que se va a serializar responde a marshal_dump, se llama a este método en lugar de a _dump. marshal_dump puede devolver un objeto de cual-quier clase (no sólo String). Una clase que implementa marshal_dump también deben implementar marshal_load, que es llamado como un método de instancia de un objeto recién asignado y se le pasa el objeto original creado por marshal_dump.
El siguiente código utiliza este nuevo marco para almacenar un objeto Time en la versión serializada de un objeto. Cuando está cargado, este objeto se pasa a marshal_load, que convierte este time a una forma imprimible, almacenando el resultado en una variable de instancia.
class TimedDump attr_reader :when_dumped def marshal_dump Time.now end def marshal_load(when_dumped) @when_dumped = when_dumped.strftime(“%I:%M%p”) endend
r Sólo lectura. Se inicia al comienzo del archivo (modo predeterminado).r+ Lectura / escritura. Se inicia al comienzo del archivo.w Sólo escritura. Trunca un archivo existente con longitud cero o crea un nuevo archivo para escritura.a Sólo escritura. Se inicia al final del archivo si este existe, o de otro modo crea un nuevo archivo para escritura.a+ Lectura / escritura. Se inicia al final del archivo si este existe, o de otro modo crea un nuevo archivo para lectura / escritura.b (sólo DOS / Windows) Modo fichero binario (puede aparecer con cualquiera de las letras clave listadas arriba.
Modo Significado

312
t = TimedDump.newt.when_dumped -> nil
str = Marshal.dump(t)
newt = Marshal.load(str)newt.when_dumped -> “10:38PM”
Constantes de MóduloMAJOR_VERSIONMINOR_VERSION
Métodos de Módulo
dump dump( obj < , io > , limit=–1 ) → io
Serializa obj y todos los objetos descendientes. Si se especifica io, los datos serializados se escribi-rán en él, de lo contrario los datos se devuelven como un String. Si se especifica limit, el recorrido de subobjetos se limitará a esa profundidad. Si el límite es negativo, no hay comprobación de profundidad.
class Klass def initialize(str) @str = str end def say_hello @str endend
o = Klass.new(“hello\n”)data = Marshal.dump(o)obj = Marshal.load(data)obj.say_hello -> “hello\n”
load load( from < , proc > ) → obj
Devuelve el resultado de la conversión de los datos serializados en from en un objeto Ruby (posible-mente asociados con los objetos subordinados). from puede ser una instancia de IO o un objeto que res-ponde a to_str. Si se especifica proc, es pasado a cada objeto a medida que se deserializa.
restore restore( from < , proc > ) → obj
Sinónimo de Marshal.load.
Módulo
ObjectSpace
El módulo ObjectSpace contiene una serie de rutinas que interactúan con la utilidad de recolección de basura y que permiten recorrer con un iteradortodos los objetos que habitan.
ObjectSpace también proporciona soporte para los finalizadores de objetos. Estos son procs que se llaman cuando un objeto específico está a punto de ser destruido por el recolector de basura.
include ObjectSpace

313
a, b, c = “A”, “B”, “C”puts “a’s id is #{a.object_id}”puts “b’s id is #{b.object_id}”puts “c’s id is #{c.object_id}”
define_finalizer(a, lambda {|id| puts “Finalizer one on #{id}” })define_finalizer(b, lambda {|id| puts “Finalizer two on #{id}” })define_finalizer(c, lambda {|id| puts “Finalizer three on #{id}” })
produce:
a’s id is 936150b’s id is 936140c’s id is 936130Finalizer three on 936130Finalizer two on 936140Finalizer one on 936150
Métodos de Módulo
_id2ref ObjectSpace._id2ref( object_id ) → obj
Convierte un identificador de objeto a una referencia al objeto. No puede ser llamado en un ID de objeto pasado como parámetro a un finalizador.
s = “I am a string” -> “I am a string”oid = s.object_id -> 936550r = ObjectSpace._id2ref(oid) -> “I am a string”r -> “I am a string”r.equal?(s) -> true
define_finalizer ObjectSpace.define_finalizer( obj, a_proc=proc() )
Añade a_proc como un finalizador, llamado cuando obj está a punto de ser destruido.
each_object ObjectSpace.each_object( < class_or_mod > ) {| obj | block }→ fixnum
Llama al bloque una vez por cada viviente y no inmediato objeto en ese proceso Ruby. Si se especifica class_or_mod, se llama al bloque sólo para las clases o módulos que coincidan (o sean una subclase) con class_or_mod. Devuelve el número de objetos encontrados. Objetos inmediatos (Fixnums, Symbols, true, false y nil) nunca se devuelven. En el siguiente ejemplo, each_object devuelve tanto los nú-meros que se han definido como varias constantes definidas en el módulo Math.
a = 102.7b = 95 # Fixnum: No se retornac = 12345678987654321count = ObjectSpace.each_object(Numeric) {|x| p x }puts “Total count: #{count}”
produce:12345678987654321102.72.718281828459053.141592653589792.22044604925031e161.79769313486232e+3082.2250738585072e308Total count: 7

314
garbage_collect ObjectSpace.garbage_collect → nil
Inicia la recolección de basura.
undefine_finalizer ObjectSpace.undefine_finalizer( obj )
Elimina todos los finalizadores para obj.
Clase
Proc < Objeto
Los objetos Proc son bloques de código que se han ligado a un conjunto de variables locales. Una vez ligado, el código puede ser llamado en diferentes contextos y acceder aún a esas variables.
def gen_times(factor) return Proc.new {|n| n*factor }end
times3 = gen_times(3)times5 = gen_times(5)
times3.call(12) -> 36times5.call(5) -> 25times3.call(times5.call(4)) -> 60
Métodos de Clase
new Proc.new { block } → un_proc Proc.new → un_proc
Crea un objeto Proc nuevo, vinculado al contexto actual. Proc.new puede ser llamado sin un bloque, sólo dentro de un método con un bloque adjunto, en cuyo caso el bloque se convierte en el objeto Proc.
def proc_from Proc.newendproc = proc_from { “hello” }proc.call -> “hello”
Métodos de Instancia
[ ] prc[ < params >* ] → obj
Sinónimo de Proc.call.
== prc== other → true o false
devuelve true si prc es lo mismo que other.
arity prc.arity → integer
Devuelve el número de argumentos requeridos por el bloque. Si el bloque se declara para no tomar argumentos, devuelve 0. Si el bloque es conocido por tener exactamente n argumentos, devuelve n. Si el bloque tiene argumentos opcionales, devuelve -(n +1), donde n es el número de argumentos obligato-rios. Un proc sin declaraciones de argumento también devuelve -1, ya que puede aceptar (e ignorar) un número arbitrario de parámetros.

315
Proc.new {}.arity -> 1Proc.new {||}.arity -> 0Proc.new {|a|}.arity -> 1Proc.new {|a,b|}.arity -> 2Proc.new {|a,b,c|}.arity -> 3Proc.new {|*a|}.arity -> 1Proc.new {|a,*b|}.arity -> 2
En Ruby 1.9, arity se define como el número de parámetros que no se puede ignorar.En 1.8, Proc.new{}.arity devuelve -1, y en 1,9 devuelve 0.
binding prc.binding → binding
Devuelve el enlace asociado con prc. Hay que tener en cuenta que del Kernel#eval acepta o un Proc o un objeto Binding como segundo parámetro.
def fred(param) lambda {}end
b = fred(99)eval(“param”, b.binding) -> 99eval(“param”, b) -> 99
call prc.call( < params >* ) → obj
Invoca el bloque, estableciendo los parámetros del bloque a los valores en params utilizando alguna semántica como de llamada a método. Devuelve el valor de la última expresión evaluada en el bloque.
a_proc = Proc.new {|a, *b| b.collect {|i| i*a }}a_proc.call(9, 1, 2, 3) -> [9, 18, 27]a_proc[9, 1, 2, 3] -> [9, 18, 27]
Si el bloque es llamado explícitamente acepta un solo parámetro. call emite un mensaje de adver-tencia, a menos que se le dé exactamente un parámetro. De otra manera, acepta encantado lo que se le dé, haciendo caso omiso de los parámetros excedentes que se le pasan y establece los parámetros sin establecer del bloque a nil.
a_proc = Proc.new {|a| a}a_proc.call(1,2,3)
produce:
prog.rb:1: warning: multiple values for a block parameter (3 for 1)from prog.rb:2
Si se quiere un bloque para recibir un número arbitrario de argumentos, hay que definirlo para aceptar *args.
a_proc = Proc.new {|*a| a}a_proc.call(1,2,3) -> [1, 2, 3]
Los bloques creados utilizando Kernel.lambda comprueban que se les llama exactamente con el número correcto de parámetros.
p_proc = Proc.new {|a,b| puts “Sum is: #{a + b}” }p_proc.call(1,2,3)p_proc = lambda {|a,b| puts “Sum is: #{a + b}” }

316
p_proc.call(1,2,3)
produce:
Sum is: 3prog.rb:3: wrong number of arguments (3 for 2) (ArgumentError)from prog.rb:3:in `call’from prog.rb:4
to_proc prc.to_proc → prc
Parte del protocolo para la conversión de objetos a objetos Proc. Las instancias de la clase Proc sim-plemente lo que devuelven es a si mismas.
to_s prc.to_s → string
Devuelve una descripción de proc, incluyendo información sobre donde se definió.
def create_proc Proc.newend
my_proc = create_proc { “hello” }my_proc.to_s -> “#<Proc:[email protected]:5>”
Clase
Regexp < Objeto
Un Regexp tiene una expresión regular, que se utiliza para comparar un patrón con cadenas. Expre-siones regulares son creados usando literales /.../ y %r... y con el constructor Regexp.new. Esta sección documenta expresiones regulares Ruby 1.8. Versiones posteriores de Ruby utilizan un motor para expresiones regulares diferente.
Constantes de Clase
EXTENDED Ignora espacios y saltos de línea en expresiones regulares.IGNORECASE Las comparaciones son case insensitive, es decir, ignora si son mayúsculas o minúsculas.MULTILINE Nueva línea es tratada como cualquier otro carácter.
Métodos de Clasecompile Regexp.compile( pattern < , options < , lang > > )→ rxp
Sinónimo de Regexp.new.
escape Regexp.escape( string ) → escaped_string
Escapa cualquier carácter que tenga un significado especial en una expresión regular. Para cualquier cadena, Regexp.escape(str)=~str será verdadero.
Regexp.escape(‘\\[]*?{}.’) -> \\\[\]\*\?\{\}\.
last_match Regexp.last_match → match Regexp.last_match( int ) → string
La primera forma devuelve el objeto MatchData generado por la comparación exitosa de patrón an-terior. Esto es equivalente a la lectura de la variable global $~. La segunda forma devuelve el enésimo campo de ese objeto MatchData.

