estadÍsticaies.julioverne.leganes.educa.madrid.org/web/attachments...permiten el tratamiento...
TRANSCRIPT

1
ESTADÍSTICA INTRODUCCIÓN Y MOTIVACIÓN La principal razón de que el Método Estadístico se haya desarrollado ampliamente en los últimos años
dentro de las Ciencias Experimentales es que éstas están sujetas a razonamientos de tipo inductivo que van
de lo particular a lo general. Sacaremos conclusiones sobre un grupo de individuos a partir de la
información que nos proporciona un subconjunto más o menos amplio de los mismos.
La expansión del Método Estadístico es tal que, de todas las disciplinas que podemos estudiar a lo largo
de toda la Enseñanza Secundaría, la Estadística es prácticamente la única que tendremos como asignatura
en la mayor parte de las carreras universitarias que podamos elegir en el futuro; desde las típicamente
consideradas experimentales, como la Medicina o la Biología, hasta carreras consideradas como de letras
como la Psicología, la Sociología o incluso la Geografía. Si decidimos no tomar el camino de la
Universidad nos encontraremos cada vez más frecuentemente con conceptos procedentes de la Ciencia
Estadística como por ejemplo el de error máximo admisible o el de nivel de confianza en cualquier
encuesta sociológica de las que habitualmente aparecen en la prensa.
El primer concepto importante que hemos de aprender es la diferencia existente entre lo que son las
estadísticas como meras colecciones de datos y que es un término que se usa para denotar los propios
datos, o números derivados de ellos, tales como los promedios. Así se habla de estadística de empleo,
estadística de accidentes,... y lo que es el Método Estadístico considerado como una disciplina científica
con entidad propia.
Es común escuchar la frase “No creo en las estadísticas”, incluso entre profesionales cercanos a la
disciplina. Efectivamente las “estadísticas” como posible ayuda a la toma de decisiones dependen de quién
y cómo se hayan tomado los datos y de si las respuestas que dan los encuestados se ajustan a su opinión
real. En este sentido los datos pueden ser susceptibles de creencia puesto que uno puede dudar de la
intención del encuestado. El Método Estadístico, tal y como está concebido en la actualidad, forma parte
del saber científico y es aceptado lo mismo que lo es, por ejemplo, la Teoría de la Relatividad en Física; no
es, por tanto, terreno de las creencias y seguirá siendo aceptado como válido hasta que alguien proponga
una nueva teoría que lo modifique.
Resumiendo, la Estadística se configura como un método científico que proporciona instrumentos para
la toma de decisiones cuando estas se adoptan en ambientes de incertidumbre, siempre que esta
incertidumbre pueda ser cuantificada en términos de probabilidad. (MARTIN PLIEGO, 1994).
El procedimiento de toma de decisiones, o de aprendizaje, en el ámbito científico consiste
básicamente en plantear una hipótesis, contrastarla mediante datos experimentales y modificarla si
no puede ser aceptada. Es precisamente en el paso de contraste en el que el Método Estadístico juega un
papel fundamental y aunque cualquier científico puede realizar una investigación sin estadística, sin
embargo es mucho más fiable si el resultado está basado en métodos estadísticos. No se concibe la
investigación aplicada actual sin la utilización de la Estadística en el proceso de inducción.

2
Cuadro 1: El método científico y su relación con la Estadística. Se han señalado en cursiva
los pasos del método directamente relacionados con la Estadística, que van desde la
recogida de los datos hasta el análisis de los mismos.

3
ESTADÍSTICA DESCRIPTIVA UNIDIMENSIONAL CONTENIDOS 1. Estadística: Conceptos básicos 2. Tablas estadísticas. Recuento y frecuencias 3. Gráficos para variables estadísticas
4. Parámetros estadísticos: cálculo, significado y propiedades.
1. Estadística: Conceptos básicos
La Estadística es la parte de las Matemáticas que se ocupa de los procedimientos que permiten el tratamiento sistemático de datos, la búsqueda de conclusiones de los mismos y la toma de decisiones tras su análisis.
En sus orígenes históricos, la Estadística estuvo ligada a cuestiones de Estado ( recuentos, censos, etc.) y es el resultado de la unión de dos disciplinas que evolucionan
independientemente hasta confluir en el siglo XIX: la 1ª es el “Cálculo de probabilidades” que nace en el s. XVII como teoría matemática de los juegos de azar y la 2ª es la “Estadística” (o ciencia del Estado, del latín status) que estudia la descripción de datos y
tiene unas raíces más antiguas. Hoy en día está presente en todos los ámbitos humanos como medio ambiente, sanidad,
educación, sociología, mercado laboral entre otros y actúa como puente entre los modelos matemáticos y los fenómenos reales.
Por otro lado, el lenguaje estadístico forma parte de la información de los medios de comunicación. El uso continuado en los mismos de tablas y gráficos estadísticos, ha
convertido en una necesidad cultural básica la lectura e interpretación de tablas y gráficos.
La Estadística estudia los métodos científicos para recoger, organizar, resumir y
analizar datos, así como para sacar conclusiones válidas y tomar decisiones
razonables basadas en tal análisis.
La parte de la Estadística que se ocupa de describir y analizar un grupo dado, sin
sacar conclusiones sobre un grupo mayor, se llama estadística descriptiva.

