estudio de la metodologÍa del programa sandy para …
TRANSCRIPT

ESTUDIO DE LA METODOLOGÍA DEL PROGRAMA SANDY PARA CÁLCULOS DE PROPAGACIÓN DE INCERTIDUMBRES
OCTUBRE 2020
Beatriz Moreno García
DIRECTOR DEL TRABAJO FIN DE GRADO:
Oscar Luis Cabellos de
Francisco
Beatr
iz M
ore
no
Ga
rcía
TRABAJO FIN DE GRADO PARA
LA OBTENCIÓN DEL TÍTULO DE
GRADUADO EN INGENIERÍA EN
TECNOLOGÍAS INDUSTRIALES

Resumen
Desde el descubrimiento de la radiactividad, las reacciones nucleares, el neutrón y la
�sión nuclear, se desarrolló una considerable base de conocimientos en física nuclear sobre
estos procesos y sus características a partir de muchos experimentos so�sticados y a tra-
vés del desarrollo de modelos avanzados tanto en fenomenología como en la comprensión
teórica.
Las aplicaciones de la ciencia nuclear son muy numerosas: energía nuclear, medicina,
seguridad, caracterización de materiales, exploración geológica, seguridad y protección
radiológica, la promesa de la energía de fusión... Han tenido y tendrán un impacto impor-
tante en la sociedad.
Los avances de estas se facilitan y estimulan cada vez más mediante un mejor mode-
lado cuantitativo de los procesos físicos a través de herramientas de ingeniería mejoradas
y mayor potencia computacional. Esto permite una reducción en el requisito de usar su-
puestos y aproximaciones en la interpretación, prueba y validación de datos.
Para sacar provecho de estos avances, los modelos físicos deben codi�carse mejor y los
datos de entrada requeridos, en particular los datos nucleares, deben ser más precisos
y completos.
Además, se requieren en formatos que sean compatibles con el software que se utiliza
para modelar. La entrada debe incluir información de covarianza completa de modo que
las incertidumbres se puedan propagar para derivar márgenes de incertidumbre de los
parámetros operativos y de diseño al nivel de con�anza deseado.
En la física y la ingeniería nucleares existe una larga tradición de proporcionar librerías
1

de datos nucleares en respuesta a las necesidades de los usuarios.
En este trabajo, se ha utilizado la librería de uso general JEFF-3.3 desarrollada por
la OECD/NEA. El esfuerzo principal de esta librería está dirigido a mejorar los datos
nucleares para aplicaciones nucleares, energéticas (�sión - reactores comerciales de �sión
y reactores avanzados de generación IV, fusión nuclear) y no-energéticas (aplicaciones
médicas, aceleradores, astrofísica, etc...).
El objetivo del Trabajo Fin de Grado es analizar las incertidumbres de los datos nu-
cleares en un experimento de criticidad muy conocido, el experimento GODIVA. Este
experimento integral de criticidad se encuentra descrito completamente en la base de
datos ICSBEP(International Criticality Safety Benchmark Evaluation Project) y utiliza
Uranio-235 como principal componente del experimento.
La criticidad se de�ne como la capacidad de un medio para mantener reacciones de
�sión en cadena. Está caracterizada por keff , un valor propio de la ec. de transporte que
se calcula como el cociente del número de neutrones generados en una generación y en la
anterior.
El valor de la keff se ha calculado mediante el código de transporte de neutrones
MCNP. Se trata de un código que permite simular el transporte de partículas mediante
técnicas de Monte Carlo (Monte Carlo N-Particle code). Utiliza librerías de datos nuclea-
res en formato ACE procesadas a partir de las librerías de datos puntuales con códigos
como NJOY a la temperatura de trabajo.
Las librerías procesadas en formato ACE para MCNP se han obtenido a través de dos
vías con diferentes códigos: la primera a través del código SANDY (utilizando NJOY
2

para obtener el formato de archivo necesario) y la segunda a partir del código FRENDY
a �n de comparar los resultados obtenidos con uno y otro.
SANDY (SAmpler of Nuclear Data and uncertaintY) es un paquete de Python que pue-
de leer, escribir y hacer operaciones con datos nucleares en formato ENDF-6. Su principal
objetivo es producir archivos perturbados de datos nucleares que incluyan la información
de incertidumbres de las propias librerías de datos nucleares.
Se ha utilizado para crear muestras de secciones e�caces (variando la sección e�caz
tanto únicamente de la �sión como la de todas las reacciones), factores de multiplica-
ción de neutrones (Nubar) y distribuciones energéticas (Prompt �ssion neutron spectra -
PFNS).
Los conjuntos de datos creados con SANDY se han tratado posteriormente con NJOY,
un código de procesamiento de datos nucleares desarrollado en el Laboratorio Nacional
de Los Álamos utilizado para convertir datos nucleares evaluados en formato ENDF en
otros formatos como en este caso el formato ACE para códigos de transporte de energía
continua Monte Carlo (MCNP).
El otro código empleado es FRENDY, un nuevo sistema de procesamiento de datos nu-
cleares desarrollado por la JAEA. FRENDY está diseñado poniendo énfasis en la facilidad
de mantenimiento, modularidad, portabilidad y �exibilidad. Para lograr estos requisitos,
FRENDY está escrito en un lenguaje orientado a objetos C ++. Los archivos de salida de
FRENDY están en formato ACE por lo que se pueden utilizar directamente como entrada
para MCNP sin necesidad de utilizar NJOY.
Se han creado muestras de archivos perturbados a partir de la información de cova-
3

rianzas de los propios datos nucleares al igual que con SANDY a �n de comparar los
resultados obtenidos por ambos. Se han comparado, además, con los resultados del pro-
yecto cooperativo internacional CIELO utilizando la metodología del código NDaST, es
decir, una aproximación de primer orden de Taylor que no tiene en cuenta efectos de
segundo orden ni las posibles no linealidades de los cálculos de transporte.
Se han utilizado 300 muestras diferentes de cada una de las variables analizadas (seccio-
nes e�caces, nubar y PFNS) generadas con cada uno de los códigos, SANDY y FRENDY.
Además de comparar las diferencias entre un código y otro, se han representado las ten-
dencias de la media y de la desviación típica con el número de archivos perturbados para
evaluar si son necesarios más para que sus valores converjan.
Se ha llegado a la conclusión de que el número de muestras empleado es su�ciente
puesto que la convergencia a los resultados �nales se observa en muchos casos incluso con
menor número de archivos perturbados.
Además, las diferencias numéricas entre las diferentes técnicas son muy escasas, si
bien la desviación típica originada por las incertidumbres de los datos nucleares es muy
superior a la experimental.
4

Abstract
Entre las múltiples fuentes de incertidumbre en los problemas nucleares, los datos
nucleares se consideran una de las más importantes. Debido a su importancia, se han
realizado numerosos esfuerzos para desarrollar métodos para propagar sus covarianzas en
modelos computacionales.
Recientemente, algunos institutos desarrollaron códigos de propagación de incerti-
dumbres basados en el muestreo estocástico (Método de Monte Carlo). En este trabajo
se evalúan los resultados obtenidos mediante dos de los códigos más actuales: SANDY y
FRENDY. Ambos códigos se aplican al análisis de criticidad de un experimento de refe-
rencia, el Modelo de 6 capas de GODIVA. Por último se realiza un análisis estadístico de
los valores obtenidos y una comparación entre ambos resultados y los obtenidos a partir
de la tecnología NDaST.
Palabras clave
Datos nucleares, Muestreo, Propagación de incertidumbres, SANDY, FRENDY
Códigos UNESCO
3320. Tecnología Nuclear
2207. Física Atómica y Nuclear
5

Índice
1. Introducción y motivación 8
2. Experimento de referencia 9
3. Datos nucleares 13
3.1. Introducción al formato ENDF-6 . . . . . . . . . . . . . . . . . . . . . . . 14
3.2. JEFF-3.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1. Uranio-235 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4. Códigos de procesamiento 23
5. NJOY 24
5.1. Módulos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
6. SANDY 28
6.1. Metodología . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
6.1.1. Secciones e�caces . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6.1.2. Factor de multiplicación en la �sión ν̄ . . . . . . . . . . . . . . . . . 32
6.1.3. Distribuciones angulares . . . . . . . . . . . . . . . . . . . . . . . . 34
6.1.4. Distribuciones energéticas . . . . . . . . . . . . . . . . . . . . . . . 34
6.2. Hipótesis y procedimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
7. FRENDY 37
7.1. Metodología . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
7.2. Hipótesis y procedimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
8. Propagación de Incertidumbres con la técnica de Montecarlo 41
9. Cálculos de Criticidad 43
6

9.1. MCNP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
9.1.1. Input MCNP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
9.1.2. Output MCNP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
10.JANIS 50
11.Resultados y conclusiones 51
11.1. SANDY a partir de MF=31 . . . . . . . . . . . . . . . . . . . . . . . . . . 51
11.2. SANDY a partir de MF=33 . . . . . . . . . . . . . . . . . . . . . . . . . . 55
11.2.1. MT=1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
11.2.2. MT=18 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
11.2.3. MT=102 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
11.3. SANDY a partir de MF=35 . . . . . . . . . . . . . . . . . . . . . . . . . . 66
11.4. FRENDY a partir de MF = 31 . . . . . . . . . . . . . . . . . . . . . . . . 70
11.5. FRENDY a partir de MF = 33 . . . . . . . . . . . . . . . . . . . . . . . . 73
11.5.1. MT = 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
11.5.2. MT = 18 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
11.6. FRENDY a partir de MF = 35 . . . . . . . . . . . . . . . . . . . . . . . . 79
11.7. Comparativa con los resultados a partir de otros métodos . . . . . . . . . . 82
12.Plani�cación y presupuesto 89
12.1. Plani�cación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
12.2. Presupuesto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
13.Siglas y abreviaturas 98
7

1. Introducción y motivación
La física de las reacciones nucleares incorpora información esencial para el diseño, el
funcionamiento y la clausura de sistemas nucleares. Los tipos de conocimiento requeridos
son tan diversos como las aplicaciones posibles. Algunos de los valores más relevantes son
las probabilidades de reacción (secciones e�caces), las probabilidades, energías y ángulos
de partículas emitidas, las probabilidades de formación de los distintos productos de �sión
y los diferentes procesos de desintegración y su partícula emitida.
Muchos de estos datos varían con la energía de la partícula incidente. Además, es im-
portante tener en cuenta las covarianzas de los datos con el �n de cuanti�car y propagar
las incertidumbres en las simulaciones.
Recientemente, con el aumento del poder computacional, algunos institutos han desa-
rrollado códigos de propagación de incertidumbres basados en el muestreo estocástico de
los datos nucleares, entre ellos podemos mencionar el método TMC [1], NUDUNA [2], el
módulo SAMPLER de SCALE 6.2 [3] y XSUSA [4].
En este trabajo se ha realizado un análisis de las incertidumbres de la librería evaluada
JEFF-3.3 en el experimento de criticidad GODIVA. Se ha utilizado el código de transpor-
te de neutrones MCNP para obtener el valor de keff , utilizando como entrada archivos
perturbados obtenidos mediante SANDY y FRENDY teniendo en cuenta las covarianzas
de la librería.
Finalmente, se ha realizado un tratamiento estadístico de los resultados y se han
comparado con los obtenidos mediante la tecnología NDaST.
8

2. Experimento de referencia
El experimentos GODIVA buscaba determinar la masa crítica de una esfera de uranio
enriquecida al 94% en peso sin recubrimiento. Se trata de uno de los experimentos mejor
realizados en el laboratorio de Los Álamos en la década de los 1950.
El experimento se realizaba con dos semiesferas de uranio enriquecido anidadas. El
conjunto superior estaba sujeto por un diafragma de acero inoxidable con un grosor de
0.015 pulgadas (el equivalente a 0.0381 cm), mientras que el conjunto inferior descansa-
ba sobre un cilindro de aluminio de pared delgada. Por control remoto, la parte inferior
se elevaba hasta entrar en contacto con el diafragma de acero para cada medición de la
multiplicación de neutrones de una pequeña fuente cercana al centro.
Figura 1: Con�guración experimental del experimento GODIVA
El análisis de este experimento condujo a la especi�cación de la masa crítica de una
esfera desnuda de HEU (Hight Enriched Uranium) denominada "Lady Godiva".
9

Se realizaron dos modelos de este experimento: la esfera Godiva desnuda y un modelo
de 6 capas, posteriormente denominado "Modelo de caparazón". Ambos son aceptables
como puntos de referencia de análisis de criticidad.
Las especi�caciones resultantes de Godiva para una keff = 1.000 con una desviación
estándar de 0.001 consisten en una esfera de uranio enriquecida al 94% sin recubrimiento
con un diámetro corregido de 6.883 pulgadas y una masa corregida de 52.42 kg, que inclu-
ye 0.02 kg, una cantidad casi insigni�cante, del Isótopo U236 y cantidades muy pequeñas
de impurezas (C, Si y Fe). Estas dimensiones son para un enriquecimiento de 235U de
93,71% en peso y una densidad de U de 18,74 g / cm3. Se estableció que la cantidad de
234U era 1,02% en peso, lo que da como resultado un contenido de 238U de 5,27% en peso.
Estas especi�caciones han sido utilizadas durante muchos años por grupos de trabajo
involucrados en la evaluación y validación de datos y códigos nucleares usados en cálculos
nucleares.
En las siguientes tablas se comparan las medidas de la esfera de GODIVA con el mo-
delo de 6 capas o de caparazón. Este último es el que se ha utilizado como punto de
referencia durante todo el trabajo. [5]
10

Región Isotopo Abundancia (% en peso)
U234 1.02
Capa 1 U235 93.26
U236 5.72
U234 1.02
Capa 2 U235 93.90
U236 5.08
U234 1.02
Capa 3 U235 93.95
U236 5.03
U234 1.02
Capa 4 U235 93.58
U236 5.40
U234 1.02
Capa 5 U235 93.89
U236 5.09
U234 1.02
Capa 6 U235 93.86
U236 5.12
Cuadro 1: Composición de cada una de las capas en el Modelo de caparazón de GODIVA
11
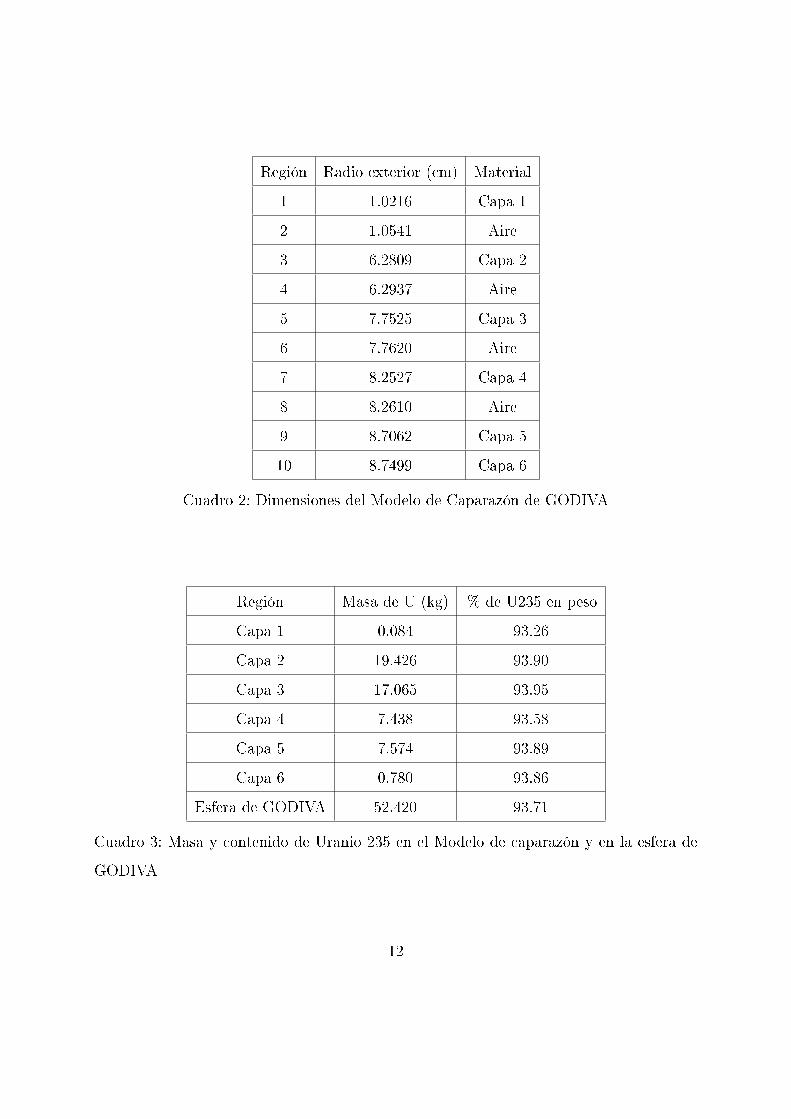
Región Radio exterior (cm) Material
1 1.0216 Capa 1
2 1.0541 Aire
3 6.2809 Capa 2
4 6.2937 Aire
5 7.7525 Capa 3
6 7.7620 Aire
7 8.2527 Capa 4
8 8.2610 Aire
9 8.7062 Capa 5
10 8.7499 Capa 6
Cuadro 2: Dimensiones del Modelo de Caparazón de GODIVA
Región Masa de U (kg) % de U235 en peso
Capa 1 0.084 93.26
Capa 2 19.426 93.90
Capa 3 17.065 93.95
Capa 4 7.438 93.58
Capa 5 7.574 93.89
Capa 6 0.780 93.86
Esfera de GODIVA 52.420 93.71
Cuadro 3: Masa y contenido de Uranio 235 en el Modelo de caparazón y en la esfera de
GODIVA
12

3. Datos nucleares
Una librería de datos nucleares de uso general debe contener toda la información de
la física de las reacciones nucleares esencial para el correcto funcionamiento y clausura de
los diferentes sistemas nucleares.
Es función de los evaluadores elaborar bases de datos de información para todos los
elementos e isótopos que puedan ser necesarios. A través de la base de datos internacional
EXFOR [6] de la OIEA (Organismo Internacional de Energía Atómica), tienen acceso a
una gran cantidad de datos experimentales para guiar este proceso. Sin embargo, solo una
pequeña fracción de una librería puede compararse directamente con las mediciones reales
como resultado de los extensos requisitos tomados para formarla.
Los modelos y códigos se desarrollan no solo para llenar los posibles vacíos, sino para
asegurar la consistencia de los datos. Debido a los desafíos fundamentales que presentan
los diferentes aspectos de la física nuclear, no existe ninguno que pueda calcular más de
una parte de los datos requeridos.
La integración de los numerosos sistemas y sus respectivas comunidades de expertos
es el principal desafío al que se enfrentan los administradores de programas de datos nu-
cleares al organizar los archivos.
Cada uno de los principales proyectos de datos nucleares de propósito general, incluidos
ENDF (Estados Unidos), JEFF (NEA Data Bank), JENDL (Japón), CENDL (China) y
ROSFOND (Rusia), desarrollan y publican librerías que incluyen numerosos isótopos.
13

3.1. Introducción al formato ENDF-6
El sistema ENDF se desarrolló para el almacenamiento y recuperación de datos nu-
cleares evaluados.
Una evaluación es el proceso de analizar los valores físicos medidos experimentalmente
(como secciones e�caces), combinándolos con las predicciones de los cálculos del modelo
nuclear para �nalmente intentar extraer los valores verdaderos de dichos parámetros. Ca-
da evaluación debe estar completa para su uso previso
La parametrización y reducción de los datos al formato tabular genera un conjunto de
datos evaluado. Si además hay disponible una descripción escrita de la preparación de un
conjunto de datos único se trata de una evaluación documentada.
Los formatos y librerías de ENDF son decididos por el Cross Section Evaluation Wor-
king Group(CSEWG), una cooperativa formada por laboratorios nacionales, industrias y
universidades en Estados Unidos y Canadá. Además, son mantenidos por el Centro Na-
cional de Datos Nucleares (NNDC).
Las versiones anteriores del formato ENDF proporcionaban representaciones para las
secciones e�caces y distribuciones de neutrones, la producción de fotones y algunas par-
tículas cargadas a partir de reacciones de neutrones, datos de interacción foto-atómica,
de dispersión de neutrones térmicos y de producción y descomposición de radionucleidos
(incluidos los productos de �sión).
La versión 6 de los formatos (ENDF-6) proporciona datos con energías incidentes más
altas, añade descripciones más completas de las distribuciones de partículas emitidas y
proporciona datos de partículas cargadas incidentes dividiendo la librería ENDF en sub-
14

librerías.
La librería ENDF/B mantenida en el Centro Nacional de Datos Nucleares (NNDC)
contiene la evaluación recomendada para cada material. Trata de ser lo más completa po-
sible; sin embargo, la integridad depende de la aplicación prevista. Por ejemplo, cuando
un usuario está interesado en realizar un cálculo de la física de un reactor o en hacer un
análisis de un blindaje, necesita datos evaluados para todas las reacciones inducidas por
neutrones cubriendo toda la gama de energías de incidencia posibles para cada material
del sistema. Además, para los neutrones secundarios se espera que el archivo contenga
información como las distribuciones angulares y de energía. Para otro cálculo, el usuario
podría estar interesado sólo en alguna activación de isótopos menores, así que estaría sa-
tisfecho por una evaluación que contenga sólo secciones e�caces de reacción. [7]
Cada evaluación ENDF se identi�ca mediante un conjunto de parámetros clave orga-
nizados en una jerarquía. A continuación se muestra una lista de estos parámetros y sus
de�niciones.
Library (NLIB, NVER, LREL, NFOR)
Una librería es una colección de evaluaciones de materiales de un grupo de evaluación re-
conocido. Cada una de estas colecciones se identi�ca con un número NLIB. Por ejemplo,
NLIB = 0 se corresponde con ENDF/B (United States Evaluated Nuclear Data File), 1
con ENDF/A (United States Evaluated Nuclear Data File),2 con JEFF (Joint Evaluated
Fission and Fusion File) o 6 con JENDL (Japan Evaluated Nuclear Data Library).
Los parámetros NVER, LREL y NFOR describen la versión, el número de lanzamiento y
el formato de la librería.
15

Partículas incidentes y tipos de datos (NSUB)
Dentro de las sublibrerías se distingue entre diferentes partículas incidentes y tipos de
datos utilizando NSUB = 10 * IPART + ITYPE. En esta fórmula, IPART = 1000 * Z
+ A de�ne la partícula incidente; siendo IPART = 0 para fotones incidentes o ningu-
na partícula incidente (datos de desintegración), IPART = 11 para electrones incidentes
y IPART = 0 para datos fotoatómicos o electroatómicos. De esta manera se tiene, por
ejemplo, NSUB = 4 para datos de desintegración radiactiva, 10 para datos de neutrones
incidentes o 12 para datos de dispersión de neutrones térmicos.
Material (MAT, MOD)
Las sublibrerías contienen los datos de diferentes materiales. Un material puede ser un
solo nucleido, un elemento natural que contiene varios isótopos o una mezcla de varios
elementos (compuesto, aleación, molécula, etc.). Un solo isótopo puede estar en el estado
fundamental o en un estado excitado. Cada material en una librería ENDF es asignado
un número de identi�cación único designado por el símbolo MAT que va de 1 a 9999.11.
Bloques de datos ENDF (File - MF)
Un File en la nomenclatura ENDF es un bloque de datos en una evaluación que describe
un cierto tipo de datos. Algunos valores relevantes son: 1 para Información General, 2
para parámetros de resonancia, 3 para secciones e�caces, 4 para distribuciones angulares
de partículas emitidas, 5 para distribuciones energéticas de partículas emitidas, 31 para la
covarianza de Nubar, 32 para la covarianza de los parámetros de resonancia, 33 para las
covarianzas de las secciones e�caces, 34 para las covarianzas de las distribución angulares y
35 para las covarianzas de las distribuciones energéticas de las partículas emitidas (PFNS).
Sección (MT)
Los diferentes bloques de datos identi�cados por MF se subdividen en secciones. Cada
16

una de ellas describe una reacción particular o un tipo particular de datos auxiliares (por
ejemplo, MT = 102 contiene datos de captura, MT = 18 contiene datos de �sión, etc.).
MT va de 1 a 999. [8]
17

3.2. JEFF-3.3
JEFF-3.3 es una librería de uso general que sirve a un amplio campo de aplicaciones de
tecnología nuclear. El desarrollo de JEFF-3.3 se centró en las necesidades de los siguientes
programas:
ASTRID (Advanced Sodium Technological Reactor for Industrial Demonstration),
un concepto francés de reactor rápido perteneciente a la Generación IV con mayor
sostenibilidad y seguridad que, además, produce una cantidad reducida de desechos
nucleares de alta actividad. Sus principales objetivos son el reciclaje múltiple de
plutonio para garantizar la sostenibilidad de los recursos naturales de uranio, la
transmutación de actínidos menores para reducir los desechos nucleares y lograr
una mayor seguridad en comparación con la Generación III.
MYRRHA (Multi-purpose Research Reactor for High-tech Applications), un reactor
de investigación desarrollado en Bélgica, que busca avanzar en el desarrollo de siste-
mas impulsados por aceleradores y promover el uso de reactores rápidos refrigerados
con plomo o con plomo y bismuto.
Los reactores de fusión ITER y DEMO. ITER se trata de un reactor tokamak que
forma parte de un proyecto internacional para demostrar la viabilidad cientí�ca y
tecnológica de la fusión como fuente de energía. DEMO es una planta de energía de
fusión nuclear de demostración (DEMOnstration power plant), que entregará una
cantidad sustancial de electricidad a la red y funcionará con un ciclo de combustible
de tritio cerrado.
IFMIF-DONES, un proyecto internacional cuyo objetivo es la construcción de una
fuente de neutrones para cuali�car los materiales que se van a utilizar en los futuros
reactores de fusión.
JEFF-3.3 también tiene como objetivo mantener o mejorar el rendimiento de los reactores
18

de agua a presión (PWR) actuales y futuros y los reactores de agua en ebullición (BWR)
para los que JEFF-3.1.1 y JEFF-3.2 demostraron un rendimiento excelente.
De particular interés son las preocupaciones por el transporte seguro, económico y
ecológico, el almacenamiento intermedio y la disposición �nal del combustible gastado.
Esto requiere cálculos precisos de transporte y agotamiento de neutrones para los análisis
de criticidad, la predicción de términos de fuente de radiación y el calor de desintegración.
Puesto que en este trabajo se ha tratado de evaluar la propagación de incertidumbres
de datos nucleares, utilizando como referencia el Modelo de 6 capas de GODIVA cuyo
principal componente es el Uranio-235 se va a proceder a explicar concretamente esta
parte de la librería JEFF-3.3. [9] [10]
19