317
/c(.)t/ =~ ‘cat’ -> 0Regexp.last_match -> #<MatchData:0x1c9468>Regexp.last_match(0) -> “cat”Regexp.last_match(1) -> “a”Regexp.last_match(2) -> nil
new Regexp.new( string < , options < , lang > > )→ rxp Regexp.new( regexp ) → new_regexp
Construye una nueva expresión regular desde pattern, que puede ser un String o un Regexp. En este último caso las opciones de expresión regular se propagan, y las nuevas opciones no pueden ser especificadas (cambia a partir de Ruby 1.8). Si options es un Fixnum, deben ser uno o más de Regexp::EXTENDED, Regexp::IGNORECASE y Regexp::POSIXLINE, or-ed conjuntamente. De otra manera, si options no es nil, la expresión regular será case insensitive. El parámetro lang habilita el so-porte multibyte para la expresión regular: n, N, o nil = none, e, E = EUC, s, S = SJIS, u, U = UTF-8.
r1 = Regexp.new(‘^[a-z]+:\\s+\w+’) -> /^[a-z]+:\s+\w+/r2 = Regexp.new(‘cat’, true) -> /cat/ir3 = Regexp.new(‘dog’, Regexp::EXTENDED) -> /dog/xr4 = Regexp.new(r2) -> /cat/i
quote Regexp.quote( string )→ escaped_string
Sinónimo de Regexp.escape.
Métodos de Instancia== rxp == other_regexp → true o false
Igualdad --Dos expresiones regulares son iguales si sus patrones son idénticos, tienen el mismo código de conjunto de carácteres, y sus valores casefold? son los mismos.
/abc/ == /abc/x -> false/abc/ == /abc/i -> false/abc/u == /abc/n -> false
=== rxp === string → true o false
Igualdad de caso --Sinónimo de REGEXP#=~ utilizado en las sentencias case.
a = “HELLO”case awhen /^[a-z]*$/; print “Lower case\n”when /^[A-Z]*$/; print “Upper case\n”else print “Mixed case\n”end
produce:
Upper case
=~ rxp =~ string → int o nil
Comparación --Compara rxp con string, devolviendo la posición de la coincidencia respecto al inicio de la cadena o nil si la comparación falla. Establece $~ al correspondiente MatchData o nil.
/SIT/ =~ “insensitive” -> nil/SIT/i =~ “insensitive” -> 5
~ ~ rxp → int o nil

318
Comparación --Compara rxp con el contenido de $_. Equivalente a rxp =~ $ _.
$_ = “input data”~ /at/ -> 7
casefold? rxp.casefold? → true o false
Devuelve el valor de la bandera case-insensitive.
inspect rxp.inspect → string
Devuelve una versión legible de rxp.
/cat/mi.inspect -> “/cat/mi”/cat/mi.to_s -> “(?mi-x:cat)”
kcode rxp.kcode → string
Devuelve el código de caracteres de la expresión regular.
/cat/.kcode -> nil/cat/s.kcode -> “sjis”
match rxp.match(string) → match o nil
Devuelve un objeto MatchData describiendo la comparación, es decir, retornando, o nil si no hay coincidencia. Esto equivale a recuperar el valor de la variable especial $~ después de una comparación normal.
/(.)(.)(.)/.match(“abc”)[2] -> “b”
options rxp.options → int
Devuelve el conjunto de bits correspondiente a las opciones utilizadas cuando se crea esa Regexp (ver Regexp.new para más detalles). Hay que tener en cuenta que se pueden configurar bits adicionales en las opciones retornadas: estos son utilizados internamente por el código de la expresión regular. Estos bits extras se ignoran si se pasan las opciones a Regexp.new.
# Vamos a ver cuáles son los valores ...Regexp::IGNORECASE -> 1Regexp::EXTENDED -> 2Regexp::MULTILINE -> 4
/cat/.options -> 0/cat/ix.options -> 3Regexp.new(‘cat’, true).options -> 1Regexp.new(‘cat’, 0, ‘s’).options -> 48
r = /cat/ixRegexp.new(r.source, r.options) -> /cat/ix
source rxp.source → string
Devuelve la cadena original del patrón.
/ab+c/ix.source -> “ab+c”
to_s rxp.to_s → string

319
Devuelve una cadena que contiene la expresión regular y sus opciones (utilizando la notación (?xx: yyy)). Esta cadena puede ser alimentada de nuevo a Regexp.new a una expresión regular con la misma semántica que la original. (Sin embargo, Regexp#== No se puede devolver verdadero cuando se comparan las dos, ya que la fuente de la propia expresión regular puede ser diferente, como muestra el ejemplo). Regexp#inspect produce una versión generalmente más legible de rxp.
r1 = /ab+c/ix -> /ab+c/ixs1 = r1.to_s -> “(?ix-m:ab+c)”r2 = Regexp.new(s1) -> /(?ix-m:ab+c)/r1 == r2 -> falser1.source -> “ab+c”r2.source -> “(?ix-m:ab+c)”
Módulo
Signal
Muchos sistemas operativos permiten enviar señales a los procesos en ejecución. Algunas señales tienen un efecto definido sobre el proceso, y otras pueden ser atrapadas a nivel de código y actuar en con-secuencia. Por ejemplo, un proceso puede atrapar la señal USR1 y utilizarla para cambiar la depuración, y puede utilizar TERM para iniciar un apagado controlado.
pid = fork do Signal.trap(“USR1”) do $debug = !$debug puts “Debug now: #$debug” end Signal.trap(“TERM”) do puts “Terminating...” shutdown() end # . . . do some work . . .endProcess.detach(pid)# Controlling program:Process.kill(“USR1”, pid)# ...Process.kill(“USR1”, pid)# ...Process.kill(“TERM”, pid)
produce:
Debug now: trueDebug now: falseTerminating...
La lista de los nombres de las señales disponibles y su interpretación depende del sistema. La se-mántica de envío de señales también puede variar entre sistemas. El envío de una señal en particular no siempre es fiable.
Métodos de Módulolist Signal.list → hash
Devuelve una lista de los nombres de las señales con los correspondientes números de señal subya-centes asignados.
Signal.list -> {“BUS”=>10, “SEGV”=>11, “KILL”=>9, “EMT”=>7, “SYS”=>12, “TERM”=>15, “IOT”=>6, “HUP”=>1, “STOP”=>17, “TRAP”=>5, “INT”=>2, “INFO”=>29, “PROF”=>27, “XCPU”=>24, “CLD”=>20,

320
“PIPE”=>13, “FPE”=>8, “VTALRM”=>26, “IO”=>23, “WINCH”=>28, “TTIN”=>21, “TSTP”=>18, “ABRT”=>6, “TTOU”=>22, “QUIT”=>3, “USR1”=>30, “CHLD”=>20, “CONT”=>19, “ILL”=>4, “USR2”=>31, “XFSZ”=>25, “URG”=>16, “ALRM”=>14, “EXIT”=>0}
trap Signal.trap( signal, proc ) → obj Signal.trap( signal ) { block } → obj
Especifica el tratamiento de las señales. El primer parámetro es un nombre de señal (una cadena como SIGALRM, SIGUSR1, etc) o un número de señal. Los caracteres SIG se pueden omitir en el nombre de la señal. El comando o bloque especifica el código que se vá a ejecutar cuando se lanza la señal. Si el co-mando es la cadena IGNORE o SIG_IGN, la señal será ignorada. Si el comando es DEFAULT o SIG_DFL, será invocado el controlador por defecto del sistema operativo. Si el comando es EXIT, el script será ter-minado por la señal. De otra manera, se ejecutará la orden o el bloque dado.
La señal especial EXIT o la señal número cero se invoca justo antes de la finalización del programa.
trap devuelve el controlador anterior de la señal dada.
Signal.trap(0, lambda { puts “Terminating: #{$$}” })Signal.trap(“CLD”) { puts “Child died” }fork && Process.wait
produce:
Terminating: 27913Child diedTerminating: 27912
Clase
Symbol < Objeto
Los objetos Symbol representan nombres en el intérprete Ruby. Éstos se generan utilizando la síntaxis literal :name y mediante los diferentes métodos to_sym. El objeto símbolo mismo creará una cadena para el nombre dado por la duración de la ejecución de un programa, independientemente del contexto o el significado de ese nombre. Por lo tanto, si Fred es una constante en un contexto, un método en otro, y una clase en un tercero, el Symbol :Fred será el mismo objeto en los tres contextos.
module One class Fred end $f1 = :Fredendmodule Two Fred = 1 $f2 = :Fredend
def Fred()end$f3 = :Fred$f1.id -> 2526478$f2.id -> 2526478$f3.id -> 2526478
Métodos de Claseall_symbols Symbol.all_symbols → array

321
Devuelve una matriz de todos los símbolos actuales en la tabla de símbolos Ruby.
Symbol.all_symbols.size -> 913Symbol.all_symbols[1,20] -> [:floor, :ARGV, :Binding, :symlink, :chown, :EOFError, :$;, :String, :LOCK_SH, :”setuid?”, :$<, :default_proc, :compact, :extend, :Tms, :getwd, :$=, :ThreadGroup, :”success?”, :wait2]
Métodos de Instanciaid2name sym.id2name → string
Devuelve la representación de cadena de sym. Antes de Ruby 1.8, los símbolos representaban típica-mente nombres, ahora pueden ser cadenas arbitrarias.
:fred.id2name -> “fred”:”99 red balloons!”.id2name -> “99 red balloons!”
inspect sym.inspect → string
Devuelve la representación de sym como un símbolo literal.
:fred.inspect -> :fred:”99 red balloons!”.inspect -> :”99 red balloons!”
to_i sym.to_i → fixnum
Devuelve un entero que es único para cada símbolo dentro de una ejecución particular de un programa.
:fred.to_i -> 9857“fred”.to_sym.to_i -> 9857
to_int sym.to_int → fixnum
Sinónimo de Symbol#to_i. Permite que los símbolos el tener un comportamiento similar al entero.
to_s sym.to_s → string
Sinónimo de Symbol#id2name.
to_sym sym.to_sym → sym
¡Los símbolos se comportan como símbolos!
Clase
UnboundMethod < Object
Ruby soporta dos tipos de métodos objetivados. La clase Method se utiliza para representar los méto-dos que están asociados con un objeto en particular: estos objetos método están obligados a ese objeto. Se pueden crear objetos método enlazados a un objeto utilizando Object#method.
Rubí también soporta métodos no consolidados, que son objetos método que no están asociados con un objeto particular. Estos pueden ser creados ya sea llamando a unbind en un objeto método vinculado o ya sea llamando a Module#instance_method.
Sólo se puede llamar a métodos sin consolidar después de haber sido asociados a un objeto. Ese ob-jeto debe ser una clase kind_of? original del método.

322
class Square def area @side * @side end def initialize(side) @side = side endend
area_unbound = Square.instance_method(:area)
s = Square.new(12)area = area_unbound.bind(s)area.call -> 144
Los métodos no consolidados son una referencia al método en el momento en que es objetivizado: los cambios posteriores a la clase base no afectará al método no consolidado.
class Test def test :original endendum = Test.instance_method(:test)class Test def test :modified endendt = Test.new
t.test -> :modifiedum.bind(t).call -> :original
Métodos de Instanciaarity umeth.arity → fixnum
Ver Method#arity (que devuelve una indicación del número de argumentos aceptados por un méto-do).
bind umeth.bind( obj ) → method
Enlaza umeth a obj. Si Klass era la clase de la cual se obtuvo originalmente umeth, obj.kind_of?(Klass) debe ser verdadero.
class A def test puts “In test, class = #{self.class}” endendclass B < Aendclass C < Bendum = B.instance_method(:test)bm = um.bind(C.new)bm.callbm = um.bind(B.new)

323
bm.callbm = um.bind(A.new)bm.call
produce:
In test, class = CIn test, class = Bprog.rb:16:in `bind’: bind argument must be an instance of B (TypeError)from prog.rb:16
Librería Estándar El intérprete Ruby viene con un gran número de clases, módulos y métodos integrados --que están disponibles como parte del programa en ejecución. Cuando se necesita una utilidad que no es parte del repertorio integrado, a menudo se encuentra en una biblioteca que puede dar lugar a un require en el programa.
Un gran número de bibliotecas de Ruby están disponibles en Internet. Sitios tales como Ruby Applica-tion Archive (http://raa.rubylang.org) y RubyForge (http://rubyforge.org) tienen grandes índices y una gran cantidad de código.
Sin embargo, Ruby también viene de serie con un gran número de bibliotecas. Algunas de éstas se han escrito en Ruby puro y estarán disponible en todas las plataformas de Ruby. Otras son extensiones de Ruby, y algunas de ellas estarán presentes sólo si su sistema es compatible con los recursos que necesi-tan. Todos se pueden incluir en su programa Ruby utilizando require. Y, a diferencia de las bibliotecas que se encuentran en Internet, se puede casi garantizar que todos los usuarios de Ruby tienen estas bi-bliotecas ya instaladas en sus máquinas.
Usted no encontrará aquí descripciones detalladas de las librerías: esto es para que consulte la docu-mentación propia de la biblioteca.
Esto que se sugiere de “consulte la documentación propia de la biblioteca” está muy bien, pero, ¿dónde podemos encontrarla? La respuesta es “depende”. Algunas bibliotecas ya han sido documentadas me-diante RDoc. Eso significa que se puede usar el comando ri para obtener su documentación. Por ejem-plo, a partir de la línea de comandos, se debe ser capaz de ver la siguiente documentación del método decode64 en la biblioteca estándar Base64.
% ri Base64.decode64--------------------------------------------------------------Base64#decode64 decode64(str)----------------------------------------------------------------------------- Returns the Base64-decoded version of str.
require ‘base64’ str = ‘VGhpcyBpcyBsaW5lIG9uZQpUaGlzIG’ + ‘lzIGxpbmUgdHdvClRoaXMgaXMgbGlu’ + ‘ZSB0aHJlZQpBbmQgc28gb24uLi4K’ puts Base64.decode64(str)
Generates:
This is line oneThis is line twoThis is line threeAnd so on...
Si no hay documentación RDoc disponible, el siguiente lugar para buscar es en la propia biblioteca. Si usted tiene una distribución de código fuente de Ruby, esto se encuentra en los subdirectorios ext/ y lib/.