4
Si una muestra es representativa de la población, es posible inferir importantes
conclusiones sobre la población a partir del análisis de la muestra. La parte de la
Estadística que trata sobre la elaboración de conclusiones para la población y del
grado de fiabilidad de las mismas se llama estadística inductiva o inferencia
estadística.
ELEMENTOS EN UN ESTUDIO ESTADÍSTICO
(CONCEPTOS QUE HAY QUE APRENDER MUY BIEN):
El primer concepto importante es el de población, que es el conjunto de elementos sobre los que
se desea información y, por tanto, sobre los cuales se va a estudiar una determinada
característica.
- Para obtener dicha información, es necesario medir o contar en cada elemento uno o
varios caracteres, pero ¡ojo! , debe poder observarse en todos y cada uno de ellos, si no,
la población no está bien elegida, por eso se dice que “la población ha de tener al menos
una característica común observable”. A cada elemento de la población se le llama
individuo.
Haremos las siguientes observaciones:
No se refiere necesariamente a un conjunto de organismos vivientes y son ejemplos de población:
- Los habitantes de un determinado país.
- Árboles de un bosque
- Establecimientos comerciales de una ciudad
- Bombillas de un determinado tipo producidas en una fábrica.
La población ha de estar muy bien definida a la hora de comenzar el estudio. Por ejemplo, en un
ensayo clínico en el que se pretende demostrar la efectividad de un tratamiento han de estar muy
claros cuáles son los criterios de inclusión de un paciente en la población (muestra) a estudiar.
Cuando el estadístico puede observar a todos los elementos de la población diremos que está
realizando un censo.
Una población puede ser finita o infinita. Por ejemplo, la población consistente en todas las
tuercas producidas por una fábrica un cierto día es finita, mientras que la determinada por todos
los posibles resultados (caras y cruces) de sucesivas tiradas de una moneda puede ser infinita.
Muestra es una parte de la población sobre la que se hace el estudio y a partir de la cual se
extraerán conclusiones extensibles a toda la población, es decir cualquier subconjunto de la
población.
La necesidad de obtener un subconjunto de la población es obvia por diversos motivos como por
ejemplo:
- Por los costes económicos de la experimentación (es decir, que sea inviable económicamente
estudiar toda la población).

5
- Porque el estudio puede implicar la destrucción del elemento (métodos de medida destructivos),
como p. Ej. estudiar la vida media de una partida de bombillas o la tensión de rotura de cables.
- Porque es muy difícil o imposible controlarla como p. Ej. la totalidad de personas que entran en
unos grandes almacenes a lo largo de una semana.
- Porque se desea conocer rápidamente ciertos datos de la población y se tardaría demasiado en
controlar a todos, por ejemplo para conocer el voto de los habitantes de un país en unas
elecciones.
Para entenderlo mejor veamos el siguiente ejemplo:
En el periódico del sábado 11/11/00 podemos leer:
Para conseguir estos datos no se puede encuestar a toda la población que está viendo la
televisión, ¡es imposible!. La parte de la población que se entrevista es la muestra.
El tamaño muestral es el número de elementos de la muestra y lo designaremos con la
letra mayúscula N.
Se llama trabajo de campo a todo lo que hay que hacer para tomar los datos estadísticos.
Para poder obtener conclusiones razonables a partir de una muestra, ésta debe estar bien
elegida, es decir, debe ser representativa de la población que se trata de estudiar.
Carácter estadístico: Se puede definir como cualidad común observable en todos y cada uno
de los individuos de una población (que puede describirse según uno o varios caracteres).
- Puede ser una cualidad numérica (resultado de un recuento o una medida como por ejemplo
“altura”) o no numérica (como por ejemplo la cualidad “color”).

6
- Así, en el caso del personal de una empresa se pueden estudiar los siguientes caracteres:
sexo, edad, cualificación, antigüedad en la empresa, salario mensual, número de hijos a su
cargo,...
- Si la población estudiada es la producción de un taller, por ejemplo la población de un lote de
piezas mecánicas fabricadas en serie, pueden describirse las unidades estadísticas según el
diámetro, el peso, o el hecho de satisfacer o no las normas de fabricación.
- Respecto al conjunto de años de 1990 a 2000, los caracteres pueden ser: el beneficio anual
de la empresa, el efectivo de asalariados o el tonelaje producido.
Modalidades
Cada uno de los caracteres estudiados puede presentar dos o varias modalidades. Son las
situaciones (R.A.E.: estado o constitución de las cosas y personas) posibles del carácter.
Deben ser a la vez incompatibles y exhaustivas, es decir, cada individuo de la población presenta una y
sólo una de las modalidades del carácter.
Tipos de caracteres:
Cualitativo ( o atributo)
- Modalidades no medibles
Ejemplos: profesión, cualificación, sexo, estado civil, color de un tipo de pintura, canal de
TV que se está viendo, etc.
Cuantitativo:
- Modalidades medibles o numerables, es decir, si a cada modalidad se le puede asignar un número.
Ejemplos: peso, talla, longitud, densidad, nº de hermanos.
- Se suelen denominar variables estadísticas (aunque haremos la observación de que algunos textos
consideran a los dos tipos de caracteres como una variable estadística).
- A su vez pueden ser:
a) Discretas: Sus posibles valores son “valores aislados”, es decir, toman a lo sumo, un número
finito de valores.
Caso más frecuente: cuando los valores posibles son números enteros o múltiplos
enteros de un número fijo.
Ejemplos: nº de hijos, nº de piezas defectuosas de un lote de 1000 piezas, número de
obreros de una obra en construcción,
En general las enumeraciones o recuentos, dan lugar a datos discretos.
b) Continuas: Sus valores son el resultado de una medida que puede tomar, al menos
teóricamente, cualquier valor de un intervalo numérico, es decir, puede tomar cualquier valor entre
dos valores dados por lo que sus valores posibles están en número infinito.
Ejemplos: Edad de un individuo, diámetro de una pieza, contenido en carbono de una
aleación, temperatura de un cuerpo, velocidad de un móvil, talla, peso, tiempo, etc.