3.2.1. Uranio-235
A �nales de la década de 1980 y principios de la de 1990, se realizó una evaluación
de resonancia Reich-Moore de 235U desde energía térmica hasta 2,25 keV utilizando el
código SAMMY. Este fue el primer intento de utilizar un método más riguroso para tener
en cuenta los efectos de interferencia en los canales de �sión. La evaluación representó
una mejora sustancial en comparación con las evaluaciones 235U anteriores basadas en
el formalismo BreitWigner de nivel único (SLBW) combinado con secciones e�caces de
fondo.
Se realizaron muy pocas pruebas comparativas integrales para evaluar la calidad antes
de su adopción en una librería evaluada. Las pruebas de referencia posteriores demos-
traron las de�ciencias de esta evaluación. En particular, estas pruebas sugirieron que se
subestimó la sección e�caz de captura en la región de energía de 22,6 a 454 eV. No se
encontraron problemas con la sección e�caz de �sión, pero si con la de captura puesto que
no se disponía de datos �ables. Además, los datos de sección e�caz de captura informa-
dos para energías de neutrones superiores a 100 eV sufrieron efectos de sesgo debido a la
normalización y las correcciones de fondo. Por lo tanto, en el proceso de evaluación no se
incluyeron datos de captura.
Posteriormente, se revisaron todos los datos utilizando los resultados de estudios com-
parativos integrales y extensos análisis de sensibilidad. Los resultados se incluyeron en las
librerías ENDF, JEFF y JENDL. El proyecto JENDL adoptó la evaluación hasta 500 eV y
utilizó una representación de resonancia sin resolver por encima de 500 eV para mejorar la
coherencia con los resultados de una evaluación comparativa de ensamblaje crítico rápido
(FCA).
La evaluación revisada produjo una sección e�caz de captura más alta que no estaba
20

respaldada por los resultados tanto de la FCA como del índice de referencia ZEUS (hmi6).
La posterior revisión de esta problemática, hizo que se recomendara considerar nuevas
mediciones de la sección captura en evaluaciones futuras. Se realizaron mediciones de la
sección e�caz de captura con la técnica de tiempo de vuelo de forma independiente en
el Instituto Politécnico Rensselaer (RPI) y en el Laboratorio Nacional de Los Alamos
(LANL).
Los resultados de estas mediciones se incluyeron en un análisis de resonancia para
actualizar los parámetros de resonancia de 235U en el rango de energía de energía térmica
a 2,25 keV. Usando los nuevos parámetros de resonancia, los resultados de los puntos de
referencia integrales podían reproducirse mejor. Desafortunadamente, los datos de sección
e�caz de �sión derivados de estos parámetros mostraron marcadas diferencias con los re-
comendados por la evaluación de estándares.
Recientemente, los datos de secciones e�caces de �sión resultantes de mediciones en
la instalación nTOF brindaron un fuerte apoyo a las recomendaciones de la evaluación
de estándares. De hecho, normalizando los datos de �sión nTOF de energía de 7.8 a 11.0
eV se obtiene como resultado una buena concordancia entre estos y las secciones e�caces
evaluadas en la región de baja energía, lo que respalda las secciones e�caces de �sión
promediadas en la región de resonancia.
Rango de resonancia resuelto en el Uranio 235
Los parámetros de resonancia para energías de neutrones entre 10-5 eV y 2.25 keV se
derivaron de un análisis de resonancia utilizando los datos experimentales que se dan en
la siguiente tabla. Estos datos incluyen la transmisión de alta resolución, la sección e�caz
de �sión y las mediciones de η.
21
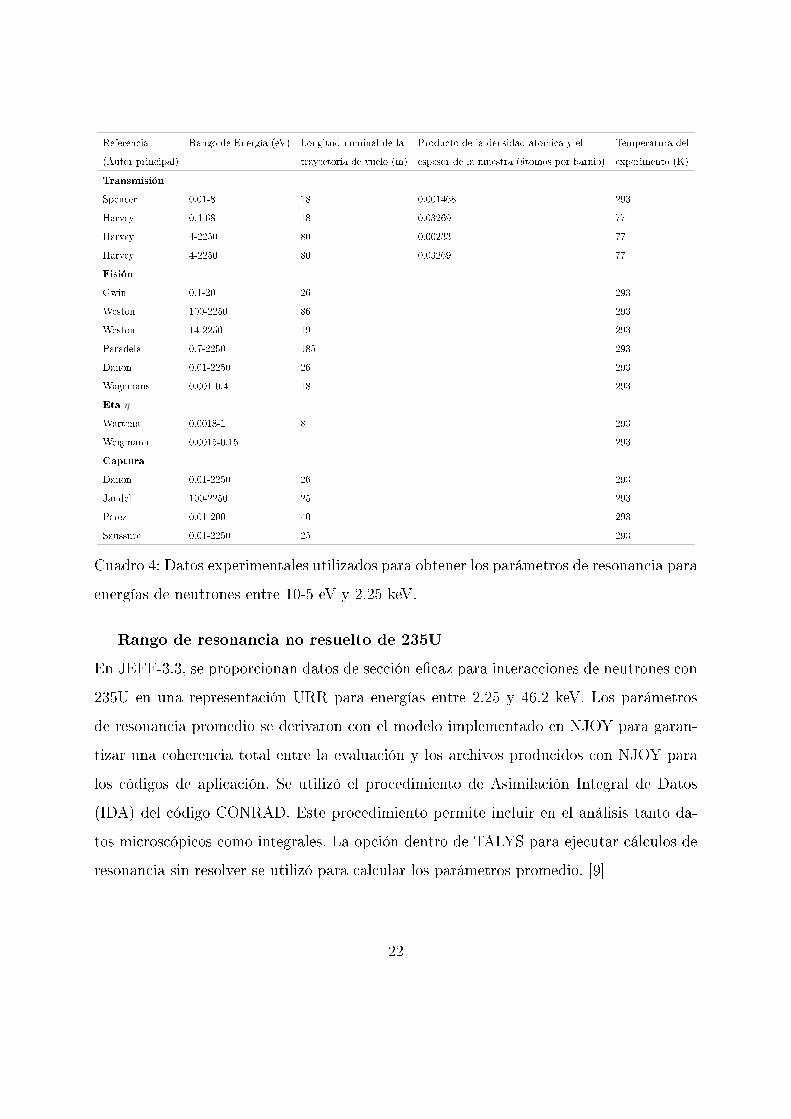
Referencia Rango de Energía (eV) Longitud nominal de la Producto de la densidad atómica y el Temperatura del
(Autor principal) trayectoria de vuelo (m) espesor de la muestra (átomos por barnio) experimento (K)
Transmisión
Spencer 0.01-8 18 0.001468 293
Harvey 0.4-68 18 0.03269 77
Harvey 4-2250 80 0.00233 77
Harvey 4-2250 80 0.03269 77
Fisión
Gwin 0.1-20 26 293
Weston 100-2250 86 293
Weston 14-2250 19 293
Paradela 0.7-2250 185 293
Danon 0.01-2250 26 293
Wagemans 0.001-0.4 18 293
Eta η
Wartena 0.0018-1 8 293
Weigmann 0.0015-0.15 293
Captura
Danon 0.01-2250 26 293
Jandel 100-2250 25 293
Perez 0.01-200 40 293
Saussure 0.01-2250 25 293
Cuadro 4: Datos experimentales utilizados para obtener los parámetros de resonancia para
energías de neutrones entre 10-5 eV y 2.25 keV.
Rango de resonancia no resuelto de 235U
En JEFF-3.3, se proporcionan datos de sección e�caz para interacciones de neutrones con
235U en una representación URR para energías entre 2.25 y 46.2 keV. Los parámetros
de resonancia promedio se derivaron con el modelo implementado en NJOY para garan-
tizar una coherencia total entre la evaluación y los archivos producidos con NJOY para
los códigos de aplicación. Se utilizó el procedimiento de Asimilación Integral de Datos
(IDA) del código CONRAD. Este procedimiento permite incluir en el análisis tanto da-
tos microscópicos como integrales. La opción dentro de TALYS para ejecutar cálculos de
resonancia sin resolver se utilizó para calcular los parámetros promedio. [9]
22

4. Códigos de procesamiento
Una vez que los conjuntos de datos evaluados se tienen en formato ENDF, se pueden
convertir en otros apropiados para pruebas y aplicaciones reales utilizando códigos de
procesamiento.
Algunos de estos códigos generan secciones e�caces puntuales y promediadas por gru-
pos para su uso en cálculos neutrónicos. Incluyen, además, funciones tales como recons-
trucción de resonancias o ensanchamiento Doppler.
El formato ENDF se ha desarrollado de tal manera que se imponen pocas restricciones
sobre el uso de los datos como entrada a los códigos que generan cualquiera de las librerías
secundarias.
23

5. NJOY
NJOY es un código de procesamiento de datos nucleares desarrollado en el Laboratorio
Nacional de Los Álamos. Se utiliza para convertir datos nucleares evaluados en formato
ENDF en otros formatos útiles para diversas aplicaciones que incluyen códigos de trans-
porte de energía continua Monte Carlo (MCNP), códigos de transporte deterministas
(PARTISN, ANISN, DORT) y códigos de celosía de reactor (WIMS, EPRI).
5.1. Módulos
NJOY consta de un conjunto de módulos principales, cada uno de los cuales realiza
una tarea de procesamiento bien de�nida. Son esencialmente programas informáticos in-
dependientes vinculados entre sí mediante archivos de entrada y salida.
Los módulos principales están respaldados por una serie de módulos subsidiarios que
proporcionan elementos como constantes físicas, rutinas de utilidad y subrutinas mate-
máticas.
Esta naturaleza modular de NJOY facilita la creacción de entradas para otros tipos
de librerías de aplicaciones o la adición de nuevas características computacionales.
Además, NJOY maneja una amplia variedad de efectos nucleares, incluyendo resonan-
cias, ensanchamiento Doppler, calentamiento (KERMA), daño por radiación, dispersión
térmica (incluidos moderadores fríos), producción de gas, neutrones y partículas cargadas
incidentes, interacciones fotoatómicas, reacciones fotonucleares, blindaje, tablas de pro-
babilidad, producción de fotones e interacciones de alta energía (a 150 MeV o más). La
salida puede incluir listados impresos, archivos de librería especiales para aplicaciones y
grá�cos Postscript.
24

En este trabajo, se ha utilizado NJOY para obtener archivos PENDF, o pointwise-
ENDF para emplear como entrada de SANDY y posteriormente para tratar los archivos
perturbados de SANDY y transformarlos a formato ACE (necesario para MCNP).
En el caso de FRENDY, los archivos obtenidos ya se encuentran en formato ACE por
lo que no es necesaria esta última transformación.
Los módulos empleados son:
NJOY dirige el �ujo de datos a través de los otros módulos y contiene una librería
de funciones comunes y subrutinas utilizadas por los otros módulos.
RECONR reconstruye secciones e�caces puntuales (dependientes de la energía) a
partir de parámetros de resonancia ENDF y esquemas de interpolación.
BROADR tiene en cuenta el efecto Doppler con lo que amplía y adelgaza las sec-
ciones e�caces puntuales.
GROUPR genera secciones e�caces multigrupo, matrices de dispersión de grupo a
grupo, matrices de producción de fotones y secciones e�caces de partículas cargadas
a partir de un archivo de entrada puntual.
ERRORR calcula matrices de covarianza multigrupo a partir de incertidumbres de
ENDF.
COVR lee la salida de ERRORR y realiza operaciones de trazado y formato de
covarianza.
ACER prepara librerías en formato ACE para el código MCNP de energía continua
de Los Alamos.
25

UNRESR calcula secciones e�caces puntuales en el rango de energía no resuelto.
El �ujo de trabajo seguido para obtener los archivos ACE necesarios es el más habitual
de NJOY.
RECONR lee un archivo ENDF y produce una tabla de datos de energía común para
todas las reacciones, denominada de unión, de manera que todas las secciones e�caces se
pueden obtener dentro de una tolerancia especi�cada por interpolación lineal.
Las secciones e�caces de resonancia se reconstruyen utilizando un método de elección
de la red de energía que incorpora control sobre el número de cifras signi�cativas generadas
y un criterio integral de resonancia para reducir el número de puntos de la red generados
para algunos materiales. Las secciones e�caces de suma (por ejemplo, total, inelástica) se
reconstruyen a partir de sus partes. Las secciones e�caces puntuales resultantes se escri-
ben en un archivo �point-ENDF� (PENDF) para uso futuro.
BROADR lee un archivo PENDF y amplía los datos teniendo en cuenta el efecto
Doppler. La rejilla de unión permite ampliar simultáneamente todas las reacciones de
resonancia, lo que se traduce en un ahorro de tiempo de procesamiento. Después de am-
pliar y reducir, las secciones e�caces de suma se reconstruyen nuevamente a partir de sus
partes. Los resultados se escriben en un nuevo archivo PENDF para uso futuro.
UNRESR produce secciones e�caces puntuales en función de la energía en el rango
no resuelto. Esto se hace para cada temperatura producida por BROADR, utilizando los
parámetros de resonancia promedio de la evaluación ENDF. Los resultados se agregan al
archivo PENDF utilizando un formato especial.
GROUPR procesa las secciones e�caces puntuales producidas por los módulos descri-
26

tos anteriormente en forma de multigrupo.
El módulo de covarianza, ERRORR, puede producir sus propias secciones e�caces
multigrupo utilizando los métodos de GROUPR o partir de un conjunto precalculado.
Las secciones e�caces y los datos de covarianza ENDF se combinan de una manera que
incluye los efectos de derivar una sección e�caz a partir de otras. Se incluyen característi-
cas especiales para procesar covarianzas para datos dados como parámetros o relaciones
de resonancia.
Los datos puntuales se pueden introducir directamente en el módulo ACER. Este
módulo prepara secciones e�caces y leyes de dispersión en formato ACE (A Compact
ENDF) para el código MCNP. Todas las secciones e�caces están representadas en una
cuadrícula de unión para interpolación lineal aprovechando la representación utilizada en
RECONR y BROADR. Las leyes para describir la dispersión y la producción de fotones
son muy detalladas de forma que proporcionan una representación �el de la evaluación
del formato ENDF con pocas aproximaciones. Los datos están organizados para acceso
aleatorio con �nes de e�ciencia. MCNP maneja el autoblindaje en el rango de energía no
resuelta usando tablas de probabilidad. [11]
27

6. SANDY
SANDY (SAmpler of Nuclear Data and uncertaintY) es un paquete de Python que
puede leer, escribir y hacer operaciones con datos nucleares en formato ENDF-6. Su prin-
cipal objetivo es producir archivos de datos nucleares que contengan ejemplos de valores
que re�ejen la información de las incertidumbres y covarianzas de las librerías evaluadas.
Esos archivos pueden ser utilizados para estudiar la propagación de incertidumbres utili-
zando técnicas como la de Montecarlo.
Para analizar archivos ENDF-6, recopilar datos nucleares, crear matrices de covarian-
za, extraer muestras de la distribución de probabilidad y realizar otras tareas relacionadas
con los datos nucleares, SANDY utiliza una interfaz de python de alto nivel.
Actualmente, SANDY puede trabajar con los siguientes datos nucleares:
Factor de multiplicación en la �sión ν̄ (MF = 31)
Parámetros de resonancia (MF = 32)
Secciones e�caces (MF = 33)
Distribuciones angulares de partículas salientes(MF = 34)
Distribuciones de energía de partículas salientes (MF = 35)
Desintegración radioactiva y rendimientos de �sión (MF = 8)
6.1. Metodología
SANDY se basa en gran medida en el trabajo de los evaluadores de datos nucleares,
ya que extrae muestras aleatorias de las matrices de covarianza que se encuentran en los
28

archivos ENDF-6. Sin embargo, los archivos ENDF-6 no proporcionan información so-
bre las funciones de distribución de probabilidad que siguen los datos nucleares, así que
SANDY toma como suposición que siguen una función normal multivariante.
Las salidas de SANDY son conjuntos de archivos de formato ENDF-6 o PENDF per-
turbados que se pueden utilizar para la propagación de la incertidumbre con técnicas
como la de Monte Carlo. Esta metodología para propagar incertidumbres se puede aplicar
a cualquier modelo, respuesta o código informático, siempre que sean compatibles con ar-
chivos en formato ENDF-6, ya sea directamente o mediante conversión de datos. Además,
los archivos perturbados no están limitados por ningún efecto implícito al procesamiento,
como son los multigrupos, el auto-blindaje o los efectos de temperatura.
Después del análisis estadístico de los archivos perturbados, se pueden cuanti�car la
media y la varianza de la muestra. SANDY no solo se puede utilizar para el estudio de la
varianza, sino que también permite estimar índices de sensibilidad global para parámetros
de entrada correlacionados y no correlacionados mediante métodos de descomposición. [12]
6.1.1. Secciones e�caces
Para perturbar correctamente las secciones e�caces, SANDY necesita que los datos
tabulados en MF3 se reconstruyan a partir de los parámetros de resonancia en MF2 y se
linealicen, de modo que para cualquier punto de energía se pueda recuperar un valor de
la sección e�caz mediante interpolación lineal.
Los archivos ENDF-6 que satisfacen estas condiciones se denominan archivos PENDF,
o pointwise-ENDF, y son reconocibles por un indicador especial en la sección MF1 /
MT451. Para producir tales archivos, es común utilizar códigos de procesamiento como
NJOY (módulo RECONR) o PREPRO (módulos RECENT y LINEAR). Hay que tener
29

en cuenta que SANDY no perturba las secciones e�caces de los archivos que no están en
formato PENDF.
Para perturbar las secciones e�caces, se puede optar por extraer las perturbaciones de
la sección MF33 en el archivo ENDF-6 original.
sandy <pendf_file> �cov <endf6_file> �samples 300 �mf 33
Sin embargo, de esta manera la información de covarianza para la región de resonancia
no se incluirá, aunque si que se proporcione la sección dedicada MF32.
La otra opción para incluir adecuadamente las contribuciones de MF32 y MF33 es
procesar el archivo ENDF-6 con el módulo NJOY ERRORR para una estructura de
multigrupos determinada y extraer perturbaciones de la matriz de covarianza procesada
escrita en el archivo de salida ERRORR.
sandy <archivo_pendf> �cov <archivo_errorr> �samples 300 �mf 33
Como ejemplo de los diferentes conjuntos de valores que se pueden obtener, a conti-
nuación se representa una muestra de 10 perturbaciones de todas las reaccionesMT=1 en
el rango de energías con mayor desviación típica para que sea más apreciable la variación.
30
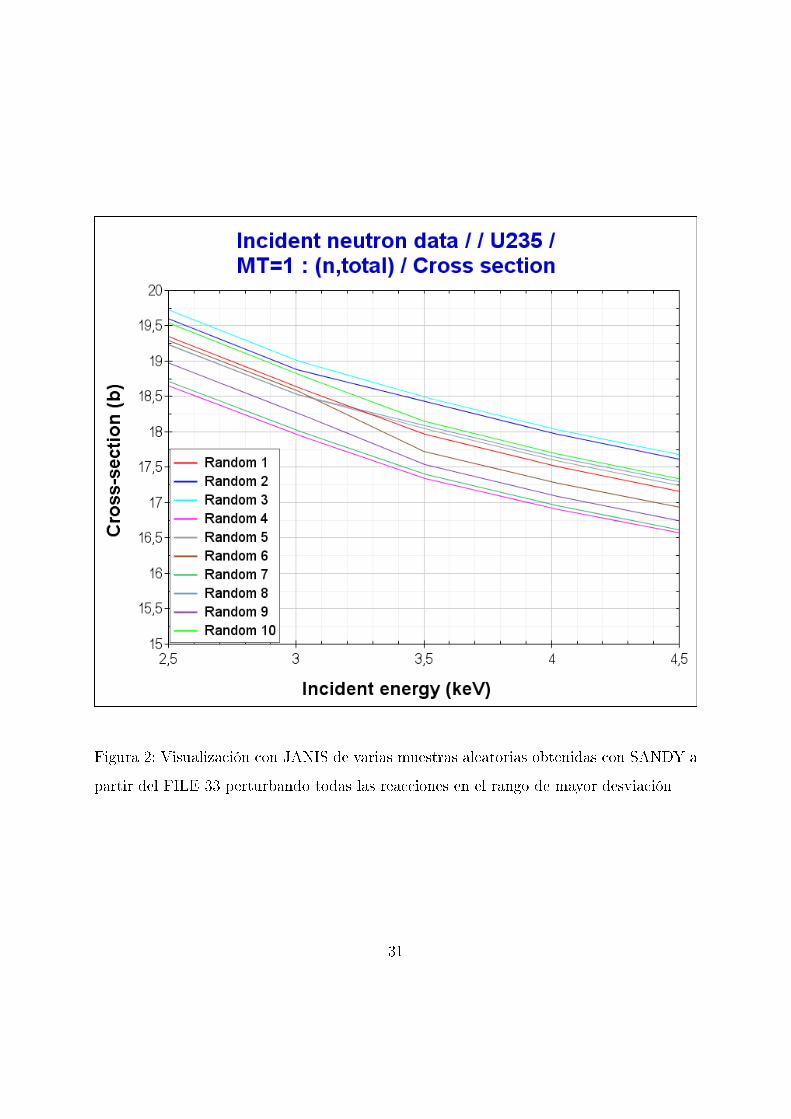
Figura 2: Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY a
partir del FILE 33 perturbando todas las reacciones en el rango de mayor desviación
31

6.1.2. Factor de multiplicación en la �sión ν̄
Las covarianzas para los factores de multiplicidad de neutrones de �sión promedio
(Nubar) se dan en MF31 para:
Neutrones de �sión totales MT = 452
Neutrones de �sión retardada MT = 455
Neutrones de �sión inmediatos
Para producir archivos perturbados en los que solo se varíen las multiplicidades de
neutrones de �sión, ha de escribirse:
sandy <endf6_file> �samples 100 �mf 31
En cuanto a las secciones e�caces, el ν̄ de �sión total redundante se reconstruye a
partir de la ν̄ de �sión inmediata y retardada.
32
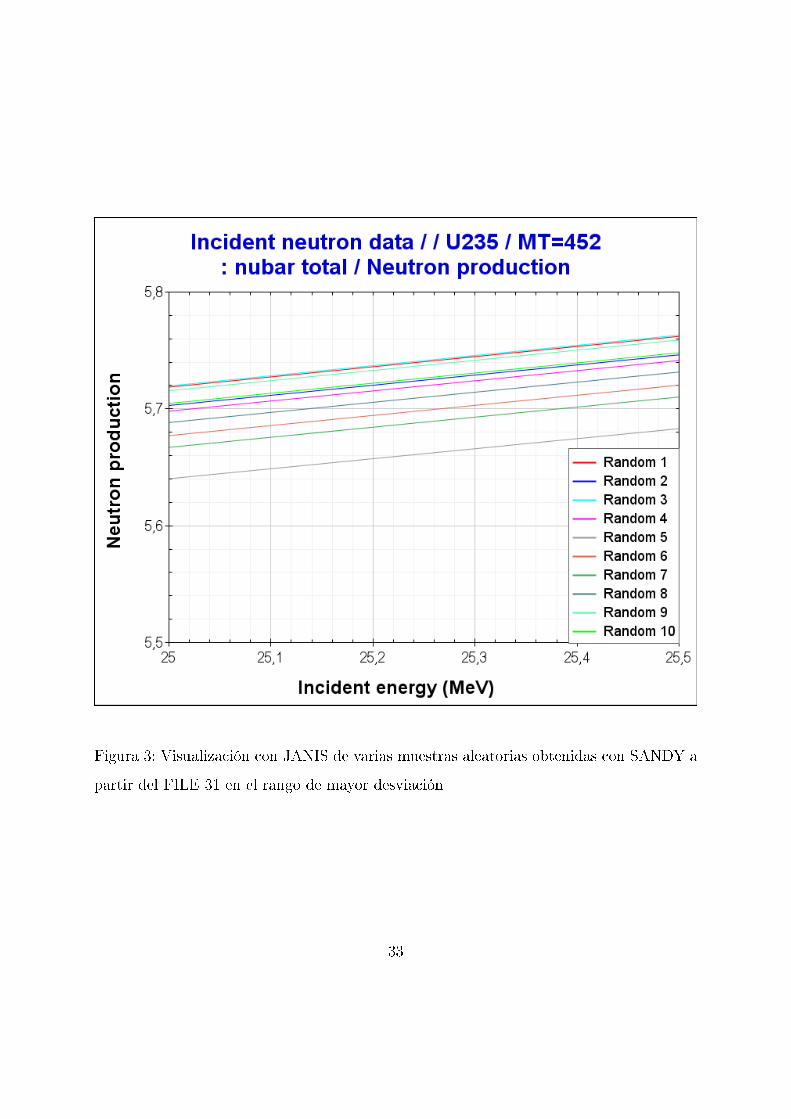
Figura 3: Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY a
partir del FILE 31 en el rango de mayor desviación
33