324
En cambio, si tiene una instalación sólo binaria, todavía se puede encontrar la fuente Ruby pura de los mó-dulos de biblioteca (normalmente en el directorio lib/ruby/1.8/ de la instalación de Ruby). A menudo, los directorios de los fuentes de las librerías contienen la documentación que el autor aún no ha convertido al formato RDoc.
Si usted todavía no puede encontrar la documentación, es el turno de Google. Muchas de las librerías estándar de Ruby también se alojan en proyectos externos. Hay autores que desarrollan de forma inde-pendiente y luego periódicamente, integran el código en la distribución estándar de Ruby. Por ejemplo, si se desea información detallada sobre la API de la biblioteca YAML, hay que buscar en Google “yaml ruby” que puede llevar a http://yaml4r.sourceforge.net/doc/. Después de admirar la obra de arte why the lucky stiff ’s, un clic y se tiene acceso a sus más de 40 páginas de manual de referencia.
El próximo puerto de escala es la lista de correo ruby-talk. Haga una pregunta (educada) allí, y lo más probable es que obtenga una respuesta erudita en cuestión de horas. Consulte la sección “Mailing Lists”, en http://www.rubylang.org/ para más detalles sobre como unirse a una lista de correo. Y si usted todavía no puede encontrar la documentación, siempre se puede seguir el consejo de Obi Wan y hacer lo que se hace cuando se documenta Ruby --utilizar la fuente. Se sorprenderá de lo fácil que es leer los fuentes reales de las bibliotecas Ruby y trabajar en los detalles de su utilización.
Como ejemplo vamos a ver aquí las librerías CGI y CGI::Session.
Librería
CGI
La clase CGI proporciona soporte para programas utilizados como scripts CGI (Common Gateway In-terface) en un servidor Web. Los objetos CGI se inicializan con los datos del entorno y desde una solicitud HTTP, y proporcionan accesores convenientes a los datos de formulario y a cookies. También se puede administrar sesiones usando una variedad de mecanismos de almacenamiento. La clase CGI proporciona también utilidades básicas para la generación de HTML y métodos de clase de escape y desesescape de solicitudes y HTML.
Nota: La implementación 1.8 de CGI introduce un cambio en la manera de acceder a los datos de for-mulario. Consulte la documentación ri de CGI#[] y CGI#params para más detalles.
Ver también: CGI:: Session.
•EscapaydesescapacaracteresespecialesendireccionesURLyHTML.Silavariable$KCODE está establecida en “u” (por UTF8), la biblioteca se convertirá desde HTML a Unicode a UTF-8 interno.
require ‘cgi’CGI.escape(‘c:\My Files’) -> c%3A%5CMy+FilesCGI.unescape(‘c%3a%5cMy+Files’) -> c:\My FilesCGI::escapeHTML(‘”a”<b & c’) -> "a"<b & c
$KCODE = “u” # Usar UTF8CGI.unescapeHTML(‘"a"<=>b’) -> “a”<=>bCGI.unescapeHTML(‘AA’) -> AACGI.unescapeHTML(‘πr²’) -> πr2
•Accedealainformacióndelasolicitudentrante.
require ‘cgi’c = CGI.newc.auth_type -> “basic”c.user_agent -> “Mozscape Explorari V5.6”
• Accede a los campos del formulario de una solicitud entrante. Suponiendo que el siguientescript se instala como test.cgi y el usuario enlaza a él mediante http://mydomain.com/test.cgi?fred=10&barney=cat.

325
require ‘cgi’c = CGI.newc[‘fred’] -> “10”c.keys -> [“barney”, “fred”]c.params -> {“barney”=>[“cat”], “fred”=>[“10”]}
•Siunformulariocontienevarioscamposconelmismonombre,loscorrespondientesvaloresseretor-narán al script como una matriz. El accesor [ ] retorna sólo el primero de estos valores --indexa el resultado del método params para obtener todos ellos. En el siguiente ejemplo asuminos que el formulario tiene tres campos llamados “name”.
require ‘cgi’c = CGI.newc[‘name’] -> “fred”c.params[‘name’] -> [“fred”, “wilma”, “barney”]c.keys -> [“name”]c.params -> {“name”=>[“fred”, “wilma”, “barney”]}
•Enviauna respuestaal navegador. (Nohaymuchagentequeutiliceesta formadegeneracióndeHTML. Considerar una de las bibliotecas de plantillas).
require ‘cgi’cgi = CGI.new(“html4Tr”)cgi.header(“type” => “text/html”, “expires” => Time.now + 30)cgi.out do cgi.html do cgi.head{ cgi.title{“Hello World!”} } + cgi.body do cgi.pre do CGI::escapeHTML( “params: “ + cgi.params.inspect + “\n” + “cookies: “ + cgi.cookies.inspect + “\n”) end end endend
•Almacenarunacookieenelnavegadordelcliente.
require ‘cgi’cgi = CGI.new(“html4”)cookie = CGI::Cookie.new(‘name’ => ‘mycookie’, ‘value’ => ‘chocolate chip’, ‘expires’ => Time.now + 3600)cgi.out(‘cookie’ => cookie) do cgi.head + cgi.body { “Cookie stored” }end
•Recuperarunacookiealmacenadapreviamente.
require ‘cgi’cgi = CGI.new(“html4”)cookie = cgi.cookies[‘mycookie’]cgi.out(‘cookie’ => cookie) do cgi.head + cgi.body { “Flavor: “ + cookie[0] }end

326
Librería
CGI::Session
CGI::Session mantiene un estado persistente de los usuarios Web en un entorno CGI. Las sesiones pueden ser residentes en memoria o se pueden almacenar en disco. Ver ri CGI::Session para más información.
require ‘cgi’require ‘cgi/session’cgi = CGI.new(“html3”)sess = CGI::Session.new(cgi, “session_key” => “rubyweb”, “prefix” => “web-session.” )if sess[‘lastaccess’] msg = “Los últimos que estuvieron aquí #{sess[‘lastaccess’]}.”else msg = “Parece que no han estado aquí por un tiempo”endcount = (sess[“accesscount”] || 0).to_icount += 1msg << “<p>Numero de visitas: #{count}”sess[“accesscount”] = countsess[“lastaccess”] = Time.now.to_ssess.closecgi.out { cgi.html { cgi.body { msg } }}
----------------------------------------------
Por último y como colofón a esta traducción libre, un extracto muy interesante de la 3ª edi-ción, en la que se documenta la versión 1.9 de este extraordinario lenguaje de programación.
Metaprogramación El telar de Jacquard, inventado hace más de 200 años, fue el primer dispositivo controlado mediante tarjetas perforadas --filas de agujeros en cada tarjeta utilizadas para controlar el patrón a tejer en la tela. Pero imaginemos que si en vez de producir tela, el telar pudiera perforar más tarjetas, y éstas podrían ali-mentar de nuevo el mecanismo. La máquina podría ser utilizada para crear nuevos programas que podrían ejecutarse. Y eso sería la metaprogramación --la escritura de código que escribe código. La programación es todo lo que trata acerca de la construcción de capas de abstracción. Para resolver éste problema está la construcción de puentes entre el implacable y mecánico mundo de silicio y el más ambiguo y fluido mundo que habitamos. Algunos lenguajes de programación --como C-- son cercanos a la máquina. La distancia desde el código C hasta el dominio de aplicación puede ser grande. Otros lenguajes --Ruby, tal vez-- proporcionan abstracciones de alto nivel y por lo tanto permiten empezar a escribir códi-go más cercano al dominio de destino. Por esta razón, la mayoría de la gente considera que un lenguaje de alto nivel puede ser un mejor lugar de partida para el desarrollo de aplicaciones (aunque van a seguir discutiendo sobre que lenguaje elegir).
Pero cuando se metaprograma, ya no se está limitado a la serie de abstracciones integradas en su lenguaje de programación. De otro modo, se pueden crear nuevas abstracciones que se integran en el lenguaje de acogida. En efecto, se está creando un nuevo y específico dominio de lenguaje de programación

327
--diseñado para que se puedan expresar los conceptos que se necesitan para resolver problemas particu-lares.
Ruby hace fácil la metaprogramación. Como resultado, los programadores de Ruby más avanzados utilizan técnicas de metaprogramación para simplificar su código. En este capítulo se muestra cómo lo hacen. No pretende ser un estudio exhaustivo de las técnicas de metaprogramación. En su lugar, vamos a ver la los principios subyacentes de Ruby para hacer posible la metaprogramación. Desde ahí, podrá inventar su propio lenguaje de metaprogramación.
Objetos y clases
Las clases y los objetos son, obviamente, el centro de Ruby. Pero a primera vista puede ser un poco confuso. Parece que hay un montón de conceptos: clases, objetos, objetos de clase, métodos de instan-cia, métodos de clase, clases singleton y clases virtuales. En realidad, sin embargo, Ruby tiene solo una única clase base y estructura de objeto.
Un objeto Ruby tiene tres componentes: un conjunto de banderas, algunas variables de instancia y una clase asociada. Una clase Ruby es un objeto de la clase Class. Contiene todas las cosas que tiene un objeto y un conjunto de definiciones de métodos y una referencia a una superclase (que a su vez es otra clase).
Y, fundamentalmente, eso es todo. A partir de aquí, se puede trabajar en los detalles de metaprogra-mación para uno mismo. Pero como siempre, el diablo se esconde en los detalles, así que vamos a pro-fundizar un poco más.
self y Llamada a Método
Ruby tiene el concepto de objeto actual (o en curso). Este objeto actual hace referencia a la variable integrada self de sólo lectura. self tiene dos funciones importantes en un programa Ruby en ejecución.
En primer lugar, self controla cómo Ruby encuentra las variables de instancia. Ya hemos dicho que todos los objetos llevan alrededor un conjunto de variables de instancia. Cuando usted accede a una va-riable de instancia, Ruby busca en el objeto referenciado por self.
En segundo lugar, self juega un papel vital en la llamada a método. En Ruby, cada llamada a método se realiza en algún objeto. Este objeto se llama el receptor de la llamada. Cuando se hace una llamada a un método como items.size, el objeto referenciado por la variable items es el receptor y size es el método a invocar.
Si se hace una llamada a método, como puts “hola”, no hay receptor explícito. En este caso, Ruby utiliza el objeto actual, self, como el receptor. Va a la clase self y busca el método (en este caso, puts). Si no puede encontrar el método en la clase, busca en la superclase de la clase y luego en la supercla-se de esa clase, deteniéndose cuando se queda sin superclases (que sucederá después de buscar en BasicObject)4. Cuando se hace una llamada a método con un receptor explícito (por ejemplo, invocar items.size), el proceso es sorprendentemente similar. El único cambio - pero de vital importancia - es el hecho de que self se cambia por la duración de la llamada. Antes de iniciar el proceso de búsqueda de métodos, Ruby establece self para el receptor (el objeto referenciado por items en este caso). Entonces, después de que la llamada retorna, Ruby restablece el valor que self tenía antes de la llamada.
Vamos a ver cómo funciona esto en la práctica. He aquí un programa simple:
class Test def one @var = 99 two
4 Si no puede encontrar el método después de haber agotado la jerarquía de clase del objeto, Ruby busca un método llamado method_missing en el receptor original, empezando desde la clase de self y luego buscando en la cadena de superclase.