7
En general, todas las magnitudes relacionadas con el espacio (longitud, superficie,...),
tiempo ( edad, duración de vida,...), masa ( peso, contenido,...) o bien con las
combinaciones de estos elementos ( velocidad, consumo de fluido, densidad,...).
Se observará, sin embargo, que la distinción entre variable estadística discreta y continua es, a veces,
arbitraria. En realidad toda medida es discreta, debido a una precisión siempre limitada. Si se afirma, no
obstante, que por ejemplo el diámetro es una variable continua se debe a la naturaleza intrínseca,
independientemente de la medida y la noción de diámetro: a priori todo valor (positivo) puede representar
un diámetro. Se convendrá entonces que una medida representa un intervalo de valores.
Por extensión de la noción de variable estadística continua, una magnitud que pueda tomar un gran
número de valores posibles -aunque sean valores aislados- será considerada como una variable
continua. Ocurre así por ejemplo en magnitudes monetarias: salario mensual de un obrero, beneficio
anual de una empresa, etc.
2. Tablas estadísticas. Recuento y frecuencias
Una vez tomados los datos, éstos se agrupan en tablas de frecuencias ( o distribuciones de
frecuencias), se representan en gráficos estadísticos y se resumen en parámetros estadísticos.
1. Cómo elaborar TABLAS DE FRECUENCIAS
Las tablas estadísticas o tablas de frecuencias presentan en una columna las modalidades del
atributo (carácter estadístico cualitativo) o los valores de la variable estadística que estamos observando.
Frente a cada uno de estos valores se pone su frecuencia absoluta fi = nº de veces que se repite cada
dato. Las tablas de datos suelen completarse con tres columnas más:
Frecuencia absoluta acumulada (Fi): suma de las frecuencia absolutas de todos los valores menores o igual que él.
Frecuencia relativa (hi): cociente entre la frecuencia absoluta de ese valor y
el número total de datos. A partir de esta columna podemos construir la columna con los porcentajes relativos a cada valor de la variable.
Frecuencia relativa acumulada (Hi): Suma de las frecuencias relativas de los valores menores o iguales que él.
Ejemplo: Número de días a la semana que practican deporte 20 alumnos
de 3º de ESO: 1; 4; 4; 1; 1; 3; 4; 3; 1; 1; 3; 2; 1; 4; 1; 1; 2; 3; 3; 3
VALORES Frecuencias Frecuencias Frec. Abs. Frec.Rel.
Absolutas Relativas Acumuladas Acumuladas
1 8 0,4 8 0,4
2 2 0,1 10 0,5
3 6 0,3 16 0,8
4 4 0,2 20 1
TOTAL 20 1
8
Si el número de observaciones es suficientemente grande (N > 30) y con valores que convenga
agrupar o si la variable es continua, se utilizan tablas con los datos agrupados en lo que se denominan
clases o intervalos*, que son cada una de las partes en las que pueden agruparse los datos que se
obtienen en un estudio estadístico cuya amplitud o longitud (diferencia entre los valores extremos del
intervalo) suele ser constante. Al punto medio del intervalo se denomina marca de clase (xi):
Si el intervalo es [ai,a i+1) es 2
1
ii
i
aax (1)
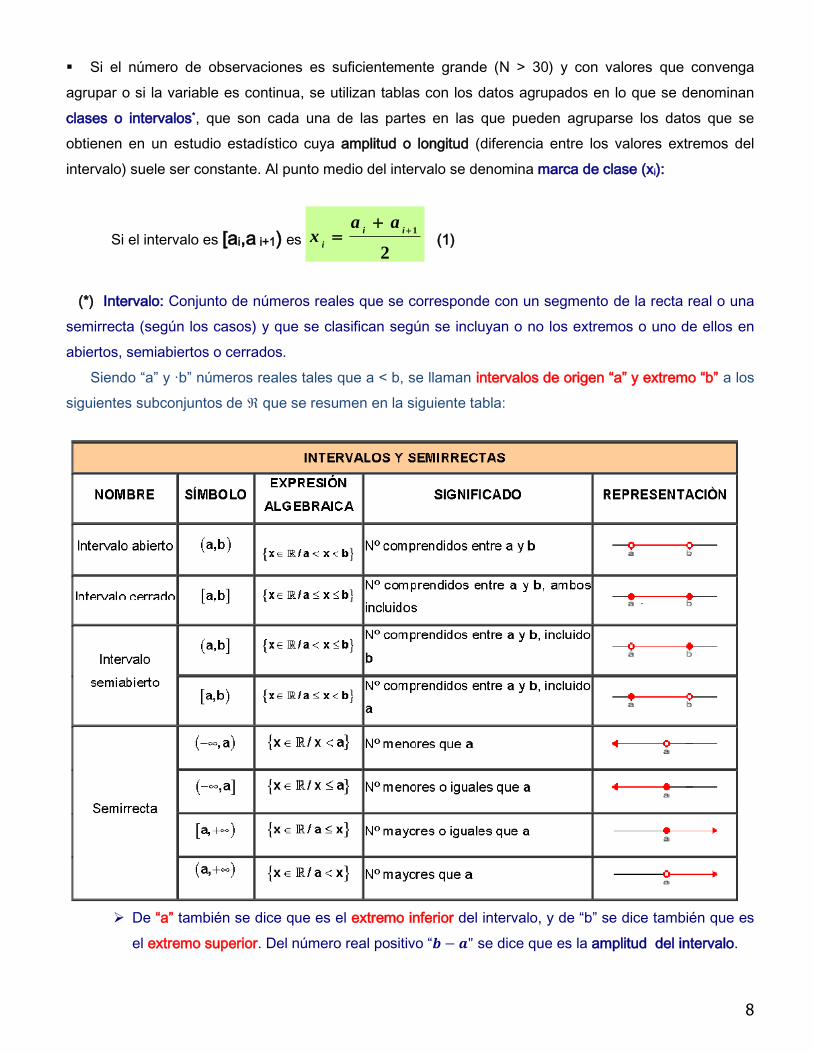
(*) Intervalo: Conjunto de números reales que se corresponde con un segmento de la recta real o una
semirrecta (según los casos) y que se clasifican según se incluyan o no los extremos o uno de ellos en
abiertos, semiabiertos o cerrados.
Siendo “a” y ·b” números reales tales que a < b, se llaman intervalos de origen “a” y extremo “b” a los
siguientes subconjuntos de ℜ que se resumen en la siguiente tabla:
De “a” también se dice que es el extremo inferior del intervalo, y de “b” se dice también que es
el extremo superior. Del número real positivo “ se dice que es la amplitud del intervalo.

