e.t.s. ingenierÍa informÁtica departamento de ciencias...
TRANSCRIPT

UNIVERSIDAD DE GRANADA E.T.S. INGENIERÍA INFORMÁTICA
Departamento de
Ciencias de la Computación e Inteligencia Artificial
TESIS DOCTORAL
Ramón Alberto Carrasco González
Granada, Junio de 2003


Lenguajes e Interfaces de Alto Nivel para Data Mining
con Aplicación Práctica a Entornos Financieros
memoria que presenta
Ramón Alberto Carrasco González
para optar al grado de
Doctor en Informática
Junio de 2003
Finalmente leída el 29 Septiembre de 2003 obteniendo la calificación de Sobresaliente-Cum Laude por unanimidad
DIRECTORA
María Amparo Vila Miranda
DEPARTAMENTO DE CIENCIAS DE LA COMPUTACIÓN E INTELIGENCIA ARTIFICIAL
E.T.S. INGENIERÍA INFORMÁTICA UNIVERSIDAD DE GRANADA


La memoria titulada “Lenguajes e Interfaces de Alto Nivel para Data Mining con Aplicación Práctica a Entornos Financieros”, que presenta D. Ramón Alberto Carrasco González para optar al grado de Doctor, ha sido realizada en el Departamento de Ciencias de la Computación e Inteligencia Artificial de la Universidad de Granada bajo la dirección de la Doctora María Amparo Vila Miranda.
Granada, junio de 2003.
El Doctorando El Director
Fdo. Ramón Alberto Carrasco González Fdo. María Amparo Vila Miranda


Agradecimientos y dedicatorias Desde estas líneas quiero agradecer a la directora de este trabajo María Amparo Vila la confianza en mí depositada y su apoyo constante. A los miembros del grupo de investigación Idbis, especialmente a José Galindo por la infinita colaboración prestada. Al matemático Jesús Salvador Álvarez por la ayuda en algunas formulaciones, aunque por otro lado sea un bayesiano recalcitrante. Al experto informático-bursátil Antonio Caba por su gran ayuda en la aplicación del análisis técnico bursátil. A Ignacio Requena por su ayuda con la aplicación de Redes Neuronales Artificiales. Al Gobierno Español y la Caja General de Ahorros por su colaboración en los proyectos de investigación TIC-1997-0931 (Diseño de una Herramienta para la Explotación de Bases de Datos, basada en Técnicas de Computación Flexible), TIC-2001-3321-C03-01 (Knowledge-based Intelligent Miner, un Sistema Inteligente para la Minería de Datos), y CICYT TIC-2002-04021-C02-02 (Fuzzy Knowledge-based Intelligent Miner, un Sistema Inteligente Difuso para la Minería de Datos). Quiero dedicar este trabajo a toda mi familia en el sentido amplio, y en el sentido menos amplio a Álvaro y Darío a los que pido disculpas por tantas tardes de “consola” (yo de ordenador y ellos de “con-sola” mente mi presencia “virtual”). Por último mi dedicación más especial es para María de los Ángeles que además de ser mi esposa he tenido la suerte de que es un gran documentalista.

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 1
Índice General CAPÍTULO 1 INTRODUCCIÓN ........................................................................................................ 11
CAPÍTULO 2 DATA MINING EN BASES DE DATOS RELACIONALES................................... 17 2.1 DATA MINING COMO ÁREA INDEPENDIENTE .................................................................................. 18
2.1.1 Técnicas de Data Mining.......................................................................................................... 20 2.1.1.1 Extracción de reglas de asociación................................................................................................. 20 2.1.1.2 Generalización de datos a nivel múltiple, resumen y caracterización............................................. 21 2.1.1.3 Clustering....................................................................................................................................... 21
2.1.1.3.1 Métodos particionales ............................................................................................................... 24 2.1.1.3.2 Métodos jerárquicos.................................................................................................................. 25 2.1.1.3.3 Métodos basados en densidad ................................................................................................... 25 2.1.1.3.4 Métodos basados en rejillas (grid) ............................................................................................ 26
2.1.1.4 Clasificación................................................................................................................................... 26 2.2 APLICACIONES PRÁCTICAS DE DATA MINING: UNA VISIÓN EMPRESARIAL ..................................... 28
2.2.1 Requerimientos y problemas en aplicaciones prácticas ........................................................... 28 2.2.2 Un marco adecuado para Data Mining: Data Warehouse....................................................... 29 2.2.3 Aplicaciones representativas relacionadas con el sector financiero........................................ 30
2.2.3.1 Marketing....................................................................................................................................... 30 2.2.3.1.1 Identificación de los mejores segmentos de mercado con “Nuggets” ....................................... 30 2.2.3.1.2 Segmentación de clientes en entidades financieras realizadas con “DataEngine” .................... 31
2.2.3.2 Estudio de características de usuarios de tarjetas en distintos puntos de venta por “Ultragem©”.. 32 2.2.3.3 Neovista© ...................................................................................................................................... 33 2.2.3.4 Inversiones financieras................................................................................................................... 35 2.2.3.5 Detección de fraude........................................................................................................................ 35
CAPÍTULO 3 MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA........................................................................ 37
3.1 MODELO RELACIONAL CLÁSICO ..................................................................................................... 39 3.1.1 Estructura e integridad de los datos......................................................................................... 39 3.1.2 Manipulación de los datos........................................................................................................ 40
3.1.2.1 Álgebra Relacional......................................................................................................................... 40 3.1.2.2 Cálculo Relacional ......................................................................................................................... 41
3.2 TEORÍA DE CONJUNTOS DIFUSOS ................................................................................................... 44 3.2.1 Conjuntos Difusos..................................................................................................................... 45 3.2.2 Conceptos sobre Conjuntos Difusos ......................................................................................... 47 3.2.3 Operaciones sobre Conjuntos Difusos ..................................................................................... 49
3.2.3.1 Unión e intersección....................................................................................................................... 50 3.2.3.2 Complemento o negación............................................................................................................... 54
3.2.4 Números difusos ....................................................................................................................... 54 3.2.4.1 El principio de extensión (Extension Principle) ............................................................................. 56 3.2.4.2 Aritmética difusa............................................................................................................................ 57
3.2.5 Teoría de la Posibilidad ........................................................................................................... 58 3.3 MODELO RELACIONAL DIFUSO ....................................................................................................... 59
3.3.1 Aproximaciones que no emplean la Lógica Difusa .................................................................. 59 3.3.1.1 Aproximación de Codd .................................................................................................................. 59 3.3.1.2 Otras aproximaciones..................................................................................................................... 59
3.3.2 Modelo básico de bases de datos.............................................................................................. 60 3.3.3 Modelo de Buckles y Petry ....................................................................................................... 60 3.3.4 Modelo de Prade y Testemale................................................................................................... 61 3.3.5 Modelo de Umano y Fukami..................................................................................................... 61 3.3.6 Modelo de Zemankova y Kaendel............................................................................................. 62

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 2
3.3.7 Modelo Generalizado para Bases de Datos Relacionales Difusas (GEFRED)........................ 62 3.3.7.1 Representación de datos imprecisos............................................................................................... 63 3.3.7.2 Manejo de datos imprecisos ........................................................................................................... 65
3.4 IMPLEMENTACIÓN DE BASES DE DATOS DIFUSAS: FIRST ............................................................... 67 3.4.1 Representación de información imprecisa ............................................................................... 69
3.4.1.1 Datos difusos o con tratamiento difuso .......................................................................................... 70 3.4.1.2 Comparadores difusos generalizados ............................................................................................. 75
3.4.2 Base de Metaconocimiento Difuso (FMB)................................................................................ 77 3.4.3 Lenguaje SQL difuso (FSQL): consulta imprecisa................................................................... 78 3.4.4 Arquitectura cliente-servidor de FSQL .................................................................................... 80
3.4.4.1 Datos: base de datos tradicional y FMB......................................................................................... 81 3.4.4.2 Servidor FSQL ............................................................................................................................... 81 3.4.4.3 Cliente FSQL ................................................................................................................................. 82 3.4.4.4 Funcionamiento del cliente-servidor de FSQL............................................................................... 82
3.4.5 Comparativa de GEFRED con respecto a su implementación FIRST ..................................... 85 3.4.5.1 Dominios susceptibles de ser tratados ............................................................................................ 85 3.4.5.2 Comparadores difusos que contemplan.......................................................................................... 86
CAPÍTULO 4 AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS ................................................................................................................ 87
4.1 AMPLIACIÓN DEL MODELO GENERALIZADO PARA BASES DE DATOS RELACIONALES DIFUSAS PARA EL MANEJO DE MÚLTIPLES TIPOS DE DATOS: GEFRED*............................................................................... 89 4.2 ADAPTACIÓN DE FIRST AL MODELO GENERALIZADO PARA BASES DE DATOS RELACIONALES DIFUSAS PARA EL MANEJO DE MÚLTIPLES TIPOS DE DATOS: FIRST*............................................................ 93
4.2.1 Representación de la información con tratamiento difuso en la base de datos........................ 95 4.2.1.1 Datos difusos o con tratamiento difuso .......................................................................................... 95 4.2.1.2 Comparadores difusos generalizados complejos ............................................................................ 96
4.2.1.2.1 Restrictividad de los comparadores difusos en FIRST*............................................................ 97 4.2.2 Base de Metaconocimiento Difuso* (FMB*)............................................................................ 97 4.2.3 Repercusiones de FIRST* en el lenguaje SQL difuso (FSQL).................................................104 4.2.4 Arquitectura cliente-servidor de FSQL en FIRST* .................................................................107
4.2.4.1 Datos y funciones de comparación difusas: base de datos Tradicional y FMB*...........................108 4.2.4.2 Servidor FSQL* ............................................................................................................................108 4.2.4.3 Funcionamiento del cliente-servidor de FSQL*............................................................................109
4.2.5 Ejemplos definiciones de nuevos tipos de datos difusos en el modelo FIRST* ......................111 4.2.5.1 Redefinición de los comparadores difusos para referenciales ordenados de FIRST usando Redes Neuronales Artificiales.......................................................................................................................................111 4.2.5.2 Medidas de similitud sobre referenciales ordenados y binarios ....................................................115
4.2.5.2.1 Medidas de similitud sobre referenciales ordenados crisps......................................................116 4.2.5.2.1.1 Modelos basados en medidas de distancia .........................................................................117 4.2.5.2.1.2 Modelos basados en medidas de correlación .....................................................................119
4.2.5.2.2 Medidas de similitud sobre Conjuntos Difusos........................................................................120 4.2.5.2.3 Medidas de similitud sobre dominios binarios.........................................................................122
4.2.5.3 Tratamiento impreciso de cadenas de caracteres y aplicación a identificación de personas..........124 4.2.6 Comparativa del modelo propuesto.........................................................................................129
CAPÍTULO 5 AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING .........................131 5.1 APLICACIÓN DE TÉCNICAS DE DATA MINING DENTRO DEL ÁMBITO DE FIRST* ...........................133
5.1.1 Clustering ................................................................................................................................133 5.1.1.1 Preliminares ..................................................................................................................................133
5.1.1.1.1 Notaciones básicas y definiciones............................................................................................133 5.1.1.1.2 Un proceso de clustering jerárquico. Dendrograma .................................................................135 5.1.1.1.3 Determinación de la partición óptima absoluta ........................................................................139 5.1.1.1.4 Selección de “buenas” particiones a partir de la matriz de distancias mediante la medida H3 .140
5.1.1.2 Clustering en FIRST* ...................................................................................................................143 5.1.2 Caracterización .......................................................................................................................146
5.1.2.1 Etiqueta lingüística........................................................................................................................147 5.1.2.2 Valor conocido..............................................................................................................................148 5.1.2.3 Valor medio...................................................................................................................................149

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 3
5.1.3 Clasificación difusa .................................................................................................................153 5.1.3.1 Clasificación difusa basada en centroides .....................................................................................154 5.1.3.2 Clasificación difusa basada en los k vecinos más cercanos ...........................................................157
5.1.4 Dependencias globales difusas................................................................................................158 5.1.4.1 Dependencias funcionales difusas y dependencias funcionales graduales ....................................159 5.1.4.2 Dependencias globales difusas en FIRST* ...................................................................................162
5.1.4.2.1 Definición de dependencias globales difusas con los operadores de FSQL .............................162 5.1.4.2.2 Obtención de dependencias globales difusas con FSQL ..........................................................164
5.2 ESQUEMA GENERAL DE DMFIRST.................................................................................................172 5.3 BASE DE METACONOCIMIENTO DIFUSO PARA DATA MINING (DMFMB).......................................175 5.4 LENGUAJE FSQL PARA DATA MINING (DMFSQL) .......................................................................180
5.4.1 Una visión de los lenguajes para Data Mining existentes.......................................................180 5.4.2 Sintaxis de dmFSQL ................................................................................................................181 5.4.3 Lenguaje de Definición de Datos (DDL) de dmFSQL.............................................................187
5.4.3.1 CREATE_MINING ......................................................................................................................187 5.4.3.2 ALTER_MINING.........................................................................................................................191 5.4.3.3 DROP_MINING ...........................................................................................................................192 5.4.3.4 GRANT_MINING ........................................................................................................................192 5.4.3.5 REVOKE_MINING......................................................................................................................193
5.4.4 Lenguaje de Manipulación de Datos (DML) de dmFSQL.......................................................193 5.4.4.1 SELECT_MINING CLUSTERING..............................................................................................193 5.4.4.2 SELECT_MINING CLASSIFICATION ......................................................................................196 5.4.4.3 SELECT_MINING FGLOBAL_DEPENDENCIES.....................................................................199
CAPÍTULO 6 DMFIRST, UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES ......................................................................................................................................203
6.1 ARQUITECTURA CLIENTE-SERVIDOR DE DMFSQL.........................................................................205 6.1.1 Datos: base de datos clásica y dmFMB...................................................................................207 6.1.2 Servidor dmFSQL....................................................................................................................207 6.1.3 Funcionamiento del cliente-servidor de dmFSQL...................................................................209
6.2 IMPLEMENTACIÓN DEL SERVIDOR DMFSQL .................................................................................211 6.2.1 Proceso: CLUSTERING ..........................................................................................................212
6.2.1.1 Proceso: obtener dendrograma ......................................................................................................215 6.2.1.2 Proceso: obtener posibles α -cortes ..............................................................................................217 6.2.1.3 Proceso: obtener partición.............................................................................................................218 6.2.1.4 Proceso: obtener SELECT clustering............................................................................................221
6.2.2 Proceso: CARACTERIZACIÓN...............................................................................................221 6.2.2.1 Proceso: crear tabla centroides ......................................................................................................223 6.2.2.2 Proceso: obtener valor etiqueta .....................................................................................................224 6.2.2.3 Proceso: obtener valor conocido ...................................................................................................224 6.2.2.4 Proceso: obtener valor medio ........................................................................................................225 6.2.2.5 Proceso: obtener SELECT caracterización....................................................................................226
6.2.4 Proceso: CLASIFICACIÓN.....................................................................................................227 6.2.4.1 Proceso: crear tabla clasificación ..................................................................................................229 6.2.4.2 Proceso: clasificar según centroides..............................................................................................229 6.2.4.3 Proceso: clasificar según k-vecinos ...............................................................................................230 6.2.4.4 Proceso: obtener SELECT clasificación........................................................................................231
6.2.5 Proceso: DEPENDENCIAS GLOBALES DIFUSAS ...............................................................232 6.2.5.1 Proceso: crear tabla DGD..............................................................................................................234 6.2.5.2 Proceso: obtener DGD ..................................................................................................................234 6.2.5.3 Proceso: obtener SELECT DGD...................................................................................................240
6.3 ALGUNAS APLICACIONES PRÁCTICAS DE DATA MINING EN EL ENTORNO DMFIRST .....................241 6.3.1 Identificación de patrones de ganancias bursátiles mediante análisis técnico bursátil ..........241
6.3.1.1 Identificación de escenarios de ganancias .....................................................................................243 6.3.1.2 Agrupamiento y descripción de las características de los escenarios ............................................247 6.3.1.3 Estrategia de compra-venta basándose en la clasificación de los valores históricos .....................253
6.3.2 Estudios sobre la distribución de trabajadores en las empresas de economía social .............265 CONCLUSIONES Y LÍNEAS FUTURAS..................................................................................................271

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 4
BIBLIOGRAFÍA .......................................................................................................................................275

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 5
Índice de Tablas Tabla 2-1. Algunos hitos en el estudio del problema del clustering................................................................. 23 Tabla 2-2. Ejemplo de los centros de cluster normalizados para c=5 clusters................................................ 32 Tabla 3-1. tipos de T-normas ........................................................................................................................... 52 Tabla 3-2. tipos de T-conormas........................................................................................................................ 53 Tabla 3-3. Tipos de datos que puede representar GEFRED............................................................................ 63 Tabla 3-4. Representación interna de Atributos Difusos Tipo 2 ...................................................................... 75 Tabla 3-5. Representación interna de Atributos Difusos Tipo 3 ...................................................................... 75 Tabla 3-6. Definición de Comparadores Difusos para Atributos Difusos de Tipo 2 ....................................... 76 Tabla 3-7. Comparadores difusos .................................................................................................................... 79 Tabla 3-8. Constantes difusas .......................................................................................................................... 80 Tabla 3-9. Comparativa de los dominios soportados en GEFRED y FIRST ................................................... 86 Tabla 4-1. Restrictividad de los comparadores difusos en FIRST* ................................................................. 97 Tabla 4-2. Constantes difusas para tipos difusos 4 en FSQL..........................................................................105 Tabla 4-3. Comparativa de los dominios soportados en GEFRED, FIRST, GEFRED* y FIRST*.................130

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 6
Índice de Definiciones Definición 3-1. Conjunto Difuso ...................................................................................................................... 45 Definición 3-2. Igualdad de Conjuntos Difusos ............................................................................................... 47 Definición 3-3. Inclusión de un conjunto difuso en otro .................................................................................. 47 Definición 3-4. Soporte de un conjunto difuso ................................................................................................. 47 Definición 3-5. α -corte de un conjunto difuso ................................................................................................ 48 Definición 3-6. Teorema de representación ..................................................................................................... 48 Definición 3-7. Conjunto difuso convexo ......................................................................................................... 48 Definición 3-8. Núcleo (Kernel) de un conjunto difuso.................................................................................... 49 Definición 3-9. Altura (Height) de un conjunto difuso ..................................................................................... 49 Definición 3-10. Conjunto difuso normalizado ................................................................................................ 49 Definición 3-11. Norma Triangular o T-norma ............................................................................................... 50 Definición 3-12. Conorma Triangular o T-conorma........................................................................................ 50 Definición 3-13. Extensión de la ley de Morgan .............................................................................................. 53 Definición 3-14. Función de pertenencia de la unión de dos Conjuntos Difusos............................................. 53 Definición 3-15. Función de pertenencia de la intersección de dos Conjuntos Difusos .................................. 53 Definición 3-16. Negación fuerte ..................................................................................................................... 54 Definición 3-17. Número difuso ....................................................................................................................... 54 Definición 3-18. Principio de extensión ........................................................................................................... 56 Definición 3-19. Distribución de posibilidad ................................................................................................... 58 Definición 3-20. Relación Difusa ..................................................................................................................... 60 Definición 3-21. Relación de Similitud............................................................................................................. 61 Definición 3-22. Dominio Difuso Generalizado............................................................................................... 63 Definición 3-23. Relación Difusa Generalizada .............................................................................................. 63 Definición 3-24. Comparador Extendido ......................................................................................................... 64 Definición 3-25. Comparador Difuso Generalizado ........................................................................................ 64 Definición 3-26. Proyección Difusa Generalizada........................................................................................... 65 Definición 3-27. Selección Difusa Generalizada ............................................................................................. 65 Definición 4-1. Dominio Complejo .................................................................................................................. 89 Definición 4-2. Dominio Difuso Generalizado Complejo ................................................................................ 89 Definición 4-3. Relación Difusa Generalizada Compleja ................................................................................ 90 Definición 4-4. Comparador Extendido Complejo........................................................................................... 90 Definición 4-5. Comparador Difuso Generalizado Complejo.......................................................................... 90 Definición 4-6. Proyección Difusa Generalizada Compleja ............................................................................ 91 Definición 4-7. Selección Difusa Generalizada Compleja ............................................................................... 91 Definición 5-1. Función distancia ...................................................................................................................134 Definición 5-2. Función similitud....................................................................................................................135 Definición 5-3. Jerarquía de partes ................................................................................................................136 Definición 5-4. Clustering jerárquico .............................................................................................................137 Definición 5-5. Relación de similitud difusa ...................................................................................................140 Definición 5-6. Dependencias funcionales ......................................................................................................159 Definición 5-7. α -β dependencia funcional difusa.......................................................................................160 Definición 5-8. Confianza de una dependencia funcional difusa ....................................................................160 Definición 5-9. Soporte de una dependencia funcional difusa ........................................................................161 Definición 5-10. α -β dependencia funcional gradual ..................................................................................161 Definición 5-11. (α i)-(β j) dependencia global difusa...................................................................................162 Definición 5-12. α -β dependencia global difusa..........................................................................................162 Definición 5-13. (α i)-(β j) dependencia funcional difusa ..............................................................................163

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 7
Definición 5-14. α -β dependencia funcional difusa.....................................................................................163 Definición 5-15. (α i)-(β j) dependencia funcional gradual ...........................................................................163 Definición 5-16. α -β dependencia funcional gradual ..................................................................................163

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 8
Índice de Figuras Figura 2-1. Dendrograma ………………………………………………………………………………………………..22 Figura 3-1. Etiquetas lingüísticas sobre edad……………………………………………………………...………….45 Figura 3-2. α-corte en un trapecio………………………………………………………………………………………46 Figura 3-3. Conjunto difuso convexo y no convexo .…………………………………………………………………47 Figura 3-4. Ejemplo: Unión e intersección de conjuntos difusos .……………………………………………….…48 Figura 3-5. Número difuso general………………………………… .…………………………………………………53 Figura 3-6. Esquema general de FIRST…………………………… .…………………………………………………65 Figura 3-7. Representación trapezoidal de una distribución de posibilidad…………………………………….. 67 Figura 3-8. Representación triangular de una distribución de posibilidad……………………………………….68 Figura 3-9. Distribución intervalar de una distribución de posibilidad …………………………………………..68 Figura 3-10. Distribuciones de posibilidad de los valores Unknown y Undefined……………………………….69 Figura 3 11. Ejemplo de tipo difuso 1 en FIRST………………………………………………………………………70 Figura 3 12. Ejemplo de tipo difuso 2 en FIRST………………………………………………………………………70 Figura 3-13. Ejemplo de tipo difuso 3 en FIRST……………………………………………………………………. 71 Figura 3-14.Distribuciones de posibilidad trapezoidales A y B.. .……………………………………………….…73 Figura 3-15. Esquema relacional de la FMB…………………… .……………………………………………...……74 Figura 3-16. Arquitectura básica para la BDRD con el Servidor FSQL ….………………………………………81 Figura 4-1. Esquema General de FIRST……………………………………….………………………………………91 Figura 4-2. Esquema relacional de la FMB*…………………………………….……………………………………96 Figura 4-3. Arquitectura básica para la BDRD con el Servidor FSQL* ….………………………………….…107 Figura 4-4. Caso conflictivo en la comparación de números difusos… ….…………………………………….. 109 Figura 5-1. Dendrograma sobre D' ……………………………………… ….……………………………………... 134 Figura 5 2. Cuantificador difuso most.………………………………………………………………………………..159 Figura 5-3. Consulta FSQL de Paso 1.1 da como resultado 3………… ….……………………………………...162 Figura 5-4. Consulta FSQL de Paso 1.2 da como resultado 4………… ….……………………………………...162 Figura 5-5. Etiquetas lingüísticas sobre tamaño y comportamiento… ….……………………………………….164 Figura 5-6. Sentencia FSQL verifica DGD(tamaño)→ (NFGT)*(NFGEQ)*(comportamiento)…...…..…….165 Figura 5-7. Sentencia FSQL verifica DGD(tamaño)→ (NFGT)*(NFGT)*(comportamiento)…....………….165 Figura 5-8. Esquema general de dmFIRST……………………………………………………....………………….167 Figura 5-9. Esquema relacional de la dmFMB………………………………………………....…………………. 173 Figura 6 1. Arquitectura básica para servidor dmFSQL.………………………………………………………….200 Figura 6 2. DFD Clustering………………………………………………………………………………………… . 208 Figura 6 3. DFD Caracterización……………………….…………………………………………………………....216 Figura 6 4. DFD Clasificación………………………………………………………………………………………..222 Figura 6 5. DFD Dependencias Globales Difusas………………………………………………………………….227 Figura 6 6. Escenario 1 de las acciones de Telefónica S.A………………………………………………………..238 Figura 6 7. Escenario 2 de las acciones de Telefónica S.A………………………………………………………..239 Figura 6 8. Escenario 3 de las acciones de Telefónica.…………………………………………………………….240 Figura 6 9. Etiquetas lingüísticas sobre el atributo williams.……………………………………………………..242 Figura 6-10. Sentencia dmFSQL para clustering y caracterización en FQ …………………………....……….243 Figura 6-11.SQL devuelto tras ejecución instrucción de clustering……………………………..……....……….244 Figura 6-12 Resultado del proceso de clustering y caracterización en FQ …………………………....……….245 Figura 6-13. Sentencia dmFSQL para validar clasificación basada en centroides…………………....……….248 Figura 6-14. Sentencia dmFSQL para validar clasificación basada en k-vecinos.…………………....……….250 Figura 6-15. Sentencia dmFSQL para clasificar según centroides contra el cluster 3……….……....……….252 Figura 6-16. SQL generado para la clasificación (visualizado en FQ)………………………………....……….253 Figura 6-17. Sentencia dmFSQL para clasificar según centroides contra el cluster 9.……………....……….255 Figura 6-18. Sentencia dmFSQL para obtención de DGD con confianza máxima…………………....……….261 Figura 6-19. Resultado obtención de DGD con confianza máxima……… …………………………....………..262

ÍNDICES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 9
Figura 6-20. SQL generado tras la obtención de las DGD (FQ)…………..…………………………....………..262 Figura 6-21. Sentencia dmFSQL para obtención de la DGD……………… …………………………....……….263 Figura 6-22 Resultado obtención de DGD (FQ)…………………………………………………………....……….264


CAPÍTULO 1- INTRODUCCIÓN
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 11
Capítulo 1 INTRODUCCIÓN
En las últimas décadas se está viviendo un aumento en el volumen de las bases de datos empresariales sin precedentes, propiciado tanto, por el avance tecnológico en los sistemas informáticos como por, el abaratamiento del precio de los mismos. Paradójicamente, este aumento exponencial en la información almacenada no acarrea un aumento, en similar proporción, de la información de interés que las empresas obtienen de sus datos almacenados. La razón hay que buscarla en el hecho que los Sistemas de Gestión de Base de Datos (SGBD) tradicionales no proporcionan herramientas adecuadas para la explotación de esta cantidad ingente de datos.
Es en este contexto en el que ha surgido el Data Mining (Minería de Datos) término
que se ha acuñado por analogía al proceso que hacen los mineros para cribar grandes cantidades de aluviones y obtener el oro. La búsqueda de “El Dorado” ahora consiste en la obtención de esta información, hasta ahora imperceptible, y que ayudará sin duda a la toma de decisiones dentro del ámbito empresarial.
Más formalmente, se puede definir Data Mining (DM en adelante) como el proceso de extracción de información de interés a partir de los datos, entendiendo que un conocimiento descubierto es de interés cuando es novedoso, potencialmente útil y de un cálculo no trivial. Entre finales de los 70 y principios de los 80 no era fácil encontrar aplicaciones de DM sobre bases de datos reales. Dentro de esos sistemas pioneros se encuentra MetaDendral, desarrollado Bachanan y Mitchell en 1978 y cuya aplicación es el descubrimiento de reglas de espectrometría. Actualmente los dominios que abarca las aplicaciones reales de DM se han ampliado enormemente, estando el sector financiero a la vanguardia en lo referente a la aplicación de dichas técnicas, aunque, para mantener ventajas respecto a la competencia, difícilmente se publican detalles profundos sobre ellas. De este modo, hoy día existen aplicaciones de DM dentro del sector financiero dirigidas a seleccionar clientes potenciales a

CAPÍTULO 1- INTRODUCCIÓN
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 12
los que enfocar la política comercial de la empresa (marketing directo) o mantener a los clientes actuales mediante un trato más directo, como el proyecto desarrollado por la empresa MIT (Management Intelligenter Technologien GmbH). Existen, así mismo, multitud de aplicaciones que gestionan inversiones financieras, así la firma LBS Capital Management usa un sistema desde 1993 compuesto de sistemas expertos, redes neuronales y algoritmos genéticos para gestionar carteras de 600 millones de dólares. Otro uso capital de DM, es la detección de fraude, como la aplicación FALCON de HNC Inc. que utiliza redes neuronales y es usada por muchos bancos para detectar transacciones de tarjetas de crédito sospechosas, o el sistema FAIS (Financial Crimes Enforcement Network AI System) de US Treasury’s que ayuda a identificar transacciones financieras que pueden tener como objetivo el blanqueo de dinero. También es posible encontrar sistemas que usan DM para predecir el prepago las hipotecas por parte de los clientes, como es el desarrollado por Mitchell Madison Group.
A pesar de, como se ha visto, la amplia aplicación de DM que existe ya hoy día, hay que tener en cuenta que se está ante una tecnología nueva, objeto de constante investigación. Bajo esta perspectiva, para que el proceso de implantación de una sistema de DM sea exitoso, ha de hacerse bajo una serie de requisitos como la existencia en la empresa de una verdadera necesidad de descubrir conocimiento (que no se quiera usar DM por el simple hecho de “estar a la última”), el contar el proyecto como un soporte organizativo suficiente y entusiasta, la disposición de datos suficientes y fiables (deseablemente incluidos en sus sistema Data Warehouse), etc.
Por otro lado, en dicha implantación práctica de DM aún hoy perdura un problema dual: técnico y humano. Dentro del primero estaría el que la mayoría de las herramientas de DM existentes no son adecuadas, en el sentido de no soportar muchas de las técnicas de descubrimiento, no ser operativas con grandes cantidades de datos (esto es, resuelven la escalabilidad pero solo hasta cierto punto) o proporcionar interfaces no amigables a usuarios de empresas. El problema humano proviene de la insuficiente preparación de los usuarios. Los usuarios técnicos de las empresas suelen estar familiarizados con los análisis dirigidos a la verificación, ocasionalmente con los modelos predictivos, pero raramente con otras técnicas de descubrimiento, por lo que, su capacidad de descubrir se encuentra muy limitada. De forma genérica las características deseables de un sistema de DM son [Fra91]:
• Lenguaje de alto nivel. El conocimiento descubierto debe ser representado en un lenguaje de alto nivel que, aunque no tiene por que ser lenguaje natural, sí debe ser comprensible por los usuarios no expertos.
• Precisión. El conocimiento descubierto debería retratar de forma precisa los contenidos de la base de datos. Las imperfecciones (ruido, datos excepcionales) deberían ser expresadas con medidas de incertidumbre.
• Eficiencia. El proceso de extracción de conocimiento debe ser eficiente y los tiempos de ejecución sobre grandes cantidades de datos deben ser predecibles y aceptables.
• Manejo de diferentes tipos de datos. Al existir diferentes tipos de datos y bases de datos en diversas aplicaciones (datos relacionales, objetos, hipertexto, etc) sería

CAPÍTULO 1- INTRODUCCIÓN
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 13
deseable que un sistema DM realizara su trabajo de una forma efectiva sobre esta diversidad de datos.
• Extracción de conocimiento interactivo en múltiples niveles de abstracción. El descubrimiento interactivo de conocimiento puede permitir al usuario refinar iterativamente la extracción de conocimiento, el enfoque y la profundidad del mismo. Además los datos y resultados de DM debería ser de ser posible ver en diferentes niveles de abstracción o desde diferentes ángulos.
Las bases de datos del mundo real además de, como se ha comentado, contener una cantidad ingente de información, frecuentemente son incompletas y tienen una mala calidad de datos (algunos estudios hablan del 12% de datos erróneos en las bases de datos de las entidades financieras españolas). Por otro lado, muchas veces es innecesario obtener resultados (reglas, agrupaciones, etc) con un alto grado de precisión ya que tanto las especificaciones del usuario, como los mismos datos, son imprecisos en sí. Por esta razón, en esta memoria se va a proponer técnicas de Computación Flexible (más comúnmente en ámbitos científicos, Soft Computing) que combinan la versatilidad de la Lógica Difusa para representar y gestionar los datos imprecisos con otras técnicas como las Redes Neuronales Artificiales para resolver el problema de DM de forma efectiva. El objetivo de esta memoria va a ser construir un sistema, que esté soportado en un modelo teórico, e implementarlo sobre un SGBD real de tal manera que sea posible la resolución de los problemas que se pueden considerar entran dentro del ámbito de DM. Se va a hacer especial hincapié en la resolución de problemas propios del sector financiero, aunque por otro lado, dado la diversidad de dicho sector (que incluye entre otros agencias de viajes, seguros, marketing, etc) el sistema a construir deberá tener gran versatilidad. Las características que debe tener un sistema de DM, que acaban de ser expuestas, son un objetivo implícito del sistema a construir. De forma rápida y general, se puede describir el contenido de esta memoria explicando brevemente los contenidos de los capítulos:
• Capítulo 1: El presente capítulo introduce la motivación y planteamiento del problema, los objetivos y la estructura de esta memoria.
• Capítulo 2: En este capítulo se da una visión global de DM como un conjunto de técnicas orientadas a obtener conocimiento implícito que sea de interés a partir de los datos existentes en la base de datos, explicándose las principales técnicas existentes. Posteriormente, se da una visión práctica de DM, con especial referencia al sector financiero detallando software comercial aplicado al efecto.
• Capítulo 3: Se hace una introducción a las bases de datos relacionales y a la teoría de Conjuntos Difusos, fijando las bases y notación sobre la que va a estar soportada una parte de esta memoria. Luego se incluyen los principales modelos publicados para dar solución al tratamiento de la información “imprecisa” en bases de datos relacionales, especialmente aquéllos que utilizan la teoría de Conjuntos Difusos. En particular, se centra en el modelo GEFRED, sobre el que se basa este trabajo. También se incluye un modelo de implantación práctica de GEFRED, llamado FIRST. El interface que usa para el acceso de forma flexible a los datos es el lenguaje FSQL. Sobre este modelo práctico se ha construido una arquitectura cliente-servidor de FSQL implementada

CAPÍTULO 1- INTRODUCCIÓN
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 14
sobre Oracle®. Por último, se hace una comparativa entre GEFRED y su implementación FIRST.
• Capítulo 4: Al confrontar un modelo que entra dentro del ámbito del “Soft Computing” como es GEFRED, con los problemas de DM, surge el problema de que el modelo no es lo suficientemente flexible respecto a la variedad de datos que puede tratar. La limitación es doble, por un lado en los tipos de datos que se pueden almacenar y, por otro lado, el tipo de tratamiento (comparadores difusos) que se les puede dar. Por tanto, se procede a la redefinición teórica del modelo, surgiendo, lo que se ha venido en llamar GEFRED* que salva las limitaciones expuestas. Posteriormente, se trasladan los cambios que conlleva GEFRED* a su implementación que pasa a llamarse FIRST*. La implementación práctica que se ha llevado a cabo de este nuevo modelo se expone en este capítulo. Seguidamente se hace una comparativa de todos los modelos surgidos, hasta ahora en el desarrollo de esta memoria, pudiéndose verificar la bondad del modelo aquí propuesto. Finalmente se introducen algunos ejemplos de definiciones y usos de nuevos tipos de datos dentro del ámbito de FIRST*.
• Capítulo 5: Una vez solucionado el problema de gestionar la información, cualquiera que sea su forma (independientemente de que ésta sea imprecisa y/o tenga ruido) se va a hacer, en este capítulo, un estudio de la posible utilidad de FIRST* en el marco de las distintas técnicas de DM, a saber: clustering, caracterización, clasificación difusa y de unas nuevas dependencias difusas entre atributos, aquí definidas, llamadas dependencias globales difusas. Para la resolución de todas estas técnicas se proponen soluciones novedosas. Basándose en dichas soluciones, se amplia el modelo FIRST* para que integre y optimice dichas funcionalidades propias de DM, creándose un nuevo modelo, que se va a venir en llamar, dmFIRST. Para este nuevo modelo se define un nuevo lenguaje de alto nivel, para la realización de DM, llamado dmFSQL. Dicho lenguaje aprovecha todo el potencial que da el usar los distintos tipos difusos del esquema, por lo que no tiene limitación alguna sobre los tipos de datos sobre los que pueda realizar DM. Su sintaxis es similar a la de FSQL (y por tanto SQL) y además tiene una propiedad importantísima: permitir el aplicar resultados previos en el proceso actual de DM, esto es, posibilita el proceso de DM con refinamiento iterativo.
• Capítulo 6: En este capítulo se expone una solución de arquitectura cliente-servidor para dmFSQL, con dos ejes fundamentales desarrollados, la dmFMB y el Servidor dmFSQL. A continuación, se expone la implementación hecha del Servidor dmFSQL, que ha sido ha sido desarrollado siguiendo estrictamente una metodología que entra dentro del ámbito de la Ingeniería de Software. De esta forma, el resultado final del producto no solo han sido los códigos fuente y objeto, sino también un modelo de datos y otro de procesos (que son suficientemente explicados durante este capítulo). La implementación finalmente se ha hecho en PL/SQL© de Oracle©. La decisión de usar este lenguaje ha sido motivada sopesando, sobre todo, el tema de la eficiencia (principalmente se ha conseguido haciendo uso de técnicas de paralelismo y gestión de cachés) y la integración con el Servidor FSQL. Finalmente, se propone el uso del servidor dmFSQL, ya implementado, en primer lugar, para crear un sistema de decisión de compra-venta de acciones dentro del ámbito del análisis técnico bursátil y, en segundo lugar, para un estudio aplicado a la economía social de Andalucía.

CAPÍTULO 1- INTRODUCCIÓN
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 15
Finalmente, se exponen las conclusiones obtenidas tras la realización de esta memoria, contrastando los resultados obtenidos con los objetivos iniciales de la misma. Así mismo, se incluyen una serie de líneas futuras de investigación a seguir.


CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 17
Capítulo 2 DATA MINING EN BASES DE DATOS RELACIONALES
En este capítulo primeramente se va a dar visión global de DM como un conjunto de técnicas orientadas a obtener conocimiento implícito (no explícito) que sea de interés a partir de los datos existentes en la base de datos. Se incluye una clasificación de las técnicas de DM según el tipo de conocimiento a descubrir. Además se quiere hacer notar las características que hacen de DM un campo de investigación autónomo y de interés por sí mismo, en el que se aplican técnicas de otros campos. En la segunda parte del capítulo se intenta dar una visión práctica de DM dentro del ámbito empresarial, con especial referencia al sector financiero. En este marco se estudian los requerimientos y problemas que suele tener la implantación práctica de los sistemas de DM. Parte de esos problemas se pueden evitar si la disponibilidad y el preprocesamiento de los datos ya están proporcionados, en cierta medida, dentro del marco de un sistema de Data Warehouse de la entidad. Esto hace que realmente hoy día sea casi inconcebible realizar un proceso de DM sin partir de un sistema de este tipo. Un sector que ha estado a la vanguardia de la aplicación de DM es el sector financiero, se hace un estudio de aplicaciones prácticas realizadas en este sector y dominios subyacentes como pueden ser el de inversiones financieras, detección de fraude y, especialmente, Marketing. Se detalla el software comercial usado, así como las técnicas empleadas por el mismo.

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 18
2.1 Data Mining como área independiente
Se puede definir Data Mining (Minería de Datos) como el proceso de extracción de información de interés a partir de los datos. Según [Fra91] un conocimiento descubierto es de interés cuando es novedoso, potencialmente útil y de un cálculo no trivial. A continuación se explican con más detalle estas tres características:
• Nuevo. Esta característica del conocimiento depende del marco de referencia que se tome. Así si un sistema descubre “si un cliente es culpable de un accidente entonces tiene una edad mayor de 16 años”. Para el sistema puede ser una información nueva pero para un usuario que está analizando reclamaciones de seguros es algo que es obvio.
• Útil. El conocimiento es útil cuando puede ayudar a conseguir un objetivo ya sea al sistema o al usuario. Retomando el ejemplo anterior, si el sistema descubre “si un cliente es culpable de un accidente entonces es probable que sea hombre” esta información es potencialmente útil a ese usuario y/o el sistema.
• No trivial. Un sistema se considera no trivial si el mismo posee algún grado de autonomía en el procesamiento de los datos y evaluación de los resultados. Los sistemas de base de datos convencionales son capaces de obtener información hasta ahora desconocida y de gran utilidad como por ejemplo el total de saldo en cuentas de clientes en el año 1997 pero que no puede ser considerado conocimiento ya que su cálculo estadístico se puede considerar trivial.
Existe, por tanto, un cierto consenso en diversos autores [Fra91, Che96, Vil97] en la
definición de DM como el proceso de extracción no trivial de información implícita, previamente desconocida y potencialmente útil (por ejemplo reglas de conocimiento, restricciones, regularidades, etc) a partir de los datos de una base de datos.
Se podría pensar que este campo de DM no tiene personalidad propia, esto es, está
integrado en otros como el de Sistemas de Aprendizaje, Estadística o Sistemas de Gestión de Base de Datos. Si bien es cierto que DM se aprovecha de dichas técnicas, existen una serie de nuevas funcionalidades deseables en DM que lo reafirman como un área independiente [Fra91, Che96]:
• Lenguaje de alto nivel. El conocimiento descubierto debe ser representado en un lenguaje de alto nivel que, aunque no tiene por que ser lenguaje natural, sí debe ser comprensible por los usuarios no expertos. En este sentido, cada vez son más típicos los interfaces de usuario gráficos y/o la posibilidad de representación del conocimiento de múltiples formas o vistas. Además esta característica de representación últimamente se ha ampliando no solo al conocimiento (resultado) sino también a las peticiones del mismo (entradas del usuario, como consultas, etc).
• Precisión. El conocimiento descubierto debería retratar de forma precisa los contenidos de la base de datos. Las imperfecciones (ruido, datos excepcionales) deberían ser expresadas con medidas de incertidumbre. Por otro lado, el uso de

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 19
estas medidas implica la necesidad de un estudio sistemático de las medidas de calidad del conocimiento descubierto.
• Eficiencia. El proceso de extracción de conocimiento debe ser eficiente y los tiempos de ejecución sobre grandes cantidades de datos deben ser predecibles y aceptables. Como consecuencia de esto, los algoritmos que use el sistema debe ser escalables a la gran cantidad de datos que, en definitiva, van a manejar.
En los últimos tiempos se han unido a estas características de sistemas DM otras:
• Manejo de diferentes tipos de datos. Al existir diferentes tipos de datos y base
de datos en diversas aplicaciones (datos relacionales, objetos, hipertexto, etc) sería deseable que un sistema DM realizara su trabajo de una forma efectiva sobre esta diversidad de datos. Sin embargo, parece utópico que se pueda construir un sistema que gestione todos los tipos de datos.
• Extracción de conocimiento interactivo en múltiples niveles de abstracción. El descubrimiento interactivo de conocimiento puede permitir al usuario refinar on line la extracción de conocimiento, el enfoque y la profundidad del mismo. Además los datos y resultados de DM debería ser de ser posible ver en diferentes niveles de abstracción o desde diferentes ángulos.
• Extracción de información desde diferentes fuentes de datos. Actualmente es un gran reto la extracción de conocimiento desde diferentes fuentes de datos que puedan estar formateados o no, con diversas semánticas, etc. Este problema está alentado por las cada vez más amplias y accesibles redes de ordenadores (incluyendo Internet). Como consecuencia surge la necesidad de algoritmos distribuidos y paralelos en DM.
• Protección y privacidad de datos. El ver los datos desde diferentes ángulos y niveles de abstracción puede ir en contra de la privacidad por lo que surge el tema interesante de estudios de medidas de seguridad para prevenir descubrimiento de información “sensible”. Sirva de ejemplo [Fra91] la controversia que provocó en EEUU una campaña publicitaria de tabaco que era dirigida a hombres, de raza negra y jóvenes, ya que la empresa había distinguido este perfil como el más susceptible de consumir.
Sin embargo, hay otros autores como [Imi96] que proclaman la carencia de identidad
de DM. De tal manera que los sistemas actualmente existentes son calificados como primera generación, los cuales están caracterizados por usar eficientes algoritmos de Aprendizaje Automático sobre grandes Bases de Datos soportadas por el Sistema de Gestión de Base de Datos (SGBD) existente. Por el contrario, en la segunda generación de sistemas de Data Mining la funcionalidad de descubrir conocimiento estaría completamente integrada y optimizada en el sistema, el cual pasaría a ser el Sistema de Gestión de Descubrimiento de Datos (SGDD). Parece lógico pensar que en las próximas décadas habrá una evolución hacia este tipo de sistemas. El término Data Mining (DM) se ha usado [Che96, Vil97] como equivalente a otros como Knowledge Discovery (KDD, descubrimiento de conocimiento), Knowledge mining from Databases, Knowledge extraction, Data Archaeology, Data Dredging, Data Analysis, etc. No obstante, existe cierta tendencia en los últimos tiempos a distinguir entre Data Mining y Knowledge

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 20
Discovery. Así en [Bra96] reducen el significado de Data Mining a la aplicación de procedimientos o algoritmos de conocimiento para revelar patrones y conocimiento novedoso, o para verificar hipótesis desarrolladas en etapas previas. Esto es, Data Mining estaría integrado dentro del campo de Knowledge Discovery, el cual constaría de etapas de preprocesamiento previas al Data Mining (identificación de datos y tareas; adquisición de datos en el entorno apropiado; integración y chequeo de datos; depuración de los datos; desarrollo de los modelos y las hipótesis...) y de postprocesamiento una vez que se ejecutado el Data Mining (pruebas y verificación del conocimiento descubierto; interpretación y uso de dicho conocimiento...). Una vez hechas estas puntualizaciones, decir que en este trabajo se considerará equivalentes los conceptos de Knowledge Discovery y Data Mining, usándose preferentemente este último. Se ha decido usar el término anglosajón en esta memoria, debido a su ya amplio uso dentro de las publicaciones en español, incluso en publicaciones de propósito general como EL PAIS, ABC o IDEAL.
2.1.1 Técnicas de Data Mining Existen diversas formas de clasificar las técnicas de DM, por ejemplo el tipo de base de datos sobre la que trabajan (relacional, transaccional, orientada a objetos, etc); el tipo de técnicas utilizadas (estadísticas, extracción basada en patrones en generalización, etc); y el tipo de conocimiento que va a ser extraído. Según este último criterio, que es el más usual, las técnicas de DM se dividen principalmente en [Fra91, Che96, Vil97]:
2.1.1.1 Extracción de reglas de asociación Se trata de descubrir asociaciones importantes entre los valores de conjuntos de atributos, de tal manera que la presencia de cualquier valor de algún conjunto en un elemento de la base de datos (registro, tupla, etc) implique la presencia de otro valor que pertenezca a otro conjunto. Por ejemplo, se puede descubrir en una base de datos transaccional que determinado valor de un atributo implica otro valor de un segundo atributo, en las transacciones. De esta manera, si la base de datos es de ventas de artículos de camping, un sistema puede llegar a descubrir que las personas que compran un saco de dormir suelen adquirir también una tienda de campaña. Estos procesos de extracción de reglas pueden suponer el estudio repetitivo de grandes Bases de Datos (por ejemplo, como ya se ha visto, transaccionales) con el objeto de encontrar diferentes patrones de asociación por lo que son necesarios algoritmos muy eficientes. Como ejemplos de algoritmos se tienen los populares Apriori, DHP y PARTITION. Existen también algoritmos sobre base de datos distribuidas como DMA [Che96b].

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 21
2.1.1.2 Generalización de datos a nivel múltiple, resumen y caracterización Estas herramientas de análisis y extracción de datos son las más extendidas, esto es, existen muchos productos comerciales que las soportan. La generación y resumen de datos muestra las características generales o una vista resumida de alto nivel sobre un conjunto de datos (de bajo nivel) especificados por el usuario dentro una base de datos. Frecuentemente es deseable presentar vistas generalizadas de los datos en múltiples niveles de abstracción. Existen dos enfoques de generalización principales:
• El enfoque del cubo. La idea general es materializar ciertos cálculos costosos que se piden con frecuencia, especialmente aquéllos que implican funciones de agregación (sumas, medias, desviación típica, etc) y almacenar estas vistas materializadas en una base de datos multidimensional que se denomina cubo de datos. Estas vistas pueden servir para soporte de decisión, descubrir conocimiento, o cualquier otra aplicación. Las funciones de agregación pueden ser precalculadas agrupándolas por diferentes conjuntos de atributos. Este enfoque tiene algunos nombre alternativos, así como algunas variantes como pueden ser “Bases de Datos multidimensionales”, “vistas materializadas” y OLAP (On-Line Analytical Processing).
• El enfoque orientado a la inducción de atributos. Se puede considerar a este enfoque como una generalización del anterior donde la consulta usada es más general que una simple cláusula de agrupamiento. El núcleo de esta técnica es el uso de una filosofía on-line en la que la generalización de datos se realiza conforme a las distribuciones de valores de atributos en un conjunto concreto de datos relevantes. Se obtiene una relación generalizada o cubo (definitivo o temporal) que puede ser usada para obtener más conocimiento interesante en un proceso de DM interactivo.
2.1.1.3 Clustering El término clustering suele traducirse en español como agrupamiento o segmentación aunque, por otro lado, vuelve a ser un término anglosajón que es ampliamente usado en las publicaciones científicas en español. En el ámbito de la Inteligencia Artificial, el clustering es la técnica de identificación de patrones de interés dentro de los llamados “algoritmos de descubrimiento” [Fraw91]. De forma breve, consiste en categorizar o agrupar registros en subclases (o clusters siguiendo con la terminología anglosajona) que reflejen patrones inherentes a los datos. Son métodos muy tradicionales que provienen de la Taxonomía Matemática. La idea básica consiste en definir algún tipo de “distancia” entre los elementos de la base de datos usando algunos de sus atributos y obtener grupos de elementos maximizando la distancia entre los distintos grupos y minimizándola entre los elementos de un mismo grupo. Las distancias usadas frecuentemente son no euclídeas e incluso no son distancias en el sentido matemático sino que

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 22
son medidas de “semejanza”. En la sección 5.1.1.1 se incluye la formalización matemática del problema del clustering.
En la tabla Tabla 2-1 se pueden observar alguno de los hitos importantes en el estudio del clustering [Gow88, Che96, Hal01]. En los últimos tiempos se está asistiendo a una continua mejora y adaptaciones de los algoritmos clásicos de tal manera que sean más eficientes de cara a la gestión de grandes cantidades de datos, estos es, para su aplicación para DM.
Año Autores Campo
Aplicación Metodología
1957 Sneath Bacteriología Análisis de Cluster Jerárquico1958 Sokal & Michener Entomología Análisis de Cluster Jerárquico1959 Williams & Lambert Ecología Análisis de Cluster Jerárquico1962 Shepard Psicometría Escalado no métrico 1963 Ward Estadística Análisis de Cluster Jerárquico1963 Sokal & Sneath Taxonomía Taxonomía Numérica 1964 Kruskal Psicometría Escalado no métrico 1967 Lance & Williams Computación Clustering Flexible 1969 Sammon Electrónica Mapeo no linear 1970 Wolfe Estadística Mezcla Normal 1970 Carrol & Chang Psicometría Escalado individual 1971 Cormack Estadística Clustering (análisis) 1971 Gabriel Estadística Biplots 1971 Jardine & Sibson Estadística Taxonomía Matemática 1971 Fisher & Van Ness Estadística Admisibilidad 1973 Gordon Biometría Clustering restringido 1973 Benzécri Estadística Análisis de los hechos 1974 Hiss Estadística Análisis de correspondencias 1974 Gower Biometría Clasificación Predictiva
Maximal 1975 Hartigan Estadística Algoritmos de Clustering 1980 Payne & Preece Estadística Claves de Diagnóstico
(análisis) 1981 Bezdek Estadística/
Informática Fuzzy c-means
1983 1984 1985
Bad Windsheim Meeting Journal of Classification Federation
1984 Michalski & Stepp Informática Clustering Conceptual 1995 Data mining CLARANS (Clustering Large
ApplicationsBased upon Randomized)
1996 Data Mining BIRCH – Algoritmo basado en Clustering Jerárquico
1998 Data Mining CURE – Algoritmo basado

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 23
en Clustering Jerárquico 1999 Data Mining ROCK – Algoritmo basado
en Clustering Jerárquico
Tabla 2-1. Algunos hitos en el estudio del problema del clustering
Existen diversos criterios por los se puede categorizar los distintos métodos de clustering:
• Tipos de variables que pueden gestionar: o Estadísticos: gestionan tipos de datos numéricos, en esta categoría se pueden
englobar prácticamente la totalidad de todos los algoritmos de clustering clásicos.
o Conceptuales: gestionan datos categóricos. Los métodos de clustering clásicos tienen el inconveniente de no poder usar alguna información adicional que se pueda tener como, por ejemplo, la forma de los grupos. El clustering conceptual [Mic84] intenta evitar tales problemas. Estos métodos trabajan con datos estructurados (por ejemplo bases de datos espaciales) y determinan los grupos no solo por la similitud entre atributos sino que también por la coherencia conceptual.
• Teoría usada para la extracción de los clusters: o Crisps: los elementos pertenecen a un solo grupo a la vez siguiendo la teoría
de conjuntos clásica. o Difusos: los elementos pueden pertenecer a varios grupos con cierto grado de
pertenencia, mediante el uso de la teoría de Conjuntos Difusos (ver 3.2). • Técnica usada para la definición de los grupos o clusters:
o Particionales. o Jerárquicos. o Basados en densidad. o Basados en rejilla (grid).
A continuación se expone con más detalle este último tipo de categorización:

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 24
2.1.1.3.1 Métodos particionales
Estos métodos descomponen el conjunto de datos en un conjunto de c grupos disjuntos. Así la definición del problema podría ser la siguiente: dado un número entero c encontrar una partición de c grupos que optimice un determinado criterio de partición. El algoritmos de clustering más populares de este tipo es el llamado c-means (c-medias) el cual caracteriza cada grupo con los valores centrales de cada una de las características (atributos) usadas en el proceso. Existen diversas variantes a este método que difieren en: la selección inicial de los c centros, los cálculos de la disimilitud y estrategias para el cálculo de los centros de los clusters. También se han hecho versiones del algoritmo que permiten trabajar con datos conceptuales (y no solo con datos numéricos) como el c-modes (c-modas) pero, quizás, la versión más importante es la variante difusa Fuzzy c-means [Bez81].
Dis
tanc
ia u
ltram
étric
a
Agrupamiento de los 6 elementos5 6 3 4 2 1
1
2
3
4
5
6
7
0
Figura 2-1. Dendrograma
Aglomerativo
Divisivo

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 25
Otro algoritmo importante de este tipo es PAM (Partitioning Around Medoids) o una versión mejorada llamada CLARA (Clustering Large Applications) que se puede aplicar a grandes bases de datos, basándose en el uso de un conjunto de ejemplos, esto, por otro lado, presenta el problema de que la eficiencia depende del conjunto de ejemplos elegido y que el resultado final también depende de la bondad del muestreo elegido. El algoritmo CLARANS (Clustering Large Applications Based upon Randomized) está basado en dos algoritmos anteriores (PAM y CLARA) siendo más eficiente y escalable que ambos.
2.1.1.3.2 Métodos jerárquicos
En la sección 5.1.1.1.2 se hace un planteamiento teórico de un proceso de clustering jerárquico. En general, estos métodos pueden ser de dos tipos:
• Los métodos jerárquicos aglomerativos son métodos de tipo ascendente. Partiendo de un agrupamiento para cada patrón del conjunto de entrenamiento, van combinando los agrupamientos más cercanos hasta que se cumpla algún criterio de parada. El proceso de agrupamiento, cuando se realiza en una única dimensión, se puede dibujar mediante un dendrograma como el de la Figura 2-1, donde la flecha indica la evolución del método de agrupamiento aglomerativo.
• A diferencia de los métodos aglomerativos, los métodos jerárquicos divisivos son de tipo descendente. Comenzando con un único agrupamiento que contiene todos los patrones del conjunto de entrenamiento, se va dividiendo este agrupamiento hasta que se verifique el criterio de parada del algoritmo. En este caso, el dendrograma de la Figura 2-1 se construiría de arriba hacia abajo tal y como índica la flecha correspondiente.
Entra las últimas tendencias de este tipo de algoritmos se encuentra BIRCH (Balanced Interative Reducing and Clustering) el cual hace uso de los llamados “árboles CF” (Clustering Feature) que son unas estructuras jerárquicas para un proceso de clustering en múltiples fases, es un algoritmo bastante eficiente aunque tiene los inconvenientes de gestionar solo tipos de datos numéricos y de ser sensible al orden en que se traten los datos de la base de datos. Otro algoritmo de este tipo es CURE (Clustering Use REpresentatives) el cual usa una representación de los grupos con múltiples puntos a la hora de obtener la distancia entre los mismos, tiene el problema de que hay que determinar a priori el número de grupos a obtener y de que solo gestiona datos numéricos. Dicho problema es subsanado por el algoritmo ROCK (Clustering Categorical Data) que maneja datos categóricos y booleanos de tal manera que une en el mismo grupo los vecinos más cercanos según una función de similitud.
2.1.1.3.3 Métodos basados en densidad
Genéricamente los dos métodos estudiados anteriormente tienen los inconvenientes de que consideran solo un punto como el representativo del grupo (centroide); de que su comportamiento es bueno ante formas convexas de similar tamaño y densidad; y de que frecuentemente hay que determinar a priori el número de grupos a obtener. Los métodos de clustering basados en densidad usan criterios locales a los grupos tales como la densidad de

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 26
conexión de los puntos. Esto hace que puedan descubrir grupos con formas arbitrarias y de poder manejar ruido, aunque por otro lado necesitan parámetros sobre la densidad para implementar la condición de parada del algoritmo. Como algoritmo representativo de este tipo está DBSCAN (Density-Based Clustering: Background) en donde un grupo se define como un conjunto maximal de puntos conectados desde el punto de vista de la densidad, de esta forma descubre grupos de forma aleatoria en bases de datos con ruido. Otro algoritmo es DENCLUE que usa celdas de rejilla manteniendo información de aquellas celdas que contienen actualmente puntos, la idea en la que se basa es modelar la media de la densidad del espacio de datos como la suma de funciones de influencia de todos los puntos del mismo.
2.1.1.3.4 Métodos basados en rejillas (grid)
Este tipo de métodos en primer lugar emplaza el espacio de datos en un número finito de celdas, que son la base para las operaciones posteriores que llevan a la conclusión del proceso de clustering. Como algoritmo interesante que usa este método se tiene STING (a STatistical INformation Grid Approach) el cual divide el espacio en celdas que contienen información estadística (media, varianza…) de cada característica numérica de los objetos que la integran, estas celdas conforman una estructura jerárquica llamado rejilla (grid) de tal manera que se representa la información del proceso de proceso de clustering en diferentes niveles, así es bastante eficiente la asignación de un nuevo elementos a la celda correspondiente. Otro algoritmo de este tipo es WaveCluster que está indicando para grandes bases de datos aunque no puede trabajar con espacios de muchas dimensiones.
2.1.1.4 Clasificación La clasificación es la segunda parte dentro de los “algoritmos de descubrimiento” [Fra91], ya que no es suficiente obtener un conjunto de grupos (clustering) sino que también es necesario “describirlos” por medio de las variables usadas. Es más, el verdadero objetivo es obtener un proceso de clasificación que permita incluir cada nuevo elemento en el correspondiente grupo conforme a los valores de sus atributos. Cualquier algoritmo de aprendizaje supervisado pretende construir un modelo de clasificación a partir de un conjunto de datos de entrada, denominado conjunto de entrenamiento, que contiene algunos ejemplos de cada una de las clases que se pretende modelar. Los casos del conjunto de entrenamiento incluyen, además de la clase a la que corresponden, una serie de atributos o características que se utilizarán para construir un modelo abstracto de clasificación. El objetivo del aprendizaje supervisado es la obtención de una descripción precisa para cada clase utilizando los atributos incluidos en el conjunto de entrenamiento. A continuación se expone formalmente el problema de la clasificación [Ber02]:

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 27
Supuesto que todos los ejemplos que el modelo construido ha de reconocer son elementos potenciales de J clases distintas denotadas ω j, se denota el conjunto de las clases como sigue Ω=ω j / j=1..J En determinadas ocasiones se extiende con una clase de rechazo ω 0 a la que se asigna todos aquellos casos para los que no se tiene una certeza aceptable de ser clasificados correctamente en alguna de las clases de Ω. De este modo, se denota como sigue al conjunto extendido de clases Ω* = Ω ∪ ω 0 Un clasificador o regla de clasificación es una función d: P → Ω* definida sobre el conjunto de posibles ejemplos P tal que para todo ejemplo X se verifica que d(X) ∈ Ω*. Haciendo uso de la teoría de los Conjuntos Difusos (ver 3.2¡Error! No se encuentra el origen de la referencia.) esta pertenencia podría ser con cierto grado con lo cual se estaría ante un problema de clasificación difusa.
La clasificación ha sido ampliamente estudiada en el contexto de sistemas de aprendizaje, pudiéndose encontrar numerosos ejemplos de algoritmos de aprendizaje automático, como los empleados en la construcción de árboles de decisión (como C4.5 o CART) o los que siguen la metodología STAR de Michalski (INDUCE o AQ, por ejemplo). Una de las técnicas de clasificación que más éxito han tenido en DM es la llamada “sistema de aprendizaje ID-3”. También se han intentado otros enfoques como los basados en redes neuronales, estadísticos y basados en conjuntos rough.

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 28
2.2 Aplicaciones prácticas de Data Mining: una visión empresarial
Entre finales de los 70 y principios de los 80 no era fácil encontrar aplicaciones de DM sobre Bases de Datos reales. Como ejemplos de sistemas se puede citar MetaDendral, aplicado al descubrimiento de reglas de espectrometría, Bachanan y Mitchell 1978); reglas de diagnóstico para la enfermedad de la soja (Michalski y Chilausky, 1980); y efectos de medicamentos en una base de datos de pacientes (Blum, 1982). Hoy día los dominios que abarca las aplicaciones reales de DM se han ampliado enormemente alcanzando sectores como el financiero, marketing, medicina, agricultura, seguros, ingenierías, física, química, militar, investigación espacial, estudios sociales, telecomunicaciones, etc.
2.2.1 Requerimientos y problemas en aplicaciones prácticas
A pesar de, como se ha visto, la amplia aplicación de DM que existe ya hoy día, hay que tener en cuenta que se está ante una tecnología nueva, bajo constante investigación. Por tanto, a la hora de elegir una aplicación práctica, de descubrir conocimiento en una base de datos, es importante seleccionarla cuidadosamente para asegurarse el éxito. En [Fra91] se exponen la siguiente secuencia de requerimientos para efectuar dicha elección (aunque por supuesto éstos pueden variar según el tipo de aplicación de que se trate):
1. Necesidad de la empresa de descubrir conocimiento. Deberían existir muchos patrones desconocidos en los datos que no son fácilmente hallables mediante el uso de técnicas estadísticas convencionales, además debería de existir alguna medida de los beneficios del conocimiento descubierto.
2. Disposición de datos suficientes y fiables. Se debe tener disponible un número mínimo de ejemplos (en [Fraw91] se proponen al menos 1000) fiables, esto es, con una proporción de ruido y datos incompletos relativamente baja. La mayoría de los campos relevantes para el conocimiento deberían estar almacenados en la base de datos, así por ejemplo, difícilmente se podrá extraer los clientes potenciales para planes de jubilación si no se tiene información sobre la edad, ingresos, etc.
3. Soporte organizativo para el proyecto. Debería haber un apoyo entusiasta e influyente en la organización donde se va a aplicar.
4. Tener un significativo, aunque insuficiente dominio del conocimiento. Sería deseable tener especificaciones del usuario como jerarquías de los códigos de los valores de los campos, reglas sobre los posibles valores de los mismos, etc. Dichas especificaciones, por supuesto, deben de estar codificadas de tal manera que sean manejables por la aplicación.
Las aplicaciones prácticas de DM también suelen tener una serie de problemas, más o
menos genéricos, entre los que se pueden encontrar [Fra91]:

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 29
• Herramientas inadecuadas. La mayoría de las herramientas solo soportan una de las técnicas de descubrimiento como es la predicción, en detrimento de otras como clustering, detección de desviaciones, etc. Las herramientas deberían soportar el proceso de DM completo (preprocesamiento, descubrimiento de conocimiento y posprocesamiento del mismo) y proporcionar un interface orientado a usuarios de empresas. Por otro lado, muchas de las actuales herramientas son inoperativas con grandes cantidades de datos, es decir, resuelven el problema de la escalabilidad pero solo hasta cierto punto.
• Problemas de Datos: indisponibilidad, variabilidad y complejidad. Existen muchas empresas donde los datos están distribuidos por toda la corporación en una diversidad de formas, mal organizados y mantenidos. El preprocesamiento de la información juega aquí por tanto un papel fundamental, como se verá en el siguiente apartado, el Data Warehouse puede aliviar en gran medida este problema. Por otro lado, existen aplicaciones que tratan de descubrir comportamientos variantes en el tiempo (por ejemplo fluctuaciones de mercados) en los que los que se estrellan muchos de los algoritmos orientados a trabajar con ficheros planos, por lo que se han desarrollado métodos de DM específicos para estos problemas. El manejo de muchos de los tipos de datos complejos almacenados hoy en multitud de base de datos (vídeo, audio, HTML, XML, etc) sigue siendo un gran reto para el DM.
• Exceso de patrones. Si la búsqueda de patrones se hace en un ámbito amplio puede provocar el descubrir un cantidad excesiva de patrones. Esto se puede evitar usando métodos de generalización, como el enfocar la búsqueda con el conocimiento previo que se tenga o adquirido por el sistema.
• Insuficiente preparación de los usuarios. Los usuarios técnicos de las empresas suelen estar familiarizados con los análisis dirigidos a la verificación, ocasionalmente con los modelos predictivos, pero raramente con otras técnicas de descubrimiento.
2.2.2 Un marco adecuado para Data Mining: Data Warehouse Cada vez es más frecuente en las empresas la implantación de sistemas Data Warehouse que permiten tener una visión corporativa, global de los datos independientemente de donde se obtengan. Data Warehouse consiste en un repositorio que selecciona los datos desde muchas fuentes de datos operacionales. La relación que se establece entre Data Warehouse y DM puede calificarse de simbiótica de tal manera que aquél proporciona el marco adecuado para que éste pueda efectuarse de forma tanto exitosa como eficiente. Esto implica que, cada vez más, surjan técnicas de DM orientadas específicamente a entornos con Data Warehouse [Aki98, Est98].
A continuación se detallan las características de sistemas Data Warehouse que son susceptibles de mejorar la aplicación de DM [Inm96]:

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 30
• Datos integrados: Sin esta característica habría que hacer un gran esfuerzo en depuración y acondicionamiento de los datos (reconstruir claves, estandarizar estructuras, etc) antes de empezar el proceso de extracción de conocimiento en sí.
• Datos detallados y resumidos: Los datos detallados son necesarios cuando dentro de DM se desea examinar los datos en su forma más granular, ya que, los bajos niveles de detalle pueden ocultar patrones importantes. Los datos resumidos evitan a DM tener que repetir análisis de este estilo.
• Datos históricos: Estos tipos de datos suelen ocultar valiosa información expresada, por ejemplo en forma de tendencias o patrones de comportamiento.
• Metadatos: Tan importante como el contenido de los datos, puede ser para DM el contexto en que se encuentran los mismos, esto es, el significado de dichos datos.
Como se ha visto, el preprocesamiento, la extracción de conocimiento y el procesamiento
del mismo forman el marco global de DM. Por lo tanto, si se aplica éste sobre sistemas Data Warehouse ese preprocesamiento estarán en gran medida ya soportado por el sistema (ateniéndonos a las características descritas) permitiendo a DM centrarse en las otras dos fases del proceso.
2.2.3 Aplicaciones representativas relacionadas con el sector financiero
El sector financiero/bancario, ampliamente automatizado desde hace bastante tiempo, ha estado a la vanguardia en lo referente a la aplicación de técnicas de DM. La mayoría de las aplicaciones y prototipos desarrollados tiene un enfoque de modelo predictivo, aunque también se usan otros tipos de modelos.
El sector financiero, cada vez más, se ha diversificado abarcando diversos dominios. De este modo, hoy día existen aplicaciones de DM dentro del sector financiero, correspondientes a Marketing, Inversiones Financieras, Detección de Fraude, etc. A continuación se exponen más detalladamente:
2.2.3.1 Marketing
La mayoría de las aplicaciones de Marketing caen dentro de una extensa área llamada base de datos de Marketing. Básicamente dicha área consiste en el uso de técnicas como consultas interactivas, segmentación, y modelos predictivos para seleccionar clientes potenciales a los que enfocar la política comercial de la empresa (marketing directo). Como ejemplos de aplicaciones se tienen las que siguen:
2.2.3.1.1 Identificación de los mejores segmentos de mercado con “Nuggets”
Nuggets© es una herramienta para DM que usa el producto software SiftAgent© una metodología de inducción de reglas que revela relaciones entre datos tanto numéricos como no

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 31
numéricos (tipo texto), además es capaz de trabajar con información incompleta y/o con ruido.
Nuggets es aplicable a un amplia rango de aplicaciones, dentro del área de Marketing destaca su uso para identificar los mejores segmentos del mercado y predecir el éxito de un determinado producto.
Su funcionamiento es como sigue:
• La entrada a Nuggets SiftAgent es un fichero de ejemplos con los datos ya preparados (extraído de una o más base de datos, posiblemente obtenido a partir de un sistema Data Warehouse) a partir del cual el sistema genera automáticamente las reglas (del tipo “if...then”).
• Estas reglas pasan a formar parte de una librería de reglas que está basada, por lo tanto, en la “experiencia” contenida en la base de datos que se está examinando.
• El usuario puede manualmente inspeccionar las reglas generadas, ejecutar consultas contra ellas, o aplicar las reglas seleccionadas a nuevos datos proporcionando predicciones y previsiones (para esto se usa la librería anteriormente mencionada).
2.2.3.1.2 Segmentación de clientes en entidades financieras realizadas con “DataEngine”
DataEngine es una herramienta software desarrollada por la empresa alemana MIT
(Management Intelligenter Technologien GmbH). Incorpora métodos convencionales (estadísticos, procesamiento de señales) y tecnología más innovadoras (enfoque basado en reglas difusas, clustering difuso, redes neuronales, y sistemas neuro-difusos) para la realización de DM y análisis de datos en conjuntos extensos de datos. Entre las aplicaciones realizadas con DataEngine se encuentra un proyecto de segmentación difusa de clientes para una entidad financiera [Web96]. Usando técnicas de segmentación difusa construye grupos de clientes homogéneos en lo referente a las características de los clientes pertenecientes al mismo grupo y heterogéneos entre los de distintos grupos. En particular, usa el algoritmo c-means (c-medias) que asigna objetos (clientes) descritos por varias características a distintas clases difusas, esto es, los objetos pertenecen a cada clase con diferente grado. De forma genérica el funcionamiento del sistema consta de las siguientes etapas:
• Selección de las características relevantes de los clientes a partir de los datos proporcionados por la entidad financiera. Esta etapa tiene una importancia crucial pues determina el criterio que se va a seguir para los agrupamientos. Las características seleccionadas deben de cumplir algunos requerimientos: tener el suficiente potencial discriminatorio, no estar correladas, ser cuantificables (para la aplicación de métodos matemáticos) y tener un nivel de escala similar. Por ejemplo, los atributos relevantes de la base de datos podría ser: edad, ingresos, crédito y saldo.