6.1.3. Distribuciones angulares
Los formatos ENDF-6 permiten almacenar distribuciones angulares en la sección MF4
de dos formas:
Tabulando la distribución de probabilidad normalizada en función de la energía
incidente;
Tabulando los coe�cientes de expansión del polinomio de Legendre en función de la
energía de neutrones incidente.
Sin embargo, las covarianzas correspondientes en MF34 solo aceptan la segunda forma.
Para ejecutar SANDY para perturbar solo las distribuciones angulares, ha de escribirse:
sandy <endf6_file> �samples 100 �mf 34
Si no se especi�ca ninguna opción, SANDY perturbará todos los coe�cientes polinomiales
de Legendre hasta cualquier orden.
6.1.4. Distribuciones energéticas
Las covarianzas para las distribuciones de energía saliente en MF35 se dan principal-
mente para espectros de neutrones de �sión rápida (PFNS) y para pocos rangos de energía
incidente, por lo que se asumen grandes correlaciones para distribuciones asociadas con
energías incidentes en el mismo rango. Además, el formato no permite correlaciones en-
tre espectros que no pertenezcan al mismo rango. Para perturbar solo distribuciones de
energía, se utiliza el siguiente código:
sandy <endf6_file> �samples 100 �mf 35
34
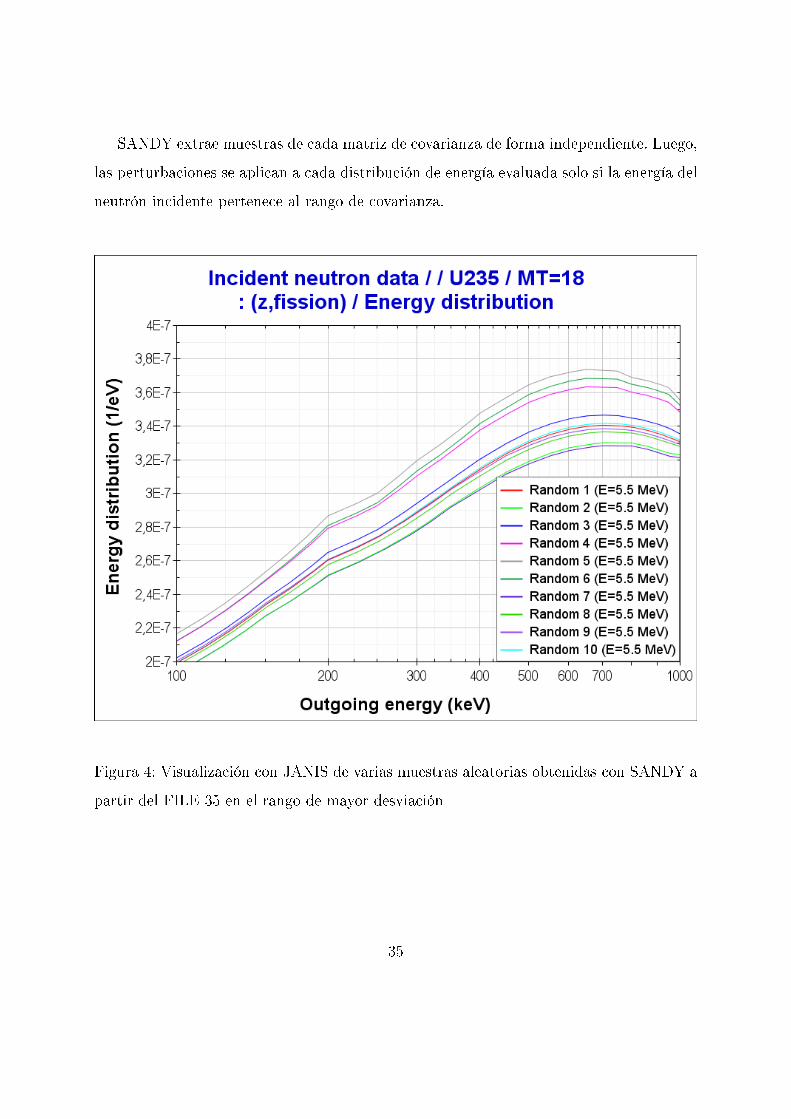
SANDY extrae muestras de cada matriz de covarianza de forma independiente. Luego,
las perturbaciones se aplican a cada distribución de energía evaluada solo si la energía del
neutrón incidente pertenece al rango de covarianza.
Figura 4: Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY a
partir del FILE 35 en el rango de mayor desviación
35

6.2. Hipótesis y procedimiento
Para evaluar la propagación de incertidumbres de datos nucleares se ha tomado una
muestra de 300 datos. Se ha supuesto que este es un tamaño considerable para el cual los
valores de la media y la desviación típica convergen lo su�ciente como para ser conside-
rados válidos.
Se ha ejecutado SANDY perturbando diferentes datos nucleares cada vez dando como
resultado muestras de los siguientes:
Secciones e�caces a partir de la información de covarianzas almacenada en MF
= 33. Se ha utilizado previamente NJOY para obtener la librería del Uranio 235 en
formato PENDF y en formato ERRORR.
Secciones e�caces a partir de la información de covarianzas almacenada en MF
= 33, perturbando únicamente las correspondientes a la reacción de �sión (MT =
18). Al igual que en el caso anterior, se ha utilizado NJOY para obtener la librería
del Uranio en formato PENDF y en formato ERRORR.
Nubar a partir de la información de covarianzas almacenada en MF = 31.
PFNS a partir de la información de covarianzas almacenada en MF = 35.
Se han obtenido un total de 1200 muestras, que han de ser procesadas posteriormente
por NJOY para ser transformadas a formato ACE, que se va a utilizar como entrada del
código MCNP.
36

7. FRENDY
La Agencia de Energía Atómica de Japón (JAEA) proporciona una librería de datos
nucleares evaluados JENDL y códigos de aplicación nuclear, por ejemplo, un sistema de
código de análisis de reactor versátil MARBLE2, un sistema de código de cálculo neutró-
nico integral SRAC, un código de Monte Carlo de propósito general MVP, y un Sistema
de código de transporte de iones PHITS.
Actualmente, las librerías de datos nucleares para estos códigos se procesan con siste-
mas combinados de sus módulos originales y otros módulos de NJOY y PREPRO.
Cuando se lanzó la nueva JENDL, estos sistemas de procesamiento a veces tenían pro-
blemas y era necesario modi�car los archivos. Además, dado que NJOY y PREPRO son
programas importados, JAEA no puede liberar su sistema de procesamiento de datos nu-
cleares. Por estas razones, con el lanzamiento de la nueva JENDL, los usuarios no podían
aplicar la nueva librería de datos nucleares a los códigos de aplicación nuclear inmedia-
tamente y tenían que esperar hasta que JAEA publicara nuevas librerías de sección e�caz.
Recientemente, se ha considerado la introducción de Datos Nucleares Generalizados
(GND) utilizando el formato XML. Dado que el formato XML es completamente diferente
del formato ENDF-6 actual, los sistemas de procesamiento de datos nucleares ampliamen-
te utilizados no pueden tratar el formato GND sin una modi�cación extensa.
Para superar estos problemas, JAEA comenzó a desarrollar un nuevo sistema de pro-
cesamiento de datos nucleares FRENDY (FRom Evaluated Nuclear Data libralY to any
application) en 2013. Para ello, se creó un equipo de desarrollo establecido en el Centro
de Ciencia e Ingeniería Nuclear de JAEA, teniendo miembros de los evaluadores de datos
nucleares y especialistas en cálculos neutrónicos. [13]
37

7.1. Metodología
FRENDY está diseñado poniendo énfasis en la facilidad de mantenimiento, modula-
ridad, portabilidad y �exibilidad. Para lograr estos requisitos, FRENDY está escrito en
un lenguaje orientado a objetos C ++. Dado que todas las clases de FRENDY están
encapsuladas, la capacidad de mantenimiento y la modularidad se mejoran en gran me-
dida con respecto a los sistemas de procesamiento de datos nucleares actuales escritos
en FORTRAN77. Además, para mejorar la portabilidad y la �exibilidad, cada clase está
cuidadosamente diseñada para minimizar la función y mantener la independencia de cada
módulo.
También se encapsulan módulos de FRENDY como la reconstrucción por resonancia
y el ensanchamiento Doppler. Estos módulos se pueden usar con otros códigos de cálculo
agregando solo unas pocas líneas. Cada módulo de FRENDY puede revisarse y ampliarse
fácilmente para las necesidades futuras. Para asegurar la calidad y con�abilidad, también
se considera la veri�cación de cada clase y función. La librería Boost Test se utiliza para
veri�car cada clase y función. Para la gestión del código fuente se utiliza el sistema de
control de versiones Git.
La versión actual de FRENDY solo admite el formato tradicional ENDF-6, pero pue-
de abordar GND u otros formatos de datos nucleares si se implementan nuevas clases de
analizador, escritor y convertidor. Genera el archivo ACE que se utiliza para los códigos
Monte Carlo de energía continua como PHITS y MCNP.
Además, los módulos de FRENDY y NJOY se pueden utilizar en combinación. Por
ejemplo, los usuarios pueden generar la librería de datos de sección e�caz multigrupo
38

utilizando el módulo GROUPR de NJOY con el archivo PENDF generado por FRENDY.
Los módulos NJOY disponibles en FRENDY son RECONR (reconstrucción de resonancia
y linealización), BROADR (ensanchamiento Doppler), GASPR (cálculo de la sección e�caz
de producción de gas), PURR (generación de tabla de probabilidad), UNRESR (cálculo
de cruz autoprotegida tipo Bondarenko) -sección), THERMR (cálculo de la sección e�caz
de la dispersión térmica), ACER (generación del archivo ACE) y MODER (modi�cación
del archivo PENDF). [14]
7.2. Hipótesis y procedimiento
Al igual que con SANDY, para evaluar la propagación de incertidumbres de datos
nucleares se ha tomado una muestra de 300 datos. Se ha supuesto que este es un tamaño
considerable para el cual los valores de la media y la desviación típica convergen lo su�-
ciente como para ser considerados válidos.
Se ha ejecutado FRENDY perturbando diferentes datos nucleares cada vez dando
como resultado muestras de los siguientes:
Secciones e�caces a partir de la información de covarianzas almacenada en MF
= 33.
Secciones e�caces a partir de la información de covarianzas almacenada en MF
= 33, perturbando únicamente las correspondientes a la reacción de �sión (MT =
18).
Nubar a partir de la información de covarianzas almacenada en MF = 31.
PFNS a partir de la información de covarianzas almacenada en MF = 35.
Se han obtenido un total de 1200 muestras que, sin embargo, no han de ser procesadas
posteriormente por NJOY pues ya se encuentran en formato ACE.
39

Se ha pretendido de esta manera veri�car que los valores obtenidos mediante ambos
procedimientos son similares.
40

8. Propagación de Incertidumbres con la técnica de
Montecarlo
La técnica de simulación de Monte Carlo se basa en simular la realidad a través del
estudio de una muestra generada de forma aleatoria. Resulta por ello de gran utilidad
en campos como el de la energía nuclear, en los que alguna información no es posible de
analizar o su coste es muy elevado.
El muestreo de Monte Carlo para la propagación de la incertidumbre consiste simple-
mente en ejecutar el mismo modelo varias veces, reemplazando cada vez los parámetros
de entrada con un nuevo conjunto de muestras. Este enfoque aporta numerosas ventajas
en comparación con otras técnicas de propagación de la incertidumbre, como la teoría
de perturbaciones, fundamentalmente por su sencillez. Su aplicación a cualquier modelo
resulta simple ya que no interactúa con él en sí, sino solo con los valores que se utilizan
como entrada. No es necesario desarrollar algoritmos complicados para calcular funciones
adjuntas para el modelo y las respuestas en estudio. Además, no se aplica solo localmente
alrededor de las mejores estimaciones de entrada, sino que puede cubrir todo el espacio
de fase de entrada y salida y puede representar efectos de cualquier orden del modelo, así
como las interacciones entre las entradas.
El mayor inconveniente de este método radica en la gran cantidad de conjuntos de
muestras que deben extraerse para garantizar la convergencia de las estadísticas de res-
puesta, es decir, para reducir el error estadístico en la mejor estimación de respuesta.
Las enormes mejoras en el rendimiento de los ordenadores en las últimas décadas, com-
binadas con las simpli�caciones del modelo y las reducciones de dimensionalidad, ayudan
a reducir el tiempo computacional de los solucionadores, lo que hace que el muestreo de
41

Monte Carlo sea una opción práctica para la propagación de la incertidumbre de los datos
nucleares. [12]
Para el análisis realizado en este trabajo, se ha estimado que 300 muestras de cada
caso serían su�cientes para garantizar esta convergencia, necesitando un tiempo de 744
segundos para la generación de cada muestra y de 20.38 minutos para la generación de
cada valor de keff con MCNP. Se han necesitado un total de 1311 horas de procesamiento
de datos.
42

9. Cálculos de Criticidad
Se de�ne la criticidad como la capacidad de un medio para mantener reacciones de
�sión en cadena. Está caracterizada por keff , valor propio de la ec. de transporte. Se
calcula como el cociente del número de neutrones generados en una generación y en la
anterior. [15]
Los análisis de criticidad tienen como objetivo demostrar la imposibilidad de que en
cualquier equipo o sistema pueda originarse originarse una reacción en cadena autososte-
nida. En caso de no ser así, los cálculos deberán determinar las condiciones de operación
y los parámetros físicos que es preciso limitar para conseguir mantener una situación sub-
crítica o bien ayudar a determinar la modi�cación de diseño que debe introducirse en el
sistema para conseguirla.
Se aplica el criterio de doble contingencia: los sistemas deben incorporar su�cientes
factores de seguridad para requerir, al menos, dos cambios improbables, independientes y
concurrentes antes de que sea posible un accidente de criticidad
Ello obliga a analizar todas las condiciones postulables, tanto en operación como en
accidente.
Los resultados del análisis de cada escenario, incluidas las incertidumbres y la valida-
ción del código, tienen que demostrar la existencia de un margen mínimo. Con carácter
general este deberá ser de 0.05 (es decir, ke�<0.95). Se podrán aceptarse margenes más
pequeños, aunque nunca inferior a 0.02 (ke�<0.98), para el caso de condiciones acciden-
tales de muy baja probabilidad.
Los cálculos se realizan habitualmente con códigos de Monte Carlo
43

Es necesario comprobar la validez de los resultados de un cálculo antes de aceptarlo.
Para ello hay que evaluar las incertidumbres debidas a los datos de entrada (como son los
datos nucleares, que es el objetivo de este trabajo), las desviaciones debidas a la herra-
mienta de cálculo y comparar los resultados con medidas experimentales.
9.1. MCNP
Es un código que permite simular el transporte de partículas mediante técnicas de
Monte Carlo (Monte Carlo N-Particle code). En MCNP el equivalente computacional de
una generación es un ciclo de keff . Se calcula keff como el ratio entre el número de neu-
trones de �sión generados en un ciclo de ke� y el número de neutrones al principio de ese
ciclo (número de neutrones de �sión producidos en una generación por neutrón de �sión
que la comenzó)
Fue desarrollado en Los Alamos y es ampliamente utilizado en diferentes plataformas
de cálculo. La última versión de MCNP es la 6 (MCNP6.1), liberada en 2014.
Utiliza librerías de datos nucleares en formato ACE procesadas a partir de las librerías
de datos puntuales con códigos como NJOY a la temperatura de trabajo.
La variación de esta temperatura induce cambios tanto en dimensiones y densidades,
como en secciones e�caces a raíz del ensanchamiento Doppler y de los cambios en el núcleo
de dispersión.
En MCNP se hace automáticamente ensanchamiento Doppler de las secciones e�caces
de dispersión elástica a la temperatura indicada en la tarjeta TMP (no ajusta las resonan-
44

cias o el núcleo de dispersión). TMP debe usarse cuando la celda no está a la temperatura
por defecto; si no, se corregirán las secciones e�caces de dispersión y total para llevarlas
a dicha Ta por defecto. [16]
9.1.1. Input MCNP
Contiene la descripción sobre la geometría del problema, la composición de cada pieza,
la localización y características de la fuente, el tipo de datos que se quieren cuanti�car
(tallies) y parámetros de control de la ejecución.
Todos estos datos se organizan en 4 secciones: title, cell, surface y data
Title: con información sobre el problema
Surface: con información de la geometría del problema. Las super�cies se de�nen
dando los coe�cientes de sus ecuaciones analíticas. Cada una de ellas se identi�can
con un número y divide el espacio en dos regiones, una positiva y la otra negativa.
Cell: completa la de�nición de la geometría del problema. Las celdas son volúmenes
que se de�nen combinando las super�cies con operadores booleanos. Al igual que
las super�cies, se identi�can con un número. Pueden estar rellenas de un material
o vacías.
Data: de�ne el resto de datos, es decir, los materiales (material command), término
fuente (SDEF command para fuentes �jas en general y KCODE command para
fuentes de criticidad), tallies (Fn command) y los parámetros de control (mode
command, imp command, nps command, print command y prdmp command)
Dentro de cada una de estas secciones hay comandos que se dan con una o más líneas
de hasta 80 caracteres que reciben el nombre de cards. [16]
45

Las unidades a emplear son:
Longitud en cm
Energía en MeV
Temperatura en MeV (kT )
Tiempo en unidades de 10−8 segundos (shakes)
Densidades atómicas en átomos/b− cm
Densidades másicas en g/cm3
Secciones e�caces en barn, 1024cm2
Calentamiento (energía en colisiones) en MeV/colisión
Ratio de pesos atómicos respecto a la masa del neutrón (1.008664967 u)
El input del experimento de referencia que utilizamos con cada una de las muestras
obtenidas es el siguiente [5]:
Idealized HEU Shell Exp from LA4208. Six Shells. 05/12/93.
1 1 4.8150E-02 -1 imp:n=1
2 7 5.0306E-05 1 -2 imp:n=1
3 2 4.8154E-02 2 -3 imp:n=1
4 7 5.0306E-05 3 -4 imp:n=1
5 3 4.8154E-02 4 -5 imp:n=1
6 7 5.0306E-05 5 -6 imp:n=1
7 4 4.8152E-02 6 -7 imp:n=1
8 7 5.0306E-05 7 -8 imp:n=1
9 5 4.8154E-02 8 -9 imp:n=1
46

10 6 4.7780E-02 9 -10 imp:n=1
11 0 10 imp:n=0
1 so 1.0216
2 so 1.0541
3 so 6.2809
4 so 6.2937
5 so 7.7525
6 so 7.7620
7 so 8.2527
8 so 8.2610
9 so 8.7062
10 so 8.7499
m1 92235.50c 4.4936E-02 92238.50c 2.7213E-03 92234.50c 4.9357E-04
m2 92235.50c 4.5244E-02 92238.50c 2.4168E-03 92234.50c 4.9357E-04
m3 92235.50c 4.5268E-02 92238.50c 2.3930E-03 92234.50c 4.9357E-04
m4 92235.50c 4.5090E-02 92238.50c 2.5690E-03 92234.50c 4.9357E-04
m5 92235.50c 4.5239E-02 92238.50c 2.4215E-03 92234.50c 4.9357E-04
m6 92235.50c 4.4874E-02 92238.50c 2.4169E-03 92234.50c 4.8974E-04
m7 7014.50c 3.5214E-05 8016.50c 1.5092E-05
kcode 100000 1.0 100 600
ksrc 0. 0. 0.
47

9.1.2. Output MCNP
MCNP usa tres estimadores para el cálculo de keff . El resultado del cálculo de criti-
cidad �nal es una combinación estadística de los tres: colisión, absorción y track-lenght.
El estimador de colisión suma para cada colisión que se produce en el material �siona-
ble el número medio de neutrones que se producirían como resultado del proceso de �sión
por 1 colisión. De esta manera, todas las colisiones contribuyen a través de la probabilidad
de �sión en el material haciendo un promedio de todos los nucleidos de ese material.
El estimador de absorción suma para cada colisión de absorción que se produce real-
mente en el nucleido �sionable del número de neutrones nacidos por �sión. Sólo contribu-
yen los eventos de absorción.
El estimador de track-lenght suma cada vez que un neutrón atraviesa una distancia d
en una celda de material �sionable el número de neutrones de �sión producidos a lo largo
de esa trayectoria.
De esta manera se obtiene un intervalo de con�anza para keff , formado a partir del
valor �nal estimado y su desviación típica.
Para los cálculos de criticidad, se supone que la fuente cambia de un ciclo a otro y
que los neutrones que mueren en un ciclo conduciendo a �siones suministran la fuente de
�sión al nuevo ciclo.
Dado que se conoce la energía de los neutrones (muestreada del espectro de �sión),
y su distribución direccional por suponerse isotropía cada vez que se inicia el ciclo, pe-
ro no su distribución espacial; se impone una iteración externa en el proceso de cálculo
48

global para estimar a partir de un valor inicial la distribución espacial de la fuente de �sión.
Tras acabar todas las generaciones G (o ciclos) se descartan las I primeras estimaciones
de keff (ciclos inactivos) hasta que la distribución espacial de �sión alcanza el equilibrio
y se evalúa el valor medio de keff a través de un análisis estadístico:
k̄ =1
G− I
G∑i=I+1
ki
Los parámetros estadísticos para realizar estos cálculos se indican mediante la tarjeta
KCODE, uno de los últimos comandos del input. En este caso es el siguiente:
kcode 100000 1.0 100 600
El primer valor es el NSRCK e indica el número de historias por ciclo, es decir, el
número de neutrones que empiezan cada ciclo. El segundo es RKK e indica el valor inicial
de keff . El tercero indica el valor de I de la fórmula anterior, es decir, el número de ciclos
saltados antes de contabilizar, tras el cual se asume que la fuente ha alcanzado el equilibrio
(el modo fundamental). El último número es el KCT e indica el número de ciclos totales.
[16]
La línea �nal del output contiene los resultados �nales, junto con la desviación de estos y
varios rangos entre los que se encuentra el valor según un porcentaje de con�anza:
final result 1.00391 0.00008 1.00383 to 1.00399 1.00376 to 1.00407
1.00370 to 1.00412
Se repite este procedimiento con cada uno de los muestreos obtenidos con ambos
códigos. Los resultados se almacenan en una excel y se analizan en el siguiente apartado.
49