9
En estadística descriptiva, cuando agrupemos los datos en intervalos, seguiremos el criterio de
que los intervalos sean cerrados por la izquierda y abiertos por la derecha, es decir, de la
forma: y haremos alguna excepción cuando convenga (por ejemplo incluir el extremo
derecho del último intervalo).
Elección de los extremos: Es conveniente que no coincidan con ningún valor de la variable.
Ahora bien, ¿cuál es el nº idóneo de clases que debemos escoger a la hora de agrupar los
datos? .
No existe una respuesta tajante a esta pregunta, existen incluso varios criterios para dar
respuesta a esta cuestión y utilizaremos el siguiente:
Criterio de Norcliffe: k= + N (k = número de clases o intervalos)
(Observación: podemos también utilizar el símbolo I = nº de intervalos)
Una vez decidido el número de intervalos, es aconsejable escoger los límites de clase
(=extremos de los intervalos) de modo que se sitúen en números “redondos” como múltiplos de
5,10, etc. siempre que sea posible y se debe procurar además que todas las clases tengan la
misma amplitud o longitud que podemos calcular así:
Si R es el rango siendo
y de esta forma obtenemos un nº entero.
Observación: el rango nos da una primera idea de la dispersión de los datos y por eso es un parámetro de
dispersión.
Además el límite superior de una clase debe coincidir con el límite inferior de la siguiente y se debe
aceptar el criterio de que los intervalos sean cerrados por la izquierda y abiertos por la derecha como
hemos comentado antes: .
Ahora bien, ¿cómo podemos calcular el primer extremo del primer intervalo para que los datos los
podamos distribuir con comodidad según todo lo anterior?. Supongamos que es “a”:
Calculamos a según la siguiente fórmula
Siendo
un número que vamos a restar al menor valor de la variable.
OBSERVACIÓN: Ni “r” ni “a” tienen por qué ser números enteros, pueden ser números decimales.

10
Una vez obtenido a sólo tenemos que ir sumando la amplitud hasta obtener el número de
intervalos calculados.
Ejercicio de explicación:
Se han medido las estaturas en centímetros de 40 alumnos de 4º de ESO, obteniéndose los siguientes datos:
165, 170, 167, 165, 172, 171, 162, 173, 170, 176, 173, 156, 167, 180,
175, 166, 160, 169, 178, 166, 164, 176, 174, 182, 167, 172, 171, 170,
173, 175, 171, 177, 170, 178, 168, 185, 173, 174, 168, 174
Haz la tabla de frecuencias.
Solución:
Todos los pasos anteriores los podemos esquematizar en “4 pasos a seguir” :
1er paso: Rango
2º paso: Número de intervalos:
33r paso: Longitud:
4º paso: Extremo izquierdo del primer intervalo [a, b):
A partir de aquí sólo tenemos que agrupar los datos de 5 en 5 empezando en 155,5 resultando la
siguiente tabla o distribución de frecuencias:
Ejercicio de aplicación (hazlo tú):
Las precipitaciones medias anuales en mm recogidas en una estación meteorológica han sido en los
últimos años:
a) Clasifica el carácter estadístico.
b) Agrupa los datos en una tabla de
frecuencias