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 32
• Preprocesamiento de los datos. El sistema por correlación estadística valida la independencia de los atributos elegidos y que no existan atributos con excesivo peso a la hora de hacer el proceso de segmentación.
• Normalización. Como cada atributo puede tener un dominio distinto se normalizan los dominios al intervalo [0,1] para hacer posible la comparación entre atributos y evitar diferentes pesos de las características en el proceso de segmentación.
• Segmentación. Una vez determinados los parámetros para los algoritmos de segmentación fuzzy c-means, así como para fuzzy Kohonen se va variando el número de grupos (cluster) entre 2 y 10 realizando el análisis de datos, esto es, calculando los valores de pertenencia de cada cliente a cada grupo y obteniendo los valores centrales (centroides) de los atributos de cada grupo, quedando así estos grupos caracterizados. Por ejemplo, véase la Tabla 3-1.
• Validación de los grupos. Como se ha visto en el punto anterior, la solución propuesta no es única, esto es, se han propuesto distinto número de grupos. Pues bien, mediante medidas de validación se determina el mejor número de grupos que puede ser encontrado en el problema en concreto.
• Verificación. Por medio de entrevistas con los usuarios expertos de la entidad financiera, implicados en el proyecto, se verifican los resultados del proceso de segmentación.
Grupo Edad Ingresos Crédito Saldo A 0.225 0.804 0.544 0.453 B 0.356 0.183 0.124 0.123 C 0.377 0.592 0.342 0.453 D 0.438 0.250 0.423 0.236 E 0.618 0.125 0.983 0.053
Tabla 2-2. Ejemplo de los centros de cluster normalizados para c=5 clusters
2.2.3.2 Estudio de características de usuarios de tarjetas en distintos puntos de venta por “Ultragem©”
Ultragem© es una compañía especializada en la realización de DM mediante tecnología
basada en DM genético, el cual consiste en la extracción automática de reglas de predicción y clasificación a partir de base de datos usando algoritmos genéticos. La primera vez que la empresa aplicó dicha tecnología fue en una entidad financiera, posteriormente se amplió el campo de uso estas técnicas.
Como aplicación en el área de Marketing, se encuentra un proyecto cuyo propósito era descubrir las características de usuarios de un determinado tipo de tarjeta (ATM) en los distintos puntos de venta como pueden ser un supermercado o una gasolinera. Algunas personas nunca usaban la tarjeta en los puntos de venta, otros usaban sus tarjetas solo un par de veces al mes, también había quienes la usaban frecuentemente. Por otro lado, existían

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 33
usuarios que eran quienes más beneficios proporcionaban a la entidad financiera promotora de la tarjeta y por lo tanto su identificación es de vital importancia para la dicha entidad.
Mediante el uso de tecnología DM genético se construyó modelos de predicción para varios niveles de uso de la tarjeta, basándose en parámetros tales como edad de cliente, saldo medio de su cuenta corriente, saldo medio de los cheques cargados por mes, etc. Por medio de este modelo, la entidad financiera es capaz de dirigir campañas promocionales a determinados clientes ajustados al perfil de “uso más frecuente de la tarjeta”.
A continuación se expone la forma en que Ultragem© realiza el DM:
• El proceso parte de una base de datos que contiene tanto los parámetros de entrada relevantes como las respuestas correctas. Este campo respuesta es esencial para el entrenamiento y evaluación del sistema de clasificación.
• En la fase de entrenamiento se usan parte de los datos (por ejemplo 2/3 de los registros de la base de datos) como entrada al sistema de DM, a estos datos se les llama conjunto de entrenamiento. A partir de los mismos se obtiene un conjunto de reglas de clasificación.
• La siguiente es la fase de test, en donde se prueba el conjunto de reglas obtenido con el resto de los datos (siguiendo con el ejemplo anterior, respecto al 1/3 restante de los registros de la base de datos) que es el llamado conjunto de test. Una medida usual de la efectividad de las reglas de clasificación es el ratio de error (número de clasificaciones incorrectas partido por el número total de clasificaciones). Por otro lado las reglas que más se usan proporcionan una mayor calidad de visión.
• El producto final es un conjunto de reglas de clasificación de alta efectividad. Las reglas son del tipo if...then, usándose en el consecuente un valor probabilístico. Cada regla define una subpoblación en el conjunto de los registros. Normalmente se generan de 10 a 20 reglas que cubren todas las posibilidades. Se puede dar el caso que dos reglas se disparen para la misma instancia (esto es, para un registro en concreto). En esta situación las probabilidades se promedian (enfoque del “escrutinio” o de la “segunda opinión”)
2.2.3.3 Neovista©
La empresa Neovista© ha desarrollado un conjunto de herramientas integradas llamado Decision Series para la consecución de descubrimiento inductivo de patrones y relaciones en Bases de Datos comerciales.
A continuación se detallan cada uno de los componentes de Decision Series (con poca información sobre los algoritmos usados, pues Neovista no la facilita) así como sus aplicaciones potenciales en Marketing:
• DecisionNet©. Utiliza en redes neuronales (una tecnología llamada HIDRA) obtiene, por tanto, las predicciones basándose en la experiencias pasadas (datos históricos en el Data Warehouse). La aplicación en el mailing directo consistiría en predecir quién responderá a una determinada campaña, basándose en anteriores

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 34
campañas de mailing. Otra aplicación comercial puede ser encontrar los productos susceptibles de ser consumidos por un cliente.
• DecisionCL©. Usa técnicas de clustering, que son las más indicadas para encontrar grupos dentro de una población que son similares. Los grupos pueden ser fijados previamente por el usuario (clustering supervisado) o ser determinados por el sistema (clustering no supervisado). Permite el uso de medidas de diferencia tanto tradicionales (Euclídea, Manhattan) como más avanzadas, incluyendo DecisionNet para predecir si dos elementos son iguales. Se puede usar en el mailing directo encontrando grupos que muestren un patrón similar de respuesta.
• DecisionGA©. Basado en algoritmos genéticos, por consiguiente es bastante apropiado cuando se quiere obtener perfiles potenciales basándose en modelos bastante poco definidos. Su aplicación dentro del Marketing podría ser para encontrar el perfil óptimo del cliente ideal para invertir una cierta cantidad por año en una fundación.
• DecisionAR©. Es un sistema que se sirve de las reglas de asociación para determinar la esperanza de que determinados eventos sucedan en el mismo instante de tiempo o seguidos de una progresión lógica de tiempo. Estos patrones normalmente se expresan como porcentajes. Una aplicación para Marketing podría ser el encontrar la esperanza de que los clientes que han ingresado una determinada cantidad de dinero en su cuenta tras una campaña de promoción ingresen esa misma cantidad pasado un mes.
Neovista© no proporciona facilidades con OLAP, en su lugar integran su sistema
mediante un interface llamado DecisionAccess, el cual proporciona conversiones entre la base de datos relacional (Informix©, Oracle©, Sysbase©, Teradata©) y las herramientas de descubrimiento de patrones vistas. DecisionAccess usa un fichero de definición de datos que describe la tabla relacional, tipos de datos de las columnas y requerimientos de conversión. Mediante el uso de esta meta-información, DecisionAccess puede leer las tablas y transformarlas en una entrada vectorizada para las herramientas de descubrimiento. Una vez terminado dicho proceso de descubrimiento el resultado usa el mismo fichero de definición de datos para trasformar los datos obtenidos en tablas relacionales.
Aunque aquí se han expuesto por separado, Neovista afirma que muchas aplicaciones son susceptibles de usar varias de estas herramientas de Decision Series simultáneamente para mejorar el entorno de DM de la empresa. Así por ejemplo, se considera una entidad financiera que quiere determinar las características de una campaña mailing directo para promoción de un determinado producto. En dicha entidad se dispone de un sistema Data Warehouse en el que hay información sobre el comportamiento de contrataciones previas del mismo producto. Pues bien, el analista financiero podría realizar los siguientes estudios:
• Determinar el perfil teórico de una prospección que podría tener un 70% de probabilidad de responder positivamente a la campaña de mailing. Este estudio podría usar un algoritmo genético para generar los perfiles de los clientes, y una vez conseguido, mediante una red neuronal se podría predecir la esperanza de que el perfil teórico pueda contratar el producto en cuestión. Este proceso iteraría hasta encontrar un perfil que determine una prospección con el umbral de probabilidad de responder positivamente indicado.

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 35
• Determinar en la base de datos de la empresa qué clientes son más similares a un perfil teórico encontrado. Esta etapa podría incluir un clustering de los clientes para agruparlos en grupos similares y entonces comparar estos grupos con el perfil teórico usando una red neuronal que determine qué clientes tiene más probabilidad de responder positivamente al mailing.
• Determinar los 10 factores asociativos que contribuyan más significativamente a la esperanza de respuesta positiva dentro del perfil ideal del cliente, mediante el uso de la herramienta de reglas de asociación.
2.2.3.4 Inversiones financieras
Existen muchas aplicaciones para análisis financiero que usan técnicas de modelos predictivos (por ejemplo regresión estadística y redes neuronales) para tareas como elegir y optimizar carteras de valores y crear modelos de mercado. Como norma general, en este tipo de modelos, se da más importancia a la precisión de la predicción que a la necesidad de la extracción de conocimiento para explicar dicha decisión.
A pesar de que, como se ha dicho, hay multitud de aplicaciones que gestionan inversiones financieras, para mantener ventajas respecto a la competencia, difícilmente se publican detalles profundos sobre ellas. Hecha esta salvedad a continuación se detallan algunos ejemplos:
• La fundación Fidelity Stock Selector usa modelos de redes neuronales para la selección de inversiones. Las decisiones de este modelo son evaluadas por técnicos de la fundación antes de adoptarlas, así no está claro en qué porcentaje ha participado la máquina en la decisión.
• La firma LBS Capital Management usa un sistema desde 1993 compuesto de sistemas expertos, redes neuronales y algoritmos genéticos para gestionar carteras de 600 millones de dólares.
• Carlberg & Associates desarrolló un modelo de redes neuronales para la predicción del índice “Standard & Poor’s 500 Index”, mediante el uso de ratios de interés, ganancias, dividendos, índice del dólar y precios del petróleo. El modelo tuvo un sorprendente éxito explicando el 96% de la variación del índice desde 1986 a 1995.
2.2.3.5 Detección de fraude
Al igual que ocurría en las aplicaciones de inversiones financieras, tanto los usuarios como los desarrolladores de este tipo de aplicaciones de detección de fraude, como es obvio, son reacios a su publicación.
Como ejemplos se pueden mencionar:
• La aplicación FALCON de HNC Inc. Utiliza redes neuronales y es usada por muchos bancos para detectar transacciones de tarjetas de crédito sospechosas.

CAPÍTULO 2- DATA MINING EN BASES DE DATOS RELACIONALES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 36
• El sistema FAIS (Financial Crimes Enforcement Network AI System) de U.S. Treasury’s Financial Crimes Enforcement Network ayuda a identificar transacciones financieras que pueden tener como objetivo el blanqueo de dinero. FAIS se encuentra con el problema de la calidad de los datos pues muchos de los mismos proviene de manuscritos (formularios goburnamentales, etc). Este sistema consiste en una combinación de componentes estándares y otros menos convencionales, y tiene una expansión potencial por las agencias de gobierno de muchos países.
• Predicción de fraude en cuentas de nueva a apertura, por parte de la empresa Ultragem©. Usando algoritmos genéticos se obtienen un conjunto de reglas que predicen la probabilidad de que una nueva cuenta sea fraudulenta. Estas probabilidades se usan para ordenar las cuentas de tal manera que aquellas cuya probabilidad sea más alta sufren una investigación por parte de los técnicos especialista en fraude de la entidad financiera.
• Predicción de préstamos fraudulentos, de la empresa Ultragem©. Otra vez mediante algoritmos genéticos se obtiene un conjunto de reglas para predecir la probabilidad de que un préstamo resulte fraudulento en los próximos 12 meses, basándose en la información de la cuenta, características demográficas del cliente y en indicadores económicos. El propósito del proyecto consiste en obtener una más clara visión de las circunstancias de este tipo de préstamos y también el de dotar de formas más precisa las correspondientes reservas para estos casos.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 37
Capítulo 3 MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
La evolución de las bases de datos comenzó con el uso, de forma elemental, de ficheros secuenciales. Con el tiempo, se fueron creando aplicaciones para estos ficheros y fueron surgiendo diversos problemas, como son la eficiencia en la recuperación de información, la redundancia, seguridad... Así, nacieron los primeros Sistemas Gestores de Bases de Datos (SGBD o DBMS, DataBase Management Systems), como programas encargados de gestionar el almacenamiento y recuperación de la información, teniendo en cuenta los aspectos y problemas que esto plantea. La arquitectura ANSI/SPARC data de 1978 y en ella se propone la división de un SGBD en tres niveles: El nivel interno, el nivel conceptual y el nivel externo. El nivel interno es el más cercano a la parte física del SGBD, y se encarga de cómo y dónde son almacenados físicamente los datos. El nivel conceptual se encarga de organizar las relaciones existentes entre los datos, describiendo las entidades, atributos, relaciones, tipos de datos, operaciones básicas y restricciones de la base de datos global. El nivel externo es el más cercano al usuario y se encarga de describir una parte de la base de datos para un usuario o grupo de usuarios particular, escondiendo el resto de la base de datos y evitando el acceso de los usuarios a información privada. Estos tres niveles son muy importantes en todos los SGBD, pero quizás el más relevante de ellos sea el nivel conceptual. Originariamente, el nivel conceptual permite la utilización de tipos de datos elementales a los que se llamará “crisp” (en contraposición a los

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 38
tipos difusos que se verán más adelante). Estos tipos de datos son, por ejemplo, datos numéricos (básicamente naturales, enteros y reales con distinta precisión), datos alfanuméricos (cadenas de caracteres de distinta longitud) y datos binarios (como ficheros de imágenes, sonido...). Además, un SGBD debe incorporar un conjunto de operaciones básicas sobre la base de datos para, por ejemplo, insertar, modificar, borrar o consultar información. De estas, las más importantes y usuales serán aquellas destinadas a la consulta de información. Por ejemplo, se pueden efectuar preguntas del tipo “dame las personas que tienen más de 17 años y menos de 25”. Las bases de datos tradicionales o clásicas no permiten el almacenamiento de conceptos “difusos” que los humanos manejan de forma cotidiana y natural. Por conceptos o información “difusa” (o fuzzy) se entiende información que encierra alguna imprecisión o incertidumbre. Por ejemplo, el concepto de persona “joven” indica claramente que la persona no tiene 80 años, pero no indica explícitamente su edad exacta. En bases de datos tradicionales se podrá almacenar la etiqueta “joven” como de forma textual (dato alfanumérico), pero esto, además de complicar el almacenamiento de edades numéricas normales, imposibilita el tratamiento apropiado de esta información. Es decir, se puede almacenar la palabra “joven”, pero no la información que ésta expresa. De este modo, cuestiones como “dame las personas que tienen menos de 40 años” no se podrán resolver, pues habrá que comparar el número 40 con la cadena de caracteres “joven”. Además, otro tipo de consultas son también imposibles de efectuar en bases de datos clásicas, como son “dame las personas que son jóvenes” o “cuya edad es cercana a joven”. Las bases de datos difusas unieron la teoría de bases de datos, principalmente del modelo relacional (apartado 3.1) con la teoría de Conjuntos Difusos (apartado 3.2¡Error! No se encuentra el origen de la referencia.), para permitir, básicamente dos objetivos: El almacenamiento de información difusa (además de información no difusa o “crisp”, por supuesto) y el tratamiento y consulta de esta información de forma difusa o flexible. Ligado a esto han surgido propuestas en multitud de sentidos, incluyendo la consulta difusa en bases de datos clásicas, sin información difusa. Algunos ejemplos de esas propuestas son expuestas en este capítulo y en el apartado 3.3.7, destacando, el modelo GEFRED como una síntesis de los modelos más relevantes publicados en la literatura.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 39
3.1 Modelo relacional clásico
En este apartado, se tratan los conceptos más relevantes y elementos más representativos de los Sistemas de Bases de Datos Relacionales (SBDR). Estos conceptos tienen que ver con tres partes bien diferenciadas: la estructura de los elementos, la integridad de los datos y la manipulación de los mismos.
3.1.1 Estructura e integridad de los datos
En relación con la estructura de los datos, se definirán los siguientes conceptos:
• Atributo, Campo o Columna son cada una de las características importantes y variables que tiene cualquier tipo de entidad u objeto y que son almacenadas en una base de datos, para reconocer a dicha entidad u objeto. No es trascendente que dicha entidad tenga otros atributos, ya que solo se tratarán aquellos que realmente interesen y que, por tanto, se deseen almacenar en una base de datos.
• Dominio es el conjunto de todos los valores posibles que puede tomar un atributo. Por tanto, todos los atributos tendrán un dominio asociado. Una característica inicial que se le exigía a los valores del dominio era la atomicidad, en el sentido de que no exista una descomposición de los mismos que aporte significado. No obstante esta premisa se ha relajado con la evolución del modelo, y actualmente se encuentran en la literatura muchas matizaciones de la misma. Un dominio puede llevar asociado un conjunto de operadores específicos del mismo. Por ejemplo, el dominio de los números enteros tiene operadores como la suma y la resta.
• Tupla es el conjunto de todos los valores concretos de todos los atributos de una determinada entidad u objeto.
• Valor de Dominio es un valor concreto de una tupla. O sea, es el valor para un atributo concreto de una entidad concreta.
• El producto cartesiano de una serie de dominios D1,D2,…,Dn, que se nota como D1×D2× …×Dn es el conjunto de todas las tuplas (x1, xs,…, xn) tales que para cualquier i, i=1,2,…,n se verifica que xi ∈ Di. Se llama relación a cualquier subconjunto del producto cartesiano de dos o más dominios. Una instancia de BD es un conjunto finito de relaciones finitas.
• Se llama cardinalidad de una relación al número de tuplas que contiene. • La ariedad o grado de una relación R ⊂ D1×D2× …×Dn es n, esto es, el número de
dominios que intervienen en su definición. • Una relación R de atributos A1,A2,…,An define lo que se llama un esquema de relación
que se nota por R(A1,A2,…,An) de manera que una relación específica R, con un conjunto concreto de tuplas, se dice que es una instancia o extensión de dicho esquema.
• No todas las instancias acordes con un determinado esquema son válidas desde el punto de vista semántico, esto es, tienen una interpretación coherente con la semántica

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 40
que lleva asociada la BD. Por ello, se introduce un conjunto de restricciones, llamadas restricciones de integridad, que se asocian a cada esquema de relación, para asegurar que se preserva el significado coherente de los datos.
• Se llama esquema de BD a un conjunto de esquemas de relación junto con un conjunto de restricciones de integridad (RI). De este modo, una instancia o estado de una BD será, pues, un conjunto de instancias de relación (una por cada esquema de relación que intervenga en el esquema de la BD). Un estado de una BD será válido, si todas las instancias de relación que contiene verifican las RI impuestas.
Un estudio más profundo del modelo relacional de BD puede verse en [Cod70, Cod82,
Dat90, Kor98, Ull89]. Desde hace un tiempo existen estudios teóricos ([Geo93]) e implementaciones prácticas de SGBD como las de Oracle© desde la versión 8.i ([Urm98]) en adelante, en los la atomicidad de los dominios se ha perdido dando lugar a la bases de datos dirigidas a objetos. A lo largo de esta memoria se introducirán también dominios más complejos de los habituales.
3.1.2 Manipulación de los datos
En este apartado se aborda el problema de la manipulación de las estructuras que aparecen en un SBDR. Esta manipulación se hace por medio de algún lenguaje formal de manejo de datos. En este sentido se distingue entre dos lenguajes:
• el Álgebra Relacional y • el Cálculo Relacional.
La diferencia esencial entre ambos es que mientras que el Álgebra proporciona una colección de operadores y operaciones explícitas, el Cálculo proporciona una notación para definir la relación resultante de una petición dada.
3.1.2.1 Álgebra Relacional
El Álgebra Relacional es un lenguaje de consulta procedimental, ya que el usuario da instrucciones al sistema para ejecutar una serie de operaciones en la BD, que calcularán los resultados deseados. Este lenguaje consta de un conjunto de operadores que toman como entrada una o dos relaciones para dar como salida una nueva relación. Los operadores básicos del Álgebra Relacional pueden agruparse de la siguiente manera:
• Operación de asignación: Es una operación especial que asigna el resultado de otras operaciones sobre relaciones a una nueva relación. Se incluye como operador para poder conservar los resultados.
• Operaciones tradicionales sobre conjuntos: o Unión: La unión de dos relaciones A y B da como resultado otra relación cuyas
tuplas pertenecen a A, a B ó a ambas.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 41
o Intersección: La intersección de dos relaciones A y B es el conjunto de tuplas que pertenecen a A y a B.
o Diferencia: La diferencia entre dos relaciones A y B es el conjunto de tuplas que pertenecen a A y no a B.
o Producto cartesiano extendido: El producto cartesiano extendido de dos relaciones A y B es el conjunto de todas las tuplas tales que cada una de ellas es la concatenación de una tupla de A con una tupla de B. La concatenación de una tupla a=(a1, a2,…, am) con otra b=(b1, b2,…, bm) es la tupla t=(a1, a2,…, am, bm+1, bm+2,…, bm+n).
Para todas ellas, excepto para el producto cartesiano, es necesario que las dos relaciones operando sean compatibles, esto es, que sean del mismo grado y que los i-ésimos atributos de las dos relaciones tengan el mismo dominio.
• Operaciones especiales: o Selección: este operador algebraico produce un subconjunto “horizontal” de una
relación específica, es decir, el subconjunto de las tuplas de una relación para el cual se cumple un predicado dado, expresado como combinación booleana de términos (comparaciones).
o Proyección: Produce un subconjunto “vertical” de una relación dada, es decir, el subconjunto obtenido al seleccionar los atributos especificados en un orden también especificado y eliminar las tuplas duplicadas.
o Reunión: La reunión de la relación A sobre el atributo x con la relación B sobre el atributo y da como resultado todas las tuplas t tales que t es la concatenación de una tupla de A con una de B tales que se verifica una condición determinada sobre x e y. Una caso particular es la equireunión, donde la condición exigida es X=Y.
o División: Divide una relación R de grado m+n entre una relación R' de grado n, produciendo una de grado m. El (m+i)-ésimo atributo de R y el i-ésimo de R' deben estar definidos sobre el mismo dominio.
3.1.2.2 Cálculo Relacional
El Cálculo Relacional es, al contrario que el Álgebra, un lenguaje no procedural de consulta, ya que el usuario solo expresa aquella información que desea obtener de la BD, pero sin especificar qué operaciones han de realizarse sobre la BD para obtenerla. Existen dos aproximaciones para dicho lenguaje: el Cálculo Relacional de Tuplas y el Cálculo Relacional de Dominios, que se describen a continuación.
Cálculo Relacional de Tuplas (CRT). Una expresión en el Cálculo Relacional de Tuplas es una expresión de la forma:
P/P(t)
que representa el conjunto de todas las tuplas t que hacen verdadera la fórmula o predicado P. Se usará t[A] para denotar el valor que tiene la tupla t para el atributo A y t ∈ R para denotar que la tupla t está en la relación R. En una misma fórmula pueden aparecer varias variables tupla. Se dice que una variable tupla es libre si no va cuantificada ni universal ni

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 42
existencialmente. Una fórmula del Cálculo Relacional de Tuplas se compone de átomos, cada uno de los cuales tiene una de las siguientes formas:
• s ∈ R, donde s es una variable tupla y R es una relación.
• s[x] θ v[y], donde s y v son variables tupla, x es un atributo sobre el que s está definida,
y es un atributo sobre el que v está definida, y θ es un operador de comparación (<, >, ≥, ≤, =). En particular, se requiere que los atributos x e y tengan dominios cuyos valores puedan ser comparados por medio de θ .
• s[x] θ c, donde s, x y θ tienen el mismo significado que en el apartado anterior, y C es una constante del dominio del atributo x.
Las fórmulas se construyen a partir de los átomos mediante las siguientes reglas:
• Un átomo es una fórmula. • Si P1 es una fórmula, entonces también los son (P1) y ¬(P1).
• Si P1 y P2 son fórmulas, también los son P1 ∧ P2,, P1 ∨ P2 y P1⇒ P2.
• Si P1(s) es una fórmula que contiene una variable de tupla libre s, entonces ∃ s ∈ R/
(P1(s)) y ∀s ∈ R/ (P1(s)) también son fórmulas.
Existe un aspecto muy importante en el Cálculo Relacional de Tuplas que debe mencionarse. Tal y como se han definido las expresiones, podría generarse una relación infinita, como por ejemplo: t/¬(t Є R) ya que existirá un número infinito de tuplas que no estén en la relación R. Dado que este tipo de expresiones no son deseables en absoluto, habrá que definir una restricción de dicho cálculo, para lo cual introducimos el concepto de dominio de una fórmula P. Intuitivamente, el dominio de P, que se notará Dom(P), es el conjunto de todos los valores representados por P, esto es, aquellos valores mencionados en P así como los valores que aparecen en una tupla mencionada en P. Decimos que una expresión t/P(t) es segura si todos los valores que aparecen en el resultado son valores de Dom(P).
El Cálculo Relacional de Tuplas restringido a expresiones seguras, es equivalente en poder expresivo al Álgebra Relacional. En [Ulm89] puede encontrarse la demostración formal de este hecho.
Cálculo Relacional de Dominios (CRD). Esta segunda forma del Cálculo Relacional usa variables de dominio, que toman valores del dominio de un atributo, en vez de valores de una tupla completa. Una expresión del Cálculo Relacional de Dominios tiene la forma:
<x1, x2,… , xn>| P(x1, x2,… , xn) donde x1,x2,… ,xn representan variables de dominio y P representa una fórmula compuesta por átomos. Un átomo en esta cálculo tiene una de las siguientes formas:

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 43
• < x1, x2,… , xn > ∈ R, donde R es una relación de n atributos y las xi son variables o
constantes de dominio. • x θ y, donde x e y son variables de dominio y θ es un operador de comparación. Es
requisito indispensable que los atributos x e y tengan dominios que puedan compararse por medio de θ .
• x θ c, donde x y θ se definen como en el caso anterior, y c es una constante del dominio del atributo sobre el que se mueve x.
Las fórmulas se construyen de igual forma que en el Cálculo Relacional de Tuplas.
Respecto al problema de la seguridad en las expresiones para el Cálculo Relacional de
Dominios, diremos que una expresión es segura, si se cumplen las siguientes condiciones:
• Todos los valores que aparecen en tuplas de la expresión son valores de Dom(P). • Cada sub-fórmula de la forma ∃ (x) (P1(x)) es verdadera si, y solo si, existe un valor x
en Dom(P1) tal que P1(x)) es verdadero. • Cada sub-fórmula de la forma ∀ (x)(P1(x)) es verdadera si, y solo si, P1(x)) es
verdadero para todos los valores x de Dom(P1)). El propósito de estas reglas es asegurar que se puede probar las sub-fórmulas para todo y existe sin tener que probar infinitas posibilidades.
Por último, decir que el Cálculo Relacional de Dominios restringido a expresiones seguras es equivalente al Cálculo Relacional de Tuplas (también restringido) y, por tanto, al Álgebra Relacional.
Un sublenguaje del Cálculo Relacional para el manejo de datos, puede verse en [Cod71].
Tanto el Álgebra Relacional como el Cálculo (en sus dos versiones) pueden verse ampliamente en [Dat90, Kor98].

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 44
3.2 Teoría de Conjuntos Difusos
En este apartado se va a introducir algunas nociones elementales sobre la teoría de Conjuntos Difusos, así como la notación utilizada al respecto a lo largo de esta memoria. En este resumen se hará hincapié en los aspectos semánticos y de representación relacionadas con esta potente herramienta. En la literatura se puede encontrar una gran cantidad de trabajos sobre esta teoría, como en [Yag87] donde hay una recopilación de algunos de los artículos más interesantes publicados sobre el tema por L.A. Zadeh. En [Dub80, Zim91] están recopilados los aspectos más importantes que constituyen la teoría de Conjuntos Difusos así como la Teoría de la Posibilidad. Una más moderna síntesis de los Conjuntos Difusos y sus aplicaciones puede verse, sobre todo, en [Pre98].
El término fuzzy procede de fuzz, que sirve para denominar la pelusa que recubre el cuerpo de los polluelos al poco de salir del huevo. Este término en inglés significa “confuso, borroso, no definido o desenfocado”. Este vocablo se traduce por flou en francés y se pronuncia “aimai” en japonés. La traducción de esta palabra al español es difuso o borroso, aunque fuzzy, en los ámbitos académico y tecnológico, está aceptado tal cual, de forma similar a como lo está bit. Fuzzy significa ambiguo o vago, en el sentido del razonamiento humano, más que en la acepción de probabilidad de algo.
La Lógica Difusa nació cuando el profesor Lotfi A. Zadeh publicó un artículo titulado Fuzzy Sets (Conjuntos Difusos) [Zad65]. En este artículo el Dr. Zadeh presentó unos conjuntos sin límites precisos los cuales, según él, juegan un importante papel en el reconocimiento de formas, interpretación de significados y, especialmente, en la abstracción (la esencia del proceso de razonamiento del ser humano).
En la lógica clásica solo es posible tratar información que sea totalmente cierta o totalmente falsa; no le es posible manipular aquella información imprecisa o incompleta inherente, frecuentemente, a los problemas. Descartar este tipo de información no es deseable ya que puede permitir la mejor resolución de los problemas. Con ello se podría decir que la Lógica Difusa es una extensión de los sistemas clásicos, como el propio Zadeh indica en [Zad92]. La Lógica Difusa es la lógica que soporta modos de razonamiento aproximados en lugar de exactos. Su importancia radica en que muchos modos de razonamiento humano, en especial el razonamiento según el sentido común, son aproximados por naturaleza.
Esta lógica es una lógica multievaluada, sus características principales, presentadas por Zadeh en la referencia antes mencionadas y otras [Zad65, Zad75, Zad78, Zad92] son:
• En la Lógica Difusa, el razonamiento exacto es considerado como un caso particular
del razonamiento aproximado. • Cualquier sistema lógico puede ser trasladado a términos de Lógica Difusa. • En Lógica Difusa, el conocimiento es interpretado como un conjunto de restricciones
flexibles, es decir, difusas, sobre un conjunto de variables.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 45
• La inferencia1 es considerada como un proceso de propagación de dichas restricciones. • En Lógica Difusa, todo problema es un problema de grados.
3.2.1 Conjuntos Difusos Los Conjuntos Difusos son una generalización de los (sub)conjuntos clásicos, en el sentido de que, los amplían pues permiten la descripción de nociones “vagas” e “imprecisas”. Relajan la restricción de los conjuntos clásicos de pertenencia o no pertenencia absoluta al mismo. Es necesario hacer notar que muchos de estos conceptos con naturaleza “imprecisa”, si no todos, responden a criterios subjetivos. Esto es, la definición de esa imprecisión depende en mayor o menor medida de la persona que la expresa. Dicha generalización conduce a que:
• La pertenencia de un elemento a un conjunto pasa a ser un concepto difuso o borroso. Para algunos elementos puede no estar clara su pertenencia o no al conjunto.
• Dicha pertenencia puede ser cuantificada por un grado. Dicho grado se denomina habitualmente como “grado de pertenencia” de dicho elemento al conjunto y toma un valor en el intervalo [0,1] ∈ ℜ por convenio.
Nótese la gran potencialidad que presenta este último punto al permitir expresar de forma cuantitativa algo cualitativo (difuso) mediante el grado de pertenencia. De forma más formal se puede definir un conjunto difuso como sigue:
Definición 3-1. Conjunto Difuso
Un Conjunto Difuso A sobre un universo de discurso Ω (intervalo finito o infinito dentro del cual el conjunto difuso puede tomar un valor) es un conjunto de pares A= μ A(x) / x : x ∈ Ω, μ A(x) ∈ [0,1] ⊂ ℜ donde μ A(x) se denomina grado de pertenencia del elemento x al conjunto difuso A. Este grado oscila entre los extremos 0 y 1 del dominio de los números reales: μ A(x) = 0, indica que x no pertenece en absoluto al conjunto difuso A.
μ A(x) = 1, indica que x pertenece totalmente al conjunto difuso A. A veces, en vez de dar una lista exhaustiva de todos los pares que forman el conjunto (valores discretos), se da una definición para la función μ A(x), llamada función característica o función de pertenencia.
Si la función de pertenencia solo produce valores del conjunto 0,1, entonces el conjunto que genera no es difuso, sino crisp2. 1 Proceso por el cual se llega a un resultado, obtener consecuencias o deducir una cosa de otra.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 46
De la definición de conjunto difuso se derivan los siguientes conceptos: • Universo de Discurso: Como se ha mencionado anteriormente, existen dos posibilidades
a la hora de establecer el intervalo de valores válido para el conjunto difuso que son a través de:
o Un universo de discurso finito o discreto:
Ω = x1, x2,…, xn Un conjunto difuso A se puede representar como: A = μ 1/x1+ μ 2/x2+…+ μ n/xn
donde μ i representa el grado de pertenencia del elemento xi, con i=1,2,…,n. Habitualmente los elementos con grado cero no se listan. Aquí el símbolo “+” no hace el papel de la suma aritmética sino que tiene el sentido de agregación y el símbolo “/” no es el operador de división sino que tiene el significado de asociación de ambos valores.
o Una función de pertenencia definida sobre un universo de discurso infinito. Así un
conjunto difuso A sobre Ω puede representarse como:
A = ∫ μ A(x) / x
• Etiqueta Lingüística: Es aquella palabra, en lenguaje natural, que expresa o identifica a un
conjunto difuso, que puede estar formalmente definido o no. Así la función de pertenencia de un conjunto difuso A, μ A(x), expresa el grado en que x verifica la categoría especificada por A. Con esta definición, se puede asegurar que en la vida cotidiana se utiliza multitud de etiquetas lingüísticas para expresar conceptos abstractos: “joven”, “viejo”, “frío”, “caliente”, “barato”, “caro”, “limpio”, “sucio”… Además, la definición intuitiva de esas etiquetas, no solo puede variar de un individuo a otro y del momento particular, sino que también varía del contexto en el que se aplique. Por ejemplo, seguramente no medirán la misma altura una persona “alta” y un edificio “alto”. La representación de Conjuntos Difusos puede ser variada y depende, fundamentalmente de la naturaleza del universo de discurso sobre el que se define el conjunto difuso.
Para ilustrar lo mencionado anteriormente tómese como ejemplo el siguiente caso:
Ejemplo 3-1
2 Podría traducirse por un valor concreto, preciso.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 47
Si se expresa el concepto cualitativo “joven” mediante un conjunto difuso, donde el eje de abcisas (eje X) representa el universo de discurso edad y el eje de ordenadas (eje Y) representa los grados de pertenencia en el intervalo [0,1]. El conjunto difuso que representa dicho concepto podría expresarse en la forma siguiente, considerando un universo discreto: Joven = 1/0,…, 1/20, 1/25, 0.9/26, 0.8/27, 0.7/28, 0.6/29, 0.5/30,…, 0.1/34 La “edad” (en años enteros) sería el universo de discurso de “joven”. La etiqueta lingüística “joven” identificaría a este conjunto difuso que se muestra gráficamente (junto con otras etiquetas lingüísticas) en la Figura 3-1.
3.2.2 Conceptos sobre Conjuntos Difusos Sobre Conjuntos Difusos se definen una serie de conceptos que permiten tratar y comparar Conjuntos Difusos:
Definición 3-2. Igualdad de Conjuntos Difusos
Dos Conjuntos Difusos A y B sobre Ω se dicen iguales si cumplen: A = B ⇔ ∀ x ∈ Ω, μ A(x)= μ B(x)
Definición 3-3. Inclusión de un conjunto difuso en otro
Dados dos Conjuntos Difusos A y B sobre Ω, se dice que A está incluido en B si cumplen: A ⊆ B ⇔ ∀ x ∈ Ω, μ A(x)≤ μ B(x)
Definición 3-4. Soporte de un conjunto difuso
El soporte (support) de un conjunto difuso A definido sobre Ω es un subconjunto de dicho universo que satisface:
0
1
Ω = Universo de Discurso
X (Edad en años)
Joven Viejo Adulto
µ(x)
150
Figura 3-1. etiquetas lingüísticas sobre edad

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 48
supp(A)=x ∈ Ω, μ A(x)>0
Definición 3-5. α -corte de un conjunto difuso
Un α -corte de un conjunto difuso A definido sobre Ω, denotado por Aα , es un subconjunto no difuso (clásico) de elementos de Ω, cuya función de pertenencia toma un valor mayor o igual que algún valor concreto α de dicho universo de discurso que satisface:
Aα =x : x ∈ Ω, μ A(x)≥ α , α ∈ [0,1] La Figura 3-2 ilustra el concepto de α -corte.
El Teorema de Representación descrito a continuación permite representar cualquier conjunto difuso A mediante la unión de sus α -cortes.
Definición 3-6. Teorema de representación
Todo subconjunto difuso A puede ser obtenido a partir de la unión de sus α -cortes:
A = ∪ α ∈ [0,1] Aα
Definición 3-7. Conjunto difuso convexo
Haciendo uso del Teorema de Representación se establece el concepto de conjunto difuso como aquel en que todos sus α-cortes son convexos: ∀ x,y ∈ Ω, ∀ λ ∈ [0,1]: μ A(λ • x+ (1- λ )• y) ≥ min(μ A(x), μ A(y))
α
µ(x)
x
Figura 3-2. α -corte en un trapecio

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 49
En la Figura 3-3 se pueden encontrar un ejemplo de conjunto difuso convexo y otro de no convexo. Por último, indicar que si dos Conjuntos Difusos son convexos, también lo es su intersección.
Definición 3-8. Núcleo (Kernel) de un conjunto difuso
El núcleo de un conjunto difuso A, definido sobre Ω es un subconjunto de dicho universo que satisface: Kern(A) = x ∈ Ω, μ A(x)=1
Definición 3-9. Altura (Height) de un conjunto difuso
La altura de un conjunto difuso A, definido sobre Ω se define como:
Hgt(A) = supx∈ Ω(μ A(x))
Definición 3-10. Conjunto difuso normalizado
Un conjunto difuso está normalizado si y solo si: ∃ x ∈ Ω, μ A(x) = Hgt(A) = 1
3.2.3 Operaciones sobre Conjuntos Difusos El hecho de que la teoría de Conjuntos Difusos generalice la teoría de conjuntos clásica, da lugar a que los Conjuntos Difusos admitan las operaciones de unión, intersección y complemento. En [Pet96] se puede encontrar éstas y otras operaciones, como la concentración (elevar al cuadrado la función de pertenencia), la dilatación (efectuar la raíz cuadrada de la función de pertenencia) y la intensificación que pueden utilizarse cuando se usan modificadores lingüísticos (linguistic hedges) como “muy” o “poco”.
C.Difuso CONVEXO C.Difuso NO CONVEXO
Figura 3-3. Conjunto difuso convexo y no convexo

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 50
3.2.3.1 Unión e intersección Tanto las T-conormas como las T-normas establecen modelos genéricos para las operaciones de unión y intersección respectivamente, las cuales deben cumplir ciertas propiedades básicas (conmutativa, asociativa, monotonicidad y condiciones frontera).
Definición 3-11. Norma Triangular o T-norma
Una norma triangular o T-norma es una operación binaria T: [0,1] 2→ [0,1] que cumple las siguientes propiedades:
• Conmutativa: x T y = y T x • Asociativa: x T (y T z) = (x T y) T z • Monotonicidad: Si x ≤ y, y w ≤ z entonces x T w ≤ y T z • Condiciones frontera: x T 0 = 0, x T 1 = x
Definición 3-12. Conorma Triangular o T-conorma
Una conorma triangular o T-conorma es una operación binaria S: [0,1] 2→ [0,1] que cumple las siguientes propiedades:
• Conmutativa: x S y = y S x • Asociativa: x S (y S z) = (x S y) S z • Monotonicidad: Si x ≤ y, y w ≤ z entonces x S w ≤ y S z • Condiciones frontera: x S 0 = x, x S 1 = 1
Existe un amplio conjunto de operadores, T-normas y T-conormas, que pueden ser utilizados como conectivos para modelar la intersección y la unión, respectivamente, como los presentados en [Dub80, Yag80, Pre98]. Los más importantes son:
0
1
Intersección Unión
Figura 3-4. Ejemplo: Unión e intersección de conjuntos difusos

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 51
• Operadores idempotentes: El máximo y el mínimo para la unión y la intersección respectivamente. Satisfacen, además de la idempotencia, la propiedad distributiva aplicada sobre ambos y son estrictamente crecientes. Estos operadores son los más utilizados por que conservan gran cantidad de las propiedades de los operadores booleanos. En [Ben76] puede encontrarse una justificación a la elección de los operadores max y min para definir los anteriores conceptos. Como ejemplo véase la Figura 3-4.
• Operadores arquimedianos: Emplean la suma probabilística, (x+y - x×y), y el producto, (x×y), para la unión y la intersección, respectivamente. Estos operadores no satisfacen la propiedad distributiva ni son idempotentes.
• Operadores acotados (bounded): Los operadores dados por, min(1,x+y) y max(0,x+y-1), representan la unión y la intersección respectivamente. Estos operadores no satisfacen la idempotencia, la propiedad distributiva ni la propiedad de absorción. Por el contrario, satisfacen las propiedades conmutativa, asociativa y de identidad.
En la Tabla 3-1 y en Tabla 3-2 se muestran las T-normas y T-conormas respectivamente más representativas y utilizadas por la bibliografía anteriormente comentada. Las T-normas y T-conormas no pueden ordenarse de mayor a menor. Sin embargo, es fácil identificar la mayor y la menor T-norma y T-conorma:
• Mayor T-norma: Función Mínimo. • Menor T-norma: Producto Drástico. • Mayor T-conorma: Suma Drástica. • Menor T-conorma: Función Máximo.
Normas triangulares o T-normas
Expresión
Mínimo )y,x(Min)y,x(f =
Producto (Algebraico) yx)y,x(f •=
Producto Drástico
⎪⎪⎩
⎪⎪⎨
⎧
=
=
=
caso otro en,0
1x siy,
1y si,x
)y,x(f
Producto Acotado [ ]pxy)1yx)(p1(,0Max)y,x(f −−++= , donde 1p −≥
Producto de Hamacher
)xyyx)(p1(pxy
)y,x(f−+−+
=, donde 0p ≥
Familia Yager
[ ] ))y1()x1(,1(Min1)y,x(f p1
pp −+−−= , donde 0p >
Familia Dubois –Prade
)p,y,x(Maxxy
)y,x(f =, donde 1p0 ≤≤
Familia Frank

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 52
⎟⎟⎠
⎞⎜⎜⎝
⎛
−−−
+=1p
)1p)(1p(1log)y,x(f
yx
p
, donde 1p ;0p ≠>
Producto de Einstein
)y1()x1(1xy
)y,x(f−+−+
=
Otras
[ ] p1
pp )y)y1(()x)x1((1
1)y,x(f
−+−+=
, donde 0p >
[ ]1y1x1
1)y,x(f
pp −+=
[ ] p1
pp )1yx,0(Max)y,x(f −+= Tabla 3-1. tipos de T-normas
Conormas Triangulares o T-conormas
Expresión
Máximo )y,x(Max)y,x(f =
Suma - Producto xyyx)y,x(f −+=
Suma Drástica
⎪⎪⎩
⎪⎪⎨
⎧
=
=
=
caso otro en,1
0x siy,
0y si,x
)y,x(f
Suma Acotada
)pxyyx,1(Min)y,x(f ++= , donde 0p ≥
Familia Sugeno
)xypyx,1(Min)y,x(f −++= , donde 0p ≥
Familia Yager
[ ] )yx,1(Min)y,x(fp1pp += , donde 0p >
Familia Dubois - Prade
)p ,y1 ,x1(Max)y1)(x1(
)y,x(f−−−−
=, donde [ ]1 ,0p ∈
Familia Frank
⎟⎟⎠
⎞⎜⎜⎝
⎛
−−−
+=−−
1p)1p)(1p(
1log)y,x(fy1x1
p
, donde 1p ;0p ≠>

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 53
Otras
xy)p1(1xy)p1(xyyx
)y,x(f−−
−−−+=
, donde 0p ≥
[ ] p1pp 1)y1()x1(,0(Max1)y,x(f −−+−−= , donde 0p >
[ ] p1pp )y1(y)x1(x1
1)y,x(f
−+−−=
, donde 0p >
[ ] p1pp 1)y1(1)x1(11
1)y,x(f
−−+−−=
, donde 0p >
Tabla 3-2. tipos de T-conormas
Definición 3-13. Extensión de la ley de Morgan
Existe una relación entre T-normas (T) y T-conormas (S) que no es otra que una extensión de la ley de Morgan: x S y = (1-x) T (1-y) Cuando una T-norma y una T-conorma satisfacen esta propiedad se dice que son conjugadas o duales.
Una vez efectuado el estudio de las T-normas y T-conormas ya se está en condiciones de abordar las definiciones formales de la unión e intersección de Conjuntos Difusos:
Definición 3-14. Función de pertenencia de la unión de dos Conjuntos Difusos
Si A y B son dos Conjuntos Difusos sobre un universo de discurso Ω, la función de pertenencia de la unión de ambos conjuntos, A∪ B, viene dada por μ A∪ B(x) = S(μ A(x), μ B(x)), x ∈ Ω donde S es una T-conorma [Sch83].
Definición 3-15. Función de pertenencia de la intersección de dos Conjuntos Difusos

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 54
Si A y B son dos Conjuntos Difusos sobre un universo de discurso Ω, la función de pertenencia de la intersección de ambos conjuntos, A∩ B, viene dada por μ A∩ B(x) = T(μ A(x), μ B(x)), x ∈ Ω donde T es una T-norma [Sch83].
3.2.3.2 Complemento o negación La noción de complemento se puede construir a partir del concepto de negación fuerte de Trillas en [Tri79]:
Definición 3-16. Negación fuerte
Una función C: [0,1] → [0,1] es una negación fuerte si satisface las siguientes condiciones:
1. C(0) = 1 2. C(C(a)) = a (involución) 3. C es estrictamente decreciente 4. C es continua
Aunque existen varios tipos de operadores que satisfacen tales propiedades o versiones relajadas de las mismas, para el complemento, se emplea principalmente la versión proporcionada por Zadeh en [Zad65], en el cual: C(x) = 1 - x Por tanto, para un conjunto difuso A sobre un universo de discurso Ω, la función de pertenencia del complemento de A, ¬A, viene dada por: μ ¬A(x) = 1 - μ A(x), x ∈ Ω
3.2.4 Números difusos El concepto de número difuso fue introducido por primera vez en [Zad75] con el propósito de analizar y manipular valores numéricos aproximados, por ejemplo: “próximo a 0”, “casi 5”, etc. El concepto ha sido refinado sucesivamente y en esta memoria se entenderá por número difuso lo siguiente [Dub85]:
Definición 3-17. Número difuso

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 55
Sea A un subconjunto difuso de Ω y μ A(x), su función de pertenencia cumpliendo:
1. A es convexo (ver Definición 3-7). 2. μ A(x) es semicontinua superiormente. 3. El soporte (ver Definición 3-4) de A es un conjunto acotado.
entonces se dirá que A es un número difuso.
La forma general de la función de pertenencia de un número difuso A (ver Figura 3-5), es la siguiente:
donde rA, sA:Ω → [0,1]; rM es no decreciente; sM es no creciente y rA(β )=h=sA(γ ) con h
∈ (0,1] y α , β , δ , γ ∈ Ω. Al número h se le denomina altura del número difuso, al intervalo [β ,γ ] intervalo modal
y a los números β -α y δ -γ holguras izquierda y derecha respectivamente. A lo largo de esta memoria se utilizará a menudo un caso particular de números difusos que se obtiene cuando consideramos a las funciones rA y sA como funciones lineales. En este caso la función de pertenencia adopta la forma:
Figura 3-5. Número difuso general
α β δ γ 0
h
[ ]]
⎪⎪
⎩
⎪⎪
⎨
⎧
∈
∈
∈
=
caso otro en0
,(x si)x(s
,x sih
),[x si)x(r
)x(A
A
Aδγ
γβ
βα
µ

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 56
[ ]]
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
∈−−
−
∈
∈−−
+
=
caso otro en0
,(x sih)x(
h
,x sih
),[x sih)x(
h
)x(Aδγ
γδγ
γβ
βααββ
µ
A un número difuso de este tipo se le denominará trapezoidal (ver Figura 3-7). Usualmente se trabajará con números difusos normalizados por lo que h=1, en este caso se podrá caracterizar un número difuso trapezoidal normalizado A, mediante el empleo de los cuatro parámetros que son realmente los imprescindibles: α , β , δ , γ .
3.2.4.1 El principio de extensión (Extension Principle) Una de las nociones más importantes en teoría de Conjuntos Difusos es el principio de extensión, propuesto en [Zad75]. Proporciona un método general que permite extender conceptos matemáticos no difusos para el tratamiento de cantidades difusas. Se usa para transformar cantidades difusas, que tengan iguales o distintos universos, según una función de transformación en esos universos. Sea A una cantidad difusa definida sobre el universo de discurso X y f una función de transformación no difusa tal que f: X → Y. El propósito es extender f en A de forma que opere sobre X y devuelva una cantidad difusa B sobre Y. Dicho objetivo se obtiene usando la composición del “sup min”, como a continuación se comenta, de forma generalizada en el caso del producto cartesiano de n universos de discursos.
Definición 3-18. Principio de extensión
Sea Ω un producto cartesiano de universos tal que Ω = Ω1 × Ω2 ×…× Ωn, y A1, A2,... , An, n Conjuntos Difusos de Ω1, Ω2,..., Ωn respectivamente, f una función desde Ω al universo Ω’, entonces un conjunto difuso B de Ω’ viene definido por:
B = ∫ Ω’ μ B(y)/y donde y = f(x1, x2,… , xn) (y ∈ Ω’), y sup min(x1, x2,… , xn) ∈ f -1(y) μ A1(x),…, μ An(x), si f -1(y) ≠ 0
μ B(y) = 0, en otro caso

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 57
3.2.4.2 Aritmética difusa Gracias al principio de extensión es posible extender las operaciones aritméticas clásicas al tratamiento de números difusos. De esta forma las cuatro operaciones principales quedan extendidas en: • Suma extendida: Dadas dos cantidades difusas A1 y A2, la función de pertenencia de la
suma A1⊕ A2 viene dada por la expresión: μ A1⊕ A2(y) = sup min μ A1(y - x), μ A2(x)) / x∈ Ω
De este modo, la suma, queda expresada en términos de la operación del supremo. La suma extendida es una operación conmutativa, asociativa y no existe el concepto de número simétrico.
• Diferencia extendida: Dadas dos cantidades difusas A1 y A2, la función de pertenencia de
la diferencia A1⊖ A2 viene dada por la expresión: μ A1⊖ A2(y) = sup min μ A1(y + x), μ A2(x)) / x∈ Ω De estas definiciones se puede obtener fácilmente que si A1 tiene n términos y A2 tiene m términos, el número de términos de A1+A2 y de A1-A2 es (n-1)+(m-1)+1, o lo que es lo mismo: n+m-1. • Producto Extendido: El producto de dos cantidades difusas A1 ⊙ A2 se obtiene:
sup minμ A1(z/y), μ A2(y)) / y∈ Ω - 0, si z ≠ 0
μ B(y) =
maxμ A1(0), μ A2(0)), en otro caso • División Extendida: La división de dos cantidades difusas A1⊘ A2 se define mediante: μ A1⊘ A2(y) = sup minμ A1(y.z), μ A2(y)) / y∈ Ω Basándose en una expresión particular del principio de incertidumbre adaptada al empleo de α -cortes y en un tipo de número difuso similar al descrito anteriormente, denominado número L-R, en [Dub80] se describen fórmulas de cálculo rápido para las anteriores operaciones aritméticas.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 58
3.2.5 Teoría de la Posibilidad Esta teoría se basa en la idea de variables lingüísticas y cómo estas están relacionadas con los Conjuntos Difusos [Zad78]. Así, se puede evaluar la posibilidad de que una determinada variable X sea o pertenezca a un determinado conjunto A, como el grado de pertenencia de los elementos de X en A.
Definición 3-19. Distribución de posibilidad
Sea un conjunto difuso A definido sobre Ω con su función de pertenencia μ A(x) y una variable X sobre Ω (que se desconoce su valor). Entonces, la proposición “X es A” define una distribución de posibilidad π A(x), de forma que se dice que la posibilidad de que X = u vale μ A(x),
para todo valor u ∈ Ω.
Como se verá en el siguiente apartado de este capítulo, dos distribuciones de posibilidad pueden ser comparadas con distintos comparadores. Los más típicos son la medida de posibilidad, “posiblemente igual”, y la medida de necesidad, “necesariamente igual”. En la Tabla 3-6 puede observarse la definición de varios comparadores de posibilidad y necesidad para dos distribuciones de posibilidad trapezoidales.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 59
3.3 Modelo relacional difuso
Para la representación y el tratamiento de información imprecisa en el ámbito de las Bases de Datos Relacionales, se han presentado varios modelos. Entre ellos, destacan:
• algunas aproximaciones que no emplean la Lógica Difusa, y que se basan en el modelo original de Codd [Cod79, Cod86, Cod87, Cod90],
• el modelo básico difuso de base de datos • el modelo de Prade y Testemale [Pra84, Pra84b, Pra87, Pra87b], • el modelo de Umano y Fukami [Fuk79, Uma80, Uma82, Uma83, Uma94], • el modelo posibilístico de Buckles y Petry [Buc82, Buc82b, Buc84, Buc89], • el modelo de Zemankova y Kaendel [Zem84, Zem85] y • el modelo GEFRED de Medina, Pons y Vila [Med94, Med94b]
A continuación se exponen brevemente estos modelos pudiendo encontrarse un estudio
detallado de los mismos en [Med94, Gal99, Pet96].
3.3.1 Aproximaciones que no emplean la Lógica Difusa
3.3.1.1 Aproximación de Codd
El primer intento de representar información imprecisa en el seno de una base de datos relacional fue el de Codd [Cod79], que después ha ido evolucionando [Cod86, Cod87, Cod90]. Este intento se produjo cuando Codd introdujo un nuevo valor, conocido como Null (nulo) en todo dominio para representar que un atributo tomaba un valor del dominio que no era conocido (pero uno de los valores del dominio en todo caso). Una comparación entre el valor Null y cualquier otro valor del dominio proporcionaba un resultado especial Quizás (propio de la Lógica Tri-valuada).
Posteriormente, este valor evolucionó en dos sub-valores denominados marcas:
• A-marca: representa un valor ausente o desconocido, pero aplicable. • I-marca: representa un valor ausente porque no es aplicable.
3.3.1.2 Otras aproximaciones
Algunas otras aproximaciones (ajenas a la Lógica Difusa) son:
• Valores por defecto: según Date [Dat86], el valor Null no había sido bien tratado en el modelo relacional, por lo cual no debía ser representado en el mismo. Para suplir su funcionalidad, proponía designar un valor de cada dominio como valor por defecto.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 60
De este modo, dicho valor sería asignado automáticamente en caso de desconocimiento.
• Rangos en valores: Grant [Gra80] extiende el modelo relacional de modo que los atributos puedan almacenar datos de tipo intervalo, y redefine los operadores relacionales de modo que su evaluación resulte en dos valores Verdad y Quizás.
• Bases de Datos Estadísticas: se deben a Wong [Won82], que trata la incertidumbre mediante la inferencia estadística. Este método percibe la consulta como un experimento estadístico en el que la información es incompleta y se centra en calcular la respuesta a la consulta como el conjunto de tuplas que minimiza los errores estadísticos.
• Bases de Datos Probabilísticas: Barbara et al. [Bar92] introdujeron un modelo desarrollado de bases de datos probabilísticas que asociaba probabilidades a los valores de los atributos, de modo que cada atributo se trataba como una distribución de probabilidad discreta.
3.3.2 Modelo básico de bases de datos
Este modelo extiende el modelo clásico mediante la adición de un grado a cada tupla. Este grado representa hasta qué punto la tupla pertenece a la relación en la que se encuentra y es un valor numérico del intervalo [0,1].
Más formalmente, se define BD Difusa como un conjunto de relaciones BD = R1, R2,…, Rm en el que cada una de ellas es una relación difusa caracterizada por una función de pertenencia como sigue:
μ Rj: U1× U2× … ×Un → [0,1] j=1… m siendo Ui el dominio del i-ésimo atributo de la relación y × el producto cartesiano.
Aunque se han construido sistemas basados en este modelo [Zad78], éste presenta el inconveniente de que cada tupla asume su carácter difuso de forma global sin que se pueda determinar la aportación difusa particular de cada uno de los atributos que la constituyen.
3.3.3 Modelo de Buckles y Petry
Este modelo presentado en [Buc82] y desarrollado en [Buc82b, Buc84] se basa en el concepto de relación de similitud [Zad71].
Definición 3-20. Relación Difusa
Una relación difusa es un subconjunto del producto cartesiano P(D1) ×…× P(Dn)
donde Di, i=1,…,n es un dominio y P(Di) es el conjunto de partes de un dominio.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 61
En este modelo pueden representarse los siguientes valores: • Conjunto finito de escalares (por ejemplo, rubio, castaño, pelirrojo). • Conjunto finito de números (por ejemplo, 15, 16, 17). • Conjunto de números difusos (por ejemplo, muy alto, alto). En cada uno de estos tipos de conjuntos, el significado es disyuntivo.
Definición 3-21. Relación de Similitud
Sea D un dominio escalar o numérico. Se define una relación de similitud que mide la similitud entre dos valores del dominio como una función: sr: D×D → [0,1]
sr(di,dj) → c
Si sr(di,dj)=0 se puede decir que di y dj son totalmente distintos, y si sr(di,dj)=1 se puede afirmar que di y dj son totalmente iguales.
Se puede establecer un umbral γ de modo que se pueda afirmar que di y dj son iguales
(o indistinguibles) si se da di y dj ≤ γ .
3.3.4 Modelo de Prade y Testemale
Dicho modelo [Pra84, Pra84b, Pra87, Pra87b] se basa en la Teoría de la Posibilidad para la representación de los datos inciertos e imprecisos (ver 3.2.5). Sea A un atributo que toma valores en un dominio D. Todo el conocimiento acerca del valor de A para una entidad concreta x se puede representar mediante una distribución de posibilidad π A(x) que es una aplicación π A(x): D×e→ [0,1].
En este modelo, π A(x) (d) = 1 implica que el valor D es totalmente posible. Además, es
necesaria la normalización de las distribuciones, es decir, debe existir al menos un valor d ∈ D
tal que π A(x) (d) = 1.
3.3.5 Modelo de Umano y Fukami
Este modelo [Fuk79, Uma80, Uma82, Uma83, Uma94] es uno de los primeros modelos de Bases de Datos Relacionales Difusas. Se basa en la Teoría de la Posibilidad (3.2.5) para la representación de la información incierta o imprecisa, al igual que el Modelo de Prade y Testemale, pero presenta una diferencia con él: el tratamiento de la información no aplicable. Introduce tres valores especiales:

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 62
• Unknown (Desconocido): establece que el atributo toma cualquier valor del dominio D
aunque desconocemos cuál de ellos. Unknown: π A(x)(d) = 1, ∀ d ∈ D
• Undefined (No aplicable): establece que el atributo no puede tomar ningún valor del dominio D puesto que no tiene sentido.
Undefined: π A(x)(d) = 0, ∀ d ∈ D • Null (nulo): representa el desconocimiento total respecto al valor que toma el atributo.
Null: 1/Unknown, 1/Undefined
Este modelo permite introducir distribuciones de posibilidad como valores de atributos y, además, una distribución de posibilidad asociada a la tupla (al conjunto de valores de atributos) que indica el grado de pertenencia de la tupla a la relación. Dicho grado de pertenencia, que se representa por μ R es una aplicación de la forma:
μ R: P(U1) ×…×P(Um) → P([0,1]) donde el símbolo × denota el producto cartesiano, P(Uj) con j=1,…,m es la colección de todas las distribuciones de posibilidad en el universo de discurso del atributo Uj del j-ésimo atributo de R.
Este modelo incluye la definición de nuevos operadores del Álgebra Relacional.
3.3.6 Modelo de Zemankova y Kaendel
Este modelo [Zem84, Zem85] representa la información de forma similar a los restantes modelos posibilísticos y desarrolla un lenguaje de manipulación de datos en el que analiza las relaciones entre posibilidad y certeza.
3.3.7 Modelo Generalizado para Bases de Datos Relacionales Difusas (GEFRED)
El modelo GEFRED (a GEneralizad model for Fuzzy RElational Databases, un Modelo
Generalizado para Bases de Datos Relacionales Difusas) [Med94, Med94b, Med95] de Medina, Pons y Vila [Med94, Med94b] surge como una integración de diversas tendencias anteriores para resolver el problema de la representación y consulta de información imprecisa en el seno del modelo relacional. GEFRED introduce además toda un Álgebra Relacional Difusa Generalizada y un Cálculo Relacional Difusos Generalizado.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 63
3.3.7.1 Representación de datos imprecisos
Definición 3-22. Dominio Difuso Generalizado
Sea D un dominio de discurso, ∏ (D) el conjunto de distribuciones de posibilidad definidas sobre D, entre las que se incluyen aquéllas que describen los valores Unknown (desconocido) y Undefined (no aplicable). Se tiene en cuenta también el valor Null (nulo). El dominio difuso generalizado se define como DG donde DG ⊆ ∏ (D) ∪ Null.
Un dominio difuso generalizado es un conjunto formado por elementos que pueden
ser los que se muestran en Tabla 3-3.
Tabla 3-3. Tipos de datos que puede representar GEFRED
Definición 3-23. Relación Difusa Generalizada
Una relación difusa generalizada, R, es un par de conjuntos (H, B), definidos como sigue:
• H es el conjunto llamado cabecera y describe la estructura de la relación mediante un conjunto de ternas “atributo-dominio-compatibilidad”(donde el último es opcional),
H = (AG1 : DG1[,CAG1]),…, (AGn : DGn[,CAGn])
1. un escalar simple (por ejemplo, Comportamiento = bueno, que se representa mediante la distribución de posibilidad 1/buena),
2. un número simple (por ejemplo, Edad = 27, que se representa mediante la distribución de posibilidad 1/27),
3. un conjunto de posibles asignaciones excluyentes de escalares (por ejemplo, Comportamiento = bueno, malo, que se representa por la distribución de posibilidad 1/bueno, 1/malo,
4. un conjunto de posibles asignaciones excluyentes de números (por ejemplo, Edad = 20, 21, que se representa mediante la distribución de posibilidad 1/20, 1/21,
5. una distribución de posibilidad construida sobre un dominio escalar (por ejemplo, Aptitud = 0.6/buena, 0.7/mala,
6. una distribución de posibilidad construida sobre un dominio numérico (por ejemplo, Edad = 0.3/20, 0.5/21, números difusos o etiquetas lingüísticas),
7. un número real en el intervalo [0,1], que se refiere al grado de acoplamiento (por ejemplo, Calidad = 0.9),
8. un valor Unknown (desconocido) con distribución de posibilidad 1/u : ∀ u ∈ U,
9. un valor Undefined (no aplicable) con distribución de posibilidad 0/u : ∀ u ∈ U, 10. un valor Null (nulo) con distribución de posibilidad Null = 1/Unknown,
1/Undefined

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 64
donde a cada atributo Aj, le subyace un dominio difuso generalizado, no necesariamente distinto, Dj, j ∈ [1, n]. Cj es el llamado atributo de compatibilidad y toma valores en [0, 1].
• B es el conjunto llamado cuerpo y está formado por una serie de tuplas generalizadas difusas distintas, donde cada tupla está compuesta por un conjunto de ternas “atributo-valor-grado” (donde este último es opcional),
B = (AG1 : di1[,ci1]),…, (AGn : din[,cin])
con i = 1,…,m y donde m es el número de tuplas de la relación, dij representa el valor del dominio que toma la tupla i sobre el atributo Aj y cij es el grado de compatibilidad asociado a este valor.
Los operadores de comparación tienen que ser flexibilizados (valga la expresión) de
modo que sea posible comparar dos valores que no sean exactamente iguales.
Definición 3-24. Comparador Extendido
Sea U el dominio de discurso considerado. Se llama comparador extendido θ a cualquier relación difusa definida sobre U y expresada como sigue: θ : U×U → [0, 1]
θ (ui, uj) → b con ui, uj ∈ U y b ∈ [0, 1].
Definición 3-25. Comparador Difuso Generalizado
Sea U un dominio de discurso, D un dominio difuso construido sobre el mismo y θ
un comparador extendido definido sobre U. Se considera una función θ θ definida como sigue: θ θ : U×U → [0, 1]
θ θ (d1, d2)→ [0, 1] Se dice que θ θ es un comparador difuso generalizado sobre D inducido por el comparador extendido θ , si cumple:
θ θ (d1, d2) = θ (v1, v2) ∀ v1, v2 ∈ U

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 65
donde d1 y d2 representan las distribuciones de posibilidad 1/v1 y 1/v2 inducidas, respectivamente, por los valores v1 y v2.
3.3.7.2 Manejo de datos imprecisos
Definición 3-26. Proyección Difusa Generalizada
Sea R una relación difusa generalizada como la de la Definición 3-23 y X un subconjunto de H definido como sigue: x ⊆ H, x = (As : Ds[,Cs ’] : s ∈ S, s’ ∈ S’; S, S’ ⊆ 1,…,n Entonces, se llama proyección difusa generalizada de R sobre x, y se nota por PX(R), a una relación difusa generalizada de la forma: HP = X
PX(R) = BP = ( As : dis [, cis’ ])
donde s ∈ S, s’ ∈ S’ y S, S’ ⊆ 1,…,n
Definición 3-27. Selección Difusa Generalizada
Sea R una relación difusa generalizada como la de la Definición 3-23, a ∈ D una
constante, θ θ un comparador difuso generalizado y γ un “umbral de cumplimiento”.
Entonces, se llama selección difusa generalizada sobre la relación R inducida por θ θ compuesto
con a y el atributo Ak, k ∈ 1,…,n y cualificada por γ , y se nota por Sθ θ (Ak,a)≥ γ (R) a la relación difusa generalizada de la forma: HS = (A1 : D1[,CA1]),…, (An : Dn[,CAn])
Sθ θ (Ak,a)≥ γ (R) = BS = (A1 : dr1[,c’r1]),…, (Ak : drk[,c’rk]),…, (An : drn[,c’rn])
con c’ rk = θ θ (drk, a) ≥ γ donde r = 1,…,m’ con m’ el número de tuplas de la selección.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 66

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 67
3.4 Implementación de bases de datos difusas: FIRST
En [Med94, Med94b] Medina, Pons y Vila expusieron un módulo para permitir extender la capacidad de un Sistema Gestor de Bases de Datos Relacionales (SGBDR) clásico a fin de representar y manipular información “imprecisa”. Este módulo, llamado FIRST (Fuzzy Interface for Relational SysTems, Interface Difuso para Sistemas Relacionales), utiliza GEFRED como modelo teórico (explicado en el epígrafe 3.3.7) y los recursos del modelo relacional clásico para poder representar este tipo de información.
Con el objeto de completar el modelo FIRST, para poder efectuar las operaciones típicas
(creación de tablas, de etiquetas, consultas flexibles...) sobre la Base de Datos Relacional Difusa (BDRD) Galindo y Medina [Med94b, Gal99] extendieron el lenguaje SQL para permitir el tratamiento de los nuevos datos. A esta extensión se le llamó FSQL (Fuzzy SQL).
La Figura 3-6 muestra el esquema general de FIRST. La idea genérica es basarse en un SGBDR convencional, así todos los desarrollos a realizar toman a dicho gestor como el elemento principal al que van dirigidas todas las peticiones.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 68
En breve, se explica cada uno de esos módulos, pudiendo encontrarse una amplia explicación sobre cada uno de ellos en [Med94, Med94b, Gal99]:
• SGBDR (Sistema Gestor de Bases de Datos Relacionales, Relational DabaBase Management System, RDBMS): Todas las operaciones concebidas para la extensión difusa aquí explicada, se traducen a peticiones al SGBDR anfitrión (en general en SQL). Las peticiones al SGBDR se realizan empleando el lenguaje SQL o FSQL, dependiendo si la consulta involucra o no relaciones y/o condiciones difusas. Las sentencias FSQL serán procesadas por el Servidor FSQL.
• BD (Base de Datos): Almacena, en formato relacional toda la información que sea de interés, igual que cualquier otra base de datos con la salvedad que permitirá el almacenamiento de información difusa en sus tablas. La forma en que se representan
BD
Base de Datos
FMB
Fuzzy Metaknowledge
Base
DIC
Diccionario del Sistema
SGBDR
Sistema Gestor de Bases de Datos Relacionales
Servidor FSQL
FQ Cliente FSQL
F Cliente FSQL
FSQL
embebido...
Catálogo del Sistema
Figura 3-6. Esquema general de FIRST

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 69
los datos en dichas tablas dependerá de la naturaleza de los mismos y se verá en los próximos apartados.
• FMB (Fuzzy Metaknowledge Base, Base de Metaconocimiento Difuso): El “diccionario” o “catálogo del sistema” de un SGBDR representa aquella parte del sistema que almacena información sobre los datos recogidos en la base de datos, asÍ como otro tipo de informaciones: Usuarios, permisos, accesos, datos de control... Dentro de este catálogo se ha incluido la FMB, que extiende esta parte del sistema a fin de que pueda recoger aquella información necesaria relacionada con la naturaleza “imprecisa” de la colección de datos a procesar. Su organización y la información que almacena se verán más adelante.
• Servidor FSQL: Su objetivo es captar las sentencias en lenguaje FSQL y traducirlas a un lenguaje que entienda el SGBDR, el lenguaje SQL. Para efectuar esta traducción usa la información almacenada en la FMB. Este Servidor está íntegramente programado en el lenguaje PL/SQL de Oracle® y se encuentra implantado como una colección de módulos almacenados en el Servidor Oracle®. El Servidor FSQL puede ser instalado en cualquier plataforma donde exista una implementación de Oracle®.
• Cliente FSQL: Se trata de un programa que hace de interfaz entre el hombre (u otro programa) y el Servidor FSQL. Este programa puede ser muy simple, pues el trabajo principal de una operación FSQL será efectuado por el Servidor FSQL. El programa Cliente FSQL puede ser programado para cualquier Sistema Operativo y en cualquier lenguaje de programación.
3.4.1 Representación de información imprecisa
Los elementos que forman parte del tratamiento impreciso pueden ser representados de diversas maneras. De ese modo, una distribución de posibilidad normalizada puede representarse mediante parábolas, hipérbolas, etc. Sin embargo, la implementación FIRST [Med94, Gal99] y, por tanto, su servidor de consultas imprecisas FSQL, construidos sobre el modelo GEFRED [Med94b, Gal99], asume la representación trapezoidal descrita por cuatro puntos que se muestra en la Figura 3-7. Esta simplificación se explica en función de la contradicción que supone representar datos intrínsecamente imprecisos mediante distribuciones de posibilidad definidas de forma altamente precisa, que además añaden el factor del incremento del coste computacional.
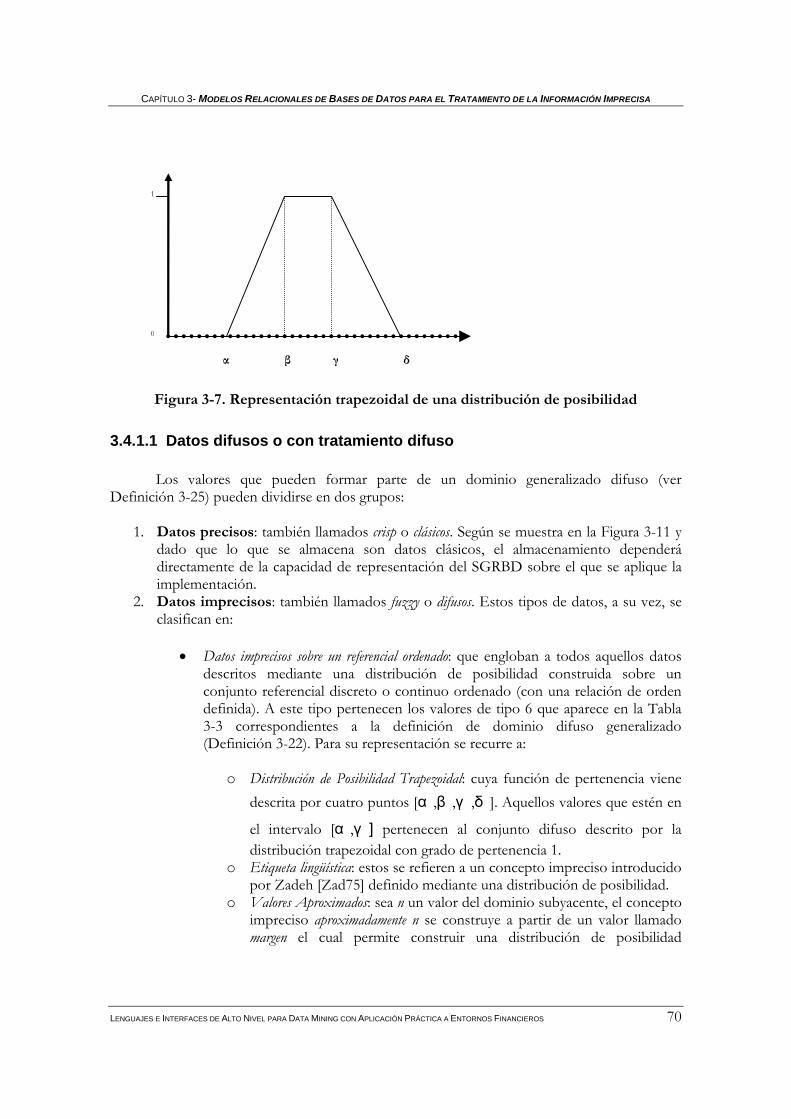
CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 70
Figura 3-7. Representación trapezoidal de una distribución de posibilidad
3.4.1.1 Datos difusos o con tratamiento difuso
Los valores que pueden formar parte de un dominio generalizado difuso (ver Definición 3-25) pueden dividirse en dos grupos:
1. Datos precisos: también llamados crisp o clásicos. Según se muestra en la Figura 3-11 y dado que lo que se almacena son datos clásicos, el almacenamiento dependerá directamente de la capacidad de representación del SGRBD sobre el que se aplique la implementación.
2. Datos imprecisos: también llamados fuzzy o difusos. Estos tipos de datos, a su vez, se clasifican en:
• Datos imprecisos sobre un referencial ordenado: que engloban a todos aquellos datos
descritos mediante una distribución de posibilidad construida sobre un conjunto referencial discreto o continuo ordenado (con una relación de orden definida). A este tipo pertenecen los valores de tipo 6 que aparece en la Tabla 3-3 correspondientes a la definición de dominio difuso generalizado (Definición 3-22). Para su representación se recurre a:
o Distribución de Posibilidad Trapezoidal: cuya función de pertenencia viene
descrita por cuatro puntos [α ,β ,γ ,δ ]. Aquellos valores que estén en
el intervalo [α ,γ ] pertenecen al conjunto difuso descrito por la distribución trapezoidal con grado de pertenencia 1.
o Etiqueta lingüística: estos se refieren a un concepto impreciso introducido por Zadeh [Zad75] definido mediante una distribución de posibilidad.
o Valores Aproximados: sea n un valor del dominio subyacente, el concepto impreciso aproximadamente n se construye a partir de un valor llamado margen el cual permite construir una distribución de posibilidad
α β γ δ
1
0
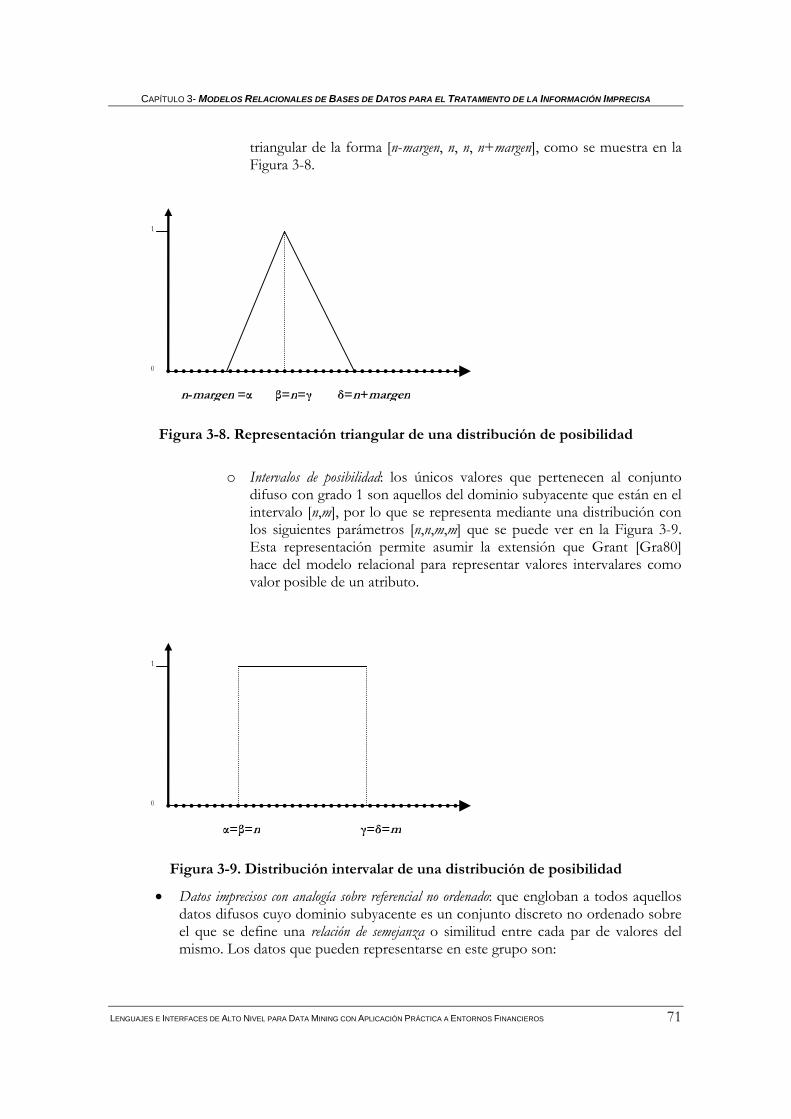
CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 71
triangular de la forma [n-margen, n, n, n+margen], como se muestra en la Figura 3-8.
Figura 3-8. Representación triangular de una distribución de posibilidad
o Intervalos de posibilidad: los únicos valores que pertenecen al conjunto
difuso con grado 1 son aquellos del dominio subyacente que están en el intervalo [n,m], por lo que se representa mediante una distribución con los siguientes parámetros [n,n,m,m] que se puede ver en la Figura 3-9. Esta representación permite asumir la extensión que Grant [Gra80] hace del modelo relacional para representar valores intervalares como valor posible de un atributo.
Figura 3-9. Distribución intervalar de una distribución de posibilidad
• Datos imprecisos con analogía sobre referencial no ordenado: que engloban a todos aquellos datos difusos cuyo dominio subyacente es un conjunto discreto no ordenado sobre el que se define una relación de semejanza o similitud entre cada par de valores del mismo. Los datos que pueden representarse en este grupo son:
α=β=n γ=δ=m
1
0
n-margen =α β=n=γ δ=n+margen
1
0

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 72
o Escalares Simples: este tipo está representado por una única pareja de datos en la que el único valor de posibilidad es 1/d, lo que quiere decir que el único valor posible es d con grado de posibilidad 1 (normalización).
o Distribución de Posibilidad sobre Escalares: este tipo se le asocia una representación del tipo d1/p1, d2/p2,… , dn/pn en la que a cada valor del dominio subyacente se le asigna un grado de pertenencia al conjunto difuso.
Para todos estos tipos difusos existen valores especiales cuyo sentido fue establecido
por Umano et al. (ver 3.3.5) y que se enumeran a continuación:
• Unknown que representa la ignorancia acerca del valor que toma un atributo. Este hecho implica que el atributo puede tomar cualquier valor del dominio con un valor de posibilidad 1, de modo que la distribución que representa este valor es 1/d, ∀ d ∈ D con D el dominio subyacente.
• Undefined que representa la situación en la que no existe ningún valor del dominio que pueda aplicarse al atributo, de modo que la distribución de posibilidad que representa esta situación es 0/d, ∀ d ∈ D donde D es el dominio subyacente.
• Null que representa la ignorancia acerca de cuál de las dos situaciones anteriores es la que se da, de modo que la distribución de posibilidad que describe la situación es 1/Unknown, 1/Undefined.
Hay que proporcionar una representación para los tres valores especiales Null, Unknown
y Undefined cuyas distribuciones de posibilidad se ven en la Figura 3-10.
Figura 3-10. Distribuciones de posibilidad de los valores Unknown y Undefined
Para recoger todos los valores que se pueden formar parte de un dominio generalizado
difuso Medina [Med94b], y Galindo [Gal99] posteriormente, plantearon tres tipos de atributos en su implementación FIRST del modelo GEFRED, sobre el sistema gestor relacional de bases de datos Oracle®. A grandes rasgos, estos atributos son:
Unknown
1
0
Undefined1
0

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 73
• Tipo difuso 1: representa datos precisos que pueden ser consultados de forma imprecisa. Un ejemplo de este tipo de datos se puede observar en la Figura 3-11.
• Tipo difuso 2: representa datos imprecisos pertenecientes a un dominio difuso construido sobre un referencial ordenado y que pueden ser consultados de forma imprecisa. Por ejemplo, obsérvese la Figura 3-12.
• Tipo difuso 3: representa datos imprecisos pertenecientes a un dominio difuso construido sobre un referencial discreto no ordenado, sobre el que se define una relación de similitud, y que pueden ser consultados de forma imprecisa. Véase la Figura 3-13.
Figura 3-11. Ejemplo de tipo difuso 1 en FIRST
Figura 3-12. Ejemplo de tipo difuso 2 en FIRST
5 10 15 20 25 30 35
1
INFANTIL ADOLESCENTE JOVEN MADURO CONSULTADO
ALMACENADO
5 10 15 20 25 30 35
1
INFANTIL ADOLESCENTE JOVEN MADURO CONSULTADO
ALMACENADO

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 74
Figura 3-13. Ejemplo de tipo difuso 3 en FIRST
En el modelo relacional los atributos toman valores en dominios de valores atómicos
(enteros, reales, cadenas de caracteres, caracteres,…) que son las unidades mínimas de información. Dicho modelo no especifica los dominios, pero cualquier SGBD construido sobre este paradigma (excepción hecha de aquellos que poseen características de orientación a objetos, que no es el que se plantea) usa únicamente valores atómicos.
En el caso de los atributos de tipo difuso 1, no es necesaria ninguna estructura adicional para la representación de valores, ya que no es la representación lo que se flexibiliza, sino la consulta.
En el caso de los atributos de tipo 2 y tipo 3, no es solo la consulta la que se flexibiliza, sino también la representación de valores. Galindo propone en [Gal99] una estructura para la representación de atributos de los tipos 2 (ver Tabla 3-4) y de los tipos 3 (ver Tabla 3-5).
Tipo de valor Atributos de tabla para valores de tipo difuso 2 FT F1 F2 F3 F4 UNKNOW 0 NULL NULL NULL NULL UNDEFINED 1 NULL NULL NULL NULL NULL 2 NULL NULL NULL NULL CRISP 3 D NULL NULL NULL LABEL 4 FUZZY_ID NULL NULL NULL INTERVALO [n,m]
5 N NULL NULL M
APROX(d) 6 D d-margen d+margen Margen
Rubio Moreno Pelirrojo Castaño
α (1,2) α (2,3) α (3,4)
α (1,3) α (2,4)
α (1,4)
CONSULTADO ALMACENADO

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 75
TRAPECIO
[α ,β ,γ ,δ ]
7 α β -α γ δ
Tabla 3-4. Representación interna de Atributos Difusos Tipo 2
En la Tabla 3-4, el atributo FT almacena el tipo de valor y los atributos F1, F2, F3 y F4
se usan para almacenar los parámetros de cada valor. Los valores NULL que aparecen en esta tabla representan valores inaplicables. Tipo de valor Atributos de tabla para valores de tipo difuso 3 FT FP1 F1 … FPn Fn UNKNOW 0 NULL … NULL NULL UNDEFINED 1 NULL … NULL NULL NULL 2 NULL … NULL NULL SIMPLE 3 P d … NULL NULL DISTR. POS. 4 p1 d1 … pn dn
Tabla 3-5. Representación interna de Atributos Difusos Tipo 3
En la Tabla 3-5, el atributo FT almacena el tipo de valor y los pares de atributos (pn,dn)
representan que el valor dn del dominio tiene un grado de posibilidad pn. Los valores NULL que aparecen en esta tabla representan valores inaplicables.
De este modo, cuando se quiera representar un atributo de tipo 2 en una relación, serán necesarias cinco atributos de tipo básico. Para representar un atributo de tipo 3, serán necesarias 2 × n+1 atributos de tipo básico, donde n es el número de valores que forman el dominio en cuestión.
3.4.1.2 Comparadores difusos generalizados
En la literatura pueden encontrarse diversos métodos de comparación de números difusos, los cuales pueden clasificarse, principalmente, en dos categorías: los que usan una función que va del conjunto de números difusos a un conjunto ordenado y los que usan relaciones difusas para el proceso de comparación. Al primer tipo pertenecen a las propuestas recogidas en [Ada80, Yag78, Yag81, Zhu91]. Sobre el segundo tipo se encuentran diferentes aproximaciones en [Bal79, Bas77, Del88, Dub83].
Los comparadores difusos implementados en FIRST se basan en este segundo tipo y se muestran en la Tabla 3-7. En la Tabla 3-6 se muestra la definición de los mismos para datos sobre referencial ordenado (ver también la Figura 3-14). Para los datos escalares, el único operador implementado es el FEQ, y se basa en la relaciones de similitud definidas por el usuario y materializadas en la FMB. Un más amplio contenido sobre todos estos comparadores se encuentra [Gal98b, Gal99].