328
end def two puts @var endend
t = Test.newt.one
produce:
99
La llamada a Test.new en la primera de las dos últimas líneas, crea un nuevo objeto de la clase Test, asignando ese objeto a la variable t. Luego, en la línea siguiente, llamamos al método t.one. Para eje-cutar esta llamada, Ruby establece self a t y luego busca en la clase de t el método one. Ruby encuentra el método definido en la línea 2 y lo llama.
Dentro del método, se establece la variable de instancia @var a 99. Esta variable de instancia se aso-ciará con el objeto actual. ¿Cuál es ese objeto? Bueno, la llamada a t.one establece self en t, por lo que en el método one, self será esa instancia particular de la de la clase Test.
En la siguiente línea, one llama a two. Como no hay receptor explícito, self no se cambia. Cuando Ruby busca el método two, lo ve en Test, la clase de t.
El método two hace referencia a una variable de instancia @var. Una vez más, Ruby busca esta varia-ble en el objeto actual y encuentra la misma variable que fué establecida por el método one.
La llamada a puts al final de two funciona de la misma manera. Una vez más, como no hay receptor explícito, self no se ve afectada. Ruby busca el método puts en la clase del objeto actual, pero no lo encuentra. A continuación, busca en la superclase de Test, la clase Object y de nuevo, no encuentra puts. Sin embargo, Object se mezcla en el módulo Kernel y los módulos mixtos o mezclados actuan como si se trataran de superclases. El módulo Kernel hace definición de puts, por lo que el método es encontrado y ejecutado.
Después de que one y two retornan, Ruby restablece self al valor que tenía antes de la llamada ori-ginal a t.one.
Esta explicación puede parecer pesada, pero la comprensión es vital para el dominio de la metaprogra-mación en Ruby.
Self y Definición de Clase
Hemos visto que llamar a un método con un receptor explícito cambia self. Tal vez sorprendentemen-te, también cambia self por una definición de clase. Esto es una consecuencia del hecho de que las defi-niciones de clases son en realidad código ejecutable en Ruby --si podemos ejecutar código, necesitamos tener un objeto actual. Una prueba simple muestra lo que este objeto es:
class Test puts “In the definition of class Test” puts “self = #{self}” puts “Class of self = #{self.class}”end
produce:
In the definition of class Testself = TestClass of self = Class

329
Dentro de una definición de clase, self se establece en el objeto de clase de la clase que se define. Esto significa que las variables de instancia establecidas en una definición de clase estarán disponible para los métodos de la clase (porque self será el mismo cuando las variables se definen y cuando los métodos se ejecutan):
class Test @var = 99 def self.value_of_var @var endend
puts Test.value_of_var
produce:
99
Singletons
Ruby permite definir los métodos que son específicos de un objeto en particular. Estos se denominan métodos singleton. Vamos a empezar con un simple objeto cadena:
animal = “cat”puts animal.upcase
produce:
CAT
Esto se traduce en la estructura de objeto que se muestra en la Figura. La variable animal apunta a un objeto que contiene (entre otras cosas) el valor de la cadena (“cat”) y un puntero a la clase del objeto String. Cuando se llama a animal.upcase, Ruby va al objeto referenciado por la variable animal y luego busca el método upcase en la clase del objeto referenciada desde el objeto animal. Nuestro animal es una cadena y por lo tanto tiene los métodos de la clase String disponibles.
Ahora vamos a hacerlo más interesante. Vamos a definir un método singleton en la cadena referencia-da por animal:
animal = “cat”def animal.speak puts “The #{self} says miaow”end

330
animal.speakputs animal.upcase produce:
The cat says miaowCAT
Ya vemos cómo la llamada a animal.speak funciona cuando nos fijamos en cómo se invocan los mé-todos. Ruby establece self al objeto cadena “cat” referenciado por animal y luego busca un método speak en la clase de ese objeto. Sorprendentemente, se encuentra. Es en principio sorprendente, porque la clase de “cat” es String, y String no tiene un método speak. Así que, ¿hace Ruby algún tipo de magia para los casos especiales de estos métodos que se definen en objetos individuales?
Afortunadamente, la respuesta es “no.” El modelo objeto de Ruby es notablemente consistente. Cuando se define el método singleton para el objeto “cat”, Ruby crea una nueva clase anónima y define el método speak en esa clase. Esta clase anónima a veces es llamada una clase singleton y otras veces una eigen-class (clase-propia). Preferimos la primera, porque enlaza con la idea de los métodos singleton.
Ruby hace de esta clase singleton la clase del objeto “cat” y hace de String (que era la clase original de “cat”) la superclase de la clase singleton. Esto se muestra en la Figura siguiente:
Ahora vamos a seguir la llamada a animal.speak. Ruby va al objeto referenciado por animal y lue-go busca en su clase el método speak. La clase del objeto animal es la clase singleton recién creada y contiene el método que necesitamos.
¿Qué pasa si en su lugar se llama a animal.upcase? El tratamiento se inicia de la misma manera: Ruby busca el método upcase en la clase singleton, pero no lo encuentra allí. A continuación, sigue las reglas normales de proceso y comienza a buscar en la cadena de superclases. La superclase de singleton es String, y Ruby encuentra el método upcase allí. Hay que tener en cuenta que aquí no hay un proce-samiento de caso especial --el método Ruby de llamada siempre funciona de la misma manera.
Singletons y Clases
Antes mencionamos que dentro de una definición de clase, self se establece al objeto de la clase que se está definiendo. Resulta que esta es la base para uno de los aspectos más elegantes del modelo de objetos de Ruby.
Recordemos que podemos definir los métodos de clase en Ruby utilizando cualquiera de estas dos formas: def self.xxx o def ClassName.xxx.

331
class Dave def self.class_method_one puts “Class method one” end def Dave.class_method_two puts “Class method two” endend
Dave.class_method_oneDave.class_method_two
produce:Class method oneClass method two
Ahora sabemos por qué las dos formas son idénticas: dentro de la definición de clase, self se esta-blece a Dave. Pero ahora que hemos visto los métodos singleton, también sabemos que, en realidad, no hay tal cosa como métodos de clase en Ruby. Ambas definiciones anteriores definen métodos singleton del objeto de la clase. Al igual que todos los otros métodos singleton, se les puede llamar a través del objeto (en este caso, la clase Dave).
Antes de crear los dos métodos singleton en la clase Dave, el puntero de clase en el objeto de clase apunta a la clase Class (ésta es una frase confusa. Otra forma de decirlo es “Dave es una clase, por lo que la clase de Dave es la clase Class,” aunque esto es bastante confuso también). La situación se parece a la Figura siguiente:
El diagrama de objetos para la clase Dave después de definir los métodos se muestra en la Figura de la página siguiente. ¿Se ve cómo se crea la clase Singleton, como se vió para el ejemplo animal? La clase se inserta como la clase de Dave, y la clase original de Dave se hace padre de esta nueva clase.
Ahora podemos unir juntos los dos usos de self, el objeto actual. Hablamos de cómo las variables de instancia se buscan en self, y hablamos de cómo los métodos singleton definidos en self se convierten en métodos de clase. Vamos a utilizar estos hechos para acceder a variables de instancia de los objetos de clase:
class Test @var = 99 def self.var @var end def self.var=(value) @var = value endendputs “Original value = #{Test.var}”Test.var = “cat”puts “New value = #{Test.var}”
produce:
Original value = 99New value = cat
Los recién llegados a Ruby comúnmente cometen el error de establecer las variables de instancia en línea en la definición de clase (como lo hicimos con @var en el código anterior) para luego tratar de acce-der a estas variables desde los métodos de instancia. Como el código ilustra, esto no funcionará, ya que las variables de instancia definidas en el cuerpo de la clase, están asociadas con el objeto de clase y no con las instancias de la clase.
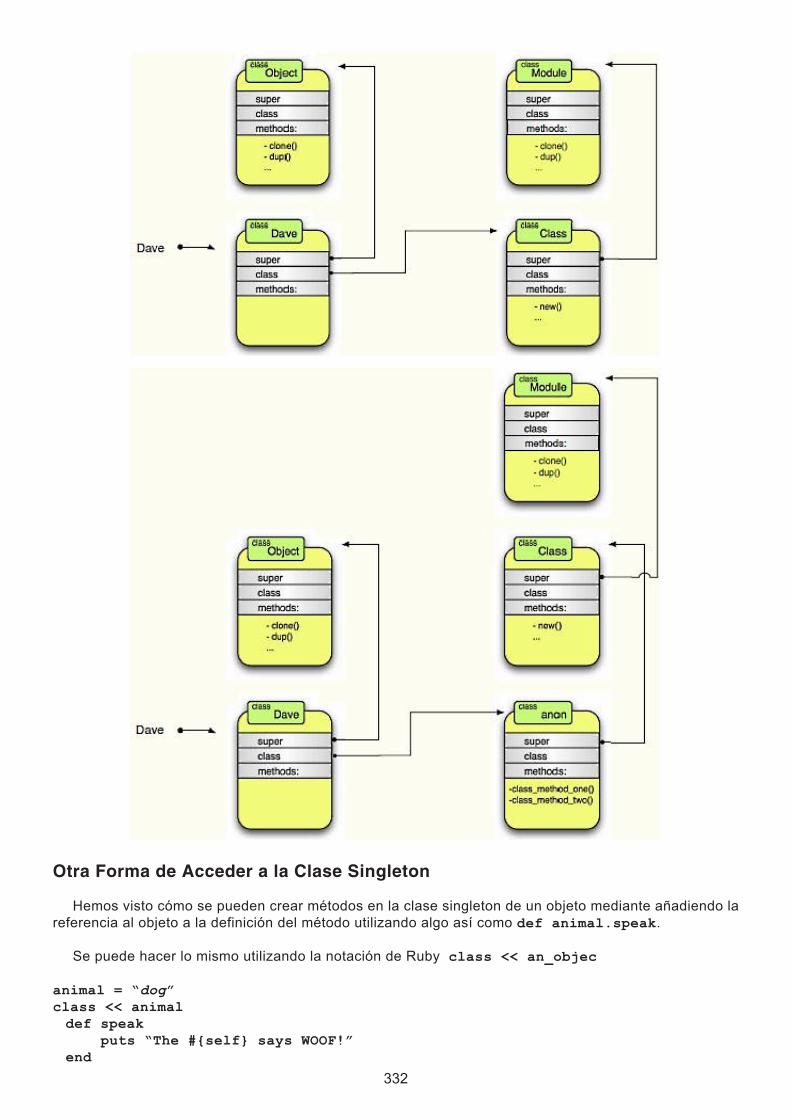
332
Otra Forma de Acceder a la Clase Singleton
Hemos visto cómo se pueden crear métodos en la clase singleton de un objeto mediante añadiendo la referencia al objeto a la definición del método utilizando algo así como def animal.speak.
Se puede hacer lo mismo utilizando la notación de Ruby class << an_objec
animal = “dog”class << animal def speak puts “The #{self} says WOOF!” end

333
end
animal.speak
produce:
The dog says WOOF!
Dentro de este tipo de definición de clase, self se establece a la clase singleton para el objeto dado (animal, en este caso). Como las definiciones de clase devuelven el valor de la última instrucción ejecu-tada en el cuerpo de la clase, podemos usar este hecho para obtener el objeto de la clase singleton:
animal = “dog”def animal.speak puts “The #{self} says WOOF!”end
singleton = class << animal def lie puts “The #{self} lies down” end self # << retorna objeto de la clase singletonend
animal.speakanimal.lieputs “Singleton class object is #{singleton}”puts “It defines methods #{singleton.instance_methods - ‘cat’.methods}”
produce:
The dog says WOOF!The dog lies downSingleton class object is #<Class:#<String:0x0000010086acf8>>It defines methods [:speak, :lie]
Hay que tener en cuenta la notación que Ruby utiliza para denotar una clase singleton: #<Class:#<String:...>>.
Ruby le va a decir cuando algún problema impide el uso de clases singleton fuera del contexto de su objeto original. Por ejemplo, no se puede crear una nueva instancia de una clase singleton:
singleton = class << “cat”; self; endsingleton.new
produce:
prog.rb:2:in ‘new’: can’t create instance of singleton class (TypeError) from /tmp/prog.rb:2:in ‘<main>’
Vamos a juntar lo que sabemos sobre las variables de instancia, self y las clases singleton. Anterior-mente hemos dicho que con métodos accesores a nivel de clase vamos a obtener y establecer el valor de una variable de instancia definida en un objeto de clase. Sin embargo, Ruby ya tiene a attr_accessor, que define los métodos getter y setter (obtenedor y establecedor). Normalmente, sin embargo, estos se definen como métodos de instancia y por lo tanto tendrán acceso a los valores almacenados en las instan-cias de una clase. Para que funcionen con las variables de instancia a nivel de clase, tenemos que invocar a attr_accessor en la clase singleton:
class Test @var = 99