10. JANIS
JANIS (JAva-based Nuclear Information Software) es un programa de visualización
diseñado para facilitar la visualización y manipulación de datos nucleares. Fue desarrolla-
do por la Agencia de Energía Nuclear de la OCDE y Aquitaine Electronique Informati-
que, como sucesor de JEF-PC (un software desarrollado en la década de 1990 por NEA,
CSNSM-Orsay y la Universidad de Birmingham). Su objetivo es permitir que el usuario
de datos nucleares acceda a valores numéricos y representaciones grá�cas sin conocimiento
previo del formato de almacenamiento. Ofrece la máxima �exibilidad para la comparación
de diferentes conjuntos de datos nucleares: bibliográ�cos (CINDA), evaluados (ENDF) y
experimentales (formato EXFOR).
Todos esos datos están disponibles a través de la red de centros de datos nucleares. Los
usuarios de JANIS pueden crear fácilmente sus propias bases de datos a partir de cualquier
archivo con formato ENDF o de librerías GENDF. Se incluyen capacidades de búsqueda
para datos de resonancia, datos de decaimiento y datos experimentales. También están
disponibles varias opciones para la manipulación de secciones e�caces (combinaciones li-
neales, productos y proporciones de conjuntos de datos y promedios de grupos). JANIS
fue desarrollado utilizando tecnología Java, ya que ofrece un paquete grá�co potente y
portátil. Funciona en casi todos los sistemas operativos informáticos (Linux, Unix, Win-
dows, Macintosh ...).
En este proyecto se ha utilizado para la correcta visualización de las perturbaciones
de datos nucleares realizadas por SANDY. [17] [18]
50
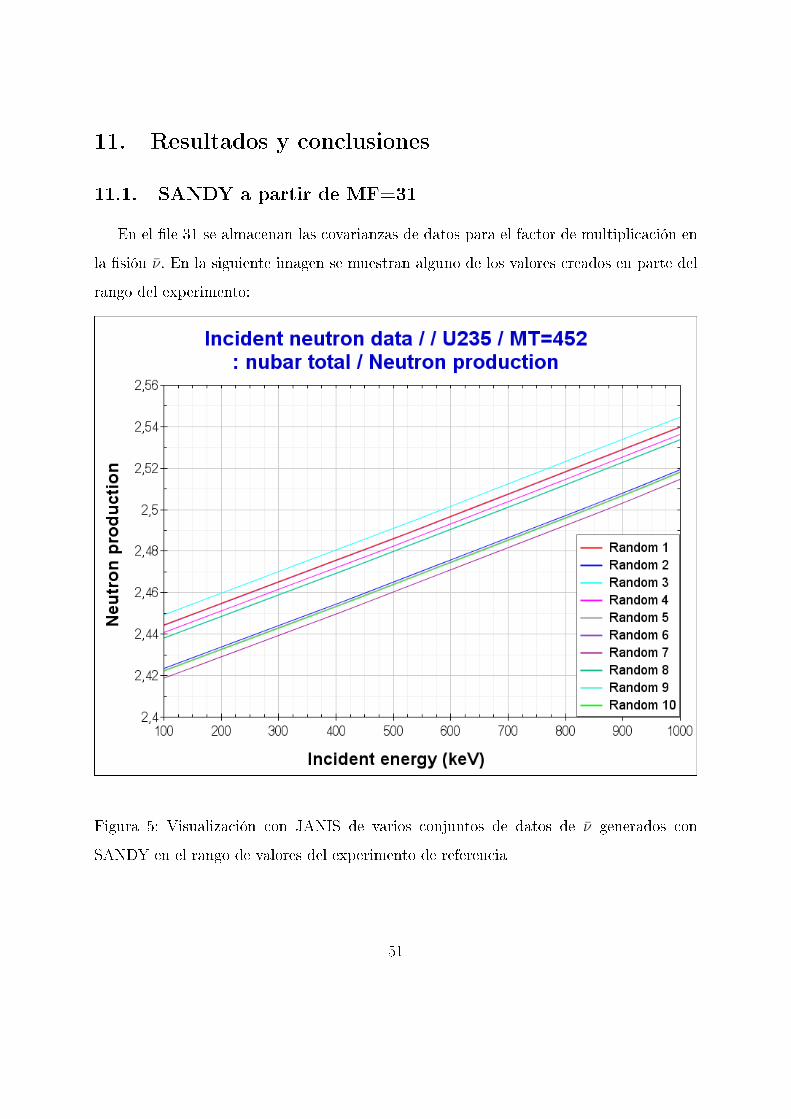
11. Resultados y conclusiones
11.1. SANDY a partir de MF=31
En el �le 31 se almacenan las covarianzas de datos para el factor de multiplicación en
la �sión ν̄. En la siguiente imagen se muestran alguno de los valores creados en parte del
rango del experimento:
Figura 5: Visualización con JANIS de varios conjuntos de datos de ν̄ generados con
SANDY en el rango de valores del experimento de referencia
51
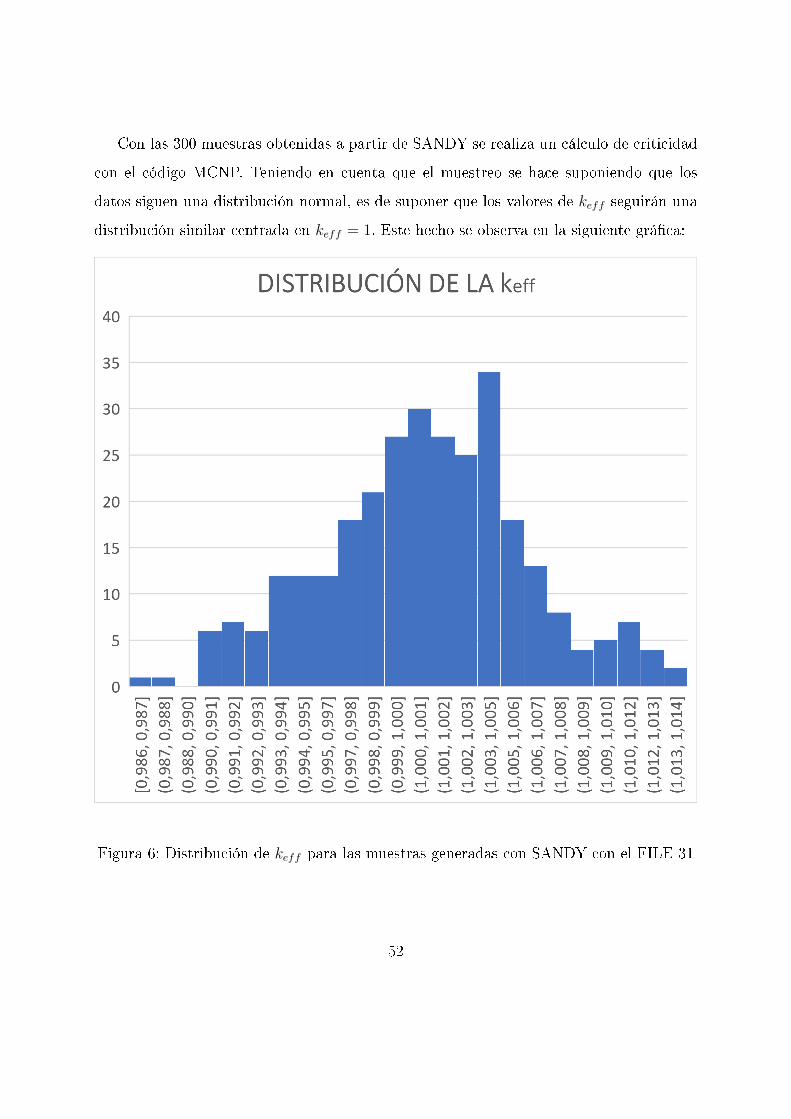
Con las 300 muestras obtenidas a partir de SANDY se realiza un cálculo de criticidad
con el código MCNP. Teniendo en cuenta que el muestreo se hace suponiendo que los
datos siguen una distribución normal, es de suponer que los valores de keff seguirán una
distribución similar centrada en keff = 1. Este hecho se observa en la siguiente grá�ca:
Figura 6: Distribución de keff para las muestras generadas con SANDY con el FILE 31
52
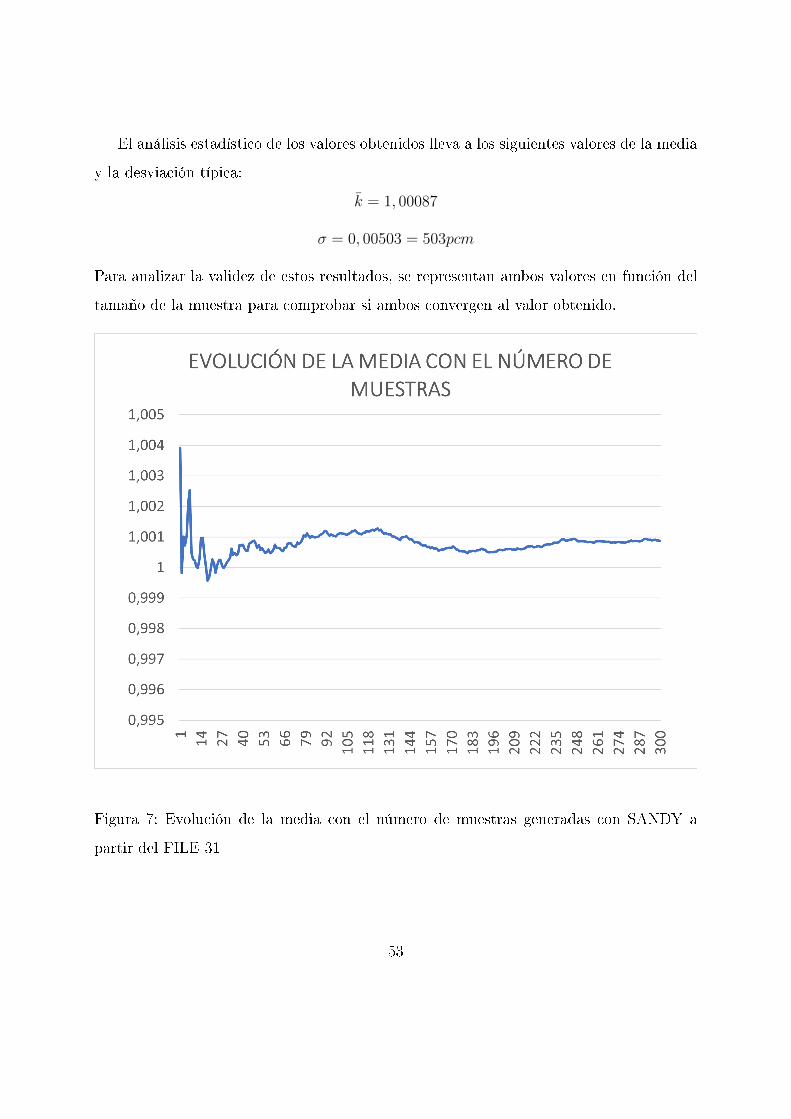
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 1, 00087
σ = 0, 00503 = 503pcm
Para analizar la validez de estos resultados, se representan ambos valores en función del
tamaño de la muestra para comprobar si ambos convergen al valor obtenido.
Figura 7: Evolución de la media con el número de muestras generadas con SANDY a
partir del FILE 31
53
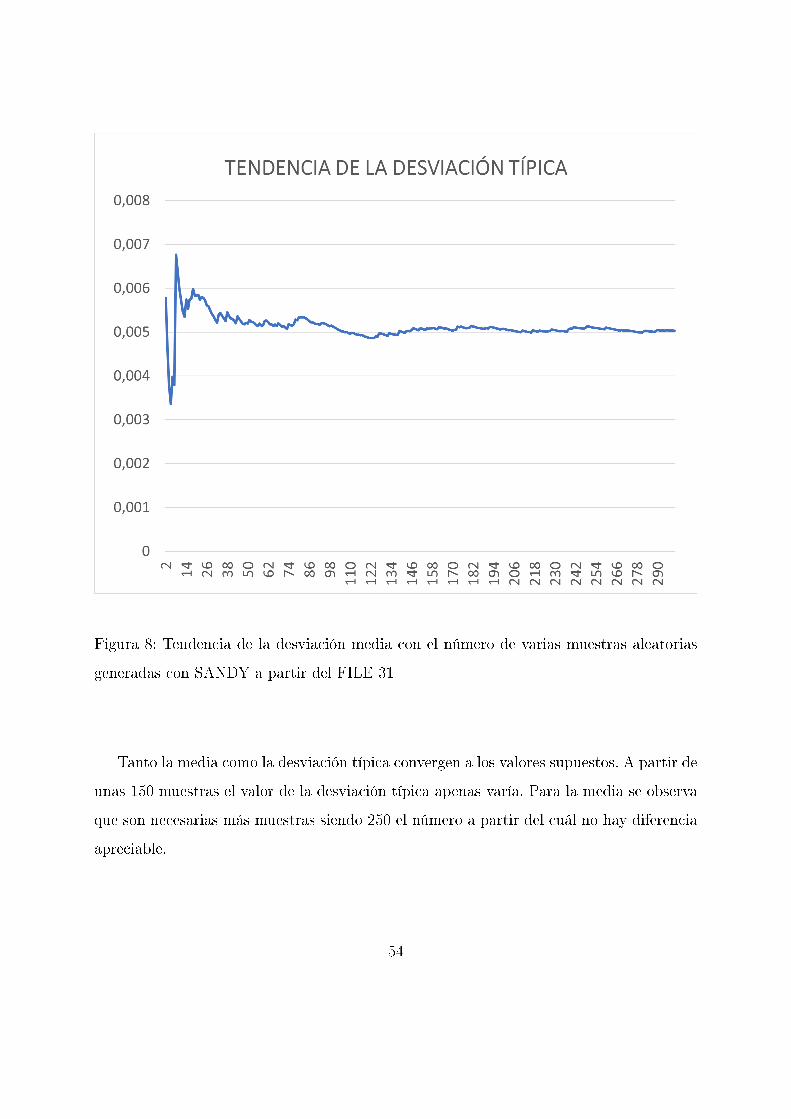
Figura 8: Tendencia de la desviación media con el número de varias muestras aleatorias
generadas con SANDY a partir del FILE 31
Tanto la media como la desviación típica convergen a los valores supuestos. A partir de
unas 150 muestras el valor de la desviación típica apenas varía. Para la media se observa
que son necesarias más muestras siendo 250 el número a partir del cuál no hay diferencia
apreciable.
54