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 76
Comp. Difuso
Significado
Definición del Comparador de Posibilidad
Definición del Comparador de Necesidad
FEQ NFEQ
Possibly / Necessarily Fuzzy Equal
B(d))min(A(d), sup Ud∈= donde U es el dominio de A, B. A(d) es el grado de posibilidad para d∈U en la distribución A
B(d))A(d),-max(1 inf Ud∈= donde U es el dominio de A, B. A(d) es el grado de posibilidad para d∈U en la distribución A
FGT NFGT
Possibly/ Necessarily Fuzzy Greater Than
caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
><=
≥=
γδδγδγγδ
γδδγ
caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
><=
≥=
γβδαβαγδ
γβδα
FGEQ NFGEQ
Possibly/ Necessarily Fuzzy Greater or Equal
caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
><=
≥=
αδβγδγαβ
αδβγ
caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
><=
≥=
αββαβααβ
αββα
FLT NFLT
Possibly/ Necessarily Fuzzy Less Than caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
>=
≤=
βααβαββα
βααβ
caso otro 0
& if ) - ( - ) - (
- if 1
BA BA A A B B
BA
BA
=
<>=
≤=
βγαδγδβα
βγαδ
FLEQ NFLEQ
Possibly/ Necessarily Fuzzy Less or EQual caso otro 0
& if ) - ( - ) - (
- if 1
BA BA B BA A
A B
BA
=
<>=
≤=
δαγβδγαβ
αδγβ
caso otro 0
& if ) - ( - ) - (
- if 1
BA BAA A B B
BA
BA
=
<>=
≤=
δγγδγδδγ
δγγα
MGT NMGT
Possibly/ Necessarily Fuzzy Much Greater Than
caso otro 0
M &M if ) - ( - ) - (
-M Mif 1
BA BA B BA A
A B
BA
=
+>+<+
=
+≥=
γδδγδγαβ
δγδγ
M es la distancia mínima para considerar dos atributos como muy separados. M se define en la FMB para cada atributo
caso otro 0
M &M if ) - ( - ) - (
-M M if 1
BA BA B BA A
A B
BA
=
+>+<+
=
+≥=
γβδαγδβα
βγδα
M es la distancia mínima para considerar dos atributos como muy separados. M se define en la FMB para cada atributo
MLT NMLT
Possibly/ Necessarily Fuzzy Much Less Than
caso otro 0
M &M if ) - ( - ) - (
-M Mif 1
BA BA B BA A
A B
BA
=
−<−>−
=
−≤=
βααββααβ
αβαβ
M es la distancia mínima para considerar dos atributos como muy separados. M se define en la FMB para cada atributo
caso otro 0
M &M if ) - ( - ) - (
-M M if 1
BA BA B BA A
A B
BA
=
−<−>−
=
−≤=
βγαδβαγδ
γβαδ
M es la distancia mínima para considerar dos atributos como muy separados. M se define en la FMB para cada atributo
Tabla 3-6. Definición de Comparadores Difusos para Atributos Difusos de Tipo 2
Figura 3-14. Distribuciones de posibilidad trapezoidales A y B

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 77
3.4.2 Base de Metaconocimiento Difuso (FMB)
Toda la información adicional sobre la estructura de los dominios y los valores que puede tomar cada atributo construido sobre un dominio generalizado difuso constituye lo que se conoce como Base de Metaconocimiento Difuso (Figura 3-15).
Las relaciones que constituyen dicha estructura tienen la siguiente finalidad:
• FUZZY_COL_LIST: contiene la lista de aquellos atributos de tabla de la base de datos que son susceptibles de tratamiento difuso. Cada atributo queda descrito en esta por una referencia a la tabla a la que pertenecen (OBJ#) y columna en la que se
Figura 3-15. Esquema relacional de la FMB

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 78
almacenan (COL#), el tipo difuso de la columna (F_TYPE), el número de valores de la distribución de posibilidad si se trata de un atributo de tipo difuso 3 (LEN) y un comentario acerca del atributo (COM). Los valores que puede tomar el atributo F_TYPE son:
o 1 para los tipos difuso 1, o 2 para los tipos difuso 2, o 3 para los tipos difuso 3.
• FUZZY_OBJECT_LIST: almacena los objetos difusos que pertenecen al dominio del atributo en cuestión. Cada uno de los objetos están representados por la tabla y columna a cuyo dominio pertenecen (OBJ# y COL#), un identificador (FUZZY_ID), un nombre (FUZZY_NAME) y un tipo de objeto (FUZZY_TYPE). Los valores que puede tomar este último atributo FUZZY_TYPE son:
o 0 para etiquetas lingüísticas de tipo trapezoidal definidas en la tabla FUZZY_LABEL_DEF,
o 1 para escalares sujetos a tratamiento mediante una relación de semejanza definida en FUZZY_NEARNESS_DEF.
o 2, 3, 4 reservadas para cualificadores y cuantificadores aún no incluidos en el modelo.
• FUZZY_LABEL_DEF: contiene información sobre las distribuciones de posibilidad trapezoidales que se asocian a etiquetas lingüísticas. Cada una de ellas está descrita por la tabla y columna a cuyo dominio pertenece (OBJ# y COL#), la etiqueta a la que se asocia (FUZZY_ID) y los parámetros que la definen α , β , γ y δ .
• FUZZY_APPROX_MUCH: contiene los parámetros margen y much para cada atributo de tipo difuso 1 o 2 los cuales se usan para la comparación de valores dentro del dominio difuso. Para cada columna (OBJ#,COL#) se almacenan dos atributos (MARGEN, MUCH).
• FUZZY_NEARNESS_DEF: contiene los valores de similitud entre cada par de valores posible en el dominio discreto de valores escalares que se asocia a un atributo de tipo difuso 3. A cada par de valores posible (FUZZY_ID1, FUZZY_ID2) del dominio discreto de escalares de un atributo de tipo difuso 3 (OBJ#, COL#) hay asociado un grado de compatibilidad (DEGREE).
• FUZZY_COMPATIBLE_COL: contiene información sobre aquellos atributos de tipo difuso 3 que comparten dominio con otro atributo difuso del mismo tipo, de modo que no sea necesario volver a definir todos los valores de dicho dominio y sus grados de compatibilidad. Para cada atributo difuso de tipo 3 que comparte dominio discreto de escalares con otro atributo (OBJ#1, COL#1) se almacena la referencia al atributo con el que comparte dominio (OBJ#2, COL#2).
3.4.3 Lenguaje SQL difuso (FSQL): consulta imprecisa
Existen dos propuestas básicas para la sintaxis y el manejo de una sentencia SELECT para datos imprecisos que son la propuesta de Bosc et al. [Bos88] y la propuesta de Galindo [Gal99], diseñada específicamente sobre el modelo GEFRED [Med94b]. De las dos propuestas, se hará hincapié en la de Galindo que es la ha sido implementada dentro del ámbito de FIRST.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 79
Galindo parte de la estructura básica de la sentencia SELECT del lenguaje de consulta
relacional SQL:
SELECT <lista_columnas> FROM <lista_tablas> WHERE <condición>;
e introduce modificaciones que permitan realizar consultas imprecisas sobre atributos de los tipos difusos que han sido definidos en este mismo apartado.
Las novedades introducidas en la sentencia son:
• Etiquetas lingüísticas, que comienzan con el símbolo $. Como ya se ha visto, pueden presentarse dos tipos de etiquetas: etiquetas asociadas a Conjuntos Difusos construidos sobre un referencial ordenado y etiquetas asociadas a valores de un referencial discreto no ordenado.
• Comparadores difusos que pueden ser de posibilidad o de necesidad. Los comparadores de posibilidad son más genéricos y su aplicación ofrece una respuesta más amplia que la devuelta en el caso de los comparadores de necesidad. Todos los comparadores difusos que pueden usarse se muestran en la Tabla 3-7. Algunos ejemplos de condiciones difusas construidas mediante estos comparadores son: Edad FGEQ Joven
Comparador Difuso para: Posibilidad Necesidad
Significado
FEQ NFEQ Igualdad difusa (Fuzzy EQual) FGT FGEQ
NFGT NFGEQ
Mayor que difuso (Fuzzy Greater Than) Mayor o igual difuso (Fuzzy Greater or Equal)
FLT FLEQ
NFLT NFLEQ
Menor que difuso (Fuzzy Less Than) Menor o igual difuso (Fuzzy Less or Equal)
MGT MLT
NMGT NMLT
Mucho mayor que (Much Greater Than) Mucho menor que (Much Less Than)
Tabla 3-7. Comparadores difusos
• THOLD<t> con t ∈ [0,1]: es un modificador que se aplica a cualquier condición para establecer el grado mínimo de cumplimiento t para que una tupla sea seleccionada como resultado. El uso del modificador se muestra en el siguiente ejemplo:
SELECT * FROM Persona WHERE Pelo FEQ Rubio THOLD 0.5 AND Altura FGT Alto THOLD 0.8;
• CDEG(<atributo>): función que puede aparecer en la parte SELECT de una
consulta (en la proyección) y que, en caso de aparecer, añade al esquema de la relación resultante de la consulta una nueva columna que recoge el grado de compatibilidad del atributo dado con el valor del criterio de selección para ese atributo.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 80
• CDEG(*): al igual que en la función anterior, esta añade una columna que recoge el grado de compatibilidad de la tupla con todo el criterio de selección.
• Carácter %: este carácter es similar al comodín usado en la parte SELECT de la consulta (en la proyección) que provoca que todas las columnas de la relación pertenezcan al esquema de la relación resultante de la consulta. Sin embargo, el uso del comodín % aparece una nueva columna por cada atributo difuso relevante en el esquema de la relación resultante que recoge el grado de compatibilidad del valor del atributo en esa tupla con el valor del atributo en el criterio de selección. Se entiende por atributo relevante a aquel que aparece en la parte WHERE de la consulta (en la selección).
• Constantes difusas: estas constantes se muestran en la tabla Tabla 3-8.
Cte. Difusa Significado Unknown Undefined Null
Valor desconocido pero aplicable Valor no aplicable Ignorancia total
A=$[α,β, γ,δ] $label [n,m] #n
Distribución de posibilidad trapezoidal (α≤β≤ γ≤δ). Ver Figura 3-7 Etiqueta lingüística Intervalo “entre n y m” (α=β=n and γ=δ=m) Valor difuso “aproximadamente n” (β=γ=n and n-α=δ=margen)
Tabla 3-8. Constantes difusas
• Condición IS: se modifica para que acepte las constantes difusas Unknown y Undefined, al igual que la constante Null. La sintaxis de una condición IS es;
<fuzzy attribute> IS [NOT] (UNKNOWN | UNDEFINED | NULL)
Nótese que el uso de la condición IS con una constante difusa y el uso del comparador difuso FEQ con la misma constante no tendrán el mismo efecto, ya que este último determina el grado de compatibilidad del atributo difuso con la constante.
3.4.4 Arquitectura cliente-servidor de FSQL
La BDRD y el Servidor FSQL [Gal99] han sido implementados, como ya se ha dicho, usando un SGBD ya existente, Oracle®. Básicamente, esto implica tres consecuencias:
1. El sistema es, quizás, más lento que si se hubiera programado a bajo nivel. 2. La tarea de implementación ha sido más simple al no tener que programar el SGBD. 3. Se aprovechan todas las ventajas del SGBD anfitrión (seguridad, eficiencia...).
El SGBD elegido fue Oracle® por su gran versatilidad, su popularidad (está implantado en
multitud de empresas y entidades) y por la posibilidad que ofrece para crear paquetes (con procedimientos y funciones) internos al sistema. Estos paquetes son creados en un lenguaje propio, PL/SQL [Urm98], que es muy eficiente en accesos a la base de datos. Por supuesto, esta arquitectura puede ser implementada en otros SGBD.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 81
La arquitectura cliente-servidor de FSQL para la BDRD está a compuesta por:
1. Datos: Base de datos tradicional y Base de Metaconocimiento Difuso, FMB (Fuzzy
Meta-knowledge Base). 2. Servidor FSQL (versión 1.2): Encargado de ocultar el procesamiento difuso al usuario. 3. Cliente FSQL: Encargado de hacer de interfaz entre el usuario y el Servidor FSQL.
A continuación se explican cada uno de estos componentes:
3.4.4.1 Datos: base de datos tradicional y FMB
Los datos pueden ser clasificados en dos categorías: La base de datos tradicional y la base de metaconocimiento difuso o FMB. La base de datos tradicional está a compuesta por los datos de las relaciones de usuario con un formato especial para almacenar atributos difusos, como se explicó o en el apartado 3.4.1.
La base de metaconocimiento difuso, FMB (Fuzzy Meta-knowledge Base) almacena
información sobre la BDRD en un formato relacional. En la FMB se almacena una lista con los atributos que admiten tratamiento difuso su Tipo de atributo difuso (1, 2 ó 3). Además, para cada atributo difuso se almacena distinta información dependiendo de su Tipo difuso, tal y como se explicó en el apartado 3.4.2.
3.4.4.2 Servidor FSQL
Como ya se ha dicho, ha sido programado íntegramente en PL/SQL por Galindo [Gal99], e incluye tres tipos de funciones:
• Función de Traducción (FSQL2SQL): Esta función, incluida en el paquete
FSQL_PKG, efectúa un análisis de la consulta FSQL. Si encuentra errores de cualquier naturaleza, genera a una tabla con todos los errores encontrados. Si no hay errores, la consulta FSQL es traducida a una sentencia en SQL. El análisis de la sentencia FSQL tiene por objeto asegurar, por un lado que la sentencia está correctamente escrita (pertenece a la gramática definida) y por otro, que tiene sentido efectuarla (por ejemplo, que usa objetos válidos). Para ello usa los típicos 3 analizadores siguientes: 1. Analizador Léxico: Asegura que todos los elementos de la sentencia están
permitidos, agrupando los caracteres en palabras (tokens). Igual que SQL, el lenguaje FSQL no es sensible a mayúsculas ni minúsculas.
2. Analizador Sintáctico: Asegura que los tokens están en un orden adecuado y que la construcción de la sentencia es correcta sintácticamente.
3. Analizador Semántico: Asegura que el significado de la sentencia es correcto y que, por tanto, tiene sentido efectuarla. Este analizador, es quien genera la

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 82
sentencia resultante en SQL que podrá incluir llamadas a los siguientes tipos de funciones.
• Funciones de Representación: Estas funciones son utilizadas para mostrar los
atributos difusos de manera que sean comprensibles por el usuario, evitando así el críptico formato interno de estos atributos.
• Funciones de Comparación Difusa: Se utilizan para comparar atributos y valores difusos y para calcular los grados de compatibilidad que devuelve la función CDEG. Lo que hace la función de Traducción, es reemplazar los atributos difusos del SELECT por llamadas a las funciones de Representación, las condiciones difusas por llamadas a las funciones de Comparación Difusa y reemplazar las llamadas a la función CDEG por llamadas a las funciones de Comparación Difusa y otras funciones si existen operadores lógicos involucrados en la condición del atributo argumento de CDEG. Las funciones implementadas en el Servidor FSQL para datos con referencial ordenado están expuestas en la Tabla 3-6.
3.4.4.3 Cliente FSQL
Es un programa independiente que sirve de interfaz entre el usuario y el Servidor FSQL. El usuario introduce la consulta FSQL (de forma directa o indirecta) y el programa Cliente se comunica con el Servidor y con la base de datos para obtener los resultados deseados. La principal función que usa directamente el Clientes la de Traducción del Servidor FSQL.
Actualmente existen varios de estos programas cliente, que básicamente son aplicaciones que permiten al usuario hacer consultas FSQL al Servidor FSQL, en el mismo sentido que permiten consultas SQL los clientes, por ejemplo, Oracle SQL*PLUS® y Navigator Pro® contra el SGBDR Oracle®:
• FQ (Fuzzy Queries) [Gal99]: Implementado en Visual Basic sobre entorno Windows XP • F (Fuzzy) [Gal99]: Implementado en lenguaje Java para que pueda ser ejecutado a
través de una red TCP/IP, como Internet o una Intranet, por ejemplo. • Visual Client for FSQL [Med96]: Implementado en Visual Basic sobre entorno Windows
XP, es un programa visual que permite la escritura de sentencias difusas sin tener que conocer la sintaxis de FSQL.
Un uso potencial del Servidor FSQL es uso embebido en otros lenguajes de programación,
como por ejemplo COBOL, C ó PL/SQL, para resolución de problemas específicos.
3.4.4.4 Funcionamiento del cliente-servidor de FSQL
El proceso de llamada del Servidor FSQL está esquematizado en la Figura 3-16. Resumiendo, para una consulta FSQL se ejecutan los siguientes pasos:
1. El programa Cliente FSQL envía a la consulta FSQL al Servidor FSQL.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 83
2. El Servidor FSQL analiza la consulta y, si es correcta, genera una sentencia SQL a partir de la consulta original en FSQL. En este paso el Servidor FSQL usa la información de la FMB.
3. Una vez ha sido generada la consulta en SQL, el programa Cliente leerá dicha consulta. Si en el paso 2 el Servidor FSQL encontró errores, entonces, en este paso se leerán dichos errores, para ser mostrados al usuario.
4. El programa Cliente enviará a la consulta SQL a cualquier base de datos que sea coherente con la FMB. Para la ejecución de esta consulta podrán usarse diversas funciones del Servidor FSQL (de Representación y Comparación Difusa), pero eso es transparente al usuario.
5. Finalmente, el Cliente recibirá los datos resultantes y los mostrará al usuario. El formato de presentación dependerá, lógicamente, del programa Cliente FSQL empleado. Los pasos 3 y 4 podrán haber sido eliminados para incrementar la eficiencia pero, de esta forma se consigue una independencia entre la fase de Traducción (pasos 1, 2 y 3) y la fase de Consulta (pasos 4 y 5). Así, es posible usar una base de datos local con el Servidor FSQL y la FMB para traducir las sentencias localmente y depurar los errores, y enviar las consultas traducidas a una base de datos remota, evitando así sobrecargar la red de comunicaciones con mensajes de error, consultas traducidas... De esta forma, la base de datos remota podrá no tener instalada la función de Traducción, aunque si requerirá tener instaladas las funciones de representación y comparación difusa.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 84
Servidor FSQL
FMB BD
clásica
Base de Datos
cliente FSQL
1.Consulta
FSQL 2.MetaConocimientoDifuso
3.Consulta
SQL
4.Consulta SQL
5.Resultados
Figura 3-16. Arquitectura básica para la BDRD con el Servidor FSQL

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 85
3.4.5 Comparativa de GEFRED con respecto a su implementación FIRST
En este apartado, se pretende hacer un estudio comparativo del modelo GEFRED respecto a su instanciación FIRST, desde dos puntos de vista:
• dominios susceptibles de ser tratados y • comparadores difusos que contemplan.
3.4.5.1 Dominios susceptibles de ser tratados
En la Tabla 3-3 se podía observar los tipos de datos susceptibles de ser tratados por GEFRED y en la Tabla 3-9 se ha hecho una exposición de las diferencias entre ambos modelos respecto a los tipos de datos que ambos pueden gestionar.
En [Med94] se hace una amplia comparativa de GEFRED con los otros modelos
explicados en 3.3, resultando que GEFRED tiene un manejo más extenso, en lo referente a los tipos de datos que puede soportar. Obviamente FIRST tiene más restricciones que GEFRED respecto a los tipos de datos que contempla, explicándose a continuación, con más detalle, las diferencias existentes entre ambos:
• Los valores excluyentes escalares no están soportados en FIRST. Así datos como, por ejemplo, por ejemplo, Comportamiento = bueno, malo (hablando en lenguaje natural, el Comportamiento es bueno ó malo), que se representa por la distribución de posibilidad 1/bueno, 1/malo, no son posibles de almacenar, ni por tanto, gestionables en FIRST.
• Los valores excluyentes numéricos no están contemplados en FIRST. Así informaciones como, por ejemplo, Edad = 20, 21 (hablando en lenguaje natural, la Edad es de 20 ó 21 años), que se representa mediante la distribución de posibilidad 1/20, 1/21, no son almacenables, ni por tanto, tratables en FIRST.
• Las distribuciones de posibilidad numéricas contempladas en FIRST son únicamente las trapezoidales.
• Los grados de compatibilidad que reflejan el nivel en que cada atributo involucrado en una sentencia de DML satisface los requisitos establecidos en la misma, están contemplados en FIRST mediante la función CDEG de FSQL (explicada en 3.4.3). El inconveniente es que no está implementado en FIRST el almacenamiento de dicho grado de compatibilidad.

CAPÍTULO 3- MODELOS RELACIONALES DE BASES DE DATOS PARA EL TRATAMIENTO DE LA INFORMACIÓN IMPRECISA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 86
Escalares Numéricos Dominio
Esquema
Simple Valores excluyentes
Distribución Posibilidad
Simple Valores excluyentes
Distribución Posibilidad
Grado Acoplamiento
Unknown Undefined Null
GEFRED Sí Sí Sí Sí Sí Sí Sí Sí FIRST Sí No Sí Sí No Sí,
trapezoidal Sí, dentro de sentencias
DML (CDEG)
Sí
Tabla 3-9. Comparativa de los dominios soportados en GEFRED y FIRST
3.4.5.2 Comparadores difusos que contemplan
La definición del comparador difuso generalizado en GEFRED (Definición 3-25) encarna gran parte de la filosofía de este modelo. De este modo, GEFRED no impone restricciones en lo respecta a la definición de comparadores difusos, sobre lo dominios que el modelo recoge. FIRST en cambio, como ya se ha dicho, se centra en los comparadores expuestos en Tabla 3-7 con dos vertientes:
• Sobre datos con referencial ordenado (dominios numéricos). Para los que se usaron, en
principio, medidas de posibilidad para su definición [Med94], ampliándose posteriormente a medidas de necesidad [Gal99]. La definición final de los mismos se encuentra en Tabla 3-6.
• Sobre datos escalares. El único comparador definido es el FEQ y se basa, como ya se ha explicado, en relaciones de similitud almacenadas en la FMB y especificadas por el usuario.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 87
Capítulo 4 AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
Como se ha visto en el epígrafe 2.1, uno de los requisitos imprescindibles en los sistemas
de DM es el manejo de múltiples tipos de datos. La definición de GEFRED supuso en su día un gran avance en este aspecto, ya que integraba a gran parte de los modelos existentes, que pasaban a considerarse como un caso particular del mismo GEFRED, también en lo que respecta a los tipos de datos que podían manejar. Sin embargo, hoy día se puede considerar que GEFRED no es lo suficientemente flexible en la variedad de datos que puede tratar, si se quieren usar de forma efectiva dentro de un contexto de DM genérico. La limitación es obviamente doble, por un lado en los tipos de datos que se pueden almacenar y, por otro lado, el tipo de tratamiento (comparadores difusos) que se les puede dar.
Los tipos de datos existentes en la actualidad toman frecuentemente formas que no son
gestionables por GEFRED, texto, hipertexto, XML, objetos, etc. Sirva como motivación al problema un ejemplo sencillo:
Imagínese una entidad financiera que quiere detectar agrupaciones familiares dentro de
su base de datos. Un criterio perfectamente válido podría ser usar el domicilio de las personas, pero al depender dicho dato de su introducción manual en la base de datos, posiblemente haya disparidad de formatos del mismo domicilio (por ejemplo, “Camino de Ronda 125, 2º” y “Cno. Ronda nº 125 – 2” serían realmente el mismo domicilio). Parece un problema perfectamente válido para FSQL ya que relajando la condición se podría obtener buenos resultados: “dame las personas cuyo domicilio tenga un grado de parecido superior al 0.95”. El problema que existe es que, como se ha dicho, GEFRED no puede gestionar dichos tipos de datos.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 88
En este capítulo se va a proceder a la redefinición de GEFRED (definido en 3.3.7) ampliándose la definición del dominio difuso generalizado, y todo lo que esto conlleva en el modelo, con las siguientes pretensiones:
• no restringir la definición a ningún dominio en concreto, • formalizar la representación de tipos de datos complejos, en el sentido de requerir más
de un atributo en el sentido clásico del mismo.
A este nuevo modelo que surge se le llamará GEFRED*, esto es, se le añadirá como sufijo del acrónimo un * que simbolice el potencial superior en cuestión de manejo de múltiples dominios.
Posteriormente, se llevarán los cambios que conlleva GEFRED* a su implementación,
que pasará a llamarse FIRST*. La implementación práctica de este nuevo modelo será expuesta en este capítulo. Se hará una comparativa de todos los modelos surgidos hasta ahora en el desarrollo de esta memoria, pudiéndose verificar la bondad del modelo aquí propuesto. Finalmente se introducirán algunos ejemplos de definiciones de nuevos tipos de datos dentro del ámbito de FIRST*.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 89
4.1 Ampliación del Modelo Generalizado para Bases de Datos Relacionales Difusas para el manejo de múltiples tipos de datos: GEFRED*
Se va a proceder a la definición de GEFRED* que está basado en GEFRED (definido en 3.3.7) de tal manera que la definición del dominio difuso generalizado va a tener un sentido más universal.
Para ello se define previamente:
Definición 4-1. Dominio Complejo
Sean una serie de dominios D1,D2,…,Dn, tal que cada Di (con i=1,2,…,n) es un dominio atómico en el sentido clásico de las Bases de Datos Relacionales y además esa serie de atributos conjuntamente implica una característica importante y variable que tiene una entidad.
Se define entonces dominio complejo y se nota como D’ al dominio descrito por D1×D2×
…×Dn, siempre y cuando esos dominios D1, D2,…,Dn modelen conjuntamente una característica importante y variable que tiene una entidad.
Y ahora, se procede a la redefinición del nuevo modelo GEFRED*:
Definición 4-2. Dominio Difuso Generalizado Complejo
Sea D’ un dominio complejo, ∏ (D’) el conjunto de distribuciones de posibilidad definidas sobre D’, entre las que se incluyen aquéllas que describen los valores Unknown (desconocido) y Undefined (no aplicable). Se considera también el valor Null (nulo). El Dominio Difuso Generalizado Complejo se define como D’G donde D’G ⊆ ∏ (D’) ∪ Null.
Los atributos que se definan sobre el dominio difuso generalizado complejo podrán tomar cualquier valor simple, excluyente o distribución de posibilidad. Dicho dominio puede implicar tanto dominios precisos, como difusos de cualquier naturaleza, siendo un caso particular los tipos de datos reflejados en la Tabla 3-3. La gestión de los tipos de datos va a ser posible mediante la definición de una serie de operaciones especiales a realizar sobre los elementos del dominio, que permitirán incorporar significado a la representación de los datos, en definitiva para que se consiga el objetivo de modelar más certeramente la realidad. En cualquier caso, todas estas capacidades de representación encontrarán en el comparador difuso generalizado complejo (que se definirá más adelante) el mecanismo mediante el que modelar su actuación.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 90
Definición 4-3. Relación Difusa Generalizada Compleja
Una relación difusa generalizada compleja, R’, es un par de conjuntos (H’, B’), definidos como sigue:
• H’ es el conjunto llamado cabecera y describe la estructura de la relación mediante un conjunto de ternas “atributo complejo-dominio complejo-compatibilidad”(donde el último es opcional),
H’ = (A’G1 : D’G1[,C’A’G1]),…, (A’Gn : D’Gn[,C’A’Gn])
donde a cada atributo A’j, le subyace un dominio difuso generalizado complejo, no necesariamente distinto, D’j, j ∈ [1, n]. C’j es el llamado atributo de compatibilidad y toma valores en [0, 1].
• B’ es el conjunto llamado cuerpo y está formado por una serie de tuplas difusas generalizadas complejas distintas, donde cada tupla está compuesta por un conjunto de ternas “atributo complejo-valor complejo-grado” (donde este último es opcional),
B’ = (A’G1 : d’i1[,c’i1]),…, (A’Gn : d’in[,c’in])
con i = 1,…,m y donde m es el número de tuplas de la relación, d’ij representa el valor del dominio complejo que toma la tupla i sobre el atributo A’j y c’ij es el grado de compatibilidad asociado a este valor complejo.
Definición 4-4. Comparador Extendido Complejo
Sea U’ el dominio complejo de discurso considerado. Se llama comparador extendido complejo θ ’ a cualquier relación difusa compleja definida sobre U’ y expresada como sigue: θ ': U’×U’ → [0, 1]
θ ’ (u’i, u’j) → b con u’i, u’j ∈ U’ y b ∈ [0, 1].
Definición 4-5. Comparador Difuso Generalizado Complejo
Sea U’ un dominio complejo de discurso, D’ un dominio difuso complejo construido sobre el mismo y θ ’ un comparador extendido complejo definido sobre U’. Se considera
una función θ ’ θ ’ definida como sigue: θ 'θ ’ : U’×U’ → [0, 1]

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 91
θ ’ θ ’ (d’1, d’2)→ [0, 1] Se dice que θ ’ θ ’ es un comparador difuso generalizado complejo sobre D’ inducido por el comparador
extendido complejo θ ’ , si cumple:
θ 'θ ’ (d’1, d’2) = θ ’ (v’1, v’2) ∀ v’1, v’2 ∈ U’ donde d’1 y d’2 representan las distribuciones de posibilidad 1/v’1 y 1/v’2 inducidas, respectivamente, por los valores complejos v’1 y v’2.
Definición 4-6. Proyección Difusa Generalizada Compleja
Sea R’ una relación difusa generalizada compleja como la de la Definición 4-3 y X’ un subconjunto de H’ definido como sigue: X’ ⊆ H’, X’ = (A’s : D’s[,C’s ’] : s ∈ S, s’ ∈ S’; S, S’ ⊆ 1,…,n Entonces, se llama proyección difusa generalizada compleja de R’ sobre X’, y se nota por P’X’(R’), a una relación difusa generalizada compleja de la forma: H’P’ = X’
P’X’(R’) = B’P’ = (A’s : d’is [, c’is’ ])
donde s ∈ S, s’ ∈ S’ y S, S’ ⊆ 1,…,n
Definición 4-7. Selección Difusa Generalizada Compleja
Sea R’ una relación difusa generalizada compleja como la de la Definición 4-3, a’ ∈ D’
una constante compleja, θ ’ θ ’ un comparador difuso generalizado complejo y γ un “umbral de cumplimiento”. Entonces, se llama selección difusa generalizada compleja sobre la relación R’ inducida por θ ’ θ ’ compuesto con a’ y el atributo A’k, k ∈ 1,…,n y
cualificada por γ , y se nota por S’θ ’θ ’ (A’k, a’)≥ γ (R’) a la relación difusa generalizada
compleja de la forma: H’S’ = (A’1 : D’1[,C’A’1]),…, (A’n : D’n[,C’A’n])
S’θ ’θ ’ (A’k, a’)≥ γ (R’) =
B’S’ = (A’1 : d’r1[,c’’r1]),…, (A’k : d’rk[,c’’rk]),…, (A’n : d’rn[,c’’rn])

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 92
con c’’ rk = θ ’ θ ’ (d’rk, a’) ≥ γ donde r = 1,…,m’ con m’ el número de tuplas de la selección.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 93
4.2 Adaptación de FIRST al Modelo Generalizado para Bases de Datos Relacionales Difusas para el manejo de múltiples tipos de datos: FIRST*
En esta sección se va a introducir el interface difuso FIRST* que tendrá como modelo
teórico a GEFRED*, explicado anteriormente. La intención es usar, en la medida de lo posible, el esquema general de FIRST (explicado en 0), que como se sabe, es el interface difuso implementado para GEFRED. Se considera como requisito imprescindible que el anterior modelo FIRST siga siendo completamente válido y está plenamente integrado en el que aquí se propone.
La Figura 4-1 muestra el esquema general de FIRST* que es, aparentemente, bastante
similar al de FIRST, pero con las siguientes salvedades, que serán ampliamente detalladas en los siguientes apartados:

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 94
• BD (Base de Datos): Aún siendo una base de datos relacional clásica, en el sentido de no soportar tipos de datos objetos, podrá almacenar los nuevos atributos que entran a formar parte de lo que se ha llamado dominio difuso generalizado complejo.
• FMB* (Fuzzy Metaknowledge Base, Base de Metaconocimiento Difuso): Esta extensión de la FMB de FIRST posibilitará implementar una visión práctica, tanto del dominio difuso generalizado complejo, como del comparador difuso generalizado complejo, anteriormente explicados.
• Servidor FSQL*: Se considera que la extensión FSQL del lenguaje SQL sigue siendo completamente válida para el nuevo modelo que ha surgido. Sin embargo, es obvio que el servidor que soporta este lenguaje debe de ser adaptado a las nuevas funcionalidades.
BD
Base de Datos
FMB* DIC
Diccionario del Sistema
SGBDR
Sistema Gestor de Bases de Datos Relacionales
Servidor FSQL*
FQ Cliente FSQL
F Cliente FSQL
FSQL
embebido...
Catálogo del Sistema
Figura 4-1. Esquema General de FIRST*

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 95
• Cliente FSQL: El nuevo Servidor FSQL* surgido no debería de tener ningún tipo de cambio respecto a los distintos programas clientes desarrollados para el Servidor FSQL.
4.2.1 Representación de la información con tratamiento difuso en la base de datos
Al igual que se ha hecho en FIRST, en este apartado se va a determinar para el nuevo
esquema FIRST*:
• La forma que toma la representación de los datos, dentro del contexto del dominio difuso generalizado complejo de GEFRED*.
• La forma de tratamiento difuso de dichos datos, dentro del ámbito del concepto de comparador difusos generalizado complejo de GEFRED*.
Se pasa a continuación a detallar cada uno de estos puntos, aunque será necesario estudiar
los elementos de FIRST* que quedan por exponer (FMB* y Servidor FSQL*) para que queden perfectamente claros.
4.2.1.1 Datos difusos o con tratamiento difuso
Dentro de un SBDR clásico, una serie de atributos del mismo implicarán un dominio difuso generalizado complejo si modelan conjuntamente una característica importante y variable que tiene una entidad y, además, permiten algún tipo de tratamiento difuso. Como puede observarse, existe un alto componente subjetivo en estas premisas, así que será el usuario en última instancia quién determine las definiciones de dichos dominios, dentro del ámbito del problema en concreto a tratar.
En FIRST, como se ha explicado, se definieron tres tipos de atributos para modelar los
distintos dominios que GEFRED acogía respecto al tratamiento difuso que se les podía dar. En el modelo FIRST* es impensable intentar delimitar los distintos tipos de datos en el mismo sentido que se ha hecho en FIRST.
Por compatibilidad con el anterior modelo, se va seguir usando en FIRST* los tres
tipos de atributos ya definidos y se va a añadir un super-tipo:
• Tipo difuso 4: representa a la serie de atributos clásicos que determinan un dominio difuso generalizado complejo y que, por tanto, pueden ser consultados de forma imprecisa.
La representación interna de un tipo difuso 4 está compuesta de:
• Atributos de datos que contienen la información en sí. Por ejemplo, si se trata de
representar una distribución trapezoidal [α ,β ,γ ,δ ] con las mismas características

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 96
que un tipo difuso 2 (ver Tabla 3-4), estos atributos sería los F1, F2, F3, F4, en donde se almacenaría correspondientemente los valores α , β -α , δ , γ .
• Atributos de metadatos, esto es, que contienen información que permiten entender los atributos de datos (tipología, etc). Este tipo de atributos no siempre son necesarios. Siguiendo con el ejemplo anterior, este atributo se correspondería con la columna FT, que indica por ejemplo (ver Tabla 3-4) si los atributos de datos contienen un valor Null, Unknown, Undefined, un trapecio, etc.
Las representaciones de los atributos de tipo 2 (ver Tabla 3-4), de los de tipo 3 (ver Tabla
3-5), y por supuesto, de los de tipo 1 (que no necesitaban ninguna estructura adicional) están ahora perfectamente recogidas dentro del nuevo tipo 4, recién introducido.
A veces puede interesar representaciones en las que los llamados atributos de datos tengan valores especiales que permitan evitar el tener que usar los atributos de metadatos. Por ejemplo, un atributo numérico que de forma lógica solo toma valores positivos, podría tener valores especiales que representaran a las constantes difusas, así -1=Null, -2=Unknown, -3=Undefined. Por supuesto, siempre la representación interna debe de estar compaginada con la implementación de los comparadores difusos generalizados complejos que se estudian a continuación.
4.2.1.2 Comparadores difusos generalizados complejos
Se decía en el párrafo anterior, que para implicar un dominio difuso generalizado complejo debía de ser posible que los atributos permitan algún tipo de tratamiento difuso. Esto se materializa en que, sobre los atributos difusos de tipo 4, debe ser posible la definición de, al menos uno, de los comparadores difusos usados en FIRST y que se mostraron en la Tabla 3-7. Quiere esto decir, que el usuario debe de definir los comparadores difusos que crea necesarios para cada tipo de atributo 4 del que se vaya a hacer un tratamiento difuso. Más formalmente, dados dos atributos A y B de tipo 4, para su tratamiento difuso es necesario definir las distintas funciones asociadas a los correspondientes comparadores difusos:
CDEG (A fcomp B) → [0,1] donde fcomp es alguno de los comparadores difusos de dicha Tabla 3-7. En el esquema propuesto no existen, por tanto, limitaciones sobre qué comparadores difusos se pueden definir para los distintos tipos difusos 4 más que la citada, esto es, que pertenezca a uno de los existentes en FIRST. Sí existen restricciones de contexto, esto es, de unos comparadores respecto al resto definidos que se explicarán en el siguiente epígrafe La semántica del comparador puede ser completamente subjetiva a quien lo defina o al problema que se esté resolviendo. Para los tipos de datos que no tienen un referencial completamente ordenado, los comparadores pueden tener un significado cuantitativo más que

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 97
cualitativo. Así en los comparadores difusos usados, la palabra “mayor” pasaría a ser “mejor” y la palabra “menor” se convertiría en “peor”. En esta coyuntura, y sirva de ejemplo, el comparador FGT (posiblemente mayor que) significaría “posiblemente mejor que”.
4.2.1.2.1 Restrictividad de los comparadores difusos en FIRST*
Hay comparadores cuyos resultados de comparación incluyen unos a otros. Por
ejemplo, en modo crisp, el resultado del comparador ≥ incluye al de >. Se dice entonces que el comparador > es más restrictivo que ≥ . Lo mismo se podría decir para los comparadores de FIRST definidos sobre referenciales ordenados. Como implicación práctica, los comparadores más restrictivos recuperarán menor o igual cantidad de tuplas y las tuplas recuperadas nunca tendrán un grado de cumplimiento mayor que con los comparadores menos restrictivos.
Con el objeto de establecer una coherencia en la definición de los distintos comparadores difusos para un mismo tipo de datos difuso 4, en la Tabla 4-1 se puede ver el orden de restrictividad de los comparadores difusos impuesto en FIRST*, por familias. Obsérvese que cualquier comparador de necesidad es más restrictivo que su correspondiente comparador de posibilidad.
Familia Comparadores difusos, de mayor a menor restrictividad Igual difuso NFEQ > FEQ Mayor difuso NFGT > FGT > NFGEQ > FGEQ Menor difuso NFLT > FLT > NFLEQ > FLEQ Mucho mayor difuso NMGT > MGT Mucho menor difuso NMLT > MLT
Tabla 4-1. Restrictividad de los comparadores difusos en FIRST*
4.2.2 Base de Metaconocimiento Difuso* (FMB*)
Toda la información adicional sobre la estructura de los dominios y los valores que puede tomar cada atributo construido sobre un dominio generalizado difuso complejo constituye lo que se conoce como Base de Metaconocimiento Difuso* (FMB*). Este ente toma más importancia, si cabe, en FIRST* que en el anterior modelo, debido a que va a hacer posible tanto la definición, como el tratamiento de los tipos difuso 4, ya introducidos.
Así la FMB* tiene los siguientes componentes:
• FMB completa de FIRST, esto es, toda la estructura relacional ya expuesta en la Figura
Figura 3-3-15. Sobre estas estructuras se han hecho algunas modificaciones para acoplarlas al nuevo modelo pero que, en modo alguno, afecta a las funcionalidades anteriores de FIRST. En breve, se detallará en que han consistido.
• Nuevas estructuras relacionales que posibilitan la definición (atributos de datos, de metadatos y etiquetas lingüísticas) y el tratamiento (comparadores difusos a usar) del tipo de dato difuso 4 y que también serán detalladas de inmediato.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 98
• Funciones de los comparadores difusos implementadas en PL/SQL, o cualquier otro lenguaje, que definen el comportamiento para los distintos tipos de datos difusos 4 y sus correspondientes comparadores difusos. Estas funciones tienen la estructura, ya determinada en el epígrafe anterior, a la que se le ha incluido una serie de parámetros que no son más que constantes que el usuario puede definir asociadas a cada tipo difuso 4 que use, que posibilitan el poder reusar las funciones que ya haya implementadas en la FMB* para otros tipos difusos 4. Estarían incluidos en estos parámetros, por ejemplo, valores que permitan normalizar datos numéricos (con el objeto de facilitar la comparación), información que modele el comparador mediante la visión subjetiva de un decisor, etc. La representación de estas funciones es:
CDEG (A fcomp B, constante_A1, constante_A2,…, constante_An_fcomp, constante_B1, constante_B2,…, constante_Bn_fcomp) → [0,1]
• Funciones de representación que definen la visualización para los distintos tipos de datos
difusos 4. Tienen una estructura muy parecida a las de los comparadores difusos, exceptuando que solo tienen como parámetro un atributo difuso tipo 4 más sus correspondientes constantes, que tienen el mismo sentido de poder reusar las funciones entre distintos tipos difusos 4. Estas funciones pueden devolver cualquier tipo de dato representable por un programa cliente del SGBDR y tienen la estructura:
FSHOW (A, constante_A1, constante_A2,…, constante_An_fshow)

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 99
Figura 4-2. Esquema relacional de la FMB*

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 100
A continuación se exponen cada una de las tablas de la FMB incluyéndose en cursiva los cambios incluidos en la implementación de la FMB* (ver Figura 4-2):
• FUZZY_COL_LIST: contiene la lista de aquellos atributos de tabla de la base de datos que son susceptibles de tratamiento difuso. Cada atributo queda descrito en esta por una referencia a la tabla a la que pertenecen (OBJ#) y columna en la que se almacenan (COL#), el tipo difuso de la columna (F_TYPE), el número de valores de la distribución de posibilidad si se trata de un atributo de tipo difuso 3 (LEN) y un comentario acerca del atributo (COM) que suele usarse para poner el nombre del atributo. Los valores que puede tomar el atributo F_TYPE son:
o 1 para los tipos difuso 1, o 2 para los tipos difuso 2, o 3 para los tipos difuso 3, o 4 para los tipos difuso 4.
• FUZZY_OBJECT_LIST: almacena los objetos difusos que pertenecen al dominio del atributo en cuestión. Cada uno de los objetos están representados por la tabla y columna a cuyo dominio pertenecen (OBJ# y COL#), un identificador (FUZZY_ID), un nombre (FUZZY_NAME) y un tipo de objeto (FUZZY_TYPE). Los valores que puede tomar este último atributo FUZZY_TYPE son:
o 0 para etiquetas lingüísticas de tipo trapezoidal definidas en la tabla FUZZY_LABEL_DEF,
o 1 para escalares sujetos a tratamiento mediante una relación de semejanza definida en FUZZY_NEARNESS_DEF.
o 2, 3, 4 reservadas para cualificadores y cuantificadores aún no incluidos en el modelo,
o 5 para las etiquetas lingüísticas definidas para un tipo de dato difuso 4 en la tabla DMFSQL_LABEL_DEFINITION.
• FUZZY_LABEL_DEF: contiene información sobre las distribuciones de posibilidad trapezoidales que se asocian a etiquetas lingüísticas. Cada una de ellas está descrita por la tabla y columna a cuyo dominio pertenece (OBJ# y COL#), la etiqueta a la que se asocia (FUZZY_ID) y los parámetros que la definen α , β , γ y δ .
• FUZZY_APPROX_MUCH: contiene los parámetros margen y much para cada atributo de tipo difuso 1 o 2 los cuales se usan para la comparación de valores dentro del dominio difuso. Para cada columna (OBJ#,COL#) se almacenan dos atributos (MARGEN, MUCH).
• FUZZY_NEARNESS_DEF: contiene los valores de similitud entre cada par de valores posible en el dominio discreto de valores escalares que se asocia a un atributo de tipo difuso 3. A cada par de valores posible (FUZZY_ID1, FUZZY_ID2) del dominio discreto de escalares de un atributo de tipo difuso 3 (OBJ#, COL#) hay asociado un grado de compatibilidad (DEGREE).
• FUZZY_COMPATIBLE_COL: contiene información sobre aquellos atributos de tipo difuso 3 que comparten dominio con otro atributo difuso del mismo tipo, de modo que no sea necesario volver a definir todos los valores de dicho dominio y sus grados de compatibilidad. Para cada atributo difuso de tipo 3 que comparte dominio discreto de escalares con otro atributo (OBJ#1, COL#1) se almacena la referencia al atributo con el que comparte dominio (OBJ#2, COL#2).

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 101
El resto de tablas forman parte única y exclusivamente de la FMB* y por tanto solo se utilizan para atributos difusos tipo 4:
• DMFSQL_COL_COL: contiene la lista de aquellos atributos de la tabla de la base de
datos que forman parte de, lo que se ha llamado, un dominio difuso generalizado complejo. Como se ha visto, este dominio se ha implementado, tanto con atributos de datos, como de metadatos, aunque ambos son definidos de igual forma en esta tabla. Cada uno de estos dominios vendrá cualificado por un único atributo existente en la tabla y definido por el par: referencia a la tabla a la que pertenecen (OBJ#) y columna en la que se almacenan (COL#). En el resto de tablas de la FMB* cada uno de los tipos difusos 4 vendrán caracterizados por este único atributo. Los atributos integrantes del dominio complejo vendrán definidos por el par: referencia a la tabla a la que pertenecen (OBJ#) y columna en la que se almacenan (COL2#). Mediante un atributo adicional, y por cuestiones de implementación, se establece un orden en cada uno de estos atributos integrantes del dominio complejo (ORDER#). En definitiva, en esta tabla se especifica la representación interna del atributo difuso tipo 4.
• DMFSQL_LABEL_DEFINITION: contiene información sobre las etiquetas lingüísticas definidas para los tipos difusos 4. Cada una de ellas está descrita por la tabla y columna a cuyo dominio pertenece (OBJ# y COL#), la etiqueta a la que se asocia (FUZZY_ID) y los parámetros que la definen (LABEL_VALUE) siguiendo un cierto orden (ORDER#).
• DMFSQL_FUNCTIONS: en esta tabla se define la referencia de las funciones tanto que implementan a los distintos comparadores difusos de los atributos difusos de tipo 4, como las funciones de representación de los mismos. Dichas funciones vienen referenciados por el identificador del paquete (PKG#) y de la función dentro del mismo (FUN#).
• DMFSQL_FUNCTIONS_COL: contiene la definición para cada atributo difuso tipo 4, prototipado, como se ha dicho, por la tabla a la que pertenece (OBJ#) y la columna (COL#), y para cada comparador difuso (FUZZY_COMP) la función que se le asocia, encontrándose ésta en el package (PKG#) e identificándose de forma únivoca (FUN#) dentro de citado package. Los comparadores difusos posibles son los de la Tabla 3-7. También es posible especificar, mediante esta tabla, la función de representación que se quiere usar para el atributo difuso de tipo 4, esto es, como se quiere visualizar el mismo en las sentencias SELECT. Para ello, el campo con el comparador difuso (FUZZY_COMP) debe tener el valor ‘FSHOW’. Esta información será ampliada cuando se exponga la arquitectura del cliente-servidor FSQL* (sección 4.2.4).
• DMFSQL_COL_PAR: contiene información de los parámetros adicionales para construir las llamadas a funciones que implica cada tipo difuso 4 respecto a cada comparador. Como se ha comentado, es tremendamente útil para la reusabilidad de la codificación de las funciones ya implementadas en la FMB*. Así para un atributo difuso tipo 4 determinado (OBJ#, COL#) y para un comparador difuso (FUZZY_COMP) se puede, opcionalmente, especificar los parámetros de la función que implica dicho comparador (PAR_VALUE) y en el orden establecido (PAR#). El valor de los parámetros puede ser (PAR_TYPE):
o ‘C’ para parámetros tipo carácter,

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 102
o ‘N’ para parámetros tipo numéricos, o ‘D’ para parámetros tipo fecha.
Cualquier atributo o serie de atributos de una tabla pueden ser definidos como un tipo difuso 4, basta con que se puedan definir los correspondientes operadores difusos sobre él. Para poner esto de manifiesto, seguidamente, se muestra un ejemplo sencillo de definición de tipo difuso 4 y las implicaciones que conlleva en la FMB*. En la última parte de este capítulo se van a presentar ejemplos más complejos de definiciones de tipos difusos 4.
Ejemplo 4-1
Sean A y B dos atributos numéricos de una relación R que pueden tomar los rangos de valores de los siguientes intervalos: A: [minA , maxA] ⊆ ℜ
B: [minB , maxB] ⊆ ℜ La identificación en el diccionario o catálogo de datos del SGBDR es la siguiente:
• Relación R: (obj#R). • Atributo A: (obj#R, col#A). • Atributo B: (obj#R, col#B).
Se quiere hacer un tratamiento difuso de dichos atributos, de tal manera que el
comparador de igualdad difusa FEQ, esté basado en la diferencia en valor absoluto de los valores de A y B normalizados en el intervalo [0,1] que es lo que normalmente se conoce como la distancia Hamming; y que la función de representación sea el dato normalizado en dicho intervalo [0,1]. Para ello, habría que definir en la FMB*:
• Atributos difusos de tipo 4 A y B, compuestos únicamente por los atributos de datos A y B respectivamente. En este caso no serían necesarios atributos de metadatos ya que se trata de atributos crisps cuyo único tratamiento difuso se refiere al uso del comparador difuso FEQ, sin ni siquiera tratamiento de las constantes difusas Null, Unknown o Undefined.
• La función de representación FSHOW, que consiste en mostrar los datos numéricos normalizados en el intervalo [0,1], se define con una función que viene identificada en el SGBDR por el código del paquete (pkg#) y de la función (NORM_0_1) y que tiene la siguiente actuación:
FSHOW (A, minA, maxA) = NORM_0_1 (A) = 1, si minA = maxA
= [(1 – maxA/( maxA – minA)) + A × (1 / (maxA – minA))], en otro caso
• El comparador difuso FEQ, que está basado en la distancia Hamming de los atributos
normalizados (el número complementario en [0,1] de dicha medida ya que lo que se desea obtener es una medida de similitud, no de disimilitud) se define con una función

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 103
que viene identificada en el SGBDR por el código del paquete (pck#) y de la función (HAMM) y que es la siguiente:
CDEG (A FEQ B, minA, maxA, minB, maxB) =
1 - |NORM_0_1 (A) - NORM_0_1 (B)|
La información que constaría en la estructura relacional de la FMB* para posibilitar el tratamiento de los atributos difusos tipo 4 A y B sería: FUZZY_COL_LIST
OBJ# COL# F_TYPE LEN COMobj#R col#A 4 1 R.A obj#R col#B 4 1 R.B DMFSQL_COL_COL
OBJ# COL# ORDER# COL2# obj#R col#A 1 col#A obj#R col#B 1 col#B DMFSQL_FUNCTIONS
PKG# FUN# pck# HAMM pck# NORM_0_1 DMFSQL_FUNCTIONS_COL
OBJ# COL# FUZZY_COMP PKG# FUN# obj#R col#A FEQ pck# HAMM obj#R col#B FSHOW pck# NORM_0_1 DMFSQL_COL_PAR
OBJ# COL# FUZZY_COMP PAR# PAR_VALUE PAR_TYPE obj#R col#A FEQ 1 minA N obj#R col#A FEQ 2 maxA N obj#R col#A FSHOW 1 minA N obj#R col#A FSHOW 2 maxA N obj#R col#B FEQ 1 minB N obj#R col#B FEQ 2 maxB N obj#R col#B FSHOW 1 minB N obj#R col#B FSHOW 2 maxB N Si además, se quisiera definir una etiqueta lingüística $valor_medio para A que sea el valor intermedio dentro del rango del dominio de dicho atributo se incluiría en la FMB*:

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 104
FUZZY_OBJECT_LIST
OBJ# COL# FUZZY_ID FUZZY_NAME FUZZY_TYPEobj#R col#A fuzzy_id# A1 $valor_medio 5 DMFSQL_LABEL_DEFINITION
OBJ# COL# FUZZY_ID ORDER# LABEL_VALUEobj#R col#A fuzzy_id# A1 1 (minA + maxA) / 2
Como puede fácilmente comprobarse, las funciones implementada en la FMB* para los atributos A y B, pueden ser usadas para cualquier atributo crisps numéricos C definidos en: C: [minC , maxC] ⊆ ℜ sin más que incluir en la FMB* la definición del atributo C en el mismo sentido que A o B.
4.2.3 Repercusiones de FIRST* en el lenguaje SQL difuso (FSQL)
Ya se ha comentado la intención de que el lenguaje FSQL (explicado en sección 3.4.3) sea perfectamente válido para el esquema FIRST*. Esto significa que la sintaxis del mismo no va a ser alterada en absoluto. Sin embargo, existen elementos dentro de esa sintaxis que solo tienen sentido para los atributos en concreto que gestiona FSQL dentro del ámbito de FIRST.
Además la introducción del modelo FIRST* con los tipos difusos 4 va a implicar
modelaciones en la semántica de algunos de los componentes de FSQL. A continuación se explican los componentes más relevantes de FSQL haciendo hincapié en dichas repercusiones semánticas que se han producido con el nuevo modelo:
• Etiquetas lingüísticas, que comienzan con el símbolo $. Como ya se ha visto, para los tipos difusos 4, es posible definir etiquetas lingüísticas en la FMB*, al igual que se podía hacer para el resto de tipos difusos. Estas etiquetas modelan valores complejos de los tipos difusos 4.
• Comparadores difusos que podían ser de posibilidad o de necesidad, y que ahora para los tipos difusos 4, aún conservando la sintaxis, va a ser el usuario quien defina su semántica (en definitiva, el significado de posiblemente ó necesariamente el comparador) a través de la definición de cada comparador difuso en la FMB*, como ya se ha visto. Gracias a la restrictividad de los comparadores difusos establecida en FIRST* (ver 4.2.1.2.1) se puede seguir diciendo que los comparadores llamados de posibilidad son más genéricos y su aplicación ofrece una respuesta más amplia que la devuelta en el caso de los comparadores de necesidad. Todos los comparadores difusos que pueden usarse se muestran en la Tabla 3-7.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 105
• THOLD<t> con t ∈ [0,1]: es un modificador que se aplica a cualquier condición para establecer el grado mínimo de cumplimiento t para que una tupla sea seleccionada como resultado. El uso del modificador no se ha alterado en absoluto con la introducción de los tipos difusos 4.
• CDEG(<atributo>): función que puede aparecer en la parte SELECT de una consulta (en la proyección) y que, en caso de aparecer, añade al esquema de la relación resultante de la consulta una nueva columna que recoge el grado de compatibilidad del atributo dado con el valor del criterio de selección para ese atributo. Para los tipos difusos 4 sigue siendo también así, sin olvidar que existe un único atributo que caracteriza a cada tipo difuso 4, como se ha visto en el estudio de la FMB*, y que es el que hay que usar como el parámetro atributo de esta función.
• CDEG(*): al igual que en la función anterior, esta añade una columna que recoge el grado de compatibilidad de la tupla con todo el criterio de selección. Los atributos difusos 4 tienen el mismo comportamiento que el resto de atributos difusos con respecto a esta función.
• Carácter %: este carácter es similar al comodín usado en la parte SELECT de la consulta (en la proyección) que provoca que todas las columnas de la relación pertenezcan al esquema de la relación resultante de la consulta. Sin embargo, el uso del comodín % aparece una nueva columna por cada atributo difuso (también para los atributos difusos 4) relevante en el esquema de la relación resultante que recoge el grado de compatibilidad del valor del atributo en esa tupla con el valor del atributo en el criterio de selección. Se entiende por atributo relevante a aquel que aparece en la parte WHERE de la consulta (en la selección).
• Constantes difusas: Las constantes para los tipos difusos 4 se muestran en la Tabla 4-2, lógicamente no es posible usar las constantes difusas específicas para los tipos difusos 2 (expuestas en la Tabla 3-8). Se introduce la constante difusa “VALUE_v1\v2\...\vn” para los tipos difusos 4 en donde cada vi (con i=1…n) representa un valor atómico de los atributos que componen el tipo difuso 4, el orden de los valores debe ser el especificado en la FMB* a la hora de definir el tipo difuso 4. Nótese que estas últimas constantes son léxica y sintácticamente iguales que las etiquetas lingüísticas de FSQL para los tipos difusos 1, 2 y 3.
Cte. Difusa Significado Unknown Undefined Null
Valor desconocido pero aplicable Valor no aplicable Ignorancia total
$VALUE_v1\v2\...\vn Constante para tipos difusos 4
Tabla 4-2. Constantes difusas para tipos difusos 4 en FSQL
• Condición IS: mediante esta condición se pueden usar las constantes difusas Unknown
y Undefined, al igual que la constante Null. Al contrario de lo que ocurría para los tipos difusos 1, 2 y 3, para los tipos difusos 4 el uso de la condición IS con una constante difusa y el uso del comparador difuso FEQ con la misma constante tendrán el mismo efecto. Si se quieren usar estas constantes difusas, es por tanto necesario definir las correspondientes etiquetas lingüísticas, esto es, $Null, $Unknown y $Undefined, y especificar por tanto su actuación respecto al comparador FEQ en la FMB*.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 106
Ejemplo 4-2
Sea la relación:
• R(dia_mes, cotización_mes_actual, cotización_mes_anterior) que contiene datos sobre la cotización bursátil de un determinado valor durante 1 mes con el siguiente significado de los atributos:
• dia_mes: llave primaria que indica el ordinal correspondiente al día hábil del mes al que se refiere la cotización (1 es el primer día hábil, 2 el segundo…).
• cotización_mes_actual: porcentaje de la cotización a cierre del día (día_mes) del valor, con respecto a la cotización a inicio de año, en el mes actual.
• cotización_mes_anterior: porcentaje de la cotización a cierre del día (día_mes) del valor, con respecto a la cotización a inicio de año, en el mes inmediatamente anterior al actual.
Si se quisiera hacer un estudio de los días del mes en los que ambos porcentajes de
cotización son aproximadamente iguales, se podría definir los atributos cotización_mes_actual y cotización_mes_anterior como atributos difusos tipo 4 en la FMB* de forma análoga a como se ha hecho para los atributos A y B del Ejemplo 4-1, teniendo en cuenta que: minA = minB = 0, maxA = maxB = 100 Así si la relación R contiene las siguientes tuplas:
dia_mes cotización_mes_actual cotización_mes_anterior 1 58.54 49.44 2 41.86 43.66 3 78.24 78.24 4 77.5 76.5 5 71.25 71.25 6 74.17 69.17 7 72.5 62.5 8 56.34 60.34 9 81.25 56.25 10 54.17 54.64 11 62.5 52.52 12 56.34 46.34 13 58.54 46.74 14 72.97 61.17 15 93.75 81.75 16 91.18 84.18 17 86.22 80.22 18 69 78 19 77.55 68.45 20 77.78 67.18

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 107
Para obtener los datos en que la cotización del mes actual coincide aproximadamente con la del mes anterior con un grado de compatibilidad de al menos el 0.95, habrá que formular la siguiente sentencia FSQL:
SELECT dia_mes, cotizacion_mes_actual, cotizacion_mes_anterior, CDEG(*) FROM R WHERE cotizacion_mes_actual FEQ cotizacion_mes_anterior THOLD 0.95 ORDER BY 1
Que devuelve la siguiente relación:
dia_mes cotización_mes_actual cotización_mes_anterior CDEG(*) 2 0.5814 0.5634 0.982 3 0.2176 0.2176 1 4 0.225 0.235 0.99 5 0.2875 0.2875 1 6 0.2583 0.3083 0.95 8 0.4366 0.3966 0.96 10 0.4583 0.4536 0.9953 Nótese que los atributos difusos tipo 4 (cotizacion_mes_actual y cotizacion_mes_anterior) son mostrados tal y como se ha definido en la FMB* para la función FSHOW, esto es, normalizados en [0, 1] (ver Ejemplo 4-1).
4.2.4 Arquitectura cliente-servidor de FSQL en FIRST*
Como ya se ha visto, la arquitectura cliente-servidor de FSQL han sido implementados usando Oracle® [Gal99]. Parte de esta arquitectura va a servir para la nueva que aquí se propone, por tanto, se seguirá usando este SGBD, además la posibilidad que ofrece Oracle® para crear paquetes (con procedimientos y funciones) internos al sistema parece muy apropiada como el entorno a usar para la parte software (definición de funciones de comparación difusas) que ahora está contenida en la FMB*. Los paquetes (packages) son creados en un lenguaje llamado, PL/SQL [Urm98], aunque no habría mayor inconveniente en usar cualquier otro tipo de lenguaje.
La nueva arquitectura cliente-servidor de FSQL* para la BDRD será bastante similar a la anterior:
1. Datos y funciones de comparación difusas: Base de datos tradicional y Base de Metaconocimiento Difuso, FMB*.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 108
2. Servidor FSQL*: Encargado de ocultar el procesamiento difuso al usuario. 3. Cliente FSQL: Encargado de hacer de interfaz entre el usuario y el Servidor FSQL*.
A continuación se explican cada uno de estos componentes:
4.2.4.1 Datos y funciones de comparación difusas: base de datos Tradicional y FMB*
Como se ha explicado en el 4.2.1, los atributos difusos de tipo 4 se van a almacenar
mediante uno o más atributos de las relaciones del usuario de la base de datos tradicional. No existe un formato especial para almacenar estos atributos difusos, aunque hay que especificar dicho formato de almacenamiento en la FMB*.
La base de metaconocimiento difuso, FMB* almacena información sobre la BDRD en
un formato relacional. Tal y como se ha explicado el apartado 4.2.2, la FMB* va a contener dos tipos de informaciones para los atributos difusos de tipo 4:
• Toda la información necesaria para el tratamiento difuso de dichos atributos: atributos clásicos que lo componen, etiquetas lingüísticas, etc.
• Definición de las funciones a usar para cada uno de los comparadores difusos que tenga sentido para cada tipo de dato en concreto.
4.2.4.2 Servidor FSQL*
Ya se ha asumido durante la exposición de este capítulo, que el lenguaje FSQL iba a ser perfectamente válido para el modelo FIRST* en lo referente a su sintaxis. Sin embargo, la semántica sí ha sido necesario adaptarla para los tipos difusos de tipo 4, como ya se ha visto en la sección 4.2.3.
A continuación se explican como actúan las tres funciones de las que está compuesto el
Servidor FSQL* para los nuevos tipos de datos difusos:
• Función de Traducción (FSQL2SQL): Esta función va a seguir actuando igual que la del servidor original, es decir, efectúa un análisis de la consulta FSQL. Si encuentra errores de cualquier naturaleza, genera a una tabla con todos los errores encontrados. Si no hay errores, la consulta FSQL es traducida a una sentencia en SQL. Para la traducción se siguen usando los tres típicos analizadores: 1. Analizador Léxico: Asegura que todos los elementos de la sentencia están
permitidos, agrupando los caracteres en palabras (tokens). No ha sufrido alteración ninguna para los tipos difusos 4.
2. Analizador Sintáctico: Asegura que los tokens están en un orden adecuado y que la construcción de la sentencia es correcta sintácticamente. Al igual que la anterior, No ha sufrido alteración ninguna para los tipos difusos 4.