11
3.Gráficos en Estadística
Si el número de datos es grande ó la variable es continua, los datos se agrupan en intervalos o
clases. Es aconsejable que todas las clases tengan la misma amplitud.
Los puntos medios de cada intervalo se llaman marcas de clase.
Podemos representar los datos en gráficos siendo los más usuales los siguientes: diagrama de
barras histogramas, polígono de frecuencias y gráfico de sectores:
a) Diagrama de barras, usado para variables cuantitativas discretas. En el eje OX se señalan los
valores de la variable y en el eje OY los valores de la frecuencia absoluta. Se levantan barras de
altura igual a la frecuencia absoluta.
b) Histograma, usado para variables continuas. En el eje OX se señalan los extremos de los
intervalos. Se construyen unos rectángulos de base la amplitud del intervalo y de altura la
frecuencia absoluta. (Si las amplitudes de los intervalos no son las mismas, no podemos hacer esto,
pues lo que tendría que ser proporcional a la frecuencia es el área del rectángulo que levantamos y
por tanto tendríamos que averiguar previamente a qué altura hay que levantarlos).
c) Polígono de frecuencias, se obtiene uniendo los puntos medios de los segmentos superiores de los
rectángulos del diagrama en el caso de variables continuas y uniendo los extremos superiores de
las barras del diagrama de barras en el caso a).
d) Gráfico de sectores, es el resultado de dividir un círculo en sectores circulares de ángulos
proporcionales a las frecuencias absolutas de cada valor de la variable. Para calcular los
grados de cada sector se divide la frecuencia entre el número de datos y se multiplica por 360.
Se utiliza para variable discreta y continua.
Ejemplos para variables discretas:
Edades fi Grados
12 6 108
13 5 90
14 3 54
15 6 108
TOTAL 20 360
0 1 2 3 4 5 6 7
12 13 14 15
frec. als
olu
ta
Edades
Alumnos de una clase
0 1 2 3 4 5 6 7
12 13 14 15
frec. als
olu
ta
Edades
Alumnos de una clase
12
13 14
15
Alumnos de una clase
12
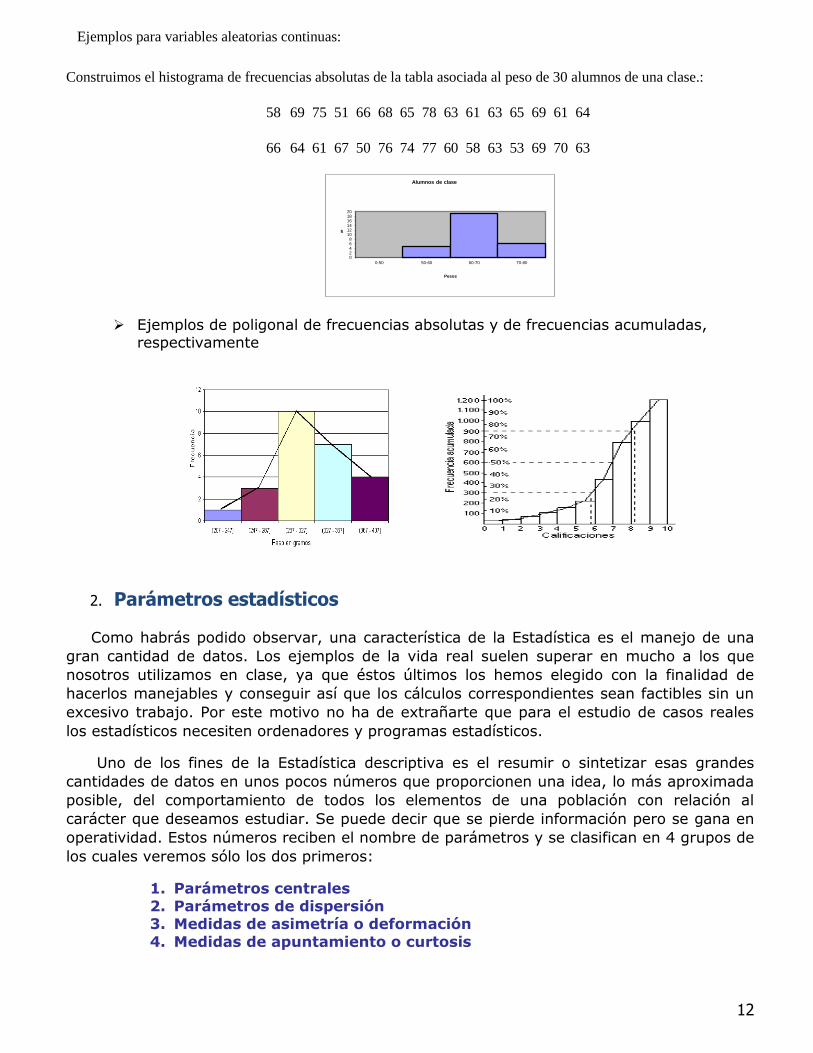
Ejemplos para variables aleatorias continuas:
Construimos el histograma de frecuencias absolutas de la tabla asociada al peso de 30 alumnos de una clase.:
58 69 75 51 66 68 65 78 63 61 63 65 69 61 64
66 64 61 67 50 76 74 77 60 58 63 53 69 70 63
Ejemplos de poligonal de frecuencias absolutas y de frecuencias acumuladas, respectivamente
2. Parámetros estadísticos
Como habrás podido observar, una característica de la Estadística es el manejo de una
gran cantidad de datos. Los ejemplos de la vida real suelen superar en mucho a los que
nosotros utilizamos en clase, ya que éstos últimos los hemos elegido con la finalidad de
hacerlos manejables y conseguir así que los cálculos correspondientes sean factibles sin un
excesivo trabajo. Por este motivo no ha de extrañarte que para el estudio de casos reales
los estadísticos necesiten ordenadores y programas estadísticos.
Uno de los fines de la Estadística descriptiva es el resumir o sintetizar esas grandes
cantidades de datos en unos pocos números que proporcionen una idea, lo más aproximada
posible, del comportamiento de todos los elementos de una población con relación al
carácter que deseamos estudiar. Se puede decir que se pierde información pero se gana en
operatividad. Estos números reciben el nombre de parámetros y se clasifican en 4 grupos de
los cuales veremos sólo los dos primeros:
1. Parámetros centrales 2. Parámetros de dispersión 3. Medidas de asimetría o deformación
4. Medidas de apuntamiento o curtosis
0 2 4 6 8
10 12 14 16 18 20
0-50 50-60 60-70 70-80
fi
Pesos
Alumnos de clase

13
Los parámetros centrales son unos números que tienen como objetivo agrupar o
centralizar los datos correspondientes a toda la población en un solo valor numérico,
representante del conjunto total.
Los principales parámetros centrales son:
La media aritmética La mediana
La moda
Los parámetros de dispersión tienen como objetivo el darnos una idea o “medida” de la
proximidad o lejanía que presentan los datos de la población respecto al valor que hemos
tomado como “central” o representante del conjunto total.
Los principales parámetros de dispersión son:
Amplitud, rango o recorrido
Desviación media Cuantiles: Cuartiles, deciles y percentiles Varianza
Desviación típica Coeficiente de variación de Pearson
4.1. MEDIDAS DE CENTRALIZACIÓN
Una medida o parámetro de centralización de una distribución estadística es
un valor que representa y resume la información de todos los datos de la distribución.
Estos parámetros centrales son de gran utilidad para el manejo de datos estadísticos.
1. MEDIA ARITMÉTICA
La media aritmética de un conjunto de valores x1 , x2, x3,............xn se obtiene sumando todos los valores y dividiendo por el número de datos n.
EJEMPLO: Calcular la media aritmética de los siguientes números:
4, 4, 4, 10, 7, 2, 10, 6, 10
33,69
106102710444
x
Si tenemos muchos datos por ejemplo 40, la fórmula anterior aunque es válida no es práctica,
pues hay que sumar 40 números y luego dividir por 40, en este caso lo que se hace es crear la
tabla estadística asociada a los datos y aplicar la fórmula:

14
La fórmula anterior se puede escribir de forma abreviada así:
el nº total de datos o tamaño muestral
Es sin duda, el parámetro estadístico central que se utiliza con más frecuencia y lo has utilizado en más
de una ocasión. ¿Cuántas veces has preguntado a tus profesores si para la nota final de curso hacen la
“media” de las notas finales de las evaluaciones?.
Por otro lado, es conveniente en que nos vayamos acostumbrando a pensar que en Estadística no
interesan los datos de un individuo particular sino que interesa el conjunto de la población y la forma en
que están distribuidos estos datos.
VENTAJAS E INCONVENIENTES DE LA MEDIA
Una de las propiedades más importantes de la media es el hecho de que este parámetro tiene en cuenta
todos los valores o datos de una población y que los cálculos necesarios para su elaboración son sencillos.
Sin embargo, presenta un inconveniente, a veces grave, que consiste en los efectos que sobre ella producen
los valores extremos que, en muchas ocasiones, son los menos significativos por su rareza o
excepcionalidad.
Ejemplo: Si en una fábrica trabajan once personas y sus sueldos respectivos son los siguientes:
Personas Sueldos (€)
2 300
3 400
1 800
2 900
2 1000
1 6000
11 9400
Este problema es uno de los que surgen al querer sintetizar en un solo número un conjunto de ellos.
Para resolver este inconveniente se utilizan otros parámetros centrales que, en algunas ocasiones, son más
representativos que la media aritmética. Así tenemos la moda y la mediana.
Antes de seguir veamos un ejercicio de aplicación:
El sueldo medio mensual será de 854,55 € que,
como podemos apreciar, es muy poco
representativo de la realidad. Esta media está
muy influenciada por el valor extremo de 6000 €
correspondiente a una sola persona

15
2. MODA
La moda (Mo) de un conjunto de datos es el dato que tiene mayor frecuencia.
Si la variable es continua, lo primero es localizar el intervalo de mayor frecuencia, que será el intervalo modal.

16
Ejemplo: Se ha aplicado un test de satisfacción en el trabajo a 88 empleadas y empleados de una fábrica,
obteniéndose los siguientes resultados:
Observa que el intervalo modal es [56,62)
Gráficamente, el valor modal se obtiene leyendo el valor proyectado sobre el eje de
abscisas.
El valor dentro del intervalo que se presume tenga la mayor frecuencia, se obtiene de la
observación del cálculo gráfico:
5,596·710
1056·
21
1
c
DD
DLiMo (fórmula anterior escrita de forma práctica)
(Para deducir fórmula “recuerda que en una proporción se verifica:db
ca
d
c
b
a
”)
En este caso: c
DD
Dx
DD
c
DD
xxc
D
xc
D
x
xLiMo
·21
1
212121
Según la definición anterior, puede ocurrir que todos los valores (datos discretos o intervalos),
tengan la misma frecuencia y en este caso no hay moda, o que tengan más de una moda (varios
datos o intervalos con la misma frecuencia), en este caso se habla de distribuciones bimodales,
trimodales o multimodales.
El parámetro moda no es tan representativo como la media aritmética pero es útil en algunas
ocasiones como podrás apreciar en los ejercicios que realices. La mayor representatividad de la
media se debe, sobre todo, a que en el cálculo de ésta intervienen todos los datos del conjunto
estadístico, mientras que en el caso de la moda esto no ocurre.
La moda es un parámetro central porque indica la mayor frecuencia, pero puede estar situada muy
cerca de los extremos.
0
5
10
15
20
25
30
[38-44) [44-50) [50-56) [56-62) [62-68) [68-74) [74-80)
fi
Puntuaciones
Satisfacción en el trabajo
D1

17
3. MEDIANA
De un conjunto ordenado de datos de menor a mayor, es aquel valor tal que la mitad de los datos son iguales o inferiores a él y la otra mitad son iguales o superiores. Se denota por M o Me
Cómo calcularla: Procedemos de forma distinta según se presenten los datos
Si el número de datos es pequeño los ordenamos:
Caso 1: Cuando el número de datos es impar:
Si los valores son 4,6,4,5,7,3,9
1º los ordenamos 3,4,4,5,6,7,9
y como son 7 datos, elegimos el dato que ocupa el lugar central que es el 5.
Caso 2: Cuando el número de datos es par:
Si los valores son 4,6,5,7,3,9. Los ordenamos 3,4,5,6,7,9, como son 6 datos cogemos los datos que ocupan el lugar 3º que es 5 y el lugar 4º que es 6. la
mediana es la media de los dos números centrales y es en este caso:
M = (5+6)/2 = 5.5
Si tenemos muchos datos, por ejemplo 30, ordenarlos es una tarea pesada, entonces lo que
se hace es ordenar los datos en una tabla, con las columnas de los valores xi , frecuencia
absoluta y frecuencia absoluta acumulada y procedemos según vamos a explicar en los
siguientes ejemplos:
Datos agrupados:
Caso 1: Si tenemos la siguiente distribución estadística
Se procede de la siguiente manera:
1º se calculan las frecuencias acumuladas absolutas y calculamos la mitad de los datos: N/2