334
class << self attr_accessor :var endend
puts “Original value = #{Test.var}”Test.var = “cat”puts “New value = #{Test.var}”
produce:
Original value = 99New value = cat
Herencia y Visibilidad
Hay una arruga oscura cuando se trata la definición de método y la herencia de clase. Dentro de una definición de clase, puede cambiar la visibilidad de un método en una clase antecesora.
Por ejemplo, se puede hacer algo como esto:
class Base def a_method puts “Got here” end private :a_methodend
class Derived1 < Base public :a_methodend
class Derived2 < Baseend
En este ejemplo, usted sería capaz de invocar un_metodo en instancias de la clase Derived1, pero en cambio, no en instancias de Base o Derived2.
Por tanto, ¿cómo logra Ruby esta hazaña de tener un método con dos visibilidades diferentes? En po-cas palabras, se engaña.
Si una subclase cambia la visibilidad de un método en uno de los antecesores, Ruby efectivamente inserta un método proxy oculto en la subclase que invoca al método original utilizando super. A continua-ción, establece la visibilidad de ese proxy para lo que se solicitó. Esto significa que el siguiente código:
class Derived1 < Base public :a_methodend
es efectivamente el mismo que este:
class Derived1 < Base def a_method(*) super end public :a_methodend
La llamada a super puede acceder a métodos de los padres independientemente de su visibilidad, por lo que la reescritura permite a la subclase reemplazar las reglas de visibilidad su antecesor. Atemoriza, ¿eh?

335
Módulos y Mixins
Sabemos que cuando se incluye un módulo en una clase Ruby, los métodos de instancia de ese módulo están disponibles como métodos de instancia de la clase.
module Logger def log(msg) STDERR.puts Time.now.strftime(“%H:%M:%S: ”) + “#{self} (#{msg})” endend
class Song include Loggerend
class Album include Loggerend
s = Song.news.log(“created”)
produce:
11:53:26: #<Song:0x0000010086aaa0> (created)
La implementación Ruby de include es muy simple: el módulo que se incluye es efectivamente aña-dido como una superclase de la clase que se define. Es como si el módulo fuera el padre de la clase en la que se mezcla. Y eso sería el final de la descripción a excepción de una pequeña pega. Debido a que el módulo es inyectado en la cadena de superclases, se debe mantener un vínculo con la clase padre original. Si no, no habría manera de atravesar la cadena de superclases para buscar métodos. Sin embar-go, usted puede mezclar el mismo módulo en diferentes clases, y estas clases podrían tener cadenas de superclase totalmente diferentes. Si hubiera sólo un objeto módulo mezclado en todas estas clases, no habría manera de hacer el seguimiento de las diferentes superclases para cada una.
Para evitar esto, Ruby utiliza un truco ingenioso. Cuando se incluye un módulo en la clase Ejemplo, Ruby crea un nuevo objeto de clase, haciéndole la superclase de Ejemplo, y luego establece la super-clase de la nueva clase a la superclase original de Ejemplo. A continuación, referencia al módulo desde este nuevo objeto de clase de tal manera que cuando se busca un método en esta clase, en realidad se busca en el módulo, como se muestra en la figura en la página siguiente.
Un bonito efecto secundario de este arreglo es que si usted cambia un módulo después de su inclusión en una clase, los cambios se reflejan en la clase (y en los objetos de la clase). De esta manera, los módu-los se comportan igual que las clases.
module Mod def greeting “Hello” endendclass Example include Modend
ex = Example.newputs “Before change, greeting is #{ex.greeting}”
module Mod def greeting “Hi”
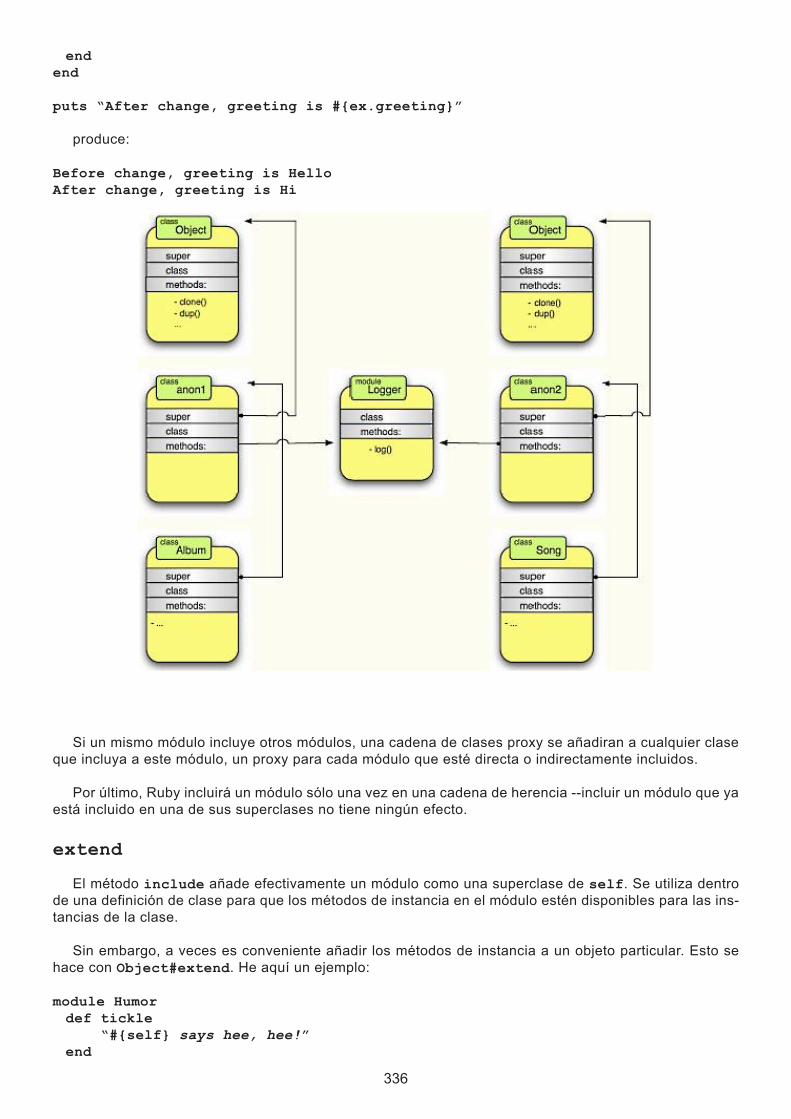
336
endend
puts “After change, greeting is #{ex.greeting}”
produce:
Before change, greeting is HelloAfter change, greeting is Hi
Si un mismo módulo incluye otros módulos, una cadena de clases proxy se añadiran a cualquier clase que incluya a este módulo, un proxy para cada módulo que esté directa o indirectamente incluidos.
Por último, Ruby incluirá un módulo sólo una vez en una cadena de herencia --incluir un módulo que ya está incluido en una de sus superclases no tiene ningún efecto.
extend
El método include añade efectivamente un módulo como una superclase de self. Se utiliza dentro de una definición de clase para que los métodos de instancia en el módulo estén disponibles para las ins-tancias de la clase.
Sin embargo, a veces es conveniente añadir los métodos de instancia a un objeto particular. Esto se hace con Object#extend. He aquí un ejemplo:
module Humor def tickle “#{self} says hee, hee!” end

337
end
obj = “Grouchy”obj.extend Humorputs obj.tickle
produce:
Grouchy says hee, hee!
Vamos a parar un segundo para pensar cómo puede implementarse esto.
Cuando Ruby ejecuta obj.tickle en este ejemplo de código, se hace el truco habitual de buscar en la clase de obj un método llamado tickle (cosquillas). Para que extend funcione, tiene que añadir los métodos de instancia del módulo Humor en la cadena de superclases para la clase de obj. Por lo tanto, al igual que con las definiciones de métodos singleton, Ruby crea una clase singleton para obj y luego incluye el módulo Humor en esa clase. De hecho, sólo para demostrar que esto es todo lo que sucede, aquí está la implementación en C de extend en el actual intérprete de Ruby 1.9:
void rb_extend_object(VALUE obj, VALUE module) { rb_include_module(rb_singleton_class(obj), module);}
Hay un truco interesante con extend. Si lo usa en una definición de clase, los métodos de módulo se convierten en métodos de clase. Esto se debe a que la llamada a extend es equivalente a self.extend, por lo que los métodos se añaden a self, que en una definición de clase es la clase misma.
He aquí un ejemplo de cómo agregar métodos de módulo a nivel de clase:
module Humor def tickle “#{self} says hee, hee!” endendclass Grouchy extend Humorend
puts Grouchy.tickle
produce:
Grouchy says hee, hee! Más adelante, vamos a ver cómo utilizar extend para añadir métodos de estilo macro a una clase.
Metaprogramación de Macros a Nivel de Clase
Si se ha utilizado Ruby para cualquier toma de tiempo, hay muchas posibilidades de haber utilizado attr_accessor, el método que define los métodos para leer y escribir las variables de instancia:
class Song attr_accessor :durationend
Si se ha escrito una aplicación en Ruby on Rails, probablemente se ha utilizado has_many:
class Album < ActiveRecord::Base has_many :tracksend

338
Ambos son ejemplos de métodos a nivel de clase que generan código entre bastidores. Debido a la forma en que se expanden en algo más grande, la gente a veces les llama métodos macro.
Vamos a crear un ejemplo trivial y luego construirlo en algo realista. Vamos a empezar por la implementa-ción de un simple método que añade capacidades de registro a instancias de una clase. Anteriormente lo hi-cimos con un módulo --esta vez lo haremos utilizando un método a nivel de clase. Esta es la primera iteración:
class Example def self.add_logging def log(msg) STDERR.puts Time.now.strftime(“%H:%M:%S: ”) + “#{self} (#{msg})” end end add_loggingend
ex = Example.newex.log(“hello”)
produce:
11:53:26: #<Example:0x0000010086b018> (hello)
Claramente esta es una pieza tonta de código. Tengan paciencia conmigo --voy a mejorar. Pero aún podemos aprender algunas cosas de él. En primer lugar, la notificación add_logging es un método de clase --se define en la clase singleton del objeto clase. Eso significa que podemos llamarlo más tarde en la definición de clase sin un receptor explícito, porque self se establece en el objeto clase dentro de una definición de clase.
Luego hay que observar que este método add_logging contiene una definición de método anidada. Esta definición interna se vá a ejecutar sólo cuando se llama al método add_logging. El resultado es que log es definido como un método de instancia de la clase Example.
Vamos a dar un paso más. Podemos definir el método add_logging en una clase y luego usarlo en una subclase. Esto funciona porque la jerarquía de la clase singleton es paralela a la jerarquía de clases regular. Como resultado, los métodos de clase en una clase padre están disponibles en la clase hija, tal como muestra el siguiente ejemplo.
class Logger def self.add_logging def log(msg) STDERR.puts Time.now.strftime(“%H:%M:%S: ”) + “#{self} (#{msg})” end endend
class Example < Logger add_loggingend
ex = Example.newex.log(“hello”)
produce:
11:53:26: #<Example:0x0000010086ac58> (hello)
Piense de nuevo en los dos ejemplos al inicio de esta sección. Ambos funcionan de esta manera. attr_accessor es un método de clase definido en la clase Module y así está disponible en todas las definiciones de módulo y clase. has_many es un método de clase definido en la clase Base dentro