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 109
3. Analizador Semántico: Asegura que el significado de la sentencia es correcto y que, por tanto, tiene sentido efectuarla. Este analizador, es quien genera la sentencia resultante en SQL que podrá incluir llamadas a las funciones de representación y de comparación difusas. Para los tipos difusos 4, las características de las llamadas a estas funciones se obtiene directamente de la FMB*.
• Funciones de Representación: Estas funciones son utilizadas para mostrar los
atributos difusos de manera que sean comprensibles por el usuario, evitando así el críptico formato interno de estos atributos. El usuario puede definir para los atributos difusos de tipo 4 la función de representación, que considere más adecuada, en la FMB*. Los atributos difusos de tipo 4 que no se ha especificado ninguna función de representación en la FMB*, son mostrados como la lista de atributos clásicos de los que está compuestos.
• Funciones de Comparación Difusa: Se utilizan para comparar atributos y valores difusos y para calcular los grados de compatibilidad que devuelve la función CDEG. Lo que hace la función de Traducción, es reemplazar los atributos difusos del SELECT por llamadas a las funciones de Representación, las condiciones difusas por llamadas a las funciones de Comparación Difusa y reemplazar las llamadas a la función CDEG por llamadas a las funciones de Comparación Difusa y otras funciones si existen operadores lógicos involucrados en la condición del atributo argumento de CDEG. Para los atributos difusos de tipo 4 se usa el contenido de la FMB* que indica cómo hacer dicha traducción.
4.2.4.3 Funcionamiento del cliente-servidor de FSQL*
Aunque el Servidor FSQL ha sufrido variaciones importantes en su interior, como se ha visto en el epígrafe anterior, la función de traducción no se ha visto alterada en absoluto, ni en sus parámetros de entrada/salida, ni en sus premisas de funcionamiento.
Es por ello que la arquitectura cliente-servidor de FSQL*, esquematizada en la Figura 4-3,
es bastante similar a la de cliente-servidor de FSQL, esquematizada en la Figura 3-16, la diferencia fundamental es la sustitución de la FMB por la FMB* y del Servidor FSQL por el Servidor FSQL*. Una vez instalados tanto el metadatos, como el servidor, los programas clientes de FSQL (FQ -Fuzzy Queries-, F –Fuzzy-, Visual Client for FSQL, usos de FSQL embebido…) siguen funcionando sin tener que sufrir alteración, ni instalación alguna.
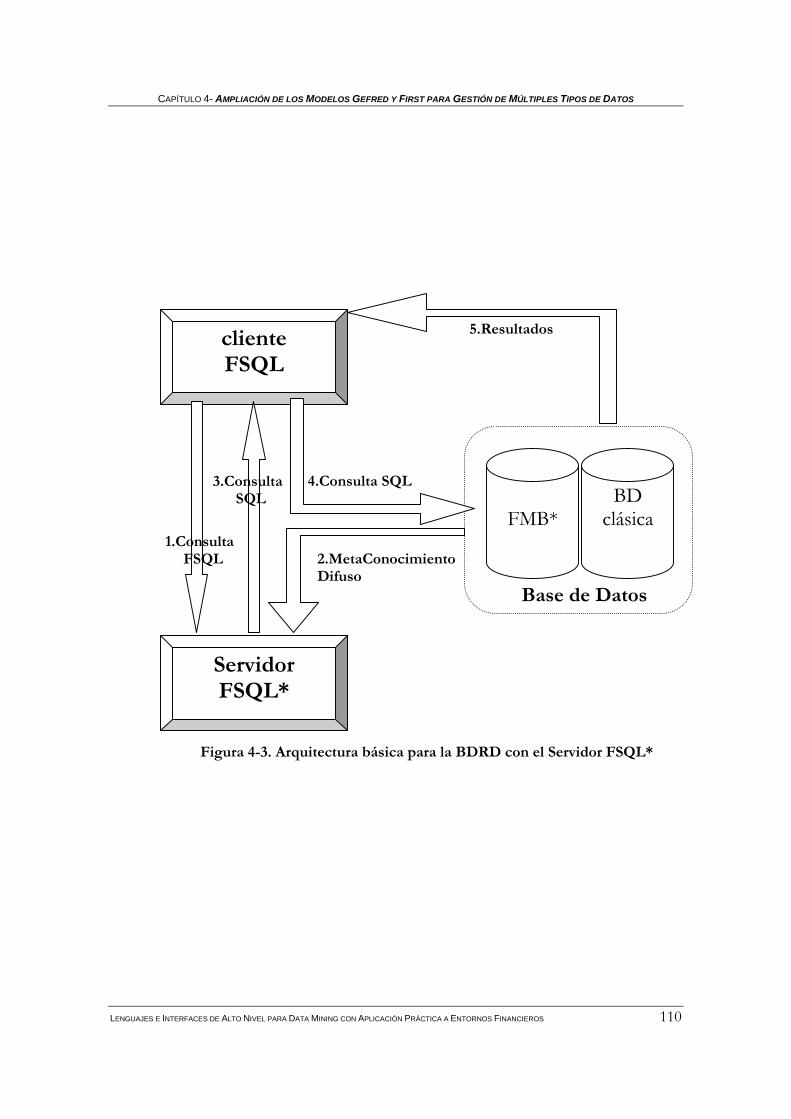
CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 110
Servidor FSQL*
FMB*
BD clásica
Base de Datos
cliente FSQL
1.Consulta
FSQL 2.MetaConocimientoDifuso
3.Consulta
SQL
4.Consulta SQL
5.Resultados
Figura 4-3. Arquitectura básica para la BDRD con el Servidor FSQL*

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 111
4.2.5 Ejemplos definiciones de nuevos tipos de datos difusos en el modelo FIRST*
Son muchas las posibilidades que se han abierto en lo que es manejo impreciso de
datos a través de la definición de los atributos difusos tipo 4: imágenes, hipertexto, HTML, XML, etc. Todo consiste en definir su forma de almacenamiento y tratamiento difuso en la FMB*. En esta sección se van a exponer, a título de ejemplo:
• Redefinición de los comparadores ya incluidos en FIRST para los atributos sobre referencial ordenado, mediante un mecanismo que tenga en cuenta la subjetividad del usuario/decisor.
• Definiciones varias de medidas de similitud (comparadores FEQ) sobre datos (crisps y difusos) sobre referenciales ordenados y sobre referenciales binarios. Estas definiciones van a ser especialmente útiles para el esquema de DM que se va a presentar en esta memoria posteriormente.
• Tratamiento de otro tipos de datos, como son las cadenas de caracteres con especial aplicación a la comparación difusa de nombres de personas o empresas.
Se pasa a explicar en más detalle cada uno de estos puntos:
4.2.5.1 Redefinición de los comparadores difusos para referenciales ordenados de FIRST usando Redes Neuronales Artificiales
El proceso de comparación de números difusos es un proceso impreciso en sí. En la
literatura pueden encontrarse diversos métodos de comparación de números difusos, los cuales suelen clasificarse en dos categorías: los que usan una función que va del conjunto de números difusos a un conjunto ordenado [Ada80, Yag78, Yag81, Zhu91] y los que usan relaciones difusas para el proceso de comparación [Bal79, Bas77, Del88, Dub83] (en la sección 4.2.5.2.2 se van incluir un estudio más amplio de comparadores FEQ para Conjuntos Difusos). Como, ya se ha visto en la sección 3.4.1.2, la implementación de FIRST usa la definición de sus comparadores de números difusos basándose en esta última tendencia. Al tomar decisiones en el mundo real, se utiliza cada vez más información imprecisa, que se modela por números difusos. En este contexto, el decisor se ve en la disyuntiva de elegir un método de comparación de números difusos de entre todos los propuestos, que se pueden contar por decenas, esto en sí mismo es un problema de decisión en ambiente difuso. Los métodos de comparación referidos son programables en ordenador, pues tienen un comportamiento conocido, pero el comportamiento del decisor no es algoritmizable, y difícilmente se le podría adaptar alguno de los métodos ante un problema real. Por ello, unos métodos intentan resumir características del decisor con un parámetro [Cam89], y otros dan intervalos de dominancia relativa [Del88], lo que puede ser de difícil interpretación para los decisores no expertos. Parece obvio que, en muchos casos, el decisor quisiera tener un método

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 112
personal, que recoja su propio criterio de comparación de números difusos, especialmente ante casos conflictivos como el que puede observarse en la Figura 4-4.
Resolver este problema parece un campo muy apropiado para las Redes Neuronales Artificiales (RNAs) (cuyos conceptos básicos se pueden estudiar en [Dub80]) ya que para la mayoría de la gente es mucho más intuitivo entrenar una RNA con los ejemplos que él mismo ha aportado que intentar especificar tal o cual método. Requena et al. propone en [Req94] un método de ordenación de números difusos que usa RNAs que se describe, someramente, a continuación:
El problema es comparar dos distribuciones de posibilidad trapezoidales A y B con A=[α A,β A,δ A,γ A] y B=[α B,β B,δ B,γ B]. Por tanto, las entradas a la red son ocho (cuatro por cada número difuso) y una salida con tres posibles valores: A<B, A=B, A>B. El objetivo del método es obtener una RNA capaz de aprender (y reproducir) diversos métodos de comparación, siempre con la misma topología de red, algoritmo de aprendizaje, e incluso entradas del conjunto de entrenamiento [Can91], de tal manera que, si distintos métodos pueden ser aprendidos con una misma estructura de RNA, algoritmo y entradas de aprendizaje, se podrá deducir que este mismo modelo servirá para aprender el comportamiento de cualquier decisor humano coherente.
La experiencia, llevada a cabo por los autores, ha usado un RNA multicapa de propagación hacia delante (feedforward) con aprendizaje supervisado, y el algoritmo de retropropagación de errores (backpropagation) para el entrenamiento. Con una estructura básica de 16 neuronas para una cada escondida y 12+6 con dos capas escondidas, valores iniciales de 0.5 y 0.1 para el ratio de aprendizaje, y considerando un conjunto de aprendizaje (con casos conflictivos incluidos) los autores obtienen una aprendizaje lo suficientemente bueno para afirmar que siempre pueden entrenar una RNA con el criterio de un decisor humano al comparar números difusos.
El objetivo, ahora, es definir los comparadores de FSQL dentro del ámbito de FIRST*,
para un tipo difuso 4, con un procedimiento basado en el método de ordenación de números difusos de Requena et al. basado en RNAs que se acaba de explicar.
Figura 4-4. Caso conflictivo en la comparación de números difusos

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 113
Se quiere comparar dos distribuciones de posibilidad trapezoidales A y B con A=[α A,β A,δ A,γ A] y B=[α B,β B,δ B,γ B] como, por ejemplo, las de la Figura 4-4. En primera instancia se definen en la FMB* los atributos A y B como atributos difusos tipo 4 con una representación interna completamente análoga a la de los atributos difusos tipo 2 (ver Tabla 3-4). Si se recuerda, CDEG se usa en FSQL para obtener el grado de cumplimiento de una condición difusa. Por lo tanto, se procederá a definir las funciones CDEG para cada comparador difuso usando el procedimiento basado en RNAs. En las definiciones de dichas funciones se supondrá que A ó B no tienen el valor de ninguna constante difusa (Null, Unknown, Undefined) ya que la definición de las funciones para dichos casos será idéntica a la que en su día hicieron Galindo, Medina et al. [Gal98b, Gal99, Med94].
Previamente, se define la función fcomp_ann (A, B, fcomp, dpc_fcompi)
donde • fcomp es un comparador difuso de posibilidad de FSQL (ver Tabla 3-7), • dpc_fcompi es el criterio personal de decisión del usuario i para cada comparador
fcomp. Este parámetro contiene toda la información sobre la RNA del método de Requena et al. entrenada por el usuario i (matriz de pesos) para el correspondiente comparador fcomp.
Así el usuario i entrena una red (basada en la RNA del método que se ha explicado) para el
comparador fcomp mediante un conjunto de ejemplos (números difusos con intersecciones incluyendo casos conflictivos). Para estos ejemplos él decide si A fcomp B es verdadero, excepto si fcomp es FEQ en cuyo caso el usuario debe de proporcionar el grado de cumplimiento dentro de este conjunto 0.2, 0.4, 0.6, 0.8. Así, los posibles valores de fcomp_ann son:
• Si fcomp ≠ FEQ entonces
1, si A fcomp B con dpc_fcompi fcomp_ann (A, B, fcomp, dpc_fcompi) =
0, en otro caso • Si fcomp = FEQ entonces fcomp_ann (A, B, fcomp, dpc_fcompi) = 0.2, 0.4, 0.6, 0.8
grado de cumplimento de A FEQ B con dpc_fcompi
Como es sabido, CDEG devuelve el grado de cumplimiento como un valor dentro del intervalo [0,1] de la condición difusa, pero la función fcomp_ann definida (para los comparadores difusos de desigualdad) solo permite ordenar las distribuciones de posibilidad A y B. De este modo, se hace necesario un método para expresar tal grado de cumplimiento. Con el objeto de expresar la distancia entre dos número difusos, Requena et. al [Req94] definen el índice personal de decisión (DPI ) como una aplicación del conjunto de los números difusos a ordenar a ℜ (números reales). Sin embargo, cuando FSQL compara A y B no tiene información sobre el resto de los números difusos ya que esta información es dinámica

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 114
(posibles valores del atributo difuso). Para resolver este problema se ha desarrollado el siguiente método.
En primera instancia, se define la función df_ann (A, fcomp, dpc_fcompi) que retorna los
valores en [0,1] y cuyo significado es el valor crisp que representa a A con el criterio del usuario i aprendido para la RNA para el comparador fcomp:
df_ann (A, fcomp, dpc_fcompi) = (a1 + a2) / 2
donde
a1 = Inf a ∈ [αA, δA] / fcomp_ann (a, A, fcomp, dpc_fcompi) = 1 a2 = Sup a ∈ [αA, δA] / fcomp_ann (A, a, fcomp, dpc_fcompi) = 1 Para la implementación de esta función se ha usado un algoritmo de búsqueda binaria
para encontrar tanto a1 como a2. En dicho algoritmo se busca una precisión de milésimas ya que, en la práctica, se observa que precisiones mayores no implican grandes mejoras en la representatividad de A.
Se tiene que Ham (a,b)max,min es una función que devuelve la diferencia absoluta entre dos
números reales a y b previamente normalizados al intervalo [0,1]. Ham (a,b)max,min = | [(1 - max/(max - min)) + a × (1 / (max - min))]
- [(1 - max/(max - min)) + b × (1 / (max - min))]| Ahora se procede a definir cada uno de los comparadores de FSQL de tal manera que, todas las funciones van a tener como parámetro de entrada, el criterio personal de decisión del usuario en concreto i para el correspondiente comparador fcomp. Es lo que se ha notado como dpc_fcompi y se almacena, por cada usuario, para cada definición, en la correspondiente tabla de la FMB* (DMFSQL_COL_PAR). Esto hace que las definiciones, que aquí se va a hacer, sean universales para este método y no dependan el entrenamiento en particular que se le haya dado a la RNA por un determinado usuario (o para un determinado problema). Además, para las siguientes definiciones se considerar que max = MáxδA,δB y min = MínαA, αB:
• CDEG (A FGT B, dpc_FGTi , dpc_FGTi) = 1, Si γA ≥ δB
= 0, Si γB ≥ δA ó fcomp_ann (A, B, FGT, dpc_FGT i)=0 Hammax,min[(df_ann(A, FGT, dpc_FGTi),
(df_ann (B, FGT, dpc_FGTi)], en otro caso

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 115
• CDEG (A FGEQ B, dpc_FGEQi , dpc_FGEQi) =
1, si γA ≥ βB
= 0, si βB ≥ δA ó fcomp_ann (A,B,FGEQ, dpc_FGEQi)=0 Hammax,min [(df_ann(A, FGEQ, dpc_FGEQi),
(df_ann(B, FGEQ, dpc_FGEQi)], en otro caso
• CDEG (A FEQ B, dpc_FEQi, dpc_FEQi) =
1, si αA=αB, βA= βB, γA=γB y δA=δB = 0, si δA < αB ó δB < αA
fcomp_ann (A , B, FEQ, dpc_FEQi), en otro caso
Para el siguiente comparador, MGT, se define AM=$[αA-M, βA-M, γA-M, δA-M] considerando que M es la mínima distancia para considerar dos atributos como muy separados. Este valor M se almacena, por supuesto, en la FMB* (tabla DMFSQL_COL_PAR).
• CDEG (A FGT B, dpc_FGTi, M, dpc_FGTi, M) =
1, si γA ≥ δB+M
= 0, si δA ≤ δB+M ó fcomp_ann (AM, B, FGT, dpc_ FGT i) = 0 Hammax,min [(df_ann (AM, FGT ,dpc_FGTi),
(df_ann (B, FGT, dpc_FGTi)], en otro caso
4.2.5.2 Medidas de similitud sobre referenciales ordenados y binarios
En las técnicas de DM, como se verá más adelante, son especialmente útiles las medidas de similitud, y hablando de entornos financieros, más si son sobre referenciales ordenados y/o binarios. Es por ello que en esta sección se va a hacer un estudio de dichas medidas que permiten comparar este tipo de objetos y evaluar su similitud. En la terminología del modelo aquí presentado, lo que se va a hacer es incluir en FIRST* distintas definiciones de los comparadores FEQ (ó NFEQ) sobre datos numéricos (tanto crisps, como difusos) y sobre datos binarios.
En los apartados siguientes se describen brevemente los distintos modelos en que se basan las medidas de similitud, para obtener más información consúltese [Dur74, Bez02] y para obtener un análisis más riguroso, de algunas medidas de las medidas aquí expuesta, desde un punto de vista psicológico examínese [Zwi87].

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 116
4.2.5.2.1 Medidas de similitud sobre referenciales ordenados crisps
En el contexto de DM, es frecuente que características de un ente sea modelada
conjuntamente por lo que en los SGBDR son varias columnas. Por ejemplo, sean las relaciones
• CLIENTES_ESPAÑA (número_cliente, saldo_medio_activo, saldo_medio_pasivo,
saldo_medio_resto) y • CLIENTES_ARGENTINA (número_cliente, saldo_medio_activo, saldo_medio_pasivo,
saldo_medio_resto), que contiene datos de las cuentas de los clientes de una entidad financiera en los países de España y Argentina respectivamente, identificados, los clientes, por la columna número_cliente. Ambas relaciones contienen:
• información de saldo medio en el año sobre productos de activo de la entidad (por ejemplo, préstamos, pólizas de créditos, avales, factoring, etc) en el atributo saldo_medio_activo;
• información sobre el saldo medio en el año contratado sobre productos de pasivo de la entidad (por ejemplo, libretas de ahorro-vista, cuentas corrientes, ahorro futuro, etc) en el atributo saldo_medio_pasivo;
• e información sobre el saldo medio en el año del resto de productos que le ha contratado a la entidad (productos en los que la entidad hace de intermediario aún no siendo propiamente de dicha entidad) en el atributo saldo_medio_resto.
Un analista de datos de dicha entidad, podría querer comparar conjuntamente los saldos
medios de clientes de ambos países. En FIRST* esto se resolvería, definiendo un tipo difuso 4, por ejemplo saldo_medio que esté compuesto por los tres atributos citados anteriormente, para cada relación. El correspondiente comparador FEQ habría que definirlo sobre estos tipos difusos 4. Como se ve, el que sean referenciales ordenados, no implica que sean dominios simples. Así formalmente, los comparadores de similitud de esta sección, van a ser definidos en caso de datos crisps sobre los atributos difusos tipo 4 x e y:
x(x1, x2, …, xJ) y(y 1, y 2, …, y J)
donde xi, yi con i=1..J son atributos crisps numéricos. Como se ve, la definición de estos tipos difusos 4 son realmente los vectores usados habitualmente en la taxonomía clásica.
Para que el proceso de comparación sea más universal, no se va a suponer que los distintos atributos xs, ys con s ∈ [1..J] estén definidos sobre el mismo dominio, esto podría

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 117
ocurrir, siguiendo con el ejemplo anterior, si los distintos saldos medios no estuviesen en la misma divisa sino que dependieran de la tabla sobre la que están (en la tabla con datos de España en euros, y la de Argentina en pesos). Esto implica que hay que hacer un proceso de normalización de los datos análogo al que se ha explicado en el Ejemplo 4-1 de tal manera que a cada xi, yi con i=1..J se le va aplicar la función Norm_0_1, para lo que habrá que incluir en la FMB* los valores mínimo y máximo de cada xi, yi. A los valores correspondientes normalizados se les va a notar como xi*, yi*. Por tanto, el formato de las funciones de comparación que se van a incluir en la FMB* es el siguiente:
CDEG (x FEQ y, (min_x1, max_x1),…, (min_xJ, max_xJ),
(min_y1, max_y1),…, (min_yJ, max_yJ)) siendo el min_xs el valor mínimo para el atributo xs y max_xs el valor máximo de dicho atributo, y de forma análoga para y.
4.2.5.2.1.1 Modelos basados en medidas de distancia
Las medidas de similitud empleadas habitualmente por los métodos de aprendizaje no supervisado (clustering) suelen formularse como medidas de disimilitud utilizando métricas de distancia.
Cualquier función d que mida distancias debe verificar las siguientes tres propiedades:
• Propiedad reflexiva:
d(x, x) = 0
• Propiedad simétrica:
d(x, y) = d(y, x)
• Desigualdad triangular:
d(x, y) ≤ d(x, z) + d(z, y)
Existe una clase particular de medidas de distancia que se ha estudiado exhaustivamente. Es la métrica r de Minkowski:
Como una medida de distancia es, en realidad, una medida de disimilitud, se puede
formular la distancia de Minkowsky como una medida de similitud de la siguiente forma: CDEG (x FEQ y, (min_x1, max_x1),…, (min_xJ, max_xJ),
rJ
j
rjjr yxyxd
1
1
),( ⎟⎟⎠
⎞⎜⎜⎝
⎛−= ∑
=

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 118
(min_y1, max_y1),…, (min_yJ, max_yJ)) = 1 - dr*(x, y) donde dr* es la métrica dr normalizada en el intervalo [0,1].
Existen tres casos particulares de la clase de funciones definida por la distancia de Minkowsky que se utilizan habitualmente en la resolución de problemas de clustering:
• La distancia Euclídea (r = 2):
cuya definición normalizada en [0,1] queda como:
• La distancia de Manhattan o l1-norma (r = 1):
que normalizada es:
• La “métrica de dominio” (conforme r tiende a 1 , la métrica de Minkowski viene determinada por la diferencia entre las coordenadas correspondientes a la dimensión para la que |xj - yj| es mayor) o Sup-norma:
cuya definición en [0,1] es:
Para la definición de los comparadores difusos generalizados complejos de igualdad, la
desigualdad triangular no ha sido exigida. Por tanto, se podrán utilizar estas medidas de
( )∑=
−=J
j
jj yxyxd1
22 ),(
∑=
−=J
j
jj yxyxd1
1 ),(
jjJj
yxMáxyxd −==
∞..1
),(
( )
J
yxyxd
J
j
jj∑=
−= 1
2**
2 ),(*
J
yxyxd
J
j
jj∑=
−= 1
**
1 ),(*
**..1
),(* jjJj
yxMáxyxd −==
∞

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 119
similitud normalizadas que no verificasen la desigualdad triangular, que de hecho, las siguientes medidas de similitud no cumplen:
4.2.5.2.1.2 Modelos basados en medidas de correlación
Para la definición de los comparadores difusos en base a estas medidas se usará la siguiente fórmula:
CDEG (x FEQ y, (min_x1, max_x1),…, (min_xJ, max_xJ),
(min_y1, max_y1),…, (min_yJ, max_yJ)) = 1 - S*(x, y) donde S* es una de las métrica de correlación normalizada en el intervalo [0,1] que aquí van a ser introducidas.
El producto escalar de dos vectores es la medida más simple de este tipo. Puede emplearse para medir la similitud existente entre vectores que representan distribuciones de clases igual que se emplea en muchos sistemas de recuperación de información para emparejar los términos de una consulta con los términos que aparecen en un documento. Matemáticamente, la medida de similitud dada por el producto escalar se define como:
que normalizada en el intervalo [0,1] queda como sigue:
También se puede medir de forma alternativa la correlación entre dos vectores para
reflejar la similitud entre dos Conjuntos Difusos a partir de la distancia euclídea d2 al cuadrado:
donde
Esta distancia estandarizada sirve de enlace con el tercer grupo de modelos que
permiten medir la similitud entre dos objetos:
∑=
=•=J
j
jjyxyxyxS1
),.(
2241),(* dNN
yxSyx⎟⎠⎞
⎜⎝⎛
+−=
)12( 2
1−= ∑
=
j
J
j
v vN
J
yxyxS
J
j
jj∑== 1
**
),(*

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 120
4.2.5.2.2 Medidas de similitud sobre Conjuntos Difusos
Los otros tipos de datos con referencial ordenado sobre los que van a ser estudiadas
sus funciones de similitud son los Conjuntos Difusos, que suelen ser modelados por distribuciones de posibilidad. Aunque realmente, en anteriores apartados ya han sido introducidas algunas comparaciones de igualdad sobre distribuciones de posibilidad trapezoidales, no siempre se usa estas representaciones (ver por ejemplo [Bor99]), así en esta sección se van a incluir definiciones que no dependen de la representación que se tome. Para la definición de los comparadores difusos se usará la siguiente fórmula:
CDEG (a FEQ b) = s(A, B)
donde a y b son los objetos que se comparan mientras que A y B representan los conjuntos de características asociados a los objetos a y b respectivamente. Una vez decidida la representación de los objetos que se comparan dentro del modelo FIRST*, habrá que instanciar las distintas definiciones de s(A, B) que en esta sección se van a dar para incluirlas en las FMB*.
Desde un punto de vista psicológico, Tversky describió la similitud como un proceso de emparejamiento de características. La similitud entre objetos puede expresarse como una combinación lineal de sus características comunes y de las características exclusivas de cada uno de ellos:
s(a, b) = θ f(A ∩ B) - α f(A - B) - β f(B - A), θ , β , α ≥ 0
donde la función f suele ser la cardinalidad del conjunto que recibe como argumento, si bien no se descartan otras posibilidades.
Cuando α = β = 1 y θ = 0, entonces -s(a, b) = f(A - B) + f(B - A). Este es el modelo propuesto por Restle para medir la disimilitud entre objetos fijándose únicamente en las características exclusivas de cada uno de ellos.
También se puede establecer α = β = 0 y θ = 1, para obtener el modelo más
simple s(a, b) = f(A ∩ B). En este caso, solo se mira las características que a y b tienen en común. Ahora es necesario, para poder acoplar el modelo en FIRST*, que se normalice la medida de similitud para que quede entre 0 y 1, para ello se usa el modelo proporcional:
con θ , β , α ≥ 0
)()()()(),(
ABfBAfBAfBAfbas
−+−+∩∩
=βα

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 121
Cuando la función f es aditiva (esto es, f(A ∪ B) = f(A) +f(B) cuando A ∩ B = ∅ ), el modelo proporcional generaliza las propuestas de otros autores:
• Gregson (α = β = 1):
• Eisler & Ekman (α = β = ½):
• Bush & Mosteller (α = 1, β = 0):
La teoría de los Conjuntos Difusos (sección 3.2) permite utilizar todos estos modelos en
conjuntos de objetos en los cuales la función de pertenencia puede variar entre 0 y 1. Como se ha visto, también define nuevos operadores para realizarlas operaciones clásicas sobre conjuntos, como la unión, la intersección o la negación. Por ejemplo, las T-normas que se muestran en la Tabla 3-1 y las T-conormas que se muestran en la Tabla 3-2 pueden emplearse para calcular intersecciones y uniones de Conjuntos Difusos de la misma forma que lo hacen algunos modelos difusos de recuperación de información.
Aunque también existen distintos cardinales difusos para medir la cardinalidad de un conjunto, aquí se empleará la cardinalidad escalar, que se define como
que permite, entre otras cosas, normalizar las funciones de pertenencia en [0,1]
La propuesta que Restle definió para conjuntos clásicos puede generalizarse de la
siguiente forma haciendo uso de los operadores de la teoría de Conjuntos Difusos: -SRestle (A, B) = [A ⃞ B]
)()(),(
BAfBAfbas
∩∩
=
)()()(2),(
BfAfBAfbas
+∩
=
)()(2),(
AfBAfbas ∩
=
)(|| xAx
A∑= µ
||)()(*
Axx A
Aµµ =

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 122
donde A ⃞ B es el conjunto difuso de los elementos que pertenecen a A pero no a B y viceversa. Utilizando la T-conorma máximo y la T-norma mínimo, dicho conjunto puede definirse como μ A⃞B(x) = máx mín μ A(x), 1 - μ B(x), mín1 - μ A(x), μ B(x) Si se emplea una función f distinta, se obtiene otra variación del modelo de Restle:
-S⃞ (A, B) = supx μ A⃞B(x) Cuando, a partir del modelo general de Tversky, se fija α = β = 0 y θ = 1 y se
vuelve a utilizar los operadores mínimo y máximo, se obtiene otra medida de similitud alternativa:
Nótese que, si se hubiese utilizado la T-norma producto en vez del mínimo, se habría obtenido una medida de similitud equivalente al producto escalar que se vio en el apartado 4.2.5.2.1.2 de esta memoria.
De forma análoga a como sucede con el modelo de Restle, se puede obtener una variación de la medida de similitud data por SMinSum. Dicha variación ha sido formulada por Enta como un índice de inconsistencia o “grado de separación”:
-SEnta(A, B) = 1 - supx μ A∩ B(x)
La siguiente medida normaliza la medida de similitud dada por SMinSum y es análoga a la propuesta de Gregson para conjuntos clásicos:
4.2.5.2.3 Medidas de similitud sobre dominios binarios
El estudio de características binarias de entes ha demostrado ser muy útil en campos
tan dispares como la Biología (para estudios de genética, clasificaciones de especies, etc) y los Sistemas. Las bases de datos financieras también suelen tener frecuentemente numerosos atributos binarios pero su explotación no suele ser más compleja que hacer un uso crisp de los mismos. Para conseguir un tratamiento más ventajoso, si un analista de datos de una entidad considera que una serie de atributos binarios implican una característica de un ente, no habría más que definir esa serie de atributos como un tipo difuso 4 y usar un comparador difuso
)(,)(min||),( xxBABAS B
x
AMinSum µµ∑=∩=
∑∑=
∪∩
=x
BA
xBA
Gregsonxxxx
BABABAS
)(),(max)(),(min
||||),(
µµµµ

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 123
apropiado, que bien podría ser uno de los que en esta sección se van a exponer. Sirva el siguiente ejemplo como motivación a este problema:
Sea la siguiente relación:
• CUENTAS (número_cuenta, indicador_nomina, indicador_pensión, indicador_domiciliación, indicador_hipoteca)
que contiene datos de las cuentas de una entidad financiera, identificadas por el número_cuenta y una serie de atributos binarios:
• indicador_nomina: indica si sobre esa cuenta se percibe nómina alguna; • indicador_pensión: indica si sobre esa cuenta se cobra pensión; • indicador_domiciliación: indica si sobre esa cuenta hay domiciliado el pago de al menos un
recibo de entes externos. • indicador_hipoteca: indica si sobre esa cuenta está vinculada a alguna hipoteca.
Un analista podría considerar que estos atributos binarios constituyen conjuntamente un
indicador económico de la cuenta, y en base a ese indicador hacer determinados estudios comparativos. Para ello, como se ha dicho, debería de definir el atributo difuso tipo 4, por ejemplo indicador_económico, compuesto por esos atributos binarios. El correspondiente comparador FEQ habría que definirlo sobre estos tipos difusos 4. Más formalmente, se va a considerar los atributos difusos tipo 4 x e y compuestos de una serie de atributos binarios:
x(x1, x2, …, xP) y(y 1, y 2, …, y P)
donde xi, yi con i=1..P son atributos binarios, es decir, cuyo dominio es un conjunto de dos valores.
No se va a exigir que los distintos atributos xs, ys con s ∈ [1..P], tengan un almacenamiento homogéneo, en el sentido, de que su dominio podrá ser 0,1, true, false, ‘S’,’N’ o cualquier conjunto de dos valores. La definición de los comparadores sí se va a hacer sobre el dominio 0,1 con el objeto de que sea más universal. Esto implica que hay que hacer un proceso de normalización de los datos de tal manera que a cada xi, yi con i=1..P se le va a indicar en la FMB* cual es el valor correspondiente al 0 y cual al 1 (en la tabla DMFSQL_COL_PAR para las filas correspondientes a PAR#=1 y PAR#=2 respectivamente). A los valores correspondiente normalizados se les va a notar como xi*, yi*. Por tanto, el formato de las funciones de comparación que se van a incluir en la FMB* es el siguiente:
CDEG (x FEQ y, (valor_0_x1, valor_1_x1),…, (valor_0_xP, valor_1_xP),
(valor_0_y1, valor_1_y1),…, (valor_0_yP, valor_1_yP)) = 1 - db(x, y)

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 124
siendo el valor_0_xs el valor que para el atributo xs va a considerarse 0 y valor_1_xs el valor que representa a 1, y de forma análoga para y; db(x, y) es alguna distancia definida sobre x e y en [0,1]. Previamente a la funciones de distancia se introducen los siguientes valores, teniendo en cuenta que k=1..P:
• nIJ: número de veces que se verifica xk*= yk* = 1, ∀ k=1..P;
• nij: número de veces que se verifica xk*= yk* = 0, ∀ k=1..P;
• niJ: número de veces que se verifica xk*= 0 y yk* = 1, ∀ k=1..P;
• nIj: número de veces que se verifica xk*= 1 y yk* = 0, ∀ k=1..P;
Así se procede a la definición de las distintas funciones distancia (para una información más amplia consultar [Dur74]):
• Sneath:
• Sokal y Michener:
• Russell y Rao:
• Sorenson:
• Rogers y Tanimoto:
4.2.5.3 Tratamiento impreciso de cadenas de caracteres y aplicación a identificación de personas
iJIjIJ
IJb
nnnn(x, y)d
++=
Pnn(x, y)d ijIJ
b+
=
Pn(x, y)d IJ
b =
iJIjIJ
IJb
nnnn(x, y)d
++=
22
iJIj
ijIJb
nnPnn(x, y)d++
+=

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 125
Es sabido que una de las características de los datos en las empresas actuales es que, a parte de ser muchos, son malos. Hay autores que estiman que la mala calidad de los datos en el sector financiero español está alrededor del 12% que además puede considerarse como el sector privado que mejor calidad de datos tiene.
Un problema que existe especialmente en el sector financiero es cuando se trata de
cotejar información electrónica sobre clientes de algún ente externo con los que la entidad posee. Formalizando el problema, la información externa estaría en la relación E, y la propia en la P:
• P (id_oficial, nombre, apellido1, apellido2, resto_campos_propios) y • E (id_oficial, nombre, apellido1, apellido2, resto_campos_externos),
con el significado de los atributos siguiente:
• id_oficial: identificador oficial de la persona (NIF, CIF, pasaporte, tarjeta de residencia, etc).
• nombre: nombre, simple o compuesto, de la persona en caso de ser ésta persona física. Para las empresas jurídicas en este campo estará incluido la razón social.
• apellido1, apellido2: apellido primero, y segundo (si lo tiene, según nacionalidad) de las personas físicas, para las jurídicas estos campos no tienen sentido, es decir, son Undefined.
El problema es que no siempre el mismo identificador oficial implica la misma persona en
las dos tablas. El uso que la entidad financiera debe hacer de los datos externos puede agravar el problema: proceder a actualizar los datos propios de los clientes (fallecidos, etc), embargar sus cuentas, actividades comerciales, etc. Es obvio, que una información con los nombres y apellidos puede ser bastante útil para validación adicional sobre si se trata de la misma persona o no.
En primer lugar, se va a introducir un comparador difuso de cadenas de caracteres, basado
en el algoritmo FERM, que ha sido desarrollado en la Universidad Politécnica de Madrid. Así dados dos atributos tipo cadena de caracteres A y B, FERM (A, B) devuelve la disimilitud en [0,1] que hay entre ambas. Si se definen A y B como tipos difusos 4, se puede definir el comparador FEQ como:
CDEG (A FEQ B) = 1 - FERM (A, B)
Se considera que la representación interna de las constantes difusas Unknown, Undefined, Null va a ser la cadena de caracteres vacía ‘ ’ para lo que se va a modificar FERM de tal manera que sea capaz de actuar, con la comparación de dos cadenas vacías FERM devolviendo que son completamente iguales. Además se modifica este algoritmo para que elimine caracteres no deseables que pudiera haber en las cadenas.
Para la comparación difusa de los nombres, se a va a definir para ambas tablas P y E en la
FMB* los atributos difusos tipo 4 nombre compuestos por (nombre, apellido1, apellido2) de esta manera el atributo crisp nombre va a prototipar al atributo difuso tipo 4 nombre. En la

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 126
implementación que se ha hecho del Servidor FSQL* si el atributo nombre es usado en un contexto difuso (en función CDEG, con algún comparador difuso, etc) lo va a considerar semánticamente como un tipo difuso 4, tratándolo sin ningún problema.
La definición que se ha hecho para el comparador FEQ para la comparación difusa de
nombres es la siguiente:

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 127
CDEG (P.nombre FEQ E.nombre, w1, w2, w3, w1, w2, w3) =
0, Si nombre, apellido1, apellido2 de P y E son ‘ ’ =
Mín [1 – FERM (P.nombre, E.nombre)] × w1, [1 – FERM (P.apellido1, E.apellido1)] × w2,
[1 – FERM (P.apellido2, E.apellido2)] × w3, en otro caso
donde w1, w2, w3 ∈ [0,1] y ∃ wi con i=1, 2, 3 / wi=1
Los wi indican la importancia de cada atributo en la comparación dependiendo del criterio personal del usuario ante el problema de que se trate, como siempre, su almacenamiento está contemplado en la FMB*. Así el atributo que suele darse más importancia es el apellido1. Para problemas más críticos, como es el de actualización de base de datos propia, se debería exigir también coincidencia alta de los tres atributos implicados, esto es, valores w1, w2, w3 próximos a 1. En otro tipo de problemas, como es de realizar una acción comercial, se podría relajar el valor w1 ya que puede ser asumible que la actividad comercial se realice sobre una persona o su hermano (con el nombre coincide en todo menos en el nombre).
Ejemplo 4-3
Se va a comprobar el funcionamiento del comparador recién definido. Para ello se tienen dos tablas P y E con la misma definición que se acaba de introducir. Los atributos difusos nombre se van a incluir en la FMB* de tal manera que w1 = w2 = w3 = 1, o lo que es lo mismo, se va a dar máxima importancia a la comparación tanto del nombre propiamente dicho, como de los apellidos. Los valores de las filas que tienen igual identificador oficial se muestran a continuación (join de ambas tablas por el campo id_oficial):
ID_OFICIAL P.NOMBRE P.APELLIDO1 P.APELLIDO2 E.NOMBRE E.APELLIDO1 E.APELLIDO2 E0 RAMON A. CARRASCO GONZALEZ RAMON CARRASCO GLEZ. E1 JUAN PEREZ RODRIGUEZ JUAN A. PERALTA RODRIGUES E2 ANTONIO CABALLERO RUIZ FRANCISCA CAVALLERO RUIZ E3 INOCENCIO CASTILLO NAJERA INOCENCIO CASTILLOS NAJERA E4 ALVARO JIMENEZ FERNANDEZ ALVARO GIMENEZ FERDEZ. E5 DARIO CRUZ ESPIGA DARIO DE LA CRUZ ESPIGA E6 MARIA GOMEZ RODRIGUEZ MARIA A. GOMEZ ROGUEZ. E7 ANGELES PELAYO AGUILA ANGELINES PELAYO AGUILAR E8 CARMEN MARIA GONZALEZ POSADAS CARMEN M. GONZALES POSADA E9 JOSE SEGURA VILLAS JOSE M. SEGURADO VILLAR E10 ESTHER VILLA ESPAÑA ESTER VILLAR ESPANA E11 MARTA LEBRIJANO MADRID MARTHA LEBRIJANO MADRID E12 ANTONIO
GONZALO CAMPOS FERNANDEZ ANTONIO
GONZALEZ CAMPOS FERNANDEZ
E13 GONZALO TORRES ESTEVEZ GONZALEZ DE LA TORRE ESTEVEZ E14 OSCAR BENITEZ DELGADO OSCAR BENNITEZ DELLGADO E15 MARIA NIETO ROMAN MARIA NIETO ROMANO E16 NEMESIO RODRIGUEZ GARCIA NEMESIO RODRIGUEZ GRACIA E17 SERENA GARCIA PIMENTEL SIRENA GARCIA PIMIENTEL E18 MARIA DEL MAR PAZ HIDALGO MARIA DEL MAR PAZ FIDALGO E19 MARIA MULAS ROMA MARIA MULA ROMA

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 128
Para verificar el grado de igualdad difusa de los nombres de ambas tablas, se construye la siguiente sentencia de FSQL en el programa cliente FQ:
en la que básicamente se proyecta los campos que contienen el atributo difuso 4 nombre, con su grado de compatibilidad difuso, de las personas coincidentes (según el identificador oficial) y el nombre en ambas tablas P y E. No se impone restricción alguna en el sentido de que dicho grado de compatiblidad supere umbral alguno, para que se muestren todos los registros de las tablas origen. El resultado de la ejecución es el siguiente:
P.NOMBRE P.APELLIDO1 P.APELLIDO2 E.NOMBRE E.APELLIDO1 E.APELLIDO2 CDEG(*) ANTONIO CABALLERO RUIZ FRANCISCA CAVALLERO RUIZ 0.1667 JUAN PEREZ RODRIGUEZ JUAN A. PERALTA RODRIGUES 0.5714 JOSE SEGURA VILLAS JOSE M. SEGURADO VILLAR 0.5714 RAMON A. CARRASCO GONZALEZ RAMON CARRASCO GLEZ. 0.625 MARIA GOMEZ RODRIGUEZ MARIA A. GOMEZ ROGUEZ. 0.625 GONZALO TORRES ESTEVEZ GONZALEZ DE LA TORRE ESTEVEZ 0.65 CARMEN MARIA GONZALEZ POSADAS CARMEN M. GONZALES POSADA 0.6667 DARIO CRUZ ESPIGA DARIO DE LA CRUZ ESPIGA 0.7 ANGELES PELAYO AGUILA ANGELINES PELAYO AGUILAR 0.8056 ALVARO JIMENEZ FERNANDEZ ALVARO GIMENEZ FERDEZ. 0.8167 SERENA GARCIA PIMENTEL SIRENA GARCIA PIMIENTEL 0.8333 ANTONIO GONZALO CAMPOS FERNANDEZ ANTONIO
GONZALEZ CAMPOS FERNANDEZ 0.875
ESTHER VILLA ESPAÑA ESTER VILLAR ESPANA 0.9167 MARTA LEBRIJANO MADRID MARTHA LEBRIJANO MADRID 0.9167 NEMESIO RODRIGUEZ GARCIA NEMESIO RODRIGUEZ GRACIA 0.95 MARIA DEL MAR PAZ HIDALGO MARIA DEL MAR PAZ FIDALGO 0.9667 INOCENCIO CASTILLO NAJERA INOCENCIO CASTILLOS NAJERA 0.9833 MARIA MULAS ROMA MARIA MULA ROMA 0.9833

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 129
OSCAR BENITEZ DELGADO OSCAR BENNITEZ DELLGADO 0.9833 MARIA NIETO ROMAN MARIA NIETO ROMANO 0.9833
En el uso práctico de este comparador, se suele considerar que dos personas son razonablemente iguales si se supera un grado de compatibilidad difusa de sus nombres de 0.6, esto significa modificar la consulta sustituyendo “THOLD 0” por “THOLD 0.6”. En este caso, las tres primera filas del resultado que se acaba de mostrar se considerarían que no son la misma persona, esto es, no serían resultado de dicha consulta.
Por último decir, que el autor de esta memoria considera que la efectividad del comparador propuesto supera ampliamente el 90% en la práctica, aunque también hay que reconocer que los datos que suelen contrastarse son bienintencionados, esto es, no son para poner a prueba un algoritmo, ya que la mayor parte de los errores suelen ser tipográficos, abreviaturas, etc. También existe un porcentaje no despreciable de datos en los que la persona realmente no es la misma, que constituye en sí la motivación de la creación de este algoritmo. La alternativa normal en las entidades financieras es incluir una comparación crisp de nombres y apellidos y las diferencias (que frecuentemente son muy numerosas) verificarlas manualmente.
4.2.6 Comparativa del modelo propuesto
La comparativa entre todos los modelos objetos de estudio en este trabajo se muestra en la Tabla 4-3. Como puntos dignos de mención en la comparativa hecha se tienen:
• Como se ha visto, en FIRST existe la opción de almacenar distribuciones de posibilidad trapezoidales sobre un referencial ordenado, y también distribuciones de posibilidad sobre escalares. El tipo difuso 4 es un marco válido para contemplar dominios que contengan distribuciones de posibilidad, siempre y cuando, estén referidas sobre marco discreto. Por tanto, además de incluir las de FIRST, sobre el tipo difuso 4 también se puede definir distribuciones de posibilidad no necesariamente trapezoidales sobre referenciales ordenados y cualquier otro tipo de distribuciones sobre referenciales no ordenados (no necesariamente sobre escalares, por ejemplo, sobre atributos de texto, etc).
• Como caso especial de tipos de datos imposibles de almacenar en FIRST se tenían los valores excluyentes numéricos. En FIRST* es posible contemplarlos sin más que definir, por ejemplo, un atributo A compuesto de una serie de atributos numéricos A1, A2,…, An de tal manera que los Ai (con i = 1..n) cumplimentados (que no sean nulos) significarán valores excluyentes de A. La función FEQ que se defina para A se podría basar en un comparador FEQ definido sobre valores simples numéricos que se aplicarían sobre cualquier valor Ai que estén cumplimentado mediante el operador lógico OR. Si A fuera un atributo difuso tipo 4, no habría problema en aplicar la misma filosofía para el almacenamiento y tratamiento de datos excluyentes.
• También se ha explicado, que con los tipos difusos 4 se pueden almacenar las constantes difusas Null, Unknow y Undefined, ya sea mediante valores especiales de los atributos de datos, o mediante la información que contienen los atributos de

CAPÍTULO 4- AMPLIACIÓN DE LOS MODELOS GEFRED Y FIRST PARA GESTIÓN DE MÚLTIPLES TIPOS DE DATOS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 130
metadatos. Por supuesto, los comparadores difusos implementados deben de ser coherentes con estas representaciones.
• La implementación de FIRST no contempla la posibilidad de trabajar con grados de acoplamiento almacenados en una tabla. Ahora, esa posibilidad es bastante sencilla sin más que definir un tipo difuso 4, que contenga alguna columna crisp numérica que indique tal grado. Como siempre, los comparadores difusos tendrán que hacer la gestión de dicho nivel de acoplamiento.
• Con los tipos difusos 4 es posible la implementación de los dominios generalizados difusos complejos (ver sección 4.2.1), teniendo en cuenta, las limitaciones obvias del SBDR.
Escalares Numéricos Dominios Difusos Complejos
Dominio Esquema
Simple Valores excluyentes
Distribución Posibilidad
Simple Valores excluyentes
Distribución Posibilidad
Grado Acoplamiento
Unknown Undefined Null
GEFRED Sí Sí Sí Sí Sí Sí Sí Sí No GEFRED* Sí Sí Sí Sí Sí Sí Sí Sí Sí FIRST Sí No Sí Sí No Sí,
trapezoidalSí, dentro de sentencias
DML (CDEG)
Sí No
FIRST* Sí Sí Sí Sí Sí Sí Sí Sí Sí
Tabla 4-3. Comparativa de los dominios soportados en GEFRED, FIRST, GEFRED* y FIRST*

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 131
Capítulo 5 AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
En el capítulo anterior se ha mostrado la implementación que se ha hecho del Interface Difuso para Sistemas Relacionales para el manejo de múltiples tipos de datos (FIRST*) que a su vez tiene como modelo teórico al Modelo Generalizado para Bases de Datos Relacionales Difusas para el manejo de múltiples tipos de datos (GEFRED*). Con estas bases, no solo se ha teorizado, sino también implementado, un modelo de BDRD sobre un SGBDR en el que el tratamiento difuso de la diversidad de dominios susceptibles de ser tratados por un sistema de DM está resuelto.
Una vez solucionado el problema de gestionar la información, cualquiera que sea su
forma, se va a hacer, en este capítulo, un estudio de la posible utilidad de FIRST* en el marco de las distintas técnicas de DM, a saber:
• Clustering: donde se propone una forma novedosa de obtención de la matriz de
distancias de la población. • Caracterización: que incluye una técnica que permite especificar el nivel de
abstracción al que se quiere describir los datos, tal y como se consideraba deseable en los sistemas de DM.
• Clasificación difusa: donde se propone dos formas novedosas de obtener la clasificación difusa, basándose en los centroides obtenidos tras la caracterización, o usando los vecinos más cercanos.
• Dependencias difusas entre atributos: donde se propone un nuevo concepto de dependencias, llamadas dependencias globales difusas, que constituyen el marco común que integra tanto las dependencias difusas como las dependencias graduales difusas.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 132
Dichas aplicaciones, que se suelen materializarse en el uso de FSQL para DM, tienen como base una serie de trabajos [Car98, Car98b, Car99, Car00, Car00b, Car01, Car02, Car02b, Car02c] realizados por el autor de esta memoria. Sin embargo el uso FSQL para estas técnicas de DM tiene algunos inconvenientes, ya que en algunos casos:
• Resuelve solo procesos parciales del proceso global de DM (por ejemplo en el clustering).
• Puede llegar a ser ineficiente. • No es fácil usar resultados previos en un nuevo proceso de DM para realizar un
proceso de refinamiento iterativo.
Es por ello necesario avanzar evolucionando el modelo FIRST* para que integre y optimice dichas funcionalidades propias de DM. De esta forma, va a surgir un nuevo modelo, que se va a venir en llamar, dmFIRST.
Para este nuevo modelo se va a definir un nuevo lenguaje de alto nivel, para la
realización de DM, llamado dmFSQL. Dicho lenguaje va a aprovechar todo el potencial que da el usar los distintos tipos difusos del esquema definido, por lo que no va a tener limitación alguna sobre los tipos de datos sobre los que pueda realizar DM. Su sintaxis va a ser similar a la de FSQL (y por tanto a SQL) y además va a tener una propiedad importantísima: va a permitir el aplicar resultados previos en el proceso actual de DM, esto es, posibilita el proceso de DM con refinamiento iterativo.
Así mismo, se va a explicar la ampliación hecha de la FMB* con el objeto de que sea útil
al nuevo esquema. La ampliación se va ha venido en llamar dmFMB (Base de Metaconocimiento Difuso para DM).

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 133
5.1 Aplicación de técnicas de Data Mining dentro del ámbito de FIRST*
En este apartado se expone detalladamente, cómo puede encajar el nuevo modelo
FIRST* en el ámbito de DM para las siguientes técnicas:
• Clustering, • caracterización, • clasificación difusa y • dependencias globales difusas.
5.1.1 Clustering En esta sección se va a introducir las bases teóricas de una posible solución al problema del clustering basándose en el método de clustering jerárquico (introducido en 2.1.1.3.2). Este proceso devuelve todas las posibles segmentaciones de la población en base a un determinado criterio. Como la solución final al problema requiere una única partición, existe dos posibilidades: obtenerla según un número prefijado de grupos a obtener o a través de algún mecanismo automático. Se proponen dos métodos de obtención de particiones automáticamente: la partición óptima absoluta y una partición óptima basada en la medida H3. Finalmente, se va a explicar como se puede encajar el proceso de resolución del clustering dentro del ámbito de FIRST* haciendo que se pueda hacer clustering sobre cualquier serie de atributos que puedan ser definidos como difusos.
5.1.1.1 Preliminares
5.1.1.1.1 Notaciones básicas y definiciones
Sea el conjunto I=I1, I2,..., In que denota n individuos de una población P1 que tiene un
conjunto de características C=C1, C2,...,CpT las cuales son observables y las posee cada individuo de I. El término observable se aplica en el sentido de características que producen tanto datos cuantitativos como cualitativos (aunque por claridad se prescindirá de estos últimos). El valor de la i-ésima característica del individuo Ij se notará con xij y entonces Xj=xij denota un vector p × 1. Por lo tanto, para un conjunto de individuos (elementos) I, el investigador tiene disponibles un conjunto de p × 1 valores de vectores X=X1, X2,..., Xn los cuales describen el conjunto I. Es importante reseñar que el conjunto X puede ser considerado como compuesto por n puntos en un espacio euclideano p-dimensional, Ep.
Sea m un entero menor que n. Basándose en los datos contenidos en el conjunto X, el
problema del clustering consiste en determinar los m clusters (grupos, subconjuntos) de

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 134
individuos en I, esto es P1, P2,..., Pm, tal que Ii pertenezca a un y solo un subconjunto, de tal manera que, aquellos individuos que son asignados al mismo cluster son similares, y los individuos de diferentes clusters son diferentes (no similares). Si los clusters (o grupos) son subConjuntos Difusos, se está ante un problema de clustering difuso, en el que un individuo puede pertenecer a diversos clusters con un determinado grado de pertenencia.
Una solución al problema del clustering es usualmente determinar una partición que
satisfaga algún criterio óptimo que puede ser dado en términos de una relación funcional, llamada función objetivo, que refleje los niveles de deseabilidad de varias particiones o agrupamientos.
Con el objeto de resolver el problema del clustering se podría definir el significado de que dos individuos Ii y Ij sean diferentes, así una solución al problema podría ser asignar el i-ésimo y j-ésimo individuos al mismo cluster si la distancia entre los puntos Xi y Xj es lo “suficientemente pequeña” y a diferentes clusters si la distancia entre ambos es lo “suficientemente grande”. A continuación se expone matemáticamente el concepto intuitivo de distancia que ha surgido.
Definición 5-1. Función distancia
Una función d(Xi, Xj) real, no negativa, se dice que es una medida de distancia si cumple las siguiente propiedades:
• Reflexiva:
d(Xi, Xj) = 0 ⇔ Xi = Xj
• Simétrica:
d(Xi, Xj) = d(Xj, Xi)
• Desigualdad triangular:
d(Xi, Xj) ≤ d(Xi, Xk) + d(Xk, Xj) donde Xi, Xj y Xk son tres vectores cualquiera en Ep.
La distancia más tradicionalmente usada ha sido la métrica de Minkowski (expuesta en la sección 4.2.5.2.1.1). El valor de la distancia entre Xi y Xj d(Xi, Xj) es equivalentemente a la distancia entre Ii y Ij con respecto a las características seleccionadas C=C1, C2,...,CpT. Es frecuente el uso de medidas heurísticas que no son propiamente una distancia, en el sentido en que se ha definido ésta. Como ejemplos se puede citar la distancia Jeffreys-Matusita.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 135
Los pares d(Xi, Xj) pueden representarse mediante la matriz de distancias D:
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
0...............
...0
...0
21
221
112
nn
n
n
dd
dddd
D
Como complemento a la noción de distancia entre Xi y Xj está la idea de similitud entre los individuos Ii y Ij. A continuación se define la similitud formalmente.
Definición 5-2. Función similitud
Una función s(Xi, Xj)=sij real, no negativa se dice que es una medida de similitud si cumple las siguientes propiedades:
• Identidad:
s(Xi, Xi) = 1
• Reflexiva:
s(Xi, Xj) = s(Xj, Xi)
• 0 ≤ s(Xi, Xj) < 1 ∀ Xi tal que Xi ≠ Xj
A la medida sij se le conoce también como coeficiente de asociación o de relación cuando el vector Xi contiene solo unos y ceros, esto es, datos binarios. Ejemplos de este tipo de coeficientes pueden encontrarse en la sección 4.2.5.2.3.
5.1.1.1.2 Un proceso de clustering jerárquico. Dendrograma
La condición de Bourbaki (del nombre del grupo de matemáticos que la desarrollaron) tambien llamada desigualdad ultramétrica consiste en lo siguiente:
d(Xi, Xj) ≤ Máx(d(Xi, Xk), d(Xk, Xj)) Como puede fácilmente observarse, la desigualdad ultramétrica es una propiedad más fuerte que la desigualdad triangular, lo que permite afirmar que toda distancia ultramétrica es una verdadera distancia. En la matriz de distancias M cada tripleta de elementos cumple la propiedad de la desigualdad triangular, si además cumple la siguiente la desigualdad ultramétrica se dice que M

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 136
es una matriz de distancias ultramétrica. Cuando los elementos de la matriz pertenecen todos al intervalo [0,1] se dice que la matriz está normalizada. Para obtener una matriz de distancias ultramétrica M’ a partir de la matriz de distancias M se pueden usar dos métodos [Gui74, Ben76]. El primero es el de M. Roux, y el segundo el de J. P. Benzécri: 1. Conversión a la matriz ultramétrica inferior maximal. Si en una tripleta cualquiera
(Xh,Xi,Xe) no se cumple al desigualdad ultramétrica, se reduce el índice de distancia más elevado, entre toda pareja de esta tripleta, haciéndolo igual al índice inferior maximal dentro de esta tripleta. Ejemplo: d(Xi,Xe) > d(Xe,Xh) > d(Xh,Xi) ⇒ d(Xi,Xe) = d(Xe,Xh) > d(Xh,Xi)
2. Conversión a la matriz ultramétrica superior minimal. Si en una tripleta cualquiera
(Xh,Xi,Xe) no se cumple al desigualdad ultramétrica, se tiene dos posibilidades para obtener la ultramétrica superior minimal:
• Elevar el índice de distancia más bajo, entre toda pareja de esta tripleta, haciéndolo
igual al índice superior maximal de esta tripleta. Ejemplo:
d(Xi,Xe) > d(Xe,Xh) > d(Xh,Xi) ⇒ d(Xi,Xe) = d(Xh,Xi) > d(Xe,Xh)
• Elevar el índice de distancia intermedio, entre toda pareja de esta tripleta, haciéndolo igual al índice superior maximal de esta tripleta. Ejemplo:
d(Xi,Xe) > d(Xe,Xh) > d(Xh,Xi) ⇒ d(Xi,Xe) = d(Xe,Xh) > d(Xh,Xi)
El método elegido se aplica sobre la matriz de distancias D, a cada una de sus posibles tripletas. Se reitera hasta que todas y cada de las tripletas cumplan la propiedad ultramétrica, habiéndose obtenido así la matriz de distancias ultramétrica D’. A partir de esta matriz ultramétrica obtenida D’ se puede construir una jerarquía, o lo que es lo mismo una multitud de particiones ordenadas que representa todas las posibles segmentaciones que puede hacerse sobre la población. De hecho la matriz ultramétrica y la jerarquia de partes son dos conceptos equivalentes [Vil79]. A continuación se pasa a definir más formalmente esta idea.
Definición 5-3. Jerarquía de partes
Sea el conjunto I que denota los n individuos de la población. A una familia H(I) de subconjuntos de I se le llama jerarquía de partes para I cuando:
1. I ∈ H(I).
2. El conjunto j asociado a cualquier elemento j de I ∈ H(I).

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 137
3. Si H, H’ ∈ H(I) y H ∩ H’ ≠ ∅ entonces H ⊂ H’ o H’ ⊂ H.
Definición 5-4. Clustering jerárquico
A una jerarquía de partes se le llama clustering jerárquico cuando está indexada, en el sentido de que ∀ H / H ∈ H(I) ∃ xH en el intervalo [0,1] que verifica lo siguiente:
1. xH = 0 si H = j ∀ j ∈ I.
2. xH’ ≤ xH ⇔ H’ ⊂ H.
Desde los resultados de Dunn, Zadeh y Bezdek [Vil79, Del96] se sabe que existe una equivalencia entre el clustering jerárquico y las distancias ultramétricas. Como representación gráfica de una jerarquía de partes se puede constuir un dendrograma o diagrama en árbol.
Ejemplo 5-1
Sea D una matriz de distancias definida así:
Mediante la aplicación del método correspondiente se obtiene la matriz ultramétrica inferior maximal, D’:
A partir de D’ se puede obtener el dendrograma que está representado gráficamente en la Figura 6-1, en donde se puede observar la jerarquía de las particiones. Así según las distancias las particiones quedan como sigue:
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
=
01057025.16065250767670
D
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
=
0105505.15.150
55250666660
'D

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 138
• Para la distancia ultramétrica = 0 las clases son:
F1 = 1; F2 = 2; F3 = 3; F4 = 4; F5 = 5; F7 = 6. • Para la distancia ultramétrica = 1.5 las clases son:
F1 = 5, 6, 3; F2 = 4; F3 = 2; F1 = 1. • Para la distancia ultramétrica = 3 las clases son:
F1 = 5, 6, 3; F2 = 4, 2; F3 = 1.
• Para la distancia ultramétrica = 6 queda la clase que agrupa a todos los elementos:
F1 = 1, 2, 3, 4, 5, 6.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 139
En la matriz ultramétrica D’ están contenidas todas las posibles particiones de la población según el criterio elegido. El siguiente problema que se plantea es escoger una partición en concreto bien sea fijando el número final de grupos a obtener, o por algún mecanismo automático de obtención de una partición óptima. A continuación se exponen dos mecanismos automáticos para ello:
• Partición óptima absoluta. • Obtención una partición óptima mediante la medida H3.
5.1.1.1.3 Determinación de la partición óptima absoluta
Dis
tanc
ia u
ltram
étric
a
5
1
2
3
4
5
6
7
0

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 140
Se plantea el problema de obtener la partición óptima absoluta, caso de que no se tenga ninguna información sobre el número de clusters a obtener, ni de la composición o forma de los mismos. Previamente se van a hacer las siguientes definiciones.
Definición 5-5. Relación de similitud difusa
Se dice que s(Xi, Xj)=sij es una relación de similitud difusa si, a las condiciones de la Definición 5-2, se le añade la siguiente:
s(Xi, Xj) ≥ Máx(Mín(s(Xi, Xk), s(Xk, Xj))
Como concepto complementario a esta definición, se puede definir la relación de distancia
difusa como 1 - sij.
A partir de una relación de similitud difusa se puede definir relaciones binarias sin más que efectuar los α -cortes (ver Definición 3-5) de esta relación en los siguientes términos:
• ∀ α tal que α ∈ [0,1] se define un α -corte (o relación binaria) de la relación difusa s a
un nivel α como:
Xi Rα Xk ⇔ s(Xi, Xk) ≥ α Se puede probar que existe equivalencia entre las clasificaciones jerárquicas y estas relaciones de similitud difusas de transitividad máx-mín [Vil79, Del96]. Considérese una jerarquía de partes y la relación de similitud difusa asociada a la misma (que viene dada por una matriz S determinada por Rα , cuyos elementos toman valores en [0,1]). De acuerdo con las propiedades de la relación de similitud, puede obtenerse una partición sin más que fijar el nivel de similitud α y calcular el α -corte de la relación (que es una relación de equivalencia). Así pues, hablando en términos absolutos, se puede afirmar [Vil79], que la mejor partición deducida de una jerarquía de partes es la obtenida a nivel de similitud 0.5, por supuesto y como ya se ha dicho, en caso de que no se tenga ningún tipo de conocimiento sobre la estructura de los datos.
5.1.1.1.4 Selección de “buenas” particiones a partir de la matriz de distancias mediante la medida H3
En este apartado se introduce un procedimiento de aprendizaje no supervisado para
seleccionar buenas (u óptimas) particiones dentro de la jerarquía de particiones. Este procedimiento está basado en la matriz de distancias.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 141
Para cualquier α comprendido en el intervalo [0,1] se denota como Aα = (aijα ) a la
matriz obtenida por medio del α -corte de la relación de similitud S, así pues:
aijα = 1 si sij ≥ α
aij
α = 0 en otro caso.
Es fácilmente demostrable que Aα es una relación de equivalencia crisp sobre I para
cualquier α . Ya que S (matriz que viene dada por la relación de similitud difusa) es una matriz finita,
contiene solo un conjunto finito de valores diferentes. Así para cualquier S (clustering jerárquico) siempre se puede identificar una secuencia finita Sk, k=1,2,...,h tal que:
0 = S1 < S2 < ... < Sh = 1; ∀ k tal que k ∈ 1,2,...,h ∃ sij tal que sij = Sk y viceversa.
Dicho de otro modo, la secuencia Sk, k=1,2,...,h determina todos los posibles α -cortes
de S, esto es, el conjunto de todas las relaciones de equivalencia diferentes asociadas a S. El problema planteado es ver cual de estas particiones representa mejor la estructura del
conjunto de objetos. Parece razonable pensar que un α -corte será óptimo si la distancia entre
su matriz de partición Aα y la matriz de similitud difusa sea mínima. A continuación se explica un criterio de búsqueda de la partición óptima basado en esta idea [Del96].
Primeramente, se procede a definir una distancia en el espacio de las matrices. Así si
A=(aij) y B=(bij) son dos matrices de la misma dimensión, su distancia se define así:
d(A,B) = máxij |aij - bij| La función objetivo, a minimizar, será la que sigue:
H3 (Sk) = d(S,ASk) Se puede observar además que para cualquier α que pertenezca a Sk, k=1, 2,..., h y
cualquier i, j que pertenezcan a 1, 2,..., n ocurre:
|sij - aijα | = sij si sij < Sα
|sij - aij
α | = 1 - sij si sij ≥ Sα

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 142
Como Zadeh estableció, se sabe también que: sij = supk Sk aij
k
y así
H3 (Sb) = máx (sij - aijα ) =
máxij supk Sk aij
k si supk Sk aijk < Sα
máxij (1 - supk Sk aij
k ) en otro caso Por tanto, conforme a las propiedades de la secuencia Sk (diferentes valores de S, en
orden ascendente), se verifica que: máxij supk Sk aij
k = Sα - 1con k tal que supk Sk aijk < Sα
míxij supk Sk aij
k = Sα con k tal que supk Sk aijk ≥ Sα
así:
H3(Sα ) = máx(Sα -1, 1 - Sα ) Para obtener la partición óptima de acuerdo con este criterio, se debe buscar el mín
H3(Sα ). Según la posición relativa de los valores en la secuencia Sk surgen las siguientes posibilidades:
1. 0 < Sα -1 < Sα < 1. Entonces H3(Sα ) = 1 - Sα > 0.5.
2. 0 < Sα -1 < 0.5 < Sα . Entonces H3(Sα ) ≤ 0.5.
3. 0 < 0.5 ≤ Sα -1 < Sα . Entonces H3(Sα ) = Sα ≥ 0.5.
El mínimo valor para H3(Sα ) se obtendrá en el rango de similitud que contenga el valor
0.5. Si existe Sα =0.5, el valor mínimo se obtendrá en el rango (Sα -1, Sα +1] y habrá dos particiones óptimas.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 143
5.1.1.2 Clustering en FIRST* Tal y como se ha definido el problema del clustering, cada individuo i de la población tienen un conjunto de p características, que se han notado como Xi=xik con k=1..p, que quieren tenerse en cuenta a la hora de segmentar la población. Para cada par de individuos de la población i y j se ha debido de definir una función distancia d(Xi, Xj) de tal manera que sea posible obtener la matriz de distancias de la población D, y en definitiva la matriz ultramétrica D’. Dentro del ámbito de FIRST*, el conjunto de las características puede ser soportado por un atributo difuso tipo 4, col_clu, definido tal y como sigue:
col_clu (x1, x2,…, xp) donde xk (con k=1..p) denota para la fila i, la característica k del i individuo de la población, esto es, xik. Si p=1 y el dominio de x1 así lo permite, col_clu puede ser también definido como un tipo difuso 1 (numérico crisp), 2 (difuso) ó 3 (escalar). Sobre el atributo difuso tipo 4 col_clu se puede definir su comparador difuso de igualdad FEQ (o análogamente NFEQ) basándose en la función distancia que se haya usado para resolver el problema del clustering: CDEG (col_cluXi FEQ col_cluXj) = 1 - d(Xi, Xj) Sea la relación id_tabla_orig_proyecto que soporta las características de los n individuos de la población sobre los que se quiere realizar un proceso de clustering. La tabla tiene el siguiente esquema.
id_tabla_orig_proyecto (row_id, col_clu) donde row_id = 1..n, denota cada uno de los individuos de la población y col_clu es el atributo difuso tal y como se ha definido anteriormente. Pues bien, suponiendo que el comparador FEQ es simétrico, la obtención de la matriz de distancias de la población se resuelve mediante la siguiente sentencia:
SELECT A1.ROW_ID AS i, A2.ROW_ID AS j, 1 - CDEG(*) AS dij FROM id_tabla_orig_proyecto A1, id_tabla_orig_proyecto A2 WHERE A1.ROW_ID < A2.ROW_ID AND A1.col_clu FEQ A2.col_clu THOLD 0;
que devuelve los identificadores de los individuos de la población i y j (con i, j =1..n) y su correspondiente distancia dij. Así pues, sobre cualquier atributo difuso 4 puede realizarse un proceso de clustering sin más que esté definido sobre él un comparador difuso de igualdad. Los tipos difusos 1, 2 y 3

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 144
llevan ya definido implícitamente dichos comparadores de igualdad y por tanto pueden ser usados en el proceso de clustering sin más. Sin embargo, existe el problema de que en FIRST* no se ha exigido que dichos comparadores difusos cumplan la propiedad simétrica, como sí se ha exigido en las funciones de similitud usadas en el proceso de clustering (ver Definición 5-2). Para resolver esto, se puede usar una función T-norma o una T-conorma (ver 3.2.3.1). Así si el comparador difuso NFEQ definido para el atributo difuso col_clu no es simétrico, se puede obtener la matriz de distancias aplicando una:
• T-norma:
SELECT A1.ROW_ID AS i, A2.ROW_ID AS j, 1 - CDEG(*) AS dij FROM id_tabla_orig_proyecto A1, id_tabla_orig_proyecto A2 WHERE A1.ROW_ID < A2.ROW_ID AND (A1.col_clu NFEQ A2.col_clu THOLD 0 AND A2.col_clu NFEQ A1.col_clu THOLD 0);
• o una T-conorma:
SELECT A1.ROW_ID AS i, A2.ROW_ID AS j, 1 - CDEG(*) AS dij FROM id_tabla_orig_proyecto A1, id_tabla_orig_proyecto A2 WHERE A1.ROW_ID < A2.ROW_ID AND (A1.col_clu NFEQ A2.col_clu THOLD 0 OR A2.col_clu NFEQ A1.col_clu THOLD 0);
Para el Servidor FSQL, las funciones que usa por defecto para la T-norma es el mínimo, y para la T-conorma el máximo, aunque ambas son configurables dentro de dicho servidor (ver [Gal99]). Aunque, como se ha explicado, el atributo difuso col_clu recoge las p características de la población, se puede generalizar más el problema del clustering suponiendo que los atributos a tener en cuenta dentro de dicho proceso de clustering son m atributos difusos. Así, sea la relación id_tabla_orig_proyecto sobre la que se quiere realizar un proceso de clustering con el siguiente esquema.
id_tabla_orig_proyecto (row_id, col_clu1, col_clu2,…, col_clum) con m ∈ ℕ
donde
• col_clu1, col_clu2,…, col_clum: son una serie de atributos difusos de cualquier tipo, definidos en la FMB*, relevantes para un proceso de clustering.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 145
Además se puede desear que la relevancia de cada atributo difuso no sea la misma dentro del proceso de clustering, así se puede definir una secuencia de pesos w_clu1, w_clu2,…, w_clum tal que w_clur ∈ [0,1] con r=1..m verificando:
donde cada w_clur indica la importancia relativa del atributo col_clur con respecto al resto de atributos relevantes para el clustering. Con este planteamiento, la obtención de la matriz de distancias de la población se resuelve mediante la siguiente sentencia:
SELECT A1.ROW_ID AS i, A2.ROW_ID AS j, 1 - (CDEG(A1. col_clu1)* w_clu1 +…+ CDEG(A1. col_clum)* w_clum) AS dij, FROM id_tabla_orig_proyecto A1, id_tabla_orig_proyecto A2 WHERE A1.ROW_ID < A2.ROW_ID AND (A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 | A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 AND A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD 0 | A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 OR A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD 0) AND … AND (A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 | A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 AND A2.col_clum fuzzy_ecompm A1.col_clum THOLD 0 | A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 OR A2.col_clum fuzzy_ecompm A1.col_clum THOLD 0);
donde fuzzy_ecompr simboliza el comparador difuso de igualdad, esto es, FEQ o NFEQ, que se desea usar para cada atributo difuso col_clur. Para cada uno de estos atributos col_clur la cláusula WHERE ha quedado con tres formas opcionales posibles (especificadas en la anterior sentencia mediante el símbolo |):
• Si fuzzy_ecompr es simétrico: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 • Si fuzzy_ecompi no es simétrico se obtiene una comparación simétrica usando dicho
comparador con una de las dos opciones siguientes:
o T-norma: A1.col_clum fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clum fuzzy_ecompr A1.col_clur THOLD 0 o T-conorma: A1.col_clum fuzzy_ecompr A2.col_clur THOLD 0 OR A2.col_clum fuzzy_ecompr A1.col_clur THOLD 0
De esta manera, la matriz de distancias D que se obtiene es simétrica, además de estar normalizada en [0,1], y está en disposición de aplicarle alguno de los métodos explicados en la sección anterior (Roux o Benzécri) para obtener la matriz de distancias ultramétrica D’, que por supuesto también estará normalizada. En dicha matriz ultramétrica están latentes todas las
∑=
=m
r
rcluw1
1 _

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 146
posibles particiones (segmentaciones) de la población. El último paso que quedaría por realizar sería elegir una partición en concreto mediante algún criterio automático (como los que han sido explicados) o en base al número de grupos a obtener. Tras este proceso de clustering, el resultado bien podría ser una relación id_tabla_result_clu análoga a la relación original que contenía las características de la población id_tabla_orig_proyecto:
id_tabla_result_clu (row_id, col_clu1, col_clu2,…, col_clum, cluster_id) con m ∈ ℕ más un nuevo atributo cluster_id = 1..num_clus con num_clus ≤ n, que indica el grupo al que finalmente ha sido asignado cada individuo i de la población. El total de grupos obtenidos será por tanto num_clus. En el apartado 6.3.1.2 pueden observarse ejemplos resueltos, mediante un proceso de clustering basado en el que se acabar de explicar, incluyendo resultados de dicho proceso.
5.1.2 Caracterización El método de clustering, propuesto en la sección anterior, ha generado como resultado la tabla id_tabla_result_clu en donde esta contenida una partición en concreto de entre todas las posibles que existen en la matriz ultramétrica o, lo que es lo mismo, tras el clustering jerárquico. De esta manera cada elemento de la población, esto es, cada fila de la tabla se le ha incluido un identificador del grupo al que pertenece (cluster_id). Otros métodos de clustering obtienen como resultado una única fila para cada grupo que son denominadas centroides, como ejemplo se puede citar el algoritmo c-means (ver 2.1.1.3.1). Por tanto, el problema que se plantea ahora es obtener las filas centroides que caractericen cada uno de los grupos obtenidos. Por tanto, se desea obtener una tabla, llamada id_tabla_result_cen, análoga a la de resultado del clustering, pero solo con un número de filas igual al número de grupos obtenidos (num_clus). Cada una de estas filas será la fila centroide del grupo en cuestión. La estructura de la tabla podría ser la siguiente:
id_tabla_result_cen(row_id, col_clu1, col_clu2,…, col_clum, cluster_id, col_clu1_avgCdeg, col_clu2_avgCdeg,…, col_clum_avgCdeg) con m ∈ ℕ
Así el problema que se plantea es obtener para cada columna col_clur con r=1..m los valores correspondientes val_cenrc que caracterizan cada grupo de los obtenidos, identificados por cluster_idc=1..num_clus. Además se desea obtener la representatividad del valor obtenido val_cenrc simbolizada como rep_cenrc ∈ [0,1] que, en definitiva, va a dar idea de la bondad del centroide. Esta representatividad va a ser almacenada en la columna col_clur_avgCdeg.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 147
La resolución de dicho planteamiento se va a hacer teniendo en cuenta el nivel de abstracción al que se desea obtener dicho valor val_cenrc para cada columna col_clur. Los niveles posibles de abstracción van a ser:
• Etiqueta lingüística: se fuerza que el centro en cuestión quede descrito por alguna de las etiquetas lingüísticas que existen para la columna en cuestión en la FMB*. Esto hace que la descripción de los grupos sea bastante entendible para el usuario asemejándose en los resultados obtenidos al clustering conceptual [Mic84]. Por el contrario, el resultado es normalmente menos representativo que con los otros niveles de abstracción.
• Valor conocido: cuando se desea obtener como centroide un valor conocido, considerando que el universo de datos conocidos está compuesto de la tabla actual y de las etiquetas lingüísticas de la FMB*. Así de este universo se elige el valor que mejor representa al cluster en cuestión.
• Valor medio: en este nivel de abstracción se desea obtener un valor para el cluster y la columna en cuestión que sea válido dentro de su dominio y que sea lo más representativo posible, no importando si es un dato conocido o extrapolado a partir de los datos de la tabla. Es por tanto el método más preciso aunque también puede llegar a ser el que produzca resultados menos entendibles para el usuario.
Seguidamente se detallan cada una de estas opciones:
5.1.2.1 Etiqueta lingüística En este caso se desea que el valor val_cenrc coincida forzosamente con una de las etiquetas lingüísticas definidas para la columna en cuestión en la FMB*. Primeramente se define Labelr = labelrl con l=1..t donde labelrl es cada una de las etiquetas definidas para la columna col_clur en la FMB* (tabla FUZZY_OBJECT_LIST). labelra con a ∈ 1, 2,…, t va a simbolizar la etiqueta más representativa de la col_clur en base al comparador fuzzy_ecompr que simboliza el comparador difuso de igualdad, esto es, FEQ o NFEQ, que se desea usar como criterio de obtención de dicha etiqueta más representativa. Por tanto el valor que se desea obtener val_cenrc = labelra. Se va a definir la función: Label_avg_cdeg (col_clur, labelrl, cluster_idc) = label_avg_cdegrlc ∈ [0,1] que devuelve la similitud label_avg_cdegrtc que hay entre la etiqueta lingüística labelrl y los valores de la columna col_clur para un cluster en concreto identificado por cluster_idc. La función se basa en la siguiente sentencia FSQL:
SELECT AVG(CDEG(*)) AS label_avg_cdegrlc FROM id_tabla_result_clu WHERE (col_clur fuzzy_ecompr labelrl THOLD 0

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 148
| col_clur fuzzy_ecompr labelrl THOLD 0 AND labelrl fuzzy_ecompr col_clur THOLD 0 | col_clur fuzzy_ecompr labelrl THOLD 0 OR
labelrl fuzzy_ecompr col_clur THOLD 0) AND cluster_id = cluster_idc; en la que la cláusula WHERE tiene distintas opciones según la simetría del comparador fuzzy_ecompr:
• Si fuzzy_ecompr es simétrico: col_clur fuzzy_ecompr labelrl THOLD 0 • Si fuzzy_ecompi no es simétrico se obtiene una comparación simétrica usando dicho
comparador con una de las dos opciones siguientes:
o T-norma: col_clur fuzzy_ecompr labelrl THOLD 0 AND labelrl fuzzy_ecompr col_clur THOLD 0 o T-conorma: col_clur fuzzy_ecompr labelrl THOLD 0 OR labelrl fuzzy_ecompr col_clur THOLD 0
Pues bien, la etiqueta elegida, esto es, val_cenrc=labelra ∈ Label va a ser aquella que cumpla la siguiente fórmula:
Label_avg_cdeg (col_clur, labelra, cluster_idc)= label_avg_cdegrac ≥ Label_avg_cdeg(col_clur, labelrl, cluster_idc), ∀ labelrl ∈ Labelr
El valor label_avg_cdegrac va a ser considerado como el grado de representatividad de la etiqueta, esto es, rep_cenrc = label_avg_cdegrac. En el apartado 6.3.1.2 puede observarse ejemplos del caracterización de atributos difusos tipo 2 mediante etiquetas lingüísticas, tal y como se acaba de explicar.
5.1.2.2 Valor conocido En este caso se desea que el valor val_cenrc sea uno de los conocidos para la columna col_clur teniendo en cuenta tanto los valores de dicha columna en la tabla id_tabla_result_clu y las etiquetas lingüísticas definidas para la columna en cuestión en la FMB*. Primeramente se define la función: Value_avg_cdeg (col_clur, v, cluster_idc) = value_avg_cdegrvc ∈ [0,1] que devuelve la similitud value_avg_cdegrtc que hay entre el valor de la columna col_clur de la fila identificada por el row_id v ∈ 1, 2,…, n y los valores de la columna col_clur para un cluster en concreto identificado por cluster_idc. La función se basa en la siguiente sentencia FSQL:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 149
SELECT AVG(CDEG(*)) AS value_avg_cdegrvc FROM id_tabla_result_clu A1, id_tabla_result_clu A2 WHERE (A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 | A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0 | A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 OR A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0)
AND A2.cluster_id = cluster_idc AND A1.row_id = v ; en la que la cláusula WHERE hay que hacer las mismas consideraciones, que en la sección anterior, según la simetría del comparador fuzzy_ecompr:
• Si fuzzy_ecompr es simétrico se usa la cláusula: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0
• Si fuzzy_ecompi no es simétrico se obtiene una comparación simétrica usando dicho comparador con una de las dos opciones siguientes:
o T-norma: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0 o T-conorma: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 OR A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0
Pues bien, el valor, de entre todos los que hay en la tabla id_tabla_result_clu, que mejor representa la columna col_clur va a ser el de la fila con row_id=v que verifique lo siguiente:
Value_avg_cdeg (col_clur, v, cluster_idc)= value_avg_cdegrvc ≥ Value_avg_cdeg(col_clur, row_id, cluster_idc), ∀ row_id = 1..n
donde value_avg_cdegrvc va a ser considerado como el grado de representatividad de dicho valor v. Finalmente, para obtener el valor conocido más representantivo se compara si la etiqueta más representativa (obtenida como se ha explicado en la anterior sección) representa mejor la columna col_clur que el valor identificado con v, esto es:
val_cenrc=labelra rep_cenrc = label_avg_cdegrac, si label_avg_cdegrac ≥ value_avg_cdegrvc
val_cenrc= valor de col_clur tal que row_id=v rep_cenrc = value_avg_cdegrvc, en otro caso
5.1.2.3 Valor medio Este nivel de abstracción se desea que el valor val_cenrc sea el más representativo aunque no sea un valor conocido, esto es, no tiene por qué ser un dato existente ni en la FMB* ni en la