11.2. SANDY a partir de MF=33
En el �le 33 se almacenan las covarianzas de datos para secciones e�caces. Se pueden
muestrear estos valores atendiendo a las covarianzas presentes entre todas las reacciones;
o bien detenerse a analizar únicamente las presentes entre algunas de ellas. En este caso,
se han creado muestras perturbando todas las reacciones (MT = 1), la reacción de �sión
(MT = 18) y la reacción de captura (MT = 102). Estas dos últimas se han creado tan-
to atendiendo a las reacciones de forma individual, como atendiendo a las dos de forma
conjunta y a la relación existente entre ambas (si bien el análisis estadístico se ha hecho
únicamente teniendo en cuenta todas las reacciones o únicamente la reacción de �sión).
11.2.1. MT=1
En este primer caso, se perturban los valores de secciones e�caces atendiendo a las
correlaciones existentes en todas las reacciones. Al igual que en el apartado anterior, se
utiliza JANIS para la visualización de algunos de los conjuntos de valores obtenido en
parte del rango del experimento de referencia a modo de ejemplo.
55
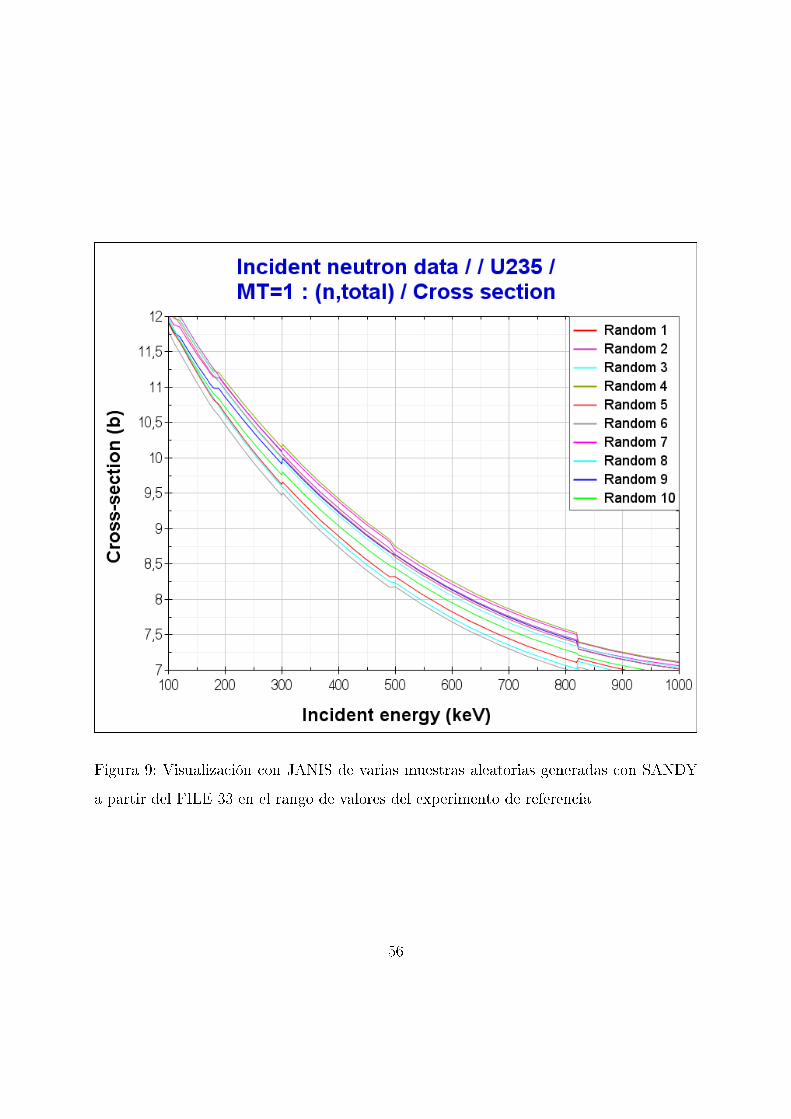
Figura 9: Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 en el rango de valores del experimento de referencia
56
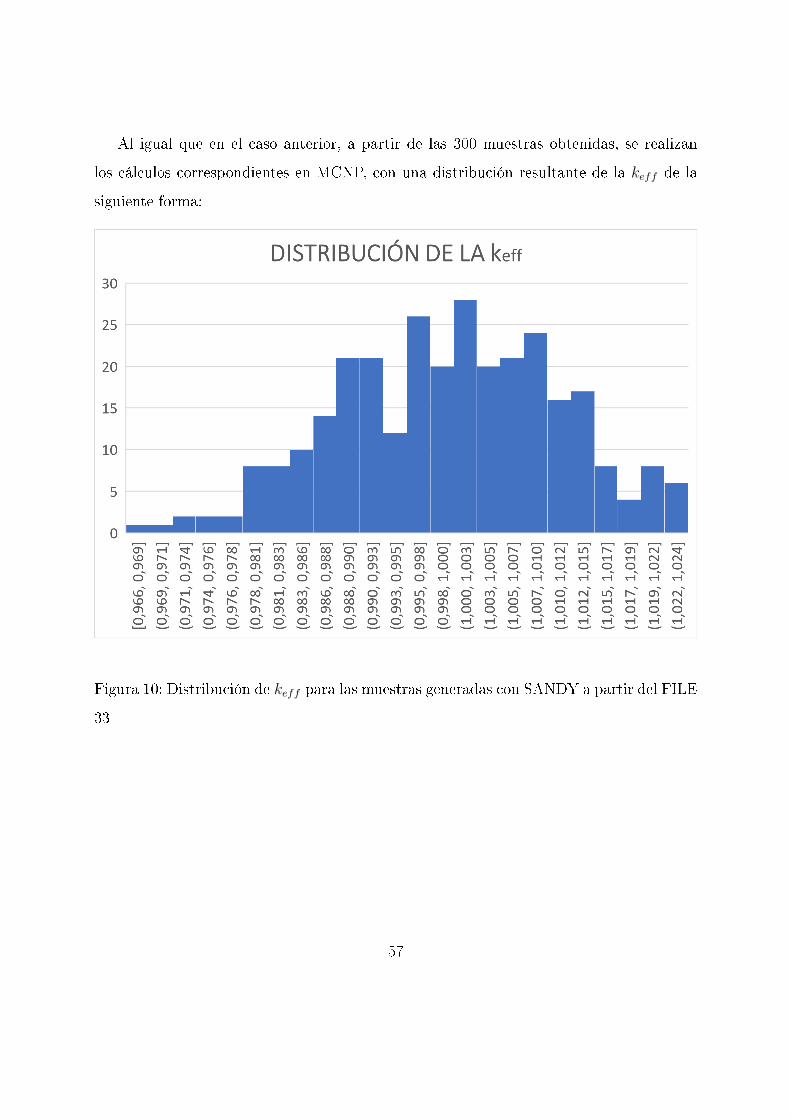
Al igual que en el caso anterior, a partir de las 300 muestras obtenidas, se realizan
los cálculos correspondientes en MCNP, con una distribución resultante de la keff de la
siguiente forma:
Figura 10: Distribución de keff para las muestras generadas con SANDY a partir del FILE
33
57
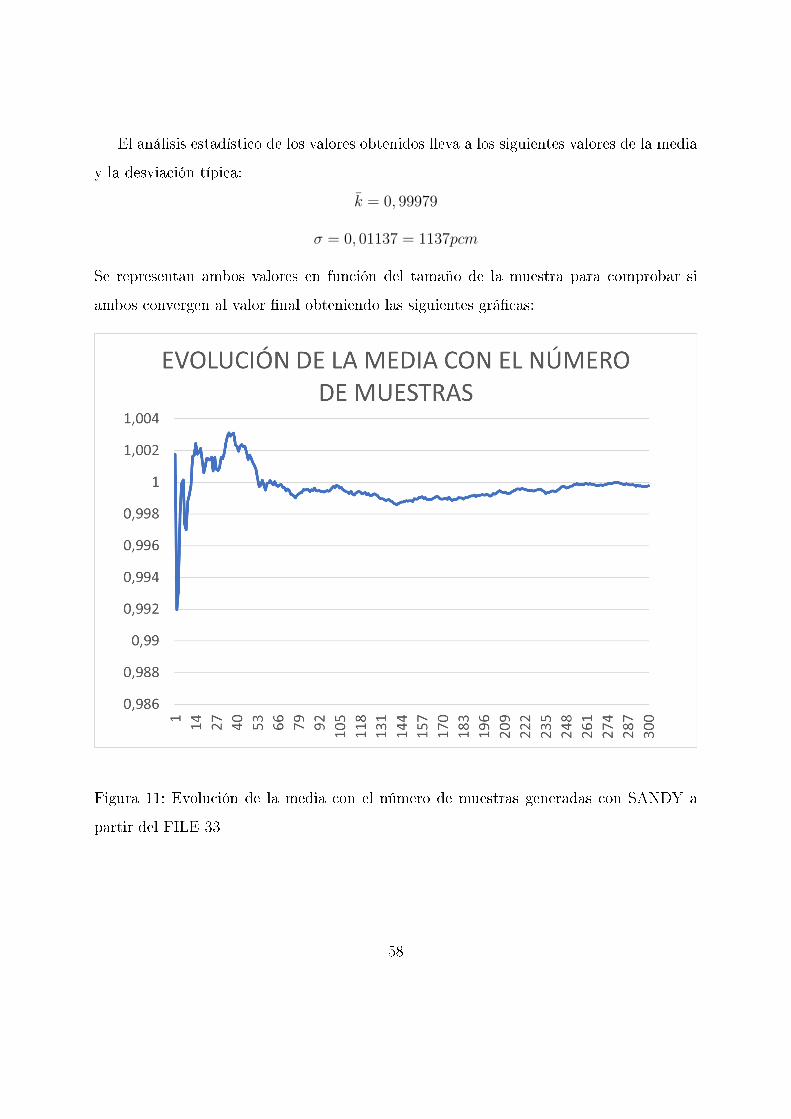
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 0, 99979
σ = 0, 01137 = 1137pcm
Se representan ambos valores en función del tamaño de la muestra para comprobar si
ambos convergen al valor �nal obteniendo las siguientes grá�cas:
Figura 11: Evolución de la media con el número de muestras generadas con SANDY a
partir del FILE 33
58
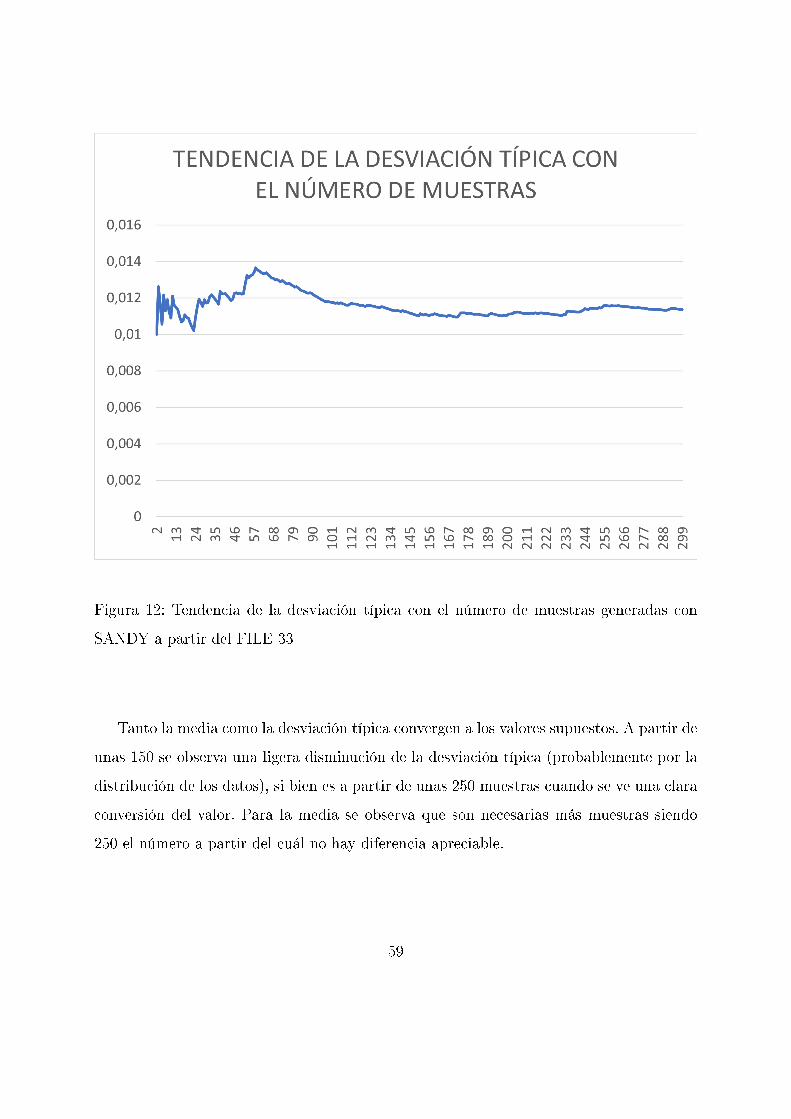
Figura 12: Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 33
Tanto la media como la desviación típica convergen a los valores supuestos. A partir de
unas 150 se observa una ligera disminución de la desviación típica (probablemente por la
distribución de los datos), si bien es a partir de unas 250 muestras cuando se ve una clara
conversión del valor. Para la media se observa que son necesarias más muestras siendo
250 el número a partir del cuál no hay diferencia apreciable.
59
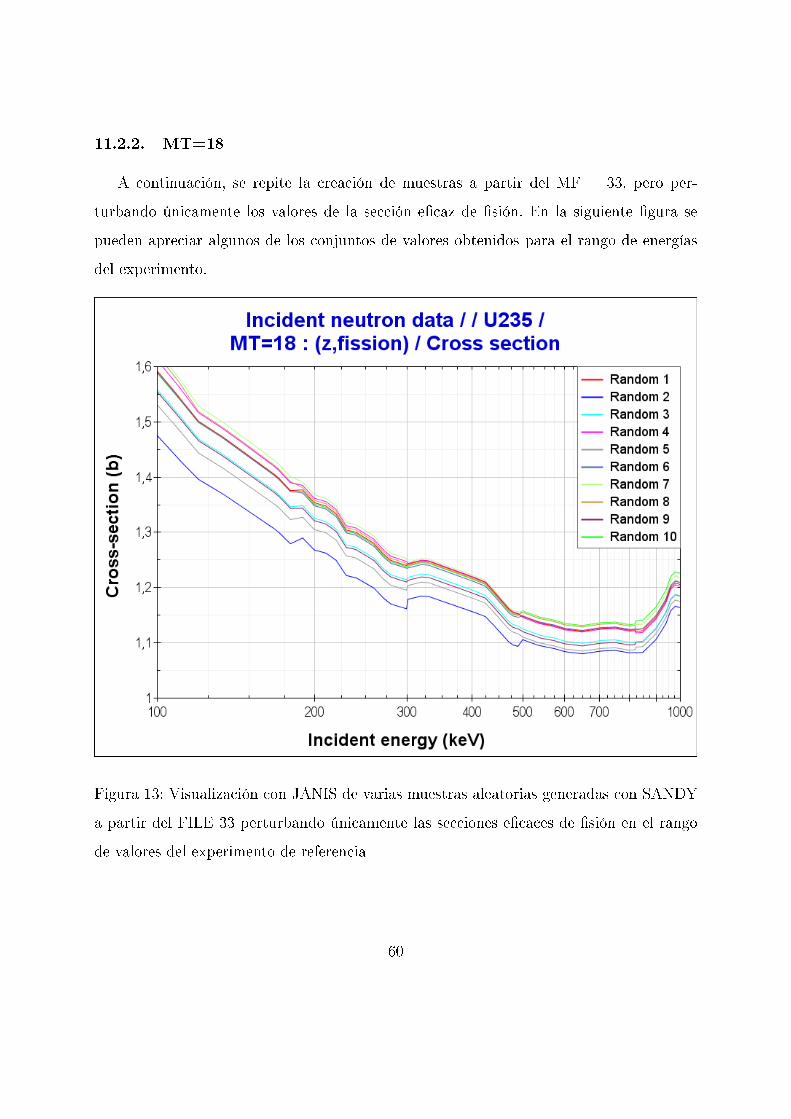
11.2.2. MT=18
A continuación, se repite la creación de muestras a partir del MF = 33, pero per-
turbando únicamente los valores de la sección e�caz de �sión. En la siguiente �gura se
pueden apreciar algunos de los conjuntos de valores obtenidos para el rango de energías
del experimento.
Figura 13: Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión en el rango
de valores del experimento de referencia
60
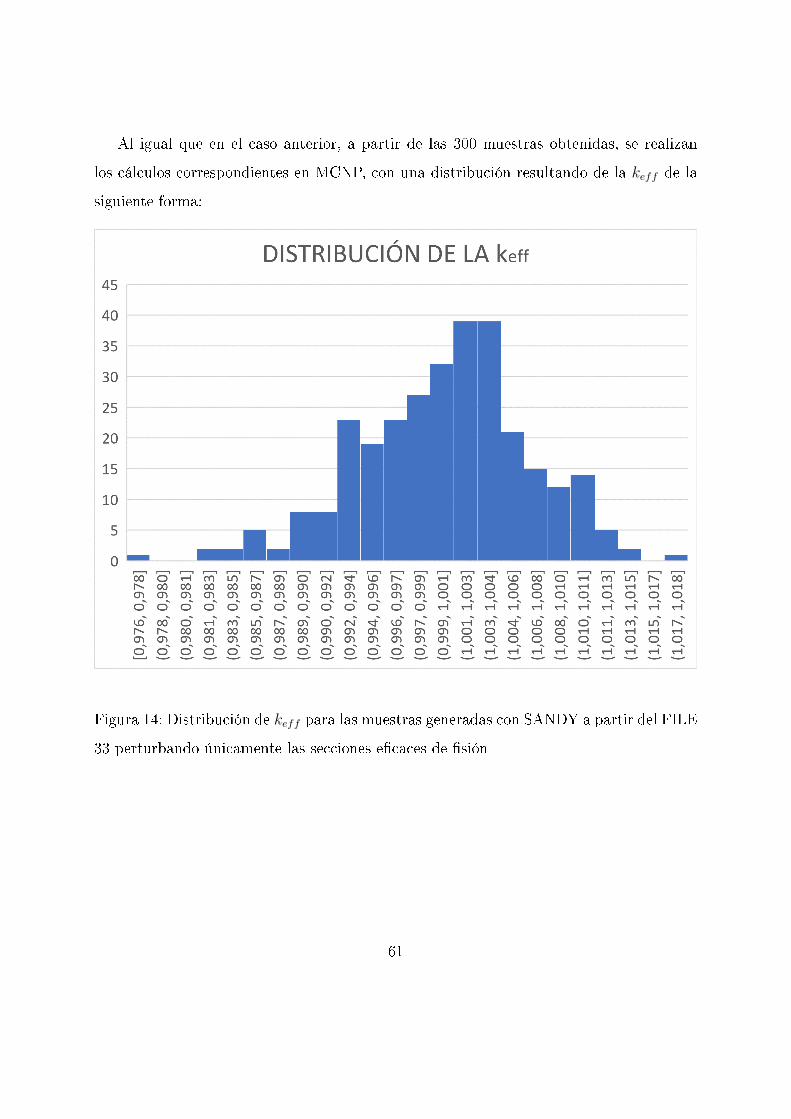
Al igual que en el caso anterior, a partir de las 300 muestras obtenidas, se realizan
los cálculos correspondientes en MCNP, con una distribución resultando de la keff de la
siguiente forma:
Figura 14: Distribución de keff para las muestras generadas con SANDY a partir del FILE
33 perturbando únicamente las secciones e�caces de �sión
61
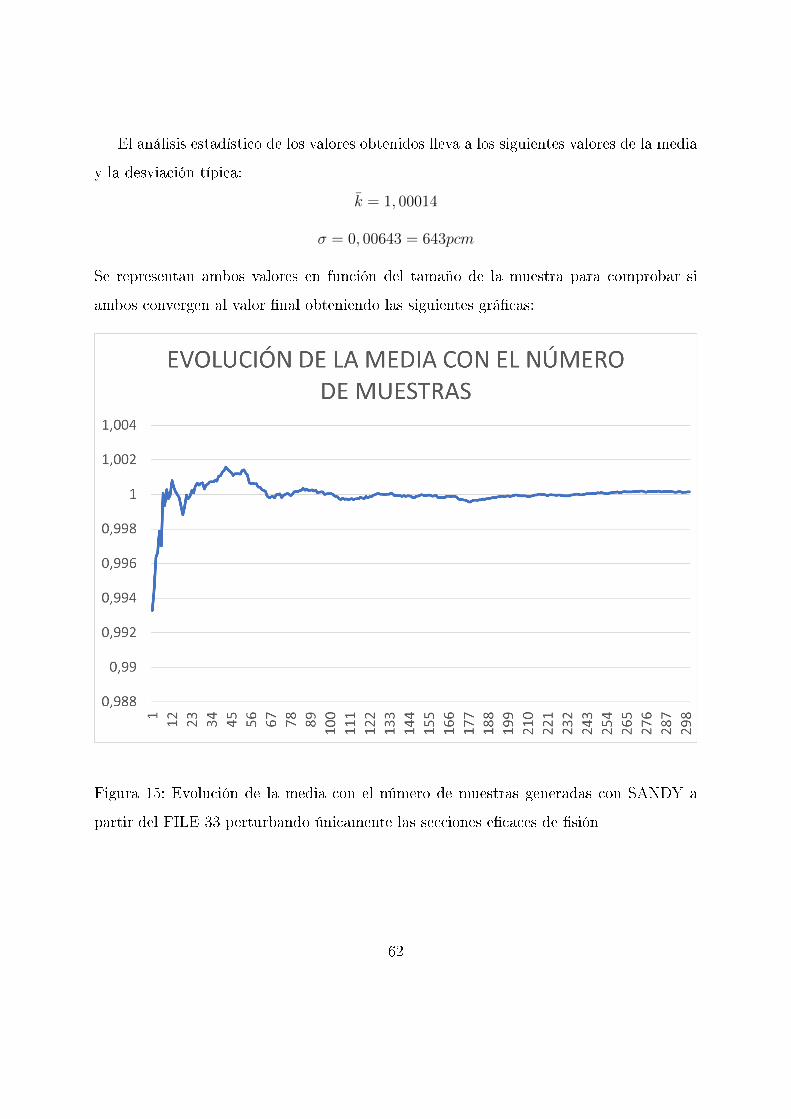
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 1, 00014
σ = 0, 00643 = 643pcm
Se representan ambos valores en función del tamaño de la muestra para comprobar si
ambos convergen al valor �nal obteniendo las siguientes grá�cas:
Figura 15: Evolución de la media con el número de muestras generadas con SANDY a
partir del FILE 33 perturbando únicamente las secciones e�caces de �sión
62
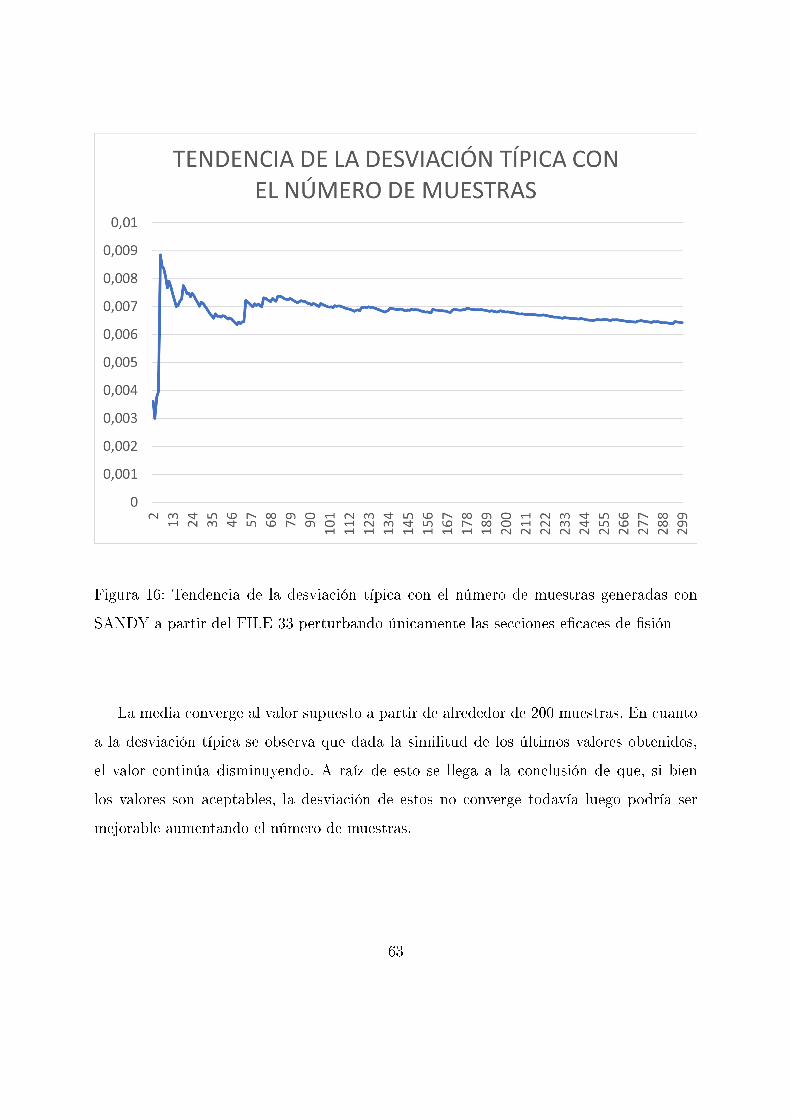
Figura 16: Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión
La media converge al valor supuesto a partir de alrededor de 200 muestras. En cuanto
a la desviación típica se observa que dada la similitud de los últimos valores obtenidos,
el valor continúa disminuyendo. A raíz de esto se llega a la conclusión de que, si bien
los valores son aceptables, la desviación de estos no converge todavía luego podría ser
mejorable aumentando el número de muestras.
63
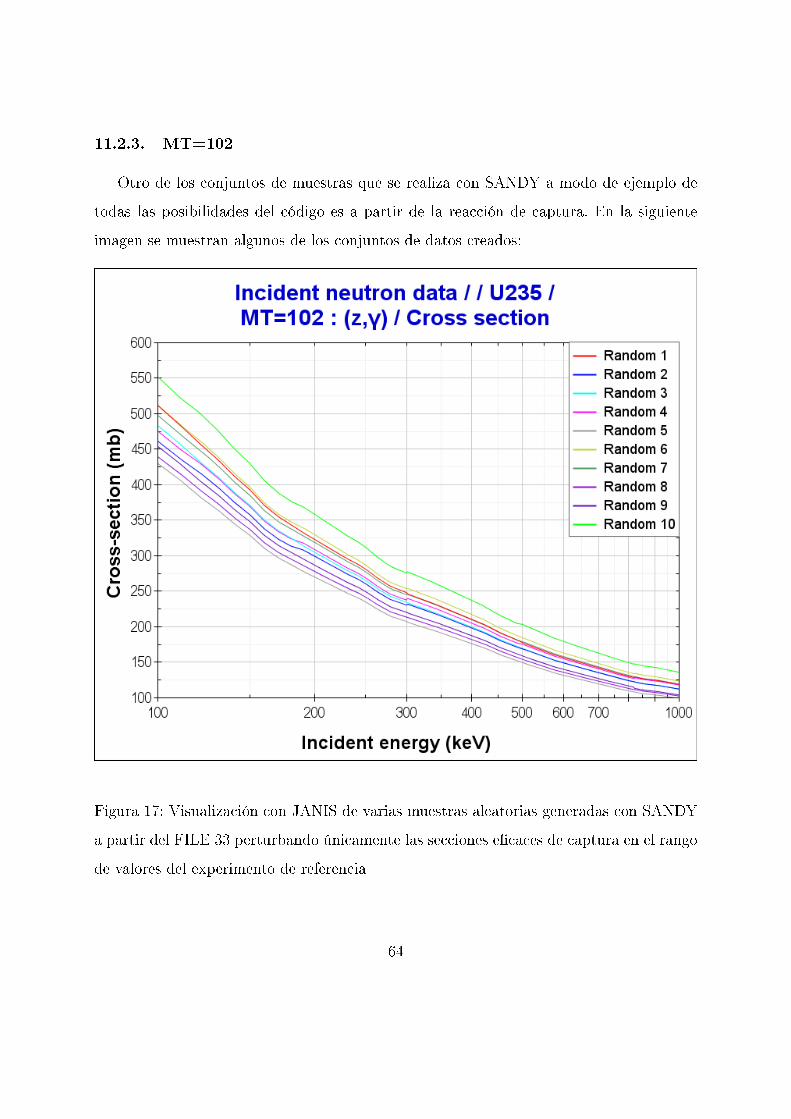
11.2.3. MT=102
Otro de los conjuntos de muestras que se realiza con SANDY a modo de ejemplo de
todas las posibilidades del código es a partir de la reacción de captura. En la siguiente
imagen se muestran algunos de los conjuntos de datos creados:
Figura 17: Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de captura en el rango
de valores del experimento de referencia
64
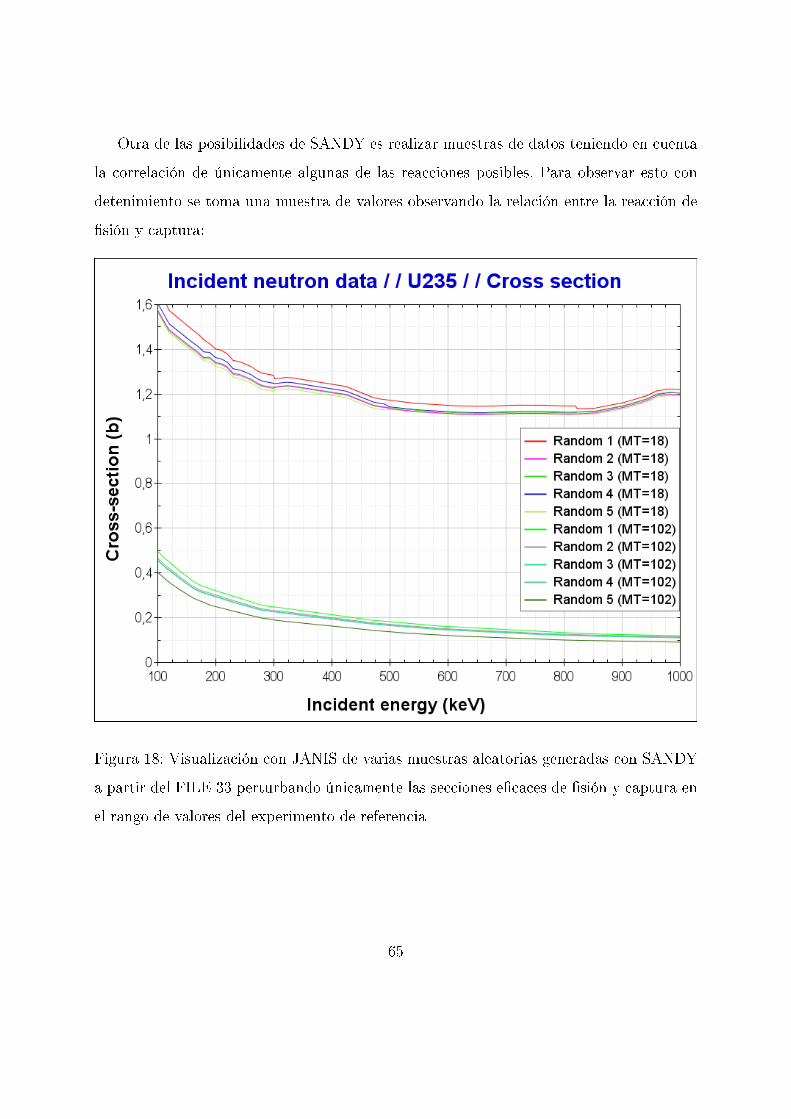
Otra de las posibilidades de SANDY es realizar muestras de datos teniendo en cuenta
la correlación de únicamente algunas de las reacciones posibles. Para observar esto con
detenimiento se toma una muestra de valores observando la relación entre la reacción de
�sión y captura:
Figura 18: Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión y captura en
el rango de valores del experimento de referencia
65
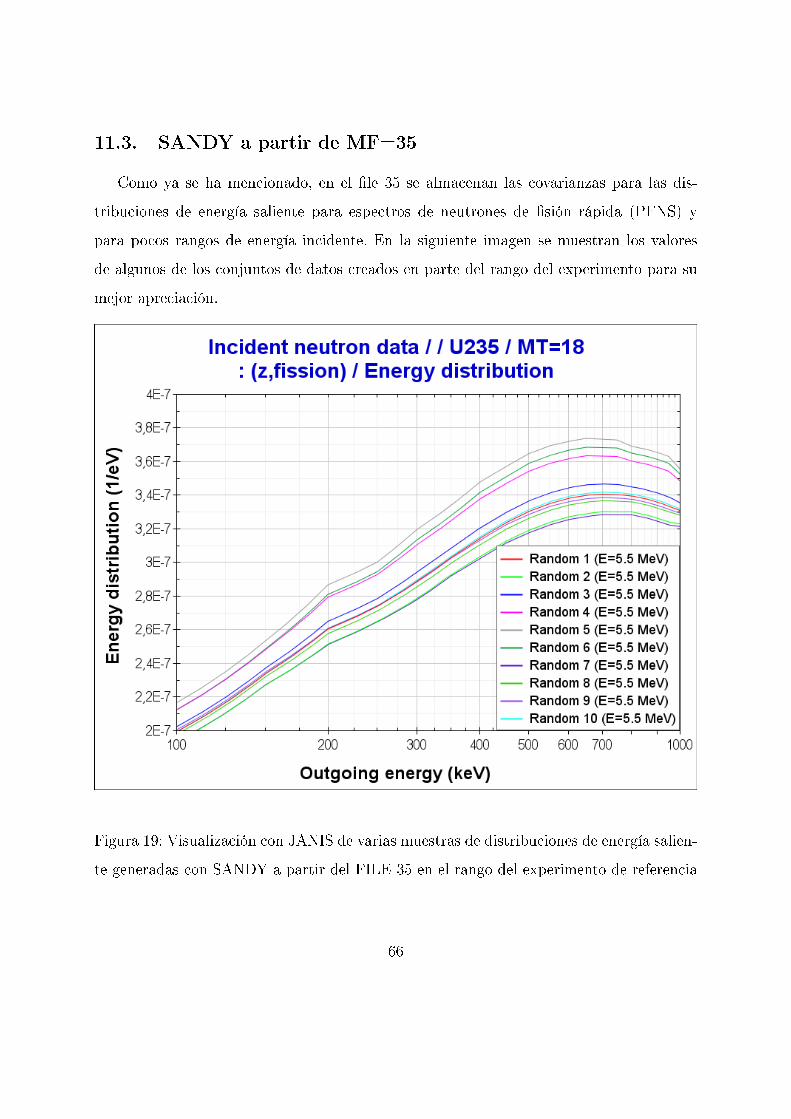
11.3. SANDY a partir de MF=35
Como ya se ha mencionado, en el �le 35 se almacenan las covarianzas para las dis-
tribuciones de energía saliente para espectros de neutrones de �sión rápida (PFNS) y
para pocos rangos de energía incidente. En la siguiente imagen se muestran los valores
de algunos de los conjuntos de datos creados en parte del rango del experimento para su
mejor apreciación.
Figura 19: Visualización con JANIS de varias muestras de distribuciones de energía salien-
te generadas con SANDY a partir del FILE 35 en el rango del experimento de referencia
66
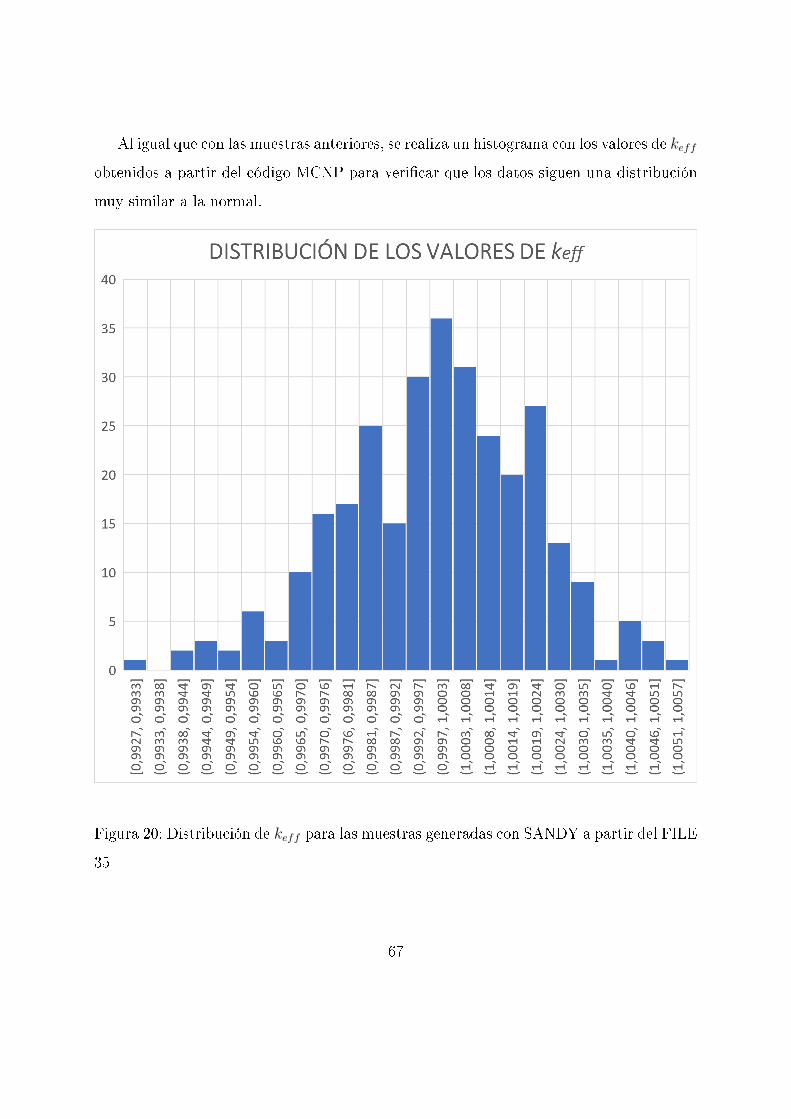
Al igual que con las muestras anteriores, se realiza un histograma con los valores de keff
obtenidos a partir del código MCNP para veri�car que los datos siguen una distribución
muy similar a la normal.
Figura 20: Distribución de keff para las muestras generadas con SANDY a partir del FILE
35
67
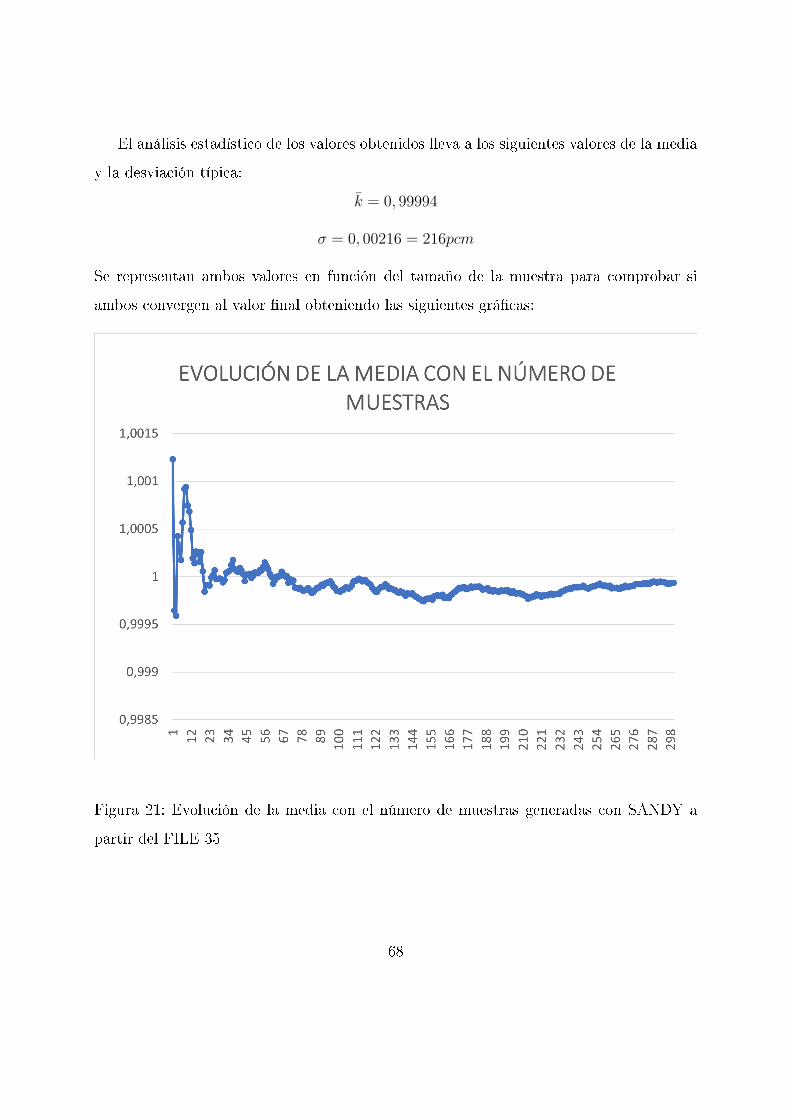
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 0, 99994
σ = 0, 00216 = 216pcm
Se representan ambos valores en función del tamaño de la muestra para comprobar si
ambos convergen al valor �nal obteniendo las siguientes grá�cas:
Figura 21: Evolución de la media con el número de muestras generadas con SANDY a
partir del FILE 35
68
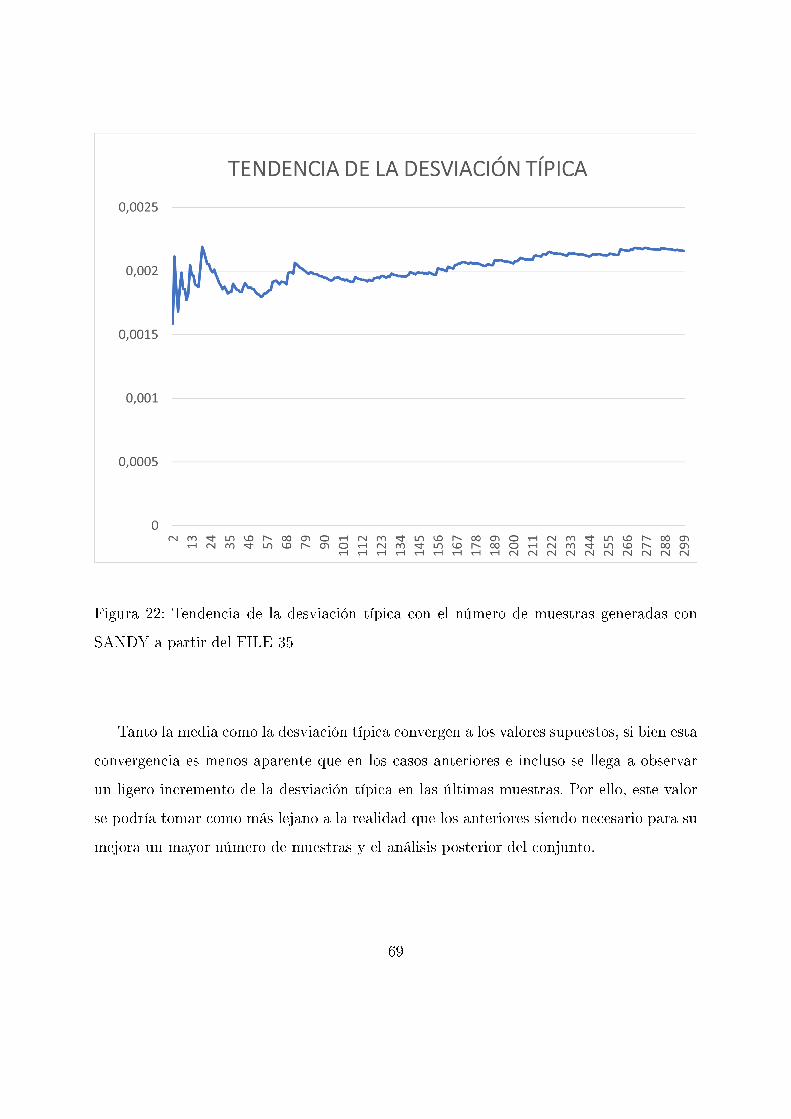
Figura 22: Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 35
Tanto la media como la desviación típica convergen a los valores supuestos, si bien esta
convergencia es menos aparente que en los casos anteriores e incluso se llega a observar
un ligero incremento de la desviación típica en las últimas muestras. Por ello, este valor
se podría tomar como más lejano a la realidad que los anteriores siendo necesario para su
mejora un mayor número de muestras y el análisis posterior del conjunto.
69
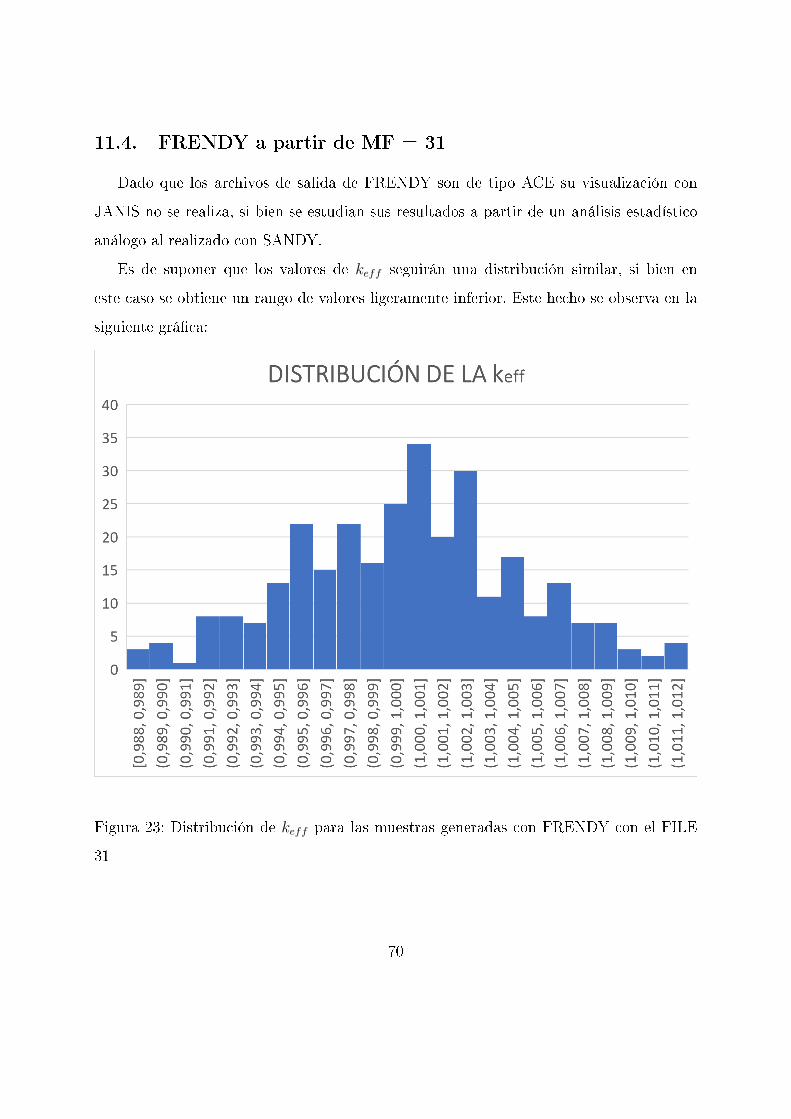
11.4. FRENDY a partir de MF = 31
Dado que los archivos de salida de FRENDY son de tipo ACE su visualización con
JANIS no se realiza, si bien se estudian sus resultados a partir de un análisis estadístico
análogo al realizado con SANDY.
Es de suponer que los valores de keff seguirán una distribución similar, si bien en
este caso se obtiene un rango de valores ligeramente inferior. Este hecho se observa en la
siguiente grá�ca:
Figura 23: Distribución de keff para las muestras generadas con FRENDY con el FILE
31
70
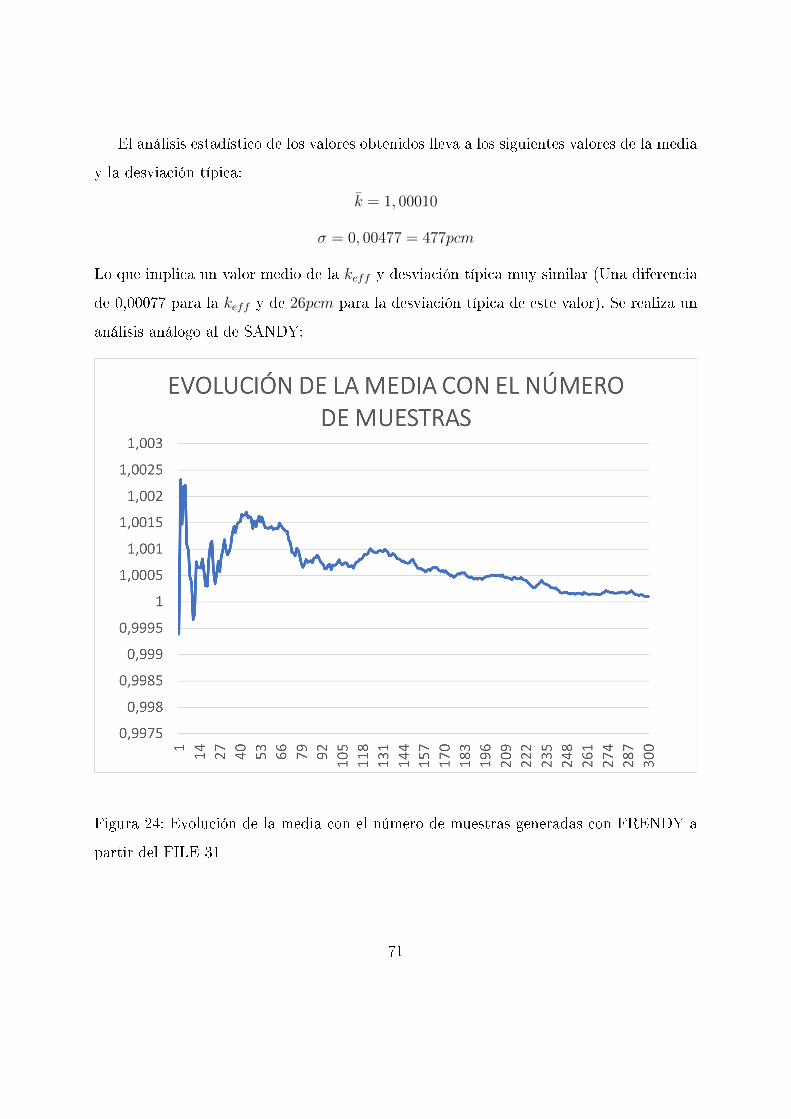
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 1, 00010
σ = 0, 00477 = 477pcm
Lo que implica un valor medio de la keff y desviación típica muy similar (Una diferencia
de 0,00077 para la keff y de 26pcm para la desviación típica de este valor). Se realiza un
análisis análogo al de SANDY:
Figura 24: Evolución de la media con el número de muestras generadas con FRENDY a
partir del FILE 31
71
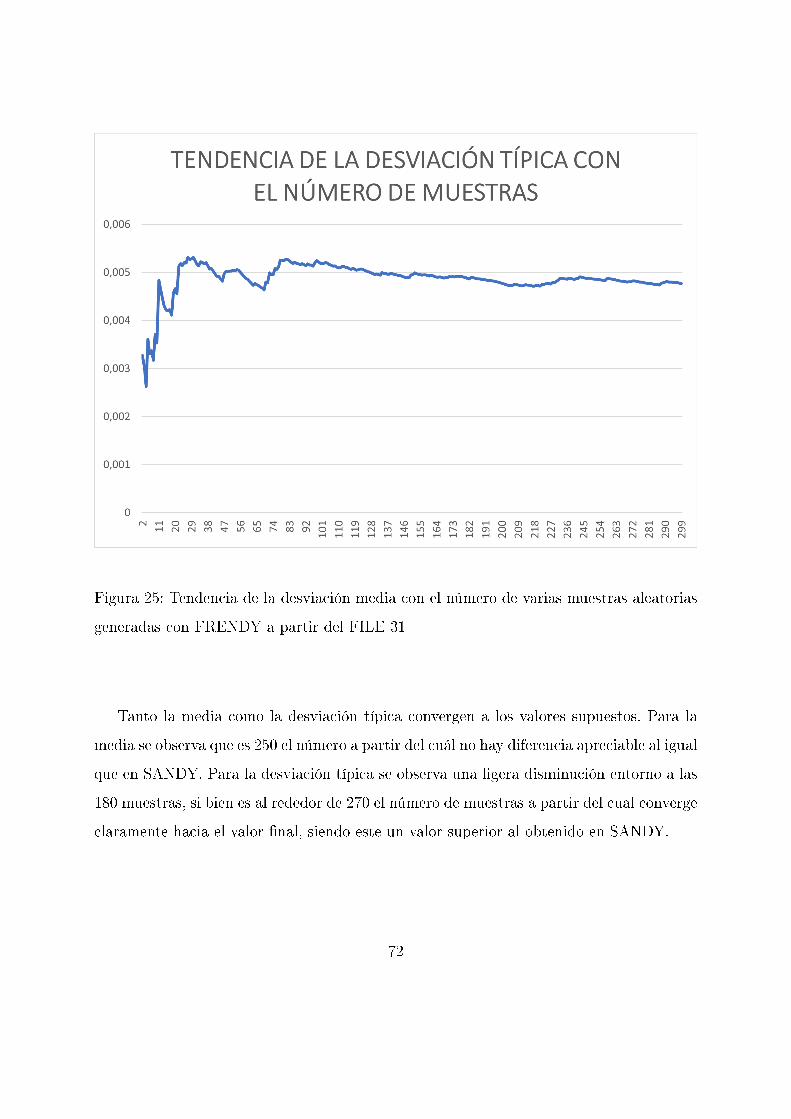
Figura 25: Tendencia de la desviación media con el número de varias muestras aleatorias
generadas con FRENDY a partir del FILE 31
Tanto la media como la desviación típica convergen a los valores supuestos. Para la
media se observa que es 250 el número a partir del cuál no hay diferencia apreciable al igual
que en SANDY. Para la desviación típica se observa una ligera disminución entorno a las
180 muestras, si bien es al rededor de 270 el número de muestras a partir del cual converge
claramente hacia el valor �nal, siendo este un valor superior al obtenido en SANDY.
72
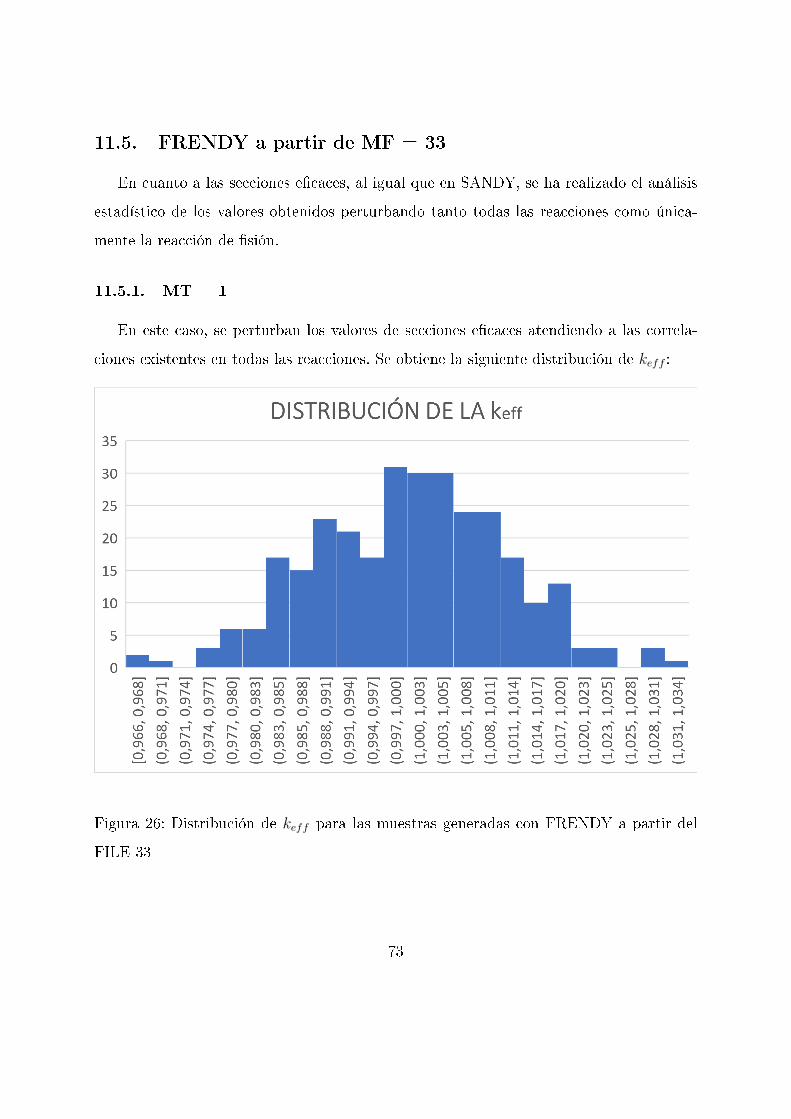
11.5. FRENDY a partir de MF = 33
En cuanto a las secciones e�caces, al igual que en SANDY, se ha realizado el análisis
estadístico de los valores obtenidos perturbando tanto todas las reacciones como única-
mente la reacción de �sión.
11.5.1. MT = 1
En este caso, se perturban los valores de secciones e�caces atendiendo a las correla-
ciones existentes en todas las reacciones. Se obtiene la siguiente distribución de keff :
Figura 26: Distribución de keff para las muestras generadas con FRENDY a partir del
FILE 33
73
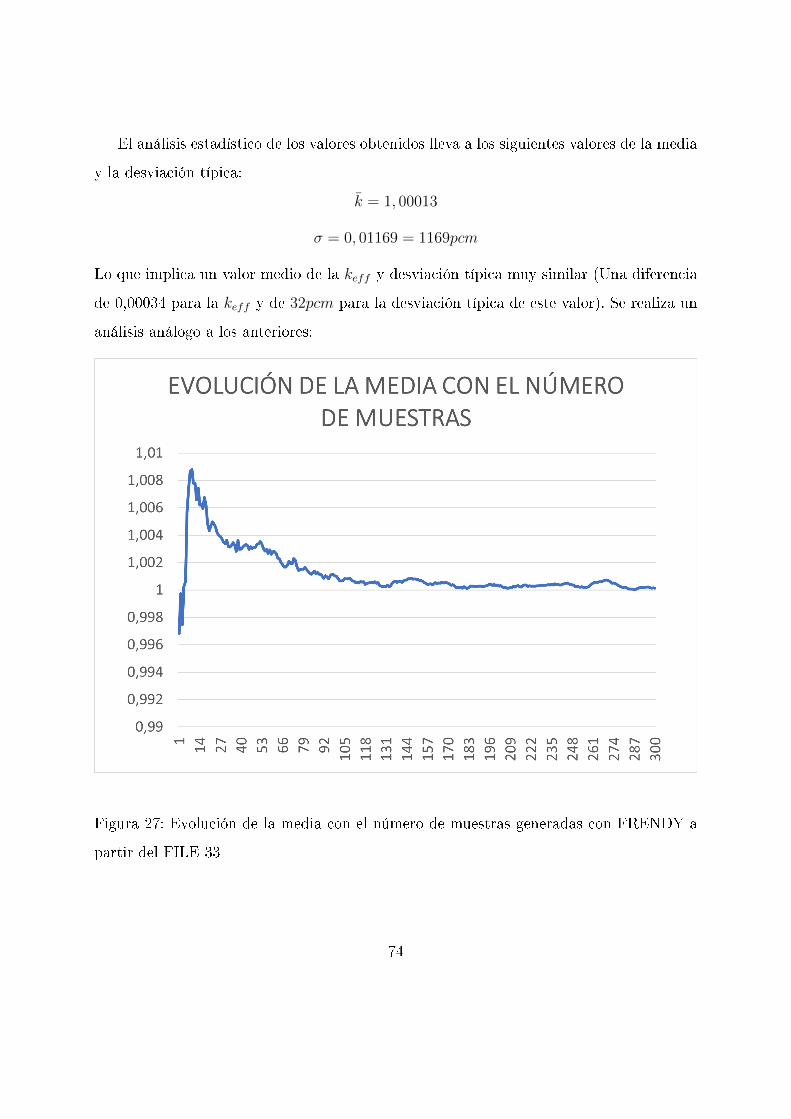
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 1, 00013
σ = 0, 01169 = 1169pcm
Lo que implica un valor medio de la keff y desviación típica muy similar (Una diferencia
de 0,00034 para la keff y de 32pcm para la desviación típica de este valor). Se realiza un
análisis análogo a los anteriores:
Figura 27: Evolución de la media con el número de muestras generadas con FRENDY a
partir del FILE 33
74
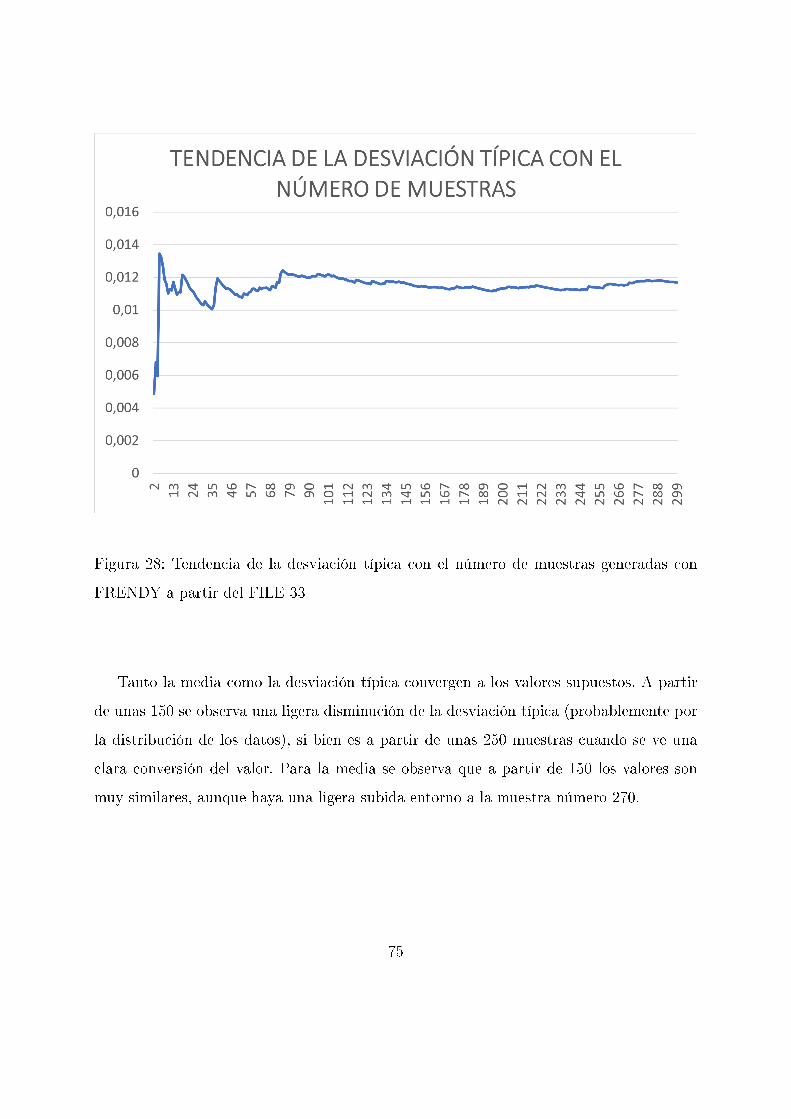
Figura 28: Tendencia de la desviación típica con el número de muestras generadas con
FRENDY a partir del FILE 33
Tanto la media como la desviación típica convergen a los valores supuestos. A partir
de unas 150 se observa una ligera disminución de la desviación típica (probablemente por
la distribución de los datos), si bien es a partir de unas 250 muestras cuando se ve una
clara conversión del valor. Para la media se observa que a partir de 150 los valores son
muy similares, aunque haya una ligera subida entorno a la muestra número 270.
75
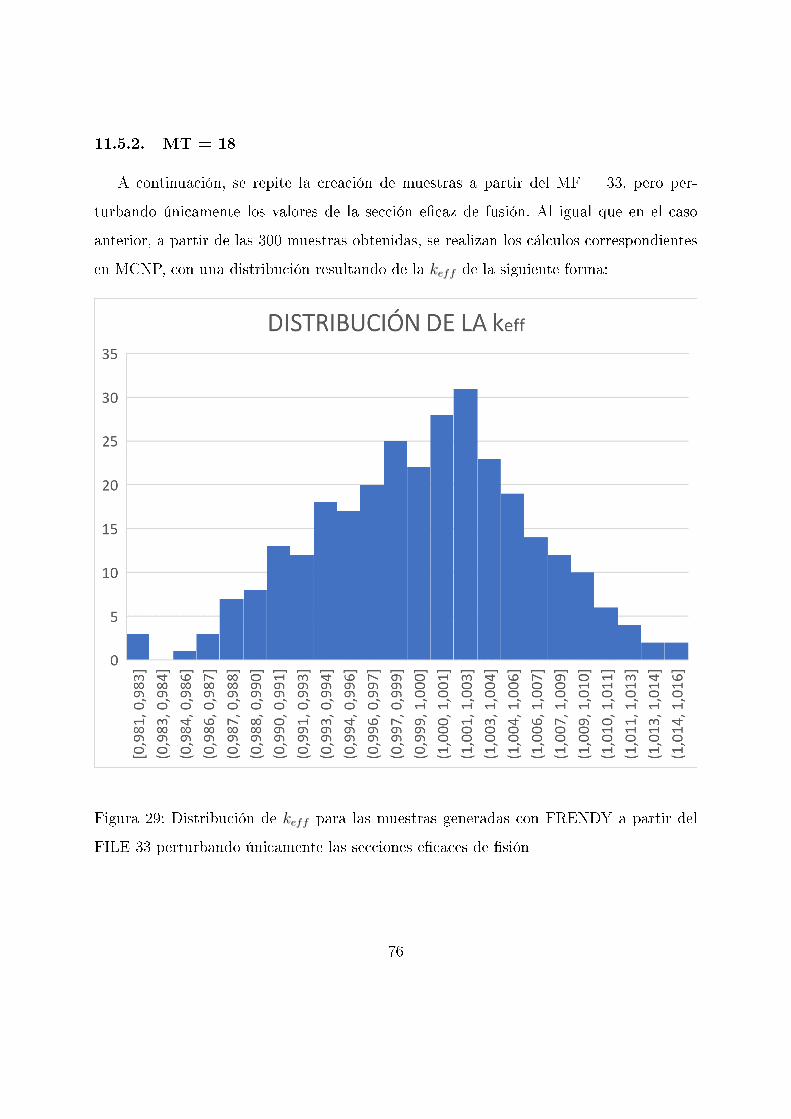
11.5.2. MT = 18
A continuación, se repite la creación de muestras a partir del MF = 33, pero per-
turbando únicamente los valores de la sección e�caz de fusión. Al igual que en el caso
anterior, a partir de las 300 muestras obtenidas, se realizan los cálculos correspondientes
en MCNP, con una distribución resultando de la keff de la siguiente forma:
Figura 29: Distribución de keff para las muestras generadas con FRENDY a partir del
FILE 33 perturbando únicamente las secciones e�caces de �sión
76
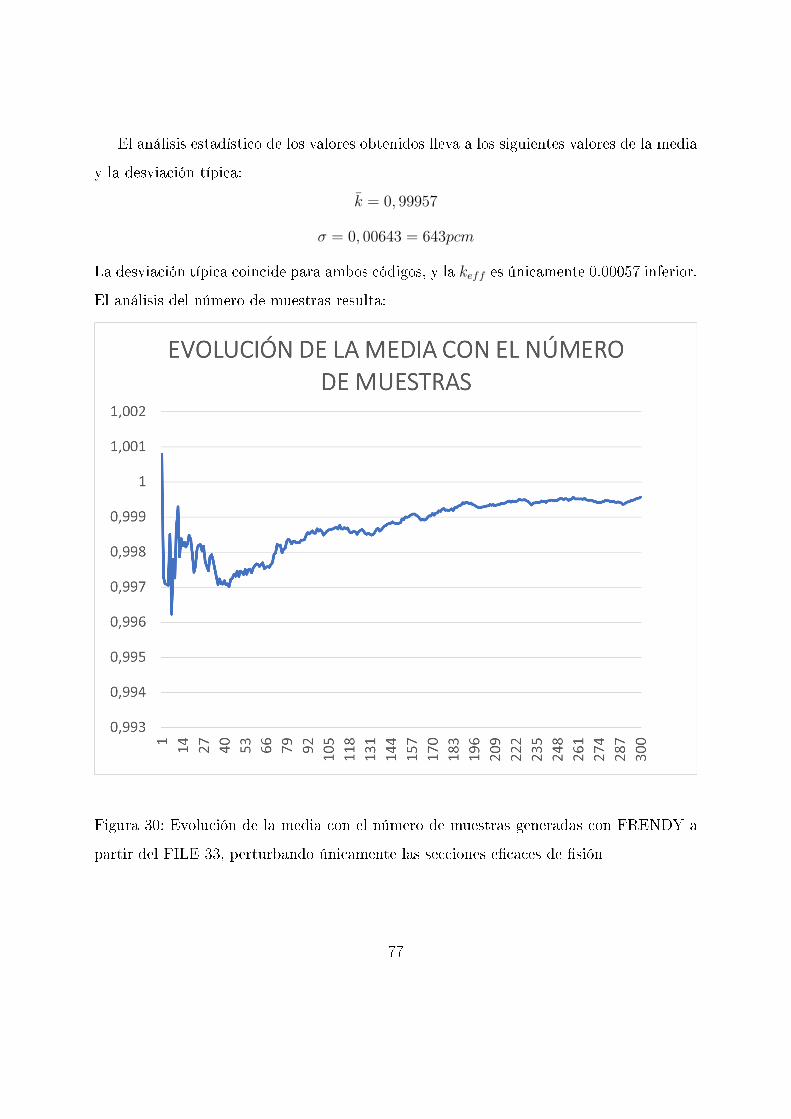
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 0, 99957
σ = 0, 00643 = 643pcm
La desviación típica coincide para ambos códigos, y la keff es únicamente 0.00057 inferior.
El análisis del número de muestras resulta:
Figura 30: Evolución de la media con el número de muestras generadas con FRENDY a
partir del FILE 33, perturbando únicamente las secciones e�caces de �sión
77
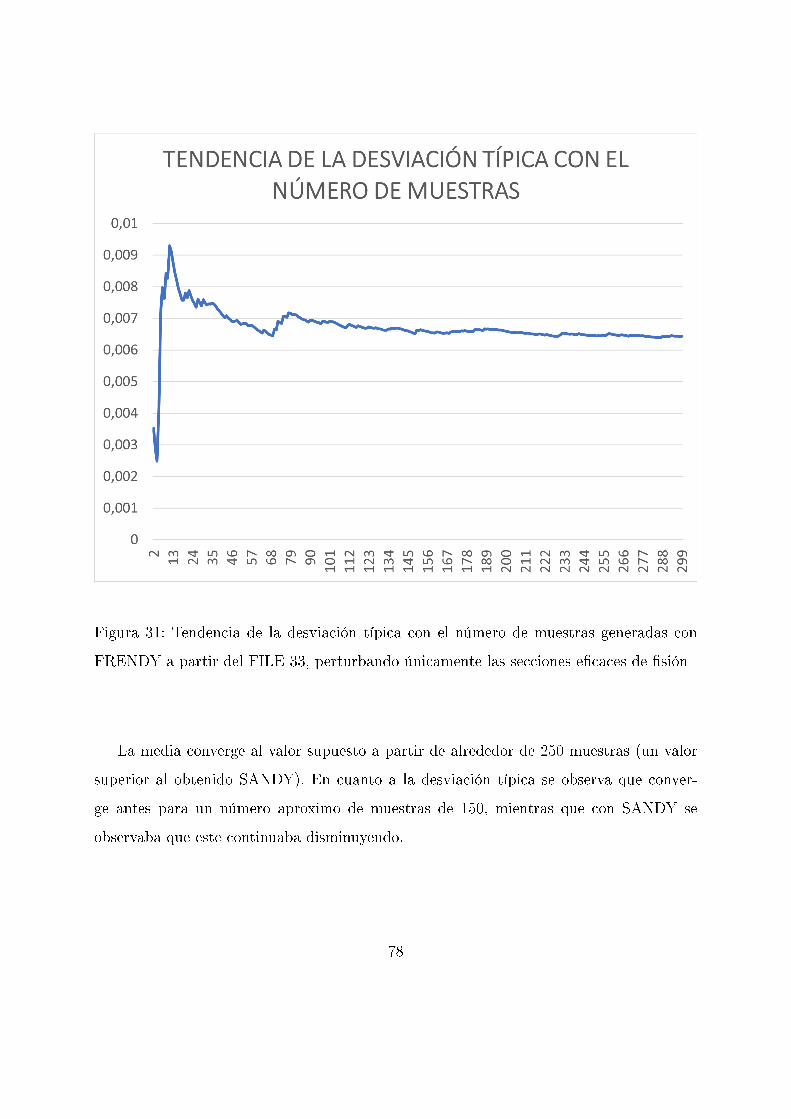
Figura 31: Tendencia de la desviación típica con el número de muestras generadas con
FRENDY a partir del FILE 33, perturbando únicamente las secciones e�caces de �sión
La media converge al valor supuesto a partir de alrededor de 250 muestras (un valor
superior al obtenido SANDY). En cuanto a la desviación típica se observa que conver-
ge antes para un número aproximo de muestras de 150, mientras que con SANDY se
observaba que este continuaba disminuyendo.
78
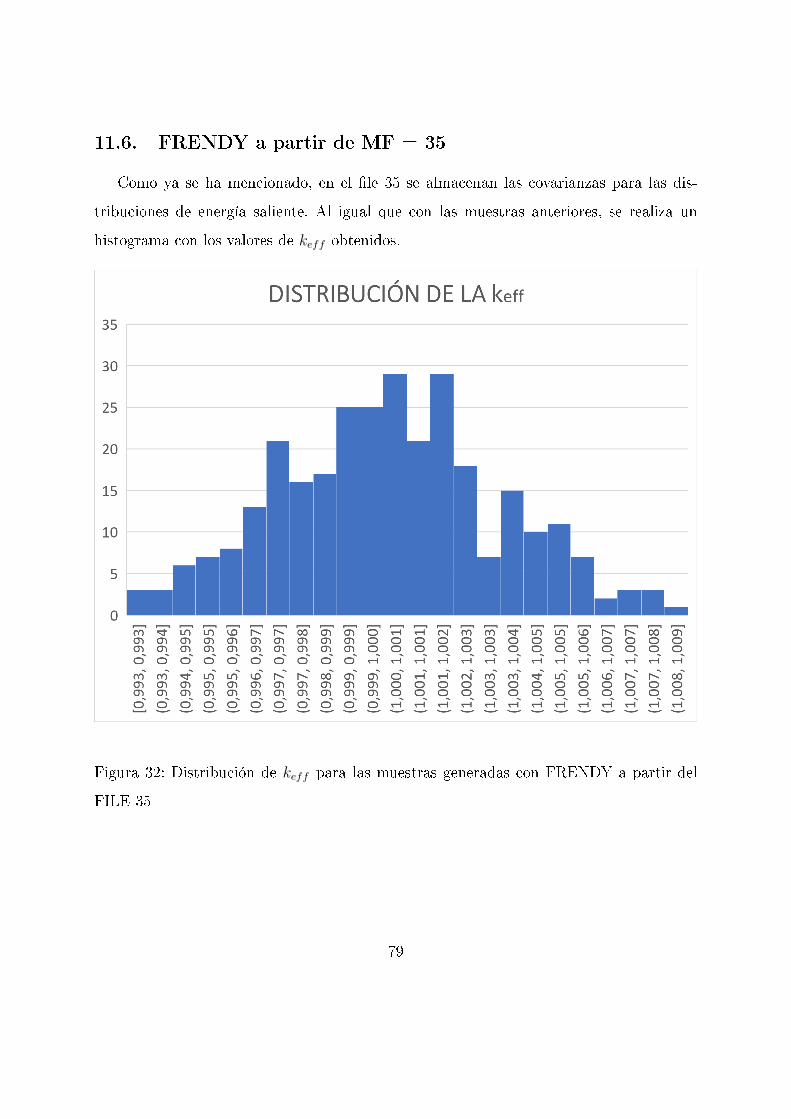
11.6. FRENDY a partir de MF = 35
Como ya se ha mencionado, en el �le 35 se almacenan las covarianzas para las dis-
tribuciones de energía saliente. Al igual que con las muestras anteriores, se realiza un
histograma con los valores de keff obtenidos.
Figura 32: Distribución de keff para las muestras generadas con FRENDY a partir del
FILE 35
79
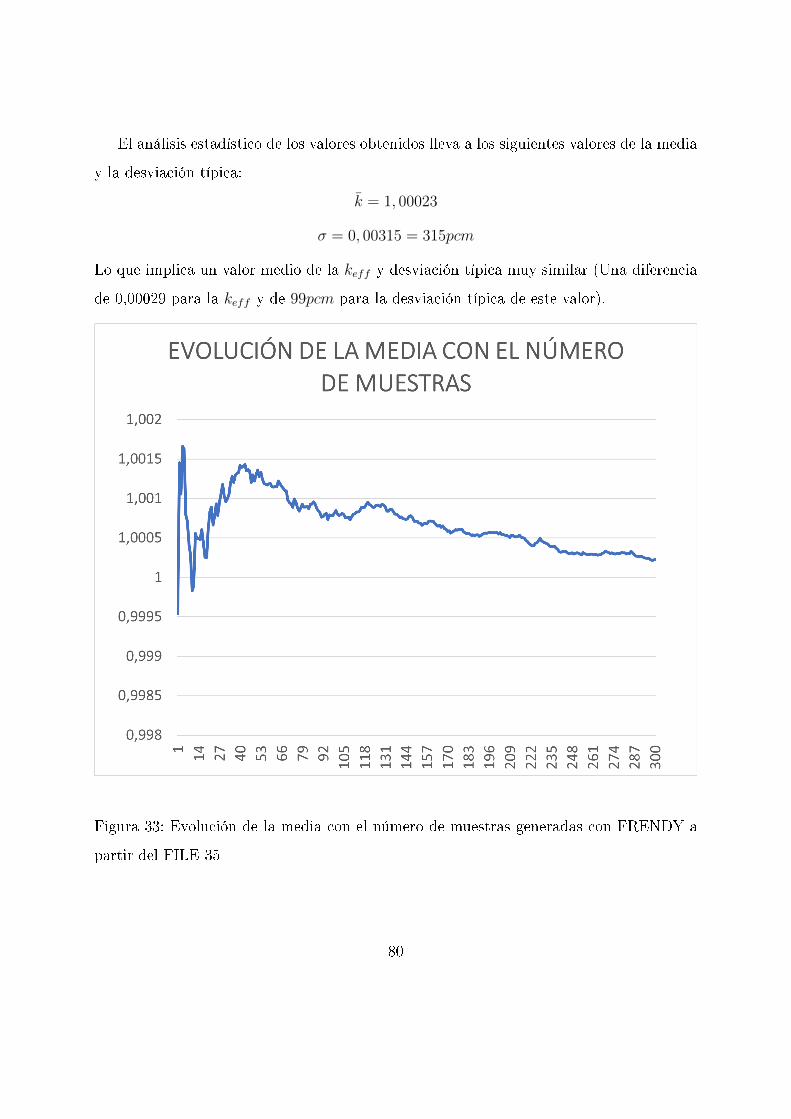
El análisis estadístico de los valores obtenidos lleva a los siguientes valores de la media
y la desviación típica:
k̄ = 1, 00023
σ = 0, 00315 = 315pcm
Lo que implica un valor medio de la keff y desviación típica muy similar (Una diferencia
de 0,00029 para la keff y de 99pcm para la desviación típica de este valor).
Figura 33: Evolución de la media con el número de muestras generadas con FRENDY a
partir del FILE 35
80
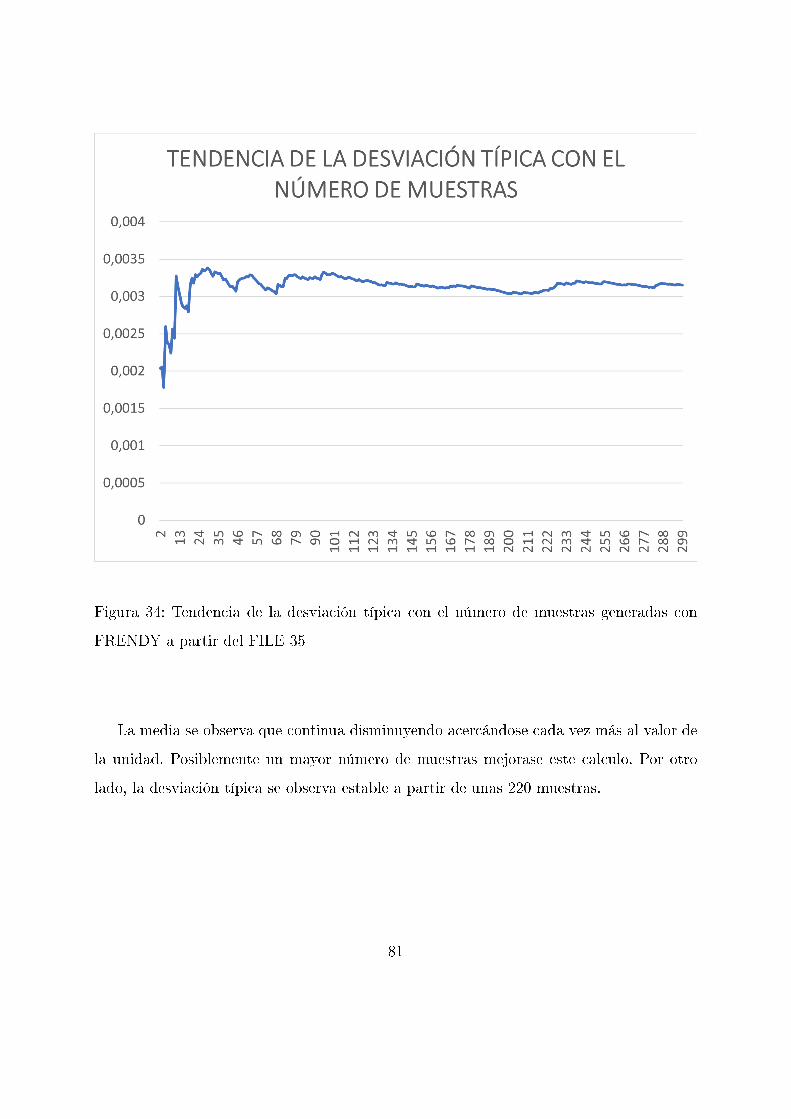
Figura 34: Tendencia de la desviación típica con el número de muestras generadas con
FRENDY a partir del FILE 35
La media se observa que continua disminuyendo acercándose cada vez más al valor de
la unidad. Posiblemente un mayor número de muestras mejorase este calculo. Por otro
lado, la desviación típica se observa estable a partir de unas 220 muestras.
81