18
Caso 2: Puede ocurrir que la mitad del número de datos coincida con la frecuencia absoluta
acumulada correspondiente a un valor de la variable estadística, por ejemplo:
Si la variable es continua, no distinguiremos si el número de datos es par o impar, tendremos
un intervalo para la mediana. Igual que se ha hecho con la moda, calculamos primero el intervalo
donde cae, aquel con frecuencia acumulada mayor o igual que n / 2 y podemos suponer que los
datos se distribuyen uniformemente en los intervalos y calcular la mediana con la siguiente fórmula:
donde Li-1, fi y c tiene el mismo significado que antes, n (o N) es el tamaño de la muestra y Fi-1 es la
frecuencia absoluta acumulada del intervalo anterior donde cae el valor de la mediana.
Ejemplo: Sea la distribución anterior:

19
Vamos a ver de dónde sale la fórmula de la mediana: Lo 1º es observar que al proyectar el valor
N/2 sobre la diagonal que hemos trazado resultan dos triángulos que están “en posición de
Tales”, por tanto, son semejantes y de ahí que sus lados sean proporcionales. (Esto es un “reucerda
que”).
Si el intervalo en el que se encuentra la mediana es [Li-1,Li) se plantea la siguiente regla de tres
con los lados de los triángulos:
xF
Nx
fc
i
ii
12
i
i
ic
f
FN·
2/1
Entonces :
De la distribución del ejemplo se deduce:
36,596·25
304456
M
También para calcular gráficamente la mediana de una distribución se puede dibujar el polígono
de porcentajes acumulados, colocando en el eje OX los valores o clases y en el eje OY los
porcentajes correspondientes. Se traza una paralela al eje OX por el punto correspondiente al
50%, que corta al polígono de porcentajes acumulados en un punto M; por éste se traza una
paralela al eje OY, que corta al eje de las X en un punto Me, que es el valor de la mediana
buscada.
Siendo:
M = Mediana
Li-1 = límite inferior del intervalo en el
que se encuentra la mediana
N/2 = mitad del nº de datos
Fi-1 = frecuencia absoluta acumulada del
intervalo anterior al intervalo en el
que encuentra M.
fi = frecuencia absoluta del intervalo en
el que se encuentra la mediana.
M = Li-1 +x = Li-1 + i
i
ic
f
FN·
2/1

20
PROPIEDADES DE LA MEDIANA
La mediana se utiliza especialmente en los casos siguientes:
Cuando el conjunto de datos estadísticos posee valores extremos excepcionales que afectan
demasiado al valor de la media
Cuando se trata de datos estadísticos agrupados en clases y las clases extremas ( o al menos
una de ellas) son abiertas; por ejemplo, si las clases fuesen: menores de 15 años, entre 15 y 24
años, entre 25 y 44 años, entre 45 y 64 años, mayores de 64 años.
La mediana, tal como se deduce de su definición, tiene la propiedad de que el cincuenta por ciento de
los datos son menores o iguales que ella y el cincuenta por ciento restante son mayores o iguales. Dicho
de otra manera: la mediana divide al conjunto de datos en dos partes iguales, dejando la mitad de ellos a
su izquierda y la mitad restante a su derecha. Esto justifica que sea un parámetro de posición central.
4. CUARTILES, DECILES Y PERCENTILES
Cuartiles. Son valores que dividen a la población en cuatro partes iguales. Los vamos a
representar por Q1, Q2 y Q3. Entre cada dos de ellos estará el 25 % de los datos. Lógicamente el segundo cuartil coincidirá con la mediana.
Deciles. Son valores que dividen a la población en diez partes iguales. Los
representaremos por D n. El quinto decil coincide con la mediana.
Percentiles. Son valores que dividen a la población en cien partes iguales. Los
representamos por PK. Evidentemente los percentiles 25, 50 y 75 coinciden con los cuartiles.
Y los percentiles 10, 20 , ... , 90 coinciden con los deciles.
El cálculo de estos parámetros, tanto para variables discretas como para variables continuas, se hace de forma similar al cálculo de la mediana.
Si la variable es discreta, para calcular un percentil, calcularemos el porcentaje de
datos que corresponde a dicho percentil, es decir, para calcular el percentil de orden "p",
calcularemos p·N/100. Si este valor no coincide con ninguna de las frecuencias absolutas
acumuladas, cogemos el primer valor de la variable cuya frecuencia absoluta acumulada supera este dato.
Si la variable es continua, primero hacemos el cálculo anterior y vemos el intervalo
que tenemos que coger y después aplicamos la siguiente fórmula, muy similar a la utilizada
para el cálculo de la mediana:
Actividad: De la misma distribución anterior calcula:
a) Q1 y Q3 b) P40 y P90

21
a) 61,626·18
556662;8,526·
15
152250·
4·
31
1
QQdosustituyenycfi
FN
r
aQi
i
ir
b)
13,726·9
732,7968
)74,682,7988·100
90
25,576·25
302,3556
)62,562,3588·100
40
:·100
·
90
90
40
40
1
P
P
P
P
resultadosustituyenycfi
FN
r
aPi
i
ir
Nota: Para el cálculo de los deciles la fórmula razonando de la misma forma es:
i
i
irc
fi
FN
r
aD ·10
·1
Observa que: los parámetros anteriores son de posición pero no central excepto los que coinciden con la mediana.
4.2. MEDIDAS DE DISPERSIÓN
Parámetros de dispersión son datos que informan de la concentración o dispersión de los datos respecto de los parámetros de centralización.
Ejemplo: Vamos a suponer que hemos realizado el mismo examen en dos grupos distintos. En uno, todos los alumnos han sacado la misma nota, un 5; en
otro, la mitad de los alumnos ha sacado un 0 y la otra mitad un 10. ¿Cuál es la media en los dos casos? ¿Se pueden considerar los dos grupos iguales si la media
coincide?
Parece entonces que no es suficiente con las medidas de centralización, hacen falta otros parámetros que informen sobre la mayor o menor concentración de los
datos respecto a la media.
Las medidas de dispersión tienen como objetivo el darnos una idea o “medida” de la
proximidad o lejanía que presentan los datos de la población respecto al valor que hemos tomado como “central” o representante del conjunto total.
Otro ejemplo: La altura media de los dos equipos de baloncesto que presentamos
a continuación tienen prácticamente la misma altura media.