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 150
tabla id_tabla_result_clu. Por supuesto, dicho valor val_cenrc debe ser válido desde el punto de vista del dominio en que esté definido la columna col_clur. Existen casos, en los que este valor medio tenga que coincidir con el un valor conocido más representativo, estudiado en la anterior sección, debido a que en FIRST* no se tiene información para extrapolar otro mejor. Esto ocurre básicamente en los tipos difusos 3 (escalares) y sobre tipos difusos 4 cuando están definidos sobre un referencial no ordenado. A continuación se explica como se va a obtener dichos valores más representativos:
• Tipos difusos 1 (crisps numéricos): val_cenrc va a ser la media aritmética de los valores de la columna col_clur para un cluster en concreto identificado por cluster_idc. La sentencia FSQL con la que se obtendría este valor podría ser la siguiente:
SELECT AVG(col_clur) AS val_cenrc FROM id_tabla_result_clu WHERE cluster_id = cluster_idc ;
• Tipos difusos 4: solamente en el caso que el tipo difuso 4 esté compuesto de atributos definidos sobre un referencial ordenado, esto es, cuando col_clur definido como (xr1, xr2,…, xrp) cumpla que xr1, xr2,…, xrp son atributos crisps numéricos. Si eso ocurre val_cenrc va a ser la media aritmética de los valores de la columnas xr1, xr2,…, xrp para un cluster en concreto identificado por cluster_idc. La sentencia FSQL con la que se obtendría este valor podría ser la siguiente:
SELECT AVG(xr1), AVG(xr2),…, AVG(xrp) AS val_cenrc FROM id_tabla_result_clu WHERE cluster_id = cluster_idc ;
• Tipos difusos 2 (difusos) si se recuerda (ver epígrafe 3.4.1.1) la forma que podían
tomar los datos de los tipos difusos 2 eran: datos precisos (crisps), intervalos de posibilidad, aproximados y distribuciones de posibilidad trapezoidales. A la hora de obtener la media de la columna col_clur se va tener en cuenta la premisa de que el valor val_cenrc no sea más preciso que los datos contenidos para la columna y el cluster en cuestión en la tabla id_tabla_result_clu. Así, si algún valor de col_clur es una distribución de posibilidad trapezoidal se va a tomar como val_cenrc el valor conocido más representativo (explicado en la sección anterior) siendo por tanto el resultado, bien una distribución de posibilidad que coincida con algún valor de la columna col_clur, o bien alguna etiqueta lingüística definida en la FMB* para dicha columna. Para el resto de casos se define:
o nc: número de filas de la tabla id_tabla_result_clu para el cluster cluster_idc. o n_crisps: número de filas tales que col_clur contiene datos precisos o crisps para el
cluster cluster_idc. o n_aprox: número de filas tales que col_clur contiene datos aproximados para el
cluster cluster_idc.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 151
o n_crisps: número de filas tales que col_clur contiene intervalos de posibilidad para el cluster cluster_idc.
Para el cálculo del valor medio se va a tener en cuenta la representación interna de la columna en cuestión que es col_clur(col_clurT, col_clur1, col_clur2, col_clur3, col_clur4) según consta en la Tabla 3-4. Previamente se va a obtener una serie de magnitudes para cada tipo posible de dato (col_clurT) existente en la tabla para el cluster en cuestión mediante la siguiente sentencia:
SELECT AVG(col_clur1) AS average1, AVG(col_clur4) AS average4, AVG(col_clur4 - col_clur1) AS average4_1, AVG((col_clur1+ col_clur4) / 2) AS average1_4_med, COUNT(*) AS nc FROM id_tabla_result_clu WHERE cluster_id = cluster_idc GROUP BY col_clurT;
que va a implicar las siguientes variables:
o Para datos crisps (col_clurT=3) media de los datos precisos (average_crips): average_crips = average1
o Para datos aproximados (col_clurT=6) media de los centros de los triángulos de posibilidad (average_aprox) y media de los márgenes de dichas distribuciones de posibilidad triangulares (average_margen):
average_aprox = average1 average_margen = average4
o Para intervalos (col_clurT=5) media de los puntos medios de los intervalos (average_inter) y media de las longitudes de los intervalos (average_long_inter):
average_inter = average1_4_med average_long_inter = average4_1
Genéricamente se va a definir avg_aprox_tipo2 como la media ponderada por el número de datos de cada tipo de la media de los datos precisos, aproximados (su centro) e intervalos (el punto medio) para el cluster cluster_idc:
avg_aprox_tipo2 = ((average_crips × n_crips) + (average_aprox × n_aprox) + (average_inter × n_inter)) / nc
De esta forma existe la siguiente casuística en el cálculo de val_cenrc dependiendo de si:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 152
o n_crisps = nc, esto es, solo existen datos precisos para esta columna y este cluster en la tabla: en este caso val_cenrc es un dato preciso cuyo cálculo coincide con el que se ha explicado para los tipos difusos 1. Por lo tanto para val_cenrc: col_clurT=3 (tipo de dato crisp) col_clur1= average1
o n_crisps + n_inter = nc, esto es, solo existen datos precisos e intervalos: en este caso val_cenrc va a ser un intervalo [nrc,mrc] con centro en la media ponderada de los puntos medios de los intervalos y de los datos precisos; y cuya amplitud va a coincidir con la media de la amplitud de todos los intervalos considerando que los datos precisos son intervalos de longitud 0. Así para val_cenrc:
col_clurT=5 (tipo de dato intervalo) col_clur1= nrc col_clur4= mrc
donde nrc y mrc se obtienen como se explica a continuación: long_inter = ((average_long_inter × n_inter) / nc) / 2 nrc = avg_aprox_tipo2 - long_inter mrc = avg_aprox_tipo2 + long_inter
o n_crisps + n_aprox = nc, esto es, solo existen datos precisos y aproximados: en este caso val_cenrc va a ser un valor aproximado con centro en la media ponderada de los centros de los aproximados y de los datos precisos; y con margen la media de los márgenes de los datos aproximados considerando que los datos precisos son aproximados con margen nulo. Esto es, centrorc= avg_aprox_tipo2 y margen margenrc = average_margen, así para val_cenrc:
col_clurT=6 (tipo de dato aproximado) col_clur1= centrorc col_clur2= centrorc - margenrc col_clur3= centrorc+ margenrc col_clur4= margenrc
o n_crisps + n_aprox + n_inter = nc, esto es, existen datos precisos, aproximados e
intervalos: en este caso val_cenrc va a ser un trapecio [arc,brc,crc,drc] que se va a obtener como el intervalo del caso anterior (con centro en la media ponderada de los datos precisos, centros de los aproximados y puntos medios de los intervalos) pero difuminado por la izquierda y derecha con el margen medio de los valores aproximados . Así para val_cenrc:
col_clurT=7 (tipo de dato trapecio) col_clur1= arc col_clur2= brc - arc col_clur3= crcc - drc col_clur4= drc donde arc, brc, crc y drc se obtienen como se explica a continuación:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 153
long_inter := ((average_long_inter × n_inter) / (n_crips + n_inter)) / 2 arc = avg_aprox_tipo2 - (long_inter + average_margen) drc = avg_aprox_tipo2 - (long_inter + average_margen) brc = avg_aprox_tipo2 - long_inter crc = avg_aprox_tipo2 + long_inter
El grado de representatividad de val_cenrc, considerado como el valor medio independientemente de su forma de computación, se va obtener como la media del grado similitud de val_cenrc respecto a todos los valores de la columna para el cluster en cuestión. La siguiente sentencia FSQL sirve para obtener dicho valor:
SELECT AVG(CDEG(*)) AS rep_cenrc FROM id_tabla_result_clu A1, id_tabla_result_cen A2 WHERE (A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 | A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0 | A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 OR A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0)
AND A1.cluster_id = A2.cluster_id AND A1.cluster_id = cluster_idc ; en la que la cláusula WHERE hay que hacer las mismas consideraciones, que las hechas anteriormente, según la simetría del comparador fuzzy_ecompr:
• Si fuzzy_ecompr es simétrico se usa la cláusula: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0
• Si fuzzy_ecompi no es simétrico se obtiene una comparación simétrica usando dicho comparador con una de las dos opciones siguientes:
o T-norma: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0 o T-conorma: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 OR
A2.col_clur fuzzy_ecompr A1.col_clur THOLD 0 En el apartado 6.3.1.2 puede observarse ejemplos del caracterización de atributos difusos tipo 4 mediante la técnica aquí explicada.
5.1.3 Clasificación difusa En la sección 2.1.1.4 se ha hecho una introducción al problema de la clasificación y la clasificación difusa. Durante la sección anterior, se ha explicado como a partir de la tabla id_tabla_orig_proyecto se ha obtenido la tabla
id_tabla_result_clu (row_id, col_clu1, col_clu2,…, col_clum, cluster_id)

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 154
como resultado del proceso de clustering y la tabla
id_tabla_result_cen(row_id, col_clu1, col_clu2,…, col_clum, cluster_id, col_clu1_avgCdeg, col_clu2_avgCdeg,…, col_clum_avgCdeg)
tras la caracterización de los distintos grupos obtenidos. Evidentemente el criterio del clustering se ha basado en los datos originales de la tabla id_tabla_orig_proyecto y se desearía poder “reproducir” dicho mecanismo de agrupamiento para cualquiera otros valores de los datos. Así, el problema que se plantea ahora es para cualquier tabla id_tabla_orig_cla que contenga, al menos, las columnas usadas como criterio de clustering id_tabla_orig_cla (col_clu1, col_clu2,…, col_clum) poder asignarle a cada columna el grupo a que pertenece (valor de cluster_id) y grado de pertenencia a dicho grupo basándose en el proceso de clustering realizado previamente. Por tanto la cuestión que se plantea entra del ámbito de la clasificación difusa. El resultado de esta clasificación podría quedar opcionalmente plasmado en una tabla id_tabla_resul_cla (col_clu1, col_clu2,…, col_clum, cluster_id, cdeg_cluster) que sería igual que la que se quiere clasificar más el atributo cluster_id que identifica al grupo al que pertenece la fila y cdeg_cluster que es un valor en [0,1] que va a indicar el grado de pertenencia de la fila al grupo en cuestión. En esta sección se van a hacer dos propuestas de clasificación difusas dentro del ámbito de FIRST*:
• clasificación basada en centroides y • clasificación basada en los k vecinos más cercanos
que pasan a destallarse a continuación:
5.1.3.1 Clasificación difusa basada en centroides En esta memoria se va a hacer una propuesta original para el proceso de clasificación. La idea consiste en obtener el grado de pertenencia de las filas de la tabla id_tabla_orig_cla a un cluster en concreto, identificado por cluster_idc, como el grado de compatibilidad difuso de FSQL (CDEG) entre las columnas de la tabla a clasificar y las columnas del centroide en cuestión. En definitiva se obtiene en qué medida se parecen difusamente los elementos a clasificar al centroide mediante el uso de los comparadores de igualdad difusos (FEQ y/o NFEQ). Por tanto, la sentencia FSQL con la que se obtendría este grado de pertenencia de los elementos de id_tabla_orig_cla al cluster cluster_idc sería la siguiente:
SELECT CDEG(*) AS cdeg_cluster

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 155
FROM id_tabla_result_cen A1, id_tabla_orig_cla A2 WHERE (A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD γ
| A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD γ AND
A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD γ
| A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD γ OR
A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD γ ) AND … AND
(A1.col_clum fuzzy_ecompm A2.col_clum THOLD γ
| A1.col_clum fuzzy_ecompm A2.col_clum THOLD γ AND
A2.col_clum fuzzy_ecompm A1.col_clum THOLD γ
| A1.col_clum fuzzy_ecompm A2.col_clum THOLD γ OR
A2.col_clum fuzzy_ecompm A1.col_clum THOLD γ ) AND A1.cluster_id = cluster_idc ; donde fuzzy_ecompr simboliza el comparador difuso de igualdad, esto es, FEQ o NFEQ, que se desea usar para cada atributo difuso col_clur. Para cada uno de estos atributos col_clur la cláusula WHERE ha quedado con tres formas opcionales posibles (especificadas en la anterior sentencia mediante el símbolo |):
• Si fuzzy_ecompr es simétrico: A1.col_clur fuzzy_ecompr A2.col_clur THOLD 0 • Si fuzzy_ecompi no es simétrico se obtiene una comparación simétrica usando dicho
comparador con una de las dos opciones siguientes:
o T-norma: A1.col_clum fuzzy_ecompr A2.col_clur THOLD 0 AND A2.col_clum fuzzy_ecompr A1.col_clur THOLD 0 o T-conorma: A1.col_clum fuzzy_ecompr A2.col_clur THOLD 0 OR
A2.col_clum fuzzy_ecompr A1.col_clur THOLD 0 El valor γ es el umbral que se establece para la clasificación, de tal manera que aquellas filas de la tabla a clasificar que no tengan un grado de pertenencia al cluster mayor o igual que este umbral no van a ser clasificados. Además, al igual que se planteó para el problema del clustering, se puede desear que la relevancia de cada atributo difuso no sea la misma dentro del proceso de clasificación, así se puede definir una secuencia de pesos w_cla1, w_cla2,…, w_clam tal que w_clar ∈ [0,1] con r=1..m verificando:
∑=
=m
r
rclaw1
1 _

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 156
donde cada w_clar indica la importancia relativa del atributo col_clur con respecto al resto de atributos relevantes para el clasificación. Para tener en cuenta dichos pesos en el proceso de clasificación habría que sustituir la obtención de cdeg_cluster en la sentencia SELECT recién propuesta por la siguiente expresión:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 157
SELECT (CDEG(A1. col_clu1)* w_cla1 +…+ CDEG(A1. col_clam)* w_clam) AS cdeg_cluster […]
siendo el resto de la sentencia igual a la anteriormente descrita. Una ventaja muy importante del método propuesto es que evita el uso de los clásicos algoritmos de clasificación que hay que aplicar tras el proceso de clustering. Mediante el uso de un lenguaje de alto nivel como FSQL dicha clasificación se efectúa interactivamente y en tiempo real, ya que la sentencia de clasificación propuesta es altamente eficiente. Pero quizás la mayor ventaja del método es lo intuitiva que puede llegar a ser para un analista de datos, debido a que, tras la obtención del resultado del proceso de clustering, esto es, de los centroides, la clasificación ya está descrita, simplemente se trata para el analista de obtener aquellos elementos que se parezcan lo suficiente a los centroides en cuestión, obteniendo además dicho grado de parecido con lo que puede ir refinando el resultado final. Realmente se ha convertido un resultado de clustering puramente crisp (lo cual también facilita la interpretación de los clusters) en un proceso de clasificación difuso. En el apartado 6.3.1.3 puede observarse ejemplos de clasificación basada en centroides incluyendo los resultados obtenidos.
5.1.3.2 Clasificación difusa basada en los k vecinos más cercanos Surge un problema cuando los centroides obtenidos, según el analista de datos en cuestión, no son lo suficientemente representativos, esto es, cuando los valores que indican dicha representatividad en la tabla id_tabla_result_cen que son col_clu1_avgCdeg, col_clu2_avgCdeg,…, col_clum_avgCdeg no llegan al mínimo requerido. Ante esta situación es posible que el usuario no quiera realizar un proceso de clasificación basándose en los centroides obtenidos. Para resolver dicha situación, se va a proponer un mecanismo de clasificación que use directamente la tabla de resultado del proceso de clustering en lugar de la tabla de centroides (que se ha considerado no representativa). La idea consiste en obtener el grado de pertenencia de cada fila de la tabla id_tabla_orig_cla a un cluster en concreto, identificado por cluster_idc, como la media del grado de compatibilidad difuso de FSQL (CDEG) entre las columnas de la tabla a clasificar y las columnas de la tabla resultado del clustering id_tabla_result_clu de aquellas k filas, de esta última tabla, que sean más parecidas a las de la tabla a clasificar. A estas k filas se les va a nombrar como los k vecinos más cercanos a la fila a clasificar. Por tanto, la sentencia FSQL con la que se obtendría el grado de pertenencia del elemento de la tabla id_tabla_orig_cla identificado de tal manera que su llave primaria (supuesto que dicha llave es la columna pk) tenga el valor pka al cluster cluster_idc usando los k (con k ∈ 1, 2,…, n) vecinos más cercanos, sería la siguiente:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 158
SELECT AVG(cdegree) AS cdeg_cluster FROM
(SELECT (CDEG(A1. col_clu1)* w_cla1 +…+ CDEG(A1. col_clam)* w_clam) AS cdegree FROM id_tabla_orig_cla A1, id_tabla_result_clu A2 WHERE (A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 | A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 AND A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD 0 | A1.col_clu1 fuzzy_ecomp1 A2.col_clu1 THOLD 0 OR A2.col_clu1 fuzzy_ecomp1 A1.col_clu1 THOLD 0) AND … AND (A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 | A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 AND A2.col_clum fuzzy_ecompm A1.col_clum THOLD 0 | A1.col_clum fuzzy_ecompm A2.col_clum THOLD 0 OR A2.col_clum fuzzy_ecompm A1.col_clum THOLD 0)
AND A1.pk = pka AND A2.cluster_id = cluster_idc ) WHERE ROWNUM <= k;
donde se deben de hacer las mismas consideraciones sobre los comparadores fuzzy_ecompr y las distintas posibilidades de la cláusula WHERE anteriormente hechas. Este método de clasificación es más preciso que el de los centroides explicado anteriormente. Por el contrario el proceso de clasificación es más ineficiente en sí, aunque por otro lado, hace innecesario el proceso de obtención de los centroides tras el proceso de clustering (si se quiere usar de forma apriorística independientemente de la representatividad de los centroides). Por otro lado, y según el caso, puede llegar a ser un método menos intuitivo para el usuario. Esto es debido a que, como se ha visto, los centroides pueden llegar a ser bastante descriptivos de los grupos que caracterizan y por tanto dicha descriptividad es heredada en el proceso de clasificación basado en centroides. Frecuentemente el éxito de un problema de clasificación se consigue si el analista de datos es capaz de justificar fácil e intuitivamente los resultados obtenidos. En el apartado 6.3.1.3 puede observarse ejemplos de clasificación basada en esta técnica incluyendo los resultados obtenidos.
5.1.4 Dependencias globales difusas Las dependencias funcionales (DFs) son características importantes de los SGBD. Su principal interés viene motivado por el hecho de que las DFs pueden capturar ciertos tipos de redundancia. Dicha redundancia, como es sabido, no es en absoluto deseable en las bases de datos ya que provoca el riesgo de inconsistencias, sobre todo, a la hora de las actualizaciones sobre dicha base de datos. Por tanto el uso de las DFs ha sido especialmente útil en el diseño de las bases de datos, de tal manera que, permite la descomposición de las relaciones en otras

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 159
evitando duplicidad de datos y sin pérdida de información. Se puede afirmar que las DFs reflejan propiedades inmutables dentro de una base de datos. Las dependencias funcionales difusas (DFDs) surgen en el marco de las Bases de Datos Relacionales Difusas. Se han propuesto varias definiciones de DFDs pero, al contrario que las DFs, un solo enfoque no ha dominado sobre el resto. Las DFDs también han sido estudiadas como una herramienta útil para el diseño de bases de datos difusas. Sin embargo, las DFDs parecen muy apropiadas para modelar propiedades mutables, esto es, existentes en las actuales manifestaciones de los datos. Por lo tanto la búsqueda de DFDs parece ser una tarea más apropiada dentro del marco de DM más que para el diseño de bases de datos difusas [Ras99]. La misma observación podría hacerse sobre las dependencias funcionales graduales (DFGs) las cuales son un tipo especial de dependencias difusas que reflejan algún tipo de monotonía en los datos [Ras99]. El objetivo de esta sección consiste en obtener tanto DFDs y DFGs, dentro del marco de FIRST*, mediante el uso de FSQL
5.1.4.1 Dependencias funcionales difusas y dependencias funcionales graduales
Como se ha comentado, hay varios enfoques para la resolución del problema de la definición de DFDs pero, a diferencia de la definición de DFs clásicas, no hay ninguno que predomine sobre el resto. Se va a comenzar describiendo brevemente el concepto clásico de DF dando después una definición general tanto de DFD como de DFG basándose en funciones difusas. Una vez hecho esto, se introducirá una definición más flexible de DFD y DFG con el objeto de gestionar casos excepcionales dentro de la manifestación de los datos.
Definición 5-6. Dependencias funcionales
La relación R con los conjuntos de atributos X=(col_ant1, col_ant2,…, col_antl), y Y=(col_con1, col_con2,…, col_conq) en su esquema verifica la DF X→ Y si y solo si, para cada instancia r de R se cumple: ∀t1, t2 ∈ r, t1[X] = t2[X] ⇒ t1[Y] = t2[Y]
El concepto de DFD dado por Cubero y Vila [Cub94] es una versión relajada de la definición clásica de DF. La idea básica consiste en reemplazar la igualdad usada en la definición de DF por una función de semejanza difusa. En la siguiente definición se expone dicha idea:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 160
Definición 5-7. α -β dependencia funcional difusa
La relación R verifica una α -β DFD X→ FTY si y solo si, para cada instancia r de R se verifica:
∀t1, t2 ∈ r, F(t1[X] ,t2[X]) ≥ α ⇒ T(t1[Y],t2[Y]) ≥ β donde F y T son funciones de semejanza difusas.
De esta definición es destacable la flexibilidad proporcionada por el uso combinado de los parámetros α y β y los diferentes tipos de relaciones de semejanza. De esta manera, si F es una medida de semejanza débil y T es una medida fuerte, se obtienen propiedades interesantes para el diseño de Bases de Datos Relacionales Difusas (descomposición de relaciones). Una detallada descripción de estos conceptos se puede encontrar en [Cub94, Cub97, Cub98]. Frecuentemente unas pocas tuplas de la bases de datos pueden hacer que la DFD no se cumpla. Para evitar esto, se podría relajar la definición de DFD dada, de tal manera que, no se forzara a todas las tuplas de la bases de datos a cumplir la anterior condición. Así se puede definir:
Definición 5-8. Confianza de una dependencia funcional difusa
Para un instancia r de R se verifica una α -β DFD X→ FTY con confianza c donde c ∈ [0,1] se define como:
caso otro en
[X])t, [X]r / F(tt t)t,t( [Y])t[Y],T(t [X])t, [X]r / F(tt t)t,t(
0 [X])t, [X]r / F(tt t)t,t( si 0
21 21,21
2121 21,21
21 21,21
⎪⎩
⎪⎨⎧
≥∈≥∧≥∈
=
=≥∈=
αβα
α
CardCardc
Cardc
donde ∧ es el operador lógico AND.
La idea básica consiste en calcular el porcentaje de tuplas tales que cumplan el antecedente y el consecuente conjuntamente con respecto a aquéllas que solo cumplen el consecuente. Es deseable que la confianza sea cercana a 1 para considerar como operativa la DFD, esto es, que se cumpla para la mayoría de los datos excepto para unas pocas excepciones. Por ejemplo, supóngase una relación R donde se tienen los atributos con los ingresos y gastos de los clientes y se quiere estudiar la DFD ingresos → FT gastos, esto es, para comprobar si similares ingresos de los clientes implica que los mismos realizan similares gastos. Si el número de tuplas de R es 100000 y de ellas que cumplan el antecedente y el consecuente se tienen 180, y que cumplan solo el antecedente se tienen 210, la confianza sería 180/210, es decir, 0.86.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 161
Dicha confianza puede ser considera suficiente para el analista de datos a la hora de aceptar la DFD, pero parece evidente que el número de filas con las que se ha obtenido no es muy grande con respecto al total que tiene la tabla. Es por ello que se va a proceder a la definición de la siguiente medida:
Definición 5-9. Soporte de una dependencia funcional difusa
Para un instancia r de R se verifica una α -β DFD X→ FTY con soporte s donde s ∈ [0,1] se define como:
⎪⎩
⎪⎨⎧
≥∧≥∈=
==
caso otro en [Y])t[Y],T(t [X])t, [X]r / F(tt t)t,t(0 si 0
2121 21,21
nCards
nsβα
donde n es el número de tuplas de la instancia r de R.
La idea consiste en calcular el porcentaje de tuplas que cumplen el antecedente y consecuente conjuntamente respecto al total de filas de la relación. De esta forma se da una idea de las filas implicadas en la obtención de la DFD con respecto al total de la tabla. Siguiendo con el ejemplo anterior, el soporte que se obtendría para la DFD ingresos → FT
gastos sería 180/100000, esto es, 0.0018. Esto podría hacer descartable dicha DFD por considerarse que no tienen un soporte suficiente. Otra forma de consideración de conexiones entre los datos de una base de datos es especificar una relación de monotonía entre los objetos, en el marco del conjunto de datos actuales, por medio de lo que se ha venido en llamar dependencias funcionales graduales (DFGs). La idea es muy parecida a la de reglas graduales, introducida por Dubois y Prade [Dub92, Dub92b]. Un ejemplo muy intuitivo de DFG es “cuanto mayor sea la entidad financiera mayores serán sus ganancias”. Se podría asumir que el concepto de DGF es similar al de DFD que se ha dado y de esta manera definir:
Definición 5-10. α -β dependencia funcional gradual
La relación R verifica una α -β DFG X→ FTY si y solo si, para cada instancia r de R se cumple: ∀t1, t2 ∈ r, F’(t1[X] ,t2[X]) ≥ α ⇒ T’(t1[Y],t2[Y]) ≥ β donde F’ y T’ son relaciones difusas del tipo: mayor que difuso (fuzzy greater than), mayor o igual que difuso (fuzzy greater than or equal to), menor que difuso (fuzzy less than), menor o igual que difuso (fuzzy less than or equal to), etc.
Se podría definir un α -β DFG X→ FTY con confianza c y soporte s en el mismo sentido que se ha hecho para la DFD (ver Definición 5-8 y Definición 5-9).

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 162
5.1.4.2 Dependencias globales difusas en FIRST* Ahora es necesario relacionar el entorno de FIRST* con las definiciones que se han hecho. Con dicho objetivo, primero se introduce una definición general de dependencias globales difusas (DGDs) basada en los comparadores difusos de FSQL y la función CDEG de dicho lenguaje. Seguidamente se muestra como se podrían calcular DGD con FSQL.
5.1.4.2.1 Definición de dependencias globales difusas con los operadores de FSQL
Definición 5-11. (α i)-(β j) dependencia global difusa
La relación R con los conjuntos de atributos X=(col_ant1, col_ant2,…, col_antl), e Y=(col_con1, col_con2,…, col_conq) donde los atributos son de tipo difuso 1, 2, 3 ó 4, verifica una (α i)-(β j) DGD X→ F*T*Y con (α i)=(α 1,α 2,…,α l) / α i∈ [0,1] ∀ i=1,…,l y
(β j)=(β 1,β 2,…,β q) / β j∈ [0,1] ∀ j=1,…,q, si y solo si, para cada instancia r de R se cumple que:
∀ t1, t2 ∈ r, ∧ i=1,2…,l[F*i(t1[col_anti],t2[col_anti]) ≥ α i] ⇒ ∧ j=1,2…,q[T*
j(t1[col_con j],t2[col_con
j]) ≥ β j] donde
F*i:UxU→ [0,1]/F*
i(A,B)=CDEG(A fuzzy_comp_anti B)
T*j:UxU→ [0,1]/T*
j(A,B)=CDEG(A fuzzy_comp_conj B)
∀ A,B ∈ U siendo U el Universo de los atributos difusos existentes en la FMB*. fuzzy_comp_anti, fuzzy_comp_conj se definen como cualquier comparador difuso de FSQL (ver Tabla 3-7) que sea aplicable a los atributos difusos A y B en cuestión.
En esta definición los umbrales que cuantifican el grado de dependencia se han especificado a nivel de cada atributo tanto del antecedente (α i) como del consecuente (β j). No habría problema en definir el concepto de DGD de tal manera que dichos umbrales sean solo uno para el antecedente (α ) y solo uno para el consecuente (β ):
Definición 5-12. α -β dependencia global difusa
La relación R con los conjuntos de atributos X=(col_ant1, col_ant2,…, col_antl), e Y=(col_con1, col_con2,…, col_conq) donde los atributos son de tipo difuso 1, 2, 3 ó 4, verifica una

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 163
α -β DGD X→ F*T*Y con α ∈ [0,1] y β ∈ [0,1] si y solo si, para cada instancia r de R se cumple que:
∀ t1, t2 ∈ r, ∧ i=1,2…,l[F*i(t1[col_anti],t2[col_anti])] ≥ α ⇒ ∧ j=1,2…,q[T*
j(t1[col_con j],t2[col_con
j])] ≥ β
∀ i=1,…,l y ∀ j=1,…,q Ahora, se puede hacer una nueva definición de DFD y de DFG como un caso particular de los nuevos conceptos definidos de DGD:
Definición 5-13. (α i)-(β j) dependencia funcional difusa
En la Definición 5-11 si fuzzy_comp_anti, fuzzy_comp_conj ∈ FEQ,NFEQ se dice
que R verifica una (α i)-(β j) DGD X→ F*T*Y.
Definición 5-14. α -β dependencia funcional difusa
En la Definición 5-12 si fuzzy_comp_anti, fuzzy_comp_conj ∈ FEQ,NFEQ se dice
que R verifica una α -β DGD X→ F*T*Y.
Definición 5-15. (α i)-(β j) dependencia funcional gradual
En la Definición 5-11 si ∃ a / a ∈ 1,2,…,l tal que se cumple para el antecedente que: fuzzy_comp_anta ∉ FEQ,NFEQ
o ∃ b / b ∈ 1,2,…,qtal que se cumple para el consecuente que:
fuzzy_comp_conb ∉ FEQ,NFEQ
Se dice que dice que R verifica una (α i)-(β j) DFG X→ F*T*Y.
Definición 5-16. α -β dependencia funcional gradual
En la Definición 5-12 si ∃ a / a ∈ 1,2,…,l tal que se cumple para el antecedente que: fuzzy_comp_anta ∉ FEQ,NFEQ

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 164
o ∃ b / b ∈ 1,2,…,qtal que se cumple para el consecuente que:
fuzzy_comp_conb ∉ FEQ,NFEQ
Se dice que dice que R verifica una α -β DFG X→ F*T*Y.
Por supuesto, se podría definir la (α i)-(β j) DGD X→ F*T*Y con confianza c y soporte s en el mismo sentido que se ha hecho para la DFD (ver Definición 5-8 y Definición 5-9). De forma análoga se definiría para la α -β DGD X→ F*T*Y. Para simplificar la notación, en las (α i)-(β j) DGD X→ F*T*Y se notará F* como
(fuzzy_comp_anti)* ∀ i=1,…,l, y de forma similar para T* que se notará con
(fuzzy_comp_conj)* ∀ j=1,…,q.
5.1.4.2.2 Obtención de dependencias globales difusas con FSQL
Sea la relación R con los conjuntos de atributos X=(col_ant1, col_ant2,…, col_antl), Y=(col_con1, col_con2,…, col_conq) donde los atributos son de tipo difuso 1, 2, 3 ó 4, y el atributo pk que es la llave primaria de dicha relación. Para determinar si R verifica una (α i)-(β j) DGD
X→ F*T*Y para una instancia r, se puede usar la sentencia FSQL con el formato general siguiente:
SELECT COUNT(*) FROM r A1, r A2 WHERE (A1.pk <> A2.pk) AND (A1.col_ant1 fuzzy_comp_ant1 A2.col_ant1 THOLD α 1
AND…AND A1.col_antl fuzzy_comp_antl A2. col_antl THOLD α l) AND
NOT (A1.col_con1 fuzzy_comp_con1 A2.col_con1 THOLD β 1
AND…AND A1.col_conq fuzzy_comp_conq A2. col_conq THOLD β q)
La idea básica consiste en calcular las tuplas que cumplen el antecedente y que no cumplen el consecuente. Por tanto, si el resultado de la consulta expuesta es 0 se puede decir que R verifica la (α i)-(β j) DGD X→ F*T*Y para la instancia r. Para comprobar si R verifica la α -β DGD X→ F*T*Y para la instancia r se usaría la
misma sentencia pero teniendo en cuenta que α =α i ∀ i=1 y β =β j ∀ j=1,…,q.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 165
Si el resultado de la anterior sentencia no es 0, podría ser que fuera motivado por un porcentaje de tuplas excepcional, para comprobar dicho extremo, se puede determinar si R verifica la (α i)-(β j) DGD X→ F*T*Y para la instancia r con confidencia c y soporte s mediante el siguiente algoritmo:
Algoritmo 5-1
• Paso 1.1: Obtener el valor cont_cumplen_ant_con como el número de tuplas que cumplen el antecedente y el consecuente a la vez:
SELECT COUNT(*) AS cont_cumplen_ant_con FROM r A1, r A2 WHERE (A1.pk <> A2.pk) AND (A1.col_ant1 fuzzy_comp_ant1 A2.col_ant1 THOLD α 1
AND…AND A1.col_antl fuzzy_comp_antl A2.col_antl THOLD α l)
AND (A1.col_con1 fuzzy_comp_con1 A2.col_con1 THOLD β 1
AND…AND A1.col_conq fuzzy_comp_conq A2.col_conq THOLD β q)
• Paso 1.2: Obtener el valor cont_cumplen_ant como el número de tuplas que cumplen el antecedente (los Paso 1.1 y 1.2 se pueden ejecutar en paralelo):
SELECT COUNT(*) AS cont_cumplen_ant FROM r A1, r A2 WHERE (A1.pk <> A2.pk) AND (A1.col_ant1 fuzzy_comp_ant1 A2.col_ant1 THOLD α 1
AND…AND A1.col_antl fuzzy_comp_antl A2. col_antl THOLD α l)
• Paso 2: Obtener el grado de confianza c y soporte s.
c = cont_cumplen_ant_con / cont_cumplen_ant s = cont_cumplen_ant_con / n
donde n es el número de tuplas de r.
• Paso 3: Para determinar si el valor de la confianza obtenida es lo suficientemente
bueno se podría comparar el valor c con algún cuantificador difuso tipo most (la mayoría) como el de la Figura 5-2. El resultado de dicha comparación daría el grado en que se cumple la proposición “para la mayoría de las tuplas se cumple la DGD”. De forma similar se podría hacer para el soporte s.
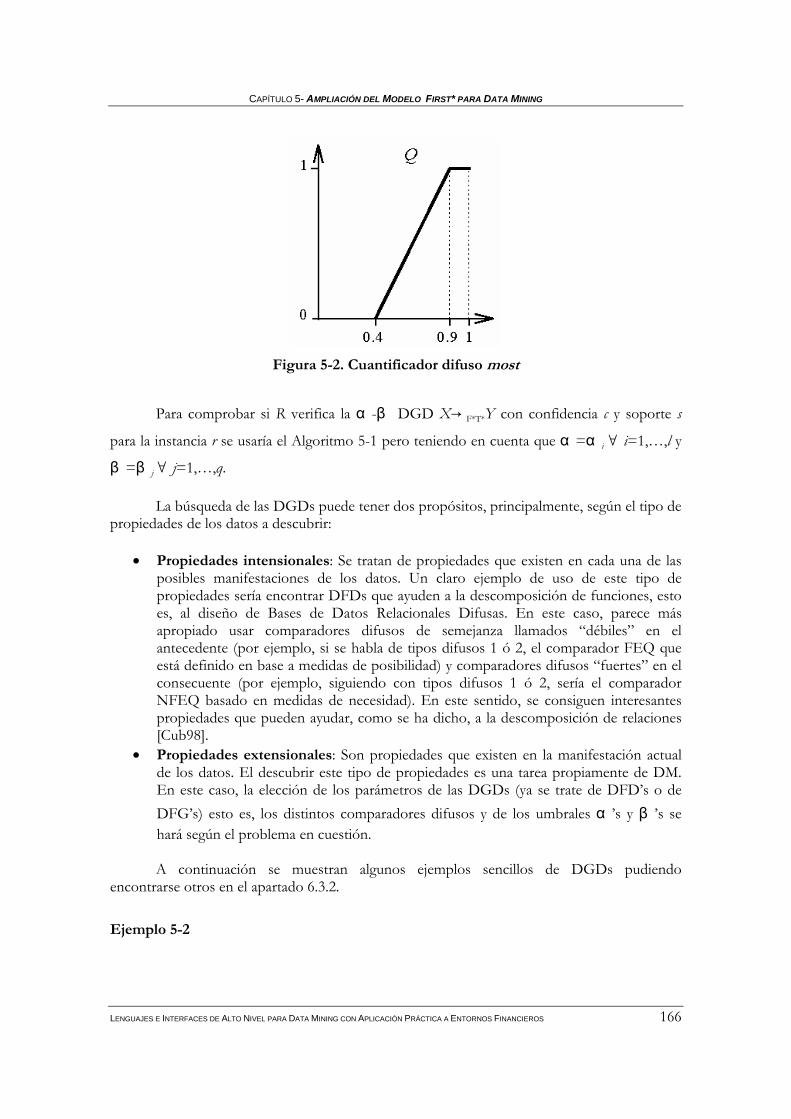
CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 166
Figura 5-2. Cuantificador difuso most
Para comprobar si R verifica la α -β DGD X→ F*T*Y con confidencia c y soporte s
para la instancia r se usaría el Algoritmo 5-1 pero teniendo en cuenta que α =α i ∀ i=1,…,l y
β =β j ∀ j=1,…,q. La búsqueda de las DGDs puede tener dos propósitos, principalmente, según el tipo de propiedades de los datos a descubrir:
• Propiedades intensionales: Se tratan de propiedades que existen en cada una de las posibles manifestaciones de los datos. Un claro ejemplo de uso de este tipo de propiedades sería encontrar DFDs que ayuden a la descomposición de funciones, esto es, al diseño de Bases de Datos Relacionales Difusas. En este caso, parece más apropiado usar comparadores difusos de semejanza llamados “débiles” en el antecedente (por ejemplo, si se habla de tipos difusos 1 ó 2, el comparador FEQ que está definido en base a medidas de posibilidad) y comparadores difusos “fuertes” en el consecuente (por ejemplo, siguiendo con tipos difusos 1 ó 2, sería el comparador NFEQ basado en medidas de necesidad). En este sentido, se consiguen interesantes propiedades que pueden ayudar, como se ha dicho, a la descomposición de relaciones [Cub98].
• Propiedades extensionales: Son propiedades que existen en la manifestación actual de los datos. El descubrir este tipo de propiedades es una tarea propiamente de DM. En este caso, la elección de los parámetros de las DGDs (ya se trate de DFD’s o de DFG’s) esto es, los distintos comparadores difusos y de los umbrales α ’s y β ’s se hará según el problema en cuestión.
A continuación se muestran algunos ejemplos sencillos de DGDs pudiendo encontrarse otros en el apartado 6.3.2.
Ejemplo 5-2

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 167
Sea STOCK_EXCHANGE una relación con el mínimo, medio y máximo precio, y la media de las ganancias de las acciones de algunas compañías españolas durante el año 1999, obtenida a partir de un sistema Data Warehouse de una entidad financiera: compañía precio_min precio_avg precio_max ganancias_avg BO. RIOJANAS 10.2 11.15 11.95 3407 HISALBA 11.42 12.61 13.2 3241 BAYER A.G. 30.5 37.91 43 1251 ELECT.VIESGO 32.1 36.11 41 1251 B.ANDALUCIA 33 34.7 41.47 2543 El objetivo es determinar “si un comportamiento similar respecto a los precios de las acciones (mínimo, medio y máximo) implica unas ganancias similares”. Por tanto lo que se intenta comprobar es la existencia de una DFD. Estos atributos con el precio y las ganancias son puramente crisps, así que para gestionarlos de forma difusa en el entorno de FIRST* se va a definir todos ellos como tipo difuso 1 en la FMB*. Para tratar dicho atributos se va a usar el valor #v, que significa “aproximadamente v”, representado mediante una distribución de posibilidad trapezoidal (ver Figura 3-8). En la FMB* se va a definir el margen=6 para precio_min, precio_avg, precio_max y margen=400 para ganancias_avg. Tras algunos ensayos probando con distintos umbrales (tanto α i como β j) los resultados obtenidos, siguiendo el Algoritmo 5-1, han sido:
• Paso 1.1, se muestra en la Figura 5-3, da como resultado cont_cumplen_ant_con=3. • Paso 1.2, se muestra en la Figura 5-4, da como resultado cont_cumplen_ant =4. • Paso 2, se obtiene una confianza de c=2/3 y un soporte s=2/4.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 168
Figura 5-3. Consulta FSQL de Paso 1.1 da como resultado 3
Figura 5-4. Consulta FSQL de Paso 1.2 da como resultado 4

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 169
Por tanto se puede afirmar que STOCK_EXCHANGE verifica:
(0.6, 0.7, 0.6)–(0.5) DFD precio_min, precio_avg, precio_max)→ (FEQ)*(NFEQ)*(ganancias_avg) con confianza c=0.67 y soporte s=0.5
• Paso 3. Se podría comparar el resultado obtenido de la confianza de la FFD con algún
tipo de cuantificador difuso como por ejemplo most de la Figura 5-2. De esta manera se puede afirmar que la DFD anterior se verifica con un umbral de cumplimiento de 0.56 para la mayoría de las tuplas.
Ejemplo 5-3
Sea CONSORCIO una relación difusa que recoge un estudio de las distintas compañías integradas dentro de un consorcio. El estudio se hace en base un indicador de tamaño y otro de comportamiento deducidos a partir de diversos indicadores de negocio, de cada una de las compañías, obtenidos a partir de un Data Warehouse. Los dos atributos tamaño y comportamiento van a ser considerados como atributos difusos de tipo 2 y en la Figura 5-5 se muestra las distintas etiquetas lingüísticas sobre ellos definidas. La tabla en cuestión tiene los siguientes datos: compañía tamaño comportamiento Financiera VERY_TALL VERY_GOOD Agencia Viajes NORMAL GOOD Seguros TALL VERY_GOOD Inmobiliaria SHORT REGULAR

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 170
El estudio que se quiere hacer es en qué forma el tamaño implica el comportamiento de las distintas compañías, en los siguientes sentidos:
• Determinar si “las compañías con tamaño mayor son las que tienen mejor o al menos igual comportamiento”. Se trata de la obtención de una DGD para la que se va a usar el comparador NFGT (necesariamente mayor difuso) para el atributo tamaño y el comparador NFGEQ (necesariamente mayor o igual difuso) para el atributo comportamiento cuya definición se puede encontrar en Tabla 3-6. Mediante la consulta FSQL de la Figura 5-7 que tiene como resultado 0 se podría afirmar que CONSORCIO verifica la siguiente DGD:
(1)–(1) DGD (tamaño) → (NFGT)*(NFGEQ)*(comportamiento)
• Determinar si “las compañías con tamaño mayor son las que tienen mejor
comportamiento”. Se trata de la obtención de una DGD para la que se va a usar el comparador NFGT (necesariamente mayor difuso) para los atributos tamaño y comportamiento. Mediante la consulta FSQL de la Figura 5-6 que tiene como resultado 0 se podría afirmar que CONSORCIO verifica la siguiente DGD:
(1)–(0.2) DGD (tamaño) → (NFGT)*(NFGT)*(comportamiento)
Tamaño
Compor-tamiento
Miles Eur
Índice Ganancias
Figura 5-5. Etiquetas lingüísticas sobre tamaño y comportamiento

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 171
Figura 5-7. Sentencia FSQL verifica DGD(tamaño)→ (NFGT)*(NFGEQ)*(comportamiento)
Figura 5-6. Sentencia FSQL verifica DGD(tamaño)→ (NFGT)*(NFGT)*(comportamiento)

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 172
5.2 Esquema general de dmFIRST Durante lo que se lleva de capítulo se han mostrado posibles utilidades del modelo para
funcionalidades que entran dentro del ámbito de DM: clustering, caracterización clasificación y dependencias globales difusas.
Ya se está en condiciones de dar un paso delante de tal manera que se va evolucionar el
modelo FIRST* para que integre y optimice dichas funcionalidades propias de DM surgiendo un nuevo modelo, que se va a venir en llamar, dmFIRST.
La Figura 5-8 se muestra el esquema general de dmFIRST que vuelve a tener como base
al anterior modelo, en este caso FIRST*, pero con elementos peculiares que pasan a enumerarse, y que serán objeto de un estudio más detallado en las siguientes secciones:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 173
• BD (Base de Datos): En ella está soportados los distintos tipos de datos que han entrado a formar parte del dominio difuso generalizado complejo, por tanto no sufre ninguna variación en el sentido que se le había dado en el modelo FIRST*.
• dmFMB (Fuzzy Metaknowledge Base for Data Mining, Base de Metaconocimiento Difuso para Data Mining): Esta extensión de la FMB* de FIRST* posibilitará implementar las distintas técnicas de DM que son objeto de esta memoria.
• Servidor dmFSQL: El lenguaje FSQL se considera que no satisface los requerimientos mínimos para ser un interface de un sistema de DM. Con dicho objetivo, se va a proceder a la definición del lenguaje dmFSQL, como extensión del mismo FSQL. El servidor de FSQL* va a quedar incluido dentro de un nuevo, llamado Servidor dmFSQL, que posibilitará el uso del lenguaje dmFSQL.
BD
Base de Datos
dmFMB DIC
Diccionario del Sistema
SGBDR
Sistema Gestor de Bases de Datos Relacionales
Servidor dmFSQLServidor FSQL*
FQ Cliente FSQL
F Cliente FSQL
dmFSQLembebido...
Catálogo del Sistema
Figura 5-8. Esquema General de dmFIRST

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 174
• Cliente FSQL: Las especificaciones de uso del Servidor dmFSQL serán las mismas que las del anterior servidor, esto posibilitará que los distintos programas clientes desarrollados sigan siendo perfectamente válidos para este nuevo servidor.
El problema genérico que se va a intentar resolver dentro de este nuevo esquema dmFIRST va a ser el siguiente: Sea la relación id_tabla_orig_proyecto sobre la que se quiere realizar un proceso de DM a cuatro niveles: clustering, caracterización, clasificación y obtención de dependencias globales difusas entre atributos, basándose en las soluciones planteadas para DM dentro la sección 5.1. La tabla tiene el siguiente esquema:
id_tabla_orig_proyecto (col_clu1, col_clu2,…, col_clum, col_ant1, col_ant2,…, col_antl, col_con1, col_con2,…, col_conq,[…]) con m, l, q ∈ ℕ
donde
• col_clu1, col_clu2,…, col_clum: son una serie de atributos difusos de cualquier tipo, definidos en la dmFMB, relevantes para un proceso de clustering, caracterización y/o clasificación.
• col_ant1, col_ant2,…, col_antl, col_con1, col_con2,…, col_conq: son también atributos difusos de cualquier tipo, definidos en la dmFMB, a partir de los cuales se quiere obtener dependencias globales difusas (DGDs) del tipo:
α -β DGD X→ F*T*Y (según Definición 5-12)
(α i)-(β j) DGD X→ F*T*Y (según Definición 5-13)
donde X=(col_ant1, col_ant2,…, col_antl), e Y=(col_con1, col_con2,…, col_conq) i=1,…,l y j=1,…,q
Se debe de tener en cuenta, que las columnas col_cluk (con k=1..m) pueden coincidir con las columnas col_anti (con i=1..l) y/o con las columnas col_conj (con j=1..q).

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 175
5.3 Base de Metaconocimiento Difuso para Data Mining (dmFMB) Como ya se ha comentado, el Servidor FSQL* (ver Sección 4.2.4.2) a partir de una
sentencia en FSQL genera código SQL. Como se ha visto, los problemas que se tratan de resolver ahora, esto es, procesos diversos de DM, no puede ser resueltos, en la mayoría de los casos con simples sentencias de FSQL (y en última instancia, pues, de SQL). Es por esto que, para el nuevo esquema, dmFIRST, se va a hacer la definición de un nuevo tipo de objeto que no existe ni en FSQL ni en SQL que se va a denominar “proyecto” (project) que tiene como misión:
• Servir de soporte para guardar las condiciones iniciales, resultados intermedios y finales del proceso de DM a realizar.
• Englobar lógicamente una serie de resultados intermedios, en forma de tablas, en dicho proceso de DM. Estos resultados intermedios estarán encaminados a agilizar el proceso de DM iterativo ya que el tener estos datos precalculados hará que, ante determinados refinamientos de los requerimientos del proceso de DM, la respuesta del sistema sea más o menos inmediata.
Así la dmFMB queda finalmente con los siguientes componentes:
• FMB completa de FIRST*, esto es, toda la estructura relacional ya expuesta en la Figura
4-2. • Nuevas estructuras relacionales que posibilitan el tratamiento del objeto proyecto
comentado.
En la Figura 5-9 se puede observar el esquema relacional completo de la dmFMB. A continuación se explican las nuevas tablas de la dmFMB:
• DMFSQL_PROJECT (alias DPR): contiene la información general sobre los proyectos de DM. Contiene los siguiente atributos:
o project_name: identificativo único del proyecto de DM. o owner#: identificativo del propietario del proyecto. Todas las tablas asociadas
al proyecto tendrán este propietario. o obj#: tabla origen de datos para la realización del proceso de DM, esto es,
id_tabla_orig_proyecto. o status_clus: estado actual del proceso de clustering:
- ‘D’: obtenido el dendrograma, o lo que es lo mismo, la matriz de distancias ultramétrica.
- ‘C’: proceso de clustering concluido, esto es, se ha obtenido una partición en concreto como resultado de dicho proceso.
o num_clus: número de cluster o grupos obtenidos tras el proceso de clustering
(si status_clus=’C’).

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 176
o num_reg_tab: número de filas en la tabla id_tabla_orig_proyecto. o num_reg_level: número de posibles α -cortes que se pueden hacer dentro del
dendrograma, esto es, posibles particiones que se pueden hacer de la población. o num_level_opt1_vila_h3: nivel del dendrograma al que se obtiene una
partición óptima basándose en el método de la medida H3 (ver sección 5.1.1.1.4).
o num_level_opt2_vila_abs: nivel del dendrograma al que se obtiene la partición óptima absoluta (ver sección 5.1.1.1.3).
o num_level_opt3_med: nivel del dendrograma al que se obtiene la partición óptima media, que es una variante de la absoluta que se basa en coger la partición determinada por el corte en el punto medio relativo del dendrograma.
o obj#_tab_clus: identificativo de la última tabla generada con una partición en concreto de la población dentro del proceso de clustering.
o obj#_tab_cen: identificativo de la última tabla de centroides generada, que caracterizan a los distintos grupos existentes en la tabla anterior.
o status_fgd: estado del proceso de obtención de DGDs:
- ‘C’: calculadas las correspondientes dependencias.
o thold_ant_fgd: umbral α si el problema es obtener una α -β DGD
X→ F*T*Y.
o thold_con_fgd: umbral β si el problema es obtener una α -β DGD
X→ F*T*Y. o confidence_fgd: confianza obtenida de la DGD. o support_fgd: soporte obtenido de la DGD. o def_table_space: especificaciones físicas para el almacenamiento de las
distintas tabla que se generen como resultado de la ejecución del proyecto. o trace_level, path_trace_file, name_trace_file: son de uso interno del
servidor de dmFSQL (que será expuesto más tarde) para gestionar trazas de ejecución que tienen como objeto devolver resultados intermedios a aplicaciones cliente (para barras de progreso por ejemplo), depuración de errores, etc.
• DMFSQL_COL_LIST (alias DCL): contiene la información sobre las distintas
columnas trascendentes para el proceso de DM de la tabla con el origen de datos del proyecto (id_tabla_orig_proyecto). Contiene los siguiente atributos:
o project_name: identificativo único del proyecto de DM. o col_type: indica el tipo procesamiento de DM para la columna:
- ‘C’: clasificación, clustering o caracterización. - ‘A’: antecedente dentro del ámbito de las DGDs. - ‘Q’: consecuente dentro del ámbito de las DGDs.
o col#: identificativo de la columna dentro de la tabla id_tabla_orig_proyecto.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 177
o weight_clu: peso por el que se pondera la columna para clustering, esto es, aquí se almacena los distintos w_clur ∈ [0,1] con r=1..m, vistos en la sección 5.1.1.2.
o fuzzy_comp_clu: comparador difuso de igualdad (FEQ o NFEQ) que se le va a aplicar a la columna en cuestión para la obtención de la matriz de distancias en el proceso de clustering (ver 5.1.1.2). Por tanto, aquí se almacena los distintos fuzzy_ecompr con r=1..m, vistos en la sección 5.1.1.2.
o log_oper_clu: caso de el comparador difuso anterior no sea simétrico, aquí se indica el operador lógico que se va a usar para obtener una comparación simétrica dentro del proceso de clustering, puede ser AND si se quiere usar una T-norma o OR si se quiere usar una t-conorma.
o abstraction_level_cen:
- ‘L’: etiqueta lingüística (definida en la dmFMB para la columna difusa id_column) que mejor describa el grupo o cluster (ver 5.1.2.1).
- ‘V’: de entre los valores conocidos de la columna en cuestión (todos los valores que hay en la tabla id_tabla_orig_proyecto para la columna, más las etiquetas lingüísticas de la dmFMB definidas para dicha columna id_column) el que mejor describa el grupo (ver 5.1.2.2).
- ‘A’: caso de tratarse de atributos sobre referencial ordenado, valor que sea válido dentro de su dominio y que sea lo más representativo posible, no importando si es un dato conocido o extrapolado a partir de los datos de la tabla (ver 5.1.2.3).
o fuzzy_comp_cen: comparador difuso de igualdad (FEQ o NFEQ) que se le
va a aplicar a la columna en cuestión para el cálculo de centroides. Por tanto, aquí se almacena los distintos fuzzy_ecompr con r=1..m, vistos en la sección 5.1.2.
o log_oper_cen: caso de el comparador difuso anterior no sea simétrico, aquí se indica el operador lógico que se va a usar para obtener una comparación simétrica dentro del proceso de caracterización, puede ser AND si se quiere usar una T-norma o OR si se quiere usar una t-conorma.
o fuzzy_comp_cla: comparador difuso de igualdad (FEQ o NFEQ) que se le va a aplicar a la columna en cuestión para el proceso de clasificación. Por tanto, aquí se almacena los distintos fuzzy_ecompr con r=1..m, vistos en la sección 5.1.3.
o log_oper_cla: caso de el comparador difuso anterior no sea simétrico, aquí se indica el operador lógico que se va a usar para obtener una comparación simétrica dentro del proceso de clasificación, puede ser AND si se quiere usar una T-norma o OR si se quiere usar una t-conorma.
o weight_cla: peso por el que se pondera la columna para clasificación, esto es, aquí se almacena los distintos w_clar ∈ [0,1] con r=1..m, vistos en la sección 5.1.3.
o fuzzy_comp_fgd: comparador difuso (ver Tabla 3-7) que se le va a aplicar a la columna en cuestión para la obtención de la DGD. Por tanto, aquí se almacena los distintos fuzzy_comp_anti para el antecedente con i=1..l, y los distintos

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 178
fuzzy_comp_conj para el consecuente con j=1..q, tal y como se explicó en la sección 5.1.4.2.2.
o thold_fgd: distintos umbrales α i y β j para cada columna del antecedente y
consecuente correspondientemente, si se trata de obtener una (α i)-(β j) DGD
X→ F*T*Y. • DMFSQL_LOG: es una tabla de uso interno del servidor de dmFSQL para gestionar
trazas de ejecución que tienen como objeto, como se ha comentado, devolver resultados intermedios a aplicaciones cliente (para barras de progreso por ejemplo), depuración de errores, etc. Aunque la utilidad práctica de estas trazas (logs) de ejecución es enorme, su importancia teórica no lo es tanto y por tanto no se va a comentar nada sobre sus campos.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 179
Figura 5-9. Esquema relacional de la dmFMB

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 180
5.4 Lenguaje FSQL para Data Mining (dmFSQL)
5.4.1 Una visión de los lenguajes para Data Mining existentes
Son varias las propuestas de lenguajes usados como interfaces en procesos de DM existentes en la actualidad. Generalizando, las distintas soluciones tienen una serie de características más o menos comunes como son:
• Sintaxis similar a SQL que, como es sabido, constituye el interface con las SBDR más
ampliamente aceptado. Aunque la sintaxis sea similar, también suele ser verdad que no permiten una expresividad tan amplia como la del mismo SQL.
• Orientación hacia una sola técnica de DM, especialmente hacia las reglas de asociación. • Carencia de la propiedad de clausura, esto es, posibilidad de aplicar el lenguaje de
consulta a un resultado previo de este mismo lenguaje, permitiendo un proceso de DM iterativo a través de dicho refinamiento de las consultas.
• Necesidad de tratamiento previo y de forma externa al lenguaje de algunos tipos de datos. Así por ejemplo, frecuentemente los lenguajes que descubren reglas de asociación necesitan técnicas de discretización previas para transformar los atributos continuos.
Entre las propuestas de lenguajes para resolver tareas propias de DM se encuentran las
siguientes:
• DMQL (Data Mining Query Language) de Han et al. [Han96]: Permite especificaciones declarativas para tareas de generación de varios tipos de reglas, entre las que se incluye, reglas de asociación, reglas discriminantes, reglas de clasificación y reglas de caracterización. El lenguaje contiene comandos para especificar conceptos jerárquicos en un nivel tanto intensivo como extensivo y aplicarlos durante las tareas de DM. El lenguaje trabaja sobre bases de datos relacionales con atributos discretos, para los continuos habría que definir un jerarquía y especificarla en la consulta (query) de DM. En principio, con el lenguaje no parece posible tratar los resultados de una consulta de DM en un posprocesamiento, con el mismo lenguaje, con el objeto de realizar DM iterativo (propiedad de clausura).
• MSQL (Mining Structured Query Language) de Imielinsky y Virmani [Imi99]: También es un lenguaje con sintaxis similar a SQL que tiene como objeto obtener reglas de asociación. Permite una expresividad equiparable a SQL además de ser capaz de aplicar sentencias MSQL a resultados de este mismo lenguaje, esto es, cumple la propiedad de clausura. Su principal operador es el GETRULES. Está implementado parcialmente dentro de un sistema llamado “Discovery Board”.
• Operador MINE RULE de Meo et al. [Meo96]: Sirve para generar reglas de asociación con una sintaxis parecida a SQL. En [Bar96] se puede encontrar la explicación de un prototipo para MBE (Mining by Example, Explorar Mediante Ejemplos), de tal manera que, a partir de ejemplos puede generar sentencias con formato MINE RULE.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 181
• Knowledge Miner de Shen et al. [Shen96]: Sistema que integra un lenguaje de bases de datos deductivas con DM. Usa meta reglas basadas en LDL++ para guiar el proceso de DM.
• fCQL (Fuzzy Classification Query Language) de Meier et al. [Mei01]: Se trata de un lenguaje para la clasificación difusa basado en la definición de variables lingüísticas por parte del usuario cuyo principal operador es el CLASSIFY. Existe una primera implementación del lenguaje que genera a partir de fCQL código SQL, cuya explicación puede encontrarse en [Ver02].
• SummarySQL de Rasmussen y Yager [Ram97]: Es una extensión de un lenguaje de consulta difuso que permite introducir sumarizaciones lingüísticas en dicha consulta difusa. Su principal utilidad es la de descubrir dependencias funcionales difusas y dependencias graduales entre atributos a través de su comando SUMMARY.
• Diversos enfoques que no llegan a ser un lenguaje propiamente dicho sino, más bien, extensiones de SQL para facilitar el proceso de DM dentro del SGBD en cuestión, como las descritas por Sarawagi et al. en [Sar98]:
o extensión del SQL con diversas primitivas tales como “KWayJoin”, “GatherJoin” y “GatherPrune” dentro del área de bases de datos relaciones dirigidas a objetos;
o enfoques de UDFs (User-Defined Functions, Funciones Definidas por el Usuario) dentro de algoritmos para DM implementados en SQL…
5.4.2 Sintaxis de dmFSQL
Como ya se ha introducido, a pesar de la importante ampliación que se ha hecho para la gestión de múltiples tipos de datos de FSQL en el entorno de FIRST*, no se considera que FSQL cumpla los requerimientos mínimos para ser considerado un lenguaje propiamente de DM. Con objeto de solucionar esto, se va a proceder a una extensión del FSQL para que resuelva tareas de DM, surgiendo el lenguaje dmFSQL (data mining Fuzzy Structured Query Lenguaje, Lenguaje de Consulta Estructurado Difuso para Data Mining). Como a su vez, FSQL era una extensión del SQL se va a cumplir lo siguiente:
SQL ⊂ FSQL ⊂ dmFSQL A pesar de esta fórmula, el uso del lenguaje natural (que por otro lado, tantas veces trae de cabeza al ámbito de la Inteligencia Artificial) hace que se use el término FSQL haciendo referencia a solo a la extensión del lenguaje propiamente dicha (y no a un nuevo lenguaje que también incluye al SQL original). En lo que respecta a dmFSQL se va a seguir la misma incorrección llamándole frecuentemente dmFSQL a lo que es propiamente la extensión del FSQL, que en esta memoria se presenta.
En la definición que se va a hacer de dmFSQL se van a seguir los siguientes criterios (ver epígrafe anterior):

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 182
• La extensión de la sintaxis va a seguir siendo similar al lenguaje SQL3. • Orientación hacia las técnicas de DM que han sido explicadas en la sección 5.1 y que se
consideran bastante útiles en el sector financiero: o clustering, o caracterización, o clasificación y o dependencias difusas entre atributos
• Posibilidad de DM iterativo, esto es, lo que se ha llamado propiedad de clausura, como la posibilidad de aplicar el lenguaje de consulta a un resultado previo de este mismo lenguaje.
• Uso de los tipos de datos difusos definidos en FIRST*, especialmente del tipo difuso 4, para manejar cualquier tipo de dato.
SQL [Dat97], y por supuesto, FSQL [Med94, Gal99] tienen una sintaxis que va en dos
vertientes: • DML (Data Manipulation Language, Lenguaje de Manipulación de Datos): Las sentencias
de este lenguaje permiten la consulta y la modificación de los datos almacenados en la base de datos. Ejemplos de comandos del DML son la sentencia SELECT (en SQL y FSQL), INSERT, DELETE y UPDATE (en SQL).
• DDL (Data Definition Language, Lenguaje de Definición de Datos): Las sentencias de este lenguaje permiten la creación y modificación de las estructuras en las que se almacenan los datos. Ejemplos de comandos de DDL (en SQL y FSQL) son CREATE (para crear objetos de la base de datos), DROP (para borrar objetos) y ALTER (para modificar objetos). En SQL existen otros comandos para controles de seguridad (GRANT y REVOKE), índices y control de almacenamiento físico de los datos. Algunos autores distinguen entre DDL y DCL (Data Control Languaje, Lenguaje de Control de Datos), dejando para este último las tareas de control (de seguridad, de almacenamiento…).
Como se ha visto, el objeto proyecto es muy importante en el nuevo esquema dmFIRST
definido, el DDL de dmFSQL va a consistir en una serie de operaciones sobre dicho objeto proyecto:
• CREATE_MINING: crear un nuevo proyecto. • ALTER_MINING: modificar un proyecto. • DROP_MINING: borrar un proyecto. • GRANT_MINING: dar permiso para la gestión de un proyecto a un usuario. • REVOKE_MINING: eliminar los permisos previamente concedidos para la gestión
de un proyecto a un usuario.
El lenguaje DML de dmFSQL va a involucrar el proceso de DM en sí, cuyas condiciones habrán sido fijadas, como se ha dicho, en un proyecto determinado. Los resultados de ejecución de este lenguaje van a ser uno o varias de estas alternativas:
3 Se hace referencia al SQL de Oracle® más que al estándar ISO/ANSI

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 183
1. Tablas: con los nombres especificados en las correspondientes sentencias de DML y
con la estructura que más tarde se explicará. Además de la tabla en sí, se devuelve una sentencia SELECT sobre la tabla generada.
2. Cumplimentación de determinados campos en el objeto proyecto: en este caso, se devolverá una sentencia SELECT de los campos de las tablas que implementan el objeto proyecto en la dmFMB (como se verán más adelante) que han sido cumplimentados como resultado de la sentencia de DML resuelta.
3. Sentencia SQL: que resuelve el proceso de DM sin creación de tabla resultado alguna. Como se ha visto en las anteriores alternativas, siempre se devuelve una sentencia SQL pero a diferencia de dicha alternativas en ésta, el resultados es solo dicha sentencia. Serán pocas las ocasiones en que esta alternativa pueda ser usada.
Como puede observarse, aunque las sentencias del DML siempre devuelven una SELECT
también pueden implicar la generación de tablas o resultados en el proyecto, esta va a ser una diferencia fundamental con el DML de FSQL.
Las sentencias DML posibles, van a tener que ver con las distintas técnicas de DM que van
a ser resultas con dmFSQL, siendo todas introducidas con el comando SELECT_MINING seguido de:
• CLUSTERING: para el proceso clustering y caracterización. • CLASSIFICATION: para el proceso de clasificación. • FGLOBAL_DEPENDENCIES: para la obtención de dependencias globales difusas
entre atributos.
A continuación se va expresar la sintaxis extendida del lenguaje dmFSQL, aunque previamente hay que hacer las siguientes consideraciones sobre la notación:
• Entre corchetes [ ] se muestran las cláusulas que son opcionales, esto es, que pueden
aparecer o no en el lenguaje. • El símbolo | muestra cláusulas que son alternativas, esto es, solo una de ellas puede
aparecer. • Se pueden usar los paréntesis para delimitar cláusulas alternativas, cuando éstas
están incluidas en cláusulas más complejas. • cadena_caracteres simboliza cualquier cadena alfanumérica. • cadena_numeros simboliza cualquier número compuesto solo de los dígitos del 0 al 9.
La sintaxis formal de la extensión dmFSQL queda expresada en la siguiente tabla:
ddl_stm create_project | alter_project | drop_project | grant_project | revoke_project ‘;’
create_project CREATE_MINING project_stm alter_project ALTER_MINING project_alter_stm drop_project DROP_MINING PROJECT id_proyecto
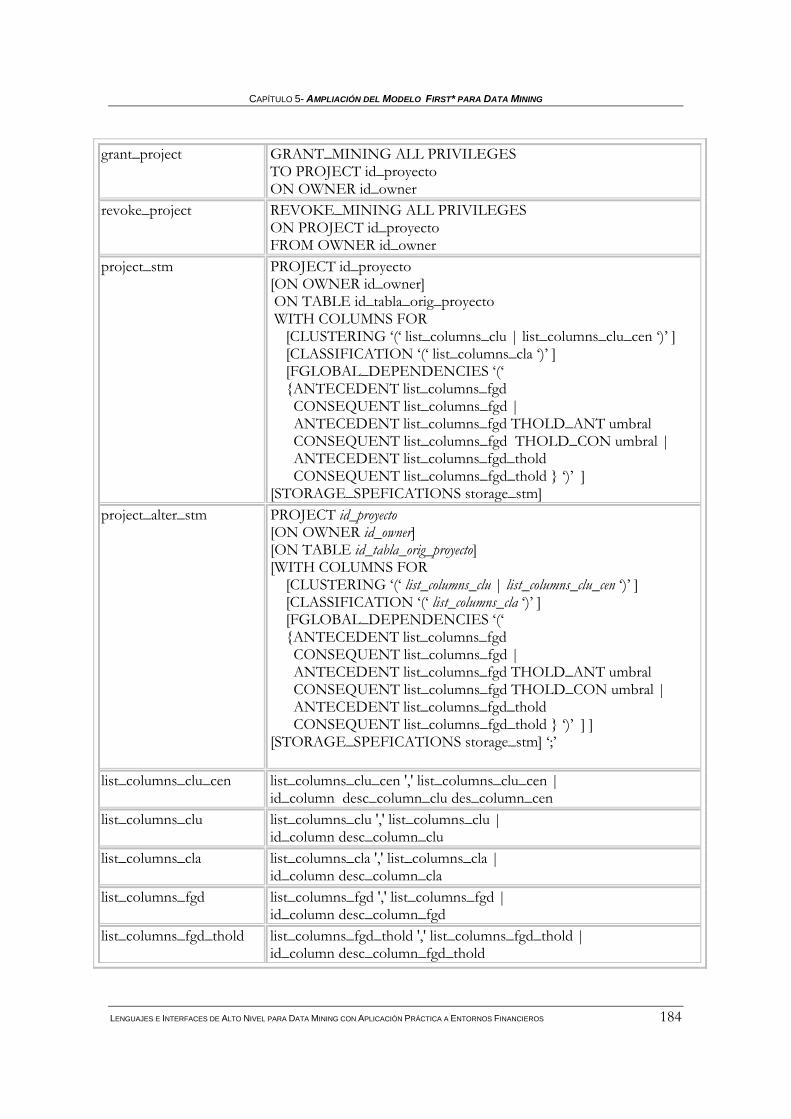
CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 184
grant_project GRANT_MINING ALL PRIVILEGES TO PROJECT id_proyecto ON OWNER id_owner
revoke_project REVOKE_MINING ALL PRIVILEGES ON PROJECT id_proyecto FROM OWNER id_owner
project_stm PROJECT id_proyecto [ON OWNER id_owner] ON TABLE id_tabla_orig_proyecto WITH COLUMNS FOR [CLUSTERING ‘(‘ list_columns_clu | list_columns_clu_cen ‘)’ ] [CLASSIFICATION ‘(‘ list_columns_cla ‘)’ ] [FGLOBAL_DEPENDENCIES ‘(‘ ANTECEDENT list_columns_fgd CONSEQUENT list_columns_fgd | ANTECEDENT list_columns_fgd THOLD_ANT umbral CONSEQUENT list_columns_fgd THOLD_CON umbral | ANTECEDENT list_columns_fgd_thold CONSEQUENT list_columns_fgd_thold ‘)’ ] [STORAGE_SPEFICATIONS storage_stm]
project_alter_stm PROJECT id_proyecto [ON OWNER id_owner] [ON TABLE id_tabla_orig_proyecto] [WITH COLUMNS FOR [CLUSTERING ‘(‘ list_columns_clu | list_columns_clu_cen ‘)’ ] [CLASSIFICATION ‘(‘ list_columns_cla ‘)’ ] [FGLOBAL_DEPENDENCIES ‘(‘ ANTECEDENT list_columns_fgd CONSEQUENT list_columns_fgd | ANTECEDENT list_columns_fgd THOLD_ANT umbral CONSEQUENT list_columns_fgd THOLD_CON umbral | ANTECEDENT list_columns_fgd_thold CONSEQUENT list_columns_fgd_thold ‘)’ ] ] [STORAGE_SPEFICATIONS storage_stm] ‘;’
list_columns_clu_cen list_columns_clu_cen ',' list_columns_clu_cen | id_column desc_column_clu des_column_cen
list_columns_clu list_columns_clu ',' list_columns_clu | id_column desc_column_clu
list_columns_cla list_columns_cla ',' list_columns_cla | id_column desc_column_cla
list_columns_fgd list_columns_fgd ',' list_columns_fgd | id_column desc_column_fgd
list_columns_fgd_thold list_columns_fgd_thold ',' list_columns_fgd_thold | id_column desc_column_fgd_thold

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 185
desc_column_clu WEIGHT_CLUSTERING ratio_peso FCOMP_CLUSTERING fuzzy_ecomp [T-NORM|T-CONORM]
desc_column_cen WEIGHT_CENTROID ratio_peso FCOMP_CENTROID fuzzy_ecomp [T-NORM|T-CONORM] ABSTRACTION_LEVEL_CENTROID LABEL|AVG|VALUE
desc_column_cla WEIGHT_ CLASSIFICATION ratio_peso COMP_CLASSIFICATION fuzzy_ecomp [T-NORM|T-CONORM]
desc_column_fgd_thold desc_column_fgd THOLD umbral desc_column_fgd FCOMP_FGLOBAL_DEPENDENCIES fuzzy_comp list_columns_clu_cen list_columns_clu_cen ',' list_columns_clu_cen |
id_column desc_column_clu des_column_cen list_columns_clu list_columns_clu ',' list_columns_clu |
id_column desc_column_clu list_columns_cla list_columns_cla ',' list_columns_cla |
id_column desc_column_cla list_columns_fgd list_columns_fgd ',' list_columns_fgd |
id_column desc_column_fgd list_columns_fgd_thold list_columns_fgd_thold ',' list_columns_fgd_thold |
id_column desc_column_fgd_thold desc_column_clu WEIGHT_CLUSTERING ratio_peso
FCOMP_CLUSTERING fuzzy_ecomp [T-NORM|T-CONORM]desc_column_cen ABSTRACTION_LEVEL_CENTROID LABEL|AVG|VALUE
[FCOMP_CENTROID fuzzy_ecomp [T-NORM|T-CONORM] ] desc_column_cla WEIGHT_ CLASSIFICATION ratio_peso
COMP_CLASSIFICATION fuzzy_ecomp [T-NORM|T-CONORM]
desc_column_fgd_thold desc_column_fgd THOLD umbral desc_column_fgd FCOMP_FGLOBAL_DEPENDENCIES fuzzy_comp storage_stm [TABLESPACE id_tablespace] [STORAGE ',' desc_storage] desc_storage INITIAL n_entero K|M desc_storage_o_no |
NEXT n_entero K|M desc_storage_o_no | MINEXTENTS n_entero|UNLIMITED desc_storage_o_no | PCTINCREASE n_entero desc_storage_o_no | FREELISTS n_entero desc_storage_o_no | FREELISTS GROUPS n_entero desc_storage_o_no | OPTIMAL NULL | n_entero K|M desc_storage_o_no
desc_storage_o_no desc_storage | dml_stm SELECT_MINING
clustering_stm | classification_stm | fgd_stm ‘,’ clustering_stm CLUSTERING id_proyecto