339
del módulo ActiveRecord de Rails y por lo tanto disponible para todas las clases de esa subclase ActiveRecord::Base.
Este ejemplo, todavía no es muy convincente. Sería más fácil aún añadir directamente el método log como un método de instancia de nuestra clase Logger. Pero, ¿qué pasa si queremos construir una ver-sión diferente del método log para cada clase que se utiliza? Por ejemplo, vamos a agregar la posibilidad de añadir una breve clase específica de identificación de cadena al inicio de cada mensaje de registro. Queremos ser capaces de decir algo como esto:
class Song < Logger add_logging “Song”end
class Album < Logger add_logging “CD”end
Para ello, vamos a definir el método log sobre la marcha. Ya no podemos utilizar una sencilla definición estilo def...end. En su lugar, usaremos define_method, uno de los pilares de la metaprogramación. define_method toma el nombre de un método y un bloque, definiendo un método con el nombre dado y con el bloque como el cuerpo del método. Cualquier argumento en la definición del bloque se convierte en parámetro para el método que se está definiendo.
class Logger def self.add_logging(id_string) define_method(:log) do |msg| now = Time.now.strftime(“%H:%M:%S”) STDERR.puts “#{now}-#{id_string}: #{self} (#{msg})” end endend
class Song < Logger add_logging “Tune”end
class Album < Logger add_logging “CD”end
song = Song.newsong.log(“rock on”)
produce:
11:53:26-Tune: #<Song:0x0000010086a230> (rock on)
Hay una sutileza importante en este código. El cuerpo del método log contiene la siguiente línea:
STDERR.puts “#{now}-#{id_string}: #{self} (#{msg})”
El valor now es una variable local, y msg es el parámetro para el bloque. Pero id_string es el pará-metro para el método add_logging que lo contiene. Es accesible en el interior del bloque debido a que las definiciones de bloque crean cierres, permitiendo que el contexto en el que se define el bloque sea trasladado y utilizado cuando se utiliza el bloque. En este caso, estamos dando un valor a partir de un mé-todo a nivel de clase y utilizándolo en un método de instancia que estamos definiendo. Este es un patrón común para crear este tipo de macros de nivel de clase.
Así como se pasan parámetros desde un método de clase al cuerpo de un método que se define, tam-bién se puede utilizar el parámetro para determinar el nombre del método o métodos a crear. He aquí un

340
ejemplo que crea un nuevo tipo de attr_accessor que registra todas las asignaciones a una variable de instancia dada:
class AttrLogger def self.attr_logger(name) attr_reader name define_method(“#{name}=”) do |val| puts “Assigning #{val.inspect} to #{name}” instance_variable_set(“@#{name}”, val) end endend
class Example < AttrLogger attr_logger :valueend
ex = Example.newex.value = 123puts “Value is #{ex.value}”ex.value = “cat”puts “Value is now #{ex.value}”
produce:
Assigning 123 to valueValue is 123Assigning “cat” to valueValue is now cat
Una vez más, se utiliza el hecho de que el bloque que define el cuerpo del método es un cierre, acce-diendo al nombre del atributo en la cadena de mensaje de registro. Hay que notar que también se hace uso del hecho de que attr_reader es simplemente un método de clase --que se puede llamar dentro de nuestro método de clase para definir el método de lectura de nuestros atributos. Hay que tener en cuenta otro detalle común de metaprogramación --usamos instance_variable_set para establecer el valor de una variable de instancia (duh). Hay un correspondiente método _get que obtiene el valor de una va-riable de instancia por su nombre.
Macros y Módulos de Clase
A veces, es perfectamente aceptable definir macros de clase en una clase y luego utilizar estos méto-dos macro en las subclases de esa clase. Otras veces sin embargo, no es apropiado utilizarlos en subcla-ses, bien porque ya tenemos la subclase de alguna otra clase o bien porque nuestro estético diseño se rebela contra algo así como una canción de una subclase de un registrador.
En estos casos, se puede utilizar un módulo que contenga la implementación de metaprogramación. Como hemos visto, utilizando extend dentro de una definición de clase se añaden métodos en un módulo como métodos de clase para la clase que se define:
module AttrLogger def attr_logger(name) attr_reader name define_method(“#{name}=”) do |val| puts “Assigning #{val.inspect} to #{name}” instance_variable_set(“@#{name}”, val) end endend
class Example

341
extend AttrLogger attr_logger :valueend
ex = Example.newex.value = 123puts “Value is #{ex.value}”ex.value = “cat”puts “Value is now #{ex.value}”
produce:
Assigning 123 to valueValue is 123Assigning “cat” to valueValue is now cat
Las cosas se ponen un poco más complicadas si se quieren añadir tanto los métodos de clase como los métodos de instancia en la clase que se define. Aquí hay una técnica, muy utilizada en la implementación del marco de trabajo de Rails. Se hace uso de un método gancho de Ruby, included, el cual es llamado automáticamente por Ruby cuando se incluye un módulo en una clase. Se le pasa el objeto clase de la clase que se define.
module GeneralLogger # Método de instancia que se añade a cualquier clase que lo incluya def log(msg) puts Time.now.strftime(“%H:%M: ”) + msg end
# módulo que contiene los métodos de clase que se añadirán module ClassMethods def attr_logger(name) attr_reader name define_method(“#{name}=”) do |val| log “Assigning #{val.inspect} to #{name}” instance_variable_set(“@#{name}”, val) end end end
# extender la clase afitriona con los métodos de clase cuando se incluyen def self.included(host_class) host_class.extend(ClassMethods) endend
class Example include GeneralLogger
attr_logger :valueend
ex = Example.newex.log(“New example created”)ex.value = 123puts “Value is #{ex.value}”ex.value = “cat”puts “Value is #{ex.value}”
produce:

342
11:53: New example created11:53: Assigning 123 to valueValue is 12311:53: Assigning “cat” to valueValue is cat
Observar cómo la devolución de llamada incluida se utiliza para extender la clase anfitriona con los métodos definidos en el módulo ClassMethods interior.
Ahora, como un ejercicio, tendrá que ejecutar el ejemplo anterior de su cabeza. Para cada línea de có-digo, calcular el valor de self. Dominando esto se domina prácticamente este tipo de metaprogramación en Ruby.
Otras Dos Formas de Definición de Clases
En el caso de que pensaramos que habíamos agotado las formas de definir las clases en Ruby, vamos a echar un vistazo a otras dos opciones.
Expresiones de Subclases
La primera forma no es realmente nada nuevo --no es más que una generalización de la sintaxis de definición de clase regular. Sabemos que podemos escribir lo siguiente:
class Parent ...endclass Child < Parent ...end
Lo que quizás no sabíamos es que la cosa a la derecha de < no tiene por qué ser sólo un nombre de clase, sino que puede ser cualquier expresión que devuelva un objeto de clase. En este ejemplo de có-digo, tenemos la constante Parent. Una constante es una simple forma de expresión, y en este caso la constante Parent contiene el objeto clase de la primera clase que hemos definido.
Ruby cuenta con una clase llamada Struct, que permite definir clases que contienen sólo atributos de datos. Por ejemplo, podríamos escribir lo siguiente:
Person = Struct.new(:name, :address, :likes)
dave = Person.new(‘Dave’, ‘TX’)dave.likes = “Programming Languages”puts dave
produce:
#<struct Person name=”Dave”, address=”TX”, likes=”Programming Languages”>
El valor de retorno de Struct.new(...) es un objeto de clase. Al asignarlo a la constante Person, se puede utilizar Person a partir de entonces como si se tratara de cualquier otra clase.
Pero queremos cambiar el método to_s de nuestra estructura. Podríamos hacerlo abriendo la clase y escribiendo el siguiente método:
Person = Struct.new(:name, :address, :likes)class Person def to_s “#{self.name} lives in #{self.address} and likes #{self.likes}” endend

343
Sin embargo, podemos hacerlo más elegante (aunque a costa de un objeto de clase adicional) escri-biendo lo siguiente:
class Person < Struct.new(:name, :address, :likes) def to_s “#{self.name} lives in #{self.address} and likes #{self.likes}” endend
dave = Person.new(‘Dave’, ‘Texas’)dave.likes = “Programming Languages”puts dave
produce:
Dave lives in Texas and likes Programming Languages
Creación de Clases Singleton
Vamos a ver algo de código Ruby:
class Exampleend
ex = Example.new
Cuando llamamos a Example.new, estamos invocando el método new en el objeto clase Example. Esto es sólo una llamada regular a método --Ruby busca el método new en la clase del objeto (la clase de Example es Class) y lo invoca. Resulta que también podemos invocar Class#new directamente:
some_class = Class.newputs some_class.class
produce:
Class
Si se le pasa a Class.new un bloque, este se utiliza como el cuerpo de la clase:
some_class = Class.new do def self.class_method puts “In class method” end def instance_method puts “In instance method” endend
some_class.class_methodobj = some_class.newobj.instance_method
produce:
In class methodIn instance method
Por defecto, estas clases serán descendientes directos de Object. Se les puede dar un padre diferen-te pasándoles la clase del padre como un parámetro:

344
some_class = Class.new(String) do def vowel_movement tr ‘aeiou’, ‘*’ endend
obj = some_class.new(“now is the time”)puts obj.vowel_movement
produce:
n*w *s th* t*m*
Podemos utilizar estas clases construidas dinámicamente para extender Ruby de maneras interesan-tes. Por ejemplo, aquí tenemos una reimplementación simple de la clase Ruby Struct:
def MyStruct(*keys) Class.new do attr_accessor *keys def initialize(hash) hash.each do |key, value| instance_variable_set(“@#{key}”, value) end end endend
Person = MyStruct :name, :address, :likesdave = Person.new(name: “dave”, address: “TX”, likes: “Stilton”)chad = Person.new(name: “chad”, likes: “Jazz”)chad.address = “CO”
puts “Dave’s name is #{dave.name}”puts “Chad lives in #{chad.address}”
produce:
Dave’s name is daveChad lives in CO
Como Toman las Clases sus Nombres
Usted puede haber notado que las clases creadas por Class.new no tienen nombre. Sin embargo, no todo está perdido. Si se asigna el objeto clase para una clase sin nombre a una constante, Ruby automáticamente nombra la clase después de la constante:
some_class = Class.newobj = some_class.newputs “Initial name is #{some_class.name}”SomeClass = some_classputs “Then the name is #{some_class.name}”puts “also works via the object: #{obj.class.name}”
produce:Initial name isThen the name is SomeClassalso works via the object: SomeClass

345
instance_eval y class_eval
Los métodos Object#instance_eval, Module#class_eval y Module#module_eval permiten establecer self en un objeto arbitrario, evaluar el código en un bloque y luego reajustar self:
“cat”.instance_eval do puts “Upper case = #{upcase}” puts “Length is #{self.length}”end
produce:
Upper case = CATLength is 3
Estas formas también toman una cadena (pero véase el recuadro resaltado con algunas notas sobre los peligros de la evaluación de cadenas):
“cat”.instance_eval(‘puts “Upper=#{upcase}, length=#{self.length}”’)
produce:
Upper=CAT, length=3
Tanto class_eval como instance_eval establecen self para la duración del bloque. Sin embargo, difieren en la manera de configurar el entorno para la definición del método. class_eval prepara las cosas como si estuviera en el cuerpo de una definición de clase, por lo que las definiciones de método definen métodos de instancia:
class MyClassend
MyClass.class_eval do def instance_method puts “In an instance method” endend
obj = MyClass.newobj.instance_method
produce:
eval es del año pasado
Usted puede haber notado que hemos estado haciendo una buena cantidad de metaprogramación --acceder a variables de instancia, definición de métodos y la creación de clases-- y todavía no hemos utilizado eval. Esto es deliberado. En los viejos tiempos de Ruby, el lenguaje carecía de muchas de estas funcionalidades de metaprogramación y eval era la única manera de lograr estos efectos. Pero eval viene con un par de inconvenientes.
En primer lugar, es lento --la llamada a eval efectivamente compila el código en la cadena antes de ejecutarlo. Pero, peor aún, eval puede ser peligroso. Si hay alguna posibilidad de datos externos --co-sas que vienen de fuera de la aplicación-- pueden terminar dentro de los parámetros a eval. Entonces tendríamos un agujero de seguridad, debido a que los datos externos pueden terminar conteniendo código arbitrario que la aplicación ejecutará a ciegas.
eval ahora se considera un método de último recurso.