22
1. Rango o recorrido de un conjunto de datos, es la diferencia entre el mayor
(M) y el menor valor (m) de los datos y usaremos la fórmula
En el ejemplo de las puntuaciones de los trabajadores el rango es:
R = = 80-38 = 42
2. Recorrido intercuartílico. Es la diferencia entre los cuartiles tercero y primero
que se explicarán más adelante. Se representa por RI (RI = Q3-Q1) y
representa la amplitud del intervalo en el que se encuentra el 50% central de los datos.
3. DESVIACIONES RESPECTO A LA MEDIA.
- La diferencia entre cada dato y la media aritmética del grupo se llaman desviaciones respecto a la
media.
- Estas diferencias pueden ser positivas, negativas o nulas.
- Las desviaciones respecto a la media, indican cómo se aparta cada dato respecto la media
aritmética.

23
4. DESVIACIÓN MEDIA.
De un conjunto de datos es la media aritmética de los valores absolutos de las desviaciones respecto a la media.
N
fxx
DM
n
i
ii
1
·
5. VARIANZA Y DESVIACIÓN TÍPICA
Varianza: Es la media de los cuadrados de las desviaciones de los datos
respecto a la media, es decir, el resultado de aplicar una de las dos siguientes fórmula equivalentes:
A veces, la varianza también se representa por la letra griega σ2
Desviación Típica: Es la raíz cuadrada de la varianza y se expresa con la letra ó σ y es el parámetro de dispersión más utilizado.
Ejemplo:

24
6. COEFICIENTE DE VARIACIÓN DE PEARSON:
Si hemos realizado un estudio estadístico en dos poblaciones diferentes, y queremos comparar resultados, no podemos acudir a la desviación típica para ver la
mayor o menor homogeneidad de los datos, sino a otro parámetro nuevo, llamado coeficiente de variación y que se define como el cociente entre la desviación típica y el
valor absoluto de la media:
Por ejemplo, en una exposición de ganado estudiamos un conjunto de vacas con
una media de 500 kilos y una desviación típica de 50 kilos. Y observamos también un conjunto de perros con una media de 40 kilos y una desviación típica de 10 kilos.
¿Qué grupo de animales es más homogéneo?
Un razonamiento falso sería decir que el conjunto de perros es más homogéneo porque su desviación típica es más pequeña, pero si calculamos el coeficiente de
variación para ambos:
CVv = 50/500 = 0.1 CVp = 10/40 = 0.25
Por tanto, es más homogéneo el conjunto de las vacas.
El valor se suele expresar en tanto por ciento. Cuanto más pequeño es este coeficiente, los datos están más concentrados alrededor de la media y por tanto más representativa es ésta.
Si es > 30% indica que la media es poco representativa como medida del promedio y es
mejor optar por la mediana y la moda.
Sirve para comparar dos distribuciones y a mayor CV, mayor es la dispersión.
Es un número positivo que no tiene dimensiones, es decir, no depende de las escalas utilizadas para medir la variable estudiada.
Este coeficiente permite comparar dos poblaciones heterogéneas.
Otro ejemplo : Observa la siguiente tabla
Edad Peso medio S
Grupo 1 11 40 2kg
Grupo 2 25 50 2kg
%4100·50
22
%5100·40
21
CV
CV

25
En ambos casos, S = 2kg , sin embargo es mayor la dispersión en el grupo de los niños que en el de los jóvenes. Es decir, la media aritmética es más representativa en el grupo de los jóvenes que en el de los niños.
Observación: Este parámetro no debe usarse cuando la media esté próxima a cero, pues
el denominador pequeño distorsiona el cociente.
ESTUDIO CONJUNTO DE X y
La media aritmética X , y la desviación típica , son los parámetros estadísticos por
antonomasia. La media es la medida central más utilizada y la desviación típica es la medida de
dispersión o variabilidad por excelencia.
En toda distribución estadística, el estudio conjunto del comportamiento conjunto de la media
aritmética y la desviación típica nos aporta numerosa información sobre la distribución de
frecuencias estudiada.
En casi todas las distribuciones estadísticas de comportamiento normal, se verifican de forma
aproximada los porcentajes descritos a continuación que, referidos a la media y la desviación
típica, expresan la distribución de datos.
Para una distribución estadística de comportamiento normal , se cumple:
En ( xx , ) está el 68,27% de los datos del total de individuos
En ( 2,2 xx ) está el 95,45% de los datos del total de individuos
En ( 3,3 xx ) está el 99,73% de los datos del total de individuos
Puntuaciones normalizadas. Si antes hemos comparado variables, también podemos estar interesados en comparar datos de distribuciones distintas y saber, cuál destaca más o
menos dentro de su grupo según la característica observada. Esto lo vamos a hacer tipificando la variable con la fórmula:
obteniendo así una nueva variable estadística de media 0 y desviación típica 1, con la que
resultará más fácil poder comparar los datos.

26
Por ejemplo, si en la exposición de ganado anterior, escogemos una vaca que pesa 550 kilos y un perro que pesa 55 kilos, ¿cuál tiene más peso dentro de su grupo?
Naturalmente no vale decir la vaca, que pesa mucho más. Tipificamos ambos valores y obtenemos:
zv = (550-500)/50 =1 zp = (55-40)/10 = 1.5
Como las dos variables tipificadas tienen la misma media y la misma desviación típica, tiene más peso el animal que tiene mayor puntuación normalizada, es decir, el perro.
Ejercicios de aplicación:

27
FIN