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 186
INTO TABLE_CLUSTERING id_tabla_result_clu [‘,’ TABLE_CENTROIDS id_tabla_result_cen] OBTAINING n_clusters|OPTIMAL_ABS|OPTIMAL_H3|OPTIMAL_MED CLUSTERS
classification_stm CLASSIFICATION id_proyecto FROM id_tabla_orig_cla [TO id_tabla_result_cla] ACCORDING_TO TABLE_CENTROIDS id_tabla_result_cen | LAST TABLE_CLUSTERING id_tabla_result_clu | LAST WITH n_vecinos NEIGHBOARD [WHERE CLUSTER_ID IS id_cluster | THE_BEST] THOLD umbral
fgd_stm FGLOBAL_DEPENDENCIES id_proyecto USING T_NORM | SINGLE THOLD_ANT_CON [WITH CONFIDENCE HIGHEST]
fuzzy_ecomp FEQ | NFEQ fuzzy_comp FEQ | FGT | FGEQ | FLT | FLEQ | MGT | MLT | NFEQ |
NGEQ | NFGT | NFGEQ | NFLT | NFLEQ | NMGT | NMLT id_proyecto id_objeto id_owner id_objeto id_tablespace id_objeto id_tabla_orig_proyecto id_objeto id_tabla_result_clu id_objeto id_tabla_result_cen id_objeto id_tabla_orig_cla id_objeto id_tabla_result_cla id_objeto ratio_peso real_0_1 umbral real_0_1 n_clusters n_entero n_vecinos n_entero id_cluster n_entero real_0_1 1 | 0 | [0] ‘.’ n_entero id_objeto cadena_caracteres n_entero cadena_numeros
Seguidamente se procede a explicar más detalladamente la semántica de los comandos del nuevo lenguaje.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 187
5.4.3 Lenguaje de Definición de Datos (DDL) de dmFSQL Mediante la definición de un proyecto se va a poder especificar cómo realizar dicho
procesos de DM. Como ya se ha introducido, el Lenguaje de Definición de Datos (DDL) de dmFSQL va ser la herramienta para la gestión del objeto proyecto, sobre el que se van a poder realizar las siguientes sentencias:
5.4.3.1 CREATE_MINING
Sirve para crear un proyecto en donde se fijan las condiciones para el proceso que se va a hacer de DM. La sintaxis simplificada es la siguiente:
CREATE_MINING PROJECT id_proyecto [ON OWNER id_owner] ON TABLE id_tabla_orig_proyecto WITH COLUMNS FOR [CLUSTERING ‘(‘ list_columns_clu | list_columns_clu_cen ‘)’ ] [CLASSIFICATION ‘(‘ list_columns_cla ‘)’ ] [FGLOBAL_DEPENDENCIES ‘(‘ ANTECEDENT list_columns_fgd CONSEQUENT list_columns_fgd | ANTECEDENT list_columns_fgd THOLD_ANT umbral CONSEQUENT list_columns_fgd THOLD_CON umbral | ANTECEDENT list_columns_fgd_thold CONSEQUENT list_columns_fgd_thold ‘)’ ] [STORAGE_SPEFICATIONS storage_stm] ‘;’
donde
• id_proyecto: es el identificador o nombre que se le da al proyecto, no puede existir otro proyecto con ese mismo nombre.
• id_owner: nombre del propietario del proyecto, si no se especifica la cláusula ON OWNER, el propietario será aquel usuario que lo cree.
• id_tabla_orig_proyecto: nombre de la tabla que va a ser objeto del proceso de DM en este proyecto. El propietario de dicha tabla debe ser el especificado en el campo anterior, id_owner.
• list_columns_clu: especificaciones sobre las columnas de la tabla id_tabla_orig_proyecto relevantes para el proceso de clustering, caso de que se haya usado la cláusula WITH COLUMNS FOR […] CLUSTERING. Estas especificaciones se basan en lo explicado en la sección 5.1.1.2, cuando se detalló el uso de FSQL para la obtención de la matriz de distancias dentro del problema de clustering jerárquico. Para cada columna col_clui con i=1..m, hay que incluir la siguiente información:
o id_column: nombre de la columna, que debe estar definida en la dmFMB como
un tipo difuso 1, 2, 3 ó 4, esto es, col_clui.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 188
o Especificaciones para el proceso de obtención de la matriz de distancias mediante la claúsula:
WEIGHT_CLUSTERING ratio_peso FCOMP_CLUSTERING fuzzy_ecomp [T-NORM|T-CONORM] donde
o ratio_peso: es un número real en [0,1] que indica el valor de ponderación o importancia que va a tener la columna en cuestión, respecto a las demás, en el proceso de clustering. La suma de los valores ratio_peso de todas las columnas para clustering debe ser 1.
o fuzzy_ecomp: es un comparador de igual difuso de FSQL (FEQ o NFEQ) que se va a usar para la obtención de la matriz de distancias, si el comparador no es simétrico, habrá que especificar la cláusula T-NORM si se quiere aplicar una T-norma para que la comparación sea simétrica, o T-CONORM si se quiere aplicar una T-conorma con el mismo fin. Como se ha explicado, las funciones que implementan estas normas pueden ser especificadas en la FMB original de FSQL (ver [Gal99]) y son por defecto el mínimo (para la T-normas) y el máximo (para las T-conormas).
• list_columns_clu_cen: Opcionalmente, si se quiere caracterizar cada unos de los grupos
surgidos del proceso de clustering mediante el mecanismo que se ha expuesto en la sección 5.1.2, habrá que hacer las especificaciones para el proceso de obtención de los centroides, añadiendo para cada columna id_column de la cláusula de clustering, recién explicada, lo siguiente:
ABSTRACTION_LEVEL_CENTROID LABEL|AVG|VALUE [FCOMP_CENTROID fuzzy_ecomp [T-NORM|T-CONORM] ]
donde se indica el nivel de abstracción, del valor de la columna, al que se quiere obtener los centroides que puede ser:
o LABEL: etiqueta lingüística (definida en la dmFMB para la columna difusa
id_column) que mejor describa el grupo o cluster (ver 5.1.2.1). o VALUE: de entre los valores conocidos de id_column (todos los valores que hay
en la tabla id_tabla_orig_proyecto para la columna id_column, más las etiquetas lingüísticas de la dmFMB definidas para dicha columna id_column) el que mejor describa el grupo (ver 5.1.2.2).
o AVG: caso de tratarse de atributos sobre referencial ordenado, valor que sea válido dentro de su dominio y que sea lo más representativo posible, no importando si es un dato conocido o extrapolado a partir de los datos de la tabla (ver 5.1.2.3).
Si el nivel de abstracción elegido es LABEL o VALUE (y también en algunos casos de AVG) hay que especificar la cláusula FCOMP_CENTROID indicando el comparador difuso de igualdad de FSQL fuzzy_ecomp y, si el comparador no es simétrico, la

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 189
correspondiente norma (en el sentido explicado anteriormente para clustering). Esta cláusula indica la forma de obtener la mejor etiqueta o el mejor valor.
• list_columns_cla: especificaciones sobre las columnas de la tabla id_tabla_orig_proyecto relevantes para el proceso de clasificación, caso de que se haya especificado la cláusula WITH COLUMNS FOR […] CLASSIFICATION. Estas especificaciones se basan en lo explicado en la sección 5.1.3, cuando se detalló el uso de FSQL para clasificación y consisten para cada columna col_clui con i=1..m, en lo siguiente:
o id_column: nombre de la columna, que debe estar definida en la dmFMB como
un tipo difuso 1, 2, 3 ó 4, esto es, col_clui.. o Especificaciones para el proceso de clasificación mediante la claúsula:
WEIGHT_ CLASSIFICATION ratio_peso FCOMP_ CLASSIFICATION fuzzy_ecomp [T-NORM|T-CONORM] donde
o ratio_peso: es un número real en [0,1] que indica el valor de ponderación o importancia que va a tener la columna en cuestión, respecto a las demás, en el proceso de clasificación. La suma de los valores ratio_peso de todas las columnas para clasificación debe ser 1.
o fuzzy_ecomp: es un comparador de igualdad difuso de FSQL (FEQ o NFEQ) que se va a usar para el proceso de clasificación. Como en el caso de clustering, si el comparador no es simétrico habrá que especificar la cláusula T-NORM si se quiere aplicar una T-norma para que la comparación sea simétrica, o T-CONORM si se quiere aplicar una T-conorma con dicho fin.
• list_columns_fgd: especificaciones sobre las columnas de la tabla id_tabla_orig_proyecto
relevantes para el proceso de obtención de dependencias globales difusas (DGDs) entre atributos, si se ha usado la cláusula WITH COLUMNS FOR […] FGLOBAL_DEPENDENCIES. Las DGDs son unas nuevas dependencias entre atributos introducidas en esta memoria y han sido estudiadas en la sección 5.1.4. Las especificaciones hay que hacerlas tanto para las columnas que corresponden al antecedente, col_anti con i=1..l (cláusula ANTECEDENT), como para las del consecuente, col_conj con j=1..q (cláusula CONSEQUENT). Dichas especificaciones consisten para cada columna en lo siguiente:
o id_column: nombre de la columna, que debe estar definida en la dmFMB como
un tipo difuso 1, 2, 3 ó 4, esto es, col_anti para el antecedente y col_conj para el consecuente.
o fuzzy_comp: es un comparador de difuso de FSQL, de entre todos los posibles, que indica el tipo de dependencia difusa se desea obtener.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 190
Si lo que se desea obtener es una α -β DGD X→ F*T*Y (ver Definición 5-12) en las
que los valores α y β han sido predeterminados por el usuario, se debe especificar para las columnas del antecedente y del consecuente dos cláusulas THOLD_ANT y THOLD_CON, respectivamente, indicando para cada una: o umbral: es un número real en [0,1] que indica el umbral mínimo que debe
satisfacer la T-norma las comparaciones difusas hechas con el comparador fuzzy_comp anteriormente descrito. En dicho umbral pues, se especifica para el antecedente el valor α , y para el consecuente el valor β .
Si no se especificara dicho umbral entonces se entiende que se quiere obtener en tiempo de ejecución, de la correspondiente sentencia de DML, el umbral de las columnas del antecedente y de las columnas que constituyen el consecuente. En este caso en el DML se determinará si lo que se desea obtener es una α -β DGD X→ F*T*Y
o una (α i)-(β j) DGD X→ F*T*Y.
• list_columns_fgd_thold: es la otra posible opción de especificaciones sobre las columnas de la tabla id_tabla_orig_proyecto relevantes para el proceso de obtención de dependencias difusas entre atributos, cuando se usa la cláusula WITH COLUMNS FOR […] FGLOBAL_DEPENDENCIES. Se usa cuando lo que se desea obtener es (α i)-(β j) DGD X→ F*T*Y (ver Definición 5-11) en las que ya se ha predeterminado
por el usuario los valores α i y β j. Las especificaciones tanto para las columnas que corresponden al antecedente (cláusula ANTECEDENT) como para las del consecuente (cláusula CONSEQUENT) son las mismas que se han descrito en el párrafo anterior, incluyendo además para cada columna id_column lo siguiente:
o umbral: es un número real en [0,1] que indica el umbral mínimo que debe
satisfacer la comparación difusa de la columna hecha con el comparador fuzzy_comp anteriormente descrito. En dicho umbrales pues, se describen para el antecedente los valores α i, y para el consecuente los β j.
Cuando se usa esta opción, no es posible usar las cláusulas THOLD_ANT y THOLD_CON que afecte a todas las columnas del antecedente y todas las del consecuente respectivamente (ya que dicha especificación se ha hecho a nivel individual de cada columna).
• storage_stm: incluye las especificaciones de almacenamiento físico de todas las tablas que
se crearán dentro del proceso de DM, que implica el proyecto que se define, cuando se ejecuten las sentencias de DML correspondientes. Estas especificaciones sirven tanto para las tablas con los resultados intermedios como las que contienen el resultado final. La sintaxis de este estamento es parecida a la que se usa en el estamento del DDL análogo de Oracle® (ver [Urm98]). Entre dichas especificaciones se encuentra el nombre del tablespace a usar, tamaño inicial de los segmentos, tamaño de las

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 191
extensiones, etc. Esta cláusula es útil usarla cuando, por cualquier motivo, no se quiere usar los parámetros de almacenamiento físico que tiene el usuario (que crea el proyecto) por defecto.
La creación de un proyecto implica, en definitiva, el incluir toda esta información descrita, que del mismo se haya especificado, en las correspondiente estructuras de la dmFMB. En el apartado 6.3 se muestran varios ejemplos prácticos de este tipo de sentencia.
5.4.3.2 ALTER_MINING
Sirve para modificar un proyecto existente alterando, en algún sentido, alguna de las características con las que se definió dicho proyecto, con su correspondiente sentencia CREATE_MINING. La sintaxis es bastante similar a la de este comando, aunque con la diferencia fundamental de que prácticamente todas las cláusulas son opcionales:
ALTER_MINING PROJECT id_proyecto [ON OWNER id_owner] [ON TABLE id_tabla_orig_proyecto] [WITH COLUMNS FOR [CLUSTERING ‘(‘ list_columns_clu | list_columns_clu_cen ‘)’ ] [CLASSIFICATION ‘(‘ list_columns_cla ‘)’ ] [FGLOBAL_DEPENDENCIES ‘(‘ ANTECEDENT list_columns_fgd CONSEQUENT list_columns_fgd | ANTECEDENT list_columns_fgd THOLD_ANT umbral CONSEQUENT list_columns_fgd THOLD_CON umbral | ANTECEDENT list_columns_fgd_thold CONSEQUENT list_columns_fgd_thold ‘)’ ] ] [STORAGE_SPEFICATIONS storage_stm] ‘;’
donde el significado de las cláusulas es el mismo que el de la sentencia CREATE_MINING, explicada en el epígrafe anterior. Solo se tienen que incluir las cláusulas que impliquen alteraciones sobre las características previas del proyecto. Por supuesto, este comando, de alteración de proyecto deja constancia, en las correspondientes estructuras de la dmFMB, de las nuevas especificaciones del mismo. El alterar un proyecto puede implicar la pérdida de los resultados intermedios (en forma de tablas) que con las sentencias DML sobre el proyecto se hubieran generado, ya que éstos pueden no ser válidos ante las nuevas especificaciones que del proyecto se hacen. En el apartado 6.3 se puede encontrar ejemplos prácticos de esta sentencia.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 192
5.4.3.3 DROP_MINING
Sirve para eliminar un proyecto existente, definido previamente con la correspondiente sentencia CREATE_MINING. La sintaxis se expresa como sigue:
DROP_MINING PROJECT id_proyecto ‘;’
donde
• id_proyecto: es el identificador del proyecto que se desea eliminar. Este comando hace desaparecer de forma permanente toda la información almacenada en la dmFMB que del proyecto hubiera. Así mismo, la eliminación de un proyecto, con esta sentencia, implica el borrado de las tablas con los resultados intermedios que se hayan generado (si es que se ha generado alguna) con el uso de sentencias DML sobre el mismo. Por tanto, es bastante conveniente usar este comando para no almacenar información sobre proyectos obsoletos y/o inservibles.
5.4.3.4 GRANT_MINING
Sirve para otorgar los permisos necesarios para que un usuario determinado pueda efectuar sentencias DML sobre un proyecto en concreto. La sintaxis es la siguiente:
GRANT_MINING ALL PRIVILEGES TO PROJECT id_proyecto ON OWNER id_owner ‘;’
donde
• id_proyecto: es el identificador del proyecto sobre el que se desean otorgar los permisos. • id_owner: nombre del usuario al que se desean otorgar dichos permisos.
Hay que hacer notar que con este comando no se modifica el propietario en sí del proyecto (para ello se usaría la sentencia ALTER_MINING). Esta sentencia solo la puede efectuar el propietario del proyecto e implica darle permisos para la gestión de la tabla objeto de DM dentro del proyecto, esto es, la tabla id_tabla_orig_proyecto. Además implica darle permisos a los resultados intermedios, en forma de tablas, que se hayan podido ya generar durante el uso de sentencias DML sobre el proyecto. En ningún caso, las tablas resultado final de las sentencias de DML se consideran parte del proyecto y por tanto sobre ellas no se efectúa acción alguna con este comando GRANT_MINING.

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 193
5.4.3.5 REVOKE_MINING
Sirve para eliminar los permisos, previamente concedidos, sobre un proyecto. El objeto es que dicho usuario no pueda efectuar sentencias DML sobre dicho proyecto. La sintaxis es bastante similar a la de la sentencia GRANT_MINING :
REVOKE_MINING ALL PRIVILEGES ON PROJECT id_proyecto FROM OWNER id_owner ‘;’
donde
• id_proyecto: es el identificador del proyecto sobre el que se desean eliminar los permisos. • id_owner: nombre del usuario al que se van a quitar dichos permisos.
Esta sentencia solo la puede efectuar el propietario del proyecto e implica quitarle los permisos para la gestión de la tabla objeto de DM dentro del proyecto, esto es, la tabla id_tabla_orig_proyecto. Además implica quitarle los permisos a los resultados intermedios, en forma de tablas, que se hayan podido ya generar durante el uso de sentencias DML sobre el proyecto. En ningún caso, las tablas resultado final de las sentencias de DML se consideran parte del proyecto y por tanto sobre ellas no se efectúa acción alguna con este comando REVOKE_MINING.
5.4.4 Lenguaje de Manipulación de Datos (DML) de dmFSQL Una vez que se ha explicado la forma de definir un proyecto mediante el Lenguaje de Definición de Datos (DDL) de dmFSQL ya se está en condiciones de realizar el proceso de DM en sí, mediante el uso del Lenguaje de Manipulación de Datos (DML) de dmFSQL. La única sentencia posible del DML es SELECT_MINING, mediante la cual, se van a poder realizar los distintos procesos de DM contemplados:
5.4.4.1 SELECT_MINING CLUSTERING Esta sentencia es el interface para realizar el proceso de clustering, y opcionalmente, caracterizar cada uno de los grupos surgidos de dicho proceso mediante una única fila llamada centroide del grupo. La sintaxis es como sigue:
SELECT_MINING CLUSTERING id_proyecto INTO TABLE_CLUSTERING id_tabla_result_clu [‘,’ TABLE_CENTROIDS id_tabla_result_cen] OBTAINING n_clusters|OPTIMAL_ABS|OPTIMAL_H3|OPTIMAL_MED CLUSTERS
donde

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 194
• id_proyecto: es el identificador del proyecto sobre el que se ha debido de realizar una
sentencia de creación (o modificación) de proyecto que incluya la cláusula WITH COLUMNS FOR […] CLUSTERING, fijando las condiciones de dicho proceso de clustering para cada columna col_clui con i=1..m. Si se va a obtener adicionalmente los centroides de cada grupo surgido del proceso de clustering, para cada columna col_clui en la misma sentencia de definición del proyecto, se ha debido especificar la cláusula ABSTRACTION_LEVEL_CENTROID en la que se fija a qué nivel de abstracción se quiere describir dicha columna del centroide.
• id_tabla_result_clu: nombre de la tabla que se va a crear como resultado del proceso de clustering, esto es, en la que queda constancia para cada una de las filas de la tabla de origen de datos en el proyecto a qué grupo se ha determinado que pertenece. La estructura de esta tabla es idéntica a la tabla original, especificada en el proyecto id_tabla_orig_proyecto, pero con dos atributos adicionales:
o ROW_ID: identificador único de cada fila de la tabla. o CLUSTER_ID: identificador del grupo o cluster al que se ha determinado que
pertenece la fila en cuestión. Ambos atributos son numéricos, pudiendo tomar valores en el intervalo [1..num_reg_tab] donde num_reg_tab es el número de filas de la tabla id_tabla_orig_proyecto. El resto de los atributos de la tabla quedará con el mismo valor que el de la tabla original. Como reseña importante, decir que, los atributos difusos de esta nueva tabla son dados de alta en la dmFMB con las mismas características, heredadas, de los correspondientes atributos de la tabla id_tabla_orig_proyecto. Esto permite que la tabla id_tabla_result_clu cumpla las mismas condiciones que la original id_tabla_orig_proyecto, y que por tanto pueda ser usada en proceso de DM posterior, o lo que es igual, hace posible que se cumpla la propiedad de clausura. El uso de la tabla id_tabla_result_clu para este post-proceso de DM va a poder ser doble:
o dentro de un nuevo proyecto que la tenga a ella como tabla origen, o o usándola como criterio de clasificación (como se explicará en la siguiente
sección).
El propietario de dicha tabla, va a ser el especificado en el proyecto (id_owner de la sentencia de DDL) y se van a tener en cuenta las especificaciones físicas definidas en el proyecto, mediante la cláusula STORAGE_SPEFICATIONS, para su creación.
• id_tabla_result_cen: nombre de la tabla que se va a crear fruto del proceso de caracterización de cada uno de los grupos obtenidos en la tabla de resultado del clustering. La estructura de esta tabla es idéntica a la de dicha tabla (id_tabla_result_clu). El número de filas que va a contener es equivalente al número de grupos se hayan creado tras el proceso de clustering (num_reg_tab) y los valores con que se van a cumplimentar cada columna, que se ha venido llamando centroide, dependen de la definición elegida a la hora de la creación (o modificación) del proyecto, en la cláusula ABSTRACTION_LEVEL_CENTROID, como ya se ha explicado. Al igual que ocurría con la tabla resultado del clustering, los atributos difusos de esta nueva tabla son dados de alta en la dmFMB con las mismas características, heredadas, de los

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 195
correspondientes atributos de la tabla id_tabla_orig_proyecto. Esto permite que la tabla id_tabla_result_cen vuelva a cumplir las mismas condiciones que la original id_tabla_orig_proyecto, y que por tanto pueda ser usada en proceso de DM posterior (propiedad de clausura). También el uso de la tabla id_tabla_result_clu para este post-proceso de DM va a poder ser doble:
o dentro de un nuevo proyecto que la tenga a ella como tabla origen, o o usándola como criterio de clasificación (como se explicará en la siguiente
sección).
El propietario de dicha tabla, va a ser el especificado en el proyecto (id_owner de la sentencia de DDL) y se van a tener en cuenta las especificaciones físicas definidas en el proyecto, mediante la cláusula STORAGE_SPEFICATIONS, para su creación.
• n_clusters: con este valor se especifica el número de grupos que se quiere obtener tras el resultado de la ejecución de la sentencia. El valor debe estar dentro del intervalo [1..num_reg_tab] donde, como ya se ha comentado, num_reg_tab es el número de filas de la tabla id_tabla_orig_proyecto.
• OPTIMAL_ABS, OPTIMAL_H3, OPTIMAL_MED: opcionalmente, si no se quiere especificar un número concreto de grupos a obtener (n_clusters) se puede dejar que sea el sistema el que lo determine, mediante el uso de estas tres palabras reservadas que implican sendos procesos de obtención del número óptimo de grupos:
o OPTIMAL_ABS: partición óptima absoluta, según lo explicado en el punto
5.1.1.1.3. o OPTIMAL_H3: partición óptima obtenida a partir de la medida H3, según se
ha visto en 5.1.1.1.4. o OPTIMAL_MED: partición óptima media, es una variante de la absoluta que
se basa en coger la partición determinada por el corte en el punto medio relativo del dendrograma.
En el apartado 6.3.1.2 se puede encontrar ejemplos de este tipo de sentencia. Como se ha explicado, el efecto fundamental de esta sentencia es la creación de la tabla id_tabla_result_clu con el resultado del clustering, y además, la tabla con los centroides id_tabla_result_cen que caracterizan a cada uno de los grupos resultados del clustering si así se ha especificado. Por compatibilidad en la forma de funcionamiento del lenguaje FSQL, que devolvía siempre una sentencia SQL, de forma adicional se va a devolver una sentencia SQL dependiendo de:
• si no se ha requerido la obtención de la tabla con los centroides, en cuyo caso la sentencia SQL que se devuelve es la siguiente:
SELECT * FROM id_tabla_result_clu ORDER BY CLUSTER_ID, col_clu1, col_clu2,…, col_clum;

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 196
donde el orden de las columnas col_clu1, col_clu2,…, col_clum es de mayor a menor ratio_peso especificado en el proyecto a la hora de su creación mediante la correspondiente cláusula WEIGHT_CLUSTERING. Como estas columnas son difusas existen dos opciones para su ordenación: usar su función de representación u ordenar según su representación interna. La elección de una u otra posibilidad ya está contemplada en Servidor de FSQL de Galindo [Gal99] así que para su uso práctico habrá que configurar el Servidor en el sentido que más interese esta ordenación para el usuario.
• se ha requerido la obtención de la tabla con los centroides, devolviéndose la sentencia SQL:
SELECT * FROM id_tabla_result_clu A, id_tabla_result_cen B, WHERE B.CLUSTER_ID = A.CLUSTER_ID ORDER BY A.CLUSTER_ID, A.col_clu1, A.col_clu2,…, A.col_clum; donde hay que hacer las mismas consideraciones que el punto anterior sobre el orden de las columnas trascendentes para clustering. Se puede observar un ejemplo de esta sentencia SQL devuelta en la Figura 6-11 y de su visualización en el programa cliente FQ en la Figura 6-12.
Como se ha visto, los resultados de esta sentencia son tablas y la información que se incluye en la dmFMB es información intermedia que facilita el proceso de DM iterativo.
5.4.4.2 SELECT_MINING CLASSIFICATION Mediante esta sentencia se va invocar al proceso de clasificación. Este proceso siempre requerirá que se haya efectuado previamente la sentencia de clustering SELECT_MINING CLUSTERING, ya que va a necesitar uno de los dos resultados posibles de dicha sentencia como criterio de clasificación: la tabla con los centroides, o la tabla completa resultado del proceso de clustering. La sintaxis es como sigue:
SELECT_MINING CLASSIFICATION id_proyecto FROM id_tabla_orig_cla [TO id_tabla_result_cla] ACCORDING_TO TABLE_CENTROIDS id_tabla_result_cen | LAST TABLE_CLUSTERING id_tabla_result_clu | LAST WITH n_vecinos NEIGHBOARD [WHERE CLUSTER_ID IS id_cluster | THE_BEST]
THOLD umbral I
donde

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 197
• id_proyecto: es el identificador del proyecto sobre el que se ha debido de realizar una sentencia de creación (o modificación) de proyecto que incluya la cláusula WITH COLUMNS FOR […] CLASSIFICATION, fijando las condiciones de dicho proceso de clasificación para cada columna col_clui con i=1..m.
• id_tabla_orig_cla: nombre de la tabla que va a ser objeto del proceso de clasificación. Esta tabla debe de tener una estructura análoga a la de la tabla origen de datos del proyecto id_tabla_orig_proyecto, al menos en el ámbito de las columnas definidas como relevantes en el proceso de clasificación, en definitiva debe tener las columnas, col_clu1, col_clu2,…, col_clum, y así mismo han debido de ser definidas en la dmFMB como los correspondientes atributos difusos.
• id_tabla_result_cla: nombre de la tabla que se va a crear como resultado del proceso de clasificación, esto es, en la que queda constancia para cada una de las filas de la tabla a clasificar en el proyecto a qué grupo o grupos se ha determinado que pertenece y qué grado de pertenencia tiene. Se trata por tanto de un mecanismo de clasificación difusa. La estructura de esta tabla es idéntica a la tabla que se quiere clasificar id_tabla_orig_cla, pero con dos atributos adicionales:
o CLUSTER_ID: identificador del grupo o cluster al que se ha determinado que
pertenece la fila en cuestión. o CDEG_CLUSTER: grado de pertenencia a dicho grupo, que es un valor en el
intervalo [0,1]. El resto de los atributos de la tabla quedará con el mismo valor que el de la tabla original. Si se quiere que se devuelva más de una clasificación para la misma fila, en esta tabla id_tabla_result_cla se repetirá tantas veces como sea necesario la misma fila de la tabla original, pero variando estos dos atributos adicionales, que indican en definitiva la clasificación que se le ha dado. De nuevo, los atributos difusos de esta nueva tabla son dados de alta en la dmFMB con las mismas características, heredadas, de los correspondientes atributos de la tabla id_tabla_orig_proyecto. Esto permite que la tabla id_tabla_result_cla cumpla las mismas condiciones que la original id_tabla_orig_proyecto, y que por tanto pueda ser usada en un post-proceso de DM, por lo que hace posible que se cumpla la propiedad de clausura, ya explicada. El propietario de dicha tabla, va a ser el especificado en el proyecto (id_owner de la sentencia de DDL) y se van a tener en cuenta las especificaciones físicas definidas en el proyecto, mediante la cláusula STORAGE_SPEFICATIONS, para su creación. Es posible no indicar esta tabla resultado de la clasificación id_tabla_result_cla en la sintaxis de la sentencia, lo que implica que como resultado de la clasificación se va a devolver una sentencia SELECT convencional de SQL. El resolver la clasificación de esta forma solo es posible en determinadas circunstancias que si no se cumplen va a provocar un error semántico, estas condiciones son no usar ninguna de las siguientes cláusulas dentro de la sentencia de SELECT_MINING CLASSIFICATION:
o ACCORDING_TO TABLE_CLUSTERING. o WHERE CLUSTER_ID IS THE_BEST.
• id_tabla_result_cen: es la tabla con los centroides a usar como criterio de clasificación si
se quiere aplicar el método de clasificación difusa basado en centroides explicado en la

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 198
sección 5.1.3.1. Dicha tabla se ha creado mediante una sentencia SELECT_MINING CLUSTERING, tal y como ya se ha comentado. También es posible no indicar explícitamente el nombre de la tabla con los centroides a usar, como criterio de clasificación, si se especifica la cláusula ACORDING_TO TABLE_CENTROIDS LAST, en cuyo caso se usa la última tabla de centroides obtenida en el proyecto en cuestión mediante una sentencia SELECT_MINING CLUSTERING.
• id_tabla_result_clu: es la tabla resultado del proceso de clustering a usar como criterio de clasificación si se quiere aplicar el método de clasificación difusa basado en los vecinos más cercanos, explicado en el punto 5.1.3.2. Dicha tabla se ha creado mediante una sentencia SELECT_MINING CLUSTERING, tal y como ya se ha comentado. También es posible no indicar explícitamente el nombre de dicha tabla si se usa la cláusula ACORDING_TO TABLE_CLUSTERING LAST, en cuyo caso se utiliza la última tabla resultado del clustering obtenida en el proyecto en cuestión mediante una sentencia SELECT_MINING CLUSTERING.
• n_vecinos: si se ha usado una tabla resultado de clustering como criterio de clasificación, no todas las filas de la tabla id_tabla_result_clu van a ser tenidas en cuenta en el proceso de clasificación, sino que para cada grupo obtenido en el proceso de clustering, aquéllas que mejor se ajusten a la fila a clasificar. Con este número n_vecinos se indica cuántas de estas filas que mejor se ajustan hay que tener en cuenta para la clasificación. Si este número es mayor que el número de filas del grupo en cuestión ser usará todas las filas del grupo.
• id_cluster: sirve para indicar si se quiere restringir la clasificación a un solo determinado grupo, obtenido durante el proceso de clustering, identificado por id_cluster. Así cada una de las filas de la tabla a clasificar (id_tabla_orig_cla) solo se va a asignar en la tabla resultado (id_tabla_result_cla) de la clasificación al grupo id_cluster. Por tanto, si se especifica, solo se usaran como criterio de clasificación las filas de la tabla especificada como criterio de clasificación (la de centroides id_tabla_result_cen, o la de resultado de clustering id_tabla_result_clu) que cumplan que su atributo identificador grupo (ID_CLUSTER) sea igual a este valor (id_cluster). Si se usa la cláusula WHERE CLUSTER_ID IS THE_BEST el único grupo al que se va asignar cada una de las filas de la tabla origen va a ser precisamente al que mayor grado de pertenencia tenga.
• umbral: va a determinar el grado mínimo de pertenencia a los distintos grupos, resultados del clustering, que van a tener que cumplir las filas resultado de la clasificación.
La sentencia para clasificar, pues, tiene dos vertientes principales en relación a como se resuelve dicho proceso de clasificación:
• Bajo determinadas circunstancias, ya explicadas, el proceso de clasificación puede llegar a ser resuelto mediante una sentencia FSQL, y en definitiva una vez hecha la traducción de dicha sentencia, mediante una simple sentencia SQL. Dicha sentencia SQL es, por tanto, la única salida generada por la sentencia de clasificación. Puede observarse un ejemplo de este tipo de sentencia FSQL en el apartado 6.3.1.3 y de su traducción a SQL en la Figura 6-16.
• Si el proceso de clasificación resulta más complejo, o bien quiere se quiere dejar constancia de la clasificación en una tabla, hay que especificar la cláusula TO

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 199
id_tabla_result_cla, generándose dicha tabla con la estructura ya comentada. En estos casos adicionalmente se devuelve la siguiente sentencia SQL:
SELECT * FROM id_tabla_result_cla ORDER BY CLUSTER_ID, CDEG_CLUSTER DESC;
En el apartado 6.3.1.3 pueden encontrarse ejemplos de sentencias DML de clasificación.
5.4.4.3 SELECT_MINING FGLOBAL_DEPENDENCIES Mediante esta sentencia se va invocar al proceso de obtención de DGDs, de tal manera que, dicho proceso determina como una serie atributos difusos (llamados antecedente) implican a otra serie de atributos difusos (llamados consecuente) tal y como se ha explicado en la sección 5.1.4. La sintaxis es como sigue:
SELECT_MINING FGLOBAL_DEPENDENCIES id_proyecto USING T_NORM | SINGLE THOLD_ANT_CON [WITH CONFIDENCE HIGHEST]
donde
• id_proyecto: es el identificador del proyecto sobre el que se ha debido de realizar una sentencia de creación (o modificación) de proyecto que incluya la cláusula WITH COLUMNS FOR […] FGLOBAL_DEPENDENCIES, fijando las condiciones de dicho proceso, de obtención de DGDs, tanto para cada columna del antecedente, col_anti con i=1..l (especificadas en la cláusula ANTECEDENT), como para cada columna del consecuente, col_conj con j=1..q (especificadas en la cláusula CONSEQUENT).
Esta sentencia sirve para el tratamiento de los dos tipos de DGDs definidos, a saber:
• α -β DGD X→ F*T*Y: para lo cual hay que usar la cláusula USING T_NORM THOLD_ANT_CON.
• (α i)-(β j) DGD X→ F*T*Y: para lo cual hay que usar la cláusula USING SINGLE THOLD_ANT_CON.
El tratamiento de las DGDs va a consistir en:
• Obtención del grado de confianza y soporte con que las DGD se cumplen: en este caso los α -β o los (α i)-(β j) se han debido de especificar a la hora de definir el proyecto. Esto es, se han debido incluir la cláusula ANTECEDENT list_columns_fgd THOLD_ANT umbral CONSEQUENT list_columns_fgd THOLD_CON umbral para

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 200
la α -β DGD X→ F*T*Y en la definición del proyecto; o en cambio se ha debido incluir ANTECEDENT list_columns_fgd_thold CONSEQUENT list_columns_fgd_thold para la (α i)-(β j) DGD X→ F*T*Y en dicha definición.
• Obtención de los umbrales α -β o (α i)-(β j) para la DGD con el criterio de obtención de un grado confianza (ver Definición 5-8) mayor posible. En este caso hay que especificar la cláusula WITH CONFIDENCE HIGHEST. El soporte de la DGD también se obtiene en este caso.
Como se ha dicho, por compatibilidad en la forma de funcionamiento del lenguaje FSQL, que devolvía siempre una sentencia SQL, de forma adicional se va a devolver una sentencia SQL dependiendo de si ha obtenido una:
• α -β DGD X→ F*T*Y en cuyo caso la sentencia SQL que se devuelve es la siguiente:
SELECT DECODE(DCL.COL_TYPE,'A','ANTECEDENT','CONSEQUENT') AS COL_TYPE C.COLUMN_NAME, DPR.THOLD_ANT_FGD, DPR.THOLD_CON_FGD, DPR.CONFIDENCE_FGD, DPR.SUPPORT_FGD FROM DPR, DCL, ALL_OBJECTS O, DBA_TAB_COLUMNS C WHERE DPR.PROJECT_NAME = id_proyecto AND DCL.PROJECT_NAME = DPR.PROJECT_NAME AND DCL.COL_TYPE IN ('A','Q') AND O.OWNER = DPR.OWNER# AND O.OBJECT_ID = DPR.OBJ# AND C.OWNER = DPR.OWNER# AND C.TABLE_NAME = O.OBJECT_NAME AND C.COLUMN_ID = DCL.COL# ORDER BY DCL.COL_TYPE, DCL.COL#;
donde se han seleccionado los datos de la dmFMB y del catálogo del sistema siguientes:
o COL_TYPE: tipo de columna ‘A’ para el antecedente y ‘C’ para el consecuente; o COLUMN_NAME: nombre de la columna (obtenido del catálogo del sistema); o THOLD_ANT_FGD: umbral α para el antecedente;
o THOLD_CON_FGD: umbral β para el consecuente; o CONFIDENCE_FGD: confianza de la DGD y o SUPPORT_FGD: soporte de la DGD.
• (α i)-(β j) DGD X→ F*T*Y en cuyo caso la sentencia SQL que se devuelve es la siguiente:

CAPÍTULO 5- AMPLIACIÓN DEL MODELO FIRST* PARA DATA MINING
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 201
SELECT DECODE(DCL.COL_TYPE,'A','ANTECEDENT','CONSEQUENT') AS COL_TYPE, C.COLUMN_NAME, DCL.THOLD_FGD, DPR.CONFIDENCE_FGD, DPR.SUPPORT_FGD FROM DPR, DCL, ALL_OBJECTS O, DBA_TAB_COLUMNS C WHERE DPR.PROJECT_NAME = id_proyecto AND DCL.PROJECT_NAME = DPR.PROJECT_NAME AND DCL.COL_TYPE IN ('A','Q') AND O.OWNER = DPR.OWNER# AND O.OBJECT_ID = DPR.OBJ# AND C.OWNER = DPR.OWNER# AND C.TABLE_NAME = O.OBJECT_NAME AND C.COLUMN_ID = DCL.COL# ORDER BY DCL.COL_TYPE,DCL.COL#;
donde se han seleccionado los datos de la dmFMB y del catálogo del sistema siguientes:
o COL_TYPE: tipo de columna ‘A’ para el antecedente y ‘C’ para el consecuente; o COLUMN_NAME: nombre de la columna (obtenido del catálogo del sistema); o THOLD_FGD: umbrales α i para el antecedente y umbrales β j para el
consecuente; o CONFIDENCE_FGD: confianza de la DGD y o SUPPORT_FGD: soporte de la DGD.
Se puede observar un ejemplo de esta sentencia SQL devuelta en la Figura 6-20.
Como se ha observado pues, esta sentencia DML a parte de visualizar los resultados en sí, deja constancia de dichos resultados en la dmFMB. Esto es muy importante para facilitar la gestión de dichos resultados en un uso de dmFSQL embebido dentro de otra aplicación. Así estos resultados podrían ser finales o intermedios dentro de otro proceso analítico. En el apartado 6.3.2 pueden encontrarse ejemplos de sentencias DML de obtención de DGD.


CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 203
Capítulo 6 dmFIRST, UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
Como se ha explicado en el capítulo anterior, la implementación hecha del modelo FIRST* ha permitido la realización de diversas técnicas de DM, sin ningún condicionante sobre los tipos de datos a manejar. Sin embargo, también se ha determinado que era necesario mejorar el modelo FIRST* para que su aplicación real a DM fuera más amplia y efectiva. De esta forma se ha definido dmFIRST, que consta de una interface de alto nivel que es el lenguaje dmFSQL. El presente capítulo va a ser la culminación práctica de este modelo dmFIRST. Así en primer lugar se va se va a exponer una solución de arquitectura cliente-servidor para dmFSQL, con dos ejes fundamentales a desarrollar, la dmFMB (que ha sido ampliamente explicada en el capítulo anterior) y el Servidor dmFSQL. En dicha arquitectura son perfectamente válidos los clientes ya existentes para FSQL. A continuación, se expone la implementación hecha del Servidor dmFSQL. El Servidor ha sido desarrollado siguiendo estrictamente una metodología que entran dentro del ámbito de la Ingeniería del Software [Pre93]. De esta forma, el resultado final del producto no solo han sido los códigos fuente y objeto, sino también un modelo de datos y otro de procesos para los que se han usado las herramientas de la empresa Platinum, ERwin© (modelo de datos) y BPwin© (modelo de procesos). El Servidor ha sido implementado finalmente en PL/SQL© de Oracle© sopesando, sobre todo, el tema de la eficiencia (imprescindible para un sistema de DM) y la integración con el Servidor FSQL. El uso de este lenguaje ha permitido aprovechar plenamente funcionalidades avanzadas del SGBD Oracle©, como son, el paralelismo y la gestión de cachés.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 204
Finalmente, se va a proponer el uso del servidor dmFSQL, ya implementado, en primer
lugar, para crear un sistema de decisión de compra-venta de acciones dentro del ámbito del análisis técnico bursátil y, en segundo lugar, para un estudio aplicado a la economía social de Andalucía.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 205
6.1 Arquitectura cliente-servidor de dmFSQL
En la sección 4.2.4 se ha explicado la anterior arquitectura presentada en esta memoria, esto es, la arquitectura de cliente-servidor de FSQL* que han sido implementada usando Oracle®. Esta arquitectura es la base para la nueva que aquí se propone, por tanto, se seguirá usando este SGBD para su implementación, aunque el modelo lógico propuesto podría ser perfectamente implantado en cualquier otro SGBD. Por otro lado, el elegir un SGBD en concreto va a permitir usar todo su potencial, en este de caso Oracle®, en pro de conseguir la eficiencia que a los sistema de DM se exige.
La nueva arquitectura cliente-servidor de dmFSQL para la BDRD queda reflejada en la
Figura 6-1 y está compuesta por los siguientes elementos:
1. Datos: Base de datos tradicional y Base de Metaconocimiento Difuso para Data Mining, dmFMB.
2. Servidor dmFSQL: Encargado de realizar los tratamientos de DM. 3. Cliente FSQL: Encargado de hacer de interfaz entre el usuario y el Servidor dmFSQL.
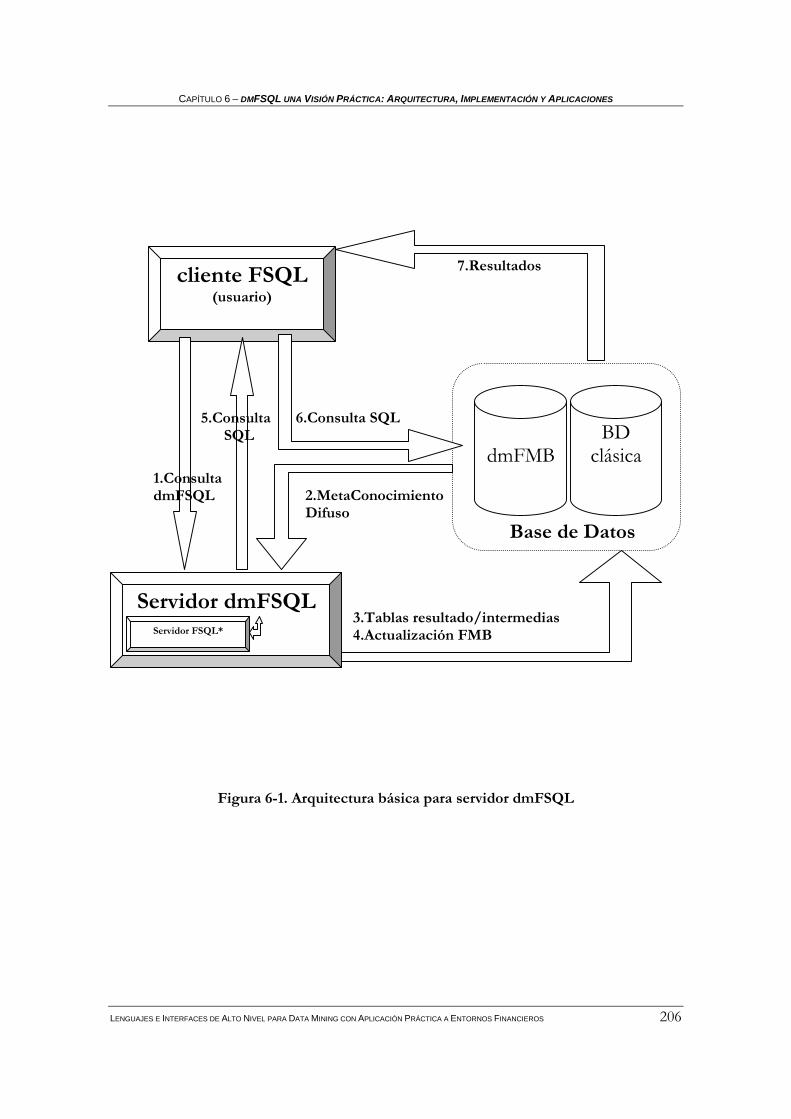
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 206
Figura 6-1. Arquitectura básica para servidor dmFSQL
Servidor dmFSQL
dmFMBBD
clásica
Base de Datos
cliente FSQL (usuario)
1.Consulta dmFSQL 2.MetaConocimiento
Difuso
5.Consulta
SQL
6.Consulta SQL
7.Resultados
3.Tablas resultado/intermedias 4.Actualización FMBServidor FSQL*

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 207
A continuación se explica cada uno de estos componentes:
6.1.1 Datos: base de datos clásica y dmFMB
Como se ha explicado en el apartado 5.3, la dmFMB contiene toda la estructura que componía la FMB* de FIRST*. Por tanto según se explicó en el punto 4.2.4.1, tanto la representación de los distintos tipos de datos (contenidos en la base de datos clásica) así como su tratamiento difuso estaban ya resueltos con la anterior FMB*.
El valor añadido que proporciona ahora la dmFMB, es que permite implementar el
objeto proyecto de DM que es fundamental para el uso del lenguaje dmFSQL.
6.1.2 Servidor dmFSQL En la definición que se ha hecho del lenguaje dmFSQL en el epígrafe 5.4 se ha considerado que este nuevo lenguaje engloba al lenguaje predecesor, esto es, FSQL. Por tanto, siguiendo la misma lógica el servidor de dmFSQL debe de englobar al servidor de FSQL*. Por otro lado, la filosofía de actuación ha sido modificar lo mínimamente posible el servidor FSQL*. Así el esquema del nuevo servidor va a ser el siguiente:
• Función de Traducción (FSQL2SQL): Esta función, incluida en el paquete FSQL_PKG, va a tener una actuación similar a la ya explicada para el servidor FSQL*. Así, efectúa un análisis de la consulta dmFSQL. Si encuentra errores de cualquier naturaleza, genera a una tabla con todos los errores encontrados. Si no hay errores, la consulta dmFSQL es resuelta y se devuelve una sentencia en SQL. El análisis de la sentencia dmFSQL tiene por objeto:
o asegurar que la sentencia está correctamente escrita (pertenece a la gramática definida);
o comprobar que tiene sentido efectuarla (por ejemplo, que usa objetos válidos); y
o además si se trata de una actuación de DM desencadenar todo el proceso de resolución de la demanda correspondiente (clustering, caracterización, clasificación y/o dependencias globales difusas).
Para ello usa los 3 analizadores siguientes:
1. Analizador Léxico: Asegura que todos los elementos de la sentencia están
permitidos, agrupando los caracteres en palabras (tokens). 2. Analizador Sintáctico: Asegura que los tokens están en un orden adecuado y que
la construcción de la sentencia es correcta sintácticamente. 3. Analizador Semántico: Asegura que el significado de la sentencia es correcto y
que, por tanto, tiene sentido efectuarla. Este analizador es el que más cambios ha sufrido de tal manera que su actuación ahora dependen de:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 208
o Si se determina que la sentencia DML o DDL de entrada es una tradicional de
FSQL (y no de dmFSQL) la actuación va seguir siendo completamente análoga a la ya explicada en la sección 4.2.4.2, esto es, para el caso de DML realiza la traducción al lenguaje SQL que incluye llamadas a las funciones de comparación y representación.
o Si se determina que la sentencia de entrada es de DDL que forma parte de la ampliación del lenguaje dmFSQL (explicada en el punto 5.4.3) se efectúa el tratamiento correspondiente que consiste básicamente en incluir información en la dmFMB y/o ejecutar sentencias de seguridad del SGBD anfitrión, tal y como se ha explicado en la sección 5.4.3.
o Si por el contrario se determina que la sentencia DML de entrada forma parte de la ampliación del lenguaje dmFSQL (explicada en el punto 5.4.4) cuyas sentencias básicamente comienza por palabras reservadas con formato sentencia_MINING (donde sentencia es una sentencia contemplada en SQL convencional, SELECT, CREATE, etc.) la actuación va a consistir en una llamada a la función dmFSQL_SEMANTICO (incluida en el paquete dmFSQL_LANG) que es la que realiza propiamente el análisis semántico de la extensión del lenguaje. Si se habla del DML de dmFSQL este análisis semántico consiste en la llamada a una de las funciones que se van a explicar a continuación, incluidas dentro del paquete dmFSQL, con parámetros de entrada capturados de la propia sentencia dmFSQL y con salida el número de errores producidos y, en su caso, una tabla con los distintos errores, o si ha sido correcta una tabla con la sentencia SQL correspondiente. Las funciones dependen de la sentencia DML correspondiente:
SELECT_MINING CLUSTERING que implica una llamada a la
función CLUSTERING con parámetros de entrada:
• id_proyecto: identificativo del proyecto. • criterio_cluster_optimo: identificativo del criterio de cluster óptimo
a usar: o OPTIMAL_ABS, o OPTIMAL_H3, o o OPTIMAL_MED.
• número_cluster_obtener: número de grupos que se quiere obtener (caso de no haberse especificado un criterio de cluster óptimo).
• id_tabla_result_clu: identificativo de la tabla resultado del clustering.
• id_tabla_result_cen: identificativo de la tabla resultado de la caracterización de los distintos grupos mediante centroides. Si no se ha especificado dicha tabla no se desencadena el correspondiente proceso de caracterización.
SELECT_MINING CLASSIFICATION que implica una llamada a la
función CLASSIFICATION con parámetros de entrada:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 209
• id_proyecto: identificativo del proyecto. • id_tabla_orig_cla: tabla que va sufrir el proceso de clasificación. • id_tabla_result_cla: tabla que se va a crear como resultado del
proceso de clasificación. • id_tabla_result_cen: tabla con los centroides a usar como criterio
de clasificación. • id_tabla_result_clu: es la tabla resultado del proceso de clustering
a usar como criterio de clasificación (si no se ha especificado la anterior).
• n_vecinos: número de filas de la tabla id_tabla_result_clu hay que considerar para la clasificación de cada fila con el mecanismo de los vecinos más cercanos.
• id_cluster: grupo obtenido durante el proceso de clustering al que se quiere restringir la clasificación.
• best_cluster: es un valor booleano de tal manera que si es TRUE indica que el grupo al que se quiere restringir la clasificación de cada fila, es aquel que mayor grado de pertenencia tenga la fila en cuestión (si no se ha especificado id_cluster).
• umbral: grado mínimo de pertenencia a los distintos grupos, resultados del clustering, que van a tener que cumplir las filas resultado de la clasificación.
SELECT_MINING FGLOBAL_DEPENDENCIES que implica una
llamada a la función FGLOBAL_DEPENDENCIES con parámetros de entrada:
• id_proyecto: identificativo del proyecto. • tipo_fgd: tipo de la DGD a obtener:
o T_NORM: si se desea obtener una α -β DGD
X→ F*T*Y.
o SINGLE: si se desea obtener una (α i)-(β j) DGD
X→ F*T*Y. • confianza_máxima: valor booleano de tal manera que si es TRUE
indica que se van a obtener los distintos umbrales α ’s y β ’s de las DGDs con el criterio de obtener una máxima confianza.
6.1.3 Funcionamiento del cliente-servidor de dmFSQL
Como se acaba de ver en el apartado anterior, la función de traducción (FSQL2SQL) sigue teniendo las mismas premisas de funcionamiento en cuanto a sus parámetros de entrada/salida que la del servidor FSQL*. Por tanto, centrándose en la parte que resuelve las sentencias DML, la arquitectura cliente-servidor de dmFSQL, esquematizada en la Figura 6-1, es bastante similar

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 210
a la de cliente-servidor de FSQL*, esquematizada en la Figura 4-3. Las diferencias fundamentales son:
• Sustitución de la FMB* por la dmFMB que permite la gestión de los proyectos de DM. • Sustitución del Servidor FSQL* por el Servidor dmFSQL, que como se ha visto,
además de generar sentencias SQL realiza los procesos de DM en sí. Así una vez instalados tanto el metadatos, como el servidor, los programas clientes de FSQL (FQ -Fuzzy Queries-, F –Fuzzy-, Visual Client for FSQL, usos de FSQL embebido…) siguen funcionando sin tener que sufrir alteración, ni instalación alguna.
El proceso de llamada del Servidor dmFSQL con una sentencia dmFSQL se puede
esquematizar en los siguientes pasos (ver Figura 6-1):
1. El programa Cliente FSQL envía a la consulta dmFSQL al Servidor dmFSQL. 2. El Servidor dmFSQL analiza la consulta y, si es correcta, genera una sentencia SQL a
partir de la consulta original en dmFSQL. En este paso el Servidor dmFSQL usa la información de la dmFMB. Opcionalmente puede desencadenar un proceso de DM de clustering y/o caracterización, clasificación y generación de DGDs.
3. Si se ha ejecutado un proceso de DM, generalmente, se guardan los resultados intermedios o finales en tablas.
4. Si se ha ejecutado un proceso de DM además se puede actualizar en la dmFMB la información del correspondiente proyecto.
5. Una vez ha sido generada la consulta en SQL, el programa Cliente leerá dicha consulta. Si en el paso 2 el Servidor dmFSQL encontró errores, entonces, en este paso se leerán dichos errores, para ser mostrados al usuario.
6. El programa Cliente enviará a la consulta SQL a cualquier base de datos que sea coherente con la dmFMB. Para la ejecución de esta consulta podrán usarse diversas funciones del Servidor dmFSQL (de Representación y Comparación Difusa), pero eso es transparente al usuario.
7. Finalmente, el Cliente recibirá los datos resultantes y los mostrará al usuario. El formato de presentación dependerá, lógicamente, del programa Cliente FSQL empleado.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 211
6.2 Implementación del Servidor dmFSQL En esta sección se va a explicar la implementación que se ha hecho del Servidor dmFSQL en lo que respecta a los procesos puramente de DM, cuyo interfaz es el lenguaje DML de dmFSQL. Como se ha visto, la función de traducción del analizador semántico se limita a generar llamadas a unas funciones que son las que realmente tienen el peso de realizar el proceso de DM. Estas funciones se implementan con una serie de procesos:
o Función CLUSTERING: es resuelta mediante los procesos de CLUSTERING y CARACTERIZACIÓN.
o Función CLASSIFICATION: es resuelta mediante el proceso CLASIFICACIÓN. o Función FGLOBAL_DEPENDENCIAS: es resuelta mediante el proceso
DEPENDENCIAS GLOBALES DIFUSAS. Para la implementación se presentan una serie de alternativas que dependen del lenguaje elegido:
1. Lenguajes genéricos (como Java, C,…) que implementan sus propios interfaces de programa para la conexión con la base de datos. Algunos de ellos incorporan bibliotecas de funciones que agilizan y simplifican la gestión de estructuras de datos de la base de datos y la comunicación con ella. Sin embargo, salvo excepciones como la del lenguaje Java, suelen presentar problemas de portabilidad de unas arquitecturas a otras. Adicionalmente, estos lenguajes requieren la presencia de una red de comunicaciones para establecer contacto y traspasar datos entre las estructuras de datos y la base de datos, mediante un mecanismo de mensajes.
2. SQL inmerso en un lenguaje anfitrión (host language) como el lenguaje Pro*C®. Esta tecnología consiste en ampliar un lenguaje existente con nuevas sentencias que permitan la comunicación con el SGBD. En el caso del lenguaje Pro*C®, el lenguaje ampliado es el lenguaje de programación C.
3. Lenguajes específicos de acceso a base de datos como el lenguaje de programación PL/SQL® de Oracle®. Este es un lenguaje de programación específico para las bases de datos relacionales implementado directamente en el SGRBD. Los módulos compilados en este lenguaje están almacenados en las bases de datos y son ejecutados por el propio SGRBD.
Las diversas alternativas presentan pros y contras que hay que tener en cuenta a la hora de la elección del lenguaje en concreto:
• Generalidad: los lenguajes más generales son los de tipo 1 seguidos de los de tipo 2 y 3. Cuanto más general sea el lenguaje permite realizar más operaciones con los datos de una forma más cómoda y sencilla. Sin embargo para los lenguajes tipo 1, salvo que estén dotados de con bibliotecas de funciones con una amplia gama de métodos para la

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 212
comunicación con la base de datos, dicha comunicación puede convertirse en un problema importante.
• Portabilidad: los lenguajes tipo 1 puede ser portables (Java) o no portables (C) cuando las bibliotecas de funciones para la comunicación tienen que estar en todos los compiladores. En su mayor parte, los lenguajes poseen un estándar que no suelen incluir bibliotecas de este tipo, lo cual hace la portabilidad difícil. En el caso de los lenguajes de tipo 3, el lenguaje está inmerso en el SGBD, lo que implica que, salvo que exista otro SGBD con el mismo lenguaje inmerso, la portabilidad sea nula.
• Eficiencia: habida cuenta del número de accesos a la base de datos y la necesidad de interoperar con ella, los lenguajes de tipo 3 se presentan como los más eficientes ya que no necesitan de una red de comunicaciones ni del paso de mensajes por la misma. Además, las instrucciones de estos lenguajes están optimizadas para cada SGBD y son capaces de manejar grandes volúmenes de datos simultáneamente.
Teniendo en cuenta estos características, el lenguaje elegido para la implementación del Servidor dmFSQL han sido el PL/SQL© de Oracle©, sopesando sobre todo el tema de la eficiencia (imprescindible para un sistema de DM) y considerando que los parámetros negativos como portabilidad y generalidad son contrarrestados por la hegemonía sin paliativos de Oracle© en el mercado empresarial actual. Además también se ha conseguido la integración plena con el Servidor FSQL* que ya estaba implementado en este lenguaje. El uso de esta plataforma ha permitido aprovechar funcionalidades del SGBD Oracle© avanzadas que aumentan enormemente la eficiencia, como por ejemplo:
• Paralelismo en el tratamiento de los accesos a base de datos. • Uso de cachés de tal manera que se evita el acceso a los datos de la base de datos de los
datos de maniobra. De todas formas, la solución aquí propuesta puede ser implementada fácilmente en cualquier tipo de lenguaje ya que ha sido desarrollada siguiendo estrictamente una metodología que entran dentro del ámbito de la Ingeniería de Software [Pre93]. De esta forma, el resultado final del producto no solo han sido los códigos fuentes sino también un modelo de datos y otro de procesos para los que se han usado las herramienas de la empresa Platinum© ERwin© (modelo de datos) y BPwin© (modelo de procesos). El modelo de datos está constituido fundamentalmente por la dmFMB (ver Figura 5-9) y una serie de tablas de maniobra y resultados que van a ser explicadas conjuntamente con el modelo de procesos del Servidor de dmFSQL:
6.2.1 Proceso: CLUSTERING En la Figura 6-2 se puede observar del diagrama de flujo de datos del proceso CLUSTERING el cual implementa la función CLUSTERING (vista en 6.1.2) con parámetros de entrada id_proyecto (identificativo del proyecto), criterio_cluster_optimo (identificativo del criterio de cluster óptimo a usar), número_cluster_obtener (número de grupos que se quiere obtener) y id_tabla_result_clu (identificativo de la tabla resultado del clustering). En este caso el

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 213
parámetro id_tabla_result_cen (identificativo de la tabla resultado de la caracterización de los distintos grupos mediante centroides) no vienen cumplimentado y por tanto no se realiza el proceso de caracterización, que será explicado más adelante. Ambos procesos, CLUSTERING y CARACTERIZACIÓN, forman conjuntamente la función CLUSTERING.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 214
Figura 6-2. DFD Clustering
dmFMB1
ObtenerDendrograma
1
id_tabla_ orig_proyecto 2
id_proyecto_ DMFSQL_D 3
Obtener
Posibles α -cortes
2
Obtener Partición
3
Obtener SELECTClustering
4
id_proyecto_ DMFSQL_L 4
id_tabla_result_clu 5
Usuario

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 215
6.2.1.1 Proceso: obtener dendrograma Descripción: Para el proyecto id_proyecto que tiene como tabla de origen de datos id_tabla_orig_proyecto, se obtiene la jerarquía de partes de la población, o lo que es equivalente, el dendrograma (hablando en términos gráficos) que queda plasmado en la tabla id_proyecto_DMFSQL_D asociada al proyecto. Para ello se usa la información de la dmFMB. Tratamientos:
• Creación de la estructura de la tabla con el resultado del clustering id_tabla_result_clu. Se obtiene dicha estructura con el siguiente esquema:
id_tabla_result_clu (row_id, col_clu1, col_clu2,…, col_clum, cluster_id) con m ∈ ℕ
que contiene las columnas para clustering de la tabla id_tabla_orig_proyecto con dos atributos adicionales:
o row_id: que se cumplimenta con un número secuencial desde 1 hasta n (número de filas de la tabla id_tabla_orig_proyecto).
o cluster_id: identificativo del cluster, este atributo en principio se genera vacío, esto es, con valor NULL.
Las columnas para clustering se cumplimentan con los mismos valores que la tabla id_tabla_orig_proyecto. Se incluye en la dmFMB toda la información de la nueva tabla id_tabla_result_clu heredándola de la tabla original id_tabla_orig_proyecto.
• Obtención de la sentencia FSQL para la generación de la matriz de distancias. A partir de los datos para clustering almacenados para el proyecto id_proyecto en la dmFMB y según lo explicado en la sección 5.1.1.2 pero tomando como referencia la tabla creada en el punto anterior, esto es, id_tabla_result_clu en lugar de la tabla id_tabla_orig_proyecto. El comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de clustering (DCL.FUZZY_COMP_CLU) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL.LOG_OPER_CLU). Los pesos de dicha sentencia w_clur se obtendrán correspondiente también de la dmFMB (DCL.WEIGHT_CLU).
Traducción de la sentencia FSQL a SQL mediante el uso del Servidor FSQL*.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 216
• Obtención de la Matriz de Distancias de la Población MatrizDis[1..n, 1..n]. Esto se lleva a cabo a partir de las sentencia anterior que ha devuelto los valores dij:
MatrizDis[1..i, 1..j] = dij ∀ i, j = 1..n
Como se vio, dij ∈ [0,1] así la a matriz de distancias está normalizada en [0,1].
• Obtención de la Matriz de Distancias Ultramétrica de la población. La matriz de distancias de la población MatrizDis, en la que cada tripleta de elementos cumple la propiedad triangular, se transforma de tal manera que además para esa tripleta se cumple la desigualdad ultramétrica. De esta manera MatrizDis se convierte en la matriz de distancias ultramétrica normalizada de la población. Para ello se usa el Algoritmo 6-1.
Por último la matriz de distancias ultramétrica se almacena en la tabla id_proyecto_DMFSQL_D asociada al proyecto que tiene la siguiente estructura lógica:
id_proyecto_DMFSQL_D (i, j, dij)
donde para cada par i, j de la población dij es la distancia ultramétrica entre ambos. En la tabla id_tabla_result_clu estos valores se identifican para cada i por la fila que cumpla rowid=i y de forma análoga para j.
Algoritmo 6-1
Entradas: • MatrizDis: matriz de distancias normalizada
Salidas: • MatrizDis: matriz de distancias ultramétrica normalizada
Repetir por siempre
* Obtención de MatrizMinMax a partir de MatrizDis Para i = 1 Hasta n - 1
Para j = i + 1 Hasta n MatrizMinMax(i, j) = 1 Para k = 1 Hasta n
maxInt = Max(matrizDis(i, k), matrizDis(k, j)) Si maxInt < matrizMinMax(i, j)
matrizMinMax(i, j) = maxInt matrizMinMax(j, i) = maxInt
Fin si Fin para cada k

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 217
Fin para cada k Fin para cada j
Fin para cada i * Si las dos matrices son iguales se finaliza * si no se toma como MatrizDis la MatrizMinMax y se itera Si MatrizMinMax=MatrizDis Salir de repetir Sino
MatrizDis=MatrizMinMax Fin si Fin repetir
6.2.1.2 Proceso: obtener posibles α -cortes Descripción:
A partir de la matriz MatrizDis, se obtienen todos los posibles α -cortes distintos de la jerarquía de partes, o del dendrograma (hablando en términos gráficos). Cada uno de estos valores implican una relación de equivalencia distinta, y por tanto un número de clusters diferente como resultado final. Estos posibles α -cortes quedan plasmados en la tabla id_proyecto_DMFSQL_L asociada al proyecto. Como se verá en el siguiente proceso, esta tabla es crucial tanto para la búsqueda de una partición con un número en concreto de clusters a obtener, como de la obtención del α -corte que implique una partición óptima. Tratamientos:
• Creación de la estructura de la tabla con los posibles α -cortes id_proyecto_DMFSQL_L con la siguiente estructura lógica:
id_proyecto_DMFSQL_L(dij, numClusters)
donde para cada distinta distancia de la matriz ultramétrica dij el atributo numClusters indica el número de grupos o clusters que se obtienen con el α -corte igual a dij.
• Carga de los datos de la tabla los posibles α -cortes a partir de la tabla con la matriz ultramétrica id_proyecto_DMFSQL_D con cada uno de los valores diferentes de dij en principio el valor del atributo numClusters no tendrá contenido, esto es, será NULL.
• Actualización de la dmFMB. Se actualizan los siguientes atributos de la tabla DPR:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 218
o status_clus: estado actual del proceso de clustering ‘D’ que indica que se ha obtenido ya la matriz ultramétrica y la de posibles α -cortes.
o num_reg_tab: número de filas n en la tabla id_tabla_orig_proyecto. o num_reg_level: número de posibles α -cortes que se pueden hacer dentro del
dendrograma, esto es, número de filas de la tabla id_proyecto_DMFSQL_L.
6.2.1.3 Proceso: obtener partición Descripción: En la tabla con la matriz ultramétrica de la población id_proyecto_DMFSQL_D está especificada la jerarquía de partes de la población. En este proceso se obtiene una partición en concreto de la población. Dicha partición se puede realizar de distintos modos según elección del usuario en la correspondiente sentencia DML. Este proceso por tanto concluye el proceso efectivo de clustering (asignación de cada elemento a un grupo en concreto) dejando los resultados en la tabla id_tabla_result_clu, esto es, se cumplimenta el atributo cluster_id especificando el identificador del cluster al que se ha asignado cada fila. Para ello se usa la información de la tabla con los posibles α -cortes de la matriz ultramétrica id_proyecto_DMFSQL_L y de la dmFMB. Tratamientos:
• Tratamientos según se haya especificado en la sentencia DML respecto al modo de realización del proceso de Clustering (obtención de una partición en concreto) teniendo en cuenta criterio_cluster_optimo (si se ha especificada algún criterio óptimo de obtención de los clusters) o número_cluster_obtener (se quiere obtener este número en concreto de grupos):
o Si criterio_cluster_optimo=OPTIMAL_ABS se desea una obtención de la
partición óptima absoluta. Dicha partición, según lo explicado en el punto 5.1.1.1.3, es aquélla que se obtiene con α -corte de 0.5. Así pues se obtendrá
mediante el uso del Algoritmo 6-2 con la entrada α _corte=0.5.
o Si criterio_cluster_optimo=OPTIMAL_H3 se desea una obtención de una partición óptima. Dicha partición, según lo explicado en el punto 5.1.1.1.4, se obtiene a partir de la teoría de Conjuntos Difusos y se basa en la medida se basa en la medida H3. Para su cálculo hay que recorrer la tabla con los posibles α -cortes de la matriz ultramétrica id_proyecto_DMFSQL_L obteniendo el valor
α _CorteÓptimo ∈ [0,1] como el mínimo valor de entre todos los valores siguientes:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 219
Máx (1 - id_proyecto_DMFSQL_L.dij de la tupla actual,
id_proyecto_DMFSQL_L.dij de la tupla anterior) Como H3 está definida sobre relaciones de similitud y se está usando relaciones de diferencia, el valor final será: α _CorteÓptimo=1 – α _CorteÓptimo. Por fin, el proceso de obtención de la partición óptima se realizará mediante del Algoritmo 6-2 con la entrada α _corte=α _CorteÓptimo.
o Si criterio_cluster_optimo= OPTIMAL_MED se desea una obtención de la partición óptima media. Dicha partición, es una variante de la absoluta que se basa en coger la partición determinada por el corte en el punto medio relativo del dendrograma. Para obtener este valor α _CorteMedio no hay más que coger
aquella fila de la tabla con los posibles α -cortes id_proyecto_DMFSQL_L que esté en el medio respecto al número de filas de la tabla y considerando que está ordenada por la distancia ultramétrica, entonces el α _CorteMedio=dij de dicha fila. Por fin, el proceso de obtención de la partición óptima se realizará mediante del Algoritmo 6-2 con la entrada α _corte=α _CorteMedio.
o Obtención de un número en concreto de grupos número_cluster_obtener. Basándose en la tabla con los posibles α -cortes id_proyecto_DMFSQL_L. Se realiza una búsqueda binaria en dicha tabla de la tupla que cumpla que numClusters=número_cluster_obtener. Para cada tupla que se trata si el valor numClusters es NULL se obtiene dicho valor como el k resultado del Algoritmo de Clustering (o lo que es lo mismo, el cardinal de CjtoClusters) con α _corte=Nivel, aunque, es posible que valor numClusters haya sido obtenido ya en anteriores ejecuciones, en cuyo caso no habría que ejecutar el algoritmo. Una vez que se tiene la tupla que cumple la condición requerida, o que más se aproxima a la solución, si no se ha hecho ya, se realiza el Algoritmo 6-2 con la entrada α _corte= dij de dicha tupla.
• Actualización de la tabla con los resultados del clustering id_tabla_result_clu. Para cada tupla de dicha tabla se obtiene en CjtoClusters un Cjtol con l=1..k / id_row ∈ Cjtol. Al atributo id_cluster se le pone el valor l como identificativo del conjunto al que pertenece.
• Actualización de la dmFMB. Se actualizan los siguientes atributos de la tabla DPR si es que han sido obtenidos durante este proceso:
o status_clus: estado actual del proceso de clustering ‘C’ que indica proceso de
clustering concluido, esto es, se ha obtenido una partición en concreto como resultado de dicho proceso. Esto no significa que no se puedan obtener con ejecuciones sucesivas de este proyecto otras particiones.
o num_level_opt1_vila_h3: nivel del dendrograma al que se obtiene una partición óptima basándose en el método de la medida H3.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 220
o num_level_opt2_vila_abs: nivel del dendrograma al que se obtiene la partición óptima absoluta.
o num_level_opt3_med: nivel del dendrograma al que se obtiene la partición óptima media.
o obj#_tab_clus: identificativo de la última tabla generada con una partición en concreto de la población dentro del proceso de clustering, esto es, de la tabla id_tabla_result_clu.
Si se vuelve a obtener una partición en concreto de la población, los valores que se han almacenado en la dmFMB no se vuelven a calcular, con la consiguiente aceleración del proceso.
Algoritmo 6-2
Entradas:
• α _corte: indica a partir de que nivel de distancia se debe tratar el dendrograma. Salidas:
• CjtoClusters: Cjto1,.., Cjtok partición de la población donde cada conjunto es una clase (k es el número de clases, esto es, número de clusters).
CjtoClusters=Ø k=0 Para cada fila de id_proyecto_DMFSQL_D / dij ≤ α _corte
Si no existe en CjtoClusters un Cjtol con l=1..k / i ∈ Cjtol
Y no existe en CjtoClusters un Cjtom con m=1..k / j ∈ Cjtom
* Se crea un nuevo cjto con los eltos i, j k=k+1 Cjtok=i, j CjtoClusters=CjtoClusters ∪ Cjtok Si existe en CjtoClusters un Cjtol con l=1..k / i ∈ Cjtol
Y no existe en CjtoClusters un Cjtom con m=1..k / j ∈ Cjtom
* Se incluye el elto j en el cjto donde se encuentra el elto i Cjtol= Cjtol ∪ j Si no existe en CjtoClusters un Cjtol con l=1..k / i ∈ Cjtol
Y existe en CjtoClusters un Cjtom con m=1..k / j ∈ Cjtom
* Se incluye el elto i en el cjto donde se encuentra el elto j Cjtom= Cjtom ∪ i

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 221
Fin si
Fin para cada * Tratamiento de los cjtos de clusters singleton Para ind = 1 Hasta DPR. num_reg_tab (n eltos de la población)
Si no existe en CjtoClusters un Cjtol con l=1..k / ind ∈ Cjtol
* Se crea un nuevo cjto con el elto i k=k+1 Cjtok=i CjtoClusters=CjtoClusters ∪ Cjtok Fin si
Fin para cada ind
6.2.1.4 Proceso: obtener SELECT clustering Descripción: Se obtiene la sentencia SQL correspondiente al proceso de clustering realizado. Tratamientos:
• Una vez construida la sentencia FSQL tal y como se explicó en la sección 5.4.4.1, se efectúa su conversión a SQL mediante llamada al Servidor FSQL* con la correspondiente función de traducción (FSQL2SQL).
6.2.2 Proceso: CARACTERIZACIÓN En la Figura 6-3 se puede observar del diagrama de flujo de datos del proceso CARACTERIZACION el cual termina de implementar la función CLUSTERING (vista en 6.1.2) con parámetro adicional id_tabla_result_cen (identificativo de la tabla resultado de la caracterización de los distintos grupos mediante centroides). Por tanto este proceso se desencadena una vez que se ha concluido el proceso de CLUSTERING en el que se ha generado la tabla id_tabla_result_clu y se ha actualizado la dmFMB con los resultados correspondientes, según se ha visto.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 222
Figura 6-3. DFD Caracterización
dmFMB 1
Crear TablaCentroides
1
id_tabla_ result_clu 2
Obtener Valor Etiqueta
2
Obtener Valor Conocido
3
Obtener SELECTCaracterización
5 id_tabla_result_cen
3
Usuario
Obtener Valor Medio
4

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 223
6.2.2.1 Proceso: crear tabla centroides Descripción: Para el proyecto id_proyecto que tiene como tabla de origen de datos id_tabla_orig_proyecto, se crea la estructura de la tabla id_tabla_result_cen que va a contener el resultado de la caracterización de los distintos grupos resultado del proceso de clustering. Para esta nueva tabla va a incluir en la dmFMB la misma información que para la tabla origen de datos haya. Así el problema que se plantea es cumplimentar cada columna de esta nueva tabla col_clur con r=1..m los valores correspondientes val_cenrc que caracterizan cada grupo de los obtenidos en la tabla id_tabla_resul_clu, identificados por cluster_idc=1..num_clus. Además se desea obtener la representatividad del valor obtenido val_cenrc simbolizada como rep_cenrc ∈ [0,1] que, en definitiva, va a dar idea de la bondad del centroide. Esta representatividad va a ser almacenada en la columna col_clur_avgCdeg. Tratamientos:
• Creación de la estructura de la tabla con el resultado de la caracterización id_tabla_result_cen. Se obtiene dicha estructura con el siguiente esquema:
id_tabla_result_cen(row_id, col_clu1, col_clu2,…, col_clum, cluster_id, col_clu1_avgCdeg, col_clu2_avgCdeg,…, col_clum_avgCdeg) con m ∈ ℕ
que contiene las columnas de la tabla resultado del clustering id_tabla_result_clu con las siguientes salvedades:
o col_clur_avgCdeg ∈ [0,1] con r=1..m: que contiene la representatividad del valor de la caracterización para la columna en cuestión.
o row_id: el significado de este atributo va a ser el número de filas que contiene el grupo en cuestión.
Se incluye en la dmFMB toda la información de la nueva tabla id_tabla_result_cen heredándola de la tabla original id_tabla_orig_proyecto. En la tabla id_tabla_result_cen se incluyen las filas con los valores de identificativos de los distintos grupos (id_cluster) y el número de filas de cada uno (row_id).