346
In an instance method
En cambio, la llamada a instance_eval en una clase, actúa como si estuviera funcionando dentro de la clase singleton de self. Por lo tanto, cualquier método que se defina se convertirá en método de clase.
class MyClassend
MyClass.instance_eval do def class_method puts “In a class method” endendMyClass.class_method
produce:In a class method
Puede ser útil recordar que, a la hora de definir los métodos, class_eval e instance_eval tienen exactamente los nombres equivocados: class_eval define los métodos de instancia e instance_eval define los métodos de clase. ¡Que sabemos...!
Ruby 1.9 introduce variantes de estos métodos. Object#instance_exec, Module#class_exec, y Module#module_exec se comportan de forma idéntica a sus contrapartes _eval pero toman sólo un bloque (es decir, no toman una cadena). Cualquier argumento dado a los métodos se pasan como paráme-tros de los bloques. Esta es una característica importante. Anteriormente, era imposible pasar una variable de instancia dentro de un bloque dado a uno de los métodos _eval --como self cambia por la llamada, estas variables salen del ámbito. Con la forma _exec, ahora se puede pasar:
@animal = “cat”“dog”.instance_exec(@animal) do |other| puts “#{other} and #{self}”end
produce:cat and dog
instance_eval y Constantes
Ruby 1.9 cambió la forma Ruby de buscar constantes cuando se ejecuta un bloque mediante instan-ce_eval y class_eval. Ruby 1.9.2 luego revertió el cambio. En Ruby 1.8 y Ruby 1.9.2, las constantes se buscan en el ámbito léxico en el que se les hace referencia. En Ruby 1.9.0, se buscan en el ámbito en el que instance_eval es llamado. En este ejemplo (artificial) se muestra el comportamiento en el mo-mento de la última vez en que se hizo este libro --que bien podría haber cambiado de nuevo en el momento en que usted lo ejecute...
module One CONST = “Defined in One” def self.eval_block(&block) instance_eval(&block) endend
module Two CONST = “Defined in Two” def self.call_eval_block One.eval_block do CONST end end

347
end
Two.call_eval_block # => “Defined in Two”
En Ruby 1.9.0, este mismo código se evaluará a “Defined in One”.
instance_eval y Lenguajes de Dominio Específico
Resulta que instance_eval tiene un papel fundamental que desempeñar en un determinado tipo de dominio específico del lenguaje (domain-specific language o DSL). Por ejemplo, podríamos escribir un simple DSL para gráficos de tortuga5. Para dibujar un conjunto de tres cuadrados de 5x5, podríamos escribir lo siguiente6:
3.times do forward(8) pen_down 4.times do forward(4) left end pen_upend
Claramente, pen_down, forward, left y pen_up se pueden implementar como métodos Ruby. Sin embargo, para llamarles sin un receptor de esta manera, o tenemos que estar dentro de una clase que los define (o es un hijo de esa clase) o tenemos que hacer los métodos globales. instance_eval al rescate. Podemos definir una clase Turtle que defina los distintos métodos que necesitamos como métodos de instancia. También vamos a definir un método walk (recorrido) que ejecutará nuestra tortuga DSL, y un método draw para dibujar la imagen resultante:
class Turtle def left; ... end def right; ... end def forward(n); ... end def pen_up; .. end def pen_down; ... end def walk(...); end def draw; ... endend
Si implementamos walk correctamente, podemos escribir lo siguiente:
turtle = Turtle.newturtle.walk do 3.times do forward(8) pen_down 4.times do forward(4) left end pen_up endendturtle.draw
5 En los sistemas de gráficos de tortuga, puede imaginar que tiene una tortuga a la que puede ordenar avan-zar n casillas, girando a la izquierda y girando a la derecha. También puede hacer que la tortuga suba y baje una pluma retráctil. Si la pluma baja, una línea dibujará el seguimiento de los movimientos posteriores de la tortuga. Muy pocas de estas tortugas existen en la naturaleza, por lo que se tienden a simular en los ordenadores.6 Sí, el forward(4) es correcto en este código. El punto inicial se dibuja siempre.

348
Así que, ¿cuál es la implementación correcta de walk? Bueno, es evidente que tiene que utilizar instance_eval, porque queremos que los comandos DSL en el bloque, llamen a los métodos en el obje-to tortuga. También tenemos que organizarlo para pasar el bloque dado al método walk para ser evaluado por la llamada instance_eval. Nuestra implementación es la siguiente:
def walk(&block) instance_eval(&block)end
Observar como capturamos el bloque en una variable y luego expandimos de nuevo la variable en un bloque en la llamada a instance_eval.
Daremos un listado completo del programa tortuga al final.
¿Es este un buen uso de instance_eval? Depende de las circunstancias. La ventaja es que el códi-go dentro del bloque parece simple --no se tiene que hacer explícito el receptor:
4.times do turtle.forward(4) turtle.leftend
Hay un inconveniente, sin embargo. Dentro del bloque, el ámbito no es el que se cree que es, por lo que este código no funcionaría:
@size = 4turtle.walk do 4.times do turtle.forward(@size) turtle.left endend
Las variables de instancia se buscan en self, y self en el bloque no es lo mismo que self en el código, que establece la variable de instancia @size. Debido a esto, la mayoría de las personas se están alejando de este estilo de bloque instance_evaled.
Métodos Gancho
En la sección anterior de Macros y Módulos de Clase, se define un método llamado included en nues-tro módulo GeneralLogger. Cuando este módulo se incluye en una clase, Ruby invoca automáticamente a este método included, permitiendo a nuestro módulo agregar métodos de clase a la clase anfitriona.
included es un ejemplo de un método gancho (a veces llamado devolución de llamada). Un método gancho es un método que escribimos, pero que Ruby llama desde dentro del intérprete cuando ocurre al-gún evento determinado. El intérprete busca estos métodos por su nombre --si se define un método en el contexto adecuado con un nombre apropiado, Ruby lo va a llamar cuando suceda el evento correspondiente.
Los métodos que se pueden invocar desde dentro del intérprete se muestran en la Figura 36 en la pá-gina siguiente. No vamos a discutirlos aquí --en su lugar, vamos a mostrar algunos ejemplos de uso. En la sección de referencia de este libro se describen los métodos individuales, y el capítulo Duck Typing, se describen los métodos de coerción con más detalle.
El Gancho Heredado
Si una clase define un método de clase llamado inherited, Ruby lo va a llamar siempre que la clase sea una subclase (es decir, siempre que una clase hereda de la original).

349
Este gancho se usa a menudo en situaciones en que una clase base debe llevar un seguimiento de sus hijos. Por ejemplo, una almacenaje en línea puede ofrecer una variedad de opciones de envío. Cada una podría estar representada por una clase separada, y cada una de estas clases puede ser una subclase de una clase de envío única (la clase Shipping por ejemplo). Esta clase padre puede hacer un seguimiento de todas las opciones de envío diferentes mediante un registro de cada clase de estas subclases. Cuando llega el momento de mostrar las opciones de envío para el usuario, la aplicación puede llamar a la clase base para pedirle una lista de las hijas:
class Shipping # Clase Base@children = [] # esta variable se encuentra en la clase, no en instancias
def self.inherited(child) @children << child end def self.shipping_options(weight, international) @children.select {|child| child.can_ship(weight, international)} endend
class MediaMail < Shipping def self.can_ship(weight, international) !international endend class FlatRatePriorityEnvelope < Shipping def self.can_ship(weight, international) weight < 64 && !international endend
class InternationalFlatRateBox < Shipping def self.can_ship(weight, international) weight < 9*16 && international endend
puts “Shipping 16oz domestic”puts Shipping.shipping_options(16, false)
puts “\nShipping 90oz domestic”puts Shipping.shipping_options(90, false)

350
puts “\nShipping 16oz international”puts Shipping.shipping_options(16, true)
produce:
Shipping 16oz domesticMediaMailFlatRatePriorityEnvelope
Shipping 90oz domesticMediaMail
Shipping 16oz internationalInternationalFlatRateBox
Los intérpretes de comandos suelen utilizar este modelo: la clase base mantiene un registro de los comandos disponibles, cada uno de los cuales se implementa en una subclase.
El Gancho method_missing
Anteriormente, hemos visto cómo Ruby ejecuta una llamada a método mediante la búsqueda del méto-do. Primero busca en la clase del objeto, después en su superclase, luego en la superclase de esa clase y así sucesivamente. Si la llamada al método tiene un receptor explícito, los métodos privados se omiten en esta búsqueda. Si el método no se encuentra en el momento en que nos quedemos sin superclases (debido a que BasicObject no tiene superclase), Ruby trata de invocar en el objeto original el método gancho method_missing. Una vez más, se sigue el mismo proceso --Ruby busca primero en la clase del objeto, entonces en su superclase, y así sucesivamente. Sin embargo, Ruby predefine su propia versión de method_missing en la clase BasicObject y por lo general, la búsqueda se detiene ahí. El método integrado method_missing básicamente plantea una excepción, ya sea un NoMethodError o un Na-meError dependiendo de las circunstancias.
La clave aquí es que method_missing es simplemente un método Ruby. Podemos reemplazar en nuestras propias clases el manejo de las llamadas a métodos de otra manera indefinida en una forma específica de aplicación.
method_missing tiene una armadura simple, pero muchas personas se equivocan:
def method_missing(name, *args, &block) # ...
El argumento name recibe el nombre del método que no se pudo encontrar y se pasa como un símbolo. El argumento args es una matriz con los argumentos que se pasaron en la llamada original. Y el argu-mento a veces olvidado block, recibe cualquier bloque que se pasó al método original.
def method_missing(name, *args, &block) puts “Called #{name} with #{args.inspect} and #{block}”end
wibblewobble 1, 2wurble(3, 4) { stuff }
produce:
Called wibble with [] andCalled wobble with [1, 2] andCalled wurble with [3, 4] and #<Proc:0x0000010086b1d0@/tmp/prog.rb:7>
Antes de profundizar demasiado en los detalles, vamos a ofrecer un consejo acerca de la etiqueta. Hay dos principales maneras en que la gente usa method_missing. La primera intercepta cada uso de un método indefinido y lo maneja. La segunda es más sutil. Intercepta todas las llamadas pero sólo se ocupa

351
de algunas de ellas. En este último caso, es importante transmitir la llamada a una superclase, si se decide el no manejar en la implementación de method_missing:
class MyClass < OtherClass def method_missing(name, *args, &block) if <some condition> # manejar llamada else super # de lo contrario pasarlo end endend
Si usted falla en pasar en las llamadas no manejadas, la aplicación ignorará las llamadas a métodos desconocidos en su clase.
Vamos a mostrar un par de usos de method_missing.
method_missing para Simular Accesores
La clase OpenStruct se distribuye con Ruby. Esto permite escribir objetos con atributos que se crean dinámicamente por asignación. Por ejemplo, se podría escribir lo siguiente:
require ‘ostruct’obj = OpenStruct.new(name: “Dave”)obj.address = “Texas”obj.likes = “Programming”
puts “#{obj.name} lives in #{obj.address} and likes #{obj.likes}”
produce:
Dave lives in Texas and likes Programming
Vamos a utilizar method_missing para escribir nuestra propia versión de OpenStruct:
class MyOpenStruct < BasicObject
def initialize(initial_values = {}) @values = initial_values end
def _singleton_class class << self self end end
def method_missing(name, *args, &block) if name[-1] == “=” base_name = name[0..-2].intern _singleton_class.instance_exec(name) do |name| define_method(name) do |value| @values[base_name] = value end end @values[base_name] = args[0] else _singleton_class.instance_exec(name) do |name| define_method(name) do