11.7. Comparativa con los resultados a partir de otros métodos
Los resultados obtenidos en este trabajo se van a comparar con los obtenidos en el pro-
yecto colaborativo CIELO (Collaborative International Evaluated Library Organisation
Pilot Project), coordinado por la NEA desde 2013. Este proyecto tomado como referencia
ha estimulado signi�cativamente los avances en la evaluación de las secciones e�caces de
los isotopos con mayor impacto en las tecnologías nucleares. [19]
Los datos comparados del proyecto CIELO utilizan la metodología del código NDaST,
una aproximación de primer orden de Taylor que no tiene en cuenta efectos de segundo
orden ni posibles no linealidades de los cálculos de transporte.
La desviación estándar total tiene en cuenta la contribución de todos los efectos debidos
a:
Secciones e�caces (�sión, captura, elástica...)
Nubar
PFNS
Con SANDY y FRENDY se calcula el térmimo debido a todas las reacciones nucleares
(MF33), pero este valor no se da en CIELO. Para calcular el valor total de la incertidumbre
se supone que secciones e�caces, nubar y PFNS son variables independientes, por lo que
se cumple que:
σ2TOTAL = σ2
secc.eficaces + σ2nubar + σ2
PFNS
Y se obtiene �nalmente la desviación estándar total como la raíz cuadrada de la
varianza total.
82
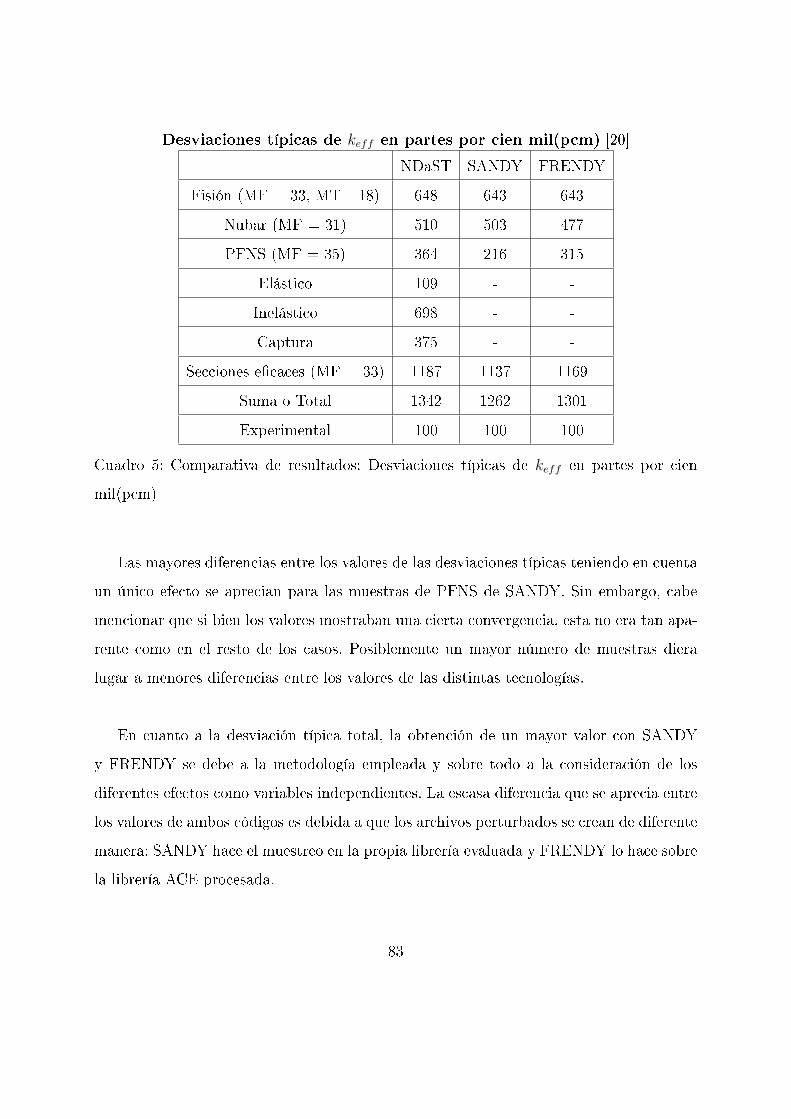
Desviaciones típicas de keff en partes por cien mil(pcm) [20]
NDaST SANDY FRENDY
Fisión (MF = 33, MT= 18) 648 643 643
Nubar (MF = 31) 510 503 477
PFNS (MF = 35) 364 216 315
Elástico 109 - -
Inelástico 698 - -
Captura 375 - -
Secciones e�caces (MF = 33) 1187 1137 1169
Suma o Total 1342 1262 1301
Experimental 100 100 100
Cuadro 5: Comparativa de resultados: Desviaciones típicas de keff en partes por cien
mil(pcm)
Las mayores diferencias entre los valores de las desviaciones típicas teniendo en cuenta
un único efecto se aprecian para las muestras de PFNS de SANDY. Sin embargo, cabe
mencionar que si bien los valores mostraban una cierta convergencia, esta no era tan apa-
rente como en el resto de los casos. Posiblemente un mayor número de muestras diera
lugar a menores diferencias entre los valores de las distintas tecnologías.
En cuanto a la desviación típica total, la obtención de un mayor valor con SANDY
y FRENDY se debe a la metodología empleada y sobre todo a la consideración de los
diferentes efectos como variables independientes. La escasa diferencia que se aprecia entre
los valores de ambos códigos es debida a que los archivos perturbados se crean de diferente
manera: SANDY hace el muestreo en la propia librería evaluada y FRENDY lo hace sobre
la librería ACE procesada.
83
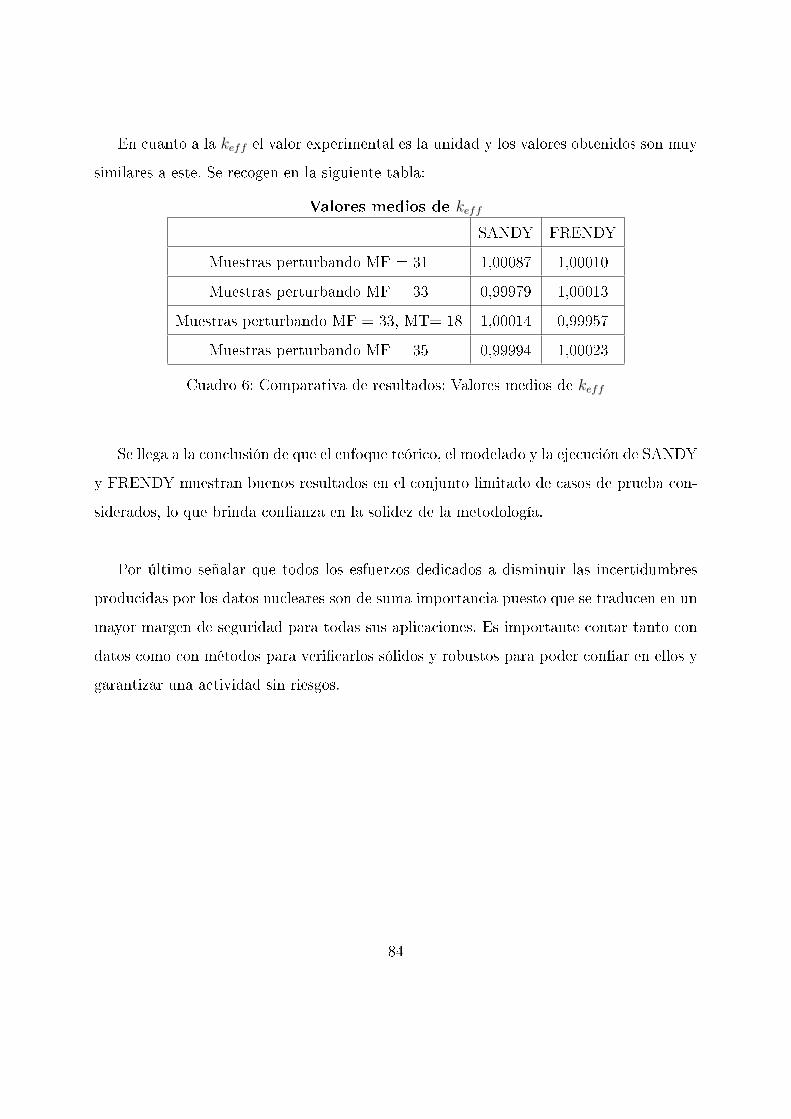
En cuanto a la keff el valor experimental es la unidad y los valores obtenidos son muy
similares a este. Se recogen en la siguiente tabla:
Valores medios de keff
SANDY FRENDY
Muestras perturbando MF = 31 1,00087 1,00010
Muestras perturbando MF = 33 0,99979 1,00013
Muestras perturbando MF = 33, MT= 18 1,00014 0,99957
Muestras perturbando MF = 35 0,99994 1,00023
Cuadro 6: Comparativa de resultados: Valores medios de keff
Se llega a la conclusión de que el enfoque teórico, el modelado y la ejecución de SANDY
y FRENDY muestran buenos resultados en el conjunto limitado de casos de prueba con-
siderados, lo que brinda con�anza en la solidez de la metodología.
Por último señalar que todos los esfuerzos dedicados a disminuir las incertidumbres
producidas por los datos nucleares son de suma importancia puesto que se traducen en un
mayor margen de seguridad para todas sus aplicaciones. Es importante contar tanto con
datos como con métodos para veri�carlos sólidos y robustos para poder con�ar en ellos y
garantizar una actividad sin riesgos.
84