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 224
6.2.2.2 Proceso: obtener valor etiqueta Descripción: Para cada columna trascendente en el proceso de clustering tal que en la dmFMB esté especificado que se desea obtener su caracterización a nivel de abstracción de etiqueta lingüística, se obtiene el valor que coincida con la etiqueta más representativa de las definidas, para la columna en cuestión, en la dmFMB y su correspondiente representatividad. Tratamientos:
• Para cada columna col_clur con r=1..m tal que se desea obtener su caracterización a nivel de abstracción de etiqueta lingüística según consta en la dmFMB (DCL.ABSTRACTION_LEVEL_CEN=’L’):
o Para cada uno de los grupos obtenidos en el proceso de clustering según constan en la tabla id_tabla_resul_clu con identificación cluster_idc=1..num_clus:
Obtener la etiqueta lingüística val_cenrc con representatividad rep_cenrc como se ha especificado en el punto 5.1.2.1, teniendo en cuenta que el comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de caracterización (DCL.FUZZY_COMP_CEN) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL. LOG_OPER_CEN).
Actualizar en la tabla resultado de la caracterización id_tabla_result_cen los valores obtenidos de caracterización y representatividad (col_clur=val_cenrc y col_clur_avgCdeg= rep_cenrc) para el cluster en cuestión (cluster_id=cluster_idc). En este proceso hay que tener en cuenta la representatividad interna del atributo difuso en cuestión, que estará bien fijada a priori (atributos difusos 1, 2 y 3 según se ha visto en 3.4.1) o se obtiene la forma de representación de la dmFMB (atributos difusos tipo 4 según lo visto en 4.2.2).
6.2.2.3 Proceso: obtener valor conocido Descripción: Para cada columna trascendente en el proceso de clustering tal que en la dmFMB esté especificado que se desea obtener su caracterización a nivel de un valor conocido, considerando que el universo de datos conocidos está compuesto de la tabla de origen de datos id_tabla_orig_proyecto y de las etiquetas lingüísticas de la dmFMB, se elige el valor que mejor representa al cluster en cuestión y su correspondiente representatividad.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 225
Tratamientos:
• Para cada columna col_clur con r=1..m tal que se desea obtener su caracterización a nivel de abstracción de mejor valor conocido según consta en la dmFMB (DCL.ABSTRACTION_LEVEL_CEN=’V’):
o Para cada uno de los grupos obtenidos en el proceso de clustering según constan en la tabla id_tabla_resul_clu con identificación cluster_idc=1..num_clus:
Obtener el valor val_cenrc (valor de la columna col_clur en la tabla id_tabla_orig_proyecto o etiqueta lingüística de la dmFMB) con representatividad rep_cenrc como se ha especificado en el punto 5.1.2.2, teniendo en cuenta que el comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de caracterización (DCL.FUZZY_COMP_CEN) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL. LOG_OPER_CEN).
Actualizar en la tabla resultado de la caracterización id_tabla_result_cen los valores obtenidos de caracterización y representatividad (col_clur=val_cenrc y col_clur_avgCdeg= rep_cenrc) para el cluster en cuestión (cluster_id=cluster_idc). En este proceso hay que tener en cuenta la representatividad interna del atributo difuso en cuestión, que estará bien fijada a priori (atributos difusos 1, 2 y 3 según se ha visto en 3.4.1) o se obtiene la forma de representación de la dmFMB (atributos difusos tipo 4 según lo visto en 4.2.2).
6.2.2.4 Proceso: obtener valor medio Descripción: Para cada columna trascendente en el proceso de clustering tal que en la dmFMB esté especificado que se desea obtener su caracterización a nivel de un valor que sea válido dentro de su dominio y que sea lo más representativo posible, no importando si es un dato conocido o extrapolado a partir de los datos de la tabla, se elige el valor que mejor representa al cluster en cuestión y se calcula su correspondiente representatividad. Tratamientos:
• Para cada columna col_clur con r=1..m tal que se desea obtener su caracterización a

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 226
nivel de abstracción de valor más representativo posible según consta en la dmFMB (DCL.ABSTRACTION_LEVEL_CEN=’A’):
o Para cada uno de los grupos obtenidos en el proceso de clustering según constan en la tabla id_tabla_resul_clu con identificación cluster_idc=1..num_clus:
Obtener el valor val_cenrc (valor extrapolado de los valores de la columna col_clur en la tabla id_tabla_orig_proyecto) con representatividad rep_cenrc como se ha especificado en el punto 5.1.2.3, teniendo en cuenta que el comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de caracterización (DCL.FUZZY_COMP_CEN) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL. LOG_OPER_CEN).
Actualizar en la tabla resultado de la caracterización id_tabla_result_cen los valores obtenidos de caracterización y representatividad (col_clur=val_cenrc y col_clur_avgCdeg= rep_cenrc) para el cluster en cuestión (cluster_id=cluster_idc). En este proceso hay que tener en cuenta la representatividad interna del atributo difuso en cuestión, que estará bien fijada a priori (atributos difusos 1, 2 y 3 según se ha visto en 3.4.1) o se obtiene la forma de representación de la dmFMB (atributos difusos tipo 4 según lo visto en 4.2.2).
6.2.2.5 Proceso: obtener SELECT caracterización Descripción: Se obtiene la sentencia SQL correspondiente al proceso de clustering realizado con obtención de los correspondientes centroides que caracterizan los distintos grupos. Tratamientos:
• Una vez construida la sentencia FSQL tal y como se explicó en la sección 5.4.4.1, se efectúa su conversión a SQL mediante llamada al Servidor FSQL* con la correspondiente función de traducción (FSQL2SQL).

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 227
.
6.2.3 Proceso: CLASIFICACIÓN En la Figura 6-4 se puede observar del diagrama de flujo de datos del proceso CLASIFICACIÓN el cual implementa la función CLASSIFICATION (vista en 6.1.2) con parámetros de entrada id_proyecto (identificativo del proyecto), id_tabla_orig_cla (tabla que va sufrir el proceso de clasificación), id_tabla_result_cla (tabla que se va a crear como resultado del proceso de clasificación), id_tabla_result_cen (tabla con los centroides a usar como criterio de clasificación), id_tabla_result_clu (tabla resultado del proceso de clustering a usar como criterio de clasificación), n_vecinos (número de filas de la tabla id_tabla_result_clu hay que considerar para la clasificación de cada fila con el mecanismo de los vecinos más cercanos), id_cluster (grupo obtenido durante el proceso de clustering al que se quiere restringir la clasificación), best_cluster (valor booleano de tal manera que si es TRUE indica que el grupo al que se quiere restringir la clasificación de cada fila, es aquel que mayor grado de pertenencia tenga la fila en cuestión) y umbral (grado mínimo de pertenencia a los distintos grupos, resultados del clustering, que van a tener que cumplir las filas resultado de la clasificación).

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 228
Figura 6-4. DFD Clasificación
dmFMB 1
Crear Tabla Clasificación
1
id_tabla_result_clu 3
Clasificar segúnCentroides
2
Obtener SELECT Clasificación
4
id_tabla_result_cla 5
Usuario
Clasificar según k-vecinos
3
id_tabla_result_cen2
id_tabla_orig_cla 4

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 229
6.2.3.1 Proceso: crear tabla clasificación Descripción: Para el proyecto id_proyecto que tiene como tabla de origen de datos id_tabla_orig_proyecto, se crea la estructura de la tabla id_tabla_result_cla que va a contener el resultado de la clasificación de las filas de la tabla id_tabla_orig_cla, esto es, contendrá la información de a qué grupo o grupos se ha determinado que pertenece y qué grado de pertenencia tiene las filas a dichos grupos. Para esta nueva tabla va a incluir en la dmFMB la misma información que para la tabla origen de datos haya. Tratamientos: Si se ha especificado que el resultado de la clasificación se va a dejar en una tabla de nueva creación llamada id_tabla_result_cla, esto es, id_tabla_result_cla no contiene un valor NULL:
• Creación de la estructura de la tabla con el resultado de la clasificación id_tabla_result_cla. Se obtiene dicha estructura con idéntico esquema que la tabla a clasificar id_tabla_orig_cla con las siguientes columnas adicionales:
o cluster_id: identificador del grupo o cluster al que se ha determinado que
pertenece la fila en cuestión.
o cdeg_cluster: grado de pertenencia a dicho grupo, que es un valor en el intervalo [0,1].
Se incluye en la dmFMB toda la información de la nueva tabla id_tabla_result_cla heredándola de la tabla original id_tabla_orig_proyecto. En la tabla id_tabla_result_cla se incluyen las filas con los valores originales de la tabla id_tabla_orig_cla.
6.2.3.2 Proceso: clasificar según centroides Descripción: En este proceso se va a efectuar el proceso efectivo de clasificación de las filas de la tabla id_tabla_orig_cla, de tal manera que, se va obtener el grado de pertenencia de las filas de la tabla id_tabla_orig_cla a un determinado grupo o grupos resultados del proceso de clustering previo, como el grado de compatibilidad difuso de FSQL (CDEG) entre las columnas de la tabla a clasificar y las columnas del centroide o centroides en cuestión contenidos en la tabla id_tabla_result_cen.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 230
Tratamientos: Si se ha especificado que el criterio de clasificación va a ser la tabla con los centroides id_tabla_result_cen, esto es, id_tabla_result_cen no contiene un valor NULL:
• Obtención de la sentencia FSQL para la clasificación basada en centroides. A partir de los datos para clasificación almacenados para el proyecto id_proyecto en la dmFMB y según lo explicado en la sección 5.1.3.1. El comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de clasificación (DCL.FUZZY_COMP_CLA) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL.LOG_OPER_CLA). Los pesos de dicha sentencia w_clar se obtendrán correspondiente también de la dmFMB (DCL.WEIGHT_CLA). También se incluirá el umbral γ que van a tener que cumplir las filas resultado de la clasificación en dicha sentencia con el valor del parámetro umbral especificado en la sentencia DML. Si se ha restringido la clasificación a un determinado cluster id_cluster se tienen en cuenta para incluirlo en dicha sentencia FSQL. Se efectúa la traducción de la sentencia FSQL a SQL mediante el uso del Servidor FSQL*. Si se ha especificado que el resultado de la clasificación no va a quedar en tabla alguna (id_tabla_result_cla contiene un valor NULL) la sentencia SQL obtenida es el resultado final de la clasificación. Si por el contrario, el resultado de la clasificación se va a dejar en la tabla id_tabla_result_cla, se incluye en dicha tabla todas las filas resultado de la sentencia SQL que se ha obtenido.
• Obtención de la clasificación de cada fila al mejor cluster. Si se ha especificado que la clasificación de cada fila debe restringirse al grupo al que mayor grado de pertenencia tenga la fila en cuestión (esto es el parámetro best_cluster tiene un valor TRUE). En este caso, basándose en la sentencia construida en el punto anterior, se realiza un proceso iterativo clasificando cada fila con todos y cada uno de los grupos obtenidos en el proceso de clustering, se selecciona solo la clasificación al grupo al que mayor grado de pertenencia tenga la fila y dicho resultado se incluye en la tabla con el resultado de la clasificación id_tabla_result_cla.
6.2.3.3 Proceso: clasificar según k-vecinos Descripción: En este proceso se va a efectuar el proceso efectivo de clasificación de las filas de la tabla id_tabla_orig_cla, como la media del grado de compatibilidad difuso de FSQL (CDEG) entre las columnas de la tabla a clasificar y las columnas de la tabla resultado del clustering id_tabla_result_clu de aquellas k filas, de esta última tabla, que sean más parecidas a las de la tabla a clasificar. A estas k filas se les va a nombrar como los k vecinos más cercanos a la fila a clasificar.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 231
Tratamientos: Si se ha especificado que el criterio de clasificación va a ser la tabla resultado del clustering id_tabla_result_cla, esto es, id_tabla_result_cla no contiene un valor NULL:
• Obtención de la sentencia FSQL para la clasificación basada en k-vecinos. A partir de los datos para clasificación almacenados para el proyecto id_proyecto en la dmFMB y según lo explicado en la sección 5.1.3.2. El comparador difuso fuzzy_ecompr es el que se ha especificado en la dmFMB, para la columna en cuestión, para dicho proceso de clasificación (DCL.FUZZY_COMP_CLA) y si este comparador no es simétrico se usará una T-norma o T-conorma según lo también especificado en la dmFMB (DCL.LOG_OPER_CLA). Los pesos de dicha sentencia w_clar se obtendrán correspondiente también de la dmFMB (DCL.WEIGHT_CLA). Si se ha restringido la clasificación a un determinado cluster id_cluster se tienen en cuenta para incluirlo en dicha sentencia FSQL. Se efectúa la traducción de la sentencia FSQL a SQL mediante el uso del Servidor FSQL*. Si no se ha especificado que la selección debe ser al mejor grupo (best_cluster es NULL) se realiza un proceso iterativo clasificando cada fila con el grupo o grupos del proceso de clustering especificados. Se selecciona solo la clasificación si supera el valor umbral que se ha especificado en la sentencia DML, dicho resultado se incluye en la tabla con el resultado de la clasificación id_tabla_result_cla.
• Obtención de la clasificación de cada fila al mejor cluster. Si se ha especificado que la clasificación de cada fila debe restringirse al grupo al que mayor grado de pertenencia tenga la fila en cuestión (esto es el parámetro best_cluster tiene un valor TRUE). En este caso, basándose en la sentencia construida en el punto anterior, se realiza un proceso iterativo clasificando cada fila con todos y cada uno de los grupos obtenidos en el proceso de clustering. Se selecciona solo la clasificación (que supere el valor umbral especificado en la sentencia DML) al grupo al que mayor grado de pertenencia tenga la fila y dicho resultado se incluye en la tabla con el resultado de la clasificación id_tabla_result_cla.
6.2.3.4 Proceso: obtener SELECT clasificación Descripción: Se obtiene la sentencia SQL correspondiente al proceso de clasificación realizado, cuando éste ha quedado plasmado en la tabla con el resultado de la clasificación id_tabla_result_cla. Tratamientos:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 232
• Una vez construida la sentencia FSQL tal y como se explicó en la sección 5.4.4.2, se efectúa su conversión a SQL mediante llamada al Servidor FSQL* con la correspondiente función de traducción (FSQL2SQL).
6.2.4 Proceso: DEPENDENCIAS GLOBALES DIFUSAS En la Figura 6-5 se puede observar del diagrama de flujo de datos del proceso DEPENDENCIAS GLOBALES DIFUSAS el cual implementa la función FGLOBAL_DEPENDENCIES (vista en 6.1.2) con parámetros de entrada id_proyecto (identificativo del proyecto), tipo_fgd (con el valor T_NORM si se desea obtener una α -β
DGD X→ F*T*Y o con el valor SINGLE si se desea obtener una (α i)-(β j) DGD X→ F*T*Y) y
confianza_máxima (si es TRUE indica que se van a obtener los distintos umbrales α ’s y β ’s de las DGDs con el criterio de obtener una máxima confianza).
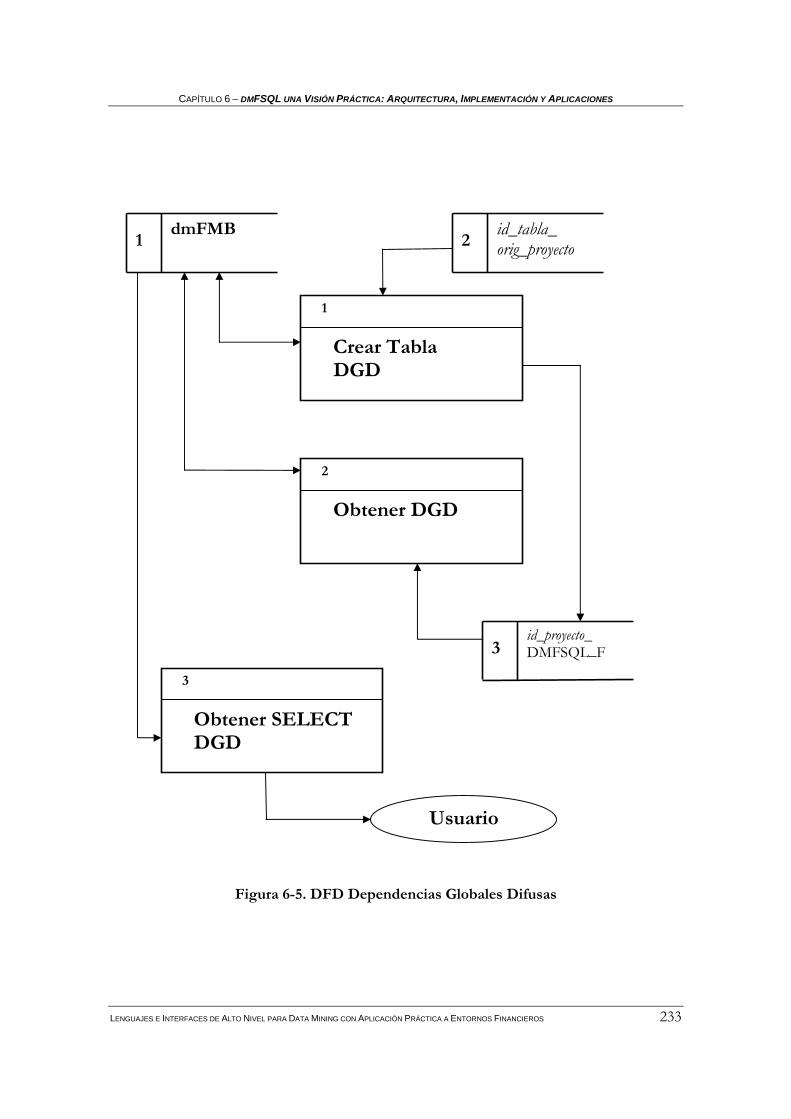
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 233
Figura 6-5. DFD Dependencias Globales Difusas
dmFMB 1
Crear TablaDGD
1
Obtener DGD
2
Obtener SELECTDGD
3
Usuario
id_proyecto_ DMFSQL_F 3
id_tabla_ orig_proyecto 2

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 234
6.2.4.1 Proceso: crear tabla DGD Descripción: Para el proyecto id_proyecto que tiene como tabla de origen de datos id_tabla_orig_proyecto, se crea la estructura de la tabla id_proyecto_DMFSQL_F que es una tabla de maniobra para la ágil obtención de las DGD. Para esta nueva tabla va a incluir en la dmFMB la misma información que para la tabla origen de datos haya. Tratamientos:
• Creación de la estructura de la tabla intermedia para obtención de las DGDs id_proyecto_DMFSQL_F. Se obtiene dicha estructura con idéntico esquema que la tabla origen de datos del proyecto id_tabla_orig_proyecto con la siguiente columna adicional:
o row_id: identificador único de cada fila.
En la tabla id_proyecto_DMFSQL_F se incluyen las filas con los valores originales de la tabla id_tabla_orig_proyecto. Se incluye en la dmFMB toda la información de la nueva tabla id_tabla_result_clu heredándola de la tabla original id_tabla_orig_proyecto.
6.2.4.2 Proceso: obtener DGD Descripción: Para el proyecto id_proyecto se realiza el proceso de obtención y/o verificación de DGDs de tal manera que, dicho proceso determina como una serie atributos difusos (llamados antecedente) implican a otra serie de atributos difusos (llamados consecuente). Como se ha explicado en la sección 5.1.4, se han definido dos tipos de DGDs, que van a ser objeto de tratamiento de este proceso: α -β DGD X→ F*T*Y (en cuyo caso el parámetro tipo_fgd tiene el
valor T_NORM) y (α i)-(β j) DGD X→ F*T*Y (en cuyo caso el parámetro tipo_fgd tiene el valor SINGLE). El proceso de las DGDs va a consistir en una de las dos siguientes opciones:
• Obtención del grado de confianza y soporte con que la DGD se cumple: en este caso los α -β o los (α i)-(β j) se han especificado a la hora de definir el proyecto y por tanto están incluidos en la dmFMB: en los atributos DPR.THOLD_ANT_FGD y DPR. THOLD_CON_FGD en el primero caso; y en los atributos DCL.THOLD_FGD en el segundo. En este caso el parámetro confianza_máxima tiene el valor FALSE.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 235
• Obtención de los umbrales α -β o (α i)-(β j) para la DGD con el criterio de obtención de un grado confianza (ver Definición 5-8) mayor posible, esto es, una DGD sin excepciones. El soporte de la DGD también se obtiene con esta opción. Aquí el parámetro confianza_máxima tiene el valor TRUE.
Los resultados obtenidos se dejan plasmados en la dmFMB. Tratamientos:
• Obtención de la sentencia FSQL para la tratamiento de DGD. En la sección 5.1.4.2.2 se han visto algunos algoritmos concernientes al tratamiento de DGDs bastante intuitivos en su relación con las definiciones de DGDs hechas aunque, por otro lado, no muy eficientes. Además dichos algoritmos no resuelven las funcionalidades que se han dado en el lenguaje dmFSQL para la obtención de DGDs. Así la sentencia FSQL que se va a usar como va a usar como base para el tratamiento de DGD es la siguiente:
SELECT CDEG(A1.col_ant1),…, CDEG(A1.col_antl), CDEG(A1.col_con1),…, CDEG(A1.col_conq), CDEG(A2.col_ant1),…, CDEG(A2.col_antl), CDEG(A2.col_con1),…, CDEG(A2.col_conq) FROM id_proyecto_DMFSQL_F A1, id_proyecto_DMFSQL_F A2 WHERE (A1.row_id < A2.row_id) AND (A1.col_ant1 fuzzy_comp_ant1 A2.col_ant1 THOLD 0 AND…AND A1.col_antl fuzzy_comp_antl A2.col_antl THOLD 0 ) AND (A1.col_con1 fuzzy_comp_con1 A2.col_con1 THOLD 0 AND…AND A1.col_conq fuzzy_comp_conq A2.col_conq THOLD 0)
El comparador difuso fuzzy_comp_anti es el que se ha especificado en la dmFMB, para la columna antecedente en cuestión (DCL.COL_TYPE=’A’) para dicho proceso de DGD (DCL.FUZZY_COMP_FGD) y el fuzzy_comp_conj es el que se ha especificado en la dmFMB, para la columna consecuente en cuestión (DCL.COL_TYPE=’Q’) para dicho proceso de DGD (DCL.FUZZY_COMP_FGD).
Se efectúa la traducción de la sentencia FSQL a SQL mediante el uso del Servidor FSQL*.
• Tratamiento de la sentencia FSQL para DGD. Se efectúa el tratamiento de dicha
sentencia con la siguiente casuística:
o confianza_máxima tiene el valor TRUE. En este caso se usa el Algoritmo 6-4 que devuelvel: confianza y soporte cuyos valores son plasmados en la dmFMB en los atributos DPR.CONFIDENCE_FGD y DPR.SUPPORT_FGD respectivamente.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 236
o confianza_máxima tiene el valor FALSE. En este caso se usa el Algoritmo 6-4 que devuelve: confianza y soporte cuyos valores son plasmados en la dmFMB en los atributos DPR.CONFIDENCE_FGD y DPR.SUPPORT_FGD respectivamente; y matrizTholdAnt_DCL [1..l] y matrizTholdCon_DCL [1..q] con los umbrales del antecedente y consecuente que son incluidos en la dmFMB en los atributos DPR.THOLD_ANT_FGD y DPR.THOLD_ANT_FGD en el caso de que tipo_fgd = T_NORM o en los atributos DCL.THOLD_FGD, de las columnas correspondiente, para el caso de que tipo_fgd = SINGLE.
Algoritmo 6-3
Salidas: • confianza: confianza de la DGD • soporte: soporte de la DGD cont_cumple_ant = 0 cont_cumple_ant_con = 0 cont_filas = 0 Para cada fila de la sentencia SELECT para tratamiento de DGD (punto anterior) * se actualiza el contador de filas de la SELECT tratadas que en realidad son * dos en cada pasada ya que se trata también el simétrico cont_filas = cont_filas + 2 * se comprueba si se cumple el antecedente
Si CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti)≥ α i
∀ i=1,…,l para tipo_fgd = SINGLE
O Si T_NORM(CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti))≥ α
∀ i=1,…,l para tipo_fgd = T_NORM cont_cumple_ant = cont_cumple_ant + 1
* se comprueba si se cumple el consecuente
Si CDEG(A1.col_conj fuzzy_comp_conj A2.col_conj) ≥ β j
∀ j=1,…,q para tipo_fgd = SINGLE
O Si T_NORM(CDEG(A1.col_conj fuzzy_comp_conj A2.col_conj))≥ β
∀ j=1,…,q para tipo_fgd = T_NORM cont_cumple_ant_con = cont_cumple_ant_con + 1 Fin si Fin si
* se comprueba si se cumple el antecedentesimétrico Si CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti) ≥ α i

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 237
∀ i=1,…,l para tipo_fgd = SINGLE
O Si T_NORM(CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti)) ≥ α
∀ i=1,…,l para tipo_fgd = T_NORM cont_cumple_ant = cont_cumple_ant + 1
* se comprueba si se cumple el consecuente simétrico
Si CDEG(A2.col_conj fuzzy_comp_conj A1.col_conj) ≥ β j
∀ j=1,…,q para tipo_fgd = SINGLE
O Si T_NORM(CDEG(A2.col_conj fuzzy_comp_conj A1.col_conj)) ≥ β
∀ j=1,…,q para tipo_fgd = T_NORM cont_cumple_ant_con = cont_cumple_ant_con + 1 Fin si Fin si
Fin para cada * cálculo final de la confianza y el soporte Si cont_cumple_ant = 0 confianza = 0 Si no confianza = cont_cumple_ant_con / cont_cumple_ant Fin si soporte = cont_cumple_ant_con /cont_filas
Algoritmo 6-4
Salidas: • matrizTholdAnt_DCL [1..l]: matriz con los umbrales de cumplimiento mínimos α i
con i=1..l para el antecedente. Si tipo_fgd = SINGLE solo se rellenará el primer elemento correspondiente al α .
• matrizTholdCon_DCL [1..q]: matriz con los umbrales de cumplimiento mínimos β j con j=1..q para el consecuente. Si tipo_fgd = SINGLE solo se rellenará el primer elemento correspondiente al β .
• confianza: confianza de la DGD • soporte: soporte de la DGD cont_cumple_ant = 0 cont_cumple_ant_con = 0 cont_filas = 0

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 238
Inicializar matrizTholdAnt_DCL [1..l] y matrizTholdCon_DCL [1..q] con valores máximos Para cada fila de la sentencia SELECT para tratamiento de DGD (punto anterior) * se actualiza el contador de filas de la SELECT tabla tratadas que en realidad son * dos en cada pasada ya que se trata también el simétrico cont_filas = cont_filas + 2 * se comprueba si se cumple el antecedente con grado mínimo
Si CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti) > 0
∀ i=1,…,l para tipo_fgd = SINGLE O Si T_NORM(CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti)) > 0
∀ i=1,…,l para tipo_fgd = T_NORM cont_cumple_ant = cont_cumple_ant + 1 * el consecuente se cumple siempre aunque sea con un umbral 0 cont_cumple_ant_con = cont_cumple_ant_con + 1
* se comprueba si los umbrales del antecedente son lo mínimos Si tipo_fgd = T_NORM
Si T_NORM(CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti)) ∀ i=1,…,l < matrizTholdAnt_DCL (1)
matrizTholdAnt_DCL (1) = T_NORM( CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti)) ∀ i=1,…,l Fin si
Sino Para i = 1 Hasta l
Si CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti) < matrizTholdAnt_DCL (i)
matrizTholdAnt_DCL (i) = CDEG(A1.col_anti fuzzy_comp_anti A2.col_anti)
Fin si Fin para cada i
Fin si * se comprueba si los umbrales del consecuente son lo mínimos Si tipo_fgd = T_NORM
Si T_NORM(CDEG(A1.col_conj fuzzy_comp_conj A2.col_ conj)) ∀ j=1,…,q < matrizTholdCon_DCL (1)
matrizTholdCon_DCL (1) = T_NORM( CDEG(A1.col_ conj fuzzy_comp_conj A2.col_ conj)) ∀ j=1,…,q Fin si

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 239
Sino Para j = 1 Hasta q
Si CDEG(A1.col_ conj fuzzy_comp_conj A2.col_ conj) < matrizTholdCon_DCL (j)
matrizTholdCon_DCL (j) = CDEG(A1.col_conj fuzzy_comp_conj A2.col_conj)
Fin si Fin para cada j
Fin si Fin si
* se comprueba si se cumple el antecedente simétrico con grado mínimo Si CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti) > 0
∀ i=1,…,l para tipo_fgd = SINGLE O Si T_NORM(CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti)) > 0
∀ i=1,…,l para tipo_fgd = T_NORM cont_cumple_ant = cont_cumple_ant + 1 * el consecuente simétrico se cumple siempre aunque sea con un umbral 0 cont_cumple_ant_con = cont_cumple_ant_con + 1
* se comprueba si los umbrales del antecedente son lo mínimos Si tipo_fgd = T_NORM
Si T_NORM(CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti)) ∀ i=1,…,l < matrizTholdAnt_DCL (1)
matrizTholdAnt_DCL (1) = T_NORM( CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti)) ∀ i=1,…,l Fin si
Sino Para i = 1 Hasta l
Si CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti) < matrizTholdAnt_DCL (i)
matrizTholdAnt_DCL (i) = CDEG(A2.col_anti fuzzy_comp_anti A1.col_anti)
Fin si Fin para cada i
Fin si * se comprueba si los umbrales del consecuente son lo mínimos Si tipo_fgd = T_NORM
Si T_NORM(CDEG(A2.col_conj fuzzy_comp_conj A1.col_ conj)) ∀ j=1,…,q < matrizTholdCon_DCL (1)
matrizTholdCon_DCL (1) = T_NORM( CDEG(A2.col_ conj fuzzy_comp_conj A1.col_ conj))

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 240
∀ j=1,…,q Fin si
Sino Para j = 1 Hasta q
Si CDEG(A2.col_ conj fuzzy_comp_conj A1.col_ conj) < matrizTholdCon_DCL (j)
matrizTholdCon_DCL (j) = CDEG(A2.col_conj fuzzy_comp_conj A1.col_conj)
Fin si Fin para cada j
Fin si Fin si
Fin para cada * cálculo final de la confianza (que es siempre máxima excepto cuando nunca se cumple el antecedente) * y el soporte Si cont_cumple_ant = 0 confianza = 0 Si no confianza = cont_cumple_ant_con / cont_cumple_ant Fin si soporte = cont_cumple_ant_con /cont_filas
6.2.4.3 Proceso: obtener SELECT DGD Descripción: Se obtiene la sentencia SQL correspondiente al proceso de obtención de DGD realizado, dicho proceso ha quedado plasmado, como se ha visto, en la dmFMB. Tratamientos:
• Una vez construida la sentencia FSQL tal y como se explicó en la sección 5.4.4.3, se efectúa su conversión a SQL mediante llamada al Servidor FSQL* con la correspondiente función de traducción (FSQL2SQL).

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 241
6.3 Algunas aplicaciones prácticas de Data Mining en el entorno dmFIRST
6.3.1 Identificación de patrones de ganancias bursátiles mediante análisis técnico bursátil
Los analistas bursátiles utilizan herramientas muy diversas para intentar comprender el mercado y prever su futuro. Estas herramientas pueden agruparse en dos grandes grupos:
• El análisis fundamental: utiliza los estados financieros de las empresas, datos del sector económico donde operan, estudios de mercado, datos relativos a la economía general, datos socio-políticos, etc. Consecuentemente, el análisis fundamental exige disponer de muchos datos, de mucho tiempo y de complejos conocimientos para poderlo efectuar.
• El análisis técnico: se basa en que el mercado proporciona la mejor información sobre la evolución futura que pueda tener el mismo y los respectivos títulos que lo integran. El análisis técnico se centra en el estudio del mercado en sí mismo. El mismo mercado descuenta todas las variables que puedan afectarle, entre ellas las estudiadas las estudiadas a través del análisis fundamental. Las hipótesis de partida que se establecen al aplicar análisis técnico son las siguientes:
o El mercado ofrece la suficiente información para poder predecir sus tendencias. o Los precios se mueven siguiendo unas determinadas tendencias, movimientos o
pautas. o Lo que ocurrió en el pasado ocurrirá en el futuro.
El análisis técnico ha hecho uso clásicamente de una serie de indicadores estadísticos como por ejemplo [Ama92]:
• Medias móviles (Moving Averages): a veces las fluctuaciones de los títulos se producen por motivos de estacionalidad. Por ejemplo, suele ser habitual que a finales del año aumenten las operaciones con fines básicamente relacionados con la fiscalidad, pero también, pueden deberse simplemente a movimientos erráticos sin que se pueda explicar racionalmente su origen. Las medias móviles ayudan a eliminar este tipo de distorsiones, ya que, atenúan las fluctuaciones y ayudan a identificar la tendencia y los posibles cambios de dirección. Se pueden calcular medias móviles de índices de un conjunto de títulos o bien de cotizaciones de un título aislado, y se deberían usar al menos 10 sesiones para su cálculo, de lo contrario podrían ser fuente de falsas alarmas. Una media móvil simple se calcula considerando que todos los precios del periodo tienen la misma consideración, su cómputo se hace dividiendo la suma de los valores obtenidos en cada una de las sesiones del periodo por el número de sesiones que tiene el plazo tomado.
• Osciladores (Oscillators): son índices que fluctúan alrededor de una banda determinada de valores posibles. Su principal aportación es que avisan de los cambios de tendencias

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 242
antes que las medias móviles. Existen varios tipos de osciladores, entre ellos se encuentran:
o Oscilador de Williams (William’s Oscillator): también se le denomina %R. Tiene un
elevado poder predictivo ya que detecta cuando una acción está sobrevalorada (sobrecomprada) o infravalorada (sobrevendida). Se calcula para un plazo determinado que va de 5 a 20 días. Utiliza el precio más alto, el más bajo y el último precio del cierre del periodo considerado. Para calcularlo se utiliza la fórmula siguiente:
%R = 100 × (A – U) / (A - B)
donde A es el precio más alto del periodo, B el precio más bajo y U el precio del último cierre. Una vez calculado el oscilador, se suele interpretar así:
%R > 80: señal de compra, %R < 20: señal de venta.
o Oscilador RSI (Relative Strenght Index): su traducción al español es índice de fuerza
relativa. Al igual que el %R indica cuando un título está sobrevalorado o infravalorado y, por tanto, también se utiliza para obtener señales de venta y de compra. Se calcula con la siguiente fórmula:
RSI = 100 – (100 / (1 + AU / AD))
donde AU es el promedio de incremento de precios cierre en relación a la sesión anterior y AD es el promedio de descenso de precios de cierre.
• Volúmenes: se entiende por volumen el número de títulos negociados en un determinado periodo (sesión, semana…). El volumen indica la fortaleza del mercado, cuando el volumen sube en fase alcista, el mercado es fuerte, cuando volumen cae en fase bajista el mercado sigue siendo fuerte.
En esta sección se va a plantear el problema de identificación de patrones de comportamiento de escenarios que proporcionan ganancias de un determinado valor bursátil, TELEFONICA S.A., mediante el uso de las técnicas clásicas del análisis técnico y las técnicas de DM implementadas en el ámbito de dmFIRST, explicadas en la memoria. El objetivo final va a ser obtener un sistema de decisión de compra-venta de acciones.
Sea la siguiente relación:
• SHARES_TELEFONICA (nombre_accion, fecha, williams, media_movil, cotizacion, volumen)
que contiene datos de las acciones de la empresa Telefónica S.A. en el Mercado Continuo de Valores de Madrid entre las fechas 01/01/1998 y 20/08/2003 donde el significado de los atributos es el siguiente:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 243
• nombre_accion: indica el valor bursátil en cuestión, en este caso siempre lleva el valor ‘TELEFONICA’;
• fecha: fecha a los que están referidos los datos; • williams: oscilador de Williams obtenido a 14 periodos tomando como referencia el
atributo fecha; • media_movil: media móvil simple obtenida a 20 periodos tomando como referencia el
atributo fecha; • cotizacion: cotización en euros de la empresa en cuestión al fin de la sesión; • volumen: volumen negociado en la sesión en cuestión.
Los pasos a seguir para la resolución del problema van a ser:
• Identificación de los distintos escenarios ideales de periodos de ganancias, teniendo en cuenta, algunos de los indicadores estadísticos del análisis técnico bursátil, anteriormente explicados.
• Agrupamiento de las características de los distintos escenarios para identificar los patrones que los caracterizan.
• Obtención de una estrategia de compra-venta basándose en la clasificación de los valores históricos de las acciones.
6.3.1.1 Identificación de escenarios de ganancias En base a las representaciones gráficas de los datos de la tabla SHARES_TELEFONICA y con las pautas de interpretación de los indicadores de análisis técnico bursátil (que en dicha tabla se incluyen) indicados en [Ama92] se obtiene tres escenarios ideales para periodos de ganancias. En las distintas gráficas se incluyen los siguientes indicadores:
• Media móvil simple: notada con MA (Moving Average) obtenida a 20 periodos, esto es, el
atributo media_movil de la tabla SHARES_TELEFONICA. • Oscilador de Williams: notado con %R, obtenido a 14 períodos, esto es, el valor del
atributo williams de la tabla SHARES_TELEFONICA. • Relative Strength Index: notado con RSI, calculado a 14 periodos, este indicador no está
incluido en la tabla SHARES_TELEFONICA ya que como puede observarse es bastante análogo al anterior %R, que ha sido representado en escala inversa para su mejor comparación con el RSI. La analogía puede ser observada en la simetría de ambos indicadores.
• Volumen: volumen de títulos negociado en la sesión, esto es, el atributo volumen de la tabla SHARES_TELEFONICA.
• Cotización: valor en euros de las acciones al cierre de la sesión, esto es, el atributo cotizacion de la tabla SHARES_TELEFONICA.
A continuación se explican los tres escenarios identificados:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 244
TELEFÓNICA – Escenario 1 En la Figura 6-6 se puede observar una primera situación ideal de ganancias con las siguientes características:
• Período: del 30/12/2002 al 28/01/2003 • Situación: partiendo como base de %R a fecha 30/12/2002 se comprueba que es
inminente un cambio de tendencia (cruce con la línea horizontal 80). Dicha tendencia se confirma el 02/01/2003 con el cruce de %R con la línea horizontal 80. Se puede comprobar igualmente que el volumen no es significativo hasta el día 07/01/2003 en el que se produce un incremento porcentualmente importante. El cruce en pendiente ascendente de la gráfica de Telefónica S.A. con MA se produce el día 03/01/2003 confirmando definitivamente la tendencia.
9eptember
16 23 30 7October
14 21 28 4 11November
18 25 2 9December
16 23 72003
13 20 27 3 10February
17 24 3March
10 17 24 31April
7
-10-20-30-40-50-60-70-80-90
-100Williams' %R (-75.926)
3540455055606570Relative Strength Index (51.200)
50000
x1000
Volume (21,499,416)
7.0
7.5
8.0
8.5
9.0
9.5
10.0
Telefonica (9.8300, 9.9100, 9.7800, 9.9100)
Figura 6-6. Escenario 1 de las acciones de Telefónica S.A.
MA
cotización

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 245
TELEFÓNICA – Escenario 2 En la Figura 6-7 se puede observar la situación ideal de ganancias con las siguientes características:
• Período: del 12/03/2003 al 31/03/2003 • Situación: partiendo como base de %R a fecha 12/03/2003 se comprueba que es
inminente un cambio de tendencia (cruce con la línea horizontal 80). La tendencia se confirma el 13/03/2003 con el cruce de %R con la línea horizontal 80. Se puede comprobar un aumento geométrico en el volumen negociado, alcanzando su cenit el 18/03/2003. El cruce en pendiente ascendente de la gráfica de Telefónica S.A. con MA se produce el día 14/03/2003 confirmando definitivamente la tendencia. La finalización del período se produce el 31/03/2003 con el cruce bajista de la curva de cotización con la MA. Previamente, el cruce de %R con la línea horizontal 20 se produce el día 24/03/2003.
4 11November
18 25 2 9December
16 23 72003
13 20 27 3 10February
17 24 3March
10 17 24 31April
7 14 22 28 1July
7 14 21 28 4Augu
-10-20-30-40-50-60-70-80-90
-100Williams' %R (-75.926)
3540455055606570Relative Strength Index (51.200)
50000
x1000
Volume (21,499,416)
7.0
7.5
8.0
8.5
9.0
9.5
10.0
Telefonica (9.8300, 9.9100, 9.7800, 9.9100)
Figura 6-7. Escenario 2 de las acciones de Telefónica S.A.
MA cotización

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 246
TELEFÓNICA – Escenario 3 En la Figura 6-8 se observa la última situación ideal de ganancias con las siguientes características:
• Periodo: del 27/06/2002 al 09/07/2002 • Situación: Partiendo como base de %R a fecha 27/06/2002 se ha producido el
cambio de tendencia con un valor de 81,22 (cruce con la línea horizontal 80). No se produce cruce alguno de la gráfica de Telefónica S.A. con MA, ni tampoco hay un cambio de volumen significativo. La finalización del período se produce el 09/07/2002 con el cruce bajista de la curva de cotización con la MA y el corte de %R con la línea horizontal 20.
15 22 29 6May
13 20 27 3June
10 17 24 1July
8 15 22 29 5August
12 19 26 2 9September
16 23 30 7October
14 21
-10-20-30-40-50-60-70-80-90
-100Williams' %R (-75.926)
20253035404550556065Relative Strength Index (51.200)
50000
x1000
Volume (21,499,416)
7.0
7.5
8.0
8.5
9.0
9.5
10.0
10.5
11.0
11.5
12.0
12.5
13.0Telefonica (9.8300, 9.9100, 9.7800, 9.9100)
Figura 6-8. Escenario 3 de las acciones de Telefónica
MA cotización

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 247
6.3.1.2 Agrupamiento y descripción de las características de los escenarios Una vez definidos los escenarios de ganancias, mediante el análisis técnico bursátil, se va a
proceder obtener grupos homogéneos de comportamiento respecto a los indicadores usados en la definición de dichos escenarios. Además se obtendrán una descripción de dichos grupos.
Para ello se van a seguir los siguientes pasos:
Paso 1 En primer lugar se obtiene el origen de datos para el proceso, que va a ser la tabla
SHARES_ESCENARIO_123 con la misma estructura que la tabla SHARES_TELEFONICA, pero con solo los datos de las fechas correspondientes a los escenarios 1, 2 y 3.
Paso 2
El segundo paso consiste en definir los distintos atributos de la tabla
SHARES_ESCENARIO_123 en el entorno de dmFIRST. La determinación que se ha tomado al respecto, se basa en la información proporcionada por el análisis técnico bursátil [Ama92] en el caso del oscilador Williams y para el resto de atributos, al no tener más información sobre ellos, se va a determinar el uso de una función de similitud basada en la distancia Hamming (puesto que solo hay que aportar valores mínimos y máximos de cada atributo). En base a todo esto, los atributos quedan definidos en la dmFMB de la siguiente manera:
• williams: aunque es un dato puramente crisp, se va a definir como tipo difuso 2 (ver
3.4.1.1). El valor del margen para valores aproximados se determina que es 10 y la distancia mínima para considerar dos valores como muy separados es de 20. Ambos valores son almacenados en la tabla de la dmFMB FUZZY_APPROX_MUCH. El objetivo de esta definición es poder expresar etiquetas lingüísticas para la gestión difusa de la interpretación del oscilador de Williams que, tal y como se ha explicado en la sección 6.3.1, en el análisis técnico bursátil clásico suele ser puramente crisp. De esta manera, y como se verá en la sección 6.3.1.3, las etiquetas van a ser muy útiles para crear un sistema de decisión de compra-venta de acciones. Las etiquetas definidas en la dmFMB son las que constan en la Figura 6-9. En FSQL la comparación difusa de los atributos crisps se lleva acabo difuminando los atributos, de tal manera que se convierten en una distribución de posibilidad triangular (ver Figura 3-8) usando el margen definido en la dmFMB ([Gal99]). Existen ocasiones que este oscilador no puede ser calculado, por ejemplo si es el primer día de cotización del valor (ver 6.3.1), por lo que puede resultar útil expresarlo mediante la constante difusa UNDEFINED.
• media_movil: se va a definir como un atributo difuso tipo 4 cuya función de comparación FEQ va a ser la distancia Hamming normalizada en [0,1] (HAMM) de forma análoga a la definición que se hecho para el atributos A del Ejemplo 4-1
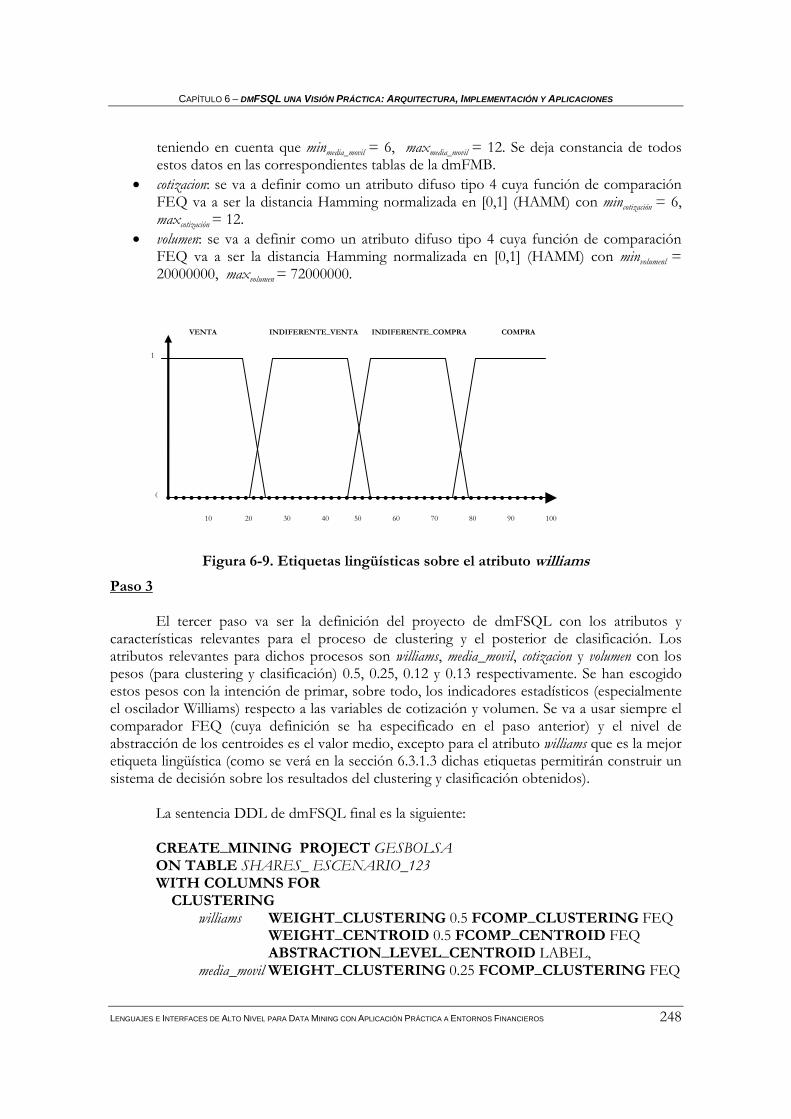
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 248
teniendo en cuenta que minmedia_movil = 6, maxmedia_movil = 12. Se deja constancia de todos estos datos en las correspondientes tablas de la dmFMB.
• cotizacion: se va a definir como un atributo difuso tipo 4 cuya función de comparación FEQ va a ser la distancia Hamming normalizada en [0,1] (HAMM) con mincotización = 6, maxcotización = 12.
• volumen: se va a definir como un atributo difuso tipo 4 cuya función de comparación FEQ va a ser la distancia Hamming normalizada en [0,1] (HAMM) con minvolumenl = 20000000, maxvolumen = 72000000.
Figura 6-9. Etiquetas lingüísticas sobre el atributo williams
Paso 3 El tercer paso va ser la definición del proyecto de dmFSQL con los atributos y características relevantes para el proceso de clustering y el posterior de clasificación. Los atributos relevantes para dichos procesos son williams, media_movil, cotizacion y volumen con los pesos (para clustering y clasificación) 0.5, 0.25, 0.12 y 0.13 respectivamente. Se han escogido estos pesos con la intención de primar, sobre todo, los indicadores estadísticos (especialmente el oscilador Williams) respecto a las variables de cotización y volumen. Se va a usar siempre el comparador FEQ (cuya definición se ha especificado en el paso anterior) y el nivel de abstracción de los centroides es el valor medio, excepto para el atributo williams que es la mejor etiqueta lingüística (como se verá en la sección 6.3.1.3 dichas etiquetas permitirán construir un sistema de decisión sobre los resultados del clustering y clasificación obtenidos). La sentencia DDL de dmFSQL final es la siguiente:
CREATE_MINING PROJECT GESBOLSA ON TABLE SHARES_ ESCENARIO_123 WITH COLUMNS FOR CLUSTERING williams WEIGHT_CLUSTERING 0.5 FCOMP_CLUSTERING FEQ WEIGHT_CENTROID 0.5 FCOMP_CENTROID FEQ ABSTRACTION_LEVEL_CENTROID LABEL, media_movil WEIGHT_CLUSTERING 0.25 FCOMP_CLUSTERING FEQ
10 20 30 40 50 60 70 80 90 100
1
VENTA INDIFERENTE_VENTA INDIFERENTE_COMPRA COMPRA
0

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 249
WEIGHT_CENTROID 0.25 FCOMP_CENTROID FEQ ABSTRACTION_LEVEL_CENTROID AVG, cotizacion WEIGHT_CLUSTERING 0.12 FCOMP_CLUSTERING FEQ WEIGHT_CENTROID 0.12 FCOMP_CENTROID FEQ ABSTRACTION_LEVEL_CENTROID AVG, volumen WEIGHT_CLUSTERING 0.13 FCOMP_CLUSTERING FEQ WEIGHT_CENTROID 0.13 FCOMP_CENTROID FEQ ABSTRACTION_LEVEL_CENTROID AVG CLASSIFICATION williams WEIGHT_CLASSIFICATION 0.5 FCOMP_ CLASSIFICATION FEQ, media_movil WEIGHT_CLASSIFICATION 0.25 FCOMP_ CLASSIFICATION FEQ, cotizacion WEIGHT_CLASSIFICATION 0.13 FCOMP_ CLASSIFICATION FEQ, volumen WEIGHT_CLASSIFICATION 0.12 FCOMP_ CLASSIFICATION FEQ;
Paso 4 El cuarto paso consiste en la ejecución del proceso de clustering y el posterior de caracterización de los distintos grupos mediante la sentencia DML de dmFSQL que aparece en la Figura 6-10.
Figura 6-10. Sentencia dmFSQL para clustering y caracterización en FQ
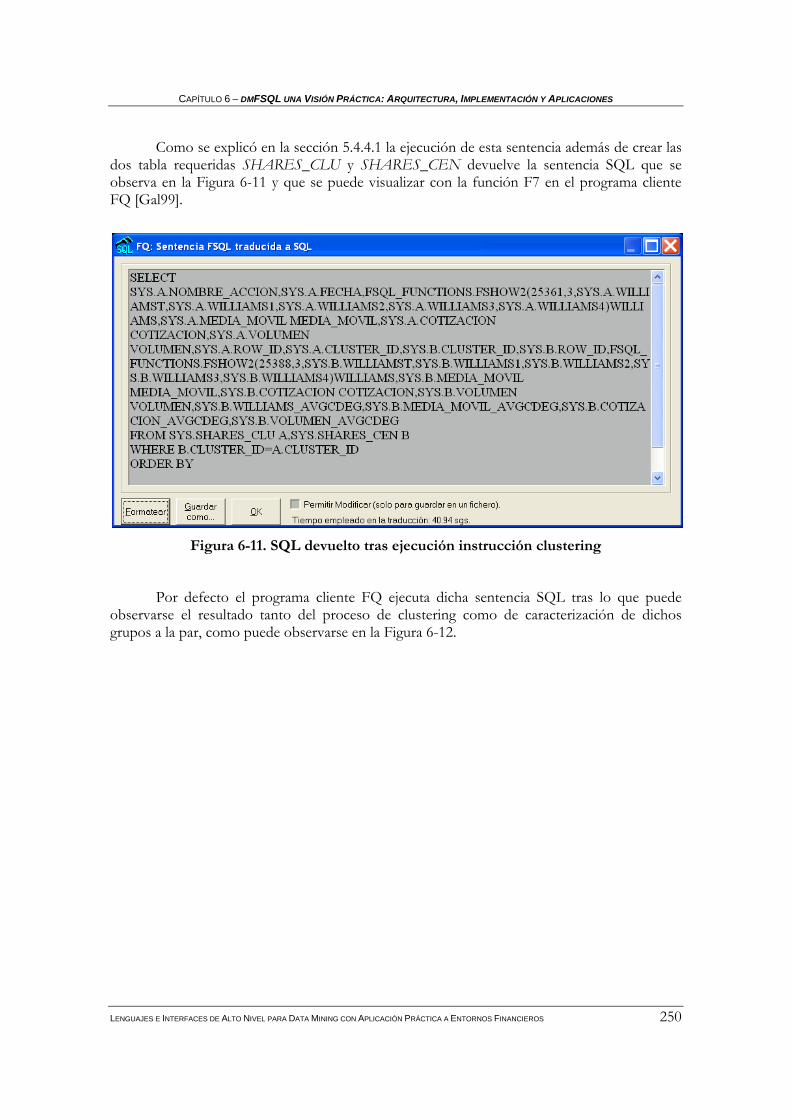
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 250
Como se explicó en la sección 5.4.4.1 la ejecución de esta sentencia además de crear las dos tabla requeridas SHARES_CLU y SHARES_CEN devuelve la sentencia SQL que se observa en la Figura 6-11 y que se puede visualizar con la función F7 en el programa cliente FQ [Gal99].
Por defecto el programa cliente FQ ejecuta dicha sentencia SQL tras lo que puede
observarse el resultado tanto del proceso de clustering como de caracterización de dichos grupos a la par, como puede observarse en la Figura 6-12.
Figura 6-11. SQL devuelto tras ejecución instrucción clustering

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 251
A continuación se muestra la tabla SHARES_CLU completa con los resultados del clustering (columna cluster_id):
NOMBRE_ACCION
FECHA WILLIAMS MEDIA_MOVIL
COTIZACION VOLUMEN ROW_ID
CLUSTER_ID
TELEFONICA 27/06/2002 81,22 9.63 8.18 60913460 1 1 TELEFONICA 01/07/2002 63,01 9.35 8.53 35476040 3 2 TELEFONICA 28/06/2002 68,57 9.49 8.5 41376576 2 2 TELEFONICA 02/07/2002 78,53 9.22 8.19 43809172 4 3 TELEFONICA 04/07/2002 82,25 8.98 8.06 36657208 6 3 TELEFONICA 03/07/2002 84,94 9.1 8.01 40781000 5 3 TELEFONICA 05/07/2002 36,02 8.87 8.92 62091816 7 4 TELEFONICA 21/03/2003 4,11 8.68 9.44 58161348 17 4 TELEFONICA 14/03/2003 41,13 8.67 8.64 53596232 12 4 TELEFONICA 17/03/2003 7,46 8.66 9.06 57982212 13 4 TELEFONICA 19/03/2003 11,76 8.68 9.31 49090556 15 5 TELEFONICA 08/07/2002 14,56 8.83 9.02 36079984 8 5 TELEFONICA 25/03/2003 20 8.7 9.18 40587968 19 5 TELEFONICA 26/03/2003 21,17 8.71 9.15 34546464 20 5 TELEFONICA 20/03/2003 21,76 8.68 9.14 43120056 16 5 TELEFONICA 09/07/2002 25,37 8.79 8.72 39128456 9 5 TELEFONICA 24/03/2003 29,41 8.7 9.02 34212984 18 5 TELEFONICA 27/03/2003 37,64 8.73 8.88 30596764 21 5 TELEFONICA 28/03/2003 39,41 8.75 8.85 25395480 22 5 TELEFONICA 31/03/2003 55,88 8.76 8.56 30204516 23 5 TELEFONICA 13/03/2003 67,37 8.7 8.27 41072768 11 5 TELEFONICA 12/03/2003 100 8.75 7.82 46629700 10 6 TELEFONICA 18/03/2003 18,51 8.67 9.14 71307672 14 7
Figura 6-12. Resultado del proceso de clustering y caracterización en FQ

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 252
NOMBRE_ACCION
FECHA WILLIAMS MEDIA_MOVIL
COTIZACION VOLUMEN ROW_ID
CLUSTER_ID
TELEFONICA 03/01/2003 43,15 9.28 9.01 20062762 26 8 TELEFONICA 02/01/2003 44,76 9.34 9.05 21707808 25 8 TELEFONICA 30/12/2002 96,02 9.41 8.52 24942650 24 8 TELEFONICA 23/01/2003 10,98 9.44 10.05 45825564 38 9 TELEFONICA 21/01/2003 12,42 9.34 10.02 42069164 36 9 TELEFONICA 24/01/2003 13,76 9.5 10.05 39648496 39 9 TELEFONICA 08/01/2003 15,78 9.18 9.59 47526000 28 9 TELEFONICA 15/01/2003 16,94 9.21 9.93 40812128 33 9 TELEFONICA 22/01/2003 20,33 9.4 9.88 51426644 37 9 TELEFONICA 09/01/2003 2,25 9.15 9.77 39843408 29 9 TELEFONICA 16/01/2003 3,38 9.25 10.18 39585216 34 9 TELEFONICA 14/01/2003 4,02 9.16 10.14 39231176 32 9 TELEFONICA 13/01/2003 7,18 9.14 10.02 38671764 31 9 TELEFONICA 07/01/2003 ,93 9.22 9.52 38492208 27 9 TELEFONICA 10/01/2003 2,06 9.14 9.89 59758976 30 10 TELEFONICA 20/01/2003 14,68 9.29 9.97 28725392 35 11 TELEFONICA 27/01/2003 80,39 9.57 9.42 62831932 40 12 TELEFONICA 28/01/2003 92,56 9.59 9.11 68249368 41 12
y la tabla SHARES_CEN con la caracterización de los distintos grupos, recordando que row_id contiene el número de tuplas caracterizadas y las columnas con el sufijo _avgcdeg muestran la representatividad de la columna en cuestión (ver 5.4.4.1):
CLUSTER_ID
ROW_ID
WILLIAMS MEDIA_MOVIL
COTIZACION
VOLUMEN WILLIAMS_AVGCDEG
MEDIA_MOVIL_AVGCDEG
COTIZACION_AVGCDEG
VOLUMEN_AVGCDEG
1 1 COMPRA 9.63 8.18 60913460 1 1 1 1 2 2 INDIFERENTE_CO
MPRA 9.42 8.52 38426308 1 0.988333333 0.9975 0.943264077
3 3 COMPRA 9.1 8.09 40415793.33 0.903333333 0.986666667 0.988333333 0.951813009 4 4 VENTA 8.72 9.02 57957902 0.5 0.9875 0.960833333 0.958060865 5 11 INDIFERENTE_VE
NTA 8.73 8.92 36730545.09 0.416363636 0.993636364 0.96030303 0.897387837
6 1 COMPRA 8.75 7.82 46629700 1 1 1 1 7 1 VENTA 8.67 9.14 71307672 1 1 1 1 8 3 INDIFERENTE_VE
NTA 9.34 8.86 22237740 0.666666667 0.992777778 0.962222222 0.965321667
9 11 VENTA 9.27 9.92 42102888 0.993636364 0.982121212 0.971666667 0.935421175 10 1 VENTA 9.14 9.89 59758976 1 1 1 1 11 1 VENTA 9.29 9.97 28725392 1 1 1 1 12 2 COMPRA 9.58 9.27 65540650 1 0.998333333 0.974166667 0.947909269
Si se exige una representatividad mínima de 0.7 para considerar el centroide como bueno, los grupos identificados por 4, 5 y 8 (cluster_id) no la superarían debido al valor de su columna williams. Si se quisiera obtener unos valores más representativos de dicho atributo se tendría que especificar en la sentencia DDL correspondiente la cláusula ABSTRACTION_LEVEL_CENTROID AVG (o VALUE) para la columna williams que indica que el nivel de abstracción, que se quiere para la caracterización, es la media (o valor más representantivo en el caso de especificar VALUE).
Esto no es más que una muestra de cómo los pasos 2, 3, 4 pueden ser refinados iterativamente hasta conseguir los resultados deseados:
• En el paso 4, se puede ensayar con el número de grupos a obtener con la sentencia DML (SELECT_MINING CLUSTERING), especificando incluso algún mecanismo de determinación automática de los grupos a obtener. Hay que hacer notar que la

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 253
primera sentencia DML que se ejecute será sensiblemente más lenta que las sucesivas ya que conlleva el cálculo de las particiones de la población (ver la implementación del proceso de clustering en 6.2.1).
• Si en el paso 4 no se concluye con un resultado satisfactorio habría que volver al paso 3, planteándose si las columnas elegidas como criterio de clustering y/o los pesos de las mismas son adecuados y, en su caso, proceder a cambiar las características del proyecto con la correspondiente sentencia DDL (ALTER_MINING). También es posible, como se ha explicado, que se quiera alterar el comparador difuso y/o el nivel de abstracción de los centroides.
• Si finalmente se concluye que los comparadores difusos de los atributos no son adecuados habría que volver al paso 1 para elegir unos más adecuados.
6.3.1.3 Estrategia de compra-venta basándose en la clasificación de los valores históricos
Se comentaba, al principio de este apartado, que una de las hipótesis del análisis técnico bursátil es considerar que lo que ocurrió en el pasado ocurrirá en el futuro. En este sentido, el estudio de los valores históricos puede ser usado para concluir actuaciones en el futuro. Como se ha visto, la tabla SHARES_TELEFONICA contiene los datos comprendidos entre las fechas 01/01/1998 y 20/08/2003 por lo que sería interesante aplicar un mecanismo de clasificación sobre dicha tabla, de tal manera que se obtengan el grado de pertenencia de las filas a algunos de los grupos que describen las características de los escenarios ganadores, obtenidos en el punto anterior. Si esa clasificación, que proporciona conocimiento acerca de que se está en circunstancias parecidas a determinados escenarios ganadores, permite tomar decisiones de compra o venta que proporcionen ganancias, según los datos de la tabla histórica, las nuevas entradas que se clasifiquen permitirán igualmente tomar decisiones acertadas en tiempo real. Por tanto, en este apartado, se va a proponer una sistema de toma de decisiones de compra y venta basándose en la identificación de situaciones parecidas al pasado y que proporcionaron beneficios. Primeramente, se va a proceder a escoger y validar algunos de los mecanismos de clasificación que proporciona dmFSQL. Seguidamente se procederá a la clasificación de situaciones de compras y de ventas. Finalmente, se propondrá un mecanismo de decisión basándose en los datos obtenidos en la clasificación. Con dicho fin se van a seguir los siguientes pasos:
Paso 1 Los centroides obtenidos en la tabla SHARES_CEN habían sido definidos con etiquetas lingüísticas para el atributo williams de tal manera que, claramente, se pueden identificar grupos típicos de compras y de ventas (en base a dicho oscilador). Por tanto, se va a usar un mecanismo de clasificación basado en tales centroides. Se podría comenzar validando dicho mecanismo de clasificación basado en centroides con respecto a los resultados del clustering, es decir, clasificando la tabla origen del clustering
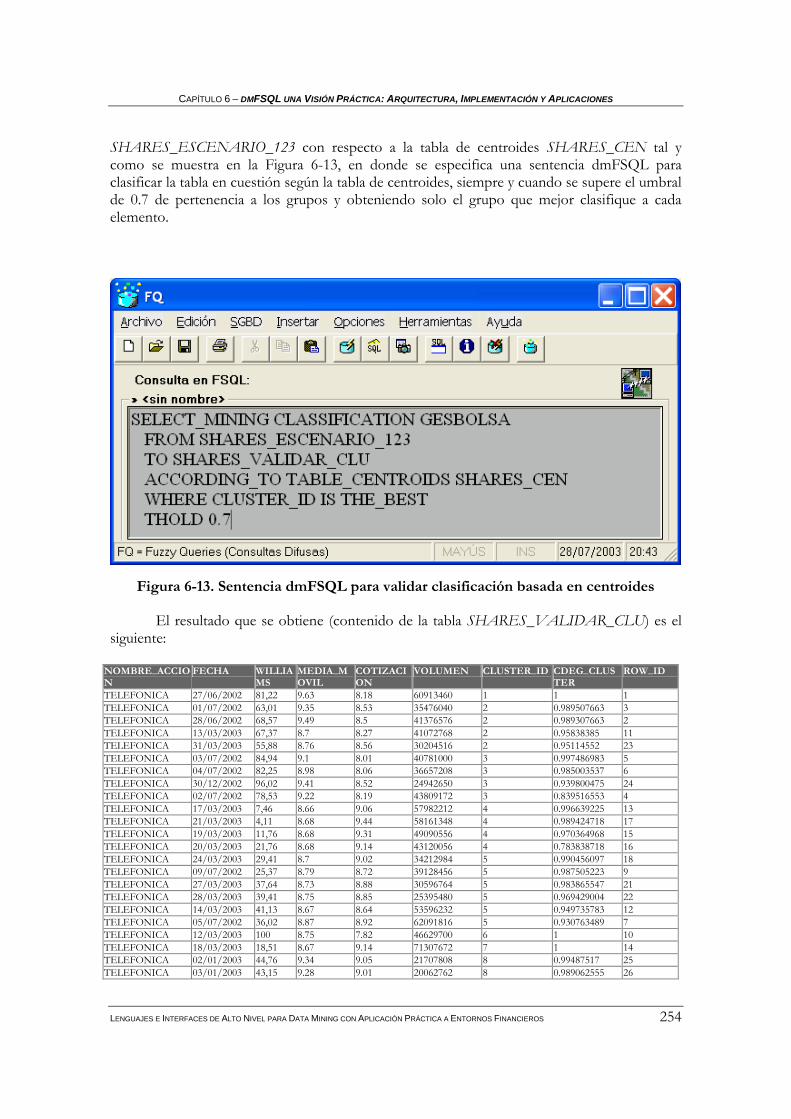
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 254
SHARES_ESCENARIO_123 con respecto a la tabla de centroides SHARES_CEN tal y como se muestra en la Figura 6-13, en donde se especifica una sentencia dmFSQL para clasificar la tabla en cuestión según la tabla de centroides, siempre y cuando se supere el umbral de 0.7 de pertenencia a los grupos y obteniendo solo el grupo que mejor clasifique a cada elemento.
El resultado que se obtiene (contenido de la tabla SHARES_VALIDAR_CLU) es el siguiente:
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN CLUSTER_ID CDEG_CLUSTER
ROW_ID
TELEFONICA 27/06/2002 81,22 9.63 8.18 60913460 1 1 1 TELEFONICA 01/07/2002 63,01 9.35 8.53 35476040 2 0.989507663 3 TELEFONICA 28/06/2002 68,57 9.49 8.5 41376576 2 0.989307663 2 TELEFONICA 13/03/2003 67,37 8.7 8.27 41072768 2 0.95838385 11 TELEFONICA 31/03/2003 55,88 8.76 8.56 30204516 2 0.95114552 23 TELEFONICA 03/07/2002 84,94 9.1 8.01 40781000 3 0.997486983 5 TELEFONICA 04/07/2002 82,25 8.98 8.06 36657208 3 0.985003537 6 TELEFONICA 30/12/2002 96,02 9.41 8.52 24942650 3 0.939800475 24 TELEFONICA 02/07/2002 78,53 9.22 8.19 43809172 3 0.839516553 4 TELEFONICA 17/03/2003 7,46 8.66 9.06 57982212 4 0.996639225 13 TELEFONICA 21/03/2003 4,11 8.68 9.44 58161348 4 0.989424718 17 TELEFONICA 19/03/2003 11,76 8.68 9.31 49090556 4 0.970364968 15 TELEFONICA 20/03/2003 21,76 8.68 9.14 43120056 4 0.783838718 16 TELEFONICA 24/03/2003 29,41 8.7 9.02 34212984 5 0.990456097 18 TELEFONICA 09/07/2002 25,37 8.79 8.72 39128456 5 0.987505223 9 TELEFONICA 27/03/2003 37,64 8.73 8.88 30596764 5 0.983865547 21 TELEFONICA 28/03/2003 39,41 8.75 8.85 25395480 5 0.969429004 22 TELEFONICA 14/03/2003 41,13 8.67 8.64 53596232 5 0.949735783 12 TELEFONICA 05/07/2002 36,02 8.87 8.92 62091816 5 0.930763489 7 TELEFONICA 12/03/2003 100 8.75 7.82 46629700 6 1 10 TELEFONICA 18/03/2003 18,51 8.67 9.14 71307672 7 1 14 TELEFONICA 02/01/2003 44,76 9.34 9.05 21707808 8 0.99487517 25 TELEFONICA 03/01/2003 43,15 9.28 9.01 20062762 8 0.989062555 26
Figura 6-13. Sentencia dmFSQL para validar clasificación basada en centroides
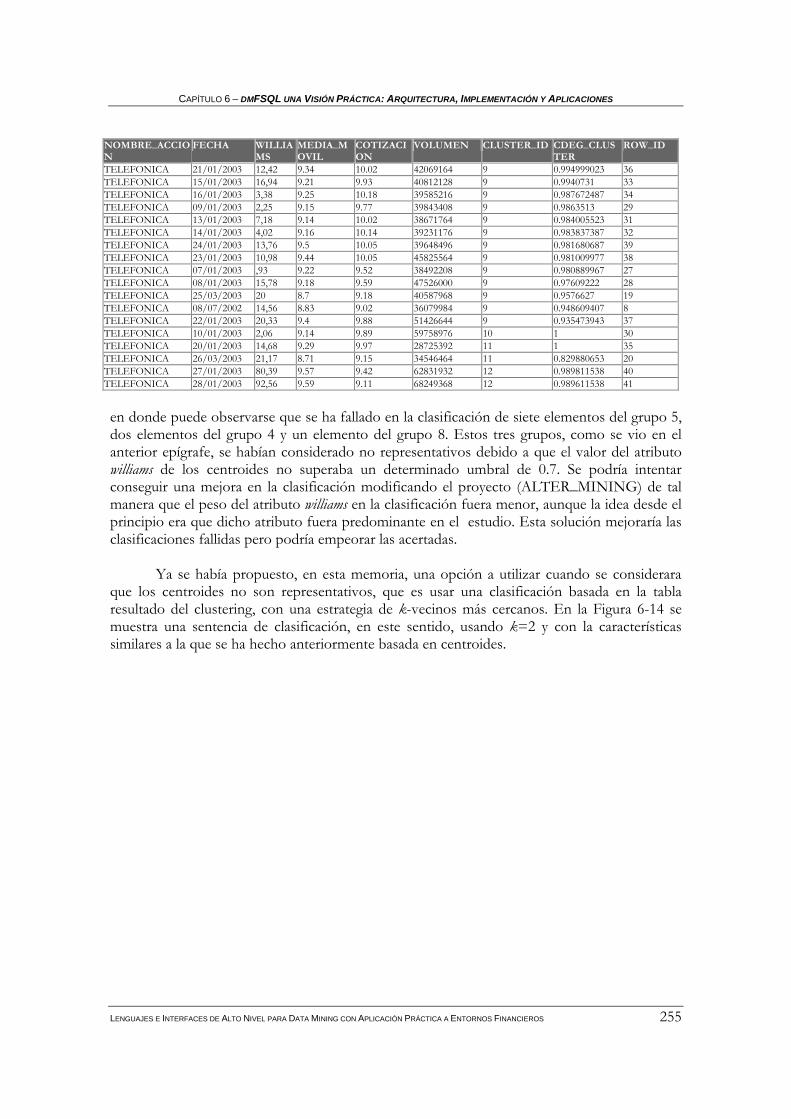
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 255
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN CLUSTER_ID CDEG_CLUSTER
ROW_ID
TELEFONICA 21/01/2003 12,42 9.34 10.02 42069164 9 0.994999023 36 TELEFONICA 15/01/2003 16,94 9.21 9.93 40812128 9 0.9940731 33 TELEFONICA 16/01/2003 3,38 9.25 10.18 39585216 9 0.987672487 34 TELEFONICA 09/01/2003 2,25 9.15 9.77 39843408 9 0.9863513 29 TELEFONICA 13/01/2003 7,18 9.14 10.02 38671764 9 0.984005523 31 TELEFONICA 14/01/2003 4,02 9.16 10.14 39231176 9 0.983837387 32 TELEFONICA 24/01/2003 13,76 9.5 10.05 39648496 9 0.981680687 39 TELEFONICA 23/01/2003 10,98 9.44 10.05 45825564 9 0.981009977 38 TELEFONICA 07/01/2003 ,93 9.22 9.52 38492208 9 0.980889967 27 TELEFONICA 08/01/2003 15,78 9.18 9.59 47526000 9 0.97609222 28 TELEFONICA 25/03/2003 20 8.7 9.18 40587968 9 0.9576627 19 TELEFONICA 08/07/2002 14,56 8.83 9.02 36079984 9 0.948609407 8 TELEFONICA 22/01/2003 20,33 9.4 9.88 51426644 9 0.935473943 37 TELEFONICA 10/01/2003 2,06 9.14 9.89 59758976 10 1 30 TELEFONICA 20/01/2003 14,68 9.29 9.97 28725392 11 1 35 TELEFONICA 26/03/2003 21,17 8.71 9.15 34546464 11 0.829880653 20 TELEFONICA 27/01/2003 80,39 9.57 9.42 62831932 12 0.989811538 40 TELEFONICA 28/01/2003 92,56 9.59 9.11 68249368 12 0.989611538 41
en donde puede observarse que se ha fallado en la clasificación de siete elementos del grupo 5, dos elementos del grupo 4 y un elemento del grupo 8. Estos tres grupos, como se vio en el anterior epígrafe, se habían considerado no representativos debido a que el valor del atributo williams de los centroides no superaba un determinado umbral de 0.7. Se podría intentar conseguir una mejora en la clasificación modificando el proyecto (ALTER_MINING) de tal manera que el peso del atributo williams en la clasificación fuera menor, aunque la idea desde el principio era que dicho atributo fuera predominante en el estudio. Esta solución mejoraría las clasificaciones fallidas pero podría empeorar las acertadas. Ya se había propuesto, en esta memoria, una opción a utilizar cuando se considerara que los centroides no son representativos, que es usar una clasificación basada en la tabla resultado del clustering, con una estrategia de k-vecinos más cercanos. En la Figura 6-14 se muestra una sentencia de clasificación, en este sentido, usando k=2 y con la características similares a la que se ha hecho anteriormente basada en centroides.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 256
El resultado que se obtiene (contenido de la tabla SHARES_VALIDAR_CLU) es el siguiente:
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN CLUSTER_ID
CDEG_CLUSTER
ROW_ID
TELEFONICA 27/06/2002 81,22 9.63 8.18 60913460 1 1 1 TELEFONICA 28/06/2002 68,57 9.49 8.5 41376576 2 0.739407663 2 TELEFONICA 01/07/2002 63,01 9.35 8.53 35476040 2 0.739407663 3 TELEFONICA 02/07/2002 78,53 9.22 8.19 43809172 3 0.741914785 4 TELEFONICA 03/07/2002 84,94 9.1 8.01 40781000 3 0.741914785 5 TELEFONICA 04/07/2002 82,25 8.98 8.06 36657208 3 0.74184526 6 TELEFONICA 17/03/2003 7,46 8.66 9.06 57982212 4 0.745559413 13 TELEFONICA 21/03/2003 4,11 8.68 9.44 58161348 4 0.745559413 17 TELEFONICA 14/03/2003 41,13 8.67 8.64 53596232 4 0.740109192 12 TELEFONICA 05/07/2002 36,02 8.87 8.92 62091816 4 0.739087995 7 TELEFONICA 24/03/2003 29,41 8.7 9.02 34212984 5 0.748074817 18 TELEFONICA 26/03/2003 21,17 8.71 9.15 34546464 5 0.748074817 20 TELEFONICA 20/03/2003 21,76 8.68 9.14 43120056 5 0.746018223 16 TELEFONICA 25/03/2003 20 8.7 9.18 40587968 5 0.746018223 19 TELEFONICA 27/03/2003 37,64 8.73 8.88 30596764 5 0.74568469 21 TELEFONICA 31/03/2003 55,88 8.76 8.56 30204516 5 0.74568469 23 TELEFONICA 08/07/2002 14,56 8.83 9.02 36079984 5 0.744957917 8 TELEFONICA 28/03/2003 39,41 8.75 8.85 25395480 5 0.742781728 22 TELEFONICA 09/07/2002 25,37 8.79 8.72 39128456 5 0.742356077 9 TELEFONICA 13/03/2003 67,37 8.7 8.27 41072768 5 0.74119461 11 TELEFONICA 19/03/2003 11,76 8.68 9.31 49090556 5 0.740836875 15 TELEFONICA 12/03/2003 100 8.75 7.82 46629700 6 1 10 TELEFONICA 18/03/2003 18,51 8.67 9.14 71307672 7 1 14 TELEFONICA 02/01/2003 44,76 9.34 9.05 21707808 8 0.746293693 25 TELEFONICA 03/01/2003 43,15 9.28 9.01 20062762 8 0.746293693 26 TELEFONICA 30/12/2002 96,02 9.41 8.52 24942650 8 0.739198114 24 TELEFONICA 13/01/2003 7,18 9.14 10.02 38671764 9 0.747684068 31
Figura 6-14. Sentencia dmFSQL para validar clasificación basada en k-vecinos