352
@values[name] end end @values[name] end endend
obj = MyOpenStruct.new(name: “Dave”)obj.address = “Texas”obj.likes = “Programming”
puts “#{obj.name} lives in #{obj.address} and likes #{obj.likes}”
produce:
Dave lives in Texas and likes Programming
Observe la forma de base de nuestra clase en BasicObject, una clase introducida en Ruby 1.9. Ba-sicObject es la raíz de la jerarquía de objetos de Ruby y contiene sólo un número mínimo de métodos:
p BasicObject.instance_methods
produce:
[:==, :equal?, :!, :!=, :instance_eval, :instance_exec, :__send__]
Esto está bien, porque significa que nuestra clase MyOpenStruct será capaz de tener atributos tales como display o clase. Si en su lugar hubiéramos basado MyOpenStruct en la clase Object, entonces-estos nombres, junto con cuarenta y nueve más, habrían sido predefinidos y por lo tanto no daría lugar a method_missing.
Observe también otro patrón común dentro de method_missing. La primera vez que referencia o asignar a un atributo de nuestro objeto, podemos acceder o actualizar los @valores hash adecuadamente. Pero también define el método que la llamada está tratando de acceder. Esto significa que la próxima vez que se utilice este atributo, se utilizará el método y no se invocará method_missing. Esto puede o no puede valer la pena dependiendo de los patrones de acceso a su objeto.
También hay que notar cómo hay que saltar a través de unos aros para definir el método. Queremos definir el método sólo para el objeto actual. Esto significa que tenemos que poner el método en la cla-se singleton del objeto. Podemos hacer esto utilizando instance_exec y define_method. Pero eso significa que tenemos que utilizar el truco class << self para obtener la clase singleton del objeto. A través de una sutil implementación interesante, define_method siempre define un método de instancia, independientemente de si se invoca a través de instance_exec o class_exec.
Sin embargo, este código revela la parte más oscura de la utilización de method_missing y BasicObject. Considere lo siguiente:
obj = MyOpenStruct.new(name: “Dave”)obj.address = “Texas”
o1 = obj.dupo1.name = “Mike”o1.address = “Colorado”
produce:
prog.rb:37:in ‘<main>’: undefined method ‘name=’ for nil:NilClass(NoMethodError)

353
El método dup no es definido por BasicObject, sino que aparece en la clase Object. Así que cuando se llama a dup, fue recogido por nuestro manejador method_missing, y justo retorna nil (porque no te-nemos todavía un atributo llamado dup). Podríamos solucionar este problema para que al menos informe de error:
def method_missing(name, *args, &block) if name[-1] == “=” # como antes... else super unless @values.has_key? name # como antes... endend
Esta clase ahora informa de un error si llamamos en ella a dup (o a cualquier otro método). Sin em-bargo, todavía no podemos hacer dup o clone (o inspect, o convertir en una cadena, etc). Aunque BasicObject parece algo natural para method_missing, puede ser más problemático de lo que parece .
method_missing como Filtro
Como muestra el ejemplo anterior, method_missing tiene algunos inconvenientes si se utiliza para interceptar todas las llamadas. Probablemente es mejor usarlo para reconocer ciertos patrones de llama-da, pasando aquellas que no reconoce a la clase padre para su manejo.
Un ejemplo de ello es la funcionalidad de buscador dinámico del módulo ActiveRecord de Ruby on Rails. ActiveRecord es la biblioteca de objeto-relacional en Rails --que permite acceder a bases de datos relacionales como si fueran depósitos de objetos. Una característica particular le permite buscar las filas que cumplen los criterios de ciertos valores dados en determinadas columnas. Por ejemplo, si a una clase Active Record denominada Book se la asigna una tabla relacional llamada books y esta incluye columnas llamadas title y author, se podría escribir lo siguiente:
pickaxe = Book.find_by_title(“Programming Ruby”)daves_books = Book.find_all_by_author(“Dave Thomas”)
Active Record no predefine todos estos métodos de búsqueda posibles. En su lugar, utiliza nuestro viejo amigo method_missing. Dentro de este método, busca las llamadas a métodos no definidos que coinci-den con el patrón /^find_(all_)?by_(.*)/7. Si el método que se invoca no coincide con este modelo o si los campos en el nombre del método no corresponden a las columnas en la tabla de la base de datos, Active Record llama a super para generar un verdadero informe method_missing.
Un Último Ejemplo
Vamos a reunir todos los temas de metaprogramación que hemos discutido en un último ejemplo, escribiendo un módulo que nos permita rastrear o trazar la ejecución de los métodos de cualquier clase mezclada en el módulo. Podríamos escribir lo siguiente:
require_relative ‘trace_calls’class Example def one(arg) puts “One called with #{arg}” endend
ex1 = Example.newex1.one(“Hello”) # no trazar para esta llamada
class Example include TraceCalls
7 También busca para /^find_or_(initialize|create)_by_(.*)/.

354
def two(arg1, arg2) arg1 + arg2 endend
ex1.one(“Goodbye”) # pero veamos el traceo de estas dosputs ex1.two(4, 5)
produce:
One called with Hello==> calling one with [“Goodbye”]One called with Goodbye<== one returned nil==> calling two with [4, 5]<== two returned 99
Podemos ver de inmediato que hay una sutileza aquí. Cuando mezclamos el módulo TraceCalls en una clase, tiene que añadir el traceo para cualquier método de instancia existente en esa clase. También tiene que hacer arreglos para añadir el traceo de los métodos que se añadan posteriormente.
Vamos a empezar con el listado completo del módulo TraceCalls:
module TraceCalls
def self.included(klass) klass.instance_methods(false).each do |existing_method| wrap(klass, existing_method) end def klass.method_added(method) # note: definición anidada unless @trace_calls_internal @trace_calls_internal = true TraceCalls.wrap(self, method) @trace_calls_internal = false end end end
def self.wrap(klass, method) klass.instance_eval do method_object = instance_method(method)
define_method(method) do |*args, &block| puts “==> calling #{method} with #{args.inspect}” result = method_object.bind(self).call(*args, &block) puts “<== #{method} returned #{result.inspect}” result end end endend
Al incluir este módulo en una clase, se invoca al método gancho included. En primer lugar, utiliza el método de reflexión instance_methods para encontrar todos los métodos de instancia existentes en la clase anfitriona (el parámetro false límita la lista a los métodos en la propia clase, y no en sus supercla-ses). Para cada método existente, el módulo llama a un método de ayuda, wrap, para añadirle algo de código de traceo. Vamos a hablar de wrap en breve.
A continuación, el método included utiliza otro gancho, method_added. Este es llamado por Ruby

355
cuando se define un método en el receptor. Hay que tener en cuenta que se define este método en la clase que se pasa al método included. Esto significa que el método será llamado cuando los métodos son añadidos a esta clase anfitriona y no en el módulo. Esto es lo que nos permite incluir TraceCalls al principio de una clase y luego añadir los métodos de esa clase --todas las definiciones método serán manejadas por method_added.
Ahora observe el código dentro del método method_added. Tenemos que lidiar con un potencial pro-blema. Como se ve cuando nos fijamos en el método wrap, se añade el seguimiento de un método crean-do una nueva versión del método que llama al antiguo. Dentro de method_added, se llama a la función wrap para añadir este trazado. Pero dentro de wrap, vamos a definir un nuevo método para manejar este envoltorio y la definición va a invocar al method_added otra vez, y entonces se llama de nuevo a wrap y así sucesivamente, hasta que la pila se agote. Para evitar esto, se utiliza una variable de instancia y se hace el envoltorio sólo si no lo hemos echo ya.
El método wrap toma un objeto de clase y el nombre de un método a envolver. Busca la definición original de este método (con instance_method) y lo guarda. A continuación, redefine este método. Este nuevo método produce salidas de trazado y luego llama al original, pasandole los parámetros y el bloque desde el envoltorio8. Fíjese en cómo se llama al método vinculando el método objeto a la instancia actual y luego invocando ese método vinculado.
La clave para entender este código y la mayoría de código de metaprogramación, es seguir los princi-pios básicos que hemos elaborado al comienzo de este capítulo --como self cambia como se llama a los métodos y se definen las clases y cómo se llama a los métodos mediante su búsqueda en la clase del re-ceptor. Si se queda atascado, haga lo que hacemos nosotros y dibuje pequeñas cajas y flechas. Creemos que es útil seguir con la convención que se utiliza en este capítulo: los vínculos de clase van a la derecha y los vínculos de superclase arriba. Dado un objeto, una llamada a método es entonces una cuestión de encontrar el objeto receptor. Se va a la derecha una vez y luego siguiendo la cadena de superclase hacia arriba es por dónde tiene que ir.
Entorno de Ejecución de Nivel Superior
Por último, hay un pequeño detalle que tenemos que cubrir para completar el entorno de la metaprogra-mación. Muchas veces en este libro hemos afirmado que todo en Ruby es un objeto. Sin embargo, hemos utilizado una y otra vez lo que parece contradecir esto --el entorno de ejecución de alto nivel de Ruby:
puts “Hola, Mundo”
No hay objeto a la vista. Nosotros, bien podríamos haber escrito alguna variante de Fortran o Basic. Sin em-bargo, cavando más profundo, nos econtraremos con objetos y clases que acechan en el más simple código.
Sabemos que el literal “Hola, Mundo” genera un String de Ruby, por lo que es un objeto. También sabemos que la pelada llamada al método puts es efectivamente lo mismo que self.puts. Pero, ¿qué es self?
self.class # => Object
En el nivel superior, estamos ejecutando el código en el contexto de algún objeto predeterminado. Cuando definimos los métodos, en realidad estamos creando (privadamente) métodos de instancia para la clase Object. Esto es bastante sutil, ya que como están en la clase Object, estos métodos están dispo-nibles en todas partes. Y ya que estamos en el contexto de Object, podemos utilizar todos los métodos de Object (incluidos los mixtos desde Kernel) en forma de función. Esto explica por qué podemos llamar a métodos Kernel tales como puts en el nivel superior (y de hecho a lo largo de todo Ruby), y es porque estos métodos son parte de cada objeto. Las variables de instancia de nivel superior también incumben a este objeto de nivel superior.
La metaprogramación es una de los más agudas herramientas de Ruby. No hay que tener miedo de usarla para elevar el nivel en que se programa. Pero al mismo tiempo, hay que usarla sólo cuando sea ne-cesario --demasiadas aplicaciones metaprogramadas pueden llegar a ser bastante oscuras rápidamente.
8 La capacidad de un bloque de tomar un parámetro de bloque fue introducido en Ruby 1.9.

356
El Progama de Gráficos Tortuga
#---# Excerpted from “Programming Ruby 1.9”,# published by The Pragmatic Bookshelf.# Copyrights apply to this code. It may not be used to create training material, # courses, books, articles, and the like. Contact us if you are in doubt.# We make no guarantees that this code is fit for any purpose. # Visit http://www.pragmaticprogrammer.com/titles/ruby3 for more book information.#---
class Turtle # directions: 0 = E, 1 = S, 2 = W, 3 = N # axis: 0 = x, 1 = y def initialize @board = Hash.new(“ “) @x = @y = 0 @direction = 0 pen_up end
def pen_up @pen_down = false end
def pen_down @pen_down = true mark_current_location end
def forward(n=1) n.times { move } end
def left @direction -= 1 @direction = 3 if @direction < 0 end
def right @direction += 1 @direction = 0 if @direction > 3 end
def walk(&block) instance_eval(&block) end
def draw min_x, max_x = @board.keys.map{|x,y| x}.minmax min_y, max_y = @board.keys.map{|x,y| y}.minmax min_y.upto(max_y) do |y| min_x.upto(max_x) do |x| print @board[[x,y]] end puts end end private

357
def move increment = @direction > 1 ? -1 : 1 if @direction.even? @x += increment else @y += increment end mark_current_location end
def mark_current_location @board[[@x,@y]] = “#” if @pen_down endend
turtle = Turtle.newturtle.walk do 3.times do forward(8) pen_down 4.times do forward(4) left end pen_up endendturtle.draw
produce:
##### ##### ###### # # # # ## # # # # ## # # # # ###### ##### #####