Referencias
[1] A. Koning and D. Rochman, �Modern nuclear data evaluation with the talys code
system,� Nuclear Data Sheets, vol. 113, no. 12, pp. 2841 � 2934, 2012. Special Issue
on Nuclear Reaction Data.
[2] C. Díez, O. Buss, A. Hoefer, D. Porsch, and O. Cabellos, �Comparison of nuclear
data uncertainty propagation methodologies for PWR burn-up simulations,� Annals
of Nuclear Energy, vol. 77, pp. 101�114, mar 2015.
[3] B. T. Rearden, K. B. Bekar, C. Celik, K. T. Clarno, M. E. Dunn, S. W. Hart,
A. M. Ibrahim, S. R. Johnson, B. R. Langley, J. P. Lefebvre, R. A. Lefebvre, W. J.
Marshall, U. Mertyurek, D. Mueller, D. E. Peplow, C. M. Perfetti, L. M. Petrie Jr,
A. B. Thompson, D. Wiarda, W. A. Wieselquist, and M. L. Williams, �Criticality
safety enhancements for scale 6.2 and beyond,� 9 2015.
[4] W. ZWERMANN, A. AURES, L. GALLNER, V. HANNSTEIN, B. KRZYKACZ-
HAUSMANN, K. VELKOV, and J. MARTINEZ, �Nuclear data uncertainty and
sensitivity analysis with xsusa for fuel assembly depletion calculations,� Nuclear En-
gineering and Technology, vol. 46, no. 3, pp. 343 � 352, 2014.
[5] C. A. A. Raphael J. LaBauve, Joseph L. Sapir, �Heu-met-fast-001,�
NEA/NSC/DOC(95)03/II, vol. II, Sept. 2002.
[6] N. Otuka, E. Dupont, V. Semkova, B. Pritychenko, A. Blokhin, M. Aikawa, S. Baby-
kina, M. Bossant, G. Chen, S. Dunaeva, R. Forrest, T. Fukahori, N. Furutachi, S. Ga-
nesan, Z. Ge, O. Gritzay, M. Herman, S. Hlava£, K. Kato, B. Lalremruata, Y. Lee,
A. Makinaga, K. Matsumoto, M. Mikhaylyukova, G. Pikulina, V. Pronyaev, A. Sa-
xena, O. Schwerer, S. Simakov, N. Soppera, R. Suzuki, S. Takács, X. Tao, S. Taova,
F. Tárkányi, V. Varlamov, J. Wang, S. Yang, V. Zerkin, and Y. Zhuang, �Towards
a more complete and accurate experimental nuclear reaction data library (exfor):
85