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 257
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN CLUSTER_ID
CDEG_CLUSTER
ROW_ID
TELEFONICA 14/01/2003 4,02 9.16 10.14 39231176 9 0.747684068 32 TELEFONICA 16/01/2003 3,38 9.25 10.18 39585216 9 0.74728245 34 TELEFONICA 09/01/2003 2,25 9.15 9.77 39843408 9 0.7459391 29 TELEFONICA 15/01/2003 16,94 9.21 9.93 40812128 9 0.7459391 33 TELEFONICA 21/01/2003 12,42 9.34 10.02 42069164 9 0.744820372 36 TELEFONICA 07/01/2003 ,93 9.22 9.52 38492208 9 0.744352667 27 TELEFONICA 24/01/2003 13,76 9.5 10.05 39648496 9 0.743412567 39 TELEFONICA 23/01/2003 10,98 9.44 10.05 45825564 9 0.742921167 38 TELEFONICA 22/01/2003 20,33 9.4 9.88 51426644 9 0.740465317 37 TELEFONICA 08/01/2003 15,78 9.18 9.59 47526000 9 0.73797176 28 TELEFONICA 10/01/2003 2,06 9.14 9.89 59758976 10 1 30 TELEFONICA 20/01/2003 14,68 9.29 9.97 28725392 11 1 35 TELEFONICA 27/01/2003 80,39 9.57 9.42 62831932 12 0.739711538 40 TELEFONICA 28/01/2003 92,56 9.59 9.11 68249368 12 0.739711538 41
en donde se puede comprobar que todos y cada uno de los elementos se ha asignado al mismo grupo que en el proceso de clustering original, aunque por otro lado, el grado de pertenencia a los grupos en cuestión es, generalmente, más bajo que con la anterior estrategia de clasificación. Como se había dicho, se va a seleccionar como mecanismo de clasificación el que está basado en los centroides, aunque por otro lado, haya descartar el estudio de los grupos que se han considerado insuficientemente representados por sus correspondientes centroides.
Paso 2 Una vez elegido el mecanismo de clasificación, en este segundo paso, se va a proceder a hacer un estudio de qué grupos se van a considerar para obtener opciones de compras y ventas:
• Compras: Se selecciona el grupo identificado por el 3 (cluster_id) de la tabla SHARES_CLU, por ser un grupo bastante homogéneo y además el más numeroso de los que tienen etiqueta de williams “compra”. El resto de los grupos, con dicha etiqueta, se descartan en base a su poco número de elementos: grupos 1, 6 y 12.
• Ventas: Se elige el grupo identificado por el 9 (cluster_id) de la tabla SHARES_CLU, por ser un grupo bastante homogéneo y además el más numeroso de los que tienen etiqueta de williams “venta”. El resto de los grupos, con dicha etiqueta, se descartan en base a tener un solo elemento (singleton) ya que son considerados como casos raros: grupos 7, 10 y 11; o por tener unos centroides poco representativos: grupo 4 (recuérdese que se va a aplicar un mecanismo de clasificación basado en centroides).
En base a esto, en la Figura 6-15 se muestra la sentencia dmFSQL para clasificar, la tabla histórica en cuestión, contra el grupo 3 (elegido para obtener opciones de compras). Como puede comprobarse en dicha sentencia, el resultado de la clasificación se deja en la tabla OPCION_COMPRAS. Se ha determinado un umbral de pertenencia al grupo de compras de 0.9, este umbral puede ajustarse según interese obtener más o menos opciones de compras.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 258
Figura 6-15. Sentencia dmFSQL para clasificar según centroides contra el cluster 3

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 259
Si no se hubiese especificado que la clasificación se va a dejar plasmada en una tabla (esto es, no existiese la cláusula TO OPCION_COMPRAS en la sentencia) esta clasificación sería un caso típico de sentencia dmFSQL que puede resolverse con una simple sentencia DML de SQL. La traducción final a SQL de la sentencia dmFSQL propuesta se muestra en la Figura 6-16.
Figura 6-16. SQL generado para la clasificación (visualizado en FQ)
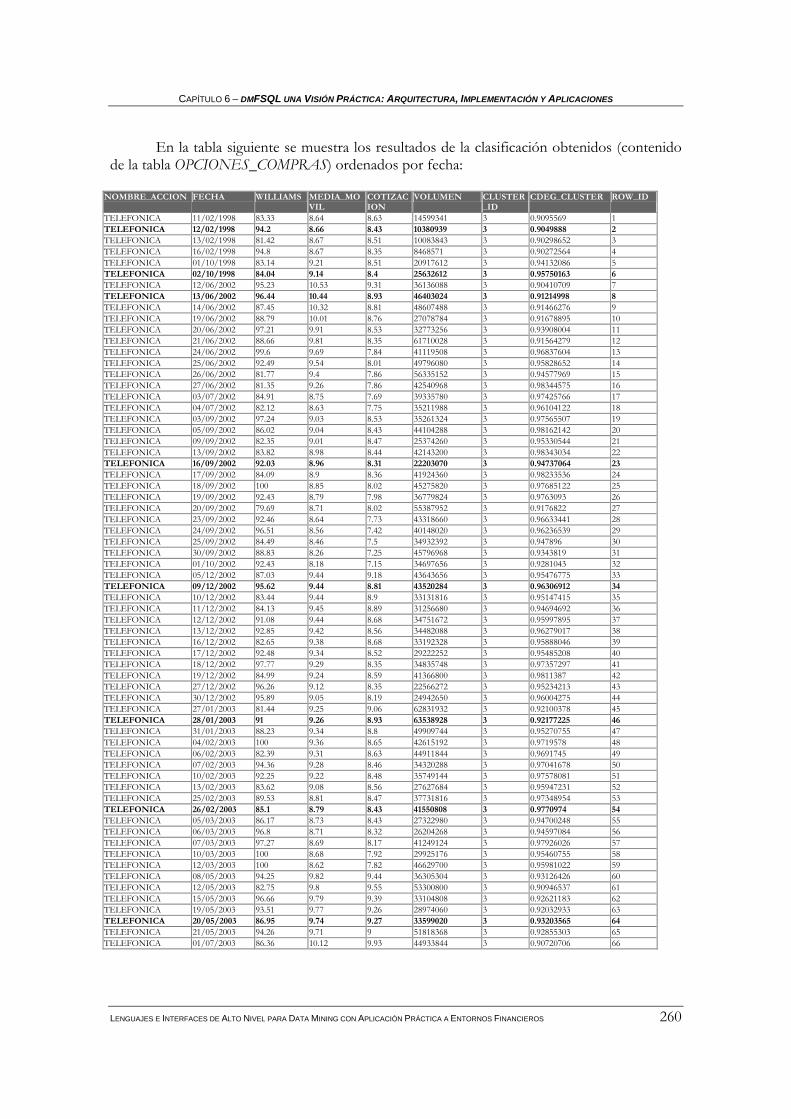
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 260
En la tabla siguiente se muestra los resultados de la clasificación obtenidos (contenido de la tabla OPCIONES_COMPRAS) ordenados por fecha:
NOMBRE_ACCION FECHA WILLIAMS MEDIA_MOVIL
COTIZACION
VOLUMEN CLUSTER_ID
CDEG_CLUSTER ROW_ID
TELEFONICA 11/02/1998 83.33 8.64 8.63 14599341 3 0.9095569 1 TELEFONICA 12/02/1998 94.2 8.66 8.43 10380939 3 0.9049888 2 TELEFONICA 13/02/1998 81.42 8.67 8.51 10083843 3 0.90298652 3 TELEFONICA 16/02/1998 94.8 8.67 8.35 8468571 3 0.90272564 4 TELEFONICA 01/10/1998 83.14 9.21 8.51 20917612 3 0.94132086 5 TELEFONICA 02/10/1998 84.04 9.14 8.4 25632612 3 0.95750163 6 TELEFONICA 12/06/2002 95.23 10.53 9.31 36136088 3 0.90410709 7 TELEFONICA 13/06/2002 96.44 10.44 8.93 46403024 3 0.91214998 8 TELEFONICA 14/06/2002 87.45 10.32 8.81 48607488 3 0.91466276 9 TELEFONICA 19/06/2002 88.79 10.01 8.76 27078784 3 0.91678895 10 TELEFONICA 20/06/2002 97.21 9.91 8.53 32773256 3 0.93908004 11 TELEFONICA 21/06/2002 88.66 9.81 8.35 61710028 3 0.91564279 12 TELEFONICA 24/06/2002 99.6 9.69 7.84 41119508 3 0.96837604 13 TELEFONICA 25/06/2002 92.49 9.54 8.01 49796080 3 0.95828652 14 TELEFONICA 26/06/2002 81.77 9.4 7.86 56335152 3 0.94577969 15 TELEFONICA 27/06/2002 81.35 9.26 7.86 42540968 3 0.98344575 16 TELEFONICA 03/07/2002 84.91 8.75 7.69 39335780 3 0.97425766 17 TELEFONICA 04/07/2002 82.12 8.63 7.75 35211988 3 0.96104122 18 TELEFONICA 03/09/2002 97.24 9.03 8.53 35261324 3 0.97565507 19 TELEFONICA 05/09/2002 86.02 9.04 8.43 44104288 3 0.98162142 20 TELEFONICA 09/09/2002 82.35 9.01 8.47 25374260 3 0.95330544 21 TELEFONICA 13/09/2002 83.82 8.98 8.44 42143200 3 0.98343034 22 TELEFONICA 16/09/2002 92.03 8.96 8.31 22203070 3 0.94737064 23 TELEFONICA 17/09/2002 84.09 8.9 8.36 41924360 3 0.98233536 24 TELEFONICA 18/09/2002 100 8.85 8.02 45275820 3 0.97685122 25 TELEFONICA 19/09/2002 92.43 8.79 7.98 36779824 3 0.9763093 26 TELEFONICA 20/09/2002 79.69 8.71 8.02 55387952 3 0.9176822 27 TELEFONICA 23/09/2002 92.46 8.64 7.73 43318660 3 0.96633441 28 TELEFONICA 24/09/2002 96.51 8.56 7.42 40148020 3 0.96236539 29 TELEFONICA 25/09/2002 84.49 8.46 7.5 34932392 3 0.947896 30 TELEFONICA 30/09/2002 88.83 8.26 7.25 45796968 3 0.9343819 31 TELEFONICA 01/10/2002 92.43 8.18 7.15 34697656 3 0.9281043 32 TELEFONICA 05/12/2002 87.03 9.44 9.18 43643656 3 0.95476775 33 TELEFONICA 09/12/2002 95.62 9.44 8.81 43520284 3 0.96306912 34 TELEFONICA 10/12/2002 83.44 9.44 8.9 33131816 3 0.95147415 35 TELEFONICA 11/12/2002 84.13 9.45 8.89 31256680 3 0.94694692 36 TELEFONICA 12/12/2002 91.08 9.44 8.68 34751672 3 0.95997895 37 TELEFONICA 13/12/2002 92.85 9.42 8.56 34482088 3 0.96279017 38 TELEFONICA 16/12/2002 82.65 9.38 8.68 33192328 3 0.95888046 39 TELEFONICA 17/12/2002 92.48 9.34 8.52 29222252 3 0.95485208 40 TELEFONICA 18/12/2002 97.77 9.29 8.35 34835748 3 0.97357297 41 TELEFONICA 19/12/2002 84.99 9.24 8.59 41366800 3 0.9811387 42 TELEFONICA 27/12/2002 96.26 9.12 8.35 22566272 3 0.95234213 43 TELEFONICA 30/12/2002 95.89 9.05 8.19 24942650 3 0.96004275 44 TELEFONICA 27/01/2003 81.44 9.25 9.06 62831932 3 0.92100378 45 TELEFONICA 28/01/2003 91 9.26 8.93 63538928 3 0.92177225 46 TELEFONICA 31/01/2003 88.23 9.34 8.8 49909744 3 0.95270755 47 TELEFONICA 04/02/2003 100 9.36 8.65 42615192 3 0.9719578 48 TELEFONICA 06/02/2003 82.39 9.31 8.63 44911844 3 0.9691745 49 TELEFONICA 07/02/2003 94.36 9.28 8.46 34320288 3 0.97041678 50 TELEFONICA 10/02/2003 92.25 9.22 8.48 35749144 3 0.97578081 51 TELEFONICA 13/02/2003 83.62 9.08 8.56 27627684 3 0.95947231 52 TELEFONICA 25/02/2003 89.53 8.81 8.47 37731816 3 0.97348954 53 TELEFONICA 26/02/2003 85.1 8.79 8.43 41550808 3 0.9770974 54 TELEFONICA 05/03/2003 86.17 8.73 8.43 27322980 3 0.94700248 55 TELEFONICA 06/03/2003 96.8 8.71 8.32 26204268 3 0.94597084 56 TELEFONICA 07/03/2003 97.27 8.69 8.17 41249124 3 0.97926026 57 TELEFONICA 10/03/2003 100 8.68 7.92 29925176 3 0.95460755 58 TELEFONICA 12/03/2003 100 8.62 7.82 46629700 3 0.95981022 59 TELEFONICA 08/05/2003 94.25 9.82 9.44 36305304 3 0.93126426 60 TELEFONICA 12/05/2003 82.75 9.8 9.55 53300800 3 0.90946537 61 TELEFONICA 15/05/2003 96.66 9.79 9.39 33104808 3 0.92621183 62 TELEFONICA 19/05/2003 93.51 9.77 9.26 28974060 3 0.92032933 63 TELEFONICA 20/05/2003 86.95 9.74 9.27 33599020 3 0.93203565 64 TELEFONICA 21/05/2003 94.26 9.71 9 51818368 3 0.92855303 65 TELEFONICA 01/07/2003 86.36 10.12 9.93 44933844 3 0.90720706 66

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 261
De forma análoga, en la Figura 6-17 se muestra la sentencia dmFSQL para clasificar, la tabla en cuestión, contra el grupo 9 (elegido para obtener opciones de ventas). Como puede comprobarse en dicha sentencia, el resultado de la clasificación se deja en la tabla OPCION_VENTAS. También se ha determinado un umbral de pertenencia al grupo de ventas de 0.9, pudiendo ajustarse según interese obtener más o menos opciones de ventas.
En la tabla siguiente se muestra los resultados de la clasificación obtenidos (contenido de la tabla OPCIONES_VENTAS) ordenados por fecha: NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN
CLUSTER_ID
CDEG_CLUSTER
ROW_ID
TELEFONICA 25/02/1998 6.79 8.7 9.26 16559250 9 0.90300314 1 TELEFONICA 02/03/1998 1.57 8.74 9.55 14188269 9 0.90548165 2 TELEFONICA 03/03/1998 3.93 8.78 9.52 12367098 9 0.90229561 3 TELEFONICA 06/03/1998 3.73 8.85 9.59 13475808 9 0.90928751 4 TELEFONICA 09/03/1998 5.22 8.9 9.68 17015376 9 0.92148907 5 TELEFONICA 10/03/1998 1.33 8.95 9.94 22816260 9 0.94172573 6 TELEFONICA 11/03/1998 9.54 9.01 10.51 40961924 9 0.97375034 7 TELEFONICA 12/03/1998 11.65 9.11 11.05 45710260 9 0.9605253 8 TELEFONICA 13/03/1998 7.51 9.24 11.15 18205592 9 0.91695239 9 TELEFONICA 16/03/1998 18.14 9.37 10.93 14574132 9 0.9104221 10 TELEFONICA 14/10/1998 13.82 9 9.72 21766746 9 0.93748711 11 TELEFONICA 15/10/1998 1.63 9.04 9.92 17026116 9 0.93254719 12 TELEFONICA 16/10/1998 3.98 9.07 10.27 23528368 9 0.94121906 13 TELEFONICA 19/10/1998 5.3 9.13 10.25 10168542 9 0.91332202 14 TELEFONICA 20/10/1998 0.8 9.2 10.57 19697876 9 0.93129613 15 TELEFONICA 21/10/1998 6.42 9.31 10.43 13137102 9 0.92043921 16 TELEFONICA 22/10/1998 13.54 9.39 10.27 11230083 9 0.91617173 17 TELEFONICA 23/10/1998 3.98 9.43 10.78 19926520 9 0.92352377 18 TELEFONICA 26/10/1998 6.74 9.5 10.78 11122287 9 0.90028964 19
Figura 6-17. Sentencia dmFSQL para clasificar según centroides contra el cluster 9

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 262
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN
CLUSTER_ID
CDEG_CLUSTER
ROW_ID
TELEFONICA 26/09/2001 7.57 10.64 10.88 33098388 9 0.90133705 20 TELEFONICA 27/09/2001 3.53 10.58 10.96 35076616 9 0.90666886 21 TELEFONICA 03/10/2001 17.25 10.46 10.94 36551692 9 0.91550621 22 TELEFONICA 04/10/2001 6.95 10.45 11.22 40797476 9 0.91965418 23 TELEFONICA 10/10/2001 6.98 10.59 11.25 41908520 9 0.91573479 24 TELEFONICA 08/07/2002 14.48 8.49 8.67 34744768 9 0.92343639 25 TELEFONICA 12/07/2002 16.27 8.29 8.51 42503600 9 0.92769195 26 TELEFONICA 16/07/2002 16.98 8.23 8.53 52374284 9 0.90284678 27 TELEFONICA 17/07/2002 16.47 8.2 9.13 57015420 9 0.90388646 28 TELEFONICA 26/07/2002 6.59 8.39 9.4 48647164 9 0.93696449 29 TELEFONICA 29/07/2002 5.82 8.45 9.64 45577056 9 0.95174936 30 TELEFONICA 19/08/2002 19.29 8.76 9.46 29381456 9 0.93942618 31 TELEFONICA 20/08/2002 15.33 8.8 9.35 21587356 9 0.92072313 32 TELEFONICA 21/08/2002 17.1 8.85 9.34 25940288 9 0.93263503 33 TELEFONICA 22/08/2002 7.23 8.89 9.48 20206768 9 0.92410383 34 TELEFONICA 23/08/2002 9.86 8.97 9.44 29493384 9 0.94800114 35 TELEFONICA 26/08/2002 17.76 8.98 9.32 10799272 9 0.90267755 36 TELEFONICA 27/08/2002 10.48 8.98 9.47 23298914 9 0.93477288 37 TELEFONICA 18/10/2002 12.79 7.78 8.53 41719532 9 0.90691533 38 TELEFONICA 22/10/2002 7.14 7.85 8.78 36053548 9 0.90217332 39 TELEFONICA 28/10/2002 11.05 8.08 9.13 40375800 9 0.92931441 40 TELEFONICA 30/10/2002 15.82 8.26 9.1 39841740 9 0.93493197 41 TELEFONICA 31/10/2002 9.67 8.34 9.21 38820984 9 0.93829304 42 TELEFONICA 04/11/2002 0 8.42 9.65 39474528 9 0.95266789 43 TELEFONICA 05/11/2002 8.21 8.52 9.53 37644152 9 0.95001061 44 TELEFONICA 18/11/2002 16.03 9.03 9.56 37528452 9 0.97164361 45 TELEFONICA 21/11/2002 10.37 9.14 9.61 45832024 9 0.97926097 46 TELEFONICA 22/11/2002 0.91 9.19 9.75 29698068 9 0.96435683 47 TELEFONICA 25/11/2002 11.2 9.24 9.77 30365588 9 0.96841392 48 TELEFONICA 27/11/2002 8 9.3 9.81 37517496 9 0.98578499 49 TELEFONICA 28/11/2002 10.21 9.34 9.89 23230244 9 0.95288108 50 TELEFONICA 29/11/2002 15.07 9.38 9.85 33031292 9 0.97296555 51 TELEFONICA 02/12/2002 16.93 9.42 9.9 39502560 9 0.98731591 52 TELEFONICA 07/01/2003 0.97 8.86 9.15 38492208 9 0.95790099 53 TELEFONICA 08/01/2003 15.62 8.83 9.22 47526000 9 0.95398513 54 TELEFONICA 09/01/2003 2.34 8.79 9.39 39843408 9 0.96330248 55 TELEFONICA 10/01/2003 2.14 8.78 9.51 52423756 9 0.94688261 56 TELEFONICA 13/01/2003 7.45 8.79 9.63 38671764 9 0.96579869 57 TELEFONICA 14/01/2003 4.16 8.81 9.75 39231176 9 0.97052297 58 TELEFONICA 15/01/2003 16.95 8.86 9.56 40812128 9 0.97213799 59 TELEFONICA 16/01/2003 3.5 8.89 9.78 39585216 9 0.97532332 60 TELEFONICA 17/01/2003 14.61 8.93 9.6 54962840 9 0.94922319 61 TELEFONICA 20/01/2003 14.61 8.98 9.6 28725392 9 0.95011219 62 TELEFONICA 21/01/2003 12.86 9.03 9.63 38161836 9 0.97462193 63 TELEFONICA 23/01/2003 14.28 9.13 9.65 45825564 9 0.97972588 64 TELEFONICA 24/01/2003 19.19 9.19 9.65 38313280 9 0.98207142 65 TELEFONICA 17/02/2003 14.28 8.98 9.03 21742504 9 0.92164783 66 TELEFONICA 18/02/2003 5.81 8.95 9.18 31026612 9 0.9450727 67 TELEFONICA 17/03/2003 6.76 8.55 9.06 57982212 9 0.91472207 68 TELEFONICA 19/03/2003 11.76 8.55 9.31 49090556 9 0.94065795 69 TELEFONICA 21/03/2003 4.11 8.58 9.44 49928704 9 0.94279042 70 TELEFONICA 25/03/2003 20 8.61 9.18 40587968 9 0.9529707 71 TELEFONICA 04/04/2003 11.76 8.78 9.39 45588800 9 0.96005559 72 TELEFONICA 07/04/2003 16.66 8.84 9.69 45010064 9 0.97039113 73 TELEFONICA 09/04/2003 17.36 9 9.68 44304404 9 0.97846958 74 TELEFONICA 14/04/2003 13.19 9.21 9.75 23366074 9 0.95057787 75 TELEFONICA 15/04/2003 5.29 9.24 9.93 30891412 9 0.9726607 76 TELEFONICA 16/04/2003 12.1 9.28 9.88 28842226 9 0.96811514 77 TELEFONICA 17/04/2003 4.45 9.31 10 21651614 9 0.94940475 78 TELEFONICA 22/04/2003 4.76 9.35 10 20789664 9 0.94574897 79 TELEFONICA 23/04/2003 18.18 9.38 9.93 37549364 9 0.98469187 80 TELEFONICA 28/04/2003 18.42 9.5 10.02 35217568 9 0.9723608 81 TELEFONICA 29/05/2003 11.84 9.51 9.6 26924020 9 0.94803851 82 TELEFONICA 02/06/2003 5.2 9.49 9.84 30765564 9 0.96293694 83 TELEFONICA 03/06/2003 5.2 9.48 9.84 29851796 9 0.96124492 84 TELEFONICA 04/06/2003 3.92 9.49 9.9 36370188 9 0.97717069 85 TELEFONICA 05/06/2003 15.23 9.49 9.81 41110584 9 0.98616007 86 TELEFONICA 06/06/2003 4.42 9.48 10.01 33716712 9 0.96994729 87 TELEFONICA 09/06/2003 15.04 9.5 9.89 19674796 9 0.93800953 88 TELEFONICA 10/06/2003 15.92 9.52 9.88 25934234 9 0.95140439 89 TELEFONICA 11/06/2003 0 9.54 10.09 36089512 9 0.97118965 90 TELEFONICA 12/06/2003 0 9.57 10.18 38736420 9 0.97409789 91 TELEFONICA 13/06/2003 12.17 9.61 10.1 33163844 9 0.96130477 92
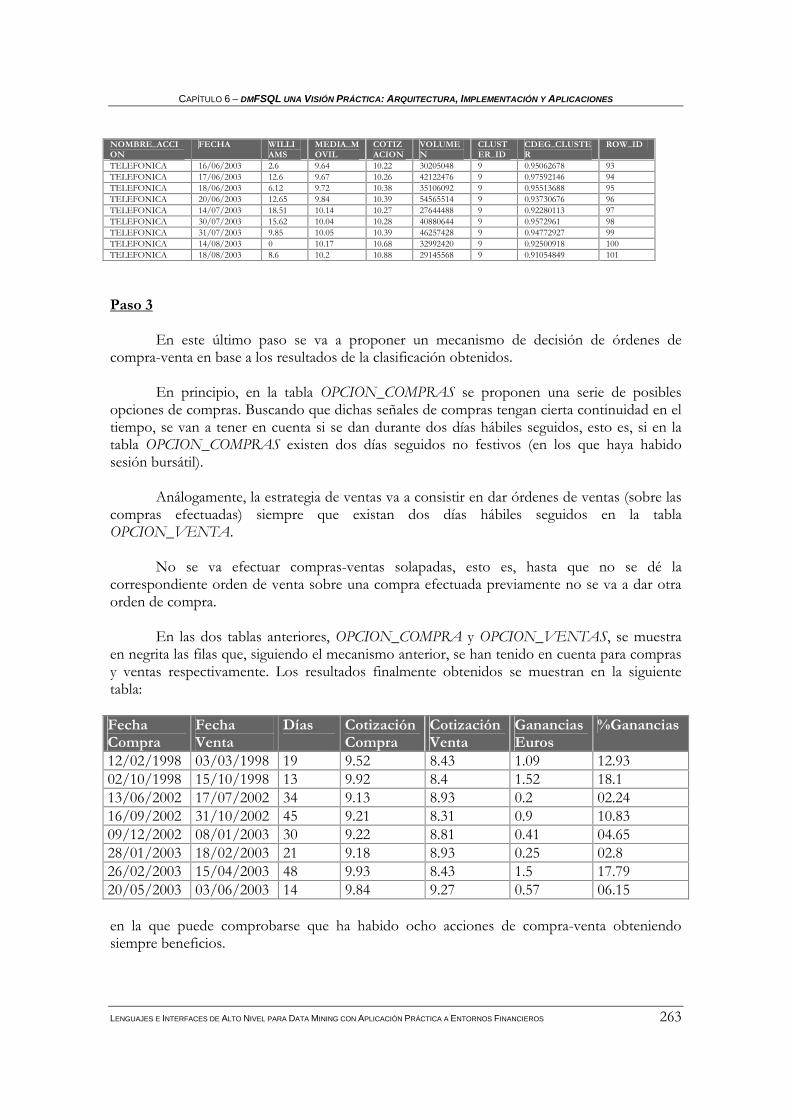
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 263
NOMBRE_ACCION
FECHA WILLIAMS
MEDIA_MOVIL
COTIZACION
VOLUMEN
CLUSTER_ID
CDEG_CLUSTER
ROW_ID
TELEFONICA 16/06/2003 2.6 9.64 10.22 30205048 9 0.95062678 93 TELEFONICA 17/06/2003 12.6 9.67 10.26 42122476 9 0.97592146 94 TELEFONICA 18/06/2003 6.12 9.72 10.38 35106092 9 0.95513688 95 TELEFONICA 20/06/2003 12.65 9.84 10.39 54565514 9 0.93730676 96 TELEFONICA 14/07/2003 18.51 10.14 10.27 27644488 9 0.92280113 97 TELEFONICA 30/07/2003 15.62 10.04 10.28 40880644 9 0.9572961 98 TELEFONICA 31/07/2003 9.85 10.05 10.39 46257428 9 0.94772927 99 TELEFONICA 14/08/2003 0 10.17 10.68 32992420 9 0.92500918 100 TELEFONICA 18/08/2003 8.6 10.2 10.88 29145568 9 0.91054849 101
Paso 3 En este último paso se va a proponer un mecanismo de decisión de órdenes de compra-venta en base a los resultados de la clasificación obtenidos. En principio, en la tabla OPCION_COMPRAS se proponen una serie de posibles opciones de compras. Buscando que dichas señales de compras tengan cierta continuidad en el tiempo, se van a tener en cuenta si se dan durante dos días hábiles seguidos, esto es, si en la tabla OPCION_COMPRAS existen dos días seguidos no festivos (en los que haya habido sesión bursátil). Análogamente, la estrategia de ventas va a consistir en dar órdenes de ventas (sobre las compras efectuadas) siempre que existan dos días hábiles seguidos en la tabla OPCION_VENTA. No se va efectuar compras-ventas solapadas, esto es, hasta que no se dé la correspondiente orden de venta sobre una compra efectuada previamente no se va a dar otra orden de compra. En las dos tablas anteriores, OPCION_COMPRA y OPCION_VENTAS, se muestra en negrita las filas que, siguiendo el mecanismo anterior, se han tenido en cuenta para compras y ventas respectivamente. Los resultados finalmente obtenidos se muestran en la siguiente tabla: Fecha Compra
Fecha Venta
Días
Cotización Compra
Cotización Venta
Ganancias Euros
%Ganancias
12/02/1998 03/03/1998 19 9.52 8.43 1.09 12.93 02/10/1998 15/10/1998 13 9.92 8.4 1.52 18.1 13/06/2002 17/07/2002 34 9.13 8.93 0.2 02.24 16/09/2002 31/10/2002 45 9.21 8.31 0.9 10.83 09/12/2002 08/01/2003 30 9.22 8.81 0.41 04.65 28/01/2003 18/02/2003 21 9.18 8.93 0.25 02.8 26/02/2003 15/04/2003 48 9.93 8.43 1.5 17.79 20/05/2003 03/06/2003 14 9.84 9.27 0.57 06.15 en la que puede comprobarse que ha habido ocho acciones de compra-venta obteniendo siempre beneficios.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 264
Si finalmente se concluye que el mecanismo es válido, todos los días habría que proceder a clasificar los datos contra los grupos 3 y 9 buscando las señales de compra y venta correspondientes. Téngase en cuenta que se pueden alterar los grados de pertenencia de dicha clasificación (que eran de 0.9) dependiendo de si se desea ser más o menos exigente en la orden de compra o de venta, ya que por exceso o por defecto pueden estar saltando un número de señales de compra-venta indeseable.

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 265
6.3.2 Estudios sobre la distribución de trabajadores en las empresas de economía social
La Sociedad de Estudios Económicos de Andalucía S.A. (ESECA) emite anualmente un informe sobre la Economía Social de Andalucía y su comparativa con el resto del Estado. En el informe del 2002 [Ese02] se incluye un estudio sobre la distribución, por división de actividad, del número de trabajadores de empresas consideradas de economía social. Dichos datos han sido recogidos en la relación EMPR_ECONOMIA_SOCIAL cuyos atributos son:
• comunidad: nombre de la comunidad autónoma; • inter_financiera: número de trabajadores en empresas de intermediación financiera; • construcción: número de trabajadores en empresas de construcción; • comercio_host: número de trabajadores en empresas de comercio y hostelería; • inmo_alq_ser_emp: número de trabajadores en empresas de actividades inmobiliarias y de
alquiler de servicios empresariales. El contenido de la tabla es el siguiente:
COMUNIDAD INTERM_FINANCIERA CONSTRUCCION COMERCIO_HOST INMO_ALQ_SER_EMP Andalucía 3775 7782 14832 2226 Aragón 899 1242 3415 448 Asturias 362 616 1677 355 Baleares 95 313 1058 138 Canarias 443 1420 2890 469 Cantabria 20 220 530 40 Cast.La Mancha 1478 3767 3934 374 Castilla León 975 1478 4004 208 Cataluña 769 7164 11271 3006 C.Valenciana 3356 4541 19595 2105 Extremadura 358 1515 2917 291 Galicia 111 1352 2644 505 Madrid 282 2599 5549 1109 Murcia 720 2883 4127 537 Navarra 462 1174 1478 600 PaísVasco 1849 3081 12293 847 La Rioja 81 50 657 33 Ceuta y Melilla 9 44 101 84
El problema que se va a plantear es estudiar “si similar número de trabajadores en empresas de intermediación financiera, en las distintos comunidades autónomas, implica similar número de trabajadores del resto de las variables”. Obviamente no existe un implicación de estos atributos desde el aspecto puramente crisps, así que se va a hacer una estudio de las DFD introducidas en esta memoria. Con dicho fin se proponen los siguientes pasos:

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 266
Paso 1 En primer lugar se va definir los distintos atributos de la tabla en el entorno de dmFIRST. La determinación que se ha tomado al respecto es definirlos como atributos difusos tipo 4 cuya función de comparación FEQ va a ser la distancia Hamming normalizada en [0,1] (HAMM) de forma análoga a la definición que se hecho para el atributos A del Ejemplo 4-1, teniendo en cuenta, para cada atributo, la cumplimentación de la dmFMB con la siguiente información:
• inter_financiera: mininter_financiera = 0, maxinter_financiera = 3800. • construccion: minconstruccion = 0, maxconstruccion = 7800. • comercio_host: mincomercio_host = 0, maxcomercio_host = 20000. • inmo_alq_ser_emp: mininmo_alq_ser_emp = 0, maxinmo_alq_ser_emp = 4900.
Paso 2 El segundo paso va ser la definición del proyecto de dmFSQL con los atributos y características relevantes para el proceso de obtención de este tipo de dependencias globales difusas. En principio, se va a estudiar si existe una implicación sin excepciones (confianza máxima) por tanto no hay que especificar ningún umbral en la definición del proyecto (son obtenidos con la correspondiente sentencia DML). La sentencia DDL de dmFSQL final es la siguiente:
CREATE_MINING PROJECT ECO_SOCIAL ON TABLE EMPR_ECONOMIA_SOCIAL WITH COLUMNS FOR FGLOBAL_DEPENDENCIES ANTECEDENT inter_financiera williams FCOMP_FGLOBAL_DEPENDENCIES FEQ CONSEQUENT construccion FCOMP_FGLOBAL_DEPENDENCIES FEQ, comercio_host FCOMP_FGLOBAL_DEPENDENCIES FEQ, inmo_alq_ser_emp FCOMP_FGLOBAL_DEPENDENCIES FEQ;
Paso 3 El tercer paso consiste en la ejecución del proceso de obtención de DGD del proyecto, expuesto en el paso anterior, mediante la sentencia DML de dmFSQL. Se va a especificar que se desean obtener los distintos umbrales de las variables implicadas, esto es la obtención de una (α i)-(β j) DGD X→ F*T*Y , y no una T-norma de los mismos. De esta forma se comprueba si existe distinto comportamiento en las variables (umbrales dispares). La sentencia DML aparece en la Figura 6-18 y el resultado visualizado por FQ tras el proceso en la Figura 6-19, que no es más que la ejecución de la sentencia SQL devuelta por el Servidor dmFSQL y que se muestra en la Figura 6-20. Como puede observarse en esta última figura, los resultados del proceso han sido almacenados en las correspondientes tablas de la dmFMB (DPR y DCL).
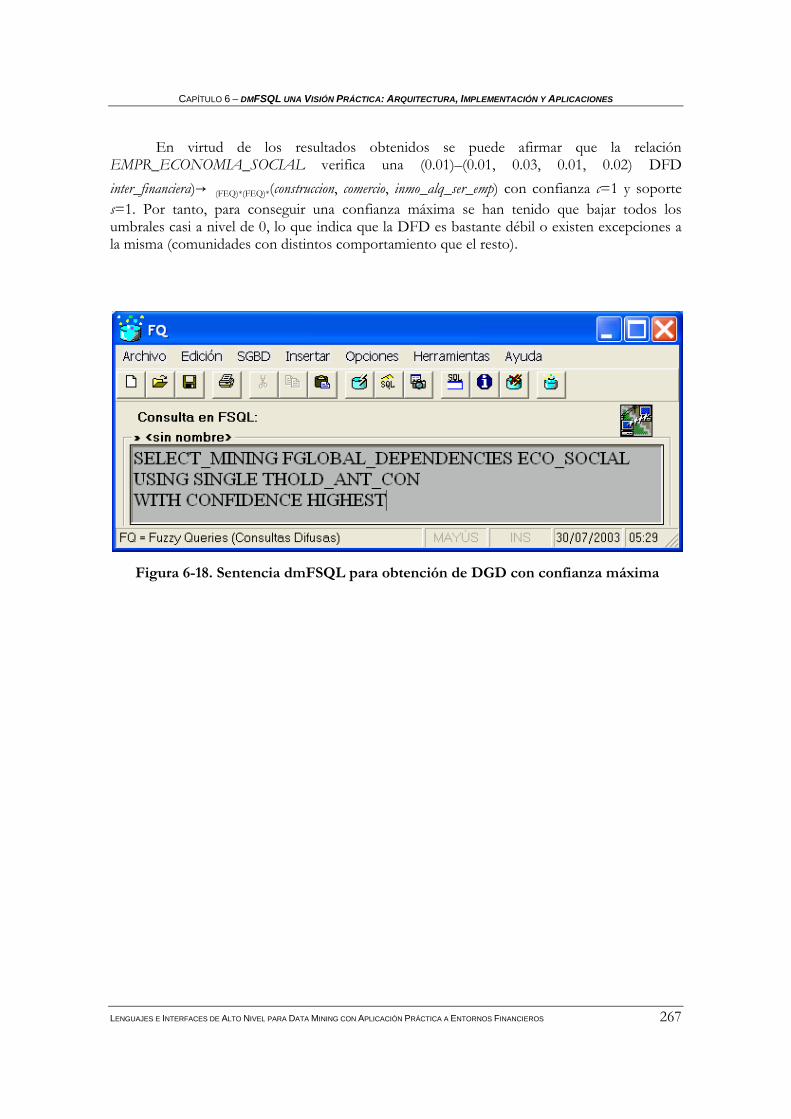
CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 267
En virtud de los resultados obtenidos se puede afirmar que la relación EMPR_ECONOMIA_SOCIAL verifica una (0.01)–(0.01, 0.03, 0.01, 0.02) DFD inter_financiera)→ (FEQ)*(FEQ)*(construccion, comercio, inmo_alq_ser_emp) con confianza c=1 y soporte s=1. Por tanto, para conseguir una confianza máxima se han tenido que bajar todos los umbrales casi a nivel de 0, lo que indica que la DFD es bastante débil o existen excepciones a la misma (comunidades con distintos comportamiento que el resto).
Figura 6-18. Sentencia dmFSQL para obtención de DGD con confianza máxima

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 268
Paso 4 Ahora se va a estudiar si han sido casos excepcionales dentro de la relación en cuestión los que han provocado que la DFD estudiada haya sido casi nula. Para ello se va modificar el proyecto especificando umbrales a nivel de antecedente y de consecuente de 0.7 (que se considera significativo). La sentencia DDL de dmFSQL que se realiza es la siguiente:
ALTER_MINING PROJECT ECO_SOCIAL ON TABLE EMPR_ECONOMIA_SOCIAL WITH COLUMNS FOR FGLOBAL_DEPENDENCIES ANTECEDENT
Figura 6-19. Resultado obtención de DGD con confianza máxima (FQ)
Figura 6-20. SQL generado tras la obtención de las DGD (FQ)

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 269
inter_financiera williams FCOMP_FGLOBAL_DEPENDENCIES FEQ THOLD_ANT 0.7 CONSEQUENT construccion FCOMP_FGLOBAL_DEPENDENCIES FEQ, comercio_host FCOMP_FGLOBAL_DEPENDENCIES FEQ, inmo_alq_ser_emp FCOMP_FGLOBAL_DEPENDENCIES FEQ THOLD_CON 0.7;
Paso 5 El quinto paso consiste, de nuevo, en la ejecución del proceso de obtención de DGD del proyecto, alterado (como se ha dicho en el paso anterior) para la obtención de una α -β
DGD X→ F*T*Y, esto es, con una T-norma sobre los umbrales del antecedente y del consecuente. La sentencia DML aparece en la Figura 6-21 y el resultado visualizado por FQ tras el proceso en la Figura 6-22. En virtud de los resultados obtenidos se puede afirmar que la relación EMPR_ECONOMIA_SOCIAL verifica una 0.7–0.7 DFD inter_financiera)→
(FEQ)*(FEQ)*(construccion, comercio, inmo_alq_ser_emp) con confianza c=0.64 y soporte s=0.44. Con lo que se puede concluir que realmente sí había muchos casos excepcionales, aunque quizás la confianza y, especialmente el soporte, no se puedan considerar los suficientemente altos para tener en cuenta la DFD.
Figura 6-21. Sentencia dmFSQL para obtencion de la DGD

CAPÍTULO 6 – DMFSQL UNA VISIÓN PRÁCTICA: ARQUITECTURA, IMPLEMENTACIÓN Y APLICACIONES
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 270
Como en los caso de clustering, caracterización y clasificación se podría intentar seguir afinando, por ejemplo, especificando umbrales distintos para cada columna del consecuente. Hay que hacer notar que las ejecuciones de DML sucesivas son sensiblemente más rápidas que la primera, justificado esta por la implementación hecha (ver 6.2.4.2).
Figura 6-22. Resultado obtención de DGD (FQ)

CONCLUSIONES Y LÍNEAS FUTURAS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 271
Conclusiones y Líneas Futuras En este trabajo se han aportado distintos resultados, entre cabe destacar los siguientes como más significativos:
• Definición del modelo teórico GEFRED* en el que es posible gestionar cualquier tipo de domino siempre que se pueda definir sobre él un comparador difuso complejo. Esto lo hace más general que GEFRED y permite que pueda ser aplicado a la resolución de problemas de DM.
• Definición e implementación del modelo FIRST* que no es más que la aplicación práctica del modelo GEFRED*. Partiendo del modelo práctico FIRST se han modificado sus componentes de tal manera que ha sido posible diseñar una arquitectura cliente-servidor para FIRST*. Parte de esta arquitectura es la FMB* (Base de Metaconocimiento Difuso) y el Servidor FSQL*. Ambos componentes han sido implementados y aplicados con éxito a la resolución de diversos problemas entre los que cabe destacar la redefinición de los comparadores difusos de FSQL mediante redes neuronales artificiales.
• Aplicación del modelo FIRST* para clustering basándose en un algoritmo de clustering jerárquico se ha conseguido realizar el proceso de clustering sin limitación alguna sobre los tipos de datos a gestionar ni sobre la imprecisión y/o ruido de los mismos, y con múltiples opciones de refinamiento. El método de clustering jerárquico elegido, permite que una vez obtenida la matriz ultramétrica, ésta pueda ser almacenada con lo que el problema de obtener la partición definitiva de la población se puede conseguir con múltiples ensayos con respuesta completamente on-line. Se ha propuesto algunos mecanismos automáticos de obtención de la partición definitiva basándose en Conjuntos Difusos.
• Aplicación del modelo FIRST* para caracterización de los distintos grupos obtenidos tras el proceso de clustering. Dicha caracterización se puede especificar a distintos niveles de abstracción, de tal manera que el usuario debe sopesar la descriptividad de los resultados con respecto a la precisión que desee. Además los resultados obtenidos indican el grado de representatividad conseguido. Nótese que si se aplica estos mecanismo de caracterización a los resultados de clustering de tal manera que toda la población se ha forzado que vaya al mismo grupo se consigue una técnica de caracterización sobre la tabla completa (esto es, se consigue una técnica de caracterización no asociada a un proceso de clustering previo).

CONCLUSIONES Y LÍNEAS FUTURAS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 272
• Aplicación del modelo FIRST* para clasificación difusa teniendo bien como referencia la caracterización de los grupos, o la tabla resultado del clustering usando un mecanismo de k-vecinos más cercanos. Esta última técnica puede ser una alternativa a usar, cuando la representatividad de los centroides no se considere suficiente. Las técnicas de clasificación difusas expuestas son bastante eficientes por lo que no habría ningún problema en aplicarlas a grandes bases de datos. Además estas técnicas son novedosas y ya existen trabajos de otros autores basados en ellas [Ver02].
• Aplicación del modelo FIRST* para dependencias globales difusas que son unas dependencias entre atributos que constituyen el marco común de las dependencias funcionales difusas [Cub94] y de las dependencias graduales difusas [Rus99]. Incluso permite la obtención de dependencias no englobadas en las anteriores, que además permite la gestión de excepciones (filas de las base de datos que no las cumplan).
• Definición e implementación del modelo dmFIRST que es la evolución del FIRST* para su uso para DM de tal manera que los procesos de clustering, caracterización, clasificación y dependencias globales difusas están completamente integrados y optimizados en el modelo. El interface con proceso de DM se realiza con el lenguaje dmFSQL aquí definido (se ha especificado tanto su DDL como su DML). Este lenguaje cumple la propiedad de clausura, de tal manera que es posible aplicar un proceso de DM a un resultado obtenido con anterioridad permitiendo el proceso de DM iterativo. Se ha diseñado una arquitectura cliente-servidor de dicho modelo. Parte de esta arquitectura es la dmFMB (Base de Metaconocimiento Difuso para Data Mining) y el Servidor dmFSQL. Ambos componentes han sido implementados y aplicados con éxito a la resolución de diversos problemas. Cabe destacar, que se han conseguido optimizaciones importantes del servidor dmFSQL usando técnicas de paralelismo y gestión de cachés.
Se considera que se han satisfecho los requerimientos expuestos en la introducción, de tal manera que, el sistema propuesto e implementado se puede catalogar como propiamente de DM, ya que cumple las características deseables de este tipo de sistemas: lenguaje de alto nivel, precisión, eficiencia, manejo de diferentes tipos de datos y extracción de conocimiento interactivo en múltiples niveles de abstracción. Los trabajos aquí presentados abren muchas líneas de investigación y desarrollo, entre ellas se podrían destacar las siguientes:
• Ampliación de las técnicas de DM que puedan realizarse dentro del ámbito de dmFIRST. Cabe destacar, que es posible dentro del actual modelo la obtención de ciertas reglas de asociación y estudio de tendencias. En este sentido, el propósito siguiente es integrar en el modelo y optimizar en su implementación dichas técnicas de DM.
• Independización de la implementación del modelo dmFIRST del SGBD sobre el que se ha construido. Aunque el uso de un lenguaje propietario de Oracle© para la implementación no se considera que haya ido en detrimento de la universalidad de la herramienta, dado la hegemonía de esta empresa a nivel mundial (y por supuesto en el sistema financiero español) una implementación, por ejemplo, en Java la haría por completo independiente del SGBD. Esta labor no se considera en absoluto complicada ya que el desarrollo del proyecto se ha hecho usando estrictamente una metodología y

CONCLUSIONES Y LÍNEAS FUTURAS
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 273
herramientas CASE que la soportan, tanto para el modelo de datos, como para el de procesos.
• Aunque los programas cliente originales de FSQL son compatibles para el nuevo lenguaje dmFSQL, sería conveniente el desarrollo de programas cliente específicos para DM, con funcionalidades que ayuden a dicho proceso: visualizaciones gráficas de los resultados, gestión versátil sobre la dmFMB a la hora del uso de sus distintos objetos (tipos de datos, proyectos, etc)…
• La opción de usar agentes inteligentes que sean los que vayan aprendiendo a ajustar los múltiples opciones de refinamiento que proporciona el modelo dmFIRST para el proceso de DM que pasaría a ser inteligente. Actualmente el grupo de investigación de la Universidad de Granada Idbis, en el que está integrado el autor de esta memoria, está desarrollando el proyecto de investigación fKIM (Fuzzy Knowledge-based Intelligent Miner) con dicho fin.
• dmFSQL se ha convertido en un entorno en el que se integran diferentes tipos de datos y comparadores, definidos de forma subjetiva, para la resolución de problemas de DM. Para la definición de los comparadores es posible usar técnicas de soft computing (redes neuronales artificiales, algoritmos genéticos, etc), estadísticas… que entran, por tanto, a formar parte de forma natural en el proceso de DM. Algunas de dichas definiciones merecería un estudio teórico en profundidad incluyendo sus implicaciones en los procesos de clustering, caracterización, clasificación y/o dependencias globales difusas. La ventaja es que las conclusiones de dicho estudio teórico puede ser fácilmente corroboradas en la práctica mediante la arquitectura implementada, que se ha presentado en esta memoria.


BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 275
Bibliografía [Ada80] J.M. Adamo, “Fuzzy Decision Trees”. Fuzzy Sets and Systems 4, pp. 207-219, 1980. [Adr97] P. Adriaans, D. Zantinge “Data Mining”. Addison Wesley Longman Limited,
Harlow, 1997. [Aki98] M.O. Akinde, O.G. Jensen, M.H. Böhlen, “Minimizing Detail Data in Data
Warehouse” in H.J. Schek, F. Saltor, I. Ramos, G. Alonso eds. “Advances in Database Technology-EDBT’98” pp. 293-307 Springer 1998.
[Ama92] O. Amat, X. Puig “Análisis Técnico Bursátil”. Ediciones Gestión 2000, S.A.,
Barcelona, 1992. [Bal79] J.F. Baldwin, N.C.F. Guild, “Comparison of Fuzzy Sets on the Same Decision
Space”. Fuzzy Sets and Systems 2, pp. 213-233, 1979. [Bar92] D. Barbara, H. Garcia-Molina, D. Porter, “The Management of Probabilistic Data”.
IEEE Trans. on Knowledge and Data Engineering, 4, pp. 487-502, 1992. [Bar98] E. Baralis, R. Meo, G. Psaila, “AMORE: Data Mining on a Relational Database” in
H.J. Schek, F. Saltor, I. Ramos, G. Alonso eds. “Advances in Database Technology-EDBT’98” pp. 39-40 Springer 1998.
[Bas77] S.M. Bass, H. Kwakernaak, “Rating and Ranking of Multiple-Aspect Alternatives
Using Fuzzy Sets”. Automatica 13, pp. 47-58, 1977. [Bla01] J.I. Blanco Medina “Deducción en Bases de Datos Relacionales Difusas”. Tesis
Doctoral, Universidad de Granada, Mayi 2001. [Ben76] J.P. Benzécri et coll. “L’analyse des données; Tome I: La taxinomie; Tome II:
L’analyse des correspondences”. Paris, Dunod, 1976. [Ber02] F. Berzal Galiano “ART Un método alternativo para la construcción de árboles de
decisión”. Tesis Doctoral, Universidad de Granada (España), Junio 2002. [Bez81] J.C. Bezdek. “Pattern Recognition with Fuzzy Objetive Function Algorithms”.
Plenum Press, New York, 1981. [Bra96] R. J. Brachman, T. Khabaza, W. Kloesgen, G. Piatetsky-Shapiro, E. Simoudis
“Mining Busines Databases”. Communication of the ACM Vol 39, No. 11 pp 42-48, 1996

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 276
[Bor99] G. Bordogna, G. Passi, “Linguistic Qualifiers of Vagueness and Uncertainty in a Fuzzy Object Oriented Data Model”. 3rd International ICSC Symposium on Soft Computing, SOCO'99, Genova (Italy), June 1999. ISBN: 3-906454-16-9.
[Bos88] P. Bosc, M. Galibourg, G. Hamon, “Fuzzy Querying with SQL: Extensions and
Implementation Aspects”. Fuzzy Sets and Systems, 28, pp. 333-349, 1988. [Buc82] B.P. Buckles, F.E. Petry, “Fuzzy Databases and their Applications”. In “Fuzzy
Information and Decision Processes”, Vol. 2. Eds. M. Gupta, E. Sanchez. North-Holand, Amsterdam, pp. 361-371, 1982.
[Buc84] B.P. Buckles, F.E. Petry, “Extending the Fuzzy Database with Fuzzy Numbers”.
Information Sciences 34, pp. 45-55, 1984. [Buc85] B.P. Buckles, F.E. Petry, “Query Languages for Fuzzy Databases”. In “Management
Decision Support Systems Using Fuzzy Sets and Possibility Theory”, Eds. J. Kacprzyk, R.R. Yager, pp. 241-252. Verlag TUV Rheinland Koln GR, 1985.
[Buc89] B.P. Buckles, F.E. Petry, H.S.Sachar, “A Domain Calculus for Fuzzy Relational
Databases”. Fuzzy Sets and Systems, 29, pp. 327-340, 1989. [Cam89] L.M. Campos, A. González, “A subjetive approach for ranking fuzzy numbers”.
Fuzzy Set and Systems, 29, pp. 145-153, 1989. [Can91] J.E. Cano, M. Delgado, I. Requena, “Comparación de Números Difusos usando
Redes Neuronales Artificiales”. I Con.Esp. T.L. Fuzzy. Granada, pp. 109-114, 1991. [Car98] R.A. Carrasco, “Data Mining: Un Prototipo para Clustering Financiero”. Trabajo de
Investigación, Universidad de Granada, Granada, Septiembre 1998. [Car98b] R.A. Carrasco, J. Galindo, M.C. Aranda, J.M. Medina, M.A. Vila, “Classification in
Databases using a Fuzzy Query Language”. In “Databases for the Millennium 2000”, eds. C.S.R. Prabhu, pp. 193-203. Ed. Tata McGraw-Hill Publishing Company Limited, 1998, ISBN: 0-07-463798-3.
[Car99] R.A. Carrasco, J. Galindo, M.A. Vila, J.M. Medina, “Clustering and Fuzzy
Classification in a Financial Data Mining Environment”. 3rd International ICSC Symposium on Soft Computing, SOCO'99, pp. 713-720, Genova (Italy), June 1999. ISBN: 3-906454-16-9.
[Car00] R.A. Carrasco, M.A. Vila, J. Galindo, J.C. Cubero, “FSQL: a Tool for Obtaining
Fuzzy Dependencies”. 8th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, IPMU'2000, pp. 1916-1919. Madrid (Spain), July 2000. ISBN: 84-95479-02-8.
[Car00b] R.A. Carrasco, M.A. Vila, J. Galindo, J.C. Cubero, “Fuzzy Global Dependencies in
Databases”. X Congreso Español sobre Tecnologías y Lógica Fuzzy

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 277
(ESTYLF'2000), pp. 175-180. Sevilla (Spain), September 2000. ISBN: 84-699-3040-0.
[Car01] R. Carrasco, J. Galindo, A. Vila, “Using Artificial Neural Network to Define Fuzzy
Comparators in FSQL with the Criterion of some Decision-Maker”. In “Bio-inspired applications of connectionism.-2001”, eds. J. Mira and A. Prieto, Lecture Notes in Computer Science (LNCS) 2085, pp. 587-594. Ed. Springer-Verlag, 2001, ISBN: 3-540-42237-4.
[Car02] R.A. Carrasco, M.A. Vila, J. Galindo, “FSQL: a Flexible Query Language for Data
Mining”. In “Enterprise Information Systems IV”, eds. M. Piattini, J. Filipe and J. Braz, pp. 68-74. Ed. Kluwer Academic Publishers, 2002, ISBN: 1-4020-1086-9.
[Car02b] R.A. Carrasco, M.A. Vila, J. Galindo, A. Urrutia “DMFSQL server prototype”, VIII
Congreso Argentino de Ciencias de la Computación, CACIC 2002, pp 86, Universidad de Buenos Aires, Buenos Aires (Argentina), Octubre 2002. (http://www.dc.uba.ar/cacic2002)
[Car02c] R.A. Carrasco, M.A. Vila, J. Galindo, “Using a Soft Computing Technique for Data
Mining Applications”, I Workshop Chileno de Bases de Datos, pp. 161-168, Copiapó (Chile), Noviembre 2002 (http://www.jcc.uda.cl). ISBN: 956-291-506-9.
[Che96] M. Chen, J. Han, P.S. Yu “Data Mining: An overview from a Data Base
Perspective”. IEEE Transac. On Knowledge and Data Engineering Vol 8-6 pp 866-883, 1996.
[Che96b] D.W. Cheung, V.T. Ng, A.W. Fu, Y. Fu “Efficient Mining of Association Rules in
Distributed Databases”. IEEE Transac. On Knowledge and Data Engineering Vol 8-6 pp 911-922, 1996.
[Cod70] E.F. Codd, “A Relational Model of Data for Large Shared Data Banks”.
Communications of the ACM, 13, Nº 6, pp. 377-387, June 1970. [Cod72] E.F. Codd, “Relational Completeness of Data Base Sublanguages”. Data Base
Systems. Courant Computer Science Symposia Series, Vol. 6, pp. 65-98, Englewood Clifs, Nueva Jersey. Prentice Hall, NY 1972.
[Cod79] E.F. Codd, “Extending the Database Relational Model to Capture More Meaning”.
ACM Trans. on Database Systems, 4, pp. 262-296, 1979. [Cod86] E.F. Codd, “Missing Information (Applicable and Inapplicable) in Relational
Databases”. ACM SIGMOD Record, Vol. 15, Nº 4, 1986. [Cod86b] E.F. Codd, “The Twelve Rules for Relational DBMS”. San Jos_e, The Relational
Institute, Technical Report EFC-6, 1986. [Cod87] E.F. Codd, “More Commentary on Missing Information in Relational Databases”.
ACM SIGMOD Record, Vol. 16, Nº 1, 1987.

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 278
[Cod90] E.F. Codd, “The Relational Model for Database Management, Versión 2”. Reading
Mass.: Addison-Wesley, 1990. [Cub94] J.C. Cubero, M.A. Vila, “A new definition of fuzzy functional dependency in fuzzy
relational databases” International J. Intelligent Systems, Vol 9, pp. 441-449, 1994. [Cub97] J.C. Cubero, J.M. Medina, O. Pons, M.A. Vila “Extensions of a Resemblance
Relation” Fuzzy Sets and Systems, Vol 86-2, pp. 197-212, 1997. [Cub98] J.C. Cubero, J.M. Medina, O. Pons, M.A. Vila “Fuzzy loss less decompositions in
databases” Fuzzy Sets and Systems, Vol 97-2, pp. 145-167, 1998. [Dat86] C.J. Date, “Null Values in Database Management”. In “Relational Database:
Selected Writings”, Ed. C.J. Date. Reading Mass.: Addison-Wesley, 1986. [Dat86b] C.J. Date, “An Introduction to Database Systems”. Addison-Wesley, 4th. edition,
1986. [Dat97] C.J. Date, Hugh Darwen, “A Guide to SQL Standard”, 4th edition. Addisson-
Wesley, 1997. ISBN 0-201-96426-0. [Del88] M. Delgado, J.L. Verdegay, M.A. Vila, “A Procedure for Ranking Fuzzy Numbers
Ussing Fuzzy Relations”. Fuzzy Sets and Systems, 26, pp. 49-62, 1988. [Del96] M. Delgado, A.F. Gómez-Skarmeta, A. Vila, “On the Use of Hierarchical Clustering
in Fuzzy Modelling”. International Journal of Approximate Reasoning, 14, pp. 237-257, 1996.
[Dub80] D. Dubois, H. Prade, “Fuzzy Sets and Systems. Theory and Applications”.
Academic Press. New York, 1980. [Dub83] D. Dubois, H. Prade, “Ranking Fuzzy Numbers in the Setting of Possibility
Theory”. Information Sciences 30, pp. 183-224, 1983. [Dub85] D. Dubois, H. Prade, “Fuzzy Number. An Overview, the Analisis of Fuzzy
Information”. J.C. Bezdek CRS Press, Boca Raton F1. USA, 1985. [Dub92] D. Dubois, H. Prade, “Gradual rules in approximate reasoning”. Information
Sciences, Vol 61, pp. 103-122, 1992. [Dub92b] D. Dubois, H. Prade, “Generalized dependencies in fuzzy databases”. In
International Conference on Information Processing and Management of Uncertainty in Knowledge Based Systems, IPMU’92, Palma de Mallorca, Spain, pp. 263-266, 1992.
[Dur74] B.S. Duran, P.L. Odell “Lecture Notes in Economics and Mathematical Systems”.
Berlin, Springer-Verlag, 1974.

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 279
[Ese02] Sociedad de Estudios Económicos de Andalucia (ESECA), “Informe sobre la Economía Social de Andalucía”. Fundación Caja de Granaday Junta de Andalucía. Granada, 2002.
[Est98] M. Ester, R. Wittmann “Incremental Generalization for Mining in a Data
Warehousing Environment” in H.J. Schek, F. Saltor, I. Ramos, G. Alonso eds. “Advances in Database Technology-EDBT’98” pp.135-149 Springer 1998.
[Fra91] W.J. Frawley, G. Piatetsky-Shapiro, C.J. Matheus “Knowledge Discovery in
Databases: An Overview” in G. Piatetsky-Shapiro, W.J. Frawley eds. “Knowlege Discovery in Databases” pp. 1-31 The AAAI Press 1991.
[Fuk79] S. Fukami, M. Umano, M. Muzimoto, H. Tanaka, “Fuzzy Database Retrieval and
Manipulation Language”, IEICE Technical Reports, Vol. 78, N _ 233, pp. 65-72, AL-78-85 Automata and Language), 1979.
[Gal98] J. Galindo, J.M. Medina, O. Pons, J.C. Cubero, “A Server for Fuzzy SQL Queries”,
in “Flexible Query Answering Systems”, eds. T. Andreasen, H. Christiansen and H.L. Larsen, Lecture Notes in Artificial Intelligence (LNAI) 1495, pp. 164-174. Ed. Springer, 1998.
[Gal98b] J. Galindo, J.M. Medina, A. Vila, O. Pons, “Fuzzy Comparators for Flexible Queries
to Databases”. Iberoamerican Conference on Artificial Intelligence, IBERAMIA'98, pp. 29-41, Lisboa (Portugal), October 1998.
[Gal99] J. Galindo, “Tratamiento de la Imprecisión en Bases de Datos Relacionales:
Extensión del Modelo y Adaptación de los SGBD Actuales''. Tesis Doctoral, Universidad de Granada (España), Marzo 1999.
[Gal01] J. Galindo, A. Urrutia, R. Carrasco, M. Piattini, “Fuzzy Constraints using the
Enhanced Entity-Relationship Model”. Proceedings published by IEEE-CS Press of XXI International Conference of the Chilean Computer Science Society (SCCC), pp. 86-94. Punta Arenas (Chile), November 2001. ISBN: 0-7695-1396-4. ISSN: 1522-4902.
[Gal02] J. Galindo, A. Urrutia, M. Piattini, R. Carrasco, “Cuatro Tipos de Restricciones
Difusas en Especializaciones”, I Workshop Chileno de Bases de Datos, pp. 79-87, Copiapó (Chile), Noviembre 2002 (http://www.jcc.uda.cl). ISBN: 956-291-506-9.
[Geo93] R. George, B. Bucles, F. Petry, “Modeling Class Hierchies in the Fuzzy Object-
Oriented Data Model”. Fuzzy Sets and Systems, 60, p. 259-272, 1993 [Gow88] J.C. Gower “Classification, Geometry and Data Analysis” in H.H. Bock, Eds.,
Classification and Related Methods of Data Analysis. North-Holland. Amsterdam, 1988, pp.3-14
[Gra80] J. Grant, “Incomplete Information in a Relational Database”. Fundamenta
Informaticae, 3, pp. 363-378, 1980.

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 280
[Hal01] M. Halkidi, Y. Batistakis, M. Vazirgiannis, “Clustering Algorithms and Validity
Measures” SSDBM, 2001. [Gui74] J.L. Guigou “Analyse des donnéss et choix à critères multiples”. Paris, Dunod, 1974. [Han96] J. Han, Y. Fu, W. Wang, W. Gong, K. Koperski, D. Li, Y. Lu, A. Rajan, N.
Stefanovic, B. Xia, O.R. Zaiane, “DBMiner: A System for Mining Knowledge in Large Relational Databases” International Conference Data Mining and Knowledge Discovery (KDD ’96), pp. 250-255, Portland, Oregon, August 1996
[Imi96] T. Imielinski, H. Mannila “A Database Perspective on Knowledge Discovery”.
Communication of the ACM Vol 39, No. 11 pp 58-64, 1996 [Imi99] T. Imielinski, A. Virmani “MSQL: A Query Language for Database Mining”. In
“Data Mining and Kowledge Discovery III”, eds. Fayyad, Mannila and Ramakrishnan, pp. 373-408. Ed. Kluwer Academic Publishers,
[Inm96] W. H. Inmon “The Data Warehouse and Data Mining”. Communication of the
ACM Vol 39, No. 11 pp 49-50, 1996 [Kor98] H. F. Korth, A. Sillberschatz. “Fundamentos de Bases de Datos”. Mc-Graw Hill, 3ª
Edición, 1998 [Med94] J.M. Medina, “Bases de Datos relacionales difusas. Modelo teórico y aspectos de su
implementación”. Tesis Doctoral, Universidad de Granada (España), Mayo 1994. [Med94b] J.M. Medina, O. Pons, M.A. Vila, “GEFRED. A Generalized Model of Fuzzy
Relational Data Bases”. Information Sciences, 76(1--2), pp. 87-109, 1994. [Med96] J.M. Medina, D. Rashid, J.L. Torralbo, R. Vela, “A Visual Client for Querying a
Fuzzy Database Server”. VI International Conference on Information Processing and Management in Knowledge-Based Systems, IPMU'1996, Vol. I, pp. 7-12. Granada (Spain), 1996.
[Mei01] A. Meier, C. Savary, G. Schindler, Y. Veryha, “Database Schema with Fuzzy
Classification and Classification Query Language” Technical report fCQL. Information Systems Research Group. University of Fribourg. Switzerland (2001).
[Meo96] R. Meo, G. Psaila, S. Ceri “A New SQL-like Operator for Mining Association
Rules”. 22nd International Conference on Very Large Data Bases , VLDB’96, pp.122-133. Bombay (India), 1996.
[Mic84] R. S. Michalski, R. E. Stepp, “Learning from observation: Conceptual Clustering” in
R. Michalski, J. Carbonell, and T. Mitchell, Eds., Machine Learning: An Artificial Intelligence Approach. Springer-Verlag. Berlin, 1984, pp.331-363.

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 281
[Ras99] D. Rasmussen, R.R. Yager, “Finding fuzzy and gradual functional dependencies with SummarySQL” Fuzzy Sets and Systems, Vol 106-2, pp. 131-142, 1999.
[Req94] I. Requena, M. Delgado, J.L. Verdegay, “Artificial neural networks learn the criteria
of a real decision-maker to compare fuzzy numbers”. Fuzzy Sets and Systems 64, pp 1-19, 1994.
[Pet96] F.E. Petry, “Fuzzy Databases: Principles and Applications” (with chapter
contribution by Patrick Bosc). International Series in Intelligent Technologies. Ed. H.-J. Zimmermann. Kluwer Academic Publishers (KAP), 1996.
[Pra84] H. Prade, C. Testemale, “Generalizing Database Relational Algebra for the
Treatment of Incomplete/Uncertain Information and Vague Queries”. Information Sciences 34, pp.115-143, 1984.
[Pra84b] H. Prade, “Lipski's Approach toIncomplete Information Databases Restated and
Generalized in the Setting of Zadeh's Possibitity Theory”. Information Systems, 9, pp.27-42, 1984.
[Pra87] H. Prade, C. Testemale, “Fuzzy Relational Databases: Representational issues and
Reduction Using Similarity Measures”. J. Am. Soc. Information Sciences 38(2), pp. 118-126, 1987.
[Pra87b] H. Prade, C. Testemale, “Representation of Soft Constraints and Fuzzy Attribute
Values by means of Possibility Distributions in Databases”. In “Analysis of Fuzzy Information”,Vol. II: “Artificial Intelligence and Decision Systems”. Ed. J. Bezdek, CRC Press., pp.213-229, 1987.
[Pra90] H. Prade, “A Two-Layer fuzzy Pattern Matching Procedure for the Evaluation of
Conditions Involving Vague Quantifiers”. Journal of Intelligent and Robotic Systems, 3, pp.93-101, 1990.
[Pre93] R.S. Pressman, “Ingeniería del Software: Un enfoque práctico”. McGraw-Hill, 3ª
edición, 1993. [Pre98] F.E. Petry, “Fuzzy Databases: Principles and Applications” (with chapter
contribution by Patrick Bosc). International Series in Intelligent Technologies. Ed. H.-J. Zimmermann. Lkuwer Academic Publishers (KAP), 1996.
[San99] D. Sánchez, “Adquisición de Relaciones entre Atributos en Bases de Datos
Relacionales”. Tesis Doctoral, Universidad de Granada (España), Diciembre 1999. [Sar98] S. Sarawagi, S. Thomas, R. Agrawal, “Integrating Association Rule Mining with
Relational Database Systems: Alternatives and Implications”. ACM SIGMOND Conference on Managament of Data, SIGMOND ’98, Seattle (USA), 1998.
[Sch83] B. Schweizer, A. Sklar, “Probabilistic Metric Spaces”. North-Holland, 1983.

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 282
[She96] W.M. Shen, K. Ong, B. Mitbander, C. Zanieolo, “Metaqueries for Data Mining ”. In Usama M. Fayyad, Gregory Piatetsky-Sha, Padhraic Smyth, and Ramasamy Uthurusamy, (Eds), Advances in Knowledge Discovery and Data Mining, Menlo Park, Canada: AAAI Press.
[Tri79] E. Trillas, “Sobre Funciones de Negación en la Teoría de Conjuntos Difusos”.
Stochastica, Vol. 3 Nº 1, pp. 47-59, 1979. [Ull82] J.D. Ullman, “Principles of Database Systems” Computer Science Press, 2nd
edition, 1982. [Uma80] M. Umano, S. Fukami, M. Mizumoto, K. Tanaka, “Retrieval Processing from Fuzzy
Databases”. Technical Reports of IECE of Japan, Vol. 80, N _ 204 (on Automata and Languages), pp. 45-54, AL80-50, 1980.
[Uma82] M. Umano, “Freedom-O: A Fuzzy Database System”. In “Fuzzy Information and
Decision Processes”. Eds. M. Gupta, E. Sanchez. North-Holand, Amsterdam, Pub. Comp., pp. 339-347, 1982.
[Uma83] M. Umano, “Retrieval from Fuzzy Database by Fuzzy Relational Algebra”. In
“Fuzzy Information , Knowledge Representation and Decision Analysis”. Eds. M. Gupta, E. Sanchez. Pergamon Press, New York, pp. 1-6, 1983.
[Uma94] M. Umano, S. Fukami, “Fuzzy Relational Algebra for Possibility-Distribution-Fuzzy-
Relational Model of Fuzzy Data”. Journal of Intelligent Information Systems, 3, pp. 7-28, 1994.
[Urm98] S. Urman, “Oracle8: Programación PL/SQL”. Oracle Press & Osborne McGraw-
Hill, 1998. [Ver02] Y. Veryha, “Implementation of Fuzzy Classification Query Language using Stored
Procedures”. In “Enterprise Information Systems IV”, eds. M. Piattini, J. Filipe and J. Braz, pp. 90-97. Ed. Kluwer Academic Publishers, 2002, ISBN: 1-4020-1086-9.
[Vil79] M.A. Vila “Nota sobre el cálculo de particiones óptimas obtenidas a partir de una
clasificación jerárquica”. Actas de la XI Reunión Nacional de I.O., Sevilla, España, 1979.
[Vil97] M.A. Vila, J.C. Cubero, J.M. Medina, O. Pons “On the use of Soft Computing
Techniques in Data Mining Problems”. Technical report #DECSAI-96-01-12. Department of Computer Science and Artificial Intelligence. Universidad de Granada. Spain (1997).
[Web96] R. Weber, “Customer Segmentation for Banks and Insurance Groups with Fuzzy
Clustering Techniques”. Fuzzy Logic, London, United Kingdom, 1996. Article Nr. 23194

BIBLIOGRAFÍA
LENGUAJES E INTERFACES DE ALTO NIVEL PARA DATA MINING CON APLICACIÓN PRÁCTICA A ENTORNOS FINANCIEROS 283
[Won82] E. A. Wong, “Statistical Approach to Incomplete Information in Database Systems”. ACM Trans. on Database Systems 7, pp. 479-488, 1982.
[Yag87] R.R. Yager, S. Ovchinnikov et al. “Fuzzy Sets and Applications: Selected Pappers by
L. A. Zadeh”. Wiley Intersc., 1987. [Zad65] L.A. Zadeh, “Fuzzy Sets”. Information Control, 8, pp. 338-353, 1965. [Zad75] L.A. Zadeh, “The Concept of a Linguistic Variable and Its Application to
Aproximate Reasoning”. Information Sci., 8, pp. 199-248, pp. 301-357, 9, pp. 43-80, 1975.
[Zad78] L.A. Zadeh, “Fuzzy Sets as a Basis for a Theory of Possibility”. Fuzzy Sets and
Systems, 1, pp. 3-28, 1978. [Zad92] Zadeh, L.: “Knowledge Representation in Fuzzy Logic”. “An Introduction to Fuzzy
Logic Applications in Intelligent Systems”. Cap. 1. Ed: Kluwer Academic Publisher, 1992.
[Zem84] M. Zemankova-Leech, A. Kandel, “Fuzzy Relational Databases - A Key to Expert
Systems”. K.oln, Germany, Verlag T . UV Rheinland, 1984. [Zem85] M. Zemankova-Leech, A. Kandel, “Implementing Imprecision in Information
Systems”. Information Sciences, 37, pp. 107-141, 1985. [Zhu91] Q. Zhu, E.S. Lee, “Comparison and ranking of fuzzy numbers”. Fuzzy Regression
Analysis. J. Kacpryk and Fedrizzi, eds. Omnitech Press, Warsaw, Poland, pp 21-44, 1991.
[Zim91] H.-J. Zimmermann, “Fuzzy Set Theory and its Applications”. 2nd Edition. Ed.
Kluwer Academic Publishers (KAP), 1991 [Zwi87] Zwick, R., Carlstein, E., Budescu, D.V. (1987). “Measures of similarity among fuzzy
concepts: A comparative analysis”. International Journal of Approximate Reasoning, 1987, 1:221-242.