International collaboration between nuclear reaction data centres (nrdc),� Nuclear
Data Sheets, vol. 120, pp. 272 � 276, 2014.
[7] O. Cabellos, �Bases de datos nucleares para la simulación de pwr,� �INGENIA-
NUCLEAR� - Diseño y Simulación de un PWR, Curso 2018-19.
[8] CSEWG, ENDF-6 Formats Manual: Data Formats and Procedures for the Evalua-
ted Nuclear Data FilesENDF/B-VI, ENDF/B-VII and ENDF/B-VIII. a. trkov, m.
herman and d. a. brown ed., 2018.
[9] OECD/NEA, �Je�-3.3.� url = https://www.oecd-
nea.org/dbdata/je�/je�33/index.html, 2018.
[10] A. J. M. Plompen, O. Cabellos, C. D. S. Jean, M. Fleming, A. Algora, M. Angelone,
P. Archier, E. Bauge, O. Bersillon, A. Blokhin, F. Cantargi, A. Chebboubi, C. Diez,
H. Duarte, E. Dupont, J. Dyrda, B. Erasmus, L. Fiorito, U. Fischer, D. Flammini,
D. Foligno, M. R. Gilbert, J. R. Granada, W. Haeck, F.-J. Hambsch, P. Helgesson,
S. Hilaire, I. Hill, M. Hursin, R. Ichou, R. Jacqmin, B. Jansky, C. Jouanne, M. A.
Kellett, D. H. Kim, H. I. Kim, I. Kodeli, A. J. Koning, A. Y. Konobeyev, S. Ko-
pecky, B. Kos, A. Krása, L. C. Leal, N. Leclaire, P. Leconte, Y. O. Lee, H. Leeb,
O. Litaize, M. Majerle, J. I. M. Damián, F. Michel-Sendis, R. W. Mills, B. Mori-
llon, G. Noguère, M. Pecchia, S. Pelloni, P. Pereslavtsev, R. J. Perry, D. Rochman,
A. Röhrmoser, P. Romain, P. Romojaro, D. Roubtsov, P. Sauvan, P. Schillebeeckx,
K. H. Schmidt, O. Serot, S. Simakov, I. Sirakov, H. Sjöstrand, A. Stankovskiy, J. C.
Sublet, P. Tamagno, A. Trkov, S. van der Marck, F. Álvarez-Velarde, R. Villari, T. C.
Ware, K. Yokoyama, and G. �erovnik, �The joint evaluated �ssion and fusion nuclear
data library, JEFF-3.3,� The European Physical Journal A, vol. 56, jul 2020.
[11] R. Macfarlane, D. W. Muir, R. M. Boicourt, I. Albert Comstock Kahler, and J. L.
Conlin, �The njoy nuclear data processing system, version 2016,� 2019.
86

[12] L. Fiorito, G. �erovnik, A. Stankovskiy, G. Van den Eynde, and P. Labeau, �Nuclear
data uncertainty propagation to integral responses using sandy,� Annals of Nuclear
Energy, vol. 101, pp. 359 � 366, 2017.
[13] S. K. Kenichi TADA and Y. NAGAYA, �Nuclear data processing code frendy version
1,� JAEA-Data/Code 2018-014, January 2019.
[14] K. Tada, Y. Nagaya, S. Kunieda, K. Suyama, and T. Fukahori, �Development and
veri�cation of a new nuclear data processing system frendy,� Journal of Nuclear
Science and Technology, vol. 54, no. 7, pp. 806�817, 2017.
[15] N. G. Herranz, �Aplicaciones a análisis de criticidad,� Apuntes de Diseño de Reactores
(ETSII UPM).
[16] N. G. Herranz, �Código mcnp,� Apuntes de Diseño de Reactores (ETSII UPM).
[17] N. Soppera, M. Bossant, and E. Dupont, �JANIS 4: An improved version of the
NEA java-based nuclear data information system,� Nuclear Data Sheets, vol. 120,
pp. 294�296, jun 2014.
[18] O. Cabellos, �Introducción a janis,� �INGENIA-NUCLEAR� - Diseño y Simulación
de un PWR, Curso 2018-19.
[19] M. Chadwick, R. Capote, A. Trkov, M. Herman, D. Brown, G. Hale, A. Kahler, P. Ta-
lou, A. Plompen, P. Schillebeeckx, M. Pigni, L. Leal, Y. Danon, A. Carlson, P. Ro-
main, B. Morillon, E. Bauge, F.-J. Hambsch, S. Kopecky, G. Giorginis, T. Kawano,
J. Lestone, D. Neudecker, M. Rising, M. Paris, G. Nobre, R. Arcilla, O. Cabellos,
I. Hill, E. Dupont, A. Koning, D. Cano-Ott, E. Mendoza, J. Balibrea, C. Paradela,
I. Durán, J. Qian, Z. Ge, T. Liu, L. Hanlin, X. Ruan, W. Haicheng, M. Sin, G. Nogue-
re, D. Bernard, R. Jacqmin, O. Bouland, C. De Saint Jean, V. Pronyaev, A. Ignatyuk,
87

K. Yokoyama, M. Ishikawa, T. Fukahori, N. Iwamoto, O. Iwamoto, S. Kunieda, C. Lu-
bitz, M. Salvatores, G. Palmiotti, I. Kodeli, B. Kiedrowski, D. Roubtsov, I. Thom-
pson, S. Quaglioni, H. Kim, Y. Lee, U. Fischer, S. Simakov, M. Dunn, K. Guber,
J. Márquez Damián, F. Cantargi, I. Sirakov, N. Otuka, A. Daskalakis, B. McDer-
mott, and S. van der Marck, �Cielo collaboration summary results: International
evaluations of neutron reactions on uranium, plutonium, iron, oxygen and hydro-
gen,� Nuclear Data Sheets, vol. 148, pp. 189 � 213, 2018. Special Issue on Nuclear
Reaction Data.
[20] OECD, �An extended summary of thecollaborative international evaluatedlibrary
organisation (cielo) pilot project,� NEA No.7498, 2019.
[21] O. Cabellos, �Example of a bayesian montecarlo (bmc) technique applied for 235u
adjustment using criticality and transmission integral benchmarks,� Workshop On
Nuclear Data Evaluation for Reactor Applications, 2018.
[22] Indeed, �Información del salario medio de un ingeniero industrial en madrid.�
url = hhttps://es.indeed.com/salaries/ingeniero-industrial-Salaries,-Comunidad-de-
Madrid, 2020.
[23] A. Tributaria, �Tabla de coe�cientes de amortización lineal,� 2015.
[24] U. of Colorado Denver, �Hpc cost calculator.� url =
https://www.ucdenver.edu/o�ces/o�ce-of-information-technology/ticr-high-
performance-computing/hpc-cost-calculator, 2020.
88

12. Plani�cación y presupuesto
12.1. Plani�cación
A continuación se muestra el diagrama de Gantt con la plani�cación del proyecto y
una tabla en la que se recogen todas las tareas indicando su orden de realización, el tiempo
de dedicación, su inicio y su �nal.
Para facilitar la correcta apreciación del diagrama de Gantt este se ha distribuido por
trimestres.
Figura 35: Primera parte del diagrama de Gantt del trabajo
89
Figura 36: Parte �nal del diagrama de Gantt del trabajo
90
1 Estudios previos 70 days 30/01/19 8:00 7/05/19 17:00
2 Repaso de Tecnología Nuclear 30 days 30/01/19 8:00 12/03/19 17:00
3 Datos nucleares 40 days 13/03/19 8:00 7/05/19 17:00 2
4 Formato ENDF 20 days 13/03/19 8:00 9/04/19 17:00
5 Librerías y Bibliotecas 20 days 10/04/19 8:00 7/05/19 17:00 4
6 SANDY 33 days 8/05/19 8:00 22/07/19 17:00 1
7 Lectura de la documentación 15 days 8/05/19 8:00 28/05/19 17:00
8 Muestreo con MF = 31 3 days 29/05/19 8:00 31/05/19 17:00 7
9 Muestreo con MF = 33 3 days 29/05/19 8:00 31/05/19 17:00 7
10 Secciones eficaces de fisión 3 days 29/05/19 8:00 31/05/19 17:00
11 Secciones eficaces de todas las reacciones 3 days 29/05/19 8:00 31/05/19 17:00
12 Muestreo con MF = 35 3 days 29/05/19 8:00 31/05/19 17:00 7
13 Redacción del apartado 15 days 3/06/19 8:00 22/07/19 17:00 8;9;12
14 JANIS 28 days 23/07/19 8:00 13/09/19 17:00 6
15 Lectura de la documentación 15 days 23/07/19 8:00 27/08/19 17:00
16 Visualización de varias muestras de SANDY 10 days 28/08/19 8:00 10/09/19 17:00 15
17 Comprobación visual del muestreo 3 days 11/09/19 8:00 13/09/19 17:00 16
18 NJOY 37 days 23/07/19 8:00 26/09/19 17:00 6
19 Lectura de la documentación previa 15 days 23/07/19 8:00 27/08/19 17:00
20 Obtención archivos ACE a partir de las muestras de SANDY 12 days 28/08/19 8:00 12/09/19 17:00 19
21 Documentación del proceso 10 days 13/09/19 8:00 26/09/19 17:00 20
22 FRENDY 33 days 27/09/19 8:00 12/11/19 17:00 1 8
23 Lectura de la documentación 15 days 27/09/19 8:00 17/10/19 17:00
24 Muestreo con MF = 31 3 days 18/10/19 8:00 22/10/19 17:00 23
25 Muestreo con MF = 33 3 days 18/10/19 8:00 22/10/19 17:00 2 3
26 Secciones eficaces de fisión 3 days 18/10/19 8:00 22/10/19 17:00
27 Secciones eficaces de todas las reacciones 3 days 18/10/19 8:00 22/10/19 17:00
28 Muestreo con MF = 35 3 days 18/10/19 8:00 22/10/19 17:00 23
29 Redacción del apartado 15 days 23/10/19 8:00 12/11/19 17:00 24;25;28
30 MCNP 85 days 13/11/19 8:00 31/03/20 17:00 18;22
31 Lectura de la documentación 15 days 13/11/19 8:00 3/12/19 17:00
32 Obtención keff con las muestras de SANDY 55 days 4/12/19 8:00 10/03/20 17:00 31
33 Obtención keff con las muestras de FRENDY 55 days 4/12/19 8:00 10/03/20 17:00 31
34 Documentación del proceso 15 days 11/03/20 8:00 31/03/20 17:00 32;33
35 Recopilación de todos los datos 30 days 1/04/20 8:00 12/05/20 17:00 30
36 Gráficas 15 days 13/05/20 8:00 2/06/20 17:00 35
37 Conclusión 10 days 3/06/20 8:00 17/07/20 17:00 35;36
38 Redacción de la memoria 30 days 20/07/20 8:00 11/09/20 17:00 37
39 Revisón 14 days 14/09/20 8:00 1/10/20 17:00 38
40 Entrega 1 day 2/10/20 8:00 2/10/20 17:00 39
Nombre Duracion Inicio Terminado Predecesores
Gantt
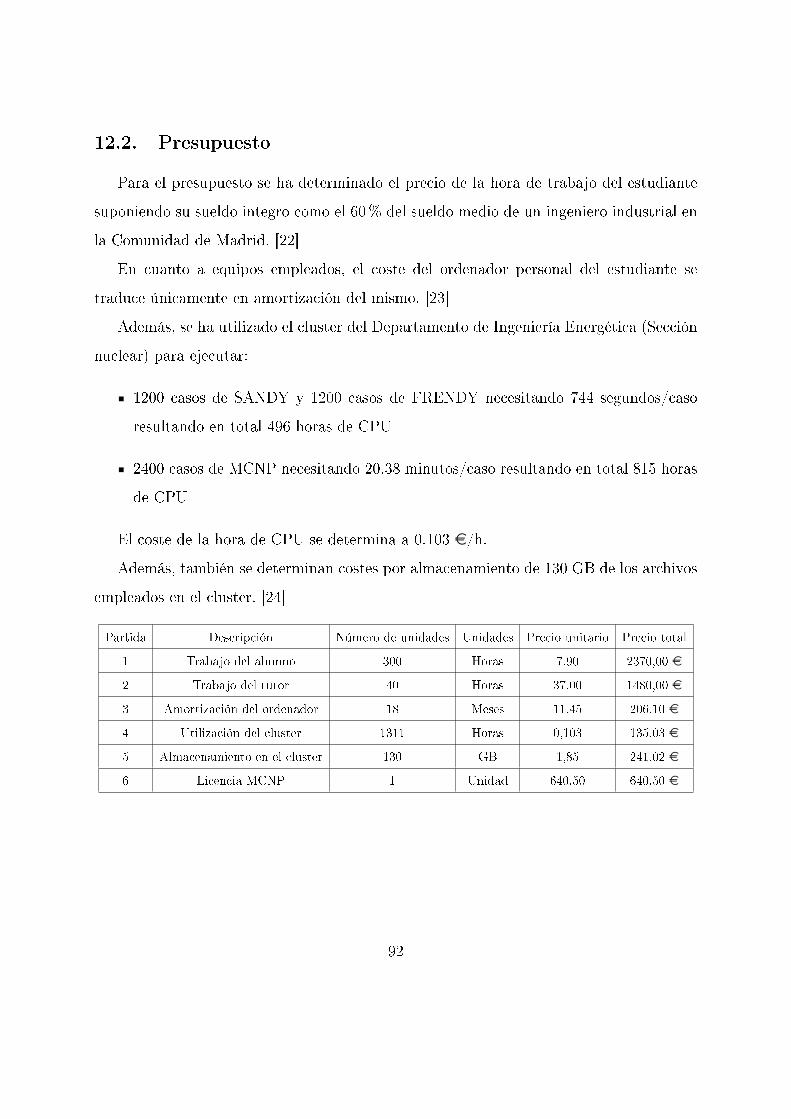
12.2. Presupuesto
Para el presupuesto se ha determinado el precio de la hora de trabajo del estudiante
suponiendo su sueldo integro como el 60% del sueldo medio de un ingeniero industrial en
la Comunidad de Madrid. [22]
En cuanto a equipos empleados, el coste del ordenador personal del estudiante se
traduce únicamente en amortización del mismo. [23]
Además, se ha utilizado el cluster del Departamento de Ingeniería Energética (Sección
nuclear) para ejecutar:
1200 casos de SANDY y 1200 casos de FRENDY necesitando 744 segundos/caso
resultando en total 496 horas de CPU
2400 casos de MCNP necesitando 20.38 minutos/caso resultando en total 815 horas
de CPU
El coste de la hora de CPU se determina a 0.103 e/h.
Además, también se determinan costes por almacenamiento de 130 GB de los archivos
empleados en el cluster. [24]
Partida Descripción Número de unidades Unidades Precio unitario Precio total
1 Trabajo del alumno 300 Horas 7,90 2370,00 e
2 Trabajo del tutor 40 Horas 37,00 1480,00 e
3 Amortización del ordenador 18 Meses 11,45 206,10 e
4 Utilización del cluster 1311 Horas 0,103 135,03 e
5 Almacenamiento en el cluster 130 GB 1,85 241,02 e
6 Licencia MCNP 1 Unidad 640,50 640,50 e
92

PRESUPUESTO EJECUCIÓN MATERIAL: 5072,65 e
GASTOS GENERALES (13%): 659,44 e
BENEFICIO INDUSTRIAL (6%): 304,36 e
TOTAL: 6036,45 e
IVA (21%): 1267,65 e
TOTAL CON IVA: 7304,10 e
PRESUPUESTO EJECUCIÓN POR CONTRATA: 7304,10 e
93

Índice de �guras
1. Con�guración experimental del experimento GODIVA . . . . . . . . . . . . 9
2. Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY
a partir del FILE 33 perturbando todas las reacciones en el rango de mayor
desviación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3. Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY
a partir del FILE 31 en el rango de mayor desviación . . . . . . . . . . . . 33
4. Visualización con JANIS de varias muestras aleatorias obtenidas con SANDY
a partir del FILE 35 en el rango de mayor desviación . . . . . . . . . . . . 35
5. Visualización con JANIS de varios conjuntos de datos de ν̄ generados con
SANDY en el rango de valores del experimento de referencia . . . . . . . . 51
6. Distribución de keff para las muestras generadas con SANDY con el FILE
31 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
7. Evolución de la media con el número de muestras generadas con SANDY
a partir del FILE 31 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
8. Tendencia de la desviación media con el número de varias muestras alea-
torias generadas con SANDY a partir del FILE 31 . . . . . . . . . . . . . . 54
9. Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 en el rango de valores del experimento de referencia . 56
10. Distribución de keff para las muestras generadas con SANDY a partir del
FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
11. Evolución de la media con el número de muestras generadas con SANDY
a partir del FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
12. Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . . 59
94

13. Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión
en el rango de valores del experimento de referencia . . . . . . . . . . . . . 60
14. Distribución de keff para las muestras generadas con SANDY a partir del
FILE 33 perturbando únicamente las secciones e�caces de �sión . . . . . . 61
15. Evolución de la media con el número de muestras generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión 62
16. Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 33 perturbando únicamente las secciones e�caces
de �sión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
17. Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de cap-
tura en el rango de valores del experimento de referencia . . . . . . . . . . 64
18. Visualización con JANIS de varias muestras aleatorias generadas con SANDY
a partir del FILE 33 perturbando únicamente las secciones e�caces de �sión
y captura en el rango de valores del experimento de referencia . . . . . . . 65
19. Visualización con JANIS de varias muestras de distribuciones de energía
saliente generadas con SANDY a partir del FILE 35 en el rango del expe-
rimento de referencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
20. Distribución de keff para las muestras generadas con SANDY a partir del
FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
21. Evolución de la media con el número de muestras generadas con SANDY
a partir del FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
22. Tendencia de la desviación típica con el número de muestras generadas con
SANDY a partir del FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . . 69
23. Distribución de keff para las muestras generadas con FRENDY con el FILE
31 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
95

24. Evolución de la media con el número de muestras generadas con FRENDY
a partir del FILE 31 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
25. Tendencia de la desviación media con el número de varias muestras alea-
torias generadas con FRENDY a partir del FILE 31 . . . . . . . . . . . . . 72
26. Distribución de keff para las muestras generadas con FRENDY a partir
del FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
27. Evolución de la media con el número de muestras generadas con FRENDY
a partir del FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
28. Tendencia de la desviación típica con el número de muestras generadas con
FRENDY a partir del FILE 33 . . . . . . . . . . . . . . . . . . . . . . . . 75
29. Distribución de keff para las muestras generadas con FRENDY a partir
del FILE 33 perturbando únicamente las secciones e�caces de �sión . . . . 76
30. Evolución de la media con el número de muestras generadas con FRENDY
a partir del FILE 33, perturbando únicamente las secciones e�caces de �sión 77
31. Tendencia de la desviación típica con el número de muestras generadas
con FRENDY a partir del FILE 33, perturbando únicamente las secciones
e�caces de �sión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
32. Distribución de keff para las muestras generadas con FRENDY a partir
del FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
33. Evolución de la media con el número de muestras generadas con FRENDY
a partir del FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
34. Tendencia de la desviación típica con el número de muestras generadas con
FRENDY a partir del FILE 35 . . . . . . . . . . . . . . . . . . . . . . . . 81
35. Primera parte del diagrama de Gantt del trabajo . . . . . . . . . . . . . . 89
36. Parte �nal del diagrama de Gantt del trabajo . . . . . . . . . . . . . . . . 90
96

Índice de cuadros
1. Composición de cada una de las capas en el Modelo de caparazón de GODIVA 11
2. Dimensiones del Modelo de Caparazón de GODIVA . . . . . . . . . . . . . 12
3. Masa y contenido de Uranio 235 en el Modelo de caparazón y en la esfera
de GODIVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4. Datos experimentales utilizados para obtener los parámetros de resonancia
para energías de neutrones entre 10-5 eV y 2.25 keV. . . . . . . . . . . . . 22
5. Comparativa de resultados: Desviaciones típicas de keff en partes por cien
mil(pcm) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6. Comparativa de resultados: Valores medios de keff . . . . . . . . . . . . . 84
97

13. Siglas y abreviaturas
ACE: A Compact ENDF
ASTRID: Advanced Sodium Technological Reactor for Industrial Demonstration
CSEWG: Cross Section Evaluation Working Group
CERN nTOF: Neutron time-of-�ight facility at CERN (France)
CIELO: Collaborative International Evaluation Library Organization
CINDA: Computer Index of Neutron Data
DEMO: DEMOnstration power plant
ENDF: Evaluated Nuclear Data File
EXFOR: Experimental Nuclear Reaction Data
FCA Fast critical assembly
FRENDY: FRom Evaluated Nuclear Data librarY to any application
HEU: Hight Enriched Uranium
HMF: Highly enriched uranium metal with fast neutrons
98

IAEA: International Atomic Energy Agency
ICSBEP: International Criticality Safety Benchmark Evaluation Project
IFMIF-DONES: Proyecto internacional cuyo objetivo es la construcción de una fuen-
te de neutrones
ITER: Reactor Tomakak de fusión
JAEA: Japan Atomic Energy Agency
JANIS: Java-based nuclear information software
JEFF: Joint Evaluated Fission and Fusion File
JENDL: Japanese Evaluated Nuclear Data Library
LANL: Los Alamos National Laboratory (United States)
MCNP: Monte Carlo N-Particle Transport Code
MYRRHA: Multi-purpose Research Reactor for High-tech Applications
NDaST: Nuclear Data Sensitivity Tool (NEA)
NNDC: National Nuclear Data Center
99

Nubar: Average number of neutrons per �ssion
NUDUNA: NUclear Data UNcertainty Analysis
OECD: Organisation for Economic Co-operation and Development
PENDF: Pointwise-ENDF
PFNS: Prompt �ssion neutron spectra
SANDY: SAmpler of Nuclear Data and uncertaintY
TMC: Total Monte Carlo
XSUSA: Cross Section Uncertainty and Sensitivity Analysis
100